
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
Checking quickly a DNS zone: a new variant of check-soa
First publication of this article on 26 December 2012
Last update on of 22 November 2014
When you want to assert rapidly whether or not a
DNS zone works fine, typical exhaustive tools
like Zonemaster may be too
slow. There is room for a light-and-fast tool and many people used to
rely on the check_soa (with an underscore) program developed by Liu
and Albitz and published with their famous book DNS and
BIND. This original program no longer seems maintained and, the
last time I tested it, did not support
IPv6. So, I wrote one more variant of "my very
own check-soa".
Like the original one, it queries each name server of a zone for the SOA record of the zone:
% check-soa fr d.ext.nic.fr. 192.5.4.2: OK: 2222258998 2001:500:2e::2: OK: 2222258998 d.nic.fr. 194.0.9.1: OK: 2222258998 2001:678:c::1: OK: 2222258998 e.ext.nic.fr. 193.176.144.6: OK: 2222258998 2a00:d78:0:102:193:176:144:6: OK: 2222258998 f.ext.nic.fr. 194.146.106.46: OK: 2222258998 2001:67c:1010:11::53: OK: 2222258998 g.ext.nic.fr. 194.0.36.1: OK: 2222258997 2001:678:4c::1: OK: 2222258997
Here, we can see that all name servers of .FR reply properly and their serial number is
2222258998. You have several options (-h to see
them all). For instance, -i will display the
response time:
% check-soa -i nl nl1.dnsnode.net. 194.146.106.42: OK: 2012122607 (3 ms) 2001:67c:1010:10::53: OK: 2012122607 (40 ms) ns-nl.nic.fr. 192.93.0.4: OK: 2012122607 (3 ms) 2001:660:3005:1::1:2: OK: 2012122607 (2 ms) ns1.dns.nl. 193.176.144.5: OK: 2012122607 (25 ms) 2a00:d78:0:102:193:176:144:5: OK: 2012122607 (38 ms) ns2.dns.nl. 2001:7b8:606::85: OK: 2012122607 (15 ms) 213.154.241.85: OK: 2012122607 (36 ms) ns3.dns.nl. 194.171.17.10: OK: 2012122607 (24 ms) 2001:610:0:800d::10: OK: 2012122607 (29 ms) ns4.dns.nl. 95.142.99.212: OK: 2012122607 (25 ms) 2a00:1188:5::212: OK: 2012122607 (34 ms) ns5.dns.nl. 194.0.28.53: OK: 2012122607 (24 ms) 2001:678:2c:0:194:0:28:53: OK: 2012122607 (33 ms) sns-pb.isc.org. 2001:500:2e::1: OK: 2012122607 (14 ms) 192.5.4.1: OK: 2012122607 (19 ms)
Sometimes, the name servers of the zone are not synchronized (it can be temporary, the DNS being only loosely consistent, or it can be permanent if there is a problem):
% check-soa xname.org ns0.xname.org. 195.234.42.1: OK: 2012081301 ns1.xname.org. 178.33.255.252: OK: 2009030502 ns2.xname.org. 88.191.64.64: OK: 2012081301 2a01:e0b:1:64:240:63ff:fee8:6155: OK: 2012081301 ns3.xtremeweb.de. 130.185.108.193: OK: 2012081301 2a01:4a0:2002:2198:130:185:108:193: OK: 2012081301
Here, ns1.xname.org lags behind.
Do note that check-soa uses a
zone, not just any domain:
% check-soa gouv.fr No NS records for "gouv.fr.". It is probably a domain but not a zone
Of course, when everything works fine, it is boring. What if there
is a problem? check-soa will display it and will
set the exit code accordingly:
% check-soa frnog.org leeloo.supracrawler.com. 193.178.138.10: OK: 2011112300 mercury.ecp-net.com. 193.178.138.20: OK: 2011112300 ns1.saitis.net. 62.220.128.88: OK: 2011112300 2001:788::88: ERROR: Timeout ns2.saitis.net. 62.220.128.98: OK: 2011112300 2001:788::98: ERROR: Timeout
Here, two name servers failed to reply in time (you can tune the
timeout with options -t and
-n). The actual problem was with IPv6
connectivity, so you can try with -4:
% check-soa -q frnog.org ns1.saitis.net. 2001:788::88: ERROR: Timeout ns2.saitis.net. 2001:788::98: ERROR: Timeout % echo $? 1 % check-soa -q -4 frnog.org % echo $? 0
In this specific case, I tested from several sites. But do note that,
quite often, networks problems and the resulting timeout will depend
on the site from which you test. check-soa sees
the Internet from just one point. Other points may be different (this
is specially true with IPv6 today.) A good
example is a test from Free (it works for every
other operator):
% check-soa -i mil CON1.NIPR.mil. 199.252.157.234: ERROR: Timeout CON2.NIPR.mil. 199.252.162.234: ERROR: Timeout EUR1.NIPR.mil. 199.252.154.234: ERROR: Timeout EUR2.NIPR.mil. 199.252.143.234: OK: 2012122703 (229 ms) PAC1.NIPR.mil. 199.252.180.234: ERROR: Timeout PAC2.NIPR.mil. 199.252.155.234: ERROR: Timeout
There are of course many other possible errors. For instance, on the TLD of Cambodia:
% check-soa kh admin.authdns.ripe.net. 193.0.0.198: ERROR: REFUSED 2001:67c:2e8:5:53::6: ERROR: REFUSED dns1.online.com.kh. 203.189.128.1: OK: 2012030124 kh.cctld.authdns.ripe.net. Cannot get the IPv4 address: NXDOMAIN ns.camnet.com.kh. 203.223.32.3: OK: 2012030124 ns.telesurf.com.kh. 203.144.66.3: ERROR: Not authoritative ns1.dns.net.kh. 203.223.32.21: OK: 2012030124 sec3.apnic.net. 2001:dc0:1:0:4777::140: OK: 2012030124 202.12.28.140: OK: 2012030124
We see three types of errors,
admin.authdns.ripe.net refuses to answer for this
TLD (it is called a "lame delegation", the TLD is delegated to a
server which does not know or does not want to answer about it,
probably because of a misunderstanding between operators),
kh.cctld.authdns.ripe.net does not exist and
ns.telesurf.com.kh replies, but is not
authoritative (it is actually an open recursive resolver, something
which is frowned upon, see RFC 5358).
By default, check-soa uses
EDNS. This can create problems with some very
old name servers:
% check-soa microsoft.com ns1.msft.net. 65.55.37.62: ERROR: FORMERR 2a01:111:2005::1:1: ERROR: FORMERR ns2.msft.net. 2a01:111:2006:6::1:1: ERROR: FORMERR 64.4.59.173: ERROR: FORMERR ns3.msft.net. 213.199.180.53: ERROR: FORMERR 2a01:111:2020::1:1: ERROR: FORMERR ns4.msft.net. 2404:f800:2003::1:1: ERROR: FORMERR 207.46.75.254: ERROR: FORMERR ns5.msft.net. 65.55.226.140: ERROR: FORMERR 2a01:111:200f:1::1:1: ERROR: FORMERR
All of Microsoft's name servers reply "FORmat
ERRor". The -r option will force back old DNS:
% check-soa -r microsoft.com ns1.msft.net. 65.55.37.62: OK: 2012122401 2a01:111:2005::1:1: OK: 2012122401 ns2.msft.net. 2a01:111:2006:6::1:1: OK: 2012122401 64.4.59.173: OK: 2012122401 ns3.msft.net. 213.199.180.53: OK: 2012122401 2a01:111:2020::1:1: OK: 2012122401 ns4.msft.net. 2404:f800:2003::1:1: OK: 2012122401 207.46.75.254: OK: 2012122401 ns5.msft.net. 65.55.226.140: OK: 2012122401 2a01:111:200f:1::1:1: OK: 2012122401
One of the points where my check-soa is an
improvment over the original is that it issues DNS requests in
parallel. So, the waiting time will depend only on the slowest server,
not on the sum of all servers. Let's try it on
Sri Lanka TLD:
% time check-soa -i lk c.nic.lk. 203.143.29.3: OK: 2012122601 (268 ms) 2405:5400:3:1:203:143:29:3: OK: 2012122601 (274 ms) d.nic.lk. 123.231.6.18: OK: 2012122601 (133 ms) l.nic.lk. 192.248.8.17: OK: 2012122601 (189 ms) m.nic.lk. 202.129.235.229: OK: 2012122601 (290 ms) ns1.ac.lk. 192.248.1.162: OK: 2012122601 (179 ms) 2401:dd00:1::162: OK: 2012122601 (300 ms) p.nic.lk. 204.61.216.27: OK: 2012122601 (4 ms) 2001:500:14:6027:ad::1: OK: 2012122601 (5 ms) pendragon.cs.purdue.edu. 128.10.2.5: OK: 2012122601 (142 ms) ripe.nic.lk. 2001:67c:e0::88: OK: 2012122601 (16 ms) 193.0.9.88: OK: 2012122601 (17 ms) t.nic.lk. 203.94.66.129: OK: 2012122601 (622 ms) check-soa -i lk 0.02s user 0.00s system 3% cpu 0.637 total
The elapsed time was only 637 ms (a bit more than the slowest server,
which was at 622), not the sum of all the delays. Parallelism is
specially important when some servers timeout. By default,
check-soa tries three times, with a waiting time
of 1.5 second (other programs have a default of 5 seconds, which is
extremely long: a DNS reply never comes back after 5 seconds!). So:
% time check-soa -i ml ciwara.sotelma.ml. 217.64.97.50: ERROR: Timeout djamako.nic.ml. 217.64.105.136: OK: 2012122100 (115 ms) dogon.sotelma.ml. 217.64.98.75: OK: 2012122100 (109 ms) ml.cctld.authdns.ripe.net. 193.0.9.95: ERROR: REFUSED (13 ms) 2001:67c:e0::95: ERROR: REFUSED (14 ms) ns-ext.isc.org. 2001:4f8:0:2::13: OK: 2012122100 (173 ms) 204.152.184.64: OK: 2012122100 (183 ms) yeleen.nic.ml. 217.64.100.112: OK: 2012122100 (124 ms) check-soa -i ml 0.01s user 0.00s system 0% cpu 4.518 total
The elapsed time, 4.518 seconds, is mostly because of the timeout (and
retries) on ciwara.sotelma.ml.
By default, check-soa retrieves the list of name servers to query
from the local resolver. If the domain is so broken that it cannot
even handle these requests, or simply if you want to test with
different name servers (for instance because the zone is not yet
delegated), you can use the -ns option to
indicate explicitely the name servers:
% check-soa -ns "a.gtld-servers.net b.gtld-servers.net" com a.gtld-servers.net. 2001:503:a83e::2:30: OK: 1416671393 192.5.6.30: OK: 1416671393 b.gtld-servers.net. 2001:503:231d::2:30: OK: 1416671393 192.33.14.30: OK: 1416671393
Are you convinced? Do you want to install it? Then, get the source code
and follow the instructions in the file
README.md. Do note that my
check-soa is written in Go
so you'll need a Go compiler. Also, it depends on the excellent godns library so you need
to install it first.
If you read the source code, there is nothing extraordinary: parallelism is very simple in Go, thanks to the goroutines so there is little extra effort to make a parallel program (one of the great strengths of Go).
I also wrote a Nagios plugin in Go to perform more or less the same tests. But the Nagios plugin does not use parallelism: since it is not an interactive program, it is less important if the elapsed time is longer.
Other versions of check-soa (or check_soa):
- The original source code.
- The one I prefer is written in Python by Alain Thivillon:
soa.py. - A Perl one, in the excellent Net::DNS library and a simpler one, written by Laurent Frigault.
- There is
check_soa.rbin dnsruby.
A recent alternative to check-soa is the
option nssearch of dig:
% dig +nodnssec +nssearch bortzmeyer.fr SOA ns3.bortzmeyer.org. hostmaster.bortzmeyer.org. 2012122602 7200 3600 604800 3600 from server 192.134.7.248 in 1 ms. SOA ns3.bortzmeyer.org. hostmaster.bortzmeyer.org. 2012122602 7200 3600 604800 3600 from server 2001:67c:2219:3::1:4 in 1 ms. SOA ns3.bortzmeyer.org. hostmaster.bortzmeyer.org. 2012122602 7200 3600 604800 3600 from server 217.70.190.232 in 2 ms.
It has several limitations: each server is tested only once, even if
it has multiple IP addresses (which can belong to different physical
machines), if stops immediately for some errors (such as a name server
which has no entry in the DNS), it does not react properly to non-EDNS
name servers like microsoft.com mentioned above, etc.
Thanks to Miek Gieben for godns and for his debugging of my code. Also, check-soa is available as a package in ArchLinux AUR.
L'article seul
Fiche de lecture : Tubes: A journey to the center of the Internet
Auteur(s) du livre : Andrew Blum
Éditeur : Harper Collins
978-0-06-199493-7
Publié en 2012
Première rédaction de cet article le 25 décembre 2012
Contrairement à ce qu'on pourrait croire en prêtant attention aux niaiseries comme le discours sur le « virtuel » ou sur le « cloud », l'Internet n'est pas un concept évaporé. Il s'appuie sur de grosses et lourdes machines, qui sucent beaucoup d'électricité, et qui sont hébergées dans de grands bâtiments industriels. Ceux-ci sont connectés par des liens bien physiques, les ondes radio étant marginales. C'est cet enracinement physique de l'Internet que décrit Andrew Blum. L'auteur vivait autrefois dans l'ignorance de l'endroit où passait son trafic Internet. Il a eu son chemin de Damas lorsqu'un écureuil insolent a eu l'audace de ronger son accès Internet. Blum a alors compris la physicalité du réseau et est parti visiter la planète pour trouver les lieux physiques d'Internet.
(Au passage, ceux qui aiment les écureuils et se demandent pourquoi une si charmante bête est peu aimée des professionnels du réseau doivent lire l'excellent article de Pierre Col.)
Car Blum regrette qu'on ne prête plus attention à cette physicalité : comme le dit Leonard Kleinrock, interrogé par l'auteur sur les lieux des débuts d'Arpanet, « Students no longer take things apart », on ne démonte plus les choses. À défaut de les démonter, Blum les visite. Il se rend dans plusieurs points d'échange et décrit de manière très vivante ces points d'interconnexion où bat le cœur du réseau. Il ne peint pas que l'état physique actuel mais aussi son histoire compliquée et conflictuelle. Le livre contient une passionnante histoire du célèbre MAE-East. Lorsque je travaillais au CNAM, c'était un endroit mythique et lointain où l'Internet, l'interconnexion des réseaux, même entre opérateurs français, se faisait. Dans le livre de Blum, on suit sa difficile naissance, mais aussi celle de son opposé Equinix. (Pendant que je lisais ce chapitre, j'ai appris la naissance d'un des tous derniers points d'échange créés, à Kinshasa, le Kinix.)
Blum visite aussi DE-CIX, AMS-IX, le LINX (contrairement à ce qu'on lit parfois chez des amateurs de sensationnalisme, ces lieux n'ont rien de secret, puisque tout le monde s'y connecte) et suit les réunions de NANOG pour y entendre les mystérieures négociations sur le peering, les exposés des acteurs essayant d'encourager les autres à peerer avec eux, en se vendant et en vendant leurs abonnés comme s'ils étaient une marchandise (« I have eyeballs. If you have content, peer with me. », en utilisant le terme péjoratif de « globes oculaires » pour parler des abonnés, supposés être des consommateurs passifs et bêtes). On croise dans le livre des figures familières de ce genre de réunions comme Sylvie LaPerrière, qui vient de rentrer au Conseil d'Administration d'AMS-IX.
Après les points d'échange, l'auteur se tourne vers les câbles sous-marins, par lesquels passent l'essentiel du trafic international. Ces câbles ne relient pas n'importe quels points. Comme « People go where things are », on s'installe là où il y a déjà quelque chose), la plupart de ces câbles atterrissent aux mêmes endroits où atterrissaient les fils du télégraphe, des lieux comme Porthcurno (un des meilleurs reportages du livre) ou 60 Hudson.
Andrew Blum a même suivi l'atterrissage d'un nouveau câble de Tata, le WACS, au Portugal, encore un passionnant récit.
Ces câbles ne sont pas posés n'importe où : la résilience de l'Internet dépend d'une répartition de ces liens à différents endroits, pour ne pas risquer qu'ils soient victimes du même problème, comme la fameuse panne de Luçon en 2006 où un tremblement de terre avait coupé plusieurs câbles d'un coup.
(Au passage, si vous aimez les histoires de pose de câbles sous-marins, vous pouvez aussi relire l'excellent reportage de Neal Stephenson.)
Après les points d'échange où se connectent les opérateurs, et les câbles qui les relient, où se trouve physiquement l'Internet ? Bien sûr dans les grands data centers où sont hébergées les données. C'est la troisième partie du livre. L'auteur revient sur le scandale de The Dalles, où Google était arrivé en terrain conquis, imposant même au maire de ne pas informer son propre conseil municipal sur les projets en cours. Et, alors que visiter les points d'échange et les stations d'atterrissage des câbles n'avait posé aucun problème au journaliste, il s'est par contre heurté à un mur en tentant de visiter un data center de Google : il n'a pas dépassé la cafétéria, où les officiels lui ont servi un excellent saumon bio et un très indigeste discours corporate comme quoi Google était formidable, « Hein, John, dit au monsieur pourquoi c'est si formidable de travailler pour Google ». Comme le note l'auteur, « Google sait tout de nous, mais nous ne pouvons rien savoir de Google ».
Très peu d'erreurs dans ce livre, qui a été soigneusement étudié et bien vérifié. La plus amusante : ARIN qualifié, p. 121, de Internet governing body. (Le RIPE-NCC, bien plus ancien, n'est guère mentionné.)
L'article seul
RFC 6781: DNSSEC Operational Practices, Version 2
Date de publication du RFC : Décembre 2012
Auteur(s) du RFC : O. Kolkman (NLnet Labs), W. Mekking (NLnet Labs), R. Gieben (SIDN Labs)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 22 décembre 2012
Comme avec toute technique fondée sur la cryptographie, le protocole DNSSEC impose, non seulement des bons algorithmes et une mise en œuvre correcte, mais surtout des procédures rigoureuses et soigneusement exécutées. C'est le but de ce RFC, qui remplace le RFC 4641 et qui explique tout ce à quoi doivent s'attendre les registres et autres administrateurs de zones DNS, grandes ou petites, qui déploieraient DNSSEC. (Le cas des serveurs DNS récursifs, par exemple les résolveurs d'un FAI, n'est pas étudié.)
Notre RFC rappelle donc des concepts de base du
DNS (notamment le fait que la réjuvénation des
modifications n'est pas instantanée) puis rappelle les différentes
clés (cf. section 1.1 pour une définition précise de clé) utilisées par DNSSEC et leurs caractéristiques souhaitables
(longueur, période maximale pendant laquelle on les utilise, lieu de
stockages, etc). Tout n'est pas encore bien connu dans ce
domaine. Certes, la racine est signée depuis
juillet 2010, ainsi que plus de 80
TLD mais, au niveau en dessous du TLD, peu de
zones sont signées (dans les 1 % de
.fr, par exemple) et
l'expérience opérationnelle peut donc encore être améliorée.
Il explique ensuite les considérations temporelles (DNSSEC utilise le temps et nécessite des horloges bien synchronisées, par exemple par NTP). Le DNS étant hiérarchique, il faut veiller, lors de toutes les manipulations, à bien rester synchronisé avec le gérant de la zone parente, dont les enregistrements de type DS (delegation signer) pointeront vers notre clé. Le but est, qu'à tout moment, une chaîne de confiance intacte aille de la clé de confiance jusqu'aux enregistrements du domaine. Si un lien de cette chaîne casse, le domaine sera marqué comme bogus (RFC 4033, section 5) et rejeté par les résolveurs validants.
Enfin, le RFC étudie le rollover, le remplacement d'une clé. Les clés ne pouvant pas raisonnablement être utilisées éternellement, il faut prévoir à l'avance les remplacements périodiques et aussi, hélas les remplacements en urgence en cas de compromission. Il faut apporter beaucoup de soin à ce remplacement, si on veut éviter que, pendant une certaine période, les données publiées dans le DNS soient invalides et donc rejetées par un résolveur DNS paranoïaque (il faut publier la nouvelle clé suffisamment à l'avance pour qu'elle soit présente partout ou bien signer tous les enregistrements avec les deux clés, l'ancienne et la nouvelle). Mon article à la conférence SATIN en 2011 avait montré que c'était loin d'être le cas : les erreurs sont fréquentes, même pour les grandes zones sérieuses.
Bref, pour un gérant de zone DNS, déployer DNSSEC, ce n'est pas uniquement signer la zone : c'est aussi mettre en place des procédures de sécurité, analogues à celle d'une autorité de certification.
Maintenant, avec la section 3, voyons les détails pratiques. D'abord, la génération et le stockage des clés cryptographiques. D'abord, un message d'espoir : en lisant ce RFC, on peut avoir l'impression d'un ensemble de tâches très compliquées, impossible à réaliser correctement. Heureusement, il existe déjà des logiciels qui, en automatisant la plupart de ces tâches, rendent les choses bien plus faciles. J'utilise pour cela OpenDNSSEC.
D'abord, avant de se lancer, il faut faire certains choix technico-politiques :
- Est-ce qu'on n'utilise qu'un type de clé ou bien est-ce qu'on sépare KSK (Key Signing Key) et ZSK (Zone Signing Key) ? Contrairement à ce qu'on lit souvent, la dichotomie entre une KSK et une ZSK n'a rien d'obligatoire, et elle complique les choses.
- Est-ce que les KSK vont être configurés par certains comme clés de confiance, à partir desquels on valide ? Cela permet d'être indépendant des autres acteurs comme la racine mais cela augmente les responsabilités.
- Quels sont les délais pertinents, par exemple le champ
Expiredu SOA, le temps de réaction souhaité en cas de problème ? Il faut aussi se demander siNOTIFY(RFC 1996) marche bien (ou si on ne peut compter que sur le paramètreRefreshde l'enregistrement SOA) et si on utiliseIXFR(RFC 1995) ouAXFR, - Quels sont les choix cryptographiques (par exemple, concernant la longueur des clés RSA) ?
Une fois ces choix faits, on pourra configurer le résultat (dans
OpenDNSSEC, fichier /etc/opendnssec/kasp.xml). Mais que choisir ?
Pour le choix entre une séparation KSK/ZSK et une clé unique, le choix est purement un problème opérationnel du côté du gestionnaire de zone. Les résolveurs ne feront pas de différence.
Un problème à garder en tête pour le stockage des clés est le risque de compromission de la clé (vol du disque sur lequel se trouve la partie privée de la clé, par exemple). Si la clé privée est sur le disque d'une machine connectée à l'Internet, le risque est plus élevé que s'il est sur une machine déconnectée et enfermée dans un coffre-fort. Encore mieux, pour les plus riches, l'usage des HSM permet d'être raisonnablement sûr qu'il n'y aura pas de vol de la clé. D'un autre côté, pour signer des enregistrements, une clé sur une machine non-connectée est certainement moins pratique. Une des façons de résoudre le dilemne est de séparer KSK et ZSK : on met la KSK en sécurité dans un endroit bien protégé (elle ne sert qu'à signer la ZSK, qui ne change pas tous les jours) et on fait les signatures des enregistrements de la zone avec la ZSK. En cas de compromission de la ZSK, son remplacement est relativement simple, puisqu'il est entièrement interne à la zone, il ne nécessite pas d'interaction avec la zone parente. (C'est ainsi, par exemple, que fonctionne la racine.)
Comme toujours en sécurité,il y a un fort risque de blinder la porte en oubliant la fenêtre : il ne sert pas à grand'chose de protéger la KSK avec des précautions de niveau militaire si les données de la zone, celles qu'on va signer, peuvent être facilement modifiées par un attaquant (encore que le RFC oublie de dire que la possession de la clé privée permette de générer des enregistrements mensongers sans que le registre s'en aperçoive). De même, le HSM empêche certes le méchant de copier la clé privée, mais il ne l'empêche pas de signer : si le pirate prend le contrôle de la machine connectée au HSM, il peut faire signer à ce dernier ce qu'il veut. Bref, il n'y a pas de solution miracle en matière de sécurité.
Séparer KSK et ZSK permet donc plus de souplesse dans la gestion de la sécurité. Mais cela rend les choses plus complexes. Si les clés sont gérés automatiquement par un outil comme OpenDNSSEC, ce n'est pas trop un problème. Sinon, il vaut peut-être mieux n'avoir qu'une clé.
Une question qui agite les milieux DNSSEC depuis de nombreuses années est celle du remplacement (rollover) des clés. Il y a deux écoles :
- Celle qui dit que les remplacements doivent être systématiques et fréquents, pour qu'ils deviennent de la routine ; elle se sépare en deux sous-écoles, une qui favorise les remplacements périodiques et une qui préfère les faire au hasard,
- Et l'école qui dit que les remplacements ne doivent se faire que s'il y a une bonne raison, par exemple une forte suspicion que la clé privée a été copiée.
Notre RFC note qu'il n'y a pas consensus sur cette question. Il note
qu'un facteur important est « est-ce que la clé est utilisée comme
clé de confiance quelque part ? », c'est-à-dire est-ce que des gens
l'ont configuré dans leur résolveur validant (directives trusted-keys ou managed-keys de
BIND et trust-anchor ou trust-anchor-file de
Unbound) ? Cela peut se faire, par exemple pour
éviter de dépendre de la hiérarchie du DNS (on peut imaginer une clé
DNSSEC de gouv.fr installée dans les résolveurs
des ministères pour être sûr de ne pas être affectés par des problèmes à
l'AFNIC ou à la racine). Notez que cela peut arriver sans le
consentement du gérant de la zone. Si ce dernier publie un DPS
(DNSSEC Practice Statement) disant en gros
caractères « n'utilisez pas notre KSK comme clé de confiance, ne vous
fiez qu'au DS de la zone parente », alors, on peut tenir pour acquis
qu'il y aura peu de cas où la KSK sera installée en dur dans les
résolveurs. Autrement, le remplacement devient bien plus compliqué car
il faut prévenir tous les gens qui ont configuré cette clé de
confiance. Certains ne seront pas joignables ou ne réagiront pas et il
faudra donc prendre le risque de casser leur accès DNSSEC. Ainsi, pour la racine (qui ne peut pas compter sur
l'enregistrement DS de la zone parente) qui est forcément clé de
confiance, on peut penser qu'il n'y aura jamais de remplacement de la
KSK originelle, la 19036, sauf en cas de compromission : cela nécessiterait de changer
trop de résolveurs.
Notez qu'il existe un mécanisme pour mettre à jour les clés de
confiance, décrit dans le RFC 5011. Comme il
n'est jamais sûr que tous les « clients » le mettent en œuvre,
il est difficile de savoir si on peut compter dessus (dans Unbound,
trust-anchor-file: "/etc/unbound/root.key"
installe une clé de confiance statique et auto-trust-anchor-file: "/var/lib/unbound/root.key"
- notez le auto- devant - installe
une clé qui pourra être mise à jour par les procédures du RFC 5011). Ces procédures n'ont jamais été testées
pour la racine.
Si on sépare KSK et ZSK, c'est normalement le bit SEP
(Secure Entry Point, cf. RFC 3757) qui les distingue (dans le cas le plus courant, la ZSK
aura un champ Flags de 256 et la KSK de 257 à
cause du bit SEP). Ce bit n'est pas utilisé par les validateurs mais
certains outils s'en servent pour trouver la KSK (par exemple le
dnssec-signzone de BIND). Si on n'a qu'une seule
clé, elle sert de KSK et doit donc avoir le bit SEP (autrement, le dnssec-signzone de BIND vous dira dnssec-signzone: fatal: No self signed KSK's found). Notez que
certains outils ne vous laisseront pas facilement n'utiliser qu'une
clé. Par exemple, avec dnssec-signzone, vous aurez le message dnssec-signzone: fatal: No non-KSK
DNSKEY found; supply a ZSK or use '-z'. et vous devrez
utiliser l'option indiquée pour signer quand même.
Un peu de cryptographie, maintenant. La durée de vie raisonnable d'une clé dépend de sa longueur. Le RFC suggère de décider d'une durée de vie, en tenant compte des contraintes opérationnelles, et d'en déduire la longueur. Une KSK qui a des enregistrements DS dans sa zone parente peut durer vingt ans sans problème, sauf si on désire tester régulièrement les procédures de remplacement ou sauf si la clé privée est compromise. Si on veut la remplacer régulièrement, une durée raisonnable proposée par le RFC est d'un an.
Quel algorithme cryptographique choisir ? Les quatre standardisés à l'heure actuelle (le RFC en cite trois mais ECDSA est apparu depuis), RSA, DSA et GOST sont bien connus et spécifiés et considérés comme fiables. En partie pour des raisons de performance, le RFC suggère la combinaison RSA/SHA-256 comme l'algorithme préféré (RFC 5702) et RSA/SHA-1 sinon.
Les algorithmes fondés sur les courbes elliptiques (GOST - RFC 5933 - et ECDSA - RFC 6605) ont des avantages importants sur RSA, notamment les clés et signatures plus petites. Mais très peu de résolveurs validant les gèrent et signer une zone uniquement avec ces algorithmes serait donc peu utile. D'autre part, même si le RFC ne le dit qu'en passant, les problèmes de brevet sont bien plus nombreux que pour RSA.
Si on a choisi RSA, il faut se décider pour une longueur de clé, suffisante pour résister à la cryptanalyse pendant la durée de vie de la clé (le RFC 3766 contient des calculs intéressants sur la solidité des clés). Comme le note le RFC, en dépit d'un FUD important, personne n'a encore annoncé la cryptanalyse d'une clé RSA de 1024 bits (le record publié est aux alentours de 700 bits). Et, le jour où cela arrivera, ce ne sera pas la fin de RSA mais la fin d'une seule clé. Bien sûr, la cryptanalyse progresse (et, le RFC oublie ce point, les meilleurs résultats ne sont pas forcément publiés) mais le RFC estime que les clés de 1024 bit sont encore sûres pour dix ans.
Néanmoins, utiliser des clés plus grandes est raisonnable si on veut une très longue durée de vie ou bien si on estime que le remplacement de la clé sera difficile (ce qui est certainement le cas de la clé de la racine). Pour ces cas, une clé de 2048 bits est donc utile. Attention, ce n'est pas gratuit, notamment la vérification est quatre fois plus lente et la signature huit fois moins rapide.
Certains férus de cryptographie peuvent tiquer à la pensée de n'utiliser que 1024 bits. Mais l'argument massue du RFC est celui de l'équilibre : on ne fait pas du DNSSEC pour le plaisir de la cryptographie. On le fait pour protéger quelque chose, par exemple un site Web de banque en ligne. Et ce genre de sites est en général protégé par TLS avec des clés qui ne sont souvent pas plus longues. Si un attaquant peut casser une clé de 1024 bits, il peut s'attaquer à TLS aussi bien qu'à DNSSEC. Avec des clés de 2048 bits, on blinde fortement la porte... alors que la fenêtre du rez-de-chaussée ne l'est pas toujours. Bref, si un brusque progrès de la cryptanalyse permet de casser ces clés de 1024 bits plus tôt que les dix ans indiqués, cela fera du bruit et cassera bien d'autres choses que DNSSEC.
Notons que, contrairement à son prédécesseur RFC 4641, notre RFC ne fait plus dépendre la solidité d'une clé du fait qu'elle soit largement utilisée ou pas. La cryptographie a évolué depuis le RFC 4641.
Où stocker ensuite ces clés ? Idéalement, sur une machine sécurisée et non connectée au réseau. On apporte les données sur cette machine, on signe et on repart avec les données signées pour les apporter au serveur de noms. C'est très sûr mais cela ne peut pas marcher si on utilise les mises à jour dynamiques du DNS (RFC 3007). Dans ce cas, il faut bien avoir la clé privée sur le serveur de noms (on parle de online key). C'est donc moins sûr et le RFC suggère, dans ce cas, que le serveur maître ne soit pas directement accessible de l'Internet (technique du hidden master, où le vrai maître n'est pas dans les enregistrements NS de la zone). Notez qu'une des motivations pour la séparation KSK/ZSK vient de là : avoir une KSK peu utilisée et dont la clé privée est stockéee de manière très sûre et une ZSK en ligne, plus vulnérable mais plus facile à changer.
Comme toujours en matière de sécurité, ces bons avis doivent être mis en rapport avec les contraintes opérationnelles et économiques. Ainsi, on peut sans doute améliorer la sécurité des clés en les gardant dans un HSM. Mais ces engins sont chers et pas pratiques pour les opérations quotidiennes.
Et la génération des clés ? C'est un aspect souvent oublié de la
sécurité cryptographique mais il est pourtant essentiel. La clé doit
être vraiment imprévisible par un attaquant et pour cela elle doit
être générée en suivant les recommandations du RFC 4086 et de NIST-SP-800-90A, « Recommendation for Random
Number Generation Using Deterministic Random Bit
Generators ». Par exemple, avec les outils de génération de
clés de BIND (dnssec-keygen), il ne faut
pas utiliser l'option -r
/dev/urandom en production, car elle n'utilise qu'un
générateur pseudo-aléatoire. (Les HSM disposent
tous d'un générateur correct.)
À noter que la version précédente de ce document, le RFC 4641 faisait une différence entre les zones DNS
selon leur place dans la hiérarchie (plus ou moins haute). Cette
distinction a disparu ici et les mêmes règles de sécurité s'appliquent
à toutes. L'une des raisons de ce choix est qu'on ne peut pas
facilement déterminer quelles zones sont importantes pour un attaquant
(grossebanque.com est peut-être plus importante
que le TLD
.td, même si ce dernier
est placé plus haut dans la hiérarchie). Cela n'empêche évidemment pas
chaque gérant de zone de devoir déterminer si sa zone est critique ou
pas, avant d'adapter les mesures de sécurité en conséquence.
La section 4 de notre RFC est ensuite consacrée au gros morceau de la gestion opérationnelle de DNSSEC : les remplacements de clés (key rollovers). Qu'on choisisse de faire des remplacements réguliers, pour qu'ils deviennent une simple routine, ou qu'on choisisse de n'en faire que lors d'évenements exceptionnels (comme une copie illégale de la clé), les remplacements sont une réalité et il faut s'y préparer. Par exemple, même si on décide de ne pas en faire systématiquement, il faut s'entrainer (et tester ses procédures) avec une zone de test. L'opération est délicate en raison de l'existence des caches DNS, qui vont garder la vieille information un certain temps. Personnellement, je déconseille fortement de faire les remplacements à la main : le risque d'erreur est bien trop grand. Il faut plutôt automatiser le processus, et avec un logiciel soigneusement débogué. L'expérience (mon article à la conférence SATIN en 2011) montre que les erreurs sont, elles aussi, une réalité.
Si on a décidé d'avoir deux clés, ZSK et KSK, leurs remplacements sont indépendants. Les ZSK sont les plus simples car elles peuvent être remplacées sans interaction avec la zone parente (pas d'échange d'enregistrements DS). Le RFC explique ensuite (en grand détail : je n'en donne qu'un court résumé ici) les deux méthodes connues pour remplacer une ZSK :
- la pré-publication de la future clé,
- et la double signature.
Dans le premier cas, on génére la nouvelle ZSK, on la publie (sans
qu'elle signe quoi que ce soit) puis, lorsque le nouvel ensemble
DNSKEY est dans tous les caches, on utilise la
nouvelle ZSK pour signer. Une fois que les signatures faites avec
l'ancienne clé ont disparu des caches, on arrête de publier l'ancienne
clé. Le remplacement est terminé. Cette description très sommaire de
l'algorithme suffit déjà, je crois, à montrer qu'il vaut mieux ne pas
le faire à la main.
Quant à la double signature (plus rare, en pratique), elle consiste à signer tout de suite avec la nouvelle clé, tout en continuant à signer avec l'ancienne, pour les caches ayant seulement l'ancienne clé.
La section 4.1.1.3 résume les avantages et inconvénients de chaque méthode. La pré-publication nécessite davantage d'étapes (ce qui est grave si on la fait à la main, et moins si on a tout automatisé). La double signature est plus coûteuse puisque la zone sera, pendant la période transitoire, bien plus grosse (les signatures forment l'essentiel de la taille d'une zone signée). Dans les deux cas, comme il n'y a pas besoin d'interagir avec la zone parente, le processus peut être entièrement automatisé et c'est bien ce que fait, par exemple, OpenDNSSEC.
Et pour remplacer une KSK ? La double signature devient alors plus
intéressante, puisque la KSK ne signe pas toute la zone, seulement
l'ensemble d'enregistrements DNSKEY. Les
problèmes de taille ne se posent donc pas. Par rapport au remplacement
d'une ZSK, la grosse différence est l'interaction avec la zone
parente. Il n'existe pas d'API standard pour le
faire. Les bureaux d'enregistrement (BE)
utilisent en général EPP - RFC 5910 - avec le registre mais
le gestionnaire de la zone, avec son BE, a typiquement une interface
Web, ou bien une API non-standard, par exemple à base de
REST (cf. aussi la section 4.3.2). L'opération nécessite donc souvent une
intervention manuelle comme décrit dans mon
article sur un exemple avec OpenDNSSEC.
Et si on a une clé unique ? Le cas est proche de celui d'un remplacement de KSK et le RFC recommande la double-signature, car c'est la solution la plus simple (et, si on n'utilise qu'une clé, c'est qu'on aime la simplicité).
La section 4.2 couvre le cas des préparatifs pour un remplacement d'urgence. On arrive le lundi matin au bureau, le coffre-fort est grand ouvert et la clé USB qui stockait la clé privée a disparu (une variante moins gênante est celle où la clé privée est détruite, mais pas copiée, par exemple en raison d'un incendie). Il faut alors remplacer cette clé et c'est bien plus facile si on a planifié avant. Notez qu'il y a toujours un compromis ici : si on supprime immédiatement l'ancienne clé, désormais compromise, une partie des résolveurs (ceux qui ont les anciennes signatures, mais pas l'ancienne clé) dans leurs caches considéreront la zone comme invalide. Mais, si on continue à diffuser l'ancienne clé, on augmente la durée pendant laquelle le voleur pourra injecter des informations mensongères. Il existe une méthode intermédiaire, faire retirer l'enregistrement DS par la zone parente. Selon les TTL en jeu, cela peut permettre de diminuer la durée du problème. Comme on le voit, il vaut mieux faire les calculs, l'analyse et le choix de la meilleure méthode avant le fatal lundi matin...
Une solution possible est d'utiliser des Standby keys, qui seront publiées (et donc dans tous les caches) mais pas utilisées pour signer, et dont la partie privée sera gardée à un endroit différent.
Le problème est évidemment plus grave si la clé en question avait
été configurée par certains comme clé de confiance dans leurs
résolveurs. Il faut alors prévenir tout le monde de la compromission,
par un message (authentifié) envoyé à plusieurs endroits, pour
maximiser les chances de toucher tout le monde. Si la clé de la racine
(ou d'un grand TLD comme .net)
était compromise, on verrait sans doute l'annonce sur dns-operations, NANOG,
Twitter, etc. Outre l'authentification de
l'annonce, la nouvelle clé devra elle aussi être authentifiée, par un
moyen non compromis : ne mettez pas la partie privée de la KSK dans le
même coffre-fort que la partie privée de votre clé PGP !
Autre cas amusant pour les gérants d'une zone DNS, le changement d'opérateurs. Par exemple, le titulaire d'une zone décide de passer d'un hébergeur DNS à un autre (notez que l'hébergeur est souvent le BE mais ce n'est pas obligatoire). Si les deux hébergeurs (en pratique, c'est évidemment le perdant qui fait des histoires) coopèrent, le problème est relativement simple. Le RFC suppose que l'ancien hébergeur ne va pas transmettre la clé privée (si elle est dans un HSM, il ne peut tout simplement pas). Dans ce cas, l'ancien hébergeur doit mettre dans la zone la clé publique du nouveau, et les signatures calculées par le nouveau avec ses clés. Le nouvel opérateur publie la même zone et, une fois le changement terminé (une fois que les clés du nouvel hébergeur sont dans tous les caches), le nouvel hébergeur peut retirer les clés et les signatures de l'ancien. Ce n'est pas très pratique (il faut échanger clés publiques et signatures). Personnellement, je trouve cet algorithme tout à fait irréaliste. Dans le DNS d'aujourd'hui, des obligations bien plus modérées (en cas de changement d'hébergeur, continuer à servir la zone jusqu'à ce que les TTL sur les enregistrements NS expirent) ne sont jamais respectées par les hébergeurs perdants, même lorsqu'elles figurent dans les obligations contractuelles. Le RFC note à juste titre que c'est un problème économique et qu'il n'a pas de solution technique.
Il reste donc le cas qui sera sans doute le plus probable, celui où l'ancien hébergeur de la zone DNS ne coopérera pas. (Techniquement, il peut même saboter activement le transfert, en publiant un enregistrement DNSKEY avec un très long TTL, pour « empoisonner » les caches.) La seule solution est alors de passer par une phase où la zone ne sera pas sécurisée par DNSSEC : le parent retire l'enregistrement DS, on attend que l'ancien DS ait disparu des caches, puis on en remet un, pointant vers une clé du nouvel hébergeur.
Quelques mesures techniques dans les résolveurs validants peuvent aider :
- Limiter les TTL qu'on accepte (RFC 2308) pour diminuer le risque d'obstruction,
- Vérifier la délégation lorsque les enregistrements NS vont expirer, pour être sûr de ne pas rester bloqué sur de vieux serveurs de noms (c'est également une protection contre l'attaque des domaines fantômes),
- Lorsque la validation échoue, réessayer après avoir viré les DNSKEY du cache.
Le gérant de la zone peut aussi aider en n'ayant pas des TTL trop longs.
Gérer proprement du DNSSEC impose une grande rigueur sur les questions temporelles. Avant DNSSEC, le temps dans le DNS était toujours relatif. Par exemple, le champ Expire de l'enregistrement SOA était relatif au moment de la dernière synchronisation avec le serveur maître. Même chose pour les TTL. Mais, avec DNSSEC, le temps devient absolu. Les dates de début et de fin de validité dans un enregistrement RRSIG, par exemple, sont absolues. Elles dépendent donc d'une horloge à l'heure.
Quelques conseils, donc, sur le temps :
- La période de validité des signatures devrait être au moins égale au TTL (autrement, des signatures encore dans le cache pourraient être expirées),
- Ne pas attendre le dernier moment pour re-signer. Cela laisse un délai pour corriger d'éventuels problèmes. Par exemple, si les signatures ont en permanence deux jours de validité devant elles, cela permet de survivre pendant un week-end, en cas d'incapacité à re-signer.
- Ne pas mettre de TTL trop bas (du genre 5 minutes) à la fois à cause de la charge sur les serveurs et aussi parce que la validation DNSSEC nécessite de récupérer beaucoup d'enregistrements et qu'il ne faut pas que leur TTL expire avant que le processus ne soit terminé.
- Pour une zone signée, avoir un Expire (dans le SOA) plus long que la durée de validité des signatures ne sert pas à grand'chose : un serveur esclave qui servirait des signatures qui ne sont plus valides serait pire qu'un serveur esclave qui ne servirait plus rien.
Bon, mais alors, quelle durée choisir pour la validité des signatures (les outils de signature de BIND mettent un mois, par défaut). C'est un compromis : une durée trop longue et on est vulnérable aux attaques par rejeu. Une durée trop courte et on risque de n'avoir pas assez de temps pour réagir en cas de problème. Une erreur dans la configuration du pare-feu, les serveurs esclaves qui ne peuvent plus se synchroniser, les signatures sur ces serveurs esclaves qui expirent et crac, la zone est invalide. Cela arrive vite. Mon opinion personnelle est qu'aujourd'hui, les procédures ne sont pas assez testées et l'expérience DNSSEC est insuffisante. Il faut donc jouer la sécurité et avoir des durées de validité longues (au moins deux semaines). Dans le futur, au fur et à mesure de la montée en compétence et de l'amélioration des logiciels, on pourra mettre des durées de validité des signatures plus courtes, fermant ainsi la porte aux attaques par rejeu.
Voilà, nous avons couvert le gros de ce RFC. La section 5, qui suit, se consacre à un problème rigolo, celui des enregistrements indiquant l'enregistrement suivant, les enregistrements next. L'un des choix importants de conception de DNSSEC était de permettre que les signatures se fassent entièrement hors-ligne. On ne pouvait donc pas prévoir toutes les questions posées au serveur et avoir une signature pour toutes les réponses « ce domaine n'existe pas ». Il y a donc des enregistrements qui disent « il n'y a pas de domaine ici », enregistrements qui sont signés pour qu'un résolveur validant puisse authentifier une réponse négative. Ces enregistrements next sont le NSEC et le NSEC3. Le premier est en clair (il indique le nom de l'enregistrement suivant celui qui n'existe pas), le second est brouillé (il indique le condensat suivant le condensat du nom qui n'existe pas). Pour l'administrateur, les NSEC sont plus pratiques, notamment au débogage. Mais ils permettent la récupération complète de la zone, en marchant de NSEC en NSEC.
Le choix entre NSEC et NSEC3 dépend du type de la zone. Si on a une
petite zone au contenu prévisible (juste l'apex, un
mail et un
www, ce qui est le cas de très nombreuses zones),
aucune raison d'utiliser NSEC3. Même chose si la zone est très
structurée et donc très prévisible (ip6.arpa,
ENUM...). Même chose si la zone est publique,
ce qui est le cas par exemple de la racine (il existe une autre raison
d'utiliser NSEC3, l'opt-out, qui intéresse surtout
les grandes zones de délégation comme certains TLD).
Autrement, si on n'est dans aucun de ces cas, si on est une assez
grande zone au contenu imprévisible et qui n'est pas publique, il est
cohérent d'utiliser NSEC3 (RFC 5155).
NSEC3 a certains paramètres à configurer (et qui sont publiés dans
l'enregistrement NSEC3PARAM). Notamment, on peut définir le nombre
d'itérations de hachage. Cette possibilité
protège des attaques par dictionnaires pré-calculés mais elle est
coûteuse et elle mène à l'exécution de code à chaque requête pour un
nom inexistant. Le RFC suggère un nombre de 100 itérations, ce qui est
colossal par rapport à ce que font la plupart des zones NSEC3
aujourd'hui (5 par défaut avec OpenDNSSEC, mais beaucoup l'abaissent, on trouve 1 pour
.fr et
.com, et même 0 pour
.org...) NSEC3 ajoute un
sel au début de l'itération et notre RFC
suggère de changer ce sel en même temps que la ZSK.
Les changements depuis le RFC 4641 sont résumés dans l'annexe E. D'abord, les erreurs connues ont été corrigées. Ensuite, la fonction de hachage SHA-256 a été ajoutée aux recommandations. La partie sur le changement d'hébergeur DNS a été ajoutée. Le modèle avec séparation KSK/ZSK ne bénéficie plus d'un privilège particulier puisque le modèle avec une seule clé est également décrit.
(Les juristes noteront que VeriSign a un brevet sur certaines des techniques présentées dans ce RFC.)
L'article seul
RFC 6821: Improving Peer Selection in Peer-to-peer Applications: Myths vs. Reality
Date de publication du RFC : Décembre 2012
Auteur(s) du RFC : E. Marocco, A. Fusco (Telecom Italia), I. Rimac, V. Gurbani (Bell Labs, Alcatel-Lucent)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF PeerToPeerResearchGroup
Première rédaction de cet article le 22 décembre 2012
Le trafic du pair-à-pair peut, on le sait, représenter une bonne part de l'activité d'un réseau, malgré les efforts de l'industrie du divertissement pour diaboliser cette technique. Il y a donc depuis plusieurs années de gros efforts de recherche pour optimiser ce trafic, notammment via l'amélioration de la sélection des pairs. Si je veux télécharger la saison 1 de Being human, et que trois pairs ont les données, auquel demander ? Le bon sens répond « au plus proche ». Mais le concept de « plus proche » est plus flou qu'il n'y parait, et, de toute façon, le logiciel pair-à-pair installé sur ma machine n'a pas forcément accès à toutes les informations nécessaires pour déterminer « le plus proche ». Il existe plusieurs solutions pour résoudre ce problème, mais notre RFC se penche plutôt sur le méta-problème : la sélection des pairs améliore-t-elle les choses ?
Tellement de choses ont été dites à ce sujet que l'ingénieur ou l'étudiant débutant qui se penche sur l'optimisation du pair-à-pair peut avoir une impression de grande confusion. Ce RFC choisit donc l'approche « retours aux faits ». Parmi toute la littérature scientifique et technique existante, peut-on trancher sur la question de l'intérêt de la sélection des pairs ?
Je préviens tout de suite que le titre de ce RFC, inutilement sensationnaliste, ne correspond pas à son contenu : le RFC ne dynamite pas de mythes, il examine un certain nombre de questions posées par la sélection des pairs et, pour chacune, en se basant sur des mesures ou des simulations déjà effectuées et publiées, fait une synthèse de leurs conclusions.
A priori, l'intérêt de la sélection est grand : comme les machines, dans un réseau pair-à-pair, ne connaissent pas la topologie sous-jacente (elles ne savent pas si les pairs sont proches ou lointains, s'ils sont joignables par des liens de peering gratuits ou par du transit payant, etc), elles risquent de ne pas choisir le meilleur pair. Une des conséquences fâcheuses sera l'utilisation d'inter-connexions lointaines, au lieu de rester dans le réseau du FAI. Il est donc logique que cette idée de sélection « intelligente » des pairs ait fait l'objet de nombreux travaux (résumés dans le RFC 6029 ; sinon, voir les articles « Can ISPs and P2P systems co-operate for improved performance? » d'Aggarwal, V., Feldmann, A., et C. Scheidler, ou « Taming the Torrent: A practical approach to reducing cross-ISP traffic in P2P systems » de Choffnes, D. et F. Bustamante, ou encore « P4P: Explicit Communications for Cooperative Control Between P2P and Network Providers » de Xie, H., Yang, Y., Krishnamurthy, A., Liu, Y., et A. Silberschatz) et qu'un groupe de travail de l'IETF, ALTO, travaille entièrement sur ce sujet (voir ses RFC 5693 et RFC 6708). (À noter que j'avais fait un exposé sur ces techniques en 2010.) L'évaluation de ces techniques n'est pas évidente, notamment de leur passage à l'échelle lorsque le réseau comprend des dizaines de millions de pairs.
Notre RFC suit le schéma suivant pour synthétiser la littérature existante :
- Décrire une croyance (un mythe, dit le RFC, terme très exagéré),
- Lister les faits (études, mesures, simulations, etc) disponibles,
- Discuter ces données,
- Conclure à la véracité ou à la fausseté de la croyance.
Naturellement, cette synthèse n'est valable qu'aujourd'hui : les progrès de la science pourront changer les conclusions. Ah et, sinon, question terminologie, en l'absence d'une norme unique du pair-à-pair, ce RFC utilise largement le vocabulaire de BitTorrent (section 2), comme le terme d'essaim pour désigner un groupe de pairs ayant les données convoitées.
Place maintenant aux croyances et à leur évaluation. La première : « la sélection des pairs permettra de diminuer le trafic entre domaines ». Les différents essais ou simulations montrent des réductions allant de 20 à 80 % (la variation importante donne une idée de la difficulté à estimer cette réduction). 70 % pour la simulation de Xie, H., Yang, Y., Krishnamurthy, A., Liu, Y., et A. Silberschatz déjà citée. 34 % en sortie et 80 % en entrée pour les mesures du RFC 5632. Et jusqu'à 99,5 % si le trafic est fortement localisé (beaucoup de pairs dans le même domaine) selon « Pushing BitTorrent Locality to the Limit » de Stevens Le Blond, Arnaud Legout et Walid Dabbous.
Bref, cette croyance est tout à fait justifiée (comme la plupart de celles citées par le RFC). On peut vraiment espérer une réduction du trafic entre opérateurs.
Cette réduction profite aux opérateurs, qui voient baisser leur facture d'interconnexion. Une autre croyance fait espérer des gains pour les utilisateurs : « la sélection des pairs se traduira par une amélioration des performances », en clair, on attendra moins longtemps pour charger la dernière ISO d'Ubuntu.
Les simulations de Xie, H., Yang, Y., Krishnamurthy, A., Liu, Y., et A. Silberschatz montrent une diminution du temps de transfert de 10 à 23 %. Celles de « Applicability and Limitations of Locality-Awareness in BitTorrent File-Sharing » par Seetharaman, S., Hilt, V., Rimac, I., et M. Ammar (article que je n'ai pas réussi à trouver en ligne et qui ne semble pas avoir été publié « officiellement ») montraient que le gain n'est pas systématique. Les mesures du RFC 5632 indiquent une augmentation du débit de 13 à 85 %. L'expérience de Choffnes, D. et F. Bustamante déjà citée a vu 31 % de gain de débit en moyenne (mais une perte dans certains cas).
La conclusion est donc plutôt « ça dépend ». En général, il y a une amélioration mais dans certains cas (capacité du lien montant faible, peu de pairs disponibles à proximité), on peut voir une dégradation. Donc, la croyance est probablement justifiée mais pas dans tous les cas.
Et l'occupation du lien réseau montant ? Cela pourrait être un effet négatif d'une meilleure sélection des pairs. Ils sont plus proches, donc on envoie plus vite les données, saturant le canal montant, souvent très petit sur les liens asymétriques comme l'ADSL ou DOCSIS. Cette crainte est-elle justifiée ?
Les mesures du RFC 5632 ne montrent pas un tel effet. Théoriquement, cela serait pourtant possible (si la sélection des pairs menait à choisir une machine mal connectée mais proche plutôt qu'une machine lointaine et ayant de fortes capacités réseau, la machine mal connectée verrait son lien montant plus utilisé). Mais, en pratique, cela ne semble pas le cas.
Autre croyance parfois entendue : la sélection des pairs va avoir une influence sur les accords de peering. Ceux-ci sont souvent fondés sur le volume de trafic échangé. Si la sélection des pairs améliore la localité, le trafic entre opérateurs va baisser, le faisant passer en dessous du seuil qu'exigent certains opérateurs pour peerer avec eux. Mais, sur ce point, on ne dispose pas de mesures ou de simulations. On ne peut faire pour l'instant qu'une analyse théorique.
Par exemple, si les deux opérateurs ont une base d'utilisateurs très différente (mettons qu'un opérateur a beaucoup de clients offrant du contenu et l'autre pas du tout), non seulement le trafic entre eux va baisser, mais il peut baisser nettement plus dans une direction que dans l'autre, remettant en cause un accord de peering fondé sur la réciprocité.
Curieusement, le RFC affirme que, si les opérateurs sont très similaires (même base d'utilisateurs, mêmes technologies d'accès), il n'y aura sans doute pas beaucoup de changement. Pourtant, comme indiqué plus haut, la seule baisse du trafic entre eux, même symétrique, peut changer les conditions du peering.
Le RFC rappele que des opérateurs ont déjà tenté d'injecter des paquets vers un autre opérateur, pour obtenir artificiellement des chiffres élevés de trafic, avant de pouvoir demander un peering (« The art of Peering: The peering playbook » de Norton). Ce n'est pas très subtil car ce trafic purement unidirectionnel apparait vite comme suspect. En revanche, avec des techniques de sélection des pairs, le même FAI peu scrupuleux pourrait faire mieux, en redirigeant systématiquement ses utilisateurs vers l'opérateur avec qui il espère négocier un accord de peering, créant ainsi un trafic nettement plus réaliste.
En conclusion (fondée sur un raisonnement purement théorique, contrairement à la grande majorité des croyances étudiées dans ce RFC), il est probable que la sélection des pairs amène à changer les accords de peering.
Et sur le transit, y aura-t-il un impact ? Là aussi, on peut imaginer des transitaires peu scrupuleux qui, en utilisant les techniques de sélection de pairs comme ALTO, redirigeront le trafic vers des clients payants, plutôt que vers des opérateurs pairs gratuits. Là encore, on ne dispose pas d'études à ce sujet. Mais, vue l'importance de la question pour le monde des opérateurs, le RFC recommande que l'on se penche sur la question. Des cas comme Sprint contre Cogent ou Cogent contre AOL illustrent bien l'extrême sensibilité du problème.
Un effet de bord négatif d'une bonne sélection des pairs avait été envisagé dans l'article Stevens Le Blond, Arnaud Legout et Walid Dabbous ci-dessus (mais les mesures faites ne montraient pas cet effet). Si la sélection marche trop bien, l'essaim de pairs va se fragmenter en plusieurs essaims, un par FAI, avec peu de communications entre eux, ce qui annulerait une partie de l'intérêt du pair-à-pair. En effet, les simulations de Seetharaman, S., Hilt, V., Rimac, I., et M. Ammar ont montré que cela pouvait se produire.
Le RFC conclut que l'effet dépend de l'algorithme utilisé. Si BitTorrent semble assez résistant à ce problème, comme montré par les mesures de Stevens Le Blond, Arnaud Legout et Walid Dabbous, d'autres algorithmes peuvent avoir le problème. Et que la croyance peut donc être justifiée dans certains cas. Attention donc, si vous concevez un algorithme de pair-à-pair à ne pas mettre tous vos œufs dans le même panier en ne sélectionnant que des pairs très proches.
Dernière croyance étudiée, celle que des caches P2P chez les FAI, combinés avec la sélection des pairs, va améliorer les choses. Un problème classique de tous les caches réseau est de les trouver, et de ne les utiliser que s'ils apportent réellement un gain. Avec la sélection des pairs, le problème est théoriquement résolu : le cache est un pair comme un autre et est sélectionné s'il est « plus proche ».
Une étude chez un FAI a montré (« Are file swapping networks cacheable? Characterizing p2p traffic » de Nathaniel Leibowitz, Aviv Bergman, Roy Ben-Shaul et Aviv Shavit) que le cache pouvait potentiellement gérer 67 % du trafic pair-à-pair. Cette croyance est donc plausible.
L'article seul
RFC 6817: Low Extra Delay Background Transport (LEDBAT)
Date de publication du RFC : Décembre 2012
Auteur(s) du RFC : S. Shalunov (BitTorrent Inc), G. Hazel (BitTorrent Inc), J. Iyengar (Franklin and Marshall College), M. Kuehlewind (University of Stuttgart)
Expérimental
Réalisé dans le cadre du groupe de travail IETF ledbat
Première rédaction de cet article le 20 décembre 2012
Alors que tant d'efforts de recherche ont été dépensés pour faire des réseaux informatiques et des protocoles qui permettent d'aller plus vite, d'attendre moins longtemps avant de voir la page d'accueil de TF1, le groupe de travail LEDBAT (Low Extra Delay Background Transport ) de l'IETF travaillait à un tout autre projet : un protocole de transport de données qui aille moins vite, de façon à être un bon citoyen du réseau, à n'utiliser celui-ci que lorsqu'il est vide et qu'on peut donc faire passer ses bits sans gêner personnne. Ce RFC décrit l'algorithme LEDBAT, un algorithme « développement durable ».
LEDBAT n'est donc pas un protocole complet, mais un algorithme de contrôle de la fenêtre de congestion, ce mécanisme par lequel les protocoles de transport évitent de saturer le réseau. Le plus connu et le plus utilisé de ces mécanismes est celui de TCP (RFC 5681) et ses objectifs sont d'utiliser le réseau à fond et d'assurer une relative égalité entre les flots de données qui se concurrencent sur ce réseau. LEDBAT, au contraire, vise avant tout à céder la place aux autre flots, non-LEDBAT.
Mais pourquoi diable voudrait-on être si généreux ? Cela peut être parce qu'on estime les autres flots plus importants : si je télécharge Plus belle la vie pendant que je passe un coup de téléphone via SIP, je souhaite que le téléchargement ne prenne pas de capacité si SIP en a besoin (c'est la différence entre applications d'« arrière-plan » comme le transfert de gros fichiers et d'« avant-plan » comme un coup de téléphone ou une session SSH interactive). Ou bien cela peut être pour profiter de réductions offertes par le réseau : après tout, un routeur ou une fibre optique ne coûtent pas plus cher à l'usage, que les octets circulent ou pas (contrairement à un autoroute ou une voie ferrée). Il serait donc logique que les transports « charognards », comme LEDBAT, qui n'utilisent la capacité réseau que lorsque personne n'en veut, reçoivent une récompense financière, par exemple une réduction des prix (parlez-en à votre FAI).
Pour les détails sur les motivations de LEDBAT et les raisons pour lesquelles des technqiues comme le shaping ne conviennent pas, voir le premier RFC du groupe LEDBAT, le RFC 6297. Ici, je vais me focaliser sur l'algorithme spécifié par LEDBAT et qui répond au cahier des charges : céder la place le plus vite possible.
Le principe de cet algorithme est simple : utiliser les variations du temps de voyage des paquets pour détecter l'approche de la congestion et refermer alors la fenêtre de transmission. TCP utilise essentiellement le taux de pertes de paquets comme indicateur (ou les marques ECN du RFC 3168). Les routeurs ayant des tampons d'entrée-sortie, lorsque la ligne de sortie est saturée, les paquets commencent à s'entasser dans ce tampon. Lorsqu'il est plein, le routeur jette des paquets (et TCP va alors réagir). On voit que l'augmentation du temps de voyage (dû au séjour dans le tampon) précède la perte de paquets. En réagissant dès cette augmentation, LEDBAT atteint son objectif de céder la place à TCP. (À noter qu'il existe des variantes de TCP qui utilisent également le temps de voyage comme indicateur de l'approche de la congestion, par exemple TCP Vegas, documenté dans « TCP Vegas: New techniques for congestion detection and avoidance » de Brakmo, L., O'Malley, S., et L. Peterson, mais voir le RFC 6297 pour un tour d'horizon général.)
Où est-ce que LEDBAT va être mis en œuvre ? Cela peut être dans un protocole de transport, par exemple comme une extension de TCP, ou bien dans l'application. LEDBAT est un algorithme, pas un protocole précis. Il peut être utilisé dans plusieurs protocoles, du moment que ceux-ci permettent l'estampillage temporel des paquets, pour que les deux machines qui communiquent puissent mesurer le temps de voyage (section 4.1).
La section 2 décrit l'algorithme exact. LEDBAT a une fenêtre de
congestion, notée cwnd qui indique combien
d'octets l'émetteur peut envoyer avant un nouvel accusé de
réception. L'émetteur met dans chaque paquet le moment où il a envoyé
ce paquet. Le récepteur regarde l'heure, en déduit le temps de voyage
(aller simple, puisque l'encombrement n'est pas forcément le même dans
les deux sens, une mesure aller-retour ne servirait pas à grand'chose) et retransmet cette indication à l'émetteur. Lorsque
celui-ci voit le temps de voyage augmenter (signe que les tampons des
routeurs se remplissent), il diminue la fenêtre de
congestion. L'émetteur notamment utilise deux paramètres,
TARGET et
GAIN. TARGET est
l'augmentation du temps de voyage en dessous de laquelle LEDBAT ne
fait rien. GAIN (qui vaut entre 0
et 1) indique le
facteur d'échelle entre l'augmentation du temps de voyage et la
réduction de la fenêtre de congestion. Plus il est élevé, plus LEDBAT
réagit rapidement et vigoureusement. Un GAIN de 1
est équivalent à TCP Reno. À noter qu'on
pourrait avoir deux valeurs de GAIN, une pour
augmenter la fenêtre de congestion et une pour la diminuer. En mettant
un GAIN plus grand pour la diminution de la
fenêtre, on garantit que LEDBAT cédera très vite la place dès le plus
petit signal d'un ralentissement.
(Pour
les amateurs de pseudo-code, une description
de l'algorithme avec cette technique figure dans le RFC.)
Bien sûr, le temps de voyage varie pour tout un tas de raisons et
il n'est pas forcément souhaitable de refermer la fenêtre de congestion à chaque
dérapage. LEDBAT filtre donc les
outliers à l'aide d'une
fonction FILTER() qui fait partie des paramètres
de l'algorithme (elle n'est pas imposée par le RFC, on peut tester
plusieurs mécanismes de filtrage des données.) Un filtre sommaire est
NULL (aucun filtrage, on accepte toutes les
mesures). Un autre plus sophistiqué est EWMA
(Exponentially-Weighted Moving
Average). Un bon filtre résiste au bruit
inévitable, mais reste sensible aux signaux indiquant une vraie
congestion.
Le temps de voyage se décompose en temps de transmission sur le
câble (qui dépend de la vitesse du médium, par exemple 100 Mb/s pour
du Fast Ethernet), temps de propagation (lié à
la vitesse de la lumière), temps d'attente dans
les tampons et temps de traitement à la
destination. Tous ces temps sont constants ou presque, à l'exception
du temps d'attente dans les tampons. Ce sont donc ses variations qui
déterminent l'essentiel des variations du temps de voyage. Pour
estimer ce temps d'attente dans les tampons, LEDBAT calcule un
temps de base (section 3.1.1) qui est le temps de voyage minimum
observé. Il permet de connaître la valeur minimale en dessous de
laquelle le temps de voyage ne pourra pas descendre. Les calculs de
fenêtre de congestion se font à partir de (temps de voyage - temps de
base), une grandeur qui part donc de zéro (les méthodes du RFC 6298 peuvent être utiles ici). L'algorithme de LEDBAT
est linéaire : la fenêtre est réduite ou
agrandie proportionnellement à cette grandeur, le facteur de
proportionnalité étant le paramètre GAIN. Autre intérêt du concept de
temps de base : en cas de changement de la route pendant la session
(par exemple, panne d'un lien et re-routage par un chemin plus long),
la mesure du temps de base pendant les N dernières secondes permettra
de voir que le trajet a changé et que les calculs doivent utiliser le
nouveau temps de base. (Le choix de N est un compromis : trop petit et
le temps de base va varier souvent, trop grand et il retardera le
moment où on détecte un changement de chemin.)
Avec son mécanisme de réduction de la fenêtre de congestion dès que le temps de voyage augmente, LEDBAT ne pousse normalement jamais jusqu'au point où il y aura des pertes de paquets. Néanmoins, celles-ci peuvent quand même survenir, et LEDBAT doit alors se comporter comme TCP, en refermant la fenêtre (section 3.2.2).
La section 4 du RFC discute ensuite de différents points
intéressants de LEDBAT. Par exemple, LEDBAT est efficace pour céder
rapidement à TCP lorsque celui-ci transfère de grandes quantités de
données. Mais cela laisse le problème des applications qui envoient
peu de données mais sont très sensibles à la
latence, comme la voix sur IP. Si la conversation téléphonique envoie peu de données,
il n'y aura jamais de remplissage des tampons, donc pas d'augmentation
du temps d'attente dans ceux-ci donc LEDBAT se croira tranquille et
enverra autant de données qu'il veut. Au moment où un des
interlocuteurs parlera, ses paquets se trouveront donc peut-être
coincés derrière un paquet LEDBAT. La seule protection contre ce
problème est le paramètre TARGET qui ne doit donc
pas être mis trop haut. La norme G.114 de
l'UIT suggère 150 ms comme étant le maximum de
retard tolérable pour le transport de la voix. LEDBAT doit donc
choisir ses paramètres pour réagir avant les 150 ms. Le RFC
recommande 100 ms pour le paramètre TARGET qui
indique l'augmentation de délai de voyage à partir de laquelle LEDBAT
réagit. (Ce paramètre TARGET détermine le temps
maximal d'attente supplémentaire dû à LEDBAT.)
Autre point subtil, la compétition entre flots LEDBAT. On sait que TCP assure la « justice » entre flots TCP : si trois flots sont en compétition, chacun aura un tiers de la capacité. LEDBAT, lui, cède à TCP. Si un flot LEDBAT et un flot TCP sont en compétition, TCP aura toute la capacité. Mais si deux flots LEDBAT parallèles se concurrencent ? L'algorithme de LEDBAT ne garantit pas de justice. En général, c'est le flot le plus récent qui va gagner : arrivant tard, dans un réseau déjà bien encombré, il mesure un temps de base très élevé et ne voit donc pas d'augmentation due au temps d'attente dans les tampons, et ne réduit donc pas sa fenêtre de congestion (« Rethinking Low Extra Delay Background Transport Protocols » de Carofiglio, G., Muscariello, L., Rossi, D., Testa, C., et S. Valenti). Pour corriger cet effet, on ne peut compter que sur le bruit : de temps en temps, les tampons se videront, le temps de voyage diminuera, et le récent arrivé corrigera sa mauvaise estimation du temps de base.
La section 5 du RFC considère les points qui sont encore ouverts à
expérimentation. Après tout, un protocole comme LEDBAT est quelque
chose de très nouveau dans le zoo de l'Internet. Par exemple, l'effet
de changement de routes pendant une session LEDBAT, modifiant le temps
de base, n'est pas encore vraiment bien connu. Quant à la valeur des
paramètres comme TARGET ou
GAIN, elle aura certainement besoin d'être
ajustée à la lumière de l'utilisation réelle. Enfin, le filtre des
mesures, qui permet d'éliminer les mesures jugées anormales, et évite
donc à LEDBAT d'ajuster brusquement sa fenêtre de congestion pour
rien, aura certainement besoin de réglages, lui aussi.
Et la sécurité de LEDBAT ? La section 6 rappelle que, même si un attaquant arrive à tromper LEDBAT sur les valeurs du temps de voyage, dans le pire des cas, il ne pourra pas le faire se comporter de manière plus gloutonne que TCP. Par contre, il pourra faire une attaque par déni de service en lui faisant croire que le délai de voyage a augmenté et que LEDBAT devrait ralentir. Pour l'instant, il n'y a pas de mécanisme contre cela.
Le bon fonctionnement de LEDBAT dépend de bonnes mesures. Les fanas de métrologie seront donc ravis de l'annexe A, qui parle des causes d'erreur dans les mesures. Le principal problème est que, pour mesurer les temps de voyage aller-simple dont a besoin LEDBAT, il faut des horloges à peu près synchronisées. Si l'émetteur met dans le paquet une heure de départ à 13 heures, 37 minutes et 56,789 secondes, que le récepteur mesure une arrivée à 13 heures, 37 minutes et 57,123 secondes et que le récepteur a 0,5 secondes de retard sur l'émetteur, il mesurera un temps de voyage de 0,334 secondes (alors qu'il est en fait de 0,834 secondes). Reprenant le vocabulaire de NTP (RFC 5905), on peut dire qu'il y a deux sources de problèmes, l'écart des horloges par rapport à une référence et le décalage (la variation de l'écart). L'écart entraine une erreur fixe dans la mesure du temps (comme dans notre exemple ci-dessus). Mais LEDBAT n'utilise pas directement le temps mais la différence entre temps actuel et temps de base. Cette erreur s'annule donc et l'écart des horloges par rapport au temps correct n'est donc pas importante pour LEDBAT.
Plus embêtant est le décalage puisque lui ne s'annulera pas. Si
l'horloge du récepteur bat plus vite que celle de l'émetteur, il aura
toujours l'impression d'un réseau très encombré, puisque ses mesures
de temps de voyage seront toujours supérieures au temps de base qu'il
avait mesuré avant. Heureusement, alors que des écarts énormes sont
souvent vus sur l'Internet (il est fréquent de voir plusieurs minutes,
voire plusieurs heures de différence entre une machine et le temps
UTC), les décalages sont typiquement bien plus
petits. Les mesures citées par le RFC 5905
indiquent des décalages courants de 100 à 200 ppm, soit 6 à 12 ms
d'erreur accumulée
par minute. Comme une machine LEDBAT limite sa mémoire (paramètre
BASE_HISTORY, pour lequel le RFC recommande
actuellement une valeur de dix minutes), et n'utilise donc que des
mesures récentes pour évaluer le temps de base, le problème reste donc
limité.
Si malgré tout, le problème se pose, il n'affectera que le cas où le récepteur a une horloge plus rapide, et en déduira donc à tort qu'il doit ralentir. Dans le cas inverse (horloge du récepteur plus lente), l'émetteur aura simplement l'impression que le temps de base augmente.
Pour corriger ce problème de décalage, on peut imaginer d'envoyer les estampilles temporelles dans les deux sens, pour que chaque machine puisse calculer ce que devrait voir l'autre, pour pouvoir détecter qu'un pair a une mauvaise mesure. Ensuite, l'émetteur pourrait corriger ses propres calculs por s'adapter à ce récepteur erroné. Il peut même calculer si le décalage est constant (horloge battant trop vite ou trop lentement, mais à une fréquence constante).
Et question mises en œuvre effectives ? LEDBAT a été testé dans des logiciels comme μTorrent Transport Protocol library. Il est l'algorithme utilisé par le microTP de BitTorrent (voir la documentation officielle de µTP). Il est aussi mise en œuvre dans Swift.
Merci à Mathieu Goessens pour sa suggestion et à André Sintzoff pour ses inlassables corrections.
L'article seul
RFC 6731: Improved Recursive DNS Server Selection for Multi-Interfaced Nodes
Date de publication du RFC : Décembre 2012
Auteur(s) du RFC : T. Savolainen (Nokia), J. Kato (NTT), T. Lemon (Nominum)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF mif
Première rédaction de cet article le 19 décembre 2012
Lorsqu'une machine connectée à l'Internet a plusieurs interfaces réseaux, et apprend (par exemple en DHCP) l'existence d'un résolveur DNS différent sur chaque interface, lequel utiliser ? Le principe de base de cette nouvelle norme est qu'il faudrait garder en mémoire chaque résolveur et utiliser à chaque fois celui qui correspond à l'interface réseau qu'on va utiliser.
Autrefois, le problème ne semblait pas crucial : après tout, un
résolveur DNS en vaut un autre, puisque tous
donnent les mêmes réponses. Mais ce n'est plus le cas aujourd'hui. Par
exemple, sur certaines interfaces, le résolveur DNS peut donner accès
à des noms de domaine privés,
strictement locaux, que les autres résolveurs ne connaissent pas. On
ne peut donc pas se contenter de prendre l'un des résolveurs au
hasard, ni même « le meilleur » résolveur car chacun peut avoir des
caractéristiques uniques (par exemple, l'un des résolveurs connait le domaine privé
foo.example et un autre un autre domaine privé bar.example). D'où cette règle de garder en mémoire tous
les résolveurs connus. (Le RFC utilise le terme de
RDNSS - Recursive DNS
Servers - pour les résolveurs.)
Ce n'est pas tout de mémoriser tous les résolveurs, encore faut-il savoir lequel utiliser. C'est le rôle de nouvelles options DHCP normalisées ici, qui permettent de distribuer les méta-informations dont le client a besoin pour savoir de quel résolveur se servir.
Si on veut mieux comprendre le problème de ces machines ayant
plusieurs interfaces réseaux, il faut lire le premier
RFC du groupe de travail MIF, le RFC 6418, qui définit le problème. Un exemple d'une telle
machine est un smartphone
qui a accès à la fois à un réseau WiFi privé et
à la 3G. Mais il y a aussi le cas où il n'y a
qu'une seule interface physique, mais plusieurs virtuelles, par
exemple un accès à l'Internet par le FAI local
et un VPN vers le réseau sécurisé de
l'entreprise. La partie la plus évidente du problème des machines à
plusieurs interfaces est celui des noms privés (section 2.1). Imaginons que la
société Foobar ait le domaine foobar.example et
qu'un sous-domaine internal.foobar.example
contienne les informations privées, spécifiques à l'entreprise et non
visibles dans le DNS public. Cela se fait en configurant spécialement
les résolveurs utilisés par les employés de l'entreprise. Par exemple, avec Unbound, pour un domaine nommé 42 et servi par 91.191.147.246 et 91.191.147.243, cela serait :
stub-zone: name: "42" stub-addr: 91.191.147.246 stub-addr: 91.191.147.243
Si un de ces employés est en voyage, connecté depuis l'hôtel,
ayant activé le VPN, et que sa machine utilise
le résolveur de l'hôtel, il ne pourra pas utiliser les noms en
internal.foobar.example. (Vous pouvez vous dire
« il faut utiliser le résolveur DNS de l'entreprise pour tout ». Mais il
sera en général plus lent et il pourra avoir ses propres limites, par
exemple ne pas pouvoir résoudre facebook.com car
le résolveur de l'entreprise censure ce nom.)
Notez aussi que le fait que l'application de ce RFC permettre de
gérer les noms de domaines privés (non rattachés à l'arbre principal
du DNS) ne signifie pas que ces noms privés soient une bonne idée,
approuvée par l'IETF. Ce point avait été une
des grosses controverses dans le groupe de travail. La section 6 donne à ce sujet des conseils pour
minimiser les risques associés à ces noms privés. (En gros, les
choisir uniques, par exemple en les suffixant du nom de
l'organisation, pour que tout le monde ne nomme pas ses machines dans
.private ou .lan.)
En général, le « bon » résolveur à utiliser dépend de l'interface
de sortie et les techniques de ce RFC sont donc à utiliser en
combinaison avec celles du RFC 4191 et du RFC 3442. Même si un nom de domaine est visible partout, il peut
se résoudre en des adresses
IP différentes selon l'interface réseau utilisé (cas
célèbre de smtp.orange.fr qui ne donne pas le
même résultat aux abonnés d'Orange et aux
autres.) On peut encore citer le cas des extensions au DNS utilisées
dans certains cas de coexistence
IPv4-IPv6 (RFC 6147).
Il peut y avoir des cas encore plus complexes et notre RFC ne prétend pas tout résoudre (section 2.3).
Avant de décrire la solution standardisée, le RFC présente trois études de cas permettant d'illustrer un problème soluble (section 3). Des études de cas plus détaillées, avec examen des pratiques actuelles, figurent dans le RFC 6419.
D'abord, le cas d'un foyer connecté à l'Internet via un FAI
ainsi qu'à un réseau privé, les deux connexions passant par le même
CPE. Ce réseau privé utilise uniquement des noms
dans un domaine qui n'apparait pas sur l'Internet (mettons
hidden.example). Pour que tout marche, du point
de vue de l'utilisateur, il faut envoyer les requêtes de résolution de
noms au résolveur du réseau privé, si le nom se termine en
hidden.example et au résolveur du FAI
autrement. Le plus simple est qu'un relais DNS
tourne sur le CPE et aiguille automatiquement les requêtes DNS vers le
bon résolveur.
Autre scénario d'usage, celui mentionné plus tôt d'un smartphone connecte à la fois au réseau 3G et à un accès WiFi local. Pour des raisons financières, on souhaite utiliser le WiFi dans le plus grand nombre de cas. Mais on peut avoir besoin d'établir certaines connexions via la 3G, soit parce que certains services ne sont que là, soit pour des raisons de sécurité (à mon avis, le RFC surestime nettement la sécurité de la 3G mais c'est une autre histoire).
Le smartphone doit donc utiliser le DNS de l'accès WiFi par défaut mais avoir des règles (par exemple une liste de destinations sensibles qu'on ne veut contacter qu'en 3G) qui imposeront l'utilisation du résolveur DNS du fournisseur de 3G.
Enfin, dernière étude de cas, celui du road warrior doté d'un accès à un (ou plusieurs) VPN de son entreprise. Aussi bien pour des raisons de sécurité que d'accès à des noms de domaines privés, on veut faire passer les accès au réseau interne de l'entreprise (requêtes DNS comprises) par le VPN. Par contre, pour consulter Facebook et YouTube, on va passer par l'accès par défaut.
La section 4 du RFC donne ensuite les règles exactes à suivre pour que tout se passe bien. Le principe essentiel est que la machine doit construire une liste de résolveurs (et pas uniquement garder le dernier annoncé) accessibles, en notant pour chacun les options envoyées par DHCP (nouvelles options décrites un peu plus loin), qui vont permettre de sélectionner le résolveur à utiliser pour une requête donnée. Par défaut, on considère que tous les résolveurs sont équivalents (donnent les mêmes résultats). Mais certains critères permettent de les distinguer :
- La confiance qu'on leur accorde (voir section 9.2 du RFC). C'est assez subjectif mais on
peut penser, par exemple, qu'un résolveur atteint par un VPN
IPsec vers son entreprise est plus digne de
confiance que le résolveur d'un
hotspot dans un
café. Certains disent même que la 3G avec son fournisseur mobile est
plus sûre (c'est l'exemple de pseudo-code dans
l'annexe C, avec
IF_CELLULARpréféré àIF_WLAN.) Cette confiance est à configurer dans le client, il n'y a pas de protocole pour la déterminer. - La préférence indiquée en DHCP (voir les nouvelles options DHCP plus loin.).
- Les domaines privés qu'ils gèrent... ou pas.
- Le fait qu'ils valident avec DNSSEC ou pas. À noter que cela peut aussi dépendre des clés DNSSEC connues. Dans le cas le plus fréquent, le résolveur ne valide qu'avec la clé de la racine du DNS. Mais, s'il a d'autres clés configurées, il faut lire l'annexe B du RFC car c'est un peu plus compliqué.
Avec tous ces critères, on peut faire une sélection intelligente du
résolveur. Ainsi, s'il faut résoudre un nom en
private.mycompany.example et qu'un seul des
résolveurs annonce ce domaine (les autres gérant l'arbre public du
DNS), c'est clair qu'il faut utiliser ce serveur, les autres ne
pourront pas répondre. Les règles de sélection exactes figurent dans
la section 4.1. Si vous préférez lire le
pseudo-code, l'annexe C contient une mise en
œuvre de cet algorithme.
Les sections 4.2 et 4.3 décrivent les nouvelles options pour DHCPv4 (RFC 2131) et DHCPv6 (RFC 8415). Elles sont quasiment identiques en v4 et v6 donc je me limite à celle de v6 :
- Son code est 74 (146 en v4),
- Elle contient l'adresse IPv6 du résolveur et la préférence attribuée à ce serveur (High, Medium ou Low),
- Elle contient une liste de domaines que le résolveur connait,
par exemple
private.company.example, (et.tout court s'il connait tous les domaines, ce qui est le cas d'un résolveur normal), ainsi qu'une liste de domaines correspondant à des préfixes IP pour les résolutions dansip6.arpa(RFC 3596).
Un client DHCP qui connait notre RFC met une demande de cette option dans sa requête et reçoit en échange la liste ci-dessus. Attention, elle est limitée en taille par les contraintes de DHCP (section 4.4), il ne faut donc pas espérer y indiquer des centaines de domaines possibles.
Une fois qu'un résolveur a été sélectionné pour une requête DNS, il
doit continuer à être utilisé si cette requête déclenche à son tour
d'autres requêtes (section 4.7). Imaginons qu'on cherche l'adresse IPv6 de
portal.company.example, on va faire une requête
AAAA portal.company.example et si on obtient une
réponse portal.company.example CNAME
www.example.com, alors, la requête ultérieure
AAAA www.example.com doit utiliser le même
résolveur, pour être cohérente, au cas où
www.example.com renvoie des adresses différentes
selon le résolveur qui demande. Programmeurs, attention, cela implique
de garder un état et de ne pas faire la sélection du résolveur de
manière indépendante pour chaque requête.
De même qu'on garde une liste de résolveurs à utiliser, il faut aussi avoir autant de caches que d'interfaces, ou vider le cache entre deux requêtes, pour éviter qu'une information venant du cache n'« empoisonne » une résolution. Et il ne faut pas oublier, lorsqu'une interface réseau disparait, de vider le cache des données apprises via cette interface (section 4.8). Le logiciel local de la machine devient donc assez compliqué !
Voilà, vous savez tout. Si le problème vous intéresse et que vous voulez creuser la question, l'annexe A de ce RFC présente « ce qui aurait pu être », les autres mécanismes qui auraient pu être choisis (comme « envoyer la requête sur toutes les interfaces réseau et prendre la première réponse qui revient »).
Actuellement, il semble que certains systèmes de Nokia et de Microsoft (Name Resolution Policy Table) utilisent déjà ce mécanisme dans leurs téléphones.
L'article seul
RFC 6793: BGP Support for Four-octet AS Number Space
Date de publication du RFC : Décembre 2012
Auteur(s) du RFC : Q. Vohra (Juniper Networks), E. Chen (Cisco Systems)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 19 décembre 2012
Un des nombres trop petits de l'Internet était la taille des numéros de système autonome. En 2007, elle était passée, avec le RFC 4893, de deux à quatre octets. Ce nouveau RFC est juste une révision mineure de cette norme.
Il est assez courant dans l'Internet que des nombres prévus très larges au début s'avèrent ridiculement petits avec la croissance du réseau. C'est bien sûr le cas des adresses IPv4, dont les 32 bits sont bien trop peu pour le nombre de machines connectées aujourd'hui, mais c'est aussi vrai pour les numéros de système autonome (AS pour autonomous system). Chacun de ces numéros identifie un système autonome de routage, au sein duquel une politique de routage cohérente peut s'appliquer. En gros, chaque opérateur a un numéro de système autonome, les plus gros en ayant plusieurs (surtout en cas de fusion ou d'acquisition).
Ces numéros sont notamment utilisés par le protocole de routage
BGP (normalisé dans le RFC 4271), pour indiquer le chemin à suivre pour
joindre un réseau. La petite fonction shell bgproute
permet d'interroger les serveurs de Route Views et affiche les numéros
de système autonomes traversés :
% bgproute 80.67.162.1 AS path: 3257 3356 20766 20766 Route: 80.67.160.0/19
On voit que le serveur de Route Views a reçu l'annonce de la part du système autonome 3257 qui l'avait lui même reçu du système autonome 3356.
Ces numéros étaient autrefois stockés sur seulement 16 bits, ce qui ne permettait que 65 535 systèmes en tout, bien trop peu pour l'Internet d'aujourd'hui, qui va des villes chinoises aux hébergeurs brésiliens. Si certains conservateurs, méprisants et élitistes, ont regretté le fait que « n'importe qui, avec une armoire et deux PC avec Quagga » veuille faire du BGP, le fait est que l'Internet touche bien plus de monde et que la population des opérateurs a augmenté. D'où le RFC 4893, qui avait fait passer la taille des numéros d'AS à 32 bits, soit quatre milliards d'opérateurs possibles.
Ces AS de quatre octets s'écrivent en notation
ASPLAIN, en
écrivant directement le nombre, par exemple
112617 (RFC 5396).
Les nouveaux AS sont ensuite annoncés par l'attribut
AS4_PATH, n° 17 dans le
registre des attributs.
Le changement lui-même est assez trivial mais, comme souvent sur Internet, le gros du travail était la gestion de la transition. Notre RFC explique avec beaucoup de soin comment un routeur BGP récent va pouvoir parler à un routeur de l'ancienne génération (le routeur doit annoncer sa capacité à gérer les AS de quatre octets avec le capability advertisment n° 65 du RFC 5492). Et comment les chemins d'AS 4-octets pourront être transmis même à travers des « vieux » routeurs, utilisant un mécanisme de tunnel (l'article de Geoff Huston l'explique très bien).
Pour cette transition, le nouveau BGP utilise un numéro d'AS
spécial, le 23456, qui sert à représenter tous
les AS 4-octets pour les anciens routeurs. Si vous voyez apparaitre ce
système autonome, par exemple en tapant un show ip
bgp sur un Cisco, c'est que votre
logiciel est trop vieux. Ceci dit, cela doit être rare de nos jours,
la gestion de ces AS sur quatre octets étant désormais présente dans
toutes les mises en œuvre sérieuses de BGP.
Les numéros d'AS sur quatre octets sont distribués par les RIR depuis des années (voir par exemple la politique du RIPE-NCC et sa FAQ). Le RIPE-NCC a publié d'intéressantes statistiques à ce sujet, notamment sur le taux de numéros d'AS 32 bits renvoyés au RIPE-NCC car le titulaire s'est aperçu, après coup, qu'il y avait quelques problèmes techniques, chez lui ou chez ses fournisseurs.
L'annexe A résume les différences par rapport au RFC 4893 : rien de vital, juste un toilettage. Notamment, la gestion d'erreurs, absente du précédent RFC, est spécifiée en détail.
L'article seul
RFC 3: Documentation conventions
Date de publication du RFC : Avril 1969
Auteur(s) du RFC : Steve Crocker (University California Los Angeles (UCLA))
Statut inconnu, probablement trop ancien
Première rédaction de cet article le 16 décembre 2012
Membre de la prestigieuse série des tous premiers RFC, publiés en même temps en 1969, ce RFC 3 expose le fonctionnement des RFC et pose donc le principe de l'ouverture des débats.
Il est ultra-court, comme l'étaient la plupart des RFC à l'époque. Mais son contenu est dense. Les deux points essentiels, qui pèseront lourdement dans le futur Internet, sont :
- Discussion libre et ouverte des idées, sans considérer les documents écrits comme étant sacrés (le sigle de RFC, Request For Comments, appel à commentaires, vient de là).
- Encouragement à publier sans se demander pendant des années si le texte est parfait.
Depuis, bien des électrons ont circulé dans les câbles. Les RFC ne sont plus des « appels à commentaires » mais des documents figés, qui ne changent pas après leur publication. Et celle-ci requiert de long et parfois pénibles débats. Mais l'idée que les idées doivent l'emporter par leur valeur et pas par un argument d'autorité reste.
La lecture de la liste des membres du Network Working Group (le futur IETF) dans ce RFC est instructive : essentiellement des étudiants, dont aucun ne pouvait imposer ses idées par ses titres et ses diplômes. Le concept de RFC vient de là.
Comme son titre l'indique, ce document contient aussi des conventions, comme le fait de numéroter les RFC (Bill Duvall était le premier RFC Editor, chargé de gérer ces numéros) et comme la longueur minimale d'un RFC (lisez le texte pour la connaître).
Merci à Laurent Chemla pour m'avoir signalé ce RFC dans un article récent.
L'article seul
Finalement, je suis enfin passé à UTF-8
Première rédaction de cet article le 15 décembre 2012
Normalement, en 2012, il y a longtemps que tout le monde est passé à UTF-8 et a abandonné le vieux Latin-1. Mais cela m'a pris plus longtemps que prévu et je viens juste de faire la transition.
Comme je l'avais expliqué dans un autre article, c'est en effet plus compliqué que ça n'en a l'air, surtout si on a accumulé au cours du temps plein de fichiers, de programmes, et de réglages spécifiques à Latin-1. Et puis, ne nous voilons pas les yeux. S'il est normal aujourd'hui d'utiliser un encodage capable de représenter tous les caractères d'un coup, en pratique, il reste encore quelques trucs qui ne marchent pas bien en UTF-8. Pour donner une idée de l'opération, j'ai dû :
- Convertir les fichiers sources de ce blog (écrits en XML avec l'encodage Latin-1) avec un petit script Python. (Pour un fichier individuel, c'est simple, on change l'encodage et le mode nxml-mode d'emacs convertit. Mais, ici, il y avait 1 500 fichiers...)
- Changer dans mon
~/.zshrcréglé à la main les variables environnement commeLC_CTYPE. Idem pour les fichiers de configuration d'autres logiciels comme le.emacsd'Emacs. - Encore faut-il avoir un terminal qui affiche UTF-8. J'ai dû abandonner mon terminal favori, wterm, qui ne gère pas UTF-8 (il existe un wterm-ml mais qui a un exécutable différent par langue : pas pratique du tout). Par contre, xterm, gnome-terminal ou lxterminal se débrouillent très bien.
- Changer ses variables d'environnement ne convertit pas par magie les fichiers texte éparpillés un peu partout sur le disque. Pour certains répertoires importantes, j'ai tout converti à grands coups de commande recode. Pour les autres, je le ferai au fur et à mesure de leurs modifications.
- Changer la configuration de mutt
(
set send_charset=us-ascii:utf-8) et tester avec les répondeurs de courrier pour être sûr que tout allait bien. - Éditer
/etc/X11/fonts/misc/xfonts-base.aliaspour mettre une police Unicode pour X11. - Remplacer des logiciels comme a2ps (qui ne gère pas du tout UTF-8). Pareil pour enscript. Il reste u2ps et uniprint, mais ils ne font hélas pas de pretty-printing. (Il existe une liste des applications non-UTF8 sur Debian.)
- Passer de l'ack-grep un peu partout pour trouver tous les occurrences de « 8859 » ou de « Latin-1 » que j'aurais pu oublier. Cela ne m'a pas empêché d'en rater certaines et d'envoyer un fichier Latin-1 étiqueté UTF-8 sur la liste Frnog...
Voyons le côté positif, je peux désormais utiliser directement et nativement tous les caractères UTF-8 non Latin-1 comme Ÿ, œ, sans compter α ou des fantaisies comme ǝpoɔıu∩...
L'article seul
Exemple d'analyse d'un problème DNS
Première rédaction de cet article le 11 décembre 2012
Ce matin, pour regarder de près l'amusant problème de la
disparation du RER C (les sites Web de
recherche d'itinéraire en Île-de-France ne
connaissent plus cette ligne et ne la proposent plus), je me suis
promené sur http://www.ratp.fr/. Cela a fortement déplu
à mon Firefox : plus de rafraîchissement des
pages, réactions très lentes, voire nulles, etc. À l'origine, un
problème DNS avec une zone très mal
configurée.
Je sais en effet que Firefox réagit de
manière pathologique
aux problèmes DNS (contrairement à Chromium) : il se bloque à attendre des réponses qui ne
viennent pas, même les autres onglets sont paralysés. Donc, il était
logique de suspecter un problème DNS. Mais quel problème ? C'est
d'autant plus difficile de le savoir que dig
donne parfois des réponses correctes et parfois
SERVFAIL (Server Failure). Il
faut regarder de plus près.
Le journal du serveur de noms, un Unbound, explique pourquoi on a des problèmes :
Dec 11 11:30:05 batilda unbound: [2631:0] info: iterator operate: query www.ratp.fr. A IN Dec 11 11:30:05 batilda unbound: [2631:0] info: processQueryTargets: www.ratp.fr. A IN Dec 11 11:30:05 batilda unbound: [2631:0] debug: out of query targets -- returning SERVFAIL Dec 11 11:30:05 batilda unbound: [2631:0] debug: return error response SERVFAIL
Dec 11 11:30:09 batilda unbound: [2631:0] info: iterator operate: query www.ratp.fr. AAAA IN Dec 11 11:30:09 batilda unbound: [2631:0] info: processQueryTargets: www.ratp.fr. AAAA IN Dec 11 11:30:09 batilda unbound: [2631:0] info: sending query: www.ratp.fr. AAAA IN Dec 11 11:30:09 batilda unbound: [2631:0] debug: sending to target: <www.ratp.fr.> 195.200.228.2#53
Pour comprendre cette incohérence (problème de réseau ? bogue
subtile ?), il faut regarder la configuration de
www.ratp.fr. Si on interroge un des serveurs
faisant autorité pour ratp.fr, on trouve une
délégation :
% dig @ns0.ratp.fr A www.ratp.fr ... ;; AUTHORITY SECTION: www.ratp.fr. 3600 IN NS altns2.ratp.fr. www.ratp.fr. 3600 IN NS altns1.ratp.fr. ;; ADDITIONAL SECTION: altns1.ratp.fr. 3600 IN A 195.200.228.2 altns2.ratp.fr. 3600 IN A 195.200.228.130 ...
OK, www.ratp.fr n'est pas dans la même zone que
ratp.fr. On note aussi qu'il n'y a que deux
serveurs de noms et que leurs adresses IP,
proches (dans le même /24) laissent supposer qu'il n'y a guère de
redondance dans cette configuration. Mais passons et interrogeons les
serveurs :
% dig @altns1.ratp.fr A www.ratp.fr ; <<>> DiG 9.9.2-P1 <<>> @altns1.ratp.fr A www.ratp.fr ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: FORMERR, id: 1960 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0 ;; WARNING: recursion requested but not available ;; WARNING: Messages has 11 extra bytes at end ;; QUESTION SECTION: ;www.ratp.fr. IN A ;; Query time: 35 msec ;; SERVER: 195.200.228.2#53(195.200.228.2) ;; WHEN: Tue Dec 11 12:47:34 2012 ;; MSG SIZE rcvd: 40
Aïe, déjà un problème. Le FORMERR veut dire
Format error et signifie que le serveur n'a pas
compris la requête. Depuis peu, dig utilise
EDNS par défaut, comme la plupart des
résolveurs, et c'est peut-être cela qui a suscité l'incompréhension de
altns1.ratp.fr. Essayons sans EDNS :
% dig +noedns @altns1.ratp.fr A www.ratp.fr ; <<>> DiG 9.9.2-P1 <<>> +noedns @altns1.ratp.fr A www.ratp.fr ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 10283 ;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0 ;; WARNING: recursion requested but not available ;; QUESTION SECTION: ;www.ratp.fr. IN A ;; ANSWER SECTION: www.ratp.fr. 300 IN A 195.200.228.150 www.ratp.fr. 300 IN A 195.200.228.50 ;; Query time: 38 msec ;; SERVER: 195.200.228.2#53(195.200.228.2) ;; WHEN: Tue Dec 11 12:49:37 2012 ;; MSG SIZE rcvd: 83
Cette fois, cela marche. Le RFC 2671, qui normalisait EDNS, date de 1999 mais, apparemment, c'est encore une technologie nouvelle pour certains.
Alors, suffit-il de se rabattre sur du vieux DNS sans EDNS ? Sauf
qu'il y a d'autres problèmes. Par exemple, alors que
www.ratp.fr est censé être une zone, les serveurs
ne répondent pas aux requêtes SOA :
% dig +noedns @altns1.ratp.fr SOA www.ratp.fr ; <<>> DiG 9.9.2-P1 <<>> +noedns @altns1.ratp.fr SOA www.ratp.fr ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 60719 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0 ;; WARNING: recursion requested but not available ;; QUESTION SECTION: ;www.ratp.fr. IN SOA ;; Query time: 35 msec ;; SERVER: 195.200.228.2#53(195.200.228.2) ;; WHEN: Tue Dec 11 13:55:35 2012 ;; MSG SIZE rcvd: 29
Refusé... Charmant. C'est pareil pour d'autres
types de données (comme TXT). Et pour tous les noms situés en dessous
de www.ratp.fr ? Le serveur répond correctement
NXDOMAIN (No such domain)
mais n'inclut pas le SOA obligatoire dans la
réponse :
dig +noedns @altns1.ratp.fr A test.www.ratp.fr ; <<>> DiG 9.9.2-P1 <<>> +noedns @altns1.ratp.fr A test.www.ratp.fr ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 16785 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0 ;; WARNING: recursion requested but not available ;; QUESTION SECTION: ;test.www.ratp.fr. IN A ;; Query time: 36 msec ;; SERVER: 195.200.228.2#53(195.200.228.2) ;; WHEN: Tue Dec 11 14:02:32 2012 ;; MSG SIZE rcvd: 34
Cela empêche le résolveur de déterminer le zone cut, la limite de la zone.
Maintenant, pourquoi est-ce que www.ratp.fr a
des serveurs de noms aussi bogués ? Le plus probable est que
ratp.fr utilise des logiciels assez classiques
mais que www.ratp.fr a été délégué, pour les
besoins du serveur Web, a une
appliance programmée avec
les pieds. De tels boîtiers sont courants, pour assurer des fonctions
comme la répartition de charge et,
écrits par des gens qui ne connaissent pas le DNS et exploités par des
gens du Web qui ne le connaissent pas non plus, ils sont fréquemment
horriblement bogués.
Mais revenons à mon problème initial. Puisque Unbound se rabat
automatiquement en « sans EDNS » lorsqu'il reçoit la réponse
FORMERR, pourquoi est-ce que cela marchait
irrégulièrement ? L'examen du journal d'Unbound le montre : on voit des
requêtes pour _443._tcp.www.ratp.fr. Il s'agit
là de requêtes DANE (RFC 6698), lancées par une extension Firefox installée sur ma
machine. Le nom n'existe pas, OK. Mais la réponse erronée, ne
comprenant pas le SOA, perturbe Unbound, l'amenant à conclure que le
serveur a un problème. Il ne l'interrogera pas ensuite, pour un
moment, renvoyant SERVFAIL. En pratique, tout
dépendra de l'ordre des requêtes (la requête habituelle en premier ou
bien la requête DANE d'abord).
Un tel phénomène (réponse erronée amenant le résolveur à conclure que le serveur est défaillant) avait déjà été observé avec le déploiement du type AAAA (pour les adresses IPv6). Le problème avait été documenté dans le RFC 4074 en 2005. Mais les auteurs d'appliances ne lisent jamais les RFC...
Si vous voulez voir la curieuse disparition du RER C, voici
l'itinéraire proposé ce matin, pour aller de la station
Champ de
Mars à la station Pont de
l'Alma (stations consécutives sur le RER C, options de
recherche "Réseau ferré" et "Le moins de correspondance"). http://www.ratp.fr/ suggère tout simplement de traverser la
Seine pour aller prendre la ligne 9 !  Si vous trouvez que les trains rampent trop bas et que vous
préférez vous envoler, la zone
Si vous trouvez que les trains rampent trop bas et que vous
préférez vous envoler, la zone www.airfrance.com a
la même architecture, et pas mal de problèmes identiques.
L'article seul
Surveillez les dates d'expiration de vos certificats X.509 !
Première rédaction de cet article le 9 décembre 2012
Dernière mise à jour le 14 septembre 2017
Un certain nombre de services sur l'Internet, notamment de serveurs Web, sont protégés par le protocole TLS, qui utilise presque toujours un certificat X.509 pour vérifier l'authenticité du serveur. Ces certificats ont une durée de vie limitée et doivent donc être renouvelés de temps en temps. Comme un certain nombre d'administrateurs ont oublié, au moins une fois, un tel renouvellement, il me semble utile de donner ce conseil : intégrez la surveillance des dates d'expiration dans votre système de supervision !
Pourquoi est-ce que les certificats expirent ? Les mauvaises langues vous diront que c'est parce que les AC veulent gagner davantage d'argent. Mais il y a quand même une bonne raison technique : comme le mécanisme de révocation de X.509 marche très mal, la durée limitée du certificat est la seule vraie protection contre un vol de la clé privée : au moins, le voleur ne pourra pas jouir du fruit de son forfait éternellement.
Les certificats ont donc une date d'expiration, que les navigateurs Web
peuvent montrer (dans les informations d'une connexion
HTTPS), ici avec deux navigateurs
différents : 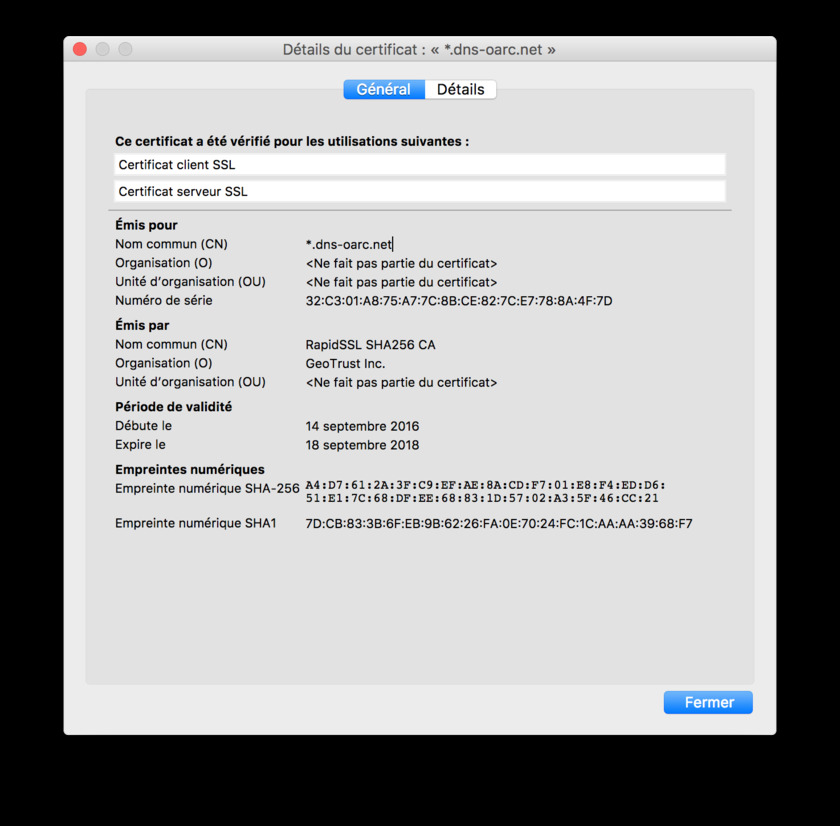
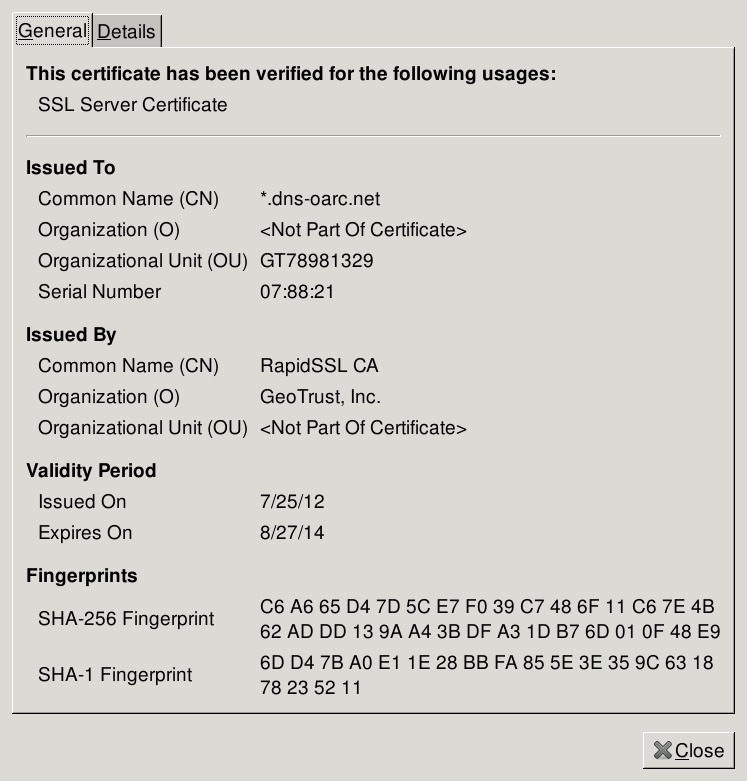 Si on préfère la ligne de commande,
OpenSSL permet d'afficher l'information :
Si on préfère la ligne de commande,
OpenSSL permet d'afficher l'information :
% openssl s_client -servername www.dns-oarc.net -connect www.dns-oarc.net:443 < /dev/null > /tmp/oarc.pem % openssl x509 -enddate -noout -in /tmp/oarc.pem notAfter=Aug 27 15:28:19 2014 GMT
Ici, on voit que le certificat de l'OARC n'expirera pas avant un an et demi.
Les clients TLS vérifient cette date et
refusent normalement la connexion avec un serveur dont le certificat a
expiré. Merci à François pour m'avoir signalé l'expiration de
admin.lautre.net qui me permet de mettre de vrais
exemples, ici avec Chrome : 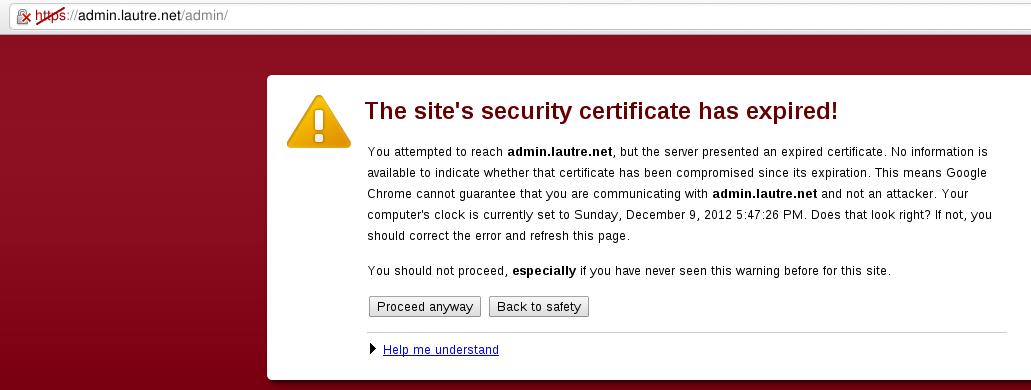
Comment éviter ce sort tragique ? Le mieux serait que l'AC prévienne ses clients lorsque le certificat va bientôt expirer. CAcert le fait, par exemple, mais toutes les AC ne le font pas. Bref, cela vaut la peine de tester l'approche de l'expiration, depuis son système de supervision habituel. On sera ainsi prévenu avant le problème.
Si on utilise Nagios, ou un de ses
compatibles, comme Icinga, les programmes de
tests standards savent en général tester. Par exemple, check_http a
l'option -C qui prend deux paramètres, un
obligatoire qui précise le nombre de jours où le certificat doit être valide avant
que le logiciel de supervision ne lance un avertissement et un
facultatif qui donne le nombre de jours où le certificat doit être valide avant
que ce logiciel ne lance une alarme critique (par défaut, c'est
lorsque le certificat a expiré que cette alarme se déclenche). Voici des exemples avec
le certificat de l'OARC qui a encore 625 jours à vivre :
% /usr/share/nagios/libexec/check_http -H www.dns-oarc.net --ssl=1 -C 700,100 WARNING - Certificate '*.dns-oarc.net' expires in 625 day(s) (08/27/2014 15:28).
Ici, on a un avertissement (WARNING) car on a demandé que le certificat ait encore 700 jours (une valeur irréaliste, mais c'est pour faire une démo de ce programme de test). Avec des valeurs plus raisonnables, check_http nous dit évidemment que tout va bien :
% /usr/share/nagios/libexec/check_http -H www.dns-oarc.net --ssl=1 -C 15,7 OK - Certificate '*.dns-oarc.net' will expire on 08/27/2014 15:28.
Par contre, avec le certificat expiré vu plus haut :
% /usr/share/nagios/libexec/check_http -H admin.lautre.net --ssl=1 -C 15,7 CRITICAL - Certificate '*.lautre.net' expired on 12/08/2012 23:59.
On peut alors mettre ce test dans sa configuration Nagios, Icinga, etc :
define service{
use generic-service
host_name my-web
service_description HTTP
check_command check_http!-H www.example.net --ssl -C 15,7
}
Ou, avec un Icinga 2, plus récent :
vars.http_vhosts["web-cert"] = {
http_uri = "/"
http_vhost = "www.example.net"
http_ssl = true
http_sni = true
http_certificate = "15,7"
}
On sera désormais prévenu par les mécanismes habituels de son logiciel
de supervision. Notez bien que d'autres programmes de test de Nagios
ont une telle option, mais pas toujours la même (c'est
-D pour check_imap, par
exemple).
Attention, toutefois. La documentation
de check_http le dit, mais de manière peu claire
(« when this option is used the URL is not
checked ») : dès qu'on active les tests du certificat,
d'autres tests sont coupés, comme celui du code de retour HTTP (200,
401, 403, etc) ou comme celui de la présence d'une chaîne de
caractères dans le contenu (option
http_string). Il faut donc la plupart du temps
faire deux tests, un avec l'option
http_certificate et l'autre sans.
Et si on n'utilise pas Nagios ou un compatible et qu'on veut faire un programme de test ? Il existe évidemment plein de programmes pour cela.
Le plus souvent cité est ssl-cert-check, qui s'appuie sur OpenSSL. On le télécharge et on l'utilise ainsi (merci à Nicolas Legrand pour ce serveur, qui a une date d'expiration proche) :
% ssl-cert-check -s dio.obspm.fr -p 443 Host Status Expires Days ----------------------------------------------- ------------ ------------ ---- dio.obspm.fr:443 Valid Feb 4 2013 57
Si le certificat a expiré, on a :
% ssl-cert-check -s admin.lautre.net -p 443 Host Status Expires Days ----------------------------------------------- ------------ ------------ ---- admin.lautre.net:443 Expired Dec 8 2012 -1
Il dispose de plusieurs options, par exemple pour indiquer quelle marge de manœuvre on accepte :
% ssl-cert-check -s dio.obspm.fr -p 443 -x 60 Host Status Expires Days ----------------------------------------------- ------------ ------------ ---- dio.obspm.fr:443 Expiring Feb 4 2013 57
Ses deux principaux inconvénients sont qu'il ne définit pas le code de
retour (ce qui le rend difficile à intégrer dans une solution de
supervision automatisée, sauf à utiliser son option
-n, conçue pour Nagios) et qu'il ne semble pas connaître le SNI
(Server Name Indication, RFC 6066), ce qui est pénible pour le cas où on a plusieurs serveurs derrière la même
adresse IP.
Autre solution, un programme écrit par Kim-Minh Kaplan, check-tls.sh. Il est conçu pour tester un groupe de serveurs
(mis dans un fichier préalablement).
À noter que le programme sslscan est très utile pour faire un audit de son serveur mais ne semble pas adapté à la supervision. (Autre possibilité, mais je n'ai pas testé, SSLyze.)
Patrick Mevzek me fait remarquer qu'il faudrait, en toute rigueur,
tester la date d'expiration, non seulement du certificat final, celui
du serveur, mais aussi celle de tous les certificats intermédiaires,
qui peuvent aussi expirer. J'ignore si les logiciels ci-dessus pensent
à cela (check-tls.sh ne le fait pas). Les certificats
intermédiaires sont ceux de professionnels de la sécurité et,
normalement, ils ont moins souvent des problèmes que les certificats
finaux. Mais il peut arriver en effet qu'un serveur stocke des
certificats intermédiaires qui ont été mis à jour par l'AC mais que l'administrateur du serveur a oublié de changer.
Bref, avec tous ces outils, l'administrateur système qui laisse un certificat expirer n'a vraiment aucune excuse.
L'article seul
RFC 6789: ConEx Concepts and Use Cases
Date de publication du RFC : Décembre 2012
Auteur(s) du RFC : B. Briscoe (BT), R. Woundy (Comcast), A. Cooper (CDT)
Pour information
Réalisé dans le cadre du groupe de travail IETF conex
Première rédaction de cet article le 6 décembre 2012
Premier RFC du groupe de travail CONEX de l'IETF, ce document expose les principes de bases du mécanisme de « publication de la congestion » (CONgestion EXposure). L'idée est d'indiquer dans les paquets la congestion prévue, pour que les équipements réseaux puissent prendre des décisions appropriées. Une fois normalisée (ce RFC 6789 n'est qu'une toute première étape), ce sera une des nombreuses techniques permettant de gérer la congestion dans les réseaux TCP/IP et notamment l'Internet.
Il n'y a pas encore de protocole normalisé pour cette « publication de la congestion » (les deux premiers utiliseront une option IPv6 et une option de TCP). Pour l'instant, notre RFC s'en tient à des usages : à quoi cela pourrait servir. La congestion est clairement une des plaies du réseau. La force de TCP/IP est de multiplexer la capacité des liens au niveau des paquets et pas des circuits. Cela permet une utilisation bien plus efficace du réseau. Mais cela ne crée pas magiquement de la capacité : quand trop de paquets rencontrent trop peu de capacité, la congestion survient. Elle se manifeste par des pertes de paquets (le routeur, n'arrivant pas à suivre, abandonne certains paquets), mais aussi par des retards (si les tampons du routeur amortissent la congestion, ils augmentent les délais d'acheminement), et par le marquage ECN (RFC 3168) de certains paquets.
Le récepteur des données est censé détecter ces signaux (un trou dans la séquence TCP, des RTT qui augmentent, les marques ECN) et il doit alors dire à l'émetteur de ralentir. Ce fonctionnement où seules les machines terminales agissent (les routeurs intermédiaires, à part éventuellement des marques ECN, n'ont pas grand'chose à faire, ils se contentent de router) est typique de l'Internet mais, dans certains cas, exposés dans ce RFC, il est insuffisant.
L'idée de base de ConEx est que l'émetteur mette dans les paquets IP qu'il envoie des indications sur la congestion qu'on lui a signalé. Ainsi, des équipements qui sont purement de niveau 3 sur le trajet peuvent être informés de la congestion (ECN les informe aussi mais ne concerne que les équipements en aval du point où est détectée la congestion, cf. figure 1 du RFC). Ainsi, le réseau pourra avoir une meilleure vision de la congestion, comptant les paquets qui vont rencontrer de la congestion aussi facilement qu'il compte aujourd'hui les paquets ou les octets.
Pourquoi est-ce important de connaître les paquets qui vont circuler dans des parties du réseau où il y a congestion ? Déjà, cela a une importance économique : un réseau ne coûte pas plus cher qu'il soit utilisé ou pas. Un trafic qui emprunte le réseau à un moment où celui-ci est peu chargé ne coûte donc rien à l'opérateur du réseau. Par contre, la congestion coûte cher puisqu'elle est le signe qu'il faut sortir son carnet de chèques pour mettre à jour le réseau, vers des capacités plus grandes. Ainsi, ConEx pourrait être une brique de base pour un système qui pénaliserait uniquement les flots de données qui contribuent à la congestion.
La section 2 présente en détail les concepts et la terminologie ConEx. D'abord, évidemment, la congestion. Tout le monde en parle mais il n'y a pas de définition rigoureuse et unique pour ce concept. Pour une analyse de ce terme, voir « The Evolution of Internet Congestion » de S. Bauer, S., D. Clark et W. Lehr. Dans ConEx, la congestion est définie comme la probabilité de perte de paquet (ou de marquage par ECN). Un autre effet de la congestion, le retard, n'est pas pris en compte (donc, ConEx ne mesurera pas l'effet du bufferbloat).
Deuxième concept, le volume de congestion. Il s'agit du nombre d'octets perdus suite à la congestion. L'idée est de rendre les émetteurs responsables : envoyer 10 Go sur un lien congestionné n'est pas la même chose que d'y envoyer quelques octets. Par exemple, si Alice envoie un fichier d'un Go sur un lien où la probabilité de perte est de 0,2 %, son volume de congestion est de 2 Mo. Si, plus tard dans la journée, elle envoie un fichier de 30 Go alors que la ligne, moins encombrée, ne perd plus que 0,1 % des paquets, elle ajoutera 3 Mo à son volume de congestion (donc, 5 Mo en tout). L'un des intérêts de cette métrique est qu'elle est très facilement mesurable par un routeur : il lui suffit de compter le volume total des paquets qu'il a dû jeter (ou marquer avec ECN, s'il utilise cette technique). C'est donc quasiment la même chose que les compteurs de volume actuels.
Troisième concept important, la congestion aval (Rest-of-path congestion ou downstream congestion dans la langue de Van Jacobson). C'est celle que le flot de données va supporter entre le point de mesure et sa destination (la congestion amont étant évidemment celle entre la source et le point de mesure : aujourd'hui, elle est bien plus difficile à mesurer si on n'utilise pas ECN).
La section 3 décrit ensuite le principal scénario d'usage envisagé pour ConEx. Si vous vous demandez « mais à quoi sert ce truc ? » depuis tout à l'heure, vous allez bientôt avoir une réponse. Soit un opérateur réseau qui a des clients. La plupart consomment peu mais certains sont des acharnés et font passer en permanence des gigaoctets à travers le réseau. L'opérateur voudrait que les mesures désagréables qu'il va prendre pour limiter la congestion frappent en priorité ces gros consommateurs.
Il va pour cela placer un équipement qui regarde les indications de congestion ConEx et va ensuite limiter le trafic en fonction de ces indications (en fonction du volume de congestion). (Les limitations de trafic habituelles visent le débit, pas la participation à la congestion. Or comme on l'a vu, débiter 100 Mb/s sur un réseau vide n'est pas du tout la même chose que de le débiter sur un réseau chargé. Il est donc dommage de limiter le débit dans tous les cas.) L'article « Policing Freedom to Use the Internet Resource Pool » de B. Briscoe, A. Jacquet et T. Moncaster, détaille ce mécanisme. La force de cette méthode est qu'aucune limite, aucune mesure contraignante et désagréable, n'est prise lorsqu'il n'y a pas de congestion (car, dans ce cas, l'usage du résau ne coûte rien). Avec ConEx, un bit n'est plus égal à un bit : celui envoyé pendant la congestion coûte plus cher au réseau et doit donc, d'une certaine façon, être « payé » par l'utilisateur.
Si l'opérateur est un FAI ADSL, un bon endroit pour mettre cette supervision de la congestion et cette limitation du trafic est sans doute le BRAS. (Voir le rapport du DSL Forum « Technical Report TR-059: Requirements for the Support of QoS-Enabled IP Services » mais il ne semble pas en ligne.)
Ainsi, les utilisateurs seront encouragés à utiliser des protocoles que notre RFC appelle « charognards » dans la mesure où ils n'utilisent que la capacité dont personne ne veut (le charognard a une mauvaise image de marque mais c'est bien à tort : il consomme les ressources négligées par tous les autres). Ces protocoles n'envoient du trafic que lorsque le réseau est inutilisé. Leur coût est donc à peu près nul pour l'opérateur. Le RFC 6297 décrit ces protocoles. Pour encourager leur usage, on ne peut pas seulement compter sur des exhortations citoyennes, dont l'écologie montre le peu d'efficacité. Il faut aussi des motivations plus pratiques.
Mais il existe d'autres approches, déjà, pour ce genre de gestion (ralentir les gros consommateurs, ceux qui sortent franchement du rang), non ? La section 3.3 les examine :
- On l'a vu, il est courant de limiter le débit, ou bien d'imposer un total de données transféré maximum (cette dernière technique est courante en 3G). Cette approche est très grossière car elle mène à sous-utiliser ou sur-utiliser le réseau. S'il n'y a pas de congestion, on va sous-utiliser le réseau, alors qu'il est libre (pire, on décourage l'utilisation de protocoles « charognards » puisque leur utilisateur serait pénalisé pour le volume envoyé, au lieu d'être récompensé pour le soin qu'il met à ne l'envoyer qu'en l'absence de congestion). S'il y a congestion, on risque de sur-utiliser le réseau car, tant que le quota n'est pas atteint, l'utilisateur n'a pas de raison de se gêner.
- Les techniques de fair queuing visent à égaliser le trafic entre les différents utilisateurs. Agissant en temps réel et n'ayant pas de mémoire, elles favorisent, sur le long terme, les plus gros consommateurs alors qu'on voudrait le contraire.
- Plus subtile, la technique décrite dans le RFC 6057 ne mesure le débit que lorsqu'il y a congestion et donc effectivement gêne pour le réseau. Mais, lors de la congestion, tout le trafic est compté comme y contribuant et cette technique, comme les deux précédentes, n'encourage absolument pas à utiliser les protocoles « charognards ».
- Dernière méthode possible, un examen plus ou moins poussé du paquet (allant jusqu'à la DPI) pour décider quelle est l'application utilisée, suivi d'une dégradation du service pour cette application particulière (par exemple BitTorrent). Elle est évidemment incompatible avec des techniques de sécurité comme IPsec et elle soulève de sérieuses questions politiques. ConEx, lui, est neutre par rapport à l'application utilisée.
Toutes ces solutions ont un autre défaut en commun : elles laissent l'utilisateur dans l'incertitude des performances qu'il obtiendra. Le principal intérêt des tarifs forfaitaires pour l'accès Internet (je parle des vrais forfaits, ceux où le prix est connu d'avance, pas de ce que les commerciaux menteurs de la téléphonie mobile appelent « forfait ») est la certitude : pas de mauvaises surprises au moment de l'arrivée de la facture. Mais cette certitude ne porte que sur les prix. Les performances, elles, peuvent varier, par exemple si le trafic émis était tel qu'on est désormais limité. Au contraire, avec Conex, l'utilisateur est en mesure de voir sa propre contribution à la congestion, et peut ajuster son comportement en fonction de cela. (À mon avis, c'est une vision un peu idéale, car elle suppose que le réseau n'agit sur les performances qu'en réponse aux indicateurs ConEx.)
Ce scénario d'usage de la section 3, informer l'opérateur sur la contribution des utilisateurs à la congestion, est le principal but de ConEx à l'heure actuelle. Les versions initiales de ce RFC traitaient sur un pied d'égalité plusieurs scénarios mais le groupe de travail, après bien des discussions, a décidé de prioritiser celui qui semblait le plus prometteur. Ceci dit, la section 4 présente quelques autres cas d'usage :
- Mesurer la contribution à la congestion non pas par utilisateur mais par opérateur. Comme les indicateurs ConEx sont vus par tous les routeurs intermédiaires (y compris les routeurs de bordure entre opérateurs), chaque opérateur peut savoir ce que chacun de ses voisins va lui apporter comme congestion (et réciproquement). De beaux débats sur la répartition des investissements à prévoir !
- Avoir de meilleures indications sur l'utilisation globale du réseau, pour mieux planifier l'avitaillement (provisioning) en capacité.
La section 5 se penche ensuite sur le déploiement de ConEx. Ce système ne nécessite pas un accord simultané de tous les acteurs (heureusement). ConEx est donc utile même si certains routeurs du trajet ne marquent pas et même si certains ne lisent pas l'information ConEx.
Par contre, il faut qu'au moins deux acteurs bougent : au moins un routeur doit marquer les paquets et au moins une machine doit réagir et signaler la congestion dans les paquets qu'elle émet. Les développeurs d'une application Ledbat (voir RFC 6297 et RFC 6817), par exemple, peuvent se lancer en espérant que cela motivera les routeurs pour s'y mettre.
Si certains paquets sont marqués par ConEx et d'autres non, que va faire le routeur ? Pour le déploiement de ConEx, il serait préférable que les paquets marqués soient favorisés d'une manière ou d'une autre. Mais comme la raison du marquage est leur contribution à la congestion, ce n'est pas forcément idéal... En outre, cela soulève un problème de sécurité (le marquage n'est pas authentifié et une machine peut mentir) sur lequel ce RFC 6789 est complètement muet (le problème sera traité dans les futurs RFC, plus concrets).
Comme ConEx va tripoter dans la couche 3, cœur de l'Internet, il risque de perturber le fonctionnement d'IP. Il faut donc considérer ConEx comme plutôt expérimental et la section 6 fait la liste des questions encore ouvertes, par exemple :
- ConEx est actuellement limité à IPv6, l'idée est que le délai de déploiement sera de toute façon tel qu'IPv6 sera largement dominant lorsque ConEx sera généralisé. Était-ce une bonne idée ?
- ConEx ne fait pas de différence entre l'auto-congestion (un utilisateur qui se gêne lui-même) et la congestion infligée aux autres (lorsqu'on encombre des ressources partagées). Moralement, il serait intéressant de séparer les deux mais n'est-ce pas trop complexe ?
- ConEx est plus ambitieux qu'ECN et s'appuie sur lui. Mais le déploiement d'ECN est très limité. Est-ce que ConEx sera quand même utile si le déploiement d'ECN en reste où il est maintenant ?
L'article seul
RFC 6808: Test Plan and Results Supporting Advancement of RFC 2679 on the Standards Track
Date de publication du RFC : Décembre 2012
Auteur(s) du RFC : L. Ciavattone (AT&T Labs), R. Geib (Deutsche Telekom), A. Morton (AT&T Labs), M. Wieser (Technical University Darmstadt)
Pour information
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 6 décembre 2012
Voici le premier RFC à mettre en application la démarche du RFC 6576, qui définissait la méthode pour faire avancer un RFC décrivant des métriques sur le chemin des normes. Si l'IETF avait une grande expérience dans la mesure du déploiement et de la qualité d'un protocole, c'était moins évident pour les métriques, ces grandeurs définies rigoureusement et qu'on cherche à mesurer. Le RFC 6576 ayant déblayé ce terrain, ceci est sa première application : l'étude de l'avancement de la métrique « délai d'acheminement d'un paquet », qui avait été normalisée dans le RFC 2679 et l'est désormais dans le RFC 7679.
Deux mises en œuvre différentes de ce RFC 2679 ont été testées, pour vérifier que leurs résultats, face aux mêmes données, étaient compatibles. C'est le cas et cela plaide en faveur du RFC 2679 : il était clair et non ambigu puisque deux équipes différentes l'ont implémenté de manière compatible. On n'a pas dit « identique » car les métriques permettent une certaine souplesse et, de toute façon, la mesure est un domaine délicat, avec plein de possibilités d'erreur. On ne vérifie donc pas que ces deux programmes donnent les mêmes résultats, mais que leurs résultats sont équivalents, aux erreurs acceptables près.
L'essentiel du RFC est constitué de la description de l'environnement de test, et des mesures effectuées. Les deux implémentations sont NetProbe et Perfas+. NetProbe utilise des paquets UDP de taille variable, et peut produire des distributions de paquets suivant Poisson (RFC 3432) ou bien tout simplement périodiques (RFC 2330). Perfas+, lui (développé par Deutsche Telekom), peut aussi utiliser TCP. Entre deux sites connectés via l'Internet, les expérimentateurs ont monté un tunnel L2TP (RFC 3931), afin de diminuer la variation dans les mesures (autrement, certains équipements sur le trajet auraient pu distribuer le trafic de test sur plusieurs liens, en hachant par exemple les adresses IP des engins de test).
Le trafic passait par netem, un module du noyau Linux qui permet d'ajouter des pertes ou des retards quelconques. (Par exemple, pour le premier test, netem avait été configuré pour ajouter 100 ms de retard, avec une variation uniforme de ±50 ms.)
Les auteurs notent avec honnêteté que les ports des commutateurs étaient en half-duplex, ce qui n'était ni prévu, ni souhaitable (mais ils s'en sont aperçu une fois les mesures faites).
Les tests ont été faits avec des distributions périodiques et de Poisson, des rythmes allant de 1 à 10 p/s et des tailles de 64, 340 et 500 octets, ce que le RFC 2330, section 15, nomme des « paquets standards » (ce qui exclut les fragments).
Des centaines de paquets ont ensuite été envoyés. En conformité avec le RFC 2679 (section 3.8.4), un traceroute a été effectué et ses résultats sont inclus dans le RFC (NetProbe permet de faire le traceroute depuis l'outil, en même temps que la mesure, pour pouvoir analyser a posteriori des résultats surprenants, par exemple des variations inexpliquées).
Étape indispensable (mais pas forcément folichonne) dans une campagne de mesures, l'étalonnage des erreurs est décrite dans la section 4. Par exemple, NetProbe n'utilise pas réellement comme moment d'envoi d'un paquet le wire time défini par le RFC 2330 (il se sert du moment d'acceptation du paquet UDP par le noyau, qui peut être différent si la machine est chargée). L'horloge de la machine est synchronisée avec NTP et la résolution de NTP (typiquement pas mieux qu'une milli-seconde) est également à prendre en compte comme source d'erreur (mais cela peut être amélioré par les méthodes décrites dans la section 4.1 : pour ces mesures, la stabilité de l'horloge est plus importante que sa justesse).
Toutes les sources de l'erreur, après évaluation, ont ensuite été données à R qui nous donne les divers intervalles d'erreur.
Perfas+, lui, utilise un récepteur GPS pour son horloge mais d'autres causes font que ses intervalles d'erreur sont plus larges (et donc moins bons) que ceux de NetProbe.
La section 5 explique ensuite ce que veut dire « équivalent ». En raison de la souplesse de la métrique, et des erreurs dans la mesure, on ne peut pas espérer que les deux logiciels affichent pile les mêmes résultats. On pose donc les limites tolérables, pour une comparaison faite avec Anderson-Darling. (Rappelons que le but de cette expérience n'était pas de mesurer un réseau, mais de savoir si la norme du RFC 2679 était suffisamment bien écrite et précise, et que les implémentations étaient donc équivalentes dans leurs résultats.)
Les tests et leurs résultats figurent en section 6. On note que, dans l'un des tests, un des deux programmes n'a pas réussi le test de l'équivalence avec lui-même (les variations provoquées par le réseau ont été trop grandes). À part ça, toutes les comparaisons Anderson-Darling ont réussi.
La section 7 n'a plus qu'à résumer la conclusion : c'est bon, les deux programmes utilisés sont statistiquement équivalents, ce qui semble indiquer que la norme qu'ils ont tous les deux implémentée était correctement définie. La métrique définie par le RFC 2679 mérite donc d'avancer sur le chemin des normes. Quelques erreurs mineures dans la norme ont été détectées et il est proposé qu'elles soient corrigées dans la prochaine version. (Voir les errata.)
À noter que l'avancement de la métrique sur le chemin des normes a nécessité une nouvelle version du RFC 2679, le RFC 7679.
Une description de l'utilisation de NetProbe sur le réseau d'AT&T est documentée en ligne.
L'article seul
My first Nagios plugin in Go
First publication of this article on 4 December 2012
An important feature of the Nagios monitoring system (or of its compatibles like the one I use, Icinga), is that you can easily write your own plugins, to test things that cannot be tested with the "standard" Nagios plugins. I wrote several such plugins in my life, to do tests which were useful to me. This one is the first I wrote in Go, and it tests a DNS zone by querying every name server, thus checking that all name servers are OK.
This is an important test because DNS is too
robust for monitoring: even with almost all the name servers down or
broken, the zone will work, thus leaving people with a feeling of
false security. Hence the idea of testing every name server of the
zone (monitoring typically requires that you test
differently from what the ordinary user does, to see potential
problems). The original idea comes from the
check_soa program, distributed in the famous book
"DNS and
BIND" (the code is available on line).
And why using Go? Well, Nagios plugins can be written in any language but I like Go: faster and lighter than Perl or Python but much easier to deal with than C. A good language for system and network programming.
Nagios plugins have to abide by a set of rules (in theory: in practice, many "quick & dirty" plugins skip many of the rules). Basically, the testing plugin receives standard arguments telling it what to test and with which parameters, and it spits out one line summarizing the results and, more important, exits with a status code indicating what happened (OK, Warning, Critical, Unknown).
That's one point where my plugin fails: the
standard Go library for parsing arguments (flag)
cannot do exactly what Nagios wants. For instance, Nagios wants
repeating options (-v increases the verbosity of
the output each time it appears) and they are not possible with the
standard module. So, in practice, my plugin does not conform to the
standard. Here is its use:
% /usr/local/share/nagios/libexec/check_dns_soa -h CHECK_DNS_SOA UNKNOWN: Help requested -4=false: Use IPv4 only -6=false: Use IPv6 only -H="": DNS zone name -V=false: Displays the version number of the plugin -c=1: Number of name servers broken to trigger a Critical situation -i=3: Maximum number of tests per nameserver -r=false: When using -4 or -6, requires that all servers have an address of this family -t=3: Timeout (in seconds) -v=0: Verbosity (from 0 to 3) -w=1: Number of name servers broken to trigger a Warning
The most important argument is the standard Nagios one,
-H, indicating the zone you want to test. For
instance, the TLD
.tf :
% /usr/local/share/nagios/libexec/check_dns_soa -H tf CHECK_DNS_SOA OK: Zone tf. is fine % echo $? 0
The return code show that everything was OK. You can test other, non-TLD, domains:
% /usr/local/share/nagios/libexec/check_dns_soa -H github.com CHECK_DNS_SOA OK: Zone github.com. is fine
The plugin works by sending a SOA request to
every name server of the zone and checking there is an answer, and it
is authoritative. With tcpdump, you can see its
activity (192.168.2.254 is the local DNS resolver):
# Request the list of name servers 12:00:39.954330 IP 192.168.2.4.58524 > 192.168.2.254.53: 0+ NS? github.com. (28) 12:00:39.979266 IP 192.168.2.254.53 > 192.168.2.4.58524: 0 4/0/0 NS ns2.p16.dynect.net., NS ns3.p16.dynect.net., NS ns1.p16.dynect.net., NS ns4.p16.dynect.net. (114) # Requests the IP addresses 12:00:40.063714 IP 192.168.2.4.37993 > 192.168.2.254.53: 0+ A? ns3.p16.dynect.net. (36) 12:00:40.064237 IP 192.168.2.254.53 > 192.168.2.4.37993: 0 1/0/0 A 208.78.71.16 (52) 12:00:40.067517 IP 192.168.2.4.47375 > 192.168.2.254.53: 0+ AAAA? ns3.p16.dynect.net. (36) 12:00:40.068085 IP 192.168.2.254.53 > 192.168.2.4.47375: 0 1/0/0 AAAA 2001:500:94:1::16 (64) # Queries the name servers 12:00:40.609507 IP 192.168.2.4.51344 > 208.78.71.16.53: 0 SOA? github.com. (28) 12:00:40.641900 IP 208.78.71.16.53 > 192.168.2.4.51344: 0*- 1/4/0 SOA (161) 12:00:40.648342 IP6 2a01:e35:8bd9:8bb0:ba27:ebff:feba:9094.33948 > 2001:500:94:1::16.53: 0 SOA? github.com. (28) 12:00:40.689689 IP6 2001:500:94:1::16.53 > 2a01:e35:8bd9:8bb0:ba27:ebff:feba:9094.33948: 0*- 1/4/0 SOA (161)
Then, you can configure Nagios (or Icinga, in my case), to use it:
define command {
command_name check_dns_soa
command_line /usr/local/share/nagios/libexec/check_dns_soa -H $HOSTADDRESS$ $ARG1$ $ARG2$
}
define hostgroup
hostgroup_name my-zones
members example.com,example.org,example.net
}
define service {
use generic-service
hostgroup_name my-zones
service_description CHECK_DNS_SOA
check_command check_dns_soa
}
Nagios (or Icinga) forces you to declare a host, even if it makes no sense in this case. So, my zones are declared as a special kind of hosts:
define host{
name dns-zone
use generic-host
check_command check-always-up
register 0
# Other options, quite ordinary
}
define host{
use dns-zone
host_name example.com
}
Nagios wants a command to check that the "host" is up (otherwise, the
"host" stays in the "pending" state for ever). That's why we
provide check-always-up which is defined as
always true:
define command{
command_name check-always-up
command_line /bin/true
}
With this configuration, it works fine and you can see nice trends
of 100 % uptime if everything is properly configured and
connected. And if it's not? Then, the plugin will report the zone as
Warning or Critical (depending on the options you used, see
-c and -w) :
% /usr/local/share/nagios/libexec/check_dns_soa -H ml CHECK_DNS_SOA CRITICAL: Cannot get SOA from ciwara.sotelma.ml./217.64.97.50: read udp 192.168.2.4:40836: i/o timeout % echo $? 2
If you are more lenient and accept two broken name servers before
setting the status as Critical, use -c 3 and
you'll just get a Warning:
% /usr/local/share/nagios/libexec/check_dns_soa -v 3 -c 3 -H ml CHECK_DNS_SOA WARNING: Cannot get SOA from ciwara.sotelma.ml./217.64.97.50: read udp 192.168.2.4:35810: i/o timeout 217.64.100.112 (SERVFAIL) % echo $? 1
This plugin is hosted at
FramaGit, where you can retrieve the code, report bugs, etc. To
compile it, see the README. You'll need the
excellent Go DNS
library first (a good way to make DNS requests from Go).
Two implementation notes: the plugin does not use one of the Go's greatest strengths, its built-in parallelism, thanks to "goroutines". This is because making it parallel would certainly decrease the wall-clock time to run the tests but, for an unattended program like Nagios, it is not so important (it would be different for an interactive program). And, second, there is a library to write Nagios plugins in Go but I did not use it because of several limitations (and I do not use performance data, where this library could be handy). Note also that other people are using Go with Nagios in a different way.
Thanks to Miek Gieben for his reading and patching.
L'article seul
Limiter le nombre de requêtes sur des scripts WSGI
Première rédaction de cet article le 3 décembre 2012
Le standard WSGI permet de développer facilement des scripts en Python pour réaliser un service accessible via le Web. Ces services nécessitent souvent pas mal de traitement côté serveur et risquent donc de faire souffrir celui-là si un client maladroit appelle le service en boucle (ou, pire, si un client méchant essaye délibérement de planter le serveur en lançant plein de requêtes). Il est donc souhaitable de limiter le nombre de requêtes.
Voici la technique que j'utilise (il y en a plein d'autres, avec Netfilter, ou avec Apache). On crée un
seau qui fuit (dans le fichier LeakyBucket.py). Chaque requête en provenance d'une
adresse IP donnée ajoute une unité dans le seau. Le temps
qui passe vide le seau. Lorsqu'une requête arrive, on vérifie si le seau
est plein et on refuse la requête autrement. Cela nécessite une entrée
par client dans la table des seaux (chaque client a un seau
différent). Avec le LeakyBucket.py, cela donne :
if buckets[ip_client].full():
# Refus
else:
buckets[ip_client].add(1)
En pratique, on va regrouper les adresses IP des clients en préfixes IP, de manière à limiter le nombre de seaux et à éviter qu'un attaquant ne disposant d'un préfixe contenant beaucoup de machines ne puisse éviter la limitation en lançant simplement beaucoup d'adresses IP différentes à l'attaque. De manière assez arbitraire, on a mis 28 bits pour IPv4 et 64 pour IPv6. Pour faire les calculs sur les adresses IP, on se sert de l'excellent module Python netaddr :
ip_client = netaddr.IPAddress(environ['REMOTE_ADDR'])
if ip_client.version == 4:
ip_prefix = netaddr.IPNetwork(environ['REMOTE_ADDR'] + "/28")
elif ip_client.version == 6:
ip_prefix = netaddr.IPNetwork(environ['REMOTE_ADDR'] + "/64")
# Et on continue comme avant :
if buckets[ip_prefix.cidr].full():
...
Et comment se manifeste le refus ? On renvoie le code HTTP 429, Too Many Requests, normalisé par le RFC 6585. En WSGI :
status = '429 Too many requests'
output = "%s sent too many requests" % environ['REMOTE_ADDR']
response_headers = [('Content-type', 'text/plain'),
('Content-Length', str(len(output)))]
start_response(status, response_headers)
return [output]
Cela donne quoi en pratique ? Testons avec curl :
% for i in $(seq 1 50); do
curl --silent --output /dev/null \
--write-out "$i HTTP status: %{http_code} ; %{size_download} bytes downloaded\n" \
https://www.bortzmeyer.org/apps/counter
done
1 HTTP status: 200 ; 278 bytes downloaded
2 HTTP status: 200 ; 278 bytes downloaded
3 HTTP status: 200 ; 278 bytes downloaded
4 HTTP status: 200 ; 278 bytes downloaded
5 HTTP status: 200 ; 278 bytes downloaded
6 HTTP status: 200 ; 278 bytes downloaded
7 HTTP status: 200 ; 278 bytes downloaded
8 HTTP status: 200 ; 278 bytes downloaded
9 HTTP status: 200 ; 278 bytes downloaded
10 HTTP status: 200 ; 278 bytes downloaded
11 HTTP status: 429 ; 36 bytes downloaded
12 HTTP status: 429 ; 36 bytes downloaded
13 HTTP status: 200 ; 278 bytes downloaded
14 HTTP status: 200 ; 278 bytes downloaded
15 HTTP status: 429 ; 36 bytes downloaded
16 HTTP status: 429 ; 36 bytes downloaded
...
On voit bien l'acceptation initiale, puis le rejet une fois le nombre
maximal de requêtes fait, puis à nouveau l'acceptation lorsque le
temps a passé. Attention en configurant la taille du seau
(default_bucket_size dans LeakyBucket.py) : il y a plusieurs
démons WSGI qui tournent et le nombre de
requêtes acceptées est donc la taille du seau multipliée par le nombre
de démons.
Comme souvent avec les mesures de sécurité, elles peuvent avoir des effets secondaires, parfois graves. Ici, le serveur alloue une table indexée par le nombre de préfixes IP. Si un attaquant méchant peut envoyer des paquets depuis d'innombrables adresses IP usurpées (c'est non trivial en TCP), il peut vous faire allouer de la mémoire en quantité impressionnante.
Si vous voulez les fichiers authentiques et complets, voir les
fichiers de ce blog (fichiers
wsgis/LeakyBucket.py et wsgis/dispatcher.py).
Merci à David Larlet pour l'amélioration du code.
L'article seul
Quelles informations envoie réellement votre navigateur Web ?
Première rédaction de cet article le 1 décembre 2012
Supposons que vous soyiez un développeur Web qui veut savoir quelles sont les informations que le serveur distant récupère de son navigateur, afin d'améliorer une application. Ou que vous soyiez simplement un curieux qui veut connaître ce qui se passe sur le réseau. Bien sûr, vous pouvez toujours demander au navigateur d'afficher cette information (par exemple avec l'extension Live HTTP Headers de Firefox). Ou vous pouvez utiliser un programme d'espionnage du réseau comme Wireshark. Mais ils ne vous donnent qu'une vision locale, ce qu'envoie le client. Si la requête est modifiée en route (routeur NAT, relais HTTP), ce que verra le serveur n'est pas forcément ce que le client aura envoyé. D'où l'intérêt des sites Web qui affichent cette information.
J'en connais trois qui permettent de retourner les données vues par le serveur sous une forme structurée, analysable par un programme (tous les trois font du JSON, cf. RFC 8259). Mais, si vous en trouvez d'autres, je suis preneur :
http://httpbin.org/est le plus riche en fonctions (possibilité de n'envoyer qu'une partie des données, possibilité d'introduire un retard artificiel, etc). Mais il ne marche qu'en IPv4.http://echohttp.com/, lui, fonctionne en IPv6.- Et j'ai réalisé un tel service,
https://www.bortzmeyer.org/apps/http, fait en WSGI. Contrairement aux précédents, son source (il est vrai que c'est assez trivial) est disponible (danswsgis/dispatcher.pydans l'archive des fichiers de ce blog). Il semble être le seul à afficher le nom correspondant à l'adresse IP du client (oui, vous pourriez faire un dig vous-même mais, dans certains cas, la résolution d'adresse en nom ne donne pas le même résultat de partout). Ce nom est dans le champorigin_name(s'il existe : toutes les adresses IP ne pointent pas vers un nom).
Voici des exemples d'utilisation avec curl, montrant le JSON produit :
% curl http://httpbin.org/get
{
"url": "http://httpbin.org/get",
"headers": {
"Content-Length": "",
"Connection": "keep-alive",
"Accept": "*/*",
"User-Agent": "curl/7.21.0 (i486-pc-linux-gnu) libcurl/7.21.0 OpenSSL/0.9.8o zlib/1.2.3.4 libidn/1.15 libssh2/1.2.6",
"Host": "httpbin.org",
"Content-Type": ""
},
"args": {},
"origin": "192.0.2.187"
}
% curl http://echohttp.com/echo
{
"version" : "HTTP/1.0",
"method" : "GET",
"path" : "/echo",
"decode_path" : {
"path" : "/echo",
"query_string" : "",
"qs" : {
},
"path_info" : [
]
},
"headers" : {
"Accept" : "*/*",
"User-Agent" : "curl/7.21.0 (i486-pc-linux-gnu) libcurl/7.21.0 OpenSSL/0.9.8o zlib/1.2.3.4 libidn/1.15 libssh2/1.2.6",
"Connection" : "close",
"X-Forwarded-For" : "2001:db8:8bd9:8bb0:da:8aa3:5f22:df56",
"X-Real-Ip" : "2001:db8:8bd9:8bb0:da:8aa3:5f22:df56",
"Host" : "echohttp.com"
},
"body" : "",
"json" : {
},
"form" : {
}
}
% curl https://www.bortzmeyer.org/apps/http
{
"origin": "2001:db8:8bd9:8bb0:da:8aa3:5f22:df56",
"headers": {
"HOST": "www.bortzmeyer.org",
"USER_AGENT": "curl/7.21.0 (i486-pc-linux-gnu) libcurl/7.21.0 OpenSSL/0.9.8o zlib/1.2.3.4 libidn/1.15 libssh2/1.2.6",
"ACCEPT": "*/*"
},
"method": "GET",
"origin_name": "test.bortzmeyer.org"
}
Bien sûr, votre navigateur Web envoie d'autres informations, par exemple par les cookies. (Une excellente application pratique de ces informations, pour montrer la facilité à repérer un utiisateur unique, est le Panopticlick.) Mais on s'est limité ici aux informations strictement HTTP.
L'article seul
RFC 6815: RFC 2544 Applicability Statement: Use on Production Networks Considered Harmful
Date de publication du RFC : Novembre 2012
Auteur(s) du RFC : S. Bradner (Harvard University), K. Dubray (Juniper Networks), J. McQuaid (Turnip Video), A. Morton (AT&T Labs)
Pour information
Réalisé dans le cadre du groupe de travail IETF bmwg
Première rédaction de cet article le 1 décembre 2012
Lors de la publication du RFC 2544, sur les tests de performances des équipements réseau, un point n'avait pas été mis assez clairement : comme tous les RFC du BMWG, le RFC 2544 ne concerne que les tests en laboratoire, dans des conditions bien contrôlées, et sans avoir peur de gêner un réseau de production. Comme certains avaient apparemment raté cette limitation, notre RFC 6815 enfonce le clou : ne faites pas les tests du RFC 2544 sur un vrai réseau !
Ce point est clairement précisé dans la charte du groupe de travail BMWG (Benchmarking Methodology Working Group). Les tests produits par ce groupe sont conçus pour des réseaux isolés (section 3 : un réseau isolé est un réseau dont le trafic de test ne sort pas et où le trafic non lié au test ne rentre pas). Il n'est pas prévu de les utiliser pour, par exemple, vérifier des SLA sur un réseau de production.
Mais pourquoi est-ce mal d'utiliser les tests BMWG sur un réseau de production ? La section 4 donne les deux raisons :
- Dans l'intérêt du test, il ne faut pas que le trafic de test soit mêlé à du trafic sans lien avec le test, si on veut que les résultats soient précis et reproductibles.
- Dans l'intérêt du réseau de production, il ne faut pas que le trafic de test (qui peut être intense, voir par exemple les tests de la capacité du réseau, qui fonctionnent en essayant de faire passer le plus de données possible) puisse rentrer en concurrence avec le trafic des vrais utilisateurs.
C'est d'ailleurs pour faciliter l'isolation et garder le trafic de
test à part qu'il existe des plages d'adresses IP dédiées aux tests, le
198.18.0.0/24 (RFC 2544,
annexe C.2.2) et le
2001:2::/48 (RFC 5180, section 8 mais notez que ce RFC comporte une grosse erreur). On peut ainsi
facilement filtrer ces plages sur ses routeurs
et pare-feux, pour empêcher du trafic de test
de fuir accidentellement.
Et si on veut quand même faire des mesures sur des réseaux de production ? Il faut alors se tourner vers un autre jeu de tests, ceux développés par le groupe de travail IPPM. Notez que cela n'est pas par hasard que cet autre jeu ne comporte pas de méthode pour la mesure de la capacité (RFC 5136) : une telle mesure perturbe forcément le réseau mesuré.
L'article seul
RFC 6814: Formally Deprecating some IPv4 Options
Date de publication du RFC : Novembre 2012
Auteur(s) du RFC : C. Pignataro (Cisco Systems), F. Gont (UTN-FRH / SI6 Networks)
Chemin des normes
Première rédaction de cet article le 29 novembre 2012
Ce très court RFC est purement administratif et n'aura pas de conséquences pratiques : il note simplement comme officiellement abandonnées neuf des options d'IPv4.
IPv4 (RFC 791, section 3.1) prévoit l'ajout d'options dans l'en-tête d'un paquet (en pratique, elles sont peu utilisées). Parmi les options enregistrées, certaines n'avaient jamais été déployées, ou bien était tombées en désuétude depuis longtemps. Lire ce RFC, c'est donc fouiller le grenier et retrouver des trucs que tout le monde croyait perdus... Le registre des options IP est mis à jour pour que ces options soient formellement retirées (et le RFC correspondant marqué comme « intérêt historique uniquement »). Ce sont :
- Stream ID (RFC 791), déjà marquée comme inutile par les RFC 1122 et RFC 1812. Elle servait à la compatibilité avec le défunt réseau SATNET, tellement oublié que même Wikipédia n'en parle pas.
- Extended Internet Protocol (RFC 1385), une tentative pour prolonger la vie d'IPv4 en attendant IPv6.
- Traceroute (RFC 1393), qui aurait permis (si elle avait été déployée, mais elle nécessitait de modifier tous les routeurs) de faire des traceroute plus économiques (cette option demandait au routeur de renvoyer un paquet d'information à la source).
- Encode, qui avait un rapport avec le chiffrement mais qui ne semble pas avoir eu de RFC.
- VISA, une expérience à l'USC qui n'est jamais allé loin.
- Address Extension (RFC 1475), un autre essai de l'époque où l'IETF cherchait un successeur à IPv4. Cette technique, TP/IX: The Next Internet, avait reçu le numéro 7 et aurait donc été IPv7 si elle avait réussi.
- Selective Directed Broadcast (RFC 1770), un projet de l'armée qui ne semble pas avoir été utilisé.
- Dynamic Packet State, une partie de DiffServ, qui n'est jamais devenue un RFC.
- Upstream Multicast Packet, un truc pour le multicast, jamais décrit dans un RFC, officiellement abandonné par le RFC 5015.
D'autres options, MTU Probe et MTU Reply, avaient déjà été « nettoyées » par le RFC 1191.
L'article seul
RFC 6770: Use Cases for Content Delivery Network Interconnection
Date de publication du RFC : Novembre 2012
Auteur(s) du RFC : G. Bertrand (France Telecom -
Orange), E. Stephan (France Telecom -
Orange), T. Burbridge, P. Eardley
(BT), K. Ma (Azuki Systems), G. Watson (Alcatel-Lucent - Velocix)
Pour information
Réalisé dans le cadre du groupe de travail IETF cdni
Première rédaction de cet article le 20 novembre 2012
Le groupe de travail CDNI de l'IETF travaille à normaliser les interfaces entre CDN pour permettre à deux de ces systèmes de distribution de contenu de coopérer pour servir un client. Ce second RFC du groupe (le premier, le RFC 6707, décrivait en détail le problème à résoudre et l'état de l'art) rassemble trois études de cas, illustrant ainsi par ces scénarios l'utilité du travail du groupe.
Un ancien effort de normalisation des CDN à l'IETF avait eu lieu, produisant des documents comme le RFC 3570, qui décrivait déjà des scénarios d'usage. Ce nouveau RFC remplace ce RFC 3570 ; la terminologie est notamment très différente et reprend celle du RFC 6707. Conjointement avec ce RFC 6707, il va servir de base au document « cahier des charges » du groupe de travail CDNI, qui sera publié en RFC 7337.
Interconnecter des CDN offre en théorie de nombreux avantages : améliorer le vécu de l'utilisateur (temps de réponse plus courts, voir le RFC 6390) et diminuer les coûts pour l'opérateur (on n'utilise que le réseau interne au lieu des lignes extérieures) notamment. Mais, actuellement, chaque CDN fonctionne de manière indépendante des autres, ce qui fait qu'il n'est pas toujours possible de récolter ces bénéfices. Voyons les trois études de cas.
D'abord (section 2), le cas d'un CDN qui a une couverture géographique insuffisante. Un opérateur de CDN est présent dans une région donnée (mettons l'Europe) mais ne peut pas fournir de service aux lecteurs en Asie ou en Amérique. Et imaginons un autre opérateur de CDN en Amérique qui n'a pas de présence en Europe. Les interconnecter permettrait au nouvel ensemble de servir les deux continents, sans que chaque opérateur n'ait eu à supporter d'énormes investissements.
Un autre cas proche est celui où un FAI a construit un CDN en interne pour distribuer du contenu dont il a les droits. Un autre fournisseur de contenu a déjà un contrat avec un autre opérateur de CDN. Dans ce cas, le FAI va recevoir un gros trafic de la part de ce CDN, qui va saturer ses liaisons externes, alors que ce contenu pourrait être distribué plus efficacement par le CDN du FAI. Pour le FAI en question, il serait utile que cet autre CDN puisse s'interconnecter avec le CDN du FAI (section 2.3), afin d'améliorer les performances et de décongestionner les liens d'interconnexion.
Deuxième étude de cas (section 3), celle où le CDN a une couverture géographique jugée suffisante mais des capacités trop petites pour la charge. Cela peut être à cause d'une énorme augmentation temporaire de la demande (effet Slashdot, dit aussi flash crowd) par exemple suite à un événement particulier. Cet événement peut être prévu - match de football à diffuser - ou imprévu. (Le RFC cite l'exemple de la vidéodiffusion du mariage d'une célébrité ; il est triste de penser que des technologies si sophistiquées servent à de telles conneries.) Le CDN menace alors de s'écrouler sous la charge. Appelons un autre CDN à son secours ! L'idée est que le gestionnaire du CDN trop petit va payer un autre CDN, s'interconnecter à lui, et que les deux CDN feront face ensemble à la charge. (Une autre solution serait d'agrandir le CDN, mais, avec l'interconnexion des CDN, on peut prendre des marges de dimensionnement moins importantes, sans pour autant perdre sa capacité de faire face à d'éventuels pics de trafic.)
Une variante de ce cas est la résilience en cas de problème, par exemple une attaque par déni de service ou une panne massive d'une partie d'un CDN (section 3.2). S'interconnecter à un autre CDN permet alors de continuer à fonctionner. Actuellement, chaque CDN doit se débrouiller seul en cas de panne.
Dernière étude de cas (section 4), celui où le CDN n'a, ni problème de couverture géographique, ni problème de capacité, mais un problème de fonctions : le client a des exigences techniques particulières que le CDN ne sait pas remplir. Par exemple, un CDN sert du contenu en HTTP mais un client réclame qu'une partie du contenu soit servie en HTTPS (qui, entre autres, nécessite des processeurs plus rapides, pour les calculs cryptographiques) qu'il ne sait pas faire. S'allier avec un CDN qui, lui, sait faire du HTTPS, permettrait de rendre le client heureux (en lui évitant de signer deux contrats). Autre exemple donné par le RFC (mais peu convaincant depuis l'échec ridicule de WAP), celui d'un client qui demanderait tout à coup un protocole de distribution qui soit spécifique aux engins mobiles, alors que le CDN habituel de ce client n'a pas mis en œuvre ce protocole.
Et, bien sûr, exemple évident, un CDN qui serait toujours, en 2012, uniquement en IPv4 et à qui des clients réclameraient qu'il utilise enfin un protocole de ce siècle, IPv6. Sous-traiter la distribution en IPv6, par le biais des protocoles d'interconnexion que concevra le groupe de travail CDNI, permettrait au CDN IPv4 d'attendre encore un peu.
Plus subtil, le cas où le CDN peut distribuer le contenu avec le protocole demandé, mais pas avec les exigences quantitatives du client (par exemple portant sur la latence). S'associer avec un autre CDN, meilleur de ce point de vue, peut être utile.
Dans ces trois cas, si on pouvait facilement interconnecter des CDN, tout irait bien et les oiseaux chanteraient plus mélodieusement. Mais, à l'heure actuelle, une telle interconnexion se heurte à l'absence totale de normes techniques (cf. RFC 6707). Chaque fois que deux CDN s'interconnectent, ils doivent développer du code spécifique à ce couple. C'est justement le travail du groupe CDNI que de spécifier ces normes techniques, en attendant leur futur développement et déploiement. Une fois que cela sera fait, l'interconnexion de deux CDN ne sera plus « que » une affaire de business... (Comme l'accord Orange/Akamai annoncé le même jour que le RFC...)
Ah, un petit point à ne pas oublier (section 5), l'application de politiques de distribution restrictives. C'est une demande courante des clients (distribuer une vidéo en Amérique du Nord seulement, par exemple, et donc barrer l'accès aux visiteurs d'autres régions, ou bien ne permettre l'accès gratuit que pendant 24 h). Cela ajoute une contrainte assez ennuyeuse à l'interconnexion de CDN : il faut aussi transmettre ces restrictions. L'annexe A.1 traite en détail ce problème.
Dernier problème lors de l'interconnexion, la marque (branding), vue en annexe A.3. Un CDN qui fait appel à un autre pour traiter une partie de son travail peut souhaiter que sa marque apparaisse quand même (par exemple, URL avec son nom de domaine). La solution d'interconnexion doit donc penser à fournir une solution à ce problème.
Merci à Gilles Bertrand pour sa relecture.
L'article seul
RFC 6797: HTTP Strict Transport Security (HSTS)
Date de publication du RFC : Novembre 2012
Auteur(s) du RFC : J. Hodges (PayPal), C. Jackson (Carnegie Mellon University), A. Barth (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF websec
Première rédaction de cet article le 20 novembre 2012
La technique HSTS (HTTP Strict Transport Security), normalisée dans ce RFC (mais déjà largement déployée) vise à résoudre une attaque contre TLS. Si un site Web est accessible en HTTPS, et qu'un méchant arrive à convaincre un utilisateur de se connecter en HTTP ordinaire à la place, le méchant peut alors monter une attaque de l'homme du milieu. Le fait que le site soit protégé par TLS n'aidera pas dans ce cas. Pour éviter cette attaque, HSTS permet à un site de déclarer qu'il n'est accessible qu'en HTTPS. Si l'utilisateur a visité le site ne serait-ce qu'une fois, son navigateur se souviendra de cette déclaration et ne fera plus ensuite de connexions non sécurisées.
Bien sûr, il n'y aurait pas de problème si l'utilisateur utilisait
systématiquement des URL
https://.... Mais les erreurs ou les oublis
peuvent arriver, l'utilisateur peut cliquer sur un lien
http://... dans un spam,
il peut être victime d'une page Web certes sécurisée mais qui contient
des images chargées via un URL http://.... Bref,
il y a encore trop de risques. D'où l'idée
d'épingler la politique de sécurité du site Web
dans le navigateur, en permettant à un site de déclarer au navigateur
« je suis sécurisé, ne reviens jamais me voir en
HTTP ordinaire » et de compter sur le fait que le navigateur
respectera automatiquement cette politique, et s'en souviendra. Cette déclaration se fera
par l'en-tête HTTP Strict-Transport-Security:, par
exemple Strict-Transport-Security: max-age=7905600.
TLS est normalisé dans le RFC 5246. (Son prédécesseur, SSL, est
dans le RFC 6101.) L'utilisation de HTTP au dessus de TLS
(HTTPS) est décrite dans le RFC 2818. Un navigateur Web va typiquement
appliquer des politiques de sécurité différentes selon que la
connexion se fait en HTTP ou en HTTPS. Un exemple typique est fourni
par les cookies du RFC 6265 : s'ils ont été envoyés par le serveur avec
l'attribut Secure, ils ne seront retransmis par
le navigateur que si la connexion est en HTTPS.
Pour vérifier l'identité du serveur en face, les navigateurs valident les certificats présentés par le serveur. Si cette vérification échoue (c'est en général suite à une erreur de l'administrateur du serveur, mais cela est parfois dû à une attaque d'un intermédiaire), le navigateur affiche typiquement un avertissement à l'utilisateur, en lui permettant de continuer de manière non sûre s'il le souhaite (cette possibilité est « officialisée » par la section 3.1 du RFC 2818). Ce mécanisme de click-through security, que le navigateur rend plus ou moins facile, est très critiqué : comme l'utilisateur veut avant tout continuer sa tâche, il va toujours chercher à passer outre l'avertissement de sécurité. C'est même une attitude raisonnable, compte tenu du fait que la plupart des erreurs d'authentification avec TLS ne sont pas des attaques, et aussi compte tenu de la difficulté, même pour un expert, d'analyser ces problèmes et de comprendre ce qui s'est passé. Deux bons articles sur les questions d'interface utilisateur liées à ce problème de sécurité sont « Crying Wolf: An Empirical Study of SSL Warning Effectiveness » de Sunshine, J., Egelman, S., Almuhimedi, H., Atri, N., et L. Cranor, puis « Stopping Spyware at the Gate: A User Study of Privacy, Notice and Spyware » de Good, N., Dhamija, R., Grossklags, J., Thaw, D., Aronowitz, S., Mulligan, D., et J. Konstan. Mais d'autres articles, non cités par ce RFC, prennent un point de vue différent, expliquant qu'ignorer les avertissements de sécurité peut être une attitude rationnelle.
Pour éviter ces risques, l'article de C. Jackson et A. Barth (deux des auteurs du RFC), « ForceHTTPS: Protecting High-Security Web Sites from Network Attacks » proposait une approche où le site Web disait à ses clients qu'ils devaient utiliser HTTPS pour se connecter. Ce RFC utilise une technique différente de celle de l'article mais l'idée est la même.
La section 2 décrit en détail le problème de sécurité. Si vous êtes plutôt intéressé par la solution, il faut sauter à la section 5. Sinon, si on continue dans l'ordre, une analyse des menaces. HSTS gère trois menaces :
- Les attaques passives. Ce sont celles où l'attaquant ne fait qu'écouter. Par exemple, sur un réseau WiFi typique, écouter est possible, que le réseau soit sécurisé ou pas (« Practical Attacks Against WEP and WPA » de Beck, M. et E. Tews). Il existe même des outils tous faits pour cela comme Aircrack L'attaquant peut alors intercepter des mots de passe, des cookies, etc. Une extension Firefox spectaculaire, Firesheep, permet d'automatiser cette tâche et de se retrouver rapidement connecté au compte Facebook de ses voisins de Starbucks. HTTPS empêche complètement ces attaques passives s'il est utilisé. Par exemple, si un site est accessible normalement à la fois en HTTP et en HTTPS, il suffit d'une seule requête HTTP, faite par accident ou oubli, et les cookies peuvent être copiés.
- Plus sophistiqué est l'attaquant actif. Il peut agir sur le DNS, ou sur le routage ou tout simplement installer un point d'accès WiFi pirate, ayant le même SSID que le vrai. Il risque plus d'être détecté mais il a ainsi des possibilités bien plus grandes. Notons que l'attaquant actif peut être un État (l'Iran s'en est fait une spécialité) et que, dans ce cas, l'attaque est bien plus facile pour lui, car il contrôle toutes les liaisons du pays. Cette fois, contre ces attaquants actifs, juste faire tourner HTTP sur TLS ne suffit plus : il faut aussi authentifier le serveur distant. Les certificats auto-signés (ou signés par une AC qui n'est pas connue du navigateur) sont dangereux car ils ne protègent pas du tout contre les attaquants actifs. Si l'on accepte les sites présentant un certificat auto-signé (ce que permettent tous les navigateurs, après un sermon sur la sécurité et l'obligation de cliquer sur un lien « je sais ce que je fais »), c'est comme si on n'utilisait pas TLS du tout puisqu'on n'est pas sûr de parler au bon site. (Une protection minimale peut être fournie par des outils comme Certificate Patrol.)
- Mais il n'y a pas que les attaquants actifs et passifs qui peuvent compromettre la sécurité de HTTP. Il y a aussi les bogues dans les sites Web. Par exemple, si une page a un contenu en Flash, et que ce contenu est chargé via une connexion non sécurisée, l'attaquant passif pourra lire les cookies et l'attaquant actif pourra remplacer le Flash par un autre code, qui fera des tas de choses vilaines chez le client. (Dans une certaine mesure, c'est également faisable avec JavaScript ou même une CSS.) Une protection contre cela est le refus, par le navigateur, de charger du « contenu de contextes de sécurité différents » (page HTML chargée en HTTPS et Flash chargé en HTTP) mais tous ne le font pas (cf. section 12.4), et beaucoup se contentent d'un avertissement qui peut facilement passer inaperçu. (À noter que ce contenu de contextes de sécurité différents est souvent appelé « contenu mixte » mais notre RFC déconseille ce terme, qui a un sens bien précis - et différent - en XML.)
Une analyse de sécurité sérieuse doit indiquer quelles sont les menaces traitées mais aussi celles qu'on ne prétend pas traiter. La section 2.3.2 liste les « non-buts » de HSTS :
- Le hameçonnage, où un utilisateur va
donner à un site Web, authentifié et utilisant HTTPS, mais pas digne
de confiance, des informations secrètes. HSTS vous protège si vous
essayez d'aller sur
https://www.mybank.example/et qu'un attaquant tente de vous détourner. Mais il ne peut rien faire si, suite à un spam, vous visitezhttps://s6712.example.net/php/mybank.example... - Les failles de sécurité dans le navigateur : HSTS ne protège que si le navigateur est fiable.
Maintenant, place à la solution. L'effet de l'épinglage HSTS sera double :
- Le client HTTP remplacera tous les URL
http://...par deshttps://...avant de se connecter. - Toute erreur de validation sera fatale, sans rémission possible.
Bref, avant de déclarer en HSTS qu'on ne doit être contacté que de manière sécurisée, il faut être sûr de soi...
La section 5 du RFC expose la solution. Comme indiqué plus haut, un
serveur HTTPS qui veut être sûr de n'être accédé qu'en HTTPS le
déclare en envoyant un en-tête
Strict-Transport-Security: (en-tête désormais
dans le registre des en-têtes). Évidemment, cet
en-tête ne sera utilisé que si la session était sécurisée avec HTTPS
(envoyé sur de l'HTTP ordinaire, il sera ignoré). La
politique HSTS du site comprend une durée de vie
maximale de l'information, et le choix d'inclure ou pas les
sous-domaines. Pour la durée de vie, cela se fait avec une valeur
max-age en secondes. Le navigateur pourra se
souvenir, pendant ce temps, que le site ne doit être accédé qu'en
HTTPS. Après, il pourra redemander (cela permet éventuellement de ne
plus avoir HSTS, si l'on veut se remettre à autoriser HTTP).
Pour les sous-domaines, c'est fait avec
une directive includeSubDomains.
La section 6 va davantage dans les détails en couvrant la syntaxe
exacte de cet en-tête. Par exemple, un max-age de
zéro spécifie que le client HTTP doit tout de suite oublier les choix
HSTS : cela revient à dire « j'arrête d'exiger HTTPS ».
Plusieurs sites Web aujourd'hui utilisent déjà HSTS. Par exemple, Gmail annonce une politique d'une durée d'un mois :
Strict-Transport-Security: max-age=2592000; includeSubDomains
Et l'EFF (qui n'utilise pas l'option
includeSubDomains mais a presque la même durée de vie) :
Strict-Transport-Security: max-age=2628000
On l'a vu, la syntaxe est simple. Les sections suivantes portent sur une
question plus complexe, le comportement des logiciels lorsqu'ils
rencontrent cette option. D'abord, le serveur (section 7). S'il veut
utiliser HSTS, il met cette option dans la réponse, si elle est
protégée par TLS. Sinon (HTTP ordinaire), le serveur ne doit pas
mettre l'en-tête HSTS et le RFC recommande une redirection (code HTTP
301, par exemple) vers un URL https://. Notons
que c'est risqué : un attaquant actif peut aussi faire des
redirections, si la requête était en HTTP. Voir l'excellente
« Transport
Layer Protection Cheat Sheet » de Coates, M., Wichers, d., Boberski, M., et T. Reguly.
Et le client HTTP (typiquement un navigateur Web) ? La section 8 lui donne des instructions : si on reçoit l'en-tête HSTS sur une session HTTP ordinaire, l'ignorer (cela peut être une blague, puisque la session n'est pas authentifiée), si on le reçoit sur HTTPS, enregistrer cette information (avec la durée de vie associée). Puis, à la prochaine visite de ce serveur (les règles exactes sont un peu plus compliquées, avec les sous-domaines, et les IDN) :
- Ne se connecter qu'en HTTPS (si le navigateur reçoit, par frappe
de l'utilisateur, ou dans une page HTML, un URL
http://..., le réécrire automatiquement enhttps://...). - N'accepter aucune erreur d'authentification (pas de dialogue « voulez-vous quand même continuer même si le certificat X.509 est pourri ? »). Si un serveur met cet en-tête, c'est que son administrateur sait ce qu'il fait et qu'il s'engage à gérer son serveur correctement (pas de certificat expiré, par exemple, cf. l'exemple à la fin).
À noter que l'en-tête HSTS doit être envoyé via le protocole réseau, pas via le contenu du document : le truc HTML <meta
http-equiv="Strict-Transport-Security" ...> est
explicitement interdit.
Les sections 11 et 12 donnent des avis aux programmeurs sur la bonne façon de mettre en œuvre ce système de sécurité. D'abord, les serveurs (section 11). Le RFC leur rappelle que le serveur ne peut pas savoir si son client respecte l'en-tête qu'on lui envoie. On ne peut donc pas compter uniquement sur HSTS pour traiter les menaces décrites en section 2.
Ensuite, le choix de la durée de vie (via l'attribut
max-age). Il y a deux approches : une durée
constante ou bien un max-age calculé à chaque
fois pour correspondre à une date d'expiration choisie. La première
est évidemment plus facile à mettre en œuvre (sur
Apache, un Header set
Strict-Transport-Security "max-age=604800" dans la
configuration ou bien dans un .htaccess
suffit). La seconde nécessite un calcul dynamique mais a l'avantage de
pouvoir faire correspondre la date d'expiration de HSTS avec une autre
date importante (le RFC suggère celle d'expiration du certificat
X.509 ; si on ne renouvelle pas le certificat, c'est une bonne chose
si HSTS cesse également).
Le RFC met aussi en garde contre les certificats auto-signés ou
bien signés par une AC non connue de certains navigateurs (comme CAcert). HSTS interdisant formellement de passer
outre un problème X.509 (pas de formulaire « voulez-vous continuer
bien que je ne connaisse pas cette AC ? »), si on active HSTS en
envoyant l'en-tête Strict-Transport-Security:, et qu'il est accepté,
on risque, si on change ensuite de certificat, d'être injoignable par tous les clients (cas où on est passé à un certificat
auto-signé) ou par une partie d'entre eux (cas où est est passé à une AC peu
connue). Rappelez-vous que HSTS est une déclaration « je suis un
parano expert en crypto et je ne ferai jamais d'erreur, n'utilisez que
HTTPS ». Réflechissez donc bien avant de l'activer.
Autre piège pour l'administrateur d'un serveur HTTPS, le cas du
includeSubDomains. Si on l'utilise, on peut
bloquer tout sous-domaine qui ne serait pas accessible en HTTPS. Si
vous gérez le domaine d'une grande entreprise, mettons
example.com, et que vous mettez un
Strict-Transport-Security: max-age=15768000 ;
includeSubDomains, alors le petit site Web que vous aviez
oublié, http://service.department.example.com/appli, qui
n'était accessible qu'en HTTP, deviendra inutilisable pour tous ceux
qui utilisent HSTS. Soyez donc sûr de vos sous-domaines avant
d'activer cette option. (Le RFC cite l'exemple d'une
AC ca.example qui veut permettre l'accès à
OCSP en HTTP ordinaire : la directive
includeSubDomains pourrait bloquer
ocsp.ca.example.) D'un autre côté, sans cette
option, vous n'êtes plus sûr de protéger les
cookies (cf. section 14.4) puisque ceux-ci peuvent
être envoyés à tout serveur d'un sous-domaine. (Avec secure, ce sera forcément en HTTPS mais pas forcément blindé par HSTS.)
Et pour les auteurs de navigateurs Web ? La section 12 leur dispense de sages conseils. D'abord, elle leur rappelle un principe central de HSTS : pas de recours pour les utilisateurs. Si un site est étiqueté en HSTS et qu'il y a un problème d'authentification, il est interdit de permettre aux utilisateurs de passer outre. HSTS est là pour la sécurité, pas pour faciliter la vie des utilisateurs. Le but est d'éviter qu'une attaque de l'Homme du Milieu soit possible parce que l'utilisateur est trop prêt à prendre des risques.
Une suggestion intéressante pour les auteurs de navigateurs est celle de livrer le logiciel avec une liste pré-définie de sites HSTS (grandes banques, etc), comme ils ont aujourd'hui une liste pré-définie d'AC. Cela permettrait de fermer une des faiblesses de HSTS, le fait que la première connexion, si elle n'est pas faite en HTTPS (et sans erreur), n'est pas sécurisée. Après, on peut imaginer que cette liste soit éditable (possibilité d'ajouter ou de retirer des sites) mais permettre de retirer un site est dangereux : un utilisateur inconscient risquerait de virer un site important et de se retrouver ainsi vulnérable. En tout cas, le RFC dit que cette possibilité de retirer un site ne doit pas être accessible à JavaScript, pour éviter qu'un logiciel malveillant dans une page Web ne s'attaque à la sécurité de HSTS.
Tout ce RFC est évidemment consacré à la sécurité mais la
traditionnelle section Security considerations
(section 14) est néanmoins utile pour évaluer les risques
restants. Ainsi, HSTS ne protège pas contre les attaques
par déni de service. Il peut même les faciliter : par
exemple, un attaquant actif peut envoyer le trafic HTTPS vers un
serveur qu'il contrôle et, si l'utilisateur accepte le certificat
invalide, le serveur pourra alors mettre un
Strict-Transport-Security: non prévu et qui
empêchera l'accès au serveur légitime dans certains cas. Autre
possibilité, si le navigateur permet à l'utilisateur ou, pire, à du
code JavaScript, d'ajouter un site à la liste locale des sites HSTS,
les sites pas accessibles en HTTPS deviendront inutilisables.
Autre problème que HSTS ne résout pas complètement : la première
connexion. Si, sur une nouvelle machine (dont la mémoire HSTS est
vide), vous vous connectez à
http://www.example.com/, HSTS ne vous protège
pas encore. Si aucun attaquant n'était là pendant la première
connexion, vous serez redirigé vers
https://www.example.com/, l'en-tête
Strict-Transport-Security: définira ce site comme
HSTS et tout sera protégé par la suite. Mais, si un attaquant était
présent au moment de cette première connexion, HSTS ne pourra rien
faire. C'est un des cas où la liste pré-définie de sites HSTS, livrée
avec le navigateur, est utile.
Dernier piège, plus rigolo, un attaquant peut découvrir (par une
combinaison de noms de domaines qu'il contrôle et d'un script tournant
sur le navigateur) si le navigateur a déjà visité tel site HSTS (car,
dans ce cas, les liens vers un URL http://...
seront automatiquement réécrits en
https://...). Cela permet une forme de flicage du
navigateur (voir la synthèse « Web
Tracking » de N. Schmucker.)
Deux annexes du RFC intéresseront les concepteurs de
protocoles. L'annexe A documente les raisons des choix effectués par
HSTS. Par exemple, la politique HSTS est indiquée par un en-tête et
pas par un cookie car les
cookies peuvent être manipulés et modifiés quand
ils sont dans la mémoire du navigateur. Autre cas qui a suscité des
discussions, le fait que le client HTTPS fasse confiance à la dernière
information reçue via
Strict-Transport-Security:. Par exemple, si un
serveur annonce un max-age d'un an le 18 novembre
2012, puis d'un mois le 19 novembre 2012, l'information expirera-t-elle le
18 novembre 2013 ou bien le 19 décembre 2012 ? Avec HSTS, c'est le
dernier en-tête qui gagne, donc l'expiration sera le 19 décembre
2012. C'est peut-être une faiblesse, question sécurité, mais cela
permet aux gérants des sites Web de corriger leurs erreurs (comme un
max-age excessif).
À propos du max-age, la même annexe explique
aussi pourquoi il indique une durée et pas une date d'expiration :
c'est pour éviter d'être dépendant de la synchronisation des
horloges. Le RFC donne une autre raison, le fait d'être ainsi
dispensé de la définition et de l'implémentation d'une syntaxe pour
représenter les dates. Cela ne me semble pas convaincant : il existe
déjà une syntaxe normalisée et largement implémentée, celle du RFC 3339. Mais, bon , la sécurité préfère des normes
simples, X.509 est un parfait exemple des résultats auxquels mènent
des normes compliquées.
Quant à l'annexe B, elle explique les différences entre HSTS et la SOP (Same-Origin Policy) du RFC 6454.
Ce RFC normalise une technique déjà largement déployée. Plusieurs sites Web envoient déjà cet en-tête et plusieurs navigateurs le reconnaissent (on trouve deux bonnes listes sur le Wikipédia anglophone).
À noter qu'il y eu des projets plus ou moins avancés de mettre cette déclaration « TLS seulement » dans le
DNS (évidemment avec
DNSSEC) plutôt que dans HTTP. Cela aurait permis de fermer la faille de la première
connexion, et de gérer le cas des autres protocoles sécurisés avec TLS. Deux exemples de cette voie (tous les deux n'ayant pas été poursuivis) : l'Internet-Draft draft-hoffman-server-has-tls et un article de George Ou.
J'ai testé HSTS avec un Chromium « Version 20.0.1132.47 Ubuntu 12.04 (144678) » et tcpdump qui écoute. Tout marche bien. L'en-tête HSTS est ignoré si le certificat n'a pas pu être validé (AC inconnue). Une fois le certificat validé (AC ajoutée au magasin du navigateur), dès que l'en-tête HSTS a été reçu, plus aucune tentative n'est faite en HTTP, le navigateur file sur le port 443 directement.
Quant à Firefox,
voici ce qu'il affiche quand un site qui avait auparavant été
accessible en HTTPS authentifié ne l'est plus (ici, parce que le
certificat a expiré) :

HSTS est également mis en œuvre dans wget (voir la documentation) et c'est activé par défaut.
Merci à Florian Maury pour sa relecture attentive. Un autre article sur HSTS est celui de Cloudflare.
L'article seul
Informations médicales sur le Web : s'y fier ?
Première rédaction de cet article le 18 novembre 2012
Le World Wide Web a permis la mise à disposition, pour beaucoup de gens, d'une quantité formidable d'informations, beaucoup n'étant accessible autrefois qu'à une petite minorité. C'est par exemple le cas des informations médicales. Mais peut-on se fier à ce qu'on trouve sur le Web ?
Bien sûr, les gens qui connaissent le Web savent déjà la réponse : « c'est comme les sources d'information traditionnelles (experts ou papier) : ça dépend ». Mais il y a des gens qui ne connaissent pas le Web et qui racontent n'importe quoi à ce sujet. On voit dans le film « La guerre est déclarée » les deux parents discuter, après avoir appris que leur enfant souffre d'une grave maladie, de la stratégie à adopter. Ils s'engagent à ne jamais chercher d'information sur l'Internet, et à se fier exclusivement aux médecins. Bonne idée ou pas ? Cela dépend.
Plus embêtant, un article « Attention Dr Google n'existe pas ! » dans « La revue des parents », magazine de la FCPE (numéro d'octobre 2012). D'abord, parce que le titre confond le Web avec un moteur de recherche particulier, celui de Google. Cela indique bien que l'auteure de l'article n'a pas les idées très claires sur le Web (sur les défauts des moteurs de recherche, cf. mon exposé ). Mais surtout embêtant car l'article défend un point de vue très réactionnaire : seuls les experts savent, il ne faut se fier à personne d'autre. Et de citer abondamment... un représentant de l'Ordre des médecins, institution créée par Vichy et dont la ligne politique est plutôt à l'opposé de celle de la FCPE. Mais, dès qu'il s'agit d'Internet, les autorités traditionnelles font bloc et organisent la résistance commune. Les intermédiaires voient leur exclusivité d'accès à l'information remise en cause et, au lieu de chercher une nouvelle façon de pratiquer leur métier, préfèrent jeter le bébé avec l'eau du bain et décréter qu'Internet, le Web et Google (notions qu'ils confondent en général complètement) sont le Mal (ce syndrome frappe beaucoup les journalistes, par exemple).
L'article note pourtant, à juste titre, que si les patients consultent le Web, c'est tout simplement qu'ils ne sont pas satisfaits de leur médecin ! Absence de réponses aux questions, consultations expédiées en vitesse, difficultés à avoir un rendez-vous, impossibilité de dialoguer avec un médecin en dehors du rendez-vous physique (mes félicitations au passage à la pédiatre de mes enfants, qui a toujours été disponible au téléphone pour les parents inquiets). Malgré quelques exceptions, c'est cela, le vécu des patients. Et le Web, lui, est toujours disponible. Avant de taper sur Google, les médecins (et les journalistes) devraient d'abord s'interroger sur leur propre pratique.
Autre erreur courante dans l'article de « La revue des parents », celle de prêter à des entités abstraites des pensées et des intentions. « Il ne faut pas croire tout ce que disent les sites », affirme bien haut le représentant de l'Ordre. Mais « les sites » ne disent rien, ce sont des humains qui écrivent les textes. Le Web ne met pas en communication des lecteurs avec des « sites » mais des humains avec d'autres humains. Ceux qui écrivent les textes qu'on peut lire sur le Web sont, comme tous les humains, capables de se tromper, de mentir... ou de donner gratuitement de l'information correcte et bien expliquée.
Plus drôle, l'accusation comme quoi l'information trouvée sur « les sites » serait douteuse car certains sites Web sont financés par la publicité qui peut les influencer. Comme si les médecins, eux, tiraient leurs informations uniquement de leur pratique et de leurs collègues, et pas des visiteurs médicaux et des brochures des laboratoires pharmaceutiques ! (Ce numéro de « La revue des parents » a, en dernière page, une publicité pour des substances bénéfiques, maigrir, « purifier l'organisme », retrouver son tonus, substances « conseillées par des experts de haut niveau ».) Cette mésinformation des médecins par la publicité est un des chevaux de bataille de la revue Prescrire.
Autre erreur fondamentale commises par ces représentants de l'autorité qui expliquent que le Web est dangereux : tout mettre dans le même panier. Il existe des tas de sites différents. Doctissimo, ce n'est pas la même chose que le blog d'un médecin et ce n'est pas la même chose qu'un site Web d'un illuminé qui vend des poudres comme dans la publicité citée ci-dessus. Au fait, il existe un effort pour labeliser les sites Web qui donnent de l'information sérieuse en médecine, le label HON que vous verrez souvent sur les sites médicaux. (Il est bien sûr contesté.)
C'est pourtant le même représentant de l'Ordre qui donne une bonne piste d'amélioration des choses : « Nous encourageons les médecins à créer leur propre blog avec des liens sûrs scientifiquement [...] pour guider les patients ». Excellente démarche (qu'il ne suit pas complètement : en tout cas Google ne trouve pas de blog à son nom - mais il est sur Twitter) : si on n'est pas satisfait de ce qui existe sur le Web (et on trouve en effet plein d'énormités), il faut diffuser de la bonne information, et pas se replier dans sa tour d'ivoire. Soyons positifs, terminons sur un bon exemple, le site de Martin Winckler.
Merci à Fil, Victoria Bohler, Julien Moragny et André Sintzoff pour leurs utiles remarques et corrections (naturellement, le ton, les idées et le choix des mots et des opinions sont de moi, pas d'eux).
L'article seul
Utiliser l'Autorité de Certification CAcert
Première rédaction de cet article le 13 novembre 2012
Dernière mise à jour le 14 novembre 2012
Comme vous le savez peut-être déjà, les sites
Web auxquels on accède avec un URL
commençant par https sont sécurisés avec le
protocole TLS (décrit dans le RFC 6347). Pour s'assurer de l'authenticité du site, avant de
commencer le chiffrement de la session, TLS se
repose sur des certificats, qui sont simplement
une la partie publique d'une clé
cryptographique plus la signature
d'un organisme auquel on doit faire confiance. Dans le format de
certificats le plus
répandu, X.509, cet organisme se nomme une
Autorité de Certification. Elles sont
typiquement chères et n'apportent pas forcément une sécurité géniale
(les forces du marché tirent les procédures de vérification vers le
bas...) Une alternative est donc d'employer une Autorité de
Certification gratuite, fonctionnant de manière simple et totalement
automatisée, CAcert.
Écartons tout de suite un faux débat : est-ce que CAcert est une « vraie » Autorité de Certification (AC), une « officielle » ? C'est un faux débat car il n'existe pas d'AC officielle : chaque éditeur de logiciels (par exemple Microsoft pour Internet Explorer et Mozilla pour Firefox) décide selon ses propres critères de quels AC sont mises ou pas dans son magasin d'AC (et ce ne sont pas forcément les mêmes). Donc, CAcert, comme toute AC, est reconnue par les gens qui lui font confiance, point. (En France, l'ANSSI publie une liste des AC « qualifiées » mais cette liste n'a rien à voir avec ce qui se trouve dans les navigateurs, la seule chose importante pour les utilisateurs.)
Mais est-ce que CAcert fournit le même niveau de sécurité que les grosses AC commerciales comme VeriSign (l'activité d'AC sous ce nom appartient désormais à Symantec) ou Comodo ? D'abord, ces AC ne sont pas forcément parfaites comme l'ont montré le piratage de Comodo ou l'Opération Tulipe Noire contre DigiNotar. Ensuite, tout dépend des menaces envisagées. S'il s'agit simplement de protéger la page d'administration du blog de votre association, payer Symantec ou Comodo est franchement exagéré.
Par contre, comme CAcert n'est pas inclus par défaut dans les magasins de tous les navigateurs, vos visiteurs utilisant HTTPS recevront peut-être le fameux avertissement comme quoi le site n'est pas authentifié par une autorité reconnue (l'intéressante étude « Crying wolf » étudie cette question des avertissements de sécurité TLS.) En pratique, le moyen le plus simple est alors d'ajouter CAcert à son navigateur. C'est simple mais, évidemment, si vous gérez un site avec beaucoup de visiteurs pas du tout informaticiens, cela peut devenir très gênant. Si vous avez un public limité, ou bien si celui-ci est plutôt geek (ceux-ci auront souvent déjà installé CAcert), c'est moins grave.
Dans votre cas, testez en
allant en https://www.cacert.org/. S'il n'y a aucun avertissement de
sécurité et que vous voyez le fameux cadenas, c'est bon, CAcert est
connu de votre navigateur. Sinon, si vous
n'avez pas encore mis CAcert dans les AC reconnues, rendez-vous en
http://www.cacert.org/index.php?id=3 (je n'ai pas mis
https puisque, à ce stade, vous ne connaissez pas
l'AC CAcert). Du point de vue sécurité, il y a à ce moment un problème
de bootstrap : pour
authentifier le site de CAcert vous avez besoin du certificat... qui
se trouve sur ce site. Si vous êtes prudent, vous allez valider le certificat
de l'AC CAcert avant de l'installer, par exemple en vérifiant son
empreinte
(13:5C:EC:36:F4:9C:B8:E9:3B:1A:B2:70:CD:80:88:46:76:CE:8F:33
en SHA-1) auprès d'un ami qui l'a déjà
installé. Par exemple, avec OpenSSL, si vous
avez téléchargé le certificat en root.crt :
% openssl x509 -fingerprint -in root.crt SHA1 Fingerprint=13:5C:EC:36:F4:9C:B8:E9:3B:1A:B2:70:CD:80:88:46:76:CE:8F:33 ...
Ensuite, installer le certificat de l'AC nécessite simplement de suivre le lien « Root Certificate (PEM Format) ». À partir de là, les certificats émis par CAcert seront acceptés par votre navigateur. Si la pensée que CAcert pourrait devenir méchant et émettre un vrai-faux certificat pour le site Web de votre banque, rassurez-vous en pensant que n'importe laquelle des centaines d'AC installées par défaut dans votre navigateur (regardez par exemple tout ce qu'il y a par défaut, de CNNIC à TÜRKTRUST Elektronik Sertifika Hizmet Sağlayıcısı) peut en faire autant.
C'est bon ? Vous pouvez visiter https://www.cacert.org/ sans avertissement de sécurité ?
Parfait, maintenant, allons demander à CAcert des certificats.
Comment fonctionne CAcert ? On se rend sur le site Web et on crée un compte,
comme sur tant d'autres sites Web. On choisit évidemment un mot de
passe sérieux. Puis on se connecte. Commençons par l'option
Domains. Normalement, votre liste de
domaines est vide à ce stade. CAcert a besoin
de connaître les domaines que vous gérez, pour signer ensuite des
certificats. Choisissez Add pour ajouter un
domaine. Vous pouvez indiquer n'importe lequel ? Non, heureusement
pas. CAcert vérifie que vous êtes bien un administrateur du domaine en
envoyant un secret qu'il a choisi à une des adresses de
courrier du domaine. Pour cela, il analyse le
résultat de whois et il se sert aussi des
adresses normalisées dans le RFC 2142. Pour le
domaine langtag.net, cela donne :
Please choose an authority email address a4edcf75406c24a90c3b19d3711c0de1-18767@contact.gandi.net root@langtag.net hostmaster@langtag.net postmaster@langtag.net admin@langtag.net webmaster@langtag.net
La première adresse venant de whois et les suivantes du RFC 2142. Les fanas de sécurité noteront deux choses : l'utilisateur de CAcert choisit quelle adresse servira, donc c'est la sécurité de l'adresse la moins protégée qui détermine la sécurité de l'ensemble. Et, deuxième point, la sécurité de CAcert dépend de celle du courrier, et des protocoles qu'il utilise, comme le DNS (CAcert n'exige pas, aujourd'hui, que les noms de domaines dans les adresses de courrier soient protégés par DNSSEC). Notez que pas mal d'AC commerciales ne font pas mieux, question vérifications !
Vous allez ensuite recevoir dans votre boîte aux lettres un message vous demandant de visiter une page Web dont l'URL est secret, pour confirmer que vous avez bien reçu le message (et que vous êtes donc bien administrateur du domaine) :
From: support@cacert.org To: a4edcf75406c24a90c3b19d3711c0de1-18767@contact.gandi.net Subject: [CAcert.org] Email Probe X-Mailer: CAcert.org Website Below is the link you need to open to verify your domain 'langtag.net'. Once your address is verified you will be able to start issuing certificates to your heart's content! http://www.cacert.org/verify.php?type=domain&domainid=227678&hash=ddefe7cdfdea431278b86216bf833b8f ...
(Le lien est à usage unique et je n'ai donc pas de crainte à le donner ici.)
Une fois la visite faite, le nom de domaine est associé à votre compte et vous le voyez dans la liste du menu Domains. Vous pouvez alors demander la signature de certificats. En effet, CAcert ne fait pas le certificat pour vous (car, alors, il connaîtrait la partie privée de la clé ). Vous devez créer un certificat, le transmettre à CAcert, qui le signe. Avec les outils d'OpenSSL, cela se passe ainsi :
[On fabrique le CSR, Certificat Signing Request] % openssl req -new -nodes -newkey rsa:2048 -keyout server.key -out server.csr -days 1000 ... Common Name (eg, YOUR name) []: www.langtag.net
Le -newkey qui demande une clé RSA de 2 048 bits est obligatoire. CAcert n'accepte plus les clés de 1 024 bits, trop vulnérables. Notez que la durée de validité demandée, ici mille jours, n'a aucune
importance, CAcert mettra sa propre durée, six mois.
Ensuite, on copie/colle le CSR (fichier d'extension
.csr) dans le formulaire sur le site de
CAcert. Ce dernier affiche, pour vérification, les informations du
certificat qu'il incluera dans le certificat final. Les informations
exclues sont celles que CAcert ne peut vérifier (donc, presque tout
sauf le nom de domaine.) Le message est « No additional
information will be included on certificates because it can not be
automatically checked by the system. ».
CAcert fournit alors un certificat qu'on copie/colle dans un fichier
d'extension .crt. On peut le vérifier avec son
OpenSSL local :
% openssl x509 -text -in server.crt
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 818193 (0xc7c11)
Signature Algorithm: sha1WithRSAEncryption
Issuer: O=Root CA, OU=http://www.cacert.org, CN=CA Cert Signing Authority/emailAddress=support@cacert.org
Validity
Not Before: Nov 13 20:55:41 2012 GMT
Not After : May 12 20:55:41 2013 GMT
Subject: CN=www.langtag.net
...
Naturellement, on n'est pas obligé d'utiliser
openssl directement, on peut aussi se servir d'un
script plus accessible comme CSRGenerator.
Et voilà, on a un beau certificat qui marche, il n'y a plus qu'à le copier là où l'attend le serveur HTTP, Apache, Nginx ou un autre.
CAcert est capable de reconnaître pas mal d'extensions de
X.509 comme les
subjectAltName, si pratiques lorsqu'il s'agit de
mettre plusieurs sites Web
derrière une seule adresse IP. Il prévient alors :
Please make sure the following details are correct before proceeding any further. CommonName: www.generic-nic.net subjectAltName: DNS:www.generic-nic.net subjectAltName: DNS:svn.generic-nic.net subjectAltName: DNS:viewvc.generic-nic.net No additional information will be included on certificates because it can not be automatically checked by the system. The following hostnames were rejected because the system couldn't link them to your account, if they are valid please verify the domains against your account. Rejected: svn.rd.nic.fr
Le nom rejeté, à la fin, est parce que le compte CAcert utilisé avait
vérifié le domaine generic-nic.net mais pas le
domaine nic.fr.
Voilà, vous pouvez maintenant vous détendre en sécurité, grâce à vos nouveaux certificats. CAcert vous préviendra lorsqu'ils seront proches de l'expiration et qu'il faudra les renouveler (naturellement, si vous êtes prudent, vous superviserez cela vous-même.)
Notez que CAcert propose d'autres services, par exemple des certificats plus vérifiés, en utilisant la communauté. Une alternative souvent citée pour avoir des certificats partiellement gratuits est StartSSL mais je n'ai pas testé.
Merci à John Doe (ah, ah) pour ses remarques et à Florian Maury pour sa relecture et son appréciation que cet article est « de loin, le plus mauvais conseil que j'ai pu lire sur ton blog ». Sur la valeur de CAcert, vous pouvez aussi lire une discussion chez OpenBSD et une chez Debian (deux systèmes qui incluent le certificat de CAcert par défaut).
L'article seul
RFC 6743: ICMP Locator Update message for ILNPv6
Date de publication du RFC : Novembre 2012
Auteur(s) du RFC : RJ Atkinson (Consultant), SN Bhatti (U. St Andrews)
Expérimental
Réalisé dans le cadre du groupe de recherche IRTF RRG
Première rédaction de cet article le 10 novembre 2012
Le protocole ILNP, décrit dans le RFC 6740, permet de séparer l'identificateur et le localisateur d'une machine. L'identificateur est stable, voire très stable, et identifie une machine, le localisateur est bien plus changeant et identifie un point d'attachement au réseau. Lors d'une communication entre deux machines, si le localisateur change, il faut pouvoir prévenir son correspondant. C'est le rôle des nouveaux messages ICMP Locator Update. Ce RFC 6743 décrit ces messages pour le cas d'IPv6.
Donc, comme déjà expliqué dans les RFC 6740 et RFC 6741, une machine ILNP peut avoir besoin de modifier dynamiquement la liste de ses localisateurs. Par exemple parce qu'elle s'est déplacée. Ou, tout simplement, parce qu'un nouvel attachement au réseau est disponible (nouveau FAI, par exemple).
Cela se fait avec des paquets ICMP envoyés au(x) correspondant(s). Ces paquets ont le type 156 et ne sont utilisés que pour ILNPv6 (ILNP sur IPv6 ; leur équivalent IPv4 est dans le RFC 6745). Le type 156 a été enregistré à l'IANA.
Leur syntaxe est décrite en section 2. Les champs les plus importants :
- Operation, qui indique si on publie une liste de localisateurs ou bien si on accuse réception d'une liste,
- Num of Locs, le nombre (> 0) de localisateurs dans le message,
- Locator(s), qui est une liste de tuples
{Locator, Preference,
Lifetime}. Locator est un
localisateur (64 bits en ILNPv6), Preference un
entier qui représente la
préférence associée à ce localisateur (plus elle est basse, plus il
est préféré, voir aussi le RFC 6742) et
Lifetime le nombre de secondes que ce localisateur
va être valide (typiquement identique au TTL de
l'enregistrement DNS
L64, cf. RFC 6742).
Lorsqu'une liste de localisateurs change pour un nœud (ajout ou retrait d'un localisateur), le nœud envoie ce message à tous ses correspondants (tous les nœuds avec lesquels il est en train de communiquer). Ceux-ci enverront un accusé de réception (même contenu, seul le champ Operation changera). Le RFC ne spécifie pas quoi faire si on ne reçoit pas d'accusé de réception (les messages ICMP peuvent se perdre). C'est volontaire : le manque d'expérience pratique avec ILNP ne permet pas encore de recommander une stratégie de rattrapage particulière (réemettre, comme avec le DNS ?)
Notez que c'est une liste complète de tous les localisateurs qui est envoyée. Elle peut donc être grosse, programmeurs, attention aux débordements de tampon si Num of locs vaut sa valeur maximale, 256.
Le message Locator Update doit être authentifié (section 6) en incluant, pour chaque correspondant, l'option IPv6 Nonce (RFC 6744) avec la valeur en service pour ce correspondant. Les messages seront ignorés si le numnique (valeur choisie de manière à être imprévisible par l'attaquant) est incorrect. (Dans les environnements où on souhaite encore plus de sécurité, on peut ajouter IPsec.)
Et comment se passera la cohabitation avec les machines IPv6 classiques ? La section 5 traite ce cas. Comme le type ICMP 156 est inconnu des machines IPv6 classiques, elles ignoreront ces messages Locator Update (RFC 4443, section 2.4).
L'article seul
RFC 6744: IPv6 Nonce Destination Option for ILNPv6
Date de publication du RFC : Novembre 2012
Auteur(s) du RFC : RJ Atkinson (Consultant), SN Bhatti (U. St Andrews)
Expérimental
Réalisé dans le cadre du groupe de recherche IRTF RRG
Première rédaction de cet article le 10 novembre 2012
Une grande partie de la sécurité d'ILNP, architecture de séparation de l'identificateur et du localisateur, dépend d'un numnique, nombre imprévisible choisi par une machine et transmis à son correspondant au début d'une session. En renvoyant ce nombre, le pair prouve qu'il est bien le même correspondant. Ce RFC décrit les détails de l'option IPv6 Nonce (numnique), utilisée pour ILNP sur IPv6.
ILNP est décrit dans le RFC 6740, avec certains détails pratiques dans le RFC 6741. Comme tous les systèmes à séparation de
l'identificateur et du localisateur, son talon d'Achille est le lien
(binding) entre l'identificateur d'une machine et
son localisateur. Si on reçoit un paquet disant « pour joindre la
machine d'identificateur 3a59:f9ff:fe7d:b647,
envoie désormais les paquets au localisateur
2001:db8:43a:c19 », faut-il le croire ?
Évidemment, non, pas sur l'Internet public en
tout cas. La solution adoptée par ILNP est d'avoir un
numnique. C'est un nombre généré de manière
imprévisible par un tiers (idéalement, ce devrait être un nombre
aléatoire), que chaque machine envoie au début de la session
ILNP. Lorsqu'un correspondant veut s'authentifier (par exemple
lorsqu'il envoie le message de changement de localisateur cité plus
haut, cf. RFC 6743), il inclura ce
numnique.
Ce numnique sera transporté, aussi bien pour le début de la session que pour les mises à jour de localisateur, dans une option Destination IPv6 (ces options sont décrites dans le RFC 2460, section 4.6). Cette option sert donc à la sécurité d'ILNP. Mais elle a aussi une autre fonction, signaler, lors du débat d'une conversation, qu'on connait ILNP et que le correspondant peut l'utiliser (la coexistence pacifique d'ILNPv6 et d'IPv6 Classic en dépend). Elle ne doit donc apparaître que dans les paquets ILNP.
L'en-tête « options pour la Destination » peut contenir plusieurs options (en pratique, à l'heure actuelle, comme le note notre RFC, il n'est quasiment jamais utilisé), mais il ne doit y avoir qu'une seule option Nonce. Si d'autres options sont quand même présentes (comme celle du RFC 5570), le RFC recommande que Nonce soit la première dans l'en-tête.
La section 2 décrit la syntaxe de cette option. Elle comporte les champs obligatoires, Option Type (0x8b dans le registre IANA), Option length (en octets ; le numnique n'a pas de longueur fixe mais au moins les valeurs de 4 et 12 octets doivent être acceptées par les mises en œuvre de ce RFC) et Nonce (la valeur du numnique, de préférence générée selon les bons principes du RFC 4086).
En l'absence de l'option Nonce dans un paquet entrant, ILNP jettera le paquet si le localisateur source n'est pas dans la liste actuellement connue et stockée dans l'ILCC (Identifier-Locator Communication Cache, cf. RFC 6741). Lorsqu'une machine ILNP change sa liste de localisateurs (section 4), elle envoie un paquet avec la nouvelle liste et ce paquet doit inclure l'option Nonce (avec un numnique correct) pour être accepté. Le RFC recommande également d'inclure cette option dans les paquets suivants, pour une durée d'au moins trois RTT, afin de se prémunir contre un éventuel réordonnancement des paquets. (Notez que cela ne règle que le cas d'un retard du Locator Update, pas le cas de sa perte. Recevoir le paquet avec le numnique correct ne suffit pas à changer les localisateurs mémorisés, ne serait que parce que ce paquet ne contient qu'un seul localisateur et pas la liste actuelle.)
Si vous êtes en train de programmer une mise en œuvre d'ILNP, lisez aussi la section 5, qui donne d'utiles conseils, notamment sur l'ILCC (qui garde en mémoire le numnique actuel de la session, c'est une des informations les plus importantes qu'il stocke).
L'Internet à l'heure actuelle ne contient que des machines IP Classic. Comment cela va t-il se passer pour les premières machines ILNP ? La section 6 décrit la compatibilité. L'option Nonce sert à deux choses, indiquer le numnique, bien sûr, mais aussi signaler qu'ILNP est utilisé. Cette nouvelle option ne doit donc pas être présente dans des paquets IP Classic. Dans les paquets ILNP, elle doit être présente dans les premiers paquets (pour signaler qu'on connait ILNP) et dans tous les messages ICMP générés par les machines ILNP (comme le Locator Update du RFC 6743). Elle peut aussi être mise dans tous les paquets mais ce n'est pas indispensable. Le RFC recommande quand même de le faire si le taux de pertes de paquets de la session est particulièrement élevé (car les paquets portant l'option pourraient être perdus).
Donc, la machine recevant le premier paquet ILNP sait que son
correspondent connait ILNP grâce à l'option Nonce. Et la machine qui
émet le premier paquet ? Comment sait-elle que le pair connait ILNP ?
La principale méthode est, comme toujours dans ILNP, via le
DNS. Comme décrit en détail dans le RFC 6742, la présence d'enregistrements
NID dans le DNS indique que la machine distante
connait ILNP. Et si l'information dans le DNS est fausse ou dépassée ?
Dans ce cas, vu le type de l'option Nonce (avec
les deux bits de plus fort poids à 10, ce qui indique que le paquet
doit être rejeté si cette option n'est pas comprise, RFC 2460, section 4.2). L'émetteur, en recevant le message ICMP
de rejet (Parameter Problem), saura qu'il ne faut plus essayer en ILNP.
Dans un monde idéal, cela s'arrêterait là. Mais les options de destination comme celle décrite ici sont rares dans l'Internet actuel et il serait bien imprudent de promettre que celle d'ILNP passera sans problème. Comme l'a montré l'expérience d'IPv4, ce qui n'est pas utilisé finit par ne plus être géré correctement, notamment par les équipements intermédiaires. Le RFC ne mentionne pas ce problème mais évoque un problème proche, se contentant de dire que les routeurs IPv6 correctement programmés devraient ignorer tout l'en-tête Destination Options (dans un monde idéal, là encore).
La section 7 revient sur les exigences de sécurité. Le numnique ne doit pas être prévisible par un attaquant extérieur, il est donc recommandé qu'il soit généré selon les règles du RFC 4086. Notez bien que cela ne sert à rien si l'attaquant est situé sur le chemin des paquets et peut les sniffer. C'est également le cas en IP Classic et le seul mécanisme vraiment sûr dans ce cas est IPsec, si on veut protéger jusqu'à la couche 3.
Si vous aimez regarder les paquets qui passent sur le réseau avec wireshark ou tcpdump, désolé, mais ces logiciels ne gèrent pas encore les options spécifiques à ILNP et ne les analyseront pas.
L'article seul
RFC 6740: ILNP Architectural Description
Date de publication du RFC : Novembre 2012
Auteur(s) du RFC : RJ Atkinson (Consultant), SN Bhatti (U. St Andrews)
Expérimental
Réalisé dans le cadre du groupe de recherche IRTF RRG
Première rédaction de cet article le 10 novembre 2012
Le protocole ILNP vient d'être spécifié dans une série de neuf RFC, dont ce RFC 6740 est le point de départ, décrivant l'architecture générale d'ILNP. ILNP appartient à la famille des protocoles à séparation de l'identificateur et du localisateur. Ces protocoles visent à résoudre une limite fondamentale de l'Internet : l'adresse IP est utilisée à la fois comme identificateur (nommer une machine, par exemple pendant la durée d'une session TCP) et comme localisateur (indiquer son point d'attachement au réseau). Cette confusion rend certaines configurations, notamment le multi-homing et la mobilité, très difficiles.
Ce n'est pas qu'ILNP soit le premier protocole à vouloir séparer ces deux fonctions. Avant de donner le feu vert à la publication de ces RFC, l'IESG a notamment examiné HIP et LISP, avant de conclure qu'ILNP avait des caractéristiques suffisamment originales pour qu'il soit intéressant qu'il soit décrit dans des RFC.
ILNP avait été choisi par les présidents du groupe de recherche Routage de l'IRTF comme étant la base des futurs travaux sur une meilleure architecture pour l'Internet (travaux décrits dans le RFC 6115). S'il faut le résumer en cinq points :
- ILNP est défini comme une architecture abstraite, avec plusieurs concrétisations possibles. Celle décrite dans ces RFC est compatible avec l'Internet actuel (une autre, plus « table rase », serait possible).
- ILNP fonctionne entièrement dans les machines terminales, les routeurs ne sont pas changés.
- Chaque machine ILNP a au moins un Identificateur et au moins un Localisateur. En IPv6, ils sont indiqués dans chaque paquet (ILNP peut aussi tourner au-dessus d'IPv4 mais c'est plus complexe.)
- Pour trouver le Localisateur d'une machine qu'on veut contacter, la méthode standard est d'utiliser le DNS (ILNP repose nettement plus sur le DNS que ses concurrents).
- Les changements de localisateur en cours de session sont faits par un nouveau message ICMP, Locator Update. Ces derniers sont sécurisés par un numnique, nombre imprévisible envoyé au début de la session.
Bon, après cette introduction rapide, voyons tout en détail. D'abord, pourquoi veut-on à tout prix séparer identificateur et localisateur ? Le mieux est de relire le RFC 4984 pour avoir tous les détails. Disons que l'actuelle confusion de l'identificateur et du localisateur est pénible pour :
- La croissance des tables de routage : pour avoir des adresss IP stables, certains réservent du PI et l'annoncent dans la table de routage globale.
- Le multi-homing : sans adresses PI, pas de moyen facile de gérer les adresses de ses fournisseurs d'accès.
- La mobilité : changer d'endroit ou de fournisseur casse les connexions TCP en cours.
Face à ces problèmes, des tas de propositions pour améliorer les mécanismes d'adressage et de nommage dans l'Internet ont été faites : RFC 814, RFC 1498, RFC 2101, RFC 2956 et bien d'autres. La conclusion était souvent la même : le mélange de fonctions d'identification d'une machine et de sa localisation dans le réseau est une mauvaise idée. Ces fonctions devraient être séparées.
Il y a un petit problème terminologique ici : les architectures où ces fonctions sont séparées sont parfois toutes appelées « séparation de l'identificateur et du localisateur ». Mais notre RFC adopte un vocabulaire plus strict. Il réserve ce terme de « séparation de l'identificateur et du localisateur » aux architectures (comme ILNP) où la séparation est faite dès le début (dans les machines terminales) et utilise le terme de « map and encapsulate » (qu'on trouve souvent abrégé en map-and-encap) aux architectures qui utilisent un tunnel pour transporter les paquets entre deux machines ne connaissant pas la séparation Identificateur/Localisateur. Selon cette terminologie, LISP, dont le nom veut dire Locator/Identifier Separation Protocol, n'est donc pas un « vrai » système « à séparation de l'identificateur et du localisateur ».
Ce RFC, le premier à lire lorsqu'on veut comprendre ILNP, est d'abord la description d'une architecture. On n'y trouvera pas de protocole, de format des paquets, etc. Les protocoles concrets viennent après, dans d'autres RFC. Deux protocoles qui mettent en œuvre l'architecture ILNP ont été définis, ILNPv4 pour IPv4 et ILNPv6 pour IPv6. Je parlerai surtout d'ILNPv6, qui est plus simple à exposer (le faible espace d'adressage d'IPv4 a nécessité quelques astuces qui rendent ILNPv4 plus difficile à comprendre).
Comme indiqué plus haut, d'autres incarnations de l'architecture ILNP peuvent être imaginées, notamment en choisissant une approche « table rase » qui ferait tourner cette architecture sur un nouveau protocole, sans relation avec IP. Mais, pour l'instant, ces hypothétiques incarnations n'ont pas été définies.
Les autres RFC à lire, une fois celui-ci achevé, sont :
- RFC 6741, « ILNP Engineering and Implementation Considerations », qui décrit les questions concrètes communes à ILNPv4 et ILNPv6,
- RFC 6742, « DNS Resource Records for ILNP », qui explique les enregistrements DNS nécessaires pour ILNP,
- RFC 6743, « ICMPv6 Locator Update message », définit le nouveau message ICMP Locator Update,
- RFC 6744, « IPv6 Nonce Destination Option for ILNPv6 », normalise la nouvelle option IPv6 permettant d'indiquer le numnique de la connexion,
- RFC 6745, « ICMPv4 Locator Update message », définit le nouveau message ICMP Locator Update pour IPv4,
- RFC 6746, « IPv4 Options for ILNP », normalise deux nouvelles options IPv4, une pour indiquer le numnique de la connexion, une pour indiquer l'identificateur (pour IPv6, il tient dans l'adresse et cette option n'est pas nécessaire),
- RFC 6747, « ARP Extension for ILNPv4 », qui décrit comment adapter le vieux protocole ARP à ILNP,
- RFC 6748, « Optional Advanced Deployment Scenarios for ILNP », explore des fonctions plus avancées d'ILNP et des perspectives plus lointaines.
Les section 2 et 3 détaillent cette architecture. Parmi les propriétés importantes de l'Identificateur, le fait qu'une machine puisse en avoir plusieurs, par exemple à des fins de protection de la vie privée : avoir le même Identificateur tout le temps permettrait la traque d'une machine à travers ses déplacements, un problème analogue à celui qui a mené au RFC 8981. Une machine peut donc utiliser plusieurs identificateurs (mais, évidemment, pas au sein d'une même session).
Si l'application ne se sert que de noms de domaine pour contacter son pair, elle est dite « bien élevée » et fonctionnera sans problèmes avec ILNP. Ce comportement est celui recommandé par le RFC 1958. Si, par contre, l'application utilise explicitement des adresses IP (le RFC cite les fichiers de configuration d'Apache), elle pourra avoir des ennuis avec ILNP, où ces adresses ont une sémantique différente.
Les connexions des protocoles de transport, comme TCP, utilisent uniquement l'identificateur, résistant ainsi aux changements de localisateurs. Une machine d'un site multi-homé peut ainsi basculer d'un FAI à l'autre sans casser ses connexions TCP (cf. section 3.4).
Notez bien que l'identificateur identifie une machine, pas une interface réseau. Sa sémantique est donc très différente de celle des adresses IPv4, IPv6, ou des Interface Identifier d'IPv6 (RFC 4219).
Cela ne signifie pas que l'identificateur puisse être utilisé directement par les applications clientes. Comme indiqué plus haut, il est plutôt recommandé de se servir du nom de domaine.
Dans cette architecture, qu'est-ce qui est le plus proche d'une adresse IP ? Probablement le couple {Identificateur, Localisateur}, I-LV (pour Identifier - Locator Vector, cf. section 3.3). Ce couple désigne une liaison, notée (I, L), entre un identificateur et un localisateur.
Bref, un paquet ILNP contiendra un I-LV source et un I-LV destination. Notez que la sémantique d'un I-LV est proche de celle d'une adresse IP mais pas identique (l'I-LV se sépare en deux, I et L, l'adresse IP est structurée différemment, avec plusieurs préfixes hiérarchiquement emboîtés, etc). Le RFC 6741 indique comment ces IL-V sont représentés dans un paquet IP.
Dans les fichiers
ou entre discussions entre humains, les identificateurs ont le format
d'un Interface Identifier IPv6 (section 3.1.2). Ce
format, normalisé dans le RFC 4291 est fondé sur
le format EUI-64 par exemple 3a59:f9ff:fe7d:b647. Si le bit « global » est mis
à 1, l'identificateur est supposé être unique au niveau mondial.
Le localisateur a une syntaxe analogue (par exemple,
2001:db8:43a:c19). Une machine peut aussi avoir plusieurs localisateurs (par exemple
parce qu'elle a plusieurs connexions réseau). Le routage sera fait sur
la base des localisateurs, comme avec IP Classique
aujourd'hui (ce n'est donc pas par hasard que le localisateur
ressemble à un préfixe IPv6). Le localisateur peut être modifié en
route (cas du NAT). Contrairement à l'identificateur, relativement stable (en
tout cas pendant la durée d'une connexion), le localisateur peut
changer souvent (par exemple en situation de mobilité). Lorsque cela
se produit, la machine avertit ses correspondants (CN pour
Correspondent Nodes) avec un message ICMP
Locator Update. Si elle veut être contactée (si
c'est un serveur), elle doit aussi mettre à jour le DNS. Ces deux
mécanismes sont décrits en détail dans le RFC 6741.
Ces identificateurs et localisateurs sont publiés dans le
DNS (cf. RFC 6742). Une
application qui veut contacter www.example.com
aujourd'hui utilise le DNS pour connaître l'adresse IP
correspondante. Demain, elle utilisera ILNP pour connaître
identificateur et localisateur. (Pour des raisons de sécurité,
DNSSEC est recommandé.)
Il est aussi précisé que l'un des buts d'ILNP est de pouvoir l'incarner dans des protocoles qui sont compatibles avec l'existant (pour permettre à ILNP et IP Classique de coexister) et déployables de manière incrémentale (ne pas exiger que tout le monde passe à ILNP d'un coup).
La section 4 explique ensuite comment se fait le routage. Alice et Bob connaissent ILNP et veulent se parler, avec, entre eux, plusieurs routeurs traditionnels ne connaissant rien à ILNP. (En terminologie ILNP, Bob est le CN - Correspondent Node.) Dans le cas le plus courant, Bob a mis son (ou ses) Identificateurs et son (ou ses) Localisateurs dans le DNS (notez que les serveurs DNS utilisés n'ont pas besoin de connaître ILNP, mais cela optimise le temps de réponse DNS s'ils le gèrent). Cela a pu être fait manuellement ou, mieux, automatiquement via les mises à jour dynamiques (de préférence sécurisées, cf. RFC 3007). Alice va faire une requête DNS (cf. RFC 6742) et récupérer ainsi Identificateur et Localisateur de Bob (notez qu'ILNP n'a pas pour l'instant de mécanisme pour récupérer un Localisateur à partir d'un Identificateur).
Alice et Bob vont avoir besoin dans leurs systèmes d'une nouvelle structure de données, l'ILCC (I-L Communication Cache, section 4.2 et RFC 6741) qui permet de se souvenir des Localisateurs actuellement en service pour un CN donné. Au début, on y met les localisateurs récupérés via le DNS.
Ensuite, en IPv6, tout est simple. Alice fabrique un paquet IPv6,
contenant l'option Nonce (numnique) du RFC 6744, et dont la source est la concaténation de son
Localisateur et de son Identificateur (avec les valeurs données plus
haut à titre d'exemple, ce sera 2001:db8:43a:c19:3a59:f9ff:fe7d:b647). La destination est formée en
concaténant Localisateur et Identificateur de Bob. Les deux adresses
ainsi fabriquées sont des adresses IPv6 tout à fait normales et les
routeurs entre Alice et Bob suivent la méthode de routage, et de
résolution d'adresses en local (NDP)
traditionnelles.
En IPv4, cela sera toutefois plus complexe (on ne peut pas mettre Identificateur et Localisateur dans les 32 bits d'une adresse IPv4, et ARP ne permet pas de résoudre un Identificateur, trop gros pour lui). Voir les RFC 6746 et RFC 6747 pour les solutions adoptées.
Comment est-ce que cela résout le problème du multi-homing, déjà cité plusieurs fois ? Comme l'explique la section 5, ILNP traite le Muti-homing en fournissant un Identificateur par machine et au moins un Localisateur par FAI. Alice utilise un des localisateurs pour le paquet initial, puis prévient Bob par un message ICMP Locator Update pour annoncer les autres. En cas de panne ou de ralentissement d'un des FAI, Bob pourra envoyer ses paquets via les autres localisateurs (l'identificateur restant inchangé).
Pour les connexions entrantes (si Alice est un serveur Web), on publiera dans le DNS tous les localisateurs et le client les essaiera tous.
Multi-homing est en fait un terme très large. Il y a plusieurs cas :
- Host multi-homing où une machine a plusieurs connexions à l'Internet. C'est relativement rare mais cela peut être, par exemple, un smartphone connecté en Wi-Fi et 3G en même temps. ILNP permet à cette machine d'utiliser les deux localisateurs, chacun issu des deux connexions possibles.
- Site multi-homing où c'est un site entier qui est connecté à plusieurs opérateurs. Le RFC cite le cas où le site a des adresses PI et les annonce en BGP (ce qui charge la table de routage globale) mais il oublie le cas où les routeurs de sortie du site font simplement du NAT vers les adresses des FAI (ce qui ne permet ni la redondance des connexions entrantes, ni la continuité des connexions TCP). Dans le scénario typique de site multi-homing avec ILNP, les routeurs du site annoncent sur le réseau local avec RA (Router Advertisement) les N préfixes des N opérateurs utilisés, et les machines les utilisent comme localisateurs. Dans ce cas, les routeurs du site n'ont pas besoin de connaître ILNP, les machines terminales font tout le travail (enregistrer les localisateurs, les abandonner s'ils ne sont plus annoncés, etc).
Dans ILNP, la mobilité est traitée quasiment comme le multi-homing (section 6). Elle est donc très différente du Mobile IP du RFC 6275. Dans les deux cas, l'identificateur reste constant pendant que le localisateur actuellement utilisé peut changer. La principale différence est le délai : en cas de mobilité rapide, les mécanismes d'ILNP peuvent être trop lents pour assurer la transition (point que le RFC oublie de mentionner).
Comme pour le multi-homing, il peut y avoir mobilité d'une machine (le smartphone cité précédemment qui, maintenant, se déplace) ou d'un réseau entier (cas d'un bateau en déplacement, par exemple, où il faudra que les machines à bord connaissent ILNP). ILNP obtient le maintien de la connectivité grâce à des localisateurs qui changent dynamiquement (même en cours de session), une mise à jour de la liste que connait le CN, grâce aux messages ICMP Locator Update et enfin les mises à jour dynamiques du DNS (RFC 2136) pour continuer à recevoir de nouvelles sessions même après déplacement.
Avec IP Classic, si le téléphone se déplace et perd la Wi-Fi, les connexions TCP en cours sont coupées. Avec ILNP, le téléphone pourra simplement utiliser le(s) localisateur(s) restant(s) (ici, celui de la 3G) et garder ses connexions.
On a vu qu'ILNP était un truc assez ambitieux, promettant de résoudre plein de problèmes. Mais, comme l'ont montré les malheurs de plusieurs protocoles, être meilleur ne suffit pas. L'inertie de la base installée est forte. Il faut donc absolument, pour qu'un nouveau protocole ait la moindre chance de réussir, des mécanismes de compatibilité avec l'existant et de déploiement incrémental (on ne peut pas exiger que tout le monde migre au même moment). La section 8 discute en détail ces points. D'abord, un paquet ILNPv6 ne se distingue en rien d'un paquet IPv6 actuel (c'est un peu plus compliqué avec ILNPv4, pour lequel le traditionnel ARP ne suffit pas, cf. RFC 6747). Cela veut dire que les routeurs, de la petite box au gros routeur du cœur de l'Internet n'auront besoin d'aucun changement. Le routeur ne sait même pas que le paquet est de l'ILNPv6 (voir le RFC 6741 sur les détails concrets des paquets ILNP). On est donc dans un cas très différent de celui d'IPv6 où il fallait modifier tous les routeurs situés sur le trajet.
Côté DNS, il faudra des nouveaux types d'enregistrement (RFC 6742). Cela ne nécessite pas de modifications des résolveurs/caches. Sur les serveurs faisant autorité, il faudra légèrement modifier le code pour permettre le chargement de ces nouveaux types.
Il serait tout de même souhaitable que les serveurs DNS, lorsqu'ils
reçoivent une requête pour des noms qui ont des enregistrements ILNP,
envoient tous ces enregistrements dans la réponse. Ce n'est pas
nécessaire (le client pourra toujours les demander après) mais cela
diminuera le temps total de traitement. (Les requêtes de type
ANY, « donne-moi tous les enregistrements que tu
as », ne renvoient pas forcément le résultat attendu, un cache n'ayant pas
forcément tous les enregistrements correspondant à un nom.)
Si Alice et Bob connaissent tous les deux ILNP et qu'Alice initie
une session avec Bob, tout se passera bien. Alice demandera
l'enregistrement DNS de type NID, le serveur lui
renverra l'identificateur de Bob, les localisateurs seront ajoutés par
le serveur DNS (s'il connait ILNP) ou demandés explicitement par Alice
par la suite. Alice générera le numnique, et l'enverra à Bob avec sa
demande de connexion (RFC 6744). Mais, dans une optique de déploiement incrémental, il
faut prévoir le cas où Alice aura ILNP et pas Bob, ou bien
l'inverse. Que se passera-t-il alors ?
Si Alice connait ILNP et pas Bob, il n'y aura pas d'enregistrement
NID dans le DNS pour Bob. Alice devra alors
reessayer avec de l'IP classique. Si un enregistrement NID était
présent à tort, Alice tentera en ILNP et enverra le numnique. Bob, en
recevant cette option inconnue, rejettera le paquet en envoyant un
message ICMP indiquant à Alice ce qui s'est passé.
Si Alice ne connait pas ILNP alors que Bob le connait, Alice ne
demandera pas le NID et ne tentera rien en
ILNP. Si Bob accepte l'IP Classic, la connexion marchera, sans
ILNP.
Vu du point de vue de Bob (qui ne connait pas les requêtes DNS qui ont été faites), la connexion est en ILNP si l'option Nonce était présente dans le paquet initial, et en IP Classic autrement.
Le RFC ne mentionne toutefois pas trois problèmes pratiques :
- Si un enregistrement DNS annonce à tort que Bob connait ILNP, Alice essaie d'abord en ILNP puis passe en IP Classic, ce qui augmentera le temps d'établissement d'une connexion.
- Plus grave, si le paquet ICMP indiquant que Bob ne connait pas ILNP est perdu ou filtré (un certain nombre de sites bloquent stupidement la totalité des messages ICMP), le délai avant qu'Alice n'essaie en IP Classic sera très long. C'est le problème connu sous le nom de « malheur des globes oculaires » (RFC 6555 et RFC 6556).
- Les options IPv6 sont très rares dans l'Internet d'aujourd'hui. Les mauvaises expériences avec les options IPv4 font qu'on peut être inquiet de leur viabilité.
Et la sécurité ? La section 7 couvre le cas particulier des interactions entre ILNP et IPsec (RFC 4301). La principale différence avec IP Classic est que l'association de sécurité IPsec se fait avec les identificateurs et plus avec les adresses.
Pour la sécurité d'ILNP en général, c'est la section 9 qu'il faut lire. En gros, ILNP a le même genre de risques qu'IP (on peut mentir sur son localisateur aussi facilement qu'on peut mentir sur son adresse IP) et les mêmes mesures de protection (comme IPsec).
Les Locator Updates d'ILNP, qui n'ont pas d'équivalent dans IP, sont protégés essentiellement par le numnique (RFC 6744). Sans cela, un méchant pourrait faire un faux Locator Update et rediriger tout le trafic chez lui. Avec le numnique, les attaques en aveugle sont extrêmement difficiles. Par contre, si l'attaquant peut espionner le trafic (par exemple s'il est sur le chemin de celui-ci), le numnique ne protège plus (c'est analogue au problème du numéro de séquence initial de TCP, cf. RFC 6528). Il faut alors chiffrer toute la session avec IPsec (selon le type de menaces, on peut aussi envisager SSH ou TLS). Cette situation n'est pas très différente de celle d'IP Classic.
Notez qu'il existe deux numniques par session, un dans chaque sens. Les chemins sur l'Internet étant souvent asymétriques, cela complique la tâche de l'attaquant (s'il n'est que sur un seul chemin, il ne trouvera qu'un seul numnique).
Autre attaque courante sur l'Internet (même si le RFC dit, curieusement, qu'elle existe mais n'est pas répandue), l'usurpation d'adresses. Il est facile de mentir sur son adresse IP. Peut-on mentir sur son Identificateur ou bien son Localisateur ? Disons que mentir sur son Identificateur est en effet facile et qu'on ne peut guère l'empêcher. Contrairement à HIP, ILNP n'a pas forcément de protection cryptographique de l'identificateur (cf. RFC 7343). Il est possible d'utiliser les adresses cryptographiques du RFC 3972, il reste à voir si cela sera déployé. Autre solution dans le futur, utiliser IPsec avec des clés indexées par l'identificateur (mais cela reste bien théorique).
En revanche, un mensonge sur le Localisateur est plus difficile. Il peut être protégé par les techniques du RFC 2827 et RFC 3704. Certains protocoles au-dessus, comme TCP avec ses numéros de séquence initiaux imprévisibles, ajoutent une autre protection.
Autre aspect de la sécurité, la vie privée. Comme le rappele la section 10, avoir un identificateur stable peut faciliter le suivi d'une machine (et donc de son utilisateur) même lorsqu'elle se déplace. Ce problème est connu sous le nom d'identity privacy. Le problème avait déjà été mentionné avec IPv6 et la solution est la même : se servir des identificateurs temporaires du RFC 8981. (Une machine ILNP n'est pas forcée de n'avoir qu'un seul identificateur.)
Autre menace, celle sur la location privacy. Non spécifique à ILNP, c'est le fait qu'on puisse connaître la localisation actuelle d'une machine via son localisateur. Le problème est très difficile à résoudre, la qualité de la connectivité étant inversement proportionnelle à la dissimulation de l'adresse. Si on force le passage par une machine relais fixe (comme le permet Mobile IP), on a une bonne protection de la vie privée... et une bonne chute des performances et de la résilience.
Si le localisateur a été publié dans le DNS, un indiscret qui veut le connaître n'a même pas besoin d'une communication avec la machine qu'il veut pister, interroger le DNS (qui est public) suffit. Si une machine veut rester discrète sur sa localisation et qu'elle n'a pas besoin d'être contactée, le mieux est qu'elle ne mette pas son localisateur dans le DNS.
Il n'existe encore aucune mise en œuvre publique d'ILNP. Un projet existe mais rien n'est encore sorti.
Pour les curieux d'histoire, la section 1.2 présente la vision des auteurs sur les différentes étapes ayant mené à ILNP. Ils remontent jusqu'en 1977 où la note IEN1 notait déjà le problème qu'il y avait à faire dépendre les connexions d'une adresse qui pouvait changer. Cette note proposait déjà une séparation de l'identificateur et du localisateur, qui n'a pas eu lieu dans TCP/IP. Par exemple, TCP utilise dans la structure de données qui identifie une connexion les adresses IP de source et de destination. Tout changement d'une de ces adresses (par exemple parce que la machine a bougé) casse les connexions TCP en cours.
Après ce choix, et quelques années plus tard, l'idée d'une séparation de l'identificateur et du localisateur est revenue, compte-tenu de l'expérience avec TCP/IP. En 1994, une note de Bob Smart repropose cette idée. Même chose en 1995 avec Dave Clark. Enfin, en 1996, Mike O'Dell propose son fameux 8+8, qui n'atteindra jamais le statut de RFC mais reste la référence historique des propositions de séparation de l'identificateur et du localisateur. (Une grosse différence entre 8+8 et ILNP est que ce dernier n'impose pas de réécriture du localisateur en cours de route).
Depuis, plusieurs autres travaux ont été faits en ce sens, mais sans déboucher sur beaucoup de déploiements. Des « vrais » protocoles de séparation de l'identificateur et du localisateur (rappelons que les auteurs ne considèrent pas LISP comme faisant partie de cette catégorie), seul HIP a connu une description dans un RFC et plusieurs mises en œuvres. ILNP offre sans doute moins de sécurité que HIP (contrairement à HIP, pas besoin d'établir une connexion avant toute communication) mais autant qu'avec l'IP actuel. Et ILNP est moins disruptif que HIP, ce qui peut être vu comme un avantage ou un inconvénient.
Quelques lectures :
- Un excellent exposé à NANOG, qui explique notamment bien la différence entre localisateur et identificateur.
- Un texte plus ancien, décrivant ILNP.
- Et bien sûr le site officiel.
L'article seul
RFC 6742: DNS Resource Records for ILNP
Date de publication du RFC : Novembre 2012
Auteur(s) du RFC : RJ Atkinson (Consultant), SN Bhatti (U. St Andrews), Scott Rose (US NIST)
Expérimental
Réalisé dans le cadre du groupe de recherche IRTF RRG
Première rédaction de cet article le 10 novembre 2012
Le système ILNP, qui vise à fournir une nouvelle (et meilleure) architecture à l'Internet, dépend du DNS pour plusieurs fonctions critiques. Plusieurs nouveaux types d'enregistrement DNS sont nécessaires et ce RFC les décrit.
Avant de lire ce RFC, il faut connaître ILNP. Le mieux est de commencer par le RFC 6740, qui décrit tout le système. Le RFC 6741 fournit ensuite quelques détails pratiques. Il faut aussi naturellement connaître les bases du DNS (RFC 1034 et RFC 1035).
C'est fait ? Vous avez lu tout cela ? Alors, place à ce nouveau RFC, le RFC 6742. ILNP utilise le DNS essentiellement pour permettre un rendez-vous entre deux machines. Celle qui veut commencer connaît le nom de l'autre mais aucune information pratique sur comment la rencontrer. Quatre types d'enregistrements sont utilisés pour cela :
NIDqui permet de trouver l'identificateur d'une machine à partir de son nom,L64etL32qui permettent de trouver le localisateur d'une machine à partir de son nom,- Et
LP, une optimisation facultative qui sera présentée plus loin.
Commençons par le NID. Un de ses rôles est
d'indiquer à la machine qui veut en contacter une autre si sa future
correspondante connait ILNP (ou bien si elle est uniquement en IP
Classic). Sa présence dans le DNS est donc un signal : « tu peux y
aller, elle parle ILNP ». Un enregistrement erroné (disant qu'une
machine a un NID alors qu'en fait elle ne parle
pas ILNP) n'est pas fatal mais ralentirait sérieusement
l'établissement de la connexion.
Le NID a reçu le numéro 104 (cf. le registre IANA) et il comporte deux champs, une
préférence et l'identificateur. Attention, ce sont les préférences les
plus faibles qui sont celles à choisir en premier. Par exemple, voici
trois NID pour
host1.example.com :
host1.example.com. IN NID 10 0014:4fff:ff20:ee64
IN NID 20 0015:5fff:ff21:ee65
IN NID 50 0016:6fff:ff22:ee66
L'identificateur 0014:4fff:ff20:ee64 est le
préféré. (La syntaxe des identificateurs et des localisateurs est
décrite dans le RFC 6740.)
Si un serveur DNS « connaît ILNP »,
c'est-à-dire qu'il a été programmé avec du code spécifique pour ILNP,
au lieu d'attribuer aux enregistrements ILNP le traitement par défaut,
il peut
optimiser, par exemple en envoyant des enregistrements non demandées
mais qui seront probablement utiles. Cette optimisation, qui
n'a rien d'obligatoire, est analogue à ce que font les
serveurs actuels pour une requête MX : si la
réponse est mail.example.com, ils incluent
également les adresses IP de
mail.example.com dans la réponse, conscients
qu'elles seront probablement nécessaires bientôt (si on demande le MX
de example.com, c'est en général pour lui envoyer
du courrier juste après). Ici, un serveur
« connaissant ILNP » à qui on demande le NID de
host1.example.com peut aussi mettre dans le
réponse des L64 et des L32,
non demandés mais qui seront probablement utiles juste après.
Le type L64 stocke des localisateurs pour
ILNPv6, c'est_à-dire ILNP tournant sur
IPv6. La présence de L64 dans le DNS indique que la
machine peut faire de l'ILNP au-dessus d'IPv6. Pour ce protocole, les
localisateurs font 64 bits, d'où le nom de ce type. Son numéro est
106. Lui aussi a une préférence, suivie par le localisateur proprement
dit.
Voici un exemple où la machine
host1.example.com a deux localisateurs, avec une préférence pour
2001:0db8:1140:1000 :
host1.example.com. IN L64 10 2001:0db8:1140:1000
IN L64 20 2001:0db8:2140:2000
Rappelez-vous que les localisateurs d'ILNPv6 ont une syntaxe qui ressemble à celle des adresses IPv6 mais il s'agit bien d'un type différent.
Quant au type L32, il stocke des localisateurs pour
ILNPv4, c'est-à-dire l'incarnation d'ILNP pour
IPv4. Leur présence dans le DNS indique que la
machine peut faire de l'ILNP au-dessus d'IPv4. Pour ce protocole, les
localisateurs font 32 bits, d'où le nom de ce type. Son numéro est
105. Il comprend une préférence, puis le localisateur proprement
dit.
Voici un exemple où la machine
host1.example.com a trois localisateurs,
10.1.2.0 étant le préféré (la machine est sans
doute multi-homée) :
host1.example.com. IN L32 10 10.1.2.0
IN L32 20 10.1.4.0
IN L32 30 10.1.8.0
Le dernier type d'enregistrement DNS, LP, est
un peu différent. Il s'agit de fournir un niveau
d'indirection. En effet, si une machine change
de localisateurs (ce qui est normal, en ILNP), et veut pouvoir être
jointe, la méthode est de mettre à jour le DNS. Or, la zone où est
déclarée la machine peut ne pas être facilement accessible en écriture
(RFC 2136 ou méthode équivalente). L'idée (voir
RFC 6740) est
donc de pointer, via un enregistrement LP, vers
une zone prévue pour les mises à jour rapides, où se trouveront les
localisateurs.
L'enregistrement LP a le numéro 107 et comprend une préférence et
un FQDN. Ce FQDN aura à son tour des
L32 ou des L64. Voici un
exemple :
host1.example.com. IN LP 10 subnet1.dynamic.example.net.
IN LP 20 subnet3.backup.example.com.
; Puis, dans la zone dynamic.example.net :
subnet1.dynamic.example.net. IN L64 50 2001:0db8:1140:1000
IN L64 100 2001:0db8:2140:2000
Avec cet exemple, si host1.example.com change de
localisateur, on ne touche pas à la zone
example.com, on ne modifie que
dynamic.example.net. Cette indirection via les
LP n'est pas indispensable mais elle aidera dans
bien des cas, lorsque la zone « principale » ne permettra pas les
mises à jour rapides. Autre avantage, toutes les machines d'un même
sous-réseau ayant le même localisateur, leurs noms pourront pointer vers
le même LP et une seule mise à jour suffira pour
tout le monde.
La section 3 synthétise ensuite l'usage de ces types
d'enregistrement. Le minimum pour une machine ILNP est un
NID + un L64 (ou
L32 en ILNPv4) :
host1.example.com. IN NID 10 0014:4fff:ff20:ee64
IN L64 10 2001:0db8:1140:1000
Si la machine est
multi-homée, on aura
plusieurs L64 :
host1.example.com. IN NID 10 0014:4fff:ff20:ee64
IN L64 10 2001:0db8:1140:1000
IN L64 20 2001:0db8:2140:2000
Si la machine est mobile, elle aura souvent intérêt à utiliser les
LP et cela donnera quelque chose du genre :
host1.example.com. IN NID 10 0014:4fff:ff20:ee64
IN LP 10 mobile-1.example.net.
; ...
mobile-1.example.net. IN L64 2001:0db8:8140:8000
Rappelons que ces enregistrements ne doivent apparaître que si la machine parle ILNP. Un de leurs rôles est de signaler qu'ILNP est disponible.
Un client ILNP qui veut récupérer ces informations ne doit pas
compter qu'elles soient toutes envoyées d'un coup (même si c'est une
optimisation recommandée). Au passage, rappelez-vous que la requête
ANY, envoyée à un résolveur, n'a pas forcément la
sémantique attendue (elle renvoie ce que le résolveur a dans son
cache, pas forcément toutes les données disponibles sur les serveurs
faisant autorité). D'autre part, même si la réponse du serveur faisant
autorité incluait tous les enregistrements, certains résolveurs
peuvent, pour des raisons de sécurité, en jeter certains. Enfin, même
si les données sont gardées dans le cache, elles expirent au bout d'un
moment et les TTL ne sont pas forcément les
mêmes pour tous les types d'enregistrement. Le client ILNP doit donc se préparer à faire
plusieurs requêtes, par exemple NID (s'il n'y a
pas de résultat, la machine distante ne parle pas ILNP) puis
LP (qui est facultatif), puis
L64 puis enfin, s'il n'y a pas de
L64, se résigner à L32.
À propos des TTL, notez qu'il est logique que les TTL soient assez
longs pour les NID (une information normalement
très stable, je dirais que plusieurs jours ne sont pas un
problème). En revanche, les L32 et
L64 peuvent avoir des TTL bien plus courts (le
RFC ne donne pas de chiffre mais, disons, moins d'une minute), surtout
si la machine ou le réseau est mobile. On peut alors s'inquiéter
« est-ce que ces courts TTL, empêchant une mise en cache sérieuse, ne
vont pas augmenter excessivement la charge sur le système DNS, et
ralentir les requêtes ? ». Mais plusieurs articles (« Reducing DNS Caching », « DNS performance and the effectiveness of caching ») ont montré que les
caches du DNS étaient surtout rentables pour l'information
d'infrastructure (enregistrements
NS et
colle). Pour les enregistrements « terminaux »
comme les adresses IP ou les localisateurs, les caches sont moins nécessaires.
Un petit mot sur la sécurité, maintenant. Comme les informations
nécessaires sont vraiment critiques (un L64
erroné et tout le trafic va à une autre machine), la section 4
recommande d'utiliser DNSSEC (RFC 4033) pour protéger ses
informations. (À l'été 2012, le déploiement de DNSSEC est très avancé,
alors que celui d'ILNP est inexistant. Il est donc raisonnable de
compter que DNSSEC sera disponible.) Lors des mises à jour dynamiques,
il faut utiliser les sécurités décrites dans le RFC 3007. Par exemple, avec le serveur de noms
Yadifa, on peut mettre à jour dynamiquement
une zone signée. On copie la clé privée (par exemple, pour une clé
générée avec dnssec-keygen pour la zone
secure.example, le fichier de la clé privée peut
être Ksecure.example.+005+05461.private) dans le
répertoire indiqué par la directive keyspath de
Yadifa et c'est tout. Les mises à jour dynamiques seront faites et
automatiquement signées. Le journal de Yadifa dira :
2012-09-25 20:54:12.754705 | server | I | update (831e) secure.example. SOA (127.0.0.1:44480) 2012-09-25 20:54:12.754749 | server | D | database: update: checking DNSKEY availability 2012-09-25 20:54:12.754778 | server | D | database: update: processing 0 prerequisites 2012-09-25 20:54:12.754791 | server | D | database: update: dryrun of 2 updates 2012-09-25 20:54:12.754828 | server | D | database: update: opening journal page 2012-09-25 20:54:12.755008 | server | D | database: update: run of 2 updates 2012-09-25 20:54:13.000526 | server | D | database: update: closed journal page
À la date de publication de ce RFC, il n'existe pas encore de logiciel DNS qui gère ILNP.
Pour finir, quelques articles sur l'idée d'utiliser le DNS pour localiser une machine mobile : « An End-To-End Approach To Host Mobility », « Reconsidering Internet Mobility » et « Mobile Host Location Tracking through DNS ».
L'article seul
RFC 6741: ILNP Engineering Considerations
Date de publication du RFC : Novembre 2012
Auteur(s) du RFC : RJ Atkinson (Consultant), SN Bhatti (U. St Andrews)
Expérimental
Réalisé dans le cadre du groupe de recherche IRTF RRG
Première rédaction de cet article le 10 novembre 2012
Le RFC 6740 décrivait l'architecture générale du mécanisme de séparation de l'identificateur et du localisateur ILNP. C'était le premier document à lire pour comprendre ILNP. Ce RFC 6741 est plus concret, exposant les questions d'ingéniérie autour d'ILNP. Il décrit surtout des points qui sont indépendants de la version d'IP utilisée, d'autres RFC couvrent les points spécifiques à IPv4 (RFC 6745 et RFC 6746) ou IPv6 (RFC 6743 et RFC 6744).
Donc, ILNP vise à fournir une meilleure architecture à l'Internet, en faisant évoluer IP vers une séparation de l'identificateur d'une machine (stable, indépendant de comment et par qui la machine est attachée au réseau) avec le localisateur (lié à l'attachement actuel au réseau, et pouvant donc changer). ILNP est décrit dans le RFC 6740 mais celui-ci ne donne qu'une vision de haut niveau, à laquelle manquent pas mal de détails. C'est le rôle de notre RFC que de combler ces manques. L'architecture ILNP peut avoir bien des incarnations concrètes, y compris par des approches « table rase » où on ne tient aucun compte de l'existant. Ce RFC 6741 présente une autre approche, plus progressive, où on essaie de déployer ILNP dans l'Internet actuel.
Vous avez bien lu le RFC 6740 d'architecture d'ILNP ou son résumé ? Alors, allons-y, plongeons nous dans les détails ILNP. D'abord, les identificateurs (section 2). Toute machine ILNP en a au moins un. Ils ne sont pas liés à une interface réseau et une machine avec N interfaces peut très bien n'avoir qu'un seul identificateur. (Notez toutefois qu'un identificateur peut être formé à partir d'une caractéristique d'une interface, comme l'adresse MAC. Mais ce n'est qu'un mécanisme de génération de l'identificateur, la carte réseau peut ensuite être changée sans affecter celui-ci.)
Les identificateurs sont des chaînes de 64 bits et la
représentation la plus simple est donc un entier non signé de 64 bits
(uint64_t dans un programme en
C, par exemple). Comme les identificateurs
d'interface d'IPv6 (section 2.5.1 du RFC 4291),
ils utilisent la syntaxe EUI-64. Cette
syntaxe décrit notamment deux bits, U et G, le premier indiquant si
l'identificateur est globalement unique ou non, et le second indiquant
s'il s'agit d'une adresse de groupe. Attention pour les programmeurs,
rien n'empêche une machine de prendre l'identificateur qu'elle veut
et, en pratique, des collisions peuvent se produire. À plusieurs
reprises, notre RFC donne des conseils à ceux qui mettent en
œuvre ILNP pour que ces collisions n'aient pas de conséquences
graves.
Si le bit U est à 1, cela indique que l'identificateur dérive de l'adresse MAC, et est donc garanti unique via l'enregistrement à l'IEEE.
Si le bit U est à 0, cela veut dire que l'identificateur n'est pas dérivé d'un registre central et n'a donc qu'une signification locale. Cela permet à ILNP de se passer d'une dépendance vis-à-vis d'une autorité unique. Autre intérêt, on peut alors générer un identificateur qui soit une clé cryptographique, par exemple (RFC 3972). On peut aussi avoir des identificateurs temporaires, pour préserver la vie privée, comme on le fait en IPv6 avec les adresses temporaires du RFC 8981.
Normalement, ce RFC n'était censé couvrir que les points indépendants de la famille d'adresses utilisée. Néanmoins, on y trouve aussi l'encodage des localisateurs et identificateurs dans un paquet IP (section 3). En IPv6, dans les champs « adresse IP » (source et destination), le localisateur prend les 64 bits de plus fort poids, et l'identificateur le reste. Grâce à cet encodage, le routeur IPv6, qui ne tient compte que du préfixe, traitera le localisateur comme un préfixe IP normal et n'aura besoin d'aucune modification pour gérer de l'ILNP. Le format du paquet ILNPv6 est en effet exactement le même que celui du paquet IPv6 classique.
C'est plus complexe en IPv4, en raison de la petite taille des champs adresse. On met donc les localisateurs dans l'adresse (source et destination), afin que les routeurs IPv4 puissent travailler comme aujourd'hui, et l'identificateur (qui fait toujours 64 bits) doit être mis dans une option IP, comme décrit dans le RFC 6746.
Et au niveau 4 (transport), qu'est-ce qui doit changer ? La principale modification est que TCP ou UDP doivent lier l'état d'une session en cours uniquement à l'identificateur et non plus à une adresse. Ainsi, le tuple traditionnel de TCP {adresse IP locale, port local, adresse IP distante, port distant}, qui identifie une connexion en cours, doit être remplacé par {identificateur local, port local, identificateur distant, port distant}, afin de bénéficier d'ILNP (notamment de la possiblité de changer d'adresse sans casser la connexion).
Attention, TCP doit normalement remplir le champ « somme de contrôle » (Checksum dans l'en-tête TCP) en incluant les deux adresses IP, locale et distante. En ILNP, il ne doit plus utiliser que les identificateurs, les localisateurs étant remplacés, pour le calcul de la somme de contrôle, par une série de bits nuls.
Un aspect d'ingéniérie très important d'ILNP est
l'ILCC, Identifier-Locator Communication
Cache. Cette structure de données, décrite en section 5,
garde trace des détails permettant de maintenir une communication avec
les CN (Correspondent Node, les machines ILNP avec
qui on parle). De tels caches existent déjà pour certains protocoles
(par exemple pour ARP, sur une machine
Unix, vous pouvez l'afficher avec la commande
arp -a -n, pour NDP, sur
Linux, avec ip -6 neighbour
show). Et ceci sans parler des informations que doit garder
TCP. Donc, le nouvel ILCC n'est pas forcément une grosse contrainte
pour les machines.
Que stocke l'ILCC ?
- Le ou les Identificateurs du nœud local, en indiquant les préférences, et s'ils sont actuellement en service (utilisables pour une nouvelle session),
- Le ou les Localisateurs du nœud local, en indiquant les préférences, et s'ils sont actuellement en service,
- Le ou les Identificateurs de chaque correspondant (CN), en indiquant les préférences, leur validité, et s'ils sont actuellement en service,
- Le ou les Localisateurs de chaque correspondant, en indiquant les préférences, leur validité, et s'ils sont actuellement en service,
- Les numniques à utiliser pour chaque correspondant, celui vers le CN et celui depuis le CN.
La validité peut être déterminée par divers moyens. Lorsque l'information a été apprise dans le DNS, c'est typiquement le TTL qui est utilisé. Toutefois, même lorsque le TTL expire, ce n'est pas une bonne idée de retirer les valeurs immédiatement (on risque de se couper d'un CN qui n'a pas mis à jour ses données assez vite). Il vaut donc mieux marquer un Localisateur comme « pas à jour mais peut-être encore utilisable si on n'a pas le choix ».
Et pour accéder à l'ILCC, quelle clé de recherche utilise-t-on ? L'identificateur, ce qui serait logique ? Raté. Pour les paquets qui contiennent un numnique, on utilise un tuple {Identificateur, Numnique} et pour les autres un tuple {Identificateur, Localisateur}. Le but de ce choix est de se prémunir contre les cas où deux machines utiliseraient le même identificateur (ce qui peut arriver, surtout avec le bit U à zéro).
On a vu qu'un des buts d'ILNP était de gérer proprement les cas où une machine change de connectivité (panne d'un lien, déplacement, etc). La section 6 explique les détails de ce cas. Lorsqu'une machine apprend qu'un de ses localisateurs ne marche plus, elle prévient ses CN (Correspondent Node) par un message ICMP Locator Update (RFC 6743 et RFC 6745). Ce message permet de retirer ou d'ajouter des localisateurs. Il est authentifié par le numnique, qui doit être identique à celui d'une session en cours (sinon, le paquet entrant ne correspond à aucune entrée dans l'ILCC, voir la section précédente).
Ça, c'est pour les sessions en cours. Pour les nouvelles, si une machine veut être contactée, elle doit mettre à jour la liste de ses localisateurs dans le DNS. ILNP dépend donc assez fortement des mises à jour dynamiques du DNS (RFC 2136 et RFC 3007), ou d'un mécanisme similaire.
Le lecteur attentif a pu remarquer plus tôt que le localisateur joue le rôle d'un préfixe IP, le routage est fondé sur lui. Mais un préfixe IP n'a pas forcément une longueur fixe. En IPv6, on peut parfaitement avoir un Tier 1 qui annonce un /32 en BGP, qui route ensuite dans son IGP des /48 et finalement un réseau local d'un client de l'opérateur qui route sur des /64. ILNP ne change rien à cela (section 7). Le localisateur comprend en fait deux parties, de longueur variable, un préfixe de localisateur et un sélecteur de réseau. Dans le cas de l'annonce BGP citée plus haut, les 64 bits du localisateur se partagent entre 32 bits de préfixe et 32 bits pour choisir un réseau.
On a vu qu'ILNP dépend énormément du DNS. Il est donc logique que ce RFC compte une une section 8 consacrée à ce service. D'abord, comme on l'a vu, pour des raisons de sécurité, ILNP recommande fortement de sécuriser les mises à jour du DNS (RFC 3007). Cette technique marche dans de nombreuses mises en œuvre du DNS (par exemple, BIND ou Active Directory l'ont depuis des années). Les clients capables d'utiliser TSIG ou une technique similaire pour mettre à jour un serveur DNS sont disponibles pour toutes les plate-formes (comme nsupdate sur Unix). Un exemple figure dans mon article sur le RFC 6742.
Pour accéder à l'information disponible, quatre nouveaux types d'enregistrement DNS sont créés par le RFC 6742 :
NIDpour stocker l'identificateur,L32etL64pour stocker des localisateurs de 32 (pour IPv4) et 64 bits,LP, pour ajouter un niveau d'indirection vers le localisateur, apportant ainsi davantage de souplesse pour les changements (qui peuvent être fréquents) des localisateurs, qui peuvent être délégués à une autre zone.
Quels TTL utiliser pour ces enregistrements ?
Le choix est particulièrement important pour les localisateurs, qui
peuvent parfois changer vite. Dans certains cas, un TTL de quelques secondes seulement
peut donc être une valeur raisonnable pour les
L32 et L64. Si cela vous
semble peu, rappelez-vous que des études comme celle de Alex C. Snoeren, Hari Balakrishnan, & M. Frans Kaashoek, « Reconsidering Internet Mobility » (dans Proceedings of 8th Workshop on Hot Topics in Operating Systems en 2002) ou celle de S. Bhatti & R. Atkinson, « Reducing DNS Caching » (dans Proc. GI2011 - 14th IEEE Global Internet Symposium en 2011) ont montré qur le cache dans
le DNS est surtout utile pour les enregistrements
d'infrastructure (type NS
et colles, c'est-à-dire adresses IP des serveurs situés dans la zone qu'ils servent), pas pour les enregistrements « terminaux » comme
AAAA ou MX.
Les enregistrements LP et
NID sont bien plus stables et peuvent, eux, avoir
des TTL de plusieurs jours. Dans le cas d'identificateurs temporaires
et/ou cryptographiquement signés, un TTL plus court est toutefois à envisager.
À noter que le RFC recommande que les machines ILNP publient dans
le DNS, non seulement les NID et
L64 spécifiques d'ILNP mais aussi des plus
traditionnels AAAA pour les machines non-ILNP. Un
serveur DNS qui connait ILNP peut également envoyer d'autorité les NID et
L64 dans la section additionnelle de la réponse
DNS. Les machines non-ILNP ignoreront ces enregistrements inconnus mais les autres pourront en
tirer profit.
L'expérience (douloureuse) d'IPv6 a montré que la possibilité d'un déploiement progressif, n'exigeant pas de tout le monde qu'il migre, était un élément nécessaire de tout nouveau protocole réseau. La section 10 de notre RFC regarde donc de près si ILNP est déployable progressivement. D'abord, les paquets ILNP, que ce soit ILNPv4 ou ILNPv6 sont indistinguables, pour les routeurs, les pare-feux et autres équipements, de paquets IPv4 et IPv6 classiques. Ils devraient donc passer sans problème sur ces équipements, sans qu'on change leurs configurations, leurs protocoles de routage, etc. ILNP, comme HIP, peut en effet être déployé uniquement sur les machines terminales, par une simple mise à jour logicielle. Pour la même raison, des machines ILNP peuvent coexister avec des machines IP Classic sur un même lien.
Je trouve que le RFC est trop optimiste : l'expérience montre que les options IP, nécessaires à ILNP, passent mal dans l'Internet IPv4 actuel et n'ont guère été testées en IPv6 (le RFC ne mentionne que le cas des pare-feux qui bloqueraient explicitement les options et pas celui de routeurs bogués). De toute façon, une exception est à prévoir, en ILNPv4 uniquement, les routeurs du réseau local devront être mis à jour pour gérer une extension d'ARP. Autre exception, certains routeurs NAT, selon la façon dont ils sont réglés, peuvent casser ILNP en réécrivant ce qu'ils croient être une adresse et qui serait un bout de l'identificateur.
Pour les applications, c'est plus compliqué. Si l'application est « bien élevée » (n'utilise que des noms de domaine, ne manipule pas explicitement d'adresses IP), elle devrait fonctionner en ILNP sans problème. Mais bien des applications ne sont pas bien élevées (FTP, SNMP...)
La section 14, consacrée aux applications et API revient en détail sur ces questions. D'abord, une bonne partie des applications existantes, notamment parmi celles écrites en C, utilise l'API dite BSD Sockets. Elle n'est pas forcément incompatible avec ILNP. Par exemple, les applications IPv6 peuvent mettre la concaténation du localisateur et de l'identificateur dans les champs de l'API prévus pour mettre une adresse IP et cela passera, puisque c'est justement l'encodage du couple {Identificateur, Localisateur} sur le câble. Néanmoins, cette API est de trop bas niveau, même sans tenir compte d'ILNP (par exemple, elle oblige à avoir un portage d'IPv4 en IPv6 alors que cette modification dans la couche 3 devrait être invisible des applications). Souhaitons donc (et pas seulement pour ILNP) que les programmeurs passent à des API plus abstraites.
Tout le monde ne programme pas en C. Pour les autres langages, il
est courant d'utiliser des API de plus haut niveau que ces
sockets. Ainsi, en Java, les
clients Web vont plutôt faire appel à la classe
java.net.URL. Ainsi, complètement isolés des
couches basses, ils passeront à ILNP sans s'en rendre compte. Même
chose pour des langages comme Ruby ou Python.
Le piège classique des API réseau est l'utilisation de références, lorsqu'Alice dit à Bob « va voir Charlie ». Ces références cassent pas mal de protocoles. Une solution pour ILNP serait de faire des références avec des FQDN.
Et pour communiquer entre machines ILNP et non-ILNP ? Le RFC recommande que les
machines ILNP gardent également l'IP Classic, approche connue sous le
nom de dual stack (être capable de parler les deux
protocoles). Une longue coexistence d'ILNP avec des machines IP est
prévue. Pour la machine qui initie la connexion, si elle trouve
un NID dans le DNS, elle tente ILNP (en mettant
l'option Nonce/numnique), sinon elle
reste en IP Classic. Si la machine distante ne gère pas ILNP (malgré
ce que raconte le DNS), elle rejettera l'option Nonce avec un message
ICMP (l'option a un type qui indique que le paquet doit être rejeté
par ceux qui ne comprennent pas l'option, cf. RFC 2460, sections 4.2 et 4.5), qui permettra à l'initiateur de voir qu'il s'est trompé et doit
réessayer en IP traditionnel.
Pour la machine qui répond aux demandes de connexion, si le paquet initial contient une option Nonce, c'est que le demandeur gère ILNP. Sinon, on s'en tient à l'IP de nos grand-mères.
Question sécurité, la section 9 est consacrée à IPsec. Il n'est pas très différent avec ILNP de ce qu'il est avec IP Classic. Le principal changement est que les associations de sécurité se font avec l'identificateur, pas avec l'adresse (elles ne changent donc pas si une machine change de localisateur). Ainsi, AH ne valide que l'identificateur (le localisateur n'est pas protégé, ce qui permet à ILNP+AH de fonctionner même en présence de NAT).
Autres questions de sécurité en section 11 : les auteurs estiment qu'ILNP n'est pas moins sûr qu'IP. Il ne l'est pas non plus forcément davantage. Un exemple typique est qu'une machine peut mentir sur son identificateur, comme elle peut mentir sur son adresse IP (les solutions sont également les mêmes, IPsec + IKE ou bien les CGA du RFC 3972).
Le principal risque nouveau est celui de faux messages ICMP Locator Update. Ils pourraient provoquer bien des dégâts, par exemple en convaincant un CN d'envoyer tous les paquets d'une machine à un attaquant. C'est pour cela que l'option Nonce est absolument indispensable, même lorsque IPsec est utilisé. À noter que cette option ne protège pas contre un attaquant situé sur le chemin, puisque ce dernier peut alors écouter le réseau et lire le numnique (la situation est exactement la même en IP Classic, par exemple avec les numéros de séquence TCP, qui ne protègent que contre les attaquants hors du chemin). On est donc bien dans un cas « sécurité pas pire qu'avec IP Classic (mais pas meilleure non plus) ». Si on veut aller plus loin en sécurité, il faut IPsec ou un équivalent.
À noter aussi que les autres messages ICMP (Packet too big, Destination unreachable, etc), ne sont pas protégés par le numnique. Ces messages sont en général émis par des équipements intermédiaires, genre routeurs, qui ne connaissent normalement pas le numnique. Comme en IP Classic, ils peuvent donc parfaitement être usurpés (cf. RFC 5927).
La sécurité inclus aussi le respect de la vie privée (section 12). Notre RFC renvoie au RFC 6740 qui discutait cette question dans le cadre d'ILNP.
Enfin, la section 13 contient diverses notes sur des problèmes pratiques. Notamment :
- Les délais de mise à jour lorsqu'une machine ILNP se déplace trop vite, par rapport à la réjuvénation du DNS. Mobile IP avait déjà ce problème. La mobilité d'un piéton, ça va, celle d'un avion va poser des problèmes.
- L'absence de garantie qu'on peut réellement joindre une machine
via le localisateur indiqué. En effet, ILNP ne teste pas cela. Par
exemple, un enregistrement
L64dans le DNS peut être erroné et rien ne l'indique au client ILNP. Comme en IP Classic, on n'est jamais sûr qu'un paquet arrivera et les logiciels doivent en tenir compte.
Comme il n'y a pas encore eu de déploiement, même limité, même de test, d'ILNP, nul doute que la liste des problèmes et questions s'allongera lorsqu'on passera à l'expérience sur le terrain.
L'article seul
PostgreSQL et les quantiles, via les « window functions »
Première rédaction de cet article le 9 novembre 2012
Le SGBD PostgreSQL dispose de tas de fonctions utiles. Une relativement peu connue est le système des « window functions » qui agissent sur un découpage d'un ensemble de tuples, s'appliquant à chaque part découpée. Cela permet notamment de travailler sur les quantiles.
Bon, avant de détailler, voyons un cas réel et concret. On a une base de données du personnel et une table stocke les salaires :
CREATE TABLE Salaries
(id SERIAL UNIQUE NOT NULL,
name TEXT UNIQUE NOT NULL,
salary INTEGER NOT NULL);
INSERT INTO Salaries (name, salary) VALUES ('John', 3000);
INSERT INTO Salaries (name, salary) VALUES ('Sandy', 2000);
...
On charge cette table (le fichier complet est disponible). Il est alors facile de trouver des choses comme le salaire moyen :
essais=> SELECT round(avg(salary)) FROM Salaries; round ------- 3417 (1 row)
ou de trier selon le salaire, ici du plus payé vers le moins payé :
essais=> SELECT name,salary FROM Salaries ORDER BY salary DESC; name | salary ---------+-------- Patt | 9600 Robert | 7000 Steve | 4000 ...
Mais on cherche des choses plus subtiles. Par exemple, le salaire moyen plait aux dirigeants pour la communication car il est relativement élevé, tiré vers le haut par quelques gros salaires. En cas de forte inégalité, ce qui est le cas dans l'entreprise de notre exemple, il est nettement moins pertinent que le le salaire médian. Il existe plusieurs méthodes pour calculer ce dernier. Par exemple, la médiane étant par définition le salaire tel que la moitié des employés gagnent davantage, un calcul approximatif (qui ignore les arrondis) est :
essais=> SELECT salary FROM salaries ORDER BY salary DESC LIMIT
(SELECT count(id) FROM salaries) / 2;
...
2900
Un moyen plus sophistiqué est de travailler sur les quantiles. Les quantiles sont les découpages des données triées en N parties égales. Si N = 100, on parle de centiles, si N = 10 de déciles, etc. Pour la médiane, on va prendre N = 2. Mais, avant cela, un petit détour par les « window functions » de PostgreSQL.
Ces fonctions opèrent sur une partie des tuples retournés par une
requête. Le découpage en parties est fait par la clause
OVER. Prenons l'exemple d'un découpage en autant
de parties qu'il y a de tuples triés, et de la « window
function » rank() qui indique la place
d'un tuple par rapport aux autres :
essais=> SELECT name,salary,rank() OVER (ORDER BY salary DESC) FROM Salaries
ORDER BY name;
name | salary | rank
---------+--------+------
Alfonso | 2300 | 14
Bill | 2900 | 8
Bob | 2800 | 10
Chris | 2900 | 8
Chuck | 3800 | 4
...
Le (ORDER BY salary DESC) après
OVER indique que les tuples vont être classés
selon le salaire décroissant. rank() va alors
s'appliquer à ce classement : Alfonso a le quatorzième salaire (en
partant du haut), Bill le huitième, etc. Notez que les ex aequo sont
possible (ici, Bill et Chris). row_number()
ferait la même chose que rank() mais sans les ex aequo.
Revenons maintenant aux quantiles. La fonction
ntile() permet de découper un ensemble de tuples
en quantiles (le nombre de quantiles étant l'argument de
ntile(), ici on utilise des terciles) :
essais=> SELECT name,salary,ntile(3) OVER (ORDER BY salary) FROM Salaries; name | salary | ntile ---------+--------+------- Sandy | 2000 | 1 ... Lou | 2600 | 2 ... Peter | 3400 | 3
Ici, Sandy est dans le tercile le plus bas
(ntile() renvoie 1) et Peter dans celui des
meilleurs salaires.
On peut utiliser les quantiles de tas de façons. Par exemple :
essais=> SELECT n,min(salary),max(salary) FROM
(SELECT name,salary,ntile(3) OVER (ORDER BY salary) as n FROM Salaries) AS q
GROUP BY n ORDER BY n;
n | min | max
---+------+------
1 | 2000 | 2500
2 | 2600 | 3000
3 | 3400 | 9600
Ici, on a la plage des salaires pour chaque tercile. Et la médiane que j'avais promise ?
essais=> SELECT n,min(salary),max(salary) FROM
(SELECT name,salary,ntile(2) OVER (ORDER BY salary) as n FROM Salaries) AS q
GROUP BY n ORDER BY n;
n | min | max
---+------+------
1 | 2000 | 2800
2 | 2900 | 9600
Elle est de 2850.
Une autre façon de représenter l'inégalité est de voir quelle part des salaires représente chaque quantile. Passons à des quintiles (N = 5) :
essais=> SELECT n, sum(salary)*100/(SELECT sum(salary) FROM Salaries) AS percentage
FROM (SELECT name,salary,ntile(5) OVER (ORDER BY salary) as n FROM Salaries) AS q
GROUP BY n ORDER BY n;
n | percentage
---+------------
1 | 13
2 | 16
3 | 18
4 | 17
5 | 33
Le quintile supérieur représente le tiers du total des salaires. (On note que c'est le seul des cinq quantiles à représenter plus que sa part, qui serait de 20 % en cas de totale égalité.)
Tout cela ne sert évidemment pas qu'aux salaires. Si on prend des requêtes DNS analysées par DNSmezzo, et qu'on étudie la répartition du trafic par résolveur, on observe que certains résolveurs n'envoient que très peu de requêtes (c'était peut-être un étudiant faisant un ou deux dig), alors que d'autres sont bien plus bavards. Ici, on étudie 447 658 requêtes reçues par un serveur faisant autorité, en IPv6. On observe 3 281 préfixes IPv6 de longueur /48. Quelle est la répartition des requêtes ?
dnsmezzo=> SELECT n,min(requests),max(requests),
to_char(sum(requests)*100/(SELECT count(id) FROM DNS_packets WHERE query AND family(src_address)=6), '99.9') AS percentage FROM
(SELECT prefix,requests,ntile(10) OVER (ORDER BY requests) AS n FROM
(SELECT set_masklen(src_address::cidr, 48) AS prefix, count(id) AS requests FROM
DNS_packets WHERE query AND family(src_address)=6
GROUP BY prefix ORDER by requests DESC) AS qinternal) AS qexternal
GROUP BY n ORDER BY n;
n | min | max | percentage
----+-----+-------+------------
1 | 1 | 1 | .1
2 | 1 | 1 | .1
3 | 1 | 2 | .1
4 | 2 | 3 | .2
5 | 3 | 4 | .2
6 | 4 | 7 | .4
7 | 7 | 14 | .8
8 | 14 | 32 | 1.6
9 | 32 | 89 | 3.9
10 | 89 | 81718 | 92.7
On voit que les cinq premiers déciles ont un trafic négligeable, et que le dixième décile, les clients les plus bavards, fait plus de 90 % des requêtes à lui seul. (En utilisant des centiles et non plus des déciles, on confirme cette grande inégalité : le centile supérieur fait 72 % des requêtes.)
Un bon tutoriel sur les « windows functions » sur PostgreSQL
(et qui couvre la clause PARTITION dont je n'ai
pas parlé ici), est en
ligne. Pour jouer avec les quantiles, il existe aussi une extension de
PostgreSQL que je n'ai pas testée, quantile. Elle est
notamment censée être plus rapide.
Ces fonctions ne sont pas spécifiques à PostgreSQL, elles sont apparues dans la norme SQL en 2003 sous le nom de « fonctions analytiques ». On les trouve dans plusieurs autres SGBD, par exemple Firebird. On les trouve dans beaucoup de questions sur StackOverflow. Merci à Malek Shabou et Pierre Yager pour leur relecture.
L'article seul
RFC 6726: FLUTE - File Delivery over Unidirectional Transport
Date de publication du RFC : Novembre 2012
Auteur(s) du RFC : T. Paila (Nokia), R. Walsh (Tampere University of Technology), M. Luby (Qualcomm), V. Roca (INRIA), R. Lehtonen (TeliaSonera)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF rmt
Première rédaction de cet article le 7 novembre 2012
Peut-on envoyer un fichier d'un ordinateur à un autre lorsque la liaison est unidirectionnelle, c'est-à-dire que les paquets ne voyagent que dans un sens ? Pas question de se servir de FTP ou de HTTP, qui reposent sur le protocole de transport TCP, qui a besoin de bidirectionnalité (car il dépend du retour des accusés de réception). Le protocole FLUTE (File Delivery over Unidirectional Transport) normalisé dans ce RFC, fournit un ensemble de mécanismes pour effectuer ce transfert. La principale application concerne le multicast, où une machine unique diffuse un fichier à plusieurs autres, qu'elle ne connait pas forcément et qui ne peuvent pas lui écrire. Un exemple typique est la distribution des mises à jour d'un gros logiciel à des milliers, voire millions, de machines dans le monde. Parmi les usages possibles, distribuer de la vidéo, une nouvelle version d'un jeu très populaire, etc.
Pour cela, FLUTE s'appuie sur le système ALC (RFC 5775) + LCT (Layered Coding Transport, RFC 5651), qui fait l'essentiel du travail. ALC+LCT sert de protocole de transport d'objets binaires, FLUTE se charge de la sémantique. FLUTE dépend aussi d'autres protocoles de la famille multicast, comme FEC (RFC 5052), qui assure la fiabilité du transport, en permettant au récepteur de détecter les erreurs.
Transférer des gros fichiers sur un réseau ouvert comme l'Internet implique également un mécanisme de contrôle de la congestion, pour éviter que l'émetteur ne noie le réseau sous les paquets, sans se rendre compte que les tuyaux sont pleins. Comme on n'a pas TCP pour limiter la congestion en détectant les paquets perdus, il faut trouver un autre mécanisme. Dans le cas de FLUTE, les récepteurs souscrivent plusieurs abonnements multicast, éventuellement de débits différents, et jonglent avec ces divers abonnements. (Sur des réseaux fermés, le contrôle de congestion de FLUTE peut se faire par encore d'autres mécanismes comme le shaping.)
Les métadonnées (les propriétés du fichier) sont transmises dans un élément XML. On y trouve entre autres :
- Un identifiant du fichier, un URI. C'est juste un identifiant, et rien ne garantit qu'on puisse récupérer le fichier à cet « endroit ».
- Un type de contenu, par exemple
text/plain. - La taille du fichier.
- Un encodage utilisé pendant le transport, par exemple la compression avec zlib (RFC 1950).
- D'éventuelles informations de sécurité comme une empreinte cryptographique ou une signature numérique.
L'élement XML <File> qui contient tout cela
est mis ensuite dans un élément
<FDT-Instance> (FDT = File
Delivery Table) qui contient également les informations
externes au fichier (comme la date limite pendant laquelle
cette information sera valable). Voici
l'exemple que donne le RFC, pour le fichier track1.mp3 :
<?xml version="1.0" encoding="UTF-8"?>
<FDT-Instance xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:ietf:params:xml:ns:fdt
ietf-flute-fdt.xsd"
Expires="2890842807">
<File
Content-Location="http://www.example.com/tracks/track1.mp3"
Content-Length="6100"
Content-Type="audio/mp3"
Content-Encoding="gzip"
Content-MD5="+VP5IrWploFkZWc11iLDdA=="
Some-Private-Extension-Tag="abc123"/>
</FDT-Instance>
Cet élément XML est transmis avec le fichier. Les informations liées à l'émission du fichier (adresse IP source qui émettra le fichier, début de l'émission, etc) sont récupérées par le destinataire par un moyen non spécifié ici (cf. section 6). Cela a pu être une description SDP (RFC 4566), une ressource sur le Web ou bien d'autres méthodes, même une configuration manuelle. Le point important est que, une fois toutes ces informations en sa possession, le récepteur FLUTE peut se préparer à recevoir le fichier, et peut vérifier sa bonne délivrance (l'émetteur, lui, n'en saura rien, puisque la liaison est unidirectionnelle).
L'envoi unidirectionnel de fichiers soulève des problèmes de sécurité particuliers (section 7, très détaillée). Si le fichier transmis est confidentiel, il doit être chiffré avant, que ce soit par un chiffrement global du fichier (par exemple avec PGP) ou en route par IPsec.
Et si l'attaquant veut modifier le fichier ? On peut utiliser une signature numérique du fichier, avant son envoi ou bien, pendant le trajet authentifier les paquets ALC avec le RFC 6584 ou bien TESLA (Timed Efficient Stream Loss-Tolerant Authentication, RFC 4082 et RFC 5776) ou encore, là aussi, IPsec. À noter que certaines de ces techniques demandent une communication bidirectionnelle minimale, par exemple pour récupérer les clés publiques à utiliser.
Ce RFC est la version 2 de FLUTE, la version 1 était normalisée dans le RFC 3926, qui avait le statut expérimental. Avec ce nouveau document, FLUTE passe sur le chemin des normes IETF. La liste des changements importants figure en section 11. Notez tout de suite que FLUTE v2 est un protocole différent, incompatible avec FLUTE v1.
Je ne connais pas les implémentations de FLUTE mais il en existe plusieurs (pour la version 1) par exemple jFlute, l'ancien MCL v3 (plus maintenue en version libre mais Expway en a une version commerciale fermée) ou MAD-FLUTE fait à l'université de Tampere.
Merci à Vincent Roca pour sa relecture attentive.
L'article seul
RFC 6782: Wireline Incremental IPv6
Date de publication du RFC : Novembre 2012
Auteur(s) du RFC : V. Kuarsingh (Rogers Communications), L. Howard (Time Warner Cable)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 7 novembre 2012
Parfois, je me dis que si on consacrait tous les efforts qui ont été voués à écrire des RFC à propos d'IPv6 à déployer IPv6 au lieu d'expliquer comment le faire, ce protocole aurait remplacé IPv4 depuis longtemps... Toujours est-il que voici un nouveau RFC, consacré à la synthèse de l'état de l'art en matière de déploiement incrémental d'IPv6 pour un opérateur filaire (FAI ADSL ou câble par exemple).
« Incrémental » car peu d'opérateurs ont la possibilité de déployer un réseau purement IPv6. Par contre, je ne sais pas pourquoi le RFC se limite au filaire, la plus grande partie de son texte peut tout à fait s'appliquer aussi bien à un opérateur mobile (genre 3G).
Plein de textes ont déjà été écrits sur ce même sujet mais les choses changent et il est peut-être bon de temps en temps de refaire une synthèse. Donc, l'idée est de prendre par la main un opérateur qui, en 2012, serait toujours en IPv4 pur (c'est donc un opérateur assez retardé techniquement), pour l'amener (à long terme !) en IPv6 pur (cf. section 3.6). Le point important à garder en mémoire est que chaque opérateur est différent et que, s'il existe plusieurs mécanismes de migration d'IPv4 vers IPv6, ce n'est pas uniquement parce que l'IETF aime écrire beaucoup de RFC, c'est surtout parce qu'il n'y a pas un mécanisme qui conviendrait miraculeusement à tous les cas (cf. le RFC 6180 qui décrivait tous ces mécanismes).
Donc, point de départ, un opérateur Internet qui a des clients en IPv4 (et qu'il n'est pas question de migrer immédiatement), qui veut déployer IPv6 mais en ne cassant pas ce qui existe, en minimisant la quantité de travail nécessaire (donc sans déployer de technologies inutiles). En outre, on veut une qualité de service optimum, donc éviter les tunnels, si possible.
Avec un tel cahier des charges, une migration soudaine de tout le réseau d'un protocole vers un autre est hors de question. Il faut une démarche progressive, où IPv6 arrive petit à petit pendant qu'IPv4 continue de fonctionner correctement. Le problème, c'est que, sur le papier, une telle approche progressive (phased approach) est très sympa mais, en pratique :
- Par suite de la procrastination d'un grand nombre d'acteurs, les adresses IPv4 sont déjà épuisées,
- Si IPv6 est mis en œuvre dans tous les logiciels et équipements sérieux, depuis de nombreuses années, il n'a pas toujours été utilisé en production avec la même intensité qu'IPv4 et des bogues traînent donc toujours,
- Le FAI ne contrôle en général pas les équipements des clients (c'est une des différences entre le FAI filaire et le mobile) et ceux-ci peuvent avoir des vieux systèmes, avec peu ou pas de gestion d'IPv6,
- Le retour à un réseau multi-protocoles (qui n'est pas une nouvelle chose : dans les années 1980, tous les réseaux locaux étaient multi-protocoles) va poser quelques problèmes opérationnels.
Le RFC rappelle que le client final, le mythique « M. Michu », ne demande pas IPv6. Il ne demande pas IPv4 non plus. Il veut un accès à l'Internet, point. C'est aux professionnels de faire en sorte que son accès fonctionne, aussi bien en IPv4 qu'en IPv6. Les deux protocoles coexisteront sur le réseau local pendant encore longtemps (section 3.1 du RFC).
La section 3 du RFC examine plus en détail ces défis pratiques. La pénurie de plus en plus aiguë d'adresses IPv4 va nécessiter du partage d'adresses IP, avec tous ses inconvénients (RFC 6269, et la section 4.2 de notre RFC). Les autres solutions (gratter les fonds de tiroir à la recherche de préfixes oubliés, acheter au marché gris ou noir des adresses vendues sans garantie) ne suffiront sans doute pas.
Mais IPv6 ne peut pas se déployer en cinq minutes. Sans même prendre en compte l'existence de vieux systèmes ne parlant qu'IPv4, l'opérateur qui va déployer IPv6 va devoir prévoir une période d'assimilation des nouvelles pratiques (IPv6 est très proche d'IPv4 mais pas identique). Souvent, les humains ne sont pas au même niveau en IPv6 qu'en IPv4, et c'est pareil pour les logiciels (pas toujours testés au feu). Si la connectivité IPv4 de l'opérateur va dépendre de sa connectivité IPv6 (comme c'est le cas avec certaines techniques comme DS-Lite - RFC 6333 - ou NAT64 - RFC 6146), un problème IPv6 va également toucher IPv4.
Il faut donc faire attention à ne pas déployer IPv6 sans supervision et de réaction adaptés. Trop souvent, des organisations ont mis un peu d'IPv6, se disant que c'était facile et sans conséquences, puis se sont aperçu après qu'un réseau non géré était moins utile : pannes IPv6 non détectées par le système de surveillance, par exemple.
Certaines des techniques de transition n'ont pas aidé, en proposant des mécanismes qui avaient l'avantage de permettre de faire de l'IPv6 rapidement, et l'inconvénient de fournir aux utilisateurs un vécu de moins bonne qualité. C'est le cas notamment avec les tunnels (tous les tunnels ne sont pas forcément mauvais mais, dans l'histoire d'IPv6, il y a eu beaucoup de problèmes à cause de certains tunnels) : ajoutant une complication supplémentaire, forçant le passage par un chemin qui n'est pas toujours optimum, les tunnels ne devraient être utilisés que lorsqu'il n'y a pas d'autre choix, et en toute connaissance de cause. L'objectif est bien de fournir de la connectivité native.
Avec ces défis en tête, la section 4 du RFC rappelle les techniques de transition et de coexistence possibles. La première citée est la catégorie des tunnels automatiques, 6to4 et Teredo, à mon avis la pire (le RFC 6343 documente certains des problèmes avec 6to4 et le RFC 7526 demande qu'il ne soit plus utilisé). Le problème de fond de ces techniques est qu'elles ne fournissent aucun moyen de contrôler le chemin de retour, ou même de savoir s'il existe. Elles ne devraient à mon avis être utilisées que si on veut décourager les gens de faire de l'IPv6
6rd (RFC 5969) bouche certains des trous de 6to4 et c'est la technique qu'a utilisé Free pour distribuer IPv6 sur son réseau, en attendant un hypothétique accès natif. Son principal avantage est qu'il limite l'investissement initial pour l'opérateur, lui permettant de croître progressivement.
DS-Lite (RFC 6333) tunnele l'IPv4 sur un réseau IPv6. Il est surtout intéressant pour un opérateur qui part de zéro (par exemple parce qu'il vient de se créer) et qui peut donc construire un réseau entièrement IPv6 (ce qui peut être difficile avec certains équipements, encore aujourd'hui), tout en ayant des clients IPv4 à satisfaire. Le CPE doit être capable de faire du DS-Lite donc cette solution marche mieux si le FAI contrôle les CPE.
NAT64 (RFC 6146) est pour le cas où les clients sont bien en IPv6 mais où certains services à l'extérieur ne sont accessibles qu'en IPv4. Elle ne semble donc pas d'une grande actualité aujourd'hui, puisque le réseau local purement IPv6 est encore dans le futur (voir RFC 6586). Elle sera plus utile lorsque les réseaux purement IPv6 devront accéder aux derniers dinosaures IPv4.
La technique de coexistence IPv4/IPv6 qui donne les meilleurs résultats, est la double pile (dual stack) où les machines ont les deux protocoles et deux adresses. Pour permettre l'étape suivante (IPv6 pur), elle nécessite un réseau entièrement IPv6 (y compris les services, par exemple le DNS). Elle ne résout pas le problème de l'épuisement des adresses IPv4 donc, pour un opérateur actuel, le vécu IPv4 restera marqué par le partage d'adresses, le CGN et autres horreurs.
À noter que j'ai fait un exposé comparant toutes ces techniques de transition en 2011 à Grenoble.
Après les défis, et les techniques disponibles, la section 5 présente les différentes phases du déploiement. Une organisation qui va passer à IPv6 peut utiliser cette section comme point de départ pour établir son propre plan de migration. Il est important de noter que ce RFC ne fournit pas un plan tout prêt adapté à tout le monde. Il fournit des lignes directrices, mais chacun doit créer son propre plan, en tenant compte de son réseau, de ses clients, de ses moyens humains et financiers. (Une vision plus technique est dans le RFC 6180.)
La section 5 liste successivement plusieurs phases. J'espère qu'en 2012, plus personne n'en est encore à la phase 0 mais on ne sait jamais... La phase 0 commence par la formation : si personne dans l'organisation (ou bien seulement un ou deux geeks) ne connait IPv6, il faut apprendre. Cela peut se faire par des formations formelles, ou en lisant des livres ou des textes sur le Web. Pour le personnel d'exécution, le RFC rappelle qu'il vaut mieux que la formation soit faite juste avant le déploiement, pour qu'elle ne soit pas oubliée lorsque le moment de s'en servir viendra. Cette phase 0 ne doit pas être purement théorique, et il faut aussi pratiquer, dans un laboratoire dédié à cet effet, à la fois pour que les gens apprennent par la pratique, et pour tester si les matériels et logiciels utilisés dans l'organisation n'ont pas de problème avec IPv6.
Armé de cette formation et de cette expérience en laboratoire, les techniciens peuvent alors commencer à planifier le futur routage IPv6 de leur réseau. Est-ce la même tâche qu'en IPv4 ? On peut argumenter dans un sens ou dans l'autre. Le RFC met plutôt l'accent sur les différences mais on peut aussi considérer que le modèle de routage est tellement proche dans les deux protocoles qu'il ne faut pas dramatiser les différences.
Outre la politique de routage, trois autres points doivent retenir l'attention de l'équipe qui conçoit le plan de migration vers IPv6 :
- La sécurité, pour laquelle IPv6 peut poser quelques différences (comme pour le routage, je les trouve mineures) : les RFC 4942, RFC 6092 et RFC 6169 contiennent des analyses utiles sur la sécurité d'IPv6 (dommage, à mon avis, que le RFC 6104 ne soit pas cité).
- L'administration des adresses IP (IPAM adaptés à IPv6) et la gestion du réseau,
- Et bien sûr les techniques de transition adaptés à cette organisation particulière.
On peut espérer qu'en 2012, la plupart des grosses organisations sérieuses ont au moins franchi la phase 0. Mais pas mal de petites organisations ne l'ont même pas encore commencé.
Étape suivante, la phase 1. Il s'agit cette fois de donner un accès IPv6 à ses clients ou utilisateurs, via des tunnels pour l'instant, car le réseau n'est pas forcément prêt pour de l'IPv6 natif partout. Par exemple, il est courant que le réseau interne d'un opérateur, équipé de routeurs récents, permette IPv6 mais que l'accès aux clients passe par des équipements qu'on ne contrôle pas complètement (par exemple des DSLAM) et qui ne sont pas prêts pour IPv6. (Notez qu'il n'est pas obligatoire de passer par toutes les phases. Si on a un réseau où on peut utiliser du natif tout de suite, nul besoin d'un détour par des tunnels.) La phase 1 peut se faire avec une technologie comme 6rd (RFC 5569), si on contrôle le CPE.
Naturellement, à cette phase 1, il n'y aura pas de miracle : on utilisera des tunnels, donc on aura les problèmes associés aux tunnels comme la MTU diminuée.
Ensuite, place à la phase 2. Cette fois, on fournit de l'IPv6 natif. Tout fonctionne en IPv6 et, surtout, avec le même niveau de qualité qu'en IPv4. C'est un point très important car un certain nombre de fournisseurs qui se vantent de permettre IPv6 ne surveillent pas automatiquement la connectivité IPv6 (laissant les clients faire cette surveillance) et, même lorsqu'on leur signale un problème, le traitent uniquement dès qu'ils ont du temps libre (alors qu'un problème IPv4 est traité immédiatement). Un niveau de service équivalent à celui d'IPv4 est crucial si on veut convaincre les clients de migrer. Si vous faites l'audit du niveau de préparation IPv6 d'un fournisseur d'accès ou d'hébergement, ce sont les meilleurs tests : 1) le monitoring est-il également fait pour IPv6 ? 2) en cas de panne IPv6, y a-t-il le même niveau de mobilisation que pour IPv4 ? (Ou bien, est-ce que le NOC réagira en se disant « ah, IPv6, c'est Richard, on va attendre qu'il revienne de vacances », ce qui est le cas de la majorité des sociétés prétendant faire de l'IPv6 aujourd'hui.)
À ce stade, il faut encore fournir le service IPv4. Compte-tenu de l'épuisement des adresses, il faudra probablement déployer du CGN/NAT444, peut-être avec l'aide de technologies comme DS-Lite (RFC 6333). Au début du déploiement, le CGN peut encore être une grosse machine centrale puis, si son usage croît, être réparti petit à petit sur d'autres machines.
Normalement, l'usage d'IPv4 devrait ensuite suffisamment baisser pour qu'on puisse passer à la phase 3, un réseau purement IPv6. En novembre 2012, au moment où j'écris ces lignes, cela semble une perspective très lointaine, sauf peut-être sur des réseaux très spécifiques. Mais cela arrivera bien un jour.
Même dans ce cas, il est possible qu'il faille fournir une connectivité IPv4 à certains clients. DS-Lite, qui tunnele le trafic IPv4 sur le réseau IPv6, est là encore utile. Si, ce qui est plus vraisemblable, on a juste besoin de permettre l'accès des clients IPv6 à des sites Web qui sont restés en IPv4, NAT64 (RFC 6144 et RFC 6146) sera sans doute la bonne solution. Mais, bon, c'est un problème pour le futur... Le RFC a un ton plutôt pessimiste et, à mon avis, voit le verre IPv6 plutôt à moitié vide.
L'article seul
RFC 6783: Mailing Lists and non-ASCII Addresses
Date de publication du RFC : Novembre 2012
Auteur(s) du RFC : J. Levine (Taughannock Networks), R. Gellens (Qualcomm)
Pour information
Réalisé dans le cadre du groupe de travail IETF eai
Première rédaction de cet article le 7 novembre 2012
Depuis la sortie du RFC 6530 et de ses petits
camarades, il existe désormais une solution normalisée pour avoir du
courrier
électronique complètement internationalisé, y compris les
adresses (arôme@café.fr...). Mais comment est-ce
que cela s'applique aux listes de diffusion ?
Peut-on avoir des listes où certains membres accepteraient les
nouvelles adresses et d'autres non ? Ce RFC,
successeur du RFC 5983, se
penche sur la question. Pour l'instant, la réponse est pessimiste : il
n'y a pas de moyen pratique de faire coexister anciens et nouveaux sur
la même liste.
Une liste de diffusion prend un message et le redistribue à N destinataires. Certains de ces N destinataires seront derrière un serveur de messagerie récent, qui gère les adresses internationalisés. Une partie de ceux-ci, en outre, auront des adresses internationalisées. Même si le destinataire, lui, n'a pas une adresse internationalisée, si l'émetteur en a une, ses messages ne pourront pas être remis aux gens qui ont les vieux logiciels.
Il y a donc un problème technique, le fait que des adresses internationalisées soient refusées par certains. Et il y a un problème humain : en communicaton bilatérale, après quelques essais, on peut toujurs trouver une solution technique qui permette la communication. Sur une liste, ce n'est plus possible, l'émetteur ne connait pas les destinataires et réciproquement. Il n'y a pas d'ajustement possible.
Autre problème : idéalement, la liste ne modifie pas le
message, à part par l'ajout de certains en-têtes spécifiques aux
listes (comme List-Unsubscribe: ou
List-Id:, normalisés dans le RFC 2369 et
RFC 2919). Toutefois, un certain nombre de listes vont plus
loin et, bien que cela soit une source d'ennuis connue, modifient d'autres
en-têtes comme Reply-To: voire, pire,
From:.
Pour synthétiser, il y a trois services différents qui peuvent marcher ou pas :
- Avoir une liste dont l'adresse est internationalisée, par
exemple
évolution-langue@académie-française.fr, - Avoir une liste qui accepte l'abonnement de personnes ayant des
adresses internationalisées, par exemple
étienne@massé.fr, - Avoir une liste qui accepte les messages émis depuis des adresses internationalisées.
Ces trois capacités sont relativement indépendantes (la deuxième et la troisième impliquent des logiciels différents donc l'une peut marcher et pas l'autre).
Le plus simple pour une liste qui veut gérer parfaitement
l'internationalisation serait de n'avoir que des abonnés qui eux-même
ont la gestion complète des adresses en Unicode
(option SMTPUTF8 de SMTP,
cf. RFC 6531). Pour cela, le mieux est de tester
lors de l'inscription, et de refuser l'abonnement de ceux qui ont le
vieux logiciel. Pour ce test, si le candidat à l'abonnement s'abonne
avec une adresse Unicode, c'est facile : s'il reçoit le message de
confirmation, c'est bon. Et s'il s'abonne avec une adresse
ASCII ? Alors, le mieux est de tester en
tentant de leur envoyer le message « répondez pour confirmer » depuis une
adresse Unicode.
Mais pour la majorité des listes, qui voudront accepter des abonnés
SMTPUTF8 et d'autres qui ne le sont pas ? (Fin
2012, très peu de serveurs de messagerie, à part en
Extrême-Orient, gèrent
SMTPUTF8.) Il n'existe pas (ou plus, cf. RFC 5504) de mécanisme de repli automatique d'un
message aux adresses Unicode vers un message traditionnel. C'est donc
au MLM (Mail List Manager, le logiciel de gestion de la liste, par exemple Mailman) de faire ce repli.
D'abord, le logiciel de gestion de la liste doit déterminer quels
abonnés sont SMTPUTF8 et lesquels ne le sont
pas. Il y a plusieurs méthodes :
- Décider que les abonnés avec une adresse Unicode peuvent recevoir du courrier entièrement internationalisé et que les abonnés avec une adresse ASCII ont un logiciel traditionnel (en pratique, cela privera certains de ces abonnés ASCII des bénéfices du courrier internationalisé),
- Tester, en envoyant un message depuis une adresse Unicode et en demandant confirmation,
- Demander à l'utilisateur de se classer lui-même comme, aujourd'hui, on lui demande s'il veut recevoir du texte ou de l'HTML.
Ensuite, il faut décider, pour chaque message entrant vers la liste,
s'il est internationalisé ou pas. Cela peut se faire en considérant
que, si l'option SMTPUTF8 a été utilisée dans la
session, le message sera marqué comme « Unicode ». Ou bien on peut
examiner les en-têtes du message, à la recherche d'adresses en
Unicode.
Les logiciels de gestion de liste réécrivent en général l'émetteur
dans l'enveloppe SMTP du message. Ils mettent
leur propre adresse (par exemple ima-bounces@ietf.org pour la liste du groupe de travail EAI, ex-IMA) ou même
ils mettent une adresse d'origine différente pour chaque abonné, pour
mieux gérer les messages de non-remise (technique
VERP). Dans les deux cas, l'adresse d'émetteur,
qui recevra les messages de non-remise, contient en général le nom de
la liste. Dans ce cas, elle sera une adresse Unicode et les serveurs
ne connaissant pas le courrier complètement internationalisé ne
pourront donc pas envoyer ces avis de non-remise
(bounces).
La section 3 contient les recommandations concrètes. D'abord, pour
les en-têtes ajoutés comme List-Id:, la
recommandation est de les mettre sous une forme purement ASCII, pour
limiter les risques, même si cet en-tête prend comme valeur un
URI (comme le fait List-Unsubscribe:) et que cet URI a un plan
(scheme) qui permet l'Unicode. Il faut dans ce cas
utiliser l'« encodage pour-cent ». Donc, pour une liste
pause-café@bavardage.fr, on aura :
List-Id: Liste de discussion en Unicode <pause-caf%C3%A9@bavardage.fr> List-Unsubscribe: <mailto:pause-caf%C3%A9-requ%C3%AAte@bavardage.fr?subject=unsubscribe> List-Archive: <http://www.example.net/listes/pause-caf%C3%A9/archives>
Dans certains cas, cela ne donnera pas un résultat lisible (par
exemple le List-Id: d'une liste en
chinois encodé en ASCII ne va pas être
tellement utile aux lecteurs...) Mais cet inconvénient semble, aujourd'hui, moins
grave que le risque de faire arriver de l'Unicode à des gens qui ne
s'y attendent pas. Une meilleure solution devra attendre une nouvelle
version des RFC 2369 et RFC 2919.
Le RFC n'a pas de recommandation pour le cas où un auteur d'un
message a une adresse Unicode et où le gestionnaire de listes essaie
de diffuser le message à un abonné n'ayant que des logiciels anciens,
ne gérant pas SMTPUTF8. Il n'y a pas de bonne
solution technique, juste des petits arrangements : réserver la liste
aux gens pouvant recevoir du courrier internationalisé (cf. plus haut
la discussion sur de telles listes), proposer aux abonnés
d'enregistrer une adresse ASCII et remplacer le
From: par cette adresse avant de transmettre ou
enfin remplacer le From: par une adresse de la
liste. Reste à programmer cela...
Je ne connais pas encore de « grand » gestionnaire de liste de diffusion qui ait des plans précis pour la mise en œuvre des adresses de courrier internationalisées. Sympa, par exemple, en est toujours au stade de la réflexion sur ce point.
Notre RFC ne contient pas de liste des
changements depuis le RFC 5983. Il y a eu réécriture complète puisque
le repli automatique et les adresses de secours
(alt-address) ont été retirées de la norme finale
du courrier internationalisé.
L'article seul
Le rapport HostExploit 2012 sur les plus grandes sources de Mal de l'Internet
Première rédaction de cet article le 31 octobre 2012
Dernière mise à jour le 12 novembre 2012
Les gérants du groupe HostExploit compilent un rapport régulier sur les plus grosses sources de Mal de l'Internet, c'est à dire les systèmes autonomes hébergeant le plus de centres de commande de botnets, le plus de serveurs de hameçonnage, envoyant le plus de spam... Un Who's who des acteurs de l'Internet, sous l'angle négatif. Dans le dernier rapport, numéroté Q32012, on note un nouveau n° 1 de ce classement, Confluence, et l'arrivée du français OVH dans le sommet.
Avant de commenter ce rapport, il convient d'être prudent et de bien prendre connaissance de la méthodologie. Celle-ci est décrite dans une annexe au rapport (le rapport est fait en Word avec des couleurs et l'annexe en LaTeX...). En gros, HostExploit utilise un certain nombre de sources qui listent des adresses IP qui ont participé à des comportements négatifs, comme héberger un serveur de malware, ou bien un serveur Zeus (voir le Zeus Tracker). De l'adresse IP, on remonte à l'AS et au pays (cette dernière information étant moins fiable). Le tout est pondéré par la taille de l'espace d'adressage annoncé par l'AS (pour éviter que les petits AS hébergant proportionnellement beaucoup de Mal ne se glissent sous la couverture du radar.)
Ces sources ne sont pas parfaites : tout n'est pas signalé, certains le sont à tort.
D'autre part, malgré mon introduction sensationnaliste, il faut bien voir que le fait qu'un AS (donc, en pratique, un opérateur ou hébergeur) soit bien placé dans la liste ne signifie pas que c'est lui qui envoie du spam ou héberge du malware. Il peut être « victime » de ses clients. Des fois, c'est même encore plus indirect : un hébergeur loue des machines, un client en prend une, son site Web se fait pirater, un serveur de hameçonnage est installé dessus et l'AS de l'hébergeur va remonter dans le classement « source de Mal ».
Alors, que contient le classement Q32012 ?
Ce classement est peu stable : un opérateur envahi par des
zombies va être mis sur des listes noires (et
ne sera donc plus intéressant pour les maîtres des zombies) ou bien va
prendre des mesures radicales (faire le ménage) et, l'année suivante,
rétrogradera loin dans le classement. Cette année, l'AS 40034,
Confluence, hébergé dans le paradis fiscal des Îles
Vierges, arrive en numéro un du classement
général (p. 9 du rapport). Coïncidence amusante, deux jours avant de lire ce dossier, je
citais le cas d'un détournement de noms de domaine (l'affaire
ben.edu),
fait via une machine chez Confluence. L'AS 16276, le français
OVH est numéro 4, en très nette
progression. (Sur la liste FRnOG, le directeur d'OVH estime
aujourd'hui, je cite, que « avec les differents BETA aux USA que nous avons
fait entre juillet et septembre, on a eu une
augmentation importante des abuses en tout genre
à partir de notre reseau. en gros, les nouveaux
"clients" hackers nous ont decouvert puis depuis
nous commandent de services. il y a 1 mois on
est arrivé au point de non retour: trop marre.
et donc il y a 3 semaines on a commencé un grand
nettoyage avant l'hiver mais en incluant un echange
avec les clients. et si pas de reponse là on hache.
vous pouvez donc lire à droite ou à gauche que "mon
serveur s'est fait bloqué pour 1 spam". oui si pas
de dialogue, pas de serveur. si pas d'action, pas
de serveur. sur spamhaus ça sera clean à la fin de
la semaine (il reste 14 alertes). et les autres rbl
c'est une question de 2 à 3 semaines. » Fin de citation)
Si on regarde le type de Mal hébergé (p. 11), on note que Confluence fait surtout de l'hébergement de Zeus alors qu'OVH est nettement moins spécialisé, on y trouve de tout. Cela semble indiquer qu'il n'y a pas de choix délibéré d'OVH, ni même d'envahissement de ses serveurs par un méchant décidé : la raison du score d'OVH est plus probablement que beaucoup de ses clients sont nuls en sécurité, installent un LAMP sans rien y connaître, se font pirater via une faille PHP, et ne corrigent pas le problème même quand on leur signale.
En attachant les AS à un pays (ce qui est parfois difficile, ainsi Confluence a été classé comme états-unienne malgré son adresse officielle aux Îles Vierges britanniques et, plus drôle, VeriSign a été classé aux Pays-Bas), on voit (p. 16) la Russie en numéro 1, ce qui ne surprendra guère, et le paradis fiscal de l'Union européenne en numéro 4. Grâce à OVH, la France est en huitième position.
Si on classe les AS en prenant chaque cause de Mal séparement, on voit que, pour l'hébergement de serveurs C&C, c'est l'AS 50465, IQhost, qui gagne, devant un autre russe. Pour le hameçonnage, les États-Unis prennent l'avantage avec l'AS 53665, Bodis. Confluence, on l'a vu, gagne nettement pour l'hébergement Zeus. Pour l'envoi du spam, les Indiens sont loin devant avec le record chez l'AS 55740, Tata.
Plus surprenant est le classement des AS où on trouve du malware (p. 26), car l'AS 26415, VeriSign (qui sert notamment pour les serveurs DNS racine exploités par cette société) et l'AS 15169, Google, se retrouvent dans les dix premiers. Le rapport ne propose pas d'explication. Pour Verisign, des explications raisonnables ont filtré mais rien de public encore. Pour Google, si, à première vue, dissimuler du code malveillant dans un Google document n'est pas évident (cela serait possible, via des fonctions de scripting), il y a déjà eu des rapports de hameçonnage où l'appât était un Google document, ce qui explique sans doute ce classement.
Maintenant, qu'est-ce qui devrait être fait ? Un AS a évidemment intérêt à nettoyer ces sources de Mal. Sinon, il va retrouver ses adresses IP dans plein de listes noires dont il est très difficile de sortir. Certains AS ont manifestement choisi de rester dans le business de l'hébergement de délinquants et se moquent de leur réputation (ils sont dans le sommet du classement depuis longtemps comme l'AS 16138, Interia). D'autres ont un problème difficile. (Ceci dit, ils pourraient commencer par traiter le courrier envoyé à abuse.) Nettoyer, OK, mais en respectant un minimum de règles. La différence de classement entre l'AS 16276 (OVH) et l'AS 14618 (Amazon), qui a un business model très proche (louer des machines rapidement et sans formalités, à des tas de clients, pas toujours compétents et pas toujours honnêtes), provient sans doute largement d'une différence d'approche entre l'Europe et les États-Unis. Aux USA, les hébergeurs se comportent comme des cow-boys : au premier signalement de problème (même injustifié), ils coupent et on n'a plus qu'à se chercher un autre hébergeur. Le fameux premier amendement à la Constitution, censé protéger la liberté d'expression, ne les arrête pas : il ne s'impose qu'à l'État. Les entreprises privées, elles, ont tout à fait le droit de s'attaquer à la liberté d'expression. WikiLeaks, qui fut client d'Amazon avant de l'être d'OVH, en sait quelque chose.
Le rapport d'HostExploit exhorte en effet les opérateurs à « agir », à « nettoyer », mais ne fournit aucune piste en ce sens (à part un conseil implicite : « tirez d'abord et enquêtez après »).
Ah, et pour les gens du DNS, à part la curieuse place de VeriSign, une nouveauté de ce rapport est l'étude des résolveurs DNS ouverts (p. 6). Ils sont une grande source d'ennuis, notamment par leur utilisation comme relais pour des attaques DoS avec amplification. Mais ils ne sont pas eux-même le résultat d'un choix délibéré par un méchant : les AS qui hébergent en proportion le plus de résolveurs ouverts (7418, Terra, ou 8167, Telesc) sont largement absents des autres classements et il n'y a donc pas de corrélation entre le nombre de résolveurs ouverts et l'hébergement d'autres sources de Mal.
Merci à Daniel Azuelos et Fabien Duchene pour leurs remarques.
L'article seul
RFC 6778: IETF Email List Archiving, Web-based Browsing and Search Tool Requirements
Date de publication du RFC : Octobre 2012
Auteur(s) du RFC : R. Sparks (Tekelec)
Pour information
Première rédaction de cet article le 31 octobre 2012
Dernière mise à jour le 31 janvier 2014
Ce RFC est le cahier des charges de l'outil d'accès aux archives des
innombrables listes de diffusion de
l'IETF. Le gros du travail de cette
organisation repose sur ces listes de diffusion, dont la plupart sont
publiques, archivées et accessibles via le
Web. Cette masse d'information est un outil
formidable pour comprendre les décisions de l'IETF et les choix
techniques effectués. Mais son volume rend l'accès à
l'information souvent difficile. L'IETF se vante de sa transparence
(tout le travail est fait en public) mais avoir toutes les discussions
accessibles ne suffit pas, si l'information est trop riche pour être
analysée. D'où l'idée de développer une
ensemble d'outils permettant d'accéder plus facilement à ce qu'on
cherche. C'est désormais accessible en https://mailarchive.ietf.org/.
Avant, la recherche était particulièrement difficile si une discussion s'étendait sur une longue période et surtout si elle était répartie sur plusieurs listes. Imaginons un auteur d'un RFC, un président de groupe de travail, ou un simple participant, qui veut retrouver toutes les discussions qui ont concerné un Internet-draft donné. Il va trouver des messages dans la liste du groupe de travail mais aussi dans celles d'une ou plusieurs directions thématiques, et peut-être aussi dans la liste générale de l'IETF. Certains ont chez eux des copies de toutes ces listes (copies parfois incomplètes) pour utiliser des outils locaux. (Au fait, personnellement, je me sers surtout de grepmail et je cherche encore un outil qui indexerait les données.)
En l'absence de copie locale, notre participant IETF courageux va compter sur la force brute, ou bien va essayer un moteur de recherche généraliste (mais il est ennuyeux pour l'IETF de devoir compter sur un outil externe pour son propre travail).
Ce n'est pas qu'il n'existait aucun outil à l'IETF. Il y a des solutions proposées sur le site de l'IETF (l'option Email Archives Quick Search). Mais elles ne couvrent pas tous les besoins, loin de là.
Quels sont ces besoins ? La section 2 en donne la liste. D'abord,
il faut une interface Web. Elle doit permettre
de naviguer dans un fil de discussion donné, ou
suivant la date. (Les outils d'archivage classique comme
MHonArc permettent déjà tous cela.) Les fils
doivent pouvoir être construits en suivant les en-têtes prévus à cet
effet (References: et
In-Reply-To:) mais aussi en se fiant au sujet
pour le cas où les dits en-têtes auraient été massacrés en route, ce
qui arrive.
Surtout, il faut une fonction de recherche. Elle doit fonctionner sur une liste, ou un ensemble de listes, ou toutes les listes. Elle doit permettre d'utiliser ces critères :
- Nom ou adresse de l'expéditeur,
- Intervalle de dates,
- Chaîne de caractères dans le sujet ou dans le corps du message,
- Chaîne de caractères dans un en-tête quelconque. Le plus
important est bien sûr le
Message-ID:lorsqu'on veut donner une référence stable d'un message (« ton idée a déjà été proposée dans<5082D93B.6000308@cnam.fr>»). Le but est de pouvoir faire circuler une référence commehttp://datatracker.ietf.org/mlarchive/msg?id=5082D93B.6000308@cnam.fr.
Et de les combiner avec les opérateurs booléens
classiques (AND, OR et
NOT).
Il n'y a pas que la recherche dans la vie, on voudrait aussi
évidemment avoir des URI stables pour chaque
message (stables et beaux). Et cet URL
devrait être mis dans le champ Archived-At: du
message avant sa distribution (cf. RFC 5064).
À propos d'URI, comme indiqué dans l'exemple de recherche via un
Message-ID: montré plus haut, notre RFC demande
que les recherches soient représentables par un URI, qui puisse être
partagé (et qui soit donc stable). Le RFC ne donne pas d'exemple mais
cela aurait pu être quelque chose comme
http://datatracker.ietf.org/mlarchive/search?subject=foobar&startdate=2002-05-01&enddate=2004-06-01&author=smith (dans la version publiée, c'est en fait quelque chose comme https://mailarchive.ietf.org/arch/search/?qdr=a&q=text%3A%28eszett%29&as=1&f_list=precis%2Cxmpp). Naturellement,
« stabilité » fait référence à l'URI, pas au résultat, qui peut varier
dans le temps (par exemple si des nouveaux messages arrivent).
La plupart des archives à l'IETF sont publiques et doivent être
accessibles anonymement mais quelques unes
nécessitent une autorisation. Dans ce cas, le cahier des charges
demande que le système d'authentification
utilisé soit celui de datatracker.ietf.org.
Difficulté supplémentaire, toutes les listes IETF ne sont pas gérées au même endroit et par le même logiciel. Les listes hébergées à l'IETF le sont avec mailman mais il existe aussi des listes hébergées ailleurs et notre cahier des charges demandent qu'elles puissent être intégrées dans ce système de recherche (par exemple en abonnant l'adresse du programme d'archivage à la liste).
Il y a aussi des cas où des archives de listes de diffusion deviennent accessibles alors qu'elles ne l'étaient pas avant et doivent être incorporées dans le corpus géré par le nouveau système. Le RFC demande qu'au moins le format d'entrée mbox (RFC 4155) soit accepté. Et qu'il serait souhaitable d'accepter aussi le maildir.
En sens inverse, le système doit permettre d'exporter les messages (un système ouvert ne l'est pas si on ne peut pas en sortir l'information pour la garder et l'étudier chez soi ; la fonction d'exportation n'a pas qu'un intérêt technique, elle est aussi un moyen de garantir la pérénnité de l'information publique). On doit pouvoir exporter une liste entière, une liste pour un intervalle de temps donné et, dans le meilleur des cas, le résultat d'une recherche (une vue, pour employer le langage des SGBD). Là encore, l'exportation en mbox est impérative et celle en maildir souhaitée.
Voilà, c'est tout, l'appel d'offres formel de
l'IAOC était en ligne. Plus rigolo pour le programmeur de cet ambitieux projet : la
section 3 lui rappelle qu'il devrait se préparer à l'arrivée du courrier électronique
internationalisé... Le produit final a été livré le 29 janvier 2014 et est disponible en https://mailarchive.ietf.org/.
L'article seul
Fiche de lecture : La cybercriminalité en mouvement
Auteur(s) du livre : Éric Freyssinet
Éditeur : Hermes-Lavoisier
9782746232884
Publié en 2012
Première rédaction de cet article le 30 octobre 2012
Un livre utile pour celui qui s'intéresse à la cybercriminalité sous tous ses aspects. En 200 pages, l'auteur, un expert du domaine, réussit à couvrir à peu près tout. Évidemment, cela veut dire que les passionnés de tel ou tel aspect resteront un peu sur leur faim mais, pour celui qui ne connait pas encore bien la cybercriminalité, voici un livre sérieux et bien expliqué.
Quand même, je trouve l'ouvrage mince, surtout pour son prix très
élevé (56 €). Mais il couvre pourtant plein de choses. On y
trouve tout le panorama de la cybercriminalité actuelle, sans
sensationnalisme et avec beaucoup de concret (et plein de références). Ainsi,
l'importance du caractère organisé et professionnel de la
cybercriminalité est bien expliqué, ainsi que l'organisation complexe
du cybercrime : le type qui écrit le malware
n'est pas celui qui gère le botnet et celui qui
commande une attaque DoS comme on commande un
livre à Amazon est encore un autre. C'est tout un écosystème qui s'est
ainsi développé. L'auteur parle d'ailleurs de
CaaS, « Crime as a Service » pour illustrer le fait
qu'on peut louer des services de délinquants. De même, l'auteur
explique bien le fonctionnement des botnets,
sujet sur lequel il participe au projet http://www.botnets.fr/.
Comme toujours en matière de sécurité (pas seulement de sécurité informatique), les questions politiques de droit et de liberté ne sont jamais loin. J'y apprends par exemple qu'il n'y a pas encore de jurisprudence pour savoir si une attaque DoS peut être assimilée au droit de manifestation. En parlant des Anonymous, l'auteur regrette que le temps passé à les pourchasser soit au détriment d'autres tâches plus utiles. Le reproche-t-il aux Anonymous ou bien aux politiciens qui mettent en avant le danger de la contestation plutôt que celui de la criminalité ? On ne le saura pas.
Globalement, l'auteur, un gendarme, n'hésite pas devant la déformation professionnelle. Il privilégie le point de vue des enquêteurs : disposer de plus de moyens mais aussi de plus de possibilités légales, de plus de données enregistrées, et de plus de contrôles (par exemple des papiers d'identité dans les cybercafés, comme obligatoires en Italie). Et, concernant, l'anonymat, j'ai été surpris de voir qu'il était considéré dans ce livre comme un privilège (pour les opposants aux dictatures féroces, uniquement) et pas comme un droit.
Ah, et puis les défenseurs fervents d'IPv6 noteront que celui-ci est accusé de compliquer les enquêtes, via les techniques de coexistence avec IPv4 qui sont nécessaires.
On peut aussi consulter la critique des Échos, la bonne analyse de Gof dans la Mare (où il reproche notamment à l'auteur de ne pas assez donner son opinion), le blog de l'auteur et le site officiel autour du livre.
L'article seul
Détournement d'un nom de domaine via le domaine des serveurs de noms
Première rédaction de cet article le 29 octobre 2012
Lorsqu'on analyse la sécurité de ses
noms de domaine, on pense à des choses comme
surveiller l'expiration et ne pas oublier de renouveller, ou bien on
pense au
piratage du registre ou
du bureau d'enregistrement par le premier
hacker chinois islamiste pédophile
venu (comme vu récemment dans
.ie) ou alors on pense à
des attaques d'encore plus haute technologie comme l'attaque
Kaminsky. Mais on pense rarement à un risque courant : un
domaine trébuche parce que le domaine de ses serveurs de noms a
trébuché. C'est ce qui vient de se produire dans deux cas,
duckworksmagazine.com et
ben.edu.
Les deux cas ont été publiés et discutés ce mois-ci sur la liste dns-operations de
l'OARC. Prenons le deuxième domaine,
ben.edu, domaine de Benedictine University (qui n'a apparemment
rien à voir avec la boisson
française). Ce domaine a deux serveurs de noms :
% dig NS ben.edu ; <<>> DiG 9.8.1-P1 <<>> NS ben.edu ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 29134 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;ben.edu. IN NS ;; ANSWER SECTION: ben.edu. 37533 IN NS ns2.bobbroadband.com. ben.edu. 37533 IN NS ns1.bobbroadband.com. ;; Query time: 0 msec ;; SERVER: ::1#53(::1) ;; WHEN: Mon Oct 29 10:11:02 2012 ;; MSG SIZE rcvd: 88
Or, le point important est que ces serveurs sont dans un autre
domaine, géré par une autre organisation et passant par un
bureau d'enregistrement (BE) qui n'a pas de rapport
avec Benedictine University
(.edu n'utilise pas de
bureaux d'enregistrement). En changeant ce domaine
bobbroadband.com, on peut changer le contenu de
ben.edu. C'est apparemment ce qui s'est produit à
partir du 25 octobre 2012 (merci à Robert Edmonds pour l'analyse) : au
lieu de son adresse IP habituelle,
38.100.120.100, ben.edu
avait tout à coup 208.91.197.132 (sur certains
sites, les autres ayant l'ancienne adresse dans les caches). Le
domaine bobbroadband.com avait expiré (ses serveurs
de noms sont passés dans le domaine
pendingrenewaldeletion.com qu'utilise le BE
Network Solutions comme purgatoire pour les
domaines non renouvelés), quelqu'un l'a apparemment
acheté, a changé les serveurs de noms (ns1432.ztomy.com). Contrôlant alors le contenu de
bobbroadband.com, il pouvait changer toutes les
zones dont les serveurs de noms étaient dans
bobbroadband.com. C'est ce qui est arrivé à
ben.edu. 208.91.197.132 (qui
est aussi l'adresse de ns1432.ztomy.com) est
enregistré... aux Îles
Vierges, paradis fiscal connu.
Le premier cas, quelques jours plus tôt, était celui de
duckworksbbs.com (et
duckworksmagazine.com), qui vend des équipements pour bateaux. Les serveurs de noms
étaient dans le domaine crystaltech.com, qui a un
BE différent de celui de duckworksbbs.com. Ce
domaine a expiré le 18 octobre (merci à Andrew Sullivan pour
l'analyse). Pour pouvoir supprimer le domaine auprès du registre de
.com (les contraintes
d'intégrité du registre interdisent normalement de supprimer un
domaine qui est utilisé par d'autres), le BE a renommé les serveurs de
noms (webterminator1.crystaltech.com est devenu
doesnotexistwebterminator1.crystaltech.com.hu...). La
sortie de la commande whois pour
duckworksbbs.com ne montrait pas ce changement, puisque le BE de
duckworksbbs.com, différent de celui de
crystaltech.com, n'était pas au courant... Les
nouveaux serveurs de noms n'existant pas dans le
DNS, le domaine
duckworksbbs.com ne marchait plus (ce qui est
moins grave que d'être détourné).
La morale de ces deux histoires ? Lorsqu'on analyse la sécurité d'un nom de domaine, il faut aussi regarder celle du nom utilisé pour les serveurs de noms. Le maillon faible est peut-être là. Essayez avec quelques domaines connus, vous verrez que le domaine sensible est souvent celui du fournisseur, pas celui du titulaire.
L'article seul
Pourquoi donner des instructions alors que donner un URL serait plus simple ?
Première rédaction de cet article le 28 octobre 2012
Dernière mise à jour le 29 octobre 2012
Mais pourquoi voit-on tant de documentations d'un site Web donner des instructions plus ou moins alambiquées pour la navigation (« allez en Aide puis Dépannage ») , alors qu'il serait si simple de donner un URL qui est sans ambiguité, et souvent tout aussi lisible ?
Pour prendre un exemple, la Préfecture de police de
Paris (je n'ai rien contre cette organisation, c'est le
premier exemple qui m'est tombé sous la main) diffuse des brochures annonçant « [Faites vos
démarches] par Internet : www.prefecturedepolice.fr Rubriques vos
démarches/Services en ligne/Prise de rendez-vous ». Notons que les
instructions singent la syntaxe des URL mais n'en sont pas. Le bon URL
est http://www.prefecturedepolice.interieur.gouv.fr/Vos-demarches/Services-en-ligne/Prises-de-rendez-vous.
Pourquoi n'avoir pas donné simplement cet URL ? Au téléphone, on peut craindre qu'il ne soit pas bien compris. Mais sur des instructions diffusées sur le papier ? Parfois, c'est parce que les URL ne sont pas lisibles (violation du principe des beaux URL). Mais, le plus souvent, c'est parce que les gens qui rédigent ces documentations ne connaissent pas les URL (ils ne savent pas qu'on peut indiquer autre chose que la page d'accueil du site) ou ne comprennent pas leur rôle.
Ou bien c'est un phénomène purement français, souvenir de l'époque du Minitel, qui n'avait pas d'équivalent des URL ? Le même phénomène se voit-il dans les autres pays ?
En attendant, voici les remarques justifiant ces instructions que j'ai reçues :
- Par Florian Maury :
recopier un URL est de l'écriture, suivre les instructions de la
lecture et quelques clics. Or, bien des gens ne tapent pas vite, même
en 2012. Comme le note Valentin Lorentz, « Une faute
de frappe, et c'est foutu ». Pierre
Beyssac a un argument analogue, l'URL ci-dessus est long à
retaper... Il suggère des raccourcisseurs d'URL
locaux, du genre
http://example.com/1149. - Par Michel Guillou, la suggestion d'utiliser plutôt un code QR sur la documentation papier.
- Par plusieurs personnes : car les URL changent, pas la navigation. Je suis très sceptique : non seulement changer les URL est une très mauvaise pratique mais la navigation change aussi, et sans doute plus souvent.
L'article seul
RFC 6733: Diameter Base Protocol
Date de publication du RFC : Octobre 2012
Auteur(s) du RFC : V. Fajardo (Telcordia Technologies), J. Arkko (Ericsson Research), J. Loughney (Nokia Research Center), G. Zorn (Network Zen)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dime
Première rédaction de cet article le 26 octobre 2012
Pendant longtemps, le seul protocole standard d'authentification entre un NAS et sa base d'utilisateurs était Radius. Diameter, normalisé dans notre RFC (qui fait suite au RFC 3588), visait à le remplacer, et est bien plus riche en fonctions.
Traditionnellement, lorsqu'un client PPP ou d'un protocole similaire se connecte à son FAI, sa session est terminée sur un NAS, équipement qui ne possède en général pas de base des utilisateurs autorisés. Il y a plusieurs raisons à cela, comme le fait que le NAS n'est en général pas un ordinateur généraliste, il a peu de moyens, notamment en place disque ou bien comme le fait qu'un FAI a typiquement plusieurs NAS (au moins un par POP), et qu'il souhaite centraliser l'authentification. (Dans le monde 802.11, le NAS est typiquement nommé AP - Access Point.)
Le mécanisme habituel est donc que le NAS soit client d'un protocole d'authentification et que le FAI gère un serveur de ce protocole, serveur qui connaitra les utilisateurs autorisés. Le même protocole assure en général également des fonctions de comptabilisation des accès, d'où le sigle AAA (Authentication, Authorization and Accounting). Le premier protocole standard en ce sens est Radius (RFC 2865), que Diameter vise à remplacer. (Un protocole privé, Tacacs, qui sera documenté dans le RFC 1492, avait également été utilisé.) Diameter avait été normalisé à l'origine dans le RFC 3588. Après une longue gestation (plusieurs années, alors qu'aucun changement de fond n'a été fait, et pas moins de trois « Last Calls » devant l'IETF), il est désormais remplacé par ce nouveau RFC 6733. Le protocole reste le même et les logiciels conformes à l'ancien et au nouveau RFC devraient interopérer.
Que reproche Diameter à Radius ? La section 1 de notre RFC détaille les faiblesses de Radius perçues par les auteurs de Diameter. Une analyse plus détaillée figure dans le RFC 3169 :
- Utilisation d'UDP, protocole de transport n'assurant pas de fiabilité,
- Pas de mécanisme de redondance standard,
- Limites de taille pour certains paramètres (par exemple la longueur d'un attribut n'est codée que sur un octet, ce qui limite les attributs à 256 caractères).
Diameter est donc plus riche et plus complexe que Radius. Diameter reprend aussi plusieurs idées de Radius comme le codage en doublets Attribut / Valeur (AVP pour Attribute-Value Pairs) ou comme l'utilisation des NAI du RFC 7542 pour coder l'identité vérifiée.
Le RFC est bien plus long et compliqué que son équivalent Radius (154 pages !). La section 1 introduit le protocole, et ses usages, et le compare aux exigences listées dans le RFC 2989.
La section 2 précise le protocole, par exemple le mécanisme de transport fait l'objet de la sous-section 2.1, qui impose au minimum TCP et SCTP (les détails sont dans le RFC 3539). Diameter écoute par défaut sur le port 3868. La 2.4 introduit le nouveau concept d'Application Identifier, valeur enregistrées auprès de l'IANA qui identifie un usage particulier de Diameter (plus riche que Radius, Diameter permet davantage d'usages). Par exemple, l'usage en tant que service d'authentification pour un NAS (Application Identifier n° 1) n'est pas dans le cœur du protocole, il est délégué au RFC 4005. D'autres RFC décrivent des applications de Diameter comme le RFC 4740 qui parle de son usage pour SIP. 2.5 parle de la différence entre connexions et sessions, une connexion étant un concept de la couche 4 alors qu'une session Diameter peut impliquer plusieurs connexions. En 2.8, on trouve le bestiaire des agents Diameter, les clients et les serveurs bien sûr mais également les relais ou bien les traducteurs, pour parler à des agents d'autres protocoles, notamment Radius.
La section 3 décrit l'en-tête des paquets
Diameter et les codes de commande qu'ils contiennent comme
Capabilities-Exchange-Request. Seuls les codes
communs à toutes les applications sont définis dans la section 3.1,
des codes aussi importants que AA-Request (demande d'authentification, l'équivalent du Access-Request de Radius) sont délégués à d'autres RFC (comme le RFC 4005).
En section 4, nous arrivons aux AVP eux-même, les doublets
attributs-valeur qui portent l'information. On notera en 4.1 un
concept désormais fréquent dans les protocoles réseaux, l'option
Mandatory qui indique pour un AVP, s'il doit
absolument être connu de l'implémentation (le dialogue Diameter avorte
autrement) ou bien s'il peut tranquillement être ignoré, par exemple
par une vieille implémentation qui ne connait pas ce nouvel AVP. La
sous-section 4.3
décrit, entre autre, les URI Diameter, de
plan aaa:,
comme
aaa://host.example.com:666:transport=stcp;protocol=diameter.
Les sections 5 à 8 spécifient les nombreuses machines à état qui doivent être mises en œuvre par les agents Diameter. Au contraire de Radius qui, comme le DNS, est purement requête/réponse, Diameter nécessite un vrai automate dans chaque agent.
La sous-section 5.2 explique comment un agent Diameter peut en trouver un autre. Avec Radius, la configuration (par exemple du serveur d'authentification) devait être manuelle. Avec Diameter, on peut utiliser SLP (RFC 2165) ou NAPTR combiné avec SRV (RFC 2782).
La section 13, sur la sécurité, est très stricte. Un agent Diameter doit pouvoir faire du TLS (mais, contrairement au RFC 3588, IPsec n'est plus qu'une possibilité secondaire).
Une bonne introduction à Diameter a été publié en http://www.interlinknetworks.com/whitepapers/Introduction_to_Diameter.pdf.
Il n'existe que trois implémentations de serveur Diameter en
logiciel libre, Free Diameter, Open Diameter et OpenBlox Diameter, et, à part la première,
elles semblent peu maintenues. (Et je ne suis pas sûr qu'OpenBlox soit vraiment libre.)
Le bilan opérationnel de Diameter est mince : beaucoup plus complexe que Radius, il ne l'a pas réellement remplacé dans son secteur, l'authentification via un NAS. Diameter semble bien être une nouvelle victime de l'effet « Deuxième système ».
Quels sont les changements par rapport au premier RFC Diameter, le RFC 3588 ? La section 1.1.3 en donne un résumé (la liste exacte est trop longue pour être incluse dans ce RFC déjà très long). Si les changements sont nombreux, ils ne sont pas suffisamment importants pour qu'on puisse parler d'un nouveau protocole. C'est le même Diameter et les nouveaux logiciels pourront parler avec les anciens. Les changements sont des clarifications, des abandons de certaines fonctions, et la correction des nombreuses erreurs du RFC précédent (à mon avis, il y a une leçon à en tirer : les spécifications compliquées sont plus difficiles à faire correctement). Certaines fonctions étaient mentionnées dans le RFC 3588 mais même pas décrites complètement. Les principaux changements :
- Plus de mécanisme pour négocier en cours de session une sécurisation de la session par le chiffrement et introduction d'un nouveau port, le 5868, pour des connexions chiffrées avec TLS dès le début. (En fait, l'ancien mécanisme reste mais uniquement pour assurer la compatibilité.)
- La demande irréaliste du RFC 3588 d'avoir toujours IPsec a été retirée.
- Simplification de plusieurs fonctions comme la découverte du pair (pour laquelle il existait un zillion de méthodes dans le RFC 3588).
- Et bien d'autres clarifications, corrections de bogue dans les machines à état, etc.
L'article seul
Surveillance de réseau avec Icinga sur un Raspberry Pi
Première rédaction de cet article le 25 octobre 2012
Dernière mise à jour le 11 novembre 2012
Je vous ai déjà parlé ici de mes essais avec le Raspberry Pi et de mon interrogation : « Bon, d'accord, ce petit ordinateur pas cher est très cool. Mais à quoi peut-il servir en vrai, à part à afficher les messages de boot du système sur mon grand écran de télé ? » Un des usages qui me semblait intéressant, vue notamment la faible consommation électrique du Pi, était de la surveillance de réseau. Cet article décrit la configuration avec le logiciel de surveillance Icinga.
L'article complet
RFC 6769: Simple Virtual Aggregation (S-VA)
Date de publication du RFC : Octobre 2012
Auteur(s) du RFC : R. Raszuk (NTT MCL), J. Heitz (Ericsson), A. Lo (Arista), L. Zhang (UCLA), X. Xu (Huawei)
Pour information
Réalisé dans le cadre du groupe de travail IETF grow
Première rédaction de cet article le 25 octobre 2012
Un des gros problèmes des routeurs de la DFZ, dans l'Internet d'aujourd'hui, est l'augmentation du nombre de routes. Il y a, en octobre 2012, environ 450 000 routes dans cette DFZ et ce nombre croît sans cesse. Ces routes doivent être mises en mémoire et la mémoire d'un routeur du cœur de l'Internet est quelque chose de compliqué, qu'on ne veut pas gaspiller. Des tas d'approches ont été proposées pour traiter ce problème. Ce RFC propose un moyen astucieux de limiter les dégâts, en permettant au routeur d'agréger les routes pour les préfixes IP proches. Ce RFC est donc très court car l'idée est simple.
Attention au terme de « table de routage », trop vague. Un routeur met des routes dans au moins deux tables, la
RIB (Routing Information
Base, la base constituée par les protocoles de routage, BGP
et ses copains OSPF et IS-IS) et la FIB (Forwarding
Information Base, typiquement placée dans la
CAM car elle doit être très rapide,
elle est consultée à chaque paquet). Actuellement, le routeur
typique met toutes les entrées de sa RIB dans sa FIB. C'est sous-optimal car la RIB a beaucoup plus
d'entrées que le routeur n'a de voisins réseau (des centaines de milliers de
routes contre parfois seulement dix ou vingt routeurs voisins). Comme la taille
de la FIB est souvent un facteur limitant (ce n'est pas le seul, donc
ce RFC ne résout pas tous les problèmes de taille), il serait intéressant d'agréger
violemment, en découplant RIB et FIB. Par exemple, si la RIB contient
une entrée pour 2001:db8:16::/48 et une autre pour 2001:db8:17::/48,
et que les deux vont vers le même voisin (ont le même next hop), mettre les deux entrées dans
la FIB est du gaspillage, une seule entrée, pour 2001:db8:16::/47,
suffirait. (Et le calcul pour déterminer ce qu'on peut agréger est
simple.)
Au passage, on peut agréger dans la FIB mais moins dans la RIB car cette dernière doit être transmise aux routeurs pairs avec qui on échange des routes. Si on agrège, c'est une « compression avec perte » et les pairs ne recevront donc pas toute l'information. Néanmoins, ce RFC permet également de ne pas installer de routes dans la RIB. Celle-ci est typiquement dans une mémoire moins coûteuse mais on souhaite diminuer, non seulement la consommation mémoire mais également le rythme de changement. Moins on aura de préfixes, moins on aura de changements à gérer.
L'avantage de l'approche naïve ci-dessus est qu'elle est déployable
unilatéralement : chaque routeur peut le faire dès aujourd'hui sans
rien demander à personne. Son
principal inconvénient est que la RIB n'est pas statique : si BGP
change le next hop (le routeur suivant pour
acheminer le paquet) de 2001:db8:17::/48, il faut désagréger en
vitesse et mettre deux entrées dans la FIB.
L'approche de ce RFC est donc un peu différente : certains routeurs de l'AS vont annoncer des préfixes virtuels (VA prefix pour Virtual Aggregation prefix). Ils seront transmis, à l'intérieur de l'AS uniquement, par les protocoles de routage habituels et tous les routeurs vont l'avoir dans leur RIB. Ces préfixes virtuels couvrent plusieurs préfixes « réels ». Les routeurs qui veulent économiser de la mémoire ne vont pas installer les préfixes réels couverts dans leur FIB. Notez bien que les préfixes virtuels ne sont pas annoncés en dehors de l'AS. Si cette solution n'est plus déployable par un routeur seul, elle l'est par un AS seul.
Un opérateur réseau va donc typiquement avoir quelques très gros routeurs qui auront dans leur FIB (et dans leur RIB) tous les préfixes. Ils annonceront en plus les préfixes virtuels. Les autres routeurs, moins gros et moins coûteux, garderont tous les préfixes uniquement dans leur RIB et ne mettront pas dans la FIB les préfixes qui sont couverts par un des préfixes virtuels. Le préfixe virtuel pourra même être la route par défaut, entraînant ainsi la non-installation dans la FIB de tous les préfixes ayant le même next hop que la route par défaut.
Un peu de vocabulaire, maintenant (section 1.1) : un FIR (FIB Installation Router) est un des gros routeurs de cœur, qui installe toutes les routes dans sa FIB, et annonce les préfixes virtuels. Un FSR (FIR Suppressing Router) est un routeur situé plus aux marges du réseau et qui n'installe pas dans sa FIB les routes couvertes par un préfixe virtuel, si elles ont le même next hop que le préfixe virtuel. (Le RFC dit « supprimer une route » pour « ne pas l'installer dans la FIB ».) Une troisième catégorie de routeurs est composé des machines actuelles, qui ne connaissent pas ce RFC, et ne peuvent donc ni émettre les préfixes virtuels, ni supprimer des routes couvertes par un tel préfixe.
La section 2 décrit en détail le fonctionnement de ce système. Un
FIR doit annoncer les préfixes virtuels en mettant dans les attributs
de l'annonce BGP un ORIGIN
(RFC 4271, section 5.1.1)
à INCOMPLETE (pour dire que la route n'a pas été
apprise par un protocole de routage). Il doit mettre
NEXT_HOP (RFC 4271, section
5.1.3) à l'adresse du routeur qui gérera toutes les routes du préfixe
virtuel. Et il doit ajouter un attribut NO_EXPORT
(RFC 1997) pour éviter que ce préfixe virtuel ne sorte de
l'AS.
Le FSR, lui, lorsqu'il reçoit de telles routes, les installe dans RIB et FIB. Il peut alors décider de supprimer de sa FIB les routes plus spécifiques ayant le même next hop. Comme vous le voyez, c'est très simple.
La section 3 du RFC se penche sur les problèmes opérationnels pratiques. D'abord, attention au fait qu'une route BGP peut être utilisée pour résoudre un next hop qui n'est pas directement connecté. Il ne faudra donc pas supprimer de la RIB de telles routes.
On l'a vu, les routeurs FSR peuvent économiser de la place non seulement en FIB mais également en RIB, en supprimant de celles-ci les routes couvertes par un préfixe virtuel. Attention, cela peut interagir avec une politique de redistribution de routes aux pairs. Si une telle politique est en place (fondée, par exemple, sur la longueur du préfixe) on peut avoir des cas où la route couverte aurait été redistribuée mais où le préfixe virtuel ne l'est pas. Dans ce cas, il ne faut pas supprimer la route couverte de la RIB (on peut toujours la supprimer de la FIB).
À noter que le groupe de travail grow avait également travaillé sur des mécanismes d'agrégation plus complexes (avec des tunnels MPLS pour joindre les routeurs annonçant les préfixes virtuels) mais que cela n'a pas abouti. Les Internet-Drafts ont été abandonnés. Un bon article de fond sur cette idée d'« agrégation virtuelle » est celui de Paul Francis et Xiaohu Xu (un des auteurs du RFC), « Extending Router Lifetime with Virtual Aggregation ».
Globalement, cela me semble une bonne idée. Avec les préfixes virtuels, ce n'est plus une solution locale au routeur mais c'est local à l'AS et donc ça reste déployable unilatéralement.
Merci à Sarah Nataf pour avoir attiré mon attention sur ce document et à Bastien Pilat et Benjamin Abadie pour leurs corrections.
L'article seul
Un exemple de remplacement de clé DNSSEC, avec OpenDNSSEC
Première rédaction de cet article le 24 octobre 2012
Si vous avez déjà un peu regardé DNSSEC,
vous avez dû noter qu'on vous suggère fortement de remplacer (to
roll over) les clés cryptographiques de
temps en temps. La nécessité de ces remplacements ne fait pas
l'unanimité, notamment en raison de sa complexité. Toutefois, avec les
outils modernes, le problème est nettement simplifié. Voici l'exemple
pas-à-pas du récent remplacement de la KSK (Key Signing
Key) du domaine bortzmeyer.fr.
Le domaine est hébergé chez moi, le serveur maître est un nsd et les clés sont gérées par OpenDNSSEC, ce qui simplifie beaucoup les choses. Le principe d'OpenDNSSEC est qu'on exprime la politique (taille des clés, remplacement, durée de vie) dans le fichier de configuration et OpenDNSSEC s'occupe de tout. Le fichier de configuration est bien documenté. Voici la configuration de la KSK (Key Signing Key) de mes zones :
<KSK> <Algorithm length="2048">8</Algorithm> <!-- 8 = RSA/SHA-256 --> <Lifetime>P2Y</Lifetime> <!-- P2Y = two years . Probably useless if we have ManualRollover set --> <Repository>SoftHSM</Repository> <ManualRollover/> </KSK>
Il existe évidemment des tas d'autres politiques possibles,
configurables dans kasp.xml, par exemple en
utilisant des Standby Keys (<Standby>1</Standby>),
où la clé est générée mais pas publiée dans le DNS.
À noter que l'utilisation de nsd nécessite un petit bricolage d'intégration avec OpenDNSSEC.
Voyons maintenant l'opération. La KSK avait le
keytag 44461. DNSviz affiche l'ancienne configuration :
 Le 5 octobre vers 1000 UTC, je lance le
processus :
Le 5 octobre vers 1000 UTC, je lance le
processus :
# ods-ksmutil key rollover --zone bortzmeyer.fr --keytype KSK
La nouvelle clé, la 3445 est créé et aussitôt publiée dans le DNS. (J'ai un moniteur de mes zones qui surveille les clés et leurs remplacements, le code est sur FramaGit, il m'a servi pour un article à la conférence SATIN et m'a prévenu tout de suite de l'arrivée de la nouvelle clé.)
Mais la nouvelle clé n'est pas utilisable tout de suite : il faut attendre la
réjuvénation complète dans le
DNS, des caches ont encore le vieil ensemble
DNSKEY. C'est pour cela qu'OpenDNS affiche pour
cette clé 3445 un état publish et pas encore active :
# ods-ksmutil key list --zone bortzmeyer.fr --verbose bortzmeyer.fr KSK active 2012-10-05 12:14:02 ... 44461 bortzmeyer.fr KSK publish 2012-10-06 00:14:03 ... 3445
(Les états d'OpenDNSSEC ont fait l'objet d'un autre article.) Les durées (par
exemple le TTL) sont configurées également dans
kasp.xml, éléments
<TTL>,
<*Safety>, etc.
Pas besoin de surveiller en permanence, OpenDNSSEC se charge de vérifier qu'il n'y aura pas d'erreur de timing (cf. RFC 7583). C'est donc seulement trois jours après que j'ai repris le dossier. 3445, toujours publiée, a changé d'état :
bortzmeyer.fr KSK ready waiting for ds-seen ... 3445
Le remplacement d'une KSK nécessite une interaction avec le
parent. OpenDNSSEC n'a pas à l'heure actuelle de code pour vérifier
que l'interaction a été faite (on peut utiliser pour cela le script de Mathieu Arnold) et l'enregistrement
DS publié. Il faut donc lui indiquer, une fois la manipulation
faite. Les bureaux d'enregistrement le font
souvent par EPP (RFC 5910, et cela peut s'automatiser, voir par exemple un script de Mathieu Arnold). Les autres passent en général par un
formulaire Web. (Une solution utilisant le DNS a depuis été normalisée dans le RFC 7344 mais n'est pas très répandue encore.)
Dans mon cas, la zone parente était
.fr donc
l'AFNIC, et le bureau d'enregistrement était
Gandi. Je demande à OpenDNSSEC le DS :
# ods-ksmutil key export --ds SQLite database set to: /var/lib/opendnssec/db/kasp.db ;active KSK DS record (SHA1): bortzmeyer.fr. 3600 IN DS 3445 8 1 53ad69094ea377347c5538f076d889af5a4f6243 ;active KSK DS record (SHA256): bortzmeyer.fr. 3600 IN DS 3445 8 2 7cc6f2980fd42b5fbf587cad5b00712bfe568343691135434b719c2bebdf450e
Et je soumets la clé à l'AFNIC, via
Gandi (je l'ai fait à la main mais, là encore, Mathieu Arnold a un script pour automatiser
cela, via l'API de Gandi)
 Le second DS a été publié quelque temps après (une
vérification technique est systématiquement faite avec Zonecheck, ce qui est particulièrement
important pour DNSSEC, plus sensible aux erreurs de configuration).
dig montrant que le second DS est bien là
(rappelez-vous bien de tester à chaque fois
avant de passer à l'étape suivante), je le dis à OpenDNSSEC :
Le second DS a été publié quelque temps après (une
vérification technique est systématiquement faite avec Zonecheck, ce qui est particulièrement
important pour DNSSEC, plus sensible aux erreurs de configuration).
dig montrant que le second DS est bien là
(rappelez-vous bien de tester à chaque fois
avant de passer à l'étape suivante), je le dis à OpenDNSSEC :
# ods-ksmutil key ds-seen --zone bortzmeyer.fr --keytag 3445 SQLite database set to: /var/lib/opendnssec/db/kasp.db Found key with CKA_ID 02656a5fe158c6e25f7c965eb9a1ca3d Key 02656a5fe158c6e25f7c965eb9a1ca3d made active Old key retired
Ainsi prévenu, OpenDNSSEC change l'état de la clé :
# ods-ksmutil key list --zone bortzmeyer.fr --verbose SQLite database set to: /var/lib/opendnssec/db/kasp.db Keys: Zone: Keytype: State: Date of next transition: ... Keytag: bortzmeyer.fr KSK retire 2012-10-09 17:52:03 ... 44461 bortzmeyer.fr KSK active 2013-10-09 13:05:24 ... 3445
L'ancienne clé, la 44461 est toujours publiée dans le DNS à ce stade. Dès que les caches auront tous le nouveau DS, elle sera abandonnée. En effet, le lendemain, elle a disparu :
# ods-ksmutil key list --zone bortzmeyer.fr --verbose SQLite database set to: /var/lib/opendnssec/db/kasp.db Keys: Zone: Keytype: State: Date of next transition: ... Keytag: bortzmeyer.fr KSK active 2013-10-09 13:05:24 ... 3445
Tout est donc terminé. Il n'a fallu que trois étapes explicites de ma part :
- Lancer le processus de remplacement avec
ods-ksmutil key rollover, - Transmettre le DS au registre, via le BE,
- Prévenir OpenDNSSEC que cette étape a été terminée, avec
ods-ksmutil key ds-seen.
Tout le reste est automatique. OpenDNSSEC s'occupe de tout et
surveille le timing (ainsi, ods-ksmutil
key export n'acceptera pas d'exporter la clé si elle n'a
pas été créée depuis assez longtemps).
L'article seul
RFC 6771: Considerations for Having a Successful "Bar BOF" Side Meeting
Date de publication du RFC : Octobre 2012
Auteur(s) du RFC : L. Eggert (NetApp), G. Camarillo (Ericsson)
Pour information
Première rédaction de cet article le 18 octobre 2012
Autrefois, du temps des débuts de l'IETF, les seules réunions ayant un statut officiel étaient les réunions formelles des groupes de travail. Avec le temps, elles sont devenues tellement formelles (et n'ayant plus guère de rapport avec un « groupe de travail ») qu'un type de réunions plus légères est apparu petit à petit, les BOF (Birds Of a Feather). Les BOF étaient au début simples et faciles à organiser, comme l'étaient les groupes de travail des débuts. Mais elles se sont ossifiées petit à petit, devenant aussi formelles qu'un groupe de travail, et ayant même leur propre RFC, le RFC 5434. Continuant cette évolution logique, des participants à l'IETF ont créé un mécanisme léger alternatif aux BOF, les Bar BOF, qui étaient comme leur nom l'indique, des réunions faites au bistrot. Maintenant, on parle de fixer des règles pour les bar BOF...
Les bar BOF sont fréquentes pendant les réunions physiques de l'IETF. Elles se réunissent souvent dans un bar, d'où elles tirent leur nom, et permettent de discuter de manière complètement informelle, de nouvelles idées qui donneront peut-être naissance plus tard à un groupe de travail, voire à un ou plusieurs RFC. Elles ne sont pas mentionnées dans l'agenda officiel et n'ont aucun statut particulier. N'importe qui peut organiser une bar BOF comme il veut (alors que l'organisation d'une BOF est désormais toute une affaire, décrite dans le RFC 5434). Elles ont déjà été mentionnées dans un RFC, le fameux Tao (RFC 6722).
La malédiction se poursuivant, certaines bar BOF sont devenues tellement formalistes qu'on peut se demander si certains ne réclameront pas bientôt statuts et règles pour ces réunions. Ce RFC 6771 essaie de bloquer cette tendance, en plaidant pour que les bar BOF restent complètement an-archiques.
Car ce n'est pas le cas : on voit de plus en plus de bar BOF tenues dans les salles de réunion (et plus au café), avec les chaises organisées comme dans une salle de classe, des orateurs situés sur l'estrade, un tour de parole, des présentations faites avec PowerPoint et, surtout, plus de boissons du tout...
Ce RFC signale que cette évolution peut être due en partie au fait que le terme bar BOF est trop proche de BOF et que les débutants mélangent les BOF (dotées d'un statut, celui du RFC 5434) et les bar BOF. C'est au point que certains participants, voulant aboutir à la création d'un groupe de travail, se sentent obligés de faire une bar BOF uniquement parce qu'ils croient qu'une règle de l'IETF impose cette étape ! Les auteurs du RFC recommandent donc de parler plutôt de « réunion parallèle » (side meeting).
Et, pour que ces réunions parallèles se passent bien, notre RFC 6771 propose quelques conseils. D'abord (section 2), comment gérer les invitations. Une réunion parallèle doit être petite (« uniquement les gens nécessaires et pas plus »). Il ne s'agit pas, comme c'est souvent le cas pour les BOF, de sonner le clairon pour ramener le maximum de gens, espérant ainsi montrer que le sujet est considéré comme important par la communauté. On ne devrait donc pas faire d'annonce publique d'une réunion parallèle (par exemple, sur une liste de diffusion). Si on le fait, on risque de manquer de chaises dans le bar, et de ne pas pouvoir s'entendre d'un bout de la réunion à l'autre, menant à des réunions excessivement formelles, avec tour de parole. (Plusieurs bar BOF ont déjà souffert de ce syndrôme « apéro Facebook ».)
Bref, pas de touristes à une réunion parallèle, uniquement « a few good people », des gens qui vont activement participer au travail (l'IETF ne décide normalement pas sur la base du nombre de participants mais sur le nombre de gens qui vont effectivement bosser). L'implication plus large de la communauté viendra après. La réunion parallèle doit avant tout rester du remue-méninges, chose qui ne se fait pas dans des grands groupes. Par définition, les idées exprimées lors d'une réunion parallèle sont incomplètes et imparfaites et il faut pouvoir les discuter franchement.
De même, on n'est pas obligé d'inviter un membre de l'IESG ou de l'IAB en croyant que cela fera plus sérieux et plus crédible.
Après le Qui, la section 3 couvre la question du Où. Comme leur nom l'indique, les bar BOF se tiennent traditionnellement dans les bars. Mais la tendance récente est de la faire souvent dans les salles d'une réunion IETF, en partie parce que cela fait plus « sérieux ». Notre RFC, qui n'hésite pas à descendre dans les détails concrets, note que les bars sont souvent bruyants, ce qui pose un problème notamment pour les non-anglophones (le bruit gène beaucoup plus lorsque la conversation est dans une langue étrangère). Pour garder la convivialité, en supprimant le bruit, le RFC recommande de choisir un restaurant calme, voire de prendre une arrière-salle du bar. Les salles de la réunion IETF sont en général trop « salle de classe », un environnement qui ne convient pas au remue-méninges entre pairs. Cet environnement est bon pour les présentations, pas pour les discussion.
Toujours concret, le RFC note enfin que se réunir dans un bar ou un restaurant permet souvent de... manger. En effet, certaines réunions IETF se tiennent dans des endroits où le ravitaillement est difficile et la réunion d'Anaheim (IETF 77) a ainsi laissé un souvenir particulièrement cuisant. Sortir est donc souhaitable.
Après le Qui et le Où, le Comment. La section 4 s'insurge contre la tendance de plus en plus marquée à singer les réunions des groupes de travail. On voit ainsi des réunions parallèles ayant un agenda formel, des présentations avec supports, des organisateurs qui se présentent comme bar BOF chair. Les auteurs de notre RFC craignent que ce cirque provoque des réactions pavloviennes chez les participants, les faisant se comporter comme si la réunion parallèle était déjà devenue un vrai groupe de travail. Ces réunions qui caricaturent les réunions officielles ne sont pas très efficaces, et elles entraînent des confusions chez certains participants qui croient qu'il s'agit de réunions officielles, simplement parce qu'elles en ont l'apparence.
Enfin, le Quand, en section 5. La principale recommendation est que les réunions parallèles, comme elles visent à commencer le travail pour résoudre un problème précis, n'ont pas forcément vocation à être toujours parallèles à une réunion IETF, elles peuvent parfaitement se tenir en parallèle d'une réunion RIPE, NANOG ou équivalent.
Et une anecdote amusante : comme obligatoire, ce RFC a une section « Sécurité ». Elle contient l'avertissement qu'on a constaté un oubli fréquent des portables dans les bars, après une réunion parallèle trop arrosée...
L'article seul
La cyberguerre n'aura pas lieu
Première rédaction de cet article le 14 octobre 2012
Un concept est très à la mode depuis deux ou trois ans, celui de cyberguerre. Les consultants en sécurité le citent à tout bout de champ, les journalistes le mettent dans leurs titres (moi aussi, vous avez remarqué ?), les politiques le brandissent en classant le risque de cyberguerre dans « l'une des principales menaces auxquelles nous devons faire face ». Y a-t-il une réalité derrière ce concept ?
Il est facile d'ironiser sur cette soi-disant « cyberguerre » en faisant remarquer qu'elle ne fait pas de cybermorts et que personne n'a encore signé de traité de cyberpaix. Il est clair que la cyberguerre n'a pas les caractéristiques habituellement associées à la guerre. La guerre, ce n'est pas seulement la violence physique, directe et organisée, contre l'autre camp (à ce compte-là, criminels et patrons voyous pourraient être qualifiés de guerriers). La guerre, c'est surtout l'engagement massif de moyens, la mobilisation (pas forcément sous l'uniforme) de tas de gens dont ce n'était pas le métier. C'est le risque, en cas de défaite, de changements radicaux (et en général négatifs) dans la vie de millions de gens. On ne parle pas de guerre pour quelques coups de feu de temps en temps, sauf quand on est un politicien malhonnête cherchant à faire parler de lui à la télé en exagérant les problèmes.
Ainsi, l'exemple souvent cité de « première cyberguerre de l'Histoire », l'attaque russe contre l'Estonie ne peut être qualifiée de guerre que par des gens qui n'ont jamais vécu une vraie guerre ! Si la Russie avait envahi l'Estonie, il y aurait eu pour les Estoniens des conséquences autrement plus graves que celui de ne pas pouvoir retirer d'argent à la banque pendant quelques jours ! Le terme de cyberguerre est ici une insulte aux victimes des vraies guerres menées par le pouvoir russe, comme celles contre la Tchétchénie ou contre la Géorgie.
Et les actions ayant des conséquences physiques, comme Stuxnet ? Ce qui fait que Stuxnet ne mérite pas d'être appelé « cyberguerre », ce n'est pas seulement le fait qu'il n'y ait pas eu de morts. C'est surtout le fait que toute action hostile d'un État voyou contre un autre (ici, le sabotage des installations nucléaires iraniennes) n'est pas forcément une guerre ou alors le terme ne veut plus rien dire. À l'extrême rigueur, on pourrait parler de « cyberguérilla » ou de « cybersabotage ». Imaginons que les services secrets israéliens ou états-uniens aient procédé à un sabotage classique, avec dépôt et mise à feu d'explosifs. Parlerait-on de guerre ? Le résultat aurait pourtant été le même.
Et c'est encore plus net pour des opérations comme Duqu ou Flame, où il n'y avait pas d'action, juste de l'espionnage. Certes, l'exploitation de failles de sécurité de MS-Windows change des méthodes de Mata Hari mais c'est simplement le progrès technique. Et ce n'est pas la « cyberguerre » pour autant, ou alors les États sont en guerre en permanence ! (Puisqu'ils s'espionnent en permanence.)
Mais, alors, pourquoi tant de gens utilisent-ils ce terme erroné de « cyberguerre » ? Dans le numéro de novembre 2010 de la revue « Réalités industrielles », on trouve un article de Nicolas Arpagian avec cet aveu touchant : « on peut reconnaître néanmoins l'efficacité [pour toucher un large public] du mot cyberguerre ». Tout est dit : « cyberguerre » est simplement un moyen, pour les consultants, d'obtenir davantage de budget et de missions, pour les journalistes, d'avoir plus de lecteurs et pour les politiques, de faire voter ce qu'ils voudraient.
C'est ainsi que le documentaire « La guerre invisible » fait défiler une longue cohorte d'ex-généraux ou ex-ministres âgés, tous reconvertis dans la cyberpeur, et tous annonçant qu'on peut faire dérailler un train ou empoisonner l'eau via l'Internet. L'un des pires de ces cyberpaniqueurs, Richard Clarke, brandit pendant toute l'émission son livre, pour qu'on n'oublie pas de l'acheter. Il est clairement dans une démarche commerciale et pas dans une tentative de sensibiliser les citoyens à un problème réel.
Pourtant, le problème n'est pas imaginaire. Il y a aura certainement dans les guerres futures, du piratage de drones, des attaques informatiques pour couper les communications de l'ennemi, etc. Mais ce n'est pas de la « cyberguerre », c'est simplement l'utilisation de moyens « cyber » pour la guerre. Si on définit la cyberguerre comme « l'utilisation du cyberespace par des groupes militaires dans le cadre de conflits armés » (Julie Horn), alors on n'a pas avancé dans la terminologie : la guerre utilise forcément les moyens techniques existants. On n'a pas parlé d'« airguerre » avec le développement des avions de combat, ou de « guerre chevaline » lorsque la cavalerie a fait ses débuts...
Est-ce un simple problème de terminologie erronée ? Non, car le terme de cyberguerre n'est pas innocent. Il ne sert pas seulement à justifier le business de quelques consultants incompétents et powerpointeurs. Il vise surtout à conditionner les esprits, à faire croire que nous sommes en guerre, et à habituer les citoyens aux habituelles restrictions, matérielles et surtout de libertés, qui sont la conséquence habituelle de la guerre. Comme le fait remarquer Peter Sommer, interrogé dans le rapport OCDE de janvier 2011, « We don't help ourselves using 'cyberwar' to describe espionage or hacktivist blockading or defacing of websites, as recently seen in reaction to WikiLeaks ». Non, en effet, cette confusion n'aide pas. Mais elle n'est pas due à la paresse intellectuelle ou au manque de sang-froid. Elle est délibérée, cherchant aussi à criminaliser toute opposition en mettant dans le même sac des opérations d'un État puissant et surarmé avec des actions plus ou moins efficaces de groupes informels. Le même Sommer ajoute à juste titre « Nor is it helpful to group trivially avoidable incidents like routine viruses and frauds with determined attempts to disrupt critical national infrastructure,. Mais une telle réserve dans l'analyse ne lui vaudra certainement pas de passer à la télévision...
Quelques bonnes lectures sur ce sujet :
- L'article d'Olivier Tesquet « Les va-t-en-cyberguerre débarquent », assez confus mais qui a le mérite d'analyser les raisons économiques du marketing de la cyberguerre,
- Parmi les experts qui refusent le terme, Arnaud Garrigues explique que « La cyberguerre n'est pas car : pas de victime, une violence inexistante ou limitée, pas toujours des objectifs politiques etc etc.... », et il fait un tour d'horizon des opinions sur ce terme,
- Une très bonne analyse de plusieurs cas médiatiques, les dégonflant sérieusement,
- Les déclarations de Bruce Schneier contre l'exagération,
- Sur son blog, Félix Aimé fait un grand tour d'horizon, très raisonnable, du sujet dans « De la cyberguerre, présentation »,
- Un bon article de John Horgan, « Don't Believe Scare Stories about Cyber War » qui remet ce terme de cyberguerre dans la longue liste des exagérations de la propagande militariste,
- L'expert en sécurité bien connu Marcus Ranum ne prend pas de gants pour dire clairement que « Cyberwar is Bullshit » (et il argumente très bien),
- Je n'ai pas eu le temps de lire la thèse de Karin Kosina (thèse en politique internationale, pas en informatique ou en sécurité) sur la cyberguerre mais elle m'a été recommandée par des gens très bien,
- Un autre article qui explique en détail l'utilisation du terme de cyberguerre pour obtenir des budgets, dans la grande tradition du complexe militaro-industriel : « The Cybersecurity-Industrial Complex »,
- Un article d'OWNI a exploré le concept de cyberguerre,
- Et, bien sûr, Jean-March Manach s'y est mis aussi avec « C'est la cyberguerrrrrrrrrre ! ».
L'article seul
RFC 6749: The OAuth 2.0 Authorization Framework
Date de publication du RFC : Octobre 2012
Auteur(s) du RFC : D. Hardt (Microsoft)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF oauth
Première rédaction de cet article le 13 octobre 2012
Le protocole OAuth a désormais sa seconde version, OAuth 2.0, normalisée dans ce RFC. OAuth permet de à un programme de s'authentifier sur le Web, pour accéder à un jeu limité de services, qu'un utilisateur lui a autorisé.
OAuth est donc un protocole d'authentification d'un tiers, le client, qui veut accéder à une ressource, par exemple un fichier, située sur un serveur et dont le contrôle revient à un propriétaire, le resource owner. (OpenID vise à authentifier un utilisateur humain, OAuth à authentifier la requête d'un programme, agissant pour le compte d'un humain.) Prenons un exemple (vous en trouverez d'autres dans le RFC, comme l'exemple classique de l'impression de photos, mais celui que j'indique a l'avantage d'être un exemple réel) : le service de microblogging Twitter permet à des utilisateurs (les propriétaires, dans la terminologie OAuth) de faire connaître au monde entier leurs pensées profondes en moins de 140 caractères. Le succès de ce service et l'existence d'une bonne (car très simple) API a poussé à l'arrivée de nombreux services tiers qui ont tous en commun de devoir accéder au compte Twitter de l'utilisateur (par exemple, Twibbon ou TwitterCounter). Une façon possible, pour ces services, d'accéder au compte Twitter de l'utilisateur est de lui demander son nom et son mot de passe. On voit les conséquences que cela peut avoir pour la sécurité : le service doit stocker le mot de passe (le fera-t-il de façon sûre ?), le service peut abuser de son privilège, puisqu'il a tous les droits du propriétaire, le serveur doit gérer l'authentification par mot de passe (pas la meilleure), retirer un droit d'accès à un service veut dire changer le mot de passe, retirant ainsi le droit d'accès à tous les services tiers, etc.
OAuth fournit
une meilleure solution : le serveur, en recevant la
requête du client, demande au
propriétaire l'autorisation :
 Cette demande se fait typiquement via un formulaire HTML.
Cette demande se fait typiquement via un formulaire HTML.
Le service tiers reçoit alors un token, une autorisation qui lui est spécifique, et ne lui donne que certains droits. Il présentera ce token au serveur pour obtenir l'accès.
Tout se fait par redirections HTTP (RFC 7231, section 6.4 et ce RFC 6749, section 3). Bien sûr, pour que cela soit sûr, il y a de nombreux détails à prendre en compte.
Si OAuth v1 (RFC 5849) était juste l'officialisaton à l'IETF d'un protocole qui avait été développé à l'extérieur, cette nouvelle version 2 marque des changements profonds, et incompatibles avec l'ancienne version. C'est d'abord une refonte de la norme, d'un seul document à un ensemble dont ce nouveau RFC 6749 n'est que le document de cadrage. Les documents décrivant effectivement le protocole ne sont pour la plupart pas encore parus (il y a par exemple un projet de RFC sur les scénarios d'usage, et un entièrement consacré à la sécurité, via une études des menaces portant sur OAuth). Seuls les RFC 6750, sur un type particulier de token, et RFC 6755 sur des URN pour OAuth, accompagnent ce nouveau OAuth. C'est aussi le passage d'un protocole relativement simple à un ensemble de protocoles, partageant un cadre commun mais n'étant plus forcément interopérables (section 1.8), puisque OAuth v2 permet bien des variantes. C'est complètement contraire aux principes posés dans le RFC 6709, sur les extensions aux protocoles. Donc, attention, un service OAuth v1 ne peut pas interagir avec un serveur OAuth v2 (quand ils existeront) ou le contraire. Les programmeurs OAuth sont encouragés à repartir de zéro, vue la différence des deux protocoles.
Une fois que Twitter a adopté ce protocole (notez que, à la date de publication de ce RFC, Twitter utilise OAuth v1 et n'a pas annoncé d'intention de passer à la v2) et documenté son usage, la plupart des services tiers l'ont intégré (par exemple Twibbon).
Lisons maintenant le RFC. Premièrement, les concepts (section 1) et le vocabulaire (section 1.1). Ce qui se jouait autrefois à deux (le client et le serveur) est désormais fréquemment une partie à trois (OAuth Love Triangle, dit Leah Culver), le client (client, Twibbon dans le cas plus haut), le serveur (server, Twitter dans le cas plus haut) et le propriétaire (resource owner, moi). Notez qu'OAuth v2 a transformé le triangle en carré, en passant à quatre rôles, le serveur ayant été séparé en deux, le serveur qui contrôle l'accès à la ressource convoitée, et celui qui donne les autorisations. En pratique, on ne sait pas encore si des serveurs suivront cette séparation.
Pour voir le cheminement complet d'une authentification OAuth, on
peut regarder la jolie
image de Yahoo (mais attention, elle utilise une ancienne terminologie) ou bien suivre l'exemple de la section 1.2 du
RFC. Si le client, le service d'impression
printer.example.com veut accéder aux photos
stockées sur le serveur photos.example.net, et
dont le propriétaire est Jane :
{kind=link}
- Le client et le serveur doivent déjà avoir un accord entre eux, préalable, avec un secret partagé pour s'authentifier. OAuth ne permet pas à un nouveau client inconnu d'en bénéficier.
- Le client doit avoir lu la documentation du serveur, qui indique entre autre les URL à contacter.
- Lorsque Jane visite le site du client, ici l'imprimeur, et
demande l'impression de ses photos, le client contacte le serveur en
HTTP pour
demander un token, une suite de nombres aléatoires
qui identifie de manière unique cette requête (on peut voir ce
token dans la copie d'écran ci-dessus, c'est le
paramètre
oauth_token). - Le client doit alors utiliser les redirections HTTP pour envoyer Jane sur le site du serveur, afin qu'elle donne l'autorisation nécessaire. Les paramètres de la redirection indiquent évidemment le token.
- Si Jane donne son accord (cela peut être un accord implicite,
voir par exemple comment fait Twitter), le serveur signe
la demande et renvoie le navigateur de celle-ci vers le client avec,
dans les paramètres, une demande approuvée et signée (paramètre
oauth_signature). - Le client peut alors demander au serveur des autorisations pour les photos, puis demander les photos elle-mêmes.
Un guide complet sur OAuth v1 est disponible en http://hueniverse.com/oauth/guide/. Une autre bonne
introduction à OAuth v1 est « Gentle introduction to OAuth ». Parmi les applications
amusantes d'OAuth, un curl OAuthisé
en http://groups.google.com/group/twitter-api-announce/browse_thread/thread/788a1991c99b66df. Un
exemple de programmation OAuth v1 pour accéder à Twitter en
Python figure dans mon article. Mais OAuth v2 ne bénéficie
pas encore de telles documentations.
OAuth v2 a suscité de nombreuses critiques, notamment sur sa complexité. Mon pronostic est qu'OAuth v2, victime du Second System Effect, ne sera guère déployé, la grande majorité des sites Web restant à la v1.
Une bonne critique qui synthétise la plupart des remarques qui ont été faites sur OAuth v2 est « OAuth 2.0 and the Road to Hell ». Eran Hammer, l'auteur, est marqué dans l'annexe C de ce RFC comme ayant participé à OAuth v2 jusqu'à la version 26 du brouillon (la version publiée est la 31). Il a ensuite cessé sa participation au projet et s'en explique dans cet article. Ses principaux arguments :
- Le cadre est trop général, ne permettant pas de garantir l'interopérabilité de deux mises en œuvre d'OAuth v2 (ce point est admis dans la section 1.8 de ce RFC 6749). C'est au point qu'un très grand nombre de protocoles incompatibles entre eux pourraient légitimement se nommer « conformes à OAuth »..
- OAuth v1 était simple et utilisable, issu d'un monde de startups Web qui voulaient une solution « bien assez bonne » et tout de suite. OAuth v2 a été chargé par des exigences de PHB comme de mentionner SAML et autres technologies des « gens de l'entreprise » (par opposition aux « gens du Web »). C'est une tendance analogue qui a tué les Web Services.
- Étant plus complexe et plus adaptable à des besoins spécifiques, OAuth v2 sera moins sûr.
L'article seul
Mesurer le temps de chargement d'un site Web, en ignorant la pub ?
Première rédaction de cet article le 8 octobre 2012
Je suis sûr qu'une partie de mes lecteurs vont apprécier le défi. Le problème a été discuté dans un groupe de travail ARCEP, où il s'agit de mesurer la qualité de l'accès à l'Internet via un FAI. Outre les mesures de bas niveau (les seules sérieuses, à mon avis), on voudrait mesurer un truc plus représentatif de l'utilisation habituelle de l'Internet, l'accès à une page Web. Mais les pages Web « importantes » contiennent souvent des tas d'élements « extérieurs » comme Google Analytics, les publicités, etc. Comment les exclure ?
Je me focalise sur l'aspect technique. Sur la question de fond, il faut se demander si c'est une bonne idée d'exclure quelque chose qui fait partie intégrante du vécu de l'utilisateur...
Le premier algorithme qui vient à l'esprit est d'exclure les
contenus externes qui sont désignés par un nom de domaine différent. Prenons la
page d'accueil de TF1, http://www.tf1.fr/. Elle référence 31 noms de
domaines différents, dont 19 sont en dehors de
tf1.fr (par exemple
w.estat.com, utilisé pour des statistiques). En
examinant ces noms à la main, les choses semblent simples : les noms
externes à tf1.fr sont bien pour du contenu
« externe », dont l'affichage n'est pas indispensable.
Maintenant, testons un autre média,
Libération. La page
http://www.liberation.fr/ contient 62 noms de domaine
(qui peuvent être des liens à suivre, pas forcément du contenu
chargé automatiquement). Mais, cette fois, le problème est que du
contenu de la page est chargé à partir de noms en dehors de
liberation.fr comme
s0.libe.com. Oui, libe.com a
le même titulaire que
liberation.fr mais allez expliquer cela à un logiciel.
À part des problèmes comme celui-ci, l'examen rapide de quelques
sites Web français populaires (bien placés dans Alexa)
semble quand même indiquer un gros effort des webmestres pour placer
le contenu sous leur nom de domaine. On trouve nettement moins de noms
de domaine appartenant à des CDN, par
exemple, alors que c'était très courant à une époque. Ce premier algorithme ne semble donc pas catastrophique mais
des différences comme libe.com
vs. liberation.fr le prennent en défaut.
Deuxième algorithme possible, utiliser les listes noires de logiciels comme Ghostery ou Adblock Plus pour éliminer le contenu « externe ».
Et y a-t-il d'autres possibilités ? Vous pouvez indiquer vos suggestions sur SeenThis.
L'article seul
Pourquoi est-ce que les licences « pas d'usage commercial » sont une mauvaise idée ?
Première rédaction de cet article le 7 octobre 2012
On trouve souvent des contenus numériques gratuitement accessibles, librement utilisables et réutilisables mais avec une règle supplémentaire : pas d'utilisation commerciale autorisée. C'est par exemple le cas, dans la galaxie Creative Commons, des licences marquées NC (Non Commercial). Mais beaucoup d'autres licences ad hoc reprennent cette idée. En revanche, les logiciels libres comme le projet GNU, ou bien une encyclopédie comme Wikipédia, n'empêchent pas l'utilisation commerciale. Pourquoi est-ce eux qui ont raison ?
A priori, cette interdiction d'utilisation commerciale est le bon sens même. Un auteur (de logiciel, de textes ou d'images, peu importe) travaille dur pour produire un contenu, qu'il permet ensuite au peuple de télécharger et d'utiliser gratuitement et sans formalités. Il ne veut pas que la Fédération du Commerce s'en empare et se fasse du fric avec son travail, alors qu'elle-même n'a rien fait. C'est ce raisonnement que se tiennent un certain nombre d'auteurs. C'est encore plus net s'ils ont des idées politiques de gauche : « je souhaite que ce travail circule en dehors du système capitaliste, et voilà pourquoi j'interdis toute utilisation commerciale ». (Notons que d'autres auteurs, n'ayant pas les mêmes convictions politiques, interdisent l'utilisation commerciale par les autres, mais en font eux-même, par exemple en produisant une version gratuite et une version qu'ils vendent. J'y reviendrai.)
Personnellement, j'ai moi-même partagé ce point de vue et mis ce genre de licences autrefois. Pourquoi ai-je changé d'avis ? La première raison est pratique et c'est pour moi la plus importante. « Utilisation commerciale » est un terme flou et qui est difficile à vérifier en pratique. Comment, vont me retorquer certains, c'est quand même évident : si on le vend, c'est commercial, sinon ça ne l'est pas.
Mais ce test est mauvais. L'archétype des logiciels libres, ceux du projet GNU était vendu à ses débuts, lorsque beaucoup de gens n'avaient pas d'accès à l'Internet (voyez « $150 GNU Emacs source code, on a 1600bpi industry standard mag tape in tar format »). Même chose pour les CD-ROM des premiers systèmes à base de Linux, vendus par ceux qui les faisaient et qui souhaitaient rentrer dans leurs frais. Cette activité « para-commerciale » a beaucoup contribué à rendre Linux accessible à tous, à l'époque où on n'avait pas BitTorrent.
Alors, si l'échange d'argent n'est pas le bon test, peut-on utiliser comme critère le fait que le vendeur fasse un profit ou pas ? Mais ce test n'est pas meilleur. Le statut d'une organisation (avec ou sans but lucratif) ne veut pas dire grand'chose : l'ARC était une organisation sans but lucratif, cela ne les empêchait pas d'être des voleurs. Sans aller jusqu'au vol, des tas d'associations 1901 brassent des fortes sommes d'argent et paient fort bien leurs dirigeants. « Sans but lucratif » n'est pour elles qu'un drapeau qu'on brandit, pas une réalité sur le terrain.
Donc, en pratique, il est très difficile de déterminer si une utilisation est commerciale ou pas. En fait, personnellement, j'ai commencé à changer sur ce point lorsque je me suis fait refuser l'intégration d'un logiciel « sans utilisation commerciale » sur le CD-ROM distribué lors d'une conférence (à l'époque, ça se faisait, l'accès à haut débit n'était pas pour tous). L'inscription à la conférence étant payante (pour couvrir les frais comme la location de la salle), l'auteur avait considéré que c'était une activité commerciale... Encore plus agaçant que le refus, les délais lors des négociations avec les auteurs (surtout lorsqu'il y en a plusieurs) et surtout l'incertitude juridique (suis-je ou ne suis-je pas commercial, telle est la question).
C'est ainsi que le blogueur qui, par exemple, met des publicités sur son site pour gagner sa vie (ou plutôt pour moins la perdre car on ne devient pas riche en bloguant) peut se demander légitimement s'il n'est pas passé commercial et s'il ne devrait pas supprimer tous les contenus sous licence « pas d'usage commercial » qu'il a repris.
C'est pour cela que le monde du logiciel libre, après quelques hésitations au début (les logiciels dans la recherche scientifique, par exemple, ont encore parfois la restriction « pas d'usage commercial »), a fini par ne plus utiliser cette restriction. Malheureusement, les licences Creative Commons ont ramené la question sur le devant en ayant une variante Non Commerciale, par exemple dans la licence Paternité - Pas d'utilisation commerciale - Partage des conditions initiales à l'identique. Beaucoup d'auteurs, voyant cette licence, se disent que c'est une bonne idée et s'en servent pour leurs œuvres, rendant ainsi plus difficile leur réutilisation.
Après le problème pratique (qui est à mon avis le principal), un autre problème des licences « usage commercial interdit » est qu'il s'agit parfois, non pas de rejeter le commerce mercantile par principe (chose que je peux comprendre) mais de le réserver à l'auteur ou à son éditeur. C'est tout à fait légal (l'auteur fait ce qu'il veut avec son œuvre), mais ce n'est pas très progressiste. (Cette démarche est défendue par Calimaq, par exemple.) Un tel usage ne devrait pas être appelé NC (Non Commercial) mais UCR (Usage Commercial Réservé à l'auteur).
Quelques articles et exemples intéressants :
- « That Blurry Line Between Commercial & Non-Commercial Use Still Troubling For Creative Commons » de Mike Masnick, met également l'accent sur le problème pratique de ces licences « non commerciales ».
- « Why Not NC (Non Commercial)" » de Kathi Fletcher, est centré sur la question de l'éducation, domaine où malheureusement pas mal de contenu est non-libre, et où une partie est sous une licence restrictive à cause de la clause « non commerciale ». Aux arguments pratiques, elle ajoute un argument plus politique, que le commerce n'est pas une mauvaise chose (on peut être en désaccord).
- « Use cases for NonCommercial license clause », un très bon texte d'Evan Prodromou où il décrit plusieurs scénarios d'usage de contenu libre et analyse, pour chacun, s'il est commercial ou pas...
- « Une autre photo de la guerre du Web » de Lionel Maurel, raconte les prétentions exorbitantes d'un lobby de photographes professionnels, qui demande (entre autres !) qu'on oblige les photographes amateurs qui publient sur le Web à utiliser une licence « pas d'usage commercial » afin de préserver le business des « professionnels ». De la même façon, les voleurs de la SACEM, non seulement se sentent autorisés à interdire à leurs membres la licence de leur choix, mais veulent forcer l'utilisation de licences NC, pour que seule la SACEM puisse faire du commerce.
- « Non à la libre diffusion ! » de Simon « Gee » Giraudot. Il reprend l'argument pratique sur l'ambiguité de la clause « pas d'usage commercial » mais il critique aussi toutes les licences Creative Commons qui restreignent les usages (« non commercial » mais pas seulement, puisqu'il existe d'autres restrictions possibles, par exemple ND « No Derivative »). Le titre provocant fait référence au fait que la libre diffusion (permise par toutes les licences Creative Commons) est bien mais insuffisante.
- La documentation sur les licences de TuxFamily est très détaillée sur la question des licences « non commerciales ».
- Dans le domaine de l'éducation, et des livres de cours en informatique, on peut citer trois ouvrages sous Creative Commons, le manuel de Terminale S dans l'option Informatique et Sciences du Numérique, sous licence NC (pas d'usage commercial), le CNP3 (livre universitaire sur les réseaux informatiques), sous licence entièrement libre, ou le « LaTeX appliqué aux sciences humaines », également sans clause NC.
- L'avis d'Eric Raymond, portant uniquement sur le caractère flou de « commercial ».
- La question de la clause « non commercial » est mentionnée (avec bien d'autres) dans l'excellent article d'Isa Vodj sur le choix d'une licence. L'auteure estime comme moi que cette clause est bien compliquée en pratique.
- Et, pour finir, un article de Calimaq favorable à la clause NC (et qui répond en partie à mon article).
Ah, et ce blog que vous êtes en train de lire ? Il est sous licence GFDL donc l'usage commercial est autorisé (ceci dit, personne n'a encore essayé...)
L'article seul
Ethernet OAM (802.1ag) sur Unix
Première rédaction de cet article le 30 septembre 2012
Pour tester des équipements réseaux ayant IP, tout le monde utilise les classiques ping et traceroute. Mais pour la couche 2, pour du simple Ethernet, peut-on faire l'équivalent, même si la machine n'a pas d'adresse IP ? Depuis quelques années, oui, une norme existe pour cela, 802.1ag. Elle est surtout mise en œuvre dans les équipements de haut de gamme. On peut l'utiliser depuis une simple machine Unix.
Si vous voulez apprendre 802.1ag, un bon document d'explication et de synthèse a été produit par Fujitsu : « Ethernet Service OAM: Overview, Applications, Deployment, and Issues » (OAM voulant dire Operations, Administration, and Management). Normalisé en 2007, 802.1ag est relativement récent dans l'histoire d'Ethernet. Autrefois, il n'existait pas d'outils de couche 2 pour tester Ethernet, il n'y avait que ceux de couche 3 comme ping et ceux de couche 1 comme les réflectomètres.
802.1ag fournit des services de test classiques, CFM LB (Connectivity Fault Management - Loop Back), équivalent des échos d'ICMP qu'utilise ping, CFM LT (Link Trace), équivalent de ce qu'utilise traceroute, etc.
Il existe une mise en œuvre de cette norme sur
Unix, dot1ag. Une bonne
introduction à ces outils a été faite dans un
exposé de leur auteur (attention, l'outil était loin d'être
fini lors de cet exposé). Voici un exemple typique, avec la
commande ethping, de ces outils :
# ethping -i eth1 00:23:8b:c9:48:f2 Sending CFM LBM to 00:23:8b:c9:48:f2 64 bytes from 00:23:8b:c9:48:f2, sequence 663084168, 0.014 ms 64 bytes from 00:23:8b:c9:48:f2, sequence 663084169, 0.015 ms 64 bytes from 00:23:8b:c9:48:f2, sequence 663084170, 0.016 ms 64 bytes from 00:23:8b:c9:48:f2, sequence 663084171, 0.014 ms 64 bytes from 00:23:8b:c9:48:f2, sequence 663084172, 0.010 ms
Et voilà, on sait que la machine d'adresse MAC
00:23:8b:c9:48:f2 est bien vivante et
joignable. Vous noterez qu'il a fallu indiquer l'interface Ethernet de
sortie puisqu'Ethernet ne fait pas de routage.
tcpdump sait décoder ces paquets 802.1ag et on voit passer :
16:26:28.789571 CFMv0 Loopback Message, MD Level 0, length 50 16:26:28.789997 CFMv0 Loopback Reply, MD Level 0, length 50
(Je vous laisse consulter l'article de Wikipédia pour découvrir ce qu'est un MD.) Notez que Wireshark sait également décoder ce protocole.
Si on augmente la bavartitude de tcpdump avec l'option
-v, on a :
16:28:38.533399 CFMv0 Loopback Message, MD Level 0, length 50
First TLV offset 4
0x0000: 1716 defa 0100 0100 0000 0000 0000 0000
0x0010: 0000 0000 0000 0000 0000 0000 0000 0000
0x0020: 0000 0000 0000 0000 0000
Sender ID TLV (0x01), length 1
End TLV (0x00), length 0
16:28:38.538023 CFMv0 Loopback Reply, MD Level 0, length 50
First TLV offset 4
0x0000: 1716 defa 0100 0100 0000 0000 0000 0000
0x0010: 0000 0000 0000 0000 0000 0000 0000 0000
0x0020: 0000 0000 0000 0000 0000
Sender ID TLV (0x01), length 1
End TLV (0x00), length 0
Là, pour décoder, il faudrait avoir accès à la norme mais l'IEEE étant un dinosaure très conservateur, cette organisation ne permet pas l'accès libre et gratuit à ses textes, hélas. (Le groupe de travail IEEE a un site Web mais qui contient très peu de choses.) Si vous êtes prêt à remplir un questionnaire (où on vous demande à quel titre vous voulez ce texte...), à indiquer votre adresse de courrier, etc, alors, cette norme fait apparemment partie du petit nombre des normes IEEE qu'on peut obtenir sans frais, en ligne.
Bon, maintenant, on a un client qui marche mais peut-on s'en servir à la maison ou dans une petite entreprise ? Non, les équipements Ethernet bas de gamme (commutateur acheté au supermarché, adaptateur CPL, Freebox) n'ont pas 802.1ag et ne répondent donc pas. Ici, on essaie de tester le commutateur d'une Freebox v6 :
# ethping -i eth1 f4:ca:e5:4d:1f:41 Sending CFM LBM to f4:ca:e5:4d:1f:41 Request timeout for 1340526005 Request timeout for 1340526006 Request timeout for 1340526007 Request timeout for 1340526008
À noter que les outils dot1ag comprennent un démon qu'on peut faire tourner sur ses machines Unix pour les tester. L'intérêt pratique est limité, bien sûr car, si la machine a suffisamment démarré pour lancer ledit démon, elle a probablement aussi acquis une adresse IP.
Et la fonction de trace (l'analogue de traceroute) ? Ici, on voit une machine située à un saut de distance :
# ethtrace -i eth1 00:23:8b:c9:48:f2
Sending CFM LTM probe to 00:23:8b:c9:48:f2
ttl 1: LTM with id 1207397526
reply from 00:23:8b:c9:48:f2, id=1207397526, ttl=0, RlyHit
En fait, ce n'est pas tout à fait exact. Il y avait un commutateur Netgear bon marché entre les deux machines. Mais comme ce dernier ne parle pas 802.1ag, il a simplement relayé les trames, comme s'il était transparent.
Merci à Ronald van der Pol pour sa relecture.
L'article seul
RFC 6708: Application-Layer Traffic Optimization (ALTO) Requirements
Date de publication du RFC : Septembre 2012
Auteur(s) du RFC : S. Kiesel (University of Stuttgart), S. Previdi (Cisco Systems), M. Stiemerling (NEC Europe), R. Woundy (Comcast Corporation), Y R. Yang (Yale University)
Pour information
Réalisé dans le cadre du groupe de travail IETF alto
Première rédaction de cet article le 30 septembre 2012
Le système Alto (Application-Layer Traffic Optimization), permettant aux machines d'un réseau pair-à-pair de trouver le meilleur pair, par exemple pour obtenir un fichier plus rapidement, avance, lentement, mais sûrement. Ce nouveau RFC spécifie le cahier des charges d'Alto.
Alto peut servir à autre chose qu'au pair-à-pair. Mais le scénario d'utilisation principal est le suivant : une machine veut accéder à un fichier. Celui-ci est offert par plusieurs pairs. Lequel choisir ? En prendre un au hasard risque de ne pas être optimum, ni pour la machine (temps de transfert du fichier plus long qu'il ne pourrait l'être), ni pour son FAI (utilisation de liens externes plus coûteux que son réseau interne). Alto vise donc à permettre à des serveurs Alto de donner à leurs clients (les machines qui veulent accéder aux fichiers) des informations sur lesquelles décider intelligemment, ou même simplement d'indiquer directement le pair à utiliser. Le groupe de travail Alto a été créé en novembre 2008, le RFC 5693, qui définit le problème à résoudre, a été publié en octobre 2009, et voici désormais le deuxième RFC du groupe, le cahier des charges du protocole. (Pour ceux qui ne connaissent pas l'IETF, et qui craignent que le travail sur le protocole ne commence qu'une fois le cahier des charges terminé, je vous rassure, ce n'est pas ainsi que fonctionne l'IETF. Le protocole est déjà bien avancé à l'époque, et a été publié dans le RFC 7285.)
Pair-à-pair ou pas, le but d'Alto est donc d'améliorer simultanément la qualité de la vie pour l'utilisateur (télécharger les chefs d'œuvre de la culture plus vite) et pour le réseau (ne pas gaspiller des ressources chères comme les lignes transocéaniques). Cela ne peut pas se faire par des mesures uniquement faites par les machines terminales. Par exemple, celles-ci peuvent faire des ping mais elles ne peuvent pas déterminer si un lien est de peering (« gratuit ») ou de transit (facturé au 95ème centile de l'usage).
Les serveurs Alto ne feront pas bouger les octets : leur seul rôle est de dire aux pairs « tu devrais plutôt causer avec lui, ça devrait aller vite ». Les pairs sont ensuite responsables de leurs décisions.
L'habituelle section de terminologie, nécessaire pour comprendre le reste du RFC, est la section 2. Attention, le RFC 5693 définissait déjà certains termes (comme client Alto et serveur Alto) qui ne sont pas répétés ici. Les termes les plus importants :
- Descripteur de groupe (Host Group Descriptor) : c'est l'information
qui définit un groupe de machines. Cela peut être un préfixe
IP (« toutes les machines en
2001:db8:1337::/32») ou un numéro d'AS (« toutes les machines joignables par l'AS 42 »). - Attribut d'une machine (Host Characteristics Attribute) : c'est une propriété attachée à une machine comme « accès Internet au forfait ».
- Critère de classement. On a dit plus haut que le but d'Alto était de sélectionner le « meilleur » pair. Mais quelle est la définition de « meilleur » ? Par exemple, cela peut être « le moins cher » ou « celui avec la plus forte capacité réseau ». Alto est un protocole pour distribuer des choix, pas un mécanisme pour décider quel est le meilleur.
- Recherche dépendante de la cible (Target-aware Query Mode) se dit d'une requête Alto où le client Alto connait une liste de pairs potentiels, envoie cette liste au serveur Alto (ainsi qu'un critère de classement) et reçoit en retour la liste triée selon le critère. (Plus exactement, le client envoie une liste de descripteurs de groupes, pas d'adresses IP des pairs potentiels.) On notera que ce mode permet au serveur de connaître les pairs potentiels de ses clients. En revanche, c'est ce mode qui permet au client de faire le moins de calculs, ce qui est utile pour les machines aux ressources réduites.
- Recherche indépendante de la cible (Target-independant Query Mode) désigne une requête Alto où le client télécharge tout ou partie des descripteurs de groupe que connait le serveur, avec leurs attributs, et fait le calcul du meilleur pair lui-même. Préservant la vie privée du client, elle lui impose davantage de calculs.
Les exigences sur le futur protocole figurent en section 3 et sont numérotées AR-n (AR pour Alto Requirment). Elles vont des plus évidentes (exigence AR-1 : les clients et serveurs Alto doivent parler le protocole Alto...) aux plus pointues. Voici les plus importantes, selon moi.
Le protocole devra gérer les descripteurs de groupe : types
multiples (AR-3), au moins les types « préfixe
IPv4 » et « préfixe
IPv6 » (AR-5) et extensible (possitibilité
d'ajouter de nouveaux types de descripteurs de groupe dans le futur,
AR-6). Les types « préfixes IP » sont, à ce stade, les types
recommandés. Donc, en deux mots, les pairs possibles seront identifiés
par leur adresse (« j'hésite entre un pair en
2001:db8:1:2::af et un pair en
192.0.2.43, tu me recommandes lequel ? »). Voir
aussi AR-7 et AR-8.
Le protocole devra permettre d'indiquer un critère de classement (AR-11) permettant de comparer les machines entre elles. Alto ne détermine pas comment on fait les calculs : il utilise le résultat (on peut tout imaginer, y compris des tables gérées à la main, par exemple en fonction du fait que les liens sont de transit ou de peering). Alto devra, là aussi, être extensible et permettre d'ajouter d'autres critères dans le futur.
Ces critères doivent être relativement stables (ne pas oublier qu'une fois un transfert de fichiers commencé, il peut durer de nombreuses heures) donc ne pas dépendre, par exemple, de l'état de congestion du réseau (AR-13). À propos de la congestion, les applications qui utiliseront Alto ne doivent pas s'en servir comme remède contre la congestion, elles doivent utiliser un protocole qui dispose de mécanismes d'évitement de la congestion, comme TCP (AR-14, et aussi AR-29).
Le critère de classement doit pouvoir être indiqué au serveur (en mode « recherche dépendante de la cible », car, dans l'autre mode, c'est le client Alto qui classe) afin qu'il l'utilise pour classer (AR-16).
Où va être situé le client Alto ? Le protocole ne l'impose pas et il y aura au moins deux positionnements possibles : directement dans l'application (le client BitTorrent, par exemple) ou bien chez un tiers qui fera une partie du travail pour le compte du client (le tracker BitTorrent, par exemple). Alto devra fonctionner dans les deux cas (AR-18 et AR-19).
Et qui va fournir ses informations au serveur Alto ? Une possibilité évidente est que ce soit le FAI, et qu'Alto devienne un service de base de l'accès Internet, comme le résolveur DNS et le serveur NTP. Mais les exigences AR-20 et AR-21 demandent que le protocole n'impose pas ce choix : il faut que des acteurs tiers puisse jouer le rôle de serveur Alto.
Le protocole doit aussi permettre la redistribution de l'information obtenue (AR-25), en indiquant des conditions de redistribution.
Comment va-t-on trouver son serveur Alto ? Il faudra décrire un mécanisme et AR-37 demande que ce mécanisme soit intégré aux protocoles existants comme PPP ou DHCP (comme c'est le cas pour découvrir un résolveur DNS).
La sécurité étant un enjeu important pour Alto (voir aussi la section 5), il faudra aussi un mécanisme d'authentification des serveurs (AR-40), des clients (AR-41), la possibilité de chiffrer (AR-42), et d'ajuster la taille des requêtes et réponses selon le niveau de confiance du client envers le serveur, ou réciproquement (AR-44). Un client devra donc pouvoir rester intentionnellement vague dans sa demande, au risque évidemment que les informations du serveur soient moins pertinentes.
Et la sécurité ? Outre le RFC 5693 qui couvrait déjà la sécurité d'Alto, la section 5 de notre RFC met l'accent sur le point le plus important, le risque de distribution d'informations sensibles.
Ce risque existe dans les deux sens, du client vers le serveur et du serveur vers le client. Le client ne souhaite pas forcément communiquer au serveur tout ce qu'il sait. Par exemple, lorsque la HADOPI espionne, un client Alto ne va pas dire à un serveur qu'il ne connait pas « je cherche une copie HD du dernier Disney ». Et, en sens inverse, un serveur Alto géré par un FAI n'est pas forcément enthousiaste à l'idée de donner des informations qui permettent de se faire une bonne idée de la configuration de son réseau, de l'identité des opérateurs avec qui il peere et autres informations confidentielles.
Même si le client ne donne pas d'informations aussi évidentes que dans l'exemple ci-dessus, un serveur malin peut déduire plein de choses des demandes que le client lui adresse (la liste des pairs potentiels, par exemple, est une information utile pour repérer les plus grosses sources de contenu en pair-à-pair).
Pour l'opérateur du serveur, le principal risque est en recherche indépendante de la cible, lorsque le client télécharge de grandes quantités d'information. Un serveur prudent ne dira donc pas tout. En outre, même si le serveur accepte de donner ces informations au client, il peut quand même s'inquiéter de ce qu'elles deviendront. Un tiers qui écoute le réseau ne va t-il pas mettre la main sur l'information confidentielle ? Et, même si l'information donnée à chaque client est limitée (par exemple, uniquement une partie des descripteurs de groupes que le serveur connait), ne risque t-on pas de voir des clients coopérer pour récupérer chacun un bout, avant de le mettre en commun ?
Le futur protocole Alto devra donc contenir des mesures pour faire face à ces problèmes : par exemple, permettre au serveur d'être délibérement incomplet ou imprécis (annoncer un préfixe IP plus général que le vrai, par exemple), authentifier clients et serveurs, chiffrer les communications contre l'écoute par TMG, etc. En revanche, le RFC écarte l'idée de DRM dans les données Alto, complexes et facilement contournables. Les acteurs Alto sont donc prévenus que les données échangées ne peuvent pas être 100 % confidentielles. Un client ou un serveur méchant pourra toujours en faire mauvais usage.
À noter que les intérêts du client et du serveur peuvent être contradictoires. Ainsi, les requêtes en mode indépendante de la cible préservent la vie privée du client (il ne dit rien sur ce qu'il va faire des données) mais oblige le servur à diffuser de l'information. Et, pour les requêtes en mode dépendant de la cible, c'est le contraire :le client se dévoile, le serveur ne prend pas de risque.
L'article seul
RFC 6730: Requirements for IETF Nominations Committee tools
Date de publication du RFC : Septembre 2012
Auteur(s) du RFC : S. Krishnan, J. Halpern (Ericsson)
Pour information
Première rédaction de cet article le 27 septembre 2012
L'IETF dispose d'une institution curieuse, le NomCom (Nominations Committee) qui est chargée de sélectionner des candidats pour des postes à l'IESG, l'IAB ou l'IAOC. Sa tâche d'examen des noms et de sélection nécessite un certain nombre d'outils informatiques, qui n'existent pas forcément tous à l'heure actuelle. Ce RFC est le cahier des charges des outils, pour servir de base aux futurs développements.
Tous les détails sur le NomCom et son fonctionnement sont spécifiés dans le RFC 7437. On peut aussi consulter le site officiel. Le NomCom dispose déjà d'un outil (accessible via le Web pour sa partie publique, mais il a aussi une partie privée, réservée aux membres du NomCom) mais qui est insuffisant. Notre nouveau RFC liste les nouveautés nécessaires pour cet outil. La première exigence, étiquetée META-001 est que le nouvel outil devra reprendre toutes les fonctions de l'ancien.
Ensuite, comme le NomCom travaille avec des données personnelles,
la plupart des exigences du cahier des charges concernent la
sécurité. Le logiciel stockera des noms, des appréciations, des
opinions sur des personnes, etc, toutes choses assez sensibles. Il faudra un système d'authentification (exigences AUTH-001
à AUTH-003), capable de
distinguer trois rôles (membre ordinaire de
l'IETF, membre du NomCom, président du
NomCom). Les membres ordinaires n'ont accès qu'à la partie
publique. Ils se servent pour cela de leur compte
datatracker.ietf.org (cf. RFC 6175, tout le monde peut se créer un compte avec cet
outil puisque tout le monde peut participer à l'IETF).
Toutes les communications seront évidemment chiffrées et l'exigence SEC-001 demande que les données stockées le soient de telle façon qu'on minimise même leur exposition accidentelle (même l'administrateur ne doit les voir que sur une action explicite de sa part). Les données seront stockées chiffrées avec la clé publique du NomCom (exigences SEC-002 à SEC-005) et seront détruites à la fin de la sélection (toutes les données ne sont pas concernées, voir plus loin).
Moins cruciales, les autres exigences portent sur le processus de désignation des candidats (exigences NOM-001 à NOM-011) et sur l'enregistrement de l'acceptation ou du rejet car un candidat peut ne pas accepter sa désignation, qui a pu être faite par un tiers (exigences AD-001 à AD-007).
Enfin, l'outil devra gérer les réponses des candidats aux questionnaires qui leur seront soumis (« que ferez-vous si vous êtes élu à l'IAB ? » (exigences QR-001 à QR-007) et surtout les retours des membres sur les candidatures (exigences FB-001 à FB-006). Ces retours, avis, et opinions forment une part essentielle du processus mais, malheureusement, les exigences d'ouverture et de sécurité ne sont pas faciles à concilier. Ainsi, les messages envoyés au NomCom par les membres sont archivés, contrairement aux autres données collectées par le NomCom (exigence FB-005).
On peut finir avec l'amusante annexe A de ce RFC, qui décrit les
commandes OpenSSL nécessaires pour la gestion
de la cryptographie dans l'outil du NomCom. La configuration (le
fichier nomcom-config.cnf) ressemble à :
[ req ] distinguished_name = req_distinguished_name string_mask = utf8only x509_extensions = ss_v3_ca [ req_distinguished_name ] commonName = Common Name (e.g., NomcomYY) commonName_default = Nomcom12 [ ss_v3_ca ] subjectKeyIdentifier = hash keyUsage = critical, digitalSignature, keyEncipherment, dataEncipherment basicConstraints = critical, CA:true subjectAltName = email:nomcom12@ietf.org extendedKeyUsage= emailProtection # modify the email address to match the year.
Et on peut générer le certificat avec :
openssl req -config nomcom-config.cnf -x509 -new -newkey rsa:2048 \ -sha256 -days 730 -nodes -keyout privateKey.pem \ -out nomcom12.cert
L'article seul
RFC 6721: The Atom "deleted-entry" Element
Date de publication du RFC : Septembre 2012
Auteur(s) du RFC : J. Snell
Chemin des normes
Première rédaction de cet article le 26 septembre 2012
Le format Atom, normalisé dans le RFC 4287, est surtout utilisé pour la syndication de contenus Web. Dans ce cas, si une entrée d'un flux Atom n'est plus publiée (remords de l'auteur ou autre raison), le client Atom n'avait pas de moyen de le savoir. Désormais, avec l'extension de ce RFC, surnommée « pierre tombale », on peut indiquer que l'absence d'une entrée est délibérée.
Rappelez-vous qu'un flux de syndication comporte un certain nombre d'entrées mais rarement la totalité des articles d'un site Web (dans le flux de ce blog, par défaut, les articles des quatre derniers mois). On ne peut donc pas dire, lorsqu'un article n'a pas d'entrée dans le flux Atom, si l'article a été supprimé ou simplement s'il n'a pas été inclus dans le flux. Si, par exemple, l'entrée a été gardée dans la mémoire locale du client de syndication, elle risque d'y rester même si l'article original a disparu du site.
Pour éviter cela, ce RFC ajoute un nouvel élément
XML à Atom. Il est défini avec la syntaxe
Relax NG (l'espace de noms XML abrégé en
at est http://purl.org/atompub/tombstones/1.0) :
deletedEntry =
element at:deleted-entry {
atomCommonAttributes,
attribute ref { atomUri },
attribute when { atomDateConstruct },
( element at:by { atomPersonConstruct }?
& element at:comment { atomTextConstruct }?
& element atom:link { atomLink }*
& element atom:source { atomSource }?
& anyElement* )
}
On note donc que la référence de l'article détruit
(ref) est obligatoire. Elle correspond à
l'attribut id d'un flux Atom, qui a la forme d'un
URI. Ainsi, cet article que vous êtes en train
de lire a l'id
tag:bortzmeyer.org,2006-02:Blog/6721 et une
pierre tombale, si je supprimais cet article, comporterait
<at:deleted-entry
ref="tag:bortzmeyer.org,2006-02:Blog/6721" ....
Comme l'attribut ref, l'attribut
when est obligatoire et contient la date et
l'heure de destruction (au format du RFC 3339). Il est particulièrement utile si une entrée est
détruite puis recréée : en examinant les dates, un client Atom peut
savoir quel est l'évènement le plus récent (la suppression ou la
création) et ignorer les autres.
Les autres attributs de l'élement
at:deleted-entry sont facultatifs. C'est le cas
par exemple de comment qui permet d'ajouter une
explication en texte libre. Voici, tiré du RFC, un exemple minimal :
<at:deleted-entry
ref="tag:example.org,2005:/entries/1"
when="2005-11-29T12:11:12Z"/>
et un exemple plus complet :
<at:deleted-entry
ref="tag:example.org,2005:/entries/2"
when="2005-11-29T12:11:12Z">
<at:by>
<name>John Doe</name>
<email>jdoe@example.org</email>
</at:by>
<at:comment xml:lang="la">Lorem ipsum dolor</at:comment>
</at:deleted-entry>
Notez bien que l'élement at:deleted-entry
n'est qu'indicatif : on ne peut évidemment pas garantir qu'un client
Atom facétieux ne va pas conserver localement (et même redistribuer)
des entrées qu'il avait gardé dans son cache et
qui ont été détruites dans le flux original.
Autre piège de sécurité : un client Atom ne doit pas croire
aveuglément tous les at:deleted-entry qu'il
rencontrerait sur le Web ! Car un méchant peut toujours publier des
pierres tombales pour un autre site que le sien. Il faut donc vérifier
l'origine (la pierre tombale doit être dans le même flux que l'article
original, ce qui peut poser des problèmes avec les
agrégateurs et autres redistributeurs) et/ou
vérifier les signatures cryptographiques
attachées (avec XML Signature).
Cette extension est mise en œuvre au moins dans AtomBeat (voir leurs intéressants exemples d'usage).
L'article seul
RFC 6707: Content Distribution Network Interconnection (CDNI) Problem Statement
Date de publication du RFC : Septembre 2012
Auteur(s) du RFC : B. Niven-Jenkins (Velocix (Alcatel-Lucent)), F. Le Faucheur (Cisco), N. Bitar (Verizon)
Pour information
Réalisé dans le cadre du groupe de travail IETF cdni
Première rédaction de cet article le 26 septembre 2012
Aujourd'hui, les CDN sont partout. Ces serveurs munis de nombreux disques et disposés dans les réseaux des FAI, au plus près de l'abonné, afin de servir du contenu numérique le plus rapidement possible, sont derrière un grand nombre de sites Web (non, ce blog n'utilise pas de CDN) et derrière bien des fournisseurs de streaming. La plus connue des entreprises de CDN est Akamai mais il en existe bien d'autres. Et c'est là que le problème commence : il n'existe aucun mécanisme d'interconnexion des CDN. Chacun utilise ses protocoles spécifiques et pas question de les faire travailler ensemble. L'IETF a donc créé un groupe de travail, CDNI, chargé de réfléchir à l'interconnexion des CDN. Ce RFC est le premier du groupe, et il essaie de définir le problème (les solutions viendront plus tard, le cahier des charges formel a été publié dans le RFC 7337).
L'extension massive des CDN est bien sûr liée à l'augmentation considérable du contenu numérique : présentations PowerPoint ennuyeuses, vidéos de chats mignons, communiqués de presse en PDF qui prennent plusieurs mégaoctets pour ne pas dire grand'chose, publicités débiles, webinars en haute définition et au contenu vide, etc. Sans le CDN, un site Web qui veut distribuer un fichier de N mégaoctets à M clients va voir N*M mégaoctets passer sur sa liaison Internet. Avec le CDN, le fournisseur de contenu (CSP dans le RFC pour Content Service Provider) n'aura à faire passer le contenu qu'une fois, vers le CDN. Le contenu sera ensuite distribué par les serveurs du CDN, situés typiquement chez les FAI (notez aussi que certains FAI ont leur propre CDN). Meilleure latence, meilleure résilience (attaques dDoS et flash crowds), meilleur débit, bref, tous les avantages.
Aujourd'hui, les CDN ne coopèrent pas. Si un fournisseur de CDN est très présent en Europe et en Amérique, mais pas en Asie, un CSP client de ce CDN verra ses clients asiatiques mécontents. Pour les satisfaire, il devra signer un contrat avec un autre CDN, très présent en Asie. Il serait pourtant plus simple que le premier fournisseur de CDN puisse s'appuyer sur l'infrastructure du second et lui transmettre données et instructions. Mais, en l'absence de normes techniques pour l'interconnexion des CDN, cela n'est possible aujourd'hui que par des arrangements privés. C'est l'une des principales motivations pour la création du groupe de travail CDNI. L'idée est que, dans le futur, le premier fournisseur de CDN cité (celui qui est trés présent en Europe et en Amérique) aura juste à signer un contrat avec le second fournisseur et, techniquement, tout se passera tout seul, il utilisera le réseau du second sans que le fournisseur de contenu n'y voit rien.
Avant d'attaquer la question de l'interconnexion, notre RFC 6707 précise qu'il vaut mieux connaître les CDN pour suivre. Si ce n'est pas le cas, il recommande la lecture des RFC 3040 qui décrit les composants d'un CDN, RFC 3466 et RFC 3570, les deux derniers étant le résultat du travail du précédent groupe de travail IETF sur les CDN. Le RFC recommande également la lecture de « A Taxonomy and Survey of Content Delivery Networks ».
La section 2 de notre RFC précise les cas où il est intéressant d'interconnecter les CDN. À la raison donnée plus haut (permettre à des CDN de s'allier pour avoir une meilleure couverture géographique), s'ajoute le désir de permettre l'interconnexion des CDN que gèrent certains FAI : en se regroupant, ils pourraient former un CDN alternatif aux CDN indépendants des FAI comme Akamai. Il y a aussi des cas où un FAI a déployé plusieurs CDN spécialisés et souhaite après les regrouper. Enfin, un dernier scénario envisagé est celui où un CDN doit faire appel temporairement à un autre (suite à une grosse panne, par exemple) et doit le faire vite, sans programmer des scripts spécifiques.
Mais qu'est-ce que veut dire « Interconnecter des CDN » ? Des essais ont déjà été tentés, montrant qu'il y avait des choses qui marchaient et d'autres qui étaient vraiment pénibles en l'absence de normes. La section 3 identifie quatre interfaces par lesquelles on voudrait connecter des CDN, et pour lesquelles il n'existe pas de normes :
- Interface de contrôle du CDN, par laquelle on démarre et arrête le service, on indique les politiques suivies (« aucun contenu ne doit pas être distribué en dehors des États-Unis », par exemple), on déclenche la copie de contenu, on vire le contenu qui ne doit plus être servi, etc.
- Interface de routage des requêtes du CDN, qui n'est pas le routage de la couche 3. Il s'agit ici de s'assurer que les requêtes des utilisateur seront routées vers un CDN et un seul (qu'il n'y ait pas de boucles « c'est lui, non c'est lui »).
- Interface de distribution des métadonnées au CDN. Ces métadonnées sont les données au sujet du contenu : ses caractéristiques techniques (HD ou pas, par exemple, pour permettre la sélection du bon fichier), informations de zonage (tel document ne doit être servi que dans telle région du Monde), etc.
- Interface de journalisation (logging) du CDN. Elle permet de faire remonter les données de trafic, à des fins de statistiques, de facturation, etc. Sans elle, un CDN hésiterait à s'associer à un autre si cela signifiait qu'il n'aurait plus accès aux données de trafic.
Vous avez noté quelque chose qui manque ? Prenez le temps de réfléchir avant de regarder le paragraphe suivant.
Une interface importante est exclue du projet CDNI : l'interface d'acquisition des données elle-mêmes. Ce n'est pas tout de s'entendre avec un autre CDN pour qu'il contribue à distribuer le contenu de vos clients, encore faut-il mettre la main sur le dit contenu ! Mais notre RFC considère le problème comme déjà largement résolu. Il existe en effet plusieurs protocoles standards, ayant toutes les caractéristiques voulues, et effectivement utilisés par les CDN (HTTP et rsync sont deux exemples typiques). En écartant ce problème des données, le groupe CDNI se focalise sur le contrôle des CDN.
Et pour les quatre interfaces citées plus haut, ne pourrait-on pas trouver des protocoles existants qui résolvent le problème, sans avoir besoin de développer quelque chose de nouveau ? La section 4 reconnait que ce serait très souhaitable, cite des protocoles intéressants (comme XMPP ou APP) et étudie cette question.
- L'interface de contrôle, dit le RFC, est un problème très ouvert et, bien qu'il soit souhaitable de réutiliser des protocoles existants, le RFC ne s'avance pas à en suggérer certains.
- Pour l'interface de routage, en revanche, notre RFC considère qu'une simple fonction requête/réponse (par exemple « tu peux gérer ça ? / oui ») suffit et que cette interface peut donc être réalisée avec des protocoles de type Web Services comme XML-RPC ou REST. Le groupe de travail n'aurait alors à normaliser que le format exact de ces services. Il y a toutefois d'autres fonctions, liées à la sélection du CDN le plus efficace pour une requête, pour lequel le RFC suggère d'étudier des techniques comme ALTO (RFC 5693).
- Même chose pour l'interface d'accès aux métadonnées, où il n'y aura pas non plus de nécessité de développer un protocole entièrement nouveau.
- L'interface de journalisation pourrait aussi utiliser des protocoles existants comme évidemment SNMP ou syslog. Attention, ils ne sont pas forcément parfaits. Par exemple, dans SNMP, la remise des notifications asynchrones - traps - n'est pas garantie - cf. annexe A.3 - ce qui est un problème pour la facturation.
Des détails sur cette réutilisation de protocoles existants figurent dans l'annexe A. Elle est particulièrement riche pour le cas de l'interface de routage, qui doit permettre des scénarios de redirection complexes (plus complexes que, par exemple, les simples 301 et 302 de HTTP). Pour la journalisation, si le protocole de transport peut être un protocole existant, il restera à spécifier le format des données transportées (les champs, leur syntaxe, leur sémantique, etc).
La traditionnelle section de sécurité (section 6) est longue car une telle interconnexion des CDN soulève plein de problèmes difficiles. C'est d'autant plus vrai que le contenu numérique servi est souvent commercial et que le fournisseur de contenu souhaite en contrôler la distribution. Dans un CDN homogène, c'est relativement facile. Mais comment faire lorsqu'on interconnecte des CDN hétérogènes ? Il va falloir faire confiance aux autres...
En outre, l'interconnexion des CDN différents va introduire des problèmes légaux, puisque les CDN en question seront peut-être gérés par des entreprises différentes, donc soumises à des lois différentes. Ainsi, une loi locale peut obliger à anonymiser plus ou moins les données envoyées sur l'interface de journalisation.
- Pour l'interface de contrôle, le principal problème de sécurité est le risque qu'un attaquant ne puisse contrôler le CDN par ce biais. Elle devra donc imposer une authentification sérieuse.
- Pour l'interface de routage, les problèmes sont très proches : imaginez un méchant renvoyant toutes les requêtes vers un CDN qui n'est pas au courant et qui se retrouverait ainsi inondé.
- L'interface des métadonnées est moins sensible mais, quand même, les informations peuvent ne pas être publiques.
- L'interface de journalisation reçoit des données confidentielles et qui doivent donc être protégées, par exemple par du chiffrement. Mais elle peut aussi être utilisée pour de la facturation (« j'ai traité ce mois-ci N requêtes de tes clients, voici la note ») et elle doit donc être protégée contre la falsification.
L'annexe B intéressera les concepteurs de protocoles et les étudiants car elle définit les non-buts, ce que le groupe CDNI n'essaiera pas de faire. Par exemple :
- L'interface entre le fournisseur de contenu et le CDN (on ne s'occupera que de l'interface entre CDN), et les éventuelles transformations de ce contenu (réencodage des vidéos entrantes, par exemple).
- L'interface entre le CDN et le consommateur (avec éventuellement authentification). Même chose pour les menottes numériques.
- Comme indiqué plus haut, la synchronisation des données entre les CDN est aussi hors-sujet.
- Les algorithmes utilisés en interne par le système de routage du CDN pour décider à quel CDN partenaire il envoie des requêtes sont considérés comme une question interne et donc non traitée par le groupe CDNI. Seule l'interface de routage est dans le domaine d'activité de ce groupe.
- Et, naturellement, tous les aspects commerciaux et juridiques sont également exclus du travail de l'IETF.
Autre partie intéressante de l'annexe B, celle consacrée aux autres groupes de travail IETF qui avaient une importance pour ce sujet :
- ALTO, bien sûr (RFC 5693), par exemple pour router les requêtes vers le « meilleur » CDN. Comme indiqué plus haut, cela n'a pas d'influence directe sur le travail de CDNI puisque l'utilisation d'ALTO (ou pas) est une décision interne à chaque CDN.
- DECADE (RFC 6646). Ce groupe travaille à réduire l'usage du « dernier kilomètre » (celui qui connecte Mme Michu à son FAI) en permettant le téléversement de contenu par Mme Michu, sur un serveur mieux placé. Le RFC estime toutefois que le rapport avec les CDN est trop lointain pour que le travail de DECADE soit directement utilisable.
- PPSP, qui n'a pas encore de RFC, mais qui travaille sur le streaming en pair-à-pair. Son sujet est plutôt l'acquisition de contenu, un point qui a été explicitement exclu de CDNI.
Enfin, pour ceux et celles qui veulent vraiment beaucoup approfondir, les Internet-Drafts qui avaient précédé le RFC contenaient également une annexe (non gardée dans le RFC final) intéressante sur les autres efforts de normalisation des CDN. On y trouve de nombreux projets, parfois toujours actifs, y compris un ancien groupe de travail IETF, CDI, qui avait produit plusieurs RFC intéressants (RFC 3466, RFC 3568 et RFC 3570). Trop ambitieux, ce groupe n'avait pas vraiment réussi à faire avancer l'interconnexion.
L'article seul
La traduction d'adresses (NAT) apporte-t-elle vraiment de la sécurité ?
Première rédaction de cet article le 16 septembre 2012
Lors des discussions techniques sur la sécurité des réseaux informatiques, on entend très souvent l'affirmation comme quoi la traduction d'adresses (le NAT) apporterait une certaine sécurité au réseau local, bloquant par défaut les connexions entrantes et protégeant ainsi un peu les machines situées derrière. Cet argument a par exemple été souvent cité lors des débats sur le déploiement d'IPv6 (dans ces débats, l'argument pro-NAT est « Avec IPv4, le réseau local dispose d'une certaine sécurité grâce au NAT, qu'il perdrait lors du passage à IPv6 où le NAT est inutile »). Quelle est la part de vérité dans cette affirmation ?
D'abord, un petit rappel pour ceux et celles qui ne connaissent pas bien le NAT. Le nom est déjà une erreur. En effet, ce qui est déployé chez l'écrasante majorité des particuliers, qui accèdent à l'Internet via une box, ce n'est pas du NAT, c'est du NAPT (voir aussi mon article sur le zoo des NAT). La différence est énorme en pratique car, avec le NAPT, il y a partage d'adresses IP ce qui n'est pas le cas avec le NAT et cela entraîne une rupture du principe « connexion de bout en bout », qui est à la base de l'Internet. NAT signifie Network Address Translation et désigne une technique où les machines du réseau local ont des adresses privées, adresses qui sont dynamiquement remplacées par des adresses publiques lors de la traversée d'un routeur NAT. Celui-ci fait la traduction dans les deux sens, vers l'extérieur (remplacement des adresses privées par des adresses publiques) et vers l'intérieur (remplacement des adresses publiques par des adresses privées). Si le NAT peut perturber certains protocoles (qui indiquent l'adresse IP utilisée dans le paquet transmis, ce qui ne marche plus si un routeur réécrit les adresses), il ne pose pas en soi de problème philosophique fondamental. L'Internet pourrait fonctionner avec le NAT (voir le RFC 6296 pour un bon exemple de NAT bien conçu).
Mais ce qui est déployé actuellement sous le nom de NAT n'est pas du NAT ! La technique que doivent supporter les utilisateurs de base, chez eux ou dans les petites entreprises ou associations est tout autre chose. Son nom exact est NAPT (Network Address and Port Translation) et, contrairement au NAT, le NAPT a deux énormes défauts :
- Il partage les adresses publiques. Typiquement, en raison de la pénurie d'adresses IPv4, on n'a qu'une seule adresse publique et toutes les adresses privées du réseau interne sont mises en correspondance avec cette unique adresse publique. Cela a des tas de conséquences fâcheuses, détaillées dans le RFC 6269.
- Comme toutes les adresses internes sont fusionnées en une seule adresse externe, comment le routeur NAPT sait-il, lorsqu'un paquet IP revient, à quelle machine interne il est destiné ? Il regarde pour cela le numéro de port qu'il a mémorisé à l'aller. Cela entraine encore d'autres conséquences désagréables, comme la difficulté pour faire marcher les protocoles sans port (par exemple ICMP).
Bon, mais je m'éloigne du sujet, va-t-on me dire, j'avais promis de parler de la sécurité, pas de faire un éreintement du NAPT. Je reviens donc sur le second point : lorsqu'un paquet sort, le routeur NAPT doit traduire {Adresse IP source privée, port source} vers {Adresse IP source publique, autre port source} et se souvenir de la correspondance qui lui permettra, lorsqu'un paquet de réponse reviendra, de trouver vers laquelle des adresses IP privées il doit le diriger. Résultat, un paquet entrant non sollicité, qui n'est pas la réponse à un paquet sortant, ne sera pas accepté puisqu'il n'y a aucune entrée dans la table pour lui.
C'est ce point qui est souvent présenté comme un avantage de sécurité. Comme un pare-feu à état, le routeur NAPT ne laisse pas passer les nouvelles connexions entrantes. Cela transforme le réseau interne en un réseau purement client, qui ne peut accéder au réseau qu'en consommateur. (Cela perturbe également les services de type pair-à-pair où tout le monde est « serveur », cf. RFC 5128. Vu la diabolisation du pair-à-pair par le puissant lobby de l'industrie du divertissement, ce défaut du NAPT peut plaire à certains...) Mais, disent les partisans de cette configuration minitélienne, cela a des conséquences positives pour la sécurité ; si des machines du réseau interne sont complètement ouvertes à tous vents, pas de problème, le routeur NAPT empêchera le méchant extérieur d'y accéder. C'est d'autant plus important que certains systèmes (Windows...) sont très peu protégés et pourraient être piratés en quelques heures, ne laissant même pas le temps d'installer les patches nécessaires. (Voir l'excellent article « Know your Enemy: Tracking Botnets ».)
Mais les avantages de sécurité du NAPT sont largement exagérés. Voyons en quoi.
Le NAPT a des limites (qui sont aussi celles des pare-feux, malheureusement souvent présentés comme des solutions miracles) :
- Le NAPT ne protège pas contre les attaques effectuées par le contenu (« charge utile ») comme les chevaux de Troie, le virus contenu dans un courrier, le malware dans une page HTML lue avec IE6...
- Et il ne protège pas contre les attaques venues de l'intérieur du réseau, pourtant les plus fréquentes. Rappelez-vous que l'attaquant humain peut être à l'extérieur et quand même lancer une attaque depuis l'intérieur, avec des techniques comme le changement DNS.
Il ne manque d'ailleurs pas d'outils automatisant tout cela et permettant à un attaquant de faire une attaque sur un réseau privé situé derrière un routeur NAT.
Aujourd'hui, il y a de moins en moins d'attaques utilisant les connexions réseau, au profit des attaques « charge utile ». C'est logique quand on voit que sur un système récent (j'ai testé avec un Android et un Ubuntu, systèmes conçus pour M. Toutlemonde), il n'y a aucun service qui écoute sur l'Internet par défaut. Testez avec nmap :
# nmap -6 2a01:e35:8bd9:8bb0:6d07:5fdb:89e9:7d00 Starting Nmap 5.00 ( http://nmap.org ) at 2012-09-16 22:00 CEST Interesting ports on 2a01:e35:8bd9:8bb0:6d07:5fdb:89e9:7d00: Not shown: 999 closed ports PORT STATE SERVICE 22/tcp open ssh Nmap done: 1 IP address (1 host up) scanned in 1.09 seconds
(le service SSH a été ajouté
explicitement après l'installation, il n'était pas activé par
défaut). Bien des services tournaient certes sur cette machine
Ubuntu mais tous n'écoutaient que sur les
adresses locales à la machine (127.0.0.1 et
::1) et n'étaient donc pas vulnérables. Le NAPT
n'aurait donc protégé contre rien.
Néanmoins, en matière de sécurité, ce n'est jamais tout blanc ou tout noir. Les programmes qui écoutent sur des ports inférieurs à 1024 sont en général particulièrement sensibles et l'idée de les protéger ne me semble pas mauvaise. On peut donc imaginer des règles plus subtiles que celle du NAPT actuel.
Mais le refus de certains d'abandonner le NAT « pour des raisons de sécurité » n'est pas rationnel, puisque le NAT n'empêche pas ces attaques. Même si on tient à la sécurité qui découle de l'usage du NAPT, rien n'interdit de faire pareil si on n'a pas de NAPT, avec un simple pare-feu avec état (c'est ce que recommande le RFC 6092 pour IPv6.)
Cette question de l'utilisation du NAT (ou plutôt, comme on l'a vu, du NAPT) pour améliorer la sécurité a fait couler beaucoup d'électrons. Parmi tous les articles existants, je préfère :
- « Is NAT a security feature? »,
- Et bien sûr le RFC 4864, premier à discuter de la question des bénéfices de sécurité du NAT.
L'article seul
RFC 6709: Design Considerations for Protocol Extensions
Date de publication du RFC : Septembre 2012
Auteur(s) du RFC : B. Carpenter, B. Aboba, S. Cheshire
Pour information
Première rédaction de cet article le 15 septembre 2012
Concevoir des protocoles de communication monolithiques qui n'évoluent jamais est une chose. Concevoir des protocoles qui soient extensibles, qui puissent, après leur conception initiale, évoluer par le biais d'extensions, est un exercice plus difficile. Cet excellent RFC de l'IAB décrit comment faire un protocole extensible et comment assurer ainsi une évolution heureuse. C'est un document avant tout destiné aux auteurs de protocoles, mais qui intéressera aussi les étudiants en réseaux informatiques et tous les techniciens curieux, qui veulent savoir comment ça marche.
Parmi les innombrables exemples de protocoles IETF qui ont été étendus, on peut citer les extensions d'internationalisation de SMTP dans le RFC 6531, la recherche floue dans IMAP avec le RFC 6203, ou les capacités BGP du RFC 5492.
Le RFC 5218 (section 2.2.1), qui décrivait les raisons du succès pour un protocole réseau, notait parmi celles-ci l'extensibilité. Beaucoup de protocoles IETF ont des mécanismes pour cette extensibilité, qui est largement reconnue comme un bon principe. Mais, si elle est mal faite, des ennuis peuvent survenir, et cela peut menacer l'interopérabilité, voire la sécurité. Le RFC sur SMTP, le RFC 5321, note ainsi (section 2.2.1) que les protocoles avec peu d'options sont partout et que ceux avec beaucoup d'options sont nulle part. Un RFC comme le RFC 1263 (consacré aux extensions de TCP) critiquait également l'abus des extensions, et ce dès 1991. Malgré cela, d'innombrables RFC normalisent des extensions à tel ou tel protocole, mais il n'existait pas encore de document d'architecture sur le principe des extensions, rôle que ce RFC ambitionne de jouer.
D'abord, une distinction importante (section 2) entre extension « majeure » et « de routine ». Les secondes sont celles qui ne modifient pas le protocole de manière substantielle (et peuvent donc être introduites avec un minimum d'examen), les premières changent le protocole sérieusement et doivent donc être étudiées de près. Le problème est particulièrement aigu si l'extension est faite par d'autres personnes que le protocole originel : les « extensionneurs » risquent de ne pas connaître certaines règles non écrites que les auteurs originaux avaient en tête. Pour éviter cela, la spécification originale d'un protocole devrait toujours expliciter les règles, et décrire comment étendre le protocole proprement.
Comment distinguer une extension majeure d'une extension de routine ? Les extensions majeures sont celles qui peuvent empêcher l'interopérabilité (la capacité de deux pairs à communiquer), perturber le fonctionnement de l'Internet, ou mettre en péril la sécurité. Cela se produit notamment :
- Si l'extension nécessite que les mises en œuvre existantes
soient modifiées. Par exemple, si un protocole a un champ de taille fixe
Foobarsur un octet et que, les 256 valeurs étant occupés, on passe à un champ de deux octets, les nouvelles mises en œuvre ne pourront pas parler aux anciennes, tout l'en-tête étant décalé à partir de ce champ (uniquement pour un octet ajouté). Il existe des méthodes pour éviter ces problèmes (par exemple utiliser des TLV au lieu des champs de taille fixe) mais elles ont aussi des inconvénients (de performance, par exemple) et, de toute façon, nécessitent d'avoir été mises dès le début dans le protocole. Un autre exemple est celui d'un protocole où les messages ont un type et où tout type inconnu fait couper la communication. Dans ce cas, ajouter un type de message, même optionnel, représente une extension majeure (là aussi, il existe des solutions, comme de spécifier dès le début que les messages de type inconnu doivent être silencieusement ignorés, cf. section 4.7). - Si l'extension change fondamentalement le modèle sous-jacent. C'est d'autant plus difficile à détecter que ce modèle n'est pas toujours explicite. Bien des RFC décrivent au bit près le format des messages mais sont très courts sur la vision de haut niveau du protocole. Le RFC donne l'exemple d'une extension qui ajouterait un état à un protocole qui était précédemment sans état.
- Des nouveaux usages du protocole peuvent aussi représenter une extension majeure. Par exemple, si des changements purement quantitatifs se produisent (trafic accru, paquets plus gros comme dans le cas d'EDNS ou encore algorithmes qui ne supportent pas le passage à l'échelle d'une utilisation plus intense).
- Si on change la syntaxe du protocole (par exemple si on inverse deux champs).
- Si on change le modèle de sécurité.
- Et, bien sûr, si on crée une extension qui ne « rentre pas » dans le modèle d'extension originellement envisagé.
Et les extensions de routine, alors, elles ressemblent à quoi ?
- Elle n'ont aucune des caractéristiques citées plus haut, qui identifient les extensions majeures.
- Elle sont opaques au protocole (les messages avec la nouvelle extension sont traités par le protocole comme ceux d'avant).
Une extension de routine ne nécessitera aucun changement sur les vieux programmes. Seuls ceux qui voudront utiliser la nouvelle extension auront à être modifiés.
Quelques exemples d'extensions de routine : les options spécifiques
à un fournisseur de DHCP (RFC 2132),
les options spécifiques à un fournisseur de
Radius (RFC 2865), les
types MIME de l'arbre vnd
(vendor), etc. Ce n'est que lorsqu'on est sûr que
l'ajout d'une extension ne sera que de la routine qu'on peut avoir des
politiques du genre « premier arrivé, premier servi » (RFC 5226), c'est-à-dire peu ou pas d'examen préalable. Et
encore, l'expérience a montré que même les extensions de routine
pouvaient poser des problèmes inattendus et qu'un examen de toutes les
extensions par un expert est souvent une bonne chose.
Une fois posée cette importante distinction entre extensions de routines et extensions majeures, la section 3 de notre RFC s'attache des bons principes architecturaux pour assurer une extensibilité heureuse :
- Limiter l'extensibilité à ce qui est « raisonnable »,
- Penser avant tout à l'interopérabilité,
- Garder les extensions compatibles avec le protocole de base,
- Ne pas permettre des extensions qui créent un nouveau protocole, incompatible avec le précédent,
- Permettre de tester les extensions,
- Bien coordonner les allocations de paramètres (noms, numéros, etc),
- Faire davantage attention aux extensions aux composants critiques de l'Internet comme le DNS ou BGP.
Premier principe, limiter l'extensibilité. Il faut essayer de ne traiter que les cas les plus courants et ne pas chercher l'extensibilité à tout prix. C'est évidemment plus facile à dire qu'à faire. Comme le note le RFC 5218, un protocole qui rencontre un « succès fou » est utilisé dans des contextes que ses concepteurs n'imaginaient pas. Alors, essayer de déterminer à l'avance les extensions qui vont être vraiment utiles... On peut donc être amené à réviser le mécanisme d'extension en cours de route.
Deuxième principe, l'interopérabilité, c'est-à-dire la capacité de deux mises en œuvre complètement différentes du même protocole à communiquer. Le RFC 4775 (section 3.1) insiste sur ce concept, qui est au cœur de la mission de l'IETF. Une extension qui empêcherait les nouveaux programmes de communiquer avec les anciens casserait cette interopérabilité et serait donc inacceptable.
D'autres familles de protocole que la famille TCP/IP avaient une approche différente : le protocole était tellement bourré d'options très larges que deux mises en œuvre toutes les deux conformes à la norme pouvaient néanmoins ne pas pouvoir communiquer car elles n'implémentaient pas les mêmes options. C'est ce qui est arrivé aux protocoles OSI et la solution adoptée avait été de créer des profils (un ensemble d'options cohérent), créant ainsi autant de protocoles que de profils (les profils différents n'interopéraient pas même si, sur le papier, c'était le même protocole). Notre RFC dit clairement que ces profils ne sont pas une solution acceptable. Le but est d'avoir des protocoles qui fonctionnent sur tout l'Internet (alors qu'OSI avait une vision beaucoup plus corporate où il n'était pas prévu de communications entre groupes d'utilisateurs différents).
En pratique, pour assurer cette interopérabilité, il faut que le mécanisme d'extension soit bien conçu, avec notamment une sémantique claire (par exemple, précisant ce que doit faire un programme qui rencontre un message d'un type inconnu, ou bien un message d'un type qui ne correspond pas à ce qu'il devrait recevoir dans son état actuel).
Le RFC note aussi qu'écrire les plus belles normes ne suffira pas si elles sont mal mises en œuvre. On constate que les problèmes liés aux extensions sont souvent dus à des implémentations qui ne le gèrent pas correctement. Un exemple est celui des options d'IP qui, bien que clairement spécifiées dès le début (RFC 791), ne sont toujours pas partout acceptées en pratique.
Et puisqu'on parle d'interopérabilité, une idée qui semble bonne mais qui a créé beaucoup de problèmes : les extensions privées. Pas mal de programmeurs se sont dit « de toute façon, ce système ne sera utilisé que dans des réseaux fermés, tant pis pour l'interopérabilité sur le grand Internet, je peux, sur mon réseau, ajouter les extensions que je veux ». Mais les prédictions ne sont que rarement 100 % vraies. Les ordinateurs portables, les smartphones et autres engins se déplacent, et les implémentations ayant des extensions privées se retrouvent tôt ou tard à parler aux autres et... paf. Même chose lorsque deux extensions privées rentrent en collision, par exemple à la suite de la fusion de deux entreprises. Imaginons que chacune d'elles ait choisi de mettre du contenu local dans un attribut DHCP de numéro 62, en pensant que, DHCP n'étant utilisé que sur le réseau local, cela ne gênerait jamais. Des années après, une des deux entreprises rachète l'autre, les réseaux fusionnent et... repaf.
Pour résoudre ce problème, on a parfois fait appel à des espaces réservés comme le fameux préfixe « X- » devant le nom d'un paramètre (RFC 822). Le RFC 6648 a mis fin à cette pratique (qui était déjà retirée de plusieurs RFC), notamment parce que les paramètres « privés », tôt ou tard, deviennent publics, et qu'alors les ennuis commencent.
Un problème proche existe pour les paramètres considérés comme « expérimentaux ». Ils ont leur utilité, notamment pour que les programmeurs puissent tester leurs créations. C'est ainsi que le RFC 4727 propose des valeurs pour les expérimentations avec de nouveaux protocoles de transport, des nouveaux ports, etc. Le RFC 3692 décrit plus en détail les bonnes pratiques pour l'utilisation de valeurs expérimentales. Elles doivent être strictement limitées au système en cours de test, et jamais distribuées sur l'Internet. Si l'expérience est multi-site, c'est une bonne raison pour ne pas utiliser de valeurs expérimentales. C'est ainsi que des expériences comme HIP et LISP ont obtenu des paramètres enregistrés, non expérimentaux, pour pouvoir être testés en multi-sites.
À noter que ces valeurs expérimentales ne sont nécessaires que
lorsque l'espace disponible est limité. Le champ Next
header d'IPv6 ne fait qu'un octet et
il est donc logique de bloquer deux valeurs réutilisables, 253 et 254,
pour expérimenter avec des valeurs non officiellement
enregistrés. Mais ce n'est pas le cas, par exemple, des champs de
l'en-tête HTTP, composés d'un grand nombre de
caractères et permettant donc des combinaisons quasi-infinies. Si on
expérimente avec HTTP, il y a donc peu de raisons de réserver des
champs expérimentaux.
Troisième principe architectural, la compatibilité avec le protocole de base. Elle implique un double effort : les auteurs du protocole original doivent avoir bien spécifié le mécanisme d'extensions. Et les auteurs d'extensions doivent bien suivre ce mécanisme. Quelques exemples de protocole où le mécanisme d'extensions est documenté en détail : EPP (RFC 3735), les MIB (RFC 4181), SIP (RFC 4485), le DNS (RFC 2671 et RFC 3597), LDAP (RFC 4521) et Radius (RFC 6158).
Quatrième principe d'architecture, faire en sorte que les extensions ne mènent pas à une scission, avec apparition d'un nouveau protocole, incompatible avec l'original. Des changements qui semblent très modérés peuvent empêcher l'interopérabilité, ce qui serait de facto un nouveau protocole. Un protocole trop extensible peut donc ne pas être une si bonne idée que cela, si cette extensibilité va jusqu'à la scission.
Comme le note le RFC 5704, écrit dans le contexte d'une grosse dispute entre l'IETF et l'UIT, la scission (fork) peut venir de l'action non coordonnée de deux SDO différentes. Mais il n'y a pas toujours besoin d'être deux pour faire des bêtises : le RFC 5421 réutilisait un code EAP, rendant ainsi le protocole incompatible avec la précédente version. L'IESG avait noté le problème (documenté dans la section IESG Note du RFC 5421) mais avait laissé faire.
Cette notion de scission est l'occasion de revenir sur un concept vu plus haut, celui de profil. Il y a deux façons de profiler un protocole :
- Retirer des obligations (ce qui peut créer de gros problèmes d'interopérabilité),
- Ajouter des obligations (rendre obligatoire un paramètre qui était facultatif).
Contrairement à la première, la seconde approche peut être une bonne idée. En réduisant le nombre de choix, elle peut améliorer l'interopérabilité. Par contre, retirer des obligations est presque toujours une mauvaise idée. Ces obligations, dans un RFC (les fameux MUST, SHOULD et MAY), sont décrites avec les conventions du RFC 2119 et ce RFC insiste bien sur le fait qu'elles doivent être soigneusement choisies. Par exemple, un MUST ne doit être utilisé que si la violation de cette obligation est effectivement dangereuse, par exemple pour l'interopérabilité. Si ce conseil a été suivi, changer un MUST en SHOULD dans un profil va donc être négatif à coup presque sûr. Et, le RFC rappelle aussi qu'un MAY veut dire « vous n'êtes pas obligés de l'implémenter » mais certainement pas « vous avez le droit de planter si l'autre machine l'utilise ».
Place au cinquième principe, les tests. On a vu que ce n'est pas tout de bien normaliser, il faut aussi bien programmer. Pour s'assurer que tout a été bien programmé, il faut tester. Cela implique d'avoir développé des jeux de tests, essayant les différents cas vicieux (par exemple, essayer toutes les possibilités du mécanisme d'extension, pour vérifier qu'aucune ne plante les programmes ne les mettant pas en œuvre). Sinon, le test sera fait dans la nature, comme cela avait été le cas du fameux attribut 99 de BGP. La norme spécifiait très clairement ce qu'un pair BGP devait faire d'un attribut inconnu, mais IOS n'en tenait pas compte et, lorsque quelqu'un a essayé d'utiliser réellement cette possibilité de la norme, il a planté une bonne partie de l'Internet européen... TLS, étudié plus en détail plus loin, fournit un autre exemple d'implémentations déplorables, bloquant le déploiement de nombreuses extensions.
Sixième grande question d'architecture, l'enregistrement des paramètres. Beaucoup de protocoles ont besoin de registres pour noter les valeurs que peuvent prendre tel ou tel champ (par exemple, il y a un registre des numéros de protocole de transport et un registre des options DHCP). Ces registres et leur bonne utilisation sont une question souvent sous-estimée de l'interopérabilté. Si un champ du paquet identifie une extension et que deux extensions incompatibles utilisent le même numéro, l'accident est inévitable. Cette collision peut être due à l'absence de registre mais on rencontre régulièrement des développeurs qui ne vérifient pas le registre et qui s'attribuent tout simplement un numéro qui leur semble libre. (Le RFC note, de manière politiquement correcte, qu'il ne peut pas « publier les noms sans embarrasser des gens ». Mais cela semble particulièrement fréquent pour les numéros de port et pour les plans d'URI.)
Les concepteurs de protocole devraient vérifier, d'abord si un des registres existants ne suffit pas et, sinon en créer un. Dans ce cas, il faut soigneusement choisir la politique d'allocation des valeurs dans ce registre. Le RFC 5226 décrit les différentes politiques possibles, de la plus laxiste à la plus stricte. Attention : choisir une politique très stricte peut avoir des effets de bord désagréables, par exemple encourager les gens à « s'auto-enregistrer », c'est-à-dire à prendre un numéro au hasard (et tant pis pour l'interopérabilité) parce que la complexité et la lenteur des procédures les ont découragés. Il peut être préférable d'avoir une approche plus ouverte du registre, qui devrait documenter ce qui existe plutôt que d'essayer de contrôler tous les enregistrements.
Enfin, septième et dernier principe architectural à garder en tête pour faire des protocoles extensibles, l'importance particulière des services critiques. Si on arrête BGP, l'Internet ne fonctionne plus. Si on arrête le DNS, il n'y a quasiment plus aucune activité possible (même si vous ne voyez pas de noms de domaine, ils sont présents dans la communication). Même chose pour certains algorithmes comme le contrôle de congestion : si on modifie cet algorithme et qu'on se trompe, on peut mettre l'Internet à genoux. Il faut donc faire dix fois plus attention lorsqu'on étend ces protocoles critiques.
Le RFC cite un exemple BGP. Il existait depuis longtemps dans les IGP comme OSPF la notion de LSA opaque (LSA = Link State Attribute, la structure de données qui contient les informations que s'échangent les routeurs). « Opaque » signifie que les routeurs n'ont pas forcément besoin de comprendre son contenu. Ils peuvent le propager sans l'analyser et cela permet des extensions intéressantes du protocole, en introduisant de nouveaux types de LSA opaques. L'expérience montre que cela marche bien.
Mais l'introduction de nouveaux attributs dans BGP ne s'est pas aussi bien passé puisque des routeurs ont réinitialisé les sessions locales si un attribut, transmis par un routeur lointain, était inconnu ou mal formé. (Cas du fameux attribut 99.)
Une fois ces sept principes en tête, la section 4 se penche sur le protocole de base. Une bonne extensibilité implique un bon protocole de base, conçu pour l'extensibilité. Cela implique :
- Une spécification bien écrite,
- Prenant en compte l'interaction avec des versions plus récentes ou plus anciennes du protocole. Cela inclut la détermination des capacités du pair, la négociation des paramètres, le traitement des extensions inconnues (nécessaire pour que les nouvelles implémentations ne plantent pas les anciennes), etc.
- Décrivant bien les principes architecturaux du protocole, ainsi que sa sécurité (pour éviter qu'une extension ne casse un modèle de sécurité bien fait mais pas assez explicite).
- Précisant clairement le modèle d'extensions et notamment quelles extensions sont majeures et lesquelles sont de routine.
- Interagissant le moins possible avec les composants critiques de l'Internet. Par exemple, si un nouveau protocole nécessite des modifications sérieuses au DNS, cela va faire hésiter.
Écrire un protocole bien extensible nécessite aussi de prêter
attention à ce qui peut sembler des petits détails. Ainsi (section
4.1), le problème des numéros de versions. Il est courant que le
protocole porte un tel numéro, permettant au pair de savoir tout de
suite s'il a affaire à une implémentation équivalente (même numéro de
version) ou pas (numéro de version plus récent ou plus ancien). Par
exemple, voici une session TLS avec l'outil
gnutls-cli de GnuTLS :
% gnutls-cli --verbose --port 443 svn.example.net ... - Version: TLS1.2
où on voit que le serveur accepte TLS version 1.2. Un tel versionnement n'est utile que si le protocole de base précise bien ce qu'il faut faire lorsqu'on rencontre une version différente. Par exemple, si un logiciel en version 1.1 rencontre un 2.0 ? Il y a plusieurs sémantiques possibles, par exemple le protocole de base peut préciser que toute version doit être un sur-ensemble de la version antérieure (le logiciel en 2.0 doit accepter toutes les commandes du 1.1). Une autre sémantique pourrait être qu'il n'y a compatibilité qu'au sein d'une même version majeure (entre 1.0, 1.1, 1.2, etc) et que donc les deux logiciels de l'exemple (1.1 et 2.0) doivent renoncer à se parler. Dans les deux cas, cela doit être clairement spécifié.
Un contre-exemple est fourni par la norme
MIME. Le RFC 1341 décrivait un en-tête
MIME-Version: mais sans dire ce que devait faire
une implémentation correcte de MIME si elle rencontrait une version
inférieure ou supérieure. En fait, ce RFC 1341 ne précisait
même pas le format de la version ! Le RFC 1521 a un peu
précisé les choses mais pas au point qu'on puisse prédire le
comportement d'une mise en œuvre de MIME face à des versions
nouvelles. Notre RFC 6709 estime donc que le
MIME-Version: n'a guère d'utilité pratique.
Pour un exemple plus positif, on peut regarder ROHC. Le RFC 3095 décrivait un certain nombre de jeux de paramètres pour la compression. À l'usage, on leur a découvert des limitations, d'où le développement de ROHCv2 (RFC 5225). Ce dernier n'est pas compatible mais ne plante pas les ROHC précédents, ils ont simplement des jeux de paramètres différents et la négociation initiale (qui n'a pas changé en v2) permet à un ROHC ayant les jeux v1 de se comprendre facilement avec un plus récent.
Quelles sont les stratégies utilisées par les protocoles pour la gestion des versions ? Il y en a plein, toutes n'étant pas bonnes. On trouve :
- Pas de gestion de versions. Le cas le plus célèbre est EAP (RFC 3748) mais c'est aussi le cas de Radius (RFC 2865). Cela les a protégé contre l'apparition de multiples versions à gérer mais, comme la demande d'extensibilité est toujours là, elle s'est manifestée de manière non officielle (voir l'étude de cas de Radius en annexe A.2).
- HMSV (Highest mutually supported version) : les deux pairs échangent les numéros de version du protocole qu'ils savent gérer et on choisit la plus élevée qui soit commune aux deux. Cela implique que la version plus élevée est toujours « meilleure » (alors que, parfois, une version supérieure retire des fonctions). Cela implique aussi que gérer une version implique aussi de gérer toutes les versions inférieures (si un pair annonce 3.5 et un autre 1.8, HMSV va choisir 1.8 alors que le pair en 3.5 ne sait pas forcément gérer cette vieille version).
- Min/Max : une variante de HMSV où on annonce non pas un numéro de version (la plus élevée qu'on gère) mais deux (la version la plus élevée qu'on gère, et la moins élevée). Ainsi, il n'y a pas besoin de gérer éternellement les vieilles versions. Dans certains cas, cela peut mener à l'échec de la négociation. Si Alice annonce 2.0->3.5 et que Bob répond avec 1.0->1.8, ils n'auront aucune version compatible (Bob est trop vieux). Au moins, cela permettra d'envoyer un message d'erreur clair.
- Considérer que les vieilles versions sont compatibles avec les récentes. L'idée est que l'implémentation récente peut envoyer ce qu'elle veut, l'ancienne devant réagir proprement (typiquement en ignorant les nouveaux messages et types). Cela a pour conséquence qu'une nouvelle version du protocole ne peut pas rendre obligatoire un message qui n'existait pas avant (puisque les vieilles implémentations ne le connaissent pas). Avec cette stratégie, qui est par exemple utilisée dans 802.1X, un logiciel n'est jamais dépassé, il peut toujours travailler avec ses successeurs.
- Majeur/mineur : pour les numéros de versions à deux champs (comme 3.5 et 1.8 plus tôt), on considère qu'il y a compatibilité tant que le champ majeur ne change pas. 3.5 peut communiquer sans problème avec 3.0 mais aussi avec 3.9. Mais 3.5 ne peut pas parler avec 2.4 ou 5.2. Les contraintes de la stratégie précédente (ignorer les types inconnus, ne pas rendre un nouveau type obligatoire) ne s'appliquent donc qu'au sein d'un même numéro majeur.
Et c'est à peu près tout. Le RFC considère qu'il ne faut pas chercher d'autres stratégies de versionnement, qui ont de fortes chances d'être trop complexes pour être mises en œuvre sans erreur.
Autre chose importante à considérer lorsqu'on normalise le protocole de base (la première version) : les champs réservés. On trouve souvent dans les RFC des phrases comme (celle-ci est extraite du RFC 1035) « Reserved for future use. Must be zero in all queries and responses. ». (Dans le cas du DNS, ils ont été utilisés par la suite pour DNSSEC, bits AD et CD. Le bit 9, selon le RFC 6195, section 2.1, avait été utilisé de manière non standard autrefois et semble donc inutilisable désormais.) Certains champs dans l'en-tête sont donc gardés pour un usage futur et, presque toujours, le RFC demande à l'envoyeur de les mettre tous à zéro et au récepteur de les ignorer, ce qui est très important : autrement, on ne pourra jamais déployer d'implémentation d'une nouvelle version du protocole, qui utiliserait ces champs qui avaient été réservés. Dans les diagrammes montrant les paquets, ces champs sont en général marqués Z (pour Zero) ou MBZ (Must Be Zero, voir par exemple le RFC 4656). Notons que bien des pare-feux, fidéles jusqu'à l'excès au principe « tout ce qui est inconnu est interdit », au lieu d'ignorer ces champs, comme l'impose le RFC, jettent les paquets où ce champ ne vaut pas zéro. Ces engins sont une des plus grosses sources de problème lorsqu'on déploie un nouveau protocole. Donc, attention, programmeurs, votre travail n'est pas de vérifier ces champs mais de les ignorer, afin de permettre les futures extensions.
Autre problème douloureux, la taille à réserver aux champs (section 4.4). Certains protocoles utilisent des champs de taille illimitée (paramètres de type texte) ou suffisamment grands pour qu'on ne rencontre jamais la limite, même après plusieurs extensions du protocole. Mais ce n'est pas toujours le cas. Tout le monde se souvient évidemment de l'espace d'adressage trop petit d'IPv4 et de la difficulté qu'il y a eu à passer aux adresses plus grandes d'IPv6 (le champ Adresse étant de taille fixe, les deux versions ne pouvaient pas être compatibles). Dans la réalité, on rencontre :
- Des champs Version trop petits, par exemple de seulement deux bits (après la version de développement et la version de production, on n'a plus que deux versions possibles).
- Des champs stockant un paramètre pour lesquels la taille était trop petite pour la politique d'allocation (cf. RFC 5226) qui avait été adoptée. Par exemple, la politique FCFS (First-come, First-served, ou « Premier arrivé, premier servi »), la plus libérale, peut vite épuiser un champ de seulement huit bits (le problème s'est posé pour le champ Method Type d'EAP dans le RFC 2284).
Si un tel problème se pose, si on voit les valeurs possibles pour un champ arriver à un tel rythme que l'épuisement est une possibilité réelle, il y a plusieurs solutions :
- Changer la politique d'allocation en la durcissant. Mais attention, une politique trop dure peut mener à des comportements comme l'auto-allocation (« je prends la valeur qui me plait et tant pis pour le registre »). C'est ce qui avait été fait pour EAP (RFC 3748, section 6.2) en passant de « Premier arrivé, premier servi » à « Norme nécessaire ». Pour éviter l'auto-allocation, diverses solutions alternatives avaient également été normalisées par ce RFC, comme la suivante :
- Permettre des valeurs spécifiques à un fournisseur (vendor). Ainsi, chaque fournisseur qui crée une extension privée, spécifique à son logiciel, peut créer ses propres types/messages.
- Agrandir le champ. La plupart des protocoles IETF ont des champs de taille fixe, pour des raisons de performance (il faut se rappeler qu'il peut y avoir beaucoup de paquets à traiter par seconde, ce n'est donc pas une optimisation de détail). Agrandir le champ veut donc en général dire passer à une nouvelle version, incompatible, du protocole.
- Récupérer des valeurs inutilisées. C'est très tentant sur le principe (il est rageant d'épuiser un espace de numérotation alors qu'on sait que certaines valeurs ont été réservées mais jamais utilisées) mais cela marche mal en pratique car il est en général très difficile de dire si une valeur est vraiment inutilisée (peut-être qu'une obscure implémentation utilisée uniquement dans un lointain pays s'en sert ?)
Un usage particulier de l'extensibilité concerne la cryptographie (section 4.5). Celle-ci demande une agilité, la capacité à changer les algorithmes de cryptographie utilisés, pour faire face aux progrès constants de la cryptanalyse (c'est bien expliqué dans la section 3 du RFC 4962). Presque tous les protocoles de cryptographie sérieux fournissent cette agilité (le RFC ne donne pas d'exemple mais je peux citer deux contre-exemples, un à l'IETF, le TCP-MD5 du RFC 2385 depuis remplacé par le meilleur RFC 5925 qui est encore très peu déployé et, en dehors de l'IETF, le protocole DNScurve). Le problème est lorsqu'un algorithme noté comme obligatoire (avant d'assurer l'interopérabilité, un ou plusieurs algorithmes sont obligatoires à implémenter, pour être sûr que deux pairs trouvent toujours un algorithme commun) est compromis au point qu'il n'est plus raisonnable de s'en servir.
Soit un algorithme non compromis est déjà très répandu dans les mises en œuvre existantes du protocole et on peut alors le déclarer obligatoire, et noter le vieil algorithme comme dangereux à utiliser. Soit il n'existe pas encore un tel algorithme répandu et on a peu de solutions : déployer du code dans la nature prend beaucoup de temps. Bref, le RFC recommande que, lorsque les signes de faiblesse d'un algorithme face à la cryptanalyse apparaissent (le RFC ne cite pas de noms mais, en 2012, on peut dire que c'est le cas de SHA-1 et RSA), on normalise, puis on pousse le déploiement de solutions de rechange (par exemple SHA-2 et ECDSA dans ces deux cas, algorithmes qui sont aujourd'hui utilisables dans la plupart des protocoles IETF). Il faut bien se rappeler que le déploiement effectif d'un algorithme normalisé peut prendre des années, pendant lesquelles la cryptanalyse continuera à progresser.
Un aspect peu connu des protocoles applicatifs de la famille IP est qu'ils peuvent parfois tourner sur plusieurs transports, par exemple TCP et SCTP (section 4.6). Cela a parfois été fait dès le début, pour avoir le maximum de possibilités mais, parfois, le protocole de couche 7 n'était prévu que pour un seul protocole de couche 4, puis a été étendu pour un autre protocole. Par exemple, utilisant TCP, il ne passait pas à l'échelle, alors on l'a rendu utilisable sur UDP. (Dans ce cas, les concepteurs du protocole devraient lire le RFC 8085 car il y a plein de pièges.)
Cela peut évidemment casser l'interopérabilité. Si le protocole Foobar est normalisé pour tourner sur TCP ou SCTP, deux mises en œuvre de Foobar, une qui ne gère que TCP et une qui ne gère que SCTP (pensez aux systèmes embarqués, avec peu de ressources, ce qui impose de limiter les choix), ne pourront pas se parler. Notre RFC conseille donc de bien réflechir à ce problème. Davantage de choix n'est pas forcément une bonne chose. D'un autre côté, si le premier protocole de transport choisi a de sérieuses limites, on pourra en ajouter un autre comme option mais il sera quasi-impossible de supprimer le premier sans casser l'interopérabilité.
Enfin, dernier casse-tête pour le concepteur de protocoles, le cas des extensions inconnues (section 4.7). Je suis programmeur, je crée un programme pour la version 1.0 du protocole, ce programme sait traiter un certain nombre de messages. Le temps passe, une version 1.1 du protocole est créé, des programmeurs la mettent en œuvre et, soudain, les copies de mon programme reçoivent des messages d'un type inconnu, car introduit dans la 1.1. Que faire ? Première approche, une règle comme quoi les extensions inconnues doivent être ignorées (silently discarded). Je reçois un tel message, je le jette. Un champ qui était à zéro acquiert une signification ? J'ignore ce champ. L'avantage de cette approche est qu'elle permet le maximum d'interopérabilité. On est sûr que les vieilles versions pourront parler avec les nouvelles, même si seules les nouvelles pourront tirer profit des extensions récentes. L'inconvénient de cette approche est qu'on ne sait même pas si les nouveaux messages sont traités ou pas. Dans le cas de la sécurité, on voudrait bien pouvoir savoir si une extension qu'on considère comme indispensable a bien été acceptée par le pair (voir par exemple la section 2.5 du RFC 5080).
Autre approche, mettre un bit Mandatory (aussi
appelé Must Understand) dans les messages. Si ce
bit est à zéro, une vieille implémentation peut ignorer le
message. Sinon, elle doit prévenir qu'elle ne sait pas le gérer (par
exemple via un message ICMP). C'est ce que font
L2TP (RFC 2661, section 4.1) ou
SIP (RFC 3261, section
8.1.1.9). Cette méthode
permet d'éviter qu'une extension cruciale soit ignorée par le
pair. Mais elle diminue l'interopérabilité : si un programme récent
l'utilise, il ne pourra pas parler avec les vieux qui ne savent pas du
tout gérer cette extension.
On peut aussi négocier les extensions gérées au début de la
session. Cela ralentit son établissement mais cela permet aux deux
pairs qui dialoguent de savoir ce que fait l'autre. Typiquement,
l'initiateur de la connexion indique ce qu'il sait gérer et le
répondeur choisit parmi ces extensions
acceptées. IKE (RFC 5996) fait cela,
HTTP et SIP aussi, via
leurs en-têtes Accept*: et Supported:.
Enfin, le concepteur d'un protocole de base, ou d'une extension à ce protocole doit lire la section 5 sur la sécurité. Elle rappelle qu'une extension à l'apparence inoffensive peut facilement introduire un nouveau risque de sécurité, ou parfois désactiver une mesure de sécurité qui était dans le protocole de base (l'ajout d'une poignée de mains dans un protocole qui était avant sans état peut créer une nouvelle occasion de DoS). L'analyse de sécurité de la nouvelle extension ne peut donc pas se contenter de reprendre celle du protocole de base, il faut s'assurer qu'il n'y ait pas de régression.
L'annexe A de notre RFC est très instructive car elle comprend trois études de cas de protocoles qui ont réussi, ou raté, leur extensibilité. La première concerne Radius (RFC 2865) grand succès mais qui, pour cette raison, a connu de fortes pressions pour son extension, pressions qui ont sérieusement secoué un protocole qui n'était pas vraiment conçu pour cela. L'idée dans le protocole de base était que les extensions se feraient en ajoutant des attributs (le protocole venait avec un certain nombre d'attributs standards dans les messages) dont la valeur pouvait avoir un nombre limité de types.
En pratique, on a constaté que, non seulement beaucoup de fournisseurs ne pouvaient pas s'empêcher de s'auto-allouer des noms d'attributs, mais aussi que bien des attributs ajoutés sortaient du modèle original (comme l'idée d'un dictionnaire, sur lesquels les correspondants se mettent d'accord et qui permet le déploiement de nouveaux attributs sans changer le code : idée astucieuse mais qui n'est pas dans le RFC 2865). La section 1 du RFC 2882, tirant un premier bilan, note qu'une des raisons de la tension est que le monde des NAS, pour lequel Radius avait été conçu, s'était beaucoup diversifié et complexifié, au delà du modèle initialement prévu. Le RFC 2882 notait aussi que certaines mises en œuvre ressemblaient à Radius (même format des messages) mais ne l'étaient pas vraiment (sémantique différente).
Un des cas compliqué est celui des types de données pour les attributs. Il était prévu d'ajouter de nouveaux attributs mais pas de nouveaux types. Il n'existe pas de registre des types définis, ni de moyen pour un client ou serveur Radius que savoir quels types gèrent son correspondant. L'utilisation d'attributs définis avec un type nouveau est donc problématique. Le RFC 6158 (section 2.1) a tenté de mettre de l'ordre dans ce zoo des types mais, publié plus de quatorze ans après la première norme Radius, il n'a pas eu un grand succès.
Radius dispose d'un mécanisme d'extensions spécifiques à un fournisseur (RFC 2865, section 6.2). Ce mécanisme a été utilisé à tort et à travers, notamment par des SDO différentes de l'IETF qui voulaient leurs propres extensions (alors que ces extensions n'avaient jamais été prévues pour être compatibles d'un fournisseur à l'autre). Autre problème, le cas des extensions « fournisseur » inconnues n'avait pas été traité. Or, certaines ont des conséquences pour la sécurité (définition d'une ACL par exemple) et il serait dommage qu'elles soient ignorées silencieusement. Le RFC 5080, section 2.5, estime que la seule solution est que les programmes mettant en œuvre Radius n'utilisent les extensions que lorsqu'ils savent (par exemple par configuration explicite) que l'autre programme les gère.
Autre protocole qui a connu bien des malheurs avec les extensions, TLS (annexe A.3). Son histoire remonte au protocole SSL, v2, puis v3, celle-ci remplacée par TLS. SSL, et TLS 1.0, n'avaient aucun mécanisme d'extension défini. Il a fallu attendre le RFC 4366 pour avoir un mécanisme normalisé permettant de nouveaux types d'enregistrements, de nouveaux algorithmes de chiffrement, de nouveaux messages lors de la poignée de mains initiale, etc. Il définit aussi ce que les mises en œuvre de TLS doivent faire des extensions inconnues (ignorer les nouveaux types, rejeter les nouveaux messages lors de la connexion). Mais, à ce moment, TLS était déjà très largement déployé et ces nouveaux mécanismes se heurtaient à la mauvaise volonté des vieilles implémentations. En pratique, les problèmes ont été nombreux, notamment pendant la négociation initiale. Ce n'est qu'en 2006 que les clients TLS ont pu considérer que SSLv2 était mort, et arrêter d'essayer d'interopérer avec lui. Encore aujourd'hui, de nombreux clients TLS restent délibérement à une version de TLS plus faible que ce qu'ils pourraient faire, pour éviter de planter lors de la connexion avec un vieux serveur (ces serveurs étant la majorité, y compris pour des sites Web très demandés). C'est ainsi que, lors de l'annonce de l'attaque BEAST en 2011, on s'est aperçu que TLS 1.1 résolvait ce problème de sécurité depuis des années... mais n'était toujours pas utilisé, de peur de casser l'interopérabilité.
Dans le futur, cela pourra même poser des problèmes de sécurité sérieux : il n'existe aucun moyen pratique de retirer MD5 de la liste des algorithmes de hachage, par exemple. TLS 1.2 (RFC 5246) permet d'utiliser SHA-256 mais tenter d'ouvrir une connexion en TLS 1.2 avec un serveur a peu de chances de marcher, le mécanisme de repli des versions n'existant que sur le papier.
Morale de l'histoire, dit notre RFC : ce n'est pas tout de faire de bonnes spécifications, il faut aussi qu'elles soient programmées correctement.
Dernier cas intéressant étudié, L2TP (RFC 2661). Fournissant dès le début des types spécifiques à un fournisseur, disposant d'un bit Mandatory pour indiquer si les types doivent être compris par le récepteur, L2TP n'a guère eu de problèmes. On pourrait imaginer des ennuis (RFC 2661, section 4.2) si un programmeur mettait un type spécifique et le bit Mandatory (empêchant ainsi toute interaction avec un autre fournisseur qui, par définition, ne connaîtra pas ce type) mais cela ne s'est guère produit en pratique.
L'article seul
RFC 6724: Default Address Selection for Internet Protocol version 6 (IPv6)
Date de publication du RFC : Septembre 2012
Auteur(s) du RFC : D. Thaler (Microsoft), R. Draves (Microsoft Research), A. Matsumoto (NTT), T. Chown (University of Southampton)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 12 septembre 2012
Lorsqu'une machine IPv6 a plusieurs adresses et qu'elle va initier une communication avec une autre machine ayant elle-même plusieurs adresses, quelle adresse choisir pour la source ? Et pour la destination ? Ce RFC donne deux algorithmes (un pour la source et un pour la destination) à suivre pour que la sélection d'adresse par défaut soit prévisible. Naturellement, il sera toujours possible, pour l'ingénieur système ou pour le programmeur, de passer outre ce choix par défaut et de choisir délibérement une autre adresse. Ce RFC remplace le RFC 3484.
Alors, quel est le problème ? En IPv6, il est courant d'avoir plusieurs adresses IP pour une machine (RFC 4291). Par exemple, si un site est multi-homé, les machines peuvent avoir une adresse par FAI. Ou bien il peut y avoir des tunnels, qui viennent avec leurs adresses. Toutes ces adresses peuvent avoir des caractéristiques variables : portée, statut (préférée, abandonnée, cf. RFC 4862), temporaire (pour des raisons de vie privée, cf. RFC 8981) ou pas... Voici un exemple sur une machine Debian ayant six adresses IPv6 :
% ip -6 addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qlen 1000
inet6 2605:4500:2:245b::f00/64 scope global
valid_lft forever preferred_lft forever
inet6 2605:4500:2:245b::bad:dcaf/64 scope global
valid_lft forever preferred_lft forever
inet6 2605:4500:2:245b::42/64 scope global
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fed9:83b3/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qlen 1000
inet6 fe80::5054:ff:fe9f:5bb1/64 scope link
valid_lft forever preferred_lft forever
Il faudra donc un mécanisme pour décider de l'adresse source à utiliser.
Quant à la machine de destination, elle peut aussi avoir plusieurs adresses, par exemple plusieurs enregistrements AAAA sont dans le DNS. Il faudra donc aussi choisir l'ordre dans lequel on essaiera les adresses de destination. À noter que ce choix peut inclure le choix entre IPv6 et IPv4. Si les deux machines (source et destination) sont en double pile, va t-on utiliser IPv4 ou IPv6 ? (Notre RFC donne la préférence à IPv6 mais voyez plus loin pour les règles exactes.)
Notez que les deux algorithmes ne rendent donc pas le même type de résultat. Pour la destination, l'algorithme produit une liste d'adresses ordonnées, pouvant mêler IPv4 et IPv6. Pour la source, il produit une adresse, la meilleure, et forcément en IPv6 (la sélection d'une adresse source IPv4 est un problème intéressant mais non couvert par ce RFC).
Soit une application en C qui appelle la routine standard
getaddrinfo() (RFC 3493) pour trouver les
adresses IP du correspondant. Dans le cas le plus fréquent, elle va
essayer toutes les adresses IP renvoyées par
getaddrinfo(), dans l'ordre où ce dernier les a
renvoyées, et l'application ne spécifiera pas son adresse source
(c'est le cas simple : les variantes sont discutées plus loin). Pour
mettre en œuvre ce RFC, getaddrinfo() va
utiliser l'algorithme de sélection de la destination, pour trier la
liste obtenue du DNS, et le noyau du système va
utiliser l'algorithme de sélection de la source pour décider de
l'adresse IP source, au moment du
connect().
À noter qu'essayer uniquement la première
adresse IP renvoyée par getaddrinfo() serait une
mauvaise stratégie : si elle est injoignable, aucune communication ne
sera possible, alors que certaines des autres adresses marchaient
peut-être. Essayer les adresses de manière strictement séquentielle
n'est pas non plus optimum et le RFC 6555
conseille de le faire en partie de manière parallèle.
Si on veut résumer les deux algorithmes utilisés, on peut dire qu'ils préfèrent former des couples source/destination où les deux adresses ont la même portée, ont la portée la plus étroite possible, sont des adresses préservant la vie privée, et, en fin de compte, partagent le plus de bits de préfixe possibles.
Comme indiqué plus haut, cet algorithme pourra toujours être
surmonté par un choix explicite du programmeur comme la directive
outgoing-interface d'Unbound (mal nommée puisque prenant comme
paramètre une adresse IP et pas une interface) ou comme, avec OpenSSH, l'option
-b sur la ligne de commande (ou bien
BindAddress dans le fichier de configuration). Ou bien un choix explicite de l'administrateur système
qui peut éditer une table des politiques (celle qui dit par exemple
que IPv6 est préféré à IPv4, ce qu'on peut changer), modifier la
préférence par défaut en faveur des adresses de préservation de la vie
privée, et permettre ou pas l'addition automatique de certaines
adresses à la table des politiques.
Que contient cette « table des politiques » ? La section 2.1 la
détaille. Elle stocke des préfixes d'adresses IP et, comme pour une
table de routage, c'est le plus spécifique (le plus long) qui
gagne. Sur un système Linux, c'est en général
le fichier /etc/gai.conf qui contient la table,
fichier que l'administrateur système peut éditer selon ses goûts
(section 10.3 du RFC). La
table par défaut contient :
Prefix Precedence Label ::1/128 50 0 ::/0 40 1 ::ffff:0:0/96 35 4 2002::/16 30 2 2001::/32 5 5 fc00::/7 3 13 ::/96 1 3 fec0::/10 1 11 3ffe::/16 1 12
La préférence est donnée aux préfixes ayant le champ
Precedence le plus élevé. Ainsi, si on a le choix
entre les adresses 2001:db8:1::cafe et
fec0::90ff:fe92:bd00, la première a une
précédence de 40 (en raison de la règle ::/0), la
seconde de 1 (en raison de la règle fec0::/10) :
rappelez-vous que c'est le préfixe le plus spécifique qui est choisi,
pas celui qui est le premier dans la table). On va donc choisir
l'adresse publique, 2001:db8:1::cafe (le préfixe
fec0::/10 a été abandonné par le RFC 3879).
Autre conséquence de cette table, IPv6 est préféré à
IPv4 (représenté par ::ffff:0:0/96, cf. RFC 4291, section 2.5.5.2). Si on veut changer cela,
par exemple parce qu'on a une connectivité IPv6 vraiment trop mauvaise
(voir le problème des globes
oculaires et la section 10.3.1 de notre RFC), on édite gai.conf ou son
équivalent et on met, par exemple (syntaxe de
gai.conf) une précédence de 100 :
precedence ::ffff:0:0/96 100
D'autres trucs Linux sont documentés dans « IPv6
Source Address Selection on Linux ». Si on travaille
sur FreeBSD, la configuration est dans
/etc/ip6addrctl.conf et
il faut donc regarder la
documentation
de ip6addrctl.
Notez que cette table peut être dynamique : une implémentation a le droit d'y ajouter des préfixes en cours de route, par exemple pour ses ULA (RFC 4193).
Autre définition importante, la notion de la longueur du préfixe
commun. Cette longueur est définie en comparant uniquement les 64
premiers bits de l'adresse. Ainsi, la longueur du préfixe commun à
2001:db8:1::bad et
2001:db8:2::bad est 32
(2001:db8 est la seule partie commune). Mais la
longueur du préfixe commun à 2001:db8:1::bad:dcaf
et 2001:db8:1::bad:cafe n'est que de 64 et pas de
112 comme on pourrait le croire à première vue. C'est parce qu'on
ignore l'Interface ID (les 64 derniers bits). C'est
un des gros changements par rapport au précédent RFC, le RFC 3484, motivé par des problèmes comme une mauvaise
interaction avec des systèmes de répartition de charge..
Et les propriétés des adresses (section 3) ? On a entre autres :
- La portée : locale au lien, locale au site, ou globale. Ainsi,
fe80::35cd:efc1:e399:3aa9a une portée inférieure à2001:4f8:3:2bc:1::64:21. - Le fait d'être l'adresse « de référence » (home address) ou l'adresse actuelle du mobile (care-of address) lorsqu'on utilise les fonctions de mobilité du RFC 6275. En pratique, elles sont très peu déployées donc on peut ne pas faire trop attention à cette propriété.
Maintenant, les algorithmes eux-mêmes. D'abord, pour le choix de
l'adresse source (sections 4 et 5). Il faut
d'abord établir une liste d'adresses candidates
pour la destination choisie. La méthode conseillée est que cet
ensemble de candidates soit la liste des adresses attachées à
l'interface réseau par laquelle les paquets vont sortir. Sur une
machine Linux, si on veut écrire à
::1, ce sera l'interface locale
(lo) et si on veut écrire à 2001:4860:4860::8888, ce sera la plupart du temps
eth0. Cela permet notamment de tenir compte des
filtres éventuels des routeurs (un FAI ne
laissera pas passer des paquets dont l'adresse source n'est pas chez
lui, cf. RFC 2827).
Une fois cette liste établie, il faut choisir l'adresse IP source (notez le singulier), parmi cet ensemble de candidates. Conceptuellement, il s'agit de trier la liste des candidates et, pour cela, il faut une fonction permettant de comparer ces adresses deux à deux. La définition de cette fonction est le cœur de notre RFC. Soient deux adresses SA et SB pour une destination D, ces huit règles permettent de les départager :
- Si SA = D, choisir SA (préférer une adresse source qui soit égale à la destination, pour les paquets locaux à la machine),
- Si la portée de SA est différente de celle de SB, choisir
l'adresse qui a la même portée que D. En gros, pour une destination
locale au lien, on préférera des adresses sources locales au
lien. Exemple : destination
2001:db8:1::1, candidates source2001:db8:3::1etfe80::1, on choisira2001:db8:3::1, - Éviter les adresses marquées comme « dépassées » (RFC 4862, section 5.5.4), qu'on doit donc classer après celles qui ne sont pas dépassées,
- Si la machine utilise Mobile IP (c'est très rare), préférer l'adresse de réference (home address) à l'adresse de connexion actuelle (care-of address),
- Préférer l'adresse correspondant à l'interface de sortie vers D. Notez que cette règle ne servira à rien si on a suivi le conseil de ne mettre dans l'ensemble des candidates que les adresses de l'interface de sortie,
- Utiliser l'étiquette (label) attribuée dans la table des politiques. On choisit de préférence l'adresse source qui a la même étiquette que l'adresse de destination,
- Préférer les adresses temporaires du RFC 8981. Si la destination est
2001:db8:1::d5e3:0:0:1et que les adresses candidates sont2001:db8:1::2(publique) et2001:db8:1::d5e3:7953:13eb:22e8(temporaire), on choisit2001:db8:1::d5e3:7953:13eb:22e8. Cette règle est un changement par rapport au prédecesseur de notre RFC, le RFC 3484. Cette préférence doit être réglable (sur Linux, c'est apparemment avec la variable sysctlnet.ipv6.conf.*.use_tempaddrqui, mise à 1, alloue des adresses temporaires et, mise à 2, fait qu'elles sont préférées), - Et enfin la dernière règle, mais qui sera souvent utilisée
(plusieurs des règles précédentes ne s'appliquent qu'à des cas
particuliers), la règle du préfixe le plus long. On choisit l'adresse
source qui a le préfixe commun avec D le plus long. Si la destination
est
2001:db8:1::1et que les adresses source possibles sont2001:db8:1::2(48 bits communs) et2001:db8:3::2(32 bits communs), on sélectionne2001:db8:1::2. - Si aucune des huit règles standards n'a suffi, si les deux adresses sont encore ex-aequo, le choix est spécifique à l'implémentation (par exemple, prendre la plus petite).
Une implémentation a le droit de tordre certaine de ces règles si elle dispose d'informations supplémentaires. Par exemple, si elle suit la RTT des connexions TCP, elle peut connaître les « meilleures » adresses et ne pas utiliser la huitième règle (préfixe le plus long).
Maintenant, il faut choisir l'adresse de destination (section 6). Cette fois, le résultat est une liste d'adresses qui seront essayées dans l'ordre. Et, contrairement au précédent, cet algorithme gère IPv6 et IPv4 ensemble (les règles de sélection de la source n'étaient valables que pour IPv6 ; par exemple la règle du plus long préfixe commun n'a guère de sens avec les courtes adresses v4). Le point de départ est la liste d'adresses récupérées en général dans le DNS. Et il y a ensuite dix règles de comparaison entre les destinations DA et DB, en tenant compte des adresses sources, S(DA) et S(DB). Beaucoup de ces règles sont proches de celles utilisées pour la sélection de la source donc je ne les réexplique pas ici :
- Éviter les destinations injoignables (la machine ne le sait pas forcément mais elle a pu acquérir cette information, par exemple via le RFC 4861, section 7.3),
- Préférer les portées identiques. Si DA et S(DA) ont une portée
identique, et que ce n'est pas le cas pour DB et S(DB), choisir
DA. Si les destinations connues sont
2001:db8:1::1et198.51.100.121, avec comme adresses source disponibles2001:db8:1::2,fe80::1et169.254.13.78, alors le premier choix est2001:db8:1::1(source2001:db8:1::2) puis198.51.100.121(source169.254.13.78). Ce n'est pas une préférence pour IPv6 (elle intervient plus tard, dans la sixième règle) mais une conséquence du fait que l'adresse IPv4169.254.13.78est locale au lien (RFC 3927), - Éviter les adresses dépassées,
- Choisir les adresses de référence en cas de mobilité,
- Choisir de préférence la destination qui aura la même étiquette que l'une de ses sources possibles,
- Préferer les destinations avec la plus haute précédence (dans la table des politiques vue plus haut). Avec la table par défaut, c'est cette règle qui mènera à faire les connexions en IPv6 plutôt qu'en IPv4 (section 10.3),
- Préférer les destinations accessibles par de l'IPv6 natif plutôt que via un tunnel. Cela n'élimine pas tous les tunnels car celui-ci peut être situé plus loin, hors de la connaissance de la machine, comme avec le 6rd - RFC 5969 - de Free),
- Préférer les portées plus spécifiques, on tentera les adresses
locales au lien avant les adresses publiques. Si on a le choix entre
les destinations
2001:db8:1::1oufe80::1, et que les sources possibles sont2001:db8:1::2oufe80::2, on préférerafe80::1(avec la sourcefe80::2), - Utiliser le plus long préfixe commun entre la source et la
destination. Si les destinations possibles sont
2001:db8:1::1et2001:db8:3ffe::1, avec comme sources possibles2001:db8:1::2,2001:db8:3f44::2oufe80::2, le premier choix est2001:db8:1::1(pour al source2001:db8:1::2) puis2001:db8:3ffe::1(pour la source2001:db8:3f44::2), - Si on arrive là, ne toucher à rien : contrairement à la sélection de la source, il n'est pas nécessaire de sélectionner une adresse, on peut tout à fait laisser l'ordre inchangé.
Le lecteur subtil a noté que l'interaction de ces règles avec le routage IP normal n'est pas évidente. Le principe de base est qu'une machine sélectionne la route de sortie avant de sélectionner l'adresse source mais la section 7 de notre RFC autorise explicitement une implémentation d'IPv6 à utiliser l'adresse source pour le choix de la route.
Voilà, les deux algorithmes sont là. Mais, si vous voulez les
mettre en œuvre et pas seulement comprendre comment ils
marchent, la section 8 est une lecture recommandée, car elle donne de
bons conseils d'implémentation. Par exemple, comme l'algorithme de
sélection de la destination a besoin de connaître les adresses sources
possibles, le RFC suggère à
getaddrinfo() de demander à la
couche 3, pour obtenir la liste des adresses
source possibles. Il sera alors capable de renvoyer une liste de
destinations déjà triée. Il peut même garder en mémoire cette liste
d'adresses, pour éviter de refaire un appel système supplémentaire à chaque fois. (Le RFC dit
toutefois que cette mémorisation ne devrait pas durer plus d'une
seconde, pour éviter d'utiliser une information dépassée.)
Et la sécurité (section 9) ? Il n'y a que des petits détails. Par exemple, en annonçant des tas d'adresses différentes pour lui-même, un méchant peut, en examinant les adresses source de ceux qui se connectent à lui, apprendre leur politique locale (pas une grosse affaire). Autre cas amusant, en sélectionnant soigneusement les adresses source ou destination, on peut influencer le chemin pris par les paquets, ce qui peut être utile par exemple pour sniffer. Mais c'est une possibilité très limitée.
Quels sont les changements de notre RFC 6724 par rapport à son prédécesseur, le RFC 3484 ? Ils sont détaillés dans l'annexe B. Les principaux (dans l'ordre à peu près décroissant d'importance) :
- Préférence désormais donnée aux adresses temporaires sur les autres, afin de mieux préserver la vie privée, désormais considérée comme plus importante (c'était déjà le cas dans plusieurs implémentations d'IPv6),
- Changement de la définition de « longueur du préfixe commun » pour se limiter aux 64 premiers bits (c'est-à-dire, excluant l'Interface ID),
- Certains changements pour mieux gérer le cas où le réseau de sortie filtre selon l'adresse source (RFC 2827 et RFC 5220),
- Ajout de la possibilité, pour une mise en œuvre d'IPv6, d'ajouter automatiquement des entrées à la table des politiques,
- Ajout d'une ligne dans la table des politiques pour les
ULA du RFC 4193
(
fc00::/7), - Ajout d'une ligne dans la table des politiques pour les adresses du défunt 6bone (RFC 3701), avec une faible préférence pour qu'elles ne soient pas sélectionnées.
À noter que les premières versions de ce RFC étaient rédigées simplement sous forme d'une liste des différences avec le RFC 3484. C'était illisible.
Enfin, une anecdote, le prédécesseur, le RFC 3484, avait
été accusé
d'un problème sérieux. Mais c'est contestable,
les responsabilités sont partagées : l'algorithme du RFC 3484
(qui ne concerne qu'IPv6) est certes discutable, l'implémentation de
Vista n'est pas géniale (extension du RFC 3484 à IPv4, où les préfixes
sont bien plus courts), la configuration de l'auteur de l'article est
mauvaise (il dépend de l'ordre des enregistrements, qui n'est pas
garanti par le DNS, c'est la même erreur qu'un programmeur C qui
dépendrait de la taille d'un int) et, pour couronner le tout, le NAT qui fait qu'une machine ne connait pas son adresse
publique.
Une intéressante discussion de certaines objections à ce RFC a eu lieu sur SeenThis.
L'article seul
RFC 6716: Definition of the Opus Audio Codec
Date de publication du RFC : Septembre 2012
Auteur(s) du RFC : JM. Valin (Mozilla Corporation), K. Vos (Skype Technologies), T. Terriberry (Mozilla Corporation)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF codec
Première rédaction de cet article le 11 septembre 2012
Il y a désormais plus de deux ans que le groupe de travail codec de l'IETF avait commencé un effort inédit de spécification d'un codec audio libre. Ce nouveau RFC est le couronnement de cet effort : Opus, le codec standard et libre est désormais officiel.
Opus n'est pas un format de fichiers, comme MP3. Il est conçu pour l'audio en temps réel (RFC 6366 pour son cahier des charges). Il est prévu pour un grand nombre d'utilisations audio distinctes : téléphonie sur IP, mais aussi, par exemple, distribution de musique en temps réel. Il est prévu pour être utilisable lorsque la capacité du réseau est minimale (dans les 6 kb/s) aussi bien que lorsqu'elle permet de faire de la haute fidélité (mettons 510 kb/s, cf. section 2.1.1). Ses deux principaux algorithmes sont la prédiction linéaire (plus efficace pour la parole) et la transformation en cosinus discrète (plus efficace pour la musique).
Le projet codec avait déjà produit deux RFC : le RFC 6366 était le cahier des charges du nouveau codec, et le RFC 6569 posait les principes de développement et d'évaluation dudit codec. Je renvoie à ces documents pour l'arrière-plan de la norme Opus. Celle-ci a été acceptée sans problèmes par le groupe de travail (c'est plutôt le mécanisme de tests qui a suscité des controverses.)
Opus présente une particularité rare à l'IETF : la norme est le code. Habituellement, à l'IETF, la norme est le texte du ou des RFC, rédigés en langue naturelle. Il existe souvent une implémentation de référence mais, en cas de désaccord entre cette implémentation et le RFC, c'est ce dernier qui gagne et le programme doit être modifié. Pour Opus, c'est tout le contraire. La moitié du RFC 6716 (180 pages sur 330, en annexe A, soit 30 000 lignes de code pas toujours bien commentées et avec plein de nombres magiques) est constituée par l'implémentation de référence (en C, langage que le RFC qualifie de « lisible par un humain », ce qui est parfois optimiste) et c'est elle qui fait autorité en cas de différence avec l'autre moitié, les explications (voir sections 1 et 6 du RFC). Ce point a suscité beaucoup de débats à l'IETF et on trouve trace des critiques, entre autres, dans l'évaluation détaillée qui avait été faite pour GenArt. L'idée de ce choix « le code est la norme » était que l'alternative (faire une spécification en langue naturelle, complète et sans ambiguité), serait bien plus de travail et, dans le cas particulier d'un codec audio, serait peut-être même irréaliste. (À noter que seul le décodeur est normatif. On peut améliorer la sortie de l'encodeur, tant que le décodeur arrive à lire ce qu'il produit.)
Le langage C étant ce qu'il est, il n'est pas étonnant que des bogues aient été découvertes depuis, corrigées dans le RFC 8251.
L'autre moitié du RFC est composé d'explications, avec beaucoup de maths.
Un codec libre est difficile à obtenir, surtout vu le nombre de brevets, la plupart futiles, qui encombrent ce domaine. Plusieurs déclarations de brevet ont été faites contre Opus : #1520, #1524, #1526, #1602, #1670, #1712 et #1741. Une liste mise à jour est disponible à l'IETF.
Comme ces codecs sont très loin de mes domaines de compétence, je ne vais pas me lancer dans des explications détaillées du fonctionnement d'Opus : lisez le code source :-) Notez que le code fait beaucoup d'arithmétique en virgule fixe (et aussi avec des entiers, bien sûr) donc attention si vous le reprogrammez dans un autre langage, les calculs doivent être exacts (voir section 1.1).
Si vous n'avez pas l'ambition de reprogrammer Opus, si vous voulez simplement une idée générale de son fonctionnement, la section 2 est faite pour vous. Opus, comme indiqué plus haut, a deux « couches », LP (prédiction linéaire) et MDCT (transformée en cosinus discrète). L'une ou l'autre (ou même les deux en même temps) est active pour encoder le signal audio, donnant ainsi à Opus la souplesse nécessaire. La couche LP est dérivée du codec Silk. Elle permet le débit variable mais aussi le constant (section 2.1.8). La couche MDCT, elle, est basée sur CELT.
Le codec Opus peut favoriser la qualité de l'encodage ou bien la consommation de ressources (processeur, capacité réseau). Cela permet d'ajuster la qualité du résultat aux ressources disponibles (section 2.1.5). Idem pour la sensibilité aux pertes de paquets : Opus peut être ajusté pour mettre plus ou moins de redondance dans les paquets. Avec le moins de redondance, on augmente la capacité mais on rend le décodage plus sensible : un paquet perdu entraîne une coupure du son.
Le format des paquets est décrit en section 3. À noter qu'Opus ne met pas de délimiteur dans ses paquets (pour gagner de la place). Il compte qu'une couche réseau plus basse (UDP, RTP, etc) le fera pour lui. Une possibilité (optionnelle dans les implémentations) de formatage avec délimiteur figure dans l'annexe B.
Chaque paquet compte au moins un octet, le TOC (Table Of Contents). Celui-ci contient notamment 5 bits qui indiquent les configurations (couches utilisées, capacité réseau utilisée et taille des trames).
Le fonctionnement du décodeur est en section 4 et celui de
l'encodeur en section 5. Mais le programmeur doit aussi lire la
section 6, qui traite d'un problème délicat, la conformité à la
spécification. Je l'ai dit, la référence d'Opus est un programme,
celui contenu dans ce RFC. Cela n'interdit pas de faire d'autres mises
en œuvre, par exemple à des fins d'optimisation, à condition qu'elles soient compatibles avec
le décodeur (c'est-à-dire que le décodeur de référence,
celui publié dans l'annexe A du RFC, doit pouvoir lire le flux audio produit
par cette mise en œuvre alternative). Pour aider aux tests, des
exemples (testvectorNN.bit) et un outil de comparaison,
opus_compare, sont fournis avec
l'implémentation de référence (les tests sont en https://opus-codec.org/testvectors/). Un outil de comparaison est nécessaire
car il ne suffit pas de comparer bit à bit la sortie de l'encodeur de
référence et d'un nouvel encodeur : elles peuvent différer, mais dans
des marges qui sont testées par opus_compare. Si
vous avez écrit votre propre encodeur, ou modifié celui de référence, les
instructions pour tester figurent en section 6.1.
Autre avertissement pour les programmeurs impétueux que les 150 pages d'explication et les 180 pages de code n'ont pas découragés : la sécurité. Opus est utilisé sur l'Internet où on trouve de tout, pas uniquement des gens gentils. La section 7 met donc en garde le programmeur trop optimiste et lui dit de faire attention :
- Si on veut chiffrer un flux Opus, il ne faut pas utiliser d'algorithme vulnérable aux attaques à texte clair connu. En effet, bien des parties du flux (comme les trames de silence ou comme les octets TOC) sont très prévisibles.
- Le décodeur doit être très robuste face à des erreurs (volontaires, ou bien provoquées par des bogues) dans le flux qu'il décode. Une programmation naïve peut mener à des accidents comme le dépassement de tampon ou, moins grave, à une consommation exponentielle de ressources (RFC 4732). L'implémentation de référence est censée être propre de ce point de vue, et résister à presque tout. Elle a été testée avec des flux audio aléatoirement modifiés, ainsi qu'avec des encodeurs faisant du fuzzing. Elle a également été testée avec Valgrind.
Le compte-rendu des tests divers se trouve dans l'Internet-Draft draft-ietf-codec-results.
L'annexe A contient le code source de l'implémentation de référence
encodée en Base64
(qu'on trouve également en ligne sur le site
Web officiel et qui est distribuée par
git en git://git.xiph.org/opus.git). Par défaut,
elle dépend de calculs en virgule flottante
mais on peut la compiler avec la macro
FIXED_POINT pour ne faire que de la virgule fixe
(voir le fichier README).
Voici un exemple d'utilisation avec la version de développement (il
n'y en avait d'autre prête à ce moment)
% export VERSION=1.0.1-rc2 % wget http://downloads.xiph.org/releases/opus/opus-$VERSION.tar.gz ... % tar xzvf opus-$VERSION.tar.gz ... % cd opus-$VERSION % ./configure ... % make ... % make check ... All 11 tests passed ...
Il n'existe pas à l'heure actuelle d'autre mises en œuvre d'Opus.
Combien de logiciels intègrent actuellement le code Opus pour lire et produire des flux audios ? Difficile à dire. L'excellent client SIP Csipsimple a Opus depuis plusieurs mois. Autre exemple, le logiciel de voix sur IP Mumble l'a promis pour bientôt.
Un bon article en français sur Opus, notamment ses performances :
« Un
codec pour les dominer tous ». Et un article de synthèse de Numérama sur ce RFC. Pour une comparaison des
performances d'Opus avec les autres, voir https://www.opus-codec.org/comparison/. Pour les nouveautés de
la version 1.1 (publiée après le RFC), voir la liste officielle.
Merci à Régis Montoya pour sa relecture.
L'article seul
Go Daddy planté, une des plus grosses pannes dans le DNS
Première rédaction de cet article le 10 septembre 2012
Dernière mise à jour le 5 octobre 2012
Go Daddy est de loin le plus gros
bureau d'enregistrement de
.com et de nombreux autres
TLD. Il sert aussi d'hébergeur
DNS. Ce soir, tous leurs serveurs de noms sont
injoignables, entraînant l'impossibilité de joindre des millions de
noms de domaine, et donc les serveurs situés
derrière. C'est l'une des plus grandes pannes qu'ait jamais connu le
DNS. Elle illustre une nouvelle fois l'importance de s'assurer de la
résilience de son service DNS, notamment par le
biais de la redondance.
Le lundi 10 septembre, il est 19h00 UTC et la panne dure depuis déjà un certain
temps (premier signalement sur la liste outages
vers 18h00 UTC). Prenons un hasard un nom de domaine hébergé
chez Go Daddy,
1stoptr.com. Tentons une interrogation :
% dig A 1stoptr.com ; <<>> DiG 9.8.1-P1 <<>> A 1stoptr.com ;; global options: +cmd ;; connection timed out; no servers could be reached
Pas de réponse. Qu'arrive-t-il aux serveurs de noms ? Demandons au
parent (VeriSign) les serveurs de noms de
1stoptr.com :
% dig @a.gtld-servers.net NS 1stoptr.com ; <<>> DiG 9.8.1-P1 <<>> @a.gtld-servers.net NS 1stoptr.com ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 38711 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 3 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 512 ;; QUESTION SECTION: ;1stoptr.com. IN NS ;; AUTHORITY SECTION: 1stoptr.com. 172800 IN NS wsc1.jomax.net. 1stoptr.com. 172800 IN NS wsc2.jomax.net. ... ;; ADDITIONAL SECTION: wsc1.jomax.net. 172800 IN A 216.69.185.1 wsc2.jomax.net. 172800 IN A 208.109.255.1
Ces deux serveurs sont bien chez Go Daddy comme on peut le vérifier avec whois :
% whois 216.69.185.1 # # The following results may also be obtained via: # http://whois.arin.net/rest/nets;q=216.69.185.1?showDetails=true&showARIN=false&ext=netref2 # NetRange: 216.69.128.0 - 216.69.191.255 CIDR: 216.69.128.0/18 OriginAS: NetName: GO-DADDY-COM-LLC NetHandle: NET-216-69-128-0-1 Parent: NET-216-0-0-0-0 NetType: Direct Allocation ...
Et ils ne répondent pas :
% dig @216.69.185.1 A 1stoptr.com ; <<>> DiG 9.7.3 <<>> @216.69.185.1 A 1stoptr.com ; (1 server found) ;; global options: +cmd ;; connection timed out; no servers could be reached
Et, surtout, c'est la même chose pour tous les serveurs de noms de
Go Daddy. Le domaine de l'hébergeur lui-même,
godaddy.com n'est pas davantage accessible :
% dig +nodnssec +nssearch godaddy.com ; <<>> DiG 9.7.3 <<>> +nodnssec +nssearch godaddy.com ;; global options: +short +cmd ;; connection timed out; no servers could be reached
Et comme pas de DNS égal pas de Web, ni d'autres services, on voit l'ampleur de la panne... Celle-ci a duré jusqu'à environ 20h40 UTC, où il y a eu une légère rémission, avant que cela ne re-plante. Finalement, le service a été rétabli quelques heures après (apparemment en migrant une partie de l'infrastructure sur la plate-forme de VeriSign). C'est donc assez long, même en cas de dDoS.
Que s'est-il passé ? Sur le moment, une personne se prétendant Anonymous a revendiqué l'action. Mais n'importe qui peut envoyer un tweet et, comme il ne donnait aucun détail technique, il était donc difficile de savoir si c'est vrai. La première déclaration officielle de Go Daddy incriminait un problème technique interne dans leurs routeurs. L'hypothèse d'une attaque par déni de service distribué aussi réussie contre une infrastructure anycastée était certes possible mais, quand même, cela aurait en effet très difficile à réussir.
Au fait, pourquoi Anonymous aurait-il attaqué Go Daddy ? Peut-être parce qu'ils aiment les éléphants ? Ou parce qu'ils sont choqués des publicités de mauvais goût de Go Daddy, à base de pinups vulgaires en bikini ? Mais Go Daddy est aussi connu pour son soutien à SOPA (voir Wikipédia), et pour être un des hébergeurs les plus rapides à censurer ses clients lorsque le gouvernement ou l'industrie du divertissement le demande (voir l'affaire JotForm ou celle de RateMyCop). Comme disent les policiers, il y a donc beaucoup trop de suspects...
Finalement, le 5 octobre, Go Daddy a publié un rapport technique très détaillé. Le problème (si on prend ce rapport au pied de la lettre mais il semble cohérent avec les faits observés) était bien dans les routeurs. Une combinaison d'incidents avait entraîné l'apparition d'un très grand nombre de routes, dépassant la capacité de la table de routage. Ces routes ont été propagées en interne, plantant ainsi la totalité des routeurs. Même une fois le problème technique analysé, la correction a été longue car chaque fois qu'un des sites de Go Daddy repartait, tout le trafic se précipitait vers lui... et le replantait.
Autres articles :
- GoDaddy's DNS Servers Down, Taking Thousands of Sites With It
- GoDaddy Outage Takes Down Millions Of Sites, Anonymous Member Claims Responsibility
- GoDaddy Gone: Can the Domain Giant Recover Its Reputation?
- Numérama, après qu'il semble bien qu'il ne s'agissait pas d'une attaque : GoDaddy dément toute attaque et parle d'un incident interne,
- Un article de Wired, Amid Outage, GoDaddy Moves DNS to Competitor VeriSign, qui contient une énorme erreur dans le titre (VeriSign n'est pas bureau d'enregistrement et donc pas concurrent de GoDaddy).
- Bon article de synthèse d'Ars Technica, GoDaddy outage makes websites unavailable for many Internet users, gâché par la même erreur que celui de Wired,
- Le blogueur de DomainNameWire a raison de faire remarquer que les journalistes devraient avoir honte : tous ont négligé le problème réel (des millions de gens ne pouvant accéder à un service) et ont sauté sur l'hypothèse, certes plus juteuse, d'une attaque d'un hacker. Et cela sur la base d'un seul et unique tweet !
- Un bon exemple de baratin intégral, avec quasiment aucun fait vérifié : Anonymous Hacker take down GoDaddy with IRC Bots. Encore mieux, la proclamation par un neuneu total qu'il a publié le code source de Go Daddy alors que le fichier RAR téléchargé contient une copie d'un logiciel libre public, et une configuration bidon avec des serveurs dont l'adresse IP est en Chine (ce qui serait étonnant de la part de Go Daddy).
Une amusante ligne de script shell pour détecter si un de vos sites Web dépend de Go Daddy (merci à climagic). À exécuter dans le répertoire où se trouve la config Apache :
grep ServerName * | grep -io "[a-z0-9-]*\.[a-z]*$" | \
sort -u | while read -r d; do whois $d | grep -q "GODADDY" &&echo $d; done # site check
L'article seul
RFC 6729: Indicating Email Handling States in Trace Fields
Date de publication du RFC : Septembre 2012
Auteur(s) du RFC : D. Crocker (Brandenburg
InternetWorking), M. Kucherawy (Cloudmark)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 7 septembre 2012
Lorsqu'on débogue un problème de courrier électronique en examinant un message reçu, le technicien
regarde souvent en premier les champs Received:
de l'en-tête. Ceux-ci indiquent les différents
MTA qui ont pris en charge le message et sont
notamment très utiles en cas de retard inattendu : ils permettent de
voir quel MTA a traîné dans la remise du message au MTA suivant. Mais
cela ne suffit pas toujours. Aujourd'hui, il est de plus en plus
fréquent que les messages soient retardés en raison d'un traitement
local à une machine, par exemple le passage par un programme de
sécurité qui met très longtemps à vérifier quelque chose. Il n'y avait
pas de moyen pratique avec les champs Received:
pour indiquer ces traitements. C'est désormais fait avec un nouvel
indicateur dans Received: :
state qui permet de signaler le passage d'un
traitement lent à un autre.
Voici un exemple d'une suite de champs
Received:. Rappelez-vous qu'elle se lit de bas en
haut :
Received: from slow3-v.mail.gandi.net (slow3-v.mail.gandi.net [217.70.178.89])
by mail.bortzmeyer.org (Postfix) with ESMTP id 5EC103AD82
for <stephane+blog@bortzmeyer.org>; Thu, 6 Sep 2012 18:26:36 +0000 (UTC)
Received: from relay4-d.mail.gandi.net (relay4-d.mail.gandi.net [217.70.183.196])
by slow3-v.mail.gandi.net (Postfix) with ESMTP id 2268638B64
for <stephane+blog@bortzmeyer.org>; Thu, 6 Sep 2012 20:21:20 +0200 (CEST)
Received: from mfilter1-d.gandi.net (mfilter1-d.gandi.net [217.70.178.130])
by relay4-d.mail.gandi.net (Postfix) with ESMTP id 0844C172094
for <stephane+blog@bortzmeyer.org>; Thu, 6 Sep 2012 20:21:10 +0200 (CEST)
Received: from relay4-d.mail.gandi.net ([217.70.183.196])
by mfilter1-d.gandi.net (mfilter1-d.gandi.net [10.0.15.180]) (amavisd-new, port
10024)
with ESMTP id 9nO2SZ5sO3KB for <stephane+blog@bortzmeyer.org>;
Thu, 6 Sep 2012 20:21:08 +0200 (CEST)
On note que la machine mfilter1-d.gandi.net a
renvoyé le message à relay4-d.mail.gandi.net d'où
il venait. Ce n'est pas une erreur,
mfilter1-d.gandi.net est la machine de filtrage
et utilise Amavis pour un certain nombre de
tests sur le message (absence de virus, par
exemple) avant de le réinjecter. Ici, cet examen a été rapide (deux
secondes, si on peut se fier aux horloges des machines) mais, s'il est
plus long (et Amavis peut être très long), il serait souhaitable de pouvoir
le marquer plus clairement.
Il existe bien des tests/vérifications/etc qui peuvent ainsi
ralentir un message : mise en quarantaine,
modération, tests anti-spam ou anti-virus,
etc. Pour les indiquer plus clairement, notre
RFC reprend le champ
Received: (défini à la section 4.4 du RFC 5321 et un des outils les plus importants du
technicien qui fait fonctionner le courrier électronique). Ce champ comprend plusieurs clauses (dans
les exemples ci-dessus, on voit les clauses from,
by, with et
for, définies dans la section 4.4 du RFC 5321). Notre RFC en ajoute une nouvelle,
state (désormais enregistrée,
section Additional-registered-clauses), qui
ressemble à ça (exemple du RFC car je n'ai pas encore trouvé de clause
state dans mes boîtes aux lettres, bien qu'il
existe apparemment déjà une mise en œuvre en production) :
Received: from newyork.example.com
(newyork.example.com [192.0.2.250])
by mail-router.example.net (8.11.6/8.11.6)
with ESMTP id i7PK0sH7021929
for <recipient@example.net>;
Fri, Feb 15 2002 18:33:29 -0800
Received: from internal.example.com
(internal.example.com [192.168.0.1])
by newyork.example.com (8.11.6/8.11.6)
with ESMTP id i9MKZCRd064134
for <secret-list@example.com>
state moderation (sender not subscribed);
Fri, Feb 15 2002 17:19:08 -0800
Ici, le MTA de newyork.example.com a décidé de ne
pas envoyer le message tout de suite mais de le soumettre à un
modérateur (avant-dernière ligne du plus ancien
Received:, clause
state). Cela suffit à expliquer le délai d'une
heure vingt entre les deux Received:, sans
imaginer une coupure réseau ou une autre panne. On voit que la clause
state indique l'entrée dans
un nouvel état (ici, l'état « en attente d'approbation par le
modérateur »), la sortie étant marquée par le
champ Received: suivant (qui, ici, n'a pas d'état
explicite). Rappelez-vous (promis, c'est la dernière fois que je le
dis) que les champs Received: se lisent de bas en
haut.
La clause state dans l'exemple ci-dessus
utilisait le mot-clé moderation. Une liste
limitative de tels mots-clés est
enregistrée (section Registered-states) et elle comprend
notamment :
auth: le message attend une authentification,content: le contenu du message va être analysé, par exemple pour s'assurer qu'il ne contient pas de spam ou de malware,moderation: passage par le modérateur,timed: message délibérement gardé, en attendant l'heure de la remise (voir RFC 4865),normal: ce mot-clé est enregistré mais, en fait, c'est celui par défaut, lorsqu'aucune clausestaten'est présente,other: il y a toujours des cas où on ne sait pas :-)
À noter que le mot-clé peut être suivi d'une barre oblique et d'une valeur (non enregistrée, on met ce qu'on
veut), on peut donc avoir
moderation/not-subscribed ou
quarantine/spam. D'autres états pourront être
enregistrés dans le futur, sous la politique « Premier arrivé, premier
servi » (cf. RFC 5226). Ce point avait été le
principal sujet de discussion avant la publication du RFC, certains
auraient préféré la politique plus restrictive « Examen par un expert ».
Les programmeurs de MTA qui veulent ajouter cette clause aux
champs Received: qu'ils écrivent ont tout
intérêt à bien lire les sections 4 et 5, qui discutent de quand utiliser la
clause state. Elle n'est pas prévue pour des
opérations différentes à l'intérieur d'un même agent. Le RFC
recommande bien qu'elle ne soit utilisée que lorsqu'on passe à un
agent différent, par exemple de Postfix à
Amavis. Autrement, on risque de se retrouver
avec plein de Received: qui rendront l'analyse
plus difficile (et risquent d'atteindre la limite des MTA, qui
rejettent les messages ayant trop de Received:,
pensant qu'ils bouclent). L'idée est de déboguer les performances et
donc cette clause est là uniquement pour les problèmes temporels,
pas pour n'importe quelle action ou changement d'état interne à l'agent.
L'article seul
Souriez, vous (enfin, votre résolveur DNS) sert à la science
Première rédaction de cet article le 6 septembre 2012
Depuis ce matin, une bonne partie des visiteurs de ce blog participe (involontairement) à une expérience de mesure du déploiement de la validation DNSSEC.
Regardez le code source de chaque page, vers le bas. Vous trouverez
un lien <a> vide vers
prefetch.validatorsearch.verisignlabs.com. Ce nom
est servi par des serveurs DNS un peu spéciaux,
qui répondent de manière inhabituelle, de manière à étudier le
comportement du résolveur qui les interroge, afin de savoir s'il fait
du DNSSEC ou pas (en France, aucun
FAI n'a encore activé la validation DNSSEC, à
ma connaissance). Si votre navigateur Web met
en œuvre le prefetching DNS (la récupération
anticipée d'informations DNS, avant tout clic de l'utilisateur), votre
résolveur contactera automatiquement les serveurs de
validatorsearch.verisignlabs.com. J'encourage
tous les gérants de sites Web à inclure
également ce petit bout de code HTML : <a href="http://prefetch.validatorsearch.verisignlabs.com"></a>. (L'ISOC le demande aussi.)
L'expérience est menée par VeriSign et il
existe une page
officielle avec, notamment, les résultats
préliminaires (un peu plus de 3 % de résolveurs validant avec DNSSEC). Attention, comme les serveurs de
validatorsearch.verisignlabs.com sont très
spéciaux, il peut y avoir des problèmes à accéder à cette page avec
certains résolveurs (par exemple Unbound).
Quelques notes sur la protection de la vie privée :
- Inclure ce code HTML dans sa page n'envoie pas seulement les données du webmestre à VeriSign mais aussi celles des innocents visiteurs. Il faut donc bien réfléchir.
- La connexion avec VeriSign est uniquement en DNS : le lien est invisible et, même si quelqu'un arrivait à cliquer dessus, l'adresse associée est celle de localhost. Il n'y aura donc jamais d'échange en HTTP avec VeriSign (donc pas de cookies ou de trucs comme ça).
- Ce n'est pas votre adresse IP que verra VeriSign mais celle de votre résolveur DNS : dans la plupart des cas, un serveur de votre FAI.
- La requête DNS ne contient rien sur le site Web que vous visitiez.
L'article seul
Quelles machines pinguer pour vérifier sa connectivité Internet ?
Première rédaction de cet article le 5 septembre 2012
Dernière mise à jour le 7 septembre 2012
Lorsqu'on met en place une infrastructure de surveillance de serveurs Internet, il est agaçant de recevoir autant d'alarmes que de serveurs surveillés, alors que c'était simplement la connectivité Internet de la sonde de surveillance qui était en panne. Tous les grands logiciels de surveillance de réseau ont une option pour éviter cela, qui permet de dire que le test d'un serveur dépend du succès d'un test sur un autre composant, par exemple le routeur de sortie (si ce dernier est en panne, il n'y a pas besoin de tester les serveurs et d'alerter si ça rate). Mais quel composant tester pour déterminer qu'on a un accès Internet qui marche ?
Avec les logiciels de la famille Nagios
comme Icinga, l'option qui permet
d'indiquer la dépendance d'une machine envers une autre se nomme
parents . Si on écrit :
define host {
host_name freebox
address 192.168.1.1
}
define host {
host_name remote-host
parents freebox
...
}
alors on déclare que la connectivité de remote-host
dépend de celle de freebox. Si on est connecté à
l'Internet par ce seul routeur, c'est logique. Si
freebox est injoignable, le reste de l'Internet
l'est aussi.
Mais si freebox fonctionne mais ne route plus ? Ou bien si quelque chose déconne
dans le réseau de Free bloquant tout accès à
l'extérieur ? C'est là qu'il est utile de tester autre chose que le
premier routeur. On voudrait en fait tester si on a toujours un accès
Internet et pouvoir écrire :
define host {
host_name remote-host
parents Internet
...
}
(Les experts Nagios/Icinga auront noté qu'il faudrait plutôt utiliser
hostdependency ou
servicedependency, pour ne même pas effectuer les
tests en cas de panne de la connectivité. Mais c'est un détail ici.)
Mais comment faire ce test ? En pinguant des
machines distantes, bien évidemment. Il « suffit » de sélectionner des
machines stables, qui répondent aux paquets
ICMP d'écho, et qui n'ont elles-mêmes que très
peu de pannes. Mais lesquelles choisir ?
Il faut bien voir que ces machines sur l'Internet, ces amers ou mires (target en
anglais) ne nous appartiennent pas. Si chaque petit réseau local, pour
tester sa connectivité, pingue
192.0.2.1 toutes les trois minutes, et qu'il y a
dix millions de petits réseaux qui le font dans le monde,
192.0.2.1 recevra 50 000 paquets/seconde, ce qui
est une charge sérieuse même pour un gros serveur. (En débit, cela ne
fera pas grand'chose car les paquets de test seront de petite
taille. Mais pour les routeurs et les serveurs, ce n'est pas que le
nombre de bits par seconde qui compte, celui des paquets par seconde
est également important, chaque paquet nécessitant un traitement,
indépendemment de sa taille.) Utiliser le premier serveur qu'on a
choisi pour des tests répétitifs, c'est comme jeter une canette vide
par terre : si une seule personne le fait, c'est juste un peu agaçant,
si tout le monde le fait, on détruit l'environnement. Ce n'est pas
parce qu'un service est publiquement accessible qu'on peut le
bombarder de requêtes pour son usage personnel. Dans le passé, il est déjà arrivé qu'un
constructeur configure (bêtement) ses machines pour utiliser un
serveur public sans autorisation, l'écroulant
ainsi sous la charge.
Qu'est-ce que cela nous laisse comme possibilités ? En posant la question, on obtient des réponses (plus ou moins dans l'ordre décroissant du nombre de suggestions) :
8.8.8.8(ou, à la rigueur,8.8.4.4, qui est sans doute moins sollicité), à savoir Google Public DNS. Un service très fiable, qui a très peu de chances de tomber en panne. Mais peut-on l'utiliser ainsi, de manière automatique, dans des tests répétés ? Cela ne figure certainement pas dans les conditions d'utilisation de ce service, et Google pourrait donc décider de couper les réponses ICMP écho du jour au lendemain (ou de mettre en place une limitation de débit).www.facebook.com(ouwww.google.com) avec l'argument « Si Facebook est en panne, de toute façon, tout l'Internet est fichu ». Cela pose un peu les mêmes problèmes que précédemment.- Pinguer un des serveurs DNS de la racine. Ils marchent en permanence (c'est sans doute un des composants les plus robustes de l'Internet), répondent à l'ICMP écho et, n'étant pas gérés dans un but lucratif, on n'est pas à la merci d'un changement soudain de politique commerciale. Mais ces serveurs ne sont pas prévus pour un tel test automatisé. Ils y résisteront, bien sûr, mais est-ce un usage légitime ? Je ne pense pas et les opérateurs des serveurs racine, interrogés, sont également de cet avis. Il faut aussi se rappeler qu'il s'agit d'un service critique : toute perturbation est à éviter.
- Pinguer un des serveurs de l'AS112 (cf. RFC 7534). Après tout, ils sont censés recevoir du n'importe quoi tout le temps. Un peu de ping ne les dérangera pas. Par contre, ils ne sont pas toujours fiables et, par la magie de l'anycast, ils peuvent être plus près que vous ne croyez, ce qui en fait de mauvaises mires pour tester le grand Internet.
- Utiliser un ensemble de sites bien connus et qui sont probablement assez stables. Si chacun se fait sa propre liste, cela diminuera la charge sur chacun de ces sites. Mais cela reste un usage non autorisé.
- Pinguer des équipements du FAI par exemple son serveur Web ou bien les
routeurs sur le trajet (après un traceroute
pour les repérer). Notez que
cela ne détecte pas le cas où la(es) liaison(s) du FAI avec l'Internet
sont en panne. Mais la plupart des pannes (comme celle de la
Freebox citée plus haut) concernent « le
dernier kilomètre » donc c'est peut-être supportable. L'avantage est
que tout le monde ne teste pas le même service (les abonnés d'un FAI
sont les seuls à tester leur FAI) et que c'est un service qu'on
paie. En tirant un peu sur la ficelle, on peut considérer que
l'abonnement inclut le droit de pinguer
www.mon-FAI.netchaque minute. Les FAI ne sont pas forcément d'accord avec cette analyse, et peuvent faire remarquer que les routeurs sont là pour router, pas pour répondre aux pings. Le mieux serait que les FAI fournissent à leurs abonnés une mire à tester, comme le fait OVH avec sa machineping.ovh.net(un service qui ne semble pas vraiment documenté) ou Free avectest-debit.free.fr(pas plus documenté). - Utiliser une mire publique, prévue pour cela et qu'on a
l'autorisation d'utiliser. (Certaines entreprises fournissent
peut-être un service de mires privées payantes mais je n'en connais
pas. Il existe aussi des mires spécifiques à un système d'exploitation
particulier comme
www.msftncsi.comqu'utilise Windows.) Je ne connais actuellement que trois mires publiques de ce genre, gérées par Team Cymru (la machinefap.cymru.com, en HTTP, elle donne plein de renseignements rigolos), par Rezopole (ping.rezopole.net) et par Demarcq (ping.demarcq.net). Elles sont peu documentées, peut-être par manque de temps et peut-être pour éviter d'attirer plein de trafic. Faudrait-il créer des services associatifs pour cet usage, comme pool.ntp.org le fait pour NTP ? Ou procéder à des échanges avec d'autres acteurs de l'Internet, comme on le fait couramment pour les serveurs DNS secondaires ?
Bref, le débat n'est pas simple. On peut encore le compliquer avec des questions comme « Vaut-il mieux utiliser les paquets ICMP echo de ping ou bien une application comme HTTP ou DNS ? ».
Merci à WBrown pour ses bonnes suggestions sur le pinguage du
FAI, à John Kristoff pour m'avoir rappelé le travail que fait Team
Cymru, à Jean-Philippe Camguilhem pour les explications sur les
dépendances dans Icinga et à Fabien Vincent pour m'avoir appris l'existence de ping.ovh.net. À noter qu'il n'existe pas en France de « service public » de mires
accessibles pour ce genre de tests mais que le
RIPE-NCC a un service similaire, les
Ancres. L'une des ancres a un nom simple à retenir, ping.ripe.net.
J'ai aussi fait un article qui décrit en détail la configuration d'Icinga pour ces mires publiques et l'usage que j'en fait.
L'article seul
RFC 6693: Probabilistic Routing Protocol for Intermittently Connected Networks
Date de publication du RFC : Août 2012
Auteur(s) du RFC : A. Lindgren (SICS), A. Doria
(Consultant), E. Davies (Folly
Consulting), S. Grasic (Lulea University of Technology)
Expérimental
Première rédaction de cet article le 1 septembre 2012
Les protocoles traditionnels de routage (comme, mettons, OSPF) sont conçus dans l'idée que les machines sont connectées et joignables en permanence, sauf rares pannes. Mais il existe des réseaux où cette hypothèse ne se vérifie pas. Par exemple, dans l'espace, domaine traditionnel du groupe de recherche DTN, il est fréquent que la communication soit l'exception plutôt que la règle. Comment router dans ces conditions ? Ce nouveau RFC propose un mécanisme de routage adapté à des connexions intermittente, Prophet.
On n'est plus dans le monde tranquille de l'Internet, avec ses connexions stables et ses problèmes connus. Ici, on est à l'IRTF, l'équivalent de l'IETF pour les recherches avancées. À l'IRTF, on étudie des problèmes comme les connexions entre vaisseaux perdus dans l'espace, ou groupes d'éleveurs samis se déplaçant en Laponie, ou encore entre objets communiquants se déplaçant sans cesse et ne venant que rarement à portée de radio des autres objets. C'est là que Prophet devient utile. (Voir le RFC 4838 pour avoir une meilleure idée des sujets sur lesquels travaille le groupe DTN.). Les protocoles de routage traditionnels (cf. section 1.3), conçus pour trouver le chemin optimum dans le graphe et pour éviter les boucles, n'ont pas réellement de sens ici (par exemple, l'émetteur et le destinataire peuvent ne jamais être allumés en même temps).
Le principe de base de Prophet est d'utiliser l'histoire des rencontres entre deux machines. Si deux engins viennent en contact radio de temps en temps, puis se re-séparent, la mise en œuvre de Prophet se souviendra de ses contacts et pourra se dire « ah, j'ai un bundle (cf. RFC 5050 et RFC 6255) à passer à Untel et, justement, je l'ai vu trois fois dans la dernière semaine, donc je garde le bundle, je devrais le revoir bientôt. » Au moment du contact, les machines Prophet échangent aussi des informations sur les machines qu'elles ont rencontré donc la décision peut aussi être « ah, j'ai un bundle à passer à Untel, je ne l'ai jamais croisé mais Machin l'a souvent fait et, justement, j'ai vu trois fois Machin dans la dernière semaine, donc je garde le bundle, je devrais revoir Machin bientôt, et je lui refilerai le bundle et la responsabilité. »
Une manière courante de résoudre ce problème est d'envoyer le message (dans l'architecture DTN, les messages sont découpés en unités de transmission appelées bundles) à tous ceux qu'on croise, qui le transmettent à leur tour à tous ceux qu'ils croisent et ainsi de suite jusqu'à ce que tout le monde l'ait eu. C'est ce qu'on appelle l'inondation et la mise en œuvre la plus connue de ce principe est dans Usenet (RFC 5537). Mais, dans Usenet, on supposait que tous les nœuds étaient intéressés par le message. Ici, un seul destinataire le veut et, pour ce cas, l'inondation fonctionne mais gaspille pas mal de ressources. Elle marche bien lorsque les ressources ne sont pas un problème mais Prophet se veut utilisable pour des réseaux d'objets communiquants, objets ayant peu de mémoire, de capacité réseau, et de processeur. Prophet adopte donc plutôt une démarche probabiliste : il ne garde que les routes les plus prometteuses, risquant ainsi de ne pas trouver de chemin vers la destination, mais limitant la consommation de ressources. Cet élagage des routes est la principale innovation de Prophet.
Pour échanger les routes (pas forcément les bundles), deux nœuds Prophet, lorsqu'ils se rencontrent, établissent un lien TCP entre eux. La mise en œuvre de Prophet doit donc pouvoir parler TCP et interagir avec le programme de gestion des bundles, pour pouvoir informer les besoins des bundles qu'on souhaite transmettre.
On notera que, comme toujours dans l'architecture DTN (Delay-Tolerant Networking, cf. RFC 4838), la transmission n'est pas synchrone : le message, découpé en bundles, va être bufferisé et pourra mettre « un certain temps » à atteindre sa destination. En outre, il est parfaitement possible que la source et la destination du message ne soient jamais allumés et joignables en même temps : on fait donc du réseautage transitif (le message d'Alice est transmis à René, qui le passe à Rose, qui l'envoit finalement au destinataire, Bob). L'annexe A contient un exemple plus détaillé.
À noter que Prophet est utilisé pour des connexions intermittentes, ce qui ne veut pas dire aléatoires. Elles peuvent au contraire être très prévisibles (cas d'engins spatiaux sur leur orbite, ou cas de déplacement d'objets sur un rythme circadien). D'autre part, Prophet n'est pas seulement utile pour le cas où les nœuds se déplacent mais aussi pour celui où ils sont fixes mais souvent en hibernation, par exemple pour économiser du courant (capteur industriel fixé dans un ouvrage d'art, par exemple). Dans les deux cas, la connectivité est intermittente et ce sont les mêmes solutions qu'on utilise. (Voir « Epidemic Routing for Partially Connected Ad Hoc Networks »).
Les détails pratiques, maintenant. Le RFC est long et il y a beaucoup de détails à prendre en compte. Ce qui suit est donc un simple résumé. La section 2 présente l'architecture de Prophet. À son cœur, la notion de « probabilité de remise [d'un message] » (delivery predictability). Notée P_, définie pour tout couple de machines (A, B), comprise entre 0 et 1, c'est la principale métrique de Prophet. Si P_(A, B) > P_(C, B), alors Prophet enverra les bundles destinés à B via C plutôt que via A. Attention, cette probabilité est asymétrique, P_(A, B) n'a aucune raison d'être égal à P_(B, A). Lorsque deux machines Prophet se rencontrent, elles échangent toutes les probabilités de remise qu'elles connaissent.
Au début, lorsqu'un nœud ne connait rien, la probabilité de
remise est indéfinie. À la première rencontre, elle passe
typiquement de 0,5 (paramètre P_encounter_first),
reflétant l'ignorance encore grande. Au fur et à mesure des
rencontres, la probabiité augmente (lentement, pour ne pas se heurter
au plafond de 1 trop vite, paramètre delta). Cette augmentation est amortie par un
intervalle minimum entre deux rencontres (paramètre
P_encounter, pour éviter qu'un lien
WiFi très instable ne se traduise par plein de
rencontres, qui seraient en fait uniquement des rétablissements du
lien). C'est un résumé, la définition complète de ce calcul figure en
section 2.1.
Vous allez peut-être vous dire « mais les rencontres du passé ne signifient pas qu'elles vont se reproduire dans le futur ». En effet, si les rencontres sont complètement dues au hasard, le passé n'est pas un bon indicateur. Mais rappelez-vous que, dans les réseaux réels, les rencontres ne sont pas complètement aléatoires.
Ces différents paramètres ne sont pas forcément les mêmes pour tous les nœuds Prophet du réseau mais il est recommandé qu'ils soient proches. La section 3.3 détaille ces paramètres.
Ah, au fait, j'ai dit « quand deux nœuds Prophet se rencontrent ». Mais comment le savent-ils, qu'ils sont en vue l'un de l'autre ? Prophet nécessite que la couche 2 transmette cette information (« new neighbor in sight »). Comme détaillé en section 2.4, si Prophet peut tourner sur des protocoles de niveau 2 différents, il faut néanmoins que tous soient capables de signaler l'arrivée ou le départ d'un voisin, ainsi que l'adresse de niveau 2 pour le joindre.
La section 3 décrit le protocole utilisé entre les nœuds Prophet. Il permet d'échanger avec le pair :
- La liste des nœuds connus (identifiés par l'EID défini dans le RFC 4838),
- Les probabilités de remise à ces nœuds,
- Les bundles à envoyer, et la réponse à ceux reçus depuis le pair.
La section 4 présente le format des messages Prophet. Ce format
utilise largement des TLV. Chacun a un type
(enregistré à
l'IANA, cf. section 7) et,
par exemple, le TLV Hello, qui sert en début de
connexion, a le type 1. Les structure de données plus complexes, comme
la table de routage, sont encodés en SDNV (RFC 6256).
La section 5 fournit ensuite les machines à états du protocole.
Et la sécurité ? Ce sujet obligatoire est traité en section 6. Ce sera vite fait : Prophet n'a à peu près aucune sécurité. Il est très vulnérable car les exigences du cahier des charges (machines avec peu de ressources, connectées seulement de manière très intermittente) rendent difficile toute conception d'un protocole de sécurité.
Prophet ne fonctionne donc que si tous les nœuds participant sont gentils et œuvrent dans le but commun. Un mécanisme de sécurité simple serait donc que tous les nœuds utilisent une authentification et que seuls les membres d'une même tribu soient autorisés à faire du Prophet ensemble.
Que pourrait-il se passer, autrement ? Un nœud peut prétendre de manière mensongère qu'il a des routes, en mettant toutes les probabilités de remise à 1 (attaque du trou noir : les autres nœuds lui confieront des bundles qu'il ne pourra pas transmettre). Il peut annoncer un identificateur qui n'est pas le sien, piquant le trafic destiné à un autre. Il peut aussi générer des tas de bundles et les transmettre à ses malheureux pairs (une attaque par déni de service). Et tout ceci serait encore pire si un réseau Prophet était connecté à l'Internet via une passerelle. Les méchants pourraient alors attaquer l'Internet, cachés derrière les faiblesses de Prophet. Bref, un nœud sadique peut faire beaucoup de dégâts, difficiles à empêcher. D'où l'importance de l'authentification, pour ne jouer qu'avec des copains de confiance.
Les sections 8 et 9 de notre RFC décrivent l'expérience existante avec les mises en œuvre de Prophet. C'est un vieux protocole, bien que le RFC ne sorte que maintenant, et il a déjà été implémenté plusieurs fois. Le première fois, écrite en Java, était pour un environnement original, Lego Mindstorms. Elle est documentée dans la thèse de Luka Birsa. Une autre mise en œuvre, en C++, a tourné sur le simulateur OmNet. Encore une autre, pour Android, est décrite dans l'article « Bytewalla 3: Network architecture and PRoPHET implementation ».
Le tout a déjà été testé dans un environnement réel, dans des montagnes du nord de la Suède, en 2006, et raconté dans « Providing connectivity to the Saami nomadic community » (avec une jolie photo de renne dans l'article).
L'article seul
RFC 6725: DNS Security (DNSSEC) DNSKEY Algorithm IANA Registry Updates
Date de publication du RFC : Août 2012
Auteur(s) du RFC : S. Rose (NIST)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsext
Première rédaction de cet article le 30 août 2012
Lors de la conception d'un protocole cryptographique, il est essentiel de permettre l'agilité des algorithmes, c'est-à-dire de changer d'algorithme pour répondre aux progrès de la cryptanalyse. C'est ainsi que DNSSEC inclut dans les enregistrements DNS de clés et de signatures un numéro qui identifie l'algorithme utilisé. Les numéros possibles sont dûment notés dans un registre IANA et ce nouveau RFC « nettoie » le registre, mettant à jour des entrées inutilisées.
Au passage, les érudits noteront que cette absence d'agilité cryptographique (l'algorithme n'est pas indiqué donc un seul algorithme est possible) est un des inconvénients de DNScurve. Mais ne digressons pas. Quels changements a apportés notre nouveau RFC 6725 ? Les numéros 4, 9 et 11, correspondant à des algorithmes qui n'ont jamais été déployés sont désormais marqués comme « réservés ». C'est tout. On ne peut pas les réaffecter (au cas où il traine dans la nature des mises en œuvre expérimentales utilisant ces algorithmes).
4 était réservé pour un algorithme à courbes elliptiques (on n'a jamais su lequel), 9 et 11 n'étaient pas officiellement affectés mais l'ont apparemment été non-officiellement.
L'article seul
RFC 6722: Publishing the "Tao of the IETF" as a Web Page
Date de publication du RFC : Août 2012
Auteur(s) du RFC : P. Hoffman (VPN Consortium)
Pour information
Première rédaction de cet article le 30 août 2012
Le fonctionnement et les particularités de l'IETF étaient traditionnellement décrits dans un RFC nommé Tao, à l'usage des débutants qui débarquaient dans ce monde merveilleux. Le dernier de ces RFC a été le RFC 4677 : désormais, pour évoluer plus facilement, le Tao est une page web ordinaire, régulièrement tenue à jour. Depuis, en juin 2024, le Tao a cessé d'être maintenu (cf. RFC 9592.
Le Tao est le document à lire absolument quand on débute à l'IETF. Il explique son fonctionnement, ses codes, ses rites, son jargon. L'IETF est à ma connaissance la seule SDO à le faire, ce qui est un gage d'ouverture. Le Tao a été d'abord publié comme RFC 1391, puis a connu de nombreuses évolutions jusqu'au RFC 4677. Mais les RFC, statiques et longs à faire publier, ne sont pas le canal idéal pour ce genre de documents, qui doit évoluer en permanence.
Désormais, le Tao est donc une page Web, et contrôlée par l'IESG, qui sera donc l'autorité responsable pour son contenu. Actuellement, cette page est encore très proche du RFC 4677 mais elle va petit à petit s'en éloigner.
Si vous voulez participer à la maintenance du Tao, cela se fait sur
la liste de diffusion
tao-discuss@ietf.org. Un éditeur (actuellement
Paul Hoffman) décide ensuite des changements qui seront transmis à
l'IESG (cette proposition est visible en
ligne). L'IESG accepte ou refuse les changements et le
secrétariat n'a plus qu'à éditer la page.
Le Tao est versionné (la version d'aujourd'hui est 20120829)
et on peut accéder aux
versions précédentes (dès qu'il y en aura plusieurs). On a donc
des identificateurs stables pour les précédentes
versions (toutes les organisations qui publient des documents
devraient en faire autant).
Il existe des traductions du Tao qu'on trouve ici ou là mais le RFC note qu'elles sont toutes non-officielles (et souvent pas à jour). Par exemple, en français, on trouve une traduction du RFC 3160 ou bien la traduction de l'ISOC-Togo.
La section 3 du RFC couvre les propositions alternatives : certains auraient préféré un wiki pour des modifications plus rapides ou plus souples, mais le choix a finalement été de privilégier la sécurité.
L'article seul
RFC 6710: Simple Mail Transfer Protocol Extension for Message Transfer Priorities
Date de publication du RFC : Août 2012
Auteur(s) du RFC : A. Melnikov (Isode), K. Carlberg (G11)
Chemin des normes
Première rédaction de cet article le 26 août 2012
Des tas d'utilisateurs du courrier électronique souhaiteraient un mécanisme de priorité,
permettant de dire que tel message est plus important que tel autre et
devrait être traité en premier. Après tout, les ressources (par
exemple la capacité disponible dans le réseau) sont souvent
insuffisantes et il serait souhaitable que les messages vraiment
urgents en profitent avant les informations envoyées par
Twitter (« vous avez un nouvel abonné »). Il n'existait pas jusqu'à présent,
pour un serveur de messagerie, de
moyen standard en SMTP de dire à un de ses
pairs quelle était la priorité d'un message. C'est désormais fait
grâce à la nouvelle extension SMTP
MT-PRIORITY.
Dans les en-têtes du message (le format des messages est normalisé
dans le RFC 5322), il existait un en-tête
standard, Priority:, décrit dans le RFC 2156. Ce dernier avait à l'origine été écrit
pour assurer l'interfaçage avec X.400. Ce
système avait été un échec complet mais l'en-tête
Priority: garde son utilité (on trouve aussi
souvent un en-tête non officiel et n'ayant pas exactement la même
sémantique, notamment par le nombre de niveaux et leur représentation,
X-Priority:.) Par contre,
l'inconvénient de noter la priorité dans le message est que cela
oblige les MTA à analyser les en-têtes, ce qui
n'est pas normalement leur rôle. De manière cohérente avec l'évolution
du courrier électronique depuis quinze ans (meilleure séparation entre
le format du RFC 5322 et le transport normalisé dans le RFC 5321), la priorité est désormais exprimable lors de la
session SMTP. (Un autre
RFC en cours d'écriture, draft-melnikov-smtp-priority-tunneling, utilisera un nouvel
en-tête, MT-Priority:, pour le cas où on doive tunneler des
messages prioritaires au dessus de MTAs qui ne gèrent pas les
priorités.) Par exemple, un MTA dont les files d'attente d'envoi de
messages sont grandes, pourra mettre au début de la file les messages
de plus forte priorité.
Notez bien que c'est une priorité, donc
relative (« ce message est très urgent, celui-ci
l'est moins ») pas d'une garantie de délai. Le courrier électronique
demeure « au mieux », sans délais certains. Les annexes de ce RFC
contiennent des discussions plus en détails sur certaines utilisations
de ces priorités. Si on ne se satisfait pas de la délivrance « au
mieux », il faut utiliser une autre extension SMTP
(DELIVERBY dans le RFC 2852 et section
5.2 de notre RFC 6710) ou regarder du côté de techniques réseaux comme
DiffServ (RFC 2474).
Notez aussi que l'une des raisons du peu de déploiement effectif de
l'en-tête Priority: est un problème de
confiance (comme souvent quand on prétend faire
de la qualité de service : tout le monde va
demander la qualité maximale). Rien ne garantit que celui qui met dans
ses messages Priority: urgent le fait à bon
escient, peut-être ajoute-t-il systématiquement cette indication pour
que ses messages aillent plus vite. Notre RFC 6710 précise
donc bien que le MTA récepteur n'est pas obligé
d'honorer les priorités de n'importe qui. Il peut ne le faire que
lorsqu'il connait l'expéditeur et lui fait confiance (voir les
mécanismes utilisés en sections 4.1 et 5.1).
Maintenant, les détails techniques (section 3) : la nouvelle extension SMTP se
nomme Priority Message Handling et est annoncée par
le mot-clé MT-PRIORITY lors de la connexion
SMTP. Par exemple (S indique le serveur et C le client) :
S: 220 example.com SMTP server here C: EHLO mua.example.net S: 250-example.com S: 250-AUTH STARTTLS S: 250-AUTH SCRAM-SHA-1 DIGEST-MD5 S: 250-SIZE 20000000 S: 250-DSN S: 250-ENHANCEDSTATUSCODES S: 250 MT-PRIORITY MIXER
(Le paramètre MIXER est le nom d'une politique de
priorités et est expliqué plus loin, section 9.2.)
La priorité du message est annoncée par un paramètre de la commande
MAIL FROM également nommé
MT-PRIORITY. Elle va de -9 (plus faible priorité)
à 9 (priorité la plus élevée). Par exemple :
C: MAIL FROM:<eljefe@example.net> MT-PRIORITY=6 S: 250 2.1.0 <eljefe@example.net> sender ok C: RCPT TO:<topbanana@example.com> S: 250 2.1.5 <topbanana@example.com> recipient ok
En pratique, tous les serveurs ne géreront pas forcément 19 niveaux distincts (il n'y en avait que 3 dans le RFC 2156). L'annexe E explique pourquoi ce choix de 19.
Cette extension est utilisable aussi bien pendant la soumission (RFC 6409) que pendant la transmission (RFC 5321), ainsi qu'en LMTP (RFC 2033).
Lorsque le MTA « serveur » gérant cette extension reçoit un message ayant une priorité
explicite, il va le traiter en fonction de cette priorité. Par défaut,
la priorité est de zéro (d'où le choix d'avoir des priorités
négatives, on voit tout de suite si la priorité est plus ou moins
importante que celle par défaut, voir annexe E pour les raisons de ce
choix). En prime, le MTA va noter cette priorité dans l'en-tête
Received: qu'il va ajouter au message. Avant
cela, le MTA aura du toutefois vérifier l'émetteur : le RFC précise
qu'on peut accepter des priorités négatives de n'importe qui mais
qu'on ne devrait accepter des positives (élevant le niveau de
priorité) que des émetteurs qu'on a authentifiés d'une manière ou
d'une autre, et à qui on fait confiance. Autrement, il serait facile
de réclamer systématiquement la plus haute priorité (9), épuisant
ainsi les ressources du serveur. Un exemple
d'une politique d'autorisation pourrait être « n'accepter de priorités
positives que depuis les utilisateurs authentifiés avec la commande
AUTH - RFC 4954 - ainsi que depuis les MTA dont
l'adresse IP a été mise dans une liste blanche,
suite à un accord bilatéral avec leur gérant ». (Voir aussi les sections
5.1 et 11.)
Naturellemnt, un MTA peut avoir des politiques plus complexes comme
de modifier automatiquement la priorité demandée en fonction de
l'émetteur (« maximum 3 pour
2001:db8:666::1:25 »). Il doit dans ce cas
prévenir l'émetteur en réponse au MAIL FROM :
C: MAIL FROM:<eljefe@example.net> MT-PRIORITY=6 ... S: 250 X.3.6 3 is the new priority assigned to the message
Lorsqu'un serveur transmet un message à un autre serveur SMTP, il
inclut la priorité, sauf évidemment si l'autre serveur n'a pas annoncé
qu'il gérait les priorités (extension
MT-PRIORITY).
Les considérations pratiques liées au déploiement de cette
extension MT-PRIORITY figurent dans la section
9. Ainsi, si on a plusieurs serveurs de courrier pour un même domaine
(via plisieurs enregistrements MX), le RFC
recommande de veiller à ce que tous ou aucun acceptent l'extension de
gestion de la priorité. Autrement, des problèmes difficiles à déboguer
vont survenir. (De toute façon, avoir plusieurs enregistrements MX est
complexe et déconseillé pour les petits
domaines, exactement pour ce genre de raisons.)
J'ai parlé un peu plus haut du paramètre « Nom de la politique de
priorité » qu'un serveur peut ajouter lorsqu'il indique qu'il gère les
priorités. La section 9.2 décrit plus en détail ce que cela
signifie. L'idée est que différentes organisations vont avoir des
politiques de priorité différentes : nombre de niveaux,
notamment. L'idée est de donner un nom à ces politiques afin de
permettre à un serveur d'indiquer quelle politiques il suit. Par
exemple, si le serveur a une politique qui ne gère que trois niveaux,
-1, 0 et 1, un message indiquant qu'il a réduit la priorité demandée
de 3 à 1 n'est pas inquiétant. Il est recommandé d'enregistrer les
politiques à l'IANA
(la section « SMTP PRIORITY extension Priority Assignment
Policy »). Ce nouveau registre est rempli selon la règle
« Norme nécessaire » du
RFC 5226. Il comprend actuellement trois
politiques, issues de normes existantes. Par défaut, la politique
appliquée est MIXER qui est celle du RFC 2156 et reprise dans l'annexe B de notre RFC 6710 :
trois niveaux de priorité seulement (-4, 0 et 4), pas de valeurs numériques définies par
défaut pour les tailles maximales des messages ou pour les délais de retransmission.
Deux autres annexes décrivent des utilisations des priorités, avec
la politique associée. L'annexe A concerne l'usage militaire
(politique STANAG4406, six niveaux, les
deux plus urgents étant étiquetés Flash et
Override). Et l'annexe C concerne les services
d'urgence (RFC 4190 et RFC 4412). Un avis personnel : il n'est sans doute
pas sérieux
d'utiliser le courrier électronique sur
l'Internet public pour des appels aux pompiers
ou des messages militaires alors que l'ennemi attaque.
Puisqu'on a parlé de l'IANA, outre ce nouveau registre, les enregistrements suivants ont été faits (section 10) :
MT-PRIORITYa été ajouté aux extensions SMTP (la section « SMTP Service Extensions »).- Quelques codes de réponse améliorés (RFC 5248) ont été enregistrés, comme X.3.6 pour indiquer que la priorité demandée a été changée ou comme X.7.16 qui signale que le message est d'une taille trop importante pour sa priorité.
Et questions mises en œuvre ? Aujourd'hui, un
Postfix typique, par exemple, ne gère pas
encore ces priorités (et répond 555 5.5.4 Unsupported
option: MT-PRIORITY=3 si on essaie.) Il existe apparemment déjà
trois MTA qui ont en interne ce concept de priorité et qui, en
l'absence de norme, la déterminaient de manière non-standard. Ils
n'ont pas encore été adaptés à ce RFC. Pour cela, l'annexe D donne
d'intéressants avis sur les stratégies d'implémentation possibles.
L'article seul
RFC 6713: The application/zlib and application/gzip media types
Date de publication du RFC : Août 2012
Auteur(s) du RFC : J.R. Levine (Taughannock Networks)
Pour information
Première rédaction de cet article le 25 août 2012
Encore un RFC qui comble un manque
ancien. Les types MIME
application/gzip et
application/zlib n'avaient jamais été
formellement enregistrés. Voici qui est fait.
Ces deux types apparaissent désormais dans le
registre IANA avec ce RFC 6713 comme référence. Rien
de nouveau, ils étaient déjà utilisés dans de nombreuses
applications. (Parfois, des types non officiels étaient utilisés comme
application/x-gzip ou encore des trucs comme application/gzipped.)
Pour ceux qui veulent apprendre ces deux techniques de compression, Zlib est spécifié dans le RFC 1950 (et a un site « officiel ») et Gzip est dans le RFC 1952 et a aussi son site. Les deux techniques sont très proches (utilisant l'algorithme Deflate du RFC 1951), la principale différence étant que Gzip inclut un en-tête et une terminaison. Il est donc plus adapté pour les fichiers (et Zlib pour le streaming).
Ah, au fait, soyez prudent : comme le dit l'inévitable section Security Considerations, les données comprimées récupérées sur l'Internet (qui est, comme le dit le sage Beigbeder, « l'empire de la méchanceté, de la bêtise ») peuvent être trompeuses. Elles peuvent prétendre être en Zlib ou en Gzip et comporter des erreurs, des pointeurs ne pointant pas au bon endroit, des champs Longueur qui n'indiquent pas la longueur, et autres choses qui peuvent mener à des accidents comme le dépassement de tampon. Programmeurs, attention.
L'article seul
RFC 6703: Reporting IP Network Performance Metrics: Different Points of View
Date de publication du RFC : Août 2012
Auteur(s) du RFC : A. Morton (AT&T Labs), G. Ramachandran (AT&T Labs), G. Maguluri (AT&T Labs)
Pour information
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 24 août 2012
Le groupe de travail IPPM de l'IETF a défini de nombreuses métriques, des définitions rigoureuses de grandeurs qu'on peut mesurer sur un réseau. Ce nouveau RFC porte sur un problème un peu différent : une fois qu'on a ces métriques, comment publier les résultats ? Quels sont les pièges de la publication ? Parmi les paramètres de la mesure, que mettre en évidence ? Ce RFC est loin de traiter en détail toutes ces questions, il décrit surtout les conséquences de deux points de vue différents : celui de l'ingénieur réseaux, intéressé surtout par les performances de son réseau, et celui du programmeur, intéressé par les performances de son application.
Il y a bien sûr un lien entre les deux : si le réseau perd beaucoup de paquets, par exemple (RFC 7680 et RFC 6673), les applications auront de moins bonnes performances. Mais, dans certains cas, les deux points de vue ne s'intéressent pas exactement à la même chose. Voyons en quoi. (À noter aussi que ce RFC 6703 ne regarde que les analyses sur le relativement long terme, au moins plusieurs heures. Et il ne se penche pas sur le problème, bien plus difficile, de la publication vers M. Toutlemonde, par exemple pour lui communiquer la QoE.)
Toute présentation de mesures nécessite évidemment de connaître l'audience. On ne va pas communiquer de la même façon vers le management et vers les techniciens, par exemple. Et, même parmi les techniciens, il existe plusieurs catégories. Ce RFC s'intéresse à la différence entre « les gens du réseau » (qui pensent planification des investissements, dépannage, SLA, etc) et « les gens des applications » qui se demandent quel va être l'effet du réseau sur les applications. Les premiers mesurent des métriques comme le taux de pertes de paquets (RFC 7680) ou comme le délai d'acheminement (RFC 7679), avec l'idée de modifier le réseau (par des investissements ou bien des changements de la configuration), si les chiffres sont défavorables. Les seconds vont ajuster les applications pour s'adapter à ces résultats, qu'ils ne peuvent pas changer.
Les recommandations de notre RFC occupent la section 3. Lorsqu'on publie des mesures, on doit notamment :
- Inclure au minimum le taux de pertes de paquets (RFC 7680) et le délai d'acheminement (RFC 7679). On notera que c'est ce que fait la commande ping, même si elle ne suit pas exactement les métriques IPPM. Notons aussi que la norme UIT Y.1540 donne une définition assez proche de celle de l'IETF.
- Indiquer la moyenne et la médiane (ce que ping ne fait hélas pas). Les deux statistiques sont utiles (et les deux ont des limites, par exemple aucune des deux ne gère proprement les distributions bimodales).
C'est le minimum. Mais on peut l'enrichir, avec d'autres métriques comme la variation du délai d'acheminement (RFC 3393), le réordonnancement des paquets (RFC 4737), la capacité (RFC 3148 et RFC 5136, le premier RFC décrivant la capacité utile et le second celle mesurée au niveau IP). Et on peut ajouter d'autres statistiques, pour ne pas être bloqués par les limites de la moyenne et de la médiane. Par exemple, minimum, maximum, « 95 percentile ».
Bon, et les deux points de vue différents dont je parlais au début, que deviennent-ils ? La section 4 du RFC examine les différentes métriques selon ces deux points de vue. Par exemple, le taux de pertes du RFC 7680 a un paramètre important : le délai d'attente avant qu'on renonce à attendre un paquet. Le RFC 7680 ne donne pas de valeur quantitative. Intuitivement, on pourrait penser que des durées de l'ordre de la demi-seconde suffisent. Après tout, on n'a jamais vu ping signaler un délai plus long, non ? Mais ce n'est pas idéal. En cas de boucle de routage, par exemple, avant que l'IGP ne converge enfin, un délai de plusieurs secondes est possible (cf. « A Fine-Grained View of High Performance Networking » à NANOG 22 ou « Standardized Active Measurements on a Tier 1 IP Backbone » dans IEEE Communications Mag. de juin 2003). Un délai long est donc recommandé. En modélisant le pire cas dans le réseau, notre RFC arrive à une recommandation de 50 secondes, qui devrait couvrir tous les cas. Revenons maintenant aux deux point de vue. L'homme (ou la femme) du réseau veut déterminer le vrai taux de perte, en étant sûr que les paquets sont vraiment perdus et pas simplement très en retard. Mais la femme (ou l'homme) des applications n'a pas besoin de tels délais d'attente : l'application ne patientera jamais autant. Pour la plupart des applications, si ça n'arrive pas en quelques secondes, c'est comme si c'était perdu.
Faut-il alors faire deux mesures pour nos deux points de vue ? C'est une possibilité. Le RFC en suggère une autre : ne faire qu'une mesure, avec le délai long, mais noter le moment où le paquet arrive et calculer le taux de pertes avec deux délais différents, pour faire deux rapports.
Et le cas des paquets erronés (par exemple car ils ont une somme de contrôle invalide) ? Pour le RFC 7680, ils sont à compter comme perdus (si le paquet est erroné, on ne peut même pas être sûr qu'il était bien pour nous). C'est le point de vue des gens du réseau. Mais les gens des applications ne sont pas toujours d'accord. Certaines applications, notamment dans le domaine de l'audio et de la vidéo temps-réel préfèrent que l'application reçoive les paquets erronés, dont on peut parfois tirer quelque chose. Notre RFC suggère donc de publier deux résultats, un en comptant les paquets erronés comme perdus, l'autre en les acceptant.
Et la métrique « délai d'acheminement des paquets », en quoi les deux points de vue l'affectent (section 5) ? Notre RFC s'oppose surtout à l'idée de présenter les paquets qui, lors de la mesure, n'arrivent pas, avec une valeur artificielle comme un nombre très grand ou comme l'infini. Quel que soit le point de vue, l'infini n'est pas une valeur utile et il vaut donc mieux considérer que le délai, pour un paquet qui n'arrive pas, est « indéfini ».
Maintenant, la capacité (sections 6 et 7). Notre RFC 6703 introduit un nouveau vocabulaire, « capacité brute » (raw capacity) pour celle du RFC 5136 (qui n'intègre pas les effets de la retransmission des paquets perdus ou erronés) et « capacité restreinte » (restricted capacity) pour celle du RFC 3148, qui intègre les actions du protocole de transport (retransmettre les données manquantes, par exemple). La capacité restreinte est donc inférieure ou égale à la capacité brute, et elle est plus proche de ce qui intéresse les utilisateurs.
D'abord, un rappel, la capacité n'est définie que pour un Type-P donné, c'est-à-dire (RFC 2330) un type de paquets (protocole, port, etc). Ensuite, le RFC 5136 définit trois métriques pour la capacité brute : capacité IP maximum (ce que le système peut faire passer), utilisation (ce qui passe effectivement, et qu'on pourrait appeler « débit » mais le RFC évite ce terme, trop galvaudé), et enfin capacité disponible (certaines applications, par exemple, voudraient simplement savoir si la capacité disponible est suffisante - supérieure à une certaine valeur). Les trois métriques sont liées : en en connaissant deux, on peut calculer la troisième. L'utilisation (et donc la capacité disponible) peut varier rapidement sur un réseau réel. Notre RFC 6703 recommande donc de moyenner sur une longue période, par exemple une minute (en notant que cinq minutes est plus fréquent, en pratique, mais peut-être trop long). D'autre part, il suggère de publier plusieurs chiffres : miminum, maximum et un intervalle (par exemple, le pourcentage de temps pendant lequel la métrique vaut entre telle et telle valeur, comme « la capacité est de X Mb/s pendant au moins 95 % du temps »). Maximum et minimum peuvent aussi être publiés sous forme d'un seul chiffre, leur ratio : (max/min = 1) => grande stabilité, (max/min = 10) => forte variabilité, etc.
Pour la capacité restreinte, un autre problème se pose : elle est
dépendante des algorithmes de contrôle de
congestion. Par exemple, avec certaines mises
en œuvre de TCP anciennes, la capacité
restreinte (celle réellement accessible aux applications) pouvait être
très inférieure à la capacité brute, par exemple parce que TCP
réagissait mal en cas de perte de paquets et ralentissait trop son
débit. Notre RFC introduit donc un nouveau concept, le « Type-C » qui
est l'ensemble des algorithmes du protocole de transport et leurs
paramètres (RFC 6349). Il est nécessaire de
publier le Type-C utilisé, avec les résultats. (Un exemple, sur
Linux, est la valeur du paramètre
sysctl
net.ipv4.tcp_congestion_control.)
Autre piège, le temps d'établissement de la connexion TCP. Si on
mesure la capacité restreinte avec quelque chose comme (sur
Unix) time wget
$GROSFICHIER, le délai pour la triple poignée de mains qui
commence toute connexion TCP peut sérieusement affecter le
résultat. Même chose avec le « démarrage en douceur » que fait TCP
avant d'atteindre l'équilibre. Il peut diminuer la capacité mesurée
(d'un autre côté, l'ignorer serait irréaliste puisque les « vraies »
connexions l'utilisent). Bref, toutes ces informations doivent être
publiées avec le résultat de la mesure.
Enfin (section 8), deux détails qui peuvent avoir leur importance : la distribution des paquets lors d'une mesure active (Poisson ? Périodique, ce que fait ping ?). Et la taille de l'échantillon (par exemple le nombre de paquets envoyés.) Ces détails doivent également être publiés.
L'article seul
RFC 6694: The "about" URI Scheme
Date de publication du RFC : Août 2012
Auteur(s) du RFC : S. Moonesamy
Pour information
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 24 août 2012
Les URI commencent par un
plan (scheme en anglais),
indiquant leur type. Un plan très répandu en pratique n'avait jamais
été normalisé : « about: ». Il permet de décrire des
URI internes au navigateur. Le plus célèbre est le
about:blank qui permet d'afficher une page
blanche. Ce plan, et ce premier URI utilisant ce plan sont désormais
officiellement spécifiés dans ce RFC.
Le plan est souvent appelé par erreur « protocole ». Mais il ne
correspond pas toujours à un protocole, comme c'est le cas de notre
about:. Celui-ci sert à tout, pages spéciales qui
n'ont pas été récupérées sur le Web, accès à la
configuration du navigateur et même amusants
œufs de Pâques. Il figure désormais dans
le registre des plans.
La section 2 indique la syntaxe formelle et la sémantique des URI
about:. Un point
important est que, contrairement aux URI http:,
il n'y a pas de structure. Tout le texte après
about: indique la ressource cherchée, sans qu'on
puisse détailler des composants dans ce texte. Certains de ces textes
sont eux-mêmes normalisés (comme le blank cité
plus haut) mais pas tous. Et, comme about: décrit
des ressources internes au navigateur, il est courant et normal que
ces URI about: soient spécifiques d'un navigateur
particulier. Attention donc aux URL about: dans cet article, certains ne
marcheront pas dans votre navigateur.
Les noms « bien connus » sont désormais enregistrés (section 5.2). Pour
l'instant, le registre
IANA ne compte que
blank (décrit sommairement en section 3) et
invalid (qui vient d'une autre norme, au
W3C) mais d'autres pourront s'y ajouter après la
publication de ce RFC. Cet enregistrement est recommandé dès qu'au
moins deux navigateurs connaissent ce nom. La procédure à suivre (cf. RFC 5226) est « premier arrivé, premier servi ». Ce principe n'a
pas fait l'objet d'un consensus immédiat à
l'IETF, certains auraient préféré une procédure
plus formelle, « Spécification nécessaire ».
Il y a même des questions de sécurité liées aux URI
about: (section 4) car ils donnent parfois accès à des
informations sensibles comme des mots de passe.
Voici maintenant quelques URI about: à tester
dans votre navigateur. N'hésitez pas à me raconter lesquels marchent
et à m'en envoyer d'autres. De manière surprenante, il n'est pas
toujours facile d'avoir de la documentation stable et fiable sur les
about:. Pour Firefox, on
peut consulter « Firefox about: pages » et pour Chrome « Google
Chrome's about: Pages » ou bien « Behind
the Scenes of Google Chrome: Optimizing and
Troubleshooting », un bon article sur les réglages de
Chrome pour maximiser les performances, qui fait beaucoup appel aux about:. Voici
les exemples. Vous noterez que je n'en ai pas fait des liens
hypertextes car des navigateurs comme Firefox n'acceptent pas tous les
liens about: dans une page Web (sans doute pour
des raisons de sécurité). Il faudra donc copier/coller :
about:blank, la page blanche,about:config, accès à la configuration du navigateur (marche sur Firefox, il offre plein de possibilités),about:about, le méta-about:, à propos de l'à-propos (marche avec Firefox et Chrome),about:robots, un joli œuf de Pâques (marche sur Firefox),about:dns, donne accès aux informations DNS, utilise avec Chrome qui joue de drôles de jeux avec le DNS. Il est très riche et des explications ne sont pas inutiles. Voir « DNS Prefetching (or Pre-Resolving) », « Google Chrome DNS Fetching », « Chrome Networking: DNS Prefetch & TCP Preconnect » ou « What does the about:dns page in Google Chrome show? ».
L'article seul
Fiche de lecture : Breaking the Maya code
Auteur(s) du livre : Michael Coe
Éditeur : Thames & Hudson
978-0-500-28133-8
Publié en 1992
Première rédaction de cet article le 24 août 2012
Un récit fabuleux sur le décryptage de l'écriture maya. L'un des participants à cette aventure, qui ne s'est terminée que dans les années 1980, a raconté tous les efforts qui ont été nécessaires pour arriver à lire cette écriture oubliée.
Attention, c'est un récit subjectif. Le monde des mayanistes est très divisé (c'est une des raisons pour lesquelles le décryptage a pris tant de temps) et Michael Coe a quelques comptes à régler. Sans compter les chocs entre les cultures différentes des linguistes, des archéologues et des épigraphistes. Bref, il a fallu bien plus longtemps pour lire l'écriture maya que pour les hiéroglyphes égyptiens, ou même que pour les hiéroglyphes hittites. Coe cite plusieurs raisons pour ce retard. Ce n'était pas le manque de documents (il y en avait davantage que pour les hiéroglyphes hittites, malgré la destruction systématiques des textes mayas par les intégristes catholiques, comme De Landa), ni le manque d'une pierre de Rosette (le même De Landa en avait écrite une, mais qui n'avait pas été interprétée correctement). Non, d'après Coe, c'était plutôt des aveuglements volontaires. Persuadés que l'écriture n'avait aucun rapport avec les langues mayas, encore largement parlées aujourd'hui, les premiers décrypteurs n'avaient tout simplement pas pris la peine d'apprendre une seule langue maya... Ensuite, leurs successeurs, ayant décidé une fois pour toutes que les Mayas n'avaient pas d'histoire et n'écrivaient que des réflexions philosophico-astronomiques, n'ont pas su lire les inscriptions même les plus simples (naissance du roi, son arrivée sur le trône, sa mort...)
Cet aveuglement pendant des années est très frappant, a posteriori, et a de quoi faire réfléchir sur la capacité humaine à ne pas se remettre en cause, même face aux plus grosses évidences.
Autre bel aveuglement : le refus acharné par les mayanistes de considérer que l'étude des autres civilisations puisse être utile. Les Mayas étaient considérés comme tellement différents que les compétences des égyptologues ou des assyriologues ne pouvaient pas servir à quoi que ce soit !
Mais il y avait aussi des erreurs techniques : l'une des plus gênantes a été l'attachement à l'idée d'écriture idéographique, c'est-à-dire qui code directement des idées, sans passer par une langue. Coe explique que cette idée est maintenant abandonnée par tous les linguistes (il n'existe pas d'écriture réellement idéographique, même si des termes erronés comme idéogramme sont encore fréquemment utilisés). Mais des gens importants s'étaient accrochés à cette théorie (qui justifiait leur absence de connaissances des langues mayas) et avaient rejeté les premières analyses correctes de l'écriture maya comme syllabaire, par Knorozov.
Il faut dire à la décharge de tous ceux qui se sont plantés que l'écriture maya n'est pas facile, notamment par sa variabilité. Le même texte peut s'écrire de plusieurs façons et les scribes ne manquaient pas d'en profiter.
Bref, plein de fausses pistes, de pistes correctes mais mal suivies (ce n'était pas tout de comprendre que l'écriture maya codait une langue maya, encore fallait-il savoir laquelle), d'expéditions épuisantes sur le terrain, de débats idéologiques vigoureux (c'était en pleine Guerre froide et les théories venues d'Union Soviétique étaient systématiquement rejetées à l'Ouest). Mieux qu'Indiana Jones, et en vrai.
On trouve beaucoup d'images de glyphes mayas libres sur Wikimedia Commons.
L'article seul
RFC 6666: A Discard Prefix for IPv6
Date de publication du RFC : Août 2012
Auteur(s) du RFC : N. Hilliard (INEX), D. Freedman (Claranet)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 21 août 2012
Une technique couramment utilisée en cas d'attaque par déni de service est le RTBH :
Remote Triggered Black Hole où la victime demande
à son FAI, via un
protocole, de jeter des
paquets sur tel ou tel critère. On utilise pour
cela les protocoles de routage standards comme
BGP ou OSPF. Même chose
lorsqu'un opérateur réseaux veut propager en interne, entre ses
routeurs, la décision de jeter ou de rediriger tel ou tel type de
paquets. Pour cela, il est bien pratique de disposer d'un préfixe IP
spécial, qui désigne le trou noir (ou l'IDS, si
on redirige le trafic vers un équipement d'analyse spécial). Il
n'existait pas de tel préfixe pour IPv6, c'est
désormais fait avec ce RFC, qui enregistre
0100::/64.
Les RFC 5635 et RFC 3882 décrivent plus en détail cette idée de RTBH dans le
cas d'une DoS. On
sélectionne les paquets en fonction de leur adresse IP source ou
destination et on les jette (trou noir) ou bien on les envoie (par
exemple via un tunnel) vers un dispositif
d'analyse. Pour configurer cela, il faut des adresses IP (plusieurs,
car on peut avoir plusieurs traitements différents selon les attaques,
donc une seule adresse IP ne suffit pas). Certains
utilisent des adresses privées ou bien les adresses IP réservées pour
la documentation (RFC 3849). Ce n'est pas très
satisfaisant (et cela peut interférer avec les politiques de filtrage
en interne, cf. section 2 du RFC) d'où le nouveau préfixe. Si on voit
0100::/64 dans la configuration d'un routeur, on
sait désormais exactement ce que cela implique.
Ce préfixe peut être propagé, à l'intérieur du réseau de l'opérateur, ou bien entre l'opérateur et ses clients, par les protocoles de routage dynamiques habituels comme OSPF. Il ne doit pas être transmis à l'extérieur et il est recommandé de le filtrer en entrée, sur les liens de peering ou de transit. Comme il sert pour gérer des attaques qui peuvent être de taille impressionnante, une fuite de ce préfixe vers un autre opérateur pourrait potentiellement entraîner un reroutage de l'attaque vers cet autre opérateur (sections 3 et 5 du RFC). Prudence, donc !
Ce préfixe 0100::/64 est désormais dans le
registre
des adresses IPv6 spéciales.
L'article seul
RFC 6701: Sanctions Available for Application to Violators of IETF IPR Policy
Date de publication du RFC : Août 2012
Auteur(s) du RFC : A. Farrel (Juniper Networks), P. Resnick (Qualcomm)
Pour information
Première rédaction de cet article le 21 août 2012
Comme toutes les organisations de normalisation, l'IETF a élaboré une série de règles pour gérer le difficile problème de l'appropriation intellectuelle et surtout des brevets. Ces règles existent depuis des années mais ce n'est que récemment, suite à deux affaires spectaculaires, que l'IETF a pris conscience du fait que la question des sanctions, en cas de violation de ces règles, n'avait jamais été sérieusement discutée. Ce RFC corrige ce manque et fait la liste des réactions possibles de l'IETF en cas de violation des règles. Disons-le tout de suite, il n'y en a pas de très dissuasives : l'IETF n'a pas le pouvoir de couper des têtes ou de condamner au bûcher. Un autre RFC, le RFC 6702, discute de l'aspect positif, comment encourager le respect des règles.
Que disent ces règles actuellement ? Documentées dans le RFC 8179, résumées sur le site Web et par l'IESG, et fréquemment rappelées pendant les réunions physiques et sur les listes de diffusion, par les fameux « Note Well », ces règles reposent sur deux piliers :
- L'IETF peut normaliser des techniques brevetées,
- Mais encore faut-il le savoir : pour cela, tout participant à l'IETF qui a connaissance, dans le cadre de son activité professionnelle, d'un brevet sur une technique en cours de normalisation doit en avertir l'IETF.
Le but est d'éviter les brevets sous-marins, par lesquels une entreprise pousse à la normalisation d'une technique, pour laquelle elle dispose de brevets, en dissimulant ces brevets pour qu'ils n'effrayent pas les normalisateurs.
La section 2 décrit plus en détail cette politique de l'IETF. D'abord, elle ne s'applique qu'aux contributeurs à l'IETF. Quelqu'un qui n'écrirait aucun document, ne prendrait jamais la parole aux réunions et ne s'exprimerait pas sur les listes de diffusion n'aurait pas à la respecter. C'est d'ailleurs la seule solution pour un employé que sa compagnie n'autorise pas à divulguer l'existence d'un brevet : se retirer du processus IETF (« Aime-la ou quitte-la »).
Cette politique est ensuite souvent rappelée aux participants, par exemple lorsqu'on s'inscrit à une liste de diffusion IETF, on est redirigé vers la page Web d'avertissement (Note Well).
Pour signaler un brevet portant sur une technologie en cours d'examen à l'IETF, cela se fait via un formulaire Web. Les déclarations sont elles-mêmes publiées sur le Web.
Que fait ensuite le groupe de travail IETF de ces déclarations ? L'IETF n'impose pas une politique unique à ses groupes de travail à ce sujet. Le groupe peut décider d'ignorer le brevet (n'oubliez pas que la grande majorité des brevets logiciels sont futiles : technologies évidentes, communes longtemps avant le brevet, etc). Il peut aussi décider de changer la technique en cours de normalisation pour contourner le brevet (et c'est la crainte de ce résultat qui motive certaines entreprises à garder leurs brevets secrets).
Naturellement, il y a des tricheurs. C'est ainsi que RIM ou Huawei (dans le RFC 6468) avaient caché leurs brevets. C'est à cause de ces tricheurs qu'il faut prévoir la possibilité de sanctions, dont la gravité doit être adapté à chaque cas.
Qui va décider de l'action à entreprendre contre les tricheurs (section 3) ? Les chefs du groupe de travail concernés, puisque ce sont eux qui connaissent le mieux tous les détails et, s'ils ne le peuvent pas, le directeur de zone (Area Director) responsable du groupe de travail.
La section 4 liste les sanctions elles-mêmes. Aucune n'est très effrayante, l'IETF n'ayant pas de pouvoirs particuliers. À noter que la liste présentée ici n'est pas exhaustive, d'autres sanctions pourront être imaginées dans le futur. Donc, en gros, par ordre de sévérité croissante, quelques-uns de ces sanctions :
- Discussion en privé avec le participant,
- Avertissement en privé,
- Avertissement public avec les noms (politique nommée en anglais name and shame),
- Refus d'accepter le tricheur comme auteur d'un document du groupe de travail (ce sont en effet les présidents du groupe de travail qui décident des auteurs), ou exclusion des documents qu'ils éditent actuellement (le droit d'auteur oblige à les mentionner dans la section Acknowledgments, même dans ce cas, il n'est pas possible de reproduire la condamnation d'Érostrate),
- Rejet complet du document et donc de la technique qu'il normalise,
- Ajout temporaire ou définitif du tricheur sur la liste noire des gens non autorisés à écrire sur la liste de diffusion du groupe de travail (RFC 3683, ce que le jargon IETF nomme une PR Action pour Posting Rights Action, notez que, depuis, le RFC sur les PR a été remplacé par le RFC 9945), la section 4.1 décrivant en détail pourquoi cette sanction est acceptable dans ce cas.
Comme toute les décisions à l'IETF, elles sont susceptibles d'appel devant l'IESG (section 5 et la section 6.5 du RFC 2026).
À noter que l'annexe A contient des indications pour ceux qui auront à choisir et appliquer les sanctions. Rien ne sera automatique et les décideurs devront faire preuve de jugement. Parmi les points qu'ils devront examiner avant de décider figurent l'ancienneté de la personne en cause dans l'IETF, le moment exact où le brevet a été révélé, la place de l'individu dans le travail en question (contributeur occasionnel ou principal ?), qualité des excuses présentées, etc.
L'article seul
RFC 6702: Promoting Compliance with Intellectual Property Rights (IPR) Disclosure Rules
Date de publication du RFC : Août 2012
Auteur(s) du RFC : T. Polk (National Institute of Standards and Technology), P. Saint-Andre (Cisco)
Pour information
Première rédaction de cet article le 21 août 2012
Les règles de l'IETF concernant la publication des brevets sur les techniques en cours de normalisation ont déjà été violées plusieurs fois, par exemple par RIM. Deux RFC viennent donc d'être publiés pour traiter ce problème : un répressif, le RFC 6701, qui dresse la liste des sanctions possibles contre les tricheurs. Et un préventif, ce RFC 6702, qui expose tous les mécanismes à mettre en œuvre pour encourager tout le monde à respecter les règles. Pour le résumer : la principale (voire unique) méthode envisagée est de rappeler les règles au bon moment, de façon à augmenter les chances qu'elles soient lues.
Que disent ces règles, au juste ? Formulées dans le RFC 8179 et répétées en ligne, elles imposent, en substance, qu'un participant à l'IETF qui connait des revendications de propriété intellectuelle (typiquement des brevets) sur une technique en cours de normalisation doit en informer l'IETF (cela se fait en ligne), qui publiera alors ces revendications. C'est tout. L'IETF n'impose que cette transparence, qui permet ensuite aux groupes de travail de prendre des décisions en toute connaissance de cause (RFC 2026, section 10.4). Le but est d'éviter les brevets sous-marins, où une entreprise fait normaliser une technologie sur laquelle elle a des brevets, qu'elle ne révèle qu'après la publication de la norme, lorsqu'il est trop tard pour chercher une alternative. Pas étonnant que cette obligation de divulgation déplaise aux maneuvriers de l'appropriation intellectuelle. Au moins deux tricheries ont été détectées, une de RIM et l'autre de Huawei (dans le RFC 6468). La seconde a été la goutte d'eau qui a fait déborder le buffer et mené à ces deux RFC qui essaient de redresser la barre. Ils ne définissent pas de nouvelles règles : les anciennes s'appliquent comme avant, ces deux nouveaux RFC disent juste comment le faire.
À noter que, comme l'ont montré l'analyse de ces deux cas, il s'agissait de tricheries délibérées. Mais il y a aussi eu des cas où la négligence ou l'ignorance ont fait que les brevets n'étaient pas annoncés à l'IETF, ou bien l'étaient en retard. Ces deux RFC vont aussi servir pour le cas où la violation des règles s'est faite de bonne foi. Car, même commis de bonne foi, ce manque de divulgation d'un brevet peut avoir des conséquences fâcheuses : un groupe de travail qui ne connaissait pas un brevet risque de négliger une piste alternative, non plombée par des brevets.
En pratique, les méthodes suggérées dans ce RFC concernent surtout les personnes ayant un rôle dirigeant à l'IETF (RFC 2418 et RFC 3669) : président de groupe de travail, directeur de zone (ceux qui forment l'IESG), etc. Ce sont ces personnes qui ont la responsabilité de faire avancer proprement le processus.
La section 3 du RFC décrit les stratégies disponibles. Il s'agit essentiellement de mieux informer les participants à l'IETF pour éviter toute inattention... ou toute fausse excuse. S'appuyant sur les conseils du RFC 3669, les responsables peuvent :
- Rappeler les règles lorsqu'un Internet-Draft va être présenté à une réunion (le président d'un groupe de travail peut refuser la discussion si le présentateur ne confirme pas que les divulgations nécessaires n'ont pas été faites),
- Rappeler les règles au moment où un Internet-Draft va être adopté par un groupe de travail,
- Rappeler les règles avant de lancer des demandes solennelles
comme le Working Group Last Call (le dernier tour
de table avant qu'un Internet-Draft ne soit
transmis par le groupe de travail à l'IESG) ou
l'IETF Last Call (les outils qui génèrent le
message envoyé à la liste
ietf-announce@ietf.orgincluent automatiquement un URL vers les divulgations de brevet pertinentes pour ce document), - Au moment où le document est transmis à un Directeur de Zone, pour examen, le texte standard inclus une question sur les divulgations de brevet.
L'idée est qu'on a plus de chance de capter l'attention des distraits si on envoie le rappel au moment où les auteurs travaillent activement sur le document, pour lui faire franchir une étape. Quant aux gens de mauvaise foi, ils auront moins de possibilités de faire croire à une erreur (« je n'avais pas vu le rappel »). Voici un exemple d'un appel à un IETF Last Call (pour le document « TCP Extensions for Multipath Operation with Multiple Addresses ») :
Date: Wed, 01 Aug 2012 09:43:18 -0700 From: The IESG <iesg-secretary@ietf.org> To: IETF-Announce <ietf-announce@ietf.org> Subject: Last Call: ... ... The IESG plans to make a decision in the next few weeks, and solicits final comments on this action. ... The following IPR Declarations may be related to this I-D: http://datatracker.ietf.org/ipr/1842/ http://datatracker.ietf.org/ipr/1843/
La même chose s'applique aux soumissions individuelles (section 4).
Un petit piège : les règles de divulgation précisent que la divulgation doit être tenue à jour. Par exemple, si un brevet qui avait simplement été déposé est accepté, le texte de la divulgation doit être modifié (section 6). Ne pas mettre à jour une divulgation est aussi sérieux que de ne pas en faire.
Si jamais vous accédez à des responsabilités à l'IETF et que vous avez à procéder vous-même à ces rappels, vous pourrez être aidé par l'annexe A de ce RFC, qui contient des messages-types qu'il n'y a qu'à copier-coller.
L'article seul
RFC 6698: The DNS-Based Authentication of Named Entities (DANE) Transport Layer Security (TLS) Protocol: TLSA
Date de publication du RFC : Août 2012
Auteur(s) du RFC : P. Hoffman (VPN Consortium), J. Schlyter (Kirei AB)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dane
Première rédaction de cet article le 19 août 2012
À chaque seconde, d'innombrables transactions sur
l'Internet sont protégées contre l'écoute et la
modification malveillante par le protocole
TLS. Ce dernier est capable de
chiffrer la session (pour la protéger contre
l'écoute par un tiers) et d'authentifier le pair avec qui
on parle (pour s'assurer qu'on n'est pas en train de communiquer avec
un usurpateur). Comment TLS authentifie t-il ? La méthode la plus
courante aujourd'hui est de se servir de
certificats X.509
vérifiés (en théorie) par une Autorité de
Certification. Ce mécanisme repose sur une confiance
aveugle dans de très nombreuses organisations, et a de nombreuses faiblesses,
comme on l'a vu en 2011 où le piratage de
plusieurs AC a permis à des attaquants d'obtenir de « vrais-faux »
certificats, y compris pour des organisations qui n'étaient pas
clientes des AC piratées. La démonstration étant ainsi faite que X.509
n'était pas digne de la confiance que certains lui accordent, il
restait à concevoir une meilleure solution. Rendue possible par le
déploiement de DNSSEC, voici
DANE (DNS-based Authentication of Named Entities) et ses enregistrements
DNS TLSA. DANE permet à
chacun de publier de manière sécurisés ses certificats, bouchant ainsi
les vulnérabilités de X.509, ou permettant même de s'en passer
complètement.
Avant de décrire DANE, il faut comprendre le fonctionnement de X.509, afin de voir pourquoi il ne garantit pas grand'chose en matière de sécurité. (La section 1 du RFC contient une description plus détaillée.) Un client qui se connecte à un serveur et qui craint, souvent à juste titre, que la session soit écoutée, voire modifiée par un attaquant situé sur le chemin, va utiliser le protocole TLS, normalisé dans le RFC 5246 pour chiffrer la session. (TLS est utilisé dans de nombreuses applications, la plus connue étant le HTTPS du RFC 2818, celui du petit cadenas dans le navigateur Web.) Ce chiffrement le protège contre l'écoute passive. Mais d'autres risques se cachent derrière. Si le client croit parler à une machine alors qu'en fait, par le biais de piratages portant sur DNS, BGP ou un autre protocole, il parle à la machine de l'attaquant, le chiffrement seul ne le protégera pas. Pour cette raison, TLS ajoute l'idée d'authentification. Le client peut vérifier que le serveur est bien ce qu'il prétend être (l'inverse, l'authentification du client par le serveur, existe aussi mais est plus rare).
Aujourd'hui, cette authentification se fait essentiellement via
X.509 (il existe d'autres voies, très
marginales, comme celle du RFC 6091). Le
principe de X.509 est le suivant. La clé
publique du serveur TLS est contenue dans un
certificat, contenant le nom du serveur, et signé par une autorité reconnue. En
vérifiant la signature, le client TLS peut s'assurer qu'il parle bien
à la machine souhaitée (on dit que TLS associe un
nom à une clé). Si un navigateur Web se connecte à
https://www.dns-oarc.net/, il doit recevoir un
certificat signé et comportant le nom
www.dns-oarc.net (la question du nom à indiquer
est très compliquée dans X.509, voir le RFC 6125). Notez qu'en fait, TLS utilise un sous-ensemble de
X.509, spécifié dans le RFC 5280 mais ce n'est
pas essentiel pour cette analyse.
Mais quelles sont les « autorités reconnues » ? La plupart du temps, elles ont été choisies et configurées par l'éditeur du logiciel utilisé. Si vous être adepte de Firefox, c'est la fondation Mozilla qui a décidé que les centaines d'autorités de certification (AC) que connait ce logiciel sont dignes de confiance.
Tout repose donc sur l'AC. Si une AC est malhonnête, ou bien a été piratée, elle peut émettre des vrais-faux certificats, qui tromperont l'utilisateur. Cette dépendance vis-à-vis d'un tiers est traditionnellement une des faiblesses les plus critiquées de X.509, d'autant plus que les dites AC, pressées par des considérations économiques, ne font pas toujours de gros efforts pour vérifier les titulaires de certificats.
Mais il y a pire. Rappelez-vous qu'il suffit à un certificat de comporter la signature d'une AC pour être accepté. Il n'y a pas de limites aux noms pour lesquelles les AC peuvent s'engager. Si l'AC DigiNotar est reconnue comme AC de confiance par un client TLS, elle peut signer des certificats pour n'importe quel nom, même si le nom est géré par une organisation qui a choisi une autre AC. C'est le problème le plus fondamental de X.509. Ce système, conçu par l'UIT, supposait que le monde se divisait en deux, une masse de clients payants et une oligarchie d'AC toutes parfaites. Ce modèle a éclaté devant la réalité des choses : les AC ne sont pas toutes parfaites. L'année 2011 a montré que cette vulnérabilité, connue depuis longtemps, n'était pas purement théorique. Le détournement de l'AC Comodo, puis le piratage de DigiNotar, au cours de l'opération Tulipe Noire, ont montré que les AC, non seulement étaient vulnérables mais que, en outre, les vrais-faux certificats marchaient bien. C'est ainsi que le gouvernement iranien a pu, suite à Tulipe Noire, obtenir de vrais-faux certificats pour Gmail (alors que Google n'était pas client de DigiNotar), lui permettant d'observer le trafic de ses citoyens.
Bon, tout cela est bien triste, mais comment DANE empêche t-il
cela ? Le principe est, plutôt que d'introduire un nouvel acteur, de
réutiliser une infrastructure existante, le
DNS avec des identificateurs existants, les
noms de domaine. Le certificat est publié dans le DNS et
signé avec DNSSEC (je
schématise : lisez plus loin pour une description complète) et le
client TLS peut alors le vérifier. Bien sûr, le piratage d'un
registre DNS (ou d'autres acteurs) permettra de
court-circuiter cette protection mais l'énorme avantage de cette
technique est qu'on n'a pas besoin de faire confiance à toute la
planète, seulement aux fournisseurs qu'on a choisi (et desquels on
dépendait déjà). Ainsi, si on
décide de fonder son identité en ligne sur un
.com, on dépend de la
sécurité de VeriSign mais seulement
de celle-ci. En cas de piratage ou de malhonnêteté de
VeriSign, seuls les .com seront affectés, les
gens qui ont un .fr (par
exemple) ne seront pas touchés.
Cette idée avait été documentée dans le RFC 6394, premier RFC du groupe de travail DANE, créé à la fois en
raison des faiblesses manifestes de X.509, et parce que le déploiement
de DNSSEC rendait réaliste une solution
alternative. Le protocole DANE réalise le cahier des charges du RFC 6394 et crée pour cela un nouveau type
d'enregistrement DNS, TLSA (ne cherchez pas une
signification à ce sigle, il n'en a officiellement pas). Tel
qu'actuellement normalisé, DANE couvre les besoins de
HTTPS mais, pour des protocoles avec une
indirection dans le DNS (comme les MX du RFC 5321 ou les
SRV du RFC 6120), c'est plus compliqué et il faudra attendre de
futurs RFC pour adapter les TLSA à ces cas.
Notez que d'autres protocoles peuvent aussi mettre leurs clés dans le DNS comme SSH avec le RFC 4255 et IPsec avec le RFC 4025.
À noter que notre RFC demande que les enregistrements DANE/TLSA soient protégés par DNSSEC mais ne précise pas comment le client le vérifie. Il existe plusieurs façons de déployer DNSSEC et notre RFC préfère ne pas trancher prématurément.
Bien, maintenant, place à DANE lui-même. Le cœur de ce
protocole est le nouveau type d'enregistrement DNS
TLSA, présenté en section 2. Il a le type 52
dans le registre IANA (cf. section 7).
Un enregistrement TLSA comprend :
- un champ « Utilisation du certificat » (Certificate usage),
- un champ « Sélecteur » (Selector),
- un champ « Méthode de correspondance » (Matching type),
- un champ « Données » (Data).
Le premier, « Utilisation du certificat », voit ses valeurs possibles enregistrées dans un nouveau registre IANA (voir aussi la section 7). On pourra ainsi ajouter de nouvelles utilisations sans modifier ce RFC. Pour l'instant, sont définies les valeurs numériques :
- 0 : l'enregistrement
TLSAest alors utilisé comme « contrainte sur l'AC ». Il spécifie un certificat qui doit être présent dans la chaîne des certificats utilisés pour la validation X.509. Il vient donc en complément de X.509. Son rôle est de lutter contre des attaques par une AC qui n'est pas celle choisie. Si on est client de GeoTrust, on peut mettre le certificat de l'AC GeoTrust dans l'enregistrementTLSAet, ainsi, un vrai/faux certificat émis par Comodo ou DigiNotar sera refusé. L'utilisation 0 est la plus traditionnelle, sans remplacer X.509 et bouchant simplement sa principale vulnérabilité. Attention si vous changez d'AC, il faudra quand même penser à mettre à jour vos enregistrementsTLSA. - 1 : l'enregistrement
TLSAindique le certificat du serveur TLS (qui devra toujours, comme dans l'utilisation 0, être validé selon les règles du RFC 5280). Il s'agit d'une « contrainte sur le certificat » et plus seulement sur l'AC. Il permet donc de se protéger contre une attaque par sa propre AC. Si elle décide d'émettre un nouveau certificat sans vous prévenir, il ne sera pas accepté. Attention en pratique, on change de certificats plus souvent que d'AC et il ne faut pas oublier de mettre à jour leTLSA. - 2 : cette fois, on quitte les rivages de X.509. Un certificat ainsi publié n'a plus besoin de passer la validation X.509 ou, plus exactement, la validation ne se fait que via l'AC qui détient ce certificat. Il s'agit donc de déclarer dans le DNS une nouvelle AC, en ignorant les AC pré-définies du client TLS. Un exemple typique est le cas d'une organisation qui est sa propre AC et émet ses propres certificats. Elle peut ainsi les voir acceptés automatiquement, sans payer une AC extérieure dont la fiabilité est douteuse.
- 3 : comme l'utilisation 2, on se passe de l'infrastructure des AC traditionnelles, et on déclare dans le DNS, non pas une AC à soi comme dans l'utilisation 2, mais un certificat. C'est l'équivalent des certificats auto-signés mais avec cette fois une preuve de validité, offerte par DNSSEC.
Depuis le RFC 7218, il y a également des mnémoniques standards pour ces valeurs, ainsi que celles des deux champs suivants.
Le sélecteur, quant à lui, fait également l'objet d'un registre IANA. Actuellement, il compte deux valeurs numériques. D'autres pourront être ajoutées, sous la seule obligation d'une spécification écrite et stable :
- 0 : l'enregistrement
TLSAcontient (dans son champ « Données ») le certificat complet. - 1 : l'enregistrement
TLSAne contient que la clé publique, omettant le reste du certificat.
Et la méthode de correspondance ? Voici un nouveau registre IANA, et ses valeurs :
- 0 : la valeur dans le champ « Données » de l'enregistrement
TLSAest la valeur exacte, à comparer bit à bit avec celle récupérée dans la session TLS. - 1 : la valeur dans le champ « Données » de l'enregistrement
TLSAest le condensat SHA-256 de celle récupérée dans la session TLS. - 2 : idem, avec SHA-512.
Enfin, le champ de données contient, selon la valeur des autres champs, le certificat ou la clé publique, éventuellement condensées.
Voici des exemples d'enregistrement TLSA au
format de présentation standard :
; Utilisation 0 (contrainte sur l'AC)
; Les données sont le condensat du certificat
_443._tcp.www.example.com. IN TLSA (
0 0 1 d2abde240d7cd3ee6b4b28c54df034b9
7983a1d16e8a410e4561cb106618e971 )
; Utilisation 1 (contrainte sur le certificat)
; Les données sont le condensat de la clé publique
_443._tcp.www.example.com. IN TLSA (
1 1 2 92003ba34942dc74152e2f2c408d29ec
a5a520e7f2e06bb944f4dca346baf63c
1b177615d466f6c4b71c216a50292bd5
8c9ebdd2f74e38fe51ffd48c43326cbc )
; Utilisation 3 (déclaration d'un certificat local)
; Le certificat entier (abrégé ici) est dans les données
_443._tcp.www.example.com. IN TLSA (
3 0 0 30820307308201efa003020102020... )
Mais quel est ce nom bizarre dans les enregistrements,
_443._tcp.www.example.com ? Décrit en section 3,
le nom de domaine des enregistrements TLSA est
la concaténation du numéro de port d'écoute du
serveur TLS, du
protocole (TCP, SCTP,
etc) et du nom du serveur TLS. Ici, les enregistrements
TLSA concernaient un serveur TLS
www.example.com écoutant en TCP
sur le port 443, donc, sans doute du HTTPS. Avec du
SMTP sur TLS, ce serait sans doute _25._tcp.mail.example.com.
À noter que cette convention de nommage est générique (pour tous les protocoles) mais qu'il est prévu que, dans le futur, d'autres conventions soient adoptées, par exemple pour des protocoles où la relation entre service et serveur est plus complexe que dans le cas d'HTTP.
Une fois ces enregistrements publiés, comment le client TLS les
utilise-t-il ? La section 4 décrit les règles à suivre. D'abord, le
client TLS doit demander les enregistrements TLSA
et vérifier s'ils sont utilisables :
- s'ils sont signés avec DNSSEC et valides, c'est bon,
- même signés correctement, si les enregistrements
TLSAcontiennent une utilisation, un sélecteur ou une méthode de correspondances inconnues, ils doivent être ignorés, - s'ils ne sont pas signés, ils doivent être ignorés (on ne peut
pas leur faire confiance), on se rabat sur du TLS classique. Même
chose si aucun des enregistrements
TLSAn'est utilisable, - s'ils sont signés et invalides, cela signifie qu'un gros problème est en cours, peut-être une tentative d'empoisonnement DNS. Le client TLS doit alors avorter sa connexion.
Le but de ces règles est de s'assurer qu'un attaquant ne peut pas
effectuer une attaque par repli, où il convaincrait le client qu'il
n'y a pas d'enregistrements TLSA (RFC 6394, section 4). DNSSEC
empêchera ce repli et DANE coupera alors la connexion TLS.
Pour les gens qui préfèrent le pseudo-code, les mêmes règles sont disponibles sous cette forme dans l'annexe B. Attention, c'est le texte de la section 4 qui est normatif, le pseudo-code n'étant là qu'à titre d'illustration. Par exemple, comme tous les pseudo-codes procéduraux, il « sur-spécifie » en indiquant un ordre d'évaluation qui n'est pas obligatoire.
Si le client TLS fait la validation DNSSEC lui-même (comme le permettent des
bibliothèques comme libunbound), rien de spécial à dire. Mais s'il confie
la validation à un résolveur externe (et se contente de tester que le
bit ad - Authentic Data - est
bien mis à un dans la réponse), il doit s'assurer que le chemin
avec ce résolveur est sûr : résolveur sur
localhost, ou bien communication avec le
résolveur sécurisée par TSIG (RFC 8945) ou
IPsec (RFC 6071). C'est
le problème dit de « la sécurité du dernier kilomètre ».
Comme vous voyez, le principe est très simple. Mais, comme souvent en sécurité, il y a plein de détails pièges derrière. La section 8 se consacre à l'examen de ces pièges. D'abord, DANE dépend de DNSSEC (RFC 4033). Si on n'a pas de DNSSEC, ou s'il est mal géré, tout s'écroule. Pas question d'envisager de déployer DANE avant d'avoir une configuration DNSSEC solide. (Au début du groupe de travail DANE à l'IETF, il était prévu que DNSSEC soit facultatif pour des utilisations comme 0 et 1, où DANE ne vient qu'en addition de X.509. Techniquement, ça se tenait mais cela compliquait l'analyse de sécurité, et les messages à faire passer. Donc, désormais, DNSSEC est obligatoire et on ne discute pas !)
DANE dépendant du DNS, cela veut dire qu'un administrateur DNS qui
devient fou ou méchant peut changer les A,
AAAA et TLSA d'un serveur et
sans que cela soit détecté. Beaucoup d'AC émettant des certificats
juste après avoir vérifié un échange de
courrier, cela ne change donc pas grand'chose
par rapport à X.509.
Par contre, si jamais le mécanisme de sécurité pour changer les
TLSA était plus faible que celui pour changer les
A et AAAA, alors, là, il y
aurait un problème. La solution est simple : tous les enregistrements
DNS doivent avoir le même niveau de sécurité.
Les enregistrements TLSA d'utilisation 0 et 1
viennent en supplément de X.509. Leur analyse de sécurité est donc
relativement simple, ils ne peuvent pas affaiblir la sécurité qui
existe. En revanche, ceux d'utilisation 2 et 3 sont nouveaux : ils
peuvent permettre des choses qui n'existaient pas en X.509. Il faut
donc bien réfléchir à l'AC qu'on indique par un certificat
d'utilisation 2. En mettant son certificat dans un enregistrement
TLSA, on lui donne tous les droits.
Comment fait-on une révocation avec DANE ? Les TTL normaux du DNS s'appliquent mais, si un méchant fait de l'empoisonnement DNS, il pourra réinjecter de vieux enregistrements. La seule protection est donc la durée de validité des signatures DNSSEC : trop courte, elle peut entraîner des risques pour la résilience de la zone (signatures expirées alors qu'on n'a pas eu le temps de les refaire), trop longue, elle permet à un méchant de continuer à utiliser un certificat normalement révoqué (attaque par rejeu, voir l'article de Florian Maury).
Au fait, petit piège avec les TTL : si tous les serveurs résolveurs gèrent les TTL proprement, il est courant que le résultat d'une requête DNS soit gardé dans l'application sans tenir compte de ces TTL, ce qui peut être gênant pour des applications qui restent ouvertes longtemps (comme un navigateur Web). Un client DANE doit donc veiller à toujours obtenir ses données d'un résolveur (ou à gérer les TTL lui-même) pour ne pas risquer de se servir de vieilles données (section 8.2).
La section 8.1 compare DANE aux AC classiques. Un registre de noms
de domaines qui fait du DNSSEC a des responsabilités qui ressemblent
assez à celles d'une AC : distribuer la clé publique (qui doit être
toujours disponible) de manière authentifiée, garder la clé privée
vraiment secrète (par exemple dans des HSM),
avoir des plans prêts d'avance pour le cas d'une compromission de la
clé, etc. D'abord, une
évidence : les acteurs de l'industrie des noms de domaine
(registres,
registrars, hébergeurs DNS)
ne sont pas meilleurs (ou pires) que les AC X.509. Comme elles, ils
peuvent être incompétents ou malhonnêtes ou se faire pirater. On peut
même penser que certains de ces acteurs ont une culture sécurité faible
ou inexistante, très inférieure à celle de la pire AC. Mais la force
de DANE ne vient pas de ce que les acteurs du DNS seraient magiquement
meilleurs que ceux de X.509. Elle vient du fait qu'on choisit ses
fournisseurs. Avec X.509, c'est la sécurité de la plus mauvaise AC
qui compte puisque n'importe quelle AC peut émettre des certificats
pour n'importe qui (la faille énorme de X.509). Avec DANE+DNSSEC, on revient à un modèle plus
sérieux en matière de sécurité : il faut faire confiance à ses
fournisseurs, certes, mais au moins on les choisit. Un déploiement
correct de DANE implique donc une évaluation des acteurs qu'on a
choisi. Si on a un .com,
on dépend de la sécurité et de l'honnêteté de
VeriSign. En revanche, un piratage du registre
de .lu n'aura pas de
conséquence. Si on choisit à la place un
.lu, on dépend de la
sécurité et de l'honnêteté de Restena mais plus
de celle de VeriSign. Et ainsi
de suite. (Tout ceci est également vrai pour les autres techniques de
pubication de clés dans le DNS comme celles du RFC 4255.)
Le DNS étant hiérarchique, il faut ajouter à ses fournisseurs directement choisis, les registres situés « au dessus ». Ainsi, une compromission de la clé privée de la racine affecterait tous les domaines (avec X.509, c'est la compromission de n'importe laquelle des centaines d'AC qui aurait ce résultat), ce qui justifie les mesures coûteuses adoptées pour gérer la clé de la racine (meilleures que celles de la plupart des AC X.509).
Comme indiqué plus haut à propos de la sécurité du dernier kilomètre, un problème classique avec DNSSEC est le lien entre l'application cliente et le résolveur validant. Le RFC recommande (section 8.3), pour une sécurité correcte, que le résolveur soit sur la même machine (c'est très facile avec des logiciels comme dnssec-trigger). Aujourd'hui où le moindre téléphone sait jouer des films en haute résolution, le temps de calcul lié à la validation cryptographique n'est plus forcément un obstacle. La section A.3 revient en détail sur ce problème du dernier kilomètre.
Les gens qui aiment les problèmes opérationnels liront avec plaisir l'annexe A, qui rassemble plein de bons conseils sur le déploiement de DANE.
Maintenant, voyons les mises en œuvre existantes de DANE/TLSA. Il faut bien voir que ce mécanisme est encore récent. On ne trouve que peu d'enregistrements TLSA dans la nature, et aucun navigateur Web connu ne gère encore le TLSA standard (DANE ne nécessite par contre aucune modification du serveur Web, uniquement du client Web, et des serveurs DNS). Néanmoins, il existe plusieurs outils.
D'abord, côté DNS. BIND et NSD peuvent tous les deux être serveur maître pour une zone qui contient des enregistrements TLSA (nsd connait DANE/TLSA à partir de la version 3.2.11). Pour un serveur esclave, pas de problème, TLSA est juste un type d'enregistrement inconnu, que le serveur peut servir sans le comprendre. Pour valider ses zones DNS, l'excellent outil validns lit et vérifie le TLSA depuis juillet 2012.
D'accord, mais un être humain normal ne va pas fabriquer les enregistrements TLSA à la main. Et, même s'il le faisait, il serait souhaitable de vérifier leur cohérence avec le certificat présenté par le serveur HTTP. C'est le rôle de l'outil Swede. Il permet, par exemple, de créer l'enregistrement TLSA à partir du certificat actuellement distribué par le serveur HTTPS :
% ./swede create www.afnic.fr No certificate specified on the commandline, attempting to retrieve it from the server www.afnic.fr. Attempting to get certificate from 192.134.4.20 Got a certificate with Subject: /1.3.6.1.4.1.311.60.2.1.3=FR/1.3.6.1.4.1.311.60.2.1.2=Ile de France/1.3.6.1.4.1.311.60.2.1.1=MONTIGNY LE BRETONNEUX/businessCategory=Non-Commercial Entity/serialNumber=0002 414757567/C=FR/ST=Ile de France/postalCode=78180/L=Montigny Le Bretonneux/OU=AFNIC/O=AFNIC/CN=www.afnic.fr _443._tcp.www.afnic.fr. IN TYPE52 \# 35 010001ed8a70a9c8783777e463232ef343aa32f2bbd6aa0182e6a0fc929b64c8e06518 Attempting to get certificate from 2001:67c:2218:2::4:20 Got a certificate with Subject: /1.3.6.1.4.1.311.60.2.1.3=FR/1.3.6.1.4.1.311.60.2.1.2=Ile de France/1.3.6.1.4.1.311.60.2.1.1=MONTIGNY LE BRETONNEUX/businessCategory=Non-Commercial Entity/serialNumber=0002 414757567/C=FR/ST=Ile de France/postalCode=78180/L=Montigny Le Bretonneux/OU=AFNIC/O=AFNIC/CN=www.afnic.fr _443._tcp.www.afnic.fr. IN TYPE52 \# 35 010001ed8a70a9c8783777e463232ef343aa32f2bbd6aa0182e6a0fc929b64c8e06518
[Le certificat est le même, qu'on accède au serveur en
IPv4 ou en IPv6 mais
Swede ne le sait pas à l'avance, d'où les deux connexions.] Notez
aussi que Swede formatte l'enregistrement DNS comme un type inconnu,
ce qui permet de le charger dans n'importe quel serveur. Il ne reste
donc qu'à mettre le _443._tcp.www.afnic.fr. IN TYPE52 \# 35
010001ed8a70a9c8783777e463232ef343aa32f2bbd6aa0182e6a0fc929b64c8e06518
dans son fichier de zone.
Swede permet également de vérifier un enregistrement TLSA existant.
Maintenant, côté « divers », la bibliothèque NSS a un
patch pour faire du TLSA mais il semble ancien en
non maintenu : https://mattmccutchen.net/cryptid/#nss-dane.
L'outil sshfp, en dépit de son nom, fait aussi du TLSA. Il devrait être remplacé par hash-slinger.
Quelques petits trucs utiles, maintenant. Pour créer une clé à partir d'un certificat (afin d'utiliser le sélecteur 1), en Python, avec M2Crypto :
from M2Crypto import X509
cert = X509.load_cert('/path/to/cert')
print cert.get_pubkey().as_der()
print cert.get_pubkey().as_text()
Avec OpenSSL, pour un sélecteur 1 (uniquement la clé) openssl x509 -pubkey
-in ... | openssl rsa -pubin | head -n -1 | tail -n +2 | base64
-d doit marcher (ajouter sha512sum - à
la fin du tube pour condenser, méthode de
correspondance 2). Pour l'extraire d'un
serveur TLS existant :
% openssl s_client -showcerts -connect mattmccutchen.net:443 < /dev/null 2> /dev/null | \
openssl x509 -pubkey | openssl rsa -pubin | \
head -n -1 | tail -n +2 | base64 -d | sha256sum -
writing RSA key
62d5414cd1cc657e3d30ea5e6d0136e92306e725413c616a51cab4b852c70a1c -
On trouve aujourd'hui des enregistrements TLSA
dans de nombreux domaines. Voici quelques exemples avec le dig de BIND 9.9.1-P2 (sorti en juillet 2012). Notez
le bit ad mais rappelez-vous qu'on ne peut s'y
fier que si le résolveur est honnête et que la
liaison avec le résolveur est protégée (même machine, ou bien TSIG,
IPsec, tunnel TLS ou méthode équivalente) :
% dig TLSA _443._tcp.dane.rd.nic.fr ... ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 3, ADDITIONAL: 5 ... ;; ANSWER SECTION: _443._tcp.dane.rd.nic.fr. 1 IN TLSA 3 0 1 63C43B664AB2EC24E5F65BF6671EE1BE48E6F12660FEEF9D7BB1EDA7 7499EDC0 _443._tcp.dane.rd.nic.fr. 1 IN RRSIG TLSA 5 6 1 20120810085609 20120711085609 24765 dane.rd.nic.fr. FXClnltKo1ZBKSHjmflwcIUIT5bo8AibfZnJJCLqhufBs4UW8HFGcdXU Hys0znMOmsoJVbeoj2GTRaNr1CoMoy/RJRMczo7CP32o6Z0m4BQeOgDf FSiGEG2YUMbwbiVyAgAQhunv1QdqFxvU+uoKCXs0LMLe/SM/vz8oHSJP 2zc= ... % dig TLSA _5269._tcp.proxima.lp0.eu ... ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 4, AUTHORITY: 5, ADDITIONAL: 5 ... ;; ANSWER SECTION: _5269._tcp.proxima.lp0.eu. 10800 IN CNAME _tlsa.proxima.lp0.eu. _5269._tcp.proxima.lp0.eu. 10800 IN RRSIG CNAME 10 5 10800 20120920174820 20120718212409 42615 lp0.eu. GjhRHziHqL9OGkOVvuukyCt7wkD1VzUs5USbBgy3lHBUpfzcxydXFEMR VUiWRwmKDslIrM33tltjKax3jYA8anet8+TTqehoQJ72M37iN2nvx7zg 5JktVDBbYXkJtwzznFADVOT+6/2K243gGh5gjibogwLo9mzUer64jvIh VGWqFOG7HIP3/l2Ajg+x7q/Pe6PPB0n75Qtuu7e8zc13DA== _tlsa.proxima.lp0.eu. 3600 IN TLSA 3 1 2 490D884C778E9031D8F1BDFB4B6E7673418BAD66CB8115E36CED911E A612B688AE7CC1909BF23391574E41865E41A51E03ECBC18FA6125A5 A14C7D2BA5E0CFF3 _tlsa.proxima.lp0.eu. 3600 IN RRSIG TLSA 10 4 3600 20120920183558 20120719092413 42615 lp0.eu. t9xaSN+Owj41DrtKEeqJhwqcAGjLAfYF+PGjOuT32+hG8MI6XgSrXBmL +HaPXF6rgAdk1BoAkwLij4kpuPu50hIZ3tefTFduO2QU1S8YVEcMys4C FDFz70tGuhcBtyODLxMIWw1zgQGLD/i8dyQnNsllgtNkuJZVJVguAOAp Y35EjlFOXR9sYbvNJnCGcpxqNEZ3FjVmKVVnoOsW+irJwQ==
À noter la section A.2.1.1 pour l'utilisation des alias avec DANE, comme dans ce dernier cas.
% dig TLSA _443._tcp.ulthar.us ... ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 5, ADDITIONAL: 5 ... ;; ANSWER SECTION: _443._tcp.ulthar.us. 3600 IN TLSA 3 1 1 7EB3A92457701C1A99742E902337BAE786B656ABAF1B13DFE3616D09 90C4F4D8 _443._tcp.ulthar.us. 3600 IN RRSIG TLSA 8 4 3600 20120812104422 20120713104422 8550 ulthar.us. nqZ16HERJMQsAklddkhlU2r9TgHL0VUNxgtxmB5lKobI/1J+i66psClv 2hUWEN2EVudYVtViRF/b2b8JOl1ZmSoTVqxk0sF3LEr4UaUJMbO99SOB PiQjXKFI9XXoKyMz71zQiPSgFMos5dAxoKEhFTpAFJI2r3Jrl8QMvFmv +xo= ... % dig TLSA _443._tcp.nohats.ca ... ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 5, ADDITIONAL: 7 ... ;; ANSWER SECTION: _443._tcp.nohats.ca. 3600 IN TLSA 1 0 1 6BCFF9A283336DD1ED99A9C40427741B5658863BD54F0A876A2BC4BF 8D822112 _443._tcp.nohats.ca. 3600 IN RRSIG TLSA 8 4 3600 20120730210435 20120716182008 28758 nohats.ca. VrY1bsk9IEijZ7yu9jiWUhgY0nsWuJGm1nDWBRI0X1iULJrJE1ZaXCFM PaoY3txlkhqPNbUq3AymKdtKXq9dtUVHF5UQCWnEm29X1YoU5I/Z5in5 VplLx3yp9pib3f7TifgC4Jw0dmYwWCr6jH2tQ1ELFaV2eDN1Li5Wizuk 0M0=
On peut vérifier le TLSA avec
OpenSSL. Ici, sur
mattmccutchen.net :
% dig +short TLSA _443._tcp.mattmccutchen.net 3 0 1 F9A682126F2E90E080A3A621134523C6DE4475C632A00CF773E6C812 A321BB25
Utilisation 3 (donc le serveur TLS doit envoyer le certificat correspondant) avec sélection 0 (tout le certificat) condensation en SHA-256. Testons :
% openssl s_client -showcerts -connect mattmccutchen.net:443 < /dev/null 2> /dev/null | \
openssl x509 -outform der | sha256sum -
f9a682126f2e90e080a3a621134523c6de4475c632a00cf773e6c812a321bb25 -
Je n'ai pas encore trouvé de vrai enregistrement TLSA pour d'autres protocoles que HTTP. C'est logique, puisque ceux-ci impliquent en général une indirection et sont donc plus complexes.
Enfin, si vous voulez un serveur HTTPS où DANE ne va
pas marcher, rogue.nohats.ca
a un enregistrement TLSA délibérement incorrect.
Autres articles sur DANE/TLSA :
- Mon article à JRES 2011 (ancien, mais plus long et explique plus en détail les motivations pour DANE)
L'article seul
RFC 6673: Round-trip Packet Loss Metrics
Date de publication du RFC : Août 2012
Auteur(s) du RFC : A. Morton (AT&T Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 16 août 2012
Tiens, le groupe de travail ippm n'avait pas encore normalisé toutes les métriques possibles ? Il restait encore des indicateurs de performance et de qualité de service qui n'avaient pas de RFC. En voici une nouvelle, le taux de pertes de paquets sur un trajet aller-retour.
La plupart des applications ont besoin d'envoyer et de recevoir des
paquets. Un exemple typique est la connexion
TCP, qui requiert que le paquet
SYN du demandeur soit transmis dans un sens et le
SYN+ACK du demandé dans l'autre sens. Sans liaison
bidirectionnelle, pas de TCP. Le taux de pertes sur le trajet aller-retour est donc
certainement utile. Il est même déjà mis en œuvre dans le
protocole TWAMP (Two-way Active Measurement Protocol, RFC 5357) mais sans que la métrique correspondante n'ait été
définie proprement, selon les règles du RFC 2330. Notre RFC 6673 comble ce manque (le RFC 7680 définissait la métrique pour le taux de
pertes en aller-simple). Attention toutefois en interprétant le
résultat : si le taux de pertes aller-retour est plus significatif
pour l'utilisateur (plus proche de son problème), il est moins adapté
pour le diagnostic car il ne dit pas dans quel sens a eu lieu la perte.
Donc, maintenant, les détails. Suivant le principe du RFC 2330, la métrique est définie pour un certain
type de paquets (on n'aura pas forcément le même taux de pertes en
UDP et en TCP, par
exemple, surtout si l'opérateur viole la neutralité du réseau), le
« Type-P ». La section 3.2 donne la liste complète
des paramètres de la mesure. À noter le Tmax qui
indique le temps maximum pendant lequel on attend la réponse (un
paquet peut donc être marqué comme perdu alors qu'il est simplement
très en retard). À noter également que la métrique est définie en
termes booléens : 0, le paquet arrive, 1, il n'arrive pas.
Première définition (section 4),
Type-P-Round-trip-Loss. La source envoie un
paquet, la destination répond et la source reçoit la réponse. Si cette
réponse arrive avant Tmax, le résultat est 0
(succès) sinon 1 (échec). Naturellement, les problèmes habituels de
mesure se posent ici, dont les RFC 7680 et RFC 2681 ont déjà discuté. À noter que la destination doit répondre
« le plus vite possible » (une des grosses faiblesses de cette
métrique, qui ne dépend pas que du réseau mais également du
« réflecteur »). La section 4.4 discute plus en détail ce problème et
suggère que la destination réponde en moins d'une seconde, ce qui ne
devrait pas être trop difficile (cela suppose que
Tmax soit très supérieur à une seconde). Notez aussi que, en l'absence de réponse, on ne peut pas
savoir si le paquet a été perdu entre source et destination, ou bien
entre destination et source (ou, pourquoi pas, si la destination était
défaillante et n'a pas renvoyé le paquet).
Ça, c'était pour un seul paquet. Pour un ensemble de paquets, la
section 5 définit
Type-P-Round-trip-Loss-<Sample>-Stream. <Sample>
doit être remplacé par le type de la
distribution des paquets (RFC 3432). Deux exemples
typiques : une distribution de Poisson ou une
distribution périodique (où les paquets sont simplement envoyés à
intervalles réguliers, comme le fait la commande
ping, dont l'option -i
permet de choisir cet intervalle). Cette grandeur sera un tableau de
valeurs logiques, 0 pour le succès et 1 pour l'échec.
On pourra ensuite dériver de ce tableau des statistiques comme
Type-P-Round-trip-Loss-<Sample>-Ratio
(section 6), qui
est la moyenne du tableau (« X % des paquets
ont été perdus »). Notez que, sur des vrais réseaux de bonne qualité
(qui perdent peu de paquets),
il faudra envoyer des dizaines de milliers de paquets pour mesurer le
taux de pertes de manière significative.
Comment mesure-t-on en pratique ces grandeurs ? La section 8 donne quelques indications. Par exemple, il aura fallu configurer les deux machines pour envoyer et recevoir (pour la source) et réfléchir (pour la destination) les paquets du Type-P choisi (qui peut être ICMP, auquel toutes les machines TCP/IP doivent répondre, mais pas forcément). Le protocole TWAMP du RFC 5357 peut être utilisé pour cela. La machine de destination ne doit pas, autant que possible, être elle-même une cause de perte de paquets et doit donc avoir notamment des tampons suffisamment larges.
Il faut aussi se préoccuper de sécurité (section 9) : comme il
s'agit de mesures actives, il faut faire attention à ne pas écrouler
le réseau sous la charge (option -f de ping...)
Et, lorsqu'on mesure sur un vrai réseau, il faut se rappeler que des
décisions de l'opérateur (par exemple de prioritiser certains flux)
peuvent fausser la mesure (c'est une des raisons pour lesquelles il
est essentiel de publier le Type-P utilisé par
exemple « Ces tests ont été faits avec des paquets
TCP SYN, port de
destination 80 »).
Et les implémentations ? Le célèbre logiciel ping mesure et affiche un taux de pertes aller-retour, sans toutefois suivre rigoureusement la définition de notre RFC. Voici un exemple (la Freebox étant tombée en panne pendant la mesure, ce qui explique le taux élevé de 34 % de pertes) :
% ping -i 0.2 ns2.nic.fr ... --- ns2.nic.fr ping statistics --- 9085 packets transmitted, 5981 received, +128 errors, 34% packet loss, time 1843752ms rtt min/avg/max/mdev = 25.068/27.514/156.796/3.477 ms, pipe 3
ping est toutefois très limité : il n'utilise qu'un seul protocole, ICMP, qui peut être filtré ou limité en débit. Autrement, toutes les implémentations de TWAMP mesurent le taux de pertes aller-retour d'une manière compatible avec ce RFC. Même chose pour Cisco IP-SLA. L'auteur du RFC note que son employeur, AT&T, a mille points de mesure TWAMP, mille points IP-SLA et mesure ce taux de pertes cent mille fois par jour (chaque point mesure toutes les quinze minutes).
L'article seul
RFC 6690: CoRE Link Format
Date de publication du RFC : Août 2012
Auteur(s) du RFC : Z. Shelby (Sensinode)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF core
Première rédaction de cet article le 16 août 2012
Le contexte de ce nouveau RFC est celui des machines ayant peu de ressources, les environnements « contraints ». Les serveurs HTTP tournant sur ces machines ont besoin d'un moyen de faire connaître la liste des services qu'ils proposent. Ce RFC propose de le faire en distribuant en REST des fichiers d'un format spécifique (normalisé ici) listant ces services. Le format s'appuie sur les liens du RFC 8288.
Le groupe de travail IETF CoRE travaille pour ces pauvres machines contraintes, n'ayant parfois qu'un processeur 8-bits et peu de mémoire, connectées par des LowPAN (RFC 4919). Il se focalise sur les applications de machine à machine, où un programme parle à un autre (et pas à un humain, comme la plupart des serveurs Web).
Le problème spécifique traité par ce RFC est celui de la
découverte des services (typiquement représentés
par un URI) offerts par une
machine. Il n'y a pas d'humain dans la boucle, pour lire un mode
d'emploi ou une documentation. Et des interfaces statiques sont trop
rigides. L'idée de ce RFC est donc de mettre ces URI sous un format
standard, dans une ressource à l'URI bien connu,
/.well-known/core (les URI
.well-known sont normalisés dans le RFC 8615). La ressource en question (cela peut être
un fichier statique ou bien elle peut être construite à la demande)
est récupérée en HTTP (GET
/.well-known/core) ou bien avec le
protocole COAP (RFC 7252). Et le format est une
concrétisation du concept de lien décrit dans le RFC 8288.
Ainsi, un client CoRE pourra récupérer la liste des variables mesurées par un capteur, par exemple. C'est évidemment très limité par rapport à un moteur de recherche, mais c'est implémentable dans des machines même très limitées.
Le RFC 8288 décrivait un concept abstrait de
lien, pour lequel il peut y avoir plusieurs
sérialisations (liens <a> de
HTML, en-têtes HTTP,
liens Atom, etc). La sérialisation normalisée
ici est conçue pour être compacte et triviale à analyser
(rappelez-vous : machines contraintes), mais les mêmes données peuvent
également être servies par des protocoles et des formats plus
classiques, si on a aussi des clients plus puissants. Le format
compact de ce RFC est identifié par le type
application/link-format.
Chaque URI indique un service hébergé (section 2 du RFC). On les écrit entre chevrons. On peut les voir comme un lien « héberge » entre le serveur et le service (« ce serveur héberge - hosts - ce service »).
Voici un exemple de liens suivant ce format, adapté de la section 5 du RFC. Le serveur permet de contrôler des capteurs de température et de lumière. Il y a donc deux services :
</sensors/temp>;if="sensor",</sensors/light>;if="sensor"
Désolé de ne pas pouvoir vous montrer d'exemple réel mais une
recherche Google
inurl:".well-known/core" ne donne pas le résultat
attendu. Trop malin, Google décide d'ignorer ce qu'il prend pour de la ponctuation.
Les URI indiqués sont relatifs. Ils sont relatifs à un contexte qui est en général
l'endroit où on a obtenu la ressource
/.well-known/core.
Ces liens, comme vous avez vu dans les exemples plus haut, peuvent contenir des attributs (section 3 du RFC). Les attributs spécifiques à ce format sont :
rt(Resource type), qui identifie le service (c'est un identificateur formel, pas un texte lisible pour les humains). Pour prendre l'exemple d'un service de mesure de la température,rtpeut être une simple chaîne de caractères commeoutdoor-temperatureou bien un URI pointant vers une ontologie commehttp://sweet.jpl.nasa.gov/2.0/phys.owl#Temperature.if(Interface), qui indique l'URI par lequel on va interagir avec le service. Plusieurs services peuvent avoir la même interface (comme dans le premier exemple donné plus haut avec le capteur de température et celui de lumière). La valeur deifpeut être un URI pointant vers une description en WADL.sz(Size), qui indique la taille maximale de la ressource qu'on va récupérer, une information essentielle pour les machines contraintes ! Cette information peut être omise si elle est inférieure à la MTU. Un exemple serait</firmware/v2.1>;rt="firmware";sz=262144.
Les attributs standards des liens peuvent aussi être utilisés, comme
title (RFC 8288, section
5.4).
Voici pour la syntaxe du fichier (de la ressource) récupérée. Et
pour le récupérer, ce fichier (cette ressource) ? La section 4 revient
en détail sur le concept d'URI bien connu (normalisé dans le RFC 5785) et sur celui utilisé par CoRE,
/.well-known/core. Un point intéressant est la
possibilité de filtrer les requêtes (section 4.1). La syntaxe est définie par un
gabarit RFC 6570 :
/.well-known/core{?search*}. ce qui permet des
requêtes comme :
?href=/foo*, pour se limiter aux liens commençant par/foo,?foo=barpour se limiter aux liens ayant un attributfoodont la valeur estbar,?foo=*pour ne garder que les liens ayant un attributfoo(valeur quelconque).
Le serveur étant une machine contrainte, il a parfaitement le droit de
ne pas mettre en œuvre les filtres (dans la libcoap, présentée
plus loin, il y a une option de compilation
--without-query-filter pour supprimer les filtres
et réduire ainsi la taille du code). Le client doit donc être prêt à
récupérer plus que ce qu'il a demandé.
Si on prend cette ressource Core :
</sensors/temp>;rt="temperature-c";if="sensor",</sensors/light>;rt="light-lux";if="sensor"
Alors une requête HTTP GET
/.well-known/core?rt=light-lux renverra (si le serveur gère
les filtres) uniquement :
</sensors/light>;rt="light-lux";if="sensor"
Des questions de sécurité à garder en tête ? Non, pas trop, dit la
section 6, qui rappelle qu'un serveur est autorisé à donner des
informations différentes selon le client, et rappelle aussi que ne
pas mettre un URI dans
/.well-known/core n'apporte pas grand'chose,
question sécurité (un attaquant peut le deviner).
Enfin, en section 7, les nombreux enregistrements à l'IANA nécessaires :
coredans le registre des bien connus,hosts(« héberge ») dans le registre des types de liens,application/link-formatdans la liste des types MIME,- Et le tout nouveau registre
des paramètres CoRE, pour l'instant presque vide. Les nouvelles
valeurs seront enregistrées en suivant, dans le RFC 5226 les politiques « IETF review » s'ils
commençent par
core, et, pour les autres, selon la politique « Spécification nécessaire ».
Les implémentations de ce RFC semblent surtout se trouver dans les
bibliothèques COAP comme libcoap, bien que COAP
soit un protocole, pas un format. Voir le fichier
net.c de cette bibliothèque. Une liste se trouve
en
bas de l'article Wikipédia.
TinyOS semble avoir un client capable de
tester un /.well-known/core, voir http://docs.tinyos.net/tinywiki/index.php/CoAP. Par contre, je
n'ai pas trouvé de
validateur en ligne.
L'article seul
RFC 6691: TCP Options and MSS
Date de publication du RFC : Juillet 2012
Auteur(s) du RFC : D. Borman (Quantum Corporation)
Pour information
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 26 juillet 2012
Le protocole TCP a une option nommée MSS (Maximum Segment Size, RFC 793, section 3.1) qui indique la taille maximale des segments (les paquets, au niveau TCP) qu'on peut recevoir. Quelle valeur y indiquer ? Faut-il tenir compte des options IP et TCP, dont la taille est variable ? Ce RFC a depuis été intégré dans la norme TCP, le RFC 9293.
Le RFC 879 semblait répondre clairement : on ne compte que
le segment lui-même, pas les en-têtes IP ou TCP. Mais le reste du RFC 879 détaillait des exemples qui ne correspondaient pas à cette
règle. Donc le RFC 1122 (section 4.2.2.6 et l'annexe A de notre RFC,
pour l'historique) revenait là-dessus. En effet, les options IP
et TCP sont de taille variable et peuvent changer pendant une
connexion TCP. La MSS ne sera alors pas optimum. La MSS ne pouvant pas
facilement changer en cours de connexion (elle est normalement envoyée
avec le paquet SYN), il était nécessaire d'avoir une
meilleure règle pour sa détermination. Cela n'a pas empêché des
RFC ultérieurs comme le RFC 2385 de se prendre les pieds dans le tapis et de formuler
les règles incorrectes pour la prise en compte des options variables
(option d'authentification, dans le cas du RFC 2385).
Notre RFC 6691 réécrit donc la règle. La nouvelle (section 2) est « La MSS devrait être la MTU moins les en-têtes fixes d'IP et de TCP, sans les options de taille variable ». Notez le « fixes ». Si l'envoyeur des données met des options IP ou TCP, il doit donc diminuer la taille des données TCP, afin de respecter la MSS. Le but est d'éviter la fragmentation IP. Autrement, en-têtes fixes + options variables + MSS pouvaient dépasser la MTU, menant à la fragmentation.
L'en-tête fixe fait 20 octets en IPv4 et 40 en IPv6. L'en-tête TCP fixe est de 20 octets. Si la MTU est de 1500 octets (celle d'Ethernet), cela donnera une MSS de 1460 octets en IPv4 et 1440 en IPv6. Comme indiqué plus haut, si on rajoute des options IP (augmentant ainsi la taille de l'en-tête), on ne pourra pas envoyer 1460 (ou 1440) octets en TCP, il faudra se serrer (diminuer le nombre d'octets envoyés). C'est le comportement actuel de toutes les mises en œuvre de TCP, désormais officiellement documenté.
La règle est simple et bien exprimée. Le reste du RFC est consacrée à la justifier.
Pour résumer (section 4), il y a quatre choix possibles lorsque des options variables sont ajoutées à un paquet (comme l'option d'authentification du RFC 2385) :
- L'expéditeur des paquets a réduit le nombre d'octets pour faire de la place et la MSS transmise par son pair tenait déjà compte des options : le paquet sera trop court et n'utilisera donc pas le réseau de manière optimum.
- L'expéditeur des paquets a réduit le nombre d'octets pour faire de la place et la MSS transmise par son pair ne tenait pas compte des options (la règle recommandée par notre RFC) : le paquet est de la bonne taille.
- L'expéditeur des paquets n'a pas réduit le nombre d'octets pour faire de la place mais la MSS transmise par son pair tenait déjà compte des options : le paquet sera de la bonne taille.
- L'expéditeur des paquets n'a pas réduit le nombre d'octets pour faire de la place alors que la MSS transmise par son pair ne tenait pas compte des options : le cas le plus ennuyeux car le paquet sera trop long et devra être fragmenté.
Comme celui qui envoie des données ne sait pas si son pair a tenu compte des options ou pas, dans la MSS qu'il a indiquée, la seule solution sûre est donc, si on utilise les options, de décroître la quantité de données envoyées. (Rappelez-vous que seul l'envoyeur des données connait avec certitude les options utilisées. Le récepteur, qui avait indiqué dans l'option MSS la taille qu'il acceptait, ne sait pas s'il y aura des options variables.) Mais, si tout le monde fait cela, ajuster la MSS pour les options ne sert plus à rien. D'où la décision de notre RFC de ne pas tenir compte des options variables dans le calcul de la MSS.
La section 5 décrit d'ailleurs d'autres raisons derrière cette décision comme le fait qu'avec la nouvelle règle, la MSS peut être diminuée par la PMTUD. Par contre, elle ne peut pas être augmentée. Il vaut donc mieux ne pas la mettre trop bas, comme cela arriverait si on essayait de tenir compte des options variables. Elle traite aussi les cas de la compression ROHC (RFC 5795) et des « jumbogrammes » du RFC 2675.
L'article seul
Mon point de vue sur le rapport Bockel
Première rédaction de cet article le 21 juillet 2012
Dernière mise à jour le 23 juillet 2012
Le monde de la sécurité informatique, notamment les gens qui travaillent sur la sécurité de l'Internet, attendait avec intérêt la publication du rapport d'information n° 681 (2011-2012) de M. Jean-Marie BOCKEL, « La cyberdéfense : un enjeu mondial, une priorité nationale ». Il n'y a pas en France trop de documents stratégico-politiques sur les menaces liées à ce fameux « cyberespace ». Certains ont ricané de quelques maladresses du rapport mais il y a d'abord de sérieux problèmes de fond.
Donc, Jean-Marie Bockel a rédigé un rapport sénatorial et plein de professionnels de l'Internet qui, d'habitude se moquent complètement de ce que peut faire, dire ou penser le Sénat parlent de ce rapport. Il y a pourtant de grandes chances que, comme tant d'autres rapports parlementaires, il finisse simplement enterré sous la poussière. Est-ce une mauvaise chose ?
Pourtant, le sujet est important. Une grande partie des activités humaines, qu'elles soient de nature économiques, politiques, créatrices ou personnelles, ont migré sur l'Internet (le « cyberespace » comme il faut dire pour faire croire qu'on a lu Gibson). Très logiquement, les comportements négatifs se sont donc également retrouvés sur l'Internet, de la criminalité à la guerre en passant par l'escroquerie, la répression étatique, la censure et le mensonge. C'est tout à fait normal. La société interagit via les réseaux et les aspects les plus désagréables de la société également. Il n'y a pas de spécificité de l'Internet à ce sujet. Mais cela ne veut pas dire qu'il faut baisser les bras et accepter les risques liés à ces activités. Pas mal de gens sont donc occupés à combattre les criminels, en ligne comme ailleurs, à lutter pour maintenir le réseau en fonctionnement malgré les attaques, et à tout faire pour que les salauds et les parasites n'aient pas la partie trop facile. La sécurité dans l'Internet est donc un enjeu important (ça y est, je fais mon Manuel Valls) et il est normal d'y consacrer du temps, des efforts et de l'argent. En soi, un rapport parlementaire sur ce sujet, appelant à mobiliser davantage de ressources pour la sécurité et à la prendre plus au sérieux, est donc une bonne chose.
La plupart des commentaires sur le rapport Bockel se sont focalisés sur une proposition extrêmiste (interdire les routeurs chinois, j'y reviendrais), ou sur une formulation malheureuse (l'usage incorrect du terme hacker et le mélange hollywoodien que fait l'auteur). Personnellement, j'ai bien ri en apprenant dans le rapport que l'insécurité sur l'Internet était de la faute de Lisbeth Salander, qui représente un personnage de pirate trop sympathique (le rapporteur n'aurait pas dit cela s'il avait lu le livre de Larsson au lieu de voir une adaptation cinématographique très lissée). J'ai également pouffé en lisant que Flame était « vingt fois plus puissant que Stuxnet ». Comment mesure-t-on la puissance d'un malware ? En quelles unités ?
Mais il n'y a pas tant de bavures que cela, le texte a manifestement été relu par des gens compétents, on n'y trouve pas ces énormités qui font la joie des geeks quand ils lisent les rapports officiels. Le texte contient des informations intéressantes (par exemple l'étude de la situation chez les autres pays comme l'Allemagne), et le Sénat a au moins l'avantage de publier ses rapports sous des formats ouverts, permettant une lecture agréable même si on est attaché au logiciel libre (je l'ai lu sur une tablette, ce qui est très difficile avec la plupart des textes officiels).
Certaines recommandations de ce rapport vont d'ailleurs dans le bon sens et le principal regret sera qu'elles n'aillent pas assez loin. Bockel critique ainsi le scandaleux article 323-3-1 qui empêche d'étudier les failles de sécurité (distribuer un logiciel comme hping ou scapy est officiellement un délit en France), mais sans oser en réclamer franchement l'abolition.
De toute façon, comme je l'avais déjà dit lors d'une conférence récente, on ne demande pas au sénateur d'être geek. Non, le problème avec ce rapport est un ou plutôt plusieurs problèmes de fond.
Le premier et le plus grave : Bockel ne parle que des menaces contre l'État et contre les entreprises privées (« dans les quinze ans à venir, la multiplication des tentatives d'attaques menées par des acteurs non étatiques, pirates +informatiques, activistes ou organisations criminelles, est une certitude. Certaines d'entre elles pourront être de grande ampleur »). Or, comme l'a bien expliqué Schneier longtemps avant moi, les menaces les plus sérieuses aujourd'hui sont celles qui pèsent contre les citoyens. Ils sont menacés à la fois par les États (qui, démocratiques ou dictatoriaux, resserrent tous la vis de plus en plus contre l'Internet) et par les entreprises privées (collectes d'informations privées, atteintes à la liberté d'expression comme lorsqu'Amazon a coupé WikiLeaks, etc). Aujourd'hui, le gros problème en sécurité informatique, c'est de protéger les citoyens contre ces puissances. Faire un rapport aussi long et détaillé sur les menaces, sans mentionner une seule fois celles contre les citoyens, c'est avoir une vision très étroite... ou bien avoir un agenda politique qui n'est pas le mien. C'est ainsi que la rapport dit qu'il y a trois conceptions, « celle défendue par certains pays dits "libéraux", comme la Suède ou les Pays-Bas, qui sont très attachés à l'espace de liberté que représente l'Internet et hostiles à toute forme de réglementation du cyberespace », celle des dictatures et... celle de la France, qui « se situe dans une position médiane ». Si je comprends bien, elle a donc vocation à se tenir à mi-chemin entre les démocraties et les dictatures...
Par exemple, le rapport mentionne plusieurs fois la nécessité d'étendre les pouvoirs de l'ANSSI, qui initialement en avait très peu, mais ne parle pas une seule fois des risques associés à ces pouvoirs, ni des moyens de limiter ces risques. L'ANSSI, contrairement à toutes les organisations sociales inventées jusqu'à présent, serait-elle miraculeusement immunisée contre les tentations d'abus de pouvoir ?
La sécurité est malheureusement souvent utilisée comme argument pour restreindre les libertés. La sécurité informatique n'est pas différente des autres, de ce point de vue. C'est ainsi que le rapport Bockel, à propos du piratage de Bercy, note bien qu'il était dû à des courriers électroniques contenant le logiciel malveillant mais explique ensuite que, dans le cadre des mesures qui ont pu être imposées après ce piratage, « l'accès à Twitter a été supprimé ». Pourtant, Twitter n'était pour rien dans le piratage. Mais c'est un grand classique que de profiter d'une crise pour imposer des mesures impopulaires.
Alors, on va me dire qu'il est normal que ce rapport se concentre sur les risques pour l'État. C'est un rapport parlementaire, destiné à des politiques, il est normal qu'il parle de leurs problèmes, laissant ceux des citoyens à d'autres études. Sauf que le rapport Bockel ne parle pas que des risques pour l'État. Il est également très prolixe quand aux risques pour les entreprises privées et, là, il dérape sérieusement. Non seulement il ne mentionne jamais les risques que font courir ces entreprises aux citoyens, mais il propose beaucoup plus de mesures pour aider le secteur commercial privé que de mesures pour protéger l'État. Ainsi, le texte cité plus haut sur les « trois conceptions », précise la position de la France en disant qu'elle est favorable « à un minimum de régulation, par exemple pour protéger le droit d'auteur ». Ce droit n'a pourtant aucun rapport avec les cybermenaces. Mais on comprend cette mention quand on sait que « droit d'auteur » est, pour beaucoup de politiques, le terme codé pour « défense acharnée des intérêts des industries du divertissement, quelles que soient les évolutions sociales et politiques ». Ce ne sont donc plus les auteurs d'attaques par déni de service qui préoccupent le rapporteur du Sénat, ce sont les copies illégales des œuvres culturelles.
Ce choix de mettre les moyens de l'État au service de la défense d'intérêts privés apparaît à d'autres endroits. Ainsi, le rapport dit qu'il faut défendre « notre savoir-faire technologique comme nos parts de marché, dans la véritable guerre économique que nous connaissons aujourd'hui ». Plus d'intérêts nationaux menacés, uniquement du business.
Autre demande du rapport, que l'« ANSSI devrait ainsi être en mesure de répondre aux demandes des entreprises, en matière d'expertise, de conseils, d'assistance et d'offre de produits labellisés ». Un service public payé avec l'argent public se transformerait donc en SSII gratuite pour les entreprises.
Puisqu'on parle de business, c'est l'occasion de revenir sur la proposition qui a été la plus remarquée et la plus commentée dans le rapport, la proposition d'interdire les routeurs chinois (par exemple ceux de Huawei), accusés d'espionner les communications et de contenir du code permettant éventuellement de perturber les communications. D'abord, du point de vue technique, il faut rappeler qu'un routeur est un engin très complexe et qu'il n'est pas facile à auditer pour détecter d'éventuelles capacités néfastes. Mais c'est le cas de tous les routeurs. Le rapporteur sénatorial nous croit-il assez naïfs pour penser que les Cisco et les Juniper états-uniens n'ont pas exactement les mêmes capacités ? Comme les Huawei, ils ne font pas tourner du logiciel libre. On n'a pas le code source et le contrôle de leurs activités est donc encore plus complexe. (Note pour mes lecteurs techniciens : si on est sérieux en matière de sécurité, le fait d'utiliser du logiciel libre est une condition nécessaire. Mais elle n'est pas suffisante. Une porte dérobée peut être cachée à bien des endroits.)
Bockel oublie aussi, lorsqu'il cite les méchancetés dont sont capables les routeurs chinois, de rappeler que la France est un grand exportateur de technologies de surveillance et de contrôle, et qu'elle fournit les pires dictateurs comme le défunt Kadhafi, dont le système de contrôle de son peuple était mis en place par une société française, Amesys, filiale de Bull. Le fait que le rapporteur s'inquiète des capacités chinoises de DPI sans mentionner ces succès du commerce extérieur français peut permettre de douter de sa bonne foi. Ou bien cette proposition anti-chinoise était tout simplement du protectionnisme déguisé ?
Ce rapport porte aussi les marques d'une tendance très fréquente en cyber-sécurité : les discours alarmistes, non soutenus par des faits (ou par des chiffres donnés sans explications) et qui servent à justifier des augmentations de budget et de pouvoir. Ce discours cyber-guerre se retrouve dans des affirmations comme celle comme quoi Conficker aurait « perturbé le fonctionnement de plusieurs hôpitaux en France et dans le monde » (une histoire qui a souvent servi lors de rapports sur la cyber-sécurité mais dont les sources sont obscures).
Il faut savoir qu'il n'existe pas de statistiques fiables sur les attaques informatiques (une situation que le rapport Bockel dénonce à juste titre, et pour laquelle il propose entre autres des signalements obligatoires à l'ANSSI). Contrairement aux cambriolages ou aux accidents de la route, personne ne sait exactement ce qui se passe et les chiffres les plus impressionnants sont toujours issus de généraux en retraite reconvertis « consultants en cyber-sécurité » et qu'on peut certainement soupçonner de forcer le trait. C'est ainsi que le rapport Bockel dit « les administrations françaises, les entreprises ou les opérateurs font aujourd'hui l'objet de manière quotidienne de plusieurs millions de tentatives d'intrusion dans les systèmes d'information », chiffre complètement invérifiable (la source n'est pas nommée) et qui, de toute façon, n'a aucune valeur scientifique puisqu'il ne définit pas ce qu'est une tentative d'intrusion et que la méthodologie de mesure n'est pas indiquée. Quant on sait que certains responsables sécurité comptent chaque paquet IP rejeté par le parefeu comme étant une tentative d'intrusion, on voit qu'on peut devenir millionaire facilement.
Pour conclure, je voudrais aussi revenir sur la sécurité informatique en général. Cela fait de nombreuses années que des experts très compétents travaillent à l'améliorer. Les résultats ne sont pas spectaculaires, en bonne partie parce que le problème est humain et pas technique. Le rapport Bockel se contente de reprendre le discours ultra-classique comme quoi c'est de la faute de l'utilisateur (il choisit des mauvais mots de passe, il clique sur les liens marqués « agrandissez votre pénis », etc). Ce n'est pas faux. Mais, en 2012, on pourrait enfin chercher à aller plus loin. Pourquoi est-ce le cas ? Pourquoi les utilisateurs préfèrent-ils accomplir leur travail plutôt que de suivre les règles de sécurité ? Pourquoi les sénateurs continuent-ils à utiliser toutes les choses que leur rapport dénonce, les logiciels non sécurisés, le nuage qui est si pratique, les smartphones et tablettes qui sont si jolis et si prestigieux ? Tant qu'on se contente d'incantations (« il faudrait que les utilisateurs fassent plus attention »), on ne risque pas d'améliorer la sécurité.
Sans compter les conseils idiots. Le rapport Bockel propose parmi « Les 10 commandements de la sécurité sur l'internet » : « tu vérifieras l'expéditeur des mails que tu reçois ». Ah bon, Jean-Marie Bockel utilise PGP ? Et comment « vérifie » t-il sinon ? Il regarde l'adresse et, plus fort que Chuck Norris, il voit si elle est fausse ? Si on reste à des slogans creux comme ces absurdes « dix commandements », on en sera encore là pour le prochain rapport parlementaire, en 2016 ou 2019.
Quelques lectures sur ce rapport :
- « Tu t'es vu quand tu parles des pirates chinois ? », sur la naissance du thème du hacker chinois,
- « Rapport Bockel : un point sur la cyberdéfense française », qui revient notamment sur l'espionnage fait par les firmes françaises,
- « Espionnage d'Internet : des firmes chinoises bientôt bannies du marché français ? », sur le cas des routeurs chinois.
- « Les hackers ont enfin fait cracker le sénat » sur une autre proposition du rapport, dont je n'ai pas parlé, celle d'embaucher des « hackers » (terme utilisé n'importe comment dans le rapport Bockel) à l'ANSSI,
- « Vers une super-ANSSI ? », article qui critique la tonalité caricaturalement pro-ANSSI du rapport,
- « Bockel au pays de l'ANSSI... », qui fait notamment remarquer qu'on ne peut pas isoler l'informatique de l'État. De même qu'un manque d'hygiène dans les quartiers pauvres d'une ville va favoriser des épidémies qui toucheront aussi les quartiers riches, la mauvaise sécurité de tant de machines non-étatiques va permettre la constitution de puissants botnets qui pourront alors représenter une menace pour la sécurité nationale,
- « Puisqu'il faut bien en parler ... », très critique notamment sur le gaspillage d'argent public que représente en général les aides de l'État au privé « À peu près tous les financements publics alloués à des entreprises dites "innovantes" se sont avérés être du détournement de fonds » et « Toute politique industrielle qui se résume à verser un gros chèque après le montage d'un dossier kafkaïen ne peut se terminer que dans la corruption et le détournement », phrases qui décrivent bien le système de copinage français et avec lesquelles je suis entièrement d'accord. Constructive, cette critique se termine par plusieurs recommandations. Je suis d'accord avec la plupart mais je trouve curieux que, comme le rapport Bockel, il propose que l'ANSSI aide gratuitement les entreprises (proposition 3). La suggestion d'un statut officiel de l'expert en sécurité (proposition 7) m'inquiète également, lorsque je vois les compétences de certains experts pourtant munis de tous les papiers.
L'article seul
RFC 6686: Resolution of The SPF and Sender ID Experiments
Date de publication du RFC : Juillet 2012
Auteur(s) du RFC : M. Kucherawy (Cloudmark)
Pour information
Réalisé dans le cadre du groupe de travail IETF spfbis
Première rédaction de cet article le 21 juillet 2012
L'IETF avait créé en 2004 un groupe de travail nommé MARID, qui avait pour tâche de normaliser un mécanisme d'authentification faible du courrier électronique par le biais de la publication dans le DNS des serveurs autorisés à envoyer du courrier pour un domaine. Deux propositions étaient sur la table, SPF et Sender ID. Microsoft avait pratiqué une intense obstruction contre SPF, pour promouvoir sa propre solution, Sender ID. En 2006, l'IETF avait cédé devant cette obstruction, en renonçant à normaliser SPF, déjà très répandu, et en publiant les deux protocoles avec le statut Expérimental : RFC 4408 pour SPF et RFC 4406 pour Sender ID. Cette solution peu courageuse avait été contestée, notamment pour le risque que la coexistence de deux protocoles incompatibles faisait peser sur la bonne délivrance du courrier. Officiellement, la retraite de l'IETF devait être provisoire : une période de deux ans d'observation était prévue, suite à laquelle des conclusions pourraient être tirées sur l'expérience. En fait, c'est seulement six ans après qu'est publié notre RFC 6686 qui conclut enfin officiellement que Sender ID est un échec total et que seul SPF est déployé et utilisé.
Le groupe de travail spfbis avait été constitué en février 2012 pour documenter les preuves du déploiement de SPF et pour réviser la spécification. Ce document est son premier RFC, et il n'a pas été facile à produire, tant les controverses étaient vives. D'une certaine façon, c'est la création de ce groupe qui avait marqué le choix définitif en faveur de SPF. Mais, en 2006, le consensus n'était pas évident, notamment face à l'opposition acharnée de Microsoft, qui tenait à pousser sa solution. Il était pourtant déjà clair à l'époque que SPF était largement déployé et que Sender ID n'était pas utilisé, même par les services appartenant à Microsoft comme Hotmail. Mais la politique politicienne l'avait emporté et l'IETF avait donc fait semblant de traiter les deux protocoles sur un pied d'égalité.
Avantage de ce délai : il a permis de récolter beaucoup plus d'informations pratiques. C'est l'une des forces de ce RFC 6686 que de présenter de nombreuses données issues de plusieurs campagnes de mesure.
Notez aussi que ce RFC ne fait pas de comparaison technique des deux protocoles. Il considère que le choix a déjà été fait par la communauté et il se contente donc d'observer ce qui tourne réellement dans la nature.
Avant les chiffres, qui constituent l'essentiel de ce document, un
petit rappel : le RFC 4408 introduisait un
nouveau type de données DNS, le type
SPF (code 99). Historiquement, SPF utilisait le
type générique TXT (code 16) et le nouveau type
SPF avait été ajouté alors que le déploiement
était déjà largement commencé. Une question secondaire à laquelle
notre RFC répond est donc « pour ceux qui utilisent SPF, avec quel
type DNS ? ».
La section 3, le cœur de notre RFC, présente donc les
résultats de différentes mesures. D'abord, trois séries de mesures
actives (faites en interrogeant le DNS sur son contenu, comme peut le
faire un logiciel comme DNSdelve) ont mesuré le
pourcentage de domaines qui publiaient des enregistrements SPF
(commençant par v=spf1) ou
Sender ID (commençant par spf2.0/, oui, Microsoft
était allé jusqu'à détourner le terme « SPF » pour brouiller davantage
la discussion ; il était prévu de critiquer ce point dans le RFC mais
le texte a dû être retiré pour ne fâcher personne).
La première étude avait été faite par Cisco à partir du million de domaines les plus populaires sur le Web selon Alexa. 39,8 % ont un enregistrement TXT d'authentification du courrier électronique. Seuls 1,3 % de ces enregistrements sont pour Sender ID.
La deuxième étude a été faite par le Trusted Domain Project, en utilisant comme liste de domaines des extraits des journaux de leurs serveurs de messagerie. Elle trouve 56,4 % de TXT d'authentification du courrier (dont 4,6 % pour Sender ID). Cette étude a également observé que certains serveurs DNS cassés répondent pour une demande de type TXT mais pas pour une demande de type SPF (ce point est couvert plus en détail par la suite, dans l'annexe A).
La troisième étude a été faite par Hotmail, à partir des domaines qui leur envoient du courrier. 46,2 % de TXT avec authentification. Hotmail, filiale de Microsoft, n'a pas publié le pourcentage de Sender ID parmi eux.
En étudiant le contenu de la zone
.fr (non mentionnée dans
le RFC, étude faite à l'AFNIC avec le logiciel
DNSdelve), on trouve
20 % de domaines ayant un enregistrement SPF. Et aucun avec Sender ID...
(la mesure a été faite en échantillonant la zone donc une poignée de
domaines ayant Sender ID a pu échapper à la mesure). 70 % de ces
domaines SPF sont dus à un seul hébergeur de courrier. À noter que
cette étude n'a pas fait de différence entre les enregistrements DNS
TXT et SPF.
Ces trois études portaient sur les enregistrements dans le DNS. Et pour les requêtes DNS, que voit-on ? Des mesures passives ont été faites (mais le RFC ne contient guère de détails), montrant très peu de requêtes de type SPF (99) et depuis un très petit nombre d'acteurs. À noter qu'on ne peut en général pas savoir, en envoyant ou en recevant du courrier, si le pair SMTP utilise SPF et/ou Sender ID.
Le serveur de noms de
.fr
d.nic.fr voit, sur ses différentes instances
anycast, 0,7 % de requêtes
TXT, et 0,1 % de requêtes SPF (données analysées
par DNSmezzo). SPF
est quand même loin devant un type comme NAPTR
mais il est nettement dominé par TXT (toutes les
requêtes TXT ne sont pas forcément pour SPF). L'abandon du type DNS SPF a ensuite
été repris dans la nouvelle norme SPF, le RFC 7208.
Reste la question des programmes qui mettent en œuvre SPF
et/ou Sender ID (section 3.2). L'offre logicielle pour Sender ID est
recensée en http://www.microsoft.com/mscorp/safety/technologies/senderid/support.mspx. Aucun
logiciel libre n'y est cité. Parmi les treize
opérateurs mentionnés, au moins un n'utilise plus Sender ID (la
dernière mise à jour date de 2007).
Celle de SPF est en http://www.openspf.net. Six
bibliothèques sont citées, vingt-deux
MTA (à la fois en logiciel libre et en
privateur), ainsi que des
patches pour les autres.
Il y a quand même un moyen de tester la présence de Sender ID dans
un MTA, via l'extension SMTP SUBMITTER (RFC 4405). Elle est utilisée pour optimiser
l'algorithme PRA du RFC 4407 en annonçant au
récepteur l'identité de l'expéditeur. Deux logiciels la mettent en
œuvre, Santronics WinServer et
McAfee MxLogic. Les journaux des fournisseurs
montrent qu'environ 11 % des sessions SMTP utilisent cette extension, mais
sans qu'on sache s'il s'agit d'un logiciel très répandu ou de
plusieurs logiciels moins populaires.
Le Trusted Domain Project a donc fait des mesures actives, se
connectant à de nombreux MTA pour leur demander les extensions qu'ils
géraient. 4,7 % annonçaient l'extension SUBMITTER
et presque tous étaient du MxLogic.
Restait une question délicate à étudier : le refus de l'IETF de
trancher entre les deux propositions SPF et Sender ID laissait ouverte
la possibilité que ces deux protocoles donnent des résultats
différents pour un même message. Par exemple que l'un l'accepte et
que l'autre le refuse. Cela serait certainement gênant, l'acceptation
ou le rejet d'un message dépendant du choix technique fait par le
récepteur. D'abord, deux études par Hotmail et par Trusted Domain
Project ont montré que, dans environ 50 % des cas, le PRA (l'identité
utilisée par Sender ID, cf. RFC 4407) et le
MAIL FROM SMTP (l'identité utilisée par SPF) sont les
mêmes.
Ensuite, le Trusted Domain Project a analysé 150 000 messages reçus et abouti à la conclusion que, dans 95 % des cas, SPF et Sender ID auraient formé le même diagnostic (acceptation ou rejet). Une analyse analogue faite par Hotmail sur un échantillon plus large (des millions de messages) trouvait moins : 80 %.
Bon, en pratique, on a rarement vu de rapports comme quoi des ingénieurs système avaient été perturbés par les différences restantes.
La section 5 analyse tous ces résultats et synthétise :
- Les enregistrements DNS de type
SPF(99) n'ont pas été adoptés et des problèmes techniques à l'utilisation d'enregistrements d'un type « nouveau » demeurent. - Les enregistrements
TXTpubliés ne le sont que rarement pour Sender ID. - Il n'y a pas de données indiquant qu'en pratique, un des deux protocoles donnerait des résultats bien meilleurs qu'un autre.
- Les mises en œuvre de SPF sont plus nombreuses et bien
mieux mantenues. L'extension SMTP
SUBMITTERest rare.
En conclusion, la section 6 estime que :
- On a assez de données issues de l'expérience pour arriver à une conclusion.
- Le type d'enregistrement DNS numéro 99,
SPF, ne sert à rien. - Presque personne n'a déployé Sender ID,
- Au contraire de SPF, très répandu. Malgré son statut officiel « Expérimental », il est bien plus déployé que certains protocoles normalisés.
Le problème des types de données DNS, déjà
mentionné plusieurs fois ci-dessus, est traité en détail dans l'annexe
A. SPF avait été créé en dehors de l'IETF et ses concepteurs n'avaient
pas suivi la voie recommandée, qui consistait à utiliser un type
d'enregistrement DNS spécifique. Au lieu de cela, ils s'étaient servis
d'un type existant, et perçu comme généraliste, TXT (code 16). Il faut
dire qu'à l'époque (le RFC ne le dit pas franchement), obtenir un
nouveau type d'enregistrement DNS à l'IANA
était très difficile.
Lorsque SPF est arrivé à l'IETF, il y avait déjà une forte base
installée, et donc une grande difficulté à migrer vers un nouveau type
d'enregistrement. Ce nouveau type, SPF (code 99),
était accompagné lors de sa création d'un plan de migration, qui a été
un échec.
Plusieurs raisons à cet échec sont identifiées par notre RFC 6686 :
- Comme déjà signalé dans la section 3, des
pare-feux configurés avec les pieds par un
stagiaire refusent parfois les types DNS inconnus (donc le
SPF), en violation du RFC 3597, - Le DNS n'est pas composé que de serveurs de noms, il y a aussi tout un ensemble de logiciels autour (par exemple les interfaces Web de gestion du contenu des zones, ou bien les bases de données qui stockaient les zones) qui auraient dû être modifiés pour adopter le nouveau type,
- La base installée utilisait
TXTet ne voyait pas de raison impérative de migrer (« faire plus propre » n'est pas une raison impérative), - Le plan était lui-même erroné : permettant au serveur de ne publier qu'un seul des deux types, et au client de n'en demander qu'un seul, il faisait que deux logiciels parfaitement conformes au RFC pouvaient être dans l'impossibilité de communiquer.
Depuis, des choses ont changé. L'allocation de nouveaux types, très pénible, a été considérablement libéralisée par le RFC 6195, suivant les recommandations du RFC 5507. Mais le déploiement effectif des nouveaux types reste un problème difficile dans l'Internet d'aujourd'hui.
L'article seul
Le Raspberry Pi, un petit ordinateur pas cher
Première rédaction de cet article le 17 juillet 2012
Dernière mise à jour le 9 octobre 2012
Depuis les premières annonces, il a déjà généré beaucoup d'articles et de messages. Poussé par un marketing vigoureux, le Raspberry Pi commence à être livré, au compte-gouttes. Les premiers retours d'expérience apparaissent donc. Voici le mien.
Le Raspberry Pi est un ordinateur, de très petit format. Le modèle B que j'ai acheté a un processeur ARM v6 à l'intérieur d'un SoC Broadcom BCM2835, 256 Mo de RAM (attention, le processeur graphique en prend une bonne partie), et plusieurs connecteurs (HDMI, USB, Ethernet, etc). C'est donc un petit engin. Ne comptez pas compiler LibreOffice dessus.
Il est livré sans boîtier ce qui permet de tout voir mais empêche
de l'utiliser en déplacement (si vous cherchez un boîtier, regardez cette discussion sur StackExchange) : 
Commandé chez Farnell/Element14 (on peut aussi aller chez RS Online mais je n'ai pas testé), il m'a coûté 32 livres. C'est donc un des ordinateurs les moins chers du marché mais attention : pour atteindre ce prix, il est vraiment vendu « sec ». Il n'y a même pas d'alimentation (et, comme il n'a pas de batterie, il faut une en permanence). Il faut donc absolument prévoir un chargeur USB (pas un PC, un vrai chargeur, débitant suffisamment pour le Pi) et une carte SD (le seul espace de stockage du Pi). Il faut aussi, de préférence, un clavier USB et une télévision avec un câble HDMI. On peut se débrouiller sans, via le réseau mais si un problème se pose, déboguer en aveugle est pénible. Donc, profitez des délais de livraison très élevés pour rassembler des accessoires. Notez que le Pi est souvent utilisé par des passionnés d'électronique et que, lorsque vous signalerez un problème sur un forum, la première réponse sera souvent « tu as vérifié la tension à la sortie du chargeur ? » Donc, un voltmètre ne sera sans doute pas inutile non plus.
Tout est bien branché ?  Il faut aussi choisir un
système d'exploitation (aujourd'hui, seulement
les systèmes basés sur Linux) et le mettre sur la
carte SD. Parmi les images officielles,
j'ai testé Raspbian (fondé sur
Debian) et
Arch Linux (toutes les deux téléchargées en
BitTorrent). Ensuite, on copie les images sur
la carte SD avec dd (très bonnes explications en ligne). Attention en branchant la carte SD, l'emplacement est fragile et la carte sort facilement, empêchant le Pi d'y accéder.
Il faut aussi choisir un
système d'exploitation (aujourd'hui, seulement
les systèmes basés sur Linux) et le mettre sur la
carte SD. Parmi les images officielles,
j'ai testé Raspbian (fondé sur
Debian) et
Arch Linux (toutes les deux téléchargées en
BitTorrent). Ensuite, on copie les images sur
la carte SD avec dd (très bonnes explications en ligne). Attention en branchant la carte SD, l'emplacement est fragile et la carte sort facilement, empêchant le Pi d'y accéder.
Alors, allons-y, branchons le chargeur, le Pi démarre (pas de bouton
On/Off). On voit défiler les messages de démarrage traditionnels de
Linux sur la télé. Vous pouvez trouver ici
tous les messages de
démarrage. Il acquiert une adresse IP
par DHCP ou en
RA. L'image Raspbian officielle actuelle n'a pas
IPv6 par défaut, il faudra l'activer en éditant
/etc/modules pour ajouter
ipv6. Ensuite, on note que SSH est bien démarré :
% sudo nmap 192.168.2.38 Starting Nmap 5.00 ( http://nmap.org ) at 2012-07-06 22:26 CEST Interesting ports on 192.168.2.38: Not shown: 998 closed ports PORT STATE SERVICE 22/tcp open ssh 111/tcp open rpcbind MAC Address: B8:27:EB:BA:90:94 (Unknown) Nmap done: 1 IP address (1 host up) scanned in 0.42 seconds
On peut alors se connecter (la documentation de l'image utilisée indique le mot de passe). Une fois connecté en SSH, on peut admirer le résultat :
% uname -a Linux raspberrypi 3.1.9+ #90 Wed Apr 18 18:23:05 BST 2012 armv6l GNU/Linux % df -h Filesystem Size Used Avail Use% Mounted on tmpfs 94M 0 94M 0% /lib/init/rw udev 10M 136K 9.9M 2% /dev tmpfs 94M 0 94M 0% /dev/shm rootfs 1.6G 1.2G 298M 80% / /dev/mmcblk0p1 75M 28M 47M 37% /boot
Et s'il ne démarre pas ? Il faut consulter l'excellent guide de dépannage et examiner les LED qui vous renseignent sur les causes du problème.
L'image Arch Linux officielle a IPv6 et SSH
par défaut. Il me semble que l'image Arch Linux marche très
bien mais Arch Linux n'est pas prévu pour les débutants Unix. À noter que, par défaut, elle n'utilise que 128 Mo de mémoire (192 pour la Debian, soit le maximum car
le processeur graphique utilise le reste). Pour avoir plus, il faut copier le
fichier /boot/arm224_start.elf en
/boot/start.elf, et redémarrer, pour bénéficier de toute la mémoire (moins ce que garde le GPU.
À noter que le Raspberry Pi, toujours pour comprimer les coûts, n'a pas d'horloge stable. Au démarrage, il retourne au 1er janvier 1970. IL faut donc définir l'heure au démarrage, le plus simple étant de se synchroniser à un serveur NTP.
Bon, mais à part à taper uname et df, à quoi sert cet engin ? D'abord, un message important : si vous voulez une solution prête à l'emploi, allez voir ailleurs. Le Pi n'est pas un truc tout fait qu'on met en marche et qu'on utilise. C'est une plate-forme pour des expérimentations, du développement, de l'apprentissage (son faible coût permet de ne pas hésiter à bricoler). J'ai testé trois utilisations possibles :
- Programmation,
- Surveillance de réseau,
- Centre multimédia.
Pour le premier usage, l'intérêt du Pi est son faible coût, qui le rend accessible aux jeunes avec peu d'argent de poche, par exemple. Toutefois, si on a déjà un PC, le Pi n'apporte pas grand'chose en plus (pour les programmeurs en C, il est toutefois utile d'avoir une autre plate-forme matérielle, pour s'habituer à écrire du code portable). Et, si le Pi est le premier ordinateur qu'on a, il faut prévoir la télé, les câbles et le clavier (ce qui renchérit sérieusement le prix) et programmer en bloquant la télé familiale, ce qui sera peut-être peu apprécié. (Il faut aussi commander des cartes SD pré-remplies, ou bien les faire faire par un copain ayant un ordinateur.)
Le Pi a tous les logiciels Unix souhaitables, par exemple le
compilateur gcc. Pour travailler avec un
langage plus moderne, j'ai fait des essais en
Go. L'un des deux compilateurs Go existants,
gc, peut produire du code pour les processeurs
ARM. Attention, cela ne marche pas du premier
coup (illegal instruction dans
math/rand) pour des raisons expliquées dans la
documentation de Go. Bref, il faut ajouter la variable d'environnement
GOARM=5 avant de compiler et, cette fois, tout
marche.
Mais rappelez-vous que le Pi est lent : alors que gc compile quasiment toujours instantanément sur un PC de bureau normal, ici, les temps de compilation sont sensibles. Cela laisse le temps de réfléchir.
Autre utilisation possible du Pi : la surveillance de réseau. Là, pas besoin de clavier et d'écran, et la faible consommation électrique du Pi permet de le laisser branché en permanence, sans remords écologiques. L'ARM est un vrai processeur moderne, on peut faire tourner des gros programmes comme Icinga. Ce dernier compile sans problème et tourne ensuite, testant les services qu'on veut tester et signalant les problèmes via son interface Web ou par courrier. Cela me semble, pour l'instant, l'utilisation la plus prometteuse du Pi, dans mon cas. J'y ai consacré un article. (Voir aussi une discussion sur le fonctionnement du Pi 24h/24.)
Troisième utilisation que j'ai testé, le multimédia. Le Pi est,
malgré ses faibles capacités quantitatives, normalement capable de
toutes les activités multimédia modernes, grâce à son accélérateur
graphique. Oui, mais voilà, peu de logiciels savent l'utiliser. C'est
en grande partie pour des raisons légales (il faut signer un
NDA avec Broadcom pour
avoir la documentation du GPU). Ainsi,
si on lance X11 (startx), puis
MPlayer sur une vidéo, on voit bien son film
mais sans son et avec un débit irrégulier. (On peut apparemment lancer
MPlayer sans X11 avec un truc comme mplayer -vo sdl -ao sdl
-framedrop -lavdopts lowres=1 mais je n'ai pas testé.) Un
témoignage typique trouvé sur le réseau donne une idée des difficultés
pratiques : « I googled, followed advice and loaded the
snd_bcm2835 kernel module. Sound now worked on the 3.5 mini jack
output, but not on the TV yet. And mplayer had completely stopped
playing video. It wasn't before I had added the line hdmi_drive=2 to
my /boot/config.txt file (see the Troubleshooting page) that I could
actually hear something on TV. But mplayer played the video even
slower. ». (Pour le concurrent de MPlayer,
vlc, voir cette
question sur StackExchange.)
Le conseil donné en général est donc d'utiliser un ensemble
logiciel complètement conçu pour le multimédia. Le plus souvent cité
est OpenELEC, que j'ai donc testé après Debian
et Arch Linux. OpenELEC est un système d'exploitation libre conçu pour faire
tourner un media center,
chargé de piloter son et image. Fondé sur
Linux, équipé du logiciel
XBMC, c'est encore assez expérimental, de mon
expérience (j'ai testé la version devel-20120704203304-r11493,
peut-être pas encore assez sèche, j'aurais peut-être dû rester à la
version 1, stable). L'installation, bien
documentée, se passe bien. Leur outil partitionne la carte SD
automatiquement (contrairement à ce qui se passe pour Debian et
Arch Linux, voir plus loin). Agacement : par défaut, lorsqu'on se
connecte en SSH, on récupère une invite avec
des couleurs inutilisables sur un fond blanc. Il faut se connecter
depuis un terminal avec fond noir pour voir quelque chose et ajouter
un ~/.profile (attention, pas un
.bash_quelquechose, le
shell n'est pas
bash) contenant :
PS1='\h \w \$ '
On se reconnecte et on peut voir quelque chose.
Il y a deux interfaces (en plus du shell SSH), une interface Web (très boguée, j'ai vite renoncé) et l'interface sur la télé, qui propose les menus classiques des media centers, accès aux vidéos, à des widgets comme la météo, etc. Les fichiers AVI et MP3 sont joués sans problème et avec une bonne qualité (connexion HDMI avec mon téléviseur Samsung).
Par contre, il y a trop de problèmes agaçants pour songer à remplacer les menus de ma Freebox par ceux de XBMC :
- Les transferts de fichier prennent un temps fou (carte Ethernet ou SD lente ? En tout cas, 3-4 Mb/s maximum, ce qui est peut-être dû au fait que la carte Ethernet se branche sur le bus USB ou tout simplement à la limite d'écriture des cartes SD), ce qui est gênant pour la vidéo. Avec ces performances, le Pi a du mal à prétendre être fait pour un media center. OpenELEC peut accéder à des fichiers sur le réseau local (partage Samba par exemple). Espérons que, la carte SD n'étant plus en jeu, ce soit plus rapide.
- Les vidéos WMV ne sont pas visibles (on a seulement le son),
- Je n'ai jamais trouvé le moyen de faire disparaître le menu quand je regarde un film,
- La molette de la souris USB n'est pas reconnue (ce qui est embêtant quand on a une liste de 500 MP3 sur l'écran),
- Afficher une image JPEG fige le logiciel (il faut faire un kill de XBMC).
Bref, comme je l'ai signalé, c'est une plate-forme de développement, pour l'instant, pas encore prête à l'emploi mais du travail intéressant en perspective pour les hackers.
À propos de hackers, ceux-ci sont en général très sensibles (et à juste titre) aux questions de liberté, notamment à celle de pouvoir faire tourner le logiciel de son choix et le modifier comme on veut. Le Raspeberry Pi est-il « libre » ? La question n'est pas simple mais on peut certainement dire qu'il est moins libre que son concurrent (concurrent dans l'esprit des gens : les deux plate-formes n'ont pas du tout les mêmes caractéristiques techniques) Arduino. Les plans de ce dernier sont tous publics alors que le Pi repose sur un circuit Broadcom dont l'interface externe n'est pas officiellement documentée. Je n'ai pas essayé l'Arduino (les modèles basés sur ce concept sont plus chers et plus difficiles à obtenir que le Pi).
Conscient de ce problème, les responsables de Raspberry Pi ont
annoncé
des ouvertures mais qui semblent très
insuffisantes. Conséquences pratiques de ce problème d'un matériel non
complètement ouvert : où est-on bloqué dans le bricolage sur le Pi ?
On peut apparemment compiler son propre noyau
(voir http://www.bootc.net/projects/raspberry-pi-kernel/
et http://elinux.org/RPi_Kernel_Compilation) mais je
ne sais pas si on ne doit pas inclure des éléments non-libres (ils
sont distribués en https://github.com/raspberrypi/firmware). Si
c'est le cas, et cela semble vraisemblable, porter, par exemple,
FreeBSD sur le Pi ne sera pas possible. (Il
existe au moins un
projet pour FreeBSD, avec des indications que ça
avance, et un autre
projet pour NetBSD.)
Enfin, un peu de technique avec un problème des images officielles
Debian et Arch Linux. Elles supposent une carte SD de 2 Go et incluent
donc une table de partition inadaptée. Le cas
est connu et
documenté. On peut réparer cela, soit après le démarrage du
système (parted ou cfdisk
pour adapter la table des partitions, puis redémarrer, puis formater
la nouvelle partition avec mke2fs, puis la monter), soit
au moment où on a écrit sur la carte SD (attention à ne pas lancer le
mke2fs sur une partition de son ordinateur, dans ce cas...). On peut aussi, au lieu de
créer une nouvelle partition sur l'espace libre, agrandir la partition
racine avec un coup de resize2fs /dev/mmcblk0p2.
Un avertissement, maintenant. Pour des raisons de coût, le Pi a été
très limité. Pas d'alimentation digne de ce nom, pas de mémoire avec
correction d'erreurs, etc. Cela veut dire que tout problème matériel
va se manifester par des bogues apparemment aléatoires. Ainsi, un
problème de tension peut apparemment entraîner
une corruption
des données. Un problème de RAM peut
faire planter le Pi aléatoirement. Enfin, les cartes
SD ne sont pas réputées pour
leur fiabilité. Bref, faites des sauvegardes. Un
moyen simple de copier la carte SD sur un PC Unix est dd
bs=1M if=/dev/sdb | gzip -9 > backup-pi-$(date
+"%Y-%m-%d").img.gz avec sdb à
remplacer par le nom du périphérique dans votre cas.
Voilà, une chose est sûre, le Pi vous permettra de passer des tas de soirées passionnantes, que ce soit pour un été pluvieux ou pour un hiver glacial, et de discuter avec plein d'autres bricoleurs. Quelques lectures :
- Avant d'acheter, une bonne comparaison des PC à bas prix (il y en a une autre sur StackExchange), et un article de PC Pro,
- Une interview du concepteur du matériel, très intéressante,
- Pour démarrer, une bonne introduction et une avec davantage de technique,
- Pour échanger avec d'autres passionnés, l'excellent site de Q&A StackExchange a une section sur le Raspberry Pi et on y discute même d'IPv6 sur le Pi,
- Le site officiel,
- Pour la vidéo, un article tentant,
- Je n'ai listé que trois usages possibles mais voici un article qui en cite dix,
- Utiliser un Raspberry Pi, un clavier externe et un Kindle comme écran, pour le voyage : KindleBerry Pi,
- Construire un supercalculateur avec plein de Raspberry Pi et du Lego, la page officielle et plein de jolies images,
- Le plus délirant de tous les projets, un cluster VMS sur des Raspberry Pi faisant tourner un émulateur Vax : « The MicroVAX 3900 hardware being emulated this time is a little more modern and somewhat smaller than the IBM 4381 processor, but the VAX architecture and OpenVMS operating system are no less impressive [...] »,
- Pour attaquer à un bas niveau, un logiciel pour mettre à jour le firmware (je ne l'ai pas testé),
L'article seul
dnspython, faire du DNS en Python
Première rédaction de cet article le 17 juillet 2012
Si on est programmeur, et qu'on veut interagir avec le DNS en Python, il existe plusieurs bibliothèques possibles (et, comme souvent en Python, de qualité variable et parfois médiocre, ce qui confusionne le nouveau programmeur qui ne sait pas à quelle bibliothèque se vouer). Mais dnspython est nettement la meilleure. Voici quelques informations de base sur cette bibliothèque.
Je vais faire un article que j'espère concret, donc on va commencer
tout de suite par un exemple. Supposons qu'on veuille récupérer le
MX de
google.com :
import dns.resolver
answers = dns.resolver.query('google.com', 'MX')
for rdata in answers:
print 'Host', rdata.exchange, 'has preference', rdata.preference
Et, si on l'utilise, on a bien le résultat attendu :
% python mx.py Host alt4.aspmx.l.google.com. has preference 50 Host alt3.aspmx.l.google.com. has preference 40 Host alt2.aspmx.l.google.com. has preference 30 Host aspmx-v4v6.l.google.com. has preference 10 Host alt1.aspmx.l.google.com. has preference 20
Ce programme utilise l'interface de haut niveau de dnspython
(dns.resolver). Elle est très simple à utiliser
mais ne permet pas de choisir toutes les options comme on veut. Il
existe aussi une interface de bas niveau, présentée plus loin.
En créant explicitement un objet Resolver
(dans le code ci-dessus, il était créé implicitement lors de l'appel à
query()), on
peut quand même configurer quelques options. Ici, on va faire de
l'EDNS pour récupérer les
DNSKEY de
.fr (la réponse fait près
de 1 500 octets, plus que la vieille limite de 512 du DNS d'autrefois) :
import dns.resolver
edns_size = 1500
myresolver = dns.resolver.Resolver()
myresolver.use_edns(0, 0, edns_size)
result = myresolver.query ('fr.', 'DNSKEY')
for item in result:
print item
Cela donne :
% python dnskey.py 257 3 8 AwEAAYz/bZVFyefKTiBBFW/aJcWX3IWH c8iI7Wi01mcZNHGC+w5EszmtHcsK/ggI u+V7lnJlHcamTNstxnSl4DAzN2Mgzux7 sqd7Jlqa+BtRoI9MO3l2yi+qE6WIViUS 0U3atm+l1SQsAgkyXlYBN52Up1jsVZ+F Nt+kKGKzvIMo8/qM3mCYxkLhazj+q4Bg 7bH+yNhHOaZ5KAiFO++8wZJK2rwrh2Yd 5LP+smStJoij42sYALLA9WPdeiSaoxpb jmpYBUQAoDUYdqLnRWOnQds0O1EO5h1P XGSIt9feZpwNbPzTfHL80q2SI1A7qRzf Z6BzA2jZU4BLCv2YhKCcWo3kfbU= 257 3 8 AwEAAc0RXL9OWfbNQj2ptM8KkzMxoHPO qPTy5GvIzQe3uVRfOXAgEQPIs4QzHS1K bQXq4UV8HxaRKjmg/0vfRkLweCXIrk7g Mn5l/P3SpQ9MyaC3IDmCZzTvtfC5F4Kp Zi2g7Kl9Btd+lJuQq+SJRTPDkgeEazOf syk95cm3+j0Sa6E8oNdPXbqyg5noq2WW PAhq3PYKBm062h5F5PCXRotYVoMiId3Z q37iIdnKmGuNbr9gBZD2stVP6B88NeuY N7yaY23RftkjCp5mw4v/GzjoRrYxzk5s YKNNYaN099ALn3Z2rVzuJqpPiOLH71dK pN+f/3YHmh4hhgImPM3ehlK0L8E= ...
La méthode use_edns nous a permis de dire qu'on
voulait de l'EDNS, version 0 (la seule actuelle ; et attention, c'est
-1 qu'il faudrait passer pour débrayer EDNS). Notez aussi le point
à la fin de fr, dnspython a du mal avec les noms
ne comportant qu'un seul composant, sauf s'ils sont terminés par un
point.
Notez enfin que les résultats sont, par défaut, affichés au format
dit « présentation » des fichiers de zone traditionnels (RFC 1035, section 5). Les enregistrements DNS ont
deux formats, un sur le
câble et un de présentation. dnspython sait lire ce format de
présentation, et l'écrire. Dans le programme précédent, on lisait
explicitement les champs de la réponse (exchange et preference). Ici, dans le second programme, on a affiché toute la réponse.
Au fait, que renvoie exactement query() ? Il
renvoie un dns.resolver.Answer qui est itérable
(donc on peut l'utiliser dans une boucle, comme dans les programmes
ci-dessus).
Et comment je sais tout cela ? Où l'ai-je appris ? dnspython a une documentation en ligne. On peut y apprendre les noms des champs du MX, les paramètres de query() ou encore la complexité du type Answer.
Si on veut afficher un type un peu complexe, mettons un
NAPTR, on doit donc lire
la documentation, on trouve les noms des champs et on peut
écrire un joli programme :
import dns.resolver
import sys
if len(sys.argv) <= 1:
raise Exception("Usage: %s domainname ..." % sys.argv[0])
for name in sys.argv[1:]:
answers = dns.resolver.query(name, 'NAPTR')
for rdata in answers:
print """
%s
Order: %i
Flags: %s
Regexp: %s
Replacement: %s
Service: %s
""" % (name, rdata.order, rdata.flags, rdata.regexp, rdata.replacement,
rdata.service)
Qui va nous donner :
% python naptr.py http.uri.arpa de.
http.uri.arpa
Order: 0
Flags:
Regexp: !^http://([^:/?#]*).*$!\1!i
Replacement: .
Service:
de.
Order: 100
Flags: s
Regexp:
Replacement: _iris-lwz._udp.de.
Service: DCHK1:iris.lwz
dnspython permet également de faire des transferts de zone (RFC 5936) :
import dns.query
import dns.zone
zone = dns.zone.from_xfr(dns.query.xfr('78.32.75.15', 'dnspython.org'))
names = zone.nodes.keys()
names.sort()
for name in names:
print zone[name].to_text(name)
L'adresse du serveur maître est ici en dur dans le code. La récupérer dynamiquement est laissé comme exercice :-)
Par défaut, l'objet Resolver a récupéré les
adresses IP des résolveurs à utiliser auprès du sytème
(/etc/resolv.conf sur
Unix). Ces adresses sont dans un tableau qu'on
peut modifier si on le désire. Ici, on affiche la liste des résolveurs :
import dns.resolver myresolver = dns.resolver.Resolver() print myresolver.nameservers
dnspython fournit également un grand nombre de fonctions de
manipulation des noms de domaine. Par exemple, pour trouver le nom
permettant les résolutions d'adresses IP en noms (requêtes
PTR), on a dns.reversename :
import dns.reversename
print dns.reversename.from_address("2001:db8:42::bad:dcaf")
print dns.reversename.from_address("192.0.2.35")
qui donne :
% python manip.py f.a.c.d.d.a.b.0.0.0.0.0.0.0.0.0.0.0.0.0.2.4.0.0.8.b.d.0.1.0.0.2.ip6.arpa. 35.2.0.192.in-addr.arpa.
Pour analyser des composants d'un nom de domaine, on a dns.name :
import dns.name parent = 'afnic.fr' child = 'www.afnic.fr' other = 'www.gouv.fr' p = dns.name.from_text(parent) c = dns.name.from_text(child) o = dns.name.from_text(other) print "%s is a subdomain of %s: %s" % (c, p, c.is_subdomain(p)) print "%s is a parent domain of %s: %s" % (c, p, c.is_superdomain(p)) print "%s is a subdomain of %s: %s" % (o, p, o.is_subdomain(p)) print "%s is a parent domain of %s: %s" % (o, p, c.is_superdomain(o)) print "Relative name of %s in %s: %s" % (c, p, c.relativize(p)) # Method labels() returns also the root print "%s has %i labels" % (p, len(p.labels)-1) print "%s has %i labels" % (c, len(c.labels)-1)
Il nous donne, comme on pouvait s'y attendre :
www.afnic.fr. is a subdomain of afnic.fr.: True www.afnic.fr. is a parent domain of afnic.fr.: False www.gouv.fr. is a subdomain of afnic.fr.: False www.gouv.fr. is a parent domain of afnic.fr.: False Relative name of www.afnic.fr. in afnic.fr.: www afnic.fr. has 2 labels www.afnic.fr. has 3 labels
Et les mises à jour dynamiques du RFC 2136 ? dnspython les permet :
import dns.query
import dns.tsigkeyring
import dns.update
keyring = dns.tsigkeyring.from_text({
'foobar-example-dyn-update.' : 'WS7T0ISoaV+Myge+G/wemHTn9mQwMh3DMwmTlJ3xcXRCIOv1EVkNLlIvv2h+2erWjz1v0mBW2NPKArcWHENtuA=='
})
update = dns.update.Update('foobar.example', keyring=keyring,
keyname="foobar-example-dyn-update.")
update.replace('www', 300, 'AAAA', '2001:db8:1337::fada')
response = dns.query.tcp(update, '127.0.0.1', port=53)
print response
Ici, on s'authentifier auprès du serveur faisant autorité en utilisant
TSIG (RFC 8945). On
remplace ensuite l'adresse IPv6 (AAAA) de
www.foobar.example par 2001:db8:1337::fada.
J'ai parlé plus haut de l'interface de bas niveau de dnspython. Elle offre davantage de possibilités mais elle est plus complexe. Des choses comme la retransmission (en cas de perte d'un paquet) doivent être gérées par le programmeur et non plus par la bibliothèque. Voici un exemple complet pour obtenir l'adresse IPv6 d'une machine :
import dns.rdatatype
import dns.message
import dns.query
import dns.resolver
import sys
MAXIMUM = 4
TIMEOUT = 0.4
if len(sys.argv) > 3 or len(sys.argv) < 2:
print >>sys.stderr, ("Usage: %s fqdn [resolver]" % sys.argv[0])
sys.exit(1)
name = sys.argv[1]
if len(sys.argv) == 3:
resolver = sys.argv[2]
else:
resolver = dns.resolver.get_default_resolver().nameservers[0]
try:
message = dns.message.make_query(name, dns.rdatatype.AAAA, use_edns=0, payload=4096,
want_dnssec=True)
except TypeError: # Old DNS Python... Code here just as long as it lingers in some places
message = dns.message.make_query(name, dns.rdatatype.AAAA, use_edns=0,
want_dnssec=True)
message.payload = 4096
done = False
tests = 0
while not done and tests < MAXIMUM:
try:
response = dns.query.udp(message, resolver, timeout=TIMEOUT)
done = True
except dns.exception.Timeout:
tests += 1
if done:
print "Return code: %i" % response.rcode()
print "Response length: %i" % len(response.to_wire())
for answer in response.answer:
print answer
else:
print "Sad timeout"
On a quand même utilisé dns.resolver pour
récupérer la liste des résolveurs. On fabrique ensuite un message DNS
avec make_query(). On fait ensuite une boucle
jusqu'à ce qu'on ait une réponse... ou que le nombre maximum
d'itérations soit atteint. Notez qu'il reste encore des tas de détails
non gérés : on n'utilise que le premier résolveur de la liste (il
faudrait passer aux suivants en cas de délai expiré), on ne bascule
pas en TCP si la réponse est tronquée, etc.
Le code ci-dessus donne, par exemple :
% python resolver-with-low-level.py www.ripe.net Return code: 0 Response length: 933 www.ripe.net. 21374 IN AAAA 2001:67c:2e8:22::c100:68b www.ripe.net. 21374 IN RRSIG AAAA 5 3 21600 20120816100223 20120717090223 16848 ripe.net. Q0WRfwauHmvCdTI5mqcqRCeNaI1jOFN8 Z0B+qwsac3VRqnk9xVGtmSjhGWPnud/0 pS858B4vUZFcq8x47hnEeA9Ori5mO9PQ NLtcXIdEsh3QVuJkXSM7snCx7yHBSVeV 0aBgje/AJkOrk8gS62TZHJwAHGeDhUsT +CvAdVcURrY=
Voilà, c'était juste une toute petite partie des possibilités de dnspython, j'espère que cela vous aura donné envie de voir le reste. Quelques autres articles :
Bonne programmation.
L'article seul
Comment on traduit « nonce » ?
Première rédaction de cet article le 13 juillet 2012
Comme mes fidèles lecteurs (et lectrices) ont l'air d'apprécier les questions de traduction, le problème du jour, motivé par la publication un de ces jours des RFC sur ILNP, est « quelle est la bonne traduction de l'anglais nonce ? ».
Rien à voir avec celui du pape. En informatique, et plus spécialement dans les protocoles réseaux, un nonce est un nombre imprévisible (de préférence aléatoire), choisi par un des participants à la communication et transmis à l'autre. Ledit autre pourra prouver qu'il est bien toujours le même en produisant ce nonce. Un éventuel attaquant, ne pouvant pas connaître (ou deviner) ce nonce, ne pourra pas usurper l'identité d'une des parties à la communication. Par exemple, les Query ID du DNS (RFC 5452) ou les ISN (numéros de séquence initiaux) de TCP (RFC 5961) sont des nonces. (Plusieurs lecteurs érudits et attentifs m'ont fait remarquer que ma description était quand même très simplifiée. J'assume.)
Les experts en sécurité auront noté que le nonce ne protège que contre un attaquant incapable d'écouter la communication. Autrement, si l'attaquant est situé sur le chemin et espionne, le nonce ne sert à rien puisque ledit attaquant le connait.
Le nonce n'est donc pas de la cryptographie et il est curieux que les Wikipédia francophones et anglophones le décrivent sous l'appellation de « Nonce cryptographique ».
Bon, mais quel terme utiliser en français ? En anglais, « nonce » veut dire « mot à usage unique ». En japonais, on dit simplement nonsu, tiré de l'anglais. On m'a cité les traductions suivantes possibles :
- Valeur de circonstance (correct mais long) voire Nom occasionnel à utilisation limitée ou Nombre à usage unique
- Hapax (traduire de l'anglais par du grec... mais respecte l'origine littéraire du terme anglais)
- Numnique (jolie idée de Steve Schnepp autour de l'idée de « nombre unique ») ou Munique (« mot unique », idée de grommeleur) ou encore Monique (« mot unique », idée de Steve Schnepp)
- Mohasard (« mot choisi au hasard »)
- Numéro jetable (idée de Ludovic Rousseau, pour faire passer l'idée que le numéro devient inutile, voir dangereux, une fois qu'il a été utilisé, mais qui ne convoie pas l'idée d'imprévisibilité)
- Défi (on le trouve dans certains articles de Wikipédia)
Qu'en dites-vous ?
Merci entre autre à Jean Rebiffé pour des tas de remarques pertinentes.
L'article seul
RFC 6646: DECoupled Application Data Enroute (DECADE) Problem Statement
Date de publication du RFC : Juillet 2012
Auteur(s) du RFC : H. Song, N. Zong (Huawei), Y. Yang (Yale University), R. Alimi (Google)
Pour information
Réalisé dans le cadre du groupe de travail IETF decade
Première rédaction de cet article le 10 juillet 2012
Dernière mise à jour le 20 septembre 2012
Le groupe de travail DECADE de l'IETF travaillait à optimiser les applications pair-à-pair notamment en leur permettant de stocker facilement des données dans le réseau (on devrait dire le cloud, pour que ce RFC se vende mieux). Ce RFC décrit précisement les problèmes que DECADE essayait de résoudre, les solutions étant prévues pour de futurs documents. Le principal problème identifié est de doter les applications P2P d'accès à des caches dans le réseau, évitant d'utiliser de manière répétée des liens coûteux et/ou lents. DECADE ayant été fermé en septembre 2012, le projet ne se conclura sans doute pas.
Ce n'est pas que ces caches n'existent pas déjà : des tas d'applications en ont. Mais ils souffrent de limites : étant souvent spécifiques à une application (BitTorrent, FlashGet, Thunder, etc), ils ne peuvent pas être réutilisés via un protocole standard, et ils n'ont pas de mécanismes de contrôle d'accès permettant, par exemple, de mettre des données dans le cache mais de limiter leur accès à certains.
Le pair-à-pair sert à beaucoup de choses (deux cas connus sont le partage de fichiers, et le streaming vidéo) et ces usages sont souvent très consommateurs de ressources réseau. Cette consommation justifie qu'on travaille activement à limiter le gaspillage. C'est particulièrement gênant pour « le dernier kilomètre », la ligne, relativement lente, qui connecte M. Toutlemonde à son FAI. Les accès actuellement commercialisés sont presque toujours asymétriques (bien plus de capacité dans le sens TF1->temps-de-cerveau que dans le sens citoyen-producteur->réseau). Si M. Toutlemonde a un gros fichier sur le disque dur de son PC à la maison, et que dix personnes le téléchargent, le gros fichier encombrera dix fois l'accès « montant » de M. Toutlemonde, à son grand dam. Il est ainsi courant que la grande majorité de la capacité montante soit prise par le pair-à-pair. M. Toutlemonde pourrait « téléverser » le fichier une fois pour toutes chez un hébergeur situé « dans le nuage » mais attention : pour qu'il conserve les avantages du pair-à-pair, cela devrait être intégré dans les applications, sans qu'il y ait besoin d'un compte Dropbox (avec acceptation de conditions d'usage qui disent que le gérant du nuage fait ce qu'il veut des données), d'un téléversement explicite, etc. Bref, que cela se fasse tout seul.
Un problème analogue à celui de M. Toutlemonde est celui de l'hébergeur dont un client a un fichier qui intéresse dix personnes à l'extérieur de l'hébergeur. Faire passer le fichier dix fois sur les coûteux liens de transit n'est pas une utilisation géniale de la capacité réseau... À noter qu'une autre voie d'optimisation, complémentaire de celle de DECADE, est celle du groupe de travail ALTO, qui consiste à faciliter la découverte de ressources proches (« télécharger localement »), comme décrit dans le RFC 5693. ALTO ne fonctionne que si le contenu est déjà disponible localement. Sinon, DECADE prend le relais. Deux autres efforts IETF qui ont un rapport avec DECADE, et lui sont complémentaires, sont PPSP, sur la conception d'un protocole de streaming en pair-à-pair (RFC 7574), et LEDBAT, sur des mécanismes permettant à des applications non critiques de céder automatiquement les ressources réseau aux autres (RFC 6297 et RFC 6817).
On l'a vu, il existe déjà des applications pair-à-pair qui ont des formes de cachage des données. Mais chacune nécessite d'être adaptée à un protocole pair-à-pair particulier, alors que le travail de DECADE est plutôt de chercher des solutions génériques, qui pourraient convenir à tout nouveau protocole. Une telle solution générique n'existe pas actuellement. Mais des projets ont déjà été définis comme les Data Lockers. Avec un tel système, le PC de M. Toutlemonde pourrait téléverser le fichier dans le nuage, là où la capacité réseau est meilleure, et les pairs de M. Toutlemonde aller le chercher là-bas, sans que M. Toutlemonde ait d'action explicite à faire, et sans qu'il gaspille les ressources du dernier kilomètre.
L'exercice de DECADE sera donc de définir un protocole d'accès standard à ces ressources de stockage dans le nuage. Ce protocole comportera deux parts : la signalisation (permettant de découvrir les caractéristiques de ces ressources) et le transfert permettant de lire et d'écrire le contenu. La difficulté sera d'identifier ce qui est suffisamment commun chez tous les protocoles, pour faire l'objet d'une normalisation. Et le protocole devra être assez souple pour s'adapter à des applications pair-à-pair qui ont des caractéristiques très différentes.
Une étude a déjà été faite par le groupe de travail DECADE sur les systèmes de stockage des données en ligne. Documentée dans le RFC 6392, elle liste les systèmes existants sur lequels aurait pu être basé le futur protocole DECADE.
Si cela vous semble encore un peu flou, vous pouvez sauter à la section 4 qui présente des études de cas pour certaines applications. Par exemple, pour BitTorrent, ce qui est envisagé est de modifier les pairs pour qu'ils envoient les blocs de données (l'unité de transfert de base de BitTorrent) non pas à chaque autre pair mais à un cache dans le réseau, en indiquant au pair où le bloc a été mis.
Un autre cas étudié est celui des distributeurs de contenu (par exemple une vidéo) et qui voudraient le mettre le plus proche possible des « globes oculaires » (les consommateurs de contenu). Garder la vidéo sur son petit site Web mal connecté ne permettra pas une distribution efficace. Faire appel à un CDN imposera l'utilisation de l'interface spécifique de ce CDN, et tout sera à recommencer en cas de changement de fournisseur. Le protocole standard mentionné plus haut résoudrait ce problème. Pour ce cas, encore plus que pour celui du pair-à-pair, il est important que celui qui met des données dans le réseau puisse indiquer les règles d'accès (par exemple, ne distribuer qu'à des utilisateurs identifiés).
Tout cela, vous vous en doutez, soulève plein de problèmes de sécurité. La section 5 les passe en revue. D'abord, il y a un risque évident de déni de service, par exemple avec un méchant stockant tellement de données qu'il remplit tout le nuage et ne laisse rien pour les autres. Il est donc crucial d'avoir des mécanismes d'authentification et d'autorisation.
Ensuite, lorsqu'on dit « distribution de contenu multimédia », « partage en pair-à-pair », on peut être sûr que des hordes de juristes vont accourir et réclamer que les règles définies par l'industrie du divertissement soient automatiquement mises en œuvre par les systèmes techniques, ici par le stockage dans le nuage. (Par exemple, distribution du contenu à certains pays seulement, pour permettre de faire payer plus un sous-ensemble des pays.) Le RFC dit sagement que ce genre de demandes est hors-sujet pour le projet DECADE.
Le fournisseur du système de stockage va en apprendre beaucoup sur les utilisateurs, ce qui peut menacer leur vie privée. Même si le contenu est chiffré, le fait que N personnes demandent le même fichier est déjà une indication utile (qu'elles ont les mêmes centres d'intérêt). Un autre risque avec un fournisseur de stockage méchant est qu'il modifie le contenu des fichiers qu'on lui a confié. Le RFC ne fournit pas de solutions pour ces deux derniers problèmes (une signature cryptographique permettrait de traiter le second).
Bref, ce n'est pas le travail qui manquait pour le groupe DECADE. Il travaillait sur les trois futurs RFC de cahier des charges pour le protocole d'accès au stockage, de description de l'architecture du système, et de l'intégration avec les protocoles existants, comme BitTorrent. Mais les difficultés colossales de ce travail ont eu raison du groupe, qui a été dissous en septembre 2012. (Après coup, le travail déjà fait a été publié dans le RFC 7069.)
L'article seul
RFC 6657: Update to MIME regarding Charset Parameter Handling in Textual Media Types
Date de publication du RFC : Juillet 2012
Auteur(s) du RFC : A. Melnikov (Isode), J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 10 juillet 2012
Lorsqu'un programme envoie des données en les étiquetant avec le
type MIME
text/quelquechose, quels sont le jeu de caractères et l'encodage
utilisés par défaut ? ASCII ?
UTF-8 ? Un autre ? Si vous l'ignorez, vous
n'êtes pas le seul. Très peu de gens connaissaient les règles
appliquées par défaut et ce
RFC choisit donc de les simplifier en les supprimant. Pour le
résumer : il n'y aura plus de
charset par défaut pour les
nouveaux types MIME text/*.
Le RFC 2046, qui normalisait ces étiquettes
MIME, disait pourtant (section 4.1.2) que le
charset par défaut était
US-ASCII (un point de vocabulaire au passage :
le terme de charset est fréquent dans les normes
IETF mais étymologiquement incorrect, puisqu'il
désigne en fait à la fois un jeu de caractères
et un encodage). Mais d'autres RFC avaient fait
d'autre choix et l'exemple le plus connu était
HTTP qui spécifiait que, lorsqu'un serveur envoie
des données sans indiquer charset, c'est qu'elles
sont en ISO 8859-1 (RFC 2616, section 3.7.1, le RFC 7231 a depuis changé cela), comme les en-têtes de la réponse
HTTP. En pratique, le serveur HTTP prudent indiquera le
charset (par exemple Content-Type: text/html; charset=UTF-8) plutôt que de compter sur cette règle mal connue.
Pire, certains types ont un mécanisme inclus dans les données pour
trouver le charset, notamment
text/html et text/xml. Bref,
il est difficile à un programme de compter sur la valeur par
défaut. Ce RFC formalise en fait un usage déjà très répandu : être explicite.
La nouvelle règle est donc « pas de valeur par défaut générique
pour tous les text/*, chaque sous-type de
text/* peut définir sa propre valeur par défaut,
y compris imposer qu'une valeur explicite soit indiquée. » Pour des
raisons de compatibilité avec l'existant, les sous-types existants ne
sont pas modifiés, la nouvelle règle s'appliquera aux nouveaux
sous-types. Notre RFC recommande en outre de choisir de ne
pas avoir de valeur par défaut et, soit
d'indiquer le charset dans le contenu (comme le
fait XML avec son <?xml
version="1.0" encoding="iso-8859-1"?>), soit de rendre
obligatoire le paramètre charset= (indication
explicite du charset).
Les nouveaux enregistrements
de sous-types MIME de text/* ne devraient donc
plus indiquer de valeur par défaut pour le
charset. Si c'est absolument nécessaire, le RFC
recommande que cette valeur soit UTF-8 (on est
en 2012 et ASCII ne devrait plus être considéré
comme le jeu de caractères par défaut).
On l'a dit, ce RFC ne change pas les sous-types existants et, par
exemple, le charset par défaut du sous-type
text/plain reste donc, lui, en ASCII.
Une alternative à l'étiquetage des données a toujours été d'essayer
de deviner le charset par diverses heuristiques. Le
RFC rappelle que cette méthode est dangereuse et déconseillée. Autre
piège, le conflit entre l'information extérieure au contenu et celle
incluse dans le contenu. Que faut-il faire avec un document XML servi
en HTTP
comme text/html; charset=iso-8859-1 et commençant par <?xml
version="1.0" encoding="utf-8"?> ? Le RFC recommande de
se fier à l'information la plus interne (ici, la déclaration XML, qui
dit que le document est en UTF-8), probablement la plus correcte.
Ce RFC 6657 est désormais celui cité à l'IANA
pour les nouveaux enregistrements dans le registre
des sous-types de text/.
L'article seul
RFC 867: Daytime Protocol
Date de publication du RFC : Mai 1983
Auteur(s) du RFC : J. Postel (University of Southern California (USC)/Information Sciences Institute)
Statut inconnu, probablement trop ancien
Première rédaction de cet article le 10 juillet 2012
Voici un RFC qui bat des records de concision. Il spécifie un protocole trivial, permettant d'obtenir l'heure d'une machine distante, et le fait en un seul paragraphe.
Le protocole daytime n'a plus un grand intérêt pratique aujourd'hui mais il a été longtemps un des outils de débogage les plus utilisés, pour vérifier la synchronisation temporelle d'une machine distante. Difficile de faire plus simple : le client daytime se connecte en TCP sur le port 13 et n'envoie rien. Le serveur envoie une ligne qui donne la date et l'heure chez lui.
Conçu pour être utilisé par des humains, le format de daytime n'est pas spécifié : n'importe quoi de lisible, en pur ASCII, conviendra (au contraire du protocole du RFC 868, conçu pour les machines, ou bien de normes ultérieures comme le RFC 3339).
Voici un exemple d'utilisation, avec telnet en client :
% telnet $REMOTESERVER daytime Trying 192.168.2.26... Connected to $REMOTESERVER. Escape character is '^]'. Tue, 10 Jul 2012 20:07:45 GMT Connection closed by foreign host.
On trouve des serveurs daytime un peu partout, en général inclus dans les mises en œuvre d'inetd. Le serveur utilisé pour le test ci-dessus est en Node.js et son code est simplement :
var net = require('net');
net.createServer(function (stream) {
var now = new Date();
stream.write(now.toUTCString());
stream.end('\r\n');
}).listen(13);
Il se lance avec :
# node daytime.js
On a vu que telnet suffit comme client daytime mais, sinon,
n'importe quel programme qui se connecte au port 13 suffit (il existe,
par exemple, un client daytime en C dans le
contrib d'echoping, daytime.c).
L'article seul
Faut-il supprimer les secondes intercalaires pour sauver l'humanité ?
Première rédaction de cet article le 2 juillet 2012
Dernière mise à jour le 6 juillet 2012
La grande panne de nombreux serveurs Linux le 1er juillet a remis sur le tapis la question des secondes intercalaires. S'il y a toujours des bogues aussi sérieuses dans le code qui les gère, ne faudrait-il pas supprimer le problème en simplifiant l'échelle de temps UTC, par la suppression de ces secondes intercalaires ?
D'abord, il faut établir clairement les responsabilités : ce comportement anormal de Linux (le meilleur article technique est celui de ServerFault, très détaillé) est une bogue. Quarante ans après la création des secondes intercalaires, il est anormal qu'il reste encore de telles bogues dans un programme répandu, alors qu'il y a déjà eu 25 secondes intercalaires, donc plein d'occasions de tester.
Ensuite, le problème n'est pas dans UTC ou dans les secondes intercalaires. Le problème est dans la Terre qui ne « tourne pas rond ». Son mouvement n'est pas constant et, pire, il n'est pas prédictible. Lorsque certains articles anti-secondes-intercalaires ont écrit « il n'est pas normal qu'on ne puisse pas calculer le temps à l'avance », ils disent une grosse bêtise. Normal ou pas, c'est ainsi que le monde réel fonctionne.
Comme on ne peut pas « patcher » la Terre, que reste-t-il comme solutions ? Les adversaires de la seconde intercalaire proposent de supprimer cette dernière d'UTC. Mais je trouve cette « solution » tout à fait inutile. Il existe déjà une échelle de temps sans secondes intercalaires et c'est TAI ! Supprimer les secondes intercalaires revient à aligner UTC sur TAI, faisant perdre l'intérêt qu'il y a à avoir deux échelles :
- TAI (qui est complètement indépendant des astres) est pratique pour les informaticiens, notamment parce que son déroulement est prévisible.
- UTC est pratique pour les gens qui mettent le nez dehors, car elle garantit que l'heure reste proche de celle des astres (le Soleil au plus haut à midi, ce genre de choses).
Les deux ont leur légitimité et leur utilité. Les gens qui réclament la suppression des secondes intercalaires pour simplifier les programmes n'ont tout simplement pas compris cela. (TAI a actuellement 35 secondes de décalage avec UTC, si bien qu'on ne voit pas encore de conséquences pratiques.)
Mais, me dira-t-on, UTC, avec ses secondes intercalaires, est bien compliqué pour des programmes qui souhaitent avoir une horloge monotone et prévisible (comme les bases de données réparties, les grandes victimes de la panne). Dans ce cas, la solution est d'utiliser TAI. Hélas, sur Unix, la situation est compliquée. Il n'y a pas de moyen simple d'accéder à TAI. Quelques solutions possibles :
- Posix a une option
CLOCK_MONOTONIC(voir la définition de clock_gettime()) qui n'est pas vraiment TAI et ne semble pas beaucoup mise en œuvre. - On peut aussi modifier le système pour ne pas appliquer la seconde intercalaire d'un coup, comme l'a fait Google qui avait besoin d'un temps monotoniquement croissant pour ses serveurs,
- Attendre qu'un patch permettant l'accès à TAI (comme celui de Richard Cochran) soit intégré dans Unix,
- Utiliser une bibliothèque comme libtai. Attention, comme elle
marche en accédant à UTC (la seule information disponible sur Unix) et
en corrigeant, elle dépend de listes de secondes intercalaires à jour,
ce qui n'est pas le cas de la distribution officielle (alors que l'IANA) distribue cette information, dans le fichier
leapseconds, et qu'elle est correcte ; pourquoi diable libtai ne l'utilise pas ?). - Sur le même principe (corriger puisqu'on connait le décalage entre TAI et UTC), un simple fichier timezone d'Alain Thivillon, bien plus simple à utiliser et très efficace.
Alain a aussi produit un script simple pour fabriquer une table des décalages UTC-TAI à partir du registre des temps à l'IANA. Voici comment on peut l'utiliser. D'abord, exécuter de temps en temps (pour mettre à jour le fichier), par exemple depuis cron :
% cd /usr/share/zoneinfo % perl /usr/local/sbin/gentai.pl Zonefile ./tai generated Zonefile ./tai compiled in Etc/TAI You can check with "TZDIR=/usr/share/zoneinfo TZ=Etc/TAI date && TZ=UTC date" Leapsecond file ./leapseconds_iana saved
Ensuite, lorsque vous avez envie de voir le temps TAI, vous définissez juste la variable d'environnement qui va bien :
% TZ=Etc/TAI date && date -u Fri Jul 6 21:00:16 TAI 2012 Fri Jul 6 20:59:41 UTC 2012
Vous voyez bien les trente-cinq secondes de décalage actuels.
À noter que cette idée d'avoir deux échelles, TAI et UTC, qui reconnait le fait qu'il y a deux populations d'utilisateurs, avec des besoins différents, est rejetée par le BIPM qui considère que deux, c'est trop, à cause du risque de confusion.
Autres lectures :
- Le bulletin C annonçant cette seconde intercalaire,
- Le débat sur la suppression de la seconde intercalaire et ma position,
- Une intéressante proposition alternative de réforme d'UTC, faisant varier l'horloge progressivement (comme dans la solution de Google) et non pas d'un coup,
- Un bon article expliquant la gestion de la seconde intercalaire par NTP,
- Une proposition concrète de Steve Allen pour résoudre ce dilemme (attention, c'est technique).
- Pour les Unixiens, un bon article sur le temps dans Unix, même UTC est mal géré (avec retour de l'horloge en arrière),
- Une vigoureuse critique de la gestion du temps dans Unix,
- Une autre, uniquement pour ceux qui supportent le ton de D. J. Bernstein.
- Sur les conséquences de la bogue Linux, l'article de Wired.
Remerciements à Steve Allen, Tony Finch, Pierre Beyssac, Alain Thivillon et Peter van Dijk pour la discussion sur TAI dans Unix. Merci à Kim-Minh Kaplan pour le rappel qu'UTC ne va jamais en arrière, c'est Unix (ou d'autres systèmes) qui le fait, ne sachant pas gérer la seconde intercalaire.
L'article seul
Exposé RPKI+ROA à la réunion FRnog
Première rédaction de cet article le 30 juin 2012
À la 19ème réunion du FRnog, le 29 juin, j'ai fait un exposé sur la RPKI. Cette technique permettra peut-être de sécuriser enfin le routage sur l'Internet.
Voici les transparents utilisés :
- Version adaptée à l'écran,
- Version adaptée à l'impression,
- Sources en LaTeX/Beamer.
La journée, qui célébrait le dixième aniversaire de FRnog, a vu également plusieurs autres exposés. Les supports devraient se trouver en ligne sur la page de FRnog19.
Il y a eu par exemple :
- Un excellent exposé d'un employé de Brocade, Jason Klee, sur les Ethernet au delà de 100 Gb/s et les nombreux problèmes techniques que cela pose, au niveau physique (les connecteurs augmentent de taille « now larger than an iPhone » et ne tiennent plus en face avant d'un routeur) comme au niveau du routeur qui a bien du mal à faire passer des paquets à cette vitesse (à 100 Gb/s, on peut avoir 150 Mp/s soit un paquet toutes les 6,72 ns).
- Un excellent exposé de Nicolas Strina (Jaguar) & Matthieu Texier (Arbor) sur les dDoS avec une étude de cas avec une des nombreuses attaques DNS qui frappent tant d'acteurs de l'Internet depuis décembre 2011. Les chiffres étaient extraits d'une étude d'Arbor : les plus grosses attaques 2011 étaient à 101 Gb/s et à 140 Mp/s, même si 70 % des attaques étudiées étaient en dessous du Gb/s.
- Une présentation de l'ARCEP (qui, curieusement, n'était jamais venue au FRnog), notamment sur le projet de collecte d'informations sur le peering.
- Un interview de Louis Pouzin et Gérard Le Lann sur Cyclades. Le Lann a eu un grand succès en montrant sa photo, avec les cheveux longs de l'époque...
- Une présentation des points d'échange Equinix et France-IX.
Bref, un programme très chargé et très intéressant.
L'article seul
Rapport sur la résilience de l'Internet en France
Première rédaction de cet article le 26 juin 2012
Hier a vu la publication du premier « Rapport sur la résilience de l'Internet en France ». Il s'agit d'étudier quantitativement la résilience de l'Internet dans ce pays (oui, je sais, l'Internet est mondial, mais il faut bien commencer quelque part). Le rapport définit donc un certain nombre d'indicateurs puis les mesure et publie le résultat.
Le rapport est un travail commun de l'ANSSI et de l'AFNIC. Il comprend deux grandes parties, une sur le protocole BGP et une sur le DNS. Dans le futur, d'autres protocoles pourront être étudiés (comme NTP). Espérons que cette édition 2011 sera suivie de bien d'autres.
Ce travail a déjà été présenté (en anglais) à une réunion OARC (supports disponibles). Il sera évoqué rapidement au prochain Frnog et surtout à la Journée du Conseil Scientifique de l'AFNIC le 4 juillet.
Sinon, sur la résilience, j'ai déjà fait un article.
L'article seul
RFC 6650: Creation and Use of Email Feedback Reports: An Applicability Statement for the Abuse Reporting Format (ARF)
Date de publication du RFC : Juin 2012
Auteur(s) du RFC : J. Falk (Return Path), M. Kucherawy (Cloudmark)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF marf
Première rédaction de cet article le 26 juin 2012
Le format ARF, normalisé dans le RFC 5965 permet à des acteurs de l'Internet (typiquemet des FAI et des gros hébergeurs de courrier comme Gmail) de s'envoyer des rapports structurés, produits et analysés automatiquement, au sujet des abus commis avec le courrier électronique, notamment du spam. Ce nouveau RFC du groupe de travail qui a conçu ARF expose comment et dans quelles circonstances utiliser ARF.
L'idée de base d'ARF était qu'un message serait détecté comme abusif (par exemple par l'utilisateur cliquant un bouton « C'est du spam ! ») et que cette détection déclencherait l'envoi d'un rapport ARF au responsable (qui pourra le faire suivre, si nécessaire). En comparaison avec un rapport non structuré, l'avantage d'ARF est que les messages ARF seront analysables par des programmes, pour rendre leur traitement plus efficace.
(Il existe des extensions à ARF pour des usages qui ne sont pas forcément des abus ou des erreurs d'authentification, comme l'extension du RFC 6430 mais elles sont encore peu déployées et pas étudiées ici.)
Ce RFC 6650 est largement inspiré d'un document externe à l'IETF, le RFC 6449. En quelque sorte, il en est la version officielle.
Les autres documents existants, comme la norme ARF (RFC 5965), sont purement techniques (définition d'un format) et ne répondent pas à des questions comme « à qui envoyer les rapports ? » ou « que faut-il mieux mettre dans un rapport ? », qui font l'objet de ce RFC.
D'abord, faut-il un accord explicite du destinataire avant d'envoyer les rapports ARF ? La section 3 considère qu'il y a deux cas, celui de deux acteurs décidant entre eux de se transmettre des rapports ARF, relatifs à leurs clients. C'est le cas le plus fréquent aujourd'hui. Et le second cas est celui où des rapports non sollicités sont envoyés à quelqu'un dont l'expéditeur pense qu'il est concerné. En l'absence d'un accord préalable, ces rapports ne feront pas forcément l'objet de la même attention.
La section 4 détaille le premier cas, les rapports attendus. En vrac, elle demande, entre autres :
- Que l'accord entre les deux acteurs soit respecté, notamment
dans le choix de l'adresse de destination
(
arf-feedback@example.net, par exemple). - Que le rapport soit à la syntaxe ARF (évidemment) et que les
éléments optionnels dans ARF soient inclus, s'ils sont disponibles
(pas de rétention délibérée). Cela concerne
Original-Mail-From,Arrival-Date,Source-IP,Original-Rcpt-To. - Pour relativiser la demande précédente, il peut y avoir occultation délibérée, pour préserver la vie privée, comme détaillé dans le RFC 6590.
- Enfin, la section 4 demande (vœu pieux ?) que le récepteur agisse lorsqu'il reçoit des rapports qui le concernent (section 4.3 du RFC 6449).
La section 5 s'attaque aux rapports inattendus, envoyés sans concertation préalable. Elle est bien plus longue puisqu'il s'agit d'embêter des gens qui n'ont rien demandé (dans le précédent cas, les deux parties ont pu se mettre d'accord sur tous ces points, qui doivent être explicités ici.) Les auteurs du RFC demandent, entre autres :
- Que le destinataire ait un moyen de ralentir le rythme d'envoi des rapports, pour que son infrastructure ne s'écroule pas sous la charge (il n'existe pas de mécanisme standard pour cela, cela doit être fait « à la main »).
- Que l'expéditeur s'assure que ses messages soient crédibles, pour diminuer le risque qu'ils soient jetés sans autre forme de procès. Cela implique notamment une authentification SPF et/ou DKIM correcte.
- Que l'expéditeur soit bien conscient qu'un traitement effectif des rapports reçus a un coût pour le destinataire et qu'il fasse donc attention à produire des rapports techniquement corrects et factuellement sérieux.
- Que l'expéditeur n'envoie pas automatiquement des rapports sur la base d'une analyse automatique. Les logiciels de classification peuvent se tromper et prendre pour du spam ce qui n'en est pas. Il serait anormal de générer un spam (le rapport ARF) en échange d'un message qui n'en est pas un. (Je vois au boulot pas mal de rapports violant cette règle, réalisés en format ARF ou pas, qui sont manifestement automatiquement émis par un logiciel, et un logiciel particulièrement débile en plus.) La section 5 de notre RFC recommande d'utiliser plutôt les messages identifiés comme spam par un humain, ou bien ceux reçus par un pot de miel.
- Que le MUA, s'il fabrique des rapports ARF, les envoie au fournisseur de service de l'utilisateur, pas au supposé responsable du message abusif. Actuellement, il existe plusieurs logiciels qui automatisent partiellement l'envoi de messages de plainte et qui, pour trouver le destinataire, font des requêtes whois au petit bonheur la chance (par exemple pour tous les AS sur le chemin suivi), avant d'envoyer la plainte à dix ou quinze adresses dont la plupart ne sont en rien responsables du message abusif. La bonne pratique est donc d'envoyer à son fournisseur, charge à lui de faire suivre intelligemment. Pour cela, il devra compter sur diverses heuristiques mais, au moins, il sait les utiliser.
- Que le rapport soit correctement rempli, indication du bon
Feedback-TYpe:(RFC 5965, section 3.1), indication de toutes les informations pertinentes, etc. Par contre, pas besoin d'hésiter avant de choisir le format ARF : les rapports qui suivent ce format sont lisibles manuellement, même si le destinataire n'a pas de logiciel adapté. - Que le destinataire agisse, sur la base des rapports
corrects. Il existe des tas de rapports incorrects (envoyés au mauvais
destinataire, par exemple) et le format ARF permet d'automatiser une
partie du triage. Par exemple, le FAI peut
regarder l'en-tête
Source-IP:du rapport et jeter sans autre forme de procès les rapports où ladite adresse IP source ne fait pas partie de ses préfixes IP. Malgré cela, il y a quand même des rapports corrects ce qui ne signifie pas qu'ils seront lus. Le RFC discute également de la délicate question de la réponse : faut-il signaler à l'envoyeur du rapport que son message a été lu et qu'on a agi ? (Actuellement, même si les rapports d'abus sont traités, l'utilisateur ne reçoit jamais de retour.) La conclusion est que ce serait souvent une bonne idée que de signaler à l'émetteur du rapport qu'il n'a pas travaillé pour rien.
Les recommandations précédentes concernaient surtout les rapports
envoyés en réponse à un message abusif, du spam par exemple. La
section 6 couvre les rapports signalant un problème
d'authentification, avec SPF ou
DKIM. Ces rapports utiliseront le
Feedback-Type: auth-failure (RFC 6591) et sont normalisés dans des documents comme le RFC 6652 et le RFC 6651. Les demandes pour cette section sont :
- Qu'on n'envoie de tels rapports qu'à ceux qui les demandent, et aux adresses de courrier qu'ils ont indiqué,
- Qu'on n'envoie pas de rapport ARF pour un problème
d'authentification d'un rapport ARF (pour éviter les boucles). C'est
aussi pour éviter ces boucles que le rapport doit être envoyé avec un
MAIL FROMvide (plus exactement ayant la valeur<>), - Qu'on fasse attention aux attaques avec amplification. Il ne faut pas qu'un méchant fabrique un faux, juste pour que l'échec de l'authentification de ce faux déclenche l'émission d'un gros rapport ARF à destination d'un pauvre FAI qui n'y est pour rien.
Quelques pièges de sécurité peuvent attendre les utilisateurs du format ARF. La section 8 en fait le tour. D'abord et avant tout, les rapports ARF peuvent être des faux, fabriqués de A à Z (afin, par exemple, de faire accuser un innocent). La confiance qu'on leur accorde doit dépendre de l'authentification de l'émetteur et de la confiance qu'on accorde à cet émetteur. (C'est un problème ancien, voir par exemple la section 4.1 du RFC 3464.)
Le modèle originalement envisagé pour ARF était celui du rapport déclenché manuellement ; un utilisateur se plaint, il clique sur le bouton « Ceci est un spam », le message est transmis au fournisseur de messagerie qui fabrique un rapport ARF et l'envoie. Le rythme d'envoi des rapports restait donc limité. Au contraire, les évolutions récentes d'ARF, notamment pour le signalement de problèmes d'authentification, vont vers des rapports déclenchés automatiquement. Un message arrive, le test SPF échoue, paf, un rapport ARF est généré et envoyé. Cela peut mener à des rythmes d'envoi bien plus grands, qui peuvent dépasser les capacités de réception et de traitement du destinataire. C'est d'autant plus ennuyeux qu'un attaquant vicieux pourrait générer exprès des problèmes d'authentification, pour déclencher ces envois massifs. Il peut donc être raisonnable de limiter le débit d'envoi de tels rapports.
Autre façon de traiter ce problème : ne pas envoyer un rapport par
incident. Le format ARF prévoit (RFC 5965,
section 3.2) d'indiquer dans le rapport combien d'incidents similaires
il couvre (champ Incidents:). On peut donc
choisir, par exemple, de n'envoyer qu'un rapport pour N incidents ou,
mieux de faire une décroissance exponentielle (un rapport par incident
pour les 10 premiers, un rapport par série de 10 incidents pour les
100 suivants, etc).
L'article seul
RFC 6652: SPF Authentication Failure Reporting using the Abuse Report Format
Date de publication du RFC : Juin 2012
Auteur(s) du RFC : S. Kitterman (Agari)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF marf
Première rédaction de cet article le 26 juin 2012
Le but principal de ce RFC est d'améliorer l'utilisation du format ARF (RFC 5965) pour rendre compte d'un problème d'authentification SPF. Ce protocole d'authentification du courrier électronique, normalisé dans le RFC 7208, n'avait pas de registre des modificateurs disponibles dans un enregistrement SPF. Ce RFC comble ce manque.
ARF est un format standard, structuré, permettant l'envoi de rapports d'incidents ou de problèmes (par exemple un spam) entre opérateurs. L'idée d'un format normalisé est de faciliter la production et la lecture automatique de ces rapports. Des extensions à ARF (RFC 6591 et RFC 6650) permettent de l'utiliser pour signaler des erreurs d'authentification.
SPF est un mécanisme d'authentification du courrier électronique qui fonctionne en listant les serveurs de courrier autorisés à émettre du courrier pour un domaine donné. Une fois l'émetteur connu, un récepteur peut alors appliquer ses politiques de sélection (accepter tous les messages en provenance de tel domaine, par exemple).
Les erreurs SPF peuvent être détectées par un récepteur de courrier, s'il fait des tests SPF, ou bien par un serveur de noms d'un domaine couvert par SPF : si on publie un enregistrement SPF spécialement fait pour cela (en utilisant les macros SPF qui permettent de récupérer plein d'informations sur la session SMTP en cours), le serveur DNS du domaine va voir passer les requêtes de vérification et pourra, par exemple, détecter une tentative d'usurpation pendant qu'elle se déroule.
Mais à qui signaler le problème ? Avant notre RFC 6652, il n'y avait pas d'autre moyen, en cas de problème SPF pour
example.net, que d'écrire à
postmaster@example.net. Désormais, la section 3
de notre RFC normalise des nouveaux modificateurs SPF, qu'on peut
inclure dans ses enregistrements, et qui permettent d'indiquer des
adresses de contact et les conditions sous lesquelles envoyer un
beau rapport ARF conforme au RFC 6591 :
ra=(Reporting Address) est le nom à utiliser à la place depostmaster. Si l'enregistrement SPF deexample.netcontientra=jimmy, on enverra l'éventuel rapport àjimmy@example.net(il n'existe aucun mécanisme pour spécifier un autre nom de domaine commevictim@somewhere.example, afin d'éviter que le gérant deexample.netpuisse faire spammer d'autres domaines).rp=(Requested report Percentage) est la proportion de problèmes SPF qui peut déclencher l'envoi d'un rapport. Si l'enregistrement SPF deexample.netcontientrp=0, il ne veut jamais être embêté par des rapports. Si l'enregistrement contientrp=100, il veut un rapport à chaque fois. Et s'il contientrp=25, il veut qu'un problème sur quatre, choisi au hasard, fasse l'objet d'un rapport. Cela permet de limiter le trafic répétitif. Notez qu'un champ du rapport ARF,Incidents:(section 3.2 du RFC 5965), permet d'indiquer que d'autres incidents sont connus mais ne font pas l'objet d'un rapport. Comme le note la section 6.2, à propos de la sécurité, le volume de rapports envoyés peut être conséquent (et pas connu à l'avance).rr=(Requested Reports) permet d'indiquer par quelle sorte de rapport on est intéressés (all= tous,f= erreurs fatales, etc, voir section 4.1).
Ces modificateurs SPF sont enregistrés dans le tout nouveau registre IANA, créé par ce RFC 6652 (section 5). Il inclut les modificateurs de la liste ci-dessus
ainsi que exp= et redirect=
qui avaient déjà été normalisés par le RFC 4408. Désormais, ce registre est ouvert à de futures
additions, selon les règles « Norme nécessaire » du RFC 5226.
Tirés de l'annexe B, voici des exemples d'enregistrements SPF du
domaine example.org
utilisant les nouveautés de notre RFC. D'abord un cas simple, avec
juste une
demande que les rapports soient envoyés à postmaster :
v=spf1 ra=postmaster -all
Un cas un peu plus compliqué, toujours avec un seul modificateur :
v=spf1 mx:example.org ra=postmaster -all
Et un cas qui utilise tous les modificateurs de ce RFC. On demande que
10 % des rapports d'erreur (pas d'échec d'authentification, non, des
erreurs lorsque l'enregistrement SPF ne peut être analysé, cf. RFC 7208, sections 2.6.6 et 2.6.7) soient envoyés à
postmaster :
v=spf1 mx:example.org -all ra=postmaster rp=10 rr=e
Il reste à voir quel sera le déploiement de ce système. Apparemment, plusieurs fournisseurs de logiciels y travaillent.
L'article seul
RFC 6640: IETF Meeting Attendees' Frequently Asked (Travel) Questions
Date de publication du RFC : Juin 2012
Auteur(s) du RFC : W. George (Time Warner Cable)
Pour information
Première rédaction de cet article le 25 juin 2012
Il n'y a pas que de gros RFC sérieux, détaillant pendant des dizaines de pages des protocoles compliqués. L'IETF est aussi une occasion de nombreuses rencontres dans le Vrai-Monde-Physique, grâce à ses réunions qui se tiennent trois fois par an dans des lieux éloignés (du point de vue de l'auteur du RFC et de ses lecteurs). Pour diminuer le stress de l'ingénieur en déplacement, il faut lui fournir de l'information. Laquelle ? Ce RFC répond à la question.
Il ne contient pas les réponses aux questions des étrangers en visite. Ces réponses dépendent du pays visité (et elles changent vite alors que les RFC sont statiques). Mais il liste les questions, de manière à ce que les indigènes puissent documenter les points importants de leur beau pays.
En effet, il y a toujours des volontaires locaux qui montent un site Web ou un Wiki pour présenter de l'information sur le site de la réunion. (Le RFC en donne des exemples.) S'ils suivent ce RFC, ils sont sûrs de n'oublier aucune question. Le RFC liste les grands sujets :
- Lister les aéroports les plus proches (avec évidemment leur code IATA puisque les participants à l'IETF les utilisent fréquemment pour nommer leurs routeurs et serveurs),
- Le meilleur moyen de se rendre de l'aéroport au lieu du meeting (la seule fois où je me suis fait agresser, pendant une réunion IETF, c'était dans le métro de Prague, où j'étais encombré de bagages).
- Des cartes à imprimer avec les adresses importantes, dans l'écriture locale, pour montrer au chauffeur de taxi. J'étais très content de les avoir, en Chine ou au Japon.
- La nourriture, le grand sujet de discussion sur la liste de diffusion des participants au meeting, les ingénieurs n'ont pas d'estomacs virtuels, et il en faut, des cookies, pour nourrir un participant à l'IETF. Les habitués d'autres conférences internationales noteront qu'il n'y a pas de déjeûner servi pendant les réunions IETF, il faut se débrouiller dans les environs, ce qui anime de nombreux débats sur la liste. Le RFC précise aussi qu'il faut indiquer les restaurants calmes, au cas où des participants veuillent travailler à un protocole compliqué (bien des protocoles TCP/IP ont été conçus dans un restaurant).
- Les prises électriques, bien sûr, car chaque membre de l'IETF se déplace avec de nombreux engins gourmands à brancher, et préfère manquer de nourriture que d'électricité pour son ordinateur. Heureusement, il existe un excellent site Web sur ce sujet. Dans la même veine, le RFC rappelle aux auteurs de sites Web ou de Wikis d'information que les participants apprécieront certainement des informations sur l'achat de cartes SIM ou les offres d'abonnement 3G locales. Même chose pour les boutiques de matériel (un autre grand classique de la liste de diffusion du meeting est « Cherche adaptateur secteur pour mon Dell Vostro, j'ai perdu le mien, une boutique qui aurait ça pas loin ? »)
- Les sujets désagréables comme les escroqueries locales ou bien ce que le RFC appelle « la faune hostile » (les réunions IETF se tenant toujours dans les grandes villes, aucun participant n'a jamais été mangé par un lion ou renversé par un rhinocéros).
Bref, un RFC pour les aventuriers, les explorateurs et les curieux. Voyagez, vous ne le regretterez pas.
L'article seul
RFC 6648: Deprecating the X- Prefix and Similar Constructs in Application Protocols
Date de publication du RFC : Juin 2012
Auteur(s) du RFC : P. Saint-Andre (Cisco), D. Crocker (Brandenburg InternetWorking), M. Nottingham (Rackspace)
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 25 juin 2012
Ce RFC met officiellement fin à une amusante
tradition, qui était un des charmes des protocoles
TCP/IP mais qui, en pratique, a causé quelques
ennuis, justifiant son abandon. Cette tradition concernait le nommage
des paramètres
dans les protocoles. Normalement, ces noms étaient
enregistrés à l'IANA pour éviter des collisions
(par exemple, il ne doit y avoir qu'un seul champ nommé
User-Agent: dans une requête
HTTP). Comme cet enregistrement nécessitait une
procédure, parfois lente et lourde, cela contrariait les gens qui
voulaient expérimenter avec une nouvelle idée, qui impliquait un
nouveau paramètre. L'habitude, avec l'appui de quelques RFC, s'était donc
répandue de donner à ces paramètres expérimentaux, non officiels, un nom
commençant par la lettre X suivie d'un tiret. Cette pratique a
rencontré plusieurs problèmes et est donc désormais fortement
déconseillée.
Le prefixe « X- » permettait de marquer clairement le nom de paramètre
comme expérimental. Sans lui, certains développeurs auraient peut-être
été tentés de s'auto-attribuer des noms, quitte à provoquer des
collisions avec d'autres développeurs. Mais le problème de l'Internet
est que les expériences durent : on invente un nouveau champ dans les
requêtes HTTP, mettons
X-recipe: pour indiquer sa recette favorite, on
se dit que c'est juste un essai, qu'on ne va pas s'embêter à demander
un nom officiel pour si peu, on
l'utilise dans un patch de
Firefox, dans un module
Apache, des gens commencent à s'en servir, on
se dit qu'il serait bon d'enregistrer un vrai nom et on s'aperçoit que
la base installée d'utilisateurs est déjà trop grande pour abandonner
le nom expérimental. C'est essentiellement pour éviter ce genre de
blocage que l'IETF vient de décider de mettre
fin à cette convention du « X- ».
Il y a d'autres protocoles que HTTP (d'où sont extraits les exemples précédents) qui utilisent de tels paramètres. Par exemple le format standard du courrier électronique (RFC 5322) ou bien les vCard (RFC 6350). Tous à un moment ou à un autre ont vu passer des paramètres dont les noms commençaient par « X- », X comme eXpérimental ou comme eXtension (SIP faisait un peu différemment avec des en-têtes dont le nom commençait par « P- », cf. RFC 5727). Une méta-information sur le paramètre, son statut expérimental, se trouvait ainsi stockée dans le nom. L'idée semblait tellement bonne qu'elle a même été codifiée par plusieurs RFC comme le RFC 822 (qui différenciait les Extension fields et les User-defined fields, section 4.1) ou comme le RFC 5545 (section 3.1). Par la suite, ces codifications ont souvent été retirées (pour le courrier, le RFC 2822 a annulé les dispositions du RFC 822).
Donc, ce nouveau RFC :
- Supprime la convention « X- », même pour les cas où elle était non-officielle et non documentée (cas de HTTP),
- Recommande à la place de nouvelles pratiques et de nouvelles conventions,
- N'interdit pas les noms de paramètres locaux ou expérimentaux : c'est la convention « X- » qui est en cause, pas l'idée de paramètres non enregistrés,
- Ne spécifie rien sur les paramètres « X- » existants, une question délicate qu'il faudra traiter au cas par cas.
Les programmeurs reçoivent (en section 2) la consigne de ne pas traiter un paramètre différemment juste sur la base de son nom. Qu'il commence par « X- » ou pas, le résultat doit être le même. (Faire autrement pourrait avoir des conséquences négatives sur la sécurité, par exemple si un programme considérait que les noms sans « X- » sont plus « sûrs » que les autres, comme expliqué en section 5.)
Quant aux créateurs de nouveaux paramètres (« Eh, je trouve qu'il
faudrait pouvoir indiquer la boisson favorite de l'utilisateur, y
a-t-il un en-tête Favorite-Drink: ? »), la section 3 leur dit que :
- Il faut s'attendre à ce que tout paramètre créé devienne un jour commun, largement déployé, non modifiable (c'est le grand problème avec la convention « X- » : les paramètres censés être expérimentaux deviennent permanents et non-modifiables),
- Il faut utiliser des noms parlants et non déjà utilisés,
- Et ne commençant pas par « X- ».
Pour limiter les risques de collision, si le paramètre n'est pas
enregistré, cette section recommande de le préfixer avec le nom de
l'organisation, à la Java, par exemple si
l'organisation se nomme Example International et a le domaine
example.com, utiliser
Example-International-Favorite-Drink: ou
Com-Example-Favorite-Drink: pour l'en-tête
experimental.
Quant aux concepteurs des futurs protocoles, la section 4 leur dit :
- N'oubliez pas de créer un registre des valeurs possibles pour les paramètres textuels, registre qui permettra d'éviter les collisions entre noms de paramètres. C'est le cas des noms de champs, utilisés entre autres par HTTP, par exemple.
- Idéalement, les procédures d'enregistrement dans ledit registre devraient être suffisamment simples et claires pour que les créateurs de paramètres (section précédente) ne soient pas tentés de choisir des noms de manière unilatérale,
- Ne faites pas de règles spécifiques pour les noms commençant par « X- ». Par exemple, ne spécifiez pas que ces noms sont interdits, ou qu'ils indiquent un type particulier de paramètre.
Reléguée en annexe A, mais essentielle, se trouve l'analyse historique de la convention « X- ». Il semble qu'elle ait été mentionnée la première fois par Brian Harvey en 1975, pour les paramètres FTP du RFC 691 (« an initial letter X be used for really local idiosyncracies »). Les RFC 737, RFC 743, RFC 775, RFC 822 ont ensuite repris l'idée, à laquelle les RFC 1123 et RFC 1154 ont donné une forme de reconnaissance officielle, en notant toutefois déjà le problème que posent des paramètres qui sont expérimentaux au début et qui deviennent normalisés sans le « X- » plus tard. On ne peut pas citer les nombreux RFC qui ont ensuite mentionné l'idée, sans forcément l'encourager. Mais même LDAP s'y était mis (RFC 4512). Par contre, cette convention n'a jamais reçu de validation au niveau de tout l'IETF : ni le RFC 2026, ni le RFC 5226 n'en parlent. Cette convention est donc (théoriquement) restée cantonnée à certains protocoles.
Les problèmes que pose cette convention « X- » ont quand même été notés assez tôt et, dès le RFC 2822, le courrier électronique arrêtait officiellement de l'utiliser. Idem pour SIP avec le RFC 5727.
Si vous voulez tout savoir des inconvénients de la convention
« X- », la partie du RFC à lire est l'annexe B, qui énumère les
problèmes. Le principal est que les paramètres ainsi nommés,
normalement locaux et/ou temporaires, tendent à fuir vers l'extérieur
et que, s'ils sont des succès, ils deviennent rapidement des
« standards de fait » (et les programmes doivent le traiter comme tel). Il faut alors se décider entre une migration
depuis le nom en « X- » et le nom officiel sans « X- », ou bien une
officialisation du nom avec « X- ». Dans les deux cas, la convention
« X- » n'aura pas aidé. Elle ne servirait que si les paramètres ainsi
nommés étaient tous des échecs qui ne restaient pas longtemps. Mais ce
n'est pas le cas. Un exemple typique est donné par les en-têtes
HTTP x-gzip et
x-compress, qui sont devenus des standards
de fait, au point que le RFC 2068 (section 3.5) conseillait de les
accepter, comme synonymes aux en-têtes standard ! (Son successeur, le
RFC 2616, a gardé cette recommandation.)
Dans le contexte du courrier électronique, on voit un phénomène
équivalent avec le conseil du RFC 5064
d'accepter X-Archived-At: comme équivalent à
Archived-At: (section 2.5). Excellent exemple
d'une expérimentation qui a tellement bien réussi qu'elle devient
ensuite une gêne. Quant au conseil de considérer les deux noms comme
équivalents, il est dangereux : les deux noms ont été définis
séparement et peuvent avoir des propriétés subtilement différentes (le
nom officiellement enregistré a souvent des règles de sécurité plus
strictes sur son usage, par exemple).
Bien sûr, il y a des gens qui défendent la convention « X- ». D'abord, il peut y avoir des cas où elle est légitime :
- Si on est absolument sûr que le paramètre ne sera jamais standardisé (l'expérience invite à la prudence...) Auquel cas l'annexe B recommande, pour éviter toute collision avec un nom officiel, de préfixer le nom du paramètre par celui de l'organisation.
- Quant un paramètre existe déjà et qu'il a le nom qu'on
voudrait. Le RFC estime que c'est une mauvaise idée. Si on a un
paramètre
priorityet qu'on est tenté de créerx-priority, il vaut mieux utiliser un synonyme (commeurgency) ou bien être créatif (get-it-there-fast). - Quant les noms doivent être très courts (c'est le cas des
étiquettes de langue du RFC 5646 où on peut utiliser
x). Mais, là, il vaut encore mieux utiliser des numéros.
Les critiques de ce RFC mettaient en avant d'autres arguments, plus philosophiques :
- Le « X- » était un signal clair du statut du paramètre (mais, on l'a vu, des paramètres « X- » sont devenus standardisés de fait).
- Les collisions entre noms sont plus facilement évitées s'il
existe une ségrégation, avec un préfixe dédié pour les noms locaux et
expérimentaux. Mais la plupart des espaces de nommage sont de grande
taille : rien n'empêche de nommer un en-tête
Very-Long-Parameter-With-Useless-Information-Just-Because-I-Can:pour être sûr qu'on ne le confonde pas avec un autre. (Les étiquettes de langue citées plus haut sont un contre-exemple, où l'espace de nommage n'est pas énorme.) - En parlant d'économie, il existe un RFC, le RFC 3692 qui recommande d'utiliser des valeurs spéciales pour les expériences ou les cas locaux. Mais cela concerne surtout les paramètres numériques, où l'espace manque souvent. Si vous avez un seul octet pour stocker une valeur, enregistrer des paramètres expérimentaux risque d'épuiser rapidement cet octet. Un exemple est celui de l'algorithme de cryptographie utilisé par DNSSEC. Il n'y a que huit bits pour l'indiquer et il faut donc allouer des valeurs prudemment. C'est pour cela que les valeurs 253 et 254 sont réservées pour les expérimentations et l'usage privé. Les paramètres alphabétiques n'ont en général pas ce problème : on n'est pas près de tomber à court de noms pour les en-têtes HTTP !
Si les gens utilisaient la convention « X- », au lieu d'enregistrer le nom de leur paramètre, ce n'est pas uniquement pour semer des chausse-trappes sous les pieds des futurs programmeurs. C'est aussi parce que l'enregistrement d'un nom a souvent été considéré (souvent à juste titre) comme excessivement compliquée et bureaucratique. Si on veut mettre effectivement fin à la convention « X- », la bonne méthode est donc aussi de libéraliser l'enregistrement, ce qu'avaient fait les RFC 3864 ou RFC 4288. Plusieurs participants à l'IETF avaient fait remarquer lors des discussions sur ce RFC que le vrai enjeu était de normaliser plus rapidement, pour éviter que les concepteurs de nouveaux paramètres ne soient tentés de s'allouer des noms de manière sauvage.
Ce RFC ne s'applique qu'aux protocoles utilisant des paramètres textuels. Lorsque le paramètre est, au contraire, identifié par sa position ou par un nombre, il n'est évidemment pas concerné.
L'article seul
Débats sur les mesures de la qualité d'accès à l'Internet
Première rédaction de cet article le 24 juin 2012
Comme le savent les lecteurs les plus fidéles, je participe à un groupe de travail de l'ARCEP qui a pour activité la définition de mesures de la qualité d'accès à l'Internet. Sur quelle base dire que le FAI X est meilleur que Y ? En mesurant, bien sûr, mais en mesurant quoi ?
Le problème est plus difficile qu'il ne semble au premier abord (d'autant plus que tous les participants ne sont pas forcément de bonne foi). Les débats au sein du comité technique (qui formulera des avis, pour la décision finale, qui sera prise bien plus haut) sont donc animés. Je ne vais pas tout trahir, juste donner une idée aux lecteurs curieux des débats et des problèmes posés. Rappelez-vous qu'il s'agit de débats en cours, et que le résultat final sera peut-être différent.
Alors, premier exemple. Un des indicateurs prévus est la rapidité
de récupération d'une page Web. On prend la
page en HTTP puis tous les objets qu'elle
contient (codes JavaScript, feuilles de style
CSS, images, etc). Ces objets peuvent inclure
des choses qui ne sont pas gérées directement par le webmestre
(publicités, notamment) et qui, pire, peuvent varier en taille selon
le demandeur (publicités ciblées). Alors, faut-il exclure les pubs ?
Le problème est de définir un algorithme précis que pourrait suivre le
programme de mesure. Tout ce qui est hébergé sous un autre nom de
domaine ? Mais il est très fréquent qu'un webmestre récupère les
contenus de www.example.com depuis un
CDN, qui utilisera un autre nom de
domaine. Tout serait plus simple si les publicités étaient marquées
clairement (<pub
href="http://www.invasionpublicitaire.example/bannerjpeg"/> ?)
mais ce n'est pas le cas.
Ce problème est un parfait exemple de la difficulté à mesurer la QoE. Beaucoup de gens affirment qu'il ne faut pas utiliser des mesures de bas niveau (comme la latence ou le taux de pertes) car « elles n'intéressent pas Mme Michu ». Selon eux, il faudrait au contraire mesurer des choses qui sont plus représentatives de l'activité de la dite Mamie du Cantal, genre le Web ou la vidéo. Mais ces mesures de haut niveau sont infiniment plus complexes, notamment parce qu'elles dépendent de millions de facteurs différents. Il est donc très tentant de les bricoler (en retirant les pubs, par exemple). Au final, elles sont d'une scientificité à peu près nulle (ou, comme disent les candidats à une élection, « les chiffres, on leur fait dire ce qu'on veut »).
Autre exemple d'un débat difficile, la télévision. La plupart des FAI imposent une offre « triple play » incluant la télévision (même si on ne la regarde jamais). Elle est typiquement envoyée sur un canal différent de l'accès Internet, pour pouvoir lui garantir le débit souhaité. La télévision peut donc sérieusement perturber l'activité Internet classique. Dans ces conditions, ne faudrait-il pas faire les mesures avec la télé allumée ? Autrement, un FAI qui ne fournirait qu'une capacité réseau tout juste suffisante pour la télé pourrait se vanter de bons chiffres immérités. Et cela serait plus réaliste (Mme Michu fait du SSH pendant que ses enfants regardent Dora.)
Mais on retombe alors dans les débats classiques des mesures « QoE ». Dès qu'on commence à bricoler tel ou tel facteur, le problème explose dans tous les sens. Faut-il tester tous les FAI avec la même qualité d'images (certains offrent basse et haute définition) ? Faut-il un facteur correcteur pour tenir compte de leurs codecs différents ? Si demain certains utilisent des codecs adaptatifs, faisant varier la qualité de l'image en réponse à la congestion, comment intégrer cela ? Bref, ces mesures trop compliquées sont très difficiles à définir rigoureusement.
Il n'y a pas que les mesures de haut niveau qui sont difficiles à définir. Pour les mesures de bas niveau (latence, perte de paquets et capacité), faut-il mesurer IPv6 ou pas ? Certains estiment qu'il est peu utilisé par Mme Michu et ne doit donc pas être mesuré. D'autres pensent que c'est une mesure techniquement pertinente (un certain nombre de réseaux offrent de moins bonnes caractéristiques en v6 qu'en v4). Mais, alors, ne risque-t-on pas de stigmatiser les FAI qui ont eu le courage de faire du v6 ?
Autre discussion sur les métriques de bas niveau, les mesures en aller-simple ou en aller-retour. Faut-il mesurer la latence sur un aller simple ou bien avec le retour, comme le fait ping ? En fait, les deux sont utiles (le RFC 7679 définit la première et le RFC 2681 la seconde). Mais on se heurte ici à de vulgaires problèmes économiques. Mesurer une latence en aller-simple ne peut pas se faire depuis un PC normal, il faut des machines spécialisées, avec stricte synchronisation d'horloges. Or, tout le monde est d'accord sur l'importance de faire ces mesures de qualité d'accès mais personne ne veut payer.
L'article seul
Apostrophes et autres non-lettres dans les noms de domaine
Première rédaction de cet article le 20 juin 2012
On me demande de temps en temps « Puis-je mettre une apostrophe dans un nom de domaine ? » La question a aussi des variantes comme « Et avec les IDN, c'est possible ? »
La réponse est complexe. En deux mots, non, vous n'y arriverez
pas. Plus exactement, vous pouvez techniquement, c'est standard (RFC 2181, section 11) et ça
marche (regardez le nom
dangerous'name.broken-on-purpose.generic-nic.net,
il a un enregistrement TXT). Mais la quasi-totalité des registres ne
vous permettront pas d'enregistrer un nom ayant une
apostrophe. Pourquoi ? Cela vient d'une vieille
règle, spécifiée dans le RFC 1123, section 2.1,
qui limite les noms de machines (et pas de
domaines) à « LDH », c'est-à-dire Letters Digits
Hyphen, excluant ainsi des non-lettres comme ', $, &, ou
%. Comme on enregistre en général un nom de domaine pour mettre des
machines en dessous, la grande majorité des registres ont choisi la
règle conservatrice. C'est ainsi que l'entreprise C&A ne peut
pas déposer c&a.fr (ou
c&a.com ou tout autre).
Et, inutile de dire, si vous tentez d'utiliser un nom contenant une
apostrophe, vous allez planter plusieurs programmes mal écrits, et
peut-être trouver une injection SQL ou
deux... (Si vous voulez planter les programmes de vos collègues,
regardez l'enregistrement MX de
dangerousrecord.broken-on-purpose.generic-nic.net...)
Ce qui est techniquement légal n'est pas forcément utilisable
en pratique.
Mais avec les IDN (RFC 5890), est-ce que les choses ne s'arrangent pas ? Non. La
norme actuelle (voir le RFC 5892) limite les
caractères autorisés aux lettres et chiffres. Les symboles restent
interdits (interdits dans la norme technique et pas simplement par les
politiques de registre). Pas de nom rigolo comme I♥NY.us. Les motivations pour cela sont diverses, allant de la
crainte pour certains programmes, comme ceux mentionnés plus haut, à des
vagues peurs sur des soi-disant « caractères dangereux »
(l'ICANN avait fait fortement pression en ce
sens). Les convertisseurs
IDN vous diront donc des choses comme
Error:: Disallowed/Unassigned 27 (U+27 étant le
point de code de l'apostrophe).
C'est très gênant pour certaines langues. Par exemple, en
hawaïen, le nom de l'archipel où on parle cette
langue est « Hawai‘i » et cette apostrophe Unicode (U+2018)
n'est pas légale. Pas moyen, donc, d'écrire
hawaii.gov correctement. Même problème pour le
breton, la ville de
Penmarc'h ne peut pas avoir
penmarc'h.fr, et même le futur
.bzh ne lui permettra pas.
Merci à Mathieu Crédou pour la discussion et pour avoir attiré mon
attention sur le
cas breton. Jonathan
L. me fait remarquer à juste titre qu'il existe
✝.ws et ☃.net, par
exemple. C'est exact. Cela peut être le résultat d'une politique de
registre plus laxiste. Ou tout simplement une survivance de l'ancienne
norme IDN (celle du RFC 3490), qui n'interdisait
pas explicitement les symboles.
L'article seul
Les chinois vont-ils diviser le DNS, laquer les canards et manger du chien ?
Première rédaction de cet article le 19 juin 2012
Pour du buzz, ça c'est du buzz. Trois employés d'opérateurs réseau chinois ont réussi à faire beaucoup parler d'eux, du DNS et de la Chine, en publiant un Internet-Draft intitulé « DNS Extension for Autonomous Internet (AIP) » et sur lequel tout le monde a déjà poussé des hurlements en criant que la Chine voulait censurer l'Internet.
D'abord, rectifions un peu le tir, au sujet des processus IETF. Le document publié, draft-diao-aip-dns, est uniquement un Internet-Draft. Ces documents, spécifiés dans le RFC 2026, peuvent être écrits par n'importe qui et sont publiés quasi-automatiquement (il n'y a que des vérifications de forme). Cela n'a donc rien d'officiel et ne signale aucun engagement particulier de l'IETF.
Ensuite, rien ne dit qu'il s'agit d'une demande officielle de la part des acteurs chinois de l'Internet. En théorie, la participation à l'IETF est individuelle et les contributeurs ne représentent pas leur employeur, a fortiori leur gouvernement. Bien sûr, en pratique, les gens n'agissent pas forcément tout seuls dans leur coin, surtout dans un pays très formaliste comme la Chine. Mais il ne faut pas forcément voir autre chose dans ce texte qu'un ballon d'essai.
Maintenant, sur le contenu, que propose ce court document ? Il a
été présenté, aussi bien par ses auteurs que par ses détracteurs comme
une révolution, « la possibilité d'avoir plusieurs Internet
autonomes » ou « un éclatement de l'Internet en entités nationales
fermées ». Remettons un peu les pieds sur terre. Le document ne
concerne pas tout l'Internet mais uniquement les noms de
domaine. Ceux-ci sont organisés de manière arborescente,
la racine tout en haut (désolé pour mes lecteurs arboriculteurs, mais
les informaticiens placent les racines des
arbres en haut), qui délègue des noms de
premier niveau à des entités qui délèguent des noms de deuxième
niveau, etc. Ainsi, le nom de domaine
www.peche.tourisme.wallonie.be est un nom du
TLD
.be, le domaine de
deuxième niveau est wallonie, celui de troisième
niveau tourisme, etc. La racine n'est pas
explicitement marquée, disons qu'elle est tout à droite, après le
be.
La proposition « AIP » décrite dans
l'Internet-Draft consiste à insérer un niveau
supplémentaire (les exemples dans le texte utilisent des noms comme
A et B) entre la racine et
le TLD. Cela créerait une « super-racine » et chacun des nouveaux TLD
(oui, c'est confus, et le fait que le document soit écrit en
chinglish n'aide pas) pourrait avoir un domaine de
second niveau nommé com ou
xxx. Il pourrait donc y avoir un
amazon.com.A et un
amazon.com.B qui seraient différents, tout comme
amazon.co.uk n'est pas forcément le même qu'amazon.co.jp.
Quel est le but de la manœuvre ? Le document n'est très clair
à ce sujet mais il laisse entendre que cela vient d'une insatisfaction
quant à la gestion de la racine actuelle, contrôlée par un unique
gouvernement, celui des États-Unis, qui peut
décider à volonté et unilatéralement qui gère
.iq, s'il y aura un
.xxx, etc.
Maintenant, analysons un peu : d'abord, du point de vue technique, la proposition est du pur pipeau. Prétendant créer un système à plusieurs racines, il crée en fait une super-racine, ne faisant ainsi que déporter le problème plus loin (qui gérera cette super-racine ? Qui décidera quels seront les noms utilisés et leurs gérants ?) C'est d'ailleurs le cas de l'écrasante majorité des innombrables propositions « multi-racines » qui flottent depuis des années. Elles jouent sur les mots, créant une nouvelle racine mais ne l'appelant pas ainsi.
Notons aussi que, dans un pays capitaliste, le fric n'est jamais bien loin. Les auteurs du draft ont pris soin de déposer un brevet sur cette idée...
Ensuite, cette proposition augmente-t-elle les possibilités de
censure ? Non. Les domaines sont déjà tous dépendants d'une loi
nationale et la censure est déjà parfaitement possible comme l'a
montré l'ICE en censurant de
nombreux domaines
.com (domaine national
états-unien).
Enfin, est-ce une bonne idée de pousser des cris d'orfraie à l'idée que la dictature chinoise (dictature qui bricole déjà le DNS et est admirée par les partis autoritaires du monde entier) pourrait contrôler son bout d'Internet ? Ces réactions sont souvent hypocrites : le gouvernement états-unien a toujours fermement refusé la moindre évolution de la gestion de la racine, la moindre ouverture, même minime, même purement symbolique. Il n'est donc pas étonnant que, face à ce contrôle mono-gouvernemental, certains pays cherchent des solutions alternatives.
L'article seul
RFC 6647: Email Greylisting: An Applicability Statement for SMTP
Date de publication du RFC : Juin 2012
Auteur(s) du RFC : M. Kucherawy (Cloudmark), D. Crocker (Brandenburg InternetWorking)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 18 juin 2012
La lutte contre le spam est un domaine où les certitudes (souvent assénées avec conviction) sont plus fortes que les faits. Prenez n'importe quel forum, en ligne ou ailleurs, où on discute des mesures qui pourraient limiter les conséquences du spam, vous y lirez et entendrez des affirmations radicales, par exemple sur l'efficacité du greylisting, sans que les affirmateurs ne se soucient d'appuyer leurs déclarations sur des mesures concrètes, faites dans la réalité. Comme le note notre RFC 6647, le greylisting est largement déployé, depuis de nombreuses années, marche bien et n'a pas d'inconvénient grave, mais il reste rejeté, sans raisons valables, par de nombreux « experts ». Ce RFC a mis du temps à sortir (il est courant à l'IETF que le texte de la norme vienne très longtemps après le déploiement) mais il changera peut-être cette perception.
Faites l'expérience vous-même : sur un MTA typique qui n'a pas encore le greylisting, activez-le, vous stopperez entre le tiers et les deux tiers du spam avant même que le premier octet de données n'ait été transmis. Si vous souhaitez, avant ou après, vous informer en détail, vous pouvez lire cet excellent RFC 6647, « Tout ce qu'il faut savoir sur le greylisting ». Il documente enfin officiellement une pratique courante depuis de nombreuses années.
Le principe du greylisting peut se résumer ainsi : on va refuser temporairement l'accès au serveur de messagerie à certains clients. Les clients normaux réessaieront, ce qu'une partie des spammeurs ne feront pas. On en sera ainsi débarrassé. La différence entre les mises en œuvre du greylisting se situe essentiellement dans les critères utilisés pour rejeter, puis pour accepter, un client SMTP.
L'idée est donc de considérer qu'un client « nouveau » est soumis au greylisting jusqu'à ce qu'il devienne « connu ». Une fois connu, on pourra le juger, par exemple sur les messages qu'il envoie. Ces mécanismes de réputation ne prenant pas en compte les nouveaux arrivants, le greylisting sert à les gérer en attendant. Sur la base de ce concept très général, le greylisting tel que déployé actuellement, consiste à renvoyer un code d'erreur SMTP, indiquant une erreur temporaire (code commençant par 4), à tout nouveau client SMTP. Les spammeurs utilisent souvent des logiciels spéciaux qui, pour de bonnes raisons, ne retentent pas de délivrer le message en cas d'erreur temporaire. Leur renoncement diminue la quantité de spam reçue. Les MTA ordinaires mettent le message dans une file d'attente, puis réessaient (c'est une fonction de base du courrier électronique, on essaie jusqu'à ce que ça passe) et verront donc leur message délivré car, au bout d'un moment, le greylisteur les considérera comme connus.
Il y a plusieurs types de greylisting et la section 2 en donne une liste. D'abord, ceux qui décident uniquement sur la base des informations de connexion (l'adresse IP et, peut-être, le nom obtenu par une requête de traduction d'adresse en nom). Le greylisting garde ensuite en mémoire les adresses des sources de courrier. Il refuse (code SMTP 421 ou équivalent) tant qu'une source n'a pas été vue depuis au moins N minutes (avec N variant typiquement entre 10 et 30).
En général, l'information est automatiquement retirée de la base lorsqu'on n'a pas vu cette source depuis X jours (typiquement entre 15 et 60). L'émetteur occasionnel devra donc montrer patte blanche à nouveau.
Naturellement, ce mécanisme peut être combiné avec une liste noire d'adresses IP (n'imposer le greylisting qu'à celles qui sont sur la liste noire) ou une liste blanche (dispenser du greylisting celles qui sont sur la liste blanche).
Avec le logiciel Postgrey, on peut avoir ce comportement (ne prendre en compte que l'adresse IP, pas le MAIL FROM
et le RCPT TO), en utilisant l'option
--auto-whitelist-clients (l'idée est que, si un
MTA réessaie plusieurs fois, il ne sert à rien de le tester pour
chaque adresse, il a montré qu'il était un « vrai » MTA.)
En laissant le client SMTP aller plus loin, et continuer la
session, on peut récolter des informations supplémentaires, qui
peuvent servir de paramètres au processus de décision du
greylisteur. C'est ainsi qu'on peut attendre le salut SMTP
(EHLO ou bien le vieux HELO)
et utiliser alors comme identificateur de la source SMTP le couple
{adresse IP, nom annoncé par EHLO}. Cela permet,
par exemple, de différencier deux clients SMTP situés derrière le même
CGN et ayant donc la même adresse IP
publique. Autrement, toutes les machines derrière un routeur
NAT bénéficieraient du passage de la première machine.
En continuant, on peut aussi récolter l'adresse de courrier
émettrice (commande SMTP MAIL FROM) et la ou les
adresses de courrier de destination (RCPT TO). Un
greylisteur qui est allé jusque là peut donc utiliser le triplet {adresse
IP, expéditeur, destinataire}. C'est la politique la plus
courante. C'est par exemple ce que fait par défaut Postgrey,
déjà cité, qui journalise ces informations (voir l'exemple plus
loin) pour pouvoir
analyser ce qui s'est passé.
Voici d'ailleurs un exemple de session SMTP. Le client est nouveau et donc greylisté :
% telnet mail.bortzmeyer.org smtp Trying 2001:4b98:dc0:41:216:3eff:fece:1902... Connected to mail.bortzmeyer.org. Escape character is '^]'. 220 mail.bortzmeyer.org ESMTP Postfix EHLO toto.example.net 250-mail.bortzmeyer.org 250-PIPELINING 250-SIZE 10000000 250-VRFY 250-ETRN 250-STARTTLS 250-ENHANCEDSTATUSCODES 250-8BITMIME 250 DSN MAIL FROM:<foo@example.net> 250 2.1.0 Ok RCPT TO:<stephane+blog@bortzmeyer.org> 450 4.7.1 <stephane+blog@bortzmeyer.org>: Recipient address rejected: Greylisted by greyfix 0.3.9, try again in 300 seconds. See http://www.kim-minh.com/pub/greyfix/ for more information.
Cinq minutes après, le client réessaie et est accepté :
% telnet mail.bortzmeyer.org smtp Trying 2001:4b98:dc0:41:216:3eff:fece:1902... Connected to mail.bortzmeyer.org. Escape character is '^]'. 220 mail.bortzmeyer.org ESMTP Postfix EHLO toto.example.net 250-mail.bortzmeyer.org 250-PIPELINING 250-SIZE 10000000 250-VRFY 250-ETRN 250-STARTTLS 250-ENHANCEDSTATUSCODES 250-8BITMIME 250 DSN MAIL FROM:<foo@example.net> 250 2.1.0 Ok RCPT TO:<stephane+blog@bortzmeyer.org> 250 2.1.5 Ok DATA 354 End data with <CR><LF>.<CR><LF>
En pratique, la grande majorité des logiciels de greylisting ne va pas
plus loin. Après tout, le but est de rejeter du spam sans consommer de
ressources et donc en réduisant la durée de la session et la capacité
réseau utilisée. Toutefois, le RFC cite la possibilité d'attendre
encore un peu et d'aller jusqu'à la réception du message (commande
SMTP DATA). Le greylisteur ne va pas forcément
analyser le corps du message, il peut aussi attendre le
DATA car certains clients bogués réagissent mal
lorsque le refus de continuer la session arrive avant
DATA. Mais le RFC note que cette analyse du
contenu du message reste possible, bien que je ne connaissais pas de
greylisteur qui le fasse. Mais Gabriel Kerneis m'en a cité un : sa-exim qui documente cette fonction. Et il y a aussi smtpf.
Naturellement, un greylisteur peut inclure d'autres informations dans sa prise de décision comme la présence de l'expéditeur dans une liste noire (RFC 5782) ou comme un motif dans le nom du client (on fait une requête pour traduire l'adresse IP en nom, et si dyn ou adsl sont dans le nom, on rejette temporairement).
Le greylisteur peut aussi avoir une liste d'exceptions, pour gérer les
cas particuliers, par exemple ceux dont on sait qu'ils ne réessaient
pas correctement, ou qui attendent trop longtemps avant de
réessayer. Par exemple, pour Postgrey, on trouve dans le fichier
/etc/postgrey/whitelist_clients une liste de
domaines dont l'émetteur de courrier est défaillant (il ne réessaie
pas) mais dont on souhaite recevoir les messages, par exemple :
... # greylisting.org: Southwest Airlines (unique sender, no retry) southwest.com ...
Comme toute technique de sécurité, le greylisting est un compromis : il a des bénéfices et il a des coûts. La section 3 est consacrée à l'examen de ces avantages et inconvénients (et la section 9 revient ensuite sur certains de ces choix). L'avantage principal est qu'une partie significative du spamware ne réessaie jamais, après le refus initial, et que la quantité de spam à traiter va donc diminuer.
L'inconvénient principal est que certains messages seront retardés. Le MTA typique réessaie par défaut au bout de 15 minutes mais c'est réglable et les gros hébergeurs de courrier augmentent en général cette durée, souvent jusqu'à 60 minutes, pour limiter la charge de leurs serveurs, dont la file d'attente est souvent très grosse. Pire, certains (comme le serveur de Southwest Airlines, cité plus haut) ne réessaient pas du tout. Dans ce dernier cas, ils sont en violation caractérisée de la norme SMTP et auront des problèmes avec bien d'autres choses que le greylisting (une coupure réseau, et hop, le courrier est fichu).
Ce problème du retard est-il sérieux ? Le courrier électronique a toujours été « au mieux », c'est-à-dire qu'une distribution immédiate ne fait pas partie du cahier des charges. Si des gens comptaient sur une délivrance instantanée, c'est qu'ils n'avaient pas compris le principe du courrier.
Le retard est de toute façon rare en pratique. Comme le greylisteur se souvient des émetteurs corrects (qui réessaient après la première rebuffade) qu'il a rencontrés, et comme la plupart des messages entrants viennent de correspondants réguliers, peu de messages sont vraiment retardés. Si on souhaite à tout prix réduire encore ce nombre, notamment en mettant en service un nouveau serveur, dont la mémoire est vide, on peut toujours envisager de pré-remplir la mémoire avec des adresses extraites du journal (le RFC cite cette possibilité, que je trouve bien compliquée et n'en valant pas la peine).
La section 4 décrit en détail les conséquences non souhaitées du greylisting. Comme pour les notices des médicaments qui préviennent des effets secondaires possibles, il faut la lire en mettant ces inconvénients en rapport des avantages (voir aussi la section 9.1, sur les compromis). Exemple de problème, si on a plusieurs serveurs de courrier (plusieurs entrées dans l'enregistrement MX), et s'ils ne partagent pas leur base d'émetteurs, un client SMTP qui, refusé par le premier, essaiera le second, puis le troisième, etc, sera ainsi retardé plusieurs fois. En parlant de MX secondaire, le RFC recommande également de configurer le primaire pour qu'il accepte les messages des secondaires sans greylisting (puisque le message a déjà été greylisté par le secondaire, a priori une machine de confiance).
Autre cas pathologique, celui d'une machine qui n'envoie du courrier que rarement. Ses informations expireront de la base avant le prochain envoi et elle sera donc souvent considérée comme « nouvelle » et donc greylistée.
Outre le retard, un effet parfois ennuyeux du greylisting est le
réordonnancement des messages. Si Alice écrit à Bob et Charlie et que
son émetteur est connu du MTA de Bob, mais pas de celui de Charlie, la
délivrance à Charlie sera retardée. Si Bob répond à Alice, et que le
MTA de Bob est connu de celui de Charlie, Charlie recevra la réponse
de Bob avant le message original d'Alice. Une note personnelle au
passage : cela montre l'importance des MUA qui
remettent les messages dans l'ordre comme mutt
avec son option set sort=date-sent (qui dépend
d'un réglage correct de la date par l'expéditeur) ou
set sort=threads (qui utilise les en-têtes du
message comme References:).
Il y a aussi des problèmes qui sont de la faute du client SMTP. S'il ne réessaie pas, il aura des problèmes avec le greylisting mais aussi avec toute panne réseau temporaire. S'il considère tous les codes d'erreur SMTP comme permanentes (alors que la section 4.2.1 du RFC 5321 est bien clair que les codes de type 4xy sont des erreurs temporaires), il aura des problèmes avec le greylisting et avec certaines erreurs sur le MTA.
Si le client SMTP utilise une adresse d'expéditeur de courrier différente pour chaque essai (une idée très baroque mais tout existe sur l'Internet), et que le greylisteur utilise cette adresse pour déterminer si un envoi est nouveau, alors, le message ne passera jamais.
Enfin, les logiciels de test des adresses de courrier peuvent avoir des problèmes avec le greylisting comme Zonecheck et sa bogue #9544.
Après cette liste de problèmes possibles, les recommandations concrètes, pour que le greylisting apporte joie et bonheur et que les problèmes restent virtuels. Elles figurent en section 5 et les principales, tirées de la longue expérience du greylisting, sont notamment :
- Mettre en œuvre le greylisting en utilisant comme tuple
définissant un visiteur le triplet {adresse IP source, adresse de
courrier en
MAIL FROM, première adresse de courrier dans leRCPT TO}. L'inclusion des adresses de courrier a notamment pour but de limiter le réordonnancement des messages. Une fois que ce test a été passé une fois, autoriser l'adresse IP quelles que soient les adresses (le MTA client a montré qu'il réessayait, de toute façon). - Permettre à l'administrateur système de
configurer la période de quarantaine imposée au nouveau client. Le RFC
définit une valeur par défaut souhaitable comme étant entre 1 minute
et 24 heures (oui, c'est large). (Avec Postgrey, c'est l'option
--delay.) - Supprimer les entrées de la base au bout d'une période
d'inactivité configurable (par défaut, d'au moins une semaine, dit le
RFC). (Avec Postgrey, c'est l'option
--max-age.) - Considérer comme adresse IP de la source un préfixe entier (par
exemple un /24 pour IPv4), pas
juste une adresse, pour le cas des pools de
serveurs SMTP (le second essai ne viendra pas forcément de la même
machine). Cela réduit également la taille de la base nécessaire, ce
qui peut être très important pour IPv6
(cf. section 7, ainsi que la section 9.2) où le nombre d'adresses potentielles est bien plus
grand. (Postgrey a une option limitée,
--lookup-by-subnet, mais où la longueur du préfixe est fixe, 24 bits en IPv4. Greyfix est plus souple.) - Permettre de définir une liste blanche d'adresses autorisées à
passer outre. (Chez Postgrey, ce sont les fichiers de configuration
comme
/etc/postgrey/whitelist_clients.) - Ne pas faire de greylisting sur le service de soumission de courrier (RFC 6409).
En revanche, notre section 5 ne recommande pas de valeur particulière pour le code de retour SMTP lorsqu'on refuse temporairement un client. 421 et 450 semblent les deux choix possibles (RFC 5321, section 4.2.2).
SMTP permet de mettre dans la réponse, outre un code numérique, un court texte. Faut-il dire explicitement que du greylisting est en action, ce qui peut aider un spammeur ? Le RFC estime que oui, pour être sympa avec les utilisateurs légitimes (c'est ce que font les deux logiciels de greylisting montrés en exemple dans cet article).
La section 6 du RFC est consacrée à la question de la mesure de l'efficacité du greylisting. Elle suggère une expérience intéressante que, à ma connaissance, personne n'a tenté : regarder si les adresses IP greylistées (et qui ne réessaient pas) sont plus souvent présentes que les autres dans les grandes DNSBL. Une corrélation indiquerait qu'on gêne bien surtout les spammeurs.
Il existe aujourd'hui des mises en œuvre du greylisting pour à peu
près tous les MTA possibles. Pour
Postfix, les deux solutions les plus courantes
en logiciel libre sont Greyfix et Postgrey. On configure Greyfix en indiquant dans le
master.cf de Postfix :
greyfix unix - n n - - spawn user=nobody argv=/usr/local/sbin/greyfix --greylist-delay 300 --network-prefix 28
Les deux options indiquées ici lui imposent de ne pas accepter un
nouveau client avant 300 secondes, et de considérer toutes les
adresses d'un même /28 comme équivalentes. (Greyfix peut aussi le
faire en IPv6, avec --network6-prefix.). Un nouveau
client rejeté est journalisé ainsi :
May 29 14:59:32 aetius postfix/smtpd[25150]: NOQUEUE: reject: RCPT from unknown[117.214.206.76]:4974: 450 4.7.1 <w3c@bortzmeyer.org>: Recipient address rejected: Greylisted by greyfix 0.3.9, try again in 300 seconds. See http://www.kim-minh.com/pub/greyfix/ for more information.; from=<viagra-soft.pills@peoplecube.com> to=<w3c@bortzmeyer.org> proto=ESMTP helo=<rkktfe.com>
Pour
Postgrey, qui tourne comme un démon séparé, ici
sur le port 10023, la
configuration se fera dans le main.cf :
smtpd_recipient_restrictions = permit_mynetworks, \
check_policy_service inet:127.0.0.1:10023
Et un client rejeté produira :
May 28 16:08:33 lilith postfix/smtpd[20582]: NOQUEUE: reject: RCPT from 241.146.12.109.rev.sfr.net[109.12.146.241]:3964: 450 4.2.0 <info@generic-nic.net>: Recipient address rejected: Greylisted, see http://postgrey.schweikert.ch/help/generic-nic.net.html; from=<banderolepub01@gmail.com> to=<info@generic-nic.net> proto=SMTP helo=<3lyw4> May 28 16:08:33 lilith postgrey[1447]: action=greylist, reason=new, client_name=241.146.12.109.rev.sfr.net, client_address=109.12.146.241, sender=banderolepub01@gmail.com, recipient=info@generic-nic.net
Une question un peu philosophique, maintenant, que ne traite guère
notre RFC. Pourquoi est-ce que les logiciels de spam courants ne réessaient
pas, après l'erreur temporaire reçue ? Cela peut sembler déroutant
puisque, de leur point de vue, ce serait la solution évidente au
greylisting. Il y a plusieurs raisons à cette passivité. L'une
est que le greylisting n'est pas universellement déployé. S'il l'était, les
choses changeraient peut-être (finalement, était-ce une bonne idée de
publier ce RFC ?) Ce point de vue est par exemple développé dans
l'Internet-Draft draft-santos-smtpgrey. Ensuite,
les spammeurs visent typiquement le volume,
pas la qualité. Pourquoi s'embêter à réessayer alors qu'il est bien
plus efficace, en terme de volume, de passer tout de suite à la
victime suivante dans la liste ? Mais il y a aussi sans doute
aussi crainte d'être repérés s'ils essaient : un
zombie essaie en général d'être discret.
De bonnes lectures :
- L'une des toutes premières publications sur le greylisting dans SAUCE, en 2001.
- Le premier article détaillé, « The Next Step in the Spam Control War: Greylisting » en 2003.
- Bien plus récent, mon article qui date de trois ans.
- Et le site « officiel ».
Merci à Kim-Minh Kaplan pour sa relecture.
L'article seul
RFC 6672: DNAME Redirection in the DNS
Date de publication du RFC : Juin 2012
Auteur(s) du RFC : S. Rose (NIST), W. Wijngaards (NLnet Labs)
Chemin des normes
Première rédaction de cet article le 18 juin 2012
Depuis sa normalisation dans le RFC 1034, le DNS a suscité le développement d'innombrables extensions, plus ou moins réalistes, plus ou moins utilisées. L'enregistrement DNAME, sujet de ce RFC, semble encore très peu utilisé : il permet de donner un synonyme à une zone entière, pas à un seul nom, comme le fait l'enregistrement CNAME. DNAME avait à l'origine été normalisé dans le RFC 2672, que notre RFC met à jour.
Les enregistrements DNAME permettent d'écrire des équivalences comme :
vivendi-environnement.fr. DNAME veolia.fr.
et un nom comme www.vivendi-environnement.fr sera
transformé en www.veolia.fr. Le but étant ici de
changer le nom de l'entreprise en Veolia sans
avoir à s'inquiéter de toutes les occcurrences de l'ancien nom qui
trainent dans des signets privés,
dans la presse écrite, sur del.icio.us,
etc. DNAME a aussi été envisagé (mais peu utilisé) pour les
délégations des sous-arbres de traduction d'adresses IP en noms
(in-addr.arpa et ip6.arpa),
afin de permettre une rénumérotation d'un réseau relativement
légère (section 6.3, qui fournit un exemple et note honnêtement que
cela ne résout qu'une petite partie du problème de la renumérotation). Il a aussi été prévu de l'utiliser pour les variantes de
domaines IDN (par exemple pour faire une
équivalence entre le domaine en chinois
traditionnel et le domaine en chinois
simplifié). Enfin, il est utilisé dans l'ONS fédéré.
En fait, les enregistrements DNAME ne sont pas aussi simples que
cela. Le DNAME ne s'applique pas réellement à la zone mais à tous les
sous-domaines de l'apex. Il faut donc dupliquer
tous les enregistrements de l'apex (typiquement, les MX et les NS). Le
vrai fichier de zone pour
videndi-environnement.fr ressemblerait plutôt à :
@ IN SOA ... Dupliquer le SOA de veolia.fr
IN NS ... Idem pour NS et MX
IN MX ...
IN DNAME veolia.fr.
; Et ça suffit, les noms comme www.vivendi-environnement.fr seront
; gérés par le DNAME.
DNAME est donc complémentaire du CNAME : celui-ci « aliase » un nom, le DNAME aliase un sous-arbre. Si on veut aliaser les deux, il faut faire comme dans le fichier de zone ci-dessus. Sinon, il faudrait DNAME et CNAME (mais on ne peut pas se servir des deux en même temps) ou bien créer un nouveau type de données (un BNAME, qui aurait les propriétés des deux, a été discuté à l'IETF).
Le tableau 1 du RFC donne des exemples de cas simples et de cas
plus tordus. Il prend trois entrées, le nom demandé (QNAME pour
Query Name), le nom du DNAME (owner
name) et la cible de ce dernier. Par exemple, avec le DNAME
ci-dessus (owner name
videndi-environnement.fr, cible
veolia.fr), un QNAME de
videndi-environnement.fr ne donnera rien (le
DNAME ne concerne que les domaines en dessous de l'apex), un QNAME de
www.videndi-environnement.fr donnera
www.veolia.fr, un QNAME de
www.research.videndi-environnement.fr donnera
www.research.veolia.fr. Attention, les chaînes
(un DNAME pointant vers un DNAME) sont légales. Du point de vue
sécurité, une chaîne est aussi forte que son maillon le plus faible et
notre RFC, comme le RFC 6604 spécifie que
DNSSEC ne doit valider une chaîne que si tous
les alias sont valides (section 5.3.3).
Pour que la redirection vers la cible soit déterministe, le RFC impose (section 2.4) qu'un seul DNAME, au maximum, existe pour un nom. BIND refuserait de charger une telle zone et nous dirait (version 9.9.1) :
23-May-2012 22:39:35.847 dns_master_load: foobar.example:20: sub.foobar.example: multiple RRs of singleton type 23-May-2012 22:39:35.847 zone foobar.example/IN: loading from master file foobar.example failed: multiple RRs of singleton type 23-May-2012 22:39:35.847 zone foobar.example/IN: not loaded due to errors.
Si on préfère tester avec l'excellent validateur de zones validns, il faut se
rappeler que ce test est considéré comme de politique locale et n'est
pas activé par défaut. Il faut donc penser à l'option
-p :
% validns -z foobar.example -p all ./foobar.example ./foobar.example:19: multiple DNAMEs
Notre RFC prévoit le cas où le client DNS pourrait ignorer les DNAME. Le serveur synthétise des enregistrements CNAME équivalents (section 3.1) et les met dans la réponse. Le TTL de ses enregistrements doit être celui du DNAME (c'est un des gros changements par rapport au RFC 2672, où le TTL du CNAME généré était de zéro).
Notez qu'un DNAME peut être créé par mise à jour dynamique du contenu de la zone (section 5.2, une nouveauté par rapport au RFC 2672), masquant ainsi tous les noms qui pouvaient exister avant, sous son nom. Avec un serveur BIND 9.9.1, avant la mise à jour, on voit un nom ayant une adresse :
% dig @127.0.0.1 -p 9053 AAAA www.sub.foobar.example ... ;; ANSWER SECTION: www.sub.foobar.example. 600 IN AAAA 2001:db8::2
et, après une mise à jour dynamique où ce programme ajoute un DNAME
pour sub.foobar.example et pointant vers example.org, on obtient :
% dig @127.0.0.1 -p 9053 AAAA www.sub.foobar.example ... ;; ANSWER SECTION: sub.foobar.example. 300 IN DNAME example.org. www.sub.foobar.example. 300 IN CNAME www.example.org.
(Si le serveur était récursif, on obtiendrait également l'adresse
IPv6 de www.example.org.)
Les DNAME sont mis en œuvre dans BIND
et nsd mais semblent
peu déployés. Si vous voulez regarder ce que
cela donne, testez testonly.sources.org qui est
un DNAME de example.org donc, par exemple,
www.testonly.sources.org existe :
% dig AAAA www.testonly.sources.org ... ;; ANSWER SECTION: testonly.sources.org. 86400 IN DNAME example.org. www.testonly.sources.org. 0 IN CNAME www.example.org. www.example.org. 171590 IN AAAA 2001:500:88:200::10
(Notez que le serveur utilisé n'a pas suivi la nouvelle règle de notre RFC 6672 et a mis un TTL de zéro.)
Selon moi, une des raisons pour le peu de déploiement de DNAME est que le problème peut se résoudre tout aussi simplement, sans changement dans le DNS, par l'utilisation d'une préprocesseur ou bien en créant un lien symbolique entre les deux fichiers de zone (si le fichier ne contient que des noms relatifs, ça marche très bien, que ce soit avec BIND ou avec nsd).
Les changements par rapport au RFC 2672 sont limités. C'est le même type d'enregistrement (numéro 39) et le même format sur le réseau. Parmi les principaux changements, le TTL du CNAME synthétisé (déjà décrit plus haut) et la disparition complète de l'utilisation d'EDNS pour signaler qu'un client connait les DNAME (cette option était normalisée dans le RFC 2672, section 4.1). L'annexe A donne la liste complète des changements.
L'article seul
RFC 6548: Independent Submission Editor Model
Date de publication du RFC : Juin 2012
Auteur(s) du RFC : N. Brownlee (University of Auckland), éditeur pour l'IAB
Pour information
Première rédaction de cet article le 18 juin 2012
Si vous n'aimez pas les RFC de procédure, et que vous ne voulez que de la technique, rassurez-vous, ce document est court : il spécifie le rôle et les qualités de l'ISE (Independent Submission Editor), celui (ou celle) qui supervise les RFC qui ne passent pas par l'IETF. (Il a par la suite été remplacé par le RFC 8730.)
Comment, ça existe ? Tous les RFC ne naissent pas au sein d'un des nombreux groupes de travail de l'IETF ? Eh oui, c'est souvent oublié, mais c'est le cas, il existe une voie indépendante qui permet à des individus de publier un RFC, quel que soit l'avis de l'IETF. Cette voie est décrite dans le RFC 4846. Autrefois, il n'existait qu'un seul RFC Editor pour examiner et préparer tous les RFC. Mais cette tâche est désormais répartie entre plusieurs éditeurs spécialisés et l'ISE est en charge de la voie indépendante.
Ce mécanisme était décrit dans le RFC 5620 (modèle du RFC Editor, « v1 »), document désormais réparti entre plusieurs RFC comme le RFC 6635 (modèle du RFC Editor, « v2 ») et ce RFC 6548.
La section 2.1 décrit les qualifications attendues de l'ISE. Ce doit être quelqu'un d'expérimenté (senior), compétent techniquement dans les sujets traités à l'IETF (ce qui fait beaucoup !), connu et reconnu de la communauté IETF, sachant écrire et corriger, connaissant très bien l'anglais, et capable de travailler dans le milieu souvent agité de l'IETF.
Sa tâche principale (section 2.2) est de maintenir la qualité des RFC de la voie indépendante, par la relecture et l'approbation des documents, avant transmission au Producteur des RFC (RFC Production Center). Mais il doit aussi traiter les errata pour les RFC de la voie indépendante, contribuer à définir les évolutions de cette voie, interagir avec les autres acteurs des RFC, et fournir des statistiques à l'IAB et l'IAOC. Il peut se faire assister par un conseil consultatif, dont il nomme les membres « at the pleasure of the ISE », dit le RFC dans une jolie formule. Il y a aussi un conseil éditorial, également nommé par l'ISE (section 3 du RFC).
Le site officiel des RFC contient une page consacrée à la voie indépendante, si cela vous tente d'y publier.
L'ISE est nommé par l'IAB, selon une procédure analogue à celle du RFC 4333. Aujourd'hui, c'est Nevil Brownlee (l'auteur du RFC), qui joue ce rôle. Il a été reconfirmé le 5 février 2012, sa première désignation avait été en 2010.
L'article seul
Exposé politique « Le geek, le technocrate et le politique ignorant »
Première rédaction de cet article le 17 juin 2012
Le 16 juin, au festival Pas Sage en Seine, j'ai eu le plaisir de faire un exposé sur la politique, notamment sur ses rapports avec la technique. Carl Sagan disait (dans son livre The Demon-Haunted World) « Thomas Jefferson may have been the last scientifically Literate President » pour déplorer le manque de culture technique des hommes politiques. Avait-il raison ? Le fond du problème est-il là ?
Le résumé de mon exposé, dans le programme, indique que je ne suis pas tout à fait d'accord avec Sagan : On lit souvent sur les forums en ligne des affirmations du genre « Pas étonnant que la loi XYZi soit débile, les politiques sont des crétins qui ne connaissent rien à la technique » D'abord, est-ce exact ? Tous les politiques sont-ils aussi ignorants que le neuneu qui, parce qu'il a écrit une fois trois lignes de PHP et suivi un séminaire SEO, croit qu'il saurait faire des lois meilleures ? Et, ensuite, même si c'est exact, même si le député, le sénateur ou le ministre est vraiment d'une ignorance crasse, est-ce pour cela que la loi est mauvaise ? Ou plutôt parce que le député ou le ministre savent ce qu'ils font, en bien ou en mal ? (HADOPI est une loi scandaleuse, pas parce que ses concepteurs sont des ignorants, mais parce qu'ils sont des vendus à l'industrie du divertissement.) D'ailleurs, faut-il que les politiques soient des experts du domaine ? Est-ce que les lois sur l'Internet doivent être faites exclusivement par les geeks, les lois sur l'agriculture uniquement par des paysans et les lois sur la santé seulement par des médecins ? Ou bien est-ce qu'on doit sortir d'une vision technocratique et admettre que la politique est un sport distinct de la technique ?
Voici les supports de l'exposé :
- Version adaptée à l'écran,
- Version adaptée à l'impression sur des arbres morts,
- Source.
La journée en question a fait l'objet d'un excellent compte-rendu dans OWNI, avec interview vidéo de votre serviteur. Et j'en profite pour citer un excellent article de Laurent Chemla à peu près sur ce thème.
L'article seul
RFC 6637: Elliptic Curve Cryptography (ECC) in OpenPGP
Date de publication du RFC : Juin 2012
Auteur(s) du RFC : A. Jivsov (Symantec Corporation)
Chemin des normes
Première rédaction de cet article le 12 juin 2012
Le format OpenPGP, normalisé dans le RFC 4880, permet de choisir parmi plusieurs algorithmes de cryptographie, afin de pouvoir suivre les progrès de la cryptanalyse. Notre tout nouveau RFC ajoute à la liste de ces algorithmes des algorithmes à courbes elliptiques, venant s'ajouter aux traditionnels RSA et DSA. Il a par la suite été intégré à la nouvelle version de la norme OpenPGP, dans le RFC 9580.
La section 3 rappelle deux ou trois choses sur les courbes elliptiques. Celles-ci sont décrites dans le RFC 6090 mais pour ceux et celles qui voudraient un cours plus scolaire, ce RFC recommande le Koblitz, « A course in number theory and cryptography », chapitre VI « Elliptic Curves » (ISBN: 0-387-96576-9, Springer-Verlag, 1987). La motivation principale pour utiliser les courbes elliptiques est qu'elles fournissent une alternative à l'augmentation régulière de la taille des clés RSA, augmentation rendue nécessaire par les avancées de la cryptanalyse. La section 13 de ce RFC fournit une estimation quantitative : la courbe elliptique P-256, avec ses 256 bits, fournit à peu près la résistance d'une clé RSA de 3 072 bits. Et la P-384 fournit environ l'équivalent de 7 680 bits RSA.
La NSA a listé une série d'algorithmes à courbes elliptiques recommandés, sous le nom de Suite B. Celle liste comprend deux algorithmes, ECDSA et ECDH, et trois courbes elliptiques (cf. norme NIST FIPS 186-3) P-256, P-384 et P-512. Ce RFC décrit donc comment intégrer la suite B au format ouvert et normalisé OpenPGP. Les deux algorithmes ont reçu les numéros 19 (pour ECDSA) et 18 (pour ECDH).
Si vous voulez l'encodage exact des paramètres de la courbe elliptique dans les données, voir les sections 6 à 8 de notre RFC. L'encodage des clés cryptographiques figure en section 9.
Au moins deux mises en œuvre d'OpenPGP ont déjà du code pour ces courbes elliptiques, celle de Symantec et le logiciel libre GnuPG. Pour ce dernier, le code est déjà dans la version de développement (tête du dépôt git) mais pas encore dans la dernière version officiellement publiée (la 2.0.19).
L'article seul
RFC 6635: RFC Editor Model (Version 2)
Date de publication du RFC : Juin 2012
Auteur(s) du RFC : O. Kolkman (IAB), J. Halpern (Ericsson)
Pour information
Première rédaction de cet article le 12 juin 2012
L'articulation compliquée entre l'IETF qui produit les normes TCP/IP et le RFC Editor qui les publie, n'a jamais cessé de faire couler de l'encre (ou d'agiter des électrons). Dans ce document, l'IAB décrit un modèle pour le RFC Editor, modèle où les fonctions de ce dernier sont éclatées en plusieurs fonctions logiques. Elles peuvent ainsi être réparties entre plusieurs groupes. Ce modèle « v2 » est une version légèrement modifiée de la première description (« v1 »), qui figurait dans le RFC 5620. À son tour, il a été remplacé (mais sans changement fondamental du modèle) par le RFC 8728.
Le document de référence actuel est le RFC 8729. Comme le rappelle la section 1, il décrit les tâches du RFC Editor de manière globale, comme si c'était forcément une seule entité (c'était, à l'origine, une seule personne, Jon Postel). La section 2 note que la tâche de RFC Editor est actuellement une partie de l'IASA et financée par son budget.
La même section 2 s'attaque à la définition du rôle du RFC Editor sous forme de fonctions séparées. Le RFC 5620 avait été le premier à décrire ces fonctions. Elles sont ici légèrement modifiées, compte-tenu de l'expérience et des problèmes rencontrés, problèmes de communication qui n'existaient évidemment pas lorsque Postel faisait tout lui-même. (Notez que notre RFC 6635 ne donne malheureusement pas la liste des changements les plus importants, par rapport à la v1 du RFC 5620. Il est vrai qu'il n'y a rien de crucial, juste de la cuisine organisationnelle.) Le terme de RFC Editor désigne collectivement toutes ces fonctions. L'IAB voit maintenant trois fonctions (voir aussi le dessin 1 de notre RFC) :
- Éditeur de la série des RFC,
- Producteur des RFC,
- Publieur des RFC,
- Enfin, l'éditeur des contributions indépendantes, qui était présent dans l'ancien RFC 5620 est désormais décrit à part, dans le RFC 6548.
Chaque section va ensuite détailler ces tâches. Il y a également des rôles de supervision, tenus par l'IAB (RFC 2850) et l'IAOC (RFC 4071).
L'Éditeur de la série des RFC (RFC Series Editor, actuellement Heather Flanagan ) est décrit en premier, en section 2.1. Il est responsable du travail à long terme, il doit définir les principes qui assurent la pérennité des RFC, réfléchir à la stratégie, développer le RFC 7322, le guide de style des RFC (ce qui inclus les délicates questions du format, de la langue des RFC, etc), etc. Il sert aussi de « visage » aux RFC, vis-à-vis, par exemple, des journalistes. L'Éditeur est censé travailler avec la communauté IETF pour les décisions politiques.
Le RFC 6635 évalue la charge de travail à un mi-temps, ce qui me semble très peu. Notre RFC décrit les compétences nécessaires (section 2.1.6) pour le poste d'Éditeur de la série des RFC, compétences en anglais et en Internet, capacité à travailler dans l'environnement... spécial de l'IETF, expérience des RFC en tant qu'auteur souhaitée, etc.
Le travail quotidien est, lui, assuré par le Producteur des RFC (RFC Production Center) dont parle la section 2.2. C'est un travail moins stratégique. Le Producteur reçoit les documents bruts, les corrige, en discute avec les auteurs, s'arrange avec l'IANA pour l'allocation des numéros de protocoles, attribue le numéro au RFC, etc.
Les RFC n'étant publiés que sous forme numérique, il n'y a pas d'imprimeur mais le numérique a aussi ses exigences de publication et il faut donc un Publieur des RFC (RFC Publisher), détaillé en section 2.3. Celui-ci s'occupe de... publier, de mettre le RFC dans le dépôt où on les trouve tous, d'annoncer sa disponibilité, de gérer l'interface permettant de soumettre les errata, de garder à jour ces errata, et de s'assurer que les RFC restent disponibles, parfois pendant de nombreuses années.
Chacune de ces fonctions pourra faire l'objet d'une attribution spécifique (à l'heure actuelle, les fonctions de Producteur et de Publieur sont assurées par le même groupe à l'AMS). La liste à jour peut être vue sur le site officiel.
Un comité joue un rôle de supervision et de contrôle du RFC Editor : le RSOC (RFC Series Oversight Committee) est décrit en section 3.
Combien cela coûte et qui choisit les titulaires des différentes fonctions ? La section 4 décrit ce rôle, dévolu à l'IAOC (RFC 4071). Le budget est publié en sur le site de l'IAOC ainsi que l'évaluation du RFC Editor. On peut aussi trouver cette information, ainsi que plein d'autres sur le fonctionnement du RFC Editor, via le site officiel).
L'article seul
Droit d'auteur et copyright, si différents que cela ?
Première rédaction de cet article le 11 juin 2012
On entend souvent dans le débat politique en France l'argument comme quoi le droit d'auteur serait une invention française, inspirée par les plus nobles principes, alors que le copyright serait la quintessence du capitalisme le plus grossier et glouton. Qu'en est-il dans le monde réel (et pas dans les cours de droit) ?
Dans l'un des innombrables questionnaires envoyés aux candidats à la dernière élection présidentielle, on trouve cette question qui, comme vous le voyez, est très légèrement orientée : « Q: Quel point de vue juridique du droit d'auteur défendez-vous : le droit d'auteur -droit moral et patrimonial des auteurs, personnes physiques- ou le Copyright, un droit purement économique pour les entreprises titulaires de droits d'exploitation sur les oeuvres ? »
Cette façon caricaturale de présenter les deux systèmes, et d'affirmer que l'un est « moral » alors que l'autre serait bassement financier est très commune en France. Je prends au hasard un journal qui traîne et je trouve (La Jaune et la Rouge, avril 2012) « La première [le copyright] repose sur une conception utilitariste et économique, mettant l'entreprise et l'exploitation des droits au cœur du système. La seconde [le droit d'auteur] est fondée sur l'humanisme, elle place la personne de l'auteur au cœur des droits. » Belle envolée lyrique, de la part de quelqu'un qui, dans le reste de l'article, défend les intérêts de l'industrie du divertissement.
Qu'en est-il dans la théorie ? En simplifiant pas mal (et je m'excuse auprès de mes lecteurs juristes), on peut dire que le droit d'auteur comprend deux droits, un droit moral qui est inaliénable (l'auteur ne peut pas le vendre, même s'il le veut absolument) et un droit patrimonial qui est une marchandise comme une autre et que l'auteur peut négocier contre de l'argent. Le copyright, disent les articles cités plus haut, ne comprend que le droit patrimonial. Conséquences pratiques ? Le droit moral garantit à l'auteur certains droits (inaliénables, on l'a vu) comme le droit de retrait qui permet à un auteur de dire « finalement, je ne veux plus qu'on publie mon livre / film / musique, arrêtez tout ». Et ceci quel que soit le contrat que son éditeur l'ait forcé à signer en profitant de ses besoins financiers.
Et en vrai ? D'abord, les choses ont évolué. Depuis que les États-Unis ont signé la convention de Berne, même eux ont une sorte de droit moral.
Mais surtout, cette fausse opposition, soigneusement mise en scène, « gentils français de gauche avec leur droit d'auteur contre méchants états-uniens capitalistes intéressés uniquement par le fric avec leur copyright » ne correspond pas à la pratique. Dans les deux cas, le créateur touche très peu et, surtout, n'a aucun contrôle effectif sur son œuvre. Certes, en théorie, le système de droit d'auteur lui donne des privilèges qu'il n'a pas avec le copyright. Mais, en pratique... Par exemple, le droit de retrait cité plus haut. Imaginez-vous un écrivain aller voir son éditeur et demander que celui-ci arrête de publier le roman ? Même s'il y arrivait, il n'aurait plus aucune chance d'être publié par la suite... Aux États-Unis comme en France, tout se fait uniquement selon les rapports de force. Un réalisateur dont les films sont des succès peut exiger le « final cut » (droit au respect de l'œuvre), et un autre n'a aucun droit, qu'on soit sous le régime du droit d'auteur ou sous celui du copyright.
Pire, cette opposition artificielle est régulièrement invoquée pour justifier les pires abus (comme l'extension de la durée du droit « d'auteur » bien après la mort dudit auteur), ou comme HADOPI. Lorsque que quelqu'un commence par une ode lyrique au droit d'auteur, création de la Révolution française et patati et patata, on peut être sûr qu'il va réclamer dans la foulée le contrôle et la répression contre ceux qui auraient l'audace de partager les œuvres de l'esprit.
Enfin, politiquement, cette opposition revient à nier que la France soit un pays capitaliste, en laissant entendre que, contrairement au mythique « monde anglo-saxon », notre système à nous échapperait aux lois d'airain de l'argent. Je sais que certains créateurs préfèrent vivre d'illusions mais ils devraient faire face à la réalité : ils sont des prolétaires et, comme tels, n'ont aucun droit.
L'opposition droit d'auteur contre copyright est donc juste de l'écran de fumée idéologique.
L'article seul
Attaques contre le DNS et limitation de trafic
Première rédaction de cet article le 11 juin 2012
L'actualité fait en ce moment la part belle aux attaques par déni de service utilisant le DNS. On observe des rapports, de longues discussions sur des listes comme NANOG ou dns-operations, mais aussi via des canaux plus discrets. Une technique est souvent discutée : la limitation de trafic, technique qui était pourtant généralement ignorée autrefois.
D'abord, un point très important : il n'y a pas un type d'attaque avec des caractéristiques bien définies. Il y a des tas de sortes d'attaques en ce moment, visant des cibles très différentes, et avec des outils bien distincts. Il ne faut donc pas essayer de trouver le coupable, ni de mettre au point une technique qui fera face efficacement à toutes les attaques.
Quelles sont les attaques par déni de service possibles via le DNS ? (Pour des raisons évidentes, je ne parle que de celles qui sont publiques et connues.) Première différenciation entre attaques, la victime :
- Le méchant peut en vouloir à un serveur DNS donné, serveur récursif ou bien faisant autorité. Il lui envoie alors des requêtes DNS en masse. Si la réponse est plus grosse que la question (ce qui est presque toujours le cas avec le DNS), le méchant obtient en même temps une amplification. Le serveur souffrira des requêtes... mais surtout des réponses qu'il génère lui-même. (Notez que des attaques par amplification ont été vues avec d'autres protocoles UDP comme SNMP, NTP - cf. mon article - et même Call of Duty.)
- Le méchant attaquant peut en vouloir à un tiers (qui a ou n'a pas de serveur DNS), il va alors tricher sur son adresse IP source (ce qui est trivial pour le protocole UDP, le plus commun pour le DNS) et envoyer les requêtes à un serveur (récursif ou faisant autorité). Le serveur va alors servir de relais et répondre à la victime (en prime, si le gérant du serveur s'en aperçoit, il va accuser la victime de l'attaquer).
Ou bien on peut classer selon l'attaquant :
- S'il a à sa disposition un botnet, il peut dire la vérité sur l'adresse source (ou pas, selon ses goûts et ses buts), et il a à sa disposition de nombreuses machines donc n'a pas forcément besoin d'une grosse amplification pour faire des dégâts.
- S'il n'a pas de botnet à utiliser, il va devoir tricher sur l'adresse IP source (utiliser la sienne le trahirait) et il ne peut pas bombarder intensivement avec ses seules machines, il va avoir besoin d'amplification.
Pour une attaque par réflexion, l'attaquant peut viser un serveur
faisant autorité (ceux-ci sont souvent de grosses machines bien
connectées et ils peuvent être très efficaces comme relais) ; il aura
intérêt à choisir des serveurs faisant autorité pour une zone qui
contient de nombreux enregistrements de grande taille. (Si vous
cherchez, c'est le champ MSG SIZE à la fin de la
sortie de dig.) Ou bien il peut viser un
serveur récursif. Ceux-ci n'acceptent normalement que les requêtes
provenant de leur réseau (RFC 5358) mais ils
sont souvent mal configurés et ouverts à tout l'Internet, ce qui les
rend très dangereux
d'autant plus qu'ils sont très nombreux. (Par exemple, bien des
CPE fournis par les FAI
sont des résolveurs ouverts.) L'attaquant peut alors utiliser des tas
de noms de domaine différents (rendant plus difficile les
contre-mesures), ou bien utiliser un domaine à lui, avec d'énormes
enregistrements qu'il choisit.
Normalement, une machine ne devrait pas pouvoir tricher sur son adresse IP (RFC 2827 et RFC 3704). Mais, en pratique, cette astuce reste largement possible.
Parmi les contre-mesures figure la limitation de trafic. J'ai déjà écrit un article sur son utilisation pour empêcher les abus sur un résolveur ouvert et un autre sur les limites de Linux/Netfilter pour limiter intelligement. Cette technique a aussi été décrite par Google. Ceux qui utilisent FreeBSD seront contents de découvrir que le serveur racine F utilise FreeBSD et est protégé par :
add pipe 1 udp from any to any 53 in pipe 1 config mask src-ip 0xffffffff buckets 1024 bw 400Kbit/s queue 3 add pipe 2 tcp from any to any 53 in pipe 2 config mask src-ip 0xffffffff buckets 1024 bw 100Kbit/s queue 3
Enfin, pour limiter l'amplification, on peut aussi empêcher le serveur de noms d'envoyer des paquets trop gros :
// BIND max-udp-size 1460 # nsd ipv4-edns-size: 1460 ipv6-edns-size: 1460
Si la réponse dépasse cette taille, le serveur mettra le bit TC (TrunCation) à 1, poussant le client à réessayer en TCP (chose qu'il ne pourra pas faire s'il ment sur son adresse IP).
Résultat des attaques actuelles et des limites des outils existants, ce ne sont pas moins de deux efforts indépendants qui sont en cours pour ajouter des fonctions de limitation de trafic à BIND, ce qui permettra peut-être un meilleur contrôle de ce service. Pour comprendre la différence entre les deux efforts, il faut se rappeler :
- Que le but de l'administrateur réseaux n'est pas juste d'arrêter l'attaque (il suffirait d'éteindre la machine), mais aussi de le faire sans perturber le service qu'il doit rendre. Pas question donc de jouer au cow-boy en bloquant aveuglément des innocents.
- Que les contre-mesures à une DoS ont souvent, lorsqu'elles sont mal conçues, la propriété d'aggraver l'attaque, par exemple en imposant au serveur une consommation de mémoire qui va l'handicaper.
La première approche vise avant tout à ne pas avoir de « faux positifs ». Elle est décrite dans la Tech Note TN-2012-1 de l'ISC sous le nom de Response Rate Limiting (DNS RRL). Et elle est mise en œuvre dans un patch de BIND récemment publié. La configuration ressemble à :
config {
// ...
rate-limit {
responses-per-second 5;
window 5;
};
}; // Not yet per-type or per-domain such as "rate-limit only ANY queries"
La deuxième approche vise à limiter la consommation mémoire sur le serveur. La plupart des mécanismes de limitation de trafic (comme ceux indiqués dans mon article ou comme ceux utilisés dans le patch ci-dessus) consomment de la mémoire proportionellement au nombre de préfixes IP attaquants (et, en IPv6, ça peut aller vite). D'où l'idée d'utiliser des filtres de Bloom pour avoir un coût qui ne dépend pas du nombre de préfixes, au prix d'un certain nombre de faux positifs (adresses IP qui seront limitées alors qu'elles n'auraient pas dû l'être ; les filtres de Bloom sont probabilistes). Cette approche est en cours de programmation.
Pour l'instant, aucune de ces deux solutions ne permet une limitation dépendant du type de requêtes, ou du nom demandé. De même, il n'y a pas encore de limitation liée au comportement du client (par exemple, limiter ceux qui re-posent la même question avant l'expiration du TTL). Un tel test du comportement ne marcherait de toute façon que pour les serveurs faisant autorité, qui ont normalement en face d'eux des résolveurs/cache. Pour les résolveurs, leurs clients n'ayant souvent pas de cache, un tel test ne serait pas possible.
Voilà, il est encore trop tôt pour dire quelle solution s'imposera. En attendant, prudence : méfiez-vous des recettes toutes faites et rappelez-vous qu'il existe plusieurs sortes d'attaque. Que diriez-vous d'un médecin qui ne connaitrait qu'un seul médicament et le prescrirait dans tous les cas ? La limitation de trafic est un médicament puissant et utile, mais qui ne doit être utilisé qu'après une analyse de l'attaque.
L'article seul
RFC 6632: An Overview of the IETF Network Management Standards
Date de publication du RFC : Juin 2012
Auteur(s) du RFC : M. Ersue (Nokia Siemens Networks), B. Claise (Cisco)
Pour information
Réalisé dans le cadre du groupe de travail IETF opsawg
Première rédaction de cet article le 2 juin 2012
Selon une vieille blague de l'informatique, « ce qu'il y a de bien avec les standards, c'est qu'il y en a beaucoup parmi lesquels choisir. » Cette blague a été reprise dans un célèbre dessin de xkcd. Le but de ce RFC est-il de prendre le relais en montrant la variété des normes IETF relatives à la gestion des réseaux TCP/IP ?
En fait, non. Le but est de s'arrêter deux secondes de développer des nouveaux protocoles et de regarder ce qui existe (il y a donc une imposante bibliographie, reflet des très nombreux RFC cités). À une époque, il y avait un rêve, celui d'un protocole unique pour la gestion des réseaux (cela devait être SNMP). L'évolution des choses fait qu'aujourd'hui, l'architecte réseaux a à sa disposition plusieurs protocoles, dont les rôles se recouvrent en bonne partie. Même chose pour le membre de l'IETF qui développe un nouveau protocole et cherche des mécanismes de gestion de ce protocole. Ce RFC est donc juste un moyen de les aider à y voir plus clair. Il peut ausssi servir aux autres SDO qui veulent se renseigner sur le travail déjà existant, pour éviter de le dupliquer. Le lecteur pressé peut sauter tout de suite à l'annexe A du RFC (résumée à la fin de cet article), qui classe rapidement les protocoles avec des tableaux synthétiques.
D'abord, c'est quoi, la gestion des réseaux ? Ce sont l'ensemble des méthodes et techniques mises en œuvre par l'administrateur réseaux pour s'assurer que le réseau va bien, prévoir ses évolutions, et réparer ses pannes. Cela va du bon vieux ping aux mécanismes les plus complexes. (Si vous suivez les débats sur la neutralité de l'Internet, vous êtes peut-être déjà tombé sur des termes comme « services gérés » ou « gestion de trafic ». Il faut savoir que ces termes relèvent de la propagande des opérateurs réseaux, qui cherchent à justifier des services privilégiés - et plus chers - en prétendant qu'ils seraient « gérés », comme si le reste de l'Internet marchait tout seul. Les termes corrects sont « services privilégiés » et « discrimination de trafic ».)
Il y a déjà eu des RFC analogues à celui-ci (section 1.2). Par exemple, le RFC 6272 faisait le tour de tous les protocoles TCP/IP (y compris ceux sur la gestion de réseaux) dans le contexte de la Smart grid. Le RFC 3535 rendait compte d'un atelier de l'IAB consacré à la gestion de réseaux, qui avait examiné la situation en 2002. Le RFC 5706 posait les règles relatives à la gestion pour tous les nouveaux protocoles IETF, imposant qu'ils prennent en compte cette gestion dès le premier RFC. Enfin, les RFC 4221 et RFC 6371 décrivent le cas spécifique de la gestion des réseaux MPLS et sont à l'origine d'un conflit de compétences avec l'UIT qui dure encore aujourd'hui (cf. RFC 5704). Plusieurs Internet-Drafts sont également en cours de rédaction sur ce sujet de l'OAM (Operations, Administration and Maintenance, ce sigle est souvent utilisé dans le monde MPLS pour parler de la gestion des réseaux).
La section 2 de notre RFC couvre les protocoles de gestion généralistes, qui peuvent servir à tout. Le premier est évidemment SNMP (section 2.1). Il s'agit en fait d'une structure modulaire, avec un modèle de données (les fameuses MIB), un mécanisme d'encodage de ces données sur le réseau et un protocole, SNMP. Le RFC de description général est le RFC 3410, pour SNMPv3. Un réseau est vu par SNMP comme un ensemble de machines gérées (les agents), une ou plusieurs machines de gestion (le ou les managers) et le protocole utilisé entre les deux (SNMP). Les variables exportées par l'agent sont décrites dans une MIB, et il en existe des dizaines de normalisées et encore plus de privées.
SNMP v1 (RFC 1157) et v2 avaient de sérieuses limites en matière de sécurité, la version officielle aujourd'hui est donc la v3, normalisée dans le RFC 3411 (mais la v1 reste très utilisée). SNMP est présent partout, pour lire les valeurs des variables des équipements réseaux, faire des statistiques, aider à déboguer les pannes, etc. C'est un des grands succès de l'IETF.
Pour décrire les données récupérées en SNMP, un cadre standard existe nommé SMI (Structure of Managed Information), actuellement en version 2, normalisée dans les RFC 2578 et RFC 2579. Ces RFC définissent entre autre le langage dans lequel sont écrits les MIB.
SNMP est, on l'a vu, très répandu, et le RFC lui consacre à juste titre de nombreuses pages, parlant de sa sécurité, du mécanisme de transport, etc. Un autre protocole très populaire pour la gestion de réseaux est syslog (section 2.2). Il est concurrent de SNMP pour le signalement de problèmes (les traps de SNMP) mais, autrement, il ne remplit pas le même rôle. syslog sert à une machine à transmettre de l'information (pas forcément une panne) en temps réel, à des fins d'alarme ou de journalisation. Décrit d'abord dans le RFC 3164, il est désormais normalisé (sous une forme bien plus riche) dans le RFC 5424. Le syslog traditionnel des débuts ne prévoyait pas de structure pour le message envoyé : c'était juste du texte libre. Le RFC 5424 a introduit la notion de messages syslog structurés, analysables par un programme.
Si syslog est très répandu (on trouve des récepteurs syslog en logiciel libre sur tous les Unix, tous les routeurs savent émettre du syslog, etc), je ne suis pas sûr que les extensions modernes, encore peu implémentées, soient souvent utilisées.
Autre protocole très répandu dans la boîte à outils de
l'administrateur réseaux, IPFIX (souvent
désigné par son ancien nom, NetFlow). La
section 2.3 décrit son rôle : IPFIX permet de récolter de
l'information statistiques sur les flots de données qui sont passés
par un routeur (« [2001:db8:1::42]:35612 a parlé à
[2001:db8:cafe::1337]:80 et il a reçu 935
ko ») et de la transmettre à une machine de gestion. Avoir des
compteurs par flot (un flot étant typiquement une connexion
TCP complète) permet d'avoir une information
plus légère que si on transmettait des données sur chaque paquet.
L'architecture d'IPFIX est décrite dans le RFC 5470 et le protocole est dans le RFC 7011. L'ancien Netflow, lui, était décrit dans le RFC 3954. IPFIX/Netflow est très répandu et la plupart des opérateurs l'utilisent pour suivre l'activité de leurs réseaux. (Le logiciel libre ntop le parle, entre autres.)
Si on veut suivre les paquets individuels, il y a le protocole PSAMP (Packet SAMPling) du RFC 5474. Il permet d'utiliser le protocole d'IPFIX pour transmettre des données sur les paquets (qu'on a pu, pour limiter le trafic, échantilloner, comme bien expliqué dans le RFC 5475).
IPFIX, syslog et SNMP (tel que réellement utilisé dans la plupart des cas, sans ses fonctions d'écriture) ne font que lire les informations. Si on veut les modifier, si on veut changer la configuration d'un routeur, par exemple, que fait-on ? SNMP avait théoriquement un mécanisme pour cela mais, en pratique, il n'est que très rarement utilisé. L'atelier de l'IAB raconté dans le RFC 3535 identifiait ce manque (section 2.4) et l'un des résultats a été le protocole NETCONF normalisé dans le RFC 6241. NETCONF permet d'envoyer des commandes de configuration (encodées en XML) à un équipement réseau. Relativement récent, NETCONF n'est pas encore d'usage universel.
Pour décrire les données manipulées par NETCONF, l'IETF a un langage, YANG (RFC 6020). Celui-ci dispose d'un certain nombre de types de données pré-existants, normalisés dans le RFC 6991. Ces types sont évidemment proches de ceux que le SMI v2 avait déjà, pour SNMP. Idéalement, il faudrait encore ajouter une traduction standard de SMI vers YANG, afin de pouvoir récupérer toutes les MIB existantes. Pour l'utilisation de NETCONF et de YANG dans une solution globale, voir le RFC 6244. YANG est encore plus récent que NETCONF et encore peu déployé.
Tous ces protocoles, SNMP, syslog, NETCONF, etc, sont génériques et peuvent servir à gérer des tas de protocoles différents. La section 3 couvre au contraire les protocoles de gestion spécifiques, liés à une tâche donnée. Elle commence avec les protocoles de gestion de l'allocation d'adresses IP (section 3.1). D'abord, DHCP (RFC 2131 et RFC 8415). Il permet de transmettre à une machine son adresse IP mais aussi plein d'autres informations de configuration comme le résolveur DNS à utiliser (RFC 3646). DHCP n'offre aucun mécanisme de sécurité et le RFC rappelle donc qu'il vaut mieux ne l'utiliser que sur des réseaux dont l'accès physique est contrôlé.
Les adresses IP peuvent aussi être configurées automatiquement, sans serveur, dans le cadre décrit par le RFC 5889.
Depuis de nombreuses années, l'Internet est en cours de transition (très lente) d'IPv4 vers IPv6. Cette transition a donné naissance à tout un ensemble de techniques spécifiques, à commencer par le RFC 4213.
Une part importante de la gestion des réseaux est la mesure des performances (section 3.4). Ce n'est pas tout d'aller bien, il faut encore aller vite. Un groupe de travail IETF spécialisé, IPPM existe depuis longtemps pour développer des métriques (des grandeurs mesurables et rigoureusement définies) pour les réseaux TCP/IP. Il a produit un document de cadrage (RFC 2330), un document sur le développement de nouvelles métriques (RFC 6390), et de nombreuses métriques comme le délai de transmission (RFC 7679), le taux de pertes (RFC 7680), la mesure de la duplication de paquets (RFC 5560), etc. Pour pouvoir mesurer effectivement ces métriques, plusieurs protocoles ont été créés comme OWAMP (One-way Active Measurement Protocol, RFC 4656).
Toujours dans cette section de protocoles divers, une part importante est dédiée à RADIUS (RFC 2865), protocole permettant l'authentification d'un client, connecté à un NAS (Network Access Server), et utilisant un serveur d'authentification partagé entre plusieurs NAS. RADIUS permet par exemple à un FAI de centraliser l'authentification afin d'éviter que chaque NAS ait une base d'utilisateurs différente. Il est très largement utilisé aujourd'hui. De nombreux RFC sont venus lui ajouter telle ou telle fonction, ou guider les programmeurs (RFC 5080).
Officiellement, RADIUS a un concurrent, Diameter (RFC 6733). Conçu après, incompatible avec la base déployée, censé résoudre des problèmes réels ou supposés de RADIUS, Diameter n'a guère eu de succès. Le RFC oublie complètement de mentionner cet échec ; RADIUS est simple et facilement implémentable, Diameter, grosse usine à gaz, ne l'a jamais réellement concurrencé.
La section 3 décrit encore plusieurs autres protocoles peu connus, mais j'arrête ici. Il y a un autre gros morceau à avaler, les modèles de données pour la gestion de réseaux (section 4). Ils sont très nombreux et couvrent beaucoup d'aspects de la gestion de réseaux. Un de mes préférés est le peu connu RMON (RFC 2819), qui modélise des sondes réseaux. Il permet de déclencher à distance, avec SNMP, des mesures du réseau.
L'annexe A, présentée au début, est une sorte de résumé pour lecteurs pressés. Elle classe les différents protocoles de gestion de réseaux (rappelez-vous que la liste est longue) selon divers critères (fonctionnement en push ou en pull, passif ou actif, extensibilité de leur modèle de données, etc)
Le premier tableau, en A.1, classe les protocoles selon leur place dans le chemin des normes (cf. RFC 2026, notre RFC ne tient pas encore compte de la réduction de ce chemin à deux entrées, dans le RFC 6410). Ainsi, SNMP est Internet standard (norme au sens propre) alors qu'IPFIX n'est que Proposed standard (projet de norme) et que DHCP n'a jamais décollé de la première étape, Draft standard (proposition de norme), en dépit de son très vaste déploiement.
Autre façon de classer, en A.2, selon les tâches à accomplir. Syslog et SNMP permettent la surveillance du réseau mais SNMP permet en outre d'agir sur la configuration de celui-ci (en pratique, il n'est guère utilisé pour cette tâche). NETCONF peut faire de la configuration, mais, si on veut mesurer les performances, ce sont SNMP et IPFIX.
Comment ces protocoles font-ils leur travail (A.3) ? SNMP et NETCONF sont pull (la machine de gestion décide quand agir), Syslog, RADIUS ou IPFIX sont purement push (ils réagissent aux événements extérieurs). Notez que SNMP a aussi une fonction Push, les notifications (auutrefois nommées traps).
Autre façon de les regarder travailler (A.4), certains protocoles sont actifs posant des questions au réseau (ping et traceroute - RFC 1470, BFD - RFC 5880, OWAMP, etc). D'autres sont passifs, observant simplement le réseau (IPFIX, PSAMP, etc).
Le travail de gestion des réseaux ne s'arrêtera jamais. Il y aura toujours de nouveaux problèmes et de nouvelles solutions. L'annexe B décrit un travail récent à l'IETF, la gestion de l'énergie, préoccupation désormais très forte, en raison de l'augmentation des coûts de l'électricité et des soucis écologiques plus présents (menant par exemple à des lois plus strictes). Actuellement, dans la gestion de réseaux, il est rare que la consommation électrique soit prise en compte. Les serveurs ne distribuent pas cette information et les logiciels de gestion ne la demandent pas. On surveille le taux de pertes de paquets, le débit, mais pas la consommation électrique au niveau de chaque machine.
Une des difficultés pour effectuer cette mesure est que la consommation électrique est souvent mieux mesurée en dehors de la machine, par exemple par une source PoE, ou bien par un bandeau électrique « intelligent ». Il faut donc travailler, entre autres, sur la liaison entre une machine et sa consommation. C'est la tâche du groupe de travail IETF EMAN (cf. RFC 6988 et RFC 7326, publiés depuis).
L'article seul
RFC 6606: Problem Statement and Requirements for 6LoWPAN Routing
Date de publication du RFC : Mai 2012
Auteur(s) du RFC : E. Kim (ETRI), D. Kaspar (Simula Research Laboratory), C. Gomez (Universitat Politecnica de Catalunya/i2CAT), C. Bormann (Universitaet Bremen TZI)
Pour information
Réalisé dans le cadre du groupe de travail IETF 6lowpan
Première rédaction de cet article le 29 mai 2012
Il y en a, des RFC produits par le groupe de travail 6lowpan, qui a pour tâche de normaliser des protocoles pour les LowPAN (Low-Power Wireless Personal Area Network), ces réseaux de toutes petites machines, limitées en puissance de calcul et en électricité (réseaux de capteurs industriels, par exemple). Parmi les questions soulevées par les LowPAN, le routage. Les liens radio 802.15.4 entre les machines ont une portée limitée et la communication entre deux machines quelconques du LowPAN nécessite parfois une transmission par un ou plusieurs routeurs intermédiaires. Les normes des couches basses, comme IEEE 802.15.4 ne spécifient pas de mécanisme pour gérer ce routage. Ce RFC 6606 est le cahier des charges pour les protocoles de routage du LowPAN, protocoles qui seront établis par d'autres groupes comme Roll, qui travaille sur un problème plus général que celui des seuls LowPAN et a normalisé le protocole RPL dans le RFC 6550. Notez qu'il y a eu d'autres RFC proches comme le RFC 5826 qui se focalise sur le cas particulier de la domotique, ou le RFC 5673, pour les réseaux industriels.
Pour réviser les caractéristiques des machines d'un LowPAN, le mieux est de lire le RFC 4919. Pour savoir comment IPv6 (le 6 dans le nom du groupe 6lowpan) fonctionne sur un LowPAN, c'est le RFC 4944. Un point important à garder en tête avant d'étudier le routage est que ce dernier consomme des ressources (courant électrique, par exemple) et qu'il faut donc limiter cette fonction aux machines les mieux pourvues.
La norme de couche 2 IEEE 802.15.4, sur laquelle s'appuient les LowPAN ne dit pas comment les topologies sont établies puis maintenues. Et elle ne spécifie pas de protocole de routage. Dans un LowPAN, on distingue traditionnellement deux formes de « routage », une en couche 2, le mesh under (brièvement mentionné dans le RFC 4944 : tout le LowPAN est un seul réseau IP), et une en couche 3 (la seule qu'on devrait normalement appeler « routage »), le route over. Le groupe Roll cité plus haut ne travaille que sur le route over (le « vrai » routage) mais notre RFC 6606 couvre les deux formes. Pour le routage, l'IETF a déjà des tas de protocoles (comme OSPF). Mais aucun ne convient aux LowPAN, en raison de leurs caractéristiques propres (notamment les faibles ressources en processeur et en puissance électrique, et le problème spécifique posé par l'hibernation).
Le RFC 4919 formulait déjà des exigences spécifiques pour les protocoles de routage du LowPAN : minimisation de la consommation de ressources, et acceptation des machines qui hibernent pendant la majorité du temps. Ce RFC 6606 reprend et détaille ces exigences.
Notez que, dans un LowPAN typique, les adresses allouées aux machines n'ont aucune chance de suivre la topologie du réseau. Il n'y a donc pas de possibilité de router par préfixe IP, d'agréger des préfixes adjacents, etc.
Il y a beaucoup de sortes de LowPAN, d'autant plus qu'on en est aux débuts et qu'on ne sait pas encore tout. La section 4 détaille les caractéristiques des différents types de LowPAN qui peuvent avoir une influence sur les algorithmes de routage. Par exemple, le nombre de machines est un des principaux (un algorithme d'inondation n'est envisageable que dans les petits réseaux). Or, un LowPAN peut aller de deux machines (cas de capteurs dans le corps humain, les Body Area Network) à des millions de machines (grande usine).
Et c'est à partir de la section 5 qu'on en arrive aux exigences explicites pour l'algorithme de routage. Elles sont numérotées Rn, de R1, à R18 mais, rassurez-vous, je ne les expliquerai pas toutes.
R1 est liée à la taille des machines du LowPAN. Elle exige un mécanisme de routage qui convienne à ces toutes petites machines. Par exemple, certaines auront si peu de mémoire qu'il faudra limiter la table de routage à 32 entrées. Le système de routage doit donc permettre de stocker une table partielle, ou fortement résumée (voir aussi R10). Pour donner une idée des contraintes, certaines machines auront entre 4 et 10 ko de mémoire vive, et seulement 48 à 128 ko de mémoire Flash, pour stocker le code du programme de routage. Un MICAz a 4ko/128ko, un TIP700CM 10ko/48ko. Il faudra donc des algorithmes simples, pour que le code tienne dans ces mémoires.
L'exigence R2 porte sur la consommation électrique : il faut un mécanisme qui la limite. Par exemple, un paquet de diffusion va potentiellement réveiller toutes les machines du lien, les forçant à traiter ce paquet. Il faut donc les éviter. Même si le temps de processeur est à économiser, il faut se rappeler que la principale cause de consommation d'électricité, de loin, est la radio. Celle du TR1000 consomme 21 mW en transmission et 15 mW en réception.
Le LowPAN fonctionnant sur 802.15.4, il doit tenir compte des caractéristiques de celui-ci. Par exemple, R3 demande que les paquets de contrôle du protocole de routage tiennent dans une seule trame 802.15.4 pour éviter toute fragmentation. D'autre part, 802.15.4 a des caractéristiques de taux de pertes et de latence qui peuvent éliminer certains algorithmes (R4 et R5 pour les détails).
Les machines d'un LowPAN étant typiquement peu fiables (déplacement, extinction, panne), les protocoles de routage doivent se préparer à trouver des routes alternatives (exigence R6). Le RFC demande moins de deux secondes de convergence si le destinataire d'un paquet s'est déplacé et seulement 0,5 seconde si seul l'expéditeur a bougé (voir aussi le RFC 5826).
Les liens radio ayant souvent des caractéristiques asymétriques, R7 demande que les protocoles de routage fonctionnent quand même dans ces conditions. Cela veut dire, par exemple, que le coût d'un lien doit être une paire {coût aller, coût retour}.
Chaque machine, dans un LowPAN, a droit à un sommeil fréquent (99 % de sommeil n'est pas impossible), pour économiser sa batterie (des capteurs industriels doivent parfois tenir cinq ans sans changement de batterie). R8 en tire les conséquences en rappelant que le routage doit marcher même si certains nœuds hibernent. Et le calcul des coûts de routage doit inclure celui de la consommation électrique (il faut éviter de choisir comme routeurs les machines limitées en énergie).
La taille des LowPAN variant considérablement, le protocole de routage doit marcher aussi bien pour un réseau urbain de plusieurs millions de machines (RFC 5548) que pour un réseau de 250 machines dans une maison (RFC 5826). Rappelez-vous les contraintes de taille mémoire : pas question de stocker une table de routage d'un million d'entrées en mémoire !
Les machines se déplacent, dans un LowPAN. Dans les environnements industriels, il faut que le réseau fonctionne malgré des déplacements jusqu'à 35 km/h (RFC 5673). Aujourd'hui, on en est loin mais, en tout cas, R12 exige des protocoles qui gèrent des réseaux qui changent, avec des machines qui bougent.
Et la sécurité, problème très crucial et très difficile pour les LoWPAN (un réseau sans-fil est toujours plus vulnérable) ? Non seulement un attaquant qui viserait le routage pourrait sérieusement perturber les communications entre les machines, mais il pourrait indirectement vider la batterie de certaines, réalisant ainsi une attaque par déni de service très efficace. L'exigence R14 impose donc aux protocoles de routage candidats de fournir des services de confidentialité, d'authentification et de vérification de l'intégrité des messages. C'est beaucoup, vous trouvez ? Et pourtant cela ne protège pas contre tout (par exemple contre une machine authentifiée, mais malveillante). De toute façon, il ne faut pas se faire d'illusion : compte-tenu du coût élevé (en processeur et donc en énergie électrique) de la plupart des techniques de sécurité (notamment de la cryptographie à clé publique), le routage des LowPAN restera très peu protégé. Le RFC n'espère qu'un compromis raisonnable (un peu de sécurité, si ça ne coûte pas trop cher).
Il semble donc, note le RFC, que cela exclut IPsec, alors qu'il serait une solution élégante au problème, car il est bien trop consommateur de ressources et trop compliqué du point de vue de la gestion des clés.
À noter que 802.15.4 dispose de mécanismes de sécurité propres. S'ils sont activés, des protocoles comme NDP deviennent relativement sûrs. (La section 6 est également à lire, si on s'intéresse à la sécurité.)
Enfin, après la sécurité, la gestion : le RFC 5706 impose de la prendre en compte dès la conception du protocole. L'exigence R18 demande donc que le futur protocole de routage des LowPAN soit gérable (test de l'état de la table de routage, compteurs d'erreurs, etc).
L'article seul
RFC 6633: Deprecation of ICMP Source Quench messages
Date de publication du RFC : Mai 2012
Auteur(s) du RFC : F. Gont (UTN-FRH / SI6 Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 29 mai 2012
Il y avait belle lurette que les messages ICMP « Répression de la source » (Source Quench) n'étaient plus utilisés. Ces messages devaient servir, à l'origine, à signaler à un émetteur qu'il exagérait et qu'il devrait ralentir l'envoi de données. Divers problèmes, notamment de sécurité, font que ces messages sont désormais ignorés par toutes les mises en œuvre de TCP/IP. Mais cet abandon de fait n'avait jamais été documenté. Voilà qui est fait, ce RFC 6633 marque donc l'abandon officiel de la répression de la source.
À l'origine, cette répression (quench) avait été normalisée dans le RFC sur ICMP pour IPv4, le RFC 792. De type 4 et de code 0, le message Source Quench était censé limiter la congestion en disant à l'émetteur qu'un récepteur n'arrivait plus à suivre. Inefficace et injuste, le Source Quench n'a jamais été très utilisé. Les routeurs ont officiellement arrêté de s'en servir avec le RFC 1812, dès 1995. Ce RFC notait déjà les limites et problèmes du Source Quench (dans sa section 4.3.3.3, qui fournissait des références).
En outre, les messages Source Quench, n'étant pas authentifiés, posaient un gros problème de sécurité : un méchant pouvait générer de faux messages pour réduire le débit de son ennemi, comme expliqué dans le RFC 5927 (et la section 8 de notre RFC). C'est d'ailleurs à cause de cela que des IDS comme Snort couinent lorsqu'ils voient passer des messages de répression de la source (voir Anderson, D., Fong, M., et A. Valdes, « Heterogeneous Sensor Correlation: A Case Study of Live Traffic Analysis », Proceedings of the 3rd Annual IEEE Information Assurance Workshop New York, NY, USA, 2002).
Restaient les protocoles de transport. Le RFC 1122 disait dans sa section 4.2.3.9 que les machines terminales devaient réagir aux Source Quench en diminuant le débit émis. La méthode recommandée pour TCP était de revenir au démarrage en douceur (RFC 5681).
De fait, le problème est réglé depuis longtemps, comme le
documentait le RFC 5927 : les mises en
œuvre de TCP et autres protocoles de
transport ignorent les messages Source Quench
depuis au moins 2005, RFC 1122 ou pas RFC 1122. L'annexe A de
notre RFC 6633 fait le tour des implémentation TCP/IP et note
que Linux a commencé à ignorer ces messages en
2004, FreeBSD,
NetBSD et Solaris depuis
2005, etc. Voici par exemple ce que fait NetBSD (fichier sys/netinet/tcp_subr.c, routine tcp_ctlinput() :
if (cmd == PRC_QUENCH)
/*
* Don't honor ICMP Source Quench messages meant for
* TCP connections.
*/
return NULL;
Bref, ce RFC ne fait que documenter l'état des choses déjà existant.
En outre, ces messages Source Quench sont largement filtrés et ont donc peu de chances d'atteindre les machines qui émettent les données. Une étude de 1994 (Floyd, S., « TCP and Explicit Congestion Notification », ACM CCR Volume 24, Issue 5) notait déjà qu'on trouvait très peu de tels messages dans la nature. À la place, les routeurs sont censés utiliser ECN (RFC 3168) et (même si le RFC ne le rappelle pas), les machines terminales doivent de toute façon réagir aux pertes de paquets en ralentissant leur émission (RFC 5681).
Donc, le Source Quench est désormais officiellement abandonné. La section 3 de notre RFC modifie le RFC 1122 en demandant aux machines terminales de ne pas émettre de tels messages et d'ignorer ceux qu'elles recevraient. La section 4 fait de même pour les routeurs. La section 9 demande à l'IANA de marquer ces messages comme abandonnés dans le registre ICMP.
Il n'y avait pas de règle précise dans le passé pour d'autres protocoles de transport comme UDP ou SCTP. Les sections 5 et 6 de notre RFC leur applique la même règle : il faut ignorer complètement les messages de répression de la source qu'on pourrait recevoir.
Ah, et puis quelqu'un avait proposé une utilisation des messages Source Quench dans le RFC 1016. Suivant l'idée générale d'abandonner ces messages, la mise en œuvre de ce RFC est donc désormais déconseillée (cf. section 7).
De toute façon, le problème aurait disparu avec IPv4 : IPv6, lui, n'a jamais eu de message Source Quench (RFC 4443).
L'article seul
Comprimer les données qu'envoie le serveur HTTP Apache
Première rédaction de cet article le 23 mai 2012
Dernière mise à jour le 11 juin 2012
Faut-il comprimer les fichiers qu'Apache envoie au navigateur Web ? Il y a du pour et du contre et la réponse dépend de pas mal de facteurs. En tout cas, après quelques tests, j'ai augmenté l'usage de la compression sur ce blog. Voici pourquoi et comment.
Le protocole HTTP permet à un client HTTP
d'indiquer qu'il sait gérer les données comprimées, avec l'en-tête
Accept-Encoding: (RFC 7231,
section 5.3.4). Lorsque le serveur HTTP reçoit cet en-tête, il peut
comprimer les données avant de les envoyer.
Mais est-ce rentable ? Il y a des données qui sont déjà comprimées (les images, en général) et il y a des cas où la capacité du réseau n'est pas le principal goulet d'étranglement, c'est souvent la latence qui est le facteur limitant.
Parmi les excellents outils de l'excellent service Google Webmasters Tools, on trouve, dans la rubrique Labs -> Site Performance, le conseil de comprimer. Si on ne le fait pas, Google dit « Enable gzip compression \ Compressing the following resources with gzip could reduce their transfer size by 22.7 KB: » et menace de rétrograder le site dans son classement. (Sur l'ensemble des conseils techniques de Google, vous pouvez évidemment consulter leur site, ou bien, en français, « Les critères de performance web pour le référencement Google ».)
Bon, avant de faire comme le demande Google, on va mesurer. Prenons
curl et lançons-le sur une page de grande
taille (779 481 octets sur le disque). On utilise l'excellente option
--write-out de curl qui permet de n'afficher que
les informations qu'on choisit :
% curl --silent \
--write-out "size = %{size_download} bytes time = %{time_total} seconds speed = %{speed_download} bytes/second\n" \
--output /dev/null http://www-remote.example.org/feed-full.atom
size = 779481 bytes time = 1.142 seconds speed = 682361.000 bytes/second
On a bien récupéré tous nos octets. Activons maintenant la compression
sur le serveur HTTP (un Apache ; j'explique
plus tard dans l'article comment c'était fait). Et disons à curl de la
demander, grâce à l'option --header pour demander
l'ajout d'un Accept-Encoding: à la requête. La
valeur de ce champ est le nom du ou des protocoles de compression
acceptés, ici gzip et deflate :
% curl --header 'Accept-Encoding: gzip,deflate' --silent \
--write-out "size = %{size_download} bytes time = %{time_total} seconds speed = %{speed_download} bytes/second\n" \
--output /dev/null http://www-remote.example.org/feed-full.atom
size = 238471 bytes time = 0.744 seconds speed = 320385.000 bytes/second
On a réduit la quantité de données de 69 %. La vitesse de transfert a diminué (la compression et la décompression prennent du temps) mais c'est compensé par la réduction de taille : le transfert prend 34 % de temps en moins, ce qui était le but. (Dans la réalité, il faut répéter la mesure plusieurs fois, sur une longue période, pour s'assurer qu'il n'y a pas d'autres phénomènes en jeu, comme la charge du réseau.)
Notez que, parmi les variables que curl permet d'afficher,
time_total inclut des temps qui ne dépendent pas
de la compression comme la résolution de noms. Il n'y a pas de
variable time_transfer qui donnerait le temps qui
nous intéresse directement. Il faudrait sans doute afficher
time_total et
time_starttransfer puis faire la soustraction.
Dans le cas précédent, le serveur HTTP était sur un autre continent que la machine qui lançait curl. Avec un serveur proche, l'écart est moins net :
# Sans compression
% curl --silent \
--write-out "size = %{size_download} bytes time = %{time_total} seconds speed = %{speed_download} bytes/second\n" \
--output /dev/null http://www-close.example.org/feed-full.atom
size = 779481 bytes time = 0.215 seconds speed = 3626353.000 bytes/second
# Avec compression
% curl --header 'Accept-Encoding: gzip,deflate' --silent \
--write-out "size = %{size_download} bytes time = %{time_total} seconds speed = %{speed_download} bytes/second\n" \
--output /dev/null http://www-close.example.org/feed-full.atom
size = 238471 bytes time = 0.162 seconds speed = 1472215.000 bytes/second
Bref, la compression est utile mais ne fait pas de miracles.
À noter que la compression peut présenter un autre avantage, celui
de diminuer le débit sur le réseau, ce qui peut être utile, par
exemple si vous êtes facturé au volume, ou tout simplement si vous
voulez épargner une ressource partagée. Voici, sur ce blog, le
résultat de l'activation (le mercredi au milieu du graphe) de la
compression des flux de syndication :  Deux semaines après, on a une vision plus large, voici la baisse du trafic réseau (semaine 21) :
Deux semaines après, on a une vision plus large, voici la baisse du trafic réseau (semaine 21) :  Et, logiquement, l'augmentation de la consommation de processeur (eh oui, on n'a rien sans rien) :
Et, logiquement, l'augmentation de la consommation de processeur (eh oui, on n'a rien sans rien) : 
Florian Maury fait remarquer à juste titre que les tests ci-dessus avec curl ont une limite : ils ne testent pas le temps de décompression chez le client. Peut-être faudrait-il faire :
% curl --header 'Accept-Encoding: gzip,deflate' $URL | gunzip -
Pensez aussi que, pour tester la différence, il faut un client HTTP qui
accepte la compression. C'est pour cela que je n'ai pas utilisé un
programme comme echoping, qui ne permet
pas d'envoyer l'en-tête Accept-Encoding:.
Sinon, si on préfère tester avec le classique outil de
benchmark
ApacheBench (ab),
il faut lui dire explicitement d'activer la compression avec l'option
-H
"Accept-Encoding: gzip,deflate". (Voir aussi un
article plus détaillé sur ApacheBench.)
Bon, et comment j'ai configuré Apache ? Le module le plus courant
est le module standard mod_deflate
et est très bien documenté. Sur
une Debian, il suffit de a2enmod
deflate && /etc/init.d/apache2 reload pour
l'activer. Toutefois, sa configuration par défaut n'inclut pas tous
les fichiers, notamment pour éviter de comprimer les images (qui le
sont déjà). Par défaut, il comprime le HTML
mais j'ai ajouté Atom, les flux de syndication
étant souvent de grande taille. Voici mon deflate.conf :
AddOutputFilterByType DEFLATE text/html text/plain text/xml AddOutputFilterByType DEFLATE text/css AddOutputFilterByType DEFLATE application/x-javascript application/javascript application/ecmascript AddOutputFilterByType DEFLATE application/rss+xml AddOutputFilterByType DEFLATE application/atom+xml # Maximum compression. Not many changes noticed when changing it. DeflateCompressionLevel 9
Ah, au fait, faut-il utiliser deflate ou gzip ? Comme le rappelle le RFC 2616, « [deflate is] The "zlib" format defined in RFC 1950 in combination with the "deflate" compression mechanism described in RFC 1951. » gzip est simplement l'algorithme de deflate avec des métadonnées en plus. Il ne devrait donc pas y avoir de différences sensibles de performance.
Une alternative à mod_deflate, que je n'ai pas testée, est le mod_pagespeed
de Google (qui fait bien d'autres choses que
comprimer). Autre alternative (signalée par Patrick Mevzek), « dans le
cas des sites assez statiques et automatisés, générer à la fois le
.html et le .html.gz. On perd
en espace disque forcément, mais zéro temps de compression par Apache,
il ne fait que servir selon le Accept-Encoding:
et pas besoin de module spécifique. [Pour les] sites qui sont générés
à partir d'un Makefile qui se charge donc de
créer les versions compressées en même temps. »
Lectures supplémentaires ? Un court article sur l'utilisation de curl pour tester la compression.
L'article seul
Faut-il être l'esclave de la racine ?
Première rédaction de cet article le 22 mai 2012
Joli titre, non ? Il fait référence à un débat récurrent chez les opérateurs DNS : faut-il qu'un résolveur DNS récupère la zone racine et la serve, afin d'être indépendant des serveurs racine et, ainsi, pouvoir survivre à une panne de ceux-ci ?
Le débat a été récemment relancé par un article intéressant de Pingdom à propos de la répartition des serveurs racine. Mais il réapparait régulièrement (voir par exemple l'ancien article « The Root of the Matter: Hints or Slaves » de David Malone). L'idée est la suivante : la zone racine est très petite (au 2012-05-22, seulement 3 505 enregistrements, sans compter les signatures DNSSEC, 1 498 noms dont 271 TLD), publiquement disponible en FTP ou via un transfert de zone. Pourquoi ne pas la récupérer sur ses machines, et modifier la configuration de son serveur résolveur pour faire autorité sur cette zone ? Ainsi, la racine pourrait tomber en panne ou bien être attaquée par des méchants (comme c'est arrivé, sérieusement, en 2007 ou, virtuellement, en 2012) sans que cela m'affecte.
Mais il n'y a pas de consensus chez les experts sur cette
question. Est-ce une bonne idée ou pas ? Le principal problème avec ce
système est que la plupart des gens qui le déploient n'assurent pas le
service après-vente. Cela semble cool, on configure son résolveur, on
se vante après sur Facebook ou sur un forum en
http://je-suis-un-neuneu/blaireaux.php mais on ne
met pas en place de surveillance automatique. Quelques mois après, le
système de mise à jour ne marche plus, la résolution DNS échoue, les
utilisateurs pleurent et certains crient « la racine du DNS est en
panne, les Mayas l'avaient prédit, nous allons
tous mourir ». Configurer un résolveur en esclave de la racine n'est
pas un problème lorsque c'est le résolveur individuel d'un gourou qui
sait ce qu'il fait. Mais c'est plus problématique lorsque Jean-Kevin
Boulet le fait en cinq minutes et s'éclipse après, laissant son
successeur régler les problèmes. Rappelez-vous, en
administration système, installer et
configurer un truc, c'est facile. Le maintenir sur le long terme,
c'est le vrai défi.
Quelques autres questions à se poser :
- Est-ce vraiment nécessaire ? La racine n'est jamais tombé une seule fois en panne, malgré plusieurs attaques. Elle est gérée par des gens autrement plus compétents que Jean-Kevin Boulet, il existe déjà beaucoup d'instances physiques de la racine et les probabilités d'une panne sont très faibles.
- Avoir une copie locale de la racine peut aussi améliorer les performances, si tous les serveurs racine existants sont très loin. (Cela peut se tester.)
- De toute façon, sur un résolveur typique, la plupart des données
de la racine sont rapidement mises en cache et les serveurs racine ne
sont plus interrogés que pour les noms inexistants (suite à une faute
de frappe, par exemple). On peut dire que les serveurs de la racine
répondent surtout
NXDOMAIN... (Sur les noms demandés, voir l'étude de Verisign.) Ceci dit, ce n'est pas une raison suffisante pour rejeter l'idée de servir la racine localement : il y a aussi les colles (les adresses IP des serveurs), que BIND retourne chercher à la racine lorsque leur durée de vie expire. - C'est bien joli d'avoir une copie locale de la racine, et d'être
ainsi à l'abri des éventuels problèmes de celle-ci. Mais la plupart
des utilisateurs voudraient aussi pouvoir continuer la résolution et
accéder à des noms sous
.comou.fr. Ces TLD ne sont pas publiquement accessibles et, de toute façon, sont trop gros pour tenir sur un résolveur typique.
Si vous voulez le faire quand même (je n'ai pas dit que c'était une bonne idée), voici quelques points à garder en tête :
- Les risques dépendent de la méthode de mise à jour utilisée. Si votre résolveur valide avec DNSSEC (une bonne idée), le principal risque est celui que, en cas de non mise à jour, les signatures expirent et soient donc refusées. Actuellement, la durée de vie des signatures à la racine est de seulement huit jours... Si votre résolveur ne valide pas, et qu'il récupère la zone racine par un transfert de zones depuis les serveurs racine, le principal risque est celui d'expiration de la zone : la durée indiquée dans l'enregistrement SOA de la racine est actuellement de sept jours. Enfin, si vous récupérez la racine en dehors du DNS, par un wget nocturne lancé par cron, il n'y a plus de risque d'expiration. Par contre, si la mise à jour ne se fait plus, vous risquez de servir à vos utilisateurs des données dépassées, un problème qui sera très difficile à déboguer (au moins, avec DNSSEC, le plantage sera franc).
- Si vous choisissez (cela semble la méthode la plus courante) de
configurer votre résolveur en esclave de la racine, rappelez-vous que
la racine ne sait pas que vous existez et vous ne recevrez donc pas
les
NOTIFY(RFC 1996). Votre copie sera donc peut-être un peu en retard (le délai d'interrogation dans le SOA de la racine est d'actuellement trente minutes). - L'ICANN essaie actuellement d'augmenter considérablement le nombre de TLD. Toutefois, même une zone de plusieurs centaines de milliers de noms est largement dans les capacités d'un serveur typique. Pas besoin de grosse machine pour servir la racine localement.
- Il n'existe pas actuellement de serveur maître officiel pour la
racine. Certains serveurs permettent le transfert de zones (RFC 5936) comme
F.root-servers.netmais rien ne garantit que cela durera. L'ICANN a, pour l'instant, des serveurs spéciaux pour ces transferts,xfr.{cjr|lax}.dns.icann.org.
Une configuration possible pour le résolveur BIND serait :
zone "." {
type slave;
masters { 192.5.5.241; 2001:500:2f::f; // F
193.0.14.129; 2001:7fd::1; // K
192.0.47.140; 2620:0:2830:202::140; 192.0.32.140; 2620:0:2d0:202::140; // ICANN
}; // RFC 4085 says it's bad to hardwire IP addresses.
file "slave/root.zone";
notify no; // Don't bother the offical roots with NOTIFY.
};
Mais rappelez-vous : il est indispensable de surveiller que tout se
passe bien et de réagir vite si la mise à jour ne se fait plus (la
racine expirera sur le résolveur en une semaine...) Pour aider à la
surveillance, et détecter une expiration proche, vous pouvez essayer
le
programme dns-slave-expire-checker ou bien attendre BIND 9.10
qui aura un rndc zonestatus.
Si vous préférez la solution d'un wget lancé
de temps en temps par cron, pensez dans votre
script à bien tout tester (ici, on suppose qu'il existe une commande
report_error qui va envoyer le message d'erreur à
un endroit où il sera lu - pas dans un fichier
journal que tout le monde ignore) :
(wget --quiet ftp://rs.internic.net/domain/root.zone.gz.sig &&
wget --quiet ftp://rs.internic.net/domain/root.zone.gz) > $LOG 2>&1
if [ $? != 0 ]; then
report_error "Cannot retrieve root zone file" < $LOG
exit 1
fi
# Now that the root is DNSSEC-signed, checking with PGP is less important
gpg --quiet --verify root.zone.gz.sig > $LOG 2>&1
if [ $? != 0 ]; then
report_error "[SECURITY] Bad signature of the root zone file" < $LOG
exit 1
fi
gunzip --to-stdout root.zone.gz > root.zone
named-checkzone . root.zone > $LOG 2>&1
if [ $? != 0 ]; then
report_error "Format invalid for root zone file" < $LOG
exit 1
fi
Pour ceux qui aiment se plonger dans l'histoire des débats, le plus gros débat sur la question avait été provoqué en 2007 par la décision de Doug Barton de mettre un système de zone racine local dans FreeBSD. Notez que l'utilisateur voyait donc le comportement de FreeBSD changer soudainement sans qu'il l'ait explicitement accepté, ce qui a beaucoup fait râler. Le débat public avait été lancé sur la liste dns-operations et s'était conclu par un retour en arrière pour FreeBSD. La configuration qui permet de mettre BIND en esclave de la racine est toujours là mais en commentaire seulement. Notez que les choses ont évolué depuis (la racine est signée, par exemple...) et donc des gens ont changé d'avis sur ce débat.
L'article seul
Limiter le trafic sur un serveur Apache, quelques approches
Première rédaction de cet article le 10 mai 2012
Dès qu'on connecte un serveur public à l'Internet, on risque des ennuis. L'un de ceux-ci est l'écroulement du serveur sous la charge, que celle-ci soit provoquée par une attaque délibérée ou tout simplement et banalement par un trafic excessif par rapport à ce que peut gérer le serveur (l'effet Slashdot). La solution la plus efficace est souvent de servir plutôt des pages statiques (dans la grande majorité des cas, les pages dynamiques sont inutiles et n'ont été utilisées que parce que la web agency pouvait facturer davantage avec du dynamique). Avec les pages statiques, seule la capacité du réseau est un facteur limitant. Mais, si le serveur Web donne accès à des applications et que ce sont les ressources consommées par celles-ci qui sont le facteur limitant ?
Il existe plein de solutions à ce problème. On peut par exemple configurer son pare-feu pour limiter le nombre d'accès (voir mon article sur la limitation de HTTP avec Netfilter). À l'autre extrémité, il y a aussi la solution, si les pages si demandées sont générées par une application, de mettre la limitation de trafic dans le code de l'application (d'ailleurs, si un de mes lecteurs a des bonnes solutions pour Mason, ça m'intéresse ; en Django, il y a la solution de Frédéric De Zorzi). On peut aussi mettre devant le serveur un relais dont l'une des tâches sera de limiter le trafic (comme par exemple Varnish).
Mais, dans cet article, je ne vais parler que des solutions fournies par Apache. Il y a plein de modules Apache qui permettent de limiter le trafic. Il est difficile de trouver des comparaisons entre eux, donc beaucoup d'administrateurs systèmes en prennent un au hasard. Ils n'ont pas les mêmes fonctions et surtout pas le même niveau de qualité (plusieurs semblent des projets abandonnés). Certains modules sont très sommaires (ce qui ne veut pas dire inutiles) comme mod_limitipconn, qui ne permet que de limiter le nombre de connexions simultanées faites par chaque adresse IP. Ou comme mod_ratelimit qui ne permet de contrôler que le débit (le nombre d'octets envoyés par seconde). Même chose apparemment pour mod_bwshare. D'autres sont plus riches comme mod_cband qui peut également limiter le nombre de requêtes par seconde, ou le nombre de connexions simultanées (comme mod_limitipconn).
Mais les deux modules les plus souvent cités pour faire de la limitation de trafic sont bien plus riches : mod_evasive et mod_security.
Commençons par mod_evasive. Une configuration typique ressemble à (avec mes commentaires) :
# Always global, no way to configure it in virtual hosts or per-directory :-( # Defines the number of top-level nodes for each child's hash table # (it is not a fixed-size table) DOSHashTableSize 4000 # Threshhold for the number of requests for the same page DOSPageCount 3 # Threshhold for the total number of requests for any object on the # site. This is per-child so it's better to set it to a low value. DOSSiteCount 20 # Interval for the page count threshhold DOSPageInterval 30 # Interval for the site count threshhold DOSSiteInterval 40 # Amount of time (in seconds) that a client will be blocked DOSBlockingPeriod 60 # Not for logs but for temp files DOSLogDir /var/lib/evasive # System command specified will be executed whenever an IP address # becomes blacklisted # TODO this one seems ignored but mod-evasive logs by default (a bad idea) # Use absolute path? DOSSystemCommand "logger -p auth.info -i -t mod-evasive '%s blacklisted'" # Whitelisting DOSWhitelist 127.0.0.* DOSWhitelist 192.134.6.* DOSWhitelist 2001:67c:2219:*
Compliquée ? Il faut dire que la documentation officielle est
serrée... Ces instructions limitent les visiteurs à trois requêtes
pour une page (vingt pour le site entier) pendant une période d'une
minute. On
trouve la documentation
dans le fichier README de la
distribution (sur une Debian, c'est dans
/usr/share/doc/libapache2-mod-evasive/README.gz). On
peut aussi consulter, à propos des
différentes variables « Installation et configuration du mod Evasive. ».
La plus grosse limitation de mod_evasive est qu'il est seulement
global. Pas moyen de le faire par virtual host ou
par répertoire. Certes, on peut mettre les directives dans un site ou
un répertoire (Apache ne proteste pas, le module se charge) mais elles
sont alors
ignorées : si on met les directives mod_evasive dans <VirtualHost>,
elles s'appliquent à tous les virtual hosts.
À lire le source, cela semble normal (il s'attache à des évenements
globaux). Et relativement logique, un outil anti-DoS doit aller vite
et ne pas faire trop de traitement. Mais ce n'est pas pratique du tout
pour un limiteur de trafic.
Pire, si un des vhosts est un serveur pour Subversion, ça
cafouille horriblement car mod_evasive interfère avec
l'authentification (premier svn co accepté, le
second fait des 401 Unauthorized).
(Sur les spécificités de mod_evasive pour une Debian, voir « Prevent DOS attacks on apache webserver for DEBIAN linux with mod_evasive ».)
Le second module Apache très souvent cité pour ce genre de travail
est mod_security. Il est bien plus générique et peut servir à beaucoup
d'autres choses. Notamment, il peut s'appliquer à seulement un
vhost ou seulement une partie du site. Mais il n'est pas trivial à configurer : sa
configuration se fait par des directives successives, évaluées en
séquence (comme avec le bon vieux
sendmail.cf ou, pour
prendre un exemple Apache, mod_rewrite). Il
est donc indispensable de lire la doc officielle.
Un exemple de configuration pour limiter le trafic (avec mes commentaires) :
# Activates mod_security
SecRuleEngine On
# Stores data here
SecDataDir /var/cache/apache2
# Phase 1 : request headers received (but nothing else)
# skip:10 : skip the next ten rules (in practice, go to the end of the rule set)
# Local network can do anything
# But ipMatch not present in Debian squeeze, we will have to wait the next version
#SecRule REMOTE_ADDR "@ipMatch 2001:67c:2219::/48 192.134.6.0/24 127.0.0.0/8" "phase:1,skip:10,nolog"
# So we use regexps in the mean time
SecRule REMOTE_ADDR "^(2001:67c:2219:|192\.134\.6|127)" "phase:1,skip:10,nolog"
# Only filters requests for this app
SecRule REQUEST_FILENAME "!^/apps/foobar" "phase:1,skip:10,nolog"
# Only filters requests for this server
SecRule REQUEST_HEADERS:Host "!www\.example\.net" "phase:1,skip:10,nolog"
# Stores the number of visits in variable IP.pagecount. Keeps it one minute
SecAction "phase:1,nolog,initcol:IP=%{REMOTE_ADDR},setvar:IP.pagecount=+1,expirevar:IP.pagecount=60"
# Denies requests when excessive
# 429 would be a better error status but mod_security rewrites it as 500 :-(
SecRule IP:PAGECOUNT "@gt 2" "phase:1,deny,status:403,msg:'Too many requests'"
Dommage, le code de retour HTTP normal pour un excès de requêtes (le 429 du RFC 6585) n'est pas reconnu par mod_security. Autrement, cela fonctionne bien et les excès sont journalisés :
[Mon May 07 12:21:30 2012] [error] [client 192.0.2.44] ModSecurity: Access denied with code 403 (phase 1). Operator GT matched 2 at IP:pagecount. [file "/etc/apache2/mods-enabled/mod-security.conf"] [line "19"] [msg "Too many requests"] [hostname "www.example.net"] [uri "/apps/foobar"] [unique_id "T6eiKsCGB-gAAHSOXEwAAABS"]
Sur l'usage de mod_security pour la limitation de trafic, on peut aussi consulter « rate limiting with mod_security », « How to limit connections per IP based on domain + string » et « Apache mod_security Setup Help? ».
Aussi bien avec mod_evasive qu'avec mod_security, la limitation est par adresse IP source. Autant dire qu'en IPv6, elle va être triviale à contourner. Je ne connais pas de moyen, avec ces deux modules, de mettre tout un préfixe (dont on spécifierait la longueur) dans la même règle.
Comme toujours avec les outils anti-méchants, rappelez-vous que ce qui marche lors d'un test avec wget, ou en laboratoire avec cent adresses IP d'attaque, va peut-être se comporter très différemment avec 20 000 zombies fous se lançant contre votre serveur. Gardez l'esprit ouvert et soyez prêt à changer de technique.
Connaissant le fanatisme des utilisateurs de nginx, nul doute que plusieurs d'entre eux m'écriront pour me dire que leur serveur HTTP est vachement meilleur et dispose de meilleurs mécanismes de limitation de trafic. Je leur laisse de la place ici pour insérer les URL de leur choix.
Merci à Patrice Bouvard et Éric van der Vlist pour leur relecture.
L'article seul
RFC 6608: Subcodes for BGP Finite State Machine Error
Date de publication du RFC : Mai 2012
Auteur(s) du RFC : J. Dong, M. Chen (Huawei Technologies), A. Suryanarayana (Cisco Systems)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 7 mai 2012
Un très court RFC pour enrichir la liste des codes d'erreur qu'un routeur BGP peut envoyer à son pair en cas de problèmes dans l'automate à états finis du protocole. Cela devrait permettre d'améliorer les messages d'erreur vus par les opérateurs de routeurs.
La section 4.5 du RFC 4271 (qui normalise
BGP), indique le mécanismes des codes d'erreur
à envoyer à un pair en cas de problèmes. Il y a les
codes (1 pour une erreur dans l'en-tête d'un
paquet, 2 pour une erreur à l'ouverture d'une session, 3 pour une
erreur lors du traitement d'une mise à jour des routes, etc) et les
sous-codes, dont la signification dépend du
code. Ainsi, lorsque le code vaut 2 (erreur lors d'une ouverture de
session BGP entre deux pairs), un sous-code 2 indique que le numéro
d'AS du pair n'est pas celui qui était configuré
(tcpdump affiche cette erreur avec BGP (NOTIFICATION: error OPEN Message Error, subcode Bad Peer AS). Lorsque le code d'erreur est 3 (erreur
lors d'un message UPDATE), le sous-code 2 veut
dire, par contre, qu'un attribut BGP envoyé par le pair est
inconnu.
Un des codes d'erreur est 5, problème dans l'automate à états finis : typiquement, un message a été reçu alors qu'il n'aurait pas dû l'être, vu l'état actuel de l'automate. Mais ce code 5 n'avait pas de sous-code (cf. RFC 4271, section 6.6) et il était donc difficile de connaître le problème exact. Ce RFC comble ce manque.
Les nouveaux sous-codes sont donc (la liste des états de l'automate est dans le RFC 4271, section 8.2) :
- 0 : erreur non spécifiée (la situation actuelle).
- 1 : message inattendu alors que l'envoyeur de l'erreur était
dans l'état
OpenSent. Par exemple, si un routeur est dans l'étatOpenSent(messageOPENenvoyé mais pas encore de réponse favorable) et reçoit un messageUPDATE(mise à jour des routes, ne devrait être envoyé que si la session est opérationnelle), alors il renverra un messageNOTIFICATIONavec le code à 5 et le sous-code à 1. - 2 : message inattendu alors que l'envoyeur de l'erreur était
dans l'état
OpenConfirm, - 3 : message inattendu alors que l'envoyeur de l'erreur était
dans l'état
Established(session BGP opérationnelle). Ce serait le cas, par exemple, d'un messageOPENreçu dans cet état.
Ces sous-codes sont enregistrés à l'IANA et de nouveaux sous-codes ne pourront être ajoutés que via un RFC sur le chemin des normes (cf. RFC 5226).
L'annonce du RFC notait qu'il existait déjà deux mises en œuvre de ces sous-codes mais j'avoue ignorer desquelles il s'agit.
L'article seul
RFC 6534: Loss Episode Metrics for IPPM
Date de publication du RFC : Mai 2012
Auteur(s) du RFC : N. Duffield (AT&T Labs-Research), A. Morton (AT&T Labs), J. Sommers (Colgate University)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 7 mai 2012
Le RFC 7680 définissait une métrique (une grandeur mesurable et spécifiée rigoureusement) pour le taux de pertes de paquets entre deux points du réseau. Mais un certain nombre de logiciels ne sont pas sensibles uniquement à la moyenne du taux de pertes mais aussi à sa répartition. Sur un flot de cent paquets, ce n'est pas la même chose d'en perdre trois, répartis au hasard, et d'en perdre trois de suite, par exemple pour certains protocoles multimédia qui encodent les différences entre paquets. Ce nouveau RFC définit donc des métriques pour caractériser les épisodes, ces pertes consécutives de paquets.
Par exemple, au taux de pertes moyen du RFC 7680, il serait intéressant d'ajouter la durée maximale d'un
épisode, ou bien la durée moyenne d'un épisode. Prenons les deux flots
suivants, où OK indique un paquet arrivé et LOST un paquet perdu : OK -
OK - LOST - LOST - LOST - OK - OK - OK - LOST - OK, puis LOST - OK -
LOST - OK - LOST - OK - LOST - OK - OK - OK.Le taux de pertes
moyen (Type-P-One-way-Packet-Loss-Average du RFC 7680) est de 0,4 (40 % de paquets perdus) dans les
deux cas. Mais la longueur maximale d'un épisode est de 3 dans le
premier cas et de 1 dans le second, ce qui peut être important pour
certains protocoles, et n'apparaissait pas dans la moyenne. Ainsi, un
flux MPEG comporte des trames plus importantes
que les autres, les I-frames, et la perte de
paquets immédiatement consécutifs à la perte d'une
I-frame est peu importante (sans la
I-frame, ils ne servent à rien).
Première leçon à tirer de ce simple exemple, la notion de perte de paquets est une notion complexe dans l'Internet, où le trafic connaît des pics brutaux. Le modèle trivial de Bernoulli, où chaque perte est indépendante des autres, est clairement inadapté. De la même façon, comme illustré au paragraphe précédent, la simple moyenne n'est pas une description quantitative suffisante du phénomène. Des modèles plus markoviens ont été proposés (voir section 7), avec la notion d'épisode (période pendant laquelle on perd tous les paquets), en modélisant par des transitions entre une période normale et un épisode de pertes. Des RFC comme le RFC 3357 ou le RFC 3611 avaient déjà exploré cette voie. Mais ces modèles ne semblent pas avoir démontré d'intérêt pratique. L'approche de notre RFC est plus empirique : observer et quantifier le phénomène, sans chercher à le modéliser. Plusieurs mesures ont déjà été proposées comme l'IDC (Index of Dispersion of Counts) mais avec peu de succès. Notre RFC représente donc une nouvelle tentative pour décrire ce phénomène.
Ce RFC 6534 utilise des paires de paquets,
l'intervalle entre deux paquets indiquant la résolution temporelle de
la mesure (les épisodes plus courts que cet intervalle ne seront pas
vus). Première métrique définie, qui sert de base (section 2),
Type-P-One-way-Bi-Packet-Loss. (Un
Bi-Packet = une paire.) La mesure donne (0, 0) si
les deux paquets sont arrivés, (1, 1) si les deux sont perdus,
etc. (Ce n'est peut-être pas intuitif mais le chiffre binaire indique
s'il y a eu une perte, donc 0 signifie le succès de la transmission.)
Ensuite, comme pour le RFC 7680, des
métriques moins élémentaires et plus utiles sont spécifiées à partir
de celle-ci. La section 3 définit
Type-P-One-way-Bi-Packet-Loss-Stream, une suite
de résultats de la métrique précédente. Pour le premier exemple de cet
article, ce sera ((0, 0), (0, 1), (1, 1), (1, 1), (1, 0), (0, 0), (0, 0), (0,
1), (1, 0)). (0, 1) indique une transition vers un épisode de perte, (1, 0) la fin de cet épisode. La section 4
précise la même suite pour le cas où les intervalles de temps entre
paquets forment une distribution
géométrique.
Jusque là, l'intérêt pratique de ces définitions semble
faible. Avec la section 5, on en arrive presque à des métriques
utilisables (mais patientez encore un peu, le RFC parle de
« proto-métriques » pour la section
5). Par exemple, Loss-Pair-Counts indique les fréquences de
chaque paire (dans l'exemple précédent 2/9 - 22 % - de (1,
1), 3/9 de (0, 0), 2/9 de (1, 0) et 2/9 de (0,
1). Bi-Packet-Loss-Episode-Duration-Number, elle,
caractérise la longueur des épisodes (2 ici, car on ne compte pas le
premier paquet des épisodes de perte).
Et ensuite, en section 6, on définit les métriques de plus haut
niveau, la
Type-P-One-way-Bi-Packet-Loss-Geometric-Stream-Ratio
pour le pourcentage de paquets perdus, la
Type-P-One-way-Bi-Packet-Loss-Geometric-Stream-Episode-Duration
pour la durée (en secondes) des épisodes, la
Type-P-One-way-Bi-Packet-Loss-Geometric-Stream-Episode-Frequency
la fréquence des épisodes de perte, etc.
Voilà, nous avons maintenant nos métriques (je vous ai épargné la définition rigoureuse, indispensable mais aride : lisez le RFC pour la connaître).
Ah, un mot pour les juristes : il y a même eu des requins pour breveter des métriques, et des bureaux des brevets pour l'accepter. Voir la déclaration #1354.
L'article seul
Commencer les sessions TCP plus vite ?
Première rédaction de cet article le 4 mai 2012
Tout le monde a envie que les réseaux aillent plus vite. Surtout Google. Un article de 2011, par des employés de cette société, « TCP Fast Open » explique un des mécanismes qui peuvent être utilisés, notamment pour les sessions TCP de courte durée. (Cette technique a, depuis, été décrite dans le RFC 7413.)
Un paradoxe de TCP,
connu depuis longtemps, est que le temps complet d'une session (par
exemple, de récupération d'un fichier) dépend souvent essentiellement
du temps d'ouverture de la session. En effet, beaucoup de sessions TCP
sont courtes (par exemple, en HTTP, on
GET /machintruc.html, on récupère une page de
cinq kilo-octets et c'est tout). Le temps de transfert des données est
négligeable par rapport au temps d'ouverture de la session, qui est
causé par la latence.
Car il faut oublier les stupides publicités des FAI qui promettent toutes des capacités mirifiques (et, en prime, ils se trompent et parlent de « bande passante », voire, pire, de « débit », notez que la capacité est définie dans le RFC 5136), des Mb/s en quantité. La capacité est bien pratique quand on télécharge la saison 2 de Rome mais, pour beaucoup d'interactions sur le Web, c'est la latence qui compte. En effet, l'ouverture d'une session TCP (RFC 793) nécessite l'échange de trois paquets :
- « Je veux te parler » (paquet
SYN), - « Je veux te parler aussi » (paquet
SYN+ACK), - « Parlons-nous, alors » (paquet
ACK).
L'acheminement de chaque paquet prend un temps certain (dixit Fernand Raynaud, mais on trouve une définition plus rigoureuse dans le RFC 7679) et le temps total d'ouverture est trois fois ce temps.
Vous ne me croyez pas ? Ce n'est pas grave, Google a mesuré pour cet article, en utilisant à la fois leurs serveurs HTTP et les mesures faites par Chrome. Première observation : la page Web moyenne fait 300 ko mais la plupart des fichiers qu'on télécharge sont petits, avec une taille moyenne de 7,3 ko et surtout une médiane de 2,4 ko. Un objet de 2,4 ko ne prend que deux paquets pour être transmis, la majorité des paquets seront donc pour l'ouverture de la connexion. Si le RTT est long, c'est lui, et pas la capacité, qui fixera le temps d'attente.
L'article montre ensuite que certaines solutions à ce problème, comme les connexions persistantes d'HTTP (RFC 7230, section 6.3), n'aident pas souvent, en pratique.
Alors, une solution évidente à ce problème de performances serait de permettre au premier paquet envoyé de porter des données. Le dialogue, pour un objet qui tient dans un seul paquet, deviendrait :
- « Je veux te parler,
GET /machintruc.html» (paquetSYN), - « Je veux te parler aussi, [contenu de
machintruc.html] » (paquetSYN+ACK), - « Parlons-nous, alors, tiens, c'est fini » (paquet ACK).
Mais cela ouvre une énorme faille de sécurité. Le premier paquet peut mentir sur son adresse IP source (au premier paquet, TCP n'a pas encore testé la réversibilité) et forcer le serveur HTTP à envoyer des données à la victime dont il a usurpé l'adresse (une attaque par réflexion et amplification, la réponse étant plus grosse que la requête).
Donc, comme Google est très fort, comment fait-il ?
- Le demandeur fait une première session TCP normale avec le
serveur, mais en incluant une option TCP,
Fast Open Cookie Request(les options TCP sont décrites dans la section 3.1 du RFC 793, les options de TCP Fast Open sont enregistrées dans le registre IANA des options expérimentales), - Le répondeur fabrique le cookie en hachant l'adresse IP du client avec une clé secrète et le transmet dans la réponse,
- Le client se souvient de ce cookie pour les connexions ultérieures.
On le voit, TCP Fast Open ne traite pas le cas de
la première connexion. Mais ce n'est pas grave : on fait en général
beaucoup de connexions TCP avec un serveur Web.
Pour les connexions ultérieures, le client enverra le
cookie dans le premier paquet, dans l'option TCP
Fast Open Cookie. Le serveur vérifiera ledit
gâteau et, s'il est correct, acceptera les données transmises dans le
premier paquet (typiquement un GET
/machintruc.html HTTP).
Naturellement, ça, ce sont les généralités. En pratique, il y a
plein de détails dont il faut s'occuper. Par exemple, TCP
Fast Open va devoir se battre contre les
middleboxes, cette plaie de
l'Internet, cf. l'excellente étude de Google « Probing the
viability of TCP extensions ». Et il y a la taille
(limitée) dans l'en-tête TCP pour les options. Et le fait qu'un accusé
de réception peut se perdre, amenant à la réémission d'un paquet
SYN (et donc à un GET reçu
deux fois : TCP Fast Open ne doit être utilisé
qu'avec des requêtes idempotentes). Mais tout cela n'a pas
arrêté les auteurs qui ont programmé cette option dans
Linux (dans les 2 000 lignes de code) et
Chrome. Résultat, avec une latence de 100 ms,
entre 6 et 16 % de gain, montant à 11-41 % pour 200 ms de latence.
À noter que cette idée d'accélérer TCP en mettant davantage d'informations plus tôt était à la base de T/TCP (RFC 1644). Ce protocole avait de sérieux défauts (cf. RFC 4614) et a officiellement été abandonné dans le RFC 6247.
L'actuel TFO (TCP Fast Open) a ensuite été décrit dans un RFC de statut « expérimental » (donc pas une « vraie » norme) en décembre 2014, dans le RFC 7413) . Mais TFO avait déjà fait l'objet de pas mal de buzz, voir par exemple l'article du Monde Informatique, celui de 01 Net ou celui de Développez. Ces articles (et surtout leurs commentaires) comportant pas mal d'erreurs, il vaut mieux revenir vers l'article du blog de Google (où TCP Fast Open n'est qu'une partie des changements proposés à TCP). L'ouverture rapide a été intégrée au noyau Linux officiel en septembre 2012, voir cet article dans LWN et cet autre, plus détaillé, avec exemple de code C. Le tout est apparu dans la version 3.6 de Linux.
L'article seul
Comment on dit « returnability » ?
Première rédaction de cet article le 3 mai 2012
Dernière mise à jour le 4 mai 2012
Un concept important est présent dans beaucoup de protocoles de la famille TCP/IP, mais pas toujours sous un nom explicite : le concept de « returnability » ou « existence d'une voie de retour » (je vais plutôt dire « réversibilité »).
Le protocole IP est unidirectionnel : si un paquet émis depuis une certaine adresse source vers une certaine destination arrive, rien ne prouve que la destination pourra répondre juste en inversant source et destination. Dans certains cas, cela marchera, mais pas dans d'autres :
- Adresse IP source usurpée, ce qui fait que le méchant ne recevra pas les réponses (technique utilisée dans des attaques en aveugle),
- Pare-feu qui laisse passer les paquets dans un seul sens,
- Routage incomplet : la transmission des paquets, dans IP, se fait uniquement sur la destination. Dans la plupart des cas, l'adresse source est ignorée, et il n'y aura pas forcément de route menant la réponse vers elle.
Certains protocoles aimeraient bien tester qu'il y a « réversibilité », autrement dit qu'on peut répondre à celui qui écrit. Par exemple, ce test permet de lutter contre les attaques effectuées en aveugle. C'est ainsi que TCP génère des numéros de séquence initiaux qui sont non prévisibles (et qui devront être utilisés par le pair), pour s'assurer que le pair reçoit bien les paquets (et n'est donc pas un attaquant aveugle). Le RFC 6528 décrit le problème de TCP et sa solution.
À l'inverse, il n'existe pas de tel test dans le DNS (qui fonctionne presque toujours sur UDP), ce qui permet les attaques par réflexion.
Aujourd'hui, ce terme de « returnability » figure dans les RFC du protocole LISP, protocole qui fait un gros usage du concept, en le nommant explicitement. LISP teste la réversibilité via des nonces, qui jouent le même rôle que les numéros de séquences initiaux de TCP. Lisez le RFC 9300, ou bien la bonne introduction de David Meyer. Vu la montée des préoccupations de sécurité, notamment contre les DoS, il est probable que le terme sera de plus en plus employé. Le protocole QUIC intègre également des tests de réversibilité.
Merci à Gaëtan pour avoir proposé « réversibilité ». On trouve aussi d'autres suggestions intéressantes lors de la discussion sur SeenThis.
L'article seul
RFC 6568: Design and Application Spaces for 6LoWPANs
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : E. Kim (ETRI), D. Kaspar (Simula Research Laboratory), N. Chevrollier (TNO), JP. Vasseur (Cisco Systems)
Pour information
Réalisé dans le cadre du groupe de travail IETF 6lowpan
Première rédaction de cet article le 1 mai 2012
Vous ne connaissez pas encore le terme de LowPAN ? Ce n'est pas grave, c'est encore assez rare. Un LowPAN est un Low-Power Wireless Personal Area Network. En gros, c'est un ensemble de petites machines (très petites : pas des ordinateurs), disposant de peu de puissance électrique, connectées souvent sans fil, et cherchant à communiquer. Le groupe de travail IETF 6lowpan établit des normes de communication pour ces LowPAN, en utilisant IPv6 (d'où le 6 au début de son nom). Ce document est son quatrième RFC. Il explique les principes de base de son travail, à travers des scénarios d'utilisation des LowPAN.
Un LowPAN typique va être, dans une exploitation agricole, l'ensemble des capteurs qui mesurent l'humidité, et des actionneurs qui déclenchent l'arrosage. La section 1 explique les douleurs du LowPAN : machines ayant peu de ressources (processeur, mémoire, courant), et connectées par des liens lents et sujets aux parasites et aux coupures (WiFi, CPL). En général, on veut en prime que ces machines soient peu chères. Résultat :
- Certaines machines du LowPAN peuvent n'avoir qu'un CPU 8-bits de 10 MHz. (Des plus chanceuses auront des CPU ARM de 32 bits à 50 MHz.)
- Certaines n'auront que quelques kilo-octets de RAM et quelques dizaines de kilo-octets de ROM. Plus élaboré, le IMote a 64 ko de RAM et une Flash de 512 ko.
- Fonctionnant souvent sur batterie, ces machines devront se limiter à une consommation de 10 à 30 mA pour la radio, limitant la puissance à 3 dBm et donc la portée à entre 30 et 100 mètres.
- La capacité de ces liens radio peut être entre 20 et 250 kb/s.
Bref, on est très loin des ordinateurs portables ou même des smartphones. Et c'est pourtant dans ces machines qu'il va falloir faire tenir le code réseau. Deux bonnes lectures sur ces environnements si différents des machines sur lesquelles l'Internet a commencé : le RFC 4919 décrit plus en détail le monde des LowPAN, le RFC 4944 normalise l'utilisation d'IPv6 sur IEEE 802.15.4.
Il existe en fait beaucoup de LowPAN différents. Suivant le document « The Design Space of Wireless Sensor Networks », la section 2 du RFC explique les axes sur lesquels se différencient les LowPAN : déploiement conçu dès le début ou bien incrémental, taille du réseau (10 machines ou 1000 ?), connectivité permanente ou intermittente (ce qui est courant lorsque les machines se déplacent), etc.
Bien, maintenant, assez de précautions, place au cœur du RFC, la section 3. Elle expose une partie des scénarios d'usage des LowPAN. Par exemple, en section 3.1, figure un usage souvent cité, la surveillance de bâtiments industriels. L'idée est que les capteurs dispersés un peu partout dans les bâtiments deviennent communiquants. Au lieu d'être relevés manuellement par un humain faisant sa ronde, ils transmettront d'eux-mêmes les résultats des mesures. De très nombreuses mesures peuvent être envisagées, comme les vibrations d'une machine (trop intenses, elles indiquent un problème) ou la température dans les entrepôts (attention à conserver la chaîne du froid). Les communications sans-fil sont ici cruciales car certaines parties de l'usine peuvent être difficiles à atteindre pour les câbles.
Comme exemple précis de ce type de surveillance, le RFC cite les salles de stockage d'un hôpital. Les globules rouges doivent être stockés entre 2 et 6°, les plaquettes entre 20 et 24°, et le plasma à -18°. Les capteurs de température sont disposés tous les 25 mètres environ, chaque emballage a une étiquette et des nœuds 6LowPAN sont placés dans les palettes. Par rapport aux axes de classification cités plus haut, on a un cas de déploiement planifié, avec un réseau de taille moyenne mais très dense, et peu de déplacements. Le débit attendu est faible mais les données peuvent être urgentes (alerte de réchauffement, par exemple). Les exigences de sécurité sont élevées. 6LowPAN peut-il convenir ? Oui, analyse cette section.
Autre cas, celui de la surveillance d'un bâtiment, pour veiller à son intégrité (section 3.2). Par exemple, un pont est construit et est truffé de capteurs et de machines LowPAN qui relèvent les capteurs et transmettent à un contrôleur. Le RFC part d'un pont de 1 000 m de long, avec 10 piliers. Chaque pilier a 5 capteurs pour mesurer le niveau de l'eau sont le pont et 5 autres qui mesurent les vibrations. Les machines LowPAN ne sont pas gênées par les murs du bâtiment, comme dans l'exemple précédent, et peuvent se voir à 100 m de distance. Tout est placé manuellement (attention à ne pas avoir un pilier dans la LoS) et ne bouge pas.
Le réseau est cette fois de petite taille, très statique. Mais sa sécurité est vitale. Dans ce cas simple, 6LowPAN convient bien (il faut juste faire attention aux placements des engins sur les piliers).
Pas d'article ou de document sur les LowPAN sans l'inévitable bla-bla sur la domotique et ses promesses d'un monde merveilleux où le réfrigérateur détectera la fin proche du stock de bières et en commandera d'autres. C'est le rôle ici de la section 3.3. Après la santé et les transports, où des vies humaines sont en jeu, cette section se penche sur le confort de l'occidental rose moyen, qui veut que sa maison high-tech s'occupe de tout pendant qu'il regarde le match de foot à la télé.
Il y a beaucoup de choses à mesurer dans une maison, la température, l'humidité, l'état des portes (ouvert ou fermé), la vidéo-surveillance (pendant qu'on est dans les délires de mauvaise science-fiction, transformons la maison en bunker avec caméra braquée sur les quartiers sensibles). En combinant avec l'idée de « Smart Grid » (réseau de distribution électrique doté de capacités de mesure et de transmission de l'information), on peut aussi imaginer de connecter ces informations avec celle du réseau électrique.
Du point de vue technique, les murs de la maison feront souvent obstacle aux communications sans fil. Le réseau devra donc permettre le routage, pour le cas où la machine qu'on veut joindre n'est pas directement visible (« Multi-hop routing »). Les fonctions de ce réseau de gadgets ne sont pas vitales, cette fois. Par contre, l'ergonomie est cruciale, le réseau devra être très simple à administrer.
Autre scénario d'usage, en section 3.4, l'assistance médicale. L'idée est de mettre les capteurs sur et dans le patient, de manière à pouvoir surveiller son état à tout moment. Pour une personne âgée à la maison, on peut imaginer quelques capteurs portés à même le corps et qui mesurent des choses commes les battements cardiaques, et d'autres capteurs dans la maison, captant les mouvements, par exemple pour pouvoir donner l'alerte en cas de chute. Les enjeux de sécurité, notamment de protection de la vie privée, sont très importants. Si le LowPAN est ici de petite taille, et que la mobilité est limitée, les contraintes de bon fonctionnement sont essentielles, puisqu'une vie humaine peut être en jeu.
Un scénario dans un univers plus technique est celui de l'automobile (section 3.5). Les nœuds LowPAN peuvent être inclus dans la route au moment de sa construction et surveiller les véhicules qui passent. Cela pose un sacré problème de durée de vie puisque les nœuds vont devoir durer autant que la route (typiquement, dix ans, avant la première réfection sérieuse qui permettra de les changer). Malgré cela, avec le temps, la densité des capteurs diminuera, au fur et à mesure des pannes. Les machines LowPAN de la route seront nombreuses mais statiques, celles des véhicules peu nombreuses mais très mobiles.
Enfin, le dernier exemple est un peu plus vert, puisqu'il concerne l'agriculture (section 3.6), celle qui, selon Jared Diamond, est à la base de la force des empires. L'idée est de mesurer à distance, via de nombreux capteurs, l'humidité, la température et l'état du sol, de manière à appliquer l'irrigation ou les pesticides au bon moment. Le RFC prend l'exemple d'une vigne de bonne taille (dans les huit hectares) où 50 à 100 machines de contrôle piloteront des centaines de capteurs. La principale difficulté, pour ces derniers, sera de résister à des conditions hostiles dehors (humidité, poussière, hommes et machines qui passent en permanence et font courir des gros risques aux fragiles capteurs), etc. Heureusement, les exigences de sécurité sont cette fois bien plus basses.
En parlant de sécurité, la section 4 y est entièrement consacrée. Elle rappelle que les machines d'un LowPAN sont souvent exposées dehors, et donc physiquement accessibles à un éventuel attaquant. Les méthodes de sécurisation doivent tenir compte de cela. La communication entre les machines du LowPAN est souvent par radio, médium qui n'offre aucune sécurité, permettant à l'attaquant de capter tout le trafic, voire d'injecter de fausses données. La cryptographie devient alors nécessaire.
Mais les machines d'un LowPAN ont des ressources, notamment d'énergie, très limitées. Elles sont donc vulnérables aux attaques par déni de service : des requêtes répétées et hop, la batterie est à plat. À cause de cela, les techniques de sécurité adoptées doivent être légères et ne pas abuser des ressources très limitées de ces petits engins. Par exemple, IPsec est probablement exagéré pour ces environnements, en raison des calculs qu'il entraîne. Cela doit évidemment s'adapter à l'usage envisagé : le nœud LowPAN qui allume une lampe n'a pas les mêmes contraintes de sécurité que celui qui contrôle un stimulateur cardiaque.
L'article seul
RFC 6585: Additional HTTP Status Codes
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : M. Nottingham (Rackspace), R. Fielding (Adobe)
Chemin des normes
Première rédaction de cet article le 1 mai 2012
Le protocole HTTP, normalisé dans le RFC 7230, utilise des réponses numériques sur trois chiffres pour indiquer le résultat de la requête. Certains de ces codes sont devenus célèbres comme le 404 pour une ressource non trouvée. Et comme l'Internet fonctionne avec des LOLcats, il existe même un ensemble de photos des réponses HTTP avec des chats (d'où sont tirées les images de cet article). Mais la liste des réponses possibles n'est pas figée et de nouveaux codes sont ajoutés de temps en temps. Ce RFC normalise quatre de ces codes.
Ces nouveaux codes permettent de préciser le code utilisé autrefois, qui était en général moins précis. Ainsi, les limiteurs de trafic utilisaient souvent, lorsqu'un client demandait trop de ressources, le code 403 (Interdiction), qui pouvait servir à bien d'autres choses. Ils ont désormais un code à eux, 429. Les nouveaux codes sont enregistrés à l'IANA.
Rappelez-vous bien que le premier chiffre indique la classe de l'erreur (RFC 7231, section 6) et qu'un serveur HTTP qui utilise un code nouveau n'a pas de souci à se faire : un client qui ne connaîtrait pas ce nouveau code peut le traiter comme le code générique commençant par le même chiffre. Pour reprendre l'excellent résumé de Dana Contreras, « HTTP response codes for dummies. 5xx: we fucked up. 4xx: you fucked up. 3xx: ask that dude over there. 2xx: cool ».
Premier cité (section 3), 428
Precondition Required (pas de jolie image de chat pour ce code). Pour éviter le problème de
la « mise à jour perdue » (un client récupère une ressource Web, la
modifie et la renvoie au serveur pour mise à jour, alors que, pendant
ce temps, un autre client a fait pareil : l'un des deux va perdre sa
mise à jour), certains serveurs HTTP exigent que les requêtes soient
conditionnelles (par exemple avec le If-Match: de
la section 3.1 du RFC 7232). Si le client n'a
pas utilisé de condition, le serveur l'enverra promener avec ce code
428 (qui doit normalement être accompagné d'un message clair indiquant
le problème) :
HTTP/1.1 428 Precondition Required
Content-Type: text/html
<html>
<head>
<title>Precondition Required</title>
</head>
<body>
<h1>Precondition Required</h1>
<p>This request is required to be conditional;
try using "If-Match".</p>
</body>
</html>
Deuxième code, 429 Too Many Requests (section 4)  Il était
apparemment assez répandu dans la nature mais n'était pas encore
normalisé. C'est désormais fait et les limiteurs de
trafic peuvent donc désormais dire clairement à leurs
clients qu'ils exagèrent :
Il était
apparemment assez répandu dans la nature mais n'était pas encore
normalisé. C'est désormais fait et les limiteurs de
trafic peuvent donc désormais dire clairement à leurs
clients qu'ils exagèrent :
HTTP/1.1 429 Too Many Requests
Content-Type: text/html
Retry-After: 3600
<html>
<head>
<title>Too Many Requests</title>
</head>
<body>
<h1>Too Many Requests</h1>
<p>I only allow 50 requests per hour to this Web site per
logged in user. Try again soon.</p>
</body>
</html>
C'est uniquement un indicateur d'une décision prise par le serveur : le RFC n'impose pas aux serveurs un mécanisme particulier pour prendre cette décision. De même, le serveur n'est pas obligé de renvoyer quelque chose (ce qui consomme des ressources), il a le droit d'ignorer purement et simplement les requêtes excessives (section 7.2).
Troisième code, en section 5, 431 Request Header Fields
Too Large  Le protocole HTTP n'impose pas de limite à la
taille des en-têtes envoyés lors d'une requête mais un serveur
donné peut avoir une telle limite. Si elle est dépassée, il peut
répondre 431. Le même code peut dire « taille totale des en-têtes trop
grande » ou « taille d'un en-tête trop grande ». Dans ce dernier cas,
la réponse doit indiquer quel en-tête :
Le protocole HTTP n'impose pas de limite à la
taille des en-têtes envoyés lors d'une requête mais un serveur
donné peut avoir une telle limite. Si elle est dépassée, il peut
répondre 431. Le même code peut dire « taille totale des en-têtes trop
grande » ou « taille d'un en-tête trop grande ». Dans ce dernier cas,
la réponse doit indiquer quel en-tête :
HTTP/1.1 431 Request Header Fields Too Large
Content-Type: text/html
<html>
<head>
<title>Request Header Fields Too Large</title>
</head>
<body>
<h1>Request Header Fields Too Large</h1>
<p>The "Example" header was too large.</p>
</body>
</html>
Ces trois premiers codes n'ont pas suscité de controverses particulières. Ce n'était pas le cas de 511 Network Authentication Required (section 6, pas de jolie image de chat pour ce code) qui indique que le client aurait dû s'authentifier. Le problème est d'architecture : ce code est utilisé pour les portails captifs qui, tant qu'on n'est pas authentifié, redirigent d'autorité toutes les requêtes HTTP vers un serveur permettant de s'authentifier. (Après l'authentification, l'adresse MAC est mémorisée par le routeur, qui ne redirige plus.) De tels portails violent sérieusement les bons principes d'architecture du Web. Mais ils existent et il était donc préférable qu'ils puissent répondre avec un code sans ambiguité. La réponse 511 inclut donc le lien vers la page de login. Elle ne doit jamais être envoyée par un serveur normal, uniquement par le relais détourneur.
Le RFC dit donc que les portails captifs sont le Mal (surtout pour les clients HTTP qui ne sont pas des navigateurs) mais que le 511 permettra de limiter les dégats. Au moins, curl ou wget comprendront tout de suite ce qui s'est passé.
Un exemple de réponse (notez l'élément
<meta> pour les navigateurs) :
HTTP/1.1 511 Network Authentication Required
Content-Type: text/html
<html>
<head>
<title>Network Authentication Required</title>
<meta http-equiv="refresh"
content="0; url=https://login.example.net/">
</head>
<body>
<p>You need to <a href="https://login.example.net/">
authenticate with the local network</a> in order to gain
access.</p>
</body>
</html>
Les réponses 511 ou, plus exactement, les redirections forcées posent des tas de problèmes de sécurité. Par exemple, elles ne viennent pas du serveur demandé, ce qui casse certains mécanismes de sécurité de HTTP comme les cookies du RFC 6265. Un problème analogue survient si on utilise TLS car le certificat X.509 ne correspondra pas au nom demandé. L'annexe B du RFC détaille les problèmes de sécurité des portails captifs et les façons de les limiter. Cela va de problèmes esthétiques (la favicon récupérée depuis le portail et qui s'accroche ensuite dans le cache du navigateur) jusqu'aux protocoles de sécurité qui risquent de prendre la réponse du portail pour l'information qu'ils demandaient (P3P, WebFinger, OAuth, etc). Ces protocoles sont souvent utilisés par des applications HTTP qui ne passent pas par un navigateur (Twitter, iTunes, le WebDAV du RFC 4918, etc). En détectant le code 511, ces applications ont une chance de pouvoir réagir proprement (en ignorant les réponses transmises avec ce code).
À l'heure actuelle, je ne pense pas qu'il y ait beaucoup de hotspots qui utilisent ce code mais cela viendra peut-être. Mais je n'en suis pas sûr, ces portails captifs étant en général programmés avec les pieds, par un auteur anonyme à qui on ne peut jamais signaler les bogues. Et je ne sais pas quels sont les clients HTTP qui le reconnaissent et agissent intelligement. Si un lecteur courageux veut enquêter...
Les images de chats citées plus haut sont également accessibles via une API REST simple. Si vous préférez les chiens, ça existe aussi.
L'article seul
Luttes dans l'Internet
Première rédaction de cet article le 28 avril 2012
Cet article date de 2002 mais n'a pas pris une ride : « Tussle in Cyberspace: Defining Tomorrow's Internet » de D. Clark, J. Wroslawski, K. Sollins et R. Braden est consacré à une question vitale : comment gérer les évolutions techniques de l'Internet alors qu'il y a bien longtemps que ses acteurs n'ont plus de vision commune, voire ont des visions opposées ? Contrastant avec le nombre de RFC, il existe très peu d'articles technico-politiques sur l'Internet. Ce papier est donc une lecture indispensable.
En effet, la plupart des articles parlant de politique au sujet de l'Internet se limitent à des sujets politiciens médiocres (comme la gestion de l'ICANN). Pendant que certains s'amusent dans ces petits sujets, il y a heureusement des auteurs qui s'attaquent aux vrais problèmes. Le point de départ de « Tussle in Cyberspace: Defining Tomorrow's Internet » est de considérer que l'architecture de l'Internet est le terrain sur lequel se déroulent certaines luttes (par exemple entre le FAI, qui veut dépenser le moins possible, et ses clients qui veulent avoir plus de Gb/s pour moins d'€). Et qu'il faut admettre ces luttes (tussle) comme inévitables, et se contenter d'organiser le terrain pour que ces luttes ne cassent pas tout et ne s'étendent pas à tout.
Notons que la vision « autrefois, tout le monde était gentil sur l'Internet » est largement imaginaire. Mais c'est vrai que, comme le note l'article, il y avait une époque où il existait une vision commune, un but commun (la connectivité universelle). Ce n'est plus le cas. La nostalgie ne servant à rien, il faut aujourd'hui se demander comment les gens qui travaillent à faire évoluer l'Internet doivent gérer ces luttes. Vouloir les supprimer est irréaliste (je prends ma casquette de marxiste orthodoxe pour noter que ce serait aussi idiot que de nier la lutte des classes, même si les auteurs de l'article ne citent pas ce cas). Vouloir décider leur résultat est dangereux (certaines forces en lutte sont puissantes). Les auteurs estiment donc que le rôle des ingénieurs aujourd'hui est, selon leur expression, de concevoir le terrain, pas de décider du résultat du match.
Ils donnent de nombreux exemples de ces luttes « irréductibles » (qu'on ne pourra pas supprimer par un appel à la bonne volonté). Il y a bien sûr les luttes entre les FAI et leurs clients (cf. la question de la neutralité de l'Internet). Il y a celles entre les partisans du partage de la culture et les gens de l'appropriation intellectuelle. Il y a celle entre les citoyens qui veulent communiquer de manière privée et les États (démocratiques ou dictatoriaux) qui veulent les espionner.
Pour chacun de ces cas, il y a apparemment des réponses techniques. Par exemple, on peut changer l'Internet pour faciliter les écoutes (projet NGN de l'UIT, sous le nom d'« interception légale », auquel avait répondu le RFC 1984). On peut au contraire chercher à rendre ces écoutes impossibles (en imposant IPsec systématiquement ?) Où on peut dire que ce n'est pas un problème technique, mais politique, et que les ingénieurs ne doivent pas intervenir pour imposer telle ou telle politique.
Car, c'est un point central de l'article, l'architecture technique n'est pas neutre. Elle va rendre plus ou moins facile telle ou telle politique. Si les auteurs ne citent pas Lawrence Lessig, on ne peut que penser à son fameux « The code is the law », qui disait à peu près la même chose.
Donc, les recommandations des auteurs aux gens qui font l'Internet de demain sont : méfiez-vous des systèmes trop rigides, qui craqueront forcément sous la pression de telle ou telle partie à la lutte. Concevez des systèmes souples, où des choix différents pourront être exprimés.
Un bon exemple donné dans l'article est celui du
DNS. Celui-ci sert à la fois à des fonctions de
nommage stable des machines et des services (pour lesquelles l'identificateur
utilisé n'a pas d'importance, il pourrait être numérique) et
d'expression d'une identité sur le réseau (avec des cas extrême comme
Amazon.com qui utilise son nom de domaine comme nom commercial). La seconde fonction mène
forcément à des conflits (tout le monde veut avoir
sex.com et
s'appeler du nom d'une marque est risqué). Il
aurait donc été préférable de séparer ces deux fonctions, laissant la
première libre de la lutte pour les noms. Cela ne résoudrait pas les
nombreux problèmes posés par cette lutte mais, au moins, elle ne
déborderait pas sur des fonctions opérationnelles utiles. Plus
généralement, il s'agit, non pas de nier la politique (et les luttes)
mais de la séparer, autant que possible (l'article est très détaillé
et reconnait bien que ce n'est pas facile), de la technique.
L'article donne d'autres exemples de lutte, comme le verrouilage chez un opérateur réseau via les adresses IP. Comme renuméroter son réseau est difficile (RFC 5887), le client va hésiter à changer de fournisseur. Il est donc important que l'Internet propose des mécanismes techniques pour que les adresses ne soient pas liées à un fournisseur. Autrement, l'architecture technique bloquerait la lutte... au détriment du client.
Bref, les gens qui conçoivent des nouveaux systèmes et des nouveaux protocoles sur l'Internet devraient passer un peu de temps à analyser les luttes qui en résulteront, et à essayer des les contenir (sans tenter de les supprimer).
L'article seul
RFC 6598: IANA-Reserved IPv4 Prefix for Shared Address Space
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : J. Weil (Time Warner Cable), V. Kuarsingh (Rogers Communications), C. Donley (CableLabs), C. Liljenstolpe (Telstra Corp), M. Azinger (Frontier Communications)
Première rédaction de cet article le 23 avril 2012
Après beaucoup de discussions pas toujours sereines,
l'IESG a finalement décidé de publier ce très
controversé RFC. Il réserve un préfixe
IPv4, 100.64.0.0/10, aux
services de partage d'adresses IP entre utilisateurs, les
CGN (Carrier-Grade NAT). Ce
faisant, il légitime ce concept de CGN, ce qui a déclenché la colère
de beaucoup.
Voyons d'abord le paysage : les adresses IPv4 sont à peu près épuisées. Mais le déploiement d'IPv6 a pris beaucoup de retard et il n'est pas, à l'heure actuelle, prêt à prendre le relais. Plusieurs FAI, notamment en Asie, ont donc commencé à déployer des systèmes où l'abonné de base n'a aucune adresse IPv4 publique. Avant cela, M. Toutlemonde n'avait certes qu'une seule adresse publique et devait faire du NAT pour donner à toutes ses machines une connectivité Internet partielle. Mais, au moins, le partage d'adresses ne se faisait qu'entre habitants du même foyer, Aujourd'hui, par manque d'adresses IPv4, les déploiements en cours repoussent le NAT dans le réseau de l'opérateur (d'où le nom de CGN, Carrier-Grade NAT, voir par exemple le RFC 6264 ou bien le RFC 6888) et le partage d'adresses publiques se fait désormais entre abonnés n'ayant rien en commun. Désormais, si votre voisin télécharge illégalement, c'est peut-être sur vous que l'HADOPI tombera...
Le partage d'adresses (documenté dans le RFC 6269) n'est pas le seul inconvénient des CGN. Ces gros routeurs NAT, gardant en mémoire l'état des flux pour des centaines ou des milliers d'abonnés, diminuent la résistance aux pannes : si on redémarre l'un d'eux, tous les abonnés perdent leurs sessions en cours. Voilà pourquoi l'idée même de CGN (qui met de l'« intelligence » dans le réseau et non pas aux extrémités) hérisse tant de gens à l'IETF.
Si on fait quand même des CGN, se pose le problème de la
numérotation des réseaux. Le réseau local de l'abonné (appelons-le
M. Li car les CGN pour des accès Internet fixe sont aujourd'hui
surtout répandus en Chine) est typiquement
numéroté avec le RFC 1918. L'opérateur ne peut
pas utiliser les adresses de ce même RFC pour son réseau, entre M. Li
et le gros CGN, à cause du risque de conflit avec le réseau local de
M. Li (sauf si l'opérateur contrôle ledit réseau, via ses
boxes). Il ne peut pas
utiliser des adresses IP publiques puisque, c'est le point de départ
de toute l'histoire, celles-ci manquent. Il faut donc un « nouveau
RFC 1918 ». C'est le rôle de ce RFC 6598, qui réserve un nouveau préfixe,
100.64.0.0/10, à cet usage. Il s'ajoute aux
autres préfixes « spéciaux » du RFC 6890. Il servira aux
machines entre le CPE (la
box) et le routeur CGN et ne sera donc typiquement
jamais vu sur l'Internet. À noter que ce
préfixe n'a rien de particulier, à part son usage officiel : on
pourrait parfaitement s'en servir pour autre chose que du CGN.
Voici le nouveau préfixe, vu avec whois :
% whois 100.64.0.0 NetRange: 100.64.0.0 - 100.127.255.255 CIDR: 100.64.0.0/10 OriginAS: NetName: SHARED-ADDRESS-SPACE-RFCTBD-IANA-RESERVED NetHandle: NET-100-64-0-0-1 Parent: NET-100-0-0-0-0 NetType: IANA Special Use RegDate: 2012-03-13 Updated: 2012-03-15
Ah, pourquoi une longueur de 10 à ce préfixe ? Un préfixe plus court (comme un /8) aurait été difficile à trouver de nos jours, et un plus long (par exemple un /12), offrant moins d'adresses, aurait obligé les FAI, dans certaines régions très peuplées, à déployer des CGN emboités... Un /10, par exemple, suffit à desservir toute l'agglomération de Tokyo (un FAI japonais ne peut donc pas avoir un seul routeur CGN pour tous le pays).
La section 4 du RFC précise l'usage attendu : chaque FAI utilisera
librement 100.64.0.0/10 et ce préfixe n'aura donc
de signification que locale. Les adresses
100.64.0.0/10 ne doivent pas
sortir sur l'Internet public (le mieux est de les filtrer en sortie
et, pour les autres FAI, en entrée, car il y aura toujours des
négligents). Ces adresses ne doivent pas non plus apparaître dans le
DNS public. Les requêtes DNS de type
PTR pour ces adresses ne doivent
pas être transmises aux serveurs DNS globaux,
comme celles pour les adresses du RFC 1918,
elles doivent être traitées par les serveurs du FAI (cf. le RFC 7793). Comme pour le
RFC 1918, c'est sans doute un vœu pieux,
et il faudra sans doute que l'AS112 (voir le RFC 7534) prenne en charge ces requêtes.
La section 3 décrit plus en détail les alternatives qui avaient été envisagées et les raisons de leur rejet. La solution la plus propre aurait évidemment été d'utiliser des adresses IPv4 globales, attribuées légitimement au FAI. Mais l'épuisement d'IPv4 rend cette solution irréaliste. Déjà, extraire un /10 des réserves n'a pas été facile.
La solution qui est probablement la plus utilisée à l'heure actuelle est celle d'utiliser un préfixe IPv4 usurpé, en se disant « de toute façon, ces adresses ne sortiront jamais sur l'Internet donc quel est le problème ? » Se servir sans demander est certainement plus rationnel, économiquement parlant, que de supplier la bureaucratie d'un RIR pour avoir des adresses. Autrefois, les FAI qui numérotaient ainsi leur réseau interne se servaient de préfixes non alloués (provoquant pas mal d'accidents au fur et à mesure de leur allocation ; même s'il n'y a pas de fuite de ces adresses, les abonnés du FAI peuvent être dans l'impossibilité de communiquer avec le détenteur légitime). Aujourd'hui, ils regardent quels sont les préfixes alloués mais non routés et les utilisent. Inutile de dire que le RFC condamne cette pratique incivique.
Le RFC 1918 n'est, on l'a vu, possible que si le FAI contrôle complètement le réseau local de M. Li et sait donc quels préfixes sont utilisés sur celui-ci, et peut ainsi choisir des préfixes qui ne rentrent pas en collision. (Cela peut aussi marcher si la box sait bien se débrouiller lorsque le même préfixe est utilisé en interne et en externe, ce qui est le cas de certaines.)
Bref, l'allocation d'un nouveau préfixe semblait la seule solution raisonnable.
La section 5 du RFC est consacrée à une longue mise en garde sur
les dangers associés aux CGN. Certaines applications peuvent avoir des
mécanismes pour découvrir l'adresse externe de la machine sur laquelle
l'application tourne (l'adresse qu'on verra sur l'Internet) et,
ensuite, faire des choses comme de demander à un pair d'envoyer des
données à cette adresse. Avec le CGN, cela a encore moins de chances
de marcher que d'habitude car les applications actuelles ne
connaissent pas encore 100.64.0.0/10 et
considéreront que ces adresses sont globalement utilisables.
Parmi les applications qui ont de fortes chances de mal marcher
dans le contexte du CGN, citons les jeux en ligne (si deux abonnés
essaient de se connecter alors qu'ils sont derrière le même CGN et ont
la même adresse publique), le pair-à-pair, et
bien sûr les applications de téléphonie avec
SIP, la géo-localisation (le CGN sera trouvé,
pas la vraie machine), certaines applications Web qui restreignent les
connexions simultanées en provenance de la même adresse IP, etc. Pour
les applications de type pair-à-pair (échange de fichier, SIP), les
techniques habituelles d'ouverture manuelle d'un
port sur le routeur (« tout ce qui est envoyé
au port 4554, transmets le à 10.4.135.21 ») ne
marchent pas avec le CGN, l'utilisateur résidentiel n'ayant
typiquement pas de moyen de configurer le routeur CGN.
Enfin, quelques bons conseils de sécurité forment la section 6 : ne
pas accepter les annonces de route pour
100.64.0.0/10 à l'entrée d'un site, les paquets
depuis ou vers ces adresses ne doivent pas franchir les frontières
d'un opérateur, etc.
Voilà, comme indiqué, cela ne s'était pas passé tout seul et l'IESG avait même dû faire une longue note détaillant le pourquoi de sa décision et expliquant que, certes, il n'y avait pas de consensus en faveur de ce projet mais qu'il n'y avait pas non plus de consensus contre. L'argument « pour » était :
- Les opérateurs vont déployer du CGN de toute façon. S'ils n'ont pas un préfixe dédié à cet usage, ils utiliseront des mauvaises méthodes, comme des préfixes squattés.
Les arguments contre étaient :
- Toute mesure qui prolonge au delà du raisonnable l'usage d'IPv4 ne fait que retarder le déploiement d'IPv6. Les efforts devraient se porter sur ce déploiement, pas sur l'acharnement thérapeuthique !
- Les opérateurs se serviront du nouveau préfixe pour étendre le RFC 1918, et pas pour l'usage attendu.
Pour d'autres articles sur ce sujet, voir celui sur le bon blog de Chris Grundemann (en anglais) ou bien celui de Jérôme Durand (en français).
L'article seul
RFC 6589: Considerations for Transitioning Content to IPv6
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : J. Livingood (Comcast)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 23 avril 2012
Ce document rassemble un certain nombre d'analyses et de conseils sur la transition vers IPv6 pour les gens qui hébergent du contenu, typiquement les sites Web. Les gérants de ces sites souhaiteraient pouvoir rendre ce contenu accessible en IPv6, sans que cela entraîne de conséquences fâcheuses pour les lecteurs. Ce RFC décrit notamment la technique du whitelisting, qui consiste à ne renvoyer d'adresses IPv6 (les enregistrements AAAA du DNS) qu'à certains réseaux, identifiés comme mettant en œuvre correctement IPv6. Cette technique a été popularisée par Google mais elle est contestée. Le RFC estime qu'elle est acceptable et qu'il est utile d'informer, non pas les sites qui la pratiquent (ils connaissent déjà) mais la communauté Internet en général.
Bien sûr, ce RFC peut être utile à d'autres qu'aux gérants de sites Web. Mais il se focalise particulièrement sur leurs besoins. Un site Web se caractérise par un gros déséquilibre : au lieu de deux pairs qui veulent communiquer, on a un fournisseur de contenu, et des clients passifs, à qui on ne peut pas demander d'effectuer des réglages particuliers. Ça doit marcher, point. En outre, les sites Web à plus fort trafic sont souvent des entreprises commerciales, qui ne veulent pas prendre de risques et n'acceptent pas même un très faible pourcentage de clients pénalisés par IPv6.
Le but est donc de migrer de gros sites Web uniquement accessible en IPv4 (la grande majorité des gros sites Web à l'heure actuelle, la principale exception étant Google) vers un accès possible en IPv4 (protocole qui ne va pas disparaître de si tôt) et IPv6.
Mais quels sont les problèmes qu'IPv6 pourrait causer ? Le site Web
typique publie son adresse dans le DNS. Pour
l'adresse IPv4, il utilise un enregistrement de
type A. Pour IPv6, de type AAAA. Ainsi, aujourd'hui,
www.bortzmeyer.org annonce deux AAAA et un A :
% dig A www.bortzmeyer.org ... ;; ANSWER SECTION: www.bortzmeyer.org. 42641 IN A 204.62.14.153 ... % dig AAAA www.bortzmeyer.org ... ;; ANSWER SECTION: www.bortzmeyer.org. 10222 IN AAAA 2605:4500:2:245b::bad:dcaf www.bortzmeyer.org. 10222 IN AAAA 2001:4b98:dc0:41:216:3eff:fece:1902 ...
Par contre, la très grande majorité des sites Web ne publient que des
A, par exemple www.gouvernement.fr :
% dig A www.gouvernement.fr ... ;; ANSWER SECTION: www.gouvernement.fr. 86383 IN CNAME www.premier-ministre.gouv.fr. www.premier-ministre.gouv.fr. 86383 IN CNAME cdn2.cdn-tech.com.c.footprint.net. cdn2.cdn-tech.com.c.footprint.net. 213 IN A 209.84.9.126 ... % dig AAAA www.gouvernement.fr ... ;; ANSWER SECTION: www.gouvernement.fr. 86358 IN CNAME www.premier-ministre.gouv.fr. www.premier-ministre.gouv.fr. 86358 IN CNAME cdn2.cdn-tech.com.c.footprint.net. ...
Certains de ces sites sont simplement gérés par des incompétents ou des paresseux, qui ne peuvent pas ou n'envisagent pas de publier des enregistrements AAAA, qui permettraient à leur lecteurs d'accéder au contenu en IPv6. Mais, dans d'autres cas, l'administrateur du site Web connaît IPv6, a refléchi, et a décidé de ne pas publier le AAAA. Pourquoi ? Parce qu'il craint le problème du malheur des globes oculaires (eyeball misery ?). J'ai décrit ce problème dans un autre article et il fait en outre l'objet de deux autres RFC, les RFC 6555 et RFC 6556. En deux mots, le malheur des globes oculaires peut venir d'une connexion IPv6 cassée, ou simplement de qualité très inférieure. Si le site Web ne publie pas d'enregistrement AAAA, le client ne tentera pas de se connecter en IPv6 et sa connexion pourrie n'aura donc pas de conséquences négatives. Mais dès que le site Web publie son AAAA, patatras, l'expérience utilisateur se dégrade sérieusement et le pauvre client doit supporter des délais, voire des pannes.
Le problème n'arriverait pas si les administrateurs réseaux prenaient autant soin de la connexion IPv6 que de l'IPv4 mais ce n'est pas toujours le cas en pratique : quand un des deux protocoles marche nettement moins bien que l'autre, aujourd'hui, c'est presque toujours IPv6. Logiciels moins testés, surveillance moins sérieuse, moindre réactivité lors des pannes, sont la triste réalité d'IPv6 chez beaucoup d'opérateurs réseaux. Un autre problème est quantitatif : certaines bogues ne se déclenchent qu'à partir d'une certaine quantité de trafic et les tests en laboratoire ne les détectent donc pas. Si un gros site Web très populaire publie tout à coup des enregistrements AAAA, on peut imaginer que l'augmentation de trafic résultante plante des équipements réseaux qui marchaient l'instant d'avant. Ou, tout simplement, dépasse leur capacité (section 2.3 de notre RFC). Prenons l'exemple d'un FAI qui déploie 6rd (RFC 5969) et le fait tourner sur trois vieux PC avec Linux (le noyau Linux a désormais 6rd en standard), cela peut marcher très bien tant que les utilisateurs font un peu de ping6 et traceroute6, et ne pas suffire si tout à coup YouTube devient accessible en IPv6.
Bien sûr, tous les sites Web ne sont pas logés à la même enseigne,
car ils n'ont pas tous le même public. http://www.ietf.org/ a un AAAA depuis très longtemps, sans
problèmes. Mais son public, les gens qui suivent le travail de
l'IETF, ne ressemble pas à celui de
TF1 : il est nettement plus soucieux de la
qualité de sa connexion et s'assure qu'elle marche en v4 et en
v6. D'autres sites Web qui ont un public moins
geek ne veulent pas prendre
le moindre risque.
Quelle est l'ampleur de ce risque ? Quelques organisations ont fait des études sur le malheur des globes oculaires et trouvent jusqu'à 0,078 % de malheureux. C'est évidemment très peu mais cela fait encore trop de monde pour un gros site Web qui a des millions de visiteurs. (Voir les études « IPv6 & recursive resolvers: How do we make the transition less painful? », « Yahoo proposes 'really ugly hack' to DNS », « Evaluating IPv6 adoption in the Internet » et « Measuring and Combating IPv6 Brokenness ».) Le risque est donc jugé inacceptable par beaucoup de gérants de gros sites Web.
Bref, il faut trouver une solution. Sinon, le risque est que les gérants de sites Web les plus timides retardent éternellement la migration vers IPv6.
Alors, quelles sont les solutions possibles (section 4) ? Comme
avec toutes les techniques de migration vers IPv6, il ne faut pas les
appliquer toutes bêtement. Chacune a ses avantages et ses
inconvénients et le choix de la meilleure technique dépend des
caractéristiques du site Web qui veut se rendre accessible en
v6. Première méthode, la plus satisfaisante techniquement, est de
résoudre le problème à la source en s'assurant que tous les clients du
site aient un IPv6 qui marche bien. C'est ainsi que cela fonctionne
pour les sites Web qui visent un public technique, comme http://www.ietf.org/ : les problèmes sont
discutés et résolus collecivement. C'est en effet la meilleure
solution sauf qu'elle est souvent impossible : au contraire de ce qui
se passe pour le site Web interne à une organisation, le site Web
public typique n'a pas de
contrôle sur la connectivité de ses clients, ni sur le logiciel
utilisé (navigateur Web, par exemple). Toutefois, s'il s'agit d'un
gros site très populaire, il peut influencer les utilisateurs en
recommandant ou en déconseillant des logiciels, des FAI, ou des
configurations, par exemple via une page Web d'aide sur le site.
Comme le problème, par exemple d'un FAI donné, a des chances de toucher tous les gros sites qui servent du contenu, ceux-ci peuvent aussi se coordonner pour faire pression sur le maillon faible. Ce genre de coordinations entre acteurs différents n'est jamais facile mais elle a eu lieu pour le World IPv6 Day . En deux mots, celle approche du problème est possible mais sans doute insuffisante.
Deuxième tactique possible, avoir des noms de domaine spécifiques à IPv6 (section
4.2). Par exemple, à la date d'écriture de cet article,
Facebook n'a pas d'enregistrement AAAA pour
www.facebook.com (attention, cela dépend du résolveur qui demande, pour les raisons expliquées plus loin) mais il en a un
pour www.v6.facebook.com. Ainsi, l'utilisateur
naïf ne risque pas d'avoir des problèmes IPv6 mais l'utilisateur plus
tenté par la technique pourra essayer l'accès en IPv6 et aider au
débogage initial. Cela permet une transition progressive, au lieu
d'ouvrir les vannes en grand d'un coup. Et cela permet de tester la
connectivité v6 du site, celle de certains de ses clients,
d'introduire IPv6 en production (si le nom en question bénéficie de la
même surveillance et des mêmes exigences de qualité de service que les
noms classiques).
Mais cette méthode ne permet pas d'aller très loin : comme il faut une action consciente de l'utilisateur pour se connecter en IPv6, le trafic restera très limité. Comme la population de testeurs n'est pas représentative, les logiciels ou FAI qui sont peu utilisés par les utilisateurs geeks ne seront pas réellement testés. Cette technique ne peut donc convenir qu'au tout début de la migration.
Une autre méthode, qui a été mise au point et popularisée par Google, et qui est la plus détaillée dans ce RFC, est le whitelisting (section 4.3). Il s'agit de configurer les serveurs DNS faisant autorité pour le domaine, afin de ne renvoyer d'enregistrements AAAA qu'aux clients dont on sait qu'ils ont de l'IPv6 correct, et qui ont été placés sur une liste blanche, indiquant les réseaux jugés corrects. Notez bien que la liste indique des réseaux, pas des machines individuelles. Non seulement il serait humainement impossible de gérer une liste de machines, mais en outre le serveur DNS faisant autorité ne voit pas la machine individuelle, il est interrogé par les résolveurs, typiquement des machines du FAI.
Cette technique ressemble donc à celle de certains systèmes de load-balancing ou de CDN (cf. sections 4.3.2 et 4.3.3, ainsi que le RFC 1794), qui eux-aussi renvoient une réponse DNS différente selon le client. Cela évoque donc aussi le split DNS (section 4.3.4) décrit dans la section 3.8 du RFC 2775. Le split DNS (conçu à l'origine pour renvoyer des réponses différentes au client du réseau local, par exemple des adresses RFC 1918) a toujours été très contesté. Les objections des sections 2.1 et 2.7 du RFC 2956 concernent surtout le fait que le FQDN n'est plus un identificateur stable, si la résolution DNS dépend du client. Cette fragmentation de l'espace de nommage est la principale raison pour laquelle beaucoup de gens n'aiment pas le whitelisting.
Déployé par Google, le whitelisting est documenté dans l'article de C. Marsan « Google, Microsoft, Netflix in talks to create shared list of IPv6 users » et dans celui de E. Kline « IPv6 Whitelist Operations ». Son principe est donc « plutôt que de résoudre le problème, masquons-le ».
Voici le whitelisting en action : je demande
l'adresse IPv6 de google.com depuis
Free, qui est whitelisté.
% dig AAAA google.com ... ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: google.com. 300 IN AAAA 2a00:1450:4007:802::1005
Par contre, depuis Orange, on n'a pas de réponse.
% dig AAAA google.com ... ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ...
Notez bien que le whitelisting est complètement indépendant du protocole utilisé pour le transport de la requête DNS. Le fait que le résolveur utilise IPv4 ou IPv6 pour interroger le serveur faisant autorité n'implique rien quant aux capacités v4 ou v6 de la machine cliente (celle sur laquelle tourne le navigateur Web). La liste blanche contient donc aussi bien des adresses IPv4 qu'IPv6.
Par définition, le fait d'être dans la liste blanche nécessite une évaluation du réseau client. Sa maintenance est donc non triviale et consomme des ressources humaines, nécessite des mesures, etc. Google peut se le permettre, mais ce n'est pas accessible à tout le monde.
Notez que cette technique nécessite d'avoir le contrôle de tous les serveurs faisant autorité sur le domaine, y compris les secondaires. Et qu'elle n'est pas toujours mise en œuvre dans les logiciels serveurs typiques, il faut donc se préparer à programmer un peu. Je n'ai pas testé mais je suppose qu'on peut mettre en œuvre le whitelisting sur BIND en utilisant les vues, avec deux fichiers de zone (un avec AAAA et un sans) et en définissant une ACL pour la liste blanche, dirigeant ses membres vers la vue ayant les AAAA :
acl v6-whitelist {
192.0.2.0/24;
2001:db8:3003::/48;
};
...
view "with-aaa" {
match-clients { v6-whitelist; };
zone "example.com" {
...
file "/etc/bind/example.com-with-aaaa";
};
};
view "external" {
match-clients { any; };
zone "example.com" {
...
file "/etc/bind/example.com-without-aaaa";
};
};
La solution n'est pas parfaite : un réseau peut avoir correctement déployé IPv6 mais un utilisateur peut avoir un navigateur Web qui a des problèmes avec IPv6. La liste blanche stockant des réseaux, les globes oculaires de cet utilisateur seront malheureux quand même. Mais cela reste une des meilleures solutions existantes.
Aujourd'hui, on l'a vu, cette solution est manuelle : les réseaux qui veulent être whitelistés soumettent leur candidature, sont évalués (ce qui peut nécessiter une interaction qui consomme donc également des ressources humaines du côté du FAI), et mis (ou pas) dans la liste. Dans le futur, on verra peut-être une automatisation de la procédure, avec des tests faits de temps en temps. Autre évolution possible, le passage en mode « liste noire » où tous les clients DNS recevraient l'enregistrement AAAA, sauf ceux explicitement listés dans la liste noire (section 4.4). Cela sera intéressant le jour où la majorité des FAI auront un IPv6 qui marche, et où seuls quelques maillons faibles subsisteront.
Un résumé des inquiétudes sur le whitelisting figure dans l'article de Brzozowski, J., Griffiths, C., Klieber, T., Lee, Y., Livingood, J., et R. Woundy, « IPv6 DNS Resolver Whitelisting - Could It Hinder IPv6 Adoption? ». Outre la fragmentation de l'espace de nommage, la principale inquiétude concerne l'introduction d'une nouvelle composante dans le réseau, qui rend le débogage plus compliqué (un principe cardinal de l'Internet est que les décisions « politiques » doivent être faites aux extrémités, pas dans des équipements intermédiaires, cf. RFC 3724 et l'article de Blumenthal, M. et D. Clark, « Rethinking the design of the Internet: The end to end arguments vs. the brave new world » et, sur le cas spécifique du DNS, la section 2.16 du RFC 3234.) Un bon exemple est donné par les résultats de dig cités plus haut : déboguer l'accès à Google va dépendre du réseau où on fait le dig. De beaux malentendus peuvent alors survenir. Mais le débat est complexe : s'il y a un large consensus sur l'importance de ne pas mettre trop d'état et de décisions dans les équipements intermédiaires (le principe « de bout en bout »), la discussion a toujours fait rage sur qu'est-ce qu'un équipement intermédiaire. Est-ce qu'un serveur DNS fait partie des middleboxes qui perturbent si souvent la connexion de bout en bout ?
Enfin, la dernière tactique de migration possible est le saut
direct (section 4.5) : activer IPv6 sur le serveur, le tester, puis
publier un AAAA normal. Cela n'est pas forcément si radical que ça car
on peut le faire nom par nom (par exemple, pour
static-content.example.com avant
www.example.com) mais c'est quand même la méthode
la plus audacieuse. À ne faire qu'une fois qu'on maîtrise bien
IPv6. Relativisons tout de même les choses : des tas de sites Web vus
par un public non technique (comme http://www.afnic.fr/)
ont un AAAA depuis de nombreuses années et sans que cela crée de
problèmes.
Si on est toutefois inquiets, on peut utiliser cette tactique, mais pendant une période limitée : on teste, on publie le AAAA pendant quelques heures, on arrête, on analyse les résultats, on corrige les éventuels problèmes et on recommence.
Pour les lecteurs pressés, la section 5 résume les étapes possibles d'un plan de transition. Là encore, pas question de l'appliquer aveuglément. Chacun doit l'adapter aux caractéristiques spécifiques de son réseau. Rappelez-vous en outre que le RFC cible les gros sites : la plupart des petits n'auront pas envie d'autant d'étapes. Voici ces étapes potentielles successives :
- Uniquement IPv4 (malheureusement la situation de la grande majorité du Web aujourd'hui),
- Activation d'IPv6 et publication par des noms spécifiques, genre
www.ipv6.example.org, - Peut-être une étape de whitelisting avec gestion manuelle,
- Peut-être suivi par une étape de whitelisting automatique,
- Le whitelisting étant prévu pour être une étape temporaire, on va le couper, une fois les problèmes résolus. (Cela peut se faire lors d'une occasion un peu solennelle comme le World IPv6 Launch le 6 juin 2012.)
- À partir de là, le site est complètement accessible en IPv6 (et en IPv4), avec le nom de domaine normal.
- La section 6.3 discute du cas, très futuriste à l'heure actuelle, où certains auront une meilleur connectivité en IPv6 qu'en IPv4. Il faudra alors mettre au point des techniques de transition pour retirer l'accès IPv4 petit à petit.
Voici, vous connaissez maintenant l'essentiel. La section 6 du RFC liste quelques points de détail. Par exemple, contrairement à ce que certains pourraient croire au premier abord, le whitelisting est tout à fait compatible avec DNSSEC (section 6.1), puisqu'il se fait sur les serveurs faisant autorité. Ceux-ci peuvent donc parfaitement signer les deux versions de la réponse, avec ou sans AAAA, et ces deux réponses pourront être vérifiés comme authentiques.
Par contre, si un résolveur DNS s'avisait de faire des manipulations analogues au whitelisting, par exemple en retirant les réponses AAAA vers des clients qu'il sait ne pas gérer IPv6 correctement, alors, là, DNSSEC détecterait la manipulation comme une tentative d'attaque, et la réponse ne pourrait pas être validée.
On a vu que la gestion d'une liste blanche représentait un certain travail. Il est donc tentant de partager les résultats de ce travail entre plusieurs acteurs. Mais attention à le faire en respectant la vie privée (section 6.2). Il n'y a pas de problèmes avec les listes actuelles, dont la granularité ne descend pas jusqu'à l'individu, mais, si des listes plus précises devaient apparaître, ce problème est à garder en tête.
L'article seul
RFC 6586: Experiences from an IPv6-Only Network
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : J. Arkko, A. Keranen (Ericsson)
Pour information
Première rédaction de cet article le 22 avril 2012
La plupart des RFC décrivent, de façon normative, un protocole ou un format qui sera ensuite déployé sur l'Internet. Mais ce document est différent : c'est un récit d'expérience, celle de deux courageux chercheurs qui, au péril de leur usage de Facebook et dans l'intérêt de la science, ont coupé IPv4 et n'ont accédé à l'Internet que via IPv6 pendant la durée de l'expérience. Les machines de l'expérience n'avaient plus du tout d'IPv4 et seule une fragile passerelle NAT64 les reliaient aux territoires barbares où régnait encore IPv4. Qu'est-ce qui marche dans ce cas ? Qu'est-ce qui ne marche pas ? Qu'est-ce qu'on peut améliorer ?
Deux réseaux ont été utilisés, un professionnel et un à la maison. Tous les deux étaient en double-pile (IPv4 et IPv6, cf. RFC 4213) depuis longtemps. Tous les deux avaient une connectivité IPv6 stable et correcte depuis des années. Il était donc temps de sortir de la « zone de confort » et d'essayer le grand large. Mais la majorité de l'Internet reste accessible en IPv4 seulement. C'est là qu'intervient NAT64 (RFC 6144), qui permet aux machines purement IPv6 d'accèder à des sites Web attardés en v4.
Ce n'est pas juste une expérience de démonstration pour montrer que les Vrais Hommes peuvent se passer du vieux protocole des mangeurs de yaourt. L'épuisement des adresses IPv4 fait que de plus en plus de FAI envisagent de déployer des réseaux uniquement IPv6, puisqu'ils n'ont plus la possibilité d'obtenir des adresses. Tester de tels réseaux en vrai est donc nécessaire. La conclusion est d'ailleurs que cela ne marche pas trop mal mais qu'il reste un certain nombre de petits problèmes qu'il serait bon de régler.
La section 3 du RFC explique l'environnement de l'expérience. Les deux réseaux (un à la maison et un au bureau) étaient un mélange classique de PC, d'appareils photos numériques, de gadgets électroniques divers et de petits routeurs du commerce, avec divers systèmes (Mac OS, Windows, Linux...). Les usages étaient également classiques, courrier, SSH, VoIP, jeu (pas dans le réseau de bureau, bien sûr), messagerie instantanée, un peu de domotique et bien sûr du Web. Il s'agissait de petits réseaux avec une dizaine d'utilisateurs au maximum.
Comme certains des utilisateurs des deux réseaux, des petits bras, avaient choisi de ne pas participer à l'expérience, il a fallu créer un réseau séparé pour celle-ci, avec un VLAN propre. Il n'y avait évidemment pas de serveur DHCP v4 sur ce réseau seulement des RA (Router Advertisement) v6.
On l'a vu, l'essentiel du Web aujourd'hui n'est accessible qu'en IPv4. Il a donc fallu mettre en place une passerelle NAT64 (RFC 6146). Elle incluait le serveur DNS64 (RFC 6147). L'installation et la configuration de cette passerelle étaient très simples pour un administrateur réseaux.
Le serveur DNS cité plus haut était publié
via les RA (RFC 6106). (À noter que Windows écrit
aussi à des serveurs DNS bien connus,
fec0:0:0:ffff::1,
fec0:0:0:ffff::2, et
fec0:0:0:ffff::.) Trouver le serveur DNS dans un
environnement IPv6 pur n'est pas trivial. Dans les environnements
mixtes, il est fréquent que le résolveur DNS à utiliser par les
clients ne soit publié qu'en v4, les clients demandant ensuite aussi
bien les enregistrements A que les AAAA en IPv4. Ici, cette méthode
n'était pas possible et les auteurs du RFC ont également testé avec
DHCP v6 (RFC 8415). Un
des charmes d'IPv6 est en effet qu'il existe deux façons de découvrir
automatiquement le résolveur DNS local, via les RA ou bien via
DHCP.
Le serveur DNS64 et la passerelle NAT64 fonctionnaient de la manière habituelle (RFC 6144) : si un client demandait un AAAA (adresse IPv6 dans le DNS) inexistant, le serveur DNS64 en synthétisait un, les paquets à destination de cette adresse étaient ensuite interceptés par la passerelle et NATés en IPv4 (la passerelle avait, elle, une adresse v4 publique). Les destinations ayant des AAAA étaient traitées normalement : la passerelle servait alors de simple routeur v6, le cas idéal d'une connectivité v6 complète.
Les résultats de l'expérience occupent le reste du RFC. La section 4 fournit une synthèse et la section 5 examine un par un les choses qui ont plus ou moins bien marché. Principale conclusion ; ça marche. Un des auteurs du RFC travaille dans un environnement IPv6 pur depuis un an et demi et est toujours vivant et en bonne santé. Certains points marchent particulièrement bien (aucun problème avec le Web). Sur un téléphone Symbian, toutes les applications ont marché (sur un Android, toutes les applications de base marchaient, mais après un bricolage pour permettre à la machine de trouver son résolveur DNS).
Les problèmes rencontrés se subdivisent en plusieurs catégories :
- Les bogues pures et simples. Un logiciel gère théoriquement IPv6 mais, en pratique, on trouve des problèmes qui n'existent pas en v4. Ces bogues sont relativement fréquentes car trop peu de tests sont faits avec IPv6.
- Pas d'IPv6 du tout, même en théorie. Cela arrive à des programmes antédiluviens (le RFC cite dict, un client RFC 2229) mais aussi, et là c'est inexcusable, à des programmes plus récents comme le logiciel privateur Skype, ou comme beaucoup de jeux.
- Des problèmes liés au protocole. Dès que le protocole transmet
des adresses IP, les ennuis commencent. La machine locale utilise
IPv6, transmet l'adresse au pair v4 avec qui elle communique grâce au
NAT64, pair qui
n'arrive pas à répondre. Un exemple est fourni par certaines
applications Web qui renvoient une page avec des
URL utilisant des adresses IPv4 littérales
(comme
http://192.0.2.80/). Ce problème est rare mais très agaçant lorsqu'il se produit. - Problèmes situés quelque part dans la couche 3, le plus fréquent étant les problèmes de MTU causés par un pare-feu mal configuré.
Bref, aucun de ces problèmes n'était un problème fondamental d'IPv6 ou de NAT64, nécessitant de revisiter le protocole. C'était « uniquement » des questions de développement logiciel.
Maintenant, avec la section 5, voyons ces problèmes cas par cas. D'abord, ceux situés dans les systèmes d'exploitation. Par exemple, Linux ne jette pas l'information acquise par les RA lorsque la connectivité réseau change, il faut faire explicitement un cycle suspension/reprise. Ensuite, le démon rdnssd, censé écouter les annonces de résolveurs DNS faites en RA, n'était pas intégré par défaut sur Ubuntu et, de toute façon, ne semblait pas très fiable. Comme pas mal de problèmes rencontrés lors de cette expérience, il s'est résolu en cours de route, avec une nouvelle version du système. Mais tout n'est pas parfait, notamment le NetworkManager qui s'obstine à sélectionner un réseau sans-fil IPv4 qui n'a pas de connectivité externe, plutôt que le réseau IPv6 pur.
Les autres systèmes ont aussi ce genre de problèmes. Ainsi, avec Mac OS X, il faut dire explicitement au système qu'IPv4 est facultatif et qu'un réseau sans IPv4 ne doit pas être considéré comme cassé et à ignorer. Et passer d'un réseau v4 à v6 nécessite des manipulations manuelles.
Pour Windows 7, le problème était avec les résolveurs DNS : Windows les affichait mais ne les utilisait pas sans action manuelle.
Android a un problème analogue. Il peut faire de l'IPv6 mais il ne sait pas sélectionner les résolveurs DNS en IPv6. Par défaut, il lui faut donc un résolveur DNS v4. Heureusement, il s'agit de logiciel libre et les auteurs ont pu résoudre ce problème eux-même avec le nouveau logiciel DDD.
En conclusion, le RFC note que tous ces systèmes ont IPv6 à leur catalogue depuis des années, parfois de nombreuses années, mais tous ces problèmes donnent à penser qu'ils n'ont jamais été sérieusement testés.
La situation des langages de programmation et des API semble meilleure, par exemple Perl qui était un des derniers grands langages à ne pas gérer complètement IPv6 par défaut semble désormais correct.
C'est moins satisfaisant pour la messagerie instantanée et la voix sur IP. Les cris les plus perçants des utilisateurs impliqués dans l'expérience avaient été provoqués par Skype, qui ne marche pas du tout en IPv6 (il a fallu utiliser un relais SSH vers une machine distante). La légende comme quoi Skype marcherait toujours du premier coup en prend donc un... coup.
Parmi les autres solutions testées, celles passant par le Web marchaient (Gmail ou Facebook, par exemple), celles fondées sur XMPP également mais les solutions commerciales fermées comme MSN, WebEx ou AOL échouent toutes. Ces solutions sont mises en œuvre dans des logiciels privateurs (on ne peut donc pas examiner et corriger le source) mais l'examen du trafic réseau montre qu'il passe des adresses IPv4 entre machines, ce qui est incompatible avec NAT64.
Et pour les applications stratégiques essentielles, je veux dire les jeux ? Ceux utilisant le Web n'ont pas de problème, pour les autres, c'est l'échec complet. En outre, aucun des ces logiciels ne produit de messages de diagnostic utilisables et le débogage est donc très difficile. Au moment des premiers tests, ni Battlefield, ni Age of Empires, ni Crysis ne fonctionnaient sur le nouveau réseau. Depuis, World of Warcraft est devenu le premier jeu majeur qui marchait en IPv6. Les jeux dont le source a été libéré (comme Quake) ont également acquis cette capacité. Les autres feraient bien d'utiliser une API réseau plus moderne... (Cf. RFC 4038.)
Pendant qu'on en est au divertissement, que devient la musique en ligne ? La plupart des boutiques reposent sur le Web et marchent donc, sauf Spotify qui réussit l'exploit d'être un des rares services accessibles via le Web qui ne fonctionne pas en IPv6.
Moins bonne est la situation des appliances comme les webcams. La plupart ne parlent pas IPv6 du tout, sourds que sont leurs constructeurs chinois aux sirènes de la modernité.
Enfin, les problèmes ne sont pas forcément avec les matériels et logiciels du réseau local. Parfois, le problème est situé chez le pair avec qui on veut communiquer comme lorsque bit.ly (le RFC cite ce cas mais sans mentionner le nom comme si l'information n'était pas déjà publique...) avait publié un enregistrement AAAA invalide : NAT64 ne peut rien dans ce cas puisque la passerelle pense que le service est accessible en IPv6. C'est l'occasion de rappeler qu'il vaut mieux ne pas publier de AAAA que d'en publier un erroné.
On l'a vu, une bonne partie de la connectivité externe des deux réseaux de test dépendait de NAT64, puisqu'une grande partie de l'Internet n'est hélas pas joignable en IPv6. La section 6 tire le bilan spécifique de ce protocole et il est très positif : pas de problèmes de fond, juste quelques bogues dans l'implémentation, corrigées au fur et à mesure.
Le cas des adresses IPv4 littérales dans les URL est irrémédiable (le DNS n'est pas utilisé donc DNS64 ne peut rien faire) mais rare. Les deux seuls cas bloquants concernaient certaines pages YouTube (tiens, pourquoi est-ce que les erreurs de bit.ly sont mentionnées sans indiquer son nom, alors que YouTube est désigné dans le RFC ?) et une page de réservation d'un hôtel qui renvoyait vers un URL contenant une adresse IPv4. Les auteurs du RFC ont mesuré les 10 000 premiers sites Web du classement Alexa et trouvé que 0,2 % des 1 000 premiers ont un URL IPv4 dans leur page (pour charger du JavaScript, du CSS ou autre), et que ce chiffre monte à 2 % pour les 10 000 premiers (ce qui laisse entendre que les premiers sont mieux gérés). Cette stupide erreur n'empêchait pas le chargement de la page, elle privait juste le lecteur d'un bandeau de publicité ou d'une image clignotante. Ce n'est donc pas un problème sérieux en pratique.
Les auteurs ont également testé avec wget
le chargement des pages d'accueil de ces 10 000 sites en comparant un
accès IPv4, un accès IPv6 sans NAT64 et le réseau de test, IPv6 pur
mais avec NAT64. En IPv4 pur, 1,9 % des sites ont au moins un problème
(pas forcément la page d'accueil elle-même, cela peut être un des
composants de cette page), ce qui donne une idée de l'état du Web. Le
RFC note toutefois que certains problèmes peuvent être spécifiques à
ce test, si le serveur refuse à wget du contenu qu'il accepterait de
donner à un navigateur Web. wget avait été configuré pour ressembler à
un navigateur (le RFC ne le dit pas mais je suppose que cela veut dire
des trucs comme --user-agent="Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:11.0) Gecko/20100101 Firefox/11.0"). Mais cela
ne suffit pas dans des cas comme l'absence d'une adresse pour un nom
de domaine, qui ne gène pas le navigateur qui ajoute
www devant à tout hasard, chose que ne fait pas
wget.
Avec le réseau IPv6 pur, 96 % des sites échouent (ce qui est logique, vu le nombre de sites Web accessible en v6). Les sites Google étaient une des rares exceptions.
Avec le réseau IPv6 aidé de la passerelle NAT64, le taux d'échec est de 2,1 %, quasiment le même qu'en IPv4 pur (la différence venant surtout des adresses IPv4 littérales).
Sur quoi doivent porter les efforts de mesure futurs (section 7) ? Le RFC estime important de mesurer plus précisement les phénomènes à l'œuvre lors d'une connexion utilisant NAT64. Certains utilisateurs ont signalé des ralentissements, mais qui ne sont pas confirmés par une analyse des paquets et des temps de réponse. S'il se passe quelque chose qui ralentit, c'est plus subtil, et cela devrait être investigué.
Compte-tenu de cette expérience, quelles conclusions en tirer (section 8) ? Comme indiqué plus haut, la principale est qu'un réseau purement IPv6 est viable. (Le RFC ne le précise pas mais je rajoute : s'il est géré par un informaticien compétent et disponible. Cette expérience n'est pas encore reproductible par M. Toutlemonde.)
Seconde grande conclusion : il reste du travail, trop de petites bogues sont encore présentes, et à beaucoup d'endroits.
Bref, aujourd'hui, il reste prudent d'utiliser plutôt la double-pile (IPv6 et IP4) pour un réseau de production. Un réseau IPv6 pur, à part pour le geek, est surtout intéressant pour des environnements très contrôlés, comme par exemple celui d'un opérateur de téléphonie mobile qui fournirait un modèle de téléphone obligatoire, permettant de s'assurer que tous les clients aient ce qu'il faut.
Comme tout ne s'arrangera pas tout seul, nos héroïques explorateurs revenant de la terre lointaine et mystérieuse où tout ne marche qu'en IPv6 suggèrent des actions à entreprendre pour se préparer à notre future vie dans ce monde :
- La découverte du résolveur DNS reste un des points qui marchent le plus mal, probablement parce qu'elle fonctionne bien en double-pile, masquant les problèmes IPv6. Par exemple, l'utilisation des annonces RA du RFC 6106 devrait être systématique et c'est loin d'être le cas, par exemple dans les divers systèmes utilisant Linux.
- Autre problème, les divers network managers, ces logiciels qui règlent le ballet des différentes composants de l'accès au réseau : même lorsque le système dispose de tous les composants qui marchent en IPv6, le network manager ne les utilise pas toujours correctement. En essayant Ubuntu, par exemple, il est clair que ce système n'a jamais été testé dans un environnement purement IPv6.
- Les pare-feux ont souvent des capacités IPv6 inférieures à celles qu'ils ont en v4.
- Plusieurs applications que les utilisateurs considèrent comme très importantes (les jeux vidéo, par exemple) ne marchent pas du tout en IPv6 : du travail pour les programmeurs, qui devraient au miminum utiliser des API qui sont indépendantes de la version d'IP.
Le RFC note que pratiquement aucune de ces actions ne nécessite d'action dans le champ de la normalisation. Cela veut dire que toutes les normes nécessaires sont là, l'IETF a terminé son travail et c'est maintenant aux programmeurs et aux administrateurs réseaux d'agir.
L'article seul
RFC 6545: Real-time Inter-network Defense (RID)
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : Kathleen M. Moriarty (EMC)
Chemin des normes
Première rédaction de cet article le 22 avril 2012
La sécurité, face aux innombrables attaques que connaissent les réseaux tous les jours, nécessite un échange d'information permanent. Ce RFC normalise donc un format permettant d'échanger et de traiter ce genre d'informations. Il sera donc peut-être un outil technique utile pour les CSIRT et les opérateurs.
La section 1 résume les problèmes de la sécurité des réseaux auxquels les opérateurs font face. Une fois l'attaque détectée, que ce soit un hameçonnage, une DoS ou une pénétration réussie dans un système connecté au réseau, il faut rédiger un rapport, transmettre à l'opérateur d'origine de l'attaque, demander à un opérateur amont de prendre des mesures pour limiter les dégâts, demander de continuer l'enquête en suivant la trace de l'attaquant, etc. Par exemple, si on veut suivre une trace de paquets dont l'adresse IP source est mensongère, et que le filtrage recommandé par le RFC 2827 n'est pas en place, il faut repérer par quel câble sont entrés ces paquets et envoyer ensuite à l'opérateur situé derrière une demande de continuation de l'enquête. Il n'y a pas de mécanisme formel pour cela. Ça se fait typiquement par téléphone ou par envoi d'un courrier en langue naturelle, ce qui augmente les coûts de traitement.
Le nouveau format, normalisé dans ce RFC 6545, se nomme RID pour Real-time Inter-network Defense et se base sur le format IODEF du RFC 5070 (désormais RFC 7970), qui lui-même utilise XML. L'apport par rapport à l'IODEF de base est de cibler la circulation d'informations en « temps réel ». RID avait d'abord été spécifié dans le RFC 6045, que notre RFC met à jour. À part le changement de statut (RID est désormais sur le chemin des normes), les changements (résumés dans la section 1.1) sont de peu d'importance.
RID vise donc à permettre la réponse immédiate à une attaque. Par exemple, lorsqu'une dDoS est perpétrée par un botnet, il faut certes retrouver les zombies mais aussi identifier le contrôleur qui les commande. RID permet de demander un suivi de la trace des premiers, puis ensuite du second.
L'opérateur a typiquement un système de gestion centralisé de son réseau, un NMS. Le futur IHS (Incident Handling System) qui recevra et enverra les messages RID devra être intégré à ce NMS. La détection de l'attaque pourra se faire manuellement, ou via un IDS mais cette question est hors-sujet pour RID, qui se contente de permettre le signalement d'attaques, une fois celles-ci détectées.
Quelles sont les obstacles que rencontrent les tentatives de remonter à la source d'une attaque ? La section 2 en donne une liste, et c'est une lecture très recommandée pour comprendre la variété des problèmes auxquels fait face l'opérateur réseau lors d'une attaque. Par exemple, certaines attaques utilisent tellement peu de paquets qu'il est difficile de les répérer. D'autre part, pour prendre rapidement une « empreinte » des paquets utilisés pour l'attaque, les techniques à base d'une fonction de hachage ont souvent été utilisées (cf. « Hash-Based IP Traceback »). Or, certaines attaques ont un contenu des paquets qui varie énormément et il est difficile de trouver une « signature » qui permettrait de dire à l'opérateur précédent « Voici ce que je cherche ». Les nombreuses techniques de traceback pour IP ont été utilisées pour déterminer quelles étaient les informations importantes à inclure dans RID. Ainsi, il est essentiel d'inclure beaucoup d'informations dans le message RID car les champs significatifs et l'attaque, permettant de repérer les paquets, peuvent être n'importe lesquels. RID permet même d'envoyer la totalité du paquet, si nécessaire.
Une fois que le message RID est prêt, que fait-on pour la communication avec les autres opérateurs et avec les CSIRT ? Les sections 3.1 et 3.2 font remarquer que le courrier électronique n'est pas forcément adapté car il peut être trop lent. Mais, de toute façon, il faut prévoir plusieurs canaux de communication car, en cas d'attaque, certains deviendront peut-être inutilisables. Un réseau distinct de celui utilisé pour le trafic « normal » peut donc être nécessaire (voir plus loin le commentaire de la section 9). Le RFC suggère qu'on peut profiter des négociations qui précèdent un accord de peering pour mettre en place un canal de communication sécurisé.
Recommandation utile ou vœu pieux ? En tout cas, la section 3.1 rappelle également que RID ne devrait être utilisé que pour lutter contre des attaques, et pas pour perpétuer des sabotages (en dénonçant un innocent dans l'espoir qu'il se fasse filtrer) ou pour censurer.
Maintenant, place au format utilisé (section 4), fondé sur IODEF (RFC 5070). Il y a cinq messages RID possibles :
Requestoù on demande à un partenaire d'examiner son réseau pour voir d'où venait l'attaque (l'idée est que, partant de celui qui a détecté l'attaque, on envoit desRequestsuccessifs en remontant peu à peu vers la source de l'attaque). Le même message sert si on a déjà identifié la source et qu'on veut juste davantage d'information.Reportoù on transmet de l'information, sans demander d'action immédiate.Queryoù on demande des détails sur une attaque dont on a entendu parler (les deux derniers types de message sont typiquement pour la communication avec un CSIRT).AcknowledgmentetResultservent à porter les résultats intermédiaires ou finaux.
La section 4.2 décrit plus en détail chacun de ces types.
La section 7 fournit plusieurs jolis exemples, que j'ai simplifié
ici. Par exemple, une Request envoyé par un
CSIRT qui a détecté une DoS et qui demande à un
opérateur réseau de tracer l'attaque. Le message est composé d'un
document RID puis du document IODEF qui décrit l'attaque :
<iodef-rid:RID> <!-- Le schéma est enregistré en
https://www.iana.org/assignments/xml-registry/ns.html -->
<iodef-rid:RIDPolicy MsgType="TraceRequest"
MsgDestination="RIDSystem">
<iodef:Node>
<iodef:Address category="ipv4-addr">192.0.2.3</iodef:Address>
</iodef:Node>
<iodef-rid:TrafficType type="Attack"/>
<iodef:IncidentID name="CERT-FOR-OUR-DOMAIN">
CERT-FOR-OUR-DOMAIN#207-1
</iodef:IncidentID>
</iodef-rid:RIDPolicy>
</iodef-rid:RID>
<!-- IODEF-Document accompanied by the above RID -->
<iodef:IODEF-Document>
<iodef:Incident restriction="need-to-know" purpose="traceback">
<iodef:DetectTime>2004-02-02T22:49:24+00:00</iodef:DetectTime>
<iodef:StartTime>2004-02-02T22:19:24+00:00</iodef:StartTime>
<iodef:ReportTime>2004-02-02T23:20:24+00:00</iodef:ReportTime>
<iodef:Description>Host involved in DOS attack</iodef:Description>
<iodef:EventData>
<iodef:Flow>
<iodef:System category="source">
<iodef:Node>
<iodef:Address category="ipv4-addr">192.0.2.35
...
Et la première réponse, qui indique que la demande de traçage a été approuvée :
<iodef-rid:RID>
<iodef-rid:RIDPolicy MsgType="RequestAuthorization"
MsgDestination="RIDSystem">
<iodef-rid:TrafficType type="Attack"/>
</iodef-rid:RIDPolicy>
<iodef-rid:RequestStatus AuthorizationStatus="Approved"/>
</iodef-rid:RID>
Et enfin la réponse finale :
<iodef-rid:RID>
<iodef-rid:RIDPolicy MsgType="Result"
MsgDestination="RIDSystem">
<iodef:Node>
<iodef:Address category="ipv4-addr">192.0.2.67</iodef:Address>
</iodef:Node>
<iodef-rid:TrafficType type="Attack"/>
<iodef:IncidentID name="CERT-FOR-OUR-DOMAIN">
CERT-FOR-OUR-DOMAIN#207-1
</iodef:IncidentID>
</iodef-rid:RIDPolicy>
<iodef-rid:IncidentSource>
<iodef-rid:SourceFound>true</iodef-rid:SourceFound>
<iodef:Node>
<iodef:Address category="ipv4-addr">192.0.2.37</iodef:Address>
</iodef:Node>
</iodef-rid:IncidentSource>
</iodef-rid:RID>
<!-- IODEF-Document accompanied by the above RID -->
<iodef:IODEF-Document>
<iodef:Incident restriction="need-to-know" purpose="traceback">
<iodef:IncidentID name="CERT-FOR-OUR-DOMAIN">
CERT-FOR-OUR-DOMAIN#207-1
</iodef:IncidentID>
<iodef:DetectTime>2004-02-02T22:49:24+00:00</iodef:DetectTime>
<iodef:StartTime>2004-02-02T22:19:24+00:00</iodef:StartTime>
...
<iodef:Expectation severity="high" action="rate-limit-host">
<iodef:Description>
Rate limit traffic close to source
</iodef:Description>
</iodef:Expectation>
<iodef:Record>
<iodef:RecordData>
<iodef:Description>
The IPv4 packet included was used in the described attack
</iodef:Description>
<iodef:RecordItem dtype="ipv4-packet">450000522ad9
0000ff06c41fc0a801020a010102976d0050103e020810d9
4a1350021000ad6700005468616e6b20796f7520666f7220
6361726566756c6c792072656164696e6720746869732052
46432e0a
</iodef:RecordItem>
</iodef:RecordData>
</iodef:Record>
</iodef:EventData>
<iodef:History>
<iodef:HistoryItem>
<iodef:DateTime>2004-02-02T22:53:01+00:00</iodef:DateTime>
<iodef:IncidentID name="CSIRT-FOR-OUR-DOMAIN">
CSIRT-FOR-OUR-DOMAIN#207-1
</iodef:IncidentID>
<iodef:Description>
Notification sent to next upstream NP closer to 192.0.2.35
</iodef:Description>
</iodef:HistoryItem>
<iodef:HistoryItem action="rate-limit-host">
<iodef:DateTime>2004-02-02T23:07:21+00:00</iodef:DateTime>
<iodef:IncidentID name="CSIRT-FOR-NP3">
CSIRT-FOR-NP3#3291-1
</iodef:IncidentID>
<iodef:Description>
Host rate limited for 24 hours
</iodef:Description>
</iodef:HistoryItem>
</iodef:History>
</iodef:Incident>
</iodef:IODEF-Document>
Comme déjà noté, l'utilisation de ces messages RID ne va pas sans risques. La section 9 les analyse. D'abord, il faut évidemment un canal sécurisé pour les transmettre. Sécurisé au sens de :
- Confidentiel, puisque les informations RID peuvent être très sensibles,
- Fiable (disponible), puisque l'attaque rendra peut-être inutilisable les canaux normaux,
- Authentifié, parce que ceux à qui on demande d'agir sur la base de messages RID voudront savoir à qui ils ont affaire.
Un canal physique dédié faciliterait l'obtention de ces propriétés mais n'est pas forcément réaliste. Le RFC recommande donc plutôt un tunnel chiffré. En combinant TLS sur le tunnel et les signatures XML du RFC 3275 sur le message, on atteint la sécurité désirée. Le protocole exact utilisé est normalisé dans un autre document, le RFC 6546. Bien qu'il utilise le chiffrement, RID ne repose pas uniquement sur la sécurité du canal et permet de chiffrer aussi le message par le chiffrement XML.
RID soulève aussi des questions liées à la protection de la
vie privée et la section 9.5 les étudie. RID
fournit le moyen de spécifier des détails comme l'extension du
« domaine de confiance » à qui on peut envoyer les informations
(élément PolicyRegion, section 4.3.3.3).
L'article seul
RFC 6604: xNAME RCODE and Status Bits Clarification
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : Donald Eastlake 3rd (Huawei)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsext
Première rédaction de cet article le 14 avril 2012
Ce RFC est très court car il avait juste à répondre à une question simple : le DNS a des mécanismes (le plus connu est l'enregistrement CNAME) permettant à un nom de domaine de pointer vers un autre. Si, en suivant cette chaîne de noms, on rencontre une erreur, que doit indiquer le code de retour dans la réponse DNS ? Le résultat de la première requête de la chaîne ou bien celui de la dernière ? Le RFC tranche dans le sens de la grande majorité des résolveurs DNS actuels : le rcode doit être celui de la dernière requête de la chaîne.
C'est tout bête, mais ce cas n'était pas clairement spécifié dans les précédents RFC sur le DNS. Si on a par exemple, dans le DNS :
www.foobar.example. IN CNAME www.nothere.example.
Alors une requête AAAA www.foobar.example
rencontrera l'alias et le résolveur continuera en demandant
www.nothere.example. Si www.nothere.example n'existe pas,
alors qu'on a demandé de l'information sur
www.foobar.example, le code de retour doit-il
être NXDOMAIN (ce nom n'existe pas) ou bien
NOERROR (on a bien trouvé un enregistrement, ici
le CNAME et
www.foobar.example existe) ? Même chose avec
d'autres types d'enregistrement « alias » comme
DNAME. (CNAME redirige un nom, DNAME redirige
les noms situés en dessous de lui.) On parle alors de xNAME pour
désigner globalement tous les types « alias ». Notez bien que, quoique
cela soit déconseillé, il peut y avoir une chaine de plus de deux
xNAME.
Avant de voir le cas du code de retour (rcode dans la terminologie DNS, pour return code), la section 2 règle celui des bits de statut. Le bit AA (Authoritative Answer) est décrit dans le RFC 1035, section 4.1.1. Il indique que la réponse vient d'un serveur faisant autorité (pas d'un cache). Dans le cas d'une chaîne de xNAME, les AA peuvent être différents à chaque étape. Mais le RFC 1035 disait clairement que le bit dans la réponse était pour le premier nom mentionné dans la section Réponse du paquet. Rien ne change ici, la spécification était claire dès le début.
Le bit AD (Authentic Data) est plus récent. Normalisé dans le RFC 4035, section 3.2.3, il indique que la réponse est correctement signée avec DNSSEC. Là encore, la règle était claire dès le début : ce bit n'est mis que si toutes les réponses dans la section Réponse (et la section Autorité) sont authentiques.
Mais le vrai problème concerne le rcode (RFC 1035, section 4.1.1) car, là, le RFC original (voir aussi
RFC 1034, section 4.3.2 et bon courage pour le
comprendre) n'était pas
clair. Le RFC 2308, dans sa section 2.1, dit qu'il faut fixer
le code de retour en fonction de la dernière
étape de la chaîne, tout en notant que tous les serveurs ne le font pas.
La section 3 fixe donc des règles précises : lorsqu'on suit une
chaîne, les étapes intermédiaires n'ont pas
d'erreur. Il ne sert donc à rien d'indiquer le résultat de la
première étape. Le code de retour doit donc être
mis en fonction de la dernière étape uniquement. Dans
l'exemple plus haut, le résultat de la requête AAAA
www.foobar.example doit donc être NXDOMAIN (domaine inexistant).
Voilà, vous pouvez arrêter la lecture ici, l'essentiel du RFC est le paragraphe précédent. Mais la section 4 apporte quelques détails sur la sécurité. Par exemple, elle rappelle que des bits comme AA ou AD ne sont pas protégés par DNSSEC. Un attaquant a donc pu les changer sans être détecté. Si on veut être sûr de leur intégrité, il faut protéger la communication avec le serveur, par exemple avec le TSIG du RFC 8945 (ou bien que le client ignore le bit AD et valide lui-même avec DNSSEC).
Si vous voulez tester vous-même que votre résolveur obéit bien aux
règles de ce RFC, vous pouvez tester avec
dangling-alias.bortzmeyer.fr qui existe mais
pointe vers un nom qui n'existe pas. Vous devez donc obtenir un
NXDOMAIN, ce qui est le cas avec la plupart des résolveurs actuels (la
question de l'implémentation de ce RFC ne se pose pas, le RFC a pris
acte du comportement très majoritaire des logiciels).
Voici un exemple avec un résolveur correct (un Unbound) :
% dig AAAA dangling-alias.bortzmeyer.fr ... ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 45331 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 6, ADDITIONAL: 1
L'article seul
RFC 6540: IPv6 Support Required for all IP-capable Nodes
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : W. George (Time Warner Cable), C. Donley (Cablelabs), C. Liljenstolpe (Telstra), L. Howard (Time Warner Cable)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 13 avril 2012
Il y a plusieurs façons de présenter ce RFC qui décrète que toute machine IP doit être capable de faire de l'IPv6. Le meilleur angle, je trouve, est de dire que c'est un RFC contre la publicité mensongère : dans l'Internet d'aujourd'hui, IP ne veut plus seulement dire IPv4. Vendre une machine ou un logiciel comme étant capable de parler IP, alors qu'elle ou il ne fait pas d'IPv6 est mensonger.
Bien sûr, en pratique, il est peu probable que ce RFC change grand'chose : les vendeurs continueront à fourguer des produits incapables de parler IPv6, protocole pourtant normalisé depuis seize ans, avec la sortie du RFC 1883 (depuis remplacé par le RFC 2460). Mais, au moins, ils ne pourront plus dire qu'il y avait une ambiguité et que certains RFC anciens parlent de « IP » pour désigner IPv4. Désormais, il est clair que « IP » veut dire IPv6 et (bien que le RFC ne le spécifie pas), si on est seulement IPv4, cela doit être annoncé comme tel et non pas sous l'étiquette « IP ».
Le succès d'IPv4 est incontestable. Il est désormais déployé absolument partout, malgré les vigoureuses oppositions des telcos traditionnels, relayés par pas mal de gouvernements (souvenez-vous des ridicules campagnes de promotion de l'ATM, censé barrer la route à IP). Mais c'est ce succès même qui a condamné IPv4. Le stock d'adresses disponibles est désormais épuisé. Un certain nombre de techniques ont été développées par acharnement thérapeutique, pour essayer de gagner encore quelques années, comme le NAT444. Toutes ont de sérieux inconvénients (cf. RFC 6269 pour un exemple).
La solution correcte, qui évite de fragiliser l'Internet par l'empilement de techniques de transition et/ou de coexistence est donc de déployer IPv6. Mais cela ne s'est pas fait tout seul. L'absence, ou la mauvaise qualité, de mise en œuvre d'IPv6 dans les logiciels a longtemps retardé ce protocole. Beaucoup de fournisseurs de logiciels se sont comportés comme si « IP » se réduisait à IPv4, IPv6 étant une addition possible mais facultative. Pendant de nombreuses années, Cisco exigeait une licence supplémentaire payante pour l'activation d'IPv6 dans IOS... Bref, des engins étaient vendus comme « IP » alors qu'ils n'étaient qu'« IPv4 ». Le problème continue aujourd'hui, empêchant la migration de progresser.
C'est particulièrement gênant dans le domaine des équipements proches du consommateur : ce dernier, à juste titre, ne se soucie pas de la version du protocole IP installé. IPv6 a été conçu justement pour ne pas changer le modèle de fonctionnement d'IP et il n'y a donc aucun avantage, pour M. Toutlemonde, à migrer vers IPv6. La migration, décision technique, ne devrait pas dépendre d'un choix explicite du consommateur, surtout si on le fait payer pour cela, comme le faisait Cisco. La migration devrait se faire au fur et à mesure que les vieilles machines et vieux logiciels sont remplacés, sans que M. Toutlemonde ne s'en rende compte.
À la décharge des vendeurs, il faut noter que tous les RFC, même ceux encore en vigueur, ne sont pas clairs là-dessus. Par exemple, le RFC 1812, qui établit les règles pour les routeurs IPv4, utilise souvent le terme IP pour désigner IPv4. Même chose pour le RFC 1122, qui normalise les machines terminales et ne mentionne pas IPv6. Aujourd'hui, le terme « IP », dans un RFC, peut indiquer IPv4 seul, IPv6 seul ou bien les deux.
La section 2 de notre RFC pose donc la règle : « IP implique IPv6 ». Plus précisément :
- Les nouvelles mises en œuvre d'IP (ou les mises à jour majeures) doivent inclure IPv6.
- La qualité du support IPv6 doit être égale ou supérieure à celle d'IPv4. On en est très loin aujourd'hui : poussés par des cahiers des charges qui exigent IPv6, certains vendeurs ajoutent un support minimum, permettant de cocher la case « IPv6 » lors de la réponse à un appel d'offres, mais en fournissant du logiciel bogué et lent.
- L'activation ou la configuration d'IPv4 ne doit pas être nécessaire.
Évidemment, ce n'est qu'un RFC. Bien des vendeurs l'ignoreront. Espérons toutefois qu'il contribuera à une meilleure information des consommateurs.
Ce document était loin d'être consensuel à l'IETF. Beaucoup de gens critiquaient le principe même d'un document d'exhortation, qui risque fort de n'être qu'un rappel de plus. Toutefois, les partisans de ce document étaient actifs et les opposants ne voyaient pas d'inconvénients graves à la publication.
L'article seul
RFC 6605: Elliptic Curve Digital Signature Algorithm (DSA) for DNSSEC
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : P. Hoffman (VPN Consortium), W. Wijngaards (NLnet Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsext
Première rédaction de cet article le 13 avril 2012
Le mécanisme de sécurité DNSSEC permet évidemment de choisir entre plusieurs algorithmes de signature cryptographique, à la fois pour pouvoir faire face aux progrès de la cryptanalyse et pour pouvoir choisir en fonction de critères particuliers (taille des clés, temps de signature et de vérification, etc). La palette de choix s'agrandit avec ce RFC qui normalise l'usage d'ECDSA, un algorithme à courbes elliptiques (le deuxième dans DNSSEC après le RFC 5933).
DNSSEC est normalisé dans le RFC 4033 et les suivants. Il permet d'authentifier les enregistrements DNS par une signature cryptographique et l'algorithme de loin le plus fréquent aujourd'hui est RSA, avec des clés de 1024 ou 2048 bits. Beaucoup de gens préfèrent les courbes elliptiques, décrites dans l'excellent RFC 6090. Notre RFC étend donc la liste des algorithmes disponibles à :
- ECDSA avec la courbe P-256 et l'algorithme de condensation SHA-256. On considère généralement que cette courbe a à peu près la résistance de RSA avec des clés de 3072 bits.
- ECDSA avec la courbe P-384 et l'algorithme de condensation SHA-384.
ECDSA est normalisé dans FIPS 186-3. Les paramètres des courbes sont pris dans le RFC 5114.
Les clés ECDSA et les signatures étant bien plus petites que celles de RSA, on peut espérer des économies sur la capacité réseau. Signer est également bien plus rapide avec ECDSA (20 fois plus dans certains tests). Par contre, vérifier les signatures est plus long (5 fois plus dans certains tests) et le processeur des résolveurs DNS validants va donc souffrir.
Au passage, notre RFC normalise aussi (section 2) l'utilisation de SHA-384 dans DNSSEC, ce qui n'avait pas été fait précédemment (mais n'a aucun rapport avec les courbes elliptiques). SHA-384 était déjà décrit dans le RFC 6234 et DNSSEC a juste eu à lui ajouter un numéro de code, 4. (La première personne qui voit un DS de numéro 4 dans la nature est priée de me le signaler, pour ma collection.)
La section 4 décrit les formats utilisés pour DNSSEC. Une clé publique ECDSA est juste une valeur, notée Q, qu'on met telle quelle dans l'enregistrement DNSKEY. La signature, elle, est faite de deux valeurs, r et s. On les concatène simplement avant de les mettre dans le RRSIG. Les codes enregistrés pour les deux nouveaux algorithmes sont 13 pour ECDSA Curve P-256 with SHA-256 et 14 pour ECDSA Curve P-384 with SHA-384. (Là encore, si quelqu'un en trouve dans la nature, je suis preneur...)
La section 6 fournit des exemples. Voici une clé et le DS correspondant, avec le premier algorithme (notez la petite taille par rapport aux DNSKEY RSA) :
example.net. 3600 IN DNSKEY 257 3 13 (
GojIhhXUN/u4v54ZQqGSnyhWJwaubCvTmeexv7bR6edb
krSqQpF64cYbcB7wNcP+e+MAnLr+Wi9xMWyQLc8NAA== )
example.net. 3600 IN DS 55648 13 2 (
b4c8c1fe2e7477127b27115656ad6256f424625bf5c1
e2770ce6d6e37df61d17 )
Et les signatures qui l'utilisent (également toutes petites) :
www.example.net. 3600 IN A 192.0.2.1
www.example.net. 3600 IN RRSIG A 13 3 3600 (
20100909100439 20100812100439 55648 example.net.
qx6wLYqmh+l9oCKTN6qIc+bw6ya+KJ8oMz0YP107epXA
yGmt+3SNruPFKG7tZoLBLlUzGGus7ZwmwWep666VCw== )
Question mises en œuvre, on notera
qu'OpenSSL, bibliothèque utilisée par de
nombreux programmes DNS, a ECDSA, avec nos deux courbes (au moins depuis la version 1.0.1,
celle que j'ai testée). C'est apparemment activé par défaut (il faut
faire un ./config no-ecdsa pour ne
pas l'avoir). Voir le source dans
crypto/ecdsa. Mais le code a été retiré de certains
systèmes (comme Fedora) en raison des
brevets, une infection fréquente pour les
courbes elliptiques.
Dans les serveurs de noms, le seul à gérer déjà ECDSA semble être PowerDNS. BIND ne semble pas avoir encore ECDSA (version 9.9, la dernière officiellement publiée). Même chose pour Unbound dans sa version 1.4.16, la dernière. nsd comprend ECDSA depuis la version 3.2.11, publiée en juillet 2012. Enfin, pour Go-DNS, c'est en cours de développement. Enfin, pour la bibliothèque ldns, ECDSA a été ajouté dans la version 1.6.13, sortie en mai 2012. Pour les autres, il va donc falloir patienter un peu. Notez que certains des registres de noms de domaine ont une liste limitative des algorithmes acceptés et que cette liste ne comprend pas forcément déjà ECDSA.
Si vous voulez regarder une zone signée avec ECDSA (c'est très rare), il y a ecdsa.isc.org.
L'article seul
RFC 6574: Report from the Smart Object Workshop
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : H. Tschofenig (Nokia Siemens Networks), J. Arkko (Ericsson)
Pour information
Première rédaction de cet article le 13 avril 2012
Traditionnellement, les engins connectés à l'Internet étaient des ordinateurs généralistes, dotés de bonnes capacités de calcul et alimentés en courant électrique à volonté. Est-ce que la famille de protocoles TCP/IP convient toujours, lorsque les machines connectées sont des petits trucs avec un processeur ridicule, et alimentés par une batterie qu'il faut faire durer le plus longtemps possible ? C'était l'objet de l'atelier Interconnecting Smart Objects with the Internet qui s'est tenu à Prague le 25 mars 2011, à l'instigation de l'IAB. Le but était d'explorer cette question, de voir si la connexion à l'Internet de ces « objets malins » était triviale, possible avec quelques adaptations des protocoles ou, pourquoi pas, irréaliste sans des changements radicaux.
L'atelier a rassemblé près de cent participants (liste complète en annexe D), la plupart ayant déjà travaillé sur l'adaptation de TCP/IP à des objets contraints (en mémoire, en alimentation, etc). Ces objets peuvent être des capteurs, des actionneurs, etc. À côté d'eux, même un smartphone est riche en capacités CPU et en énergie électrique.
Rappelons que l'IAB, qui a produit ce RFC, est en charge du travail d'architecture à l'IETF. Ce comité ne s'occupe pas des protocoles individuels (dont le développement, dans les groupes de travail IETF, est piloté par l'IESG) mais du maintien et du développement d'une architecture saine pour l'Internet, avec une insistance sur le travail à long terme.
Une de ces questions à long terme est celle du passage d'un Internet composé uniquement d'ordinateurs à un Internet auquel sont attachés, entre autres, des engins qu'on qualifie du terme générique d'« objets » et qui ont en commun de sévères restrictions matérielles, rendant parfois difficile un attachement normal à l'Internet. Pour les développements liés à ces objets, les gens du marketing ont inventé le terme ridicule d'« Internet des objets » (IoT en anglais pour « Internet of Things »). Mais, même si le terme est grotesque, il y a une vraie question technique : l'Internet est-il accessible à des objets contraints en ressources ?
Connecter ces objets présente souvent des avantages (pour des capteurs, cela permet de les interroger à distance, alors qu'auparavant il fallait qu'un humain se déplace pour les lire), et certains le sont déjà, en utilisant des protocoles privés. Mais la tendance actuelle est de migrer vers les protocoles standard de l'Internet. Cela se reflète entre autres dans les groupes de travail IETF, dont plusieurs planchent sur cet Internet des Trucs : Constrained RESTful Environments (CoRE), IPv6 over Low power WPAN (6LowPAN), Routing Over Low power and Lossy networks (ROLL) ou Light-Weight Implementation Guidance (LWIG).
C'est que le travail d'ingéniérie n'est pas facile : il faut jongler entre des exigences contradictoires, la sécurité, le prix, l'utilisabilité, la protection de la vie privée (ces objets sont souvent liés à notre vie quotidienne), la longévité sous batterie, etc. (Le RFC cite, sur cette questions des exigences contradictoires, l'excellent article « Tussle in Cyberspace: Defining Tomorrow's Internet ».)
L'atelier de l'IAB partait de la constatation que les protocoles actuels de l'Internet, d'IPv4 à IPv6, d'UDP à TCP et jusqu'à bien sûr HTTP, fonctionnent même sur les objets contraints. Il en existe déjà dans la nature. Une première question était « quel bilan tirer de ces premiers déploiements ? ». Une autre était « quels sont les problèmes pas encore résolus ? ».
En quoi ces objets sont-ils contraints ? Que leur manque-t-il exactement, par rapport à un ordinateur classique ? La section 2 détaille leurs propriétés :
- Très limités en alimentation électrique, ces engins doivent se mettre en sommeil fréquemment. Cela fait un sérieux changement de paradigme pour les protocoles Internet, habitués aux ordinateurs toujours en marche.
- Très limités en capacité réseau, ces objets ont souvent moins de 100 kb/s disponibles et parfois seulement 10 ou 20 ! En outre, leur connectivité est fréquemment affectée par des taux de pertes de paquets importants.
- Très limités en mémoire, les appareils en question ne peuvent pas stocker du code ou des données compliquées. Par exemple, la carte Arduino n'a que 2 ko de RAM et 32 ko de mémoire flash.
- Liée au problème de la consommation électrique, il y a aussi la faible capacité des processeurs. Pour moins consommer, ils sont souvent lents.
- Peu ou pas d'interface utilisateur (encore moins qu'un routeur), et donc difficiles à configurer.
- Enfin, il y a des limitations de taille physique. Si la traditionnelle carte ATX fait 305x244 mm, la CoreExpress, conçue pour l'embarqué, ne fait que 58x65 mm.
La loi de Moore, souvent citée pour relativiser ces limites, ne suffit pas. Les gains qu'elle permet sont souvent utilisés pour réduire coûts et consommation électrique, pas pour augmenter la puissance.
Place à l'atelier lui-même, maintenant. Avec 70 papiers acceptés (la liste complète figure en annexe B du RFC), il n'est pas facile à synthétiser. La section 3 de notre RFC essaie quand même d'indiquer les grands lignes de la réflexion. Quatre grandes questions structuraient l'atelier, les questions d'architecture, les points soulevés par les nœuds dormants, la sécurité et le routage. Commençons par l'architecture, section 3.1.
Première question d'architecture, parle-t-on de connecter ces objets contraints à l'Internet (singulier, et avec une majuscule, car c'est une entité unique comme l'Atlantique ou l'Himalaya) ou bien à des réseaux utilisant TCP/IP, mais qui ne sont pas forcément reliés à l'Internet ? Après tout, les capteurs et actionneurs dans une usine n'ont pas forcément besoin de se connecter à YouTube et, même si le RFC ne le rappelle pas, du point de vue sécurité, il est irresponsable de relier un SCADA à l'Internet. (Le RFC cite un cas moins grave, celui des fontaines devant l'hôtel Bellagio, à Las Vegas, fontaines qui sont électroniquement contrôlées à distance mais qui n'ont pas besoin d'être sur le même réseau que les clients dans leurs chambres, cf. l'exposé de B. Dolin à l'atelier.) Même chose pour les smart grids qui n'ont rien à gagner (et beaucoup à perdre) à être joignables depuis l'Internet. Bref, l'IETF doit-elle séparer clairement le cas des objets connectés à l'Internet et celui des objets reliés à TCP/IP ? Du point de vue purement économique, il est clair qu'il vaut mieux un seul réseau, comme l'a rappelé Cullen Jennings, qui prédisait que tour le monde serait connecté au même Internet, car c'était plus simple et moins coûteux.
Une autre question d'architecture fondamentale est celle des protocoles spécifiques à un domaine d'application. Prenons l'exemple d'une ampoule électrique du futur. Grâce aux normes, on la branche au réseau et elle acquiert une adresse IP (grâce à DHCP ou NDP), trouve un serveur DNS, on peut la pinguer. On peut même imaginer qu'elle ait un serveur HTTP et tout client HTTP peut alors s'y connecter. Mais pour une tâche simple pour laquelle elle est conçue, éclairer, il n'y a pas de norme. Une commande de base « allume-toi » n'est pas normalisée. Comment s'assurer que l'objet, non seulement sera connecté (ping), mais pourra interagir avec son environnement, selon ses capacités ? Les protocoles de couche 3, 4 et même 7 ne suffisent pas. Il va falloir mettre au point des modèles (des classes, dirait-on en programmation objet, dont le nom est bien adapté ici), pour exploiter ces objets « intelligents ».
Un des principes de base de l'Internet, qui est défié par l'arrivée massive des objets connectés, est celui comme quoi l'intelligence est uniquement aux extrémités et le réseau fournit uniquement un service de base (faire passer les paquets). Avec des objets assez limités en ressources, on pourrait imaginer de revisiter ce principe et de mettre de l'« intelligence » dans le réseau. Parmi les services pour lesquels ce serait un bon endroit, on peut imaginer :
- La localisation, à savoir indiquer à l'objet où il se trouve. Il ne s'agit pas uniquement des coordonnées GPS mais aussi de l'environnement (« tu es dans un hôpital », « tu es dehors »).
- Routage fondé sur les noms, où les couches basses sauraient utiliser directement le nom d'une ressource (par exemple « Lampe »), sans passer par des résolutions en identificateurs de plus bas niveau. C'est relativement simple à faire pour un petit réseau local, où un contrôleur peut diffuser à tous « Lampe, allume-toi », et où la lampe se reconnait et s'exécute, mais bien plus complexe dans les grands réseaux. La question n'a pas fait l'objet d'un consensus à l'atelier, loin de là.
Deuxième grande question après l'architecture, le sommeil des objets (section 3.2). Pour économiser l'énergie, beaucoup de ces objets contraints s'endorment souvent. Pour qu'une pile AAA tienne des mois, il faut que l'objet dorme pendant 99, voire 99,9 % du temps. Chaque bit, chaque aller-retour sur le réseau, et chaque milli-seconde d'activité radio (une activité qui consomme beaucoup de courant) est précieux. Or, la plupart des protocoles TCP/IP sont conçus autour de l'idée que les machines sont allumées en permanence, qu'elles peuvent garder un état et répondre à tout moment à un paquet, même non sollicité. Mais, lorsque la simple attente d'un éventuel message consomme du courant, cette idée n'est plus valable : les objets contraints sont plus souvent endormis qu'éveillés, contrairement aux ordinateurs classiques.
Pire, lorsqu'un nœud se réveille après une période de sommeil, son adresse IP a pu être prise par un autre. Il va donc devoir se lancer dans une procédure coûteuse pour obtenir une adresse. Il peut toutefois économiser des efforts s'il met en œuvre les méthodes DNS (Detecting Network Attachment) des RFC 4436 et RFC 6059. Autre piège, si l'objet est mobile, après son réveil, il a pu bouger pour un tout autre endroit.
Pour gérer ces machines « Belle au bois dormant », les solutions envisagées lors de l'atelier étaient :
- Ne plus considérer comme acquis que les machines sont toujours allumées, lorsqu'on conçoit un protocole. Prévoir une réduction des fonctions du protocole, ou bien des intermédiaires, toujours allumés, qui reçoivent les messages et les stockent (on nomme cela un sleep proxy, comme dans la norme ECMA-393). Autre solution, que les machines communiquent leurs heures de réveil à leurs pairs, comme dans 802.11.
- Réduire le prix d'une connexion initiale au réseau. Actuellement, l'arrivée sur un nouveau réseau (et un nœud mobile, lorsqu'il se réveille, doit toujours supposer qu'il est sur un nouveau réseau) met en jeu des protocoles coûteux en énergie comme DHCP ou NDP. Peut-on réduire ce coût, surtout pour les machines qui savent qu'elles ne sont pas mobiles ?
- Réduire le coût des échanges de messages. Préferer les protocoles qui limitent le bla-bla (plus le dialogue est long, plus il faut rester allumé longtemps), les encodages qui ne consomment pas trop d'octets (donc, attention à XML),
- Penser au coût total en énergie : le RFC cite l'exemple de l'absurdité de la domotique où des ampoules allumées et éteintes par un contrôleur consomment soi-disant moins d'énergie... alors que le bilan global est négatif, à cause de la consommation du contrôleur et du réseau.
Troisième grande question explorée lors de l'atelier, la sécurité (section 3.3). Il faut évidemment la prendre en compte dès le début (RFC 3552 et RFC 4101). L'idéal est que la sécurité soit intégrée dans le début, au lieu d'être une option qu'on oublie d'activer. Mais les défis pour les objets contraints sont énormes. Les calculs qu'impose la cryptographie ne vont pas dans le sens de l'économie d'énergie. D'autre part, l'absence d'une interface utilisateur commode limite sérieusement la configuration qui peut être faite (pas moyen de demander à l'administrateur d'entrer un mot de passe compliqué). Les protocoles de sécurité de l'IETF permettent de gérer tous les cas, mais ils peuvent être trop riches et on peut défendre l'idée de profils, de restrictions ne gardant, par exemple, que certains algorithmes de cryptographie. Le choix ne sera pas évident car il existe des exigences contradictoires. Par exemple, les algorithmes à base de courbes elliptiques (RFC 6090) sont souvent moins consommateurs de ressources matérielles mais sont bien plus encombrés de brevets.
Enfin, les objets communiquants ayant vocation à être partout (à l'usine, au bureau, mais aussi à la maison et, pourquoi pas, dans notre propre corps), les questions de protection de la vie privée sont cruciales. Pas question qu'un sniffer puisse espionner la communication entre le frigo et le supermarché, apprenant ainsi mes habitudes, mes heures de présence, etc. (Dans ce cas, le principal danger pour la vie privée vient probablement du supermarché et, là, le chiffrement des communications n'aide pas.)
Mais l'algorithme de cryptographie n'est pas tout : l'expérience de l'usage de la cryptographie dans l'Internet a montré que les problèmes de gestion des clés cryptographiques étaient souvent bien pires.
Enfin, dernière grande question analysée à Prague, le routage (section 3.4). Les objets communiquants peuvent être trop loin les uns des autres pour se parler directement et il peut être nécessaire de passer par un routeur. Comment les objets et les routeurs vont-ils apprendre les routes disponibles ? Il existe deux approches, mesh-under et route-over. La première n'est pas vraiment du routage, elle consiste à résoudre le problème au niveau 2. Les objets ont ensuite tous l'impression d'être sur le même réseau local. L'autre approche, le route-over, met en place des vrais routeurs IP. Cela implique donc un protocole de routage et celui officiel à l'IETF pour cette tâche est le RPL du RFC 6550 (mais il en existe d'autres, comme le Babel du RFC 8966).
Les protocoles de routage pour les objets contraints font face à de nombreux défis. Par exemple, en filaire classique, les caractéristiques (latence, perte de paquets) sont les mêmes pour toutes les machines attachées au même lien. Ici, c'est par contre loin d'être le cas. Le groupe de travail roll avait été formé pour étudier ce problème (qui avait déjà été abordé par le RFC 3561) et il avait produit plusieurs RFC de débroussaillage et de définition du problème (RFC 5867, RFC 5826, RFC 5673, RFC 5548), avant de définir RPL. Notez que le problème suscite des controverses. Un RFC d'étude comparée des différents protocoles de routage avait été abandonné par le groupe roll (manque de consensus pour avancer). Et, à l'atelier, les polémiques n'ont pas manqué, comme la défense d'AODV par Thomas Clausen dans son article.
Alors, à la fin, peut-on faire une synthèse ? La section 4 s'y essaie. Premier thème décrit, la sécurité. La consommation de temps de processeur (et donc d'électricité) par la cryptographie est une sérieuse limite à la sécurisation des objets communicants. La difficulté de la gestion des clés en est une autre. Notre RFC 6574 recommande d'y travailler sérieusement sur ce dernier point, en donnant comme exemple le mécanisme d'appariement de Bluetooth qui combine harmonieusement sécurité et simplicité. Un groupe de travail de l'IETF avait été formé sur cette question, enroll, mais avait échoué. Peut-être le travail devra-t-il être repris par le nouveau groupe lwig.
Quant à la question des algorithmes cryptographiques « développement durable » (à consommation de ressources réduite), un groupe de recherche de l'IRTF existe, cfrg. Par exemple, le futur SHA-3 a prévu de prendre en compte ce problème (dont l'importance n'était pas perçue pour les algorithmes précédents de la famille).
Assurer l'interopérabilité n'est pas évident lorsque des objets ont une mémoire limitée et ne peuvent pas stocker le code correspondant à tous les algorithmes existants. Le RFC rappelle que plus de cent algorithmes de cryptographie sont définis pour TLS, dont certains sont officiellement déconseillés depuis cinq ou parfois dix ans, mais toujours répandus dans la nature : une mise en œuvre de TLS qui veut être sûre de pouvoir communiquer avec tout le monde a besoin de les connaitre. Les nouveaux algorithmes à consommation d'énergie réduite pourraient encore aggraver ce problème. Faut-il créer un nouvel algorithme, avec les problèmes d'appropriation intellectuelle, avec les difficultés de déploiement, juste pour économiser 20 % de la consommation électrique ? Le RFC laisse entendre que le gain de consommation devrait être nettement plus élevé pour que le jeu en vaille la chandelle.
Un autre thème choisi pour la conclusion est justement celui de la consommation électrique. Il existe une liste de discussion active pour cela, recipe, et l'article de Margaret Wasserman à l'atelier fournit un bon point de départ pour ceux qui veulent s'engager dans ce travail.
Quant à la question du réseau « centré sur le contenu », le RFC conclut que c'est encore bien trop nébuleux et qu'il n'y a pas de travail concret de normalisation à envisager. Il s'agit de recherche pure pour l'instant.
Sur l'architecture, le RFC plaide en faveur d'un futur document de synthèse de l'IAB expliquant comment tous les protocoles Internet marchent ensemble dans ce contexte des objets contraints et communiquants. Le RFC 6272 fournit un bon exemple d'un tel travail.
Dans la lignée de l'exemple de l'ampoule électrique, le RFC insiste aussi sur l'importance de développer des modèles de données (« Une ampoule a deux états, allumé et éteint ») permettant de créer des applications (ici, de contrôle de l'ampoule). La question est « est-ce bien le travail de l'IETF, puisqu'il faut à chaque fois une expertise spécifique d'un domaine ? ».
Pour la partie « découverte » de services ou de machines, le RFC recommande de travailler avec mDNS ou équivalent.
Pour le routage, notre section de conclusion suggérait de travailler entre autres sur la question des « sous-réseaux couvrant plusieurs liens » (RFC 4903). L'essentiel du travail sur le routage pour les objets communiquants continue au sein du groupe roll.
Notez enfin le récent groupe de travail homenet qui travaille sur les problèmes de domotique (voir son RFC 7368).
La liste des présentations à l'atelier figure dans l'annexe B. On trouve en ligne la page officielle de l'atelier, les articles présentés (une impressionnante masse de bons documents à lire), les supports des présentations, et les notes prises pendant l'atelier.
L'article seul
RFC 6591: Authentication Failure Reporting using the Abuse Report Format
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : H. Fontana
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF marf
Première rédaction de cet article le 13 avril 2012
Le format ARF, normalisé dans le RFC 5965, permet d'envoyer des rapports structurés (analysables par un programme) à propos d'un message électronique abusif, spam ou hameçonnage, par exemple. Ce RFC 6591 spécifie une extension à ARF pour le cas où le problème avec le message est un échec d'un mécanisme d'authentification. On peut ainsi prévenir l'émetteur que quelqu'un essaie d'usurper son identité ou, plus fréquemment aujourd'hui, qu'il y a une erreur dans la configuration de ses mécanismes d'authentification.
Par exemple, si le message est authentifié par
SPF (RFC 7208 et RFC 6652), il arrive
assez souvent que l'émetteur se mette à utiliser un
MTA non prévu et non listé dans
l'enregistrement SPF. Si ce dernier se termine par un
-all, l'usage de ce MTA va se traduire par une
erreur d'authentification. L'extension ARF décrite ici permettra de
transmettre un rapport à l'émetteur, pour qu'il corrige.
L'extension consiste en un nouveau type de rapport ARF,
auth-failure (section 3.1), rejoignant les
rapports existants (comme
abuse ou fraud). Un rapport
de ce type va comporter, dans sa seconde partie (celle qui est
structurée, la première étant en langue naturelle et la troisième
étant le message original), les champs suivants. À noter que certains étaient déjà définis
par le RFC 5965 mais peuvent avoir des exigences
différentes ici (par exemple, être obligatoires pour les rapports
auth-failure alors qu'ils étaient optionnels pour
les autres). Les nouveaux sont désormais dans le
registre IANA. Commençons par les champs obligatoires :
Auth-failure:Nouveauté de ce RFC, il indique en un mot la raison de l'échec. Les valeurs possibles sontadsp(cf. RFC 5617),bodyhash(le condensat cryptographique du corps du message ne correspond pas à la signature),revoked(signature DKIM expirée),signature(signature DKIM invalide, cf. RFC 6651),spf(échec SPF, RFC 6652).Authentication-Results:Normalisé dans le RFC 7001, il indique les paramètres d'authentification et les raisons de l'échec.Reported-Domain:Le nom de domaine annoncé par l'expéditeur.
D'autres champs sont recommandés ou simplement optionnels :
Original-Envelope-Id:Un identifiant unique pour la transaction SMTP (cf. section 2.2.1 du RFC 3464)Original-Mail-From:Source-IP:Delivery-Result:Ce dernier indique la décision qui a été prise après l'échec de l'authentification (jeter le message, le distribuer quand même, etc)
Il peut en outre y avoir des champs spécifiques à certaines techniques
d'authentification. Par exemple, pour DKIM
(RFC 6376), les champs
DKIM-Domain:, DKIM-Identity:
et DKIM-Selector: ou pour SPF le champ
SPF-DNS:..
Voici un exemple (annexe B du RFC) de rapport ARF sur un échec d'authentification DKIM, par suite d'une incohérence entre le contenu effectif et ce qu'indiquait la signature :
Message-ID: <433689.81121.example@mta.mail.receiver.example>
From: "SomeISP Antispam Feedback" <feedback@mail.receiver.example>
To: arf-failure@sender.example
Subject: FW: You have a new bill from your bank
Date: Sat, 8 Oct 2011 15:15:59 -0500 (CDT)
MIME-Version: 1.0
Content-Type: multipart/report;
boundary="------------Boundary-00=_3BCR4Y7kX93yP9uUPRhg";
report-type=feedback-report
Content-Transfer-Encoding: 7bit
--------------Boundary-00=_3BCR4Y7kX93yP9uUPRhg
Content-Type: text/plain; charset="us-ascii"
Content-Disposition: inline
Content-Transfer-Encoding: 7bit
This is an authentication failure report for an email message
received from a.sender.example on 8 Oct 2011 20:15:58 +0000 (GMT).
For more information about this format please see [this memo].
--------------Boundary-00=_3BCR4Y7kX93yP9uUPRhg
Content-Type: message/feedback-report
Content-Transfer-Encoding: 7bit
Feedback-Type: auth-failure
User-Agent: Someisp!Mail-Feedback/1.0
Version: 1
Original-Mail-From: anexample.reply@a.sender.example
Original-Envelope-Id: o3F52gxO029144
Authentication-Results: mta1011.mail.tp2.receiver.example;
dkim=fail (bodyhash) header.d=sender.example
Auth-Failure: bodyhash
DKIM-Canonicalized-Body: VGhpcyBpcyBhIG1lc3NhZ2UgYm9keSB0
aGF0IGdvdCBtb2RpZmllZCBpbiB0cmFuc2l0LgoKQXQgdGhlIHNhbWU ...
DKIM-Domain: sender.example
DKIM-Identity: @sender.example
DKIM-Selector: testkey
Arrival-Date: 8 Oct 2011 20:15:58 +0000 (GMT)
Source-IP: 192.0.2.1
Reported-Domain: a.sender.example
Reported-URI: http://www.sender.example/
--------------Boundary-00=_3BCR4Y7kX93yP9uUPRhg
Content-Type: text/rfc822-headers
Content-Transfer-Encoding: 7bit
Authentication-Results: mta1011.mail.tp2.receiver.example;
dkim=fail (bodyhash) header.d=sender.example;
spf=pass smtp.mailfrom=anexample.reply@a.sender.example
Received: from smtp-out.sender.example
by mta1011.mail.tp2.receiver.example
with SMTP id oB85W8xV000169;
Sat, 08 Oct 2011 13:15:58 -0700 (PDT)
DKIM-Signature: v=1; c=relaxed/simple; a=rsa-sha256;
s=testkey; d=sender.example; h=From:To:Subject:Date;
bh=2jUSOH9NhtVGCQWNr9BrIAPreKQjO6Sn7XIkfJVOzv8=;
b=AuUoFEfDxTDkHlLXSZEpZj79LICEps6eda7W3deTVFOk4yAUoqOB
4nujc7YopdG5dWLSdNg6xNAZpOPr+kHxt1IrE+NahM6L/LbvaHut
KVdkLLkpVaVVQPzeRDI009SO2Il5Lu7rDNH6mZckBdrIx0orEtZV
4bmp/YzhwvcubU4=
Received: from mail.sender.example
by smtp-out.sender.example
with SMTP id o3F52gxO029144;
Sat, 08 Oct 2011 13:15:31 -0700 (PDT)
Received: from internal-client-001.sender.example
by mail.sender.example
with SMTP id o3F3BwdY028431;
Sat, 08 Oct 2011 13:15:24 -0700 (PDT)
Date: Sat, 8 Oct 2011 16:15:24 -0400 (EDT)
Reply-To: anexample.reply@a.sender.example
From: anexample@a.sender.example
To: someuser@receiver.example
Subject: You have a new bill from your bank
Message-ID: <87913910.1318094604546@out.sender.example>
--------------Boundary-00=_3BCR4Y7kX93yP9uUPRhg--
Le but de l'authentification du courrier électronique étant d'améliorer la sécurité, il n'est pas étonnant que la section 6, considérée aux problèmes de sécurité, soit particulièrement détaillée. Quelques points à garder en tête, donc. Par exemple, les rapports ARF eux-même peuvent être des faux. Il ne faut agir de manière automatique sur un de ces rapports que s'ils ont été authentifiés d'une manière ou d'une autre. Ensuite, générer automatiquement des rapports ARF peut ouvrir une voie à l'attaque par déni de service : un méchant pourrait envoyer plein de messages délibèrement faux, pour déclencher l'émission massive de rapports ARF.
Il existe apparemment déjà au moins un générateur d'ARF qui gère cette extension. PayPal et Hotmail ont déjà annoncé leur intention de l'utiliser.
L'article seul
Utiliser OpenDNSSEC avec un serveur maître NSD
Première rédaction de cet article le 12 avril 2012
Gérer proprement DNSSEC n'est pas trivial : un certain nombre d'opérations de gestion des clés et de renouvellement des signatures doivent se faire dans un ordre précis, à certains moments. Si on le fait à la main, une erreur ou un oubli est vite arrivé et, comme illustré par mon article à SATIN 2011, de tels erreurs ou oublis sont fréquents. D'où l'intérêt d'utiliser une solution logicielle qui automatise tout cela, en l'occurrence OpenDNSSEC. Les exemples donnés dans la documentation sont pour un serveur DNS maître utilisant BIND. Et si on se sert de NSD ?
Ce dernier présente bien des avantages, notamment de rapidité, et aussi sans doute de sécurité, en raison d'un code bien plus court. Mais il n'a pas l'équivalent de la commande rndc de BIND, commande qui permet à OpenDNSSEC de signaler au serveur de noms qu'il a fini, et que la zone doit être rechargée. Il va donc falloir un peu plus de travail.
Les commandes à faire sur NSD, après la génération d'un nouveau fichier de zones par le signeur d'OpenDNSSEC, sont :
# Reconstruire la base de données de nsd nsdc rebuild # Charger la nouvelle base nsdc reload # Prévenir les esclaves nsdc notify
Il faut en outre être root pour les lancer. Le
signeur d'OpenDNSSEC tourne typiquement sous un autre nom (avec le
paquetage Debian, il utilise le compte
opendnssec). Il faut donc commencer par faire un
programme setuid qui appelle les deux commandes
ci-dessus. Pas besoin de programmer, Russell Harmon l'a fait et a
publié le résultat
(j'en garde une copie locale en opendnssec-nsd-reload.c).
Ce simple programme en C appelle les trois commandes ci-dessus. Il doit ensuite être installé setuid pour exécuter ces commandes sous root. Cela peut se faire avec un simple Makefile :
.PHONY: all clean
CHGRP := /bin/chgrp
CHMOD := /bin/chmod
CFLAGS := -Wall -Wextra -Werror
DEST := /usr/local/sbin
INSTALL := /usr/bin/install
all: opendnssec-nsd-reload
clean:
$(RM) opendnssec-nsd-reload
opendnssec-nsd-reload: opendnssec-nsd-reload.c
$(CC) $(CFLAGS) $(LDFLAGS) -o $@ $<
install: opendnssec-nsd-reload
$(INSTALL) opendnssec-nsd-reload $(DEST)
$(CHGRP) opendnssec $(DEST)/opendnssec-nsd-reload
$(CHMOD) o=,g=x,u=rwxs $(DEST)/opendnssec-nsd-reload
Une fois ce programme installé avec make install, on peut le tester, vérifier qu'il
recharge bien le serveur (nsd[xxx]: signal received,
reloading... dans le journal).
Ensuite, il faut dire à OpenDNSSEC de l'appeler dès qu'il a fini de
signer. Cela se fait dans le fichier de configuration
conf.xml :
<NotifyCommand>/usr/local/sbin/opendnssec-nsd-reload</NotifyCommand>
Et voilà, lorsque OpenDNSSEC a fini de signer, il appelle la commande
indiquée dans l'élement NotifyCommand et c'est
tout.
Le programme est très simple et on peut facilement le
modifier. Attention, toutefois, il est setuid et les bogues dans de
tels programmes peuvent se payer cher. Pour des fonctions
supplémentaires, comme de journaliser le
rechargement, je préfère les faire dans un bête script shell qui
appelera opendnssec-nsd-reload ensuite. Voici un
exemple d'un tel script :
#!/bin/sh
logger -i -t OpenDNSSEC-signer -p daemon.info \
"Reloading nsd, modification in zone $1 (file $2)"
/usr/local/sbin/opendnssec-nsd-reload
et on l'appelera (s'il se nomme
run-opendnssec-nsd-reload) :
<NotifyCommand>/usr/local/sbin/run-opendnssec-nsd-reload %zone %zonefile</NotifyCommand>
(Notez les deux macros %zone et
%zonefile, fournies par OpenDNSSEC.)
Si tout marche bien, on verra dans le journal des choses comme :
Apr 11 10:16:42 aetius OpenDNSSEC-signer[18571]: \
Reloading nsd, modification in zone bortzmeyer.fr (file /var/lib/opendnssec/signed/bortzmeyer.fr)
Et voilà, désormais, tout est automatique, il n'y a plus qu'à surveiller.
L'article seul
RFC 6564: An uniform format for IPv6 extension headers
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : S. Krishnan (Ericsson), j h. woodyatt (Apple), E. Kline (Google), J. Hoagland (Symantec), M. Bhatia (Alcatel-Lucent)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 10 avril 2012
IPv6 permet l'insertion, entre l'en-tête de taille fixe du paquet, et les données de la couche 4, d'un ou plusieurs en-têtes d'extensions, qui modifient le comportement du paquet. L'analyse de ces en-têtes d'extension par un programme a toujours été difficile car ils n'ont pas un format cohérent. Ce RFC résout le problème en décrétant que, au moins pour les futurs en-têtes, ils devront suivre un format identique, permettant de les sauter sans même en comprendre le contenu.
Ces en-têtes d'extension sont normalisés dans la section 4 du RFC 2460. La plupart suivent le schéma « un octet pour indiquer le type de l'en-tête suivant, un octet pour indiquer la longueur de cet en-tête, puis les données » mais pas tous (notamment, l'en-tête de fragmentation a une syntaxe différente). Si on veut écrire un programme d'analyse des paquets IPv6, on doit donc connaître tous les types d'en-tête (il n'y en a, après tout, pas beaucoup) et traiter chacun spécialement. Mais cela ne résout pas le problème des futurs en-têtes : si un nouvel en-tête est créé (comme cela avait été le cas dans le RFC 5533), et qu'il commence à apparaître sur le réseau, les programmes d'analyse vont souffrir.
Outre les programmes d'analyse, on peut citer d'autres logiciels qui souhaitent regarder à l'intérieur des paquets, y compris avant que le paquet n'atteigne sa destination (section 1 du RFC). Par exemple les pare-feux veulent accéder à la couche transport, et ils doivent le faire à la vitesse du réseau physique (si on a un Ethernet 1 Gb/s, on veut que les paquets soient analysés au même rythme), ce qui implique le recours à des circuits électroniques relativement simples (les ASIC) qui n'ont pas la possibilité de faire tourner du code arbitrairement complexe. Or, aujourd'hui, tout nouvel en-tête IPv6 est à peu près sûr d'invalider ces pare-feux.
Ne peut-on pas s'en tirer en disant qu'il vaut mieux éviter de définir de nouveaux en-têtes d'extension ? C'est l'option que rappelle la section 3, qui note que l'en-tête Destination Options (section 4.6 du RFC 2460) est déjà très général : il permet d'inclure plusieurs options différentes, chacune identifiée par son type et encodée sous forme TLV. Le RFC recommande donc que les concepteurs de nouvelles idées pour IPv6 réutilisent l'en-tête Destination Options autant que possible. Au cas où un concepteur de protocole décide de créer un nouvel en-tête, il doit désormais expliquer en détail pourquoi l'en-tête Destination Options ne convient pas à son but.
Notez que l'en-tête Destination Options, comme son nom l'indique, ne doit normalement être traité que par la machine de destination (les routeurs, notamment, n'ont pas besoin de le gérer ou de le connaître, sauf à des fins de statistique). Si on veut transporter des options qui sont analysées par les routeurs, on a l'en-tête Hop-by-hop Options. En pratique, il n'est pas du tout évident que ce dernier fonctionne : comme chaque routeur du trajet doit en tenir compte, il ouvre une voie d'attaque possible et il semble que bien des routeurs l'ignorent complètement, voire jettent sans autre forme de procès les paquets qui le contiennent. Quoi qu'il en soit, notre RFC 6564 précise qu'il ne faut pas créer de nouveaux en-têtes ayant cette sémantique « examen par chaque routeur ». Non seulement la création d'en-têtes est déconseillée, mais elle ne doit se faire qu'avec la sémantique « examen par la destination seulement ».
Bien, maintenant qu'on a sérieusement refroidi les concepteurs de protocole qui auraient pensé à créer un nouvel en-tête, la section 4 fixe les règles à suivre au cas où on ne serait pas encore découragé. Les éventuels nouveaux en-têtes devront désormais tous suivre le modèle de la plupart des en-têtes existants et commencer par un octet indiquant l'en-tête suivant (typiquement, cela sera les données de la couche Transport, les valeurs possibles sont dans un registre), puis un octet indiquant la longueur de l'en-tête. Cela devrait rendre un peu plus facile l'analyse des futurs en-têtes, s'il y en a de créés.
Rappelez-vous que cela n'affecte que les futurs en-têtes. Pour analyser les existants (notamment l'en-tête Fragment qui ne suit pas ce schéma, cf. section 5), il faut garder le code existant. La section 6 rappele d'ailleurs que le traitement des en-têtes reste un problème pas complètement résolu pour les équipements intermédiaires, par exemple parce qu'il peut y avoir plusieurs en-têtes, chaînés, parce que leur ordre est important, et parce que le traitement des en-têtes peut influer celui de la charge utile. Personnellement, je pense que la première mise en œuvre d'IPv6 qui essaiera d'utiliser vraiment les en-têtes aura de vilaines surprises... Cela sera encore pire avec un nouvel en-tête, qui ne fait pas partie des anciens.
Notez aussi que tout le problème traité par ce RFC a une faible importance pratique : on ne trouve quasiment pas d'en-têtes d'extension dans les paquets IPv6 qui circulent aujourd'hui.
Donc, désormais, une implémentation d'analyse d'IPv6 (comme la mienne, que j'ai eu la flemme de modifier) peut adopter la stratégie suivante :
- Si c'est un en-tête connu, le traiter selon sa spécification.
- Si c'est un en-tête inconnu et que le next header est un en-tête connu ou bien un protocole de transport connu, sauter l'en-tête inconnu (en utilisant le second octet, qui indique la taille). C'est là la nouveauté de notre RFC 6564.
- Si c'est un en-tête inconnu et que le suivant n'est pas connu non plus, le problème reste ouvert (tenter de suivre la chaîne ? C'est dangereux car on peut se retrouver au milieu d'un protocole de transport inconnu, pour lesquels les règles de notre RFC ne s'appliquent pas) et n'est pas modifié par notre RFC.
L'article seul
RFC 6596: The Canonical Link Relation
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : M. Ohye, J. Kupke
Pour information
Première rédaction de cet article le 9 avril 2012
Depuis le RFC 5988, il existe un mécanisme
standard pour exprimer les types des liens entre deux ressources sur le
Web. Ce très court RFC
spécifie un nouveau type de lien, canonical, qui
permet d'indiquer quel est l'URI
canonique
d'une ressource Web.
Le but de ces liens est de permettre d'exprimer l'idée « Quel que soit l'URI que vous avez utilisé pour arriver sur cette ressource, sachez que l'URI canonique, la référence, est celui indiqué par ce lien. » Cela permet notamment à un moteur de recherche de n'indexer les ressources que sous l'URI canonique (au cas où du contenu soit dupliqué sous plusieurs URI). Cela permet également à un navigateur de ne mémoriser que l'URI canonique, sans d'éventuels paramètres (options d'affichage, identificateurs de session et autres trucs qui viennent souvent polluer les URI).
L'auteur qui place un lien canonical doit donc
veiller à ce que l'URI canonique désigne bien une ressource qui mérite
ce titre (identique à la ressource de départ, ou un sur-ensemble de
celle-ci, ce dernier cas est explicitement autorisé par le RFC). Voir
la section 5 qui donne de bons conseils aux auteurs.
Par contre, l'URI canonique ne doit notamment pas :
- Être la source d'une redirection HTTP (sinon, par définition, il n'est pas canonique).
- Ne doit pas spécifier un URI canonique autre que lui-même (en d'autres termes, pas le doit de faire des chaînes).
- Ne doit évidemment pas renvoyer 404 lorsqu'on essaie d'y accéder.
La section 4 donne des exemples concrets. Si la version canonique
d'une ressource est désignée par l'URI
http://www.example.com/page.php?item=purse, alors
les URI
http://www.example.com/page.php?item=purse&category=bags
ou
http://www.example.com/page.php?item=purse&category=bags&sid=1234
qui sont des URI possibles de la même ressource peuvent indiquer
http://www.example.com/page.php?item=purse comme
canonique.
Pour cela, deux techniques, le classique lien
HTML avec l'attribut rel :
<link rel="canonical"
href="http://www.example.com/page.php?item=purse">
Il est également utilisable en version relative :
<link rel="canonical" href="page.php?item=purse">
Et la deuxième technique (pratique notamment pour les ressources qui ne sont pas en HTML, une image, par exemple), l'en-tête HTTP (section 3 du RFC 8288) :
Link: <http://www.example.com/page.php?item=purse>; rel="canonical"
Pour prendre un exemple réel, si on demande à
Wikipédia (qui fait face à des homonymies
nombreuses) l'URL http://fr.wikipedia.org/wiki/M%C3%A9lenchon, on est redirigé
vers la page sur Jean-Luc Mélenchon qui
contient :
<link rel="canonical" href="/wiki/Jean-Luc_M%C3%A9lenchon" />
qui indique que la page canonique est celle avec le nom complet.
Le nouveau type canonical est désormais enregistré à l'IANA.
Petit avertissement de sécurité (section 7). Si une ressource est modifiée par un attaquant, il peut mettre un lien vers un URI canonique de son choix. Bien sûr, il pourrait aussi massacrer complètement la ressource. Mais le changement d'URI canonique est discret et risquerait de ne pas être noté par un humain, alors même que certaines implémentations en tiendraient compte, par exemple pour apport du trafic à l'URI de l'attaquant.
Qui gère aujourd'hui ce type de liens ? Chez les moteurs de recherche, Google le fait (voir leurs articles « Specify your canonical », « Supporting rel="canonical" HTTP Headers », l'article de conseils pratiques « About rel="canonical" » et enfin « Handling legitimate cross-domain content duplication »). Pareil chez Yahoo (« Fighting Duplication: Adding more arrows to your quiver ») et Bing (« Partnering to help solve duplicate content issues »). Par contre, je ne sais pas si les sites de bookmarking comme del.icio.us ou SeenThis font ce travail de canonicalisation.
L'article seul
RFC 6590: Redaction of Potentially Sensitive Data from Mail Abuse Reports
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : J. Falk (Return Path), M. Kucherawy (Cloudmark)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF marf
Première rédaction de cet article le 8 avril 2012
Il est fréquent qu'un message électronique contienne de l'information sensible ou personnelle, ne serait-ce que le nom des parties qui communiquent. Si ce message doit être transmis, comme faisant partie d'un rapport de problème, cette information doit être protégée. Ce RFC décrit un cadre général pour la retouche des messages. Le terme de « retouche » désigne l'opération d'occultation des parties confidentielles (notez que le redaction de l'original en anglais est un faux-ami, il ne signifie pas « rédaction »).
Le format ARF est normalisé dans le RFC 5965. Ce format standard permet de transmettre un rapport structuré (donc analysable automatiquement, par un programme) indiquant du spam, du hameçonnage ou tout autre abus. ARF permet également d'inclure dans le rapport le message qui a déclenché le processus de plainte. Mais ce message peut contenir des informations confidentielles, qu'on ne souhaite pas partager avec un tiers (sans compter les obligations légales comme, en France, la loi Informatique & Libertés). Le message est donc parfois retouché (redacted dans la langue de Katy Perry) avant d'être transmis. La section 8.5 du RFC 5965 décourage plutôt cette pratique (l'information occultée était peut-être nécessaire à la compréhension du rapport) mais cette approche « au diable la vie privée, la fin justifie les moyens » est très contestée et ce RFC 6590 adopte une vue plus raisonnable. L'occultation est désormais considérée comme justifiée.
L'important est donc plutôt de donner des conseils pratiques. Il y
a des bonnes et des mauvaises façons d'occulter. Ainsi, remplacer
toutes les parties locales des adresses
(stephane+blog dans mon adresse
stephane+blog@bortzmeyer.org) par la même chaîne
de caractères (mettons xxxxx@bortzmeyer.org) fait
perdre beaucoup d'information : on ne sait plus si deux rapports
concernent le même utilisateur.
La section 3 de notre RFC conseille donc plutôt :
- D'utiliser une transformation cohérente : deux chaînes identiques doivent donner le même résultat après occultation, et deux chaînes différentes doivent donner deux résultats différents.
- De décider clairement quelles parties du message sont privées (par exemple, uniquement les parties locales des adresses, comme dans mon premier exemple) et de n'appliquer les transformations qu'à celles-ci.
- De respecter la syntaxe des élements de protocole : si la transformation d'une partie locale d'une adresse donne une chaîne comportant un @ (caractère illégal dans une partie locale d'adresse), il faut l'encoder pour que l'adresse reste syntaxiquement légale, évitant ainsi de planter l'analyseur.
En appliquant ces règles, on a partiellement anonymisé le rapport, tout en permettant l'identification de tendances (par exemple, que le spam est plus souvent envoyé à certains utilisateurs).
Mais quelle opération de transformation utiliser ? Après la section 3 qui posait les principes, la section 4 s'occupe de technique. Ce RFC ne normalise pas une opération de transformation particulière. Si ROT13, qui est réversible, ne devrait pas être utilisé, les méthodes possibles incluent un hachage cryptographique (comme dans le RFC 2104) ou le remplacement des noms par un identifiant interne (numéro de client, par exemple).
Voici l'exemple qui figure dans l'annexe A du RFC. Le message de spam originel était :
From: alice@example.com To: bob@example.net Subject: Make money fast! Message-ID: <123456789@mailer.example.com> Date: Thu, 17 Nov 2011 22:19:40 -0500 Want to make a lot of money really fast? Check it out! http://www.example.com/scam/0xd0d0cafe
Ici, le récepteur, le FAI
example.net est furieux et veut transmettre un
rapport à example.com pour lui demander de faire
cesser ces spams. example.net va occulter le nom
du destinataire (son client), avec SHA-1 et la
clé potatoes, qui sera concaténé au nom avant
hachage, le résultat étant encodé en
Base64. Cela donnera :
% echo -n potatoesbob | openssl sha1 -binary | openssl base64 -e rZ8cqXWGiKHzhz1MsFRGTysHia4=
On va pouvoir alors construire un rapport ARF incluant :
From: alice@example.com To: rZ8cqXWGiKHzhz1MsFRGTysHia4=@example.net Subject: Make money fast! Message-ID: <123456789@mailer.example.com> Date: Thu, 17 Nov 2011 22:19:40 -0500 Want to make a lot of money really fast? Check it out! http://www.example.com/scam/0xd0d0cafe
Attention, en pratique, il existe pas mal de pièges. Par exemple,
comme le note la section 5.3, l'information confidentielle peut se
trouver aussi à d'autres endroits et des techniques de corrélation
peuvent permettre de retrouver l'information occultée. Globalement,
les messages retouchés selon ce RFC ne fourniront
pas une forte confidentialité. Ainsi, le champ
Message-ID: peut permettre, en examinant le
journal du serveur de
messagerie (celui de example.com dans
l'exemple précédent), de retrouver
émetteur et destinataire. C'est pour cette raison que le RFC n'impose
pas l'usage de la cryptographie : elle
n'apporterait pas grand'chose en sécurité.
Même chose pour les informations non structurées, par exemple le texte du message : il peut contenir des indications permettant de remplir les cases occultées (section 6).
D'une manière générale, il faut garder en mémoire qu'il existe de puissantes techniques de désanonymisation comme illustré par exemple par les articles « A Practical Attack to De-Anonymize Social Network Users » de Gilbert Wondracek, Thorsten Holz, Engin Kirda et Christopher Kruegel ou bien « Robust De-anonymization of Large Sparse Datasets » de Arvind Narayanan et Vitaly Shmatikov.
L'article seul
RFC 6556: Testing Eyeball Happiness
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : F. Baker (Cisco)
Pour information
Première rédaction de cet article le 7 avril 2012
Le problème du bonheur des globes oculaires (eyeball happiness) fait l'objet de recherches actives en ce moment. Il s'agit de s'assurer que, lorsqu'un service Internet (par exemple un site Web) est accessible à la fois en IPv4 et en IPv6, l'utilisateur (le propriétaire des globes oculaires) sera heureux (il verra le site très vite), que sa connectivité IPv6 fonctionne correctement ou pas. L'incertitude à ce sujet est la principale cause du très faible nombre de sites Web qui ont un enregistrement AAAA (adresse IPv6) dans le DNS aujourd'hui.
Ce RFC ne propose pas de solution : issu de travaux menés notamment au sein du groupe de travail benchmarks de l'IETF, il propose simplement de mesurer ce bonheur des globes oculaires, de manière à ce qu'on puisse comparer les solutions. On pourra alors retenir les meilleures, de manière à faire sauter ce qui est aujourd'hui un sérieux obstacle au déploiement d'IPv6.
La section 1 du RFC résume le problème de base : si on a une connectivité où plusieurs préfixes IP sont possibles (un IPv4 et un IPv6, ou bien plusieurs IPv6), et que l'application choisit comme source le « mauvais » (celui qui a la moins bonne connectivité, voire pas de connectivité du tout), quelles seront les conséquences pratiques ? L'établissement de la session en sera-t-il ralenti ? Comment TCP va-t-il réagir (RFC 5461) ?
L'algorithme naïf pour l'application est de récupérer une liste
d'adresses possibles pour la destination, via
getaddrinfo(), et d'essayer chaque
adresse successivement. Si certaines timeoutent, le
temps total d'établissement de la connexion (attendre l'expiration du
délai de garde, puis essayer l'adresse suivante) va largement dépasser
les capacités de l'utilisateur même le plus patient (cela peut
dépasser la minute, la valeur exacte dépend de nombreux paramètres). Les globes
oculaires seront malheureux.
C'est à cause de cela que, alors que plus de 40 % des zones dans
.fr ont une adresse IPv6
pour leur service DNS (mesures faites en janvier 2012), seules moins d'1 % en ont une pour leur service
Web. C'est parce que le DNS a été prévu pour résister aux pannes dès
le début (le résolveur se souvient de quelles adresses marchent, pour
une zone) et que l'ajout d'un AAAA cassé n'a
pas de conséquences graves. Au contraire, le Web n'a pas de mécanisme
natif pour assurer la haute disponibilité et un AAAA cassé se paie
très cher en temps d'attente pour les clients. Beaucoup de gérants de
sites Web préfèrent donc ne pas courir le risque, même s'il ne
frapperait qu'une petite minorité de leurs clients.
L'idée de ce RFC, présentée en section 2, est de quantifier ce problème. Le but est d'aboutir à des chiffres indiquant, pour un système donné (nommé Alice), le temps qu'il met à ouvrir une session avec un service (nommé Bob) dont certaines adresses sont incorrectes. Plusieurs cas d'incorrection peuvent se présenter :
- Un routeur jette les paquets mais transmet un message ICMP administratively prohibited ou bien destination unreachable,
- Un routeur jette silencieusement les paquets (cible
DROPdans iptables par exemple), - Un programme intermédiaire génère un
RST(reset) TCP, - Un problème de MTU fait que les paquets au delà d'une certaine taille ne sont pas transmis. Normalement, la découverte de la MTU du chemin (RFC 1191, RFC 1981) fait que ce problème ne doit jamais se produire. En pratique, des configurations incorrectes (blocage aveugle de tout ICMP) font qu'il arrive quand même.
Le test doit être fait pour tous ces cas car rien ne dit que l'application réagira de la même façon à tous ces problèmes. Le plus important est sans doute celui de la perte silencieuse des paquets, car c'est le pire : si l'application réagit bien même dans ce cas, elle s'en tirera sans doute dans les autres. Si on n'en teste qu'un, cela doit donc être celui-ci. (C'est ce que dit le RFC. En pratique, le cas des problèmes de MTU est souvent aussi grave, et il ne se détecte qu'après l'ouverture de la session, lorsqu'on commence à envoyer de gros paquets.)
La section 2.2 explique la procédure, notamment le fait qu'on intègre le temps de la requête DNS préalable (ce que je trouve contestable, mais les raisons ne sont pas expliquées). Les métriques elle-mêmes sont en section 2.3. On mesure le temps entre la première requête DNS et la fin de l'établissement de la connexion TCP, qui est le moment où l'application peut commencer à travailler. Cela se nomme le Session Setup Interval. Si on garde les temps minimum (meilleur cas, probablement celui où la première tentative réussie) et maximum (pire cas, lorsqu'il aura fallu essayer toutes les adresses de la cible), on les nomme Minimum Session Setup Interval et Maximum Session Setup Interval. Le reste du RFC est composé de détails concrets pour qui voudrait effectuer cette mesure. Telle qu'elle est définie (avec des notions comme « l'arrivée du dernier but »), elle n'est pas triviale, voire pas possible à mettre en œuvre sur une machine Unix normale.
Il existe aussi une métrique « qualitative », où on décrit le
trafic observé (Attempt Pattern). Cela peut être
simple (« Un paquet TCP SYN est envoyé
successivement à toutes les adresses, à des intervalles de X
milli-secondes ») mais aussi très complexe. Mon article sur les algorithmes en
donne quelques exemples.
L'article seul
RFC 6582: The NewReno Modification to TCP's Fast Recovery Algorithm
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : T. Henderson (Boeing), S. Floyd (ICSI), A. Gurtov (University of Oulu), Y. Nishida (WIDE Project)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 7 avril 2012
Même les plus vieux protocoles, comme TCP, continuent à évoluer, dans l'environnement toujours changeant qu'est l'Internet. Pour lutter contre le principal ennemi d'un protocole de transport, la congestion, de nouveaux algorithmes sont régulièrement mis au point. Même des années après leur spécification, on trouve des choses à corriger ou améliorer. Ainsi, l'algorithme NewReno, originellement proposé par le RFC 2582 en 1999, puis normalisé par le RFC 3782 en 2004, voit avec ce nouveau RFC sa description évoluer très légèrement, pour répondre aux problèmes rencontrés.
La référence pour la lutte de TCP contre la congestion est le RFC 5681. Ce dernier spécifie quatre algorithmes possibles, et autorise des modifications limitées à ces algorithmes, par exemple en utilisant les accusés de réception sélectifs (SACK, RFC 2883) ou bien en utilisant les accusés de réception partiels (ceux qui ne couvrent pas la totalité des données encore en transit). C'est le cas de NewReno et ce RFC remplace l'ancienne définition de NewReno (celle du RFC 3782).
Un peu d'histoire de NewReno (section 1) : l'algorithme de retransmission rapide (Fast Recovery) de TCP avait d'abord été mis en œuvre dans une version de BSD connue sous le nom de Reno. (L'article original est toujours en ligne, ainsi qu'une comparaison des méthodes.) L'idée de base de la retransmission rapide est de retransmettre les accusés de réception lorsqu'arrivent des paquets dont les numéros de séquence sont supérieurs à ceux attendus (section 5 de notre RFC ; cette retransmission indique la perte de paquets intermédiaires). L'émetteur commence alors tout de suite à retransmettre, sans attendre l'expiration du délai de garde normal. Le problème est que l'émetteur ne sait pas exactement ce qu'il faut retransmettre. Par exemple, avec une MSS de 1460 octets et un numéro de séquence initial (ISN) de 67891, si un émetteur envoie cinq paquets, il sera satisfait lorsqu'il recevra un accusé de réception pour l'octet 75191. S'il reçoit des accusés de réception dupliqués pour l'octet 70811, cela veut dire que deux paquets sont arrivés, puis que le paquet n° 4 ou le n° 5 est arrivé, déclenchant l'émission des accusés de réception dupliqués. L'émetteur va alors retransmettre le paquet n° 3. Mais doit-il aussi renvoyer les n° 4 et n° 5 ? L'émetteur ne le sait pas, les accusés de réception n'indiquent pas les octets reçus hors-séquence, sauf à utiliser les SACK du RFC 2883. NewReno avait justement été conçu pour ce cas où on ne peut pas ou bien où on ne veut pas utiliser les accusés de réception sélectifs (SACK). Son principe est, pendant la retransmission rapide, de regarder si les accusés de réception couvrent tous les paquets transmis (accusé de réception pour l'octet 75191) ou bien seulement une partie (par exemple, accusé de réception pour l'octet 72271). Dans ce cas (accusés de réception partiels), on sait qu'il y a perte de plusieurs paquets et on peut retransmettre tout de suite (ici, le paquet n° 4).
NewReno est donc une légère modification, située uniquement chez l'émetteur, à l'algorithme de retransmission rapide (« OldReno » ?). Cette modification est déclenchée par la réception, une fois la retransmission rapide commencée, d'accusès de réception partiels. Elle consiste en la réémission de paquets supplémentaires, suivant le paquet qu'« OldReno » retransmettait déjà.
Si vous voulez tous les détails, la section 3 précise le nouvel algorithme. Comme il ne nécessite des modifications que chez l'émetteur des données, il n'affecte pas l'interopérabilité des mises en œuvre de TCP. Évidemment, SACK serait une meilleure solution, donnant à l'émetteur toute l'information nécessaire mais, en son absence, NewReno améliore les performances en évitant d'attendre inutilement l'expiration d'un délai de garde.
Il existe quelques variations à NewReno, moins importantes que la différence entre OldReno et NewReno. Ces variations possibles sont documentées dans l'ancien RFC, le RFC 3782 et citées dans l'annexe A.
NewReno est aujourd'hui bien établi et éprouvé. L'ancien RFC, le RFC 3782 contenait des éléments en sa faveur (notamment via des simulations), qui semblent inutiles aujourd'hui et ont donc été retirés.
Globalement, les principaux changements depuis le RFC 3782 sont le retrait de nombreuses parties qui n'apparaissent plus aussi importantes qu'à l'époque. Le lecteur qui veut approfondir le sujet, et pas uniquement programmer NewReno correctement, peut donc lire le RFC 3782 pour découvrir d'autres discussions. Autrement, les changements sont de détail, et résumés dans l'annexe B.
Merci à Didier Barvaux pour sa relecture.
L'article seul
RFC 6573: The Item and Collection Link Relations
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : M. Amundsen
Pour information
Première rédaction de cet article le 7 avril 2012
Depuis le RFC 5988, il existe un mécanisme standard pour exprimer les types des liens entre deux ressources sur le Web. Ce très court RFC documente deux types récemment ajoutés, permettant de dire qu'une ressource (une page HTML, un fichier, etc) est membre d'une collection de ressources ou, à l'inverse, qu'une ressource désigne une collection et indique quels sont ses membres.
Ces deux types, collection et
item (l'un étant le réciproque de l'autre) sont d'ores et déjà largement utilisées par
d'autres normes comme OpenSearch
(section 4.5.4.1 de la
norme), Maze ou Collection+JSON.
La section 2 définit complètement ces deux
relations. item est utilisé dans une ressource
qui représente une collection, pour identifier les membres de cette
collection. Un exemple en HTML pour un
catalogue de produits serait, avec l'attribut rel :
<h1>Product Group X Listing</h1>
...
<a href="..." rel="item">View Product X001</a>
<a href="..." rel="item">View Product X002</a>
...
Ce code exprime le fait que chacun des produits est un élement (item) de la collection qu'est la page qui contieent ce code.
Comme l'indique le RFC 8288 (successeur du
RFC 5988), les liens peuvent se représenter
autrement qu'en HTML (toutes les ressources Web ne sont pas forcément
des pages en HTML), par exemple avec l'en-tête
HTTP Link:. On peut donc
avoir dans une réponse HTTP :
HTTP/1.1 200 OK ... Link: <...>; rel="item"; title="View Product X001" Link: <...>; rel="item"; title="View Product X002"
En section 2.2, on trouve le deuxième type de lien celui qui, en sens inverse du précédent, va d'un élément vers la(les) collection(s) dont il est membre :
<a href="..." rel="collection">Return to Product Group X</a>
Là aussi, on peut utiliser les en-têtes HTTP :
HTTP/1.1 200 OK ... Link: <...>; rel="collection"; title="Return to Product Group X"
Les deux types ont été ajoutés au registre IANA.
L'article seul
RFC 6555: Happy Eyeballs: Success with Dual-Stack Hosts
Date de publication du RFC : Avril 2012
Auteur(s) du RFC : D. Wing, A. Yourtchenko (Cisco)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 7 avril 2012
Une question récurrente qu'IPv6 pose aux développeurs d'application et aux administrateurs système qui déploieront ces applications ensuite est celle d'une machine accessible à la fois en IPv4 et IPv6. Si le pair cherchant à joindre cette machine croit avoir IPv6 mais que sa connectivité ne marche pas, ou mal, l'application arrivera-t-elle à se rabattre en IPv4 très vite ou bien imposera-t-elle à l'utilisateur un long délai avant de détecter enfin le problème ? Cette question est connue comme « le bonheur des globes oculaires » (les dits globes étant les yeux de l'utilisateur qui attend avec impatience la page d'accueil de YouPorn) et ce RFC spécifie les exigences pour l'algorithme de connexion du client, afin de rendre les globes oculaires le plus heureux possible. (Il a depuis été remplacé par un RFC plus général, ne se limitant pas à IPv6, le RFC 8305.)
La section 1 rappelle les données du problème : on veut évidemment que cela marche aussi bien en IPv6 qu'en IPv4 (pas question d'accepter des performances inférieures) or, dans l'état actuel du déploiement d'IPv6, bien des sites ont une connexion IPv6 totalement ou partiellement cassée. Si un serveur a IPv4 et IPv6 et que son client n'a qu'IPv4, pas de problème. Mais si le client a IPv6, tente de l'utiliser, mais que sa connexion est plus ou moins en panne, ses globes oculaires vont souffrir d'impatience. Certains fournisseurs (notamment Google) ont résolu le problème en n'annonçant leur connectivité IPv6 (via le DNS et les enregistrements AAAA) qu'à certains réseaux, configurés manuellement après examen de la qualité effective de leur connectivité. Cette approche, nommée « whitelisting » ne passe évidemment pas à l'échelle. Même pour Google, c'est un travail colossal que d'évaluer le réseau de tous les sites Internet.
(À noter que deux lecteurs m'ont fait remarquer que YouPorn n'est pas un bon exemple, puisqu'il ne publie pas d'adresse IPv6. C'est vrai et cela montre que mes lecteurs connaissent bien YouPorn.)
La bonne solution est donc que l'application elle-même gère le problème (ou, sinon l'application elle-même, la bibliothèque logicielle qu'elle utilise et où se trouve la fonction de connexion). Il existe plusieurs algorithmes pour cela, déjà largement déployés. Ce RFC normalise les caractéristiques que doivent avoir ces algorithmes. Si on suit ce RFC, le trafic (IP et DNS) va légèrement augmenter (surtout si la connectivité IPv6 marche mal ou pas du tout) mais la qualité du vécu de l'utilisateur va être maintenue, même en présence de problèmes, ce qui compense largement. Autrement, il existerait un risque élevé que certains utilisateurs coupent complètement IPv6, plutôt que de supporter ces problèmes de délai de connexion.
La section 3 revient dans l'histoire, pour montrer que le problème n'est pas nouveau. En 1994, le RFC 1671 disait « The dual-stack code may get two addresses back from DNS; which does it use? During the many years of transition the Internet will contain black holes. » (Au passage, cela montre la stupidité de la légende, fréquemment entendue, comme quoi les problèmes de la transition IPv4->IPv6 n'auraient pas été étudiés à l'avance.) Tout le reste de notre RFC 6555 est consacré à répondre à cette question. La cible principale est composée des protocoles de transport avec connexion (TCP, SCTP), les protocoles sans connexion comme UDP soulevant d'autres questions (s'ils ont une sémantique requête/réponse, comme dans ICE, les algorithmes de ce RFC peuvent être utilisés).
Le RFC rejette l'idée d'utiliser des noms différents pour les deux familles (comme
www.ipv6.example.com), car cela complique le
partage de noms (envoi d'un URL à un copain,
par exemple).
Donc, on a un nom de machine qu'on veut contacter, mettons
www.example.com, avec deux adresses associées,
une par famille (voir les sections 5.3 et 5.4 pour le cas avec plus de deux adresses). Avec l'algorithme naïf
qu'utilisent certains logiciels, et une connexion IPv6 qui marche mal,
voici la séquence d'évenements :
- L'initiateur de la connexion utilise le DNS pour demander les enregistrements A (adresse IPv4) et AAAA (IPv6). (Notez qu'il n'existe pas de type de requête DNS pour avoir les deux enregistrements d'un coup, il faut donc deux requêtes. Voir aussi la section 5.4.)
- Il récupère
192.0.2.1et2001:db8::1. - Il tente IPv6 (sur Linux, l'ordre des
essais est réglable dans
/etc/gai.conf). L'initiateur envoie un paquet TCPSYNà2001:db8::1. - Pas de réponse (connexion IPv6 incorrecte). L'initiateur réessaie, deux fois, trois fois, faisant ainsi perdre de nombreuses secondes.
- L'initiateur renonce, il passe à IPv4 et envoie un paquet TCP
SYNà192.0.2.1. - Le répondeur envoie un
SYN+ACKen échange, l'initiateur réplique par unACKet la connexion TCP est établie.
Le problème de cet algorithme naïf est donc la longue attente lors des essais IPv6. On veut au contraire un algorithme qui bascule rapidement en IPv4 lorsqu'IPv6 ne marche pas, sans pour autant gaspiller les ressources réseau en essayant par exemple toutes les adresses en même temps.
L'algorithme recommandé (section 4, cœur de ce RFC) aura donc la tête :
- L'initiateur de la connexion utilise le DNS pour demander les enregistrements A (adresse IPv4) et AAAA (IPv6).
- Il récupère
192.0.2.1et2001:db8::1. Il sait donc qu'il a plusieurs adresses, de famille différente. - Il tente IPv6. L'initiateur envoie un paquet
TCP
SYNà2001:db8::1, avec un très court délai de garde. - Pas de réponse ? L'initiateur
passe à IPv4 tout de suite. Il envoie un paquet TCP
SYNà192.0.2.1. - Le répondeur envoie un
SYN+ACKen échange, l'initiateur réplique par unACKet la connexion TCP est établie.
Si le répondeur réagit à une vitesse normale en IPv6, la connexion sera établie en IPv6. Sinon, on passera vite en IPv4, et l'utilisateur humain ne s'apercevra de rien. Naturellement, si le DNS n'avait rapporté qu'une seule adresse (v4 ou v6), on reste à l'algorithme traditionnel (« essayer, patienter, ré-essayer »).
La section 4 précise ensuite les exigences auxquelles doit obéir
l'algorithme. D'abord, il est important de ne pas tester IPv4 tout de
suite. Les premiers algorithmes « bonheur des globes oculaires »
envoyaient les deux paquets SYN en même
temps,
gaspillant des ressources réseau et serveur. Ce double essai faisait
que les équipements IPv4 du réseau avaient autant de travail qu'avant,
alors qu'on aurait souhaité les retirer du service petit à petit. En
outre, ce test simultané fait que, dans la moitié des cas, la
connexion sera établie en IPv4, empêchant de tirer profit des
avantages d'IPv6 (cf. RFC 6269). Donc, on
doit tester en IPv6 d'abord, sauf si on se
souvient des tentatives précédentes (voir plus loin la variante « avec
état ») ou bien si l'administrateur système a délibérement configuré
la machine pour préférer IPv4.
L'avantage de cet algorithme « IPv6 d'abord puis rapidement basculer en IPv4 » est qu'il est sans état : l'initiateur n'a pas à garder en mémoire les caractéristiques de tous ses correspondants. Mais son inconvénient est qu'on recommence le test à chaque connexion. Il existe donc un algorithme avec état, où l'initiateur peut garder en mémoire le fait qu'une machine (ou bien un préfixe entier) a une adresse IPv6 mais ne répond pas aux demandes de connexion de cette famille. Le RFC recommande toutefois de re-essayer IPv6 au moins toutes les dix minutes, pour voir si la situation a changé. De plus, un changement de connectivité (détecté par le DNA des RFC 4436 ou RFC 6059) doit entraîner un vidage complet de l'état (on doit oublier ce qu'on a appris, qui n'est plus pertinent).
Une conséquence de l'algorithme recommandé est que, dans certains
cas, les deux connexions TCP (v4 et v6) seront
établies (si le SYN IPv6 voyage lentement et que
la réponse arrive après que l'initiateur de la connexion se soit
impatienté et soit passé à IPv4). Cela peut être intéressant dans certains cas rares, mais le
RFC recommande plutôt d'abandonner la connexion perdante (la
deuxième). Autrement, cela pourrait entraîner des problèmes avec, par
exemple, les sites Web qui lient un
cookie à l'adresse IP du
client, et seraient surpris de voir deux connexions avec des adresses différentes.
Voilà, l'essentiel du RFC est là. La section 5 donne quelques détails en plus. Par exemple, l'algorithme des globes oculaires heureux est astucieux, mais tend à masquer les problèmes. Si un site Web publie les deux adresses mais que sa connectivité IPv6 est défaillante, aucun utilisateur ne lui signalera puisque, pour eux, tout va bien. Il est donc recommandé que le logiciel permette de débrayer cet algorithme, afin de tester la connectivité avec seulement v4 ou seulement v6, ou bien que le logiciel indique quelque part ce qu'il a choisi, pour mieux identifier d'éventuels problèmes v6.
D'autre part, vous avez peut-être remarqué que j'ai utilisé des
termes vagues (« un certain temps ») pour parler du délai entre, par
exemple, le premier SYN IPv6 et le premier
SYN IPv4. La section 5.5 donne des idées
quantitatives en suggérant entre 150 et 250 ms entre deux
essais (les navigateurs actuels sont plutôt du côté de 300 ms). C'est quasiment imperceptible à un utilisateur humain devant
son navigateur Web, tout en évitant de surcharger le réseau
inutilement. Les algorithmes avec état ont le droit d'être plus
impatients, puisqu'ils peuvent se souvenir des durées d'établissement
de connexion précédents.
Autre problème pratique, l'interaction avec la politique de sécurité des navigateurs Web (RFC 6454). Pour limiter les risques d'attaque par changement DNS (croire qu'on se connecte au même serveur HTTP alors que c'est en fait un autre), les navigateurs ne doivent pas changer de famille d'adresse (v4 en v6 ou réciproquement) une fois la session commencée.
Enfin, les implémentations. La section 6 donne les exemples de
Firefox et Chrome, très
proches de ce que décrit le RFC. D'autres
possibilités sont disponibles en ligne, en
Erlang ou en
C. Une version pour
Go avait été affichée en http://www.pastie.org/1528545 (en voici une sauvegarde locale).
Enfin, pour un exemple de test du malheur des globes oculaires, voir « Experiences of host behavior in broken IPv6 networks ». Ou bien « Evaluating the Effectiveness of Happy Eyeballs » qui contient d'intéressantes mesures.
L'article seul
On ne peut pas analyser tous les protocoles avec Netfilter
Première rédaction de cet article le 4 avril 2012
Dernière mise à jour le 27 juin 2012
Le système de traitement des paquets
Netfilter est intégré dans le
noyau Linux depuis des
années. Il permet de créer des pare-feux, de
faire de la limitation de
trafic et bien d'autres choses encore. Il permet de n'appliquer
une règle qu'à certains paquets, selon le protocole de transport utilisé, selon les adresses IP ou les ports source ou destination, etc. Pour les
autres cas, le module u32 permet de chercher des
correspondance dans n'importe quelle partie du paquet. Peut-on
analyser tous les protocoles avec u32 ? (Attention, il va y avoir du binaire dans l'article.)
Prenons l'exemple du DNS. Certains champs du
paquet DNS sont accessibles via un écart fixe par rapport au début du
paquet. Ceux-là sont faciles à chercher avec
u32. La syntaxe de ce dernier n'est pas triviale,
mais il existe un excellent
tutoriel. 0>>22&0x3C@ fait
sauter l'en-tête IPv4. La longueur de l'en-tête
(qui n'est pas constante) se trouve dans quatre bits du premier octet
du paquet IP. On décale de 22 bits pour avoir ces bits et pour les
multiplier par quatre (l'unité de longueur est le mot de quatre
octets, cf. RFC 791, section 3.1), on
masque avec 0x3c pour
n'extraire que la longueur et on se déplace de cette quantité dans le
paquet (c'est le rôle du signe @). Ensuite, on
indique le déplacement après l'en-tête, pour
UDP (le protocole le plus courant pour le DNS),
c'est huit octets d'en-tête (RFC 768). Donc,
0>>22&0x3C@8 nous fait sauter les en-têtes
IPv4 et UDP et arriver au début du paquet DNS.
Imaginons qu'on veuille sélectionner uniquement les requêtes, pas
les réponses. Le RFC 1035, section 4.1.1, nous
apprend que le bit permettant de différencier requêtes et réponses est
le premier du troisième octet du paquet. Il est à zéro lorsque le
paquet est une requête. On peut le sélectionner avec
10&0x80000000=0x0 (se déplacer de 10 octets,
les huit d'UDP et les deux du premier champ DNS, le Query
ID, puis masquer avec les quatre octets 0x80000000 - un bit à
un - et tester). En combinant tout cela, on peut utiliser
iptables pour faire une règle qui ne s'appliquera qu'aux
requêtes DNS :
iptables --append ${CHAIN} --destination ${DEST} \
--protocol udp --destination-port 53 \
--match u32 --u32 "0>>22&0x3C@10&0x80000000=0x0" \
--jump ${ACTION}
Pour n'avoir que les réponses, on utiliserait 0x80000000=0x80000000 pour tester si le bit est à un.
Une alternative est d'utiliser l'opérateur de décalage de
u32, le >> pour ne
garder que le bit QR avant de le tester :
8>>15&0x01=0 au lieu de
10&0x4000=0x0000. (Il existe une
application pratique, avec exemple, au filtrage des réponses.)
Maintenant, supposons qu'on veuille mettre en place une
limitation de trafic par exemple pour faire
face à une attaque par déni de service. J'avais
déjà écrit un article à
ce sujet où on limitait toutes les
requêtes DNS. Maintenant, si je fais face à une attaque spécifique,
par exemple utilisant les requêtes de type ANY en
raison de leur fort taux d'amplification (la réponse est bien plus
grosse que la requête) : puis-je appliquer une règle Netfilter
seulement aux paquets où la requête est de type ANY ?
Le problème est que, si les premiers champs du paquet DNS (comme
Flags) sont à une distance fixe du début du
paquet, ce n'est plus le cas par la suite. u32
sait traiter les cas (comme l'en-tête IPv4) où la distance est
indiquée dans le paquet mais ne sait pas faire une analyse complète
(en termes pédants, u32 n'est pas un
langage de Turing).
Or, dans un paquet DNS (cf. RFC 1035, section
4.1.2), le type de requête (champ
QTYPE pour Query Type) est
situé après une structure compliquée, le nom
demandé (champ QNAME pour Query
Name). Le langage d'u32 ne connait que
décalage et masquage, alors qu'il nous faudrait des tests et des
boucles (ou bien la
récursion), pour pouvoir suivre les différents
composants (labels) du QNAME
(qui peuvent être en nombre quelconque). Si u32 n'a pas
cela, d'ailleurs, ce n'est pas par paresse ou ignorance de son auteur,
mais parce que ce langage est conçu pour des analyses ultra-rapides,
et dont la durée est prévisible (ce qui n'est plus le cas dès qu'on
met des boucles).
Donc, limiter uniquement les requêtes ANY ne semble pas possible avec
Netfilter. C'est pour cela que les exemples DNS qu'on trouve sur le
Web ne traitent que des cas simples comme les attaques dites NS . (
Upward
Referrals) où le QNAME est
toujours le même (en l'occurrence un simple point, la
racine du DNS). On peut alors filtrer avec
0>>22&0x3C@20>>24=0 (sauter 20 octets
pour arriver au QNAME qui doit être uniquement
composé d'un octet longueur valant zéro).
Une solution astucieuse est de commencer par la
fin du paquet et non pas son début, pour tomber
sur le QTYPE avant le
QNAME. Mais cela ne marche pas non plus car les
requêtes DNS modernes ont en général à la fin une section
additionnelle, également de longueur variable (conséquence du RFC 6891).
Damien Wyart me signale qu'un module DNS pour Netfilter, qui
résoudrait ce problème, est en cours de
développement. Je ne l'ai pas encore testé, mais, à la lecture, ce code a le même défaut que pas mal de règles iptables ou
tcpdump qu'on trouve sur le Web. Il analyse le paquet DNS en partant
de la fin, pour éviter d'avoir à décoder le QNAME. Résultat, il ne
marche pas du tout avec EDNS, qui ajoute une section additionnelle à
la fin.
Une solution partielle, qui ne résoudrait pas le cas général,
serait de faire une règle spécifique à un nom de domaine, si l'attaque
utilise toujours le même
(car on connait alors la longueur du QNAME et on peut le sauter). C'est
limité mais mieux que rien. Comme l'attaquant peut changer facilement
le QNAME utilisé, le mieux est d'utiliser
un petit programme qui prenne en paramètre un nom et
fabrique le code u32. C'est le cas du script generate-netfilter-u32-dns-rule.py :
% python generate-netfilter-u32-dns-rule.py --qname isc.org 0>>22&0x3C@20&0xFFFFFFFF=0x03697363&&0>>22&0x3C@24&0xFFFFFFFF=0x036f7267&&0>>22&0x3C@28&0xFF000000=0x00000000
Le programme peut aussi s'utiliser ainsi dans un script shell :
# L'action donnée ici est juste un exemple
action="LOG --log-prefix DNS-ANY-query-$domain"
rule=$(python generate-netfilter-u32-dns-rule.py --qname $domain --qtype ANY)
iptables --append ${CHAIN} --destination ${DEST} --protocol udp --destination-port 53 \
--match u32 --u32 "$rule" \
--jump ${action}
Autre approche, voici (dû à Frédéric Bricout) les
commandes tc pour faire une limitation de trafic à 2 kb/s,
exclusivement sur les requêtes ripe.net (0472697065 = ripe
- avec la longueur en premier octet, 036e6574 = net) :
tc qdisc add dev eth1 root handle 1: htb default 30
tc filter add dev eth1 parent 1: protocol ip prio 10 u32 \
match u32 0x04726970 0xffffffff at 40 match u32 0x65036e65 0xffffffff at 44 \
match u32 0x740000ff 0xffffffff at 48 police rate 2kbit buffer 10k drop flowid :1
Une autre idée, que j'emprunte à Kim Minh Kaplan, consiste à jouer sur la longueur des noms demandés :
iptables -N DNSratelimit # Y ajouter les règles de limitations de débit iptables -N DNSrules # Empêche les requêtes ANY pour . iptables -A DNSrules -j DNSratelimit -m u32 --u32 "0>>22&0x3C@20&0xFFFFFF00=0x0000FF00" # Empêche les requêtes ANY pour un TLD # 21 = 20 pour IP+UDP+DNS + 1 pour l'octet de longueur iptables -A DNSrules -j DNSratelimit -m u32 --u32 "0>>22&0x3C@20>>24&0xFF@21&0xFFFFFF00=0x0000FF00" # Envoyer les requêtes DNS à la bonne chaîne iptables -A INPUT -p udp --dport 53 -j DNSrules --match u32 --u32 "0>>22&0x3C@10&0x80000000=0"
Il faudrait aussi y ajouter des règles pour éviter certains traitements erronnés, etc. Malheureusement cette technique se heurte à une autre limitation de u32 :
# Empêche les requêtes pour domaine directement sous un TLD # 22 is 20 for IP+UDP+DNS and 2 length byte iptables -A DNSrules -m u32 --u32 "0>>22&0x3C@20>>24&0xFF@21>>24&0xFF@22&0xFFFFFF00=0x0000FF00"
Ce code échoue :
iptables v1.4.12.2: u32: at char 48: too many operators Try `iptables -h' or 'iptables --help' for more information.
Et, effectivement, la documentation stipule « no more than 10 numbers (and 9 operators) per location ». Donc, cette voie ne semble pas idéale.
Maintenant, la question philosophique : les concepteurs du format des paquets DNS auraient-ils dû faire un format plus amical aux analyseurs ?
Merci à Kim Minh Kaplan pour sa relecture attentive du code binaire et pour la bogue détectée.
L'article seul
La journée du 31 mars sur les serveurs racine du DNS
Première rédaction de cet article le 31 mars 2012
Le 12 février dernier, des individus anonymes annonçaient une attaque sur la racine du DNS pour le 31 mars. Que s'est-il effectivement passé ?
L'article complet
RFC 6570: URI Template
Date de publication du RFC : Mars 2012
Auteur(s) du RFC : J. Gregorio (Google), R. Fielding (Adobe), M. Hadley (MITRE), M. Nottingham (Rackspace), D. Orchard (Salesforce.com)
Chemin des normes
Première rédaction de cet article le 28 mars 2012
Beaucoup d'applications Web utilisent des URI (RFC 3986) qui peuvent être décrits par un gabarit (template), avec des variables qui seront incarnées pour produire l'URI final. Ce RFC, issu d'une coopération entre l'IETF et le W3C normalise un langage (déjà largement déployé) pour ces gabarits.
La section 1.1 du RFC fournit quelques exemples d'URI obéissant à un gabarit. Par exemple, des pages personnelles identifiées par le tilde :
http://example.com/~fred/ http://example.com/~mark/
ou des entrées d'un dictionaire :
http://example.com/dictionary/c/cat http://example.com/dictionary/d/dog
ou encore un moteur de recherche :
http://example.com/search?q=cat&lang=en http://example.com/search?q=chien&lang=fr
À chaque fois, le patron de conception sous-jacent est assez clair. Le langage décrit dans ce RFC 6570 permet d'abstraire ce patron dans un gabarit d'URI. Les trois exemples cités plus haut pourront être décrits :
http://example.com/~{username}/
http://example.com/dictionary/{term:1}/{term}
http://example.com/search{?q,lang}
Cela permet d'abstraire un URI, en montrant clairement au lecteur le processus de construction. Cela contribue donc à la création de beaux URL, qui ne sont pas simplement des identificateurs opaques, mais qui peuvent être compris par l'utilisateur du Web.
En dehors de l'intérêt intellectuel, quelle est l'utilité de ce
système ? Il permet notamment la création automatique d'URI, à partir
de gabarits et de valeurs pour les variables (comme la variable
term dans le deuxième exemple ci-dessus). Les
protocoles fondés sur REST en seront
ravis. Ainsi, le gabarit
http://www.example.com/foo{?query,number} combiné
avec les variables {query: "mycelium", number: 100} va donner
http://www.example.com/foo?query=mycelium&number=100. Si
query n'était pas défini, cela serait simplement http://www.example.com/foo?number=100.
Pour prendre des exemples réels, on peut décrire les URL
d'OpenStreetMap comme tirés du gabarit
http://www.openstreetmap.org/?{lon,lat} et ceux
de Wikipédia comme faits à partir de
http://fr.wikipedia.org/wiki/{topic}.
La section 1.2 explique qu'il existe en
fait plusieurs niveaux pour le langage de description de gabarits. Une
mise en œuvre donnée s'arrête à un certain niveau, les premiers
étant les plus simples. Le
niveau 1 fournit simplement l'expansion des
variables (qui sont placées entre accolades), avec échappement. Si
var vaut "Bonjour le monde", l'expansion de
{var} sera
Bonjour%20le%20monde.
Le niveau 2 ajoute un opérateur
+ pour les variables
pouvant contenir des caractères spéciaux, et le
# pour les identificateurs
de fragment. Si path vaut "/foo/bar",
{path} est expansé en
%2Ffoo%2Fbar alors que
{+path} donnera /foo/bar. Et
avec la variable var valant "Bonjour le monde", l'expansion de
{#var} sera
#Bonjour%20le%20monde permettant de construire
des URI avec un identificateur pointant vers un point précis du
document. Par exemple, les URL des Internet-Drafts
dans la file d'attente de l'éditeur des RFC ont
le gabarit
http://www.rfc-editor.org/queue2.html{#draftname}
avec, par exemple, draftname égal draft-ietf-lisp.
Au niveau 3, cela devient bien plus riche : on
a plusieurs variables dans une expression (le gabarit
map?{x,y} devient l'URI
map?1024,768 si x=1024 et y=768). Et on gagne
surtout les paramètres multiples (séparés par
&) si utilisées dans les
formulaires Web : le gabarit
{?x,y} devient
?x=1024&y=768.
Enfin, le niveau 4 ajoute des modificateurs
après le nom de la variable. Par exemple, :
permet d'indiquer un nombre limité de caractères (comme dans le
term:1 que j'ai utilisé au début, qui indique la
première lettre). Et le * indique une variable
composite (une liste ou un
dictionnaire) qui doit être elle-même
expansée. Si la variable couleurs vaut la liste
{rouge, bleu, vert}, le gabarit (de niveau 1)
{couleurs} donnera
rouge,bleu,vert alors que la gabarit de niveau 4
{?couleurs*} vaudra
?couleurs=rouge&couleurs=bleu&couleurs=vert.
Des mécanismes similaires à ces gabarits existent dans d'autres
langages comme OpenSearch ou
WSDL. Par exemple, le gabarit décrivant les URL
du moteur de recherche de mon blog a la
forme http://www.bortzmeyer.org/search{?pattern}
et, dans dans sa description
OpenSearch, on trouve la même information (quoique structurée différemment).
Comme l'explique la section 1.3, cette nouvelle norme vise à unifier le langage de description de gabarits entre les langages, tout en restant compatible avec les anciens systèmes. Normalement, la syntaxe des gabarits d'URI est triviale à analyser, tout en fournissant la puissance expressive nécessaire. Il s'agit non seulement de générer des URI à partir d'un patron, mais aussi de pouvoir capturer l'essence d'un URI, en exprimant clairement comment il est construit.
La section 2 décrit rigoureusement la syntaxe. En théorie, un analyseur qui ne gère que le niveau 1 est acceptable. Toutefois, le RFC recommande que tous les analyseurs comprennent la syntaxe de tous les niveaux (même s'ils ne savent pas faire l'expansion), ne serait-ce que pour produire des messages d'erreurs clairs (« This feature is only for Level 3 engines and I'm a poor Level 2 program. » .
Cette section contient donc la liste complète des caractères qui ont une signification spéciale pour le langage de gabarits, comme +, ? ou &, ainsi que de ceux qui sont réservés pour les futures extensions (comme = ou @). En revanche, $ et les parenthèses sont exprèssement laissés libres pour d'autres langages qui voudraient décrire une part de l'URI.
Ensuite, la section 3 se consacre aux détails du processus d'expansion qui,
partant d'un gabarit et d'un ensemble de valeurs, va produire un
URI. Notez qu'une variable qui n'a pas de valeur ne donne pas un 0 ou
un N/A ou quoi que ce soit de ce genre. Elle
n'est pas expansée. Donc, le gabarit {?x,y} avec
x valant 3 et y n'étant pas défini, devient
?x=3 et pas
?x=3&y=NULL. Si x n'était pas défini non
plus, le résultat serait une chaîne vide (sans même le point
d'interrogation).
Est-ce que ces gabarits peuvent poser des problèmes de sécurité ? La section 4 regarde cette question et conclus que cela dépend de qui fournit le gabarit, qui fournit les variables, et comment va être utilisé l'URI résultant (aujourd'hui, les mises en œuvre existantes les utilisent dans des contextes très variés). Par exemple, des variables contenant du code JavaScript peuvent être dangereuses si l'URI résultant est traité par ce langage. Des attaques de type XSS sont donc parfaitement possibles si le programmeur ne fait pas attention.
Pour les programmeurs, l'annexe A contient un ensemble de recommandations sur la mise en œuvre de ce RFC, ainsi qu'un algorithme possible pour cette mise en œuvre. Il existe plusieurs mises en œuvre de ce RFC. Malheureusement, toutes celles que j'ai essayées semblent limitées au niveau 1 et ne le disent pas clairement.
Le code Python en http://code.google.com/p/uri-templates/ (niveau 1 et un bout du niveau 2) :
import uritemplate
import simplejson
import sys
vars = {"foo": "bar/"}
def test_print(template):
actual = uritemplate.expand(template, vars)
print actual
test_print("http://www.example.org/thing/{foo}")
test_print("http://www.example.org/thing/{+foo}")
On obtient :
http://www.example.org/thing/bar%2F http://www.example.org/thing/bar/
Avec le module Perl URI::Template (niveau 1), on peut écrire :
use URI::Template;
my $template = URI::Template->new( 'http://example.com/{foo}' );
my $uri = $template->process( foo => 'Hello World/' );
print $uri, "\n";
Le code Haskell en http://hackage.haskell.org/cgi-bin/hackage-scripts/package/uri-template (niveau 1 seulement) écrit ainsi :
module Main(main) where
import Network.URI.Template
testEnv :: TemplateEnv
testEnv =
addToEnv "foo" "Hello World/" $
addToEnv "x" "1024" $
addToEnv "y" "768" $
newEnv
main :: IO ()
main = do
putStrLn (expand testEnv "http://example.org/{foo}")
return ()
Donne :
% runhaskell Test.hs http://example.org/Hello%20World%2f
L'article seul
RFC 6569: Guidelines for Development of an Audio Codec Within the IETF
Date de publication du RFC : Mars 2012
Auteur(s) du RFC : JM. Valin (Mozilla), S. Borilin
(SPIRIT DSP), K. Vos, C. Montgomery
(Xiph.Org Foundation), R. Chen (Broadcom Corporation)
Pour information
Réalisé dans le cadre du groupe de travail IETF codec
Première rédaction de cet article le 27 mars 2012
Constatant l'absence d'un codec entièrement libre (pas plombé par des brevets, pas contrôlé par une société unique, implémentable en logiciel libre), l'IETF s'est lancée dans la spécification d'un codec satisfaisant. Le RFC 6366 donnait le cahier des charges technique du futur codec (le produit final, publié dans le RFC 6716) et ce nouveau RFC donne les considérations portant sur le processus de développement (processus déjà bien entamé) : méthodologie d'évaluation des propositions, mécanisme de vérification de la compatibilité des implémentations, questions de propriété intellectuelle. Une tâche difficile, accomplie dans une ambiance pas toujours sereine, les questions du multimédia étant toujours délicates.
Le développement d'un nouveau codec est une tâche d'ampleur, compte-tenu des exigences très strictes du RFC 6366 et du fait que le marché est déjà encombré de codecs complètement fermés, ou bien à moitié libres. L'IETF n'avait pas imposé que le codec libre soit entièrement nouveau : la sélection et/ou l'adaptation d'un codec existant sont des plans possibles. La section 2 du RFC résume le processus. Au moment où sort ce RFC, une partie des étapes a déjà été franchie. Les principales sont :
- Documenter les exigences techniques (fait dans le RFC 6366, un document à lire, notamment pour se rappeler que l'économie de capacité réseau par la compression n'est qu'un des critères de qualité technique pour un codec, d'autres, comme la latence sont aussi importants),
- Proposer des candidats répondant à ces exigences (voir par exemple l' Internet-Draft Definition of the Opus Audio Codec),
- Compte-tenu de l'importance de l'appropriation intellectuelle dans ce secteur, pourri de brevets du sol au plafond, surveiller en permanence les divulgations de brevets, imposées par le RFC 3979, mais pas toujours respectées. Il est particulièrement important que ces divulgations soient faites à temps puisqu'elles peuvent sérieusement influencer les choix du groupe de travail.
- Identifier forces et faiblesses de chaque proposition,
- Créer le codec préféré, qui pourra incorporer des bouts des autres propositions,
- Développer l'implémentation de référence et les mécanismes de tests permettant de s'assurer que toutes les mises en œuvre sont compatibles. (Ces mécanismes de test étaient un des points suscitant le plus de débats.)
Comment s'assurer, tout au long du développement, que le codec sera
de qualité suffisante, pour ne pas avoir de mauvaise surprise à la fin
du projet ? Il faudra tester le logiciel au fur et à mesure (section
3) en utilisant des méthodes comme PESQ (norme
UIT P.862) et PEAQ (UIT BS.1387). Pour des changements
plus fondamentaux, il faudra utiliser les méthodologies d'évaluation
subjective comme MUSHRA (UIT BS.1534). Et, comme l'IETF
travaille depuis toujours dans un environnement ouvert, il faudra bien
sûr impliquer toute la communauté Internet dans ses essais (le code du
codec Opus est donc librement accessible en
http://git.xiph.org/?p=opus.git). C'est d'autant plus
important que l'IETF n'a pas de « laboratoires de test » propres et
que tous les tests devront être faits à l'extérieur (une raison de
plus pour que l'implémentation de référence soit publiquement disponible).
La section 4 du RFC revient sur les détails de la spécification et sert de guide aux auteurs du futur RFC. Elle précise notamment ce que devrait imposer la spécification et ce qui devrait être laissé aux décisions des programmeurs. D'abord, la décision est prise que l'implémentation de référence aura le pas sur le texte de la spécification, en cas de désaccord. C'est inhabituel à l'IETF, où la règle est en général l'inverse, pour éviter que les particularités d'une implémentation ne figent la norme. Mais le monde des codecs est très complexe et la spécification complète et parfaite un art difficile. Au moins, en décrétant que « le code fait la loi », on est sûr d'avoir une référence précise en cas de litige.
Le principe général sera d'essayer de limiter les obligations dans la norme, donc de ne pas abuser des MUST du RFC 2119. En pratique, cela veut dire que seul le décodeur du flux audio aura besoin d'être rigoureusement défini, les encodeurs pourront s'améliorer avec le temps et faire des choix radicalement différents.
Avoir un programme comme description faisant autorité présente plusieurs risques. L'un d'eux est de « sur-spécification » : faudra-t-il qu'une implémentation compatible donne le même résultat, au bit près, que l'implémentation de référence ? Cela rendrait très difficile le travail des programmeurs pour certaines architectures (le couple CPU/DSP ne permet pas forcément de produire un résultat au bit près, en tout cas pas en gardant des performances maximales). Le principe est donc qu'il n'est pas nécessaire de faire exactement comme le programme de référence, mais de faire quelque chose qui n'est soit pas distinguable à l'oreille.
La section 5 est consacrée au problème douloureux mais, dans le secteur du multimédia, indispensable, de la propriété intellectuelle. Les effets néfastes de celle-ci sur la mise en œuvre et le déploiement des codecs audios sont bien connus. Par exemple, les coûts de licence des brevets éliminent les petits acteurs, qui sont souvent à l'origine de l'innovation. En outre, même si les conditions de la licence sont raisonnables financièrement, elles sont souvent incompatibles avec le logiciel libre (par exemple, exiger une licence pour la distribution, même si la licence est gratuite, empêche l'intégration du logiciel dans un logiciel libre, qui ne met aucune restriction à la distribution).
Bref, libre, c'est mieux que contraint. Des tas de codecs tout à fait valables techniquement posent des problèmes légaux, qui limitent leur déploiement. L'IETF rappelle donc dans ce RFC sa préférence pour des techniques non plombées par la propriété intellectuelle. Le problème est difficile à résoudre car à peu près tout a été breveté (les organismes de dépôt des brevets ne font aucun effort pour refuser les brevets futiles). Même si l'IETF adopte un codec qui semble non breveté, rien ne garantit qu'il ne sera pas frappé soudainement par un brevet sous-marin, un brevet auquel son détenteur ne donne aucune publicité, attendant qu'il soit déployé pour réclamer de l'argent.
Compte-tenu des brevets futiles (qui couvrent à peu près tous les algorithmes possibles et qu'on ne peut invalider que par un long et incertain procès), compte-tenu de l'état de l'art en matière de codec, compte-tenu du fait qu'une technologie peut être brevetée dans certains pays et pas d'autres, l'IETF ne promet donc pas de normaliser un codec complètement libre, ce qui serait une mission impossible (à part peut-être en se limitat à de très vieux codecs, conçus il y a tellement longtemps que tous les brevets ont forcément expiré). Mais elle promet de chercher sérieusement (même si les codecs libres ont de moins bonnes performances techniques) et, dans le pire des cas, de préférer les codecs où les licences des brevets sont gratuites (RF, pour royalty-free). Rappelez-vous toutefois que le plus gros problème pour obtenir une licence n'est pas forcément l'argent, cela peut être le processus bureaucratique de longues négociations avec un bataillon d'avocats qui ont beaucoup de temps libre et vous font lanterner. Il y a des licences gratuites qui coûtent très cher en temps passé !
Cela suppose évidemment que l'IETF soit au courant des brevets existants. Les participants à l'IETF doivent l'informer des brevets qu'ils connaissent (RFC 3979, section 6). Mais cette règle a déjà été violée. Par exemple, dans le cas du groupe de travail Codec, Huawei n'a publié son brevet US 8,010,351 que bien tard, en affirmant qu'il était dans le portefeuille d'une entreprise récemment acquise par Huawei.
D'autres SDO travaillent sur des codecs. Comment l'IETF doit-elle gérer ses relations avec ces organisations (section 6) ? On trouve dans la liste l'UIT (notamment le Study Group 16), le groupe MPEG de l'ISO, ETSI, 3GPP... L'IETF a déjà pris position nettement contre la concurrence des SDO et le développement non coordonné de protocoles, dans le RFC 5704. Ce RFC pose comme principe que, pour chaque protocole ou format, une et une seule SDO doit être responsable. Mais ce n'est pas un problème ici. Soit le groupe de travail codec approuve un codec existant, géré par une autre SDO et celle-ci continuera comme avant, l'IETF aura juste dit « le codec préféré de l'IETF est le codec XXX ». Soit l'IETF développe un nouveau codec (éventuellement dérivé, mais différent, d'un codec existant) et il n'y aura alors pas de concurrence. Les règles du RFC 5704 découragent le concurrence pour un même format ou protocole, pas pour une même catégorie (deux organisations peuvent travailler sur deux codecs différents, même si ces deux codecs visent le même « marché »).
L'IETF appelle bien sûr les experts en codecs audio des autres SDO à donner leur avis sur son travail mais considère que ce n'est pas indispensable : le groupe codec rassemble d'ores et déjà suffisamment de compétences. Cette participation éventuelle des autres SDO peut prendre la forme de contributions individuelles (un expert peut être membre à la fois du SG16 de l'UIT et du groupe codec de l'IETF), ou par le mécanisme plus formelle des liaisons. En tout cas, il existe des choses utiles chez les autres SDO (par exemple dans les mécanismes de test), comme documenté dans le RFC 3356.
Je l'ai indiqué, le groupe de travail codec a travaillé sous forte pression. Parmi les trolls des débats, je me souviens de la proposition que le problème du coût des licences soit relativisé, car un codec techniquement supérieur fait économiser de la capacité réseau (meilleure compression) et donc justifie de payer une licence...
Actuellement, dans la catégorie « nouveaux codecs », le groupe de travail n'a qu'un seul candidat, Opus (autrefois nommé Harmony) et qui a donc été normalisé finalement en septembre 2012 (RFC 6716). Si vous vous intéressez aux tests pratiques de ce codec, voir le document Summary of Opus listening test results.
L'article seul
RFC 6550: RPL: IPv6 Routing Protocol for Low power and Lossy Networks
Date de publication du RFC : Mars 2012
Auteur(s) du RFC : T. Winter, P. Thubert (Cisco
Systems), A. Brandt (Sigma
Designs), T. Clausen (LIX, École
Polytechnique), J. Hui (Arch Rock
Corporation), R. Kelsey (Ember
Corporation), P. Levis (Stanford
University), K. Pister (Dust
Networks), R. Struik, JP. Vasseur (Cisco Systems)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF roll
Première rédaction de cet article le 26 mars 2012
Il y a beaucoup d'intérêt en ce moment pour un (largement mythique) « Internet des objets » qui mèle des fantasmes domotiques éculés (le réfrigérateur qui commande tout seul des bières à Carrefour via l'Internet, lorsqu'il est vide), l'arrivée massive d'ordinateurs qui ne sont pas considérés comme des ordinateurs (smartphones, tablettes, télévisions connectées), la connexion à des réseaux TCP/IP d'équipements très modestes, et la diffusion de plus en plus large d'étiquettes RFID. Pour les ordinateurs (un smartphone, bien plus puissant que l'ordinateur qu'embarquait les vaisseaux Apollo, mérite tout à fait ce titre), un des enjeux de l'Internet des objets est le routage des paquets IP. Ces « objets » ont des ressources électriques limitées, et sont souvent connectés par des liens radio de qualité médiocre. Les protocoles de routage traditionnels ne sont pas très adaptés à cette situation. Le groupe de travail ROLL de l'IETF travaille sur ce problème et vient de produire son protocole « officiel », RPL (Routing Protocol for LLNs où un LLN est un Low power and Lossy Network, un réseau où mêmes les routeurs ont peu de courant et où pas mal de paquets se perdent en route). Le groupe ROLL a déjà produit plusieurs RFC détaillant les demandes de ces LLNs : RFC 5867, RFC 5826, RFC 5673 et RFC 5548. Il a également normalisé l'algorithme de distribution utilisé par RPL, Trickle (RFC 6206).
Un exemple de LLNs est un groupe de capteurs dispersés un peu partout dans un bâtiment industriel : ce sont des petites machines par rapport au smartphone typique, fonctionnant sur batteries ou sur piles, ils doivent faire attention à leur consommmation électrique. Connectés par radios, ils n'ont en général pas la possibilité de parler directement aux gros routeurs de la salle machines, située à des dizaines de mètres. Certains des objets doivent donc tenir le rôle de routeur, relayant les communications de leurs camarades (la distinction entre routeur et machine terminale est d'ailleurs assez floue dans RPL). Il leur faut donc un protocole de routage pour trouver les chemins possibles et les protocoles existants comme OSPF n'ont jamais été conçus pour ce genre de missions (par exemple, OSPF émet des messages même lorsqu'il n'y a pas de changements, ce qui peut vider une batterie rapidement). Le « public » visé est donc composé de machines avec des processeurs 16bits, quelques ko de RAM et de Flash, dans des réseaux où il peut y avoir des milliers de tels engins.
RPL est la solution technique à ce problème du routage. Je préviens tout de suite mes fidèles lecteurs que ce RFC est très long et que je n'ai pas tout suivi, loin de là. Il n'y aura donc pas ici de cours sur RPL mais juste la mise en évidence de certains points intéressants (si vous ne lisez qu'une partie du RFC, la section 3 est une description de haut niveau de RPL). Notez qu'il existe d'autres protocoles de routage répondant à peu près à ce cahier des charges, notamment Babel (RFC 8966).
Pour distribuer l'information sur les routes et les routeurs, RPL utilise l'algorithme Trickle (RFC 6206).
RPL essaie de construire un graphe acyclique, qui est lui-même divisé en sous-graphes acycliques, chacun enraciné dans une et une seule destination (RPL les nomme DODAG pour Destination-Oriented Direct Acyclic Graphs). Tout le trafic pour une destination donnée a ainsi la garantie de l'atteindre, sans boucler. Le graphe est orienté : les informations de routage indiquent si le paquet progressera « vers le haut » ou bien « vers le bas » et cette orientation joue un rôle essentiel dans la prévention des boucles (section 11.2). L'annexe A décrit en détail un exemple de fonctionnement.
Pour optimiser les routes, RPL est paramétré avec une fonction nommée OF (pour Objective Function). Des concepts comme celui de distance sont définis par cette fonction. Des réseaux différents peuvent utiliser des OF différents (une qui cherche le chemin le plus court, une qui cherche à ne pas utiliser comme routeur les machines n'ayant pas de connexion au courant électrique, etc), même s'ils utilisent tous RPL. Ces fonctions sont enregistrées à l'IANA (section 20.5). La section 14 décrit les règles auxquelles doivent obéir ces fonctions.
RPL nécessite des liens bidirectionnels. Ce n'est pas toujours évident d'avoir de tels liens dans le monde des ondes radio. RPL doit donc tester la bidirectionnalité des liens avec un potentiel routeur, par exemple en utilisant le protocole du RFC 5881. Comme tout bon protocole TCP/IP, RPL peut fonctionner sur un grand nombre de modèles de réseaux physiques (cf. RFC 3819). Les communications du protocole RPL utiliseront ensuite des paquets ICMP (RFC 4443) de type 155.
Conçu pour des réseaux de machines ayant peu de capacités, et qu'on ne peut pas aller toutes configurer à la main, RPL a par défaut peu de sécurité. Dans le mode de base, n'importe quelle machine peut se joindre au réseau et se faire désigner comme routeur. Dans le mode « pré-installé », les machines doivent connaître une clé pour joindre le réseau. Dans le mode de sécurité maximale, dit « authentifié », il y a deux clés, une pour devenir un nœud ordinaire, et une pour devenir un routeur. (Voir la section 10 pour tous les détails sur la sécurité.)
RPL est un protocole de routage (routing), c'est-à-dire de construction de routes. Il ne change pas le modèle de transmission (forwarding) d'IP, celui que suivent les nœuds une fois les routes connues. Néanmoins, la section 11 donne quelques conseils intéressants sur la façon dont les machines peuvent limiter les problèmes lors de la transmission des paquets. Par exemple, une machine peut faire partie de plusieurs réseaux RPL (on dit « plusieurs instances RPL ») et elle doit faire attention en routant des paquets entre deux instances car les protections contre les boucles ne s'appliquent plus. Une solution possible est d'ordonner les instances (on peut transmettre les paquets destinés à un réseau seulement vers un réseau dont le numéro d'instance est supérieur).
L'ingénieur réseaux qui devra installer et configurer un réseau utilisant RPL peut aller regarder tout de suite la section 18 : elle explique la gestion de ces réseaux et les paramètres qu'on peut avoir à configurer, dans l'esprit du RFC 5706. Évidemment, c'est toujours préférable lorsqu'il n'y a rien à configurer et que cela marche tout seul (RFC 1958, section 3.8). C'est particulièrement vrai pour le type de réseaux auxquels est destiné RPL, des réseaux composés de nombreuses machines planquées un peu partout. Néanmoins, si on veut configurer, il y a quelques boutons à tourner comme le choix du numéro d'instance RPL (section 18.2.3) qui permet d'avoir plusieurs réseaux RPL différents dans un même endroit.
Enfin, la section 19 est la traditionnelle section sur la sécurité. Comme résumé au début de cet article, RPL offre forcément peu de sécurité : les réseaux ad hoc pour lesquels il est prévu ne s'y prêtent guère (difficulté à configurer chaque machine, par exemple pour y indiquer une clé, ou bien ressources limitées des machines, ce qui limite l'usage de la cryptographie). RPL fournit néanmoins des mécanismes de sécurité mais il est à parier qu'ils ne seront pas souvent déployés.
Comme souvent de nos jours, une bonne partie des efforts du groupe de travail a été dépensé en discussions sur les différentes brevets plombant le protocole. Il a finalement été décidé de foncer mais les juristes peuvent regarder les différentes prétentions à l'appropriation qui pèsent sur RPL.
Quelles implémentations sont disponibles ? Selon le groupe de travail, elles seraient déjà plus de dix, mais je n'ai pas de liste. Ce qui est sûr, c'est que deux tests d'interopérabilité ont déjà eu lieu, sous la houlette de l'IPSO et du consortium Zigbee. La section 16 intéressera certainement les implémenteurs car elle récapitule les choses importantes qu'il faut savoir pour que toutes les mises en œuvre de RPL coopèrent.
Un résumé de synthèse sur RPL est « "The Internet of Things" takes a step forward with new IPv6 routing protocol », écrit par un employé de Cisco (entreprise qui a fondé l'alliance IPSO en septembre 2008).
L'article seul
RFC 6576: IPPM standard advancement testing
Date de publication du RFC : Mars 2012
Auteur(s) du RFC : R. Geib (Deutsche Telekom), A. Morton (AT&T Labs), R. Fardid (Cariden Technologies), A. Steinmitz (Deutsche Telekom)
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 26 mars 2012
Pour déterminer si un protocole de communication est bien décrit dans les RFC qui le normalisent, l'IETF a une méthode simple, tester si les différentes mises en œuvre de ce protocole interopèrent proprement entre eux (par exemple, on vérifie qu'un client HTTP parle au serveur HTTP avec succès). Ce genre de tests est maintenant fréquent, et sert de base à l'avancement des RFC sur le chemin des normes (de simple proposition au statut de norme complète). Mais, lorsqu'un RFC spécifie, non pas un protocole mais une métrique, c'est-à-dire une grandeur mesurable, comment fait-on pour vérifier que le RFC est correct et est bien implémenté ? Ce nouveau RFC de l'inépuisable groupe de travail IPPM propose une solution : on mesure le même phénomène avec les différentes mises en œuvre et les chiffres obtenus doivent être identiques (ou suffisamment proches pour être statistiquement équivalents). Cette méthode permettra aux RFC décrivant les métriques d'avancer sur le chemin des normes : si les résultats sont les mêmes, on considérera que cela semble indiquer que la métrique est définie clairement et sans ambiguité. (Si les résultats sont différents, cela pourra être dû à une bogue dans l'un des systèmes, ou à un RFC confus, qui n'a pas été compris de la même façon par tous les développeurs.)
Le chemin des normes, qui comportait trois étapes du temps du RFC 2026, n'en a plus que deux depuis le RFC 6410. Un des critères d'avancement d'une norme est l'interopérabilité entre des mises en œuvre indépendantes. Cette interopérabilité devait autrefois se démontrer par des tests explicites (RFC 5657) mais, aujourd'hui, le simple déploiement massif suffit (nul besoin de tester HTTP pour voir tous les jours dans l'Internet que clients et serveurs se parlent...). Tout cela est très bien pour les protocoles de communication. Mais pour des métriques ? On peut avoir plusieurs mises en œuvre indépendantes, qui sont largement déployées, sans que cela ne prouve qu'elles soient cohérentes entre elles. La section 5.3 du RFC 5657 prévoit explicitement le cas des normes qui ne sont pas des protocoles de communication mais ne fournit guère de solutions. L'analyse du groupe IPPM est qu'il est quand même possible de tester explicitement des définitions de métriques et que l'identité (aux variations statistiques près) des chiffres obtenus par deux mesures du même phénomène réseau est l'équivalent de l'interopérabilité. (Notez qu'IPPM a aussi quelques protocoles à son actif, comme ceux du RFC 4656 et RFC 5357, dont l'interopérabilité peut être testée par des moyens classiques.)
Pour les métriques, l'idée va donc être de générer un phénomène réseau contrôlé, avant de le faire mesurer par les différents systèmes. (Mesurer un phénomène réel, non contrôlé, est plus difficile car cela implique que les différentes mesures soient parfaitement synchronisées, pour observer exactement la même chose. Tous les systèmes de mesure n'ont pas forcément ce mécanisme de synchronisation.) Un exemple complet figure dans l'annexe A, avec la métrique « délai d'acheminement », et c'est une lecture très recommandée si tout cela vous semble trop abstrait.
La section 2 détaille cette idée de base. Inspirée du RFC 2330, elle part du principe qu'une mesure doit être reproductible (on mesure le même phénomène deux fois, et les résultats doivent être identiques, aux fluctuations statistiques près). En pratique, mesurer exactement « le même phénomène » implique de prêter attention à de nombreux détails, par exemple à la stabilité des routes (sur l'Internet, le délai d'acheminement entre deux points peut varier brusquement, si BGP recalcule les routes à ce moment). D'autre part, si la métrique a des options, les deux mesures doivent évidemment utiliser les mêmes options. Et, en raison des variations du phénomène, l'échantillon mesuré doit être assez grand pour que la loi des grands nombres rende ces variations négligeables. La section 2 dit clairement qu'on n'envisage pas de mesurer des singletons (par exemple, pour le délai d'acheminement, le délai d'un seul paquet).
Une fois ces précautions comprises, comment détermine-t-on la conformité d'une mesure à la spécification de la métrique (section 3) ? D'abord, dans la grande majorité des cas, les critères de comparaison vont dépendre de la métrique, et doivent donc être définis spécifiquement pour chaque métrique (l'annexe A fournit un exemple complet). Ensuite, on va comparer deux mesures (qui peuvent avoir été faites dans le même laboratoire, ou bien dans des endroits différents.) La méthode statistique de comparaison recommandée est le test d'Anderson-Darling K. Entre deux mesures d'un même phénomène, on veut un niveau de confiance d'Anderson-Darling K d'au moins 95 %.
Selon l'environnement de test, il va falloir faire attention à des techniques comme la répartition de charge qui peuvent envoyer le trafic par des chemins distincts, une bonne chose pour les utilisateurs, mais une plaie pour les métrologues (cf. RFC 4928).
Compte-tenu de tous les pièges que détaille la section 3 (le gros du RFC), il est nécessaire de documenter soigneusement (RFC 5657 et section 3.5 de notre RFC) l'environnement de test : quelle était la métrique mesurée, quelle était la configuration de test, tous les détails sur le flot de paquets (débit, taille, type, etc).
Si on trouve des différences entre deux mesures de la même métrique, sur le même phénomène, alors il faudra se lancer dans un audit soigneux pour déterminer où était la racine du problème : bogue dans une implémentation ou manque de clarté de la spécification, cette seconde raison étant un bon argument pour ne pas avancer la métrique sur le chemin des normes et pour l'améliorer.
Si vous voulez en savoir plus que le test d'Anderson-Darling, il est documenté dans le rapport technique 81 de l'Université de Washington, par Scholz, F. et M. Stephens, « K-sample Anderson-Darling Tests of fit, for continuous and discrete cases ». Le test Anderson-Darling K est faisable en R : voir le paquetage « adk: Anderson-Darling K-Sample Test and Combinations of Such Tests ». Une implémentation d'Anderson-Darling K en C++ figure dans l'annexe B du RFC.
L'annexe A contient un exemple complet de test d'une métrique, en l'occurrence le délai d'acheminement d'un paquet, tel que défini par le RFC 2679 (le test complet sera documenté dans un futur RFC, actuellement l'Internet-Draft « Test Plan and Results for Advancing RFC 2679 on the Standards Track »). Par exemple, on met le délai d'attente maximum (une option de la métrique) à 2 secondes, on mesure un flot de paquets à qui on impose un délai d'une seconde, grâce à un dispositif qui introduit délibérement des problèmes réseaux (un impairment generator ; ce genre de traitement peut se faire sur un Unix courant), on vérifie qu'ils sont tous comptés, on passe le délai imposé à 3 secondes, et on vérifie qu'on n'obtient plus aucun résultat (la grandeur « délai d'acheminement » est indéfinie si le paquet n'arrive pas avant le délai maximum, RFC 2679, section 3.6).
Ce n'est évidemment pas le seul test. L'annexe A propose également de tester le délai d'acheminement (qui va jusqu'à la réception du dernier bit du paquet, RFC 2679, section 3.4) en faisant varier la taille des paquets, mettons à 100 et 1500 octets. Les implémentations testées doivent mesurer la même augmentation du délai d'acheminement (qui ne dépendra que du temps de transmission supplémentaire, que devra supporter le plus gros des paquets). Autre test, mesurer le délai, puis imposer un retard N, les différentes mesures doivent voir la même augmentation du délai.
Le premier RFC à avoir testé cette démarche a été le RFC 2679, dont le rapport d'avancement a été publié dans le RFC 6808.
L'article seul
RFC 6538: HIP Experiment Report
Date de publication du RFC : Mars 2012
Auteur(s) du RFC : T. Henderson (Boeing), A. Gurtov (HIIT)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF hiprg
Première rédaction de cet article le 25 mars 2012
Le protocole HIP, normalisé dans le RFC 4423, est maintenant stable depuis des années et a fait l'objet de plusieurs essais sur le terrain. Ce RFC de l'IRTF documente certains de ces essais concrets et indique les leçons à en tirer.
Le groupe de recherche hip de l'IRTF a travaillé sur ce sujet de 2004 à 2009. Pendant cette période, un certain nombre de mises en œuvre de HIP ont été programmées et plusieurs bancs de test ont été montés. La section 7 du RFC donne une liste exhaustive des expériences menées, notamment chez Boeing et dans le projet InfraHIP, qui gère des serveurs HIP publics. (Notez que, HIP fonctionnant au dessus d'IP, deux machines HIP peuvent communiquer au dessus de l'Internet public sans problème.) Ce RFC est le compte-rendu de ces expériences, sur les points suivants :
- Implémenter HIP, qu'est-ce que ça coûte, comme efforts ?
- Déployer HIP, quels sont les problèmes ?
- Une fois que HIP marche, quelles conséquences pour les applications ?
- Qu'en pensent les opérateurs ?
- Et la vie privée, que va-t-elle devenir ?
D'abord, la mise en œuvre (section 2). HIP est un protocole pour les machines terminales, pas pour les routeurs. Implémenter HIP, c'est donc modifier Linux ou Windows, sans toucher à ses Cisco ou D-Link. Il existe aujourd'hui trois de ces modifications sous une licence libre :
- HIP4BSD, pour FreeBSD,
- HIPL, pour Linux,
- et OpenHIP, la seule qui fonctionne entièrement en mode utilisateur, et qui tourne sur Linux, Windows XP/Vista/7, and Apple OS X.
L'expérience montre bien qu'implémenter un nouveau protocole n'est pas du yakafokon et que plein de pièges insoupçonnés se cachent dans le code. La section 2.1 résume ce qu'il faut modifier au noyau pour intégrer HIP. Les applications fonctionnent comme avant, un HIT (le condensat cryptographique d'une clé HIP) ayant la même forme qu'une adresse IPv6 (avec le préfixe ORCHID du RFC 4843). En section 2.2, c'est le cas d'une implémentation en dehors du noyau qui est couvert (notez que certaines mises en œuvre d'HIP sont mixtes, par exemple avec le traitement des paquets dans le noyau et la cryptographie dans un démon à part). Cela permet de faire fonctionner HIP sur des systèmes qu'on n'a pas le droit de modifier comme Microsoft Windows.
Dans tous les cas, quels ont été les problèmes rencontrés ? En l'absence de système de résolution, manipuler les HIT à la main, se les échanger, etc, a été pénible. Des systèmes de résolution existent désormais (mettre les HIT dans le DNS sous forme d'enregistrements AAAA, comme le propose le RFC 5205, utiliser une DHT dédiée à HIP, etc) et OpenHIP les a tous programmés. Et il y a aussi le mode opportuniste de HIP, où on se connecte sans connaître a priori le HIT du pair. Mais aucune solution n'est à 100 % parfaite.
Le mode
opportuniste du RFC 5201, section 4.1.6 a posé
des problèmes avec l'interface
sockets, car le HIT du pair
distant n'est pas encore connu au moment du
connect(). De toute façon, ce mode a
l'inconvénient de ne pas être très sécurisé (il fonctionne en mode
TOFU - Trust On First Use - puisque, la première fois qu'on parle à un
pair, on doit accepter son HIT en lui faisant une confiance
aveugle). HIPL a mis en œuvre ce mode. OpenHIP également, avec
une option explicite (-o), débrayée par
défaut. Le problème de sécurité est particulièrement crucial lorsqu'il
s'agit d'applications traditionnelles, qui ne connaissent pas HIP et
ne peuvent donc pas formuler de souhaits, ou interactivement demander
confirmation à l'utilisateur, ce que peuvent faire les applications
récentes qui utilisent le RFC 6317.
Quant au DNS, certains administrateurs de zones DNS n'ont pas aimé qu'on mette des HIT sous le nom d'AAAA, arguant que c'était un détournement de la sémantique du AAAA.
Autre problème, lorsqu'on connait le HIT du pair (on ne fait donc pas de mode opportuniste) mais pas son adresse IP. Pour lui envoyer des paquets, il faudra alors une résolution, pour trouver cette adresse. Des essais ont été faits avec OpenDHT, ou bien avec le DNS. HIPL a même tenté, pour le cas particulier du LAN, d'envoyer un paquet de diffusion, un peu comme on fait en NDP. Cela a paniqué certains antivirus Windows qui considéraient toute diffusion avec un protocole inconnu comme un danger.
Parmi les nombreuses autres questions que décrit le RFC en tenant compte de l'expérience des programmeurs HIP, celui de la gestion des HI (Host Identifiers, l'identité d'une machine HIP, dont le HIT est le condensat cryptographique). Une machine peut avoir plusieurs identités (par exemple pour protéger la vie privée, voir plus loin), et laquelle doit-elle utiliser lorsqu'elle se connecte à un pair ? Dans quelle mesure le choix doit-il être fait par l'utilisateur ? (Intéressant problème d'interface.) Plus gênant, puisque HIP repose sur des clés cryptographiques, comment stocker les clés privées sur la machine ? Toutes les implémentations actuelles utilisent un fichier appartenant à root en mode 0600 (ce qui interdit la lecture par les utilisateurs ordinaires). Cela ne suffit pas si, par exemple, un attaquant a un accès physique à la machine. La solution serait alors de stocker les clés dans un TPM mais aucune mise en œuvre de HIP n'a encore tenté le coup.
Cette section comprend également un problème qui, à mon avis, est plutôt de déploiement que de programmation, l'interaction avec les pare-feux. HIP est un protocole (le numéro 139 des protocoles IP, TCP étant 6, UDP 17 et OSPF 89) marqué comme expérimental et qui est globalement peu connu. Il n'y a donc pas de règle pour lui dans les règles configurées par défaut et le pare-feu refusant tout ce qui n'est pas explicitement autorisé, les paquets HIP se retrouvent bloqués. Il n'est pas forcément trivial de modifier les règles sans tout casser (le RFC rapporte que celles par défaut de SUSE ont plus de cent entrées) et, de toute façon, l'utilisateur qui veut déployer HIP n'a pas forcément le contrôle du pare-feu. Heureusement, HIP peut tourner sur UDP (au lieu de directement sur IP) ce qui limite les problèmes.
Bien que HIP ait été surtout conçu pour IPv6, et que son déploiement massif ne semble pas devoir précéder celui d'IPv6, toutes les mises en œuvre de HIP ont choisi de gérer également IPv4. Comme on ne peut absolument pas faire rentrer un condensat cryptographique sérieux dans les 32 bits d'une adresse IPv4, il faut ajouter le concept de LSI (Local Scope Identifier), un alias local à la machine pour référencer un HI donné.
Plus amusant, HIP permet également de faire tourner des applications IPv6 sur un réseau IPv4 (et réciproquement), ce qui fonctionne sur tous les codes cités.
Bref, les programmeurs ont bien travaillé et HIP fonctionne sur plusieurs plate-formes. Quelles leçons peuvent être tirées ? Il n'y a pas eu beaucoup de tests de performances, notamment pour comparer les implémentations en mode noyau et en mode utilisateur. Il semble que, sur une machine généraliste et pour des usages typiques, le mode utilisateur (le plus lent) est acceptable.
Le choix entre les deux modes peut dépendre de bien d'autres choses. Par exemple, HIPL avait une mise en œuvre des fonctions de gestion de clés dans le noyau, mais les développeurs du noyau Linux l'ont rejeté, arguant que d'autres protocoles comme IKE faisaient cette gestion en mode utilisateur et qu'il n'y avait pas de raison de l'intégrer dans le noyau. (Il faut dire aussi que c'était un gros patch, qui touchait à beaucoup d'endroits du noyau.)
La section 3 aborde ensuite les points liés au déploiement, notamment à l'effet sur les infrastructures. La section sur le DNS (extensions HIP du RFC 5205) est curieusement incompréhensible (qu'est-ce qu'un binary blob format ?) mais, de toute façon, les serveurs DNS peuvent servir des types de données qu'il ne connaissent pas, donc peu de problèmes à attendre.
Plus sérieux, le cas des middleboxes. Les NAT sont hostiles à HIP comme à beaucoup de choses (problème décrit dans le RFC 5207). HIP peut par exemple chiffrer même la connexion initiale, empêchant le routeur NAT de comprendre ce qui se passe. Le mécanisme de rendez-vous du RFC 5204 pourrait aider à résoudre les problèmes du NAT mais il n'a pour l'instant été testé qu'en laboratoire.
Et l'infrastructure de résolution ? Une mise en œuvre de résolution de HIT en adresses IP via OpenDHT a été faite pour HIPL et OpenHIP. OpenDHT est désormais arrêté mais un nouveau projet a pris le relais, Hi3, qui tourne sur PlanetLab. Au cours des premiers essais, le débogage s'est révélé très pénible, et les middleboxes qui bloquent tout une énorme source de frustration.
Une solution d'avenir pourrait être de mêler DNS (déploiement massif, compatibilité avec le logiciel existant) et DHT (bonne résistance aux pannes, bonne efficacité même dans un espace plat, celui des clés cryptographiques). Par exemple, une organisation ferait tourner une DHT pour stocker les HI ou les HIT de ses machines, connectée avec le DNS pour les clients extérieurs. Ensuite, ces DHT locales pourraient être interconnectées petit à petit. Un test a été fait en modifiant BIND pour qu'il interroge une DHT (Bamboo) pour les HIT. Les performances ont été plutôt mauvaises, et se dégradant vite avec la charge, donc des travaux supplémentaires sont nécessaires.
Et pour les applications ? L'expérience du déploiement d'IPv6 a montré qu'il était plus facile de mettre à jour l'infrastructure que les applications. La section 4 explore les conséquences de HIP sur celles-ci. Il y a deux sortes d'applications : celles qui connaissent HIP et celles qui ne le connaissent pas (la quasi-totalité, aujourd'hui : le RFC 5338 explique comment faire tourner HIP avec les applications traditionnelles).
Par exemple, HIPL a testé une bibliothèque
dynamique (chargée avec LD_PRELOAD) qui change le comportement du résolveur,
permettant aux applications de se connecter à un pair HIP sans s'en
rendre compte. Un Firefox et un
Apache non modifiés ont ainsi pu se parler en
HIP. L'avantage de cette méthode est de permettre de choisir,
application par application, qui va faire du HIP (cette finesse de
choix pouvant être considérée comme un avantage ou comme un
inconvénient). Une autre solution serait de passer par des relais
applicatifs mais elle ne semble pas avoir été testée encore.
HIP a même réussi à fonctionner avec des applications qui utilisent des références (passer son adresse IP au pair pour qu'il vous envoie ensuite des messages) comme FTP. D'autres applications seraient peut-être moins tolérantes mais, de toute façon, en raison du NAT, les applications qui se servent de références ont déjà beaucoup de problèmes dans l'Internet d'aujourd'hui.
Une des raisons pour lesquelles il peut être intéressant de mettre une gestion de HIP explicite dans les applications est la performance : l'établissement d'une connexion est plus long en HIP et certaines applications (par exemple un navigateur Web) peuvent être très sensibles à cette latence supplémentaire. Elles pourraient alors choisir de laisser tomber la sécurité de HIP au profit de la vitesse.
Continuons dans les problèmes concrets : quelle va être l'expérience de l'administrateur réseaux qui, le premier, tentera de déployer HIP ? Pour l'instant, aucun ne l'a fait mais. HIP peut tourner entièrement dans les machines terminales, sans que le réseau soit impliqué. Si celui-ci l'est, il aura peut-être les problèmes suivants (détaillés en section 5) :
- Choix des HI (Host Identities). Celles-ci peuvent être générées par les machines toutes seules, et c'est comme cela que tout le monde fait aujourd'hui. Mais certains administrateurs pourraient préférer le faire eux-même, de manière à connaître les HI de leur réseau. Par exemple, ils généreraient les HI, les signeraient éventuellement avec leur PKI, et les mettraient dans une base AAA, exportant ensuite la configuration d'équipements comme les pare-feux.
- Le monde étant ce qu'il est, la sécurité que fournit HIP, surtout en combinaison avec le mode ESP d'IPsec (qui est très intégrée à HIP) peut ne pas plaire à tout le monde. Si Big Brother veut espionner le trafic, que va pouvoir dire l'administrateur réseaux ? Le groupe de recherche HIP n'a pas trouvé de solution à ce dilemne.
- Autre question posée par le chiffrement, celui de la consommation de ressources, notamment pour les engins les moins pourvus comme les smartphones. Toutefois, au cours d'essais HIP et ESP avec une tablette Nokia N770, les performances sont restées acceptables (3,27 Mb/s en WiFi contre 4,86 sans HIP ni ESP). Le RFC ne dit pas quelle a été la consommation électrique....
- Autre problème typique d'administrateur réseaux, le filtrage. Aujourd'hui, le filtrage va souvent contre la sécurité, par exemple bien des pare-feux bloquent IPsec ou HIP. Normalement, HIP améliore la sécurité puisqu'on peut authentifier les HI (les identités des machines, celles-ci signant leurs paquets). Il ne reste plus qu'à configurer les ACL du pare-feu pour filtrer en fonction du HI. Notons que, contrairement aux adresses IP, celles-ci ne sont pas agrégeables en préfixes et il faut donc typiquement une ACL par machine. Quant au filtrage par nom et plus par HI, il dépend d'un enregistrement sécurisé des HI dans le DNS, qui n'est pas disponible à l'heure actuelle.
- Ceci n'a pas empêché l'université de Technologie d'Helsinski de modifier iptables pour produire un pare-feu HIP. Cela nécessite un état car le pare-feu doit se souvenir de l'échange initial HIP pour reconnaître ensuite les paquets chiffrés liés à cette session (le SPI IPsec figure dans les paquets HIP I2 et R2).
La section 6 du RFC s'attaque ensuite à un difficile problème, celui de la vie privée des utilisateurs. HIP permet enfin de doter chaque machine sur l'Internet d'une véritable identité, indépendante de sa position dans le réseau, qu'on peut vérifier avec la cryptographie. Mais ce gain en sécurité peut se payer en terme de vie privée : si mon ordinateur portable a HIP, je me connecte à un site Web HIP depuis chez moi, et depuis l'hôtel et, sans cookies ou autres techniques de suivi Web, le serveur peut reconnaitre que c'est la même machine (les adresses autoconfigurées d'IPv6 avaient un problème du même genre, qui a été résolu par le RFC 4941).
Pire, dans certains cas, un tiers qui écoute le réseau peut apprendre l'identité des deux machines, même si le reste de la session est chiffré.
HIP permet d'utiliser des HIT non publiés (RFC 5201, sections 5.1.2 et 7) mais cela suppose que le destinataire les accepte (ce qui serait logique pour un serveur public, qui ne se soucie pas en général de l'identité de ses clients). Globalement, la protection de la vie privée dans HIP n'est pas encore suffisante mais des travaux sont en cours. Mon opinion personnelle est que la meilleure solution serait analogue à celle du RFC 4941 : des identificateurs jetables, créés pour une courte période (voire pour une seule session) et abandonnés après. Cela nécessite de faire attention aux autres identificateurs (comme l'adresse IP) qui doivent changer en même temps que le HI (sinon, l'attaquant pourrait faire le rapprochement). L'Université Technologique d'Helsinski a déjà une mise en œuvre expérimentale de cette idée.
HIP n'est pas la seule architecture de séparation du localisateur et de l'identificateur. La section 8 du RFC résume les autres expériences en cours. Il ne va pas de soi que cette séparation soit une bonne idée. C'est même un point de vue très controversé, comme l'avait montré l'échec du NSRG (Name Space Research group). Parmi les efforts récents :
- Les groupes de travail multi6 et shim6 qui ont mené au RFC 5533, solution qui a des ressemblances avec HIP (d'ailleurs, OpenHIP implémente à la fois HIP et shim6), ce qui a permis de concevoir des API proches (RFC 6316 et RFC 6317).
- Le groupe de recherche RRG a exploré de nombreuses solutions pour le routage de demain, comme LISP ou ILNP, documentant le résultat dans le RFC 6115.
L'article seul
ROVER, un système alternatif pour sécuriser BGP
Première rédaction de cet article le 22 mars 2012
Le protocole de routage BGP, sur lequel repose tout l'Internet, est connu pour son absence de sécurité. N'importe quel maladroit peut annoncer les routes d'un autre opérateur et détourner ou couper le trafic. Il existe une solution de sécurisation, normalisée et activement déployée, RPKI+ROA. Mais cette solution, plutôt complexe, ne fait pas que des heureux. Une alternative vient d'être annoncée, ROVER (ROute Origin VERification).
ROVER a été présenté par Joe Gersch à l'atelier OARC à
Teddington. Le principe est le suivant : si on
est le titulaire du préfixe IP
2001:db8:179::/48, on a a priori la délégation
DNS pour l'arbre dit « inverse »,
9.7.1.0.8.b.d.0.1.0.0.2.ip6.arpa. On peut alors
publier dans cet arbre des enregistrements DNS spéciaux qui
indiqueront l'AS d'origine autorisé. Un
validateur situé près du routeur testera si les préfixes reçus ont un
enregistrement ROVER correspondant. Le routeur n'aura qu'à lui
demander ce résultat (le système RPKI+ROA a un fonctionnement
analogue, le routeur ne valide pas lui-même). On a alors
les mêmes possibilités qu'avec les ROA du RFC 6482. Et la sécurité ? Pour que ROVER ait un sens, il faut
évidemment signer les enregistrements avec
DNSSEC.
Par rapport à la solution RPKI+ROA, on a donc :
Voyons un exemple concret avec le banc de test. Je me crée un
compte et je demande l'état du préfixe
2001:67c:217c::/48 (le site Web du banc de test
offre plusieurs moyens de remplir l'information, à partir d'un numéro
d'AS, d'un nom, etc). J'obtiens le résultat suivant : 
J'accepte le choix proposé (autoriser les fournisseurs de transit mais pas les peerings) et je demande le fichier de zone, qui est produit automatiquement, avec les AS actuels :
; This is a reverse-DNS zone containing Secure Routing Records
; for the CIDR address block 2001:67c:217c::/48 owned by (RIPE Network Coordination Centre)
;
; Created by bortzmeyer(bortzmeyer+rover@nic.fr) on 2012-03-22
;
; This zone is for test purposes only and is hosted at the shadow zone located on
; the public internet at 'in-addr.arpa.secure64.com'. It is signed with DNSSEC.
;
$TTL 3600
$ORIGIN c.7.1.2.c.7.6.0.1.0.0.2.ip6.arpa.secure64.com.
@ IN SOA ns1.secure64.com. hostmaster.secure64.com. (
2012032200 ; serial number in date format
14400 ; refresh, 4 hours
3600 ; update retry, 1 hour
604800 ; expiry, 7 days
600 ; minimum, 10 minutes
)
IN NS ns1.secure64.com.
IN NS ns2.secure64.com.
$ORIGIN c.7.1.2.c.7.6.0.1.0.0.2.ip6.arpa.secure64.com.
@ IN TYPE65400 \# 0
; RLOCK deny all route announcements except those authorized
@ IN TYPE65401 \# 8 000009b600000898
; 2001:67c:217c::/48 SRO AS2486 (NIC-FR-DNS-UNICAST-PARIS2) with transit AS2200 (FR-RENATER)
@ IN TYPE65401 \# 8 000009b60000201a
; 2001:67c:217c::/48 SRO AS2486 (NIC-FR-DNS-UNICAST-PARIS2) with transit AS8218 (NEO-ASN)
Quelques points d'explication : ROVER est loin d'être normalisé donc
les enregistrements DNS utilisés n'ont pas de nom mais utilisent les
numéros réservés pour l'expérimentation
(TYPE65400 et
TYPE65401). Pour la même raison, ils apparaissent
en hexadécimal. Les commentaires à la ligne suivante donnent
l'enregistrement en clair, tel qu'il apparaîtra lorsqu'il sera
normalisé. Un RLOCK impose que les routes sous ce
préfixe soient sécurisées par ROVER. Un SRO
(Secure Route Origin) indique un
AS d'origine autorisé (ici, 2486, avec deux transitaires,
Renater et Neo).
Joe Gersch a annoncé avoir testé les performances : pour un routeur qui démarre à froid, et doit donc vérifier les 400 000 routes de l'Internet d'aujourd'hui, les requêtes DNS prennent moins de quatre minutes.
ROVER est actuellement décrit dans deux Internet-Drafts, « DNS Resource Records for BGP Routing Data » et « Reverse DNS Naming Convention for CIDR Address Blocks ». Il sera officiellement présenté à la réunion IETF à Paris la semaine prochaine.
Au fait, c'est très bien pour IPv6 mais pour
IPv4, où les frontières des organisations
tombent rarement sur une frontière d'octet ? Les auteurs proposent un
nouveau schéma de nommage pour l'arbre « inverse »
in-addr.arpa. L'idée est que, si le préfixe ne
s'arrête pas sur une frontière d'octet, on ajoute un
m suivi des bits restants. Ainsi,
129.82.64.0/18 devient
1.0.m.82.129.in-addr.arpa (le 01 au début étant
le 64 du préfixe, deux bits car le reste de la division de 18 par 8
est 2). C'est dans ce 1.0.m.82.129.in-addr.arpa
qu'on mettra les enregistrements SRO (ici, pour l'AS 65536) :
1.0.m.82.129.in-addr.arpa. IN SRO 65536
Un autre article sur Rover, en anglais, pas trop mal mais inutilement sensationnaliste a été publié par The Register.
L'article seul
Mesure de la résilience de l'Internet en France : mon exposé à l'OARC
Première rédaction de cet article le 21 mars 2012
À l'occasion de la réunion de l'OARC aujourd'hui à Teddington, j'ai présenté le futur rapport sur la résilience de l'Internet en France. Ce rapport a été produit conjointement par l'ANSSI et l'AFNIC et vise à mesurer quantitativement les indicateurs de la résilience de l'Internet, c'est-à-dire de la capacité de ce dernier à continuer à fonctionner même en présence de pannes ou d'attaques. Le rapport final a été publié quelques mois après.
Le support de mon exposé en donne un résumé :
- Version adaptée à la lecture sur écran,
- Version adaptée à l'impression.
L'article seul
Les jolis traceroute d'Orange/3G
Première rédaction de cet article le 20 mars 2012
Le service 3G d'Orange « Business Everywhere » est lent, peu fiable et plusieurs ports sont filtrés. Mais il a surtout des traceroutes intéressants.
Quelle que soit l'adresse IPv4 visée, on obtient :
% traceroute -n 192.134.1.2 traceroute to 192.134.1.2 (192.134.1.2), 30 hops max, 60 byte packets 1 10.164.9.9 1591.659 ms 1591.616 ms 1591.668 ms 2 10.164.9.10 1591.696 ms 1591.746 ms 1591.773 ms 3 192.134.1.2 1593.102 ms 1593.298 ms 1593.477 ms 4 192.134.1.2 1595.120 ms 1595.325 ms 1600.930 ms 5 192.134.1.2 51.193 ms 59.476 ms 61.251 ms 6 192.134.1.2 59.223 ms 59.256 ms 59.301 ms 7 192.134.1.2 53.772 ms 61.100 ms 61.184 ms ...
Drôle de réseau, l'Internet par Orange. Quelqu'un sait-il à quelle adresse écrire pour signaler le problème ?
L'article seul
RFC 6561: Recommendations for the Remediation of Bots in ISP Networks
Date de publication du RFC : Mars 2012
Auteur(s) du RFC : J. Livingood (Comcast), N. Mody (Comcast), M. O'Reirdan (Comcast)
Pour information
Première rédaction de cet article le 20 mars 2012
Une des plus grosses menaces sur la sécurité de l'Internet réside dans les zombies, ces machines Windows contaminées par du logiciel malveillant et qui obéissent désormais à un maître qui leur ordonne, selon sa volonté, de lancer une dDoS, d'envoyer du spam, etc. Ce RFC documente le point de vue d'un gros FAI, Comcast, sur le problème. La partie que je trouve la plus riche est celle sur le difficile problème de la notification des utilisateurs.
Il n'existe pas de solution miracle contre les zombies. C'est comme cela que je lis ce document qui, malgré son nom, propose peu de remèdes. Et certaines des solutions relèvent plus d'une logique « business » (se débarrasser d'un problème) que d'une volonté d'améliorer l'Internet (le document se réclame du MAAWG, cartel de gros opérateurs très tentés par le nettoyage civilisateur).
Le RFC commence par un peu de terminologie (section 1). Bot est l'abrévation de robot et désigne dans ce RFC un zombie, une machine qui n'obéit plus à son propriétaire légitime mais au « maître des zombies » (bot master), qui les contrôle à distance. Le logiciel qui transforme une innocente machine en zombie a typiquement été installé en trompant l'utilisateur (« Click here to install over 200 000 HOT pictures of REAL CHICKS! »), ou bien en profitant d'une faille de sécurité de ses logiciels, ou encore en essayant plein de mots de passe jusqu'à en trouver un qui marche. Le RFC note qu'il existe des gentils robots (par exemple pour interagir automatiquement sur les canaux IRC) mais qu'il ne se consacre qu'aux méchants, aux robots malveillants. Petite colère au passage : le mot anglais malicious veut dire « malveillant » et pas « malicieux » comme on le voit souvent stupidement traduit.
Les bots sont ensuite regroupés en bandes, les botnets, un groupe de zombies obéissant au même maître. Les activités des botnets sont très variées, envoi de spam, de spim, de spit, dDoS, hébergement de relais ou de sites de hameçonnage, hébergement de contenu illégal, fraude aux clics, etc.
Pendant longtemps, le protocole de communication favori des bot herders (ceux qui créent les botnets et les entretiennent) était IRC (RFC 1459). Muni d'une seule machine maître (le C3C, Command and Control Center), le botnet était assez facile à neutraliser : une fois le maître déconnecté, les zombies ne savaient plus quoi faire. Aujourd'hui, les botnets sont plus perfectionnés : utilisation de protocoles plus variés (HTTP, plus discret et moins filtré, a remplacé IRC), souvent en pair à pair, le tout largement chiffré.
Quelles sont les conséquences des actions du botnet ? Pour les victimes (ceux qui reçoivent le spam ou qui sont attaqués par déni de service), elles sont évidentes (pour le spam, voir « Spamalytics: An Empirical Analysis of Spam Marketing Conversion »). Pour l'utilisateur de la machine, c'est surtout la consommation de ressources, qui diminue les performances attendues. Mais pour le FAI, ces zombies ont aussi un coût : capacité réseau utilisée mais aussi atteinte à la réputation du FAI. Ses adresses IP courent un risque élevé de se retrouver sur des listes noires dont il est difficile de sortir. Certaines des opérations du botnet peuvent mettre en danger des ressources Internet critiques (voir le « Emerging Cyber Threats Report for 2009 » et « Distributed Denial of Service Attacks: Explanation, Classification and Suggested Solutions" »).
Le FAI est évidemment bien situé pour détecter la présence de bots, et pour prévenir les utilisateurs. Notons toutefois que, le concept de neutralité du réseau étant tabou chez les FAI, les risques pour ladite neutralité si le FAI s'engage dans ce combat ne sont pas mentionnés dans le RFC.
Personne ne pense bien sûr que des solutions parfaites existent : la lutte entre les bot herders d'un côté, et les FAI et les utilisateurs de l'autre, n'est pas près de se terminer. Toutefois, affirme le RFC dans sa section 2, on peut espérer limiter les dégâts et réduire la taille des botnets, les rendant ainsi moins dangereux.
La section 3, consacrée à doucher les éventuels enthousiasmes, dit d'ailleurs bien que l'éradication des bots est une tâche difficile. Elle note que la seule méthode parfaite sur une machine est « Réinstallez votre système d'exploitation », un remède assez radical et donc peu susceptible d'être suivi... Et le RFC fait remarquer que même cette approche ne suffit pas (voir l'exposé « Persistent BIOS Infection », ou le cas d'engins fermés, comme certains smartphones ou consoles de jeu, où l'utilisateur n'a même pas la liberté d'installer le système d'exploitation).
Maintenant, place à l'action. La première étape est de détecter les zombies dans le réseau. Cela peut se faire par l'analyse passive du trafic, ou bien par les plaintes, même si peu de FAI les traitent. Idéalement, ces plaintes devraient être transmises sous un format structuré, permettant leur analyse automatique, comme les formats ARF (RFC 5965) ou IODEF (RFC 7970). Le document évoque aussi la possibilité de recherches actives, comme le permet un outil comme nmap, bien que de telles recherches ne soient pas forcément légales (cela dépend du pays, note le RFC). Le RFC déconseille néanmoins ces méthodes actives, pas tant sur leur caractère intrusif que sur leur inefficacité (le bot ne va pas forcément se signaler lors du balayage).
Le RFC insiste sur la nécessité de détecter vite, si nécessaire au détriment de la justesse des résultats (tirer d'abord, réflechir ensuite...)
Parmi les techniques passives disponibles, le document cite aussi l'analyse des flux Netflow (RFC 3954, mais depuis remplacé par le IPFIX du RFC 5470) ou bien les méthodes à base de DNS, très à la mode en ce moment, notamment grâce au travail des chercheurs de Georgia Tech (voir par exemple David Dagon, Wenke Lee, « Global Internet Monitoring Using Passive DNS », Cybersecurity Applications & Technology Conference for Homeland Security, 2009). Ces méthodes fondées sur l'observation du trafic DNS ont été utilisées dans le cas de Conficker (les zombies font des demandes de résolution pour les noms de domaine générés par l'algorithme de Conficker, ce dernier n'utilisant pas de noms câblés en dur, cf. l'excellent rapport « An Analysis of Conficker's Logic and Rendezvous Points »). Mais combien de FAI, qui n'arrivent déjà pas à fournir un service correct à leurs utilisateurs, ont les moyens, la compétence et le temps de mener ce genre d'études ?
Idéalement, le FAI devrait non seulement détecter mais également identifier l'infection spécifique, les remèdes pouvant varier.
La partie la plus intéressante du RFC, à mon avis, concerne la notification des utilisateurs. Comment les prévenir que leur machine, infectée, est devenue un zombie ? Et le faire de façon à ce qu'ils comprennent et agissent ? Toutes les techniques de communication possibles avec les utilisateurs sont soigneusement passées en revue, mais aucune ne semble parfaite.
Voici donc les principales techniques envisagées :
- Courrier électronique. Un des problèmes
est qu'il risque de ne pas être lu immédiatement. Un autre est qu'il
soit classé comme spam. Enfin, les méchants
peuvent essayer d'envoyer de faux messages pour brouiller les pistes
(du genre « Nous avons reçu notification d'une alerte de sécurité sur
votre compte, connectez-vous à
http://igotyou.biz/phishing.asppour indiquer vos coordonnées »...). Ce dernier point est notamment développé en section 9 : il est très difficile d'imaginer un système de notification qui ne puisse pas être détourné par les hameçonneurs. - Appel téléphonique. Ils coûtent cher (il n'y a pas que le prix de l'appel, il y a surtout celui de l'employé appelant, si on choisit de faire faire l'appel par des gens compétents). Ils peuvent être considérés comme du spam (par exemple, Bouygues Telecom appelle régulièrement ses clients pour proposer des offres commerciales nouvelles et sans intérêt, et le robot humain qui appelle, avec un fort accent étranger, n'est jamais capable de répondre à la moindre question concrète : de nombreux clients raccrochent donc dès la première minute de ces spams.). Pire, si l'utilisateur utilise un système de voix sur IP sur son ordinateur, le logiciel malveillant peut décider de ne pas répondre aux appels du FAI. Et puis, le téléphone est le plus mauvais média pour donner des instructions techniques complexes.
- Courrier postal. Très cher et très lent.
- Enfermement dans un jardin clos (walled garden). L'idée de base est de configurer les routeurs du FAI pour détourner automatiquement tout le trafic en provenance du bot. Les communications avec le port 80, celui de HTTP, sont alors transmises à un site Web portant le message de notification et les instructions pour remédier au problème. Le jardin peut être totalement clos ou bien laisser passer vers certains services externes (un exemple typique étant Windows Update). La méthode est très brutale mais efficace : l'utilisateur ne peut pas ne pas voir les messages et, en attendant, le bot ne peut plus faire grand mal. Mais, en raison de sa brutalité, elle soulève bien des problèmes. Par exemple, les services autres que le Web (pensons à la voix sur IP) sont coupés, sans avertissement possible. Si le FAI s'est trompé (et que la machine n'était pas réellement infectée), le client va être furieux, et à juste titre. On risque de devoir donc laisser passer certains services par la porte du jardin, et la maintenance de la liste de ces services va être coûteuse. Le FAI doit aussi décider sur quels critères il laissera l'utilisateur sortir du jardin clos. Sur sa simple parole ou bien après un examen (forcément très intrusif) de la machine (d'autant plus que l'utilisateur typique a plusieurs machines derrière le routeur NAT...) ? Et faut-il faire passer un test de Turing aux demandeurs pour vérifier que c'est bien l'utilisateur et pas le bot qui demande l'ouverture du jardin clos ?
- Messagerie instantanée. C'est rapide et simple. Ce serait sans doute la méthode idéale si tous les utilisateurs utilisaient un tel service et y étaient connectés en permanence. Et il y a le risque de spim.
- SMS. L'utilisateur lira probablement le message, et en peu de temps. Cela suppose que le FAI garde trace des numéros de téléphone de ses clients et que ceux-ci ne considèrent pas le message comme du spam. En outre, les contraintes de taille du SMS posent un drôle de défi au rédacteur du message.
- Le RFC mentionne aussi la possibilité d'utiliser un canal public
pour les notifications, par exemple d'utiliser un haut-parleur dans une
gare ou un café pour crier « Votre attention, s'il vous plait, nous
venons de découvrir que la machine
18:03:73:66:e5:68est infectée par un logiciel malveillant. Son propriétaire est prié de la désinfecter de toute urgence. » Cela peut être utile dans ces environnements, où l'administrateur du réseau n'a pas de lien particulier avec ses utilisateurs et ne sait pas comment les contacter.
À noter que toutes ces méthodes ne produisent pas de bons résultats au cas, le plus fréquent aujourd'hui, où les adresses IP sont partagées. Dans une entreprise de 500 personnes, montrer la notification aux 500 utilisateurs alors que seul l'administrateur système peut agir est probablement contre-productif. Si le FAI connaît les coordonnées dudit administrateur, il vaut certainement mieux lui écrire directement.
Cette discussion (section 5) des difficultés à attirer l'attention de ses propres clients sur un problème sérieux est la plus concrète du document. Mais elle pose plus de questions qu'elle n'apporte de réponses. Vous vous demandez peut-être quelle solution a finalement retenue Comcast ? Décrite dans le RFC 6108, elle consiste à modifier le contenu des pages Web vues par l'utilisateur pour y insérer une fenêtre-polichinelle d'avertissement.
La seule section qui ait un rapport direct avec le titre (section 6), sur les remèdes est, par contre, très courte, peut-être à juste titre, étant donné la difficulté à traiter les zombies. On les a détecté, on a notifié l'utilisateur, maintenant, que faire ? Le RFC suggère aux FAI de créer un site Web dédié à cet usage, où utilisateurs et administrateurs système pourront accéder à diverses documentations et outils. Les textes visant les utilisateurs sont difficiles à écrire : il faut les motiver pour agir (le bot peut être très discret, et l'utilisateur n'a alors rien détecté de problématique pour lui), sans les paniquer, et il faut expliquer rapidement car l'utilisateur ne lira pas de longs textes. Le RFC cite comme exemple d'introduction pour capter l'attention : « What is a bot? A bot is a piece of software, generally installed on your machine without your knowledge, which either sends spam or tries to steal your personal information. They can be very difficult to spot, though you may have noticed that your computer is running much more slowly than usual or you notice regular disk activity even when you are not doing anything. Ignoring this problem is risky to you and your personal information. Thus, bots need to be removed to protect your data and your personal information. »
La tâche de désinfection peut être difficile (surtout sur des engins comme les consoles de jeu, qui ne donnent typiquement pas accès au système) et, dans tous les cas, l'utilisateur n'a en général pas de compétences techniques : les instructions de désinfection doivent donc être très concrètes et détaillées.
Donc, sous forme d'une liste, voici quelques-unes des étapes que le RFC recommande de ne pas oublier, dans les conseils donnés aux utilisateurs :
- Faites des sauvegardes de vos fichiers (un bon avis, indépendamment de l'infection par le malware).
- Mettez à jour votre système (Windows Update avec Microsoft Windows, par exemple).
- Ne pas hésiter à demander l'aide d'un professionnel. Ce conseil du RFC est évidemment raisonnable (la tâche peut être trop complexe pour l'utilisateur ordinaire) mais me laisse perplexe : pour les soins aux machines de M. Toutlemonde, on trouve plein de gourous autoproclamés, dont les compétences en informatique sont en général à peine supérieures à celles de leurs clients. Ces derniers, ne connaissant pas le sujet, ne peuvent pas distinguer un vrai expert d'un Jean-Kevin Michu qui se prend pour un gourou parce qu'il a déjà installé une fois un Windows en partant de zéro. Ce problème me semble un des plus sérieux pour M. Toutlemonde « à qui faire confiance ? »
- Si l'utilisateur a l'intention de porter plainte, il faut faire l'inverse : ne pas nettoyer la machine mais la laisser intacte pour l'enquête (comme la scène du crime entourée du ruban jaune, dans les séries policières états-uniennes). Aux États-Unis, l'organisme national en charge est l'Internet Crime Complaint Center. (Quel est l'équivalent en France ?) Le RFC note toutefois en termes diplomatiquement polis qu'il y a peu de chance que la police se dérange parce que M. Toutlemonde a un virus sur sa machine... (Et j'ajoute que c'est parce que la police est occupée avec des crimes plus graves comme par exemple le partage de la culture.)
Et si l'utilisateur ne peut pas ou ne veut pas réparer (section 7) ? Le RFC note que c'est évidemment un problème non-technique et a une approche très états-unienne, « shoot them » (supprimer l'abonnement et déconnecter l'utilisateur).
Le document rend aussi un hommage obligatoire à la nécessite de préserver la vie privée des utilisateurs (sections 4 et 10), sans trop s'attarder sur comment concilier surveillance rapprochée et respect de la vie privée. Un intéressant problème à la fois politique et légal. Voir aussi la section 8 sur les problèmes que pose le partage de données entre l'utilisateur, le FAI et éventuellement les autorités. L'annexe A donne une liste d'organisations privées qui peuvent être intéressés par ces données (liste de machines infectées, pour faire une liste noire, par exemple) et les publier.
À noter qu'une autre faiblesse de ce document est que, pour éviter de déchaîner les avocats de Microsoft, le fait que la quasi-totalité des zombies soient aujourd'hui des machines Windows est tout simplement absent...
L'article seul
RFC 6544: TCP Candidates with Interactive Connectivity Establishment (ICE)
Date de publication du RFC : Mars 2012
Auteur(s) du RFC : J. Rosenberg (Skype), A. Keranen (Ericsson), B. Lowekamp (Skype), A. Roach (Tekelec)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF mmusic
Première rédaction de cet article le 20 mars 2012
Le protocole ICE, normalisé dans le RFC 8445, permet de traverser des obstacles comme les routeurs NAT, en essayant plusieurs techniques successives. ICE fonctionne en proposant une liste d'adresses candidates et en testant ensuite ces candidates (avec STUN, notamment) jusqu'à ce qu'on en trouve une qui passe. Dans le RFC originel sur ICE, ces candidates ne pouvaient être testées qu'en UDP. Désormais, notre RFC 6544 permet des candidates TCP (ainsi qu'un mélange des deux).
ICE vise surtout les applications pair-à-pair notamment pour le multimédia (par exemple, pour la télé-conférence). Pourquoi est-ce important de pouvoir faire du TCP ? La section 1 rappelle que certains protocoles ne marchent qu'avec TCP (comme le MSRP du RFC 4975) et que certains protocoles ont certes la possibilité d'utiliser UDP mais peuvent choisir TCP dans certains cas (RTP, RFC 4571, par exemple). C'est évidemment surtout utile dans le cas où on utilise TURN (RFC 5766), protocole qui est parfois le seul à passer certains routeurs NAT, en utilisant un relais TCP.
En général, pour les protocoles qui se servent d'ICE, UDP sera préférable (l'annexe A explique pourquoi). Dans les autres cas, ce nouveau RFC leur permet de faire enfin du TCP. (Et cette possibilité est désormais enregistrée à l'IANA.)
La section 3 résume les changements dans ICE liés à ce nouveau service. Mais c'est assez simple. Il y a trois sortes de candidats TCP, les actifs (qui vont ouvrir la connexion eux-mêmes), les passifs (qui attendent) et les S-O (Simultaneous Open) qui peuvent faire les deux. Dans la liste testée, le type du candidat est indiqué et ICE, pour tester une adresse, va évidemment les apparier en fonction du type (une adresse active avec une passive mais pas avec une autre active, par exemple). Le reste sera fait par de l'ICE normal, comme en UDP. Un petit piège : les messages STUN utilisés par ICE sont sur le même port que le trafic applicatif. Pour un protocole à messages comme UDP, il fallait donc marquer les messages pour les distinguer du trafic STUN. Pour un protocole à flot continu de données, comme TCP, il a fallu introduire un marquage, celui du RFC 4571 (conçu pour RTP mais qui peut être utilisé avec tout flot TCP).
Les détails de l'offre initiale figurent en section 4, par exemple la priorité accordée à UDP, lorsque le choix existe. S'il n'existe pas, on utilisera TCP, avec une adresse active, qui a plus de chances de pouvoir sortir du NAT.
Comme avec UDP, l'offre d'adresses candidates est encodée en SDP, avec un nouvel attribut pour différencier les adresses utilisées en TCP selon qu'elles soient actives ou passives. L'annexe C du RFC contient plusieurs exemples de descriptions SDP, par exemple, pour un appel audio :
v=0 o=jdoe 2890844526 2890842807 IN IP4 10.0.1.1 ... m=audio 45664 TCP/RTP/AVP 0 ... a=connection:new a=candidate:1 1 TCP 2128609279 10.0.1.1 9 typ host tcptype active a=candidate:2 1 TCP 2124414975 10.0.1.1 8998 typ host tcptype passive a=candidate:3 1 TCP 2120220671 10.0.1.1 8999 typ host tcptype so ...
Cet exemple ne montre que des candidats TCP, un de chaque sorte.
Et comment trouver toutes les adresses candidates possibles ? La section 5 donne quelques idées. Attention, plus il y a de candidates, et comme il faut tester chaque couple possible source/destination, plus les tests seront longs.
Les fanas de programmation noteront l'annexe B, qui explique que les opérations à effectuer avec ICE ne correspondent pas tout à fait à l'utilisation habituelle des sockets. Notamment, il s'agit, sur la même socket, d'initier des nouvelles connexions (vers le serveur STUN) et d'en recevoir (depuis les pairs distants). Le pseudo-code suivant est suggéré :
for i in 0 to MAX
sock_i = socket()
set(sock_i, SO_REUSEADDR)
bind(sock_i, local) /* Réserver les "sockets" et les lier à un
port */
listen(sock_0)
connect(sock_1, stun)
connect(sock_2, remote_a)
connect(sock_3, remote_b)
L'article seul
RFC 6563: Moving A6 to Historic Status
Date de publication du RFC : Mars 2012
Auteur(s) du RFC : S. Jiang (Huawei), D. Conrad (Cloudflare), B. Carpenter (Univ. of Auckland)
Pour information
Première rédaction de cet article le 13 mars 2012
Un peu de rangement dans le DNS : en
2000, un nouveau type d'enregistrement DNS, le
A6, avait été créé pour gérer plus facilement les
adresses IPv6 dans le DNS. N'ayant finalement
pas marché comme espéré, il vient d'être officiellement abandonné. Le
RFC 2874, qui le normalisait, devient « intérêt historique seulement ».
Le type officiel pour représenter les adresses
IPv6 dans le DNS était
le AAAA, introduit par le RFC 1886
(aujourd'hui RFC 3596). Très proche du type
A d'IPv4, il n'offrait pas
de services particuliers, par exemple pour gérer la rénumérotation
d'un réseau. Si on avait dans son fichier de zone :
www IN AAAA 2001:db8:33::1 mail IN AAAA 2001:db8:33::fada
et qu'on passe du réseau 2001:db8:33::/48 au
2001:db8:bad::/48, il fallait faire un
rechercher/remplacer pour changer toutes les adresses. Le type
A6, du RFC 2874, fournissait un système
plus souple, découplant le préfixe et l'adresse.
Évidemment, le fait d'avoir deux types pour les adresses IPv6 a
entraîné pas mal de confusion (section 2.5). Il est même possible que cela ait
contribué au retard du déploiement d'IPv6. En
2002, les RFC 3363 et RFC 3364 critiquaient A6 et il était reclassé
« expérimental ». Cela n'a apparemment pas suffit à éclaircir les
choses et notre RFC 6563 met aujourd'hui
A6 comme « d'intérêt historique seulement », ce
qui devrait enlever toute ambiguité. Le seul type pour représenter les
adresses IP dans le DNS est donc AAAA.
Mais que reprochait-on à A6, finalement ? La
section 2 de ce RFC résume les principaux problèmes (le RFC 3363 donne davantage de détails) :
- Latence accrue au moment de la résolution de noms (puisque
A6implique plusieurs requêtes DNS non-parallélisables, et sur des serveurs différents), - Probabilité d'échec plus élevée (il suffit qu'une des sous-requêtes de la chaîne échoue pour que la résolution soit impossible),
- Difficultés associées au franchissement de frontières
administratives : certes, le principe même d'
A6était de permettre de déléguer plus facilement, en mettant les différents enregistrements nécessaires dans des organisations différentes. Mais l'expérience d'A6(comme celle des enregistrements de colle dans la zone parente, ou celle desPTRdein-addr.arpa) a montré qu'il était très difficile de synchroniser de tels enregistrements « trans-frontières » et qu'ils se prêtaient mal à l'automatisation, - Complexité de la maintenance puisque le changement d'un
composant
A6peut affecter de nombreuses adresses IP, qu'on ne voit pas (le reste des données peut être dans une autre zone, et même avoir des TTL différents, rendant la prévision des résultats difficile), - Et enfin risques de sécurité, la résolution d'un nom en adresse IPv6 dépendant de davantage d'acteurs ; la compromission de l'un d'eux pouvait affecter beaucoup de monde.
La section 3 décrit l'usage effectif d'A6,
depuis que certaines versions de BIND (de 9.0 à
9.2, puis abandonné dans les versions ultérieures) ont
ajouté la gestion de ce type d'enregistrements. De même, certaines
versions de la GNU libc ont fait des requêtes
A6. Mais, aujourd'hui, l'analyse du trafic
sur deux serveurs DNS de la racine montre très peu de trafic
a6 Les statistiques sur les serveurs de
.fr gérés par
l'AFNIC montrent que A6
n'a pas disparu. Il ne fait certes
que 0,2 % des requêtes (contre 8 % pour AAAA)
mais il est le dixième type d'enregistrement
demandé, devant des types comme SPF, SSHFP,
NAPTR ou DNSKEY, normalement bien plus
« officiels ». Cela illustre le conservatisme des administrateurs
système (qui gardent en production de très vieilles versions de leurs logiciels).
La section 4 expose les conséquences de la reclassification de
A6 comme n'ayant qu'un intérêt historique. Les
gérants de zone DNS doivent retirer ces enregistrements (s'ils
existaient encore), les clients DNS doivent arrêter de demander des
A6 et les
serveurs DNS doivent désormais traiter ce type comme inconnu (RFC 3597) lors de la réception d'une requête. (Le type
A6 faisait partie de ceux pour lesquels le
serveur DNS devait faire un traitement spécial.) Comme c'est déjà
largement le cas, ce RFC n'aura sans doute pas de conséquence pratique.
L'article seul
Fiche de lecture : Guns, germs and steel
Auteur(s) du livre : Jared Diamond
Éditeur : Norton
978-0-393-31755-8
Publié en 1997
Première rédaction de cet article le 12 mars 2012
Un livre très ambitieux de Jared Diamond, puisqu'il s'agit d'étudier en un seul bouquin les causes du succès militaire de certaines civilisations sur d'autres. Pourquoi Pizarre a-t-il conquis l'empire inca au lieu que ce soit Atahualpa qui s'empare de l'Espagne et fasse prisonnier Charles Ier ? Pourquoi, demande un ami papou de l'auteur, les Européens ont-il envahi la Nouvelle-Guinée, alors que celle-ci était peuplée depuis aussi longtemps que l'Europe ? Un extra-terrestre qui aurait visité la Terre vers 5 000 avant notre ère aurait eu bien du mal à dire sur quel continent naîtrait les armées les plus puissantes.
Je ne pense pas qu'il puisse y avoir une seule réponse à des questions aussi complexes. Et Diamond est prudent, notant bien qu'on ne peut pas tout expliquer dans un seul livre, même de 500 pages. Sa thèse se déploie en deux parties. D'abord, la constatation que ceux qui ont envahi les autres étaient ceux qui avaient trois armes importantes : les fusils, les microbes et l'acier. Les fusils, bien sûr, car, dans la plupart des rencontres armées, ils ont assuré la victoire. L'acier car, même si on n'a pas de fusils, c'est lui qui est à la base de toute industrie. Et les microbes car, dans les guerres d'invasion, ils ont tué bien plus de monde que les fusils. L'empire inca était déjà ravagé par les maladies lorsque les conquistadores sont arrivés. Et la civilisation indienne du Mississipi a complètement disparu sans qu'un Européen n'ait eu à tirer un coup de feu : les germes ont suffi.
Mais, dit Diamond, cela ne fait que repousser l'explication. Pourquoi les Européens avaient-ils des armes à feu et des armes en métal, et pas les Indiens ? Et pourquoi les micro-organismes pathogènes étaient-ils d'un seul côté (seule la syphilis aurait traversé l'Atlantique en sens inverse) ? Pour les armes, une réponse possible est que les Indiens (ou les Papous, ou les aborigénes australiens ou les autres colonisés) étaient moins intelligents que les Européens. Diamond n'a pas de mal à réfuter cette thèse raciste en comparant le sort d'un Papou lâché dans le métro de New-York avec celui d'un New-yorkais dans la jungle de Nouvelle-Guinée. Les deux se débrouilleront aussi mal... et aussi bien si on les laisse dans leur environnement habituel. Selon Diamond, la principale source de la différence réside dans l'agriculture. Bien sûr, elle existait en Amérique ou en Nouvelle-Guinée. Mais, plus limitée et apparue bien plus tard, elle ne pouvait pas nourrir de telles concentrations de population, et les royaumes des pays colonisés n'avaient pas eu le temps d'atteindre un stade de développement permettant de mettre au point acier et canons, contrairement à ce qui fut développé en Eurasie.
Pire, ces peuples n'avaient que peu ou pas d'animaux domestiques, ces animaux étant à la fois des armes de guerre (le cheval...) et surtout la cause de la résistance aux germes qui seront fatals à tant de peuples : vivant au contact étroit de nombreux animaux, les habitants du continent eurasiatique avaient depuis longtemps établi un modus vivendi avec les organismes pathogènes.
Mais pourquoi une agriculture intense et précoce en Eurasie et pas dans le reste du monde ? Ce n'est pas le climat (plusieurs régions d'Amérique, comme la Californie, abriteront une agriculture très productive après l'arrivée des Européens). Ce n'est pas un refus ou une incapacité des peuples locaux (ils adopteront souvent très vite les animaux ou végétaux européens, par exemple le cheval chez les Indiens d'Amérique du Nord). Selon Diamond, la raison principale est de disponibilité d'espèces domesticables. La plupart des espèces animales et végétales ne le sont pas et la preuve en est que très peu d'espèces se sont ajoutées au cours des siècles, à celles qui sont domestiquées ou cultivées depuis l'Antiquité. Je dois dire que c'est une des choses que j'ignorais complètement : tous les animaux ne sont pas domesticables, loin de là. La chance des Eurasiatiques a été que la plupart des espèces animales qui convenaient (notamment chez les grands mammifères) étaient chez eux. L'Eurasie avait également un gros avantage pour les végétaux (le blé est plus productif que le maïs américain). Les villes sont donc apparues plus vite, puis la technologie, puis les fusils.
Autre facteur qui a contribué au développement plus rapide des techniques en Eurasie, l'orientation du continent. Lorsqu'une masse terrestre est orientée Est-Ouest, comme l'Eurasie, hommes, plantes et animaux peuvent voyager en restant à peu près à la même latitude, donc au même climat. Les idées et les plantes et animaux cultivables et domestiquables peuvent donc se diffuser. Les Chinois domestiquent le poulet et l'Europe en profite rapidement. Les cochons sont domestiqués dans le Croissant fertile et les Chinois l'ajoutent à leur bétail quelques siècles plus tard. Toute l'Eurasie profitait donc des inventions mises au point sur le continent. (La théorie qui explique les différences entre les civilisations essentiellement par l'environnement est connue sous le nom de déterminisme environnemental.)
Au contraire, l'Afrique est plutôt orientée Nord-Sud, avec les barrières du Sahara et de la forêt équatoriale, qui empêchent les inventions agricoles de passer. Les cultures du croissant fertile n'ont ainsi atteint l'Afrique du Sud, où le climat méditerranéen leur convenait, qu'avec les bateaux européens.
Même chose en Amérique, où les empires aztéque et inca restèrent séparés. L'invention de l'écriture par les Mayas n'atteignit pas l'empire Inca (sans doute le plus vaste empire jamais créé sans écriture), et les animaux domestiques (chien au Nord, cobaye et alpaga au Sud) ne passèrent jamais d'un empire à l'autre.
La puissance que donnait l'agricuture, avec la production massive de nourriture, est illustrée chez Diamond par bien d'autres phénomènes que la colonisation. Ainsi, un chapitre passionnant explique le peuplement de l'Afrique par les fermiers bantous, qui ont peu à peu déplacé ou remplacé les anciens peuples (Pygmées et Hottentots). Même chose pour le peuplement de la Chine.
Donc, un livre touffu, qui vulgarise très bien plein d'idées intéressantes. La recherche scientifique future infirmera peut-être une partie de ces affirmations mais j'apprécie l'effort pédagogique de l'auteur et les innombrables voyages qu'il nous fait faire.
Dommage qu'il ait ajouté aux dernières éditions du livre un mot sur les extensions de ses idées au management des entreprises. C'est qu'on ne gagne pas tellement sa vie en étudiant les oiseaux en Nouvelle-Guinée. Diamond pose donc sa candidature pour une activité de consultant, payé pour ses conférences, et se sent obligé de faire une pseudo-analyse des succès de Microsoft...
Pour deux bons articles critiques (pas au sens négatif) sur ce livre, voir « The World According to Jared Diamond » et « History Upside Down ».
L'article seul
Ajouter un en-tête Destination aux paquets IPv6
Première rédaction de cet article le 11 mars 2012
Le protocole IPv6 permet de définir des options dans le paquet IPv6, options qui vont s'insérer entre l'en-tête IPv6 et les données. Comment les définir depuis son programme ? On trouve très peu d'informations à ce sujet sur le Web. Alors, voici comment je fais, en C.
Lorsqu'on voulait mettre des valeurs quelconques dans un paquet IPv4, la technique la plus utilisée était celle des « prises brutes » (raw sockets) où on peut définir chaque bit à sa convenance. Elle est mal normalisée et dangereuse (il est facile de produire des paquets invalides). IPv6 préfère donc une autre approche, normalisée dans le RFC 3542, où des primitives de plus haut niveau sont fournies pour changer des choses dans le paquet. Mais le moins qu'on puisse dire est que le RFC n'est pas spécialement convivial (pas un seul exemple) et qu'on trouve peu de tutoriels en ligne... J'avais besoin d'insérer dans les paquets une option « Destination » (RFC 8200, section 4.6) et je n'ai rien trouvé nulle part. La deuxième édition du livre de Stevens n'est guère prolixe et un des rares exemples est même carrément faux.
Bref, en repartant du RFC 3542, sections 8 et 9, voici comment insérer une
option Destination dans un paquet IPv6 sortant : il existe deux
méthodes, une par paquet, à base de msghdr qu'on
passe à sendmsg, et une globale,
affectant tous les paquets envoyés sur la prise, à base de
inet6_opt_*. C'est cette dernière que
j'utilise. Le principe est de constituer l'en-tête Destination à l'aide
des routines inet6_opt_*, puis d'utiliser
setsockopt pour l'attacher à la
prise. L'en-tête sera alors ajouté à chaque paquet sortant. D'abord,
quelques constantes dont on aura besoin :
#define MIN_EXTLEN 8 #define EXT_TYPE 11
Ici, MIN_EXTLEN est la longueur minimale d'un
en-tête Destination, en octets (attention en lisant les paquets en binaire : le
champ Hdr Ext Len de l'en-tête est en unités de 8
octets et, en prime, il part de zéro ; l'interface du RFC 3542 nous dispense heureusement de ces particularités). Quant aux options contenues
dans l'en-tête Destination, on n'en mettra qu'une, de type 11, actuellement non
affecté. (Notez que les deux bits de poids le plus fort
encodent le comportement attendu du récepteur, s'il ne connait pas
l'option. Pour 11, ces deux bits sont à zéro, indiquant au récepteur
qu'il doit ignorer cette option, s'il ne la comprend pas.)
On crée ensuite la prise comme d'habitude. Puis on va fabriquer l'en-tête Destination. D'abord :
char *ext_buffer; ext_buffer = malloc(MIN_EXTLEN); ext_offset = inet6_opt_init(ext_buffer, MIN_EXTLEN); ext_buffer[0] = SOL_UDP;
Ici, ext_buffer va contenir l'option
Destination. Pour l'initialiser, on indique juste la taille (en
multiples de 8, obligatoirement). Rappelez-vous que la taille indiquée
ici n'est pas dans les mêmes unités, ni avec le même point de départ,
que ce qui apparaîtra dans le paquet sur le câble. Lisez donc bien le
RFC 3542, qui normalise l'API et pas
le RFC 2460 qui normalise le protocole. À ce
stade, ext_buffer contient {0x11, 0x00}, où le
0x11 désigne UDP, l'en-tête qui suivra notre
en-tête Destination. À chaque étape, ext_offset
indiquera la taille de ext_buffer en octets
On ajoute ensuite notre option EXT_TYPE :
char *ext_option;
uint8_t value;
ext_option = malloc(MIN_EXTLEN);
ext_offset =
inet6_opt_append(ext_buffer, MIN_EXTLEN, ext_offset, EXT_TYPE,
sizeof(value), 1,
&ext_option);
On a indiqué la taille de l'option
(sizeof(value), notez que
inet6_opt_append ajoutera tout seul la taille
pour indiquer le type et la longueur, les options étant encodées en
TLV) et l'alignement
désiré (1, c'est-à-dire pas de
contraintes). ext_option nous donnera accès au
contenu de l'option. ext_buffer vaut {0x11, 0x00,
0x0b, 0x01, 0xd0} où 0x0b est le type de notre option, 0x01 sa
longueur et 0xd0 une valeur quelconque puisqu'on n'a encore rien
indiqué (elle va donc dépendre de votre implémentation, 0xd0 est ce que
j'obtiens sur ma machine).
Maintenant, on met l'option à une certaine valeur, ici 9 :
value = 9: inet6_opt_set_val(ext_option, 0, &value, sizeof(value)
Et c'est fait, ext_buffer vaut {0x11, 0x00,
0x0b, 0x01, 0x09}.
Si on voulait mettre plusieurs options dans l'en-tête Destination,
on continuerait à appeler inet6_opt_append et
inet6_opt_set_val. Mais je vais m'arrêter
ici. (Notez toutefois que inet6_opt_*, plus loin,
ajoutera automatiquement une option de remplissage.)
On termine le travail :
ext_offset = inet6_opt_finish(ext_buffer, MIN_EXTLEN, ext_offset);
Cet appel à inet6_opt_finish n'est pas juste pour
faire joli. N'oubliez pas que l'en-tête Destination doit être composé
d'un multiple de 8 octets. Et nous n'en avons que 5 (type, longueur de
l'en-tête, type de l'unique option, longueur de l'unique option,
valeur de l'unique option, tous à 1
octet). inet6_opt_finish va donc être chargé du
remplissage
(padding). Après cette fonction,
ext_buffer vaudra {0x11, 0x00,
0x0b, 0x01, 0x09, 0x01, 0x01, 0x00}. Les trois derniers octets sont
ceux de l'option PadN (RFC 2460, section 4.2),
également en TLV :
un octet de type, un de longueur et un de données.
Voilà, à ce stade, on a un ext_buffer, de
longueur ext_offset, qui
contient un bel en-tête Destination, avec toutes les options
souhaitées, on n'a plus qu'à l'attacher à la prise :
setsockopt(sd, IPPROTO_IPV6, IPV6_DSTOPTS, ext_buffer, ext_offset);
Désormais, tout envoi de paquet par la prise sd
incluera cet en-tête :
sendto(sd, message, (size_t) messagesize, 0, result->ai_addr,
result->ai_addrlen);
Sur Linux, il faut être
root malheureusement, pour ajouter l'en-tête Destination. (Emmanuel Thierry me fait remarquer que c'est un peu plus compliqué : il faut avoir le privilège CAP_NET_RAW - requis pour ouvrir
une prise brute, pas nécessairement être root.
Donc on peut suggérer plutôt l'utilisation de setcap 'CAP_NET_RAW+eip' /chemin/vers/le/binaire.
Ou bien démarrer en root, et dès le démarrage du programme ne garder que ce privilège et abandonner le reste.)
On peut voir le résultat avec tcpdump :
15:31:41.020647 IP6 (hlim 64, next-header unknown (60) payload length: 26) \
2a01:e35:8bd9:8bb0:a0a7:ea9c:74e8:d397 > 2001:4b98:dc0:41:216:3eff:fece:1902: \
DSTOPT (opt_type 0x0b: len=1) (padn) \
42513 > 42: [udp sum ok] UDP, length 10
Le next-header unknown est l'en-tête Destination,
qui a en effet le numéro 60. tcpdump a quand même reconnu cet en-tête
DSTOPT et vu l'option de type 11 et le
PadN. Ensuite, il a bien vu l'UDP vers le port 42. Avec
tshark, c'est moins bien :
Internet Protocol Version 6
0110 .... = Version: 6
[0110 .... = This field makes the filter "ip.version == 6" possible: 6]
.... 0000 0000 .... .... .... .... .... = Traffic class: 0x00000000
.... .... .... 0000 0000 0000 0000 0000 = Flowlabel: 0x00000000
Payload length: 26
Next header: IPv6 destination option (0x3c)
Hop limit: 64
Source: 2a01:e35:8bd9:8bb0:a0a7:ea9c:74e8:d397 (2a01:e35:8bd9:8bb0:a0a7:ea9c:74e8:d397)
Destination: 2001:4b98:dc0:41:216:3eff:fece:1902 (2001:4b98:dc0:41:216:3eff:fece:1902)
Destination Option
Next header: UDP (0x11)
Length: 0 (8 bytes)
User Datagram Protocol, Src Port: 42513 (42513), Dst Port: name (42)
Source port: 42513 (42513)
Destination port: name (42)
Length: 18
tshark a tout juste trouvé qu'il y avait un en-tête Destination de longueur 8, sans pouvoir l'analyser. Wireshark affiche au moins le contenu de l'option, en hexadécimal.
Si vous aimez lire le C, voici le programme que j'ai utilisé.
L'article seul
Limiter le trafic d'un serveur DNS (notamment d'un récursif ouvert)
Première rédaction de cet article le 3 mars 2012
Il peut y avoir plusieurs raisons de limiter le trafic entrant dans un serveur DNS. Pour protéger le serveur lui-même ? Non, pas tellement, car, sur un serveur faisant autorité, cela consomme en général moins de ressources sur la machine pour répondre, que pour décider si on accepte de répondre. Sur un résolveur (un serveur récursif), la limitation du trafic peut déjà être plus utile. Mais elle est surtout indispensable si on gère un résolveur ouvert, accessible à tout l'Internet. Dans ces conditions, une forme de limitation de trafic est indispensable, car, sinon, on ne risque pas que ses propres ressources, mais celles des autres ; un serveur récursif ouvert est en effet une cible tentante pour des attaques par réflexion et amplification.
Le problème est connu depuis des années (mon premier article date de 2006) et le RFC 5358 dit clairement que ces serveurs récursifs ouverts sont fortement déconseillés. Toutefois, si on tient absolument à avoir un serveur DNS récursif ouvert, comment peut-on limiter le risque de devenir le relais de l'attaque, le complice involontaire d'une attaque par déni de service ?
La solution réside dans la limitation de trafic. Elle peut se faire sur un boîtier posé en avant du serveur (il en existe plusieurs modèles, tous très chers et au logiciel non libre). Ces boîtiers ont souvent de sérieuses restrictions quant au trafic accepté (si vous en évaluez un, regardez s'il laisse passer IPv6, EDNS, DNSSEC, etc). Et puis, pour un serveur connecté à l'Internet, il est toujours plus simple et plus cohérent qu'il assure sa propre protection.
Si le serveur tourne sur Linux, on a tout ce qu'il faut dans Netfilter. On trouve en ligne une quantité formidable de documentations sur Netfilter et sa commande iptables. Mais presque toutes ne parlent que des connexions TCP et utilisent donc un mécanisme qui garde un état, ce qui est coûteux en ressources (j'ai moi aussi fait un article sur le filtrage pour un service TCP). Le trafic DNS du résolveur étant en général strictement « un paquet pour la requête, un paquet pour la réponse », des solutions Netfilter comme les modules « state » ou « connlimit » n'ont sans doute guère d'intérêt (tous les paquets entrants seront dans l'état « nouveau flot, jamais encore vu »).
La meilleure solution me semble donc être avec le module « hashlimit », qui ne garde pas d'état par « session » (il faut évidemment un peu d'état pour chaque préfixe IP). Par exemple :
# iptables -A INPUT -p udp --dport 53 -m hashlimit \ --hashlimit-name DNS --hashlimit-above 20/second --hashlimit-mode srcip \ --hashlimit-burst 100 --hashlimit-srcmask 28 -j DROP
Cela permet 20 requêtes par seconde à chaque préfixe /28, avec un pic à 100
requêtes si nécessaire (le trafic sur l'Internet est très variable,
avec des pics importants). Si iptables vous répond Unknown
arg `--hashlimit-above', c'est que vous avez une version
trop ancienne pour faire de la limitation de trafic sérieuse (les
options que j'utilise sont apparues avec la 1.4.)
Notez bien que cette règle s'applique à toutes les requêtes DNS, quels que soient le nom demandé et le type de données demandé. Il existe des solutions pour se limiter à certaines requêtes mais, avec le protocole DNS, ce n'est pas facile.
julienth37 a adapté à IPv6 (masque de préfixe plus long) :
# ip6tables -A INPUT -p udp -m udp --dport 53 -m hashlimit \ --hashlimit-above 10/sec --hashlimit-burst 20 --hashlimit-mode srcip --hashlimit-name DNS \ --hashlimit-srcmask 64 -j DROP
Testons le un peu avec queryperf. Avec un cache rempli et la limitation de trafic :
Statistics: Queries sent: 10000 queries Queries completed: 7039 queries Queries lost: 2961 queries Percentage completed: 70.39% Percentage lost: 29.61%
On peut aussi demander à Netfilter ce qu'il a vu :
# iptables -v -n -L INPUT Chain INPUT (policy ACCEPT 21341 packets, 3194K bytes) pkts bytes target prot opt in out source destination 2944 190K DROP udp -- * * 0.0.0.0/0 0.0.0.0/0 udp dpt:53 limit: above 20/sec burst 100 mode srcip srcmask 28
Et le nombre de paquets jetés correspond en effet à celui des requêtes pour lesquelles queryperf n'a pas eu de réponse. On a donc limité l'attaquant (queryperf est, par défaut, nettement moins agressif qu'un vrai attaquant, qui enverrait les paquets à un rythme plus soutenu et en perdrait donc davantage).
Notez que la même machine, sans règle de limitation du trafic, fait :
Statistics: Queries sent: 10000 queries Queries completed: 9981 queries Queries lost: 19 queries Percentage completed: 99.81% Percentage lost: 0.19%
Bien sûr, un vrai test serait plus complexe : il faudrait un grand nombre de machines clientes, pour tenter d'épuiser les ressources du résolveur DNS utilisé comme relais. Mais c'est un premier pas vers la sécurisation d'un serveur récursif ouvert.
Un exemple d'un résolveur ouvert, pour de bonnes raisons est celui de l'OARC, pour tester DNSSEC. Un autre est celui de Telecomix, pour fournir un service de résolution qui ne censure pas. Bien sûr, la majorité des résolveurs ouverts le sont par négligence et ignorance et les non-administrateurs de ces machines ne la protégeront sans doute pas par un limiteur de trafic mais, pour les rares résolveurs ouverts sérieux, c'est une bonne idée.
L'article seul
RFC 6468: Sieve Notification Mechanism: SIP MESSAGE
Date de publication du RFC : Février 2012
Auteur(s) du RFC : A. Melnikov (Isode), B. Leiba (Huawei), K. Li (Huawei)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sieve
Première rédaction de cet article le 3 mars 2012
Je vais peut-être décevoir certains lecteurs mais, dans cet article, je ne parlerai pas du contenu du RFC mais uniquement du scandale de brevets qui l'a accompagné. En violation des règles de l'IETF, Huawei avait dissimulé l'existence d'un brevet que cette compagnie détenait sur le sujet de ce RFC.
Techniquement, ce RFC est simple : c'est une extension au langage de filtrage de courrier Sieve (RFC 5228) pour notifier des destinataires de l'arrivée d'un message, en utilisant le protocole SIP (RFC 3261). Comme les organismes de dépôt des brevets acceptent tout et n'importe quoi, on peut breveter une idée aussi simple... (Le brevet ne semble pas avoir encore été publié mais nul doute qu'il ne le sera : je n'ai pas trouvé de serveur permettant de lire les brevets chinois comme ce CN 200710076523.4 mais une version états-unienne existe aussi, le US Patent 20090204681.)
Le problème n'est pas que la technologie soit brevetée. Les règles de l'IETF ne l'interdisent pas. Le problème est que Huawei a dissimulé ce brevet, pour être sûr que le RFC soit adopté malgré cette menace (c'est ce qu'on nomme un brevet sous-marin). Et cette dissimulation, elle, est interdite par l'IETF (RFC 8179). Mais les entreprises capitalistes n'ont manifestement pas peur des règles de l'IETF, celle-ci n'ayant pas de dents pour mordre les contrevenants...
Laissons Adam Roach résumer ce qui s'est passé (message envoyé à la liste de diffusion générale de l'IETF) : Just to make sure I understand the sequence of events:
- 1. August 21, 2007: Huawei files a patent (CN 200710076523.4) on using SIP for SIEVE notifications. The inventor is listed as a single Huawei employee.
- 2. August 30, 2007: That same Huawei employee and two additional authors publish an IETF draft ( draft-melnikov-sieve-notify-sip-message-00) on using SIP for SIEVE notifications.
- 3. September 2007 - September 2011: The SIEVE working group discusses and improves the IETF draft.
- 4. October 6, 2011: The IESG approves the IETF draft for publication as an RFC.
- 5. December 14th, 2011: Huawei files an IPR disclosure with the IETF informing it of patent CN 200710076523.4
La publication du 14 décembre 2011 à laquelle il fait allusion est la #1658. Une version plus récente est la #1681.
Le 25 janvier 2012, l'IESG a relancé l'IETF (Second Last Call, un terme bien orwellien) pour demander un avis sur la publication du RFC, malgré la divulgation du brevet sous-marin. Suite à cela, le RFC a été publié. L'IETF n'avait aucun moyen de représailles, à part refuser le RFC (qui ne posait aucun problème technique).
Aucune sanction n'a été prise, l'IETF n'avait pas de mécanisme évident pour cela. Une discussion a commencé, qui a mené à la publication de deux RFC, un répressif, le RFC 6701 (qui liste des sanctions, de l'annonce publique de la tricherie, méthode du name and shame, jusqu'au retrait des Internet-Drafts des mains des tricheurs, en passant par la suspension de leur droit d'écriture dans les listes IETF, selon les principes du RFC 2418 et surtout du RFC 3683 - depuis remplacé par le RFC 9945), et un préventif, le RFC 6702.
À noter que Huawei n'est pas la première société à agir ainsi, RIM en avait fait autant.
L'article seul
RFC 6557: Procedures for Maintaining the Time Zone Database
Date de publication du RFC : Février 2012
Auteur(s) du RFC : E. Lear, P. Eggert
Première rédaction de cet article le 3 mars 2012
Vous aviez peut-être suivi l'affaire il y a quelques mois : une société d'astrologie (!) a fait un procès au responsable de la base de données des fuseaux horaires, base utilisée ensuite par des tas de logiciels dans le monde (notamment les logiciels libres). La société prétendait qu'elle était propriétaire des données. Comme le responsable de la base, Arthur David Olson, est un simple individu, sans moyens financiers (la justice, c'est seulement pour les riches), il a cédé. Désormais, cette base est gérée par l'IANA, et ce RFC documente les procédures de gestion.
La solution trouvée, confier cette base à l'ICANN, permet au moins de se mettre à l'abri des trolls, l'ICANN ayant beaucoup d'argent et d'avocats. Au moins, les millions de dollars stockés par l'ICANN, à titre de précaution juridique en cas de procès vont servir à quelque chose d'utile. Mais, en attendant, c'est un nouveau pan de la gouvernance de l'Internet qui passe d'un volontaire bénévole, aidé par quelques internautes, à une grosse bureaucratie politicienne, très lente et très chère.
Le registre est donc désormais en ligne à l'IANA. La section 7 du RFC discute les questions de propriété intellectuelle associées.
Quelques articles sur le sujet :
- Sur Slashdot, en anglais,
- Sur Wired, en anglais,
- Sur Linuxfr, en français.
- L'annonce de l'EFF se félicitant que le troll ait finalement cédé, mais oublie de dire qu'il est trop tard : l'ancien mode de gestion est bien fini.
L'article seul
RFC 6541: DKIM Authorized Third-Party Signers
Date de publication du RFC : Février 2012
Auteur(s) du RFC : M. Kucherawy (Cloudmark)
Expérimental
Première rédaction de cet article le 1 mars 2012
Depuis la sortie de la norme DKIM
d'authentification du courrier électronique
(originellement RFC 4871, désormais RFC 6376), il y a des incompréhensions sur ce que
DKIM garantit réellement. Beaucoup d'utilisateurs croient que,
lorsqu'un message prétend venir de joe@example.net et
qu'il est signé par DKIM, on peut être sûr que le message vient de
joe@example.net. Rien n'est plus
faux. DKIM garantit tout autre chose. Il dit que l'identité du
domaine signeur, dans le champ DKIM-Signature:,
est correcte, et que ce domaine prend la responsabilité du message. Résultat, il y a un fossé entre ce qu'espère
l'utilisateur et ce que DKIM livre effectivement. Ce
RFC expérimental propose une solution pour
combler ce fossé.
Voici une signature DKIM typique, envoyée par le service 23andme :
From: 23andMe Research Team <donotreply@23andme.com>
...
DKIM-Signature: v=1; q=dns/txt; a=rsa-sha256; c=relaxed/relaxed; s=132652; d=23andme.ccsend.com;
h=to:subject:mime-version:message-id:from:date:sender:list-unsubscribe:reply-to;
bh=87HtUCQR/Puz+14IeKPwOPzfeG32vY3BDJBMB74Kv+w=;
b=Omftsz+Y3ZbbSbaPWZadKuy8aP35ttpXKTTPdjY4VGttx82q5igLb2r14U3sFI7a+9OXpKODHqOC3HKz1hPQ3GW1L...
On y voit que le domaine 23andme.ccsend.com prend la
responsabilité de ce message (on peut vérifier l'authenticité de cette
déclaration en vérifiant cryptographiquement la signature, qu'on a récupéré dans le DNS, pour le nom 132652._domainkey.23andme.ccsend.com) mais que le
message dit avoir été envoyé par 23andme.com. Peut-on
vérifier cette prétention ? Non, pas avec DKIM. Celui-ci ne fournit,
et c'est un choix de conception délibéré, aucun mécanisme pour lier la
signature à l'« identité » de l'émetteur (notez au passage que le
concept d'identité d'un émetteur de courrier est déjà très flou).
Notre RFC 6541 propose un moyen de faire cette liaison : un domaine peut publier dans le DNS qu'il autorise des tiers à signer ses messages et à les garantir ainsi.
DKIM permettait déjà de déléguer la signature à des tiers (RFC 6376, sections 2.6 et 3.5) mais pas de dire « je fais entièrement confiance à tel domaine pour signer mes messages). C'est ce que fournit cette nouvelle norme, ATPS (Authorized Third-Party Signers).
Quels sont les parties en présence (sections 2 et 3) ?
- L'émetteur du
message est celui dont le domaine apparait dans le
From:du message (RFC 5322). - Le signeur est un tiers autorisé à signer avec DKIM. Il met
son propre domaine dans le champ
d=de la signature. - Le vérificateur est le récepteur du message, qui voudrait bien vérifier que le message vient effectivement du domaine de l'émetteur.
Dans le monde réel, l'émetteur va par exemple être une entreprise avec une
infrastructure de messagerie sommaire, ne permettant pas de signer, et
le signeur ATPS va être son sous-traitant. Pour faire connaître cette
relation d'affaires entre l'émetteur et son sous-traitant, ATPS permet à
l'émetteur de publier dans le DNS un enregistrement
TXT annonçant ce lien. Le vérificateur pourra alors
récupérer cet enregistrement et se dire « le message est signé par
provider.example, le message prétend être émis
par customer.example, or le domaine
customer.example contient bien un enregistrement
ATPS désignant provider.example comme signeur
autorisé »
La section 4 contient les détails techniques du protocole. D'abord,
quel va être le nom de l'enregistrement TXT dans le domaine émetteur ?
(Au fait, l'annexe B explique pourquoi utiliser TXT et pas un nouveau type.) Il peut
être directement le nom du domaine du signeur mais aussi une
version encodée de ce nom. Ensuite, que contient la signature DKIM en
cas d'utilisation d'ATPS ? Deux nouveaux champs,
atps= et atpsh= (désormais
dans le registre IANA) apparaissent. Si le champ
d= contiendra, comme avant, le nom de domaine du
signeur, le nouveau champ atps= contiendra le nom
de domaine de celui pour lequel on signe, l'émetteur. Le vérificateur
testera si la valeur d'atps= correspond à l'en-tête
From: (ATPS est ignoré s'ils ne correspondent
pas), fait une requête DNS pour le type TXT, et vérifie qu'on obtient
bien une réponse positive.
Le nom de domaine interrogé pour le type TXT est, dans le cas le
plus simple, le
DOMAINE-SIGNEUR._atps.DOMAINE-ÉMETTEUR. Si
atpsh= contient autre chose que
none, alors DOMAINE-SIGNEUR
est remplacé par un condensé de son nom.
S'il y a une réponse positive, c'est-à-dire un enregistrement TXT,
c'est que c'est bon (pour plus de sécurité, l'enregistrement TXT doit
contenir d=DOMAINE-SIGNEUR). Si on récupère NXDOMAIN (nom
non existant) ou bien NOERROR mais pas
d'enregistrement TXT, c'est que la vérification a échoué. Le signeur
n'est en fait pas autorisé à signer pour l'émetteur (section 5). Le vérificateur
peut prendre une décision comme de mettre un résultat
d'authentification dans les en-têtes du message (cf. section 8.2 pour
la création d'un nouveau type d'authentification,
dkim-atps, mis dans le registre IANA nomalisé par le RFC 7001).
Et les ADSP (Author Domain Signing Practices) du RFC 5617 ? Ce protocole permet à un domaine émetteur d'annoncer si ses messages sont signés ou non avec DKIM. La section 6 de notre RFC prévoit qu'ATPS doit être testé avant ADSP.
Ce RFC est seulement expérimental. L'idée même d'ATPS est fortement
contestée (les questions de sécurité et de confiance sont toujours
sensibles...) et le besoin s'est fait sentir d'un essai en vrai, pour
déterminer si ATPS marche bien ou pas. ATPS est déjà mis en
œuvre dans OpenDKIM (il faut configurer
avec les options --enable-atps --enable-xtags),
bibliothèque utilisée notamment par sendmail. Il inclut même un outil pour générer les enregistrements TXT. Les auteurs d'ATPS ont promis
de tester et de décrire dans un document ultérieur le résultat de ces
tests.
Quelques points particuliers de sécurité (section 9) :
- La condensation des noms des domaines signeurs avant de faire la requête DNS ne vise pas à fournir la moindre confidentialité, mais simplement à obtenir des noms de taille fixe et connue, ce qui est plus pratique pour les requêtes DNS.
- Et, naturellement, publier un enregistrement ATPS revient à sous-traiter une partie de sa sécurité au signeur. Comme toute sous-traitance, il faut donc bien vérifier à qui on fait confiance.
Notez que le RFC ne fournit pas un seul exemple complet de signature avec ATPS et je n'en ai pas encore trouvé dans ma boîte aux lettres.
L'article seul
RFC 6537: Host Identity Protocol Distributed Hash Table Interface
Date de publication du RFC : Février 2012
Auteur(s) du RFC : J. Ahrenholz (Boeing)
Expérimental
Réalisé dans le cadre du groupe de recherche IRTF hiprg
Première rédaction de cet article le 1 mars 2012
Dans tout protocole réseau séparant le localisateur et l'identificateur, il y a une grosse question : comment relier les deux ? Comment, lorsqu'on ne connait que l'identificateur d'une machine, trouver son localisateur afin de lui envoyer un paquet ? Le protocole HIP a plusieurs solutions possibles et ce RFC de l'IRTF en propose une nouvelle : faire appel à une DHT.
Dans HIP, l'identificateur est la partie publique d'une clé cryptographique, et le localisateur une adresse IP. Notre RFC 6537 propose de stocker la correspondance entre les deux dans une DHT. En outre, un second service est proposé, celui permettant de trouver l'identificateur à partir d'un nom de domaine. En fait, ce RFC ne décrit pas tellement la DHT, mais simplement l'interface entre la machine HIP et un service de résolution (qui pourrait aussi bien être mis en œuvre autrement ; le titre du RFC est donc trompeur).
Pourquoi, d'ailleurs, une DHT ? Comme l'expose la section 1, une des bonnes raisons est que l'espace de nommage des identificateurs est plat : il n'y a pas de hiérarchie permettant des résolutions efficaces comme avec le DNS. Les DHT permettent justement de résoudre des noms situés dans un espace plat aussi efficacement que les protocoles reposant sur des noms hiérarchiques.
Petit détail au passage, le protocole de ce RFC n'utilise pas directement les identificateurs (HI pour Host Identifier) mais leur condensat, le HIT (Host Identifier Tag). Il y a donc deux services, nom->HIT et HIT->adresses.
Le DNS est très optimisé depuis longtemps (et il existe un autre travail en cours pour résoudre les identificateurs HIP en localisateurs avec le DNS) mais explorer de nouvelles techniques est toujours intéressant. Il s'agit donc d'un travail plutôt expérimental, où plein de questions n'ont pas encore de réponse.
Une expérience concrète a été faite en utilisant la DHT Bamboo, écrite en Java, et
qui formait la base du service OpenDHT (service qui tournait sur
PlanetLab et a été fermé en 2009). Comme toute DHT, ou d'ailleurs
comme toute table (les dictionnaires de
Python, les hashes de
Perl, les java.util.Dictionary de Java,
etc), OpenDHT fournissait trois primitives, put,
get et remove. La première
permet de stocker une valeur, sous un certain index (on dit souvent
« clé » mais je l'ai évité pour ne pas risquer une confusion avec les
clés cryptographiques), la seconde de récupérer une valeur dont on
connait l'index, et la troisième (rm dans la
documentation) de supprimer une valeur. Dans
OpenDHT, ces trois primitives étaient appelées via le protocole
XML-RPC.
La section 2 décrit précisement cette interface XML-RPC. Elle avait été choisie parce qu'OpenDHT fournissait un service simple et gratuit accessible aux chercheurs. Les index pouvaient avoir jusqu'à 20 octets, les valeurs jusqu'à 1024. Toutes les entrées étaient temporaires, OpenDHT les supprimant au plus une semaine après leur insertion (un problème classique des DHT et du pair-à-pair en général est sa vulnérabilité aux méchants, ici à des machines insérant des quantités énormes de données pour faire une DoS).
Outre les paramètres cités plus haut (l'index et la valeur pour
put, l'index pour get et
rm), OpenDHT imposait quelques autres paramètres
comme le TTL du précédent paragraphe, comme un
identifiant de l'application, ou comme un mot de passe permettant de
fournir un peu de
sécurité.
Une fois qu'on a compris l'interface XML-RPC d'OpenDHT et ses paramètres, comment l'utilise-t-on pour HIP ? C'est l'objet de la section 3 et des suivantes. D'abord, on définit en section 3 une structure de données, le HDRR (HIP DHT Resource Record). Son format binaire est le même que celui d'un paquet HIP (RFC 5201, section 5, le HDRR a le numéro 20 dans le registre IANA), c'est-à-dire essentiellement une suite de paramètres encodés en TLV. Il n'a donc rien à voir avec le Resource Record DNS du RFC 5205.
Ces paramètres sont surtout des HI (Host Identifier, identificateurs), des HIT (rappelez-vous que c'est un condensat cryptographique du HI) et des localisateurs (les adresses IP, v4 ou v6). On peut aussi y trouver un certificat, au format du RFC 6253 ou une signature HIP. Ces deux derniers paramètres pourraient, dans une DHT spécialisée, être utilisée pour vérifier que la machine qui enregistre un localisateur pour un identificateur donné est bien autorisée à le faire (cd. RFC 7343, c'est une des forces de HIP, que d'avoir des clés cryptographique comme identificateur, cela permet de signer ses paquets et d'éviter ainsi l'usurpation). Toutefois, cela n'est pas mis en œuvre dans Bamboo, DHT généraliste qui ne sert pas qu'à HIP. Le problème de la DHT spécialisée en HIP est de toute façon plus complexe que cela : par exemple, les vérifications cryptographiques nécessaires faciliteraient une éventuelle attaque par déni de service contre la DHT (HIP évite ce problème par un protocole d'établissement de connexion conçu à cet effet, cf. RFC 5201, section 4.1.1).
Puis, la section 4 décrit le protocole de requête. Il fournit deux services :
- Étant donné un nom, trouver le HIT. Le nom est typiquement un FQDN. Notez que le RFC 5205 fournit une autre solution à ce problème, en utilisant le DNS.
- Étant donné un HIT, trouver le ou les localisateurs.
Il n'y a pas de requête directe du nom vers les localisateurs. La première correspondance, nom->HIT, est supposée relativement stable (une machine HIP n'a guère de raisons de changer d'identificateur). La seconde correspondance est typiquement variable, voire très variable en cas de mobilité (RFC 5206).
Le reste, ce sont des détails techniques. Par exemple, l'index utilisé pour la requête à la DHT dans le premier cas n'est pas réellement le nom mais un SHA-1 du nom car les index OpenDHT sont limités à vingt octets. Autre point qu'il a fallu régler, les HIT sont typiquement représentés comme des adresses IPv6 ORCHID (RFC 7343), et donc tous les HIT commencent par les mêmes 28 bits (la longueur du préfixe ORCHID). Pour une DHT, qui utilise un hachage des index pour trouver le nœud responsable du stockage des données correspondantes, cela risquerait de causer une répartition très inégale, certains pairs de la DHT étant plus chargés que d'autres. Lors de la deuxième requête (HIT->localisateurs), on n'utilise donc comme index que les 100 derniers bits du HIT.
Une fois ces détails de syntaxe réglés, la section 5 décrit la chorégraphie des requêtes. D'abord, pour trouver un identificateur (ou bien son HIT) à partir d'un nom de domaine, faut-il utiliser le DNS, comme le prévoit le RFC 5205 ou bien le service DHT décrit dans ce RFC 6537 ? La réponse dépend des cas. Tout le monde n'a pas forcément le contrôle des serveurs de noms du domaine souhaité et, même si c'est le cas, tous les serveurs de noms ne permettent pas forcément d'ajouter des enregistrements DNS de type HIP dans leur domaine (testez avec l'interface de votre hébergeur DNS pour voir...) Donc, la solution DHT est intéressante au moins dans ces cas.
On l'a vu, les localisateurs changent, c'est normal. Quand faut-il faire la requête HI->localisateur ? Si on la fait très à l'avance, les localisateurs seront peut-être usagés lorsqu'on s'en servira. Si on la fait au moment de la connexion, on peut ralentir celle-ci de manière intolérable. Le RFC suggère donc de faire les requêtes à l'avance, et, si la première tentative de connexion échoue, de refaire une requête de résolution avant de tenter la deuxième connexion.
Les informations enregistrées dans OpenDHT ont une durée de vie (le
paramètre ttl de la requête, mais la DHT peut
aussi supprimer les données avant l'expiration de celui-ci, par
exemple s'il faut faire de la place). Une machine HIP doit donc penser
à mettre à jour régulièrement ses entrées dans la DHT, pour s'assurer
qu'il y a toujours quelque chose. Et, naturellement, si l'information
change, la machine doit prévenir la DHT dès que possible.
La DHT étant globale, les adresses IP privées (RFC 1918) ne doivent pas être publiées dans la DHT. Si une machine HIP est coincée derrière un routeur NAT, elle doit, si elle veut être contactée, enregistrer l'adresse du serveur HIP de rendez-vous (RFC 5204).
OpenDHT présentait quelques particularités qui pouvaient surprendre
la machine HIP tentant de stocker ses identificateurs et
localisateurs. Par exemple, un put ne remplace
pas la donnée précédente, il s'y ajoute. Et rien ne garantit que
l'ordre dans lequel seront renvoyés les HDRR sera celui dans lequel
ils ont été insérés. Il faut donc identifier le plus récent (le HDRR a
un paramètre Update ID, dont je n'avais pas
encore parlé, juste pour cela). Le mieux serait de penser à faire
le ménage et virer explicitement ses vieilles informations.
Notez d'ailleurs que, le nom n'étant pas authentifié, on peut voir
plusieurs machines s'enregistrer sous le même nom. En attendant un
système d'authentification du nom (certificat
X.509 portant ce nom en sujet ?), il est
recommandé de tester et de choisir un autre nom, si celui qu'on
voulait est déjà pris (ce qui ne devrait pas arriver, avec les noms de
domaine, mais la DHT ne vérifie pas que celui qui enregistre
www.google.com a le droit).
Autre problème pratique, le choix de la passerelle XML-RPC vers
OpenDHT. Il en existait plusieurs, d'une fiabilité douteuse (OpenDHT
était un projet de recherche, qui ne visait pas à fournir un service
fiable à 100 %) et le client doit donc être prêt à détecter une panne
et à passer sur une autre passerelle (OpenDHT fournissait un service
anycast,
opendht.nyuld.net, qui facilitait cette
tâche.)
À propos de qualité de service, le RFC note aussi qu'OpenDHT ne
garantissait pas de temps de réponse, et que les opérations
put et get peuvent être
lentes, ce à quoi les clients de la DHT doivent se préparer.
Pour approfondir davantage les questions de sécurité (point faible classique de toutes les DHT), la section 7 fait un examen complet des problèmes que pose cette solution. Concernant le contenu de l'information, l'attaque peut être menée par un client de la DHT qui enregistre délibérement des informations fausses, ou bien par un pair participant à la DHT qui modifie les informations avant de les rendre. En l'absence d'un mécanisme tiers d'authentification des données (la DHT de CoDoNS utilisait DNSSEC pour cela), il n'y a pas grand'chose à faire. On l'a dit, c'est un problème récurrent avec toutes les DHT. Le RFC dit que les paranoïaques n'ont pas d'autres solutions que d'échanger les HIT à la main (ensuite, même si la DHT renvoie de mauvais localisateurs, le protocole HIP permettra de vérifier qu'on ne se connecte pas à une machine pirate). Dans le futur, une solution serait peut-être d'utiliser des certificats numériques.
Je l'ai dit, le protocole HIP garantit au moins, par la signature des paquets échangés lors de la connexion, qu'on se connecte bien à la machine possédant l'identificateur voulu. Pour un attaquant, enregistrer dans la DHT de fausses correspondances HIT->localisateur ne permet donc pas de détourner vers une machine pirate. Pour ce stade, la seule possibilité de l'attaquant est d'enregistrer plein de correspondances bidons, pour faire une attaque par déni de service.
La seule solution à long terme à cette attaque serait que la DHT vérifie les données avant de les enregistrer, et donc connaisse HIP. Elle pourrait tester que la signature incluse dans la requête corresponde à la clé publique (l'identificateur). Cette vérification laisserait la DHT vulnérable à d'autres attaques par déni de service, où l'attaquant ferait beaucoup de requêtes et imposerait donc beaucoup de vérifications. Pour parer cela, on peut imaginer une DHT qui impose que ses clients la contactent en HIP, réutilisant ainsi les protections anti-DoS de HIP. Et cela permettrait de s'assurer que le client n'enregistre des localisateurs que pour lui.
À noter enfin que OpenLookup est un exemple d'un service fournissant la même interface qu'OpenDHT même si, derrière, ce n'est pas une DHT.
L'article seul
RFC 6547: RFC 3627 to Historic Status
Date de publication du RFC : Février 2012
Auteur(s) du RFC : W. George (Time Warner Cable)
Pour information
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 1 mars 2012
Un très court RFC qui se contente de déclarer formellement que le RFC 3627 n'a plus qu'un intérêt historique. La principale recommendation de ce vieux RFC, que les liens point-à-point ne soient pas numérotés en IPv6 avec un /127, a été annulée par le RFC 6164, qui recommande au contraire cette pratique.
L'article seul
Vider le cache d'un résolveur DNS, pour un seul domaine
Première rédaction de cet article le 26 février 2012
Dernière mise à jour le 2 mars 2012
Lorsqu'on administre un résolveur DNS, il arrive que les informations concernant un domaine soient erronées, et qu'il faille les oublier, les supprimer du cache. La plupart des administrateurs système redémarrent le démon. Mauvaise méthode, trop radicale (elle fait perdre l'intégralité du cache). Tous les logiciels résolveurs sérieux permettent au contraire de ne supprimer qu'un seul domaine du cache.
Il peut y avoir plusieurs raisons pour ces mauvaises données dans le cache : empoisonnement délibéré (attaque Kaminsky), erreur dans le domaine (comme la panne de .SE), embrouille DNSSEC (signature expirée...), etc. Normalement, aucune de ces causes n'est permanente. Mais, comme le résolveur DNS a un cache, une fois la mauvaise information acquise, il va la garder pendant une durée indiquée par le TTL alors qu'on voudrait, sachant que le problème a été corrigé, repartir tout de suite du bon pied.
À ce stade, beaucoup d'administrateurs système ont appliqué la
méthode Windows : « dans le doute, reboote » et
redémarré le serveur DNS voire, pour les plus windowsiens, toute la
machine. Le résultat est qu'ils perdent la totalité du cache et qu'ils
privent de service DNS les clients pendant quelques secondes ou
quelques minutes. Une bien meilleure méthode est de ne vider
(to flush, dans la langue de Jean
Auel) que le domaine en cause
(foobar.example dans les exemples qui suivent).
Avec Unbound, cela se fait ainsi :
# unbound-control flush_zone foobar.example ok removed 78 rrsets, 60 messages and 1 key entries
Et, avec BIND :
# rndc flushname foobar.example
Notez au passage que, pour d'évidentes raisons de sécurité, ces
commandes ne sont en général accessibles qu'à
root (elles nécessitent la lecture d'un fichier
de configuration contenant les informations d'authentification,
fichier lisible par root seul, autrement vous aurez un message comme
fopen:Permission
denied:bss_file.c:356:fopen('/etc/unbound/unbound_control.pem','r')
ou comme open: /etc/bind/rndc.key: permission denied).
Les deux commandes n'ont pas tout à fait la même sémantique (merci
à David Gavarret pour le rappel). unbound-control
flush_zone vide récursivement tous les noms situés sous le
nom indiqué (la commande unbound-control
flush est son équivalent en non-récursif). Au contraire,
BIND n'a qu'une commande, flushname, et elle est
non-récursive. On ne peut donc pas l'utiliser pour des cas comme celui
de .se cité plus haut, où
il fallait vider le cache de tous les noms se terminant par
.se. BIND 9.9 (pas encore sorti aujourd'hui)
apportera la commande rndc flushtree qui lui
donnera les mêmes possibilités qu'à Unbound.
Ces deux commandes (celle pour Unbound et celle pour BIND)
nécessitent une certaine configuration pour assurer
l'authentification. Elle est typiquement faite automatiquement lors de
l'installation mais cela peut dépendre du
paquetage utilisé. Pour Unbound, il faut en
outre veiller à ce que le fichier de configuration
unbound.conf contienne control-enable:
yes. La création des clés X.509
utilisées par Unbound pour l'authentification se fait avec un
programme livré avec Unbound :
# unbound-control-setup setup in directory /etc/unbound generating unbound_server.key Generating RSA private key, 1536 bit long modulus ......................++++ ..................++++ e is 65537 (0x10001) generating unbound_control.key Generating RSA private key, 1536 bit long modulus ...........................++++ ..............................................++++ e is 65537 (0x10001) create unbound_server.pem (self signed certificate) create unbound_control.pem (signed client certificate) Signature ok subject=/CN=unbound-control Getting CA Private Key Setup success. Certificates created. Enable in unbound.conf file to use
Pour BIND, la configuration par défaut inclus en général ce qu'il faut
avec un fichier /etc/bind/rndc.key lu par le
serveur et par rndc. Si ce n'est pas le cas, voir la fin
de mon article sur le RFC 6168, qui donne tous
les détails.
Vous pouvez tester que la configuration fonctionne avec une commande inoffensive comme :
# unbound-control status
ou :
# rndc status
Par contre, je n'ai pas d'expérience pratique de cette technique avec le troisième grand logiciel libre sur ce créneau, PowerDNS recursor. Mais Jean-Eudes Onfray s'en est chargé et voici ses conclusions :
# /usr/bin/rec_control wipe-cache foobar.example
Pour les versions antérieures à 3.1, il faut ajouter un point à la fin du domaine :
# /usr/bin/rec_control wipe-cache foobar.example.
Comme la rndc flushname de BIND, cette commande est non-récursive.
Quant au serveur DNS de Windows, il est très difficile de trouver de l'information fiable et je n'ai pas testé. Mais Clément Fender l'a fait et voici ses conclusions :
J'ai rapidement maquetté (deux serveurs DNS : un hébergeur et un résolveur) et longuement pris le temps de tester sur un environnement composé de deux serveurs fonctionnant sous Windows 2008. J'ai établi les conclusions suivantes :
- les commandes que vous proposiez (
DnsCmd 127.0.0.1 /NodeDelete foobar.example foobar.example), et celles énoncées sur Technet, n'ont pas fonctionné. - afin d'obtenir le résultat escompté (suppression du cache des informations d'une zone) je suis (après moult essais) parvenu à faire fonctionner la commande décrite plus loin.
C:\Users\Administrateur> dnscmd 127.0.0.1 /nodedelete . dns1.zone. /tree
Êtes-vous sûr de vouloir supprimer le noud ? (o/n)y
Le serveur DNS 127.0.0.1 a supprimé le noud au niveau de dns1.zone. :
Statut = 0 (0x00000000)
La commande s'est terminée correctement.
Cette commande a aussi supprimé les informations relatives à des zones filles de dns1.zone.
Il faut indiquer le commutateur /tree car sans son utilisation, la commande abouti mais ne supprime
que les enregistrement directement liés à la zone (SOA et NS). Les enregistrements A présents
directement dans cette zone ne sont pas supprimés du cache.
Pour la commande utilisant le commutateur /zonedelete, elle fonctionne mais ne répond
pas au besoin exprimé : elle n'agit pas sur les information stockées en cache sur le serveur. Dans
mon cas de maquettage, elle a abouti à la suppression pure et simple de la configuration du
redirecteur conditionnel ... sans toucher aux informations stockées en
cache.
C:\Users\Administrateur> dnscmd 127.0.0.1 /zonedelete dns1.zone.
Êtes-vous sûr de vouloir supprimer la zone ? (o/n)y
Le serveur DNS 127.0.0.1 a supprimé la zone dns1.zone. :
Statut = 0 (0x00000000)
La commande s'est terminée correctement.
Afin de supprimer du cache un enregistrement d'adresse (A) présent dans la zone :
C:\Users\Administrateur> dnscmd 127.0.0.1 /nodedelete . arecord.dns1.zone.
Êtes-vous sûr de vouloir supprimer le noud ? (o/n)y
Le serveur DNS 127.0.0.1 a supprimé le noud au niveau de arecord.dns1.zone. :
Statut = 0 (0x00000000)
La commande s'est terminée correctement.
Attention cependant sur les versions françaises du système, si l'on n'utilise pas le commutateur /f pour
forcer, à la demande de confirmation (invitant à saisir o/n) il faut répondre y(es) car o ne
fonctionne pas. (Fin du compte-rendu de Clément Fender.)
Et, enfin, certains résolveurs DNS publics offrent une interface Web pour vider le cache pour un domaine donné. C'est par exemple le cas de Google Public DNS.
Petit avertissement : dans les entretiens d'embauche pour recruter un administrateur système, je pose cette question :-)
L'article seul
RFC 6497: BCP 47 Extension T - Transformed Content
Date de publication du RFC : Février 2012
Auteur(s) du RFC : M. Davis (Google), A. Phillips (Lab126), Y. Umaoka (IBM), C. Falk (Infinite Automata)
Pour information
Première rédaction de cet article le 23 février 2012
Le RFC 5646, qui normalise les étiquettes de langue, prévoit un mécanisme d'extension pour ajouter à ces étiquettes des informations maintenues dans des registres extérieurs. Ces extensions sont identifiées par une lettre unique et une nouvelle extension est ajoutée par notre RFC 6497, « T » (pour transformation), qui permet d'indiquer les transformations qu'a subies un texte (par exemple une traduction), en se référant au registre CLDR.
Le RFC 5646 est également connu sous
l'identificateur « BCP 47 » (BCP pour Best Common
Practice), ce qui explique le titre de notre RFC 6497. Les transformations qu'on pourra noter dans une
étiquette de langue sont notamment la
translittération, la
transcription et la
traduction. Sans cette extension « T », on ne
peut étiqueter que l'état actuel du document. Par exemple,
pes-Latn désignerait un texte en
persan dans l'alphabet
latin (ce qui est inhabituel) ; l'extension « T » permettra
d'écrire pes-Latn-t-pes-arab, indiquant que le
texte persan a été translittéré ou transcrit depuis l'alphabet
arabe. Autre exemple, donné dans le
RFC, une carte
d'Italie pour des japonais où les noms des villes ont été
translittérés en Katakana. N'indiquer que
ja (langue japonaise) pour
ce texte serait insuffisant. Cette information sur la source, donnée
par l'extension « T » est souvent
importante, pour aider à comprendre certaines particularités du
texte (comme des fautes lors de la traduction). Le mécanisme des variantes du RFC 5646 ne
suffisait pas pour cela, d'où la nouvelle extension. C'est la deuxième
enregistrée, après la « U » du RFC 6067. Le
mécanisme d'extension est normalisé dans le RFC 5646,
sections 2.2.6 et 3.7. Les extensions sont enregistrées dans
le registre IANA.
Parfois, il existe des méthodes standard de translittération ou de transcription. C'est par exemple le cas de celles spécifiées par l'UNGEGN. La nouvelle extension « T » permet également d'indiquer comment et par quelle méthode standard un texte a été translittéré ou transcrit.
Maintenant, les détails techniques : l'extension est notée par un
t suivi d'une étiquette de langue légale (section
2, notamment 2.2). Ainsi,
es-t-pid signifie que le texte est en
espagnol, traduit du piaroa. Mais, comme le texte après
t peut être une étiquette de langue complète, on
peut noter bien plus de détails, comme l'écriture utilisée (comme dans
l'exemple du perse plus haut). Comme l'étiquette de langue doit
comporter obligatoirement une langue en première position, si celle-ci
n'est pas connue ou tout simplement pas pertinente (rappelez-vous que
la différence principale entre translittération et transcription est
que la première ne dépend pas de la langue, c'est
une opération purement mécanique sur les caractères), on la note par
und, ce qui veut dire « inconnue ». Ainsi,
und-Latn-t-und-cyrl signifie que le texte a été
translittéré de l'alphabet cyrillique vers le
latin (par exemple par l'algorithme ISO 9),
sans tenir compte des langues en jeu.
Enfin, il est possible d'indiquer le mécanisme de transformation,
en utilisant le séparateur m0, puis l'organisme
qui spécifie ces mécanismes, puis un identificateur d'un mécanisme
particulier. Ainsi,
und-Cyrl-t-und-latn-m0-ungegn-2007 est du texte
en alphabet latin, transformé en cyrillique, suivant la spécification
UNGEGN de 2007. D'autres séparateurs que m0 seront peut-être créés dans le futur.
Quels termes peut-on mettre après m0 ? Ce qui
vous passe par la tête ? Non. Il faut suivre la section 3 du document
Unicode UTR #35. C'est
d'ailleurs le consortium Unicode qui est
l'autorité gérant l'extension « T » (section 2.4). Cela a suscité de
vigoureuses discussions (pourquoi pas
l'IETF ?). La conséquence en a été la
définition d'un mécanisme plus ouvert pour soumettre des propositions
de changement. Si on veut
enregistrer de nouvelles possibilités (section 2.6), cela se fait en
créant un ticket en http://cldr.unicode.org/index/bug-reports/.
La liste complète des possibilités de mécanismes de transformation
figure dans un fichier structuré (section 2.9), librement accessible
en http://cldr.unicode.org/index/downloads. Ce point a suscité
beaucoup de débats sur la liste de diffusion de l'ancien groupe de
travail LTRU. En effet, le fichier
officiel est un gros .zip rempli de tas de choses qui n'ont rien à
voir. Il faut donc tout télécharger puis trier (les transformations
sont dans le répertoire common/transforms).
L'article seul
Diminuer une attaque DoS avec Netfilter sur Linux
Première rédaction de cet article le 20 février 2012
Une des plaies de l'Internet est la quantité d'attaques par déni de service (DoS pour denial of service) que l'administrateur réseaux doit gérer. Tout service connecté à l'Internet se voit régulièrement attaqué pour des raisons financières (extorsion), politiques (je critique la politique du gouvernement d'Israël, les sionistes DoSent mon site), ou simplement parce qu'un type veut s'amuser ou frimer devant ses copains. Il n'existe actuellement pas de recettes magiques pour faire face à ces attaques, je voudrais juste ici présenter et discuter les méthodes disponibles avec Netfilter, le pare-feu de Linux.
Évidemment, je ne prétends pas faire un guide général de toutes les mesures anti-DoS en un article de blog. Il existe des tas de DoS différentes, et l'administrateur réseaux doit, à chaque fois, analyser la situation et produire une réponse appropriée. Non, mon but est bien plus limité, expliquer les différentes façons de limiter le trafic entrant avec Netfilter, et discuter leurs avantages et inconvénients.
Car un des charmes (?) de Netfilter (au fait, il est parfois nommé par le nom de sa commande principale, iptables) est qu'il existe des tas de modules pour assurer telle ou telle fonction, et que ces modules se recouvrent partiellement, fournissant certaines fonctions mais pas d'autres. Et, s'il existe un zillion d'articles et de HOWTO sur la configuration d'iptables pour limiter une DoS, la plupart ne décrivent qu'un seul de ces modules, laissant l'ingénieur perplexe : pourquoi celui-ci et pas un autre ?
Commençons par le commencement. Vous êtes responsables d'un site Web, une DoS est en cours, des tas de paquets arrivent vers le port 80, faisant souffrir le serveur HTTP, qui n'arrive plus à répondre. Vous ne pouvez pas intervenir sur le trafic en amont, avant même qu'il ne passe par votre liaison Internet, cela nécessite la coopération du FAI (pas toujours évidente à obtenir, surtout si on ne s'est pas renseigné à l'avance sur les démarches à suivre). Vous pouvez parfois intervenir sur le serveur lui-même, Apache, par exemple, a tout un tas de modules dédiés à ce genre de problèmes. Mais, ici, je vais me concentrer sur ce qu'on peut faire sur Linux, ce qui fournira des méthodes qui marchent quel que soit le serveur utilisé.
D'abord, deux avertissements importants, un général et un spécifique. Le général est que les DoS sont souvent courtes et que la meilleure stratégie est parfois de faire le gros dos et d'attendre. Des contre-mesures mal conçues ou irréfléchies ont de bonnes chances d'aggraver le problème au lieu de le résoudre. Ne vous précipitez donc pas.
Et l'autre avertissement concerne le risque de se DoSer soi-même, avec certaines contre-mesures, lorsque la contre-mesure nécessite d'allouer un état, c'est-à-dire de se souvenir de quelque chose. Par exemple, si vous voulez limiter le trafic par adresse IP, vous devez avoir quelque part une table indexée par les adresses, table où chaque entrée contient le trafic récent de cette adresse. Si l'attaquant peut mobiliser beaucoup d'adresses différentes (en IPv6, c'est trivial mais, même en IPv4, c'est possible, surtout s'il n'a pas besoin de recevoir les paquets de réponse et peut donc utiliser des adresses usurpées), il peut faire grossir cette table à volonté, jusqu'à avaler toute la mémoire. Ainsi, vos propres contre-mesures lui permettront de faire une DoS encore plus facilement...
Il n'est évidemment pas possible de faire de la limitation de trafic (rate-limiting) sans état mais il faut chercher à le minimiser.
Commençons par le module le plus simple, l'un des plus connus et, je crois, un des premiers, connlimit. connlimit utilise le système de suivi de connexions (connection tracking) de Linux. Ce système permet au noyau de garder trace de toutes les connexions en cours. Il sert à bien des choses, par exemple au NAT ou au filtrage avec état. S'appuyant dessus, connlimit permet de dire, par exemple « vingt connexions HTTP en cours, au maximum » :
% iptables -A INPUT -p tcp --dport 80 -m connlimit \
--connlimit-above 20 -j DROP
S'appuyant sur un système qui conserve trace de toutes les connexions en cours, le suivi de connexions est fragile si l'attaquant peut fabriquer beaucoup de connexions en peu de temps, saturant ainsi les tables de connexion, même si on ne filtre pas par adresse mais globalement, comme dans l'exemple ci-dessus.
Évidemment, vingt connexions, c'est peu, et c'est partagé entre tous, attaquants et utilisateurs légitimes. On peut donc demander à ce que la restriction se fasse par préfixe /28 (valeur un peu arbitraire, je sais) :
% iptables -A INPUT -p tcp --dport 80 -m connlimit \
--connlimit-above 20 --connlimit-mask 28 -j DROP
Comme les modules suivants, connlimit est documenté dans la page de manuel d'iptables.
Comme connlimit repose sur le suivi de connexions de Linux, les
outils existants comme iptstate permettent de suivre l'activité de la
machine et le nombre de connexions auquel elle fait face. Quant à
l'efficacité du filtrage, on peut regarder les statistiques de
Netfilter avec iptables -n -v -L INPUT pour voir
combien de paquets ont déclenché la règle ci-dessus, et ont donc été
jetés. (On peut aussi remplacer la cible DROP par
une cible qui enregistre dans un journal les
paquets refusés. Mais c'est déconseillé en cas de DoS, comme toute
opération qui met vos ressources à la merci de l'attaquant. Celui-ci
pourrait bien remplir le disque dur qui stocke le journal, avec ses tentatives.)
connlimit ne peut travailler qu'avec le nombre actuel de
connexions. Si on veut travailler avec des paquets individuels, on a
le module recent. Il permet plein de choses
amusantes en testant si une machine a envoyé « récemment » un paquet de
ce type. L'utilisation la plus courante pour faire face à un trafic
intense se fait en deux temps : lorsqu'on voit passer le paquet
intéressant, noter l'adresse IP de la machine dans une
table (--set). Lorsqu'un paquet de même type que celui vu « récemment »
repasse (--rcheck ou --update), le jeter.
% iptables -A INPUT -p tcp --dport 80 --tcp-flags SYN SYN -m recent \
--set --name Web
% iptables -A INPUT -p tcp --dport 80 --tcp-flags SYN SYN -m recent \
--update --name Web --seconds 5 --hitcount 10 -j DROP
Ici, on met les adresses IP dans une table nommée
Web. On peut afficher son contenu avec
cat /proc/net/xt_recent/Web pour surveiller le
bon fonctionnement. On ne teste que les
paquets TCP de type SYN,
ceux envoyés pour créer une nouvelle connexion (on aurait pu remplacer
--tcp-flags SYN SYN par -m state
--state NEW mais cette commande est à état, ce qui est
toujours déconseillé face à une DoS).
Ensuite (seconde ligne), on teste si on a vu au moins 10 paquets de
ce modèle pendant les 5 dernières secondes et, si oui, on jette le
paquet (tout en mettant à jour la table, le
--update).
Voici un exemple des deux règles après quelques essais, 6 paquets ont été refusés :
% iptables -n -v -L INPUT
Chain INPUT (policy ACCEPT 53068 packets, 11M bytes)
pkts bytes target prot opt in out source destination
47 2820 tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:80flags: 0x02/0x02 recent: SET name: Web side: source
6 360 DROP tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:80flags: 0x02/0x02 recent: UPDATE seconds: 5 hit_count: 10 name: Web side: source
Attention à la quantité de mémoire consommée (pour éviter de se DoSer soi-même). Elle se configure au chargement du module dans le noyau (avec modprobe, par exemple). Les valeurs par défaut sont très faibles et devraient sans doute être changées pour notre cas :
ip_list_tot: nombre d'adresses enregistrées par table,ip_pkt_list_tot: nombre de paquets enregistrés par adresse.
Malheureusement, il ne semble pas que le module recent permette d'utiliser des préfixes (par exemple de longueur 26 ou 28) mais seulement des adresses IP. C'est une sérieuse limitation en cas de DoS, où on souhaite limiter la taille de l'état enregistré, et on on soupçonne que l'attaquant n'a pas qu'une seule machine à sa disposition.
Voyons alors un autre module, limit. Il permet, en utilisant l'algorithme du seau qu'on remplit, de limiter le rythme d'arrivée d'un certain type de paquets :
% iptables -A INPUT -p tcp --dport 80 --tcp-flags SYN SYN -m limit \
--limit 3/second --limit-burst 7 -j ACCEPT
% iptables -A INPUT -p tcp --dport 80 --tcp-flags SYN SYN -j DROP
Ici, on accepte les paquets TCP SYN tant qu'il y en a moins de 3 par
seconde, et on les jette au-delà. Notez le
--limit-burst qui permet une tolérance jusqu'à 7
paquets. Ce genre de réglages est en général indispensable pour le
trafic Internet, qui est très irrégulier, avec des pics qui peuvent
être tout à fait légitimes.
Ce module est très simple. Mais le module limit, comme recent, ne permet pas de travailler par préfixe IP.
Tournons nous vers notre quatrième (!) et dernier module de
limitation du trafic, hashlimit. Il permet de
regrouper les adresses en préfixes et dispose également de la
possibilité de gérer plusieurs tables de préfixes. Ici, on a nommé la
table Web (on peut l'afficher avec cat
/proc/self/net/ipt_hashlimit/Web) :
% iptables -A INPUT -p tcp --dport 80 --tcp-flags SYN SYN -m hashlimit \ --hashlimit-name Web --hashlimit-above 3/second --hashlimit-mode srcip \ --hashlimit-burst 7 --hashlimit-srcmask 28 -j DROP
On regroupe les adresses IP par préfixes de longueur 28. Et on admet 3 paquets par seconde. Ce module représente, à mon avis, la meilleure combinaison entre souplesse et consommation de mémoire (toujours dangereuse en cas de DoS).
Voilà, j'espère que cela a pu aider un peu, je termine avec trois conseils :
- Préparez votre réaction avant l'attaque, car, pendant, on est stressé, la machine réagit lentement, on a plus de mal.
- Gardez votre sang-froid : la plupart des attaques ne durent pas.
- N'hésitez pas à demander l'aide de votre opérateur / hébergeur / etc, il connait sans doute le problème et a des mécanismes en place pour y faire face, peut-être plus efficaces que ceux présentés ici.
Cet article ne concernait que TCP. Si vous voulez sécuriser un service UDP, voyez mon autre article.
L'article seul
RFC 6532: Internationalized Email Headers
Date de publication du RFC : Février 2012
Auteur(s) du RFC : A. Yang (TWNIC), S. Steele (Microsoft), N. Freed (Oracle)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF eai
Première rédaction de cet article le 18 février 2012
Dans l'ensemble des RFC qui décrivent les adresses de courrier électronique internationalisées (c'est-à-dire pouvant utiliser tout le répertoire Unicode), celui-ci se consacre au nouveau format des en-têtes, complétant celui normalisé dans le RFC 5322.
Désormais, on peut avoir dans un message un en-tête comme :
From: Stéphane Bortzmeyer <stéphane@sources.org>
Oui, avec du vrai UTF-8, y compris dans l'adresse proprement dite, pas seulement dans les commentaires, et encore, à condition de les surencoder selon le RFC 2047 comme c'était le cas avant (méthode inélégante et inefficace). Cette possibilité d'utiliser directement UTF-8 avait été créée par le RFC 5335, qui n'avait que le statut « Expérimental ». Désormais, ce mécanisme est complètement normalisé, en partie parce que de plus en plus de logiciels savent traiter directement l'UTF-8.
L'un des éditeurs du RFC travaille à TWNIC, le
registre chinois de .tw. Les
Chinois ont, fort logiquement, été
particulièrement actifs dans tout le processus EAI (Email Addresses Internationalization). Celui-ci visait à
terminer l'internationalisation du courrier électronique, qui avait
passé une étape décisive en novembre 1996, avec la sortie du RFC 2045 sur MIME. Mais cette norme MIME
n'internationalisait que le corps des messages. EAI permet
d'internationaliser également les en-têtes comme
From:, Subject: ou Received: (mais
pas, par exemple, Date:, qui restera en ASCII pur ; Date: est censé
être analysé par le MUA et présenté ensuite à
l'utilisateur dans sa langue).
EAI comprend plusieurs RFC, par exemple le RFC 6530
définit le cadre général, le RFC 6531, l'utilisation des
adresses Unicode dans SMTP (avec l'extension
SMTPUTF8), les RFC ou futurs RFC sur
POP (RFC 5721) ou IMAP (RFC 5738) et notre RFC 6532, qui se concentre sur le format des messages. Il
suppose que le transport sera « 8-bits clean », c'est-à-dire
laissera passer les octets qui codent les données UTF-8 sans les
modifier (le cas des vieux systèmes qui ne gèrent pas proprement les
caractères non-ASCII est délibérement laissé de côté).
Concrètement, que change donc ce RFC ? La section 3 détaille ce qui est modifié, par extension de la grammaire du RFC 5322) :
- La grammaire ABNF qui décrit les en-têtes est changée (sections 3.1 et 3.2) pour accepter des caractères UTF-8, de préférence normalisés en NFC (cf. RFC 5198). Déjà très complexe, cette grammaire devient ainsi réellement difficile.
- L'en-tête
Message-ID:est traité à part (section 3.3). Les caractères UTF-8 y sont autorisés mais déconseillés (le RFC rappelle que cet en-tête sert à former automatiquement d'autres en-têtes commeIn-Reply-To:). - La syntaxe des adresses (telles qu'on les trouve dans des
en-têtes comme
From:ouTo:) est modifiée pour accepter UTF-8. Pour les sites qui utilisent une adresse électronique comme identificateur, comme le fait Amazon.com, ce sera un intéressant défi ! - Un nouveau type MIME est créé,
message/global, pour permettre d'identifier un message EAI (section 3.7). Les messages de ce type ne doivent être transportés qu'avec des protocoles 8-bits clean comme celui du RFC 6531. - Les noms des en-têtes restent en ASCII seul, ce n'est que leur contenu qui peut être en UTF-8. Pour utiliser le vocabulaire du RFC 2277, les noms des en-têtes sont un élement de protocole, qui n'a pas besoin d'être exprimé dans la langue de l'utilisateur.
Parmi les conséquences pratiques de ce changement, il faut noter que les programmeurs qui écrivent des logiciels traitant le courrier doivent désormais gérer Unicode, même s'ils se contentent d'analyser les en-têtes... L'époque du courrier traité avec des scripts shell est bien passée.
Autre point important pour les programmeurs, les limites de taille des en-têtes (qui étaient de 998 caractères maximum et 78 recommandés) changent de sémantique (section 3.4) puisque, en UTF-8, un caractère ne fait plus forcément un octet. Les limites sont désormais de 998 octets et 78 caractères (cette seconde limite étant conçue pour tenir sur l'écran). Attention aussi à la section 4, qui rappelle le risque de débordement de tampons.
La section 4 liste également quelques conséquences pour la sécurité comme le fait qu'un mécanisme d'authentification devra être prêt à gérer plusieurs adresses pour la même personne (car, pendant un certain temps, plusieurs utilisateurs auront à la fois une adresse en Unicode et une en ASCII pur).
Les changements depuis le RFC 5335 sont résumés dans la section 6 du RFC 6530. Le principal est la suppression de la possibilité de repli (downgrading) automatique vers des adresses en ASCII pur.
L'article seul
RFC 6531: SMTP Extension for Internationalized Email
Date de publication du RFC : Février 2012
Auteur(s) du RFC : J. Yao (CNNIC), W. Mao (CNNIC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF eai
Première rédaction de cet article le 18 février 2012
Dans la grande série des RFC décrivant les adresses de courrier internationalisées, ce document traite des modifications au protocole SMTP. Il succède au RFC 5336, qui avait créé ces modifications mais qui n'avait que le statut « Expérimental ». Désormais, ces extensions internationales sont sur le Chemin des Normes de l'IETF.
Plusieurs RFC composent la nouvelle norme EAI ou « Email Addresses Internationalized » (cf. RFC 6530). Les deux principaux concernent le format des messages (RFC 6532) et le dialogue entre deux serveurs de messagerie, suivant le protocole SMTP. Ce dernier cas est couvert dans notre RFC 6531.
Les adresses de courrier en Unicode ne sont
pas en effet compatibles avec le SMTP « brut ». Ainsi, la commande
RCPT TO qui permet d'indiquer le destinataire, ne
prend en paramètre que de l'ASCII. Et les en-têtes du
courrier peuvent désormais être en UTF-8 (RFC 6532). Il faut donc
étendre SMTP (actuellement normalisé en RFC 5321) pour
permettre de l'UTF-8 en paramètre de commandes
comme MAIL FROM et RCPT
TO. Cette extension se signale avec l'option
SMTPUTF8 (l'ancien RFC, le
RFC 5336, utilisait UTF8SMTP), dont l'usage permet de vérifier que le
MTA situé en face comprend bien la nouvelle
norme (sections 1 et 2 du RFC).
La section 3 forme le gros du RFC en spécifiant rigoureusement le nouveau protocole. Voyons d'abord un exemple de dialogue SMTP avec la nouvelle extension (C est le client - l'appelant - et S le serveur - l'appelé). Notre RFC 6531 ne modifie pas SMTP (RFC 5321), il l'étend :
S: 220 mail.example.org ESMTP Foobar (Debian/GNU) C: EHLO mail.iloveunicode.example S: 250-mail.example.org 250-ENHANCEDSTATUSCODES 250-8BITMIME 250-SMTPUTF8 250 DSN C: MAIL FROM:<stéphane@internet-en-coopération.fr> SMTPUTF8 S: 250 2.1.0 Ok C: RCPT TO: <françoise@comptabilité.example.org> S: 250 2.1.5 Ok
Notez les deux adresses, chacune comprenant des caractères non-ASCII, à gauche et à droite du @.
Les serveurs qui mettent en œuvre l'extension
SMTPUTF8 doivent également accepter la très
ancienne extension 8BITMIME (RFC 6152)
qui permet, depuis belle lurette, de ne pas se limiter à l'ASCII dans
le contenu des messages, sans pour autant nécessiter des encodages
comme Quoted-Printable (en dépit de ce que
prétend une légende tenace).
Les sections 3.1 et 3.2 présentent la nouvelle extension,
SMTPUTF8 (enregistrée à l'IANA, cf. section 4.1). Les extensions SMTP sont définies par
le RFC 5321, section 2.2. Un MTA peut annoncer
qu'il accepte SMTPUTF8, permettant à son pair, s'il l'accepte également,
d'utiliser des adresses UTF-8. C'est également cette section qui
définit ce que doit faire un MTA lorsqu'il tente de transmettre un
message internationalisé à un ancien MTA qui ne gère pas cette
extension. Trois solutions sont possibles, dont le rejet complet du message
(retour à l'expéditeur) et un effort pour trouver une route
alternative, passant par des serveurs plus modernes (le RFC 5336 avait un quatrième mécanisme, le repli
- downgrade - qui a été abandonné après usage, car
trop complexe et trop imprédictible).
La section 3.3 décrit la nouvelle syntaxe pour les adresses. L'ancienne était limitée à ASCII mais très permissive (bien qu'on trouve, notamment derrière les formulaires Web, énormément de logiciels de « vérification » bogués). En gros, la syntaxe est qu'une adresse est formée de deux parties, la partie locale et le nom de domaine, tous les deux séparés par l'arobase. La nouveauté est que les deux parties peuvent désormais être en Unicode, avec peu de restrictions sur la partie locale (le nom de domaine étant soumis aux restrictions du RFC 5890).
Il y a plein d'autres détails dans cette section 3, comme celui
(section 3.7.1) que
le paramètre de la commande EHLO (un nom de
machine) doit être encodé en Punycode puisque,
à ce stade, on ne sait pas encore si SMTPUTF8 est accepté ou pas.
Les changements depuis le RFC 5336 sont
résumés dans la section 6 du RFC 6530. Le
principal est la suppression de la possibilité de
repli (downgrading)
automatique vers des adresses en ASCII pur. Le paramètre ALT-ADDRESS disparait donc.
Cette extension de SMTP ne semble pas mise en œuvre dans les
grands logiciels libres classiques comme
sendmail ou exim. Pour
Postfix, l'auteur a clairement exprimé son
manque d'enthousiasme. Il existe des
patches non-officiels
développés en Chine, pour Postfix http://www.cdnc.org/gb/news/src-EAI.tar.gz (l'archive comprend
également d'autres logiciels, d'où sa taille) et pour sendmail
http://www.cdnc.org/gb/news/twnic.zip. La société
chinoise Coremail est en train de travailler à un produit commercial
basé sur ces patches.
L'article seul
RFC 6533: Internationalized Delivery Status and Disposition Notifications
Date de publication du RFC : Février 2012
Auteur(s) du RFC : C. Newman (Sun Microsystems), A. Melnikov (Isode)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF eai
Première rédaction de cet article le 18 février 2012
Dans l'ensemble des RFC sur l'internationalisation des adresses de courrier électronique, ce document traite le cas des accusés de réception (MDN, pour Message Disposition Notification) et avis de non-remise (DSN pour Delivery Status Notification).
Puisque les RFC 6531 et RFC 6532 permettent désormais d'utiliser des adresses de courrier électroniques internationalisées, c'est-à-dire utilisant tout le jeu de caractères Unicode, il faut prévoir le cas où les courriers provoquent l'envoi d'avis de remise ou de non-remise (DSN pour Delivery Status Notification, RFC 3461 et RFC 3464) et d'accusés de réception (MDN, pour Message Disposition Notification, RFC 8098). C'est l'objet de ce RFC, qui met à jour les anciens documents qui limitaient ces accusés et avis au jeu ASCII. Il fait suite au RFC 5337, qui n'était qu'expérimental. Désormais, les adresses de courrier en Unicode font partie des normes de l'Internet.
Le format des DSN dans le RFC 3464 parle de « types
d'adresse ». Les adresses en UTF-8 du RFC 6532 sont un nouveau type d'adresses. Si le
serveur SMTP accepte l'extension SMTPUTF8 du RFC 6531 et l'extension DSN du RFC 3461, il doit
permettre d'utiliser ce type dans le paramètre ORCPT
(Original Recipient, section 4.2 du RFC 3461). Si le
serveur n'accepte pas SMTPUTF8, l'adresse à utiliser dans les DSN doit
être encodée en 7bits, selon les règles exposées dans cette section 3. Par
exemple, stéphane@bortzmeyer.org peut s'écrire
st\x{E9}phane@bortzmeyer.org. (La
section 3 détaille plus complètement le traitement des adresses UTF-8,
et notamment les différentes formes qu'elles peuvent prendre, et les
encodages de certains caractères, comme l'espace ou la barre oblique
inverse, normalisé par le RFC 3461.)
Une fois réglé le problème de la représentation des adresses, la
section 4 traite les DSN en UTF-8. Les DSN traditionnels étaient
composés d'un objet MIME de type
multipart/report (RFC 6522) comportant trois objets
décrivant le problème (un objet conçu pour être lu par un humain, un
message/delivery-status et le message originel,
message/rfc822). Pour le courrier
internationalisé, de nouveaux types ont été créés :
message/global-delivery-statusqui, contrairement à son prédécesseurmessage/delivery-status, accepte l'UTF-8 et permet donc de placer directement les adresses UTF-8, sans encodage en ASCII. En outre, il dispose d'un nouveau champ, Localized-Diagnostic, qui permet de stocker des messages lisibles par un humain. La langue de ces messages est indiquée par une étiquette de langue (RFC 5646). (Le champ Diagnostic-Code est désormais en UTF-8, mais dans la langue par défaut du système, cf.i-defaultdans le RFC 2277.)message/globalqui remplacemessage/rfc822(dont le nom, hommage au vieux RFC 822, était de toute façon dépassé). À noter que le terme global (mondial) utilisé pour noter ce type avait fait l'objet de vives discussions et même d'un vote. Cet objet permet de transporter le message original (si on ne transporte que les en-têtes, on utilisemessage/global-headers).
On peut noter que la norme MIME (RFC 2046) interdisait l'usage de l'option
Content-Transfer-Encoding pour les objets de type
message/* mais cette règle a été assouplie par le
RFC 5335.
La section 5 traite des MDN (Message Disposition
Notification, RFC 3798). Ils ne sont pas très
différents des DSN et ont un format très proche, avec un type MIME message/global-disposition-notification.
La section 6 traite des registres
IANA. Le type « UTF-8 » est ajouté au registre des types d'adresses
(section 6.1), et les nouveaux types MIME qui avaient été créés par
les premiers RFC expérimentaux, comme
message/global sont ajoutés au registre des types MIME (sections 6.3
à 6.5).
Enfin, la section 7 est dédiée aux questions de sécurité. Il y a les problèmes de sécurité classiques des DSN et des MDN : non authentifiés, ils permettent de faire croire qu'un message a échoué, alors qu'il a bien été délivré, ou le contraire. Et les DSN et MDN reçus sont souvent émis en réponse à des messages faux, qui n'avaient pas été émis par l'utilisateur. D'autre part, le RFC nous prévient que des DSN ou des MDN délibérement incorrects peuvent être envoyés par un attaquant dans l'espoir de profiter d'erreur dans la programmation des analyseurs, par exemple pour déclencher un débordement de tampon. Le risque est plus important s'il y a beaucoup d'encodage, le décodage pouvant faire varier la taille des données.
Quels sont les changements depuis le RFC expérimental, le RFC 5337 ? L'annexe A les résume, les principaux étant la suppression de tout ce qui concernait le mécanisme de repli (downgrade), mécanisme complexe qui avait été normalisé pour gérer les cas où un serveur sur le chemin ne pouvait pas transmettre les adresses en UTF-8. Trop délicat, ce mécanisme a été retiré de la version normalisée de ces adresses.
L'article seul
RFC 6530: Overview and Framework for Internationalized Email
Date de publication du RFC : Février 2012
Auteur(s) du RFC : J. Klensin, Y. Ko (ICU)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF eai
Première rédaction de cet article le 18 février 2012
Parmi les protocoles utilisés sur
Internet, presque tous sont internationalisés
depuis longtemps. Le dernier gros manque concernait les adresses de
courrier électronique, obligées de s'en tenir à
stephane@internet-en-cooperation.fr alors qu'on voudrait pouvoir
écrire à
stéphane@internet-en-coopération.fr. Désormais,
nous avons une solution standard, Internationalized
Email Addresses.
Bien sûr, pour l'exemple ci-dessus, le gain n'est pas évident. Mais il l'est beaucoup plus si vous voulez écrire votre adresse avec l'écriture arabe ou chinoise. (Cf. section 3 pour la description du problème, section qui exprime clairement le fait qu'un Chinois a le droit d'avoir une adresse en sinogrammes, comme un Occidental jouit des avantages d'une adresse en caractères latins.)
Le contenu des courriers était internationalisé
depuis longtemps, au moins depuis MIME (RFC 1341 à l'origine, en juin 1992). De même, certains en-têtes
comme le sujet ou même comme le nom de l'expéditeur dans le champ
From: - mais pas son adresse - pouvaient être
internationalisés via MIME (RFC 2047). Mais les adresses ne l'étaient pas
encore et ce manque de cohérence (possibilité d'utiliser des écritures
non-latines à certains endroits mais pas à d'autres) rendait le
courrier peu attirant pour M. Ali ou M. Wu. Notre RFC, qui remplace le RFC 4952 qui
n'était qu'expérimental, décrit le cadre général de l'internationalisation
des adresses de courrier. Il y avait depuis longtemps des messages internationaux, il y a désormais également des adresses internationales.
Il y a deux parties à l'adresse (décrites dans le RFC 5322) : la partie locale, à gauche du @ et le nom de domaine à droite. Si ce nom de domaine, depuis la sortie du RFC 3490, en mars 2003, peut s'écrire en Unicode (norme IDN), le courrier exigeait toujours un nom de domaine en ASCII donc un message de non-délivrance, par exemple, allait affichait la forme Punycode du nom. Ce n'était pas une vraie internationalisation.
Le cadre d'internationalisation du courrier couvre plusieurs aspects, couverts chacun par un RFC. Ce RFC expose l'architecture générale. La section 5 décrit le fonctionnement du nouveau système.
SMTP est modifié pour permettre une nouvelle
extension, SMTPUTF8, indiquant le support du courrier internationalisé (RFC 6531).
Le format des messages (RFC 5322) est modifié
pour permettre d'inclure de l'Unicode, encodé
en UTF-8, directement dans les en-têtes, comme
le champ To: (RFC 6532). Les autres charsets (comme
UTF-32) ne sont pas prévus.
Le format des accusés de réception est modifié pour permettre des rapports de remise ou de non-remise lorsque l'expéditeur ou le destinataire avaient des adresses Unicode (RFC 6533).
Plusieurs autres protocoles « auxiliaires » seront également
modifiés, par exemple pour les listes de
diffusion (RFC 6783) ou pour
IMAP et POP. Même chose
pour des formats comme les IRI de plan
mailto: (section 11.1 de notre RFC, RFC 3987 et RFC 6068).
Notons (section 11.2 du RFC) que les adresses de courrier sont utilisés en de nombreux
endroits, par exemple comme identificateurs sur certains sites Web de
commerce électronique, comme Amazon et que ces
utilisateurs vont également devoir s'adapter. Quant on voit le nombre
de sites, supposés professionnels, qui continuent à interdire des
adresses de courrier légales, on mesure
l'ampleur
du travail. La section 10, elle aussi, décrit des questions
liées à l'interface utilisateur. Par exemple, elle rappelle qu'il y a
toujours eu des cas délicats dans la syntaxe, dont il est plus
prudent de se tenir à l'écart. Ainsi, la partie gauche d'une adresse
est sensible à la casse donc, en théorie, on
pourrait avoir une adresse Stephane@bortzmeyer.fr
et que le courrier bêtement envoyé à
stephane@bortzmeyer.fr n'atteindrait pas. Inutile
de dire que peu de MTA mettent en œuvre
une telle distinction... Dans le cas des adresses internationalisées,
il faut donc prendre garde à la canonicalisation
Unicode. Au minimum, il faudrait accepter la canonicalisation en
NFC de toute adresse, car cette
canonicalisation aura peut-être lieu quelque part dans le chemin, qu'on le veuille ou pas.
Les changements par rapport à l'ancien cadre (RFC 4952 et ses copains) sont décrits dans les sections 6 et 12. La section 6 fait en outre le bilan de la phase expérimentale. Désormais, les adresses de courrier internationalisées ont le statut de norme et non plus de simple expérience. Le principal changement technique, de loin, est la suppression du repli. Le repli (downgrading, cf. RFC 5504 et RFC 5825) était prévu pour le cas où un émetteur internationalisé rencontrerait un récepteur qui ne l'est pas, nécessitant une modification des adresses en ASCII. En effet, contrairement à HTTP, le courrier ne fonctionne pas de bout en bout et le message est relayé par plusieurs serveurs, qu'on ne connaît pas forcément a priori.
Le repli était certainement la partie la plus complexe : modifier un message est toujours une opération délicate, notamment en présence de signatures cryptographiques (section 11.3), que le repli ne doit pas invalider ! Tellement complexe que sa mise en œuvre s'est avérée très délicate et que les différentes implémentations avaient du mal à interagir. En outre, l'expérience a montré que le fait de devoir gérer deux adresses (celle en Unicode et une en ASCII pour le repli), sans lien sécurisé entre les deux, était une belle source de problèmes. Résultat, par rapport aux RFC de la phase expérimentale, le repli a été abandonné. Désormais, un courrier internationalisé ne pourra tout simplement pas être transmis à travers les vieux serveurs, ce sera au MUA ou à l'utilisateur de trouver une solution de rechange (cf. section 8, qui détaille les solutions). On note que la phase expérimentale, dont beaucoup de RFC ne sortent jamais, a été ici utile, permettant, par la pratique, d'atteindre un très large consensus sur un point qui était précédemment fortement discuté.
Un deuxième changement technique important par rapport aux premiers RFC sur ce sujet est que, en SMTP, le client aussi bien que le serveur doit signaler sa volonté d'utiliser les nouvelles adresses.
La section 8 décrit plus en détail la marche à suivre si le serveur suivant ne gère pas les adresses Unicode (par exemple, on peut prévoir que certains administrateurs activeront les adresses Unicode sur le serveur de courrier principal du domaine et oublieront le MX secondaire). Elle n'est pas normative puisque c'est largement une question d'interface utilisateur, quelque chose que l'IETF ne fait pas normalement. Comme le note cette section, le meilleur repli est celui fait manuellement par l'utilisateur, car celui-ci est intelligent et motivé. Néanmoins, si on tient à faire du repli automatique, il peut être fait par le MUA, ou bien par une future extension au protocole de soumission (RFC 4409). Ça, c'était pour le cas où le serveur ancien était le premier de la chaîne. Et si le problème d'un serveur non-Unicode survient en cours de route, lorsqu'un MTA se rend compte que le MTA suivant ne convient pas ? La section 9 rappelle qu'il est désormais strictement interdit aux MTA de tripoter le message et il n'y a donc rien d'autre à faire que d'indiquer une erreur, qui sera remontée à l'utilisateur.
Et si le problème survient une fois le message délivré, parce que le protocole de récupération n'a pas été adapté aux adresses Unicode ? Le problème est là encore formellement en dehors du cadre, le RFC notant juste que le MDA peut faire un repli automatique s'il le juge utile.
Cette extension du courrier ne semble pas encore implémentée officiellement dans les logiciels classiques de courrier, malgré la longue période des RFC expérimentaux.
L'article seul
My SamKnows probe just installed
First publication of this article on 15 February 2012
Last update on of 30 September 2012
I just received and installed my SamKnows box, currently distributed in many households in Europe, to measure Internet access performance and characteristics.
This measurement program is driven by the European Commission. There are many details in the online FAQs.
The probe (named "Whitebox") is much larger than the RIPE
Atlas. Here is the device:
 The Terms of Use (which I do not find on
the public part of the Web site) forbid me to give public information
about the SamKnows box (without a prior written authorization) but I
decided I can at least publish the picture. Once connected to the
local network, it starts active measurements to various points on the
Internet and reports them to its controller.
The Terms of Use (which I do not find on
the public part of the Web site) forbid me to give public information
about the SamKnows box (without a prior written authorization) but I
decided I can at least publish the picture. Once connected to the
local network, it starts active measurements to various points on the
Internet and reports them to its controller.
In theory, the wired machines in my home should be connected to the SamKnows box, not to my router (a Freebox). This allows the probe to monitor if there is actual traffic and to postpone measurements in order not to interfere. But this raises technical issues (I did not check but I'm not sure that the probe has Gigabit Ethernet ports) and of course big privacy issues. So, in the mean time, I just connected the probe to the router, side by side with my machines.
arpwatch told me the IP address of the Whitebox. Checking with nmap, the machine seems to have only one port opened:
% nmap 192.168.2.30 Starting Nmap 5.00 ( http://nmap.org ) at 2012-02-17 14:19 CET Interesting ports on 192.168.2.30: Not shown: 999 closed ports PORT STATE SERVICE 2222/tcp open unknown
A SSH server runs on this port but the user has no access:
% telnet 192.168.2.30 2222 Trying 192.168.2.30... Connected to 192.168.2.30. Escape character is '^]'. SSH-2.0-dropbear_0.53.1
A few hours after, I received the identifiers required to see the result of the measurements by "my" probe. There is a dashboard on the Web where the results of the measurements are displayed (the measurements themselves are described in detail in a paper). Consistent with the very closed nature of the SamKnows box, the images are only readable if you use the proprietary Flash software. Otherwise, you get just rows of raw data, for instance, for the DNS resolver response time :
Date / Minimum (Ms) / Maximum (Ms) / Average (Ms) / Number of Tests 2012-02-17 13:00:00 22.43 24.52 23.48 4 2012-02-17 12:00:00 22.42 24.67 23.23 4 2012-02-17 11:00:00 22.72 23.97 23.30 4 2012-02-17 10:00:00 22.88 24.37 23.81 4 2012-02-17 09:00:00 22.35 24.17 23.24 4 ...
Even if you accept to install Flash, the right-click function "Save
image locally" does not work at all (from searching the Web, it seems a knows bug in the
library, which noone fixed). So, to show you pictures, I had to take a
screenshot:
 You can see here the downstream throughput of my connection at
home, for the last nine months. Note the big decrease in September.
You can see here the downstream throughput of my connection at
home, for the last nine months. Note the big decrease in September.
Its software is apparently built over OpenWrt but the entire source code is unfortunately not available (the Atlas has the same limitation), only a part of it. The box is closed and the Terms of Use prevent any tinkering with it.
Damien Wyart examined the question more closely and reports: "the box seems based on TP-Link machines, tl-wr741nd and wr1043nd. These two boxes work fine with OpenWrt".
L'article seul
Peut-on vraiment parler de « propagation » DNS ?
Première rédaction de cet article le 14 février 2012
Dernière mise à jour le 1 avril 2026
On trouve souvent, sur les forums en ligne, des allusions à une « propagation » des informations stockées dans le DNS. Par exemple, une phrase comme « Les informations ont été modifiées au registre, il faut maintenant attendre 24 à 48 heures leur propagation ». Ce terme est-il correct ?
Je ne pense pas. « propagation » fait penser à un mouvement qui se déroule tout seul, une fois la source modifiée. C'est effectivement le fonctionnement de certains protocoles réseau comme BGP (RFC 4271) ou bien Usenet (RFC 5537) où, une fois injectées dans le système, les nouveautés se propagent en effet, sans autre intervention, de machine en machine, jusqu'à atteindre tout l'Internet.
Mais le DNS (RFC 1034) ne fonctionne pas comme cela. Il est pull et pas push, c'est-à-dire que l'information ne se propage pas toute seule mais est demandée par les clients, les résolveurs. Ceux-ci la gardent ensuite dans leur cache, leur mémoire, et reviennent aux serveurs faisant autorité lorsque la durée de séjour dans la mémoire arrive à son terme. Si un résolveur n'avait pas l'information dans son cache, il la demande et il aura tout de suite l'information à jour, sans « propagation ». S'il l'a dans son cache, attendre une hypothétique propagation ne changera rien, l'information nouvelle n'arrivera pas avant l'expiration des données.
Notez au passage que cette expiration est commandée par la source : celle-ci indique dans les données le TTL, c'est-à-dire la durée de vie des données. La source (le serveur faisant autorité) peut donc parfaitement commander le processus de mise à jour, contrairement à ce qui se passe pour BGP, où le routeur d'origine n'a aucune influence sur la propagation. C'est parce que la source (le domaine faisant autorité) choisit le TTL qu'il est possible (et même recommandé), lors d'un changement de données (par exemple migration d'un serveur Web vers un nouvel hébergeur, avec une nouvelle adresse IP) d'abaisser le TTL à l'avance, de manière à ce que la transition soit sans douleur, puis de le remonter après.
Donc, le terme « propagation » est mauvais, car il fait penser à un
modèle de mise à jour qui n'est pas celui du DNS. Il vaut donc mieux
utiliser un autre terme. Il n'en existe pas de standard alors j'adopte
un terme proposé par Michel Py : « réjuvénation ». Il existe dans le
dictionnaire et sonne bien. Je souhaite qu'on dise désormais
des choses comme « L'AFNIC vient de modifier .fr, il faut maintenant attendre la
réjuvénation des données. »
Avec un outil de débogage DNS comme dig, on peut bien voir ce processus de réjuvénation :
% dig A www.cfeditions.com ... ;; ANSWER SECTION: www.cfeditions.com. 43 IN A 178.33.202.53
La réponse a été trouvée et le temps restant à vivre dans le cache est de 43 secondes (le second champ). Si on recommence deux minutes plus tard, ce temps aura été dépassé et le résolveur devra réjuvéner les données :
% dig A www.cfeditions.com ... ;; ANSWER SECTION: www.cfeditions.com. 120 IN A 178.33.202.53
Et voilà, on est reparti pour une durée de 120 secondes, celle déterminée par le serveur faisant autorité. Vérifions en lui demandant directement :
% dig @ns6.gandi.net A www.cfeditions.com ... ;; ANSWER SECTION: www.cfeditions.com. 120 IN A 178.33.202.53
Cette durée est extrêmement basse (beaucoup trop) mais c'était pour illustrer le fait qu'elle était sous le commandement exclusif du gestionnaire du domaine. Autrefois, les TTL typiques étaient de 24 à 48 heures, d'où la légende « le temps de propagation dans le DNS est de 24 à 48 h ». Aujourd'hui, les durées les plus courantes sont de 4 à 12 h bien que certains abusent et indiquent des durées ridiculement courtes.
Alors, bien sûr, les experts DNS parmi mes lecteurs vont dire que c'est plus compliqué que cela. Il existe d'autres causes aux délais de mise à jour comme la réactivité de l'hébergeur DNS lorsqu'on modifie une zone via le panneau de contrôle, la réactivité du registre lorsqu'on lui envoie des modifications (il fut un temps où il était courant que les TLD ne soient modifiés qu'une ou deux fois par jour), la synchronisation entre les serveurs faisant autorité (en général quasi-instantanée depuis le RFC 1996 mais il peut y avoir des problèmes), etc. Ceci dit, les délais les plus longs sont bien en général dus aux caches des résolveurs.
D'autres termes à proposer à la place ? J'ai entendu « actualisation » mais je le trouve moins joli. « mise à jour » ? « expiration du cache » (trop technique et pas assez littéraire) ? « rébiscoulation » (le verbe « rébiscouler » est utilisé dans le Sud-Ouest de la France au sens de « remonter, requinquer ») ? « regain » ? « rafraîchissement » (trop de risques de confusion avec le champ Refresh de l'enregistrement SOA, qui a un autre sens) ? « reviviscence » (qu'on peut aussi écrire « réviviscence ») ?
Un outil intéressant pour regarder la fraîcheur des informations
DNS en demandant à des résolveurs DNS ouverts (accessibles à tous) est
http://www.migrationdns.com/. Un autre, qui offre
plusieurs possibilités intéressantes (demander à des résolveurs
ouvertes, demander aux serveurs faisant autorité, etc) est http://www.preshweb.co.uk/cgi-bin/dns-propagation-tracker.pl. Citons
enfin http://www.whatsmydns.net/.
En anglais, j'ai vu la proposition de dire « DNS engagement » par analogie avec le vocabulaire des marketeux et des influenceurs. Et j'ai noté deux articles sur le même thème « Why You Should Not Call It “Propagation” » et le plus sérieux « DNS propagation does not exist ».
Et pour finir, un bon résumé par Wesley George pendant une réunion IETF : « if you need to pull it, put it in DNS, if you need to push it, put it in BGP ».
L'article seul
RFC 6506: Supporting Authentication Trailer for OSPFv3
Date de publication du RFC : Février 2012
Auteur(s) du RFC : M. Bhatia (Alcatel-Lucent), V. Manral (Hewlett Packard), A. Lindem (Ericsson)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ospf
Première rédaction de cet article le 14 février 2012
La version 2 du protocole de routage OSPF avait un mécanisme d'authentification (annexe D du RFC 2328). Lors de la conception de la version 3 (qui permettait notamment d'ajouter IPv6), ce mécanisme avait été abandonné, l'idée étant que l'IETF avait déjà un mécanisme d'authentification plus général, IPsec, et qu'il « suffisait » de l'utiliser. Selon cette analyse, il n'y avait plus besoin de doter chaque protocole de son propre mécanisme d'authentification. C'était très bien sur le papier. Mais, en pratique, le déploiement d'IPsec est très limité, à la fois en raison de sa complexité et du caractère imparfait de ses implémentations. Résultat, les utilisateurs d'OPSFv3 n'ont, la plupart du temps, pas déployé de mécanisme de sécurité du tout. En voulant faire trop propre, on a donc diminué la sécurité du routage. Ce RFC (depuis remplacé par le RFC 7166) corrige le tir en dotant enfin OSPFv3 d'un mécanisme d'authentification léger et réaliste.
OSPFv3 est normalisé dans le RFC 5340, dont le titre (« OSPF pour IPv6 ») est trompeur car, depuis le RFC 5838, OSPFv3 peut gérer plusieurs familles d'adresses et peut donc, en théorie, remplacer complètement OSPFv2. En pratique, toutefois, ce n'est pas encore le cas, notamment pour le problème de sécurité qui fait l'objet de ce RFC : contrairement aux autres protocoles de routage internes, OSPFv3 ne disposait d'aucun mécanisme d'authentification. N'importe quel méchant sur le réseau local pouvait se proclamer routeur et envoyer de fausses informations de routage. L'argument répété était « pas besoin de mécanisme spécifique à OSPFv3, utilisez les mécanismes IPsec, comme expliqué dans le RFC 4552 ». Mais on constate que cette possibilité a été très peu utilisée. Le RFC se contente de noter que c'est parce que IPsec est mal adapté à certains environnements comme les MANET mais il ne parle pas des autres environnements, où IPsec est simplement rejeté en raison de la difficulté à trouver une implémentation qui marche, et qu'un administrateur système normal arrive à configurer.
IPsec a également des faiblesses plus fondamentales pour des protocoles de routage comme OSPF. Ainsi, les protocoles d'échange de clés comme IKE ne sont pas utilisables tant que le routage ne fonctionne pas. Pour résoudre le problème d'œuf et de poule, et parce que les communications OSPF sont de type un-vers-plusieurs (et pas un-vers-un comme le suppose IKE), le RFC 4552 prône des clés gérées manuellement, ce qui n'est pas toujours pratique.
Enfin, l'absence de protection contre le rejeu affaiblit la sécurité d'IPsec dans ce contexte, comme le note le RFC 6039.
La solution proposée figure en section 2. L'idée est d'ajouter à la fin du packet OSPF un champ qui contienne un condensat cryptographique du paquet et d'une clé secrète, comme pour OSPFv2 (RFC 5709) (D'autres types d'authentification pourront être utilisés dans le futur, un registre IANA des types a été créé.) Les options binaires du paquet, au début de celui-ci (RFC 5340, section A.2), ont un nouveau bit, en position 13, AT (pour Authentication Trailer, désormais dans le registre IANA), qui indique la présence ou l'absence du champ final d'authentification (tous les paquets n'ont pas ce champ Options, donc le routeur devra se souvenir des valeurs de ce champ pour chaque voisin).
Pour chaque couple de routeurs ainsi protégés, il y aura un certain nombre de paramètres, qui forment ce qu'on nomme un accord de sécurité (security association, section 3) :
- Un identifiant sur 16 bits, manuellement défini, le Security Association ID. L'émetteur le choisit et le récepteur le lit dans le paquet. Cette indirection va permettre de modifier des paramètres comme les clés cryptographiques (ou même l'algorithme cryptographique), tout en continuant le routage.
- L'algorithme utilisé, par exemple HMAC-SHA1 ou HMAC-SHA512,
- La clé,
- Des paramètres temporels indiquant, par exemple, à partir de quand la clé sera valide.
Une fois qu'on a toutes ces informations, qu'est-ce qu'on met dans le paquet OSPF envoyé sur le câble ? La section 4 décrit le mécanisme. Le champ final d'authentification (Authentication Trailer) est composé notamment de l'identifiant d'un accord de sécurité (SA ID, décrit au paragraphe précédent, et qui permet au récepteur de trouver dans sa mémoire les paramètres cryptographiques liés à une conversation particulière), d'un numéro de séquence (qui sert de protection contre le rejeu ; il est augmenté à chaque paquet émis ; il comprend 64 bits, après une très longue discussion dans le groupe de travail, certains auraient préféré 32 bits) et du condensat cryptographique du paquet concaténé avec la clé (la section 4.5 décrit l'algorithme en détail et notamment quels champs du paquet sont inclus dans les données condensées).
Le routeur qui reçoit un paquet utilisant l'authentification (il le sait grâce au bit AT qui était notamment présent dans les paquets OSPF Hello) va accéder au champ d'authentification (le champ Longueur du paquet OSPF lui permet de savoir où commence le champ d'authentification, éventuellement en tenant compte du bloc Link-Local Signaling du RFC 5613, un routeur doit donc gérer au moins en partie ce dernier RFC s'il veut authentifier). Le récepteur refait alors le calcul cryptographique et vérifie si le champ final d'authentification est correct. Le calcul est très proche de celui du RFC 5709 à part l'inclusion de l'adresse IPv6 source.
Supposons que nous soyons administrateur réseaux et que nos routeurs gèrent tous ce nouveau RFC. Comment déployer l'authentification sans tout casser ? La section 5 recommande de migrer tous les routeurs connectés au même lien simultanément. Autrement, les routeurs qui n'utilisent pas l'authentification ne pourront pas former d'adjacences OSPF avec ceux qui l'utilisent. Le RFC prévoit un mode de transition, où le routeur envoie le champ final d'authentification mais ne le vérifie pas en entrée mais l'implémentation de ce mode n'est pas obligatoire.
La section 6 contient l'analyse de sécurité de cette nouvelle extension d'OSPF. Elle rappelle qu'elle ne fournit pas de confidentialité (les informations de routage seront donc accessibles à tout espion). Son seul but est de permettre l'authentification des routeurs, résolvant les problèmes notés par le RFC 6039. À noter que cette extension ne permet pas d'authentifier un routeur particulier mais simplement de s'assurer que l'émetteur est autorisé à participer au routage sur ce lien (tous les routeurs ont la même clé). La clé, rappelle cette section 6, devrait être choisie aléatoirement, pour ne pas être trop facile à deviner (cf. RFC 4552).
À ma connaissance, il n'existe pas encore d'implémentation de cette option dans le logiciel d'un routeur.
L'article seul
RFC 6520: Transport Layer Security (TLS) and Datagram Transport Layer Security (DTLS) Heartbeat Extension
Date de publication du RFC : Février 2012
Auteur(s) du RFC : R. Seggelmann, M. Tuexen (Muenster Univ. of Appl. Sciences), M. Williams
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 8 février 2012
Dernière mise à jour le 8 avril 2014
Le protocole de cryptographie TLS ne disposait pas en standard de mécanisme de « battement de cœur », permettant de tester qu'une connexion est toujours vivante. C'est désormais chose faite. Grâce à la nouvelle extension de TLS, normalisée dans ce RFC, deux pairs TLS peuvent s'assurer, par un mécanisme standard, que l'autre pair est bien là, et répond.
Savoir si l'autre partie de la connexion est toujours là est souvent utile en matière de réseau. Les sessions qui utilisaient TLS (RFC 5246) ou DTLS (RFC 6347) ne disposaient pas d'un moyen générique de tester si le cœur du pair battait toujours. Les applications devaient donc envoyer des données inutiles et attendre une réponse. Une autre solution était de faire une renégociation (RFC 5246, section 7.4.1) mais cette opération est coûteuse en calculs cryptographiques. C'était encore pire avec DTLS, qui est parfois utilisé dans des applications unidirectionnelles, où aucune réponse applicative n'est prévue.
Désormais, les mises en œuvre de TLS qui gèrent la nouvelle
extension, Heartbeat, pourront envoyer des
messages HeartbeatRequest, auxquels le pair devra
répondre avec un HeartbeatResponse. Cette
extension est spécifiée au moment de la négociation (section 2), dans
les messages Hello (RFC 5246, section
7.4.1). Dans la syntaxe vaguement analogue à ASN.1 de TLS, la
nouvelle extension est décrite par :
enum {
peer_allowed_to_send(1),
peer_not_allowed_to_send(2),
(255)
} HeartbeatMode;
struct {
HeartbeatMode mode;
} HeartbeatExtension;
Le mode peer_not_allowed_to_send est là pour
indiquer qu'une machine veut utiliser l'extension pour tester son pair
mais qu'elle-même ne répondra pas aux requêtes
HeartbeatRequest. La nouvelle extension est enregistrée à l'IANA (numéro 15).
Une fois que les deux parties se sont mises d'accord, quel est le protocole pour l'utilisation de cette extension (section 3) ? Le test des battements de cœur fonctionne au-dessus du Record Protocol de TLS, auquel il ajoute deux messages :
enum {
heartbeat_request(1),
heartbeat_response(2),
(255)
} HeartbeatMessageType;
Un message HeartbeatRequest peut arriver à tout
moment pendant une session, le pair doit alors répondre par un
HeartbeatResponse. D'autres types que Requête et
Réponse seront peut-être un jour créés, et enregistrés dans le nouveau registre IANA.
Lorsque la session protégée par TLS fonctionne au dessus d'un
protocole fiable, comme TCP, c'est tout. La
couche de transport se chargera des éventuelles
retransmissions. Si
la session TLS utilise un protocole non-fiable comme UDP,
l'émetteur du HeartbeatRequest doit se préparer,
en l'absence de réponse, à réémettre le message (RFC 6347, section 4.2.4).
Et le contenu des messages (section 4) ? Une charge utile est autorisée :
struct {
HeartbeatMessageType type;
uint16 payload_length;
opaque payload[HeartbeatMessage.payload_length];
opaque padding[padding_length];
} HeartbeatMessage;
Le contenu du champ payload est quelconque. La
réponse doit inclure le même contenu (elle doit être un écho de la
requête).
La section 5 du RFC décrit ensuite deux cas d'utilisation pratique
de cette extension. Le premier est celui de la découverte de la
MTU du chemin, pour laquelle DTLS n'avait pas
de mécanisme (RFC 6347, section 4.1.1.1). La
méthode, inspirée du RFC 4821, est simplement d'utiliser des
HeartbeatRequest de plus en plus gros, jusqu'à ce
qu'on n'obtienne plus de réponse, auquel cas on sait qu'on a trouvé la
MTU maximale.
L'autre usage de cette extension est le test de bonne santé du
pair, comme expliqué au début de cet article. Le RFC recommande de ne
pas en abuser, et de n'émettre les
HeartbeatRequest qu'à des intervalles de
plusieurs fois le RTT.
Il existe déjà au moins une mise en œuvre de ce mécanisme de
battement de cœur. OpenSSL l'aura à
partir de la 1.0.1 (le code est déjà dans les versions de
développement, l'extension - option heartbeats - est apparemment compilée par défaut). Pour GnuTLS, ce n'est encore
qu'un projet. Comme souvent en informatique, quand on ajoute du code,
on ajoute des bogues. C'est ainsi que la mise en œuvre de cette
extension dans OpenSSL a été à l'origine de la faille CVE-2014-0160,
dite « HeartBleed ».
L'article seul
La longue marche de la sécurité du routage Internet : une étape importante, RPKI+ROA
Première rédaction de cet article le 4 février 2012
On le sait, le protocole BGP (normalisé dans le RFC 4271), sur lequel repose tout l'Internet, car c'est lui qui permet à l'information de routage de circuler entre les opérateurs, ce protocole, donc, est peu sûr. N'importe qui peut annoncer n'importe quelle route, dire « Je suis Google, envoyez-moi toutes les requêtes Google » et les autres le croient. Résoudre cette vulnérabilité n'est pas trivial, pour des raisons essentiellement non techniques. Néanmoins, le manque d'un mécanisme standard pour valider les routes était une des faiblesses du routage Internet. Une série de RFC vient de partiellement combler ce déficit.
Écrits par le groupe de travail IETF SIDR (Secure Inter-Domain Routing), ces RFC décrivent une série de protocoles, règles et formats qui permettent de sécuriser une partie de BGP. À eux seuls, ils sont loin de résoudre le problème, qui est très complexe. Mais ils fournissent des briques sur lesquelles seront bâties les solutions ultérieures.
Ces annonces de route anormales sont relativement banales sur l'Internet. Pour ne citer que trois exemples relativement récents :
- Le 24 février 2008, Pakistan Telecom annonce les adresses de YouTube et prive le monde de ce service pendant plusieurs heures,
- Le 8 avril 2010, China Telecom annonce les adresses d'une bonne partie de l'Internet et attire ainsi leur trafic,
- Le 23 juin 2011, OpenTransit fait la même erreur et détourne également une partie du trafic. Les abonnés au service d'alarme BGPmon reçoivent des avis de détournement.
Toutes étaient des erreurs et pas des attaques. Néanmoins, le risque que cette même faiblesse soit exploitée pour des attaques est réel. Celles-ci seront sans doute plus subtiles que les trois grosses bavures citées plus haut, et utiliseront sans doute des techniques de furtivité comme celle de Kapela & Pilosov.
Mais alors, pourquoi malgré autant d'attaques (n'exagérons rien : il n'y en a pas tous les mois), n'a-t-on pas encore déployé une solution de sécurité ? Parce que le problème est compliqué. Le routage sur l'Internet n'est pas hiérarchique. Les relations entre opérateurs sont un graphe plutôt complexe, et un opérateur qui est situé loin ne sait pas ce qui est normal : après tout, qui me dit que YouTube n'a pas subitement changé de fournisseur pour s'installer au Pakistan ? Même si un être humain peut trouver cela bizarre, le pauvre routeur BGP n'a pas de moyen de décider si une annonce est normale ou pas.
Il y a en fait deux choses qu'on peut vouloir authentifier dans
une annonce BGP. Imaginons qu'un routeur reçoive une annonce pour le
préfixe 2001:db8:666::/48 et que le chemin des
AS traversés soit 64496 65550
65543 (rappelez-vous que le chemin se lit de droite à
gauche, l'annonce initiale a donc été faite par l'AS 65543). Le
routeur peut se demander « Est-ce que 65543 était bien autorisé à
annoncer ce préfixe ? », ce qu'on appelle la validation de
l'origine. Et il peut aussi s'interroger « Est-ce que 65550
avait le droit de relayer cette annonce ? Et 64496 ? ». C'est la
validation du chemin. La première est
relativement simple (il n'y a pas tant de préfixes IP que cela et ils
sont normalement tous enregistrés dans les bases des
RIR, et les origines changent rarement). La
seconde est bien plus complexe (explosion combinatoire du nombre de
possibilités, relations entre opérateurs qui ne sont pas dans les
bases des RIR, changements fréquents) et ne
sera traitée que dans un deuxième temps.
Il y a donc eu de nombreuses tentatives de résoudre ce problème de sécurité (une liste partielle figure à la fin de cet article). Attention d'ailleurs en lisant ce qu'on trouve sur l'Internet : vous extrayerez des tas de propositions dépassées ou abandonnées.
L'approche choisie par le groupe SIDR est modulaire : il n'y a pas une technique unique qui résout tout mais un ensemble d'outils, à combiner selon les cas. À la base, se trouve la RPKI, une IGC hiérarchique, partant de l'IANA et des RIR, permettant de produire des certificats attestant de la « possession » d'une ressource (un préfixe IP, un numéro d'AS, etc). L'émission de ces certificats a été un des premiers pas concrets.
Une fois les certificats émis, les titulaires des ressources (typiquement, des adresses IP) créent des objets signés, les ROA (Route Origin Authorizations). Ces ROA et les certificats sont distribués sur l'Internet (pas en temps réel) et tout routeur peut les consulter pour savoir si une annonce est légitime. Pour éviter de charger le routeur avec des calculs cryptographiques, la validation sera typiquement faite par une machine spécialisée, le validateur, que le routeur interrogera avec un protocole simple.
Voici la longue liste des 14 (!) RFC qui viennent de paraître sur ce sujet. L'ordre ci-dessous est leur ordre d'importance décroissante (selon moi) :
- RFC 6480, An Infrastructure to Support Secure Internet Routing, le plus important, décrit l'architecture générale du système et notamment l'infrastructure de clés publiques, la RPKI (Resource Public Key Infrastructure).
- RFC 6483, Validation of Route Origination using the Resource Certificate PKI and ROAs, décrit le mécanisme de validation de l'origine (le premier AS) d'une route, en utilisant les techniques ci-dessus.
- RFC 6481, A Profile for Resource Certificate Repository Structure, décrit la structure du dépôt des objets de la RPKI (certificats et ROA).
- RFC 6488, Signed Object Template for the Resource Public Key Infrastructure, spécifie le profil CMS des objets signés,
- RFC 6482, A Profile for Route Origin Authorizations (ROAs), décrit le format concret des ROA (Route Origin Authorization), les objets signés cryptographiquement qui permettent d'autoriser un AS à annoncer l'origine d'une route.
- RFC 6486, Manifests for the Resource Public Key Infrastructure, sur les manifestes, ces listes d'objets signés, elles-mêmes signées, et qui seront distribuées dans les dépôts de la RPKI,
- RFC 6487 A Profile for X.509 PKIX Resource Certificates, spécifie le profil (la restriction) pour les certificats numériques utilisés dans la RPKI,
- RFC 6493, The RPKI Ghostbusters Record, indique comment préciser dans le certificat les informations permettant de contacter le titulaire de la ressource.
- RFC 6490, Resource Certificate PKI (RPKI) Trust Anchor Locator, indique comment trouver les certificats racine (il a depuis été remplacé par le RFC 7730),
- RFC 6492, A Protocol for Provisioning Resource Certificates, le protocole d'avitaillement des certificats entre l'AC et ses clients,
- RFC 6484, Certificate Policy (CP) for the Resource PKI (RPKI), où sont exposés les principes de la politique que devraient suivre les AC de la RPKI,
- RFC 6491, RPKI Objects issued by IANA, décrit les objets que va devoir signer l'IANA pour amorcer le processus (typiquement, les réseaux « spéciaux », normalement non annoncés en BGP),
- RFC 6489, CA Key Rollover in the RPKI,
- Et enfin RFC 6485, The Profile for Algorithms and Key Sizes for use in the Resource Public Key Infrastructure, qui spécifie les algorithmes de cryptographie utilisés par la RPKI.
En outre, quelques mois après, est sorti le RFC 6810, sur RTR (RPKI/Router Protocol) le protocole de communication entre le routeur BGP et son validateur, typiquement un serveur Unix spécialisé. Et le RFC 6811, décrivant plus précisement la validation de préfixes.
Quelles sont les chances d'adoption de RPKI+ROA, sachant que d'innombrables protocoles de sécurité de l'IETF ont été peu ou pas déployés (IPsec, PGP, etc) ? Tout le monde dit en effet vouloir davantage de sécurité mais, en pratique, personne ne veut en payer le prix. Les systèmes de sécurité sont lourds, contraignants, et ne semblent pas en valoir la peine. Il est possible que des des mesures a posteriori (via des systèmes d'alerte) suffisent à gérer le problème de la sécurité de BGP.
Sinon, ce système soulève des tas de questions liées à la gouvernance, comme c'est souvent le cas des mécanismes de sécurité. Quelques exemples :
- Faut-il une racine unique de certification ? Sur le papier, tout le monde dit oui (par exemple le NRO ou bien l'IAB ; notez que les conflits dont parle l'IAB se sont déjà produits) mais, en pratique, les membres du NRO n'en veulent pas et le candidat évident pour cette racine unique, l'IANA, n'a donc qu'un rôle minime. Pour l'instant, chaque RIR est racine de certification et il faut donc avoir cinq certificats racine. L'IGP a produit une critique de la déclaration de l'IAB.
- RPKI+ROA augmente le pouvoir des RIR, via les révocations, ce qui est une nouveauté. Avant, les RIR n'intervenaient pas dans le routage, uniquement dans l'allocation des adresses. Un RIR pouvait en théorie révoquer une allocation, mais cela n'avait aucune conséquence pratique. Avec la RPKI, le RIR émettra une révocation X.509 et les routeurs ROA arrêteront automatiquement d'accepter la route... Le RIR aura donc désormais un rôle opérationnel. Comme l'explique très bien l'excellent article de l'IGP Building a new governance hierarchy: RPKI and the future of Internet routing and addressing, cela peut changer les rôles des acteurs de la gouvernance de l'Internet et la RPKI devrait donc être discutée politiquement, pas uniquement techniquement (une version plus longue de cet article est « Negotiating a New Governance Hierarchy: An Analysis of the Conflicting Incentives to Secure Internet Routing » par Brenden Kuerbis et Milton Mueller). Pour l'instant, les partisans de la RPKI considèrent que le problème doit être relativisé car le contrôle final est entre les mains du cache validateur qui croit qui il veut. S'il ne veut pas utiliser les trust anchors des RIR, il le peut. (Il peut aussi ne pas valider du tout, ou bien accepter les routes invalides, surtout s'il n'y a pas de routes alternatives.) Concernant spécifiquement le RIPE-NCC, leur politique quant à une éventuelle révocation de routes est que ce n'est pas possible.
- Discussions animées au sein de la communauté quant à l'intérêt pour le RIR de travailler dans cette direction. En novembre 2011, celle du RIPE a voté pour la poursuite du projet (voir les articles de Malcolm et de Michele Neylon).
Pour le fonctionnement concret du système RPKI+ROA, et des exemples, voir mon autre article.
Dans le futur, des travaux auront lieu pour valider le chemin et non plus seulement l'origine comme le fait notre nouveau système (le cahier des charges de ce projet a été publié dans le RFC 7353). Après des propositions comme Secure BGP, le futur protocole se nommera probablement BGPSEC car, contrairement au système qui vient d'être normalisé, il sera une modification de BGP. Humour par Hugo Salgado : si l'actuel BGP, sans sécurité, est BGPbrut, RPKI+ROA est un BGPdemisec - à moitié sécurisé - et le futur protocole sera, logiquement, BGPsec...
Quelques articles intéressants :
- Une introduction pour grands débutants par l'APNIC.
- Un court résumé technique qui avait été fait à l'IETF.
- Un tutoriel RIPE, rappelant l'effort du RIPE-NCC.
- Une proposition alternative, où on ne valide pas les routes mais où on ne les adopte que prudemment, Pretty Good BGP.
- Mes transparents à FRnog19 sur la RPKI,
- Une autre alternative à RPKI+ROA, plus simple, ROVER,
- Un très bon article général, très détaillé, sur RPKI+ROA puis le passage à BGPsec.
L'article seul
Les logiciels pour vérifier les annonces de routes, avec RPKI et ROA
Première rédaction de cet article le 4 février 2012
Un ensemble de RFC vient de sortir, décrivant un mécanisme pour sécuriser les annonces de route sur l'Internet (actuellement, on peut annoncer à peu près ce qu'on veut avec BGP...). Quels sont les logiciels existants qui permettent de regarder ces annonces et/ou de les vérifier ?
Avant de voir l'offre logicielle, il faut rappeler en deux mots comment fonctionne ce système de sécurisation. Les détenteurs de ressources Internet (une ressource est typiquement un préfixe d'adresses IP) obtiennent des certificats numériques prouvant qu'ils sont titulaires de cette ressource. L'ensemble de ces certificats et des entités qui les émettent (typiquement les RIR et LIR) forment la RPKI, Resource Public Key Infrastructure. Muni de son certificat, le titulaire peut émettre des ROA (Route Origin Authorization), des objets signés avec la clé du certificat, qui déclarent quel AS a le droit d'annoncer quel préfixe. L'idée est que les routeurs BGP, recevant une annonce, vont vérifier s'il existe un objet signé authentifiant cette annonce. Sinon, ils peuvent décider de rejeter l'annonce ou bien baisser sa priorité.
Ça, c'est le principe. En pratique, pour que le système passe à l'échelle, pour éviter que les routeurs ne passent leur temps à de coûteuses opérations cryptographiques, une nouvelle classe de machine est introduite, les caches de validation. Ce sont typiquement des serveurs Unix, installés près des routeurs (probablement un cache par POP), qui recevront les ROA, les valideront et diront juste au routeur quelles sont les annonces acceptables. (Ce modèle de déploiement n'est pas le seul obligatoire mais ce sera probablement celui utilisé au début.)
Il y a donc plusieurs classes de logiciels en jeu :
- Les logiciels permettant d'émettre les certificats de la RPKI. Ils seront sans doute analogues à ce qu'utilisent les autorités de certification actuelles. Dans le futur, ils seront probablement intégrés aux logiciels d'IPAM. Je n'ai pas d'expérience avec de tels logiciels. Notez qu'un certain nombre d'acteurs (par exemple le RIPE-NCC) proposent des interfaces Web permettant de leur sous-traiter la gestion des certificats et des ROA.
- Les logiciels des caches de validation, permettant de recevoir les objets signés et de dire lesquels sont valides et lesquels ne le sont pas.
- Les logiciels à bord des routeurs, intégrés au système d'exploitation dudit routeur, et permettant de communiquer avec le cache de validation.
Pour la première catégorie, je l'ai dit, je n'ai pas d'expérience. Il existe des logiciels spécialisés comme celui du RIPE.
Pour la seconde catégorie, les logiciels pour gérer un cache de validation, il existe deux importantes suites logicielles sous une licence libre, les outils du RIPE-NCC et rcynic. On peut aussi, pour certaines fonctions simples, utiliser des outils existants comme OpenSSL. Enfin, il existe des interfaces Web ou whois permettant de parler à des caches de validation publics.
Voyons d'abord la suite du RIPE-NCC. Elle est disponible en ligne. Elle est écrite en Java et on récupère donc un code binaire qu'on peut exécuter directement si on a un JRE. (Les exemples ci-dessous ont été faits avec la version 1, la version 2 a changé bien des choses mais est trop récente pour que j'ai eu le temps de la tester.)
% certification-validator -h
usage: For detailed usage scenarios see README file. Options:
...
-p,--print Show the certificate repository object in a
...
-v,--verbose Show all validation steps
--version Show version information
Mais le logiciel n'est rien sans les données. Il faut aussi télécharger les objets de la RPKI. Suivant le RFC 6481, le dépôt est accessible en rsync. Ainsi :
% rsync -av rsync://rpki.ripe.net/repository RPKI-repository
va installer sur votre disque dur tous les objets existants (fin 2011, sur le dépôt du RIPE, ils sont environ 3 000, des statistiques publiques sont disponibles). Une fois que c'est fait, on peut les afficher. D'abord, un certificat :
% certification-validator --print -f \
RPKI-repository/64/71d07d-c9f8-4368-87ea-162d1075dfaa/1/q3C8zU6hYpb7zVqmpjlVY5B_BWE.cer
Serial: 85871
Subject: CN=q3C8zU6hYpb7zVqmpjlVY5B_BWE
Not valid before: 2010-12-14T15:26:48.000Z
Not valid after: 2011-07-01T00:00:00.000Z
Resources: 85.118.184.0/21, 93.175.146.0/23, 2001:7fb:fd02::/47
Ensuite, une liste de révocations :
% certification-validator --print -f \
RPKI-repository/42/a01f82-9193-4199-95a8-83ae5d9c832f/1/vIp8GBZHR75QzAcTIHtf0IcdB3g.crl
CRL type: X.509
CRL version: 2
Issuer: CN=bc8a7c18164747be50cc0713207b5fd0871d0778
Authority key identifier: vIp8GBZHR75QzAcTIHtf0IcdB3g=
Number: 629
This update time: 2011-09-21T14:44:51.000Z
Next update time: 2011-09-22T14:44:51.000Z
Revoked certificates serial numbers and revocation time:
Le principal service de ce système de sécurité est de valider les ROA. Ces ROA sont distribués via rsync comme ci-dessus mais aussi disponibles en ligne. Affichons-en un :
% certification-validator --print -f roa-5574190.roa
Content type: 1.2.840.113549.1.9.16.1.24
Signing time: 2011-01-11T19:04:18.000Z
ASN: AS559
Prefixes:
193.5.26.0/23 [24]
193.5.152.0/22 [24]
193.5.168.0/22 [24]
193.5.22.0/24
193.5.54.0/23 [24]
193.5.58.0/24
193.5.60.0/24
193.5.80.0/21 [24]
On voit donc que tous ces préfixes peuvent être légitimement annoncés par l'AS 559. Mais avant de conclure cela, encore faut-il vérifier que le ROA est valide. On peut le valider en ligne. En local, il faut indiquer au validateur les clefs de confiance à utiliser (typiquement, les certificats des RIR, à partir desquels se fait toute la validation). Ces clés (trust anchors) sont accessibles en ligne. Une fois récupérées, on peut valider, ici avec la clé du RIPE :
% certification-validator -t tal/ripe-ncc-root.tal \
-f roa-5574190.roa --output-dir .
17:11:44,179 INFO rsync://rpki.ripe.net/ta/ripe-ncc-ta.cer is VALID
17:11:45,587 INFO rsync://rpki.ripe.net/ta/ripe-ncc-ta.crl is VALID
17:11:45,593 INFO rsync://rpki.ripe.net/ta/u75at9r0D4JbJ3_SFkZXD7C5dmg.cer is VALID
17:11:46,975 INFO rsync://rpki.ripe.net/repository/33/36711f-25e1-4b5c-9748-e6c58bef82a5/1/u75at9r0D4JbJ3_SFkZXD7C5dmg.crl is VALID
17:11:46,978 INFO rsync://rpki.ripe.net/repository/33/36711f-25e1-4b5c-9748-e6c58bef82a5/1/Uz_7R2AURj1tzQ3QylGlM-hEgx0.cer is VALID
17:11:48,183 INFO rsync://rpki.ripe.net/repository/29/c8c6f6-595c-45b1-a76e-bd192676c9bb/1/Uz_7R2AURj1tzQ3QylGlM-hEgx0.crl is VALID
17:11:48,186 INFO file:/home/bortzmeyer/tmp/roa-5574190.roa is VALID
Le logiciel a affiché toute la chaîne de validation, de la clé du RIR, jusqu'au ROA, en passant par tous les certificats intermédiaires.
La version 2 de l'outil du RIPE semble avoir supprimé les outils en ligne de commande (?) mais apporte un serveur Web qui écoute par défaut sur le port 8080 (il y a aussi un serveur RTR, cf. RFC 6810) et permet de gérer les ROA et leur validation. Par exemple, on peut définir des listes blanches de préfixe qui seront acceptés même en cas d'erreur de validation (un problème qui sera sans doute fréquent au début). On peut récupérer les anciennes versions du logiciel sur le serveur du RIPE.
Pour gérer un cache de validation, ou tout simplement pour explorer
la RPKI ou déboguer des problèmes de routage, une alternative aux
outils du RIPE-NCC est rcynic. On ne peut pas
dire qu'il brille par la convivialité de sa documentation, ni par le
support disponible, mais il
marche très bien. La compilation (rcynic est écrit en
C et en Python) à partir du dépôt
Subversion est simple (./configure &&
make && sudo make install), mais il ne faut
pas utiliser l'option
--with-system-openssl de
configure en raison de la bogue Debian citée plus
bas et aussi parce que rcynic nécessite un OpenSSL très récent
(sinon, vous aurez à la compilation des erreurs concernant
v3_addr_validate_path). rcynic s'installe ensuite
dans une jail. Le script
d'installation a fait une partie du travail mais pas tout (testé sur
une machine Ubuntu). rcynic est livré avec de
nombreux programmes mais peu d'explications de leur rôle.
rpkid est pour les LIR (ou RIR), qui émettent des
certificats (première catégorie de logiciels, dans ma classification
plus haut). Pour
les opérateurs réseau qui gèrent des routeurs, il faut utiliser
rcynic.
Pour terminer la configuration de la jail, en
/var/rcynic/lib, j'ai
dû faire :
# Pour lancer facilement les programmes dans la prison # aptitude install chrootuid # Installation des bibliothèques dynamiques dans la prison # cp /lib/libpopt.so.0* /lib/i386-linux-gnu/libacl.so.1* /lib/i386-linux-gnu/libattr.so.1* /lib/i386-linux-gnu/libnss* /lib/i386-linux-gnu/libresolv* /lib/ld-linux.so.2* /lib/i386-linux-gnu/libc.so.6 /var/rcynic/lib # cp /etc/nsswitch.conf /var/rcynic/etc # Sinon, plein de messages "Host unknown"
La grande majorité des problèmes de configuration de la
jail vient de la résolution de noms. Pour tester,
copier ping dans la jail,
puis chmod u+s /var/rcynic/bin/ping puis enfin :
% sudo chrootuid /var/rcynic rcynic /bin/ping www.google.com ping: unknown host www.google.com
Ici, il y a un problème, il faut donc vérifier que les fichiers indispensables ont bien été copiés, comme indiqué plus haut.
Ensuite, on édite /var/rcynic/etc/rcynic.conf
si on veut changer des paramètres. rcynic récupère lui-même les objets
de la RPKI. La première fois, c'est très long (cela peut prendre
plusieurs heures). Ensuite, on doit juste exécuter la commande de
temps en temps, par exemple depuis cron :
# chrootuid /var/rcynic rcynic /bin/rcynic -s -c /etc/rcynic.conf rcynic[18606]: Finished, elapsed time 3:03:54
Une fois qu'on a les données, on peut examiner un ROA :
% print_roa RPKI-repository/ff/cf59fc-653f-44eb-aca1-c5d1f27b532d/1/tyIST2Kt6P8tIxIthqPHxCj6lSY.roa
Certificates: 1
CRLs: 0
SignerId[0]: b7:22:12:4f:62:ad:e8:ff:2d:23:12:2d:86:a3:c7:c4:28:fa:95:26 [Matches certificate 0] [signingTime(U) 110104093105Z]
eContentType: 1.2.840.113549.1.9.16.1.24
version: 0 [Defaulted]
asID: 15533
addressFamily: 1
IPaddress: 62.73.128.0/19
IPaddress: 213.212.64.0/18
addressFamily: 2
IPaddress: 2001:4138::/32
ou bien chercher un ROA en fonction d'un préfixe (chose que je n'ai pas trouvé le moyen de faire avec les outils du RIPE) :
% find_roa /var/rcynic 193.5.26.0/23 ASN 3303 prefix 193.5.26.0/23 ROA /var/rcynic/data/authenticated.2011-10-04T09:48:34Z/rpki.ripe.net/repository/29/c8c6f6-595c-45b1-a76e-bd192676c9bb/1/jOKSK_yZRVOwOqhy2iwg0AYnuV4.roa ASN 559 prefix 193.5.26.0/23 ROA /var/rcynic/data/authenticated.2011-10-04T09:48:34Z/rpki.ripe.net/repository/29/c8c6f6-595c-45b1-a76e-bd192676c9bb/1/tm9aENV_7W2xYpYsy5I1u134w8o.roa % ./find_roa /var/rcynic 62.73.128.0/19 ASN 15533 prefix 62.73.128.0/19 ROA /var/rcynic/data/authenticated.2011-10-04T09:48:34Z/rpki.ripe.net/repository/ff/cf59fc-653f-44eb-aca1-c5d1f27b532d/1/fpVFMoMEoV76BKX7gig21v-MDts.roa
Notez qu'il existe deux ROA pour le premier préfixe, car deux AS sont
autorisés à l'annoncer. Notez aussi que les ROA se trouvent dans le
répertoire authenticated. rcynic valide les
objets au fur et à mesure de leur récupération et son programme
find_roa ne cherche que parmi les objets
validés (les clés de confiance sont livrées avec rcynic, il n'est pas
nécessaire de les récupérer explicitement). Si on veut plus de détails sur les ROA trouvés par
find_roa, on peut appeler
print_roa sur le fichier trouvé :
% print_roa /var/rcynic/data/authenticated.2011-10-04T09:48:34Z/rpki.ripe.net/repository/ff/cf59fc-653f-44eb-aca1-c5d1f27b532d/1/fpVFMoMEoV76BKX7gig21v-MDts.roa
Certificates: 1
CRLs: 0
SignerId[0]: 7e:95:45:32:83:04:a1:5e:fa:04:a5:fb:82:28:36:d6:ff:8c:0e:db [Matches certificate 0] [signingTime(U) 110615123707Z]
eContentType: 1.2.840.113549.1.9.16.1.24
version: 0 [Defaulted]
asID: 15533
addressFamily: 1
IPaddress: 176.62.128.0/21
IPaddress: 62.73.128.0/19
IPaddress: 213.212.64.0/18
addressFamily: 2
IPaddress: 2001:4138::/32
Et comment trouver, non pas le (ou les) ROA mais le certificat
correspondant à un préfixe IP donné ? La seule méthode que je
connaisse consiste en un examen systèmatique du dépôt (ici, on cherche
le titulaire de 98.128.4.0/24) :
% for file in $(find /var/rcynic/data/authenticated.2011-10-31T13:36:08Z -name '*.cer'); do
RESULT=$(openssl x509 -inform DER -text -in $file | grep 98.128.4)
if [ ! -z "$RESULT" ]; then
echo $file
fi
done
/var/rcynic/data/authenticated.2011-10-31T13:36:08Z/rgnet.rpki.net/rpki/rgnet/635/hAK3Zfkl-_L6YZNsUM2T3i8GeVs.cer
Et hop,
/var/rcynic/data/authenticated.2011-10-31T13:36:08Z/rgnet.rpki.net/rpki/rgnet/635/hAK3Zfkl-_L6YZNsUM2T3i8GeVs.cer
contient le certificat convoité.
Si vous voulez tester votre cache validateur, le RIPE annonce des routes avec des ROA, dont certains délibérement invalides, pour tester.
Après ces deux paquetages, développés spécialement pour la RPKI, les outils génériques. Si on préfère utiliser les outils traditionnels, OpenSSL permet de voir les certificats de la RPKI (ils sont normalisés dans le RFC 6487, et utilisent la syntaxe standard de X.509) :
% openssl x509 -inform DER -text \
-in ./RPKI-repository/64/71d07d-c9f8-4368-87ea-162d1075dfaa/1/q3C8zU6hYpb7zVqmpjlVY5B_BWE.cer
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 85871 (0x14f6f)
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN=5XxoZDVUZvaNYJcVATAgTQ2ifLQ
Validity
Not Before: Dec 14 15:26:48 2010 GMT
Not After : Jul 1 00:00:00 2011 GMT
Subject: CN=q3C8zU6hYpb7zVqmpjlVY5B_BWE
...
X509v3 extensions:
X509v3 Subject Key Identifier:
AB:70:BC:CD:4E:A1:62:96:FB:CD:5A:A6:A6:39:55:63:90:7F:05:61
X509v3 Authority Key Identifier:
keyid:E5:7C:68:64:35:54:66:F6:8D:60:97:15:01:30:20:4D:0D:A2:7C:B4
X509v3 Basic Constraints: critical
CA:TRUE
X509v3 Key Usage: critical
Certificate Sign, CRL Sign
Authority Information Access:
CA Issuers - URI:rsync://rpki.ripe.net/ta/5XxoZDVUZvaNYJcVATAgTQ2ifLQ.cer
Subject Information Access:
CA Repository - URI:rsync://rpki.ripe.net/repository/1a/08941d-c629-44be-9708-fc9c3753f8cd/1/
1.3.6.1.5.5.7.48.10 - URI:rsync://rpki.ripe.net/repository/1a/08941d-c629-44be-9708-fc9c3753f8cd/1/q3C8zU6hYpb7zVqmpjlVY5B_BWE.mft
X509v3 CRL Distribution Points:
...
Mais les extensions du RFC 3779, cruciales pour la RPKI, sont juste affichées en binaire :
sbgp-ipAddrBlock: critical
0%0.....0....Uv....]..0.....0.... .....
Le problème est en fait que, sur ma machine
Debian, OpenSSL a bien le code nécessaire mais
il n'est pas compilé avec la bonne option. Il faut recompiler avec
./config enable-rfc3779 ce que ne fait hélas pas
Debian (vous pouvez insister pour ce changement via la bogue #630790, notez que la non-prise en compte
du RFC 3779 était peut-être due à CVE-2011-4577.).
Une fois OpenSSL compilé avec les bonnes options, on voit le
certificat entier :
X509v3 Certificate Policies: critical
Policy: 1.3.6.1.5.5.7.14.2
sbgp-ipAddrBlock: critical
IPv4:
85.118.184.0/21
93.175.146.0/23
IPv6:
2001:7fb:fd02::/47
Il existe d'autres outils qui affichent le X.509 et qui semblent capable d'afficher proprement du CMS, comme Legion of Bouncy Castle mais je ne les ai pas testés.
Enfin, dernière façon de regarder et de valider les objets de la RPKI, les services hébergés, comme celui de BGPmon. Il est accessible entre autres par whois :
% whois -h whois.bgpmon.net " --roa 28001 200.7.86.0/23"
0 - Valid
------------------------
ROA Details
------------------------
Origin ASN: AS28001
Not valid Before: 2011-01-07 02:00:00
Not valid After: 2012-08-05 03:00:00
Trust Anchor: repository.lacnic.net
Prefixes: 200.7.86.0/23 (max length /24)
2001:13c7:7012::/47 (max length /47)
2001:13c7:7002::/48 (max length /48)
200.3.12.0/22 (max length /24)
% whois -h whois.bgpmon.net " --roa 2801 200.7.86.0/23"
2 - Not Valid: Invalid Origin ASN, expected 28001
On voit que l'AS 28001 a le droit d'annoncer
200.7.86.0/23 (le ROA autorise également trois
autres préfixes) mais que le 2801 n'a pas le droit.
Dans le même état d'esprit (validateur accessible via le réseau),
on peut aussi se servir d'un looking
glass comme celui de LACNIC ou de leur service REST (voyez par exemple l'état de l'annonce http://www.labs.lacnic.net/rpkitools/looking_glass/rest/valid/cidr/200.7.84.0/23/).
Maintenant, troisième catégorie, il faut aussi du logiciel sur le routeur lui-même, pour interroger le cache validant. Pour les mises en œuvre de BGP libres comme Quagga, on peut utiliser, par exemple, bgp-srx. Le LACNIC a documenté l'état du logiciel, et la façon de s'en servir, pour plusieurs modèles de routeurs : JunOS, et Quagga. Le RIPE-NCC a produit une documentation pour les Juniper et Cisco.
Si on veut jouer avec un vrai routeur
vivant, EuroTransit a configuré des routeurs
Juniper publiquement accessibles par telnet :
193.34.50.25 et
193.34.50.26. Utilisateur "rpki", mot de passe
"testbed" et le tout est
documenté. Il y a aussi juniper.rpki.netsign.net (rpki/testbed).
% telnet 193.34.50.25
Trying 193.34.50.25...
Connected to 193.34.50.25.
Escape character is '^]'.
RPKI testbed router
connected to RIPE RPKI Validator (cache server)
hosted by EuroTransit GmbH
For further information about this RPKI testbed:
http://rpki01.fra2.de.euro-transit.net
Unauthorized access prohibited
Authorized access only
This system is the property of EuroTransit GmbH
Disconnect IMMEDIATELY if you are not an authorized user!
Contact 'noc@nmc.euro-transit.net' for help.
lr1.ham1.de (ttyp0)
login: rpki
Password:
Last login: Tue Dec 13 19:31:05 from 213.211.192.18
--- JUNOS 10.3I built 2011-04-05 18:23:14 UTC
rpki@lr1.ham1.de>
[La validation sur ce Juniper]
rpki@lr1.ham1.de> show validation statistics
Total RV records: 1517
Total Replication RV records: 2976
Prefix entries: 1412
Origin-AS entries: 1517
Memory utilization: 446892 bytes
Policy origin-validation requests: 13907256
Valid: 41302
Invalid: 39656
Unknown: 13826298
BGP import policy reevaluation notifications: 27490
inet.0, 27490
inet6.0, 0
[Les communications avec le cache, suivant le protocole RTR.]
rpki@lr1.ham1.de> show validation session
Session State Flaps Uptime #IPv4/IPv6 records
195.13.63.18 Up 1015 00:53:27 1207/310
rpki@lr1.ham1.de> show validation database origin-autonomous-system 15533
RV database for instance master
Prefix Origin-AS Session State Mismatch
62.73.128.0/19-19 15533 195.13.63.18 valid
176.62.128.0/21-21 15533 195.13.63.18 valid
213.212.64.0/18-18 15533 195.13.63.18 valid
2001:4138::/32-32 15533 195.13.63.18 valid
IPv4 records: 3
IPv6 records: 1
[Notez le maxlength exprimé sous forme de deux chiffres, toujours
identiques ici mais qui ne le sont pas forcément.]
Et si on veut un Cisco ? telnet rpki-rtr.ripe.net, utilisateur « ripe », pas de mot de passe :
rpki-rtr>show ip bgp rpki table
1187 BGP sovc network entries using 104456 bytes of memory
1280 BGP sovc record entries using 25600 bytes of memory
Network Maxlen Origin-AS Source Neighbor
24.232.0.0/16 32 10318 0 193.0.19.44/8282
31.3.8.0/21 21 5524 0 193.0.19.44/8282
...
rpki-rtr>show ip bgp 62.73.128.0
BGP routing table entry for 62.73.128.0/19, version 1865228
Paths: (2 available, best #1, table default)
Not advertised to any peer
Refresh Epoch 1
12654 50300 15533
193.0.4.1 from 193.0.4.28 (193.0.4.28)
Origin IGP, localpref 110, valid, external, best
path 58970BAC RPKI State valid
Refresh Epoch 1
12654 50300 15533, (received-only)
193.0.4.1 from 193.0.4.28 (193.0.4.28)
Origin IGP, localpref 100, valid, external
path 58970B68 RPKI State valid
[Regardez la dernière ligne, ci-dessus.]
Il faudra aussi apprendre à déboguer les annonces invalides. Si on se fie à l'expérience d'un autre système de sécurité, DNSSEC, il y aura des plantages, et souvent. Mais On n'a pas le choix: tant qu'on ne déploie pas pour de bon, ça ne marchera pas.
Autres logiciels que je n'ai pas eu le temps de tester (il existe une liste à peu près à jour) :
- RPSTIR, un validateur/cache
Quelques autres lectures sur ce sujet :
- Pour Cisco, BGP Origin Validation, exposé de Roque Gagliano à Swinog. Il décrit le protocole entre le routeur et le validateur (au dessus de SSH) et contient des exemples Cisco IOS.
- Un bon article de Jérôme Durand en français.
- Une bonne synthèse sur la RPKI, avec une bonne discussion à la fin.
- Les transparents du RPKI Workshop Routing Lab à la réunion Nanog de Denver (le même atelier avait été fait à la réunion RIPE de Vienne) : pour JunOS et pour Cisco IOS.
- La documentation officielle pour JunOS.
- Le retout d'expérience de Tim Hoffman avec JunOS,
- Un état des outils de la RPKI qui avait été présenté à l'IETF en mars 2011.
- Une intéressante étude quantitative sur une journée de fonctionnement de la RPKI.
- Déploiement et utilisation de la RPKI au point d'échange de Lyon.
- Plein d'information au RIPE-NCC.
L'article seul
RFC 6483: Validation of Route Origination using the Resource Certificate PKI and ROAs
Date de publication du RFC : Février 2012
Auteur(s) du RFC : G. Huston (APNIC), G. Michaelson (APNIC)
Pour information
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 4 février 2012
Ce document s'inscrit dans la longue liste des RFC sur la sécurisation du routage BGP. Il décrit la sémantique des ROA (Route Origin Authorization), ces objets qui expriment l'autorisation du titulaire d'un préfixe IP à ce que ce préfixe soit annoncé initialement par un AS donné. La syntaxe des ROA, elle, figure dans le RFC 6482.
Les ROA (Route Origin Authorization) sont issus
de la RPKI, l'IGC du
routage (RFC 6480). Ce sont des objets signés qu'un routeur
BGP peut vérifier lorsqu'il reçoit une
annonce. Ainsi, si un routeur BGP voit son pair lui dire « je connais
un chemin vers 192.0.2.0/24 et son chemin
d'AS est 64498 65551 65540 »,
le routeur peut vérifier que l'AS 65540 a bien été autorisé, par le
titulaire du préfixe 192.0.2.0/24, à annoncer
cette route (l'origine, le premier AS, est le
plus à droite ; ce RFC ne permet de valider que l'origine, pas le
chemin complet, donc on ne peut rien dire au sujet de la présence des AS 64498
et 65551). Les clés utilisées pour les signatures sont contenues
dans des certificats
X.509 suivant le format Internet standard (RFC 5280) avec des extensions pour stocker des informations comme
les adresses IP (RFC 3779). Ces certificats permettent de vérifier que le
signataire était bien titulaire de la ressource (ici, le préfixe
192.0.2.0/24). Quant au format des ROA, on l'a
dit, il figure dans le RFC 6482.
Tout d'abord (section 2 du RFC), que se passe-t-il pendant la validation d'une annonce de route et quels sont les résultats possibles ? Une route est composée d'un ensemble de préfixes IP, d'un chemin d'AS et de quelques attributs. L'origine, la seule chose vérifiée par les ROA, est le premier AS du chemin (donc le plus à droite). S'il y a eu agrégation, et que le premier élément du chemin est un ensemble d'AS, l'origine est inconnue.
L'engin qui fait la validation (nommé RP, pour Relying
Party, c'est le routeur
BGP, ou bien une machine spécialisée à laquelle il a sous-traité ce
travail) est supposé avoir accès à tous les ROA valides (ce RFC ne
décrit pas comment, a priori, ce sera le protocole standard de
récupération des préfixes validés, protocole nommé RTR, normalisé dans le RFC 6810). Il cherche les ROA s'appliquant à
l'annonce qu'il veut valider. Si un ROA correspond, l'annonce est
valide. Un ROA pour un préfixe donné
s'applique à tous les préfixes plus spécifiques (ceux où le masque est
plus long). Ainsi, si un ROA dit « l'AS 65540 a le
droit d'annoncer 192.0.2.0/24 », alors une annonce de
192.0.2.128/25 (plus spécifique) est invalide (même si
l'origine est la même, cf. le tableau Route's validity
state). Toutefois, l'utilisation du champ
maxLength dans le ROA permet d'accepter des
préfixes plus spécifiques (jusqu'à maxLength). Si une annonce ne
correspond à aucun ROA, elle est dans l'état « inconnu » (également
appelé « non trouvé »). Au début du déploiement, évidemment, la plupart des
annonces seront dans l'état inconnu, puisque peu de ROA seront
émis. Mais dès qu'un opérateur crée un ROA pour un de ses préfixes,
tous les sous-préfixes non signés deviennent invalides (la RPKI suit
le modèle hiérarchique des adresses IP). L'algorithme exact est décrit
à la fin de la section 2. (Ceux qui ont suivi toute l'histoire de ce
RFC avant sa publication noteront que l'algorithme initial était bien
plus complexe.)
Maintenant, que faire de ce résultat ? La section 3 explique comment utiliser cet état (valide, invalide, inconnu) pour sélectionner une route (rappelez-vous qu'un routeur BGP typique reçoit plusieurs routes possibles pour chaque préfixe et qu'il doit choisir). En gros, le routeur doit préférer les routes valides, puis les inconnues. Mais la décision est locale : le RFC n'impose rien, notamment il ne dit pas si le routeur doit ignorer complètement les annonces invalides ou, a fortiori, les inconnues (la très grande majorité, au début du déploiement de ce système). Autre piège : la vitesse de propagation des ROA ne sera pas forcément celle des routes, et une annonce peut arriver avant le ROA correspondant.
Le problème est similaire à celui que connaissent les résolveurs DNS avec DNSSEC. Rejeter les réponses DNS non signées, aujourd'hui, reviendrait à rejeter la majorité des réponses. (Une autre expérience de DNSSEC est que les réponses invalides sont beaucoup plus souvent dues à des erreurs du gentil administrateur systèmes qu'à des attaques par les méchants.) Pour BGP, le problème est plus complexe car il est normal de recevoir plusieurs routes vers la même destination. Sans rejeter les annonces inconnues, le routeur peut donc décider de les faire passer après les valides. Et, s'il n'y a qu'une seule route pour une destination donnée, et que l'annonce est invalide, il vaut peut-être mieux l'accepter que de couper la communication avec le réseau concerné (la résilience de l'Internet le recommande).
Donc, pour résumer la section 3 : chaque administrateur réseaux configure son routeur comme il veut, pour décider du sort des annonces inconnues, et même pour celui des annonces invalides. Un exemple en syntaxe IOS serait :
route-map rpki permit 10 match rpki invalid set local-preference 50 route-map rpki permit 20 match rpki unknown set local-preference 100 route-map rpki permit 30 match rpki valid set local-preference 200
Dans cet exemple, tous les états sont acceptés, mais avec des préférences différentes.
Il est également possible à un titulaire de préfixe d'interdire complètement l'utilisation de ce préfixe, en créant un ROA où le numéro d'AS est mis à zéro (section 4). L'AS 0 est réservé dans le registre IANA et ne doit jamais apparaître dans une annonce réelle.
Une fois une route validée, pendant combien de temps garde-t-elle son état ? Question facile à laquelle la section 5 répond : la durée de validité est celle du certificat qui a signé le ROA (rappelez-vous que les ROA indiquent l'AS d'origine, et que c'est une information relativement stable). Si on veut annuler un ROA avant, il faut révoquer le certificat qui l'a signé.
La section 6 rassemble les considérations de sécurité des ROA : d'abord, elle rappelle qu'il y a un risque réel de se tirer dans le pied. Si on publie un ROA pour un préfixe, les préfixes plus spécifiques deviennent aussitôt invalides. Si on a de ces préfixes plus spécifiques, il faut donc penser à leur créer un ROA avant de publier le ROA le plus général.
Voilà, si vous voulez mettre tout cela en pratique, lisez mon article sur les logiciels de la RPKI.
L'article seul
RFC 6493: The RPKI Ghostbusters Record
Date de publication du RFC : Février 2012
Auteur(s) du RFC : R. Bush (Internet Initiative Japan)
Intérêt historique uniquement
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 4 février 2012
Les certificats de la RPKI, qui permettent de sécuriser le routage sur l'Internet en prouvant un droit à utiliser telle ou telle adresse IP, ne portent pas en clair de nom de titulaire. Cela peut être un problème dans certains cas opérationnels. Par exemple, une route reçue en BGP est refusée par le routeur, l'administrateur réseaux enquête, découvre un certificat qui a expiré, et voudrait prévenir le responsable qu'il a fait une boulette. Mais comment trouver le responsable ? Ou, selon la phrase culte du film Ghostbusters, « Who you gonna call? ». Ce RFC résout le problème en permettant de mettre une vCard dans le certificat, indiquant qui contacter en cas de problème.
Il n'y a guère de doute que ce genre de problèmes sera fréquent. La
RPKI permet de distribuer des
certificats numériques disant « le titulaire de
la clé privée de ce certificat est responsable du préfixe IP
2001:db8:137::/48 ». Ce certificat est ensuite
utilisé pour signer les ROA (Route
Origin Authorization) qui indiquent quel
AS peut annoncer ce préfixe. Si on se fie à
l'expérience du déploiement d'autres technologies à base de
cryptographie dans
l'Internet (par exemple
DNSSEC), il y aura des problèmes : préfixes
trop génériques, interdisant des annonces plus spécifiques,
certificats expirés, oubli de créer un nouvel ROA lorsqu'on contracte
avec un nouveau transitaire BGP, etc. Ceux et
celles qui détecteront les problèmes auront donc besoin de contacter
les responsables, dans l'espoir qu'ils agissent.
Or, les métadonnées dans les certificats de la RPKI ne contiennent pas d'identificateurs utilisables par les humains (cf. RFC 6484). D'où l'idée de ce RFC, de mettre une vCard (plus exactement un profil restrictif des vCards du RFC 6350) dans un objet RPKI signé (la description de la syntaxe générique de ces objets est dans le RFC 6488).
Arrivé à ce stade, vous vous demandez peut-être « pourquoi un nouveau format au lieu d'utiliser les données des RIR, telles que publiées via whois ? ». La réponse est que l'enregistrement Ghostbusters identifie le responsable du certificat, qui n'est pas forcément le même que celui de la ressource (adresse IP ou numéro d'AS). Et puis, en pratique, les bases des RIR ne sont pas toujours correctes. Comme le chemin de mise à jour de l'enregistrement Ghostbuster est différent, peut-être sera-t-il parfois correct lorsque la base du RIR ne le sera pas ?
De toute façon, l'enregistrement Ghostbuster est facultatif. Un certificat peut en avoir zéro, un ou davantage. La section 3 du RFC fournit un exemple :
BEGIN:VCARD
VERSION:4.0
FN:Human's Name
ORG:Organizational Entity
ADR;TYPE=WORK:;;42 Twisty Passage;Deep Cavern;WA;98666;U.S.A.
TEL;TYPE=VOICE,TEXT,WORK;VALUE=uri:tel:+1-666-555-1212
TEL;TYPE=FAX,WORK;VALUE=uri:tel:+1-666-555-1213
EMAIL:human@example.com
END:VCARD
En fait, cette vCard est embarquée dans un objet de la RPKI, qu'on peut lire avec des outils comme openssl. Voici un exemple sur un objet réel :
% openssl asn1parse -inform DER \
-in b-hiK-PPLhH4jThJ700WoJ3z0Q8.gbr
...
60:d=5 hl=3 l= 139 prim: OCTET STRING :BEGIN:VCARD
VERSION:3.0
EMAIL:michael.elkins@cobham.com
FN:Michael Elkins
N:Elkins;Michael;;;
ORG:Cobham Analytic Solutions
END:VCARD
...
Le sous-ensemble de vCard qui est accepté dans les chasseurs de
fantômes est décrit en section 4. La définition est très restrictive :
ne sont acceptées que les propriétés VERSION (qui
doit valoir au moins 4, vous noterez que les enregistrements réels
cités plus haut
sont donc illégaux), FN,
ORG, ADR,
TEL et EMAIL (un
enregistrement qui inclus N, comme ci-dessus, est
donc illégal).
Ensuite (section 5), la vCard est embarquée dans un objet CMS signé (RFC 6488 ; la validation de ces enregistrements se fait de la même façon que pour les autres objets de la RPKI). Le type (OID) est 1.2.840.113549.1.9.16.1.35, ce qu'on voit dans la sortie d'openssl :
% openssl asn1parse -inform DER \
-in owCgRbSAAkKS9W-MFbSAd7Bru2c.gbr
...
44:d=4 hl=2 l= 11 prim: OBJECT :1.2.840.113549.1.9.16.1.35
57:d=4 hl=3 l= 195 cons: cont [ 0 ]
60:d=5 hl=3 l= 192 prim: OCTET STRING :BEGIN:VCARD
VERSION:3.0
ADR:;;5147 Crystal Springs;Bainbridge Island;Washington;98110;US
EMAIL:randy@psg.com
FN:Randy Bush
N:Bush;Randy;;;
ORG:RGnet\, LLC
TEL:+1 206 356 8341
END:VCARD
L'objet CMS est enfin mis dans un fichier d'extension
.gbr. Fin 2011, on n'en trouvait que très peu
dans les dépôts de la RPKI.
Attention, toutes ces données sont publiques. Comme le rappelle la section 8, sur la sécurité, publier ses informations dans un enregistrement Ghostbuster et vous risquez d'être harcelé par des commerciaux au téléphone ou bien spammé.
D'autre part, l'entité qui signe l'objet ne garantit nullement que les informations sont correctes. Elle garantit juste que ces informations ont bien été mises par le titulaire de la ressource (préfixe IP ou AS) correspondante. Celui-ci a pu mettre un numéro de téléphone ou une adresse de courrier bidon...
L'article seul
RFC 6488: Signed Object Template for the Resource Public Key Infrastructure
Date de publication du RFC : Février 2012
Auteur(s) du RFC : M. Lepinski, A. Chi, S. Kent (BBN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 4 février 2012
Le système de sécurisation de BGP et du routage sur l'Internet, qui tourne autour de la RPKI, utilise des objets numériques signés cryptographiquement pour représenter les autorisations d'annoncer telle ou telle route. Ces objets sont définis avec la syntaxe CMS et le profil que normalise ce RFC.
Le contenu typique de ces objets est une autorisation du genre «
L'AS 64641
est autorisé à annoncer le préfixe 192.0.2.0/24
». Ils sont ensuite signés avec les clés contenues dans les
certificats qui identifient le titulaire de ces
ressources (ici, seul le titulaire de
192.0.2.0/24 peut émettre l'autorisation
ci-dessus). Ces certificats suivent le format du RFC 6487.
Les objets d'autorisation utilisent la syntaxe de CMS (RFC 5652), celle-ci permettant de réutiliser les nombreux outils CMS existants (dont plusieurs en logiciel libre, voir mon article sur les outils de la RPKI). Sur cette syntaxe CMS est bâti le gabarit présenté par ce RFC 6488, qui s'applique à tous les objets de la RPKI. Enfin, sur ce gabarit, est bâti la syntaxe précise de chaque type d'objet. Par exemple, les ROA (Route Origination Authorization), une classe particulière d'objets, sont normalisés dans le RFC 6482.
La syntaxe est décrit dans la section 2 du RFC. CMS utilisant
ASN.1, le profil de notre RFC 6488
est décrit en ASN.1. On part de la définition
SignedData du RFC 5652 :
SignedData ::= SEQUENCE {
version CMSVersion,
digestAlgorithms DigestAlgorithmIdentifiers,
encapContentInfo EncapsulatedContentInfo,
certificates [0] IMPLICIT CertificateSet OPTIONAL,
crls [1] IMPLICIT RevocationInfoChoices OPTIONAL,
signerInfos SignerInfos }
et on y ajoute quelques restrictions ou précisions. Par exemple, le
digestAlgorithm doit être un de ceux spécifiés
dans le RFC 6485. Même méthode pour les
métadonnées de signature :
SignerInfo ::= SEQUENCE {
version CMSVersion,
sid SignerIdentifier,
digestAlgorithm DigestAlgorithmIdentifier,
signedAttrs [0] IMPLICIT SignedAttributes OPTIONAL,
signatureAlgorithm SignatureAlgorithmIdentifier,
signature SignatureValue,
unsignedAttrs [1] IMPLICIT UnsignedAttributes OPTIONAL }
Les objets de la RPKI doivent être encodés en DER. La liste des règles sémantiques à respecter figure dans la section 3.
Je le rappelle, ce profil, bien que spécialisé par rapport à CMS, est encore très générique. Chaque classe d'objets signés va donc nécessiter son propre RFC, remplissant les blancs indiqués par la section 4 :
- Indiquer un OID pour la classe en question (1.2.840.113549.1.9.16.1.24 pour les ROA ou 1.2.840.113549.1.9.16.1.26 pour les manifestes du RFC 6486),
- Définir la syntaxe du champ
encapContentInfo(qui contient les données effectivement signées), - Indiquer les règles spécifiques de validation (pour un ROA : que le certificat signeur ait été émis pour le préfixe indiqué dans le ROA), s'ajoutant aux règles génériques de CMS (validité de la signature).
Ces classes d'objets sont ensuite enregistrés à l'IANA (section 6).
Notez bien que la sécurité que fournissent ces objets signés est d'authentification et d'intégrité. Les données ne sont pas chiffrées et donc pas confidentielles (section 5). C'est logique, les tables BGP et les informations dans les IRR sont publiques.
L'article seul
RFC 6481: A Profile for Resource Certificate Repository Structure
Date de publication du RFC : Février 2012
Auteur(s) du RFC : G. Huston (APNIC), R. Loomans (APNIC), G. Michaelson (APNIC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 4 février 2012
La RPKI, cette infrastructure de certificats utilisée pour sécuriser le routage sur l'Internet, repose sur un certain nombre d'objets (certificats mais aussi révocations et surtout les objets signés qui expriment les autorisations, les ROA). Ce RFC décrit comment ils sont stockés dans les points de publication à partir desquels ils sont distribués au monde entier. Cela permet de consolider facilement les données obtenues auprès de plusieurs points de publication. (Il n'est pas obligatoire qu'une copie de la RPKI soit complète.)
Rappelez-vous en effet que les routeurs n'accèdent pas aux informations de la RPKI lorsqu'ils en ont besoin (ce qui ferait dépendre le routeur de serveurs extérieurs) mais à l'avance en chargeant dans un validateur la totalité des informations, que le validateur va ensuite vérifier avant de passer au routeur. Comment se présentent ces informations ? Chacun fait comme il veut mais il existe une forme recommandée, celle de notre RFC 6481.
Dans ce format recommandé, chaque objet va être un fichier. Ces
fichiers vont être placés dans une arborescence de répertoires,
référencée par un URI (typiquement de type
rsync:).
Dans les exemples ci-dessous, j'utiliserai une copie locale de la RPKI obtenue au RIPE-NCC, avec les outils logiciels de ce même RIPE-NCC (voir mon article sur ces outils).
À chaque point de publication (typiquement, chaque
AC, c'est-à-dire en pratique chaque opérateur
réseau), on trouve un manifeste qui liste les
objets publiés. Le fichier a l'extension .mft, le type MIME application/rpki-manifest (cf. section 7.1 du RFC) et
son nom est un condensat cryptographique de la
clé publique de l'AC (en suivant par exemple la section 2.1 du RFC 4387). Voici le contenu d'un tel manifeste, à un petit point
de publication (seulement quatre ROA) :
% certification-validator -print -file Sxe2vn2-fqZLB5Q578V0Vzf_RfQ.mft
Serial: 39571085
Subject: CN=779caa1de4e5938149c831b097a86ee561bf12f3
Not valid before: 2011-10-31T03:42:07.000Z
Not valid after: 2011-11-01T03:42:07.000Z
...
Filenames and hashes:
1c_GrZeKKzG5b9BI9Iu4fEEG-QU.roa 20aade4dd3e303103b7facb0d462d89e0cc74753c99bf35a8ff28d16e48f7e6a
1sOqx9K6uCNTcCTMIe7f5P1bZX0.roa 7e9c4c0be54d180b05743abbd6163f0a812c43d4db59fe0550eb2446ceedbb7e
4nKGhPF4_7JKjwwBrTCXgE_4YYg.roa f1f55d72eb6e66c36b6312c4c6484a83156d32b7e01067a6a3449327095e409f
Sxe2vn2-fqZLB5Q578V0Vzf_RfQ.crl 39ec393db6b9a8ec6289304a5c1982ab17ef3bfc5feaffaf4a30174af9054966
TZw7cXuBc5b9BOlBHqCtAEgTZ-w.roa bd7aa3efae357a8591a7b5d708ccb509ad30f791063ea6fe9aa53730d95cb680
On trouve également des révocations, dans
des fichiers ayant l'extension .crl (et le type MIME application/pkix-crl qui vient du RFC 2585) :
% certification-validator -print -file Sxe2vn2-fqZLB5Q578V0Vzf_RfQ.crl
CRL type: X.509
CRL version: 2
Issuer: CN=Sxe2vn2-fqZLB5Q578V0Vzf_RfQ
Authority key identifier: Sxe2vn2-fqZLB5Q578V0Vzf_RfQ=
Number: 790
This update time: 2011-10-31T03:42:07.000Z
Next update time: 2011-11-01T03:42:07.000Z
Revoked certificates serial numbers and revocation time:
32399600 2011-09-10T05:40:48.000Z
On trouve bien sûr les certificats, encodés au format
DER et stockés dans des fichiers ayant
l'extension .cer et le type MIME application/pkix-cert :
% certification-validator -print -file Fx2dYP3STZSiTUjLGrM8oDkK4Ys.cer Serial: 18282008 Subject: CN=Fx2dYP3STZSiTUjLGrM8oDkK4Ys Not valid before: 2011-01-12T02:39:31.000Z Not valid after: 2012-07-01T00:00:00.000Z Resources: 46.254.48.0/21
Notez qu'il s'agit d'un format standard donc
OpenSSL peut l'afficher aussi (pour voir les
ressources gérées, ici 46.254.48.0/21, il faut un
OpenSSL compilé avec l'option RFC 3779) :
% openssl x509 -inform DER -text -in Fx2dYP3STZSiTUjLGrM8oDkK4Ys.cer
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 18282008 (0x116f618)
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN=u75at9r0D4JbJ3_SFkZXD7C5dmg
Validity
Not Before: Jan 12 02:39:31 2011 GMT
Not After : Jul 1 00:00:00 2012 GMT
Subject: CN=Fx2dYP3STZSiTUjLGrM8oDkK4Ys
...
sbgp-ipAddrBlock: critical
IPv4:
46.254.48.0/21
Et, bien sûr, le dépôt contient des autorisations d'annonces de
route, les ROA (Route Origination
Authorization), normalisés dans le RFC 6482. Elles sont contenues
dans des fichiers d'extension .roa et ont le type MIME application/rpki-roa :
% certification-validator -print -file FiUGfSV6BgZqFlJnQ7SSq_700w8.roa
Content type: 1.2.840.113549.1.9.16.1.24
Signing time: 2011-04-11T15:07:23.000Z
ASN: AS56595
Prefixes:
46.226.0.0/21
2a00:a600::/32
Le ROA ci-dessus autorise l'AS 56595 à annoncer
des routes pour 46.226.0.0/21 et
2a00:a600::/32. À noter que la suite logicielle
rcynic permet également l'affichage de
ROA :
% print_roa FiUGfSV6BgZqFlJnQ7SSq_700w8.roa
Certificates: 1
CRLs: 0
SignerId[0]: 16:25:06:7d:25:7a:06:06:6a:16:52:67:43:b4:92:ab:fe:f4:d3:0f [Matches certificate 0] [signingTime(U) 110411150723Z]
eContentType: 1.2.840.113549.1.9.16.1.24
version: 0 [Defaulted]
asID: 56595
addressFamily: 1
IPaddress: 46.226.0.0/21
addressFamily: 2
IPaddress: 2a00:a600::/32
La section 3 décrit ensuite les caractéristiques souhaitées du serveur qui va publier toutes ces informations. Il doit notamment être très fiable : même si le serveur n'est évidemment pas accédé de manière synchrone, à chaque mise à jour BGP, il doit néanmoins être accessible la grande majorité du temps, puisque toute panne empêchera les mises à jour de la base et aura potentiellement des conséquencees opérationnelles sur le routage. C'est une tâche nouvelle, par exemple pour les RIR, qui n'avaient pas de rôle opérationnel avant.
Ce serveur doit utiliser rsync (cf. RFC 5781) et peut aussi utiliser d'autres protocoles en prime. Grâce à rsync, la commande :
% rsync -av rsync://rpki.ripe.net/repository /var/RPKI
va vous récupérer tous les objets décrits ici, tels qu'ils sont
distribués par le RIPE-NCC, et les mettre dans
le répertoire /var/RPKI. rsync travaillant de
manière incrémentale, seules les nouveautés seront chargées, pas la
totalité de la base (sauf la première fois).
Cette commande peut donc être placée dans le crontab de la machine qui fera la validation. Toutefois, la section 3 recommande des techniques plus subtiles, à base de copie dans un dépôt temporaire puis de renommage (ce que font automatiquement les outils de rcynic), avant d'éviter une incohérence si le rsync est interrompu et qu'on n'a récupéré qu'une partie de la base.
Cette copie locale de la RPKI dans le validateur (machine qui sera proche des routeurs qui l'interrogeront) permettra de fonctionner même en cas de panne des serveurs de distribution (cf. section 5).
Attention à la sécurité, nous avertit la section 6. Les
informations de la RPKI sont publiques, il n'y a donc pas besoin de
confidentialité, mais il est essentiel que leur
intégrité soit préservée. Le protocole rsync utilisé plus haut ne
fournit aucune garantie en ce sens. En fait, la protection des données
est complètement assurée par les signatures faites avec les clés
contenues dans les certificats. Il ne faut donc
pas utiliser les informations RPKI récupérées
avant d'avoir validé (vérifié les signatures). C'est ce que fait
automatiquement rcynic en déplaçant les données validées dans un
répertoire nommé authenticated :
% pwd /var/rcynic/data % ls -lt total 12 lrwxrwxrwx 1 rcynic rcynic 34 Oct 31 15:42 authenticated -> authenticated.2011-10-31T13:36:08Z lrwxrwxrwx 1 rcynic rcynic 34 Oct 31 15:42 authenticated.old -> authenticated.2011-10-31T11:36:11Z drwxr-xr-x 15 rcynic rcynic 4096 Oct 31 15:42 authenticated.2011-10-31T13:36:08Z drwxr-xr-x 15 rcynic rcynic 4096 Oct 31 14:31 authenticated.2011-10-31T11:36:11Z drwxr-xr-x 17 rcynic rcynic 4096 Oct 31 11:31 unauthenticated
Les extensions des différents fichiers stockés figurent dans un registre IANA.
L'article seul
RFC 6480: An Infrastructure to Support Secure Internet Routing
Date de publication du RFC : Février 2012
Auteur(s) du RFC : M. Lepinski, S. Kent (BBN Technologies)
Pour information
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 4 février 2012
Les techniques de sécurisation de BGP du groupe de travail SIDR viennent d'être publiées. Elles reposent sur une infrastructure de clés publiques cryptographiques, la RPKI (Resource Public Key Infrastructure). Ce RFC décrit cette RPKI, fondation de tous les systèmes de sécurisation du routage dans l'Internet, ainsi que l'architecture générale du système.
Le principe est le suivant : le titulaire d'un préfixe IP a un certificat lui permettant de signer des objets, par lesquels il autorise tel ou tel AS à annoncer ce préfixe. Ces signatures peuvent être ensuite vérifiées par les routeurs, qui rejetteront les erreurs et les tentatives de piratage.
La section 1 résume les trois composants essentiels de la solution, qui permettra de protéger le routage BGP (RFC 4271) :
- La RPKI, l'infrastructure de gestion de clés, dont la hiérarchie est plaquée sur l'actuelle hiérarchie d'allocation des adresses (IANA -> RIR -> LIR, etc),
- Des objets numériques signés (par les clés contenues dans les certificats de la RPKI), les routing objects, qui expriment les autorisations de routage,
- Le mécanisme de distribution de ces objets, pour que les routeurs y aient accès afin de valider les annonces BGP.
Dans un premier temps, cette solution permettra de valider l'origine des annonces BGP (le premier AS, cf. RFC 6483). Plus tard, elle pourra servir de base à des solutions plus globales, encore en cours de développement, comme soBGP ou Secure Border Gateway Protocol (Secure-BGP).
La correspondance entre le graphe des certificats et celui existant pour allouer des ressources comme les adresses IP évite de réinventer une nouvelle classe d'acteurs. Cela ne veut pas dire que les rapports de force ne vont pas être modifiés. Ainsi, à l'heure actuelle, un RIR peut toujours, techniquement, retirer un préfixe à un LIR, mais cela n'aura pas de conséquence pratique, le RIR n'ayant aucun rôle dans le routage. Demain, avec la RPKI, le RIR enverra une révocation et les routeurs considéreront la route comme invalide... Il y a donc bien renforcement des pouvoirs de la hiérarchie, comme l'analysait un article de l'IGP.
Techniquement, peu de protocoles ou de formats nouveaux sont développés. Ainsi, les certificats de la RPKI sont du X.509, avec les extensions déjà existantes de l'IETF, RFC 5280, plus celles permettant de représenter des ressources (adresses IP et numéros d'AS), normalisées dans le RFC 3779 et suivant le profil du RFC 6487. Les objets signés (cf. RFC 6488) utilisent quant à eux le format CMS (RFC 5652).
Le premier des trois composants, la RPKI (Resource Public
Key Infrastructure), est décrit en section 2. L'idée est que
c'est le titulaire d'une plage d'adresses IP qui
décide comment elle peut être routée et par qui. Les certificats
permettent donc d'attester que telle entité est bien le titulaire (ce
qui se fait actuellement en consultant la base du RIR, par exemple via
whois). L'IANA va donc
signer les plages qu'elle alloue aux RIR (cette étape est optionelle,
voir plus loin), les RIR signent les plages qu'ils allouent aux LIR et
ainsi de suite si nécessaire (il y a des cas plus complexes, pour les
NIR, ou bien pour les adresses
PI, ou encore lorsqu'un titulaire sous-alloue
une partie de ses adresses). Lorsqu'un certificat affirmera « je
suis titulaire du 192.0.2.0/24 », il sera ainsi
possible de remonter la chaîne, jusqu'à une référence de confiance
(l'IANA ou bien l'ensemble des RIR) pour vérifier cette
assertion. Donc, bien que le routage dans l'Internet ne soit
pas hiérarchique, l'allocation l'est, et la RPKI
s'appuie là-dessus.
Les exemples ci-dessus portent sur des adresses IP mais le raisonnement est le même pour les numéros d'AS, d'où ce nom collectif de ressources (adresses IP et numéros d'AS).
Il faut bien noter que ces certificats, s'ils sont techniquement des certificats X.509 comme les autres, ont une sémantique différente; Le fait qu'une CA signe un certificat ne dit pas qu'elle certifie l'identité contenu dans le certificat mais qu'elle certifie le lien entre une ressource et un titulaire. Ces certificats sont davantage d'autorisation que d'authentification. Le RFC recommande simplement de mettre comme nom (X.509 appelle cela le subject) un identificateur spécifique à la CA, par exemple un numéro de client.
Comme cette sémantique est différente, et qu'il n'y a pas les risques juridiques associés aux certificats d'authentification classiques, il n'y a donc pas de nécessiter d'utiliser les CA existantes, ni de raison d'hésiter, pour un opérateur, à devenir CA. Les certificats fournis aux entités intermédiaires (typiquement les LIR) doivent être des certificats CA, autorisant le titulaire à émettre lui-même des certificats (la signature de chaque objet nécessite la création d'un certificat pour cet objet, cf. section 2.2). Les sites terminaux, en général, n'auront pas besoin de certificats du tout (sauf s'ils sont multi-homés avec des adresses PI, cf. section 7.3.2).
Les certificats finaux (section 2.3), ceux qui n'auront pas besoin d'avoir le bit CA à un, servent pour signer les objets (l'intérêt de créer un certificat juste pour signer un objet est de permettre une révocation, en réutilisant les mécanismes existants de X.509).
Pour vérifier, les validateurs (les routeurs BGP, ou bien les machines à qui ces routeurs sous-traiteront le travail), auront besoin de certificats « racine ». Comme en général pour X.509, le choix de ces certificats est une question politique locale et n'est pas spécifiée par la norme. Le RFC évite ainsi (section 2.4) l'épineuse question politique de savoir s'il faut configurer le validateur avec le certificat de l'IANA (donnant à celle-ci un grand pouvoir) ou bien avec les certificats des cinq RIR (court-circuitant ainsi l'IANA).
La section 3, elle, décrit les objets qu'on va signer, les
ROA (Route Origination
Authorization). La RPKI va dire « il est le titulaire de
192.0.2.0/24 » et le ROA va ajouter « l'AS 64641
est autorisé à annoncer 192.0.2.0/24 » (le ROA
n'autorise que l'origine, pas les AS ultérieurs qui relaieront
l'annonce). Le ROA est donc tout au bout du graphe des
autorisations. On pourrait donc avoir une chaîne comme :
Le format des ROA est décrit en RFC 6482 et leur utilisation dans la validation des annonces BGP en RFC 6483. Le format est une spécialisation du format générique des objets de la RPKI, décrit dans le RFC 6488, lui-même issu de CMS. Chaque ROA contient un numéro d'AS, un ou plusieurs préfixes que cet AS a l'autorisation d'« originer » et (facultativement) une longueur maximale des sous-préfixes. Notez bien qu'il n'y a qu'un AS. Si plusieurs AS ont le droit d'être à l'origine des annonces de ces préfixes, il faut créer plusieurs ROA. Il n'y a pas de durée de validité dans le ROA, la validité est celle du certificat.
La distribution des ROA se fait essentiellement par le
système de dépôts décrit dans la section 4 mais pourrait se faire dans
le futur par d'autres moyens, comme les messages BGP UPDATE.
On l'a vu, la validation des routes suppose que les validateurs (les
routeurs BGP eux-même, ou bien des machines spécialisées à qui les
routeurs sous-traitent l'opération) aient accès à tous les ROA. (Ce
n'est pas un nombre énorme, typiquement un seul par route visible
mondialement.) Un mécanisme est proposé pour créer un dépôt distribué
de ROA, accessible à la demande (les mécanismes où les ROA seraient
poussés vers les validateurs, par exemple par BGP, ne sont pas encore
définis). Le dépôt est décrit en détail dans le RFC 6481.
Le dépôt n'est pas spécialement « de confiance ». Ce sont les signatures sur les ROA qui comptent, pas l'endroit où ils ont été récupérés. C'est d'autant plus vrai que le RFC encourage à recopier le dépôt, pour faciliter l'accès.
Le dépôt pourra offrir un choix de protocoles d'accès (section 4.3). Notre RFC décrit juste les fonctions de ces protocoles :
- Téléchargement en bloc de toutes les données (rappelez-vous que le validateur est supposé avoir une vue complète). Les données sont donc réellement publiques.
- Ajout d'une donnée, ou modification d'une donnée existante.
Des tas de protocoles offrent ces fonctions (par exemple HTTP/REST, même s'il n'est pas cité). Pour éviter que chaque acteur du routage ne déploie un protocole d'accès différent, rendant la vie des clients infernale, notre RFC impose que chaque copie soit accessible en lecture avec rsync, garantissant ainsi un mécanisme toujours disponible. On désigne donc la copie avec un URI rsync (RFC 5781) et on y accède par :
% rsync -av rsync://rpki.ripe.net/repository /where/i/want/RPKI-repository
Les experts en sécurité ont peut-être noté un peu de hand waving dans les paragraphes précédents. J'ai dit que la sécurité du dépôt était peu importante puisque ce sont les signatures des ROA qui font foi et que l'endroit où on les a trouvé ne compte donc pas. Mais si un méchant arrive à modifier un dépôt et supprime un ROA ? La signature ne protège pas contre ce genre de problèmes. La RPKI a donc un système de manifestes, des listes d'objets signés, listes elle-même signées et mises dans le dépôt (section 5 et RFC 6486).
Le dépôt sera donc massivement distribué, et les validateurs encouragés à garder des copies locales. La section 6 décrit ce processus, où le validateur obtient la copie de tous les objets (ROA, certificats, manifestes, etc), valide la signature des manifestes, puis vérifie leur contenu, et vérifie la signature des objets indiqués dans le manifeste.
Comme avec tous les caches, cette copie pose le problème de la fraîcheur des informations. Le cache ne contient-il pas des informations dépassées ? La section 6 n'est pas très bavarde sur ce point. À l'heure actuelle, ces informations de routage sont assez stables (on ne change pas d'AS d'origine tous les mois) donc le problème n'est pas trop aigü.
La section 7 décrit la vie du dépôt, et les opérations courantes. Les acteurs du routage devront donc désormais penser à la mise à jour de ce dépôt. Dans le futur, l'émission de ces certificats se fera peut-être automatiquement, en même temps que l'allocation des ressources. Aujourd'hui, ce n'est pas encore le cas.
La section 7.3 décrit en détail les aspects pratiques de cette gestion des ROA. Il va falloir acquérrir de nouveaux réflexes, notamment celui de créer et signer des ROA lors de tout changement de la politique de routage. Comme l'absence d'un ROA pour une annonce donnée pourra être interprété comme un détournement, et mener à un refus de l'annonce BGP par les routeurs validants, il y aura plein de possibilité de « se tirer une balle dans le pied ». Les opérateurs devront donc appliquer le principe « make before break », c'est-à-dire créer le ROA signé bien avant d'annoncer la route (pour permettre à tous les dépôts et tous les caches d'être à jour) et, en sens inverse, arrêter l'annonce longtemps avant de signer la révocation du ROA correspondant (et s'assurer qu'il existe un autre ROA, pour la nouvelle annonce).
Cela ne s'applique qu'aux opérateurs, pas au client final. Le site qui a des adresses PA et est connecté à un seul opérateur, n'a rien à faire, les ROA seront émis par l'opérateur. Ce site ne participe donc pas à la RPKI. En revanche, un site multi-homé peut, dans certains cas, avoir à émettre des ROA. Par exemple, s'il a un préfixe PA qu'il fait relayer par deux opérateurs, il doit créer un ROA pour cela (et donc obtenir un certificat depuis l'opérateur qui lui a affecté le préfixe PA) ou demander à l'opérateur de le faire pour lui. Si les adresses sont PI, le site doit émettre un ROA avec son propre AS en origine, en utilisant le certificat reçu avec le préfixe PI.
Si vous souhaitez appronfondir la question, une liste d'articles à lire se trouve dans mon article général. Si vous voulez pratiquer et voir la RPKI en action, regardez mon article sur les logiciels.
L'article seul
RFC 6487: A Profile for X.509 PKIX Resource Certificates
Date de publication du RFC : Février 2012
Auteur(s) du RFC : G. Huston, G. Michaelson, R. Loomans (APNIC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 4 février 2012
La norme de certificats numériques X.509 est d'une telle complexité (comme beaucoup de productions des comités de l'UIT) qu'il est à peu près impossible de la mettre en œuvre complètement et correctement. La plupart de ses utilisations se font sur un profil de la norme, c'est-à-dire une restriction des usages possibles. De tels profils ont permis l'utilisation pratique de X.509, notamment sur l'Internet. Le profil décrit dans ce RFC a été conçu pour les certificats décrivant le « droit d'utilisation » des ressources Internet, ce qui veut dire, dans le monde du routage, les adresses IP et numéros d'AS (collectivement : les INR pour Internet Number Resources). Ces certificats ainsi profilés seront ensuite ceux utilisés pour la RPKI, afin de sécuriser le routage sur l'Internet.
Rappelons le principe : des certificats sont
émis par une autorité, l'AC. Ces certificats suivent le profil décrit ici,
qui est lui-même dérivé du profil PKIX du RFC 5280, de loin le plus répandu sur
l'Internet. Ces certificats permettent à l'autorité de dire « le
titulaire de ce certificat a le droit d'utiliser les adresses
2001:db8:f33::/48, par exemple de les annoncer
en BGP », en utilisant les extensions INR du
RFC 3779. L'engin qui va valider les routes
(c'est typiquement une machine spécialisée, agissant pour le compte
d'un routeur) fera une validation X.509 de la chaîne des certificats,
plus quelques vérifications spécifiques aux INR (par exemple, dans
certains cas, le certificat peut autoriser une route plus spécifique)
et dira ensuite si la route est valide, ou bien si elle est émise par
un attaquant (ou un maladroit qui a mal configuré BGP).
Donc, un certificat de la RPKI est un certificat PKIX. Les principaux points de notre nouveau profil (section 4) sont le fait que le sujet est un nom choisi par l'AC, la présence obligatoire des extensions INR (Internet Number Resources) du RFC 3779 (le certificat prouve le droit d'usage des préfixes IP indiqués dans ces extensions), et l'indication d'un dépôt accessible en rsync où se trouvent les CRL. Les sections 2 à 6 donnent tous les détails sur ces points.
Quant à la validation des certificats, elle fait l'objet de la section 7, qui précise les points généraux de la section 6 du RFC 5280. Notamment, un certificat peut être accepté même si le préfixe d'adresses présenté est plus spécifique (davantage de bits dans le masque).
La section 8 explique ensuite (et justifie) les principaux choix qui ont été faits lors de la conception de ce profil. Par exemple, notre profil ne permet pas d'utiliser des extensions X.509 autres que celles décrites dans ce RFC. Le but est d'utiliser les certificats dans un environnement bien défini, pour un usage limité, et il s'agit donc de limiter au maximum les risques de non-interopérabilité (un problème fréquent avec X.509, norme conçue par un comité et d'une très grande complexité ; bien des parties de la norme n'ont jamais été testées sur le terrain et nul ne sait comment réagiraient les implémentations). En outre, la RPKI est conçu pour être utilisée dans un contexte opérationnel (le routage sur l'Internet) et il était donc raisonnable de sacrifier l'extensibilité.
Quant au choix du nom du sujet, la RPKI n'étant pas centralisée, et n'ayant pas de système d'allocation arborescente des noms, on ne peut pas espérer avoir des noms uniques. Le RFC conseille donc aux AC (les RIR et les opérateurs réseau) d'adopter un schéma de nommage qui garantisse l'unicité au sein d'une même AC (rappelez-vous que, contrairement à l'utilisation de X.509 dans le cas de TLS, le nom du sujet n'est pas utilisé par la RPKI et n'est donc pas vérifié). Cela peut même être une valeur aléatoire comme un UUID.
L'annexe A du RFC fournit un exemple d'un certificat à ce
profil. Mais on peut aussi l'obtenir en regardant un vrai certificat
de la RPKI avec openssl (attention, il faut
s'assurer qu'il ait été compilé avec l'option
enable-rfc3779, ce qui n'est pas le
cas chez Debian) :
% openssl x509 -inform DER -text -in \
./RPKI-repository/33/36711f-25e1-4b5c-9748-e6c58bef82a5/1/wdWccNZAgvBWFvBZNDJDWLtf-KQ.cer
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 78697736 (0x4b0d508)
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN=u75at9r0D4JbJ3_SFkZXD7C5dmg
Validity
Not Before: May 13 07:43:52 2011 GMT
Not After : Jul 1 00:00:00 2012 GMT
Subject: CN=wdWccNZAgvBWFvBZNDJDWLtf-KQ
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:99:d8:66:8b:26:15:22:fd:8e:45:c2:32:79:eb:
a4:36:d0:6d:47:18:34:d4:ad:17:bf:6f:82:d7:a3:
85:d9:80:ea:9f:59:31:6d:da:9f:b5:e0:36:67:e0:
f0:00:1b:96:2d:71:3e:5f:35:e0:f9:98:ee:fa:9f:
3e:6b:ab:9e:18:a6:ad:3c:fd:7a:50:6d:a5:42:4c:
bd:2d:02:f0:2a:7a:e6:66:bf:d5:b1:83:f1:19:02:
fe:90:21:d2:e3:b3:cc:91:a4:a6:6f:70:be:65:62:
7f:97:c1:43:2e:2c:a5:b2:14:79:e0:f5:5e:4b:c2:
aa:ed:13:d0:f2:4d:47:ac:53:fd:82:78:ef:c9:cd:
94:ea:52:10:56:88:80:bc:ca:ad:92:46:ef:4c:ae:
aa:ae:ae:02:d6:af:ae:2a:4e:dc:8b:c9:43:57:27:
84:1f:5a:82:ff:d7:24:ac:25:67:66:5f:70:d1:d6:
45:4b:a5:1d:c2:6f:bf:ae:14:3d:e4:2b:50:35:72:
ea:52:1c:b2:7d:15:12:15:07:d1:86:bb:2b:4b:ba:
47:1c:3e:37:b7:2c:ab:a6:4e:d3:16:54:84:96:92:
37:b6:6c:5c:3b:61:f1:73:9e:9c:9b:b8:ad:33:f8:
e0:19:9e:6a:dc:30:a6:45:90:f7:90:bb:d2:f9:65:
5b:53
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Subject Key Identifier:
C1:D5:9C:70:D6:40:82:F0:56:16:F0:59:34:32:43:58:BB:5F:F8:A4
X509v3 Authority Key Identifier:
keyid:BB:BE:5A:B7:DA:F4:0F:82:5B:27:7F:D2:16:46:57:0F:B0:B9:76:68
X509v3 Basic Constraints: critical
CA:TRUE
X509v3 Key Usage: critical
Certificate Sign, CRL Sign
Authority Information Access:
CA Issuers - URI:rsync://rpki.ripe.net/ta/u75at9r0D4JbJ3_SFkZXD7C5dmg.cer
Subject Information Access:
CA Repository - URI:rsync://rpki.ripe.net/repository/72/f82cc3-00a3-4229-92ff-e5992b4b3fad/1/
1.3.6.1.5.5.7.48.10 - URI:rsync://rpki.ripe.net/repository/72/f82cc3-00a3-4229-92ff-e5992b4b3fad/1/wdWccNZAgvBWFvBZNDJDWLtf-KQ.mft
X509v3 CRL Distribution Points:
Full Name:
URI:rsync://rpki.ripe.net/repository/33/36711f-25e1-4b5c-9748-e6c58bef82a5/1/u75at9r0D4JbJ3_SFkZXD7C5dmg.crl
X509v3 Certificate Policies: critical
Policy: 1.3.6.1.5.5.7.14.2
sbgp-ipAddrBlock: critical
IPv4:
81.27.128.0/20
IPv6:
2a00:8980::/32
Signature Algorithm: sha256WithRSAEncryption
8f:03:51:23:44:85:92:42:54:37:a2:22:53:66:0a:ab:be:a7:
...
2e:31:d5:0d
-----BEGIN CERTIFICATE-----
MIIFLDCCBBSgAwIBAgIEBLDVCDANBgkqhkiG9w0BAQsFADAmMSQwIgYDVQQDDBt1
...
-----END CERTIFICATE-----
Voyez notamment :
- Le sujet (nom du titulaire du certificat) unique, ici
CN=wdWccNZAgvBWFvBZNDJDWLtf-KQgénéré à partir d'un condensat cryptographique, - L'indication de l'endroit où on peut récupérer les CRL
(
rsync://rpki.ripe.net/repository/33/36711f-25e1-4b5c-9748-e6c58bef82a5/1/u75at9r0D4JbJ3_SFkZXD7C5dmg.crl), - Le certificat de l'AC
(
rsync://rpki.ripe.net/ta/u75at9r0D4JbJ3_SFkZXD7C5dmg.cer), - Les extensions du RFC 3779, ici le bloc
mal nommé
sbgp-ipAddrBlock, qui contient un préfixe IPv4 et un IPv6 (attention, pour les voir, il faut un openssl compilé avec la bonne option).
L'article seul
RFC 6492: A Protocol for Provisioning Resource Certificates
Date de publication du RFC : Février 2012
Auteur(s) du RFC : G. Huston, R. Loomans, B. Ellacott (APNIC), R. Austein (ISC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 4 février 2012
La RPKI est l'infrastructure de création et de distribution de certificats pour les titulaires de ressources Internet (essentiellement les adresses IP), afin de sécuriser le routage sur l'Internet. Ce RFC normalise un protocole de communication pour réclamer ces certificats (avitaillement, ou provisioning). Il sera typiquement utilisé entre les RIR et les LIR.
Les termes exacts utilisés par le RFC sont Émetteur (Issuer), en général un RIR, qui va donc être une AC, et Destinataire (Subject), qui sera un FAI ou autre opérateur réseau. Le RIR distribue des INR (Internet Number Resource, ce sont les adresses IP et les numéros d'AS, collectivement nommés Ressources) et les certificats prouvant le droit du Destinataire à utiliser ces INR. Notez qu'un Destinataire peut être Émetteur pour des ressources qu'il redistribuera, par exemple à des opérateurs plus petits.
Le trafic attendu rend nécessaire d'automatiser l'avitaillement des
certificats. Cela se fait avec un simple protocole (section 3), qui
est une extension de HTTP. Le client HTTP fait
une requête POST (RFC 7231,
section 4.3.4), de type MIME
application/rpki-updown. Le protocole est
strictement requête/réponse (synchrone). Aussi bien le corps de
la requête, que celui de la réponse du serveur, sont au format
CMS (RFC 5652), encodé en DER. Le
profil CMS est défini en section 3.1. CMS permet de transporter les
signatures des différents objets (et les métadonnées associées comme
la date de signature) mais le gros du contenu est un
élément XML stocké dans le CMS sous le nom de
RPKIXMLProtocolObject.
Cet élément XML est forcément
<message>. Il forme l'essentiel de la requête ou de la
réponse. Sa grammaire est décrite en Relax NG en
section 3.7.
Quelles sont les opérations possibles ? Elles sont indiquées par
l'attribut type de la requête. Par exemple, le client peut demander une
liste des ressources que lui a alloué le serveur, avec
type="list". La réponse arrivera sous forme d'une
séquence d'éléments <class>. Ou bien il peut demander un
certificat pour une nouvelle ressources avec
type="issue".
Naturellement, vu que tout le but de l'exercice est d'augmenter la sécurité du routage dans l'Internet, les implémenteurs et les utilisateurs de ce RFC devraient bien faire attention à la section 4, qui couvre la sécurité de ce protocole d'avitaillement. Le RFC précise que l'Émetteur et le Destinataire doivent s'authentifier (par les siognatures contenues dans les messages CMS), en utilisant des lettres de créance qu'ils ont échangé précédemment (par un moyen non spécifié). On note que TLS n'est pas utilisé par ce protocole (ce fut une chaude discussion au sein du groupe de travail), CMS fournissant tous les services de sécurité nécessaires.
Je ne connais pas encore de mise en œuvre publique de ce protocole mais plusieurs RIR ont annoncé qu'ils auraient des serveurs prêts pour la sortie du RFC.
L'article seul
RFC 6491: RPKI Objects issued by IANA
Date de publication du RFC : Février 2012
Auteur(s) du RFC : T. Manderson, L. Vegoda (ICANN), S. Kent (BBN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 4 février 2012
La RPKI est le système de distribution de
certificats et d'objets signés avec les clés de
ces certificats, qui permet de poser les
bases d'une sécurisation du routage dans l'Internet, en
permettant aux titulaires des ressources (préfixes d'adresses IP,
notamment), d'autoriser tel ou tel opérateur et uniquement ceux-ci, à
utiliser ces ressources. Certains préfixes ne sont pas alloués à un
utilisateur, ils dépendent directement de
l'IANA et ce RFC 6491 est donc
consacré à lister les tâches de l'IANA pour ces préfixes. Par exemple,
l'IANA devra émettre et signer un objet disant « Personne ne peut
annoncer de route vers 198.51.100.0/24 (ce
préfixe étant réservé, par le RFC 5737, à la
documentation) ».
Rappelons que les responsabilités de l'IANA vis-à-vis de l'IETF sont fixées par le RFC 2860. Pour le cas particulier de la RPKI (RFC 6480), l'IANA va devoir verrouiller l'usage des préfixes IP qu'elle gère (section 1). Ces préfixes sont utilisées pour la documentation ou réservés pour d'autres usages. Comme personne ne doit les router, l'IANA va émettre des ROA (RFC 6482) négatifs, c'est-à-dire prouvant que ces adresses ne sont pas routables. Un routeur BGP validant (RFC 6483) va alors pouvoir les rejeter, si jamais ils apparaissent dans des annonces de routes. Ces ROA négatifs sont officiellement appelés « AS0 ROA », le numéro d'AS zéro étant invalide (il ne doit jamais être dans un chemin d'AS). La section 4 du RFC 6483 détaille ce concept de désaveu de route.
Ce désaveu s'applique aux préfixes qui sont prévus pour ne jamais apparaître dans la table de routage globale (section 5), ainsi qu'à ceux qui ne sont pas actuellement alloués et donc toujours à l'IANA (aujourd'hui, cela ne concerne plus qu'IPv6, cf. section 6). Les adresses « spéciales » (section 7, voir aussi le RFC 6890) se divisent, elles, en deux : celles prévues pour être routées globalement, pour lesquelles l'IANA ne doit rien faire, et celles non prévues pour être routées, et pour lesquelles il y aura donc un AS0 ROA.
La liste des préfixes figure en annexe A du RFC. On y trouve les
suspects habituels, le préfixe 169.254.0.0/16 ou fe80::/10 des
adresses locales au lien, les préfixes privés des RFC 1918 et RFC 4193, les préfixes réservés à la documentation... Tous
ceux-ci ne seront jamais routés sur l'Internet.
Avant de commencer à émettre ces ROA, l'IANA devra évidemment établir une CA (section 10). Cette CA devra utiliser les extensions à X.509 du RFC 3779. Elle devra aussi publier la liste de ses objets (j'avoue n'avoir pas trouvé où c'était documenté sur le site de l'IANA...).
L'article seul
RFC 6482: A Profile for Route Origin Authorizations (ROAs)
Date de publication du RFC : Février 2012
Auteur(s) du RFC : M. Lepinski, S. Kent, D. Kong (BBN Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 4 février 2012
Un nouveau sigle va devoir être appris par les administrateurs réseaux et sera sans doute souvent prononcé dans les discussions sur les listes de diffusion d'opérateurs : ROA, pour Route Origin Authorizations, ces objets signés cryptographiquement qui permettent à un routeur BGP de valider l'origine d'une route. Dans la très longue liste des RFC décrivant ce système de sécurité, notre court RFC 6482 décrit le format des ROA. Il a depuis été remplacé par le RFC 9582.
Ces ROA (Route Origin
Authorizations) sont, à bien des égards, le cœur du
système de sécurisation du routage de
l'Internet (dont l'architecture générale est
décrite dans le RFC 6480). Ils expriment des autorisations
d'annonce, par exemple « L'AS 64641
est autorisé à annoncer le préfixe 192.0.2.0/24
» et sont signés par le titulaire de la ressource (ici, le titulaire
du préfixe 192.0.2.0/24).
Le format des ROA est tiré de la norme CMS (RFC 5652), précisée par le profil générique des objets de la RPKI, dans le RFC 6488. Ce dernier RFC précise, dans sa section 4, les points spécifiques à normaliser pour chaque classe d'objets de la RPKI. Dans le cas des ROA, ces blancs sont remplis ainsi :
- L'OID de la classe « ROA » est 1.2.840.113549.1.9.16.1.24 (section 2),
- Le contenu du ROA est composé (section 3) d'un numéro d'AS (celui qui est autorisé à être à l'origine de la route) et d'un ou plusieurs préfixes IP (un seul dans l'exemple plus haut), qui sont les préfixes où cet AS peut être à l'origine,
- Des règles de validation spécifiques au ROA sont indiquées (section 4).
Le contenu précis, tel qu'indiqué dans la section 3, est, en ASN.1 :
RouteOriginAttestation ::= SEQUENCE {
version [0] INTEGER DEFAULT 0,
asID ASID,
ipAddrBlocks SEQUENCE (SIZE(1..MAX)) OF ROAIPAddressFamily }
où asID est le numéro d'AS, et
ipAddrBlocks la liste des préfixes. Les
ROAIPAddressFamily sont composées de
ROAIPAddress et celles-ci ont un attribut
intéressant, maxLength, qui indique la longueur
maximale des sous-préfixes que peut annoncer cet AS. Par exemple, en
IPv6, un maxLength de 56
indiquera qu'on peut annoncer un /56 mais pas un /60. L'autre attribut
d'une ROAIPAddress est le préfixe, représenté
selon les règles du RFC 3779.
La section 4 décrit quant à elle les règles de validation spécifiques aux ROA : aux règles génériques des objets de la RPKI, elle ajoute l'obligation de vérifier que les adresses indiquées dans le ROA figurent bien dans le certificat signataire (c'est-à-dire que c'est bien le titulaire des adresses qui a émis le ROA). Mais il vaut mieux consulter le RFC 6483 pour avoir tous les détails.
À noter qu'on ne peut mettre qu'une seule signature par ROA. Une des vives discussions du groupe de travail SIDR avait porté sur la possibilité de signatures multiples, afin de gérer certaines relations complexes entre clients et opérateurs, mais cela avait finalement été rejeté.
On peut récupérer tous les ROA des préfixes
RIPE en https://certification.ripe.net/certification/public/all-roas. Si
on en télécharge un, on peut afficher ce contenu avec l'outil du même
RIPE-NCC :
% certification-validator --print -f roa-5574190.roa
Content type: 1.2.840.113549.1.9.16.1.24
Signing time: 2011-01-11T19:04:18.000Z
ASN: AS559
Prefixes:
193.5.26.0/23 [24]
193.5.152.0/22 [24]
193.5.168.0/22 [24]
193.5.22.0/24
193.5.54.0/23 [24]
193.5.58.0/24
193.5.60.0/24
193.5.80.0/21 [24]
ou bien avec l'outil de l'ARIN, rcynic :
% print_roa /home/bortzmeyer/tmp/roa-5574190.roa
Certificates: 1
CRLs: 0
SignerId[0]: b6:6f:5a:10:d5:7f:ed:6d:b1:62:96:2c:cb:92:35:bb:5d:f8:c3:ca [Matches certificate 0] [signingTime(U) 110111190418Z]
eContentType: 1.2.840.113549.1.9.16.1.24
version: 0 [Defaulted]
asID: 559
addressFamily: 1
IPaddress: 193.5.26.0/23-24
IPaddress: 193.5.152.0/22-24
IPaddress: 193.5.168.0/22-24
IPaddress: 193.5.22.0/24
IPaddress: 193.5.54.0/23-24
IPaddress: 193.5.58.0/24
IPaddress: 193.5.60.0/24
IPaddress: 193.5.80.0/21-24
Comme les ROA sont en CMS, on peut aussi tenter sa chance avec des logiciels qui traitent du CMS générique. Ils ne comprendront pas tout mais pourront au moins afficher une partie de la structure :
% openssl asn1parse -inform DER -in RFZr0zO7xjc1bNCEVboVjI8JZlw.roa
0:d=0 hl=2 l=inf cons: SEQUENCE
2:d=1 hl=2 l= 9 prim: OBJECT :pkcs7-signedData
...
1340:d=7 hl=2 l= 9 prim: OBJECT :contentType
1351:d=7 hl=2 l= 13 cons: SET
1353:d=8 hl=2 l= 11 prim: OBJECT :1.2.840.113549.1.9.16.1.24
1366:d=6 hl=2 l= 28 cons: SEQUENCE
1368:d=7 hl=2 l= 9 prim: OBJECT :signingTime
1379:d=7 hl=2 l= 15 cons: SET
1381:d=8 hl=2 l= 13 prim: UTCTIME :110406122632Z
1396:d=6 hl=2 l= 47 cons: SEQUENCE
...
De même, les outils génériques ASN/1 comme dumpasn1 peuvent permettre de récupérer une partie de l'information dans le ROA. D'autres outils pour jouer avec les ROA sont présentés dans mon article sur les logiciels de la RPKI.
Un exposé d'Arnaud Fenioux à l'assemblée générale du France-IX en septembre 2017 montrait l'utilisation de ces ROA au France-IX.
L'article seul
RFC 6518: Keying and Authentication for Routing Protocols (KARP) Design Guidelines
Date de publication du RFC : Février 2012
Auteur(s) du RFC : G. Lebovitz, M. Bhatia (Alcatel-Lucent)
Pour information
Réalisé dans le cadre du groupe de travail IETF karp
Première rédaction de cet article le 2 février 2012
Dans l'ensemble du travail engagé pour améliorer la sécurité du routage sur l'Internet, un sous-problème important est celui de la gestion des clés. En cryptographie, c'est souvent par une faiblesse dans cette gestion que les systèmes de sécurité sont compromis. Le groupe de travail KARP de l'IETF est occupé à améliorer les protocoles de gestion de clés et son premier RFC, ce RFC 6518, expose les propriétés attendues des futurs protocoles de gestion des clés des routeurs.
Prenons par exemple N routeurs OSPF qui veulent s'authentifier les uns les autres. La technique du RFC 2328 est d'avoir un secret partagé par tous les routeurs du même réseau local. Les messages OSPF sont concaténés avec ce secret, le résultat de la concaténation est ensuite condensé cryptographiquement, ce qui permettra au destinataire de s'assurer que l'émetteur connaissait bien le secret. Ce secret partagé est une clé cryptographique. Qui va la générer ? Comment la distribuer de façon sûre ? Comment la changer facilement et rapidement si le secret est compromis (ou, tout simplement, si un employé quitte l'entreprise) ? Ce genre de questions est la problématique de gestion de clés. Dans le cas d'OSPF, actuellement, la quasi-totalité des opérateurs de routeurs fait cela à la main (on se logue sur chaque routeur et on change le secret...) ou, à la rigueur, via un protocole général de configuration des routeurs. Peut-on faire mieux ? C'est en tout cas ce que va essayer de faire le groupe KARP (les deux RFC suivants de KARP ont été le RFC 6862, sur l'analyse des menaces, et le RFC 6863, sur l'analyse spécifique du protocole OSPF).
C'est que les mécanismes actuels ne sont pas satisfaisants. Comme le rappelle la section 1 du RFC, lors d'un colloque en 2006 (cf. RFC 4948), les participants avaient dénoncé la vulnérabilité des routeurs aux tentatives de prise de contrôle et appelé à durcir leur sécurité. Quatre axes d'amélioration avaient été identifiés, améliorer la gestion des routeurs (groupe de travail OPSEC), améliorer les IRR, valider les annonces de route (groupe de travail SIDR), et enfin sécuriser les communications entre routeurs (groupe de travail KARP), ce qui fait l'objet de ce RFC. Les informations de routage sont échangées via un protocole et la protection de ce protocole se fait par la cryptographie. Qui dit cryptographie dit clés. Lorsqu'un routeur cherche une clé pour protéger un message, où demande-t-il ? Pour l'instant, il n'y a pas de mécanisme standard et KARP va essayer d'en développer un. Le plus courant aujourd'hui est la gestion manuelle des clés (l'opérateur configure les clés, les change à la main - lorsqu'il y pense, les communique via PGP, SCP voire sans aucune sécurité) mais le RFC estime que le futur est dans des mécanismes automatisés de gestion de clés, les KMP (pour Key Management Protocol). Un KMP, par exemple, change automatiquement les clés au bout d'une période pré-définie.
Compte-tenu de la variété des protocoles de routage, et du transport qu'ils utilisent, ce sera un mécanisme abstrait, pas un protocole précis (ce RFC 6518 n'a donc pas d'implémentation, il définit juste un cadre). Plus précisement, KARP va concevoir les interfaces abstraites entre le système de gestion de clés et le protocole de routage, puis, pour chaque protocole de routage, la correspondance entre cette interface abstraite et le protocole réel. Un projet ambitieux.
Maintenant, au boulot. Qu'est-ce qui est déjà fait dans ce RFC ? La
section 2 classe les protocoles de routage selon leurs
propriétés. L'idée est que les protocoles de routage qui partagent les
mêmes propriétés pourront, avec un peu de chance, utiliser les mêmes
mécanismes de gestion de clés. Première propriété, le type de
message. Certains protocoles sont de type un-vers-un : les messages
d'un routeur sont envoyés à un autre routeur. Les
UPDATE BGP (RFC 4271) fonctionnent
ainsi. Mais c'est aussi le cas de LDP (RFC 5036), de BFD (RFC 5880) et même d'OSPF (RFC 2328) dans certaines conditions (liens point
-à-point). D'autres protocoles fonctionnent en un-vers-plusieurs. Un
routeur diffuse sur le réseau local l'information de routage. C'est le
mode de fonctionnement le plus courant d'OSPF et c'est aussi celui de
RIP (RFC 2453). Enfin,
il y a les protocoles utilisés pour le multicast.
Deuxième propriété pour classer les protocoles de routage, proche de la précédente mais pas identique, le fait que la clé soit par groupe ou par pair. Dans BGP ou LDP, les clés sont individuelles, on a une clé différente par pair. Dans OSPF, la clé est la même pour tous les pairs d'un groupe.
La section 3 liste ensuite les points auxquels il faut penser lorsqu'on envisage un protocole de gestion de clés, un KMP. Le RFC 4107 fournit les bases générales et notre RFC l'adapte aux protocoles de routage. Entre autres, il faudra penser aux paramètres à passer avec le système de gestion de clés, comme la durée de vie pour les clés, l'identificateur de l'association de sécurité (SPI dans IPsec, KeyID dans TCP-AO, etc), l'algorithme de chiffrement et plusieurs autres.
Deux points sont soulignés par le RFC, les questions particulières des clés asymétriques (section 3.1) et le cycle de vie des clés (section 3.2). Les clés asymétriques sont souvent une bonne solution aux problèmes de sécurité : déjà utilisées par les routeurs (lorsqu'ils sont administrés via SSH), générées sur le routeur, elles peuvent n'avoir jamais besoin de le quitter (le RFC ne le dit pas clairement mais on peut même imaginer un petit HSM dans le routeur). Générées aléatoirement, elles ne peuvent pas être devinées comme le sont tant de mots de passe choisis par des humains. Il faut juste faire attention à leur taille, pour limiter les risques des attaques par force brute (RFC 3766). L'algorithme classique pour ces clés est RSA mais les algorithmes à base de courbes elliptiques commencent à se répandre, et permettent d'utiliser des clés plus courtes.
Quant au cycle de vie des clés, notre RFC insiste surtout sur la nécessité d'avoir des remplacements (rollover) de clés qui soient discrets : un remplacement de clés ne devrait pas casser les sessions de routage existantes, car cela imposerait des recalculs lourds des tables de routage, se propageant dans tout le réseau, et entraînant parfois des perturbations dans la connectivité. (Le RFC ne le cite pas mais la traditionnelle authentification MD5 de BGP - RFC 2385 - n'a pas cette propriété. Changer la clé impose de relancer les sessions BGP. C'est sans doute une des raisons pour lesquelles ces clés ne sont jamais changées, même quand tout le monde les connait.)
Pourquoi, d'ailleurs, faut-il changer les clés de temps en temps ? Il peut y avoir des raisons cryptographiques (progrès de la cryptanalyse, mais le RFC note qu'en pratique, ce sont les cas les plus rares, des problèmes moins prestigieux scientifiquement sont bien plus communs), des raisons liées au personnel (départ d'un ingénieur qui connaissait les clés), des raisons plus urgentes (compromission d'une machine où étaient stockées des clés). Même s'il n'y a aucune raison immédiate de changer, un remplacement des clés de temps en temps peut être nécessaire pour s'assurer qu'un attaquant qui a obtenu une clé et l'utilise discrètement (de manière purement passive), ne puisse pas profiter de son butin éternellement.
Lorsque les procédures de changement de clés sont manuelles, les changements peuvent être en eux-mêmes une source de vulnérabilité (l'erreur est humaine...).
Après ces préliminaires, la section 4 dessine le travail futur. Il y a deux chantiers génériques (indépendants du protocole de routage) importants, le premier étant un pré-requis du second :
- Doter tous les protocoles de routage de mécanismes leur permettant l'agilité des algorithmes (changer d'algorithme facilement, contrairement au RFC 2385, qui ne permettait que MD5) et celle des clés (changer de clés sans casser les sessions entre routeurs). À l'heure actuelle, c'est très loin d'être le cas.
- Une fois ces mécanismes en place, développer un KMP, un Key Management Protocol permettant la gestion et le remplacement automatique des clés. Ce dernier protocole devrait être aussi indépendant du protocole de routage que possible.
Pour que les mécanismes nouveaux aient des chances de succès, ils doivent pouvoir être déployés sans ajouter de complexité par rapport à ce que font déjà les opérateurs (qui connaissent SSH, TCP-MD5, HTTPS et les certificats, etc). Le but n'est pas de faire un système qui empêche l'opérateur de faire une erreur (comme d'utiliser « foobar » comme mot de passe pour tous les systèmes) mais de faire un système qui soit utilisé dans le monde réel, et pour cela, la simplicité et la déployabilité sont des critères essentiels (mais très souvent oubliés par les experts en sécurité, qui se soucient davantage de faire des systèmes parfaits que des systèmes déployables, cf. section 6).
Avec une gestion manuelle des clés, on ne peut gérer de manière raisonnablement sûre que des petits réseaux. La deuxième étape sera donc de déployer le mécanisme de gestion automatique.
Le travail d'amélioration de chaque protocole de routage est décrit en section 4.2 sous forme d'une liste de tâches :
- Analyser le protocole actuel pour déterminer de façon précise quels sont ses mécanismes de sécurité présents,
- Déterminer ce qui lui manque pour atteindre le premier état de sécurité souhaité (agilité des algorithmes et possibilité de changer de clés en vol),
- Analyse des étapes nécessaires pour aller du premier point au deuxième sans tout casser, en faisant particulièrement attention aux questions de déployabilité dans le monde existant,
- Analyser le futur KMP (protocole de gestion de clés) pour ce protocole de routage particulier : a-t-il des demandes spécifiques ?
- Déterminer ce qui manque pour atteindre le deuxième état de sécurité (gestion automatique des clés),
- Normaliser l'adaptation du KMP à ce protocole et déployer le résultat.
On l'a vu en section 2, KARP classe les protocoles de routage en catégories selon leurs propriétés. La section 5 examine les points qui sont spécifiques à chaque catégorie. BGP, LDP et quelques autres sont dans la catégorie « messages un-vers-un et clés par pair ». BGP fonctionne toujours sur TCP, LDP parfois sur TCP et parfois sur UDP. Pour le cas de TCP, une bonne partie du travail a déjà été faite dans le groupe TCPM, avec la technique d'authentification AO (RFC 5925) qui a les propriétés voulues pour la première phase du travail de KARP (agilité des algorithmes et changement de clé facile). Il ne reste donc que le cas de LDP sur UDP.
Pour la catégorie « un-vers-plusieurs avec clés par groupe », qui comprend OSPF, IS-IS et RIP, rien de générique n'est fait. Le problème est ici bien plus difficile, d'autant plus que ces protocoles n'utilisent pas en général de protocole de transport standard, et ne peuvent donc pas réutiliser un mécanisme fourni par la couche 4 (comme peut le faire BGP avec AO). Ceci dit, le RFC 7166 fournit une méthode d'authentification pour OSPF qui, grâce à une indirection, fournit l'agilité de l'algorithme de chiffrement, qu'on peut changer en vol.
BFD est un cas à part et qui nécessitera sa propre équipe. Par exemple, il est beaucoup plus sensible aux délais que les autres. Pour lui, une milliseconde est très longue.
On l'a vu, ce RFC répète régulièrement qu'il est essentiel de prévoir un déploiement incrémental des nouveaux mécanismes de sécurité. Pas question d'ignorer l'existant. La section 6 insiste sur ce point. Contrairement à une attitude fréquente chez les experts en sécurité, qui est de chercher une solution parfaite, KARP va essayer de trouver des solutions qui puissent être déployées par étapes, sans casser le routage actuel, même si ces solutions ne sont pas les meilleures, question sécurité. Par exemple, les routeurs configurés avec les nouveaux mécanismes doivent pouvoir interagir sans ennuis avec les vieux routeurs non sécurisés.
Un des problèmes de sécurité les plus difficiles dans l'Internet est celui des attaques par déni de service (section 7). Ces attaques touchent aussi les routeurs et les protocoles de routage. Il ne faut donc pas que les nouvelles techniques conçues dans le cadre du groupe KARP aggravent le problème. Par exemple, les calculs cryptographiques peuvent être coûteux, surtout pour les ressources matérielles souvent limitées des routeurs, et les protocoles ne doivent donc pas permettre à un attaquant de faire faire au routeur une énorme quantité de ces calculs. Pour éviter cela, il faut permettre au routeur de faire des vérifications non-cryptographiques, donc bien plus légères, avant de se lancer dans les calculs compliqués. Par exemple, le RFC 5082 utilise le TTL du paquet entrant (quelque chose de trivial à vérifier) pour empêcher certaines attaques. Il est important, dans le cadre de KARP, de développer et de documenter de telles alternatives. D'autre part, le protocole doit être conçu de manière à ce que ce soit l'initiateur de la connexion (un attaquant potentiel) qui ait le plus de travail cryptographique à faire, et qui doive maintenir un état pendant ce temps.
La section 9 du RFC, la traditionnelle section sur la sécurité, détaille quelques points précis qui n'avaient pas trouvé leur place dans le reste du RFC. Par exemple, il est important de considérer aussi si le protocole de routage qu'on veut protéger est un IGP ou un EGP (certains protocoles peuvent être utilisés pour les deux, comme BGP avec son mode iBGP). Les deux sont sans doute aussi importants mais les menaces et les solutions ne seront pas forcément les mêmes. Un routeur purement interne et qui n'a aucun accès à l'Internet est ainsi sans doute moins menacé qu'un routeur BGP posé sur un point d'échange avec des dizaines d'autres routeurs inconnus.
Autre question transversale, celle des clés partagées ou uniques. Faut-il utiliser la même clé à plusieurs endroits ? Le débat est simple : c'est la sécurité (clés uniques !) contre la commodité (clés partagées). Actuellement, dans la grande majorité des environnements, les opérateurs ont choisi la commodité, réutilisant la même clé à plusieurs endroits. Les clés des routeurs sont stables dans l'espace (utilisées dans plusieurs routeurs) et dans le temps (on les change rarement, voire jamais et certains routeurs gardent la même clé toute leur vie). L'un des buts de KARP est de casser ce dilemne « sécurité ou commodité » en fournissant des mécanismes de gestion de clés qui soient sûrs (clés uniques) tout en étant faciles à déployer.
Enfin, la section 9.4 discute du dernier problème transversal, la distribution des clés. La méthode la plus courante aujourd'hui est un mécanisme « hors-bande », par exemple l'administrateur qui se connecte en SSH au routeur et entre manuellement les clés dans la configuration. Ça ne passe pas tellement à l'échelle (il faudrait automatiser les connexions SSH, par exemple avec Capistrano, pour faire l'opération sur N routeurs). Et changer toutes les clés en cas, par exemple de départ d'un administrateur (ou, pire, en cas de compromission de la clé) est trop lent. L'approche d'un KMP, protocole de gestion de clés, est donc préférée par KARP, comme nous l'avons déjà vu. Mais le RFC ne cache pas que le KMP a ses propres problèmes : lenteur au début (davantage de calculs cryptographiques) et surtout risques liés au manque de maturité des programmes, les KMP étant encore chose récente.
Une des possibilités envisagées est de réutiliser un KMP existant comme IKE, adapté au monde du routage, mais tournant en dehors du protocole de routage. L'autre possibilité est un nouveau KMP, embarqué dans le protocole de routage. Mais la décision n'est pas encore prise.
L'article seul
RFC 6528: Defending Against Sequence Number Attacks
Date de publication du RFC : Février 2012
Auteur(s) du RFC : F. Gont (SI6 Networks / UTN-FRH), S. Bellovin (Columbia University)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 2 février 2012
Ce court RFC spécifie les précautions que doit prendre une mise en œuvre de TCP pour éviter qu'un attaquant ne puisse deviner le numéro de séquence initial. Rien de nouveau, les précautions en question étant programmées dans TCP depuis de nombreuses années, juste un rappel et une mise à jour du précédent RFC sur ce sujet, le RFC 1948. Il a depuis été intégré dans le RFC 9293.
Pour comprendre le problème de sécurité des numéros de séquence, et les solutions présentées dans ce RFC, il vaut mieux revenir à l'attaque qui exploitait les anciennes vulnérabilités. C'est fait dans l'annexe A du RFC, que je reprends ici.
Le but de l'attaquant est de s'en prendre à un serveur qui autorise par adresse IP. À l'époque du RFC 1948, cela concernait rsh mais, de nos jours, SSH a complètement remplacé cet archaïque protocole. Aujourd'hui, ce serait plutôt un serveur DNS qui authentifie le transfert de zones ainsi, ou bien un serveur SMTP qui autorise seulement certaines adresses IP à passer par lui - même s'il ferait mieux de se servir du RFC 4954, ou encore un serveur HTTP qui ne permet l'invocation de certaines actions qu'aux utilisateurs de certaines adresses. En deux mots, dès que l'autorisation se fait par adresse IP uniquement, il faut s'assurer que vous utilisez un TCP qui mette en œuvre les recommandations de ce RFC 6528.
On le sait, il est trivial pour un attaquant d'envoyer des paquets avec une fausse adresse IP source (le RFC 2827, censé l'empêcher, n'étant quasiment pas déployé). Mais, dans ce cas, l'attaquant ne reçoit pas les réponses. Or, si on veut maintenir une connexion TCP avec sa victime, il faut lui envoyer des paquets avec les données qu'elle attend, notamment le numéro de port et les numéros de séquence. Sinon, la victime va jeter ces paquets TCP qui lui sembleront anormaux. Pour les numéros de port, le RFC 6056 s'en occupe. Pour les numéros de séquence, voyons ce qui se passe. Tout paquet TCP doit inclure ces numéros, un pour chaque sens de la conversation (RFC 793, section 3.3). Ce numéro identifie l'octet suivant à envoyer. Une ouverture de connexion TCP normale ressemble donc, pour le cas où Alice veut parler à Bob, à :
- Alice->Bob: [SYN] ISNa, null (Alice envoie un paquet TCP où le bit
SYNest mis, avec un numéro de séquence initial ISNa - ISN = Initial Sequence Number.) - Bob->Alice: [SYN] ISNb, ACK(ISNa+1) (Bob répond qu'il est d'accord, envoie son propre ISN - rappelez-vous qu'il y a deux séquences d'octets, une dans chaque direction - et accuse réception de l'ISN d'Alice.)
- Alice->Bob: [] ISNa, ACK(ISNb+1) (Alice est d'accord et cela termine la « triple poignée de mains » qui ouvre une connexion TCP.)
Voici d'ailleurs, vu par tcpdump, un exemple d'ouverture de connexion (vers le dépôt git de Linux) :
% tcpdump -S -n -r tmp/3wayhandshake.pcap reading from file tmp/3wayhandshake.pcap, link-type EN10MB (Ethernet) 09:47:53.086347 IP 192.134.6.69.39859 > 149.20.4.72.9418: Flags [S], seq 3366079112, ... 09:47:53.242880 IP 149.20.4.72.9418 > 192.134.6.69.39859: Flags [S.], seq 3075029842, ack 3366079113, ... 09:47:53.242910 IP 192.134.6.69.39859 > 149.20.4.72.9418: Flags [.], ack 3075029843, ...
Le S entre crochets indique un paquet
SYN. L'option -S est là pour indiquer à tcpdump
d'afficher les numéros de séquence absolus, tels qu'ils sont envoyés
sur le câble (par défaut, il montre des numéros relatifs, sauf pour
les paquets SYN). On note aussi que tcpdump
n'affiche pas le premier numéro de séquence s'il n'y a pas de données,
et n'affiche pas le second si le bit ACK n'est
pas mis.
Le deuxième paquet n'a été accepté par Alice que parce qu'il contenait un numéro de séquence attendu. Même chose pour le troisième. Un attaquant qui procéderait au hasard, envoyant des numéros de séquence quelconques, n'aurait aucune chance que ses paquets soient acceptés. Imaginons maintenant que l'attaquant puisse connaître les numéros de séquence utilisés. Bob fait confiance à Alice mais Mallory, l'attaquant, va se faire passer pour Alice. Mallory n'est pas situé sur le chemin entre Alice et Bob (sinon, cela serait trivial, il lui suffirait d'écouter le réseau) :
- AliceM->Bob: [SYN] ISNa, null (Mallory, utilisant l'adresse
source d'Alice, envoie un paquet TCP où le bit
SYNest mis, avec un numéro de séquence initial ISNa.) - Bob->Alice: [SYN] ISNb, ACK(ISNa+1) (Bob répond qu'il est d'accord, envoie son propre ISN et accuse réception de l'ISN qu'il croit venir d'Alice. Mallory ne recevra pas ce paquet, qui ira à la vraie Alice. Mallory ne sait donc pas ce que vaut ISNb, et doit deviner. En cas de divination juste, son paquet suivant est accepté.)
- AliceM->Bob: [] ISNa, ACK(ISNb+1) (Mallory, utilisant l'adresse source d'Alice, termine la triple poignée de mains. Bob croit qu'il est connecté à Alice alors qu'il va accepter les paquets de Mallory.)
Et comment Mallory a-t-il trouvé le numéro de séquence que va utiliser Bob ? Le RFC originel, le RFC 793 ne mettait pas du tout en garde contre cette attaque, inconnue à l'époque (1981). Il ne se préoccupait que du risque de collision accidentel entre deux connexions et suggérait donc un algorithme où l'ISN était simplement incrémenté toutes les quatre micro-secondes, ce qui le rendait très prévisible (l'attaquant ouvre une connexion, regarde l'ISN, et sait quel va être celui de la prochaine connexion). Le premier article décrivant une faiblesse dans les mises en œuvre de TCP, faiblesse permettant de trouver le prochain numéro de séquence, a été publié en 1985 (Morris, R., A Weakness in the 4.2BSD UNIX TCP/IP Software, CSTR 117, AT&T Bell Laboratories). À l'époque, elle était suffisante pour établir des sessions rsh avec la victime.
À noter qu'Alice, elle, reçoit l'accusé de réception de Bob, auquel
elle ne s'attend pas. Elle va donc émettre un paquet
RST qui va fermer la connexion. Diverses
techniques permettent à l'attaquant de réussir quand même (par exemple
en montant au même moment une attaque DoS
contre Alice pour ralentir ses paquets, donnant à l'attaque le temps de réussir).
C'est pour répondre à cette attaque que le RFC 1948 avait été écrit en 1996,
documentant la pratique qui était devenue courante, de générer des
numéros de séquence, sinon aléatoires, en tout cas
imprévisibles. (Un article plus récent et plus détaillé sur la
vulnérabilité initiale était celui de Shimomura, T., Technical
details of the attack described by Markoff in NYT,
envoyé sur Usenet, en
comp.security.misc, Message-ID:
<3g5gkl$5j1@ariel.sdsc.edu>, en 1995.) Notre RFC 6528 met à jour ce RFC 1948. La section 2 expose les principes d'un bon algorithme de
génération d'ISN (Initial Sequence Number), la
section 3 décrit l'algorithme proposé. Commençons par celui-ci. Il
tient en une formule :
ISN = M + F(localip, localport, remoteip, remoteport)
où M est un compteur qui s'incrémente toutes les quatre micro-secondes, et F une fonction pseudo-aléatoire, qui va prendre comme paramètre le tuple qui identifie une connexion TCP (adresse IP locale, port local, adresse IP distante, port distant). F ne doit pas être prévisible de l'extérieur et le RFC suggère une fonction de hachage cryptographique, comme MD5 (RFC 1321), hachant le tuple ci-dessus après l'avoir concaténé à une clé secrète. La sécurité reposera sur cette clé, l'algorithme de hachage utilisé étant sans doute connu. On peut envisager qu'elle soit générée aléatoirement (vraiment aléatoirement, en suivant le RFC 4086), ou configurée à la main (en espérant que l'ingénieur système ne choisira pas « toto »). Il est recommandé de la changer de temps en temps.
Notez que, bien que MD5 ait de nombreuses faiblesses cryptographiques pour d'autres utilisations, il est parfaitement sûr pour celle-ci (et bien plus rapide que ses concurrents).
La section 2, elle, définissait le cahier des charges :
qu'attend t-on d'un algorithme de sélection de l'ISN ? D'abord, il
n'est pas forcé d'empêcher des vieux paquets IP
qui traînent dans le réseau d'être acceptés. Pour cela, il vaut mieux
compter sur l'état TIME_WAIT de TCP (après la fin
d'une connexion, garder l'état pendant deux MSL - Maximum
Segment Life, cf. RFC 7323). Ça ne
marche pas forcément si les connexions sont créées à un rythme très
rapide mais c'est la seule solution sûre (mais consommant de la mémoire). On peut lire à ce sujet deux
articles sur les générateurs d'ISN, leurs avantages et inconvénients, « Strange Attractors and TCP/IP Sequence
Number Analysis » et « Strange Attractors and TCP/IP
Sequence Number Analysis - One Year Later ».
Compte-tenu de ces risques, une génération aléatoire de l'ISN suffirait. Mais elle aurait l'inconvénient de de ne pas permettre de deviner si un nouveau paquet TCP appartient à une ancienne connexion ou pas. L'idée de base de ce RFC est donc de créer un espace de numéros de séquence par identificateur TCP (le tuple {adresse IP locale, port local, adresse IP distante, port distant}) et, dans chacun de ces espaces, de suivre les règles d'incrémentation progressive de l'ISN du RFC 793.
Pour ceux qui veulent pousser l'analyse de sécurité, la section 4
prend de la hauteur et rappelle quelques points importants. D'abord
que la vraie solution serait évidemment de protéger les paquets IP par
de la cryptographie comme le fait
IPsec, ou au niveau TCP comme le fait le TCP-AO
du RFC 5925 (TLS ou
SSH ne suffisent pas, ils n'empêchent pas une
attaque par déni de service avec des faux
paquets TCP RST).
La section 4 fait aussi remarquer que rien n'est parfait et que l'algorithme proposé dans notre RFC a des effets de bord, comme de permettre le comptage du nombre de machines qui se trouvent derrière un routeur NAT, ce qui peut être une information qu'on souhaiterait garder privée.
Et, surtout, elle rappelle que toutes les précautions de notre RFC 6528 ne s'appliquent que si l'attaquant est en dehors du chemin entre les deux pairs TCP. S'il est sur le chemin et qu'il peut écouter le réseau, elles ne servent à rien.
Quels sont les changements depuis le RFC 1948 ? Il n'y a pas de changement sur le fond (l'algorithme est le même donc un TCP compatible avec le RFC 1948 l'est également avec le RFC 6528). Les changements sont résumés dans l'annexe B. Le statut du RFC a changé (désormais sur le chemin des normes), les exemples maintenant dépassés par l'évolution des techniques ont été mis à jour ou supprimés,
On l'a dit, les précautions décrites dans ce RFC sont présentes
dans les implémentations depuis longtemps. Pour un exemple de mise en œuvre de cet algorithme, on peut
regarder le code source de NetBSD. Il se trouve
en sys/netinet/tcp_subr.c. Son comportement est
contrôlé par la variable sysctl
iss_hash. Mise à 1, elle indique qu'il faut
utiliser l'algorithme ci-dessus. À 0, qu'il faut utiliser une valeur
aléatoire. Prenons le premier cas, celui de notre RFC. On voit la
génération du secret (un nombre aléatoire, issu de
cprng_strong()) puis le hachage
MD5 de l'identifiant de connexion avec le secret :
/*
* If we haven't been here before, initialize our cryptographic
* hash secret.
*/
if (tcp_iss_gotten_secret == false) {
cprng_strong(kern_cprng,
tcp_iss_secret, sizeof(tcp_iss_secret), 0);
tcp_iss_gotten_secret = true;
}
/*
* Compute the base value of the ISS. It is a hash
* of (saddr, sport, daddr, dport, secret).
*/
MD5Init(&ctx);
MD5Update(&ctx, (u_char *) laddr, addrsz);
MD5Update(&ctx, (u_char *) &lport, sizeof(lport));
MD5Update(&ctx, (u_char *) faddr, addrsz);
MD5Update(&ctx, (u_char *) &fport, sizeof(fport));
MD5Update(&ctx, tcp_iss_secret, sizeof(tcp_iss_secret));
MD5Final(hash, &ctx);
memcpy(&tcp_iss, hash, sizeof(tcp_iss));
return (tcp_iss);
Pour Linux (remerciements au passage à @ackrst), il faut regarder le
net/core/secure_seq.c qui contient à peu près la
même chose (la variable net_secret est
initialisée au tout début de ce fichier) :
__u32 secure_tcp_sequence_number(__be32 saddr, __be32 daddr,
__be16 sport, __be16 dport)
{
u32 hash[MD5_DIGEST_WORDS];
hash[0] = (__force u32)saddr;
hash[1] = (__force u32)daddr;
hash[2] = ((__force u16)sport << 16) + (__force u16)dport;
hash[3] = net_secret[15];
md5_transform(hash, net_secret);
L'article seul
Adaptation automatique d'un éditeur à divers encodages ?
Première rédaction de cet article le 1 février 2012
Dernière mise à jour le 2 février 2012
On lit parfois que le changement de
l'encodage par défaut sur une machine
Unix est simple, on modifie une variable d'environnement, par exemple LC_CTYPE
et c'est tout. C'est oublier les fichiers existants : changer la
variable d'environnement ne va pas magiquement les convertir. Est-ce
que l'éditeur emacs s'adaptera tout seul au cas
où on a un mélange de fichiers avec l'ancien et le nouvel
encodage ?
Ce problème est un des obstacles quand on veut migrer un
$HOME rempli de fichiers accumulés depuis des
années, par exemple depuis Latin-1 vers UTF-8. Convertir tous les fichiers n'est pas forcément réaliste, surtout
si on travaille en commun avec des personnes qui ont un autre encodage
par défaut. Mais un éditeur comme
Emacs n'est-il pas assez intelligent pour
s'adapter tout seul ? Testons-le, sur une
Debian version stable (nom de code
squeeze). Lorsqu'on ouvre un fichier avec Emacs,
un caractère à gauche de la barre d'état indique l'encodage (« 1 »
pour du Latin-1, « u » pour de
l'UTF-8, etc ; si on veut qu'Emacs soit plus
explicite, M-x describe-current-coding-system
affiche l'encodage actuel).
Avec du texte seul sans aucun marquage, c'est fichu : Emacs ne peut
pas connaître l'encodage (sauf à tenter des heuristiques plus ou moins
fiables) donc c'est manuellement, lorsqu'on ouvre le fichier, qu'on
doit changer l'encodage (C-x RET f ou bien dans
les menus Options -> Mule -> Set coding systems) s'il ne correspond pas à l'encodage par
défaut.
Avec du XML et l'excellent mode Emacs nxml-mode, tout marche bien. Emacs bascule
automatiquement dans le bon mode en regardant si la première ligne est
<?xml version="1.0" encoding="utf-8"?> ou
bien <?xml version="1.0"
encoding="iso-8859-1"?>. (C'est bien l'en-tête qui compte :
si on triche et qu'on met du Latin-1 en le marquant comme UTF-8, Emacs
passe en mode UTF-8 quand même.) On peut donc travailler avec des
fichiers XML qui sont un mélange d'encodages sans problèmes.
Avec LaTeX, formidable, le mode LaTeX
détecte l'encodage et Emacs s'adapte. Comme pour XML, il n'inspecte
pas le document, il regarde juste s'il y a
\usepackage[latin1]{inputenc} ou bien \usepackage[utf8]{inputenc}.
Et en Python, langage de programmation qui
permet (voir le PEP-263) de
mettre de l'Unicode dans le source ? Le mode
Python d'Emacs détecte la mention # -*- coding: latin-1
-*- ou bien # -*- coding: utf-8 -*- et
s'adapte correctement.
Décidemment, tout semble bien se passer, à part le triste début avec le texte seul. Essayons un autre format de données qu'XML, JSON (RFC 4627). JSON ne permet qu'un seul encodage, UTF-8 (et n'a donc pas d'option pour en indiquer un autre). Patatras, malgré cela, le mode JSON d'Emacs n'est pas assez intelligent pour passer en Unicode automatiquement et l'édition devient pénible.
Et enfin, pour du texte reST
(reStructuredText, celui utilisé pour CNP3) ? Les programmes
qui traitent ce format trouvent tout seuls si l'entrée est en UTF-8 ou
pas (je ne connais pas de moyen de l'indiquer dans le
source). Mais le mode Emacs rst (paquetage
python-docutils chez Debian) ne le fait hélas pas.
Si de courageux lecteurs veulent tester Emacs avec d'autres langages, qu'ils n'hésitent pas à m'envoyer les résultats, que je publierai ici, avec mes remerciements.
On l'a vu, le problème dans certains formats (texte brut,
notamment), est l'absence de mécanisme pour marquer explicitement
l'encodage. Emacs ne semble pas pratiquer le content
sniffing, cet examen des octets pour essayer de déduire
l'encodage (notons que cette méthode est imparfaite, par exemple elle
ne permet pas de distinguer Latin-1 de
Latin-9). Emacs a une solution générique pour
ce problème de marquage de l'encodage (merci à @T1B0 pour le rappel), mettre
une ligne contenant -*- coding: THEENCODING -*-
au début du fichier (on précède en général la ligne avec un signe
indiquant un commentaire du langage considéré). Cela ne résout pas
vraiment le problème du texte seul (la ligne en question sera
affichée, déroutant les lecteurs, grep,
etc). Mais cela traite bien le problème de
reStructuredText. En mettant au début :
.. -*- coding: utf-8 -*-
Tout marche.
En conclusion, si on change l'encodage de son système, on n'y coupera pas de convertir les fichiers texte.
Et les autres éditeurs ? Mes lecteurs ont-ils des expériences à ce
sujet ? J'ai fait quelques essais avec vim et
il ne semble pas capable de s'adapter, par exemple à un fichier XML en
UTF-8. En cas de modification du texte, il écrit selon la
locale courante, produisant
des fichiers XML qui ne sont pas bien formés. Mais il a des capacités
de détection automatique de l'encodage par heuristiques
successives. Par défaut, elles ne sont pas activées mais, si on met
dans son ~/.vimrc :
set fileencodings=ucs-bom,utf-8,iso88591
Alors, vim cherchera un BOM, puis testera UTF-8 puis enfin se rabattra sur Latin-1. Merci à Olivier Mengué pour cet utile information !
L'article seul
Quel nom vérifier dans un certificat X.509, si on a été redirigé ?
Première rédaction de cet article le 27 janvier 2012
Une discussion animée vient d'avoir lieu sur la liste du groupe de travail IETF DANE, qui travaille à permettre l'utilisation de certificats dans le DNS (en simplifiant, il s'agit de remplacer X.509 par DNSSEC, voir mon exposé aux JRES). La question était « Lorsqu'il y a eu des redirections vers un autre nom de domaine, quel nom chercher dans le certificat ? Celui de départ ? Celui d'arrivée ? »
Prenons un exemple concret pour voir. Supposons un protocole nommé
PDP (pour Pur Distribution Protocol) qui permet
de récupérer des contenus (musique, films, etc) qui avaient été
auparavant chargés sur un serveur. Pour trouver le serveur adéquat,
mettons que cet hypothétique PDP utilise les
enregistrements SRV du
DNS (RFC 2782), afin
d'assurer la répartition de charge, et la résistance aux
pannes. Mettons que le domaine microupload.example
ait deux serveurs, on aurait quelque chose comme :
_pdp._tcp.microupload.example. SRV 0 0 6642 content.example.com.
SRV 1 0 6642 content.backup.example.
Vu les priorités (le premier chiffre après
SRV), le second serveur ne sera utilisé qu'en cas
de panne du premier. Mais, et c'est là que ça devient intéressant, on
va supposer que PDP, pour échapper à des gens malintentionnés qui
voudraient savoir ce qu'on télécharge, chiffre toutes ses communications avec
TLS et authentifie le serveur avec
X.509. Imaginons que le premier serveur soit en
panne à ce moment et que le client PDP se connecte donc à
content.backup.example. À quel nom doit
être le certificat de ce dernier ?
microupload.example parce que c'est le point de
départ de la transaction ? content.backup.example
parce que c'est le nom du serveur ? Prenez le temps de réflechir à
cette question cinq minutes, et essayez de faire une liste des raisons
en faveur du premier choix et de celles en faveur du second. Il est
probable que vous en oublierez, car le problème est compliqué.
Vous y êtes ? Vous avez vraiment cherché ? Bon, alors, maintenant, des éléments de réponse. Le problème du groupe DANE avait été enregistré comme ticket #28 mais, si vous n'avez pas lu le RFC 6394, ce n'est pas trop grave, la question n'est pas du tout spécifique à DANE. Elle a même fait l'objet d'un RFC entier, le RFC 6125, que je trouve personnellement peu lisible. Son principal mérite est de montrer que la question de l'identité n'est pas triviale du tout et qu'elle peut signifier des choses différentes selon la personne.
Et la question n'est pas non plus spécifique aux enregistrements SRV comme dans l'exemple ci-dessus. On aurait la même question, par exemple avec des MX.
Alors, une liste de raisons en faveur du premier choix, utiliser le
nom de départ (ici, microupload.example) :
- Le nom de départ est celui que voit l'utilisateur. C'est celui en lequel il a confiance. C'est le nom du service, pas celui du serveur du moment.
- Si la résolution DNS n'est pas sécurisée (par exemple avec DNSSEC), rien ne prouve que le SRV obtenu est légitime. X.509 ne servirait à rien dans ce cas. (Notez que, dans le cas spécifique de DANE, DNSSEC est obligatoire donc, si on décide que le nom utilisé par DANE sera le premier, il sera sécurisé par DNSSEC de toute façon.)
Et les raisons d'utiliser au contraire le nom d'arrivée, ici
content.backup.example ?
- Dans le cas d'un serveur qui héberge des services pour des milliers de domaines différents, il faudra gérer beaucoup de certificats.
- Il existe plusieurs méthodes pour avoir plusieurs certificats sur la même machine. Si la méthode choisie est de mettre tous les noms dans un même certificat, celui qui se connecte peut apprendre la liste de tous les clients (au sens affaires, pas au sens protocole réseau) du serveur juste en regardant le certificat.
- Dans le cas où le serveur n'est pas géré par la même organisation que le domaine (ce qui est fréquent aujourd'hui), une stricte coordination sera nécessaire. Si le domaine acquiert un nouveau certificat, il leur faudra s'assurer qu'il est bien installé sur le serveur.
Bref, tester le domaine de départ est en général meilleur du point de vue sécurité, mais tester le domaine d'arrivée facilite en général le déploiement.
Mais, puisque le problème est connu depuis longtemps, que spécifient les différents RFC sur les protocoles qui utilisent TLS ? Eh bien, souvent, ce n'est pas clair. Essayez de lire le RFC 3207 pour voir ce que devrait faire un bon client SMTP, par exemple. Le vocabulaire peu stable du RFC ne permet guère de trancher. L'avis dominant est toutefois que SMTP doit utiliser le domaine d'arrivée. Donc, s'il y a un MX :
michu.example. IN MX 10 mail.provider.example
Alors, le MTA qui essaiera de transmettre du
courrier en TLS à monsieur@michu.example
cherchera sur l'autre MTA un certificat portant le nom de
mail.provider.example.
Mais, et c'est là que cela devient amusant, d'autres protocoles ont pu faire des choix différents ! C'est ainsi que XMPP spécifie le contraire, on doit utiliser le domaine du début, avant toute redirection (RFC 6120, section 5.4.3.1). Et pour HTTP ? Ce dernier n'utilise pas d'enregistrement DNS de redirection (comme les MX ou les SRV). Il ne reste donc comme possibilité de piège, au niveau DNS, que les CNAME. Ceux-ci sont délicats car, contrairement aux SRV ou MX, la bibliothèque qui fait la résolution ne donne pas forcément à l'application (ici, le navigateur), une indication sur la présence ou non d'un alias (un enregistrement CNAME). Le RFC 2818 n'est pas parfaitement clair mais semble de toute façon avoir choisi aussi l'approche « domaine de départ » (ici, celui qui est dans l'URI).
Et que va faire le groupe DANE ? La question n'est pas encore définitivement tranchée mais ce sera probablement « chaque protocole se débrouille » car il est trop difficile de spécifier un choix qui convienne à tous.
L'article seul
Changer une base PostgreSQL de « tablespace »
Première rédaction de cet article le 22 janvier 2012
Un des principaux mécanismes de gestion de l'espace disque dans PostgreSQL est le tablespace. Un tablespace est un répertoire où on place des données du SGBD. Mais, si on change d'avis, comment changer une base de tablespace ?
La tablespace par défaut d'une base se déclare à la création :
% createdb --tablespace grosdisque experience
Ici, la base "experience" est créée sur le
tablespace "grosdisque" (créé précédemment par
CREATE
TABLESPACE). On peut afficher les
tablespaces par défaut des bases avec le catalogue
système de PostgreSQL :
=> SELECT datname AS database, spcname AS tablespace, spclocation AS directory
FROM pg_database INNER JOIN pg_tablespace
ON pg_tablespace.oid = pg_database.dattablespace;
database | tablespace | directory
-------------------+--------------------+---------------
template1 | pg_default |
essais | pg_default |
experience | grosdisque | /some/where/big
...
Et si on s'est trompé, si on a oublié de mettre la base sur le bon
tablespace, si la base a grossi au delà de ce qui
était prévu ? Depuis la version 8.4 de PostgreSQL, il existe un moyen
simple, la commande ALTER
DATABASE :
essais=> ALTER DATABASE experience SET TABLESPACE autreendroit; ERROR: database "experience" is being accessed by other users DETAIL: There are 1 other session(s) using the database. (Ah oui, il faut qu'aucune session n'accède à la table, ce qui peut être contraignant.) essais=> ALTER DATABASE experience SET TABLESPACE autreendroit; ALTER DATABASE
Et si on gère une base dans une version antérieure de PostgreSQL,
et qu'on ne peut pas migrer ? Rien n'est perdu. Il y a bien sûr la
solution « bourrin » d'une commande pg_dump,
d'une re-création de la base sur le nouveau
tablespace, puis d'un
pg_restore. C'est très lent, et cela empêche
d'accéder à la base en écriture pendant ce temps.
Une solution plus astucieuse est documentée par Lode : elle utilise le fait que le tablespace n'est pas forcément par base mais peut être configuré par table et qu'il est possible, même avant la version 8.4 de PostgreSQL, de changer une table de tablespace. Le principe est donc :
essais=> ALTER DATABASE experience SET default_tablespace = autreendroit; (Cette première commande changera le tablespace pour les *futures* tables.) essais=> ALTER TABLE premiere_table SET TABLESPACE autreendroit; essais=> ALTER TABLE deuxieme_table SET TABLESPACE autreendroit; ...
Oui, il faut le faire pour toutes les tables, et pour les index également. Ce n'est pas très pratique. Lode automatisait avec PHP, je préfère le faire avec le shell :
% psql --tuples-only -c 'SELECT tablename FROM pg_tables' experience > tmp/tables % for table in $(cat tmp/tables); do echo $table psql -c "ALTER TABLE $table SET TABLESPACE autreendroit;" experience done
Et même chose avec les index :
% psql --tuples-only -c 'SELECT indexname FROM pg_indexes' experience > tmp/indexes % for idx in $(cat tmp/indexes); do echo $idx psql -c "ALTER INDEX $idx SET TABLESPACE autreendroit;" experience done
C'est bien plus rapide que sauvegarder/restaurer. Rappelez-vous bien que cela ne change pas le tablespace de la base. Il apparaîtra toujours comme l'ancien. Mais toutes les données seront bien dans le nouveau tablespace.
Après, à vous de voir si cela ne serait pas plus simple de migrer vers un PostgreSQL >= 8.4. Mais les grosses bases de données sont souvent des choses fragiles, avec lesquelles on ne peut pas jouer comme on veut. J'ai récemment utilisé la vieille méthode pour une base qu'il aurait été risqué de migrer.
L'article seul
Panne Wi-Fi d'une Freebox v5
Première rédaction de cet article le 21 janvier 2012
Dernière mise à jour le 23 janvier 2012
Il m'est arrivé quelque chose de curieux avec mon ancienne Freebox, une v5. Elle servait entre autres de borne Wi-Fi. Et tout à coup, son signal Wi-Fi est devenu dix fois plus faible, non captable par beaucoup d'appareils.
Elle avait plusieurs clients différents, par exemple un smartphone HTC Desire, une tablette Packard Bell Liberty Pad, un ordinateur portable Dell, etc. Tous étaient contents et pouvaient se connecter de tout l'appartement. Et, un soir, fini. Le signal avait terriblement baissé. Le smartphone ne voyait plus rien. Plus de Wi-Fi pour lui. La tablette pouvait encore se connecter, mais uniquement lorsqu'elle était dans la même pièce que la Freebox. L'ordinateur portable avait la puce la plus sensible : il y arrivait encore de tout l'appartement, mais avec de fréquentes déconnexions.
Bien que le problème ait frappé tous mes appareils en même temps, j'ai cherché si le problème ne venaient pas d'eux (par exemple, s'il ne fallait pas que j'essaie un autre fichier binaire « radio » sur CyanogenMod pour le smartphone). J'ai aussi tenté de changer le canal Wi-Fi de la Freebox, sans résultat.
Le problème a été résolu lors du remplacement de la Freebox v5 par une v6 Révolution. Tout refonctionne comme avant. C'était donc bien un problème matériel (comme me l'avait suggéré un employé de Free, lors d'une réception officielle prestigieuse). La v5 accusait son (pourtant jeune) âge et ses circuits commençaient à casser.
De quoi philosopher sur la fragilité des engins numériques que nous accumulons chez nous.
Au fait, j'ai renvoyé l'ancienne Freebox à Free (elles ne sont pas vendues mais mises à la disposition de l'abonné). Quelqu'un sait comment prévenir Free qu'elle ne marche pas bien et ne doit donc pas être utilisée ? Sans passer par le support officiel, ses heures d'attente et ses questions débiles « avez-vous rebooté votre ordinateur ? ». Selon @LALIGNEDEFREE, les Freebox de retour sont systématiquement testées et il n'est donc pas nécessaire de signaler un problème.
J'ai obtenu de suggestions intéressantes (mais trop tard pour tester, la boîte étant repartie) :
- De @fuktop13 et de nombreux autres : ce serait un problème d'alimentation électrique. Lorsque celle-ci faiblit, certaines fonctions de la boîte sont plus affectées que d'autres. Il faudrait alors changer ladite alimentation. Le nombre de témoignages reçus (y compris par des employés de Free) me pousse à privilégier cette théorie.
- De @RenaudGuerin, l'idée que ce pourrait être un faux contact avec l'antenne (qui est externe, sur la Freebox v5).
- Jean-Philippe Pick suggère un problème logiciel : le logiciel de la boîte est mis à jour automatiquement au démarrage de celle-ci (je n'ai pas fait attention si cela avait été le cas avant la panne) et une nouvelle version aurait pu avoir des problèmes avec la puce Ralink de la Wi-Fi.
L'article seul
RFC 6347: Datagram Transport Layer Security version 1.2
Date de publication du RFC : Janvier 2012
Auteur(s) du RFC : E. Rescorla (RTFM), N. Modadugu
(Stanford University)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 21 janvier 2012
Le protocole de cryptographie TLS, normalisé dans le RFC 5246, ne s'appliquait traditionnellement qu'à TCP. Les applications utilisant UDP, comme le fait souvent la téléphonie sur IP, ne pouvaient pas utiliser TLS pour protéger leur trafic contre l'écoute ou la modification des données. Mais cette limitation a disparu avec DTLS, qui permet de protéger du trafic UDP. Ce RFC met à jour DTLS (initialement normalisé dans le RFC 4347) pour TLS 1.2. (Depuis, la version 1.3 est sortie, dans le RFC 9147.)
TLS ne tournait que sur TCP car il avait besoin d'un transport fiable, garantissant que les données arrivent toutes, et dans l'ordre. Le grand succès de TLS (notamment utilisé pour HTTP et IMAP) vient de sa simplicité pour le programmeur : rendre une application capable de faire du TLS ne nécessite que très peu de code, exécuté juste avant l'envoi des données. Par contre, cela laissait les applications UDP comme SIP non protégées (section 1 de notre RFC). Les solutions existantes comme IPsec ne sont pas satisfaisantes (cf. RFC 5406), notamment parce qu'elles n'offrent pas la même facilité de déploiement que TLS, qui tourne typiquement dans l'application et pas dans le noyau.
DTLS a été conçu pour fournir TLS aux applications UDP. Il offre les mêmes services que TLS : garantie de l'intégrité des données et confidentialité.
La section 3 explique les principes de DTLS : protégé ou pas par DTLS, UDP a la même sémantique, celle d'un service de datagrammes non fiable. D'autre part, DTLS est une légère modification de TLS : il en garde les principales propriétés, bonnes ou mauvaises.
Mais pourquoi ne peut-on pas faire du TLS normal sur UDP ? Parce que TLS n'a pas été conçu pour tourner au dessus d'un protocole non fiable. TLS organise les données en enregistrements (records) et il ne permet pas de déchiffrer indépendamment les enregistrements. Si l'enregistrement N est perdu, le N+1 ne peut pas être déchiffré. De même, la procédure d'association initiale de TLS (handshake) ne prévoit pas de perte de messages et ne se termine pas si un message est perdu.
Le premier problème fait l'objet de la section 3.1. La dépendance des enregistrements TLS vis-à-vis de leurs prédécesseurs vient du chaînage cryptographique (le chiffrement par chaînage - stream cipher - est donc supprimé en DTLS) et de fonctions anti-rejeu qui utilisent un numéro de séquence, qui est implicitement le rang de l'enregistrement. DTLS résout le problème en indiquant explicitement le rang dans les enregistrements.
Et la question de l'association initiale est vue dans la section 3.2. Pour la perte de paquets lors de l'association, DTLS utilise un système de retransmission (section 3.2.1) et pour l'éventuelle réorganisation des paquets, DTLS introduit un numéro de séquence (section 3.2.2). En prime, DTLS doit gérer la taille importante des messages TLS (souvent plusieurs kilo-octets), qui peut être supérieure à la MTU. DTLS permet donc une fragmentation des paquets au niveau applicatif, un message pouvant être réparti dans plusieurs enregistrements (section 3.2.3).
Enfin, l'anti-rejeu a été modifié pour tenir compte du fait que la duplication de paquets, en UDP, n'est pas forcément malveillante (sections 3.3 et 4.1.2.6).
La définition formelle du nouveau protocole est en section 4. DTLS étant une légère évolution de TLS, la définition se fait uniquement en listant les différences avec TLS. Il faut donc garder le RFC 5246 sous la main.
Dans le Record Protocol de TLS, l'enregistrement spécifié dans la section 6.2.1 du RFC 5246 gagne deux champs (section 4.1) :
struct {
ContentType type;
ProtocolVersion version;
uint16 epoch; // NOUVEAU
uint48 sequence_number; // NOUVEAU
uint16 length;
opaque fragment[DTLSPlaintext.length];
} DTLSPlaintext;
notamment le numéro de séquence sequence_number
(qui était implicite dans TLS, puisque TCP garantissait l'ordre des
messages). Pour éviter la fragmentation et les
ennuis associés, les mises en œuvre de DTLS doivent déterminer
la MTU du chemin et n'envoyer que des
enregistrements plus petits que cette MTU (section 4.1.1).
Contrairement à IPsec, DTLS n'a pas la notion d'identificateur d'association. Une machine qui reçoit du TLS doit trouver l'association toute seule, typiquement en utilisant le tuple (adresse IP, port).
En toute rigueur, DTLS n'est pas spécifique à UDP, il peut marcher sur n'importe quel protocole de transport ayant une sémantique « datagrammes ». Certains de ces protocoles, comme DCCP (cf. RFC 5238), ont leur propres numéros de séquence et ils font donc double emploi avec ceux de DTLS. Petite inefficacité pas trop grave.
Au niveau du Hanshake protocol, les modifications que DTLS apporte à TLS font l'objet de la section 4.2. Les trois principales sont :
- L'ajout d'un gâteau pour limiter les risques de DoS,
- Modification des en-têtes pour gérer les pertes ou réordonnancements des paquets (section 4.2.2),
- Ajouts de minuteries pour détecter les pertes de paquets (section 4.2.4).
Les gâteaux de DTLS sont analogues à ceux de
Photuris ou
IKE (section
4.2.1). Le message ClientHello de la section
7.4.1.2 du RFC 5246 y gagne un champ :
opaque cookie<0..32>; // NOUVEAU
Évidemment, ils ne protègent pas contre un attaquant qui utilise sa vraie adresse IP, puisque celui-ci pourra lire la réponse.
OpenSSL gère DTLS depuis la version 0.9.8
(on peut aussi consulter le site Web du
développeur). Un exemple d'utilisation se trouve dans http://linux.softpedia.com/get/Security/DTLS-Client-Server-Example-19026.shtml. Il
me reste à inclure ce protocole dans echoping. GnuTLS
a un support DTLS plus récent.
Et les nouveautés de DTLS 1.2 par rapport au 1.0 du RFC 4347 ? (Il n'y a pas eu de DTLS 1.1.) Elles sont résumées dans la section 8. La principale nouveauté est que DTLS est désormais défini par rapport à TLS 1.2 et non plus 1.0. Cela a notamment permis d'inclure les numéros de séquence explicites de TLS 1.1, nécessaires contre l'attaque BEAST (section 4.1.2.1). Une autre nouveauté est la section 4.1.2.7 qui discute le traitement des paquets invalides. Contrairement à TLS, DTLS peut fonctionner en présence de tels paquets, avec une sémantique proche de celle d'UDP : les laisser tomber et attendre que l'application se débrouille (en demandant leur réémission ou bien en passant à autre chose). Enfin, d'autres clarifications ont été apportées, par exemple à la détection de la PMTU ou bien à l'enregistrement dans les registres IANA.
Une très bonne description de la conception de Datagram TLS et des choix qui ont été faits lors de sa mise au point, se trouve dans l'article The Design and Implementation of Datagram TLS, écrit par les auteurs du RFC. C'est une lecture très recommandée.
L'article seul
RFC 6471: Overview of Email DNS-Based List (DNSBL) Best Practice
Date de publication du RFC : Janvier 2011
Auteur(s) du RFC : C. Lewis (Nortel
Networks), M. Sergeant (Symantec Corporation), J. Levine (Taughannock Networks)
Pour information
Première rédaction de cet article le 19 janvier 2012
En raison de l'importance du problème du spam (et d'autres comportements tout aussi nuisibles), un grand nombre de sites utilisent des listes noires des gens avec qui on ne veut pas communiquer (DNSBL pour DNS-based Black List). Ces listes sont souvent distribuées via le DNS, et gérées par des organismes très divers, dont le niveau de sérieux et d'honnêteté est très variable. La question étant très polémique, documenter le comportement attendu de ces organismes n'a pas été une mince affaire. Ce RFC 6471 décrit donc ce qu'on espère d'un gérant de DNSBL.
Rien ne dit qu'il sera suivi, bien sûr. Mais l'espoir est que ce document serve à faire évoluer les choses dans le bon sens. À noter que le groupe en charge de ce RFC, l'Anti-Spam Research Group de l'IRTF, n'a pas toujours réussi à se mettre d'accord sur le comportement idéal de la DNSBL. Dans ces cas, ce RFC 6471 se contente d'indiquer des recommandations sur la forme (« le gérant de DNSBL devrait documenter ce qu'il fait » si le RFC ne peut pas dire ce qui devrait être fait). La section 1.4 rappelle d'ailleurs que les règles de l'IRTF n'imposent pas de consensus au sein du groupe avant publication. À noter que ce RFC ne parle pas de protocole, les questions purement techniques étant traitées dans le RFC 5782.
Le sujet est tellement polémique que je ne vais pas forcément me contenter d'un compte-rendu neutre, objectif et ennuyeux de ce RFC et que je risque de glisser quelques opinions personnelles, pour lesquelles je demande l'indulgence de mes lecteurs. C'est que les DNSBL sont un marécage de gens bizarres, de racketteurs (« pour être retiré de notre liste, il faut payer »), d'éradicateurs (« nous avons mis les trois-quarts de l'Afrique en liste noire ») et de quelques personnes sérieuses. Le groupe ASRG représente plutôt le point de vue des éradicateurs (« dans le doute, on filtre »).
La section 1 du RFC rappelle ce qu'est une DNSBL et comment elle fonctionne. Les détails techniques du fonctionnement de ce service sont exposés dans le RFC 5782. L'idée est de publier dans le DNS les noms de domaine des méchants, ou bien les adresses IP de leurs serveurs de messagerie. Le serveur qui reçoit du courrier peut alors, en consultant le DNS (ce qui est simple et rapide), prendre connaissance de la « note » attribuée au domaine ou à l'adresse IP par le gérant de la DNSBL. Sur la base de cette note, il peut alors décider de filtrer, de contrôler plus étroitement, etc. Rappelons-bien que c'est le destinataire qui décide quoi faire du courrier, pas le gérant de la DNSBL, qui se contente de publier une information. Au bout du compte, c'est le gérant du serveur de messagerie de destination qui est responsable de l'usage qu'il fait de cette information. Beaucoup sont irresponsables, et filtrent aveuglément sur la base de listes noires sur lesquelles ils n'ont même pas pris la peine de se renseigner.
Comme le DNS est une technique éprouvée, très fiable et rapide, cet
usage original des DNSBL s'est étendu. On voit aujourd'hui des DNSWL
(listes blanches, désignant ceux qui ont droit à un traitement de
faveur), listes d'URI dont la présence dans un
courrier indique un spam, etc. On voit aussi des changements dans
l'usage de ces listes. Très binaire autrefois (l'adresse IP est
présente dans la liste noire => on rejette le message), il est
devenu plus souple, les résultats d'une recherche dans la liste noire
étant souvent un facteur de décision parmi d'autres
(SpamAssassin fonctionne ainsi). Poursuivant
cette idée d'utiliser le DNS pour récupérer de l'information, on voit
aussi des services de géolocalisation utilisant
le DNS et d'autres encore plus techniques (je me sers beaucoup du
domaine aspath.routeviews.org de Route Views, qui permet de
récupérer les informations de routage d'une
adresse). Enfin, les listes distribuées par le DNS sont désormais
utilisées pour bien d'autres choses que le courrier, par exemple pour
du contrôle d'accès à des serveurs IRC ou des
formulaires Web. Bref, on peut tout faire avec le DNS, qui a cessé il y bien
longtemps d'être uniquement un service qui « traduit des noms de domaine en
adresses IP ».
Quelles sont les DNSBL aujourd'hui ? Il y a de tout, certaines sont privées, gérées par une organisation pour son besoin propre, d'autres publiques et gratuites, d'autres payantes (beaucoup de DNSBL sont gratuites en dessous d'un certain seuil d'utilisation et payantes ensuite). On estime qu'il existe plus de 700 listes publiques, la plus ancienne ayant été créée en 1997. À cette époque, les spammeurs utilisaient leurs propres machines et c'est en grande partie en raison des DNSBL, qui distribuaient rapidement les adresses de ces machines, que les spammeurs sont passés à d'autres tactiques (comme les relais de courrier ouverts), tactiques à lesquelles les DNSBL ont dû s'adapter.
Il n'y a pas que le statut juridique et administratif qui différencient les DNSBL actuelles. Elles se différencient également par leurs politiques (comment une entrée est-elle ajoutée à la base et, plus important, comment elle est retirée) et, comme le note pudiquement le RFC, les DNSBL se différencient aussi par le niveau d'honnêteté de leurs responsables.
Justement, cette politique (qui va être mis dans la liste noire, sur quels critères ?) est un point de controverse permanent. Des cow-boys qui vous blacklistent un /20 entier parce qu'une adresse a envoyé un spam, aux gens sérieux qui prennent beaucoup de temps et d'effort avant d'ajouter une adresse à la base, il y a un large spectre d'opinions. Ce RFC 6471 n'essaie pas de trancher entre ces opinions. Il ne dit pas quelle est la bonne politique, simplement que le gérant de la DNSBL doit documenter ses critères d'inclusion et d'exclusion, et faire ensuite réellement ce qu'il annonce (ce qui est très loin d'être le cas). C'est ensuite à l'utilisateur de la DNSBL (l'administrateur d'un serveur de messagerie qui décide d'interroger cette base avant d'accepter un message) de s'informer et de s'assurer que la politique de la DNSBL lui convient.
La section 1.2 fournit une bonne check-list pour ledit utilisateur, sous forme d'une série de questions à se poser avant d'utiliser une DNSBL. Par exemple (entre parenthèses, une étude de l'application de cette check-list à Spamhaus, pour sa liste SBL) :
- Est-ce que les politiques d'inclusion et d'exclusion suivies par la liste sont nettement marquées sur son site Web ? Sont-elles claires ? (Pour la SBL, la réponse est oui, pour l'inclusion et l'exclusion.)
- Existe-t-il une évaluation indépendante de cette liste, permettant de comparer la théorie et la pratique ? (Je n'en sais rien, pour la SBL.)
- Qu'en pensent vos pairs, les collègues qui travaillent dans des conditions analogues aux vôtres ? Comme le note justement le RFC, les DNSBL baignent souvent dans un climat de rude controverse. Il faut bien vérifier que les opinions sur une liste sont formulées par des gens qui s'y connaissent, et pas par Jean-Kevin Boulet qui crie bien fort « Ouais, cette liste est super, marche trop bien ». (La SBL est une des listes les plus utilisées et Spamhaus une organisation ancienne et appréciée.)
Il faut en outre réviser ces questions de temps en temps, les listes évoluent et plus d'une a cessé tout fonctionnement.
Le RFC enfonce le clou à plusieurs reprises : c'est
l'utilisateur qui est responsable, au final, pas la
DNSBL. Certes, c'est un plaidoyer pour les gérants de DNSBL
(« ce n'est pas nous qui filtrons », remarque courante des DNSBL face aux contestations) mais cela reflète la
réalité. Filtrer avec une DNSBL, c'est sous-traiter une partie
de sa sécurité, c'est confier les décisions à d'autres (la section 4
revient sur ce point et rappelle que des DNSBL ont déjà listé
0/0 c'est-à-dire tout l'Internet). Il est donc
crucial d'évaluer les sous-traitants. Le
postmaster responsable
comprend ce point : la DNSBL exprime une opinion, mais c'est lui qui
décide d'agir sur la base de cette opinion.
Bref, quels sont les conseils effectifs de ce RFC 6471 ? Ils commencent en section 2. D'abord, la transparence de l'offre. La DNSBL doit écrire noir sur blanc quels sont les critères pour être mis dans la liste noire et quels sont ceux pour être enlevés. Par exemple, une liste qui s'appuie sur un pot de miel peut avoir comme critère d'ajout « On ajoute toute adresse IP qui a envoyé au moins trois messages dans une semaine aux adresses du pot de miel » et comme critère de retrait « On retire toute adresse qui n'a rien écrit au pot de miel depuis deux mois ». Cette politique doit ensuite être suivie rigoureusement et honnêtement. Dans la jungle des DNSBL, on a déjà vu des gérants de liste qui ajoutaient à la liste noire les adresses IP des gens qui les critiquaient (spite listing)... Il y a des tas de politiques raisonnables, l'important est de se tenir à celle publiée. Si on prétend gérer une liste de relais de courrier ouverts, on ne doit pas y mettre des adresses IP pour une autre raison, même en rapport avec le spam.
La transparence n'empêche pas des politiques dingues, mais ouvertement assumées par le gérant de la liste. Un bel exemple est chez UCEprotect, qui menace directement les critiques « Should you want to contact us, you should keep this in mind and behave rationally and calmly in order not to aggravate your situation. [...] Applying legal action or other pressure against us will result in your IP address and/or your network range being listed in our database. ».
À noter que cette règle de transparence n'impose pas de donner tous les détails. Par exemple, l'opérateur de la liste ne va évidemment pas publier les adresses du pot de miel, cela détruirait complètement son efficacité.
Ensuite, la traçabilité. La DNSBL devrait maintenir un historique des ajouts et retraits, avec les raisons, et publier cet historique. Là encore, l'historique publié peut être expurgé mais il doit contenir suffisamment d'informations pour qu'un utilisateur (ou l'administrateur d'une machine listée dans la liste noire) puisse comprendre pourquoi. Si on prend (un peu au hasard), la liste CBL, on trouve juste : « IP Address X.Y.Z.170 is listed in the CBL. It appears to be infected with a spam sending trojan or proxy. It was last detected at 2011-12-17 12:00 GMT (+/- 30 minutes), approximately 4 hours ago. », ce qui est un peu court.
Beaucoup de gérants de DNSBL sont du genre « éradicateur » et n'hésitent pas devant les dommages collatéraux. Le RFC dit d'ailleurs franchement qu'on ne fait pas d'omelette sans casser d'œufs. Ainsi, il arrive que des listes répondent pour des adresses qui n'ont pas eu de comportement malveillant mais font partie du même préfixe (mettre dans la liste tout un /28 lorsqu'une seule adresse IPv4 de ce /28 a mal agi, par exemple). Le RFC recommande que cette pratique d'élargissement soit clairement documentée.
L'entrée dans la liste est une chose. Mais, avec la plupart des DNSBL, les problèmes sont encore pires pour sortir de la liste. Même quand l'entrée est correctement faite, et à juste titre, on peut avoir des difficultés incroyables pour se faire rayer de la liste. Par exemple, une machine Windows devient un zombie, crache du spam à tout va, et se retrouve « noirlistée », ce qui est normal. Ensuite, l'administrateur système prend les choses en main, reformate le disque, installe NetBSD à la place, et va tenter de « délister » la machine, désormais propre. Avec la plupart des DNSBL, il aura un mal fou. Être enregistré dans une liste est facile, la quitter est très très dur. C'est le même problème lorsqu'une organisation disparait et que ses adresses IP sont récupérées par une autre, qui va s'apercevoir, mais trop tard, que le RIR lui a passé des adresses plombées par une mauvaise réputation.
Le RFC demande donc que les gérants de liste changent de perspective. Au lieu de considérer le retrait comme une opération en soi, toute la liste devrait être considérée comme temporaire et la sortie devrait être automatique au bout d'un moment.
Quelle durée avant cette expiration automatique ? Cela dépend de comment est constituée la liste. Si elle est faite manuellement, sur la base d'informations relativement statiques, comme les allocations de préfixes IP, alors les durées de vie peuvent être longues. Si la détection est automatique (par exemple une liste noire de relais HTTP ouverts), alors une durée de vie très courte est plus raisonnable. Ainsi, la machine dont la configuration a été corrigée disparaîtra vite de la liste et la machine qui rechute sera vite réadmise dans la liste. Dans tous les cas, le RFC demande que la politique d'expiration soit elle aussi publiée. Des informations comme « dernière vérification le tant » sont très précieuses pour évaluer la qualité d'une entrée de la base.
Autre bonne pratique, la fourniture d'un canal privé pour demander le retrait d'une entrée dans la base. Il est nécessaire qu'un tel canal soit disponible. Cela peut être aussi simple qu'une adresse de courrier ou qu'un formulaire Web. Mais, en tout cas, une DNSBL ne devrait pas exiger de discussion publique de la demande de retrait. (Oui, certaines le font, comme forme de punition des administrateurs systèmes qui ont fait preuve de négligence, et laissé leur machine être utilisée pour le spam.)
Et, bien sûr, la DNSBL doit fournir un canal de communication qui
ne soit pas lui-même bloqué par la DNSBL... Si l'administrateur de
192.0.2.25 veut demander le retrait de cette
adresse de la liste, et que le canal des demandes de retrait est une
adresse de courrier, sur un serveur qui utilise la DNSBL, on se
retrouverait dans une situation très kafkaïenne. Bien sûr, ces adresses de demande de
retrait reçoivent beaucoup de spam mais le filtrage qui les protège
devrait être très prudent, pour ne pas rejeter des demandes
légitimes.
Les réponses à ces demandes de retrait devraient être raisonnablement rapides. Le RFC suggère deux jours (et sept au grand maximum).
Certaines DNSBL n'acceptent de demandes de retrait de la liste noire que lorsqu'il y a eu une forme d'authentification que le demandeur est bien en charge de l'adresse en question (vérification de l'adresse de courrier dans les bases des RIR, par exemple). Cette pratique est déconseillée car une telle authentification est souvent très difficile à fournir dans l'Internet d'aujourd'hui.
Le RFC recommande même de sérieusement envisager la possibilité de retirer automatiquement les adresses incriminées, sur simple requête (politique dite « pas de question » car on ne demande rien au demandeur). Si l'inscription dans la liste est le résultat d'un test automatique, l'adresse IP « coupable » sera très vite remise, de toute façon. Si on craint une guerre d'ajout/retrait dans la base, il suffit de mettre une limitation au rythme des requêtes (par exemple, deux retraits maximum en vingt-quatre heures) ou de détecter ces guerres et de verrouiller alors l'adresse dans la base. Une telle politique « pas de question » permet de corriger très vite les erreurs dans la base, et ne diminue pas sensiblement l'efficacité globale de la DNSBL (qui ne dépend pas de quelques adresses). Enfin, cette politique permet de désamorcer les (nombreux) conflits entre les gérants de la DNSBL et les responsables des adresses noirlistées.
On l'a vu, ce RFC ne veut pas trancher la question de savoir si une politique d'ajout dans la liste est correcte ou pas. Par contre, la liste des bonnes pratiques demande qu'il y ait symétrie entre la politique d'ajout et celle de retrait. Normalement, si une adresse est ajoutée pour une raison X, et que X cesse d'être vrai, l'adresse devrait être retirée. Par exemple, si une DNSBL stocke les adresses IP des relais de courrier ouverts, elle devrait retirer les adresses qui ne sont plus de tels relais (parce que l'administrateur a réparé la configuration). Cette recommandation du RFC va à l'encontre de la pratique de certaines DNSBL de punir les gérants des machines en question, en demandant une autocritique publique, voire carrément de l'argent, pour être délisté.
Enfin, dernière bonne pratique dans la section 2, cette question du paiement. Le RFC explique qu'il est normal qu'une DNSBL fasse payer ses clients pour y accéder (la définition d'une DNSBL commerciale, après tout). Mais faire payer les administrateurs système, responsables des adresses listées, est, comme le dit le RFC avec euphémisme « proche du racket ». Pour convaincre les administrateurs de listes noires que cette pratique devrait être abandonnée, le RFC note que, même lorsqu'elle est faite avec les meilleures intentions du monde, elle est susceptible de déclencher des réactions négatives, et de mettre en péril le principe même des DNSBL.
Les points traités dans la section 2 étaients de nature plutôt
politique. La section 3 touche plutôt aux questions
techniques. Quelles sont les bonnes pratiques opérationnelles ? Il y
en a plusieurs, par exemple l'importance de disposer d'un ensemble de
serveurs de noms suffisant pour faire face à la charge. Il s'agit non
seulement de la charge normale, mais également de celle, bien plus
élevée, qui surviendra lors d'une dDoS (les
spammeurs n'ont pas le sens de l'humour et les attaques par déni de
service contre les listes noires ne sont pas rares). Pour être sûr que
le nom de domaine « principal » de l'opérateur (mettons
spamhaus.org) soit à l'écart des problèmes, le
RFC conseille que la DNSBL soit dans un sous-domaine délégué, avec ses
propres serveurs de noms :
% dig NS sbl-xbl.spamhaus.org ; <<>> DiG 9.7.3 <<>> NS sbl-xbl.spamhaus.org ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16914 ;; flags: qr rd ra; QUERY: 1, ANSWER: 21, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;sbl-xbl.spamhaus.org. IN NS ;; ANSWER SECTION: sbl-xbl.spamhaus.org. 86400 IN NS b.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS 5.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS 0.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS k.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS d.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS o.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS x.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS h.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS l.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS 2.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS 4.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS i.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS 3.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS r.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS f.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS g.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS t.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS 8.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS q.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS 1.ns.spamhaus.org. sbl-xbl.spamhaus.org. 86400 IN NS c.ns.spamhaus.org. ;; Query time: 341 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Sat Dec 17 17:40:40 2011 ;; MSG SIZE rcvd: 388
Un des problèmes récurrents avec les DNSBL est que la plupart des
administrateurs système ne testent jamais si leur configuration est
toujours bonne, et lorsqu'une DNSBL cesse son activité, elle continue
à être interrogée. Pour éviter cela, certaines DNSBL en fin de vie ont
choisi la solution radicale de lister la totalité de l'Internet. À
chaque adresse, elles répondaient qu'elle était listée. Pour détecter
rapidement ce genre de problèmes, le RFC rappelle qu'on peut tester
127.0.0.1. Cette adresse ne devrait jamais
apparaître dans une DNSBL. Si elle le fait, c'est que la liste a un
gros problème et ne devrait plus être utilisée. Si la liste comprend
des noms de domaines et pas des adresses IP, c'est le domaine
invalid qui joue ce rôle. (Le RFC 5782 donne des détails sur ces conventions. D'autres
domaines réservés par le RFC 2606 peuvent être
utiles comme test.)
Néanmoins, la première responsabilité est celle du gérant de la liste : s'il arrête le service, il doit le faire proprement (prévenir sur son site Web au moins un mois à l'avance, etc) et surtout pas en se mettant soudain à lister tout l'Internet dans sa base. Il est important de garder le nom de domaine actif : si celui-ci était libéré, un méchant pourrait l'enregistrer et monter une fausse liste noire, qui serait utilisée par tous les clients distraits qui ont oublié de changer leur configuration.
Du point de vue technique, la méthode recommandée est de changer les serveurs de noms de la zone où se trouve la liste pour des adresses IP qui ne peuvent pas exister, par exemple celles réservées pour la documentation (RFC 5735). Ainsi, on est sûr que le domaine ne marchera pas et qu'aucun enregistrement ne sera retourné, montrant bien aux clients que la liste n'est plus en service. Par exemple, avec la syntaxe standard des fichiers de zone DNS :
dnsbl.example.com. 604800 IN NS u1.example.com.
604800 IN NS u2.example.com.
u1.example.com. 604800 IN A 192.0.2.1
u2.example.com. 604800 IN A 192.0.2.2
Le RFC a aussi des recommandations opérationnelles à faire pour le cas spécifiques des DNSBL qui listent les adresses IP de machines présentant une certaine vulnérabilité (relais SMTP ou HTTP ouverts, par exemple), détectée par un programme. D'abord, le programme ne devrait pas tester des machines préventivement (la question est controversée : certains défendent la légitimité de balayages systématiques de tout l'Internet, d'autres ne sont pas d'accord). Il ne devrait le faire que si quelque chose (un rapport d'envoi de spam, par exemple) attire l'attention sur des machines spécifiques.
Ensuite, une fois une adresse listée, les tests périodiques qui visent à évaluer si la machine est toujours vulnérable devraient être relativement espacés (pas plus d'une fois par jour). Et, bien sûr, le test ne doit pas avoir d'effet négatif (pas d'envoi de grandes quantités de données, par exemple).
Les logiciels qui sont derrière la DNSBL, comme tous les logiciels, ont des bogues. Et les utilisateurs d'une DNSBL peuvent faire des erreurs de configuration. Il est donc important que tout soit vérifié et testé et que des procédures soient en place pour faire face aux problèmes (par exemple, le gérant de la DNSBL doit être prêt à vider manuellement la base ou une partie de celle-ci, si une erreur entraîne le listage erronée d'adresses IP).
À noter que le Wikipédia anglophone a un intéressant tableau de comparaison des DNSBL.
Pour résumer, on a vu que ce RFC résultait d'un compromis entre ceux qui voulaient des listes noires opérant comme elles le voulaient et ceux qui souhaitaient les rendre un peu plus responsables. Le compromis a été de donner peu de recommandations concrètes excepté de documenter les choix effectués. À l'heure actuelle, le moins qu'on puisse dire est que la plupart des listes noires ne font même pas ce minimum...
L'article seul
RFC 6522: The Multipart/Report Media Type for the Reporting of Mail System Administrative Messages
Date de publication du RFC : Janvier 2012
Auteur(s) du RFC : M. Kucherawy (Cloudmark)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 17 janvier 2012
Un court RFC pour un format simple : le type
MIME multipart/report
permet d'envoyer des rapports structurés au sujet d'un message. Ce RFC est la
dernière version de la norme sur
multipart/report, marquée par un léger allègement
des règles d'utilisation.
Pas de grands changements, sinon. L'idée de base de
multipart/report est de pouvoir faire des
messages à propos des messages. Par exemple, un avis de non-remise
(RFC 3461) est un message disant qu'un message
n'a pu être remis, et intégrant le message originel. Un rapport
ARF (RFC 5965) est un message disant qu'un message est
abusif (spam, par exemple) et intégrant
également le message originel. D'où l'idée d'avoir un type commun pour
tous ces « messages sur les messages », et c'est
multipart/report, normalisé dans notre RFC 6522, qui succède au RFC 3462 (qui
succédait lui-même au RFC 1892). Ce type
multipart/report est très largement utilisé
depuis longtemps, et par de nombreux logiciels.
La présentation détaillée du type « rapport » figure en section 3. Voici d'abord un exemple d'un tel message, ici pour indiquer une non-délivrance, généré par un MTA Postfix :
Date: Wed, 11 Jan 2012 13:45:44 +0000 (UTC)
From: MAILER-DAEMON@bortzmeyer.org (Mail Delivery System)
Subject: Undelivered Mail Returned to Sender
To: bortzmeyer@nic.fr
Auto-Submitted: auto-replied
MIME-Version: 1.0
Content-Type: multipart/report; report-type=delivery-status;
boundary="154CD3AC2C.1326289544/mail.bortzmeyer.org"
Content-Transfer-Encoding: 8bit
This is a MIME-encapsulated message.
--154CD3AC2C.1326289544/mail.bortzmeyer.org
Content-Description: Notification
Content-Type: text/plain; charset=us-ascii
[La première partie du rapport, lisible par un humain.]
This is the mail system at host mail.bortzmeyer.org.
I'm sorry to have to inform you that your message could not
be delivered to one or more recipients. It's attached below.
--154CD3AC2C.1326289544/mail.bortzmeyer.org
Content-Description: Delivery report
Content-Type: message/delivery-status
[La deuxième partie du rapport, conçue pour être analysée par des
programmes.]
Reporting-MTA: dns; mail.bortzmeyer.org
X-Postfix-Queue-ID: 154CD3AC2C
X-Postfix-Sender: rfc822; bortzmeyer@nic.fr
Arrival-Date: Wed, 11 Jan 2012 12:24:50 +0000 (UTC)
Final-Recipient: rfc822; nothere@nowhere.example
Action: failed
Status: 5.4.4
Diagnostic-Code: X-Postfix; Host or domain name not found. Name service error
for name=nowhere.example type=AAAA: Host not found
--154CD3AC2C.1326289544/mail.bortzmeyer.org
Content-Description: Undelivered Message
Content-Type: message/rfc822
Content-Transfer-Encoding: 8bit
[Puis le message originel, dans la troisième partie du rapport.]
Notez le paramètre report-type, qui a ici la
valeur delivery-status. (Cela serait
feedback-report pour du ARF.)
Notez surtout le découpage en trois parties (la dernière est optionnelle) :
- Une partie qui contient un message en format libre et en langue naturelle.
- Une partie structurée (dans l'exemple ci-dessus, avec la syntaxe
message/delivery-statusdu RFC 3464). - Le message originel.
Si on trouve le message originel trop gros, la troisième partie
peut se composer uniquement des en-têtes du message. Elle aura alors
le type message/rfc822-headers (section 4 de
notre RFC).
Naturellement, les messages multipart/report
ne sont pas plus authentifiés que les autres messages : il faut donc
éviter d'agir automatiquement lors de leur réception (section 7).
Le seul changement de fond depuis le RFC 3462
concerne une ancienne restriction :
multipart/report ne pouvait apparaître qu'au plus
haut niveau du message (rappelez-vous que MIME
est récursif, un message MIME peut contenir d'autres messages
MIME). Cela interdisait, par exemple, de faire un
multipart/report au sujet d'un
multipart/report. Il semble bien que personne ne
mettait en œuvre cette restriction et ce nouveau RFC 6522 l'a donc supprimé. (Voir section 1.)
L'article seul
RFC 6462: Report from the Internet Privacy Workshop
Date de publication du RFC : Janvier 2012
Auteur(s) du RFC : A. Cooper (Center for Democracy and Technology)
Pour information
Première rédaction de cet article le 17 janvier 2012
Après une très longue période d'ignorance quasi-complète des problèmes de protection de la vie privée, l'IETF a évolué et on n'entend plus gère ses participants écarter d'un revers de main ces questions, en disant « Nous, on fait juste de la technique, tout ça, c'est de la politique, ça ne nous concerne pas. » De nos jours, au contraire, la prise de conscience est nette et l'IETF a désormais une activité structurée autour de la notion de vie privée, activité qui se traduit par un programme dédié et une liste de diffusion. Faut-il aller plus loin ? C'était une des questions posées lors de l'Atelier « Internet Privacy Workshop 2010 », atelier qui s'est tenu du 8 au 9 décembre 2010 à Cambridge et dont ce RFC est le compte-rendu. (L'auteure travaille pour une ONG qui lutte pour les libertés sur l'Internet.)
Pas de décisions à attendre tout de suite, donc. On en est à un stade d'exploration. L'atelier de Cambridge était coorganisé par l'IETF, le MIT et le W3C pour voir ce que les SDO pouvaient faire en terme de protection de la vie privée. On est loin d'un accord unanime (et le résumé du RFC dit bien qu'aucun des organismes présents n'a de position officielle sur ces questions) mais au moins quelques pistes de travail émergent. L'IETF étant chargé de produire des spécifications concrètes, une bonne partie de l'atelier a porté, non pas sur des discours généraux sur la vie privée, mais sur les tâches envisageables.
La question de la protection de la vie privée sur l'Internet est immense et couvre beaucoup de domaines très différents. Certains problèmes apparaissent de manière récurrente, le fingerprinting (la détermination d'une identité à partir de traces numériques qui n'étaient a priori pas conçues pour cela), la fuite d'informations, la difficulté à distinguer les partenaires primaires (à qui on a donné directement de l'information) des tiers (qui ont eu de l'information sans qu'on interagisse explicitement avec eux), le manque d'informations des utilisateurs sur les avantages et inconvénients d'une meilleure protection, etc. (Notons que le RFC mentionne les faiblesses des utilisateurs, mais pas l'aggressivité avec laquelle les capitalistes collectent et revendent de l'information privée.) Le RFC note que la vie privée n'est pas un absolu et que, par exemple, la protéger peut influer négativement sur l'utilisabilité d'un service. Bref, il y a pour l'instant davantage de défis que de solutions (section 1).
Plus précisement, de quoi a-t-on parlé pendant l'atelier (les supports présentés sont disponibles en ligne) ? La section 2 résume tout cela. D'abord, une discussion technique (section 2.1). Commençons par l'adresse IP. Elle donne souvent bien trop d'informations (il est trivial de remonter d'une adresse IP à un utilisateur, ce qui explique pourquoi elle est considérée comme une donnée personnelle). Certains protocoles offrent des risques particuliers comme certaines techniques de mobilité, qui permettent de suivre un utilisateur à la trace.
C'est d'ailleurs dans le cas de l'adresse IP qu'on trouve un des rares exemples d'une technologie IETF spécialement développée pour répondre à des craintes concernant la vie privée : les adresses IP temporaires du RFC 4941, qui sont partiellement aléatoires, et regénérées de temps en temps, pour éviter le suivi de l'utilisateur.
Autre mécanisme bien connu pour empêcher le suivi par l'adresse IP : le routage en oignon, surtout connu grâce à Tor. Ce service route les paquets à travers plusieurs nœuds distincts, chiffrant leur contenu à chaque fois. Seuls les premiers et derniers nœuds voient le message en clair. Observer le trafic ne permet de trouver, au pire, que l'origine (si on espionne au début), ou bien que la destination (si on espionne à la fin).
Mais Tor n'est pas parfait : le contenu des messages peut donner des indications sur l'origine (cookies, par exemple, pour une requête HTTP). Si on veut vraiment être anonyme, utiliser Tor ne suffit pas : il faut aussi couper bien des choses sur son navigateur, à commencer par Flash et JavaScript, et certains peuvent considérer cela comme un problème. Comme souvent en sécurité, rien n'est gratuit. Protéger sa vie privée peut nécessiter des sacrifices.
Les participants à l'atelier ont également planché sur le mode private browsing qu'offrent certains navigateurs. C'est un mode dans lequel le navigateur ne stocke pas localement les identifiants de session (comme les cookies). Son but n'est pas de protéger contre un suivi de l'utilisateur par le serveur mais de protéger contre d'autres utilisateurs du même poste client. L'expérience indique que beaucoup d'utilisateurs ne comprennent pas la différence et croient que le private browsing leur procure une navigation sans flicage. C'est un exemple d'un autre problème courant en sécurité : les utilisateurs ne comprennent pas les risques.
Enfin, dernière discussion technique, sur les propositions Do Not Track, qui permettent à un utilisateur d'indiquer clairement aux sites Web qu'il ne veut pas être suivi à la trace. Pour l'instant, ce ne sont que des propositions, sans accord technique ou politique.
Après ces discussions techniques, l'atelier s'est demandé quel
pouvait être le rôle des SDO dans cette
histoire. Dans le passé, il n'y a pas eu d'appproche systématique de
la vie privée dans les protocoles IETF. Cela ne veut pas dire que rien
n'a été fait : certains RFC ont été entièrement conçus pour résoudre
un problème de vie privée (comme le RFC 4941
pour IPv6 ou le RFC 3323 pour
SIP). Certains services particulièrement
sensibles ont bénéficié de davantage d'efforts, par exemple
l'indication de présence (RFC 2778) ou bien sûr
la géolocalisation (RFC 3693). Un protocole
comme ALTO (RFC 5693) a
également vu ses problèmes de vie privée étudiés dès le début. Le cas
d'ALTO est difficile car le protocole est d'autant plus efficace que
l'utilisateur révèle beaucoup de choses sur lui (en demandant à
l'oracle « Je veux télécharger
le fichier Serge Reggiani - Les Loups Sont Entrés
Dans Paris.mp3 de taille 4732679 octets et de
MD5
2d79e0d7e25c8c10c9879cefcef4102a et voici la
liste complète des pairs BitTorrent qui l'ont »
par rapport au plus discret mais moins efficace
« je voudrais savoir si le pair 2001:db8:1::1 est
plus ou moins rapide que le
2001:db8:67e::34a:1ff3 »).
La protection de la vie privée a pas mal de rapports avec la sécurité (la section 8 discute du rapprochement de ces deux concepts) et la sécurité est un bon exemple d'une préoccupation transverse (elle affecte tous les protocoles) qui était largement ignorée au début de l'IETF et a vu son rôle de plus en plus pris en compte. L'IETF a ainsi bâti une culture de la sécurité. Ainsi, depuis le RFC 1543, tous les RFC doivent inclure une section Security Considerations pour exposer l'analyse sécurité du protocole. Elle peut être vide mais elle doit être présente avec une mention expliquant pourquoi les auteurs du RFC ont consciemment laissé la section vide. Cette obligation bureaucratique n'est évidemment pas suffisante et l'IETF a ajouté une direction de la sécurité, un RFC dédié pour guider les auteurs de RFC (RFC 3552), de nombreux tutoriels pour auteurs de RFC aux réunions physiques, etc. La même méthode peut-elle être appliquée à la vie privée ? (Le RFC 2828, qui rassemble la terminologie IETF sur la sécurité, contient des termes liés à la protection de la vie privée.)
Le W3C a également procédé à un effort semblable. Un de ses premiers grands efforts a été P3P, un mécanisme pour permettre aux sites Web d'exprimer de manière formelle leur politique de gestion des données personnelles. P3P est un langage riche, qui permet d'indiquer des politiques complexes. Mais il a été très peu adopté en pratique. Opinion personnelle : comme pour la neutralité du réseau, tout le monde prétend que l'information du consommateur résout tous les problèmes, qu'il suffit d'annoncer sa politique et que le marché choisira. Mais personne ne veut le faire réellement. P3P permettait d'exprimer les politiques de protection des données personnelles en des termes simples et non ambigus et c'était évidemment intolérable pour les e-commerçants, qui préfèrent infliger à l'utilisateur des privacy policies de vingt pages écrites en langage légal.
Après ce tour d'horizon du travail effectué et des acteurs en place, l'atelier s'est attaqué aux défis (section 3). Quels sont les grands problèmes à résoudre ?
D'abord, la trop grande facilité à identifier un utilisateur donné
par les informations que donne le logiciel qu'il utilise : adresse IP,
champs de la requête HTTP comme
User-Agent: ou
Accept-Language:, cookies
(RFC 6265), et plein
d'autres paramètres font qu'on peut identifier un utilisateur ou une
machine bien trop souvent. C'est ce
qu'on nomme le fingerprinting et c'est bien
démontré par le Panopticlick.
Comme dans toute réunion de geeks, les participants à l'atelier ont évidemment pris plaisir à explorer en détail des techniques de fingerprinting particulièrement rigolotes comme d'envoyer du code JavaScript qui va transmettre au serveur la liste des polices installées dans le navigateur (elle est souvent unique).
Capturés par un simple script WSGI sur le
serveur (testez-le en https://www.bortzmeyer.org/apps/env
; les variables d'environnement dont le nom commence par
HTTP_ sont les en-têtes de la requête HTTP), voici une partie de ce
qu'envoie un Firefox typique, depuis une machine
Ubuntu :
HTTP_ACCEPT_CHARSET: ISO-8859-1,utf-8;q=0.7,*;q=0.7 HTTP_USER_AGENT: Mozilla/5.0 (Ubuntu; X11; Linux i686; rv:8.0) Gecko/20100101 Firefox/8.0 HTTP_ACCEPT: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 HTTP_ACCEPT_LANGUAGE: en-us,en;q=0.5 HTTP_ACCEPT_ENCODING: gzip, deflate
Cette combinaison d'options et de numéros de version est probablement unique, ou en tout cas rare sur le Web, et identifie donc assez bien une machine (sans même avoir besoin de cookie). Une telle combinaison a par exemple déjà été utilisée pour confondre un agresseur agissant pour le compte de l'industrie du divertissement.
Ces informations n'étaient pas prévues pour cet usage (par exemple, les adresses IP étaient prévues pour router les paquets, pas pour identifier une machine ou une personne). Mais remplacer ces informations par des mécanismes qui empêchent ou limitent le fingerprinting ne sera pas trivial. D'autant plus que pas mal de gens se sont habitués à les utiliser dans ce but et qu'il sera de plus en plus difficile de revenir en arrière. Ainsi, le fingerprinting est souvent utilisé pour détecter des fraudes, ou pour fournir du contenu adapté (et le RFC, qui est gentil et évite les sujets qui fâchent, ne cite pas les applications répressives du fingerprinting, pour identifier l'auteur d'un délit abominable, comme de partager des œuvres d'art). Il y aura probablement beaucoup de désaccords sur le compromis entre vie privée et service « amélioré » grâce au fingerprinting.
Au minimum, l'IETF et le W3C vont essayer de documenter les points qui, dans les protocoles courants (TCP, HTTP, SIP), facilitent le fingerprinting.
Un problème proche est celui de la fuite d'informations (section 3.2) : des
mécanismes conçus pour des motifs tout à fait honorables transmettent
néanmoins plus d'information qu'ils ne le devraient. Ainsi, le champ
Referer: dans une requête HTTP permet de savoir
d'où vient un visiteur Web (ce qui est utile) mais révèle également
des choses comme les ID de session (lorsqu'ils sont mis dans l'URL), les termes de recherche
utilisés, etc. Voici un exemple vu dans le
journal de mon blog (les informations trop sensibles ont été modifiées). On voit les termes de recherche utilisés dans Google :
192.0.2.70 - - [16/Dec/2011:17:08:53 +0000] "GET /1383.html HTTP/1.0" 200 3291 "http://www.google.fr/url?sa=t&rct=j&q=aide+rfc+dns...
Le contrôle sur les données privées repose normalement sur la possibilité de distinguer les récepteurs primaires des données des tiers (section 3.3). Ainsi, si je me connecte sur SeenThis, ce site est récepteur primaire de mes données et je ne suis pas surpris qu'il récolte des informations sur moi. Il s'agissait d'un choix conscient et informé de ma part. Mais l'examen du code source de ce site montre qu'il fait appel au service Google Analytics et donc, sans l'avoir demandé, sans même le savoir, je transmets également des données à Google, un tiers qui peut alors récolter des données sans que je l'ai choisi.
Le cas ci-dessus est relativement simple. Mais dans le Web d'aujourd'hui, on trouve d'autres cas où la distinction entre destinataire primaire et tiers est moins évidente. Un utilisateur qui met un widget amusant sur une page peut le considérer comme primaire alors que le navigateur (par exemple pour retourner les cookies) le traitera comme un tiers, et l'inverse existe également.
Enfin, le dernier grand défi est celui de l'information de l'utilisateur (section 3.4). La plupart du temps, le flicage de ce dernier se fait discrètement, sans qu'il se rende compte de l'immense quantité de données qui est collectée à son insu. La seule information disponible est composée de « policy statements » écrits dans un jargon juridique délibérement confus, conçu pour protéger le patron de l'entreprise et pas pour informer l'utilisateur. Le RFC note que des informations cruciales (comme la durée de conservation des données) en sont souvent absentes. Opinion personnelle : c'est pour cela que les mécanismes du marché - l'entreprise publie sa politique et le consommateur est libre de continuer ou pas - ne fonctionnent pas et qu'il faut des lois comme la loi I&L. Le marché suppose une information parfaite et des acteurs symétriques, ce qui n'est pas du tout le cas ici.
Le problème est d'autant plus sérieux que, si le technicien se doute bien de tout ce que le site Web peut apprendre sur son visiteur, l'utilisateur ordinaire n'a souvent pas pas idée de la quantité de traces numériques qu'il laisse.
Il est donc nécessaire de travailler à une meilleure information. P3P était un bon effort dans ce sens. Mais comme c'était un langage riche, il était difficile de traduire une politique P3P de manière claire pour l'utilisateur. Les efforts actuels portent plutôt sur un nombre limité d'icônes qui pourraient devenir largement connues (un panneau « danger, ici votre vie privée est menacée »...) Un exemple est le projet Common Terms.
La section 4 étudie ensuite les défis liés au déploiement des bonnes pratiques. D'abord (section 4.1), le problème que les mesures techniques sont génériques, alors que les menaces effectives sont souvent spécifiques à un contexte donné. La vie privée n'est pas un concept binaire. Il y a d'autres stades que « complètement privé » et « public ». Mais il est très difficile de traiter cette complexité par des mesures techniques.
Par exemple, les solutions situées en couche 3 comme les adresses IP temporaires du RFC 4941 résolvent certes certains problèmes (le serveur qui reconnaît un visiteur récurrent uniquement sur son adresse) mais ne protège pas du tout contre un FAI ou un État qui essaie d'associer une adresse à un utilisateur. Selon la menace envisagée, ces adresses temporaires sont donc efficaces... ou pas du tout.
Il ne faut donc pas évaluer les solutions techniques en leur demandant de résoudre tous les problèmes possibles. Il ne serait pas raisonnable pour l'IETF d'exiger de ses protocoles qu'ils empêchent complètement toute atteinte à la vie privée. Il faut plutôt dire clairement quels sont les risques et qui (le programmeur, l'utilisateur, la loi) est chargé de les traiter.
Autre problème délicat de déploiement de solutions de protection de la vie privée : la tension entre l'utilisabilité et la protection (section 4.2). Comme souvent en matière de sécurité, il va falloir faire des choix douloureux. Les tenants du Roi Marché ont beau jeu de faire remarquer que les utilisateurs, lorsqu'ils ont le choix, vont vers les services qui violent le plus leur vie privée (Facebook, Google, etc) en échange d'applications sympas et qui brillent. La principale faiblesse de cet argument est qu'il suppose que l'utilisateur est parfaitement conscient des risques, et de ce qui peut lui arriver, ce qui est très optimiste.
Un bon exemple de ce compromis est donné par Tor. Celui-ci fournit une bonne protection mais complique et ralentit (en raison du nombre d'étapes de routage) la navigation. Résultat, il reste peu utilisé, en bonne partie parce que les utilisateurs font un calcul coût/bénéfice (peu informé, d'ailleurs) et décident que leur vie privée n'est pas assez importante pour justifier ce coût.
Avec Tor, le coût de la protection est élevé. Mais même des mesures
bien plus légères ont des coûts. Supprimer l'en-tête
Referer: des requêtes HTTP améliore certainement
la protection. Mais certains sites Web proposent une vue différente
selon la valeur de ce champ et, en le supprimant, on se prive de ce
service. Reste à savoir qui va décider du compromis, et sur quelles informations : comment exposer
ce choix (« Do not send Referer headers ») dans une
interface utilisateur, de manière qui permette un choix raisonné ?
Alors même que l'effet de ce choix va dépendre des sites (dans la
plupart des cas, le Referer: est inutile au
client Web.)
Ces problèmes d'utilisabilité sont cruciaux. Le RFC cite l'exemple de SIP, où un mécanisme normalisé de protection des requêtes contre l'écoute existe (RFC 3261, section 23) mais il n'est pas utilisé en pratique car trop contraignant.
Dernier obstacle au déploiement de techniques respectant davantage la vie privée, la difficulté à trouver les bonnes motivations (section 4.3). Les différents acteurs impliqués ne feront pas d'effort s'ils n'ont pas une motivation pour cela. Cela peut être la crainte du gendarme, la conviction que cela leur apportera plus de clients ou simplement le souci d'utiliser les meilleures techniques (ces trois motivations sont rarement présentes en même temps). La crainte du gendarme est discutée en section 4.3.1. Traditionnellement, beaucoup de services proposés sur l'Internet sont gratuits et la possibilité de vendre les données personnelles des utilisateurs est l'une des voies les plus évidentes pour gagner de l'argent. Comme l'illustre un dessin célèbre, « soit l'utilisateur est le client, soit il est la marchandise ». Dans un tel contexte, il n'y a pas de motivation économique à respecter la vie privée, bien au contraire. Les diverses autorités de régulation ont fini par froncer les sourcils, ce qui a mené les fournisseurs de ces services à publier de longues politiques d'utilisation des données sur leur site. Comme le note le RFC, ces politiques, écrites sans effort pédagogique, visent plutôt à protéger le fournisseur du service qu'à informer correctement et complètement l'utilisateur. Le RFC note à juste titre que ces problèmes ne se corrigeront pas tout seuls et qu'une approche régulatrice est nécessaire (cf. le rapport de la FTC de 2010 sur l'importance d'avoir des politiques publiques mieux écrites).
Le RFC soutient que cette tendance doit continuer : sans forte pression des régulateurs, de la loi, le patronat Internet va toujours essayer de concéder le moins de vie privée possible aux utilisateurs. Un exemple d'une telle pression est la directive européenne qui parle des cookies, indiquant qu'ils ne doivent pas être utilisés sans le consentement des utilisateurs.
Le cas de P3P, déjà cité, est un bon exemple de ce problème des motivations (section 4.3.2). L'idée de base était que les logiciels du côté du client allaient pouvoir lire et comprendre les politiques de protection de la vie privée et automatiquement réagir (par exemple en n'envoyant pas de cookies aux sites dont la politique était trop peu protectrice de la vie privée). C'est une idée très états-unienne : les acteurs libres s'informent mutuellement de leurs pratiques et décident ensuite librement, en adultes majeurs, informés et consentants, de poursuivre ou pas la relation. Si on croit qu'il y a égalité (d'information, de moyens de traitement, de pouvoir) entre le patron de Facebook et M. Michu, utilisateur de Facebook, cela peut marcher. Sinon, on préfère l'approche européenne où certaines pratiques sont interdites, qu'il y ait ou pas consentement de la marchandise, pardon, de l'utilisateur.
Donc, P3P permettait d'automatiser ce processus d'information et de décision. Microsoft a pris une décision importante en choisissant, dans Internet Explorer 6, de n'envoyer des cookies aux tiers que si ceux-ci avaient une politique P3P. Comme n'importe quelle politique, même outrageusement prédatrice, était acceptée par Internet Explorer, la plupart des sites Web se sont pliés à cette décision et ont copié/collé la première politique P3P qu'ils trouvaient (souvent l'exemple pris sur le site du W3C). Cette expérience menée grâce à Internet Explorer (les autres auteurs de navigateurs n'ont fait aucun effort et n'ont jamais intégré P3P) a permis de mettre en évidence une limite de P3P : le site qui publie sa politique peut mentir (« Nous ne vendons pas vos données personnelles »). Aucun mécanisme légal ou autre ne l'en empêche. (Voir par exemple l'article « Token Attempt: The Misrepresentation of Website Privacy Policies through the Misuse of P3P Compact Policy Tokens ».)
Le cas illustre bien la question des motivations : pour qu'ils reçoivent des cookies d'Internet Explorer, les sites devaient publier du P3P. Alors, ils l'ont fait (motivation technique). Il n'y avait pas de pression légale ou régulatrice pour dire la vérité dans ces politiques P3P, alors ils ne l'ont pas fait (pas de motivation légale). Les clients (en partie à cause de l'absence de gestion de P3P par les navigateurs) ne donnaient pas la préférence aux sites publiant du bon P3P, alors les sites n'ont pas cherché à l'améliorer (pas de motivation commerciale).
Il sera intéressant de voir si cela marche mieux en sens inverse : pour la géolocalisation, le RFC 4119 et le RFC 6280 fonctionnent de manière opposée à P3P, en permettant aux utilisateurs d'indiquer leurs choix en matière de protection des données personnelles. Ils sont normalement plus motivés que les entreprises capitalistes pour cela.
Bien sûr, on est ici très loin des questions techniques que se posent normalement les SDO. Mais la compréhension de ces enjeux économiques et légaux est nécessaire, si on veut que les futures techniques de protection de la vie privée aient plus de succès que P3P.
Conclusion, en section 5, quel est le plan d'action pour les SDO ?
Pour l'IETF, la synthèse est que cela va être compliqué. L'IETF
normalise des protocoles dans les couches
basses, sans présupposer d'un usage particulier, alors que
les menaces pour la vie privée sont très dépendantes du contexte. Il
va donc être difficile de trouver des réponses générales, dans les
protocoles IETF. Cela ne veut pas dire qu'il ne faut rien faire. Le
travail a déjà commencé autour d'une série de recommandations pour les
auteurs de RFC (rassemblées dans le
Internet-Draft,
draft-morris-privacy-considerations, qui a évolué depuis et a été publié en RFC 6973).
Les participants à l'atelier étaient tous d'accord sur la nécessité de poursuivre également le travail technique, par exemple sur les leçons apprises de Tor, ainsi que sur les capacités (plus fortes que prévues) de fingerprinting des protocoles existants.
Et le W3C ? Il est probablement mieux placé pour améliorer la protection de la vie privée, puisque les normes du W3C sont plus proches de l'utilisateur, et utilisées dans un contexte plus spécifique. Contrairement à l'IETF, le W3C peut se restreindre au Web.
L'annexe A résume quels sont les documents bruts disponibles pour ceux qui veulent approfondir leur connaissance des travaux de cet atelier :
- Les minutes des discussions,
- Les présentations,
- Et les article soumis (l'annexe C du RFC en contient la liste) comme le « Thoughts on Adding "Privacy Considerations" to Internet Drafts » d'Alissa Cooper (l'auteure du RFC) et John Morris.
L'article seul
Le TLD du Gabon en panne depuis quatre mois
Première rédaction de cet article le 12 janvier 2012
Depuis septembre 2011, le TLD du
Gabon,
.ga est en panne
quasi-complète. Quelle est la panne exacte ? Pourquoi cette panne ?
Que fait le gouvernement ? Quelles sont les conséquences pour le reste
du DNS ?
La panne a commencé le 13 septembre mais ses conséquences n'ont pas
été visibles tout de suite. Le serveur maître à
Libreville a commencé par refuser à ses
esclaves les transferts de zone (RFC 5936). Le
champ « expiration » dans l'enregistrement SOA
de .ga étant de 42 jours,
les esclaves ont fini par renoncer le 27 octobre, répondant
SERVFAIL (Server Failure) :
% dig @b.hosting.nic.fr. SOA ga. ... ;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 48352 ...
Cela concerne les deux esclaves extérieurs, un à l'AFNIC et un au RIPE-NCC. Et les deux serveurs situés dans le pays ? Leur comportement est plus bizarre. Souvent, ils ne répondent pas (et ce n'est pas un problème réseau, puisqu'un ping fonctionne) :
% ping -c 3 nyali.inet.ga PING nyali.inet.ga (217.77.71.33) 56(84) bytes of data. 64 bytes from nyali.inet.ga (217.77.71.33): icmp_req=1 ttl=241 time=366 ms 64 bytes from nyali.inet.ga (217.77.71.33): icmp_req=2 ttl=241 time=365 ms 64 bytes from nyali.inet.ga (217.77.71.33): icmp_req=3 ttl=241 time=377 ms --- nyali.inet.ga ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 1999ms rtt min/avg/max/mdev = 365.277/369.877/377.792/5.664 ms % dig @nyali.inet.ga. SOA ga. ; <<>> DiG 9.7.3 <<>> @nyali.inet.ga. SOA ga. ; (1 server found) ;; global options: +cmd ;; connection timed out; no servers could be reached
Plus rigolo, la réponse peut dépendre du type de données demandé :
% dig @nyali.inet.ga. ga. SOA ; <<>> DiG 9.7.3 <<>> @nyali.inet.ga. ga. SOA ; (1 server found) ;; global options: +cmd ;; connection timed out; no servers could be reached % dig @nyali.inet.ga. ga. NS ; <<>> DiG 9.7.3 <<>> @nyali.inet.ga. ga. NS ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16007 ;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 6 ;; QUESTION SECTION: ;ga. IN NS ;; ANSWER SECTION: ga. 15900 IN NS ns-ga.ripe.net. ga. 15900 IN NS nyali.inet.ga. ga. 15900 IN NS b.hosting.nic.fr. ga. 15900 IN NS ogooue.inet.ga. ...
Lorsqu'ils répondent, le code de retour renvoyé par les serveurs est
FORMERR si on a essayé avec EDNS0 (RFC 2671), ce qui est pourtant le comportement normal
d'un résolveur DNS (rappelez-vous que dig, par
défaut, n'avait pas le même comportement qu'un vrai résolveur, il n'activait
pas EDNS0 ; ce comportement par défaut a changé récemment) :
% dig +bufsize=1400 @nyali.inet.ga. ga. ANY ; <<>> DiG 9.7.3 <<>> +bufsize=1400 @nyali.inet.ga. ga. ANY ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: FORMERR, id: 4032 ;; flags: qr rd ra; QUERY: 0, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0 ;; Query time: 370 msec ;; SERVER: 217.77.71.33#53(217.77.71.33) ;; WHEN: Thu Jan 12 11:13:11 2012 ;; MSG SIZE rcvd: 12 % dig @nyali.inet.ga. ga. ANY ; <<>> DiG 9.7.3 <<>> @nyali.inet.ga. ga. ANY ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 32644 ;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 4, ADDITIONAL: 6 ;; QUESTION SECTION: ;ga. IN ANY ;; ANSWER SECTION: ga. 7189 IN NS ogooue.inet.ga. ga. 7189 IN NS ns-ga.ripe.net. ga. 7189 IN NS nyali.inet.ga. ga. 7189 IN NS b.hosting.nic.fr. ...
Comme il n'y a plus guère de logiciels serveurs qui ne gèrent pas EDNS0, douze ans après sa normalisation, le plus probable est qu'il y a devant le serveur DNS une middlebox boguée (pléonasme, vu le niveau de qualité du logiciel de la plupart de ces équipements). C'est sans doute elle qui répond aux ping, et massacre les questions et/ou les réponses DNS.
Si on ne met pas EDNS0, le serveur répond, mais sans le bit AA
(Authoritative Answer), ce qui est anormal pour un
serveur faisant autorité (vues les données renvoyées en réponse à une requête ANY, il est probable que ce serveur ne contienne plus les données de la zone .ga). Donc, on peut dans certains cas, certains jours, avoir une
réponse des serveurs de .ga mais uniquement si on
les interroge sans EDNS0. Certains résolveurs se rabattent
automatiquement sur le vieux DNS, sans EDNS0, lorsqu'ils ne reçoivent
pas de réponse. Pour le cas où ils
reçoivent FORMERR, le RFC 2671, section 5.3 dit qu'ils doivent en effet réessayer, ce que Christophe Deleuze a testé rapidement :
il semble que BIND9 répète la requête sans EDNS0, et cache l'info (n'utilise plus
EDNS0 avec ce serveur dans les requêtes suivantes). Unbound répète la requête sans EDNS0 mais semble ne pas cacher l'info,
car il retente avec EDNS0 à la prochaine requête.
Donc, dans beaucoup de cas,
.ga est quasiment inutilisable.
Que s'est-il passé ? Sans être sur place, et sans nouvelles des gérants du TLD, on ne peut que faire des hypothèses. Le plus probable est que le vrai serveur est en panne et que la middlebox, placée devant (une mauvaise architecture, mais passons), n'assure plus qu'une partie des fonctions (je sais, cela n'explique pas tout). Le fait d'avoir plusieurs serveurs DNS faisant autorité n'aide pas lorsque le maître est panne trop longtemps (les 42 jours de grâce étant écoulés).
Pourquoi personne ne répare-t-il ? Le problème aurait dû être
détecté par les administrateurs de .ga,
Gabon Télécom. Sinon, il a été signalé par
courrier électronique en décembre 2011 (et pas
seulement à des adresses en .ga, évidemment), et
par fax, pour augmenter les
chances de réussite. Aucune réaction. Il faut bien se rappeler deux
choses : les bases de données des administrateurs de TLD (ici, la
base IANA sur
.GA) sont maintenues par les administrateurs eux-mêmes. S'ils
sont empêchés, ou bien irresponsables, la base va dériver petit à
petit et les informations (noms, numéros, etc) devenir dépassées. Et,
d'autre part, la réparation nécessite que quelqu'un agisse (les pannes
ne se réparent pas seules). Le Gabon n'est pas
un état de droit et une des conséquences de ce système politique est
que personne ne prend d'initiatives (c'est trop risqué). Donc, tous
les officiels restent les bras ballants. Le problème n'est pas
d'argent (le Gabon est un pays relativement riche, grâce au pétrole),
ni la compétence (des tas de gens compétents sur l'Internet sont prêts
à aider leurs collègues gabonais, si ceux-ci répondaient) mais de
responsabiité.
Et pour le reste de l'arbre du DNS, quelles conséquences ? À peu près aucune. La structure non-centralisée du DNS fait que la panne d'un TLD n'affecte pas les autres. Contrairement à ce que prétend l'ICANN (qui justifie ainsi les tarifs colossaux de ses nouveaux TLD), un TLD n'a rien de particulier. C'est un domaine comme un autre ; s'il est en panne, cela ne gène que ses utilisateurs.
À noter qu'un problème du même genre était survenu au Tchad.
Merci à Ed Lewis pour son premier signalement du problème, grâce à son script magique de suivi des TLD, et à Jean-Philippe Pick pour des informations supplémentaires.
L'article seul
Changer de serveur résolveur DNS facilement
Première rédaction de cet article le 8 janvier 2012
Dernière mise à jour le 9 janvier 2012
La sortie, le 30 décembre 2011, du décret n° 2011-2122 relatif aux modalités d'arrêt de l'accès à une activité d'offre de paris ou de jeux d'argent et de hasard en ligne non autorisée, décret qui permet à l'ARJEL de demander le blocage d'un site de paris ou de jeux en ligne, a ramené sur le devant de la scène la question du blocage via le DNS. En effet, le décret dit explicitement « Lorsque l'arrêt de l'accès à une offre de paris ou de jeux d'argent et de hasard en ligne non autorisée a été ordonné, [...] les [FAI] procèdent à cet arrêt en utilisant le protocole de blocage [sic] par nom de domaine (DNS) ». Il existe plusieurs façons de comprendre cette phrase. Si le FAI décide de mettre en œuvre cet arrêt en configurant ses résolveurs DNS pour mentir, un moyen simple de contourner cette censure sera alors pour les utilisateurs de changer de résolveur DNS. Est-ce simple ? Est-ce réaliste ? Des logiciels peuvent-ils aider ?
D'abord, un petit rappel de vocabulaire, car j'ai déjà lu pas mal
d'articles sur le sujet, où l'auteur est plein de bonne volonté et
veut vraiment aider les autres à contourner la censure, mais où il ne
connait pas vraiment le DNS et où il utilise un
vocabulaire approximatif, voire complètement faux. Il y a
deux sortes de serveurs DNS : la première, ce
sont les
serveurs faisant autorité, qui sont ceux qui
contiennent les données (par exemple, les serveurs de
DENIC ont la liste de tous les noms de domaine en
.de, des serveurs de la société NS14
font autorité pour le domaine shr-project.org, etc).
L'ARJEL ou un autre censeur ne peut pas
toujours agir sur eux car ils peuvent être situés en dehors de la
juridiction française.
Et il y a les résolveurs DNS. Ils ne connaissent au démarrage aucune donnée et servent uniquement de relais et de caches (stockage temporaire de données). Ils sont typiquement gérés par votre FAI ou bien par le service informatique de votre boîte. Ce sont eux qui sont indiqués à la machine cliente (en général par le protocole DHCP), qui les utilisera à chaque fois qu'elle aura une question (c'est-à-dire pas moins d'une centaine de fois pour la seule page d'accueil de CNN).
Si on veut censurer en France l'accès à un site de jeu en ligne, par le protocole DNS, c'est un bon endroit pour attaquer. Il en existe d'autres, mais que je garde pour d'autres articles. Modifier le comportement du résolveur est facile (les logiciels ont déjà ce qu'il faut pour cela) et certains FAI le faisaient déjà pour des raisons financières.
Mais c'est aussi une technique de censure relativement facile à contourner : l'utilisateur de la machine cliente peut changer la configuration de son système pour utiliser d'autres résolveurs que ceux de son FAI, par exemple ceux de Telecomix, qui promettent de ne pas censurer. C'est cette technique qui est discutée dans cet article.
Si vous lisez les forums un peu au hasard, vous trouverez souvent
des allusions à cette méthode, de la part de geeks
vantards qui affirment bien haut « rien à foutre de leur censure à la
con, je change mon DNS car je suis un top-eXpeRz et je surfe sans
filtrage ». La réalité est plus complexe. Prenons l'exemple d'une
machine Ubuntu (il y a peu près les mêmes
problèmes sur Windows ou
Mac OS X). La liste des résolveurs DNS utilisés figure dans le fichier /etc/resolv.conf. Suffit-il
d'éditer ce fichier, comme on le lit souvent (et bien à tort) ?
- Déjà, il faut rappeler au frimeur de forum que la grande majorité des utilisateurs de l'Internet n'ont même pas idée qu'ils peuvent choisir (et je ne parle pas seulement du résolveur DNS, mais aussi du navigateur, du système d'exploitation, etc). Si on veut que la solution soit accessible à tout le monde, pas seulement à quelques geeks auto-proclamés, elle doit être simple.
- Même sur Ubuntu, tout le monde ne sait pas éditer un fichier système (surtout qu'il faut être root).
- Le frimeur à grande gueule qui écrit sur
forum.blaireaux.com/index.phpdécouvrira vite, s'il essayait ce qu'il prêche, qu'éditerresolv.confn'est pas la bonne méthode, car le client DHCP effacera ses modifications à la prochaine connexion. Il faut modifier la configuration dudit client DHCP (cela varie énormément selon le système et le logiciel installé ; sur ma Debian, en ce moment, c'est/etc/resolvconf/resolv.conf.d/head). - Sur certains systèmes d'exploitation, changer un réglage aussi banal est très difficile. Par exemple, sur Android (merci à Aissen pour les informations), les serveurs DNS utilisés sur le réseau mobile ne sont pas modifiables et, sur le Wi-Fi, on ne peut les changer que si on coupe DHCP. Comme la publicité fait tout son possible pour migrer les utilisateurs vers les accès Internet sur téléphone mobile, bien plus contrôlés et moins libres, l'avenir est inquiétant.
- Une fois qu'on sait quel fichier éditer et comment, reste la question, que mettre dans ce fichier ? Il existe plusieurs résolveurs publics situés en dehors du pouvoir de l'ARJEL, et le plus souvent cité est OpenDNS. Intéressant paradoxe : pour échapper à la censure et garder sa liberté de citoyen, on utilise un résolveur menteur, qui pratique lui-même la censure (et parfois se trompe). Utiliser OpenDNS, c'est se jeter dans le lac pour éviter d'être mouillé par la pluie. Sans compter leurs autres pratiques, comme l'exploitation des données personnelles (le résolveur DNS utilisé sait tout de vous... chaque page Web visitée lui envoie au moins une requête...). À noter qu'on peut avoir aussi un résolveur local à sa machine, ce point est traité un peu plus loin.
À noter que tous les cas ne peuvent pas être couverts dans un article. Par exemple, on peut aussi envisager de changer les réglages DNS sur la box si elle sert de relais DNS pour le réseau local vers les « vrais » résolveurs.
Pour résoudre tous ces problèmes, on peut écrire des documentations (exemples à la fin de cet article). Mais la plupart des utilisateurs auront du mal à les suivre et je pense donc que la bonne solution est la disponibiité d'un logiciel qui automatise tout cela. Quel serait le cahier des charges d'un tel logiciel ?
- Tourne sur les systèmes utilisés par M. Toutlemonde (Windows, Android, Ubuntu, etc).
- Indépendant de l'application (le DNS ne sert pas que pour le Web) et marche donc avec tous les services (c'est pourquoi je n'ai pas discuté dans cet article des extensions Firefox comme MAFIAAFire ou DeSOPA - ce dernier ayant en outre un mode de fonctionnement très bizarre).
- Simple à utiliser.
- Vient avec une liste pré-définie de bons résolveurs. Je préférerais que cette liste n'inclue pas les résolveurs menteurs comme ceux d'OpenDNS. En tout cas, il est impératif qu'on puisse ajouter les résolveurs de son choix.
- M. Toutlemonde va certainement avoir des problèmes pour décider s'il
doit se servir de « Telecomix » ou « Comodo » ou « Level-3 » pour ne
citer que quelque uns des résolveurs publics les plus fameux. Il
faudrait donc que le logiciel teste ces résolveurs automatiquement,
pour leurs performances, bien sûr (la plupart des articles trouvés sur
le Web sur le thème « comment choisir son résolveur DNS ? » ne
prennent en compte que leur vitesse, pas leur sincérité, contrairement
à cet article) mais aussi pour leur obéissance à la censure. Le
logiciel devrait venir avec une liste de domaines peut-être censurés
(
wikileaks.org, etc) et tester les réponses des résolveurs candidats. Ce n'est pas facile à faire car il faut aussi connaître les bonnes réponses, et elles peuvent changer. Peut-être le logiciel devrait-il interroger des résolveurs de confiance pour avoir cette information ? Le fait de tester pourrait même permettre de choisir automatiquement un résolveur, ce qui serait certainement meilleur pour M. Toutlemonde. - Autre cas vicieux (merci à Mathieu Goessens), celui des résolveurs DNS qui, en violation des bonnes pratiques, contiennent des données spécifiques qu'on ne trouve pas dans le DNS public. C'est le cas de pas mal de portails captifs de hotspots, par exemple. dnssec-trigger gère ce problème en ayant un mode spécial, manuellement activé, « Hotspot sign-on ». Mais il y a pire : certains FAI (notamment Orange) utilisent des données non publiques pour certains services réservés aux clients (VoIP, serveur SMTP de soumission, etc) donc une solution qui gère la connexion initiale ne suffit pas. La seule solution dans ce cas est d'avoir un mécanisme d'aiguillage qui envoie les requêtes pour certains domaines à certains résolveurs.
Un tel logiciel est vulnérable à un blocage du port
53. Si cette mesure se répand, il faudra aussi que le logiciel
teste s'il peut atteindre des résolveurs publics et des serveurs faisant autorité, ou bien s'il
faut passer à d'autres méthodes comme de
tunneler le DNS sur TLS,
port 443, comme le permet déjà Unbound, dans sa
version de développement. D'autres attaques suivront alors (par
exemple des FAI qui annonceront les adresses
8.8.8.8 et 8.8.4.4 sur leur
propre réseau, pour se faire passer pour Google
Public DNS, profitant du fait que ce service n'est pas
authentifié).
Compte-tenu de ce cahier des charges, quels sont les logiciels qui conviennent aujourd'hui ? Il n'en existe aparemment qu'un seul, DNS Jumper (je ne suis pas sûr d'avoir mis un lien vers le site officiel, ce logiciel n'a pas de références bien précises et, son source n'étant pas distribué, on peut être inquiet de ce qu'il fait). DNS Jumper tourne sur Windows, assure les quatre premières fonctions de mon cahier des charges mais pas l'avant-dernière : il ne vérifie pas que le résolveur est digne de confiance. Il est décrit, par exemple, dans « Easily Switch Between 16 DNS Servers with DNS Jumper » (l'article est un peu ancien, le logiciel s'est perfectionné depuis), ou, en français, dans « DNS Jumper - Changez rapidement de serveurs DNS ».
Les autres logiciels restent à écrire (un truc comme DNS Helper ne compte pas, puisqu'il ne permet de changer... que pour les DNS de Google). Mais que les censeurs ne se réjouissent pas, les logiciels vont vite sortir, écrire un tel programme n'est pas un exploit technique, et la demande est forte, avec le décret ARJEL déja cité pour la France, SOPA pour les États-Unis, etc.
Sur le problème général de changer manuellement ses résolveurs DNS, un bon article est « How to Change DNS Server » de Remah (Windows seulement). Pour Mac OS, un bon article est « Disabling DNS servers from DHCP ».
Quelques petits détails techniques pour finir : on peut
parfaitement installer un serveur DNS résolveur sur sa propre
machine (enfin, sur un ordinateur portable, pas sur un
smartphone). La résolution DNS sera alors
entièrement sous le contrôle d'un logiciel qu'on gère, fournissant
ainsi le maximum de sécurité. Le processus
n'est pas très compliqué sur Unix, ni même sur
Windows (merci à Gils Gayraud et Mathieu Bouchonnet pour leur aide sur Windows). On peut le rendre encore plus simple avec des logiciels
astucieux comme dnssec-trigger, qui ne teste
pas la censure (son but est tout autre) mais pourrait servir de point
de départ à un paquetage simple d'installation, vraiment utilisable
par M. Toutlemonde (ce n'est pas encore le cas). Par contre, un tel
résolveur local a des conséquences négatives sur l'infrastructure du
DNS : comme il n'y a plus de cache partagé (avec le résolveur/cache du
FAI, une requête pour www.bortzmeyer.org reste en
mémoire et bénéficie à tous les clients du FAI),
les serveurs faisant autorité verront leur charge s'accroître.
Pour éviter cet inconvénient, une des solutions serait pour le résolveur local de faire suivre les requêtes aux résolveurs du FAI (de tels résolveurs sont nommés forwarders). Mais cela implique de détecter lorsque le résolveur du FAI ment, pour le court-circuiter dans ce cas. DNSSEC fournit une piste intéressante pour cela mais, début 2012, les résolveurs ayant cette fonction forwarder (BIND et Unbound) n'ont pas de tel service de détection et de contournement.
Pire encore, on peut combiner le résolveur local (ou le remplacer)
avec des fichiers statiques locaux (/etc/hosts
sur Unix, C:\WINDOWS\system32\drivers\etc\hosts
sur Windows) mais la maintenance de tels fichiers serait un
cauchemar.
Cela ne veut pas dire que cela n'arrivera pas : dans ce maelstrom d'attaques et de contre-attaques, les solutions les plus mauvaises seront certainement déployées par certains acteurs et le futur est sombre pour le système de résolution de noms.
L'article seul
Exposé « Peut-on se passer de moteurs de recherche ? » à l'install-party du CRANS
Première rédaction de cet article le 6 janvier 2012
Dernière mise à jour le 14 janvier 2012
Le samedi 14 janvier, le CRANS organisait une install party à l'ENS à Cachan. J'y ai fait un exposé sur le thème « Peut-on se passer de moteurs de recherche ? ». Toutes les informations sont disponibles sur le site officiel (la vidéo devrait y apparaître un de ces jours).
L'introduction est « Aujourd'hui, beaucoup d'utilisateurs dépendent entièrement d'un moteur de recherche pour toute navigation sur l'Internet. On entend même des enseignants de collège dire aux élèves « Pour aller sur Wikipédia, tapez "wikipedia" dans Google » Pourquoi est-ce une mauvaise idée ? Quels sont les inconvénients des moteurs de recherche ? Que se passe-t-il lorsqu'une panne ou la censure modifie le résultat d'une recherche ? Quels sont les points forts des moteurs de recherche, où ils sont utiles ? À quoi sert le DNS et pourquoi est-ce important de comprendre les noms de domaine ? »
Les transparents sont disponibles :
- Version adaptée à l'écran,
- Version adaptée à l'impression,
- Source en LaTeX/Beamer.
Et, si vous n'avez pas pu venir, ce n'est pas grave, Norman a fait une excellente vidéo sur le sujet, « Maintenant, j'ai Google » (également disponible chez Google).
L'article seul
Amer ou mire ?
Première rédaction de cet article le 3 janvier 2012
Lorsqu'on effectue une mesure active sur un réseau informatique, un agent de mesure vise une cible distante connue, et le résultat de ce test nous servira à en déduire les performances du réseau. Comment nommer cette cible ? En français, les deux termes les plus courants semblent amer et mire.
Un exemple d'un tel test est l'utilisation d'une simple commande ping :
% ping -c 3 www.arcep.fr PING www.arcep.fr (81.200.177.80) 56(84) bytes of data. 64 bytes from bastet.publicis-technology.com (81.200.177.80): icmp_req=1 ttl=51 time=74.8 ms 64 bytes from bastet.publicis-technology.com (81.200.177.80): icmp_req=2 ttl=51 time=70.3 ms 64 bytes from bastet.publicis-technology.com (81.200.177.80): icmp_req=3 ttl=51 time=73.0 ms --- www.arcep.fr ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2003ms rtt min/avg/max/mdev = 70.399/72.760/74.808/1.826 ms
Ici, ma machine, l'agent de mesure local, teste le réseau avec l'amer
ou mire www.arcep.fr. Un exemple plus
sophistiqué ? Le protocole TWAMP du RFC 5357, et de nombreux autres.
Le premier terme, amer, vient de la navigation maritime et désigne normalement un repère fixe et connu, sur lequel l'équipage d'un bateau peut faire des tests. C'est une jolie origine et ça fait penser aux pirates, donc ça embête la HADOPI, ce qui est très bien. C'est le terme privilégié dans ce blog.
Le second mot, mire, vient de la géodésie (et n'a rien à voir avec la mire de l'ORTF). Il est utilisé par exemple par l'ARCEP (voir sa consultation publique lancée fin 2011, question n° 19).
On pourrait sans doute trouver encore d'autres candidats comme balise.
Et en anglais ? Contrairement à ce qui arrive souvent en informatique, la situation n'y est pas meilleure. On trouve parfois beacon mais qui, dans le domaine des réseaux informatiques, désigne plus souvent un système qui émet spontanément (au lieu de simplement répondre à une sollicitation), comme par exemple les beacons BGP du RIPE. Dans les RFC, on trouve souvent simplement target, que je trouve trop militaire, ou bien landmark, qui est quasiment l'équivalent d'amer.
L'article seul
L'ARJEL, ou la censure au service du fric
Première rédaction de cet article le 2 janvier 2012
Si l'ARJEL est moins connue des internautes que l'HADOPI, les gens qui suivent de près l'actualité de l'Internet savent qu'elle est à la pointe de la censure, ayant été la première organisation en France à ordonner le bloquage de sites Web aux FAI. Mais dans quels buts ?
Après l'affaire Stan James, qui avait fait connaître l'ARJEL aux internautes, cette organisation vient de récidiver avec un décret (« n° 2011-2122 du 30 décembre 2011 relatif aux modalités d'arrêt de l'accès à une activité d'offre de paris ou de jeux d'argent et de hasard en ligne non autorisée ») qui impose aux FAI de bloquer l'accès aux sites de jeux d'argent en ligne listés par ladite ARJEL. Sur le moment, les commentateurs ont surtout noté que ce décret était le premier texte de censure à mentionner explicitement le DNS et à l'imposer comme mécanisme de blocage.
Mais cette remarque, quoique factuellement exacte, ne répond pas à la question « pourquoi faut-il bloquer l'accès à ces sites ? ». On le fait pour la pédo-pornographie (loi LOPPSI qui, en théorie, limite la censure à cette raison), ou pour défendre le modèle d'affaires des ayant-trop-de-droits (dans le contexte de la loi HADOPI, même si celle-ci ne mentionne pas explicitement de censure). La pédo-pornographie, c'est grave, aucun doute là-dessus. Même chose sur la baisse des revenus de l'industrie du divertissement. C'est très grave et il faut réprimer impitoyablement ceux qui voudraient partager la culture.
Mais l'ARJEL, qui ne s'occupe pas de pédo-pornographie ou de show business, pourquoi veut-elle censurer ? Parce que les jeux d'argent sont immoraux, avec la pression qu'ils exercent sur les plus faibles, pour les pousser à jeter leur argent en l'air dans des jeux qui ne leur rapportent rien, que des déceptions ? Mais non, voyons, ce n'est pas la raison, puisqu'il existe des jeux légaux. Prendre l'argent dans les poches des plus vulnérables a été pendant longtemps un monopole de la Française des Jeux mais, désormais, d'autres acteurs peuvent participer. À condition de verser une part des revenus de leur sale métier à l'État (pardon, on dit « payer des impôts »). Et c'est là que la censure intervient. Pour protéger le business de ceux qui paient une part à l'État, il faut interdire les autres. Le décret cité plus haut permet donc cette censure.
L'ARJEL fait valoir que les sites de jeux en ligne légaux ne sont pas uniquement légaux parce qu'ils paient mais aussi parce qu'ils respectent certaines obligations, comme d'afficher un petit avertissement « attention, le jeu est dangereux ». Mais c'est un argument très hypocrite : on sait que le jeu est dangereux, mais on gagne de l'argent avec.
À noter que cette extension des impôts via les jeux en ligne fait l'objet d'un fort consensus gauche-droite, la gauche a déjà sa place à l'ARJEL, via la responsable des questions numériques chez François Hollande, qui avait pourtant essayé de cacher son rôle à l'ARJEL (à l'ENA, personne ne l'avait prévenue qu'il était difficile en 2011 de garder secrètes ce genre d'informations ?).
Cet article a été repris par le Monde et par l'Informaticien qui l'ont tous les deux attribué, bien à tort, à mon employeur (qui n'y est pour rien). Apparemment, la même chose arrive à Tristan Nitot donc je ne me plains pas.
L'article seul
Articles des différentes années : 2026 2025 2024 2023 2022 2021 2020 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}