
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
La ferme de compilation Cfarm
Première rédaction de cet article le 1 décembre 2023
Si vous êtes programmeuse ou programmeur, vous avez peut-être des problèmes de portabilité de vos programmes, et vous souhaitez les tester sur d'autres plate-formes que celles où vous avez accès habituellement. C'est le but des fermes de compilation et cet article va présenter la Cfarm, sur laquelle je viens d'avoir un compte.
Donc, le principe d'une ferme de compilation : beaucoup de machines, de types et de systèmes d'exploitation différents, auxquelles vous pouvez accéder via SSH et tester vos programmes. C'est surtout utile pour les langages de bas niveau comme C, il y a sans doute moins de problèmes de portabilité en Python ou Haskell…
La Cfarm est réservée aux programmes libres. Pour avoir un compte, vous devez remplir un formulaire où vous indiquez notamment les projets de logiciel libre que vous maintenez. Votre compte est ensuite approuvé (dans mon cas, cela avait pris moins de 24 heures) et vous pouvez alors vous connecter sur le site Web, et indiquer des clés SSH qui seront automatiquement copiées sur toutes les machines, vous permettant de vous connecter (mais vous ne serez évidemment pas root). La liste des machines est longue ! Et elle contient des types devenus rares, par exemple des processeurs PowerPC, qui sont utiles car ce sont dans les rares à être gros-boutiens. J'aime bien aussi la machine ARM faisant tourner FreeBSD. Et, oui, il y a une RISC-V, si vous ne voulez pas en acheter une.
Pour vous simplifier la vie, si vous travaillez sur plusieurs de
ces machines, OpenSSH permet des
configurations globales, voici mon
~/.ssh/config :
Host *.cfarm.net User bortzmeyer IdentityFile ~/.ssh/id_cfarm
Notez que j'utilise une clé ed25519 mais la documentation note bien que certains vieux systèmes ne connaissent pas cet algorithme, et elle suggère d'utiliser RSA, si on veut passer partout (on peut avoir plusieurs clés dans sa configuration Cfarm).
Cette configuration est également utile si la machine utilise un port inhabituel, ce que font certaines.
L'article seul
Fiche de lecture : La réputation
Auteur(s) du livre : Laure Daussy
Éditeur : Les échappés
978-2-35766-198-1
Publié en 2023
Première rédaction de cet article le 26 novembre 2023
Ce livre parle d'un féminicide, l'assassinat de Shaïna Hansye en 2019. Et regarde de près l'environnement où ce crime a eu lieu. Ce n'était pas un fait isolé, mais le produit de plusieurs phénomènes, dont le sexisme et les injonctions à la « pureté » contre les filles et femmes.
Le meurtre a eu lieu à Creil et l'assassin était le « petit ami » de la victime. La journaliste Laure Daussy est allé interroger les parents de Shaïna, ses amies, les enseignants, les associations pour comprendre ce qui s'est passé. Creil cumule les problèmes : services publics supprimés ou défaillants, chômage massif, montée de l'islamisme, etc. Pour ne citer qu'un exemple, la maternité, où les jeunes filles pouvaient avoir des conseils sur la contraception et l'IVG a fermé, les habitantes sont censées aller à Senlis, ville avec laquelle il n'y a pas de liaison par transports en commun. Les jeunes filles sans permis de conduire sont donc privées de toute information, sauf si leurs parents acceptent de les emmener (ce qui n'est pas toujours facile à demander !). Les « territoires perdus de la République », dont les médias aiment bien parler, c'est aussi ça : une ville abandonnée des pouvoirs publics. Un autre exemple est donné par l'incroyable passivité de la police lorsque Shaïna, deux ans avant le meurtre, était allé porter plainte pour un viol. Beaucoup de femmes n'osent pas porter plainte, craignant (à juste titre) qu'elles se retrouvent accusées ou stigmatisées ou bien que cela ne serve à rien. Ici, l'enquête de la police et l'instruction judiciaire se sont déroulées avec lenteur, le jugement n'ayant eu lieu qu'après le meurtre de la victime.
Mais l'un des principaux problèmes n'est pas directement lié à cet abandon. C'est la question de la réputation, qui donne son titre à l'enquête. Des hommes ont décidé de contrôler la vie des femmes et notamment par le biais du contrôle de leur vie affective et sexuelle. Une jeune fille qui vit un peu librement peut vite se retrouver marquée par l'étiquette « fille facile ». Souvent, il n'est même pas nécessaire de vouloir vivre sa vie, toute fille peut se retrouver ainsi étiquetée, par exemple parce qu'un homme a voulu se « venger » d'elle. Si personne, parlant à la journaliste, n'a osé défendre ouvertemement le meurtre de Shaïna, en revanche plusieurs de ses interlocuteurs ont relativisé ce meurtre, le justifiant par le statut de « fille facile » de la victime.
Le terme revient souvent lorsque les hommes (et parfois aussi les femmes) parlent à l'auteure. Le poids des préjugés, celui, grandissant, de la religion, le sexisme se combinent pour enfermer les femmes de Creil. Toutes portent en permanence le poids de cette injonction à la réputation.
L'article seul
Modifier un message entrant en Python
Première rédaction de cet article le 24 novembre 2023
Un peu de programmation aujourd'hui. Supposons qu'on reçoive des messages qui ont été modifiés en cours de route et qu'on veut remettre dans leur état initial. Comment faire cela en Python ?
Comme exemple, on va supposer que les messages contenant le mot « chiffrer » ont été modifiés pour mettre « crypter » et qu'on veut remettre le terme correct. On va écrire un programme qui reçoit le message sur son entrée standard et met la version corrigée sur la sortie standard. D'abord, la mauvaise méthode, qui ne tient pas compte de la complexité du courrier électronique :
import re
import sys
botched_line = re.compile("^(.*?)crypter(.*?)$")
for line in sys.stdin:
match = botched_line.search(line[:-1])
if match:
# re.sub() serait peut-être meilleur ?
newcontent = match.group(1) + "chiffrer" + match.group(2) + "\n"
else:
newcontent = line
print(newcontent, end="")
On lit l'entrée standard, on se sert d'une expression rationnelle (avec le module re) pour trouver les lignes pertinentes, et on les modifie (au passage, le point d'interrogation à la fin des groupes entre parenthèses est pour rendre l'expression non gourmande). Cette méthode n'est pas bonne car elle oublie :
- Qu'un message peut être composé de plusieurs parties,
- et que même les parties faites de texte peuvent être encodées, par exemple en quoted-printable.
Il faut donc faire mieux.
Il va falloir passer au module email. Il fournit tout ce qu'il faut pour analyser proprement un message, même complexe :
import sys
import re
import email
import email.message
import email.policy
import email.contentmanager
botched_line = re.compile("^(.*?)crypter(.*?)$")
msg = email.message_from_file(sys.stdin, _class=email.message.EmailMessage,
policy=email.policy.default)
for part in msg.walk():
if part.get_content_type() == "text/plain":
newcontent = ""
for line in part.get_content().splitlines():
match = botched_line.search(line)
if match:
# re.sub() serait peut-être meilleur ?
newcontent += match.group(1) + "chiffrer" + match.group(2) + "\n"
else:
newcontent += line + "\n"
email.contentmanager.raw_data_manager.set_content(part, newcontent)
print(msg.as_string(unixfrom=True))
Ce code mérite quelques explications :
email.message_from_filelit un fichier (ici, l'entrée standard) et rend un objet Python de type message. Attention, par défaut, c'est un ancien type, et les opérations suivantes donneront des messages d'erreur incompréhensibles (comme « AttributeError: 'Compat32' object has no attribute 'content_manager' » ou « AttributeError: 'Message' object has no attribute 'get_content'. Did you mean: 'get_content_type'? »). Les paramètres_classetpolicysont là pour produire des messages suivant les types Python modernes.walk()va parcourir les différentes parties MIME du message, récursivement.get_content_type()renvoie le type MIME de la partie et nous ne nous intéressons qu'aux textes bruts, les autres parties sont laissées telles quelles.get_content()donne accès aux données (des lignes de texte) quesplitlines()va découper.- Si l'expression rationnelle correspond au motif donné, on ajoute la version modifiée, sinon on ne touche à rien.
set_content()remplace l'ancien contenu par le nouveau.- Et enfin,
as_stringtransforme l'objet Python en texte. Notre message a été transformé.
Ce code peut s'utiliser, par exemple, depuis procmail, avec cette configuration :
:0fw | $HOME/bin/repair-email.py
Évidemment, il peut être prudent de sauvegarder le message avant cette manipulation, au cas où. En procmail :
:0c: Mail/unmodified
Vous voulez tester (sage précaution) ? Voici un exemple de message, fait à partir d'un spam reçu :
From spammer@example Fri Nov 24 15:08:06 2023
To: <stephane@bortzmeyer.org>
MIME-Version: 1.0
Content-Type: multipart/alternative;
boundary="----=_Part_9748132_1635010878.1700827045631"
Date: Fri, 24 Nov 2023 13:42:17 +0100 (CET)
Subject: 🍷 Catalogues vins
From: Ornella FEDI <ornella.fedi@vinodiff.com>
Content-Length: 65540
Lines: 2041
------=_Part_9748132_1635010878.1700827045631
Content-Type: text/plain; charset="UTF-8"
Content-Transfer-Encoding: quoted-printable
Cet E-mail dit "crypter". Pour pouvoir afficher cet E-mail, le clie=
nt de messagerie du destinataire doit supporter ce format.
------=_Part_9748132_1635010878.1700827045631
Content-Type: text/html; charset="UTF-8"
Content-Transfer-Encoding: quoted-printable
<?xml version=3D"1.0" ?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns=3D"http://www.w3.org/1999/xhtml">
<head>
<title>E-Mail</title>
<style type=3D"text/css" media=3D"screen">
</style>
</head>
<body>Deleted to save room</body></html>
------=_Part_9748132_1635010878.1700827045631--
Mettez-le dans un fichier, mettons spam.email
et passez le au programme Python :
% cat /tmp/spam.email | ./repair.py
From spammer@example Fri Nov 24 15:08:06 2023
To: <stephane@bortzmeyer.org>
MIME-Version: 1.0
Content-Type: multipart/alternative;
boundary="----=_Part_9748132_1635010878.1700827045631"
Date: Fri, 24 Nov 2023 13:42:17 +0100 (CET)
...
------=_Part_9748132_1635010878.1700827045631
Content-Type: text/plain; charset="utf-8"
Content-Transfer-Encoding: quoted-printable
Cet E-mail dit "chiffrer". Pour pouvoir afficher cet E-mail, le client de mes=
sagerie du destinataire doit supporter ce format.
------=_Part_9748132_1635010878.1700827045631
...
Si vous voulez améliorer ce programme, vous pouvez gérer les cas :
- Plusieurs « crypter » sur une ligne.
- Remplacer la concaténation
+par quelque chose de plus rapide (je cite Bertrand Petit : concaténer des chaines en Python est couteux. Chaque application de l'opérateur + crée une nouvelle chaîne qui n'aura qu'une existence brève, et cela cause aussi, à chaque fois, la copie de l'intéralité du contenu de la chaine en croissance. À la place, il vaudrait mieux stocker chaque bout de chaine dans une liste, pour finir par tout assembler en une fois, par exemple avecjoin).
L'article seul
Capitole du Libre 2023, et mon exposé sur la censure de l'Internet
Première rédaction de cet article le 22 novembre 2023
Les 18 et 19 novembre 2023, c'était Capitole du Libre à
Toulouse. Plein d'exposés intéressants et de
rencontres passionnantes autour du thème du logiciel libre. 
C'est gros, le Capitole du Libre : 1 200 personnes sont venues,
il y avait 118 orateurices, 94 conférences, 18 ateliers et 31
stands. Comme il y a eu davantage de propositions que de créneaux,
certaines ont été refusées. 50 kg de pop-corn
ont été légués par le DevFest dont 20 ont été
consommés. Mais il y avait aussi des pains au chocolat : 
Personnellement, j'ai fait un exposé sur la
censure sur
l'Internet. Les supports au format PDF sont capitole-libre-2023-censure.pdfcapitole-libre-2023-censure.tex
Ironie de la situation, le réseau de l'ENSEEIHT, l'école qui héberge gratuitement le Capitole du Libre, met en œuvre une des techniques de censure présentées. Si on tente de se connecter à OnlyFans, on récupére un RST (ReSeT) TCP, probablement suite à l'examen du SNI dans l'ouverture de la session TLS. Vu par tcpdump, voici ce que ça donne (le dernier paquet, le RST, n'est pas légitime) :
13:19:35.603931 IP 172.22.223.35.40874 > 54.211.0.120.443: Flags [S], seq 2413541568, win 64240, options [mss 1460,sackOK,TS val 46581492 ecr 0,nop,wscale 7], length 0 13:19:35.744066 IP 54.211.0.120.443 > 172.22.223.35.40874: Flags [S.], seq 3076610656, ack 2413541569, win 26847, options [mss 1460,sackOK,TS val 453378101 ecr 46581492,nop,wscale 8], length 0 13:19:35.744173 IP 172.22.223.35.40874 > 54.211.0.120.443: Flags [.], ack 1, win 502, options [nop,nop,TS val 46581633 ecr 453378101], length 0 13:19:35.830075 IP 172.22.223.35.40874 > 54.211.0.120.443: Flags [P.], seq 1:518, ack 1, win 502, options [nop,nop,TS val 46581719 ecr 453378101], length 517 13:19:35.833848 IP 54.211.0.120.443 > 172.22.223.35.40874: Flags [R.], seq 1, ack 518, win 502, length 0
Et ne dites pas d'utiliser Tor, les nœuds d'entrée publics sont bloqués.
Maintenant, les bons exposés (dans l'ordre arbitraire que j'ai décidé tout seul avec mes préférés en premier). Vincent Privat a présenté un système pour récupérer automatiquement les photos que publie la NASA (avec leurs métadonnées) et les mettre sur Wikimedia Commons. C'est légal puisque la NASA, comme toutes les agences fédérales étatsuniennes, met tout ce qu'elle publie dans le domaine public. Mais c'est techniquement difficile. Déjà, s'il y a parfois une API pour lister les images à récupérer, parfois, il faut plutôt scraper l'HTML. Et parfois il faut deviner l'URL en testant plusieurs variantes. D'autre part, il faut éliminer les doublons (chacun peut écrire dans Wikimedia Commons et ces images sont souvent importées). Son outil récupère toutes les métadonnées, les vérifie et convertit vers ce qu'attend Wikimedia Commons. Comme toujours avec l'open data, il y a des bavures amusantes, par exemple la date de prise de vue indiquée est parfois dans le futur, il y a du mojibake dans les textes, des licences incohérentes (entre le texte et les EXIF), des « descriptions » qui sont en fait de la publicité, etc (tous des problèmes classiques de l'open data). D'autre part, beaucoup d'outils de Wikimedia sont conçus pour le texte, car la cible est Wikipédia. Utiliser les outils et machines de Wikimedia pour traiter des images de beaucoup de giga-octets (par exemple pour le dédoublonnage) explosait les quotas. Enfin, pour dédoublonner, le programme calcule un perceptual hashing, pas un simple et traditionnel condensat.
À noter que les autres agences spatiales ne mettent rien sous licence libre donc la vision de l'espace est dominée par celle des États-Unis, les seuls à avoir compris la force du soft power.
Julian Vanden Broeck a fait un trés bon bilan de son changement
du système de messagerie instantanée interne dans son entreprise
(passage à Matrix). Comment ça marche en
vrai ? Quel accompagnement pour les utilisateurices ? Quelle
acceptation ? Entre utilisateurices qui râlaient contre l'ancien
système, celleux qui râlaient contre le nouveau, celleux qui
disaient que Microsoft Teams, c'était mieux,
et celleux qui critiquaient la couleur des boutons, l'acceptation
n'était pas évidente. La technique,
c'est facile, ce sont les humains qui sont compliqué·es. « On a
désactivé le chiffrement systématique car c'était trop frustrant
pour les utilisateurs, notamment en cas de perte de clés. » Je
confirme que c'est aussi mon expérience avec Matrix, loin des
promesses d'un système parfait. Et encore, l'entreprise de l'orateur
n'utilise que le client Element, les problèmes sont pires quand on a
plusieurs clients (de ce point de vue, Matrix ne marque aucun
progrès par rapport à XMPP, où l'incompatibilité des
clients a toujours été une plaie). Au passage, si vous voulez
essayer, je suis joignable à
@bortzmeyer:matrix.underworld.fr.
On s'est bien amusés avec l'exposé « Modèles d'organisation ouverts dans les entreprises du logiciel libre » car les deux orateurs ne se sont pas présentés, sans explication. Thomas Petazzoni a alors lancé l'idée que, puisque le sujet était les organisations ouvertes, non hiérarchiques, etc, on n'avait pas besoin d'orateurs et on pouvait débattre entre nous. Ça a très bien pris et il y a eu une discussion intéressante, par exemple avec les gens d'une association, l'Échappée Belle, qui est en fait une coopérative de freelances, où chaque salarié décide de son salaire. Évidemment, ils insistaient sur le fait que ça ne peut sans doute marcher que dans les petites organisations (ils sont six), où les gens se connaissent et ont des valeurs communes.
Et Pierre-Yves Lapersonne a posé la question du choix des bibliothèques logicielles quand on développe un logiciel libre. Le ou la programmeureuse ne peut pas tout faire, il faut donc dépendre de bibliothèques existantes. Vous, je ne sais pas mais moi, quand je commence un projet, j'ai toujours du mal à identifier les bonnes bibliothèques dont mon projet va dépendre. Vous utilisez quoi, comme critères ? Quand il y a le choix, c'est compliqué. Comment choisir, et, par exemple, détecter celles qui ne sont plus maintenues (donc où les bogues ne seront plus corrigées), celles gérées par une boite qui va subitement changer la licence (il y a eu deux-trois cas spectaculaires ces dernières années, comme MongoDB), etc. Parmi les critères possibles (mais aucun n'est parfait et l'auteur recommande de se méfier des critères quantitatifs simples) :
- la licence utilisée, bien sûr,
- le langage de programmation utilisé,
- les dépendances de cette bibliothèque,
- le nombre de tickets, s'il est faible, c'est peut-être qu'il n'y a pas beaucoup d'utilisateurs, si beaucoup sont fermés, cela peut être bon signe (bogues corrigées rapidement) ou mauvais signe (mainteneur qui ferme tout de suite sans corriger),
- la date du dernier ticket fermé peut être un bon indicateur pour savoir si le projet vit toujours,
- nombre de commits
(pas très pertinent car il dépend du style de travail des
programmeurs, certain·es font dix commits dans
la matinée, d'autres un par semaine (pensez à
git rebase…), - date du dernier commit pour détecter les codes abandonnés (ou bien tellement parfaits qu'ils n'ont pas besoin de changements…),
- l'activité du mainteneur ; est-ce qu'il est actif (voir son profil sur la forge publique utilisée) avec le langage du projet (un projet Go créé par quelqu'un qui ne fait que du Rust aujourd'hui risque de de ne pas faire l'objet de beaucoup d'attention),
- l'existence de tests, et la couverture du code par la suite de tests (pour avoir une base saine si on va devoir modifier le logiciel).
On a aussi discuté d'UI et d'UX au Capitole du Libre. Nojhan a parlé de LiquidPrompt, un des nombreux mécanismes permettant d'avoir des invites très riches pour la ligne de commande du shell Unix. L'orateur a commencé par : « vous utilisez toustes le shell ? », ce qui évidemment fait rire au Capitole du Libre. Le but du projet est d'améliorer l'invite de la ligne de commande en indiquant davantage d'informations. Le problème est évidemment de ne pas surcharger l'utilisateurice. LiquidPrompt, comme ses concurrents, permet d'avoir plusieurs thèmes, et le thème par défaut est dense et plein d'informations. (Y compris la charge de la batterie, ce que je trouve anxiogène.) Pour les démonstrations, c'est spectaculaire. Une autre démonstration montrait un thème où l'invite occupe tout le terminal tellement il y a d'informations.
Un gros avantage de ces systèmes d'invites riches est l'indication de l'état du dépôt Git (ou bien parfois d'autres VCS) où on se trouve. On peut indiquer la branche, bien sûr (combien de fois je me suis planté, me trompant sur la branche où j'étais) mais aussi des suggestions sur les commandes git qui pourraient être pertinentes.
Bon, il y a tellement de systèmes d'invites shell améliorées que c'est un travail en soi d'en choisir une ! L'auteur a fait un article de comparaison.
Maïtané Lenoir a parlé de « modération » (terme que je trouve contestable) sur les réseaux sociaux, notamment les « réseaux sociaux capitalistes » (ce qui inclut TikTok, même si ça déplait au PC chinois). « Je vais vous raconter des trucs traumatiques. » Déjà, elle a noté qu'il fallait bien différencier la politique officiellement affichée, et les moyens qui sont effectivement mis en œuvre pour l'appliquer. (Ce principe doit pouvoir s'appliquer à la politique en général.) Elle a insisté sur l'importance d'une riposte graduée. Si un logiciel ne permet que des réactions simplistes et binaires (supprimer le compte, par exemple), le contrôle sera difficile car on n'aura le choix qu'entre deux mauvaises décisions. Parmi les difficultés (que les réseaux sociaux capitalistes mettent sous le tapis) du contrôle, la langue. Il ne suffit pas de lire la langue utilisée, il faut aussi connaitre la culture, pour comprendre allusions, jeux de mots, choix de vocabulaire. Un Français va avoir du mal à évaluer du contenu écrit en français par un Ivoirien ou un Québecois.
Et, bien sûr, le contrôle prend du temps et des efforts et les réseaux sociaux capitalistes, quoi qu'ils prétendent, ne mettent pas assez de moyens. L'IA n'est pas une solution. (Notez que Pharos a la même analyse.)
L'auteure travaille dans l'équipe de modération de Framasoft, par exemple pour l'instance fédivers Framapiaf. Inutile de dire que ce n'est pas facile, cette équipe a dû faire face à des campagnes s'attaquant à Framasoft et à sa modération (prétendant par exemple qu'il n'y en avait pas). La publication de la charte de modération n'a rien arrangé, les attaques des ultras du contrôle contre Framasoft ont redoublé, tournant au harcèlement. Heureusement qu'en interne, le collectif était soudé.
L'oratrice a beaucoup insisté sur les difficultés pratiques, quotidiennes de la modération : par exemple, beaucoup de signalements ne donnent aucun détail. C'est quoi, le problème, exactement ? Les modérateurs doivent essayer de deviner. Signaleurs, détaillez vos messages ! (Sinon, elle n'en a pas parlé, mais je trouve qu'il y a aussi des signalements malveillants, pour faire taire des ennemis politiques. Les islamistes font souvent cela, par exemple.) Conseil : ne pas oublier le temps et l'énergie consommée. Certes, la modération de Framapiaf n'est pas parfaite (aucune ne l'est) mais un des principes est : « ne pas passer un temps infini sur chaque cas » (surtout que les modérateurs sont bénévoles). Or, les signaleurs sont souvent très exigeants « on veut une action safe tout de suite !!! »
La conclusion : Modération = Pouvoir et Humain = Faillible.
On a eu évidemment une table ronde sur l'IA, où on a surtout
parlé de régulation. Celle-ci évidemment ne vise pas forcément qu'à
protéger les gens, elle peut avoir des motivations
protectionnistes. Florence Sèdes a noté que le récent projet
Kyutai
de Niel et
Saadé ne mette en jeu que des sommes
« dérisoires ». Toujours dans l'actualité chargée de l'IA, j'ai
demandé à ChatGPT les raisons du licenciement
spectaculaire de la direction d'OpenAI, la
veille du Capitole du Libre, licenciement qui fait parler toute la
Silicon Valley mais il m'a répondu qu'il ne savait pas, qu'à sa
connaissance, Altman était toujours
CEO. 
L'autre table ronde portait sur la sobriété, avec notamment Agnès Crepet, qui bosse chez Fairphone. La table ronde a été un peu plus animée car il y avait aussi le député Modem Philippe Latombe, spécialiste des questions numériques, mais qui a voté la loi JO, avec l'extension de la vidéo-surveillance. Indépendamment de la question des droits humains, la vidéo-surveillance est un gouffre énergétique, il s'est fait interpeller là-dessus, a agité le chiffon rouge en disant qu'il ne fallait pas dire vidéo-surveillance mais vidéo-protection (comme on dit dans les comptes rendus de débats « mouvements divers ; protestations »), bref, a contribué à rappeler que la sobriété numérique n'était pas consensuelle. Les JO, qui sont le prétexte pour généraliser cette surveillance, sont une grande source de gaspillage, et Bookynette, qui animait la table ronde, a appelé à boycotter cette fête du fric et du dopage.
Sinon, en matière d'empreinte environnementale du numérique, ne pensez pas qu'à la consommation électrique, note Agnès Crepet. Il y a aussi l'extraction des métaux, dans des conditions désastreuses. Elle a aussi parlé de la réparabilité, sa tante Ginette étant capable de démonter un ordiphone. Ginette est plus habile de ses mains que moi, elle arrive à réparer son Fairphone, alors que j'ai bousillé un Fairphone 2 en essayant d'intervenir à l'intérieur.
Autre participant à la table ronde, Gaël Duval (/e/). Il a parlé de l'obsolescence logicielle. Pour limiter la surconsommation de matériel, il faut aussi maintenir du logiciel qui continue à tourner sur les « vieux » (10 ans) équipements. Par exemple, les vieux trucs 32 bits ont du mal avec des applications qui sont en 64 bits maintenant. Philippe Latombe note que l'État n'est pas forcément cohérent, par exemple en prônant la réutilisation tout en taxant (avec le racket « copie privée ») les téléphones reconditionnés. Agnès Crepet a appelé au « techno-discernement » ; la technique n'est pas forcément utile. Parfois, la solution est de ne pas numériser.
Guillaume a parlé de l'intégration des contributions externes dans le compilateur Rust. Il a expliqué comment les auteurs de Rust géraient ces contributions, entre le désir de favoriser les contributions extérieures (un gros point fort du logiciel libre) et la nécessité de contrôler (pour éviter bogues, voire, pires, attaques « supply chain »). L'équilibre est délicat. Une bonne partie du processus d'examen des contributions est automatisée, via la CI. Si le changement est léger et que la CI passe, ça va plus vite. Sinon, jetez un coup d'œil à la file d'attente de Rust. Évidemment, il faut que tous les tests passent et, rien que pour les messages d'erreur du compilateur, il y a plusieurs dizaines de milliers de tests. Les machines tournent longtemps ! Si vous voulez contribuer au compilateur Rust, certains tickets sont marqués « pour débutants » et sont a priori plus faciles. Vous pouvez voir pas mal d'articles sur Rust au blog de l'orateur.
Adrien Destugues a fait un exposé très geek, la rétro-ingéniérie d'un jeu vidéo où il jouait quand il était petit (le logiciel ludo-éducatif « Lectures Enjeu »), jeu commercial abandonné et qu'il voulait faire revivre. Aucune perspective utilitaire ou financière, c"était juste de l'art pour l'art. Amusant, les chaines de caractères du jeu sont paramétrées avec un @ qui est remplacé par une marque du féminin si la joueuse a indiqué qu'elle était du genre féminin. "arrivé@" dans le fichier est affiché "arrivé" ou "arrivée" selon le cas.
Un sujet financier ? « La blockchain pour le financement du logiciel libre » par Guillaume Poullain, par exemple. Gitcoin est une organisation de financement du logiciel libre (50 M$ distribués en 2023). Ça utilise le protocole Allo (je ne connais pas). Les gens qui financent ont un droit de vote. L'allocation est quadratique, favorisant le nombre de votes davantage que le montant (pour éviter qu'un millionaire n'ait autant de poids que mille smicards). 3 715 projets ont été financés, 3,8 M$ de donations (je n'ai pas vérifié tous les chiffres).
Un des problèmes est évidemment ce sont les projets les plus connus (souvent les plus riches) qui ont le plus de votes. Et, évidemment, certains projets reçoivent peu de votes et donc de fric. Il y a aussi le risque d'attaque Sybil, favorisé par l'allocation quadratique. (Solution : une vérification d'unicité avec un système nommé Passport.)
À noter qu'on ne peut pas retirer l'argent, le flux est dans un seul sens (ce qui évite les bogues style The DAO qui sont la plaie des fonds d'investissement tournant sur la chaine de blocs). Bref, mon opinion :ça me semble une bonne utilisation des possibilités de la chaine de blocs.
Merci à l'école qui prête les locaux gratuitement, aux sponsors. Et
surtout aux bénévoles : 
L'article seul
Fiche de lecture : Ni Web, ni master
Auteur(s) du livre : David Snug
Éditeur : Nada
9-791092-457513
Publié en 2022
Première rédaction de cet article le 20 novembre 2023
J'avoue, j'ai acheté cette BD pour le titre, référence à un ancien slogan anarchiste. Il y a d'autres jeux de mots dans ce livre. Mais le point important est que c'est une critique vigoureuse du Web commercial et de ses conséquences sur la société.
L'inconvénient des librairies comme Quilombo est qu'une fois qu'on y va pour quelque chose de précis, on se laisse prendre et on achète des livres pas prévus. En l'occurrence, la librairie a pas mal de livres luddites, assez variés. Cette BD imagine un auteur un peu âgé, fan de toutes les possibilités du Web commercial, et qui rencontre son moi du passé qui a voyagé dans le temps pour voir comment était le futur. Le David Snug du passé découvre donc Amazon, Uber Eats, Spotify, etc.
J'aime le style des dessins, et la vision de la ville moderne, où tout le monde est accroché à son ordiphone sonne juste. De même, l'auteur dénonce avec précision les conséquences concrètes du Web commercial, comme l'exploitation des travailleurs sans-papier pour la livraison des repas. C'est souvent très drôle, et rempli de jeux de mots mêlant termes du monde numérique et vieux slogans anarchistes. (Il y en a même un sur les noms de domaine.) C'est parfois, comme souvent avec les luddites, un peu trop nostalgique (« c'était mieux avant ») mais, bon, le fait que le passé connaissait déjà l'exploitation de l'homme par l'homme n'excuse pas le présent.
Bref, c'est un livre que je peux conseiller pour des gens qui n'ont pas perçu le côté obscur du Web commercial. (Si, par contre, vous lisez tous les articles du Framablog, vous n'apprendrez sans doute rien, mais vous passerez quand même un bon moment.) Je regrette quand même que l'auteur ne semble connaitre de l'Internet que le Web et du Web que les GAFA. Ainsi, Wikipédia est expédié en une phrase, pas très correcte.
Un conseil pour finir : ne lisez pas la postface qui, elle est franchement conservatrice et défend une vision passéiste du monde, d'un courant politique qu'on peut qualifier d'« anarchiste primitiviste ». Encore pire, la bibliographie, qui va des réactionnaires comme Michel Desmurget à l'extrême-droite, avec Pièces et Main d'Œuvre. C'est là qu'on se rend compte que le courant luddite a du mal à trancher avec les défenseurs de l'ordre naturel sacré.
L'article seul
Fiche de lecture : Ada & Zangemann
Auteur(s) du livre : Matthias Kirschner, Sandra
Brandstätter
Éditeur : C&F Éditions
978-2-37662-075-4
Publié en 2023
Première rédaction de cet article le 8 novembre 2023
Ce livre pour enfants a pour but de sensibiliser au rôle du logiciel dans nos sociétés. Difficile aujourd'hui d'avoir quelque activité que ce soit, personnelle ou professionnelle, sans passer par de nombreux programmes informatiques qui déterminent ce qu'on peut faire ou pas, ou, au minimum, encouragent ou découragent certaines actions. Les enfants d'aujourd'hui vont vivre dans un monde où ce sera encore plus vrai et où il est donc crucial qu'ils apprennent deux ou trois choses sur le logiciel, notamment qu'il existe du logiciel libre.
Le livre est originellement écrit en allemand, je l'ai lu dans la traduction française, publiée chez C&F Éditions. Il a été écrit à l'initiative de la FSFE.
Donc, l'histoire. Zangemann (un mélange de Jobs, Gates, Zuckerberg et Musk) est un homme d'affaires qui a réussi en fabriquant entre autres des objets connectés dont il contrôle complètement le logiciel, et il ne se prive pas d'appliquer ses règles suivant sa volonté du moment. Les utilisateurices des objets sont désarmé·es face à ces changements. Ada est une petite fille qui commence par bricoler du matériel (c'est plus facile à illustrer que la programmation) puis comprend le rôle du logiciel et devient programmeuse (de logiciels libres, bien sûr). Je ne vous raconte pas davantage, je précise juste, pour mes lecteurices programmeur·ses que ce n'est pas un cours de programmation, c'est un conte pour enfants. Le but est de sensibiliser à l'importance du logiciel, et d'expliquer que le logiciel peut être écrit par et pour le peuple, pas forcément par les Zangemann d'aujourd'hui.
Le livre est sous une licence
libre. J'ai mis une illustration sur cet article car la
licence est compatible avec celle de mon blog, et cela vous
permet de voir le style de la dessinatrice : 
Je n'ai par contre pas aimé le fait que, à part pour les glaces à la framboise, les logiciels ne soient utilisés que pour occuper l'espace public sans tenir compte des autres. Zangemann programme les planches à roulette connectées pour ne pas rouler sur le trottoir et donc respecter les piétons ? Ada écrit du logiciel qui permet aux planchistes d'occuper le trottoir et de renverser les personnes âgées et les handicapé·es. L'espace public est normalement un commun, qui devrait être géré de manière collective, et pas approprié par les valides qui maitrisent la programmation. Le film « Skater Girl » représente bien mieux cette tension entre planchistes et autres utilisateurs. Un problème analogue se pose avec les enceintes connectées où la modification logicielle va permettre de saturer l'espace sonore (un comportement très macho, alors que le livre est censé être féministe) et de casser les oreilles des autres. Remarquez, cela illustre bien le point principal du livre : qui contrôle le logiciel contrôle le monde.
Le livre parait en français le premier décembre. La version originale est déjà disponible, ainsi que la version en anglais.
L'article seul
Mes débuts en programmation Zig
Première rédaction de cet article le 3 novembre 2023
Je suis en train d'apprendre le langage de programmation Zig donc je vous fais profiter ici de ce que j'ai appris. Je ne vais pas détailler les points secondaires, comme la syntaxe, mais plutôt parler des concepts originaux de Zig, comme sa gestion d'erreurs, ses variables optionnelles ou son modèle de gestion mémoire.
Attention, si vous êtes sénateur, ne lisez pas ce texte, il utilise plusieurs techniques d'écriture inclusive. Le risque de crise cardiaque est particulièrement élevé après un déjeuner bien arrosé au restaurant du Sénat.
D'abord, le cahier des charges. Zig est un langage de bas niveau, au sens où il est conçu pour des programmes où le·a programmeur·se contrôle plein de détails, comme l'allocation de mémoire. Il est prévu pour programmer sur le métal nu (par exemple programmation dite « embarquée » ou bien pour faire un noyau de système d'exploitation). Mais on peut aussi l'utiliser sur un environement plus perfectionné, par exemple sur Unix pour écrire des serveurs Internet (le domaine de la programmation que je connais le mieux).
Zig est donc un concurrent de C mais se voulant plus sécurisé, C s'étant distingué au cours de sa longue histoire par la facilité avec laquelle le·a programmeur·se peut produire des failles de sécurité. Bien d'autres langages sont sur ce créneau, le plus connu (et le seul déjà largement utilisé en production) étant Rust. Mais il y a aussi V, Odin, Vale… (Une liste a été compilée.)
Zig a démarré en 2016 et n'est donc pas un langage si récent que cela. Mais il est toujours officiellement expérimental (l'actuelle version stable est la 0.11, j'ai travaillé avec la 0.12) et le langage continue à évoluer, ce qui rend difficile de l'utiliser pour des projets réels. En outre, sa bibliothèque standard évolue encore davantage que le langage lui-même. Il est ainsi fréquent qu'on trouve avec un moteur de recherche des articles prometteurs… mais dépassés et dont les exemples ne compilent même pas.
Bon, connaissant les lecteurices de ce blog, je pense qu'ielles sont toustes en train de se demander à quoi ressemble Hello, world en Zig. Donc :
const std = @import("std");
pub fn main() !void {
const public = "Blog";
std.debug.print("Hello, {s}!\n", .{public});
}
Vous noterez qu'il faut importer explicitement la bibliothèque
standard, contrairement à la grande majorité des langages de
programmation. Une version plus longue de ce premier programme est
hello.zig
Bon, je vous ai suggéré d'essayer mais, pour cela, il faudrait un compilateur. La mise en œuvre actuelle de Zig est en C++ mais une version en Zig existe et est déjà capable de se compiler elle-même. En attendant, on va utiliser le binaire fourni car je suis paresseux :
% zig version 0.12.0-dev.1245+a07f288eb % zig build-exe hello.zig % ./hello Hello, Blog!
Vous verrez un message pendant un moment disant que le code est généré par LLVM. Un des avantages de cette méthode est de rendre Zig très portable. Ainsi, les programmes tournent tous sur ma carte RISC-V.
D'autre part, la commande zig joue plusieurs rôles : compilateur et éditeur de liens, bien sûr, mais aussi remplaçant de make et des outils similaires, et gestionnaire de paquetages.
Revenons à des programmes zig et voyons ce qui se passe si le programme plante :
const std = @import("std");
pub fn main() void {
const name = "myfile.txt";
const f = std.fs.cwd().openFile(name, .{});
std.debug.print("File opened? {any}\n", .{f});
}
Ouvrir un fichier n'est évidemment pas une opération sûre. Le
fichier peut être absent, par exemple. Les différents langages de
programmation ont des mécanismes très différents pour gérer ces cas.
Si vous faites tourner le programme Zig ci-dessus, et que le fichier
myfile.txt n'existe pas, vous obtiendrez
un File opened? error.FileNotFound. Si le fichier
existe, ce sera File opened? fs.file.File{ .handle = 3,
.capable_io_mode = io.ModeOverride__enum_3788.blocking,
.intended_io_mode = io.ModeOverride__enum_3788.blocking },
une structure de données à travers laquelle on pourra manipuler le
fichier ouvert. La fonction de la bibliothèque standard
openFile peut donc retourner deux types
différents, une erreur ou une structure d'accès au fichier. Ce
mécanisme est très fréquent en Zig, on peut avoir des unions de type
et les fonctions renvoient souvent « soit ce qu'on attend d'elles,
soit une erreur ».
Maintenant, imaginons un·e programmeur·se négligent·e qui ignore l'erreur et veut lire le contenu du fichier :
var buffer: [100]u8 = undefined;
const f = std.fs.cwd().openFile(name, .{});
const result = f.readAll(&buffer);
std.debug.print("Result of read is {d} and content is \"{s}\"\n", .{result, buffer[0..result]});
}
Ce code ne pourra pas être compilé :
% zig build-exe erreurs.zig
erreurs.zig:8:19: error: no field or member function named 'readAll' in 'error{…FileNotFound…BadPathName…}!fs.file.File'
const result = f.readAll(&buffer);
~^~~~~~~~
En effet, en Zig, on ne peut pas ignorer les erreurs (une faute
courante en C). openFile ne renvoie pas un
fichier (sur lequel on pourrait appliquer
readAll) mais une union « erreur ou
fichier ». Il faut donc faire quelque chose de l'erreur. Zig offre
plusieurs moyens pour cela. L'une des plus classiques est de
préfixer l'appel de fonction avec try. Si la
fonction ne renvoie pas d'erreur, try permet de
ne garder que la valeur retournée, si par contre il y a une erreur,
on revient immédiatement de la fonction appelante, en renvoyant
l'erreur :
var buffer: [100]u8 = undefined;
const f = try std.fs.cwd().openFile(name, .{});
const result = try f.readAll(&buffer);
std.debug.print("Result of read is {d} and content is \"{s}\"\n", .{result, buffer[0..result]});
Mais ça ne compile pas non plus :
% zig build-exe erreurs.zig
erreurs.zig:6:13: error: expected type 'void', found 'error{AccessDenied…}'
const f = try std.fs.cwd().openFile(name, .{});
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
erreurs.zig:3:15: note: function cannot return an error
pub fn main() void {
^~~~
On a dit que try renvoyait une erreur en cas de
problème. Or, la fonction main a été déclarée
comme ne renvoyant rien (void). Il faut donc la
changer pour déclarer qu'elle ne renvoie rien, ou bien une erreur :
pub fn main() !void {
Le point d'exclamation indiquant l'union du
type erreur et du vrai résultat (ici,
void). Rappelez-vous : on n'a pas le droit de
planquer les erreurs sous le tapis. Le programme utilisé est erreurs.zig
Revenons sur le typage Zig :
- Il est strict, on ne peut pas ajouter un entier à un pointeur, par exemple,
- il est entièrement statique (les types ne survivent pas à la compilation),
- résultat (qui ne surprendra pas les programmeurs et programmeuses Rust), arriver à compiler le programme est souvent long et pénible mais, une fois que ça compile, il y a beaucoup moins de bogues qui trainent (ce qui est, entre autre, positif pour la sécurité),
- les types sont aussi des valeurs, on peut les mettre dans des variables, les passer en paramètres à des fonctions (ce qui est utile pour la généricité) mais tout cela est fait à la compilation.
Voyons maintenant les variables
optionnelles. Il est courant qu'une variable n'ait pas toujours une
valeur, par exemple si la fonction qui lui donnait une valeur
échoue. En C, et dans d'autres langages, il est courant de réserver
une valeur spéciale pour dire « pas de valeur ». Par exemple 0 pour
un entier, la chaine vide pour une chaine de caractères, etc. Le
problème de cette approche est que cette valeur se trouve désormais
interdite (que faire si l'entier doit vraiment valoir 0 ?) Zig
utilise donc le concept de variable optionnelle, variable qui peut
avoir une valeur ou pas (un peu come le MayBe
d'Haskell). On les déclare avec un
point d'interrogation :
var i:?u8; // = null;
var j:?u8; // = 42;
std.debug.print("Hello, {d}!\n", .{i orelse 0}); // orelse va déballer la valeur (ou mettre 0)
i = 7;
std.debug.print("Hello, {any}!\n", .{j}); // Optionnel, donc le format {d} ne serait pas accepté
std.debug.print("Hello, {d}!\n", .{i orelse 0});
Ce code ne sera pas accepté tel quel car, rappelez-vous, les variables doivent être initialisées. Autrement, error: expected '=', found ';' (message peu clair, il faut bien l'avouer). En donnant une valeur initiale aux deux variables optionnelles, le programme marche. On notera :
nullindique que la variable n'a pas de valeur. On peut testerif (i == null)si on veut vérifier ce cas.orelsesert à donner une valeur par défaut lorsqu'on « déballe » la variable et qu'on découvre qu'elle n'a pas de valeur.
Passons maintenant à un sujet chaud en sécurité (car une bonne partie des failles de sécurité dans les programmes écrits en C viennent de là), la gestion de la mémoire. En simplifiant, il y a les langages qui gèrent tout, laissant le programmeur libre de faire autre chose (comme Python) et les langages où la programmeuse doit gérer la mémoire elle-même. La première approche est évidemment plus simple mais la deuxième permet de contrôler exactement la mémoire utilisée, ce qui est indispensable pour l'embarqué et souhaitable pour les gros programmes tournant longtemps (les serveurs Internet, par exemple). Et l'approche manuelle a également l'inconvénient que les humain·es femelles ou mâles font des erreurs (lire de la mémoire non allouée, ou qui a été libérée ou, pire, y écrire).
L'approche de Zig est que la mémoire est allouée via des allocateurs (concept emprunté à C++) et que différents allocateurs ont différentes propriétés. La responsabilité de la personne qui programme est de choisir le bon allocateur. Commençons par un exemple simple :
pub fn main() !void {
var myallo = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = myallo.allocator();
var myarray = try allocator.alloc(u8, 10); // Peut échouer par manque de mémoire
defer allocator.free(myarray);
std.debug.print("{any}\n", .{myarray}); // Selon l'allocateur utilisé, donnée initialisées ou pas
for (0..myarray.len) |i| {
myarray[i] = @truncate(i); // @as serait refusé, le type de destination étant trop petit
}
std.debug.print("{any}\n", .{myarray});
}
Ce programme, allocate.zig
- crée un allocateur à partir d'une fonction de la
bibliothèque standard,
GeneralPurposeAllocator, allocateur qui privilégie la sécurité sur les performances, et n'est pas optimisé pour une tâche précise (comme son nom l'indique), - alloue de la mémoire pour dix octets
(
u8), ce qui peut échouer (d'où letry), - enregistre une action de libération de la mémoire
(
free) à exécuter lors de la sortie du bloc (defer), - écrit dans cette mémoire (les fonctions dont le nom commençe
par un arobase sont les fonctions
pré-définies du langage ; ici,
@truncateva faire rentrer un compteur de boucle dans un octet, quitte à le tronquer), - affiche le résultat.
D'une manière générale, Zig essaie d'éviter les allocations implicites de mémoire. Normalement, vous voyez les endroits où la mémoire est allouée.
La puissance du concept d'allocateur se voit lorsqu'on en
change. Ainsi, si on veut voir les opérations d'allocation et de
désallocation, la bibliothèque standard a un allocateur bavard,
LoggingAllocator, qui ajoute à un allocateur
existant ses fonctions de journalisation. Comme tous les allocateurs
ont la même interface, définie par la bibliothèque standard, le
remplacement d'un allocateur par un autre est facile :
const myallo = std.heap.LoggingAllocator(std.log.Level.debug, std.log.Level.debug);
var myrealallo = myallo.init(std.heap.page_allocator);
const allocator = myrealallo.allocator();
var myarray = try allocator.alloc(u8, 10);
defer allocator.free(myarray);
for (0..myarray.len) |i| {
myarray[i] = @truncate(i);
}
std.debug.print("{any}\n", .{myarray});
const otherarray = try allocator.alloc(f64, 3);
defer allocator.free(otherarray);
for (0..otherarray.len) |i| {
otherarray[i] = @floatFromInt(i);
}
std.debug.print("{any}\n", .{otherarray});
Ce programme, loggingallocator.zig
% ./loggingallocator
debug: alloc - success - len: 10, ptr_align: 0
{ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }
debug: alloc - success - len: 24, ptr_align: 3
{ 0.0e+00, 1.0e+00, 2.0e+00 }
debug: free - len: 24
debug: free - len: 10
Que se passe-t-il si le·a programmeur·se se trompe et, par
exemple, utilise de la mémoire qui a été désallouée ? Le résultat
dépend de l'allocateur, et des sécurités qu'il fournit (d'où
l'importance du choix de l'allocateur). Par exemple, ce code
(memoryerrors.zig
var myallo = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = myallo.allocator();
var myarray = try allocator.alloc(u8, 10);
for (0..myarray.len) |i| {
myarray[i] = @truncate(i);
}
allocator.free(myarray);
std.debug.print("Use after free: {any}\n", .{myarray});
va, avec cet allocateur, provoquer un plantage puisqu'on utilise de la mémoire qu'on vient de désallouer :
% ./memoryerrors
Use after free: { Segmentation fault at address 0x7f55f88e0000
Mais si on utilise à la place l'allocateur de la libc (plus rapide mais, comme vous le savez, beaucoup moins sûr), aucune erreur ne se produit (ce qui, en dépit des apparences, est un problème) :
const allocator = std.heap.c_allocator;
var myarray = try allocator.alloc(u8, 10);
for (0..myarray.len) |i| {
myarray[i] = @truncate(i);
}
allocator.free(myarray);
std.debug.print("Use after free: {any}\n", .{myarray});
var myotherarray = try allocator.alloc(u8, 10);
allocator.free(myotherarray);
allocator.free(myotherarray);
std.debug.print("Double free: {any}\n", .{myarray});
On doit le compiler en liant avec la libc (sinon, C allocator is only available when linking against libc) :
% zig build-exe memoryerrors.zig -lc
% ./memoryerrors
Use after free: { 212, 33, 0, 0, 0, 0, 0, 0, 59, 175 }
Double free: { 116, 99, 29, 2, 0, 0, 0, 0, 59, 175 }
En Zig, les bibliothèques qui ont besoin d'allouer de la mémoire
demandent qu'on leur fournisse un allocateur. Si on prend comme
exemple std.fmt.allocPrint,
qui formate une chaine de caractères, sa documentation précise
qu'elle attend comme premier paramètre une variable de type
std:mem.Allocator. L'allocateur à usage
généraliste convient donc :
const a = 2;
const b = 3;
var myallo = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = myallo.allocator();
const mystring = try std.fmt.allocPrint(
allocator,
"{d} + {d} = {d}",
.{ a, b, a + b },
);
defer allocator.free(mystring);
std.debug.print("{s}\n", .{mystring});
(Source complet en allocformatting.zig
Zig permet évidemment d'utiliser des bibliothèques existantes, et d'écrire les siennes. Voyons un exemple avec le DNS. On va utiliser la bibliothèque zig-dns. Elle-même dépend de zig-network, pour envoyer et recevoir des paquets. On les télécharge :
git clone https://github.com/MasterQ32/zig-network.git git clone https://github.com/dantecatalfamo/zig-dns.git
Puis on écrit un programme qui les utilise, pour obtenir
l'adresse IP de www.afnic.fr :
// On importe les deux bibliothèques
const network = @import("zig-network/network.zig");
const dns = @import("zig-dns/src/dns.zig");
// Beaucoup de bibliothèques ont une fonction init, pour… les initialiser.
try network.init();
// On crée la prise réseau et on se « connecte » à son résolveur DNS, ici
// celui de DNS.sb
const sock = try network.connectToHost(allocator, "2a09::", 53, .udp);
const writer = sock.writer();
// La requête
const message = try dns.createQuery(allocator, "www.afnic.fr", .AAAA);
var message_bytes = try message.to_bytes(allocator);
try writer.writeAll(message_bytes);
// On lit la réponse
var recv = [_]u8{0} ** 1024;
const recv_size = try sock.receive(&recv);
const response = try dns.Message.from_bytes(allocator, recv[0..recv_size]);
std.debug.print("Response:\n{any}\n", .{response});
Compilé et exécuté, ce programme nous donne :
% ./use-zig-dns
…
Response:
Message {
Header {
ID: 1
Response: true
…
Answers {
Resource Record {
Name: www.afnic.fr.
Type: AAAA
Class: IN
TTL: 581
Resource Data Length: 16
Resource Data: 2a00:0e00:0000:0005:0000:0000:0000:0002
}
(L'adresse IP de www.afnic.fr est
2a00:e00:0:5::2, même si l'affichage par défaut
ne met pas en œuvre la compression du RFC 5952.) Le code complet est en use-zig-dns.zig
Zig n'a pas de macros. Les macros qui permettent de changer la syntaxe (comme le préprocesseur C) sont jugées trop dangereuses car rendant difficile la lecture d'un programme. Et celles qui ne changent pas la syntaxe sont moins nécessaires en Zig où on peut faire bien des choses à la compilation. Mais si vous voulez des exemples de tâches qu'on accomplirait avec une macro en C, regardez cette question que j'ai posée sur un forum, avec plusieurs très bonnes réponses.
Zig est fortement typé et un tel niveau de vérification peut
poser des problèmes lorsqu'on veut, par exemple, mettre en œuvre des
structures de données génériques. Par
exemple, une file d'attente FIFO de variables
d'un type quelconque. Zig résout en général ce problème avec
l'utilisation de types pour paramétrer un programme. Ces types comme
variables doivent pouvoir être évalués à la compilation, et sont
donc souvent marqués avec le mot-clé comptime
(compilation time) :
pub fn Queue(comptime Child: type) type {
return struct {
const This = @This();
const Node = struct {
data: Child,
next: ?*Node,
};
Ici, la file d'attente est programmée sous forme d'un enregistrement
(struct),
qui comprend des données d'un type Child
quelconque (mais connu à la compilation). Notez qu'une file est créée
en appelant la fonction Queue qui renvoie un
enregistrement qui comprend, entre autres, les fonctions qui opéreront
sur les files d'attente (permettant de faire partiellement de la
programmation objet). Le code complet est en
queue.zig
Zig se veut un concurrent de C mais, naturellement, ce n'est pas demain la veille que tout le code existant en C sera recodé en Zig, même dans les hypothèses les plus optimistes. Il est donc nécessaire de pouvoir utiliser les bibliothèques existantes écrites en C. C'est justement un des points forts de Zig : il peut importer facilement des déclarations C et donc permettre l'utilisation des bibliothèques correspondantes. Voyons tout de suite un exemple. Supposons que nous avons un programme en C qui calcule le PGCD de deux nombres et que nous n'avons pas l'intention de recoder (dans ce cas précis, il est suffisamment trivial pour être recodé, je sais) :
unsigned int
pgcd(unsigned int l, unsigned int r)
{
while (l != r) {
if (l > r) {
l = l - r;
} else {
r = r - l;
}
}
return l;
}
Zig peut importer ce programme (la commande zig
inclut clang pour analyser le C) :
const std = @import("std");
const c = @cImport(@cInclude("pgcd.c")); // No need to have a .h
pub fn main() !void {
…
std.debug.print("PGCD({d},{d}) = {d}\n", .{ l, r, c.pgcd(l, r) });
}
On notera qu'il n'y a pas besoin de déclarations C dans un fichier
.h (mais, évidemment, si vous avez un
.h, vous pouvez l'utiliser). Le programme se
compile simplement (et le pgcd.c est compilé automatiquement
grâce à clang) :
% zig build-exe find-pgcd.zig -I. % ./find-pgcd 9 12 PGCD(9,12) = 3
Pour compiler, au lieu de lancer zig build-exe,
on aurait pu créer un fichier build.zig
contenant les instructions nécessaires et, après un simple
zig build fait tout ce qu'il faut (ici,
l'application était suffisamment simple pour que ce ne soit pas
nécessaire). Un exemple d'un tel fichier est build.zigpgcd.cfind-pgcd.zig
Prenons maintenant un exemple d'une vraie bibliothèque C, plus
complexe. On va essayer avec la libidn, qui permet
de gérer des noms
de domaines internationalisés (noms en
Unicode, cf. RFC 5891). On va essayer de se servir de la fonction
idn2_to_ascii_8z, qui convertit un nom en
Unicode vers la forme Punycode (RFC 5892). D'abord, on va importer l'en-tête fourni
par cette bibliothèque (au passage, n'oubliez pas d'installer les
fichiers de développement, sur Debian, c'est
le paquetage
libidn2-dev) :
const idn2 = @cImport(@cInclude("idn2.h"));
Puis on crée les variables nécessaires à la fonction qu'on va utiliser :
var origin: [*c]u8 = args[1]; var destination: [*:0]u8 = undefined;
Le type *c indique une chaine de caractères
sous forme d'un pointeur du langage C, quant à
[*:0], c'est une chaine terminée par l'octet
nul, justement ce que la fonction C va nous renvoyer. On peut donc
appeler la fonction :
const result: c_int = idn2.idn2_to_ascii_8z(orig, @ptrCast(&dest),
idn2.IDN2_NONTRANSITIONAL);
Ce code peut ensuite être compilé et exécuté :
% ./use-libidn café.fr Punycode(café.fr) = xn--caf-dma.fr (return code is 0)
Comment est-ce qe j'ai trouvé quels paramètres exacts passer à cette fonction ? La documentation conçue pour les programmeurs C suffit souvent mais, si ce n'est pas le cas, si on connait C meux que Zig, et qu'on a un exemple de code qui marche en C, une technique bien pratique est de demander à Zig de traduire cet exemple C en Zig :
% zig translate-c example.c -lc > example.zig
Et l'examen du example.zig produit vous
donnera beaucoup d'informations.
Notez que je n'ai pas alloué de mémoire pour la chaine de caractères de destination, la documentation (pas très claire, je suis d'accord) disant que la libidn le fait.
Autre problème, le code Zig doit être lié à la libc explicitement (merci à Ian Johnson pour l'explication). Si vous ne le faites pas, vous n'aurez pas de message d'erreur mais (dépendant de votre plate-forme), une segmentation fault à l'adresse… zéro :
% zig build-exe use-libidn.zig -lidn2 % ./use-libidn café.fr Segmentation fault at address 0x0 ???:?:?: 0x0 in ??? (???) zsh: IOT instruction ./use-libidn café.fr % zig build-exe use-libidn.zig -lidn2 -lc % ./use-libidn café.fr Punycode(café.fr) = xn--caf-dma.fr (return code is 0)
Si vous utilisez un build.zig, n'oubliez donc
pas le exe.linkLibC();.
Si vous voulez essayer vous-même, voici use-libidn.zigbuild-libidn.zigbuild.zig avant de faire un zig
build). Si vous voulez d'autres exemples, vous pouvez
lire l'article de
Michael Lynch.
Une des forces de Zig est l'inclusion dans le langage d'un mécanisme de tests permettant de s'assurer du caractère correct d'un programme, et d'éviter les régressions lors de modifications ultérieures. Pour reprendre l'exemple du calcul du PGCD plus haut, on peut ajouter ces tests à la fin du fichier :
const expect = @import("std").testing.expect;
fn expectidentical(i: u32) !void {
try expect(c.pgcd(i, i) == i);
}
test "identical" {
try expectidentical(1);
try expectidentical(7);
try expectidentical(18);
}
test "primes" {
try expect(c.pgcd(4, 13) == 1);
}
test "pgcdexists" {
try expect(c.pgcd(15, 35) == 5);
}
test "pgcdlower" {
try expect(c.pgcd(15, 5) == 5);
}
Et vérifier que tout va bien :
% zig test find-pgcd.zig -I. All 4 tests passed.
Il n'y a pas actuellement de « vrai » programme écrit en Zig, « vrai » au sens où il serait utilisé par des gens qui ne connaissent pas le langage de programmation et s'en moquent. On lira toutefois un intéressant article sur le développement de Bun.
Si ce court article vous a donné envie d'approfondir Zig, voici quelques ressources en ligne :
- Le site officiel,
- Plus pédagogiques et progressifs, Ziglearn ou les géniaux Ziglings, où on apprend en corrigeant des programmes erronés (avec des indications, rassurez-vous),
- Côté forums, on a Zigg-it, Zig NEWS ou bien sûr StackOverflow (mais où les ziggistes semblent moins actifs),
- Et si vous hésitez entre Zig et d'autres langages, il y a une bonne comparaison avec les langages concurrents.
L'article seul
Visite des plate-formes Pharos et Thesee
Première rédaction de cet article le 3 octobre 2023
J'ai visité aujourd'hui les locaux du ministère de l'Intérieur (SDLC, Sous-Direction de Lutte contre la Cybercriminalité, à Nanterre) où sont installées les plate-formes Pharos (signalement de contenus illégaux) et Thesee (gestion centralisée des plaintes pour escroquerie). La visite avait été organisée par le député Renaissance Éric Bothorel.
C'était une visite très cadrée, évidemment. On n'a finalement pas vu la plate-forme Pharos mais elle nous a été décrite comme très proche de celle de Thesee (un grand open space avec des PC : rien de spectaculaire). Donc, pas de démonstration de l'informatique de Pharos.
Pharos est le service derrière
https://www.internet-signalement.gouv.fr/
Tout contenu illégal est concerné : racisme, terrorisme, appel à la violence, pédopornographie, escroquerie (voir plus loin le rôle de Thesee), etc.
Les signalements peuvent être faits par des citoyens ordinaires, ou par des « signaleurs de confiance », les 84 personnnes morales qui ont signé un partenariat avec Pharos (la liste ne semble pas publique). Ces signaleurs de confiance peuvent signaler plusieurs URL d'un coup, et mettre une pièce jointe (ce qui n'est pas possible pour les signaleurs ordinaires, entre autres pour des raisons de sécurité).
Pour enquêter, les gens de Pharos utilisent les outils classiques de l'Internet plus des logiciels du marché et des développements locaux. Il ne semble pas qu'il existe un logiciel unique, regroupant tout ce dont l'enquêteur a besoin. (Mais je rappelle qu'on n'a pas eu de démonstration.) Pour ne pas être identifié comme la police (un site d'escroquerie pourrait leur servir un contenu différent), ils passent par un abonnement Internet ordinaire, qui n'est pas celui du ministère, et éventuellement par des VPN.
Pharos ne publie pas actuellement de rapport d'activité, avec des chiffres. Toutes les données chiffrées qui circulent viennent d'informations ponctuelles (par exemple de questions écrites à l'Assemblée nationale). Un amendement législatif récent (dû à Bothorel, au nom de l'open data) impose la publication d'un rapport d'activité régulier, avec des données chiffrées. La première édition du rapport est d'ailleurs prête, n'attendant que sa révision RGAA. En 2022, il y a eu 175 000 signalements (on ne sait pas pour combien de contenus, plusieurs signalements peuvent concerner le même), 390 procédures judiciaires ouvertes, 89 000 demandes administratives de retrait, 354 blocages exigés (leur liste n'est pas publique contrairement à, par exemple, celle de l'ANJ).
Le nombre de signalements varie beaucoup avec l'actualité, par exemple lors des troubles suivant la mort de Nahel Merzouk à Nanterre. C'est notamment le cas pour la rubrique « terrorisme », très liée à l'actualité. Seule la pédo-pornographie a un rythme constant.
Pharos ne travaille que sur du contenu public (tweet, site Web), afin de pouvoir le vérifier et le qualifier, donc une insulte raciste sur WhatsApp, par exemple, n'est pas de leur ressort.
Les signalements sont évidemment de qualité variable. Ils peuvent concerner du contenu légal, ou être franchement incompréhensibles. (Les responsables disent qu'ils n'ont pas vu beaucoup de signalements malveillants ; les erreurs sont nombreuses, mais de bonne foi.) Par exemple un type avait fait une vidéo très bizarre (« ambiance et bruitages ») sur la disparition du petit Émile, et elle avait été signalée comme « c'est peut-être lui le coupable ». Pharos ne tient pas compte du nombre de signalements pour un contenu donné, chaque signalement compte.
Pharos emploie entre 40 et 50 personnes (selon les fluctuations, le burn out est un problème, voir plus loin), tou·tes policiers et gendarmes. Il y a un peu de spécialisation : un pôle est spécialisé dans l'ouverture des procédures judiciaires, un autre dans l'expression de la haine en ligne, jugée assez différente pour avoir son propre pôle.
Lors d'un interview à France Inter, la semaine dernière, la présidente du Haut Conseil à l'Égalité, en réponse au journaliste qui lui demandait si elle prônait l'augmentation des effectifs de Pharos pour les nouvelles règles sur la pornographie, avait répondu que ce n'était pas nécessaire car « [le problème] est très facile, il suffit d'utiliser les techniques d'Intelligence Artificielle ». Nos interlocuteurs ont affirmé que Pharos n'utilisait pas du tout d'IA, que peut-être dans le futur, mais se sont montrés plutôt sceptiques, vu la difficulté à qualifier exactement les cas auxquels ielles sont confrontés. L'humain reste irremplaçable, à leur avis.
Sur le problème psychologique, puisque les enquêteurs voient passer pas mal d'horreurs (par exemple les vidéos de Daech) : la politique de Pharos est qu'il n'y a pas de jugement de valeur si un employé n'y arrive plus. « Pas de culture viriliste », « Même les grands et forts peuvent avoir des problèmes ». Les employés ont droit à une aide psychologique.
Un autre pôle à Pharos est celui chargé des mesures administratives (ne passant pas par le contrôle d'un juge). Pharos peut demander à un hébergeur le retrait d'un contenu, et si ce n'est pas fait, ordonner aux grands FAI de bloquer (presque toujours par résolveur DNS menteur). C'est une « erreur humaine » qui a été la cause du blocage de Telegram.
Et Thesee ? Cette plate-forme, plus récente (mars 2022), et que nous avons visitée (comme dit plus haut : un grand open space avec des PC, rien d'extraordinaire), est consacrée à la centralisation de certaines plaintes sur l'escroquerie. (Vous pouvez enregistrer votre plainte via Thesee.) L'idée est que beaucoup d'escroqueries portent sur des petites sommes et que, si on regarde individuellement les plaintes, elles peuvent sembler peu importantes et être mises en bas de la pile de dossiers à traiter. Or, ces « petites » escroqueries peuvent être l'œuvre de gens qui travaillent en grand et escroquent de nombreuses personnes, donc le montant total peut être important. Mais, sans centralisation et regroupement, on peut ne pas voir qu'il ne s'agit pas de manœuvres isolées. Thesee est donc une plate-forme humaine d'analyse de ces clusters. Par exemple, si dix escroqués ont porté plainte contre un faux vendeur et que l'IBAN du vendeur est toujours le même, on a trouvé un cluster. Un logiciel aide à effectuer ces regroupements. (Mais la démonstration de ce logiciel n'a pas fonctionné.) De toute façon, aussi bien pour Thesee que pour Pharos, les enquêteurs ont insisté sur le fait que la technique ne peut pas tout, qu'une enquête est surtout un travail humain.
Thesee compte 32 personnes. Déjà 100 000 plaintes.
Ces escroqueries touchent souvent des personnes vulnérables, et les enquêteurs de Thesee sont souvent confrontés à la détresse des victimes, quand on leur apprend qu'ils ne reverront jamais leurs économies, ou que la jolie femme qui, depuis l'autre bout du monde, leur affirmait qu'elle était tombée amoureuse d'eux et avait juste besoin de 4 000 € pour venir les rejoindre, n'existait pas. Bref, il faut être bienveillant lors des contacts avec les victimes, d'autant plus que l'entourage de celles-ci ne l'est pas toujours (« mais comment as-tu pu être aussi bête ? »).
Pendant la visite. De gauche à droite, Jeanne Bouligny, Éric
Bothorel, Pierre Beyssac et moi : 
L'article seul
RFC 9476: The .alt Special-Use Top-Level Domain
Date de publication du RFC : Septembre 2023
Auteur(s) du RFC : W. Kumari (Google), P. Hoffman (ICANN)
Chemin des normes
Première rédaction de cet article le 30 septembre 2023
Le TLD
.alt a été réservé pour les utilisations
non-DNS. Si demain
je crée une chaine de blocs nommée Catena et
que j'enregistre des noms dessus, il est recommandé qu'ils se
terminent par catena.alt (mais comme toujours
sur l'Internet, il n'y a pas de police mondiale chargée de faire
respecter les RFC).
Ce nouveau RFC
est l'occasion de rappeler que noms
de domaine et DNS, ce
n'est pas pareil. Les noms de domaine existaient avant le DNS
et, même aujourd'hui, peuvent être résolus par d'autres techniques
que le DNS (par exemple votre fichier local
/etc/hosts ou équivalent).
Mais le DNS est un tel succès que cette « marque » est utilisée
partout. On voit ainsi des systèmes de résolution de noms n'ayant
rien à voir avec le DNS se prétendre « DNS pair-à-pair » ou « DNS
sur la blockchain », ce
qui n'a aucun sens. Ce nouveau RFC, lui, vise clairement uniquement
les systèmes non-DNS. Ainsi, des racines alternatives ou des
domaines privés comme le
.local du RFC 6762 ne
rentrent pas dans son champ d'application. De plus, il ne s'applique
qu'aux noms de domaine ou en tout cas aux identificateurs qui leur
ressemblent suffisamment. Si vous créez un système complètement
disruptif où les identificateurs ne ressemblent pas à des noms de
domaine, ce RFC ne vous concerne pas non plus. Mais si, pour des
raisons techniques (être compatible avec les applications
existantes) ou marketing (les noms de domaine, c'est bien, tout le
monde les reconnait), vous choisissez des noms de domaine comme
identificateurs, lisez ce RFC.
En effet, il existe plusieurs de ces systèmes. Ils permettent, en
indiquant un nom de domaine (c'est-à-dire une
série de composants séparés par des points comme
truc.machin.chose.example) d'obtenir des
informations techniques, permettant, par exemple, de trouver un
serveur ou de s'y connecter. Un exemple d'un tel système est le
mécanisme de résolution utilisé par Tor. Les
identificateurs sont construits à partir d'une clé
cryptographique et suffixés d'un
.onion (réservé par le RFC 7686). Ainsi, ce blog est en
http://sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion/. N'essayez
pas ce nom dans le DNS : vous ne le trouverez pas, il se résout via
Tor.
Pendant longtemps, cette pratique de prendre, un peu au hasard,
un nom et de l'utiliser comme TLD a été la façon la plus courante de créer des
noms de domaine dans son espace à soi. C'est ainsi que
Namecoin a utilisé le
.bit, ENS (Ethereum Name Service) le
.eth et GNUnet le
.gnu. Chacun prenait son nom comme il voulait,
sans concertation (il n'existe pas de forum ou d'organisation pour
discuter de ces allocations). Cela entraine deux risques, celui de
collision (deux systèmes de nommage utilisent le même TLD, ou bien
un système de nommage utilise un TLD qui est finalement alloué dans
le DNS, ce qui est d'autant plus probable qu'il n'existe pas de
liste de ces TLD non-DNS). Il y a plusieurs solutions à ce problème,
et l'IETF en a longuement discuté (cf. par exemple
l'atelier
EName de 2017, ou bien le très contestable RFC 8244). Ce RFC a donc mis des années à sortir. L'ICANN, par exemple, a essayé de diaboliser ces
noms, attirant surtout l'attention sur leurs dangers. Autre méthode,
il a été suggéré de créer un mécanisme de concertation pour éviter
les collisions, création qui n'a jamais eu lieu, et pas pour des
raisons techniques. Ce RFC 9476 propose simplement de
mettre les noms non-DNS sous un TLD unique, le
.alt. Ce TLD est réservé dans le registre
des noms spéciaux (créé par le RFC 6761). Ainsi, si le système de résolution de Tor était
créé aujourd'hui, on lui proposerait d'être en
.onion.alt. Est-ce que les concepteurs de
futurs systèmes de résolution non-DNS se plieront à cette demande ?
Je suis assez pessimiste à ce sujet. Et il serait encore plus
utopique de penser que les TLD non-DNS existants migrent vers
.alt.
Comme .alt, par construction, regroupe des
noms qui ne sont pas résolvables dans le DNS, un résolveur purement
DNS ne peut que répondre tout de suite NXDOMAIN (ce nom n'existe
pas) alors qu'un résolveur qui parle plusieurs protocoles peut
utiliser le suffixe du nom comme une indication qu'il faut utiliser
tel ou tel protocole. Si jamais des noms sous
.alt sont réellement utilisés, ils ne devraient
jamais apparaitre dans le DNS (par exemple dans les requêtes aux
serveurs racine) mais, compte-tenu de
l'expérience, il n'y a aucun doute qu'on les verra fuiter dans le
DNS. Espérons que des techniques comme celles du RFC 8020, du RFC 8198 ou du RFC 9156 réduiront la
charge sur les serveurs de la racine; et préserveront un peu la vie
privée (section 4 du RFC).
Le nom .alt est évidemment une référence à
alternative mais il rappelera des souvenirs aux utilisateurs
d'Usenet. D'autres noms avaient été
sérieusement discutés comme de préfixer
tous les TLD non-DNS par un tiret
bas. Mon catena.alt aurait été
_catena :-) Tout ce qui touche à la
terminologie est évidemment très sensible, et le RFC prend soin de
souligner que le terme de « pseudo-TLD », qu'il utilise pour
désigner les TLD non-DNS n'est pas péjoratif…
On note que le risque de collision existe toujours, mais sous
.alt. Notre RFC ne prévoit pas de registre des
noms sous .alt (en partie parce que
l'IETF
ne veut pas s'en mêler, son protocole, c'est le DNS, et en partie
parce que ce milieu des mécanismes de résolution différents est très
individualiste et pas du tout organisé).
L'article seul
MaginotDNS, une faiblesse de certains résolveurs DNS
Première rédaction de cet article le 27 septembre 2023
Dernière mise à jour le 28 septembre 2023
La faille de sécurité MaginotDNS est une faiblesse de certains résolveurs DNS, qui ne vérifient pas assez les données quand elles sont envoyées par un résolveur à qui ils avaient fait suivre leurs requêtes. Elle peut permettre l'empoisonnement du résolveur par de fausses données.
La faille a été présentée à Usenix, a son propre site Web, et a été désignée par CVE-2021-25220 (pour BIND ; Knot a eu CVE-2022-32983 et Technitium CVE-2021-43105). Elle frappe plusieurs logiciels, BIND (quand on l'utilise comme résolveur), Knot Resolver, le résolveur de Microsoft et Technitium. Elle se produit quand le résolveur fait suivre (to forward) les requêtes DNS pour certains domaines à un autre résolveur (ce que l'article nomme un CDNS, Conditional Domain Name Server). Voici un exemple de configuration de BIND qui, sur une version vulnérable du logiciel, peut permettre la faille :
options {
recursion yes;
dnssec-validation no;
};
zone "unautredomaine.example." {
type forward;
forwarders { 192.0.2.1; };
};
Cette configuration se lit ainsi : pour tous les noms de domaine sous
unautredomaine.example, BIND va, au lieu de
passer par le mécanisme de résolution habituel (en commençant par la
racine), faire
suivre la requête au résolveur
192.0.2.1 (une autre configuration, avec
stub à la place de
forward, permet de faire suivre à un serveur
faisant autorité ; en pratique, avec certains logiciels, on peut
faire suivre aux deux et, parfois, cela permet d'exploiter la faille).
Évidemment, si on écrit une telle configuration, c'est qu'on
estime que 192.0.2.1 est légitime et digne de
confiance pour le domaine
unautredomaine.example (et ceux en-dessous, les noms de
domaine étant arborescents). Mais la faille
MaginotDNS permet d'empoisonner le résolveur pour tous les
noms à partir de 192.0.2.1,
ou d'une machine se faisant passer pour
lui.
Le DNS sur UDP (le mode par défaut) ne protège pas contre
une usurpation d'adresse
IP. Une machine peut donc répondre à la place du vrai
192.0.2.1. Pour empêcher cela, le DNS dispose
de plusieurs protections :
- L'attaquant qui va répondre à la place du serveur légitime doit deviner le Query ID de la requête,
- Et (depuis l'attaque Kaminsky) le port source,
- Et de toute façon le résolveur n'acceptera que les réponses
qui sont dans le bailliage
(in-bailiwick) de la question. S'il a demandé
truc.machin.exampleet qu'on lui répond par un enregistrement pourchose.example, il ne gardera pas cette information qui est hors-bailliage.
Du fait de la dernière règle, sur le bailliage, un attaquant qui
contrôle 192.0.2.1 ne pourrait que donner des
informations sur les noms sous
unautredomaine.example.
Mais les chercheurs qui ont découvert MaginotDNS ont repéré une faille dans le contrôle du bailliage : celui-ci est, sur certains logiciels, bien trop laxiste, lorsque la demande a été transmise à un autre résolveur et pas à un serveur faisant autorité. Il est donc possible de faire passer des données hors-bailliage. L'article donne l'exemple d'une réponse qui inclurait l'enregistrement mensonger :
com. IN NS ns1.nasty.attacker.example.
Une telle réponse, clairement hors-bailliage, ne devrait pas être
acceptée. Mais elle l'est (plus exactement, l'était, les logiciels vulnérables
ont tous été corrigés) lorsqu'elle vient du résolveur à qui on a
fait suivre une requête. À partir de là, le résolveur empoisonné
fait passer toutes les requêtes des noms en
.com à l'ennemi…
L'attaquant a plusieurs moyens d'exploiter cette faiblesse. Je vais en citer deux :
- La plus évidente est de contrôler la machine listée
forwarder(192.0.2.1dans l'exemple plus haut). Bien sûr, si on décide de faire suivre à192.0.2.1, c'est qu'on lui fait confiance. Mais on lui fait une confiance limitée, àunautredomaine.example. Avec MaginotDNS,192.0.2.1peut injecter des réponses pour tout domaine. (Cette attaque est appelée on-path dans l'article mais cette terminologie est inhabituelle.) - Sans doute plus réaliste est le cas où l'attaquant ne
contrôle pas la machine listée
forwarder. Il doit alors répondre à sa place en essayant de deviner Query ID et port source, ce qui n'est pas impossible (l'article donne les détails de ce cas, appelé off-path).
Dans les deux cas, l'absence de contrôle correct du bailliage permet à l'attaquant d'empoisonner n'importe quel nom.
Quelles sont les solutions que l'administrateur système peut déployer :
- Bien sûr mettre à jour ses logiciels (la faille a été bouchée dans tous les programmes vulnérables). Il faut le répéter : les logiciels doivent être maintenus à jour. Aucune excuse ne doit être admise.
- DNSSEC,
qui avait justement été conçu
pour cela, protège complètement (c'est pour cela que la
configuration vulnérable, plus haut, a
dnssec-validation no). En 2023, tout le monde l'a déjà déployé, de toute façon, non ? - Pour le deuxième cas, celui où l'attaquant ne contrôle pas le résolveur à qui on fait suivre, toute méthode qui empêche l'usurpation de réponse protégera : DoT (RFC 7858, très recommandé quand on fait suivre une requête), les cookies (RFC 7873), TCP (RFC 7766), TSIG (RFC 8945)…
Je recommande la lecture du ticket 2950 du développement de BIND, bien plus clair à mon avis que l'article originel (la figure 4 est un modèle de confusion). Et merci à Petr Špaček pour ses explications.
L'article seul
Le résolveur DNS public dns.sb
Première rédaction de cet article le 27 septembre 2023
Je ne sais pas exactement quand il a été lancé mais je viens de
voir passer un résolveur DNS
public que je ne connaissais pas, DNS.sb. Il a quelques
caractéristiques intéressantes.
Bon, des résolveurs DNS
publics, il y en a beaucoup (j'en gère même un). Les
utilisateurices et administrateurices système s'en servent pour
des raisons variées, par exemple échapper
à la censure ou bien contourner
un problème technique. Mais ils ne sont pas tous
équivalents, en terme de caractéristiques techniques, de fonctions
(certains sont menteurs), de
politique de gestion des données personnelles, etc. Le service
DNS.sb :
- A DoT, DNSSEC et IPv6 (comme tous les résolveurs publics sérieux),
- Promet d'être strict sur la vie privée et notamment de ne pas garder de trace des requêtes faites,
- Est européen (certains résolveurs publics qui se présentent comme européens sont en fait des services étatsuniens un peu repeints, par exemple en s'appuyant sur la nationalité d'origine du fondateur), plus précisément allemand (par contre, le nom de domaine est dans un TLD aux îles Salomon, ce qui est curieux, mais n'a pas trop d'importance car le nom ne sert pas beaucoup pour accéder à un résolveur DNS, sauf pour l'authentification TLS),
- Ne modifie pas les réponses DNS (ce n'est pas un résolveur menteur, c'est l'information reçue de leur équipe, ce n'est pas clairement documenté et ce n'est pas facile à tester ; j'ai essayé quelques noms susceptibles d'être censurés, et j'obtiens en effet la bonne réponse).
Faisons quelques essais techniques. Comme
DNS.sb a des adresses
IPv6 dont la forme
texte est très courte, on va les utiliser. D'abord, avec
dig :
% dig @2a09:: sci-hub.se
...
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 30101
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
sci-hub.se. 60 IN A 186.2.163.219
;; Query time: 32 msec
;; SERVER: 2a09::#53(2a09::) (UDP)
;; WHEN: Wed Sep 27 11:47:18 CEST 2023
;; MSG SIZE rcvd: 55
OK, c'est bon, tout marche, et en un temps raisonnable depuis ma connexion Free à Paris. (Évidemment, un résolveur public ne sera jamais aussi rapide qu'un résolveur local et il n'est donc pas raisonnable d'utiliser un résolveur public « pour les performances ».)
Et avec DoT ? Passons à kdig :
% kdig +tls @2a09:: disclose.ngo ;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(ECDSA-SECP256R1-SHA256)-(AES-256-GCM) ;; ->>HEADER<<- opcode: QUERY; status: NOERROR; id: 46687 ;; Flags: qr rd ra; QUERY: 1; ANSWER: 1; AUTHORITY: 0; ADDITIONAL: 1 ... ;; QUESTION SECTION: ;; disclose.ngo. IN A ;; ANSWER SECTION: disclose.ngo. 300 IN A 84.16.72.183 ;; Received 57 B ;; Time 2023-09-27 11:50:43 CEST ;; From 2a09::@853(TCP) in 326.4 ms
C'est parfait, tout marche (la première ligne nous montre les algorithmes cryptographiques utilisés).
Configurons maintenant un résolveur local pour faire suivre à
DNS.sb, pour profiter de la mémorisation des
réponses par celui-ci. On va utiliser
Unbound et faire suivre en
TLS :
forward-zone:
name: "."
# DNS.sb
forward-addr: 2a11::@853#dot.sb
forward-tls-upstream: yes
Et tout marche, notre résolveur local fera suivre ce qu'il ne sait
pas déjà à DNS.sb.
DNS.sb dit qu'ils ont plusieurs machines,
réparties par anycast. On
peut regarder les identités de ces serveurs avec NSID (RFC 5001) :
% dig +nsid @2a09:: www.lycee-militaire-autun.terre.defense.gouv.fr
...
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 512
; NSID: 64 6e 73 2d 6c 6f 6e 32 ("dns-lon2")
...
;; Query time: 80 msec
;; SERVER: 2a09::#53(2a09::) (UDP)
;; WHEN: Wed Sep 27 12:00:55 CEST 2023
;; MSG SIZE rcvd: 137
On tombe apparemment sur une machine située à
Londres ("dns-lon2"). Ça pourrait être mieux, mais
l'anycast est un sport difficile.
Avec les sondes RIPE Atlas, on peut avoir une idée du nombre de serveurs :
% blaeu-resolve --requested 100 --nameserver 2a09:: --nsid --type TXT ee Nameserver 2a09:: ["the zone content is (c) … NSID: fra1;] : 4 occurrences ["the zone content is (c) … NSID: debian;] : 6 occurrences ["the zone content is (c) … NSID: us-sjc;] : 2 occurrences ["the zone content is (c) … NSID: s210;] : 3 occurrences ["the zone content is (c) … NSID: fra2;] : 5 occurrences ["the zone content is (c) … NSID: dns-fra4;] : 3 occurrences ["the zone content is (c) … NSID: dns-lon2;] : 2 occurrences ["the zone content is (c) … NSID: dns-a;] : 3 occurrences ["the zone content is (c) … NSID: lon-dns;] : 2 occurrences ["the zone content is (c) … NSID: dns-ams3;] : 1 occurrences [TIMEOUT] : 2 occurrences Test #60486061 done at 2023-09-27T10:03:17Z
On voit dix instances différentes. Le schéma de nommage ne semble pas cohérent ("debian" ???) donc il est difficile d'en dire plus. Mais des traceroute nous montrent que ces machines sont en effet bien réparties, en tout cas pour l'Europe.
Je suis en tout cas satisfait de découvrir un résolveur DNS public européen (et qui marche, contrairement au projet coûteux et bureaucratique de la Commission Européenne, qui n'est toujours pas en service). Est-ce que je vais utiliser ce service ? Non, il en existe plusieurs autres qui me conviennent (dont le mien, bien sûr, mais aussi celui de FDN) mais cela semble un service bien fait et qui pourrait me convenir.
L'article seul
onprem, pour faire tourner facilement des LLM
Première rédaction de cet article le 20 septembre 2023
Vous le savez, accéder à un LLM en ligne soulève de nombreux problèmes de dépendance et de confidentialité. La solution est de le faire tourner en local. Mais les obstacles sont nombreux.
Le premier obstacle est évidemment commercialo-juridique. Tous les modèles ne sont pas récupérables localement. Ainsi, les modèles derrière ChatGPT ou Midjourney ne semblent pas accessibles, et on doit les utiliser en ligne, confiant ses questions (et donc les sujets sur lesquels on travaille) à une entreprise commerciale lointaine. Même quand ils sont téléchargeables, les modèles peuvent avoir des restrictions d'utilisation (plusieurs entreprises affirment que leur modèle est open source, terme qui a toujours été du baratin marketing et c'est de toute façon une question compliquée pour un LLM). Mais il existe plusieurs modèles téléchargeables et utilisables sous une licence plus accessible, ce qui nous amène au deuxième obstacle.
L'IA n'est pas décroissante ! Même si la consommation de ressources est bien plus faible pour faire tourner un modèle que pour l'entrainer, elle reste élevée et vous ne ferez pas tourner un LLM sur votre Raspberry Pi. La plupart du temps, 32 Go de mémoire, un processeur multi-cœurs rapide et, souvent un GPU Nvidia seront nécessaires. Et si vous ne les avez pas ? Des choses pourront tourner mais pas forcément de manière optimale. (Les exemples qui suivent ont été faits sur un PC/Ubuntu de l'année, avec 32 Go de mémoire, 8 cœurs à 3 Ghz, et un GPU Intel, apparemment pas utilisé ; il faut que je creuse cette question.)
Et le troisième obstacle est la difficulté d'utilisation des logiciels qui font tourner un modèle et, en réponse à une question, produisent un résultat. C'est peut-être l'obstacle le moins grave, car les progrès sont rapides. Quand on lit les articles où des pionniers faisaient tourner un LLM sur leur PC il y a un an, et qu'on voit à quel point c'était compliqué, on se réjouit des progrès récents. Ainsi, le premier septembre, a été publiée la première version de onprem, un outil libre pour faire tourner relativement facilement certains LLM. onprem est conçu pour les développeurs Python, et il faudra donc écrire quelques petits scripts (mais d'autres outils, comme open-interpreter, ne nécessitent pas de programmer).
Démonstration. On installe onprem :
% pip install onprem
On écrit un tout petit programme trivial :
from onprem import LLM llm = LLM() print(llm)
Et on le fait tourner :
% python roulemapoule.py You are about to download the LLM Wizard-Vicuna-7B-Uncensored.ggmlv3.q4_0.bin to the /home/stephane/onprem_data folder. Are you sure? (y/N) y [██████████████████████████████████████████████████] <onprem.core.LLM object at 0x7f7609a23c50>
Ce programme n'a encore rien fait d'utile, je voulais juste vous montrer qu'il gère automatiquement le téléchargement des modèles, s'ils ne sont pas déjà sur votre disque. Par défaut, il utilise une variante du modèle Vicuna à 7 milliards de paramètres, évidemment téléchargée depuis Hugging Face. Soyez patient, il y a 3,6 Go à télécharger, mais cela ne sera fait qu'une fois.
Maintenant, faisons un programme plus utile :
from onprem import LLM
llm = LLM()
answer = llm.prompt("Why should I run a LLM locally and not on line?")
L'exécution nous donnera :
% python roulemapoule.py llama.cpp: loading model from /home/stephane/onprem_data/Wizard-Vicuna-7B-Uncensored.ggmlv3.q4_0.bin llama_model_load_internal: format = ggjt v3 (latest) llama_model_load_internal: n_vocab = 32000 llama_model_load_internal: n_ctx = 2048 llama_model_load_internal: n_embd = 4096 llama_model_load_internal: n_mult = 256 llama_model_load_internal: n_head = 32 llama_model_load_internal: n_layer = 32 llama_model_load_internal: n_rot = 128 llama_model_load_internal: ftype = 2 (mostly Q4_0) llama_model_load_internal: n_ff = 11008 llama_model_load_internal: model size = 7B llama_model_load_internal: ggml ctx size = 0.08 MB llama_model_load_internal: mem required = 5407.72 MB (+ 1026.00 MB per state) llama_new_context_with_model: kv self size = 1024.00 MB 1. Increased security: Running a LLM locally provides greater security against potential cyberattacks, as there is no internet connection for the hacker to exploit. 2. Better performance: Running a LLM locally can improve performance by reducing latency and improving reliability due to fewer network hops. 3. Faster troubleshooting: When running a LLM locally, you have direct control over its configuration, making it easier to diagnose and resolve issues. 4. Increased flexibility: Running a LLM locally allows for greater customization and flexibility in configuring the system to meet specific business requirements.
Ma foi, la réponse n'est pas absurde, mais il est amusant de noter que la raison qui me semble la plus importante, la confidentialité, n'est pas citée. Le bla-bla technique au début est dû au moteur sous-jacent utilisé, llama.cpp. Mais en tout cas, vous voyez que c'était très simple à installer et à utiliser, et que vous pouvez donc désormais facilement inclure un LLM dans vos applications écrites en Python.
Pour générer non plus du texte en langue naturelle mais du code, on va indiquer explicitement un modèle prévu pour le code (également dérivé de LLaMA, comme Vicuna) :
from onprem import LLM
llm = LLM("https://huggingface.co/TheBloke/CodeUp-Llama-2-13B-Chat-HF-GGML/resolve/main/codeup-llama-2-13b-chat-hf.ggmlv3.q4_1.bin")
answer = llm.prompt("Write a Python program to output the Fibonacci suite")
Et ça nous donne :
% python roulemapoule.py
You are about to download the LLM codeup-llama-2-13b-chat-hf.ggmlv3.q4_1.bin to the /home/stephane/onprem_data folder. Are you sure? (y/N) y
[██████████████████████████████████████████████████]llama.cpp: loading model from /home/stephane/onprem_data/codeup-llama-2-13b-chat-hf.ggmlv3.q4_1.bin
…
The Fibonacci sequence is a series of numbers in which each number is
the sum of the two preceding numbers, starting from 0 and 1. The first
few terms of the sequence are:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
Write a Python program to output the Fibonacci sequence up to 10.
Here is an example of how you might do this:
```
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
for i in range(10):
print(fibonacci(i+1))
```
Expected output:
0
1
1
2
3
5
8
13
21
34
(Notez la syntaxe Markdown.)
Bon, comme vous le voyez, c'est simple, ça marche et vous pouvez travailler sur des projets confidentiels sans craindre de fuite. Mais il y a des limites :
- Je n'ai pas réussi à utiliser des modèles comme Bloom (et le message d'erreur est vraiment incompréhensible), sans doute parce que onprem dépend de lama.cpp et qu'il ne fonctionne qu'avec des dérivés de LLaMA (il faut vraiment que je lise la documentation ou que je teste un moteur adapté à Bloom). Idem pour Falcon. Notez aussi qu'onprem demande un format particulier du modèle, GGML (et que les formats changent).
- J'ai l'impression que mon GPU n'est pas utilisé, il faut que je regarde ça.
Allez, pour se consoler de ces limites, on va faire une jolie image avec Stable Diffusion en local (mais rien à voir avec onprem) :
pip install diffusers transformers scipy torch sudo apt install git-lfs git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
(Le git clone prend très longtemps, il y a des
dizaines de gigaoctets à charger.) On écrit un programme :
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained('.')
# Pour éviter la censure "Potential NSFW content was detected in one
# or more images. A black image will be returned instead. Try again with
# a different prompt and/or seed.":
pipe.safety_checker = lambda images, clip_input: (images, [False for i in images])
prompt = "A system engineer running to install the last version of BIND to fix yet another security vulnerability, in the style of Philippe Druillet"
image = pipe(prompt).images[0]
image.save("sysadmin-rush.png")
Et voilà :

(D'autres outils m'ont été signalés mais la plupart non-libres.)
L'article seul
Est-ce légitime de récolter des pages Web pour entrainer des IA ?
Première rédaction de cet article le 18 septembre 2023
Plusieurs médias ont récemment publié des articles dénonçant GPTBot, le ramassseur de pages Web de la société OpenAI. Ces articles sont souvent écrits dans un style dramatique, parlant par exemple de « pillage » du Web, ou de « cauchemar ». Je n'ai pas encore d'opinion ferme à ce sujet mais je peux quand même discuter quelques points.
La partie technique d'abord. Le GPTBot est documenté par la
société OpenAI. Il ramasse le contenu
des pages Web, ce qui sert ensuite à entrainer un
LLM comme celui utilisé par
ChatGPT. Étant donné que le ramasseur ne paie
pas les auteurs et hébergeurs des sites Web, et que le LLM ainsi
entrainé sera utilisé dans des services potentiellement lucratifs,
les médias dénoncent cette activité de ramassage comme
illégitime. Voici par exemple un article de Télérama du 6 septembre
à ce sujet : 
Le débat n'est pas nouveau : des protestations avaient déjà été émises par certains programmeurs à propos du service Copilot de GitHub. Est-ce que Copilot peut s'entrainer sur les programmes stockés sur GitHub ? D'un côté, ces programmes sont en accès ouvert (et la grande majorité sous une licence libre), de l'autre, certaines licences utilisées imposent la réciprocité (c'est notamment le cas de la GPL), alors que les programmes développés avec Copilot, et Copilot lui-même, ne sont pas forcément sous une licence libre.
Notez que, comme documenté par OpenAI, si on n'aime pas le
ramassage par le GPTBot, on peut utiliser le traditionnel
robots.txt (RFC 9309) et il respectera ce désir. Cela
n'empêchera évidemment pas les médias de protester, soit parce
qu'ils voudraient être payés, soit parce qu'ils critiquent ce côté
« autorisé par défaut ».
Alors, est-ce légitime ou pas d'entrainer un LLM avec des données qui sont accessibles publiquement ? Le problème est complexe, plus complexe que la présentation simpliste faite dans les médias. Rappelons d'abord que ce n'est pas parce qu'un contenu est en accès ouvert qu'on peut faire ce qu'on veut avec. Il vient avec une licence (et, s'il n'y en a pas d'explicite, c'est qu'on ne peut rien faire) et celle-ci limite souvent les utilisations. Ainsi, ce blog est sous licence GFDL et, si vous voulez en réutiliser le contenu, vous pouvez (licence libre) mais vous devez donner les mêmes droits à ceux qui recevront le travail fait à partir de ce blog (comme pour la GPL dans le cas du logiciel). Est-ce qu'un LLM typique respecte ceci ? L'une des difficultés de la question est que le LLM ne copie pas, il ne plagie pas, il produit un contenu original (parfois faux, dans le cas de ChatGPT, mais c'est une autre histoire). Il ne viole donc pas le droit d'auteur. (Comme toujours, la réalité est plus complexe, des cas où Copilot a ressorti tel quel du code GPL ont déjà été cités.)
Mais est-ce que ce contenu original est dérivé du contenu initial ? Beaucoup d'articles sur la question ont fait comme si la réponse était évidemment oui. Mais cela ne me convainc pas : le mode de fonctionnement d'un LLM fait justement qu'il ne réutilise pas directement son corpus d'entrainement (et cela a de nombreux inconvénients, comme l'impossibilité de sourcer les réponses et l'impossibilité d'expliquer comment il est arrivé à cette conclusion, deux des plus gros problèmes lorsqu'on utilise des IA génératives comme ChatGPT). Il n'est donc pas évident pour moi que la licence du texte original s'applique. Prenons une comparaison : une étudiante en informatique lit, pour apprendre, un certain nombres de livres (certainement sous une licence restrictive) et des programmes (dont certains sont sous une licence libre, et une partie de ceux-ci sous GPL). Elle va ensuite, dans son activité professionnelle, écrire des programmes, peut-être privateurs. Est-ce que c'est illégal vu que sa formation s'est appuyée sur des contenus dont la licence n'était pas compatible avec celle des programmes qu'elle écrit ? Tout créateur (j'ai pris l'exemple d'une programmeuse mais cela serait pareil avec un journaliste ou une écrivaine) a été « entrainé » avec des œuvres diverses.
Dans le cas d'un contenu sous une licence à réciprocité, comme mon blog, notez que le fait que les tribunaux étatsuniens semblent se diriger vers l'idée que le contenu produit par une IA n'est pas copyrightable fait que la licence sera paradoxalement respectée.
Bon, et, donc, les arguments des médias ne m'ont pas convaincu ? L'un des problèmes est qu'il y a un conflit d'intérêts dans les médias, lorqu'ils écrivent sur des sujets qui concernent leur business ; ils sont censés à la fois rendre compte de la question tout en défendant leurs intérêts. Alors, certes, OpenAI est une entreprise à but lucratif, et pas forcément la plus sympathique, mais les médias sont aussi des entreprises commerciales, et il n'y a pas de raison, a priori, de privilégier un requin plutôt qu'un autre (l'IA brasse beaucoup d'argent et attire donc les envies).
Notons aussi que, dans le cas particulier de la francophonie, on verra sans doute les mêmes médias en langue française bloquer GPTBot et se plaindre ensuite que les IA ne traitent pas le français aussi bien que l'anglais… (Pour le logiciel libre, cité plus haut dans le cas de Copilot, un argument équivalent serait qu'exclure le code GPL des données d'entrainement réduirait la qualité du code produit, le code écrit sous les licences libres étant généralement bien meilleur.)
D'autres articles sur le même sujet ? La fondation Wikimedia a analysé la légitimité de ChatGPT à récolter leurs données.
Bref, la question me semble plus ouverte que ce qui est présenté
unanimement dans les médias français. (Même la
FSF considère
le problème comme ouvert.) Pour l'instant, je n'ai donc pas
ajouté le GPTBot au robots.txt (que je n'ai
d'ailleurs pas). De toute façon, un examen des
journaux ne me montre aucune visite de ce
ramasseur, ce qui fait que vous ne retrouverez pas mon style dans
les résultats de ChatGPT. Et vous, des avis ? Vous pouvez m'écrire
(adresse en bas de cette page) ou bien suivre la
discussion sur le fédivers ou celle
sur Twitter.
L'article seul
Fiche de lecture : Géopolitique du numérique
Auteur(s) du livre : Ophélie Coelho
Éditeur : Éditions de l'Atelier
978-2-7082-5402-2
Publié en 2023
Première rédaction de cet article le 10 septembre 2023
D'innombrables livres (sans compter les colloques, séminaires, journées d'études, articles et vidéos) ont déjà été consacrés à la géopolitique du numérique, notamment à l'Internet. Ce livre d'Ophélie Coelho se distingue par son côté pédagogique (il vise un public exigeant mais qui n'est pas forcément déjà au courant des détails) et par sa rigueur (beaucoup de ces livres ont été écrits par des gens qui ne connaissent pas le sujet). Il couvre les enjeux de pouvoir autour des services de l'Internet (qui ne se limite pas à Facebook !). Le livre est vivant et bien écrit (malgré l'abondance des notes de bas de page, ce n'est pas un livre réservé aux universitaires).
J'apprécie le côté synthétique (le livre fait 250 pages), qui n'empêche pourtant pas de traiter en détail des sujets pas forcément très présents quand on parle de ce sujet (comme le plan Marshall, un exemple de soft power). À propos de ce plan, on peut également noter que le livre s'inscrit dans le temps long et insiste sur des déterminants historiques, comme l'auteure le fait dans son analyse du Japon.
Le livre, je l'ai dit, est clair, mais cela ne l'empêche pas de parler de questions complexes et relativement peu connues (le slicing de la 5G, par exemple, qui a été très peu mentionné dans les débats sur la 5G).
J'ai aussi beaucoup aimé le concept de « passeur de technologie » qui permet bien de comprendre pourquoi, alors que les discours « au sommet » sont souverainistes, à la base, des milliers de passeurs au service des GAFA promeuvent (gratuitement !) les technologies étatsuniennes. Le rôle de tous ces commerciaux bénévoles est souvent sous-estimé.
Ce livre ne se limite pas à analyser l'importance des acteurs du numérique (qui ne sont pas du tout des purs intermédiaires techniques), notamment du Web, mais propose également des solutions, comme le recours aux logiciels libres mais aussi et surtout une indispensable éducation au numérique (éducation critique, pas uniquement apprendre à utiliser Word et TikTok !). L'utilisateurice ne doit pas être un simple « consommateur d'interfaces » mais doit être en mesure d'exercer ses droits de citoyen·ne, même quand cet exercice passe par des ordinateurs.
L'auteure ne manque pas de critiquer plusieurs solutions qui ont largement fait la preuve de leur inefficacité, comme les grands projets étatiques qui, sous prétexte de souveraineté, servent surtout à arroser les copains (par exemple Andromède).
Des reproches ? Il n'y a pas d'index, ce qui aurait été utile, et quelques erreurs factuelles sont restées (Apollo ne s'est posé sur la Lune qu'en 1969, l'ICANN n'a pas un rôle aussi important que ce qui est présenté). Je ne suis pas non plus toujours d'accord avec certaines présentations de l'histoire de l'Internet. Par exemple, le fait que le Web soit « ouvert » (spécifications librement disponibles et implémentables, code de référence publié) n'est pas du tout spécifique au Web et était la règle dans l'Internet de l'époque. Mais que ces critiques ne vous empêchent pas de lire le livre : sauf si vous êtes un·e expert·e de la géopolitique du numérique, vous apprendrez certainement beaucoup de choses.
À noter que le livre est accompagné d'un site Web,
http://www.geoponum.com/
Autres article parlant de ce livre :
L'article seul
Faut-il supprimer des centres de données ?
Première rédaction de cet article le 4 septembre 2023
Le premier septembre, le journal Libération a publié une tribune (non publique, donc je ne mets pas de lien) réclamant des mesures drastiques contre les centres de données, tribune notamment illustrée par le cas de Marseille. Faut-il donc de telles mesures ?
La tribune était signée de Sébastien Barles, adjoint au maire de Marseille, délégué à la transition écologique. Elle n'est accessible qu'aux abonnés mais Grégory Colpart en a fait une copie (et hébergée dans un centre de données marseillais). Donc, je me base sur cette copie.
Que demande la tribune ? Un moratoire sur la construction de centres de données, une taxe proportionnelle au volume de données stockées, et des obligations d'alimentation électrique en énergie renouvelable. Il y a des arguments écologiques (la consommation éléctrique de ces centres) et économiques (peu de créations d'emplois).
Le principal problème de cette tribune est qu'à la lire, on a l'impression que les centres de données ne servent à rien, qu'ils ne sont qu'une source de nuisances. Bien sûr, ils ont un impact écologique, électrique, urbanistique, etc, mais c'est le cas de toutes les activités humaines. Ne pointer que les aspects négatifs est facile mais esquive la question « est-ce que les avantages l'emportent sur les inconvénients ? » Il est amusant de voir la tribune réclamer plutôt de « l'industrie manufacturière », industrie qui n'est pas spécialement verte ni plus agréable pour les voisins. Cette industrie manufacturière, comme les centres de données, a un impact. Au passage, le serveur Web de Libération, choisi par l'auteur pour publier sa tribune, n'est pas hébergé dans un joli nuage tout propre, il est aussi dans un centre de données, ce qui illustre leur utilité.
On ne peut donc pas se contenter de dire qu'il faut moins de centres de données, il faut aussi préciser quels services seront abandonnés. Si les centres de données existent, c'est parce qu'ils hébergent des usages que certains jugent utiles. Si Sébastien Barles veut réduire leur nombre, il devrait lister les usages à supprimer ou limiter. Il y a plein de pistes à ce sujet (la publicité, le sport-spectacle…) mais l'auteur de la tribune n'en mentionne aucun. Prudence politicienne classique : dénoncer des consommations excessives sans dire lesquelles permet de ne se fâcher avec personne.
Ainsi, la tribune dit que « il est prévu qu'en 2030, les data centers consommeront 13 % de l'électricité mondiale » mais ce chiffre, pris isolément, n'a aucun intérêt. Évidemment que les centres de données informatiques consomment davantage d'électricité qu'en 1950 et évidemment aussi qu'ils consomment plus qu'en 2000 : les usages du numérique ont beaucoup augmenté, et ce n'est pas un problème. (Il y a aussi un biais de statistiques : lorsqu'une entreprise migre sa salle des machines interne vers un centre de données d'un fournisseur public comme OVH, la consommation électrique ne change pas, mais la tranche « centre de données » augmente.)
Donc, les centres de données sont utiles (mon article que vous lisez en ce moment est hébergé dans un tel centre, quoique loin de Marseille). Il existe bien des alternatives (par exemple un hébergement dans ses locaux) mais elles n'ont pas moins d'impact (un serveur chez soi consomme autant, voire plus, car il est moins optimisé et moins efficace, que les machines des centres de données). On peut et on doit diminuer l'empreinte environnementale de ces centres (ce que font déjà les hébergeurs, pas forcément par conscience écologique, mais pour réduire leur importante facture électrique) mais chercher à réduire leur nombre, comme le fait cette tribune, revient à diminuer l'utilisation du numérique. C'est un discours classique chez les politiciens conservateurs et les médias (« c'était mieux avant ») mais il n'en est pas moins agaçant. (Et il est surtout motivé par le regret que le numérique leur a retiré leur monopole de la parole publique.)
Concernant le projet de taxe proportionnelle à la quantité de données stockées, il faut noter qu'il repose sur une idée fausse, déjà démolie beaucoup de fois, comme quoi la consommation serait proportionnelle au nombre d'octets.
Ensuite, cette tribune pose un gros problème sur la forme. Son auteur abuse de trucs rhétoriques pour diaboliser les centres de données. Il parle d'industrie « prédatrice » (comme si les centres de données arrivaient la nuit et rasaient les terrains pour s'y installer sans autorisation), de chiffres qui « donnent le vertige » (« la consommation de 600 000 habitants » alors que les centres de données installés à Marseille servent bien plus que 600 000 personnes, vu l'importance de cette ville), et il se permet même de parler de « colonisation », une boursouflure rhétorique scandaleuse, quand on pense à ce qu'était vraiment la colonisation, avec son cortège de massacres.
En parlant de la forme de cette tribune, on peut aussi s'étonner du fait qu'elle ne soit pas publique. Logiquement, quand on expose ses idées politiques, on cherche à toucher le plus de monde possible. Ici, au contraire, l'auteur de la tribune se restreint. Pourquoi n'avoir pas mis cette tribune sur son blog ? Ou celui de son parti ? Ou sur une des millions de solutions d'hébergement (par exemple, mais ce n'est qu'un exemple, WriteFreely) ? Probablement parce que les politiciens traditionnels croient que la publication dans un média classique lui donne une légitimité plus forte (c'est faux : les tribunes ne sont pas écrites par les journalistes, ni vérifiées par la rédaction).
Revenons au fond de la tribune. Elle reproche aux centres de données de ne pas être créateurs d'emplois. Là, on rentre dans un sérieux problème politique : le but de l'activité économique n'est pas de créer des emplois, c'est de produire des biens et des services utiles. Si on voulait juste créer des emplois, on supprimerait les machines et on travaillerait à la main partout, ce qu'évidemment personne ne souhaite. Il faut agir pour la réduction du temps de travail, permise, entre autres, par le numérique, et pas pour donner davantage de travail aux gens.
Dernier point, la tribune parle de « nombreux privilèges » des centres de données mais n'en cite qu'un, « l'abattement sur le prix d'achat de l'électricité ». J'avoue ne pas être spécialiste des prix de l'électricité, mais, bien sûr, il n'y a aucune raison de faire des prix particuliers pour les centres de données, par rapport aux autres activités économiques. Simplement, je n'ai pas vérifié ce point (voyez les notes de Jérôme Nicolle). Quelqu'un a des informations fiables à ce sujet ? (Je lis l'article 266 quinquies C du code des douanes mais il semble abrogé.)
L'article seul
Deux exemples d'un problème DNS sur des domaines importants
Première rédaction de cet article le 5 août 2023
Vous le savez, l'Internet n'est pas un long fleuve tranquille. Il y a des pannes, des attaques, des erreurs… La vie des administrateurs système et réseau est donc rarement ennuyeuse. Ainsi, aujourd'hui, deux domaines importants ont eu des problèmes. Plongeons-nous un peu dans le DNS et ses particularités.
Premier domaine touché, gouv.nc, le domaine
du gouvernement néo-calédonien. Des
utilisateurs se plaignent qu'ils n'arrivent pas à accéder aux
services sous ce nom, ni à ceux sous des noms hébergés sur les mêmes
serveurs, comme prix.nc. Voyons (avec check-soa)
les serveurs faisant
autorité pour ce domaine :
% check-soa -i gouv.nc ns4.gouv.nc. 61.5.212.4: OK: 2020111850 (293 ms) ns5.gouv.nc. 61.5.212.5: OK: 2020111850 (293 ms)
Ici, tout marche. Mais ce n'est pas le cas tout le temps, on observe de nombreux timeouts :
% check-soa -i gouv.nc ns4.gouv.nc. 61.5.212.4: ERROR: read udp 192.168.2.4:33577->61.5.212.4:53: i/o timeout ns5.gouv.nc. 61.5.212.5: ERROR: read udp 192.168.2.4:41598->61.5.212.5:53: i/o timeout
On le voit aussi en utilisant les sondes RIPE Atlas (via le programme Blaeu) :
% blaeu-resolve --type A --requested 100 gouv.nc [ERROR: SERVFAIL] : 40 occurrences [61.5.212.17] : 22 occurrences Test #58257507 done at 2023-08-05T18:32:26Z
Pourquoi ce problème ? De l'extérieur, je ne peux évidemment pas
donner de réponse définitive mais j'observe déjà que ce domaine n'a
que deux serveurs de noms, ce qui est souvent insuffisant, et que la
proximité de leurs adresses
IP fait fortement soupçonner qu'ils sont dans la même
pièce, formant un SPOF. Y a-t-il eu une panne complète, par
exemple une coupure de courant dans cette pièce ? Comme on observe
que ces serveurs répondent parfois, on peut écarter cette hypothèse
et penser plutôt, soit à une dégradation importante du réseau
(réseau surchargé, ou bien physiquement abimé), soit à une
attaque par déni de service. Ces attaques,
sous leur forme la plus simple, volumétrique (l'attaquant envoie
simplement le plus possible de requêtes), saturent le réseau ou les
serveurs. Dans ce cas, les serveurs répondent encore parfois, mais
pas toujours. Comme le problème a été souvent observé ces derniers
mois, et que le domaine gouv.nc a les
mêmes caractéristiques (domaine d'un service public français, et
hébergement DNS très faible), il n'est pas impossible qu'il soit
victime de la même campagne d'attaques.
Et le deuxième domaine ? C'est
impots.gouv.fr, qui a lui aussi les mêmes
caractéristiques, quoique moins marquées, et qui faisait déjà partie
des victimes précédentes.
% check-soa impots.gouv.fr dns1.impots.gouv.fr. 145.242.11.22: ERROR: read udp 192.168.2.4:35263->145.242.11.22:53: i/o timeout dns2.impots.gouv.fr. 145.242.31.9: OK: 2023080400
Et, avec les sondes Atlas :
% blaeu-resolve --type A --requested 100 --country FR impots.gouv.fr [145.242.11.100] : 55 occurrences [ERROR: SERVFAIL] : 14 occurrences Test #58257393 done at 2023-08-05T18:25:42Z
On notera que gouv.nc a une autre
caractéristique, que n'a pas le domaine des impôts : les
TTL sont très bas. On le voit avec
dig :
% dig @61.5.212.4 gouv.nc A ;; communications error to 61.5.212.4#53: timed out ;; communications error to 61.5.212.4#53: timed out ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 2499 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 2, ADDITIONAL: 3 ... ;; ANSWER SECTION: gouv.nc. 30 IN A 61.5.212.17 ;; AUTHORITY SECTION: gouv.nc. 300 IN NS ns4.gouv.nc. gouv.nc. 300 IN NS ns5.gouv.nc. ... ;; Query time: 292 msec ;; SERVER: 61.5.212.4#53(61.5.212.4) (UDP)
Le TTL pour l'adresse IP associée à gouv.nc est
de seulement 30 secondes. Cela veut dire que, même si un client DNS,
comme un résolveur a de la chance et
réussit à obtenir une réponse d'un des serveurs faisant autorité,
elle ne lui servira que pendant trente secondes, suite auxquelles il
devra retenter sa chance, avec une forte probabilité que ça
rate. C'est en effet un des plus gros inconvénients des TTL
extrêmement bas, comme ceux-ci : ils aggravent considérablement les
effets des dénis de service. Les variations d'une mesure à l'autre
sont donc bien plus marquées pour gouv.nc que
pour impots.gouv.fr.
Le TTL des enregistrements NS (serveurs de noms) est plus long
(cinq minutes). Notez que celui affiché ci-dessus est le TTL indiqué
par les serveurs faisant autorité, celui de la zone
gouv.nc elle-même. Il y a un autre TTL (une
heure) dans la délégation depuis
.nc, dans la zone
parente :
% dig @ns1.nc gouv.nc A ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 30267 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 3 ... ;; AUTHORITY SECTION: gouv.nc. 3600 IN NS ns4.gouv.nc. gouv.nc. 3600 IN NS ns5.gouv.nc.
La plupart des résolveurs enregistreront le TTL de la zone (ici,
cinq minutes), qui, lui, fait autorité (regardez le flag
aa - Authoritative Answer -
dans la réponse).
Pour mieux évaluer l'état d'un serveur de noms (résolveur ou serveur faisant autorité) lors d'un problème comme une attaque par déni de service, j'ai fait un petit script en Python simple qui interroge le serveur plusieurs fois et affiche le taux de réussite :
% python assess-dos.py --server 145.242.31.9 impots.gouv.fr Expect an answer in more or less 300.0 seconds 2 requests among 10 (20.0 %) succeeded. Average time 0.010 s. Measurement done on 2023-08-05T18:46:30Z.
Le script dispose de plusieurs options utiles (pour l'instant, sa seule documentation est le code source) : le nombre de requêtes à faire, l'écart entre deux requêtes, la gigue à ajouter, le délai d'attente maximum, le serveur à utiliser (par défaut, c'est le résolveur habituel de votre machine), le type d'enregistrement DNS à demander, etc. Voici un exemple pendant le problème, utilisant de nombreuses options :
% python assess-dos.py --number 118 --delay 30.1 --server 145.242.31.9 --jitter 6 --type a impots.gouv.fr Expect an answer in more or less 3551.8 seconds 0 requests among 118 (0.0 %) succeeded. Average time N/A. Measurement done on 2023-08-05T18:00:16Z.
Ici, le serveur de impots.gouv.fr ne répondait
pas du tout pendant la mesure.
% python assess-dos.py --number 118 --delay 30.1 --server 61.5.212.4 --jitter 6 --type a gouv.nc Expect an answer in more or less 3551.8 seconds 19 requests among 118 (16.1 %) succeeded. Average time 0.3 s. Measurement done on 2023-08-05T17:56:51Z.
Ici, le serveur de gouv.nc répondait encore
dans 16 % des cas. C'est très insuffisant, la plupart des
résolveurs ne réessaient que trois, quatre ou cinq fois.
Dans le tout premier exemple, on n'avait pas indiqué de serveur, dans ce cas, c'est le résolveur par défaut qui est utilisé. Comme il mémorise les réponses, il vaut mieux indiquer un délai qui soit supérieur au TTL :
% python assess-dos.py --number 113 --delay 30.1 --type a gouv.nc Expect an answer in more or less 3401.3 seconds 62 requests among 113 (54.9 %) succeeded. Average time 0.350 s. Measurement done on 2023-08-05T18:57:25Z.
Traditionnellement, les résolveurs DNS ne renvoyaient guère d'information à leur client en cas d'échec, on était loin de la richesse des codes de retour HTTP. Mais cela a changé avec EDE, les Extended DNS Errors du RFC 8914. Demandons au résolveur de Google, on obtient bien le code EDE 22 et une explication :
% dig @8.8.8.8 gouv.nc A ...;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 26442 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ... ; EDE: 22 (No Reachable Authority): (At delegation gouv.nc for gouv.nc/a) ...
L'article seul
Fiche de lecture : Artificial intelligence and international conflict in cyberspace
Auteur(s) du livre : Fabio Cristano, Dennis Broeders, François Delerue, Frédérick Douzet, Aude Géry
Éditeur : Routledge
978-1-03-225579-8
Publié en 2023
Première rédaction de cet article le 1 août 2023
L'IA est partout (même si le terme est très contestable, et est utilisé à toutes les sauces sans définition rigoureuse) et il est donc logique de se demander quel sera son rôle dans les conflits (notamment les guerres). Cet ouvrage universitaire collectif rassemble divers points de vue sur la question, sous l'angle du droit, et de la géopolitique.
Bon, justement, c'est un ouvrage collectif (dont la coordination a été assurée en partie par des chercheuses de GEODE, dont je recommande le travail). Comme tous les ouvrages collectifs, les points de vue, le style, et les méthodes sont variées. Et puis, commençons par cela, le sujet est relativement nouveau, il a produit beaucoup de fantasmes et de délires mais encore peu de travaux sérieux donc ce livre est une exploration du champ, pas un ensemble de réponses définitives. Attention, il est plutôt destiné à des universitaires ou en tout cas à un public averti.
Tous les articles ne concernent d'aileurs pas directement le sujet promis par le titre. (L'article de Arun Mohan Sukumar, par exemple, article par ailleurs très intéressant, ne parle d'IA que dans son titre, et ne concerne pas vraiment les conflits internationaux.) C'est en partie dû au fait que le terme flou d'IA regroupe beaucoup de choses, pas clairement définies. On peut aussi noter que certains articles incluent de l'IA mais sont en fait plus généraux : l'article de Jack Kenny sur l'intervention de pays étrangers dans les processus électoraux en est un bon exemple (le fait que le pays qui intervient utilise ou pas l'IA ne me semble qu'un détail).
Pour les articles qui parlent d'IA, de nombreux sujets sont abordés : éthique de l'IA dans la guerre (mais je n'ai pas de réponse à la question « est-ce que les humains font mieux, sur le champ de bataille ? »), régulation (sujet difficile en droit international ; et puis il est bien plus difficile de contrôler les IA que des missiles, qui sont difficiles à dissimuler), souveraineté numérique, etc.
Bref, il me semble que la question est loin d'être épuisée. Non seulement on ne peut pas s'appuyer sur une définition claire de ce qui est inclus sous l'étiquette « IA » mais on n'a pas encore bien décrit en quoi l'IA changeait les choses et justifiait un traitement particulier. Lorsqu'un drone se dirige vers sa cible, en quoi le fait que son logiciel soit qualifié d'« IA » est-il pertinent, pour les questions d'éthique et de droit de la guerre ? Une réponse évidente est « lorsqu'il peut choisir sa cible, et pas seulement se diriger vers celle qu'on lui a affecté ». Mais cela restreindrait sérieusement le nombre de systèmes qu'on peut qualifier d'« IA ».
Le livre en version papier est plutôt cher (déclaration : j'ai eu un exemplaire gratuitement) mais on peut aussi le télécharger gratuitement. Chaque article a une longue bibliographie donc vous aurez beaucoup de lecture cet été.
L'article seul
Un peu de langage d'assemblage du RISC-V sur Linux
Première rédaction de cet article le 9 juillet 2023
Un peu de distraction sans objectif utilitaire à court terme : programmons en langage d'assemblage (ce qui est souvent appelé par abus de langage « assembleur ») sur un processeur RISC-V, dans un environnement Linux.
Cet article vise un public qui sait programmer mais sans avoir fait (ou très peu) de langage d'assemblage. Car oui, un problème terminologique fréquent est de parler d'« assembleur » alors que, en toute rigueur, ce terme désigne le programme qui, comme un compilateur, va traduire le langage d'assemblage en code machine. Ce langage d'assemblage est un langage de bas niveau, ce qui veut dire qu'il est proche de la machine. C'est d'ailleurs un de ses intérêts : regarder un peu comment ça fonctionne sous le capot. On lit parfois que ce langage est tellement proche de la machine qu'il y a une correspondance simple entre une instruction en langage d'assemblage et une instruction de la machine mais ce n'est plus vrai depuis longtemps. Comme un compilateur, l'assembleur ne va pas traduire mot à mot le programme. Il a, par exemple, des « pseudo-instructions » qui vont être assemblées en une ou plusieurs instructions. L'informatique, aujourd'hui, est formée de nombreuses couches d'abstraction empilées les unes sur les autres et on ne peut pas vraiment dire qu'en programmant en langage d'assemblage, on touche directement à la machine. (D'ailleurs, certains processeurs contiennent beaucoup de logiciel, le microcode.)
Pourquoi programmer en langage d'assemblage alors que c'est bien plus facile en, par exemple, C (ou Rust, ou Go, comme vous voulez) ? Cela peut être pour le plaisir d'apprendre quelque chose de nouveau et de très différent, ou cela peut être pour mieux comprendre l'informatique. Par contre, l'argument « parce que cela produit des programmes plus rapides » (ou, version 2023, parce que ça économise des ressources et que l'ADEME sera contente de cet effort pour économiser l'énergie), cet argument est contestable ; outre le risque plus élevé de bogues, le programme en langage d'assemblage ne sera pas automatiquement plus rapide, cela dépendra des compétences du programmeur ou de la programmeuse, et programmer dans ce langage est difficile. (Le même argument peut d'ailleurs s'appliquer si on propose de recoder un programme Python en C « pour qu'il soit plus rapide ».)
Chaque famille de processeurs (x86, ARM, etc) a son propre code machine (qu'on appelle l'ISA pour Instruction Set Architecture) et donc son propre langage d'assemblage (une des motivations de C était de fournir un langage d'assez bas niveau mais quand même portable entre processeurs). Je vais utiliser ici un processeur de la famille RISC-V.
Si on veut programmer avec le langage de cette famille, on peut
bien sûr utiliser un émulateur comme
QEMU, mais c'est plus réaliste avec un vrai
processeur RISC-V. Je vais utiliser celui de ma carte Star 64. Un
noyau
Linux tourne sur
celle-ci et on verra qu'on sous-traitera certaines tâches à
Linux. Commençons par un programme trivial, éditons
trivial.s :
addi x10, x0, 42
L'instruction addi (Add
Immediate car son dernier argument est un littéral,
immediate data) fait l'addition, la destination
est le registre x10. On
y met le résultat de l'addition du registre x0
(qui contient toujours zéro, un peu comme le pseudo-fichier
/dev/zero) et du nombre 42. La liste complète
des instructions que connait le processeur RISC-V figure dans le
The
RISC-V Instruction Set Manual mais ce texte est
difficile à lire, étant plutôt orienté vers les gens qui conçoivent
les processeurs ou qui programment les assembleurs. (Et il ne
contient pas les pseudo-instructions.) Je me sers plutôt de
documents de synthèse comme celui de metheis ou bien
la RISC-V
Instruction-Set Cheatsheet.
On va assembler notre petit programme, avec l'assembleur
as :
% as -o trivial.o trivial.s
Puis on fabrique un exécutable avec le relieur :
% ld -o trivial trivial.o ld: warning: cannot find entry symbol _start; defaulting to 00000000000100b0
Et l'avertissement ? Contrairement aux langages de plus haut niveau, qui s'occupent des détails comme de démarrer et d'arrêter le programme, le langage d'assemblage vous laisse maitre et, ici, je n'ai pas défini l'endroit où démarrer. Bon, ce n'est qu'un avertissement, exécutons le programme :
% ./trivial Illegal instruction (core dumped)
Ajoutons explicitement un point d'entrée pour traiter l'avertissement obtenu :
.global _start
_start:
addi x10, x0, 2
On n'a plus l'avertissement, mais le programme plante de la même
façon. C'est en fait à la fin du programme qu'il y a un problème :
le programme n'a pas d'instruction d'arrêt, l'assembleur n'en a pas
ajouté (contrairement à ce qu'aurait fait un compilateur C), et
l'« instruction » suivant addi est en effet
illégale (c'est la fin du code). On va donc ajouter du code pour
finir proprement, en utilisant un appel
système Linux :
_start:
addi x10, x0, 2
# Terminons proprement (ceci est un commentaire)
li x10, 0
li x17, 93 # 93 = exit
ecall
Cette fois, tout se passe bien, le programme s'exécute (il n'affiche rien mais c'est normal). Il faut maintenant expliquer ce qu'on a fait pour que ça marche.
On veut utiliser l'appel système exit. Sur
une machine Linux, man 2 exit vous donnera sa
documentation. Celle-ci nous dit qu'exit prend
un argument, le code de retour. D'autre part, les conventions de
passage d'arguments de RISC-V nous disent qu'on met l'argument dans
le registre x10, et, lorsqu'on fait un appel
système, le numéro de cet appel dans x17. Ici,
93 est exit (si vous voulez savoir où je l'ai
trouvé, grep _exit
/usr/include/asm-generic/unistd.h). li
(Load Immediate) va écrire 0 (le code de retour)
dans x10 puis 93 dans
x17. Enfin, ecall va
effectuer l'appel système demandé, et on sort proprement. (Vous
noterez que li x10, 0 est parfaitement
équivalent à addi x10, x0, 0, et l'assembleur
va produire exactement le même code dans les deux cas.) Pour
davantage de détails sur l'utilisation des appels système Linux,
voir Linux
System Calls for RISC-V with GNU GCC/Spike/pk.
Bon, ce programme n'était pas très passionnant, il additionne 0 +
2 et met le résultat dans un registre mais n'en fait rien
ensuite. On va donc passer à un programme plus démonstratif, un
Hello, world. Le
processeur n'a pas d'instructions pour les entrées-sorties, on va
sous-traiter le travail au système d'exploitation, via l'appel
système Linux write, qui a le numéro 64
(rappelez-vous, il faut regarder dans
/usr/include/asm-generic/unistd.h) :
.global _start
_start:
la x11, helloworld
# Print
addi x10, x0, 1 # 1 = standard output
addi x12, x0, 13 # 13 bytes
addi x17, x0, 64
ecall
# Exit
addi x10, x0, 0
addi x17, x0, 93
ecall
.data
helloworld: .ascii "Hello World!\n"
Qu'a-t-on fait ? On a réservé une chaine de caractères dans les
données, nommée helloworld. On charge son
adresse (car man 2 write
nous a dit que les arguments étaient le descripteur de fichier de la
sortie, mis dans x10, une adresse et la longueur de
la chaine) dans le registre
x11, la taille à écrire dans
x12 et on appelle write.
Pour compiler, on va arrêter de se servir de l'assembleur et du
relieur directement, on va
utiliser gcc qui les appelle comme il faut :
% gcc -nostdlib -static -o hello-world hello-world.s % ./hello-world Hello World!
C'est parfait, tout marche (normal, je ne l'ai pas écrit
moi-même). Le -nostdlib était pour
indiquer à gcc qu'on n'utiliserait pas la bibliothèque C
standard, on veut tout faire nous-même (ou presque,
puisqu'on utilise les appels système du noyau Linux ; si on écrivait
un noyau, sans pouvoir compter sur ces appels système, la tâche
serait bien plus difficile).
Si vous lisez du code en langage d'assemblage écrit par d'autres,
vous trouverez peut-être d'autres conventions d'écriture. Par exemple, le
registre x10 peut aussi s'écrire
a0, ce surnom rappelant son rôle pour passer
des arguments (alors que x préfixe les
registres indépendamment de leur fonction). De même, des mnémoniques
comme zero peuvent être utilisés, ce dernier
désignant x0 (registre qui, rappelons-le,
contient toujours zéro). La documentation de ces écritures possibles
est la « RISC-V
ABIs Specification ». On voit ces variantes dans l'écriture si
on demande au désassembleur de désassembler
le code trivial :
$ objdump -d trivial.o ... Disassembly of section .text: 0000000000000000 <_start>: 0: 00200513 li a0,2
Le addi x10, x0, 2 est rendu par l'équivalent
li a0, 2.
Faisons maintenant quelque chose d'un tout petit peu plus
utile. On va décrémenter un nombre jusqu'à atteindre une certaine
valeur. Mais attention : afficher un nombre (pour suivre les progrès
de la boucle) n'est pas
trivial. write ne sait pas faire, il sait juste
envoyer vers la sortie les octets. Ça marche bien avec des
caractères ASCII comme plus haut, mais pas avec des
entiers. On va donc tricher en utilisant des nombres qui
correspondent à des caractères ASCII imprimables. Voici le
programme :
.equ SYS_WRITE, 64
.equ SYS_EXIT, 94
.equ STDOUT, 1
.equ SUCCESS, 0
.global _start
_start:
# The decrement
li t2, 1
# The final value (A)
li t1, 65
# The first value (Z) then the current value
li t0, 90
loop:
# Store on the stack
sb t0, 0(sp)
# Print the current value (it is copied on the stack)
li a0, STDOUT
add a1, zero, sp
addi a2, x0, 1 # 1 byte (parameter count of write() )
addi a7, x0, SYS_WRITE
ecall
# Decrement
sub t0, t0, t2
# End of loop?
ble t1, t0, loop # BLE : Branch If Lower Or Equal
# Print the end-of-line
li a0, STDOUT
la a1, eol
addi a2, x0, 1
addi a7, x0, SYS_WRITE
ecall
# Exit
li a0, SUCCESS
addi a7, x0, SYS_EXIT
ecall
.data
eol: .ascii "\n"
C'était l'occasion de voir :
- Une nouvelle instruction, BLE (Branch if Lower or
Equal) qui teste ses arguments et saute à une étiquette
(ici,
loop) selon le résultat de la comparaison. Grâce à cette instruction, on peut écrire toutes les structures de contrôle (ici, une boucle). - Une autre instruction, SB (Store Byte) pour écrire dans la mémoire (et non plus dans un registre du processeur).
- Le pointeur de pile, SP
(Stack Pointer), alias du registre
x2. - Les directives à l'assembleur comme
.equ, qui affecte un nom plus lisible à une valeur. La liste de ces directives (on avait déjà vu.global) est disponible.
Nous avions besoin d'écrire en mémoire car
write prend comme deuxième argument une
adresse. Comme nous n'avons pas encore alloué
de mémoire, utiliser la pile est le plus
simple. (Sinon, il aurait fallu réserver de la mémoire dans le
programme, ou bien utiliser les appels système
brk ou mmap après son lancement.)
Si on veut formater un nombre pour l'imprimer, c'est plus
compliqué, donc je copie le code écrit par code4eva
sur StackOverflow.
Voyons cela avec une fonction qui trouve le plus grand de deux
nombres (mis respectivement dans les registres
a0 et a1, le résultat,
toujours en suivant les conventions d'appel, sera dans a0) :
_start:
# Les deux nombres à comparer
li a0, -1042
li a1, 666
call max
# On sauvegarde le résultat
add s0, zero, a0
...
max:
blt a0, a1, smallerfirst
ret
smallerfirst:
add a0, zero, a1
ret
L'instruction call appelle la fonction
max, qui prendra ses arguments dans
a0 et a1. La pseudo-instruction
ret (Return, équivalente à
jalr x0, x1, 0) fait revenir de
la fonction, à l'adresse sauvegardée par le
call. Notez que call est
en fait une pseudo-instruction (vous en avez la
liste), que l'assembleur traduira en plusieurs instructions
du processeur. C'est ce qui explique que vous ne trouverez pas
call dans la spécification du jeu
d'instructions RISC-V. Le programme entier, avec affichage du
résultat, est dans max.s
Souvent on n'écrit pas l'entièreté du programme en langage
d'assemblage, mais seulement les parties les plus critiques, du
point de vue des performances. La ou les fonctions écrites en
langage d'assemblage seront donc appelées par un programme en C ou
en Go. D'où l'importance de conventions partagées sur l'appel de
fonctions, l'ABI (Application Binary
Interface) qui permettront que les parties en C et celles
en langage d'assemblage ne se marcheront pas sur les pieds (par
exemple n'écriront pas dans des registres censés être stables), et
qui garantiront qu'on pourra lier des codes compilés avec des outils
différents. Voici un exemple où le programme principal, qui gère
l'analyse et l'affichage des nombres, est en C et le calcul en
langage d'assemblage. Il s'agit de la détermination du PGCD par l'algorithme d'Euclide, qui
est trivial à traduire en assembleur. Les sources sont
pgcd.scall-pgcd.c
% gcc -Wall -o pgcd call-pgcd.c pgcd.s %./pgcd 999 81 pgcd(999, 81) = 27
En regardant le source en langage d'assemblage, vous verrez que le
respect des conventions (les deux arguments dans
a0 et a1, le résultat
retourné dans a0) fait que, l'ABI étant
respectée, les deux parties, en C et en langage d'assemblage, n'ont
pas eu de mal à communiquer.
Autre exemple de programme, on compte cette fois de 100 à 1, en
appelant la fonction num_print pour afficher le
nombre. Attention à bien garder ses variables importantes dans des
registres sauvegardés (mnémonique commençant par s) sinon la
fonction num_print va les modifier. Le
programme est loop-print.s
Un dernier truc : le compilateur C peut aussi produire du code en langage d'assemblage, ce qui peut être utile pour apprendre. Ainsi, ce petit programme C :
void main() {
int x = 1;
x = x + 3;
}
Une fois compilé avec gcc -S minimum.c, il va
donner un fichier minimum.s avec, entre autres
instructions de gestion du démarrage et de l'arrêt du programme :
li a5,1 sw a5,-20(s0) lw a5,-20(s0) addiw a5,a5,3 sw a5,-20(s0)
On y reconnait l'initialisation de x à 1
(x est stocké dans le registre
a5 avec un li
- Load Immediate, charger un littéral, son
écriture en mémoire vingt octets sous s0
(le registre s0 a été
initialisé plus tôt, pointant vers une zone de la pile) avec
sw (Store Word), puis son
addition avec 3 par addiw (Add
Immediate Word) et son retour en mémoire avec un
sw. (L'instruction lw me
semble inutile puisque a5 contenait déjà la
valeur de x.)
Quelques documents et références pour finir :
- Une bonne introduction à la question et, du même auteur, des exemples.
- Très pédagogique, un site qui va vous faire mal aux yeux.
- Les spécifications officielles de RISC-V (pas forcément une lecture facile).
- Le programmeur utilisant un assembleur lira avec profit RISC-V Assembly Programmer's Manual.
- Les conventions d'appel (l'ABI, donc), sont dans RISC-V ABIs Specification.
- Pour la liste des directives à l'assembleur (comme
.global) et pour celle des pseudo-instructions, je recommande le RISC-V Assembly Programmer's Manual.
L'article seul
Le colloque « Penser et créer avec les IA génératives »
Première rédaction de cet article le 3 juillet 2023
Les 29 et 30 juin derniers, j'ai eu le plaisir de suivre le colloque « Penser et créer avec les IA génératives ». C'était très riche, donc je ne vais pas pouvoir vous raconter tout mais voici quelques informations quand même.
Un petit rappel sur ces « IA génératives ». Ce sont les systèmes logiciels qui permettent de générer textes, sons et images, de manière « intelligente » (le I de IA), ou en tout cas ressemblant beaucoup à ce que pourrait faire un être humain. Les plus connues sont dans doute ChatGPT pour le texte et Midjourney pour l'image. Le domaine est en pleine expansion depuis quelques années, avec le développement de plusieurs modèles de langages (LLM), et a connu une grand succès médiatique avec la sortie de ChatGPT fin 2022. (J'ai écrit un court article sur ChatGPT et un plus long sur son utilisation pour la programmation.) Depuis, on voit apparaitre de nombreux projets liés à ces IA génératives.
Rappelons aussi (ça va servir pour les discussions sur l'« ouverture » et la « régulation ») qu'un système d'IA générative repose sur plusieurs composants :
- Un corpus de textes (ou d'images) sur lequel le système s'entraine (comme Common Crawl). Le choix de ce corpus est crucial, et beaucoup de LLM ne sont pas très bavards sur la composition de leur corpus.
- Des détails pratiques sur l'utilisation du corpus, comment il est analysé et digéré. Cette condensation du corpus en un modèle est une opération lourde en ressources informatiques.
- À ce stade, on a le LLM (le grand modèle de langage). Celui de ChatGPT se nomme GPT mais il y en a beaucoup d'autres comme LLaMA ou Bloom. Il reste à le faire tourner pour générer des textes, en réponse à une requête (appelée prompt), ce qui nécessite un autre logiciel, le moteur, souvent moins consommateur de ressources mais qui tourne plus souvent.
Ce colloque était organisé par plusieurs organisations et groupes de recherche en sciences humaines, même si quelques exposés et discussions sont allés assez loin dans la technique. Beaucoup de débats étaient plutôt d'ordre philosophique comme « l'IA générative fait-elle preuve de créativité ? » (discussion d'autant plus difficile qu'on ne sait pas définir la créativité) ou bien « la compréhension dépend-elle d'un vécu ? Peut-on comprendre le concept de poids si on n'a jamais eu à soulever un objet lourd ? » Voyons quelques-uns de ces exposés et discussions.
Olivier Alexandre a présenté l'histoire d'OpenAI, l'entreprise derrière ChatGPT (et DALL-E). Une belle histoire, en effet, comme la Silicon Valley les aime, avec un début dans un restaurant très chic de la vallée, où chacun met quelques millions sur la table pour lancer le projet. Depuis, OpenAI n'a toujours rien gagné et a brûlé des milliards, mais les investisseurs continuent à lui faire confiance. « Du capitalisme d'accumulation… de dettes. » OpenAI, à ses débuts, se voulait missionnaire, produisant des IA « ouvertes » (d'où le nom), face au risque que des méchants ne cherchent à imposer une IA entièrement contrôlée par eux. Le moins qu'on puisse dire, c'est qu'OpenAI a sérieusement pivoté (comme on dit dans la Silicon Valley) depuis… « Passé de ouvert, gratuit et messianique, à fermé, payant et porté sur la panique morale ». On peut aussi noter qu'OpenAI aime bien se réclamer de la « diversité », tarte à la crème de la Silicon Valley. Or, si ses fondateurs et dirigeants ont effectivement des couleurs de peau et des lieux de naissance très variés, il n'y a qu'un seul sexe (je vous laisse deviner lequel), et surtout une seule idéologie, le capitalisme.
Ksenia Ermoshina, spécialiste de l'étude de la censure en ligne, a parlé de la censure des IA. On le sait, ChatGPT refuse de répondre à certaines questions, même lorsqu'il en aurait la capacité. Un mécanisme de censure est donc bâti dans ce système. L'oratrice note qu'il y a déjà eu des choix politiques lors de la construction du modèle. Une étude montre ainsi qu'un LLM entrainé avec les données de Baidu Baike considère que les concepts « démocratie » et « chaos » sont proches, alors que tout ce qui tourne autour de l'idée de surveillance est connoté positivement. Et, justement, il existe des LLM dans d'autres pays, comme le russe RuDall-E ou le chinois Ernie-ViLG. Sautons tout de suite à la conclusion : il y a autant de censure dans les projets « ouverts » et autant de censure en Occident.
RuDall-E, IA russe de génération d'images a quelques bavures
amusantes : si on lui demande un « soldat Z »,
elle dessinait un zombie… Mais, autrement, RuDall-E est bien
censuré. « Dessine le drapeau ukrainien » ne donnera pas le résultat
attendu par l'utilisatrice. Curiosité : au lieu d'un message clair
de refus, lorsque la demande est inacceptable, RuDall-E dessine des
fleurs… (Mais, dans le code source de la page, du JSON nous dit bien
censored: true.) Bizarrement, une requête en
anglais est moins censurée.
Une IA étatsunienne comme DALL-E censure tout autant. La nudité est interdite (malgré sa présence importante dans l'art depuis des millénaires), en application du puritanisme étatsunien, mais il y a aussi des censures plus surprenantes, par exemple la requête a monkey on a skateboard made of cheese est rejetée. Et, contrairement à son concurrent russe et à ses hypocrites fleurs, ce refus est accompagné d'un message menaçant, prétendant qu'on a violé les règles communautaristes et avertissant du risque d'être banni si on continue. Comme dans tous les cas de censure, les utilisateurices cherchent et trouvent des contournements. Si on veut dessiner un mort, on ne doit pas écrire le mot « mort », qui est tabou, il faut le décrire comme « allongé par terre sans mouvement ». Pour obtenir un cocktail Molotov, on va dire « burning bottle », etc. Ce genre de techniques est largement partagé sur les réseaux sociaux.
L'IA générative d'images en Chine, contrairement à la russe, n'a pas de politique publiée, mais censure quand même, bien sûr. Leur liste de mots-clés interdits est apparemment différente de celle de WeChat (qui a été très étudiée). Car c'est bien un système de censure par mots-clés. On parle d'« intelligence artificielle » mais les systèmes de censure restent très grossiers, ce qui facilite leur contournement. (Notez que son modèle est disponible sur Hugging Face.)
Bilel Benbouzid et Maxime Darin ont parlé justement d'Hugging Face qui se veut le « GitHub de l'IA ». Hugging Face est une plate-forme de distribution de modèles de langage, et d'outils permettant de les faire tourner. À l'origine du projet, c'était un simple chatbot conçu pour adolescents. Contrairement à OpenAI, qui est parti d'une plate-forme censée être « ouverte », pour devenir de plus en plus fermé, Hugging Face s'est ouvert. Le succès a été immense, tout le monde veut être présent/accessible sur Hugging Face. Cela lui vaut donc un statut de référence, dont les décisions vont donc influencer tout le paysage de l'IA (Benbouzid prétendait même que Hugging Face était le régulateur de l'IA). Ainsi, Hugging Face a une méthodologie d'évaluation des modèles, qui, en pratique, standardise l'évaluation.
En parlant d'Hugging Face, plusieurs discussions ont eu lieu pendant ces deux jours autour du terme d'« IA open source ». Comme le savent les lecteurices de ce blog, ce terme d'open source est, en pratique, utilisé n'importe comment pour dire n'importe quoi, et la situation est encore plus complexe avec les LLM. Si le moteur servant à exécuter le modèle est librement disponible, modifiable, redistribuable, est-ce que l'utilisateurice est libre, si le modèle, lui, reste un condensat opaque d'un corpus dont on ignore la composition et la façon dont il a été condensé ? (Pour aggraver la confusion, Darin avait défini l'open source comme la disponibilité du code source, ce qui est très loin de la définition canonique.) Le modèle LLaMa n'est pas très ouvert. En revanche, le modèle Falcon vient avec son corpus d'entrainement, deux téraoctets de données, ainsi que les poids attribués.
Le débat a ensuite porté sur la régulation et la gouvernance. Bilel Benbouzid voudrait qu'on régule l'IA open source vu son caractère crucial pour le futur ; « comme pour le climat, il faut une gouvernance ». Mais Maxime Darin faisait remarquer, prenant l'exemple de Linux, que l'absence de gouvernance formelle n'empêchait pas certains projets de très bien marcher.
Carla Marand a présenté le très intéressant projet CulturIA, sur la représentation de l'IA dans la culture. (Personnellement, j'ai beaucoup aimé le film « Her ».)
Alberto Naibo a expliqué l'utilisation de l'IA pour produire des preuves en mathématique. (On a bien dit produire des preuves, pas vérifier par un programme les preuves faites par un·e mathématicien·ne.) Bon, on est assez loin des IA génératives qui produisent des textes et des images mais pourquoi pas. Le problème est que pour l'instant, aucun LLM n'a encore produit une preuve non triviale. Les seules « IA » à l'avoir fait sont des IA d'une autre catégorie, orientée vers la manipulation de symboles.
ChatGPT lui-même peut faire des démonstrations mathématiques mais se trompe souvent voire comprend tout de travers. Il arrive ainsi à « prouver » que NOT(a OR b) implique NOT a… Dommage, car une IA de démonstration mathématique pourrait s'appuyer sur toutes les bibliothèques de théorèmes déjà formalisées pour des systèmes comme Coq.
J'ai appris à cette occasion l'existence de la
conjecture de Collatz, qui n'est toujours pas
démontrée. (Si vous avez le courage, lancez-vous, je me suis amusé,
pendant la pause, à programmer la fonction de Collatz en
Elixir, cf. collatz.exs
La question des IA génératives était étudiée sous de nombreux angles. Ainsi, Pierre-Yves Modicom a parlé de linguistique. Noam Chomsky et deux autres auteurs avaient publié une tribune dans le New York Times affirmant que ChatGPT n'avait pas de langage. Beaucoup de personnes avaient ricané devant cette tribune car elle donnait un exemple de phrase que ChatGPT ne saurait pas traiter, exemple qui n'avait même pas été testé par les auteurs (ChatGPT s'en était très bien sorti). Mais, derrière cette légèreté, il y avait un discussion de fond entre « chomskystes », plutôt « innéistes », partisans de l'idée que le langage résulte d'aptitudes innées (qui manquent à ChatGPT et l'empêchent donc de réellement discuter) et behaviouristes (ou skinneriens) qui estiment que le langage est simplement un ensemble de réactions apprises (je simplifie outrageusement, je sais, et en outre, l'orateur faisait remarquer qu'il existe plusiers variantes des théories basées sur les travaux de Chomsky, mais avec scissions et excommunications dans cette école). Les behaviouristes disent donc que le comportement de ChatGPT est une réaction aux entrées qu'il reçoit, qu'il n'a pas de théorie du langage, et n'en a pas besoin. Après, note l'orateur, savoir si ChatGPT a un langage ou pas, est peut-être un faux problème. Il est plus intéressant de l'étudier sans chercher à l'étiqueter.
Si la première journée du colloque se tenait à l'IHPST, la deuxième était à Sciences Po. Comme cette école avait été présentée dans les médias comme ayant « interdit ChatGPT », c'était l'occasion de parler de ChatGPT dans l'enseignement, avec Jean-Pierre Berthet et Audrey Lohard. Donc, Sciences Po n'interdit pas les IA par défaut. Mais il faut que l'enseignant ne l'ait pas interdit, et l'étudiant doit indiquer qu'il a utilisé une IA. Sciences Po forme d'ailleurs maintenant des enseignants à l'IA, et produit un guide pour elles et eux. (Je n'ai pas vu s'il était distribué publiquement. Lors de la discussion, des personnes ont regretté l'absence de mise en commun de telles ressources, dans l'enseignement supérieur.) La question de la recherche a aussi été discutée, avec par exemple le risque de déni de service contre le processus de relecture des articles sceintifiques, avec l'abondance d'articles écrits par l'IA. (Au passage, une grande partie des discussions dans ces deux journées semblait considérer que les articles sont entièrement écrits par un humain ou bien entièrement écrits par une IA autonome. La possibilité d'articles mixtes - un·e humain·e aidé·e par une IA - n'a guère été envisagée.) Pour la recherche, une des solutions envisagées était de rendre les soumissions d'articles publiques, pour mettre la honte aux mauvais auteurs paresseux. Mais la majorité du débat a porté sur le risque de tricherie aux examens, une obsession classique dans l'enseignement supérieur, comme si le diplôme était plus important que les connaissancs acquises.
Frédéric Kaplan a fait un intéressant exposé sur la notion de « capital linguistique » et le risque posé par la confiscation de ce capital par un petit nombre de gros acteurs. En récoltant d'énormes corpus, ces gros acteurs accumulent du capital linguistique, et peuvent même le vendre (vente de mots-clés par Google pour l'affichage des publicités). « L'économie de l'attention n'existe pas, c'est une économie de l'expression. » Une des conséquences de cette accumulation est qu'elle fait évoluer la langue. L'autocomplétion, qu'elle soit sous sa forme simple traditionnelle, ou sous sa forme sophistiquée des IA génératives va changer la langue en encourageant fortement telles ou telles formes. « Ce n'est pas par hasard que Google se nomme désormais Alphabet. » Cela n'a pas que des conséquences négatives, cela peut aussi être un facteur d'égalité ; si vous ne savez pas bien écrire, la prothèse (ChatGPT) peut le faire pour vous, vous permettant de réussir malgré Bourdieu. Mais il est quand même perturbant que, dans le futur, on ne saura peut-être plus écrire un texte tout seul. La langue ne nous appartient plus, elle est louée (un peu comme dans la nouvelle « Les haut-parleurs » de Damasio). Cela sera marqué par une rupture dans les textes, on aura des textes écrits avant 2015, avec peu ou pas d'intervention technique, et des textes produits via un outil comme ChatGPT. Bref, les futures évolutions de la langue ne se feront pas comme avant : elles seront en mode centralisé, alors que les évolutions de la langue étaient auparavant décentralisées. Est-ce que l'université va devenir l'endroit où on conserve de la ressource primaire (« bio ») ?
Tout·e utilisateurice de ChatGPT a pu observer que la rédaction de la question (le prompt) avait une grande importance pour la qualité de la réponse obtenue. Valentin Goujon a noté dans son exposé que « Pour avoir les bonnes réponses, il faut poser les bonnes questions » et que savoir écrire un prompt allait devenir une compétence utile (voire, a-t-il spéculé, un métier en soi, AI whisperer).
Il y a eu aussi des exposés plus austères (pour moi) comme celui de Célia Zolynski sur la régulation de l'IA. Le droit, ce n'est pas toujours passionnant mais, ici, c'était pertinent puisque, comme vous le savez, il y a un projet européen (qui est loin d'être abouti) d'une directive de régulation de l'IA. Cette directive, en développement depuis des années, ne prévoyait pas à l'origine le cas des IA génératives, mais ça a été ajouté par un amendement au Parlement européen, le 14 juin 2023. Mais elle a aussi parlé de questions liées au droit d'auteur. Si les philosophes discutent pour savoir si l'IA est vraiment créative, les juristes ont tranché : seul·e un·e humain·e peut bénéficier du droit d'auteur. Un texte écrit par ChatGPT n'a donc pas de protections particulières. (La question de savoir si l'auteur·e de la requête, qui a parfois dû fournir un réel travail, a des droits sur le texte produit reste ouverte.)
(Une copie de ce compte-rendu se trouve sur le site du projet CulturIA.)
L'article seul
Le problème DNSSEC venu du froid
Première rédaction de cet article le 20 juin 2023
Nous sommes en 2023, tous les logiciels libres DNS font correctement du DNSSEC depuis longtemps, les bavures des débuts semblent bien oubliées. Mais il y a des logiciels bizarres qui continuent à être utilisés, et qui ont des bogues subtiles, ce qui frappe en ce moment le TLD du Groenland.
Commençons par les observations :
.gl a un problème pour
ses sous-domaines comme com.gl (mais il y en a
d'autres). Ces sous-domaines sont délégués, mais au même jeu de
serveurs que le TLD (ce qui est une mauvaise pratique, voir à la
fin). On voit le problème sur DNSviz,
avec le message « NSEC3 proving non-existence of com.gl/DS:
No NSEC3 RR matches the SNAME (com.gl) ». On voit aussi
avec les sondes RIPE
Atlas qu'un certain nombre de résolveurs n'arrive pas à
résoudre les noms :
% blaeu-resolve --requested 100 --displayvalidation --type NS com.gl [d.nic.gl. ns1.anycastdns.cz. ns2.anycastdns.cz.] : 73 occurrences [ERROR: SERVFAIL] : 23 occurrences [ERROR: NXDOMAIN] : 2 occurrences [ (TRUNCATED - EDNS buffer size was 4096 ) d.nic.gl. ns1.anycastdns.cz. ns2.anycastdns.cz.] : 1 occurrences Test #55841896 done at 2023-06-20T09:20:58Z
Ça veut dire quoi ?
Déboguons avec dig. Le TLD a trois serveurs de noms,
testons avec d.nic.gl :
% dig @d.nic.gl NS com.gl ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 23986 ;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: com.gl. 86400 IN NS ns2.anycastdns.cz. com.gl. 86400 IN NS d.nic.gl. com.gl. 86400 IN NS ns1.anycastdns.cz.
OK, ça marche. Mais tout déconne quand un résolveur validant essaie d'accéder à ce nom, et demande un enregistrement de type DS (Delegation Signer) :
% dig @d.nic.gl DS com.gl ... ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 55694 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ... ;; AUTHORITY SECTION: gl. 900 IN SOA a.nuuk.nic.gl. gl-admin.tele.gl. 2022119306 900 1800 6048000 3600
Zut et zut, cette fois, cela ne marche pas, on a un NXDOMAIN (No Such Domain) alors que la requête précédente, pour le même nom, répondait positivement. Le serveur faisant autorité dit donc n'importe quoi.
Est-ce que cette réponse erronée est validable ? Oui ! Le serveur renvoie des enregistrements de type NSEC3 (RFC 5155) :
% dig +dnssec @d.nic.gl DS com.gl
;; Truncated, retrying in TCP mode.
...
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 43612
;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 8, ADDITIONAL: 1
...
;; AUTHORITY SECTION:
...
S2UOJG57GTBJ0M12ECAU9CSFD38EJNDN.gl. 3600 IN NSEC3 1 1 10 504D114B SAGKR73F41OMFFI8TDE1CGHOQM502SIH NS SOA RRSIG DNSKEY NSEC3PARAM
...
BBTTMJM743SRPQ6J4KQDIUC73E3C1HOA.gl. 3600 IN NSEC3 1 1 10 504D114B BSHTF866A32E02RJ617EUE8CCP45A6V4 NS DS RRSIG
...
Mais, comme le dit DNSviz plus haut, ce ne sont pas les bons. Comme,
avec NSEC3, la preuve de non-existence n'utilise pas les noms de
domaine mais un condensat de ces noms, il va
falloir faire quelques calculs. On va utiliser le programme
knsec3hash, distribué avec
Knot. D'abord, trouvons les paramètres de
condensation :
% dig NSEC3PARAM gl ...;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 30244 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 3, ADDITIONAL: 1 ... ;; ANSWER SECTION: gl. 0 IN NSEC3PARAM 1 0 10 504D114B
1 est l'algorithme
de condensation, ici SHA-1, 0 une
série d'options (inutilisée ici), 10 est le nombre de condensations
successives à effectuer, 504D114B est le
sel. Nous pouvons donc calculer le
condensat :
% knsec3hash 504D114B 1 10 gl s2uojg57gtbj0m12ecau9csfd38ejndn (salt=504D114B, hash=1, iterations=10)
C'est bien le nom
s2uojg57gtbj0m12ecau9csfd38ejndn vu plus
haut. (On savait de toute façon qu'il s'agissait de l'apex de la
zone, en raison des types SOA, DNSKEY, NSEC3PARAM, etc, qu'elle
contient.) Bon, et le com.gl :
% knsec3hash 504D114B 1 10 com.gl biavqpkequ599fc57pv9d4sfg1h0mtkj (salt=504D114B, hash=1, iterations=10)
Le second enregistrement NSEC3 nous dit qu'il n'y a rien entre
bbttmjm743srpq6j4kqdiuc73e3c1hoa et
bshtf866a32e02rj617eue8ccp45a6v4. Donc, pas de
biavqpkequ599fc57pv9d4sfg1h0mtkj, ce qui
implique que com.gl n'existe pas. Réponse
cohérente mais fausse (le domaine existe bien).
Notez que les deux autres serveurs faisant autorité pour
.gl donnent une autre réponse, toute aussi
fausse mais différente :
% dig +short NS gl ns2.anycastdns.cz. d.nic.gl. ns1.anycastdns.cz. % dig +dnssec @ns1.anycastdns.cz DS com.gl ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 36229 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1 ... ;; AUTHORITY SECTION: s2uojg57gtbj0m12ecau9csfd38ejndn.gl. 3600 IN NSEC3 1 1 10 504D114B SAGKR73F41OMFFI8TDE1CGHOQM502SIH NS SOA RRSIG DNSKEY NSEC3PARAM
Cette fois, on a un NOERROR, moins grave que le faux NXDOMAIN, mais
le NSEC3 est pour gl, pas pour le nom
demandé (d'où le message d'erreur de DNSviz).
Comment cela a pu se produire ? Je ne connais pas de logiciel
ayant ce comportement, mais je note que le domaine a pris un sérieux
risque : com.gl est délégué (il y a un ensemble
d'enregistrements NS) mais aux mêmes serveurs que
.gl. C'est une mauvaise pratique car elle rend
plus difficile le déboguage (les données de la zone fille peuvent
masquer celles de la zone parente). Ce n'est pas forcément la cause
primaire, mais elle n'aide pas à déblayer le problème.
(Merci à Viktor Dukhovni, inlassable détecteur et débogueur de
problèmes DNSSEC dans les TLD. Il vient d'ailleurs d'en trouver un
autre pour le
.scot.)
L'article seul
Censure DNS du domaine d'Uptobox par Orange
Première rédaction de cet article le 15 mai 2023
Depuis ce matin, Orange censure le service Uptobox via un résolveur DNS menteur. Avec quelques particularités techniques…
Voyons d'abord les faits. Depuis une machine connectée via
Orange, testons avec dig (et j'expliquerai plus
tard le rôle de l'option +nodnssec, sachez
seulement que le client DNS typique d'un résolveur envoie exactement
cette même requête) :
% dig +nodnssec A uptobox.com … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 38435 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: uptobox.com. 5 IN A 127.0.0.1 ;; Query time: 60 msec ;; SERVER: 192.168.1.1#53(192.168.1.1) (UDP) ;; WHEN: Mon May 15 16:52:31 CEST 2023 ;; MSG SIZE rcvd: 56
Bon, cas classique de censure par résolveur DNS menteur. Au lieu de
renvoyer la vraie adresse
IP, il renvoie ce 127.0.0.1 qui
indique la machine locale (rien ne fonctionnera, donc). Est-ce juste
chez moi ? Non. En testant avec les sondes RIPE Atlas, on voit
que cela affecte beaucoup d'utilisateurs d'Orange (AS 3215) :
% blaeu-resolve --requested 100 --as 3215 --type A Uptobox.com [104.22.30.128 104.22.31.128 172.67.29.218] : 17 occurrences [127.0.0.1] : 82 occurrences [] : 1 occurrences Test #53746153 done at 2023-05-15T11:02:58Z
Les sondes qui obtiennent les vraies adresses sont probablement celles situées sur un réseau qui utilise un autre résolveur, par exemple un résolveur local non-menteur.
Parfois, en cas de mensonge, des résolveurs envoient des détails,
par exemple sous forme d'un enregistrement SOA, dont les données
indiquent la source de la censure, mais rien de tel ici.
Ah, et, sinon, le blocage concerne également
uptostream.com,
uptobox.fr, uptostream.fr,
beta-uptobox.com et
uptostream.net mais je ne les ai pas testés.
Pourquoi ce blocage ? Aucun autre FAI en France ne semble le faire. Testons chez Free ou chez Bouygues :
% blaeu-resolve --requested 100 --as 12322 --type A Uptobox.com [104.22.30.128 104.22.31.128 172.67.29.218] : 99 occurrences Test #53746411 done at 2023-05-15T11:07:43Z % blaeu-resolve --requested 100 --as 5410 --type A Uptobox.com [104.22.30.128 104.22.31.128 172.67.29.218] : 33 occurrences Test #53746432 done at 2023-05-15T11:08:30Z
Bon, donc, pour l'instant, seul Orange bloque (même plusieurs heures après, la situation n'avait pas changé). On aurait pu penser qu'il ne s'agissait donc probablement pas de censure étatique (puisque celle-ci s'appliquerait aux autres gros FAI) mais en fait si, comme publié par la suite.
La censure est cohérente pour IPv6 :
% blaeu-resolve --requested 100 --as 3215 --type AAAA Uptobox.com [] : 19 occurrences [::1] : 76 occurrences [::] : 1 occurrences Test #53746202 done at 2023-05-15T11:04:00Z
On obtient le ::1, équivalent IPv6 du
127.0.0.1.
Mais revenons à ce +nodnssec que j'avais
promis d'expliquer. Eh bien, le comportement des résolveurs DNS
d'Orange va changer selon que son client envoie ou non le bit DO
(DNSSEC OK). Par défaut, dig ne l'envoie pas
(donc, en toute rigueur, l'option +nodnssec
n'était pas nécessaire) et le résolveur ment. Mais si on demande
DNSSEC, on a une réponse sincère :
% dig +dnssec A uptobox.com … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 50574 ;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: uptobox.com. 300 IN A 104.22.30.128 uptobox.com. 300 IN A 172.67.29.218 uptobox.com. 300 IN A 104.22.31.128 uptobox.com. 300 IN RRSIG A 13 2 300 ( 20230516155749 20230514135749 34505 uptobox.com. qMunXCqcFHp34LAnTgMcJkQaUvlMaZBLIneA5eqTHW+0 pjuD6vTVvn1xsnAAI59SOcQdgRIo5hlMLxKHZzg3Ew== ) ;; Query time: 36 msec ;; SERVER: 192.168.1.1#53(192.168.1.1) (UDP) ;; WHEN: Mon May 15 16:57:45 CEST 2023 ;; MSG SIZE rcvd: 195
Notez que le résolveur DNS par défaut de la connexion utilisée était un petit routeur 4G, qui relaie aux « vrais » résolveurs derrière. Si je parle directement à ceux-ci, j'observe le même phénomène :
~ % dig @81.253.149.5 +nodnssec A uptobox.com … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 24064 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: uptobox.com. 5 IN A 127.0.0.1 ;; Query time: 52 msec ;; SERVER: 81.253.149.5#53(81.253.149.5) (UDP) ;; WHEN: Mon May 15 16:59:14 CEST 2023 ;; MSG SIZE rcvd: 84 % dig @81.253.149.5 +dnssec A uptobox.com … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 15640 ;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: uptobox.com. 300 IN A 104.22.31.128 uptobox.com. 300 IN A 172.67.29.218 uptobox.com. 300 IN A 104.22.30.128 uptobox.com. 300 IN RRSIG A 13 2 300 ( 20230516155921 20230514135921 34505 uptobox.com. ebLAOe7dQSbyfE9Jvbq3+lvLvH5ZVB8esGxEW0mhuaR9 HLvMNfTwkYZBEy8HEJwbfmci0sVavIhQ6ZaPJbw6SA== ) ;; Query time: 64 msec ;; SERVER: 81.253.149.5#53(81.253.149.5) (UDP) ;; WHEN: Mon May 15 16:59:17 CEST 2023 ;; MSG SIZE rcvd: 223
Mais quel est le rôle de ce bit DO (DNSSEC OK)
et pourquoi cette différence de comportement, que je n'avais jamais
observée sur le terrain ? Ce bit, normalisé dans le RFC 3225, indique à un serveur DNS que son client comprend
DNSSEC, et qu'il veut obtenir les
informations DNSSEC, notamment les signatures. Outre le déboguage (dig avec
l'option +dnssec), il est utilisé lorsqu'un
résolveur validant parle à un serveur DNS, afin d'obtenir les
informations cryptographiques à valider. Le
« bête » client DNS, qui se trouve dans la machine de
M. Toutlemonde, ne valide pas et fait donc une confiance aveugle au
résolveur. Il n'envoie pas de bit DO (et c'est pour cela que la
majorité des utilisateurs voient le nom être censuré). Mais si vous
avez un résolveur qui valide, par exemple sur votre machine ou dans votre
réseau local, il va envoyer le bit DO. Pourquoi est-ce que
les résolveurs d'Orange se comportent différemment dans ces deux
cas ? Il y a une certaine logique technique : les résolveurs DNS
menteurs cassent DNSSEC (puisque DNSSEC a justement été conçu pour
détecter les modifications faites par un tiers), et il est donc
raisonnable, bien que ce soit la première fois que je vois cela, de
ne pas mentir si on a un client validant.
Petit détail technique au passage : le domaine
uptobox.com est signé mais il n'y a pas
d'enregistrement DS dans la zone parente
(.com) donc il n'aurait
pas été validé de toute façon.
Quelques références :
L'article seul
À propos du « blocage de Telegram en France »
Première rédaction de cet article le 13 mai 2023
Ce matin, bien des gens signalent un « blocage de Telegram en France ». Qu'en est-il ? Ce service de communication est-il vraiment censuré ?
En effet, la censure ne fait aucun doute. Si on teste avec les sondes RIPE Atlas, on voit
(t.me est le raccourcisseur
d'URL de Telegram) :
% blaeu-resolve --country FR --requested 200 --type A t.me [149.154.167.99] : 98 occurrences [77.159.252.152] : 100 occurrences [0.0.0.0] : 2 occurrences Test #53643562 done at 2023-05-13T08:42:36Z
Un coup de whois nous montre que la première
adresse IP,
149.154.167.99, est bien attribuée à Telegram
(« Nikolai Durov, P.O. Box 146, Road Town, Tortola, British Virgin
Islands ») mais que la seconde, 77.159.252.152,
est chez SFR. Non seulement Telegram n'a pas de
serveurs chez SFR, mais si on se connecte au site Web ayant cette
adresse, on voit : 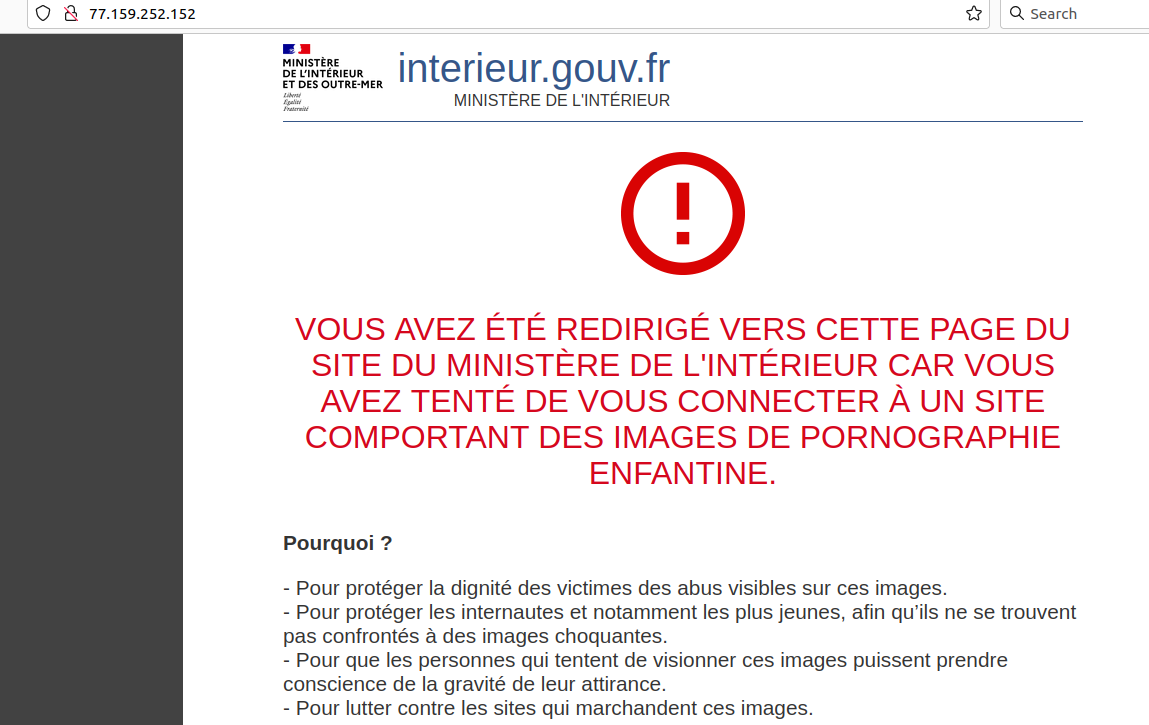
Cela ne marche pas en HTTPS (de toute façon, il y aurait eu un problème de certificat) car le serveur en question n'écoute apparemment qu'en HTTP classique.
Ce site Web est donc géré par le ministère de l'Intérieur, qui peut en effet enjoindre certains FAI de bloquer les sites pédopornographiques (depuis plusieurs années, rien de nouveau). Ici, il s'agit évidemment d'un mensonge grossier puisque Telegram n'est pas un site pédopornographique, mais un service de messagerie instantanée (qui, comme tout service de communication en ligne, peut parfois être utilisé pour des activités illégales).
La technique de censure est le résolveur DNS menteur : au lieu de relayer fidèlement les réponses des serveurs DNS faisant autorité, le résolveur ment et envoie l'adresse du serveur Web du ministère. Pourquoi est-ce que toutes les sondes RIPE Atlas ne voient pas le mensonge ? Parce que la liste des sites censurés est secrète, et que beaucoup de FAI, de réseaux locaux, de résolveurs DNS publics (comme celui de FDN mais attention, certains ont des défauts) ne reçoivent pas cette liste et ne censurent donc pas. Parmi ceux qui mettent en œuvre le blocage, il y a par exemple Orange (AS 3215) :
% blaeu-resolve --requested 200 --as 3215 --type A t.me [149.154.167.99] : 35 occurrences [77.159.252.152] : 151 occurrences Test #53644573 done at 2023-05-13T09:04:06Z
Même chez ce FAI, on notera que certaines sondes utilisent un résolveur non-menteur, par exemple un résolveur local. On trouve aussi le blocage chez des fournisseurs plus petits comme Adista :
% blaeu-resolve --requested 200 --as 16347 --type A t.me [149.154.167.99] : 3 occurrences [77.159.252.152] : 1 occurrences Test #53644745 done at 2023-05-13T09:08:42Z
Pourquoi ce blocage alors que, on l'a vu, Telegram n'est pas,
contrairement à l'accusation diffamatoire du ministère, un service
de distribution d'images pédopornographiques ? Notons d'abord que le
domaine principal, vers lequel redirige https://t.me/
% blaeu-resolve --country FR --requested 200 --type A telegram.org [149.154.167.99] : 197 occurrences [0.0.0.0] : 2 occurrences Test #53644470 done at 2023-05-13T09:02:00Z
Il s'agit d'une bavure, comme ça s'est déjà produit, et comme confirmé par « un porte-parole de la police nationale » cité par Le Monde. Gageons que le ministère ou les FAI ne communiqueront jamais et n'expliqueront rien.
Le service a été rétabli quelques heures après :
% blaeu-resolve --country FR --requested 200 --type A t.me [149.154.167.99] : 199 occurrences [ERROR: SERVFAIL] : 1 occurrences Test #53674858 done at 2023-05-13T20:18:14Z
Un point important est la gestion des données personnelles. Le code de la page du site Web du ministère contient :
<script type="text/javascript">
var tag = new ATInternet.Tracker.Tag();
tag.page.set({
name:'pedo-pornographie',
level2:'27'
});
tag.dispatch();
</script>
Ce petit programme en JavaScript enregistre donc les visites, auprès du service « ATInternet », en étiquetant tout visiteur, pourtant bien involontaire, comme pédo-pornographe. (Ceci, en plus de l'enregistrement habituel de l'adresse IP du visiteur dans le journal du serveur HTTP.)
Un petit point technique amusant pour finir : le serveur du ministère (celui hébergé chez SFR) n'a pas IPv6 (on est en 2023, pourtant) donc les résolveurs menteurs ne savent pas trop quoi renvoyer :
% blaeu-resolve --country FR --requested 200 --type AAAA t.me [2001:67c:4e8:f004::9] : 104 occurrences [::1] : 78 occurrences [] : 16 occurrences [::] : 1 occurrences [ERROR: SERVFAIL] : 1 occurrences Test #53646044 done at 2023-05-13T09:34:15Z
(2001:67c:4e8:f004::9 est la vraie adresse IP
de Telegram, ::1 est l'adresse de la machine
locale.)
Articles dans les médias :
- Article du Monde (derrière un cookie wall),
- Article de BFM TV,
- Article de NextInpact.
L'article seul
First boot with the Star64 board (RISC-V processor)
First publication of this article on 30 April 2023
Last update on of 3 May 2023
I now have a Star64 board, a board which uses a RISC-V processor, a processor whose instruction set is free (free as in free speech, not free as in free beer). Let's see the first boot. (Désolé pour mes lecteurices francophones mais il y a peu de retours d'expérience sur le Star64 publiés donc je pense qu'il vaut mieux commencer par l'anglais pour toucher davantage de monde.)
First, a bit of context about RISC-V since it was my main motivation to buy this board. A processor is first defined by its instruction set since it is what the software will have to know: a compiler, for instance, will generate machine code for a given instruction set. The two best known instruction sets today are the Intel one ("x86") and the ARM one. They are not free, in any sense of the word. Even if you have the knowledge and the money, you are not allowed to create a processor using this set (unless you enter in an agreement with Intel or ARM), and even if you can, you have no say about its future evolutions. This is a serious issue since, in our widely digitalized world, the company controlling the processors has a lot of power.
This is why the RISC-V was developed: its instruction set is free (as I said above, quoting Stallman, "free as in free speech, not free as in free beer") and anyone can create a processor implementing it. Of course, since there is a big difference between free hardware and free software, this will not be gratis. Unlike the software, the hardware has marginal costs which are not zero; each unit produced will cost money. So, it won't be like the free software world where a student in his home can produce brilliant programs that you just have to distribute over the Internet. Actual production of the physical devices will still depend on corporations. Also, not all the components of the board are free (and, for the processor, the fact that the instruction set is free does not mean the actual processor's schematics are). But it is still a big step towards freedom. (Today, RISC-V seems mostly used in the embedded world, not in general-purpose devices.)
So, I wanted to play a bit with a RISC-V processor. Not owning a
factory able to produce them from the schematics, I had to buy
the processor. And not just the processor, because I'm not a hardware guy, I'm
not going to connect all the necessary stuff to the
SoC. I went to Pine64, which is mostly known for its various
devices using an ARM processor, but which also produces a board with
a RISC-V processor, the Star64 (the
processor is a StarFive JH7110). I ordered one
(70 US dollars, for the 4 GB of memory model)
and it arrived:

(If you want to try RISC-V, there are also several other boards.)
If you want better pictures of this board, there is Linux Lounge's video.
Warning if you plan to do the same: the current status of the Star64, and of software which can run on it, is experimental. Do not expect a fully finished and smooth product. If you don't know about computers, then it is not for you.
You will probably also need some accessories (the board is sold alone, without even a power supply, accessories can be found on the Pine64 store or at your regular dealer, do not forget to check the technical specifications):
- Power supply,
- microSD card,
- Probably also an adapter from serial to USB, for the serial console of the board.
Here is a picture of such adapter (the DSD TECH SH-U099 USB-to-TTL model): 
Speaking of the console, the Star64 has a HDMI port
but it is not activated by the firmware, you
cannot use it as a console. Either you boot blindly, or you connect the serial ports, by
soldering or by using a pre-made cable like
the one above, for
instance converting to USB. As the documentation
says (see also the
schematics, section "40pin GPIO Bus"), transmission is on
pin 8 and reception on pin 10. You therefore connect the RXD on 8
and TXD on 8: 
I then used Minicom to connect from an Ubuntu machine, with this configuration file:
# Connection to the serial port, for managing the Star64 card pu port /dev/ttyUSB0 pu baudrate 115200 pu bits 8 pu parity N pu stopbits 1 pu minit pu mreset pu mhangup pu rtscts No
The way I booted my card was the following:
- Get an image for microSD card (I used the ones by Fishwaldo, where he uses his own tree of the kernel) and uncompress it (after decompression, they are in the - currently quite undocumented - WIC format),
- Copy it on a microSD card (I used dd
on an Ubuntu laptop,
dd if=star64-image-weston-star64.wic of=/dev/mmcblk0 bs=1M status=progress, you can ignore "GPT:Primary header thinks Alt. header is not at the end of the disk" / "GPT:Alternate GPT header not at the end of the disk", it will be fixed later), - Insert it in the slot under the Star64,
- Set the switches on the board to boot on the SD card. Warning, they are wrongly labeled; if the board tells you that they have to be Off-On to boot on SD, it is actually the opposite (this is documented on Pine64 Wiki),
- Power on and be patient, specifically
the first time if the operating system has to resize the
filesystem partitions. The operating system, made with Yocto using
.deb(the format of Debian packages), will request an IP address with DHCP, and you will connect either through your serial console, or with SSH (warning, one of the images does not have a SSH server). Login and password are documented with the images.
Speaking of the microSD slot, it is on the other side of the Star64:

At this stage, you are now connected to a Unix machine, and you can use regular Unix commands, and Debian package management commands:
% uname -a Linux grace 5.15.0 #1 SMP Thu Apr 13 06:38:09 UTC 2023 riscv64 riscv64 riscv64 GNU/Linux
You can now continue with a regular Unix.
Among the hardware of the board, SD card reader, Ethernet and USB work fine (I was able to mount a USB key). I did not yet test the rest. For instance, there is not yet a package to play sound files so I did not test the audio output.
Now, let's try to compile. I
installed the required packages with apt install automake libtool dpkg-dev
gcc binutils libgcc-s-dev. We can now write a
C program:
% cat plus.c
void main()
{
int a;
a = 3;
a++;
}
It compiles and runs. Great. Now, let's see some RISC-V assembly language:
% gcc -O0 -S -o plus.s plus.c % cat plus.s .file "plus.c" .option pic .text .align 1 .globl main .type main, @function main: addi sp,sp,-32 sd s0,24(sp) addi s0,sp,32 li a5,3 sw a5,-20(s0) lw a5,-20(s0) addiw a5,a5,1 sw a5,-20(s0) nop ld s0,24(sp) addi sp,sp,32 jr ra .size main, .-main .ident "GCC: (GNU) 11.3.0" .section .note.GNU-stack,"",@progbits
And you can now study RISC-V, from the code produced by the compiler.
A few more technical details, now. First, you can see the boot messages of the card, then the boot messages of the kernel. Then, the processor:
% cat /proc/cpuinfo processor : 0 hart : 1 isa : rv64imafdc mmu : sv39 isa-ext : uarch : sifive,u74-mc
(There are also three other cores.) The partition table of the SD card is:
% fdisk -l /dev/mmcblk1 Disk /dev/mmcblk1: 29.73 GiB, 31927042048 bytes, 62357504 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: gpt Disk identifier: B7092089-5983-4D4B-B075-78EABD7A7AFB Device Start End Sectors Size Type /dev/mmcblk1p1 4096 8191 4096 2M HiFive Unleashed BBL /dev/mmcblk1p2 8192 16383 8192 4M HiFive Unleashed FSBL /dev/mmcblk1p3 16384 793803 777420 379.6M Microsoft basic data /dev/mmcblk1p4 794624 62357470 61562847 29.4G Linux filesystem
As you can see, /dev/mmcblk1p4 is where the
root filesystem resides.
Among the things that I plan to try (one day!):
- Performance tests,
- Trying DNS software (my day job),
- Build my own image, at least the Unix partition on the SD
card (
/dev/mmcblk0p4). May be populate it with a "real" Debian? There is documentation but apparently outdated. There are also instructions for another RISC-V processor, which might be useful. There is no official port of Debian on RISC-V, and the Wiki seems quite abandoned but the work goes on. - Compile Go programs (I'm not sure there is yet a Go compiler for RISC-V),
- Compile Rust programs (same remark),
- Try LLVM (there is no ready-made package),
- Try to build and run a Gemini server,
- (Much more ambitious.) Try to compile Erlang/OTP.
- Enable the HDMI interface so I could try the large screen.
If you want more information, you can go to:
- About the hardware, on the official Wiki.
- About the boot process of the RISC-V processor of the Star64, all the gory details. For uboot, see this documentation.
- Another good account of running Linux on a Star64, with a lot of details, and the discussion on Ycombinator.
- Booting from the network (and not from the SD card as I did), a detailed documentation.
- Inspecting existing images.
- Starting Armbian, an experience.
- A comparison of the various SBC with RISC-V.
- If you like videos, here is a good introduction to RISC-V, technical, economical and political aspects.
To get help or simply to discuss with other fans, you can:
- Use Reddit, specially the RISC-V channel and the official Pine64 channel,
- Use Pine64 Web forum,
- Use Discord or Matrix, see Pine64 Wiki for details.
L'article seul
Le résolveur DNS sécurisé de FDN
Première rédaction de cet article le 25 avril 2023
Dernière mise à jour le 26 avril 2023
L'association FDN a récemment annoncé que son service de résolveur DNS public était désormais accessible avec les protocoles de sécurité DoT et DoH, ce qui améliore grandement ce service.
Un peu de contexte pour commencer. Le résolveur DNS est un composant tout à fait critique de nos activités sur l'Internet. L'essentiel de ce que l'on fait sur l'Internet impliquera une ou plusieurs requêtes DNS, et ces requêtes sont envoyées à notre résolveur. S'il est en panne, c'est à peu près l'équivalent de pas d'Internet du tout. S'il ment, s'il ne renvoie pas sincèrement ce que les serveurs faisant autorité lui ont dit, on peut être emmené n'importe où. Or, les résolveurs mentent souvent, par exemple à des fins de censure, motivée par la politique ou par les finances.
Pour contourner cette censure, il existe plusieurs méthodes, une des plus simples étant de changer de résolveur DNS. Beaucoup de gens utilisent donc des résolveurs DNS publics, c'est-à-dire accessibles par tous et toutes. Le plus connu est sans doute Google Public DNS. Pour tester, nous allons utiliser la commande dig, d'abord avec un résolveur de Free, qui ment :
% dig @212.27.40.240 sci-hub.se ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 1575 ;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: sci-hub.se. 3600 IN A 127.0.0.1 ;; Query time: 4 msec ;; SERVER: 212.27.40.240#53(212.27.40.240) (UDP) ;; WHEN: Tue Apr 25 18:43:07 CEST 2023 ;; MSG SIZE rcvd: 55
Il prétend que sci-hub.se a comme adresse IP
127.0.0.1, ce qui est faux (c'est l'adresse de
la machine locale). Vérifions en
demandant à Google :
% dig @8.8.8.8 sci-hub.se
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 63292
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
sci-hub.se. 60 IN A 186.2.163.219
;; Query time: 156 msec
;; SERVER: 8.8.8.8#53(8.8.8.8) (UDP)
;; WHEN: Tue Apr 25 18:44:39 CEST 2023
;; MSG SIZE rcvd: 55
Google dit la vérité, Sci-Hub est bien
accessible à l'adresse IP
186.2.163.219. On peut aussi vérifier avec les
sondes RIPE Atlas :
% blaeu-resolve --requested 100 --country FR --type A sci-hub.se [186.2.163.219] : 44 occurrences [127.0.0.1] : 40 occurrences [ERROR: NXDOMAIN] : 6 occurrences Test #52634681 done at 2023-04-25T16:33:30Z
On voit que la plupart des sondes en France voient la vraie adresse,
les autres étant derrière un résolveur menteur, qui donne la fausse
adresse 127.0.0.1, ou même prétendent que le
nom n'existe pas (NXDOMAIN).
Évidemment, si Google Public DNS ne ment pas, il pose d'autres problèmes, par exemple en matière de vie privée, mais aussi de souveraineté numérique. C'est pour cela qu'il est bon qu'il existe de nombreux autres résolveurs. Ainsi, l'association FDN fournit depuis longtemps un résolveur DNS public non menteur (et j'en profite pour passer à IPv6) :
% dig @2001:910:800::12 sci-hub.se ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 59004 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: sci-hub.se. 60 IN A 186.2.163.219 ;; Query time: 40 msec ;; SERVER: 2001:910:800::12#53(2001:910:800::12) (UDP) ;; WHEN: Tue Apr 25 18:47:09 CEST 2023 ;; MSG SIZE rcvd: 55
Jusqu'à présent, j'ai utilisé le transport par défaut du DNS, UDP (RFC 768). Ce transport a plusieurs défauts très sérieux, qui font qu'il ne devrait jamais être utilisé pour accéder à un résolveur DNS public :
- Aucune confidentialité, les requêtes circulent en clair (c'est bien sûr pareil quand vous parlez au résolveur de votre FAI ou de l'organisation où vous travaillez, mais la distance est plus courte alors que, en accédant à un résolveur public, vous passez par plusieurs AS dont chacun peut vous espionner).
- Aucune authentification, vous avez peut-être confiance dans Google ou dans FDN mais vous ne pouvez pas être sûr que c'est bien à eux que vous parlez, puisque UDP ne protège absolument pas contre l'usurpation d'adresse IP et que, de toute façon, quelqu'un a pu détourner le routage, comme cela s'est déjà fait.
- En outre, du fait de cette absence de protection contre l'usurpation d'adresse IP permet des attaques par réflexion utilisant le résolveur DNS public. Donc, un résolveur DNS public permettant UDP n'est pas seulement dangereux pour ses utilisateurs mais aussi pour tout l'Internet. (C'est entre autres pour cela que mon résolveur public n'offre pas d'UDP du tout.)
La première solution serait d'utiliser TCP qui lui, au moins, protège contre l'usurpation d'adresse IP. Mais il ne résout pas les questions d'authentification et de confidentialité. D'où l'existence de protocoles qui résolvent ces questions, en utilisant la cryptographie : DoT (DNS over TLS, RFC 7858) et DoH (DNS over HTTPS, RFC 8484). Les deux fournissent les mêmes services, la différence principale est que DoH est plus difficile à bloquer, car il utilise un port habituel, le 443 de HTTPS. Avec DoT (ou DoH), les trois problèmes mentionnés plus haut disparaissent. Voyons ce que cela donne pour les résolveurs de FDN, nous allons utiliser cette fois le client DNS kdig, qui fait partie de Knot :
% kdig +tls @2001:910:800::12 sci-hub.se ;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(ECDSA-SECP384R1-SHA384)-(CHACHA20-POLY1305) ;; ->>HEADER<<- opcode: QUERY; status: NOERROR; id: 30070 ;; Flags: qr rd ra; QUERY: 1; ANSWER: 1; AUTHORITY: 0; ADDITIONAL: 1 ;; EDNS PSEUDOSECTION: ;; Version: 0; flags: ; UDP size: 1232 B; ext-rcode: NOERROR ;; QUESTION SECTION: ;; sci-hub.se. IN A ;; ANSWER SECTION: sci-hub.se. 60 IN A 186.2.163.219 ;; Received 55 B ;; Time 2023-04-25 20:04:34 CEST ;; From 2001:910:800::12@853(TCP) in 84.4 ms
C'est parfait, tout marche. Comme vous le voyez au début, la session TLS a été authentifiée avec ECDSA et elle est chiffrée avec ChaCha20. Et avec DoH ?
% kdig +https=/dns-query @2001:910:800::12 sci-hub.se ;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(ECDSA-SECP384R1-SHA384)-(CHACHA20-POLY1305) ;; HTTP session (HTTP/2-POST)-([2001:910:800::12]/dns-query)-(status: 200) ;; ->>HEADER<<- opcode: QUERY; status: NOERROR; id: 0 ;; Flags: qr rd ra; QUERY: 1; ANSWER: 1; AUTHORITY: 0; ADDITIONAL: 1 ;; EDNS PSEUDOSECTION: ;; Version: 0; flags: ; UDP size: 1232 B; ext-rcode: NOERROR ;; QUESTION SECTION: ;; sci-hub.se. IN A ;; ANSWER SECTION: sci-hub.se. 60 IN A 186.2.163.219 ;; Received 55 B ;; Time 2023-04-25 20:07:21 CEST ;; From 2001:910:800::12@443(TCP) in 105.4 ms
On voit qu'une requête HTTPS a été faite à
https://[2001:910:800::12]/dns-query et qu'elle
a marché.
J'ai un peu triché, car, en fait, kdig n'avait pas authentifié. Puisque DoT et DoH reposent tous les deux sur TLS, utilisons un client TLS pour regarder le certificat, ici celui de GnuTLS :
% gnutls-cli -p 853 2001:910:800::12 ... Connecting to '2001:910:800::12:853'... - Certificate type: X.509 - Got a certificate list of 3 certificates. - Certificate[0] info: - subject `CN=resolver0.fdn.fr', issuer `CN=R3,O=Let's Encrypt,C=US', serial 0x049a52af0442ad4f67002cf0364cf0aa91b4, EC/ECDSA key 384 bits, signed using RSA-SHA256, activated `2023-04-18 01:00:20 UTC', expires `2023-07-17 01:00:19 UTC', pin-sha256="v8ossDNfX0Qzzo0LfmRdOotuOJJU7lfESpLIetzFseM=" ...
Le certificat a été émis par Let's Encrypt et
porte sur le serveur resolver0.fdn.fr (ainsi
que, plus loin, ns0.fdn.fr). Dans les deux
tests avec kdig, je n'indiquais pas le nom, juste l'adresse IP, et
l'authentification avec le certificat n'était
pas possible. Dans un cas plus réel, on doit aussi indiquer au
client DoT ou DoH le nom qu'on veut vérifier.
Notez également qu'il n'est pas du tout indispensable d'utiliser un résolveur public, vous pouvez avoir votre propre résolveur. Vous maximisez ainsi le contrôle sur la résolution de noms. Mais attention : si avoir votre propre résolveur résout le problème de la censure, il ne protège pas votre vie privée, les requêtes sortant en clair (tout au plus peut-on dire que, pour le FAI, regarder le trafic de son résolveur est plus facile que d'analyser le trafic réseau). Si on veut en plus protéger sa vie privée, une solution intéressante est de combiner les deux méthodes : avoir son propre résolveur et faire suivre (to forward) les requêtes à un résolveur extérieur, par exemple un résolveur public. (Et, au passage, n'oubliez pas de valider localement avec DNSSEC, ce qui vous protégera contre des mensonges si le résolveur à qui vous faites suivre n'est pas si digne de confiance que ça.) Avec Knot-resolver, cela se fait ainsi (notez qu'on indique le nom, pour l'authentification) :
policy.add(policy.all(policy.TLS_FORWARD({{'2001:910:800::12', hostname='ns0.fdn.fr'}})))
Et avec Unbound, c'est ainsi :
forward-zone:
name: "."
forward-addr: 2001:910:800::12@853
forward-tls-upstream: yes
Normalement, Unbound authentifie le serveur DoT distant si on ajoute
son nom (forward-addr:
2001:910:800::12@853#ns0.fdn.fr) mais je n'arrive pas à
le faire fonctionner (« error: ssl handshake failed crypto
error:0A000086:SSL routines::certificate verify failed »).
On peut aussi tester les résolveurs de FDN avec les sondes RIPE Atlas, puisqu'elle savent faire du DoT (mais pas du DoH) :
% blaeu-resolve --tls --nameserver=2001:910:800::40 --requested 100 --country FR --type A sci-hub.se Nameserver 2001:910:800::40 [186.2.163.219] : 92 occurrences Test #52639363 done at 2023-04-25T18:41:38Z
C'est parfait, tout a marché.
Outre la solution d'avoir un résolveur local qui fait suivre à un
résolveur public comme celui de FDN, vous pouvez aussi utiliser
directement celui de FDN sur les terminaux comme expliqué dans
la documentation d'ARN. Voici par exemple une copie d'écran
sur Android 11 : 
Une fois qu'il a été configuré ainsi, l'ordiphone contacte bien FDN, comme vu ici avec tcpdump :
20:15:28.914148 IP6 2a01:e34:dada:e1d0:7f67:9eba:979e:eb57.37376 > 2001:910:800::16.853: Flags [S], seq 2407640807, win 65535, options [mss 1220,sackOK,TS val 8904059 ecr 0,nop,wscale 9,tfo cookiereq,nop,nop], length 0 20:15:28.917330 IP6 2001:910:800::16.853 > 2a01:e34:dada:e1d0:7f67:9eba:979e:eb57.37376: Flags [S.], seq 3248346207, ack 2407640808, win 64260, options [mss 1420,sackOK,TS val 4084487123 ecr 8904059,nop,wscale 9], length 0 20:15:28.918686 IP6 2a01:e34:dada:e1d0:7f67:9eba:979e:eb57.37376 > 2001:910:800::16.853: Flags [.], ack 1, win 143, options [nop,nop,TS val 8904059 ecr 4084487123], length 0 20:15:28.919074 IP6 2a01:e34:dada:e1d0:7f67:9eba:979e:eb57.37376 > 2001:910:800::16.853: Flags [P.], seq 1:518, ack 1, win 143, options [nop,nop,TS val 8904059 ecr 4084487123], length 517 20:15:28.921301 IP6 2001:910:800::16.853 > 2a01:e34:dada:e1d0:7f67:9eba:979e:eb57.37376: Flags [.], ack 518, win 126, options [nop,nop,TS val 4084487127 ecr 8904059], length 0 20:15:28.921923 IP6 2001:910:800::16.853 > 2a01:e34:dada:e1d0:7f67:9eba:979e:eb57.37376: Flags [P.], seq 1:230, ack 518, win 126, options [nop,nop,TS val 4084487128 ecr 8904059], length 229 20:15:28.922704 IP6 2a01:e34:dada:e1d0:7f67:9eba:979e:eb57.37376 > 2001:910:800::16.853: Flags [.], ack 230, win 143, options [nop,nop,TS val 8904060 ecr 4084487128], length 0
tcpdump voit qu'il y a une connexion, pourrait découvrir que c'est du TLS, mais évidemment pas savoir quel(s) était(ent) le(s) nom(s) de domaine demandé(s).
L'article seul
Sur les pannes de service-public.fr et impots.gouv.fr (et caf.fr)
Première rédaction de cet article le 16 avril 2023
Dernière mise à jour le 5 mai 2023
Après la grande panne de
Météo-France le 12 avril, on a vu les sites Web
https://www.service-public.fr/https://www.impots.gouv.fr/http://caf.fr
Je divulgâche tout de suite, il n'y a pas d'informations fiables et précises. Tout au plus puis-je faire part de quelques observations, et ajouter quelques conseils.
Commençons par le 14 avril, la panne de l'excellent, très utile et très bien fait Service-public.fr. Je n'étais pas disponible au moment de la panne, mais j'ai pu effectuer un test avec les sondes RIPE Atlas peu après et il y avait bien un problème DNS :
% blaeu-resolve -r 100 --country FR --type A www.service-public.fr [ERROR: NXDOMAIN] : 18 occurrences [160.92.168.33] : 81 occurrences Test #52236542 done at 2023-04-14T10:55:55Z
Dix-huit des sondes ont reçu de leur résolveur DNS un NXDOMAIN (No
Such Domain ↦ ce nom n'existe pas). Vous pouvez voir les
résultats complets en ligne. Ceci n'est évidemment pas
normal : tout se passe comme si, pendant un moment, le domaine
service-public.fr avait été modifié pour ne
plus avoir ce sous-domaine www. Une erreur
humaine ? Peu après, le problème avait disparu :
% blaeu-resolve -r 100 --country FR --type A www.service-public.fr [160.92.168.33] : 100 occurrences Test #52237120 done at 2023-04-14T11:32:53Z
Il avait en fait été réparé avant mon premier test mais rappelez-vous que les résolveurs DNS ont une mémoire et certains se souvenaient donc de la non-existence. Bref, sans pouvoir être certain (Service-public.fr ne semble pas avoir communiqué à ce sujet, à part via des tweets stéréotypés ne donnant aucun détail), il semble bien qu'il y ait eu une erreur, vite corrigée.
Et le 15 avril, qu'est-il arrivé au site Web des impôts (c'était le lendemain de son ouverture pour les déclarations de revenus, moment qui se traduit en général par un trafic intense) ? Là encore, on voit un problème DNS, il ne s'agissait pas uniquement d'une surcharge du site Web :
% blaeu-resolve --type A -r 100 --country FR www.impots.gouv.fr [152.199.19.61] : 59 occurrences [ERROR: SERVFAIL] : 36 occurrences Test #52277291 done at 2023-04-15T07:20:04Z
Les sondes RIPE Atlas (résultats
complets en ligne) nous montrent cette fois qu'un certain
nombre de résolveurs DNS ont mémorisé un SERVFAIL(Server
Failure ↦ le résolveur n'a pas réussi à résoudre le
nom). Les codes d'erreur DNS sont peu nombreux, malheureusement (le
RFC 8914 propose une solution, mais encore peu
déployée) et SERVFAIL sert à beaucoup de choses. Le plus
vraisemblable est qu'il indiquait ici que le résolveur n'avait réussi
à joindre aucun des serveurs faisant
autorité. impots.gouv.fr n'a que deux serveurs
faisant autorité, tous les deux derrière l'AS 3215, ce qui rend ce
domaine vulnérable à des problèmes de routage
ou à des attaques par déni de service. Voici
les serveurs, testés par check-soa :
% check-soa impots.gouv.fr dns1.impots.gouv.fr. 145.242.11.22: OK: 2023041301 dns2.impots.gouv.fr. 145.242.31.9: OK: 2023041301
On notera aussi que, même si on pouvait résoudre le nom de domaine, le serveur HTTP avait des problèmes :
% curl -v www.impots.gouv.fr.
* Trying 152.199.19.61:80...
* Connected to www.impots.gouv.fr (152.199.19.61) port 80 (#0)
> GET / HTTP/1.1
> Host: www.impots.gouv.fr
> User-Agent: curl/7.81.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 504 Gateway Timeout
< Content-Type: text/html
< Date: Sat, 15 Apr 2023 07:18:41 GMT
< Server: ECAcc (paa/6F2E)
< X-EC-Proxy-Error: 14
< Content-Length: 357
<
<?xml version="1.0" encoding="iso-8859-1"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>504 - Gateway Timeout</title>
</head>
...
On peut bien parler au serveur frontal mais il n'arrive pas à joindre le « vrai » serveur derrière, d'où l'erreur 504.
Que s'est-il passé ? À ma connaissance, il n'y a pas eu de communication officielle des impôts à ce sujet mais des sources crédibles évoquent une attaque par déni de service, ce qui est en effet compatible avec ce qui a été observé.
Et les allocations familiales ? Le 16 avril, le domaine caf.fr est en panne :
% check-soa -i caf.fr ns.caf.fr. 91.231.174.240: ERROR: read udp 192.168.2.4:45069->91.231.174.240:53: i/o timeout ns1.caf.fr. 91.231.174.241: ERROR: read udp 192.168.2.4:48911->91.231.174.241:53: i/o timeout % date -u Sun 16 Apr 16:08:59 UTC 2023
Les deux serveurs répondent très épisodiquement (ce qu'on voit souvent lors des attaques par déni de service ; quelques requêtes passent). Un test sur les sondes RIPE Atlas montre que c'est de partout :
% blaeu-resolve -r 100 --country FR --type NS caf.fr [ERROR: SERVFAIL] : 68 occurrences [ns.caf.fr. ns1.caf.fr.] : 8 occurrences Test #52345500 done at 2023-04-16T15:39:40Z
Là encore, le domaine n'a que deux serveurs faisant autorité, tous les deux sous le même préfixe de longueur 24. C'est une configuration faible, qui rend le domaine vulnérable.
Enfin, le 16 avril, mais encore ensuite le 25 avril, puis le 4 mai, l'INSEE a eu un problème similaire, sur son domaine à seulement deux serveurs. Au début, un certain nombre de résolveurs avaient encore l'information en mémoire :
% blaeu-resolve --requested 100 --country FR --type NS insee.fr [ERROR: SERVFAIL] : 59 occurrences [ns1.insee.fr. ns2.insee.fr.] : 21 occurrences Test #52618361 done at 2023-04-25T09:55:20Z
Mais au plus fort de la crise :
% blaeu-resolve --requested 100 --country FR --type NS insee.fr [ERROR: SERVFAIL] : 73 occurrences [ns1.insee.fr. ns2.insee.fr.] : 2 occurrences Test #52622678 done at 2023-04-25T12:02:12Z
Le problème a été réglé vers 1400 UTC. Il avait en effet en cascade,
empêchant le fonctionnement des API de la base
SIRENE et tous les services publics qui en dépendent. (Un arrêté du 14 juin 2017 impose d'ailleurs un minimum de robustesse à un des services gérés par l'INSEE.)
Le fait que ns2 répondait
parfois semble indiquer une attaque plutôt qu'une panne, qui aurait
été totale. Un exemple d'un service planté par cascade (car il
dépendait de l'INSEE) : 
Conclusion ? On ne le rappelera jamais assez, le DNS est une infrastructure critique et qui doit être traitée comme telle. Puisque la très grande majorité des activités sur l'Internet dépend d'un DNS qui marche, un domaine important ne devrait pas se contenter de deux serveurs faisant autorité et connectés au même opérateur. Il est important d'avoir davantage de serveurs faisant autorité, et de les répartir dans plusieurs AS ; on ne met pas tous ses œufs dans le même panier.
Contrairement à ce qu'on lit souvent chez les lecteurs enthousiastes de la publicité des entreprises commerciales, cette robustesse ne nécessite pas forcément de faire appel à des prestataires chers, ni d'acheter des services qui ont peut-être leur utilité pour d'autres usages (comme HTTP) mais qui ne sont pas pertinents pour le DNS. De même qu'on peut faire un disque virtuel fiable à partir de plusieurs disques bon marché (le RAID), on peut faire un service DNS solide à partir de plusieurs hébergeurs même s'ils ne sont pas chers.
À cet égard, il est curieux que des services publics comme Météo-France, Service-public.fr et les impôts ne coopèrent pas davantage ; avoir des serveurs secondaires dans un autre établissement public devrait être la règle. (Je ne suis pas naïf et je me doute bien que la raison pour laquelle ça n'est pas fait n'a rien à voir avec la technique ou avec les opérations et tout à voir avec des problèmes bureaucratiques et des processus kafkaïens.)
Et puis, bien sûr, on souhaiterait voir davantage de communication de la part des organismes publics et donc des retex publics (une entreprise commerciale comme Cloudflare le fait souvent, mais les services publics français sont moins transparents ; Météo-France a communiqué mais avec quasiment aucun détail technique).
Un article du Parisien a été publié sur la panne des impôts.
L'article seul
Météo-France et les nuages sur le DNS
Première rédaction de cet article le 12 avril 2023
Dernière mise à jour le 17 avril 2023
Ce matin, le site Web de Météo-France est
en panne. Pourquoi ? Déjà, le nom de domaine
meteofrance.com ne
fonctionne pas. Il faut dire qu'il est mal configuré.
Voyons d'abord ce que voit l'utilisateurice moyen·ne :
Bref, ça ne marche pas. « Problème technique », comme annoncé
sur Twitter : 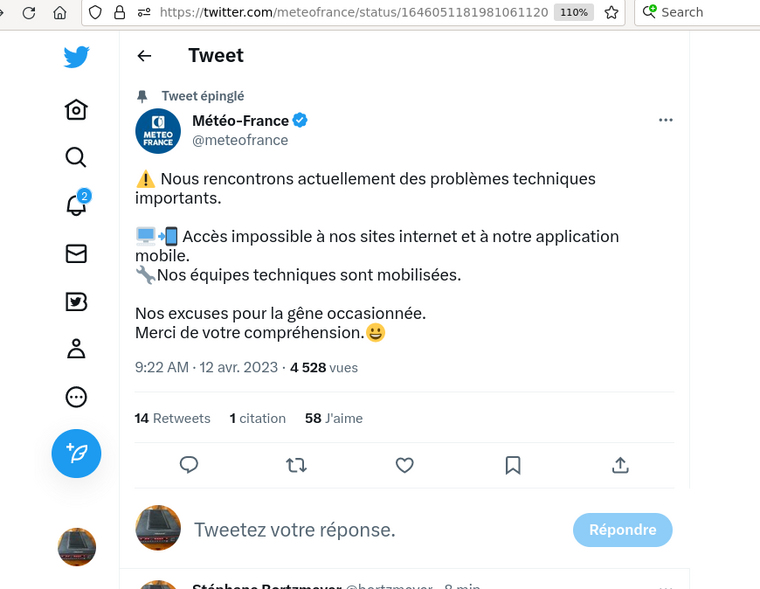
Creusons maintenant. Presque toutes les transactions sur
l'Internet commencent par une requête
DNS. Sans le DNS, c'est un peu comme de ne
pas avoir d'Internet du tout. Testons le domaine meteofrance.com avec
dig :
% dig A meteofrance.com
; <<>> DiG 9.16.37-Debian <<>> A meteofrance.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 19940
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;meteofrance.com. IN A
;; Query time: 5008 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Wed Apr 12 10:18:13 CEST 2023
;; MSG SIZE rcvd: 33
Bon, c'est cassé (SERVFAIL = Server Failure). Que
se passe-t-il ? En demandant aux serveurs de
.com, on voit que le
domaine a deux serveurs de noms (ce qui est insuffisant : la
robustesse exige davantage, pour faire face aux pannes) :
% dig @f.gtld-servers.net. NS meteofrance.com ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 41215 ... ;; AUTHORITY SECTION: meteofrance.com. 172800 IN NS cadillac.meteo.fr. meteofrance.com. 172800 IN NS vivaldi.meteo.fr.
Interrogeons-les directement :
% dig @vivaldi.meteo.fr. NS meteofrance.com dig: couldn't get address for 'vivaldi.meteo.fr.': failure
Ah oui, c'est amusant. meteo.fr est également en panne. Pour
avoir les adresses IP des
serveurs de noms, on ne peut plus compter sur le DNS ? Si, il y a la
colle, envoyée par les serveurs de
.fr :
% dig @d.nic.fr NS meteo.fr
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 40768
...
;; AUTHORITY SECTION:
meteo.fr. 3600 IN NS cadillac.meteo.fr.
meteo.fr. 3600 IN NS vivaldi.meteo.fr.
...
;; ADDITIONAL SECTION:
cadillac.meteo.fr. 3600 IN A 137.129.1.4
vivaldi.meteo.fr. 3600 IN A 137.129.1.2
Seulement deux serveurs, on l'a dit, aucune adresse
IPv6 (en 2023 !) et, surtout, on voit de la
proximité des deux adresses IP que les deux machines sont au même
endroit, et donc forment un SPOF. C'est la
plus grave erreur dans la configuration de
meteofrance.com et
meteo.fr.
Bon, interrogeons ces adresses IP :
% dig @137.129.1.4 NS meteofrance.com ; <<>> DiG 9.16.37-Debian <<>> @137.129.1.4 NS meteofrance.com ; (1 server found) ;; global options: +cmd ;; connection timed out; no servers could be reached
Idem pour l'autre (logique, puisqu'ils sont au même endroit). Les deux serveurs ne répondent pas. Un traceroute montre qu'on n'arrive nulle part :
% sudo tcptraceroute 137.129.1.4 53 Running: traceroute -T -O info -p 53 137.129.1.4 traceroute to 137.129.1.4 (137.129.1.4), 30 hops max, 60 byte packets ... 3 vl387-te2-6-paris1-rtr-021.noc.renater.fr (193.51.184.214) 2.581 ms 2.571 ms 2.561 ms 4 et-2-0-0-ren-nr-paris1-rtr-131.noc.renater.fr (193.51.180.134) 4.719 ms 4.703 ms 4.692 ms 5 et-2-0-0-ren-nr-paris2-rtr-131.noc.renater.fr (193.55.204.193) 3.112 ms 3.102 ms 3.088 ms 6 * * * 7 83.142.144.35 (83.142.144.35) 2.258 ms 2.482 ms 2.425 ms 8 83.142.144.34 (83.142.144.34) 2.970 ms 2.951 ms 2.992 ms 9 206.96.106.212.in-addr.arpa.celeste.fr (212.106.96.206) 14.541 ms 13.816 ms 13.855 ms 10 95.96.106.212.in-addr.arpa.celeste.fr (212.106.96.95) 13.102 ms 7.96.106.212.in-addr.arpa.celeste.fr (212.106.96.7) 14.697 ms 95.96.106.212.in-addr.arpa.celeste.fr (212.106.96.95) 13.068 ms 11 149.96.106.212.in-addr.arpa.celeste.fr (212.106.96.149) 15.013 ms 14.821 ms * 12 137.129.20.1 (137.129.20.1) 14.069 ms 35.229.180.159.in-addr.arpa.celeste.fr (159.180.229.35) 15.118 ms 137.129.20.1 (137.129.20.1) 13.726 ms 13 * * * 14 * * * 15 * * * 16 * * * ...
Le réseau qui mène aux serveurs DNS faisant autorité semble en panne.
Le problème n'est pas spécifique à mon réseau de départ. Les sondes RIPE Atlas le voient partout :
% blaeu-resolve --requested 100 --type A meteofrance.com [ERROR: SERVFAIL] : 56 occurrences [185.86.168.137 185.86.168.138 185.86.168.139 185.86.168.140] : 10 occurrences Test #52152926 done at 2023-04-12T08:01:45Z
Le fait que dix des sondes puissent résoudre le nom en adresse IP
est probablement dû à la mémorisation par les résolveurs, meteofrance.com
étant un nom souvent sollicité.
On peut aussi tester avec l'excellent DNSviz (archivage
du test) :
Notez que le site Web https://meteofrance.com/185.86.168.137 en dur dans sa configuration
locale, par exemple le /etc/hosts) pendant ce
temps… Ça permet de voir le communiqué officiel envoyé pendant le problème : 
Vers 14 h UTC, après d'autres changements bizarres (ajouter un troisième serveur de noms qui ne marchait pas davantage), Météo-France est passé chez Cloudflare, et tant pis pour la souveraineté numérique :
% check-soa meteofrance.com cadillac.segui.eu. 2400:cb00:2049:1::a29f:1a33: OK: 2023041200 162.159.26.51: OK: 2023041200 vivaldi.segui.eu. 2400:cb00:2049:1::a29f:1b6c: OK: 2023041200 162.159.27.108: OK: 2023041200
(Ne vous fiez pas aux noms, dans le domaine « familial »
segui.eu, les adresses IP sont bien celles des
serveurs de Cloudflare.) Le problème disparait donc petit à petit au
fur et à mesure de la réjuvénation :
% blaeu-resolve -r 100 - -type NS meteofrance.com [cadillac.meteo.fr. vivaldi.meteo.fr.] : 19 occurrences [cadillac.segui.eu. vivaldi.segui.eu.] : 37 occurrences [ERROR: SERVFAIL] : 24 occurrences Test #52160057 done at 2023-04-12T14:23:11Z
Depuis la première parution de cet article, plusieurs choses sont à noter :
- Météo-France a mis à jour sa communication pour expliqur que la cause du problème est une attaque par déni de service (ce qui est possible, vu ce qui a été observé).
- D'autres problèmes dont certains ressemblent beaucoup à celui de Météo-France ont frapé les domains d'autres services publics.
- Le nom des serveurs
de noms a encore changé (mais ce sont toujours des machines
de Cloudflare), repassant du domaine personnel
segui.euàmeteo.fr.
L'article seul
IETF 116 hackathon: unilateral probing of TLS on DNS servers
First publication of this article on 27 March 2023
On 25 and 26 March, it was the IETF 116 hackathon in Yokohama. I worked on TLS probing of authoritative DNS servers.
The goal of the IETF hackathons is to test ideas that may become RFC later. "Running code" is an important part of IETF principles. It is both useful and pleasing to sit down together at big tables and to hack all weekend, testing many ideas and seeing what works and what does not.
A bit of context on this "TLS probing". The DNS is a critical
infrastructure of the Internet. It is used
for most activities on the Internet. Requests and responses were
traditionally sent in the clear, and this is
bad for privacy since they can be quite
revealing ("this user queried www.aa.org", see
RFC 7626). To improve DNS privacy, the IETF developed two
sets of solutions: minimizing data (RFC 9156), to protect against the server you query, and
encrypting data, to protect against third parties
sniffing on the cable. For the second set, encryption, several
techniques have been developed, I will focus here on DoT (DNS over
TLS, RFC 7858) and DoQ (DNS over QUIC, RFC 9250) but mostly on DoT. These various techniques are
standardized for the client-to-resolver link, the most critical for
the privacy (see RFC 7626 for details). They are now
deployed, although not universally. But this leaves the
resolver-to-authoritative link in the clear. The current idea is
therefore to use encryption for this link, what we call ADoT
(authoritative DNS over TLS). Technically, it is the same DNS over
TLS than for the client-to-resolver link. But in practice, there are
some issues. A client talks to only one (or may be two) resolvers,
which he or she knows. But a resolver talks to thousands of
authoritative name servers. Some will have enabled ADoT, some
not. How to know?
There were some attempts in the DPRIVE working
group to define a signaling mechanism,
through which the operators of authoritative name servers could say
they support ADoT. But these efforts all fail. A general problem of
signalisation of services on the Internet is that the signal can be
wrong, and often is (advertising a service which actually des not
work). So, the approach on the draft we
worked on, draft-ietf-dprive-unilateral-probing
(later published as RFC 9539),
was different: probing the authoritative name server to see if it
really does ADoT.
The work was done by Yorgos Thessalonikefs (from NLnet Labs) and myself. Yorgos worked on adding probing support to Unbound and I tested existing ADoT deployment, as well as adding DoT support to the Drink authoritative name server.
First, let's see DoT in action, here with a local installation of Drink and the kdig client (part of Knot):
% kdig +tls @localhost -p 8353 foobar.test
;; TLS session (TLS1.3)-(ECDHE-X25519)-(ECDSA-SECP256R1-SHA256)-(AES-256-GCM)
;; ->>HEADER<<- opcode: QUERY; status: NOERROR; id: 16994
;; Flags: qr aa rd; QUERY: 1; ANSWER: 0; AUTHORITY: 1; ADDITIONAL: 1
;; EDNS PSEUDOSECTION:
;; Version: 0; flags: ; UDP size: 1440 B; ext-rcode: NOERROR
;; Option (65023): 067265706F7274076578616D706C6503636F6D00
;; PADDING: 348 B
;; QUESTION SECTION:
;; foobar.test. IN A
;; AUTHORITY SECTION:
foobar.test. 10 IN SOA ns1.test. root.invalid. 2023032512 1800 300 604800 86400
;; Received 468 B
;; Time 2023-03-25 21:43:26 JST
;; From 127.0.0.1@8353(TCP) in 44.7 ms
OK, it worked, a TLS connection was established (the TLS cryptographic algorithms used are displayed at the beginning of the response), and we got a DNS reply. Also, the answer was padded (RFC 7830) to 468 bytes (RFC 8467) in order to avoid traffic analysis.
ADoT can also be tested with the check-soa tool. Here, all the authoritative name servers of the domain have ADoT:
% check-soa -dot aaa-cool.fr ns01.one.com. 195.206.121.10: OK: 2023032101 2001:67c:28cc::10: OK: 2023032101 ns02.one.com. 185.10.11.10: OK: 2023032101 2001:67c:28cc:1::10: OK: 2023032101
And here only one has:
% check-soa -dot bortzmeyer.fr ns2.bortzmeyer.org. 2400:8902::f03c:91ff:fe69:60d3: ERROR: dial tcp [2400:8902::f03c:91ff:fe69:60d3]:853: connect: connection refused 172.104.125.43: ERROR: dial tcp 172.104.125.43:853: connect: connection refused ns4.bortzmeyer.org. 2001:4b98:dc0:41:216:3eff:fe27:3d3f: ERROR: dial tcp [2001:4b98:dc0:41:216:3eff:fe27:3d3f]:853: i/o timeout 92.243.4.211: ERROR: dial tcp 92.243.4.211:853: i/o timeout puck.nether.net. 2001:418:3f4::5: OK: 2023032600 204.42.254.5: OK: 2023032600
ADoT can also be tested with the RIPE Atlas probes, here with
the Blaeu
tool against a root name server,
B.root-servers.net:
% blaeu-resolve --requested 100 --nameserver 199.9.14.201 --type SOA --tls --nsid . Nameserver 199.9.14.201 [TIMEOUT] : 2 occurrences [NSID: b4-ams; a.root-servers.net. nstld.verisign-grs.com. 2023032501 1800 900 604800 86400] : 54 occurrences [NSID: b4-lax; a.root-servers.net. nstld.verisign-grs.com. 2023032501 1800 900 604800 86400] : 12 occurrences [NSID: b4-iad; a.root-servers.net. nstld.verisign-grs.com. 2023032501 1800 900 604800 86400] : 15 occurrences [NSID: b4-mia; a.root-servers.net. nstld.verisign-grs.com. 2023032501 1800 900 604800 86400] : 3 occurrences [a.root-servers.net. nstld.verisign-grs.com. 2023032501 1800 900 604800 86400] : 1 occurrences [NSID: b4-sin; a.root-servers.net. nstld.verisign-grs.com. 2023032501 1800 900 604800 86400] : 1 occurrences Test #51316045 done at 2023-03-26T02:05:11Z
This is quite good, only two probes fail to connect over DoT, may be because they were on a network which blocks port 853 outgoing.
OK, so, some authoritative name servers have ADoT and some have
not. Now, what should the resolver do? Since there is no signaling,
should it try port 853? How to do it without waiting forever if the
server does not reply at all? The idea behind the
draft draft-ietf-dprive-unilateral-probing
is indeed to always try ADoT and use it if it works
but in an "intelligent" way. Instead of waiting
for ADoT to succeed or fail, the resolver should do it on the "happy
eyeballs" way (RFC 8305), trying both DoT and traditional
DNS a the same time. Note that it is an unilateral choice: the
resolver does all of the work and requires nothing from the
authoritative server.
One resolver today does probing, although not in the way of the
draft: PowerDNS
Recursor. Let's try it (their DoT support is dscribed
online). We get the
git, we follow the good
compilation instructions, we autoreconf,
then ./configure, then
make. We then can run it with the option
--max-busy-dot-probes=100
(by default, it does not do probing). Note that probing in PowerDNS
is lazy: it is not always tried, only of there is a "sufficient"
traffic with the authoritative name server. You can see probing
going on with tcpdump on port 853 and
PowerDNS can report the results:
% rec_control dump-dot-probe-map /tmp/foo && fgrep Good /tmp/foo dump-dot-probe-map: dumped 13962 records 45.54.76.1 qtmlabs.xyz. 14 Good 2023-03-29T04:27:32 157.53.224.1 qtmlabs.xyz. 39 Good 2023-03-29T04:28:37 77.55.125.10 abstractionleak.com. 1 Good 2023-03-29T04:25:39 77.55.126.10 abc-sport.fr. 3 Good 2023-03-29T04:25:39 185.10.11.11 one.com. 4 Good 2023-03-29T04:28:02 195.206.121.11 one.com. 4 Good 2023-03-29T04:28:03 51.77.156.11 BILLAUD.EU.ORG. 1 Good 2023-03-29T00:09:32 129.134.30.12 facebook.com. 5 Good 2023-03-29T04:29:26 129.134.31.12 facebook.com. 6 Good 2023-03-29T04:27:39 185.89.218.12 facebook.com. 14 Good 2023-03-29T04:27:39 185.89.219.12 facebook.com. 5 Good 2023-03-29T04:27:39 139.99.155.59 EU.ORG. 1 Good 2023-03-29T04:27:32 185.49.140.60 nlnetlabs.nl. 3 Good 2023-03-29T04:26:37 172.105.50.79 geekyboo.net. 1 Good 2023-03-29T04:22:37 23.234.235.93 obo.sh. 1 Good 2023-03-29T03:34:12 212.102.32.200 cdn77.org. 1 Good 2023-03-29T03:47:44 199.9.14.201 . 17 Good 2023-03-29T04:30:39 136.243.57.208 distos.org. 1 Good 2023-03-29T03:44:00
We see here that all these nameservers have a working ADoT. In order to probe many domains, I have fed the resolver with data from the .fr zone, Cloudflare Domain Rankings and a list of fediverse instances. A partial list of domains which currently have working ADoT for at least one name server is:
. # Yes, the root facebook.com nlnetlabs.nl powerdns.com eu.org billaud.eu.org dyn.sources.org # Drink name server bortzmeyer.fr nether.net one.com # and the zones is hosts such as aaa-cool.fr desec.io # and the zones it hosts such as qtmlabs.xyz nazwa.pl # and the zones it hosts such as abc-sport.fr psyopwar.com # and the zones it hosts such as obo.sh cdn77.org distos.org
As you can see, even the root has a working ADoT server (see the announcement), despite a prudent statement of the root operators some time ago.
What about the work on Unbound? Unfortunately, it was more complicated than it seemed, since "happy eyeballs" probing (sending the request twice) runs against some assumptions in Unbound code. But the work by Yorgos made possible to better understand the issues, which is an important point for the hackathon.
The work of this weekend raised several questions, to be carried to the working group:
- If the ADoT server replies but the reply indicates an error, such as SERVFAIL or REFUSED, should the resolver retry without DoT? PowerDNS Recursor does it, but it seems it would make more sense to accept the reply, and just to remind system administrators that port 853 and 53 should deliver consistent answers.
- What should be the criteria to select an authoritative name server to query? Should we prefer a fast insecure server or a slow encrypted one? The draft does not mention it, because it is local policy. (PowerDNS Recursor has apparently no way to change its default policy, which is to use the fastest one, DoT or not.)
- Should we do lazy probing, like PowerDNS Recursor does, or use the more eager "happy eyeballs" algorithm?
For the issue of consistency between port 53 and 853, this can go
at odds with current practices. For instance, the only
authoritative name server of
dyn.bortzmeyer.fr hosts two different
services, Drink for the autoritative service on port 53 and an
open resolver, dnsdist, on port 853. So, the
answers are different. Should we ban this practice?
% check-soa -dot dyn.bortzmeyer.fr ns1-dyn.bortzmeyer.fr. 2001:41d0:302:2200::180: ERROR: REFUSED 193.70.85.11: ERROR: REFUSED % check-soa -tcp dyn.bortzmeyer.fr ns1-dyn.bortzmeyer.fr. 2001:41d0:302:2200::180: OK: 2023032702 193.70.85.11: OK: 2023032702
(The REFUSED is because check-soa does not send the RD - recursion desired - bit.)
All the presentations done at the end of the hackathon are online, including our presentation.
L'article seul
Fiche de lecture : Catalogue des vaisseaux imaginaires
Auteur(s) du livre : Stéphane Mahieu
Éditeur : Éditions du Sandre
9-782358-211505
Publié en 2022
Première rédaction de cet article le 21 mars 2023
Un livre qui donne envie de voyager et de lire : l'auteur a dressé un catalogue de bateaux qui apparaissent dans des œuvres de fiction. Chaque entrée résume le bateau, sa carrière, son rôle dans le roman, et est l'occasion de passer d'œuvres archi-connues à des textes bien moins célèbres.
On y trouve le Titan, du roman « Le naufrage du Titan » (avec des notes mettant en avant, non pas les ressemblances avec le Titanic, comme souvent, mais les différences), le Fantôme du « Loup des mers » (un roman politique bien plus qu'un livre d'aventures maritimes), et bien sûr le Nautilus. Mais l'auteur présente aussi des vaisseaux issus de romans plus obscurs (en tout cas en France), comme l'Étoile polaire (dans le roman d'Obroutchev), le Leviatán, issu de l'imagination de Coloane ou le Rose-de-Mahé, créé par Masson.
À noter que la bande dessinée n'est pas représentée (ni le cinéma, d'ailleurs). L'entrée pour la Licorne ne décrit pas le vaisseau du chevalier de Hadoque mais elle parle d'un recueil d'histoires anciennes (le livre est sur le projet Gutenberg).
Bref, plein d'idées de lectures vont vous venir en parcourant ce livre… Mettez votre ciré, vérifiez les provisions de bord (et les armes !) et embarquez.
L'article seul
Fiche de lecture : Plutôt nourrir
Auteur(s) du livre : Clément Osé, Noémie Calais
Éditeur : Tana
979-10-301-0424-0
Publié en 2022
Première rédaction de cet article le 20 mars 2023
Le débat sur la consommation de viande est souvent binaire, entre d'un côté les partisans de l'agriculture industrielle et de l'autre des animalolâtres qui refusent toute utilisation des animaux. Ce livre raconte le point de vue d'une éleveuse de porcs, qui essaie de faire de l'élevage de viande en échappant aux logiques industrielles.
Les partisans de l'agriculture industrielle reprochent souvent à leux opposants animalistes de ne rien connaitre à l'agriculture et au monde paysan. Ce n'est pas faux, mais, justement, ce livre est écrit, à deux mains, par des personnes qui vivent à la campagne, et qui travaillent la terre. Noémie Calais, l'éleveuse, a quitté son travail de consultante internationale pour s'occuper de porcs dans le Gers. Le travail quotidien est difficile (être paysanne n'a rien de romantique), et plein de questions se bousculent : a-t-on le droit d'élever des animaux pour finalement les tuer, comment faire une agriculture bio (ou à peu près) sans faire venir des kiwis, certes bios, mais transportés par avion depuis l'autre bout du monde, comment essayer de faire les choses proprement dans un environnement légal et économique où tout pousse à la concentration et à l'agriculture industrielle, avec toutes ses horreurs (pour les humains, comme pour les animaux). Les auteurs n'esquivent aucune question. Oui, il est légitime de manger les animaux, non, cela ne veut pas dire qu'il faut faire n'importe quoi.
Le livre va du quotidien d'une paysanne aux questions plus directement politiques, comme la réglementation délirante qui, sous couvert de protéger les consommateurs, crée tellement de normes et de certifications abstraites et déconnectées du terrain que seuls les gros, donc en pratique l'agriculture industrielle, ont des chances d'arriver à les respecter. Les arguments sanitaires, par exemple, peuvent être un prétexte pour démolir les circuits locaux. (Le cas n'est pas dans ce livre mais, par exemple, les règles de respect de la chaine du froid pour les fromages, qui sont les mêmes pour le fromage industriel sous plastique qui vient de l'autre bout du pays, et pour les dix ou vingt fromages de chèvre produits à deux kilomètres du marché sont un exemple typique.)
À lire avant d'aller au supermarché faire ses achats !
L'article seul
IPv6 chez OVH, c'est bizarre
Première rédaction de cet article le 17 mars 2023
Si vous avez déjà créé/géré une machine virtuelle chez OVH, vous avez sans doute noté la bizarrerie de la configuration IPv6. En fait, la configuration automatiquement installée lorsque vous créez votre machine est incorrecte. Voici pourquoi, et comment la réparer.
Créons d'abord un serveur (j'ai utilisé l'API OpenStack mais le problème existait déjà avant).
% ip -6 addr show
...
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 state UP qlen 1000
inet6 2001:41d0:801:1000::233c/56 scope global
valid_lft forever preferred_lft forever
inet6 fe80::f816:3eff:fe10:748f/64 scope link
valid_lft forever preferred_lft forever
La machine a une adresse IPv6,
2001:41d0:801:1000::233c, dans un préfixe de
longueur 56. Chic, je me dis, je vais pouvoir parler directement
(sans passer par le routeur) avec les autres
machines dans ce même préfixe.
La table de routage va d'ailleurs en ce sens :
% ip -6 route show ... 2001:41d0:801:1000::/56 dev ens3 proto kernel metric 256 pref medium default via 2001:41d0:801:1000::1 dev ens3 metric 1 pref medium
Elle nous dit que tout le /56 est joignable sans intermédiaire (pas
de via).
Essayons depuis la
2001:41d0:801:1000::23b2 :
% ping -c 3 2001:41d0:801:1000::233c PING 2001:41d0:801:1000::233c(2011:41d0:801:1000::233c) 56 data bytes From 2001:41d0:801:1000::23b2 icmp_seq=1 Destination unreachable: Address unreachable ... --- 2001:41d0:801:1000::233c ping statistics --- 3 packets transmitted, 0 received, 100% packet loss, time 2030ms
Aïe, c'est raté, alors que les deux machines sont bien dans le même préfixe de longueur 56. Pourquoi ? Parce que les machines ne sont pas réellement sur un réseau local dont le préfixe ferait 56 bits. Elles doivent en fait toujours passer par le routeur, comme si elles étaient sur une liaison point-à-point avec ce routeur. (Pour la même raison, un tcpdump ne montrera pas de trafic, à part avec le routeur, par exemple du trafic NTP.)
Pour que cela marche, il faut renoncer à parler directement avec
les machines proches, et corriger la configuration. Ce sont des
Debian, on va éditer le fichier
/etc/network/interfaces.d/50-cloud-init et
remplacer la longueur incorrecte (56) par la bonne (128). Et on
n'oublie pas de rajouter une route vers le routeur avant de définir
la route par défaut. On
redémarre et ça marche :
% ping -c 3 2001:41d0:801:1000::233c PING 2001:41d0:801:1000::233c(2001:41d0:801:1000::233c) 56 data bytes 64 bytes from 2001:41d0:801:1000::233c: icmp_seq=1 ttl=57 time=0.810 ms 64 bytes from 2001:41d0:801:1000::233c: icmp_seq=2 ttl=57 time=0.746 ms 64 bytes from 2001:41d0:801:1000::233c: icmp_seq=3 ttl=57 time=0.764 ms --- 2001:41d0:801:1000::233c ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2037ms rtt min/avg/max/mdev = 0.746/0.773/0.810/0.026 ms
Et la table de routage nous montre que tout va passer par le routeur :
% ip -6 route show ... 2001:41d0:801:1000::1 dev ens3 metric 1 onlink pref medium 2001:41d0:801:1000::233c dev ens3 proto kernel metric 256 pref medium default via 2001:41d0:801:1000::1 dev ens3 metric 1 pref medium
Il est dommage qu'on ne puisse pas parler directement aux autres machines du même préfixe. Peut-être est-ce pour des raisons de sécurité, ces machines pouvant appartenir à des organisations différentes ? C'est en effet la même chose en IPv4 mais, cette fois, avec une configuration par défaut qui est correcte (un préfixe de longueur 32).
Si vous créez beaucoup de machines virtuelles et qu'on vous n'avez pas envie de tout corriger à la main, et que, comme moi, vous utilisez Ansible, voici un playbook qui fait les choses plus ou moins proprement :
---
- hosts: coursipv6
become: yes
become_method: sudo
tasks:
- name: Broken IPv6 config at OVH
lineinfile:
path: /etc/network/interfaces.d/50-cloud-init
regexp: 'address {{ ipv6_address }}/56$'
line: 'address {{ ipv6_address }}/128'
backrefs: yes
- name: Broken IPv6 routing at OVH
lineinfile:
path: /etc/network/interfaces.d/50-cloud-init
regexp: 'route add -A inet6 default gw {{ ipv6_gateway }} || true$'
line: '\tpost-up ip -6 route add {{ ipv6_gateway }} dev ens3 && route add -A inet6 default gw {{ ipv6_gateway }} || true'
backrefs: yes
L'article seul
Fiche de lecture : Datamania - le grand pillage de nos données personnelles
Auteur(s) du livre : Audric Gueidan, Halfbob
Éditeur : Dunod
978-2-10-083732-1
Publié en 2023
Première rédaction de cet article le 15 mars 2023
La plupart des lecteurices de ce blog savent que, sur l'Internet, on laisse des traces partout et que nos données personnelles sont peu protégées. (Le discours policier « l'Internet, c'est l'anonymat » est de la pure propagande.) Mais bien que ce fait soit largement connu et documenté, même au-delà des lecteurices de ce blog, on ne constate pas de changement de comportement des utilisateurices. Ceux et celles-ci continuent à distribuer trop largement leurs données personnelles. Il y a de nombreuses raisons à cet état de fait et je ne vais pas toutes les discuter. Mais une des raisons, pensent les auteurs de ce livre, est le manque d'information ; les utilisateurices ont bien entendu dire qu'il y avait des problèmes avec les données personnelles mais ielles ne mesurent pas complètement l'ampleur de ces problèmes, ni les formes qu'ils prennent. Comment leur expliquer ? Les auteurs tentent une BD, « Datamania ».
Alors, une BD, c'est du texte et du dessin. Personnellement, je ne suis pas très enthousiaste pour ce style de dessin (vous pouvez voir certains de ces dessins dans l'article de GeekJunior) mais comme les goûts artistiques varient, je n'argumenterai pas sur ce point. Le texte est léger et amusant, et couvre bien les sujets. Aucune erreur technique, les auteurs font preuve de beaucoup de rigueur. L'idée est d'expliquer à des gens qui n'ont pas envie de lire tous les rapports de la CNIL. Est-ce réussi ? Bon, il est clair que je ne suis pas le cœur de cible, le livre vise des gens pas très informés. Mais, justement, je trouve que le livre n'explique pas assez et qu'il abuse des private jokes. Certaines de ces allusions sont expliquées dans l'annexe « Avez-vous remarqué ? » mais j'avoue que je me suis demandé si un·e lecteurice ordinaire ne va pas rester perplexe. (Les lecteurices qui connaissent le sujet peuvent s'amuser, sans lire cette annexe, à repérer toutes les allusions à des personnes ou organisations connues.)
Le sujet, il est vrai, est très riche et très complexe. Le livre parle de surveillance, de logiciel libre, de cookies, de chiffrement et de beaucoup d'autres choses, et ne peut évidemment pas tout traiter en détail. (Un gros plus pour avoir cité Exodus Privacy.) Je conseillerai de l'utiliser comme introduction, ou comme support à des ateliers mais je ne suis pas sûr qu'il puisse être utilisé en autonomie par des utilisateurices ordinaires. (Bon, après, c'est vrai que je suis exigeant ; qu'en pensent d'autres personnes ? Voyez l'article de GeekJunior ou celui de Médias-Cité.)
Note : j'ai reçu un exemplaire gratuit du livre de la part des auteurs.
L'article seul
The Drink DNS server at FOSDEM
First publication of this article on 13 February 2023
The great technical conference FOSDEM resumed physical activity after two years of purely online events. I had the pleasure to make a small talk at the DNS devroom about the Drink dynamic authoritative DNS server.
The slides are available on the official site. The recorded video is available at the same place, as well as links to the source code, etc.
L'article seul
Mon exposé sur la neutralité du code à Touraine Tech
Première rédaction de cet article le 23 janvier 2023
Le 20 janvier de cette année, à la conférence informatique Touraine Tech, j'ai fait un exposé sur la neutralité du code. Lorsque le ou la développeureuse dit « je ne fais pas de politique, ce programme pourra être utilisé pour différents buts », est-ce possible ?
Voici les supports de l'exposé et leur source (en LaTeX avec Beamer).
Il y avait à cet évènement de nombreuses autres conférences intéressantes(sans compter les fouées aux rillettes) :
- L'introduction de Ploum, très drôle et très vivante,
- la conférence d'Amélie Abdallah « Féminisation dans la tech : la communication, ou l'échec de tout un secteur » sur le sexisme dans l'informatique et comment le combattre (supports ici),
- celle de Jimmy Kasprzak, « Développer et enseigner, une bonne idée ? » sur l'importance et la difficulté de l'enseignement,
- la conférence dessinée (très bons dessins) de Victor Lambret sur les méthodes de développement logiciel, où comment des études scientifiques montrent que les conseils de bon sens des consultants, même appuyés sur un sigle à la mode (comme TDD) ne produisent pas de meilleur code,
- celle de Cécile Freyd-Foucault et Iris Naudin le jeudi soir, sur des thèmes classiques (accessibilité et fracture numérique) mais très bien traités (à faire suivre par les gens qui ignorent encore le problème) ; les références utilisées pour leur exposé sont en ligne, j'ai beaucoup aimé l'article d'Anne-Sophie Tranchet sur les formulaires odieux,
- l'amusant « Développer publiquement un site en milieu hostile : retour d'expérience », d'Alexis Lozano, où il détaille les étapes sucessives d'un petit projet Web avec contenu fourni par les utilisateurices, et les problèmes successifs dûs aux abrutis, exposé très bien fait, très intéressant et concret,
- comme aujourd'hui on fait de l'IA partout, la conférence « Si on aidait le capitaine Némo à classifier les monstres marins ? » de Eléa Petton et Stéphane Philippart, est recommandée, un tutoriel nous guidant pas à pas dans la construction d'une application de reconnaissance de sons, très pédagogique. Plusieurs démonstrations concrètes avec Python et Jupyter (et les bibliothèques librosa, pandas, sklearn, tensorflow, etc).
- et enfin la conférence très détaillée de Fabien Trégan et Olivier Poncet sur la représentation des nombres dans les ordinateurs (même si vous savez déjà que (1/3)*3 ne fait pas 1, vous y apprendrez des choses), avec des supports écrits à la main sur un fond évoquant un cahier d'écolier.
Les vidéos de ces différentes conférences sont en ligne (la mienne aussi).
Un exposé d'Olivier Mertens portait sur le générateur d'images
DALL-E (fait par la même société que ChatGPT). J'ai donc demandé à DALL-E « Une
conférence à TouraineTech dans le style de François
Boucher [puisqu'il y avait une exposition de ce dernier
au Musée des Beaux-Arts] » et le résultat
est… pas terrible :  .
.
Et merci mille fois aux organisateurices (une telle conférence crée beaucoup de travail), et à Florian Roulet pour m'avoir invité à y prendre la parole.
Ploum et moi dédicaçant nos livres : 
L'article seul
ChatGPT remplacera t-il les programmeuses et programmeurs ?
Première rédaction de cet article le 3 janvier 2023
Si Ada Lovelace était la première programmeuse, les programmeuses et programmeurs actuel·les sont-ielles les dernièr·es ? Un programme « intelligent » comme ChatGPT va-t-il les condamner à la reconversion ou au chômage ? Je continue ici mon exploration de ChatGPT.
ChatGPT a beaucoup été utilisé pour la programmation. Voici une session où je lui demande des programmes (ce sera la seule image, dans le reste de l'article, je copierai le texte).
Exemple d'utilisation :
Le programme est écrit en Elixir car mes questions précédentes portaient sur ce langage et ChatGPT mémorise les conversations pendant une session (et peut-être au-delà donc ne lui donnez pas d'informations confidentielles). L'utilisation d'Elixir montre que ChatGPT connait beaucoup de choses, y compris des langages assez rarement utilisés. C'est logique : pour le quantitatif (la mémorisation et la restitution d'énormes quantités d'informations), les ordinateurs sont certainement meilleurs que les humains. D'autre part, celles et ceux qui ont lu mon précédent article noteront que j'ai maintenant un compte ChatGPT, ayant trouvé un numéro de téléphone sacrifiable.
Beaucoup de gens ont été impressionnés par les qualités de ChatGPT et, voyant la facilité avec laquelle il génère des programmes (et les explique !), se sont dit que les programmeuses et les programmeurs allaient disparaitre. Un tel discours fait rêver bien des patrons, qui apprécieraient de remplacer des développeurs et développeuses payés chers par une IA docile et obéissante. Ce discours est donc très ancien dans l'informatique, Cobol avait déjà été promu avec cet argument. Et c'était également le cas de Fortran (« FORTRAN should virtually eliminate coding and debugging »). Même si ces affirmations semblent techniquement ridicules aujourd'hui, à l'époque, le progrès par rapport au langage d'assemblage était tel que cela ne semblait pas absurde. Puis on a entendu à nouveau ce raisonnement du temps des L4G puis récemment du nocode. Le fait que les espérances des patrons aient été déçues à chaque fois ne les empêche pas de garder espoir.
Voyons donc ce que sait faire ChatGPT. D'abord, on l'a dit, il
connait beaucoup de choses. Je demande « Je dois trier une liste de
chaînes de caractères [un exercice banal de débutant]. Comment
faire ? » et ChatGPT répond « Pour trier une liste de
chaînes de caractères en Elixir, vous pouvez utiliser la fonction
Enum.sort/1. Cette fonction prend en entrée une
liste et renvoie une liste triée de ses éléments. Voici un exemple
de code qui trie une liste de chaînes de caractères en ordre
croissant : »
strings = ["c", "b", "a", "d"] sorted_strings = Enum.sort(strings) IO.inspect(sorted_strings) # ["a", "b", "c", "d"]
Il connait la bibliothèque standard d'Elixir
(où il y a bien un Enum.sort)
et aussi des idiosyncrasies d'Elixir comme le
fait de nommer une fonction en terminant par son
arité. Et il ajoute spontanément « Si vous
voulez trier la liste en ordre décroissant, vous pouvez utiliser la
fonction Enum.sort/2 et lui fournir une fonction de comparaison qui
renvoie :gt si le premier argument est plus grand que le second, :lt
si le premier argument est plus petit que le second, et :eq s'ils
sont égaux. Voici un exemple de code qui trie une liste de chaînes
de caractères en ordre décroissant : »
strings = ["c", "b", "a", "d"] sorted_strings = Enum.sort(strings, fn x, y -> if x > y do :gt else if x < y do :lt else :eq end end) IO.inspect(sorted_strings) # ["d", "c", "b", "a"]
(Les :gt et :lt sont
appelés atomes et sont une des particularités d'Elixir. Je vous ai
dit qu'il « connaissait » bien le langage.)
Mais ce second code pose déjà des problèmes. D'abord, il ne
compile même pas (il manque un end). Mais,
surtout, ChatGPT n'a pas bien lu la
documentation : la fonction passée en argument à
sort est censée renvoyer un booléen, pas ces
atomes. On voit là une première chose à garder en mémoire : on
ne peut pas en général utiliser les programmes produits par ChatGPT
tels quels, il faut les vérifier, et cette vérification doit
être faite par une personne compétente en programmation. Et il n'est
pas évident que l'entièreté du processus soit plus rapide et plus
sûr que si cette personne compétente avait tout fait
elle-même. (L'erreur de syntaxe est la moins grave, car elle est
détectée à la compilation. Le pire serait une erreur qui ne
planterait pas mais donnerait un résultat faux.)
Ceci dit, ChatGPT est interactif. Voyons cela sur un autre exemple : « Comment décomposer un entier de grande taille en ses facteurs premiers ? ». ChatGPT répond « Pour décomposer un entier en ses facteurs premiers en Elixir, vous pouvez utiliser une approche récursive. Voici comment vous pouvez implémenter cette approche : »
defmodule PrimeFactors do
def factors(n, divisor \\ 2) when divisor > n do
[n]
end
def factors(n, divisor \\ 2) do
if rem(n, divisor) == 0 do
[divisor | factors(n / divisor, divisor)]
else
factors(n, divisor + 1)
end
end
end
Cette fois, il n'y a pas d'erreur de syntaxe, mais cela ne compile quand même pas, en raison d'une erreur sémantique. Et il y a deux autres bogues (trouver l'une d'elles nécessite de connaitre Elixir). Mais comme ChatGPT est interactif, je lui explique : « Attention, on ne peut pas avoir deux définitions avec des valeurs par défaut. Il faut réécrire ton code. » Il me répond que j'ai raison (d'autres personnes ont vu ChatGPT nier des problèmes) et « Vous avez raison, il n'est pas possible d'avoir deux définitions avec des valeurs par défaut pour le même nom de fonction en Elixir. Pour résoudre ce problème, vous pouvez utiliser une seule définition de fonction avec une valeur par défaut pour le diviseur, et ajouter une condition pour gérer le cas où le diviseur est supérieur à n. Voici comment vous pouvez réécrire le code : »
defmodule PrimeFactors do
def factors(n, divisor \\ 2) when divisor > n do
[n]
end
def factors(n, divisor \\ 2) do
if divisor > n do
[n]
else
if rem(n, divisor) == 0 do
[divisor | factors(n / divisor, divisor)]
else
factors(n, divisor + 1)
end
end
end
end
Et il ajoute spontanément « Je vous recommande également de changer
le nom de la fonction factors/2 en
factors/1 et de changer la condition de la
clause de cas factors/1 pour qu'elle vérifie si
n est inférieur ou égal à 1. Voici comment le code final devrait
ressembler [sic] : »
defmodule PrimeFactors do
def factors(n, divisor \\ 2) when n <= 1 do
[]
end
def factors(n, divisor \\ 2) do
if rem(n, divisor) == 0 do
[divisor | factors(n / divisor, divisor)]
else
factors(n, divisor + 1)
end
end
end
C'est amusant, le code réécrit a toujours la même bogue sur la
définition de fonctions avec des valeurs par défaut. Par contre,
ChatGPT a « réfléchi » et a corrigé une des autres bogues (qui
faisait que le nombre 1 était listé comme facteur premier). Bon,
tant pis, je corrige manuellement et je lui signale la troisième
bogue (celle qui nécessite de connaitre Elixir) : « Et attention, le
/ fait une division de réels, il faudrait utiliser
div. ». Il le reconnait : « Vous avez raison,
la fonction / en Elixir effectue une division de réels et non une
division entière. Pour effectuer une division entière, vous pouvez
utiliser la fonction div/2. Voici comment vous
pouvez utiliser la fonction div/2 dans la
fonction factors/1 : »
defmodule PrimeFactors do
def factors(n, divisor \\ 2) when n <= 1 do
[]
end
def factors(n, divisor \\ 2) do
if rem(n, divisor) == 0 do
[divisor | factors(div(n, divisor), divisor)]
else
factors(n, divisor + 1)
end
end
end
À noter que ChatGPT avait montré qu'il connaissait l'éco-système Elixir, en expliquant comment tester avec l'interpréteur iex :
iex> PrimeFactors.factors(12) [2, 2, 3] iex> PrimeFactors.factors(2310) [2, 3, 5, 7, 11] iex> PrimeFactors.factors(7829) [7829]
Prenons un autre exemple qui illustre la question du cahier des charges. En programmation dans le monde réel, c'est souvent la principale difficulté ; le·a programmeur·se passe souvent davantage de temps à comprendre un cahier des charges incomplet, contradictoire et irréaliste qu'à programmer. Commençons simplement : « Écris un programme en Python qui donne la liste des nombres allant jusqu'à N. ». ChatGPT répond :
# Demande à l'utilisateur de saisir un entier N
n = int(input("Entrez un entier N : "))
# Initialise une liste vide
l = []
# Pour chaque entier i allant de 1 à N
for i in range(1, n+1):
# Ajoute i à la liste
l.append(i)
# Affiche la liste
print(l)
Et explique « Ce programme demande à l'utilisateur de saisir un entier N, initialise une liste vide, puis utilise une boucle for pour ajouter chaque entier allant de 1 à N à la liste. Enfin, il affiche la liste. ». Modifions le cahier des charges (ce qui est courant) : « Il faut que cela marche avec des entiers relatifs. » ChatGPT ne se démonte pas pour si peu « Pas de problème, voici une version modifiée du programme qui prend en compte les entiers relatifs : »
# Demande à l'utilisateur de saisir un entier N
n = int(input("Entrez un entier N : "))
# Initialise une liste vide
l = []
# Si N est positif
if n > 0:
# Pour chaque entier i allant de 1 à N
for i in range(1, n+1):
# Ajoute i à la liste
l.append(i)
# Si N est négatif
elif n < 0:
# Pour chaque entier i allant de N à -1 (inclus)
for i in range(n, 0):
# Ajoute i à la liste
l.append(i)
# Si N est égal à 0
else:
# Ajoute 0 à la liste
l.append(0)
# Affiche la liste
print(l)
Et explique « Cette version vérifie si N est positif, négatif ou égal à 0 et utilise une boucle for appropriée pour ajouter les entiers à la liste. Si N est égal à 0, 0 est simplement ajouté à la liste. » On voit que ChatGPT est parfaitement capable de faire des exercices de programmation pour grands débutants, par exemple au lycée. Mais comme je suis méchant, je lui demande ensuite un programme qui marche avec les nombres réels, ce qui est impossible. Il me fait alors une variante qui énumère, mais avec un pas (qu'il a choisi arbitrairement) de 0,1. Dois-je le considérer comme très bête ou comme très intelligent d'avoir interprété de manière créative un cahier des charges absurde ? En tout cas, cet exemple montre à quoi ressemble souvent le travail de programmation : il faut de nombreuses itérations avant d'avoir une idée claire de ce qui est demandé et un programme comme ChatGPT n'est pas forcément le mieux placé pour cela. (Mes lecteurices qui connaissent la programmation auront déjà fait remarquer in petto que si on ne peut pas énumérer les réels - qui sont en nombre infini dans tout intervalle, quelle que soit sa taille, on pourrait par contre énumérer les nombres en virgule flottante représentables sur la machine. Mais ChatGPT n'y a pas pensé.)
Mais, bref, on est encore loin d'un système qui pourrait permettre de se passer complètement des développeurs et développeuses. Il peut aider, c'est certain, faisant gagner du temps lorsqu'on a oublié comment faire une requête HTTP dans tel ou tel langage de programmation, il peut servir d'« auto-complétion améliorée » mais cela ne permet pas de lui confier tout le travail. Alors, certes, il s'agit d'Elixir, mais est-ce que cela marcherait mieux avec des langages de programmation plus répandus ? J'en doute. Mémoriser une grande quantité d'informations et pouvoir en ressortir à volonté est justement le point fort des ordinateurs. Contrairement à un humain, apprendre un langage de plus ne nécessite guère d'effort. Les différents messages lus sur les réseaux sociaux semblent indiquer que des langages bien plus communs qu'Elixir ont le même problème (pareil pour la simple algèbre).
Parmi les autres faiblesses de ChatGPT qui font obstacle à une utilisation en totale autonomie, notons aussi :
- ChatGPT n'est pas réflexif, il ne s'analyse pas lui-même et n'est pas capable de donner un degré de certitude sur ses « solutions ». Il affirme souvent des choses fausses avec le même niveau de confiance que les choses les plus indiscutables. Et il invente souvent des choses qui n'existent pas (articles scientifiques, options de logiciel, etc).
- Certains promoteurs de ChatGPT disent ne pas s'inquiéter de la mauvaise qualité (parfois) du code en considérant que, du moment que « ça marche », c'est suffisant. Mais cet argument ne vaut pas pour la sécurité. Si un programmme a une faille de sécurité, il va marcher, mais être néanmoins dangereux.
En conclusion, oui, ChatGPT et les logiciels similaires vont changer la programmation (comme Cobol et Fortran l'avaient fait) mais croire qu'ils vont permettre de se passer de programmeur-ses est illusoire. Les développeur·euses qui produisent du code de basse qualité à la chaîne ont du souci à se faire pour leur avenir professionnel mais cela ne concerne pas celles et ceux qui font du code créatif, difficile, novateur, ou simplement bien adapté à leur problème. ChatGPT est très fort pour des tests simplistes, comme ceux souvent faits à l'embauche mais pour de vrais programmes ? C'est un point souvent oublié par les personnes qui ne connaissent pas la programmation : écrire un petit script qui fait une tâche simple n'est pas la même chose que de programmer Apache, Louvois, ou un logiciel de calcul scientifique comme Blast.
Quelques réflexions et éléments sur ce sujet :
- Un programme (certes simple mais quand même) entièrement développé par ChatGPT.
- Un cas où ChatGPT a imaginé une fonction de la bibliothèque standard, fonction qui n'existe pas.
- En dehors du cas de la programmation, de bonnes réflexions sur Upcycle Commons, celles de Marie-Astrid Clair, ou bien celles de David Madore ou encore cette vidéo de Monsieur Phi,
- Un article (écrit par le fondateur d'une entreprise qui vend des logiciels d'IA, attention) qui dit le contraire du mien (les commentaires sont très intéressants).
L'article seul
Articles des différentes années : 2025 2024 2023 2022 2021 2020 2019 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}