
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
RFC 9910: Registration Data Access Protocol (RDAP) Regional Internet Registry (RIR) Search
Date de publication du RFC : Janvier 2026
Auteur(s) du RFC : T. Harrison (APNIC), J. Singh (ARIN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 8 janvier 2026
Le protocole RDAP, successeur de whois, n'est pas utilisé que par les registres de noms de domaine. Il sert aussi chez les RIR, pour obtenir des informations sur les entités qui sont derrière une adresse IP (ou un AS). RDAP dispose dès le début de fonctions de recherche (regardez le RFC 9082) mais ce nouveau RFC ajoute des choses en plus.
Traditionnellement, les serveurs whois des RIR disposaient de fonction de recherche « avancées » comme la possibilité de chercher par valeur (« quels sont tous les préfixes IP de tel titulaire ? »). L'idée de ce RFC est de permettre la même chose en RDAP. RDAP de base permet les recherches des informations associées à une adresse IP :
% curl -s https://rdap.db.ripe.net/ip/2001:41d0:302:2200::180 | jq .
{
"handle": "2001:41d0::/32",
"name": "FR-OVH-20041115",
"country": "FR",
"parentHandle": "2001:4000::/23",
…
"status": [
"active"
],
"entities": [
{
"handle": "OK217-RIPE",
…
"text",
"Octave Klaba"
…
En plus de ip, ce RFC ajoute
ips (section 2.1) qui permet une recherche sur
tous les préfixes dont le nom correspond à un certain motif (ici,
tous ceux d'OVH) :
% curl -s https://rdap.db.ripe.net/ips\?name="FR-OVH-*" | jq '.ipSearchResults.[].handle' "109.190.0.0 - 109.190.255.255" "135.125.0.0 - 135.125.255.255" "137.74.0.0 - 137.74.255.255" "141.94.0.0 - 141.95.255.255" "145.239.0.0 - 145.239.255.255" "147.135.128.0 - 147.135.255.255" "149.202.0.0 - 149.202.255.255" "152.228.128.0 - 152.228.255.255" "159.173.0.0 - 159.173.255.255" "162.19.0.0 - 162.19.255.255" …
J'ai utilisé ici curl et jq mais, évidemment, l'avantage de RDAP est que vous pouvez utiliser un client dédié ou bien n'importe quel logiciel qui sait faire du HTTP et du JSON.
Et chez un autre RIR :
% curl -s https://rdap.arin.net/registry/ips\?name='CLOUDFLARE*' | \
jq '.ipSearchResults.[].handle'
"NET-104-16-0-0-1"
"NET-108-162-192-0-1"
"NET-156-146-101-152-1"
"NET-162-158-0-0-1"
"NET-172-64-0-0-1"
"NET-173-245-48-0-1"
"NET-198-41-128-0-1"
"NET-199-27-128-0-1"
"NET6-2606-4700-1"
De la même façon, vous pouvez chercher par numéro d'AS :
% curl -s https://rdap.db.ripe.net/autnums\?name="*NIC-FR*" | \
jq '.autnumSearchResults.[].handle'
"AS2483"
"AS2484"
"AS2485"
"AS2486"
La section 3 décrit ensuite des moyens de trouver les objets parents et enfants (puisque l'allocation des adresses IP est hiérarchique, toute adresse est dans un préfixe plus général et contient des préfixes plus spécifiques, cf. la section 3.2.1 du RFC) :
% curl -s https://rdap.db.ripe.net/ips/rirSearch1/rdap-up/2001:41d0:302:2200::180 | \
jq '.handle'
"2001:41d0::/32"
% curl -s https://rdap.db.ripe.net/ips/rirSearch1/rdap-down/2001:4000::/23 | \
jq '.ipSearchResults.[].handle'
"2001:4000::/32"
"2001:4010::/32"
"2001:4018::/29"
"2001:4020::/32"
…
Notez la relation (rdap-up et
rdap-down). Notez aussi que
rdap-up renvoie au maximum un objet alors que
rdap-down peut en renvoyer plusieurs
(cf. section 4.2), et c'est pour cela qu'il a fallu itérer en jq (le
.[] parcourt le tableau). Quant au
rirSearch1, le 1 indique la version de cette
extension de recherche chez les RIR (désormais enregistrée
à l'IANA).
Et les recherches inverses, telles que décrites dans le RFC 9536 ? La section 5 du RFC les présente et voici un exemple qui marche (trouver tous les préfixes de Webflow) :
% curl -s 'https://rdap.arin.net/registry/ips/reverse_search/entity?handle=WEBFL' | \
jq '.ipSearchResults.[].handle'
"NET-198-202-211-0-1"
"NET6-2620-CB-2000-1"
Un serveur RDAP qui gère les extensions de ce RFC doit le signaler dans ses réponses (section 6) :
…
"rdapConformance" : [ "geofeed1", "rirSearch1", "ips", "cidr0",
"rdap_level_0", "nro_rdap_profile_0", "redacted" ],
…
Mais aussi dans les liens donnés dans les réponses (ici, en réponse
à une requête traditionnelle ip) :
"links": [
{
"value": "https://rdap.db.ripe.net/ip/2001:41d0:302:2200::180",
"rel": "rdap-up",
"href": "https://rdap.db.ripe.net/ips/rirSearch1/rdap-up/2001:41d0::/32",
"type": "application/rdap+json"
},
Et bien sûr dans les réponses d'aide :
% curl -s https://rdap.arin.net/registry/help
{
"rdapConformance" : [ "nro_rdap_profile_0", "rdap_level_0", "cidr0", "nro_rdap_profile_asn_flat_0", "arin_originas0", "rirSearch1", "ips", "ipSearchResults", "autnums", "autnumSearchResults", "reverse_search" ],
"notices" : [ {
"title" : "Terms of Service",
"description" : [ "By using the ARIN RDAP/Whois service, you are agreeing to the RDAP/Whois Terms of Use" ],
"links" : [ {
"value" : "https://rdap.arin.net/registry/help",
"rel" : "terms-of-service",
"type" : "text/html",
"href" : "https://www.arin.net/resources/registry/whois/tou/"
} ]
…
Les fonctions de recherche, c'est très bien mais c'est, par construction, indiscret. La section 8 de notre RFC détaille les risques de ces extensions de recherche pour la vie privée (relire le RFC 7481 est une bonne idée).
Les extensions de ce RFC, rirSearch1,
ips, autnums,
ipSearchResults et
autnumSearchResults ont été enregistrées
à l'IANA (section 10 du RFC). Les relations
rdap-up, rdap-down,
rdap-top et rdap-bottom
sont dans le registre
des liens (RFC 8288). Et le registre
des recherches inverses inclut désormais
fn, handle,
email et role, avec leur
correspondance en JSONPath.
Et question mise en œuvre et déploiement, on a quoi ? ARIN et RIPE ont annoncé avoir programmé les extensions de ce RFC mais elles ne sont pas forcément accessibles via le serveur RDAP public, entre autre pour les raisons de vie privée discutées dans la section 8. Aujourd'hui, comme vous le voyez dans les exemples ci-dessus, au moins ARIN et RIPE rendent une partie de ces extensions utilisables.
L'article seul
Quel risque que des satellites se tamponnent ?
Première rédaction de cet article le 12 décembre 2025
Il y a beaucoup, mais vraiment beaucoup, de satellites au-dessus de nos têtes, notamment sur les orbites basses. Risquent-ils de se tamponner ? Oui, montre cette étude : en l'absence de réaction de leurs opérateurs, il y aurait une collision tous les 2,8 jours.
Le risque de collision entre satellites est connu depuis longtemps. Le cas le plus fameux est bien sûr la collision du 10 février 2009 (cf. le bilan récent « Subsequent Assessment of the Collision between Iridium 33 and COSMOS 2251 »). Les conséquences d'un choc direct sont évidemment la destruction des deux satellites mais le principal problème est surtout la nuée de débris ainsi créée, et les nombreuses collisions secondaires qu'elle peut entrainer. En cas d'éparpillement des satellites impliqués, l'orbite peut devenir inutilisable.
Mais l'espace est grand et un satellite est petit, non ? Les collisions devraient être rares. Ce serait le cas s'il y avait peu de satellites. Mais de nos jours, avec les méga-constellations, le nombre de satellites est tel que la probabilité de collision a sérieusement augmenté. Et puis un satellite en orbite basse fait beaucoup de tours de la Terre, augmentant le risque. C'est comme jouer à la roulette russe en essayant souvent.
Peut-on quantifier ce risque ? C'est ce que tente l'article « An Orbital House of Cards: Frequent Megaconstellation Close Conjunctions ». Les auteurices ont développé un indice, spirituellement appelé « CRASH clock » (pour Collision Realization And Significant Harm), exprimé sous forme d'une durée, et qui indique l'intervalle moyen entre collisions. Je vous laisse lire l'article pour les détails du calcul (comme toutes les modélisations, c'est compliqué et certains facteurs ne sont pas connus avec précision). Mais ce qui est inquiétant est le résultat : le CRASH clock qui était de 121 jours avant l'arrivée des méga-constellations est descendu à 2,8 jours, en grande partie grâce à Starlink.
Bon mais, en pratique, on ne voit pas de collision tous les 2,8 jours, non ? C'est parce que les opérateurs des satellites surveillent les environs et actionnent de temps en temps les moteurs pour s'éloigner d'un risque de collision. On ne voit donc pas souvent d'accident. Le risque est qu'un événement survienne qui empêche ces réactions pendant quelques jours. Les auteurices imaginent un problème logiciel important chez un des opérateurs, voire sur plusieurs, ou bien une crise socio-politique importante sur Terre, ou tout simplement une tempête solaire, qui pourrait perturber les communications pendant une durée significative par rapport au CRASH clock. (Le risque des tempêtes solaires n'est pas purement théorique.) Le CRASH clock indique donc ce qui se passerait lors d'un de ces événements. Les opérateurs de satellites ne peuvent pas se permettre une interruption de leur travail, même de seulement quelques heures.
L'article seul
RFC 9824: Compact Denial of Existence in DNSSEC
Date de publication du RFC : Septembre 2025
Auteur(s) du RFC : S. Huque (Salesforce), C. Elmerot
(Cloudflare), O. Gudmundsson
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 12 décembre 2025
Plus fort que le chat de Schrödinger qui était à la fois mort et vivant, ce RFC permet à un nom de domaine d'être à la fois existant et non-existant. Plus précisément, il permet de fournir une preuve cryptographique avec DNSSEC, prouvant que le nom existe (alors qu'il n'existe pas) mais n'a pas les données demandées. Cette technique (autrefois connue sous le nom de « black lies », et largement déployée) est particulièrement adaptée au cas des signatures générées dynamiquement, mais a l'inconvénient de « mentir » sur l'existence du nom.
Pour comprendre, il faut revenir à un problème agaçant pour
DNSSEC : le déni d'existence. Ce terme
désigne le fait de prouver qu'un nom, ou qu'un certain type de
données pour un nom, n'existe pas. Car DNSSEC fonctionne en
signant les données. Mais en
cas de non-existence, il n'y a rien à signer. DNSSEC a donc ajouté
un type d'enregistrement nommé NSEC qui encadre le nom manquant. Et
ces enregistrements, eux, sont signés. Un enregistrement NSEC affirme
« ce nom n'existe pas » en donnant le nom précédent et le nom
suivant (ici, la réponse d'un serveur racine
à qui on a demandé www.trump alors que le
TLD
.trump n'existe pas) :
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 65362 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 1 … travelersinsurance. 86400 IN NSEC trust. NS DS RRSIG NSEC
On obtient un NXDOMAIN (ce nom n'existe pas), zéro réponse (la
section Answer est vide) et l'enregistrement NSEC nous dit qu'il n'y
a rien entre travelersinsurance et
trust. Comme il est signé (je n'ai pas montré
les signatures), nous avons une preuve de non-existence.
Et si le nom existe, mais n'a pas de données du type
demandé ? J'interroge mon résolveur sur la localisation
associée au nom www.iis.se :
% dig +dnssec www.iis.se LOC … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 39872 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1 … www.iis.se. 480 IN NSEC xmpp01.iis.se. A AAAA RRSIG NSEC …
Le NOERROR est normal (le nom existe) mais la section Answer est
vide (puisqu'il n'y a pas d'enregistrement de type LOC) et le NSEC
nous dit que le nom existe bien (le nom suivant étant
xmpp01.iis.se.) mais n'a comme type
d'enregistrement que A, AAAA, RRSIG et NSEC. On a donc prouvé que le
LOC n'existe pas.
Bon, tout ça, c'est du DNSSEC classique, tel que normalisé dans les RFC 4034 et RFC 4035. Ça marche, mais cela a des inconvénients, notamment pour les signatures générées dynamiquement. Cela nécessite plusieurs NSEC (il faut aussi montrer qu'il n'y a pas de joker), avec leurs signatures.
CDE (Compact Denial of Existence, alias
black lies) fonctionne (section 3 du RFC) en
calculant un intervalle minimal entre les noms, comme le faisaient
les white lies du RFC 4470. Mais, contrairement à eux, CDE fait partir cet
intervalle du nom demandé. Par exemple, si on demande
foobar.example et que ce nom n'existe pas, les
white lies fabriqueront un NSEC allant de
~.foobaq~.example à
foobar!.example alors que les black
lies de notre RFC feront un NSEC allant de
foobar.example à
\000.foobar.example. Cet intervalle démarrant
au nom de domaine demandé, il ne faut plus jamais renvoyer de
NXDOMAIN, uniquement des NODATA (NOERROR mais avec une section
Answer vide).
Voici un exemple de black lie chez Cloudflare (qui a déployé CDE il y a longtemps) :
% dig +dnssec doesnotexistcertainly.cloudflare.com … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 43853 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1 … ;; AUTHORITY SECTION: doesnotexistcertainly.cloudflare.com. 300 IN NSEC \000.doesnotexistcertainly.cloudflare.com. RRSIG NSEC TYPE128 … ;; Query time: 14 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) (UDP) ;; WHEN: Fri Dec 12 14:10:39 CET 2025 ;; MSG SIZE rcvd: 400
Mais puisqu'on ne renvoie jamais de NXDOMAIN, comment distinguer
un nom qui n'existe pas d'un nom qui n'a simplement pas le type
demandé ? La section 2 du RFC présente le type NXNAME (enregistré avec le numéro 128, d'où le TYPE128
ci-dessus). Sa présence dans le NSEC indique que le nom n'existe
pas. Comparez la réponse ci-dessus avec celle-ci, où le nom existe,
mais pas le type (hex.pm
est chez
Cloudflare et n'a pas d'adresse
IPv6 associée à son nom) :
% dig +dnssec hex.pm AAAA … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 5431 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1 … hex.pm. 1800 IN NSEC \000.hex.pm. A NS SOA HINFO MX TXT LOC SRV NAPTR CERT SSHFP RRSIG NSEC DNSKEY TLSA SMIMEA HIP CDS CDNSKEY OPENPGPKEY SVCB HTTPS URI CAA
La longue liste de types dans le NSEC (mais sans le NXNAME/TYPE128) est due au fait que le serveur, qui génère des NSEC (et des signatures) dynamiquement ne connait pas la vraie liste donc il met tout ce qu'il connait.
Un résolveur qui connait les NXNAME peut donc refabriquer un code de retour NXDOMAIN et l'envoyer à ses clients (section 5 du RFC). Un nouveau booléen dans la question envoyée aux serveurs faisant autorité, le CO (Compact Answers OK) peut être utilisé pour dire au serveur faisant autorité qu'il peut répondre avec un NXDOMAIN, le client DNS qui met le CO indique qu'il saura lire et interpréter le NXNAME. (Le CO a été enregistré à l'IANA, le premier booléen d'une requête EDNS à être enregistré depuis DO il y a vingt-quatre ans.) Cette possibilité de rétablissement du NXDOMAIN ne semble pas très souvent mise en œuvre actuellement.
Notez (section 4) qu'on peut utiliser CDE avec NSEC3 mais que cela n'a aucun intérêt, vu que la compacité de l'intervalle des noms empêche déjà l'énumération des noms.
Enfin, si vous aimez les détails, l'annexe A du RFC discute des raisons des choix faits, et des alternatives étudiées (et même testées dans la nature), mais non retenues.
CDE est largement déployé aujourd'hui, notamment chez Cloudflare,
déjà cité, mais aussi chez d'autres hébergeurs utilisant la
signature dynamique, comme NS1. En logiciel libre, Knot permet le CDE. Il y a
aussi une implémentation (mais qui n'a pas été maintenue
synchrone avec le RFC) dans mon serveur Drink. Elle fut
développée lors d'un hackathon
IETF. Elle n'est pas activée par défaut, il faut changer un
paramètre dans le source (lib/drink/dnssec.ex).
L'article seul
RFC 9868: Transport Options for UDP
Date de publication du RFC : Octobre 2025
Auteur(s) du RFC : J. Touch, C. Heard
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 5 décembre 2025
Des protocoles de transport, comme TCP, ont le concept d'options, ajoutées à l'en-tête et permettant de régler divers paramètres. Ce RFC ajoute ce concept à UDP et standardise quelques options. Désormais, il y a des moyens standards de faire du « ping » en UDP.
Mais comment ajouter des options à un vénérable protocole (UDP a été normalisé en 1980, dans le RFC 768), qui n'a pas de place pour cela dans son en-tête très minimal ? L'astuce est que UDP indique une taille de paquet qui peut être différente de celle indiquée par IP. Si elle est supérieure, les octets ainsi disponibles peuvent stocker des options, à la fin du paquet. Ce sera donc un pied (trailer) et pas un en-tête.
Voici un paquet UDP simplifié (j'ai aussi mis une partie de l'en-tête IP) analysé par tshark :
Internet Protocol Version 6, Src: 2a04:cec0:10fc:5bd8:efd1:79bb:7356:4583, Dst: 2001:db8::1
0110 .... = Version: 6
…
Payload Length: 56
Next Header: UDP (17)
Hop Limit: 64
Source Address: 2a04:cec0:10fc:5bd8:efd1:79bb:7356:4583
Destination Address: 2001:db8::1
User Datagram Protocol, Src Port: 57560 (57560), Dst Port: domain (53)
Source Port: 57560 (57560)
Destination Port: domain (53)
Length: 56
…
UDP payload (48 bytes)
Vous avez vu ? Il y a deux champs qui indiquent la longueur du paquet UDP, un dans l'en-tête IP (Payload length) et un dans l'en-tête UDP (Length). Ici, les deux sont identiques, ce qui est le cas « normal ». Mais s'ils sont différents ? C'est le point de départ de ce RFC. Les options se nicheront dans la différence entre la longueur du paquet UDP et celle du paquet IP qui l'encapsule, dans une zone connue sous le nom de surplus (surplus area). Normalement, elles seront ainsi ignorées de tous les vieux programmes (mais il y a parfois eu des bogues).
Comme TCP (RFC 9293), les protocoles de transport SCTP (RFC 9260) et DCCP (RFC 4340) ont dans leur en-tête un espace réservé pour d'éventuelles options. Pas UDP. C'est ce manque que comble notre RFC. Comme UDP est un protocole sans connexion, ces options ne serviront que pour un seul paquet (alors que TCP peut les garder pour toute la connexion). Des options, dans les autres protocoles de transport, il y en a plein. Pour TCP, le RFC cite par exemple, la dilatation de fenêtres (RFC 7323), l'authentification (RFC 5925) et d'autres. On en trouve pour des protocoles avec état (comme TCP, où elles vont s'appliquer à toute la connexion) ou sans état (comme IP, où elles ne s'appliquent qu'au paquet qui les porte). Comme vu plus haut, seul UDP (RFC 768) n'avait pas le moyen d'ajouter des options.
À quoi vont servir ces options (section 5 du RFC) ? À court
terme, à permettre des mécanismes de
fragmentation, de test (« ping UDP »), etc. À
plus long terme (mais ce n'est pas encore normalisé), elles rendront
possible d'ajouter de l'authentification ou
du chiffrement à UDP (DTLS, RFC 9147 chiffre mais ne protège pas l'en-tête de
la couche Transport). On pourra aussi faire de la découverte de la
MTU du
chemin, comme spécifié dans le RFC 9869. Et enfin, cela
pourra permettre d'augmenter la taille des paquets DNS comme proposé dans
draft-heard-dnsop-udp-opt-large-dns-responses.
La section 6 du RFC spécifie le cahier des charges de ces options UDP :
- UDP est sans état (sans connexion) et doit le rester.
- UDP est unidirectionnel et doit le rester. Les protocoles requête/réponse (comme le DNS) sont bâtis sur UDP mais doivent s'occuper de faire correspondre requêtes et réponses sans l'aide d'UDP.
- Les options UDP n'ont pas de taille maximale (à part celle du paquet UDP lui-même, 65 536 octets).
- Les options UDP ne visent pas à remplacer des protocoles existants. Le « ping UDP » ne cherche pas à être équivalent au ping utilisant ICMP. Après tout, UDP est fait pour être minimal, et il doit le rester.
- Les options UDP ne constituent pas un protocole à elles seules : un protocole situé au-dessus d'UDP va devoir spécifier bien des détails (par exemple le RFC 9869 qui décrit le protocole PLPMTUD).
- Tout le mécanisme est conçu pour qu'un logiciel ancien, qui ne connaisse pas ces options, fonctionne comme aujourd'hui.
Un peu de terminologie avant d'attaquer les détails, notamment (section 3) :
- Option sûre (SAFE option) : option qui pourra être ignorée par un receveur qui ne la comprend pas. Elle ne modifie pas la compréhension du paquet.
- Option non sûre (UNSAFE option) : option qui ne doit pas être ignorée, car elle modifie la compréhension du paquet (par exemple car elle indique qu'il est chiffré).
La description technique de l'emplacement des options figure en section 7 du RFC. Le champ Longueur de l'en-tête UDP, qui a toujours été redondant avec celui d'IP, peut désormais prendre une valeur inférieure à celle du champ dans IP (mais supérieure à huit, la taille de l'en-tête UDP). La différence entre les deux longueurs est la taille du surplus, la zone à la fin du paquet où se logent les options (qui ne sont donc pas dans l'en-être mais dans le pied). Notez qu'il n'y a pas d'obligation que le surplus soit aligné sur des multiples (2 ou 4) d'octets. Si les longueurs IP et UDP sont identiques, c'est qu'il n'y a pas d'options.
La structuration du surplus en options est dans la section 8. Le surplus commence avec un champ de deux octets qui est une somme de contrôle. Cet OCS (Option CheckSum) est une somme de contrôle Internet traditionnelle (RFC 791, section 3.1, et RFC 1071). Pourquoi cette somme de contrôle alors qu'UDP en a déjà une ? Pour détecter les cas où un autre mécanisme jouerait avec la différence des champs Longueur d'IP et d'UDP et aurait son propre pied, distinct de celui normalisé dans notre RFC. Simple somme de contrôle, l'OCS ne joue pas un rôle en sécurité, il ne sert qu'à vérifier que le surplus est bien utilisé conformément à la norme sur les options UDP. (Les options sont ignorées si l'OCS n'est pas correcte, voir la section 14.) La section 18 insiste sur ce point : comme cette distinction entre deux champs Longueur est ancienne, il est possible que certains s'en servaient et il faut donc faire face à la possibilité que des paquets UDP aient des champs Longueur différents sans pour autant avoir des options telles que normalisées ici. L'OCS est donc aussi une sorte de nombre magique mais en plus fort, puisqu'il n'est pas statique.
Comme toujours, il faut prévoir le cas de middleboxes boguées qui calculeraient la somme de contrôle UDP sur tout le paquet IP, au lieu de s'arrêter à la longueur indiquée dans l'en-tête UDP. L'OCS est conçu pour annuler l'effet d'une telle bogue (merveille des sommes de contrôle, qui n'ont pas de dispersion des résultats). La somme de contrôle UDP étant optionnelle (mais c'est évidemment très déconseillé), l'OCS l'est aussi (et peut donc valoir zéro). Rappelez-vous que ce qui marchait avant en UDP doit encore marcher avec les options donc, par défaut, même si l'OCS est incorrect, le paquet doit être transmis aux applications réceptrices.
À propos de middleboxes, le RFC précise aussi (section 16) que les options sont de bout en bout et ne doivent pas être modifiées par les équipements intermédiaires (mais cela risque de rester un vœu pieux). Des tests effectués ont montré que des systèmes d'exploitation courants (Linux, macOS, Windows) n'avaient pas de problème en recevant des paquets UDP contenant des options (section 18). Ils n'envoient à l'application que la partie du paquet indiquée par le champ Longueur d'UDP, et ignorent donc les options, qu'on peut donc envoyer sans craindre de perturber les systèmes pré-existants. Toutefois, au moins un objet connecté (non nommé par le RFC) passe tout le datagramme (y compris, donc, le surplus contenant les options) à l'application. Et au moins un IDS, l'Alcatel-Lucent Brick considère les paquets UDP ayant des options comme des attaques (les IDS sont un des facteurs importants de l'ossification de l'Internet car ils interprètent tout ce qui ne colle pas à leur vision étroite comme une attaque).
Les options suivent la somme de contrôle et la plupart sont encodées selon un classique schéma TLV, comme pour la plupart des options TCP (RFC 9293, section 3.1). Les deux exceptions à cet encodage TLV sont les options NOP (un seul octet, qui vaut un, cette option, comme son nom l'indique, ne sert à rien, à part éventuellement à aligner les données) et EOL (End Of Options, un seul octet, qui vaut zéro, elle indique la fin de la liste d'options). Autrement, les options sont en TLV, le premier octet indiquant le type, la longueur faisant un octet (un mécanisme existe pour des options faisant plus de 255 octets). Les options sûres ont un type de 0 à 191, les autres sont non sûres. Parmi les options sûres enregistrées par notre RFC, outre EOL et NOP, on trouve entre autres (section 11) :
- APC (Additional Payload Checksum), type 2, qui ajoute une somme de contrôle plus forte (CRC32c, la même que celle utilisée dans iSCSI, RFC 3385 et SCTP).
- FRAG (Fragmentation), type 3, qui permet une fragmentation au niveau UDP. Peut se combiner avec MDS (Maximum Datagram Size, type 4), qui indique la taille maximale qu'un récepteur peut accepter sans que le datagramme soit fragmenté.
- REQ (Echo Request, type 6) et RES (Echo Response, type 7) permettent de faire un « ping UDP ». (Plus propre que les trucs abusivement baptisés « ping UDP » comme cet exemple ou celui-ci.)
- TIME, type 8, permet d'envoyer et de recevoir l'heure, sous forme d'une estampille temporelle de quatre octets. C'est l'analogue de l'option TCP Timestamp (RFC 7323, section 3). UDP ne garantit pas que ces estampilles correspondent à l'heure officielle, juste qu'elles seront monotones (toujours croissantes).
- AUTH (Authentication), n'est pas
réellement spécifiée. Son type, 9, est réservé mais les autres
points sont repoussés à un futur RFC, peut-être à partir de
l'Internet-Draft
draft-touch-tsvwg-udp-auth-opt.
Les options EOL, NOP et quelques autres doivent normalement être reconnues par toutes les mises en œuvres des options UDP (cf. section 14).
Et les options non sûres ? Rappelons que ce sont celles qui modifient l'interprétation du contenu du paquet. On y trouve (section 12 du RFC) entre autres :
- UCMP (Unsafe Compression), type 192, pour des contenus comprimés.
- UENC (Unsafe Encryption), type 193, pour des contenus chiffrés.
Ces deux options ne sont pas autrement spécifiées, seul un type est réservé. Le reste devra être précisé dans un RFC ultérieur.
De nouvelles options seront peut-être rajoutées dans le futur au registre des options (section 13 du RFC). La politique IANA (section 26) est « action de normalisation » ou « approbation par l'IESG », donc des procédures assez lourdes (RFC 8126) : il ne sera pas facile d'ajouter des options.
Question mise en œuvre, ce n'est pas forcément trivial à faire soi-même. Pour pouvoir lire et à plus forte raison écrire des options UDP, il faut actuellement court-circuiter UDP et écrire directement au-dessus d'IP (raw sockets) ou pire, dans certains cas, directement sur le réseau. Notre RFC propose des extensions à l'API socket pour lire et écrire les options (avec aussi des variables sysctl) mais je ne connais pas encore de système d'exploitation qui les intègre. Notez que ces API ne permettent pas d'influencer l'ordre des options, et c'est exprès.
Une difficulté supplémentaire vient du fait qu'UDP est sans état, sans connexion. D'une part, les options ne peuvent pas être négociées lors de l'établissement de la connexion (puisqu'il n'y a pas de connexion), d'autre part, elles doivent être répétées dans chaque paquet (puisqu'il n'y a pas d'état). Le RFC précise donc (section 19) qu'il faut ignorer les options qu'on ne connait pas (du moins celles marquées comme sûres). D'autre part il impose qu'on passe les données à l'application même si on ne comprend pas les options. Ah, et aussi, les options UDP sont conçues pour l'unicast essentiellement.
Et leurs conséquences pour la sécurité (section 25 du RFC) ? Fondamentalement, les options UDP ne posent pas plus (ou pas moins…) de problèmes de sécurité que les options TCP, qui sont normalisées depuis longtemps. Comme pour TCP, elles ne sont pas sécurisées par TLS (ici, DTLS, RFC 9147), TLS qui protège uniquement les données applicatives. Si vous voulez les protéger, il faudra attendre la spécification des futures options AUTH (qui fournira à peu près le même service que le AO de TCP, normalisé dans le RFC 5925) et UENC. Ou alors, protégez toute la couche transport avec IPsec (RFC 4301).
Mais il y a un autre danger, dans la façon dont vont être traitées les options UDP par le récepteur. Si celui-ci boucle imprudemment, en attendant juste l'option EOL, le risque de débordement est élevé. Ou si le récepteur alloue de la mémoire en utilisant le champ Longueur d'UDP puis y copie tout le paquet, les options faisant alors déborder son tampon.
Voilà, je n'ai pas tout détaillé, la section 25 est longue, lisez-la.
Un petit point d'histoire (section 4) : pourquoi diable UDP a-t-il ce champ Longueur, alors que celui d'IP suffisait, d'autant plus que l'en-tête UDP est de taille fixe ? Aucun autre protocole de transport ne fait cela (à part peut-être Teredo, RFC 6081). Le RFC note que des historiens de l'Internet ont été consultés mais sans résultat. Les raisons de ce choix (qu'on apprécie aujourd'hui mais qui est resté sans utilité pratique pendant 45 ans) restent mystérieuses. Permettre de placer plusieurs paquets UDP dans un seul datagramme IP ? Pour remplir les paquets de manière à ce qu'ils soient alignés sur des multiples d'octets ? Aucune explication ne semble satisfaisante et les archives sont muettes.
Notez aussi que d'autres propositions avaient été faites pour
ajouter des options à UDP, comme celle décrite dans
l'Internet Draft
draft-hildebrand-spud-prototype.
Autre question que vous vous posez peut-être : et UDP-Lite (RFC 3828) ? Lui aussi jouait avec la différence des champs Longueur d'IP et d'UDP, pour indiquer la partie du paquet couverte par la somme de contrôle. De ce fait, le mécanisme d'options ne peut pas être utilisé pour UDP-Lite (section 17).
Et les mises en œuvre concrètes ? Il n'existe pas, à ma connaissance, de serveurs de test publics sur l'Internet. Mais vous avez une liste des programmes existants (je n'en ai pas vu en Python utilisant Scapy, ce qui serait pourtant une expérience intéressante).
D'autres lectures sur ces options UDP ? Vous avez l'article de Raffaele Zullo et les supports d'un de ses exposés, qui expliquent bien la question. Et, sinon ChatGPT, consulté s'en ne s'en est pas trop mal tiré, inventant un mécanisme qui ressemble à celui de TCP.
L'article seul
Fletcher, l'outil de dessin de schémas de Typst
Première rédaction de cet article le 1 décembre 2025
Vous le savez, j'ai expérimenté récemment l'outil de formatage de textes Typst. Un de ses intérêts est de disposer d'un langage pour réaliser des schémas, nommé Fletcher. Voici quelques points intéressants de Fletcher.
Fletcher est sur le même créneau que des systèmes comme Asymptote (que j'utilise jusqu'à présent), Graphviz ou TikZ : un langage pour décrire les schémas techniques, qui évite de passer du temps avec la souris en essayant de placer ses éléments de schémas au bon endroit. Fletcher est écrit avec le langage de programmation de Typst, et s'appuie sur le système CeTZ.
Sans plus tarder, un exemple de code en Fletcher :
#import "@preview/fletcher:0.5.8" as fletcher: diagram, node, edge
#diagram(
{
node([Un], stroke: 1pt)
node((rel: (1, 1)), [Deux], stroke: 1pt)
node((rel: (-1, 1)), [Trois], stroke: 1pt)
edge(auto, auto, [Par ici], "->")
}
)
Compilé avec typst compile --format png
simple-fletcher-1.typ, il donne :
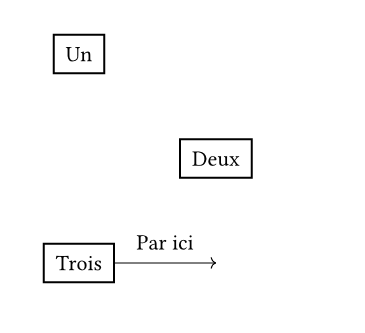
Voyons les détails :
- Il faut importer le paquetage Fletcher (il sera téléchargé la première fois qu'on compile).
- On dessine trois boites ; par défaut, la bordure est de taille nulle donc on demande une bordure d'un point.
- La première boite est, par défaut, placée à l'origine des coordonnées, les deux suivantes sont placées relativement à la boite précédente (l'axe des X va vers la droite, celui des Y vers le bas, ce qui est un peu déconcertant mais c'est documenté).
- On termine avec une flèche, sans s'embêter à indiquer où elle s'accroche donc elle est mise sur le dernier élément dessiné. Notez la façon d'indiquer la forme de la flèche, avec un exemple sous forme d'une chaine de caractères.
Maintenant, si on veut davantage de contrôle sur le placement, on va donner des noms aux objets (et puis on met des valeurs par défaut pour les boites) :
#import "@preview/fletcher:0.5.8" as fletcher: diagram, node, edge
#diagram(
// Valeurs par défaut pour les nœuds
node-stroke: 2pt,
node-shape: fletcher.shapes.house,
{
node([Un], name: <un>)
node((rel: (1, 1)), [Deux], name: <deux>)
node((rel: (-1, 1), to: <un>), [Trois], name: <trois>)
node((rel: (3, 4), to: <deux>), [Quatre], name: <quatre>)
edge(<un>, <deux>, [Par ici], "->")
}
)
Et cela donne : 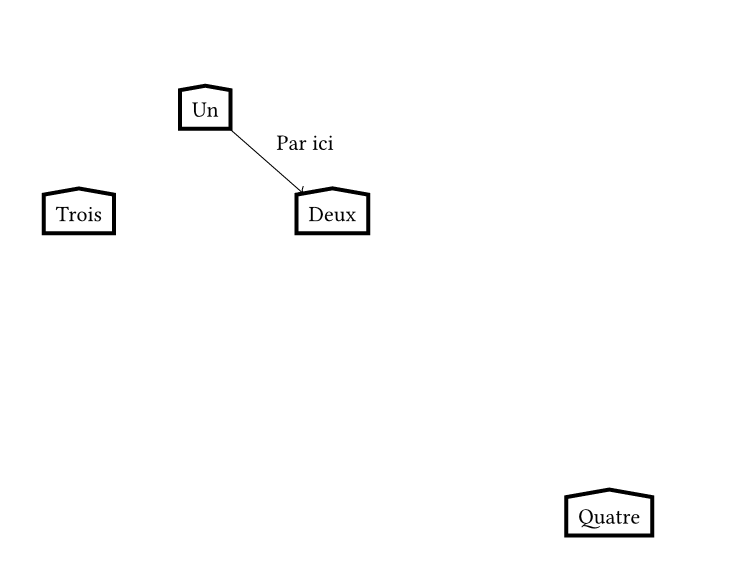
Vous noterez, dans le deuxième essai :
- La boite Trois est désormais relative à la boite Un, pas à la dernière boite placée.
- L'image s'agrandit automatiquement (regardez la boite Quatre, qui est placée assez loin).
- La flèche est explicitement accrochée à deux des boites, et placée automatiquement au bon endroit.
Pour un exemple plus réaliste, je vous ai mis un schéma de la
résolution DNS et
un autre de l'arborescence des noms
de domaine, avec le PDF (ce que produit Typst par défaut) et le
source : fletcher-resolution-dns.pdf, fletcher-resolution-dns.typ, fletcher-arbre-domaines.pdf et fletcher-arbre-domaines.typ. La combinaison de coordonnées
relatives, et de flèches qu'on accroche à des boites, sans se
préoccuper de donner des coordonnées, est très agréable.
Voilà, bien sûr, Fletcher est beaucoup plus riche que cela et vous pouvez faire bien d'autres choses, n'hésitez pas à lire la très complète documentation.
L'article seul
Fiche de lecture : Un pacte avec le diable
Auteur(s) du livre : Michel Tedoldi
Éditeur : Espaces Libres
978-2-226-49957-8
Publié en 2023
Première rédaction de cet article le 1 décembre 2025
Après la Seconde Guerre mondiale, la France a récupéré un certain nombre de scientifiques et d'ingénieurs nazis, notamment pour travailler dans l'aéronautique et le spatial. Un phénomène bien moins connu que la récupération analogue faite par les Étatsuniens.
Car tout le monde sait que von Braun et ses complices ont échappé à toute poursuite après la guerre car les États-Unis avaient besoin d'eux pour construire des missiles, domaine où l'Allemagne était très en avance. L'Union Soviétique a fait pareil, quoique plus discrètement. Et la France, qui, ayant été occupée des années par les nazis, aurait pu hésiter à les embaucher ? Elle l'a fait aussi. Ce petit livre résume ce qu'on sait sur ce recrutement de nazis après 1945. Qui étaient-ils ? Combien ? Que sont-ils devenus ? (Ils sont restés à travailler en France et y sont morts tranquillement.)
Un petit mot sur ma famille, à ce sujet : mon père avait travaillé à Vernon, haut lieu de l'aérospatial français, à l'époque où il y avait encore pas mal d'ex-nazis qui y étaient présents. Ils ne se cachaient pas spécialement, et tout le monde savait donc que la France avait recruté des Allemands. Mais l'affaire a été plutôt refoulée de la mémoire collective. L'un des ingénieurs a même eu une rue à son nom, débaptisée il y a seulement un an.
Même le PCF avait bruyamment approuvé cette embauche, le stalinien Jacques Duclos déclarant dans un discours public à Decize « Ceux qui critiquent l'installation des Allemands à Decize ne pourraient être que des collaborateurs. »
Bref, ce livre est un ajout utile à l'histoire de France.
L'article seul
Typst, un compilateur de texte
Première rédaction de cet article le 19 novembre 2025
Au Capitole du Libre de novembre 2025, j'ai suivi l'exposé de Patrick Massot sur Typst, un concurrent possible de LaTeX. Je ne suis pas un expert de Typst, je n'ai pas encore écrit de vrai texte avec donc ce qui suit est un résumé de l'exposé, agrémenté de quelques essais.
Typst est un compilateur de texte, un système où vous tapez du texte et du formatage avec un éditeur quelconque, texte qui sera ensuite traduit dans des formats de distribution comme PDF. Les avantages de ces compilateurs (ou formatteurs), comme noté par Patrick Massot, sont la reproductibilité, la possibilité de choisir librement son éditeur, la flexibilité, et la possibilité d'automatiser la production de documents. Typst est donc une alternative à LaTeX ou à Pandoc+Markdown. C'est évidemment un logiciel libre, sinon on n'en parlerait pas à Capitole du Libre. Il se veut plus perfectionné que Pandoc+Markdown (par exemple pour des documents complexes avec de la mathématique) et plus simple à utiliser que LaTeX, avec une syntaxe moins tordue (pas difficile) et des messages d'erreur plus clairs (pas difficile non plus).
Voici un très simple document (tant que ça reste aussi simple, la syntaxe ressemble vaguement à Markdown) :
= J'essaie Typst Ça marche. Je peux *insister* ou faire des listes : + liberté + égalité + fraternité == Des maths $E = m c^2$ == Du texte plus long #text(red)[ On peut colorier. ] J'ai pas envie de tout taper. #lorem(100)
On le compile :
% typst compile essai.typ
Et on obtient un PDF.
Comme promis, les messages d'erreur sont clairs et précis, grosse différence avec LaTeX :
% typst compile essai.typ error: unclosed delimiter ┌─ essai.typ:15:9 │ 15 │ #set text( │ ^
Si on veut de l'HTML (option actuellement présentée comme expérimentale et, comme vous le verrez dans l'exemple suivant, la mathématique n'est pas traitée) :
% typst compile --features html --format html essai.typ warning: html export is under active development and incomplete = hint: its behaviour may change at any time = hint: do not rely on this feature for production use cases = hint: see https://github.com/typst/typst/issues/5512 for more information warning: equation was ignored during HTML export ┌─ essai.typ:11:0 │ 11 │ $e = m c^2$ │ ^^^^^^^^^^^
Aucun CSS n'est produit, le texte en rouge n'est donc pas colorié. Bref, la production de HTML est à l'heure actuelle très limitée. Pour cela, Pandoc est une meilleure solution, car il sait lire le Typst, même les formules mathématiques :
% pandoc -i essai.typ -o essai.html
Typst dispose d'innombrables autres possibilités, lisez la documentation pour en avoir une idée. On peut créer ses propres fonctions (Typst inclut un langage de programmation complet), définir des gabarits, etc. Il existe déjà plein de paquetages rigolos pour Typst sur le dépôt officiel, notamment pour l'écriture d'articles techniques et scientifiques. Voyons un exemple avec le paquetage atomic :
// (Ceci est un commentaire.) https://typst.app/universe/package/atomic #import "@preview/atomic:1.0.0" = Un essai d'un paquetage Typst *atomic* permet de dessiner des atomes, avec leurs électrons. Ici, le plutonium. // Cf. Article Wikipédia « Électrons par niveau d’énergie 2, 8, 18, 32, 24, 8, 2 » #atomic.atom(94,239, "Pu", (2, 8, 18, 32, 24, 8, 2))
(Attention, à la première utilisation, il faut être connecté à l'Internet, le paquetage étant téléchargé.) Compilé, cela donnera ce joli PDF.
De la même façon, vous pouvez faire des supports de présentation, avec touying qui est donc un concurrent de Beamer :
#import "@preview/touying:0.6.1": * #import themes.simple: * #show: simple-theme = Mon exposé Le sujet de l'exposé == Première diapo Je mets du texte. == Deuxième diapo Je continue. Et encore.
Ah, et comment ai-je installé Typst ? C'est bien documenté. Il n'y a apparemment pas de paquetage de Typst existant, pour aucun système, mais Typst fournit des binaires (déjà compilés). Comme je préfère vérifier que les sources compilent, je l'ai compilé moi-même :
% cargo install --locked typst-cli
Typst est écrit en Rust et compiler du Rust est souvent une expérience frustrante. Sur un Ubuntu stable :
error: cannot install package `typst-cli 0.14.0`, it requires rustc 1.88 or newer, while the currently active rustc version is 1.75.0 `typst-cli 0.11.1` supports rustc 1.74
Eh oui, comme trop souvent avec Rust, il faut la toute, vraiment toute dernière version du compilateur, le langage changeant tout le temps. (J'ai donc fait mes tests sur une Debian unstable.)
Est-ce que je vais utiliser Typst ? Je ne sais pas encore. Le logiciel est déjà très utilisable, en tout cas sur un système d'exploitation très récent. Je vais faire les supports de ma présentation au prochain SplinterCon en Typst, ce sera une occasion de tester. L'une de mes inquiétudes est la gestion du projet. Typst est à 100 % du logiciel libre (licence Apache) mais son développement est apparemment étroitement contrôlé par une seule entreprise, qui commercialise des extensions privatrices à Typst et dont il n'est pas certain qu'ils acceptent d'ouvrir le projet.
Quelques autres ressources :
- Le tutoriel officiel est très bien.
- Typst est bien documenté.
- Les exemples utilisés dans la présentation de Patrick Massot :
git clone https://codeberg.org/pmassot/typst_cdl2025.
L'article seul
Capitole du Libre 2025 (et un exposé sur les types de média)
Première rédaction de cet article le 19 novembre 2025
Dernière mise à jour le 19 décembre 2025
Les 15 et 16 novembre s'est tenue à
Toulouse Capitole du Libre,
conférence consacrée aux logiciels
libres mais pas que. Quelques notes suivent, entre autres
sur l'exposé que j'ai fait sur les types de
média (comme text/html pour ce blog).
Le poète toulousain Louis-Catherine Vestrepain, dont la statue
n'est pas trop éloignée du lieu où se
tient Capitole du Libre : 
Capitole du Libre, c'est gros, avec beaucoup de monde, et un programme chargé (93 exposés, 1 400 participants, 10 kg de café, 500 repas aux camions de nourriture, 10 mètres carrés de pizzas pour les bénévoles). Je ne vais donc pas parler de tout. Déjà, j'ai suivi un exposé et un atelier qui font l'objet d'articles séparés :
- L'exposé sur le compilateur de texte Typst, un concurrent de LaTeX,
- L'atelier (donc, avec de la pratique) sur le mécanisme eBPF, qui permet de développer plus facilement des programmes dans le noyau Linux, ici un programme qui intercepte et autorise (ou pas) les requêtes DNS.
Autres moments passionnants :
- L'exposé de Natouille sur « C’est quoi l’UX design et pourquoi le libre aurait à y gagner en intégrant ces profils ? », où elle rappelait que la conception d'UX, ce n'est pas juste pour les cliquodromes et que tout logiciel peut avoir intérêt à avoir une démarche UX, et, entre autres, que les développeureuses devraient parler avec leurs utilisateurices et les observer. « Le design, c'est faire des produits utilisables, limiter frictions, risques et déceptions » et « Il y a utile, utilisable et utilisé. Instagram est utilisé, le site des impôts est utile, un site / logiciel bien conçu est utilisable ».
- La présentation par Bookynette de l'escape game (en cartes) de l'April pour faire connaitre le logiciel libre.
- L'exposé sur Ceph m'a plutôt convaincu que cette solution de stockage réparti n'était pas pour moi, pas parce que le logiciel n'est pas bon mais parce qu'il traite un problème bien précis qui n'est pas forcément le mien : avoir des données qui soient toujours disponibles, en les stockant dans des endroits bien distincts. Chaque fichier confié à Ceph est divisé en objets et chaque objet se retrouve sur plusieurs disques de plusieurs serveurs. L'interface de Ceph peut être du S3, un système de fichiers accessible comme un partage réseau ou même un block device. Ceph en lui-même ne remplace pas les sauvegardes. On peut toutefois utiliser des snapshots qui, à condition qu'ils ne soient pas accessibles aux clients, protègent contre erreurs humaines et rançongiciels.
- La présentation de Skeptikon « Le logiciel libre est un projet politique » insistait sur la lutte contre les mensonges et le discours anti-scientifique. Dans le contexte de la montée de l'extrême-droite, le logiciel libre est une des armes pour préserver sa liberté.
- Et puis, il n'a pas été présenté à Capitole du Libre mais saviez-vous qu'il existe un langage de programmation conçu et maintenu à Toulouse, Smala ?
De mon côté, j'ai fait un exposé sur les types de
médias (également appelés types MIME, vous savez, les
text/plain, image/png et
autres haptics/ivs). Voici les supports et
leur source
(en LaTeX, pas en Typst) et la vidéo.
Et j'ai participé à la table ronde « Souveraineté numérique : pourquoi le logiciel libre est stratégique », avec Ludovic Dubost et Nicolas Vivant, animée par Aline Paponaud. L'idée (assez consensuelle parmi les participants) était qu'il n'y a pas de vraie souveraineté sans logiciel libre, entre autres parce que remplacer un GAFA étatsunien par un GAFA français qui ferait exactement la même chose n'a pas beaucoup d'intérêt. Le logiciel libre permet la souveraineté de l'utilisateurice, pas seulement celle de l'État.
Photos et vidéos sont disponibles, les
photos sur https://photos.capitoledulibre.org/https://videos.capitoledulibre.org/
Ah, et le quotidien la Dépêche a fait un article très louangeur.
Bref, soutenez Capitole du Libre :  .
.
L'article seul
Atelier sur eBPF au Capitole du Libre
Première rédaction de cet article le 19 novembre 2025
Dernière mise à jour le 20 novembre 2025
Au Capitole du Libre de novembre 2025, j'ai participé à un passionnant atelier de Maxime Chevallier et Alexis Lothoré sur la programmation réseau en eBPF. Le but était de mettre en œuvre un bloqueur de publicité (ou autre contenu qu'on ne voulait pas voir), agissant via les requêtes DNS, que le programme va intercepter et analyser.
eBPF désigne à la fois un jeu d'instructions machine, normalisé dans le RFC 9669, et un système permettant de produire des programmes utilisant ce jeu d'instructions, et des les installer dans le noyau Linux. eBPF permet ainsi d'ajouter des fonctions au noyau, sans modifier et recompiler celui-ci (ce qui est vraiment une tâche difficile) et sans redémarrer la machine. Je vous renvoie à mon article sur le RFC 9669 pour plus de détail. Un exemple d'utilisation de eBPF dans le contexte du DNS est dans le serveur NSD.
Le cahier des charges de l'atelier était d'écrire (en C) et de faire tourner un programme
eBPF qui va regarder toutes les requêtes DNS de la machine, les comparer à une liste
de blocage, et stopper ces requêtes si le nom de domaine est dans cette liste. Si vous
avez un peu de temps, je recommande de faire l'exercice vous-même,
téléchargez le support de l'atelier (git clone
https://github.com/bootlin/ebpf-workshop-cdl), lisez le
fichier Readme.md (il est en anglais) et
essayez. Cet article que vous lisez est plutôt destiné aux gens qui
veulent la solution.
Comme le système eBPF sur Linux n'est pas d'une clarté parfaite,
il vaut mieux commencer par un programme trivial. Attention, comme
indiqué dans le Readme.md, ça marchera… ou pas,
selon la version exacte du système d'exploitation que vous utilisez
(j'ai tout fait sur une Ubuntu
stable, la version 24.04). Quelques paquetages à
installer :
% sudo apt install linux-tools-common build-essential clang libbpf-dev
Après cela, si, quand vous essayez de lancer bpftool, vous avez :
% bpftool
WARNING: bpftool not found for kernel 6.14.0-112033
You may need to install the following packages for this specific kernel:
linux-tools-6.14.0-112033-tuxedo
linux-cloud-tools-6.14.0-112033-tuxedo
You may also want to install one of the following packages to keep up to date:
linux-tools-tuxedo
linux-cloud-tools-tuxedo
N'essayez pas d'installer les paquetages cités, ça ne servira sans doute pas. À la place, installez à la main :
% git clone --recurse-submodules https://github.com/libbpf/bpftool.git % cd src % make % sudo make install
Maintenant, écrivons le programme trivial qui ne fait pas grand'chose :
% cat hello.bpf.c
#include <linux/bpf.h>
#include <linux/pkt_cls.h>
#include "bpf/bpf_helpers.h"
#include "bpf/bpf_endian.h"
SEC("tc")
int hello(struct __sk_buff *skb)
{
bpf_printk("Hello, world !");
return TC_ACT_OK;
}
char __license[] SEC("license") = "GPL";
Ce programme crée une fonction (qui sera donc exécutée par le noyau), qui sera appelée à chaque paquet réseau et affichera le classique « Bonjour, tout le monde », avant de laisser passer le paquet. Compilons-le en eBPF :
% clang -Wall -g -O1 -target bpf -c hello.bpf.c -o hello.bpf.o
Pour des raisons que je ne comprends pas bien, les options
-g et surtout -On avec n > 0
semblent indispensables. Apparemment (c'est peu documenté), l'optimisation est
nécessaire pour retirer du code qui, autrement, serait refusé par le
vérificateur. Regardez la documentation « Clang
implementation notes » et l'article
« Building BPF
applications with libbpf-bootstrap » (« -g is mandatory to make Clang emit BTF information. -O2 is also necessary for BPF compilation).
La compilation va produire du code eBPF :
% file hello.bpf.o hello.bpf.o: ELF 64-bit LSB relocatable, eBPF, version 1 (SYSV), with debug_info, not stripped
Le désassembleur par défaut ne connait pas eBPF :
% objdump -d hello.bpf.o hello.bpf.o: file format elf64-little objdump: can't disassemble for architecture UNKNOWN!
Mais il y en a un autre qui marche (suivez le RFC 9669) mais je le trouve moins joli :
% llvm-objdump -d hello.bpf.o
hello.bpf.o: file format elf64-bpf
Disassembly of section tc:
0000000000000000 <hello>:
0: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0x0 ll
2: b7 02 00 00 0f 00 00 00 r2 = 0xf
3: 85 00 00 00 06 00 00 00 call 0x6
4: b7 00 00 00 00 00 00 00 r0 = 0x0
5: 95 00 00 00 00 00 00 00 exit
Bon, ce n'est pas tout de produire un binaire eBPF, il faut le
charger dans le noyau, et dire au noyau de l'exécuter pour chaque
paquet sortant. Il existe plusieurs méthodes pour cela (on peut
aussi écrire son propre programme qui fait le chargement), on va
utiliser tc,
et attacher le code eBPF à l'interface réseau active, ici
wlp1s0 :
% sudo tc qdisc add dev wlp1s0 clsact % sudo tc filter add dev wlp1s0 egress bpf direct-action object-file hello.bpf.o sec tc
(La syntaxe de tc est merveilleuse. Sur les noyaux Linux plus
récents bpftool prog load fichier.o chemin
suivi de bpftool net attach tcx_egress pinned chemin dev
interface devrait pouvoir charger puis attacher des
programmes, sans utiliser tc.) Une fois que tout cela est fait sans erreur, on peut afficher les
messages :
% sudo bpftool prog tracelog irq/80-iwlwifi:-928 [011] b.s3. 200018.139564: bpf_trace_printk: Hello, world ! irq/81-iwlwifi:-929 [008] b.s3. 200018.139564: bpf_trace_printk: Hello, world ! Socket Thread-576739 [000] b..1. 200018.139832: bpf_trace_printk: Hello, world ! Socket Thread-576739 [000] b..1. 200018.139976: bpf_trace_printk: Hello, world ! …
Et voilà, à chaque paquet sortant (la directive egress dans l'appel à tc), on a un message affiché.
Comme eBPF inclut un vérificateur qui examine le code avant de l'exécuter (pour éviter qu'un programme eBPF bogué ne plante tout le noyau), des erreurs apparemment innocentes (comme d'aller visiter de la mémoire en dehors de nos variables) va se traduire par des erreurs au chargement, assez difficiles à déboguer :
libbpf: prog 'dns_filter': BPF program load failed: Permission denied libbpf: prog 'dns_filter': -- BEGIN PROG LOAD LOG -- 0: R1=ctx() R10=fp0 ; int dns_filter(struct __sk_buff *skb) @ dns-filter.bpf.c:107 0: (bf) r7 = r1 ; R1=ctx() R7_w=ctx() 1: (b7) r6 = 0 ; R6_w=0 ... 124: (bf) r3 = r1 ; R1_w=scalar(id=253) R3_w=scalar(id=253) 125: (0f) r3 += r2 ; R2_w=0 R3_w=scalar(id=253+0) 126: (71) r3 = *(u8 *)(r3 +0) R3 invalid mem access 'scalar' processed 9460 insns (limit 1000000) max_states_per_insn 4 total_states 129 peak_states 129 mark_read 128 -- END PROG LOAD LOG -- libbpf: prog 'dns_filter': failed to load: -13 libbpf: failed to load object 'dns-filter.bpf.o' Unable to load program
Si vous voyez cela, dites-vous que votre programme doit être trop laxiste et, pour reprendre une expression utilisée par les animateurs de l'atelier, qu'il jardine en dehors de ses plate-bandes.
Maintenant, revenons au vrai projet. L'atelier était prévu pour
une découverte progressive, et c'est ce que vous ferez si vous
suivez le support de l'atelier mentionné plus tôt (git clone
https://github.com/bootlin/ebpf-workshop-cdl). Ici, je vais
simplement présenter le résultat final. Mon code complet (légèrement
différent de celui qui figure en correction dans les documents de
l'atelier) est dns-filter.bpf.c
La liste des domaines bloqués est un dictionnaire, structure de données fournie par eBPF pour communiquer entre le programme dans le noyau, et l'extérieur :
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 2);
__type(key, int);
__type(value, char[253]);
} blocklist SEC(".maps");
On va utiliser beaucoup de structures de données TCP/IP dont la
description est déjà fournie par Linux (comme struct
udphdr pour un en-tête UDP). Il n'y en a apparemment pas pour le DNS,
donc on la crée :
struct dnshdr {
__be16 trans_id;
__be16 flags;
__be16 nr_quest;
__be16 nr_answ;
__be16 nr_auth_rr;
__be16 add_rr;
};
Pour l'analyse des paquets, on va charger les octets dans nos
structures de données, à partir d'un index (la variable
offset) avec la fonction BPF
bpf_skb_load_bytes. Voici les étapes :
/* Ce paquet est-il un paquet IP ? Chargeons-le dans ethdhr avant de
regarder son champ Protocol. */
ret = bpf_skb_load_bytes(skb, offset, ðhdr, sizeof(ethhdr));
if (ret) {
return TC_ACT_OK;
}
if ((ethhdr.h_proto != __bpf_constant_htons(ETH_P_IPV6)) &&
(ethhdr.h_proto != __bpf_constant_htons(ETH_P_IP))) {
return TC_ACT_OK;
}
Si une fonction échoue (j'ai omis ce test par la suite mais dans le vrai code, il faut le mettre, rappelez-vous que le vérificateur vous surveille), ou bien si le paquet n'est pas de l'IP, on le laisse passer (on renvoie OK à tc). Ensuite, après avoir sauté l'en-tête IP (attention, il n'a pas la même taille en IPv4 et IPv6), on regarde si c'est bien de l'UDP, et s'il utilise bien le port 53 du DNS :
if (l4_proto != IPPROTO_UDP) {
return TC_ACT_OK;
}
ret = bpf_skb_load_bytes(skb, offset, &udph, sizeof(udph));
if (__bpf_constant_ntohs(udph.dest) != 53) {
return TC_ACT_OK;
}
On va ensuite récupérer le nom de domaine demandé (attention à l'analyse d'un paquet DNS, lisez bien le RFC 9267) :
offset += sizeof(dnsh); ret = parse_query(skb, offset, query, 253); ctx.query = query;
On va ensuite tester ce nom query pour voir
s'il est dans la liste de blocage, avec
bpf_for_each_map_elem. Notez le code de retour
TC_ACT_SHOT, qui dit à tc de jeter le paquet
sans autre forme de procès.
bpf_for_each_map_elem(&blocklist, dns_check, &ctx, 0);
if (ctx.match) {
bpf_printk("*REJECTED* DNS query of %s", query);
return TC_ACT_SHOT;
}
bpf_printk("Accepted DNS query of %s", query);
return TC_ACT_OK;
Reste un petit détail : il faut peupler cette liste de blocage
(la variable blocklist, de type
dictionnaire). Une méthode possible est
d'utiliser la commande bpftool mais, évidemment, en vrai, on
écrirait un programme avec une interface utilisateur plus agréable :
% sudo bpftool map update name blocklist key 0 0 0 0 value $(printf '%-253s' x.com | tr ' ' '\0' | xxd -i -c 253| tr -d ,)
Armé de tout cela, on peut utiliser cette suite de commandes pour compiler le programme, attacher l'eBPF via tc, remplir la liste de blocage et regarder le résultat :
#!/bin/sh sudo tc qdisc del dev wlp1s0 clsact sudo tc qdisc add dev wlp1s0 clsact clang -Wall -g -O1 -target bpf -c dns-filter.bpf.c -o dns-filter.bpf.o sudo tc filter add dev wlp1s0 egress bpf direct-action object-file dns-filter.bpf.o sec tc sudo bpftool map update name blocklist key 0 0 0 0 value $(printf '%-253s' x.com | tr ' ' '\0' | xxd -i -c 253| tr -d ,) sudo bpftool map update name blocklist key 1 0 0 0 value $(printf '%-253s' facebook.com | tr ' ' '\0' | xxd -i -c 253| tr -d ,) sudo bpftool prog tracelog
Testons-le :
% ping facebook.com ping: facebook.com: Temporary failure in name resolution % ping bootlin.com PING bootlin.com (87.98.181.233) 56(84) bytes of data. 64 bytes from bootlin.com (87.98.181.233): icmp_seq=1 ttl=49 time=15.8 ms
Et, affiché par bpftool :
systemd-resolve-1112 [000] b..1. 208052.900167: bpf_trace_printk: *REJECTED* DNS query of facebook.com systemd-resolve-1112 [000] b..1. 208052.900183: bpf_trace_printk: *REJECTED* DNS query of facebook.com systemd-resolve-1112 [005] b..1. 208264.967434: bpf_trace_printk: Accepted DNS query of bootlin.com
Objectif atteint. On peut aller boire une bière. Notez que vous pouvez afficher la liste de blocage :
% sudo bpftool map dump name blocklist
[{
"key": 0,
"value": "x.com"
},{
"key": 1,
"value": "facebook.com"
}
]
Quelques détails toutefois. D'abord, le programme de filtrage étant sommaire, il ne bloque que le nom exact dans la liste, pas ses sous-domaines :
% dig facebook.com ;; communications error to 127.0.0.53#53: timed out … ;; no servers could be reached % dig www.facebook.com … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 54041 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: www.facebook.com. 2724 IN CNAME star-mini.c10r.facebook.com. star-mini.c10r.facebook.com. 29 IN A 157.240.253.35 ;; Query time: 22 msec ;; SERVER: 127.0.0.53#53(127.0.0.53) (UDP) ;; WHEN: Mon Nov 17 16:08:00 CET 2025 ;; MSG SIZE rcvd: 90
Corriger cette limite est laissé au lecteur ou à la lectrice (notez toutefois que dans l'atelier, il y avait environ vingt participants et pas de participante).
Ensuite, puisque tc va purement et simplement jeter le paquet, le client DNS n'aura aucune information, réessaiera et finira par laisser tomber mais au bout d'un délai qui est certainement pénible pour l'utilisateur. Il vaudrait mieux fabriquer une réponse mensongère, genre NXDOMAIN. Je ne suis pas sûr que cela soit facilement faisable avec tc mais il existe d'autres façons d'exécuter de l'eBPF donc le problème est certainement soluble.
Enfin, le DNS ne marche pas que sur UDP, il fonctionne aussi sur TCP (RFC 7766). Le programme ci-dessus peut donc être facilement contourné :
% dig @9.9.9.9 facebook.com
;; communications error to 9.9.9.9#53: timed out
…;; no servers could be reached
% dig +tcp @9.9.9.9 facebook.com
…
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 24690
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
…
;; ANSWER SECTION:
facebook.com. 30 IN A 57.144.222.1
;; Query time: 7 msec
;; SERVER: 9.9.9.9#53(9.9.9.9) (TCP)
;; WHEN: Mon Nov 17 16:16:59 CET 2025
;; MSG SIZE rcvd: 63
Là encore, si vous voulez perfectionner ce programme, n'hésitez pas (mais c'est plus difficile, une requête DNS peut se retrouver répartie dans deux paquets IP différents).
Merci aux organisateurs de cet excellent atelier, Alexis Lothoré et Maxime Chevallier, et à Quentin Monnet pour un déboguage de cet article.
L'article seul
Cafouillage DNSSEC sur un de mes domaines personnels
Première rédaction de cet article le 6 novembre 2025
Dernière mise à jour le 8 novembre 2025
Ce matin, si vous avez testé, un de mes domaines personnels,
bortzmeyer.fr, présentait des problèmes
DNSSEC. Que s'est-il passé ? Était-ce de ma
faute ? Va-t-on tous mourir ?
Le signalement a été fait par un collègue (via
Matrix puisqu'il était en télétravail et pas
moi) : son résolveur DNS
répondait SERVFAIL (SERver FAILure) pour
l'enregistrement de type TXT de
bortzmeyer.fr. C'est le type utilisé pour
SPF donc c'est
ennuyeux (le domaine principal, bortzmeyer.org,
avait le même problème) :
% dig bortzmeyer.fr TXT ; <<>> DiG 9.20.15-1~deb13u1-Debian <<>> bortzmeyer.fr TXT ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 28082 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ; EDE: 6 (DNSSEC Bogus) ;; QUESTION SECTION: ;bortzmeyer.fr. IN TXT ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) (UDP) ;; WHEN: Thu Nov 06 08:17:48 UTC 2025 ;; MSG SIZE rcvd: 48
On voit que c'est un problème DNSSEC puisque l'EDE (Extended DNS Error, cf. RFC 8914) nous le dit (« 6 (DNSSEC Bogus) ») et aussi parce que, si on désactive la validation (cd = Checking Disabled), ça marche :
% dig +cd bortzmeyer.fr TXT ; <<>> DiG 9.20.15-1~deb13u1-Debian <<>> +cd bortzmeyer.fr TXT ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 44332 ;; flags: qr rd ra cd; QUERY: 1, ANSWER: 5, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ; EDE: 6 (DNSSEC Bogus) ;; QUESTION SECTION: ;bortzmeyer.fr. IN TXT ;; ANSWER SECTION: bortzmeyer.fr. 45 IN TXT "DNS is innocent" bortzmeyer.fr. 45 IN TXT "v=spf1 mx -all" bortzmeyer.fr. 45 IN TXT "BTC" "1HtNJ6ZFUc9yu9u2qAwB4tGdGwPQasQGax" bortzmeyer.fr. 45 IN RRSIG TXT 13 2 86400 ( 20251113173453 20251030142433 32088 bortzmeyer.fr. J1arZUBP+G5nc54zetyD45rqDyURJeZyFjRRkixQrPok BPxNkyt1RHzdH78a0rM93Zzu0q+N/zzxMQScl0KVHw== ) bortzmeyer.fr. 45 IN RRSIG TXT 13 2 86400 ( 20251113215344 20251030142433 32088 bortzmeyer.fr. bWAlKMSQPDALOeEmwwfh47qGjloBK3YRH3rGydVJBis4 lFIsIsE09bkqviBiGyjNqpS/loFaiMS4FRIeh06jwg== ) ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) (UDP) ;; WHEN: Thu Nov 06 08:17:51 UTC 2025 ;; MSG SIZE rcvd: 372
Le résultat de dig donne aussi une première explication : il y a deux signatures DNSSEC, faites avec la même clé, la 32088. Ce n'est pas normal. (Les enregistrements des autres types, comme SOA ou MX, n'avaient pas de problème.)
Le test avec Zonemaster montrait que les enregistrements NSEC3, qui servent à prouver la non-existence d'un nom ou d'un type d'enregistrement, étaient également cassés. Le test avec DNSviz donne une idée du problème : « RRSIG bortzmeyer.fr/TXT alg 13, id 32088: The cryptographic signature of the RRSIG RR does not properly validate. ».
Un test avec les sondes RIPE Atlas montre que le problème n'est pas local. Toutes les sondes utilisant un résolveur DNS validant voient le problème (les seules où ça marche sont celles qui ne valident pas) :
% blaeu-resolve --displayvalidation --requested 200 --type TXT bortzmeyer.fr [ERROR: SERVFAIL] : 147 occurrences ["btc" "1htnj6zfuc9yu9u2qawb4tgdgwpqasqgax" "dns is innocent" "v=spf1 mx -all"] : 31 occurrences Test #136108974 done at 2025-11-06T08:24:58Z
L'explication du problème a été trouvée en examinant les fichiers de zone, avant et après la signature. Dans le fichier non signé, celui que j'édite, on trouve cette ligne :
; Type WALLET, enregistré à l'IANA, mais pas encore connu des logiciels @ IN TYPE262 \# 39 03425443 223148744E4A365A465563397975397532714177423474476447775051617351476178
Mais dans le fichier signé par OpenDNSSEC, on trouve :
bortzmeyer.fr. 86400 IN TXT "BTC" "1HtNJ6ZFUc9yu9u2qAwB4tGdGwPQasQGax"
Le type 262 (WALLET) est devenu un type 16 (TXT). Ce n'est pas du tout normal, c'est clairement une bogue du signeur d'OpenDNSSEC (la bibliothèque ldns, voir plus loin). Creusons un peu. Le type WALLET est un type d'enregistrement, et ce type est officiellement enregistré à l'IANA. Cela fait plus d'un an qu'il est annoncé dans mes domaines personnels. Comme, à l'époque, il n'était pas connu des logiciels, j'ai utilisé la syntaxe des types inconnus, syntaxe normalisée depuis plus de vingt ans, dans le RFC 3597. La traduction en TXT n'a pas de sens, car, si l'enregistrement de type WALLET a bien des données structurées comme le TXT, c'est un type différent. Le signeur a apparemment calculé une signature pour les TXT, une pour le WALLET, puis traduit le WALLET en TXT, cassant tout (les signatures s'appliquent à un ensemble d'enregistrements, pas à un enregistrement unique, donc deux TXT n'ont qu'une signature) :
bortzmeyer.fr. 86400 IN TXT "v=spf1 mx -all" bortzmeyer.fr. 86400 IN TXT "DNS is innocent" bortzmeyer.fr. 86400 IN RRSIG TXT 13 2 86400 20251113215344 20251030142433 32088 bortzmeyer.fr. bWAlKMSQPDALOeEmwwfh47qGjloBK3YRH 3rGydVJBis4lFIsIsE09bkqviBiGyjNqpS/loFaiMS4FRIeh06jwg== bortzmeyer.fr. 86400 IN TXT "BTC" "1HtNJ6ZFUc9yu9u2qAwB4tGdGwPQasQGax" bortzmeyer.fr. 86400 IN RRSIG TXT 13 2 86400 20251113173453 20251030142433 32088 bortzmeyer.fr. J1arZUBP+G5nc54zetyD45rqDyURJeZyF jRRkixQrPokBPxNkyt1RHzdH78a0rM93Zzu0q+N/zzxMQScl0KVHw==
C'est ce fichier erroné (l'erreur cassait aussi les chaines NSEC3) qui a été produit et distribué aux serveurs faisant autorité, provoquant les problèmes détectés. La rupture des NSEC3 se voyait lorsqu'on demandait un nom non existant (ici avec les sondes Atlas) :
% blaeu-resolve --displayvalidation --requested 200 --type TXT doesnotexist.bortzmeyer.fr [ERROR: SERVFAIL] : 144 occurrences [ERROR: NXDOMAIN] : 28 occurrences Test #136110101 done at 2025-11-06T08:35:32Z
Ce problème a été signalé sur la liste de diffusion d'OpenDNSSEC. Notez que ce logiciel est en fin de vie (son successeur, Cascade, est actuellement en version alpha) donc je ne sais pas encore si la bogue sera traitée.
Pour réparer le problème, j'ai retiré l'enregistrement WALLET et tout remarche. Ça va mieux (ici, certains résolveurs avaient encore les données erronées dans leur mémoire) :
% blaeu-resolve --displayvalidation --requested 200 --type TXT bortzmeyer.fr ["dns is innocent" "v=spf1 mx -all"] : 65 occurrences [ (Authentic Data flag) "dns is innocent" "v=spf1 mx -all"] : 128 occurrences [ERROR: SERVFAIL] : 4 occurrences [] : 1 occurrences Test #136145680 done at 2025-11-06T14:29:36Z
Le plus curieux est que cette bogue se soit déclenchée en l'absence de tout changement. Douze jours auparavant, il y avait le même fichier de zone (l'enregistrement WALLET datait de plus d'un an) et tout allait bien. Une mise à jour de ldns a apoporté la bogue.
Celle-ci a été signalée, bogue ldns #285 et corrigée mais pas encore forcément déployée partout.
Quelle(s) leçon(s) à en tirer ? Que l'informatique, c'est compliqué, que les logiciels ont des bogues et que, si on est très intolérant aux problèmes, il ne faut pas chercher les cas exotiques. Et que le bon fonctionnement de l'Internet ne repose pas sur des règles bureaucratiques et des processus mais sur la réactivité, à la fois pour signaler les problèmes (merci à Marc van der Wal pour cela), et pour les traiter lorsqu'ils sont signalés.
L'article seul
Fiche de lecture : Les génies des mers
Auteur(s) du livre : Bill François
Éditeur : Champs
978-2-0804-9396-5
Publié en 2023
Première rédaction de cet article le 5 novembre 2025
Vous aimez les trucs qu'il y a dans l'eau, genre poissons, langoustes ou autres bestioles bien plus bizarres ? Pas pour les manger, non, mais pour s'instruire. Dans ce livre très vivant, vous apprendrez certainement plein de choses sur les habitant·es des mers.
L'auteur raconte les caractéristiques les plus étonnantes d'un bon nombre de « génies des mers » (connaitre un peu de physique peut aider, car l'auteur utilise souvent des concepts de cette science). Comment l'exocet arrive à « voler » (divulgâchage : il ne vole pas) ; pourquoi n'y a-t-il pas de petits animaux à sang chaud dans les mers ; comment le cachalot gère sa respiration avant de plonger (autre divulgâchage : il ne remplit pas ses poumons d'air, cela l'empêcherait de plonger) ; pourquoi les torpilles qui vivent dans l'Amazone produisent du courant sous une tension plus élevée ; pourquoi le requin du Groenland vit si vieux… Et il y en a beaucoup d'autres, parfois connus, parfois inconnus (de moi).
C'est bien écrit, très dynamique, et, après l'avoir lu, vous aurez envie de plonger dans l'océan le plus proche pour aller voir de vous-même.
L'article seul
Noms de domaines internationalisés : affichage pendant un transfert
Première rédaction de cet article le 3 novembre 2025
Puisque je suis occupé à transférer beaucoup de noms de domaine vers un autre Bureau d'Enregistrement (BE), c'est l'occasion de se demander « et si c'est un nom de domaine internationalisé, que se passe-t-il ? ».
Sur les transferts d'un BE à un autre, j'ai déjà commis un article sur ce
sujet. Mais j'ai dû, depuis, transférer un IDN,
potamochère.fr. Vous
savez que les IDN sont, pour des raisons complexes (et non, ce n'est
pas parce que le DNS est limité à ASCII,
essayez vous-même, vous verrez) encodés en
Punycode (RFC 3492). potamochère.fr est donc encodé
en xn--potamochre-66a.fr. Normalement, ce n'est
qu'un détail technique, invisible aux utilisateurs mais, hélas,
dix-neuf ans après la sortie du premier RFC sur les IDN (RFC 3490), certains logiciels continuent à présenter à
l'utilisateur la forme en Punycode, en violation du RFC 2277.
Ainsi, le BE gagnant permet de commander le transfert en
utilisant la forme en joli Unicode lisible
mais, lors de l'affichage de la liste des serveurs actuels, le BE
gagnant montre du Punycode : 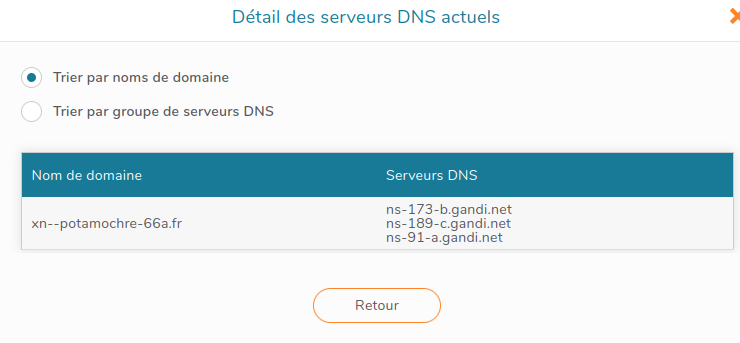
Même chose pour la configuration des serveurs : 
Ce qui est amusant est que les courriers de ce même BE respectent tous le bon encodage et sont donc lisibles :
Subject: [potamochère.fr] Notification de transfert From: support@netim.com Date: Sun, 2 Nov 2025 12:19:26 +0100 (CET) 02/11/2025 Cher client, Ceci est une notification au sujet du transfert de votre domaine potamochère.fr vers NETIM.
Alors qu'en général, le courrier est moins internationalisé que le Web.
D'un BE à l'autre, les choses sont différentes. Par exemple, chez le BE perdant :
Subject: [GANDI] IMPORTANT: Transfert sortant vers un autre prestataire du domaine xn--potamochre-66a.fr From: no-reply@gandi.net Date: Sun, 02 Nov 2025 11:20:29 -0000 A l'attention de : Stéphane Bortzmeyer Transfert du nom de domaine: xn--potamochre-66a.fr Registrar demandeur: <NETIM SARL>
Et idem sur leur serveur Web : 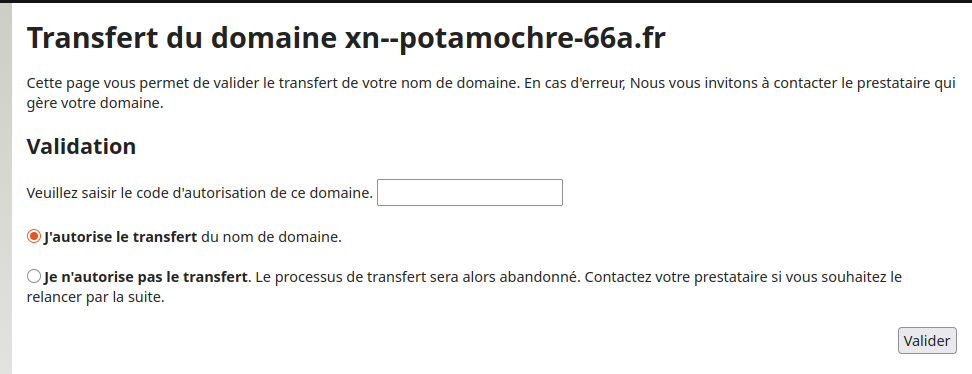
Corriger tous les endroits où l'IDN n'est pas traité proprement va prendre du temps…
L'article seul
Suite des tests du logiciel de gestion DNSSEC Cascade
Première rédaction de cet article le 2 novembre 2025
J'ai déjà parlé de Cascade, un logiciel actuellement en développement, qui automatise un certain nombre de tâches nécessaires pour DNSSEC, comme la re-signature ou le remplacement des clés. Le projet avance vite donc voyons quelques nouveaux essais.
D'abord, puisque Cascade tire son nom du traitement en plusieurs étapes d'une tâche, avec la possibilité d'insérer des validations à chaque étape, essayons la validation manuelle (j'ai déjà montré la validation automatique dans mon précédent article). Comme pour la validation automatique, vous pouvez valider la zone avant la signature et/ou après. Comme pour la validation automatique, vous devez indiquer, dans le fichier qui décrit une politique de gestion, que des examens (review) sont obligatoires :
% cat /etc/cascade/policies/default.toml … [loader.review] required = true … [signer.review] required = true …
Par contre, et contrairement à ce qui se passe pour la validation
automatique, vous n'indiquez pas de programme à
exécuter (hook). Cela signifiera, pour Cascade,
qu'il faut une validation manuelle. Vous rechargez alors les
politiques (cascade policy reload) et (c'est
une bogue de la version de développement), vous redémarrez le
serveur. Lorsqu'une nouvelle version d'une zone est prête, et que
vous l'indiquez au serveur (cascade zone reload
example.org), vous voyez ceci :
% cascade zone status example.org Status report for zone 'example.org' using policy 'default' ✔ Waited for a new version of the example.org zone ✔ Loaded version 2025102700 Loaded at 2025-10-27T08:47:38+00:00 (13s ago) Loaded 243 B and 4 records from the filesystem in 0 seconds • Waiting for approval to sign version 2025102700 ! Zone will be held until manually approved Approve with: cascade zone approve --unsigned example.org 2025102700 Reject with: cascade zone reject --unsigned example.org 2025102700
La zone n'est pas encore signée, vous devez la
valider. (Rappelez-vous qu'on peut imposer une validation de la zone
non signée, de la zone signée, ou bien des deux.) Et Cascade vous
indique comment faire, mais pas comment récupérer la zone à
signer. Pour cela, le plus simple est un transfert de zones (RFC 5936) depuis le serveur indiqué par les
directives .servers dans la configuration de Cascade.
% cat /etc/cascade/config.toml … [loader] review.servers = ["127.0.0.1:4541", "[::1]:4541"] [signer] review.servers = ["127.0.0.1:4542", "[::1]:4542"] … % dig @127.0.0.1 -p 4541 example.org AXFR …
On peut alors examiner la zone. Mettons qu'elle nous satisfasse. On
va alors suivre les instructions qu'affichait cascade zone
status :
% cascade zone approve --unsigned example.org 2025102700 Approved unsigned zone 'example.org' with serial number 2025102700
Personnellement, je ne vois pas trop l'intérêt d'examiner manuellement la zone non signée (on pourrait aussi examiner le fichier de zone qu'on a donné à Cascade) et je vais plutôt regarder la zone signée, qui est servie sur un autre port.
Autre activité, Cascade permet également d'automatiser une opération délicate : le remplacement des clés. Cette opération est nécessaire si on découvre qu'une clé privée a été compromise. Et on peut aussi estimer que le remplacement est utile, même en l'absence de compromission, pour pratiquer les procédures et vérifier que tout se passera bien lorsqu'on aura vraiment besoin d'un remplacement. Supposons une politique avec deux clés, la KSK (Key Signing Key, qui ne signe que les clés) et la ZSK (Zone Signing Key, qui signe le reste). D'abord, l'état initial :
% dig +multi +dnssec internautique.fr DNSKEY … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 30159 ;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: internautique.fr. 3600 IN DNSKEY 257 3 15 ( IDypc2j/kbE3iHtnbry715I6jwgVEPMLz1+QV9GNgMA= ) ; KSK; alg = ED25519 ; key id = 33113 internautique.fr. 3600 IN DNSKEY 256 3 15 ( K+sBrJFESzsLwD6AFGW+zZrydRjk5QRtbshG4AKV/jI= ) ; ZSK; alg = ED25519 ; key id = 56167 internautique.fr. 3600 IN RRSIG DNSKEY 15 2 3600 ( 20251109195246 20251025195246 33113 internautique.fr. ARucHmrIB8ivtduHEzphj2SJEGRZ7BlP5c7686dD2DTy TDJpZc9Rcerrh5okki3rKKOsFMqOwXunlNl+cgGcBA== ) … ;; WHEN: Mon Oct 27 09:06:13 CET 2025
Nous avons dans le DNS la KSK, d'identification 33113, et la ZSK, d'identification 56167. C'est aussi ce que nous dit Cascade :
% cascade zone status --detailed internautique.fr
…
✔ Published version 2025102612
Published zone available on 127.0.0.1:8053
DNSSEC keys:
ZSK tagged 56167:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+56167.key
Actively used for signing
KSK tagged 33113:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+33113.key
Actively used for signing
Details:
key file:///var/db/cascade/keys/Kinternautique.fr.+015+56167.key expires at 2025-11-02T14:51:53Z
key file:///var/db/cascade/keys/Kinternautique.fr.+015+33113.key expires at 2025-12-26T14:51:53Z
Et c'est aussi ce qu'on peut voir avec DNSviz. Maintenant, commençons le remplacement de la ZSK :
% cascade keyset internautique.fr zsk start-roll Manual key roll for internautique.fr successful
Et voici le résultat, une nouvelle ZSK est apparue, la 30906 :
% cascade zone status --detailed internautique.fr
Status report for zone 'internautique.fr' using policy 'default'
✔ Waited for a new version of the internautique.fr zone
✔ Loaded version 2025101721
Loaded at 2025-10-26T14:51:53+00:00 (17h 16m 7s ago)
Loaded 333 B and 7 records from the filesystem in 0 seconds
✔ Waited for approval to sign version 2025101721
✔ Approval received to sign version 2025101721, signing requested
✔ Signed version 2025101721 as version 2025102701
Signing requested at 2025-10-27T08:07:36+00:00 (24s ago)
Signing started at 2025-10-27T08:07:36+00:00 (24s ago)
Signing finished at 2025-10-27T08:07:36+00:00 (24s ago)
Collected 8 records in 0s, sorted in 0s
Generated 6 NSEC(3) records in 0s
Generated 8 signatures in 0s (8 sig/s)
Inserted signatures in 0s (8 sig/s)
Took 0s in total, using 1 threads
Current action: Finished
✔ Waited for approval to publish version 2025102701
✔ Published version 2025102701
Published zone available on 127.0.0.1:8053
DNSSEC keys:
KSK tagged 33113:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+33113.key
Actively used for signing
ZSK tagged 30906:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+30906.key
ZSK tagged 56167:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+56167.key
Actively used for signing
Details:
ZskRoll: CacheExpire1(3600)
Wait until 2025-10-27T09:07:36Z to let caches expire
For the next step run:
cascade keyset internautique.fr zsk cache-expired1
automation is enabled for this step.
key file:///var/db/cascade/keys/Kinternautique.fr.+015+33113.key expires at 2025-12-26T14:51:53Z
key file:///var/db/cascade/keys/Kinternautique.fr.+015+30906.key expires at 2025-11-03T08:07:27Z
key file:///var/db/cascade/keys/Kinternautique.fr.+015+56167.key expires at 2025-11-02T14:51:53Z
À la fin, c'est bon, le remplacement s'est fait sans autre intervention, et en respectant les durées nécessaires pour que, à tout moment, tous les résolveurs DNS de la planète aient un chemin de validation complet, depuis la racine :
% cascade zone status --detailed internautique.fr
Status report for zone 'internautique.fr' using policy 'default'
✔ Waited for a new version of the internautique.fr zone
✔ Loaded version 2025101721
Loaded at 2025-10-26T14:51:53+00:00 (23h 45m 37s ago)
Loaded 333 B and 7 records from the filesystem in 0 seconds
✔ Waited for approval to sign version 2025101721
✔ Approval received to sign version 2025101721, signing requested
✔ Signed version 2025101721 as version 2025102705
Signing requested at 2025-10-27T12:07:56+00:00 (2h 29m 34s ago)
Signing started at 2025-10-27T12:07:56+00:00 (2h 29m 34s ago)
Signing finished at 2025-10-27T12:07:56+00:00 (2h 29m 34s ago)
Collected 8 records in 0s, sorted in 0s
Generated 5 NSEC(3) records in 0s
Generated 8 signatures in 0s (8 sig/s)
Inserted signatures in 0s (8 sig/s)
Took 0s in total, using 1 threads
Current action: Finished
✔ Waited for approval to publish version 2025102705
✔ Published version 2025102705
Published zone available on 127.0.0.1:8053
DNSSEC keys:
KSK tagged 33113:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+33113.key
Actively used for signing
ZSK tagged 30906:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+30906.key
Actively used for signing
Details:
key file:///var/db/cascade/keys/Kinternautique.fr.+015+30906.key expires at 2025-11-03T08:07:27Z
key file:///var/db/cascade/keys/Kinternautique.fr.+015+33113.key expires at 2025-12-26T14:51:53Z
Vous pouvez admirer l'état final dans DNSviz.
Maintenant, remplaçons la KSK. C'est un peu plus délicat car il y
a une opération manuelle à faire, auprès de la zone parente
(.fr dans notre
cas).
On voit l'état initial sur DNSviz. Démarrons l'opération :
% cascade keyset internautique.fr ksk start-roll
Manual key roll for internautique.fr successful
% cascade zone status --detailed internautique.fr
Status report for zone 'internautique.fr' using policy 'default'
✔ Waited for a new version of the internautique.fr zone
✔ Loaded version 2025101721
Loaded at 2025-10-26T14:51:53+00:00 (1day 19h 29m 50s ago)
Loaded 333 B and 7 records from the filesystem in 0 seconds
✔ Waited for approval to sign version 2025101721
✔ Approval received to sign version 2025101721, signing requested
✔ Signed version 2025101721 as version 2025102801
Signing requested at 2025-10-28T10:21:36+00:00 (7s ago)
Signing started at 2025-10-28T10:21:36+00:00 (7s ago)
Signing finished at 2025-10-28T10:21:36+00:00 (7s ago)
Collected 8 records in 0s, sorted in 0s
Generated 7 NSEC(3) records in 0s
Generated 8 signatures in 0s (8 sig/s)
Inserted signatures in 0s (8 sig/s)
Took 0s in total, using 1 threads
Current action: Finished
✔ Waited for approval to publish version 2025102801
✔ Published version 2025102801
Published zone available on 127.0.0.1:8053
DNSSEC keys:
KSK tagged 49915:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+49915.key
Actively used for signing
ZSK tagged 30906:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+30906.key
Actively used for signing
KSK tagged 33113:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+33113.key
Actively used for signing
Details:
KskRoll: CacheExpire1(3600)
Wait until 2025-10-28T11:21:36Z to let caches expire
For the next step run:
cascade keyset internautique.fr ksk cache-expired1
automation is enabled for this step.
key file:///var/db/cascade/keys/Kinternautique.fr.+015+49915.key expires at 2025-12-28T10:21:27Z
key file:///var/db/cascade/keys/Kinternautique.fr.+015+33113.key expires at 2025-12-26T14:51:53Z
key file:///var/db/cascade/keys/Kinternautique.fr.+015+30906.key expires at 2025-11-03T08:07:27Z
La nouvelle KSK, la 49915, est publiée. Une fois le temps nécessaire écoulé (toujours cette histoire de la mémorisation, par les résolveurs, des données), Cascade nous dit qu'il faut maintenant changer la DS :
% cascade zone status --detailed internautique.fr
Status report for zone 'internautique.fr' using policy 'default'
✔ Waited for a new version of the internautique.fr zone
✔ Loaded version 2025101721
Loaded at 2025-10-26T14:51:53+00:00 (1day 23h 59m 24s ago)
Loaded 333 B and 7 records from the filesystem in 0 seconds
✔ Waited for approval to sign version 2025101721
✔ Approval received to sign version 2025101721, signing requested
✔ Signed version 2025101721 as version 2025102806
Signing requested at 2025-10-28T14:22:01+00:00 (29m 15s ago)
Signing started at 2025-10-28T14:22:01+00:00 (29m 15s ago)
Signing finished at 2025-10-28T14:22:01+00:00 (29m 15s ago)
Collected 8 records in 0s, sorted in 0s
Generated 7 NSEC(3) records in 0s
Generated 8 signatures in 0s (8 sig/s)
Inserted signatures in 0s (8 sig/s)
Took 0s in total, using 1 threads
Current action: Finished
✔ Waited for approval to publish version 2025102806
✔ Published version 2025102806
Published zone available on 127.0.0.1:8053
DNSSEC keys:
KSK tagged 33113:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+33113.key
Actively used for signing
KSK tagged 49915:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+49915.key
Actively used for signing
ZSK tagged 30906:
Reference: file:///var/db/cascade/keys/Kinternautique.fr.+015+30906.key
Actively used for signing
Details:
KskRoll: Propagation2
Check that all nameservers of the parent zone have the following RRset (or equivalent):
internautique.fr. 3600 IN DS 49915 15 2 0ADF31249F82B92BC7A8068CB2D6117C35F78E5994F1AFF7BCFE6999A71F5091
For the next step run:
cascade keyset internautique.fr ksk propagation2-complete <ttl>
automation is enabled for this step.
Automatic key roll state:
Roll KskRoll, state Propagation2:
Wait until the new DS RRset has propagated to all nameservers
of the parent zone. Try again after 2025-10-28T15:22:01Z
key file:///var/db/cascade/keys/Kinternautique.fr.+015+30906.key expires at 2025-11-03T08:07:27Z
key file:///var/db/cascade/keys/Kinternautique.fr.+015+33113.key expires at 2025-12-26T14:51:53Z
key file:///var/db/cascade/keys/Kinternautique.fr.+015+49915.key expires at 2025-12-28T10:21:27Z
Vous avez vu, à la fin ? Il faut placer la DS
internautique.fr. 3600 IN DS 49915 15 2
0ADF31249F82B92BC7A8068CB2D6117C35F78E5994F1AFF7BCFE6999A71F5091
dans la zone parente, ce qui se fait typiquement via l'interface
(Web ou API) de son BE.
Ce sera la seule opération manuelle qu'il faudra faire. 
L'ancienne KSK sera supprimée automatiquement en temps utile. (Ici, la 33113 est encore présente, et les clés seront signées avec les deux KSK.)
Dans l'opération précédente, on avait deux clés, la KSK et la ZSK. C'est la configuration la plus courante. Mais elle n'est pas obligatoire. Elle avait été promue à une époque car elle résolvait un problème spécifique à l'algorithme de cryptographie RSA : ce dernier laissait le choix entre des clés courtes, compactes et rapides mais peu sûres, et des clés longues, dont les avantages et inconvénients étaient à l'opposé. Avec RSA, avoir une ZSK courte et changée souvent, ainsi qu'une KSK longue et changée plus rarement, était logique. Mais avec les algorithmes comme ceux fondés sur des courbes elliptiques, ce n'est plus utile. Autant n'avoir qu'une clé, qu'on nomme souvent CSK, pour Common Signing Key. Dans Cascade, cela se configure dans la politique (rappelez-vous que vous pouvez avoir plusieurs politiques, donc qu'une même instance de Cascade peut gérer des zones avec CSK et des zones avec KSK/ZSK) :
% cat /etc/cascade/policies/one-key.toml … use-csk = true
Et voici ce qu'affiche Cascade :
% cascade zone status --detailed cours-dns.fr
Status report for zone 'cours-dns.fr' using policy 'one-key'
✔ Waited for a new version of the cours-dns.fr zone
✔ Loaded <serial number not yet known>
Loaded at 2025-10-31T13:23:23+00:00 (1day 5h 36m 3s ago)
Loaded 261 B and 5 records from the filesystem in 0 seconds
✔ Waited for approval to sign <serial number not yet known>
• Approval received to sign <serial number not yet known>, signing requested
DNSSEC keys:
CSK tagged 50973:
Reference: file:///var/db/cascade/keys/Kcours-dns.fr.+015+50973.key
Actively used for signing
Details:
key file:///var/db/cascade/keys/Kcours-dns.fr.+015+50973.key expires at 2026-10-30T13:01:19Z
Et vous pouvez voir graphiquement la clé unique avec DNSviz.
Allez, un autre point, la technique utilisée pour indiquer les noms absents. DNSSEC en permet deux, les NSEC du RFC 4034 et les NSEC3 du RFC 5155. Cascade permet de configurer l'un ou l'autre dans la politique :
type = "nsec" # type = "nsec3"
Ah, et une nouveauté relativement récente de Cascade, un moyen simple de tester si le démon tourne bien :
% cascade health Ok
Ce qui est très pratique dans une supervision automatisée :
% sudo -u nagios /usr/local/lib/nagios/plugins/check_cascade Cascade OK
L'article seul
Transférer un nom de domaine d'un Bureau d'Enregistrement à un autre
Première rédaction de cet article le 16 octobre 2025
Dans beaucoup de TLD, le ou la simple titulaire ne peut pas acheter directement un nom de domaine, il faut passer par un Bureau d'Enregistrement (BE). Le transfert, l'opération qui consiste à changer de bureau d'enregistrement, est parfois une opération frustrante. Je suis en train de transférer mes noms de domaine personnels (et ils sont tous signés avec DNSSEC) donc voici quelques notes, au cas où.
Dans le cas de .fr,
l'obligation de passer par un BE est dans
la loi : « L'attribution des noms de domaine est assurée par
les offices d'enregistrement [sic ; il s'agit des
registres], par l'intermédiaire des
bureaux d'enregistrement. » (article L45-4 du Code des
postes et des communications électroniques). Pour les TLD sous contrat avec
l'ICANN, cette obligation est dans le contrat
entre l'ICANN et le registre. Vous pouvez trouver le nom du BE via
les
différents outils d'accès à l'information, cette information
est publique.
Le choix d'un BE est une opération complexe, déroutante pour la ou le titulaire d'un nom de domaine. Et on peut être amené à changer de BE, par exemple pour des raisons tarifaires. Ainsi, je transfère en ce moment mes domaines personnels, l'ancien BE, qui était une entreprise indépendante, ayant été racheté par un grand groupe qui a immédiatement considérablement augmenté les tarifs. (Problème courant quand une petite entreprise est rachetée par un grand groupe : celui-ci se dépêche de supprimer tout ce qui faisait l'intérêt de la petite entreprise pour les clients. On a vu cela avec Capitaine Train, par exemple.) Ces noms de domaine ont deux particularités :
- L'hébergeur DNS, c'est moi. Je n'utilise pas, ni avant le transfert, ni après, les services d'hébergement DNS que fournissent la plupart des BE. Il n'y a donc pas de données DNS à transférer, les serveurs faisant autorité restent les mêmes.
- Les domaines sont signés avec DNSSEC.
Outre les contraintes techniques, le transfert est une opération délicate puisque les deux BE, le perdant et le gagnant, sont a priori des concurrents et que certains BE perdants font preuve d'une extrême mauvaise volonté, essayant de retenir de force leur client par tous les moyens. Le transfert est donc piloté par le BE gagnant, puisqu'il est le plus motivé à ce que l'opération réussisse. Et, pour compliquer encore la question, il faut noter qu'il y a un problème de sécurité : un transfert peut être malveillant, par exemple parce qu'un méchant essaie de détourner un nom de domaine à son profit.
Les règles qui encadrent le transfert d'un nom de domaine varient
selon les registres. Durant ma migration,
j'ai transféré du .org,
du .net et du
.fr.
Le cheminement normal est le suivant :
- Le ou la titulaire est prudent, teste qu'ielle a bien tous les éléments (mots de passe, etc) et ne commence pas le transfert la veille d'un jour où il faut absolument que le nom de domaine marche. N'attendez pas non plus le dernier moment avant l'expiration. Vouloir grapiller quelques euros peut vous coûter cher.
- La ou le titulaire du nom va sur l'interface Web du futur BE, le gagnant (ou bien utilise l'API de ce BE) et demande le transfert d'un nom. On paie ce transfert.
- Pour des raisons de sécurité évidentes, ce n'est pas fait immédiatement et automatiquement. Des mesures de sécurité sont appliquées.
- Une fois le transfert validé, le registre met à jour sa base de données, indiquant le nouveau BE, et le titulaire est prévenu (typiquement par courrier).
Voici la demande faite auprès d'un BE gagnant (ici, Netim) :

Ensuite, comme je l'ai dit, il faut s'assurer que la demande de
transfert n'est pas en fait une tentative de détournement du nom de
domaine. La principale mesure de sécurité est nommée, selon les BE,
code d'autorisation, clé d'autorisation, code de transfert,
auth code, authInfo… C'est un
mot de passe qui a été généré par l'ancien BE et transmis au
registre, et qui, indiqué par le titulaire au nouveau BE, permet de
vérifier que la demande est légitime. (Si vous êtes fana de
technique et de sécurité, le RFC 9154 propose
une technique alternative.) Voici ici l'obtention de ce
code sur l'ancien BE (ici, Gandi). Je vous rassure, le code affiché
n'est plus le bon : 
Il existe d'autres façons de transmettre ce mot de passe au titulaire, par exemple par courrier électronique, ce qui permet de valider l'adresse mais expose à pas mal de risques de sécurité. La sécurité, ce n'est de toute façon jamais simple et il faut rappeler que, s'il y a des BE qui tentent de gêner les transferts sortants, en invoquant la sécurité, il y a également des malveillants qui tentent de profiter d'une sécurité trop faible pour détourner un nom. Un compromis est donc nécessaire.
Typiquement, vous recevez une notification du BE perdant vous informant de la demande de transfert, ce qui peut permettre de s'y opposer, si elle n'était pas légitime. En effet, pour éviter qu'un BE de mauvaise volonté ne bloque le transfert indéfiniment en ne donnant pas accès au code d'autorisation, le transfert est typiquement effectué automatiquement au bout d'un certain temps. Faites donc bien attention aux messages de votre BE ! Et rappelez-vous qu'il y a autant de transferts légitimes retardés ou bloqués par des procédures kafkaïennes qu'il y a de domaines détournés parce que les procédures de sécurité étaient insuffisantes. J'en profite pour insister sur ce point : gérez vos noms de domaines. Que vous soyez particulier, profession libérale, association, petite entreprise, pensez à désigner plusieurs personnes responsables qui vont recevoir les messages du BE et les lire, et agir. Vous trouvez facilement en ligne d'innombrables témoignages de gens qui ont perdu leur nom de domaine par négligence.
Voici un exemple de message reçu de l'ancien BE (ici, Gandi) :
Subject: [GANDI] IMPORTANT: Transfert sortant vers un autre prestataire du domaine sources.org From: no-reply@gandi.net To: [Moi] Date: Mon, 01 Sep 2025 13:50:47 -0000 X-Mailer: Gandi Notification Mailer v1.2.12 Vous êtes contacté car vous êtes inscrit comme contact du nom de domaine suivant. A l'attention de : Stéphane Bortzmeyer Transfert du domaine: sources.org Registrar demandeur: <NETIM SARL> GANDI a été notifié d'une demande de transfert pour ce nom de domaine. GANDI a reçu à la date 2025-09-01 13:44:18Z une notification selon laquelle vous avez demandé le transfert de ce nom de domain vers un autre bureau d'enregistrement. Si vous souhaitez poursuivre le transfert, vous n'avez pas besoin de répondre à cette notification. Faute de réponse de votre part avant le 2025-09-06 13:44:18, le transfert sera automatiquement validé. Vous pouvez cependant accélérer ou refuser le transfert, en vous rendant à cette adresse avant le 2025-09-06 13:44:18: [URL où il faudra taper le code d'autorisation].
Vérifiez ensuite avec un RDDS que le domaine a bien été transféré. Ici, on va utiliser le classique client whois :
% whois cyberstructure.fr … domain: cyberstructure.fr status: ACTIVE … registrar: NETIM
Parfait, le domaine est bien passé chez Netim.
Revenons à la technique : pensez à vérifier (avec des outils
comme Zonemaster et DNSviz) le domaine après le
transfert. J'ai vu par exemple un BE qui, lors d'un transfert
entrant, limitait le nombre de serveurs faisant autorité à cinq et
supprimait silencieusement les autres. Un exemple avec
dig, où on interroge un des serveurs faisant
autorité pour .fr :
% dig @d.nic.fr cyberstructure.fr NS … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 18712 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 9, ADDITIONAL: 1 … ;; AUTHORITY SECTION: cyberstructure.fr. 3600 IN NS fns1.42.pl. cyberstructure.fr. 3600 IN NS ns4.bortzmeyer.org. cyberstructure.fr. 3600 IN NS fns2.42.pl. cyberstructure.fr. 3600 IN NS ns2.afraid.org. cyberstructure.fr. 3600 IN NS puck.nether.net. cyberstructure.fr. 3600 IN NS ns2.bortzmeyer.org. cyberstructure.fr. 3600 IN NS ns1.bortzmeyer.org.
Et vérifiez que la liste des serveurs faisant autorité pour votre
domaine est la bonne. (Attention, la mise à jour des serveurs du
domaine parent peut ne pas être immédiate ; pour
.fr, à l'heure actuelle, c'est toutes les dix minutes.)
Et DNSSEC ? Vous avez peut-être remarqué, sur l'image où le BE perdant affichait le code d'autorisation, un avertissement sur DNSSEC. La sécurité supplémentaire qu'apporte DNSSEC se paie d'une complication supplémentaire pendant le transfert : si on utilise le BE comme hébergeur (ce n'est pas mon cas), il faut, soit assurer le passage d'une clé DNSSEC à une autre (ce qui, étant donné le fait que les résolveurs DNS mémorisent des informations, va nécessiter la publication simultanée de deux clés, et une collaboration étroite entre les deux BE, dont je rappelle qu'ils sont concurrents), soit supprimer DNSSEC temporairement, ce que conseille ici le BE. Dans mon cas, comme je suis mon propre hébergeur, il n'y a pas trop de problèmes, à part qu'entre Gandi et Netim, l'enregistrement DS (Delegation Signer) a été supprimé lors du transfert (chaque BE dit que c'est de la faute de l'autre) et qu'il a donc fallu le rétablir ensuite (voyez ci-dessus le point sur l'importance d'un test technique après transfert).
Voilà, dans mon cas, les choses se sont plutôt bien passées, il
n'y a pas eu de blocage, et les transferts ont été bouclés en une
heure ou deux. Il me reste à transférer le domaine de ce blog
bortzmeyer.org, que j'ai gardé pour la fin ; la
méthode de bon sens est en effet de commencer par les domaines les
moins importants.
L'article seul
Le résolveur DNS public de Freifunk München
Première rédaction de cet article le 16 octobre 2025
Allez, encore un résolveur DNS public européen, celui de Freifunk München. Rien d'extraordinaire mais rappelez-vous que, dans ce domaine, pluralisme et diversité sont cruciaux.
Des résolveurs DNS publics, il y en a beaucoup (j'en gère même un). Les utilisateurices et administrateurices système s'en servent pour des raisons variées, par exemple échapper à la censure. Mais ils ne sont pas tous équivalents, en terme de caractéristiques techniques, de fonctions (certains sont menteurs), de politique de gestion des données personnelles, etc. Le service de Freifunk München :
- A DoT, DoH, DNSSEC et IPv6 (comme tous les résolveurs publics sérieux),
- Promet d'être strict sur la vie privée et notamment de ne pas garder de trace des requêtes faites,
- Est européen (certains résolveurs publics qui se présentent comme européens sont en fait des services étatsuniens un peu repeints, par exemple en s'appuyant sur la nationalité d'origine du fondateur), plus précisément allemand (par contre, le nom de domaine est dans un TLD étatsunien, ce qui est curieux, mais n'a pas trop d'importance car le nom ne sert pas beaucoup pour accéder à un résolveur DNS, sauf pour l'authentification TLS).
Faisons quelques essais techniques. Les adresses et noms à
utiliser sont
185.150.99.255, 5.1.66.255,
2001:678:e68:f000::, 2001:678:ed0:f000::,
dot.ffmuc.net,
https://doh.ffmuc.net/dns-query et
doq.ffmuc.net (je n'ai pas testé ce dernier).
D'abord, avec
dig :
% dig @2001:678:ed0:f000:: sci-hub.se
…
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 24707
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
…
;; ANSWER SECTION:
sci-hub.se. 60 IN A 186.2.163.219
;; Query time: 34 msec
;; SERVER: 2001:678:ed0:f000::#53(2001:678:ed0:f000::) (UDP)
;; WHEN: Thu Oct 16 14:38:17 CEST 2025
;; MSG SIZE rcvd: 55
OK, c'est bon, tout marche, et en un temps raisonnable depuis ma connexion Free à Paris. (Évidemment, un résolveur public ne sera jamais aussi rapide qu'un résolveur local et il n'est donc pas raisonnable d'utiliser un résolveur public « pour les performances ».)
Et avec DoT ?
% dig +tls @2001:678:ed0:f000:: liberation.fr … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 31755 ;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: liberation.fr. 300 IN A 3.165.113.53 liberation.fr. 300 IN A 3.165.113.101 liberation.fr. 300 IN A 3.165.113.127 liberation.fr. 300 IN A 3.165.113.118 ;; Query time: 62 msec ;; SERVER: 2001:678:ed0:f000::#853(2001:678:ed0:f000::) (TLS) ;; WHEN: Thu Oct 16 14:40:02 CEST 2025 ;; MSG SIZE rcvd: 106
Et du DoH ?
% kdig +https=https://doh.ffmuc.net/dns-query @185.150.99.255 bortzmeyer.fr NS
;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-128-GCM)
;; HTTP session (HTTP/2-POST)-(doh.ffmuc.net/dns-query)-(status: 200)
;; ->>HEADER<<- opcode: QUERY; status: NOERROR; id: 0
;; Flags: qr rd ra ad; QUERY: 1; ANSWER: 7; AUTHORITY: 0; ADDITIONAL: 1
;; EDNS PSEUDOSECTION:
;; Version: 0; flags: ; UDP size: 512 B; ext-rcode: NOERROR
;; PADDING: 238 B
…
;; ANSWER SECTION:
bortzmeyer.fr. 85495 IN NS ns2.1984hosting.com.
bortzmeyer.fr. 85495 IN NS ns0.1984.is.
bortzmeyer.fr. 85495 IN NS ns4.bortzmeyer.org.
bortzmeyer.fr. 85495 IN NS ns-global.kjsl.com.
bortzmeyer.fr. 85495 IN NS puck.nether.net.
bortzmeyer.fr. 85495 IN NS ns2.bortzmeyer.org.
bortzmeyer.fr. 85495 IN NS ns2.1984.is.
;; Received 468 B
;; Time 2025-10-16 14:42:39 CEST
;; From 185.150.99.255@443(HTTPS) in 91.2 ms
C'est parfait, tout marche. Pour la dernière requête, celle faite avec DoH, notez que le résolveur valide bien les domaines signés.
Configurons maintenant un résolveur local pour faire suivre à
ffmuc, pour profiter de la mémorisation des
réponses par celui-ci. On va utiliser
Unbound et faire suivre en
TLS :
forward-zone:
name: "."
# Freifunk München
forward-addr: 2001:678:ed0:f000::@853#dot.ffmuc.net
forward-tls-upstream: yes
Et tout marche, notre résolveur local fera suivre ce qu'il ne sait
pas déjà à ffmuc.
ffmuc a-t-il plusieurs machines,
réparties par anycast ? On
peut regarder les identités de ces serveurs avec NSID (RFC 5001) :
% dig +nsid @5.1.66.255 www.phy.cam.ac.uk
…
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 512
; NSID: 64 6f 74 2e 66 66 6d 75 63 2e 6e 65 74 ("dot.ffmuc.net")
;; QUESTION SECTION:
;www.phy.cam.ac.uk. IN A
;; ANSWER SECTION:
www.phy.cam.ac.uk. 3591 IN CNAME tm-128-232-132-117.tm.uis.cam.ac.uk.
tm-128-232-132-117.tm.uis.cam.ac.uk. 3600 IN A 128.232.132.117
…
Le NSID est juste le nom du service. Un test avec les sondes RIPE Atlas montre qu'il n'y a en effet qu'un seul serveur.
Notez enfin que la configuration technique de ce service est publique ainsi que celle des autres services.
Est-ce que je vais utiliser ce service ? Non, il en existe plusieurs autres qui me conviennent (dont le mien, bien sûr, mais aussi celui de FDN) mais avoir le choix est une bonne chose.
L'article seul
Premiers essais avec Cascade, le logiciel pour gérer ses zones DNSSEC
Première rédaction de cet article le 13 octobre 2025
Annoncé officiellement le 7 octobre, Cascade est le successeur d'OpenDNSSEC. Ce programme sert à gérer automatiquement les opérations répétitives liées à DNSSEC comme la re-signature ou le remplacement d'une clé. (Notez que Cascade évolue vite en ce moment et que cet article ne sera pas mis à jour. J'en écrirai d'autres.)
OpenDNSSEC est, depuis 15
ans, le logiciel utilisé par mes domaines personnels (comme
bortzmeyer.org par lequel vous êtes passé pour
voir cet article) mais aussi par plusieurs TLD comme
.fr. Mais il est désormais en fin de vie (cela
a été
annoncé le 3 octobre), il n'y a plus que les mises à jour de
sécurité. La même organisation, NLnet Labs, a développé un
successeur, Cascade. Celui-ci
est actuellement en alpha (ne l'utilisez pas pour la
production !) et voici un premier essai.
DNSSEC, contrairement à ce qui se passe avec le DNS d'antan, nécessite des actions périodiques. La plus évidente est la re-signature, car les signatures DNSSEC ont une date d'expiration (pour éviter les attaques par rejeu). Ici, cette signature expire le 18 octobre 2025 (le « 20251018235702 ») :
% dig +dnssec cyberstructure.fr TXT
…
;; ANSWER SECTION:
cyberstructure.fr. 86400 IN TXT "v=spf1 mx -all"
cyberstructure.fr. 86400 IN RRSIG TXT 13 2 86400 (
20251018235702 20251004235301 34065 cyberstructure.fr.
Hg/ModpW3pTLgUIcgp7yrVUxUyVAXdEIOtfONpN3pxG0
…
Mais il y a aussi la nécessité de pouvoir changer les clés cryptographiques utilisées, par exemple en cas de compromission, avérée ou suspectée. (La plupart des organisations changent les clés systématiquement, compromission ou pas, notamment pour être sûr de pouvoir le faire sans incident le jour où ça sera vraiment indispensable.) Cascade, comme OpenDNSSEC avant lui, automatise toutes ces tâches.
Cascade est développé en Rust, le langage à la mode, et qui pourrait remplacer une bonne partie du logiciel d'infrastructure de l'Internet, qui est quasi-uniquement en C (et C++). Il doit son nom au fait qu'une zone DNS qu'on va signer passe par plusieurs étapes successives, où on peut insérer différentes opérations, par exemple de validation.
Jouons donc un peu avec Cascade (j'ai bien dit que c'était en version alpha ; ne le faites pas en production). Notez que vous pouvez lire la documentation officielle au lieu de cet article. Mais j'ai bien dit que le logiciel était en version alpha, ne vous étonnez pas s'il manque beaucoup de choses dans la documentation (et dans le code, bien sûr). Il existe déjà des paquetages tout faits (mais évidemment pas encore distribués avec votre système d'exploitation) mais on va compiler, c'est plus amusant. Il faut donc une version de Rust qui marche. Rust est très pénible, avec ses changements permanents, qui font que certain·es conseillent même de récupérer et d'installer automatiquement une nouvelle version du compilateur chaque nuit. Mais, bon, la version qui est dans Debian stable (la version 13 de Debian) marche bien. Cascade est un logiciel libre, et il est hébergé sur GitHub :
% git clone https://github.com/NLnetLabs/cascade.git … # Installer les dépendances % apt install cargo pkg-config libssl-dev … % rustc --version rustc 1.85.0 (4d91de4e4 2025-02-17) (built from a source tarball) % cd cascade % cargo build …
Et vous n'avez plus qu'attendre que votre machine compile quelques
centaines de crates
Rust. Vous vous retrouvez alors avec deux exécutables,
./target/debug/cascade et
./target/debug/cascaded. Le second est le
démon qui va tourner en permanence. (Si vous
venez d'OpenDNSSEC, notez qu'il n'y a cette fois qu'un seul démon.)
Notez que ce démon, bien qu'il inclue un serveur DNS minimal, ne doit
pas être exposé sur l'Internet. La
configuration recommandée est de l'utiliser comme serveur maitre
caché, sur lequel s'alimenteront un ou plusieurs des serveurs faisant autorité pour
vos domaines. (Si vous venez d'OpenDNSSEC, notez que Cascade ne sait
actuellement pas écrire la zone sur le disque, il faut faire un
transfert de zones, cf. RFC 5936.) Le premier
exécutable, lui, est le programme que vous lancez pour accomplir
telle ou telle tâche, et qui parle au démon, qui fera le boulot.
Sinon, une autre solution, pour compiler, est de suivre les instructions :
cargo install --locked --git https://github.com/nlnetlabs/cascade cargo install --locked --branch keyset --git https://github.com/nlnetlabs/dnst
Et les exécutables atterriront dans votre ~/.cargo/bin.
Regardons les options des deux programmes :
% ./target/debug/cascade
Usage: cascade [OPTIONS] <COMMAND>
Commands:
config Manage Cascade's configuration
zone Manage zones
policy Manage policies
keyset Execute manual key roll or key removal commands
hsm Manage HSMs
template Print example config or policy files
Options:
-s, --server <IP:PORT> The cascade server instance to connect to [default: 127.0.0.1:4539]
--log-level <LEVEL> The minimum severity of messages to log [default: warning] [possible values: trace, debug, info,
warning, error, critical]
-h, --help Print help
-V, --version Print version
% ./target/debug/cascaded -h
Usage: cascaded [OPTIONS]
Options:
--check-config
Check the configuration and exit
--state <PATH>
The global state file to use
-c, --config <PATH>
The configuration file to load
--log-level <LEVEL>
The minimum severity of messages to log [possible values: trace, debug, info, warning, error, critical]
-l, --log <TARGET>
Where logs should be written to [possible values: stdout, stderr, file:<PATH>, syslog]
-d, --daemonize
Whether Cascade should fork on startup
-h, --help
Print help
-V, --version
Print version
Si vous avez procédé comme moi, un dernier truc à compiler, il nous faut aussi cascade-dnst, par la même organisation :
% cargo install --locked --branch keyset --git https://github.com/nlnetlabs/dnst
Vérifiez bien que les exécutables sont dans votre
PATH (par exemple, que
~/.cargo/bin y soit). Pour le démon, vous
pouvez aussi utiliser la variable
dnst-binary-path dans le
config.toml.
Pour utiliser Cascade, vous devrez, comme avec OpenDNSSEC, définir une politique (quel algorithme de cryptographie, quelle durée de vie des signatures, quand remplacer les clés, etc), indiquer quelles zones Cascade doit gérer, et avoir un serveur faisant autorité qui va récupérer la zone sur Cascade.
Maintenant, configurons le logiciel, toujours en suivant la
documentation. (Si vous oubliez cette étape, vous aurez un
message « Cascade couldn't be configured: could not load
the config file '/etc/cascade/config.toml': No such file or
directory (os error 2) ».) Vous avez avec Cascade un
fichier de configuration d'exemple,
./etc/config.template.toml, à la syntaxe
TOML. Le fichier d'exemple peut être utilisé
tel quel dans beaucoup de cas. J'ai juste modifié les paramètres de
journalisation :
[daemon]
log-level = "debug"
log-target = { type = "file", path = "/dev/stdout"}
# Mais log-target = { type = "syslog" } est bien aussi.
Lançons maintenant le démon (voyez plus loin les mécanismes pour
l'avoir en permanence). D'abord, on crée les répertoires configurés
dans le config.toml :
% sudo mkdir /var/lib/cascade % sudo chown $USER /var/lib/cascade % sudo mkdir /etc/cascade/policies
Puis on y va :
% ./target/debug/cascaded [2025-10-09T15:56:07.480Z] INFO cascaded: State file not found; starting from scratch … [2025-10-09T15:56:09.182Z] DEBUG cascade::state: Saved the global state (to '/var/lib/cascade/state.db') …
Maintenant que le démon tourne, testons le programme de contrôle :
% ./target/debug/cascade zone list %
Pas de message d'erreur, mais pas de zones configurées, c'est normal. (Si le démon ne tournait pas, vous auriez eu « [2025-10-09T15:59:37.183Z] ERROR cascade: Error: HTTP request failed: error sending request for url (http://127.0.0.1:4539/zone/) ».)
Maintenant, il faut créer une politique. La plus courte est :
version = "v1"
mais elle n'est pas très utile. Pour avoir un point de départ, on va demander à Cascade de nous générer un exemple :
% ./target/debug/cascade template policy > mypolicy.toml
(On peut aussi utiliser l'exemple en
etc/policy.template.toml.)
La politique contient l'algorithme de cryptographie utilisé (j'ai
choisi Ed25519, cf. RFC 8080) :
algorithm = "ED25519"
Je n'ai rien changé d'autre.
On copie le fichier
en /etc/cascade/policies/default.toml (on peut
évidemment avoir plusieurs politiques, je vous laisse choisir les
noms). Et on indique à Cascade de la charger (ce n'est à faire
qu'une fois, ce sera mémorisé) :
% ./target/debug/cascade policy reload
Policies reloaded:
- default added
% ./target/debug/cascade policy list
default
% ./target/debug/cascade policy show default
default:
zones: <none>
…
signer:
serial policy: date counter
signature inception offset: 86400 seconds
signature validity offset: 1209600 seconds
denial: NSEC
…
Bon, on peut maintenant ajouter une zone à gérer.
On crée un fichier de zone (je l'ai mis dans
/etc/cascade/zones mais vous faites comme vous
voulez). Et on dit à Cascade d'y aller, en indiquant la politique à
suivre :
% ./target/debug/cascade zone add --source /etc/cascade/zones/rutaba.ga --policy default rutaba.ga Added zone rutaba.ga
Et voilà :
% ./target/debug/cascade zone list rutaba.ga % ./target/debug/cascade zone status rutaba.ga Status report for zone 'rutaba.ga' using policy 'default' ✔ Waited for a new version of the rutaba.ga zone ✔ Loaded version 2025100901 Loaded at 2025-10-09T16:40:36+00:00 (17s ago) Loaded 246 B and 5 records from the filesystem in 0 seconds ✔ Auto approving signing of version 2025100901, no checks enabled in policy. ✔ Approval received to sign version 2025100901, signing requested ✔ Signed version 2025100901 as version 2025100902 Signing requested at 2025-10-09T16:40:36+00:00 (17s ago) Signing started at 2025-10-09T16:40:36+00:00 (17s ago) Signing finished at 2025-10-09T16:40:36+00:00 (17s ago) Collected 5 records in 0s, sorted in 0s Generated 4 NSEC(3) records in 0s Generated 5 signatures in 0s (5 sig/s) Inserted signatures in 0s (5 sig/s) Took 0s in total, using 1 threads Current action: Finished ✔ Auto approving publication of version 2025100902, no checks enabled in policy. ✔ Published version 2025100902 Published zone available on 127.0.0.1:4543
(L'option --detailed après
status vous donnera… des détails.)
Vous pouvez maintenant récupérer la zone signée :
% dig @localhost -p 4543 rutaba.ga AXFR
…
rutaba.ga. 600 IN SOA ns4.bortzmeyer.org. hostmaster.bortzmeyer.org. (
2025100902 ; serial
…
rutaba.ga. 3600 IN DNSKEY 257 3 15 (
oQjxu7aDwhDyqZbqPfx0e3I4Y+UowV0eYlssuXgiMw0=
) ; KSK; alg = ED25519 ; key id = 57782
…
rutaba.ga. 600 IN NS ns4.bortzmeyer.org.
rutaba.ga. 600 IN NS ns1.bortzmeyer.org.
…
rutaba.ga. 600 IN RRSIG SOA 15 2 600 (
20251023164036 20251008164036 64849 rutaba.ga.
xn3KC4qzitoUz5ABlJDTtMd9VGPU2l8dYpsd4bYjeCqo
vpjBdWcBbwwk1HENj5ESCLEIobpjNS3/rA4qidUvCg== )
rutaba.ga. 600 IN RRSIG NS 15 2 600 (
20251023164036 20251008164036 64849 rutaba.ga.
gWrzM1jYO7GJ234bH8JDejrxMhwtHrGWjxRM30gz37Fb
dxnSv2/DiAgOt5OhdTPKYc7+IX4gLR1DPAUlJgXqDA== )
rutaba.ga. 600 IN RRSIG DNSKEY 15 2 3600 (
20251023163739 20251008163739 57782 rutaba.ga.
t3wZ31rY7TgXY+QZXd/Yy7QtTmYdJy6v7Kuj6IN8G+m4
GycTLLn9W3lXErMS7f93RfkvXfERrwzbHqrTp1/oDg== )
…
;; Query time: 1 msec
;; SERVER: ::1#4543(localhost) (TCP)
;; WHEN: Thu Oct 09 16:43:24 UTC 2025
;; XFR size: 15 records (messages 1, bytes 1201)
(On verra plus loin comment configurer le « vrai » serveur de noms pour utiliser cette zone.)
Comme OpenDNSSEC, Cascade regarde sa montre pour savoir si un
délai suffisant s'est écoulé (rappelez-vous que les résolveurs DNS ont une mémoire, et que cela a
une grande importance opérationnelle ; dans le DNS, rien n'est
jamais instantané). Mais, contrairement à OpenDNSSEC, il demande au
résolveur local des tests (à l'heure actuelle, la machine qui fait
tourner Cascade doit donc avoir accès à un résolveur qui marche). En
attendant, cascade zone status --detailed vous
affichera des choses comme :
Roll AlgorithmRoll, state Propagation1:
Wait until the new DNSKEY RRset has propagated to all nameservers.
Try again after 2025-10-09T16:47:42Z
Voyons plutôt une fonction essentielle de Cascade : les étapes de
validation. Pour l'instant, je n'en ai configuré aucune. Mais, en
production, on veut éviter à tout prix ces ennuyeuses erreurs, qui plantent DNSSEC et
toute la zone. On va donc forcément valider la zone signée avant de
la publier. Le principe est d'écrire un programme (typiquement un
script shell) qui va lancer un programme de validation comme validns ou le
dnssec-verify de
BIND. On peut avoir cette étape de validation
avant la signature (pour tester le fichier de zone original) ou
après (ce que je fais ici). Essayons pour commencer avec un script
de validation méchant qui refuse tout :
% cat /etc/cascade/reviews/always-reject.sh
#!/bin/sh
logger "Rejecting ${CASCADE_ZONE} of serial ${CASCADE_SERIAL} from ${CASCADE_SERVER}"
♯ Cascade va utiliser le code de retour pou savoir si la zone est
# validée ou pas.
exit 1
On configure la politique (pas la configuration générale : valider ou pas fait partie de la politique) :
% cat /etc/cascade/policies/default.toml … # How signed zones are reviewed. [signer.review] required = true cmd-hook = "/etc/cascade/reviews/always-reject.sh"
On recharge la politique (cascade policy
reload) et la validation est configurée (Cascade étant en
version alpha, pour l'instant, il faut redémarrer le démon mais ce
n'est pas normal). Le résultat est l'attendu :
% ./target/debug/cascade zone status rutaba.ga … • Waiting for approval to publish version 2025101004 Configured to invoke /etc/cascade/reviews/always-reject.sh x An error occurred that prevents further processing of this zone version: x Signed zone was rejected at the review stage.
Et dans le journal du démon :
[2025-10-10T06:32:49.335Z] INFO cascade::units::zone_server: [RS2]: Executed hook '/etc/cascade/reviews/always-reject.sh' for signed zone 'rutaba.ga' at serial 2025101004
[2025-10-10T06:32:49.339Z] DEBUG cascade::units::zone_server: [RS2]: Hook '/etc/cascade/reviews/always-reject.sh' exited with status exit status: 1
[2025-10-10T06:32:49.339Z] DEBUG cascade::targets::central_command: [CC]: Event received: ReviewZone { name: Name(rutaba.ga.), stage: Signed, serial: Serial(2025101004), decision: Reject }
…
[2025-10-10T06:32:49.339Z] DEBUG cascade::targets::central_command: [CC]: Event received: SignedZoneRejectedEvent { zone_name: Name(rutaba.ga.), zone_serial: Serial(2025101004) }
Écrivons maintenant un script plus sérieux. Il va obtenir la zone
à valider via un transfert de zones. Notez que le
port utilisé est obtenu via une variable
d'environnement ; Cascade sert la zone sur des ports différents
selon qu'elle a été validée ou pas (cf. les paramètres
servers dans config.toml). Donc, le « vrai » serveur,
présenté plus loin, n'utilisera pas le même port. Voici le script de
validation utilisable en production :
% cat /etc/cascade/reviews/validate-signed.bash
#!/bin/bash
# Yes, bash is required, to parse CASCADE_SERVER
set -e
logger -p daemon.notice -t cascade "Validating ${CASCADE_ZONE} of serial ${CASCADE_SERIAL} from ${CASCADE_SERVER}"
# Parsing magic by mozzieongit
SERVER=${CASCADE_SERVER%:*}
SERVER_IP="${SERVER//[\[\]]/}" # remove brackets from IPv6
SERVER_PORT=${CASCADE_SERVER##*:} # Using double '##' in case its an IPv6
tmp_zone=$(mktemp /tmp/.cascade_zone.XXXXXXXXXX)
# Clean when leaving
trap "rm -f ${tmp_zone}; exit 1" 1 2 3 15
trap "rm -f ${tmp_zone}" EXIT
# Too bad dig logs some errors on standard output :-(
dig @${SERVER_IP} -p ${SERVER_PORT} ${CASCADE_ZONE} AXFR > ${tmp_zone}
# validns does not handle Ed25519
# validns -z ${CASCADE_ZONE} -p all ${tmp_zone}
# or:
dnssec-verify -q -o ${CASCADE_ZONE} ${tmp_zone}
# Or:
# ldns-verify ${tmp_zone}
# Le code de retour du programme de vérification va être celui du script.
Et la zone est acceptée :
[2025-10-10T07:01:01.462Z] DEBUG cascade::units::zone_server: [RS2] Received command: SeekApprovalForSignedZone { zone_name: Name(rutaba.ga.), zone_serial: Serial(2025101001) }
[2025-10-10T07:01:01.462Z] INFO cascade::units::zone_server: [RS2]: Seeking approval for signed zone 'rutaba.ga' at serial 2025101001.
[2025-10-10T07:01:01.463Z] INFO cascade::units::zone_server: [RS2]: Executed hook '/etc/cascade/reviews/validns.sh' for signed zone 'rutaba.ga' at serial 2025101001
[2025-10-10T07:01:01.485Z] INFO domain::net::server::middleware::cookies: preprocess; request_ip=127.0.0.1
[2025-10-10T07:01:01.485Z] INFO domain::net::server::middleware::xfr::service: AXFR for rutaba.ga from 127.0.0.1:35159
[2025-10-10T07:01:01.498Z] DEBUG cascade::units::zone_server: [RS2]: Hook '/etc/cascade/reviews/validns.sh' exited with status exit status: 0
[2025-10-10T07:01:01.498Z] DEBUG cascade::targets::central_command: [CC]: Event received: ReviewZone { name: Name(rutaba.ga.), stage: Signed, serial: Serial(2025101001), decision: Approve }
[2025-10-10T07:01:01.498Z] INFO cascade::targets::central_command: [CC]: Passing back zone review
Bon, maintenant, configurons un « vrai » serveur de noms pour
charger la zone et la servir à tous les résolveurs de
l'Internet. J'utilise nsd. Dans le
nsd.conf, je mets :
zone:
name: "internautique.fr"
zonefile: "/var/lib/nsd/%s.zone"
request-xfr: AXFR 127.0.0.1@8053 NOKEY
allow-notify: 127.0.0.1 NOKEY
# Mettre ici les autres serveurs faisant autorité, qu'il faut notifier et autoriser.
On va autoriser 127.0.0.1 (la machine locale,
où tourne Cascade) à nous notifier les changements de la zone
signée, et on demandera les transferts de zone à cette même machine,
sur le port où écoute Cascade (ici 8053). nsd va alors charger la
zone, éventuellement notifier les autres serveurs faisant autorité
et tout roule.
Si vous connaissez DNSSEC, vous avez vu qu'il manque une étape : ajouter l'enregistrement DS (Delegation Signer) dans la zone parente. Cascade n'affiche pas ce DS tout de suite, il sait que les résolveurs ont une mémoire et il attend d'avoir vu la zone signée publiée et que la durée configurée soit écoulée. En version alpha, cette étape ne marche pas toujours donc on va le faire à la main (ne le faites pas en production !) :
% dig @127.0.0.1 -p 8053 AXFR internautique.fr > /tmp/internautique.fr
% dnssec-dsfromkey -f /tmp/internautique.fr internautique.fr
internautique.fr. IN DS 30790 15 2 BB8987B69144BFB6863D9F86983EE1FB465629CDB3EE8DC43EE6B7C11056598F
Et c'est ce DS qu'on va transmettre à la zone parente (peut-être via son BE). Les programmes de test disponibles en ligne montrent une configuration (presque) correcte : Zonemaster et DNSviz.
Avant-dernière chose à faire : faire tourner le démon en permanence sur la machine. Cascade vient avec un fichier de configuration pour systemd mais une bogue subtile l'empêche actuellement de fonctionner. J'ai donc utilisé un plus classique script rc.local :
% cat /etc/boot.d/cascade
#!/bin/sh
# You may change this one:
DEBUG=1
set -e
# Don't touch
export PATH=${PATH}:/home/cascade/.cargo/bin
if [ ${DEBUG} -ge 1 ]; then
DAEMON_OPTS="--log-level debug"
export RUST_BACKTRACE=full
else
DAEMON_OPTS="--log-level info"
fi
# Does not work with su (for unknown reasons): "Permission denied"
sudo -E -u cascade /home/cascade/.cargo/bin/cascaded --daemonize ${DAEMON_OPTS} --state=/var/lib/cascade/state.db --config=/etc/cascade/config.toml
# su -p cascade -c '/home/cascade/.cargo/bin/cascaded --state=/var/lib/cascade/state.db --config=/etc/cascade/config.toml'
Enfin, quand on sera en production, il faudra évidemment superviser Cascade. J'utilise un petit script qui suit l'API Nagios :
% cat /usr/local/lib/nagios/plugins/check_cascade
#!/bin/sh
# Simple Nagios/Icinga plugin for Cascade.
USAGE="Usage: $0 -e string_to_expect"
TEMP=$(getopt -o "e:h" -- "$@")
if [ $? != 0 ]; then
echo $USAGE
exit 1
fi
eval set -- "$TEMP"
while true ; do
case "$1" in
-e) EXPECTED=$2; shift 2;;
-h) echo $USAGE; exit 3;;
--) shift ; break ;;
*) echo "Internal error!"; exit 3 ;;
esac
done
logger "Test Cascade, expect \"${EXPECTED}\""
E_OUT=$(/home/cascade/.cargo/bin/cascade zone list 2>/dev/null)
if [ $? -ne 0 ];
then
echo "Cascade did not respond"
exit 2
fi
if [ ! -z "${EXPECTED}" ]; then
L_CNT=$(echo ${E_OUT} | grep "${EXPECTED}" 2>/dev/null | wc -l)
if [ ${L_CNT} -eq 0 ]; then
echo "Cascade zone list did not return a match on ${EXPECTED}"
exit 2
fi
fi
echo "Cascade OK ${S_OUT}"
exit 0
Et qui se configure comme cela dans Icinga :
object CheckCommand "cascade" {
command = [ PluginContribDir + "/check_cascade" ]
arguments = {
"-e" = "$cascade_expect$",
}
}
object Host "ayla-cascade" {
import "generic-host"
check_command = "remote_always_true"
vars.cascade = true
vars.cascade_expect="internautique\\.fr"
}
Et en conclusion, un peu d'opéra, avec l'air « Cascader la vertu » de La Belle Hélène, interprété par Gaëlle Arquez.
L'article seul
RFC 9861: KangarooTwelve and TurboSHAKE
Date de publication du RFC : Octobre 2025
Auteur(s) du RFC : B. Viguier (ABN AMRO Bank), D. Wong
(zkSecurity), G. Van Assche
(STMicroelectronics), Q. Dang
(NIST), J. Daemen (Radboud
University)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF cfrg
Première rédaction de cet article le 13 octobre 2025
Vous trouvez qu'il n'y a pas assez d'algorithmes en cryptographie ? En voici quatre de plus, ici pour condenser cryptographiquement des données, plus rapidement que les algorithmes existants.
Il s'agit de quatre fonctions, TurboSHAKE128 et TurboSHAKE256 (variantes de TurboSHAKE) ainsi que de KT128 et KT256 (variantes de Kangaroo Twelve qui est décrit dans cet article). Toutes sont des XOF (eXtendable Output Function), des fonctions dont le résultat peut être infiniment long (comme ce que produit un générateur pseudo-aléatoire), mais qu'on tronque à la valeur souhaitée (cf. section 2.1). Kangaroo Twelve (section 3) est bâti sur TurboSHAKE et apporte le parallélisme : il permet de répartir le travail sur plusieurs processeurs alors que SHA-3 et TurboSHAKE sont strictement séquentiels. TurboSHAKE (section 2), lui, est bâti sur Keccak (qui est aussi la base de SHA-3, la cryptographie, c'est compliqué). D'ailleurs, le logiciel qui met en œuvre les algorithmes de ce RFC est développé par l'équipe de Keccak.
Ne comptez pas sur moi pour des explications cryptographiques détaillées, je n'y connais rien, lisez les sections 2 et 3 du RFC. Mais Sakura, le système utilisé par Kangaroo Twelve pour répartir le travail semble intéressant (cf. l'article original).
En section 4 du RFC, vous trouverez comment utiliser Kangaroo Twelve pour faire un MAC (on condense le message puis on condense la concaténation de la clé et du résultat de la première condensation).
Et si vous voulez mettre en œuvre Kangaroo Twelve vous-même, la
section 5 vous offre de nombreux vecteurs de
test. Mais, avant, regardez l'annexe A qui vous offre du
pseudo-code et rappelle qu'il y a une
implémentation en C, XKCP (par l'équipe Keccak)
et une en Python,
décrite dans l'article « KangarooTwelve: fast
hashing based on Keccak-p » (les vecteurs de test
du RFC viennent de là, normal, ce sont les mêmes auteurs). Enfin,
une
troisième est en Zig.
Commençons en Python (j'ai fait une copie du code de l'article dans
kangarootwelve.pytest-kangarootwelve.py
KT128(M=ptn(17 bytes), C=`00`^0, 32):
`6B F7 5F A2 23 91 98 DB 47 72 E3 64 78 F8 E1 9B
0F 37 12 05 F6 A9 A9 3A 27 3F 51 DF 37 12 28 88`
Le programme affiche :
% python test-kangarootwelve.py 6b f7 5f a2 23 91 98 db 47 72 e3 64 78 f8 e1 9b 0f 37 12 05 f6 a9 a9 3a 27 3f 51 df 37 12 28 88
Ce qui est bien la bonne valeur.
Et avec XKCP, compilons la bibliothèque et le programme de test test-kangarootwelve.c
git submodule update --init make generic64/libXKCP.so gcc -I ./bin/generic64/libXKCP.so.headers -L ./bin/generic64 test-kangarootwelve.c -lXKCP # ou # gcc -I ./bin/generic64/libXKCP.so.headers test-kangarootwelve.c ./bin/generic64/libXKCP.so LD_LIBRARY_PATH=./bin/generic64 ./a.out
Et le programme affiche bien le vecteur de test indiqué dans le RFC.
Kangaroo Twelve a été ajouté au registre IANA, et les quatre algorithmes sont dans le registre de COSE (RFC 8152).
L'article seul
RFC 9859: Generalized DNS Notifications
Date de publication du RFC : Septembre 2025
Auteur(s) du RFC : J. Stenstam (The Swedish Internet
Foundation), P. Thomassen (deSEC, Secure Systems
Engineering), J. Levine (Standcore
LLC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 5 octobre 2025
Vous le savez, le protocole DNS permet plusieurs sortes de messages, identifiés par un code d'opération. Si le classique QUERY, pour demander à résoudre un nom en informations pratiques, est le plus connu, il y a aussi le UPDATE (modifier les données), le DSO (DNS Stateful Operations) et quelques autres. Et puis il y a le NOTIFY, qui sert à indiquer à un serveur DNS qu'il y a quelque chose de nouveau et d'intéressant. NOTIFY est surtout connu pour son utilisation afin de… notifier un serveur secondaire que le primaire a une nouvelle version de la zone (c'est dans le RFC 1996). Ce nouveau RFC généralise le concept et permet d'utiliser NOTIFY pour d'autres choses comme un changement dans la liste des serveurs faisant autorité ou un changement de clé DNSSEC.
Si vous avez oublié à quoi servait initialement NOTIFY, relisez le RFC 1996. Il permettait de donner une indication (uniquement une indication, le NOTIFY ne fait pas autorité) comme quoi il faudrait envisager un nouveau transfert de zone (RFC 5936) pour mettre à jour un serveur. Cela permettait des mises à jour plus rapides qu'avec le système traditionnel où chaque serveur esclave devait de temps en temps demander à son maître s'il y avait du nouveau. Mais il y a d'autres cas où un serveur DNS voudrait dire à un autre qu'il y a quelque chose à regarder, par exemple si une nouvelle clé doit être utilisée. D'où l'extension d'utilisation que permet notre RFC 9859. Elle ne change pas le protocole, elle se contente d'utiliser plus largement une fonction existante.
Bon, mais c'est bien joli de dire qu'on peut notifier pour bien
des choses mais on notifie qui ? Dans le cas traditionnel d'une
nouvelle version de la zone, le primaire savait qu'il devait
notifier ses secondaires, qu'il connait (après tout, il doit leur
autoriser le transfert de zone et, dans le pire des cas, il peut
toujours regarder l'ensemble d'enregistrements NS de sa zone). Mais
si on généralise le NOTIFY, on peut ne pas savoir qui notifier (les
autres mécanismes de notification, comme une API ou comme la mise à
jour dynamique du RFC 2136, ont d'ailleurs le
même problème). La section 3 du RFC couvre ce problème. La méthode
recommandée est de publier un enregistrement de type DSYNC, normalisé
dans notre RFC, section 2. Il se place sous le nom
_dsync de la zone :
sousdomaine._dsync IN DSYNC CDS NOTIFY 5359 cds-scanner.example.net.
Notez qu'un joker est possible, par exemple :
*._dsync IN DSYNC CDS NOTIFY 5359 cds-scanner.example.net. *._dsync IN DSYNC CSYNC NOTIFY 5359 cds-scanner.example.net.
Ce nom _dsync a été ajouté dans le registre
des noms précédés d'un trait bas (RFC 8552).
Voici un autre exemple
d'enregistrement DSYNC :
_dsync.example.net. IN DSYNC CDS NOTIFY 5359 cds-scanner.example.net.
Que dit-il ? Qu'example.net, a priori un
hébergeur DNS, voudrait que ses clients, lorsqu'ils ont un nouvel
enregistrement CDS (indiquant l'activation d'une nouvelle clé
DNSSEC, cf. RFC 8078),
notifient cds-scanner.example.net sur le
port 5359. Ce nouveau type DSYNC a été ajouté
au registre des types, avec la valeur 66.
La section 4.1 détaille comment on trouve le serveur à qui
envoyer la notification en utilisant
_dsync. Imaginons qu'on gère
extra.sub.exodus-privacy.eu.org et qu'on
veuille notifier la zone parente. On insère le composant
_dsync après le premier composant (cela donne
extra._dsync.sub.exodus-privacy.eu.org) et on
fait une requête pour ce nom et le type DSYNC. Si ça marche, c'est
bon, sinon, on utilise le SOA dans la réponse pour trouver la zone
parente, et on met le _dsync devant. Si ça ne
donne toujours rien, on retire les composants avant la zone parente
et on recommence. Donc, on interrogera successivement (jusqu'au
premier succès),
extra._dsync.sub.exodus-privacy.eu.org,
extra.sub._dsync.exodus-privacy.eu.org et
_dsync.exodus-privacy.eu.org.
Et le NOTIFY dans l'enregistrement DSYNC d'exemple plus haut ? C'est le plan (scheme, à ne pas confondre avec le code d'opération - opcode - NOTIFY) car DSYNC, dans le futur, pourra servir à autre chose que les notifications. Pour l'instant, dans le nouveau registre des plans, il n'y a que NOTIFY mais dans le futur, d'autres pourront être ajoutés (suivant la politique « Examen par un expert » du RFC 8126).
Comment utiliser ce mécanisme de notification généralisé pour
traiter les enregistrements CDS et CDNSKEY des RFC 7344, RFC 8078 et RFC 9615 ? Ces enregistrements servent à signaler à la zone
parente la disponibilité de nouvelles clés DNSSEC. La section 4 de
notre RFC détaille comment le mécanisme de notification permet
d'indiquer qu'un CDS ou un CDNSKEY a changé. Cela évite au
gestionnaire de la zone parente de balayer toute la zone ce qui,
pour un TLD
de plusieurs millions de noms comme
.fr serait long et
pénible. La solution de ce RFC 9859 est donc de
chercher les DSYNC puis d'envoyer les NOTIFY, au moins deux, un pour
le type CDS et un pour le type CDNSKEY (on ne sait pas forcément à
l'avance lesquels utilisent la zone parente). La zone parente doit
effectuer les mêmes vérifications que lorsqu'elle a détecté un
nouveau CDS (ou CDNSKEY) : RFC 9615 si on
active une zone signée pour la première fois et RFC 7344 et RFC 8078 autrement.
Les messages utilisant le code d'opération NOTIFY sont censés produire une réponse (RFC 1996, section 4.7). Si aucune réponse n'arrive avant l'expiration du délai de garde, on réessaie. Si on a trop réessayé, on peut signaler le problème avec la technique du RFC 9567.
Il est important de se souvenir qu'une notification n'est pas sérieusement authentifiée, et que le récepteur doit donc, s'il choisit d'agir sur une notification, être prudent. Dans le RFC 1996, rien de grave ne pouvait arriver, le récepteur du NOTIFY demandait juste le SOA de la zone puis, si nécessaire, un transfert de zone. Mais avec les CDS et CDNSKEY, des attaques plus sérieuses sont possibles et le destinataire de la notification doit donc effectuer davantage de vérifications (par exemple, si la zone est déjà signée, faire une requête pour le CDS ou le CDNSKEY et vérifier que la réponse est valide et sécurisée, si elle ne l'est pas, faire tous les contrôles du RFC 9615). La notification elle-même n'est pas un problème de sécurité (elle dit juste « tu devrais regarder cela »), c'est l'action qui en résulte qui doit être bien réfléchie. Voilà pourquoi les notifications, même généralisées, ne sont pas plus sécurisées que cela. (Voir aussi la section 5 du RFC, qui insiste sur ce point ; la notification peut accélérer les choses mais ne doit pas à elle-même changer quelque chose.) Il est quand même préférable de limiter le nombre de notifications qu'on traite, au cas où un client malveillant vous bombarde de notifications.
Ces notifications généralisées pourront aussi s'utiliser pour les CSYNC du RFC 7477.
Qui met en œuvre ce RFC à l'heure actuelle ? Des opérateurs comme
deSEC ont annoncé que c'était
en cours, côté client. Côté serveur, les registres de
.ch et
.se ont annoncé que
c'était en cours, ou bien prévu.
Voici un exemple d'un client en Python (utilisant dnspython) qui notifie pour un nouveau CDS :
import dns.message
import dns.query
import dns.opcode
notify = dns.message.make_query("bortzmeyer.fr", "CDS")
notify.set_opcode(dns.opcode.NOTIFY)
response = dns.query.udp(notify, "192.0.2.211")
print(response)
Et en C ? Vous pouvez
utiliser le programme d'exemple generalized-notify.c
% gcc -o generalized-notify -Wall generalized-notify.c -lldns % ./generalized-notify bortzmeyer.fr 192.0.2.211 Reply code: NOERROR
Je note à ce sujet que certains serveurs faisant autorité, lorsqu'ils ne font pas autorité pour le domaine signalé, répondent REFUSED, ce qui est logique, mais on voit aussi des FORMERR ou NXDIOMAIN (!), sans doute parce que le type CDS ne leur plait pas.
L'annexe A du RFC prend de la hauteur et décrit plus en détail le
problème du balayage DNS. Comment savoir qu'il y a du nouveau, sans
tout examiner (dans le cas du SOA, au rythme indiqué par le champ
Refresh ; mais il n'y a pas de telle solution pour les CDS et
CDNSKEY). Le DNS traditionnel ne marchait que sur un modèle
pull (et c'est pour cela qu'il est faux de parler
de propagation DNS) mais les
NOTIFY du RFC 1996 introduisaient un peu de
push. Heureusement car balayer
.com à la recherche de
nouveaux enregistrements serait lent (et attirerait probablement
l'attention des IDS). Pour les CDS et CDNSKEY, cela serait
d'autant plus agaçant qu'ils seront a priori peu nombreux et que la
plupart des requêtes ne donneront donc rien.
L'article seul
RFC 9874: Best Practices for Deletion of Domain and Host Objects in the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Septembre 2025
Auteur(s) du RFC : S. Hollenbeck (Verisign Labs), W. Carroll (Verisign), G. Akiwate (Stanford University)
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 5 octobre 2025
Dans un registre de noms de domaine, il existe une classe d'objets pour les domaines et parfois une pour les serveurs de noms (hosts). C'est en se basant sur les objets de ces classes que des informations sont ensuite publiées dans le DNS. Que se passe-t-il si on retire un objet de ces classes, alors que d'autres objets en dépendaient ? Va-t-on scier une branche sur laquelle quelqu'un est assis ? Ce RFC fait le point sur les solutions existantes, notant que certaines sont moins bonnes que d'autres, notamment pour la sécurité.
Prenons un exemple simple : le domaine
monbeaudomaine.example est enregistré auprès du
registre
du TLD .example. Ses
serveurs de noms sont ns1.domaine-d-un-copain.example et
ns1.hébergeur.example et on va supposer que le
registre de .example traite les serveurs de
noms comme une classe distincte dans sa base de données. Maintenant,
supposons que le domaine
domaine-d-un-copain.example soit supprimé parce
que son titulaire n'en voit plus l'utilité. Que va devenir le
serveur de noms
ns1.domaine-d-un-copain.example ? Il existe de
nombreuses façons de traiter ce problème, et c'est le rôle de ce RFC
de les analyser toutes.
Ainsi, la section 3.2.2 du RFC 5731 dit que
ce n'est pas bien de détruire un domaine si des objets de type
serveur de noms sont sous ce domaine. Dans l'exemple précédent, le
registre de .example aurait refusé la
suppression de
domaine-d-un-copain.example. Mais cela laisse
le problème entier : si le titulaire ne veut plus payer et donc veut
supprimer le domaine, que faire ?
Un cas similaire se produit si on veut supprimer un serveur de
noms. Si le client EPP demande au serveur EPP
du registre de .example la suppression de
l'objet ns1.domaine-d-un-copain.example, que
doit faire le registre, sachant que ce serveur de noms est utilisé
par monbeaudomaine.example ? La section 3.2.2
du RFC 5732 dit que le registre devrait
refuser la suppression. C'est d'autant plus gênant que, dans le
modèle RRR (Registrant-Registrar-Registry), domaine et serveur(s) peuvent
être gérés par des BE différents, n'ayant
pas le droit de toucher aux objets des autres BE.
Vous pouvez trouver des bonnes explications et des exemples réels dans les supports d'une présentation qui avait été faite à l'IETF.
Quelles sont donc les recommandations concrètes de ce RFC ? La section 6 les résume. Au choix :
- Renommer les serveurs de noms vers le nom d'un serveur maintenu par le client EPP (le BE), comme décrit dans la section 5.1.3.4.
- Demander au client EPP de supprimer les serveurs de noms mais avec possibilité de rétablissement (RFC 3915) comme décrit en section 5.2.2.3.
- Renommer les serveurs de noms dans un nom de domaine
spécial, dont il est garanti qu'il ne sera jamais utilisé, comme décrit en
section 5.1.4.3. Pour éviter d'avoir à créer une nouvelle entrée
dans le registre des noms de domaine
spéciaux, le nom
sacrificial.invalid, utilisant un TLD existant, est recommandé.
Le protocole EPP permet de changer le nom
d'un serveur de noms (section 3.2.5 du RFC 5732). Une pratique déjà observée est donc de renommer les
serveurs de noms. Dans l'exemple ci-dessus, recevant la demande de
suppression de domaine-d-un-copain.example, le
registre (ou le BE s'il le peut) renommerait
ns1.domaine-d-un-copain.example en, mettons,
ns1.domaine-d-un-copain.renamed.invalid. Ici,
.invalid, TLD réservé
par le RFC 6761, ne poserait pas vraiment de
problème mais renommer dans un domaine ouvert à l'enregistrement
pourrait créer un risque de sécurité, si le domaine de destination
n'existe pas, un méchant pouvant alors l'enregistrer et être ainsi en
mesure de répondre aux requêtes DNS.
La section 3 du RFC explique brièvement pourquoi les RFC 5731 et RFC 5732 déconseillent fortement de permettre la suppression d'un domaine tant que des serveurs de noms dans ce domaine existent. Il y a deux risques de sécurité si on détruisait le domaine en laissant les serveurs de noms tels quels dans la base de données du registre : un de déni de service (le nom ne se résout plus et le serveur va donc être inutile) et un de détournement (si un méchant peut ré-enregistrer le nom de domaine supprimé). Il y a aussi le problème de la colle orpheline, décrit dans le rapport du SSAC, « Comment on Orphan Glue Records in the Draft Applicant Guidebook ».
Si la clé qui identifie un serveur de noms est un numéro quelconque et pas son nom, on peut renommer le serveur sans changer les délégations, ce qui est particulièrement utile si le client EPP n'a pas le droit de changer des délégations qui appartiennent à un autre client du registre. Le nouveau nom ne va en général pas être associé à un serveur opérationnel : on sacrifie un serveur pour pouvoir supprimer le domaine parent. Mais cela entraine quelques risques (section 4 du RFC et l'article d' Akiwate, G., Savage, S., Voelker, G., et K. Claffy, « Risky BIZness: Risks Derived from Registrar Name Management »). Si on renomme vers un nom actuellement inexistant, le domaine peut être détourné si un malveillant enregistre ensuite ce domaine.
Compte tenu de tout cela, la section 5 du RFC étudie les différentes pratiques possibles, leurs avantages et leurs inconvénients. Pour les illustrer, je vais utiliser une base de données simple, décrite en SQL (les essais ont été faits avec PostgreSQL). Voici par exemple une création d'une telle base :
CREATE TABLE Domains (name TEXT UNIQUE);
-- Ici, la table Nameservers n'offre aucune valeur ajoutée par rapport
-- au fait de tout mettre dans Domains. Mais ce ne sera pas le cas par
-- la suite.
CREATE TABLE Nameservers (name TEXT UNIQUE);
CREATE TABLE Delegation (domain TEXT REFERENCES Domains(name),
server TEXT REFERENCES Nameservers(name));
INSERT INTO Domains VALUES ('monbeaudomaine.example');
INSERT INTO Domains VALUES ('domaine-d-un-copain.example');
INSERT INTO Nameservers VALUES ('ns1.domaine-d-un-copain.example');
INSERT INTO Nameservers VALUES ('ns1.hébergeur.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example', 'ns1.domaine-d-un-copain.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example', 'ns1.hébergeur.example');
Dans ce premier cas très simple, la suppression du domaine
domaine-d-un-copain.example est triviale :
registry=> DELETE FROM Domains WHERE name='domaine-d-un-copain.example'; DELETE 1
Mais elle laisse la possibilité de colle
orpheline et surtout d'un détournement de monbeaudomaine.example si
quelqu'un ré-enregistre
domaine-d-un-copain.example. Ce premier essai
n'est pas conforme aux exigences des RFC 5731
et RFC 5732. On va essayer de
faire mieux.
Si on interdit (à juste titre) la suppression d'un domaine lorsque des serveurs de noms sont nommés dans ce domaine, on peut arriver à supprimer un domaine en supprimant d'abord les serveurs de noms qui sont nommés dans ce domaine (section 5.2) :
CREATE TABLE Domains (name TEXT UNIQUE);
-- Ajout d'une dépendance au domaine parent, pour éviter les suppressions.
CREATE TABLE Nameservers (name TEXT UNIQUE, parent TEXT REFERENCES Domains(name));
CREATE TABLE Delegation (domain TEXT REFERENCES Domains(name),
server TEXT REFERENCES Nameservers(name));
INSERT INTO Domains VALUES ('monbeaudomaine.example');
INSERT INTO Domains VALUES ('domaine-d-un-copain.example');
INSERT INTO Domains VALUES ('hébergeur.example');
-- Pour une vraie base, on écrirait du code SQL qui extrait le parent
-- automatiquement.
INSERT INTO Nameservers VALUES ('ns1.domaine-d-un-copain.example', 'domaine-d-un-copain.example');
INSERT INTO Nameservers VALUES ('ns1.hébergeur.example', 'hébergeur.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example', 'ns1.domaine-d-un-copain.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example', 'ns1.hébergeur.example');
registry=> DELETE FROM Domains WHERE name='domaine-d-un-copain.example';
ERROR: update or delete on table "domains" violates foreign key constraint "nameservers_parent_fkey" on table "nameservers"
DETAIL: Key (name)=(domaine-d-un-copain.example) is still referenced from table "nameservers".
-- Ce comportement est ce que recommandent les RFC 5731 et 5732.
-- Cela oblige le client à supprimer les serveurs de noms d'abord, ce qui à
-- son tour nécessite potentiellement de changer les délégations :
registry=> DELETE FROM Delegation WHERE server = 'ns1.domaine-d-un-copain.example';
DELETE 1
registry=> DELETE FROM Nameservers WHERE name='ns1.domaine-d-un-copain.example';
DELETE 1
registry=> DELETE FROM Domains WHERE name='domaine-d-un-copain.example';
DELETE 1
Ici, il y a eu suppression explicite des serveurs de noms par le
client (section 5.2.2.1). Cela peut poser des problèmes de permission, dans le cadre du
système RRR, si tous les objets ne sont pas
chez le même BE. Mais la suppression explicite est
une des trois solutions recommandées, notamment si on ajoute la
possibilité de rétablir l'état précédent (commande EPP
<restore>, RFC 3915).
On peut aussi envisager une suppression implicite (section 5.2.1.1), le registre se
chargeant du nettoyage (c'est le rôle
de la directive SQL ON DELETE
CASCADE) :
CREATE TABLE Domains (name TEXT UNIQUE);
CREATE TABLE Nameservers (name TEXT UNIQUE,
parent TEXT REFERENCES Domains(name) ON DELETE CASCADE);
CREATE TABLE Delegation (domain TEXT REFERENCES Domains(name) ON DELETE CASCADE,
server TEXT REFERENCES Nameservers(name) ON DELETE CASCADE);
INSERT INTO Domains VALUES ('monbeaudomaine.example');
INSERT INTO Domains VALUES ('domaine-d-un-copain.example');
INSERT INTO Domains VALUES ('hébergeur.example');
-- Pour une vraie base, on écrirait du code SQL qui extrait le parent
-- automatiquement.
INSERT INTO Nameservers VALUES ('ns1.domaine-d-un-copain.example', 'domaine-d-un-copain.example');
INSERT INTO Nameservers VALUES ('ns1.hébergeur.example', 'hébergeur.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example', 'ns1.domaine-d-un-copain.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example', 'ns1.hébergeur.example');
registry=> SELECT Domains.name,Nameservers.name FROM Domains,Delegation,Nameservers WHERE Delegation.domain=Domains.name AND Delegation.server=Nameservers.name;
name | name
------------------------+---------------------------------
monbeaudomaine.example | ns1.domaine-d-un-copain.example
monbeaudomaine.example | ns1.hébergeur.example
(2 rows)
registry=> DELETE FROM Domains WHERE name='domaine-d-un-copain.example';
DELETE 1
-- Serveur de noms et délégation ont été détruits en cascade. Ce n'est
-- pas déraisonnable mais c'est quand même un peu effrayant.
registry=> SELECT Domains.name,Nameservers.name FROM Domains,Delegation,Nameservers WHERE Delegation.domain=Domains.name AND Delegation.server=Nameservers.name;
name | name
------------------------+-----------------------
monbeaudomaine.example | ns1.hébergeur.example
(1 row)
Cette solution est simple et efficace mais détruire implicitement des objets de la base de données peut inquiéter les responsables de cette base. Et cela peut laisser un domaine avec trop peu de serveurs de noms pour assurer sa continuité de service voire, dans le pire des cas, sans serveurs du tout. Et il serait bon de prévenir le client de cette suppression implicite, par exemple par le mécanisme de poll d'EPP (RFC 8590).
Si on interdit (à juste titre, le RFC le recommande) la suppression d'un
domaine lorsque des serveurs de noms sont nommés dans ce domaine, une
solution possible est de
renommer les serveurs avant de supprimer le domaine (section 5.1). Le nouveau nom
permet d'indiquer clairement la raison du renommage. Mais ce
renommage laisse dans la base des « déchets » qu'il faudra nettoyer
un jour. Cette catégorie
contient de nombreuses variantes. Par exemple, on peut renommer dans
un TLD spécial (RFC 6761), ici, .invalid :
CREATE TABLE Domains (name TEXT UNIQUE);
-- On introduit un identificateur du serveur de noms qui n'est *pas*
-- son nom, pour permettre le renommage.
CREATE TABLE Nameservers (id SERIAL UNIQUE, name TEXT UNIQUE,
parent TEXT REFERENCES Domains(name));
CREATE TABLE Delegation (domain TEXT REFERENCES Domains(name),
server INTEGER REFERENCES Nameservers(id));
INSERT INTO Domains VALUES ('monbeaudomaine.example');
INSERT INTO Domains VALUES ('domaine-d-un-copain.example');
INSERT INTO Domains VALUES ('hébergeur.example');
-- Pour le renommage, un nom qui indique clairement le but :
INSERT INTO Domains VALUES ('renamed.invalid');
-- Pour une vraie base, on écrirait du code SQL qui extrait le parent
-- automatiquement.
INSERT INTO Nameservers (name, parent) VALUES ('ns1.domaine-d-un-copain.example', 'domaine-d-un-copain.example');
INSERT INTO Nameservers (name, parent) VALUES ('ns1.hébergeur.example', 'hébergeur.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example',
(SELECT id FROM Nameservers WHERE name='ns1.domaine-d-un-copain.example'));
INSERT INTO Delegation VALUES ('monbeaudomaine.example',
(SELECT id FROM Nameservers WHERE name='ns1.hébergeur.example'));
registry=> SELECT Domains.name,Nameservers.name FROM Domains,Delegation,Nameservers WHERE Delegation.domain=Domains.name AND Delegation.server=Nameservers.id;
name | name
------------------------+---------------------------------
monbeaudomaine.example | ns1.domaine-d-un-copain.example
monbeaudomaine.example | ns1.hébergeur.example
(2 rows)
registry=> UPDATE Nameservers SET name='ns1.domaine-d-un-copain.example.renamed.invalid', parent='renamed.invalid' WHERE id=1;
UPDATE 1
registry=> DELETE FROM Domains WHERE name='domaine-d-un-copain.example';
DELETE 1
registry=> SELECT Domains.name,Nameservers.name FROM Domains,Delegation,Nameservers WHERE Delegation.domain=Domains.name AND Delegation.server=Nameservers.id;
name | name
------------------------+-------------------------------------------------
monbeaudomaine.example | ns1.domaine-d-un-copain.example.renamed.invalid
monbeaudomaine.example | ns1.hébergeur.example
(2 rows)
Par contre, il ne faut pas utiliser .alt, qui
est explicitement réservé aux protocoles non-DNS (RFC 9476). Notez que certains serveurs EPP peuvent tester le
nom des serveurs de noms et refuser des TLD « inconnus ».
Dans la nature, on a pu observer d'autres pratiques, comme de
renommer dans un sous-domaine de as112.arpa, nom
garanti ne pas exister (RFC 7535), mais qui
n'est pas censé servir à cela (RFC 6305). On a
vu aussi des renommages vers des résolveurs DNS publics, ce qui est
également une horreur, la délégation doit être faite vers des serveurs faisant
autorité, pas des résolveurs.
Certains clients EPP maintiennent des serveurs de noms actifs qui
servent pour le renommage. Cela fait davantage de travail mais cela
protège contre le détournement. Le DNS va continuer à fonctionner
normalement. On pourrait aussi imaginer des serveurs de noms actifs, répondant
NXDOMAIN (« ce domaine n'existe pas »), qui soient
gérés collectivement (section 5.1.4.4) ; un tel service serait
certainement utile. On pourrait même créer un nom de domaine pour ce
service (sacrificial.arpa ?) mais personne ne
l'a encore fait. Pour l'instant, la solution des serveurs maintenus
par le client EPP (section 5.1.3.4) fait partie des trois solutions
recommandées. Le client prudent doit bien verrouiller le domaine dans
lequel ces serveurs sont nommés (enregistrement multi-années,
verrouillage par le registre, etc).
On peut aussi renommer les serveurs de noms vers un nom
non-existant dans un TLD existant. Ça s'est déjà vu mais il ne faut
surtout pas faire cela : un attaquant pourrait enregistrer le nom et
capter ainsi le trafic (.invalid n'a pas ce
problème). Idem si le nom n'est pas sous votre contrôle. Un exemple
est donné par le domaine lenvol.re : ses
serveurs de noms étaient ns.hostin.io,
ns.hostin.mu et
ns.hostin.re. Lors de la suppression de
hostin.re en octobre 2024, le dernier serveur
de noms a été renommé
host1.renamedbyregistry.com (et, en dépit du
nom, pas par le registre). Ce domaine
renamedbyregistry.com étant enregistré, et par
un autre BE, on voit le risque.
% whois lenvol.re domain: lenvol.re status: ACTIVE … nserver: host1.renamedbyregistry.com nserver: ns.hostin.io nserver: ns.hostin.mu
D'autres noms qui utilisaient ce même serveur ont également le problème :
% dig @d.nic.fr savanna.re. NS … ;; AUTHORITY SECTION: savanna.re. 3600 IN NS host1.renamedbyregistry.com. savanna.re. 3600 IN NS ns.hostin.mu. savanna.re. 3600 IN NS ns.hostin.io. ;; Query time: 8 msec ;; SERVER: 2001:678:c::1#53(d.nic.fr) (UDP) ;; WHEN: Tue Jun 24 14:33:32 CEST 2025
En lecture supplémentaire, notre RFC recommande le rapport « SSAC 125 "Report on Registrar Nameserver Management" », ainsi que l'article « Risky BIZness: Risks Derived from Registrar Name Management ».
L'article seul
Utiliser des paquetages de Debian unstable via Ansible
Première rédaction de cet article le 4 octobre 2025
Bon, c'est un article d'ultra-niche. Mais, comme j'ai eu du mal à faire fonctionner cette configuration, je me dis que je peux la décrire, et que peut-être quelqu'un·e trouvera cet article un jour via un moteur de recherche, et que cela lui servira. Donc, le problème était : soit un ensemble de machines Debian configurées via Ansible. Un paquetage dont j'avais besoin n'était que dans la version Debian unstable. Comment l'installer via le module Ansible apt ?
D'abord, je détaille le problème. Pour une formation DNSSEC, je gère N machines virtuelles tournant sous Debian. Le paquetage d'OpenDNSSEC, qui était dans les précédentes versions de Debian, a été retiré de l'actuelle version stable, la version 13, alias « trixie ». La configuration que j'utilisais d'habitude avec Ansible et son module apt n'est donc pas utilisable telle quelle pour installer OpenDNSSEC.
Il y a bien sûr plusieurs solutions à ce problème (mais pas celle des backports, OpenDNSSEC n'y est pas) :
- Ne pas utiliser de paquetage du tout, compiler OpenDNSSEC moi-même et l'installer sur les machines via d'autres modules Ansible qui permettent de copier exécutables et fichiers de configuration. Pas pratique ; cela fait perdre un des gros avantages de l'utilisation de Debian, son excellent système de paquetages.
- Utiliser le successeur d'OpenDNSSEC (qui est officiellement retiré), Cascade. Pas de paquetage (donc on revient au point précédent) et, en plus, Cascade est loin d'être utilisable.
- Utiliser la version unstable de Debian au lieu de la stable. Pour des travaux pratiques dans une formation, le risque d'utiliser unstable est moins grave qu'en production mais, quand même, je ne voudrais pas qu'un problème surgisse pendant les exercices.
- Créer un paquetage Debian sur une machine
stable (en utilisant le source du paquetage de unstable), le copier vers les machines virtuelles
et l'installer avec
dpkg -i. À la réflexion, c'est sans doute ce que j'aurais dû faire, mais il n'est pas garanti que cela aurait bien marché.
J'ai finalement choisi une autre voie : utiliser
stable mais permettre l'installation de
paquetages qui existent dans unstable. Bien que
déconseillée
par Debian, cette méthode est assez banale et on trouve en
ligne plein d'instructions sur comment la réaliser. Une
configuration simple est, dans
/etc/apt/sources.list.d/unstable.sources :
Types: deb deb-src URIs: mirror+file:///etc/apt/mirrors/debian.list Suites: sid Components: main Signed-By: /usr/share/keyrings/debian-archive-keyring.gpg
(sid est le petit nom de la version
unstable. Si vous avez vu Toy
Story, vous savez pourquoi.)
Avec cela, vous pouvez maintenant installer des paquetages
d'unstable mais attention, vous ne voulez pas que
ces paquetages remplacent vos paquetages stable
existants ! Il faut donc aussi donner une basse priorité à
unstable, avec un /etc/apt/preferences.d/99unstable :
Package: * Pin: release a=unstable Pin-Priority: 1
Désormais, après le prochain apt update, un apt install quelquechose
installera bien la version stable du paquetage
« quelquechose », qui a une priorité supérieure. Et apt
install opendnssec installera la version
d'unstable puisqu'il n'y en a pas dans stable.
Tout cela est classique et bien connu, et ça marche. Mais depuis Ansible, patatras. Le module apt d'Ansible prétend qu'il n'existe pas d'OpenDNSSEC, alors que ça marche en ligne de commande avec apt. Voici la configuration du module :
tasks:
…
- name: install packages
apt: # https://docs.ansible.com/ansible/latest/collections/ansible/builtin/apt_module.html
name: [truc, machin, opendnssec]
state: present
C'est apparemment parce que Ansible ajoute à apt une option qui lui dit de n'utiliser que stable et je n'ai pas trouvé le moyen de couper cette option.
La solution est donc de faire deux tâches Ansible, une pour
stable et une pour unstable,
en utilisant le paramètre
default_release. Voici ma configuration
complète et qui marche :
tasks:
…
- name: "Copy apt sources"
copy:
src: apt-unstable.sources
dest: /etc/apt/sources.list.d/unstable.sources
- name: "Copy apt preferences"
copy:
src: apt-preferences.txt
dest: /etc/apt/preferences.d/99unstable
- name: "Update Repository cache"
apt: # https://docs.ansible.com/ansible/latest/collections/ansible/builtin/apt_module.html
update_cache: true
upgrade: dist
cache_valid_time: 3600
force_apt_get: true
- name: install packages
apt:
name: [truc, chose, machin]
state: present
- name: install unstable packages
apt:
name: [opendnssec, softhsm2]
default_release: sid
state: latest
Notez le state: latest. Si on laisse à la
valeur par défaut, present, Ansible produit un
message d'erreur incohérent prétendant que sid
n'est pas dans les sources.
L'article seul
Articles des différentes années : 2026 2025 2024 2023 2022 2021 2020 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}