
Les RFC (Request For Comments) sont les documents de référence de l'Internet. Produits par l'IETF pour la plupart, ils spécifient des normes, documentent des expériences, exposent des projets...
Leur gratuité et leur libre distribution ont joué un grand rôle dans le succès de l'Internet, notamment par rapport aux protocoles OSI de l'ISO organisation très fermée et dont les normes coûtent cher.
Je ne tente pas ici de traduire les RFC en français (un projet pour cela existe mais je n'y participe pas, considérant que c'est une mauvaise idée), mais simplement, grâce à une courte introduction en français, de donner envie de lire ces excellents documents. (Au passage, si vous les voulez présentés en italien...)
Le public visé n'est pas le gourou mais l'honnête ingénieur ou l'étudiant.
RFC 8999: Version-Independent Properties of QUIC
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : M. Thomson (Mozilla)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 28 mai 2021
Ce RFC, qui fait partie de la première fournée sur QUIC, décrit les invariants du protocole QUIC, les choses qui ne changeront pas dans les futures versions de QUIC.
Comme tous les protocoles Internet, QUIC doit faire face à l'ossification, cette tendance à rendre les changements impossibles, en raison du nombre de composants du réseau qui refusent tout comportement qu'ils n'attendaient pas, même si c'était une évolution prévue ou en tout cas possible. Une des méthodes pour limiter cette ossification est la documentation d'invariants, des parties du protocole dont on promet qu'elles ne changeront pas dans les futures versions. Tout le reste peut bouger et les équipements comme les middleboxes peuvent donc s'appuyer sur ce RFC pour faire les choses proprement, en sachant ce qui durera longtemps, et ce qui est susceptible d'évoluer.
La section 15 du RFC 9000 explique le principe des versions de QUIC. QUIC est actuellement à la version 1. C'est la seule pour l'instant. Mais si une version 2 (puis 3, puis 4…) apparait un jour, il faudra négocier la version utilisée entre les deux parties (section 6 du RFC 9000). Ces nouvelles versions pourront améliorer le protocole, répondant à des phénomènes qui ne sont pas forcément prévisibles. Par exemple QUIC v1 utilise forcément TLS pour la sécurité (RFC 9001), mais les futures versions pourront peut-être utiliser un autre protocole cryptographique, plus sûr, ou plus rapide. L'expérience de nombreux protocoles IETF est qu'il est difficile de déployer une nouvelle version d'un protocole déjà en place, car il y a toujours des équipements dans le réseau qui faisaient des suppositions sur le protocole, qui ne sont plus vraies avec la nouvelle version (et, souvent même pas avec l'ancienne…) et qui pertuberont, voire couperont la communication. D'où cette idée de documenter les invariants, en indiquant donc clairement que tout ce qui n'est pas invariant… peut changer. Un exemple d'invariant est « A QUIC packet with a long header has the high bit of the first byte set to 1. All other bits in that byte are version specific. ». Actuellement (version 1), le deuxième bit vaut forcément 1 (RFC 9000, section 17.2), mais ce n'est pas un invariant : les autres versions feront peut-être différemmment.
Concevoir des invariants est tout un art. Trop d'invariants et QUIC ne peut plus évoluer. Pas assez d'invariants et ils ne servent plus à rien. Ainsi, il semble difficile de faire un répartiteur de charge qui marche avec toutes les futures versions de QUIC (pas assez d'invariants pour lui).
Et dans les paquets, qu'est-ce qui sera invariant ? (Petit rappel au passage, un datagramme UDP peut contenir plusieurs paquets QUIC.) Il y a deux sortes de paquets, les longs et les courts. (Plus rigoureusement, ceux à en-tête long et ceux à en-tête court.) On les distingue par le premier bit. Tous les autres bits du premier octet sont spécifiques d'une version particulière de QUIC, et ne sont donc pas invariants. Ce premier octet est suivi d'un numéro de version sur 32 bits (aujourd'hui, forcément 1, sauf en cas de négociation de version, non encore spécifiée), puis du connection ID de la destination (attention : longueur variable, dans les paquets longs, il est encodé sous forme longueur puis valeur, cela permettra d'avoir des identificateurs de connexion très longs dans le futur) puis, mais seulement pour les paquets longs, du connection ID de la source. Tout le reste du paquet dépend de la version de QUIC utilisée.
Notez que la longueur des paquets n'étant pas dans les invariants, on ne peut même pas trouver combien il y a de paquets QUIC dans un datagramme de manière indépendante de la version.
L'identificateur de connexion est une donnée opaque : la façon de le choisir pourra varier dans le futur.
Bien sûr, spécifier rigoureusement les invariants n'empêchera pas les middleboxes de tirer des fausses conclusions et, par exemple, de généraliser des comportements de la version 1 de QUIC à toutes les versions ultérieures (section 7 du RFC). L'annexe A donne une liste (sans doute incomplète) des suppositions qu'un observateur pourrait faire mais qui sont erronées. QUIC essaie de réduire ce qu'on peut observer, en chiffrant au maximum, afin de limiter ces suppositions erronées, mais il reste des choses visibles, qui ne sont pas forcément invariantes. Le RFC écrit ces suppositions de manière neutre, en notant qu'elles sont fausses. J'ai préféré rédiger en insistant sur leur fausseté. Donc, rappelez-vous que, notamment dans les futures versions de QUIC :
- QUIC n'utilise pas forcément TLS,
- les paquets longs peuvent apparaitre même après l'établissement de la connexion,
- il n'y aura pas toujours de phase de connexion au début,
- le dernier paquet avant une période de silence n'est pas forcément uniquement un accusé de réception,
- les numéros de paquet ne croissent pas forcément de un à chaque paquet,
- ce n'est pas toujours le client qui parle le premier,
- les connection ID peuvent changer très vite,
- le second bit du premier octet, parfois appelé à tort le « QUIC bit », n'est pas forcément à un, et il avait même été proposé de le faire varier (ce qu'on appelle le graissage, cf. RFC 8701),
- et plusieurs autres points.
À noter que le numéro de version n'apparait que dans les paquets longs. Un programme qui observe des paquets QUIC de versions différentes ne peut donc analyser les paquets courts que s'il a mémorisé les numéros de versions correspondant à chaque connection ID de destination qu'il voit.
Autre point important : il n'y a pas d'invariant qui identifie un paquet QUIC. Pas de nombre magique ou de chose équivalente. Donc, aucun moyen d'être raisonnablement sûr que ce qui passe est du QUIC. C'est bien sûr volontaire, pour augmenter les chances que la neutralité soit respectée. Mais cela peut amener des middleboxes agressives à essayer de deviner si c'est bien du QUIC ou pas, en se trompant. (Le « QUIC bit » n'est évidemment pas une preuve suffisante, il peut s'agir d'un autre protocole où ce bit vaut 1.)
L'article seul
RFC 8998: ShangMi (SM) Cipher Suites for TLS 1.3
Date de publication du RFC : Mars 2021
Auteur(s) du RFC : P. Yang (Ant Group)
Pour information
Première rédaction de cet article le 11 mars 2021
La cryptographie est un outil essentiel pour la sécurité sur les réseaux numériques. N'avoir comme algorithmes de cryptographie que des algorithmes développés à l'étranger peut être jugé dangereux pour la sécurité nationale. Des pays comme la Russie et, bien sûr, les États-Unis, recommandent ou imposent des algorithmes « nationaux ». La Chine s'y met, avec les algorithmes de chiffrement ShangMi (« SM »), dont ce RFC décrit l'utilisation dans TLS.
Comme ces algorithmes sont obligatoires en Chine pour certaines applications (comme c'est le cas de l'algorithme russe Magma décrit dans le RFC 8891), il était nécessaire que TLS (RFC 8446) puisse les utiliser, indépendamment de l'opinion des cryptographes « occidentaux » à leur sujet. Ce RFC traite de deux algorithmes de chiffrement symétrique (« SM4 ») avec chiffrement intègre, une courbe elliptique (« curveSM2 «), un algorithme de condensation (« SM3 »), un algorithme de signature (« SM2 ») utilisant curveSM2 et SM3, et un d'échange de clés fondé sur ECDHE sur SM2. (Au passage, saviez-vous qu'il existe une courbe elliptique française officielle ?)
On notera que les Chinois n'ont pas poussé leurs algorithmes qu'à l'IETF, certains sont aussi normalisés à l'ISO (ISO/IEC 14888-3:2018, ISO/IEC 10118-3:2018 et ISO/IEC 18033-3:2010).
Le RFC ne décrit pas les algorithmes eux-mêmes, uniquement comment les utiliser dans le contexte de TLS 1.3 (RFC 8446). Si vous êtes curieux, les normes chinoises sont :
- Pour l'algorithme de condensation SM3 : Norme GBT.32905-2016.
- Pour l'algorithme de chiffrement symétrique SM4 : Norme GBT.32907-2016.
- Pour l'algorithme de signature SM2 : normes GBT.32918.2-2016 et GBT.32918.5-2016.
Les deux algorithmes de chiffrement symétrique sont désormais dans
le
registre IANA sous les noms de
TLS_SM4_GCM_SM3 et
TLS_SM4_CCM_SM3. L'algorithme de signature,
sm2sig_sm3 est dans le
registre approprié. La courbe elliptique
curveSM2 a été ajoutée
à un autre registre.
Je ne connais pas de mise en œuvre de ces algorithmes dans les bibliothèques TLS habituelles. Si vous avez des informations… Mais Wireshark va bientôt savoir les afficher.
Ah, et si vous vous intéressez à l'Internet en Chine, je vous recommande le livre de Simone Pieranni, Red Mirror.
L'article seul
RFC 8997: Deprecation of TLS 1.1 for Email Submission and Access
Date de publication du RFC : Mars 2021
Auteur(s) du RFC : L. Velvindron (cyberstorm.mu), S. Farrell (Trinity College Dublin)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF uta
Première rédaction de cet article le 24 mars 2021
Dans le cadre général de l'abandon des versions 1.0 et 1.1 du protocole TLS (cf. RFC 8996), ce RFC déclare que ces vieilles versions ne doivent plus être utilisées pour le courrier (mettant ainsi à jour le RFC 8314).
Ce RFC 8314 spécifiait l'usage de TLS pour la soumission et la récupération de courrier. Sa section 4.1 imposait une version minimale de TLS, la 1.1. Cette 1.1 étant officiellement abandonnée pour obsolescence dans le RFC 8996, la version minimale est maintenant la 1.2. C'est tout, ce RFC est simple et court.
L'article seul
RFC 8996: Deprecating TLSv1.0 and TLSv1.1
Date de publication du RFC : Mars 2021
Auteur(s) du RFC : K. Moriarty (Dell EMC), S. Farrell (Trinity College Dublin)
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 24 mars 2021
Dernière mise à jour le 25 mars 2021
Ce RFC est très court, car il s'agit juste de formaliser une évidence : les versions 1.0 et 1.1 du protocole de cryptographie TLS ne devraient plus être utilisées, elles souffrent de diverses failles, notamment de sécurité. Les seules versions de TLS à utiliser sont la 1.2 (recommandée depuis 2008 !) et la 1.3 (publiée en 2018). Ainsi, une bibliothèque TLS pourra retirer tout le code correspondant à ces versions abandonnées, ce qui diminuera les risques (moins de code, moins de bogues).
Que reproche-t-on exactement à ces vieux protocoles (section 1 du RFC) ?
- Ils utilisent des algorithmes de cryptographie dépassés et dangereux, par exemple TLS 1.0 impose de gérer Triple DES, et SHA-1 est utilisé à plusieurs endroits. Un des points les plus problématiques à propos des vieilles versions de TLS est en effet leur dépendance vis-à-vis de cet algorithme de condensation SHA-1. Celui-ci est connu comme vulnérable.
- Ils ne permettent pas d'utiliser les algorithmes modernes, notamment le chiffrement intègre.
- Indépendamment des défauts de ces vieux protocoles, le seul fait d'avoir quatre versions à gérer augmente les risques d'erreur, pouvant mener à des attaques par repli.
- Des développeurs de bibliothèques TLS ont manifesté leur souhait de retirer les vieilles versions de TLS, ce qui implique leur abandon officiel par l'IETF.
- Pour davantage de détails sur les faiblesses reprochées aux vieilles versions de TLS, regardez le rapport SP800-52r2 du NIST ou bien le RFC 7457. S'il existe bien des contournements connus pour certaines de ces vulnérabilités, il est quand même plus simple et plus sûr d'abandonner ces anciennes versions 1.0 et 1.1.
Désormais, la programmeuse ou le programmeur qui veut faire mincir son code en retirant TLS 1.0 et 1.1 peut, si des utilisateurs contestent, s'appuyer sur cette décision de l'IETF. Désormais, la règle est simple : le client ne doit pas proposer TLS 1.0 et 1.1, et s'il le fait le serveur ne doit pas l'accepter. Cela concerne de nombreux RFC, qui mentionnaient 1.0 et 1.1, et tous n'ont pas encore été mis à jour. Ainsi, le RFC 7562 est toujours d'actualité, simplement la mention qu'il fait de TLS 1.1 est réputée supprimée. De même, le RFC 7525, qui résume les bonnes pratiques d'utilisation de TLS doit désormais se lire en oubliant les quelques endroits où il cite encore TLS 1.1. D'autres RFC avaient déjà été abandonnés, comme par exemple le RFC 5101.
Donc, pour résumer les points pratiques de ce RFC (sections 4 et 5) :
- N'utilisez pas TLS 1.0. Le client TLS ne doit pas le
proposer dans son
ClientHello, le serveur TLS ne doit jamais l'accepter. - N'utilisez pas TLS 1.1. Le client TLS
ne doit pas le proposer dans son
ClientHello, le serveur TLS ne doit jamais l'accepter.
Si vous êtes programmeu·r·se, virez le code de TLS 1.0 et 1.1 de vos logiciels. (OpenSSL a prévu de le faire en 2022.) Notez que certains protocoles récents comme Gemini ou DoH (RFC 8484) imposaient déjà TLS 1.2 au minimum.
Comme le note la section 7 du RFC, suivre les recommandations de
sécurité exposées ici va affecter l'interopérabilité : on ne pourra
plus communiquer avec les vieilles machines. J'ai à la maison une
vieille tablette pour laquelle le
constructeur ne propose pas de mise à jour logicielle et qui,
limitée à TLS 1.0, ne peut d'ores et déjà plus se connecter à
beaucoup de sites Web en HTTPS. L'obsolescence
programmée en raison de la sécurité… Plus grave, des
organisations peuvent être coincées avec une vieille version de TLS
sur des équipements, par exemple de contrôle industriel, qu'on ne
peut pas mettre à jour. (Lors des discussions à l'IETF sur ce RFC,
des personnes avaient suggéré d'attendre que le niveau d'utilisation
de TLS 1.0 et 1.1 tombe en dessous d'une certaine valeur, avant
d'abandonner officiellement ces protocoles. L'IETF a finalement
choisi une approche plus volontariste. Mais pensez aux
établissements comme les hôpitaux, avec tous les systèmes contrôlés
par des vieux PC pas mettables à jour.) Comme toujours en sécurité,
il n'y a pas de solution parfaite, uniquement des compromis. Le site de test TLS https://www.ssllabs.com/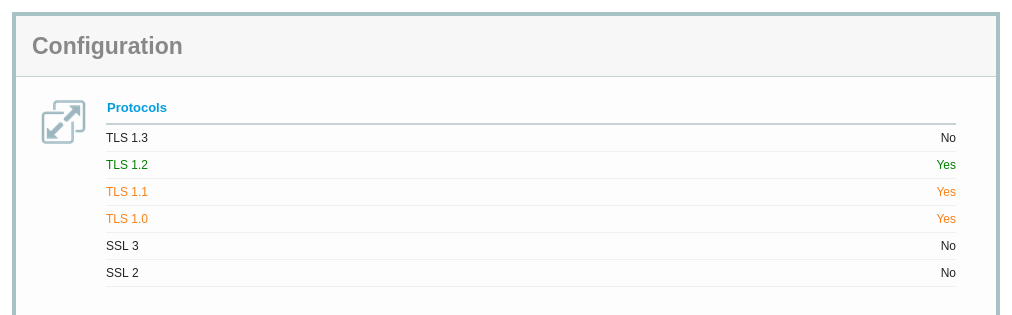
Au contraire, voici ce qu'affiche un
Firefox récent
quand on essaie de se connecter à un vieux site Web qui n'accepte
toujours pas TLS 1.2 : 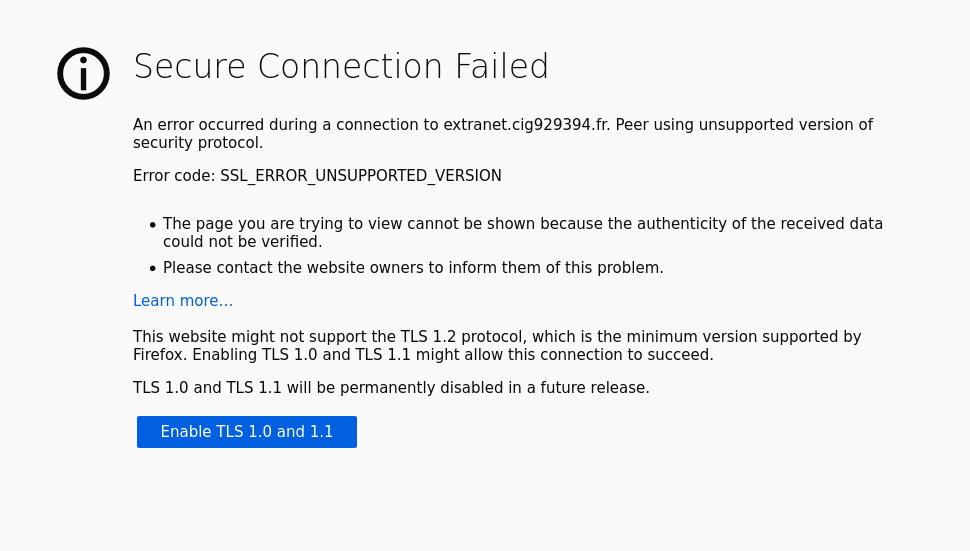
À noter que DTLS 1.0 (RFC 4347) est également abandonné. Cela laisse DTLS 1.2, le 1.1 n'ayant jamais été normalisé, et le 1.3 n'étant pas prêt à l'époque (il a depuis été publié dans le RFC 9147).
Les RFC 2246 (TLS 1.0) et RFC 4346 (TLS 1.1) ont été officiellement reclassifiés comme n'ayant plus qu'un intérêt historique. Le RFC 7507 est également déclassé, le mécanisme qu'il décrit n'étant utile qu'avec TLS 1.0 et 1.1.
L'article seul
RFC 8989: Additional Criteria for Nominating Committee Eligibility
Date de publication du RFC : Février 2021
Auteur(s) du RFC : B.E. Carpenter (Univ. of Auckland), S. Farrell (Trinity College Dublin)
Expérimental
Première rédaction de cet article le 8 février 2021
L'épidémie de Covid-19 a remis en cause pas mal de choses dans nos sociétés, certaines fois très gravement. En moins dramatique, elle oblige l'IETF à adapter ses processus, étant donné qu'aucune réunion en présentiel n'a pu se tenir en 2020 et qu'on ne sait pas quand cela pourra reprendre. Or, la présence physique aux réunions était nécessaire pour se qualifier pour le NomCom, le comité de nomination. Ce RFC propose à titre expérimental de nouveaux critères de sélection. (Ces critères sont devenus officiels avec le RFC 9389.)
Ce NomCom a pour tâche, décrite dans le RFC 8713, de désigner des personnes nommées pour remplir certains rôles à l'IETF. Il est composé de volontaires qui, normalement, doivent avoir participé en présentiel à un minimum de réunions IETF. Aujourd'hui, comme vous le savez, les réunions physiques ne sont plus possibles (à l'heure où j'écris, la réunion de San Francisco est très incertaine). Ce RFC modifie donc les règles pour l'année 2021 (le RFC 8788 avait déjà traité le cas de 2020). Il est officiellement expérimental (cf. RFC 3933) ; si les vaccins tiennent leur promesse, l'idée pourra être abandonnée et on reviendra aux pratiques d'avant. Mais, à l'heure actuelle, personne ne peut faire de pronostics sérieux dans ce domaine… (En octobre 2021, l'« expérience » a été prolongée.) Peut-être faudra-t-il se résigner à une modification permanente du RFC 8713 (section 2 de notre RFC).
En attendant que le futur s'éclaircisse, les règles pour cette année sont donc modifiées (section 4). Au lieu du seul critère de présence physique aux réunions, on accepte désormais pour sièger au NomCom les gens qui ont participé aux réunions en ligne (qui nécessitent une inscription et un enregistrement de « présence »), ou bien ont été président d'un groupe de travail ou bien auteur d'au moins deux RFC dans les cinq dernières années. Comme pour le critère précédent de présence physique, le but (section 3) est de vérifier que les membres du NomCom connaissent bien l'IETF.
D'autres critères auraient été possibles, mais ont été rejetés (section 5), comme l'écriture d'Internet-Drafts ou l'envoi de messages sur les listes de diffusion de l'IETF. Notez que la qualité des contributions à l'IETF ne rentre pas en ligne de compte, car elle est subjective.
Pour déterminer la liste des critères, le RFC se fonde sur une analyse de données (annexe A). Les données de départ ne sont pas parfaites (si quelqu'un s'inscrit à une réunion sous le nom de John Smith et à la suivante en mettant J. A. Smith, il apparaitra comme deux personnes différentes) mais c'est mieux que rien. Les jolis diagrammes de Venn en art ASCII montrent que les nouveaux critères permettent en effet d'élargir l'ensemble des volontaires potentiels, et que les critères rejetés n'auraient de toute façon pas eu d'influence.
L'expérience a fait l'objet d'un rapport publié en septembre 2021.
L'article seul
RFC 8985: The RACK-TLP Loss Detection Algorithm for TCP
Date de publication du RFC : Février 2021
Auteur(s) du RFC : Y. Cheng, N. Cardwell, N. Dukkipati, P. Jha (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 23 février 2021
Ce RFC normalise un nouvel algorithme pour la détection de paquets perdus dans TCP. Dans des cas comme celui où l'application n'a rien à envoyer (fin des données, ou attente d'une requête), RACK-TLP détecte les pertes plus rapidement, en utilisant des mesures fines du RTT, et en sollicitant des accusés de réception dans de nouveaux cas.
Pour comprendre cet algorithme et son intérêt, il faut revoir à quoi sert un protocole de transport comme TCP. Les données sont transmises sous forme de paquets (au format IP, dans le cas de l'Internet), paquets qui peuvent être perdus en route, par exemple si les files d'attente d'un routeur sont pleines. Le premier travail d'un protocole de transport est de réémettre les paquets perdus, de façon à ce que les applications reçoivent bien toutes les données (et dans l'ordre car, en prime, les paquets peuvent arriver dans le désordre, ce qu'on nomme un réordonnancement, qui peut être provoqué, par exemple, lorsque deux chemins sont utilisés pour les paquets). Un protocole de transport a donc besoin de détecter les pertes. Ce n'est pas si évident que cela. La méthode « on note quand on a émis un paquet et, si on n'a pas reçu d'accusé de réception au bout de N millisecondes, on le réémet » fonctionne, mais elle serait très inefficace. Notamment, le choix de N est difficile : trop court, et on déclarerait à tort des paquets comme perdus, réémettant pour rien, trop long et et ne détecterait la perte que trop tard, diminuant la capacité effective.
Le RFC original sur TCP, le RFC 793, expliquait déjà que N devait être calculé dynamiquement, en tenant compte du RTT attendu. En effet, si l'accusé de réception n'est pas arrivé au bout d'une durée égale au RTT, attendre davantage ne sert à rien. (Bien sûr, c'est plus compliqué que cela : le RTT peut être difficile à mesurer lorsque des paquets sont perdus, il varie dans le temps, puisque le réseau a pu changer, et il peut y avoir des temps de traitement qui s'ajoutent au RTT, il faut donc garder un peu de marge.) Armé de cette mesure dynamique du RTT, TCP peut calculer un RTO (Retransmission TimeOut, RFC 793, section 3.7) qui donne le temps d'attente. Le concept de RTO a été ensuite détaillé dans le RFC 6298 qui imposait un minimum d'une seconde (ce qui est beaucoup, par exemple à l'intérieur d'un même centre de données).
Mais d'autres difficultés surgissent ensuite. Par exemple, les accusés de réception de TCP indiquent le dernier octet reçu. Si on envoie trois paquets (plus rigoureusement trois segments, le terme utilisé par TCP) de cent octets, et qu'on reçoit un accusé de réception pour le centième octet indique que le premier paquet est arrivé mais ne dit rien du troisième. Peut-être est-il arrivé et que le second est perdu. Dans ce cas, la réémission du troisième paquet serait du gaspillage. Les accusés de réception cumulatifs de TCP ne permettent pas au récepteur de dire qu'il a reçu les premier et troisième paquets. Les SACK (Selective Acknowledgments) du RFC 2018 ont résolu ce problème. Dans l'exemple ci-dessus, SACK aurait permis au récepteur de dire « j'ai reçu les octets 0 - 100 et 200 - 300 [le second nombre de chaque bloc indique l'octet suivant le bloc] ».
Ensuite, on peut optimiser l'opération en n'attendant pas le RTO, dont on a vu qu'il était souvent trop long. L'idée de base est que, si le récepteur reçoit des données qui ne sont pas dans l'ordre attendu (le troisième paquet, alors qu'on n'a toujours pas vu le second), on renvoie un accusé de réception pour les données déjà reçues et déjà confirmées. Lorsque l'émetteur reçoit un accusé de réception qu'il a déjà vu (en fait, plusieurs), il comprend que des données manquent et il peut réémettre tout de suite, même si le RTO n'est pas écoulé. Ce mécanisme d'accusés de réception dupliqués (DUPACK, pour DUPlicate ACKnowledgment) a été décrit dans le RFC 5681, puis le RFC 6675. Une de ses faiblesses, que corrige notre RFC, est qu'il ne peut pas être utilisé à la fin d'une transmission, puisqu'il n'y a plus de données qui arrivent, empêchant le récepteur de détecter les pertes ou réordonnancements, et obligeant à attendre le RTO.
Et enfin, il faut se rappeler que le protocole de transport a une autre importante responsabilité : s'il doit s'assurer que toutes les données arrivent, et donc réémettre les paquets manquants, il doit aussi le faire en évitant la congestion (RFC 5681). Si des paquets se perdent, c'est peut-être que le réseau est saturé et réémettre trop brutalement pourrait encore aggraver la situation. Ceci dit, l'algorithme RACK-TLP décrit dans notre RFC ne traite que de la détection de pertes, les méthodes précédentes pour le contrôle de congestion restent valables. (C'est une des nouveautés de RACK-TLP : il sépare la détection de pertes du contrôle de congestion, pour lequel il existe plusieurs algorithmes comme le NewReno du RFC 6582 ou le CUBIC du RFC 8312. Ce découplage permet de faire évoluer séparement les algorithmes, et rend donc le système plus souple.)
Voici, désolé pour cette introduction un peu longue, on peut maintenant passer au sujet principal de ce RFC, RACK-TLP. Cet algorithme, ou plutôt ces deux algorithmes, vont être plus efficaces (détecter les pertes plus vite) que DUPACK, notamment à la fin d'une transmission, ou lorsqu'il y a des pertes des paquets retransmis, ou encore des réordonnancements fréquents des paquets (section 2.2 de notre RFC). RACK (Recent ACKnowledgment) va utiliser le RTT des accusés de réception pour détecter certaines pertes, alors que TLP (Tail Loss Probe) va émettre des paquets de données pour provoquer l'envoi d'accusés de réception par le récepteur.
La section 3 du RFC donne une vision générale des deux algorithmes. Commençons par RACK (Recent ACKnowledgment). Son but va être de détecter plus rapidement les pertes lorsque un paquet arrive au récepteur dans le désordre (paquet des octets 200 à 300 alors que le précédent était de 0 à 100, par exemple). Il va utiliser SACK (RFC 2018) pour cela, et RACK dépend donc du bon fonctionnement de SACK (section 4) et en outre, au lieu de ne regarder que les numéros de séquence contenus dans les ACK, comme le faisait DUPACK, il va également regarder le temps écoulé depuis l'émission d'un paquet. Les détails figurent en section 6 du RFC.
Quant à TLP (Tail Loss Probe), son rôle est de titiller le récepteur pour que celui-ci émette des accusés de récéption, même s'il n'en voyait pas la nécessité. Par exemple, si on arrive à la fin d'une session, l'émetteur a fini d'envoyer ses paquets, mais pas encore reçu les accusés de réception. Aucun envoi ne déclenchera donc DUPACK. Le principe de TLP est donc de solliciter un accusé de réception pour voir si on obtient un duplicata. RACK pourra alors utiliser cet accusé dupliqué. (Les deux algorithmes sont forcément utilisés ensemble, on n'utilise pas TLP sans RACK.) Les détails de TLP sont dans la section 7.
La résolution doit être meilleure qu'un quart du RTT. À l'intérieur d'un centre de données, cela implique de pouvoir compter les microsecondes, et, sur l'Internet public, les millisecondes.
La section 9 du RFC discute des avantages et inconvénients de RACK-TLP. Le gros avantage est que tout segment de données envoyé, même si c'est une retransmission, peut permettre de détecter des pertes. C'est surtout intéressant lorsqu'on est à la fin des données (et il n'y a donc plus rien à transmettre) ou lorsque des retransmissions sont perdues. Outre le cas de la fin du flot de données, les propriétés de RACK-TLP sont également utiles lorsque l'application garde la connexion ouverte mais n'a temporairement rien à transmettre (cas de sessions interactives, ou de protocoles requête/réponse comme EPP, où il ne se passe pas forcément quelque chose en permanence).
Mais comme la perfection n'existe pas en ce bas monde, RACK-TLP a aussi des inconvénients. Le principal est qu'il oblige à garder davantage d'état puisqu'il faut mémoriser l'heure de départ de chaque segment (contrairement à ce que proposait le RFC 6675), et avec une bonne résolution (un quart du RTT, demande le RFC). Une telle résolution n'est pas facile à obtenir dans un centre de données où les RTT sont très inférieurs à la milliseconde. Ceci dit, certaines mises en œuvre de TCP font déjà cela, même si, en théorie, elles pourraient se contenter de moins.
RACK-TLP coexiste avec d'autres algorithmes de détection de pertes, comme le classique RTO (RFC 6298) mais aussi avec ceux des RFC 7765, RFC 5682 et RFC 3522. De même, il coexiste avec divers algorithmes de contrôle de la congestion (RFC 5681, RFC 9937) puisqu'il se contente de détecter les pertes, il ne décide pas de comment on évite la congestion. En gros, RACK-TLP dit « ce segment est perdu » et la décision de réémission de celui-ci passera par l'algorithme de contrôle de la congestion, qui verra quand envoyer ces données à nouveau.
RACK-TLP est explicitement conçu pour TCP, mais il pourra aussi être utilisé dans le futur avec d'autres protocoles de transport, comme le futur QUIC.
RACK-TLP ne date pas d'aujourd'hui et il est déjà mis en œuvre dans Linux, FreeBSD et dans des systèmes d'exploitation moins connus comme Windows.
L'article seul
RFC 8984: JSCalendar: A JSON Representation of Calendar Data
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : N. Jenkins, R. Stepanek (Fastmail)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF calext
Première rédaction de cet article le 20 juillet 2021
Beaucoup d'applications gèrent des agendas, avec des réunions à ne pas oublier, des évènements récurrents, des rendez-vous précis. Le format traditionnel d'échange de ces applications est iCalendar, normalisé dans le RFC 5545 (ou, dans sa déclinaison en JSON, jCal, dans le RFC 7265). Ce RFC propose une syntaxe JSON mais, surtout, un modèle de données très différent, JSCalendar. Le but est de remplacer iCalendar.
Les principes de base ? Simplicité (au moins dans les cas simples, car les calendriers sont des bêtes compliquées…), uniformité (autant que possible, une seule façon de représenter un évènement), tout en essayant de permettre des conversions depuis iCalendar (RFC 5545 et RFC 7986), donc en ayant un modèle de données compatible. JSCalendar, comme son nom l'indique, utilise JSON, plus exactement le sous-ensemble i-JSON, normalisé dans le RFC 7493.
Bon, mais pourquoi ne pas avoir gardé iCalendar ? Parce qu'il est trop complexe avec plusieurs formats de date, parce que ses règles de récurrence sont ambigües et difficiles à comprendre, parce que sa syntaxe est mal définie. jCal n'a pas ce dernier problème mais il garde tous les autres. On voit même des logiciels utiliser leur propre représentation en JSON des données iCalendar au lieu d'utiliser jCal. Bref, JSCalendar préfère repartir, sinon de zéro, du moins d'assez loin.
Voici un exemple très simple et très minimal de représentation d'un évènement en JSCalendar :
{
"@type": "Event",
"uid": "a8df6573-0474-496d-8496-033ad45d7fea",
"updated": "2020-01-02T18:23:04Z",
"title": "Some event",
"start": "2020-01-15T13:00:00",
"timeZone": "America/New_York",
"duration": "PT1H"
}
Comme avec iCalendar, les données JSCalendar peuvent être échangées par courrier ou avec n'importe quel autre protocole de son choix comme JMAP ou WebDAV.
Avant d'attaquer ce format JSCalendar, rappelez-vous qu'il utilise JSON et que la terminologie est celle de JSON. Ainsi, on nomme « objet » ce qui, selon le langage utilisé, serait un dictionnaire ou un tableau associatif. Ensuite, outre les types de base de JSON, JSCalendar a des types supplémentaires (section 1), notamment :
Id, un identificateur, pour que les objets aient un nom simple et unique (c'est une chaîne de caractères JSON). On peut par exemple utiliser un UUID (RFC 9562). Dans l'exemple ci-dessus, le membreuidde l'objet est unId.UTCDateTime, une date-et-heure (un instant dans le temps) au format du RFC 3339 dans une chaîne de caractères JSON, est obligatoirement en UTC. Un tel type est intéressant pour les évènements internationaux comme une vidéoconférence. Dans l'exemple ci-dessus, le membreupdatedest de ce type.LocalDateTime, une date-et-heure selon le fuseau horaire local. Un tel type est utile pour les évènements locaux, comme un pique-nique. Dans l'exemple ci-dessus, qui concerne une réunion en présentiel,startest de ce type. On a besoin des deux types, à la fois parce que les évènements en distanciel et en présentiel n'ont pas les mêmes besoins, et aussi parce que le décalage entre les deux peut varier. Les calendriers, c'est compliqué et le RFC cite l'exemple de laLocalDateTime2020-10-04T02:30:00qui n'existe pas à Melbourne car le passage à l'heure d'été fait qu'on saute de 2h à 3h, mais qui peut apparaitre dans les calculs (start+ une durée) ou bien si les règles de l'heure d'été changent.Durationest une durée, exprimée comme en iCalendar (PT1Hpour « une heure » dans l'exemple ci-dessus, ce seraitP1Ypour une année). Gag : une journée (P1D) ne fait pas forcément 24 heures, par exemple si on passe à l'heure d'été pendant cette journée.SignedDuration, une durée qui peut être négative.TimeZoneId, un identifiant pour un fuseau horaire, pris dans la base de l'IANA, par exempleEurope/Paris.PatchObjectest un pointeur JSON (ces pointeurs sont normalisés dans le RFC 6901) qui permet de désigner un objet à modifier.Relationest un objet, et plus un simple type scalaire comme les précédents. Il permet d'indiquer une relation entre deux objets, notamment vers un objet parent ou enfant..Linkest également une relation et donc un objet, mais vers le monde extérieur. Il a des propriétés commehref(dont la valeur est, comme vous vous en doutez, un URI) oucidqui identifie le contenu vers lequel on pointe, dans la syntaxe du RFC 2392.
Les types de JSCalendar figurent dans un registre IANA, qu'on peut remplir avec la procédure « Examen par un expert » du RFC 8126.
Bien, maintenant que nous avons tous nos types, construisons des objets. Il y en a de trois types (section 2) :
Event(l'exemple ci-dessus, regardez sa propriété@type) est un évènement ponctuel, par exemple une réunion professionnelle ou une manifestation de rue. Il a une date-et-heure de départ, et une durée.Taskest une tâche à accomplir, elle peut avoir une date-et-heure limite et peut avoir une durée estimée.Groupest un groupe d'évènements JSCalendar.
JSCalendar n'a pas de règles de canonicalisation (normalisation)
générales, car cela dépend trop de considérations sémantiques que le
format ne peut pas connaitre. Par exemple, JSON permet des
tableaux, et JSCalendar utilise cette
possibilité mais, quand on veut décider si deux tableaux sont
équivalents, doit-on tenir compte de l'ordre des éléments
([1, 2] == [2, 1]) ? Cela dépend de
l'application et JSCalendar ne fixe donc pas de règles pour ce
cas. (Un cas rigolo et encore pire est celui des valeurs qui sont
des URI
puisque la canonicalisation des URI dépend du plan -
scheme.)
Quelles sont les propriétés typiques des objets JSCalendar (section 4) ? On trouve notamment, communs aux trois types d'objets (évènement, tâche et groupe) :
@type, le type d'objet (Eventdans l'exemple ci-dessus, un des trois types possibles).uid(a8df6573-0474-496d-8496-033ad45d7feadans l'exemple), l'identificateur de l'objet (il est recommandé que ce soit un des UUID du RFC 9562).prodID, un identificateur du logiciel utilisé, un peu comme leUser-Agent:de HTTP. Le RFC suggère d'utiliser un FPI.updated, une date-et-heure de typeUTCDateTime.titleetdescription, des chaînes de caractères utiles.locations(notez le S) qui désigne les lieux physiques de l'évènement. C'est compliqué. Chaque lieu est un objet de typeLocationqui a comme propriétés possibles un type (tiré du registre des types de lieux créé par le RFC 4589), et une localisation sous forme de latitude et longitude (RFC 5870).- Tous les évènements ne sont pas dans le monde physique,
certains se produisent en ligne, d'où le
virtualLocations, qui indique des informations comme l'URI (via la propriété du même nom). Ainsi, une conférence en ligne organisée par l'assocation Parinux via BigBlueButton aura commevirtualLocations{"@type": "VirtualLocation", "uri": "https://bbb.parinux.org/b/ca--xgc-4r3-n8z", …}. colorpermet de suggérer au logiciel une couleur à utiliser pour l'affichage, qui est une valeur RGB en hexadécimal ou bien un nom de couleur CSS.
Et je suis loin d'avoir cité toutes les propriétés possibles, sans compter celles spécifiques à un type d'objet.
Pour le cas de locations, le RFC fournit un
exemple de vol international (quand il était encore possible de prendre
l'avion) :
{
"...": "",
"title": "Flight XY51 to Tokyo",
"start": "2020-04-01T09:00:00",
"timeZone": "Europe/Berlin",
"duration": "PT10H30M",
"locations": {
"418d0b9b-b656-4b3c-909f-5b149ca779c9": {
"@type": "Location",
"rel": "start",
"name": "Frankfurt Airport (FRA)"
},
"c2c7ac67-dc13-411e-a7d4-0780fb61fb08": {
"@type": "Location",
"rel": "end",
"name": "Narita International Airport (NRT)",
"timeZone": "Asia/Tokyo"
}
}
}
Notez les UUID pour identifier les lieux, et le changement de fuseau horaire entre le départ et l'arrivée. Si l'évènement a lieu à la fois en présentiel et en distanciel (ici, le concert est dans un lieu physique identifié par ses coordonnées géographiques, mais aussi diffusé en ligne), cela peut donner :
{
"...": "",
"title": "Live from Music Bowl: The Band",
"description": "Go see the biggest music event ever!",
"locale": "en",
"start": "2020-07-04T17:00:00",
"timeZone": "America/New_York",
"duration": "PT3H",
"locations": {
"c0503d30-8c50-4372-87b5-7657e8e0fedd": {
"@type": "Location",
"name": "The Music Bowl",
"description": "Music Bowl, Central Park, New York",
"coordinates": "geo:40.7829,-73.9654"
}
},
"virtualLocations": {
"1": {
"@type": "VirtualLocation",
"name": "Free live Stream from Music Bowl",
"uri": "https://stream.example.com/the_band_2020"
}
},
...
Les fournisseurs de logiciel peuvent ajouter des propriétés
définies par eux. Dans ce cas, le RFC recommande fortement qu'ils
les nomment en les faisant précéder d'un nom de domaine identifiant le fournisseur. Si
celui-ci a example.com et veut une propriété
toto, il la nommera
example.com:toto. C'est évidemment une solution
temporaire, les fournisseurs ont tout intérêt à enregistrer ces
propriétés pour qu'elles puissent servir à tout le monde. Le
mécanisme d'enregistrement de nouvelles propriétés est « Examen par
un expert » (RFC 8126) et les propriétés sont
dans un
registre IANA.
Passons maintenant à un aspect compliqué mais indispensable des
calendriers : les règles de récurrence, comme « Réunion de service
tous les premiers lundis du mois à 10 h, sauf jour férié ». Il est
important de maintenir ces évènements récurrents sous forme de
règles, et de ne pas de les instancier immédiatement, car
l'application des règles peut donner des résultats différents dans
le futur. JSCalendar permet une propriété
recurrenceRules qui décrit ces règles de
récurrence et évidemment une
excludedRecurrenceRules car s'il n'y a pas
d'exceptions, ce n'est pas drôle. Exprimer les règles n'est pas
facile. L'idée est de spécifier la récurrence sous forme d'une série
de règles, chacune indiquant une fréquence (annuelle, mensuelle, etc), à
chaque fois à partir de la propriété start, le
calendrier utilisé (qui doit être un des calendriers disponibles
dans CLDR), la marche à suivre quand une règle
produit une date invalide dans ce calendrier (annuler l'évènement,
le mettre avant, le mettre après), et plein d'autres propriétés
optionnelles comme le jour du mois (« réunion tous les 6 du mois »),
de la semaine (« tous les mercredis »), etc. Il faut ensuite
plusieurs pages au RFC pour expliquer la façon subtile dont les
règles sont appliquées, et se combinent. Les exceptions de la
excludedRecurrenceRules fonctionnent de la même
façon, et sont ensuite soustraites des dates-et-heures sélectionnées
par les règles.
Le RFC fournit cet exemple de récurrence : le premier
avril arrive tous les ans (et dure une journée, notez le
duration) :
{
"...": "",
"title": "April Fool's Day",
"showWithoutTime": true,
"start": "1900-04-01T00:00:00",
"duration": "P1D",
"recurrenceRules": [{
"@type": "RecurrenceRule",
"frequency": "yearly"
}]
}
Alors qu'ici, on fait du yoga une demi-heure chaque jour à 7 h du matin :
{
"...": "",
"title": "Yoga",
"start": "2020-01-01T07:00:00",
"duration": "PT30M",
"recurrenceRules": [{
"@type": "RecurrenceRule",
"frequency": "daily"
}]
}
Bon, ensuite, quelques détails pour aider le logiciel à classer
et présenter les évènements. Un évènement peut avoir des propriétés
comme priority (s'il y a deux réunions en même
temps, laquelle choisir ?), freeBusyStatus
(est-ce que cet évènement fait que je doive être considéré comme
occupé ou est-il compatible avec autre chose ?),
privacy (cet évènement peut-il être affiché
publiquement ?), participationStatus (je
viendrai, je ne viendrai pas, je ne sais pas encore…), et plein
d'autres encore.
Il y a aussi des propriétés concernant d'autres sujets, par
exemple l'adaptation locale. Ainsi, la propriété
localizations indique la ou les langues à utiliser (leur valeur est une
étiquette de langue du RFC 5646).
Toutes les propriétés vues jusqu'à présent étaient possibles pour tous les types d'objets JSCalendar (évènement, tâche et groupe). D'autres propriétés sont spécifiques à un ou deux types :
- Les évènements (
Event) peuvent avoir entre autres unstart(unLocalDateTimequi indique le début de l'évènement) et unduration(la durée de l'évènement). - Les tâches (
Task) peuvent avoir unstartmais aussi unduequi indique la date où elles doivent être terminées, et unpercentComplete(pour les chefs de projet…). - Les groupes (
Group) ont, par exemple,entries, qui indique les objets qui sont membres du groupe.
Les fichiers à ce format JSCalendar sont servis sur l'Internet
avec le type
application/jscalendar+json.
Pour terminer, voyons un peu la sécurité de JSCalendar (section 7). Évidemment, toutes les informations stockées dans un calendrier sont sensibles : rares sont les personnes qui accepteraient de voir la totalité de leur agenda être publiée ! Celui-ci permet en effet de connaitre le graphe social (les gens qu'on connait), les lieux où passe la personne, ses habitudes et horaires, bref, que des choses personnelles. Toute application qui manipule des données JSCalendar doit donc soigneusement veiller à la confidentialité de ces données, et doit les protéger.
Le risque d'accès en lecture n'est pas le seul, la modification non autorisée de l'agenda serait également un problème, elle pourrait permettre, par exemple, de faire déplacer une personne en un lieu donné. D'autres conséquences d'une modification pourraient toucher la facturation (location d'une salle pendant une certaine durée) ou d'autres questions de sécurité (activer ou désactiver une alarme à certains moments). L'application qui manie du JSCalendar doit donc également empêcher ces changements non autorisés.
Notez que ces problèmes de sécurité ne concernent pas le format à proprement parler, mais les applications qui utilisent ce format. Rien dans JSCalendar, dans ce RFC, ne le rend particulièrement vulnérable ou au contraire protégé, tout est dans l'application.
Les règles de récurrence sont complexes et, comme tout programme, elles peuvent entrainer des conséquences imprévues, avec consommation de ressources informatiques associées. Un exemple aussi simple que la session de yoga quotidienne citée plus haut pourrait générer une infinité d'évènements, si elle était mise en œuvre par une répétition systématique, jusqu'à la fin des temps. Les programmes doivent donc faire attention lorsqu'ils évaluent les règles de récurrence.
L'un des buts d'un format standard d'évènements est évidemment l'échange de données. Il est donc normal et attendu qu'une application de gestion d'agenda reçoive des objets JSCalendar de l'extérieur, notamment via l'Internet. On voit souvent du iCalendar en pièce jointe d'un courrier, par exemple. Il ne faut pas faire une confiance aveugle à ces données venues d'on ne sait où, et ne pas tout intégrer dans le calendrier du propriétaire. L'authentification du courrier (par exemple avec DKIM, RFC 6376) aide un peu, mais n'est pas suffisante.
Les fuseaux horaires sont une source de confusion sans fin. Un utilisateur qui n'est pas attentif, lorsqu'on lui dit qu'un évènement a lieu à 10h30 (UTC-5) peut croire que c'est 10h30 de son fuseau horaire à lui. (Et encore, ici, j'ai indiqué le fuseau horaire de manière lisible, contrairement à ce que font la plupart des Étatsuniens, qui utilisent leurs sigles à eux comme PST, ou ce que font les Français qui n'indiquent pas le fuseau horaire, persuadés qu'ils sont que le monde entier est à l'heure de Paris.) Cette confusion peut être exploitée par des méchants qui utiliseraient les fuseaux horaires de manière délibérement peu claire pour tromper quelqu'un sur l'heure d'un évènement. (Dans la série Mad Men, les hommes qui ne supportent pas l'arrivée d'une femme dans le groupe lui donnent des informations trompeuses sur les heures de réunion, pour qu'elle manque ces évènements.)
Où trouve-t-on du JSCalendar à l'heure actuelle ? Mobilizon ne l'a pas encore (l'action « Ajouter à mon agenda » exporte du iCalendar). Fastmail annonce qu'ils gèrent JSCalendar (mais apparemment seulement dans les échanges JMAP, pas avec l'import/export normal). Cyrus l'a aussi (si vous avez des détails, ça m'intéresse). Pour le cas des récurrences, vous avez une intéressante mise en œuvre en Python. Attention, il y a aussi plein de logiciels qui s'appellent « jscalendar » (notamment des widgets JavaScript pour afficher un calendrier dans un formulaire Web) mais qui n'ont aucun rapport avec ce RFC.
L'article seul
RFC 8982: Registration Data Access Protocol (RDAP) Partial Response
Date de publication du RFC : Février 2021
Auteur(s) du RFC : M. Loffredo, M. Martinelli (IIT-CNR/Registro.it)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 10 février 2021
Le protocole de récupération d'informations auprès d'un registre RDAP peut parfois rapporter une grande quantité d'informations pour chaque objet récupéré (un nom de domaine, par exemple). Le RDAP originel ne permettait pas au serveur de ne renvoyer qu'une information partielle s'il trouvait que cela faisait trop. C'est désormais possible avec l'extension de ce RFC.
Le but est évidemment d'économiser les ressources du serveur, aussi bien que celles du client, en récupérant et en transférant moins de données. Avant notre RFC, la seule solution était de tout envoyer au client, même s'il n'en utiliserait pas la plus grande partie. (Si, au lieu de ne vouloir qu'une partie de chaque objet, on veut une partie des objets, il faut regarder le RFC 8977.)
Ce RFC étend donc le langage de requêtes de RDAP (normalisé dans
le RFC 9082), avec un paramètre
fieldSet (section 2 de notre RFC) qui permet de
sélectionner une partie des champs de la réponse. Voici un exemple
d'URL pour
une requête de tous les noms de domaine de
.com :
https://rdap.verisign.example/domains?name=*.com&fieldSet=afieldset
Et comment on connait les champs possibles ? Notre RFC introduit
un subsetting_metadata qui indique l'ensemble
de champs courant, et les ensembles possibles, chacun identifié par
un nom, et comportant les liens (RFC 8288) à
utiliser. (Vous aurez une erreur HTTP 400 si vous êtes assez
vilain·e pour faire une requête RDAP avec un ensemble inexistant.)
Et pour savoir si le serveur RDAP que vous interrogez accepte cette
nouvelle extension permettant d'avoir des réponses partielles,
regardez si subsetting apparait dans le tableau
rdapConformance de la réponse du serveur (cette
extension est désormais dans le
registre IANA). Voici l'exemple que donne le RFC :
{
"rdapConformance": [
"rdap_level_0",
"subsetting"
],
...
"subsetting_metadata": {
"currentFieldSet": "afieldset",
"availableFieldSets": [
{
"name": "anotherfieldset",
"description": "Contains some fields",
"default": false,
"links": [
{
"value": "https://example.com/rdap/domains?name=example*.com
&fieldSet=afieldset",
"rel": "alternate",
"href": "https://example.com/rdap/domains?name=example*.com
&fieldSet=anotherfieldset",
"title": "Result Subset Link",
"type": "application/rdap+json"
}
]
},
...
]
},
...
"domainSearchResults": [
...
]
}
Mais il y a encore plus simple que de regarder
subsetting_metadata : notre RFC décrit, dans sa
section 4, trois ensembles de champs standards qui, espérons-le,
seront présents sur la plupart des serveurs RDAP :
id, qui ne renvoie dans la réponse que les identificateurs des objets (handlepour les contacts,unicodeNamepour les noms de domaine, etc).brief, un peu plus bavard, qui renvoie l'information minimale (telle qu'estimée par le serveur) sur les objets.full, qui renvoie la réponse complète (actuellement, avant le déploiement de ce RFC 8982, c'est la valeur par défaut).
Un exemple de réponse avec l'ensemble id, où on
n'a que le nom (ASCII) des domaines :
{
"rdapConformance": [
"rdap_level_0",
"subsetting"
],
...
"domainSearchResults": [
{
"objectClassName": "domain",
"ldhName": "example1.com",
"links": [
{
"value": "https://example.com/rdap/domain/example1.com",
"rel": "self",
"href": "https://example.com/rdap/domain/example1.com",
"type": "application/rdap+json"
}
]
},
{
"objectClassName": "domain",
"ldhName": "example2.com",
"links": [
{
"value": "https://example.com/rdap/domain/example2.com",
"rel": "self",
"href": "https://example.com/rdap/domain/example2.com",
"type": "application/rdap+json"
}
]
},
...
]
}
Quelles mises en œuvre sont disponibles ? Il en existe une
chez
.it mais elle n'est
accessible sur leur serveur de test que si on est
authentifié.
Comme RDAP, contrairement à whois, permet l'authentification des clients (RFC 7481), on pourra imaginer des cas où l'ensemble complet de la réponse ne sera envoyé qu'à certains utilisateurs (section 8).
L'annexe A du RFC revient sur un choix sur lequel je suis passé rapidement : le fait que le client spécifie le nom d'un ensemble pré-défini de champs, plutôt que la liste des champs qui l'intéressent, ce qui serait plus souple. Mais cela aurait été compliqué pour les structures JSON profondes (il faudrait une syntaxe riche et peu lisible), et cela aurait compliqué les autorisations : que faire si un client demande deux champs et qu'il n'est autorisé que pour un seul ? Outre ces questions génériques de tout protocole utilisant JSON, il y avait des problèmes spécifiques à RDAP, comme le fait que le contenu sur une entité peut être réparti dans plusieurs structures JSON (ah, le jCard…) Des solutions existent, comme le langage de requêtes CQL, mais il a semblé trop coûteux pour un intérêt limité.
L'article seul
RFC 8981: Temporary Address Extensions for Stateless Address Autoconfiguration in IPv6
Date de publication du RFC : Février 2021
Auteur(s) du RFC : F. Gont (SI6 Networks), S. Krishnan (Kaloom), T. Narten, R. Draves (Microsoft Research)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 1 mars 2021
Une des particularités d'IPv6 est de disposer d'un mécanisme, l'autoconfiguration sans état qui permet à une machine de se fabriquer une adresse IP globale sans serveur DHCP. Autrefois, ce mécanisme créait souvent l'adresse IP à partir de l'adresse MAC de la machine et une même machine avait donc toujours le même identifiant (IID, Interface IDentifier, les 64 bits les plus à droite de l'adresse IPv6), même si elle changeait de réseau et donc de préfixe. Il était donc possible de « suivre à la trace » une machine, ce qui pouvait poser des problèmes de protection de la vie privée. Notre RFC, qui remplace le RFC 4941 fournit une solution, sous forme d'un mécanisme de création d'adresses temporaires, partiellement aléatoires (ou en tout cas imprévisibles). Les changements sont assez importants depuis le RFC 4941, qui traitait un peu les adresses IPv6 temporaires comme des citoyennes de deuxième classe. Désormais, elles sont au contraire le choix préféré.
L'autoconfiguration sans état (SLAAC, pour Stateless
Address Autoconfiguration), normalisée dans le RFC 4862, est souvent présentée comme un des gros
avantages d'IPv6. Sans nécessiter de serveur
central (contrairement à DHCP), ce mécanisme permet à chaque machine
d'obtenir une adresse globale (IPv4, via le
protocole du RFC 3927, ne permet que des
adresses purement locales) et unique. Cela se fait en concaténant un
préfixe (par exemple
2001:db8:32:aa12::), annoncé par le
routeur, à un identifiant
d'interface (par exemple
213:e8ff:fe69:590d, l'identifiant de mon PC
portable - les machines individuelles, non partagées, comme les
ordiphones sont particulièrement sensibles
puisque la connaissance de la machine implique celle de son maître),
typiquement dérivé de l'adresse MAC.
Partir de l'adresse MAC présente des avantages (quasiment toute
machine en a une, et, comme elle est relativement unique, l'unicité
de l'adresse IPv6 est obtenue facilement) mais aussi un
inconvénient : comme l'identifiant d'interface est toujours le même,
cela permet de reconnaître une machine, même lorsqu'elle change de
réseau. Dès qu'on voit une machine
XXXX:213:e8ff:fe69:590d (où XXXX est le
préfixe), on sait que c'est mon PC. Un tiers qui écoute le réseau
peut ainsi suivre « à la trace » une machine, et c'est pareil pour
les
machines avec lesquelles on correspond sur l'Internet.
Or, on ne peut pas cacher son adresse IP, il faut l'exposer pour
communiquer. Le RFC 7721 analyse le problème
plus en détail (voir aussi le RFC 7707).
Les sections 1.2 et 2 de notre RFC décrivent la question à résoudre. Elles notent entre autre que le problème n'est pas aussi crucial que l'avaient prétendu certains. En effet, il existe bien d'autres façons, parfois plus faciles, de suivre une machine à la trace, par exemple par les fameux petits gâteaux de HTTP (RFC 6265) mais aussi par des moyens de plus haute technologie comme les métadonnées de la communication (taille des paquets, écart entre les paquets) ou les caractéristiques matérielles de l'ordinateur, que l'on peut observer sur le réseau. Parmi les autres méthodes, notons aussi que si on utilise les adresses temporaires de notre RFC 8981 mais qu'on configure sa machine pour mettre dynamiquement à jour un serveur DNS avec cette adresse, le nom de domaine suffirait alors à suivre l'utilisateur à la trace !
La section 2.2 commence à discuter des solutions possibles. DHCPv6 (RFC 3315, notamment la section 12) serait évidemment une solution, mais qui nécessite l'administration d'un serveur. L'idéal serait une solution qui permette, puisque IPv6 facilite l'existence de plusieurs adresses IP par machine, d'avoir une adresse stable pour les connexions entrantes et une adresse temporaire, non liée à l'adresse MAC, pour les connexions sortantes, celles qui « trahissent » la machine. C'est ce que propose notre RFC, en générant les adresses temporaires selon un mécanisme pseudo-aléatoire (ou en tout cas imprévisible à un observateur extérieur).
Enfin, la section 3 décrit le mécanisme de protection lui-même. Deux algorithmes sont proposés mais il faut bien noter qu'une machine est toujours libre d'en ajouter un autre, le mécanisme est unilatéral et ne nécessite pas que les machines avec qui on correspond le comprennent. Il suffit que l'algorithme respecte ces principes :
- Les adresses IP temporaires sont utilisées pour les connexions sortantes (pour les entrantes, on a besoin d'un identificateur stable, un serveur n'a pas de vie privée),
- Elles sont… temporaires (typiquement quelques heures),
- Cette durée de vie limitée suit les durées de vie indiquées par SLAAC, et, en prime, on renouvelle les IID (identifiants d'interface) tout de suite lorsque la machine change de réseau, pour éviter toute corrélation,
- L'identifiant d'interface est bien sûr différent pour chaque interface, pour éviter qu'un observateur ne puisse détecter que l'adresse IP utilisée en 4G et celle utilisée en WiFi désignent la même machine,
- Ces adresses temporaires ne doivent pas avoir de sémantique visible (cf. RFC 7136) et ne pas être prévisibles par un observateur.
Le premier algorithme est détaillé dans la section 3.3.1 et nécessite l'usage d'une source aléatoire, selon le RFC 4086. On génère un identifiant d'interface avec cette source (attention, certains bits sont réservés, cf. RFC 7136), on vérifie qu'il ne fait pas partie des identifiants réservés du RFC 5453, puis on la préfixe avec le préfixe du réseau.
Second algorithme possible, en section 3.3.2, une génération à partir de l'algorithme du RFC 7217, ce qui permet d'utiliser le même algorithme pour ces deux catégories d'adresses, qui concernent des cas d'usage différents. Le principe est de passer les informations utilisées pour les adresses stables du RFC 7217 (dont un secret, pour éviter qu'un observateur ne puisse déterminer si deux adresses IP appartiennent à la même machine), en y ajoutant le temps (pour éviter la stabilité), à travers une PRF comme SHA-256. Plus besoin de générateur aléatoire dans ce cas.
Une fois l'adresse temporaire générée (les détails sont dans la section 3.4), et testée (DAD), il faut la renouveler de temps en temps (sections 3.5 et 3.6, cette dernière expliquant pourquoi renouveler une fois par jour est plus que suffisant). L'ancienne adresse peut rester active pour les connexions en cours mais plus pour de nouvelles connexions.
Notez que le RFC impose de fournir un moyen pour activer ou débrayer ces adresses temporaires, et que cela soit par préfixe IP, par exemple pour débrayer les adresses temporaires pour les adresses locales du RFC 4193.
Maintenant que l'algorithme est spécifié, la section 4 du RFC reprend de la hauteur et examine les conséquences de l'utilisation des adresses temporaires. C'est l'occasion de rappeler un principe de base de la sécurité : il n'y a pas de solution idéale, seulement des compromis. Si les adresses temporaires protègent davantage contre le « flicage », elles ont aussi des inconvénients comme de rendre le débogage des réseaux plus difficile. Par exemple, si on note un comportement bizarre associé à certaines adresses IP, il sera plus difficile de savoir s'il s'agit d'une seule machine ou de plusieurs. (Le RFC 7217 vise justement à traiter ce cas.)
Et puis les adresses temporaires de notre RFC ne concernent que l'identifiant d'interface, le préfixe IP reste, et il peut être révélateur, surtout s'il y a peu de machines dans le réseau. Si on veut vraiment éviter le traçage par adresse IP, il faut utiliser Tor ou une technique équivalente (cf. section 9).
L'utilisation des adresses temporaires peut également poser des problèmes avec certaines pratiques prétendument de sécurité comme le fait, pour un serveur, de refuser les connexions depuis une machine sans enregistrement DNS inverse (un nom correspondant à l'adresse, via un enregistrement PTR). Cette technique est assez ridicule mais néanmoins largement utilisée.
Un autre conflit se produira, note la section 8, si des mécanismes de validation des adresses IP source sont en place dans le réseau. Il peut en effet être difficile de distinguer une machine qui génère des adresses IP temporaires pour se protéger contre les indiscrets d'une machine qui se fabrique de fausses adresses IP source pour mener une attaque.
Quelles sont les différences entre le précédent RFC et celui-ci ? La section 5 du RFC résume les importants changements qu'il y a eu depuis le RFC 4941. Notamment :
- Abandon de MD5 (cf. RFC 6151),
- Autorisation de n'avoir que des adresses temporaires (le RFC 4941 imposait qu'une adresse stable reste présente),
- Autoriser les adresses temporaires à être utilisées par défaut, ce qui était déjà le cas en pratique sur la plupart des systèmes d'exploitation (depuis l'époque du RFC 4941, la gravité de la surveillance de masse est mieux perçue),
- Réduction de la durée de vie recommandée, et recommandation qu'elle soit partiellement choisie au hasard, pour éviter que toutes les adresses soient refaites en même temps,
- Un algorithme de génération des identifiants d'interface, reposant sur une mémoire stable de la machine, a été supprimé,
- Un autre a été ajouté, se fondant sur le RFC 7217,
- Intégration des analyses plus détaillées qui ont été faites de la sécurité d'IPv6 (RFC 7707, RFC 7721 et RFC 7217),
- Correction des bogues.
Passons maintenant aux mises en œuvre. L'ancienne norme, le RFC 4941, est appliqué par presque tous les
systèmes d'exploitation, souvent de manière plus protectrice de la
vie privée, par exemple en étant activé par défaut. Les
particularités de notre nouveau RFC ne sont pas toujours d'ores et
déjà présentes. Ainsi, il existe des patches
pour
FreeBSD et pour
Linux mais pas forcément intégrés aux versions
officielles. Sur
Linux, le paramètre sysctl qui contrôle ce protocole est
net.ipv6.conf.XXX.use_tempaddr où XXX est le
nom de l'interface réseau, par exemple eth0. En
mettant dans le fichier /etc/sysctl.conf :
# Adresses temporaires du RFC 8981 net.ipv6.conf.default.use_tempaddr = 2
On met en service les adresses temporaires, non « pistables » pour
toutes les interfaces (c'est le sens de la valeur
default). Pour s'assurer que les réglages soient bien pris en
compte, il vaut mieux faire en sorte que le module
ipv6 soit chargé tout de suite (sur
Debian, le mettre dans
/etc/modules) et que les interfaces fixes aient
leur propre réglage. Par exemple, sur Debian,
on peut mettre dans /etc/network/interfaces :
iface eth2 inet dhcp pre-up sysctl -w net.ipv6.conf.eth2.use_tempaddr=2
Ou alors il faut nommer explicitement ses interfaces :
net.ipv6.conf.eth0.use_tempaddr = 2
Notez aussi
qu'ifconfig n'affiche pas quelles
adresses sont les temporaires (mais ip addr
show le fait).
Notons que l'adresse « pistable » est toujours présente mais
vient s'y ajouter une adresse temporaire choisie au hasard. Selon
les règles du RFC 6724, rappelées dans la
section 3.1 de notre RFC, c'est cette adresse temporaire qui sera
choisie, en théorie, pour les connexions sortantes (voir aussi le
RFC 5014 pour une API permettant de contrôler ce
choix). Avec Linux, il faut pour cela que
use_tempaddr vale plus que un (sinon, l'adresse
temporaire est bien configurée mais pas utilisée par
défaut). ifconfig affichera donc :
wlan0 Link encap:Ethernet HWaddr 00:13:e8:69:59:0d
...
inet6 addr: 2001:db8:32:aa12:615a:c7ba:73fb:e2b7/64 Scope:Global
inet6 addr: 2001:db8:32:aa12:213:e8ff:fe69:590d/64 Scope:Global
puis, au démarrage suivant, l'adresse temporaire (la première ci-dessus) changera :
wlan0 Link encap:Ethernet HWaddr 00:13:e8:69:59:0d
...
inet6 addr: 2001:db8:32:aa12:48a9:bf44:5167:463e/64 Scope:Global
inet6 addr: 2001:db8:32:aa12:213:e8ff:fe69:590d/64 Scope:Global
Sur NetBSD, il n'y a qu'une seule variable
syscvtl pour toutes les interfaces. Il suffit donc de mettre dans
/etc/sysctl.conf :
net.inet6.ip6.use_tempaddr=1
Pour que l'adresse temporaire soit utilisée par défaut, c'est
net.inet6.ip6.prefer_tempaddr. Sur
FreeBSD, je n'ai pas essayé, mais je suppose
que les variables sysctl au nom bien parlant
net.inet6.ip6.use_tempaddr et
net.inet6.ip6.prefer_tempaddr sont là pour
cela.
L'article seul
RFC 8980: Report from the IAB Workshop on Design Expectations vs. Deployment Reality in Protocol Development
Date de publication du RFC : Février 2021
Auteur(s) du RFC : J. Arkko, T. Hardie
Pour information
Première rédaction de cet article le 20 février 2021
L'atelier de l'IAB DEDR (Design Expectations vs. Deployment Reality) s'est tenu à Kirkkonummi en juin 2019 (oui, il faut du temps pour publier un RFC de compte-rendu). Son but était, par delà la constatation que le déploiement effectif des protocoles conçus par l'IETF ne suit pas toujours les attentes initiales, d'explorer pourquoi cela se passait comme cela et ce qu'on pouvait y changer.
Souvent, lors de la mise au point d'un nouveau protocole, les personnes qui y travaillent ont en tête un modèle de déploiement. Par exemple, pour le courrier électronique, l'idée dominante était qu'il y aurait souvent un serveur de messagerie par personne. On sait que ce n'est pas la situation actuelle. En raison de soucis de sécurité, de pressions économiques et/ou politiques, et d'autres facteurs, on a aujourd'hui un courrier nettement plus centralisé, avec un caractère oligopolistique marqué, dominé par une poignée d'acteurs qui dictent les règles. Cette centralisation n'est pas souhaitable (sauf pour les GAFA). Mais où est-ce que le dérapage a commencé ? Parfois, cela a été rapide, et parfois cela a pris beaucoup de temps.
Quelques exemples :
- Le courrier électronique, on l'a dit, était conçu autour de l'idée qu'il y aurait beaucoup de serveurs, gérés par des acteurs différents. (À une époque, dans le monde universitaire, il était courant que chaque station de travail ait un serveur de courrier, et ses propres adresses.) Aujourd'hui, il est assez centralisé, chez des monstres comme Gmail et Outlook.com. Un des facteurs de cette centralisation est le spam, contre lequel il est plus facile de se défendre si on est gros.
- Le DNS
avait été prévu pour une arborescence de noms assez profonde
(l'exemple traditionnel était l'ancien domaine de premier niveau
.usqui était découpé en entités géographiques de plus en plus spécifiques). Mais l'espace des noms est aujourd'hui plus plat que prévu. On voit même des organisations qui ont, mettons,example.comet qui, lançant un nouveau produit, mettonsfoobar, réserventfoobar.com, voirefoobar-example.comau lieu de tout simplement créerfoobar.example.com(ce qui serait en outre moins cher). Un autre exemple de centralisation est la tendance à abandonner les résolveurs locaux (qui, il est vrai, sont souvent mal gérés ou menteurs) pour des gros résolveurs publics comme Google Public DNS ou Quad9 (et cette centralisation, contrairement à ce qui est souvent prétendu, n'a rien à voir avec DoH). - Le Web est également un exemple de déviation des principes originels, vers davantage de centralisation. Le concept de base est très décentralisé. N'importe qui peut installer un serveur HTTP sur son Raspberry Pi et faire partie du World Wide Web. Mais cela laisse à la merci, par exemple, des dDoS ou, moins dramatiquement, de l'effet Slashdot (même si un site Web statique peut encaisser une charge importante). On constate que de plus en plus de sites Web dépendent donc de services centralisés, CDN ou gros relais comme Cloudflare.
- Et ça ne va pas forcément s'arranger avec de nouvelles technologies, par exemple l'apprentissage automatique, qui sont difficiles à décentraliser.
L'IAB avait produit un RFC sur la question « qu'est-ce qui fait qu'un protocole a du succès », le RFC 5218. Dans un autre document, le RFC 8170, l'IAB étudiait la question des transitions (passage d'un protocole à un autre, ou d'une version d'un protocole à une autre). L'atelier de Kirkkonummi avait pour but de poursuivre la réflexion, en se focalisant sur les cas où les suppositions de base n'ont pas tenu face à la réalité.
L'agenda de l'atelier était structuré en cinq sujets, le passé (qu'avons-nous appris), les principes (quelles sont les forces à l'œuvre et comment les contrer ou les utiliser), la centralisation (coûts et bénéfices), la sécurité et le futur (fera-t-on mieux à l'avenir et savons-nous comment). 21 articles ont été reçus (ils sont en ligne), et 30 personnes ont participé.
Sur le passé, l'atelier a étudié des exemples de déploiement de protocoles, comme PKIX, DNSSEC, le NAT, l'IoT, etc. Souvent, ce qui a été effectivement déployé ne correspondait pas à ce qui était prévu. Par exemple, un protocole très demandé n'a pas eu le succès attendu (c'est le cas de DNSSEC : tout le monde réclame de la sécurité, mais quand il faut travailler pour la déployer, c'est autre chose) ou bien il n'a pas été déployé comme prévu. C'est d'autant plus vrai que l'IETF n'a pas de pouvoir : elle produit des normes et, ensuite, d'autres acteurs décident ou pas de déployer, et de la manière qu'ils veulent (le « marché » sacré). Le RFC cite quelques leçons de l'expérience passée :
- Les retours du terrain arrivent toujours trop tard, bien après que la norme technique ait été bouclée. C'est particulièrement vrai pour les retours des utilisateurs individuels (ceux que, d'après le RFC 8890, nous devons prioriser).
- Les acteurs de l'Internet font des choses surprenantes.
- On constate la centralisation mais on ne peut pas forcément l'expliquer par les caractéristiques des protocoles. Rien dans HTTP ou dans SMTP n'impose la centralisation qu'on voit actuellement.
- En revanche, certaines forces qui poussent à la centralisation sont connues : cela rend certains déploiements plus faciles (c'est un argument donné pour refuser la décentralisation). Et les solutions centralisées ont nettement la faveur des gens au pouvoir, car ils préfèrent travailler avec un petit nombre d'acteurs bien identifiés. (C'est pour cela qu'en France, tous les hommes politiques disent du mal des GAFA tout en combattant les solutions décentralisées, qui seraient plus difficiles à contrôler.)
- On ne sait pas toujours si un nouveau protocole sera vraiment utile ou pas (cf. la 5G et le porno dans l'ascenseur).
- Il est facile de dire que l'IETF devrait davantage interagir avec tel ou tel groupe, mais certains groupes sont difficiles à toucher (le RFC 8890 détaille ce problème).
Sur les principes, on a quand même quelques conclusions solides. Par exemple, il est clair qu'un nouveau protocole qui dépend de plusieurs autres services qui ne sont pas encore déployés aura davantage de mal à s'imposer qu'un protocole qui peut s'installer unilatéralement sans dépendre de personne. Et puis bien sûr, il y a l'inertie. Quand quelque chose marche suffisamment bien, il est difficile de la remplacer. (Le RFC donne l'exemple de BGP, notamment de sa sécurité.) Et cette inertie génère le phénomène bien reconnu de la prime au premier arrivant. Si un protocole fournit un nouveau service, un remplaçant aura le plus grand mal à s'imposer, même s'il est meilleur, face au tenant du titre. Le monde du virtuel est lourd et ne bouge pas facilement. Quand un protocole a eu un succès fou (terme défini et discuté dans le RFC 5218), le remplacer devient presque impossible. Autre principe analysé : l'IETF ne devrait de toute façon pas avoir d'autorité sur la façon dont ses protocoles sont déployés. Ce n'est pas son rôle et elle n'a pas de légitimité pour cela. Et, on l'a dit, les usages sont durs à prévoir. L'atelier a aussi constaté que certains modèles de déploiement, qui s'appliquent à beaucoup de cas, n'avaient pas été prévus et planifiés. C'est le cas de l'extrême centralisation, bien sûr, mais également le cas de « tout via le Web » qui fait que tout nouveau service sur l'Internet tend à être accessible uniquement à distance, avec les protocoles et les formats du Web. Cela tend à créer des silos fermés, même s'ils utilisent des protocoles ouverts. (C'est en réponse à ce problème qu'a été créée la licence Affero.)
Concernant le troisième sujet, la centralisation, l'atelier a constaté que la tendance à la centralisation n'est pas toujours claire dès le début. Le RFC cite l'exemple (très mauvais, à mon avis) de DoH. Autre constatation, la sécurité, et notamment le risque d'attaques par déni de services réparties est un puissant facteur de centralisation. Si vous voulez gérer un site Web sur un sujet controversé, avec des opposants puissants et prêts à tout, vous êtes quasiment obligé de faire appel à un hébergement de grande taille (face aux dDoS, la taille compte). Ceci dit, l'atelier a aussi identifié des forces qui peuvent aller en sens contraire à la centralisation. Une fédération peut mieux résister aux attaques (qui ne sont pas forcément techniques, cela peut être aussi la censure) qu'un gros silo centralisé, le chiffrement peut permettre même aux petits de limiter la surveillance exercée par les gros, les navigateurs Web peuvent adopter de meilleures pratiques pour limiter les données envoyées à la grosse plate-forme à laquelle on accède (toute cette liste du RFC est d'un optimisme souvent injustifié…), l'interopérabilité peut permettre davantage de concurrence (cf. le bon rapport du Conseil National du Numérique), et certaines tendance lourdes peuvent être combattues également par des moyens non-techniques (le RFC cite la régulation, ce qui n'est pas facilement accepté par les libertariens, même si ceux-ci ne sont pas plus nombreux à l'IETF qu'ailleurs).
Quatrième sujet, la sécurité. Traditionnellement, le modèle de menace de l'Internet (RFC 3552 mais aussi RFC 7258) est que tout ce qui est entre les deux machines qui communiquent peut être un ennemi. Cela implique notamment le choix du chiffrement de bout en bout. Toutefois, ce modèle de menace ne marche pas si c'est l'autre pair qui vous trahit. Ainsi, utiliser TLS quand vous parlez à Facebook vous protège contre des tiers mais pas contre Facebook lui-même. À l'heure où tant de communications en ligne sont médiées par des GAFA, c'est un point à prendre en considération. (Attention à ne pas jeter le bébé avec l'eau du bain ; le chiffrement de bout en bout reste nécessaire, mais n'est pas suffisant. Certains FAI remettent en cause le modèle de menace traditionnel pour combattre ou restreindre le chiffrement, en faisant comme si les GAFA étaient les seuls à faire de la surveillance.) Les participants à l'atelier sont plutôt tombés d'accord sur la nécessité de faire évoluer le modèle de menace mais il faudra veiller à ce que ne soit pas un prétexte pour relativiser l'importance du chiffrement, qui reste indispensable. À noter une autre limite d'un modèle de menace qui ne mentionnerait que les tiers situés sur le trajet : non seulement la partie distante (par exemple Facebook) peut être une menace, mais votre propre machine peut vous trahir, par exemple si vous n'utilisez pas du logiciel libre.
Enfin, cinquième et dernier sujet, le futur. L'IETF n'a pas de pouvoir contraignant sur les auteurs de logiciels, sur les opérateurs ou sur les utilisateurs (et heureusement). Elle ne peut agir que via ses normes. Par exemple, pour l'Internet des Objets, le RFC 8520 permet davantage d'ouverture dans la description des utilisations qu'un objet fera du réseau. Outre la production de bonnes normes, l'IETF peut être disponible quand on a besoin d'elle, par exemple comme réserve de connaissance et d'expertise.
La conclusion du RFC (section 5) indique que le problème est complexe, notamment en raison de la variété des parties prenantes : tout le monde n'est pas d'accord sur les problèmes, et encore moins sur les solutions. (Il n'existe pas de « communauté Internet », à part dans des discours politiciens.) D'autre part, certains des problèmes n'ont pas de solution évidente. Le RFC cite ainsi les dDoS, ou le spam. Cette absence de solution satisfaisante peut mener à déployer des « solutions » qui ont un rôle négatif. Le RFC note ainsi à juste titre que l'absence d'une solution de paiement en ligne correcte (anonyme, simple, bon marché, reposant sur des normes ouvertes, etc) pousse à faire dépendre la rémunération des créateurs de la publicité, avec toutes ses conséquences néfastes. Et l'Internet fait face à de nombreux autres défis stratégiques, comme la non-participation des utilisateurs aux questions qui les concernent, ou comme la délégation de décisions à des logiciels, par exemple le navigateur Web.
On l'a dit, la conclusion est que l'IETF doit se focaliser sur ce qu'elle sait faire et bien faire, la production de normes. Cela implique :
- Travailler sur une mise à jour du modèle de menace cité plus haut,
- Réfléchir aux mesures qui peuvent être prises pour limiter la centralisation,
- Mieux documenter les principes architecturaux de l'Internet, notamment le principe de bout en bout,
- Travailler sur les systèmes de réputation (cf. RFC 7070),
- Etc.
Un autre compte-rendu de cet atelier, mais très personnel, avait été fait par Geoff Huston.
L'article seul
RFC 8978: Reaction of Stateless Address Autoconfiguration (SLAAC) to Flash-Renumbering Events
Date de publication du RFC : Mars 2021
Auteur(s) du RFC : F. Gont (SI6 Networks), J. Zorz (6connect), R. Patterson (Sky UK)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 11 mars 2021
Au moment où je commençais à écrire cet article, mon FAI a trouvé drôle de changer le préfixe IPv6 attribué à mon réseau à la maison. Cela a parfaitement illustré le problème que décrit ce RFC : comment réagissent les machines IPv6 qui ont obtenu une adresse dynamique lors d'une rénumérotation brutale et sans avertissement ? En résumé : ça ne se passe pas toujours bien.
Posons le problème. Notre RFC se concentre sur le cas des machines qui ont obtenu une adresse par le système SLAAC (StateLess Address AutoConfiguration), normalisé dans le RFC 4862. Le routeur émet des messages RA (Router Advertisement) qui indiquent quel est le préfixe d'adresses IP utilisé sur le réseau local. Les machines vont alors prendre une adresse dans ce préfixe, tester qu'elle n'est pas déjà utilisée et c'est parti. Le routeur n'a pas besoin de mémoriser quelles adresses sont utilisées, d'où le terme de « sans état ». L'information distribuée par ces RA a une durée de vie, qui peut être de plusieurs jours, voire davantage.
Maintenant, envisageons un changement du préfixe, quelle que soit sa raison. Si ce changement est planifié, le routeur va accepter les deux préfixes, il va annoncer le nouveau mais l'ancien marchera encore, pendant la durée de vie qui était annoncée, et tout le monde sera heureux et communiquera. Mais si le changement de préfixe n'est pas planifié ? Par exemple, si le routeur obtient lui-même le préfixe dynamiquement (par exemple par le DHCP-PD du RFC 9915) puis qu'il redémarre et qu'il n'avait pas noté le préfixe précédent ? Il ne pourra alors pas continuer à router l'ancien préfixe, que les machines du réseau local utiliseront encore pendant un certain temps, à leur grand dam.
C'est ce qui s'est passé le 19 janvier 2021 (et les jours suivants), lorsque Free a subitement renuméroté les préfixes IPv6 d'un bon nombre de clients. Free n'utilise pas DHCP-PD, je suppose que les Freebox étaient configurées par un autre procédé, en tout cas, les utilisateurs n'ont pas été prévenus. Sur le réseau local, les machines avaient acquis les deux préfixes, l'ancien, conservé en mémoire, et le nouveau. Et l'ancien préfixe ne marchait plus (n'était pas routé), entrainant plein de problèmes. (Notons que l'adresse IPv4 avait également été changée mais ce n'est pas le sujet ici.) Il a fallu redémarrer toutes les machines, pour qu'elles oublient l'ancien préfixe. Une illustration parfaite du problème qui a motivé ce RFC : SLAAC avait été prévu pour des préfixes qui changent rarement et de manière planifiée (avec réduction préalable de la durée de vie, pour que la transition soit rapide). Les surprises, qu'elles soient dues à un problème technique ou simplement au manque de planification, ne sont pas prises en compte.
À part le mode Yolo de Free, dans quelles conditions aura-t-on de ces renumérotages brutaux, ces flash-renumbering events ? Un exemple est celui où le RA qui doit annoncer la fin de l'ancien préfixe (avec une durée de vie nulle) s'est perdu (le multicast n'est pas toujours fiable). Mais, de toute façon, envoyer ce RA d'avertissement suppose de savoir qu'un nouveau préfixe a remplacé l'ancien. Or, cette information n'est pas toujours disponible. Un exemple est celui où il n'y a même pas de RA d'avertissement, car le CPE obtient son préfixe IPv6 par DHCP-PD (Prefix Delegation, RFC 9915, section 6.3), avant de le redistribuer sur le réseau local en SLAAC. Si ce CPE redémarre, et n'a pas de mémoire permanente, il va peut-être obtenir un autre préfixe via DHCP-PD, ce qui fera un flash-renumbering event sur le réseau local. (Il peut aussi y avoir désynchronisation entre la durée de vie des RA faits via SLAAC et la durée du bail DHCP. En théorie, c'est interdit, mais certains CPE où les deux protocoles sont gérés par des modules logiciels différents font cette erreur.)
La Freebox n'utilise apparemment pas DHCP-PD mais le même problème d'ignorance du préfixe précédent peut survenir si la mise à jour des box est faite par un autre moyen de synchronisation. Bref, des tas de choses peuvent aller mal, particulièrement si l'opérateur réseau est négligent (ce qui a été le cas de Free) mais même parfois s'il essaie de bien faire. À partir de là, si certaines machines du réseau local continuent à utiliser l'ancien préfixe, leurs paquets seront probablement jetés par le routeur et aucune communication ne sera possible.
Le RFC 4861 suggère, dans sa section 6.2.1, pour les durées de validité des préfixes annoncés, des valeurs très élevées (une semaine pour la durée préférée et un mois pour la durée maximale). En cas de renumérotation brutale, c'est beaucoup trop (voir aussi la section 2.2), une machine pourrait rester déconnectée pendant une semaine, voire davantage. Divers trucs permettent d'améliorer un peu les choses, mais avec d'autres inconvénients. Il n'y a pas de méthode propre pour nettoyer les machines du réseau local de la mauvaise information. Bien sûr, le mieux serait qu'il n'y ait pas de renumérotation brutale mais ne nous faisons pas d'illusions : cela arrivera et il faut des solutions pour réparer.
La section 2 du RFC analyse en détail certains aspects du problème. Ainsi, est-ce qu'on ne pourrait pas tout simplement attribuer des préfixes IP fixes aux clients ? Cela simplifierait certainement beaucoup de choses. Mais une étude récente indique qu'un tiers des FAI britanniques utilisent des préfixes dynamiques pour IPv6. C'est certainement pénible pour les clients qui veulent, par exemple, héberger un serveur. Mais c'est un état des choses qu'il va falloir traiter. Même si ces FAI changeaient leurs pratiques, des problèmes subsisteraient, par exemple avec des routeurs à la maison qui sous-alloueraient des préfixes plus spécifiques à une partie de la maison et le feraient de façon dynamique. D'autant plus que l'idéal serait que les clients aient le choix, les adresses fixes pouvant (RFC 7721) poser des problèmes de vie privée (le RFC 4941 ne fait varier que la partie de l'adresse IP spécifique à la machine). Ainsi, la DPA allemande suggère de ne pas les utiliser.
Le fond du problème est évidemment que le routeur qui émet des RA n'a aucun moyen de supprimer les préfixes anciens s'il ne les connait pas. S'ils les connaissait, cela serait trivial, en les annonçant avec une durée de vie de zéro mais attention, lisez plus loin. Dans les cas de redémarrage d'un routeur qui n'a pas de mémoire permanente, ce qui est oublié est oublié et le routeur ne peut pas dire « ce préfixe n'existe plus ». Mais même si le routeur connait les anciens préfixes, il y a un piège avec le point e) de la section 5.5.3 du RFC 4862 : on ne peut pas réduire la durée de vie en dessous de deux heures. C'est déjà mieux qu'une semaine mais c'est encore trop long. Autre piège, même une fois qu'un préfixe n'est plus utilisé pour de nouvelles communications, il peut encore servir pour répondre aux anciennes, donc est encore considéré comme valide pour ce réseau, ce qui fait qu'il n'est pas possible de communiquer avec le nouveau titulaire de ce préfixe (s'il y en a un).Par exemple ce patch Linux viole le RFC 4862 pour permettre une meilleure robustesse en cas de renumérotation.
Autre sujet sur lequel il faudrait peut-être améliorer les protocoles, l'interaction entre DHCP et SLAAC, qui reste peu spécifiée. Au minimum, le logiciel dans le routeur qui reçoit les préfixes par DHCP-PD devrait transmettre au logiciel qui envoie les RA quelles sont les durées de vie à utiliser pour qu'elles soient cohérentes avec la durée du bail DHCP.
Bon, et qu'est-ce qu'on peut faire aujourd'hui pour atténuer les conséquences du problème ? Comme dit plus haut, on pourrait n'utiliser que des préfixes fixes, mais cela ne semble pas réaliste. On pourrait surtout changer les paramètres SLAAC pour des valeurs plus réalistes, en mettant 45 minutes comme durée de vie préférée et 90 minutes comme durée maximale de validité. De telles valeurs conviendraient mieux à la grande majorité des réseaux que les valeurs du RFC 4861. En l'absence de mécanisme pour invalider rapidement les anciens préfixes, de courtes durées de vie sont préférables. Dans certains cas (si on est sûrs qu'il n'y aura pas de rénumérotation brutale et/ou si des machines sont longtemps déconnectées du réseau), des valeurs plus longues peuvent être préférables.
L'article seul
RFC 8977: Registration Data Access Protocol (RDAP) Query Parameters for Result Sorting and Paging
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : M. Loffredo (IIT-CNR/Registro.it), M. Martinelli (IIT-CNR/Registro.it), S. Hollenbeck (Verisign Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 24 janvier 2021
Le protocole RDAP, normalisé notamment dans les RFC 9082 et RFC 9083, permet de récupérer des informations structurées sur des trucs (oui, j'ai écrit « trucs ») enregistrés auprès d'un registre, par exemple des domaines auprès d'un registre de noms de domaine. Voici un RFC tout juste publié qui ajoute à RDAP la possibilité de trier les résultats et également de les afficher progressivement (paging). C'est évidemment surtout utile pour les requêtes de type « recherche », qui peuvent ramener beaucoup de résultats.
Avec des requêtes « exactes » (lookup dans le RFC 9082), le problème est moins grave. Ici, je cherche juste de l'information sur un nom de domaine et un seul :
% curl https://rdap.nic.bzh/domain/chouchen.bzh
...
"events" : [
{
"eventDate" : "2017-07-12T10:18:12Z",
"eventAction" : "registration"
},
{
"eventDate" : "2020-07-09T09:49:06Z",
"eventAction" : "last changed"
},
...
Mais si je me lançais dans une recherche plus ouverte
(search dit le RFC 9082),
avec par exemple la requête domains (notez le S
à la fin, cf. RFC 9082, section 3.2.1), le
nombre de résultats pourrait être énorme. Par exemple, si je
demandais tous les domaines en
.bzh avec
https://rdap.nic.bzh/rdap/domains?name=*.bzh,
j'aurais une réponse d'une taille conséquente. (Et je ne vous dis pas
pour .com…)
En pratique, cette requête ne fonctionnera pas car je ne connais aucun registre qui autorise les recherches RDAP aux utilisateurs anonymes. Ceux-ci ne peuvent faire que des requêtes exactes, à la fois pour épargner les ressources informatiques (cf. la section 7 du RFC sur la charge qu'impose les recherches), et pour éviter de distribuer trop d'informations à des inconnus pas toujours bien intentionnés. Pour effectuer ces recherches, il faut donc un compte et une autorisation. Autrement, vous récupérez un code 401, 403 ou bien carrément une liste vide.
Et si vous avez une telle autorisation, comment gérer une masse importante de résultats ? Avec le RDAP originel, vous récupérez la totalité des réponses, que vous devrez analyser, et ce sera à vous, client, de trier. (Si le serveur n'envoie qu'une partie des réponses, pour épargner le client et ses propres ressources, il n'a malheureusement aucun moyen de faire savoir au client qu'il a tronqué la liste.) C'est tout le but de notre RFC que de faire cela côté serveur. Des nouveaux paramètres dans la requête RDAP vont permettre de mieux contrôler les réponses, ce qui réduira les efforts du client RDAP, du serveur RDAP et du réseau, et permettra d'avoir des résultats plus pertinents.
La solution ? La section 2 de notre RFC décrit les nouveaux paramètres :
count: le client demande à être informé du nombre de trucs que contient la liste des réponses.sort: le client demande à trier les résultats.cursor: ce paramètre permet d'indiquer un endroit particulier de la liste (par exemple pour la récupérer progressivement, par itérations successives).
Par exemple,
https://example.com/rdap/domains?name=example*.com&count=true
va récupérer dans .com (si le registre de
.com acceptait cette requête…) tous les noms de
domaine dont le nom commence par example, et
indiquer leur nombre. Une réponse serait, par exemple :
"paging_metadata": {
"totalCount": 43
},
"domainSearchResults": [
...
]
(paging_metadata est expliqué plus loin.)
Pour le paramètre sort, le client peut
indiquer qu'il veut un tri, sur quel critère se fait le tri, et que
celui-ci doit être dans l'ordre croissant (a
pour ascending) ou décroissant
(d pour descending). Ainsi,
https://example.com/rdap/domains?name=*.com&sort=name
demande tous les noms en .com triés par
nom. https://example.com/rdap/domains?name=*.com&sort=registrationDate:d
demanderait tous les noms triés par date d'enregistrement, les plus
récents en premier.
L'ordre de tri dépend de la valeur JSON du résultat (comparaison
lexicographique
pour les chaînes de caractères et numérique pour les nombres), sauf
pour les adresses IP, qui
sont triées selon l'ordre des adresses et pour les dates qui sont
triées dans l'ordre chronologique. Ainsi, l'adresse
9.1.1.1 est inférieure à
10.1.1.1 (ce qui n'est pas le cas dans l'ordre
lexicographique). Le RFC fait remarquer que tous les SGBD
sérieux ont des fonctions pour traiter ce cas. Ainsi, dans
PostgreSQL, la comparaison des deux chaînes
de caractères donnera :
=> SELECT '10.1.1.1' < '9.1.1.1'; t
Alors que si les adresses IP sont mises dans une colonne ayant le
type correct (INET), on a le bon résultat :
=> SELECT '10.1.1.1'::INET < '9.1.1.1'::INET; f
Après le sort=, on trouve le nom de la
propriété sur laquelle on trie. C'est le nom d'un membre de l'objet
JSON de la réponse. Non, en fait, c'est plus compliqué que
cela. Certains membres de la réponse ne sont pas utilisables (comme
roles, qui est multi-valué) et des informations
importantes (comme registrationDate cité en
exemple plus haut) ne sont pas explicitement dans la réponse. Notre
RFC définit donc une liste de propriétés utilisables, et explique
comment on les calcule (par exempe,
registrationDate peut se déduire des
events). Plutôt que ces noms de propriétés, on
aurait tout pu faire en JSONpath ou JSON
Pointer (RFC 6901) mais ces deux syntaxes sont
complexes et longues
($.domainSearchResults[*].events[?(@.eventAction='registration')].eventDate
est le JSONPath pour registrationDate). La
mention en JSONPath du critère de tri est donc facultative.
Et, bien sûr, si le client envoie un nom de propriété qui n'existe pas, il récupérera une erreur HTTP 400 avec une explication en JSON :
{
"errorCode": 400,
"title": "Domain sorting property 'unknown' is not valid",
"description": [
"Supported domain sorting properties are:"
"'aproperty', 'anotherproperty'"
]
}
Et le troisième paramètre, cursor ? Ce RFC
fournit deux méthodes pour indiquer où on en est dans la liste des
résultats, la pagination par décalage (offset
pagination) et celle par clé (keyset
pagination, qu'on trouve parfois
citée sous le nom ambigu de cursor
pagination, qui désigne plutôt une méthode avec état sur
le serveur). Ces deux méthodes ont en commun de ne
pas nécessiter d'état du côté du serveur. La
pagination par décalage consiste à fournir un décalage depuis le
début de la liste et un nombre d'éléments désiré, par exemple
« donne-moi 3 éléments, commençant au numéro 10 ». Elle est simple à
mettre en œuvre, par exemple avec SQL :
SELECT truc FROM Machins ORDER BY chose LIMIT 3 OFFSET 9;
Mais elle n'est pas forcément robuste si la base est modifiée pendant ce temps : passer d'une page à l'autre peut faire rater des données si une insertion a eu lieu entretemps (cela dépend aussi de si la base est relue à chaque requête paginée) et elle peut être lente (surtout avec RDAP où la construction des réponses prend du temps, alors que celles situées avant le début de la page seront jetées). L'autre méthode est la pagination par clé où on indique une caractéristique du dernier objet vu. Si les données sont triées, il est facile de récupérer les N objets suivants. Par exemple en SQL :
SELECT truc FROM Machins WHERE chose > [la valeur] ORDER BY chose LIMIT 3;
Un inconvénient de cette méthode est qu'il faut un champ (ou un
ensemble de champs) ayant un ordre (et pas de duplicata). RDAP rend
cela plus difficile, en agrégeant des informations provenant de
différentes tables (cf. l'annexe B du RFC). (Voir des descriptions
de cette pagination par clé dans « Paginating
Real-Time Data with Keyset Pagination » ou
« Twitter
Ads API », pour Twitter.)
RDAP permet les deux méthodes, chacune ayant ses avantages et ses
inconvénients. L'annexe B du RFC explique plus en détail ces
méthodes et les choix faits. (Sinon, en dehors de RDAP, un bon
article sur le choix d'une méthode de pagination, avec leur mise en
œuvre dans PostgreSQL est « Five
ways to paginate in Postgres, from the basic to the
exotic ».) Pour RDAP, un
https://example.com/rdap/domains?name=*.com&cursor=offset:9,limit:3
récupérerait une page de trois éléments, commençant au dixième, et
https://example.com/rdap/domains?name=*.com&cursor=key:foobar.com
trouverait les noms qui suivent foobar.com.
Notez qu'en réalité, vous ne verrez pas directement le décalage, la
clé et la taille de la page dans l'URL : ils sont encodés pour
permettre d'utiliser des caractères quelconques (et aussi éviter que
le client ne les bricole, il est censé suivre les liens, pas
fabriquer les URL à la main). Les exemples du RFC utilisent
Base64 pour l'encodage, en notant qu'on peut
certainement faire mieux.
La capacité du serveur à mettre en œuvre le tri et la pagination
s'indiquent dans le tableau rdapConformance
avec les chaînes sorting et
paging (qui sont désormais dans le
registre IANA). Par exemple (pagination mais pas tri) :
"rdapConformance": [
"rdap_level_0",
"paging"
]
Il est recommandé que le serveur documente ces possibilités dans
deux nouveaux éléments qui peuvent être présents dans une réponse,
sorting_metadata et
paging_metadata. Cela suit les principes
d'auto-découverte de HATEOAS. Dans la
description sorting_metadata, on a
currentSort qui indique le critère de tri
utilisé, et availableSorts qui indique les
critères possibles. Chaque critère est indiqué avec un nom
(property), le fait qu'il soit le critère par
défaut ou pas, éventuellement une expression JSONPath
désignant le champ de la réponse utilisé et enfin une série de liens
(RFC 8288) qui vont nous indiquer les URL à
utiliser. Pour paging_metadata, on a
totalCount qui indique le nombre d'objets
sélectionnés, pageSize qui indique le nombre
récupérés à chaque itération, pageNumber qui
dit à quelle page on en est et là encore les liens à suivre. Ce
pourrait, par exemple, être :
"sorting_metadata": {
"currentSort": "name",
"availableSorts": [
{
"property": "registrationDate",
"jsonPath": "$.domainSearchResults[*].events[?(@.eventAction==\"registration\")].eventDate",
"default": false,
"links": [
{
"value": "https://example.com/rdap/domains?name=example*.com&sort=name",
"rel": "alternate",
"href": "https://example.com/rdap/domains?name=example*.com&sort=registrationDate",
"title": "Result Ascending Sort Link",
"type": "application/rdap+json"
},
{
"value": "https://example.com/rdap/domains?name=example*.com&sort=name",
"rel": "alternate",
"href": "https://example.com/rdap/domains?name=example*.com&sort=registrationDate:d",
"title": "Result Descending Sort Link",
"type": "application/rdap+json"
}
]
...
Ici, sorting_metadata nous indique que le tri
se fera sur la base du nom, mais nous donne les URL à utiliser pour
trier sur la date d'enregistrement. Quant à la pagination, voici un
exemple de réponse partielle, avec les liens permettant de récupérer
la suite :
"paging_metadata": {
"totalCount": 73,
"pageSize": 50,
"pageNumber": 1,
"links": [
{
"value": "https://example.com/rdap/domains?name=example*.com",
"rel": "next",
"href": "https://example.com/rdap/domains?name=example*.com&cursor=wJlCDLIl6KTWypN7T6vc6nWEmEYe99Hjf1XY1xmqV-M=",
"title": "Result Pagination Link",
"type": "application/rdap+json"
}
]
L'idée de permettre le contrôle des réponses via des nouveaux
paramètres (count, sort et
cursor, présentés ci-dessus), vient entre autre
du protocole OData. Une autre solution aurait
été d'utiliser des en-têtes HTTP (RFC 7231). Mais
ceux-ci ne sont pas contrôlables depuis le
navigateur, ce qui aurait réduit le nombre de
clients possibles. Et puis cela rend plus difficile
l'auto-découverte des extensions, qui est plus pratique via des
URL, cette
auto-découverte étant en général considérée comme une excellente
pratique REST.
Il existe à l'heure actuelle une seule mise en œuvre de ce RFC
dans le RDAP non public de .it.
La documentation est en ligne.
Notre RFC permet donc de ne récupérer qu'une partie des objets qui correspondent à la question posée. Si on veut plutôt récupérer une partie seulement de chaque objet, il faut utiliser le RFC 8982.
L'article seul
RFC 8976: Message Digest for DNS Zones
Date de publication du RFC : Février 2021
Auteur(s) du RFC : D. Wessels (Verisign), P. Barber (Verisign), M. Weinberg (Amazon), W. Kumari (Google), W. Hardaker (USC/ISI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 10 février 2021
Ce nouveau RFC normalise un mécanisme pour ajouter aux zones DNS un condensat qui permet de vérifier leur intégrité. Pourquoi, alors qu'on a TSIG, TLS et SSH pour les transporter, et PGP et DNSSEC pour les signer ? Lisez jusqu'au bout, vous allez voir.
Le nouveau type d'enregistrement DNS créé par ce RFC se nomme ZONEMD et sa
valeur est un condensat de la zone. L'idée
est de permettre au destinataire d'une zone DNS de s'assurer qu'elle
n'a pas été modifiée en route. Elle est complémentaire des
différentes techniques de sécurité citées plus haut. Contrairement à
DNSSEC, elle protège une zone, pas un enregistrement.
Revenons un peu sur la terminologie. Une zone (RFC 8499, section 7) est un ensemble d'enregistrements servi par les mêmes serveurs. Ces serveurs reçoivent typiquement la zone depuis un maître, et utilisent souvent la technique AXFR (RFC 5936) pour cela. Ce transfert est souvent (mais pas toujours) protégé par le mécanisme TSIG (RFC 8945), qui permet de s'assurer que la zone est bien celle servie par le maître légitime. D'autres techniques de transfert peuvent être utilisées, avec leur propre mécanisme de sécurité. On peut par exemple utiliser rsync sur SSH. Les zones sont souvent stockées dans des fichiers de zone, du genre :
@ IN SOA ns4.bortzmeyer.org. hostmaster.bortzmeyer.org. (
2018110902
7200
3600
604800
43200 )
IN NS ns4.bortzmeyer.org.
IN NS ns2.bortzmeyer.org.
IN NS ns1.bortzmeyer.org.
IN NS puck.nether.net.
IN MX 0 mail.bortzmeyer.org.
IN TXT "v=spf1 mx -all"
IN A 92.243.4.211
IN AAAA 2001:4b98:dc0:41:216:3eff:fe27:3d3f
www IN CNAME ayla.bortzmeyer.org.
sub IN NS toto.example.
Donc, les motivations de notre RFC sont d'abord le désir de pouvoir vérifier une zone après son transfert, indépendamment de la façon dont elle a été transférée. Une zone candidate évidente est la racine du DNS (cf. section 1.4.1), publiquement disponible, et que plusieurs résolveurs copient chez eux (RFC 8806). Ensuite, l'idée est de disposer d'un contrôle minimum (une somme de contrôle) pour détecter les modifications accidentelles (le rayon cosmique qui passe). Un exemple de modification accidentelle serait une troncation de la fin de la zone, d'habitude difficile à détecter puisque les fichiers de zone n'ont pas de marques de fin (contrairement à, par exemple, un fichier JSON). Notez que la « vraie » vérification nécessite DNSSEC. Si la zone n'est pas signée, le mécanisme décrit dans ce RFC ne fournit que la somme de contrôle : c'est suffisant contre les accidents, pas contre les attaques délibérées. Mais, de toute façon, tous les gens sérieux utilisent DNSSEC, non ?
Il existe de nombreuses techniques qui fournissent un service qui ressemble plus ou moins à un des deux services mentionnés ci-dessus. L'un des plus utilisés est certainement TSIG (RFC 8945). Beaucoup de transferts de zone (cf. RFC 5936) sont ainsi protégés par TSIG. Il a l'inconvénient de nécessiter un secret partagé entre serveur maître et serveur esclave. SIG(0) (RFC 2931) n'a pas cet inconvénient mais n'est quasiment jamais mis en œuvre. Toujours dans la catégories des protections du canal, on a TLS et l'IETF travaille sur un mécanisme de protection des transferts par TLS, mais on peut aussi imaginer d'utiliser simplement DoT (RFC 7858).
Ceci dit, toutes ces techniques de protection du canal ont le même défaut : une fois le transfert fait, elles ne servent plus à rien. Pas moyen de vérifier si le fichier est bien le fichier authentique. Ainsi, un serveur faisant autorité qui charge une zone à partir d'un fichier sur le disque ne peut pas vérifier que ce fichier n'a pas été modifié. Bien sûr, les protections fournies par le système de fichiers offrent certaines garanties, mais pas parfaites, par exemple si un programme a planté et laissé le fichier dans un état invalide (oui, ça s'est déjà produit). Bref, on préférerait une protection des données et pas seulement du canal.
Alors, pourquoi ne pas simplement utiliser DNSSEC,
qui fournit effectivement cette sécurité des données ? Le problème
est que dans une zone, seules les informations faisant autorité sont
signées. Les délégations (vers un sous-domaine, comme
sub.bortzmeyer.org dans l'exemple plus haut) et
les colles (adresses IP des serveurs de noms qui sont dans la zone
qu'ils servent) ne sont pas signés. Pour une zone comme la racine,
où il n'y a quasiment que des délégations, ce serait un problème. Et
ce serait encore pire avec les zones qui utilisent NSEC3 (RFC 5155) avec opt-out puisqu'on
ne sait même plus si un nom non-signé existe ou pas. Donc, DNSSEC
est très bien, mais ne suffit pas pour notre cahier des charges.
On a d'autres outils pour la sécurité des données, le plus évident étant PGP (RFC 9580). D'ailleurs, ça tombe bien, la racine des noms de domaine est déjà distribuée avec une signature PGP :
% wget -q https://www.internic.net/domain/root.zone % wget -q https://www.internic.net/domain/root.zone.sig % gpg --verify root.zone.sig root.zone gpg: Signature made Wed Jan 13 08:22:50 2021 CET gpg: using DSA key 937BB869E3A238C5 gpg: Good signature from "Registry Administrator <nstld@verisign-grs.com>" [unknown] gpg: WARNING: This key is not certified with a trusted signature! gpg: There is no indication that the signature belongs to the owner. Primary key fingerprint: F0CB 1A32 6BDF 3F3E FA3A 01FA 937B B869 E3A2 38C5
Notez que Verisign utilise une signature détachée du fichier. Cela permet que le fichier reste un fichier de zone normal et chargeable, mais cela casse le lien entre la signature et le fichier. Bref, cela ne résout pas complètement le problème. (Les historiens et historiennes s'amuseront de noter qu'une autre solution, très proche de celle de notre RFC, figurait déjà dans le RFC 2065, mais qu'elle n'avait eu aucun succès.)
Bon, passons maintenant à la solution (section 1.3). On l'a dit,
le principe est d'avoir un enregistrement de type
ZONEMD qui contient un
condensat de la zone. Il est généré par le
responsable de la zone et quiconque a téléchargé la zone, par
quelque moyen que ce soit, peut vérifier qu'il correspond bien à la
zone. En prime, si la zone est signée avec DNSSEC, on peut
vérifier que ce ZONEMD est authentique.
Du fait que ce condensat couvre l'intégralité de la zone, il faut
le recalculer entièrement si la zone change, si peu que ce
soit. Cette solution ne convient donc pas aux grosses zones très
dynamiques (comme
.fr). Dans le futur, le
ZONEMD est suffisamment extensible pour que des
solutions à ce problème lui soient ajoutées. En attendant,
ZONEMD convient mieux pour des zones comme la
racine (rappel, elle est disponible en ligne),
ou comme la zone d'une organisation. La
racine est un cas particulièrement
intéressant car elle est servie par un grand nombre de serveurs,
gérés par des organisations différentes. Sans compter les gens qui
la récupèrement localement (RFC 8806). Le
contrôle de son intégrité est donc crucial. Il y a une discussion en
ce moment au sein du RZERC pour proposer l'ajout
de ZONEMD dans la racine.
Pour la zone d'une organisation, notre RFC rappelle qu'il est
recommandé d'avoir une diversité des serveurs de nom, afin d'éviter
les SPOF et que c'est donc une bonne idée
d'avoir des serveurs esclaves dans d'autres organisations. Comme
cette diversité peut entrainer des risques (le serveur esclave
est-il vraiment honnête ? le transfert s'est-il bien passé ?), là
aussi, la vérification de l'intégrité s'impose. Autre scénario
d'usage, les distributions de fichiers de zone, comme le fait
l'ICANN avec CZDS ou comme le fait le
registre du .ch (téléchargez
ici). D'une manière générale, ce contrôle supplémentaire ne
peut pas faire de mal.
Plongeons maintenant dans les détails techniques avec la section
2 du RFC, qui explique le type d'enregistrement
ZONEMD (code
63). Il se trouve forcément à l'apex
de la zone. Il comprend quatre champs :
- Numéro de série, il permet de s'assurer qu'il couvre bien la zone qu'on veut vérifier (dont le numéro de série est dans le SOA).
- Plan, la méthode utilisée pour génerer le condensat. Pour l'instant, un seul plan est normalisé, nommé Simple, il fonctionne par un calcul sur l'entièreté de la zone. On peut ajouter des plans au registre, selon la procédure « Spécification nécessaire ».
- Algorithme, est l'algorithme de condensation utilisé, SHA-384 ou SHA-512 à l'heure actuelle mais on pourra en ajouter d'autres au registre (« Spécification nécessaire », là encore).
- Et le condensat lui-même.
Question présentation dans les fichiers de zone, ça ressemble à :
example.com. 86400 IN ZONEMD 2018031500 1 1 (
FEBE3D4CE2EC2FFA4BA99D46CD69D6D29711E55217057BEE
7EB1A7B641A47BA7FED2DD5B97AE499FAFA4F22C6BD647DE )
Ici, le numéro de série est 2018031500, le plan 1 (Simple) et l'algorithme de condensation SHA-384.
Il peut y avoir plusieurs ZONEMD dans un
fichier, ils doivent avoir des couples {Plan, Algorithme}
différents. (Le but est de fournir plusieurs techniques de
vérification, et de permettre de passer en souplesse de l'une à
l'autre.)
Comment exactement se fait le calcul du condensat ? La section 3
le détaille. D'abord, on supprime de la zone les éventuels
ZONEMD existants, et on place un
ZONEMD bidon (il en faut un, en cas de
signature DNSSEC, pour éviter de casser la signature). Si on a
DNSSEC, on signe alors la zone (et il faudra re-faire le
RRSIG du ZONEMD après), on
canonicalise la zone (le condensat est calculé sur le format « sur
le câble » pas sur le format texte), et on calcule ensuite le
condensat sur la concaténation des enregistrements (à l'exclusion du
ZONEMD bidon, qui avait été mis pour DNSSEC, et
de sa signature). On génère ensuite le vrai ZONEMD, puis, si on a
DNSSEC, on recalcule sa signature. Autant dire que vous ne le ferez
pas à la main ! L'endroit logique pour faire ce calcul du
ZONEMD est dans le logiciel qui fait les
signatures DNSSEC. Notez que, contrairement à DNSSEC, tous les
enregistrements sont utilisés, y compris ceux qui ne font pas
autorité comme les délégations et les colles.
Un mot sur la canonicalisation. Tout calcul d'un condensat cryptographique doit se faire sur des données canonicalisées, c'est-à-dire mises sous une forme canonique, une forme unique et standardisée. Comme le changement d'un seul bit change complètement le condensat, il ne faut pas laisser des petites variations de détail (par exemple, pour le DNS, entre noms comprimés et non-comprimés) à l'imagination de chaque programmeur. Voilà pourquoi notre RFC spécifie rigoureusement une forme canonique (par exemple, les noms ne doivent pas être comprimés).
La vérification se fait de la même façon (section 4 du RFC). On
vérifie que le numéro de série est le même, on
canonicalise, on concatène, on condense et on vérifie qu'on trouve
bien ce qui était dans le ZONEMD. (S'il y a
plusieurs ZONEMD, le premier qui marche
suffit.) Le mieux est évidemment de tout valider avec DNSSEC, en
plus.
La section 6 de notre RFC revient sur la sécurité du
ZONEMD, ce qu'il garantit et ce qu'il ne
garantit pas. D'abord, le point le plus important : sans DNSSEC,
ZONEMD n'est qu'une somme de
contrôle, il garantit l'intégrité mais pas
l'authenticité, et il ne protège donc que contre les modifications
accidentelles (ce qui est déjà très bien !) Le bit flipping sera détecté mais pas
l'attaque délibérée et soignée. Ainsi, sans DNSSEC, un attaquant
n'aurait, par exemple, qu'à retirer l'enregistrement
ZONEMD de la zone avant de faire ses
modifications (une attaque par repli).
D'autre part, les algorithmes de cryptographie vieillissent (RFC 7696)
et
ZONEMD ne peut donc pas garantir de sécurité
sur le long terme. D'ailleurs, sur le long terme, on n'aurait
probablement plus les clés DNSSEC disponibles.
Plus drôle, ZONEMD permet, comme toute
technique de sécurité, de nouveaux modes de déni de service, comme
l'a déjà expérimenté tout utilisateur de la cryptographie. Comme le
condensat est strictement binaire (il colle aux données, ou pas du
tout), la zone entière peut être considérée comme invalide si un
problème modifie ne serait-ce qu'un seul bit. Le souci de
l'intégrité de la zone et celui de sa disponibilité sont ici
en conflit, et le responsable de la zone doit choisir.
Si vous aimez les comparatifs de performance, la section 7 du RFC
discute de chiffres. Par exemple, une zone de 300 000
enregistrements a été ZONEMDifiée en deux
secondes et demi sur un serveur ordinaire. C'est encore trop lent
pour être utilisable sur des zones comme
.com mais cela montre
que des grandes zones qui ne changent pas trop souvent peuvent être
protégées.
Et question mises en œuvre, ça se passe comment ? J'ai testé
l'excellente bibliothèque ldns. Le code avec
calcul de ZONEMD devrait être publié dans une
version officielle en 2021 mais, en attendant,
c'est déjà dans git, en https://github.com/NLnetLabs/ldnsZONEMD (ici, avec la zone d'exemple montrée
au début de cet article). On génère une clé, puis on signe, avec
calcul de ZONEMD :
% ./ldns-keygen -a ED25519 bortzmeyer.org Kbortzmeyer.org.+015+00990 % ./ldns-signzone -o bortzmeyer.org -z 1:1 bortzmeyer-org.zone Kbortzmeyer.org.+015+00990 % cat bortzmeyer-org.zone.signed ... bortzmeyer.org. 3600 IN ZONEMD 2018110902 1 1 b1af60c3c3e88502746cf831d2c64a5399c1e3c951136d79e63db2ea99898ba9f2c4f9b29e6208c09640aaa9deafe012 bortzmeyer.org. 3600 IN RRSIG ZONEMD 15 2 3600 20210215174229 20210118174229 990 bortzmeyer.org. FJ98//KDBF/iMl1bBkjGEBT3eeuH/rJDoGRDAoCBEocudLbA7F/38qwLpsPkr7oQcgbkLzhyHA7BXG/5fAwkAg==
(L'argument 1:1 signifie plan Simple et
algorithme SHA-384.) On peut ensuite vérifier la zone. Si elle a
un enregistrement ZONEMD, il est inclus dans
la vérification :
% ./ldns-verify-zone bortzmeyer-org.zone.signed Zone is verified and complete
Si je modifie une délégation (qui n'est pas protégée par DNSSEC mais
qui l'est par ZONEMD) :
% ./ldns-verify-zone bortzmeyer-org.zone.signed There were errors in the zone
Il y a aussi les dns-tools des gens
du .cl. Pour
BIND, c'est en
cours de réflexion. Apparemment,
Unbound y travaille également. Voir aussi
l'exposé
de Verisign à la réunion OARC de juillet 2022. Des tests sont en cours
(septembre 2022).
Depuis, un bon article de Jan-Piet Mens a expliqué le fonctionnement pratique de ZONEMD, et les outils utilisables.
L'article seul
RFC 8975: Network Coding for Satellite Systems
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : N. Kuhn (CNES), E. Lochin (ENAC)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF nwcrg
Première rédaction de cet article le 23 janvier 2021
Prenons de la hauteur (c'est le cas de le dire). Les communications via satellite posent des tas de problèmes techniques. L'envoi de chaque bit coûte cher, et dans certains cas d'usage, les pertes de paquets sont nombreuses, et on cherche donc à optimiser. Ce RFC explique comment on peut utiliser le network coding pour améliorer les performances de ces liaisons. Mais c'est encore un travail en cours.
Le network coding est un mécanisme d'encodage des données qui combine différentes données dans une même chaîne de bits, avant de les re-séparer à l'autre bout. Dans le cas le plus trivial on fait un XOR des données. Mais il y a d'autres moyens comme la convolution. Le network coding n'est pas un algorithme unique mais une classe de méthodes. Ces méthodes permettent de faire voyager davantage de données sur un même canal et/ou de diminuer le délai de transmission total, en ajoutant de la redondance. Le nom de network coding venait de l'encodage réalisé dans le réseau, pour tenir compte de sa topologie. Mais on peut utiliser des techniques du même genre de bout en bout (c'est le cas de FEC, dans le RFC 5052). (Je vous laisse en apprendre davantage sur Wikipédia). La question de l'encodage des données étant complexe, je vous renvoie également au RFC 8406 qui décrit le travail du groupe Network Coding de l'IRTF et définit les notions importantes.
Une idée de la latence dans une liaison satellite ? Le RFC observe que le RTT est typiquement de 0,7 secondes (deux passages par le satellite, la limite de la vitesse de la lumière, et le temps de traitement).
On peut se servir des satellites pour des tas de choses dans le domaine des télécommunications mais ce RFC se focalise sur l'accès à l'Internet par satellite, tel que normalisé par l'ETSI dans « Digital Video Broadcasting (DVB); Second Generation DVB Interactive Satellite System (DVB-RCS2); Part 2: Lower Layers for Satellite standard ». (Le RFC recommande également l'article de Ahmed, T., Dubois, E., Dupe, JB., Ferrus, R., Gelard, P., et N. Kuhn, « Software-defined satellite cloud RAN ».)
Le RFC décrit des scénarios où le network coding permet de gagner en capacité et en latence effective, en encodant plus efficacement les communications. Par exemple, en combinant le trafic de deux utilisateurs, on obtient parfois une quantité de données à transmettre qui est inférieure à celle de deux transmissions séparées, économisant ainsi de la capacité. Le RFC cite également l'exemple du multicast où, lorsqu'un des destinataires n'a pas reçu un paquet, on peut, pour éviter de faire attendre tout le monde, utiliser le network coding pour ré-envoyer les données en même temps que la suite du transfert. Là encore, la combinaison de toutes les données fait moins d'octets que lors de transmissions séparées. Cela pourrait s'adapter à des protocoles multicast comme NORM (RFC 5740) ou FLUTE (RFC 6726).
Le network coding permet également d'ajouter de la redondance aux données, sinon gratuitement, du moins à un « coût » raisonnable. Cela peut servir pour les cas de pertes de données comme le précédent. Un autre cas de perte est celui où la liaison satellite marche bien mais c'est tout près de l'utilisateur, par exemple dans son WiFi, que les paquets se perdent. Vu la latence très élevée des liaisons satellite, réémettre a des conséquences très désagréables sur la capacité effective (et sur le délai total). Une solution traditionnellement utilisée était le PEP (qui pose d'ailleurs souvent des problèmes de neutralité). Vous pouvez voir ici un exemple où le résultat est plutôt bon. Mais avec le chiffrement systématique, ces PEP deviennent moins efficaces. Cela redonne toute son importance au network coding.
Enfin, des pertes de paquets, avec leurs conséquences sur la latence car il faudra réémettre, se produisent également quand un équipement terminal passe d'une station de base à l'autre. Là encore, le network coding peut permettre d'éviter de bloquer le canal pendant la réémission.
Tout cela ne veut pas dire que le network coding peut être déployé immédiatement partout et va donner des résultats mirifiques. La section 4 du RFC décrit les défis qui restent à surmonter. Par exemple, les PEP (RFC 3135) ont toujours un rôle à jouer dans la communication satellitaire mais comment combiner leur rôle dans la lutte contre la congestion avec le network coding ? Faut-il réaliser cet encodage dans le PEP (RFC 9265) ? D'autre part, le network coding n'est pas complètement gratuit. Comme tout ajout de redondance, il va certes permettre de rattrapper certaines pertes de paquet, mais il occupe une partie du réseau. Et dans quelle couche ajouter cette fonction ? (Les couches hautes ont l'avantage de fenêtres - le nombre d'octets en transit - plus grandes, alors que les couches basses ne voient pas plus loin que le bout du paquet.)
Outre l'utilisation de satelittes pour la connectivité Internet des Terriens, il y a aussi une utilisation des communications spatiales pour échanger avec des vaisseaux lointains. La latence très élevée et l'indisponibilité fréquente de la liaison posent des défis particuliers. C'est ce qu'on nomme le DTN (Delay/Disruption Tolerant Network, décrit dans le RFC 4838). Le network coding peut aussi être utilisé ici, comme présenté dans l'article de Thai, T., Chaganti, V., Lochin, E., Lacan, J., Dubois, E., et P. Gelard, « Enabling E2E reliable communications with adaptive re-encoding over delay tolerant networks ».
Et, comme le rappelle la section 9 du RFC, il faut aussi tenir compte du chiffrement, qui est évidemment obligatoire puisque les liaisons avec les satellites peuvent trop facilement être écoutées.
Merci à Nicolas Kuhn et Emmanuel Lochin pour leur relecture attentive, sans laquelle il y aurait bien plus d'erreurs. (Je me suis aventuré très en dehors de mon domaine de compétence.) Les erreurs qui restent sont évidemment de mon fait.
L'article seul
RFC 8973: DDoS Open Threat Signaling (DOTS) Agent Discovery
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : M. Boucadair (Orange), T. Reddy (McAfee)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 13 janvier 2021
Le protocole DOTS, normalisé dans les RFC 8811, RFC 9132 et RFC 8783, sert à coordonner la réponse à une attaque par déni de service, entre la victime de l'attaque (le client DOTS) et un service d'atténuation de l'attaque (le serveur DOTS). Mais comment le client trouve-t-il son serveur ? Il peut y avoir une configuration manuelle, mais ce RFC propose aussi des moyens automatiques, basés sur un choix de plusieurs techniques, dont DHCP et NAPTR.
Attention, cela permet de trouver le serveur, mais pas le fournisseur du service d'atténuation. Car il faut un accord (souvent payant) avec ce fournisseur, et un échange de mécanismes d'authentification. Cette partie doit se faire manuellement. Le protocole de notre RFC prend ensuite le relais.
Notez aussi qu'il n'y a pas un seul moyen de découverte du serveur. La section 3 du RFC explique en effet que, vu la variété des cas d'utilisation de DOTS, on ne peut pas s'en tirer avec un seul mécanisme. Parfois le client a un CPE géré par le FAI, sur lequel on peut s'appuyer pour trouver le serveur DOTS, et parfois pas. Parfois, il faudra utiliser les résolveurs DNS d'un opérateur et parfois ce ne sera pas nécessaire. Parfois l'atténuateur est le FAI et parfois pas. Bref, il faut plusieurs solutions.
Voyons d'abord la procédure générale (section 4). Personnellement, je pense que le client DOTS doit donner la priorité aux configurations manuelles (DOTS est un système de sécurité, un strict contrôle de ce qui se passe est préférable). Mais le RFC ne décrit pas les choses ainsi. Il expose trois mécanismes, le premier, qualifié de configuration explicite, étant composé de deux techniques très différentes, la configuration manuelle ou bien DHCP. À noter au passage que la configuration manuelle peut indiquer le nom ou l'adresse IP mais, si elle indique l'adresse IP, le nom sera quand même obligatoire car il servira pour la vérification du certificat.
L'ordre des préférences entre ces mécanismes est imposé, pour que le résultat de la découverte soit prédictible. D'abord l'explicite (manuel ou DHCP, section 5), puis la résolution de service (section 6) puis la découverte de service (section 7).
Première technique automatique à utiliser, DHCP (section 5). Ce protocole va être utilisé pour récupérer le nom du serveur DOTS (le nom et pas seulement l'adresse IP car on en aura besoin pour authentifier la session TLS). Avec DHCPv6 (RFC 9915), l'option DHCP pour récupérer le nom est 141 en IPv6 et 147 pour IPv4. Une autre option permet de récupérer les adresses IP du serveur DOTS.
Deuxième technique, la résolution de service. Il faut partir d'un
nom, qui peut être configuré manuellement ou bien obtenu par
DHCP. Ce n'est pas le nom du serveur DOTS, contrairement au cas en
DHCP pur, mais celui du domaine dans lequel le client DOTS se
« trouve ». On va alors utiliser S-NAPTR (RFC 3958) sur ce
nom, pour obtenir les noms des serveurs. L'étiquette à utiliser est
DOTS pour le service (enregistré
à l'IANA) et signal (RFC 9132) ou data (RFC 8783) pour le protocole (également
à l'IANA). Par exemple si le client DOTS est dans le domaine
example.net, il va faire une requête DNS de type NAPTR. Si le
domaine comportait un enregistrement pour le service DOTS, il est
choisi, et on continue le processus (compliqué !) de NAPTR
ensuite. Si on cherche le serveur pour le protocole de
signalisation, on pourrait avoir successivement quatre requêtes
DNS :
example.net. IN NAPTR 100 10 "" DOTS:signal.udp "" signal.example.net. signal.example.net. IN NAPTR 100 10 "s" DOTS:signal.udp "" _dots-signal._udp.example.net. _dots-signal._udp.example.net. IN SRV 0 0 5000 a.example.net. a.example.net. IN AAAA 2001:db8::1
Troisième technique, la découverte de service (DNS-SD) du RFC 6763. On cherche alors un enregistrement de
type PTR dans _dots-signal.udp.example.net. Il
nous donnera un nom pour lequel on fera une requête
SRV.
DOTS servant en cas d'attaque, il faut prévoir la possibilité que l'attaquant tente de perturber ou de détourner ce mécanisme de découverte du serveur. Par exemple, on sait que DHCP n'est pas spécialement sécurisé (euphémisme !). D'autre part, DOTS impose TLS, il faut donc un nom à vérifier dans le certificat (oui, on peut mettre des adresses IP dans les certificats mais c'est rare). Quant aux techniques reposant sur le DNS, le RFC conseille d'utiliser DNSSEC, ce qui semble la moindre des choses pour une technique de sécurité. Il suggère également de faire la résolution DNS via un canal sûr par exemple avec DoT (RFC 7858) ou DoH (RFC 8484).
Apparemment, il existe au moins une mise en œuvre de DOTS qui inclut les procédures de découverte de notre RFC, mais j'ignore laquelle.
L'article seul
RFC 8972: Simple Two-Way Active Measurement Protocol Optional Extensions
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : G. Mirsky, X. Min (ZTE Corp), H. Nydell (Accedian Networks), R. Foote (Nokia), A. Masputra (Apple), E. Ruffini (OutSys)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 22 janvier 2021
Le protocole STAMP, normalisé dans le RFC 8762, est un protocole pour piloter des mesures de performance vers un réflecteur qui renverra les paquets de test. Ce nouveau RFC étend STAMP pour ajouter un identificateur de session, et la possibilité d'ajouter des tas d'options sous forme de TLV.
Commençons par l'identificateur de session. Une session STAMP est normalement identifiée par le tuple classique {protocole (forcément UDP), adresse IP source, adresse IP destination, port source, port destination}. Ce n'est pas toujours pratique donc notre RFC ajoute un identificateur explicite, le SSID (STAMP Session Identifier). Il fait deux octets et est choisi par l'envoyeur. Mais où le mettre dans le paquet ? Le format original prévoyait qu'une partie du paquet STAMP soit composée de zéros, et c'est dans cette partie qu'on logera le SSID. Donc, si, après l'estimation de l'erreur de mesure, on trouve deux octets qui ne sont pas nuls, c'est le SSID.
La section 4 liste les TLV qui peuvent désormais être ajoutés aux paquets STAMP. Ces TLV sont situés à la fin du paquet STAMP. Ils commencent par une série de bits qui indiquent si le réflecteur connait le TLV en question, et si le réflecteur a détecté des problèmes par exemple un TLV à la syntaxe incorrecte (cf. le registre IANA). Les principaux TLV sont :
- Le type 1 permet de faire du remplissage, pour créer des paquets de la taille souhaitée,
- Le type 2 demande au réflecteur des informations sur son adresse MAC et autres identificateurs,
- Le type 3 demande une estampille temporelle (avec en prime indication de la méthode de synchronisation d'horloge utilisée, par exemple NTP),
- Le type 8 permet de vérifier l'intégrité du paquet par HMAC (voir la section 6 du RFC pour les détails),
- Etc.
Si cela ne suffit pas, d'autres types de TLV pourront être créés dans le futur et mis dans le registre IANA. La politique d'enregistrement (cf. RFC 8126) est « examen par l'IETF » pour la première moitié de la plage disponible et « premier arrivé, premier servi » ensuite.
L'article seul
RFC 8970: IMAP4 Extension: Message Preview Generation
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : M. Slusarz (Open-Xchange)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF extra
Première rédaction de cet article le 19 décembre 2020
Le protocole IMAP d'accès aux boites aux lettres (RFC 3501) continue à évoluer et reçoit de nouvelles extensions. Celle normalisée dans ce RFC permet au client IMAP, le MUA, de ne récupérer qu'une partie du message, afin d'afficher un avant-gout de celui-ci à l'utilisateur humain, qui pourra ainsi mieux choisir s'il veut lire ce message ou pas.
Il y a déjà des clients de
messagerie qui présentent le début du message mais, sans
l'extension de ce RFC, cela nécessite de tout récupérer (un
FETCH BODYSTRUCTURE pour savoir quelle partie
MIME récupérer, suivi d'un FETCH
BODY, et sans possibilité de les exécuter en parallèle)
avant de ne sélectionner qu'une partie. Au contraire, avec
l'extension PREVIEW (« avant-gout »), c'est le
serveur IMAP qui va sélectionner cet avant-gout. Avantages : une
présélection qui est identique sur tous les clients, moins de
travail pour le client et surtout moins de données
transmises. Avant, le client était forcé de récupérer beaucoup de
choses car il ne pouvait pas savoir à l'avance combien d'octets
récolter avant de générer l'avant-gout. Si le message était du
texte brut, OK, mais si c'était de
l'HTML, il
pouvait être nécessaire de ramasser beaucoup d'octets de formatage
et de gadgets avant d'en arriver au vrai contenu. (Ou bien, il
fallait procéder progressivement, récupérant une partie du message,
puis, si nécessaire, une autre, ce qui augmentait la latence.)
Donc, concrètement, comment ça se passe ? La section 3 de notre
RFC décrit l'extension en détail. Elle a la forme d'un attribut
PREVIEW qui suit la commande
FETCH (RFC 3501, section
6.4.5). Voici un exemple, la commande étant étiquetée
MYTAG01 :
Client : MYTAG01 FETCH 1 (PREVIEW) Serveur : * 1 FETCH (PREVIEW "Bonjour, voulez-vous gagner plein d'argent rapidement ?") MYTAG01 OK FETCH complete.
Idéalement, le serveur renvoie toujours le même avant-gout pour un message donné (mais le RFC ne l'impose pas car cela peut être difficile dans certains cas, par exemple en cas de mise à jour du logiciel du serveur, qui change l'algorithme de génération des avant-gouts).
La syntaxe formelle
de l'attribut PREVIEW est
en section 6 du RFC.
Le format de l'avant-gout est forcément du texte brut, encodé en UTF-8, et ne doit pas avoir subi d'encodages baroques comme Quoted-Printable. Sa longueur est limitée à 256 caractères (caractères Unicode, pas octets, attention si vous programmez un client et que votre tampon est trop petit).
Le contenu de l'avant-gout est typiquement composé des premiers caractères du message. Cela implique qu'il peut contenir des informations privées et il ne doit donc être montré qu'aux clients qui sont autorisés à voir le message complet.
Parfois, le serveur ne peut pas générer un avant-gout, par exemple si le message est chiffré avec OpenPGP (RFC 4880) ou bien si le message est entièrement binaire, par exemple du PNG. Dans ces cas, le serveur est autorisé à renvoyer une chaîne de caractères vide.
Si le serveur génère un avant-gout lui-même (du genre « Image de
600x600 pixels, prise le 18 décembre 2020 », en utilisant les
métadonnées de l'image), il est recommandé
qu'il choisisse la langue indiquée par
l'extension LANGUAGE (RFC 5255).
Comme l'avant-gout n'est pas forcément indispensable pour l'utilisateur, le RFC suggère (section 4) de le charger en arrière-plan, en affichant la liste des messages sans attendre tous ces avant-gouts.
Le serveur IMAP qui sait générer ces avant-gouts l'annonce via la
capacité PREVIEW, qui est notée dans le
registre des capacités. Voici un exemple :
Client :
MYTAG01 CAPABILITY
Serveur :
* CAPABILITY IMAP4rev1 PREVIEW
MYTAG01 OK Capability command completed.
Client :
MYTAG02 FETCH 1 (RFC822.SIZE PREVIEW)
Serveur :
* 1 FETCH (RFC822.SIZE 5647 PREVIEW {200}
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Curabitur aliquam turpis et ante dictum, et pulvinar dui congue.
ligula nullam
)
MYTAG02 OK FETCH complete.
Attention si vous mettez en œuvre cette extension, elle nécessite davantage de travail du serveur, donc un client méchant pourrait surcharger ledit serveur. Veillez bien à authentifier les clients, pour retrouver le méchant (section 7 du RFC).
L'article seul
RFC 8968: Babel Routing Protocol over Datagram Transport Layer Security
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : A. Decimo (IRIF, University of Paris-Diderot), D. Schinazi (Google LLC), J. Chroboczek (IRIF, University of Paris-Diderot)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 12 janvier 2021
Le protocole de routage Babel, normalisé dans le RFC 8966, n'offre par défaut aucune sécurité. Notamment, il n'y a aucun moyen d'authentifier un routeur voisin, ni de s'assurer que les messages suivants viennent bien de lui. Sans même parler de la confidentialité de ces messages. Si on veut ces services, ce RFC fournit un moyen : sécuriser les paquets Babel avec DTLS.
La sécurité est évidemment souhaitable pour un protocole de routage. Sans elle, par exemple, une méchante machine pourrait détourner le trafic. Cela ne veut pas dire qu'on va toujours employer une solution de sécurité. Babel (RFC 8966) est conçu entre autres pour des réseaux peu ou pas gérés, par exemple un événement temporaire où chacun apporte son PC et où la connectivité se fait de manière ad hoc. Dans un tel contexte, déployer de la sécurité ne serait pas facile. Mais, si on y tient, Babel fournit désormais deux mécanismes de sécurité (cf. RFC 8966, section 6), l'un, plutôt simple et ne fournissant pas de confidentialité, est décrit dans le RFC 8967, l'autre, bien plus complet, figure dans notre RFC et repose sur DTLS (qui est normalisé dans le RFC 9147). DTLS, version datagramme de TLS, fournit authentification, intégrité et confidentialité.
L'adaptation de DTLS à Babel est décrite dans la section 2 du
RFC. Parmi les problèmes, le fait que DTLS soit très asymétrique
(client-serveur) alors que Babel est pair-à-pair, et le fait que
DTLS ne marche qu'en unicast alors que Babel peut
utiliser unicast ou
multicast. Donc, chaque routeur Babel doit être
un serveur DTLS, écoutant sur le port 6699
(qui n'est pas le 6696 du Babel non sécurisé). Le routeur Babel
continue à écouter sur le port non chiffré, et, lorsqu'il entend un
nouveau routeur s'annoncer en multicast, il va
tenter de communiquer en DTLS avec lui. Puisque DTLS, comme TLS, est
client-serveur, il faut décider de qui sera le client et qui sera le
serveur : le routeur de plus faible adresse sera le client (par
exemple, fe80::1:2 est inférieure à
fe80::2:1. Le serveur différencie les sessions
DTLS par le port source ou par les connection
identifiers du RFC 9146. Comme avec
le Babel non chiffré, les adresses IPv6 utilisées doivent être des
adresses locales au lien. Client et serveur doivent s'authentifier,
en suivant les méthodes TLS habituelles (chacun doit donc avoir un
certificat).
Une fois que la session DTLS est en marche, les paquets Babel
unicast passent sur cette session et sont donc
intégralement (du premier au dernier octet) protégés par le
chiffrement. Pour que la sécurité fournie par DTLS soit ne soit pas
compromise, le routeur ne doit plus envoyer à son voisin de paquets
sur le port non chiffré, à part des paquets
Hello qui sont transmis en
multicast (pour lequel DTLS ne marche pas) et qui
permettent de découvrir d'éventuels nouveaux voisins (la règle
exacte est un peu plus compliquée, regardez le RFC). On ne peut donc
plus envoyer d'information en multicast (à part
les Hello). En réception, un nœud Babel
sécurisé doit ignorer les paquets non protégés par DTLS, sauf
l'information de type Hello.
Une stricte sécurité nécessite qu'un routeur Babel sécurisé
n'accepte plus de voisins qui ne gèrent pas DTLS, et ignore donc
tous leurs paquets sauf ceux qui contiennent un
TLV Hello. Autrement,
les communications non sécurisées ficheraient en l'air la
confidentialité de l'information. Si on veut
une sécurité plus relaxée, un nœud peut faire tourner les deux versions
du protocole, sécurisée et non sécurisée, mais
alors, exige le RFC, uniquement sur des interfaces réseau différentes.
Comme toutes les fois où on rajoute des données, on risque de dépasser la MTU. La section 3 du RFC nous rappelle qu'il faut éviter d'envoyer des paquets qui seront fragmentés et donc qu'il faut éviter de fabriquer des paquets qui, après chiffrement, seraient plus gros que la MTU.
Rien n'est parfait en ce bas monde et l'ajout de DTLS, s'il résout quelques problèmes de sécurité, ne fait pas tout, et même parfois ajoute des ennuis. La section 5 du RFC rappelle ainsi qu'un méchant pourrait tenter des négociations DTLS nombreuses avec une machine afin de la faire travailler pour rien (une variante de Slowloris). Limiter le nombre de connexions par client n'aiderait pas puisqu'il pourrait toujours mentir sur son adresse IP.
Même en faisant tourner Babel sur DTLS, les messages de type
Hello peuvent toujours être envoyés sans
protection, et donc manipulés à loisir. Un routeur Babel doit donc
toujours être capable d'utiliser des Hello
unicast et protégés.
Et puis bien sûr, limitation classique de TLS, authentifier un routeur voisin et sécuriser la communication avec lui ne signifie pas que ce voisin est honnête ; il peut toujours mentir, par exemple en annonçant des routes vers des préfixes qu'il ne sait en fait pas joindre.
À ma connaissance, il n'existe pas encore de mise en œuvre de ce RFC.
L'article seul
RFC 8967: Message Authentication Code (MAC) Authentication for the Babel Routing Protocol
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : C. Dô, W. Kołodziejak, J. Chroboczek (IRIF, University of Paris-Diderot)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 12 janvier 2021
Le protocole de routage Babel, normalisé dans le RFC 8966, avait à l'origine zéro sécurité. N'importe quelle machine pouvait se dire routeur et annoncer ce qu'elle voulait. Le RFC 7298 avait introduit un mécanisme d'authentification. Ce nouveau RFC le remplace avec un nouveau mécanisme. Chaque paquet est authentifié par HMAC, et les routeurs doivent donc partager une clé secrète.
Comme, par défaut, Babel croit aveuglément ce que ses voisins lui racontent, un méchant peut facilement, par exemple, détourner du trafic (en annonçant une route de plus forte préférence). Le problème est bien connu mais n'a pas de solution simple. Par exemple, Babel permet à la fois de l'unicast et du multicast, le second étant plus difficile à protéger. Une solution de sécurité, DTLS, spécifiée pour Babel dans le RFC 8968, résout le problème en ne faisant que de l'unicast. Notre RFC choisit une autre solution, qui marche pour l'unicast et le multicast. Chaque paquet est authentifié par un MAC attaché au paquet, calculé entre autres à partir d'une clé partagée.
La solution décrite dans ce RFC implique que tous les routeurs connectés au réseau partagent la clé secrète, et que tous ces routeurs soient eux-mêmes de confiance (l'authentification n'implique pas l'honnêteté du routeur authentifié, point très souvent oublié quand on parle d'authentification…) En pratique, c'est un objectif difficile à atteindre, il nécessite un réseau relativement bien géré. Pour un rassemblement temporaire où tout le monde partage sa connectivité, faire circuler ce mot de passe partagé sera difficile.
Ce mécanisme a par contre l'avantage de ne pas nécessiter que les horloges soient correctes ou synchronisées, et ne nécessite pas de stockage de données permanent (ce qui serait contraignant pour, par exemple, certains objets connectés).
Pour que tout marche bien et qu'on soit heureux et en sécurité, ce mécanisme d'authentification compte sur deux pré-requis :
- Une fonction MAC sécurisée (évidemment), c'est-à-dire qu'on ne puisse pas fabriquer un MAC correct sans connaitre la clé secrète,
- Que les nœuds Babel arrivent à ne pas répéter certaines valeurs qu'ils transmettent. Cela peut se faire avec un générateur aléatoire correct (RFC 4086) mais il existe aussi d'autres solutions pour générer des valeurs uniques, non réutilisables.
En échange de ces garanties, le mécanisme de ce RFC garantit l'intégrité des paquets et le rejet des rejeux (dans certaines conditions, voir le RFC).
La section 2 du RFC résume très bien le protocole : quand un routeur Babel envoie un paquet sur une des interfaces où la protection MAC a été activée, il calcule le MAC et l'ajoute à la fin du paquet. Quand il reçoit un paquet sur une des interfaces où la protection MAC a été activée, il calcule le MAC et, s'il ne correspond pas à ce qu'il trouve à la fin du paquet, le paquet est jeté. Simple, non ? Mais c'est en fait un peu plus compliqué. Pour protéger contre les attaques par rejeu, la machine qui émet doit maintenir un compteur des paquets envoyés, le PC (Packet Counter). Il est inclus dans les paquets envoyés et protégé par le MAC.
Ce PC ne protège pas dans tous les cas. Par exemple, si un routeur Babel vient de démarrer, et n'a pas de stockage permanent, il ne connait pas les PC de ses voisins et ne sait donc pas à quoi s'attendre. Dans ce cas, il doit ignorer le paquet et mettre l'émetteur au défi de répondre à un numnique qu'il envoie. Le voisin répond en incluant le numnique et son nouveau PC, prouvant ainsi qu'il ne s'agit pas d'un rejeu.
Petite difficulté, en l'absence de stockage permanent, le PC peut revenir en arrière et un PC être réutilisé. Outre le PC, il faut donc un autre nombre, l'index. Celui-ci n'est, comme le numnique utilisé dans les défis, jamais réutilisé. En pratique, un générateur aléatoire est une solution raisonnable pour fabriquer numniques et index.
La section 3 du RFC décrit les structures de données qu'il faut utiliser pour mettre en œuvre ce protocole. La table des interfaces (RFC 8966, section 3.2.3), doit être enrichie avec une indication de l'activation de la protection MAC sur l'interface, et la liste des clés à utiliser (Babel permet d'avoir plusieurs clés, notamment pour permettre le remplacement d'une clé, et le récepteur doit donc les tester toutes). Il faut également ajouter à la table des interfaces l'index et le PC décrits plus haut.
Quant à la table des (routeurs) voisins (RFC 8966, section 3.2.4), il faut y ajouter l'index et le PC de chaque voisin, et le numnique.
Enfin la section 4 détaille le fonctionnement. Comment calculer le MAC (avec un pseudo-en-tête), où mettre le TLV qui indique le PC, et celui qui contient la ou les MAC (dans la remorque, c'est-à-dire la partie du paquet après la longueur explicite), etc. La section 6 fournit quant à elle le format exact des TLV utilisés : le MAC TLV qui stocke le MAC, le PC TLV qui indique le compteur, et les deux TLV qui permettent de lancer un défi et d'obtenir une réponse, pour se resynchroniser en cas d'oubli du compteur. Ils ont été ajoutés au registre IANA.
Les gens de l'opérationnel aimeront la section 5, qui décrit comment déployer initialement cette option, et comment effectuer un changement de clé. Pour le déploiement initial, il faut configurer les machines dans un mode où elles signent mais ne vérifient pas les paquets entrants (il faut donc que les implémentations aient un tel mode). Cela permet de déployer progressivement. Une fois tous les routeurs ainsi configurés, on peut activer le mode normal, avec signature et vérification. Pour le remplacement de clés, on ajoute d'abord la nouvelle clé aux routeurs, qui signent donc avec les deux clés, l'ancienne et la nouvelle, puis, une fois que tous les routeurs ont la nouvelle clé, on retire l'ancienne.
Un petit bilan de la sécurité de ce mécanisme, en section 7 : d'abord un rappel qu'il est simple et qu'il ne fournit que le minimum, l'authentification et l'intégrité des paquets. Si on veut d'avantage, il faut passer à DTLS, avec le RFC 8968. Ensuite, certaines valeurs utilisées doivent être générées sans que l'attaquant puisse les deviner, ce qui nécessite, par exemple, un générateur de nombres aléatoires sérieux. D'autant plus que la taille limitée de certaines valeurs peut permettre des attaques à la force brute. Si, par exemple, les clés dérivent d'une phrase de passe, il faut une bonne phrase de passe, plus une fonction de dérivation qui gêne ces attaques, comme PBKDF2 (RFC 2898), bcrypt ou scrypt (RFC 7914).
Et, comme toujours, il y a la lancinante menace des attaques par déni de service, par exemple en envoyant des paquets délibérement conçus pour faire faire des calculs cryptographiques inutiles aux victimes. C'est pour limiter leurs conséquences que, par exemple, Babel impose de limiter le rythme d'envoi des défis, pour éviter de s'épuiser à défier un attaquant.
Je n'ai pas vu quelles mises en œuvre de Babel avaient ce mécanisme. il ne semble pas dans la version officielle de babeld, en tout cas, même si il y a du code dans une branche séparée. Et ce n'est pas encore dans une version officielle de BIRD mais le code est déjà écrit.
Le RFC ne décrit pas les changements depuis le RFC 7298 car il s'agit en fait d'un protocole différent, et incompatible (ce ne sont pas les mêmes TLV, par exemple).
Merci à Juliusz Chroboczek pour sa relecture.
L'article seul
RFC 8966: The Babel Routing Protocol
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : J. Chroboczek (IRIF, University of Paris-Diderot), D. Schinazi (Google LLC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 12 janvier 2021
Le travail sur les protocoles de routage ne désarme pas, motivé à la fois par les avancées de la science et par les nouvelles demandes (par exemple pour les réseaux ad hoc). Ainsi Babel est un protocole de routage, de la famille des protocoles à vecteur de distance, qui vise notammment à réduire drastiquement les probabilités de boucle. Il avait été décrit originellement dans le RFC 6126 ; ce nouveau RFC ne change pas fondamentalement le protocole Babel (quoique certains changements ne seront pas compris par les vieilles versions) mais il a désormais le statut de norme, et des solutions de sécurité plus riches. Ce manque de sécurité était la principale critique adressée à Babel.
Il y a deux familles de protocole de routage, ceux à vecteur de distance comme l'ancêtre RIP et ceux à états des liens comme OSPF (RFC 2328). Ce dernier est aujourd'hui bien plus utilisé que RIP, et à juste titre. Mais les problèmes de RIP n'ont pas forcément la même ampleur chez tous les membres de sa famille, et les protocoles à vecteurs de distance n'ont pas dit leur dernier mot.
Babel s'inspire de protocoles de routage plus récents comme DSDV. Il vise à être utilisable, à la fois sur les réseaux classiques, où le routage se fait sur la base du préfixe IP et sur les réseaux ad hoc, où il n'y a typiquement pas de regroupement par préfixe, où le routage se fait sur des adresses IP « à plat » (on peut dire que, dans un réseau ad hoc, chaque nœud est un routeur).
L'un des principaux inconvénients du bon vieux protocole RIP est sa capacité à former des boucles lorsque le réseau change de topologie. Ainsi, si un lien entre les routeurs A et B casse, A va envoyer les paquets à un autre routeur C, qui va probablement les renvoyer à A et ainsi de suite (le champ « TTL » pour IPv4 et « Hop limit » dans IPv6 a précisement pour but d'éviter qu'un paquet ne tourne sans fin). Babel, lui, évitera les boucles la plupart du temps mais, en revanche, il ne trouvera pas immédiatement la route optimale entre deux points. La section 1.1 du RFC spécifie plus rigoureusement les propriétés de Babel.
Babel peut fonctionner avec différentes métriques pour indiquer
les coûts de telle ou telle route, le protocole lui-même étant
indépendant de la métrique utilisée (cf. annexe A du RFC pour des
conseils sur les choix). D'ailleurs, je vous recommande la lecture
de l'Internet-Draft
draft-chroboczek-babel-doesnt-care,
pour mieux comprendre la philosophie de Babel.
Autre particularité de Babel, les associations entre deux machines pourront se faire même si elles utilisent des paramètres différents (par exemple pour la valeur de l'intervalle de temps entre deux « Hello » ; cf. l'annexe B pour une discussion du choix de ces paramètres, les compromis que ce choix implique entre intensité du trafic et détection rapide des changements, et les valeurs recommandées pour ces paramètres). Le RFC annonce ainsi que Babel est particulièrement adapté aux environnements « sans-fil » où certaines machines, devant économiser leur batterie, devront choisir des intervalles plus grands, ou bien aux environnements non gérés, où chaque machine est configurée indépendamment.
Je l'ai dit, rien n'est parfait en ce bas monde, et Babel a des limites, décrites en section 1.2. D'abord, Babel envoie périodiquement toutes les informations dont il dispose, ce qui, dans un réseau stable, mène à un trafic total plus important que, par exemple, OSPF (qui n'envoie que les changements). Ensuite, Babel a des mécanismes d'attente lorsqu'un préfixe disparait, qui s'appliquent aux préfixes plus généraux. Ainsi, lorsque deux préfixes deviennent agrégés, l'agrégat n'est pas joignable immédiatement.
Comment Babel atteint-il ses merveilleux objectifs ? La section 2 détaille les principes de base du protocole, la 3 l'échange de paquets et la 4 l'encodage d'iceux. Commençons par les principes. Babel est fondé sur le bon vieil algorithme de Bellman-Ford, tout comme RIP. Tout lien entre deux points A et B a un coût (qui n'est pas forcément un coût monétaire, c'est un nombre qui a la signification qu'on veut, cf. section 3.5.2). Le coût est additif (la somme des coûts d'un chemin complet faisant la métrique du chemin, section 2.1 et annexe A), ce qui veut dire que Métrique(A -> C) - pour une route passant par B >= Coût(A -> B) + Coût(B -> C). L'algorithme va essayer de calculer la route ayant la métrique le plus faible.
Un nœud Babel garde trace de ses voisins nœuds en
envoyant périodiquement des messages Hello et
en les prévenant qu'ils ont été entendus par des messages
IHU (I Heard You). Le
contenu des messages Hello et
IHU permet de déterminer le coût.
Pour chaque source (d'un préfixe, pas d'un paquet), le nœud garde trace de la métrique vers cette source (lorsqu'un paquet tentera d'atteindre le préfixe annoncé) et du routeur suivant (next hop). Au début, évidemment la métrique est infinie et le routeur suivant indéterminé. Le nœud envoie à ses voisins les routes qu'il connait. Si celle-ci est meilleure que celle que connait le voisin, ce dernier l'adopte (si la distance était infinie - route inconnue, toute route sera meilleure).
L'algorithme « naïf » ci-dessus est ensuite amélioré de plusieurs façons : envoi immédiat de nouvelles routes (sans attendre l'émission périodique), mémorisation, non seulement de la meilleure route mais aussi de routes alternatives, pour pouvoir réagir plus vite en cas de coupure, etc.
La section 2.3 rappelle un problème archi-connu de l'algorithme
de Bellman-Ford : la facilité avec laquelle des boucles se
forment. Dans le cas d'un réseau simple comme celui-ci A annonce une route de métrique 1 vers S,
B utilise donc A comme routeur suivant, avec une métrique de 2. Si
le lien entre S (S = source de l'annonce) et A casse
comme B continue à publier une route
de métrique 2 vers S, A se met à envoyer les paquets à B. Mais B les
renvoie à A, créant ainsi une boucle. Les annonces ultérieures ne
résolvent pas le problème : A annonce une route de métrique 3,
passant par B, B l'enregistre et annonce une route de métrique 4
passant par A, etc. RIP résout le problème en ayant une limite
arbitraire à la métrique, limite qui finit par être atteinte et
stoppe la boucle (méthode dite du « comptage à l'infini »).
Cette méthode oblige à avoir une limite très basse pour la métrique. Babel a une autre approche : les mises à jour ne sont pas forcément acceptées, Babel teste pour voir si elles créent une boucle (section 2.4). Toute annonce est donc examinée au regard d'une condition, dite « de faisabilité ». Plusieurs conditions sont possibles. Par exemple, BGP utilise la condition « Mon propre numéro d'AS n'apparaît pas dans l'annonce. ». (Cela n'empêche pas les micro-boucles, boucles de courte durée en cas de coupure, cf. RFC 5715.) Une autre condition, utilisée par DSDV et AODV (RFC 3561), repose sur l'observation qu'une boucle ne se forme que lorsqu'une annonce a une métrique moins bonne que la métrique de la route qui a été retirée. En n'acceptant que les annonces qui améliorent la métrique, on peut donc éviter les boucles. Babel utilise une règle un peu plus complexe, empruntée à EIGRP, qui tient compte de l'histoire des annonces faites par le routeur.
Comme il n'y a pas de miracles en routage, cette idée de ne pas accepter n'importe quelle annonce de route a une contrepartie : la famine. Celle-ci peut se produire lorsqu'il existe une route mais qu'aucun routeur ne l'accepte (section 2.5). EIGRP résout le problème en « rédémarrant » tout le réseau (resynchronisation globale des routeurs). Babel, lui, emprunte à DSDV une solution moins radicale, en numérotant les annonces, de manière strictement croissante, lorsqu'un routeur détecte un changement dans ses liens. Une route pourra alors être acceptée si elle est plus récente (si elle a un numéro de séquence plus élevé), et un routeur Babel peut demander explicitement aux autres routeurs d'incrémenter ce nombre, pour accélérer la convergence. Ce numéro n'est par contre pas utilisé pour sélectionner la meilleure route (seule la métrique compte pour cela), uniquement pour voir si une annonce est récente.
À noter que tout se complique s'il existe plusieurs routeurs qui annoncent originellement la même route (section 2.7 ; un exemple typique est la route par défaut, annoncée par tous les routeurs ayant une connexion extérieure). Babel gère ce problème en associant à chaque préfixe l'identité du routeur qui s'est annoncé comme origine et considère par la suite ces annonces comme distinctes, même si le préfixe est le même. Conséquence : Babel ne peut plus garantir qu'il n'y aura pas de boucle (Babel essaie de construire un graphe acyclique mais l'union de plusieurs graphes acycliques n'est pas forcément acyclique). Par contre, il pourra détecter ces boucles a posteriori et les éliminer plus rapidement qu'avec du comptage vers l'infini.
Notez aussi que chaque routeur Babel est libre de rejeter les
routes qui lui semblent déraisonnables, comme
127.0.0.1/32, sans affecter le fonctionnement
du protocole (le détail de cette question du filtrage des routes est
dans l'annexe C.)
Voilà pour les principes. Et le protocole ? La section 3 le décrit. Chaque routeur a une identité sur huit octets (le plus simple est de prendre l'adresse MAC d'une des interfaces). Les messages sont envoyés dans des paquets UDP et encodés en TLV. Le paquet peut être adressé à une destination unicast ou bien multicast. Les TLV peuvent contenir des sous-TLV dans leur partie Valeur.
Un routeur Babel doit se souvenir d'un certain nombre de choses (section 3.2), notamment :
- Le numéro de séquence, qui croît strictement,
- La liste des interfaces réseau où parler le protocole,
- La liste des voisins qu'on a entendus,
- La liste des sources (routeurs qui ont été à l'origine de l'annonce d'un préfixe). Elle sert pour calculer les critères d'acceptation (ou de rejet) d'une route. Babel consomme donc plus de mémoire que RIP, qui ne connait que son environnement immédiat, alors qu'un routeur Babel connaît tous les routeurs du réseau.
- Et bien sûr la table des routes, celle qui, au bout du compte, sera utilisée pour la transmission des paquets.
Les préfixes annoncés sont sans rapport avec la version du protocole IP utilisée pour transporter l'annonce. Un préfixe IPv4 peut donc être envoyé en IPv6. Le RFC recommande de faire tourner Babel sur IPv6, même si le réseau est en partie en IPv4.
Les messages Babel ne bénéficient pas d'une garantie de délivrance (c'est de l'UDP, après tout), mais un routeur Babel peut demander à ses voisins d'accuser réception (section 3.3). La décision de le demander ou pas découle de la politique locale de chaque routeur. Si un routeur ne demande pas d'accusé de réception, l'envoi périodique des routes permettra de s'assurer que, au bout d'un certain temps, tous les routeurs auront toute l'information. Les accusés de réception peuvent toutefois être utiles en cas de mises à jour urgentes dont on veut être sûr qu'elles ont été reçues.
Comment un nœud Babel trouve t-il ses voisins ? La section 3.4 décrit ce mécanisme. Les voisins sont détectés par les messages Hello qu'ils émettent. Les messages IHU (I Heard You) envoyés en sens inverse permettent notamment de s'assurer que le lien est bien bidirectionnel.
Les détails de la maintenance de la table de routage figurent en section 3.5. Chaque mise à jour envoyée par un nœud Babel est un quintuplet {préfixe IP, longueur du préfixe, ID du routeur, numéro de séquence, métrique}. Chacune de ces mises à jour est évaluée en regard des conditions de faisabilité : une distance de faisabilité est un doublet {numéro de séquence, métrique} et ces distances sont ordonnées en comparant d'abord le numéro de séquence (numéro plus élevée => distance de faisabilité meilleure) et ensuite la métrique (où le critère est inverse). Une mise à jour n'est acceptée que si sa distance de faisabilité est meilleure.
Si la table des routes contient plusieurs routes vers un préfixe donné, laquelle choisir et donc réannoncer aux voisins (section 3.6) ? La politique de sélection n'est pas partie intégrante de Babel. Plusieurs mises en œuvre de ce protocole pourraient faire des choix différents. Les seules contraintes à cette politique sont qu'il ne faut jamais réannoncer les routes avec une métrique infinie (ce sont les retraits, lorsqu'une route n'est plus accessible), ou les routes infaisables (selon le critère de faisabilité cité plus haut). Si les différents routeurs ont des politiques différentes, cela peut mener à des oscillations (routes changeant en permanence) mais il n'existe pas à l'heure actuelle de critères scientifiques pour choisir une bonne politique. On pourrait imaginer que le routeur ne garde que la route avec la métrique le plus faible, ou bien qu'il privilégie la stabilité en gardant la première route sélectionnée, ou encore qu'il prenne en compte des critères comme la stabilité du routeur voisin dans le temps. En attendant les recherches sur ce point, la stratégie conseillée est de privilégier la route de plus faible métrique, en ajoutant un petit délai pour éviter de changer trop souvent. Notez que la méthode de calcul des métriques n'est pas imposée par Babel : tant que cette méthode obéit à certains critères, notamment de monotonie, elle peut être utilisée.
Une fois le routeur décidé, il doit envoyer les mises à jour à ses voisins (section 3.7). Ces mises à jour sont transportées dans des paquets multicast (mais peuvent l'être en unicast). Les changements récents sont transmis immédiatement, mais un nœud Babel transmet de toute façon la totalité de ses routes à intervalles réguliers. Petite optimisation : les mises à jour ne sont pas transmises sur l'interface réseau d'où la route venait, mais uniquement si on est sûr que ladite interface mène à un réseau symétrique (un Ethernet filaire est symétrique mais un lien WiFi ad hoc ne l'est pas forcément).
Un routeur Babel peut toujours demander explicitement des annonces de routes à un voisin (section 3.8). Il peut aussi demander une incrémentation du numéro de séquence, au cas où il n'existe plus aucune route pour un préfixe donné (problème de la famine, section 3.8.2.1).
La section 4 spécifie l'encodage des messages Babel sur le
réseau. C'est un paquet UDP, envoyé à une adresse
multicast (ff02::1:6 ou
224.0.0.111) ou bien
unicast, avec un TTL de 1
(puisque les messages Babel n'ont jamais besoin d'être routés), et
un port source et
destination de
6696. En IPv6, les adresses IP de
source et de destination unicast sont locales au
lien et en IPv4 des adresses du réseau
local.
Les données envoyées dans le message sont typées et la section
4.1 liste les types possibles, par exemple
interval, un entier de 16 bits qui sert à
représenter des durées en centisecondes (rappelez-vous que, dans
Babel, un routeur informe ses voisins de ses paramètres temporels,
par exemple de la fréquence à laquelle il envoie des
Hello). Plus complexe est le type
address, puisque Babel permet d'encoder les
adresses par différents moyens (par exemple, pour une adresse IPv6
locale au lien, le préfixe
fe80::/64 peut être omis). Quant à l'ID du
routeur, cet identifiant est stocké sur huit octets.
Ensuite, ces données sont mises dans des TLV, eux-même placés derrière
l'en-tête Babel, qui indique un nombre magique (42...) pour
identifier un paquet Babel, un numéro de version (aujourd'hui 2) et
la longueur du message. (La fonction
babel_print_v2 dans le code de
tcpdump est un bon moyen de découvrir les
différents types et leur rôle.) Le message est suivi d'une remorque
qui n'est pas comptée pour le calcul de la longueur du message, et
qui sert notamment pour l'authentification
(cf. RFC 8967). La remorque, une
nouveauté qui n'existait pas explicitement dans le RFC 6126, est elle-même composée de TLV. Chaque TLV, comme son
nom l'indique, comprend un type (entier sur huit bits), une longueur
et une valeur, le corps, qui peut comprendre
plusieurs champs (dépendant du type). Parmi les types existants :
- 0 et 1, qui doivent être ignorés (ils servent si on a besoin d'aligner les TLV),
- 2, qui indique une demande d'accusé de réception, comme le Echo Request d'ICMP (celui qui est utilisé par la commande ping). Le récepteur doit répondre par un message contenant un TLV de type 3.
- 4, qui désigne un message
Hello. Le corps contient notamment le numéro de séquence actuel du routeur. Le type 5 désigne une réponse auHello, le IHU, et ajoute des informations comme le coût de la liaison entre les deux routeurs. - 6 sert pour transmettre l'ID du routeur.
- 7 et 8 servent pour les routes elles-mêmes. 7 désigne le
routeur suivant qui sera utilisé (next hop) pour
les routes portées dans les TLV de type 8. Chaque TLV
Update(type 8) contient notamment un préfixe (avec sa longueur), un numéro de séquence, et une métrique. - 9 est une demande explicite de route (lorsqu'un routeur n'a plus de route vers un préfixe donné ou simplement lorsqu'il est pressé et ne veut pas attendre le prochain message). 10 est la demande d'un nouveau numéro de séquence.
Les types de TLV sont stockés dans un registre IANA. On peut en ajouter à condition de fournir une spécification écrite (« Spécification nécessaire », cf. RFC 8126). Il y a aussi un registre des sous-TLV.
Quelle est la sécurité de Babel ? La section 6 dit franchement qu'elle est, par défaut, à peu près inexistante. Un méchant peut annoncer les préfixes qu'il veut, avec une bonne métrique pour être sûr d'être sélectionné, afin d'attirer tout le trafic.
En IPv6, une protection modérée est fournie par le fait que les adresses source et destination sont locales au lien. Comme les routeurs IPv6 ne sont pas censés faire suivre les paquets ayant ces adresses, cela garantit que le paquet vient bien du réseau local. Une raison de plus d'utiliser IPv6.
Ce manque de sécurité dans le Babel original du RFC 6126 avait suscité beaucoup de discussions à l'IETF lors de la mise de Babel sur le chemin des normes (voir par exemple cet examen de la direction de la sécurité). Normalement, l'IETF exige de tout protocole qu'il soit raisonnablement sécurisé (la règle figure dans le RFC 3365). Certaines personnes s'étaient donc vigoureusement opposées à la normalisation officielle de Babel tant qu'il n'avait pas de solution de sécurité disponible. D'autres faisaient remarquer que Babel était quand même déployable pour des réseaux fermés, « entre copains », même sans sécurité, mais les critiques pointaient le fait que tôt ou tard, tout réseau fermé risque de se retrouver ouvert. D'un autre côté, sécuriser des réseaux « ad hoc », par exemple un lot de machines mobiles qui se retrouvent ensemble pour un événement temporaire, est un problème non encore résolu.
Un grand changement de notre RFC est de permettre la signature des messages. Deux mécanismes existent, décrits dans les RFC 8967 (signature HMAC, pour authentifier, la solution la plus légère) et RFC 8968 (DTLS, qui fournit en plus la confidentialité). (Notons que, en matière de routage, la signature ne résout pas tout : c'est une chose d'authentifier un voisin, une autre de vérifier qu'il est autorisé à annoncer ce préfixe.)
J'ai parlé plus haut de la détermination des coûts des liens. L'annexe A du RFC contient des détails intéressants sur cette détermination. Ainsi, contrairement aux liens fixes, les liens radio ont en général une qualité variable, surtout en plein air. Déterminer cette qualité est indispensable pour router sur des liens radio, mais pas facile. L'algorithme ETX (décrit dans l'article de De Couto, D., Aguayo, D., Bicket, J., et R. Morris, « A high-throughput path metric for multi-hop wireless networks ») est recommandé pour cela.
L'annexe D est consacrée aux mécanismes d'extension du protocole, et reprend largement le RFC 7557, qu'elle remplace. Babel prévoyait des mécanismes d'extension en réservant certaines valeurs et en précisant le comportement d'un routeur Babel lors de la réception de valeurs inconnues. Ainsi :
- Un paquet Babel avec un numéro de version différent de 2 doit être ignoré, ce qui permet de déployer une nouvelle future version de Babel sans que ses paquets ne cassent les implémentations existantes,
- Un TLV de type inconnu doit être ignoré (section 4.3), ce qui permet d'introduire de nouveaux types de TLV en étant sûr qu'ils ne vont pas perturber les anciens routeurs,
- Les données contenues dans un TLV au-delà de sa longueur indiquée, ou bien les données présentes après le dernier TLV, devaient, disait le RFC 7557 qui reprenait le RFC 6126, également être silencieusement ignorées (au lieu de déclencher une erreur). Ainsi, une autre voie d'extension était possible, pour glisser des données supplémentaires. Cette voie est désormais utilisée par les solutions de signature comme celle du RFC 8966.
Quelles sont donc les possibilités d'extensions propres ? Cela commence par une nouvelle version du protocole (l'actuelle version est la 2), qui utiliserait des numéros 3, puis 4... Cela ne doit être utilisé que si la nouvelle version est incompatible avec les précédentes et ne peut pas interopérer sur le même réseau.
Moins radicale, une extension de la version 2 peut introduire de nouveaux TLV (qui seront ignorés par les mises en œuvre anciennes de la version 2). Ces nouveaux TLV doivent suivre le format de la section 4.3. De la même façon, on peut introduire de nouveaux sous-TLV (des TLV contenus dans d'autres TLV, décrits en section 4.4).
Si on veut ajouter des données dans un TLV existant, en
s'assurant qu'il restera correctement analysé par les anciennes
mises en œuvre, il faut jouer sur la différence entre la taille
explicite (explicit size) et la taille effective
(natural size) du TLV. La taille explicite est
celle qui est indiqué dans le champ Length
spécifié dans la section 4.3. La taille effective est celle déduite
d'une analyse des données (plus ou moins compliquée selon le type de
TLV). Comme les implémentations de Babel doivent ignorer les données
situées après la taille explicite, on peut s'en servir pour ajouter
des données. Elles doivent être encodées sous forme de sous-TLV,
chacun ayant type, longueur et valeur (leur format exact est décrit
en section 4.4).
Enfin, après le dernier TLV (Babel est transporté sur UDP, qui indique une longueur explicite), on peut encore ajouter des données, une « remorque ». C'est ce que fait le RFC 8966.
Bon, mais alors quel mécanisme d'extension choisir ? La section 4 fournit des pistes aux développeurs. Le choix de faire une nouvelle version est un choix drastique. Il ne devrait être fait que si la nouvelle version est réellement incompatible avec la précédente.
Un nouveau TLV, ou bien un nouveau sous-TLV d'un TLV existant est
la solution à la plupart des problèmes d'extension. Par exemple, si
on veut mettre de l'information supplémentaire aux mises à jour de
routes (TLV Update), on peut créer un nouveau
TLV « Update enrichi » ou bien un sous-TLV de
Update qui contiendra l'information
supplémentaire. Attention, les conséquences de l'un ou l'autre choix
ne seront pas les mêmes. Un TLV « Update
enrichi » serait totalement ignoré par un Babel ancien, alors qu'un
TLV Update avec un sous-TLV
d'« enrichissement » verrait la mise à jour des routes acceptée,
seule l'information supplémentaire serait perdue.
Il existe désormais, pour permettre le développement d'extensions, un registre IANA des types de TLV et un des sous-TLV (section 5 du RFC) et plusieurs extensions s'en servent déjà.
Enfin, l'annexe F du RFC résume les changements depuis le premier RFC, le RFC 6126, qui documentait la version 2 de Babel. On reste en version 2 car le protocole de notre RFC reste essentiellement compatible avec le précédent. Il y a toutefois trois fonctions de ce protocole qui pourraient créer des problèmes sur un réseau où certaines machines sont restées au RFC 6126 :
- Les messages de type
Helloen unicast sont une nouveauté. L'ancien RFC ne les mentionnait pas. Cela peut entrainer une mauvaise interprétation des numéros de séquence (qui sont distincts en unicast et multicast). - Les messages
Hellopeuvent désormais avoir un intervalle entre deux messages qui est nul, ce qui n'existait pas avant. - Les sous-TLV obligatoires (section 4.4) n'existaient pas avant et leur utilisation peut donc être mal interprétée par les vieilles mises en œuvre de Babel (le TLV englobant va être accepté alors qu'il devrait être rejeté).
Bref, si on veut déployer le Babel de ce RFC dans un réseau où il
reste de vieilles mises en œuvre, il faut prendre garde à ne pas
utiliser ces trois fonctions. Si on préfère mettre à jour les vieux
programmes, sans toutefois y intégrer tout ce que contient notre
RFC, il faut au minimum ignorer (ou bien gérer correctement) les
Hello en unicast, ou bien
avec un intervalle nul, et il faut ignorer un TLV qui contient un
sous-TLV obligatoire mais inconnu.
Il y a d'autres changements depuis le RFC 6126 mais qui ne sont pas de nature à affecter l'interopérabilité ; voyez le RFC pour les détails.
Vous pourrez trouver plus d'informations sur Babel en lisant le RFC, ou bien sur la page Web officielle. Si vous voulez approfondir la question des protocoles de routage, une excellente comparaison a été faite par David Murray, Michael Dixon et Terry Koziniec dans « An Experimental Comparison of Routing Protocols in Multi Hop Ad Hoc Networks » où ils comparent Babel (qui l'emporte largement), OLSR (RFC 7181) et Batman (ce dernier est dans le noyau Linux officiel). Notez aussi que l'IETF a un protocole standard pour ce problème, RPL, décrit dans le RFC 6550. Si vous aimez les vidéos, l'auteur de Babel explique le protocole en anglais.
Qu'en est-il des mises en œuvre de ce protocole ? Il existe une
implémentation
d'exemple, babeld, assez éprouvée
pour être disponible en paquetage dans plusieurs systèmes, comme babeld dans
Debian ou dans
OpenWrt, plateforme très souvent utilisée
pour des routeurs libres (cf. https://openwrt.org/docs/guide-user/services/babeld). babeld
ne met pas en œuvre les solutions de sécurité des RFC 8966 ou RFC 8967. Une
autre implémentation se trouve dans Bird. Si
vous voulez écrire votre implémentation, l'annexe E contient
plusieurs conseils utiles, accompagnés de calculs, par exemple sur
la consommation mémoire et réseau. Le RFC proclame que Babel est un
protocole relativement simple et, par exemple, l'implémentation de
référence contient environ 12 500 lignes de C.
Néanmoins, cela peut être trop, une fois compilé, pour des objets (le RFC cite les fours à micro-ondes...) et l'annexe E décrit donc des sous-ensembles raisonnables de Babel. Par exemple, une mise en œuvre passive pourrait apprendre des routes, sans rien annoncer. Plus utile, une mise en œuvre « parasite » n'annonce que la route vers elle-même et ne retransmet pas les routes apprises. Ne routant les paquets, elle ne risquerait pas de créer des boucles et pourrait donc omettre certaines données, comme la liste des sources. (Le RFC liste par contre ce que la mise en œuvre parasite doit faire.)
L'article seul
RFC 8965: Applicability of the Babel Routing Protocol
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : J. Chroboczek (IRIF, University of Paris-Diderot)
Pour information
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 12 janvier 2021
Comme tout bon protocole, le protocole de routage Babel, normalisé dans le RFC 8966 ne fait pas de miracles et ne marche pas dans tous les cas. Il est donc utile de savoir quels sont les cas où Babel est efficace et utile. Ce RFC s'applique à identifier et documenter les créneaux pour Babel.
C'est qu'il en existe beaucoup de protocoles de routage internes à un AS. Le RFC cite OSPF (RFC 5340) et IS-IS (RFC 1195), qui ont la faveur des grands réseaux gérés par des professionnels, mais je trouve que Babel se situe plutôt du côté de protocoles prévus pour des réseaux moins organisés, comme Batman ou RPL (RFC 6550). Je vous laisse lire le RFC 8966 pour voir comment fonctionne Babel. Disons juste que c'est un protocole à vecteur de distances (comme RIP - RFC 2453 - mais sans ses inconvénients) et qui considère la faisabilité de chaque route potentielle avant de l'ajouter, supprimant ainsi le risque de boucles. En refusant des routes qui pourraient peut-être créer une boucle, le risque est la famine, l'absence de route pour une destination, risque dont Babel se protège avec un mécanisme de numéro de séquence dans les annonces.
La section 2 de notre RFC explicite les caractéristiques de Babel, les bonnes et les mauvaises. D'abord, la simplicité. Babel est conceptuellement simple, ce qui facilite les analyses du protocole, et aussi sa mise en œuvre. Comme le note le RFC, Babel peut être expliqué en un micro-siècle. Et question programmation, le RFC cite une mise en œuvre de Babel réalisée en deux nuits (le RFC ne dit pas ce que le ou la programmeur·e faisait de jour…)
Ensuite, la résistance. Babel ne dépend que de quelques propriétés simples du réseau et peut donc fonctionner dans un large éventail de situations. Babel demande juste que les métriques soient strictement monotones croissantes (emprunter le chemin A puis le B, doit forcément coûter strictement plus cher que de juste prendre le chemin A, autrement des boucles pourraient se former) et distributives à gauche (cf. « Metarouting » de Griffin et Sobrinho). En revanche, Babel n'exige pas un transport fiable (les paquets ont le droit de se perdre, ou de doubler un autre paquet) et n'exige pas que la communication soit transitive (dans les liens radio, il peut arriver que A puisse joindre B et B puisse parler à C, sans que pour autant A puisse communiquer directement avec C). Des protocoles comme OSPF (RFC 5340) ou IS-IS sont bien plus exigeants de ce point de vue.
Babel est extensible : comme détaillé dans
l'annexe C du RFC 8966, le protocole
Babel peut être étendu. Cela a été fait, par exemple, pour permettre
du routage en fonction de la source (RFC 9079)
ou bien du routage en fonction du RTT (RFC 9616). Il y a aussi des
extensions qui n'ont pas (encore ?) été déployées comme du routage
en fonction des fréquences radio (draft-chroboczek-babel-diversity-routing)
ou en fonction du ToS (draft-chouasne-babel-tos-specific).
Mais Babel a aussi des défauts, notamment :
- Babel envoie périodiquement des messages, même quand il n'y a eu aucun changement. Cela permet de ne pas dépendre d'un transport fiable des paquets mais c'est du gaspillage lorsque le réseau est stable. Un grand réseau très stable et bien géré a donc plutôt intérêt à utiliser des protocoles comme OSPF, pour diminuer le trafic dû au routage. À l'autre extrémité, certains réseaux de machines contraintes (par exemple tournant uniquement sur batterie) n'auront pas intérêt à utiliser un protocole comme Babel, qui consomme de l'énergie même quand le réseau n'a pas changé.
- Avec Babel, chaque routeur connait toute la table de routage. Si des routeurs sont limités en mémoire, cela peut être un problème, et des protocoles comme AODV (RFC 3561), RPL (RFC 6550) ou LOADng sont peut-être plus adaptés.
- Babel peut être lent à récupérer lorsqu'il fait de l'agrégation de préfixes, et qu'une route plus spécifique est retirée.
Babel a connu plusieurs déploiements dans le monde réel (section 3). Certains de ces déploiements étaient dans des réseaux mixtes, mêlant des parties filaires, routant sur le préfixe, et des parties radio, avec du routage mesh sur les adresses IP. Babel a aussi été déployé dans des overlays, en utilisant l'extension tenant compte du RTT, citée plus haut. Il a aussi été utilisé dans des réseaux purement mesh. Voir à ce sujet les articles « An experimental comparison of routing protocols in multi hop ad hoc networks » et « Real-world performance of current proactive multi-hop mesh protocols ». Ces réseaux utilisent traditionnellement plutôt des protocoles comme OLSR (RFC 7181). Enfin, Babel a été déployé dans des petits réseaux non gérés (pas d'administrateur système).
Et la sécurité, pour finir (section 5). Comme tous les protocoles à vecteur de distance, Babel reçoit l'information de ses voisins. Il faut donc leur faire confiance, un voisin menteur peut annoncer ce qu'il veut. En prime, si le réseau sous-jacent n'est pas lui-même sécurisé (par exemple si c'est du WiFi sans WPA), il n'y a même pas besoin d'être routeur voisin, toute machine peut tripoter les paquets.
Pour empêcher cela, il y a deux solutions cryptographiques, dans les RFC 8967 (la solution la plus simple) et RFC 8968 (plus complexe mais plus sûre et qui fournit en prime de la confidentialité). La solution avec le MAC, normalisée dans le RFC 8967, est celle recommandée car elle convient mieux au caractère de la plupart des réseaux utilisant Babel. (Le RFC n'en parle apparamment pas, mais notez qu'authentifier le voisin ne résout pas complètement le problème. On peut être authentifié et mentir.)
Enfin, si on n'utilise pas de solution de confidentialité, un observateur peut déduire des messages Babel la position d'un routeur WiFi qui se déplacerait, ce qui peut être considéré comme un problème.
Sinon, pour creuser cette question de l'applicabilité de Babel, vous pouvez lire le texte, très vivant, « Babel does not care ».
L'article seul
RFC 8963: Evaluation of a Sample of RFCs Produced in 2018
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : C. Huitema (Private Octopus)
Pour information
Première rédaction de cet article le 23 janvier 2021
On raconte souvent que la publication d'un RFC prend longtemps, très longtemps, trop longtemps, et on dit parfois que cela est dû à une bureaucratie excessive dans le processus de publication. Peut-on objectiver cette opinion ? Dans ce RFC, l'auteur étudie le trajet de plusieurs RFC (pris au hasard) publiés en 2018 et regarde où étaient les goulets d'étranglement, et ce qui a pris du temps. Les RFC étudiés ont mis en moyenne trois ans et quatre mois à être publiés, depuis le premier document écrit jusqu'à la publication finale. (Mais il y a de grandes variations.) La majorité du temps est passée dans le groupe de travail, ce ne sont donc pas forcément les étapes « bureaucratiques » qui retardent.
Heureusement pour cette étude, le DataTracker enregistre les différentes étapes de la vie d'un document et permet donc au chercheur de travailler sur des données solides. Mais attention, si les données sont fiables, leur interprétation est toujours délicate. Et, si une métrique devient un objectif, elle cesse d'être une bonne métrique. Si l'IETF ne cherchait qu'à raccourci le délai de publication, ce serait simple, il suffirait d'approuver sans discussion et immédiatement toutes les propositions, même mauvaises. (Ce qu'on nomme le rubber stamping en anglais.)
La section 2 expose la méthodologie suivie. D'abord, déterminer les dates importantes dans la vie d'un RFC. Tous les RFC ne suivent pas le même parcours, loin de là. Le cas typique est celui d'un document individuel, qui est ensuite adopté par un groupe de travail, approuvé par l'IESG, puis publié par le RFC Editor. Dans cette analyse, trois périodes sont prises en compte :
- Le temps de traitement dans le groupe de travail, qui part de la première publication et s'arrête au dernier appel à l'IETF,
- Le temps de traitement par l'IETF, qui part du dernier appel à l'IETF et se termine par l'approbation par l'IESG,
- Le temps de traitement par le RFC Editor, qui part de l'approbation par l'IESG et se termine par la publication en RFC.
Ainsi, pour le dernier RFC publié au moment où j'écris cet article (et qui n'est donc pas pris en compte dans l'analyse, qui couvre des RFC de 2018), pour ce RFC 9003, on voit sur le DataTracker qu'il a été documenté pour la première fois en décembre 2017, adopté par un groupe de travail en avril 2018, soumis à l'IESG en avril 2020, a eu un IETF Last Call en juin 2020, a été approuvé par l'IESG en novembre 2020 et enfin publié en RFC début janvier 2021. Mais beaucoup d'autres RFC suivent un autre parcours. Pour la voie indépendante (décrite dans le RFC 4846), l'analyse de ce RFC 8963 considère l'approbation par l'ISE (Independent Submission Editor) comme terminant la première période et l'envoi au RFC Editor comme terminant la deuxième.
Les vingt RFC qui sont utilisés dans l'étude ont été pris au hasard parmi ceux publiés en 2018. Le RFC reconnait que c'est un échantillon bien petit mais c'est parce que les données disponibles ne fournissaient pas toutes les informations nécessaires et qu'il fallait étudier « manuellement » chaque RFC, ce qui limitait forcément leur nombre. Je ne vais pas lister ici tous les RFC étudiés, juste en citer quelques uns que je trouve intéressant à un titre ou l'autre :
- Le RFC 8446 est un très gros morceau. C'est la nouvelle version d'un protocole absolument critique, TLS. Non seulement le RFC est gros et complexe, mais le souci de sécurité a entrainé des études particulièrement poussées. Et, pour couronner le tout, ce RFC a été au cœur de polémiques politiques, certains reprochant à cette version de TLS d'être trop efficace, d'empêcher d'accéder aux données. La phase finale chez le RFC Editor, dite « AUTH48 » (car elle se fait normalement en 48 heures…) n'a pas pris moins de deux mois ! C'est en partie dû à une nouveauté de l'époque, utiliser GitHub pour suivre les changements à apporter. Pour chaque RFC étudié, l'auteur note également son succès ou insuccès en terme de déploiement et TLS 1.3 est un succès massif, avec des dizaines de mises en œuvre différentes et une présence très forte sur l'Internet.
- Le RFC 8324 est un cas très différent. Consacré à une série d'opinions sur le DNS et ses évolutions récentes, il ne s'agit pas, contrairement au précédent, d'une norme IETF, mais d'une contribution individuelle. N'engageant que son auteur, elle ne nécessite pas le même niveau d'examen. C'est donc ce RFC qui est le titulaire du record dans l'étude : neuf mois seulement entre la première publication et le RFC.
- Le RFC 8429 avait pour but de documenter l'abandon de plusieurs protocoles de cryptographie désormais dépassés. A priori très simple et très consensuel, il a été retardé par une discussion plus bureaucratique à propos de ses conséquences exactes sur le RFC 4757, puis par un délai très long d'un des auteurs à répondre lors de la phase finale (« AUTH48 » a pris trois mois).
- Le RFC 8312 portait aussi sur un sujet consensuel, l'algorithme de lutte contre la congestion CUBIC étant aujourd'hui largement adopté. Mais il a quand même pris des années, en partie car, justement, CUBIC étant consensuel et largement déployé, il ne semblait pas crucial de le documenter. (Rappelez-vous que le travail à l'IETF est fait par des volontaires.)
- Le RFC 8492 a également pris longtemps car c'était un projet individuel, dont l'auteur n'avait pas le temps de s'occuper, ce qui explique des longs délais à certains points. En outre, il a été retardé par la nécessité d'attendre un changement de politique d'enrgistrements dans certains registres à l'IANA, changements qui dépendaient de TLS 1.3, qui prenait du temps.
- Un autre RFC qui a souffert du fait que même ses auteurs ne le considéraient pas comme urgent a été le RFC 8378, un projet très expérimental et dont la publication en RFC a pris plus de quatre ans.
- Un des buts de l'étude était de voir s'il y avait une corrélation entre le délai total et certaines caractéristiques du RFC, par exemple sa longueur. Mais le RFC 8472, quoique simple, a pris plus de trois ans, en partie pour un problème bureaucratique sur le meilleur groupe de travail à utiliser.
- En revanche, le RFC 8362 n'a pas de mal à expliquer le temps qu'il a pris : il modifie sérieusement le protocole OSPF et nécessite des mécanismes de transition depuis les anciennes versions, qui ont eux-même pris du temps.
Bien, après cette sélection d'un échantillon de RFC, qu'observe-t-on (section 4 de notre RFC) ? Le délai moyen entre le premier Internet Draft et la publication en RFC est de trois ans et trois mois. Mais les variations sont telles que cette moyenne n'a guère de sens (c'est souvent le cas avec la moyenne). Le plus malheureux est le RFC 8492, six ans et demi au total, mais ce cas n'est pas forcément généralisable. Pour les RFC de l'IETF, où le délai moyen est presque le même, le temps passé dans le groupe de travail est de deux ans et neuf mois, à l'IESG de trois à quatre mois et à peu près pareil chez le RFC Editor. Bref, 80 % du temps se passe en « vrai » travail, dans le groupe, les passages plus « bureaucratiques » n'occupent que 20 % du temps et ne sont donc pas les principaux responsables des délais.
L'étude regarde aussi des échantillons de RFC publiés en 2008 et en 1998 (en utilisant cette fois, à juste titre, des valeurs médianes) et note que le délai était à peu près le même en 2008 mais qu'il était trois à quatre fois plus court en 1998.
Et la partie purement éditoriale, chez le RFC Editor ? On a vu qu'elle prenait de trois à quatre mois. C'est quatre en moyenne mais si on exclut l'extrême RFC 8492, c'est plutôt trois mois, ce que je trouve plutôt court pour relire et préparer des documents longs et complexes, où une coquille peut être très gênante (ce ne sont pas des romans !) Quelles sont les caractéristiques des RFC que l'on pourrait corréler à ce délai chez le RFC Editor ? L'étude montre une corrélation entre le délai et la longueur du document, ce qui n'est pas surprenant. Même chose pour la corrélation entre le nombre de changements faits depuis l'approbation par l'IESG et la publication. (Une des tâches du RFC Editor est de faire en sorte que les RFC soient en bon anglais alors que beaucoup d'auteurs ne sont pas anglophones.) Plus étonnant, le nombre d'auteurs ne diminue pas le délai, au contraire, il l'augmente. Un nouveau cas de « quand on ajoute des gens au projet, le projet n'avance pas plus vite » ? Il ne faut pas oublier qu'il existe une zone grise entre « changement purement éditorial », où le RFC Editor devrait décider, et « changement qui a des conséquences techniques » et où l'approbation des auteurs est cruciale. Il n'est pas toujours facile de s'assurer de la nature d'un changement proposé par le RFC Editor. Et, si le changement a des conséquences techniques, il faut mettre les auteurs d'accord entre eux, ce qui est long (ils peuvent être dans des fuseaux horaires différents, avec des obligations professionnelles différentes) et peut soulever des désaccords de fond.
Et pour la voie indépendante ? Trois des RFC de l'échantillon étaient sur cette voie. Ils ont été publiés plus vite que sur la voie IETF, ce qui est logique puisqu'ils ne nécessitent pas le consensus de l'IETF (voir le RFC 8789). En revanche, le fait que la fonction d'ISE (Independant Stream Editor, cf. RFC 8730) soit une tâche assurée par un seul volontaire peut entrainer des retards ce qui a été le cas, ironiquement, de ce RFC 8963.
L'étude se penche aussi sur le nombre de citations dont bénéficie chaque RFC (section 5) car elle peut donner une idée sommaire de leur impact. Elle a utilisé l'API de Semantic Scholar. Par exemple, pour le RFC 8483, publié l'année de l'étude mais pas inclus dans l'échantillon :
% curl -s https://api.semanticscholar.org/v1/paper/10.17487/rfc8483\?include_unknown_references=true \ jq .
On voit qu'il est cité une fois, précisément par ce RFC. En revanche, le RFC 8446, sur TLS 1.3 est cité pas moins de 773 fois :
% curl -s https://api.semanticscholar.org/v1/paper/10.17487/rfc8446\?include_unknown_references=true | \ jq .citations\|length 773
C'est de très loin le plus « populaire » dans le corpus (l'échantillon étudié). C'est bien sûr en partie en raison de l'importance critique de TLS, mais c'est aussi parce que TLS 1.3 a été étudié par des chercheurs et fait l'objet d'une validation formelle, un sujet qui génère beaucoup d'articles dans le monde académique. C'est aussi le cas du RFC 8312, sur Cubic, car la congestion est également un sujet de recherche reconnu. Notez que le passage du temps est impitoyable : les RFC des échantillons de 2008 et 1998 ne sont quasiment plus cités (sauf le RFC 2267, qui résiste). Est-ce que le nombre de citations est corrélé à l'ampleur du déploiement ? Dans le cas des RFC 8446 et RFC 8312, on pourrait le croire, mais le RFC 8441 a également un très vaste déploiement, et quasiment aucune citation. À l'inverse, un RFC qui a un nombre de citations record, le RFC 5326, n'a quasiment pas eu de déploiement, mais a excité beaucoup de chercheurs académiques (et même médiatique, vu son sujet cool), ce qui explique le nombre de citations. Bref, le monde de la recherche et celui des réseaux n'ont pas des jugements identiques.
On avait noté que le RFC 2267 était beaucoup cité. Or, il n'est plus d'actualité, ayant officiellement été remplacé par le RFC 2827. Mais les citations privilégient la première occurrence, et ne reflètent donc pas l'état actuel de la normalisation.
Bon, on a vu que les citations dans le monde de la recherche ne reflétaient pas réellement l'« importance » d'un RFC. Et le nombre d'occurrences dans un moteur de recherche, c'est mieux ? L'auteur a donc compté le nombre de références aux RFC dans Google et Bing. Il y a quelques pièges. Par exemple, en cherchant « RFC8441 », Bing trouve beaucoup de références à ce RFC 8441, qui parle de WebSockets, mais c'est parce qu'il compte des numéros de téléphone se terminant par 8441, ou des adresses postales « 8441 Main Street ». Google n'a pas cette amusante bogue. Ceci dit, il est noyé par le nombre très élevé de miroirs des RFC, puisque l'IETF permet et encourage ces copies multiples (contrairement aux organisations de normalisation fermées comme l'AFNOR). Ceci dit, les RFC 8441 et RFC 8471 sont plus souvent cités, notamment car ils apparaissent fréquemment dans les commentaires du code source d'un logiciel qui les met en œuvre. Le « test Google » est donc assez pertinent pour évaluer le déploiement effectif.
Quelles conclusions en tirer (section 6 du RFC) ? D'abord, si on trouve le délai de publication trop long, il faut se focaliser sur le temps passé dans le groupe de travail, car c'est clairement le principal contributeur au délai. [En même temps, c'est logique, c'est là où a lieu le « vrai » travail.] Malheureusement, c'est là où le DataTracker contient le moins d'information alors que les phases « bureaucratiques » comme le temps passé à l'IESG bénéficient d'une traçabilité plus détaillée. Ainsi, on ne voit pas les derniers appels (Last Calls) internes aux groupes de travail. Bien sûr, on pourrait rajouter ces informations mais attention, cela ferait une charge de travail supplémentaire pour les présidents des groupes de travail (des volontaires). Récolter des données pour faire des études, c'est bien, mais cela ne doit pas mener à encore plus de bureaucratie.
Du fait que l'étude ne porte que sur des RFC effectivement publiés, elle pourrait être accusée de sensibilité au biais du survivant. Peut-être que les RFC qui n'ont pas été publiés auraient aussi des choses à nous dire ? L'abandon d'un projet de normalisation est fréquent (pensons par exemple à DBOUND ou RPZ) et parfaitement normal et souhaitable ; toutes les idées ne sont pas bonnes et le travail de tri est une bonne chose. Mais, en n'étudiant que les RFC publiés, on ne peut pas savoir si le tri n'a pas été trop violent et si de bonnes idées n'en ont pas été victimes. L'IETF ne documente pas les abandons et une étude de drafts sans successeur pourrait être intéressante.
Pour terminer, je me suis amusé à regarder ce qu'il en était des trois RFC que j'ai écrit :
- Le RFC 7626 a été publié moins de deux ans après le premier document ce qui, on l'a vu, est inférieur à la moyenne. Fortement poussé par l'engagement de l'IETF à agir après les révélations de Snowden, il n'a guère connu d'obstacles.
- Le RFC 7816 a pris deux ans. Il a passé à peine plus d'un mois chez le RFC Editor, ce qui est très peu. Comme le précédent, il faisait partie d'un projet porteur, visant à améliorer le respect de la vie privée dans le DNS. Il a connu des objections techniques mais son statut « Expérimental » ne nécessite pas une solution parfaite. Une partie du temps a été passée dans un problème dont le RFC 8963 ne parle pas : une histoire de brevets et de négociations juridico-politiques.
- Le RFC 8020 est le seul des trois à être sur le chemin des normes, en théorie bien plus exigeant. Mais il bat tous les records en n'ayant mis qu'un an à être publié. C'est en partie parce qu'il est simple, et relativement consensuel (il y a quand même eu des objections, par exemple sur le danger qu'il pouvait poser si la zone n'était pas signée avec DNSSEC).
L'article seul
RFC 8961: Requirements for Time-Based Loss Detection
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : M. Allman (ICSI)
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 24 novembre 2020
Vous savez certainement que l'Internet fait circuler les données sous forme de paquets indépendants, et qu'un paquet peut toujours être perdu, par exemple parce qu'un rayon cosmique agressif est passé à ce moment-là ou, moins spectaculaire, parce que les files d'un routeur étaient pleines et qu'il a dû se résigner à laisser tomber le paquet. Des protocoles existent donc pour gérer ces pertes de paquets, ce qui implique de les détecter. Et comment sait-on qu'un paquet a été perdu ? C'est plus complexe que ça n'en a l'air, et ce RFC tente d'établir un cadre générique pour la détection de pertes.
Ne tournons pas autour du pot : la seule façon fiable de savoir
si un paquet a été perdu, c'est d'attendre qu'il arrive (ce que le
RFC nomme, dans son titre, time-based loss
detection) et, s'il n'arrive pas, de le déclarer
perdu. Plus précisément, pour l'émetteur (car le récepteur ne sait
pas forcément qu'on lui a envoyé un paquet), on émet un paquet et on
attend une confirmation qu'il a été reçu (avec TCP, cette
confirmation sera le ACK, avec le DNS sur UDP, ce sera la réponse DNS). Si la
confirmation n'a pas été reçue, s'il y a timeout,
c'est qu'un paquet (la demande, ou bien l'accusé de réception) n'est
pas arrivé. Mais attendre combien de temps ? Si on attend peu de
temps (mettons 100 millisecondes), on risque de considérer le paquet
comme perdu, alors que le voyage était simplement un peu long (en
100 ms, vous ne pouvez même pas faire un aller-retour entre la
France et les
Philippines, ne serait-ce qu'à cause de la
limite de la vitesse de la lumière). Et si on attend longtemps
(mettons 5 secondes), on ne pourra pas réagir rapidement aux pertes,
et la latence perçue par l'utilisateur
sera insupportable (la sensation de « vitesse » pour l'utilisateur
dépend davantage de la latence que de la capacité). Il faut donc faire un compromis
entre réactivité et justesse.
Il existe d'autres méthodes que l'attente pour détecter des pertes, par exemple TCP et SCTP utilisent aussi les accusés de réception sélectifs (RFC 2018, RFC 9260 dans sa section 3.3.4 et RFC 6675) mais aucune de ces autres méthodes ne détecte toutes les pertes, et la détection par absence de réponse reste donc indispensable.
L'Internet, vous le savez, est un ensemble compliqué de réseaux, reliés par des câbles très variés (et quelques liens radio), avec des débits bien différents et changeant d'un moment à l'autre. Tout chemin d'une machine à l'autre va avoir un certain nombre de propriétés (qui varient dans le temps) telles que la latence ou la capacité. Et le taux de perte de paquets, qui nous intéresse ici. (Voir aussi le RFC 7680.)
Notre RFC suppose que la perte de paquets est une indication de congestion (RFC 5681). Ce n'est pas vrai à 100 %, surtout sur les liens radio, où des paquets peuvent être détruits par des perturbations électro-magnétiques sans qu'il y ait congestion, mais c'est quand même proche de la vérité.
Et, au fait, pourquoi détecter la perte de paquets ? Pourquoi ne pas tout simplement ignorer le problème ? Deux raisons :
- Pour pouvoir envoyer des données de manière fiable, il faut détecter les paquets manquants, afin de pouvoir demander leur retransmission. C'est ce que fait TCP, par exemple, sans quoi on ne pourrait pas transmettre un fichier en étant sûr qu'il arrive complet.
- Puisque la perte de paquets signale en général qu'il y a congestion, détecter cette perte permet de ralentir l'envoi de données et donc de lutter contre la congestion.
Résultat, beaucoup de protocoles ont un mécanisme de détection de pertes : TCP (RFC 6298), bien sûr, mais aussi SCTP (RFC 9260), SIP (RFC 3261), etc.
Le RFC cite souvent l'article de Allman, M. et Paxson V, « On Estimating End-to-End Network Path Properties » donc vous avez le droit d'interrompre votre lecture ici pour lire cet article avant de continuer.
Reprenons, avec la section 2 du RFC, qui explique les buts et non-buts de ce RFC :
- Ce RFC ne change aucun protocole existant, les RFC restent les mêmes, vous n'avez pas à réapprendre TCP,
- Ce RFC vise surtout les RFC futurs, qui auraient intérêt à se conformer aux principes énoncés ici (c'est par exemple le cas si vous développez un nouveau protocole au-dessus d'UDP et que vous devez donc mettre en œuvre la détection de pertes),
- Ce RFC n'impose pas des règles absolues, il donne des principes qui marchent dans la plupart des cas, c'est tout.
Nous arrivons maintenant à la section 4 du RFC, qui liste les exigences auxquelles doivent obéir les mécanismes de détection de pertes. (En pratique, les mécanismes existants collent déjà à ces exigences mais elles n'avaient pas été formalisées.) Un petit retour sur la notion de latence, d'abord. On veut savoir combien de temps attendre avant de déclarer un paquet perdu. Cette durée se nomme RTO (Retransmission TimeOut). Les latences dans l'Internet étant extrêmement variables, il serait intéressant de faire dépendre le RTO de la latence. Mais quelle latence ? Le temps d'aller-retour entre deux machines est le temps qu'il faut à un paquet IP pour aller de la machine A à la machine B plus le temps qu'il faut à un paquet IP pour aller de B à A. On ne peut pas mesurer directement ce temps, car le temps de traitement dans la machine B n'est pas forcément connu. Dans le cas de l'ICMP Echo utilisé par ping, ce temps est considéré comme négligeable, ce qui est assez correct si l'amer est une machine Unix dont le noyau traite l'ICMP Echo. Cela l'est moins si l'amer est un routeur qui traite les réponses ICMP à sa plus basse priorité. Et cela l'est encore moins si un client DNS essaie d'estimer la latence vers un résolveur. Si le résolveur avait la réponse dans sa mémoire, le temps de traitement est faible. S'il devait demander aux serveurs faisant autorité, ce temps peut être bien supérieur à la latence. Le RFC distingue donc RTT (Round-Trip Time), la vraie latence, et FT (Feedback Time) qui est ce qu'affichent ping, dig et autres outils. La machine qui veut savoir combien de temps attendre une réaction de la machine en face, avant de déclarer qu'un paquet est perdu, a tout intérêt à avoir une idée du FT.
Certaines des exigences du RFC sont quantitatives. Ainsi, tant qu'on n'a pas mesuré le FT (au début de la session), le RFC requiert que le RTO soit d'au moins une seconde, pour ne pas surcharger le réseau avec des réémissions, et parce que la perte étant interprétée comme un signe de congestion, un RTO trop faible amènerait à réduire la quantité de données qu'on peut envoyer, diminuant ainsi la capacité effective. Sans compter le problème de l'ambiguïté. Si on a réémis un paquet, et qu'une réponse revient, était-elle pour le paquet initial ou pour la réémission ? Dans le doute, il ne faut pas utiliser le temps mesuré pour changer son estimation du RTO. Et c'est une des raisons pour lesquelles il faut prendre son temps pour les premières mesures. Ah, au fait, pourquoi une seconde et pas 0,75 ou 1,25 ? Cela vient d'une analyse quantitative des RTT typiques de l'Internet, exposée dans l'annexe A du RFC 6298.
Après plusieurs mesures, on connait mieux le FT et on peut abaisser le RTO. Il n'y a pas de durée minimale, donc on peut s'approcher de zéro tant qu'on veut.
Le RFC dit aussi que le RTO (Retransmission TimeOut, le délai d'attente) doit se mesurer à partir de plusieurs observations du FT, pour éviter une mesure faussée par un cas extrême. Et il faut refaire ces observations souvent car le réseau change ; les vieilles mesures n'ont pas d'intérêt. C'est ce que fait TCP avec son smoothed RTT, utilisant la moyenne mobile exponentielle (RFC 6298).
L'Internet étant ce qu'il est, il est recommandé de s'assurer qu'un méchant ne puisse pas facilement fausser cette mesure en injectant des faux paquets. Pour TCP, cette assurance est donnée par le caractère imprévisible du numéro de séquence initial, si l'attaquant n'est pas sur le chemin (RFC 5961). Si on veut une protection contre un attaquant situé sur le chemin, il faut de la cryptographie.
Le RFC recommande de refaire l'évaluation du RTO au moins une fois par RTT et, de préference, aussi souvent que des données sont échangées. TCP le fait une fois par RTT et, si on utilise le RFC 7323, à chaque accusé de réception.
Le RFC rappelle qu'en l'absence d'indication du contraire, une perte de paquets doit être considérée comme un indicateur de congestion, et qu'il faut donc ralentir (RFC 5681, pour le cas de TCP).
Et, dernière exigence, en cas de perte de paquets, le RTO doit croitre exponentiellement, pour s'ajuster rapidement à la charge du réseau. On pourra réduire le RTO lorsqu'on aura la preuve que les paquets passent et qu'on reçoit des accusés de réception et/ou des réponses. Dans tous les cas, le RFC limite le RTO à 60 secondes, ce qui est déjà énorme (je n'ai jamais vu une réponse revenir après une durée aussi longue).
Enfin, la section 5 discute des exigences posées et de leurs limites. La tension entre le désir de réactivité (un RTO faible) et celui de mesures correctes (un RTO plus important, pour être raisonnablement sûr de ne pas conclure à tort qu'il y a eu une perte) est une tension fondamentale : on n'aura jamais de solution parfaite, juste des compromis. Il existe des techniques qui permettent de mieux détecter les pertes (l'algorithme Eifel - RFC 3522, le F-RTO du RFC 5682, DSACK - RFC 2883 et RFC 3708…) mais elles ne sont pas complètes et l'attente bornée par le RTO reste donc nécessaire en dernier recours.
Le noyau Linux a mis en œuvre plusieurs techniques non normalisées (par exemple des modifications du RFC 6298) sans que cela ne crée apparemment de problèmes. D'une manière générale, les algorithmes de détection de pertes de TCP, SCTP ou QUIC sont largement compatibles avec les exigences de ce RFC.
L'article seul
RFC 8959: The "secret-token" URI Scheme
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : M. Nottingham
Pour information
Première rédaction de cet article le 30 janvier 2021
Enregistrer une clé
privée (ou tout autre secret) dans un dépôt public (par
exemple sur GitHub) est un gag courant. La
nature des VCS fait qu'il est souvent difficile de
retirer cette clé. Pour limiter un peu les dégâts, ce RFC enregistre
un nouveau plan d'URI, secret-token:, qui
permettra de marquer ces secrets, autorisant par exemple le VCS à
rejeter leur enregistrement.
Ce RFC se
focalise sur les secrets qui sont « au porteur » (bearer
tokens) c'est-à-dire que leur seule connaissance suffit à
les utiliser ; aucune autre vérification n'est faite. Ce peut être
un mot de passe, une clé d'API, etc. Voici un
exemple avec une clé GitLab (je vous rassure,
je l'ai révoquée depuis) : 
La révélation de ces secrets via un enregistrement accidentel,
par exemple dans un dépôt logiciel public, est un grand
classique. Lisez par exemple le témoignage « I
Published My AWS Secret Key to GitHub », ou une
aventure similaire, « Exposing
your AWS access keys on Github can be extremely costly. A personal
experience. », un avertissement
de Github à ses utilisateurs, ou enfin une étude
détaillée publiée à NDSS. Un git add de
trop (ou bien un secret mis dans le code source) et, au prochain
commit, le secret se
retrouve dans le dépôt, puis publié au premier git
push.
L'idée de ce RFC est de marquer clairement ces secrets pour que, par exemple, des audits du dépôt les repèrent plus facilement. Ou pour que les systèmes d'intégration continue puissent les rejeter automatiquement.
Le plan d'URI est simple (section 2 du RFC) :
la chaîne secret-token: suivie du secret. Un
exemple serait
secret-token:E92FB7EB-D882-47A4-A265-A0B6135DC842%20foo
(notez l'échappement du caractère
d'espacement). Par exemple avec les secrets au porteur
pour HTTP
du RFC 6750, cela donnerait un envoi au serveur :
GET /authenticated/stuff HTTP/1.1 Host: www.example.com Authorization: Bearer secret-token:E92FB7EB-D882-47A4-A265-A0B6135DC842%20foo
Le plan secret-token: est désormais dans le
registre IANA.
Je n'ai pas encore trouvé d'organisation qui distribue ces secrets au porteur en utilisant ce plan d'URI mais il semble que GitHub soit tenté.
L'article seul
RFC 8958: Updated Registration Rules for URI.ARPA
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : T. Hardie
Première rédaction de cet article le 3 décembre 2020
Le domaine uri.arpa a été créé par le RFC 3405 pour stocker dans le DNS des règles gouvernant la
résolution d'URI via des enregistrements NAPTR. Ce
nouveau RFC
introduit un très léger changement des procédures d'enregistrement
dans ce domaine uri.arpa.
À titre d'exemple de ces règles, vous pouvez regarder la règle pour les URN.
En effet, le RFC 3405 parlait d'un IETF tree qui avait été créé par le RFC 2717 (dans sa section 2.2) mais supprimé par le RFC 4395. Notre RFC 8958 prend simplement acte de cette suppression et retire les mentions IETF tree du RFC 3405.
L'article seul
RFC 8956: Dissemination of Flow Specification Rules for IPv6
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : C. Loibl (next layer Telekom GmbH), R. Raszuk (NTT Network Innovations), S. Hares (Huawei)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 1 janvier 2021
Il existe un mécanisme de diffusion des règles de filtrage IP, FlowSpec, normalisé dans le RFC 8955. Ce mécanisme permet d'utiliser BGP pour envoyer à tous les routeurs d'un AS les mêmes règles, ce qui est très pratique, par exemple pour bloquer une attaque sur tous les routeurs d'entrée du domaine. Le FlowSpec original ne gérait qu'IPv4, voici son adaptation à IPv6.
En fait, il n'y avait pas grand'chose à faire. Après tout, IPv6 n'est pas un nouveau protocole, juste une nouvelle version du même protocole IP. Des concepts cruciaux, comme la définition d'un préfixe en préfixe/longueur, ou comme la règle du préfixe le plus spécifique restent les mêmes. Ce RFC est donc assez simple. Il ne reprend pas l'essentiel du RFC 8955, il ajoute juste ce qui est spécifique à IPv6. (À l'IETF, il avait été proposé de fusionner les deux documents mais, finalement, il y a un RFC générique + IPv4, le RFC 8955, et un spécifique à IPv6, notre RFC 8956.)
Petit rappel sur FlowSpec : les règles de filtrage sont transportées en BGP, les deux routeurs doivent annoncer la capacité « multi-protocole » (les capacités sont définies dans le RFC 5492) définie dans le RFC 4760, la famille de l'adresse (AFI pour Address Family Identifier) est 2 (qui indique IPv6) et le SAFI (Subsequent Address Family Identifier) est le même qu'en IPv4, 133.
Le gros de notre RFC (section 3) est l'énumération des différents
types d'identifiant d'un trafic à filtrer. Ce sont les mêmes
qu'en IPv4 mais avec quelques adaptations. Ainsi, le type 1,
« préfixe de destination » permet par exemple de dire à ses routeurs
« jette à la poubelle tout ce qui est destiné à
2001:db:96b:1::/64 ». Son encodage ressemble
beaucoup à celui en IPv4 mais avec un truc en plus, le décalage
(offset) depuis le début de l'adresse. Avec un
décalage de 0, on est dans le classique préfixe/longueur mais on
peut aussi ignorer des bits au début de l'adresse avec un décalage
non-nul.
Le type 3, « protocole de niveau supérieur » est l'un de ceux dont la définition IPv6 est la plus différente de celle d'IPv4. En effet, IPv6 a les en-têtes d'extension (RFC 8200, section 4), une spécificité de cette version. Le champ « Next header » d'IPv6 (RFC 8200, section 3) n'a pas la même sémantique que le champ « Protocole » d'IPv4 puisqu'il peut y avoir plusieurs en-têtes avant celui qui indique le protocole de couche 4 (qui sera typiquement TCP ou UDP). Le choix de FlowSpec est que le type 3 désigne le dernier champ « Next header », celui qui identifie le protocole de transport, ce qui est logique, c'est bien là-dessus qu'on veut filtrer, en général. Rappelez-vous au passage que d'analyser les en-têtes d'extension IPv6 pour arriver au protocole de transport n'est hélas pas trivial. Et il y a d'autres pièges, expliqués dans les RFC 7112 et RFC 8883.
Autre type d'identifiant qui est différent en IPv6, le type 7, ICMP. Si le protocole est très proche, les types et les codes ne sont en effet pas les mêmes. Ainsi, l'un des types les plus célèbres, Echo Request, utilisé par ping, vaut 8 en IPv4 et 138 en IPv6.
Les autres types se comportent en IPv6 exactement comme en IPv4. Par exemple, si vous voulez dire à vos routeurs de filtrer sur le port, les types 4, 5 et 6, dédiés à cet usage, ont le même encodage et la même sémantique qu'en IPv4 (ce qui est logique, puisque le port est un concept de couche 4).
FlowSpec est aujourd'hui largement mis en œuvre dans les logiciels de routage, y compris en IPv6. Vous pouvez consulter à ce sujet le rapport de mise en œuvre. Si vous voulez jouer avec FlowSpec, le code Python d'exemple de l'annexe A est disponible en ligne.
L'article seul
RFC 8955: Dissemination of Flow Specification Rules
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : C. Loibl (next layer Telekom GmbH), S. Hares (Huawei), R. Raszuk (Bloomberg LP), D. McPherson (Verisign), M. Bacher (T-Mobile Austria)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 1 janvier 2021
Lorsqu'on a un grand réseau compliqué, diffuser à tous les routeurs des règles de filtrage, par exemple pour faire face à une attaque par déni de service, peut être complexe. Il existe des logiciels permettant de gérer ses routeurs collectivement mais ne serait-il pas plus simple de réutiliser pour cette tâche les protocoles existants et notamment BGP ? Après tout, des règles de filtrage sont une forme de route. On profiterait ainsi des configurations existantes et de l'expérience disponible. C'est ce que se sont dit les auteurs de ce RFC. « FlowSpec » (nom officieux de cette technique) consiste à diffuser des règles de traitement du trafic en BGP, notamment à des fins de filtrage. Ce RFC remplace le RFC FlowSpec original, le RFC 5575, le texte ayant sérieusement changé (mais le protocole est presque le même).
Les routeurs modernes disposent en effet de nombreuses capacités de traitement du trafic. Outre leur tâche de base de faire suivre les paquets, ils peuvent les classifier, limiter leur débit, jeter certains paquets, etc. La décision peut être prise en fonction de critères tels que les adresses IP source et destination ou les ports source et destination. Un flot (flow) est donc défini comme un tuple rassemblant les critères d'acceptation d'un paquet IP. Notre RFC 8955 encode ces critères dans un attribut NLRI (Network Layer Reachability Information est décrit dans la section 4.3 du RFC 4271) BGP, de manière à ce qu'ils puissent être transportés par BGP jusqu'à tous les routeurs concernés. Sans FlowSpec, il aurait fallu qu'un humain ou un programme se connecte sur tous les routeurs et y rentre l'ACL concernée.
Pour reconnaitre les paquets FlowSpec, ils sont marqués avec le SAFI (concept introduit dans le RFC 4760) 133 pour les règles IPv4 (et IPv6 grâce au RFC 8956) et 134 pour celles des VPN.
La section 4 du RFC donne l'encodage du NLRI. Un message
UPDATE de BGP est utilisé, avec les attributs
MP_REACH_NLRI et
MP_UNREACH_NLRI du RFC 4760 et un NLRI FlowSpec. Celui-ci compte plusieurs
couples {type, valeur} où l'interprétation de la valeur dépend du
type (le type est codé sur un octet). Voici les principaux types :
- Type 1 : préfixe de la destination, représenté par un octet
pour la longueur, puis le préfixe, encodé comme traditionnellement
en BGP (section 4.3 du RFC 4271). Ainsi, le
préfixe
10.0.1.0/24sera encodé (noté en hexadécimal)01 18 0a 00 01(type 1, longueur 24 - 18 en hexa - puis le préfixe dont vous noterez que seuls les trois premiers octets sont indiqués, le dernier n'étant pas pertinent ici). - Type 2 : préfixe de la source (lors d'une attaque DoS, il est essentiel de pouvoir filtrer aussi sur la source).
- Type 3 : protocole (TCP, UDP, etc).
- Types 4, 5 et 6 : port (source ou destination ou les deux). Là encore, c'est un critère très important lors du filtrage d'une attaque DoS. Attention, cela suppose que le routeur soit capable de sauter les en-têtes IP (y compris des choses comme ESP) pour aller décoder TCP ou UDP. Tous les routeurs ne savent pas faire cela (en IPv6, c'est difficile).
- Type 9 : options activées de TCP, par exemple uniquement les
paquets
RST.
Tous les types de composants sont enregistrés à l'IANA.
Une fois qu'on a cet arsenal, à quoi peut-on l'utiliser ? La section 5 détaille le cas du filtrage. Autrefois, les règles de filtrage étaient assez statiques (je me souviens de l'époque où tous les réseaux en France avaient une ACL, installée manuellement, pour filtrer le réseau de l'EPITA). Aujourd'hui, avec les nombreuses DoS qui vont et viennent, il faut un mécanisme bien plus dynamique. La première solution apparue a été de publier via le protocole de routage des préfixes de destination à refuser. Cela permet même à un opérateur de laisser un de ses clients contrôler le filtrage, en envoyant en BGP à l'opérateur les préfixes, marqués d'une communauté qui va déclencher le filtrage (à ma connaissance, aucun opérateur n'a utilisé cette possibilité, en raison du risque qu'une erreur du client ne se propage). De toute façon, c'est très limité en cas de DoS (par exemple, on souhaite plus souvent filtrer sur la source que sur la destination). Au contraire, le mécanisme FlowSpec de ce RFC donne bien plus de critères de filtrage.
Cela peut d'ailleurs s'avérer dangereux : une annonce FlowSpec trop générale et on bloque du trafic légitime. C'est particulièrement vrai si un opérateur accepte du FlowSpec de ses clients : il ne faut pas permettre à un client de filtrer les autres. D'où la procédure suggérée par la section 6, qui demande de n'accepter les NLRI FlowSpec que s'ils contiennent un préfixe de destination, et que ce préfixe de destination est routé vers le même client qui envoie le NLRI (notez que cette règle a été assouplie par le RFC 9117). Ainsi, un client ne peut pas déclencher le filtrage d'un autre puisqu'il ne peut influencer que le filtrage des paquets qui lui sont destinés.
Au fait, en section 5, on a juste vu comment indiquer les
critères de classification du trafic qu'on voulait filtrer. Mais
comment indiquer le traitement qu'on veut voir appliqué aux paquets
ainsi classés ? (Ce n'est pas forcément les jeter : on peut vouloir
être plus subtil.) FlowSpec utilise les communautés étendues du RFC 4360. La valeur sans doute la plus importante
est 0x8006, traffic-rate, qui permet de
spécifier un débit maximal pour les paquets qui correspondent aux
critères mis dans le NLRI. Le débit est en octets/seconde. En
mettant zéro, on demande à ce que tous les paquets classés soient
jetés. (Mais on peut aussi indiquer des paquets/seconde, c'est une
nouveauté de ce RFC.) Les autres valeurs possibles permettent des
actions comme de modifier les bits DSCP du trafic classé.
Comme toutes les armes, celle-ci peut être dangereuse pour celui qui la manipule. La section 12 est donc la bienvenue, pour avertir de ces risques. Par exemple, comme indiqué plus haut, si on permet aux messages FlowSpec de franchir les frontières entre AS, un AS maladroit ou méchant risque de déclencher un filtrage chez son voisin. D'où l'importance de la validation, n'accepter des règles FlowSpec que pour les préfixes de l'AS qui annonce ces règles.
Ensuite, comme tous les systèmes de commande des routeurs à distance, FlowSpec permet de déclencher un filtrage sur tous les routeurs qui l'accepteront. Si ce filtrage est subtil (par exemple, filtrer tous les paquets plus grands que 900 octets), les problèmes qui en résultent seront difficiles à diagnostiquer.
FlowSpec a joué un rôle important dans la panne Level 3 / CenturyLink d'août 2020. Et, avant cela, dans la panne CloudFlare du 3 mars 2013, où des critères incorrects (une taille de paquet supérieure au maximum permis par IP) avaient été envoyés à tous les routeurs. Ce n'est pas une bogue de FlowSpec : tout mécanisme de diffusion automatique de l'information à N machines différentes a le même problème potentiel. Si l'information était fausse, le mécanisme de diffusion transmet l'erreur à tous... (Dans le monde des serveurs Unix, le même problème peut se produire avec des logiciels comme Chef ou Puppet. Lisez un cas rigolo avec Ansible.) Comme le prévient notre RFC : « When automated systems are used, care should be taken to ensure the correctness of the automated system. » Toutefois, contrairement à ce que laisse entendre le RFC, il n'y a pas que les processus automatiques qui injectent des erreurs : les humains le font aussi.
Si vous voulez en apprendre plus sur FlowSpec :
- Excellent exposé très détaillé (en anglais) de Frédéric Gabut-Deloraine à une réunion FRnOG,
- Excellent exposé général (en anglais) sur le BGP concret, par Thomas Mangin, avec quelques transparents sur FlowSpec à la fin,
- Un article en français sur LinuxFr, avec exemples de configuration d'ExaBGP,
- Exposé (en anglais) de Jean-Marc Uzé, détaillant le cas des attaques par déni de service,
- Le projet du projet Cymru d'un serveur FlowSpec public (mais je ne sais pas ce qu'il est devenu depuis 2011),
- Un exposé sur l'utilisation de FlowSpec à Cloudflare (écrit avant la panne).
Si vous vous intéressez à l'utilisation de BGP lors d'attaques par déni de service, vous pouvez aussi consulter les RFC 3882 et RFC 5635.
Les changements depuis la norme originale, le RFC 5575, sont résumés dans l'annexe B. Parmi les principaux :
- Le RFC 7674 a été intégré ici, et n'est donc plus d'actualité,
- Les comparaisons entre les valeurs indiquées dans les règles FlowSpec et les paquets qu'on voit passer sont désormais spécifiées plus strictement, avec du code d'exemple (en Python) dans l'annexe A,
- Les actions fondées sur le trafic peuvent désormais s'exprimer en nombre de paquets et plus seulement en nombre d'octets (certaines attaques par déni de service sont dangereuses par leur nombre de paquets, même si ces paquets sont petits).
FlowSpec est utilisé depuis dix ans et de nombreuses mises en œuvre existent (cf. la liste). Sur les Juniper, on peut consulter leur documentation en ligne.
L'article seul
RFC 8953: Coordinating Attack Response at Internet Scale 2 (CARIS2) Workshop Report
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : K. Moriarty (Dell Technologies)
Pour information
Première rédaction de cet article le 17 décembre 2020
Voici le compte-rendu de la deuxième édition de l'atelier CARIS (Coordinating Attack Response at Internet Scale), un atelier de l'ISOC consacré à la défense de l'Internet contre les différentes attaques possibles, par exemple les dDoS. Cet atelier s'est tenu à Cambridge en mars 2019. Par rapport au premier CARIS, documenté dans le RFC 8073, on note l'accent mis sur les conséquences du chiffrement, désormais largement répandu.
Les problèmes de sécurité sur l'Internet sont bien connus. C'est tous les jours qu'on entend parler d'une attaque plus ou moins réussie contre des infrastructures du réseau. Ainsi, Google a été victime d'une grosse attaque en 2017 (mais qui n'a été révélée que des années après). Mais, pour l'instant, nous n'avons pas de solution miracle. L'idée de base des ateliers CARIS est de rassembler aussi bien des opérateurs de réseau, qui sont « sur le front » tous les jours, que des chercheurs, des fournisseurs de solutions de défense, et des CSIRT, pour voir ensemble ce qu'on pouvait améliorer. Pour participer, il fallait avoir soumis un article, et seules les personnes dont un article était accepté pouvait venir, garantissant un bon niveau de qualité aux débats, et permettant de limiter le nombre de participants, afin d'éviter que l'atelier ne soit juste une juxtaposition de discours.
La section 2 du RFC présente les quatorze papiers qui ont été acceptés. On les trouve en ligne.
Le but de l'atelier était d'identifier les points sur lesquels des progrès pourraient être faits. Par exemple, tout le monde est d'accord pour dire qu'on manque de professionnel·le·s compétent·e·s en cybersécurité mais il ne faut pas espérer de miracles : selon une étude, il manque trois millions de personnes dans ce domaine et il n'y a simplement aucune chance qu'on puisse les trouver à court terme. Plus réaliste, l'atelier s'est focalisé sur le déploiement du chiffrement (TLS 1.3, normalisé dans le RFC 8446, le futur - à l'époque - QUIC, et pourquoi pas le TCPcrypt du RFC 8548), déploiement qui peut parfois gêner la détection de problèmes, et sur les mécanismes de détection et de prévention. Une importance particulière était donnée au passage à l'échelle (on ne peut plus traiter chaque attaque individuellement et manuellement, il y en a trop).
Bon, maintenant, les conclusions de l'atelier (section 4). Première session, sur l'adoption des normes. C'est une banalité à l'IETF que de constater que ce n'est pas parce qu'on a normalisé une technique de sécurité qu'elle va être déployée. Beaucoup de gens aiment râler contre l'insécurité de l'Internet mais, dès qu'il s'agit de dépenser de l'argent ou du temps pour déployer les solutions de sécurité, il y a moins d'enthousiasme. (J'écris cet article au moment de la publication de la faille de sécurité SadDNS. Cela fait plus de dix ans qu'on a une solution opérationnelle contre la famille d'attaques dont SadDNS fait partie, DNSSEC et, pourtant, DNSSEC n'est toujours pas déployé sur la plupart des domaines.) Commençons par un point optimiste : certaines des technologies de sécurité de l'IETF ont été largement déployées, comme SSL (RFC 6101), remplacé il y a quinze ans par TLS (RFC 8446). L'impulsion initiale venait clairement du secteur du commerce électronique, qui voulait protéger les numéros des cartes de crédit. Lié à TLS, X.509 (RFC 5280) est aussi un succès. Cette fois, l'impulsion initiale est plutôt venue des États. (X.509 doit être une des très rares normes UIT survivantes sur l'Internet.)
Moins directement lié à la sécurité, SNMP (RFC 3410) est aussi un succès, même s'il est en cours de remplacement par les techniques autour de YANG comme RESTCONF. Toujours pour la gestion de réseaux, IPfix (RFC 7011) est également un succès, largement mis en œuvre sur beaucoup d'équipements réseau.
Par contre, il y a des semi-échecs et des échecs. Le format de
description d'incidents de sécurité IODEF
(RFC 7970) ne semble pas très répandu. (Il a
un concurrent en dehors de l'IETF, STIX - Structured Threat Information eXpression, qui
ne semble pas mieux réussir.) IODEF est utilisé par des CSIRT
mais souffre de son niveau de détail (beaucoup d'opérationnels
veulent des synthèses, pas des données brutes) et, comme toutes les
techniques d'échange d'information sur les questions de sécurité,
souffre également des problèmes de confiance qui grippent la
circulation de l'information. Autre technique de sécurité
excellente mais peu adoptée, DANE (RFC 7671). Malgré de nombreux efforts de promotion (comme
https://internet.nl
Un autre cas fameux de non-succès, même s'il n'est pas directement lié à la sécurité, est IPv6 (RFC 8200).
Deuxième session, les protocoles nouveaux. L'atelier s'est penché sur le format MUD (Manufacturer Usage Description, RFC 8520) qui pourrait aider à boucher une petite partie des trous de sécurité de l'Internet des objets. Il a également travaillé l'échange de données et les problèmes de confiance qu'il pose. Comme à CARIS 1, plusieurs participants ont noté que cet échange de données reste gouverné par des relations personnelles. La confiance ne passe pas facilement à l'échelle. L'échange porte souvent sur des IOC et un standard possible a émergé, MISP.
Une fois le problème détecté, il reste à coordonner la réaction, puisque l'attaque peut toucher plusieurs parties. C'est encore un domaine qui ne passe guère à l'échelle. L'Internet n'a pas de mécanisme (technique mais surtout humain) pour coordonner des centaines de victimes différentes. Des tas d'obstacles à la coordination ont été mentionnés, des outils trop difficiles à utiliser en passant par les obstacles frontaliers à l'échange, les obligations légales qui peuvent interdire l'échange de données, et bien sûr le problème récurrent de la confiance. Vous vous en doutez, pas plus qu'au premier atelier, il n'y aura eu de solution parfaite découverte pendant les sessions.
La session sur la surveillance a vu plusieurs discussions intéressantes. Ce fut le cas par exemple du problème de la réputation des adresses IP. Ces adresses sont souvent des IOC et on se les échange souvent, ce qui soulève des questions liées à la vie privée. (Un des papiers de l'atelier est « Measured Approaches to IPv6 Address Anonymization and Identity Association », de David Plonka et Arthur Berger , qui explique la difficulté de l'« anonymisation » des adresses IP si on veut qu'elles restent utiles pour les opérationnels.) L'exploitation correcte de ces adresses IP nécessite de connaitre les plans d'adressage utilisés (si une adresse IPv6 se comporte mal, faut-il bloquer tout le préfixe /64 ? Tout le /48 ?). Il n'y a pas de ressources publiquement disponibles à ce sujet, qui permettrait de connaitre, pour une adresse IP donnée, l'étendue du préfixe englobant. (Je ne parle évidemment pas du routage, pour lequel ces bases existents, mais de la responsabilité.) Une des suggestions était d'étendre les bases des RIR. Une autre était de créer une nouvelle base. Le problème est toujours le même : comment obtenir que ces bases soient peuplées, et correctement peuplées ?
Une des questions amusantes lorsqu'on essaie de déboguer un problème de communication entre deux applications est de savoir quoi faire si la communication est chiffrée. Il n'est évidemment pas question de réclamer une porte dérobée pour court-circuiter le chiffrement, cela créerait une énorme faille de sécurité. Mais alors comment faire pour savoir ce qui se dit ? On a besoin de la coopération de l'application. Mais toutes les applications ne permettent pas facilement de journaliser les informations importantes et, quand elles le font, ce n'est pas dans un format cohérent. D'où une suggestion lors de l'atelier de voir s'il ne serait pas envisageable de mettre cette fonction dans les compilateurs, pour avoir un mécanisme de journalisation partout disponibles.
Pendant qu'on parle de chiffrement, une autre question est celle de l'identification d'une machine ou d'un protocole par le fingerprinting, c'est-à-dire en observant des informations non chiffrées (taille des paquets, temps de réponse, variations permises par le protocole, etc). Le fingerprinting pose évidemment des gros risques pour la vie privée et beaucoup de travaux sur des protocoles récents (comme QUIC) visaient à limiter son efficacité.
Pour résumer l'atelier (section 6 du RFC), plusieurs projets ont été lancés pour travailler sur des points soulevés dans l'atelier. À suivre, donc.
L'article seul
RFC 8952: Captive Portal Architecture
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : K. Larose (Agilicus), D. Dolson, H. Liu (Google)
Pour information
Réalisé dans le cadre du groupe de travail IETF capport
Première rédaction de cet article le 1 décembre 2020
Les portails captifs sont ces insupportables pages Web vers lesquels certains réseaux d'accès en WiFi vous détournent pour vous faire laisser des données personnelles avant d'avoir accès à l'Internet. Très répandus dans les hôtels et aéroports, ils utilisent pour ce détournement des techniques qui sont souvent celles des attaquants, et ils posent donc de graves problèmes de sécurité, sans parler de l'utilisabilité. Le groupe de travail CAPPORT de l'IETF travaille à définir des solutions techniques qui rendent ces portails captifs un peu moins pénibles. Ce RFC décrit l'architecture générale du système, d'autres RFC décrivant les solutions partielles.
Vu de l'utilisateurice, la connexion à
l'Internet sur pas mal de
hotspots se fait ainsi :
on accroche le réseau WiFi, on se rend à une page Web
quelconque et, au lieu de la page demandée, on est détourné vers une
page des gérants du hotspot, qui vous montre de
la publicité, exige des données personnelles (et parfois une
authentification) et l'acceptation de
conditions d'utilisation léonines, avant de continuer. Si la page
que vous vouliez visiter était en HTTPS, ce qui est le cas le
plus courant aujourd'hui, vous aurez probablement en outre un
avertissement de sécurité. Certains systèmes
d'exploitation, comme Android, ou
certains navigateurs,
comme Firefox,
détectent automatiquement la captivité, suspendent leurs autres
activités, et vous proposent d'aller directement à une page du
portail. Mais ça reste pénible, par exemple parce que c'est
difficile à automatiser. (Un exemple d'automatisation en
shell avec curl que j'ai récupéré
en ligne est hotel-wifi.sh
Techniquement, la mise en œuvre du concept de portail captif se fait en général actuellement en détournant le trafic HTTP (via un transparent proxy) ou avec un résolveur DNS menteur, qui donne l'adresse IP du portail en réponse à toute requête. L'annexe A du RFC résume les mises en œuvre actuelles de portails captifs, et les méthodes utilisées pour pouvoir se connecter le moins mal possible. La machine qui veut savoir si elle est derrière un portail captif va typiquement faire une requête HTTP vers un URL connu et contrôlé par le fournisseur de l'application ou du système d'explication. Cet URL est appelé le canari. (Au lieu ou en plus de HTTP, on peut faire un test DNS sur un nom de domaine où on connait le résultat, au cas où le portail captif fonctionne avec un résolveur menteur. Attention, DNS et HTTP peuvent donner des résultats différents, détournement DNS mais pas HTTP, ou bien le contraire.) Notez que toutes les techniques avec un canari peuvent mener à des faux négatifs si le canari est connu et que le gardien derrière le portail captif le laisse passer, via une règle spécifique.
Notre RFC choisit d'être positif et donne une liste des exigences auxquelles essaie de répondre les solutions développées dans le groupe de travail. Ces exigences peuvent aussi être lues comme une liste de tous les inconvénients des portails captifs actuels. Un échantillon de ces exigences :
- Ne pas détourner les protocoles standards de l'Internet comme HTTP, et, d'une manière générale, ne pas se comporter comme un attaquant (alors que les portails actuels violent systématiquement la sécurité en faisant des attaques de l'intermédiaire).
- Ne pas détourner non plus le DNS, puisque la solution doit être compatible avec DNSSEC, outil indispensable à la sécurité du DNS.
- Travailler au niveau IP (couche 3) et ne pas être dépendant d'une technologie d'accès particulière (cela ne doit pas marcher uniquement pour le WiFi).
- Les machines terminales doivent avoir un moyen simple et sûr
d'interroger leur réseau d'accès pour savoir si elles sont
captives, sans compter sur le détournement de protocoles Internet,
sans avoir besoin de « canaris »,
d'URI
spéciaux qu'on tester, comme le
detectportal.firefox.comde Firefox. - Les solutions déployées ne doivent pas exiger un navigateur Web, afin d'être utilisable, par exemple, par des machines sans utilisateur humain (les portails actuels plantent toutes les applications non-Web, comme la mise à jour automatique des logiciels). Ceci dit, le RFC se concentre surtout sur le cas où il y a un utilisateur humain.
L'architecture décrite ici repose sur :
- L'annonce aux machines clients d'un URI qui sera l'adresse de l'API à laquelle parler pour en savoir plus sur le portail captif. Cette annonce peut se faire en DHCP (RFC 8910) ou en RA (même RFC). Mais elle pourra aussi se faire avec RADIUS ou par une configuration statique.
- L'information donnée par le portail captif à la machine cliente, lui disant notamment si elle est en captivité ou pas.
Plus concrètement, le RFC liste les composants du problème et donc des solutions. D'abord, la machine qui se connecte (user equipment, dans le RFC). Pour l'instant, la description se limite aux machines qui ont un navigateur Web, même si elles sont loin d'être les seules, ou même les plus nombreuses. Pour que tout marche comme il faut, cette machine doit pouvoir récupérer l'URI de l'API du portail captif (par exemple, elle doit avoir un client DHCP), doit pouvoir gérer le fait que certaines de ses interfaces réseaux sont derrière un portail captif et pas les autres (RFC 7556), doit pouvoir notifier l'utilisateur qu'il y a un tel portail (et attention au hameçonnage !), et ce serait bien qu'il y a ait un moyen de dire aux applications « on est encore en captivité, n'essayez pas de vous connecter tout de suite ». Un exemple de cette dernière demande est fournie par Android où l'utilisation du réseau par défaut ne passe de la 4G au WiFi qu'une fois qu'Android a pu tester que l'accès WiFi n'était pas en captivité. Enfin, si la machine gère l'API des portails captifs, elle doit évidemment suivre toutes les règles de sécurité, notamment la validation du certificat.
Ensuite, deuxième composant, le système de distribution d'informations dans le réseau (provisioning service), DHCP ou RA. C'est lui qui va devoir envoyer l'URI de l'API à la machine qui se connecte, comme normalisé dans le RFC 8910.
Troisième composant, le serveur derrière l'API. Il permet de se
passer des « canaris », des tests du genre « est-ce que j'arrive à
me connecter à
https://detectportal.example ? », il y a juste
à interroger l'API. Cette API (RFC 8908) doit
permettre au minimum de connaitre l'état de la connexion (en
captivité ou pas), et d'apprendre l'URI que l'humain devra visiter
pour sortir de captivité (« j'ai lu les 200 pages de textes
juridiques des conditions d'utilisation, les 100 pages du code de
conduite et je les accepte inconditionnellement »). Elle doit
utiliser HTTPS.
Enfin, il y a le composant « gardien » (enforcement) qui s'assure qu'une machine en captivité ne puisse effectivement pas sortir ou en tout cas, ne puisse pas aller en dehors des services autorisés (qui doivent évidemment inclure le portail où on accepte les conditions). Il est typiquement placé dans le premier routeur. L'architecture présentée dans ce RFC ne change pas ce composant (contrairement aux trois premiers, qui devront être créés ou modifiés).
Parmi ces différents composants qui interagissent, l'un d'eux mérite une section entière, la section 3, dédiée à la machine qui se connecte (user equipment) et notamment à la question de son identité. Car il faut pouvoir identifier cette machine, et que les autres composants soient d'accord sur cette identification. Par exemple, une fois que le portail captif aura accepté la connexion, il faudra que le système « gardien » laisse désormais passer les paquets. Pour cette identification, plusieurs identificateurs sont possibles, soit présents explicitement dans les paquets, soit déduits d'autres informations. On peut imaginer, par exemple, utiliser l'adresse MAC ou l'adresse IP. Ou bien, pour les identificateurs qui ne sont pas dans le paquet, l'interface physique de connexion. Le RFC liste leurs propriétés souhaitables :
- Unicité,
- Difficulté à être usurpé par un attaquant (sur ce point, les adresses MAC ou IP ne sont pas satisfaisantes, alors que l'interface physique est parfaite ; diverses techniques existent pour limiter la triche sur l'adresse IP comme le test de réversibilité),
- Visibilité pour le serveur derrière l'API (selon la technique de développement utilisée, l'adresse MAC peut être difficile ou impossible à récupérer par ce serveur ; idem pour l'interface physique),
- Visibilité pour le gardien.
Notons que l'adresse IP a l'avantage d'être un identificateur qui n'est pas local au premier segment de réseau, ce qui peut permettre, par exemple, d'avoir un gardien qui soit situé un peu plus loin.
Armé de tous ces éléments, il est possible de présenter le traitement complet (section 4). Donc, dans l'ordre des évènements, dans le monde futur où ces différents RFC auront été déployés :
- La machine de l'utilisateur se connecte au réseau, et obtient des informations en DHCP ou RA,
- Parmi ces informations, l'URI de l'API du portail captif (options du RFC 8910),
- La machine parle à cette API en suivant le RFC 8908, ce qui lui permet d'apprendre l'URI de la page du portail captif prévue pour les humains,
- L'utilisateur humain lit les CGU (ah, ah) et les accepte,
- Le gardien est prévenu de cette acceptation et laisse désormais passer les paquets,
- L'utilisateur peut enfin regarder Joséphine, ange gardien sur Salto.
Si tout le monde joue le jeu, et que les techniques conformes à l'architecture décrite dans ce RFC sont déployées, les portails captifs, quoique toujours pénibles, devraient devenir plus gérables. Hélas, il est probable que beaucoup de déploiements ne soient jamais changé, notamment dans les environnements où le client est… captif (hôtels, aéroports) et où il n'y a donc aucune motivation commerciale pour améliorer les choses. Les logiciels vont donc devoir continuer à utiliser des heuristiques de type canari pendant une très longue période, car ils ne pourront pas compter sur des portails captifs propres.
Tout cela laisse ouvert quelques problèmes de sécurité, que la section 6 étudie. D'abord, fondamentalement, il faut faire confiance au réseau d'accès. Via DHCP et RA, il peut vous conduire n'importe où. (Le RFC 7556 discute de cette difficulté à authentifier le réseau d'accès.) Des protections comme l'authentification du serveur en TLS limitent un peu les dégâts mais ne résolvent pas tout. Ceci dit, c'est pour cela que notre RFC impose l'utilisation de HTTPS pour accéder à l'API. Mais, d'une manière générale, le réseau d'accès, et le portail captif qu'il utilise, a tous les pouvoirs. Il peut par exemple vous bloquer l'accès à tout ou partie de l'Internet, même après que vous ayez accepté les conditions d'utilisation.
Il y a aussi des questions de vie privée. L'identificateur de la machine qui se connecte peut être détourné de son usage pour servir à surveiller un utilisateur, par exemple. Les bases de données utilisées par les différents composants de cette architecture de portail captif doivent donc être considérées comme contenant des données personnelles. L'utilisateur peut changer ces identificateurs (pour l'adresse MAC, avec un logiciel comme macchanger) mais cela peut casser son accès Internet, si le gardien utilise justement cet identificateur.
L'article seul
RFC 8950: Advertising IPv4 Network Layer Reachability Information (NLRI) with an IPv6 Next Hop
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : S. Litkowski, S. Agrawal, K. Ananthamurthy (Cisco), K. Patel (Arrcus)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF bess
Première rédaction de cet article le 20 novembre 2020
Le protocole de routage BGP annonce des préfixes qu'on sait joindre, avec l'adresse IP du premier routeur à qui envoyer les paquets pour ce préfixe. (Ce routeur est appelé le next hop.) BGP a une extension, BGP multi-protocoles (RFC 4760) où les préfixes annoncés (NLRI pour Network Layer Reachability Information) ne sont plus forcément de la même famille que les adresses utilisées dans la session BGP. On peut donc annoncer des préfixes IPv6 sur une session BGP établie en IPv4 et réciproquement. Notre RFC, qui succède au RFC 5549 avec quelques petits changements, étend encore cette possibilité en permettant que le next hop ait une adresse de version différente de celle du préfixe.
Normalement, BGP multi-protocoles (RFC 4760) impose la version (IPv4 ou IPv6) du next hop via l'AFI (Address Family Identifier) et le SAFI (Subsequent Address Family Identifier) indiqués dans l'annonce (cf. la liste actuelle des AFI possible et celle des SAFI). Ainsi, un AFI de 1 (IPv4) couplé avec un SAFI valant 1 (unicast), lors de l'annonce d'un préfixe IPv4, impose que l'adresse du routeur suivant soit en IPv4. Désormais, cette règle est plus libérale, le routeur suivant peut avoir une adresse IPv6. Cela peut faciliter, par exemple, la vie des opérateurs qui, en interne, connectent des ilots IPv4 au-dessus d'un cœur de réseau IPv6 (cf. RFC 4925). Notez que cela ne règle que la question de l'annonce BGP. Il reste encore à router un préfixe IPv4 via une adresse IPv6 mais ce n'est plus l'affaire de BGP.
Il y avait déjà des exceptions à la règle comme quoi le préfixe
et l'adresse du routeur suivant étaient de la même famille. Ainsi,
le RFC 6074 permettait cela pour le couple AFI 25
(L2VPN) / SAFI 65
(VPLS). Mais le couple AFI 2 / SAFI 1 (IPv6 /
unicast) ne permet pas de telles exceptions (RFC 2545). Une astuce (RFC 4798 et RFC 4659) permet de s'en
tirer en encodant l'adresse IPv4 du next hop dans
une adresse IPv6. (Oui, ::192.0.2.66 est une
adresse IPv4 encodée dans les seize octets d'IPv6, cf. RFC 4291, section 2.5.5.2.) Quant au cas inverse
(AFI IPv4, routeur suivant en IPv6), elle fait l'objet de notre RFC.
Lorsque l'adresse du next hop n'est pas de la famille du préfixe, il faut trouver la famille, ce qui peut se faire par la taille de l'adresse du next hop (quatre octets, c'est de l'IPv4, seize octets, de l'IPv6). C'est ce que propose le RFC 4684.
L'extension permettant la liberté d'avoir des next hop dans une famille différente du préfixe est spécifiée complètement en section 4. Elle liste les couples AFI / SAFI pour lesquels on est autorisé à avoir un next hop IPv6 alors que le préfixe est en IPv4. Le routeur BGP qui reçoit ces annonces doit utiliser la longueur de l'adresse pour trouver tout seul si le next hop est IPv4 ou IPv6 (la méthode des RFC 4684 et RFC 6074).
L'utilisation de cette liberté nécessite de l'annoncer à son pair BGP, pour ne pas surprendre des routeurs BGP anciens. Cela se fait avec les capacités du RFC 5492. La capacité se nomme Extended Next Hop Encoding et a le code 5. Cette capacité est restreinte à certains couples AFI / SAFI, listés dans l'annonce de la capacité. Par exemple, le routeur qui veut annoncer une adresse IPv6 comme next hop pour de l'unicast IPv4 va indiquer dans le champ Valeur de la capacité 1 / 1 (le couple AFI /SAFI) et le next hop AFI 2.
La section 2 du RFC résume les changements depuis le RFC 5549, que notre RFC remplace. L'encodage de l'adresse du next hop change dans le cas des VPN, et, pour les VPN MPLS, extension de l'exception au multicast. Bref, rien de bien crucial.
L'article seul
RFC 8949: Concise Binary Object Representation (CBOR)
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : C. Bormann (Universität Bremen
TZI), P. Hoffman (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 5 décembre 2020
Il existait un zillion de formats binaires d'échange de données ? Et bien ça en fera un zillion plus un. CBOR (Concise Binary Object Representation) est un format qui utilise un modèle de données très proche de celui de JSON, mais est encodé en binaire, avec comme but principal d'être simple à encoder et décoder, même par des machines ayant peu de ressources matérielles. Normalisé à l'origine dans le RFC 7049, il est désormais spécifié dans ce nouveau RFC. Si le texte de la norme a changé, le format reste le même.
Parmi les autres formats binaires courants, on connait ASN.1 (plus exactement BER ou DER, utilisés dans plusieurs protocoles IETF), EBML ou MessagePack mais ils avaient des cahiers des charges assez différents (l'annexe E du RFC contient une comparaison). CBOR se distingue d'abord par sa référence à JSON (RFC 8259), dont le modèle de données sert de point de départ à CBOR, puis par le choix de faciliter le travail des logiciels qui devront créer ou lire du CBOR. CBOR doit pouvoir tourner sur des machines très limitées (« classe 1 », en suivant la terminologie du RFC 7228). Par contre, la taille des données encodées n'est qu'une considération secondaire (section 1.1 du RFC pour une liste prioritisée des objectifs de CBOR). Quant au lien avec JSON, l'idée est d'avoir des modèles de données suffisamment proches pour qu'écrire des convertisseurs CBOR->JSON et JSON->CBOR soit assez facile, et pour que les protocoles qui utilisent actuellement JSON puissent être adaptés à CBOR sans douleur excessive. CBOR se veut sans schéma, ou, plus exactement, sans schéma obligatoire. Et le but est que les fichiers CBOR restent utilisables pendant des dizaines d'années, ce qui impose d'être simple et bien documenté.
La spécification complète de CBOR est en section 3 de ce RFC. Chaque élément contenu dans le flot de données commence par un octet dont les trois bits de plus fort poids indiquent le type majeur. Les cinq bits suivants donnent des détails. Ce mécanisme permet de programmeur un décodeur CBOR avec une table de seulement 256 entrées (l'annexe B fournit cette table et l'annexe C un décodeur en pseudo-code très proche de C). Pour un entier, si la valeur que codent ces cinq bits suivants est inférieure à 24, elle est utilisée telle quelle. Sinon, cela veut dire que les détails sont sur plusieurs octets et qu'il faut lire les suivants (la valeur des cinq bits codant la longueur à lire). Selon le type majeur, les données qui suivent le premier octet sont une valeur (c'est le cas des entiers, par exemple) ou bien un doublet {longueur, valeur} (les chaînes de caractères, par exemple). L'annexe A de notre RFC contient de nombreux exemples de valeurs CBOR avec leur encodage.
Quels sont les types majeurs possibles ? Si les trois premiers
bits sont à zéro, le type majeur, 0, est un entier non signé. Si les
cinq bits suivants sont inférieurs à 24, c'est la valeur de cet
entier. S'ils sont égaux à 24, c'est que l'entier se trouve dans
l'octet suivant l'octet initial, s'ils sont égaux à 25, que l'entier
se trouve dans les deux octets suivants, et ainsi de suite (31 est
réservé pour les tailles indéterminées, décrites plus
loin). L'entier 10 se représentera donc 00001010, l'entier 42 sera
00011000 00101010, etc. Presque pareil pour un type majeur de 1,
sauf que l'entier sera alors signé, et négatif. La valeur sera -1
moins la valeur encodée. Ainsi, -3 sera 00100010. Vous voulez
vérifier ? L'excellent terrain de jeu http://cbor.me
vous le permet, essayez par exemple http://cbor.me?diag=42.
Le type majeur 2 sera une chaîne d'octets (principal ajout par
rapport au modèle de données de JSON). La longueur est codée
d'abord, en suivant la même règle que pour les entiers. Puis
viennent les données. Le type 3 indique une chaîne de caractères et
non plus d'octets. Ce sont forcément des caractères
Unicode, encodés en
UTF-8 (RFC 3629). Le
champ longueur (codé comme un entier) indique le nombre d'octets de
l'encodage UTF-8, pas le nombre de caractères (pour connaître ce
dernier, il faut un décodeur UTF-8). Vous voulez des exemples ?
Connectez-vous à http://www.cbor.me/?diag=%22lait%22
et vous voyez que la chaîne « lait » est représentée par
646c616974 : 64 = 01100100, type majeur 3 puis une longueur de
4. Les codes ASCII suivent (rappelez-vous qu'ASCII est
un sous-ensemble d'UTF-8). Avec des caractères non-ASCII comme http://www.cbor.me/?diag=%22caf%C3%A9%22, on aurait
65636166c3a9 (même type majeur, longueur 5
octets, puis les caractères, avec c3a9 qui code
le é en UTF-8).
Le type majeur 4 indique un tableau. Rappelez-vous que CBOR utilise un modèle de données qui est très proche de celui de JSON. Les structures de données possibles sont donc les tableaux et les objets (que CBOR appelle les maps). Un tableau est encodé comme une chaîne d'octets, longueur (suivant les règles des entiers) puis les éléments du tableau, à la queue leu leu. La longueur est cette fois le nombre d'éléments, pas le nombre d'octets. Les éléments d'un tableau ne sont pas forcément tous du même type. Les tableaux (et d'autres types, cf. section 3.2) peuvent aussi être représentés sans indiquer explicitement la longueur ; le tableau est alors terminé par un élément spécial, le break code. Par défaut, un encodeur CBOR est libre de choisir la forme à longueur définie ou celle à longueur indéfinie, et le décodeur doit donc s'attendre à rencontrer les deux.
Le type majeur 5 indique une map (ce qu'on appelle objet en JSON et dictionnaire ou hash dans d'autres langages). Chaque élément d'une map est un doublet {clé, valeur}. L'encodage est le même que pour les tableaux, la longueur étant le nombre de doublets. Chaque doublet est encodé en mettant la clé, puis la valeur. Donc, le premier scalaire est la clé de la première entrée de la map, le deuxième la valeur de la première entrée, le troisième la clé de la deuxième entrée, etc.
Les clés doivent être uniques (une question problématique en JSON où les descriptions existantes de ce format ne sont ni claires ni cohérentes sur ce point).
Je passe sur le type majeur 6, voyez plus loin le paragraphe sur les étiquettes. Le type majeur 7 sert à coder les flottants (encodés ensuite en IEEE 754) et aussi d'autres types scalaires et le break code utilisé dans le paragraphe suivant. Les autres types scalaires, nommés « valeurs simples » (simple values) sont des valeurs spéciales comme 20 pour le booléen Faux, 21 pour le Vrai, et 22 pour le néant. Elles sont stockées dans un registre IANA.
Dans la description ci-dessus, les types vectoriels (tableaux,
chaînes, maps) commencent par la longueur du
vecteur. Pour un encodeur CBOR, cela veut dire qu'il faut connaître
cette longueur avant même d'écrire le premier élément. Cela peut
être contraignant, par exemple si on encode au fil de l'eau
(streaming) des données en cours de
production. CBOR permet donc d'avoir des longueurs
indéterminées. Pour cela, on met 31 comme « longueur » et cette
valeur spéciale indique que la longueur n'est pas encore connue. Le
flot des éléments devra donc avoir une fin explicite cette fois, le
break code. Celui-ci est représenté par un
élément de type majeur 7 et de détails 31, donc tous les bits de
l'octet à 1. Par exemple, http://cbor.me/?diag=%28_%20%22lait%22%29 nous montre que la
chaîne « lait » ainsi codée (le _ indique
qu'on veut un codage en longueur indéterminée) sera
7f646c616974ff. 7f est le type majeur 3, chaîne de caractères, avec
la longueur 31, indiquant qu'elle est indéterminée. Puis suit la
chaîne elle-même (les chaînes indéterminées en CBOR sont faites par
concaténation de châines de longueur déterminée), puis le
break code ff.
La même technique peut être utilisée pour les chaînes d'octets et de caractères, afin de ne pas avoir à spécifier leur longueur au début. Cette possibilité de listes de longueur indéterminée a été ajoutée pour faciliter la vie du streaming.
Revenons au type majeur 6. Il indique une étiquette (tag), qui sert à préciser la sémantique de l'élément qui suit (cf. section 3.4). Un exemple typique est pour indiquer qu'une chaîne de caractères est un fait une donnée structurée, par exemple une date ou un numéro de téléphone. Un décodeur n'a pas besoin de comprendre les étiquettes, il peut parfaitement les ignorer. Les valeurs possibles pour les étiquettes sont stockées dans un registre IANA, et on voit que beaucoup ont déjà été enregistrées, en plus de celles de ce RFC (par exemple par le RFC 8746 ou par le RFC 9132).
Quelques valeurs d'étiquette intéressantes ? La valeur 0 indique une date au format du RFC 3339 (une chaîne de caractères). La valeur 1 étiquette au contraire un entier, et indique une date comme un nombre de secondes depuis le 1er janvier 1970. Les valeurs négatives sont autorisées mais leur sémantique n'est pas normalisée (UTC n'est pas défini pour les dates avant l'epoch, surtout quand le calendrier a changé).
Les valeurs 2 et 3 étiquettent une chaîne d'octets et indiquent qu'on recommande de l'interpréter comme un grand entier (dont la valeur n'aurait pas tenu dans les types majeurs 0 ou 1). Les décodeurs qui ne gèrent pas les étiquettes se contenteront de passer à l'application cette chaîne d'octets, les autres passeront un grand entier.
Autre cas rigolos, les nombres décimaux non entiers. Certains ne peuvent pas être représentés de manière exacte sous forme d'un flottant. On peut alors les représenter par un couple [exposant, mantisse]. Par exemple, 273,15 est le couple [-2, 27315] (l'exposant est en base 10). On peut donc l'encoder en CBOR sous forme d'un tableau de deux éléments, et ajouter l'étiquette de valeur 4 pour préciser qu'on voulait un nombre unique.
D'autres étiquettes précisent le contenu d'une chaîne de caractères : l'étiquette 32 indique que la chaîne est un URI, la 34 que la chaîne est du Base64 (RFC 4648) et la 36 que cela va être un message MIME (RFC 2045). Comme l'interprétation des étiquettes est optionnelle, un décodeur CBOR qui n'a pas envie de s'embêter peut juste renvoyer à l'application cette chaîne.
Une astuce amusante pour finir les étiquettes, et la spécification du format : l'étiquette 55799 signifie juste que ce qui suit est du CBOR, sans modifier sa sémantique. Encodée, elle sera représentée par 0xd9d9f7 (type majeur 6 sur trois bits, puis détails 25 qui indiquent que le nombre est sur deux octets puis le nombre lui-même, d9f7 en hexa). Ce nombre 0xd9d9f7 peut donc servir de nombre magique. Si on le trouve au début d'un fichier, c'est probablement du CBOR (il ne peut jamais apparaître au début d'un fichier JSON, donc ce nombre est particulièrement utile quand on veut distinguer tout de suite si on a affaire à du CBOR ou à du JSON).
Maintenant que le format est défini rigoureusement, passons à son utilisation. CBOR est conçu pour des environnements où il ne sera souvent pas possible de négocier les détails du format entre les deux parties. Un décodeur CBOR générique peut décoder sans connaître le schéma utilisé en face. Mais, en pratique, lorsqu'un protocole utilise CBOR pour la communication, il est autorisé (section 5 du RFC) à mettre des restrictions, ou des informations supplémentaires, afin de faciliter la mise en œuvre de CBOR dans des environnements très contraints en ressources. Ainsi, on a parfaitement le droit de faire un décodeur CBOR qui ne gérera pas les nombres flottants, si un protocole donné n'en a pas besoin.
Un cas délicat est celui des maps (section 5.6). CBOR ne place guère de restrictions sur le type des clés et un protocole ou format qui utilise CBOR voudra souvent être plus restrictif. Par exemple, si on veut absolument être compatible avec JSON, restreindre les clés à des chaînes en UTF-8 est souhaitable. Si on tient à utiliser d'autres types pour les clés (voire des types différents pour les clés d'une même map !), il faut se demander comment on les traduira lorsqu'on enverra ces maps à une application. Par exemple, en JavaScript, la clé formée de l'entier 1 est indistinguable de celle formée de la chaîne de caractères "1". Une application en JavaScript ne pourra donc pas se servir d'une map qui aurait de telles clés, de types variés.
On a vu que certains éléments CBOR pouvaient être encodés de différentes manières, par exemple un tableau peut être représenté par {longueur, valeurs} ou bien par {valeurs, break code}. Cela facilite la tâche des encodeurs mais peut compliquer celle des décodeurs, surtout sur les machines contraintes en ressources, et cela peut rendre certaines opérations, comme la comparaison de deux fichiers, délicates. Existe-t-il une forme canonique de CBOR ? Pas à proprement parler mais la section 4.1 décrit la notion de sérialisation favorite, des décodeurs étant autorisés à ne connaitre qu'une sérialisation possible. Notamment, cela implique pour l'encodeur de :
- Mettre les entiers sous la forme la plus compacte possible. L'entier 2 peut être représenté par un octet (type majeur 0 puis détails égaux à 2) ou deux (type majeur 0, détails à 24 puis deux octets contenant la valeur 2), voire davantage. La forme recommandée est la première (un seul octet). Même règle pour les longueurs (qui, en CBOR, sont encodées comme les entiers).
- Autant que possible, mettre les tableaux et les chaînes sous la forme {longueur, valeurs}, et pas sous la forme où la longueur est indéfinie.
Tous les encodeurs CBOR qui suivent ces règles produiront, pour un même jeu de données, le même encodage.
Plus stricte est la notion de sérialisation déterministe de la section 4.2. Là encore, chacun est libre de la définir comme il veut (il n'y a pas de forme canonique officielle de CBOR, rappelez-vous) mais elle ajoute des règles minimales à la sérialisation favorite :
- Trier les clés d'une map de la plus petite à la plus grande. (Selon leur représentation en octets, pas selon l'ordre alphabétique.)
- Ne jamais utiliser la forme à longueur indéfinie des tableaux et chaînes.
- Ne pas utiliser les étiquettes si elles ne sont pas nécessaires.
Autre question pratique importante, le comportement en cas d'erreurs. Que doit faire un décodeur CBOR si deux clés sont identiques dans une map, ce qui est normalement interdit en CBOR ? Ou si un champ longueur indique qu'on va avoir un tableau de 5 éléments mais qu'on n'en rencontre que 4 avant la fin du fichier ? Ou si une chaîne de caractères, derrière son type majeur 3, n'est pas de l'UTF-8 correct ? D'abord, un point de terminologie important : un fichier CBOR est bien formé si sa syntaxe est bien celle de CBOR, il est valide s'il est bien formé et que les différents éléments sont conformes à leur sémantique (par exemple, la date après une étiquette de valeur 0 doit être au format du RFC 3339). Si le document n'est pas bien formé, ce n'est même pas du CBOR et doit être rejeté par un décodeur. S'il n'est pas valide, il peut quand même être utile, par exemple si l'application fait ses propres contrôles. Les sections 5.2 et 5.3 décrivent la question. CBOR n'est pas pédant : un décodeur a le droit d'ignorer certaines erreurs, de remplacer les valeurs par ce qui lui semble approprié. CBOR penche nettement du côté « être indulgent avec les données reçues » ; il faut dire qu'une application qui utilise CBOR peut toujours le renforcer en ajoutant l'obligation de rejeter ces données erronées. Un décodeur strict peut donc s'arrêter à la première erreur. Ainsi, un pare-feu qui analyse du CBOR à la recherche de contenu malveillant a tout intérêt à rejeter les données CBOR incorrectes (puisqu'il ne sait pas trop comment elles seront interprétées par la vraie application). Bref, la norme CBOR ne spécifie pas de traitement d'erreur unique. Je vous recommande la lecture de l'annexe C, qui donne en pseudo-code un décodeur CBOR minimum qui ne vérifie pas la validité, uniquement le fait que le fichier est bien formé, et l'annexe F, qui revient sur cette notion de « bien formé » et donne des exemples.
Comme CBOR a un modèle de données proche de celui de JSON, on aura souvent envie d'utiliser CBOR comme encodage efficace de JSON. Comment convertir du CBOR en JSON et vice-versa sans trop de surprises ? La section 6 du RFC se penche sur ce problème. Depuis CBOR vers JSON, il est recommandé de produire du I-JSON (RFC 7493). Les traductions suivantes sont suggérées :
- Les entiers deviennent évidemment des nombres JSON.
- Les chaînes d'octets sont encodées en Base64 et deviennent des chaînes de caractères JSON (JSON n'a pas d'autre moyen de transporter du binaire).
- Les chaînes de caractères deviennent des chaînes de caractères JSON (ce qui nécessite d'en échapper certains, RFC 8259, section 7).
- Les tableaux deviennent des tableaux JSON et les maps des objets JSON (ce qui impose de convertir les clés en chaînes UTF-8, si elles ne l'étaient pas déjà).
- Etc.
En sens inverse, de JSON vers CBOR, c'est plus simple, puisque JSON n'a pas de constructions qui seraient absentes de CBOR.
Pour les amateurs de futurisme, la section 7 discute des éventuelles évolutions de CBOR. Pour les faciliter, CBOR a réservé de la place dans certains espaces. Ainsi, le type majeur 7 permettra d'encoder encore quelques valeurs simples (cela nécessitera un RFC sur le chemin des normes, cf. RFC 8126 et la section 9.1 de notre RFC). Et on peut ajouter d'autres valeurs d'étiquettes (selon des règles qui dépendent de la valeur numérique : les valeurs les plus faibles nécessiteront une procédure plus complexe, cf. section 9.2).
CBOR est un format binaire. Cela veut dire, entre autres, qu'il n'est pas évident de montrer des valeurs CBOR dans, mettons, une documentation, contrairement à JSON. La section 8 décrit donc un format texte (volontairement non spécifié en détail) qui permettra de mettre des valeurs CBOR dans du texte. Nulle grammaire formelle pour ce format de diagnostic : il est prévu pour l'utilisation par un humain, pas par un analyseur syntaxique. Ce format ressemble à JSON avec quelques extensions pour les nouveautés de CBOR. Par exemple, les étiquettes sont représentées par un nombre suivi d'une valeur entre parenthèses. Ainsi, la date (une chaîne de caractères étiquetée par la valeur 0) sera notée :
0("2013-10-12T11:34:00Z")
Une map de deux éléments sera notée comme en JSON :
{"Fun": true, "Amt": -2}
Même chose pour les tableaux. Ici, avec étiquette sur deux chaînes de caractères :
[32("http://cbor.io/"), 34("SW5zw6lyZXogaWNpIHVuIMWTdWYgZGUgUMOicXVlcw==")]
L'annexe G du RFC 8610 ajoute quelques extensions utiles à ce format de diagnostic.
Lors de l'envoi de données encodées en CBOR, le type MIME à
utiliser sera application/cbor. Comme l'idée est d'avoir des formats
définis en utilisant la syntaxe CBOR et des règles sémantiques
spécifiques, on verra aussi sans doute des types MIME utilisant la
notation plus du RFC 6839, par exemple
application/monformat+cbor.
Voici par exemple un petit service Web qui envoie la date
courante en CBOR (avec deux étiquettes différentes, celle pour les
dates au format lisible et celle pour les dates en nombre de
secondes, et en prime celles du RFC 8943). Il a été réalisé avec la bibliothèque
flunn. Il utilise le type MIME
application/cbor :
% curl -s https://www.bortzmeyer.org/apps/date-in-cbor | read-cbor - ... Tag 0 String of length 20: 2020-11-16T15:02:24Z Tag 1 Unsigned integer 1605538944 ...
(Le programme read-cbor est présenté plus loin.)
Un petit mot sur la sécurité (section 10) : il est bien connu qu'un analyseur mal écrit est un gros risque de sécurité et d'innombrables attaques ont déjà été réalisées en envoyant à la victime un fichier délibérement incorrect, conçu pour déclencher une faille de l'analyseur. Ainsi, en CBOR, un décodeur qui lirait une longueur, puis chercherait le nombre d'éléments indiqué, sans vérifier qu'il est arrivé au bout du fichier, pourrait déclencher un débordement de tampon. Les auteurs de décodeurs CBOR sont donc priés de programmer de manière défensive, voire paranoïaque : ne faites pas confiance au contenu venu de l'extérieur.
Autre problème de sécurité, le risque d'une attaque par
déni de
service. Un attaquant taquin peut envoyer un fichier
CBOR où la longueur d'un tableau est un très grand nombre, dans
l'espoir qu'un analyseur naïf va juste faire
malloc(length) sans se demander si cela ne
consommera pas toute la mémoire.
Enfin, comme indiqué plus haut à propos du traitement d'erreur, comme CBOR ne spécifie pas de règles standard pour la gestion des données erronées, un attaquant peut exploiter cette propriété pour faire passer des données « dangereuses » en les encodant de telle façon que l'IDS n'y voit que du feu. Prenons par exemple cette map :
{"CodeToExecute": "OK",
"CodeToExecute": "DANGER"}
Imaginons qu'une application lise ensuite la donnée indexée par
CodeToExecute. Si, en cas de clés dupliquées,
elle lit la dernière valeur, elle exécutera le code dangereux. Si un
IDS lit la première valeur, il ne se sera pas inquiété. Voilà une
bonne raison de rejeter du CBOR invalide (les clés dupliquées sont
interdites) : il peut être interprété de plusieurs façons. Notez
quand même que ce problème des clés dupliquées, déjà présent en
JSON, a suscité des discussions passionnées à l'IETF, entre ceux
qui réclamaient une interdiction stricte et absolue et ceux qui
voulaient laisser davantage de latitude aux décodeurs. (La section
5.6 est une bonne lecture ici.)
Pour les amateurs d'alternatives, l'annexe E du RFC compare CBOR à des formats analogues. Attention, la comparaison se fait à la lumière du cahier des charges de CBOR, qui n'était pas forcément le cahier des charges de ces formats. Ainsi, ASN.1 (ou plutôt ses sérialisations comme BER ou DER, PER étant nettement moins courant puisqu'il nécessite de connaître le schéma des données) est utilisé par plusieurs protocoles IETF (comme LDAP) mais le décoder est une entreprise compliquée.
MessagePack est beaucoup plus proche de CBOR, dans ses objectifs et ses résultats, et a même été le point de départ du projet CBOR. Mais il souffre de l'absence d'extensibilité propre. Plusieurs propositions d'extensions sont restées bloquées à cause de cela.
BSON (connu surtout via son utilisation dans MongoDB) a le même problème. En outre, il est conçu pour le stockage d'objets JSON dans une base de données, pas pour la transmission sur le réseau (ce qui explique certains de ses choix). Enfin, MSDTP, spécifié dans le RFC 713, n'a jamais été réellement utilisé.
Rappelez-vous que CBOR prioritise la simplicité de l'encodeur et du décodeur plutôt que la taille des données encodées. Néanmoins, un tableau en annexe E.5 compare les tailles d'un même objet encodé avec tous ces protocoles : BSON est de loin le plus bavard (BER est le second), MessagePack et CBOR les plus compacts.
Une liste des implémentations est publiée en https://cbor.io/. Au moins quatre existent, en Python,
Ruby, JavaScript et
Java. J'avais moi-même
écrit un décodeur CBOR très limité (pour un besoin ponctuel) en Go. Il est disponible ici et son seul rôle est
d'afficher le CBOR sous forme arborescente, pour aider à déboguer un
producteur de CBOR. Cela donne quelque chose du genre :
% ./read-cbor test.cbor Array of 3 items String of length 5: C-DNS Map of 4 items Unsigned integer 0 => Unsigned integer 0 Unsigned integer 1 => Unsigned integer 5 Unsigned integer 4 => String of length 70: Experimental dnstap client, IETF 99 hackathon, data from unbound 1.6.4 Unsigned integer 5 => String of length 5: godin Array of indefinite number of items Map of 3 items Unsigned integer 0 => Map of 1 items Unsigned integer 1 => Array of 2 items Unsigned integer 1500204267 Unsigned integer 0 Unsigned integer 2 => Map of indefinite number of items Unsigned integer 0 => Array of 2 items Byte string of length 16 Byte string of length 16 ...
L'annexe G de notre RFC résume les changements depuis le RFC 7049. Le format reste le même, les fichiers CBOR d'avant sont toujours du CBOR. Il y a eu dans ce nouveau RFC des corrections d'erreurs (comme un premier exemple erroné, un autre, et encore un), un durcissement des conditions d'enregistrement des nouvelles étiquettes pour les valeurs les plus basses, une description plus détaillée du modèle de données (la section 2 est une nouveauté de notre RFC), un approfondissement des questions de représentation des nombres, etc. Notre RFC 8949 est également plus rigoureux sur les questions de sérialisation préférée et déterministe. L'étiquette 35, qui annonçait qu'on allait rencontrer une expression rationnelle a été retirée (le RFC note qu'il existe plusieurs normes pour ces expressions et que l'étiquette n'est pas définie de manière assez rigoureuse pour trancher).
L'article seul
RFC 8948: Structured Local Address Plan (SLAP) Quadrant Selection Option for DHCPv6
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : CJ. Bernardos (UC3M), A. Mourad (InterDigital)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dhc
Première rédaction de cet article le 2 décembre 2020
Les adresses MAC sur 48
bits, normalisées par l'IEEE, ont un bit qui indique si
l'adresse découle d'un plan mondial et est donc globalement unique,
ou bien si elle a été allouée via une méthode locale. Plus
récemment, l'IEEE a découpé l'espace local en quatre quadrants, pouvant avoir
des poltiques différentes. Depuis qu'on peut allouer ces adresses
MAC locales par DHCP (RFC 8947), il serait intéressant de choisir son
quadrant. C'est ce que permet la nouvelle option DHCP
QUAD normalisée dans ce nouveau RFC.
Tout·e étudiant·e en réseaux informatiques a appris le découpage des adresses MAC de 48 bits via le bit U/L (Universal/Local). Les adresses avec ce bit à 1 sont gérées localement (et donc pas forcément uniques au niveau mondial). En 2017, l'IEEE a ajouté un nouveau concept, le SLAP (Structured Local Address Plan). L'espace des adresses locales est découpé en quadrants, identifiés par deux bits (troisième et quatrième position dans l'adresse) :
- 01 Extended Local Identifier où l'adresse commence par le CID (Company ID), qui identifie l'organisation,
- 11 Standard Assigned Identifier où l'adresse est allouée en suivant un protocole normalisé par l'IEEE (qui, à ma connaissance, n'est pas encore publié, il se nommera IEEE P802.1CQ: Multicast and Local Address Assignment),
- 00 Administratively Assigned Identifier où l'adresse est entièrement gérée localement, sans préfixe ou protocole standard (avant SLAP, toutes les adresses locales étaient gérées ainsi),
- 10 est réservé pour des idées futures.
De son côté, l'IETF a, dans le RFC 8947, normalisé une option de DHCPv6 qui permet d'obtenir des adresses MAC par DHCP.
Or, dans certains cas, une machine pourrait vouloir choisir le quadrant dans lequel son adresse MAC se situe. Le RFC cite l'exemple d'objets connectés qui voudraient une adresse dans le quadrant ELI (Extended Local Identifier) pour avoir l'identifiant du fabricant au début de l'adresse, sans pour autant que le fabricant ne soit obligé d'allouer à la fabrication une adresse unique à chaque objet. Par contre, des systèmes qui changeraient leur adresse MAC pour éviter la traçabilité préféreraient sans doute un adresse dans le quadrant AAI (Administratively Assigned Identifier). L'annexe A du RFC est très intéressante de ce point de vue, décrivant plusieurs scénarios et les raisons du choix de tel ou tel quadrant.
Notre nouveau RFC ajoute donc une option au protocole DHCP
que normalisait le RFC 9915. Elle se nomme
QUAD et repose sur l'option
LLADDR du RFC 8947. Le
client met cette option QUAD dans la requête
DHCP, pour indiquer son quadrant favori. Le serveur ne l'utilise pas
dans la réponse. Soit il est d'accord pour allouer une adresse MAC
dans ce quadrant et il le fait, soit il propose une autre
adresse. (Rappelez-vous qu'en DHCP, le client propose, et le serveur
décide.) Le client regarde l'adresse renvoyée et sait ainsi si sa
préférence pour un quadrant particulier a été satisfaite ou pas.
La section 4 décrit les détails de l'option
QUAD. Elle permet d'exprimer une liste de
quadrants, avec des préférences associées. L'option est désormais
enregistrée
à l'IANA (code 140).
Pour l'instant, je ne connais pas de mise en œuvre de ce RFC que ce soit côté client ou serveur.
L'article seul
RFC 8947: Link-Layer Addresses Assignment Mechanism for DHCPv6
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : B. Volz (Cisco), T. Mrugalski (ISC), CJ. Bernardos (UC3M)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dhc
Première rédaction de cet article le 2 décembre 2020
L'utilisation de DHCP pour attribuer des adresses IP est bien connue. Ce nouveau RFC spécifie comment utiliser DHCP pour attribuer des adresses MAC.
Dans quels cas est-ce utile ? La principale motivation vient des environnements virtualisés où on crée des quantités industrielles de machines virtuelles. C'est le cas chez les gros hébergeurs, par exemple, ou bien dans les organisations qui ont d'immenses fermes de machines. Si les adresses MAC de ces machines sont attribuées au hasard, le risque de collision est important, d'autant plus qu'il n'y a pas de protocole de détection de ces collisions. (Sur le risque de collision, notamment en raison du paradoxe de l'anniversaire, voir le RFC 4429, annexe A.1.) Bien sûr, les adresses MAC n'ont pas besoin d'être uniques au niveau mondial, mais la taille de certains réseaux L2 fait que la collision est un réel problème. Un autre scénario est celui des objets connectés (RFC 7228), où leur nombre pourrait menacer l'espace d'adressage OUI. L'idée est donc de récupérer ces adresses MAC auprès d'un serveur DHCP, ce qui évitera les collisions.
En effet, le protocole DHCP, normalisé pour sa version IPv6 dans le RFC 9915, ne sert pas qu'à attribuer des adresses IP. On peut s'en servir pour n'importe quel type de ressources. Et il offre toutes les fonctions nécessaires pour gérer ces ressources, et de nombreuses mises en œuvre déjà bien testées. Notre RFC va donc s'appuyer dessus pour les adresses MAC de 48 bits (EUI-48) d'IEEE 802 (et peut-être dans le futur pour d'autres types d'adresses).
Dans ces adresses de 48 bits, un bit nous intéresse particulièrement, le U/L. Comme son nom l'indique (U = universal, L = local), il indique si l'adresse suit le mécanisme d'allocation de l'IEEE (et est donc a priori unique au niveau mondial) ou bien si l'adresse est gérée selon des règles locales. Les adresses allouées via DHCP seront en général des adresses à gestion locale. Étant purement locales (aucune garantie quant à leur unicité), elles ne doivent pas être utilisées pour fabriquer le DUID - DHCP Unique Identifier - de DHCP (cf. RFC 9915, section 11). Notez aussi que la norme IEEE 802c découpe l'espace local en quatre parties (détails dans l'annexe A du RFC ou, pour les courageuses et les courageux, dans la norme 802c). Pendant qu'on parle de l'IEEE, leur norme 802 1CQ prévoit un mécanisme d'affectation des adresses MAC, qui peut être un concurrent de celui de ce RFC. Le RFC 8948 fournit un moyen de choisir l'un de ces quadrants.
Un peu de terminologie est nécessaire pour suivre ce RFC (section 3). Un bloc d'adresses est une suite consécutive d'adresses MAC. IA_LL désigne une Identity Association for Link-Layer Address et c'est une option DHCP (code 138) qui va beaucoup servir. Autre option DHCP, LLADDR (code 139) qui est l'option qui va servir à transporter les adresses MAC.
La section 4 du RFC présente les principes de déploiement de la solution. Il y a notamment deux scénarios envisagés :
- Le mode relais, où le client DHCP ne sera pas le destinataire final des adresses MAC. Par exemple, dans le cas de la virtualisation, le client DHCP sera l'hyperviseur qui demandera un bloc d'adresses qu'il attribuera ensuite aux machines virtuelles qu'il crée. Le serveur DHCP verra donc un client très gourmand, demandant de plus en plus d'adresses MAC.
- Le mode direct, où le client DHCP sera la machine utilisatrice de l'adresse MAC. C'est notamment le mode envisagé pour l'IoT, chaque objet demandant son adresse MAC. Comme il faudra bien une adresse MAC pour faire du DHCP afin de demander une adresse MAC, les objets utiliseront les adresses temporaires normalisées dans IEEE 802.11. Comme l'adresse MAC changera une fois allouée, il faut veiller à ne pas utiliser des commutateurs méchants qui bloquent le port en cas de changement d'adresse.
Bon, sinon, le fonctionnement de l'allocation d'adresses MAC
marche à peu près comme celui de l'allocation d'adresses IP. Le
client DHCP envoie un message Solicit incluant
une option IA_LL qui contient elle-même une option LLADDR qui
indique le type d'adresse souhaitée et peut aussi inclure une
suggestion, si le client a une idée de l'adresse qu'il voudrait. Le
serveur répond avec Advertise contenant
l'adresse ou le bloc d'adresses alloué (qui ne sont pas forcément
ceux suggérés par le client, comme toujours avec DHCP). Si
nécessaire, il y aura ensuite l'échange habituel
Request puis Reply. Bref,
du DHCPv6 classique. Le client devra renouveler l'allocation au
bout du temps indiqué dans le bail (le serveur peut toujours donner
l'adresse sans limite de temps, cf. RFC 9915,
section 7.7). Le client peut explicitement abandonner l'adresse,
avec un message Release. On l'a dit, ça se
passe comme pour les adresses IP.
Les fanas du placement exact des bits liront la section 10, où
est décrit l'encodage de l'option IA_LL et de la « sous-option »
LLADDR. C'est là qu'on trouvera l'indication des blocs d'adresses
MAC, encodés par la première adresse puis la taille du bloc
(-1). Ainsi, 02:04:06:08:0a / 3 indique un bloc
qui va de 02:04:06:08:0a à
02:04:06:08:0d. Pendant qu'on parle de bits,
notez que les bits indiquant diverses caractéristiques de l'adresse
MAC figurent dans le premier octet, et que la transmission se fait
en commençant par le bit le moins significatif (IEEE 802 est
petit-boutien pour les bits). Ainsi,
l'adresse citée plus haut, 02:04:06:08:0a a un
premier octet qui vaut 2, soit 00000010 en binaire, ce qui sera
transmis comme 01000000. Le premier bit est le M, qui indique ici
qu'il s'agit d'une adresse
unicast, le second est
U/L, indiquant ici que c'est bien une adresse locale, les deux bits
suivants sont une nouveauté de IEEE
802c et indiquent le quadrant des adresses (cf. annexe A du
RFC, puis le RFC 8948).
Quelques conseils pour les administrateurs des serveurs DHCP qui feront cette allocation d'adresses MAC figurent en section 11 du RFC. Par exemple, il ne faut allouer que des adresses locales (bit U/L à 1).
Les deux nouvelles options, IA_LL et LLADDR ont été mises dans le registre IANA.
Pour finir, l'annexe A du RFC résume la norme IEEE 802c. Dans la norme IEEE 802 originale, il y avait, comme indiqué plus haut, un bit U/L qui disait si l'adresse était gérée selon des règles locales (et n'était donc pas forcément unique au niveau mondial). 802c ajoute à ces adresses locales la notion de quadrant, découpant l'espace local en quatre. Après le bit M (unicast ou groupe) et le bit U/L (local ou pas). deux bits indiquent dans quel quadrant se trouve l'adresse :
- 01 est Extended Local, des adresses qui comportent un identifiant de l'organisation, le CID (Company ID), et qui sont donc apparemment garanties uniques à l'échelle de la planète,
- 11 est Standard Assigned, elles sont affectées par le protocole IEEE concurrent de celui du RFC,
- 00 est Administratively Assigned, ce sont
les « vraies » adresses locales, attribuées comme on veut (comme
l'était la totalité de l'espace des adresses locales autrefois,
les adresses d'exemple plus haut
(
02:04:06:08:0aet suivantes sont dans ce quadrant), - 10 est réservé pour un usage futur.
Un mécanisme de sélection du quadrant est normalisé dans le RFC 8948.
Pour l'instant, je ne connais pas de mise en œuvre de ce RFC que ce soit côté client ou serveur.
L'article seul
RFC 8945: Secret Key Transaction Authentication for DNS (TSIG)
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : F. Dupont (ISC), S. Morris (ISC), P. Vixie (Farsight), D. Eastlake 3rd (Futurewei), O. Gudmundsson (Cloudflare), B. Wellington (Akamai)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 1 décembre 2020
Le DNS a des vulnérabilités à plusieurs endroits, notamment des risques d'usurpation, qui permettent de glisser une réponse mensongère à la place de la bonne. Il existe plusieurs solutions pour ces problèmes, se différenciant notamment par leur degré de complexité et leur facilité à être déployées. TSIG (Transaction SIGnature), normalisé dans ce RFC (qui remplace le RFC 2845), est une solution de vérification de l'intégrité du canal, permettant à deux machines parlant DNS de s'assurer de l'identité de l'interlocuteur. TSIG est surtout utilisé entre serveurs DNS maîtres et esclaves, pour sécuriser les transferts de zone (aujourd'hui, presque tous les transferts entre serveurs faisant autorité sont protégés par TSIG).
TSIG repose sur l'existence d'une clé secrète, partagée entre les deux serveurs, qui sert à générer un HMAC permettant de s'assurer que le dialogue DNS a bien lieu avec la machine attendue, et que les données n'ont pas été modifiées en route. L'obligation de partager une clé secrète le rend difficilement utilisable, en pratique, pour communiquer avec un grand nombre de clients. Mais, entre deux serveurs faisant autorité pour la même zone, ce n'est pas un problème (section 1.1 du RFC). On peut gérer ces secrets partagés manuellement. Même chose entre un serveur maître et un client qui met à jour les données par dynamic update (RFC 2136).
Bien sûr, si tout le monde utilisait DNSSEC partout, le problème de sécuriser le transfert de zones entre serveurs faisant autorité serait moins grave (mais attention, DNSSEC ne signe pas les délégations et les colles, cf. la section 10.2 de notre RFC). En attendant un futur lointain « tout-DNSSEC », TSIG fournit une solution simple et légère pour éviter qu'un méchant ne se glisse dans la conversation entre maître et esclave (par exemple grâce à une attaque BGP) et ne donne à l'esclave de fausses informations. (Il existe aussi des solutions non-DNS comme de transférer la zone avec rsync au dessus de SSH. Notez d'autre part que TSIG peut servir à d'autres choses que le transfert de zones, comme l'exemple des mises à jour dynamiques cité plus haut. Par contre, pour sécuriser la communication entre le client final et le résolveur, il vaut mieux utiliser DoT - RFC 7858 - ou DoH - RFC 8484.)
Comment fonctionne TSIG ? Les sections 4 et 5 décrivent le protocole. Le principe est de calculer, avec la clé secrète, un HMAC des données transmises, et de mettre ce HMAC (cette « signature ») dans un pseudo-enregistrement TSIG qui sera joint aux données, dans la section additionnelle. À la réception, l'enregistrement TSIG (obligatoirement le dernier de la section additionnelle) sera extrait, le HMAC calculé et vérifié.
Pour éviter des attaques par rejeu, les données sur lesquelles portent le HMAC incluent l'heure. C'est une des causes les plus fréquentes de problèmes avec TSIG : les deux machines doivent avoir des horloges très proches (section 10, qui recommande une tolérance - champ Fudge - de cinq minutes).
Le format exact des enregistrements TSIG est décrit en section 4. L'enregistrement est donc le dernier, et est mis dans la section additionnelle (voir des exemples plus loin avec dig et tshark). Le type de TSIG est 250 et, évidemment, ces pseudo-enregistrements ne doivent pas être gardés dans les caches. Plusieurs algorithmes de HMAC sont possibles. Un est obligatoire et recommandé, celui fondé sur SHA-256 (que j'utilise dans les exemples par la suite). On peut toujours utiliser SHA-1 et MD5 (avant que vous ne râliez : oui, SHA-1 et MD5 ont de gros problèmes mais cela n'affecte pas forcément leur utilisation en HMAC, cf. RFC 6151). Un registre IANA contient les algorithmes actuellement possibles (cf. aussi section 6 du RFC).
Le nom dans l'enregistrement TSIG est le nom de la clé (une
raison pour bien le choisir, il inclut typiquement le nom des deux
machines qui communiquent), la classe est
ANY, le TTL nul et les données contiennent
le nom de l'algorithme utilisé, le moment de la signature, et bien
sûr la signature elle-même.
Le fait que la clé soit secrète implique des pratiques de
sécurité sérieuses, qui font l'objet de la section 8. Par
exemple, l'outil de génération de clés de BIND crée des fichiers en
mode 0600, ce qui veut dire lisibles uniquement
par leur créateur, ce qui est la moindre des choses. Encore faut-il
assurer la sécurité de la machine qui stocke ces fichiers. (Voir
aussi le RFC 2104).
Voyons maintenant des exemples concrets où
polly (192.168.2.27) est
un serveur DNS maître pour la zone example.test
et jadis (192.168.2.29)
un serveur esclave. Pour utiliser TSIG afin d'authentifier un
transfert de zone entre deux machines, commençons avec BIND. Il faut
d'abord générer une clé. Le programme
tsig-keygen, livré avec BIND, génère de
nombreux types de clés (d'où ses nombreuses options). Pour TSIG, on
veut du SHA-256 (mais tsig-keygen connait
d'autres algorithmes) :
% tsig-keygen -a HMAC-SHA256 polly-jadis
key "polly-jadis" {
algorithm hmac-sha256;
secret "LnDomTT+IRf0daLYqxkstFpTpmFfcOvyxtRaq2VhHSI=";
};
(Avant BIND 9.13, le programme à utiliser était
dnssec-keygen, qui ne fait désormais plus que
du DNSSEC.) On a donné à la clé le nom des
deux machines entre lesquelles se fera la communication (le nom est
affiché dans le journal lors d'un transfert réussi, et à plusieurs
autres endroits, donc il vaut mieux le choisir long et descriptif),
plus un chiffre pour distinguer d'éventuelles autres clés. La clé
est partagée entre ces deux machines. On met alors la clé dans la
configuration de BIND, sur les deux machines
(tsig-keygen produit directement de la
configuration BIND). Naturellement, il faut transférer la clé de
manière sécurisée entre les deux machines, pas par courrier
électronique ordinaire, par exemple. Sur le serveur maître, on
précise que seuls ceux qui connaissent la clé peuvent transférer la
zone :
zone "example.test" {
type master;
file "/etc/bind/example.test";
allow-transfer { key polly-jadis; };
};
Les autres clients seront rejetés :
Apr 6 17:45:15 polly daemon.err named[27960]: client @0x159c250 192.168.2.29#51962 (example.test): zone transfer 'example.test/AXFR/IN' denied
Mais, si on connait la clé, le transfert est possible (ici, un test avec dig) :
% dig -y hmac-sha256:polly-jadis:LnDomTT+IRf0daLYqxkstFpTpmFfcOvyxtRaq2VhHSI= @polly.sources.org AXFR example.test ; <<>> DiG 9.16.1-Debian <<>> -y hmac-sha256 @polly.sources.org AXFR example.test ; (1 server found) ;; global options: +cmd example.test. 86400 IN SOA polly.sources.org. hostmaster.sources.org. 2020040600 7200 3600 604800 43200 example.test. 86400 IN NS polly.sources.org. example.test. 86400 IN SOA polly.sources.org. hostmaster.sources.org. 2020040600 7200 3600 604800 43200 polly-jadis. 0 ANY TSIG hmac-sha256. 1586195193 300 32 pJciUWLOkg1lc6J+msC+dzYotVSOr8PSXgE6fFU3UwE= 25875 NOERROR 0 ;; Query time: 10 msec ;; SERVER: 192.168.2.27#53(192.168.2.27) ;; WHEN: Mon Apr 06 17:46:33 UTC 2020 ;; XFR size: 3 records (messages 1, bytes 267)
On voit que dig affiche fidèlement tous les enregistrements, y
compris le pseudo-enregistrement de type TSIG qui contient la
signature. Un point de sécurité, toutefois (merci à Jan-Piet Mens
pour sa vigilance) : avec ce -y, quiconque a un
compte sur la même machine Unix peut voir la clé avec
ps. Il peut être préférable de la mettre dans un
fichier et de dire à dig d'utiliser ce fichier (dig -k
polly-jadis.key …).
Maintenant que le test marche, configurons le serveur BIND esclave :
// To avoid copy-and-paste errors, you can also redirect tsig-keygen's
// output to a file and then include it in named.conf with 'include
// polly-jadis.key'.
key "polly-jadis" {
algorithm hmac-sha256;
secret "LnDomTT+IRf0daLYqxkstFpTpmFfcOvyxtRaq2VhHSI=";
};
zone "example.test" {
type slave;
masters {192.168.2.27;};
file "example.test";
};
server 192.168.2.27 {
keys {
polly-jadis;
};
};
et c'est tout : l'esclave va désormais utiliser TSIG pour les transferts de zone. Le programme tshark va d'ailleurs nous afficher les enregistrements TSIG :
Queries
example.test: type AXFR, class IN
Name: example.test
[Name Length: 12]
[Label Count: 2]
Type: AXFR (transfer of an entire zone) (252)
Class: IN (0x0001)
Additional records
polly-jadis: type TSIG, class ANY
Name: polly-jadis
Type: TSIG (Transaction Signature) (250)
Class: ANY (0x00ff)
Time to live: 0
Data length: 61
Algorithm Name: hmac-sha256
Time Signed: Apr 6, 2020 19:51:36.000000000 CEST
Fudge: 300
MAC Size: 32
MAC
[Expert Info (Warning/Undecoded): No dissector for algorithm:hmac-sha256]
[No dissector for algorithm:hmac-sha256]
[Severity level: Warning]
[Group: Undecoded]
Original Id: 37862
Error: No error (0)
Other Len: 0
Et si l'esclave est un nsd et pas un BIND ? C'est le même principe. On configure l'esclave :
key:
name: polly-jadis
algorithm: hmac-sha256
secret: "LnDomTT+IRf0daLYqxkstFpTpmFfcOvyxtRaq2VhHSI="
zone:
name: "example.test"
zonefile: "example.test"
allow-notify: 192.168.2.27 NOKEY
request-xfr: 192.168.2.27 polly-jadis
Et le prochain nsd-control transfer example.test (ou bien la
réception de la notification) déclenchera un transfert, qui sera
ainsi enregistré :
Apr 07 06:46:48 jadis nsd[30577]: notify for example.test. from 192.168.2.27 serial 2020040700 Apr 07 06:46:48 jadis nsd[30577]: [2020-04-07 06:46:48.831] nsd[30577]: info: notify for example.test. from 192.168.2.27 serial 2020040700 Apr 07 06:46:48 jadis nsd[30565]: xfrd: zone example.test written received XFR packet from 192.168.2.27 with serial 2020040700 to disk Apr 07 06:46:48 jadis nsd[30565]: [2020-04-07 06:46:48.837] nsd[30565]: info: xfrd: zone example.test written received XFR packet from 192.168.2.27 with serial 2020040700 to disk
Pour générer des clés sans utiliser BIND, on peut consulter mon autre article sur TSIG.
On l'a vu, TSIG nécessite des horloges synchronisées. Une des
erreurs les plus fréquentes est d'oublier ce point. Si une machine
n'est pas à l'heure, on va trouver dans le journal des échecs TSIG
comme (section 5.2.3 du RFC), renvoyés avec le code de retour DNS
NOTAUTH (code 9) et un code
BADTIME dans l'enregistrement TSIG joint :
Mar 24 22:14:53 ludwig named[30611]: client 192.168.2.7#65495: \
request has invalid signature: TSIG golgoth-ludwig-1: tsig verify failure (BADTIME)
Ce nouveau RFC ne change pas le protocole du RFC 2845. Un ancien client peut interopérer avec un nouveau serveur, et réciproquement. Seule change vraiment la procédure de vérification, qui est unilatérale. Une des motivations pour la production de ce nouveau RFC venait de failles de sécurité de 2016-2017 (CVE-2017-3142, CVE-2017-3143 et CVE-2017-11104). Certes, elle concernaient des mises en œuvre, pas vraiment le protocole, mais elles ont poussé à produire un RFC plus complet et plus clair.
Le débat à l'IETF au début était « est-ce qu'on en profite pour réparer tout ce qui ne va pas dans le RFC 2845, ou bien est-ce qu'on se limite à réparer ce qui est clairement cassé ? » Il a été tranché en faveur d'une solution conservatrice : le protocole reste le même, il ne s'agit pas d'un « TSIG v2 ».
L'article seul
RFC 8943: Concise Binary Object Representation (CBOR) Tags for Date
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : M. Jones (Microsoft), A. Nadalin (Independent), J. Richter (pdv Financial Software GmbH)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 21 novembre 2020
Le format de données CBOR, normalisé dans le RFC 8949, possède un certain nombre de types de données de base, et un mécanisme d'extensions, les étiquettes (tags). Ce RFC spécifie deux nouvelles étiquettes, pour indiquer des dates.
Le RFC 8949 déclarait déjà deux types pour les estampilles temporelles, l'étiquette 0 pour une chaîne de caractères dont le contenu est une estampille au format du RFC 3339 (avec la date et l'heure), et l'étiquette 1 pour une estampille sous la forme d'un nombre de secondes depuis l'epoch. Dans ce nouveau RFC sont ajoutées deux étiquettes, 100 pour un entier qui va stocker le nombre de jours depuis l'epoch, et 1004 pour une date seule (sans heure) au format du RFC 3339. L'epoch est celle de la norme Posix 1 / IEEE Standard 1003.1, le 1 janvier 1970. Dans les deux cas, comme on ne stocke pas l'heure, des considérations comme le fuseau horaire ou les secondes intercalaires sont inutiles. Quant au calendrier utilisé, c'est le grégorien.
Dans ce calendrier, John Lennon (je reprends l'exemple du RFC…) est né le 9 octobre 1940 et mort le 8 décembre 1980. (Les dates utilisées dans ce RFC n'incluent pas l'heure.) Pour la première étiquette, 100, qui indique le nombre de jours depuis l'epoch, l'auteur d'I Am the Walrus est né le -10676. C'est un nombre négatif puisque l'epoch utilisée est le 1 janvier 1970, après sa naissance. Lennon est mort le 3994. Pour le cas de la deuxième étiquette, 1004, il est né le 1940-10-09 et mort le 1980-12-08, suivant le format du RFC 3339. Le jour (lundi, mardi, mercredi…) est explicitement non mentionné, si on en a besoin, il faut le recalculer.
Les deux formats, en nombre de jours depuis l'epoch, et en RFC 3339 ont l'avantage que les comparaisons de date sont triviales, une simple comparaison d'entiers dans le premier cas, de chaînes de caractères dans le suivant, suffit.
Petit piège des dates indiquées sans l'heure, un même événement peut survenir à deux dates différentes selon le fuseau horaire. Ainsi, une vidéoconférence qui a lieu, à Tokyo, le 12 octobre à 10h00 sera considérée par les habitants d'Honolulu comme se tenant le 11 octobre à 15h00.
Les deux étiquettes ont été enregistrées à l'IANA. La valeur 100 pour la première a été choisie car 100 est le code ASCII de 'd' (pour date).
Si vous voulez un fichier CBOR utilisant ces deux étiquettes,
vous pouvez appeler le service
https://www.bortzmeyer.org/apps/date-in-cbor
qui vous renvoie un tableau avec les quatre façons de servir une
date en CBOR, les deux standards du RFC 8949,
et les deux de notre RFC. Ici, on utilise le programmme read-cbor pour afficher
plus joliment :
% wget -q -O - https://www.bortzmeyer.org/apps/date-in-cbor | ./read-cbor -
Array of 5 items
...
Tag 0
String of length 20: 2020-11-21T06:44:33Z
Tag 1
Unsigned integer 1605941073
Tag 100
Unsigned integer 18587
Tag 1004
String of length 10: 2020-11-21
L'article seul
RFC 8942: HTTP Client Hints
Date de publication du RFC : Février 2021
Auteur(s) du RFC : I. Grigorik, Y. Weiss (Google)
Expérimental
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 9 février 2021
Aux débuts du Web,
il allait de soi que le contenu renvoyé à un client était identique
quel que soit le client. On demandait un article scientifique, le
même article était donné à tout le monde. La séparation du contenu
et de la présentation que permet HTML faisait en sorte que ce contenu
s'adaptait automatiquement aux différents clients et notamment à
leur taille. Mais petit à petit l'habitude s'est prise d'envoyer un
contenu différent selon le client. C'était parfois pour de bonnes
raisons (s'adapter à la langue de
l'utilisateur) et parfois pour des mauvaises (incompréhension de la
séparation du contenu et de la présentation, ignorance du Web par
des commerciaux qui voulaient contrôler l'apparence exacte de la
page). Cette adaptation au client peut se faire en tenant compte des
en-têtes envoyés par le
navigateur dans sa requête, notamment
l'affreux User-Agent:, très indiscret et en
général mensonger. Mais la tendance actuelle est de ne pas utiliser
systématiquement ces en-têtes, très dangereux pour la vie
privée et parfois inutiles : si le serveur HTTP n'adapte pas le
contenu en fonction des en-têtes, pourquoi les envoyer ? Ce nouveau
RFC propose une
solution : un en-tête Accept-CH: envoyé par le
serveur qui indique ce que le serveur va faire
des en-têtes d'indication envoyés par le client (client
hints) dans ses futures requêtes. Il s'agit d'un projet
Google, déjà mis en œuvre dans
Chrome mais, pour l'instant, seulement avec
le statut « Expérimental ».
Le Web a toujours été prévu pour être accédé par des machines très différentes, en terme de taille d'écran, de logiciels utilisés, de capacités de traitement. Sans compter les préférences propres à l'utilisateur, par exemple sa langue. C'est ainsi que, par exemple, les lignes de texte ne sont pas définies dans le source en HTML, elles seront calculées dynamiquement par le navigateur qui, lui, connait la largeur de la fenêtre. Mais il a été difficile de faire comprendre cela à des marketeux habitués de la page imprimée et qui insistaient pour contrôler tout au pixel près.
Bref, il y a longtemps que des gens qui ne connaissent pas le Web
font n'importe quoi, par exemple en regardant l'en-tête
User-Agent: (RFC 7231,
section 5.5.3) et en ajustant le contenu Web à cet en-tête, ce qui
nécessite une base de données de tous les
User-Agent: possibles puisque chaque nouvelle
version d'un navigateur peut changer les choses. (D'où ces
User-Agent: ridicules et mensongers qu'on voit
aujourd'hui, où chaque navigateur met le nom de tous les autres, par
exemple Edge annonce Mozilla/5.0
(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/68.0.2704.79 Safari/537.36 Edge/18.014.) Ces
techniques sont évidemment très mauvaises : elles compliquent les
serveurs, elles ne permettent pas de gérer le cas d'un nouveau
navigateur (sauf à ce qu'il annonce les noms de ces prédécesseurs
dans User-Agent:, ce qui se fait couramment),
elles ne permettent pas facilement à l'utilisateur ou à son
navigateur de savoir quels critères ont été utilisés par le serveur
pour adapter le contenu. Et elles sont très indiscrètes, exposant
par défaut bien plus d'informations que ce qui est nécessaire au
serveur pour adapter son contenu. C'est ainsi que des
services comme Panopticlick ou
Am I
unique? peuvent fonctionner, démontrant la
possibilité d'identifier un utilisateur sans
biscuits, avec juste du
fingerprinting passif.
Un site Web peut aussi ajuster son contenu en fonction d'un utilisateur particulier, suivi, par exemple, par les biscuits du RFC 6265, ou via des paramètres dans l'URL mais cela complique les choses, par exemple en obligeant à mettre des informations dans l'URL de chaque ressource du site Web.
Une meilleure solution, au moins en théorie, est la négociation de contenu
HTTP (RFC 7231, section 3.4.1) :
le client utilise alors des en-têtes bien définis (comme
Accept-Language: pour la
langue) auxquels le serveur peut répondre par
un contenu spécifique. La négociation de contenu pose
toutefois un problème, note le RFC, c'est que les en-têtes sont
systématiquement envoyés par le client, qui ne sait pas si le
serveur en fera quelque chose. Cela peut notamment avoir des
conséquences en terme de vie
privée, un client pouvant être identifié par le jeu
complet des en-têtes qu'il envoie, même en l'absence de biscuits de
traçage. (En outre, pour le cas particulier de la langue, la
négociation de contenu n'aide guère car elle ne prend pas en compte
des questions comme la
notion de version originale.)
Au contraire, estime le RFC (avec pas mal d'optimisme), le mécanisme décrit ici peut potentiellement être davantage protecteur, en obligeant le serveur à annoncer quelles informations il va utiliser et en n'envoyant les informations permettant l'ajustement du contenu que lorsqu'elles sont explicitement demandées.
En quoi consiste ce mécanisme, justement ? La section 2 du RFC le
décrit. Un en-tête CH (Client Hint, indication
par le client) est un en-tête HTTP qui va envoyer des données
permettant au serveur de modifier le contenu. Les clients HTTP (les
navigateurs Web, par exemple) envoient les en-tête CH en fonction de
leur propre configuration, et des demandes du serveur, via l'en-tête
Accept-CH:. Le projet de spécification
« Client
Hints Infrastructure » discute de telles politiques
et donne un jeu minimal d'indications qui n'identifient pas trop le
client. Notre RFC ajoute que, par défaut, le client HTTP ne devrait
pas envoyer de données autres que celles contenues dans ce jeu
minimal. On verra bien si les navigateurs Web suivront cette
recommandation. En tout cas, le RFC insiste bien sur le risque
d'identification (fingerprinting), avec toute
technique où le client exprime des préférences. Notez qu'à l'heure
actuelle, les indications client ne sont pas encore spécifiées, mais
il existe des
propositions.
Si le client envoie des en-têtes CH (Client
Hint), le serveur peut alors ajuster son contenu. Comme
celui-ci dépend des en-têtes CH, le serveur doit penser à ajouter un
en-tête Vary: (RFC 7231,
section 7.1.4). Le serveur doit ignorer les indications qu'il ne
comprend pas (ce qui permettra d'en déployer des nouvelles sans tout
casser).
Comment est-ce que le serveur HTTP indique qu'il accepte le
système des indications client (client hints) ?
La section 3 de notre RFC décrit l'en-tête
Accept-CH: (Accept Client
Hints) qui sert à indiquer que le serveur connait bien ce
système. Il figure désormais dans le
registre des en-têtes. Accept-CH: est un
en-tête structuré (RFC 9651)
et sa valeur est une liste des indications qu'il accepte. Ainsi :
Accept-CH: CH-Example, CH-Example-again
indique que le serveur HTTP connait le système décrit dans notre RFC
et qu'il utilise deux indications client,
CH-Example et
CH-Example-again. (À l'heure actuelle, il
n'y a pas encore d'indications client normalisées, donc le RFC et
cet article utilisent des exemples bidons.)
Voici un exemple plus complet. Le serveur veut savoir quel logiciel utilise le client et sur quel système d'exploitation. Il envoie :
Accept-CH: Sec-CH-UA-Full-Version, Sec-CH-UA-Platform
(UA = User Agent, le client HTTP, il s'agit ici
de propositions
d'indications client ; Sec- et
CH- sont expliqués plus loin.) Le navigateur va
alors, dans ses requêtes suivantes, et s'il est d'accord, envoyer :
Sec-CH-UA: "Examplary Browser"; v="73" Sec-CH-UA-Full-Version: "73.3R8.2H.1" Sec-CH-UA-Platform: "Windows"
(Notez que cet exemple particulier suppose que
Sec-CH-UA: est envoyé systématiquement, même
non demandé, point qui est encore en discussion.)
Ce système des indications client pose évidemment des problèmes
de sécurité, analysés dans la section 4. D'abord, si les indications
client ont été conçues pour mieux respecter la vie privée, elles ne
sont pas non plus une solution magique. Un serveur malveillant peut
indiquer une liste très longue dans son
Accept-CH: espérant que les clients naïfs lui
enverront plein d'informations. (Notons que les chercheurs en
sécurité pourront analyser les réponses des serveurs HTTP et
compiler des listes de ceux qui abusent, contrairement au système
actuel où le serveur peut capter l'information de manière purement
passive.) Le client prudent ne doit envoyer au serveur que ce qui
est déjà accessible audit serveur par d'autres moyens (API
JavaScript par exemple). Et il doit tenir
compte des critères suivants :
- Entropie : il ne faut pas envoyer d'information rare, qui pourrait aider à identifier une machine. Indiquer qu'on tourne sur Windows n'est pas bien grave, cela n'est pas rare. Mais un client tournant sur Plan 9 ne devrait pas s'en vanter auprès du serveur.
- Sensibilité : les informations sensibles ne devraient pas être envoyées (le RFC ne donne pas d'exemple mais cela inclut certainement la localisation).
- Stabilité : les informations qui changent rapidement ne devraient pas être envoyées.
À noter que des indications apparemment utiles, comme la langue, peuvent être dangereuses ; s'il s'agit d'une langue rare, elle peut aider à l'identification d'un utilisateur, s'il s'agit de la langue d'une minorité persécutée, elle peut être une information sensible.
Le RFC recommande (reste à savoir si cela sera suivi) que les
clients HTTP devraient lier le Accept-CH: à une
origine (RFC 6454) et n'envoyer donc les informations qu'à
l'origine qui les demande. Ils devraient également être
configurables, permettant à l'utilisateur d'envoyer plus ou moins
d'informations selon son degré de méfiance. (Le RFC n'en parle pas,
mais j'ajoute que la valeur par défaut - très bavarde ou au
contraire très discrète - est un choix crucial, car peu
d'utilisateurs changeront ce réglage.) Et le RFC demande que tout
logiciel client permette également la discrétion totale, en
n'envoyant aucune indication client. (André Sintzoff me fait
remarquer à juste titre que « l'absence d'information est déjà une
information ». Signaler qu'on ne veut pas être suivi à la trace peut
vous signaler comme élement suspect, à surveiller.)
La liste des indications à envoyer pour chaque origine doit évidemment être remise à zéro lorsqu'on effectue des opérations de nettoyage, comme de supprimer les biscuits.
La même section 4 donne des conseils aux auteurs de futures
indications client. On a vu qu'à l'heure actuelle aucune n'était
encore normalisée mais des projets existent
déjà, notamment pour remplacer
User-Agent:. Un des choix cruciaux est de
décider si les indications peuvent être générées par une application
(typiquement du code JavaScript exécuté par
le navigateur Web) ou bien seulement par le client. Les secondes
sont évidemment plus sûres et c'est pour cela que leur nom est
préfixée par Sec- (pour
Secure). C'est une idée qui vient de la spécification
Fetch.
Toujours côté nommage des indications client, le RFC recommande
que le nom soit préfixé de CH- pour
Client Hints, ce qui peut permettre de les
distinguer facilement.
À l'heure actuelle, Chromium met déjà en œuvre ce système des indications client.
L'article seul
RFC 8941: Structured Field Values for HTTP
Date de publication du RFC : Février 2021
Auteur(s) du RFC : M. Nottingham (Fastly), P-H. Kamp (The Varnish Cache Project)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 9 février 2021
Plusieurs en-têtes HTTP sont structurés,
c'est-à-dire que le contenu n'est pas juste une suite de caractères
mais est composé d'éléments qu'un logiciel peut analyser. C'est par
exemple le cas de Accept-Language: ou de
Content-Disposition:. Mais chaque en-tête ainsi
structuré a sa propre syntaxe, sans rien en commun avec les autres
en-têtes structurés, ce qui en rend l'analyse pénible. Ce nouveau
RFC (depuis
remplacé par le RFC 9651) propose donc
des types de données et des algorithmes que les futurs en-têtes qui
seront définis pourront utiliser pour standardiser un peu l'analyse
d'en-têtes HTTP. Les en-têtes structurés existants ne seront pas
changés, pour préserver la compatibilité.
Imaginez : vous êtes un concepteur ou une conceptrice d'une extension au protocole HTTP qui va nécessiter la définition d'un nouvel en-tête. La norme HTTP, le RFC 7231, section 8.3.1, vous guide en expliquant ce à quoi il faut penser quand on conçoit un en-tête HTTP. Mais même avec ce guide, les pièges sont nombreux. Et, une fois votre en-tête spécifié, il vous faudra attendre que tous les logiciels, serveurs, clients, et autres (comme Varnish, pour lequel travaille un des auteurs du RFC) soient mis à jour, ce qui sera d'autant plus long que le nouvel en-tête aura sa syntaxe spécifique, avec ses amusantes particularités. Amusantes pour tout le monde, sauf pour le programmeur ou la programmeuse qui devra écrire l'analyse.
La solution est donc que les futurs en-têtes structurés réutilisent les éléments fournis par notre RFC, ainsi que son modèle abstrait, et la sérialisation proposée pour envoyer le résultat sur le réseau. Le RFC recommande d'appliquer strictement ces règles, le but étant de favoriser l'interopérabilité, au contraire du classique principe de robustesse, qui mène trop souvent à du code compliqué (et donc dangereux) car voulant traiter tous les cas et toutes les déviations. L'idée est que s'il y a la moindre erreur dans un en-tête structuré, celui-ci doit être ignoré complètement.
La syntaxe est spécifiée en ABNF (RFC 5234) mais le RFC fournit aussi des algorithmes d'analyse et, malheureusement, exige que, en cas de désaccord entre les algorithmes et la grammaire, ce soit les algorithmes qui l'emportent.
Voici un exemple fictif d'en-tête structuré très simple
(tellement simple que, si tous étaient comme lui, on n'aurait sans
doute pas eu besoin de ce RFC) :
Foo-Example: est défini comme ne prenant qu'un
élément comme valeur, un entier compris entre 0 et 10. Voici à quoi
il ressemblera en HTTP :
Foo-Example: 3
Il accepte des paramètres après un
point-virgule, un seul paramètre est défini,
foourl dont la valeur est un URI. Cela pourrait
donner :
Foo-Example: 2; foourl="https://foo.example.com/"
Donc, ces solutions pour les en-têtes structurés ne serviront que pour les futurs en-têtes, pas encore définis, et qui seront ajoutés au registre IANA. Imaginons donc que vous soyez en train de mettre au point une norme qui inclut, entre autres, un en-tête HTTP structuré. Que devez-vous mettre dans le texte de votre norme ? La section 2 de notre RFC vous le dit :
- Inclure une référence à ce RFC 8941.
- J'ai parlé jusqu'à présent d'en-tête structuré mais en fait ce RFC 8941 s'applique aussi aux pieds (trailers) (RFC 7230, sections 4.1.2 et 4.4 ; en dépit de leur nom, les pieds sont des en-têtes eux aussi). La norme devra préciser si elle s'applique seulement aux en-têtes classiques ou bien aussi aux pieds.
- Spécifier si la valeur sera une liste, un dictionnaire ou
juste un élément (ces termes sont définis en section 3). Dans
l'exemple ci-dessus
Foo-Example:, la valeur était un élément, de type entier. - Penser à définir la sémantique.
- Et ajouter les règles supplémentaires sur la valeur du
champ, s'il y en a. Ainsi, l'exemple avec
Foo-Example:imposait une valeur entière entre 0 et 10.
Une spécification d'un en-tête structuré ne peut que rajouter des contraintes à ce que prévoit ce RFC 8941. S'il en retirait, on ne pourrait plus utiliser du code générique pour analyser tous les en-têtes structurés.
Rappelez-vous que notre RFC est strict : si une erreur est présente
dans l'en-tête, il est ignoré. Ainsi, s'il était spécifié que la
valeur est un élément de type entier et qu'on trouve une chaîne de
caractères, on ignore l'en-tête. Idem dans l'exemple ci-dessus si on
reçoit Foo-Example: 42, la valeur excessive
mène au rejet de l'en-tête.
Les valeurs peuvent inclure des paramètres (comme le
foourl donné en exemple plus haut), et le RFC
recommande d'ignorer les paramètres inconnus, afin de permettre
d'étendre leur nombre sans tout casser.
On a vu qu'une des plaies du Web était le laxisme trop grand dans l'analyse des données reçues (c'est particulièrement net pour HTML). Mais on rencontre aussi des cas contraires, des systèmes (par exemple les pare-feux applicatifs) qui, trop fragiles, chouinent lorsqu'ils rencontrent des cas imprévus, parce que leurs auteurs avaient mal lu le RFC. Cela peut mener à l'ossification, l'impossibilité de faire évoluer l'Internet parce que des nouveautés, pourtant prévues dès l'origine, sont refusées. Une solution récente est le graissage, la variation délibérée des messages pour utiliser toutes les possibilités du protocole. (Un exemple pour TLS est décrit dans le RFC 8701.) Cette technique est recommandée par notre RFC.
La section 3 du RFC décrit ensuite les types qui sont les briques de base avec lesquelles on va pouvoir définir les en-têtes structurés. La valeur d'un en-tête peut être une liste, un dictionnaire ou un élément. Les listes et les dictionnaires peuvent à leur tour contenir des listes. Une liste est une suite de termes qui, dans le cas de HTTP, sont séparés par des virgules :
ListOfStrings-Example: "foo", "bar", "It was the best of times."
Et si les éléments d'une liste sont eux-mêmes des listes, on met ces listes internes entre parenthèses (et notez la liste vide à la fin) :
ListOfListsOfStrings-Example: ("foo" "bar"), ("baz"), ("bat" "one"), ()
Le cas des listes vides avait occupé une bonne partie des discussions à l'IETF (le vide, ça remplit…) Ainsi, un en-tête structuré dans la valeur est une liste a toujours une valeur, la liste vide, même si l'en-tête est absent.
Un dictionnaire est une suite de termes nom=valeur. En HTTP, cela donnera :
Dictionary-Example: en="Applepie", fr="Tarte aux pommes"
Et nous avons déjà vu les éléments simples dans le premier
exemple. Les éléments peuvent être de type
entier,
chaîne de
caractères, booléen,
identificateur, valeur binaire, et un dernier type plus exotique
(lisez le RFC pour en savoir plus). L'exemple avec
Foo-Example: utilisait un entier. Les exemples
avec listes et dictionnaires se servaient de chaînes de
caractères. Ces chaînes sont encadrées de
guillemets (pas
d'apostrophes). Compte-tenu des
analyseurs HTTP existants, les chaînes
doivent hélas être en ASCII (RFC 20). Si on veut envoyer de l'Unicode, il faudra utiliser
le type « contenu binaire » en précisant l'encodage (sans doute
UTF-8). Quant aux booléens, notez qu'il faut
écrire 1 et 0 (pas true et
false), et préfixé d'un point
d'interrogation.
Toutes ces valeurs peuvent prendre des paramètres, qui sont eux-mêmes une suite de couples clé=valeur, après un point-virgule qui les sépare de la valeur principale (ici, on a deux paramètres) :
ListOfParameters: abc;a=1;b=2
J'ai dit au début que ce RFC définit un modèle abstrait, et une sérialisation concrète pour HTTP. La section 4 du RFC spécifie cette sérialisation, et son inverse, l'analyse des en-têtes (pour les programmeu·r·se·s seulement).
Ah, et si vous êtes fana de formats structurés, ne manquez pas l'annexe A du RFC, qui répond à la question que vous vous posez certainement depuis plusieurs paragraphes : pourquoi ne pas avoir tout simplement décidé que les en-têtes structurés auraient des valeurs en JSON (RFC 8259), ce qui évitait d'écrire un nouveau RFC, et permettait de profiter du code JSON existant ? Le RFC estime que le fait que les chaînes de caractères JSON soient de l'Unicode est trop risqué, par exemple pour l'interopérabilité. Autre problème de JSON, les structures de données peuvent être emboîtées indéfiniment, ce qui nécessiterait des analyseurs dont la consommation mémoire ne peut pas être connue et limitée. (Notre RFC permet des listes dans les listes mais cela s'arrête là : on ne peut pas poursuivre l'emboîtement.)
Une partie des problèmes avec JSON pourrait se résoudre en se limitant à un profil restreint de JSON, par exemple en utilisant le RFC 7493 comme point de départ. Mais, dans ce cas, l'argument « on a déjà un format normalisé, et mis en œuvre partout » tomberait.
Enfin, l'annexe A note également qu'il y avait des considérations d'ordre plutôt esthétiques contre JSON dans les en-têtes HTTP.
Toujours pour les programmeu·r·se·s, l'annexe B du RFC donne quelques conseils pour les auteur·e·s de bibliothèques mettant en œuvre l'analyse d'en-têtes structurés. Pour les aider à suivre ces conseils, une suite de tests est disponible. Quant à une liste de mises en œuvre du RFC, vous pouvez regarder celle-ci.
Actuellement, il n'y a dans le registre
des en-têtes qu'un seul en-tête structuré, le
Accept-CH: du RFC 8942. Sa valeur est une liste d'identificateurs. Mais
plusieurs autres en-têtes structurés sont en préparation.
Si vous voulez un exposé synthétique sur ces en-têtes structuré, je vous recommande cet article par un des auteurs du RFC.
Voyons maintenant un peu de pratique avec une des mises en œuvre citées plus haut, http_sfv, une bibliothèque Python. Une fois installée :
% python3 >>> import http_sfv >>> my_item=http_sfv.Item() >>> my_item.parse(b"2") >>> print(my_item) 2
On a analysé la valeur « 2 » en déclarant que cette valeur devait être un élément et, pas de surprise, ça marche. Avec une valeur syntaxiquement incorrecte :
>>> my_item.parse(b"2, 3")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/stephane/.local/lib/python3.6/site-packages/http_sfv-0.9.1-py3.6.egg/http_sfv/util.py", line 57, in parse
ValueError: Trailing text after parsed value
Et avec un paramètre (il sera accessible après l'analyse, via le
dictionnaire Python params) :
>>> my_item.parse(b"2; foourl=\"https://foo.example.com/\"")
>>> print(my_item.params['foourl'])
https://foo.example.com/
Avec une liste :
>>> my_list.parse(b"\"foo\", \"bar\", \"It was the best of times.\"")
>>> print(my_list)
"foo", "bar", "It was the best of times."
Et avec un dictionnaire :
>>> my_dict.parse(b"en=\"Applepie\", fr=\"Tarte aux pommes\"")
>>> print(my_dict)
en="Applepie", fr="Tarte aux pommes"
>>> print(my_dict["fr"])
"Tarte aux pommes"
L'article seul
RFC 8937: Randomness Improvements for Security Protocols
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : C. Cremers (CISPA Helmholtz Center for Information Security), L. Garratt (Cisco Meraki), S. Smyshlyaev (CryptoPro), N. Sullivan, C. Wood (Cloudflare)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF cfrg
Première rédaction de cet article le 17 octobre 2020
Tout le monde sait désormais que la génération de nombres aléatoires (ou, plus rigoureusement, de nombres imprévisibles, pseudo-aléatoires) est un composant crucial des solutions de sécurité à base de cryptographie, comme TLS. Les failles des générateurs de nombres pseudo-aléatoires, ou bien les attaques exploitant une faiblesse de ces générateurs sont les problèmes les plus fréquents en cryptographie. Idéalement, il faut utiliser un générateur sans défauts. Mais, parfois, on n'a pas le choix et on doit se contenter d'un générateur moins satisfaisant. Ce nouveau RFC décrit un mécanisme qui permet d'améliorer la sécurité de ces générateurs imparfaits, en les nourrissant avec des clés privées.
Un générateur de nombres pseudo-aléatoires cryptographique (CSPRNG, pour Cryptographically-Strong PseudoRandom Number Generator) produit une séquence de bits qui est indistinguable d'une séquence aléatoire. Un attaquant qui observe la séquence ne peut pas prédire les bits suivants.
On les nomme générateur pseudo-aléatoires car un générateur réellement aléatoire devrait être fondé sur un phénomène physique aléatoire. Un exemple classique d'un tel phénomène, dont la théorie nous dit qu'il est réellement aléatoire, est la désintégration radioactive. Des exemples plus pratiques sont par exemple des diodes forcées de produire un bruit blanc (comme dans le Cryptech). (Ou alors un chat marchant sur le clavier ?) Mais, en pratique, les ordinateurs se servent de générateurs pseudo-aléatoires, ce qui suffit s'ils sont imprévisibles à un observateur extérieur.
Beaucoup de solutions de sécurité,
même en l'absence de cryptographie, dépendent de cette propriété
d'imprévisibilité. Ainsi, TCP, pour protéger contre un attaquant aveugle
(situé en dehors du chemin du paquet), a besoin de numéros de
séquence initiaux qui soient imprévisibles (RFC 5961). Et la cryptographie consomme
énormément de ces nombres pseudo-aléatoires. Ainsi, TLS (RFC 8446) se sert de tels nombres à de nombreux endroits, par
exemple les numniques utilisés dans le
ClientHello, sans compter les nombres
pseudo-aléatoires utilisés lors de la génération des clés de
session. La plupart des autres protocoles de
chiffrement dépendent de tels nombres que
l'attaquant ne peut pas prévoir.
Réaliser un générateur pseudo-aléatoire sur une machine aussi déterministe qu'un ordinateur n'est pas facile, en l'absence de source quantique comme un composant radioactif. (Cf. RFC 4086.) La solution adoptée la plus simple est d'utiliser une fonction qui calcule une séquence de nombres pseudo-aléatoires d'une manière que, même en observant la séquence, on ne puisse pas deviner le nombre suivant (la mathématique fournit plusieurs fonctions pour cela). Comme l'algorithme est en général connu, et que l'ordinateur est déterministe, s'il connait le premier nombre, la graine, un observateur pourrait calculer toute la séquence. La graine ne doit donc pas être connue des observateurs extérieurs. Elle est par exemple calculée à partir d'éléments qu'un tel observateur ne connait pas, comme des mouvements physiques à l'intérieur de l'ordinateur, ou bien provoqués par l'utilisateur.
De tels générateurs pseudo-aléatoires sont très difficiles à réaliser correctement et, en cryptographie, il y a eu bien plus de failles de sécurité dues à un générateur pseudo-aléatoire que dues aux failles des algorithmes de cryptographie eux-mêmes. L'exemple le plus fameux était la bogue Debian, où une erreur de programmation avait réduit drastiquement le nombre de graines possibles (l'entropie). Un autre exemple amusant est le cas du générateur cubain qui oubliait le chiffre 9.
Mais le générateur pseudo-aléatoire peut aussi être affaibli délibérement, pour faciliter la surveillance, comme l'avait fait le NIST, sur ordre de la NSA, en normalisant le générateur Dual-EC avec une faille connue.
Obtenir une graine de qualité est très difficile, surtout sur des appareils ayant peu de pièces mobiles, donc peu de mouvements physiques qui pourraient fournir des données aléatoires. Un truc avait déjà été proposé : combiner la graine avec la clé privée utilisée pour la communication (par exemple en prenant un condensat de la concaténation de la graine avec la clé privée, pour faire une graine de meilleure qualité), puisque la clé privée est secrète. L'idée vient du projet Naxos. (Cela suppose bien sûr que la clé privée n'ait pas été créée par la source qu'on essaie d'améliorer. Elle peut par exemple avoir été produite sur un autre appareil, ayant davantage d'entropie.) Le problème de cette approche avec la clé privée, est que les clés privées sont parfois enfermées dans un HSM, qui ne les laisse pas sortir.
La solution proposée par notre RFC est de ne pas utiliser directement la clé secrète, mais une signature de la graine. C'est une valeur qui est imprévisible par un observateur, puisqu'elle dépend de la clé privée, que l'attaquant ne connait pas. Ainsi, on peut obtenir une séquence de nombres pseudo-aléatoires que l'observateur ne pourra pas distinguer d'une séquence réellement aléatoire, même si la graine initiale n'était pas terrible.
L'algorithme exact est formulé dans la section 3 du RFC. Le Nième nombre pseudo-aléatoire est l'expansion (RFC 5869, section 2.3) de l'extraction (RFC 5869, section 2.2) d'un condensat de la signature d'une valeur qui ne change pas à chaque itération de la séquence, ce qui fait que cet algorithme reste rapide. (J'ai simplifié, il y a d'autres paramètres, notamment la valeur « normale » de la séquence, initiée à partir de la graine.) La signature doit évidemment être secrète (sinon, on retombe dans le générateur pseudo-aléatoire d'avant ce RFC). La fonction de signature doit être déterministe (exemple dans le RFC 6979). La « valeur qui ne change pas à chaque itération » peut, par exemple (section 4 du RFC) être l'adresse MAC de la machine mais attention aux cas de collisions (entre VM, par exemple). Une autre valeur constante est utilisée par l'algorithme et peut, par exemple, être un compteur, ou bien l'heure de démarrage. Ces deux valeurs n'ont pas besoin d'être secrètes.
Une analyse de sécurité de ce mécanisme a été faite dans l'article « Limiting the impact of unreliable randomness in deployed security protocols ». Parmi les points à surveiller (section 9), la nécessité de bien garder secrète la signature, ce qui n'est pas toujours évident notamment en cas d'attaque par canal auxiliaire.
À propos de générateurs pseudo-aléatoires, je vous recommande cet article très détaillé en français sur la mise en œuvre de ces générateurs sur Linux.
Merci à Kim Minh Kaplan pour une bonne relecture.
L'article seul
RFC 8932: Recommendations for DNS Privacy Service Operators
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : S. Dickinson (Sinodun IT), B. Overeinder (NLnet Labs), R. van Rijswijk-Deij (NLnet Labs), A. Mankin (Salesforce)
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 25 octobre 2020
Vous gérez un résolveur DNS qui promet de protéger la vie privée des utilisateurs et utilisatrices ? Alors, vous serez certainement intéressé par ce nouveau RFC qui rassemble les bonnes pratiques en matière de gestion d'un tel résolveur, et explique comment documenter la politique du résolveur, les choix effectués. On y trouve une bonne analyse des questions de sécurité, une discussion de ce qui doit être dans une politique, une analyse comparée des politiques, et même un exemple de politique.
Depuis la publication du RFC 7626, les
risques pour la vie privée
posés par l'utilisation du DNS sont bien connus. Par exemple, un de ces
risques est que le trafic DNS entre une machine terminale et le
résolveur est en clair et peut
donc trivialement être écouté, ce qui est d'autant plus gênant que
ce trafic inclut toutes les informations (il n'y a pas de
minimisation possible de la question, par exemple). Un autre risque
est que le gérant du résolveur voit forcément tout le trafic, même
si on chiffre le trafic
entre la machine terminale et lui. Il peut abuser de cette confiance
qu'on lui fait. Une des solutions possibles face à ces risques est
d'utiliser, non pas le résolveur annoncé par le réseau d'accès à
l'Internet mais un résolveur extérieur, à qui vous faites confiance,
et avec qui vous communiquez de manière chiffrée. De tels résolveurs
existent. Certains sont publics (accessibles à tous), gérés par des
GAFA comme Cloudflare
(avec son résolveur 1.1.1.1) ou gérés par des
associations ou bien des individus (vous trouverez une liste
partielle à la fin
du README de ce logiciel). D'autres de ces résolveurs sont
réservés à tel ou tel groupe ou organisation.
Le problème pour l'utilisateur est celui du choix : lequel prendre ? Pour cela, il faut déjà que ceux et celles qui gèrent le résolveur aient documenté leurs pratiques et qu'on leur fasse confiance pour respecter leurs promesses. C'est l'un des buts de ce RFC : fournir un cadre général de description des pratiques d'un résolveur « vie privée », pour faciliter la tâche des rédacteurs et rédactrices de ces documents, dans l'esprit du RFC 6841, qui faisait la même chose pour DNSSEC. Notre RFC n'impose pas une politique particulière, il décrit juste les choix possibles, et ce qu'il ne faut pas oublier de mettre dans son RPS, son Recursive operator Privacy Statement.
Optimiste, notre RFC estime que des promesses formelles de strict préservation de la vie privée des utilisateurs seraient même un avantage pour les résolveurs ayant de tels engagements, leur apportant davantage d'utilisateurs. L'expérience du Web avec le succès des GAFA, entreprises capitalistes captatrices de données personnelles, même lorsqu'une alternative libre et respectueuse de la vie privée existe, me fait douter de ce pronostic.
Notez que la question du choix d'un résolveur est une question complexe. Le RFC cite par exemple le fait qu'avoir un résolveur stable, utilisé pour toutes les connexions d'une machine mobile, peut permettre à ce résolveur de vous suivre, lorsque vous changez de réseau d'accès.
La section 2 décrit le domaine d'applicabilité de ce document : il vise les gérants de résolveurs DNS, pas les utilisateurs finaux, ni les gérants de serveurs faisant autorité. Suivant les principes des RFC 6973 et RFC 7626, il va se pencher sur ce qui arrive aux données en transit sur l'Internet, aux données au repos sur un des serveurs (journaux, par exemple) et aux données transmises pour effectuer le travail (requêtes envoyées par un résolveur aux serveurs faisant autorité, lorsque la réponse n'est pas déjà dans la mémoire du résolveur).
La section 5 est le cœur de notre RFC, elle décrit les
recommandations concrètes. Pour illustrer ces recommandations, je
dirai à chaque fois comment elles ont été mises en œuvre sur le
résolveur sécurisé que je gère,
dot.bortzmeyer.fr &
https://doh.bortzmeyer.fr/. Non pas qu'il soit
le meilleur, le plus rapide, le plus sûr ou quoi que ce soit
d'autre. Mais parce qu'il met en œuvre les recommandations de ce
RFC, et que je sais qu'il respecte sa politique
affichée. Ces notes sur mon résolveur apparaitront entre
crochets.
D'abord, en transit, les communications faites en clair peuvent être écoutées par un surveillant passif et, pire, modifiées par un attaquant actif (section 5.1 du RFC). La première recommandation va de soi, il faut chiffrer. Un résolveur DNS public qui n'aurait pas de chiffrement (comme ceux actuellement proposés par certaines associations) n'a guère d'intérêt du point de vue de la vie privée. Pour ce chiffrement, deux techniques normalisées, DoT (DNS sur TLS, RFC 7858 et RFC 8310) et DoH (DNS sur HTTPS, RFC 8484). [Mon résolveur les déploie toutes les deux.] Il existe aussi un DNS sur DTLS (RFC 8094) mais qui n'a eu aucun succès, et des techniques non normalisées comme DNSCrypt, ou une forme ou l'autre de VPN vers le résolveur. Le RFC note que le chiffrement protège le canal, pas les données, et qu'il ne dispense donc pas de DNSSEC (cf. section 5.1.4). [Évidemment mon résolveur valide avec DNSSEC.] Un avantage des canaux sécurisés créés avec DoT ou DoH est qu'il y a beaucoup moins de risque que DNSSEC soit bloqué (cf. RFC 8027).
[Beaucoup de techniciens ont tendance à limiter la protection de la vie privée au chiffrement. C'est un exemple de fascination pour une technique complexe, au détriment d'autres mesures moins geek, qui sont présentées plus loin. Le chiffrement est nécessaire mais certainement pas suffisant.]
Chiffrer n'est pas très utile si on n'a pas authentifié celui avec qui on communique. Un attaquant actif peut toujours tenter de se faire passer pour le serveur qu'on essaie de joindre, par exemple par des attaques BGP ou tout simplement en injectant dans son réseau les routes nécessaires (comme le cas turc). Il faut donc authentifier le résolveur. DoT ne présentait guère de solutions satisfaisantes à l'origine, mais ça s'est amélioré avec le RFC 8310. Un résolveur DoT doit donc présenter un certificat qui permette son authentification ou bien publier sa clé publique (SPKI Subject Public Key Info, mais son utilisation est aujourd'hui déconseillée, car elle rend difficile le changement de clé). Le certificat peut contenir un nom ou une adresse IP. S'il contient un nom, il faut que le client connaisse ce nom, pour l'authentifier (un résolveur DNS traditionnel n'était connu que par son adresse IP). Ainsi, le certificat du résolveur Quad9 contient nom(s) et adresse(s) IP :
% openssl s_client -showcerts -connect 9.9.9.9:853 | openssl x509 -text
...
Subject: C = US, ST = California, L = Berkeley, O = Quad9, CN = *.quad9.net
...
X509v3 Subject Alternative Name:
DNS:*.quad9.net, DNS:quad9.net, IP Address:9.9.9.9, IP Address:9.9.9.10, IP Address:9.9.9.11, IP Address:9.9.9.12, IP Address:9.9.9.13, IP Address:9.9.9.14, IP Address:9.9.9.15, IP Address:149.112.112.9, IP Address:149.112.112.10, IP Address:149.112.112.11, IP Address:149.112.112.12, IP Address:149.112.112.13, IP Address:149.112.112.14, IP Address:149.112.112.15, IP Address:149.112.112.112, IP Address:2620:FE:0:0:0:0:0:9, IP Address:2620:FE:0:0:0:0:0:10, IP Address:2620:FE:0:0:0:0:0:11, IP Address:2620:FE:0:0:0:0:0:12, IP Address:2620:FE:0:0:0:0:0:13, IP Address:2620:FE:0:0:0:0:0:14, IP Address:2620:FE:0:0:0:0:0:15, IP Address:2620:FE:0:0:0:0:0:FE, IP Address:2620:FE:0:0:0:0:FE:9, IP Address:2620:FE:0:0:0:0:FE:10, IP Address:2620:FE:0:0:0:0:FE:11, IP Address:2620:FE:0:0:0:0:FE:12, IP Address:2620:FE:0:0:0:0:FE:13, IP Address:2620:FE:0:0:0:0:FE:14, IP Address:2620:FE:0:0:0:0:FE:15
...
[Mon résolveur, lui, utilise Let's Encrypt,
qui ne permet pas encore (cf. RFC 8738) de mettre
une adresse IP dans le certificat. Il n'y a donc que le nom. On peut
aussi l'authentifier avec sa clé publique (SPKI), qui vaut
eHAFsxc9HJW8QlJB6kDlR0tkTwD97X/TXYc1AzFkTFY=.]
Puisqu'on parle de certificats : le RFC note à juste
titre que les opérateurs de serveurs DNS ne sont pas forcément
experts en la matière, sauf à demander de l'aide à leurs collègues
HTTP qui
gèrent ces certificats depuis longtemps. Le RFC recommande donc
d'automatiser (par exemple avec ACME, cf. RFC 8555),
et de superviser les
certificats (c'est le B A BA, mais combien d'administrateurs
système ne le font toujours pas ?).
Le RFC a également des recommandations techniques sur les protocoles utilisés. En effet :
- TLS ne protège pas contre toutes les attaques (cf. RFC 7457),
- L'analyse de trafic reste notamment possible (cf. l'article de Haya Shulman « Pretty Bad Privacy: Pitfalls of DNS Encryption », et celui de Silby, S., Juarez, M., Vallina-Rodriguez, N., et C. Troncosol, « DNS Privacy not so private: the traffic analysis perspective »).
Il est donc conseillé de suivre les recommandations TLS du RFC 7525, de n'utiliser que des versions récentes
de TLS. Un rappel, d'ailleurs : les services comme SSLabs.com peuvent
parfaitement tester votre résolveur DoH. [J'ai une bonne note.]
Il est également conseillé de faire du remplissage (RFC 7830 et RFC 8467 ou bien, pour DoH, avec le remplissage HTTP/2), et de ne pas imposer des fonctions qui sont dangereuses pour la vie privée comme la reprise de session TLS (RFC 5077), ou comme les cookies (DNS, RFC 7873 ou HTTP, RFC 6265). [Le logiciel que j'utilise pour mon résolveur, dnsdist, semble faire du remplissage DNS, mais je n'ai pas testé.]
Question non plus de sécurité mais de performance, le RFC recommande de gérer les requêtes en parallèle, y compris de pouvoir donner des réponses dans le désordre (RFC 7766) et de maintenir les sessions TLS ouvertes (RFC 7766 et RFC 7828, voire RFC 8490). [Le logiciel utilisé sur mon résolveur, dnsdist, ne sait pas encore générer des réponses dans un ordre différent de celui d'arrivée.]
Le résolveur DNS est un composant crucial de l'utilisation de l'Internet. S'il est en panne, c'est comme si tout l'Internet est en panne. La disponibilité du résolveur est donc une question cruciale. Si les pannes sont trop fréquentes, les utilisateurs risquent de se rabattre sur des solutions qui ne respectent pas leur vie privée, voire sur des solutions non sécurisées. Le risque est d'autant plus élevé qu'il y a des attaques par déni de service visant les résolveurs DNS (cf. cet article de l'AFNIC). Le RFC recommande donc de tout faire pour assurer cette disponibilité. [Mon propre résolveur, étant un projet personnel, et installé sur un VPS ordinaire, n'est certainement pas bien placé de ce point de vue.]
Bien sûr, il faut fournir aux utilisateurs des services qui protègent la vie privée les mêmes options qu'aux autres visiteurs : résolveur non menteur, validation DNSSEC, etc. (Il existe des services où les choix sont exclusifs et où, par exemple, choisir un résolveur non menteur prive de DNSSEC.)
La protection de la vie privée ne plait pas à tout le monde. Les partisans de la surveillance ont défendu leur point de vue dans le RFC 8404 en réclamant de la visibilité sur le trafic, justement ce que le chiffrement veut empêcher. Ce RFC 8932 essaie de ménager la chèvre et le chou en signalant aux opérateurs de résolveurs chiffrants qu'ils ont toujours accès au trafic en clair, en prenant les données après leur déchiffrement, sur le résolveur. C'est ce que permet, par exemple, la technologie dnstap. Après tout, TLS ne protège qu'en transit, une fois arrivé sur le résolveur, les données sont en clair. [Mon résolveur ne copie pas le trafic en clair, qui n'est jamais examiné. Le logiciel utilisé est capable de faire du dnstap, mais a été compilé sans cette option.] Notez que ce RFC 8932 reprend hélas sans nuances les affirmations du RFC 8404 comme quoi il est légitime d'avoir accès aux données de trafic.
Une technique courante pour mettre en œuvre un résolveur avec TLS est de prendre un résolveur ordinaire, comme BIND, et de le placer derrière un relais qui terminera la session TLS avant de faire suivre au vrai résolveur, typiquement situé sur la même machine pour des raisons de sécurité. Des logiciels comme stunnel, haproxy ou nginx permettent de faire cela facilement, et fournissent des fonctions utiles, par exemple de limitation du trafic. Mais cela ne va pas sans limites. Notamment, avec cette méthode, le vrai résolveur ne voit pas l'adresse IP du client, mais celle du relais. Cela interdit d'utiliser des solutions de sécurité comme les ACL ou comme RRL (Response Rate Limiting). [Mon résolveur utilise un relais, mais avec un logiciel spécialisé dans le DNS, dnsdist. dnsdist peut résoudre le problème de la mauvaise adresse IP en utilisant le PROXY protocol mais je n'utilise pas cette possibilité.]
Nous avons vu jusqu'à présent le cas des données en transit, entre le client et le résolveur DNS. La réponse principale aux problèmes de vie privée était le chiffrement. Passons maintenant au cas des données « au repos », stockées sur le résolveur, par exemple dans des journaux, ou dans des pcap (ou équivalent) qui contiennent le trafic enregistré (section 5.2). Évidemment, pour qu'un service puisse se prétendre « protecteur de la vie privée », il faut qu'une telle rétention de données soit très limitée, notamment dans le temps (c'est un des principes du RGPD, par exemple). Si on garde de telles données pour des raisons légitimes (statistiques, par exemple), il est recommandé de les agréger afin de fournir un peu d'anonymisation. (La lecture recommandée sur ce point est le RFC 6973.) Pour des problèmes à court terme (analyser et comprendre une attaque par déni de service en cours, par exemple), le mieux est de ne pas stocker les données sur un support pérenne, mais de les garder uniquement en mémoire. [Mon résolveur n'enregistre rien sur disque. Des statistiques fortement agrégées sont possibles mais, à l'heure actuelle, ce n'est pas fait.]
Si le chiffrement est le principal outil technique dont on dispose pour protéger les données lorsqu'elles se déplacent d'une machine à l'autre, il est moins utile lorsque des données sont enregistrées sur le serveur. Ici, l'outil technique essentiel est la minimisation des données. C'est le deuxième pilier d'une vraie protection de la vie privée, avec le chiffrement, mais elle est très souvent oubliée, bien que des textes juridiques comme le RGPD insistent sur son importance. Mais attention, minimiser des données n'est pas facile. On a fait de gros progrès ces dernières années en matière de ré-identification de personnes à partir de données qui semblaient minimisées. Comme le note le RFC, il n'y a pas de solution générale, largement acceptée, qui permette de minimiser les données tout en gardant leur utilité. C'est pour cela que quand un décideur sérieux et sûr de lui affirme bien fort « Ne vous inquiétez pas de cette base de données, tout est anonymisé », vous pouvez être raisonnablement sûr qu'il est soit malhonnête, soit incompétent ; réellement anonymiser est très difficile.
Cela fait pourtant quinze ou vingt ans qu'il y a des recherches actives en « anonymisation », motivées entre autre par la volonté de partager des données à des fins de recherches scientifiques. Mais le problème résiste. Et les discussions sont difficiles, car les discoureurs utilisent souvent une terminologie floue, voire incorrecte (par mauvaise foi, ou par ignorance). Notre RFC rappelle donc des points de terminologie (déjà abordés dans le RFC 6973) :
- Anonymiser, c'est faire en sorte qu'on ne puisse plus distinguer un individu d'un autre individu. C'est une propriété très forte, difficile à atteindre, puisqu'il s'agit de supprimer toute traçabilité entre différentes actions. En général, il faut supprimer ou tronquer une bonne partie des données pour y arriver.
- Pseudonymiser, c'est remplacer un identificateur par un autre. (Le RFC parle de remplacer la « vraie » identité par une autre mais il n'existe pas d'identité qui soit plus vraie qu'une autre.) Ainsi, remplacer une adresse IP par son condensat SHA-256 est une pseudonymisation. Avec beaucoup de schémas de pseudonymisation, remonter à l'identité précédente est possible. Ici, par exemple, retrouver l'adresse IP originale est assez facile (en tout cas en IPv4).
Quand un politicien ou un autre Monsieur Sérieux parle d'anonymisation, il confond presque toujours avec la simple pseudonymisation. Mais la distinction entre les deux n'est pas toujours binaire.
Dans les données d'un résolveur DNS, l'une des principales
sources d'information sur l'identité de l'utilisateur est l'adresse
IP source (cf. RFC 7626, section 2.2). De
telles adresses sont
clairement des données personnelles et il serait donc
intéressant de les « anonymiser ». De nombreuses techniques, de
qualité très variable, existent pour cela, et le RFC les présente
dans son annexe B, que je décris à la fin de cet article. Aucune de
ces techniques ne s'impose comme solution idéale marchant dans tous
les cas. (À part, évidemment, supprimer complètement l'adresse IP.)
Notez qu'il existe d'autres sources d'information sur le client que
son adresse IP, comme la question posée (s'il demande
security.debian.org, c'est une machine
Debian) ou comme le
fingerprinting des caractéristiques techniques de
sa session. Le problème est évidemment pire avec DoH, en raison des
innombrables en-têtes HTTP très révélateurs que les navigateurs
s'obstinent à envoyer (User-Agent:, par
exemple). Dans certains cas, on voit même des équipements comme la
box ajouter
des informations précises sur le client.
Ces données stockées sur le résolveur peuvent parfois rester uniquement dans l'organisation qui gère le résolveur, mais elles sont parfois partagées avec d'autres. (Méfiez-vous des petites lettres : quand on vous promet que « nous ne vendrons jamais vos données », cela ne veut pas dire qu'elles ne seront pas partagées, juste que le partageur ne recevra pas directement d'argent pour ce partage.) Le partage peut être utile pour la science (envoi des données à des chercheurs qui feront ensuite d'intéressants articles sur le DNS), mais il est dangereux pour la vie privée. Comme exemple d'organisation qui partage avec les universités, voir SURFnet et leur politique de partage. [Mon résolveur ne partage avec personne.]
Après les données qui circulent entre le client et le résolveur, puis le cas des données stockées sur le résolveur, voyons le cas des données envoyées par le résolveur, pour obtenir la réponse à ses questions (section 5.3 du RFC). Bien sûr, cela serait très bien si le résolveur chiffrait ses communications avec les serveurs faisant autorité, mais il n'existe actuellement pas de norme pour cela (des propositions ont été faites, et des tests menés, mais sans résultat pour l'instant).
Et, de toute façon, cela ne protègerait que contre un tiers, pas
contre les serveurs faisant autorité qui enregistrent les questions
posées. Face à ce risque, la principale recommandation du RFC
est d'utiliser la QNAME minimisation (RFC 9156) pour réduire ces données, en application
du principe général « ne pas envoyer plus que ce qui est
nécessaire ». [Mon résolveur DoT/DoH fait appel à un résolveur qui fait
cela.] Seconde recommandation, respecter les consignes ECS
(RFC 7871) : si le client demande à ce que les
données ECS soient réduites ou supprimées, il faut lui
obéir. [Mon résolveur débraye ECS avec la directive dnsdist
useClientSubnet=false.] (Notez
que, par défaut, cela permet toujours au résolveur de transmettre
aux serveurs faisant autorité l'adresse de son client…)
Deux autres façons, pour le résolveur, de limiter les données qu'il envoie aux serveurs faisant autorité :
- Générer des réponses à partir de sa mémoire (RFC 8020 et RFC 8198),
- avoir une copie locale de la racine, privant les serveurs racine d'informations (RFC 8806).
[Sur mon résolveur DoH/DoT, le vrai résolveur qui tourne derrière,
un Unbound, a les options
harden-below-nxdomain et
aggressive-nsec, qui mettent à peu près en
œuvre les RFC 8020 et RFC 8198.] On peut aussi imaginer un résolveur qui envoie des
requêtes bidon, pour brouiller les informations connues du serveur
faisant autorité, ou, moins méchamment, qui demande en avance (avant
l'expiration du TTL) des données
qui sont dans sa mémoire, sans attendre une requête explicite d'un
de ses clients, pour casser la corrélation entre un client et une
requête. Pour l'instant, il n'existe pas de recommandations
consensuelles sur ces techniques. Enfin, un résolveur peut aussi
faire suivre toutes ses requêtes à un résolveur plus gros
(forwarder), au-dessus d'un lien sécurisé. Cela a
l'avantage que le gros résolveur, ayant une mémoire plus importante,
enverra moins de données aux serveurs faisant autorité, et que sa
base de clients plus large rendra plus difficile la
corrélation. Évidemment, dans ce cas, le danger peut venir du gros
résolveur à qui on fait tout suivre, et le choix final n'est donc
pas évident du tout. [Mon résolveur ne fait pas suivre à un gros
résolveur public, aucun ne me semblant satisfaisant. Comme il a peu
de clients, cela veut dire que les données envoyées aux serveurs
faisant autorité peuvent être un problème, question vie privée.]
Une fois que cette section 5 du RFC a exposé tous les risques et
les solutions possibles, la section 6 parle de la RPS,
Recursive operator Privacy Statement, la
déclaration officielle des gérants d'un résolveur à ses clients,
exposant ce qu'ils ou elles font, et ce qu'elles ou ils ne font pas
avec les données. (Au début du développement de ce RFC, la RPS se
nommait DROP - DNS Recursive Operator Privacy
statement, ce qui était plus drôle.) Notre RFC recommande
très fortement que les opérateurs d'un résolveur DNS publient une
RPS, l'exposition de leur politique. Le but étant de permettre aux
utilisateurs humains de choisir en toute connaissance de cause un
résolveur ayant une politique qu'ils acceptent. Évidemment, il y a
des limites à cette idée. D'abord, les utilisateurs ne lisent pas
forcément les conditions d'utilisation / codes de conduite et autres
textes longs et incompréhensibles. (Le RFC propose des
recommandations sur la rédaction des RPS, justement pour diminuer ce
problème, en facilitant les comparaisons.) [Mon résolveur a une RPS
publique, accessible en https://doh.bortzmeyer.fr/policy
Le RFC propose un plan pour la RPS. Rien n'est évidemment obligatoire dans ce plan, mais c'est une utile liste pour vérifier qu'on n'a rien oublié. Le but est de faire une RPS utilisable, et lisible, et le plan ne couvre pas donc d'éventuelles questions financières (si le service est payant), et ne prétend pas être un document juridique rigoureux, puisqu'elle doit pouvoir être lue et comprise.
Parmi les points à considérer quand on écrit une RPS :
- Le statut des adresses IP : bien préciser qu'elles sont des données personnelles,
- le devenir des données : collectées ou non, si elles sont collectées, partagées ou non, gardées combien de temps,
- si les données sont « anonymisées », une description détaillée du processus d'anonymisation (on a vu que la seule proclamation « les données sont anonymisées », sans détail, était un signal d'alarme, indiquant que l'opérateur se moque de vous),
- les exceptions, car toute règle doit permettre des exceptions, par exemple face à une attaque en cours, qui peut nécessiter de scruter avec tcpdump, même si on se l'interdit normalement,
- les détails sur l'organisation qui gère le résolveur, ses partenaires et ses sources de financement,
- et l'éventuel filtrage des résultats (« DNS menteur ») : a-t-il lieu, motifs de filtrage (noms utilisés pour la distribution de logiciel malveillant, par exemple), loi applicable (« nous sommes enregistrés en France donc nous sommes obligés de suivre les lois françaises »), mécanismes de décision internes (« nous utilisons les sources X et Y de noms à bloquer »)…
L'opérateur du résolveur qui veut bien faire doit également communiquer à ses utilisateurs :
- Les écarts par rapport à la politique affichée, s'il a fallu en urgence dévier des principes,
- les détails techniques de la connexion (est-ce qu'on accepte seulement DoH, seulement DoT, ou les deux, par exemple), et des services (est-ce qu'on valide avec DNSSEC ?),
- les détails de l'authentification du résolveur : nom à valider, clé publique le cas échéant.
Un autre problème avec ces RPS est évidemment le risque de
mensonge. « Votre vie privée est importante », « Nous nous engageons
à ne jamais transmettre vos données à qui que ce soit », il serait
très naïf de prendre ces déclarations pour argent comptant. Le RFC
est réaliste et sa section 6.2 du RFC parle des mécanismes qui
peuvent permettre, dans le cas idéal, d'augmenter légèrement les
chances que la politique affichée soit respectée. Par exemple, on
peut produire des transparency reports où on
documente ce qu'on a été forcés de faire (« en raison d'une
injonction judiciaire, j'ai dû ajouter une règle pour bloquer
machin.example »). Des vérifications techniques
peuvent être faites de l'extérieur, comme
l'uptime, le remplissage
ou la minimisation des requêtes. De tels outils existent pour la
qualité TLS des serveurs, comme SSLlabs.com, déjà
cité, ou Internet.nl. [Opinion
personnelle : beaucoup de tests d'Internet.nl ne sont pas pertinents
pour DoH.] Plus fort, on peut recourir à des audits externes, qui augmentent normalement
la confiance qu'on accorde à la RPS, puisqu'un auditeur indépendant
aura vérifié sa mise en œuvre. [Mon avis est que c'est d'une
fiabilité limitée, puisque l'auditeur est choisi et payé par
l'organisation qui se fait auditer… Et puis, même si vous êtes
root sur les machines de l'organisation
auditée, ce qui n'arrive jamais, s'assurer que, par exemple, les
données sont bien détruites au bout du temps prescrit est
non-trivial.] Cloudflare est ainsi audité
(par KPMG) et vous pouvez lire le
premier rapport (très court et sans aucun détail sur le
processus de vérification).
L'annexe A du RFC liste les documents, notamment les RFC, qui sont pertinents pour les opérateurs de résolveurs promettant le respect de la vie privée. On y trouve les normes techniques sur les solutions améliorant la protection de l'intimité, mais aussi celles décrivant les solutions qui peuvent diminuer la vie privée, comme ECS (RFC 7871), les cookies DNS (RFC 7873), la reprise de sessions TLS (RFC 5077, un format pour stocker des données sur le trafic DNS (RFC 8618, mais il y a aussi le traditionnel pcap), le passive DNS (RFC 8499), etc.
L'annexe C du RFC cite une intéressante comparaison, faite en 2019, de diverses RPS (Recursive operator Privacy Statement, les politiques des gérants de résolveurs). Comme ces RPS sont très différentes par la forme, une comparaison est difficile. Certaines font plusieurs pages, ce qui les rend longues à analyser. Aujourd'hui, en l'absence de cadres et d'outils pour éplucher ces RPS, une comparaison sérieuse par les utilisateurs n'est pas réaliste. Quelques exemples réels : la RPS de mon résolveur (la seule en français), celle de PowerDNS, celle de Quad9, celle de Cloudflare… Mozilla a développé, pour son programme TRR (Trusted Recursive Resolve), une liste de critères que les résolveurs qui veulent rejoindre le programme doivent respecter. Une sorte de méta-RPS. [Apparemment, le seul truc qui me manque est le transparency report annuel.]
L'annexe D du RFC contient un exemple de RPS. Elle ne prétend pas être parfaite, et il ne faudrait surtout pas la copier/coller directement dans une vraie RPS mais elle peut servir de source d'inspiration. Notez également qu'elle est écrite en anglais, ce qui ne conviendra pas forcément à un service non-étatsunien. Parmi les points que j'ai notés dans cette RPS (rappelez-vous qu'il s'agit juste d'un exemple et vous n'avez pas à l'utiliser telle quelle) :
- L'engagement à ne pas conserver les données en mémoire stable utilise un terme technique (does not have data logged to disk) pour parler d'un type de support stable particulier, ce qui peut encourager des trucs comme d'enregistrer sur un support stable qui ne soit pas un disque.
- Cette déclaration liste la totalité des champs de la requête DNS qui sont enregistrés. L'adresse IP n'y est pas (remplacée par des données plus générales comme le préfixe annoncé dans BGP au moment de l'analyse).
- La RPS s'engage à ne pas partager ces données. Mais des extraits ou des agrégations des données peuvent l'être.
- Des exceptions sont prévues, permettant aux administrateurs de regarder les données de plus près en cas de suspicion de comportement malveillant.
- Le résolveur est un résolveur menteur, bloquant la résolution des noms utilisés pour des activités malveillantes (C&C d'un botnet, par exemple). Hypocritement, la RPS d'exemple affirme ensuite ne pas faire de censure.
- La RPS promet que l'ECS ne sera pas envoyé aux serveurs faisant autorité.
On a dit plus haut que l'« anonymisation » d'adresses IP était un art très difficile. L'annexe B de notre RFC fait le point sur les techniques existantes, leurs avantages et inconvénients. C'est une lecture très recommandée pour ceux et celles qui veulent réellement « anonymiser », pas juste en parler. Un tableau résume ces techniques, leurs forces et leurs faiblesses. Le problème est de dégrader les données suffisamment pour qu'on ne puisse plus identifier l'utilisateur, tout en gardant assez d'informations pour réaliser des analyses. À bien des égards, c'est la quadrature du cercle.
Pour mettre de l'ordre dans les techniques d'« anonymisation », le RFC commence par lister les propriétés possibles des techniques (cf. RFC 6235). Il y a entre autres :
- Maintien du format : la donnée « anonymisée » a la même
syntaxe que la donnée originale. Ainsi, ne garder que les 64
premiers bits d'une adresse IP et mettre les autres à zéro
préserve le format
(
2001:db8:1:cafe:fafa:42:1:b53devient2001:db8:1:cafe::, qui est toujours une adresse IP). Par contre, condenser ne garde pas le format (le condensat SHA-256 de cette adresse deviendrait98a09452f58ffeba29e7ca06978b3d65e104308a7a7f48b0399d6e33c391f663). - Maintien du préfixe : l'adresse « anonymisée » garde un préfixe (qui n'est pas forcément le préfixe original, mais qui est cohérent pour toutes les adresses partageant ce préfixe). Cela peut être utile pour les adresses IP mais aussi pour les adresses MAC, où le préfixe identifie le fabricant.
Pour atteindre nos objectifs, on a beaucoup de solutions (pas forcément incompatibles) :
- Généralisation : sans doute l'une des méthodes les plus efficaces, car elle réduit réellement la quantité d'information disponible. C'est réduire la précision d'une estampille temporelle (par exemple ne garder que l'heure et oublier minutes et secondes), approximer une position (en ne gardant qu'un carré de N kilomètres de côté), remplacer tous les ports TCP et UDP par un booléen indiquant simplement s'ils sont supérieurs ou inférieurs à 1 024, etc.
- Permutation : remplacer chaque identificateur par un autre, par exemple via un condensat cryptographique.
- Filtrage : supprimer une partie des données, par exemple, dans une requête DNS, ne garder que le nom demandé.
- Et bien d'autres encore.
L'annexe B rentre ensuite dans les détails en examinant plusieurs techniques documentées (rappelez-vous que les responsables des données sont souvent très vagues, se contentant d'agiter les mains en disant « c'est anonymisé avec des techniques très avancées »). Par exemple, Google Analytics permet aux webmestres de demander à généraliser les adresses IP en mettant à zéro une partie des bits. Comme le note le RFC, cette méthode est très contestable, car elle garde bien trop de bits (24 en IPv4 et 48 en IPv6).
Plusieurs des techniques listées ont une mise en œuvre dans du logiciel publiquement accessible, mais je n'ai pas toujours réussi à tester. Pour dnswasher, il faut apparemment compiler tout PowerDNS. Une fois que c'est fait, dnswasher nous dit ce qu'il sait faire :
% ./dnswasher -h Syntax: dnswasher INFILE1 [INFILE2..] OUTFILE Allowed options: -h [ --help ] produce help message --version show version number -k [ --key ] arg base64 encoded 128 bit key for ipcipher -p [ --passphrase ] arg passphrase for ipcipher (will be used to derive key) -d [ --decrypt ] decrypt IP addresses with ipcipher
dnswasher remplace chaque adresse IP dans un fichier pcap par une autre adresse, attribuée dans l'ordre. C'est de la pseudonymisation (chaque adresse correspond à un pseudonyme et un seul), le trafic d'une adresse suffit en général à l'identifier, par ses centres d'intérêt. Traitons un pcap de requêtes DNS avec ce logiciel :
% ./dnswasher ~/tmp/dns.pcap ~/tmp/anon.pcap Saw 18 correct packets, 1 runts, 0 oversize, 0 unknown encaps % tcpdump -n -r ~/tmp/anon.pcap 15:28:49.674322 IP 1.0.0.0.41041 > 213.251.128.136.53: 51257 [1au] SOA? toto.fr. (36)
L'adresse 1.0.0.0 n'est pas la vraie, c'est le
résultat du remplacement fait par dnswasher. En revanche,
213.251.128.136 est la vraie adresse. dnswasher
ne remplace pas les adresses quand le port
est 53, considérant que les serveurs n'ont pas de vie privée,
contrairement aux clients.
Dans l'exemple ci-dessus, on n'avait pas utilisé de clé de
chiffrement, et dnswasher remplace les adresses IP avec
1.0.0.0, 1.0.0.1, etc. En
rajoutant l'option -p toto où toto est notre clé
(simpliste) :
15:28:49.674322 IP 248.71.56.220.41041 > 213.251.128.136.53: 51257 [1au] SOA? toto.fr. (36)
L'adresse est remplacée par une adresse imprévisible, ici
248.71.56.220. Cela
marche aussi en IPv6 :
15:28:49.672925 IP6 b4a:7e80:52fe:4003:6116:fcb8:4e5a:b334.52346 > 2001:41d0:209::1.53: 37568 [1au] SOA? toto.fr. (36)
(Une adresse comme
b4a:7e80:52fe:4003:6116:fcb8:4e5a:b334.52346 ne
figure pas encore dans les plages d'adresses attribuées.)
TCPdpriv, lui, préserve le préfixe des adresses IP. À noter qu'il n'est pas déterministe : les valeurs de remplacement seront différentes à chaque exécution.
On peut aussi chiffrer l'adresse IP, en utilisant une clé qu'on garde secrète. Cela a l'avantage qu'un attaquant ne peut pas simplement faire tourner l'algorithme sur toutes les adresses IP possibles, comme il le peut si on utilise une simple condensation. C'est ce que fait Crypto-PAn.
Comme chaque logiciel a sa propre façon de remplacer les adresses IP, cela peut rendre difficile l'échange de données et le travail en commun. D'où le projet ipcipher. Ce n'est pas du code, mais une spécification (avec des pointeurs vers des logiciels qui mettent en œuvre cette spécification). Au passage, je vous recommande cet article à ce sujet. La spécification ipcipher peut être mise en œuvre, par exemple, avec le programme ipcrypt, qui traite des fichiers texte au format CSV :
% cat test2.csv foo,127.0.0.1 bar,9.9.9.9 baz,204.62.14.153 sha,9.9.9.9 % ./ipcrypt test2.csv 1 e foo,118.234.188.6 bar,142.118.72.81 baz,235.237.54.9 sha,142.118.72.81
Notez le déterminisme : 9.9.9.9 est toujours
remplacé par la même adresse IP.
Enfin, des structures de données rigolotes peuvent fournir d'autres services. C'est ainsi que les filtres de Bloom peuvent permettre de savoir si une requête a été faite, mais sans pouvoir trouver la liste des requêtes. Un exemple d'application aux données DNS est l'article « Privacy-Conscious Threat Intelligence Using DNSBLOOM ».
L'article seul
RFC 8927: JSON Type Definition
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : U. Carion (Segment)
Expérimental
Première rédaction de cet article le 7 novembre 2020
Il existe plusieurs langages pour décrire la structure d'un document JSON. Aucun ne fait l'objet d'un clair consensus. Sans compter les nombreux programmeurs qui ne veulent pas entendre parler d'un schéma formel. Ce nouveau RFC décrit un de ces langages, JTD, JSON Type Definition. Une de ses particularités est que le schéma est lui-même écrit en JSON. Son cahier des charges est de faciliter la génération automatique de code à partir du schéma. JTD est plus limité que certains langages de schéma, afin de faciliter l'écriture d'outils JTD.
On l'a dit, il n'existe pas d'accord dans le monde JSON en faveur d'un langage de schéma particulier. La culture de ce monde JSON est même souvent opposée au principe d'un schéma. Beaucoup de programmeurs qui utilisent JSON préfèrent l'agilité, au sens « on envoie ce qu'on veut et le client se débrouille pour le comprendre ». Les mêmes désaccords existent à l'IETF, et c'est pour cela que ce RFC n'est pas sur le chemin des normes, mais a juste l'état « Expérimental ».
JSON est normalisé dans le RFC 8259. D'innombrables fichiers de données sont disponibles au format JSON, et de très nombreuses API prennent du JSON en entrée et en rendent en sortie. La description des structures de ces requêtes et réponses est typiquement faite en langage informel. C'est par exemple le cas de beaucoup de RFC qui normalisent un format utilisant JSON comme le RFC 9083, les RFC 8620 et RFC 8621, le RFC 7033, etc. Une des raisons pour lesquelles il est difficile de remplacer ces descriptions en langue naturelle par un schéma formel (comme on le fait couramment pour XML, par exemple avec Relax NG) est qu'il n'y a pas d'accord sur le cahier des charges du langage de schéma. JTD (JSON Type Definition) a des exigences bien précises (section 1 du RFC). Avant de comparer JTD à ses concurrents (cf. par exemple l'annexe B), il faut bien comprendre ces exigences, qui influent évidemment sur le langage :
- Description sans ambiguïté de la structure du document JSON (d'accord, cette exigence est assez banale, pour un langage de schéma…),
- Possibilité de décrire toutes les constructions qu'on trouve dans un document JSON typique,
- Une syntaxe qui doit être facile à lire et à écrire, aussi bien pour les humains que pour les programmes,
- Et, comme indiqué plus haut, tout faire pour faciliter la génération de code à partir du schéma, la principale exigence de JTD ; l'idée est que, si un format utilise JTD, un programme qui analyse ce format soit en bonne partie générable uniquement à partir de la description JTD.
Ainsi, JTD a des entiers sur 8, 16 et 32
bits, qu'un générateur de code peut traduire directement en (le RFC
utilise des exemples C++)
int8_t, int16_t, etc, mais
pas d'entiers de 64 bits, pourtant admis en JSON mais peu portables
(cf. annexe A.1). JTD permet de décrire les propriétés d'un objet
(« objet », en JSON, désigne un dictionnaire)
qu'on peut traduire en struct ou
std::map C++.
Les fans de théorie des langages et de langages formels noteront que JTD n'est pas lui-même spécifié en JTD. Le choix ayant été fait d'un format simple, JTD n'a pas le pouvoir de se décrire lui-même et c'est pour cela que la description de JTD est faite en CDDL (Concise Data Definition Language, RFC 8610).
La syntaxe exacte est spécifiée en section 2, une fois que vous avez (re)lu le RFC 8610. Ainsi, la description de base, en CDDL, d'un membre d'un objet JSON est :
properties = (with-properties // with-optional-properties)
with-properties = (
properties: { * tstr => { schema }},
? optionalProperties: { * tstr => { schema }},
? additionalProperties: bool,
shared,
)
Ce qui veut dire en langage naturel que le schéma JTD peut avoir un
membre properties, lui-même ayant des membres
composés d'un nom et d'un schéma. Le schéma peut être, entre autres,
un type, ce qui est le cas dans l'exemple ci-dessous. Voici un
schéma JTD trivial, en JSON comme il se doit :
{
"properties": {
"name": {
"type": "string"
},
"ok": {
"type": "boolean",
"nullable": true
},
"level": {
"type": "int32"
}
}
}
Ce schéma accepte le document JSON :
{
"name": "Foobar",
"ok": false,
"level": 1
}
Ou bien ce document :
{
"name": "Durand",
"ok": null,
"level": 42
}
(L'élément nullable peut valoir
null ; si on veut pouvoir omettre complètement
un membre, il faut le déclarer dans
optionalProperties, pas properties.) Par contre, cet autre document n'est pas
valide :
{
"name": "Zig",
"ok": true,
"level": 0,
"extra": true
}
Car il y a un membre de trop, extra. Par
défaut, JTD ne le permet pas mais un schéma peut comporter
additionalProperties: true ce qui les
autorisera.
Ce document JSON ne sera pas accepté non plus :
{
"name": "Invalid",
"ok": true
}
Car la propriété level ne peut pas être absente.
Un exemple plus détaillé, et pour un cas réel, figure dans l'annexe C du RFC, en utilisant le langage du RFC 7071.
JTD ne permet pas de vrai mécanisme d'extension mais on peut
toujours ajouter un membre metadata dont la
valeur est un objet JSON quelconque, et qui sert à définir des
« extensions » non portables.
Jouons d'ailleurs un peu avec une mise en œuvre de JTD. Vous en trouverez plusieurs ici, pour divers langages de programmation. Essayons avec celui en Python. D'abord, installer le paquetage :
% git clone https://github.com/jsontypedef/json-typedef-python.git % cd json-typedef-python % python setup.py build % python setup.py install --user
(Oui, on aurait pu utiliser pip install jtd à
la place.)
Le paquetage n'est pas livré avec un script exécutable, on en crée
un en suivant la
documentation. Il est simple :
#!/usr/bin/env python3
import sys
import json
import jtd
if len(sys.argv) != 3:
raise Exception("Usage: %s schema json-file" % sys.argv[0])
textSchema = open(sys.argv[1], 'r').read()
textJsonData = open(sys.argv[2], 'r').read()
schema = jtd.Schema.from_dict(json.loads(textSchema))
jsonData = json.loads(textJsonData)
result = jtd.validate(schema=schema, instance=jsonData)
print(result)
Si le fichier JSON correspond au schéma, il affichera un tableau vide, sinon un tableau contenant la liste des erreurs :
% ./jtd.py myschema.json mydoc1.json []
(myschema.json contient le schéma d'exemple
plus haut et mydoc1.json est le premier exemple
JSON.) Si, par contre, le fichier JSON est invalide :
% ./jtd.py myschema.json mydoc3.json [ValidationError(instance_path=['extra'], schema_path=[])]
(mydoc3.json était l'exemple avec le membre
supplémentaire, extra.)
Une particularité de JTD est de normaliser le mécanisme de
signalement d'erreurs. Les erreurs doivent être formatées en JSON
(évidemment…) avec un membre instancePath qui
est un pointeur JSON (RFC 6901) indiquant la partie invalide du document, et un
membre schemaPath, également un pointeur, qui
indique la partie du schéma qui invalidait cette partie du document
(cf. le message d'erreur ci-dessus, peu convivial mais
normalisé).
JTD est spécifié en CDDL donc on peut tester ses schémas avec les outils CDDL, ici un outil en Ruby :
% gem install cddl --user
Ensuite, on peut valider ses schémas :
% cddl jtd.cddl validate myschema.json %
Si le schéma a une erreur (ici, j'ai utilisé le type
char, qui n'existe pas) :
% cddl jtd.cddl validate wrongschema.json
CDDL validation failure (nil for {"properties"=>{"name"=>{"type"=>"char"}, "ok"=>{"type"=>"boolean", "nullable"=>true}, "level"=>{"type"=>"int32"}}}):
["char", [:text, "timestamp"], nil]
["char", [:text, "timestamp"], null]
(Oui, les messages d'erreur de l'outil cddl
sont horribles.)
Et avec l'exemple de l'annexe C, le reputon du RFC 7071 :
% cddl jtd.cddl validate reputon.json %
C'est parfait, le schéma du RFC est correct, validons le fichier JSON tiré de la section 6.4 du RFC 7071 :
% ./jtd.py reputon.json r1.json []
Si jamais il y a une erreur (ici, on a enlevé le membre
rating) :
% ./jtd.py reputon.json r1.json [ValidationError(instance_path=['reputons', '0'], schema_path=['properties', 'reputons', 'elements', 'properties', 'rating'])]
Une intéressante annexe B fait une comparaison de JTD avec CDDL. Par exemple, le schéma CDDL :
root = "PENDING" / "DONE" / "CANCELED"
accepterait les mêmes documents que le schéma JTD :
{ "enum": ["PENDING", "DONE", "CANCELED"]}
Et celui-ci, en CDDL (où le point d'interrogation indique un terme facultatif) :
root = { a: bool, b: number, ? c: tstr, ? d: tdate }
reviendrait à ce schéma JTD :
{
"properties": {
"a": {
"type": "boolean"
},
"b": {
"type": "float32"
}
},
"optionalProperties": {
"c": {
"type": "string"
},
"d": {
"type": "timestamp"
}
}
}
Merci à Ulysse Carion pour sa relecture.
L'article seul
RFC 8925: IPv6-Only-Preferred Option for DHCPv4
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : L. Colitti, J. Linkova (Google), M. Richardson (Sandelman), T. Mrugalski (ISC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dhc
Première rédaction de cet article le 17 octobre 2020
Si une machine a IPv6 et est ravie de n'utiliser que ce protocole, pas la peine pour un serveur DHCP de lui envoyer une des rares adresses IPv4 restantes. Ce nouveau RFC décrit une option de DHCP-IPv4 qui permet au client de dire au serveur « je n'ai pas vraiment besoin d'IPv4 donc, s'il y a IPv6 sur ce réseau, tu peux garder les adresses IPv4 pour les nécessiteux ».
Idéalement, l'administrateur réseaux qui configure un nouveau réseau voudrait le faire en IPv6 seulement, ce qui simplifierait son travail. Mais, en pratique, c'est difficile (le RFC 6586 décrit une telle configuration). En effet, beaucoup de machines ne sont pas encore entrées dans le XXIe siècle, et ne gèrent qu'IPv4 ou, plus exactement, ont besoin d'IPv4 pour au moins certaines fonctions (comme des versions de Windows qui avaient IPv6 mais ne pouvaient parler à leur résolveur DNS qu'au-dessus d'IPv4). Il faut donc se résigner à gérer IPv4 pour ces machines anciennes. Mais, vu la pénurie d'adresses IPv4, il est également souhaitable de ne pas allouer d'adresses IPv4 aux machines qui n'en ont pas besoin.
La solution la plus courante à l'heure actuelle est de mettre les machines antédiluviennes et les machines modernes dans des réseaux séparés (VLAN ou SSID différents, par exemple, comme c'est fait aux réunions IETF ou RIPE), le réseau pour les ancêtres étant le seul à avoir un serveur DHCPv4 (RFC 2131). Cela a plusieurs inconvénients :
- Cela complique le réseau et son administration,
- Le risque d'erreur est élevé (utilisateur sélectionnant le mauvais SSID dans le menu des réseaux Wi-Fi accessibles, par exemple).
L'idéal serait de n'avoir qu'un réseau, accueillant aussi bien des machines IPv6 que des machines IPv4, sans que les machines IPv6 n'obtiennent d'adresse IPv4, dont elles n'ont pas besoin. On ne peut pas demander aux utilisateurs de débrayer complètement IPv4, car les machines mobiles peuvent en avoir besoin sur des réseaux purement IPv4 (ce qui existe encore). La machine IPv6 ne sachant pas, a priori, si le réseau où elle se connecte est seulement IPv4, seulement IPv6 ou accepte les deux, elle va donc, logiquement, demander une adresse IPv4 en DHCP, et bloquer ainsi une précieuse adresse IPv4. Retarder cette demande pour voir si IPv6 ne suffirait pas se traduirait par un délai peu acceptable lorsque le réseau n'a pas IPv6.
Notre RFC résout ce problème en créant une nouvelle option pour les requêtes et réponses DHCP v4 : dans la requête, cette option indique que le client n'a pas absolument besoin d'une adresse IPv4, qu'il peut se passer de ce vieux protocole, si le réseau a de l'IPv6 bien configuré et, dans la réponse, cette option indique que le réseau fonctionne bien en « IPv6 seulement ». Et comment fait-on si on veut joindre un service IPv4 depuis un tel réseau ? Il existe des techniques pour cela, la plus répandue étant le NAT64 du RFC 6146, et la réponse du serveur DHCP indique également qu'une de ces techniques est présente.
La section 1.2 précise quelques termes importants pour comprendre les choix à effectuer pour le client et pour le serveur DHCP :
- Capable de faire de l'IPv6 seule (IPv6-only capable host) : une machine terminale qui peut se débrouiller sans problème sans adresse IPv4,
- Nécessite IPv4 (IPv4-requiring host) : le contraire,
- IPv4 à la demande (IPv4-on-demand) : le scénario, rendu possible par ce RFC, où le même réseau accueille des machines capables de faire de l'IPv6 seul, et des machines qui nécessitent IPv4 ; ce réseau se nomme « Essentiellement IPv6 » (IPv6-mostly network), et fournit NAT64 (RFC 6146) ou une technique équivalente,
- En mode seulement IPv6 (IPv6-only mode) : état d'une machine capable de faire de l'IPv6 seule et qui n'a pas reçu d'adresse IPv4,
- Réseau seulement en IPv6 (IPv6-only network) : un réseau qui ne fournit pas du tout d'IPv4 et ne peut donc pas accueillir les machines qui nécessitent IPv4 (c'est un tel réseau qui sert de base à l'expérience du RFC 6586),
- Notez que le cas d'un réseau qui non seulement serait seulement en IPv6 mais en outre ne fournirait pas de technique comme celle de NAT64 (RFC 6146) n'apparait pas dans le RFC. Un tel réseau ne permettrait pas aux machines terminales de joindre les services qui sont restées en IPv4 seulement comme MicrosoftHub ou l'Élysée.
La section 2 du RFC résume ensuite les bonnes raisons qu'il y a pour signaler au réseau, via l'option DHCP, qu'on se débrouille très bien avec IPv6 seul :
- Il semble logique que la nouvelle option, qui veut dire « je n'ai pas réellement besoin d'IPv4 » soit envoyée via le protocole qui sert à demander les adresses IPv4,
- Tout le monde a déjà DHCP v4 et, surtout, utiliser le protocole existant n'introduit pas de nouvelles vulnérabilités (permettre à un nouveau protocole de couper IPv4 sur les machines terminales serait un risque de sécurité important),
- Comme il faut ajouter explicitement l'option aux requêtes et aux réponses, IPv4 ne sera coupé que si le client et le serveur DHCP sont tous les deux d'accord pour cela,
- Ce système n'ajoute aucun retard à la configuration via DHCP, le client qui envoie l'option alors que le réseau ne permet pas IPv6 seul, aura son adresse IPv4 aussi vite qu'avant (pas d'aller-retours de négociation),
- DHCP permet des résultats qui dépendent du client, donc, sur un même réseau, le serveur DHCP pourra économiser les adresses IPv4 en en n'envoyant pas aux machines qui peuvent s'en passer, tout en continuant à en distribuer aux autres.
La section 3 du RFC présente l'option elle-même. Elle contient le code 108 (IPv6-only Preferred), enregistré à l'IANA (cf. section 5), la taille de l'option (toujours quatre, mais précisée car c'est l'encodage habituel des options DHCP, cf. RFC 2132) et la valeur, qui est, dans la réponse, le nombre de secondes que le client peut mémoriser cette information, avant de redemander au serveur DHCP.
Le logiciel client DHCP doit donc offrir un moyen à son administrateur pour activer « je me débrouille très bien en IPv6 », et cela doit être par interface réseau. Dans ce cas, le client DHCP doit envoyer l'option décrite dans notre RFC. La décision d'activer le mode « IPv6 seul » peut aussi être prise automatiquement par le système d'exploitation, par exemple parce qu'il détecte que 464XLAT (RFC 6877) fonctionne. De même, des objets connectés qui ne parlent qu'à des services accessibles en IPv6 pourraient être livrés avec l'option « IPv6 seul » déjà activée.
Outre le côté « je suis un bon citoyen, je ne gaspille pas des ressources rares » qu'il y a à ne pas demander d'adresse IPv4, cette option permet de couper un protocole réseau inutile, diminuant la surface d'attaque de la machine.
Côté serveur DHCP, il faut un moyen de configurer, pour chaque réseau, si on accepte l'option « IPv6 me suffit ». Si elle est activée, le serveur, lorsqu'il recevra cette option dans une requête (et uniquement dans ce cas), la mettra dans sa réponse, et n'attribuera pas d'adresse IPv4. On voit donc que les vieux clients DHCP, qui ne connaissent pas cette option et ne l'inclueront donc pas dans leurs requêtes, ne verront pas de changement, ils continueront à avoir des adresses IPv4 comme avant (s'il en reste…).
A priori (section 4 du RFC), l'administrateurice du serveur DHCP ne va pas activer cette option si son réseau ne fournit pas un mécanisme permettant aux machines purement IPv6 de joindre des services purement IPv4 (par exemple le mécanisme NAT64 du RFC 6146). En effet, on ne peut pas s'attendre, à court terme, à ce que tous les services Internet soient accessibles en IPv6. Activer l'option « IPv6 seul » sans avoir un mécanisme de traduction comme NAT64 n'est réaliste que sur des réseaux non-connectés à l'Internet public.
Un petit mot sur la sécurité, juste pour rappeler que DHCP n'est pas vraiment sécurisé et que l'option « v6 seul » a pu être mise, retirée ou modifiée suite aux actions d'un attaquant. Cela n'a rien de spécifique à cette option, c'est un problème général de DHCP, contre lequel il faut déployer des protections comme le DHCP snooping.
Au moment de la sortie du RFC, je ne connaissais pas encore de mise en œuvre de cette option. Mais elle n'est pas trop dure à ajouter, elle n'a rien de très nouveau ou d'extraordinaire et, en 2022, Android et iOS l'envoyaient, comme le montre une étude faite pendant une réunion RIPE.
Un dernier mot : le RFC 2563 prévoyait une option pour couper l'auto-configuration des adresses IPv4. Elle peut être utilisée en même temps que l'option de notre RFC, qu'elle complète assez bien.
L'article seul
RFC 8923: A Minimal Set of Transport Services for End Systems
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : M. Welzl, S. Gjessing (University of Oslo)
Pour information
Réalisé dans le cadre du groupe de travail IETF taps
Première rédaction de cet article le 22 octobre 2020
Ce nouveau RFC s'incrit dans le travail en cours à l'IETF pour formaliser un peu plus les services que la couche transport offre aux applications. Le RFC 8095 décrivait tous les services possibles. Ce nouveau RFC 8923 liste les services minimums, ceux à offrir dans presque tous les cas.
Comme le note le RFC 8095, les applications tournant sur la famille de protocoles TCP/IP ne peuvent en général pas aujourd'hui exprimer les services attendus de la couche transport. Elles doivent choisir un protocole de transport (comme TCP ou UDP), même si ce protocole ne convient pas tout à fait. Toute l'idée derrière le travail du groupe TAPS de l'IETF est de permettre au contraire aux applications d'indiquer des services (« je veux un envoi de données fiable et dans l'ordre, avec confidentialité et intégrité ») et que le système d'exploitation choisisse alors la solution la plus adaptée (ici, cela pourrait être TCP ou SCTP avec TLS par dessus, ou bien le futur QUIC). De la même façon qu'un langage de programmation de haut niveau utilise des concepts plus abstraits qu'un langage de bas niveau, on pourrait ainsi avoir une interface de programmation réseau de plus haut niveau que les traditionnelles prises normalisées par Posix. Ce RFC ne normalise pas une telle API, il décrit seulement les services attendus. La liste des services possibles est dans le RFC 8095, et les protocoles qui les fournissent sont documentés dans le RFC 8303 et RFC 8304. Le cœur de notre nouveau RFC 8923 est la section 6, qui liste les services minimum attendus (je vous en dévoile l'essentiel tout de suite : établissement de connexion, fin de connexion, envoi de données, réception de données).
À noter que les services minimums exposés ici peuvent être mis en œuvre sur TCP, et, dans certains cas, sur UDP. TCP offre un ensemble de services qui est quasiment un sur-ensemble de celui d'UDP, donc, sur le seul critère des services, on pourrait n'utiliser que TCP. (Exercice : quelle(s) exception(s) trouvez-vous ?) Comme il s'agit de services de la couche transport aux applications, l'implémentation peut être faite d'un seul côté (il n'est pas nécessaire que les deux partenaires qui communiquent le fassent).
Et, si vous lisez le RFC, faites attention à la section 2 sur la terminologie, section qui reprend le RFC 8303 : une fonction (Transport Feature) est une fonction particulière que le protocole de transport va effectuer, par exemple la confidentialité, la fiabilité de la distribution des données, le découpage des données en messages, etc, un service (Transport Service) est un ensemble cohérent de fonctions, demandé par l'application, et un protocole (Transport Protocol) est une réalisation concrète d'un ou plusieurs services.
Comment définir un jeu minimal de services (section 3 du RFC) ? D'abord, il faut définir les services « sémantiques » (functional features) que l'application doit connaitre. Par exemple, l'application doit savoir si le service « distribution des données dans l'ordre » est disponible ou pas. Et il y a les services qui sont plutôt des optimisations comme l'activation ou la désactivation de DSCP ou comme l'algorithme de Nagle. Si l'application ignore ces services, ce n'est pas trop grave, elle fonctionnera quand même, même si c'est avec des performances sous-optimales.
La méthode utilisée par les auteurs du RFC pour construire la liste des services minimums est donc :
- Catégorisation des services du RFC 8303 (sémantique, optimisation…) ; le résultat de cette catégorisation figure dans l'annexe A de notre RFC,
- Réduction aux services qui peuvent être mis en œuvre sur les protocoles de transport qui peuvent passer presque partout, TCP et UDP,
- Puis établissement de la liste des services minimum.
Ainsi (section 4 du RFC), le service « établir une connexion » peut être mis en œuvre sur TCP de manière triviale, mais aussi sur UDP, en refaisant un équivalent de la triple poignée de mains. Le service « envoyer un message » peut être mis en œuvre sur UDP et TCP (TCP, en prime, assurera sa distribution à l'autre bout, mais ce n'est pas nécessaire). En revanche, le service « envoyer un message avec garantie qu'il soit distribué ou qu'on soit notifié », s'il est simple à faire en TCP, ne l'est pas en UDP (il faudrait refaire tout TCP au dessus d'UDP).
La section 5 du RFC discute de divers problèmes quand on essaie de définir un ensemble minimal de services. Par exemple, TCP ne met pas de délimiteur dans le flot d'octets qui circulent. Contrairement à UDP, on ne peut pas « recevoir un message », seulement recevoir des données. Certains protocoles applicatifs (comme DNS ou EPP) ajoutent une longueur devant chaque message qu'ils envoient, pour avoir une sémantique de message et plus de flot d'octets. TCP n'est donc pas un strict sur-ensemble d'UDP.
Pour contourner cette limitation, notre RFC définit (section 5.1) la notion de « flot d'octets découpé en messages par l'application » (Application-Framed Bytestream). Dans un tel flot, le protocole applicatif indique les frontières de message, par exemple en précédant chaque message d'une longueur, comme le fait le DNS.
Autre problème amusant, certains services peuvent être d'assez bas niveau par rapport aux demandes des applications. Ainsi, le RFC 8303 identifie des services comme « couper Nagle », « configurer DSCP » ou encore « utiliser LEDBAT ». Il serait sans doute plus simple, pour un protocole applicatif, d'avoir une configuration de plus haut niveau. Par exemple, « latence minimale » désactiverait Nagle et mettrait les bits qui vont bien en DSCP.
Nous arrivons finalement au résultat principal de ce RFC, la section 6, qui contient l'ensemble minimal de services. Chaque service est configurable via un ensemble de paramètres. Il est implémentable uniquement avec TCP, et d'un seul côté de la connexion. Dans certains cas, TCP fournira plus que ce qui est demandé, mais ce n'est pas un problème. Je ne vais pas lister tout cet ensemble minimal ici, juste énumérer quelques-uns de ses membres :
- Créer une connexion, avec des paramètres comme la fiabilité demandée,
- Mettre fin à la connexion,
- Envoyer des données, sans indication de fin de message (cf. la discussion plus haut),
- Recevoir des données.
Pour l'envoi de données, les paramètres sont, entre autres :
- Fiabilité (les données sont reçues à l'autre bout ou, en tout cas, l'émetteur est prévenu si cela n'a pas été possible) ou non,
- Contrôle de congestion ou non, sachant que si l'application ne demande pas de contrôle de congestion au protocole de transport, elle doit faire ce contrôle elle-même (RFC 8085),
- Idempotence,
- Etc.
Pour la réception de données, le service est juste la réception d'octets, un protocole applicatif qui veut des messages doit utiliser les « flots d'octets découpés par l'application » décrits en section 5.1.
On notera que la sécurité est un service, également, ou plutôt un ensemble de services (section 8 du RFC). Dans les protocoles IETF, la sécurité est souvent fournie par une couche intermédiaire entre la couche de transport et la couche application à proprement parler. C'est ainsi que fonctionne TLS, par exemple. Mais la tendance va peut-être aller vers l'intégration, avec QUIC.
L'article seul
RFC 8922: A Survey of the Interaction Between Security Protocols and Transport Services
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : T. Enghardt (TU Berlin), T. Pauly (Apple), C. Perkins (University of Glasgow), K. Rose (Akamai Technologies), C.A. Wood (Cloudflare)
Pour information
Réalisé dans le cadre du groupe de travail IETF taps
Première rédaction de cet article le 22 octobre 2020
Quels sont les services de sécurité fournis par les protocoles de transport existants ? Ce nouveau RFC fait le point et examine ces services de sécurité pour un certain nombre de ces protocoles, comme TLS, QUIC, WireGuard, etc. Cela intéressera tous les gens qui travaillent sur la sécurité de l'Internet.
Ce RFC est issu du groupe de travail IETF TAPS, dont le projet est d'abstraire les services que rend la couche Transport pour permettre davantage d'indépendance entre les applications et les différents protocoles de transport. Vous pouvez en apprendre plus dans les RFC 8095 et RFC 8303.
Parmi les services que fournit la couche Transport aux applications, il y a la sécurité. Ainsi, TCP (si le RFC 5961 a bien été mis en œuvre et si l'attaquant n'est pas sur le chemin) protège assez bien contre les usurpations d'adresses IP. Notez que le RFC utilise le terme de « protocole de transport » pour tout ce qui est en dessous de l'application, et utilisé par elle. Ainsi, TLS est vu comme un protocole de transport, du point de vue de l'application, il fonctionne de la même façon (ouvrir une connexion, envoyer des données, lire des réponses, fermer la connexion), avec en prime les services permis par la cryptographie, comme la confidentialité. TLS est donc vu, à juste titre, comme un protocole d'infrastructure, et qui fait donc partie de ceux étudiés dans le cadre du projet TAPS.
La section 1 du RFC explique d'ailleurs quels protocoles ont été intégrés dans l'étude et pourquoi. L'idée était d'étudier des cas assez différents les uns des autres. Des protocoles très répandus comme SSH (RFC 4251), GRE (avec ses extensions de sécurité du RFC 2890) ou L2TP (RFC 5641) ont ainsi été écartés, pas parce qu'ils sont mauvais mais parce qu'ils fournissent à peu près les mêmes services que des protocoles étudiés (par exemple SSH vs. TLS) et ne nécessitaient donc pas d'étude séparée. Plus animée, au sein du groupe de travail TAPS, avait été la discussion sur des protocoles non-IETF comme WireGuard ou MinimaLT. Ils ne sont pas normalisés (et, souvent, même pas décrits dans une spécification stable), mais ils sont utilisés dans l'Internet, et présentent des particularités suffisamment importantes pour qu'ils soient étudiés ici. En revanche, les protocoles qui ne fournissent que de l'authentification, comme AO (RFC 5925) n'ont pas été pris en compte.
Comme c'est le cas en général dans le projet TAPS, le but est de découvrir et de documenter ce que les protocoles de transport ont en commun, pour faciliter leur choix et leur utilisation par l'application. Par contre, contrairement à d'autres cas d'usage de TAPS, il n'est pas prévu de permettre le choix automatique d'un protocole de sécurité. Pour les autres services, un tel choix automatique se justifie (RFC 8095). Si une application demande juste le service « transport d'octets fiable, j'ai des fichiers à envoyer », lui fournir TCP ou SCTP revient au même, et l'application se moque probablement du protocole choisi. Mais la sécurité est plus compliquée, avec davantage de pièges et de différences subtiles, et il est donc sans doute préférable que l'application choisisse explicitement le protocole.
La section 2 du RFC permet de réviser la terminologie, je vous renvoie à mon article sur le RFC 8303 pour la différence entre fonction (Transport Feature) et service (Transport Service).
Et la section 3 s'attaque aux protocoles eux-mêmes. Elle les classe selon qu'ils protègent n'importe quelle application, une application spécifique, l'application et le transport, ou bien carrément tout le paquet IP. Le RFC note qu'aucune classification n'est parfaite. Notamment, plusieurs protocoles sont séparés en deux parties, un protocole de connexion, permettant par exemple l'échange des clés de session, protocole utilisé essentiellement, voire uniquement, à l'ouverture et à la fermeture de la session, et le protocole de chiffrement qui traite les données transmises. Ces deux protocoles sont plus ou moins intégrés, de la fusion complète (tcpcrypt, RFC 8548) à la séparation complète (IPsec, où ESP, décrit dans le RFC 4303, ne fait que chiffrer, les clés pouvant être fournies par IKE, spécifié dans le RFC 7296, ou par une autre méthode). Par exemple, TLS décrit ces deux protocoles séparement (RFC 8446) mais on les considérait comme liés… jusqu'à ce que QUIC décide de n'utiliser qu'un seul des deux.
Bon, assez d'avertissements, passons à la première catégorie, les protocoles qui fournissent une protection générique aux applications. Ils ne protègent donc pas contre des attaques affectant la couche 4 comme les faux paquets RST. Le plus connu de ces protocoles est évidemment TLS (RFC 8446). Mais il y a aussi DTLS (RFC 9147).
Ensuite, il y a les protocoles spécifiques à une application. C'est par exemple le cas de SRTP (RFC 3711), extension sécurisée de RTP qui s'appuie sur DTLS.
Puis il y a la catégorie des protocoles qui protègent le transport ce qui, par exemple, protège contre les faux RST (ReSeT), et empêche un observateur de voir certains aspects de la connexion. C'est le cas notamment de QUIC, normalisé depuis. QUIC utilise TLS pour obtenir les clés, qui sont ensuite utilisées par un protocole sans lien avec TLS, et qui chiffre y compris la couche Transport. Notons que le prédécesseur de QUIC, développé par Google sous le même nom (le RFC nomme cet ancien protocole gQUIC pour le distinguer du QUIC normalisé), n'utilisait pas TLS.
Toujours dans la catégorie des protocoles qui protègent les couches Transport et Application, tcpcrypt (RFC 8548). Il fait du chiffrement « opportuniste » (au sens de « sans authentification ») et est donc vulnérable aux attaques actives. Mais il a l'avantage de chiffrer sans participation de l'application, contrairement à TLS. Bon, en pratique, il n'a connu quasiment aucun déploiement.
Il y a aussi MinimaLT, qui intègre l'équivalent de TCP et l'équivalent de TLS (comme le fait QUIC).
Le RFC mentionne également CurveCP, qui fusionne également transport et chiffrement. Comme QUIC ou MinimaLT, il ne permet pas de connexions non-sécurisées.
Et enfin il y a les protocoles qui protègent tout, même IP. Le plus connu est évidemment IPsec (RFC 4303 et aussi RFC 7296, pour l'échange de clés, qui est un protocole complètement séparé). Mais il y a aussi WireGuard qui est nettement moins riche (pas d'agilité cryptographique, par exemple, ni même de négociation des paramètres cryptographiques ; ce n'est pas un problème pour des tunnels statiques mais c'est ennuyeux pour un usage plus général sur l'Internet). Et il y a OpenVPN, qui est sans doute le plus répandu chez les utilisateurs ordinaires, pour sa simplicité de mise en œuvre. On trouve par exemple OpenVPN dans tous des systèmes comme OpenWrt et donc dans tous les routeurs qui l'utilisent.
Une fois cette liste de protocoles « intéressants » établie, notre RFC va se mettre à les classer, selon divers critères. Le premier (section 4 du RFC) : est-ce que le protocole dépend d'un transport sous-jacent, qui fournit des propriétés de fiabilité et d'ordre des données (si oui, ce transport sera en général TCP) ? C'est le cas de TLS, bien sûr, mais aussi, d'une certaine façon, de tcpcrypt (qui dépend de TCP et surtout de son option ENO, normalisée dans le RFC 8547). Tous les autres protocoles peuvent fonctionner directement sur IP mais, en général, ils s'appuient plutôt sur UDP, pour réussir à passer les différentes middleboxes qui bloquent les protocoles de transport « alternatifs ».
Et l'interface avec les applications ? Comment ces différents protocoles se présentent-ils aux applications qui les utilisent ? (Depuis, voir le RFC 9622.) Il y a ici beaucoup à dire (le RFC fournit un tableau synthétique de quelles possibilités et quels choix chaque protocole fournit aux applications). L'analyse est découpée en plusieurs parties (les services liés à l'établissement de la connexion, ceux accessibles pendant la session et ceux liés à la terminaison de la connexion), chaque partie listant plusieurs services. Pour chaque service, le RFC dresse la liste des différents protocoles qui le fournissent. Ainsi, la partie sur l'établissement de connexion indique entre autres le service « Extensions au protocole de base accessibles à l'application ». Ce service est fourni par TLS (via ALPN, RFC 7301) ou QUIC mais pas par IPsec ou CurveCP. De même le service « Délégation de l'authentification » peut être fourni par IPsec (par exemple via EAP, RFC 3748) ou tcpcrypt mais pas par les autres.
La section 7 rappelle que ce RFC ne fait qu'analyser les protocoles existants, il ne propose pas de changement. D'autre part, cette section note que certaines attaques ont été laissées de côté (comme celle par canal secondaire ou comme l'analyse de trafic).
La section 8 sur la vie privée rappelle ces faiblesses ; même si l'un des buts principaux du chiffrement est d'assurer la confidentialité, la plupart des protocoles présentés laissent encore fuiter une certaine quantité d'information, par exemple les certificats en clair de TLS (avant la version 1.3).
L'article seul
RFC 8915: Network Time Security for the Network Time Protocol
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : D. Franke (Akamai), D. Sibold, K. Teichel (PTB), M. Dansarie, R. Sundblad (Netnod)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ntp
Première rédaction de cet article le 1 octobre 2020
Ce nouveau RFC spécifie un mécanisme de sécurité pour le protocole de synchronisation d'horloges NTP. Une heure incorrecte peut empêcher, par exemple, de valider des certificats cryptographiques. Ou fausser les informations enregistrées dans les journaux. Ce mécanisme de sécurité NTS (Network Time Security) permettra de sécuriser le mode client-serveur de NTP, en utilisant TLS pour négocier les clés cryptographiques qui serviront à chiffrer le trafic NTP ultérieur..
La sécurité n'était pas jugée trop importante au début de NTP : après tout, l'heure qu'il est n'est pas un secret. Et il n'y avait pas d'application cruciale dépendant de l'heure. Aujourd'hui, les choses sont différentes. NTP est un protocole critique pour la sécurité de l'Internet. NTP a quand même un mécanisme de sécurité, fondé sur des clés secrètes partagées entre les deux pairs qui communiquent. Comme tout mécanisme à clé partagée, il ne passe pas à l'échelle, d'où le développement du mécanisme « Autokey » dans le RFC 5906. Ce mécanisme n'a pas été un grand succès et un RFC a été écrit pour préciser le cahier des charges d'une meilleure solution, le RFC 7384. La sécurité de l'Internet repose de plus en plus que l'exactitude de l'horloge de la machine. Plusieurs systèmes de sécurité, comme DNSSEC ou X.509 doivent vérifier des dates et doivent donc pouvoir se fier à l'horloge de la machine. Même criticité de l'horloge quand on veut coordonner une smart grid, ou tout autre processus industriel, analyser des journaux après une attaque, assurer la traçabilité d'opérations financières soumises à régulation, etc. Or, comme l'explique bien le RFC 7384, les protocoles de synchronisation d'horloge existants, comme NTP sont peu ou pas sécurisés. (On consultera également avec profit le RFC 8633 qui parle entre autre de sécurité.)
Sécuriser la synchronisation d'horloge est donc crucial aujourd'hui. Cela peut se faire par un protocole extérieur au service de synchronisation, comme IPsec, ou bien par des mesures dans le service de synchronisation. Les deux services les plus populaires sont NTP (RFC 5905) et PTP. Aucun des deux n'offre actuellement toutes les fonctions de sécurité souhaitées par le RFC 7384. Mais les protocoles externes ont un inconvénient : ils peuvent affecter le service de synchronisation. Par exemple, si l'envoi d'un paquet NTP est retardé car IKE cherche des clés, les mesures temporelles vont être faussées. Le paquet arrivera intact mais n'aura pas la même utilité.
Les menaces contre les protocoles de synchronisation d'horloge sont décrites dans le RFC 7384. Les objectifs de notre RFC sont d'y répondre, notamment :
- Permettre à un client d'authentifier son maître, via X.509 tel que l'utilise TLS,
- Protéger ensuite l'intégrité des paquets (via un MAC).
- En prime, mais optionnel, assurer la confidentialité du contenu des paquets.
- Empêcher la traçabilité entre les requêtes d'un même client (si un client NTP change d'adresse IP, un observateur passif ne doit pas pouvoir s'apercevoir qu'il s'agit du même client).
- Et le tout sans permettre les attaques par réflexion qui ont souvent été un problème avec NTP.
- Passage à l'échelle car un serveur peut avoir de très nombreux clients,
- Et enfin performances (RFC 7384, section 5.7).
Rappelons que NTP dispose de plusieurs modes de fonctionnement
(RFC 5905, section 3). Le plus connu et sans
doute le plus utilisé est le mode client-serveur (si vous faites sur
Unix un ntpdate
ntp.nic.fr, c'est ce mode que vous utilisez). Mais il y
aussi un mode symétrique, un mode à diffusion et le « mode » de contrôle
(dont beaucoup de fonctions ne sont pas normalisées). Le mode
symétrique est sans doute celui qui a le plus d'exigences de
sécurité (les modes symétriques et de contrôle de NTP nécessitent
notamment une protection réciproque contre le
rejeu, qui nécessite de maintenir un état de
chaque côté) mais le mode client-serveur est plus répandu, et pose
des difficultés particulières (un serveur peut avoir beaucoup de
clients, et ne pas souhaiter maintenir un état par client). Notre
RFC ne couvre que le mode client-serveur. Pour ce mode, la solution
décrite dans notre RFC 8915 est d'utiliser TLS afin que
le client authentifie le serveur, puis d'utiliser cette session TLS
pour générer la clé qui servira à sécuriser du NTP classique, sur
UDP. Les serveurs
NTP devront donc désormais également écouter en TCP, ce qu'ils ne
font pas en général pas actuellement. La partie TLS de NTS
(Network Time Security, normalisé dans ce RFC) se
nomme NTS-KE (pour Network Time Security - Key
Exchange). La solution à deux protocoles peut sembler
compliquée mais elle permet d'avoir les avantages de TLS (protocole
éprouvé) et d'UDP (protocole rapide).
Une fois qu'on a la clé (et d'autres informations utiles, dont les cookies), on ferme la session TLS, et on va utiliser la cryptographie pour sécuriser les paquets. Les clés sont dérivées à partir de la session TLS, suivant l'algorithme du RFC 5705. Quatre nouveaux champs NTP sont utilisés pour les paquets suivants (ils sont présentés en section 5), non TLS. Dans ces paquets se trouve un cookie qui va permettre au serveur de vérifier le client, et de récupérer la bonne clé. Les cookies envoyés du client vers le serveur et en sens inverse sont changés à chaque fois, pour éviter toute traçabilité, car ils ne sont pas dans la partie chiffrée du paquet. Notez que le format des cookies n'est pas spécifié par ce RFC (bien qu'un format soit suggéré en section 6). Pour le client, le cookie est opaque : on le traite comme une chaîne de bits, sans structure interne.
On a dit que NTS (Network Time Security) utilisait TLS. En fait, il se restreint à un profil spécifique de TLS, décrit en section 3. Comme NTS est un protocole récent, il n'y a pas besoin d'interagir avec les vieilles versions de TLS et notre RFC impose donc TLS 1.3 (RFC 8446) au minimum, ALPN (RFC 7301), les bonnes pratiques TLS du RFC 7525, et les règles des RFC 5280 et RFC 6125 pour l'authentification du serveur.
Passons ensuite au détail du protocole NTS-KE (Network
Time Security - Key Establishment) qui va permettre, en
utilisant TLS, d'obtenir les clés qui serviront au
chiffrement symétrique ultérieur. Il est
spécifié dans la section 4 du RFC. Le serveur doit écouter sur le
port ntske
(4460 par défaut). Le client utilise
ALPN (RFC 7301) pour
annoncer qu'il veut l'application ntske/1. On établit la session TLS, on échange des
messages et on raccroche (l'idée est
de ne pas obliger le serveur à garder une session TLS ouverte pour
chacun de ses clients, qui peuvent être nombreux).
Le format de ces messages est composé d'un champ indiquant le type du message, de la longueur du message, des données du message, et d'un bit indiquant la criticité du type de message. Si ce bit est à 1 et que le récepteur ne connait pas ce type, il raccroche. Les types de message actuels sont notamment :
- Next Protocol Negotiation (valeur 1) qui indique les protocoles acceptés (il n'y en a qu'un à l'heure actuelle, NTP, mais peut-être d'autres protocoles comme PTP suivront, la liste est dans un registre IANA),
- Error (valeur 2) qui indique… une erreur (encore un registre IANA de ces codes d'erreur, qui seront sans doute moins connus que ceux de HTTP),
- AEAD Algorithm Negotiation (valeur 3) ; NTS impose l'utilisation du chiffrement intègre (AEAD pour Authenticated Encryption with Associated Data) et ce type de message permet de choisir un algorithme de chiffrement intègre parmi ceux enregistrés,
- New Cookie (valeur 5), miam, le serveur envoie un cookie, que le client devra renvoyer (sans chercher à la comprendre), ce qui permettra au serveur de reconnaitre un client légitime ; le RFC recommande d'envoyer plusieurs messages de ce type, pour que le client ait une provision de cookies suffisante,
- Server Negotiation (valeur 6) (et Port Negotiation, valeur 7), pour indiquer le serveur NTP avec lequel parler de façon sécurisée, serveur qui n'est pas forcément le serveur NTS-KE.
D'autres types de message pourront venir dans le futur, cf. le registre.
Une fois la négociation faite avec le protocole NTS-KE, tournant sur TLS, on peut passer au NTP normal, avec le serveur indiqué. Comme indiqué plus haut, quatre champs supplémentaires ont été ajoutés à NTP pour gérer la sécurité. Ils sont présentés dans la section 5 de notre RFC. Les clés cryptographiques sont obtenues par la fonction de dérivation (HKDF) du RFC 8446, section 7.5 (voir aussi le RFC 5705). Les clés du client vers le serveur sont différentes de celles du serveur vers le client (ce sont les clés c2s et s2c dans l'exemple avec ntsclient montré plus loin).
Les paquets NTP échangés ensuite, et sécurisés avec NTS, comporteront l'en-tête NTP classique (RFC 5905, section 7.3), qui ne sera pas chiffré (mais sera authentifié), et le paquet original chiffré dans un champ d'extension (cf. RFC 5905, section 7.5, et RFC 7822). Les quatre nouveaux champs seront :
- L'identifiant du paquet (qui sert à détecter le rejeu), il sera indiqué (cf. section 5.7) dans la réponse du serveur, permetant au client de détecter des attaques menées en aveugle par des malfaisants qui ne sont pas situés sur le chemin (certaines mises en œuvre de NTP utilisaient les estampilles temporelles pour cela, mais elles sont courtes, et en partie prévisibles),
- Le cookie,
- La demande de cookies supplémentaires,
- Et le principal, le champ contenant le contenu chiffré du paquet NTP original.
On a vu que le format des cookies n'était pas imposé. Cela n'affecte pas l'interopérabilité puisque, de toute façon, le client n'est pas censé comprendre les cookies qu'il reçoit, il doit juste les renvoyer tels quels. La section 6 décrit quand même un format suggéré. Elle rappelle que les cookies de NTS sont utilisés à peu près comme les cookies de session de TLS (RFC 5077). Comme le serveur doit pouvoir reconnaitre les bons cookies des mauvais, et comme il est préférable qu'il ne conserve pas un état différent par client, le format suggéré permet au serveur de fabriquer des cookies qu'il pourra reconnaitre, sans qu'un attaquant n'arrive à en fabriquer. Le serveur part pour cela d'une clé secrète, changée de temps en temps. Pour le cas un peu plus compliqué où un ou plusieurs serveurs NTP assureraient le service avec des cookies distribués par un serveur NTS-KE séparé, le RFC recommande que les clés suivantes soient dérivées de la première, par un cliquet et la fonction de dérivation HKDF du RFC 5869.
Quelles sont les mises en œuvre de NTS à l'heure actuelle ? La
principale est dans chrony (mais dans le
dépôt git seulement, la version 3.5 n'a pas
encore NTS). chrony est
écrit en C et comprend un
client et un serveur. NTS est compilé par défaut (cela peut être
débrayé avec l'option --disable-nts du script
./configure), si et seulement si les
bibliothèques sur lesquelles s'appuie chrony (comme la bibliothèque
cryptographique nettle) ont tout ce qu'il
faut. Ainsi, sur une Ubuntu stable,
./configure n'active pas l'option NTS alors que
ça marche sur une Debian instable (sur cette
plate-forme, pensez à installer les paquetages
bison et asciidoctor,
./configure ne vérifie pas leur présence). Cela
se voit dans cette ligne émise par ./configure
(le +NTS) :
% ./configure ... Checking for SIV in nettle : No Checking for SIV in gnutls : Yes Features : +CMDMON +NTP +REFCLOCK +RTC -PRIVDROP -SCFILTER -SIGND +ASYNCDNS +NTS +READLINE +SECHASH +IPV6 -DEBUG
Autre serveur ayant NTS, NTPsec. (Développement sur Github.) Écrit en
C. C'est ce code qui est
utilisé pour deux serveurs NTS publics,
ntp1.glypnod.com:123 et
ntp2.glypnod.com:123 (exemples plus loin).
Il y a également une
mise en œuvre de NTS en FPGA (sur Github). La même organisation gère deux
serveurs NTP publics, nts.sth1.ntp.se:4460 et
nts.sth2.ntp.se:4460. Elle a publié une
bonne synthèse de ses travaux et un article
plus détaillé.
Dernier serveur public ayant NTS, celui de
Cloudflare, time.cloudflare.com. Il
utilise sans doute nts-rust, écrit par
Cloudflare (en Rust).
Les autres mises en œuvre de NTS semblent assez expérimentales, plutôt de la preuve de concept pas très maintenue. Il y a :
https://gitlab.com/MLanger/nts/https://github.com/Netnod/nts-poc-pythonhttps://gitlab.com/hacklunch/ntsclient
Voici un exemple avec ntsclient et les serveurs publics mentionnés plus haut. Vérifiez que vous avez un compilateur Go puis :
% git clone https://gitlab.com/hacklunch/ntsclient.git % make % ./ntsclient --server=ntp1.glypnod.com:123 -n Network time on ntp1.glypnod.com:123 2020-07-14 09:01:08.684729607 +0000 UTC. Local clock off by -73.844479ms.
(Le serveur devrait migrer bientôt vers le port 4460.)
Si on veut voir plus de détails et toute la machinerie NTS (le
type
de message 4 est AEAD, le type 5 le
cookie, l'algorithme
15 est AEAD_AES_SIV_CMAC_256) :
% ./ntsclient --server=ntp1.glypnod.com:123 -n --debug
Conf: &main.Config{Server:"ntp1.glypnod.com:123", CACert:"", Interval:1000}
Connecting to KE server ntp1.glypnod.com:123
Record type 1
Critical set
Record type 4
Record type 5
Record type 5
Record type 5
Record type 5
Record type 5
Record type 5
Record type 5
Record type 5
Record type 0
Critical set
NTSKE exchange yielded:
c2s: ece2b86a7e86611e6431313b1e45b02a8665f732ad9813087f7fc773bd7f2ff9
s2c: 818effb93856caaf17e296656a900a9b17229e2f79e69f43f9834d3c08194c06
server: ntp1.glypnod.com
port: 123
algo: 15
8 cookies:
[puis les cookies]
Notez que les messages de type 5 ont été répétés huit fois, car, conformément aux recommandations du RFC, le serveur envoie huit cookies. Notez aussi que si vous voulez analyser avec Wireshark, il va par défaut interpréter ce trafic sur le port 123 comme étant du NTP et donc afficher n'importe quoi. Il faut lui dire explicitement de l'interpréter comme du TLS (Decode as...). On voit le trafic NTS-KE en TCP puis du trafic NTP plus classique en UDP.
Enfin, la section 8 du RFC détaille quelques points de sécurité qui avaient pu être traités un peu rapidement auparavant. D'abord, le risque de dDoS. NTS, décrit dans notre RFC, apporte une nouveauté dans le monde NTP, la cryptographie asymétrique. Nécessaire pour l'authentification du serveur, elle est bien plus lente que la symétrique et, donc, potentiellement, un botnet pourrait écrouler le serveur sous la charge, en le forçant à faire beaucoup d'opérations de cryptographie asymétrique. Pour se protéger, NTS sépare conceptuellement l'authentification (faite par NTS-KE) et le service NTP à proprement parler. Ils peuvent même être assurés par des serveurs différents, limitant ainsi le risque qu'une attaque ne perturbe le service NTP.
Lorsqu'on parle de NTP et d'attaques par déni de service, on pense aussi à l'utilisation de NTP dans les attaques par réflexion et amplification. Notez qu'elles utilisent en général des fonctions non-standard des serveurs NTP. Le protocole lui-même n'a pas forcément de défauts. En tout cas, NTS a été conçu pour ne pas ajouter de nouvelles possibilités d'amplification. Tous les champs envoyés par le serveur ont une taille qui est au maximum celle des champs correspondants dans la requête du client. C'est par exemple pour cela que le client doit envoyer un champ de demande de cookie, rempli avec des zéros, pour chaque cookie supplémentaire qu'il réclame. Cela peut sembler inutile, mais c'est pour décourager toute tentative d'amplification.
Cette section 8 discute également la vérification du
certificat du serveur. Bon, on suit les
règles des RFC 5280 et RFC 6125, d'accord. Mais cela laisse un problème amusant : la
date d'expiration du certificat. Regardons celui des serveurs
publics cités plus haut, avec gnutls-cli :
% gnutls-cli ntp1.glypnod.com:123 Processed 126 CA certificate(s). Resolving 'ntp1.glypnod.com:123'... Connecting to '104.131.155.175:123'... - Certificate type: X.509 - Got a certificate list of 2 certificates. - Certificate[0] info: - subject `CN=ntp1.glypnod.com', issuer `CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US', serial 0x04f305691067ef030d19eb53bbb392588d07, RSA key 2048 bits, signed using RSA-SHA256, activated `2020-05-20 02:12:34 UTC', expires `2020-08-18 02:12:34 UTC', pin-sha256="lLj5QsLH8M8PjLSWe6SNlXv4fxVAyI6Uep99RWskvOU=" Public Key ID: sha1:726426063ea3c388ebcc23f913b41a15d4ef38b0 sha256:94b8f942c2c7f0cf0f8cb4967ba48d957bf87f1540c88e947a9f7d456b24bce5 Public Key PIN: pin-sha256:lLj5QsLH8M8PjLSWe6SNlXv4fxVAyI6Uep99RWskvOU= - Certificate[1] info: - subject `CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US', issuer `CN=DST Root CA X3,O=Digital Signature Trust Co.', serial 0x0a0141420000015385736a0b85eca708, RSA key 2048 bits, signed using RSA-SHA256, activated `2016-03-17 16:40:46 UTC', expires `2021-03-17 16:40:46 UTC', pin-sha256="YLh1dUR9y6Kja30RrAn7JKnbQG/uEtLMkBgFF2Fuihg=" - Status: The certificate is trusted. - Description: (TLS1.3-X.509)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) - Options: - Handshake was completed
On a un classique certificat Let's Encrypt, qui expire le 18 août 2020. Cette date figure dans les certificats pour éviter qu'un malveillant qui aurait mis la main sur la clé privée correspondant à un certificat puisse profiter de son forfait éternellement. Même si la révocation du certificat ne marche pas, le malveillant n'aura qu'un temps limité pour utiliser le certificat. Sauf que la vérification que cette date d'expiration n'est pas atteinte dépend de l'horloge de la machine. Et que le but de NTP est justement de mettre cette horloge à l'heure… On a donc un problème d'œuf et de poule : faire du NTP sécurisé nécessite NTS, or utiliser NTS nécessite de vérifier un certificat, mais vérifier un certificat nécessite une horloge à l'heure, donc que NTP fonctionne. Il n'y a pas de solution idéale à ce problème. Notre RFC suggère quelques trucs utiles, comme :
- Prendre un risque délibéré en ne vérifiant pas la date d'expiration du certificat,
- Chercher à savoir si l'horloge est correcte ou pas ; sur un
système d'exploitation qui dispose de
fonctions comme
ntp_adjtime, le résultat de cette fonction (dans ce cas, une valeur autre queTIME_ERROR) permet de savoir si l'horloge est correcte, - Permettre à l'administrateur système de configurer la validation des dates des certificats ; s'il sait que la machine a une horloge matérielle sauvegardée, par exemple via une pile, il peut demander une validation stricte,
- Utiliser plusieurs serveurs NTP et les comparer, dans l'espoir qu'ils ne soient pas tous compromis (cf. RFC 5905, section 11.2.1).
Comme toujours avec la cryptographie, lorsqu'il existe une version non sécurisée d'un protocole (ici, le NTP traditionnel), il y a le risque d'une attaque par repli, qui consiste à faire croire à une des deux parties que l'autre partie ne sait pas faire de la sécurité (ici, du NTS). Ce NTP stripping est possible si, par exemple, le client NTP se rabat en NTP classique en cas de problème de connexion au serveur NTS-KE. Le RFC recommande donc que le repli ne se fasse pas par défaut, mais uniquement si le logiciel a été explicitement configuré pour prendre ce risque.
Enfin, si on veut faire de la synchronisation d'horloges
sécurisée, un des problèmes les plus difficiles est l'attaque par
retard (section 11.5 du RFC). Le MAC empêche un attaquant actif de
modifier les messages mais il peut les retarder, donnant ainsi au
client une fausse idée de l'heure qu'il est réellement (RFC 7384, section 3.2.6 et Mizrahi, T.,
« A game theoretic analysis of delay attacks against time
synchronization protocols », dans les Proceedings
of Precision Clock Synchronization for Measurement Control and
Communication à ISPCS 2012). Ce dernier article n'est pas
en ligne mais, heureusement, il y a Sci-Hub
(DOI 10.1109/ISPCS.2012.6336612).
Les contre-mesures possibles ? Utiliser plusieurs serveurs, ce que fait déjà NTP. Faire attention à ce qu'ils soient joignables par des chemins différents (l'attaquant devra alors contrôler plusieurs chemins). Tout chiffrer avec IPsec, ce qui n'empêche pas l'attaque mais rend plus difficile l'identification des seuls paquets de synchronisation.
Revenons au mode symétrique de NTP, qui n'est pas traité par notre RFC. Vous vous demandez peut-être comment le sécuriser. Lors des discussions à l'IETF sur NTS, il avait été envisagé d'encapsuler tous les paquets dans DTLS mais cette option n'a finalement pas été retenue. Donc, pour le symétrique, la méthode recommandée est d'utiliser le MAC des RFC 5905 (section 7.3) et RFC 8573. Et le mode à diffusion ? Il n'y a pas pour l'instant de solution à ce difficile problème.
Et la vie privée (section 9) ? Il y a d'abord la question de la non-traçabilité. On ne veut pas qu'un observateur puisse savoir que deux requêtes NTP sont dues au même client. D'où l'idée d'envoyer plusieurs cookies (et de les renouveler), puisque, autrement, ces identificateurs envoyés en clair trahiraient le client, même s'il a changé d'adresse IP.
Et la confidentialité ? Le chiffrement de l'essentiel du paquet NTP fournit ce service, les en-têtes qui restent en clair, comme le cookie, ne posent pas de problèmes de confidentialité particuliers.
Un petit mot maintenant sur l'historique de ce RFC. Le projet
initial était plus ambitieux
(cf. l'Internet-Draft
draft-ietf-ntp-network-time-security). Il
s'agissait de développer un mécanisme abstrait, commun à NTP et
PTP/IEEE 1588 (alors que ce RFC 8915 est spécifique à NTP). Un autre groupe de travail
IETF TICTOC continue
de son côté mais ne fait plus de sécurité.
Si vous voulez des bonnes lectures sur NTS, autres que le RFC, il y a un article sur la sécurité NTP à la conférence ISPCS 17, « New Security Mechanisms for Network Time Synchronization Protocols ») (un des auteurs de l'article est un des auteurs du RFC). C'est un exposé général des techniques de sécurité donc il inclut PTP mais la partie NTP est presque à jour, à part la suggestion de DTLS pour les autres modes, qui n'a finalement pas été retenue). Les supports du même article à la conférence sont sur Slideshare. Et cet article est résumé dans l'IETF journal de novembre 2017, volume 13 issue 2. Il y a aussi l'article de l'ISOC, qui résume bien les enjeux.
L'article seul
RFC 8914: Extended DNS Errors
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : W. Kumari (Google), E. Hunt
(ISC), R. Arends (ICANN), W. Hardaker
(USC/ISI), D. Lawrence (Oracle +
Dyn)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 24 octobre 2020
Un problème classique du DNS est qu'il n'y a pas assez de choix pour le
code de retour renvoyé par un serveur DNS. Contrairement à la richesse des codes de retour HTTP, le
DNS est très limité. Ainsi, le code de retour
SERVFAIL (SERver FAILure)
sert à peu près à tout, et indique des erreurs très différentes
entre elles. D'où ce nouveau RFC qui normalise un mécanisme permettant des
codes d'erreur étendus, les EDE, ce qui facilitera le diagnostic des
problèmes DNS.
Ces codes de retour DNS (RCODE, pour Response
CODE) sont décrits dans le RFC 1035,
section 4.1.1. Voici un exemple de requête faite avec dig. Le code de
retour est indiqué par l'étiquette status:. Ici,
c'est REFUSED, indiquant que le serveur faisant autorité pour
google.com ne veut pas répondre aux requêtes
pour mon .org :
% dig @ns1.google.com AAAA www.bortzmeyer.org ; <<>> DiG 9.11.3-1ubuntu1.12-Ubuntu <<>> @ns1.google.com AAAA www.bortzmeyer.org ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 4181 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 512 ;; QUESTION SECTION: ;www.bortzmeyer.org. IN AAAA ;; Query time: 7 msec ;; SERVER: 2001:4860:4802:32::a#53(2001:4860:4802:32::a) ;; WHEN: Sat Jun 20 11:07:13 CEST 2020 ;; MSG SIZE rcvd: 47
Codés sur seulement quatre bits, ces codes de retour ne peuvent
pas être très nombreux. Le RFC 1035 en
normalisait six, et quelques
autres ont été ajoutés par la suite, mais sont rarement vus
sur le terrain. En pratique, les plus fréquents sont
NOERROR (pas de problème),
NXDOMAIN (ce nom de domaine n'existe pas) et
SERVFAIL (la plupart des autres erreurs). Notez
que le RFC 1034 n'utilisait pas ces sigles à
l'origine ils ont été introduits après.
On l'a dit, ces codes de retour sont insuffisants. Lorsqu'un
client DNS reçoit SERVFAIL, il doit essayer de
deviner ce que cela voulait dire. Lorsqu'on parle à un résolveur, le
SERVFAIL indique-t-il un problème de validation
DNSSEC ? Ou bien que les serveurs faisant autorité sont
injoignables ? Lorsqu'on parle à un serveur faisant
autorité, le SERVFAIL indiquait-il que
ce serveur n'avait pas pu charger sa zone (peut-être parce que le
serveur maître était injoignable) ? Ou bien un autre problème ?
L'un des scénarios de débogage les plus communs est celui de
DNSSEC. Au moins, il existe un truc simple :
refaire la requête avec le bit CD
(Checking Disabled). Si ça marche
(NOERROR), alors on est raisonnablement sûr que
le problème était un problème DNSSEC. Mais cela ne nous dit pas
lequel (signatures expirées ? clés ne correspondant pas à la
délégation ?). DNSSEC est donc un des principaux demandeurs d'erreurs
plus détaillées.
Alors, après cette introduction (section 1 du RFC), la solution
(section 2). Les erreurs étendues (EDE, pour Extended DNS Errors) sont transportées via une option
EDNS (RFC 6891) dans la
réponse. Cette option comporte un type (numéro 15)
et une longueur (comme toutes les options EDNS) suivis d'un code
d'information (sur deux octets) et de texte libre, non structuré (en
UTF-8, cf. RFC 5198, et
attention à ne pas le faire trop long, pour éviter la troncation
DNS). Les codes d'information possibles sont dans un
registre à l'IANA. En ajouter est simple, par la procédure
« Premier Arrivé, Premier Servi » du RFC 8126.
Cette option EDNS peut être envoyée par le serveur DNS, quel que
soit le code de retour (y compris donc
NOERROR). Il peut y avoir plusieurs de ces options. La seule condition
est que la requête indiquait qu'EDNS est accepté par le client. Le
client n'a pas à demander explicitement des erreurs étendues et ne
peut pas forcer l'envoi d'une erreur étendue, cela dépend uniquement
du serveur.
Les codes d'information initiaux figurent en section 4 du RFC. Le RFC ne précise pas avec quels codes de retour les utiliser (ce fut une grosse discussion à l'IETF…) mais, évidemment, certains codes d'erreur étendus n'ont de sens qu'avec certains codes de retour, je les indiquerai ici. Voici quelques codes d'erreur étendus :
- 0 indique un cas non prévu, le texte qui l'accompagne donnera des explications.
- 1 signale que le domaine était signé, mais avec uniquement
des algorithmes inconnus du résolveur. Il est typiquement en
accompagnement d'un
NOERRORpour expliquer pourquoi on n'a pas validé (en DNSSEC, un domaine signé avec des algorithmes inconnus est considéré comme non signé). - 3 (ou 19, pour le
NXDOMAIN) indique une réponse rassise (RFC 8767). Voir aussi le 22, plus loin. - 4 est une réponse fabriquée de toutes pièces par un
résolveur menteur. Notez qu'il existe
d'autres codes, plus loin, de 15 à 17,
permettant de détailler les cas de filtrage. 4 est typiquement en
accompagnement d'un
NOERRORpuisqu'il y a une réponse. - 6 vient avec les
SERVFAILpour indiquer que la validation DNSSEC a déterminé un problème (signature invalide ou absente). Plusieurs autres codes traitent des problèmes DNSSEC plus spécifiques. - 7 vient également avec
SERVFAILpour le cas des signatures expirées (sans doute un des problèmes DNSSEC les plus fréquents). - Trois codes viennent pour les cas où le résolveur refuse de répondre pour ce domaine, et le dit (au lieu, ou en plus, de fabriquer une réponse mensongère). Ce sont 15 (réponse bloquée par une décision de l'administrateur du résolveur), 16 (réponse bloquée par une décision extérieure, typiquement l'État, et il ne sert donc à rien de se plaindre à l'administrateur du résolveur, c'est de la censure) et 17 (réponse bloquée car le client a demandé qu'on filtre pour lui, par exemple parce qu'il a choisi de bloquer les domaines liés à la publicité, cf. l'exemple plus loin). 16 est donc à peu près l'équivalent du 451 de HTTP, normalisé dans le RFC 7725. Gageons que les résolveurs menteurs en France se garderont bien de l'utiliser…
- 18 accompagne en général
REFUSEDet indique au client qu'il n'est pas le bienvenu (par exemple une requête à un résolveur venue de l'extérieur du réseau local). - 22 indique qu'un résolveur n'a pu joindre aucun des
serveurs faisant autorité. Ce code peut accompagner une réponse
rassise ou bien un
SERVFAIL. J'en profite pour vous rappeler que, si vous gérez une zone DNS, attention à sa robustesse : évitez les SPOF. Ayez plusieurs serveurs faisant autorité, et dans des lieux séparés (et de préférence dans des AS distincts).
Voici un exemple où un résolveur se présentant comme « pour les
familles » ment sur la réponse à une requête pour
pornhub.com et ajoute l'EDE 17, puisque c'est
l'utilisateur qui, en choisissant ce résolveur public, a demandé ce
filtrage :
% dig @1.1.1.3 pornhub.com ; <<>> DiG 9.18.28-0ubuntu0.24.04.1-Ubuntu <<>> @1.1.1.3 pornhub.com ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 34585 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ; EDE: 17 (Filtered) ;; QUESTION SECTION: ;pornhub.com. IN A ;; ANSWER SECTION: pornhub.com. 60 IN A 0.0.0.0 ;; Query time: 9 msec ;; SERVER: 1.1.1.3#53(1.1.1.3) (UDP) ;; WHEN: Wed Sep 25 14:48:50 CEST 2024 ;; MSG SIZE rcvd: 62
Le client DNS qui reçoit un code d'erreur étendu est libre de l'utiliser comme il le souhaite (les précédentes versions de ce mécanisme prévoyaient des suggestions faites au client mais ce n'est plus le cas). Le but principal de cette technique est de fournir des informations utiles pour le diagnostic. (Une discussion à l'IETF avait porté sur des codes indiquant précisément si le problème était local - et devait donc être soumis à son administrateur système - ou distant, auquel cas il n'y avait plus qu'à pleurer, mais cela n'a pas été retenu. Notez que la différence entre les codes 15 et 16 vient de là, du souci d'indiquer à qui se plaindre.)
Attention à la section 6 du RFC, sur la sécurité. Elle note
d'abord que certains clients, quand ils reçoivent un
SERVFAIL, essaient un autre résolveur (ce qui
n'est pas une bonne idée si le SERVFAIL était
dû à un problème DNSSEC). Ensuite, les codes d'erreur étendus ne
sont pas authentifiés (comme, d'ailleurs, les
codes de retour DNS habituels), sauf si on utilise, pour parler au
serveur, un canal sécurisé comme DoT (RFC 7858) ou DoH (RFC 8484). Il ne faut
donc pas s'y fier trop aveuglément. Enfin, ces codes étendus vont
fuiter de l'information à un éventuel observateur (sauf si on
utilise un canal chiffré, comme avec DoT ou DoH) ; par exemple, 18
permet de savoir que vous n'êtes pas le bienvenu sur le serveur.
Et, désolé, je ne connais pas de mise en œuvre de cette option à l'heure actuelle. J'avais développé le code nécessaire pour Knot lors du hackathon de l'IETF à Prague en mars 2019 (le format a changé depuis donc ce code ne peut pas être utilisé tel quel). La principale difficulté n'était pas dans le formatage de la réponse, qui est trivial, mais dans le transport de l'information, depuis les entrailles du résolveur où le problème était détecté, jusqu'au code qui fabriquait la réponse. Il fallait de nouvelles structures de données, plus riches.
Sinon, le RFC mentionne le groupe Infected Mushroom. Si vous voulez voir leurs clips…
L'article seul
RFC 8910: Captive-Portal Identification in DHCP and Router Advertisements (RAs)
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : W. Kumari (Google), E. Kline (Loon)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF capport
Première rédaction de cet article le 22 septembre 2020
Les portails captifs sont une des plaies de l'accès à l'Internet. À défaut de pouvoir les supprimer, ce nouveau RFC propose des options aux protocoles DHCP et RA pour permettre de signaler la présence d'un portail captif, au lieu que la malheureuse machine ne doive le détecter elle-même. Il remplace le RFC 7710, le premier à traiter ce sujet. Il y a peu de changements de fond mais quand même deux modifications importantes. D'abord, il a fallu changer le code qui identifiait l'option DHCP en IPv4 (du code 160 au 114). Et ensuite l'URI annoncé sur le réseau est désormais celui de l'API et pas une page Web conçue pour un humain.
On trouve de tels portails captifs en de nombreux endroits où de l'accès Internet est fourni, par exemple dans des hôtels, des trains ou des cafés. Tant que l'utilisateur ne s'est pas authentifié auprès du portail captif, ses capacités d'accès à l'Internet sont très limitées. Quels sont les problèmes que pose un portail captif ?
- Le plus important est qu'il détourne le trafic normal : en cela, le portail captif est une attaque de l'Homme du Milieu et a donc de graves conséquences en terme de sécurité. Il éduque les utilisateurs à trouver normal le fait de ne pas arriver sur l'objectif désiré, et facilite donc le hameçonnage. Au fur et à mesure que les exigences de sécurité augmentent, ces portails captifs seront, on peut l'espérer, de plus en plus mal vus.
- Le portail captif ne marche pas ou mal si la première connexion est en HTTPS, ce qui est, à juste titre, de plus en plus fréquent. Là encore, il éduque les utilisateurs à trouver normaux les avertissements de sécurité (« mauvais certificat, voulez-vous continuer ? »).
- Le portail captif n'est pas authentifié, lui, et l'utilisateur est donc invité à donner ses informations de créance à un inconnu.
- En Wifi, comme l'accès n'est pas protégé par WPA, le trafic peut être espionné par les autres utilisateurs.
- Spécifique au Web, le portail captif ne marche pas avec les activités non-Web (comme XMPP). Même les clients HTTP non-interactifs (comme une mise à jour du logiciel via HTTP) sont affectés.
Pourquoi est-ce que ces hôtels et cafés s'obstinent à imposer le passage par un portail captif ? On lit parfois que c'est pour authentifier l'utilisateur mais c'est faux. D'abord, certains portails captifs ne demandent pas d'authentification, juste une acceptation des conditions d'utilisation. Ensuite, il existe une bien meilleure solution pour authentifier, qui n'a pas les défauts indiqués plus haut. C'est 802.1X, utilisé entre autres dans eduroam (voir RFC 7593). La vraie raison est plutôt une combinaison d'ignorance (les autres possibilités comme 802.1X ne sont pas connues) et de désir de contrôle (« je veux qu'ils voient mes publicités et mes CGU »).
L'IETF travaille à développer un protocole complet d'interaction avec les portails captifs, pour limiter leurs conséquences. En attendant que ce travail soit complètement terminé, ce RFC propose une option qui permet au moins au réseau local de signaler « attention, un portail captif est là, ne lance pas de tâches - comme Windows Update - avant la visite du portail ». Cette option peut être annoncée par le serveur DHCP (RFC 2131 et RFC 9915) ou par le routeur qui envoie des RA (RFC 4861).
Cette option (section 2 du RFC) annonce au client qu'il est derrière un portail captif et lui fournit l'URI de l'API à laquelle accéder (ce qui évite d'être détourné, ce qui est grave quand on utilise HTTPS). Les interactions avec l'API de ce serveur sont spécifiées dans le RFC 8908.
Les sections 2.1, 2.2 et 2.3 de notre RFC donnent le format de l'option en DHCP v4, DHCP v6 et en RA. Le code DHCP v4 est 114 (un changement de notre RFC), le DHCP v6 est 103 et le type RA est 37. Pour la création d'options DHCPv6 avec des URI, voir le RFC 7227, section 5.7.
Un URI spécial,
urn:ietf:params:capport:unrestricted est
utilisé pour le cas où il n'y a pas de portail
captif. (Cet URI spécial est enregistré
à l'IANA, avec les autres suffixes du RFC 3553.)
Bien que la première version de ce RFC date de plus de quatre
ans, la grande majorité des réseaux d'accès avec portail captif
n'annoncent toujours pas la présence de ce portail et il faudra
encore, pendant de nombreuses années, que les machines terminales
« sondent » et essaient de détecter par elles-même s'il y a un
portail captif ou pas. Elles font cela, par exemple, en essayant de
se connecter à une page Web connue (comme http://detectportal.firefox.com/
% curl http://detectportal.firefox.com/ success
Et ici lorsqu'il y a un portail captif qui détourne le trafic :
% curl -v http://detectportal.firefox.com/ > GET / HTTP/1.1 > Host: detectportal.firefox.com > User-Agent: curl/7.58.0 > Accept: */* > < HTTP/1.1 302 Moved Temporarily < Server: nginx < Date: Mon, 27 Jul 2020 18:29:52 GMT ... < Location: https://wifi.free.fr/?url=http://detectportal.firefox.com/ < <html> <head><title>302 Found</title></head> <body bgcolor="white"> <center><h1>302 Found</h1></center> <hr><center>nginx</center> </body> </html>
La section 5 de notre RFC étudie les conséquences de cette option pour la sécurité. Elle rappelle que DHCP et RA ne sont pas sécurisés, de toute façon. Donc, un méchant peut envoyer une fausse option « il y a un portail captif, allez à cet URI pour vous authentifier » mais le même méchant peut aussi bien annoncer un faux routeur et ainsi recevoir tout le trafic... Si on n'utilise pas des précautions comme le RA Guard (RFC 6105) ou le DHCP shield (RFC 7610), on ne peut de toute façon pas se fier à ce qu'on a obtenu en DHCP ou RA.
Il est même possible que cette option nouvelle améliore la sécurité, en n'encourageant pas les utilisateurs à couper les mécanismes de validation comme la vérification des certificats, contrairement à ce que font les portails captifs actuels, qui se livrent à une véritable attaque de l'Homme du Milieu.
Pour DHCP, la plupart des serveurs permettent de servir une option quelconque, en mettant ses valeurs manuellement et une future mise à jour ne servira donc qu'à rendre l'usage de cette option plus simple. (Pour RA, c'est plus complexe, cf. l'expérience lors d'une réunion IETF.) Autrement, je ne connais pas encore de mise en œuvre côté clients DHCP ou RA, mais il semble (je n'ai pas testé personnellement) que ça marche sur iOS à partir de la version 14.
L'annexe B de notre RFC cite les changements depuis le RFC 7710. Les principaux :
- L'ajout de l'URN
urn:ietf:params:capport:unrestrictedpour le cas où il n'y a pas de portail captif, - le changement de l'option DHCP en IPv4, suite à la collision avec les produits Polycom,
- l'URI envoyée désigne désormais une API et plus una page Web ordinaire (contrairement à ce que dit l'annexe B de notre RFC, il ne s'agit pas d'une clarification mais d'un vrai changement),
- les noms (et plus seulement les adresses IP) sont acceptés dans l'URI,
- et plusieurs éclaircissements et précisions.
L'article seul
RFC 8909: Registry Data Escrow Specification
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : G. Lozano (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 14 novembre 2020
Prenons un registre, par exemple un registre de noms de domaine. Des tas de gens comptent sur lui. Si ce registre disparait en emportant sa base de données, ce serait une catastrophe. Il est donc nécessaire de garder les données à part, ce qu'on nomme un séquestre (escrow). Ce RFC décrit un format standard pour les données de séquestre, indépendant du type de registre (même si la demande prioritaire est pour les registres de noms de domaine). Il s'agit d'un format générique, qui sera complété par des spécifications pour les différents types de registre, par exemple le RFC 9022 pour les registres de noms de domaine.
L'idée (section 1 du RFC) est donc que le registre dépose à intervalles réguliers une copie de sa base de données auprès de l'opérateur de séquestre. Il ne s'agit pas d'une sauvegarde. La sauvegarde est conçue pour faire face à des accidents comme un incendie. Le séquestre, lui, est conçu pour faire face à une disparition complète du registre, par exemple une faillite si le registre est une entreprise commerciale. Ou bien une redélégation complète du domaine à un autre registre. Les sauvegardes, non standardisées et liées à un système d'information particulier, ne peuvent pas être utilisées dans ces cas. D'où l'importance d'un format standard pour un séquestre, précisément ce que normalise notre RFC. Lors d'une défaillance complète de l'ancien registre, l'opérateur de séquestre transmettra les données de séquestre au nouveau registre, qui pourra l'importer dans son système d'information, qui sera alors prêt à prendre le relais. Pour un registre de noms de domaine, le dépôt des données de séquestre devra comprendre la liste des noms, les titulaires et contacts pour chacun des noms, les serveurs de noms, les enregistrements DS (utilisés pour DNSSEC), etc. Par contre, certaines informations ne pourront pas être incluses, comme les parties privées des clés utilisées pour DNSSEC (qui sont peut-être enfermées dans un HSM) et le nouveau registre aura donc quand même un peu de travail de réparation.
Ainsi, la
convention entre l'État et l'AFNIC
pour la gestion du .fr
prévoit dans sa section 5 que « L'Office
d'enregistrement [sic] s'engage à mettre en place et à maintenir sur
le sol français un séquestre de données quotidien ». Même
chose pour les TLD sous contrat avec l'ICANN. Le Base
Registry Agreement impose un séquestre dans sa
spécification 2 « DATA ESCROW
REQUIREMENTS ». Elle dit « Deposit’s
Format. Registry objects, such as domains, contacts, name servers,
registrars, etc. will be compiled into a file constructed as
described in draft-arias-noguchi-registry-data-escrow, see Part A,
Section 9, reference 1 of this Specification and
draft-arias-noguchi-dnrd-objects-mapping, see Part A, Section 9,
reference 2 of this Specification (collectively, the “DNDE
Specification”). ». [Le document
draft-arias-noguchi-registry-data-escrow est
devenu ce RFC 8909.] L'ICANN reçoit actuellement 1 200
séquestres, pour chaque TLD qu'elle régule, les dépôts ayant lieu
une fois par semaine.
Ces exigences sont tout à fait normales : la disparition d'un
registre de noms de domaine, s'il n'y avait pas de séquestre,
entrainerait la disparition de tous les noms, sans moyen pour les
titulaires de faire valoir leurs droits. Si
.org disparaissait sans
séquestre,
bortzmeyer.org n'existerait plus, et si un
registre prenait le relais avec une base de données vide, rien ne me
garantit d'obtenir ce nom, l'adresse de ce blog devrait donc
changer. Cette question de continuité de
l'activité de registre, même si des organisations disparaissent, est
la motivation pour ce RFC (section 3).
Un exemple de service de « registre de secours » (third-party beneficiary, dans la section 2 du RFC, on pourrait dire aussi backup registry) est l'EBERO (Emergency Back-End Registry Operator) de l'ICANN, décrit dans les « Registry Transition Processes ».
Ce RFC ne spécifie qu'un format de données. Il ne règle pas les questions politiques (faut-il faire un séquestre, à quel rythme, qui doit être l'opérateur de séquestre, qui va désigner un registre de secours, etc).
Passons donc à la technique (section 5). Le format est du
XML.
L'élément racine est <deposit>
(dépôt). Un attribut type indique si ce dépôt
est complet (la totalité des données) ou bien incrémental
(différence avec le dépôt précédent). L'espace de
noms est
urn:ietf:params:xml:ns:rde-1.0, enregistré
à l'IANA (voir la section 8). RDE signifie Registry
Data Escrow. Parmi les éléments obligatoires sous
<deposit>, il y a :
<watermark>qui indique le moment où ce dépôt a été fait, au format du RFC 3339 (section 4). On peut traduire watermark par jalon, point de synchronisation, point d'étape ou marque.<rdeMenu>, diverses métadonnées.<contents>contient les données (rappelez-vous que ce RFC est générique, le format exact des données, qui dépend du type de registre, sera dans un autre RFC).<deletes>ne sert que pour les dépôts incrémentaux, et indique les objets qui ont été détruits depuis la dernière fois.- Eh non, il n'y a pas d'élément
<adds>; dans un dépôt incrémental, les éléments ajoutés sont sous<contents>.
Voici un exemple très partiel d'un dépôt complet :
<?xml version="1.0" encoding="UTF-8"?>
<d:deposit xmlns:d="urn:ietf:params:xml:ns:rde-1.0"
xmlns:myobj="urn:example:my-objects-1.0"
type="FULL" id="20201006" resend="0">
<d:watermark>2020-10-06T13:12:15Z</d:watermark>
<d:rdeMenu>
<d:version>1.0</d:version>
<d:objURI>urn:example:my-objects-1.0</d:objURI>
</d:rdeMenu>
<d:contents>
<myobj:object>
<myobj:value>42</myobj:value>
</myobj:object>
</d:contents>
</d:deposit>
Dans cet exemple, le fichier XML contient un dépôt complet, fait le
6 octobre 2020, et dont le contenu est un seul élément, de valeur
42. (Pour un vrai dépôt lors d'un séquestre d'un registre de noms
de domaine, on aurait, au lieu de
<myobj:object>, les domaines, leurs
titulaires, etc.) Vous avez des exemples un peu plus réalistes dans
les sections 11 à 13 du RFC.
Attention si vous utilisez des dépôts incrémentaux, l'ordre des
<contents> et
<deletes> compte : il faut mettre les
<deletes> en premier.
La syntaxe complète est décrite dans la section 6 du RFC, en XML Schema. Du fait de l'utilisation de XML, l'internationalisation est automatique, on peut par exemple mettre les noms des contacts en Unicode (section 7).
Le format décrit dans ce RFC est seulement un format. Des tas de
questions subsistent si on veut un système de séquestre complet, il
faut par exemple spécifier un mécanisme de transport des données
entre le registre et l'opérateur de séquestre (par exemple avec
SSH, ou bien un
POST HTTPS). Pour l'ICANN, c'est spécifié
dans l'Internet-Draft
draft-lozano-icann-registry-interfaces.
Il faut également se préoccuper de tout ce qui concerne la sécurité. La section 9 du RFC rappelle que, si on veut que les données de séquestre soient confidentielles (pour un registre de noms de domaine, les coordonnées des titulaires et contacts sont certainement en bonne partie des données personnelles, cf. section 10), il faut chiffrer la communication entre le registre et l'opérateur de séquestre. Et il faut bien sûr tout authentifier. L'opérateur de séquestre doit vérifier que le dépôt vient bien du registre et n'est pas un dépôt injecté par un pirate, le registre doit vérifier qu'il envoie bien le dépôt à l'opérateur de séquestre et pas à un tiers. Comme exemple des techniques qui peuvent être utilisées pour atteindre ce but, l'ICANN cite OpenPGP (RFC 9580, désormais) : « Files processed for compression and encryption will be in the binary OpenPGP format as per OpenPGP Message Format - RFC 4880, see Part A, Section 9, reference 3 of this Specification. Acceptable algorithms for Public-key cryptography, Symmetric-key cryptography, Hash and Compression are those enumerated in RFC 4880, not marked as deprecated in OpenPGP IANA Registry, see Part A, Section 9, reference 4 of this Specification, that are also royalty-free. ».
Comme le séquestre ne servirait qu'en cas de terminaison complète du registre, on peut penser que le registre actuel n'est pas très motivé pour assurer ce service (et c'est pour cela qu'il doit être imposé). Il y a un risque de négligence (voire de malhonnêté) dans le production des dépôts. Voici pourquoi l'opérateur de séquestre doit tester que les dépôts qu'il reçoit sont corrects. Au minimum, il doit vérifier leur syntaxe. Ici, on va se servir de xmllint pour cela. D'abord, on utilise un schéma pour les données spécifiques de notre type de registre. Ici, il est très simple, uniquement des données bidon :
% cat myobj.xsd
<?xml version="1.0" encoding="utf-8"?>
<schema targetNamespace="urn:example:my-objects-1.0"
xmlns:myobj="urn:example:my-objects-1.0"
xmlns:rde="urn:ietf:params:xml:ns:rde-1.0"
xmlns="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified">
<annotation>
<documentation>
Test
</documentation>
</annotation>
<element name="object" type="myobj:objectType" substitutionGroup="rde:content"/>
<complexType name="objectType">
<complexContent>
<extension base="rde:contentType">
<sequence>
<element name="value" type="integer"/>
</sequence>
</extension>
</complexContent>
</complexType>
</schema>
Ensuite, on écrit un petit schéma qui va importer les deux schémas, le nôtre (ci-dessus), spécifique à un type de registre, et le schéma du RFC, générique :
% cat wrapper.xsd <?xml version="1.0" encoding="utf-8"?> <schema targetNamespace="urn:example:tmp-1.0" xmlns="http://www.w3.org/2001/XMLSchema"> <import namespace="urn:ietf:params:xml:ns:rde-1.0" schemaLocation="rde.xsd"/> <import namespace="urn:example:my-objects-1.0" schemaLocation="myobj.xsd"/> </schema>
Ensuite, on produit le dépôt :
% cat test.xml
<?xml version="1.0" encoding="UTF-8"?>
<d:deposit xmlns:d="urn:ietf:params:xml:ns:rde-1.0"
xmlns:myobj="urn:example:my-objects-1.0"
type="FULL" id="20201006" resend="0">
<d:watermark>2020-10-06T13:12:15Z</d:watermark>
<d:rdeMenu>
<d:version>1.0</d:version>
<d:objURI>urn:example:my-objects-1.0</d:objURI>
</d:rdeMenu>
<d:contents>
<myobj:object>
<myobj:value>42</myobj:value>
</myobj:object>
</d:contents>
</d:deposit>
Et on n'a plus qu'à valider ce dépôt :
% xmllint --noout --schema wrapper.xsd test.xml
test.xml validates
Si les données étaient incorrectes (dépôt mal fait), xmllint nous préviendrait :
% xmllint --noout --schema wrapper.xsd test.xml
test.xml:12: element value: Schemas validity error : Element '{urn:example:my-objects-1.0}value': 'toto' is not a valid value of the atomic type 'xs:integer'.
test.xml fails to validate
Idéalement, il faudrait même que l'opérateur de séquestre teste un chargement complet des données dans un autre logiciel de gestion de registre (oui, je sais, c'est beaucoup demander). Bon, s'il vérifie la syntaxe, c'est déjà ça.
L'article seul
RFC 8908: Captive Portal API
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : T. Pauly (Apple), D. Thakore (CableLabs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF capport
Première rédaction de cet article le 22 septembre 2020
Un des nombreux problèmes posés par les portails captifs est l'interaction avec le portail, par exemple pour accepter les CGU et continuer. Ces portails ne sont en général prévus que pour une interaction avec un humain. Ce RFC décrit une API ultra-simple qui permet à des programmes, au moins de savoir s'il y a un portail, quelles sont ses caractéristiques et comment sortir de captivité.
L'API suit les principes du RFC 8952. Elle permet donc de récupérer l'état de la captivité (est-ce que j'ai un accès à l'Internet ou pas), et l'URI de la page Web avec laquelle l'humain devra interagir.
Comment est-ce que la machine qui tente de se connecter a appris l'existence de l'API et son URI d'entrée ? Typiquement via les options de DHCP ou de RA décrites dans le RFC 8910. On accède ensuite à l'API avec HTTPS (RFC 2818). Il faudra naturellement authentifier le serveur, ce qui peut poser des problèmes tant qu'on n'a pas un accès à l'Internet complet (par exemple à OCSP, RFC 6960, et à NTP, RFC 5905, pour mettre l'horloge à l'heure et ainsi vérifier que le certificat n'a pas encore expiré). De même, des certificats intermédiaires qu'il faut récupérer sur l'Internet via Authority Information Access (AIA, section 5.2.7 du RFC 5280) peuvent poser des problèmes et il vaut mieux les éviter.
L'API elle-même est présentée en section 5 du RFC. Le contenu est
évidement en JSON (RFC 8259), et
servi avec le type application/captive+json. Dans
les réponses du serveur, l'objet JSON a obligatoirement un membre
captive dont la valeur est un booléen et qui
indique si on on est en captivité ou pas. Les autres membres
possibles sont :
user-portal-uriindique une page Web pour humains, avec laquelle l'utilisateur peut interagir,venue-info-urlest une page Web d'information,can-extend-session, un booléen qui indique si on peut prolonger la session, ce qui veut dire que cela peut être une bonne idée de ramener l'humain vers la page Webuser-portal-urilorsque la session va expirer,seconds-remaining, le nombre de secondes restant pour cette session, après quoi il faudra se reconnecter (sican-extend-sessionest à Vrai),bytes-remaining, la même chose mais pour des sessions limitées en quantité de données et plus en temps.
Ces réponses de l'API peuvent contenir des données spécifiques au
client, et donc privées. Auquel cas, le serveur doit penser à
utiliser Cache-control: private (RFC 9111) ou un mécanisme
équivalent, pour éviter que ces données se retrouvent dans des
caches.
Un exemple complet figure en section 6 du RFC. On suppose que le
client a découvert l'URL
https://example.org/captive-portal/api/X54PD39JV
via un des mécanismes du RFC 8910. Il
envoie alors une requête HTTP :
GET /captive-portal/api/X54PD39JV HTTP/1.1 Host: example.org Accept: application/captive+json
Et reçoit une réponse :
HTTP/1.1 200 OK
Cache-Control: private
Date: Mon, 02 Mar 2020 05:07:35 GMT
Content-Type: application/captive+json
{
"captive": true,
"user-portal-url": "https://example.org/portal.html"
}
Il sait alors qu'il est en captivité, et que l'utilisateur doit
aller en https://example.org/portal.html pour
accepter des CGU léonines, s'authentifier,
etc. Une fois que c'est fait, il peut continuer à faire des requêtes
à l'API et avoir, par exemple :
{
"captive": false,
"user-portal-url": "https://example.org/portal.html",
"venue-info-url": "https://flight.example.com/entertainment",
"seconds-remaining": 326,
"can-extend-session": true
}
D'autres membres de l'objet JSON pourront apparaitre, selon la procédure « Spécification nécessaire » (RFC 8126), un registre IANA a été créé pour les stocker.
Un peu de sécurité pour finir (section 7 du RFC). Le protocole de notre RFC impose l'utilisation de HTTPS (donc de TLS) ce qui règle pas mal de problèmes, notamment de confidentialité et d'authentification. À noter donc (mais cela en vaut la peine) que cela complique un peu les choses pour l'administrateur du portail captif, qui ne peut pas se contenter de HTTP en clair, et qui doit avoir un certificat valide. (Cet argument de la complexité avait été mentionné lors des discussions à l'IETF, où certains trouvaient notre RFC trop exigeant.) Combien de fois ai-je vu des portails captifs avec un certificat auto-signé et/ou expiré !
Mais attention, TLS va seulement sécuriser le fait qu'on se connecte bien au serveur indiqué via les méthodes du RFC 8910. Or, comme ces méthodes ne sont pas elle-mêmes très sûres, la sécurité du portail captif ne doit jamais être surestimée.
Le protocole décrit dans le RFC 8910 et dans ce RFC a été testé lors de réunions IETF, sur le grand réseau de ces réunions. En dehors de cela, il n'y a pas encore de déploiement. Je crains que, vu la nullité technique de la plupart des points d'accès WiFi, vite installés, mal configurés et plus maintenus après, il ne faille attendre longtemps un déploiement significatif.
L'article seul
RFC 8906: A Common Operational Problem in DNS Servers: Failure To Communicate
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : M. Andrews (ISC), R. Bellis (ISC)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 23 septembre 2020
Normalement, le protocole DNS est très simple : le client écrit au serveur, posant une question, et le serveur répond. Il peut répondre qu'il ne veut pas ou ne sait pas répondre, mais il le dit explicitement. Cela, c'est la théorie. En pratique, beaucoup de serveurs DNS bogués (ou, plus fréquemment, situés derrière une middlebox boguée) ne répondent pas du tout, laissant le client perplexe se demander s'il doit réeessayer différemment ou pas. Ce nouveau RFC documente le problème et ses conséquences. Il concerne surtout la question des serveurs faisant autorité.
(Cette absence de réponse est en général due, non pas aux serveurs DNS eux-même, qui sont la plupart du temps corrects de ce point de vue, mais plutôt à ces middleboxes codées avec les pieds et mal configurées, que certains managers s'obstinent à placer devant des serveurs DNS qui marcheraient parfaitement sans cela. Ainsi, on voit des pare-feux inutiles mis parce que « il faut un pare-feu, a dit l'auditeur » et qui bloquent tout ce qu'ils ne comprennent pas. Ainsi, par exemple, le pare-feu laissera passer les requêtes de type A mais pas celles de type NS, menant à une expiration du délai de garde. La section 4 de notre RFC détaille ces erreurs communes des middleboxes.)
Voici un exemple d'un service DNS bogué. Le domaine
mabanque.bnpparibas est délégué à deux serveurs
mal configurés (ou placés derrière une middlebox
mal faite), sns6.bnpparibas.fr et
sns5.bnpparibas.net :
% dig @sns6.bnpparibas.fr A mabanque.bnpparibas ; <<>> DiG 9.11.5-P4-5.1-Debian <<>> @sns6.bnpparibas.fr A mabanque.bnpparibas ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 57381 ;; flags: qr aa rd ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0 ;; WARNING: recursion requested but not available ;; QUESTION SECTION: ;mabanque.bnpparibas. IN A ;; ANSWER SECTION: mabanque.bnpparibas. 30 IN A 159.50.187.79 ;; Query time: 24 msec ;; SERVER: 159.50.105.65#53(159.50.105.65) ;; WHEN: Wed Jun 17 08:21:07 CEST 2020 ;; MSG SIZE rcvd: 53 % dig @sns6.bnpparibas.fr NS mabanque.bnpparibas ; <<>> DiG 9.11.5-P4-5.1-Debian <<>> @sns6.bnpparibas.fr NS mabanque.bnpparibas ; (1 server found) ;; global options: +cmd ;; connection timed out; no servers could be reached
Face à un service aussi mal fait, le client DNS est très désarmé. Est-ce que le serveur a ignoré la requête ? Est-ce que le paquet a été perdu (c'est l'Internet, rien n'est garanti) ? Dans le deuxième cas, il faut réessayer, dans le premier, cela ne servirait à rien, qu'à perdre du temps, et à en faire perdre à l'utilisateur. Le client peut aussi supposer que l'absence de réponse est due à telle ou telle nouveauté du protocole DNS qu'il a utilisé, et se dire qu'il faudrait réessayer sans cette nouveauté, voire ne jamais l'utiliser. On voit que ces services grossiers, qui ne répondent pas aux requêtes, imposent un coût conséquent au reste de l'Internet, en délais, en trafic réseau, et en hésitation à déployer les nouvelles normes techniques.
Il n'y a aucune raison valable pour une absence de réponse ?
Notre RFC en note
une : une attaque par déni de service en
cours. Dans ce cas, l'absence de réponse est légitime (et, de toute
façon, le serveur peut ne pas avoir le choix). En dehors d'une telle
attaque, le serveur doit répondre, en utilisant
un des codes de retour DNS existants, qui couvrent tous les cas
possibles (de NOERROR, quand tout va bien, à
REFUSED, le refus délibéré, en passant par
SERVFAIL, l'impossibilité de produire une
réponse sensée). Ici, un cas où je demande à un serveur de
.fr des informations sur
un .com, qu'il n'a
évidemment pas, d'où le refus explicite (cf. le champ
status:) :
% dig @d.nic.fr A www.microsofthub.com ; <<>> DiG 9.11.5-P4-5.1-Debian <<>> @d.nic.fr A www.microsofthub.com ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 4212 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1432 ; COOKIE: 452269774eb7b7c574c779de5ee9b8e6efe0f777274b2b17 (good) ;; QUESTION SECTION: ;www.microsofthub.com. IN A ;; Query time: 4 msec ;; SERVER: 2001:678:c::1#53(2001:678:c::1) ;; WHEN: Wed Jun 17 08:32:06 CEST 2020 ;; MSG SIZE rcvd: 77
Le RFC note qu'il n'y a pas que l'absence de réponse, il y a aussi parfois des réponses incorrectes. Ainsi, certains serveurs (ou, là encore, la middlebox placée devant eux) copient le bit AD de la requête dans la réponse au lieu de déterminer par eux-mêmes si ce bit - qui signifie Authentic Data - doit être mis dans la réponse.
Donc, ne pas répondre, c'est mal, et égoïste. Mais quelles sont les conséquences exactes de cette absence de réponse ? Parmi elles :
- Pendant longtemps, les résolveurs DNS, face à une absence de réponse, réessayaient sans EDNS, ce qui résolvait parfois le problème, mais a sérieusement gêné le déploiement d'EDNS.
- Même problème avec les nouvelles utilisations d'EDNS.
- Un comportement fréquent des pare-feux est de bloquer les requêtes demandant des types de données qu'ils ne connaissent pas. La liste connue de ces pare-feux est toujours très réduite par rapport à la liste officielle, ce qui se traduit par une grande difficulté à déployer de nouveaux types de données DNS. C'est une des raisons derrière l'échec du type SPF (cf. RFC 6686). Cela encourage l'usage de types de données fourre-tout comme TXT.
- Même problème pour le déploiement de DANE et de son type TLSA.
- Le RFC ne cite pas ce cas, mais ne pas répondre peut aussi dans certains cas faciliter des attaques par empoisonnement d'un résolveur, cf. l'attaque SLIP.
Quels sont les cas où il est particulièrement fréquent qu'il n'y ait pas de réponse, ou bien une réponse erronée ? La section 3 en décrit un certain nombre (et le RFC vient avec un script qui utilise dig pour tester une grande partie de ces cas). Elle rappelle également les réponses correctes attendues. Par exemple, une requête de type SOA (Start Of Authority) à un serveur faisant autorité pour une zone doit renvoyer une réponse (contrairement aux serveurs de BNP Paribas cités plus haut, qui ne répondent pas). Même si le type de données demandé est inconnu du serveur, il doit répondre (probablement NOERROR s'il n'a tout simplement pas de données du type en question).
On voit parfois également des serveurs (ou plutôt des combinaisons serveur / middlebox boguée située devant le serveur) qui achoppent sur les requêtes utilisant des options (flags) DNS spécifiques. Ici, l'option Z fait que le serveur de la RATP ne répond plus :
% dig @193.104.162.15 +noedns +noad +norec +zflag soa ratp.fr ; <<>> DiG 9.11.5-P4-5.1-Debian <<>> @193.104.162.15 +noedns +noad +norec +zflag soa ratp.fr ; (1 server found) ;; global options: +cmd ;; connection timed out; no servers could be reached
Alors qu'il marche parfaitement sans cette option :
% dig @193.104.162.15 +noedns +noad +norec soa ratp.fr ; <<>> DiG 9.11.5-P4-5.1-Debian <<>> @193.104.162.15 +noedns +noad +norec soa ratp.fr ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 30635 ;; flags: qr aa; QUERY: 1, ANSWER: 1, AUTHORITY: 4, ADDITIONAL: 2 ;; QUESTION SECTION: ;ratp.fr. IN SOA ;; ANSWER SECTION: ratp.fr. 3600 IN SOA ns0.ratp.fr. hostmaster.ratp.fr. 2020051201 21600 3600 4204800 300 ... ;; ADDITIONAL SECTION: ns0.ratp.fr. 3600 IN A 193.104.162.15 ns1.ratp.fr. 3600 IN A 193.104.162.14 ;; Query time: 6 msec ;; SERVER: 193.104.162.15#53(193.104.162.15) ;; WHEN: Mon May 18 17:42:33 CEST 2020 ;; MSG SIZE rcvd: 213
Autre exemple, l'option AD (Authentic Data) dans la requête, qui indique que le client espère une validation DNSSEC, déclenche parfois des bogues, comme de ne pas répondre ou bien de répondre en copiant aveuglément le bit AD dans la réponse. La section 6 du RFC détaille un cas similaire, celui des serveurs qui réutilisent une réponse déjà mémorisée, mais pour des options différentes dans la requête.
Et les opérations (opcodes) inconnus ? Des
opérations comme NOTIFY ou
UPDATE n'existaient pas au début du DNS et
d'autres seront encore ajoutées dans le futur. Si le serveur ne
connait pas une opération, il doit répondre
NOTIMP (Not
Implemented). Ici, avec l'opération 1
(IQUERY, ancienne mais abandonnée par le RFC 3425) :
% dig @d.nic.fr +opcode=1 toto.fr ; <<>> DiG 9.11.5-P4-5.1+deb10u1-Debian <<>> @d.nic.fr +opcode=1 toto.fr ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: IQUERY, status: NOTIMP, id: 20180 ;; flags: qr; QUERY: 0, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1432 ; COOKIE: 71f9ced2f29076a65d34f3ed5ef2f718bab037034bb82106 (good) ;; Query time: 4 msec ;; SERVER: 2001:678:c::1#53(2001:678:c::1) ;; WHEN: Wed Jun 24 08:47:52 CEST 2020 ;; MSG SIZE rcvd: 51
Au contraire, voici un serveur qui répond incorrectement
(REFUSED au lieu de
NOTIMP) :
% dig @ns3-205.azure-dns.org. +noedns +noad +opcode=15 +norec microsoft.com ; <<>> DiG 9.11.5-P4-5.1+deb10u1-Debian <<>> @ns3-205.azure-dns.org. +noedns +noad +opcode=15 +norec microsoft.com ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: RESERVED15, status: REFUSED, id: 41518 ;; flags: qr; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0 ;; QUESTION SECTION: ;microsoft.com. IN A ;; Query time: 22 msec ;; SERVER: 2a01:111:4000::cd#53(2a01:111:4000::cd) ;; WHEN: Wed Jun 24 09:16:19 CEST 2020 ;; MSG SIZE rcvd: 31
Soyons positifs : c'était bien pire il y a encore seulement cinq ou
dix ans, malgré des tests techniques obligatoires dans certains
registres comme
Zonecheck pour
.fr. Des efforts comme
le DNS Flag
Day ont permis d'arranger sérieusement les choses.
Bien sûr, les serveurs DNS doivent accepter les requêtes venant sur TCP et pas seulement sur UDP. Cela a toujours été le cas, mais le RFC 7766 rend cette exigence encore plus stricte. Il y a fort longtemps, l'outil de test Zonecheck de l'AFNIC testait ce fonctionnement sur TCP, et avait attrapé beaucoup d'erreurs de configuration, suscitant parfois des incompréhensions de la part d'administrateurs système ignorants qui prétendaient que le DNS n'utilisait pas TCP.
Et il y a bien sûr EDNS (RFC 6891). Introduit après la norme originale du DNS, mais
quand même ancienne de plus de vingt ans, EDNS est toujours mal
compris par certains programmeurs, et bien des
middleboxes déconnent toujours sur des
particularités d'EDNS. Déjà, un serveur doit répondre aux requêtes
EDNS (même si lui-même ne connait pas EDNS, il doit au moins
répondre FORMERR). Ensuite, s'il connait EDNS,
il doit gérer les numéros de version d'EDNS (attention, la version
actuelle est la 0, il n'y a pas encore eu de version 1 mais, pour
qu'elle puisse être déployée un jour, il ne faut pas que les
serveurs plantent sur les versions supérieures à zéro). EDNS permet
d'indiquer des options (la liste complète est dans un
registre IANA) et les options inconnues doivent être ignorées
(autrement, on ne pourrait jamais déployer une nouvelle option).
Pour tester si vos serveurs gèrent correctement tous ces cas, le
RFC (section 8) vient avec une série de commandes utilisant
dig, dont
il faudra analyser le résultat manuellement en suivant le RFC. J'en
ai fait un script de test, check-dns-respond-rfc8906.sh. Si vous testez vos serveurs avec ce script, faites-le depuis
l'extérieur (pour intégrer dans le test les éventuelles
middleboxes, cf. section 4). Un exemple
d'exécution du test :
% ./check-dns-respond-rfc8906.sh cyberstructure.fr 2001:4b98:dc0:41:216:3eff:fe27:3d3f >& /tmp/mytest.txt
Et il vous reste à lire le fichier des résultats et à comparer avec les résultats attendus.
L'article seul
RFC 8905: The 'payto' URI scheme for payments
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : F. Dold (Taler Systems SA), C. Grothoff (BFH)
Pour information
Première rédaction de cet article le 26 octobre 2020
Le paiement de services ou de biens est un problème crucial sur
l'Internet. En l'absence de mécanisme simple, léger et respectant la
vie privée, on n'a aujourd'hui que des solutions centralisées dans
des gros monstres, comme Amazon pour vendre
des objets physiques, ou YouTube pour
monétiser ses vidéos. Ce RFC ne propose pas de solution magique mais il
spécifie au moins une syntaxe pour indiquer un mécanisme de
paiement : le plan d'URI payto:, qui
permettra peut-être un jour de faciliter les paiements.
Le paysage d'aujourd'hui est le suivant. Si vous êtes un créateur (d'articles, de vidéos, de dessins, peu importe) et que vous voulez être payé pour vos créations (ce qui est tout à fait légitime), vous n'avez comme solutions que de faire appel à du financement participatif (style Liberapay ou Ulule) ou bien de passer par une grosse plate-forme comme YouTube, qui imposera ses règles, comme la captation de données personnelles. Sans compter le contrôle du contenu, qui fait qu'une vidéo parlant de sujets sensibles sera démonétisée. (Voyez par exemple cette vidéo de Charlie Danger où, à partir de 10:45 et surtout 11:45, elle explique comment YouTube n'a pas aimé sa vidéo sur l'IVG et ce qui en est résulté.) Mais cette solution d'hébergement sur un GAFA est sans doute la plus simple pour le créateur, et elle ne dépend pas de la bonne volonté des lecteurs/spectacteurs. Lorsqu'on discute avec un·e vidéaste de son hébergement chez Google et qu'on lui propose d'utiliser plutôt un service libre et décentralisé fait avec PeerTube, la réponse la plus fréquente est « mais je perdrais la monétisation, et je ne peux pas vivre seulement d'amour et d'eau fraîche ». Je l'ai dit, il n'existe pas encore de solution parfaite à ce problème. Pour un cas plus modeste, celui de ce blog, j'ai tenté Flattr et Bitcoin mais avec très peu de succès.
Ce nouveau RFC
ne propose pas une solution de paiement, juste un moyen de faire des
URI qu'on
pourra mettre dans ces pages Web pour pointer vers un mécanisme de
paiement. Par exemple, payto://bitcoin/1HtNJ6ZFUc9yu9u2qAwB4tGdGwPQasQGax?amount=BITCOIN:0.01&message="Ce%20blog%20est%20super"payto: (ce
qu'aucun ne fait à l'heure actuelle), que vous cliquez puis
confirmez, je recevrai 0,01 bitcoin. (Notez qu'il existe une syntaxe
spécifique à Bitcoin, pour un paiement, décrite dans le BIP 0021, et qui
ressemble beaucoup à celle du RFC.)
Un peu de technique maintenant : les plans d'URI
(scheme) sont définis dans le RFC 3986, section 3.1. Vous connaissez certainement des plans
comme http: ou mailto:. Le
plan payto: est désormais dans le
registre IANA des plans. Après le plan et les deux
barres se trouve l'autorité. Ici, elle
indique le type de paiement. Notre RFC en décrit certains (comme
bitcoin montré dans l'exemple) et on pourra en
enregistrer d'autres. L'idée est de pouvoir présenter à
l'utilisateur un mécanisme uniforme de paiement, quel que soit le
type de paiement. (À l'heure actuelle, si vous acceptez les
paiements par Flattr et
PayPal, vous devez mettre deux boutons
différents sur votre site Web, et qui déclencheront deux expériences
utilisateur très différentes. Sans compter les traqueurs qu'il y a
probablement derrière le bouton de Paypal.)
Question interface utilisateur, le RFC recommande que le navigateur permette ensuite à l'utilisateur de choisir le compte à utiliser, s'il en a plusieurs et, bien sûr, lui demande clairement une confirmation claire. Pas question qu'un simple clic déclenche le paiement ! (Cf. section 8 du RFC, qui pointe entre autres le risque de clickjacking.) Notez aussi que le RFC met en garde contre le fait d'envoyer trop d'informations (par exemple l'émetteur) dans le paiement, ce qui serait au détriment de la vie privée.
On peut ajouter des options à l'URI (section 5 du RFC). Par
exemple la quantité à verser (amount,
cf. l'exemple Bitcoin plus haut, le code de la monnaie, s'il a trois
lettres, devant être
conforme à ISO 4217, le
Bitcoin n'ayant pas de code officiel, j'ai utilisé un nom plus long),
receiver-name et
sender-name, message (pour
le destinataire) et
instruction, ce dernier servant à préciser le
traitement à faire par l'organisme de paiement.
Voici un autre exemple d'URI payto:, après
Bitcoin, IBAN (ISO
20022) : payto://iban/DE75512108001245126199?amount=EUR:200.0&message=helloiban,
l'option message correspond à ce que
SEPA appelle unstructured remittance
information et instruction au
end to end identifier.
Puisqu'il y a une option permettant d'envoyer un message, la section 6 du RFC note qu'il n'y a pas de vrai mécanisme d'internationalisation, entre autres parce qu'on ne peut pas garantir de manière générale comment ce sera traité par les établissements de paiement.
Outre Bitcoin et IBAN, déjà vus, notre RFC enregistre plusieurs
autres types de mécanismes de paiement. ACH, BIC/Swift et UPI appartiennent au
monde bancaire classique. Le type ilp vient,
lui, du monde Internet, comme Bitcoin, est pour les paiements via
InterLedger, s'appuyant sur les adresses
InterLedger. Et il y a aussi un type
void, qui indique que le paiement se fera en
dehors du Web, par exemple en liquide.
Cette liste n'est pas fermée, mais est stockée dans un registre évolutif, registre peuplé selon la politique « Premier arrivé, premier servi ». Vous noterez que ce registre n'est pas géré par l'IANA mais par GANA.
La section 7 indique les critères
d'enregistrement souhaitables d'un nouveau type (les enregistrements
existants peuvent servir d'exemple) : fournir des références
précises, trouver un nom descriptif, préférer un nom neutre à celui
d'un organisme particulier, etc. J'ai regardé ces critères pour le
cas de PayPal, mécanisme de paiement très
répandu sur l'Internet, mais ce n'était pas évident. Même si on
spécifie des URI du genre
payto://paypal/smith@example.com, il ne serait
pas évident pour le navigateur de les traduire en une requête PayPal
(PayPal privilégie l'installation de son propre bouton actif, ou
bien le système PayPal.me). Bref, je n'ai pas continué mais si
quelqu'un de plus courageux veut enregistrer le type
paypal, il n'est pas nécessaire d'être
représentant officiel de PayPal, et ce n'est pas trop
difficile. Idem pour d'autres systèmes de paiement par encore
spécifiés comme Liberapay. Notez que le
système conçu par les auteurs du RFC, Taler,
n'est pas encore enregistré non plus.
L'article seul
RFC 8904: DNS Whitelist (DNSWL) Email Authentication Method Extension
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : A. Vesely
Pour information
Première rédaction de cet article le 18 septembre 2020
Le RFC 8601 décrit un en-tête pour le
courrier qui
indique le résultat d'une tentative
d'authentification. Cet en-tête Authentication-Results: permet
plusieurs méthodes d'authentification, telles que SPF ou DKIM. Notre nouveau
RFC 8904 ajoute une nouvelle méthode,
dnswl (pour DNS White List), qui indique le
résultat d'une lecture dans une liste blanche, ou liste
d'autorisation via le DNS. Ainsi, si le client SMTP avait son
adresse IP dans cette liste, un en-tête Authentication-Results: d'authentification
positive sera ajouté.
Accéder via le DNS à des listes blanches (autorisation) ou des
listes noires (rejet) de MTA est une pratique courante dans la gestion du
courrier. Elle
est décrite en détail dans le RFC 5782. Typiquement, le serveur SMTP qui voit une connexion entrante
forme un nom de domaine à partir de l'adresse IP du client SMTP et fait une requête DNS
pour ce nom et le type de données A (adresse IP). S'il obtient une
réponse non-nulle, c'est que l'adresse IP figurait dans la liste
(blanche ou noire). On peut aussi faire une requête de type TXT pour
avoir du texte d'information. Ensuite, c'est au serveur SMTP de
décider ce qu'il fait de l'information. La liste (noire ou blanche)
lui donne une information, c'est ensuite sa responsabilité de
décider s'il accepte ou rejette la connexion. La décision n'est pas
forcément binaire, le serveur peut décider d'utiliser cette
information comme entrée dans un algorithme de calcul de la
confiance (« il est listé dans bl.example, 20
points en moins dans le calcul »).
Les plus connues des listes sont les listes noires (liste de
clients SMTP mauvais) mais il existe aussi des listes blanches
(liste de clients SMTP qu'on connait et à qui on fait confiance), et
elles font l'objet de ce RFC. Il crée une nouvelle méthode pour
l'en-tête Authentication-Results:, permettant ainsi d'enregistrer, dans un message, le
fait qu'il ait été « authentifié » positivement via une liste
blanche. On peut après se servir de cette « authentification » pour,
par exemple, vérifier que le nom de
domaine annoncé dans l'enregistrement TXT correspondant
soit celui attendu (dans l'esprit de DMARC
- RFC 7489 - ce qui est d'ailleurs très
casse-gueule mais c'est une autre histoire).
Et le RFC fait un rappel utile : se servir d'une liste (noire ou blanche) gérée à l'extérieur, c'est sous-traiter. Cela peut être pratique mais cela peut aussi avoir des conséquences néfastes si la liste est mal gérée (comme le sont la plupart des listes noires, adeptes du « on tire d'abord et on négocie après »). Comme le dit le RFC, « vous épousez la politique du gérant de la liste ». Lisez aussi le RFC 6471, au sujet de la maintenance de ces listes.
La nouvelle méthode d'authentification
(dnswl, section 2 de notre RFC) figure
désormais dans le
registre IANA des méthodes d'authentification, spécifié dans
le RFC 8601 (notamment section 2.7). Notre
RFC 8904 décrit également les propriétés (RFC 8601, section 2.3 et RFC 7410) associées à cette authentification.
La méthode dnswl peut renvoyer
pass (cf. le RFC 8601
pour ces valeurs renvoyées), qui indique que l'adresse IP du client
est dans la liste blanche interrogée, none
(client absent de la liste), ou bien une erreur (si la résolution
DNS échoue). Contrairement à d'autres méthodes, il n'y a pas de
résultat fail, ce qui est logique pour une
liste blanche (qui liste les gentils et ne connait pas les
méchants). Les principales propriétés possibles sont :
dns.zone: le nom de domaine de la liste blanche,policy.ip: l'adresse IP renvoyée par la liste blanche, elle indique de manière codée les raisons pour lesquelles cette adresse est dans la liste,policy.txt: l'enregistrement TXT optionnel, peut indiquer le nom de domaine associé à ce client SMTP,dns.sec: indique si la requête DNS a été validée avec DNSSEC (yessi c'est le cas,nosi la zone n'est pas signée,nasi le résolveur ne sait pas valider).
Le type dns pour les propriétés est une
nouveauté de ce RFC, désormais enregistrée
à l'IANA.
La section 3 de notre RFC décrit l'enregistrement de type TXT qui donne des explications sur la raison pour laquelle l'adresse IP est dans la liste blanche (cf. RFC 5782, sections 2.1 et 2.2). Par exemple, il permet d'indiquer le domaine concerné (ADMD, ADministrative Management Domain, cf. RFC 8601 pour ce concept).
Tiré de l'annexe A du RFC, voici un exemple d'un message qui a
reçu un Authentication-Results:, qui contient les quatre propriétés indiquées plus haut :
Authentication-Results: mta.example.org;
dnswl=pass dns.zone=list.dnswl.example dns.sec=na
policy.ip=127.0.10.1
policy.txt="fwd.example https://dnswl.example/?d=fwd.example"
Il se lit ainsi : le MTA
mta.example.org estime son client authentifié
par la méthode dnswl (DNS White
List) de ce RFC. La liste blanche a renvoyé la valeur
127.0.10.1 (sa signification exacte dépend de
la liste blanche) et le TXT associé disait que le client SMTP
appartenait au domaine fwd.example.
Dans l'exemple plus détaillé du RFC, le message avait été
retransmis d'une manière qui cassait SPF et n'aurait donc pas été accepté sans la
liste blanche, qui certifie que fwd.example est
un retransmetteur connu et légitime.
Enfin, la section 5 du RFC traite de sécurité. Notamment, elle insiste sur le fait que le DNS n'est pas, par défaut, protégé contre diverses manipulations et qu'il est donc recommandé d'utiliser DNSSEC (ce que ne fait pas la liste blanche d'exemple citée plus loin).
Voyons maintenant des exemples avec une liste blanche réelle,
https://www.dnswl.org/2001:67c:2218:2::4:12. On inverse l'adresse
(par exemple, avec ipv6calc -a 2001:67c:2218:2::4:12) et
on fait une requête sous list.dnswl.org :
% dig A 2.1.0.0.4.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0.8.1.2.2.c.7.6.0.1.0.0.2.list.dnswl.org ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 1634 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 8, ADDITIONAL: 11 ... ;; ANSWER SECTION: 2.1.0.0.4.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0.8.1.2.2.c.7.6.0.1.0.0.2.list.dnswl.org. 7588 IN A 127.0.9.1 ... ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Sat Jul 04 09:16:37 CEST 2020 ;; MSG SIZE rcvd: 555
Que veut dire la valeur retournée, 127.0.9.1 ?
On consulte la
documentation de la liste et on voit que 9 veut dire
Media and Tech companies (ce qui est exact) et 1
low trustworthiness. Il s'agit de la confiance
dans le classement, pas dans le serveur. Pour le même serveur, la
confiance est plus grande en IPv4 (3 au lieu de 1) :
% dig A 12.4.134.192.list.dnswl.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 266
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
12.4.134.192.list.dnswl.org. 10788 IN A 127.0.9.3
...
;; Query time: 0 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Sat Jun 20 12:31:57 CEST 2020
;; MSG SIZE rcvd: 72
Et les enregistrements TXT ? Ici, il valent :
% dig TXT 2.1.0.0.4.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0.8.1.2.2.c.7.6.0.1.0.0.2.list.dnswl.org ... ;; ANSWER SECTION: 2.1.0.0.4.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0.8.1.2.2.c.7.6.0.1.0.0.2.list.dnswl.org. 8427 IN TXT "nic.fr https://dnswl.org/s/?s=8580"
En visant l'URL
indiquée, on peut avoir tous les détails que la liste blanche
connait de ce serveur. (Je n'ai pas investigué en détail mais j'ai
l'impression que certains serveurs faisant autorité pour le domaine
dnswl.org renvoient des NXDOMAIN à tort, par
exemple sur les ENT - Empty Non-Terminals - ce
qui pose problème si votre résolveur utilise une QNAME
minimisation - RFC 9156 - stricte.)
Pour utiliser cette liste blanche depuis votre MTA favori, vous pouvez regarder la documentation de dnswl.org. par exemple, pour Courier, ce sera :
-allow=list.dnswl.org
(Tous les détails dans la documentation de
Courier). Pour Postfix, voyez la section dédiée
dans la documentation de
dnswl.org. SpamAssassin, quant à lui,
utilise dnswl.org par défaut.
L'article seul
RFC 8903: Use cases for DDoS Open Threat Signaling
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : R. Dobbins (Arbor Networks), D. Migault (Ericsson), R. Moskowitz (HTT Consulting), N. Teague (Iron Mountain Data Centers), L. Xia (Huawei), K. Nishizuka (NTT Communications)
Pour information
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 31 mai 2021
Le travail autour de DOTS (DDoS Open Threat Signaling) vise à permettre la communication, pendant une attaque par déni de service, entre la victime et une organisation qui peut aider à atténuer l'attaque. Ce nouveau RFC décrit quelques scénarios d'utilisation de DOTS. Autrement, DOTS est normalisé dans les RFC 8811 et ses copains.
Si vous voulez un rappel du paysage des attaque par déni de service, et du rôle de DOTS (DDoS Open Threat Signaling) là-dedans, je vous recommande mon article sur le RFC 8612. Notre RFC 8903 ne fait que raconter les scénarios typiques qui motivent le projet DOTS.
Par exemple, pour commencer, un cas simple où le fournisseur d'accès Internet d'une organisation est également capable de fournir des solutions d'atténuation d'une attaque. Ce fournisseur (ITP dans le RFC, pour Internet Transit Provider) est sur le chemin de tous les paquets IP qui vont vers l'organisation victime, y compris ceux de l'attaque. Et il a déjà une relation contractuelle avec l'utilisateur. Ce fournisseur est donc bien placé, techniquement et juridiquement, pour atténuer une éventuelle attaque. Il peut déclencher le système d'atténuation, soit à la demande de son client qui subit une attaque, soit au contraire contre son client si celui-ci semble une source (peut-être involontaire) d'attaque. (Le RFC appelle le système d'atténuation DMS pour DDoS Mitigation Service ; certains opérateurs ont des noms plus amusants pour le DMS comme OVH qui parle d'« aspirateur ».)
Dans le cas d'une demande du client, victime d'une attaque et qui souhaite l'atténuer, le scénario typique sera qu'une machine chez le client (un pare-feu perfectionné, par exemple), établira une session DOTS avec le serveur DOTS inclus dans le DMS du fournisseur d'accès. Lorsqu'une attaque est détectée (cela peut être automatique, avec un seuil pré-défini, ou bien manuel), la machine du client demandera l'atténuation. Pendant l'atténuation, le client pourra obtenir des informations de la part du DMS du fournisseur. Si l'attaque se termine, le client pourra décider de demander l'arrêt de l'atténuation. Notez que la communication entre le client DOTS (chez la victime) et le serveur DOTS (chez le fournisseur d'accès) peut se faire sur le réseau « normal » (celui qui est attaqué) ou via un lien spécial, par exemple en 4G, ce qui sera plus cher et plus compliqué mais aura l'avantage de fonctionner même si l'attaque sature le lien normal.
Ce scénario simple peut aussi couvrir le cas du réseau domestique. On peut imaginer une box disposant de fonctions de détection d'attaques (peut-être en communiquant avec d'autres, comme le fait la Turris Omnia) et d'un client DOTS, pouvant activer automatiquement l'atténuation en contactant le serveur DOTS du FAI.
Le second cas envisagé est celui où le fournisseur d'accès n'a pas de service d'atténuation mais où le client (mettons qu'il s'agisse d'un hébergeur Web), craignant une attaque, a souscrit un contrat avec un atténuateur spécialisé (de nombreuses organisations ont aujourd'hui ce genre de services, y compris sans but lucratif). Dans ce cas, il faudra « détourner » le trafic vers cet atténuateur, avec des trucs DNS ou BGP, qui sont sans doute hors de portée de la petite ou moyenne organisation. L'accord avec l'atténuateur doit prévoir la technique à utiliser en cas d'attaque. Si c'est le DNS, la victime va changer ses enregistrements DNS pour pointer vers les adresses IP de l'atténuateur (attention au TTL). Si c'est BGP, ce sera à l'atténuateur de commencer à annoncer le préfixe du client (attention aux règles de sécurité BGP, pensez IRR et ROA), et au client d'arrêter son annonce. Le reste se passe comme dans le scénario précédent.
L'article seul
RFC 8901: Multi-Signer DNSSEC Models
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : S. Huque, P. Aras (Salesforce), J. Dickinson (Sinodun), J. Vcelak (NS1), D. Blacka (Verisign)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 25 septembre 2020
Aujourd'hui, il est courant de confier l'hébergement de ses serveurs DNS faisant autorité à un sous-traitant. Mais si vous avez, comme c'est recommandé, plusieurs sous-traitants et qu'en prime votre zone, comme c'est recommandé, est signée avec DNSSEC ? Comment s'assurer que tous les sous-traitants ont bien l'information nécessaire ? S'ils utilisent le protocole standard du DNS pour transférer la zone, tout va bien. Mais hélas beaucoup d'hébergeurs ne permettent pas l'utilisation de cette norme. Que faire dans ce cas ? Ce nouveau RFC explique les pistes menant à des solutions possibles.
Pourquoi est-ce que des hébergeurs DNS ne permettent pas d'utiliser la solution normalisée et correcte, les transferts de zone du RFC 5936 ? Il peut y avoir de mauvaises raisons (la volonté d'enfermer l'utilisateur dans un silo, en lui rendant plus difficile d'aller voir la concurrence) mais aussi des (plus ou moins) bonnes raisons :
- Si l'hébergeur signe dynamiquement les données DNS,
- Si l'hébergeur produit dynamiquement des données DNS (ce qui implique de les signer en ligne),
- Si l'hébergeur utilise des trucs non-standards, par exemple pour mettre un CNAME à l'apex d'une zone.
Dans ces cas, le transfert de zones classique n'est pas une solution, puisqu'il ne permet pas de transmettre, par exemple, les instructions pour la génération dynamique de données.
Résultat, bien des titulaires de noms de domaine se limitent donc à un seul hébergeur, ce qui réduit la robustesse de leur zone face aux pannes… ou face aux conflits commerciaux avec leur hébergeur.
La section 2 de notre RFC décrit les modèles possibles pour avoir à
la fois DNSSEC et plusieurs
hébergeurs. Si aucune des trois raisons citées plus haut ne
s'applique, le cas est simple : un hébergeur (qui peut être le
titulaire lui-même, par exemple avec un serveur maître caché) signe
la zone, et elle est transférée ensuite, avec clés et signatures,
vers les autres. C'est tout simple. (Pour information, c'est par
exemple ainsi que fonctionne
.fr, qui a plusieurs
hébergeurs en plus de l'AFNIC : les serveurs dont le nom comprend
un « ext » sont sous-traités.)
Mais si une ou davantage des trois (plus ou moins bonnes) raisons citées plus haut s'applique ? Là, pas de AXFR (RFC 5936), il faut trouver d'autres modèles. (Et je vous préviens tout de suite : aucun de ces modèles n'est géré par les logiciels existants, il va falloir faire du devops.) Celui présenté dans le RFC est celui des signeurs multiples. Chaque hébergeur reçoit les données non-signées par un mécanime quelconque (par exemple son API) et les signe lui-même avec ses clés, plus exactement avec sa ZSK (Zone Signing Key). Pour que tous les résolveurs validants puissent valider ces signatures, il faut que l'ensemble des clés, le DNSKEY de la zone, inclus les ZSK de tous les hébergeurs de la zone. (Un résolveur peut obtenir les signatures d'un hébergeur et les clés d'un autre.) Comment faire en sorte que tous les hébergeurs reçoivent les clés de tous les autres, pour les inclure dans le DNSKEY qu'ils servent ? Il n'existe pas de protocole pour cela, et le problème n'est pas purement technique, il est également que ces hébergeurs n'ont pas de relation entre eux. C'est donc au titulaire de la zone d'assurer cette synchronisation. (Un peu de Python ou de Perl avec les API des hébergeurs…)
Il y a deux variantes de ce modèle : KSK unique (Key Signing Key) et partagée, ou bien KSK différente par hébergeur. Voyons d'abord la première variante, avec une seule KSK. Elle est typiquement gérée par le titulaire de la zone, qui est responsable de la gestion de la clé privée, et d'envoyer l'enregistrement DS à la zone parente. Par contre, chaque hébergeur a sa ZSK et signe les données. Le titulaire récupère ces ZSK (par exemple via une API de l'hébergeur) et crée l'ensemble DNSKEY, qu'il signe. (Le RFC note qu'il y a un cas particulier intéressant de ce modèle, celui où il n'y a qu'un seul hébergeur, par exemple parce que le titulaire veut garder le contrôle de la KSK mais pas gérer les serveurs de noms.)
Deuxième variante du modèle : chaque hébergeur a sa KSK (et sa ZSK). Il ouvre son API aux autres hébergeurs pour que chacun connaisse les ZSK des autres et puisse les inclure dans l'ensemble DNSKEY. Le titulaire doit récolter toutes les KSK, pour envoyer les DS correspondants à la zone parente. Le remplacement d'une KSK (rollover) nécessite une bonne coordination.
Dans ces deux modèles, chaque serveur faisant autorité connait toutes les ZSK utilisées, et un résolveur validant récupérera forcément la clé permettant la validation, quel que soit le serveur faisant autorité interrogé, et quelle que soit la signature que le résolveur avait obtenue (section 3 du RFC). À noter qu'il faut que tous les hébergeurs utilisent le même algorithme de signature (section 4 du RFC) puisque la section 2.2 du RFC 4035 impose de signer avec tous les algorithmes présents dans l'ensemble DNSKEY.
En revanche, les hébergeurs ne sont pas forcés d'utiliser le même mécanisme de déni d'existence (NSEC ou NSEC3, cf. RFC 7129). Chacun peut faire comme il veut (section 5 de notre RFC) puisqu'une réponse négative est toujours accompagnée de ses NSEC (ou NSEC3). Évidemment, si un hébergeur utilise NSEC et un autre NSEC3, le gain en sécurité de NSEC3 sera inutile.
Comme signalé plus haut, le remplacement (rollover) des clés, déjà une opération compliquée en temps normal, va être délicat. La section 6 du RFC détaille les procédures que l'on peut suivre dans les cas « une seule KSK » et « une KSK par hébergeur ».
La discussion plus haut supposait qu'il y avait deux clés, la KSK et la ZSK, ce qui est le mode le plus fréquent d'organisation des clés. Mais ce n'est pas obligatoire : on peut avec n'avoir qu'une seule clé (baptisée alors CSK, pour Common Signing Key). Dans ce cas, il n'y a qu'un seul modèle possible, chaque hébergeur a sa CSK. Cela ressemble au modèle « une KSK par hébergeur » : le titulaire de la zone doit récolter toutes les CSK et envoyer les DS correspondants à la zone parente (section 7 du RFC).
Cette configuration DNSSEC à plusieurs signeurs peut fonctionner avec les enregistrements CDS et CDNSKEY des RFC 7344 et RFC 8078 (section 8 de notre RFC). Dans le premier modèle « une seule KSK », le titulaire de la zone crée CDS et/ou CDNSKEY qu'il envoie à tous les hébergeurs avec les autres données. Dans le deuxième modèle « une KSK par hébergeur », il faut échanger les CDS et/ou CDNSKEY pour que chaque hébergeur ait les enregistrements des autres.
On voit que dans cette configuration, il est nécessaire de communiquer, au moins entre le titulaire de la zone et ses hébergeurs. Ces hébergeurs doivent fournir une API, typiquement de type REST. Notre RFC ne normalise pas une telle API mais sa section 9 indique les fonctions minimum qu'elle doit fournir :
- Permettre de récupérer les enregistrements DNSKEY (pour obtenir la ZSK),
- Pour le premier modèle (une seule KSK), permettre d'indiquer l'ensemble DNSKEY complet et signé,
- Pour le deuxième modèle, permettre d'indiquer les ZSK des autres hébergeurs,
- Et idem pour les CDS et CDNSKEY.
Autre problème pratique avec la co-existence de plusieurs hébergeurs DNS, qui signent eux-mêmes la zone, la taille des réponses. Comme il faut inclure toutes les ZSK dans l'ensemble DNSKEY, les réponses aux requêtes DNSKEY vont forcément être d'assez grande taille (section 10). Le RFC fait remarquer que les algorithmes cryptographiques utilisant les courbes elliptiques ont des clés plus courtes et que cela peut aider.
Enfin, dans la section 12, dédiée aux questions de sécurité restantes, le RFC note que ces mécanismes à plusieurs signeurs nécessitent d'avoir confiance dans chacun des signeurs. Au contraire, le système où le maître signe tout et transfère ensuite aux serveurs esclaves ne demande aucune confiance dans les hébergeurs.
Allez, un joli dessin pour terminer (trouvé
ici) : 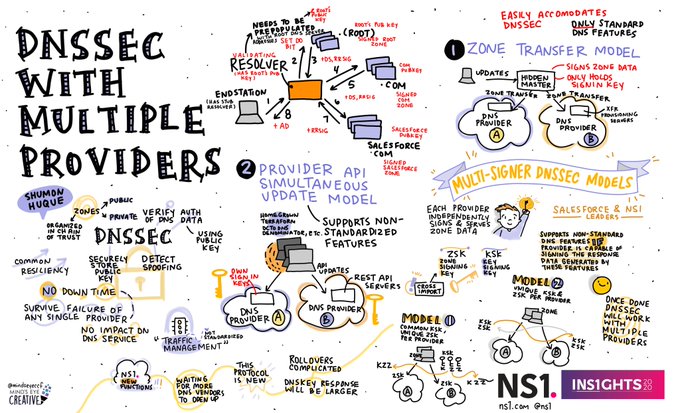 .
.
L'article seul
RFC 8900: IP Fragmentation Considered Fragile
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : R. Bonica (Juniper Networks), F. Baker, G. Huston (APNIC), R. Hinden (Check Point Software), O. Troan (Cisco), F. Gont (SI6 Networks)
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 12 septembre 2020
Un concept important d'IP est la fragmentation, le découpage d'un paquet trop gros en plusieurs fragments, chacun acheminé dans un datagramme différent. Excellente idée sur le papier, la fragmentation est handicapée, dans l'Internet actuel, par les nombreuses erreurs de configuration de diverses middleboxes. Ce nouveau RFC constate la triste réalité : en pratique, la fragmentation marche mal, et les machines qui émettent les paquets devraient essayer de faire en sorte qu'elle ne soit pas utilisée.
Rappelons d'abord ce qu'est la fragmentation, dans IP. Tout lien entre deux machines a une MTU, la taille maximale des datagrammes qui peuvent passer. C'est par exemple 1 500 octets pour l'Ethernet classique. Si le paquet IP est plus grand, il faudra le fragmenter, c'est-à-dire le découper en plusieurs fragments, chacun de taille inférieure à la MTU. En IPv4, n'importe quel routeur sur le trajet peut fragmenter un paquet (sauf si le bit DF - Don't Fragment - est mis à un dans l'en-tête IP), en IPv6, seule la machine émettrice peut fragmenter (tout ce passe comme si DF était systématiquement présent).
Ces fragments seront ensuite réassemblés en un paquet à la destination. Chacun étant transporté dans un datagramme IP différent, ils auront pu arriver dans le désordre, certains fragments ont même pu être perdus, le réassemblage est donc une opération non-triviale. Historiquement, certaines bogues dans le code de réassemblage ont même pu mener à des failles de sécurité.
Une légende urbaine s'est constituée petit à petit, racontant que les fragments, en eux-mêmes, posaient un problème de sécurité. C'est faux, mais ce genre de légendes a la vie dure, et a mené un certain nombre d'administrateurs de pare-feux à bloquer les fragments. Le RFC 7872 faisait déjà le constat que les fragments, souvent, n'arrivaient pas à destination. Outre ce RFC, on peut citer une étude très ancienne, qui montre que le problème ne date pas d'aujourd'hui, « "Fragmentation Considered Harmful (SIGCOMM '87 Workshop on Frontiers in Computer Communications Technology) ou, pour le cas spécifique du DNS, la plus récente « IPv6, Large UDP Packets and the DNS ».
La section 2 de notre RFC explique en grand détail la fragmentation IP. Notez par exemple qu'IPv4 impose (RFC 791, section 3.2) une MTU minimale de 68 octets mais, en pratique, on a toujours au moins 576 octets (ou, sinon, une autre fragmentation/réassemblage, dans la couche 2). IPv6, lui, impose (RFC 8200), 1 280 octets. Il a même été suggéré de ne jamais envoyer de paquets plus grands, pour éviter la fragmentation. Un Ethernet typique offre une MTU de 1 500 octets, mais elle peut être réduite par la suite en cas d'utilisation de tunnels.
Chaque lien a sa MTU mais ce qui est important, pour le paquet, c'est la MTU du chemin (Path MTU), c'est-à-dire la plus petite des MTU rencontrées sur le chemin entre le départ et l'arrivée. C'est cette MTU du chemin qui déterminera si on fragmentera ou pas. (Attention, le routage étant dynamique, cette MTU du chemin peut changer dans le temps.) Il est donc intéressant, pour la machine émettrice d'un paquet, de déterminer cette MTU du chemin. Cela peut se faire en envoyant des paquets avec le bit DF (Don't Fragment, qui est implicite en IPv6) et en regardant les paquets ICMP renvoyés par les routeurs, indiquant que la MTU est trop faible pour ce paquet (et, depuis le RFC 1191, le message ICMP indique la MTU du lien suivant, ce qui évite de la deviner par essais/erreurs successifs.) Cette procédure est décrite dans les RFC 1191 et RFC 8201. Mais (et c'est un gros mais), cela suppose que les erreurs ICMP « Packet Too Big » arrivent bien à l'émetteur et, hélas, beaucoup de pare-feux configurés par des ignorants bloquent ces messages ICMP. D'autre part, les messages ICMP ne sont pas authentifiés (RFC 5927) et un attaquant peut générer de fausses erreurs ICMP pour faire croire à une diminution de la MTU du chemin, affectant indirectement les performances. (Une MTU plus faible implique des paquets plus petits, donc davantage de paquets.)
Quand une machine fragmente un paquet (en IPv4, cette machine peut être l'émetteur ou un routeur intermédiaire, en IPv6, c'est forcément l'émetteur), elle crée plusieurs fragments, dont seul le premier porte les informations des couches supérieures, comme le fait qu'on utilise UDP ou TCP, ou bien le numéro de port. La description détaillée figure dans le RFC 791 pour IPv4 et dans le RFC 8200 (notamment la section 4.5) pour IPv6.
Voici un exemple où la fragmentation a eu lieu, vu par
tcpdump (vous pouvez récupérer le
pcap complet en dns-frag-md.pcap2605:4500:2:245b::bad:dcaf a fait une requête
DNS à 2607:5300:201:3100::2f69, qui est un des
serveurs faisant autorité pour le TLD
.md. La réponse a dû
être fragmentée en deux :
% tcpdump -e -n -r dns-frag-md.pcap 16:53:07.968917 length 105: 2605:4500:2:245b::bad:dcaf.44104 > 2607:5300:201:3100::2f69.53: 65002+ [1au] ANY? md. (43) 16:53:07.994555 length 1510: 2607:5300:201:3100::2f69 > 2605:4500:2:245b::bad:dcaf: frag (0|1448) 53 > 44104: 65002*- 15/0/16 SOA, RRSIG, Type51, RRSIG, RRSIG, DNSKEY, DNSKEY, RRSIG, NS dns-md.rotld.ro., NS nsfr.dns.md., NS nsb.dns.md., NS ns-ext.isc.org., NS nsca.dns.md., NS ns-int.dns.md., RRSIG (1440) 16:53:07.994585 length 321: 2607:5300:201:3100::2f69 > 2605:4500:2:245b::bad:dcaf: frag (1448|259)
Le premier paquet est la requête, le second est le premier fragment de la réponse (qui va des octets 0 à 1447), le troisième paquet est le second fragment de cette même réponse (octets 1448 à la fin). Regardez les longueur des paquets IP, et le fait que seul le premier fragment, qui porte l'en-tête UDP, a pu être interprété comme étant du DNS.
Notez que certaines versions de traceroute
ont une option qui permet d'afficher la MTU du lien (par exemple
traceroute -n --mtu IP-ADDRESS.)
Les couches supérieures (par exemple UDP ou TCP) peuvent ignorer ces questions et juste envoyer leurs paquets, comptant qu'IP fera son travail, ou bien elles peuvent tenir compte de la MTU du chemin, par exemple pour optimiser le débit, en n'envoyant que des paquets assez petits pour ne pas être fragmentés. Cela veut dire qu'elles ont accès au mécanisme de découverte de la MTU du chemin, ou bien qu'elles font leur propre découverte, via la procédure PLPMTUD (Packetization Layer Path MTU Discovery) du RFC 4821 (qui a l'avantage de ne pas dépendre de la bonne réception des paquets ICMP).
Bon, maintenant qu'on a vu la framentation, voyons les difficultés qui surviennent dans l'Internet d'aujourd'hui (section 3 du RFC). D'abord, chez les pare-feux et, d'une manière générale, tous les équipements intermédiaires qui prennent des décisions en fonction de critères au-dessus de la couche 3, par exemple un répartiteur de charge, ou un routeur qui enverrait les paquets à destination du port 443 vers un autre chemin que le reste des paquets. Ces décisions dépendent d'informations qui ne sont que dans le premier fragment d'un datagramme fragmenté. Décider du sort des fragments suivants n'est pas évident, surtout si on veut le faire sans maintenir d'état. Un pare-feu sans état peut toujours essayer d'accepter tous les fragments ultérieurs (ce qui pourrait potentiellement autoriser certaines attaques) ou bien tous les bloquer (ce qui arrêterait du trafic légitime fragmenté). Et les pare-feux avec état ne sont pas une solution idéale, puisque stocker et maintenir cet état est un gros travail, qui plante souvent, notamment en cas d'attaque par déni de service.
Certains types de NAT ont également des problèmes avec la fragmentation. Ainsi, les techniques A+P (RFC 6346) et CGN (RFC 6888) nécessitent toutes les deux que les fragments soient réassemblés en un seul paquet, avant de traduire.
Qui dit fragmentation dit réassemblage à un moment. C'est une opération délicate, et plusieurs programmeurs se sont déjà plantés en réassemblant sans prendre de précautions. Mais il y a aussi un problème de performance. Et il y a les limites d'IPv4. L'identificateur d'un fragment ne fait que 16 bits et cela peut mener rapidement à des réutilisations de cet identificateur, et donc à des réassemblages incorrects (les sommes de contrôle de TCP et UDP ne sont pas toujours suffisantes pour détecter ces erreurs, cf. RFC 4693). IPv6, heureusement, n'a pas ce problème, l'identificateur de fragment faisant 32 bits.
On l'a dit plus haut, la fragmentation, et surtout le réassemblage, ont une longue histoire de failles de sécurité liées à une lecture trop rapide du RFC par le programmeur qui a écrit le code de réassemblage. Ainsi, les fragments recouvrants sont un grand classique, décrits dans les RFC 1858, RFC 3128 et RFC 5722. Normalement, le récepteur doit être paranoïaque, et ne pas faire une confiance aveugle aux décalages (offset) indiqués dans les paquets entrants, mais tous les programmeurs ne sont pas prudents. Il y a aussi le risque d'épuisement des ressources, puisque le récepteur doit garder en mémoire (le réassemblage implique le maintien d'un état) les fragments pas encore réassemblés. Un attaquant peut donc épuiser la mémoire en envoyant des fragments d'un datagramme qui ne sera jamais complet. Et il y a des identificateurs de fragment non-aléatoires, qui permettent d'autres attaques, documentées dans le RFC 7739 ou dans des articles comme « Fragmentation Considered Poisonous de Herzberg et Shulman (cf. aussi mon résumé). Enfin, la fragmentation peut aider à échapper au regard des IDS (cf. « Insertion, Evasion and Denial of Service: Eluding Network Intrusion Detection »).
Un autre problème très fréquent avec la fragmentation est causé par la configuration erronée de pare-feux. Souvent, des administrateurs réseau incompétents bloquent les messages ICMP Packet Too Big, nécessaires pour la découverte de la MTU du chemin. C'est de leur part une grosse erreur (expliquée dans le RFC 4890) mais cela arrive trop souvent. Résultat, si la MTU du chemin est inférieure à la MTU du premier lien, la machine émettrice envoie des paquets trop gros, et ne sait pas que ces paquets n'ont pas pu passer. On a donc créé un trou noir (les paquets disparaissent sans laisser de trace).
Ce bloquage injustifié des messages ICMP peut également être dû à des causes plus subtiles. Par exemple, si un pare-feu laisse sortir tous les paquets mais, en entrée, n'autorise que les paquets dont l'adresse IP source a été utilisée comme destination récemment, alors, les erreurs ICMP, émises par des routeurs intermédiaires et ayant donc une adresse IP source jamais vue, seront jetées. Notre RFC note que cette bogue dans les pare-feux est apparemment assez fréquente dans les boxes.
Toujours côté mauvaise configuration, le RFC cite aussi le problème des routeurs qui jettent les paquets ayant options ou extensions qu'ils ne connaissent pas, ce qui peut inclure les fragments. L'analyse du RFC 7872, ou celle dans l'article de Huston « IPv6, Large UDP Packets and the DNS », montre bien que ce problème est fréquent, trop fréquent. Ainsi, même si la découverte de la MTU du chemin se passe bien, les fragments n'arriveront pas à destination. Pourquoi cette mauvaise configuration ? C'est évidemment difficile à dire, cela peut aller de logiciels bogués jusqu'à un choix délibéré d'un administrateur réseau ignorant qui a vaguement entendu une légende urbaine du genre « les fragments sont un risque de sécurité ».
Dans les cas précédents, la perte du message ICMP Packet Too Big était clairement de la faute d'un humain, l'administrateur du pare-feu. Mais il peut y avoir des obstacles plus fondamentaux au bon fonctionnement de la découverte de la MTU du chemin. Par exemple, si un serveur DNS anycasté envoie un paquet trop gros, et qu'un routeur intermédiaire envoie le message Packet Too Big, ledit message ira vers l'adresse anycast du serveur, et atterrira peut-être vers une autre instance du serveur DNS, si le routeur qui a signalé le problème n'est pas dans le même bassin d'attraction que le client original. Le message ICMP ne sera donc pas reçu par l'instance qui aurait eu besoin de l'information. Le problème est d'autant plus génant que le DNS est le plus gros utilisateur d'UDP, et est donc particulièrement sensible aux problèmes de fragmentation (TCP gère mieux ces problèmes, avec la négociation de MSS).
Une variante du problème anycast survient lorsque le routage est unidirectionnel. Si l'émetteur n'est pas joignable, il ne recevra pas les messages ICMP. (Le cas est cité par le RFC mais me semble peu convaincant ; il y a peu de protocoles où l'émetteur peut se passer de recevoir des réponses. Et beaucoup de routeurs jettent les paquets pour lesquels ils n'ont pas de voie de retour, cf. RFC 3704.)
Maintenant qu'on a présenté en détail les problèmes liés à la fragmentation IP dans l'Internet actuel, quelles sont les approches possibles pour traiter ce problème ? La section 4 du RFC les présente. D'abord, les solutions situées dans la couche Transport. Comme indiqué plus haut, TCP peut éviter la fragmentation en découpant les données en segments dont chacun a une taille inférieure à la MTU du chemin (paramètre MSS, Maximum Segment Size). Cela suppose que la MSS soit réglée à une telle valeur (cf. mon article). Cela peut être manuel (si on sait qu'on va toujours passer par un tunnel avec faible MTU, on peut toujours configurer sa machine pour réduire la MSS), cela peut utiliser la procédure classique de découverte de la MTU du chemin ou bien cela peut utiliser la découverte de MTU sans ICMP du RFC 4821. D'autres protocoles que TCP peuvent fonctionner ainsi, comme DCCP (RFC 4340) ou SCTP (RFC 9260). À noter qu'UDP, lui, n'a pas de tel mécanisme, même si des travaux sont en cours pour cela (ils ont débouché sur le RFC 9869).
Pour TCP, la méthode manuelle se nomme TCP clamping et peut se faire, par exemple avec Netfilter en mettant sur le routeur :
% iptables -t mangle -A FORWARD -p tcp -m tcp --tcp-flags SYN,RST SYN \
-j TCPMSS --clamp-mss-to-pmtu
La méthode avec ICMP, on l'a vu, est fragile car les messages ICMP peuvent être bloqués. La méthode sans ICMP consiste pour TCP, en cas de détection de perte de paquets, à envoyer des paquets plus petits pour essayer de s'ajuster à la MTU du chemin. (Bien sûr, des paquets peuvent se perdre pour d'autres raisons que la MTU trop basse, et la mise en œuvre de cette technique est donc délicate.)
Autre solution, plutôt que d'impliquer la couche Transport, faire appel à la couche Application. Le RFC 8085 conseille aux applications qui font de l'UDP d'essayer d'éviter la fragmentation. Par exemple, si vous gérez un serveur DNS avec NSD, cela peut se faire en mettant dans le fichier de configuration :
ipv4-edns-size: 1432 ipv6-edns-size: 1432
Vous pouvez voir le résultat sur, par exemple, un des serveurs
faisant autorité pour .bostik :
% dig +ignore @d.nic.fr DNSKEY bostik
; <<>> DiG 9.11.5-P4-5.1-Debian <<>> +ignore @d.nic.fr DNSKEY bostik
; (2 servers found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 12029
;; flags: qr aa tc rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 1432
; COOKIE: ef8669d08e2d9b26bb1a8ab85e21830a8931f9ab23403def (good)
;; QUESTION SECTION:
;bostik. IN DNSKEY
;; Query time: 2 msec
;; SERVER: 2001:678:c::1#53(2001:678:c::1)
;; WHEN: Fri Jan 17 10:48:58 CET 2020
;; MSG SIZE rcvd: 63
Vous voyez que le serveur n'envoie pas de réponses de taille
supérieure à 1 432 octets (la OPT
PSEUDOSECTION). Au moment du test, la réponse faisait
1 461 octets, d'où le flag
tc (TRuncated). Normalement,
un client DNS, voyant que la réponse a été tronquée, réessaie en TCP
(j'ai mis l'option +ignore à dig pour empêcher
cela et illustrer le fonctionnement du DNS.)
En parlant du DNS, la section 5 du RFC liste des applications pour lesquelles la fragmentation joue un rôle important :
- Le DNS utilise encore largement UDP (malgré le RFC 7766) et, notamment avec DNSSEC, les réponses peuvent nettement excéder la MTU typique. C'est en général le premier protocole qui souffre, quand la fragmentation ne marche pas, d'autant plus que la grande majorité des échanges sur l'Internet commence par des requêtes DNS. Le client DNS peut limiter la taille des données envoyées, via EDNS (RFC 6891) et le serveur peut également avoir sa propre limite. Le serveur qui n'a pas la place de tout mettre dans la réponse peut, dans certains cas, limiter les données envoyées (en omettant les adresses de colle, par exemple) et si ça ne suffit pas, indiquer que la réponse est tronquée, ce qui doit mener le client à réessayer avec TCP (que tout le monde devrait gérer mais certains clients et certains serveurs, ou plutôt leurs réseaux, ont des problèmes avec TCP, comme illustré dans « Measuring ATR »). L'importance de la fragmentation pour le DNS fait que le DNS Flag Day de 2020 est consacré à ce sujet.
- Le protocole de routage OSPF utilise également UDP mais le problème est moins grave, car c'est un protocole interne, pas utilisé sur l'Internet public, l'administrateur réseau peut donc en général s'assurer que la fragmentation se passera bien. Et, de toute façon, la plupart des mises en œuvre d'OSPF limitent la taille de leurs messages pour être sûr de rester en dessous de la MTU.
- L'encapsulation des paquets IP (pas vraiment la couche Application mais quand même un usage répandu) peut également créer des problèmes avec la fragmentation (cf. RFC 4459.) Cela concerne des protocoles comme IP-in-IP (RFC 2003), GRE (RFC 2784 et RFC 8086), et d'autres. Le RFC 7588 décrit une stratégie générale pour ces protocoles.
- Le RFC note que certains protocoles, pour des raisons de performance, assument tout à fait d'envoyer de très grands paquets et donc de compter sur une fragmentation qui marche. Ce sont notamment des protocoles qui sont conçus pour des milieux très particuliers, comme LTP (RFC 5326) qui doit fonctionner en présence d'énormes latences.
Compte-tenu de tout ceci, quelles recommandations concrètes donner ? Cela dépend évidemment du public cible. La section 6 de notre RFC donne des conseils pour les concepteurs et conceptrices de protocoles et pour les différents types de développeurs et développeuses qui vont programmer des parties différentes du système. D'abord, les protocoles, sujet principal pour l'IETF. Compte-tenu des importants problèmes pratiques que pose la fragmentation dans l'Internet actuel, le RFC prend une décision douloureuse : plutôt que de chercher à réparer l'Internet, on jette l'éponge et on ne conçoit plus de protocoles qui dépendent de la fragmentation. De tels protocoles ne seraient raisonnables que dans des environnements fermés et contrôlés. Comme souvent à l'IETF, le choix était difficile car il faut choisir entre les principes (la fragmentation fait partie d'IP, les composants de l'Internet ne doivent pas l'empêcher) et la réalité d'un monde de middleboxes mal programmées et mal gérées. Comme pour la décision de faire passer beaucoup de nouveaux protocoles sur HTTPS, le choix ici a été de prendre acte de l'ossification de l'Internet, et de s'y résigner.
Pour ne pas dépendre de la fragmentation, les nouveaux protocoles peuvent utiliser une MTU suffisamment petite pour passer partout, ou bien utiliser un système de découverte de la MTU du chemin suffisamment fiable, comme celui du RFC 4821. Pour UDP, le RFC renvoie aux recommandations de la section 3.2 du RFC 8085.
Ensuite, les conseils aux programmeurs et programmeuses. D'abord, dans les systèmes d'exploitation. Le RFC demande que la PLPMTUD (RFC 8899) soit disponible dans les bibliothèques proposées aux applications.
Ensuite, pour ceux et celles qui programment les middleboxes, le RFC rappelle quand même qu'elles doivent respecter les RFC sur IPv4 (RFC 791) et IPv6 (RFC 8200). Pour beaucoup de fonctions assurées par ces boitiers (comme le filtrage), cela implique de réassembler les paquets fragmentés, et donc de maintenir un état. Les systèmes avec état sont plus compliqués et plus chers (il faut davantage de mémoire) ce qui motive parfois à préférer les systèmes sans état. Ceux-là n'ont que deux choix pour gérer la fragmentation : violer les RFC ou bien jeter tous les fragments. Évidemment, aucune de ces deux options n'est acceptable. Le RFC demande qu'au minimum, si on massacre le protocole IP, cela soit documenté. (Ces middleboxes sont souvent traitées comme des boites noires, installées sans les comprendre et sans pouvoir déboguer les conséquences.)
Enfin, les opérateurs des réseaux doivent s'assurer que la PMTUD fonctionne, donc émettre des Packet Too Big si le paquet est plus gros que la MTU, et ne pas bloquer les paquets ICMP. Notre RFC permet toutefois de limiter leur rythme (RFC 1812 et RFC 4443). En tout cas, comme le rappelle le RFC 4890, filtrer les paquets ICMP Packet Too Big est mal !
De la même façon, le RFC rappelle aux opérateurs réseau qu'on ne doit pas filtrer les fragments. Ils sont utiles et légitimes.
Notez que les recommandations de ce RFC peuvent sembler contradictoires : on reconnait que la fragmentation marche mal et qu'il ne faut donc pas compter dessus mais, en même temps, on rappelle qu'il faut se battre pour qu'elle marche mieux. En fait, il n'y a pas de contradiction, juste du réalisme. L'Internet n'ayant pas de Chef Suprême qui coordonne tout, on ne peut pas espérer qu'une recommandation de l'IETF soit déployée immédiatement partout. On se bat donc pour améliorer les choses (ne pas bloquer les fragments, ne pas bloquer les messages ICMP Packet Too Big) tout en étant conscient que ça ne marchera pas à 100 % et que les administrateurs système et réseau doivent en être conscients.
L'article seul
RFC 8899: Packetization Layer Path MTU Discovery for Datagram Transports
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : G. Fairhurst, T. Jones (University of Aberdeen), M. Tuexen, I. Ruengeler, T. Voelker (Muenster University of Applied Sciences)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 12 septembre 2020
Ce RFC qui vient d'être publié décrit une méthode pour découvrir la MTU d'un chemin sur l'Internet (Path MTU, la découverte de la MTU du chemin se nommant PMTUD pour Path MTU Discovery). Il existe d'autres méthodes pour cette découverte, comme celle des RFC 1191 et RFC 8201, qui utilisent ICMP. Ici, la méthode ne dépend pas d'ICMP, et se fait avec les datagrammes normaux de la couche 4 (ou PL, pour Packetization Layer). Elle étend la technique du RFC 4821 à d'autres protocoles de transport que TCP (et SCTP).
Mais, d'abord, pourquoi est-ce important de découvrir la MTU maximale du chemin ? Parce que, si on émet des paquets qui sont plus gros que cette MTU du chemin, ces paquets seront jetés, au grand dam de la communication. En théorie, le routeur qui prend cette décision devrait fragmenter le paquet (IPv4 seulement), ou bien envoyer à l'expéditeur un message ICMP Packet Too Big mais ces fragments, et ces messages ICMP sont souvent bloqués par de stupides pare-feux mal gérés (ce qu'on nomme un trou noir). On ne peut donc pas compter dessus, et ce problème est connu depuis longtemps (RFC 2923, il y a vingt ans, ce qui est une durée insuffisante pour que les administrateurs de pare-feux apprennent leur métier, malgré le RFC 4890). La seule solution fiable est de découvrir la MTU du chemin, en envoyant des paquets de plus en plus gros, jusqu'à ce que ça ne passe plus, montrant ainsi qu'on a découvert la MTU.
Le RFC donne aussi quelques raisons plus subtiles pour lesquelles la découverte classique de la MTU du chemin ne marche pas toujours. Par exemple, s'il y a un tunnel sur le trajet, c'est le point d'entrée du tunnel qui recevra le message ICMP Packet Too Big, et il peut faillir à sa tâche de le faire suivre à l'émetteur du paquet. Ou bien, en cas de routage asymétrique, le message ICMP peut être jeté car il n'y a pas de route de retour.
Et ce n'est pas tout que le message ICMP revienne à l'émetteur, encore faut-il que celui-ci l'accepte. Les messages ICMP n'étant pas authentifiés, une machine prudente va essayer de les valider, en examinant le paquet originel contenu dans le message ICMP, et en essayant de voir s'il correspond à du trafic en cours. Si le routeur qui émet le message ICMP n'inclut pas assez du paquet original (malgré ce que demande le RFC 1812) pour que cette validation soit possible, le message ICMP « Vous avez un problème de taille » sera jeté par l'émetteur du paquet original. Et il peut y avoir d'autres problèmes, par exemple avec le NAT (cf. RFC 5508). Autant de raisons supplémentaires qui font que la découverte de la MTU du chemin ne peut pas compter sur les messages ICMP.
Notre RFC utilise le terme de couche de découpage en paquets (Packetization Layer, PL). Il désigne la couche où les données sont séparées en paquets qui seront soumis à IP. C'est en général la couche de transport (protocoles TCP, DCCP, SCTP, etc) mais cela peut aussi être fait au-dessus de celle-ci. Ce sigle PL donne naissance au sigle PLPMTUD, Packetization Layer Path MTU Discovery. Contrairement à la classique PMTUD (Path MTU Discovery) des RFC 1191 et RFC 8201, la PLPMTUD ne dépend pas des messages ICMP. C'est la PL, la couche de découpage en paquets qui se charge de trouver la bonne taille, en envoyant des données et en regardant lesquelles arrivent. La PLPMTUD est plus solide que la traditionnelle PMTUD, qui est handicapée par le blocage fréquent d'ICMP (cf. RFC 4821, qui a introduit ce terme de PLPMTUD, et RFC 8085).
La découverte de la MTU du chemin par le PL est ancienne pour TCP (RFC 4821). Et pour les autres protocoles de transport ? C'est l'objet de notre RFC. Pour UDP, le RFC 8085 (section 3.2) recommande d'utiliser une telle procédure (sauf si les couches inférieures fournissent l'information). Et, pour SCTP, la section 10.2 du RFC 4821 le recommandait également mais sans donner de détails, désormais fournis par notre nouveau RFC.
Un peu de vocabulaire avant de continuer la lecture du RFC (section 2) : un trou noir est un endroit du réseau d'où des paquets ne peuvent pas sortir. Par exemple, parce que les paquets trop gros sont jetés, sans émission de messages ICMP, ou bien avec des messages ICMP filtrés. Un paquet-sonde est un paquet dont l'un des buts est de tester la MTU du chemin. Il est donc de grande taille, et, en IPv4, a le bit DF (Don't Fragment), qui empêchera la fragmentation par les routeurs intermédiaires. Ceci étant défini, attaquons-nous au cahier des charges (section 3 du RFC). Le RFC 4821 était très lié à TCP, mais la généralisation de la PLPMTUD qui est dans notre nouveau RFC va nécessiter quelques fonctions supplémentaires :
- Il faut évidemment qu'on puisse envoyer des paquets-sonde, donc mettre le bit DF à 1 (en IPv4).
- Surtout, il faut un mécanisme de notification de la bonne
arrivée du paquet. En TCP (ou SCTP, ou
QUIC), il est inclus dans le protocole, ce
sont les accusés de réception (
ACK). Mais pour UDP et des protocoles similaires, il faut ajouter ce mécanisme de notification, ce qui implique en général une coopération avec l'application (par exemple, pour le DNS, le client DNS peut notifier le PL qu'il a reçu une réponse à sa question, prouvant ainsi que le datagramme est passé). - Les paquets-sonde peuvent se perdre pour d'autres raisons que la MTU, la congestion, par exemple. La méthode de PLPMTUD doit donc savoir traiter ces cas, par exemple en réessayant. (D'autant plus que le paquet-sonde ne sert pas forcément qu'à la PLPMTUD, il peut aussi porter des données utiles.)
- Et, même si la PLPMTUD ne dépend pas d'ICMP, il est quand même recommandé d'utiliser les messages PTB (Packet Too Big) si on en reçoit (cf. section 4.6). Attention toutefois à faire des efforts pour les valider : rien n'est plus facile pour un attaquant que d'envoyer de faux PTB pour réduire la MTU et donc les performances. Une solution sûre est de ne pas changer la MTU en recevant un PTB, mais d'utiliser ce PTB comme indication qu'il faut re-tester la MTU du chemin tout de suite.
En parlant de validation, cela vaut aussi pour les paquets-sonde (section 9 du RFC) : il faut empêcher un attaquant situé hors du chemin d'injecter de faux paquets. Cela peut se faire par exemple en faisant varier le port source (cf. section 5.1 du RFC 8085), comme le fait le DNS.
La section 4 du RFC passe ensuite aux mécanismes concrets à utiliser. D'abord, les paquets-sonde. Que doit-on mettre dedans, sachant qu'ils doivent être de grande taille, le but étant d'explorer les limites du chemin ? On peut utiliser des données utiles (mais on n'en a pas forcément assez, par exemple les requêtes DNS sont toujours de petite taille), on peut utiliser uniquement des octets bidons, du remplissage (mais c'est ennuyeux pour les protocoles qui doivent avoir une faible latence, comme le DNS, qui n'ont pas envie d'attendre pour envoyer les vraies données), ou bien on peut combiner les deux (des vraies données, plus du remplissage). Et, si on utilise des données réelles, il faut gérer le risque de perte, et pouvoir réémettre. Le RFC ne donne pas de consigne particulière aux mises en œuvre de PLPMTUD, les trois stratégies sont autorisées.
Ensuite, il faut évidemment un mécanisme permettant de savoir si le paquet-sonde est bien arrivé, si le protocole de transport ne le fournit pas, ce qui est le cas d'UDP, ce qui nécessite une collaboration avec l'application.
Dans le cas où le paquet-sonde n'arrive pas, il faut détecter la perte. C'est relativement facile si on a reçu un message ICMP PTB mais on ne veut pas dépendre uniquement de ces messages, vu les problèmes d'ICMP dans l'Internet actuel. Le PL doit garder trace des tailles des paquets envoyés et des pertes (cf. le paragraphe précédent) pour détecter qu'un trou noir avale les paquets de taille supérieure à une certaine valeur. Il n'est pas facile de déterminer les seuils de détection. Si on réduit la MTU du chemin au premier paquet perdu, on risque de la réduire trop, alors que le paquet avait peut-être été perdu pour une tout autre raison. Si on attend d'avoir perdu plusieurs paquets, on risque au contraire de ne pas réagir assez vite à un changement de la MTU du chemin (changement en général dû à une modification de la route suivie).
(J'ai parlé de MTU du chemin mais PLMTUD détecte en fait une valeur plus petite que la MTU, puisqu'il y a les en-têtes IP.)
Si vous aimez les détails des protocoles, les machines à état et la liste de toutes les variables nécessaires, la section 5 du RFC est pour vous, elle spécifie complètement la PLMTUD pour des protocoles utilisant des datagrammes. Cette section 5 est générique, et la section 6 décrit les détails spécifiques à un protocole de transport donné.
Ainsi, pour UDP (RFC 768) et UDP-Lite (RFC 3828), le protocole de transport n'a tout simplement pas les mécanismes qu'il faut pour faire de la PLPMTUD ; cette découverte de la MTU du chemin doit être faite par l'application, dans l'esprit du RFC 8085. L'idéal serait que cette PLPMTUD soit mise en œuvre dans une bibliothèque partagée, pour éviter que chaque application ne la réinvente mal. Mais je ne connais pas actuellement de telle bibliothèque.
Le RFC insiste sur le fait que l'application doit, pour effectuer cette tâche, pouvoir se souvenir de quels paquets ont été envoyés, donc mettre dans chaque paquet un identificateur, comme le Query ID du DNS.
Pour SCTP (RFC 9260), c'est un peu plus facile, puisque SCTP, comme TCP, a un système d'accusé de réception. Et les chunks de SCTP fournissent un moyen propre d'ajouter des octets au paquet-sonde pour atteindre la taille souhaitée (cf. RFC 4820), sans se mélanger avec les données des applications.
Pour le protocole QUIC, la façon de faire de la PLMTUD est spécifiée dans le RFC 9000. DCCP, lui, n'est pas spécifiquement cité dans cette section.
Ah, et quelles mises en œuvre de protocoles font déjà comme décrit dans ce RFC ? À part divers tests, il parait (mais je n'ai pas vérifié personnellement) que c'est le cas pour SCTP dans FreeBSD, et dans certains navigateurs Web pour WebRTC (WebRTC tourne sur UDP et rappelez-vous qu'en UDP, il faut une sérieuse coopération par l'application pour faire de la PLPMTUD). Côté QUIC, il y a lsquic, qui gère les techniques de notre RFC.
L'article seul
RFC 8891: GOST R 34.12-2015: Block Cipher "Magma"
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : V. Dolmatov (JSC "NPK Kryptonite"), D. Baryshkov (Auriga)
Pour information
Première rédaction de cet article le 15 septembre 2020
Ce RFC décrit un algorithme russe de chiffrement symétrique, « GOST R 34.12-2015 », surnommé Magma. N'attendez pas de ma part des conseils sur l'utilisation ou non de cet algorithme, je résume juste le RFC.
GOST est le nom des normes de l'organisme de normalisation officiel en Russie (et, par abus de langage, leurs algorithmes sont souvent cités sous le nom de « GOST » tout court). Cet organisme a normalisé plusieurs algorithmes de chiffrement symétrique dont Kuznyechik (décrit dans le RFC 7801) et l'ancien « GOST 28147-89 » (RFC 5830). Ce dernier est remplacé par « GOST R 34.12-2015 », qui fait l'objet de ce RFC. (La norme russe officielle est disponible en ligne mais, de toute façon, le russe plus la cryptographie, ce serait trop pour moi). Comme d'autres algorithmes de cryptographie normalisés par GOST, Magma a été développé en partie par le secteur public (Service des communications spéciales et d'information du Service fédéral de protection de la Fédération de Russie) et par le secteur privé (InfoTeCS). Le décret n° 749 du 19 juin 2015, pris par l'Agence fédérale pour la régulation technique et la métrologie en a fait un algorithme russe officiel.
Du fait de ce caractère officiel, si vous vendez des produits ou des prestations de sécurité en Russie, vous serez probablement obligés d'inclure les algorithmes GOST.
Je vous laisse lire le RFC pour la description de l'algorithme (ou l'original russe, si vous lisez le russe). Notez que, contrairement à son prédécesseur (cf. RFC 5830, sections 5 à 7), il ne décrit pas les modes utilisables, chacun choisit celui qui lui semble adapté.
Question mises en œuvre, il y en a une compatible avec WebCrypto, ou bien une pour OpenSSL.
L'article seul
RFC 8890: The Internet is for End Users
Date de publication du RFC : Août 2020
Auteur(s) du RFC : M. Nottingham
Pour information
Première rédaction de cet article le 28 août 2020
Ah, mais c'est une excellente question, ça. L'Internet est pour qui ? Qui sont les « parties prenantes » et, parmi elles, quelles sont les plus importantes ? Plus concrètement, la question pour l'IETF est « pour qui bossons-nous ? » Quels sont les « clients » de notre activité ? Ce RFC de l'IAB met les pieds dans le plat et affirme bien haut que ce sont les intérêts des utilisateurs finaux qu'il faut considérer avant tout. Et explique aussi comment prendre en compte ces intérêts, en pratique. C'est donc un RFC 100 % politique.
Il y a encore quelques personnes à l'IETF qui ne veulent pas voir les conséquences de leur travail (« la technique est neutre ») ou, pire, qui ne veulent en retenir que les conséquences positives. Mais les activités de l'IETF, comme la production des RFC, est en fait politique, affirme ce document. Car l'Internet est aujourd'hui un outil crucial pour toute la vie sociale, il a permis des changements importants, il a enrichi certains et en a appauvri d'autres, il a permis l'accès à un savoir colossal librement accessible, et il a facilité le déploiement de mécanismes de surveillance dont Big Brother n'aurait jamais osé rêver. Et toute décision apparemment « purement technique » va avoir des conséquences en termes de ce qui est possible, impossible, facile, ou difficile sur le réseau. Compte-tenu de leur impact, on ne peut pas dire que ces décisions ne sont pas politiques (section 1 du RFC).
Une fois qu'on reconnait que ce qu'on fait est politique, se pose la question : pour qui travaille-t-on ? Dresser la liste des « parties prenantes », les intéressé·e·s, les organisations ou individus qui seront affectés par les changements dans l'Internet est une tâche impossible ; c'est quasiment tout le monde. Le RFC donne une liste non limitative : les utilisateurs finaux, les opérateurs réseau, les écoles, les vendeurs de matériel, les syndicats, les auteurs de normes (c'est nous, à l'IETF), les programmeurs qui vont mettre en œuvre les normes en question, les ayant-droits, les États, les ONG, les mouvements sociaux en ligne, les patrons, la police, les parents de jeunes enfants… Tous et toutes sont affectés et tous et toutes peuvent légitimement réclamer que leurs intérêts soient pris en compte. Ce n'est pas forcément au détriment des autres : un changement technique peut être bénéfique à tout le monde (ou, en tout cas, être bénéfique à certains sans avoir d'inconvénients pour les autres). Mais ce n'est pas toujours le cas. Pour prendre un exemple classique (mais qui n'est pas cité dans ce RFC), voyons le chiffrement : l'écriture du RFC 8446, qui normalisait la version 1.3 de TLS, a remué beaucoup de monde à l'IETF car le gain en sécurité pour les utilisateurs finaux se « payait » par de moindres possibilités de surveillance pour les États et les patrons. Ici, pas question de s'en tirer en disant que tout le monde serait heureux : il fallait accepter de faire des mécontents.
Bon, là, c'étaient les grands principes, maintenant, il faut devenir un peu concret. D'abord, qui sont ces « utilisateurs finaux » ? Si on veut donner la priorité à leurs intérêts, il faudrait les définir un peu plus précisément. La section 2 explique : ce sont les humains pour qui l'Internet rend un service. Cela n'inclut donc pas les professionnels qui font marcher le réseau : les utilisateurs finaux du protocole BGP ne sont pas les administrateurs réseau, qui configurent les routeurs BGP, mais les gens à qui le réseau en question permet de communiquer.
Le RFC note que ces utilisateurs finaux ne forment donc pas un groupe homogène. Ils ont des intérêts différents et des opinions différentes. (Je suis personnellement très agacé par les gens qui, dans les réunions de « gouvernance Internet », plastronnent qu'ils représentent « les utilisateurs ». Comme la mythique « société civile », les utilisateurs ne sont pas d'accord entre eux.) Parfois, le désaccord est au sein du même individu, lorsqu'il occupe plusieurs rôles. Même dans un seul rôle, l'utilisateur final peut être le siège de tensions, par exemple entre la protection de sa vie privée et la facilité d'utilisation du réseau, deux objectifs honorables mais qui sont parfois difficiles à concilier.
Le RFC note aussi que l'utilisateur final peut… ne pas être un utilisateur, ou en tout cas pas directement. Si on prend une photo de moi et qu'on la met sur le Web avec un commentaire, je suis concerné, même si je n'utilise pas du tout l'Internet. Même chose si j'entre dans un magasin truffé de capteurs qui détectent mes mouvements et les signalent. Les utilisateurs finaux, au sens de ce RFC, peuvent donc être des utilisateurs indirects.
Une fois qu'on sait qui sont les utilisateurs finaux, pourquoi faudrait-il prioriser leurs intérêts ? La section 3 rappelle d'abord que l'IETF a une longue histoire d'affirmation de cette priorité. Le tout premier RFC, le RFC 1, disait déjà « One of our goals must be to stimulate the immediate and easy use by a wide class of users. » (Bon, le RFC 1 parlait d'accessibilité et de facilité d'usage plutôt que de politique, mais c'est une jolie référence.) La charte de l'IETF, dans le RFC 3935, est plus précise : « The IETF community wants the Internet to succeed because we believe that the existence of the Internet, and its influence on economics, communication, and education, will help us to build a better human society. ». Et, encore plus explicite, « We embrace technical concepts such as decentralized control, edge-user empowerment and sharing of resources, because those concepts resonate with the core values of the IETF community. These concepts have little to do with the technology that's possible, and much to do with the technology that we choose to create. ». Bref, le but est le bonheur de l'humanité, et celle-ci est composée des utilisateurs finaux.
(Pour ne fâcher personne, le RFC oublie de signaler l'existence d'autres RFC qui au contraire donnent explicitement la priorité à d'autres parties prenantes, par exemple les gérants du réseau dans le RFC 8404.)
Le RFC note que le progrès quantitatif (davantage de machines connectées, une capacité réseau plus importante, une latence plus faible) n'est pas un but en soi car l'Internet peut être utilisé pour des mauvaises causes (surveiller les utilisateurs, exercer un pouvoir sur eux). La technique pouvant être utilisée pour le bien comme pour le mal, les améliorations techniques (comme présentées en couleur rose par les techno-béats, par exemple les promoteurs de la 5G) ne doivent pas être considérées comme forcément positives.
Après ces arguments humanistes, le RFC mentionne aussi des arguments plus internes au réseau. D'abord, d'un point de vue égoïste, l'IETF a tout intérêt à garder la confiance de ces utilisateurs finaux, car l'IETF perdrait sa pertinence et son rôle si elle se mettait, par exemple, uniquement à la remorque des vendeurs de matériel ou de logiciel. (Ou même si elle était simplement vue comme se mettant à cette remorque.)
On pourrait même voir les utilisateurs se détourner massivement, non seulement du travail de l'IETF, mais aussi de l'Internet en général, si leurs intérêts ne sont pas mis en premier. Prioriser les utilisateurs finaux aide aussi à lutter contre certaine formes de technophobie.
Maintenant, on a défini les utilisateurs finaux, affirmé qu'il fallait penser à eux et elles en premier, et expliqué pourquoi. Il reste le comment. C'est bien joli de dire, dans une grande envolée « nous pensons avant tout à M. et Mme Toutlemonde » mais, concrètement, cela veut dire quoi ? La section 4 du RFC décortique les conséquences pratiques du choix politique.
D'abord, déterminer ce qui est bon pour les utilisateurs n'est pas évident. Paradoxalement, le fait que les participants à l'IETF connaissent et comprennent très bien le fonctionnement de l'Internet n'aide pas, au contraire ; cela rend plus difficile de se mettre à la place des utilisateurs finaux. Pourtant, on l'a vu, l'IETF se réclame depuis longtemps d'une vague « Internet community » mais sans trop savoir qui elle est. Une solution évidente au problème « quels sont les intérêts des utilisateurs finaux ? » serait de leur demander. C'est plus facile à dire qu'à faire, mais c'est en effet la première chose à envisager : se rapprocher des utilisateurs.
Cela ne va pas de soi. Déjà, le travail de l'IETF est très pointu techniquement, et nécessite une forte expertise, sans compter la nécessité de se familiariser avec la culture spécifique de l'IETF. les utilisateurs finaux qu'on veut prioriser ne sont pas des experts techniques. Pire, les connaissances qu'ils ont sur l'Internet ne sont pas seulement insuffisantes, elles sont souvent fausses. Bref, inviter M. ou Mme Toutlemonde sur les listes de diffusion de l'IETF n'est pas la bonne approche.
Les États sont prompts à dire « pas de problème, les utilisateurs ont une représentation, et c'est nous ». Il suffirait donc que les envoyés de ces États participent à l'IETF et on aurait donc automatiquement accès à « la voix des utilisateurs ». Il y a déjà de ces envoyés qui participent à l'IETF. (À chaque réunion, il y a au moins une personne avec un badge NSA, sans compter ceux qui n'ont pas le badge, mais ont le même employeur.) La question de leur représentativité (l'envoyé du gouvernement français est-il vraiment le porte-parole des soixante millions d'utilisateurs français ?) a été une des questions essentielles lors des discussions menant à ce RFC. Chaque gouvernement prétend qu'il est représentatif. C'est clairement faux pour les dictatures mais cela ne veut pas dire que les démocraties sont parfaites, sans compter la difficulté de classer les pays dans l'une ou l'autre catégorie. Bref, personne n'a envie de transformer l'IETF en un organisme multi-gouvernemental paralytique, comme l'ONU. (Les experts en « gouvernance Internet » noteront que l'ICANN a le même genre de problèmes, et son GAC - Governmental Advisory Committee - ne satisfait personne.)
À ce sujet, bien que cela ne soit pas mentionné explicitement dans le RFC, il faut aussi dire que les envoyés des États sont en général contraints par un processus de décision interne très rigide, et ne peuvent pas s'exprimer librement. Cela ne colle évidemment pas avec le mécanisme de discussion très ouvert et très vif de l'IETF. Je me souviens d'une réunion où deux personnes portant la mention FBI sur leur badge étaient venus me parler de problèmes avec un des documents sur lesquels je travaillais. Lorsque je leur ai fait remarquer que leurs analyses, assez pertinentes, devraient être faites dans la réunion officielle du groupe de travail et pas juste dans les couloirs, ils m'avaient répondu que leurs supérieurs ne les y autorisaient pas. Difficile d'envisager une participation effective des États dans ces conditions.
Bon, si on ne fait pas appel aux États, à qui ? Le RFC mentionne la classique « société civile » dont personne ne sait trop en quoi elle consiste, mais à qui tout le monde rend hommage. Selon l'interlocuteur, « société civile » peut vouloir dire « tout le monde sauf l'État » (incluant, par exemple, le MEDEF), ou bien « tous les individus » ou encore « tous les individus organisés (associations, syndicats, etc) » sans compter ceux qui disent « société civile » pour « les gens qui sont d'accord avec moi ». (Disons franchement les choses : l'un des problèmes de fond de la « gouvernance de l'Internet » est qu'il n'y a que peu ou pas de représentation des utilisateurs. Tout le monde parle pour eux et elles, mais ielles n'ont pas de voix propre. Ce syndrome « tout le monde se réclame de l'utilisateur final » avait été très net, par exemple, lors des débats sur DoH, mais aussi dans d'autres questions de gouvernance.)
Mais le RFC note à juste titre qu'il existe des organisations qui ont sérieusement travaillé les sujets politiques liés à l'Internet, et qui connaissent donc bien les problèmes, et les conséquences des choix techniques. (En France, ce serait par exemple La Quadrature du Net, Framasoft et certainement plusieurs autres.) Bien que rien ne garantisse leur représentativité, note le RFC, ces organisations sont sans doute le premier canal à utiliser pour essayer de comprendre les intérêts des utilisateurs finaux. La recommandation est donc d'essayer d'identifier ces groupes et de travailler avec eux.
L'accent est mis sur la nécessité d'aller les voir, de ne pas juste leur dire « venez participer à l'IETF » (ils n'ont pas forcément le temps ou les moyens, et pas forcément envie de se lancer dans ce processus). Outre ses réunions formelles et ses listes de diffusion, l'IETF a quelques canaux de communication plus adaptés mais certainement très peu connus (« venez à la Bar BoF, on en parlera autour d'une bière »). Idéalement, c'est l'IETF qui devrait prendre l'initiative, et essayer d'aller vers les groupes organisés d'utilisateurs, par exemple en profitant des réunions existantes. Le RFC recommande de faire davantage d'efforts de sensibilisation, faire connaitre le travail de l'IETF, ses enjeux, etc. (Mon expérience est qu'il est très difficile de faire s'intéresser les gens à l'infrastructure de l'Internet, certes moins sexy qu'une page d'accueil colorée d'un site Web. Après tout, on ne peut pas faire boire un âne qui n'a pas soif.)
Le RFC donne un exemple d'un atelier ayant réuni des participants à l'IETF, et des gens qui n'ont pas l'habitude d'aller à l'IETF, sur un sujet assez chaud politiquement, la réunion ESCAPE, documentée dans le RFC 8752.
On peut aussi penser que cette tâche de sensibilisation à l'importance de la normalisation, et à ses conséquences politiques, ne devrait pas revenir entièrement à l'IETF, qui n'est pas forcément bien préparée à cela. Le RFC cite à juste titre l'Internet Society, qui fait en effet un important travail dans ce domaine.
Le RFC continue avec une section sur le concept de systèmes
centrés sur l'utilisateur. Il part de l'exemple du Web, certainement un des plus gros
succès de l'Internet. Dans le Web, l'IETF normalise le protocole
HTTP (le
W3C faisant
le reste). La norme HTTP, le RFC 7230 décrit
explicitement le rôle du client HTTP, appelé user
agent dans la norme (et c'est de là que vient l'en-tête
HTTP User-Agent:). À noter que le RFC mélange
client HTTP et navigateur Web : le client
d'un serveur HTTP n'est pas forcément un navigateur. Quoi qu'il en
soit, la discussion continue sur le navigateur : celui-ci sert
d'intermédiaire entre l'utilisateur et le serveur Web. Au lieu d'un
client spécifique d'un service, et qui a accès à toute la machine de
l'utilisateur pour faire sa tâche, le passage par cet intermédiaire
qu'est le navigateur permet de créer un bac à sable. Quelles que
soient les demandes faites par le serveur Web, il ne sera pas
possible de sortir du bac à sable et, par exemple, de lire et
d'écrire arbitrairement des fichiers sur la machine de
l'utilisateur.
Au contraire, les services sur le Web qui exigent l'installation d'un client local demandent à l'utilisateur une confiance aveugle : ces clients peuvent faire des choses que le navigateur bloquerait normalement. Ce n'est pas par hasard que les sites des médias demandent si souvent l'installation de leur « app » quand on navigue depuis un ordiphone : ces clients locaux ont bien plus de possibilité, notamment de pistage et de surveillance que ce qui est possible via le navigateur.
(Le RFC ne mentionne pas un autre moyen de créer la confiance : le logiciel libre. La totalité de ces « apps » sont du logiciel privateur. Si le logiciel est sous une licence libre, il y a nettement moins de craintes à avoir lorsqu'on l'installe.)
Le RFC estime que le fait d'avoir défini explicitement le user agent et ses propriétés a facilité le succès du Web, en permettant la création de cet intermédiaire de confiance qu'est le navigateur Web, un exemple de système « centré sur l'utilisateur ». Bien sûr, cette vision est très contestable. Le RFC note par exemple que, à vouloir tout faire passer par le Web, on aboutit à des navigateurs qui sont devenus très complexes, ce qui se paie en sécurité et en performances. En outre, cette complexité diminue la concurrence : il n'y a que très peu de navigateurs et beaucoup de composants cruciaux, comme WebKit sont communs à plusieurs navigateurs, diminuant la diversité et le choix. Aujourd'hui, créer un nouveau navigateur en partant de zéro semble impossible, ce qui a de lourdes conséquences sur la distribution du pouvoir dans le Web.
Mais le RFC estime que c'est quand même une meilleure approche que celle, par exemple, de l'Internet des objets, où il n'y a pas de norme d'interaction entre l'utilisateur et le système, pas de « système centré sur l'utilisateur », ce qui fait que l'utilisateur doit faire une confiance aveugle à des systèmes opaques, dont la mauvaise qualité (notamment en sécurité) et la mauvaise éthique ont déjà été largement montrées.
On a dit plus haut que, dans le meilleur des cas, le travail de l'IETF menait à des solutions qui étaient positives pour tout le monde. L'IETF peut alors laisser les différentes parties prenantes interagir (cf. l'article « Luttes dans l'Internet », même si, aujourd'hui, je traduirais tussle par un terme moins violent que lutte). Mais ce cas idéal n'est pas systématique. Parfois, les solutions techniques normalisées dans les RFC ne sont positives que pour certains, et neutres pour d'autres (ne leur apportent aucun avantage). Et parfois, c'est pire, les solutions sont négatives pour certains. Dans le monde réel, fait de différences d'opinion et d'intérêts (et de lutte des classes, ajouterait un marxiste), il ne faut pas être naïf : on ne va pas plaire à tout le monde. Conformément aux principes établis plus haut, le RFC affirme que, si une solution envisagée a forcément des conséquences négatives, il faut faire en sorte que ces conséquences négatives ne soient pas supportées par les utilisateurs finaux, mais par d'autres parties prenantes.
L'IETF a déjà été confrontée à de tels choix, et a documenté cette décision, par exemple dans les RFC 7754 (sur le filtrage), RFC 7258 et RFC 7624 (sur la surveillance), RFC 7288 (sur les pare-feux des machines terminales) et enfin RFC 6973 (sur la vie privée).
Le RFC note aussi que certaines décisions politiques de l'IETF peuvent être correctes mais insuffisantes. Ainsi, le RFC 3724 insiste sur l'importance du modèle de bout en bout. Mais cela ne suffit pas si c'est la machine avec qui on communique qui trahit. Chiffrer grâce à HTTPS quand on parle avec un GAFA n'est une protection que contre les tiers, pas contre le GAFA.
Au sujet des GAFA, le RFC note que la concentration des services dans les mains d'un petit groupe de sociétés est un problème pour les utilisateurs. Il affirme aussi que cela peut être encouragé par des propriétés du protocole IETF. (C'est nettement plus contestable : quelles sont les caractéristiques de SMTP qui expliquent la concentration du courrier chez Gmail et Outlook.com ? Cet argument semble plutôt une allusion maladroite aux débats sur DoH.)
Comme indiqué au début, les utilisateurs finaux ne forment pas un groupe homogène. Ils n'ont ni les mêmes intérêts, ni les mêmes opinions. Cela peut entrainer des difficultés pour l'application du principe « les utilisateurs d'abord ». Par exemple, dans un cas hypothétique où une solution technique entrainerait des conséquences positives pour les utilisateurs d'un pays et négatives dans un autre pays, que faire ? Le RFC suggère de privilégier l'évitement des conséquences négatives. Dans certains cas, il ne sera pas possible de les éviter complètement, et il faudra vraiment faire des compromis. Mais, au moins, il ne faudra pas cacher le problème sous le tapis, et bien documenter ce compromis.
Le principe « les utilisateurs d'abord » s'applique aussi à l'IETF elle-même. Le RFC se termine en affirmant qu'il ne faut pas que l'IETF privilégie ses propres besoins. Ainsi, s'il faut compliquer la tâche des auteurs de RFC pour mieux préserver les intérêts de l'utilisateur, eh bien il faut le faire. De même, dit le RFC, la beauté de l'architecture technique n'est pas un but en soi, elle doit passer après les intérêts des utilisateurs finaux.
En anglais, vous pouvez aussi lire la synthèse qu'avait publié l'auteur du RFC, où il s'exprime plus librement que dans le RFC, par exemple sur DoH. Un article de synthèse, allant plus loin que le RFC a été écrit par Vesna Manojlovic. D'autre part, la norme HTML (du W3C) a une mention qui va dans le même esprit que ce RFC : « In case of conflict, consider users over authors over implementors over specifiers over theoretical purity. » (les mauvaises langues pourront faire remarquer que ce mépris de la « theoretical purity » explique le b...l technique qu'est le Web). Ou, en sens opposé, un article qui s'était vigoureusement opposé à cet empouvoirement des utilisateurs.
L'article seul
RFC 8886: Secure Device Install
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : W. Kumari (Google), C. Doyle
(Juniper Networks)
Pour information
Réalisé dans le cadre du groupe de travail IETF opsawg
Première rédaction de cet article le 6 octobre 2020
Quand vous êtes opérateur réseau et que vous avez à installer une nouvelle machine, par exemple un routeur, dans un centre de données lointain, vous avez deux solutions : envoyer un employé faire l'installation sur place, ce qui peut être coûteux, ou bien demander à la société qui gère le centre de données de le faire pour vous, ce qui n'est pas forcément génial question sécurité, puisque, selon la façon dont c'est fait, ils auront peut-être la possibilité de regarder ou de bricoler la configuration de la machine. Ce nouveau RFC propose un moyen simple d'améliorer la sécurité dans le deuxième cas, en chiffrant un fichier de configuration avec la clé publique de la machine. Celle-ci pourra le déchiffrer après téléchargement, en utilisant sa clé privée. (Cette solution nécessitera donc un changement des équipements pour que chacun ait une paire clé publique / clé privée.)
Précisons la question à résoudre. Ce problème est une variante d'un problème bien classique en informatique, celui du bootstrap. Par exemple, si la nouvelle machine est protégée par un mot de passe, il faut bien rentrer ce mot de passe la première fois. Si c'est un employé du centre de données qui le fait, il connaitra le mot de passe. Et si on le change juste après ? Rien ne dit qu'il n'aura pas laissé une porte dérobée. Il n'y a pas de solution générale et simple à ce problème. Notre RFC se contente d'une solution partielle, qui améliore la sécurité.
On va donc s'imaginer à la place de la société Machin, un gros opérateur réseau dont l'essentiel des équipes est à Charleville-Mézières (pourquoi pas ?). La société a des POP dans beaucoup d'endroits, et la plupart du temps dans ces centres de données qu'elle ne contrôle pas, où elle loue juste de l'espace. Comme les équipements réseau tombent parfois en panne, ou, tout simplement, ne parviennent plus à gérer le trafic toujours croissant, la société doit de temps en temps installer de nouveaux matériels, routeurs, commutateurs, etc. Si le centre de données où il faut installer est proche de Charleville-Mézières, tout va bien : un employé de l'opérateur Machin se rend sur place, le fabricant du routeur a déjà livré la nouvelle machine, il n'y a plus qu'à la racker et à la configurer (« Enter the password for the administrative account ») ou, en tout cas, faire une configuration minimale qui permettra de faire ensuite le reste via SSH, RESTCONF (RFC 8040) ou une autre technique d'administration à distance.
Mais supposons que la machine à installer, mettons que ce soit un gros routeur, doive être placé chez un centre de données éloigné, mettons Singapour (exemple choisi parce que c'est vraiment loin). Même avant la pandémie de Covid-19, un voyage à Singapour n'était guère raisonnable, du point de vue du temps passé, et du point de vue financier. Mais les centres de données ont tous un service d'action à distance (remote hands) où un employé de la société qui gère le centre peut appuyer sur des boutons et taper des commandes, non ? C'est en effet très pratique, mais ce service est limité à des cas simples (redémarrer…) et pas à une configuration complète. Celle-ci poserait de toute façon un problème de sécurité car l'employé en question aurait le contrôle complet de la machine pendant un moment.
(Une autre solution, apparemment non mentionnée dans le RFC, est que le fabricant du routeur livre à Charleville-Mézières l'appareil, qui soit alors configuré puis envoyé à Singapour. Mais cela impose deux voyages.)
Bon, et une solution automatique ? La machine démarre, acquiert une adresse IP, par exemple par DHCP (RFC 2131 et RFC 9915), et charge sa configuration sous forme d'un fichier récupéré, par exemple avec TFTP (RFC 1350). Mais cette configuration peut contenir des informations sensibles, par exemple des secrets RADIUS (RFC 2865). TFTP n'offre aucune sécurité et ce n'est pas très rassurant que de laisser ces secrets se promener en clair dans le centre de données singapourien. Il existe des contournements variés et divers pour traiter ces cas, mais aucun n'est complètement satisfaisant.
Bref, le cahier des charges de notre RFC est un désir de confidentialité des configurations du nouveau routeur. (Il y a une autre question de sécurité importante, l'authenticité de cette configuration, mais elle n'est pas traitée dans ce RFC. Des solutions, un peu complexes, existent, comme SZTP - RFC 8572 ou BRSKI - RFC 8995.) La solution présentées dans notre RFC n'est pas complète. Elle améliore les procédures d'installation (voir par exemple la documentation de celle de Cisco) mais ne prétend pas résoudre tout le problème.
Ce RFC ne spécifie pas un protocole, mais décrit une méthode, que chaque constructeur d'équipements réseau devra adapter à ses machines et à leurs particularités. Cette méthode est conçue pour ces équipements (routeurs et commutateurs, notamment), mais pourrait être adaptée à des engins comme les serveurs. Mais en attendant, ce RFC se focalise sur le matériel réseau.
La section 2 du RFC résume la solution. Elle nécessite que la machine à configurer ait un mécanisme de démarrage automatique de l'installation (autoinstall ou autoboot dans les documentations), permettant d'obtenir une adresse IP (typiquement avec DHCP) puis de récupérer un fichier de configuration (typiquement avec TFTP mais cela peut être HTTP ou un autre protocole de transfert de fichiers, les options DHCP 66 - Server-Name - ou 150 - TFTP server address pouvant être utilisées pour indiquer le serveur). Le nom du fichier est par exemple issue de l'option DHCP 67 - Bootfile-Name.
La méthode nécessite un identificateur, comme le numéro de série ou bien l'adresse MAC de l'équipement réseau qui est en cours d'installation. (Rien n'interdit d'utiliser un autre identificateur, par exemple un UUID - RFC 9562, mais l'avantage du numéro de série est qu'il est en général marqué sur la machine et facilement accessible, donc la personne dans le centre de données à Singapour peut le lire et le transmettre à la société Machin.)
Le RFC donne un exemple concret. La société Machin commande un nouveau routeur à un fabricant de routeur, mettons Truc, en indiquant l'adresse de livraison à Singapour. Truc doit indiquer à Machin le numéro de série de l'engin. Et il faut qu'une paire clé publique / clé privée spécifique à cet engin soit générée, la clé publique étant communiquée à l'acheteur (Machin). [Cette étape est l'une des deux seules que ne font pas les routeurs actuels.] Pendant que le routeur voyage vers Singapour, un employé de Machin prépare la configuration du routeur, et la chiffre avec la clé publique de ce routeur particulier. Puis il la place sur le serveur de fichiers, indexée par le numéro de série. Les employés du centre de données mettent le routeur dans l'armoire et le câblent. Le routeur démarre et voit qu'il n'a pas encore été configuré. Il récupère une adresse IP puis contacte le serveur de fichiers. Il récupère la configuration, la déchiffre [deuxième étape qui n'est pas encore mise en œuvre dans un routeur typique d'aujourd'hui] et l'installe. Désormais, le routeur est autonome. Les équipes de l'opérateur Machin peuvent le contacter par les moyens habituels (SSH, par exemple). Un éventuel attaquant pourra regarder le trafic ou, plus simplement, demander le fichier de configuration au serveur de fichiers, mais il ne pourra pas le déchiffrer.
Cette solution ne nécessite que peu de changements aux mécanismes d'aujourd'hui. La section 3 du RFC décrit ce que les fabricants de routeurs devront faire, pour qu'elle soit disponible. Le routeur devra disposer d'une paire clé publique / clé privée, générée lors de sa fabrication. Et le fabricant doit pouvoir accéder à cette clé facilement (les clés cryptographiques ne peuvent typiquement pas être affichées sur un petit écran LCD…), afin de la communiquer à l'acheteur. (On peut aussi envisager le RFC 7030 ou bien le RFC 8894.) Le fabricant de routeurs doit avoir un mécanisme de communication de ces clés au client. (Comme il s'agit de clés publiques, il n'est pas indispensable que ce soit un mécanisme confidentiel, mais il faut évidemment qu'un tiers ne puisse pas y ajouter des clés de son choix.) Le RFC recommande X.509 (RFC 5280) comme format pour ces clés, même s'il n'y a pas forcément besoin des méta-données de X.509 comme la date d'expiration.
Et le client, l'acheteur du routeur ? La section 4 décrit ce qu'il doit faire. Il faut réceptionner et transmettre le numéro de série du routeur (typiquement, cela veut dire une communication entre le service Achats et les Opérations, ce qui n'est pas toujours facile), puis récupérer la clé publique. Et enfin, il faut chiffrer la configuration (le RFC suggère S/MIME - RFC 5751).
Quelques détails supplémentaires figurent en section 5. Par exemple, si le routeur le permet (il faut du haut de gamme…), la clé privée peut être stockée dans un TPM. (Le RFC suggère également de jeter un œil à la Secure Device Identity de la norme IEEE Std 802-1AR.)
Et la section 7 du RFC revient sur la sécurité de ce mécanisme. Il sera de toute façon toujours préférable à la solution actuelle, qui est de transmettre la configuration en clair. Mais cela ne veut pas dire que tout soit parfait. Ainsi, un attaquant qui a un accès physique à la machine pendant son trajet, ou bien une fois qu'elle est arrivée dans le centre de données, peut extraire la clé privée (sauf si elle est stockée dans un TPM) et déchiffrer à loisir.
On a dit au début que le but de ce RFC n'était pas de trouver un moyen d'authentifier la configuration. (Une signature ne serait pas réaliste, car il y a peu de chances que le fabricant mette les clés publiques de chaque opérateur dans le routeur.) Un attaquant qui contrôle, par exemple, le réseau sur lequel se trouve l'équipement réseau qui se configure, peut donc diriger les requêtes TFTP vers un serveur de son choix et envoyer une configuration « pirate » à cet équipement. (Il peut même la chiffrer puisque la clé publique de l'équipement sera sans doute facilement accessible publiquement, pour faciliter la tâche du client.)
Et, bien sûr, rien ne protège contre un vendeur malhonnête. Si le fabricant du routeur ou du commutateur est malveillant (ou piraté par un de ses employés, ou par un pirate extérieur), il peut tout faire. C'est le problème de la supply chain en sécurité, et il est très difficile à résoudre. (Cf. les craintes concernant les pratiques de Huawei mais il serait naïf de penser que seuls les fabricants chinois soient malhonnêtes. Voyez aussi mon article sur les portes dérobées dans les routeurs.)
Si vous aimez le concret, l'annexe A du RFC donne les commandes
OpenSSL pour effectuer les différentes
manipulations décrites par ce RFC. (J'ai modifié les commandes du
RFC, qui ne marchaient pas pour moi.) Le fabricant du routeur va
d'abord générer la paire de clés sur le routeur, la clé publique
étant ensuite emballée dans un certificat
(SN19842256 étant le numéro de série du
routeur), et auto-signer :
% openssl req -new -nodes -newkey rsa:2048 -keyout key.pem -out SN19842256.csr ... Common Name (e.g. server FQDN or YOUR name) []:SN19842256 ... % openssl req -x509 -days 36500 -key key.pem -in SN19842256.csr -out SN19842256.crt
L'opérateur réseau va fabriquer un fichier de configuration (ici, trivial) :
% echo 'Test: true' > SN19842256.cfg
Ensuite, récupérer la clé (SN19842256.crt) et
chiffrer la configuration :
% openssl smime -encrypt -aes-256-cbc -in SN19842256.cfg -out SN19842256.enc -outform PEM SN19842256.crt % cat SN19842256.enc -----BEGIN PKCS7----- MIIB5gYJKoZIhvcNAQcDoIIB1zCCAdMCAQAxggGOMIIBigIBADByMFoxCzAJBgNV BAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEwHwYDVQQKDBhJbnRlcm5ldCBX ...
On copie ensuite la configuration chiffrée sur le serveur de fichiers.
Lorsque le routeur démarre, il charge ce fichier et exécute une commande de déchiffrement :
% openssl smime -decrypt -in SN19842256.enc -inform PEM -out config.cfg -inkey key.pem % cat config.cfg Test: true
Pour l'instant, aucun fabricant de routeur ne semble avoir annoncé une mise en œuvre de ce RFC. Comme le RFC décrit un mécanisme générique, et pas un protocole précis, les détails dépendront sans doute du vendeur.
L'article seul
RFC 8884: Research Directions for Using Information-Centric Networking (ICN) in Disaster Scenarios
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : J. Seedorf (HFT Stuttgart - Univ. of Applied Sciences), M. Arumaithurai (University of Goettingen), A. Tagami (KDDI Research), K. Ramakrishnan (University of California), N. Blefari Melazzi (University Tor Vergata)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF icnrg
Première rédaction de cet article le 24 octobre 2020
Si vous aimez les films catastrophe, voici un RFC pour vous ; il explore l'utilisation de l'ICN lors de grands désastres. N'espérez pas trouver de solutions, c'est un travail purement théorique. (Comme beaucoup de choses qui touchent à l'ICN.)
L'ICN (Information Centric Networking) ? C'est quoi ? Il s'agit d'une approche des réseaux informatiques où tout est vu comme du contenu, auquel les clients veulent accéder. Les routeurs ICN vont donc se charger de récupérer l'information, sans se soucier d'où elle vient. L'ICN est décrit dans des documents comme le RFC 7476 et le RFC 7927.
Parmi tous les RFC, il n'y a pas que l'ICN qui peut apporter des idées neuves en matière de robustesse lors de grandes catastrophes. Le DTN (RFC 9171), réseau acceptant les déconnexions fréquentes, est également une bonne approche. En effet, en cas de désastre, il est sûr que le réseau sera affecté, et le concept « stocke et réessaie » de DTN est donc un outil utile. Mais ICN offre des possibilités supplémentaires. D'ailleurs, le RFC 7476 (section 2.7.2) citait déjà cette possibilité d'utiliser l'ICN en cas de catastrophe. L'idée est que la couche réseau peut aider à partiellement contourner les problèmes post-catastrophe. Les applications ont leur rôle à jouer également, bien sûr, mais ce n'est pas l'objet de ce RFC.
La section 2 du RFC liste des cas d'usage. Comme déjà le RFC 7476, on commence par le tremblement de terre de Tohoku, qui avait détruit une partie importante de l'infrastructure, notamment en ce qui concerne la fourniture d'électricité. Or, après une telle catastrophe, il y a une grosse demande de communication. Les autorités veulent envoyer des messages (par exemple par diffusion sur les réseaux de téléphonie mobile), transmettre des informations, distribuer des consignes. Les habitants veulent donner des nouvelles à leurs proches, ou bien en recevoir. Les victimes veulent savoir où se trouvent les secours, les points de ravitaillement, etc.
Les gens de l'ICN étant toujours à la recherche de subventions, ils citent fréquemment les thèmes à la mode, qui promettent l'attention des pouvoirs publics. C'est ainsi que la liste des cas d'usage inclus évidemment le terrorisme (pourquoi pas la cyberguerre, tant qu'on y est ?). Dans ce cas, des difficultés supplémentaires surviennent : les attaquants peuvent effectuer des attaques par déni de service pour empêcher l'utilisation du réseau, si l'attaque elle-même ne l'a pas arrêté, ils peuvent surveiller l'utilisation du réseau pour, par exemple, découvrir des cibles intéressantes pour une nouvelle attaque, ils peuvent envoyer des messages mensongers pour créer une panique, etc. Le problème est donc plus difficile que celui d'une catastrophe naturelle.
Aujourd'hui, les réseaux existants ne permettent pas forcément de traiter les cas de catastrophes, même « simplement » naturelles. La section 3 du RFC liste les principaux défis qu'il faudrait traiter pour cela :
- On s'attend à ce que le réseau soit fragmenté par la catastrophe. Certains composants seront alors inaccessibles. Pensez à l'accès aux serveurs DNS racine si on est dans un îlot où il n'existe aucune instance de ces serveurs. Tous les systèmes centralisés seront inutilisables si on est du mauvais côté de la coupure. Par exemple, les systèmes de téléphonie mobile existants dépendent souvent de composants centraux comme le HLR. Un réseau utilisable pendant les catastrophes doit donc pouvoir fonctionner même en cas de fragmentation.
- Un service qui est très souvent centralisé est celui de l'authentification. Même quand le système peut marcher en pair-à-pair, la possibilité de l'utiliser dépend souvent d'une authentification centrale. Même quand il y a décentralisation, comme avec une PKI, il peut être nécessaire de passer d'abord par une ou plusieurs racines, qui peuvent être injoignables pendant la catastrophe. Créer un système d'authentification décentralisé est un sacré défi. Le RFC note que la chaîne de blocs n'est pas une solution, puisque celle-ci ne fonctionne plus s'il y a fragmentation (ou, plus exactement, chaque groupe de participants risque de voir sa portion de la chaîne invalidée lorsque le réseau sera à nouveau complètement connecté).
- En cas de catastrophe, il sera peut-être nécessaire de donner une priorité à certains messages, ceux liés à la coordination des secours, par exemple. C'est d'autant plus important à réaliser que la capacité du réseau sera réduite et que les arbitrages seront donc difficiles.
- Dans un réseau sérieusement endommagé, où la connectivité risque fort d'être intermittente, il ne sera pas toujours possible d'établir une liaison de bout en bout. Il faudra, beaucoup plus qu'avec l'Internet actuel, compter sur le relayage de machine en machine, avec stockage temporaire lorsque la machine suivante n'est pas joignable. C'est justement là où DTN est utile.
- Enfin, dans la situation difficile où se trouveront tous les participants, l'énergie sera un gros problème ; peu ou pas de courant électrique, pas assez de fuel pour les groupes électrogènes, et des batteries qui se vident vite (comme dans le film Tunnel, où le héros doit surveiller en permanence la batterie de son ordiphone, et économiser chaque joule).
Bon, ça, ce sont les problèmes. Maintenant, en quoi est-ce que l'ICN peut aider ? Plusieurs arguments sont avancés par le RFC (dont certains, à mon avis, plus faibles que d'autres) :
- L'ICN, c'est une de ses principales caractéristiques, route en fonction du nom du contenu convoité, pas en fonction d'une adresse IP. Cela peut permettre, dit le RFC, de survivre lorsque le réseau est coupé. (L'argument me semble douteux : il suppose qu'en cas de fragmentation, le contenu sera présent des deux côtés de la coupure. Mais on peut en dire autant des adresses IP. Contrairement à ce que racontent toujours les promoteurs de l'ICN, il y a bien longtemps que les adresses IP n'ont plus de rapport avec un lieu physique). C'est d'autant plus vrai si le système de résolution des noms est complètement décentralisé. (Là encore, ICN et système classique sont à égalité : l'un et l'autre peuvent utiliser un système centralisé, un système décentralisé, ou un système pair-à-pair pour la résolution de noms).
- Un point fort de l'ICN est que l'authentification et l'intégrité ne sont pas assurés par la confiance dans le serveur d'où on a obtenu le contenu, mais par une certification portée par l'objet (typiquement une signature). Certains mécanismes de nommage mettent même l'intégrité dans le nom (cf. RFC 6920). Cela permet de récupérer du contenu n'importe où, ce qui est utile si le serveur d'origine est injoignable mais que des copies circulent. On peut ainsi vérifier l'authenticité de ces copies.
- ICN utilise beaucoup les caches, les mémoires dans lesquelles sont stockées les objets. Avec l'ICN, chaque routeur peut être un cache. Là aussi, cela peut aider beaucoup si le serveur d'origine n'est plus joignable.
- Et ICN est bien adapté aux techniques à base de DTN (cf. par exemple RFC 9171), où il n'y a pas besoin de connectivité permanente : on transmet simplement le contenu en mode « stocke et fais suivre ».
En parlant de DTN, notons que DTN seul manque de certaines fonctions que pourrait fournir l'ICN. C'est le cas par exemple du publish/subscribe. Dans certains cas, ces fonctions pourraient être ajoutées au DTN, comme présenté dans « Efficient publish/ subscribe-based multicast for opportunistic networking with self-organized resource utilization » (par Greifenberg, J. et D. Kutscher) ou bien « A Socio-Aware Overlay for Publish/Subscribe Communication in Delay Tolerant Networks » (par Yoneki, E., Hui, P., Chan, S., et J. Crowcroft).
La section 4 du RFC précise ensuite les scénarios d'usage, et les exigences qui en découlent. Par exemple, pour le scénario « diffuser de l'information aux gens », la question de l'authentification est cruciale, de fausses informations diffusées par un malveillant ou par un plaisantin pourraient avoir des conséquences graves.
Est-ce que l'ICN peut assurer ces missions, là, aujourd'hui ? Clairement non, et la section 5 du RFC décrit tout ce qu'il reste à faire (rappelez-vous que l'ICN, c'est de la recherche fondamentale). Par exemple, dans le contexte envisagé, celui d'une vraie catastrophe, il est possible que les données doivent être transportées par des « mules », des porteurs physiques (on peut penser au RFC 1149 mais aussi, plus sérieusement, à UUCP où les messages étaient parfois transportés ainsi, notamment dans les pays du Sud). Cette proposition est envisagée dans l'article de Tagami, A., Yagyu, T., Sugiyama, K., Arumaithurai, M., Nakamura, K., Hasegawa, T., Asami, T., et K. Ramakrishnan, « Name-based Push/Pull Message Dissemination for Disaster Message Board ».
Enfin, la section 5 du RFC décrit ce qui reste à faire (l'ICN est aujourd'hui incapable d'assurer les missions décrites au début de ce RFC). La première chose serait d'évaluer en vrai les solutions ICN existantes. Un test à la prochaine catastrophe ?
À noter que le travail ayant mené à ce RFC a été fait en partie dans le cadre du projet GreenICN.
L'article seul
RFC 8883: ICMPv6 Errors for Discarding packets Due to Processing Limits
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : T. Herbert (Intel)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 25 septembre 2020
Dans l'Internet, un routeur est toujours autorisé à jeter un paquet quand il ne peut pas le traiter, parce que ses files d'attente sont pleines, par exemple. Après tout, à l'impossible, nul n'est tenu, et les protocoles de transport et d'application savent à quoi s'attendre, et qu'ils devront peut-être gérer ces paquets perdus. Mais un routeur peut aussi jeter un paquet parce que des caractéristiques du paquet rendent impossible le traitement. Dans ce cas, il serait sympa de prévenir l'émetteur du paquet, pour qu'il puisse savoir que ses paquets, quoique légaux, ne peuvent pas être traités par certains routeurs. Notre nouveau RFC crée donc plusieurs nouveaux messages ICMP pour signaler à l'émetteur d'un paquet IPv6 qu'il en demande trop au routeur, par les en-têtes d'extension IPv6 qu'il ajoute.
La section 1 du RFC commence par lister les cas où un routeur peut légitimement jeter des paquets IPv6, même si les ressources matérielles du routeur ne sont pas épuisées :
- Voyons d'abord le cas des en-têtes d'extension pris individuellement. IPv6 permet d'ajouter aux paquets une chaîne d'en-têtes successifs (RFC 8200, section 4). Ces en-têtes peuvent être de taille variable (c'est le cas de Destination Options, qui peut contenir plusieurs options). Il n'y a pas de limite absolue à leur nombre, uniquement la contrainte qu'ils doivent tenir dans un datagramme, donc la taille de cette chaîne doit être inférieure à la MTU du chemin. Normalement, les routeurs ne regardent pas ces en-têtes (sauf Hop by Hop Options) mais certains équipements réseau le font (cf. RFC 7045). Si, par exemple, l'équipement a, dans son code, une limite du genre « maximum 100 octets par en-tête et au plus trois options dans les en-têtes à options », alors, il jettera les paquets excédant ces limites. (S'il n'a pas de limites, cela peut augmenter sa vulnérabilité à certaines attaques par déni de service.)
- Il peut aussi y avoir une limite portant sur la taille totale de la chaîne, pour les mêmes raisons, et avec les mêmes conséquences.
- Dans certains cas, les routeurs qui jettent le paquet ont tort, mais cela ne change rien en pratique : comme ils vont continuer à le faire, autant qu'ils puissent signaler qu'ils l'ont fait, ce qui est le but de ce RFC.
La section 2 du RFC définit donc six nouveaux codes pour indiquer les problèmes, à utiliser avec le type ICMP 4 (Parameter Problem, cf. RFC 4443, section 3.4). Petit rappel : les messages ICMP ont un type (ici, 4) et les messages d'erreur d'un même type sont différenciés par un code qui apporte des précisions. Ainsi, le type 1, Destination Unreachable, peut servir par exemple pour des messages d'erreur ICMP de code 1 (filtrage par décision délibérée), 4 (port injoignable), etc. Les codes de notre RFC sont dans le registre IANA. Les voici :
- 5, en-tête suivant inconnu (Unrecognized Next Header type encountered by intermediate node) : normalement, les routeurs ne doivent pas rejeter les en-têtes inconnus, juste les passer tel quels mais, s'ils le font, qu'au moins ils l'indiquent, avec ce code. (On a vu que l'approche de ce RFC est pragmatique.)
- 6, en-tête trop gros (Extension header too big).
- 7, chaîne d'en-têtes trop longue (Extension header chain too long).
- 8, trop d'en-têtes (Too many extension headers).
- 9, trop d'options dans un en-tête (Too many options in extension header) : à envoyer si le nombre d'options dans, par exemple, l'en-tête Hop-by-hop options, est trop élevé. Petit rappel : certains en-têtes (Destination Options et Hop-by-hop Options) sont composites : ils comportent une liste d'une ou plusieurs options.
- 10, option trop grosse (Option too big) : à envoyer si on rencontre une option de taille trop importante dans un en-tête comme Destination options.
Et la section 3 définit un nouveau code pour le type d'erreur Destination Unreachable, le code 8, en-têtes trop longs (Headers too long). Il a également été mis dans le registre IANA. Les messages utilisant ce code suivent le format du RFC 4884.
Et que fait-on quand on envoie ou reçoit des erreurs ICMP liées au traitement des en-têtes ? La section 4 du RFC rappelle les règles. D'abord, il faut évidemment suivre le RFC 4443, par exemple la limitation du rythme d'envoi des erreurs (RFC 4443, section 2.4f). Et, à la réception d'un message d'erreur ICMP, il est crucial de le valider (n'importe quelle machine sur l'Internet a pu générer ce message, en mentant sur son adresse IP source). Pour cela, on peut utiliser la portion du paquet original qui a été incluse dans le message d'erreur : il faut vérifier qu'elle correspond à une conversation en cours (connexion TCP existante, par exemple). Ensuite, il y a des règles spécifiques aux erreurs de ce RFC :
- On n'envoie qu'une erreur ICMP, même si plusieurs problèmes étaient survenus pendant le traitement d'un paquet (par exemple trop d'en-têtes et un total trop long). La section 4.1 donne la priorité à suivre pour savoir quelle erreur privilégier.
- À la réception, on peut ajuster son comportement en fonction de l'erreur signalée, par exemple envoyer moins d'en-têtes si l'erreur était le code 8, Too many extension headers. Si les en-têtes IPv6 ont été gérés par l'application, il faut la prévenir, qu'elle puisse éventuellement changer son comportement. Et s'ils ont été ajouté par le noyau, c'est à celui-ci d'agir différemment.
La section 5 rappelle un point d'ICMP qu'il vaut mieux garder en tête. ICMP n'est pas fiable. Les messages d'erreur ICMP peuvent se perdre, soit, comme tout paquet IP, parce qu'un routeur n'arrivait pas à suivre le rythme, soit parce qu'une middlebox sur le trajet jette tous les paquets ICMP (une erreur de configuration fréquente quand les amateurs configurent un pare-feu cf. RFC 8504). Bref, il ne faut pas compter que vous recevrez forcément les messages indiqués dans ce RFC, si vos paquets avec en-têtes d'extension ne sont pas transmis.
La même section 5 explique les motivations pour ce RFC : on constate une tendance à augmenter le nombre et la taille des en-têtes d'extension IPv6. Cela peut être pour faire du routage influencé par la source, pour de l'OAM (RFC 9486), ou pour d'autres innovations récentes.
Comme indiqué au début, cette augmentation peut se heurter aux limites des routeurs. La section 5.2.3 donne des exemples concrets. Les routeurs ne sont pas du pur logiciel, beaucoup de fonctions sont mises dans du matériel spécialisé. Ainsi, les circuits de traitement des paquets peuvent ne pas avoir de notion de boucle. Pour traiter les en-têtes d'extension ou les options dans un en-tête, la solution évidente qu'est la boucle n'est pas disponible, et on fait donc un petit nombre de tests suivis d'un saut. Le nombre maximal de tests est donc limité.
Enfin, la section 6 de notre RFC discute des questions de sécurité. Il y a le problème du filtrage par les pare-feux (voir le RFC 4890) mais aussi le risque (assez lointain, je trouve) que l'observation de la génération de ces nouveaux messages d'erreur donnent des indications à un observateur sur le logiciel utilisé. C'est un problème commun à tous les choix optionnels. En tout cas, le RFC recommande que l'envoi de ces messages d'erreur soit configurable.
Actuellement, il ne semble pas qu'il existe déjà de mise en œuvre de ce RFC.
L'article seul
RFC 8880: Special Use Domain Name 'ipv4only.arpa'
Date de publication du RFC : Août 2020
Auteur(s) du RFC : S. Cheshire (Apple), D. Schinazi (Google)
Chemin des normes
Première rédaction de cet article le 1 septembre 2020
La technique NAT64 pour permettre à des
machines d'un réseau purement IPv6
d'accéder à des services toujours uniquement en
IPv4 repose sur un préfixe IPv6 spécial,
utilisé pour donner l'impression aux machines IPv6 que le service
archaïque a de l'IPv6. Dans certains cas, il est pratique que
toutes les machines du réseau connaissent ce préfixe. Une
technique possible a été proposée dans le RFC 7050, utilisant un nom de domaine prévu à cet effet,
ipv4only.arpa. Mais ce nom de domaine n'avait
pas été documenté rigoureusement comme nom de domaine spécial. C'est
désormais fait, avec ce nouveau RFC.
Le NAT64 est normalisé dans le RFC 6146, et la découverte, par une machine, du
préfixe IPv6 utilisé, est dans le RFC 7050. Ce dernier RFC
avait créé le nom de
domaine ipv4only.arpa, mais sans
préciser clairement son statut, et notamment sans demander son
insertion dans le registre
des noms de domaine spéciaux. (Cette bavure bureaucratique
est d'ailleurs mentionnée dans le RFC 8244.)
Le but de notre nouveau RFC 8880 est de réparer cet
oubli et de documenter proprement le nom de domaine spécial
ipv4only.arpa.
Un petit rappel si vous n'avez pas le courage de lire le RFC 7050 : le problème qu'on cherche à résoudre
est celui d'une machine qui voudrait bénéficier de
NAT64 mais sans utiliser systématiquement
le résolveur DNS64 (RFC 6147). Pour cela, elle émet une requête DNS de type AAAA (adresse
IPv6) pour le nom ipv4only.arpa. Comme son
nom l'indique, ce nom n'a que des données de type A (adresses
IPv4). Si on récupère des adresses IPv6, c'est que le résolveur
DNS faisait du DNS64, et on peut déduire le préfixe IPv6 utilisé
de la réponse. Sans DNS64, on aura une réponse normale, rien sur
IPv6, et deux adresses stables en IPv4 :
% dig AAAA ipv4only.arpa
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 18633
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1
...
;; AUTHORITY SECTION:
ipv4only.arpa. 3600 IN SOA sns.dns.icann.org. noc.dns.icann.org. (
2020040300 ; serial
7200 ; refresh (2 hours)
3600 ; retry (1 hour)
604800 ; expire (1 week)
3600 ; minimum (1 hour)
)
;; Query time: 95 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Thu May 07 15:22:20 CEST 2020
;; MSG SIZE rcvd: 127
% dig A ipv4only.arpa
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 2328
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 14, ADDITIONAL: 27
...
;; ANSWER SECTION:
ipv4only.arpa. 86400 IN A 192.0.0.170
ipv4only.arpa. 86400 IN A 192.0.0.171
...
;; Query time: 238 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Thu May 07 14:24:19 CEST 2020
;; MSG SIZE rcvd: 1171
En quoi est-ce que ce nom ipv4only.arpa
est « spécial » (section 2 du RFC) ? D'abord, il n'y a aucune
raison de le visiter en temps normal, il n'a aucune ressource
utile, et ses deux adresses IP sont stables et bien
connues. Paradoxalement, si on l'interroge, c'est qu'on espère un
mensonge, l'apparition d'adresses IPv6 qui ne sont pas dans la
zone originale. Ce nom de domaine permet en fait une communication
de la machine terminale vers un intermédiaire (le résolveur DNS),
pour savoir ce qu'il fait. C'est en cela que
ipv4only.arpa est spécial.
Mais, rappelez-vous, le RFC 7050 avait
oublié de déclarer ipv4only.arpa comme étant
spécial. Résultat, les différents logiciels qui traitent des noms
de domaine le traitent de la manière normale et, comme le note la
section 3 de notre RFC, cela a quelques conséquences ennuyeuses :
- Si la machine NAT64 utilise un résolveur DNS différent de celui du
réseau local, par exemple un résolveur public,
ipv4only.arpapeut ne pas donner le résultat attendu, - Les résolveurs DNS64 doivent faire une résolution normale
ipv4only.arpaalors qu'ils devraient avoir le droit de tout gérer localement et de fabriquer des réponses directement.
Bref, il fallait compléter le RFC 7050, en suivant le cadre du RFC 6761. Ce RFC 6761 impose de lister, pour chaque catégorie de logiciel, en quoi le nom de domaine est spécial. C'est fait dans la section 7 de notre RFC, qui indique que :
- Pour les utilisateurs finaux, pour les applications, pour
les serveurs faisant autorité, et
pour les résolveurs qui ne font que faire suivre à un résolveur
plus gros (ce qui est typiquement le cas de celui des
boxes),
rien de particulier, ils et elles peuvent traiter
ipv4only.arpacomme un domaine normal. Si elles le désirent, les applications peuvent résoudre ce nomipv4only.arpaet apprendre ainsi si un résolveur DNS64 est sur le trajet, mais ce n'est pas obligatoire. - Les bibliothèques qui gèrent la résolution de noms (comme
la libc sur Unix)
doivent par contre considérer
ipv4only.arpacomme spécial. Notamment, elles doivent utiliser le résolveur configuré par le réseau (par exemple via DHCP) pour résoudre ce nom. Le demander à un résolveur public n'aurait en effet pas de sens. - Les résolveurs qui ne font pas de DNS64 traitent
ipv4only.arpacomme normal, et leurs clients apprendront donc ainsi que leur résolveur ne fait pas de DNS64. - Les résolveurs DNS64 vont synthétiser des adresses IPv6 en
réponse aux requêtes de type AAAA pour
ipv4only.arpa, et leurs clients apprendront donc ainsi que leur résolveur fait du DNS64, et sauront quel préfixe IPv6 est utilisé. Ils n'ont pas besoin de consulter les serveurs faisant autorité, qui ne pourraient rien leur apprendre qui n'est pas déjà dans le RFC. L'annexe A du RFC donne un exemple de configuration pour BIND pour attendre cet objectif.
À noter qu'outre ipv4only.arpa, notre RFC
réserve deux autres noms spéciaux,
170.0.0.192.in-addr.arpa et
171.0.0.192.in-addr.arpa, pour permettre la
« résolution inverse ». Contrairement à
ipv4only.arpa, ils ne sont pas actuellement
délégués, et un résolveur normal, qui ne connait pas DNS64,
répondra donc NXDOMAIN (ce nom n'existe pas).
Sinon, la section 5 de notre RFC est dédiée à la sécurité et
note notamment que les noms synthétisés ne peuvent évidemment pas
être validés avec DNSSEC. C'est pour cela que la délégation
de ipv4only.arpa n'est même pas
signée. (C'est un changement depuis le RFC 7050, qui demandait au contraire une zone signée, ce
que ipv4only.arpa avait été au début.)
Vu par les sondes RIPE Atlas, voici les réponses de résolveurs à ce domaine spécial :
% blaeu-resolve -r 1000 -q AAAA ipv4only.arpa
[] : 986 occurrences
[64:ff9b::c000:aa 64:ff9b::c000:ab] : 4 occurrences
[2a01:9820:0:1:0:1:c000:aa 2a01:9820:0:1:0:1:c000:ab] : 1 occurrences
[2a0a:e5c0:0:1::c000:aa 2a0a:e5c0:0:1::c000:ab] : 1 occurrences
Test #24069173 done at 2020-02-24T14:49:43Z
Sur mille sondes Atlas, la grande majorité ne trouve pas d'adresse
IPv6 pour ipv4only.arpa ce qui, comme le nom
de domaine l'indique, est le comportement par défaut. Quelques
sondes sont derrière un résolveur DNS64, utilisant en général le
préfixe bien connu du RFC 7050 (les réponses
64:ff9b::…), mais parfois d'autres préfixes
(NSP - Network-Specific Prefix - dans la
terminologie du RFC 7050).
L'article seul
RFC 8877: Guidelines for Defining Packet Timestamps
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : T. Mizrahi (Huawei Smart Platforms iLab), J. Fabini (TU Wien), A. Morton (AT&T Labs
Pour information
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 24 septembre 2020
De nombreux protocoles Internet contiennent un champ où se trouve une estampille temporelle (timestamp en anglais), une indication de date et d'heure. Mais chaque protocole a défini le format de cette estampille de son côté, il n'y a pas de format standard. Ce nouveau RFC essaie de mettre un peu d'ordre là-dedans en proposant aux concepteurs de futurs protocoles :
- Trois formats standards, parmi lesquels choisir, pour avoir un format tout fait,
- Des conseils pour les cas où un protocole définirait (ce qui est sans doute une mauvaise idée) un nouveau format.
Dans quels cas des protocoles contiennent dans leurs données une estampille temporelle ? Cela peut être bien sûr parce que le protocole est voué à distribuer de l'information temporelle, comme NTP (RFC 5905). Mais cela peut être aussi parce que le protocole a besoin d'indiquer le moment d'un événement, par exemple pour mesurer une latence (OWAMP, RFC 4656 ou les extensions à TCP du RFC 7323). La section 6 du RFC présente une liste non exhaustive de protocoles qui utilisent des estampilles temporelles, ce qui fournit d'autres exemples comme MPLS (RFC 6374), IPFIX (RFC 7011), TRILL (RFC 7456), etc. Il serait souhaitable que les formats de ces estampilles soient normalisés. Ainsi, utiliser le format de NTP dans un autre protocole permettrait facilement d'utiliser le temps NTP, sans perte de précision. Et la standardisation des formats permettait de les mettre en œuvre dans du matériel, comme les horloges. Bref, si vous concevez des protocoles réseau et qu'ils intègrent une information temporelle, lisez ce RFC.
Pour suivre la suite du RFC, il faut un peu de vocabulaire, rappelé en section 2. Notamment :
- Erreur sur l'estampille : la différence entre une estampille et une horloge de référence. Elle est de zéro quand tout est parfaitement à l'heure, ce qui n'arrive évidemment jamais dans le monde réel.
- Exactitude de l'estampille : la moyenne des erreurs.
- Précision de l'estampille : l'écart-type des erreurs.
- Résolution temporelle de l'estampille : le temps minimal qu'un format permet de représenter. Si on a un format texte HH:MM:SS (heures:minutes:secondes), la résolution sera de une seconde.
- Période de bouclage : le temps au bout duquel on reviendra à la valeur de départ. C'est la fameuse bogue de l'an 2000 : si on stocke les années sur deux chiffres, la période de bouclage vaut cent ans. Si on stocke les estampilles sous forme d'un entier de 32 bits signé, et que la résolution est d'une seconde, cette période de bouclage est de 68 ans.
Les formats recommandés par le RFC sont décrits en section 4. Pourquoi trois formats plutôt qu'un seul ? Parce que tous les protocoles réseau n'ont pas forcément les mêmes contraintes en terme de taille du champ, de résolution temporelle, ou d'intégration avec d'autres protocoles (sur un système d'exploitation conçu pour des PC connectés à l'Internet, utiliser le format de NTP est sans doute le plus raisonnable, mais pour du matériel de métrologie complexe, celui de PTP peut être une meilleure idée).
D'abord, le grand classique, le format de NTP (RFC 5905, section 6). Il est très répandu sur l'Internet, et utilisé dans de nombreux protocoles (RFC 6374, RFC 4656, RFC 5357, et bien d'autres). Il stocke l'estampille sous forme d'un entier de 32 bits pour les secondes depuis l'epoch 1900, et d'un autre entier de 32 bits pour les fractions de seconde. Sa taille totale est de 64 bits, sa résolution de 2 puissance -32 seconde, soit 0,2 milliardièmes de seconde. Et sa période de bouclage est de 136 ans.
NTP a un autre format, sur seulement 32 bits, pour les cas où la taille compte, par exemple des objets contraints. Dans ce cas, le nombre de secondes et la fraction de seconde sont sur 16 bits chacun. Cela lui donne une période de bouclage très courte, seulement 18 heures.
Et le troisième format standard proposé est celui de PTP, dans sa version « tronquée » à 64 bits. Ce format est utilisé dans les RFC 6374, RFC 7456 ou RFC 8186. Il est surtout intéressant lorsqu'il faut interagir avec de l'instrumentation utilisant PTP. Sa résolution est d'une nanoseconde, sa période de bouclage est la même que celle de NTP mais comme son epoch est en 1970, cela remet le prochain bouclage à 2106.
(Vous noterez que notre RFC ne parle que des formats binaires
pour représenter les estampilles temporelles. Il existe également
des formats texte, notamment celui du RFC 3339, utilisé par exemple dans les RFC 5424, RFC 5646, RFC 6991, ou RFC 7493. Les formats de
HTTP
- en-têtes Date: et
Last-Modified: - ainsi que
l'Internet Message Format - IMF, RFC 5322 -
n'utilisent hélas pas le RFC 3339.)
Deux exemples d'utilisation de ces formats binaires standards sont donnés dans notre RFC, aux sections 6.1 et 6.2, si vous êtes un ou une concepteur(trice) de protocoles qui veut inclure une estampille temporelle.
Mais, si, malgré les sages conseils du RFC, vous êtes l'auteur(e) d'un protocole et vous voulez quand même créer votre propre format binaire pour indiquer date et heure, y a-t-il des règles à suivre ? (À part la règle « ne le faites pas ».) Oui, la section 3 du RFC donne des indications (la plupart sont assez évidentes) :
- Bien documenter les raisons pour lesquelles vous tenez absolument à votre format à vous,
- indiquer évidemment la taille de chaque champ et la boutianité (ce sera du gros boutien par défaut),
- indiquer les unités utilisées, et l'epoch,
- documenter le moment du bouclage, et les solutions prévues pour quand il sera atteint,
- et ne pas oublier de gérer les secondes intercalaires.
À propos de secondes intercalaires, que vous utilisiez un format à vous, ou bien la méthode recommandée d'un format existant, pensez aux aspects liés à la synchronisation des horloges entre elles (section 5 du RFC), sauf pour les cas d'horloges complètement isolées (mais les RFC sont écrits pour l'Internet, donc il est prévu de communiquer). Quel(s) protocole(s) utiliser, quelle référence de temps (UTC ? TAI ?), et comment gérer ces fameuses secondes intercalaires. Que faut-il faire si l'horloge recule, faut-il faire un changement brusque ou bien du smearing (cf. RFC 8633), etc.
Un avant-dernier détail : parfois, le format de l'estampille temporelle, et ses propriétés, sont décrits dans le protocole, ou dans un modèle formel, par exemple en YANG. C'est ce que fait OWAMP (RFC 4656) avec le champ donnant une estimation de l'erreur de mesure (section 4.1.2 du RFC 4656). Notre RFC nomme ces « méta » champs « champs de contrôle » et donne quelques règles à suivre quand on les utilise : extensibilité (on aura toujours besoin d'autre chose), taille (assez gros mais pas trop…), importance (obligatoire ou optionnel), catégorie (statique ou dynamique).
Enfin, il y a évidemment la question de la sécurité (section 9). Il est bien sûr obligatoire dans la description d'un protocole de fournir une analyse de sa sécurité (RFC 3552). Cela doit inclure les conséquences des estampilles temporelles sur la sécurité. Par exemple, de telles estampilles, si elles sont transmises en clair, peuvent renseigner un observateur sur les performances d'un réseau. Et, si elle ne sont pas protégées contre les modifications non autorisées (ce qui peut se faire, par exemple, avec un MAC), un attaquant peut fausser sérieusement le fonctionnement d'un protocole en changeant la valeur des estampilles.
Autre problème de sécurité, un attaquant actif qui retarderait délibérement les messages. Cela perturberait évidemment tout protocole qui utilise le temps. Et, contrairement à la modification des estampilles, cela ne peut pas se résoudre avec de la cryptographie. Enfin, la synchronisation des horloges est elle-même exposée à des attaques (RFC 7384). Si on déploie NTP sans précautions particulières, un attaquant peut vous injecter une heure incorrecte.
L'article seul
RFC 8875: Working Group GitHub Administration
Date de publication du RFC : Août 2020
Auteur(s) du RFC : A. Cooper (Cisco), P. Hoffman (ICANN)
Pour information
Réalisé dans le cadre du groupe de travail IETF github
Première rédaction de cet article le 29 août 2020
Certains groupes de travail IETF, ou bien certains participant·e·s à la normalisation au sein de cette organisation, utilisent le service GitHub de Microsoft pour gérer le processus de production des normes. Ce RFC donne des conseils pratiques aux groupes de travail qui utilisent GitHub. Il suit les principes généraux énoncés dans le RFC 8874, en étant plus concret, davantage orienté « tâches ».
Il s'agit cependant juste de conseils : des groupes peuvent parfaitement faire différemment, des individus peuvent utiliser GitHub (ou un service libre équivalent, ce que le RFC ne mentionne guère) en suivant d'autres méthodes. Le RFC concerne surtout les groupes de travail qui se disent que GitHub pourrait être intéressant pour eux, mais qui ne sont pas sûr de la meilleure manière de faire. Les groupes plus expérimentés qui utilisent GitHub parfois depuis des années savent déjà.
La section 2 du RFC décrit le processus recommandé pour le cycle de vie du groupe de travail. Ce processus peut s'automatiser, GitHub ayant une API documentée. Je ne sais pas si à l'heure actuelle cette automatisation est réellement utilisée par l'IETF Secretariat, mais le RFC suggère l'usage d'outils comme ietf-gh-scripts ou comme i-d-template.
Le RFC demande que l'interface utilisée par les directeurs de
zones IETF et les présidents des groupes de travail dans le
DataTracker
permette de créer une organisation GitHub. Elle doit être nommée
ietf-wf-NOMDUGROUPE (en pratique, cette
convention semble rarement suivie), les directeurs de la zone doivent
en être les propriétaires et les présidents du groupe doivent avoir
le statut d'administrateur (voyez par exemple les membre du groupe GitHub
QUIC). Elle est ensuite indiquée depuis le
DataTracker (cf. par exemple pour le groupe
capport). Il n'est pas possible actuellement d'associer
clairement les identités GitHub aux identités IETF (ça a été
demandé mais l'identité sur l'Internet est un sujet
complexe).
De même qu'il faudrait pouvoir créer facilement une organisation
dans GitHub, il serait bien de pouvoir créer facilement un nouveau
dépôt, et de le peupler avec les fichiers minimaux
(LICENSE - en suivant ces
principes, README,
CONTRIBUTING - en s'inspirant de ces
exemples, etc). L'outil i-d-template
fait justement cela.
Une fois organisation et dépôt(s) créés, le groupe peut se mettre
à travailler (section 3 du RFC). Un des points importants est la
sauvegarde. Il est crucial de sauvegarder
tout ce qui est mis dans GitHub au cas où, par exemple, Microsoft
déciderait tout à coup de limiter l'accès ou de le rendre
payant. Les listes de diffusion de l'IETF sont archivées via MailArchive, mais tout ce
qui se passe sur GitHub doit l'être également. Pour les documents,
c'est facile, git est un VCS décentralisé,
avoir une copie complète (avec l'historique) du dépôt est le
comportement par défaut. L'IETF n'a donc qu'à faire un git
fetch toutes les heures pour stocker une copie.
Il reste les tickets et les pull requests. Ils (elles ?) ne sont pas gérés par git. Il faut alors utiliser l'API de GitHub pour les sauvegarder.
Ce risque de pertes, si on ne fait pas de sauvegarde, fait d'ailleurs partie des risques mentionnés dans la section 4, sur la sécurité. Par contre, ce RFC ne mentionne pas les risques plus stratégiques liés à la dépendance vis-à-vis d'un système centralisé. C'est pour cela que certains documents sont développés en dehors de GitHub, par exemple le RFC 9156, successeur du RFC 7816 était sur un GitLab, FramaGit.
L'article seul
RFC 8874: Working Group GitHub Usage Guidance
Date de publication du RFC : Août 2020
Auteur(s) du RFC : M. Thomson (Mozilla), B. Stark (AT&T)
Pour information
Réalisé dans le cadre du groupe de travail IETF git
Première rédaction de cet article le 29 août 2020
De nombreux groupes de travail de l'IETF utilisent GitHub pour coordonner leur travail dans cet organisme de normalisation. Ce nouveau RFC donne des règles et des conseils à suivre dans ce cas. Personnellement, je déplore qu'il ne contienne pas de mise en garde contre l'utilisation d'un service centralisé extérieur à l'IETF.
L'IETF développe des normes pour l'Internet, notamment la plupart des RFC. Ce travail met en jeu des documents, les brouillons de futurs RFC, des discussions, des problèmes à résoudre. Les discussions sont assez complexes, durent souvent des mois, et nécessitent de suivre pas mal de problèmes, avec beaucoup d'éléments à garder en tête. Bref, des outils informatiques peuvent aider. Mais attention, l'IETF a des particularités (cf. RFC 2418). D'abord, tout doit être public, le but étant que le développement des normes soit aussi transparent que possible. Et il ne s'agit pas que de regarder, il faut que tous les participants (l'IETF est ouverte) puissent intervenir. Ensuite, tout doit être archivé, car il faudra pouvoir rendre compte au public, même des années après, et montrer comment l'IETF est parvenue à une décision. (D'autres SDO, comme l'AFNOR, sont bien plus fermées, et n'ont pas ces exigences d'ouverture et de traçabilité.)
Traditionnellement, l'IETF n'avait que peu d'outils de travail en
groupe et chacun se débrouillait de son côté pour suivre le travail
tant bien que mal. Mais les choses ont changé et l'IETF a désormais
une importante série d'outils, aussi bien les « officiels »,
maintenus par un prestataire extérieur, AMSL,
que des officieux, disponibles sur https://tools.ietf.org/
- Le service d'accès et de recherche dans les archives des listes de diffusion, MailArchive.
- Le service de suivi des documents DataTracker (regardez par exemple où en est HTTP/3).
Il n'y a pas par contre de VCS (dans les outils officieux, il y a un
service Subversion) ou de mécanisme de
suivi de tickets (il y a un
Trac officieux en https://trac.ietf.org/
Un VCS est pourtant un outil très utile, et pas seulement pour les programmeurs. Travaillant en général sur des fichiers texte quelconques, il permet de coordonner le travail de plusieurs personnes sur un document, que celui-ci soit du code source ou bien un Internet-Draft. C'est le cas par exemple du VCS décentralisé git, très utilisé aujourd'hui.
On peut utiliser git tout seul, d'autant plus que le fait qu'il doit décentralisé ne nécessite pas d'autorité de coordination (c'est ainsi qu'est développé le noyau Linux, par exemple). Mais beaucoup de programmeurs (ou d'auteurs d'Internet Drafts) utilisent une forge complète, intégrant un VCS mais aussi un système de gestion de rapports, un wiki et d'autres fonctions. La plus connue de ces forges est GitHub, propriété de Microsoft. Comme souvent avec les réseaux sociaux (GitHub est le Facebook du geek), la taille compte : plus il y a de gens sur le réseau social, plus il est utile. C'est pour cela qu'il y a des fortes pressions à la centralisation, et une difficulté, en pratique, à partir, sauf à perdre les possibilités de coopération (c'est pour cela que prétendre qu'il y a consentement des utilisateurs aux pratiques déplorables des réseaux sociaux centralisés est une farce : on n'a pas le choix). L'utilisation de GitHub n'est évidemment pas obligatoire à l'IETF mais elle est répandue. Regardez par exemple le groupe de travail QUIC, celui sur HTTP, ou celui sur les portails captifs. GitHub est également utilisé en dehors des groupes de travail, par exemple pour les résultats et présentations des hackathons. Le but de ce RFC est de fournir quelques règles utiles (mais facultatives) pour les groupes qui travailleront sur GitHub. Un autre RFC, le RFC 8875, est plus concret, donnant des règles précises de configuration de GitHub pour un groupe de travail.
L'introduction du RFC rappelle juste en passant qu'il existe d'autres forges comme Bitbucket et du logiciel libre qui permet d'installer diverses forges locales. Ainsi, le logiciel de GitLab permet d'installer des forges indépendantes comme FramaGit. (J'ai récemment migré tous mes dépôts vers un GitLab.) C'est FramaGit qui est utilisé pour le développement de la norme sur la QNAME minimisation, le RFC 9156, qui a remplacé le RFC 7816. Mais GitHub est de loin le plus utilisé et, par exemple, pour le successeur du RFC 7816, quasiment tous les contributeurs avaient été obligés de se créer un compte sur FramaGit, ils n'en avaient pas avant. Le RFC ne rappelle même pas les dangers qu'il y a à utiliser un service centralisé, géré par une entreprise privée. Si GitLab est mentionné dans le RFC, la possibilité d'une instance IETF (gérée par l'actuel prestataire qui administre les ressources IETF, AMSL) n'apparait pas. Simple question d'argent ou problème plus fondamental ?
Bon, au boulot, maintenant, quelles sont les règles listées par ce RFC ? (Rappel : ce RFC reste à un haut niveau, les instructions précises sont dans le RFC 8875.) D'abord, comment décider d'utiliser (ou non) GitHub (section 3 du RFC) ? Fondamentalement, ce sont les présidents du groupe qui décident, après consultation avec les directeurs de la zone (une zone regroupe plusieurs groupes de travail). Ils vont également définir les conditions d'utilisation (par exemple, décider d'utiliser le système de rapports - issues - ou pas). Notez que, même si le groupe en tant que tel n'utilise pas GitHub, certains contributeurs peuvent évidemment s'en servir pour leurs besoins propres. D'une manière générale, le travail fait sur GitHub n'a pas d'autorité particulière, c'est juste un élément parmi d'autres pour le groupe. Ainsi, ce n'est pas parce qu'un ticket est fermé sur GitHub que le groupe de travail est lié par cette fermeture et ne peut plus discuter le point en question.
Le groupe peut ensuite créer un dépôt par document, ce qui est recommandé (c'est ce que fait le groupe capport) ou bien, s'il préfère, un seul dépôt pour tous les documents du groupe (sans aller jusque là, le groupe QUIC met tous les documents de base du protocole dans le même dépôt).
Les documents sont a priori en XML, format standard des documents IETF (cf. RFC 7991) mais on a le droit d'utiliser Markdown (cf. RFC 7328). Par contre, les formats doivent être du texte, pas de binaire comme avec LibreOffice, binaire qui passerait mal avec git (pas moyen de voir les différences d'une version à l'autre).
Ensuite, un peu de paperasserie (section 2 du RFC), avec les
règles administratives. Le RFC recommande de créer une organisation
dans GitHub pour chaque groupe de travail qui utilise GitHub (il n'y
a pas d'organisation « IETF »). Les propriétaires de cette
organisation doivent être les directeurs de la zone dont fait partie
le groupe, et les présidents ou présidentes du groupe. Les auteurs
des documents doivent évidemment avoir un accès en écriture. Les
dépôts du groupe de travail sur GitHub doivent être clairement
documentés, indiquant la charte du groupe, sa politique, sa gestion
des contributeurs (fichier CONTRIBUTING, que
GitHub met en avant), etc. Et il faut évidemment pointer sur la
politique générale de l'IETF, le Note
Well (qui est tout le temps cité dans les réunions
physiques, mais qui doit également être connu des gens qui
n'interagissent que via GitHub). En sens inverse, le dépôt GitHub
doit être clairement indiqué sur les pages du groupe sur le site de
l'IETF, et sur les Internet-Drafts produits.
Un des intérêts d'une forge comme GitHub est qu'on dispose de plusieurs moyens de contribuer à un projet. Lesquels utiliser pour des documents IETF (section 4 du RFC) ? Il y a d'abord le système de suivi des questions. Il permet de noter les questions en cours et les décisions prises peuvent être inscrites dans le ticket, avant de le fermer. D'un coup d'œil, on peut voir facilement le travail en cours, et ce qui reste à faire. Dans chaque ticket, on peut voir l'ensemble des éléments liés à une question. Le système de suivi de questions (issue tracker) de GitHub permet bien d'autres choses, comme l'affectation d'un ticket à une personne. Un service très utile est l'étiquetage des questions (« rédaction » pour un texte mal écrit, « technique » pour un problème technique, etc). Comme dans la plupart des cas, le RFC n'impose pas une politique de gestion des étiquettes, seulement le fait qu'il y ait une politique et qu'elle soit communiquée aux participants. Même chose pour la politique de fermeture des tickets (un sujet parfois sensible).
Une fonction qui a beaucoup contribué à la popularité du GitHub est la possibilité de pull request (qui a une bonne traduction en français ? Alexis La Goutte suggère « demande d'intégration »), c'est-à-dire d'enregistrer une série de modifications qui sont collectivement soumises à l'approbation ou au rejet d'un responsable. Cela permet de proposer une contribution sans avoir l'autorisation d'écriture dans le dépôt, tout en permettant une grande traçabilité des contributions. C'est la méthode conseillée par le RFC pour soumettre des contributions significatives, notamment en raison de cette traçabilité. Par contre, il n'est pas conseillé de discuter de questions complexes dans les commentaires de la pull request ; comme la requête peut être modifiée, les commentaires risquent de devenir décalés par rapport au dernier état de la pull request.
GitHub permet d'avoir un flux de syndication pour les dépôts. C'est ce que j'utilise personnellement pour suivre les activités des dépôts qui m'intéressent. Mais il existe d'autres méthodes comme l'outil github-notify-ml, très utilisé à l'IETF.
J'ai dit plusieurs fois que ce RFC n'imposait pas une façon d'utiliser GitHub pour un groupe de travail IETF. Il y a plusieurs politiques possibles, chaque groupe de travail peut faire différemment, l'important étant que les participants au groupe soient au courant. Pour faciliter le choix, la section 5 du RFC propose un jeu de politiques typiques, parmi lesquelles on peut choisir. Elles sont classées de la plus élémentaire, à celle qui utilise le plus les possibilités de GitHub :
- Dans le cas le plus simple, le groupe travaille comme avant, il ne se sert que GitHub que pour stocker les documents, notamment les Internet-Drafts et leur historique.
- Plus élaborée, une politique avec utilisation du système de suivi des questions, mais où les discussions ont toujours lieu ailleurs que sur GitHub, les tickets ne stockant que les questions en cours et leur résolution. (Comme le note le RFC, c'est difficile à garantir, les discussions s'invitent souvent sur les tickets.)
- Encore plus githubienne, la politique où cette fois la discussion a officiellement lieu sur les tickets GitHub. La liste de diffusion (le principal outil officiel des groupes de travail IETF) a le dernier mot mais le gros du travail a été fait sur le système de gestion de tickets. Attention : cela veut dire qu'une bonne partie des explications et justifications à un RFC vont rester sur une plate-forme privée, qui peut changer sa politique à sa guise, ce qui pourrait faire perdre à l'IETF une partie de son histoire (la section 10 du RFC revient sur cette question). Le RFC ne contient pas de mise en garde à ce sujet, alors que le problème s'est déjà produit.
La section 5 discute également des politiques de nommage pour les étiquettes. Au minimum, il faut des étiquettes pour différencier les détails (« coquille dans le deuxième paragraphe ») des questions de fond. Ensuite, les étiquettes peuvent être utilisées pour :
- L'état d'un ticket (« en discussion », « consensus approximatif », « repoussé à une future version du protocole »).
- La partie du protocole concernée.
- Ou d'autres cas comme par exemple le marquage des tickets considérés comme complètement hors-sujet.
Une notion importante à l'IETF est celle de consensus. L'IETF ne vote pas (dans une organisation sans adhésion explicite, qui aurait le droit de vote ?) et prend normalement ses décisions par consensus (cf. RFC 2418). Pour estimer s'il y a consensus ou pas, les présidents du groupe de travail peuvent utiliser tous les moyens à leur disposition (section 7 du RFC) dont GitHub, mais doivent s'assurer, sur la liste de diffusion officielle du groupe, qu'il s'agit bien d'un consensus. (Certains participants ou participantes peuvent ne pas utiliser GitHub, et il faut quand même tenir compte de leur avis.)
Le RFC note aussi (section 8) que, parmi les fonctions de GitHub, l'intégration continue peut être très utile. Par exemple, si les documents rédigés comportent des extraits dans un langage formel (comme YANG ou Relax NG), mettre en place un système d'intégration continue permet de détecter les erreurs rapidement, et de présenter automatiquement la dernière version, automatiquement vérifiée, des documents.
La section 9 du RFC donne quelque conseils aux auteurs (editors dans le RFC car le concept d'auteur est délicat, pour des documents collectifs). Avec GitHub, il y aura sans doute davantage de contributions extérieures (par exemple sous forme de pull requests), puisque le processus de soumission est plus facile pour les gens qui ne sont pas à l'IETF depuis dix ans. C'est bien l'un des buts de l'utilisation d'une forge publique. Mais cela entraine aussi des difficultés. Des tickets vont être dupliqués, des pull requests être plus ou moins à côté de la plaque, etc. Les auteurs doivent donc se préparer à un travail de tri important.
Enfin, la section 10, consacrée à la sécurité, détaille plusieurs des problèmes que pose l'utilisation de GitHub. D'abord, il y a la dépendance vis-à-vis d'une plate-forme extérieure à l'IETF ; si GitHub est en panne, perturbant le fonctionnement d'un ou plusieurs groupes de travail, l'IETF ne peut rien faire. (Le caractère décentralisé de git limite un peu l'ampleur du problème.) Ensuite, il y a la nécessité de faire des sauvegardes, y compris des tickets (qui ne sont pas, eux, gérés de manière décentralisée). Le RFC 8875 donne des consignes plus précises à ce sujet. Et il y a le risque de modifications non souhaitées, si un participant ayant droit d'écriture se fait pirater son compte. Le fait que tout soit public à l'IETF, et que git permette assez facilement de revenir en arrière sur des modifications, limitent l'importance de cette menace mais, quand même, il est recommandé que les auteurs sécurisent leur compte (par exemple en activant la MFA). En revanche, un autre risque n'est pas mentionné dans le RFC, celui du blocage par GitHub des méchants pays. GitHub bloque ou limite l'accès à certains pays et ne s'en cache d'ailleurs pas.
Dernier problème avec GitHub, non mentionné dans le RFC (merci à Alexis La Goutte pour l'observation) : l'IETF travaille de nombreuses années à développer et promouvoir IPv6 et GitHub n'a toujours que les adresses de la version du siècle précédent.
L'article seul
RFC 8863: Interactive Connectivity Establishment Patiently Awaiting Connectivity (ICE PAC)
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : C. Holmberg (Ericsson), J. Uberti (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ice
Première rédaction de cet article le 19 janvier 2021
Le protocole ICE, normalisé dans le RFC 8445 permet de découvrir et de choisir, quand on est coincé derrière un routeur NAT, les adresses IP que vos correspondants verront. Parfois, au début du processus ICE, il n'y a pas d'adresses acceptables. Au lieu de renoncer tout de suite, ce nouveau RFC modifie le RFC 8445 pour demander qu'on patiente un peu : des adresses IP acceptables peuvent apparaitre par la suite.
Résumons le fonctionnement de base d'ICE. ICE sert lorsqu'une des deux machines qui correspondent a le malheur d'être derrière du NAT : le but est de choisir une paire d'adresses IP, pour les deux machines qui correspondent. ICE compte sur des protocoles comme STUN pour la découverte d'adresses possibles. Ensuite, il teste ces adresses et réussit lorsque la communication a pu s'établir avec l'autre machine. Un effet de bord de ce processus est qu'il « crée » parfois de nouvelles adresses IP possibles, qu'il faut donc ajouter à la liste et tester. Le problème que résout notre nouveau RFC est que ces nouvelles adresses peuvent être détectées trop tard, alors qu'ICE a déjà renoncé à trouver une paire qui marche. La solution ? Attendre un peu, même si la liste des paires candidates est vide, ou qu'aucune des paires d'adresses de la liste n'a marché.
La section 3 de notre RFC note que le problème n'est pas si fréquent en pratique car ICE est lent ; cela prend du temps d'établir la liste des paires d'adresses IP possibles, et de les tester, d'autant plus qu'on ne reçoit pas forcément tout de suite un rejet, il faut souvent attendre la fin du délai de garde. Bref, la plupart du temps, les nouvelles adresses apparaissant en cours de route auront le temps d'être intégrées à la liste des paires à tester. Il y a toutefois quelques cas où le risque d'échec complet existe. Par exemple, si une machine purement IPv6 essaie de contacter une machine purement IPv4, aucune paire d'adresses IP satisfaisante ne sera trouvée, menant ICE à renoncer tout de suite. Or, si le réseau local de la machine IPv6 avait NAT64, la connexion reste possible, il faut juste tester et apprendre ainsi qu'une solution existe. Cela demande un peu de patience.
La section 4 formalise la solution : un chronomètre global est créé, le PAC timer (PAC pour Patiently Awaiting Connectivity) et mis en route au tout début du processus ICE. ICE ne doit pas renoncer, même s'il croit ne plus avoir de solutions, avant que ce chronomètre n'ait mesuré au moins 39,5 secondes (cette durée vient du RFC 5389, section 7.2.1, mais peut être modifiée dans certains cas).
L'article seul
RFC 8832: WebRTC Data Channel Establishment Protocol
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : R. Jesup (Mozilla), S. Loreto
(Ericsson), M. Tuexen (Muenster Univ. of
Appl. Sciences)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF rtcweb
Première rédaction de cet article le 19 janvier 2021
Ce RFC est un des composants de WebRTC. Il spécifie comment on établit le canal de communication des données entre deux pairs WebRTC.
WebRTC est résumé dans le RFC 8825 et la notion de « canal de communication de données » est dans le RFC 8831. Ces données sont protégées par DTLS et transportées en SCTP (RFC 8261).
Le principe est de connecter deux flux de données WebRTC, un entrant
et un sortant, pour faire un seul canal bi-directionnel. Le
protocole est simple, reposant sur seulement deux messages, un
DATA_CHANNEL_OPEN envoyé sur le flux sortant,
auquel le pair WebRTC répond par un
DATA_CHANNEL_ACK qui va arriver sur le flux
entrant. Pour éviter les ouvertures simultanées (un protocole à
deux messages n'est pas très robuste), le client DTLS
utilise des flux ayant un identificateur (stream
identifier) pair, et le serveur des flux à
identificateurs impairs. Le format de ces deux messages est décrit
dans la section 5 du RFC.
Les paquets SCTP contiennent un PPID (Payload Protocol IDentifier, RFC 9260, section 3.3.1 et 15.5) qui indique le protocole applicatif qui utilise SCTP. Dans le cas de notre protocole d'établissement de canal WebRTC, DCEP (Data Channel Establishement Protocol), le PPID vaut 50 (et figure dans le registre IANA sous le nom de WebRTC DCEP).
L'article seul
RFC 8831: WebRTC Data Channels
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : R. Jesup (Mozilla), S. Loreto (Ericsson), M. Tuexen (Muenster Univ. of Appl. Sciences)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF rtcweb
Première rédaction de cet article le 19 janvier 2021
Ce RFC décrit le canal de données (à l'exclusion de l'audio et de la vidéo) entre deux navigateurs Web se parlant avec WebRTC. Ce canal utilise le protocole de transport SCTP.
Le canal de données WebRTC est une modélisation d'un tuyau virtuel entre les deux parties qui communiquent, tuyau dans lequel circuleront les données. SCTP (RFC 9260) n'est pas utilisé pour les données « multimédia » comme la vidéo ou l'audio, mais seulement en cas de transfert d'autres données. On peut ainsi utiliser WebRTC pour se transmettre un fichier. (Je ne connais pas à l'heure actuelle de service WebRTC permettant cela. Vous avez un exemple ?) Le multimédia, lui, passe via SRTP, les données nécessitant une plus grande fiabilité passent par SCTP lui-même transporté sur DTLS (RFC 9147) lui même sur UDP. Du fait de cette encapsulation, vous ne verrez pas SCTP avec un logiciel comme Wireshark. La raison pour laquelle UDP est utilisé ? Permettre le passage des données même à travers le pire routeur NAT (cf. RFC 6951).
La section 3 de notre RFC décrit certains scénarios d'usage. Notons que dans certains, la fiabilité du canal de données n'est pas indispensable :
- Un jeu en ligne, où on est informé des mouvements des autres joueurs,
- Des notifications pendant une visioconférence du genre « Mamadou a coupé son micro »,
- Des transferts de fichiers (pour l'anecdote, ce n'est pas le point où les systèmes précédant WebRTC, comme IRC ou XMPP, se débrouillaient le mieux…),
- Le bavardage textuel entre les participants à une visioconférence.
La section 4, elle, décrit les exigences du canal de données. Notamment :
- Possibilité d'avoir plusieurs canaux simultanés,
- Transfert fiable des données (ce que la vidéo, par exemple, n'exige pas),
- Contrôle de congestion (cf. RFC 8085),
- Authentification et confidentialité (RFC 8826 et RFC 8827),
- Ne pas laisser fuiter d'informations, comme l'adresse IP locale.
La section 5 décrit une solution à ces exigences, l'utilisation de SCTP sur DTLS. SCTP (RFC 9260) fournit (entre autres) le contrôle de congestion (par contre, on n'utilise pas ses capacités de multihoming). Son encapsulation dans DTLS est décrite dans le RFC 8261. DTLS lui fournit authentification et confidentialité. L'utilisation d'ICE (RFC 8445) lui permet de passer à travers les routeurs NAT et certains pare-feux.
Petit détail : le fait de mettre SCTP sur DTLS (et non pas le
contraire comme dans le RFC 6083) fait que,
si DTLS est mis en œuvre dans l'espace
utilisateur du système
d'exploitation, SCTP devra l'être aussi. (Voir par exemple
third_party/usrsctp/usrsctplib dans le code
de Chromium, qui vient de https://github.com/sctplab/usrsctp
Quelques extensions de SCTP sont nécessaires (section 6) comme celles du RFC 6525, du RFC 5061 (enfin, une partie d'entre elles) et du RFC 3758.
La section 6 décrit les détails protocolaires de l'ouverture du canal de données, puis de son utilisation et enfin de sa fermeture.
Pour les programmeurs, cette bibliothèque WebRTC met en œuvre, entre autres, le canal de données.
L'article seul
RFC 8827: WebRTC Security Architecture
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : E. Rescorla (RTFM)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF rtcweb
Première rédaction de cet article le 19 janvier 2021
Le système WebRTC permet des communications audio et vidéo entre deux navigateurs Web. Comme tout service Internet, il pose des problèmes de sécurité (RFC 8826), et ce RFC étudie l'architecture générale de WebRTC, du point de vue de la sécurité, et comment résoudre les problèmes.
D'abord, il faut réviser les généralités sur
WebRTC (RFC 8825). WebRTC a pour but de permettre à deux
utilisateurs ou utilisatrices de navigateurs
Web de s'appeler et de bavarder en audio et vidéo. Pas
besoin d'installer un logiciel de communication spécifique (comme
le Skype de
Microsoft, ou comme un
softphone tel que
Twinkle), il suffit d'un navigateur
ordinaire. Pour permettre cela, WebRTC repose sur une
API JavaScript
normalisée par le W3C et sur un ensemble de
protocoles normalisés par l'IETF, et
résumés dans le RFC 8825. Si on
prend l'exemple du service WebRTC
FramaTalk, Alice et Bob visitent
tous les deux https://framatalk.org/
Cela soulève plein de problèmes de sécurité amusants, étudiés dans le RFC 8826, et que notre RFC 8827 tente de résoudre.
Toute solution de sécurité dépend d'un modèle de confiance (section 3 de notre RFC). Si on ne fait confiance à rien ni personne, on ne peut résoudre aucun problème de sécurité. Pour WebRTC, la racine de toute confiance est le navigateur. C'est lui qui devra faire respecter un certain nombre de règles. (En conséquence de quoi, si le navigateur n'est pas de confiance, par exemple parce qu'il s'agit de logiciel non libre, ou bien parce que vous êtes sur une machine sur laquelle vous n'avez aucun contrôle, par exemple un cybercafé, tout est fichu.) Mais le navigateur ne suffit pas, il faut également faire confiance à des entités extérieures, comme le site Web où vous allez récupérer le code JavaScript. Certaines de ces entités peuvent être authentifiées par le navigateur, ce qui donne certaines garanties. Et d'autres, hélas, ne le peuvent pas. Dans la première catégorie, on trouve :
- Les sites Web où le navigateur vérifie un
certificat, dans une connexion
HTTPS. Vous vous connectez à
https://framatalk.org/https), vous êtes sûr que c'est bien Framasoft derrière. - Les pairs WebRTC authentifiés par une technique comme DTLS-SRTP.
Le reste des entités avec qui on communique est considéré comme potentiellement malveillant, et il faut donc se méfier (mais, évidemment, dans la vie, on ne communique pas qu'avec des gens qu'on connait bien et à qui on fait confiance : ce serait trop limité).
Pour revenir aux entités authentifiées, notez qu'on n'a parlé que d'authentification, pas de confiance. La cryptographie permet de vérifier qu'on parle bien au diable, pas que le diable est honnête !
La section 4 résume le fonctionnement général de WebRTC, afin
de pouvoir analyser sa sécurité, et définir une architecture de
sécurité. Notez que WebRTC permet pas mal de variantes et que le
schéma présenté ici est un cas « typique », pas forcément
identique partout dans tous ses détails. Donc, ici,
Alice et Bob veulent se parler. Tous les
deux utilisent un navigateur. Chacun va visiter le site Web du
service qu'ils utilisent, mettons
https://meet.example/ (en
HTTPS, donc, avec
authentification via un certificat). Ils récupèrent un code
JavaScript qui, appelant
l'API WebRTC, va
déclencher l'envoi d'audio et de vidéo, transportés sur
SRTP, lui-même sur
DTLS (les données en dehors du
« multimédia » passent sur du SCTP sur DTLS). Avant d'autoriser l'accès au micro et
à la caméra, chaque navigateur demandera l'autorisation à son
utilisat·eur·rice. Quant au fait que la machine en face accepte de
recevoir (en direct, en pair-à-pair) ce déluge de données
multimédia, la vérification sera faite par
ICE (cf. RFC 8826, section 4.2). ICE n'intervient qu'à la connexion
initiale, des messages périodiques seront nécessaires pendant la
communication pour s'assurer qu'il y a toujours consentement à recevoir. Pendant l'échange de données audio
et vidéo, le site Web
https://meet.example/ va assurer la
signalisation et, par exemple, si Alice part, indiquer à Bob qu'il
n'y a plus personne en face (notez que cet échange entre site Web
et utilisateur ne se fait pas avec un protocole normalisé). Notre RFC ajoute une possibilité :
qu'Alice et Bob utilisent un fournisseur d'identité, permettant à
chacun d'identifier et d'authentifier l'autre (par exemple via
OpenID Connect).
Ce cas où les deux participant·e·s partagent le même serveur
est le cas le plus courant aujourd'hui (c'est ce que vous verrez
si vous faites une visioconférence via
https://meet.jit.si/
Armés de ces informations, nous pouvons lire la section 6, qui plonge dans les détails techniques. D'abord, la securité de la connexion entre navigateur et site Web. Elle dépend de HTTPS (RFC 2818), de la vérification du certificat, bien sûr (RFC 6125 et RFC 5280) et de la vérification de l'origine (RFC 6454). La sécurité entre les pairs qui communiquent impose également l'usage de la cryptographie et il faut donc utiliser SRTP (RFC 3711) sur DTLS (RFC 9147 et RFC 5763). Pas question de faire du RTP en clair directement sur UDP ! Le niveau de sécurité (par exemple les paramètres TLS choisis) doivent être accessibles à l'utilisateur.
Ensuite, la securité de l'accès au micro et à la caméra. Le site Web qu'on visite peut être malveillant, et le navigateur ne permet évidemment pas à du code JavaScript de ce site d'ouvrir silencieusement la caméra. Il demande donc la permission à l'utilisateur, qui ne la donne que s'il était vraiment en train de passer un appel. De même, le navigateur doit afficher si micro et caméra sont utilisés, et ne doit pas permettre à du code JavaScript de supprimer cet affichage.
Dans WebRTC, l'échange des données audio et vidéo se fait en pair-à-pair, directement entre Alice et Bob. Il y a donc le risque qu'un méchant envoie plein de données vidéo à quelqu'un qui n'a rien demandé (la section 9.3 détaille le risque de déni de service). Il faut donc vérifier le consentement à recevoir. Comme indiqué plus haut, cela se fait avec ICE (RFC 8445). Comme le consentement initial n'est pas éternel, et comme on ne peut pas se fier aux accusés de réception, que DTLS n'envoie pas, ni aux réponses (il n'y en a pas forcément, par exemple si on regarde juste une vidéo), il faut envoyer de temps en temps des nouveaux messages ICE (cf. RFC 7675).
Parmi les questions de sécurité liées à WebRTC, il en est une qui a fait beaucoup de bruit, celle de la vie privée, notamment le problème de l'adresse IP qui est transmise au pair avec qui on communique. (Notez que le serveur du site Web où on se connecter initialement verra toujours, lui, cette adresse IP, sauf si on utilise une technique comme Tor.) Notre RFC impose donc, en cas d'appel entrant, de ne pas commencer la négociation ICE avant que l'utilisatrice n'ait décidé de répondre à l'appel, et que WebRTC permette de décider de n'utiliser que TURN, qui ne communique pas l'adresse IP au pair puisqu'on ne se parle plus directement, mais via le relais TURN. Évidemment, cela se fait au détriment des performances (les détails sont dans la section 9.2).
On a vu plus haut que les deux pairs qui communiquent peuvent désirer s'authentifier (sans se fier au site Web qu'ils utilisent pour la signalisation), par exemple via des fournisseurs d'identité externes (comme FranceConnect ?) C'est notamment indispensable pour une fédération puisque, dans ce cas, on n'a même plus de site Web commun. La section 7 de notre RFC détaille ce cas. WebRTC ne normalise pas une technique unique (comme OAuth) pour cela (WebRTC est un cadre, pas vraiment un protocole, encore moins un système complet), mais fixe quelques principes. Notamment, l'utilisateur s'authentifie auprès du fournisseur d'identité, pas auprès du site Web de signalisation. Le navigateur Web doit donc faire attention à tout faire lui-même et à ne pas laisser ce site Web interférer avec ce processus.
Enfin, il reste des problèmes de sécurité de WebRTC qui ne sont pas couverts par le RFC 8826 ni par les précédentes sections de notre RFC 8827. Ainsi, il est important que le code JavaScript téléchargé depuis le site Web du fournisseur de service WebRTC ne puisse pas directement fabriquer des messages chiffrés et signés pour DTLS, car il pourrait alors fabriquer de vraies/fausses signatures. Tout doit passer par le navigateur qui est le seul à pouvoir utiliser les clés de DTLS pour chiffrer et surtout signer.
Une bonne analyse de la sécurité de WebRTC se trouve en « A Study of WebRTC Security ».
L'article seul
RFC 8825: Overview: Real Time Protocols for Browser-Based Applications
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : H. Alvestrand (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF rtcweb
Première rédaction de cet article le 19 janvier 2021
WebRTC sert à faire communiquer en temps réel (avec audio et vidéo) deux navigateurs Web. Il est déjà largement déployé, ce RFC arrive bien après la bataille, et décrit les généralités sur WebRTC. Ce protocole est complexe et offre beaucoup de choix au concepteur d'applications.
En fait, WebRTC n'est pas vraiment un protocole. Deux applications utilisant WebRTC peuvent parfaitement être dans l'incapacité de communiquer. WebRTC est plutôt un cadre (framework) décrivant des composants, parmi lesquels le concepteur d'applications choisira. Vu cette complexité, ce RFC 8825 est un point de départ nécessaire, pour comprendre l'articulation des différents composants. D'ailleurs, il y a un abus de langage courant : WebRTC désigne normalement uniquement l'API JavaScript normalisée par le W3C. La communication sur le réseau se nomme rtcweb, et c'est le nom de l'ex-groupe de travail à l'IETF. Mais tout le monde fait cet abus de langage et moi aussi, j'utiliserai WebRTC pour désigner l'ensemble du système.
L'auteur du RFC est un « vieux de la vieille » et a vu passer beaucoup de protocoles. Il est donc logique qu'il commence par quelques rappels historiques en section 1. L'idée de faire passer de l'audio et de la vidéo sur l'Internet est aussi ancienne que l'Internet lui-même, malgré les prédictions pessimistes des telcos, qui avaient toujours prétendu que cela ne marcherait jamais. (La variante d'aujourd'hui est « si on ne nous laisse pas violer la neutralité du réseau, la vidéo ne marchera jamais ».)
Mais c'est vrai que les débuts ont été laborieux, la capacité du réseau étant très insuffisante, et les processeurs trop lents. Ça s'est amélioré par la suite. Mais si le matériel a progressé, les protocoles continuaient à manquer : il existe bien sûr des protocoles standards pour traiter certains aspects de la communication (comme SIP - RFC 3261 - pour la signalisation) mais, pour une communication complète, il faut un jeu de protocoles couvrant tous les aspects, de la signalisation à l'encodage du flux vidéo, en passant par les identificateurs à utiliser (comme les adresses de courrier électronique), et qu'on puisse compter sur ce jeu, de même qu'on peut compter sur la disponibilité de clients et serveurs HTTP, par exemple. Comme le note l'auteur, « la Solution Universelle s'est avérée difficile à développer ». (Cela a d'ailleurs laissé un boulevard à des entreprises privées, proposant un produit très fermé et complètement intégré comme le Skype de Microsoft.)
Depuis quelques années, la disponibilité très répandue de navigateurs Web ayant des possibilités très avancées a changé la donne. Plus besoin d'installer tel ou tel plugin, telle ou telle application, désormais, les possibilités qu'offre HTML5 sont largement répandues, et accessibles en JavaScript via une API standard. Un groupe de travail du W3C développe de nouvelles possibilités et WebRTC peut donc être vu comme un effort commun du W3C et de l'IETF. C'est sur ces nouvelles possibilités du navigateur que se fonde WebRTC (son cahier des charges figure dans le RFC 7478).
Notre RFC note que WebRTC change pas mal l'architecture des techniques de communication temps-réel et multimédia. Autant les solutions fondées sur SIP comptaient sur des éléments intermédiaires dans le réseau pour travailler (par exemple des ALG), autant WebRTC est nettement plus « bout en bout », et utilise la cryptographie pour faire respecter ce principe, bien menacé par les FAI.
Question histoire, WebRTC a lui-même eu une histoire compliquée. La première réunion du groupe à l'IETF a eu lieu en 2011, pour une fin prévue en 2012. En fait, il y a eu des retards, et même une longue période d'arrêt du travail. Ce RFC de survol de WebRTC, par exemple, a vu sa première version publiée il y a huit ans. Le premier RFC du projet n'a été publié qu'en 2015. Globalement, ce fut l'un des plus gros efforts de l'IETF, mais pas le plus efficace en terme de rapidité. Le groupe de travail rtcweb a finalement été clos en août 2019, le travail étant terminé.
La section 2 de notre RFC résume les principes de WebRTC : permettre une communication audio, vidéo et données la plus directe possible entre les deux participants. Ce RFC 8825 est la description générale, les protocoles effectifs figurent dans d'autres RFC comme le RFC 8832 pour le protocole de création du canal de données ou le RFC 8831 pour la communication via le canal de données. Techniquement, WebRTC a deux grandes parties :
- La spécification du protocole, faite à l'IETF, dans les RFC 8832 et RFC 8831.
- L'API JavaScript permettant le développement des clients tournant dans les navigateurs Web, API normalisée par le W3C dans « WebRTC 1.0: Real-time Communication Between Browsers » et « Media Capture and Streams ».
La section 2 décrit également le vocabulaire, si vous voulez réviser des concepts comme la notion de protocole ou de signalisation.
La section 3 de notre RFC présente l'architecture
générale. Chaque navigateur WebRTC se connecte à un serveur Web où
il récupère automatiquement un code
JavaScript qui appelle les fonctions
WebRTC, qui permettent d'accéder au canal de données, ouvert avec
l'autre navigateur, et aux services multimédia de son ordinateur
local (le micro, la caméra, etc). On y voit notamment (figure 2)
que les données (la voix, la vidéo, etc) passent directement
(enfin, presque, voir plus loin) entre les deux navigateurs, alors
que la signalisation se fait entre les deux serveurs Web. On note,
et c'est très important, que WebRTC ne gère que le canal de
données, pas celui de signalisation, qui peut utiliser SIP (RFC 3261), XMPP (RFC 6120) ou même un protocole privé. C'est entre autres
pour cette raison que deux services WebRTC différents ne peuvent
pas forcément interopérer. Voici un schéma de WebRTC lorsque les
deux parties se connectent au même site Web (la signalisation est
alors faite à l'intérieur de ce site) : 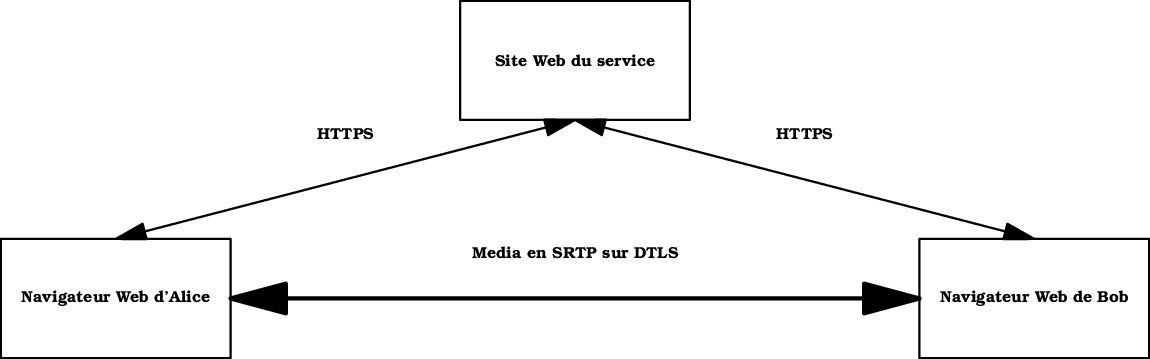
Et ici une image d'une fédération, où les deux parties qui communiquent utilisent
des services différents, mais qui se sont mis d'accord sur un
protocole de signalisation : 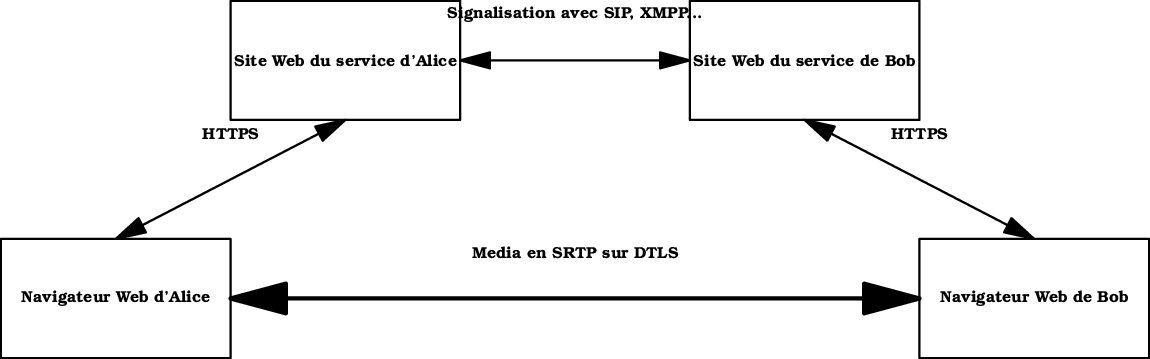
Le canal de données nécessite déjà beaucoup de spécifications, notamment le transport et l'encodage du contenu. Il est spécifié dans le RFC 8831.
Le transport, justement (section 4 du RFC). Il faut envoyer les données à l'autre navigateur, et assurer la retransmission des données perdues, le contrôle de congestion, etc. Tout cela est décrit dans le RFC 8835. Ce RFC spécifie, pour transporter les données multimédia, l'utilisation de SRTP sur DTLS, lui-même sur UDP (cf. RFC 8834). Des systèmes de relais comme TURN (RFC 5766) peuvent être nécessaires si les deux malheureux navigateurs Web soint coincés derrière des middleboxes méchantes, NAT ou pare-feu par exemple.
Ce n'est pas tout d'avoir un protocole de transport. Il faut aussi découper les données d'une manière compréhensible par l'autre bout (framing, section 5 de notre RFC). WebRTC utilise RTP (RFC 3550, et voir aussi le RFC 8083) et SRTP (RFC 3711 et RFC 5764). Le RFC 8834 détaille leur utilisation. La sécurité est, elle, couverte dans les RFC 8826 et RFC 8827. L'établissement du canal de données est normalisé dans le RFC 8832 et le canal de données lui-même dans le RFC 8831.
On le sait, les formats d'audio et de vidéo sont un problème compliqué, le domaine est pourri de brevets souvent futiles, et la variété des formats rend difficile l'interopérabilité. Notre RFC impose au minimum l'acceptation des codecs décrits dans le RFC 7874 pour l'audio (Opus est obligatoire) et RFC 7742 pour la vidéo (H.264 et VP8, après une longue lutte). D'autres codecs pourront s'y ajouter par la suite.
La section 7 mentionne la gestion des connexions, pour laquelle la solution officielle est le JSEP (JavaScript Session Establishment Protocol, RFC 8829).
La section 9 du RFC décrit les fonctions locales (l'accès par
le navigateur aux services de la machine qui l'héberge). Le RFC
rappelle que ces fonctions doivent inclure des choses comme la
suppression d'écho, la protection de la vie
privée (demander l'autorisation avant d'accéder à la caméra…) Le
RFC 7874 fournit des détails. Ici, un
exemple d'une demande d'autorisation par
Firefox : 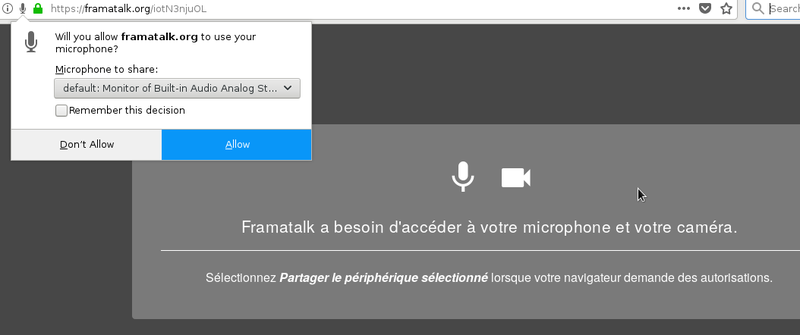
Parmi les logiciels qui permettent de faire du WebRTC, on peut
citer Jitsi, qui est derrière
le service Framatalk, mais
qui est également accessible via d'autres services comme
https://meet.jit.si/
Regarder du trafic WebRTC avec un logiciel comme Wireshark est frustrant, car tout est chiffré. Pour Jitsi, on voit beaucoup de STUN, pour contourner les problèmes posés par le NAT, puis du DTLS évidemment impossible à décrypter.
Il y a de nombreux autres logiciels avec WebRTC. C'est le cas par exemple de PeerTube mais attention, seul l'échange de vidéo entre pairs qui regardent au même moment utilise WebRTC (plus exactement WebTorrent, qui utilise WebRTC). La récupération de la vidéo depuis le serveur se fait en classique HTTPS.
Si vous voulez voir une session WebRTC, le mieux est d'utiliser
un service comme https://appr.tc/
Console (Webdeveloper tools) Firefox
9.569: Initializing; server= undefined.
Puis l'établissement des canaux nécessaires :
37.252: Opening signaling channel.
39.348: Joined the room.
39.586: Retrieved ICE server information.
39.927: Signaling channel opened.
39.930: Registering signaling channel.
39.932: Signaling channel registered.
Là, Firefox vous demande l'autorisation d'utiliser micro et caméra, que vous acceptez :
44.452: Got access to local media with mediaConstraints:
'{"audio":true,"video":true}'
44.453: User has granted access to local media.
Le navigateur peut alors utiliser ICE (RFC 8445) pour trouver le bon moyen de communiquer avec le pair (dans mon test, les deux pairs étaient sur le même réseau local, et s'en aperçoivent, ce qui permet une communication directe par la suite) :
44.579: Creating RTCPeerConnnection with:
config: '{"rtcpMuxPolicy":"require","bundlePolicy":"max-bundle","iceServers":[{"urls":["stun:74.125.140.127:19302","stun:[2a00:1450:400c:c08::7f]:19302"]},{"urls":["turn:74.125.140.127:19305?transport=udp","turn:[2a00:1450:400c:c08::7f]:19305?transport=udp","turn:74.125.140.127:19305?transport=tcp","turn:[2a00:1450:400c:c08::7f]:19305?transport=tcp"],"username":"CP/Bl+UXXXXXXX","credential":"XXXXXXXXXXX=","maxRateKbps":"8000"}],"certificates":[{}]}';
constraints: '{"optional":[]}'.
44.775: Created PeerConnectionClient
On peut alors négocier les codecs à utiliser (ici VP9) :
44.979: Set remote session description success.
44.980: Waiting for remote video.
44.993: No preference on audio receive codec.
44.993: Prefer video receive codec: VP9
Et, ici, on voit passer le descripteur de session (section 7 de notre RFC), au format SDP (RFC 4566 et RFC 3264, et notez la blague entre SDP et le film 300) :
44.997: C->WSS: {"sdp":"v=0\r\no=mozilla...THIS_IS_SDPARTA-60.5.1 6947646294855805442 0 IN IP4 0.0.0.0\r\ns=-\r\nt=0 0\r\na=fingerprint:sha-256 23:80:53:8A:DD:D7:BF:77:B5:C7:4E:0F:F4:6D:F2:FB:B8:EE:59:D1:91:6A:F5:21:11:22:C0:E3:E0:ED:54:39\r\na=group:BUNDLE 0 1\r\na=ice-options:trickle\r\na=msid-semantic:WMS *\r\nm=audio 9 UDP/TLS/RTP/SAVPF 111 126\r\nc=IN IP4 0.0.0.0\r\na=sendrecv\r\na=extmap:1 urn:ietf:params:rtp-hdrext:ssrc-audio-level\r\na=extmap:9 urn:ietf:params:rtp-hdrext:sdes:mid\r\na=fmtp:111 maxplaybackrate=48000;stereo=1;useinbandfec=1\r\na=fmtp:126 0-15\r\na=ice-pwd:bb7169d301496c0119c5ea3a69940a55\r\na=ice-ufrag:3d465335\r\na=mid:0\r\na=msid:{d926a161-3011-48af-9236-06e15377dfea} {a2597b07-7e80-47fe-8542-761dd93efb94}\r\na=rtcp-mux\r\na=rtpmap:111 opus/48000/2\r\na=rtpmap:126 telephone-event/8000/1\r\na=setup:active\r\na=ssrc:2096893919 cname:{e60fd6dc-6c2d-4132-bb6a-1178e1611d16}\r\nm=video 9 UDP/TLS/RTP/SAVPF 98\r\nc=IN IP4 0.0.0.0\r\na=recvonly\r\na=extmap:2 urn:ietf:params:rtp-hdrext:toffset\r\na=extmap:3 http://www.webrtc.org/experiments/rtp-hdrext/abs-send-time\r\na=extmap:9 urn:ietf:params:rtp-hdrext:sdes:mid\r\na=fmtp:98 max-fs=12288;max-fr=60\r\na=ice-pwd:bb7169d301496c0119c5ea3a69940a55\r\na=ice-ufrag:3d465335\r\na=mid:1\r\na=rtcp-fb:98 nack\r\na=rtcp-fb:98 nack pli\r\na=rtcp-fb:98 ccm fir\r\na=rtcp-fb:98 goog-remb\r\na=rtcp-mux\r\na=rtpmap:98 VP9/90000\r\na=setup:active\r\na=ssrc:4025254123 cname:{e60fd6dc-6c2d-4132-bb6a-1178e1611d16}\r\n","type":"answer"}
Et c'est bon, tout marche :
45.924: Call setup time: 1399ms.
Du fait de son caractère pair-à-pair (les données sont échangées, autant que le NAT le permet, directement entre les navigateurs), WebRTC soulève des questions de vie privée. Votre correspondant va voir votre adresse IP. Le point est discuté plus longuement dans le RFC 8826. (PeerTube met en bas un mot d'avertissement à ce sujet.)
WebRTC est présent depuis pas mal d'années dans tous les navigateurs graphiques comme Firefox, Chrome ou Edge. Côté bibliothèques, il existe de nombreuses mises en œuvre de WebRTC comme OpenWebRTC (abandonné depuis) ou comme l'implémentation de référence. Il y a également du WebRTC dans des serveurs comme Asterisk, WebEx ou MeetEcho (ce dernier étant utilisé par l'IETF pour ses réunions à distance). Mais rappelez-vous que WebRTC n'est pas un ensemble cohérent permettant l'interopérabilité. Vous pouvez avoir deux services WebRTC qui n'arrivent pas à interagir, et ce n'est pas une bogue, c'est un choix de conception.
Et, pour finir, quelques lectures et activités supplémentaires :
- Pour tester votre environnement (micro, caméra, etc) et
votre réseau (beaucoup de réseaux sont truffés de
middleboxes
hostiles), un bon site de test,
https://test.webrtc.org/ - Vous pouvez voir les statistiques d'activité WebRTC dans
votre navigateur, en
chrome://webrtc-internalsopera://webrtc-internalsabout:webrtc - Un bon tutoriel sur WebRTC, très détaillé, écrit plutôt du point de vue du programmeur JavaScript écrivant un client,
- Un bon résumé de WebRTC, plutôt du point de vue de « comment ça marche »,
- Le site « officiel » du projet,
- Le groupe de travail au W3C.
- L'annonce officielle de la publication des normes.
L'article seul
RFC 8820: URI Design and Ownership
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : M. Nottingham
Première rédaction de cet article le 1 juillet 2020
Ah, les URI... Comme ces identificateurs sont très
souvent vus et manipulés par un grand nombre d'utilisateurs, ils
suscitent forcément des passions et des discussions sans fin. Ce
RFC de bonne
pratique s'attaque à un problème fréquent : les applications ou
extensions qui imposent des contraintes sur l'URI, sans que cela
soit justifié par le format de ces URI. Par exemple, on voit des
CMS
imposer, au moment de l'installation, que le CMS soit accessible par
un URI commençant par le nom du logiciel. S'il s'appelle Foobar, on
voit parfois des logiciels qui ne marchent que si l'URI commence par
http://www.example.org/Foobar/. Pourquoi est-ce
une mauvaise idée et que faudrait-il faire à la place ? (Ce document
remplace le RFC 7320, dans le sens d'un plus
grand libéralisme : moins de directives et davantage de
suggestions.)
Ce RFC est destiné aux concepteurs d'application (par exemple les API REST) et aux auteurs de protocoles qui étendent les protocoles existants.
D'abord, l'argument d'autorité qui tue : la norme des URI, le RFC 3986, dit clairement que la structure d'un URI
est déterminé par son plan
(scheme en anglais) et que donc l'application n'a
pas le droit d'imposer des règles supplémentaires. Les deux seuls
« propriétaires » sont la norme décrivant le plan (qui impose une
syntaxe, et certains éléments, par exemple le nom du serveur avec le
plan http://) et l'organisation qui contrôle
cet URI particulier (par exemple, toujours pour
http://, l'organisation qui contrôle le
domaine dans
l'URI). Imposer des règles, pour une application ou une extension,
c'est violer ce principe de propriété. (Il est formalisé dans une
recommandation du W3C, section 2.2.2.1.)
Un exemple de structure dans les URI est l'interprétation du
chemin (path en anglais) comme étant un endroit
du système de fichiers. Ainsi, bien des
serveurs HTTP, en voyant l'URI
http://www.example.org/foo/bar/toto.html,
chercheront le fichier en
$DOCUMENT_ROOT/foo/bar/toto.html. C'est une
particularité de la mise en œuvre de ce serveur, pas une obligation
du plan d'URI http://. Un autre exemple est
l'utilisation de l'extension du nom de fichier comme moyen de
trouver le type de média de
la ressource. (« Ça se termine en .png ? On
envoie le type image/png. ») Ces deux cas ne
violent pas forcément le principe de propriété des URI car
l'utilisateur, après tout, choisit son serveur.
Mais, dans certains cas, l'imposition d'une structure (autre que celle déjà imposée par la norme du plan d'URI) a des conséquences néfastes :
- Risque de collisions entre deux conventions différentes.
- Risque d'instabilité si on met trop d'informations dans l'URI (voir la section 3.5.1 du document « Architecture of the World Wide Web, Volume One », cité plus haut). Pour reprendre l'exemple de l'extension du fichier, si on change le format de l'image de PNG en JPEG, l'URI changera, ce qui est néfaste.
- Rigidité accrue. Si un logiciel impose d'être installé en
/Foobarcomme dans l'exemple au début, il contraint les choix pour l'administrateur système (et si je veux des URI avec un chemin vide, genrehttp://foobar.example.org/, je fais quoi ?) - Risque que le client fasse des suppositions injustifiées. Si
une spécification décrit le paramètre
sigcomme étant forcément une signature cryptographique, il y a une possibilité qu'un logiciel client croit, dès qu'il voit un paramètre de ce nom, que c'est une signature.
Donc, pour toutes ces raisons, notre RFC déconseille fortement de rajouter des règles de structure dans les URI. Ces règles diminuent la liberté du propriétaire de l'URI.
Qui risque de violer ce principe ? Les auteurs d'applications,
comme dans l'exemple Foobar plus haut, mais aussi des gens qui font
des extensions aux URI, par le biais de nouvelles spécifications
(par exemple pour mettre des signatures ou autres métadonnées dans
l'URI). En revanche, ce principe ne s'applique pas au propriétaire
lui-même, qui a évidemment le droit de définir ses règles pour la
gestion de ses URI (exemple : le webmestre
qui crée un schéma de nommage des URI de son site
Web). Et cela ne s'applique pas non plus au cas où le
propriétaire de l'URI reçoit lui-même une délégation pour gérer ce
site (par exemple, un RFC qui crée un registre IANA et
spécifie la structure des URI sous
https://www.iana.org/ est dans son droit,
l'IANA agissant sur délégation de l'IETF). Le principe ? On
n'interdit pas de mettre de la structure dans les URI, on dit juste
qui a le droit de le faire.
La partie normative de notre RFC est la section 2. Elle explicite
le principe. D'abord, éviter de contraindre l'usage d'un plan
particulier. Par exemple, imposer http:// peut
être trop contraignant, certaines applications ou extensions
pourraient marcher avec d'autres plans d'URI comme par exemple
file:// (RFC 8089).
D'autre part, si on veut une structure dans les URI d'un plan
particulier, cela doit être spécifié dans le document qui définit le
plan (RFC 7230 pour
http://, RFC 6920 pour
ni:, etc) pas dans une extension faite par
d'autres (« touche pas à mon plan »).
Les URI comprennent un champ « autorité » juste après le
plan. Les extensions ou applications ne doivent
pas imposer de contraintes particulières sur ce
champ. Ainsi, pour http://, l'autorité est un
nom de domaine et notre
RFC ne permet pas qu'on lui mette des contraintes (du genre « le
premier composant du nom de domaine doit commencer par
foobar-, comme dans
foobar-www.example.org »).
Même chose pour le champ « chemin », qui vient après
l'autorité. Pas question de lui ajouter des contraintes (comme dans
l'exemple du CMS qui imposerait /Foobar comme
préfixe d'installation). La seule exception est la définition des
URI bien connus du RFC 8615 (ceux dont le
chemin commence par /.well-known). Le RFC 6415 donne un exemple d'URI bien connus, avec
une structure imposée.
Autre conséquence du principe « bas les pattes » et qui est, il
me semble, plus souvent violée en pratique, le champ « requête »
(query). Optionnel, il se trouve après le
point d'interrogation dans l'URI. Notre RFC
interdit aux applications d'imposer l'usage des requêtes, car cela
empêcherait le déploiement de l'application dans d'autres contextes
où, par exemple, on veut utiliser des URI sans requête (je dois dire
que mes propres applications Web violent souvent ce principe). Quant
aux extensions, elles ne doivent pas contraindre le format des
requêtes. L'exemple cité plus haut, d'une extension hypothétique,
qui fonctionnerait par l'ajout d'un paramètre
sig aux requêtes pour indiquer une signature
est donc une mauvaise idée. Une telle extension causerait des
collisions (applications ou autres extensions qui voudraient un
paramètre de requête nommé sig) et des risques
de suppositions injustifié (un logiciel qui se dirait « tiens, un
paramètre sig, je vais vérifier la signature,
ah, elle est invalide, cet URI est erroné »). Au passage, les
préfixes n'aident pas. Supposons qu'une extension, voulant limiter
le risque de collisions, décide que tous les paramètres qu'elle
définit commencent par myapp_ (donc, la
signature serait myapp_sig). Cela ne supprime
pas le risque de collisions puisque le préfixe lui-même ne serait
pas enregistré.
(Sauf erreur, Dotclear gère bien cela, en
permettant, via les « méthodes de lecture »
PATH_INFO ou QUERY_STRING
d'avoir les deux types d'URI, sans requête ou bien avec.)
Pourtant, HTML lui-même fait cela, dans la norme 4.01, en restreignant la syntaxe lors de la soumission d'un formulaire. Mais c'était une mauvaise idée et les futures normes ne devraient pas l'imiter.
Comme précédemment, les URI bien connus ont, eux, droit à changer
la syntaxe ou contraindre les paramètres puisque, d'une certaine
façon, l'espace sous .well-known est délégué à
l'IETF et n'est plus « propriété » de l'autorité.
Dernier champ de l'URI à étudier, l'identificateur de fragment (ce qui est après le croisillon). Les définitions d'un type de média (RFC 6838) ont le droit de spécifier la syntaxe d'un identificateur de fragment spécifique à ce type de média (comme ceux du texte brut, dans le RFC 5147). Les autres extensions doivent s'en abstenir sauf si elles normalisent une syntaxe pour de futurs types de médias (comme le fait le RFC 6901).
Bon, assez de négativité et d'interdiction. Après les « faites pas ci » et les « faites pas ça », la section 3 de notre RFC expose les alternatives, les bonnes pratiques pour remplacer celles qui sont interdites ici. D'abord, si le but est de faire des liens, il faut se rappeler qu'il existe un cadre complet pour cela, décrit dans le RFC 8288. Une application peut utiliser ce cadre pour donner la sémantique qu'elle veut à des liens. Autre technique rigolote et peu connue, les gabarits du RFC 6570, qui permettent de gérer facilement le cas de données spécifiques à l'application dans un URI.
Et, comme cité plusieurs fois, les URI bien connus du RFC 8615 sont un moyen de déclarer sa propre structure sur des URI. Par contre, ils sont censés avoir un usage limité (accéder à des métadonnées avant de récupérer une ressource) et ne sont pas un moyen générique d'échapper aux règles qui nous dérangent !
Les changements depuis le premier RFC qui avait décrit ces règles
(RFC 7320) sont résumés dans l'annexe A. En
gros, moins d'interdictions, et davantage de conseils. Par exemple,
la règle comme quoi une application ne devrait pas empêcher
l'utilisation de futurs plans (comme file: en
plus de http:) n'utilise maintenant plus le
vocabulaire normatif du RFC 2119 et est donc
désormais davantage un avis. De même, pour le composant « requête »
de l'URI, l'interdiction de spécifier sa syntaxe dans les
applications n'est désormais plus une règle absolue. Autre cas, le
RFC 7320 parlait négativement, non seulement
du préfixe de chemin d'URI fixe (le /Foobar
dans mes exemples) mais même d'une partie fixe du chemin, y compris
si elle n'était pas au début du chemin. Cela avait suscité
des débats houleux dans la discussion du RFC 9162 (successeur du RFC 6962) et cette restriction a donc été
supprimée.
L'article seul
RFC 8811: DDoS Open Threat Signaling (DOTS) Architecture
Date de publication du RFC : Août 2020
Auteur(s) du RFC : A. Mortensen (Forcepoint), T. Reddy (McAfee), F. Andreasen (Cisco), N. Teague (Iron Mountain), R. Compton (Charter)
Pour information
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 18 août 2020
Ce nouveau RFC décrit l'architecture du système DOTS (Distributed-Denial-of-Service Open Threat Signaling), un ensemble de mécanismes pour permettre aux victimes d'attaques par déni de service de se coordonner avec les fournisseurs de solution d'atténuation. C'est juste l'architecture, les protocoles concrets sont dans d'autres RFC, comme le RFC 9132.
Il n'y a pas besoin d'expliquer que les attaques par déni de service sont une plaie. Tout le monde en a déjà vécu. Une des approches pour atténuer l'effet d'une de ces attaques est de sous-traiter votre trafic à un tiers, l'atténuateur (« Victor, atténuateur ») qui va recevoir les données, les classer, et jeter ce qui est envoyé par l'attaquant. Cette approche nécessite de la communication entre la victime et l'atténuateur, communication qui se fait actuellement de manière informelle (téléphone…) ou via des protocoles privés. L'idée de DOTS (Distributed-Denial-of-Service Open Threat Signaling) est d'avoir des protocoles normalisés pour ces fonctions de communication. Les scénarios typiques d'utilisation de DOTS sont décrits dans le RFC 8903.
Dans le cas le plus fréquent, DOTS sera utilisé entre des organisations différentes (la victime, et le fournisseur de solutions anti-dDoS). A priori, ils auront une relation contractuelle (du genre contrat, et paiement) mais cette question ne fait pas l'objet du RFC, qui mentionne seulement l'architecture technique. Mais en tout cas, ce caractère multi-organisations va nécessiter des mécanismes d'authentification sérieux (le cahier des charges complet de DOTS est le RFC 8612).
La section 1 de notre RFC rappelle également que DOTS, par définition, sera utilisé dans des moments difficiles, pendant une attaque (RFC 4732), et qu'il est donc conçu en pensant à des cas où les ressources sont insuffisantes (les paquets ont du mal à passer, par exemple). Parfois, il y aura un lien intact entre le client DOTS et le serveur, ou bien un réseau dédié pour cette communication, ou encore une qualité de service garantie pour les échanges DOTS, mais on ne pourra pas toujours compter dessus. DOTS doit fonctionner sur l'Internet normal, possiblement affecté par l'attaque. C'est un élément à systématiquement garder en tête lorsqu'on examine le protocole DOTS, et qui explique bien des choix, comme UDP pour le protocole de signalisation du RFC 9132.
D'autre part, les RFC sur DOTS décrivent des techniques, pas des politiques. Comment on définit une attaque DoS, à partir de quand on déclenche l'atténuation, comment on choisit un atténuateur, toutes ces questions dépendent de la victime, chacun peut faire des choix différents.
Ceci étant posé, place à la description de haut niveau de DOTS, en section 2. Dans le cas le plus simple, il y a :
- La victime, qui héberge un client DOTS,
- L'atténuateur, qui héberge un serveur DOTS.
Et client et serveur DOTS communiquent avec les deux protocoles DOTS, celui de signalisation (RFC 9132) et celui de données (RFC 8783). Il y a donc deux canaux de communication. DOTS permet également des schémas plus complexes, par exemple avec plusieurs serveurs, à qui le client demande des choses différentes, ou bien avec des serveurs différents pour la signalisation et pour les données. Notez bien que DOTS est uniquement un protocole de communication entre la victime et l'atténuateur qui va essayer de la protéger. Comment est-ce que l'atténuateur filtre, ou comment est-ce qu'on lui envoie le trafic à protéger, n'est pas normalisé. De même, DOTS ne spécifie pas comment le serveur répond aux demandes du client. Le serveur peut refuser d'aider, par exemple parce que le client n'a pas payé. (Pour l'envoi du trafic à protéger, il y a deux grandes techniques, fondées sur BGP ou sur DNS. Le trafic une fois filtré est ensuite renvoyé à la victime. Une autre solution est d'avoir le mitigateur dans le chemin en permanence.)
On a vu qu'il y avait deux canaux de communication. Celui de signalisation, normalisé dans le RFC 9132 sert surtout à demander à l'atténuateur une action de protection, et à voir quelles réponses l'atténuateur donne. C'est ce canal qui devra fonctionner au plus fort de l'attaque, ce qui lui impose des contraintes et des solutions particulières. Le canal de données, spécifié dans le RFC 8783, n'est pas en toute rigueur indispensable à DOTS, mais il est quand même pratique : il sert à envoyer des informations de configuration, permettant au client de spécifier plus précisement ce qu'il veut protéger et contre qui. Par exemple, il va permettre de donner des noms à des ressources (une ressource peut être, par exemple, un ensemble de préfixes IP), envoyer une liste noire d'adresses d'attaquants à bloquer inconditionnellement, une liste blanche de partenaires à ne surtout pas bloquer, à définir des ACL, etc. En général, ce canal de données s'utilise avant l'attaque, et utilise des protocoles habituels, puisqu'il n'aura pas à fonctionner pendant la crise.
Le RFC note aussi que DOTS n'a de sens qu'entre partenaires qui ont une relation pré-existante (par exemple client / fournisseur payant). Il n'y a pas de serveur DOTS public. L'authentification réciproque du client et du serveur est donc nécessaire, d'autant plus qu'on utilise DOTS pour faire face à des attaques et que l'attaquant peut donc chercher à subvertir DOTS.
Le serveur DOTS doit non seulement authentifier le client mais aussi l'autoriser à demander une mitigation pour telle ou telle ressource (préfixe IP ou nom de domaine). Par exemple, le serveur DOTS peut utiliser les IRR pour déterminer si son client est vraiment légitime pour demander une intervention sur telle ressource. Mais il pourrait aussi utiliser ACME (RFC 8738).
Typiquement, le client établit une session de signalisation avec le serveur, qu'il va garder pendant l'attaque. Il n'y a pas actuellement de norme sur comment le client trouve le serveur DOTS. On peut supposer qu'une fois l'accord avec le serveur fait, le gérant du serveur communique au client le nom ou l'adresse du serveur à utiliser.
La section 3 du RFC détaille certains points utiles. À lire si vous voulez comprendre toute l'architecture de DOTS, notamment les configurations plus complexes, que j'ai omises ici.
Et si vous vous intéressez aux mises en œuvre de DOTS, elles sont citées à la fin de mon article sur le RFC 9132.
L'article seul
RFC 8810: Revision to Capability Codes Registration Procedures
Date de publication du RFC : Août 2020
Auteur(s) du RFC : J. Scudder (Juniper Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 18 août 2020
Un petit RFC purement bureaucratique : un léger changement, dans le sens de la libéralisation, des procédures d'enregistrement d'une capacité BGP dans le registre IANA de ces capacités.
Les routeurs BGP ont des capacités optionnelles que ne partagent pas forcément leurs pairs, comme par exemple la gestion du redémarrage en douceur (RFC 4724) ou bien la configuration du filtrage sortant (RFC 5291). Il est donc utile de pouvoir annoncer formellement ce qu'on sait faire et ce qu'on ne sait pas faire. L'annonce des capacités BGP est normalisée dans le RFC 5492. Elle se fait en envoyant un code numérique, d'un octet. La liste des codes possibles figure dans un registre IANA. Une partie des codes, allant de 128 à 255, était réservée pour l'utilisation locale. Cette plage est désormais éclatée en trois, en utilisant la terminologie de politiques d'enregistrement du RFC 8126 :
- De 128 à 238 : « Premier Arrivé, Premier Servi », la politique d'enregistrement la plus libérale qui soit,
- De 239 à 254 : « Utilisation à des fins expérimentales », ce qui est proche de l'ancien « Utilisation privée » mais en insistant sur le côté temporaire de l'utilisation,
- 255 : réservé pour un usage futur, par exemple pour indiquer une indirection vers un code étendu, si on a un jour besoin de plus de 255 capacités BGP (un octet, c'est peu, mais il n'y a actuellement que 25 capacités enregistrées).
Les deux autres plages, de 1 à 63 (« Examen par l'IETF ») et de 64 à 127 (« Premier Arrivé, Premier Servi ») ne changent pas depuis le RFC 5492.
Lorsqu'on change une politique d'enregistrement, il faut se demander quoi faire des utilisations précédentes. Puisque la plage considérée était utilisable en privé, des gens ont pu légitimement s'en servir et annoncer des codes de capacité. En 2015, les auteurs de ce RFC avaient cherché les utilisations de cette plage et trouvé une liste (pas forcément complète), souvent composée de codes qui ont reçu un « vrai » numéro après, liste qui est présentée dans le RFC, et ajoutée au registre IANA. Et, bien sûr, comme avec tout registre, il y a toujours le risque de squatteurs s'appropriant tel ou tel code sans suivre les procédures (cf. RFC 8093).
L'article seul
RFC 8808: A YANG Data Model for Factory Default Settings
Date de publication du RFC : Août 2020
Auteur(s) du RFC : Q. Wu (Huawei), B. Lengyel
(Ericsson), Y. Niu (Huawei)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF netmod
Première rédaction de cet article le 17 septembre 2020
Ce RFC décrit un modèle YANG pour permettre la « remise aux réglages d'usine » d'un équipement, quand celui-ci est trop bizarrement configuré pour qu'il y ait une autre solution que l'effacement radical.
YANG (RFC 6020) est un langage de description des équipements réseau et de leurs capacités, afin de permettre de la gestion automatisée de ces équipements via des protocoles comme NETCONF (RFC 6241) ou RESTCONF (RFC 8040).
Ce RFC définit
un nouveau RPC,
factory-reset, qui va remettre tous les
réglages de la machine aux réglages qu'elle avait à la sortie
d'usine. C'est l'équivalent YANG de manipulations physiques comme
« appuyez sur les boutons Power et VolumeDown simultanément pendant
cinq secondes » ou bien « insérez un trombone dans ce petit trou ».
La section 2 du RFC décrit plus précisément ce que veut dire
« retourner aux réglages d'usine ». Les entrepôts
(datastore, cf. RFC 6020,
RFC 7950 et RFC 8342)
comme <running> reprennent les valeurs
qu'ils contenaient lorsque l'équipement a quitté l'usine. Toutes les
données générées depuis sont jetées. Cela inclut (le RFC utilise des
exemples de répertoires Unix, que je reprends
ici, mais ce sont juste des exemples, l'équipement n'utilise pas
forcément Unix) les certificats
(/etc/ssl), les journaux
(/var/log), les fichiers temporaires
(/tmp), etc. Par contre, il faut garder des
informations qui étaient spécifiques à cet engin particulier (et
différent des autres du même modèle) mais qui ont été fixés avant le
premier démarrage, par exemple des identificateurs uniques ou des
clés privées (RFC 8995) ou mots
de passe générées automatiquement au début du cycle de vie. Les
données sensibles doivent être effacées de manière sûre, par exemple
en écrivant plusieurs fois sur leur emplacement (cf. section 6). À
noter que cette remise au début peut couper la communication avec la
machine de gestion : l'équipement se comportera comme s'il sortait
du carton, ce qui peut nécessiter une configuration nouvelle.
Notre RFC normalise également un nouvel entrepôt
(datastore),
factory-default, qui contient ces réglages
d'usine et permet donc à un client NETCONF ou RESTCONF de savoir en
quoi ils consistent. Appeler factory-reset
revient donc à appliquer factory-default. Cet
entrepôt suit les principes du RFC 8342,
annexe A, et est en lecture seule.
La section 4 présente le module complet, qui est disponible en
ietf-factory-default.yang. Il s'appuie sur le module du RFC 8342 et
sur celui du RFC 8341.
L'URN de ce
RFC,
urn:ietf:params:xml:ns:yang:ietf-factory-default
a été enregistré à
l'IANA (registre du RFC 3688), et le
module ietf-factory-default dans le registre
des modules.
Quelques mots sur la sécurité pour terminer. Comme le but de ce
module est de permettre à des clients NETCONF ou RESTCONF d'appeler
ce RPC
factory-reset, et que ce RPC a des
conséquences… sérieuses pour l'équipement, il faut comme d'habitude
veiller à ce que les accès NETCONF et RESTCONF soient bien sécurisés
(par exemple via SSH,
cf. RFC 6242 et via les contrôles d'accès du
RFC 8341).
L'article seul
RFC 8807: Login Security Extension for the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Août 2020
Auteur(s) du RFC : J. Gould, M. Pozun (VeriSign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 8 août 2020
Le protocole EPP d'avitaillement de ressources (par exemple de noms de domaine) a un mécanisme de sécurité très simple, à base de mots de passe indiqués lors de la connexion. Ce mécanisme avait plein de limitations ennuyeuses, dans le RFC original, et ce nouveau RFC vise à les réduire.
L'authentification dans EPP est décrite
dans le RFC 5730, section 2.9.1.1 (voir
aussi sa section 7). Le client EPP envoie un mot de passe, qui doit
faire entre 6 et 16 caractères (cf. le type
pwType dans le schéma
XSD du RFC 5730, section 4.1). Le
client peut changer son mot de passe en indiquant un nouveau mot via le
protocole
EPP, sans avoir à passer par un autre service. En outre, la session EPP est typiquement portée sur TLS, ce qui assure la
confidentialité du mot de passe, et la
possibilité d'ajouter une authentification par le biais d'un
certificat client. Mais c'est tout. Le RFC 5730 ne permet pas de mot de passe plus long,
ne permet pas au client de savoir combien de tentatives erronées
ont eu lieu, ne permet pas d'indiquer l'expiration d'un mot de passe
(si ceux-ci ont une durée de vie limitée) et ne permet pas au
serveur EPP d'indiquer, s'il refuse un nouveau mot de passe,
pourquoi il le juge inacceptable.
Cette extension à EPP figure désormais dans le registre des extensions, créé par le RFC 7451.
Notre RFC
ajoute donc plusieurs nouveaux éléments XML qui peuvent apparaitre en EPP
(section 3). D'abord, la notion d'évènement. Un évènement permet
d'indiquer, dans un élément <event> :
- l'expiration d'un mot de passe,
- l'expiration du certificat client,
- la faiblesse d'un algorithme cryptographique,
- la version de TLS, par exemple pour rejeter une version trop basse,
- les raisons du rejet d'un nouveau mot de passe (« le mot de passe doit comporter au moins une majuscule, une minuscule, un chiffre arabe, un chiffre romain, une rune et un hiéroglyphe », et autres règles absurdes mais fréquentes),
- des statistiques de sécurité, comme le nombre de connexions refusées suite à un mot de passe incorrect.
En utilisant loginSec comme abréviation pour
l'espace de noms de l'extension EPP de ce
RFC, urn:ietf:params:xml:ns:epp:loginSec-1.0,
voici un exemple d'évènement, indiquant qu'il faudra bientôt changer
de mot de passe :
<loginSec:event
type="password"
level="warning"
exDate="2020-04-01T22:00:00.0Z"
lang="fr">
Le mot de passe va bientôt expirer.
</loginSec:event>
On pourrait voir aussi cet évènement indiquant le nombre de connexions ratées, ce qui peut alerter sur une tentative de découverte du mot de passe par force brute :
<loginSec:event
type="stat"
name="failedLogins"
level="warning"
value="100"
duration="P1D"
lang="fr">
Trop de connexions ratées.
</loginSec:event>
Si on utilise des mots de passe qui suivent les nouvelles règles,
il faut l'indiquer en mettant dans l'ancien élément
<pw> la valeur
[LOGIN-SECURITY]. Si elle est présente, c'est
qu'il faut aller chercher le mot de passe dans le nouvel élément
<loginSec:pw> (idem pour un changement de
mot de passe).
La section 4 du RFC donne les changements pour les différentes
commandes EPP. Seule <login> est
concernée. Ainsi, <login> gagne un
élément <loginSec:userAgent> qui permet
d'indiquer le type de logiciel utilisé côté client. Mais le
principal ajout est évidemment
<loginSec:pw>, qui permet d'utiliser les
mots de passe aux nouvelles règles (mots de passe plus longs, par
exemple). Il y a aussi un
<loginSec:newPw> pour indiquer le nouveau
mot de passe à utiliser. Notez que, si le mot de passe comprend des
caractères Unicode, il est recommandé qu'ils
se conforment au RFC 8265 (profil
OpaqueString).
Voici un exemple d'une commande
<login> nouveau style :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<login>
<clID>ClientX</clID>
<pw>[LOGIN-SECURITY]</pw>
...
</login>
<extension>
<loginSec:loginSec
xmlns:loginSec=
"urn:ietf:params:xml:ns:epp:loginSec-1.0">
<loginSec:userAgent>
<loginSec:app>EPP SDK 1.0.0</loginSec:app>
<loginSec:tech>Vendor Java 11.0.6</loginSec:tech>
<loginSec:os>x86_64 Mac OS X 10.15.2</loginSec:os>
</loginSec:userAgent>
<loginSec:pw>this is a long password not accepted before</loginSec:pw>
</loginSec:loginSec>
</extension>
...
</command>
</epp>
Et une réponse positive du serveur EPP à cette connexion, mais qui avertit que le mot de passe va expirer le 1er juillet :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<response>
<result code="1000">
<msg>Command completed successfully</msg>
</result>
<extension>
<loginSec:loginSecData
xmlns:loginSec=
"urn:ietf:params:xml:ns:epp:loginSec-1.0">
<loginSec:event
type="password"
level="warning"
exDate="2020-07-01T22:00:00.0Z"
lang="en">
Password expiring in a week
</loginSec:event>
</loginSec:loginSecData>
</extension>
...
</response>
</epp>
Et, ici, lorsqu'un client a voulu changer son mot de passe expiré,
avec <loginSec:newPw>, mais que le nouveau
mot de passe était trop simple (cf. les recommandations
de l'ANSSI) :
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<response>
<result code="2200">
<msg>Authentication error</msg>
</result>
<extension>
<loginSec:loginSecData
xmlns:loginSec=
"urn:ietf:params:xml:ns:epp:loginSec-1.0">
<loginSec:event
type="password"
level="error"
exDate="2020-03-24T22:00:00.0Z">
Password has expired
</loginSec:event>
<loginSec:event
type="newPW"
level="error"
lang="fr">
Mot de passe vraiment trop trivial.
</loginSec:event>
</loginSec:loginSecData>
</extension>
...
</response>
</epp>
Le schéma complet figure dans la section 5 du RFC.
Un changement plus radical aurait été de passer à un cadre d'authentification plus général comme SASL (RFC 4422) mais l'IETF a choisi une évolution plus en douceur.
À l'heure actuelle, je ne connais que deux mises en œuvre de ce
RFC, dans le SDK
de Verisign, en https://www.verisign.com/en_US/channel-resources/domain-registry-products/epp-sdks
L'article seul
RFC 8806: Running a Root Server Local to a Resolver
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : W. Kumari (Google), P. Hoffman (ICANN)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 19 juin 2020
Toute résolution DNS commence par la racine (de l'arbre des noms de domaine). Bien sûr, la mémorisation (la mise en cache) des réponses fait qu'on n'a pas besoin tout le temps de contacter un serveur racine. Mais c'est quand même fréquent et les performances de la racine sont donc cruciales. L'idée documentée dans ce RFC est donc d'avoir en local un serveur esclave de la racine, copiant celle-ci et permettant donc de répondre localement aux requêtes. Ce RFC remplace le premier RFC qui avait documenté l'idée, le RFC 7706, avec des changements significatifs, notamment vers davantage de liberté (le précédent RFC restreignait sérieusement les possibilités).
Le problème est particulièrement important pour les noms qui
n'existent pas. Si les TLD existants comme
.com ou
.fr vont vite se
retrouver dans la mémoire (le cache) du résolveur DNS, les fautes de
frappe ou autres cas où un TLD n'existe pas vont nécessiter la
plupart du temps un aller-retour jusqu'au serveur racine le plus
proche. Les réponses négatives seront également mémorisées mais 1)
il y a davantage de noms non existants que de noms existants 2) le
TTL est plus court
(actuellement deux fois plus court). Ces noms non existants
représentent ainsi la majorité du trafic de la racine.
Bien qu'il existe aujourd'hui des centaines de sites dans le monde où se trouve une instance d'un serveur racine, ce nombre reste faible par rapport au nombre total de réseaux connectés à l'Internet. Dans certains endroits de la planète, le serveur racine le plus proche est assez lointain. Voici les RTT en millisecondes avec les serveurs racine observés depuis un réseau tunisien (notez les deux serveurs qui répondent bien plus vite que les autres, car ils ont une instance à Tunis) :
% check-soa -4 -i .
a.root-servers.net.
198.41.0.4: OK: 2015112501 (54 ms)
b.root-servers.net.
192.228.79.201: OK: 2015112501 (236 ms)
c.root-servers.net.
192.33.4.12: OK: 2015112501 (62 ms)
d.root-servers.net.
199.7.91.13: OK: 2015112501 (23 ms)
e.root-servers.net.
192.203.230.10: OK: 2015112501 (18 ms)
f.root-servers.net.
192.5.5.241: OK: 2015112501 (69 ms)
g.root-servers.net.
192.112.36.4: OK: 2015112501 (62 ms)
h.root-servers.net.
128.63.2.53: OK: 2015112501 (153 ms)
i.root-servers.net.
192.36.148.17: OK: 2015112501 (67 ms)
j.root-servers.net.
192.58.128.30: OK: 2015112501 (55 ms)
k.root-servers.net.
193.0.14.129: OK: 2015112501 (72 ms)
l.root-servers.net.
199.7.83.42: ERROR: Timeout
m.root-servers.net.
202.12.27.33: OK: 2015112501 (79 ms)
Ces délais peuvent sembler courts mais ils ne forment qu'une partie du travail de résolution, il est donc légitime de vouloir les réduire encore.
En outre, ces requêtes à la racine peuvent être observées, que ce soit par les opérateurs de serveurs racine, ou par des tiers sur le projet, ce qui n'est pas forcément souhaitable, question vie privée (cf. RFC 7626).
Donc, l'idée de base de ce RFC est de :
- Mettre un serveur esclave de la racine sur sa machine, configuré pour ne répondre qu'aux requêtes de cette machine,
- Configurer le résolveur pour interroger d'abord ce serveur.
Cette idée est documentée dans ce RFC mais n'est pas encouragée (c'est un très vieux débat, dont j'avais déjà parlé). En effet, cela ajoute un composant à la résolution (le serveur local faisant autorité pour la racine), composant peu ou pas géré et qui peut défaillir, entrainant ainsi des problèmes graves et difficiles à déboguer. Mais pourquoi documenter une idée qui n'est pas une bonne idée ? Parce que des gens le font déjà et qu'il vaut mieux documenter cette pratique, et en limiter les plus mauvais effets. C'est pour cela, par exemple, que notre RFC demande que le serveur racine local ne réponde qu'à la même machine, pour limiter les conséquences d'une éventuelle défaillance à une seule machine.
Pas découragé ? Vous voulez encore le faire ? Alors, les détails
pratiques. D'abord (section 2 du RFC), les pré-requis. DNSSEC est
indispensable (pour éviter de se faire refiler un faux fichier de
zone par de faux serveurs racine). Ensuite (section 3), vous mettez
un serveur faisant autorité (par exemple NSD ou Knot) qui écoute sur une des adresses
locales (en 127.0.0.0/8,
IPv6 est moins pratique car il ne fournit
paradoxalement qu'une seule adresse locale à la machine) et qui est
esclave des serveurs racine. À noter que votre serveur, n'étant pas
connu des serveurs racine, ne recevra pas les notifications (RFC 1996) et sera donc parfois un peu en retard sur
la vraie racine (ce qui n'est pas très grave, elle bouge peu).
Il est important de lister plusieurs serveurs maîtres dans sa configuration. En effet, si la mise à jour de la racine dans votre serveur esclave échoue, ce sera catastrophique (signatures DNSSEC expirées, etc) et cette configuration locale, contrairement à la « vraie » racine, n'a aucune redondance. (Une autre raison pour laquelle ce n'est pas une idée géniale.) Quels serveurs maîtres indiquer ? Certains serveurs racine permettent le transfert de zone (RFC 5936) mais ce n'est jamais officiel, ils peuvent cesser à tout moment (l'annexe A du RFC donne une liste et discute de ce choix). Une raison de plus de se méfier.
Il est donc important d'avoir un mécanisme de supervision, pour être prévenu si quelque chose échoue. On peut par exemple interroger le numéro de série dans l'enregistrement SOA de la racine et vérifier qu'il change.
Ensuite, une fois ce serveur faisant autorité configuré, il ne reste qu'à indiquer à un résolveur (comme Unbound) de l'utiliser (toujours section 3 du RFC).
Voici un exemple testé. J'ai choisi NSD et Unbound. Le RFC, dans son annexe B, donne plusieurs autres exemples, tous utilisant le même serveur comme résolveur et comme serveur faisant autorité. C'est en général une mauvaise idée mais, pour le cas particulier de ce RFC, cela peut se défendre.
D'abord, la configuration de NSD (notez la longue liste de
maîtres, pour maximiser les chances que l'un d'eux fonctionne ;
notez aussi l'adresse IP choisie,
127.12.12.12) :
# RFC 8806
server:
ip-address: 127.12.12.12
zone:
name: "."
request-xfr: 199.9.14.201 NOKEY # b.root-servers.net
request-xfr: 192.33.4.12 NOKEY # c.root-servers.net
request-xfr: 192.5.5.241 NOKEY # f.root-servers.net
request-xfr: 192.112.36.4 NOKEY # g.root-servers.net
request-xfr: 193.0.14.129 NOKEY # k.root-servers.net
request-xfr: 192.0.47.132 NOKEY # xfr.cjr.dns.icann.org
request-xfr: 192.0.32.132 NOKEY # xfr.lax.dns.icann.org
request-xfr: 2001:500:200::b NOKEY # b.root-servers.net
request-xfr: 2001:500:2f::f NOKEY # f.root-servers.net
request-xfr: 2001:7fd::1 NOKEY # k.root-servers.net
request-xfr: 2620:0:2830:202::132 NOKEY # xfr.cjr.dns.icann.org
request-xfr: 2620:0:2d0:202::132 NOKEY # xfr.lax.dns.icann.org
Le démarrage de NSD (notez qu'il faut patienter un peu la première fois, le temps que le premier transfert de zone se passe) :
[2020-05-04 17:51:05.496] nsd[25649]: notice: nsd starting (NSD 4.3.1) [2020-05-04 17:51:05.496] nsd[25649]: notice: listen on ip-address 127.12.12.12@53 (udp) with server(s): * [2020-05-04 17:51:05.496] nsd[25649]: notice: listen on ip-address 127.12.12.12@53 (tcp) with server(s): * [2020-05-04 17:51:05.600] nsd[25650]: notice: nsd started (NSD 4.3.1), pid 25649 [2020-05-04 17:51:08.380] nsd[25649]: info: zone . serial 0 is updated to 2020050400
C'est bon, on a transféré la zone. Testons (notez le bit AA - Authoritative Answer - dans la réponse) :
% dig @127.12.12.12 SOA . ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 24290 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 13, ADDITIONAL: 27 ... ;; ANSWER SECTION: . 86400 IN SOA a.root-servers.net. nstld.verisign-grs.com. 2020050400 1800 900 604800 86400 ... ;; Query time: 3 msec ;; SERVER: 127.12.12.12#53(127.12.12.12) ;; WHEN: Mon May 04 17:51:51 CEST 2020 ;; MSG SIZE rcvd: 868
C'est bon.
Maintenant, la configuration d'Unbound (différente de celle du RFC, qui utilise Unbound à la fois comme résolveur et comme serveur faisant autorité) :
server:
# RFC 8806
do-not-query-localhost: no
# Requires a slave auth. running (normally, nsd)
stub-zone:
name: "."
stub-prime: no
stub-addr: 127.12.12.12
(John Shaft me fait remarquer que la directive
stub-first devrait permettre d'utiliser le
mécanisme de résolution classique si la requête échoue, ce qui
apporterait une petite sécurité en cas de panne du serveur local
faisant autorité pour la racine.) Et le test :
% dig www.cnam.fr ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 30881 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; ANSWER SECTION: www.cnam.fr. 86400 IN CNAME kaurip.cnam.fr. kaurip.cnam.fr. 3600 IN A 163.173.128.40 ...
Ça a marché. Avec tcpdump, on voit le trafic (faible, en raison du cache) vers le serveur racine local :
18:01:09.865224 IP 127.0.0.1.54939 > 127.12.12.12.53: 55598% [1au] A? tn. (31) 18:01:09.865359 IP 127.12.12.12.53 > 127.0.0.1.54939: 55598- 0/8/13 (768)
Pour BIND, et d'autres logiciels, consultez l'annexe B du RFC.
À noter qu'il existe un brevet futile (comme tous les brevets...) de Verisign sur cette technique : déclaration #2539 à l'IETF. Il portait sur l'ancien RFC mais il est peut-être aussi valable (ou aussi ridicule) avec le nouveau.
La section 1.1 de notre RFC documente les changements depuis le
RFC 7606. Le principal est que le serveur
racine local n'a plus l'obligation d'être sur une adresse IP locale
à la machine (comme ::1). Les autres
changements, qui reflètent l'expérience pratique avec cette
technique, après plus de quatre ans écoulés, vont en général dans le
sens de la « libéralisation ». Il y a moins de restrictions que dans
le RFC 7706.
L'article seul
RFC 8801: Discovering Provisioning Domain Names and Data
Date de publication du RFC : Juillet 2020
Auteur(s) du RFC : P. Pfister, E. Vyncke (Cisco), T. Pauly (Apple), D. Schinazi (Google), W. Shao (Cisco)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 29 juillet 2020
Vous vous demandez certainement, chère lectrice et cher lecteur, ce qu'est un PvD (ProVisioning Domain). Cette notion n'est pas nouvelle, mais elle n'avait été formalisée rigoureusement qu'avec le RFC 7556. Un PvD est un domaine de l'Internet où des règles cohérentes de configuration du réseau s'appliquent. Au sein, d'un PvD, il y a un résolveur DNS à utiliser, des adresses IP spécifiques, des règles de routage et de sécurité que n'ont pas forcément les autres PvD. Ce nouveau RFC décrit une option IPv6 qui permet au PvD de signaler explicitement son existence, via un RA (Router Advertisement.)
La notion de PvD (ProVisioning Domain) est utile pour les machines qui ont plusieurs connexions, à des réseaux (et donc peut-être des PvD) différents, par exemple un ordinateur connecté à la fois à un FAI grand public et au VPN de l'entreprise. Il y a des PvD implicites : une machine qui connait le concept de PvD affecte un PvD implicite à chaque réseau et, par défaut, ne considère pas que le résolveur DNS de l'un convient pour les autres. Et il y a des PvD explicites, et c'est à eux qu'est consacré ce RFC. Un PvD explicite a un identificateur, qui a la syntaxe d'un FQDN. Attention, même si l'identificateur est un nom de domaine, le terme de « domaine » (le D de PvD) ne doit pas être confondu avec le sens qu'il a dans le DNS. L'intérêt d'un PvD explicite est qu'il permet d'avoir plusieurs domaines distincts sur la même interface réseau, et qu'on peut y associer des informations supplémentaires, récupérées sur le réseau ou bien préconfigurées.
On l'a vu, le concept de PvD avait été décrit dans le RFC 7556. Ce que notre nouveau RFC 8801 rajoute, c'est :
- Une option aux RA (Router Advertisement, RFC 4861) pour indiquer aux machines IPv6 du réseau le PvD explicite,
- Un mécanisme pour récupérer, en HTTPS, de l'information de configuration du réseau, pour les cas où cette information ne tiendrait pas dans le message RA. Elle est évidemment codée en JSON.
Le RA va donc indiquer le ou les identificateurs du ou des PvD du réseau. Notez qu'on peut avoir aussi le même PvD sur plusieurs réseaux, par exemple le Wi-Fi et le filaire chez moi font partie du même PvD et ont les mêmes règles et la même configuration.
Dans un monde idéal, l'utilisatrice dont
l'ordiphone a à la fois une connexion
4G, une connexion Wi-Fi et un VPN par dessus, aurait un
PvD pour chacun de ces trois réseaux différentes, et pourrait donc
décider intelligemment quelle interface utiliser pour quel type de
trafic. Par exemple, une requête DNS pour
wiki.private.example.com (le
wiki interne de l'entreprise) sera envoyée
uniquement via le VPN, puisque les résolveurs des réseaux publics ne
connaissent pas ce domaine. Autre exemple, l'information envoyée
pour chaque PvD pourrait permettre aux applications de faire passer
le trafic important (la vidéo en haute définition, par exemple),
uniquement sur le réseau à tarification forfaitaire.
Bon, assez de considérations sur les PvD, passons aux nouvelles normes décrites dans ce RFC. D'abord, l'option RA. Elle est décrite dans la section 3. C'est très simple : une nouvelle option RA est créée, la 21, « PvD ID Router Advertisement Option », suivant le format classique des options RA, TLV (Type-Longueur-Valeur). Elle contient, entre autres :
- Un bit nommé H qui indique que le client peut récupérer des informations supplémentaires en HTTP (c'est détaillé en section 4 du RFC),
- Un bit nommé L qui indique que ce PvD est également valable pour IPv4,
- Un bit nommé R qui indique que le RA contient un autre RA (détails en section 5),
- Et bien sûr l'identificateur (PvD ID) lui-même, sous la forme d'un FQDN.
Si jamais il y a plusieurs PvD sur le réseau, le routeur doit envoyer des RA différents, il n'est pas autorisé à mettre plusieurs options PvD dans un même RA.
Que va faire la machine qui reçoit une telle option dans un RA ?
Elle doit marquer toutes les informations de configuration qui
étaient dans le RA comme étant spécifiques à ce PvD. Par exemple, si
la machine a deux interfaces, et reçoit un RA sur chacune, ayant des
PvD différents, et donnant chacun l'adresses d'un résolveur DNS
(RFC 8106), alors ce résolveur ne doit être
utilisé que pour le réseau où il a été annoncé (et avec une adresse
IP source de ce réseau). Rappelez-vous que différents résolveurs DNS
peuvent donner des résultats différents, par exemple un des réseaux
peut avoir un Pi-hole qui donne des réponses
mensongères, afin de bloquer la publicité. (En parlant du DNS, des
détails sur cette question complexe figurent dans la section 5.2.1
du RFC 7556.) Autre exemple, si on utilise un
VPN vers son
employeur, les requêtes DNS pour les ressources internes
(congés.rh.example.com…) doivent être envoyées
au résolveur de l'employeur, un résolveur extérieur peut ne pas être
capable de les résoudre. En fait, tous les cas où la réponse DNS
n'est pas valable publiquement nécessitent d'utiliser le bon
résolveur DNS. C'est aussi ce qui se passe avec
NAT64 (RFC 6147).
Idem pour d'autres informations de configuration comme le routeur par défaut : elles doivent être associées au PvD. Une machine qui connait les PvD ne peut donc pas se contenter d'une table simple listant le résolveur DNS, le routeur par défaut, etc. Elle doit avoir une table par PvD.
Si la machine récupère par ailleurs des informations de configuration avec DHCP, elle doit également les associer à un PvD, par exemple en utilisant comme PvD implicite celui de l'interface réseau utilisée.
Et pour IPv4, si le bit L est à un ? Dans ce cas, l'information IPv4 reçue sur la même interface doit être associée à ce PvD. (Notez que si plusieurs PvD sur la même interface ont le bit L, on ne peut rien décider, à part que quelqu'un s'est trompé.)
Les machines qui partagent leur connexion (tethering), ce qui est fréquent pour les connexions mobiles comme la 4G (RFC 7278), doivent relayer le RA contenant l'option PvD vers le réseau avec qui elles partagent (comme elles relaient d'autres messages similaires, cf. RFC 4389). Cela permettra à des techniques qui facilitent le partage, comme la délégation de préfixe du RFC 9915, de bien fonctionner. Même si la machine partageuse ne reçoit pas d'option PvD, il est recommandé qu'elle en ajoute une pour le bénéfice des engins avec qui elle partage sa connectivité.
Tout cela, c'était pour une machine PvD-aware, une machine qui sait ce qu'est un PvD et qui sait le gérer. Mais avec du vieux logiciel, écrit avant le concept de PvD, que se passe-t-il ? Une machine munie de ce logiciel va évidemment ignorer l'option PvD du RA et donc utiliser un seul résolveur DNS, un seul routeur par défaut pour tous les cas. Elle aura sans doute beaucoup de problèmes si plusieurs interfaces réseau sont actives et, en pratique, il vaudra mieux n'avoir qu'une seule interface à un moment donné.
Nous avons vu plus haut que, si le bit H dans l'option PvD est à
1, la machine peut obtenir davantage d'informations (PvD
Additional Information) en HTTP. Cette information sera encodée
en I-JSON (RFC 7493.)
Pourquoi ne pas avoir mis ces informations dans le RA ? Parce
qu'elles sont trop grosses ou, tout simplement, pas critiques, et
pouvant être ignorées. Et on les récupère où, ces informations ? Si
le PvD est radio.example.com, l'URL à utiliser est
https://radio.example.com/.well-known/pvd
(préfixe .well-known désormais enregistré.)
Attention, on ne doit tenter d'accéder à cet URL que si le bit H
était à 1. C'est du HTTPS (RFC 2818) et il
faut donc vérifier le certificat (cf. RFC 6125.) Vous voyez qu'on ne peut pas choisir un
PvD au hasard : il faut qu'il soit un nom de domaine qu'on contrôle, et pour lequel
on peut obtenir un certificat. Si on configure un des ces affreux
portails captifs, il
faut s'assurer que les clients auront le droit de se connecter au
serveur HTTP indiqué.
Les données auront le type application/pvd+json. Elles
contiennent obligatoirement :
- Le PvD,
- une date d'expiration, au format RFC 3339,
- les préfixes IP du PvD.
Ainsi que, si on veut :
- les domaines où chercher les noms qui ne sont pas des FQDN,
- une indication que ce PvD n'a pas de connexion à l'Internet.
D'autres membres peuvent être présents, un registre IANA existe et, pour y ajouter des termes, c'est la procédure « Examen par un expert » du RFC 8126.
Voici un exemple, avec le PvD smart.mpvd.io
(qui a servi à un hackathon
IETF) :
% curl https://smart.mpvd.io/.well-known/pvd
{
"name": "PvD for smart people",
"prefixes": ["2001:67c:1230:101::/64", "2001:67c:1230:111::/64"],
"noInternet": false,
"metered": false,
"captivePortalURL" : "https://smart.mpvd.io/captive.php"
}
On notera que le membre expires manque, ce qui
n'est pas bien, et que le membre identifier, qui devrait
indiquer le PvD, est également absent, ce qui est encore plus mal. On voit qu'il
s'agissait d'une expérimentation. Voici ce qu'aurait dû être l'objet
JSON :
{
"identifier": "smart.mpvd.io",
"expires": "2020-04-08T15:30:00Z",
"prefixes": ["2001:67c:1230:101::/64", "2001:67c:1230:111::/64"],
"noInternet": false,
"name": "PvD for smart people",
"metered": false,
"captivePortalURL" : "https://smart.mpvd.io/captive.php"
}
Si vous connaissez d'autres serveurs d'information PvD, indiquez-les moi. Mais il est probable que la plupart ne seront accessibles que depuis un réseau interne.
Voilà, vous savez l'essentiel désormais. La section 5 du RFC ajoute quelques considérations pratiques. D'abord, le bit R qui permettait à une option PvD d'inclure un RA. À quoi ça sert ? L'idée est que, pendant longtemps, la plupart des réseaux accueilleront un mélange de machines qui connaissent les PvD, et de machines qui ne sont pas conscientes de ce concept. Le bit R sert à envoyer des informations qui ne seront comprises que des premières. Par exemple, on met un préfixe dans le RA et, dans l'option PvD, un autre RA qui contient un autre préfixe. Les machines qui connaissent les PvD verront et utiliseront les deux préfixes, celles qui ne connaissent pas les PvD ignoreront l'option et n'auront que le premier préfixe. On peut également envoyer deux RA, un ne contenant pas d'option PvD, et un en contenant une (plus le « vrai » RA).
Un peu de sécurité, pour finir (section 6). D'abord, il faut bien se rappeler que les RA, envoyés en clair et non authentifiés, n'offrent aucune sécurité. Il est trivial, pour un méchant connecté au réseau, d'envoyer de faux RA et donc de fausses options PvD. En théorie, des protocoles comme IPsec ou SEND (RFC 3971) peuvent sécuriser les RA mais, en pratique, on ne peut guère compter dessus. Les seules solutions de sécurisation effectivement déployées sont au niveau 2, par exemple 802.1X combiné avec le RFC 6105. Ce n'est pas un problème spécifique à l'option PvD, c'est la sécurité (ou plutôt l'insécurité) des RA.
Ah, et un petit mot sur la vie
privée (section 7 du RFC). La connexion au serveur HTTP
va évidemment laisser des traces, et il est donc recommandé de la
faire depuis une adresse source temporaire (RFC 8981), et sans envoyer User-Agent: ou
cookies.
Question mise en œuvre, il y a eu du code libre pour des tests (incluant une modification du noyau Linux, et un dissecteur pour Wireshark) mais je ne sais pas ce que c'est devenu et où en sont les systèmes d'exploitation actuels.
L'article seul
RFC 8799: Limited Domains and Internet Protocols
Date de publication du RFC : Juillet 2020
Auteur(s) du RFC : B. E. Carpenter (Univ. of Auckland), B. Liu (Huawei)
Pour information
Première rédaction de cet article le 15 juillet 2020
Il y a depuis longtemps un débat sur l'architecture de l'Internet : dans quelle mesure faut-il un Internet uniforme, où tout est pareil partout, et dans quelle mesure faut-il au contraire des particularités qui ne s'appliquent que dans telle ou telle partie de l'Internet ? Bien sûr, la réponse n'est pas simple, et ce nouveau RFC explore la question et discute ses conséquences, par exemple pour le développement des normes.
Sur le long terme, la tendance est plutôt au développement de règles locales, et de services qui ne sont accessibles que d'une partie de l'Internet. Le NAS avec les photos de famille accessible uniquement depuis la maison, le site Web permettant aux employés d'indiquer leurs demandes de congés, qu'on ne peut voir que depuis le réseau de l'entreprise, parce qu'on y est présent physiquement, ou bien via le VPN, les lois d'un pays qu'il essaie, avec plus ou moins de succès, d'appliquer sur son territoire… Mais, d'abord, une précision : le terme « local » ne signifie pas forcément une région géographique précise. « Local » peut, par exemple, désigner le réseau d'une organisation spécifique, qui y applique ses règles. « Local » peut être un bâtiment, un véhicule, un pays ou bien un réseau s'étendant au monde entier.
À noter que certains ont poussé cette tendance très loin en estimant que l'Internet allait se fragmenter en réseaux distincts, ne communiquant plus, voire que cela avait déjà été fait. C'est clairement faux, aujourd'hui, comme l'explique bien, par exemple, le RFC 7754, ou bien Milton Mueller dans son livre « Will The Internet Fragment? ». On peut toujours visiter ce blog depuis tous les réseaux connectés à l'Internet…
Un petit point de terminologie : le RFC utilise le terme « domaine » pour désigner une région de l'Internet ayant des règles spécifiques. Ce terme ne doit pas être confondu avec celui de « nom de domaine » qui désigne quelque chose de tout à fait différent. « Domaine », dans ce RFC, est plutôt utilisé dans le même sens que dans les RFC 6398 et RFC 8085, pour indiquer un « domaine administratif ». C'est un environnement contrôlé, géré par une entité (entreprise, association, individu) et qui peut définir des règles locales et les appliquer.
Aujourd'hui, le concept de « domaine local » ou « domaine limité » n'est pas vraiment formalisé dans l'Internet. Des RFC comme le RFC 2775 ou le RFC 4924 ont plutôt défendu l'inverse, la nécessité de maintenir un Internet unifié, insistant sur le problème des middleboxes intrusives (RFC 3234, RFC 7663 et RFC 8517). Actuellement, il y a déjà une fragmentation de l'Internet en ilots séparés, puisque certaines fonctions ne marchent pas toujours, et qu'on ne peut donc pas compter dessus. C'est le cas par exemple des en-têtes d'extension IPv6 (RFC 7872), de la découverte de la MTU du chemin (RFC 4821) ou de la fragmentation (RFC 8900). Sans compter le filtrage par les pare-feux. Bref, tous ces problèmes font que, de facto, l'Internet n'est plus transparent, et que des communications peuvent échouer, non pas en raison d'une panne ou d'une bogue, mais en raison de règles décidées par tel ou tel acteur sur le trajet. Donc, en pratique, on a des « domaines limités » mais sans que cela soit explicite, et cela joue un rôle important dans l'utilisation du réseau.
Si on avait des « domaines limités » ou « domaines locaux » explicites, quel serait le cahier des charges de ce concept ? La section 3 du RFC donne quelques idées à ce sujet. Par exemple, ces scénarios sont envisagés :
- Un cas d'usage évident est le réseau de la maison, où des politiques spécifiques à ce logement sont tout à fait légitimes (par exemple, utilisation de Pi-hole pour bloquer les publicités). Typiquement non géré par des professionnels (voire pas géré du tout…), il doit marcher « à la sortie de la boîte ». Le RFC 7368 donne davantage de détails sur cette notion de réseau à la maison.
- Le réseau interne d'une petite entreprise est souvent proche du réseau de la maison : politique locale (donc « domaine limité ») mais personne de compétent pour s'en occuper. Par contre, il est parfois installé par des professionels (mais attention, « professionnel » ≠ « compétent »).
- Sujet à la mode, le réseau dans un véhicule. À l'intérieur du véhicule, il y a des exigences spécifiques, liées à la sécurité, et qui justifient des règles locales.
- Les réseaux SCADA ont également d'excellentes raisons d'avoir une politique locale, notamment en sécurité (cf. RFC 8578).
- Toujours dans le domaine industriel, il y a aussi les réseaux de capteurs et, plus généralement, l'IoT. Ils demandent également des règles locales spécifiques et, en prime, posent parfois des problèmes techniques ardus. C'est encore pire si les objets sont contraints en ressources matérielles (RFC 7228).
- Plus science-fiction, un autre scénario où on ne peut pas suivre les règles de l'Internet public et où il faut des règles locales, les DTN (RFC 4838).
- Les grands réseaux internes d'une organisation, répartie sur plusieurs sites physiques, peuvent également être concernées par le concept de politique locale. Notez qu'un seul RFC parle d'eux, à propos d'IPv6, le RFC 7381.
- Il y a aussi le cas du réseau semi-fermé d'un opérateur. Le réseau est utilisé par des clients de cet opérateur, et celui-ci a une offre réservée à certains, qui propose des garanties de service (avec des techniques comme EVPN ou VPLS). (Le RFC n'en parle pas, mais attention, ici, on commence à s'approcher de la question de la neutralité de l'Internet.)
- Et enfin (mais je n'ai pas recopié toute la liste du RFC), il y a les centres de données où, là encore, une organisation souhaite avoir une politique locale.
Bref, le cas est fréquent. On se dit, en regardant tous ces scénarios où un réseau, quoique connecté à l'Internet, a de très bonnes raisons d'avoir des règles locales spécifiques, qu'il serait bon qu'une organisation de normalisation, comme l'IETF, trouve une solution générale. Le problème est que, justement, chaque politique locale est différente. Néanmoins, les auteurs du RFC suggèrent de réfléchir à une nouvelle façon d'analyser les propositions à l'IETF, en ne considérant pas simplement leur usage sur l'Internet public (le vrai Internet, dirais-je) mais aussi ce qui se passera sur ces domaines limités.
Le RFC cite aussi le cas de protocoles qu'on avait cru pouvoir déployer sur l'Internet public mais qui en fait n'ont marché que dans des environnements fermés. Ce fut le cas bien sûr de RSVP (RFC 2205). Ses auteurs avaient pensé qu'un protocole de réservation de ressources pourrait marcher sur un réseau public, oubliant que, dans ce cas, chaque égoïste allait évidemment se réserver le plus de ressources possibles. (Ce n'est pas un problème spécifique à RSVP : aucun mécanisme de qualité de service ne peut marcher sur un réseau public décentralisé. Imaginez un bit « trafic très important, à ne jamais jeter » ; tout le monde le mettrait à 1 !)
Bon, maintenant qu'on a décrit les scénarios d'usage, quelle(s) solution(s) ? La section 4 du RFC liste quelques exemples de techniques conçues spécialement pour des domaines limités. Notons que le RFC parle des techniques en couche 3, la couche 2 étant évidemment toujours pour un domaine local (encore que, avec TRILL - RFC 6325, la couche 2 peut aller loin). Par exemple :
- DiffServ (RFC 2464), puisque la signification des bits utilisés est purement locale.
- RSVP, déjà cité.
- La virtualisation de réseaux, qui permet de créer un domaine local au-dessus de réseaux physiques divers. Idem pour celle dans les centres de données (RFC 8151).
- Le SFC du RFC 7665, qui permet d'attacher des instructions particulières aux paquets (encodées selon le RFC 8300), instructions qui n'ont évidemment de sens que dans un domaine local.
- Dans un genre analogue, il y a aussi le routage par les segments (RFC 8402).
- L'IETF a une série d'adaptations des protocoles Internet spécialement conçues pour le cas de la maison, collectivement nommées Homenet (RFC 7368, RFC 7788).
- Avec IPv6, d'autres possibilités amusantes existent. L'étiquette de flot (RFC 6294) peut permettre de marquer tel ou tel flot de données, pour ensuite lui appliquer une politique spécifique. Les en-têtes d'extension permettent de déployer des techniques comme le routage via des segments, cité plus haut. (Le fait que ces en-têtes passent mal sur l'Internet public - cf. RFC 7045 et RFC 7872 n'est pas un problème dans un domaine limité.) Et la grande taille des adresses IPv6 permet d'encoder dans l'adresse des informations qui seront ensuite utilisées par les machines du domaine.
- Et enfin je vais citer les PvD (ProVisioning Domain) du RFC 7556, qui formalisent cette notion de domaine local, et lui donnent un cadre.
La section 5 du RFC conclut qu'il peut être souhaitable d'avoir des protocoles explicitement réservés à des domaines limités, et pour qui les règles pourraient être différentes de celles des protocoles conçus pour le grand Internet ouvert. Le RFC donne un exemple : si faire ajouter des en-têtes d'extension à un paquet IPv6 par le réseau qu'il traverse serait une abominable violation de la neutralité, en revanche, dans un domaine local, pourquoi ne pas se dire que ce serait possible, et peut-être intéressant dans certains cas ? Pour de tels protocoles, on ne pourrait pas garantir leur interopérabilité sur l'Internet, mais ils pourraient former une intéressante addition au socle de base du travail de l'IETF, qui sont les protocoles de l'Internet public.
Une fois posée l'opinion que les protocoles « à usage local » sont intéressants (et qu'ils existent déjà), comment les améliorer ? Actuellement, comme le concept de « domaine limité » n'est pas explicitement défini, le domaine est créé par la configuration des machines, des pare-feux, des résolveurs DNS, des ACL, du VPN… Un processus compliqué et où il est facile de se tromper, surtout avec le BYOD, le télétravail… Imaginez un serveur HTTP privé, qui ne sert que le domaine. Comment le configurer pour cela ? Compter sur les pare-feux ? Mettre des ACL sur le serveur (ce qui nécessite de connaître la liste, évolutive, des préfixes IP du domaine) ? Définir un domaine nécessite d'avoir un intérieur et un extérieur, et que chaque machine, chaque application, sache bien de quel côté elle est (ou à l'interface entre les deux, si elle sert de garde-frontière). Et, quand on est à l'intérieur, et qu'on envoie ou reçoit un message, il est important de savoir si on l'envoie à l'extérieur ou pas, si on le reçoit de l'intérieur ou pas. Bref, actuellement, il n'y a pas de solution propre permettant de répondre à cette question.
Le RFC définit alors un cahier des charges pour qu'on puisse définir des règles locales et que ça marche. Notamment :
- Comme tout truc sur l'Internet, le domaine devrait avoir un identificateur. Le RFC suggère que ce soit une clé publique cryptographique, pour permettre les authentifications ultérieures. (Le RFC 7556, sur les PvD, propose plutôt que ce soit un simple FQDN.)
- Il serait bien sympa de pouvoir emboîter les domaines (un domaine limité dans un autre domaine limité).
- Les machines devraient pouvoir être dans plusieurs domaines.
- Idéalement, les machines devraient pouvoir être informées des domaines qu'elles peuvent rejoindre, pour pouvoir choisir.
- Évidemment, tout cela devrait être sécurisé. (Par exemple avec un mécanisme d'authentification de la machine.)
- Il faudrait un mécanisme de retrait. (Une machine quitte le domaine.)
- Ce serait bien de pouvoir savoir facilement si telle machine avec qui on envisage de communiquer est dans le même domaine que nous.
- Et enfin on voudrait pouvoir accéder facilement aux informations sur la politique du domaine, par exemple sur ses règles de filtrage. (Exemple : un domaine limité de l'employeur interdisant de contacter tel ou tel service.)
À l'heure actuelle, tout ceci relève du vœu pieux.
Une motivation fréquente des domaines locaux (ou limités) est la sécurité. La section 7 de notre RFC, dédiée à ce sujet, fait remarquer qu'on voit souvent des gens qui croient que, dans un domaine limité, on peut réduire la sécurité car « on est entre nous ». Cela oublie, non seulement le fait que la plupart des menaces sont internes (par une malhonnêteté ou par une infection), mais aussi celui qu'un protocole qu'on croyait purement interne se retrouve parfois utilisé en extérieur. Un exemple classique est le site Web « interne » pour lequel on se dit que HTTPS n'est pas nécessaire. Si, suite à un problème de routage ou de pare-feu, il se retrouve exposé à l'extérieur, il n'y aura pas de seconde chance.
Enfin, l'annexe B du RFC propose une taxonomie des domaines limités : utile si vous voulez creuser la question.
L'article seul
RFC 8793: Information-Centric Networking (ICN): Content-Centric Networking (CCNx) and Named Data Networking (NDN) Terminology
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : B. Wissingh (TNO), C. Wood (University of California Irvine), A. Afanasyev (Florida International University), L. Zhang (UCLA), D. Oran (Network Systems Research & Design, C. Tschudin (University of Basel)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF icnrg
Première rédaction de cet article le 18 juin 2020
Le terme d'ICN (Information-Centric Networking) désigne un paradigme de communication où tout est du contenu : plus d'adresses IP ou de noms de domaine, on désigne chaque ressource par un nom. Il en existe plusieurs déclinaisons comme le NDN (Named Data Networking) ou le CCNx (Content-Centric Networking). Ce nouveau RFC décrit le vocabulaire de ces deux déclinaisons.
La section 1 du RFC résume les concepts essentiels de l'ICN. Il s'agit d'une architecture de réseaux où le composant de base est un contenu auquel on veut accéder. Pour récupérer, mettons, une image de chaton, on donnerait le nom de cette image et elle arriverait sur votre écran. Dans cette architecture, la notion de machine disparait, il n'y a que du contenu. En théorie, cela permettra de faire du multicast, et de la mémorisation (caching) de contenu par les éléments du réseau, transformant chaque routeur en serveur miroir.
Le concept se décline ensuite en plusieurs architectures, utilisant des terminologies très variables, et peu normalisées. Toutes ne sont pas couvertes dans ce RFC, qui se focalise sur les sujets sur lesquels l'IRTF a le plus travaillé, NDN et CCNx (RFC 8569.)
La section 2 de notre RFC contient une description générale de l'ICN. Il y a un demandeur (requestor), également appelé consommateur, qui voudrait du contenu, mettons une photo de Scarlett Johansson. Il va manifester un intérêt (Interest) qui est un message demandant du contenu. Un ou plusieurs nœuds du réseau (l'équivalent des routeurs, mais la principale différence est qu'ils peuvent stocker du contenu) vont alors faire suivre cet intérêt jusqu'à une machine qui se trouve avoir le contenu en question, soit parce qu'elle en est la source (le producteur), soit parce qu'elle en a une copie. La machine répondra alors avec des données (Data) qui seront relayées en sens inverse, jusqu'au demandeur. Il y a donc deux types de messages, qui pourraient s'appeler requête et réponse mais que, dans le monde ICN, on nomme Intérêt et Données. Le message d'Intérêt contient le nom du contenu convoité. Chaque protocole particulier d'ICN a une façon différente de construire ces noms. Comme le message de Données arrive via plusieurs relais, l'authentification de ce message ne peut pas être déduit de sa source. Il faut qu'il soit signé, ou bien que le nom soit auto-certificateur, par exemple parce que le nom est un condensat du contenu. (Attention, l'authentification n'est pas la même chose que la confiance. Si un message est signé de la porte-parole du gouvernement, cela prouve qu'il vient bien d'elle, pas qu'elle dit la vérité. Voir la section 6 du RFC.)
Pour faire son travail, le nœud ICN va avoir besoin de trois base de données :
- La FIB (Forwarding Interest Base), les moyens de joindre les données,
- La PIT (Pending Interest Table), les requêtes en cours,
- Le stockage (Content Store), puisque tout nœud ICN peut stocker les données qu'il voit passer, pour les transmettre la fois d'après.
Parfois, les données sont de grande taille. En ICN, on dit qu'on va segmenter ces données en plusieurs messages. Le RFC utilise le terme de paquet pour une unité de données après la segmentation. Ces paquets sont potentiellement plus gros que la MTU et on parle de trame (frame) pour l'unité qui passe sur le réseau, après le découpage du paquet.
Une fois qu'on a ce résumé en tête, on peut passer aux termes utilisés dans l'ICN. C'est la section 3 du RFC, le gros morceau. Je ne vais pas les lister tous ici, je fais un choix arbitraire. Attention, comme il s'agit d'un domaine de recherche, et peu stabilisé, il y a beaucoup de synonymes. On a :
- ICN (Information-Centric Networking) ; c'est un concept dont le CCNx du RFC 8569 est une des déclinaisons possibles.
- L'immuabilité est une notion importante en ICN ; si le nom d'un contenu est un condensat du contenu, l'objet est immuable, tout changement serait un nouvel objet, avec un nouveau nom.
- Le contenu est produit par des producteurs et récupéré par des consommateurs. Il sera relayé par des transmetteurs (forwarders, un peu l'équivalent des routeurs.) Si le transmetteur stocke les données, pour accélérer les accès ultérieurs, on l'appelle une mule. La transmission est dite vers l'amont (upstream) quand il s'agit des Intérêts et vers l'aval (downstream) pour les Données et les rejets (lorsqu'un Intérêt ne correspond à aucune donnée connue).
- Un transmetteur peut être à état, ce qui signifie qu'il se souvient des Intérêts qu'il a transmis (dans sa PIT), et qu'il utilisera ce souvenir pour transmettre les Données qui seront envoyées en réponse.
- Un Intérêt peut ne pas être satisfait si on ne trouve aucune Donnée qui lui correspond (zut, pas de photo de Scarlet Johansson). Un rejet (Interest NACK) est alors renvoyé au demandeur. Notez que beaucoup de schémas d'ICN ont des noms hiérarchiques et que, dans ce cas, la correspondance dans la FIB entre un Intérêt et une interface se fait sur le préfixe le plus long.
- Un des points importants de l'ICN est la possibilité pour les nœuds intermédiaires de mémoriser les données, pour faciliter leur distribution (stockage dans le réseau, ou In-network storage). Cette mémorisation ne se fait en général pas systématiquement mais uniquement quand l'occasion se présente (opportunistic caching). Cela améliore la distribution de contenus très populaires mais cela soulève des gros problèmes de vie privée, puisque tous les nœuds intermédiaires, les transmetteurs, doivent pouvoir voir ce qui vous intéresse. (Une photo de Scarlet Johansson, ça va. mais certains contenus peuvent être plus sensibles.)
- Comme IP, ICN sépare le routage (construire les bases comme la FIB) et la transmission (envoyer des messages en utilisant ces bases).
- Un lien est un paquet de données qui contient le nom d'un autre contenu. Une indirection, donc.
- Et le nom, au fait, concept central de l'ICN ? Il est typiquement hiérarchique (plusieurs composants, parfois également appelés segments, je vous avais prévenu qu'il y avait beaucoup de synonymes) pour faciliter la transmission. Le début d'un nom se nomme un préfixe. Le nom peut indiquer la localisation d'un contenu ou bien peut être sémantique (indiquant le contenu). Dans ICN, on utilise en général le terme d'identificateur (packet ID) pour les identificateurs cryptographiques, calculés par condensation. Si le nom est l'identificateur, on parle de nommage à plat. (Et, évidemment, cela sera plus dur à router, il faudra sans doute une DHT.)
- L'ICN a une notion de version. Dans le cas de noms hiérarchiques, la version d'un contenu peut être mise dans le nom.
- Avec ICN, les propriétés de sécurité du contenu ne peuvent pas être garanties par le serveur où on l'a récupéré. Il faut donc une sécurité des données et pas seulement du canal. L'intégrité est vérifiée par la cryptographie, l'authenticité par une signature et la confidentialité par le chiffrement. Tout cela est classique. Plus délicate est la question de la confidentialité des noms, puisqu'elle empêcherait le nœuds intermédiaires de savoir ce qui est demandé, et donc de faire leur travail.
L'article seul
RFC 8792: Handling Long Lines in Content of Internet-Drafts and RFCs
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : K. Watsen (Watsen Networks), E. Auerswald, A. Farrel (Old Dog Consulting), Q. Wu (Huawei Technologies)
Pour information
Réalisé dans le cadre du groupe de travail IETF netmod
Première rédaction de cet article le 3 juillet 2020
Le sujet peut sembler un point de détail sans importance mais, dans un RFC, tout compte. Que serait une norme si les exemples de code et les descriptions en langage formel avaient la moindre ambiguïté ? C'est le cas par exemple des lignes trop longues : comment les couper pour qu'on comprenne bien ce qui s'est passé ? Ce RFC propose deux méthodes.
Le cas principal est celui des modules YANG (RFC 7950) et c'est pour cela que ce RFC sort du groupe de travail netmod. Mais le problème concerne en fait tous les cas où on veut mettre dans un RFC du texte dans un langage formel et que les lignes dépassent ce qui est généralement considéré comme acceptable. Notre RFC formalise deux solutions, toutes les deux traditionnelles et déjà souvent utilisées, mettre une barre inverse après les lignes coupées, ou bien mettre cette barre inverse et une autre au début de la ligne suivante. Donc, dans le premier cas, le texte :
Il n'est pas vraiment très long, mais c'est un exemple.
Ce texte, coupé à quarante-cinq caractères, donnerait :
Il n'est pas vraiment très long, mais c'est \ un exemple.
Ou bien :
Il n'est pas vraiment très long, mais c'est \
un exemple.
Et, avec la seconde solution :
Il n'est pas vraiment très long, mais c'est \ \un exemple.
Si la forme officielle des RFC n'est plus le texte brut depuis le RFC 7990, il y a toujours une version en texte brut produite, suivant le format décrit dans le RFC 7994. Il impose notamment des lignes de moins de 72 caractères. Or, les exemples de code, ou les textes décrits en un langage formel (modules YANG, ABNF, ou ASN.1, par exemple), dépassent facilement cette limite. Les outils actuels comme xml2rfc ne gèrent pas vraiment ce cas, se contentant d'afficher un avertissement, et laissant l'auteur corriger lui-même, d'une manière non officiellement standardisée.
Désormais, c'est fait, il existe un tel standard, ce nouveau RFC,
standard qui
permettra notamment de bien traiter les textes contenus dans
l'élement <sourcecode> (RFC 7991, section 2.48) du source du RFC. Naturellement, rien
n'interdit d'utiliser cette norme pour autre chose que des RFC
(section 2 du RFC).
Les deux stratégies possibles, très proches, sont « une seule barre inverse » et « deux barres inverses ». Dans les deux cas, un en-tête spécial est mis au début, indiquant quelle stratégie a été utilisée, pour qu'il soit possible de reconstituer le fichier original.
Dans le premier cas, la stratégie à une seule barre inverse (section 7 du RFC), une ligne est considérée pliée si elle se termine par une barre inverse. La ligne suivante (moins les éventuels espaces en début de ligne) est sa suite. Dans le deuxième cas, la stratégie à deux barres inverses (section 8), une autre barre inverse apparait au début des lignes de continuation.
Différence pratique entre les deux stratégies ? Avec la première
(une seule barre inverse), le résultat est plus lisible, moins
encombré de caractères supplémentaires. Par contre, comme les
espaces au début de la ligne de continuation sont ignorés, cette
stratégie va échouer pour des textes comportant beaucoup d'espaces
consécutifs. La deuxième est plus robuste. La recommandation du RFC
est donc d'essayer d'abord la première stratégie, qui produit des
résultats plus jolis, puis, si elle échoue, la deuxième. L'outil
rfcfold, présenté plus loin, fait exactement
cela par défaut.
La section 4 rappellait le cahier des charges des solutions adoptées :
- Repli des lignes automatisable (cf. le script
rfcfoldprésenté à la fin), notamment pour le cas où un RFC ou autre document est automatiquement produit à partir de sources extérieures, - Reconstruction automatisable du fichier original, pour qu'on puisse réutiliser ce qu'on a trouvé dans un RFC en texte brut, ce qui est déjà utilisé par les outils de soumission d'Internet-Drafts, qui extraient le YANG automatiquement et le valident, pratique qui pourrait être étendu à XML et JSON, et qui assure une meilleure qualité des documents, dès la soumission.
En revanche, la section 5 liste les « non-buts » : il n'est pas prévu que les solutions fonctionnent pour l'art ASCII. Et il n'est pas prévu de gérer les coupures spécifiques à un format de fichier. Les stratégies décrites dans ce RFC sont génériques. Au contraire, des outils comme pyang ou yanglint connaissent la syntaxe de YANG et peuvent plier les lignes d'un module YANG plus intelligemment (cf. aussi RFC 8340).
L'annexe A du RFC contient un script bash
qui met en œuvre les deux stratégies (le script rfcfold.bash
% ./rfcfold.bash -s 1 -i /tmp/i.txt -o /tmp/t.txt && cat /tmp/t.txt
========== NOTE: '\' line wrapping per RFC 8792 ===========
[{"af":6,"avg":23.4686283333,"dst_addr":"2001:67c:2218:e::51:41","ds\
t_name":"2001:67c:2218:e::51:41","dup":0,"from":"2a01:4240:5f52:bbc4\
::ba3","fw":5020,"group_id":26102101,"lts":30,"max":23.639063,"min":\
23.285885,"msm_id":26102101,"msm_name":"Ping","mver":"2.2.1","prb_id\
":1000276,"proto":"ICMP","rcvd":3,"result":[{"rtt":23.480937},{"rtt"\
:23.639063},{"rtt":23.285885}],"sent":3,"size":64,"src_addr":"2a01:4\
240:5f52:bbc4::ba3","step":null,"stored_timestamp":1593694541,"times\
tamp":1593694538,"ttl":52,"type":"ping"},{"af":6,"avg":65.9926666667\
...
Et avec la deuxième stratégie :
% ./rfcfold.bash -s 2 -i /tmp/i.txt -o /tmp/t.txt && cat /tmp/t.txt|more
========== NOTE: '\\' line wrapping per RFC 8792 ==========
[{"af":6,"avg":23.4686283333,"dst_addr":"2001:67c:2218:e::51:41","ds\
\t_name":"2001:67c:2218:e::51:41","dup":0,"from":"2a01:4240:5f52:bbc\
\4::ba3","fw":5020,"group_id":26102101,"lts":30,"max":23.639063,"min\
\":23.285885,"msm_id":26102101,"msm_name":"Ping","mver":"2.2.1","prb\
\_id":1000276,"proto":"ICMP","rcvd":3,"result":[{"rtt":23.480937},{"\
\rtt":23.639063},{"rtt":23.285885}],"sent":3,"size":64,"src_addr":"2\
\a01:4240:5f52:bbc4::ba3","step":null,"stored_timestamp":1593694541,\
\"timestamp":1593694538,"ttl":52,"type":"ping"},{"af":6,"avg":65.992\
L'option -r du script permet d'inverser,
c'està-dire de reconstituer le fichier original à partir du fichier
aux lignes pliées.
L'outil rfcfold n'a pas de connaissance des
formats de fichiers et coupe donc brutalement, y compris au milieu
d'un nom de variable. Un outil plus intelligent (section 9.3)
pourrait couper au bon endroit, par exemple, pour XML, juste avant le
début d'un élément XML.
L'article seul
RFC 8789: IETF Stream Documents Require IETF Rough Consensus
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : J. M. Halpern (Ericsson), E. K. Rescorla (Mozilla)
Première rédaction de cet article le 18 juin 2020
Un très court RFC pour une décision de clarification : les RFC publiés par l'IETF (qui ne sont pas la totalité des RFC) doivent recueillir l'accord (le consensus) de l'IETF.
Oui, cela parait assez évident, mais ce n'était pas écrit (le RFC 2026 n'était pas clair à ce sujet). Il existe plusieurs voies (streams) pour les RFC et l'une des voies est nommée IETF stream. Pour être ainsi publié, le RFC doit avoir recueilli le fameux consensus approximatif de l'IETF. Les autres voies, comme la voie indépendante, n'ont pas cette obligation.
Notez que cette obligation de consensus approximatif existait pour les RFC sur le chemin des normes mais pas pour ceux pour information ou expérimentaux. La nouvelle règle tient en une phrase : sur la voie IETF, l'IESG doit veiller à ce que tout RFC, même expérimental, recueille un consensus approximatif. Les documents qui ne réunissent pas un tel consensus peuvent toujours être publiées en RFC via d'autres voies comme la voie indépendante (cf. RFC 8730), ou celle de l'IRTF (cf. RFC 7418).
Certaines décisions précédentes (comme celle de l'IESG en 2007) se posaient déjà la question, mais sans interdire de telles publications.
Notez que le RFC ne rappelle pas comment on vérifie ce consensus approximatif. Un des moyens est via un dernier appel lancé sur la liste de diffusion de l'IETF avant l'approbation. (Voici un exemple récent, notez le Stream: IETF dans l'outil de suivi.)
L'article seul
RFC 8788: Eligibility for the 2020-2021 Nominating Committee
Date de publication du RFC : Mai 2020
Auteur(s) du RFC : B. Leiba (FutureWei Technologies)
Première rédaction de cet article le 28 mai 2020
Un très court RFC sorti dans l'urgence pour résoudre un petit problème politique. Les membres du NomCom (Nominating Committee) de l'IETF sont normalement choisis parmi des gens qui étaient à au moins trois des cinq précédentes réunions physiques de l'IETF. Que faire lorsqu'elles ont été annulées pour cause de COVID-19 ? (Ces critères sont ensuite devenus officiels avec le RFC 9389.)
Déjà deux réunions physiques ont été annulées, IETF 107 qui devait se tenir à Vancouver et IETF 108, qui devait se tenir à Madrid. Elles ont été remplacées par des réunions en ligne.
Le NomCom est un groupe qui désigne les membres de certaines instances de l'IETF. Les règles pour faire partie du NomCom sont exprimées dans le RFC 8713. Sa section 4.14 mentionne qu'un de ces critères est la présence à trois des cinq précédentes réunions physiques. Or, deux des réunions physiques de 2020 ont été annulées en raison de l'épidémie. Faut-il alors ne pas les compter dans « les cinq précédentes réunions » ? Ou bien compter la participation aux réunions en ligne comme équivalente à une réunion physique ?
La section 3 du RFC expose le choix fait : les réunions annulées ne comptent pas et le critère d'éligibilité au NomCom se fonde donc sur la participation à trois des cinq dernières réunions physiques qui se sont effectivement tenues. Cette interprétation n'a pas suscité d'objections particulières.
La même section 3 insiste sur le fait qu'il s'agit d'une décision exceptionnelle, ne s'appliquant que pour cette année, et qu'elle ne crée pas de nouvelles règles pour le futur.
L'article seul
RFC 8785: JSON Canonicalization Scheme (JCS)
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : A. Rundgren, B. Jordan (Broadcom), S. Erdtman (Spotify AB)
Pour information
Première rédaction de cet article le 29 juin 2020
Des opérations cryptographiques comme la signature sont nettement plus simples lorsqu'il existe une forme canonique des données, une représentation normalisée qui fait que toutes les données identiques auront la même représentation. Le format de données JSON n'a pas de forme canonique standard, ce RFC documente une des canonicalisations possibles, JCS (JSON Canonicalization Scheme).
Pourquoi canonicaliser ? Parce que deux documents JSON dont le contenu est identique peuvent avoir des représentations texte différentes. Par exemple :
{"foo": 1, "bar": 3}
et
{
"foo": 1,
"bar": 3
}
représentent exactement le même objet JSON. Mais la signature de ces deux formes textuelles ne donnera pas le même résultat. Pour les mécanismes de signature de JSON (comme JWS, décrit dans le RFC 7515), il serait préférable d'avoir un moyen de garantir qu'il existe une représentation canonique de l'objet JSON. Ce RFC en propose une. Je vous le dis tout de suite, la forme canonique de l'objet ci-dessus sera :
{"bar":3,"foo":1}
JSON est normalisé dans le RFC 8259. Il n'a pas de canonicalisation standard. Comme c'est une demande fréquente, plusieurs définitions d'une forme canonique de JSON ont été faites (cf. annexe H du RFC), comme Canonical JSON ou comme JSON Canonical Form. Mais aucune n'est encore la référence. (Vous noterez que ce RFC n'est pas une norme.) Cette situation est assez embêtante, alors que XML, lui, a une telle norme (cf. XML Signature).
Notez que la solution décrite dans ce RFC se nomme JCS, mais qu'il y a aussi un autre JCS, JSON Cleartext Signature.
Parmi les concepts importants de la proposition de ce RFC, JCS :
La section 3 du RFC décrit les opérations qui, ensemble, forment la canonicalisation JCS. À partir de données en mémoire (obtenues soit en lisant un fichier JSON, ce que je fais dans les exemples à la fin, soit en utilisant des données du programme), on émet du JSON avec :
- Pas d'espaces entre les éléments
lexicaux (
"foo":1et pas"foo": 1), - Représentation des nombres en suivant les règles de
sérialisation « ES6 » citées plus haut
(
3000000au lieu de3E6, c'est la section 7.12.2.1 de ES6, si vous avez le courage, les puissances de 10 où l'exposant est inférieur à 21 sont développées), - Membres des objets (rappel : un objet JSON est un
dictionnaire) triés
(
{"a":true,"b":false}et non pas{"b:"false,"a":true}), - Chaînes de caractères en UTF-8.
Concernant le tri, André Sintzoff me fait remarquer que les règles de tri de JSON sont parfois complexes. Évidentes pour les caractères ASCII, elles sont plus déroutantes en dehors du BMP.
Plusieurs annexes complètent ce RFC. Ainsi, l'annexe B fournit des exemples de canonicalisation des nombres.
Et pour les travaux pratiques, on utilise quoi ? L'annexe A du
RFC contient une mise en œuvre en JavaScript,
et l'annexe G une liste d'autres mises en œuvre (que vous
pouvez aussi trouver en
ligne). Ainsi, en npm, il y a
https://www.npmjs.com/package/canonicalizehttps://github.com/erdtman/java-json-canonicalization
Commençons avec Python, et https://github.com/cyberphone/json-canonicalization/tree/master/python3
{
"numbers": [333333333.33333329, 1E30, 4.50,
2e-3, 0.000000000000000000000000001],
"string": "\u20ac$\u000F\u000aA'\u0042\u0022\u005c\\\"\/",
"literals": [null, true, false]
}
Et ce programme :
from org.webpki.json.Canonicalize import canonicalize import json import sys raw = open(sys.argv[1]).read() data = canonicalize(json.loads(raw)) print(data.decode())
On obtient :
% git clone https://github.com/cyberphone/json-canonicalization.git
% export PYTHONPATH=json-canonicalization/python3/src
% ./canonicalize.py test.json
{"literals":[null,true,false],"numbers":[333333333.3333333,1e+30,4.5,0.002,1e-27],"string":"€$\u000f\nA'B\"\\\\\"/"}
Et en Go ? Avec le même fichier JSON de départ, et ce programme :
package main
import ("flag";
"fmt";
"os";)
import "webpki.org/jsoncanonicalizer"
func main() {
flag.Parse()
file, err := os.Open(flag.Arg(0))
if err != nil {
panic(err)
}
data := make([]byte, 1000000)
count, err := file.Read(data)
if err != nil {
panic(err)
}
result, err := jsoncanonicalizer.Transform(data[0:count])
if err != nil {
panic(err);
} else {
fmt.Printf("%s", result);
}
}
On arrive au même résultat (ce qui est bien le but de la canonicalisation) :
% export GOPATH=$(pwd)/json-canonicalization/go
% go build canonicalize.go
% ./canonicalize.py test.json
{"literals":[null,true,false],"numbers":[333333333.3333333,1e+30,4.5,0.002,1e-27],"string":"€$\u000f\nA'B\"\\\\\"/"}
Comme notre RFC contraint le JSON à suivre le sous-ensemble I-JSON (RFC 7493), si le texte d'entrée ne l'est pas, il va y avoir un problème. Ici, avec un texte JSON qui n'est pas du I-JSON (deux membres de l'objet principal ont le même nom) :
% cat test3.json
{
"foo": 1,
"bar": 3,
"foo": 42
}
% ./canonicalize test3.json
panic: Duplicate key: foo
(Un autre code en Go est en https://github.com/ucarion/jcs
L'excellent programme jq n'a pas d'option
explicite pour canonicaliser, mais Sébastien Lecacheur me fait
remarquer que les options -c et
-S donnent apparemment le même résultat (y
compris sur les nombres, ce qui ne semble pas documenté) :
% cat example.json
{
"foo": 1,
"bar": 3000000000000000000000000000000,
"baz": true
}
% jq -cS . example.json
{"bar":3e+30,"baz":true,"foo":1}
Par contre, je n'ai rien trouvé sur ce formateur en ligne.
Comme il y a un brevet pour tout, notez qu'apparemment VMware prétend avoir inventé la canonicalisation JSON (cf. ce signalement, et le commentaire « The patent is effectively a JSON based "remake" of XML's "enveloped" signature scheme which in the submitter's opinion makes it invalid. »).
L'article seul
RFC 8783: Distributed Denial-of-Service Open Threat Signaling (DOTS) Data Channel Specification
Date de publication du RFC : Mai 2020
Auteur(s) du RFC : M. Boucadair (Orange), T. Reddy (McAfee)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 31 mai 2020
Le système DOTS (Distributed Denial-of-Service Open Threat Signaling) est conçu pour permettre la coordination des défenseurs pendant une attaque par déni de service (cf. RFC 8612). Pour cela, DOTS a deux protocoles, le protocole de signalisation, à utiliser en cas de crise, et le protocole de données, pour les temps plus calmes. Ce dernier fait l'objet de ce RFC.
Pourquoi deux protocoles ? Parce qu'il y a deux sortes de données : celles urgentes, de petite taille, transmises dans le feu de l'attaque, au moment où le réseau marche mal, c'est le domaine du protocole « signalisation », du RFC 9132. Et les données de grande taille, moins urgentes, mais qui doivent être transmises de manière fiable. Et c'est le but de notre RFC. Il y a donc deux canaux entre le client DOTS, qui demande de l'aide, et le serveur DOTS qui fournit des mécanismes d'atténuation des attaques : le canal « signalisation » du RFC 9132, et le canal « données », de notre RFC. Ce canal de données va servir, par exemple, à transporter :
- La liste des préfixes IP qu'il faudra protéger. (Notez que le serveur ne va pas forcément les accepter, il peut faire des vérifications),
- Des règles de filtrage, que le serveur appliquera en cas de crise (par exemple « laisse passer uniquement ce qui va vers le port 53 » ou bien « jette tout ce qui est à destination du port 666 », ou encore « voici une liste des préfixes vraiment importants, les seuls qu'il faudra accepter en cas de DDoS »).
Pour lire le reste du RFC, ne ratez pas la section 2, sur le vocabulaire à utiliser. Notamment, le terme d'ACL est utilisé dans un sens plus général que celui du RFC 8519.
Bon, le protocole, maintenant (section 3). Comme il n'a pas
besoin de fonctionner en permanence, même dans les cas d'attaque,
contrairement au protocole de signalisation, et comme il a par
contre besoin de fiabilité, il va utiliser des technologies
classiques : RESTCONF (RFC 8040) au-dessus de TLS (et donc au-dessus de TCP). RESTCONF
utilise HTTP donc on aura les méthodes classiques,
GET, DELETE, etc. Par
exemple, le client DOTS qui veut récupérer des informations sur la
configuration commence par faire un GET. Les données
sont encodées en JSON (RFC 8259). Elles
sont spécifiées dans un module YANG (RFC 7950) et on passe du modèle YANG à l'encodage
concret en suivant les règles du RFC 7951.
La connexion entre le client DOTS et le serveur peut être
intermittente (on se connecte juste le temps de faire un
GET, par exemple) ou bien permanente, ce qui
est pratique si le client faite des requêtes régulières, ou bien si
le serveur pousse des notifications (section 6.3 du RFC 8040).
Ah, et j'ai parlé de client et de serveur DOTS. Comment est-ce que le client trouve le serveur ? Cela peut être fait manuellement, ou bien via la procédure de découverte du RFC 8973.
Les détails sur ce qu'on peut récupérer en DOTS ? Ils sont dans
la section 4, sous forme d'un module YANG,
nommé ietf-dots-data-channel (désormais dans
le
registre IANA). Par exemple, dans ce module, les ACL permettent d'indiquer les
adresses IP et les protocoles de transport concernés, ainsi que les actions à
entreprendre (laisser passer le paquet, jeter le paquet, etc), comme
avec n'importe quel pare-feu. Le serveur DOTS agit donc
comme un pare-feu distant. Si le serveur l'accepte, on peut aussi
mettre des ACL portant sur les protocoles de la couche 4, par exemple pour filtrer sur
le port.
Bon, passons maintenant à la pratique. Nous allons utiliser le
serveur public de test
dotsserver.ddos-secure.net. Comme le protocole
de données de DOTS repose sur RESTCONF (RFC 8040) qui
repose lui-même sur HTTP, nous allons utiliser curl comme client. Ce serveur public exige
un certificat client, que nous récupérons
en ligne. Ensuite, je crée un alias
pour simplifier les commandes ultérieures :
% alias dotsdata='curl --cacert ./ca-cert.pem --cert ./client-cert.pem --key ./client-key.pem --header "Content-type: application/yang-data+json" --write-out "\n%{http_code}\n"'
Et enregistrons-nous, pour indiquer un identificateur de client DOTS :
% cat register.json
{
"ietf-dots-data-channel:dots-client": [
{
"cuid": "s-bortzmeyer"
}
]
}
% dotsdata --request POST --data @register.json https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/
201
Voilà, l'utilisateur s-bortzmeyer est
enregistré (201 est le code de retour HTTP
Created ; si cet identificateur avait déjà
existé, on aurait récupéré un 409 - Conflict).
Quand on aura fini, on pourra le détruire :
% dotsdata --request DELETE https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/dots-client=MONIDENTIFICATEUR 204
Suivant la logique REST de RESTCONF, l'identité du client figure dans l'URL.
Maintenant, créons un alias pour le préfixe
2001:db8::/32 :
% cat create-alias.json
{
"ietf-dots-data-channel:aliases": {
"alias": [
{
"name": "TEST-ALIAS",
"target-prefix": [
"2001:cafe::/32"
]
}
]
}
}
% dotsdata --request POST --data @create-alias.json https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/dots-client=s-bortzmeyer
{"ietf-restconf:errors":{"error":{"error-type":"application","error-tag":"invalid-value","error-message":"alias: post failed: dots r_alias: TEST-ALIAS: target_prefix \"2001:cafe::/32\" is not supported within Portal ex-portal1 (1.1.1.69,1.1.1.71,1.1.2.0/24,2001:db8:6401::/96)"}}}
400
Aïe, ça a raté (400 = Bad request). C'est parce que, comme nous le dit le message d'erreur, un vrai serveur DOTS n'accepte pas qu'un client joue avec n'importe quelle adresse IP, pour d'évidentes raisons de sécurité. Il faut prouver (par un moyen non spécifié dans le RFC) quels préfixes on contrôle, et ce seront les seuls où on pourra définir des alias et des ACL. Ici, le serveur de test n'autorise que trois préfixes, indiqués dans sa documentation et dans le message d'erreur. Reprenons :
% cat create-alias.json
{
"ietf-dots-data-channel:aliases": {
"alias": [
{
"name": "TEST-ALIAS",
"target-prefix": [
"2001:db8:6401::f00/128"
]
}
]
}
}
% dotsdata --request POST --data @create-alias.json https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/dots-client=s-bortzmeyer
201
Ouf, c'est bon, vérifions que l'alias a bien été créé :
% dotsdata --request GET --data @create-alias.json https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/dots-client=s-bortzmeyer/aliases
{"ietf-dots-data-channel:aliases":{"alias":[{"name":"TEST-ALIAS","pending-lifetime":10078,"target-prefix":["2001:db8:6401::f00/128"]}]}}
200
C'est parfait, on va essayer de demander du filtrage, maintenant. D'abord, les capacités du serveur dans ce domaine :
% dotsdata --request GET --data @create-alias.json https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/capabilities | jq .
...
"ipv6": {
"length": true,
"protocol": true,
"destination-prefix": true,
"source-prefix": true,
"fragment": true
},
"tcp": {
"flags": true,
"flags-bitmask": true,
"source-port": true,
"destination-port": true,
"port-range": true
},
Bien, le serveur sait filtrer sur la longueur des paquets, sur les
adresses IP source et destination, et il sait traiter spécifiquement
les fragments. Et il sait filtrer le TCP sur divers critères, comme
les ports source et destination. On va lui demander de filtrer tout
ce qui vient de 2001:db8:dead::/48 :
% cat install-acl.json
{
"ietf-dots-data-channel:acls": {
"acl": [
{
"name": "TEST-ACL",
"type": "ipv6-acl-type",
"activation-type": "activate-when-mitigating",
"aces": {
"ace": [
{
"name": "TEST-RULE",
"matches": {
"ipv6": {
"source-ipv6-network": "2001:db8:dead::/48"
}
},
"actions": {
"forwarding": "drop"
}
}
]
}
}
]
}
}
% dotsdata --request POST --data @install-acl.json https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/dots-client=s-bortzmeyer
201
Parfait, le serveur a accepté notre ACL. Le paramètre
activation-type indiquait de ne pas filtrer
tout de suite mais seulement lorsqu'une atténuation serait activée
(activate-when-mitigating). Vous avez vu les
fonctions les plus importantes du protocole de données de DOTS. En
cas d'attaque, il ne vous reste plus qu'à utiliser le protocole de
signalisation (RFC 9132) pour utiliser alias
et ACLs.
Quelques considérations de sécurité, maintenant, en section 10 du RFC. La sécurité est évidemment cruciale pour DOTS puisque, si on l'utilise, c'est qu'on a des ennemis et qu'ils nous attaquent. Les préfixes IP qu'on veut protéger ou au contraire qu'on veut filtrer sont par exemple une information confidentielle (elle pourrait aider l'attaquant). Le RFC impose donc la cryptographie pour protéger les communications, en utilisant TLS, et avec chiffrement intègre. Même avec TLS et ce chiffrement intègre, comme la couche transport n'est pas protégée, un attaquant actif pourrait perturber la communication, par exemple en injectant des paquets TCP RST (qui coupent la connexion). Il existe un mécanisme de protection, AO, normalisé dans le RFC 5925, mais il est très peu déployé en pratique.
La cryptographie ne protège pas contre un client DOTS malveillant, ou simplement mal configuré. Le serveur doit donc vérifier que le client a le droit de protéger tel ou tel préfixe IP. Autrement, un client DOTS pourrait demander le filtrage du préfixe d'un de ses ennemis. Le RFC ne spécifie pas quel mécanisme utiliser pour cette vérification, mais cela peut être, par exemple, l'utilisation des registres des RIR, qui indiquent qui est le titulaire légitime d'un préfixe.
Le protocole de ce RFC peut utiliser des noms de domaine pour configurer les ACL. Dans ce cas, le serveur doit veiller à sécuriser la résolution DNS, à la fois contre des manipulations, grâce à DNSSEC, et contre la surveillance, en utilisant du DNS chiffré comme dans le RFC 7858.
Pour les mises en œuvre de ce protocole, voyez mon article sur le RFC 9132. Mais le protocole de notre RFC étant fondé sur HTTPS, on peut dans une certaine mesure utiliser des outils existants comme, vous l'avez vu, curl.
L'article seul
RFC 8782: Distributed Denial-of-Service Open Threat Signaling (DOTS) Signal Channel Specification
Date de publication du RFC : Mai 2020
Auteur(s) du RFC : T. Reddy (McAfee), M. Boucadair (Orange), P. Patil (Cisco), A. Mortensen (Arbor Networks), N. Teague (Iron Mountain Data Centers)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 31 mai 2020
Le protocole DOTS (Distributed Denial-of-Service Open Threat Signaling) vise à permettre au client d'un service anti-dDoS de demander au service de mettre en route des mesures contre une attaque. Ce RFC décrit le canal de signalisation de DOTS, celui par lequel passera la demande d'atténuation de l'attaque. Suite à un petit problème YANG, ce RFC a été remplacé depuis par le RFC 9132.
Si vous voulez mieux comprendre DOTS, il est recommandé de lire le RFC 8612, qui décrit le cahier des charges de ce protocole, et le RFC 8811, qui décrit l'architecture générale. Ici, je vais résumer à l'extrême : un client DOTS, détectant qu'une attaque par déni de service est en cours contre lui, signale, par le canal normalisé dans ce RFC, à un serveur DOTS qu'il faudrait faire quelque chose. Le serveur DOTS est un service anti-dDoS qui va, par exemple, examiner le trafic, jeter ce qui appartient à l'attaque, et transmettre le reste à son client.
Ces attaques par déni de service sont une des plaies de l'Internet, et sont bien trop fréquentes aujourd'hui (cf. RFC 4987 ou RFC 4732 pour des exemples). Bien des réseaux n'ont pas les moyens de se défendre seuls et font donc appel à un service de protection (payant, en général, mais il existe aussi des services comme Deflect). Ce service fera la guerre à leur place, recevant le trafic (via des manips DNS ou BGP), l'analysant, le filtrant et envoyant ce qui reste au client. Typiquement, le client DOTS sera chez le réseau attaqué, par exemple en tant que composant d'un IDS ou d'un pare-feu, et le serveur DOTS sera chez le service de protection. Notez donc que client et serveur DOTS sont chez deux organisations différentes, communiquant via le canal de signalisation (signal channel), qui fait l'objet de ce RFC.
La section 3 de notre RFC expose les grands principes du
protocole utilisé sur ce canal de signalisation. Il repose sur
CoAP, un équivalent léger de HTTP, ayant beaucoup
de choses communes avec HTTP. Le choix d'un protocole différent de
HTTP s'explique par les spécificités de DOTS : on l'utilise quand ça
va mal, quand le réseau est attaqué, et il faut donc pouvoir
continuer à fonctionner même quand de nombreux paquets sont
perdus. CoAP a les caractéristiques utiles pour DOTS, il est conçu
pour des réseaux où il y aura des pertes, il tourne sur UDP, il permet des
messages avec ou sans accusé de réception, il utilise peu de
ressources, il peut être sécurisé par DTLS… TCP est également
utilisable mais UDP est préféré, pour éviter le
head-of-line
blocking. CoAP est normalisé dans le RFC 7252. Parmi les choses à retenir, n'oubliez pas
que l'encodage du chemin dans l'URI est un peu spécial, avec une option
Uri-Path: par segment du chemin (RFC 7252, section 5.10.1). Par abus de langage,
j'écrirai « le client CoAP demande
/foo/bar/truc.cbor » alors qu'il y aura en fait
trois options Uri-Path: :
Uri-Path: "foo" Uri-Path: "bar" Uri-Path: "truc.cbor"
Par défaut, DOTS va utiliser le port 4646 (et non pas le port par
défaut de CoAP, 5684, pour éviter toute confusion avec d'autres
services tournant sur CoAP). Ce port a été choisi pour une bonne
raison, je vous laisse la chercher, la solution est à la fin de cet
article. Le plan d'URI sera coaps ou
coaps+tcp (RFC 7252,
section 6, et RFC 8323, section 8.2).
Le fonctionnement de base est simple : le client DOTS se connecte au serveur, divers paramètres sont négociés. Des battements de cœur peuvent être utilisés (par le client ou par le serveur) pour garder la session ouverte et vérifier son bon fonctionnement. En cas d'attaque, le client va demander une action d'atténuation. Pendant que celle-ci est active, le serveur envoie de temps en temps des messages donnant des nouvelles. L'action se terminera, soit à l'expiration d'un délai défini au début, soit sur demande explicite du client. Le serveur est connu du client par configuration manuelle, ou bien par des techniques de découverte comme celles du RFC 8973.
Les messages sont encodés en CBOR (RFC 8949). Rappelez-vous que le modèle de données
de CBOR est très proche de celui de JSON, et notre RFC spécifie donc les
messages avec une syntaxe JSON, même si ce n'est pas l'encodage
utilisé sur le câble. Pour une syntaxe formelle des messages, le RFC
utilise YANG (cf. RFC 7951). Le type MIME des messages
est application/dots+cbor.
La section 4 du RFC décrit les différents messages possibles plus
en détail. Je ne vais pas tout reprendre ici, juste donner quelques
exemples. Les URI commencent toujours par
/.well-known/dots
(.well-known est normalisé dans le RFC 8615, et dots est
désormais enregistré
à l'IANA). Les différentes actions ajouteront au chemin dans
l'URI /mitigate pour les demandes d'actions
d'atténuation, visant à protéger de l'attaque,
/hb pour les battements de cœur, etc.
Voici par exemple une demande de protection, effectuée avec la méthode CoAP PUT :
Header: PUT (Code=0.03)
Uri-Path: ".well-known"
Uri-Path: "dots"
Uri-Path: "mitigate"
Uri-Path: "cuid=dz6pHjaADkaFTbjr0JGBpw"
Uri-Path: "mid=123"
Content-Format: "application/dots+cbor"
{
... Données en CBOR (représentées en JSON dans le RFC et dans
cet article, pour la lisibilité).
}
L'URI, en notation traditionnelle, sera donc
/.well-known/dots/mitigate/cuid=dz6pHjaADkaFTbjr0JGBpw/mid=123. CUID
veut dire Client Unique IDentifier et sert à
identifier le client DOTS, MID est Mitigation
IDentifier et identifie une demande d'atténuation
particulière. Si ce client DOTS fait une autre demande de
palliation, le MID changera mais le CUID sera le même.
Que met-on dans le corps du message ? On a de nombreux champs définis pour indiquer ce qu'on veut protéger, et pour combien de temps. Par exemple, on pourrait avoir (je rappelle que c'est du CBOR, format binaire, en vrai) :
{
"ietf-dots-signal-channel:mitigation-scope": {
"scope": [
{
"target-prefix": [
"2001:db8:6401::1/128",
"2001:db8:6401::2/128"
],
"target-port-range": [
{
"lower-port": 80
},
{
"lower-port": 443
}
],
"target-protocol": [
6
],
"lifetime": 3600
}
]
}
}
Ici, le client demande qu'on protège
2001:db8:6401::1 et
2001:db8:6401::2 (target
veut dire qu'ils sont la cible d'une attaque, pas qu'on veut les
prendre pour cible), sur
les ports 80 et 443,
en TCP, pendant une heure. (lower-port seul,
sans upper-port indique un port unique, pas un
intervalle.)
Le serveur va alors répondre avec le code 2.01 (indiquant que la requête est acceptée et traitée) et des données :
{
"ietf-dots-signal-channel:mitigation-scope": {
"scope": [
{
"mid": 123,
"lifetime": 3600
}
]
}
}
La durée de l'action peut être plus petite que ce que le client a demandé, par exemple si le serveur n'accepte pas d'actions trop longues. Évidemment, si la requête n'est pas correcte, le serveur répondra 4.00 (format invalide), si le client n'a pas payé, 4.03, s'il y a un conflit avec une autre requête, 4.09, etc. Le serveur peut donner des détails, et la liste des réponses possibles figure dans des registres IANA, comme celui de l'état d'une atténuation, ou celui des conflits entre ce qui est demandé et d'autres actions en cours.
Le client DOTS peut ensuite récupérer des informations sur une action de palliation en cours, avec la méthode CoAP GET :
Header: GET (Code=0.01) Uri-Path: ".well-known" Uri-Path: "dots" Uri-Path: "mitigate" Uri-Path: "cuid=dz6pHjaADkaFTbjr0JGBpw" Uri-Path: "mid=123"
Ce GET
/.well-known/dots/mitigate/cuid=dz6pHjaADkaFTbjr0JGBpw/mid=123
va renvoyer de l'information sur l'action d'identificateur (MID)
123 :
{
"ietf-dots-signal-channel:mitigation-scope": {
"scope": [
{
"mid": 123,
"mitigation-start": "1507818393",
"target-prefix": [
"2001:db8:6401::1/128",
"2001:db8:6401::2/128"
],
"target-protocol": [
6
],
"lifetime": 1755,
"status": "attack-stopped",
"bytes-dropped": "0",
"bps-dropped": "0",
"pkts-dropped": "0",
"pps-dropped": "0"
}
]
}
}
Les différents champs de la réponse sont assez évidents. Par
exemple, pkts-dropped indique le nombre de
paquets qui ont été jetés par le protecteur.
Pour mettre fin aux actions du système de protection, le client utilise évidemment la méthode CoAP DELETE :
Header: DELETE (Code=0.04) Uri-Path: ".well-known" Uri-Path: "dots" Uri-Path: "mitigate" Uri-Path: "cuid=dz6pHjaADkaFTbjr0JGBpw" Uri-Path: "mid=123"
Le client DOTS peut se renseigner sur les capacités du serveur avec
un GET de /.well-known/dots/config.
Ce RFC décrit le canal de signalisation de DOTS. Le RFC 8783, lui, décrit le canal de données. Le canal de signalisation est prévu pour faire passer des messages de petite taille, dans un environnement hostile (attaque en cours). Le canal de données est prévu pour des données de plus grande taille, dans un environnement où les mécanismes de transport normaux, comme HTTPS, sont utilisables. Typiquement, le client DOTS utilise le canal de données avant l'attaque, pour tout configurer, et le canal de signalisation pendant l'attaque, pour déclencher et arrêter l'atténuation.
Les messages possibles sont modélisés en YANG. YANG est normalisé dans le RFC 7950. Notez que YANG avait été initialement créé pour décrire les commandes envoyées par NETCONF (RFC 6241) ou RESTCONF (RFC 8040) mais ce n'est pas le cas ici : DOTS n'utilise ni NETCONF, ni RESTCONF mais son propre protocole basé sur CoAP. La section 5 du RFC contient tous les modules YANG utilisés.
La mise en correspondance des modules YANG avec l'encodage
CBOR figure dans la section 6. (YANG permet
une description abstraite d'un message mais ne dit pas, à lui tout
seul, comment le représenter en bits sur le réseau.) Les clés CBOR
sont toutes des entiers ; CBOR permet d'utiliser des chaînes de
caractères comme clés mais DOTS cherche à gagner de la place. Ainsi,
les tables de la section 6 nous apprennent que le champ
cuid (Client Unique
IDentifier) a la clé 4, suivie d'une chaîne de caractères
en CBOR. (Cette correspondance est désormais un
registre IANA.) D'autre part, DOTS introduit une étiquette
CBOR, 271 (enregistrée
à l'IANA, cf. RFC 8949, section 3.4)
pour marquer un document CBOR comme lié au protocole DOTS.
Évidemment, DOTS est critique en matière de sécurité. S'il ne fonctionne pas, on ne pourra pas réclamer une action de la part du service de protection. Et s'il est mal authentifié, on risque de voir le méchant envoyer de faux messages DOTS, par exemple en demandant l'arrêt de l'atténuation. La section 8 du RFC rappelle donc l'importance de sécuriser DOTS par TLS ou plutôt, la plupart du temps, par son équivalent pour UDP, DTLS (RFC 9147). Le RFC insiste sur l'authentification mutuelle du serveur et du client, chacun doit s'assurer de l'identité de l'autre, par les méthodes TLS habituelles (typiquement via un certificat). Le profil de DTLS recommandé (TLS est riche en options et il faut spécifier lesquelles sont nécessaires et lesquelles sont déconseillées) est en section 7. Par exemple, le chiffrement intègre est nécessaire.
La section 10 revient sur les questions de sécurité en ajoutant
d'autres avertissements. Par exemple, TLS ne protège pas contre
certaines attaques par déni de service, comme un paquet TCP RST
(ReSeT). On peut sécuriser la communication avec
TCP-AO (RFC 5925) mais c'est un vœu pieux, il
est très peu déployé à l'heure actuelle. Ah, et puis si les
ressources à protéger sont identifiées par un nom de domaine, et pas une adresse ou un
préfixe IP (target-fqdn au lieu de
target-prefix), le RFC dit qu'évidemment la
résolution doit être faite avec DNSSEC.
Question mises en œuvre, DOTS dispose d'au moins quatre implémentations, dont l'interopérabilité a été testée plusieurs fois lors de hackathons IETF (la première fois ayant été à Singapour, lors de l'IETF 100) :
Notez qu'il existe des serveurs de test DOTS
publics comme
coaps://dotsserver.ddos-secure.net:4646.
Ah, et la raison du choix du port 4646 ? C'est parce que 46 est le code ASCII pour le point (dot en anglais) donc deux 46 font deux points donc dots.
L'article seul
RFC 8781: Discovering PREF64 in Router Advertisements
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : L. Colitti, J. Linkova (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 25 avril 2020
Lors qu'on utilise le système NAT64, pour permettre à des machines situées sur un réseau purement IPv6 de parler avec des machines restées en seulement IPv4, il faut utiliser un résolveur DNS spécial ou bien connaitre le préfixe utilisé pour la synthèse des adresses IPv6. Ce nouveau RFC décrit une option RA (Router Advertisement) pour informer les machines du préfixe en question.
NAT64 est normalisé dans le RFC 6146 et son copain DNS64 dans le RFC 6147. Il permet à des machines situées dans un
réseau n'ayant qu'IPv6 de parler à des
machines restées uniquement sur le protocole du siècle dernier,
IPv4. Le principe est que, pour parler à la
machine d'adresse 192.0.2.1, la machine
purement IPv6 va écrire à 64:ff9b::192.0.2.1
(soit 64:ff9b::c000:201.) C'est le routeur
NAT64 qui changera ensuite le paquet IPv6 allant vers
64:ff9b::192.0.2.1 en un paquet IPv4 allant
vers 192.0.2.1. NAT64 est, par exemple,
largement utilisé dans les grandes réunions internationales comme
l'IETF
ou le FOSDEM, où le réseau WiFi par
défaut est souvent purement IPv6. Mais pour que la machine émettrice
pense à écrire à 64:ff9b::192.0.2.1, il faut
qu'elle connaisse le préfixe à mettre devant les adresses IPv4
(64:ff9b::/96 n'est que le préfixe par défaut.)
La solution la plus courante, DNS64, est que le résolveur DNS mente, en fabriquant des
adresses IPv6 pour les machines n'en ayant pas, dispensant ainsi les
machines du réseau local IPv6 de tout effort. Mais si l'émetteur
veut faire sa résolution DNS lui-même, ou bien utiliser un autre
résolveur, qui ne fabrique pas les adresses v6 ? Une alternative est
donc que cet émetteur fasse lui-même la synthèse. Pour cela, il faut
lui fournir le préfixe IPv6 du routeur NAT64.
Cela résoudra le problème de la machine qui ne veut pas utiliser le résolveur DNS64 :
- Car elle veut faire la validation DNSSEC toute seule comme une grande,
- ou car elle veut se servir d'un résolveur extérieur, accessible via DoT (RFC 7858) ou DoH (RFC 8484),
- ou bien que l'administrateur du réseau local ne fournit tout simplement pas de résolveur DNS64,
- ou encore car elle veut pouvoir utiliser des adresses IPv4
littérales, par exemple parce qu'on lui a passé
l'URL
http://192.0.2.13/, dans lequel il n'y a pas de nom à résoudre, - ou enfin parce qu'elle utilise 464XLAT (RFC 6877) pour lequel la connaissance du préfixe IPv6 est nécessaire.
Pourquoi envoyer cette information avec les RA (Router Advertisements) du RFC 4861 plutôt que par un autre mécanisme ? La section 3 du RFC explique que c'est pour être sûr que le sort est partagé ; si le routeur qui émet les RA tombe en panne, on ne recevra plus l'information, ce qui est cohérent, alors qu'avec un protocole séparé (par exemple le PCP du RFC 7225), on risquait de continuer à annoncer un préfixe NAT64 désormais inutilisable. En outre, cela diminue le nombre de paquets à envoyer (l'information sur le préfixe NAT64 peut être une option d'un paquet RA qu'on aurait envoyé de toute façon.) Et, en cas de changement du préfixe, le protocole du RFC 4861 permet de mettre à jour toutes les machines facilement, en envoyant un RA non sollicité.
Enfin, l'utilisation des RA simplifie le déploiement, puisque toute machine IPv6 sait déjà traiter les RA.
L'option elle-même est spécifiée dans la section 4 du RFC. Outre les classiques champs Type (valeur 38) et Longueur (16 octets), elle comporte une indication de la durée de validité du préfixe, un code qui indique la longueur du préfixe (le mécanisme classique préfixe/longueur n'est pas utilisé, car toutes les longueurs ne sont pas acceptables), et le préfixe lui-même.
La section 5 explique comment les machines doivent utiliser cette option. Elle s'applique à tous les préfixes IPv4 connus. Si on veut router certains préfixes IPv4 vers un routeur NAT64 et d'autres préfixes vers un autre routeur, il faut quand même que les adresses IPv6 soient dans le même préfixe, et router ensuite sur les sous-préfixes de ce préfixe. Un autre problème découlant de ce choix d'avoir un préfixe IPv6 unique pour tout est celui des préfixes IPv4 qu'on ne veut pas traduire, par exemple des préfixes IPv4 purement internes. Il n'y a pas à l'heure actuelle de solution. De toute façon, l'option décrite dans notre RFC est surtout conçu pour des réseaux purement IPv6, et qui n'auront donc pas ce problème.
Attention, le préfixe IPv6 reçu est spécifique à une interface réseau. La machine réceptrice devrait donc le limiter à cette interface. Si elle a plusieurs interfaces (pensez par exemple à un ordiphone avec WiFi et 4G), elle peut recevoir plusieurs préfixes pour le NAT64, chacun ne devant être utilisé que sur l'interface où il a été reçu (cf. RFC 7556.)
Un petit mot sur la sécurité pour terminer. Comme toutes les annonces RA, celle du préfixe NAT64 peut être mensongère (cf. le RFC 6104 au sujet de ces « RAcailles ».) La solution est la même qu'avec les autres options RA, utiliser des techniques « RA guard » (RFC 6105.)
À noter qu'une annonce mensongère d'un préfixe IPv6 prévue pour le NAT64 affectera évidemment les adresses IPv4 qu'on tente de joindre (parfois au point de les rendre injoignables) mais pas les adresses IPv6, qui ne sont pas traduites et donc non touchées par cet éventuel RA tricheur. Comme une machine qui arrive à émettre et à faire accepter des RAcailles peut déjà facilement réaliser un déni de service, on voit que l'option de ce nouveau RFC n'aggrave pas les choses, en pratique.
Le RFC conclut que la procédure de validation des préfixes de la section 3.1 du RFC 7050 n'est pas nécessaire, si on a ce RA Guard.
À l'heure actuelle, il ne semble pas que cette option soit souvent mise en œuvre, que ce soit dans les émetteurs ou dans les récepteurs. Mais Wireshark sait déjà le décoder.
L'article seul
RFC 8773: TLS 1.3 Extension for Certificate-Based Authentication with an External Pre-Shared Key
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : R. Housley (Vigil Security)
Expérimental
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 31 mars 2020
L'authentification dans TLS se fait typiquement, soit à partir d'un certificat, soit par une clé partagée à l'avance. Ce nouveau RFC spécifie une extension de TLS qui permet d'utiliser ces deux méthodes en même temps.
Rappelons d'abord qu'il y a deux sortes de clés partagées à l'avance (PSK, pour Pre-Shared Key) : celles qui ont été négociées dans une session précédentes (resumption PSK) et celles qui ont été négociées par un mécanisme extérieur (envoi par pigeon voyageur sécurisé…), les external PSK. Ce RFC ne concerne que les secondes. Les certificats et les clés partagées à l'avance ont des avantages et des inconvénients. Les certificats ne nécessitent pas d'arrangement préalable entre client et serveur, ce qui est pratique. Mais il faut se procurer un certificat auprès d'une AC. Et les certificats, comme ils reposent sur des algorithmes comme RSA ou ECDSA, sont vulnérables aux progrès de la cryptanalyse, par exemple en utilisant un (futur) ordinateur quantique. Utiliser une clé partagée à l'avance n'est pas forcément commode (par exemple quand on veut la changer) mais cela peut être plus sûr. Or, la norme TLS actuelle (RFC 8446) ne permet d'utiliser qu'une seule des deux méthodes d'authentification. Si on les combinait ? L'ajout d'une clé externe permettrait de rendre l'authentification plus solide.
Le principe est simple : notre RFC spécifie une extension à TLS,
tls_cert_with_extern_psk (valeur
33.) Le client TLS l'envoie dans son
ClientHello. Elle indique la volonté de
combiner certificat et PSK. Elle est accompagnée d'extensions
indiquant quelle est la clé partagée à utiliser. Si le serveur TLS
est d'accord, il met l'extension
tls_cert_with_extern_psk dans son message
ServerHello. (Le serveur ne peut pas décider
seul de l'utilisation de cette extension, il faut que le client ait
demandé d'abord.)
Les clés ont une identité, une série d'octets sur lesquels client
et serveur se sont mis d'accord avant (PSK = Pre-Shared
Key, clé partagée à l'avance.) C'est cette identité qui
est envoyée dans l'extension pre_shared_key, qui
accompagne tls_cert_with_extern_psk. La clé
elle-même est bien sûr un secret, connu seulement du client et du
serveur (et bien protégée : ne la mettez pas sur un fichier lisible
par tous.) Voyez la section 7 du RFC pour une discussion plus
détaillée de la gestion de la PSK.
Une fois que client et serveur sont d'accord pour utiliser l'extension, et ont bien une clé en commun, l'authentification se fait via le certificat (sections 4.4.2 et 4.4.3 du RFC 8446) et en utilisant ensuite, non pas seulement la clé générée (typiquement par Diffie-Hellman), mais la combinaison de la clé générée et de la PSK. L'entropie de la PSK s'ajoute donc à celle de la clé générée de manière traditionnelle.
Du point de vue de la sécurité, on note donc que cette technique de la PSK est un strict ajout à l'authentification actuelle, donc on peut garantir que son utilisation ne diminuera pas la sécurité.
Il n'y a apparemment pas encore de mise en œuvre de cette extension dans une bibliothèque TLS.
Notez qu'il s'agit apparemment du premier RFC à mentionner explicitement les calculateurs quantiques, et les risques qu'ils posent pour la cryptographie.
L'article seul
RFC 8770: Host Router Support for OSPFv2
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : K. Patel (Arrcus), P. Pillay-Esnault
(PPE
Consulting), M. Bhardwaj, S. Bayraktar
(Cisco)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ospf
Première rédaction de cet article le 13 avril 2020
Le protocole de routage OSPF, dans sa version 2, a une particularité amusante : dès qu'une machine participe au protocole, et échange des messages avec les autres, elle va être considérée comme un routeur, à qui on peut envoyer du trafic à faire suivre. Or, on peut souhaiter observer le routage sans être soi-même routeur. D'où ce RFC, qui prévoit un moyen de mettre dans les messages : « je suis juste un observateur, ne m'envoie pas de paquets à router ».
Dans quels cas trouve-t-on ces machines qui participent à un protocole de routage mais ne veulent pas transmettre les paquets des autres ? La section 1 du RFC cite plusieurs cas, dont :
- Un routeur en train de redémarrer et qui n'est pas encore prêt à transmettre des paquets,
- Un routeur surchargé de travail et qui souhaite demander qu'on arrête de l'utiliser (mais qui a besoin de continuer à connaitre les routes existantes),
- Des réflecteurs de route.
La solution proposée dans ce RFC est d'ajouter aux messages OSPF un bit, le bit H (Host bit). Lors du calcul des routes avec SPF (section 16.1 du RFC 2328, qui normalise OSPF version 2), les routeurs ayant le bit H seront exclus. Ce bit utilise un des bits inutilisés du LSA (Link State Advertisement) de routeur (RFC 2328, section A.4.2), et il est enregistré à l'IANA.
Difficulté classique quand on modifie un protocole, surtout ancien et très répandu, comme OSPF, la cohabitation entre anciens et récents logiciels. Que se passe-t-il si un réseau mêle des routeurs qui envoient le bit H et d'autres qui ne connaissent pas ce bit ? La section 5 explique la solution : en utilisant les extensions du RFC 7770, un LSA Router Information est envoyé, indiquant qu'on sait gérer le bit H (capacité Host Router, cf. le registre IANA.) Les routeurs connaissant notre RFC ne tiendront compte du bit H que si tous les routeurs de la zone OSPF ont annoncé cette capacité.
L'article seul
RFC 8767: Serving Stale Data to Improve DNS Resiliency
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : D. Lawrence (Oracle), W. Kumari (Google),
P. Sood (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 1 avril 2020
Ce nouveau RFC autorise les résolveurs DNS à servir des « vieilles » informations aux clients (« vieilles » parce que le TTL est dépassé), si et seulement si les serveurs faisant autorité ne sont pas joignables (par exemple parce qu'ils sont victimes d'une attaque par déni de service.) Cela devrait rendre le DNS plus robuste en cas de problèmes. Le principe est donc désormais « mieux vaut du pain rassis que pas de pain du tout ».
Normalement, avant ce RFC, le DNS fonctionne ainsi : le client interroge un résolveur. Ce résolveur :
- Soit possède l'information dans sa mémoire (dans son cache), et le TTL de cette information, TTL originellement choisi par le serveur faisant autorité, n'est pas encore dépassé ; le résolveur peut alors renvoyer cette information au client.
- Soit n'a pas l'information (ou bien le TTL est dépassé) et le résolveur doit alors demander aux serveurs faisant autorité, avant de transmettre le résultat au client.
C'est ce que décrit le RFC 1035, notamment sa section 3.2.1. Ici, faite avec dig, une interrogation DNS, les données étant déjà dans le cache (la mémoire), ce qui se voit au TTL qui n'est pas un chiffre rond :
% dig NS assemblee-nationale.fr ... ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 57234 ;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: assemblee-nationale.fr. 292 IN NS ns2.fr.claradns.net. assemblee-nationale.fr. 292 IN NS ns1.fr.claradns.net. assemblee-nationale.fr. 292 IN NS ns0.fr.claradns.net. ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Thu Feb 20 11:09:57 CET 2020 ;; MSG SIZE rcvd: 120
Mais que se passe-t-il si le résolveur a des données, que le
TTL est expiré, mais que
les serveurs faisant autorité sont en panne (cas d'autant plus
fréquent que beaucoup de domaines ont trop peu de serveurs, et qu'il
y a souvent des SPOF), injoignables (par exemple suite à un
problème de routage) ou bien victimes d'une
DoS, comme
cela arrive trop souvent ? Dans ce cas, le résolveur ne peut pas
vérifier que les données sont à jour (alors que ce sera souvent le
cas) et doit renvoyer une réponse SERVFAIL (Server
Failure) qui empêchera le client d'avoir les informations
qu'il demande. Dommage : après tout, peut-être que le client voulait
se connecter au serveur imap.example.net qui,
lui, marchait, même si les serveurs DNS faisant autorité pour
example.net étaient en panne. C'est l'une des
motivations pour cette idées des données rassises. Comme le note
Tony Finch, cela rendra plus facile le débogage des problèmes
réseau. Au lieu d'un problème DNS mystérieux, qui masque le problème
sous-jacent, les opérateurs verront bien mieux ce qui se
passe. (Quasiment toutes les opérations sur l'Internet commencent
par une requête DNS, et les problèmes réseau sont donc souvent
perçus comme des problèmes DNS, même si ce n'est pas le cas.)
De tels problèmes sont relativement fréquents, et le RFC et moi vous recommandons l'excellent article « When the Dike Breaks: Dissecting DNS Defenses During DDoS ».
C'est pour cela que notre RFC prévoit, dans des cas exceptionnels, d'autoriser le résolveur à outrepasser le TTL et à renvoyer des données « rassises ». En temps normal, rien ne change au fonctionnement du DNS mais, si les circonstances l'exigent, le client recevra des réponses, certes peut-être dépassées, mais qui seront mieux que rien. Le compromis habituel entre fraîcheur et robustesse est donc déplacé un peu en faveur de la robustesse.
Bref, depuis la sortie de notre RFC, un résolveur est autorisé à servir des données rassises, si les serveurs faisant autorité ne répondent pas, ou bien s'ils répondent SERVFAIL (Server Failure.) Il doit dans ce cas (section 4 du RFC) mettre un TTL strictement positif, la valeur 30 (secondes) étant recommandée, pour éviter que ses clients ne le harcèlent, et aussi parce qu'un TTL de zéro (ne pas mémoriser du tout) est parfois mal compris par certains clients DNS bogués (cf. section 6).
La section 5 donne un exemple de comment cela peut être mis en œuvre. Elle suggère d'utiliser quatre délais :
- Le temps maximal pendant lequel faire patienter le client, 1,8 secondes étant la durée recommandée (par défaut, dig patiente 5 secondes, ce qui est très long),
- Le temps maximal pour avoir une réponse, typiquement entre 10 et 30 secondes (le résolveur va donc continuer à chercher une réponse, même s'il a déjà répondu au client car le précédent temps maximal était dépassé),
- L'intervalle entre deux essais quand on n'a pas réussi à obtenir une réponse, 30 secondes est le minimum recommandé, pour éviter de rajouter à une éventuelle DDoS en demandant sans cesse aux serveurs faisant autorité,
- L'âge maximal des données rassises, avant qu'on décide qu'elles sont vraiment trop vieilles. Le RFC suggère de mettre entre 1 et 3 journées.
Si le résolveur n'a pas eu de réponse avant que le temps maximal pendant lequel faire patienter le client soit écoulé, il cherche dans sa mémoire s'il n'a pas des données rassises et, si oui, il les envoie au client. (C'est la nouveauté de ce RFC.)
La section 6 donne quelques autres conseils pratiques. Par exemple, quel âge maximal des données rassises choisir ? Une durée trop courte diminuera l'intérêt de ce RFC, une durée trop longue augmentera la consommation mémoire du résolveur. Une demi-journée permet d'encaisser la grande majorité des attaques par déni de service. Une semaine permet d'être raisonnablement sûr qu'on a eu le temps de trouver les personnes responsables (c'est souvent beaucoup plus dur qu'on ne le croit !) et qu'elles résolvent le problème. D'où la recommandation du RFC, entre 1 et 3 jours.
Pour la consommation de mémoire, il faut aussi noter que, si la limite du résolveur a été atteinte, on peut prioriser les données rassises lorsqu'on fait de la place, et les sacrifier en premier. On peut aussi tenir compte de la « popularité » des noms, en supprimant en premier les noms les moins demandés. Attention, un tel choix pourrait pousser certains à faire des requêtes en boucle pour les noms qu'ils trouvent importants, de manière à les faire considérer comme populaires.
Beaucoup de résolveurs ont deux mémoires séparées, une pour les
données demandées par les clients, et une pour les données obtenues
lors du processus de résolution lui-même. Ainsi, lorsqu'un client
demande le MX de
foobar.example, et que les serveurs faisant
autorité pour foobar.example seront
ns0.op.example et
ns1.op.example, le résolveur devra à un moment
découvrir l'adresse IP de ns0 et
ns1.op.example (une « requête tertiaire », pour
reprendre la terminologie du RFC 7626.) Cette
adresse IP sera mémorisée, mais pas dans la même mémoire que le MX
de foobar.example, car ces données n'ont pas
forcément le même niveau de confiance (il peut s'agir de colles, par
exemple, et pas de données issues d'un serveur faisant autorité). Le
RFC autorise également à utiliser des données rassises pour cette
seconde mémoire, donc pour la cuisine interne du processus de
résolution. Ainsi, si un TLD est injoignable (comme c'était arrivé au
.tr en décembre
2015, suite à une attaque par déni de service), les serveurs
de noms sous ce TLD resteront peut-être utilisables, pour des
nouvelles requêtes.
Notez que le client du résolveur n'a aucun moyen de dire s'il accepte des données rassises, ou bien s'il veut uniquement du frais. Il avait été discuté à l'IETF une option EDNS permettant au client de signaler son acceptation de vieilles données, mais cette option n'a pas été retenue (section 9), le but étant de fournir une technique qui marche avec les clients actuels, afin de renforcer la robustesse du DNS dès maintenant. Ce point est sans doute celui qui avait suscité les plus chaudes discussions.
La section 10 discute de quelques problèmes de sécurité liés au fait de servir des données rassises. Par exemple, une attaque existante contre le DNS est celle des « domaines fantômes » où un attaquant continue à utiliser un domaine supprimé (par exemple parce qu'il servait à distribuer du logiciel malveillant) en comptant sur les mémoires des résolveurs. (Voir à ce sujet l'artricle « Cloud Strife: Mitigating the Security Risks of Domain-Validated Certificates ».) Le fait de servir des données rassises pourrait rendre l'attaque un peu plus facile, mais pas plus : après tout, la réponse NXDOMAIN (ce domaine n'existe pas) de la zone parente supprime toutes les entrées de ce domaine dans la mémoire. D'autre part, un attaquant pourrait mettre hors d'état de service les serveurs faisant autorité pour une zone afin de forcer l'utilisation de données anciennes. Ceci dit, sans ce RFC, un attaquant ayant ce pouvoir peut faire des dégâts plus graves, en bloquant tout service.
À noter que notre RFC change également les normes précédentes sur un autre point, l'interprétation des TTL lorsque le bit de plus fort poids est à un (section 4). Le RFC 2181 disait (dans sa section 8) « Implementations should treat TTL values received with the most significant bit set as if the entire value received was zero. ». C'était pour éviter les problèmes d'ambiguité entre entiers signés et non signés. Le RFC 8767 change cette règle dit désormais clairement que le TTL est un entier non signé et que ces valeurs avec le bit de plus fort poids à un sont des valeurs positives. Il ajoute qu'elles sont tellement grandes (plus de 68 ans…) qu'elles n'ont pas d'intérêt pratique et doivent donc être tronquées (un TTL de plus d'une semaine n'a pas de sens et les résolveurs sont donc invités à imposer cette limite). Donc, en pratique, cela ne change rien.
Questions mises en œuvre, de nombreux résolveurs offrent un moyen de servir les données anciennes. L'idée est loin d'être nouvelle, elle existait avant le RFC, et était largement acceptée, quoique violant la norme technique. Bref, les données rassises existent déjà un peu partout. Ainsi, les logiciels privateurs Nomimum and Xerocole (utilisés par Akamai) peuvent le faire. Idem pour OpenDNS. Du côté des logiciels libres, BIND, Knot et Unbound ont tous cette possibilité, à des degrés divers.
Pour Unbound, les versions avant la 1.10 ne permettaient pas de suivre rigoureusement notre RFC 8767. Les options étaient (je cite le fichier de configuration d'exemple) :
# Serve expired responses from cache, with TTL 0 in the response, # and then attempt to fetch the data afresh. # serve-expired: no # # Limit serving of expired responses to configured seconds after # expiration. 0 disables the limit. # serve-expired-ttl: 0 # # Set the TTL of expired records to the serve-expired-ttl value after a # failed attempt to retrieve the record from upstream. This makes sure # that the expired records will be served as long as there are queries # for it. # serve-expired-ttl-reset: no
Notez donc qu'avec serve-expired, Unbound
servait des données rassises avant même de vérifier si les serveurs
faisant autorité étaient joignables. À partir de la version 1.10,
cette configuration fonctionne et colle au RFC :
# Enable serve-expired serve-expired: yes # Time to keep serving expired records. serve-expired-ttl: 86400 # One day # Do not reset the TTL above on failed lookups serve-expired-ttl-reset: no # default # TTL to reply with expired entries serve-expired-reply-ttl: 30 # default # Time to wait before replying with expired data serve-expired-client-timeout: 1800
Si on met serve-expired-client-timeout à zéro
(c'est la valeur par défaut), on garde l'ancien comportement (qui ne
respecte ni les anciens RFC, ni le nouveau.)
Pour BIND, la possibilité de se contenter de vieilles données a été introduite dans la version 9.12. Les options pertinentes sont :
stale-answer-enable: active le service d'envoi de données dépassées, uniquement si les serveurs faisant autorité sont injoignables, ce qui est la recommandation du RFC,max-stale-ttl: l'âge maximal des données rassises (une semaine par défaut),stale-answer-ttl: le TTL des valeurs retournées, une seconde par défaut (alors que le RFC suggère trente secondes).
Et sur Knot ? Knot est modulaire et la
possibilité de servir des données dépassées est dans un module
Lua séparé, serve_stale
(cf. modules/serve_stale/README.rst dans le
source). Il sert des données dépassées pendant au maximum une
journée. Il n'est apparemment configurable qu'en éditant le source Lua.
L'article seul
RFC 8765: DNS Push Notifications
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : T. Pusateri, S. Cheshire
(Apple)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnssd
Première rédaction de cet article le 23 juin 2020
Lorsqu'une donnée DNS change dans les serveurs faisant autorité, les clients ne seront prévenus que lorsqu'ils reviendront demander, et cela peut être long s'ils ont mémorisé l'ancienne valeur. Ce RFC propose une autre approche, où les données DNS sont poussées vers les clients au lieu d'attendre qu'ils tirent.
Qu'est-ce qui fait que des données DNS changent ? Cela peut être l'administrateur système qui a changé la zone et rechargé le serveur faisant autorité. Ou bien il y a pu y avoir mise à jour dynamique (RFC 2136). Ou encore d'autres mécanismes. Dans tous les cas, certains clients DNS (par exemple pour la découverte de services du RFC 6763) aimeraient bien être prévenus tout de suite (et voir la nouvelle imprimante du réseau local apparaitre dans la liste). Le DNS est purement pull et ces clients voudraient un peu de push.
Cette idée de protocoles push, où on envoie les données vers les clients au lieu d'attendre qu'il les réclame, est nouvelle pour le DNS mais ancienne dans l'Internet (modèle publish/subscribe ou design pattern Observateur). Parmi les protocoles IETF, XMPP peut fonctionner ainsi (cf. XEP0060).
Il y a quand même un peu de push dans une variante du DNS, mDNS (RFC 6762, section 5.2), où les changements peuvent être poussés vers une adresse IP multicast. Mais des protocoles comme la découverte de services du RFC 6763 peuvent aussi fonctionner sans multicast et cette solution ne leur convient donc pas. Il existait une solution non-standard, LLQ (Long-Lived Queries), décrite dans le RFC 8764 et mise en œuvre dans les produits Apple (cf. RFC 6281). Utilisant UDP, elle ne convient guère au DNS moderne.
Il existe aujourd'hui un mécanisme plus pratique pour déployer des fonctions comme le push : DSO (DNS Stateful Operations, RFC 8490), qui repose sur des connexions de longue durée, sur TCP (et TLS pour la sécurité). La solution push est donc bâtie sur DSO, et il est donc bon d'avoir lu le RFC 8490 avant celui-ci.
La section 3 de notre RFC présente le protocole DNS
push. Un client s'abonne à un service de notification et,
une fois abonné, il reçoit les nouveautés. Quand il n'a plus besoin
des données, le client se déconnecte. L'abonnement est valable pour
un certain couple {nom de
domaine, type de données}. Client et serveur utilisent
le mécanisme DSO du RFC 8490. Comment le
client trouve-t-il le serveur ? Ce n'est pas forcément un des
serveurs listés comme faisant autorité pour la zone. Il peut être
trouvé en demandant à son résolveur normal (s'il accepte DSO, le
client peut tenter sa chance) dans le DNS, puis, si ça ne marche
pas, via une requête SRV pour le nom
_dns-push-tls._tcp.LA-ZONE (cf. section 6, et
son enregistrement
à l'IANA). Rappelez-vous que, si un serveur DNS accepte DSO
mais pas DNS push, il répondra avec un code
de retour DNS DSOTYPENI (RFC 8490, section 5.1.1).
Pour éviter de trop charger le serveur, le client ne doit s'abonner que s'il a une bonne raison, par exemple parce qu'une fenêtre de sélection d'une imprimante est ouverte, et qu'il veut la rafraichir en permanence. Lorsque le client va s'endormir ou estomper son écran pour économiser sa batterie, il devrait se désabonner d'abord. En tout cas, le mécanisme DNS push ne devrait pas être utilisé 24x7, ce n'est pas son but. (Et c'est inutile, le mécanisme est suffisamment rapide pour pouvoir être invoqué seulement quand on en a besoin.)
De toute façon, le serveur n'est pas obligé d'accepter tous les clients qui se présentent. Il peut rejeter les abonnements s'il manque de ressources (section 4 du RFC).
Comment est-ce que le client demande du DNS
push ? En s'abonnant, une fois la session DSO établie. Il
envoie une requête
de type DSO SUBSCRIBE (la syntaxe des
TLV DSO est dans le RFC 8490, section 5.4.4). Dans les données de la requête se
trouvent le nom de domaine et le type de données qui intéressent le
client. Le serveur répond alors NOERROR (ou
bien un code DNS d'erreur s'il y a un problème, par exemple
REFUSED si le serveur ne veut pas) et envoie
une réponse de type SUBSCRIBE (même type que la
requête, c'est le bit QR de l'en-tête DNS qui permet de différencier
requête et réponse). Il est parfaitement légitime pour un client de
s'abonner à un nom de domaine qui n'existe pas encore, et le serveur
ne doit donc jamais répondre NXDOMAIN.
Une fois l'abonnement accepté, le client attend tranquillement
et, lorsqu'un changement survient, le serveur envoie des messages de
type DSO PUSH (code 0x0041). Les
données contenues dans ce message sont formatées comme les messages
DNS habituels, avec une exception : un TTL valant 0xFFFFFFFF signifie que l'ensemble
d'enregistrements concerné a été supprimé.
À la fin, quand le client n'est plus intéressé, il envoie un
message DSO UNSUBSCRIBE (code 0x0042). Encore
plus radical, le client peut mettre fin à la session DSO, annulant
ainsi tous ses abonnements.
Et la sécurité de ce DNS push (section 7 du RFC) ? DNS push impose l'utilisation de TLS (donc on a du DSO sur TLS sur TCP). Le client doit authentifier le serveur selon le profil strict du RFC 8310. Ensuite, DNSSEC est recommandé pour la découverte du serveur DNS push, lorsqu'on utilise les requêtes SRV, puis DANE pour vérifier le serveur auquel on se connecte (RFC 7673).
Ensuite, DNS push permet d'utiliser les données précoces du RFC 8446 (section 2.3), ce qui permet de diminuer la latence. Mais elles posent quelques problèmes de sécurité : plus de confidentialité persistante, et risque de duplication des messages. D'autre part, si on utilise la reprise de session du RFC 8446 (section 2.2), il faut noter que, si elle permet de ne pas recommencer toute la session TLS, en revanche, elle ne garde pas les abonnements DNS push, que le client devra donc renouveler.
Désolé, mais je ne connais pas encore de mise en œuvre de ce RFC, à part dans le monde Apple.
L'article seul
RFC 8763: Deployment Considerations for Information-Centric Networking (ICN)
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : A. Rahman (InterDigital Communications), D. Trossen (InterDigital Europe), D. Kutscher (University of Applied Sciences Emden/Leer), R. Ravindran (Futurewei)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF icnrg
Première rédaction de cet article le 17 avril 2020
Ce nouveau RFC annonce [mais c'est très prématuré] que l'ICN est désormais une technologie mûre et qu'il est temps de se pencher sur les problèmes pratiques de déploiement. Il documente ces problèmes, et des solutions possibles. Il décrit aussi des expériences de déploiement (très limitées et qui ont souvent disparu.)
Si vous voulez réviser le concept d'ICN, lisez le RFC 8793. Il y a plusieurs façons (section 4 du RFC) d'envisager le déploiement des techniques « fondées sur le contenu » (ICN) :
- Une table rase, où on remplace complètement l'Internet existant par une solution à base d'ICN. Cela implique que les actuels routeurs soient tous changés, pour des machines faisant tourner un logiciel comme NFD. (Inutile de dire que c'est complètement irréaliste.)
- Un déploiement de l'ICN comme réseau de base, avec une couche TCP/IP au-dessus, pour continuer à faire tourner l'Internet classique. Cela pose les mêmes problèmes que la table rase.
- Un déploiement de l'ICN au-dessus de l'Internet existant, un réseau virtuel, quoi, comme on faisait pour IPv6 au début. C'est le seul déploiement effectif qu'ait connu l'ICN pour l'instant, avec des idées comme CCNx sur UDP. Cela permet l'expérimentation et le déploiement progressif.
- De l'ICN « sur les côtés » du réseau. On peut envisager une
épine dorsale qui reste en TCP/IP, avec des réseaux extérieurs en
ICN, et des passerelles entre les deux. Ces réseaux extérieurs en
ICN pourraient concerner, par exemple,
l'IoT (cf.
draft-irtf-icnrg-icniot), et les passerelles transformeraient du CoAP (RFC 7252) en ICN et réciproquement. - Les technologies qui permettent de découper un réseau physique en plusieurs tranches, chacune abritant un réseau virtuel, comme la 5G, pourraient permettre de faire cohabiter harmonieusement ICN et TCP/IP sur la même infrastructure physique.
- Enfin, on peut imaginer, tant qu'on y est, des déploiements mixtes, mêlant les différentes approches citées ci-dessus.
La section 5 du RFC décrit de manière plus détaillées des chemins de migration possibles. Et la section 6 décrit quelques expériences qui ont effectivement eu lieu (on peut aussi lire le RFC 7945) :
- Le projet FP7 PURSUIT (documenté dans un article IEEE non public) se positionnait comme une approche de table rase mais, en pratique, a été déployé par dessus l'Internet existant. Il a compté jusqu'à 70 nœuds. Comme tous les projets ICN, il a été abandonné à la fin des subventions. (Pour s'amuser, regardez ce qu'est devenu le site Web du projet.)
- Le projet NDN de la NSF a également effectué un déploiement (environ 100 nœuds) sur l'Internet existant.
- Le projet ICN 2020 a produit des rapports sur ses réalisations au-dessus de TCP/IP, avec 37 nœuds ICN.
- Le projet UMOBILE a été déployé entre autre sur le réseau communautaire Guifi, avec dix Raspberry Pi. C'est raconté dans « Information-Centric Multi-Access Edge Computing Platform for Community Mesh Networks ».
Ces projets tournaient sur l'Internet d'aujourd'hui. Mais il y avait aussi d'autres projets qui se situaient plus bas dans le modèle en couches :
- POINT et RIPE ont également utilisé Guifi mais cette fois en étant directement sur le WiFi, avec TCP/IP par dessus. l'ICN.
- Un autre projet concret a connecté 60 nœuds en 6LoWPAN, en utilisant RIOT, et est documenté dans « Information Centric Networking in the IoT: Experiments with NDN in the Wild ».
- Signalons enfin (mais le RFC en liste d'autres) le projet Doctor, sur lequel a été testé le transport de trafic HTTP réel.
Le RFC note qu'aucun de ces déploiements n'a dépassé mille utilisateurs. Pour moi, il s'agissait clairement d'expérimentation et appeler ça « déploiement » est trompeur.
La section 7 du RFC discute des points qui manquent pour des déploiements significatifs, notamment question normalisation. La liste est longue. Le RFC note entre autres :
- Le problème des applications ; un navigateur Web existant n'a aucun moyen de savoir s'il doit récupérer un contenu en ICN ou par des moyens classiques. Aucune API ne permet au programmeur de contrôler ce choix. De même, aucune API vaguement standard n'existe pour utiliser les capacités de l'ICN.
- Le nommage des objets dans l'ICN n'est pas normalisé, quoique il existe des tentatives comme celle du RFC 6920 (voir aussi les RFC 8569 et RFC 8609.)
- Et il y a tous les autres problèmes pratiques, comme l'OAM…
- La sécurité a droit à sa propre section, la 10. (Voir aussi le RFC 7945.) Elle n'a guère été testée en vrai pour l'instant, à part peut-être dans le projet Doctor (voir « Content Poisoning in Named Data Networking: Comprehensive Characterization of real Deployment », une étude détaillée de l'attaque par empoisonnement du contenu, où un méchant producteur essaie d'envoyer du contenu malveillant aux clients, ou bien « A Security Monitoring Plane for Named Data Networking Deployment », les deux articles se sont spécialement concentrés sur NFD.) Compte-tenu de l'expérience de l'Internet, cela sera pourtant un point crucial.
L'article seul
RFC 8762: Simple Two-way Active Measurement Protocol
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : G. Mirsky (ZTE), G. Jun (ZTE), H. Nydell (Accedian Networks), R. Foote (Nokia)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 20 mars 2020
Ce nouveau RFC décrit un protocole simple pour piloter des mesures comme celle de la latence ou comme le taux de pertes de paquets entre deux points. Il fonctionne pour des mesures aller-simple (unidrectionnelles) et aller-retour (bidirectionnelles.)
Mais, vous allez me dire, il existe déjà un tel protocole, TWAMP, normalisé dans le RFC 5357, et dans quelques RFC suivants comme le RFC 6038. TWAMP est mis en œuvre dans plusieurs systèmes, et fonctionne. Le problème est que TWAMP est riche et complexe, et que sa simplifiation TWAMP Light (annexe 1 du RFC 5357) est apparemment insuffisamment spécifiée, menant à des problèmes d'interopérabilité. Voir par exemple le rapport « Performance Measurement from IP Edge to Customer Equipment using TWAMP Light ».
Les grandes lignes de STAMP (Simple Two-way Active Measurement Protocol) sont décrites dans la section 3 de notre RFC. Comme TWAMP, STAMP sépare les fonctions de contrôle du test, et le test lui-même. Contrairement à TWAMP, la norme STAMP ne décrit que le test (rappelez-vous que STAMP se veut plus simple que TWAMP). Le contrôle est fait de l'extérieur, par des programmes en ligne de commande, par Netconf ou par un autre moyen.
Avec STAMP, il y a deux acteurs, le Session-Sender qui envoie les paquets, et le Session-Reflector, qui répond. Les paquets sont de l'UDP vers le port 862, et contiennent un numéro de séquence qui permet d'associer requête et réponse. (La réponse contient davantage de données que la requête, mais la requête est remplie, pour avoir la même taille, afin d'éviter les attaques avec amplification.) STAMP a deux modes de fonctionnement (section 4 du RFC) :
- Sans état ; le Session-Reflector ne se souvient pas des numéros de séquence déjà vus, il se contente de répondre à chaque paquet, en recopiant le numéro dans la réponse.
- Avec état ; le Session-Reflector se souvient des numéros de séquence. Ce mode permet, par exemple, de calculer le taux de perte de paquets (en voyant les trous dans la séquence) dans chaque direction, alors que le mode sans état est limité au bidirectionnel (trajet aller/retour, sans pouvoir distinguer la contribution de l'aller et celle du retour.)
Le paquet STAMP inclus, outre le numéro de séquence déjà cité, une estampille temporelle, par défaut au format utilisé par NTP (cf. RFC 5905, section 6.) Un accord entre les deux parties (souvenez-vous que STAMP ne décrit pas comment l'envoyeur et le réflecteur sont coordonnés) permet d'utiliser d'autres formats comme celui de PTP (RFC 8186.)
L'authentification n'est pas indispensable et, si on ne l'utilise pas, le paquet peut être modifié par un attaquant actif qui cherche à fausser les mesures. STAMP a également une possibilité d'authentification, où le paquet contient en outre un HMAC (RFC 2104, et section 4.4 de notre RFC.)
Dans sa réponse, le Session-Reflector envoie un paquet qui indique son propre numéro de séquence, sa propre estampille temporelle, et les numéros de séquence et estampille temporelle du paquet reçu. (En outre, dans le mode avec état, le Session-Reflector enregistre les informations du paquet entrant.) Au retour, le Session-Sender peut donc calculer le RTT, la gigue et le taux de pertes. (Dans le mode avec état, le Session-Reflector peut lui aussi calculer ces informations, qui auront l'avantage de ne concerner qu'une seule direction des paquets.)
Notez que STAMP n'a aucune confidentialité. Si on veut empêcher un méchant de lire les informations, il faut emballer le tout, par exemple dans IPsec ou DTLS. Ce point est un de ceux qui avaient suscité les plus vives discussions à l'IETF, certains regrettant qu'il n'y ait pas de sécurité standard.
Notez également qu STAMP et TWAMP-Light peuvent partiellement interopérer, puisque le format de paquets et la sémantique sont les mêmes (en non authentifié, uniquement.)
Je n'ai pas trouvé de mise en œuvre de STAMP, ni en logiciel libre, ni en privateur. Je ne connais pas non plus de liste de serveurs STAMP publics.
L'article seul
RFC 8761: Video Codec Requirements and Evaluation Methodology
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : A. Filippov (Huawei), A. Norkin (Netflix), J.R. Alvarez (Huawei)
Pour information
Réalisé dans le cadre du groupe de travail IETF netvc
Première rédaction de cet article le 17 avril 2020
Si vous passez toutes vos soirées avachi·e devant un écran à regarder des séries sur Netflix, ce RFC est pour vous. Il est le cahier des charges d'un futur codec vidéo libre pour l'Internet. Ce codec devra gérer beaucoup de cas d'usage différents.
Concevoir un codec vidéo n'est jamais facile. Il y a beaucoup d'exigences contradictoires, par exemple minimiser le débit en comprimant, tout en n'exigeant pas de la part du processeur trop de calculs. Ce RFC, le premier du groupe de travail netvc de l'IETF, se limite au cas d'un codec utilisé au-dessus de l'Internet, mais cela fait encore plein d'usages différents, du streaming à la vidéoconférence en passant par la vidéosurveillance (celle que les politiciens hypocrites appellent la vidéoprotection, mais le RFC est plus sincère et utilise le bon terme.)
Le problème est d'autant plus difficile que plein de choses peuvent aller mal sur l'Internet, les paquets peuvent être perdus, les bits modifiés en route, etc. En pratique, tous ces incidents n'ont pas la même probabilité : les pertes sont bien plus fréquentes que les corruptions, par exemple. Si on n'est pas trop pressés (cas du téléchargement), TCP ou d'autres protocoles de transport similaires fournissent une bonne solution. Si on a des exigences temporelles plus fortes (diffusion en direct, « temps réel »), il faut parfois renoncer à TCP et, soit utiliser des réseaux idéaux (managed networks, dit le RFC, qui reprend le terme marketing de certains opérateurs qui tentent de nous faire croire qu'il existerait des réseaux sans pertes), soit trouver d'autres moyens de rattraper les pertes et les erreurs.
Depuis qu'on fait de la vidéo sur l'Internet, c'est-à-dire depuis très longtemps (malgré les prédictions des opérateurs de télécommunications traditionnels qui étaient unanimes, dans les années 1990, pour dire que cela ne serait jamais possible), toute une terminologie a été développée pour communiquer sur ce sujet. La section 2 de notre RFC rappelle les sigles importants, et quelques termes à garder en tête. Ainsi, la « compression visuellement sans perte » désigne les méthodes de compression avec perte, mais dont on ne voit pas d'effet secondaire à l'œil nu.
La section 3 de notre RFC fait ensuite le tour des applications de la vidéo sur l'Internet, pour cerner de plus près leurs caractéristiques et leurs exigences propres. (Le cahier des charges proprement dit sera en section 4.) Chaque cas d'usage est accompagné d'un tableau indiquant la résolution et la fréquence des trames souhaitées. On commence évidemment par le streaming (un des auteurs du RFC travaille chez Netflix.) Pouvoir regarder Le Messie via l'Internet est un objectif crucial. Comme les clients sont variés, et que les conditions de leur accès Internet varient en permanence (surtout s'il y a des liens radio), le codec doit tout le temps s'adapter, et pour cela tenir compte des caractéristiques de la perception humaine. L'encodage est typiquement fait une fois et une seule, lorsque la vidéo est chargée sur les serveurs. Pour cet usage :
- On peut accepter un encodeur complexe et coûteux en ressources, puisque l'encodage sera fait sur de grosses machines, et une seule fois,
- Le décodeur, par contre, doit être simple, car beaucoup de monde devra faire le décodage, et pas forcément sur des machines performantes,
- En entrée, il faut pouvoir accepter beaucoup de formats, et de types de contenus, parfois avec des particularités (le grain d'un film peut être délibéré, l'encodage ne doit pas le supprimer).
Proche du streaming mais quand même différent, il y a le partage de vidéos, usage popularisé par YouTube mais également accessible en utilisant du logiciel libre et décentralisé, comme PeerTube. C'est le monde de l'UGC : M. Michu filme des violences policières avec son petit ordiphone (ou avec sa GoPro), et les diffuse au monde entier grâce aux services de partage de vidéos.
Après le streaming et le partage de vidéos, la télévision sur IP. Il s'agit de distribuer de la télévision traditionnelle sur IP, pour permettre de se réduire le cerveau en regardant Hanouna. Cet usage se décompose en deux groupes : l'unicast, où on envoie l'émission à un seul destinataire, c'est la VoD, et le multicast où on diffuse à un grand nombre d'utilisateurs simultanément. Ce dernier est sans doute de moins en moins utilisé, à part pour les événements sportifs et les cérémonies. Le RFC se concentre sur la distribution de télévision au-desus d'un réseau « géré » (comme si les autres ne l'étaient pas…) où on peut garantir une certaine QoS. C'est par exemple le cas d'un FAI qui envoie les chaînes de télévision aux boxes des abonnés. Si on diffuse un match de foot, on souhaite que le but qui décide du sort du match atteigne les ordinateurs sans trop de retard sur les hurlements bestiaux de supporters utilisant la diffusion hertzienne, hurlements qu'on entendra dehors. Pour compliquer un peu les choses, on souhaite que l'utilisateur puisse mettre en pause, reprendre, etc.
Et la vidéoconférence ? Là aussi, le délai d'acheminement est crucial, pour qu'on n'ait pas l'impression de parler avec un astronaute perdu sur Mars. (Le RFC suggère 320 millisecondes au grand maximum, et de préférence moins de 100 ms.)
Il y a aussi le partage d'écran, où on choisit de partager l'écran de son ordinateur avec une autre personne. Comme pour la vidéoconférence, il faut du temps réel, encoder au fur et à mesure avec le plus petit retard possible.
Et les jeux vidéo, alors ? Les jeux ont souvent un contenu riche (beaucoup de vidéos). Dans certains cas, le moteur de jeu est quelque part sur l'Internet et, à partir d'un modèle 3D, génère des vidéos qu'il faut envoyer aux joueurs. Là encore, il faut être rapide : si un joueur flingue un zombie, les autres participants au jeu doivent le voir « tout de suite ». (Nombreux détails et exemples, comme GeForce Grid ou Twitch, dans le document N36771 « Game streaming requirement for Future Video Coding », de l'ISO/IEC JTC 1/SC 29/WG 11.)
Enfin, le RFC termine la liste des applications avec la vidéosurveillance. Dans le roman « 1984 », George Orwell ne donne aucun détail technique sur le fonctionnement du télécran, et notamment sur la connexion qui permet au Parti de savoir ce qui se passe chez Winston. Ici, l'idée est de connecter les caméras de vidéosurveillance à l'Internet et de faire remonter les flux vidéo à un central où on les regarde et où on les analyse. Comme l'État peut souhaiter disposer de très nombreuses caméras, le coût matériel est un critère important.
Après cet examen des cas d'usage possibles, la section 4 du RFC est le cahier des charges à proprement parler. D'abord, les exigences générales, qui concernent toutes les applications. Évidemment, le futur codec vidéo de l'Internet doit encoder efficacement, donc, dit le RFC, mieux que les codecs existants, H.265 ou VP9. Évidemment encore, l'interopérabilité entre les différentes mises en œuvre du codec est cruciale, et cela dépend en partie de l'IETF, qui devra écrire une norme claire et cohérente. Cette norme se déclinera en profils, qui limiteront certains aspects du codec, pour des cas d'usages spécifiques.
Le RFC exige également qu'il soit possible de gérer des extensions au format, pour les questions futures, tout en maintenant la compatibilité (un nouveau décodeur doit pouvoir décoder les vieilles vidéos). Le format doit permettre huit bits de couleur (par couleur) au minimum, et de préférence douze, gérer le YCbCr, permettre des résolutions quelconques, autoriser l'accès direct à un point donné de la vidéo, et bien d'autres choses encore. Et le tout doit pouvoir marcher en temps réel (aussi bien l'encodage que le décodage.) Par contre, pour l'encodage de haute qualité, le RFC autorise les encodeurs à être jusqu'à dix fois plus complexes que pour les formats existants : les ressources des ordinateurs croissent plus vite que la capacité des réseaux, et il est donc raisonnable de faire davantage d'efforts pour encoder.
Les réseaux sont imparfaits, et il faut donc gérer les erreurs. Outre les mécanismes présents dans la couche transport, le RFC demande que des mécanismes spécifiques à la vidéo soient également inclus dans le format. En parlant de couche transport, comme le but est de faire un codec vidéo pour l'Internet, le RFC rappelle l'importance de prévoir comment encapsuler le futur format dans les protocoles de transport existants.
Les exigences ci-dessus étaient impératives. Il y en a également des facultatives, par exemple un nombre de bits pour coder chaque couleur allant jusqu'à 16, la gestion du RGB, celle du transparence… Toujours dans les demandes facultatives, le RFC note qu'il serait bon que le format choisi n'empêche pas le parallélisme dans le traitement des vidéos, ce qui implique, par exemple, qu'on ne soit pas obligé de traiter toutes les images précédant une image pour encoder celle-ci. Et qu'on puisse utiliser des algorithmes qui soient acceptables pour les SIMD/GPU.
Ce n'est pas tout de faire une liste au Père Noël avec toutes les jolies choses qu'on voudrait voir dans le nouveau format, encore faut-il une bonne méthodologie pour évaluer les futures propositions. La section 5 décrit les tests à effectuer, avec plusieurs débits différents. Ces tests seront ensuite faits en comparant un codec de référence (HEVC ou VP9) aux codecs candidats pour répondre à ce cahier des charges. Comme le codec utilisera certainement des techniques dépendant de la perception humaine, ces tests « objectifs » ne suffisent pas forcément, et le RFC prévoit également des tests subjectifs, avec la procédure MOS (cf. le document ISO/IEC « PDTR 29170-1 », première partie.)
Et un petit point de sécurité pour finir : le RFC rappelle qu'encodeur et surtout décodeur doivent être paranoïaques, afin d'éviter qu'une vidéo un peu inhabituelle ne mène à des consommations de ressources déraisonnables, voire épuisant la machine.
Pour l'instant, le candidat sérieux pour répondre à ce cahier des charges est le codec AV1, notamment poussé par l'Alliance for Open Media. Mais il ne semble pas tellement se rapprocher de la normalisation formelle. Le groupe de travail ne semble plus très actif.
L'article seul
RFC 8758: Deprecating RC4 in Secure Shell (SSH)
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : L. Camara, L. Velvindron (cyberstorm.mu)
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 29 avril 2020
L'algorithme de chiffrement symétrique RC4, trop fragile, est abandonné depuis longtemps. Ce nouveau RFC le retire officiellement de SSH. Notre RFC remplace donc le RFC 4345, dont le statut devient « Intérêt historique seulement ».
L'utilisation de RC4 dans SSH avait été enregistrée dans le RFC 4253, et précisée dans ce RFC 4345, désormais abandonné. Les faiblesses de RC4 sont connues depuis longtemps, et ont été documentées dans le RFC 7465. Résultat, RC4 est retiré peu à peu des protocoles Internet (cf. par exemple le RFC 8429.) Désormais, RC4 disparait également de SSH, et le registre IANA des algorithmes a été mis à jour en ce sens.
OpenSSH a retiré RC4 il y a longtemps :
% ssh -V OpenSSH_7.6p1 Ubuntu-4ubuntu0.3, OpenSSL 1.0.2n 7 Dec 2017 % ssh -Q cipher 3des-cbc aes128-cbc aes192-cbc aes256-cbc rijndael-cbc@lysator.liu.se aes128-ctr aes192-ctr aes256-ctr aes128-gcm@openssh.com aes256-gcm@openssh.com chacha20-poly1305@openssh.com
(RC4 apparaissait comme arcfour, pour des
raisons légales.)
L'article seul
RFC 8753: Internationalized Domain Names for Applications (IDNA) Review for New Unicode Versions
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : J. Klensin, P. Faltstrom (Netnod)
Chemin des normes
Première rédaction de cet article le 16 avril 2020
La norme IDN, qui permet depuis 2003 les noms de domaine en Unicode était autrefois liée à une version particulière d'Unicode. La révision de cette norme en 2010 a libérédélivré IDN d'une version spécifique. La liste des caractères autorisés n'est plus statique, elle est obtenue par l'application d'un algorithme sur les tables Unicode. Tout va donc bien, et, à chaque nouvelle version d'Unicode, il suffit de refaire tourner l'algorithme ? Hélas non. Car, parfois, un caractère Unicode change d'une manière qui casse la compatibilité d'IDN et qui, par exemple, rend invalide un nom qui était valide auparavant. La norme IDN prévoit donc un examen manuel de chaque nouvelle version d'Unicode pour repérer ces problèmes, et décider de comment les traiter, en ajoutant une exception spécifique, pour continuer à utiliser ce caractère, ou au contraire en décidant d'accepter l'incompatibilité. Ce nouveau RFC ne change pas ce principe, mais il en clarifie l'application, ce qui est d'autant plus nécessaire que les examens prévus n'ont pas toujours été faits, et ont pris anormalement longtemps, entre autre en raison de l'absence de consensus sur la question.
Le RFC à lire avant celui-ci, pour réviser, est le RFC 5892. Il définit l'algorithme qui va décider, pour chaque caractère Unicode, s'il est autorisé dans les noms de domaine ou pas. À chaque version d'Unicode (la dernière est la 13.0), on refait tourner l'algorithme. Bien qu'Unicode soit très stable, cela peut faire changer un caractère de statut. Si un caractère auparavant interdit devient autorisé, ce n'est pas grave. Mais si l'inverse survient ? Des noms qui étaient légaux cessent de l'être, ne laissant le choix qu'entre deux solutions insatisfaisantes, supprimer le nom, ou bien ajouter une exception manuelle (procédure qui n'est pas parfaitement définie dans le RFC 5892, qui sera faite, si tout va bien, par de nouveaux RFC.)
[Notez que ce RFC affirme que les registres sont responsables des noms qu'ils autorisent, point de vue politique et non technique, contestable et d'ailleurs contesté.]
En quoi consiste donc le nouveau modèle d'examen qui accompagne la sortie d'une nouvelle version d'Unicode ? La section 3 du RFC l'expose. D'abord faire tourner l'algorithme du RFC 5892, puis noter les caractères qui ont changé de statut. Cela doit être fait par un expert nommé par l'IESG (DE, pour Designated Expert, actuellement Patrik Fältström, un des auteurs du RFC.) Puis réunir un groupe d'experts (il faut un groupe car personne n'est compétent dans tous les aspects d'IDN à la fois, ni dans toutes les écritures normalisées, cf. annexe B ; si l'IETF n'a pas de problèmes à trouver des experts en routage, elle doit par contre ramer pour avoir des experts en écritures humaines.) La recommandation pour ce groupe est d'essayer de préserver le statut des caractères et donc, si nécessaire, de les ajouter à une table d'exceptions (le RFC 6452 avait pris la décision opposée.) Le fait d'avoir des experts explicitement nommés va peut-être permettre d'éviter le syndrome du « il faudrait que quelqu'un s'en occupe » qui avait prévalu jusqu'à présent.
La promesse de publier les tables résultant de l'algorithme du RFC 5892 n'ayant pas été tenue (ce qui a fait râler), le RFC espère que cette fois, le travail sera fait. (Elle a finalement été faite deux ans plus tard dans le RFC 9233.)
L'annexe A résume les changements depuis le RFC 5892 (qui n'est pas remplacé, juste modifié légèrement) :
- Séparer explicitement l'examen des nouvelles versions d'Unicode en deux, la partie algorithmique et la partie plus politique,
- Désigner un groupe d'experts pour cette deuxième partie,
- Et quelques autres détails pratico-bureaucratiques sur l'organisation du travail.
La section 2 du RFC rappelle l'histoire d'IDN. La norme originale, le RFC 3490 définissait l'acceptabilité de chaque caractère dans un nom de domaine. Lorsqu'une nouvelle version d'Unicode sortait, il n'y avait pas de mécanisme pour décider d'accepter ou non les nouveaux caractères. Il aurait fallu refaire un nouveau RFC pour chaque version d'Unicode (il y en a environ une par an.) La version 2 d'IDN, dans le RFC 5890, a changé cela, en décidant de normaliser l'algorithme et non plus la liste des caractères. L'algorithme, décrit en détail dans le RFC 5892, utilise les propriétés indiquées dans la base de données Unicode (cf. la norme, sections 4 et 3.5) pour décider du sort de chaque caractère. Dans un monde idéal, ce sort ne change pas d'une version d'Unicode à l'autre. Si les propriétés Unicode des caractères sont stables, le statut (accepté ou refusé) restera le même, l'algorithme ne servant vraiment que pour les nouveaux caractères introduits par la nouvelle version d'Unicode. Mais, bien qu'Unicode fasse certaines promesses de stabilité, elles ne sont pas totales : un caractère peut donc se retrouver accepté une fois, puis refusé. Le RFC 5892 prévoyait donc, à juste titre, un examen manuel, et le RFC 5892 décrivait une table d'exceptions permettant de maintenir la compatibilité (section 2.7). Cette table aurait pu être remplie au fur et à mesure, pour conserver une certaine stabilité. Mais un tel examen n'a été fait qu'une fois, pour Unicode 6, dans le RFC 6452, suite à quoi il a été décidé de ne pas ajouter d'exceptions (et donc de laisser des noms devenir invalides.) En 2015, l'IAB avait demandé que les mises à jour soient suspendues, suite au « problème » (dont tout le monde n'est pas convaincu) du caractère arabe bāʾ avec hamza (ࢡ, U+08A1). Puis, en 2018, avait insisté sur l'importance de terminer ce travail. Deux ans après, ce n'est toujours pas fait. Donc, en pratique, IDNA version 2 n'a pas encore tenu sa promesse de pouvoir être mis à jour « presque » automatiquement.
À noter un autre problème avec la nouvelle version d'IDN : le fait qu'un caractère soit autorisé ou pas dépend d'un algorithme, et non plus d'une table statique. Mais, pour faciliter la vie des utilisateurs, l'IANA avait produit des tables en appliquant l'algorithme aux données Unicode. Il a toujours été prévu que ces tables soient juste une aide, qu'elles ne fassent pas autorité mais, malheureusement, certaines personnes les ont compris comme étant la référence, ce qui n'était pas prévu. Comme ces tables IANA n'ont pas été mises à jour au fur et à mesure des versions d'Unicode, le problème devient sérieux. Le RFC demande à l'IANA de modifier la description des tables pour insister sur leur caractère non-normatif (« It should be stressed that these are not normative in that, in principle, an application can do its own calculations and these tables can change as IETF understanding evolves. ».)
J'ai écrit que tout le monde n'était pas convaincu de la nature du problème. Il y a en effet un désaccord de fond au sujet d'Unicode, entre ceux qui considèrent que toutes les lettres se valent, que toutes les écritures doivent avoir le même statut et, ceux, souvent des utilisateurs de l'alphabet latin, que la diversité dérange et qui voudraient mieux contrôler les caractères « dangereux », en utilisant des arguments de sécurité contestables. La question est d'autant plus sérieuse que les retards de mise à jour d'IDN (qui est toujours en version 6 alors qu'Unicode est en version 13) handicape surtout les utilisateurs des écritures les plus récemment ajoutées dans Unicode, en général des peuples minoritaires et peu présents dans le business international. Le retard n'est donc pas forcément gênant de la même manière pour tout le monde…
L'article seul
RFC 8752: Report from the IAB Workshop on Exploring Synergy between Content Aggregation and the Publisher Ecosystem (ESCAPE)
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : M. Thomson, M. Nottingham
Pour information
Première rédaction de cet article le 1 mai 2020
Ce RFC est le compte-rendu d'un atelier de l'IAB qui s'est tenu en juillet 2019 au sujet du Web Packaging, une proposition technique permettant de regrouper un ensemble de pages Web en un seul fichier, pouvant être distribué par des moyens non-Web, tout en étant authentifié. Web Packaging (ou WebPackage) est un concentré de pas mal d'enjeux technico-politiques actuels.
Pour en savoir plus sur ce projet, vous pouvez consulter l'actuel dépôt du projet, géré par le WICG. (Il y avait un projet W3C à un moment mais qui a été abandonné). Vous pouvez commencer par ce document. (Il y a aussi un brouillon à l'IETF, et un nouveau groupe de travail, wpack.) Le projet avait été lancé à l'origine par Google.
La proposition a suscité pas mal de discussions, voire de contestations. N'est-ce pas encore un plan diabolique de Google pour entuber les webmestres ? L'IAB a donc organisé un atelier, joliment nommé ESCAPE (Exploring Synergy between Content Aggregation and the Publisher Ecosystem) au sujet du Web Packaging. Cela permettait notamment de faire venir des gens qui sont plutôt du côté « création de contenus » (entreprises de presse, par exemple), et qui viennent rarement au W3C et jamais à l'IETF. Cet atelier s'est tenu à Herndon en juillet 2019. Il n'avait pas pour but de prendre des décisions, juste de discuter. Vous pouvez trouver les documents soumis par les participants sur la page de l'atelier. Je vous recommande la lecture de ces soumissions.
Le principe de base de Web Packaging est de séparer l'écriture du contenu et sa distribution, tout en permettant de valider l'origine du contenu (l'annexe B du RFC décrit Web Packaging plus en détail). Ainsi, un des scénarios d'usage (section 2 du RFC) serait que le crawler de Google ramasse un paquetage de pages et de ressources sur un site Web, l'indexe, et puisse ensuite servir directement ce paquetage de pages et autres ressources au client qui a utilisé le moteur de recherche, sans renvoyer au site original. Et tout cela avec des garanties d'origine et d'authenticité, et en faisant afficher par le navigateur dans sa barre d'adresses l'URL original. Un autre usage possible serait la distribution de sites Web censurés, par des techniques pair-à-pair, tout en ayant des garanties sur l'origine (sur ce point particulier, voir aussi la section 3.3 du RFC). Notez que ces techniques font que le site original ne connait pas les téléchargements, ce qui peut être vu comme une bonne chose (vie privée) ou une mauvaise (statistiques pour le marketing). Et puis les inquiétudes vis-à-vis de Web Packaging ne viennent pas uniquement des problèmes pour avoir des statistiques. Des éditeurs ont dit lors de l'atelier qu'il étaient tout simplement inquiets des « copies incontrôlées ». En outre, l'argument de vie privée est à double tranchant : le site d'origine du contenu ne voit pas les téléchargements, mais un autre acteur, celui qui envoie le Web Packaging le voit.
Séparer création de contenu et distribution permet également la consultation hors-ligne, puisque un paquetage Web Packaging peut être auto-suffisant. Cela serait très pratique, par exemple pour Wikipédia. Actuellement, il existe des trucs plus ou moins pratiques (HTTrack…) mais le Web Packaging rendrait cette activité plus agréable. Notez que les participants à l'atelier ne se sont pas mis d'accord sur le caractère indispensable ou pas de la signature dans ce cas.
Potentiellement, un système comme Web Packaging pourrait également changer le monde du livre électronique : tout site Web pourrait être facilement « ebookisé ». Une amusante discussion à l'atelier a eu lieu sur l'intérêt des signatures. Comme souvent en cryptographie, les signatures ont une durée de validité limitée. Sept jours est proposé, par défaut, mais Moby Dick a été écrit il y a 61 000 jours.
Dernier scénario d'usage envisagé, l'archivage du Web. Ce n'est pas trivial, car il ne suffit pas de copier la page HTML, il faut garder toutes les ressources auxiliaires, d'où l'intérêt de Web Packaging. Et la signature serait utile là aussi, pour vérifier que l'archive est sincère. (Voir aussi le RFC 7089).
La section 3 du RFC discute ensuite la difficile question de la relation entre les producteurs de contenu et les intermédiaires comme Google. Par exemple, si un producteur de contenu sous-traite la distribution du contenu à un CDN, il doit lui faire confiance pour ne pas modifier le contenu. Web Packaging, avec son système de signature, résoudrait le problème. D'un autre côté, ça fait encore un format de plus dans lequel il faut distribuer le contenu, un coût pas forcément négligeable, et qui frappera de manière disproportionnée les petits producteurs, ou les moins pointus techniquement. Certains participants en ont profité pour râler contre AMP.
Comme toute nouvelle technique, Web Packaging pourrait mener à des déplacements de pouvoir dans l'écosystème du Web. Mais il est très difficile de prévoir ces effets (cf. RFC 5218). Est-ce que Web Packaging va favoriser les producteurs de contenu, les intermédiaires, les utilisateurs ? La section 4 du RFC explore la question. Par exemple, un des risques est la consolidation du pouvoir des gros intermédiaires. Si Facebook peut directement servir des paquetages Web, sans passer par le site original, les performances seront bien meilleures pour les paquetages déjà chargés par Facebook, qui gagnera donc en pouvoir. D'un autre côté, Web Packaging pourrait mener au résultat inverse : l'authentification des paquetages rendrait la confiance en l'intermédiaire inutile. (Personnellement, j'apprécie dans l'idée de Web Packaging que cela pourrait encourager le pair-à-pair, dont le RFC ne parle quasiment pas, en supprimant l'inquiétude quant à l'authenticité du contenu.)
La section 4 couvre d'autres questions soulevées par le concept de Web Packaging. Par exemple, il ne permet pas facilement d'adapter le contenu à l'utilisateur puisque, au moment de fabriquer le paquetage, on ne sait pas qui le lira. Une solution possible serait, pour un même site Web, de produire plusieurs paquetages et de laisser l'utilisateur choisir, mais elle complexifie encore le travail des producteurs. (Personnellement, je pense que beaucoup de ces adaptations sont mauvaises, par exemple l'adaptation au navigateur Web dans l'espoir de contrôler plus étroitement l'apparence, et cela ne me chagrine donc pas trop si elles seraient plus difficiles.)
Et la sécurité ? Un mécanisme de distribution par paquetages Web signés envoyés par divers moyens serait un changement profond du mécanisme de sécurité du Web. Actuellement, ce mécanisme repose essentiellement sur TLS, via HTTPS (RFC 2818). Mais c'est très insuffisant ; TLS ne protège que le canal, pas les données. Si un site Web a des miroirs, HTTPS ne va pas protéger contre des miroirs malveillants ou piratés. Et, comme noté plus haut, si un contenu Web est archivé, et distribué, par exemple, par Internet Archive, comment s'assurer de son authenticité ? L'absence d'un mécanisme d'authentification des données (Object-based security) est une des plus grosses faiblesses du Web (malgré des essais anciens mais jamais déployés comme celui du RFC 2660), et Web Packaging, qui sépare la validation du contenu de sa distribution, pourrait contribuer à traiter le problème. Ceci dit, l'expérience de la sécurité sur l'Internet montre aussi que tout nouveau système amène de nouvelles vulnérabilités et il faudra donc être prudent.
Et la vie privée ? De toute façon, quand on récupère un contenu, qu'il soit sous forme de paquetages ou de pages Web classiques, on donne au serveur des informations (et HTTP est terriblement bavard, il n'y a pas que l'adresse IP qui est transmise). Il semble qu'au moins, Web Packaging n'aggrave pas les nombreux problèmes du Web. (Personnellement, je pense qu'il pourrait même les limiter mais l'analyse exacte est compliquée. À l'heure actuelle, si vous suivez un lien depuis Facebook, le site Web d'origine et Facebook sont au courant. Avec Web Packaging seul Facebook le saurait. Est-ce un progrès ?)
La technologie AMP, très controversée a souvent été mentionnée pendant l'atelier. Elle n'a pas de rapport direct avec Web Packaging mais elle sort de la même société, et est souvent présentée comme faisant partie d'un même groupe de technologies modernes. La section 5 du RFC discute donc des problèmes spécifiques à AMP.
Je n'ai pas regardé les outils existants pour faire du Web Packaging donc ce site n'est pas encore sous forme de paquetage.
L'article seul
RFC 8749: Moving DNSSEC Lookaside Validation (DLV) to Historic Status
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : W. Mekking, D. Mahoney (ISC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 27 mars 2020
DLV (DNSSEC Lookaside Validation) était un mécanisme permettant de contourner le fait que plusieurs zones DNS importantes, dont la racine, n'étaient pas signées. Jamais très utilisé, et aujourd'hui inutile, DLV est ici officiellement abandonné, et les RFC le décrivant sont reclassés « intérêt historique seulement ».
Normalement, DNSSEC (RFC 4033 et
suivants) suit le modèle de confiance du DNS. La résolution DNS part de la racine,
puis descend vers les domaines de premier niveau, de deuxième
niveau, etc. De même, un résolveur validant avec DNSSEC connait la
clé publique
de la racine, s'en sert pour valider la clé du premier niveau, qui
sert ensuite pour valider la clé du deuxième niveau, etc. C'est
ainsi que DNSSEC était prévu, et qu'il fonctionne aujourd'hui. Mais
il y a eu une période de transition, pendant laquelle la racine, et
la plupart des TLD, n'étaient pas signés. Le résolveur validant
aurait donc dû gérer autant de clés publiques qu'il y avait de zones
signées. Pour éviter cela, DLV (DNSSEC Lookaside
Validation) avait été
créé. Le principe de DLV était de mettre les clés des zones signées
dans une zone spéciale (par exemple
dlv.operator.example) et que les résolveurs
cherchent les clés à cet endroit. Ainsi, le résolveur validant
n'avait besoin que de la clé de la zone DLV. DLV a bien rempli son
rôle, et a sérieusement aidé au déploiement de DNSSEC. Mais,
aujourd'hui, les choses sont différentes, la racine (depuis 2010) et tous les
TLD importants sont signés (1 389 TLD sur 1 531 sont signés,
.fr l'a également été en
2010), et DLV n'a donc plus de raison d'être.
Bien sûr, il reste encore des zones de délégation non signées et donc en théorie des gens qui pourraient avoir besoin de DLV. Mais le consensus était clair à l'IETF sur l'abandon de DLV, car (section 3 de notre RFC) :
- Le maintien de DLV risque de décourager les zones manquantes de signer (« pas la peine, les gens n'ont qu'à utiliser DLV »),
- Toute occasion de simplifier le code des résolveurs (plus besoin du cas spécial de DLV) est bonne à prendre, et améliore la sécurité,
- D'ailleurs, tous les résolveurs n'ont pas DLV et donc, de toute façon, il ne remplace pas un chemin de validation « normal ».
Il n'y avait en pratique d'une seule zone DLV sérieuse,
dlv.isc.org, et elle a
été arrêtée en 2017, il ne reste donc de toute façon plus
d'utilisateurs connus de DLV.
Donc (section 4 de notre RFC), les deux RFC qui décrivaient DLV, le RFC 4431 et le RFC 5074
passent du statut « Pour information » à celui de « Intérêt
historique seulement ». (Vous pouvez consulter les détails
du processus.) Même chose pour le type d'enregistrement DNS
DLV (code 32769), qui apparait désormais dans
le
registre IANA comme (OBSOLETE).
L'article seul
RFC 8748: Registry Fee Extension for the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : R. Carney (GoDaddy), G. Brown (CentralNic Group), J. Frakes
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 15 mars 2020
Historiquement, le protocole EPP d'avitaillement des
ressources Internet (notamment les noms de domaine) n'indiquait pas le prix de
création ou de renouvellement d'un nom. Typiquement, tous les noms
coûtaient le même prix. Mais certains
registres préfèrent vendre plus cher
sex.example que
suitedelettressanstropdesignification.example. D'où
cette extension EPP qui permet d'indiquer le coût d'un nom de
domaine particulier, extension qui est aujourd'hui très
répandue.
Il y a donc deux logiques possibles, une purement technique (les noms de domaine ont tous le même coût pour le registre et devraient donc coûter pareil au client) et une logique business, où on essaie de faire payer le client plus cher pour les noms les plus demandés. Aux débuts d'EPP (ou de son prédécesseur RGP, dans le RFC 3915), il allait de soi qu'il n'y avait qu'un prix puisque les coûts réels sont les mêmes pour tous les domaines, mais ce n'est plus le cas aujourd'hui. Il faut donc pouvoir informer sur les prix, EPP n'étant pas juste un canal technique mais aussi un canal de vente. Comme cela avait été dit lors d'une discussion à l'IETF, « Arguably, in a situation where many TLDs are now offering domains at various pricing tiers (with no further policy requirements), general availability is no longer just a matter of "domain taken/reserved/valid?", but also of "how much is the registrant willing to pay?". »
L'ancien modèle était donc :
- Certaines opérations sur les objets avitaillés (cf. RFC 5730) sont
payantes, typiquement
<create>,<renew>et<transfer>, d'autres gratuites (par exemple<update>), - Le prix est le même pour tous les domaines,
- Ce prix n'est pas indiqué via le canal EPP, on le découvre dans la documentation fournie par le registre.
Le nouveau modèle, où le tarif est indiqué via le canal EPP, permet d'avoir des prix différents par domaine, mais permet également de découvrir automatiquement le tarif, sans se plonger dans la documentation.
La section 3 du RFC décrit ce qui se passe dans chaque commande
EPP facturable. L'extension utilise un espace de noms
XML qui vaut
urn:ietf:params:xml:ns:epp:fee-1.0 (abrégé à
fee: dans les exemples du RFC mais bien sûr,
comme toujours avec les espaces de noms XML, chacun choisit son
abréviation.)
Voici un exemple où le client vérifie la disponibilité d'un domaine
et son prix, avec <check> :
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<check>
<domain:check
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.net</domain:name>
</domain:check>
</check>
<extension>
<fee:check xmlns:fee="urn:ietf:params:xml:ns:epp:fee-1.0">
<fee:currency>USD</fee:currency>
<fee:command name="create">
<fee:period unit="y">2</fee:period>
</fee:command>
</fee:check>
</extension>
</command>
</epp>
Le client a demandé quel était le prix en dollars étatsuniens pour
une réservation de deux ans. Ici, le serveur lui répond que le
domaine est libre (avail="1") :
...
<resData>
<domain:chkData
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:cd>
<domain:name avail="1">example.net</domain:name>
</domain:cd>
</domain:chkData>
</resData>
<extension>
<fee:cd avail="1">
<fee:objID>example.net</fee:objID>
<fee:class>standard</fee:class>
<fee:command name="create" standard="1">
<fee:period unit="y">2</fee:period>
<fee:fee
description="Registration Fee"
refundable="1"
grace-period="P5D">10.00</fee:fee>
</fee:command>
...
Et qu'il en coûtera dix dollars. Notez que le prix dépend de la
commande (d'où le <fee:command
name="create"> chez le client, et dans la réponse) ;
un renouvellement peut coûter moins cher qu'une création, par
exemple. Notez aussi que le RFC ne spécifie pas comment le prix est
déterminé ; cela peut être configuré manuellement par le registre,
ou bien suivre un algorithme (prix plus élevé si le nom est dans un
dictionnaire, ou s'il fait moins de N caractères…)
Le serveur EPP aurait pu refuser, si les paramètres étaient inconciliables avec sa politique :
<fee:cd avail="0">
<fee:objID>example.net</fee:objID>
<fee:reason>Only 1 year registration periods are
valid.</fee:reason>
</fee:cd>
En quelle monnaie sont indiqués les coûts ? Un élément XML
<fee:currency> va permettre de
l'indiquer. Sa valeur est un code à trois lettres tiré de la norme ISO 4217, par exemple
EUR pour l'euro et
CNY pour le yuan. Si le
registre se fait payer, non pas dans une monnaie reconnue mais dans
une unité de compte privée (des « crédits » internes, par exemple),
il peut utiliser le code XXX. Le serveur ne
doit pas faire de conversion monétaire. S'il a
indiqué des coûts en dollars étatsuniens et
que le client indique ce qu'il paie en pesos
mexicains, le serveur doit rejeter la commande (ce qui
est logique, vu la volatilité des taux de conversion.)
Cette extension à EPP permet également d'indiquer des périodes pendant lesquelles les objets, par exemple les noms de domaine, sont enregistrés. L'unité de temps (mois ou année) est indiquée également.
L'extension permet également d'indiquer des actions commerciales comme une remise, un remboursement (par exemple en cas d'utilisation de la période de grâce du RFC 3915), etc.
Un mécanisme courant chez les registres est d'avoir un compte par client, où le client dépose une certaine somme, d'où les créations ultérieures de noms de domaine sont déduites. Cela donne au registre de la trésorerie, et cela simplifie la comptabilité. L'extension de ce RFC permet de consulter le montant restant (balance) et d'indiquer si l'épuisement de ce compte signifie un arrêt des opérations payantes, ou bien si le serveur fait crédit au client.
Les prix peuvent dépendre du nom de domaine
(hotels.example étant plus cher que
fzoigqskjjazw34.example) mais aussi de la phase
actuelle des enregistrements. Par exemple, une phase initiale, dite
de « lever de soleil » (RFC 8334) pour un
nouveau domaine d'enregistrement peut avoir des prix plus
élevés.
Le serveur peut exiger que le client marque son approbation en indiquant, dans ses requêtes, le prix à payer (section 4). Voilà ce que cela donnerait pour la commande de création :
...
<command>
<create>
<domain:create
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.net</domain:name>
<domain:period unit="y">2</domain:period>
<domain:registrant>jd1234</domain:registrant>
...
</domain:create>
</create>
<extension>
<fee:create xmlns:fee="urn:ietf:params:xml:ns:epp:fee-1.0">
<fee:currency>USD</fee:currency>
<fee:fee>10.00</fee:fee>
</fee:create>
</extension>
</command>
Pour une demande de vérification de disponibilité
(<check>), le serveur peut répondre que
le domaine n'est pas libre si le client n'utilise pas l'extension de
coût. Le principe est que, si un <check>
indique qu'un domaine est libre, un
<create> avec les mêmes
extensions ou la même absence d'extension doit
réussir. « Libre » veut donc dire « libre, aux conditions que tu as
indiquées ».
Les détails de l'extension dans toutes les commandes EPP figurent en section 5, et le schéma en section 6.
L'extension décrite dans le RFC a été ajoutée au registre des extensions EPP, spécifié par le RFC 7451.
Cette extension EPP est déjà mise en œuvre par CentralNic et par d'autres registres mais attention, pas forcément avec la version du RFC, cela peut être des brouillons antérieurs.
L'article seul
RFC 8746: Concise Binary Object Representation (CBOR) Tags for Typed Arrays
Date de publication du RFC : Février 2020
Auteur(s) du RFC : C. Bormann (Universitaet Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 29 février 2020
Ce nouveau RFC étend le format de fichiers CBOR (normalisé dans le RFC 8949) pour représenter des tableaux de données numériques, et des tableaux multidimensionnels.
Le format CBOR est en effet extensible par des étiquettes (tags) numériques qui indiquent le type de la donnée qui suit. Aux étiquettes définies dans la norme originale, le RFC 8949, ce nouveau RFC ajoute donc des étiquettes pour des types de tableaux plus avancés, en plus du type tableau de base de CBOR (qui a le type majeur 4, cf. RFC 8949, et dont les données ne sont pas forcément toutes de même type).
Le type de données « tableau de données numériques » est utile pour les calculs sur de grandes quantités de données numériques, et bénéficie de mises en œuvres adaptées puisque, opérant sur des données de même type, contrairement aux tableaux CBOR classiques, on peut optimiser la lecture des données. Pour comprendre l'utilité de ce type, on peut lire « TypedArray Objects » (la spécification de ces tableaux dans la norme ECMA de JavaScript, langage dont CBOR reprend le modèle de données) et « JavaScript typed arrays » (la mise en œuvre dans Firefox).
La section 2 spécifie ce type de tableaux dans CBOR. Un tableau typé (typed array) est composé de données numériques de même type. La représentation des nombres (par exemple entiers ou flottants) est indiquée par l'étiquette. En effet, il n'y a pas de représentation canonique des nombres dans un tableau typé (contrairement aux types numériques de CBOR, types majeurs 0, 1 et 7) puisque le but de ces tableaux est de permettre la lecture et l'écriture rapides de grandes quantités de données. En stockant les données sous diverses formes, on permet de se passer d'opérations de conversion.
Il n'y a pas moins de 24 étiquettes (désormais enregistrées dans
le
registre IANA des étiquettes CBOR) pour représenter toutes
les possibilités. (Ce nombre important, les étiquettes étant codées
en général sur un seul octet, a suscité des discussions dans le
groupe de travail, mais se justifie par le caractère très courant de
ces tableaux numériques. Voir la section 4 du RFC.) Par exemple,
l'étiquette 64 désigne un tableau typé d'octets (uint8),
l'étiquette 70 un tableau typé d'entiers de 32 bits non
signés et petit-boutiens
(uint32), l'étiquette 82 un tableau typé de
flottants IEEE 754 de 64 bits
gros-boutiens, etc. (CBOR est normalement gros-boutien, comme tous
les protocoles et formats Internet, cf. section 4 du RFC.) Les
étiquettes ne sont pas attribuées arbitrairement, chaque nombre
utilisé comme étiquette encode les différents choix possibles dans
les bits qui le composent. Par exemple, le quatrième bit de
l'étiquette indique si les nombres sont des entiers ou bien des
flottants (cf. section 2.1 du RFC pour les détails).
Le tableau typé est ensuite représenté par une simple chaîne d'octets CBOR (byte string, type majeur 2). Une mise en œuvre générique de CBOR peut ne pas connaitre ces nouvelles étiquettes, et considérera donc le tableau typé comme une bête suite d'octets.
La section 3 de notre RFC décrit ensuite les autres types de tableaux avancés. D'abord, les tableaux multidimensionnels (section 3.1). Ils sont représentés par un tableau qui contient deux tableaux unidimensionnels. Le premier indique les tailles des différentes dimensions du tableau multidimensionnel, le second contient les données. Deux étiquettes, 40 et 1040, sont réservées, pour différencier les tableaux en ligne d'abord ou en colonne d'abord. Par exemple, un tableau de deux lignes et trois colonnes, stocké en ligne d'abord, sera représenté par deux tableaux unidimensionnels, le premier comportant deux valeurs, 2 et 3, le second comportant les six valeurs, d'abord la première ligne, puis la seconde.
Les autres tableaux sont les tableaux homogènes (étiquette 41), en section 3.2. C'est le tableau unidimensionnel classique de CBOR, excepté que tous ses élements sont du même type, ce qui peut être pratique au décodage, pour les langages fortement typés. Mais attention : comme rappelé par la section 7 du RFC, consacrée à la sécurité, le décodeur doit être prudent avec des données inconnues, elles ont pu être produites par un programme malveillant ou bogué, et donc non conformes à la promesse d'homogénéité du tableau.
La section 5 de notre RFC donne les valeurs des nouvelles étiquettes dans le langage de schéma CDDL (RFC 8610).
L'article seul
RFC 8744: Issues and Requirements for Server Name Identification (SNI) Encryption in TLS
Date de publication du RFC : Juillet 2020
Auteur(s) du RFC : C. Huitema (Private
Octopus)
Pour information
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 29 juillet 2020
Le but du protocole de cryptographie TLS est de protéger une session contre l'écoute par un indiscret, et contre une modification par un tiers non autorisé. Pour cela, TLS chiffre toute la session. Toute la session ? Non, certaines informations circulent en clair, car elles sont nécessaires pour la négociation des paramètres de chiffrement. Par exemple, le SNI (Server Name Indication) donne le nom du serveur qu'on veut contacter. Il est nécessaire de le donner en clair car la façon dont vont se faire le chiffrement et l'authentification dépendent de ce nom. Mais cela ouvre des possibilités aux surveillants (savoir quel serveur on contacte, parmi tous ceux qui écoutent sur la même adresse IP) et aux censeurs (couper sélectivement les connexions vers certains serveurs). Il est donc nécessaire de protéger ce SNI, ce qui n'est pas facile. Ce nouveau RFC décrit les objectifs, mais pas encore la solution. Celle-ci reposera sans doute sur la séparation entre un frontal général qui acceptera les connexions TLS, et le « vrai » service caché derrière.
C'est que le problème est difficile puisqu'on est face à un dilemme de l'œuf et de la poule. On a besoin du SNI pour chiffrer alors qu'on voudrait chiffrer le SNI. Le RFC note qu'il n'y aura sans doute pas de solution parfaite.
Cela fait longtemps que le SNI (normalisé il y a longtemps, dans
le RFC 3546, et aujourd'hui dans le RFC 6066) est connu pour les risques qu'il pose
pour la vie privée. Les autres canaux de
fuite d'information sont fermés petit à petit (par exemple le
DNS, avec les RFC 9156, RFC 7858 et RFC 8484), souvent en utilisant TLS (RFC 8446). Même l'adresse
IP de destination, qu'on ne peut pas cacher, perd de sa
signification lorsque de nombreux services sont hébergés derrière la
même adresse IP (c'est particulièrement vrai pour les gros
CDN). Mais
ces services comptent sur le SNI (Server Name
Indication), transporté en clair dans le message TLS
ClientHello, pour le démultiplexage des
requêtes entrantes, et ce SNI tend donc à devenir le maillon faible
de la vie privée, l'information la plus significative qui reste en
clair. Voici, vu par tshark,
un exemple de ClientHello, avec un SNI
(server_name, affiche tshark) :
...
Secure Sockets Layer
TLSv1 Record Layer: Handshake Protocol: Client Hello
Content Type: Handshake (22)
Version: TLS 1.0 (0x0301)
Length: 233
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Length: 229
Version: TLS 1.2 (0x0303)
...
Extension: server_name (len=22)
Type: server_name (0)
Length: 22
Server Name Indication extension
Server Name list length: 20
Server Name Type: host_name (0)
Server Name length: 17
Server Name: doh.bortzmeyer.fr
Résultat, le SNI est souvent utilisé de manière intrusive, le RFC 8404 donnant de nombreux exemples. Par exemple,
il permet de censurer finement (si le SNI indique
site-interdit.example, on jette les paquets,
s'il indique site-commercial.example, on laisse
passer). Il permet de
shaper le trafic vers
certains sites, en violation de la neutralité du réseau. Il permet aussi de
laisser passer certains sites, lorsqu'on fait une attaque
de l'homme du milieu, par exemple une entreprise qui
fait de l'inspection HTTPS
systématique peut utiliser le SNI pour en exempter certaines sites
sensibles, comme ceux des banques ou des plate-formes médicales. Et,
bien sûr, le SNI peut être passivement observé à des fins de
surveillance (RFC 7258).
On peut s'amuser à noter que ces risques pour la vie privée
n'avaient pas été notés dans la section « Sécurité » des RFC de
normalisation de SNI, comme le RFC 6066. C'est
peut-être parce qu'à l'époque, les éventuels attaquants avaient des
moyens plus simples à leur disposition. (Je me souviens de
discussions à l'IETF « à quoi bon masquer le SNI puisque le
DNS révèle
tout ? » ; c'était avant le RFC 7626.) Il
restait un endroit où le nom du service était en clair, c'était le
certificat renvoyé par le serveur TLS
(subjectAltName) mais, depuis TLS 1.3 (RFC 8446), lui aussi est chiffré. Aujourd'hui, les
progrès de la sécurité font que le moyen le plus simple de savoir à
quel service un internaute se connecte devient souvent le SNI.
Notez toutefois que tout le monde n'est pas d'accord sur la nécessité de chiffrer le SNI. Certains craignent que cette nécessité débouche sur une solution compliquée et fragile. D'autres ne veulent tout simplement pas priver surveillants et censeurs d'un mécanisme si pratique. En réponse à cette dernière objection (cf. RFC 8404), le RFC note que la méthode recommandée (section 2.3 du RFC), si on peut surveiller et filtrer, est de le faire dans les machines terminales. Après tout, si l'organisation contrôle ces machines terminales, elle peut les configurer (par exemple avec le certificat de l'intercepteur) et si elle ne les contrôle pas, elle n'a sans doute pas le droit d'intercepter les communications.
La solution est évidente, chiffrer le SNI. Ce ne sont pas les propositions qui ont manqué, depuis des années. Mais toutes avaient des inconvénients sérieux, liés en général à la difficulté du bootstrap. Avec quelle clé le chiffrer puisque c'est justement le SNI qui aide le serveur à choisir la bonne clé ?
La section 3 de notre RFC énumère les exigences auxquelles va devoir répondre la solution qui sera adoptée. (Rappelez-vous qu'il s'agit d'un travail en cours.) C'est que beaucoup de solutions ont déjà été proposées, mais toutes avaient de sérieux problèmes. Petit exercice avant de lire la suite : essayez de concevoir un protocole de chiffrement du SNI (par exemple « le SNI est chiffré avec la clé publique du serveur, récupérée via DANE » ou bien « le SNI est chiffré par une clé symétrique qui est le condensat du nom du serveur [vous pouvez ajouter du sel si vous voulez, mais n'oubliez pas d'indiquer où le trouver] ») et voyez ensuite si cette solution répond aux exigences suivantes.
Par exemple, pensez à la possibilité d'attaque par rejeu. Si le SNI est juste chiffré avec une clé publique du serveur, l'attaquant n'a qu'à observer l'échange, puis faire à son tour une connexion au serveur en rejouant le SNI chiffré et paf, dans la réponse du serveur, l'attaquant découvrira quel avait été le service utilisé. La solution choisie doit empêcher cela.
Évidemment, la solution ne doit pas imposer d'utiliser un secret partagé (entre le serveur et tous ses clients), un tel secret ne resterait pas caché longtemps.
Il faut aussi faire attention au risque d'attaque par déni de service, avec un méchant qui générerait plein de SNI soi-disant chiffrés pour forcer des déchiffrements inutiles. Certes, TLS permet déjà ce genre d'attaques mais le SNI peut être traité par une machine frontale n'ayant pas forcément les mêmes ressources que le vrai serveur.
Autre chose importante quand on parle de protéger la
vie privée : il ne faut pas se distinguer
(Do not stick out). Porter un masque du
Joker dans la rue pour protéger son anonymat
serait sans doute une mauvaise idée, risquant au contraire d'attirer
l'attention. La solution choisie ne doit donc pas permettre à, par
exemple, un état policier, de repérer facilement les gens qui sont
soucieux de leur vie privée. Une extension spécifique du
ClientHello serait dangereuse, car triviale à
analyser automatiquement par un système de surveillance massive.
Il est évidemment souhaitable d'avoir une confidentialité persistante, c'est-à-dire que la compromission d'une clé privée ne doit pas permettre de découvrir, a posteriori, les serveurs auxquels le client s'était connecté. Simplement chiffrer le SNI avec la clé publique du serveur ne convient donc pas.
L'hébergement Web d'aujourd'hui est souvent compliqué, on peut avoir un frontal géré par une société d'hébergement, et des machines gérées par le client de l'hébergeur derrière, par exemple. Ou bien plusieurs clients de l'hébergeur sur la même machine physique, voire sur la même machine virtuelle avec certaines hébergements mutualisés. Cela peut être utile pour certaines solutions, par exemple le fronting où une machine frontale reçoit une demande de connexion TLS pour elle puis, une fois TLS démarré, reçoit le nom du vrai serveur, et relaie vers lui. Si la machine frontale relaie pour beaucoup de serveurs, cela fournit une assez bonne intimité. Mais cela nécessite de faire confiance à la machine frontale, et le risque d'attaque de l'homme du milieu (qui nous dit que ce frontal est le frontal légitime choisi par le serveur TLS ?) augmente. Or, plus la machine frontale protège des serveurs, plus elle est un objectif tentant pour la police ou les pirates.
Ah, et j'ai parlé du Web mais la solution doit évidemment fonctionner avec d'autres protocoles que HTTPS. Par exemple, le DNS sur TLS du RFC 7858 ou bien IMAP (RFC 8314) doivent fonctionner. Même pour HTTP, certaines particularités de HTTP peuvent poser problème, et il est donc important que la future solution de chiffrement de SNI soit agnostique, pour marcher avec tous les protocoles. Et elle doit également fonctionner avec tous les protocoles de transport, pas seulement TCP, mais aussi DTLS ou QUIC.
Le RFC note aussi qu'il serait bon d'avoir une solution de chiffrement de la négociation ALPN (RFC 7301). ALPN est moins indiscret que SNI mais il renseigne sur l'application utilisée.
Puisque j'ai parlé plus haut du fronting, cela
vaut la peine de parler du fronting HTTP car
c'est une technique courante, aussi bien pour échapper à la censure
que pour protéger la vie privée. La section 4 du RFC lui est
consacrée. Elle est décrite dans l'article de Fifield, D., Lan, C.,
Hynes, R., Wegmann, P., et V. Paxson, « Blocking-resistant
communication through domain fronting ». Le
principe est que le client TLS établit une connexion avec le système
de fronting puis, une fois le chiffrement TLS en
marche, le client demande la connexion avec le vrai serveur. Un
surveillant ne pourra voir que l'utilisation d'un service de
fronting, pas le nom du vrai service (le SNI en
clair dira, par exemple,
fronting.example.net). En pratique, cela marche
bien avec HTTPS si le serveur de fronting et le
vrai serveur sont sur le même système : il suffit alors d'indiquer
le domaine du fronting dans le SNI et le vrai
domaine dans les en-têtes Host: de HTTP. Cela
ne nécessite aucune modification du protocole TLS.
Le fronting a quelques limites :
- Le client doit trouver un service acceptant de faire du fronting. (Ce qui n'est pas évident.)
- Le client doit configurer son logiciel pour utiliser un service de fronting.
- Il faut évidemment faire confiance au service de fronting, qui est, d'une certaine façon, un homme du milieu. (Ceci dit, si serveur de fronting et vrai serveur sont au même endroit, cela n'implique pas de faire confiance à un nouvel acteur.) Le problème est d'autant plus crucial qu'il n'existe pas de moyen standard, pour un serveur, d'authentifier publiquement le service de fronting par lequel on peut y accéder. Des variantes du fronting existent, qui limitent ce problème, par exemple en faisant du HTTPS dans HTTPS, si le serveur de fronting l'accepte.
- Cela ne marche qu'avec HTTP, puisque cela utilise le fait que les requêtes HTTP indiquent le vrai serveur de destination. (C'est d'ailleurs une des raisons pour lesquelles a été développé DoH, spécifié dans le RFC 8484.)
À noter que les trames ORIGIN du RFC 8336 peuvent être utiles en cas de
fronting, pour indiquer le contenu venant du
« vrai » serveur.
Voilà, vous connaissez maintenant le problème, l'IETF est en train de travailler aux solutions, ce sera finalement publié dans le RFC 9849, en 2026.
L'article seul
RFC 8740: Using TLS 1.3 with HTTP/2
Date de publication du RFC : Février 2020
Auteur(s) du RFC : D. Benjamin (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 24 février 2020
Voici un très court RFC, pour résoudre un petit problème d'interaction entre TLS 1.3 et HTTP/2. (Mais ne le lisez pas, il a depuis été intégré au RFC 9113.)
Les anciennes versions du protocole de sécurité TLS avaient un mécanisme de renégociation des paramètres de la session, permettant de changer certains paramètres même après que la session ait démarré. C'était parfois utilisé pour l'authentification du client TLS, par exempe lorsqu'un serveur HTTP décide de demander ou pas un certificat client en fonction de la requête dudit client. Or, dans la version 2 de HTTP, HTTP/2, normalisée à l'origine dans le RFC 7540, il peut y avoir plusieurs requêtes HTTP en parallèle. On ne peut donc plus corréler une requête HTTP avec une demande de certificat. Le RFC 7540 (section 9.2.1) interdit donc d'utiliser la renégociation.
Mais la nouvelle version de TLS, la 1.3, spécifiée dans le RFC 8446, a supprimé complètement le mécanisme de renégociation. À la place, un mécanisme d'authentification spécifique a été normalisé (section 4.6.2 du RFC 8446.) Or, ce mécanisme pose les mêmes problèmes que la rénégociation avec le parallélisme que permet HTTP/2. Il fallait donc l'exclure aussi, ce qui n'avait pas été remarqué tout de suite. C'est ce que fait notre RFC. Pas d'authentification après la poignée de main initiale, elle est incompatible avec HTTP/2 (ou avec le futur HTTP/3, d'ailleurs, qui permet également des requêtes en parallèle) et elle doit déclencher une erreur.
À noter que la renégociation était également utilisée pour dissimuler le vrai certificat serveur, par exemple pour contourner certaines solutions de censure. Comme TLS 1.3 chiffre désormais le certificat serveur, la renégociation n'est plus utile pour ce scénario. En outre, la renégociation avait posé quelques problèmes de sécurité (cf. une faille fameuse, et le RFC 7457.)
Outre la renégociation, il y a d'autres messages qui peuvent
survenir après la poignée de main initiale. C'est le cas des
KeyUpdate (RFC 8446,
sections 4.6.3 et 7.2) mais ils concernent la session TLS entière,
pas juste une requête HTTP, donc ils sont compatibles avec le
parallélisme de HTTP/2. Quant aux
NewSessionTicket (RFC 8446, section 4.6.1), ils dépendent, eux, de la requête
HTTP, mais leur interaction avec HTTP/2 est prévue et documentée
dans le RFC 8470, et ils sont donc
acceptés. De toute façon, depuis, le problème a été réglé par le
remplacement du RFC 7540 par le RFC 9113.
L'article seul
RFC 8739: Support for Short-Term, Automatically-Renewed (STAR) Certificates in Automated Certificate Management Environment (ACME)
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : Y. Sheffer
(Intuit), D. Lopez, O. Gonzalez de
Dios, A. Pastor Perales (Telefonica
I+D), T. Fossati (ARM)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF acme
Première rédaction de cet article le 12 mars 2020
Quand une Autorité de Certification (AC) émet un certificat numérique, une question de sécurité se pose : que se passe-t-il si un attaquant met la main sur la clé privée associée à ce certificat, et peut donc usurper l'identité du titulaire légitime ? La réponse traditionnelle était la révocation du certificat par l'AC dès qu'elle est prévenue. Pour diverses raisons, ce processus de révocation est peu fiable, ce qui laisse comme seule ligne de défense l'expiration du certificat. C'est le rôle du champ « Not After » dans un certificat. Pour la sécurité, on voudrait que la date d'expiration soit proche, pour ne pas laisser un éventuel attaquant profiter de son forfait trop longtemps. Mais ce n'est pas très pratique pour le titulaire que de renouveller son certificat très souvent, même avec un protocole comme ACME qui permet l'automatisation. Ce nouveau RFC propose une extension à ACME, qui autorise des certificats de très courte durée de vie (quelques jours seulement) mais renouvellés encore plus facilement qu'avec le ACME classique.
Petit rappel sur ACME : ce protocole, normalisé dans le RFC 8555, permet d'obtenir de manière automatique un certificat correspondant à une identité qui est, la plupart du temps, un nom de domaine. Comme ACME permet l'automatisation, il résout le problème de la révocation en utilisant des certificats dont la durée de vie se compte en mois et plus en années. Ainsi, l'AC Let's Encrypt émet des certificats qui durent trois mois. Mais même trois mois, ça peut être long, si quelqu'un a piqué votre clé privée et se sert de ce certificat. Si on souhaite des certificats durant quelques jours, peut-on utiliser ACME ? En théorie, oui, mais, en pratique, l'AC pourrait ne pas aimer cette charge supplémentaire, et puis que ferait le titulaire si l'AC était indisponible pendant 48 h et qu'on ne puisse pas renouveller le certificat ?
D'où l'idée des certificats STAR (Short-Term,
Automatically-Renewed), initialement décrits dans
l'article « Towards
Short-Lived Certificates », de Topalovic, E.,
Saeta, B., Huang, L., Jackson, C., et D. Boneh, puis dans
l'Internet-Draft
draft-nir-saag-star. Les
certificats seront de très courte durée de vie, et publiés un peu à
l'avance par l'AC, sans demande explicite du client. Celui-ci pourra
par contre demander l'interruption de la série de certificats, si sa
clé privée a été compromise.
La section 2 de notre RFC explique le déroulement des
opérations. Le client (IdO, pour Identifier
Owner) demande à l'AC une série de certificats STAR, l'AC,
aux intervalles indiqués, crée et publie les certificats, à tout
moment, l'IdO peut arrêter la série. Commençons par le commencement,
le démarrage de la série. C'est du ACME classique (RFC 8555), avec ses défis (par exemple, l'IdO doit prouver
qu'il contrôle bien le nom de
domaine qui sert d'identité). L'IdO doit envoyer
l'extension ACME nommée auto-renewal. L'AC
indique au client où seront publiés les certificats de la série.
Ensuite, la publication de la série. Tous les certificats de la série utilisent la même clé privée. (Par défaut, les clients ACME classiques créent une nouvelle clé pour chaque renouvellement du certificat.) Ces certificats sont publiés à l'URL annoncé à la fin de la phase précédente.
Lorsqu'il le souhaite, l'IdO peut demander à l'AC d'interrompre la publication de la série de certificats. Notez qu'on ne révoque jamais ces certificats STAR, puisque de toute façon ils expirent très vite.
Les détails du protocole figurent en section 3 du RFC. Ainsi,
l'objet auto-renewal (désormais dans le registre des champs de l'objet Order) a
plusieurs champs intéressants, comme start-date
(début de la série), end-date (fin de la série,
mais elle pourra se terminer plus tôt, en cas d'annulation
explicite), lifetime (durée de vie des
certificats, notez que la valeur réelle dépendra de la politique de
l'AC, cf. section 6.2). Voici un exemple de cet objet, à ajouter aux requêtes de
demande de certificat :
"auto-renewal": {
"start-date": "2019-01-10T00:00:00Z",
"end-date": "2019-01-20T00:00:00Z",
"lifetime": 345600, // 4 days
"lifetime-adjust": 259200 // 3 days
}
Les champs possibles dans un auto-renewal sont
listés dans un registre IANA. D'autres
champs pourront être ajoutés dans le futur, en suivant la politique
« Spécification nécessaire » (RFC 8126.)
L'objet Order
(section 7.1.6 du RFC 8555 sera en état
ready tant que la série des certificats
continuera.
L'AC annoncera sa capacité à faire du STAR (ici à la fin de son annonce) :
{
"new-nonce": "https://example.com/acme/new-nonce",
"new-account": "https://example.com/acme/new-account",
"new-order": "https://example.com/acme/new-order",
...
"meta": {
"terms-of-service": "https://example.com/acme/terms/2017-5-30",
...
"auto-renewal": {
"min-lifetime": 86400,
"max-duration": 31536000,
"allow-certificate-get": true
}
}
}
Pour arrêter la série avant end-date, le
client ACME mettra cet état à canceled :
POST /acme/order/ogfr8EcolOT HTTP/1.1
Host: example.org
Content-Type: application/jose+json
{
"protected": base64url({
"alg": "ES256",
"kid": "https://example.com/acme/acct/gw06UNhKfOve",
"nonce": "Alc00Ap6Rt7GMkEl3L1JX5",
"url": "https://example.com/acme/order/ogfr8EcolOT"
}),
"payload": base64url({
"status": "canceled"
}),
"signature": "g454e3hdBlkT4AEw...nKePnUyZTjGtXZ6H"
}
Le serveur ACME répondra alors 403 à toutes les requêtes de
récupération d'un certificat de la série annulée, de préférence en
ajoutant (RFC 7807)
urn:ietf:params:acme:error:autoRenewalCanceled. (Cette
erreur, et quelques autres, ont été ajoutées au registre des erreurs ACME.)
Comme vous avez vu, la théorie est simple. Maintenant, il y a un certain nombre de détails opérationnels sur lesquels il faut se pencher, détaillés en section 4. D'abord, le problème des horloges. Les certificats X.509 utilisent partout des temps (la date limite de validité, par exemple) et le respect de ces temps dépend de l'horloge de la machine. Si votre ordinateur a deux mois d'avance, il considérera les certificats comme expirés alors qu'ils ne devraient pas l'être. C'est un problème général de la cryptographie, comme montré par l'article « Where the Wild Warnings Are: Root Causes of Chrome HTTPS Certificate Errors », qui signale que des déviations de plusieurs jours chez les clients ne sont pas rares. Mais c'est évidemment plus grave avec des certificats à très courte durée de vie. Si on a des certificats Let's Encrypt classiques, qui durent trois mois et qu'on renouvelle une semaine avant leur expiration, même si l'horloge du client déconne de plusieurs jours, ça passera. En revanche, avec les certificats STAR, la désynchronisation des horloges aura des conséquences dans bien plus de cas.
La décision d'utiliser STAR ou pas, et le choix de la durée de vie des certificats, va dépendre de la population d'utilisateurs qu'on attend. Le RFC note que les problèmes d'horloge sont bien plus fréquents sur Windows que sur Android, par exemple.
Autre risque avec STAR, la charge supplémentaire pour les journaux Certificate Transparency (RFC 9162). Si STAR devenait le principal mode d'émission de certificats (c'est peu probable), leur trafic serait multiplié par cent. Avant la publication de ce RFC, de nombreuses discussions avec le groupe de travail IETF trans et avec les opérateurs des principaux journaux ont montré qu'il n'y avait a priori pas de risque, ces journaux peuvent encaisser la charge supplémentaire.
Questions mises en œuvre de STAR, il y a eu une scission (non publique ?) de Boulder, le serveur de Let's Encrypt et du client certbot pour y ajouter STAR. Il y a également un client et serveur avec STAR dans Lurk.
La section 6 de notre RFC revient sur les questions de sécurité
liées à STAR. Ainsi, comme l'expiration remplace la révocation, on
ne peut plus exiger la suppression immédiate d'un certificat. (Mais,
on l'a dit, la révocation marche tellement mal en pratique que ce
n'est pas une grande perte.) En cas de compromission de la clé
privée, on peut demander l'arrêt de l'émission des certificats mais
(et cela ne semble pas mentionné par le RFC), si on perd son compte
ACME, ou simplement le numnique ACME, on
ne peut plus annuler cette émission, et on doit attendre
l'expiration de la séquence (indiquée par
end-date.)
L'article seul
RFC 8738: Automated Certificate Management Environment (ACME) IP Identifier Validation Extension
Date de publication du RFC : Février 2020
Auteur(s) du RFC : R. Shoemaker (ISRG)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF acme
Première rédaction de cet article le 1 mars 2020
Dernière mise à jour le 7 mars 2025
Le protocole ACME, surtout connu via son utilisation par l'AC Let's Encrypt, permet de prouver la « possession » d'un nom de domaine, pour avoir un certificat comprenant ce nom. Ce court RFC spécifie une extension à ACME qui permet de prouver la « possession » d'une adresse IP, ce qui permettra d'obtenir via ACME des certificats utilisant une adresse.
Le protocole ACME est normalisé dans le RFC 8555. Son principe est qu'on demande un certificat pour un identificateur (à l'heure actuelle, forcément un nom de domaine) et que le serveur ACME va alors vous défier de prouver que vous contrôlez bien ce nom, par exemple en publiant une chaîne de caractères choisie par le serveur dans un serveur HTTP accessible via ce nom de domaine. Or, les identificateurs dans les certificats PKIX ne sont pas forcément des noms de domaine. Les adresses IP, par exemple, sont prévues. Examinons les certificats du résolveur DNS public Quad9 :
% openssl s_client -connect 9.9.9.9:853 -showcerts | openssl x509 -text
...
X509v3 Subject Alternative Name:
DNS:*.quad9.net, DNS:quad9.net, IP Address:9.9.9.9, IP Address:9.9.9.10, IP Address:9.9.9.11, IP Address:9.9.9.12, IP Address:9.9.9.13, IP Address:9.9.9.14, IP Address:9.9.9.15, IP Address:149.112.112.9, IP Address:149.112.112.10, IP Address:149.112.112.11, IP Address:149.112.112.12, IP Address:149.112.112.13, IP Address:149.112.112.14, IP Address:149.112.112.15, IP Address:149.112.112.112, IP Address:2620:FE:0:0:0:0:0:9, IP Address:2620:FE:0:0:0:0:0:10, IP Address:2620:FE:0:0:0:0:0:11, IP Address:2620:FE:0:0:0:0:0:12, IP Address:2620:FE:0:0:0:0:0:13, IP Address:2620:FE:0:0:0:0:0:14, IP Address:2620:FE:0:0:0:0:0:15, IP Address:2620:FE:0:0:0:0:0:FE, IP Address:2620:FE:0:0:0:0:FE:9, IP Address:2620:FE:0:0:0:0:FE:10, IP Address:2620:FE:0:0:0:0:FE:11, IP Address:2620:FE:0:0:0:0:FE:12, IP Address:2620:FE:0:0:0:0:FE:13, IP Address:2620:FE:0:0:0:0:FE:14, IP Address:2620:FE:0:0:0:0:FE:15
...
On voit qu'outre des noms comme quad9.net, ce
certificat inclut aussi des adresses IP comme
9.9.9.9 et
2620:fe::9. Mais un tel certificat ne pouvait
pas s'obtenir automatiquement via ACME.
Notre RFC
résout ce problème en ajoutant un nouveau type d'identificateur
ACME, ip (section 3 du RFC). Les types
d'identificateurs ACME sont décrits dans la section 9.7.7 du RFC 8555. Le nouveau type ip a
été placé dans le
registre IANA des types d'identificateur. La valeur doit être
une adresse IP sous forme texte (normalisée très sommairement dans
la section 2.1 du RFC 1123 pour
IPv4, et dans la section 4 du RFC 5952 pour IPv6.)
Comme il s'agit d'authentifier des adresses IP, le défi ACME de
type dns-01 n'est pas pertinent et ne doit pas
être utilisé (section 7). Par contre, on peut (section 4 du RFC)
utiliser les défis http-01 (RFC 8555, section 8.3) et le récent
tls-alpn-01 (RFC 8737).
Pour le défi HTTP, le serveur ACME va se connecter en
HTTP à l'adresse IP indiquée, en mettant
cette adresse dans le champ Host:. Pour le défi
TLS avec ALPN, le certificat doit contenir un
subjectAltName de type
iPAddress. Un piège : contrairement au champ
Host: de HTTP, l'adresse IP nue ne peut pas
être utilisée dans le SNI (RFC 6066, « Currently, the only server names
supported are DNS hostnames »). Il faut donc utiliser un
nom dérivé de l'adresse, en in-addr.arpa ou
ip6.arpa. Par exemple, si on veut un certificat
pour 2001:db8::1, il faudra mettre
1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.arpa
dans le SNI.
Un défi utilisant la « résolution inverse » (via une requête DNS
dans in-addr.arpa ou
ip6.arpa) avait été envisagé mais n'a pas été
retenu (les domaines de la « résolution inverse » sont en général
mal maintenus et il est difficile d'obtenir des entrées dans ces
domaines).
La section 9 de notre RFC étudie les conséquences de cette extension pour la sécurité. Le principal point à noter est que ce RFC ne spécifie qu'un mécanisme. L'AC a toute liberté pour définir une politique, elle peut par exemple refuser par principe les adresses IP dans les certificats, comme elle peut les accepter avec des restrictions ou des contrôles supplémentaires. Par exemple, il ne serait pas raisonnable d'allouer de tels certificats pour des adresses IP appartenant à des plages très dynamiques, pouvant changer d'utilisateur très souvent.
Côté mise en œuvre, pour le serveur Boulder (celui utilisé par Let's Encrypt), le code permettant de mettre en œuvre ce RFC a été inclus le 6 mars 2025 (la discussion est ici).
L'article seul
RFC 8737: Automated Certificate Management Environment (ACME) TLS Application-Layer Protocol Negotiation (ALPN) Challenge Extension
Date de publication du RFC : Février 2020
Auteur(s) du RFC : R. Shoemaker (ISRG)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF acme
Première rédaction de cet article le 1 mars 2020
Ce court RFC normalise un mécanisme d'authentification lors d'une session ACME, permettant de prouver, via TLS et ALPN, qu'on contrôle effectivement le domaine pour lequel on demande un certificat.
Le protocole ACME
(RFC 8555) laisse le choix entre plusieurs
mécanismes d'authentification pour répondre aux défis du serveur
ACME « prouvez-moi que vous contrôlez réellement le domaine pour lequel vous me
demandez un certificat ! ». Le RFC 8555 propose un défi fondé sur HTTP
(http-01), dans sa section 8.3, et un défi
utilisant le DNS
(dns-01), dans sa section 8.4. Notez que le
défi HTTP est fait en clair, sans HTTPS. Or, outre la sécurité
de TLS,
certains utilisateurs d'ACME auraient bien voulu une solution
purement TLS, notamment pour les cas où la terminaison de TLS et
celle de HTTP sont faites par deux machines différentes (CDN, répartiteurs de charge TLS,
etc.)
D'où le nouveau défi normalisé par ce RFC, tls-alpn-01. Il
repose sur le mécanisme ALPN, qui avait été normalisé dans le RFC 7301. Déjà mis en œuvre dans des
AC comme Let's
Encrypt, il permet une vérification plus solide. Ce type
de défi figure maintenant dans le
registre des types de défis ACME. Notez qu'il existait déjà
un type utilisant TLS, tls-sni-01 / tls-sni-02,
mais qui avait des
failles, autorisant un utilisateur d'un serveur TLS à obtenir
des certificats pour d'autres domaines du même
serveur. tls-sni est aujourd'hui abandonné.
Les détails du mécanisme figurent dans la section 3 de notre
RFC. Le principe est que le serveur ACME se connectera en TLS au
nom de domaine indiqué
en envoyant l'extension ALPN avec le nom d'application
acme-tls/1 et vérifiera dans le
certificat la présence d'un
token, choisi aléatoirement par le serveur ACME,
token que le client ACME avait reçu sur le canal
ACME. (Ce nom d'application, acme-tls/1 est
désormais dans le
registre des applications ALPN.)
Bien sûr, c'est un peu plus compliqué que cela. Par exemple, comme le client ACME va devenir le serveur TLS lors du défi, il lui faut un certificat. La section 3 du RFC explique les règles auxquelles doit obéir ce certificat :
- Auto-signé, puisqu'on n'est pas encore authentifié auprès de l'AC,
- Un
subjectAlternativeName(RFC 5280) qui a comme valeur le nom de domaine à valider, - Une extension
acmeIdentifier(mise dans le registre des extensions aux certificats PKIX), qui doit être marquée comme critique, pour éviter que des clients TLS passant par là et n'ayant rien à voir avec ACME s'en servent, et dont la valeur est l'autorisation ACME (RFC 8555, section 8.1).
Le client ACME doit ensuite configurer ce qu'il faut sur son serveur
TLS pour que ce soit ce certificat qui soit retourné lors d'une
connexion TLS où le SNI vaut le domaine à valider et où ALPN
vaut acme-tls/1. Il annonce alors au serveur
ACME qu'il est prêt à répondre au défi. Le serveur ACME se connecte
au serveur TLS (créé par le client ACME) et fait les vérifications
nécessaires (nom de domaine dans le certificat, nom qui doit être un
A-label, donc en Punycode,
et extension du certificat acmeIdentifier
contenant la valeur indiquée par le serveur ACME lors du défi).
Une fois la vérification faite, le serveur ACME raccroche : ces
certificats ne sont pas conçus pour échanger de vraies données sur
la session TLS créée. D'ailleurs, les certificats auto-signés créés
pour le type de défi tls-alpn-01 ne permettent
pas d'authentification au sens du RFC 5280. Pour la même raison, le client TLS (créé par le
serveur ACME) n'est pas obligé d'aller jusqu'au bout de
l'établissement de la
session TLS.
La section 5 de notre RFC fait le point sur quelques suppositions
faites au sujet de la mise en œuvre de TLS, suppositions importantes
pour ACME. D'abord, si plusieurs organisations ou personnes
partagent la même adresse IP, ce qui est
courant en cas d'hébergement plus ou moins mutualisé, ACME compte
bien que leurs configurations TLS soient séparées, pour éviter
qu'une de ces entités puisse obtenir un certificat pour une autre,
hébergée au même endroit (cf. annexe A du RFC, qui décrit le
comportement surprenant de certains hébergeurs.) ACME espère
également que les serveurs TLS vont respecter le RFC 7301 en rejetant l'application
acme-tls/1 s'ils ne la connaissent
pas. (Certains programmeurs paresseux ont peut-être fait en sorte
que le serveur TLS accepte n'importe quelle application signalée en
ALPN.)
L'AC Let's Encrypt accepte déjà ce type de défi depuis juillet 2018. (Le RFC est en retard par rapport au déploiement effectif.) Le client ACME dehydrated permet d'utiliser le nouveau type de défi. Cet article utilise nginx côté serveur, avec son module SSL PreRead, qui permet d'aiguiller une requête en fonction de l'ALPN, mais, personnellement, je n'ai pas réussi (ça peut être un problème avec la gestion des modules dans le paquetage Debian de nginx, gestion quasiment pas documentée.)
Côté serveur, on a aussi ce qu'il faut dans Apache, avec le module
mod_md
(cf. plus précisement ce point
de la documentation.) Son utilisation est décrite
dans un article de Marc Framboisier (et sa
suite).
Côté client ACME, d'autres clients gèrent ce type de défi, mais pas encore certbot (cf. le ticket #6724 .)
L'article seul
RFC 8731: Secure Shell (SSH) Key Exchange Method using Curve25519 and Curve448
Date de publication du RFC : Février 2020
Auteur(s) du RFC : A. Adamantiadis (libssh), S. Josefsson (SJD AB), M. Baushke (Juniper Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 29 février 2020
Cela fait déjà pas mal de temps que des mises en œuvre du protocole SSH intègrent les courbes elliptiques « Bernstein », comme Curve25519. Ce RFC est donc juste une formalité, la normalisation officielle de cette utilisation.
SSH est normalisé dans le RFC 4251. C'est peut-être le protocole cryptographique de sécurisation d'un canal Internet le deuxième plus répandu, loin derrière TLS. Il permet de se connecter de manière sécurisée à une machine distante. En application du principe d'agilité cryptographique (RFC 7696), SSH n'est pas lié à un algorithme cryptographique particulier. Le protocole d'échange des clés, normalisé dans le RFC 4253, permet d'utiliser plusieurs algorithmes. Le RFC 5656 a étendu ces algorithmes aux courbes elliptiques.
Les courbes Curve25519 et
Curve448, créées par Daniel Bernstein, sont décrites dans le RFC 7748. Depuis des années, elles s'imposent
un peu partout, à la place des courbes
NIST comme P-256. La
libssh a ces courbes depuis des années,
sous l'ancien nom de
curve25519-sha256@libssh.org. Notre
RFC ne fait qu'officialiser ces
algorithmes, sous les nouveaux noms de
curve25519-sha256 et
curve448-sha512.
La section 3 du RFC décrit les détails de l'utilisation de ces algorithmes pour l'échange de clé. La méthode est proche de l'ECDH de la section 4 du RFC 5656.
Voici un exemple de session utilisant cet algorithme, avec OpenSSH 7.6 :
% ssh -v ...
...
debug1: SSH2_MSG_KEXINIT sent
debug1: SSH2_MSG_KEXINIT received
debug1: kex: algorithm: curve25519-sha256
L'article seul
RFC 8730: Independent Submission Editor Model
Date de publication du RFC : Février 2020
Auteur(s) du RFC : N. Brownlee (The University of Auckland), R. Hinden (Check Point Software)
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Si vous n'aimez pas les RFC de procédure, et que vous ne voulez que de la technique, rassurez-vous, ce document est court : il spécifie le rôle et les qualités de l'ISE (Independent Submission Editor), celui (ou celle) qui supervise les RFC qui ne passent pas par l'IETF. Il remplace le RFC 6548, remplacement nécessaire compte tenu de la nouvelle structure adminstrative de l'IETF, introduite par le RFC 8711.
Comment, ça existe, des RFC non-IETF ? Tous les RFC ne naissent pas au sein d'un des nombreux groupes de travail de l'IETF ? Eh oui, c'est souvent oublié, mais c'est le cas, il existe une voie indépendante qui permet à des individus de publier un RFC, quel que soit l'avis de l'IETF. Cette voie est décrite dans le RFC 4846. Autrefois, il n'existait qu'un seul RFC Editor pour examiner et préparer tous les RFC. Mais cette tâche est désormais répartie entre plusieurs éditeurs spécialisés et l'ISE est en charge de la voie indépendante.
Ce mécanisme de répartition des tâches pour les RFC est décrit dans le RFC 8728 (modèle du RFC Editor, « v2 ») et ce RFC 8730.
La section 2.1 décrit les qualifications attendues de l'ISE. Ce doit être quelqu'un d'expérimenté (senior), compétent techniquement dans les sujets traités à l'IETF (ce qui fait beaucoup !), connu et reconnu de la communauté IETF, sachant écrire et corriger, connaissant très bien l'anglais, et capable de travailler dans le milieu souvent agité de l'IETF.
Sa tâche principale (section 2.2) est de maintenir la qualité des RFC de la voie indépendante, par la relecture et l'approbation des documents, avant transmission au Producteur des RFC (RFC Production Center). Mais il doit aussi traiter les errata pour les RFC de la voie indépendante, contribuer à définir les évolutions de cette voie, interagir avec les autres acteurs des RFC, et fournir des statistiques à l'IAB et l'IETF LLC (cf. RFC 8711). Il peut se faire assister par un conseil consultatif, dont il nomme les membres « at the pleasure of the ISE », dit le RFC dans une jolie formule. Il y a aussi un conseil éditorial, également nommé par l'ISE (section 3 du RFC).
Le site officiel des RFC contient une page consacrée à la voie indépendante, si cela vous tente d'y publier.
L'ISE est nommé par l'IAB. Aujourd'hui, c'est Adrian Farrel, qui joue ce rôle.
Il y a peu de changements depuis le RFC précédent, le RFC 6548, essentiellement le remplacement de l'ancienne structure administrative de l'IETF (l'IAOC) par la nouvelle (l'IETF LLC).
L'article seul
RFC 8729: The RFC Series and RFC Editor
Date de publication du RFC : Février 2020
Auteur(s) du RFC : R. Housley (Vigil Security), L. Daigle (Thinking Cat)
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Les RFC, qui incluent notamment les normes techniques de l'Internet, sont en général réalisés par l'IETF mais sont publiés par une entitée séparée, le RFC editor. Ce RFC documente les RFC, et le rôle du RFC Editor. Il remplace le RFC 4844, avec assez peu de changements, essentiellement l'adaptation à la nouvelle structure administrative de l'IETF, décrite dans le RFC 8711.
Comme pour beaucoup de choses dans l'Internet, la définition exacte des rôles des différents acteurs n'avait pas été formalisée car personne n'en ressentait le besoin. Au fur et à mesure que l'Internet devient une infrastructure essentielle, cette absence de formalisation est mal ressentie et la politique actuelle est de mettre par écrit tout ce qui était implicite auparavant.
C'est le cas du rôle du RFC Editor. Autrefois le titre d'une seule personne, Jon Postel, ce nom désigne désormais une organisation plus complexe. Relire les RFC avant publication, les corriger, leur donner un numéro et assurer leur distribution, tels sont les principaux rôles du RFC Editor.
Notre RFC décrit le but des RFC (section 2) : « documenter les normes de l'Internet, et diverses contributions ». Puis, il explique le rôle du RFC Editor, sa place dans le processus de publication et les fonctions qu'il doit assurer (le cahier des charges de l'IETF avait été publié dans le RFC 4714). Pour plus de détails sur le travail, on peut consulter le site Web du RFC Editor.
Il faut noter (section 5 du RFC) que le RFC editor reçoit des textes candidats par plusieurs voies. Si la plus connue est celle de l'IETF, il peut aussi publier des RFC d'autres origines notamment ceux des soumissions indépendantes (RFC 4846). Il est supervisé par l'IAB et par la nouvelle IETF LLC (RFC 8711.) Le fonctionnement détaillé du RFC Editor et son organisation figurent dans le RFC 8728.
Le RFC editor a une mission difficile puisqu'il doit agir avec prudence, voire avec conservatisme, pour assurer la qualité et la disponibilité des RFC pendant de très longues périodes.
Il y a peu de changements depuis le RFC précédent sur ce sujet (le RFC 4844), essentiellement le remplacement de l'ancienne IAOC par l'IETF LLC décrite dans le RFC 8711.
L'article seul
RFC 8728: RFC Editor Model (Version 2)
Date de publication du RFC : Février 2020
Auteur(s) du RFC : O. Kolkman, J. Halpern (Ericsson), R. Hinden (Check Point Software)
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
L'articulation compliquée entre l'IETF qui produit les normes TCP/IP et le RFC Editor qui les publie, n'a jamais cessé de faire couler de l'encre (ou d'agiter des électrons). Dans ce document, l'IAB décrit un modèle pour le RFC Editor, modèle où les fonctions de ce dernier sont éclatées en plusieurs fonctions logiques. Elles peuvent ainsi être réparties entre plusieurs groupes. Ce RFC remplace le RFC 6635, avec peu de changements : c'est toujours le modèle « v2 » du modèle RFC Editor. Il a depuis été remplacé par une version 3, assez différente, décrite dans le RFC 9920.
Le document de référence actuel est le RFC 8729. Comme le rappelle la section 1, il décrit les tâches du RFC Editor de manière globale, comme si c'était forcément une seule entité (c'était, à l'origine, une seule personne, Jon Postel). La section 2 note que la tâche de RFC Editor est actuellement une partie de l'IASA (dont la récente réforme, décrite dans le RFC 8711, a nécessité ce nouveau RFC) et financée par son budget.
La même section 2 s'attaque à la définition du rôle du RFC Editor sous forme de fonctions séparées. Elles sont ici légèrement modifiées, compte-tenu de l'expérience et des problèmes de communication rencontrés, problèmes de communication qui n'existaient évidemment pas lorsque Postel faisait tout lui-même. Le terme de RFC Editor désigne collectivement toutes ces fonctions. L'IAB voit maintenant trois fonctions (voir aussi le dessin 1 de notre RFC) :
- Éditeur de la série des RFC,
- Producteur des RFC,
- Publieur des RFC,
- Enfin, l'éditeur des contributions indépendantes, décrit à part, dans le RFC 8730.
Chaque section va ensuite détailler ces tâches. Il y a également des rôles de supervision, tenus par l'IAB (RFC 2850) et l'IETF LLC (RFC 8711).
L'Éditeur de la série des RFC (RFC Series Editor, poste actuellement vacant depuis le départ d'Heather Flanagan) est décrit en premier, en section 2.1. Il ou elle est responsable du travail à long terme, il doit définir les principes qui assurent la pérennité des RFC, réfléchir à la stratégie, développer le RFC 7322, le guide de style des RFC, de la langue des RFC, etc. Il sert aussi de « visage » aux RFC, vis-à-vis, par exemple, des journalistes. L'Éditeur est censé travailler avec la communauté IETF pour les décisions politiques. Désigné par l'IAB, il ou elle sera formellement un employé de l'IETF LLC, la structure administrative de l'IETF.
Le RFC 8728 évalue la charge de travail à un mi-temps, ce qui me semble très peu. Notre RFC décrit les compétences nécessaires (section 2.1.6) pour le poste d'Éditeur de la série des RFC, compétences en anglais et en Internet, capacité à travailler dans l'environnement... spécial de l'IETF, expérience des RFC en tant qu'auteur souhaitée, etc.
Le travail quotidien est, lui, assuré par le Producteur des RFC (RFC Production Center) dont parle la section 2.2. C'est un travail moins stratégique. Le Producteur reçoit les documents bruts, les corrige, en discute avec les auteurs, s'arrange avec l'IANA pour l'allocation des numéros de protocoles, attribue le numéro au RFC, etc.
Les RFC n'étant publiés que sous forme numérique, il n'y a pas d'imprimeur mais le numérique a aussi ses exigences de publication et il faut donc un Publieur des RFC (RFC Publisher), détaillé en section 2.3. Celui-ci s'occupe de... publier, de mettre le RFC dans le dépôt où on les trouve tous, d'annoncer sa disponibilité, de gérer l'interface permettant de soumettre les errata, de garder à jour ces errata, et de s'assurer que les RFC restent disponibles, parfois pendant de nombreuses années.
Chacune de ces fonctions pourra faire l'objet d'une attribution spécifique (à l'heure actuelle, les fonctions de Producteur et de Publieur sont assurées par le même groupe à l'AMS). La liste à jour peut être vue sur le site officiel.
Un comité joue un rôle de supervision et de contrôle du RFC Editor : le RSOC (RFC Series Oversight Committee) est décrit en section 3.
Combien cela coûte et qui choisit les titulaires des différentes fonctions ? La section 4 décrit ce rôle, dévolu à l'IETF LLC ( IETF Administration Limited Liability Company, cf. RFC 8711). Le budget est publié en sur le site de l'IETF LLC et on y trouvera aussi les futures évaluations du RFC Editor. On peut aussi trouver cette information, ainsi que plein d'autres sur le fonctionnement du RFC Editor, via le site officiel).
Comme indiqué plus haut, il n'y a pas de grand changement depuis le RFC 6635, juste le remplacement de l'ancienne IAOC par l'IETF LLC. La version 3, dans le RFC 9920, a apporté davantage de changements.
L'article seul
RFC 8726: How Requests for IANA Action Will be Handled on the Independent Stream
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : A. Farrel (Independent Submissions Editor)
Pour information
Première rédaction de cet article le 20 novembre 2020
Tous les RFC ne viennent pas de l'IETF. Certains sont publiés sur la voie indépendante, sous la responsabilité de l'ISE (Independent Submissions Editor). Certains de ces RFC « indépendants » créent ou modifient des registres IANA. Comment traiter ces demandes à l'IANA ?
Ce travail de l'ISE (Independent Submissions
Editor, actuellement Adrian Farrel, l'auteur de ce RFC, et
également des contes « Tales from the wood ») est
documenté dans le RFC 4846. Cet ancien RFC (il
date d'avant la création de l'ISE, qui avait été faite par le RFC 5620, puis précisée par le RFC 6548 puis enfin le RFC 8730) ne donne que peu de détails sur les relations avec
l'IANA, nécessaires si le RFC « indépendant »
demande la création d'un nouveau registre, ou la modification d'un
registre existant. Ces registres IANA sont en https://www.iana.org/protocols
Pour les registres existants (section 2 du RFC), l'ISE est évidemment tenu par ce RFC 8126. Si un RFC de la voie indépendante ajoute une entrée à un registre IANA, il doit suivre la politique qui avait été définie pour ce registre. Cela va de soi. D'autre part, un RFC « indépendant » ne représente pas, par définition, l'IETF, et ne peut donc pas créer d'entrées dans un registre dont la politique est « Examen par l'IETF » ou « Action de normalisation ». Pour la même raison, un RFC de la voie indépendante ne peut pas changer la politique d'un registre qui n'avait pas été créé par un RFC de la voie indépendante (section 3).
Et la création de nouveaux registres (section 4 de notre RFC) ? En général, un RFC « indépendant » ne devrait pas le faire, puisqu'il s'agit de documents qui n'ont pas bénéficié du même examen que les RFC de la voie IETF. La seule exception est la possibilité de créer un sous-registre s'il existe un registre à la politique « ouverte » (« Spécification nécessaire », « Examen par un expert », « RFC nécessaire » ou « Premier Arrivé, Premier Servi ») et que le sous-registre correspond à une entrée ajoutée par le RFC indépendant. L'une des raisons de ce choix est d'éviter de donner trop de travail à l'IANA, en multipliant les registres.
Certaines politiques d'allocation dans un registre IANA nécessitent un expert. La section 5 de notre RFC précise que la voie indépendante ne nommera pas d'expert et que donc aucun des sous-registres éventuellement créés n'aura la politique « Examen par un expert ».
Enfin, la section 6 traite le cas du transfert du contrôle d'un registre. Il n'y aura jamais de transfert depuis la voie IETF vers la voie indépendante (une fois qu'un registre est « officiel », il le reste) mais l'inverse peut arriver, par exemple si un protocole initialement décrit dans un RFC « indépendant » passe finalement sur le chemin des normes.
L'article seul
RFC 8724: SCHC: Generic Framework for Static Context Header Compression and Fragmentation
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : A. Minaburo (Acklio), L. Toutain (IMT-Atlantique), C. Gomez (Universitat Politecnica de Catalunya), D. Barthel (Orange Labs), JC. Zuniga (SIGFOX)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lpwan
Première rédaction de cet article le 16 avril 2020
Ce nouveau RFC décrit un mécanisme de compression des données, et de fragmentation des paquets, optimisé pour le cas des réseaux à longue distance lents connectant des objets contraints en ressources, ce qu'on nomme les LPWAN (Low-Power Wide Area Network, par exemple LoRaWAN.) L'un des buts est de permettre l'utilisation des protocoles Internet normaux (UDP et IPv6) sur ces LPWAN. SCHC utilise un contexte de compression et décompression statique : il n'évolue pas en fonction des données envoyées.
Le LPWAN (RFC 8376) pose en effet des défis particuliers. Il a une faible capacité, donc chaque bit compte. Il relie des objets ayant peu de ressources matérielles (par exemple un processeur très lent). Et la batterie n'a jamais assez de réserves, et émettre sur un lien radio coûte cher en énergie (1 bit reçu ou transmis = 1-1000 microjoules, alors qu'exécuter une instruction dans le processeur = 1-100 nanojoules.) . Le but de l'IETF est de pouvoir utiliser IPv6 sur ces LPWAN et la seule taille de l'en-tête IPv6 est un problème : 40 octets, dont plusieurs champs « inutiles » ou redondants, et qui auraient donc tout intérêt à être comprimés.
Trois choses importantes à retenir sur SCHC (Static Context Header Compression) :
- N'essayez pas de prononcer le sigle « èsse cé hache cé » : on dit « chic » en français, et « sheek » en anglais.
- Comme tout algorithme de compression, SCHC repose sur un contexte commun au compresseur et au décompresseur, contexte qui regroupe l'ensemble des règles suivies pour la compression et la décompression. Mais, contrairement aux mécanismes où le contexte est dynamiquement modifié en fonction des données transmises, ici le contexte est statique ; il n'évolue pas avec les données. Cela élimine notamment tout risque de désynchronisation entre émetteur et récepteur. (Contrairement à des protocoles comme ROHC, décrit dans le RFC 5795.)
- SCHC n'est pas un protocole précis, c'est un cadre générique, qui devra être incarné dans un protocole pour chaque type de LPWAN. Cela nous promet de nouveaux RFC dans le futur. L'annexe D liste les informations qu'il faudra spécifier dans ces RFC.
Si les LPWAN posent des problèmes particuliers, vu le manque de ressources disponibles, ils ont en revanche deux propriétés qui facilitent les choses :
- Topologie simple, avec garantie que les paquets passent au même endroit à l'aller et au retour,
- Jeu d'applications limité, et connu à l'avance, contrairement à ce qui arrive, par exemple, avec un ordiphone.
La section 5 de notre RFC expose le fonctionnement général de SCHC. SCHC est situé entre la couche 3 (qui sera typiquement IPv6) et la couche 2, qui sera une technologie LPWAN particulière, par exemple LoRaWAN (pour qui SCHC a déjà été mis en œuvre, et décrit dans le RFC 9011). Après compression, le paquet SCHC sera composé de l'identificateur de la règle (RuleID), du résultat de la compression de l'en-tête, puis de la charge utile du paquet. Compresseur et décompresseur doivent partager le même ensemble de règles, le contexte. Le contexte est défini de chaque côté (émetteur et récepteur) par des mécanismes non spécifiés, par exemple manuellement, ou bien par un protocole d'avitaillement privé. Chaque règle est identifiée par son RuleID (section 6 du RFC), identificateur dont la syntaxe exacte dépend d'un profil de SCHC donc en pratique du type de LPWAN. (Rappelez-vous que SCHC est un mécanisme générique, les détails concrets de syntaxe sont spécifiés dans le profil, pas dans SCHC lui-même. Par exemple, pour LoRaWAN, c'est dans le RFC 9011.)
Les règles sont expliquées dans la section 7. Chaque règle comporte plusieurs descriptions. Chaque description comprend notamment :
- L'identificateur du champ concerné (SCHC ne traite pas l'en-tête globalement, mais champ par champ), par exemple « port de destination UDP ».
- Longueur et position du champ.
- Valeur cible (TV, Target Value), qui est la valeur à laquelle on va comparer le champ.
- Opérateur de comparaison (MO, pour Matching Operator), l'égalité complète, par exemple, ou bien l'égalité de seulement les N bits de plus fort poids.
- Action (CDA, Compression Decompression Action), qui indique quoi faire si le contenu du champ correspond à la valeur cible. Par exemple, ne pas transmettre le champ (si sa valeur est une valeur connue), ou bien (pour le décompresseur) recalculer la valeur à partir des données. La liste des actions possibles figure dans un tableau en section 7.4. (Elle est fixée une fois pour toutes, il n'est pas prévu de procédure d'enregistrement de nouvelles possibilités.)
L'algorithme est donc : pour chaque description dans une règle, voir si elle correspond au champ visé, en utilisant l'opérateur de comparaison et la valeur cible. Si toutes les descriptions collent, appliquer les actions, et envoyer les données comprimées, précédées de l'identificateur de la règle. Un RuleID spécial est utilisé pour attraper tout le reste, les paquets qui ne seront pas comprimés car aucune règle ne correspondait.
Prenons un exemple : la règle de RuleID 1 a
deux descriptions, qui disent
que les champs X et Y de l'en-tête ont une valeur connue (indiquée
dans la valeur cible), mettons respectivement 42 et « foobar ». Dans
ce cas, les actions de compression (CDA, Compression
Decompression Action) peuvent être simplement « omets ces
champs » (not-sent). Le décompresseur, à
l'autre bout, a la même règle (rappelez-vous que le contexte,
l'ensemble des règles, est statique). Lorsque qu'il voit passer un
paquet comprimé avec la règle 1, il crée simplement les deux champs,
avec les valeurs définies dans la règle (valeurs TV, Target
Value.)
Un exemple figure en section 10 du RFC, avec des règles pour
comprimer et décomprimer les en-têtes IPv6 et UDP. Ainsi, le champ
Version d'IPv6 vaut forcément 6. On met donc la valeur cible (TV) à
6, l'opérateur de comparaison (MO) à « ignorer » (on ne teste pas
l'égalité, on est sûr d'avoir 6, si le paquet est correct), et
l'action (CDA) à not-sent (ne pas envoyer). Le
champ Longueur, par contre, n'a pas de valeur cible, l'opérateur de
comparaison est « ignorer », et l'action est
compute (recalculer à partir des données).
Pour UDP, on peut également omettre les ports source et destination si, connaissant l'application, on sait qu'ils sont fixes et connus, et on peut également recalculer le champ Longueur, ce qui évite de le transmettre. La somme de contrôle est un peu plus compliquée. IPv6 en impose une (RFC 8200, section 8.1) mais autorise des exceptions. Ne pas l'envoyer peut exposer à des risques de corruption de données, donc il faut bien lire le RFC 6936 et le RFC 6282 avant de décider d'ignorer la somme de contrôle. Les règles complètes pour UDP et IPv6 sont rassemblées dans l'annexe A du RFC.
Outre la compression, SCHC permet également la fragmentation (section 8 du RFC). La norme IPv6 (RFC 8200) dit que tout lien qui fait passer de l'IPv6 doit pouvoir transmettre 1 280 octets. C'est énorme pour du LPWAN, où la MTU n'est parfois que de quelques dizaines d'octets. Il faut donc effectuer fragmentation et réassemblage dans la couche 2, ce que fait SCHC (mais, désolé, je n'ai pas creusé cette partie, pourtant certainement intéressante .)
La section 12 de notre RFC décrit les conséquences de SCHC sur la sécurité. Par exemple, un attaquant peut envoyer un paquet avec des données incorrectes, dans l'espoir de tromper le décompresseur, et, par exemple, de lui faire faire de longs calculs, ou bien de générer des paquets de grande taille, pour une attaque avec amplification. Comme toujours, le décompresseur doit donc se méfier et, entre autres, ne pas générer de paquets plus grands qu'une certaine taille. Question sécurité, on peut aussi noter que SCHC n'est pas vulnérable aux attaques comme CRIME ou BREACH, car il traite les différents champs de l'en-tête séparément.
La fragmentation et le réassemblage amènent leurs propres risques, qui sont bien connus sur l'Internet (d'innombrables failles ont déjà été trouvées dans les codes de réassemblage de paquets fragmentés.) Par exemple, une attaque par déni de service est possible en envoyant plein de fragments, sans jamais en envoyer la totalité, forçant le récepteur à consommer de la mémoire pour stocker les fragments en attente de réassemblage. Là encore, le récepteur doit être prudent, voire paranoïaque, dans son code. Par contre, les attaques utilisant la fragmentation pour se dissimuler d'un IDS ne marcheront sans doute pas, puisque SCHC n'est utilisé qu'entre machines directement connectées, avec probablement aucun IDS sur le lien.
Merci à Laurent Toutain pour avoir attrapé une sérieuse erreur dans cet article et à Dominique Barthel pour sa relecture très attentive.
L'article seul
RFC 8722: Defining the Role and Function of IETF Protocol Parameter Registry Operators
Date de publication du RFC : Février 2020
Auteur(s) du RFC : D. McPherson, O. Kolkman (ISOC), J.C. Klensin, G. Huston (APNIC), Internet Architecture Board
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Ce RFC officiel de l'IAB décrit le rôle de l'opérateur des registres des protocoles utilisé par l'IETF. Des tas de protocoles normalisés par cet organisme ont besoin de garder une trace des noms ou numéros réservés (par exemple les numéros de port de TCP ou UDP, les numéros d'options DHCP, etc.) C'est le rôle de l'opérateur du registre qui garde ces réservations (aujourd'hui, essentiellement l'IANA). Ce RFC remplace le RFC 6220, suite à la création de la nouvelle structure administrative de l'IETF, dans le RFC 8711.
L'IETF n'assure pas ce rôle d'opérateur du registre elle-même. Elle se focalise sur la production de normes (les RFC) et délègue la gestion du registre. Pourquoi les valeurs en question ne sont-elles pas directement mises dans les RFC ? Parce qu'elles évoluent plus vite que la norme elle-même. Ainsi, l'enregistrement d'un nouveau type d'enregistrement DNS est un processus bien plus souple que de modifier un RFC et la liste de tels types ne peut donc pas être figée dans un RFC (ceux-ci ne sont jamais modifiés, seulement remplacés, et cela n'arrive pas souvent).
Mais on ne peut pas non plus laisser chacun définir ses propres paramètres, car cela empêcherait toute interprétation commune. D'où cette idée d'un registre des paramètres. Les règles d'enregistrement dans ce registre, la politique suivie, sont décrites pour chaque norme dans la section IANA considerations du RFC, en utilisant le vocabulaire et les concepts du RFC 8126 (pour les types d'enregistrements DNS, cités plus haut, les détails sont dans le RFC 6895).
Plusieurs autres SDO suivent ce même principe de séparation entre la normalisation et l'enregistrement (en revanche, les groupes fermés d'industriels qui tentent d'imposer leur standard ne séparent pas en général ces deux fonctions). Par exemple, l'ISO définit, pour la plupart de ses normes, une Registration Authority ou bien une Maintenance Agency qui va tenir le registre. (Exemples : l'opérateur du registre de ISO 15924 est le consortium Unicode et celui du registre de ISO 639 est SIL. Contre-exemple : l'opérateur du registre de ISO 3166 est l'ISO elle-même.) Pourquoi cette séparation ? Les raisons sont multiples mais l'une des principales est la volonté de séparer la politique de base (définie dans la norme) et l'enregistrement effectif, pour gérer tout conflit d'intérêts éventuel. Un opérateur de registre séparé peut être plus indépendant, afin de ne pas retarder ou bloquer l'enregistrement d'un paramètre pour des raisons commerciales ou politiques. Notons aussi que bien d'autres fonctions liées à l'IETF sont également assurées à l'extérieur, comme la publication des RFC.
Contre-exemple, celui du W3C, qui utilise très peu de registres et
pas d'opérateur de registre officiel séparé. En pratique, c'est
l'IANA qui gère plusieurs registres Web, comme celui des
URI
bien
connus (RFC 8615), celui des types
de fichiers (comme application/pdf ou
image/png), celui des en-têtes
(utilisés notamment par HTTP), etc. En
dehors de l'IANA, le W3C a quelques registres gérés en interne
comme celui de
Xpointer. Pour le reste, la politique du W3C est plutôt
qu'un registre est un point de passage obligé et que de tels
points ne sont pas souhaitables.
Dans le cas de l'IETF, les documents existants sont le RFC 2026, qui décrit le processus de
normalisation mais pas celui d'enregistrement. Ce dernier est
traditionnellement connu sous le nom de « fonction IANA » (d'où la
section IANA considerations des RFC) même si,
en pratique, ce n'est pas toujours l'IANA qui l'effectue. (Les
registres de l'IANA sont en https://www.iana.org/protocols/.)
La section 2 du RFC expose donc le rôle et les responsabilités
du(des) opérateur(s) de registres de paramètres. Celui(ceux)-ci,
nommés avec majuscules IETF Protocol Parameter Registry
Operator, seront choisis par l'IETF LLC
(RFC 8711). J'ai mis le pluriel car
l'IANA n'assure pas actuellement la totalité
du rôle : il existe d'autres opérateurs de registres, en général
sur des tâches très secondaires comme par exemple le RIPE-NCC pour
l'enregistrement en
e164.arpa
(ENUM, cf. RFC 6116). Dans le futur, on pourrait imaginer un rôle
moins exclusif pour l'IANA.
La section 2.1 est la (longue) liste des devoirs qu'implique le rôle d'opérateur de registre. Il y a bien sûr le tenue du registre à proprement parler mais ce n'est pas tout. En voici une partie :
- Donner des avis sur les futurs RFC (concrètement, relire les sections IANA considerations à l'avance, pour voir si elles ne poseraient pas de problèmes insurmontables au registre).
- Suivre les RFC : l'opérateur du registre n'est pas censé déterminer la politique mais l'appliquer. Si un RFC dit que l'enregistrement dans tel registre se fait sans contrainte, l'opérateur du registre ne peut pas refuser un enregistrement, par exemple. Chaque registre a une politique d'enregistrement, expliquée dans le RFC correspondant (les règles générales figurent dans le RFC 8126).
- Bien indiquer dans chaque registre les références notamment le numéro du RFC qui normalise ce registre et pour chaque paramètre enregistré dans le registre, indiquer la source de ce paramètre et la date d'enregistrement.
- En cas de désaccord ou de problème, se tourner vers l'IESG, seule habilitée à trancher.
- Diffuser gratuitement les registres qui
sont tous publics par défaut (contrairement à ce qui se passe chez
l'ultra-dinosaure ISO). Un exemple est le registre de
DHCP, en
https://www.iana.org/assignments/bootp-dhcp-parameters/. - Maintenir les listes de diffusion spécifiées pour certains registres, par exemple lorsque l'enregistrement nécessite un examen par un expert, sous l'œil du public.
- Produire des rapports réguliers à destination de l'IAB, suivant le RFC 2860 mais aussi suivant l'accord supplémentaire qui l'a complété, et à destination de toute l'IETF. Aujourd'hui, cela se fait sous la forme de l'exposé IANA qu'il y a à chaque plénière de l'IETF. Ces rapports incluent des points comme les performances de l'opérateur du registre (délai de traitement, par exemple).
- Ne pas oublier que les droits de propriété intellectuelle sur ces registres sont gérés par l'IETF Trust (RFC 4371).
Après cette description des devoirs de l'opérateur du registre, la section 2 continue avec les devoirs des autres acteurs. En section 2.2, ceux de l'IAB, qui supervise l'opérateur du registre : l'IAB procède à la délégation formelle du registre, après que l'IETF LLC ait identifié les candidats. L'IAB décide, l'IETF LLC gère la relation avec l'opérateur.
En section 2.3, le rôle de l'IESG : celui-ci s'occupe de la partie technique, vérifier que les RFC comportent une bonne section IANA considerations, identifier les experts techniques si le RFC précise que l'enregistrement est précédé d'une évaluation technique (exemple : le RFC 5646, où l'enregistrement d'une langue dans le registre des langues est précédé d'une telle évaluation par un linguiste), répondre aux questions de l'opérateur du registre si celui-ci a un problème pratique.
En section 2.4, le rôle de l'IETF Trust (RFC 4371). Il gère la propriété intellectuelle de l'IETF donc est « propriétaire » du contenu des registres. Enfin, en section 2.5, le rôle de l'IETF LLC, bras administratif de l'IETF, qui est de gérer au quotidien les relations avec l'opérateur du registre. (C'est la principale nouveauté de ce RFC, par rapport au RFC 6220, que le remplacement de l'ancienne structure par cette IETF LLC.)
Voilà, l'essentiel était là mais la section 3 rajoute quelques détails.
L'article seul
RFC 8721: Advice to the Trustees of the IETF Trust on Rights to Be Granted in IETF Documents
Date de publication du RFC : Février 2020
Auteur(s) du RFC : J. Halpern (Ericsson)
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Une fois les droits de publication, et de modification, offerts par le(s) auteur(s) d'un RFC à l'IETF trust, quels droits ce dernier va-t-il transmettre aux lecteurs et lectrices d'un RFC ? Le RFC 5378 spécifie les droits « entrants » à l'IETF trust, et notre RFC 8721 spécifie les droits sortants : que puis-je faire avec un RFC ? Ai-je le droit de le lire ? De le redistribuer ? De le traduire ? Ce RFC est une légère modification du RFC 5377, qu'il remplace. Le but de cette modification était de s'adapter à la nouvelle structure administrative de l'IETF, décrite dans le RFC 8711. Notamment, l'ancien IAOC (RFC 4071) disparait.
La section 1 du RFC rappelle un point important : c'est
l'IETF trust qui décide. Le RFC 8721, publié par l'IETF, n'est qu'indicatif et ne fixe que des
grands principes. Le texte exact de la licence des RFC est écrit
par l'IETF trust (http://trustee.ietf.org/license-info/ et il existe aussi
une FAQ sur
ces textes.) La section 2 revient d'ailleurs sur les raisons de ce
choix (pouvoir s'adapter aux changements légaux aux ÉUA, pays de
l'IETF trust et de l'ISOC).
On pourra trouver ce texte standard, ce boilerplate, sur le site du Trust dans la Trust Legal Provisions.
La section 2 du RFC décrit les buts que suit l'IETF en publiant des RFC (cf. RFC 3935). Clairement, l'élaboration d'une licence doit se faire en gardant ces buts à l'esprit : faire fonctionner l'Internet le mieux possible, notamment en assurant l'interopérabilité des mises en œuvres des protocoles TCP/IP.
La section 3 explique l'articulation de ce RFC avec le RFC 5378 : les droits sortants (ceux que l'IETF trust accorde aux utilisateurs) doivent être inférieurs ou égaux aux droits entrants (ceux que l'auteur a accordé à l'IETF trust). Autrement dit, l'IETF ne peut pas donner de droits qu'elle n'a pas. Si l'auteur d'un RFC interdit toute modification à son texte, le RFC publié ne permettra pas de modifications (et ne pourra d'ailleurs pas être publié sur le chemin des normes).
La section 4 s'attaque aux droits que l'IETF trust devrait donner aux utilisateurs :
- Droit de publier et de republier (section 4.1), une très ancienne politique de l'IETF,
- Droit (évidemment) d'implémenter la technique décrite dans le RFC (section 4.3). C'est ici qu'apparait la distinction entre code et texte. (Le code inclut également le XML, l'ASN.1, etc.) Par un mécanisme non spécifié dans le RFC (cela a été choisi par la suite comme une liste publiée par l'IETF trust), le code est marqué spécialement (entre <CODE BEGINS> et <CODE ENDS>, comme défini dans la Trust Legal Provisions) et l'implémenteur aura davantage de droits sur le code, notamment le droit de modification. Cela ne résout pas, et de loin, tous les problèmes. Par exemple, cela ne permet pas de modifier du texte d'un RFC qui est inclus dans la documentation d'un logiciel.
- Droit de modifier le texte ? Non, ce droit est exclu par la section 4.4, en tout cas pour le texte (le code inclus dans les RFC reste modifiable, pour permettre son intégration dans des logiciels libres.)
Comme indiqué plus haut, il n'y a pas de changements de fond depuis le RFC 5377, uniquement la suppression des références à l'ancien IAOC (IETF Administrative Oversight Committee).
L'article seul
RFC 8720: Principles for Operation of Internet Assigned Numbers Authority (IANA) Registries
Date de publication du RFC : Février 2020
Auteur(s) du RFC : R. Housley (Vigil Security), O. Kolkman (Internet Society)
Pour information
Première rédaction de cet article le 28 février 2020
Traditionnellement, le fonctionnement de la normalisation dans l'Internet sépare deux fonctions : l'IETF développe les normes techniques (qui sont publiées dans les RFC, documents immuables) et un opérateur de registres techniques, actuellement l'IANA, gère les nombreux registres qui stockent les paramètres des protocoles de l'IETF. Au contraire des RFC, ces registres changent tout le temps. Ce nouveau RFC décrit les principes de haut niveau sur lesquels repose le fonctionnement de ces registres. Il remplace le RFC 7500, sans changement crucial, juste en intégrant la nouvelle organisation administrative de l'IETF, qui voit le remplacement de l'IAOC par l'IETF LLC.
Ces registres sont cruciaux pour le bon fonctionnement de
l'Internet. Presque tous les protocoles Internet dépendent d'un ou
de plusieurs registres. Aujourd'hui, il existe plus de 2 000 registres à l'IANA (la liste complète est en https://www.iana.org/protocols). Les valeurs stockées
peuvent être des nombres, des chaînes de caractères, des adresses,
etc. Leur allocation peut être centralisée
(tout est à l'IANA) ou décentralisée, avec
l'IANA déléguant à des registres qui à leur tour délèguent, comme
c'est le cas pour les noms de
domaine et pour les adresses IP.
Notons aussi que, pendant longtemps, la gestion des registres et
la publication des RFC étaient assurés par le même homme, Jon Postel à l'ISI. Aujourd'hui, les deux opérations sont
complètement séparées, https://www.iana.org/ et https://www.rfc-editor.org/.
L'IANA n'a pas de pouvoirs de police : le respect des registres IANA dépend uniquement de la bonne volonté générale. Évidemment, la pression est forte pour respecter ces registres, puisque le bon fonctionnement de l'Internet en dépend. Ce RFC présente les principes sur lesquels ces registres reposent (sections 2 et 3 du RFC) :
- Unicité des identificateurs. C'est l'un des principaux buts
des registres, s'assurer que qu'il n'y a qu'un seul
.frou.org, ou que l'algorithme 13 de DNSSEC désigne bien ECDSA pour tout le monde. - Stabilité. Les registres doivent tenir plus longtemps que la page Web corporate moyenne. Leur contenu existant ne doit pas changer sauf s'il y a une très bonne raison.
- Prédictabilité. Le processus d'enregistrement doit être prévisible et ne pas comporter de soudaines surprises (« finalement, il faut tel papier en plus »). Parfois, un jugement humain est nécessaire (cf. RFC 8126) donc le processus n'a pas à être algorithmique, ni à être limité dans le temps, mais il ne doit pas soudainement ajouter des étapes non prévues.
- Publicité. Les registres doivent être publics (en pratique, le principal mode de distribution est via le Web). Ce n'est pas si évident que cela, les dinosaures attardés de la normalisation, comme l'AFNOR, l'ISO ou l'IEEE ne le font pas.
- Ouverture. Le processus qui détermine les politiques d'enregistrement doit être ouvert à tous ceux qui désirent participer. Dans presque tous les cas, c'est l'IETF qui détermine cette politique (les exceptions sont importantes comme la gestion de la racine des noms de domaine), via un RFC développé en effet dans un processus ouvert. Le RFC 8126 détaille les politiques IANA possibles. (Parmi elles, certaines nécessitent un examen par un expert, le jugement humain mentionné plus haut.)
- Transparence. La gestion des registres ne doit pas être opaque. On peut écrire à l'IANA, ou bien passer les voir Away From Keyboard pendant les réunions IETF, où l'IANA a toujours un stand.
- Redevabilité. L'IANA doit rendre compte de sa gestion. Selon le RFC 8722, la supervision de la fonction IANA incombe à l'IAB (RFC 2850). En outre, l'IETF LLC (RFC 8711) a un SLA avec l'actuel opérateur de la fonction IANA, l'ICANN. L'IAB et l'IETF LLC sont eux-même redevables devant une communauté plus large, via le processus NomCom (RFC 8713). Pour les adresses IP et les ressources associées, le RFC 7249 fait gérer la redevabilité par les RIR (RFC 7020). Ceux-ci sont des organisations ouvertes et eux-même redevables devant leurs membres. (Avez-vous noté quel registre n'était pas mentionné comme bon exemple par le RFC ?)
La section 5 décrit le changement depuis le prédécesseur, le RFC 7500. Il ne s'agit que d'un changement bureaucratique ; l'ancienne IAOC (IETF Administrative Oversight Committee) a été, dans le RFC 8711, remplacée par une nouvelle structure, l'IETF LLC (Limited Liability Company), nécessitant la mise à jour du RFC 7500.
L'article seul
RFC 8719: High-Level Guidance for the Meeting Policy of the IETF
Date de publication du RFC : Février 2020
Auteur(s) du RFC : S. Krishnan (Kaloom)
Réalisé dans le cadre du groupe de travail IETF mtgvenue
Première rédaction de cet article le 28 février 2020
Le groupe mtgvenue de l'IETF était chargé de définir une politique pour le choix des lieux pour les réunions physiques de l'IETF. Ce nouveau RFC pose le principe général d'une rotation entre divers continents. Le RFC 8718 décrit ensuite les détails.
L'IETF a trois réunions physiques par an. L'idée est d'avoir en moyenne (mais pas forcément pour chaque année) une réunion en Amérique du Nord, une en Europe et une en Asie (cf. cette présentation de la politique « 1-1-1 ».) Le but est de répartir les coûts et temps de voyage entre les différents participants. Cette politique était jusqu'à présent informelle, ce RFC la documente officiellement. Elle se base sur la répartition constatée des participants à l'IETF. Notez que les frontières exactes des continents sont volontairement laissées floues, pour ne pas se lier les mains dans certains cas (demandez-vous si le Mexique est en Amérique du Nord, ou si Chypre est en Europe ou en Asie…)
Certaines réunions, dites « exploratoires » peuvent se tenir dans d'autres continents. L'IETF a fait une fois une réunion à Buenos Aires, et une fois à Adelaide.
Sur la base de cette politique « 1-1-1 », les décisions effectives seront prises en suivant le RFC 8718. Et, bien sûr, la politique n'est pas 100 % rigide. L'Internet change, les participants à l'IETF également, et d'autres lieux deviendront envisageables.
L'article seul
RFC 8718: IETF Plenary Meeting Venue Selection Process
Date de publication du RFC : Février 2020
Auteur(s) du RFC : E. Lear (Cisco Systems)
Réalisé dans le cadre du groupe de travail IETF mtgvenue
Première rédaction de cet article le 28 février 2020
La question de la sélection du lieu pour les réunions physiques de l'IETF a toujours suscité des discussions passionnées, d'autant plus que chaque participant, et son chat, a un avis. Il y a de nombreux critères (coût, distance, agréments du lieu, goûts personnels…) Ce nouveau RFC décrit le nouveau mécanisme par lequel est sélectionné un lieu, et les critères à respecter.
En théorie, venir aux réunions physiques n'est pas indispensable. L'IETF, organisme de normalisation technique de l'Internet, travaille, étudie les propositions, les amende, les approuve ou les rejette entièrement en ligne (avec l'aide de quelques outils comme le DataTracker). Ceci dit, en pratique, venir aux trois réunions physiques par an aide certainement à faire avancer son sujet favori. Ces réunions rassemblent des centaines de participants IETF pendant une semaine et sont l'occasion de nombreuses discussions. À noter que, pendant la réunion, une liste de discussion permet également des bavardages généralisés, où les conseils sur les bons bars et restaurants rencontrent les avis sur la meilleure route vers l'aéroport, et des récriminations sur les ascenseurs, l'air conditionné, le manque de cookies, etc. Ce RFC sort d'ailleurs au moment exact où l'IETF se déchire sur l'opportunité ou non de maintenir la réunion de Vancouver malgré l'épidémie.
La reponsabilité du choix d'un lieu pour les réunions incombe à l'IASA (IETF Administrative Support Activity, RFC 8711). Ce RFC ne lui supprime pas cette responsabilité mais lui fournit des éléments à prendre en compte. L'IETF a trois rencontres physiques par an, s'inscrivant dans le cadre de ses missions, qui sont décrits dans le RFC 3935. (Notez que certains participants contestent ces rencontres physiques, considérant qu'une organisation de normalisation des protocoles Internet pourrait se « réunir » en ligne.) La section 2 du RFC décrit les principes fondamentaux à prendre en compte pour le choix du lieu de la réunion :
- Permettre la participation du plus grand nombre, quel que soit leur pays d'origine, ce qui implique que les pays ayant une politique de visa très restrictive, comme les États-Unis, sont déconseillés,
- Et cela implique également que l'IETF préfère se tenir à l'écart des pays qui discriminent selon le genre, la couleur de peau, l'orientation sexuelle, etc ; c'est d'ailleurs un tel cas, soulevé par Ted Hardie, qui avait été à l'origine de la création du groupe mtgvenue, lorsque le choix de se réunir à Singapour avait été contesté en raison des lois homophobes de ce pays,
- Un accès Internet de qualité est évidemment nécessaire, et non censuré ; cela avait donné lieu à de sévères discussions lors de la réunion (la seule jusqu'à ce jour) en Chine (le RFC note aussi, dans sa section 7, que la vie privée est importante et que les participants doivent être informés d'une éventuelle surveillance),
- Le but est de travailler, et cela implique un environnement qui s'y prête bien, par exemple la possibilité de réunions informelles dans les environs, et dans de bonnes conditions (RFC 6771),
- Le coût est un problème crucial, beaucoup de participants n'étant pas financés par une entreprise ou un gouvernement.
En revanche, la même section 2 cite des non-objectifs :
- À part les cas de discrimination cités plus haut, qui concernent directement les participants à l'IETF, le choix du lieu de la réunion n'a pas pour objectif de valider ou de critiquer la politique du gouvernement local, ou les mœurs locales,
- Avoir le maximum de participants n'est pas un but en soi, les réunions IETF n'ont pas un objectif commercial,
- Et, évidemment, il n'y aura pas de critères touristiques (ah, les réunions à Minneapolis en hiver…)
Compte-tenu de ces objectifs de haut niveau, la section 3 du RFC liste les critères. D'abord, ceux qui sont impératifs :
- L'endroit précis de la réunion (en général un grand hôtel, mais parfois un centre de conférences) doit fournir assez d'espace pour toutes les activités,
- Il doit être accessible aux handicapés en fauteuil roulant (d'autres formes de handicap sont mentionnées plus loin, avec des critères moins stricts),
- Il doit pouvoir être connecté à l'Internet dans de bonnes conditions (IPv4 et IPv6, pas de NAT, capacité suffisante, etc ; notez que, la plupart du temps, le lieu ne fournit pas cela par défaut et c'est à l'IETF de tout installer et configurer avant la réunion).
Il y a ensuite les critères importants. Évidemment, l'idéal serait de trouver un endroit qui satisfasse tous les critères mais, en général, ce n'est pas possible. Le choix sera toujours un compromis. Il faut donc déterminer quels critères on peut accepter de sacrifier, et c'est la raison pour laquelle il n'y a finalement que trois critères impératifs. Les critères importants mais non impératifs sont :
- Le lieu doit être raisonnablement accessible d'un grand nombre d'endroits (la réunion de Buenos Aires, la seule qui se soit tenue en Amérique latine, avait été très critiquée de ce point de vue, le coût total et le temps total de voyage avaient été très importants, par rapport à, disons, New York ou Singapour),
- Il doit être possible de trouver une organisation locale qui participe à l'organisation, et des sponsors qui acceptent de financer (les frais d'inscription, pourtant très élevés, ne couvrent pas tout le budget),
- Les barrières à l'entrée (typiquement les visas) doivent être le plus basses possibles (là encore, cela dépend du participant : pour aller en France, la barrière pour un Slovène est basse, la Slovénie étant dans Schengen, celle pour un Malien est bien plus haute ; c'est donc le « coût » total qu'il faut considérer),
- Le lieu doit offrir des conditions de sécurité acceptables (critère parfois subjectif, les États-uniens, par exemple, voient souvent le reste du monde comme une jungle, et des habitants de Chicago ou Los Angeles s'inquiètent parfois à l'idée d'aller à Yokohama…),
- Par ailleurs, il faut suivre les principes (assez généraux) du RFC 8719.
Il faut se rappeler que l'IETF est internationale, et que la notion de « lieu éloigné » dépend donc du participant, c'est le coût total de voyage qui compte, pas celui de telle ou telle personne, d'où la politique « 1-1-1 », une réunion en Amérique du Nord, puis une en Europe, puis une en Asie, politique qui vise à répartir les coûts sur les divers participants
Pour l'endroit exact de la réunion (en général un grand hôtel), il y a des critères supplémentaires :
- De la place pour les réunions informelles (couloirs, annexes, bars et cafétérias, etc) et des endroits où se rencontrer dans les environs, puisque, comme souvent dans les réunions formelles, le travail le plus important se fait en dehors des salles de réunion (on voit souvent des petits groupes écrire des Internet-Drafts assis dans les couloirs),
- Prix « conformes aux tarifs d'affaire habituels » (ce qui est déjà très cher, si on prend en compte les habitudes étatsuniennes).
Dans le cas typique, l'IETF se tient dans un grand hôtel pour hommes d'affaires riches. (La dernière (au moment de l'écriture de cet article) réunion, à Montréal, était au Fairmont.) Et les participants au budget voyage le plus important logent sur place. Il existe aussi des overflow hotels où logent les moins riches. Dans l'hôtel principal et, parfois, dans les overflow hotels, on dispose du réseau IETF même dans sa chambre. Ce réseau est installé par une équipe de volontaires de l'IETF avant la réunion (les réseaux des hôtels sont en général catastrophiques, pas d'IPv6, pas de DNSSEC, des ports filtrés, etc, une réunion à Paris avait battu les records). Beaucoup de participants vont chez Airbnb ou carrément en auberge de jeunesse et doivent alors se débrouiller pour le réseau.
Les ingénieurs et ingénieures sont des êtres humains et doivent donc manger. D'où des critères concernant nourriture et boisson :
- Disponibilité de ressources alimentaires proches, pour tous les goûts, toutes les bourses, tous les critères, par exemple de santé ; j'ai déjà vu des conférences dans des resorts isolés, où on était obligés de se contenter de l'offre locale, souvent très chère,
- Ces ressources doivent être disponibles sous forme de restaurants mais aussi de magasins pour ceux qui préfèrent ensuite aller manger dehors (il n'y a pas de repas servi, aux réunions IETF).
Enfin, il y a des critères sur des points variés :
- Il est préférable que tout soit au même endroit, pour éviter les déplacements,
- Il est préférable qu'on puisse revenir, et qu'il y ait des contrats pour plusieurs évenements, avec prix réduits.
Même si tous ces critères ne sont pas impératifs, mis ensemble, ils sont très exigeants. Des gens demandent parfois pourquoi, par exemple, il n'y a jamais eu de réunion de l'IETF en Inde, pays certainement important pour l'Internet. C'est entre autres en raison de spécificités locales, par exemple la difficulté d'obtention des visas. (Cf. cette discussion.)
On notera que les critères sont finalement peu nombreux. De très nombreuses autres propositions avaient été faites, qui risquaient de mener à un catalogue de critères, très épais et, de toute façon, impossibles à satisfaire simultanément. Le rapport « droits humains » notait que certains critères pouvaient être incompatibles entre eux (une personne aveugle voudrait pouvoir être accompagnée de son chien guide, et une autre personne est allergique aux chiens, voire en a une phobie.)
C'est ainsi que des critères comme la disponibilité d'une crèche ont été retirés (notez que le RIPE le fait et que l'IETF va tenter le coup), de même que la demande de toilettes non genrées, qui était dans certaines versions du projet de RFC.
Comme vous vous en doutez, la discussion à l'IETF sur ce RFC n'a pas été évidente. De toute façon, la décision sur le choix d'un lieu reviendra à l'IASA, sauf pour les critères impératifs, qui nécessiteront une discussion générale.
L'article seul
RFC 8716: Update to the IETF Anti-Harassment Procedures for the Replacement of the IETF Administrative Oversight Committee (IAOC) with the IETF Administration LLC
Date de publication du RFC : Février 2020
Auteur(s) du RFC : P. Resnick (Episteme Technology Consulting LLC), A. Farrel (Old Dog Consulting)
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Les procédures de l'IETF en cas de harcèlement lors des réunions physiques ou en ligne sont décrites dans le RFC 7776. Ce RFC 7776 reste d'actualité, il n'est modifié que sur un point : le remplacement de l'ancienne IAOC (IETF Administrative Oversight Committee) par les institutions du projet « IASA version 2 », décrit dans le RFC 8711.
On peut résumer notre nouveau RFC 8716 simplement : partout où, dans le RFC 7776, il y a écrit IAOC, remplacer par IETF LLC (IETF Administration Limited Liability Company, cf. RFC 8711), et partout où il y a écrit IAD (IETF Administrative Director), remplacer par IETF Executive Director. C'est tout.
L'article seul
RFC 8715: Discussion of the IASA 2.0 Changes as They Relate to the IETF Trust
Date de publication du RFC : Février 2020
Auteur(s) du RFC : J. Arkko (Ericsson)
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Le passage de la structure administrative de l'IETF vers « IASA 2.0 » (IASA = IETF Administrative Support Activity, cf. RFC 8711) a nécessité des changements dans la manière dont les membres de l'IETF Trust sont désignés. Ces changements sont décrits dans le RFC 8714, et expliqués brièvement dans ce court RFC.
Petit rappel : l'IETF Trust gère la
propriété intellectuelle de l'IETF, comme la
marque ou comme le nom de domaine ietf.org et, bien sûr, comme les RFC, dont la licence dépend
formellement de cet IETF Trust. Cet IETF
Trust est enregistré
aux États-Unis. Au début, les membres de l'IAOC (IETF
Administrative Oversight Committee) étaient également
membres de l'IETF Trust. L'IAOC ayant été
supprimé par le RFC 8711, il fallait
donc changer les règles de désignation, ce qu'a fait le RFC 8714.
Lors des discussions sur la création de l'« IASA 2 » (IETF Administrative Support Activity, deuxième version), il avait été envisagé de fusionner l'IETF Trust avec la nouvelle structure, l'IETF LLC. Finalement, l'IETF Trust reste une organisation indépendante. Les raisons ? D'abord, une volonté de minimiser les changements liés au projet « IASA 2 », ensuite, l'observation du fait que le travail de l'IETF Trust est assez différent de celui de la IETF LLC (décrite dans le RFC 8711). L'IETF Trust a une activité calme, avec peu ou pas de problèmes urgents à résoudre, et les changements sont rares.
Mais comme il fallait bien tenir compte de la disparition de l'IAOC, le choix a été de réduire la taille de l'IETF Trust, plutôt que de créer un mécanisme alternatif à l'IAOC (puisque, comme indiqué plus haut, l'IETF Trust ne demande pas beaucoup de travail). Les cinq membres sont désignés par le comité de nomination de l'IETF (« NomCom »), par l'IESG et par l'ISOC. Pour ce dernier cas, le RFC note qu'on aurait pu utiliser l'IETF LLC et pas l'ISOC, mais que l'ISOC semblait plus adaptée, pour une tâche qui est assez politique (l'IETF LLC est normalement purement administrative).
Sinon, vous pouvez voir ici un appel à candidatures du NomCom pour l'IETF Trust.
L'article seul
RFC 8714: Update to the Process for Selection of Trustees for the IETF Trust
Date de publication du RFC : Février 2020
Auteur(s) du RFC : J. Arkko (Ericsson), T. Hardie
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Un RFC purement bureaucratique, faisant partie de la série des RFC sur la nouvelle structure administrative de l'IETF, décrite dans le RFC 8711. Celui-ci change légèrement la manière dont sont désignés les membres de l'IETF Trust, la structure qui gère la propriété intellectuelle de l'IETF.
Cet IETF Trust avait été créé pour s'occuper de toutes les questions liées aux marques, noms de domaine, droits sur les RFC, etc. C'était aussi la seule solution pour récupérer partiellement des droits qui avaient été détournés par CNRI. Il était spécifié dans le RFC 4371 que les membres de l'IAOC (IETF Administrative Oversight Committee) étaient automatiquemement membres de l'IETF trust.
La section 3 de notre RFC contient le changement important : comme la nouvelle structure administrative de l'IETF, décrite dans le RFC 8711 supprime l'ancienne IAOC, les membres de l'IETF trust ne seront plus issus de l'IAOC. Les cinq membres de l'IETF Trust sont désignés, pour trois d'entre eux par le comité de nomination de l'IETF (RFC 8713), pour l'un par l'IESG et pour le dernier par l'ISOC. Leur mandat est de trois ans mais le RFC prévoit des mandats plus courts pour certains, pour lisser la transition.
Un exemple du processus de sélection des trois membres « NomCom » (comité de nomination) se trouve en ligne. Regardez l'appel aux nominations (ou bien celui-ci). Comme vous le voyez avec le premier exemple, le processus de remplacement de l'ancien IETF trust a été fait bien avant la publication formelle de ce RFC.
Les raisons de ce changement sont décrites plus longuement dans le RFC 8715.
L'article seul
RFC 8713: IAB, IESG, IETF Trust and IETF LLC Selection, Confirmation, and Recall Process: Operation of the IETF Nominating and Recall Committees
Date de publication du RFC : Février 2020
Auteur(s) du RFC : M. Kucherawy, R. Hinden (Check Point Software), J. Livingood (Comcast)
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Voici un nouveau RFC « bureaucratique » autour des processus menant au choix et à la désignation des membres d'un certain nombre d'organismes de la galaxie IETF, comme l'IAB ou l'IESG. Ce RFC remplace le RFC 7437, mais il y a peu de changements ; les principaux portent sur les conséquences de la nouvelle structure administrative de l'IETF, « IASA 2 », décrite dans le RFC 8711.
Ce RFC concerne la désignation des membres de l'IAB, de l'IESG et de certains membres de la IETF LLC (voir la section 6.1 du RFC 8711) et de l'IETF Trust. Il ne concerne pas l'IRTF et ses comités propres. Il ne concerne pas non plus le fonctionnement quotidien de ces comités, juste la désignation de leurs membres.
Le processus tourne autour d'un comité nommé NomCom (pour Nominating Committee, comité de nomination).Comme expliqué en section 2, il faut bien différencier les nommés (nominee), les gens dont les noms ont été soumis au NomCom pour occuper un poste à l'IAB, l'IESG, à l'IETF LLC ou à l'IETF Trust, des candidats (candidate) qui sont les gens retenus par le NomCom. Le NomCom, comme son nom l'indique, n'a pas de pouvoir de désignation lui-même, celle-ci est décidée (on dit officiellement « confirmée ») par un organisme différent pour chaque comité (l'IAB pour l'IESG, l'ISOC pour l'IAB, l'IESG pour l'IETF Trust, etc). Une fois confirmé, le candidat devient... candidat confirmé (confirmed candidate). Et s'il n'est pas confirmé ? Dans ce cas, le NomCom doit se remettre au travail et proposer un ou une autre candidat·e.
La section 3 de notre RFC explique le processus général : il faut désigner le NomCom, le NomCom doit choisir les candidats, et ceux-ci doivent ensuite être confirmés. Cela peut sembler compliqué, mais le but est d'éviter qu'une seule personne ou une seule organisation puisse mettre la main sur l'IETF. Le processus oblige à travailler ensemble.
À première vue, on pourrait penser que le NomCom a un vaste pouvoir mais, en fait, au début du processus, il ne peut pas décider des postes vacants, et, à sa fin, il n'a pas le pouvoir de confirmation.
Un point important et souvent oublié est celui de la confidentialité (section 3.6 du RFC). En effet, l'IETF se vante souvent de sa transparence, tout doit être public afin que chacun puisse vérifier que tout le processus se déroule comme prévu. Mais le travail du NomCom fait exception. Toutes ses délibérations, toutes les informations qu'il manipule, sont confidentielles. Autrement, il serait difficile de demander aux personnes nommées de fournir des informations personnelles, et les personnes extérieures au NomCom qui sont interrogées hésiteraient à s'exprimer franchement sur tel ou tel candidat. Et la publicité des débats risquerait d'encourager des campagnes de soutien extérieures au NomCom, et du lobbying, toutes choses qui sont formellement interdites. La section 9, sur la sécurité, revient sur cette importance de la confidentialité : puisque le NomCom enquête littéralement sur les nommés, il peut récolter des informations sensibles et il doit donc faire attention à les garder pour lui.
Le résultat est annoncé publiquement. Voici, par exemple, l'annonce de la sélection des membres de l'IESG, début 2019.
Et le NomCom lui-même, comment est-il choisi (section 4) ? De ses quatorze membres, seuls dix ont le droit de vote. D'abord, les dix membres du NomCom votants doivent répondre à un certain nombre de critères (section 4.14) : ils doivent avoir été physiquement présents à trois des cinq précédentes réunions de l'IETF (c'est une des exceptions au principe comme quoi la participation à l'IETF n'impose pas de venir aux réunions physiques), et c'est vérifié par le secrétariat de l'IETF (chaque participant peut facilement voir sur sa page sur le Datatracker s'il est éligible ou pas.) Et ils doivent (évidemment), être très familiers avec les processus internes de l'IETF. Une fois qu'on a un ensemble (pool) de volontaires qui acceptent de participer au NomCom (voyez un appel à volontaires typique), comment choisit-on les dix membres de plein exercice ? Eh bien, c'est là que c'est amusant, ils sont choisis au hasard... Il n'existe en effet pas de critères consensuels sur la meilleure méthode de choix des membres du NomCom (rappelez-vous qu'à l'IETF, on ne peut pas voter, puisqu'il n'y a pas de notion de « membre » et donc pas de corps électoral rigoureusement défini). Le tirage au sort se fait selon la méthode, ouverte et publiquement vérifiable, spécifiée par le RFC 3797. Voici par exemple les sources de données aléatoires pour 2018 et un exemple de résultat.
Une fois sélectionnés, les membres du NomCom se mettent au travail (section 5 du RFC). Ils ne sont bien sûr pas éligibles pour les postes qu'il vont devoir pourvoir. Lorsqu'ils doivent prendre une décision, le NomCom vote (une procédure rare à l'IETF). Les nominations peuvent être faites par n'importe quel participant à l'IETF, y compris le nommé lui-même. La décision de retenir tel ou tel nommé comme candidat doit s'appuyer sur sa connaissance de l'IETF et ses qualifications pour le poste (qui ne sont pas forcément les mêmes pour tous les comités : par exemple, l'IETF LLC nécessite des compétences administratives qui sont moins importantes à l'IAB). L'IETF étant une organisation de grande taille, le NomCom ne connait pas forcément tout le monde, et peut donc aller à la « pêche aux informations » en consultant des gens extérieurs sur tel ou tel nommé.
Le « mandat » typique dure deux ans (trois à l'IETF LLC et au Trust). Il n'y a pas de limite au nombre de « mandats » mais le NomCom peut évidemment décider de donner la priorité aux nommés qui n'ont pas encore eu de mandat, ou pas encore effectué beaucoup de mandats.
Les informations récoltées par le NomCom, et ses discussions sont archivées (mais non publiques : voir plus haut au sujet de la confidentialité). Ces archives sont directement utiles s'il faut, par exemple, remplir un poste et qu'on ne veut pas recommencer le processus de zéro pour certains nommés.
Les humains étant ce qu'ils sont, il y aura des désaccords en interne. Comment le NomCom gère-t-il les contestations (section 6) ? Idéalement, le NomCom doit essayer de les régler tout seul (ne serait-ce que pour préserver la confidentialité déjà mentionnée). Si cela ne marche pas, le problème est transmis à l'ISOC, qui nomme un arbitre, dont les décisions sont définitives (pas d'appel).
J'ai parlé ici surtout de pourvoir des postes, mais il peut aussi y avoir révocation (recall, section 7) d'un membre d'un des comités concernés. Cette révocation peut être demandé par au moins vingt participants à l'IETF, qui doivent être éligibles au NomCom, à l'ISOC. Un Recall Committee est alors créé, et peut décider à la majorité des trois quarts d'une révocation, sur la base des griefs présentés par les signataires de la demande de révocation.
Bien des choses au sujet du NomCom ne sont pas écrites, et la tradition orale joue un rôle important dans son fonctionnement. L'annexe C rassemble plusieurs grains de sagesse issus de cette tradition. Par exemple, avoir été président d'un groupe de travail IETF est considéré comme une bonne préparation à l'IESG. Il y a aussi des considérations sur l'équilibre global entre les membres d'un comité. Il ne s'agit pas seulement que chaque membre soit individuellement bon, il faut aussi que le comité rassemble des gens de perspectives différentes (âge, expérience, région d'origine, monde académique vs. entreprises à but lucratif, etc). La tradition orale recommande aussi d'éviter qu'une même organisation n'occupe trop de postes dans un comité. Même si les gens de cette organisation ne forment pas un bloc, l'impression donnée serait mauvaise pour l'IETF.
L'annexe B de notre RFC contient les changements depuis le RFC 7437. Rien de crucial, mais on notera :
L'article seul
RFC 8712: The IETF-ISOC Relationship
Date de publication du RFC : Février 2020
Auteur(s) du RFC : G. Camarillo (Ericsson), J. Livingood (Comcast)
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
L'IETF, l'organisme qui écrit les normes techniques de l'Internet fait partie de la galaxie des nombreuses organisations qui ont un rôle plus ou moins formel dans le fonctionnement du réseau. Ce nouveau RFC décrit les relations de l'IETF avec un autre de ces organismes, l'Internet Society (ISOC). Ce RFC remplace le RFC 2031, notamment pour s'adapter à la nouvelle structuration de l'IETF, dite « IASA 2 » (IASA veut dire IETF Administrative Support Activity).
Historiquement, l'IETF n'était qu'un sigle et une idée. Il n'y avait pas d'organisation formelle de l'IETF. Au début, cela marchait bien comme cela, mais des inquiétudes se sont fait jour. Si l'IETF n'existe pas juridiquement, qui est responsable des RFC ? Si une entreprise mécontente d'un RFC fait un procès, chose courante aux États-Unis, à qui va-t-elle le faire ? Aux individus auteurs du RFC ? C'est entre autres en raison de ce genre de risques que l'IETF s'est mise sous un parapluie juridique, celui de l'Internet Society (ISOC), organisation créée pour donner une structure à l'Internet, permettant par exemple d'avoir un budget, d'empêcher des escrocs de déposer la marque « Internet », pour faire du lobbying, etc. C'est donc l'ISOC qui est la représentation juridique de l'IETF, mais aussi de l'IAB et de l'IRTF. (Cela date de 1995, via un groupe de travail qui se nommait Poised, qui a lancé l'effort de formalisation des processus IETF.) Si une entreprise, motivée par des juristes aussi méchants que dans un roman de Grisham, veut faire un procès en raison d'un RFC, elle doit faire un procès à l'ISOC (qui a ses propres bataillons de juristes).
La relation exacte entre l'IETF et l'ISOC était spécifiée dans le RFC 2031. Depuis, a émergé le concept d'« IASA » (IASA veut dire IETF Administrative Support Activity), une structuration plus forte des activités non techniques de l'IETF. Encore depuis, la création de « IASA 2 », dans le RFC 8711, a changé les choses, nécessitant le remplacement du RFC 2031. L'IASA version 2 créé une nouvelle structure, l'IETF LLC (LLC veut dire Limited Liability Company), qui est une filiale de l'ISOC.
Assez d'histoire, voyons d'abord, les principes (section 2 de notre RFC). L'ISOC a dans ses missions d'encourager et d'aider le développement de normes techniques ouvertes, ce qui correspond au rôle de l'IETF. Le but est donc d'être efficace, et de produire des bonnes normes, librement accessibles, et via un processus ouvert.
La section 3 précise la répartition des rôles : à l'IETF le développement des normes, à l'ISOC la partie juridique et financière. L'ISOC ne doit pas intervenir dans les choix techniques.
Cela ne veut pas dire que l'ISOC se contente de regarder. La section 4 du RFC rappelle qu'elle contribue au choix des membres du NomCom (qui fait les nominations à certains postes, cf. RFC 8713), de l'IAB, et qu'elle sert d'appel ultime en cas de conflit. D'autre part, l'ISOC est membre de certaines organisations très formelles, comme l'UIT, et sert donc de relais pour l'IETF auprès de cette organisation (RFC 6756).
L'ISOC a aussi un rôle de popularisation des technologies Internet et de sensibilisation à certains enjeux. Par exemple, elle a créé le programme Deploy 360, qui promeut notamment DNSSEC et IPv6.
Et en sens inverse (section 5 du RFC), l'IETF a une représentation au conseil d'administration de l'ISOC (RFC 3677).
Du point de vue juridique, rappelons que l'IETF LLC est rattachée à l'ISOC comme décrit dans l'accord entre l'IETF et l'ISOC d'août 2018 (oui, il a fallu du temps pour publier ce RFC…) Notez que le RFC qualifie la LLC de disregarded (ignorée, négligée) mais c'est en fait le sens fiscal de disregarded qui compte : la LLC ne paie pas d'impôts, l'ISOC le fait pour elle.
L'IETF a une structure pour gérer sa propriété intellectuelle, l'IETF Trust, créée par le RFC 5378, puis mise à jour dans les RFC 8715 et RFC 8714. C'est l'IETF Trust qui gère les marques, le copyright, etc. C'est officiellement cet IETF Trust qui vous donne le droit de lire et de distribuer les RFC. La nouvelle structure ne change pas le rôle de l'IETF Trust.
Enfin, le fric (qui fait tourner le monde). La section 7 du RFC rappelle que c'est souvent l'ISOC qui finance les activités de l'IETF. Les détails financiers sont en ligne.
Voilà, cela fait déjà beaucoup de choses à savoir, et c'est bien sûr encore pire si on inclut tous les RFC de la nouvelle structuration IASA mais il faut se rappeler que cette complexité est en partie volontaire. D'abord, il faut éviter la domination d'une organisation unique qui contrôlerait tout, et ensuite certaines organisations nécessitent des compétences spécifiques (par exemple, à l'IETF, il faut être pointu sur les questions techniques).
L'article seul
RFC 8711: Structure of the IETF Administrative Support Activity, Version 2.0
Date de publication du RFC : Février 2020
Auteur(s) du RFC : B. Haberman (Johns Hopkins University), J. Hall (CDT), J. Livingood (Comcast)
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Le sigle IASA (IETF Administrative Support Activity) désigne les structures qui font le travail administratif, non-technique, pour l'IETF. L'actvité de l'IETF est de produire des normes (sous forme de RFC) et cette activité nécessite toute une organisation et des moyens concrets, des employés, des logiciels, des déclarations pour le fisc, des serveurs, des réunions, et c'est tout cela que gère l'IASA. Dans sa première version, qui avait été spécifiée dans le RFC 4071 en 2005, l'IASA était gérée par l'ISOC, et était surtout formée par l'IAOC (IETF Administrative Oversight Committee). Dans cette « version 2 » de l'IASA, l'IAOC disparait, et l'essentiel des tâches revient à un nouvel organisme, une LLC (Limited Liability Company). Ce nouveau RFC remplace le RFC 4071 et décrit cette IETF Administration LLC et ses relations avec l'IETF.
L'IETF était à l'origine une structure informelle, des ingénieurs qui se réunissaient, discutaient, et écrivaient des RFC. Petit à petit, elle a grossi et s'est structurée (certains diraient « bureaucratisée »). La précédente structure était encore assez légère, reposant largement sur l'ISOC. L'IETF ayant continué à grossir, les enjeux ont continué à devenir de plus en plus importants pour la société dans son ensemble, il a été nécessaire de créer une organisation propre, la LLC (Limited Liability Company). Le conseil d'administration de cette LLC assurera les tâches qui étaient auparavant celles de l'IAOC. Les différents RFC qui mentionnaient l'IAOC ont été mis à jour pour cela (d'où la publication, entre autres, des RFC 8721, RFC 8714 ou RFC 8716). De même, l'ancienne fonction d'IAD IETF Administrative Director, la personne qui dirigeait le travail de l'IASA, est supprimée et ses tâches passent au directeur de la LLC, avec le titre de IETF Executive Director. C'était auparavant Portia Wenze-Danley mais Jay Daley lui a succédé le 24 octobre 2019.
C'est donc désormais cette « IETF LLC » qui est la structure légale de l'IETF mais aussi de l'IRTF, de l'IAB et, partiellement, du RFC Editor.
Cette réorganisation très importante ne change pourtant rien au processus de production des normes, qui, lui, reste couvert par le RFC 2026 (et ses nombreuses mises à jour, comme le RFC 6410). Cette écriture des normes techniques n'est pas pilotée par l'IASA mais par l'IESG et l'IAB (cf. RFC 2850). Même chose pour le travail de l'IRTF (RFC 2014). Si vous ne vous intéressez qu'à la technique, vous pouvez donc sauter le reste de cet article, qui ne parlera que de gouvernance et de droit.
Aucun changement non plus pour les procédures d'appels en cas de désaccord, ou pour les nominations (RFC 8713).
Comme la LLC n'a pas beaucoup de moyens, et que l'activité de l'IETF se déroule dans un environnement parfois compliqué, notamment du point de vue juridique (risque de procès), l'IETF continue de s'appuyer sur l'Internet Society (ISOC). L'accord entre LLC et ISOC est disponible en ligne. Voir aussi le RFC 8712.
La section 4 de notre RFC définit un certain nombre de termes, et pose les principes qui régissent la LLC. Parmi les définitions :
- LLC (Limited Liability Company, le nom complet est IETF Administration LLC) : le nouvel organisme, créé par le projet « IASA [version] 2 », qui gérera la partie « administrative » de l'IETF ; c'est le représentant légal de l'IETF.
- Directeur (IETF LLC Executive Director) : la personne qui dirigera la LLC. Ce rôle remplace l'ancien IAD.
- Conseil d'Administration (IETF LLC Board) : le groupe de personnes qui supervise la LLC (le directeur s'occupant des opérations quotidiennes).
Le LLC va donc s'occuper :
- Des réunions physiques, un gros travail organisationnel,
- Des finances, et de la récolte de fonds,
- De la conformité aux lois et réglements divers. (La LLC est enregistrée aux États-Unis et doit donc suivre les lois de ce pays.)
Elle ne s'occupera pas du développement des normes (le travail central de l'IETF, qui ne relève pas de cette gestion administrative).
Les principes que lesquels va s'appuyer la LLC pour cela :
- Transparence (il faut rendre des comptes aux participants à l'IETF). Tout doit être public par défaut. C'est le cas, enre autres, des requêtes judiciaires reçues, des rapports et audits ou bien des réunions du conseil d'administration (comme son séminaire de janvier 2020.) Voir aussi le rapport de l'activité de la LLC présentée à la réunion IETF de novembre 2019, à Singapour.
- Réactivité face aux demandes des participants à l'IETF.
- Minimisation des risques, notamment financiers.
La section 5 du RFC expose la structure choisie pour mettre en pratique ces principes. Un directeur (aujourd'hui Jay Daley) pour les fonctions opérationnelles du quotidien, et plusieurs employés (traditionnellement, l'IETF fonctionnait avec une équipe très réduite, mais cela n'est plus possible aujourd'hui). Mais une spécificité de l'IETF est aussi son caractère associatif et fondé sur le volontariat. De nombreux participants à l'IETF donnent de leur temps pour effectuer des fonctions de support de l'IETF. C'est ainsi que, pendant longtemps, les outils logiciels de travail en groupe étaient tous développés et maintenus par des participants volontaires. De même, la gestion du réseau pendant les réunions, ou bien les activités de sensibilisation et d'éducation sont traditionnellement assurées en dehors des cadres organisés. Le but de la LLC n'est pas d'absorber tous ces efforts. Au contraire, le RFC insiste sur l'importance pour la LLC de travailler avec les volontaires, sans chercher à les remplacer.
Et qui est membre du conseil d'administration de la LLC ? La section 6 l'explique (cela avait été une des discussions les plus vives lors de la création de la LLC). Certains membres sont nommés par l'IESG, d'autres par l'ISOC. Vous pouvez voir sur le site Web de la LLC la liste des membres actuels.
L'argent étant une question évidemment cruciale, la section 7 discute le financement de la LLC. (Au fait, les informations financières sont elles aussi en ligne, pour la transparence. Et voici le plan pour le budget 2020.) Bien évidemment, le RFC précise que les éventuels dons, par exemple d'entreprises, ne donnent aucun droit particulier et ne permettent pas de donner des consignes à la LLC (du moins en théorie). L'argent ainsi récolté doit servir uniquement aux activités IETF, et proches (comme l'IRTF).
La LLC doit obéir à un certain nombre de règles, détaillées en section 8, et développées dans ses politiques publiques. Par exemple, la LLC doit avoir des politiques internes contre la corruption, ou en faveur de la protection des données personnelles. D'autre part, sa nature d'organisation officiellement enregistrée aux États-Unis l'oblige à appliquer certaines lois états-uniennes comme les sanctions contre ceux que le gouvernement de Washington va qualifier de terroristes. Pour l'instant, l'IETF n'a jamais pris de décision dans des domaines politiquement délicats comme celui-ci. Mais dans le futur ? Compte-tenu de l'actuelle crise entre le gouvernement Trump et Huawei, faudra-t-il un jour se demander si les employés de Huawei doivent être exclus des réunions ? Cela signifierait sans doute la fin de l'IETF.
Pour résumer les principaux changements entre l'« IASA 1 » (RFC 4071) et l'« IASA 2 » décrite par ce RFC : L'IAOC et l'IAD disparaissent, remplacés par la LLC, son conseil d'administration et son directeur.
L'article seul
RFC 8709: Ed25519 and Ed448 Public Key Algorithms for the Secure Shell (SSH) Protocol
Date de publication du RFC : Février 2020
Auteur(s) du RFC : B. Harris, L. Velvindron (cyberstorm.mu)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 26 février 2020
Un très court RFC, juste pour ajouter au protocole SSH les algorithmes de signature Ed25519 et Ed448. Ces algorithmes sont déjà disponibles dans OpenSSH.
Ce protocole SSH est normalisé dans le RFC 4251, et a de nombreuses mises en œuvre, par exemple dans le logiciel libre OpenSSH. Pour authentifier le serveur, SSH dispose de plusieurs algorithmes de signature. Ce nouveau RFC en ajoute deux, dont Ed25519, qui avait été normalisé dans le RFC 8032. (En toute rigueur, l'algorithme se nomme EdDSA et Ed25519 est une des courbes elliptiques possibles avec cet algorithme. Mais je reprends la terminologie du RFC.) À noter que les courbes elliptiques sous-jacentes peuvent également être utilisées pour l'échange de clés de chiffrement, ce que décrit le RFC 8731.
La section 3 de notre RFC donne les détails techniques, suivant
le RFC 4253. L'algorithme se nomme
ssh-ed25519. Son copain avec la courbe
elliptique Ed448 est ssh-ed448. Ils sont tous
les deux enregistrés à l'IANA.
Le format de la clé publique est la chaîne "ssh-ed25519" suivie
de la clé, telle que décrite dans le RFC 8032,
section 5.1.5 (et 5.2.5 pour Ed448). Avec OpenSSH, vous pouvez la
voir dans ~/.ssh/id_ed25519.pub. Les signatures
sont faites selon la technique du RFC 8032,
sections 5.1.6 et 5.2.6. Leur format est décrit en section 6, et la
vérification de ces signatures en section 7, en suivant la procédure
des sections 5.1.7 et 5.2.7 du RFC 8032.
La façon la plus courante de vérifier la clé publique du serveur SSH auquel on se connecte est le TOFU. Si on préfère une vérification plus sérieuse, on peut utiliser les clés SSH publiées dans le DNS, méthode décrite dans le RFC 4255, utilisant des enregistrements de type SSHFP. Cela fait longtemps que ces enregistrements peuvent utiliser Ed25519 (cf. RFC 7479) et notre RFC ajoute le cas de Ed448, par exemple :
example.net. IN SSHFP 6 2 ( a87f1b687ac0e57d2a081a2f282672334d90ed316d2b818ca9580ea384d924 01 )
(Il est enregistré à l'IANA.)
Ed25519 a été ajouté à OpenSSH en janvier 2014
(donc bien avant la publication de ce RFC.) C'est l'option
-t de ssh-keygen qui
permet de sélectionner cet algorithme :
% ssh-keygen -t ed25519 -f /tmp/ed25519 Generating public/private ed25519 key pair. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /tmp/ed25519. Your public key has been saved in /tmp/ed25519.pub. The key fingerprint is: SHA256:VEN6HVM0CXq+TIflAHWCOQ88tfR35WXQZ675mLIhIIs stephane@godin The key's randomart image is: +--[ED25519 256]--+ | o==O+*++| | oB* B.+*| | o o== oo=| | . . o.= .o| | . S + oo | | . o . o oo | | E . . + + | | ...o .| | .o | +----[SHA256]-----+
À noter que OpenSSH 7.6 n'a pas ed448. D'une manière générale, ed25519 a été beaucoup plus souvent mise en œuvre dans les clients et serveurs SSH.
L'article seul
RFC 8701: Applying Generate Random Extensions And Sustain Extensibility (GREASE) to TLS Extensibility
Date de publication du RFC : Janvier 2020
Auteur(s) du RFC : D. Benjamin (Google)
Pour information
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 29 janvier 2020
Ce nouveau RFC s'attaque à un problème fréquent dans l'Internet : des programmeurs paresseux, incompétents ou pressés par les délais imposés mettent en œuvre un protocole normalisé (comme TLS) sans bien lire les normes, et notamment sans tenir compter des variations que la norme permet. Ils programment rapidement, testent avec une ou deux implémentations trouvées et, si ça marche, en déduisent que c'est bon. Mais dès qu'une autre implémentation introduit des variantes, par exemple un paramètre optionnel et qui n'était pas utilisé avant, la bogue se révèle. Le cas s'est produit de nombreuses fois. Notre RFC propose une solution disruptive : utiliser délibérément, et au hasard, plein de variantes d'un protocole, de façon à détecter rapidement les programmes écrits avec les pieds. C'est le principe de GREASE (Generate Random Extensions And Sustain Extensibility), la graisse qu'on va mettre dans les rouages de l'Internet pour que ça glisse mieux. Ce RFC 8701 commence par appliquer ce principe à TLS.
Le problème n'est évidemment pas spécifique à TLS, on l'a vu arriver aussi dans BGP lorsqu'on s'est aperçu que la simple annonce d'un attribut BGP inconnu pouvait planter les routeurs Cisco. Là aussi, le « graissage » (tester systématiquement des valeurs non allouées pour les différents paramètres, pour vérifier que cela ne plante rien) aurait bien aidé. D'où le projet « Use it or lose it », décrit dans le RFC 9170. dont GREASE est un cas particulier. Ce RFC analyse le problème des options non utilisées et recommande de les utiliser systématiquement, pour habituer les logiciels à voir ces options.
Le principe de GREASE (Generate Random Extensions And Sustain Extensibility) est donc de faire en sorte que clients et serveurs TLS (RFC 8446) annoncent, pour différents paramètres de la connexion, des valeurs qui ne correspondent à rien. Ainsi, les middleboxes boguées, installées au milieu de la communication parce que le commercial qui les vendait était convaincant, seront vite détectées, au lieu que le problème demeure dormant pendant des années et soit subitement révélé le jour où on essaie des valeurs légales mais nouvelles, comme dans le cas de l'attribut 99.
Qu'est-ce qui est variable dans TLS ? Beaucoup de choses, comme
la liste des algorithmes de cryptographie
ou comme les extensions. Dans TLS, le client annonce ce qu'il sait
faire, et le serveur sélectionne dans ce choix (RFC 8446, section 4.1.3). Voici un exemple vu par tshark, d'abord le message du client
(Client Hello), puis la réponse du serveur
(Server Hello) :
Secure Sockets Layer
TLSv1 Record Layer: Handshake Protocol: Client Hello
Content Type: Handshake (22)
Handshake Protocol: Client Hello
Version: TLS 1.2 (0x0303)
Cipher Suites (28 suites)
Cipher Suite: TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384 (0xc02c)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)
...
Extension: ec_point_formats (len=4)
Type: ec_point_formats (11)
EC point formats Length: 3
Elliptic curves point formats (3)
EC point format: uncompressed (0)
...
Extension: SessionTicket TLS (len=0)
Type: SessionTicket TLS (35)
Extension: encrypt_then_mac (len=0)
Type: encrypt_then_mac (22)
Extension: signature_algorithms (len=48)
Type: signature_algorithms (13)
Signature Hash Algorithms (23 algorithms)
Signature Algorithm: ecdsa_secp256r1_sha256 (0x0403)
Signature Hash Algorithm Hash: SHA256 (4)
Signature Hash Algorithm Signature: ECDSA (3)
...
Secure Sockets Layer
TLSv1.2 Record Layer: Handshake Protocol: Server Hello
Content Type: Handshake (22)
Version: TLS 1.2 (0x0303)
Handshake Protocol: Server Hello
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)
Compression Method: null (0)
Extensions Length: 13
Extension: renegotiation_info (len=1)
Type: renegotiation_info (65281)
Length: 1
Renegotiation Info extension
Renegotiation info extension length: 0
Extension: ec_point_formats (len=4)
Type: ec_point_formats (11)
...
Le client propose de nombreux algorithmes de cryptographie, comme
TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384, et
plusieurs extensions comme le format pour les courbes
elliptiques (normalisé dans le RFC 8422), les tickets du RFC 5077, le chiffrement
avant le MAC du RFC 7366 et des
algorithmes de signature. Le serveur choisit l'algorithme de
chiffrement
TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,
accepte l'extension sur le format des courbes elliptiques, et, puisque
le client était d'accord (via l'indication d'un algorithme de
chiffrement spécial), le serveur utilise l'extension de
renégociation.
Les valeurs inconnues (par exemple une nouvelle extension) doivent être ignorées (RFC 8446, section 4.1.2). Si ce n'était pas le cas, si une valeur inconnue plantait la partie située en face, il ne serait pas possible d'introduire de nouveaux algorithmes ou de nouvelles extensions, en raison des déploiements existants. Prenons les algorithmes de cryptographie, enregistrés à l'IANA. Si un nouvel algorithme apparait, et reçoit une valeur, comment vont réagir, non seulement les pairs avec qui on communique en TLS, mais également tous ces boitiers intermédiaires installés souvent sans raison sérieuse, et pour lesquels il n'existe pas de mécanisme pratique de remontée des problèmes ? Si leurs programmeurs avaient lu la norme, ils devraient ignorer ce nouvel algorithme, mais on constate qu'en pratique, ce n'est souvent pas le cas, ce qui rend difficile l'introduction de nouveaux algorithmes. Dans le pire des cas, le boitier intermédiaire jette les paquets portant les valeurs inconnues, sans aucun message, rendant le débogage très difficile.
D'où les métaphores mécaniques : dans l'Internet d'aujourd'hui, bien des équipements sur le réseau sont rouillés, et il faut les graisser, en faisant travailler les parties qui ne sont normalement pas testées. C'est le principe de GREASE que d'envoyer des valeurs inconnues pour certains paramètres, dans l'espoir de forcer les mises en œuvre de TLS, surtout celles dans les boitiers intermédiaires, à s'adapter. Une méthode darwinienne, en somme.
La section 2 de notre RFC indique les valeurs choisies pour ces annonces. C'est délibérement qu'elles ne sont pas contiguës, pour limiter le risque que des programmeurs paresseux ne testent simplement si une valeur est incluse dans tel intervalle. Il y a un jeu de valeurs pour les algorithmes de cryptographie et les identificateurs ALPN (RFC 7301), un pour les extensions, un pour les versions de TLS, etc. Toutes sont enregistrées à l'IANA, dans le registre respectif. Par exemple, pour les extensions TLS, (cf. leur liste), les valeurs, 2570, 6682, 10794 et plusieurs autres sont réservées pour le graissage. (Il fallait les réserver pour éviter qu'une future extension TLS ne reçoive le même numéro, ce qui aurait cassé la compatibilité avec les logiciels GREASE.)
Une fois ces valeurs réservées par notre RFC, le client TLS
peut, au hasard, ajouter ces valeurs dans, par exemple, la liste
des algorithmes de cryptographie qu'il gère, ou la liste des
extensions qu'il propose. Si jamais le serveur les accepte (dans
son ServerHello), le client doit rejeter la
connexion ; le but de ces valeurs était de tester les logiciels,
elles ne doivent jamais être sélectionnées. Notez que c'est le
comportement normal d'un client TLS d'aujourd'hui de refuser
proprement les valeurs inconnues. De même, un serveur normal
d'aujourd'hui va ignorer ces valeurs inconnues (et donc ne jamais
les sélectionner). Si tout le monde suit la norme, l'introduction
des valeurs GREASE ne va rien changer. Les règles de la section 3
ne sont qu'un rappel de règles TLS qui ont toujours existé.
La section 4 de notre RFC traite le cas un peu plus difficile
où le serveur propose et le client accepte. C'est par exemple ce
qui arrive quand le serveur demande au client de s'authentifier,
en envoyant un CertificateRequest. Le serveur
peut là aussi utiliser GREASE et indiquer des extensions ou des
algorithmes de signature inconnus, et le client doit les ignorer
(sinon, si le client sélectionne ces valeurs, le serveur doit
rejeter un tel choix).
La section 5 du RFC précise dans quels cas utiliser les valeurs GREASE et lesquelles. Le but étant de révéler les problèmes, le RFC recommande de choisir les valeurs aléatoirement. (Si un programme envoyait toujours la même valeur GREASE, il y aurait un risque que des programmes en face ignorent spécifiquement cette valeur, alors qu'il faut ignorer toutes les valeurs inconnues.) Par contre, pour un même partenaire TLS, il vaut mieux un certain déterminisme, sinon les problèmes seront difficiles à déboguer (parfois, ça marche, parfois, ça ne marche pas…)
Enfin, la section 7 du RFC discute des conséquences de l'absence de graissage sur la sécurité. Si certaines mises en œuvre de TLS résistent mal aux options inconnues, cela peut encourager le repli, c'est-à-dire à réessayer sans les options. Ainsi, un attaquant actif pourrait facilement forcer une machine à ne pas utiliser des options qui rendraient des attaques ultérieures plus compliquées. Les attaques par repli étant particulièrement dangereuses, il est important de ne pas se replier, et donc de s'assurer qu'on peut réellement utiliser toutes les possibilités du protocole. Cela veut dire entre autres que, si une machine TLS utilisant GREASE a du mal à se connecter, elle ne devrait pas essayer sans GREASE : cela annnulerait tous les bénéfices qu'on attend du graissage. Le principe de robustesse est mauvais pour la sécurité.
À noter que Chrome a déjà mis en œuvre ce principe, et que ça semble bien fonctionner. L'article « HTTPS : de SSL à TLS 1.3 », surtout consacré à la version 1.3 de TLS, montre à quoi ressemble les options GREASE pour Wireshark (« Unknown »).
À noter qu'un concept équivalent existe dans HTTP/3, Reserved Stream Types et Reserved Frame Types (RFC 9113, sections 6.2.3 et 7.2.9). Pour HTTP/2 (RFC 7540), où les trames de type inconnu devraient être ignorées, l'expérience a déjà prouvé qu'elles ne l'étaient pas toujours.
L'article seul
RFC 8700: Fifty Years of RFCs
Date de publication du RFC : Décembre 2019
Auteur(s) du RFC : H. Flanagan (RFC Editor)
Pour information
Première rédaction de cet article le 24 décembre 2019
Ce nouveau RFC marque le cinquantième anniversaire des RFC. Le RFC 1 avait en effet été publié le 7 avril 1969. Ce RFC 8700, publié avec un certain retard, revient sur l'histoire de cette exceptionnelle série de documents.
Il y avait déjà eu des RFC faisant le bilan de la série, à l'occasion d'anniversaires, comme le RFC 2555 pour le trentième RFC, et le RFC 5540 pour le quarantième. La série a évidemment commencé avec le RFC 1, cinquante ans auparavant, et donc dans un monde très différent. À l'époque, les RFC méritaient leur nom, ils étaient été en effet des « appels à commentaires », prévus non pas comme des références stables, mais comme des étapes dans la discussion. En cinquante ans, les choses ont évidemment bien changé, et les RFC sont devenus des documents stables, intangibles, et archivés soigneusement. Logiquement, le processus de création des RFC a également évolué, notamment vers un plus grand formalisme (on peut même dire « bureaucratie »).
Plus de 8 500 RFC ont été publiés (il existe quelques trous dans la numérotation ; ainsi, le RFC 26 n'a jamais existé…) Les plus connus sont les normes techniques de l'Internet. La description précise de HTTP, BGP ou IP est dans un RFC. Mais d'autres RFC ne normalisent rien (c'est le cas du RFC 8700, sujet de cet article), ils documentent, expliquent, suggèrent… Tous les RFC ont en commun d'être publiés puis soigneusement gardés par le RFC Editor, une fonction assurée par plusieurs personnes, et aujourd'hui animée par Heather Flanagan, auteure de ce RFC 8700, mais qui a annoncé son départ.
Cette fonction a elle aussi une histoire : le premier RFC Editor était Jon Postel. À l'époque c'était une fonction informelle, tellement informelle que plus personne ne sait à partir de quand on a commencé à parler du (ou de la) RFC Editor (mais la première mention explicite est dans le RFC 902). Postel assurait cette fonction en plus de ses nombreuses autres tâches, sans que cela n'apparaisse sur aucune fiche de poste. Petit à petit, cette fonction s'est formalisée.
Les changements ont affecté bien des aspects de la série des RFC, pendant ces cinquante ans. Les premiers RFC étaient distribués par la poste ! Au fur et à mesure que le réseau (qui ne s'appelait pas encore Internet) se développait, ce mécanisme de distribution a été remplacé par le courrier électronique et le FTP anonyme. Autre changement, les instructions aux auteurs, données de manière purement orales, ont fini par être rédigées. Et l'équipe s'est étoffée : d'une personne au début, Postel seul, le RFC Editor a fini par être une tâche assurée par cinq à sept personnes. Autrefois, la fonction de RFC Editor était liée à celle de registre des noms et numéros, puis elle a été séparée (le registre étant désormais PTI). Puis la fonction de RFC Editor a été structurée, dans le RFC 4844, puis RFC 5620, enfin dans le RFC 6635. Et l'évolution continue, par exemple en ce moment avec le changement vers le nouveau format des documents (voir RFC 7990). Dans le futur, il y aura certainement d'autres changements, mais le RFC Editor affirme son engagement à toujours prioriser la stabilité de la formidable archive que représentent les RFC, et sa disponibilité sur le long terme (RFC 8153).
La section 2 du RFC rappelle les grands moments de l'histoire des RFC (je n'ai pas conservé toutes ces étapes dans la liste) :
- Avril 1969, premier RFC, le RFC 1,
- 1971, premier RFC distribué via le réseau, le RFC 114,
- 1977, premier RFC publié le premier avril, le RFC 748,
- 1986, création de l'IETF,
- 1998, début du projet de récupération et de restauration des vieux RFC perdus,
- 1998, mort de Jon Postel, le « père de la série des RFC » (cf. RFC 2441),
- 2009, publication du RFC 5620, qui décrit à peu près le modèle d'aujourd'hui,
- 2010, les RFC ne sont plus gérés à l'ISI, mais chez une organisation spécialisée,
- 2011, une des nombreuses réformes des RFC, l'abandon des trois niveaux de normalisation, documenté dans le RFC 6410,
- 2013, début du projet de changement du format (RFC 6949) et d'abandon du texte brut,
- 2017, passage au zéro papier (RFC 8153).
Dans la section 3 de ce RFC, plusieurs personnes ayant vécu de l'intérieur l'aventure des RFC écrivent. Steve Crocker, dans la section 3.1, rappelle les origines des RFC (qu'il avait déjà décrites dans le RFC 1000). Il insiste sur le fait que les débuts étaient… peu organisés, et que la création de la série des RFC n'était certainement pas prévue dés le départ. Elle doit beaucoup aux circonstances. Le réseau qui, après bien des évolutions, donnera naissance à l'Internet a été conçu vers 1968 et a commencé à fonctionner en 1969. Quatre machines, en tout et pour tout, le constituaient, un Sigma 7, un SDS 940, un IBM 360/75 et un PDP-10. Le point important est qu'il s'agissait de machines radicalement différentes, un des points distinctifs de l'Internet, qui a toujours dû gérer l'hétérogénéité. Un byte n'avait pas la même taille sur toutes ces machines. (Le terme français octet est apparu bien plus tard, lorsque la taille de huit bits était devenue standard.)
Crocker décrit la première réunion de ce qui allait devenir le Network Working Group puis, très longtemps après l'IETF. Rien n'était précisement défini à part « il faut qu'on fasse un réseau d'ordinateurs » et persone ne savait trop comment le faire. La principale conclusion de la réunion avait été « il faudrait faire une autre réunion ». Dès le début, le réseau qui allait permettre de travailler à distance était donc un prétexte à des réunions AFK. (L'ironie continue aujourd'hui, où l'IETF réfléchit à avoir des réunions entièrement en ligne.)
L'espoir des étudiants comme Crocker était qu'un monsieur sérieux et expérimenté vienne expliquer ce qu'on allait devoir faire. Mais cet espoir ne s'est pas matérialisé et le futur Network Working Group a donc dû se débrouiller.
Parmi les idées les plus amusantes, le groupe avait réfléchi à la création d'un langage portable permettant d'envoyer du code sur une autre machine qui l'exécuterait. Ce lointain prédécesseur de JavaScript se nommait DEL (pour Decode-Encode Language) puis NIL (Network Interchange Language). Mais en attendant le travail matériel avançait, la société BBN ayant obtenu le contrat de construction des IMP (à peu près ce qu'on appelerait plus tard routeurs). La répartition des tâches entre le NWG et BBN n'était pas claire et le groupe a commencé de son côté à documenter ses réflexions, créant ainsi les RFC. Le nom de ces documents avait fait l'objet de longs débats. Le Network Working Group n'avait aucune autorité officielle, aucun droit, semblait-il, à édicter des « normes » ou des « références ». D'où ce titre modeste de Request for Comments ou « Appel à commentaires ». Cette modestie a beaucoup aidé au développement du futur Internet : personne ne se sentait intimidé par l'idée d'écrire des documents finaux puisque, après tout, ce n'était que des appels à commentaires. C'était d'autant plus important que certains des organismes de rattachement des participants avaient des règles bureaucratiques strictes sur les publications. Décréter les RFC comme de simples appels à commentaires permettait de contourner ces règles.
Le premier « méta-RFC » (RFC parlant des RFC) fut le RFC 3, qui formalisait cette absence de formalisme. De la même façon, il n'existait pas encore vraiment de RFC Editor, même si Crocker attribuait les numéros, et que le SRI gardait une archive non officielle. Mais deux principes cardinaux dominaient, et sont toujours vrais aujourd'hui : tout le monde peut écrire un RFC, nul besoin de travailler pour une grosse entreprise, ou d'avoir un diplôme ou un titre particulier, et tout le monde peut lire les RFC (ce qui n'a rien d'évident : en 2019, l'AFNOR ne distribue toujours pas librement ses normes.)
Dans la section 3.2, Vint Cerf décrit les changements ultérieurs. En 1971, Jon Postel est devenu RFC Editor (titre complètement informel à cette époque). Cette tâche était à l'époque mélée à celle d'attribution des numéros pour les protocoles, désormais séparée. Postel s'occupait à la fois du côté administratif du travail (donner un numéro aux RFC…) et de l'aspect technique (relecture et révision), tâche aujourd'hui répartie entre diverses organisations comme l'IESG pour les RFC qui sont des normes. C'est pendant cette « période Postel » que d'autres personnes sont venues rejoindre le RFC Editor comme Joyce Reynolds ou Bob Braden. Jon Postel est décédé en 1998 (cf. RFC 2468).
Leslie Daigle, dans la section 3.3 de notre RFC, rappelle la longue marche qu'a été la formalisation du rôle de RFC Editor, le passage de « bon, qui s'en occupe ? » à un travail spécifié par écrit, avec plein de règles et de processus. (Daigle était présidente de l'IAB au moment de la transition.) Le travail était devenu trop important en quantité, et trop critique, pour pouvoir être assuré par deux ou trois volontaires opérant « en douce » par rapport à leurs institutions. Une des questions importantes était évidemment la relation avec l'IETF. Aujourd'hui, beaucoup de gens croient que « les RFC, c'est l'IETF », mais c'est faux. Les RFC existaient bien avant l'IETF, et, aujourd'hui, tous les RFC ne sont pas issus de l'IETF.
Parmi les propositions qui circulaient à l'époque (début des années 2000) était celle d'une publication complètement automatique. Une fois le RFC approuvé par l'IESG, quelqu'un aurait cliqué sur Publish, et le RFC se serait retrouvé en ligne, avec un numéro attribué automatiquement. Cela aurait certainement fait des économies, mais cela ne réglait pas le cas des RFC non-IETF, et surtout cela niait le rôle actif du RFC Editor en matière de contenu du RFC. (Témoignage personnel : le RFC Editor a joué un rôle important et utile dans l'amélioration de mes RFC. C'est vrai même pour les RFC écrits par des anglophones : tous les ingénieurs ne sont pas des bons rédacteurs.) D'un autre côté, cela résolvait le problème des modifications faites de bonne foi par le RFC Editor mais qui changeaient le sens technique du texte.
La solution adoptée est décrite dans le RFC 4844, le premier à formaliser en détail le rôle du RFC Editor, et ses relations complexes avec les autres acteurs.
Nevil Brownlee, lui, était ISE, c'est-à-dire Independent Submissions Editor, la personne chargée de traiter les RFC de la voie indépendante (ceux qui ne viennent ni de l'IETF, ni de l'IAB, ni de l'IRTF.) Dans la section 3.4, il revient sur cette voie indépendante (d'abord décrite dans le RFC 4846). En huit ans, il a été responsable de la publication de 159 RFC… Avant, c'était le RFC Editor qui décidait quoi faire des soumissions indépendantes. Comme le rappelle Brownlee, le logiciel de gestion de cette voie indépendante était un simple fichier texte, tenu par Bob Braden.
Le principal travail de l'ISE est de coordonner les différents acteurs qui jouent un rôle dans ces RFC « indépendants ». Il faut trouver des relecteurs, voir avec l'IANA pour l'allocation éventuelle de numéros de protocoles, avec l'IESG pour s'assurer que ce futur RFC ne rentre pas en conflit avec un travail de l'IETF (cf. RFC 5742), etc. Ah, et c'est aussi l'ISE qui gère les RFC du premier avril.
Puis c'est la RFC Editor actuelle, Heather Flanagan qui, dans la section 3.5, parle de son expérience, d'abord comme simple employée. La charge de travail atteignait de tels pics à certains moments qu'il a fallu recruter des personnes temporaires (au nom de l'idée que la publication des RFC devait être un processus léger, ne nécessitant pas de ressources permanentes), ce qui a entrainé plusieurs accidents quand des textes ont été modifiés par des employés qui ne comprenaient pas le texte et introduisaient des erreurs. L'embauche d'employés permanents a résolu le problème.
Mais il a fallu aussi professionnaliser l'informatique. Le RFC Editor qui travaillait surtout avec du papier (et un classeur, le fameux « classeur noir ») et quelques outils bricolés (la file d'attente des RFC était un fichier HTML édité à la main), a fini par disposer de logiciels adaptés à la tâche. Finies, les machines de Rube Goldberg !
Dans le futur, bien sûr, les RFC vont continuer à changer ; le gros projet du moment est le changement de format canonique, du texte brut à XML. Si l'ancien format avait de gros avantages, notamment en terme de disponibilité sur le long terme (on peut toujours lire les anciens RFC, alors que les outils et formats à la mode au moment de leur écriture sont depuis longtemps oubliés), il avait aussi des inconvénients, comme l'impossibilité d'utiliser d'autres caractères que l'ASCII. Le RFC 7990 décrit le nouveau format, actuellement en cours de déploiement.
Autres lectures :
- Pour ce cinquantième anniversaire, Darius Kazemi commente un RFC par jour et c'est passionnant,
- Article de Dan York.
L'article seul
RFC 8689: SMTP Require TLS Option
Date de publication du RFC : Novembre 2019
Auteur(s) du RFC : J. Fenton (Altmode Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF uta
Première rédaction de cet article le 28 novembre 2019
Ah, la sécurité, c'est toujours compliqué. Pour le courrier électronique, par exemple, SMTP peut être fait sur TLS, pour garantir la confidentialité et l'intégrité du message. Mais TLS est optionnel. Cela entraine deux problèmes : si la politique du MTA est laxiste, le message risque de passer en clair à certains moments, et si elle est stricte, le message risque d'être rejeté alors que l'expéditeur aurait peut-être préféré qu'il passe en clair. Ce nouveau RFC fournit deux mécanismes, un pour exiger du TLS à toutes les étapes, un au contraire pour demander de la bienveillance et de la tolérance et d'accepter de prendre des risques.
SMTP
(RFC 5321) a une option nommée
STARTTLS (normalisée dans le RFC 3207), qui permet, si le pair en face l'accepte, de passer
la session SMTP sur TLS, assurant ainsi sa
sécurité. STARTTLS a plusieurs problèmes,
notamment son caractère optionnel. Même avec des sessions SMTP
entièrement TLS (sans STARTTLS, cf. RFC 8314), le problème demeure. Que doit faire un
MTA s'il ne peut
pas lancer TLS, parce que le MTA en face ne l'accepte pas, ou parce
que son certificat est invalide (RFC 6125) ou
encore car DANE (RFC 7672) est
utilisé et que le certificat ne correspond pas ? Jusqu'à présent, la
décision était prise par chaque MTA et, comme SMTP repose sur le
principe du relayage, l'émetteur original ne pouvait pas exprimer
ses préférences, entre « je suis parano, j'ai lu le bouquin de Snowden, j'exige du TLS
tout le temps » et « je m'en fous, je suis inconscient, je crois que
je n'ai rien à cacher, je
veux que le message soit envoyé, même en clair ». La politique des
serveurs SMTP était typiquement de privilégier la distribution du
message plutôt que sa sécurité. Désormais, il possible pour
l'émetteur de donner ses préférences : l'option SMTP
REQUIRETLS permet d'exiger du TLS tout le
temps, et l'en-tête TLS-Required: (bien mal
nommé) permet d'indiquer qu'on préfère au contraire la délivrance du
message à sa sécurité.
En général, aujourd'hui, les MTA acceptent d'établir la session TLS, même si
le certificat est invalide. En effet, dans le
cas contraire, peu de messages seraient livrés, les certificats dans
le monde du courrier étant fréquemment
invalides, à l'opposé de ce qui se passe dans le monde du Web, où les navigateurs sont bien plus
stricts. Pour durcir cette politique par défaut, et aussi parce
qu'un attaquant actif peut retirer l'option
STARTTLS et donc forcer un passage en clair, il existe
plusieurs mécanismes permettant de publier une politique, comme
DANE (RFC 7672) et
MTA-STS (RFC 8461). Mais elles sont contrôlées par le récepteur, et on
voudrait permettre à l'émetteur de donner son avis.
Commençons par REQUIRETLS, l'extension
SMTP. (Désormais dans le registre IANA des
extensions SMTP.) Il s'agit pour l'émetteur d'indiquer qu'il
ne veut pas de laxisme : il faut du TLS du début à la fin, et,
évidemment, avec uniquement des certificats valides. En utilisant
cette extension, l'émetteur indique qu'il préfère que le message ne
soit pas distribué, plutôt que de l'être dans de mauvaises
conditions de sécurité. Cette extension peut être utilisée entre
deux MTA, mais aussi quand un MUA se connecte au premier MTA, pour une
soumission de message (RFC 6409). Voici un
exemple (« C: » = envoyé par le client, « S: » = envoyé par le
serveur) :
S: 220 mail.example.net ESMTP C: EHLO mail.example.org S: 250-mail.example.net Hello example.org [192.0.2.1] S: 250-SIZE 52428800 S: 250-8BITMIME S: 250-REQUIRETLS C: MAIL FROM:<roger@example.org> REQUIRETLS S: 250 OK C: RCPT TO:<editor@example.net> S: 250 Accepted C: DATA S: 354 Enter message, ending with "." on a line by itself (Le message) C: . S: 250 OK C: QUIT
(Le lecteur ou la lectrice astucieux aura remarqué qu'il y a un
piège, le risque qu'un attaquant actif ne retire le
REQUIRETLS du client ou bien du serveur. Ce cas
est traité plus loin.)
Dans l'exemple ci-dessus, le serveur a annoncé qu'il savait faire
du REQUIRETLS, et le client a demandé à ce que
l'envoi depuis roger@example.org soit protégé
systématiquement par TLS. Cela implique que pour toutes les sessions
SMTP suivantes :
- L'enregistrement MX soit résolu en utilisant DNSSEC (ou alors on utilise MTA-STS, RFC 8461),
- Le certificat soit valide et soit authentifié par une AC ou par DANE,
- Le serveur suivant doit accepter la consigne REQUIRETLS (on veut une chaîne complète, de l'émetteur au récepteur).
Puisque l'idée est d'avoir du TLS partout, cela veut dire qu'un MTA
qui reçoit un message marqué REQUIRETLS doit
noter cette caractéristique dans sa base et s'en souvenir, puisqu'il
devra passer cette exigence au serveur suivant.
Si le serveur en face ne sait pas faire de
REQUIRETLS (ou, pire, pas de TLS), l'émetteur
va créer une erreur
commençant par 5.7 (les erreurs SMTP étendues sont décrites dans le
RFC 5248) :
REQUIRETLS not supported by server: 5.7.30 REQUIRETLS needed
Et l'en-tête TLS-Required: ? (Ajouté dans le
registre IANA des en-têtes.) Il fait
l'inverse, il permet à l'émetteur de spécifier qu'il préfère la
distribution du message à la sécurité, et qu'il faut donc débrayer
les tests qu'on pourrait faire. Ce nom de
TLS-Required: est mal choisi, car cet en-tête
ne peut prendre qu'une seule valeur, no (non),
comme dans cet exemple amusant du RFC :
From: Roger Reporter <roger@example.org>
To: Andy Admin <admin@example.com>
Subject: Certificate problem?
TLS-Required: No
Date: Fri, 18 Jan 2019 10:26:55 -0800
Andy, there seems to be a problem with the TLS certificate
on your mail server. Are you aware of this?
Roger
Si l'en-tête est présent, le serveur doit être plus laxiste que
d'habitude et accepter d'envoyer le message même s'il y a des
problèmes TLS, même si la politique normale du serveur serait de
refuser. Bien sûr, TLS-Required: no n'interdit
pas d'utiliser TLS, si possible, et l'émetteur doit quand même
essayer. Notez aussi que les MTA sont libres de leur politique et qu'on peut
parfaitement tomber sur un serveur SMTP qui refuse de tenir compte
de cette option, et qui impose TLS avec un certificat correct, même
en présence de TLS-Required: no.
(Le lecteur ou la lectrice astucieux aura remarqué qu'il y a un
piège, le risque qu'un attaquant actif n'ajoute
TLS-Required: no. Ce cas est traité plus
loin.)
Ah, et si on a les deux, REQUIRETLS et
TLS-Required: no ? La section 4.1 du RFC couvre
ce cas, en disant que la priorité est à la sécurité (donc,
REQUIRETLS).
La section 5 de notre RFC couvre le cas des messages d'erreur
générés par un MTA lorsqu'il ne peut pas ou ne veut pas envoyer le
message au MTA suivant (ou au MDA). Il
fabrique alors un message envoyé à l'expéditeur
(bounce, en anglais, ou message de non-distribution). Ce message contient
en général une bonne partie, voire la totalité du message
original. Sa confidentialité est donc aussi importante que celle du
message original. Si celui-ci était protégé par
REQUIRETLS, le courrier d'erreur doit l'être
aussi. Le MTA qui génère ce courrier d'erreur doit donc lui-même
activer l'extension REQUIRETLS. (Notez que,
comme le chemin que suivra cet avis de non-remise ne sera pas
forcément le même que celui suivi par le message originel, s'il y a
un serveur non-REQUIRETLS sur le trajet, le
courrier d'erreur ne sera pas reçu.)
Si un logiciel ré-émet un message (par exemple un gestionnaire de
liste de diffusion transmettant aux membres
de la liste, cf. RFC 5598), il devrait,
idéalement, appliquer également le REQUIRETLS
sur le message redistribué. Le RFC ne l'impose pas car, en pratique,
cela risquerait d'empêcher la réception du message par beaucoup.
Notre RFC se termine par une longue
section 8 sur la sécurité, car les problèmes qu'essaie de résoudre
ces solutions sont complexes. Le cas des attaques
passives est facile : TLS protège presque parfaitement
contre elles. Mais les attaques actives
soulèvent d'autres questions. REQUIRETLS mènera
à un refus des connexions SMTP sans TLS, protégeant ainsi contre
certaines attaques actives comme le SSL
stripping ou comme une attaque de
l'Homme du Milieu avec un mauvais
certificat. (Cette dernière attaque est facile aujourd'hui dans le
monde du courrier, où bien des serveurs SMTP
croient aveuglément tout certificat présenté.)
REQUIRETLS protège également contre beaucoup
d'attaques via le DNS, en exigeant
DNSSEC (ou, sinon,
MTA-STS).
Par contre, REQUIRETLS ne protège pas contre
un méchant MTA qui prétendrait gérer REQUIRETLS
mais en fait l'ignorerait. De toute façon, SMTP sur TLS n'a jamais
protégé des MTA intermédiaires, qui ont le texte du message en
clair. Si on veut se protéger contre un tel MTA, il faut utiliser
PGP (RFC 9580) ou
équivalent. (Par contre, le risque de l'ajout d'un
TLS-Required: no par un MTA malveillant ne
semble pas traité dans le RFC ; PGP ne protège pas contre cela.)
Il peut y avoir un conflit entre TLS-Required:
no et la politique du MTA, qui tient absolument à
vérifier les certificats des serveurs auxquels il se connecte, via
PKIX ou via DANE. Le RFC laisse
entendre que le dernier mot devrait revenir à l'expéditeur, au moins
si le message a été envoyé via TLS et donc pas modifié en route. (Le
cas d'un message reçu en clair - donc pas sécurisé - et demandant de
ne pas exiger TLS reste ouvert…)
Et pour finir, l'exemple de session SMTP où le serveur annonçait
qu'il gérait REQUIRETLS (en disant
250-REQUIRETLS) était simplifié. Si la session
commençait en clair, puis passait à TLS après, avec la commande
STARTTLS, le client doit recommencer la session
une fois TLS activé, pour être sûr que ce qu'annonce le serveur est réel.
Bien qu'il y ait déjà des programmeurs ayant travaillé sur ce RFC, je ne trouve encore rien du tout dans le source de Postfix, le MTA que j'utilise, même dans la version expérimentale.
L'article seul
RFC 8674: The "safe" HTTP Preference
Date de publication du RFC : Décembre 2019
Auteur(s) du RFC : M. Nottingham
Pour information
Première rédaction de cet article le 5 décembre 2019
Ce nouveau RFC
définit une nouvelle préférence qu'un client HTTP peut envoyer au
serveur. « safe » (sûr) indique que le client
ne souhaite pas recevoir du contenu qu'il trouve contestable.
Je vous arrête tout de suite : vous allez me demander « mais qui
définit du contenu contestable ? Ça dépend des gens » et, je vous
rassure, l'auteur du RFC a bien vu le
problème. La préférence safe est juste une
possibilité technique, le RFC ne définit pas ce qui est sûr et ce
qui ne l'est pas, cela devra se faire dans un autre cadre, une
discussion à ce sujet serait bien trop casse-gueule pour
l'IETF. En pratique, le résultat de
l'utilisation de cette préférence dépendra de bien des choses, comme
la politique du serveur (le RFC dit « the cultural context
of the site »), et une éventuelle relation pré-existante
entre le serveur et un utilisateur particulier. Le RFC donne quand
même une indication : safe peut vouloir dire
« adapté aux mineurs ».
Il y a manifestement une demande, puisque bien des
sites Web ont un mode « sûr », où on peut
sélectionner « je ne veux pas voir des choses que je n'aime
pas ». Notez que, dans ces cas, la définition de ce qui est sûr ou
pas dépend du site Web. S'ils est géré aux
États-Unis, « sûr » sera sans doute « aucune
nudité humaine », en Arabie saoudite,
« aucune femme visible », etc. Ce mode « sûr » des sites Web n'est
pas pratique pour l'utilisateurice, car il nécessite de sélectionner
l'option pour chaque site, et de se créer un compte, soit explicite,
soit implicite via les
cookies (RFC 6265). À moins que le mode « sûr » soit le mode par défaut
et, dans ce cas, ce sont les gens qui n'en voudront pas qui auront
du travail. D'où l'idée, très controversée à l'IETF, de
configurer cela dans le navigateur Web (ou
bien dans le système d'exploitation, pour que
tous les clients HTTP le fassent), qui va indiquer au serveur
les préférences (un peu comme le Do Not
Track, dont on sait qu'il est largement ignoré
par les sites Web). La technique utilisée est celle des préférences
HTTP, normalisées dans le RFC 7240,
préférences dont je rappelle que leur respect par le serveur est
optionnel. La préférence safe envoyée par le
client est donc à prendre comme un appel à « faire au mieux » et
« je te fais confiance pour la définition de "sûr" », pas plus.
La section 2 de notre RFC est plus concrète, présentant la
syntaxe exacte de safe. Voici un exemple de
requête HTTP exprimant cette préférence :
GET /foo.html HTTP/1.1 Host: www.example.org User-Agent: ExampleBrowser/1.0 Prefer: safe
La préférence est enregistrée
à l'IANA. Le RFC impose que les requêtes « sûres » soient
faites en HTTPS, pour éviter la surveillance spécifique
des gens qui demandent du safe (et qui peuvent
être des enfants), et pour éviter qu'un intermédiaire ne bricole la
requête, ajoutant ou enlevant cette préférence. Une réponse possible
à la requête ci-dessus serait :
HTTP/1.1 200 OK Transfer-Encoding: chunked Content-Type: text/html Preference-Applied: safe Server: ExampleServer/2.0 Vary: Prefer
Le Vary: (RFC 7231,
section 7.1.4) indique aux relais/caches intermédiaires qu'ils
doivent tenir compte de la valeur de Prefer:
avant de renvoyer la page mémorisée à un autre client.
Si vous voulez tester en vrai, la page https://www.bortzmeyer.org/apps/pornPrefer: safe ou pas. Voici un exemple avec
curl :
% curl --header "Prefer: safe" https://www.bortzmeyer.org/apps/porn
Le code est du Python/WSGI et se résume à :
def porn(start_response, environ):
# Apache/WSGI always give us one Prefer: header even if the client sent several.
preferences = re.split("\s*,\s*", environ['HTTP_PREFER'])
safe = False
for pref in preferences:
if pref.lower() == 'safe':
safe = True
break
begin = """<html><head>..."""
end = """</body></html>"""
safe_content = """<p>Safe ..."""
unsafe_content = """<p>Unsafe ..."""
if safe:
output = begin + safe_content + end
else:
output = begin + unsafe_content + end
status = '200 OK'
response_headers = [('Content-type', 'text/html'),
('Content-Length', str(len(output)))]
start_response(status, response_headers)
return [output]
Cette préférence semble répondre à une forte demande, puisqu'elle est déjà reconnue :
- Dans Internet Explorer (cf. la documentation),
- Dans Bing (cf. Bing),
- Dans les boitiers Cisco (cf. la documentation).
La section 3 du RFC rassemble quelques informations de sécurité :
- HTTPS est indispensable, sinon un
intermédiaire pourra ajouter (ou retirer) la préférence
safe, - Paradoxalement,
safepeut être dangereux puisqu'il transmet une information supplémentaire au serveur, aidant au fingerprinting, - On n'a évidemment aucune garantie que le serveur a bien
adapté le niveau du contenu à ce qu'on voulait. Le RFC fait même
remarquer qu'un serveur sadique pourrait envoyer du contenu
« pire » lorsque la préférence
safeest présente.
Enfin, l'annexe A donne quelques conseils aux auteurs de
navigateurs quant à la mise en œuvre de cette
préférence. L'UI n'est pas évidente. Il est
crucial de ne pas donner à l'utilisateur ou l'utilisatrice
l'impression que cette préférence fournirait des garanties. Le RFC
suggère un texte plus prudent pour une case à
cocher « Demander du contenu "sûr" aux sites Web ». Et
l'annexe B a des conseils pour les gérants de sites Web comme, par
exemple, ne pas permettre aux utilisateurs de demander (via leur
profil, par exemple) d'ignorer la préférence
safe puisqu'elle a pu être placée par un
logiciel de contrôle parental.
Ce RFC a le statut « pour information » et a été publié sur la voie indépendante (cf. RFC 5742) puisqu'il n'a pas fait l'objet d'un consensus à l'IETF (euphémisme…) Les principales objections étaient :
- « Sûr » n'a pas de définition précise et universelle, le terme est vraiment trop vague,
- Les navigateurs Web envoient déjà beaucoup trop d'informations aux serveurs, en ajouter une, qui pourrait, par exemple, permettre de cibler les mineurs, n'est pas forcément une bonne idée.
L'article seul
RFC 8659: DNS Certification Authority Authorization (CAA) Resource Record
Date de publication du RFC : Novembre 2019
Auteur(s) du RFC : P. Hallam-Baker, R. Stradling (Sectigo), J. Hoffman-Andrews (Let's Encrypt)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lamps
Première rédaction de cet article le 22 novembre 2019
Ce RFC décrit un mécanisme pour renforcer un peu la sécurité des certificats. Il normalise les enregistrements CAA (Certification Authority Authorization), qui sont publiés dans le DNS, et indiquent quelles AC sont autorisées à émettre des certificats pour ce domaine. Le but est de corriger très partiellement une des plus grosses faiblesses de X.509, le fait que n'importe quelle AC peut émettre des certificats pour n'importe quel domaine, même si ce n'est pas un de ses clients. Ce RFC remplace l'ancienne définition de CAA, qui était dans le RFC 6844.
CAA est donc une technique très différente de DANE (RFC 6698), les seuls points communs étant l'utilisation du DNS pour sécuriser les certificats. DANE est déployé chez le client TLS, pour qu'il vérifie le certificat utilisé, CAA est surtout dans l'AC, pour limiter le risque d'émission d'un certificat malveillant (par exemple, CAA aurait peut-être empêché le faux certificat Gmail du ministère des finances.) Disons que CAA est un contrôle supplémentaire, parmi ceux que l'AC doit (devrait) faire. Les clients TLS ne sont pas censés le tester (ne serait-ce que parce que l'enregistrement CAA a pu changer depuis l'émission du certificat, la durée de vie de ceux-ci étant en général de plusieurs mois). CAA peut aussi servir à des auditeurs qui veulent vérifier les pratiques d'une AC (même avertissement : le certificat a pu être émis alors que l'enregistrement CAA était différent.)
La section 4 de notre RFC présente l'enregistrement CAA. Il a été ajouté au registre des types d'enregistrements sous le numéro 257. Il comprend une série d'options (flags) et une propriété qui est sous la forme {clé, valeur}. Un nom peut avoir plusieurs propriétés. Pour l'instant, une seule option est définie (un registre existe pour les options futures), « issuer critical » qui indique que cette propriété est cruciale : si on ne la comprend pas, le test doit être considéré comme ayant échoué et l'AC ne doit pas produire de certificat.
Les principales propriétés possibles sont (la liste complète est dans le registre IANA) :
issue, la principale, qui indique une AC autorisée à émettre des certificats pour ce domaine (l'AC est indiquée par son nom de domaine),issuewild, idem, mais avec en plus la possibilité pour l'AC d'émettre des certificats incluants des jokers,iodef, qui indique où l'AC doit envoyer d'éventuels rapports d'échec, pour que le titulaire du nom de domaine puisse les corriger. Un URL est indiqué pour cela, et le rapport doit être au format IODEF (RFC 7970).
Voici par exemple quel était l'enregistrement CAA de mon domaine personnel :
% dig CAA bortzmeyer.org ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 61450 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 3, AUTHORITY: 7, ADDITIONAL: 7 ... ;; ANSWER SECTION: bortzmeyer.org. 26786 IN CAA 0 issue "cacert.org" bortzmeyer.org. 26786 IN CAA 0 issuewild "\;" ...
Il indique que seule l'AC CAcert peut
créer un certificat pour ce domaine (et sans les jokers). Bon, c'est
un peu inutile car CAcert ne teste pas les enregistrements CAA, mais
c'était juste pour jouer. Je n'ai pas mis d'iodef
mais il aurait pu être :
bortzmeyer.org. CAA 0 iodef "mailto:security@bortzmeyer.org"
Et, dans ce cas, l'AC peut écrire à
security@bortzmeyer.org, avec le rapport IODEF
en pièce jointe.
Attention, l'enregistrement CAA est valable pour tous les
sous-domaines (et ce n'est pas une option,contrairement à, par
exemple, HSTS du RFC 6797, avec
son includeSubDomains). C'est pour cela que
j'avais dû retirer l'enregistrement ci-dessus, pour avoir des
certificats pour les sous-domaines, certificats faits par une autre
AC. (Depuis, j'ai mis deux enregistrements CAA, pour les deux AC
utilisées, les autorisations étant additives, cf. section 4.2 du RFC.)
Des paramètres peuvent être ajoutés, le RFC cite l'exemple d'un numéro de client :
example.com. CAA 0 issue "ca.example.net; account=230123"
Une fois les enregistrements CAA publiés, comment sont-ils utilisés (section 3) ? L'AC est censée interroger le DNS pour voir s'il y a un CAA (on note que DNSSEC est très recommandé, mais n'est pas obligatoire, ce qui réduit le service déjà faible qu'offre CAA). S'il n'y en a pas, l'AC continue avec ses procédures habituelles. S'il y a un CAA, deux cas : il indique que cette AC peut émettre un certificat pour le domaine, et dans ce cas-là, c'est bon, on continue avec les procédures habituelles. Second cas, le CAA ne nomme pas cette AC et elle doit donc renoncer à faire un certificat sauf s'il y a une exception configurée pour ce domaine (c'est la deuxième faille de CAA : une AC peut facilement passer outre et donc continuer émettre de « vrais/faux certificats »).
Notez que le RFC ne semble pas évoquer la possibilité d'imposer la présence d'un enregistrement CAA. C'est logique, vu le peu de déploiement de cette technique mais cela veut dire que « qui ne dit mot consent ». Pour la plupart des domaines, la vérification du CAA par l'AC ne changera rien.
Notez que, si aucun enregistrement CAA n'est trouvé, l'AC est
censé remonter l'arbre du DNS. (C'est pour cela que SSL [sic] Labs trouvait un
enregistrement CAA pour
mercredifiction.bortzmeyer.org : il avait utilisé
le CAA du domaine parent, bortzmeyer.org.) Si
example.com n'a pas de CAA, l'AC va tester
.com, demandant ainsi à
Verisign si son client peut avoir un
certificat et de qui. Cette erreur consistant à grimper sur l'arbre
avait déjà été dénoncée dans le RFC 1535, mais apparemment
la leçon n'a pas été retenue. Au moins, ce RFC corrige une grosse
erreur du RFC 6844, en limitant cette montée
de l'arbre au nom initialement cherché, et pas aux alias
(enregistrements DNS CNAME) éventuels.
Enfin, la section 5 du RFC analyse les différents problèmes de sécurité que peut poser CAA :
- Le respect de l'enregistrement CAA dépend de la bonne volonté de l'AC (et CAA ne remplace donc pas DANE),
- Sans DNSSEC, le test CAA est vulnérable à des attaques par exemple par empoisonnement (le RFC conseille de ne pas passer par un résolveur normal mais d'aller demander directement aux serveurs faisant autorité, ce qui ne résout pas le problème : le programme de test peut se faire empoisonner, lui aussi, d'autant plus qu'il prend sans doute moins de précautions qu'un résolveur sérieux),
- Et quelques autres risques plus exotiques.
Le CA/Browser Forum avait décidé que le test des CAA serait obligatoire à partir du 8 septembre 2017. (Cf. la décision.) Comme exemple, parmi les enregistrements CAA dans la nature, on trouve celui de Google, qui autorise deux AC :
% dig CAA google.com ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 55244 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: google.com. 86400 IN CAA 0 issue "pki.goog" google.com. 86400 IN CAA 0 issue "symantec.com" ...
(Le TLD
.goog est apparemment utilisé par Google pour
son infrastructure, .google étant plutôt pour
les choses publiques.) Notez que gmail.com,
souvent détourné par des gouvernements et des entreprises qui
veulent surveiller le trafic, a également un enregistrement CAA. Le
célèbre SSL [sic] Labs
teste la présence d'un enregistrement CAA. S'il affiche
« DNS Certification Authority Authorization (CAA) Policy
found for this domain », c'est bon. Regardez le
cas de Google.
Quelques lectures et ressources pour finir :
- Un bon article de synthèse par SSL Labs.
- Une aide interactive pour fabriquer un enregistrement CAA. Si vous avez un très vieux serveur DNS, et qu'il refuse de charger les enregistrements CAA, vous allez devoir utiliser la syntaxe générique du RFC 3597. Comme elle est un peu compliquée, le service ci-dessus, ainsi que ce service en ligne peuvent vous aider, en affichant à l'ancienne syntaxe.
- Cet article détaillé écrit par une AC note un grand nombre de problèmes et de limites de CAA.
- Dès le lendemain du début des tests CAA par les AC, Comodo (la société des auteurs du RFC) avait déjà violé les règles et émis un certificat qui n'aurait pas dû l'être.
- Let's Encrypt
vérifie bien les enregistrements CAA. Si on a un CAA indiquant une
autre AC, même pour un
domaine parent du domaine pour lequel on veut un certificat, Let's
Encrypt refuse avec une erreur de type
urn:acme:error:caa, « CAA record for DOMAIN_NAME prevents issuance ». Le monde étant cruel, et les logiciels souvent bogués, cela a d'ailleurs entrainé un amusant problème.
La section 7 de ce RFC décrit les changements depuis le RFC 6844. Sur la forme, le RFC a été profondément
réorganisé. Sur le fond, le principal changement est que la
procédure de montée dans l'arbre du DNS, très dangereuse, a été
légèrement sécurisée en la limitant au nom lui-même, et pas aux
alias. En effet, le RFC 6844 prévoyait que, si
on cherchait le CAA de something.example.com,
qu'on ne le trouvait pas,
et que something.example.com était en fait un
alias vers other.example.net, on remonte
également l'arbre en partant de
example.net. Cette idée a été heureusement
abandonnée (mais, pour something.example.com,
on testera quand même example.com et
.com, donc le registre
de .com garde la possibilité de mettre un CAA
qui s'appliquera à tous les sous-domaines…)
Autre changement, la section 6, sur les questions de déploiement, qui intègre l'expérience pratique obtenue depuis le RFC 6844. Notamment :
- Certaines middleboxes boguées (pléonasme) bloquent les requêtes des types DNS inconnus et, apparemment, ne sont mises à jour que tous les vingt ans donc CAA est encore considéré comme inconnu,
- Certains serveurs faisant autorité sont programmés avec les pieds et répondent mal pour les types de données DNS qu'ils ne connaissent pas (ce n'est évidemment pas le cas des logiciels libres sérieux comme BIND, NSD, Knot, PowerDNS, etc.)
Le reste des changements depuis le RFC 6844
porte sur des points de détails comme une clarification de la
grammaire, ou bien des précisions sur la sémantique des
enregistrements CAA lorsque des propriétés comme
issue sont absentes.
L'article seul
RFC 8656: Traversal Using Relays around NAT (TURN): Relay Extensions to Session Traversal Utilities for NAT (STUN)
Date de publication du RFC : Février 2020
Auteur(s) du RFC : T. Reddy (McAfee), A. Johnston (Villanova University), P. Matthews (Alcatel-Lucent, apparemment en fait Nokia, J. Rosenberg (jdrosen.net)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tram
Première rédaction de cet article le 23 février 2020
Le protocole TURN, que décrit notre RFC, est le dernier recours des applications coincées derrière un routeur NAT et qui souhaitent communiquer avec une application dans la même situation (cf. RFC 5128). Avec TURN, le serveur STUN ne se contente pas d'informer sur l'existence du NAT et ses caractéristiques, il relaie chaque paquet de données. Ce nouveau RFC remplace la définition originelle de TURN (dans le RFC 5766), et inclut plusieurs changements qui étaient jusqu'à présent spécifiés dans des RFC séparés, comme IPv6 ou DTLS, et ajoute la possibilité de relayer les messages ICMP.
Être situé derrière un routeur NAT n'est jamais une situation enviable. De nombreuses applications fonctionnent mal ou pas du tout dans ce contexte, nécessitant des mécanismes spécifique de traversée des NAT. Le socle de tous ces mécanismes de traversée est STUN (RFC 8489), où le client STUN (notre machine bloquée par le NAT) communique avec un serveur STUN situé dans le monde libre pour apprendre sa propre adresse IP externe. Outre cette tâche de base, des extensions à STUN permettent d'aider davantage le client, c'est par exemple le cas de TURN que normalise notre RFC.
L'idée de base est que deux machines Héloïse et Abélard, chacune peut-être située derrière un NAT, vont utiliser STUN pour découvrir s'il y a un NAT entre elles (sinon, la communication peut se faire normalement) et, s'il y a un NAT, s'il se comporte « bien » (tel que défini dans les RFC 4787 et RFC 5382). Dans ce dernier cas, STUN seul peut suffire, en informant les machines de leur adresse extérieure et en ouvrant, par effet de bord, un petit trou dans le routeur pour permettre aux paquets entrants de passer.
Mais, parfois, le NAT ne se comporte pas bien, par exemple parce
qu'il a le comportement « address-dependent
mapping » (RFC 4787, section
4.1). Dans ce cas, il n'existe aucune solution permettant le
transport direct des données entre Héloïse et Abélard. La solution
utilisée par tous les systèmes pair-à-pair, par exemple en
téléphonie sur Internet, est de passer par un
relais. Normalement, le serveur STUN ne sert
qu'à un petit nombre de paquets, ceux de la
signalisation et les données elles-mêmes (ce
qui, en téléphonie ou en vidéo sur IP, peut représenter un très gros volume) vont
directement entre Héloïse et Abélard. Avec TURN, le serveur STUN
devient un relais, qui transmet les paquets de données.
TURN représente donc une charge beaucoup plus lourde pour le serveur, et c'est pour cela que cette option est restreinte au dernier recours, au cas où on ne peut pas faire autrement. Ainsi, un protocole comme ICE (RFC 8445) donnera systématiquement la préférence la plus basse à TURN. De même, le serveur TURN procédera toujours à une authentification de son client, car il ne peut pas accepter d'assurer un tel travail pour des inconnus (l'authentification - fondée sur celle de STUN, RFC 8489, section 9.2 - et ses raisons sont détaillées dans la section 5). Il n'y aura donc sans doute jamais de serveur TURN complètement public mais certains services sont quand même disponibles comme celui de Viagénie.
TURN est défini comme une extension de STUN, avec de nouvelles
méthodes et de nouveaux attributs (enregistrés à
l'IANA). Le client TURN envoie donc une requête STUN, avec
une méthode d'un type nouveau, Allocate, pour
demander au serveur de se tenir prêt à relayer (les détails du
mécanisme d'allocation figurent dans les sections 6 et 7). Le client
est enregistré par son adresse de transport
(adresse IP publique et port). Par exemple, si Héloise a pour
adresse de transport locale 10.1.1.2:17240
(adresse IP du RFC 1918 et port n° 17240), et
que le NAT réécrit cela en 192.0.2.1:7000, le
serveur TURN (mettons qu'il écoute en
192.0.2.15) va, en réponse à la requête
Allocate, lui allouer, par exemple,
192.0.2.15:9000 et c'est cette dernière adresse
qu'Héloïse va devoir transmettre à Abélard pour qu'il lui envoie des
paquets, par exemple RTP. Ces paquets arriveront donc au serveur
TURN, qui les renverra à 192.0.2.1:7000, le
routeur NAT les transmettant ensuite à
10.1.1.2:17240 (la transmission des données
fait l'objet des sections 11 et 12). Pour apprendre l'adresse
externe du pair, on utilise ICE ou bien un protocole de
« rendez-vous » spécifique (RFC 5128.) Un
exemple très détaillé d'une connexion faite avec TURN figure dans la
section 20 du RFC.
Ah, et comment le serveur TURN a-t-il choisi le port 9000 ? La section 7.2 détaille les pièges à éviter, notamment pour limiter le risque de collision avec un autre processus sur la même machine, et pour éviter d'utiliser des numéros de port prévisibles par un éventuel attaquant (cf. RFC 6056).
Et pour trouver le serveur TURN à utiliser ? Il peut être marqué
en dur dans l'application, mais il y a aussi la solution de
découverte du RFC 8155. Pour noter l'adresse d'un serveur TURN,
on peut utiliser les plans d'URI
turn: et turns: du RFC 7065.
TURN fonctionne sur IPv4 et IPv6. Lorsqu'IPv4 et IPv6 sont possibles, le serveur TURN doit utiliser l'algorithme du RFC 8305, pour trouver le plus rapidement possible un chemin qui fonctionne.
TURN peut relayer de l'UDP, du TCP (section 2.1), du TLS ou du DTLS, mais le serveur TURN enverra toujours de l'UDP en sortie (une extension existe pour utiliser TCP en sortie, RFC 6062) La section 3.1 explique aussi pourquoi accepter du TCP en entrée quand seul UDP peut être transmis : la principale raison est l'existence de pare-feux qui ne laisseraient sortir que TCP. La meilleure solution, recommandée par le RFC, serait quand même qu'on laisse passer l'UDP, notamment pour WebRTC (RFC 7478, section 2.3.5.1 et RFC 8827.)
Ah, et à propos d'UDP, notre RFC recommande d'éviter la fragmentation, et donc d'envoyer vers le pair qui reçoit les données des paquets UDP suffisamment petits pour ne pas avoir besoin de la fragmentation, celle-ci n'étant pas toujours bien gérée par les middleboxes.
Les données peuvent circuler dans des messages STUN classiques
(nommés Send et Data,
cf. section 11) ou bien dans des canaux virtuels
(channels, sortes de sous-connexions, section 12)
qui permettent d'éviter de transmettre les en-têtes STUN à chaque
envoi de données.
Enfin, la section 21, très détaillée, note également que TURN ne peut pas être utilisé pour contourner la politique de sécurité : l'allocation ne se fait que pour une adresse IP d'un correspondant particulier (Abélard), TURN ne permet pas à Héloïse de faire tourner un serveur. Ce point permet de rassurer les administrateurs de pare-feux et de leur demander de ne pas bloquer TURN.
Autre point important de cette section sur la sécurité : comme certains messages ne sont pas authentifiés, un méchant peut toujours envoyer au client des messages qui semblent venir du serveur et réciproquement. Le problème existe, mais c'est un problème plus général d'IP. TURN ne le résout pas mais ne l'aggrave pas (section 21.1.4). Pour le cas du multimédia, on peut par exemple utiliser SRTP (RFC 3711) pour empêcher cette attaque.
Comme TURN relaie les paquets, au lieu de simplement les router, l'adresse IP source va identifier le serveur TURN et pas le vrai expéditeur. Un méchant pourrait donc être tenté d'utiliser TURN pour se cacher. Il peut donc être utile que le serveur TURN enregistre les données comme l'adresse IP et le port de ses clients, pour permettre des analyses a posteriori.
Une question intéressante est celle du traitement des en-têtes IP (voir la 3.6). TURN travaille dans la couche 7, il n'est pas un « routeur virtuel » mais un relais applicatif. En conséquence, il ne préserve pas forcément des en-têtes comme ECN ou comme le TTL. D'ailleurs, un serveur TURN tournant comme une application sans privilèges particuliers n'a pas forcément accès aux valeurs de l'en-tête IP. Tout cela permet son déploiement sur des systèmes d'exploitation quelconque, où il n'est pas forcément facile de changer ces en-têtes. Pour la même raison, la découverte traditionnelle de MTU (RFC 1191) à travers TURN ne marche donc pas.
À propos d'implémentations, il existe plusieurs mises en œuvre libres de TURN, comme turnserver, CoTurn, Restund ou Pion.
Les changements depuis les RFC précédents, notamment le RFC 5766, sont résumés dans les sections 24 et 25 :
- Notre RFC intègre le RFC 6156, qui
ajoutait IPv6 à TURN. Le client peut
spécifier la version d'IP souhaitée, avec le nouvel attribut
REQUESTED-ADDRESS-FAMILYet il y a de nouveaux codes d'erreur comme 440 ou 443, - TURN peut maintenant accepter du DTLS en entrée,
- La découverte du serveur (RFC 8155)
et les plans d'URI
turn:etturns:(RFC 7065) ont été intégrés, - TURN relaie désormais l'ICMP.
L'article seul
RFC 8642: Policy Behavior for Well-Known BGP Communities
Date de publication du RFC : Août 2019
Auteur(s) du RFC : J. Borkenhagen (AT&T), R. Bush (IIJ & Arrcus), R. Bonica (Juniper Networks), S. Bayraktar (Cisco Systems)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF grow
Première rédaction de cet article le 3 novembre 2019
Le protocole d'annonces de routes BGP permet d'attacher aux annonces des étiquettes, les communautés, qui sont des métadonnées pour les routes. Certaines valeurs sont réservées pour des communautés « bien connues » qui sont censées donner le même résultat partout. Mais ce n'est pas vraiment le cas, comme l'explique ce RFC, qui demande qu'on améliore la situation.
Les communautés sont normalisées dans le RFC 1997, qui décrit par la même occasion le concept de communauté bien connue. Celles-ci sont enregistrées à l'IANA. Voici un exemple d'annonce BGP avec des communautés :
TIME: 11/03/19 09:14:47 TYPE: BGP4MP/MESSAGE/Update FROM: 89.149.178.10 AS3257 TO: 128.223.51.102 AS6447 ASPATH: 3257 8966 17557 136030 138368 NEXT_HOP: 89.149.178.10 COMMUNITY: 3257:4000 3257:8102 3257:50001 3257:50110 3257:54900 3257:54901 65535:65284 ANNOUNCE 103.131.214.0/24
Cette annonce du préfixe 103.131.214.0/24
contient sept communautés, dont une bien connue,
65535:65284 (0xFFFFFF04 en
hexadécimal), NOPEER, normalisée dans le RFC 3765.
Le RFC estime que le RFC 1997 était un peu trop flou, et que cela explique partiellement les différences que nous observons aujourd'hui.
Ainsi, le changement d'une communauté par la politique
locale d'un AS. Un routeur
BGP qui reçoit une annonce avec des
communautés peut évidemment modifier ces communautés (typiquement en
ajouter, mais parfois aussi en enlever). Tous les modèles de
routeurs permettent donc de modifier les communautés, entre autres
en fournissant une commande, appelée
set ou un nom de ce genre, qui remplace les communautés
par un autre ensemble de communautés. Toutes les communautés ? Non,
justement, c'est là qu'est le problème : sur certains routeurs, les
communautés bien connues sont épargnées par cette opération, mais pas
sur d'autres routeurs.
(Personnellement, cela me semble un problème d'interface utilisateur, qui ne concerne pas vraiment le protocole. Mais je cite l'opinion du RFC, qui trouve cette différence de comportement ennuyeuse, par exemple parce qu'elle peut créer des problèmes si un technicien, passant sur un nouveau type de routeur, suppose qu'une commande ayant le même nom va avoir la même sémantique.)
La section 4 du RFC liste les comportements constatés sur les routeurs :
- Sur Junos OS,
community setremplace toutes les communautés, bien connues ou pas, - Sur les Brocade NetIron,
set communitya le même effet, - Même chose sur VRP de Huawei,
avec
community set, - Idem sur SR OS,
avec
replace, - Sur IOS XR,
set communityremplace toutes les communautés sauf certaines communautés bien connues, commeNO_EXPORT, ces communautés doivent être retirées explicitement si on veut un grand remplacement ; la liste des communautés ainsi préservées n'est même pas la liste enregistrée à l'IANA, - Sur OpenBGPD,
set communityne supprime aucune des communautés existantes, qu'elles soient bien connues ou pas.
La section 5 de notre RFC souhaite donc que, pour les futures communautés spécifiées dans de futurs RFC, le comportement (remplaçable ou pas) soit précisé par l'IETF.
À destination, cette fois, des gens qui font le logiciel des routeurs, la section 6 suggère :
- De ne pas changer le comportement actuel, même pour améliorer la cohérence, même si une communauté change de statut (devenant bien connue) car ce changement serait trop perturbant,
- Mais de documenter soigneusement (apparemment, ce n'est pas
fait) le comportement des commandes de type
set; que font-elles aux communautés bien connues ?
Quant aux opérateurs réseau, le RFC leur rappelle qu'on ne peut
jamais être sûr de ce que vont faire les AS
avec qui on s'appaire, et qu'il vaut mieux vérifier avec eux ce
qu'ils font des NO_EXPORT ou autres communautés
bien connues qu'on met dans les annonces qu'on leur envoie.
L'article seul
RFC 8633: Network Time Protocol Best Current Practices
Date de publication du RFC : Juillet 2019
Auteur(s) du RFC : D. Reilly (Orolia USA), H. Stenn
(Network Time Foundation), D. Sibold
(PTB)
Réalisé dans le cadre du groupe de travail IETF ntp
Première rédaction de cet article le 27 octobre 2019
Le protocole NTP, qui sert à synchroniser les horloges sur l'Internet, est probablement un des plus vieux protocoles encore en service. Il est normalisé dans le RFC 5905. Ce nouveau RFC ne change pas la norme, il rassemble simplement un ensemble de bonnes pratiques pour l'utilisation de NTP. Sa lecture est donc très recommandée à toutes les personnes qui gèrent la synchronisation d'horloges dans leur organisation.
Bien sûr, tout dépend des niveaux d'exigence de cette organisation. Quel écart entre les horloges acceptez-vous ? Quel est le risque d'une attaque délibérée contre les serveurs de temps que vous utilisez ? À vous de lire ces bonnes pratiques et de les adapter à votre cas.
Le RFC commence par un conseil de sécurité réseau général (section 2). NTP est fondé sur UDP, ce qui signifie que le protocole de transport ne protège pas contre les usurpations d'adresses. Et comme les réponses NTP sont souvent bien plus grosses (en octets) que les questions, des attaques par réflexion et amplification sont possibles, et effectivement observées dans la nature. (Le RFC recommande également la lecture de « Technical Details Behind a 400Gbps NTP Amplification DDoS Attack », de « Taming the 800 Pound Gorilla: The Rise and Decline of NTP DDoS Attacks » et de « Attacking the Network Time Protocol ».) Il est donc nécessaire que les opérateurs réseau déploient les mesures « BCP 38 » contre les usurpations d'adresses IP.
Après ce conseil général, qui concerne également d'autres protocoles, comme DNS ou SNMP, la section 3 du RFC se penche sur les bonnes pratiques de configuration de NTP. Évidemment, il faut maintenir les logiciels à jour (ce qu'on oublie plus facilement lorsqu'il s'agit d'un protocole d'infrastructure, comme NTP).
Moins évidente, la nécessité d'avoir plusieurs sources de
temps. Une source donnée peut être malveillante, ou tout
simplement incorrecte. Or, NTP peut utiliser plusieurs sources, et
trouver le temps correct à partir de ces sources (les détails sont
dans le RFC 5905, et dans le livre de
D. Mills, « Computer network time synchronization: the
Network Time Protocol ».) Trois sources sont le minimum,
quatre sont recommandées, si, bien sûr, elles sont suffisamment
diverses, et dignes de confiance. (Au passage,
Renater gère une liste de
serveurs NTP en France mais elle ne semble pas à jour,
chronos.cru.fr n'existe plus, il y manque le serveur de
l'AFNIC, ntp.nic.fr, etc.)
Ce conseil de chercher plusieurs serveurs suppose évidemment
que ces serveurs sont indépendants : s'ils prennent tous le temps
depuis une même source et que celle-ci est déréglée ou
malveillante, avoir plusieurs serveurs ne suffira pas. Il est donc
également nécessaire de veiller à la diversité des horloges
sous-jacentes. Avoir plusieurs serveurs mais connectés à des
horloges du même vendeur fait courir le risque d'un problème
commun à toutes. La diversité doit aussi s'appliquer au choix du
type d'horloge : si on utilise plusieurs horloges, mais toutes
fondées sur des constellations de
satellites, une tache solaire va les perturber tous en même
temps. Autre risque : un problème DNS
supprimant le nom de
domaine, comme c'était arrivé à
usno.navy.mil (l'USNO), en
décembre 2018 et surtout à ntp.org en janvier
2017 (cf. cette
discussion ou bien celle-ci).
Autre question, les messages de contrôle de NTP. Introduits
dans l'annexe B du RFC 1305, qui normalisait
la version 3 de NTP, ils n'ont pas été conservés pour la version 4
(RFC 5905). (Un projet existe à
l'IETF pour les remettre,
cf. draft-ietf-ntp-mode-6-cmds.) Utiles à l'administrateur
système pour la gestion de ses serveurs, ces messages
peuvent être dangereux, notamment en permettant des attaques par réflexion, avec
amplification. La bonne pratique est donc de ne pas les
ouvrir au monde extérieur, seulement à son réseau. Des exemples de
configurations restrictives figurent à la fin de cet article.
Il est évidemment nécessaire de superviser ses serveurs NTP, afin de s'assurer qu'ils sont en marche, et, surtout, du fait qu'ils soient bien synchronisés. Des exemples, utilisant Icinga, figurent à la fin de cet article.
Un serveur NTP qui sert des dizaines de milliers de clients
peut nécessiter beaucoup de ressources réseau. Il est donc
important de n'utiliser comme serveur que des serveurs qu'on est
autorisé à questionner (ce qui est le cas des serveurs publics
comme ntp.nic.fr). Il existe hélas de
nombreux exemples d'abus de serveurs NTP, le
plus célèbre étant sans doute celui du serveur de
Poul-Henning Kamp par
D-Link.
Pour permettre à tous et toutes de synchroniser leurs horloges, le projet « NTP Pool » a été créé. De nombreux volontaires mettent à la disposition de tous leurs serveurs NTP. L'heure ainsi distribuée est en général de bonne qualité mais, évidemment, le projet ne peut fournir aucune garantie. Il convient bien pour les configurations par défaut distribuées avec les logiciels, ou pour des machines non critiques. Autrement, il faut utiliser des serveurs « de confiance ».
Pour l'utiliser, il faut regarder les
instructions (elles existent aussi en
français). En gros, on doit indiquer comme serveurs NTP des
noms pris sous pool.ntp.org et ces noms
pointeront, au hasard, vers des machines différentes, de manière à
répartir la charge. Voici un exemple (avec un serveur français) :
% dig +short A 0.fr.pool.ntp.org 5.196.192.58 51.15.191.239 92.222.82.98 162.159.200.123
Mais quelque temps après, les adresses IP auront changé.
% dig +short A 0.fr.pool.ntp.org 80.74.64.2 212.83.154.33 94.23.99.153 37.187.5.167
Voici un
exemple de configuration avec le serveur NTP habituel, dans son
ntp.conf :
pool 0.fr.pool.ntp.org iburst
pool 1.fr.pool.ntp.org iburst
pool 2.fr.pool.ntp.org iburst
pool 3.fr.pool.ntp.org iburst
Ainsi, on aura quatre serveurs, pointant vers des adresses réparties dans le lot. Avec OpenNTPd, ce serait :
servers fr.pool.ntp.org
L'administrateur système ne pense pas
toujours à ajuster la configuration, donc beaucoup de fournisseurs
de logiciels ont un
sous-domaine de pool.ntp.org, utilisé
dans les configurations livrées avec leurs serveurs NTP. Par
exemple, pour OpenWrt, le fichier de
configuration par défaut contiendra :
server 0.openwrt.pool.ntp.org iburst
server 1.openwrt.pool.ntp.org iburst
server 2.openwrt.pool.ntp.org iburst
server 3.openwrt.pool.ntp.org iburst
Un problème récurrent des horloges sur
l'Internet est celui des
secondes intercalaires. La
Terre étant imparfaite, il faut de temps en
temps corriger le temps
universel avec ces secondes intercalaires. Jusqu'à
présent, on a toujours ajouté des secondes, puisque la Terre
ralentit, mais, en théorie, on pourrait avoir à en
retirer. Il existe un temps qui n'a pas ce problème,
TAI, mais, outre qu'il s'éloigne petit à
petit du temps astronomique, il n'a pas été retenu dans les normes
comme POSIX (ou NTP,
qui ne connait qu'UTC…) Il faut donc gérer les soubresauts d'UTC,
et c'est une source de bogues sans fin. Les secondes intercalaires
ne sont pas prévisibles longtemps à l'avance (je vous avait dit
que la Terre est imparfaite) et il faut donc lire
les bulletins de l'IERS (en l'occurrence le bulletin C)
pour se tenir au courant. Notez que ce bulletin n'est pas écrit
sous une forme structurée, lisible par un programme, donc on
pourra préférer le leap-seconds.list,
disponible en plusieurs endroits. Pour un
serveur NTP, une autre solution est d'utiliser des horloges qui
distribuent de l'information sur les secondes intercalaires
prévues. C'est le cas du GPS ou de
DCF77. Dans ce cas, le serveur NTP peut se
préparer un peu à l'avance (ce qui n'évite pas les bogues…)
Autre problème amusant, noté par le RFC, le leap smearing, qui consiste à lisser l'arrivée d'une seconde intercalaire au lieu de brutalement décaler l'horloge d'une seconde. Lors de la seconde intercalaire de juin 2015, certains serveurs NTP faisaient du leap smearing et pas d'autres, ce qui semait la confusion chez les clients qui avaient un mélange de ces deux types de serveurs. Le leap smearing n'est pas conforme à la norme NTP et ne doit donc pas être utilisé sur des serveurs NTP publics, d'autant plus que le protocole ne permet pas de savoir si le serveur utilise ce smearing ou pas. Dans un environnement fermé, par contre, on fait évidemment ce qu'on veut.
Concernant ce leap smearing, le RFC note qu'il peut poser des problèmes juridiques : l'horloge de la machine ne sera pas en accord avec l'heure légale, ce qui peut créer des histoires en cas, par exemple, d'accès des autorités aux journaux.
Passons maintenant aux mécanismes de sécurité de NTP (section 4
du RFC). L'analyse des risques a été faite dans le RFC 7384, notre RFC rappelle les moyens de faire face à ces
risques. Il y a bien sûr les clés partagées (la directive
keys /etc/ntp/ntp.keys dans le serveur NTP
classique). NTP n'a pas de mécanisme de distribution de ces clés,
il faut le faire en dehors de NTP (copier
/etc/ntp/ntp.keys…), ce qui ne marche donc
pas pour des serveurs publics. (Comme il y a toujours des lecteurs
qui me disent « mais c'est pas pratique de recopier les clés à la
main sur toutes les machines », je rappelle l'existence
d'Ansible, et autres outils analogues.) À
noter que le seul algorithme de
condensation normalisé pour l'utilisation
de ces clés est MD5, clairement dangereux
(RFC 6151). Ceci dit, d'autres algorithmes
sont parfois acceptés par les mises en œuvre de NTP, cf. RFC 8573. (Opinion
personnelle : MD5 vaut mieux que pas de sécurité du tout.)
Et… c'est tout. Il n'existe pas actuellement d'autre mécanisme de sécurité pour NTP. Le système Autokey, normalisé dans le RFC 5906 a été abandonné, en raison de ses vulnérabilités. Un travail était en cours à l'époque pour lui concevoir un successeur, ce qui a donné le RFC 8915.
La section 5 de notre RFC résume les bonnes pratiques en matière de sécurité NTP :
- Éviter les fuites d'information que permettent les requêtes de contrôle. Les articles de Malhotra, A., Cohen, I., Brakke, E., et S. Goldberg, « Attacking the Network Time Protocol », de Van Gundy, M. et J. Gardner, « Network Time Protocol Origin Timestamp Check Impersonation Vulnerability » (CVE-2015-8138) et de Gardner, J. et M. Lichvar, « Xleave Pivot: NTP Basic Mode to Interleaved » (CVE-2016-1548) documentent des attaques rendues possibles par ce côté trop bavard de NTP. C'est ainsi par exemple que Shodan se permettait de repérer des adresses IPv6 à analyser, pour compenser le fait que l'espace d'adressage IPv6 est trop gros pour le balayer systématiquement (RFC 7707).
- Surveiller les attaques connues, par exemple avec Suricata.
- NTP a un mécanisme de répression des requêtes, le KoD (Kiss-o'-Death, RFC 5905, section 7.4), qui permet de calmer les clients qui suivent la norme (un attaquant l'ignorera, bien sûr).
- La diffusion des informations NTP à
tout le réseau local, pratique pour diminuer l'activité NTP
(directives
broadcastetbroadcastclientdans le serveur NTP), ne devrait se faire que si ledit réseau est de confiance et que les informations sont authentifiées. - Même chose pour le mode symétrique (entre pairs qui
s'échangent les informations NTP, directive
peer).
Enfin, la section 6 du RFC couvre le cas particulier des systèmes embarqués. Par exemple, les objets connectés ont une fâcheuse tendance à rester en service des années sans mise à jour. S'ils ont été configurés en usine avec une liste de serveurs NTP, et que certains de ces serveurs disparaissent ensuite, l'objet risque de ne plus pouvoir se synchroniser ou, pire, il va matraquer une machine innocente qui a récupéré l'adresse d'un serveur NTP (cf. RFC 4085). Il est donc important que les clients NTP puissent mettre à jour la liste de leurs serveurs. D'autre part, la liste doit évidemment être correcte dès le début, et ne pas inclure des serveurs NTP, même publics, sans leur autorisation. Une solution simple est de passe par le le projet « NTP Pool ».
L'annexe A de notre RFC rassemble des conseils qui sont
spécifiques à une mise en œuvre de NTP, celle de la Network Time
Foundation, le « code NTP original »
(paquetage ntp sur
Debian ou ArchLinux).
Pour obtenir une variété de sources, le
démon « ntpd » fourni a la directive
pool, qui permet de désigner un ensemble de
serveurs :
pool 0.debian.pool.ntp.org iburst
pool 1.debian.pool.ntp.org iburst
pool 2.debian.pool.ntp.org iburst
pool 3.debian.pool.ntp.org iburst
NTP a la possibilité de recevoir des messages de contrôle (annexe B du RFC 1305). Cela peut être dangereux, et il est recommandé d'en restreindre l'accès. Avec le serveur habituel ntpd, c'est bien documenté (mais cela reste complexe et pas intuitif du tout). Voici un exemple :
restrict default noquery nopeer nomodify notrap
restrict ::1
restrict 2001:db8:b19:3bb0:: mask ffff:ffff:ffff:ffff:: notrust
restrict 2001:db8:2fab:e9d0:d40b:5ff:fee8:a36b nomodify
Dans cet exemple, la politique par défaut (première ligne) est de
ne rien autoriser. Toute machine qui tenterait de parler au
serveur NTP serait ignorée. Ensuite, la machine locale
(::1, deuxième ligne) a tous les droits
(aucune restriction). Entre les deux (troisième ligne), les
machines du réseau local
(2001:db8:b19:3bb0::/64) ont le droit de
parler au serveur seulement si elles sont authentifiées
cryptographiquement. Enfin, la machine
2001:db8:2fab:e9d0:d40b:5ff:fee8:a36b a le
droit de lire le temps chez nous mais pas de le modifier.
On avait parlé plus haut de l'importance de superviser ses services de temps. Voici une configuration avec Icinga pour faire cela :
apply Service "ntp-time" {
import "generic-service"
check_command = "ntp_time"
assign where (host.address || host.address6) && host.vars.ntp
}
...
object Host "foobar" {
...
vars.ntp = true
Avec cette configuration, la machine foobar sera
supervisée. On peut tester depuis la ligne de commande que le
monitoring plugin arrive bien à lui parler :
% /usr/lib/nagios/plugins/check_ntp_time -H foobar NTP OK: Offset 7.331371307e-06 secs|offset=0.000007s;60.000000;120.000000;
Si la réponse avait été CRITICAL - Socket timeout after 10
seconds, on aurait su que le serveur refuse de nous parler.
Ah, et puisqu'on a parlé de sécurité et de protéger (un peu) NTP par la cryptographie, voici un exemple (non, ce ne sont pas mes vrais clés, je vous rassure) :
% cat /etc/ntp/ntp.keys ... 13 SHA1 cc5b2e7c400e778287a99b273b19dc68369922b9 # SHA1 key % cat /etc/ntp.conf ... keys /etc/ntp/ntp.keys trustedkey 13
Avec cette configuration (le fichier ntp.keys
peut être généré avec la commande ntp-keygen), le serveur NTP acceptera les messages
protégés par la clé numéro 13. Sur le client, la configuration sera :
keys /etc/ntp/ntp.keys server SERVERNAME key 13
Quelques petits trucs pour finir. Avec ntpd, comment voir l'état des pairs avec qui ont est connectés ? Ici, on a configuré l'utilisation du pool :
% ntpq -pn
remote refid st t when poll reach delay offset jitter
==============================================================================
0.debian.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
1.debian.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
2.debian.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
3.debian.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
-162.159.200.123 10.19.11.58 3 u 25 128 377 1.381 -2.439 0.199
-164.132.45.112 43.13.124.203 3 u 8 128 377 5.507 -1.423 0.185
+212.83.145.32 193.200.43.147 2 u 4 128 377 1.047 -1.823 0.455
+5.196.160.139 145.238.203.14 2 u 12 128 377 5.000 -0.981 0.291
-163.172.61.210 145.238.203.14 2 u 8 128 377 1.037 -0.888 0.246
*82.64.45.50 .GPS. 1 u 71 128 377 11.116 -1.178 0.549
-178.249.167.0 193.190.230.65 2 u 3 128 377 6.233 -1.026 0.145
-194.57.169.1 145.238.203.14 2 u 2 128 377 10.660 -0.931 0.233
-151.80.124.104 193.204.114.232 2 u 16 128 377 4.888 -1.414 0.354
Autre commande utile, pour comparer l'heure locale avec les serveurs NTP :
% ntpdate -q ntp.nic.fr server 2001:67c:2218:2::4:12, stratum 2, offset 0.000520, delay 0.03194 server 2001:67c:2218:2::4:13, stratum 2, offset 0.000746, delay 0.03175 server 192.134.4.12, stratum 2, offset 0.000509, delay 0.03127 server 192.134.4.13, stratum 2, offset 0.000596, delay 0.04376 28 Oct 10:54:08 ntpdate[18996]: adjust time server 192.134.4.12 offset 0.000509 sec
Et avec un serveur NTP complètement différent ? Essayons avec OpenNTPD :
% cat /etc/ntpd.conf
# No way to restrict per IP address :-( Use a firewall
listen on *
servers fr.pool.ntp.org
sensor *
Avec cette configuration, la machine va se synchroniser au
pool, cequ'on pourra vérifier avec ntpctl :
% sudo ntpctl -s all
4/4 peers valid, clock synced, stratum 4
peer
wt tl st next poll offset delay jitter
162.159.200.123 from pool fr.pool.ntp.org
1 10 3 23s 30s -2.270ms 4.795ms 0.027ms
193.52.136.2 from pool fr.pool.ntp.org
1 10 2 32s 34s -1.904ms 18.058ms 1.788ms
91.121.96.146 from pool fr.pool.ntp.org
* 1 10 3 0s 31s -1.147ms 1.872ms 0.069ms
62.210.213.21 from pool fr.pool.ntp.org
1 10 2 1s 34s -0.367ms 4.989ms 0.067ms
L'article seul
RFC 8631: Link Relation Types for Web Services
Date de publication du RFC : Juillet 2019
Auteur(s) du RFC : E. Wilde
Pour information
Première rédaction de cet article le 21 juillet 2019
Le Web, ce sont les pages auxquelles on accède depuis son navigateur, avec les textes à lire et les images à regarder. Mais ce sont aussi de nombreuses applications, avec une API, prévues pour être utilisées depuis un programme spécifique, pas depuis le navigateur Web. Ces Web services ont un ou plusieurs URL pour les appeler, et des ressources supplémentaires comme la documentation. Ce nouveau RFC décrit un type de liens hypertextes permettant de trouver l'URL de la documentation d'un service.
Normalement, on peut interagir avec un service Web sans connaitre les détails à l'avance. La négociation de contenu, par exemple (RFC 7231, sections 3.4 et 5.3) permet de choisir dynamiquement le type de données. En combinant les outils de l'architecture Web (URI, HTTP, etc), on peut créer des services plus simples que les anciennes méthodes compliquées, type CORBA. (Le terme de service REST est souvent utilisé pour ces services modernes et simples.) Mais cela ne dispense pas complètement de documentation et de description des services. (La documentation est du texte libre, conçue pour les humains, la description est sous un format structuré, et conçue pour les programmes.) Il faut donc, pour accéder à un service, trouver documentation et description. C'est ce que propose ce RFC, avec de nouveaux types de liens (les types de liens sont décrits dans le RFC 8288).
Notez bien que ce RFC ne dit pas comment doit être écrite la documentation, ou sous quel format structurer la description. Un format de description courant aujourd'hui est OpenAPI, fondé sur JSON. Mais il en existe d'autres comme RAML (fondé sur YAML) ou RSDL, si vous avez des expériences concrètes sur ces langages, ou des opinions sur leurs avantages et inconvénients, je suis intéressé. (Dans le passé, on utilisait parfois WSDL). Ce RFC fournit juste un moyen de trouver ces descriptions. (En prime, il permet également de trouver l'URL d'un service décrivant l'état actuel d'un service, permettant d'informer, par exemple, sur des pannes ou sur des opérations de maintenance.)
Parfois, documentation et description sont fusionnées en un seul ensemble de ressources. Dans ce cas, on n'est pas obligé d'utiliser notre RFC, on peut se contenter du type de lien décrit dans le RFC 5023.
Les quatre nouveaux types de liens (section 4 du RFC) sont :
service-docpour indiquer où se trouve la documentation (écrite pour des humains),service-descpour donner accès à la description (conçue pour des programmes),service-metapour l'URI des méta-informations diverses sur le service, comme des informations à caractère juridique (politique « vie privée » du service, par exemple),statuspour l'état actuel du service.
Ces types sont notés dans le registre IANA des types de liens (section 6 du RFC).
Un exemple dans un document HTML serait, pour indiquer la documentation :
<link rel="service-doc" type="text/html" title="My documentation"
href="https://api.example.org/documentation.html"/>
Et dans les en-têtes HTTP, ici pour indiquer la description :
Link: <https://api.example.org/v1/description.json> rel="service-desc";
type="application/json"
Si vous voulez voir un exemple réel, il y en a un dans le DNS Looking Glass. Les en-têtes HTTP, et le code HTML contiennent un lien vers la documentation.
La section 5 est consacrée à
status, qui permet d'indiquer une ressource
sur le Web donnant des informations sur l'état du
service. On peut voir par exemple la page de Github ou
bien celle de
CloudFlare. (Évidemment, il est recommandé qu'elle soit hébergée sur
une infrastructure différente de celle du service dont elle
indique l'état de santé, pour éviter que le même problème
DNS, BGP ou autre ne
plante le service et son bulletin de santé en même temps. C'est ce
que ne fait pas la page
de Framasoft, qui utilise le même nom de domaine.) Aucune obligation sur le contenu
auquel mène le lien, cela peut être un texte conçu pour un humain
ou pour un programme.
Quelques considérations de sécurité pour finir (section 7 du RFC). D'abord, toute documentation peut être utilisée par les gentils utilisateurs, mais aussi par les méchants attaquants. Il peut donc être prudent de ne donner dans la documentation que ce qui est nécessaire à l'utilisation du service. D'autre part, la description (ce qui est en langage formel, analysable par un programme) peut permettre davantage d'automatisation. C'est bien son but, mais cela peut aider les attaquants à automatiser les attaques. Sans même parler d'attaque délibérée, le RFC note aussi que cette automatisation, utilisée par un programme client mal écrit, peut mener à une charge importante du service si, par exemple, le client se met à utiliser sans limitation toutes les options qu'il découvre.
Enfin, tout programmeur et toute programmeuse sait bien que les documentations ne sont pas toujours correctes. (Ou, plus charitablement, qu'elles ne sont pas toujours à jour.) Le programme client ne doit donc pas faire une confiance aveugle à la documentation ou à la description et doit se préparer à des comportements imprévus de la part du service.
À part le DNS Looking Glass, je n'ai pas encore trouvé de service Web qui utilise ces types de liens. Si vous en voyez un, vous me prévenez ?
L'article seul
RFC 8624: Algorithm Implementation Requirements and Usage Guidance for DNSSEC
Date de publication du RFC : Juin 2019
Auteur(s) du RFC : P. Wouters (Red Hat), O. Sury (Internet Systems Consortium)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 2 septembre 2019
Quel algorithme de cryptographie choisir pour mes signatures DNSSEC, se demande l'ingénieur système. Lesquels doivent être reconnus par le logiciel que j'écris, s'interroge la programmeuse. Il y a bien un registre IANA des algorithmes normalisés mais c'est juste une liste non qualifiée, qui mêle des algorithmes de caractéristiques très différentes. Ce nouveau RFC vise à répondre à cette question en disant quels sont les algorithmes recommandés. Il remplace l'ancien RFC 6944, qui est modifié considérablement. Notamment, il marque l'avantage désormais donné aux courbes elliptiques par rapport à RSA. Et il a depuis été remplacé par le RFC 9904.
La précédente liste d'algorithmes possibles datait donc du RFC 6944. D'autres algorithmes ont été ajoutés par la suite. Certains sont devenus populaires. Par exemple, ECDSA est maintenant suffisamment répandu pour qu'un résolveur validant ne puisse plus raisonnablement l'ignorer. D'autres algorithmes ont été peu à peu abandonnés, par exemple parce que les progrès de la cryptanalyse les menaçaient trop.
Aujourd'hui, le développeur qui écrit ou modifie un signeur (comme ldns, utilisé par OpenDNSSEC) ou un logiciel résolveur validant (comme Unbound ou Knot) doit donc se taper pas mal de RFC mais aussi pas mal de sagesse collective distillée dans plusieurs listes de diffusion pour se faire une bonne idée des algorithmes que son logiciel devrait gérer et de ceux qu'il peut laisser tomber sans trop gêner ses utilisateurs. Ce RFC vise à lui simplifier la tâche, en classant ces algorithmes selon plusieurs niveaux.
Notre RFC 8624 détermine pour chaque algorithme s'il est indispensable (MUST, nécessaire pour assurer l'interopérabilité), recommandé (RECOMMENDED, ce serait vraiment bien de l'avoir, sauf raison contraire impérieuse), facultatif (MAY, si vous n'avez rien d'autre à faire de vos soirées que de programmer) ou tout simplement déconseillé (NOT RECOMMENDED), voire à éviter (MUST NOT, pour le cas de faiblesses cryptographiques graves et avérées). Il y a deux catégorisations, une pour les signeurs (le cas de l'administratrice système cité au début), et une pour les résolveurs qui valideront. Par exemple, un signeur ne devrait plus utiliser RSA avec SHA-1, vu les faiblesses de SHA-1, mais un résolveur validant doit toujours le traiter, car des nombreux domaines sont ainsi signés. S'il ignorait cet algorithme, bien des zones seraient considérées comme non signées.
La liste qualifiée des algorithmes se trouve dans la section 3 : ECDSA avec la courbe P-256, et RSA avec SHA-256, sont les seuls indispensables pour les signeurs. ED25519 (RFC 8080) est recommandé (et sera probablement indispensable dans le prochain RFC). Plusieurs algorithmes sont à éviter, comme DSA, GOST R 34.10-2001 (RFC 5933) ou RSA avec MD5 (RFC 6151). Tous les autres sont facultatifs.
Pour les résolveurs validants, la liste des indispensables et des recommandés est un peu plus longue. Par exemple, ED448 (RFC 8080) est facultatif pour les signeurs mais recommandé pour les résolveurs.
La même section 3 justifie ces choix : RSA+SHA-1 est l'algorithme de référence, celui qui assure l'interopérabilité (tout logiciel compatible DNSSEC doit le mettre en œuvre) et c'est pour cela qu'il reste indispensable pour les résolveurs, malgré les faiblesses de SHA-1. RSA+SHA-256 est également indispensable car la racine et la plupart des TLD l'utilisent aujourd'hui. Un résolveur qui ne comprendrait pas ces algorithmes ne servirait pas à grand'chose. RSA+SHA-512 ne pose pas de problème de sécurité, mais a été peu utilisé, d'où son statut « non recommandé » pour les signeurs.
D'autre part, le RFC insiste sur le fait qu'on ne peut pas changer le statut d'un algorithme trop vite : il faut laisser aux ingénieurs système le temps de changer leurs zones DNS. Et les résolveurs sont forcément en retard sur les signeurs : même si les signeurs n'utilisent plus un algorithme dans leurs nouvelles versions, les résolveurs devront continuer à l'utiliser pour valider les zones pas encore migrées.
Depuis le RFC 6944, ECDSA a vu son utilisation augmenter nettement. Les courbes elliptiques sont clairement l'avenir, d'où leur statut mieux placé. Ainsi, une zone DNS qui n'était pas signée et qui va désormais l'être devrait choisir un algorithme à courbes elliptiques, comme ECDSA ou EdDSA (RFC 8032 et RFC 8080). Avec ECDSA, il est recommandé d'utiliser l'algorithme déterministe du RFC 6979 pour générer les signatures. Les zones actuellement signées avec RSA devraient migrer vers les courbes elliptiques. Une chose est sûre, la cryptographie évolue et ce RFC ne sera donc pas éternel.
Le RFC note d'ailleurs (section 5) que le remplacement d'un algorithme cryptographique par un autre (pas juste le remplacement d'une clé) est une opération complexe, à faire avec prudence et après avoir lu les RFC 6781 et RFC 7583.
Ah, et parmi les algorithmes à courbes elliptiques, GOST (RFC 5933) régresse
car l'ancien algorithme R 34.10-2001 a été remplacé par un nouveau qui n'est
pas, lui, normalisé pour DNSSEC. L'algorithme venant du GOST avait été
normalisé pour DNSSEC car les gérants du
.ru disaient qu'ils ne
pouvaient pas signer avec un algorithme étranger mais, finalement,
ils ont utilisé RSA, ce qui diminue sérieusement l'intérêt des
algorithmes GOST.
Outre les signeurs et les résolveurs, le RFC prévoit le cas des registres, qui délèguent des zones signées, en mettant un enregistrement DS dans leur zone. Ces enregistrements DS sont des condensats de la clé publique de la zone fille, et, ici, SHA-1 est à éviter et SHA-256 est indispensable.
Aujourd'hui, les mises en œuvre courantes de DNSSEC sont en général compatibles avec ce que demande le RFC. Elles sont parfois trop « généreuses » (RSA+MD5 encore présent chez certains), parfois un peu trop en retard (ED448 pas encore présent partout).
L'article seul
RFC 8621: The JSON Meta Application Protocol (JMAP) for Mail
Date de publication du RFC : Août 2019
Auteur(s) du RFC : N. Jenkins (FastMail), C. Newman
(Oracle)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF jmap
Première rédaction de cet article le 14 août 2019
Ce nouveau RFC décrit un remplaçant pour le traditionnel protocole IMAP, remplaçant fondé sur le cadre JMAP (JSON Meta Application Protocol, RFC 8620).
Le protocole décrit dans ce RFC fournit les mêmes services qu'IMAP (RFC 9051) : accéder aux boîtes aux lettres de courrier, chercher dans ces boîtes, gérer les messages (détruire les inutiles, par exemple), etc. Par rapport à IMAP, outre l'utilisation du format JSON, l'accent est mis sur la synchronisation rapide, l'optimisation pour les clients mobiles, et sur la possibilité de notifications. JMAP est sans état (pas besoin de connexion permanente). Ce « JMAP pour le courrier » s'appuie sur JMAP, normalisé dans le RFC 8620. JMAP est un protocole générique, qui peut servir à synchroniser bien des choses entre un client et un serveur (par exemple un agenda, ou bien une liste de contacts). Par abus de langage, je vais souvent dire « JMAP » dans cet article alors que je devrais normalement préciser « JMAP pour le courrier », premier « utilisateur » du JMAP générique.
JMAP manipule différents types d'objets. Le plus important est
sans doute Email (section 4 du RFC), qui
modélise un message. Il s'agit d'une représentation de haut
niveau, le client JMAP n'a pas à connaitre tous les détails de
l'IMF (Internet Message Format, RFC 5322), de
MIME (RFC 2045),
etc. Un objet de type Email a une liste
d'en-têtes et un corps, et JMAP fournit des méthodes pour accéder
aux différentes parties du corps. Il y a même plusieurs
représentations d'un message, pour s'adapter aux différents
clients. Par exemple, un message MIME est normalement un
arbre, de profondeur quelconque, mais un
client JMAP peut décider de demander une représentation aplatie,
avec juste une liste d'attachements. (La plupart des MUA présentent à
l'utilisateur une vue aplatie de l'objet MIME.) Voilà pourquoi
l'objet Email a plusieurs propriétés, le
client choisissant à laquelle il accède :
bodyStructure: l'arbre MIME, c'est la représentation la plus « authentique »,textBody: une liste des parties MIME à afficher quand on préfère du texte,htmlBody: une liste des parties MIME à afficher quand on préfère de l'HTML,attachments: la liste des « pièces jointes » (rappelez-vous que le concept de « pièces jointes » a été créé pour l'interface avec l'utilisateur ; il n'a pas de sens en MIME, qui ne connait qu'un arbre avec des feuilles de différents types).
Les en-têtes doivent pouvoir être internationaux (RFC 6532).
Un message a évidemment des métadonnées, parmi lesquelles :
id, un identifiant du message (ce n'est pas leMessage-ID:, c'est attribué par le serveur JMAP), contrairement à IMAP, l'identificateur d'un message ne change pas, même quand le message change de boîte, et il peut apparaitre dans plusieurs boîtes à la foisblobIf, un identifiant du message représenté sous la forme d'une suite d'octets, à analyser par le client, par opposition à l'objet de haut niveau identifié parid,size, la taille du message,keywords, des mots-clés, parmi lesquels certains, commençant par un dollar, ont une signification spéciale.
En IMAP, les mots-clés spéciaux sont précédés d'une
barre inverse. En JMAP, c'est le
dollar. Parmi ces mots-clés,
$seen indique que le message a été lu,
$answered, qu'on y a répondu,
$junk, que le serveur l'a classé comme
spam, etc. Ces mots-clés sont dans un
registre IANA.
Et quelles opérations sont possibles avec les objets de type
Email ? Ce sont les opérations génériques de
JMAP (RFC 8620, section 5). Ainsi,
on peut récupérer un message avec
Email/get. Cette requête :
[[ "Email/get", {
"ids": [ "f123u456", "f123u457" ],
"properties": [ "threadId", "mailboxIds", "from", "subject",
"receivedAt", "header:List-POST:asURLs",
"htmlBody", "bodyValues" ],
"bodyProperties": [ "partId", "blobId", "size", "type" ],
"fetchHTMLBodyValues": true,
"maxBodyValueBytes": 256
}, "#1" ]]
peut récupérer, par exemple, cette valeur :
[[ "Email/get", {
"accountId": "abc",
"state": "41234123231",
"list": [
{
"id": "f123u457",
"threadId": "ef1314a",
"mailboxIds": { "f123": true },
"from": [{ "name": "Joe Bloggs", "email": "joe@example.com" }],
"subject": "Dinner on Thursday?",
"receivedAt": "2013-10-13T14:12:00Z",
"header:List-POST:asURLs": [
"mailto:partytime@lists.example.com"
],
"htmlBody": [{
"partId": "1",
"blobId": "B841623871",
"size": 283331,
"type": "text/html"
}, {
"partId": "2",
"blobId": "B319437193",
"size": 10343,
"type": "text/plain"
}],
"bodyValues": {
"1": {
"isTruncated": true,
"value": "<html><body><p>Hello ..."
},
"2": {
"isTruncated": false,
"value": "-- Sent by your friendly mailing list ..."
}
}
}
],
"notFound": [ "f123u456" ]
}, "#1" ]]
Notez que le client a demandé deux messages, mais qu'un seul, le
f123u457, a été trouvé.
Tout aussi indispensable, Email/query
permet de demander au serveur une recherche, selon de nombreux
critères comme la date, les mots-clés, ou bien le contenu du corps
du message.
Email/set permet de modifier un message,
ou d'en créer un (qu'on pourra ensuite envoyer avec
EmailSubmission, décrit plus loin). Notez qu'il n'y a pas de
Email/delete. Pour détruire un message, on
utilise Email/set en changeant la propriété
indiquant la boîte aux lettres, pour mettre la boîte aux lettres
spéciale qui sert de poubelle (rôle = trash).
Comme IMAP, JMAP pour le courrier a la notion de boîte aux lettres (section 2 du RFC). Une boîte (vous pouvez appeler ça un dossier ou un label si vous voulez) est un ensemble de messages. Tout message est dans au moins une boîte. Les attributs importants d'une boîte :
- Un nom unique (par exemple Vacances ou Personnel), en Unicode (RFC 5198),
- Un identificateur attribué par le serveur (et a priori moins lisible par des humaines que ne l'est le nom),
- Un rôle, optionnel, qui indique à quoi sert la boîte, ce
qui est utile notamment si le serveur peut être utilisé en JMAP
et en IMAP. Ainsi, le rôle
inboxidentifie la boîte où le courrier arrive par défaut. (Les rôles figurent dans un registre IANA créé par le RFC 8457.) - Certains attributs ne sont pas fixes, par exemple le nombre total de messages contenus dans la boîte, ou bien le nombre de messages non lus.
- Les droits d'accès (ACL, cf. RFC 4314.) Les permissions sont par boîte, pas par message.
Ensuite, on utilise les méthodes JMAP pour accéder aux boîtes
(révisez donc le RFC 8620, qui décrit
le JMAP générique). Ainsi, pour accéder à une boîte,, on utilise
la méthode JMAP Mailbox/get, qui utilise le
/get JMAP (RFC 8620, section 5.1). Le paramètre
ids peut être nul, cela indique alors qu'on
veut récupérer tous les messages (c'est ce qu'on fait dans
l'exemple ci-dessous).
De même, pour effectuer une recherche sur le serveur, JMAP
normalise la méthode /query (RFC 8620, section 5.5) et JMAP pour le courrier peut
utiliser Mailbox/query.
Par exemple, si on veut voir toutes les boîtes existantes, le client JMAP envoie le JSON :
[[ "Mailbox/get", {
"accountId": "u33084183",
"ids": null
}, "0" ]]
et reçoit une réponse du genre (on n'affiche que les deux premières boîtes) :
[[ "Mailbox/get", {
"accountId": "u33084183","state": "78540",
"state": "78540",
"list": [{
"id": "MB23cfa8094c0f41e6",
"name": "Boîte par défaut",
"role": "inbox",
"totalEmails": 1607,
"unreadEmails": 15,
"myRights": {
"mayAddItems": true,
...},
{
"id": "MB674cc24095db49ce",
"name": "Personnel",
...
Notez que state est l'identificateur d'un
état de la boîte. Si on veut ensuite récupérer les changements, on
pourra utiliser Mailbox/changes avec comme
paramètre "sinceState": "88540".
Dans JMAP, les messages peuvent être regroupés en fils de discussion (threads, section 3 du RFC). Tout message est membre d'un fil (parfois membre unique). Le RFC n'impose pas de méthode unique pour constituer les fils mais suggère :
- D'utiliser les en-têtes du RFC 5322
(
In-Reply-To:ouReferences:indiquant leMessage-Id:d'un autre message). - Et de vérifier que les messages ont le même sujet (après avoir supprimé des préfixes comme « Re: »), pour tenir compte des gens qui volent les fils. Cette heuristique est imparfaite (le sujet peut avoir changé sans pour autant que le message soit sans rapport avec le reste du fil).
On peut ensuite accéder aux fils. Le client envoie :
[[ "Thread/get", {
"accountId": "acme",
"ids": ["f123u4", "f41u44"]
}, "#1" ]]
Et récupère les fils f123u4 et
f41u44 :
[[ "Thread/get", {
"accountId": "acme",
"state": "f6a7e214",
"list": [
{
"id": "f123u4",
"emailIds": [ "eaa623", "f782cbb"]
},
{
"id": "f41u44",
"emailIds": [ "82cf7bb" ]
}
...
Un client qui vient de se connecter à un serveur JMAP va
typiquement faire un Email/query sans
conditions particulières, pour recevoir la liste des messages (ou
alors en se limitant aux N messages les plus récents),
puis récupérer les fils de discussion correspondants avec
Thread/get, récupérer les messages
eux-mêmes. Pour diminuer la latence, JMAP permet au client
d'envoyer toutes ces requêtes en une seule fois (batching), en disant pour
chaque requête qu'elle doit utiliser le résultat de la précédente
(backreference, membre JSON resultOf).
JMAP permet également d'envoyer des messages. Un client JMAP
n'a donc besoin que d'un seul protocole, contrairement au cas
courant aujourd'hui
où il faut IMAP et
SMTP,
configurés séparement, avec, trop souvent, l'un qui marche et l'autre pas. Cela simplifie
nettement les choses pour l'utilisateur. Cela se fait avec le type
EmailSubmission (section 7 du RFC). Deux
importantes propriétés d'un objet de type
EmailSubmission sont
mailFrom, l'expéditeur, et
rcptTo, les destinataires. Rappel important
sur le courrier électronique : il y a les adresses indiquées dans
le message (champs To:,
Cc:, etc, cf. RFC 5322), et les adresses indiquées dans l'enveloppe
(commandes SMTP comme MAIL
FROM et RCPT TO, cf. RFC 5321). Ces adresses ne sont pas forcément
identiques. Lorsqu'on apprend le fonctionnement du courrier
électronique, la distinction entre ces deux catégories d'adresses
est vraiment cruciale.
Un EmailSubmission/set va créer l'objet
EmailSubmission, et
envoyer le message. Ici, on envoie à
john@example.com et
jane@example.com un message (qui avait été créé
par Email/set et qui avait l'identificateur
M7f6ed5bcfd7e2604d1753f6c) :
[[ "EmailSubmission/set", {
"accountId": "ue411d190",
"create": {
"k1490": {
"identityId": "I64588216",
"emailId": "M7f6ed5bcfd7e2604d1753f6c",
"envelope": {
"mailFrom": {
"email": "john@example.com",
"parameters": null
},
"rcptTo": [{
"email": "jane@example.com",
"parameters": null
},
...
]
}
}
},
"onSuccessUpdateEmail": {
"#k1490": {
"mailboxIds/7cb4e8ee-df87-4757-b9c4-2ea1ca41b38e": null,
"mailboxIds/73dbcb4b-bffc-48bd-8c2a-a2e91ca672f6": true,
"keywords/$draft": null
}
}
}, "0" ]]
Anecdote sur l'envoi de courrier : les premières versions de
« JMAP pour le courrier » utilisaient une boîte aux lettres
spéciale, nommée Outbox, où on mettait les
messages à envoyer (comme dans ActivityPub).
JMAP a d'autres types d'objets amusants, comme
VacationResponse (section 8), qui permet de
faire envoyer un message automatiquement lorsqu'on est absent
(l'auto-répondeur du serveur doit évidemment suivre le RFC 3834, pour éviter de faire des bêtises comme
de répondre à une liste de diffusion). On
crée un objet avec VacationResponse/set et
hop, l'auto-répondeur est amorcé.
Et je n'ai pas parlé de tout, par exemple JMAP permet de pousser des changements depuis le serveur vers le client, si la boîte aux lettres est modifiée par un autre processus (RFC 8620, section 7).
JMAP a le concept de
capacités (capabilities),
que le serveur annonce au client, dans un objet JSON (rappel :
JSON nomme « objets » les
dictionnaires), et sous la forme d'un URI. JMAP pour le courrier
ajoute trois capacités au registre des
capacités JMAP,
urn:ietf:params:jmap:mail pour dire qu'on
sait gérer le courrier,
urn:ietf:params:jmap:submission, pour dire
qu'on sait en envoyer (cf. RFC 6409, sur ce
concept de soumission d'un message), et
urn:ietf:params:jmap:vacationresponse pour
dire qu'on sait gérer un auto-répondeur.
Le courrier électronique pose plein de problèmes de sécurité
intéressants. La section 9 de notre RFC les détaille. Par exemple,
les messages en HTML sont particulièrement dangereux. (Il
est toujours amusant de voir des entreprises de sécurité
informatique envoyer leur newsletter en HTML,
malgré les risques associés, qui sont aujourd'hui bien connus.) Le
RFC rappelle donc aux clients JMAP (mais c'est valable pour tous
les MUA) que du
JavaScript dans le message peut changer son
contenu, qu'un message en HTML peut récupérer du contenu sur
l'Internet (via par exemple un <img
src=…), ce qui trahit le
lecteur et fait fuiter des données privées, que
CSS,
quoique moins dangereux que JavaScript, permet également des trucs
assez limites, que les liens en HTML ne pointent pas toujours vers
ce qui semble (<a
href="http://evil.example/">cliquez ici pour aller sur le site
de votre banque https://good-bank.example</a>),
etc. Pour faire face à tous ces dangers du courrier en HTML, le
RFC suggère de nettoyer le HTML avant de l'envoyer au
client. Attention, outre que c'est une modification du contenu, ce
qui est toujours délicat politiquement, le faire proprement est
difficile, et le RFC recommande fortement d'utiliser une
bibliothèque bien testée, de ne pas le faire soi-même à la main
(il y a trop de pièges). Par exemple, en
Python, on peut utiliser lxml, et son module
Cleaner, ici en mode extrémiste qui retire
tout ce qui peut être dangereux :
from lxml.html.clean import Cleaner
...
cleaner = Cleaner(scripts=True, javascript=True, embedded=True, meta=True, page_structure=True,
links=True, remove_unknown_tags=True,
style=True)
Mais il est probablement impossible de complètement sécuriser HTML dans le courrier. Le RFC explique à juste titre que HTML augmente beaucoup la surface d'attaque. Une organisation soucieuse de sécurité ne devrait pas traiter le HTML dans le courrier.
La soumission du courrier (cf. RFC 6409) pose également des problèmes de sécurité. Imaginez un client JMAP piraté et qui serve ensuite à envoyer du spam de manière massive, utilisant le compte de l'utilisateur ignorant de ce piratage. Les MTA qui acceptent du courrier ont des mécanismes de défense (maximum N messages par heure, avec au plus M destinataires par message…) mais ces mécanismes marchent d'autant mieux que le serveur a davantage d'information. Si la soumission via JMAP est mise en œuvre par un simple relais vers un serveur SMTP de soumission, certaines informations sur le client peuvent être perdues. De tels relais doivent donc veiller à transmettre au serveur SMTP toute l'information disponible, par exemple via le mécanisme XCLIENT.
JMAP a été développé essentiellement au sein de FastMail, qui le met en œuvre sur ses serveurs. Il existe une page « officielle » présentant le protocole, qui explique entre autres les avantages de JMAP par rapport à IMAP. Vous y trouverez également des conseils pour les auteurs de clients, très bien faits et qui donnent une bonne idée de comment le protocole marche. Ce site Web est un passage recommandé.
On y trouve également une liste de mises en œuvre de JMAP. Ainsi, le serveur IMAP bien connu Cyrus a déjà JMAP en expérimental. Le MUA K-9 Mail a, quant à lui, commencé le travail.
L'article seul
RFC 8620: The JSON Meta Application Protocol (JMAP)
Date de publication du RFC : Juillet 2019
Auteur(s) du RFC : N. Jenkins (Fastmail), C. Newman (Oracle)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF jmap
Première rédaction de cet article le 6 septembre 2019
Le protocole JMAP, JSON Meta Application Protocol, permet de bâtir des mécanismes d'accès à des objets distants (par exemple des boîtes aux lettres, ou des agendas), en envoyant et recevant du JSON au dessus de HTTPS. Son principal « client » est le protocole « JMAP for mail », un concurrent d'IMAP normalisé dans le RFC 8621.
Au début, JMAP était même conçu uniquement pour l'accès au courrier, comme l'indique son nom, qui évoque IMAP. Mais, dans le cadre de la normalisation de JMAP, est apparu le désir de séparer le protocole générique, adapté à toutes sortes d'objets distants, du protocole spécifique du courrier. D'où les deux RFC : ce RFC 8620 normalise le protocole générique, alors que le RFC 8621 normalise « JMAP for mail ». Dans le futur, d'autres protocoles fondés sur JMAP apparaitront peut-être, par exemple pour l'accès et la synchronisation d'un agenda (en concurrence avec le CalDAV du RFC 4791, donc).
Parmi les concepts techniques importants de JMAP, notons :
- Utilisation de JSON (RFC 8259) pour encoder les données, parce que tout le monde utilise JSON aujourd'hui,
- Transport sur HTTPS (RFC 2818 et RFC 7230), là encore comme tout le monde aujourd'hui, avec toutes les propriétés de sécurité de HTTPS (notamment, le client JMAP doit authentifier le serveur, typiquement via un certificat),
- Possibilité de regrouper (batching) les requêtes en un seul envoi, pour les cas où la latence est élevée,
- Possibilité de notification par le serveur (push), pour éviter l'interrogation répétée par le client (polling),
- Un mécanisme de transfert incrémental des objets, pour limiter le débit sur le réseau.
Du fait de l'utilisation de JSON, il est bon de réviser le vocabulaire JSON, notamment le fait qu'un objet (object) JSON est en fait un dictionnaire.
Outre les types de données de base de JSON, comme les booléens,
les chaînes de caractères
et les entiers, JMAP définit quelques types à lui, notamment le
type Id, qui stocke l'identificateur d'un
objet. Syntaxiquement, c'est une chaîne de caractères
LDH (Letter-Digit-Hyphen, lettres ASCII, chiffres et trait d'union). Par exemple, dans le RFC 8621, la première boîte aux lettres mentionnée a comme
identificateur MB23cfa8094c0f41e6. Notre RFC
crée aussi le type Date, puisque JSON ne
normalise pas les dates. Ce type utilise le format du RFC 3339.
À ce stade, je peux avouer que j'ai fait un abus de langage. J'ai parlé de JSON mais en fait JMAP utilise un sous-ensemble de JSON, nommé I-JSON, et décrit dans le RFC 7493, afin d'éviter certaines ambiguités de JSON (section 8.4 de notre RFC). Tout le contenu échangé en JMAP doit être du I-JSON. D'ailleurs, si vous connaissez un logiciel libre qui vérifie qu'un texte JSON est du I-JSON, je suis preneur.
JMAP nécessite que le client se connecte au serveur (section 2 du RFC, sur la session). Pour cela, il lui faut l'URL du serveur (rappelez-vous que JMAP tourne sur HTTPS), qui peut être obtenu manuellement, ou par un processus de découverte décrit plus loin. Et il faut évidemment les moyens d'authentification (par exemple nom et phrase de passe), ceux-ci n'étant pas précisés dans notre RFC. Un mécanisme unique avait été prévu mais avait suscité trop de controverses à l'IETF. Finalement, les mécanismes utilisables sont ceux habituels de HTTPS (enregistrés à l'IANA). Lors de la connexion, le serveur va envoyer un objet JSON décrivant entre autres ses capacités, comme la taille maximale des objets téléversés, ou comme les extensions gérées (comme le « JMAP for mail » du RFC 8621). Voici un exemple (tiré du RFC, car je n'ai pas trouvé de serveur JMAP où je pouvais avoir facilement un compte pour tester, si vous en avez un, n'hésitez pas à m'écrire) :
{
"capabilities": {
"urn:ietf:params:jmap:core": {
"maxSizeUpload": 50000000,
"maxSizeRequest": 10000000,
...
"collationAlgorithms": [
"i;ascii-numeric",
"i;ascii-casemap",
"i;unicode-casemap"
]
},
"urn:ietf:params:jmap:mail": {}
"urn:ietf:params:jmap:contacts": {},
"https://example.com/apis/foobar": {
"maxFoosFinangled": 42
}
},
"accounts": {
"A13824": {
"name": "john@example.com",
"isPersonal": true,
"isReadOnly": false,
"accountCapabilities": {
"urn:ietf:params:jmap:mail": {
"maxMailboxesPerEmail": null,
"maxMailboxDepth": 10,
...
},
"urn:ietf:params:jmap:contacts": {
...
}
...
"apiUrl": "https://jmap.example.com/api/",
...
Notez que ce serveur annonce qu'il sait faire du JMAP pour le
courrier (RFC 8621, cf. la ligne
urn:ietf:params:jmap:mail) et qu'il a
également une extension privée,
https://example.com/apis/foobar. Les
capacités publiques sont dans un registre
IANA. On peut ajouter des capacités par la procédure
(cf. RFC 8126) « Spécification nécessaire »
pour les capacités marquées « fréquentes »
(common), et par la procédure « Examen par un
expert » pour les autres.
La méthode standard pour découvrir le serveur JMAP, si on n'en
connait pas l'URL, est d'utiliser un enregistrement
SRV (RFC 2782, mais voir aussi
le RFC 6186) puis un URL bien
connu. Imaginons que le domaine soit
example.net. On cherche le SRV pour
_jmap._tcp.example.net. (jmap
a donc été ajouté au registre des
services.) On récupère alors le
nom du serveur et le port (a priori, ce
sera 443, le port standard de HTTPS). Et on n'a plus qu'à se
connecter à l'URL bien connu (RFC 8615), à
https://${hostname}[:${port}]/.well-known/jmap.
jmap figure à cet effet dans le registre des URL bien connus. (Notez
que l'étape SRV est facultative, certains clients iront
directement au /.well-known/jmap.) Ainsi, si vous utilisez JMAP pour le courrier, et que votre
adresse est gerard@example.net, vous partez
du domaine example.net et vous suivez
l'algorithme ci-dessus. (Je ne sais pas pourquoi JMAP n'utilise
pas plutôt le WebFinger du RFC 7033.)
Puisqu'on utilise le DNS pour récupérer ces enregistrements SRV, il est évidemment recommandé de déployer DNSSEC.
Une fois qu'on a récupéré le premier objet JSON décrit plus
haut, on utilise la propriété (le membre, pour parler JSON) apiUrl de cet
objet pour faire les requêtes suivantes (section 3 du RFC). On utilise la méthode
HTTP POST, le type
MIME application/json, et on
envoie des requêtes en JSON, qui seront suivies de réponses du
serveur, également en JSON. Les méthodes JMAP (à ne pas confondre
avec les méthodes HTTP comme GET ou
POST) sont écrites sous la forme
Catégorie/Méthode. Il existe une catégorie
Core pour les méthodes génériques de JMAP et
chaque protocole utilisant JMAP définit sa (ou ses) propre(s)
catégorie(s). Ainsi, le RFC 8621 définit les
catégories Mailbox,
Email (un message), etc. Comme
Core définit une méthode
echo (section 4, le ping de
JMAP), qui ne fait que renvoyer les données, sans les comprendre, un exemple de requête/réponse peut
être :
[[ "Core/echo", {
"hello": true,
"high": 5
}, "b3ff" ]]
[[ "Core/echo", {
"hello": true,
"high": 5
}, "b3ff" ]]
(Oui, la réponse - le second paragraphe - est identique à la question.)
En cas d'erreur, le serveur devrait renvoyer un objet décrivant le problème, en utilisant la syntaxe du RFC 7807. Une liste des erreurs connues figure dans un registre IANA.
Il existe des noms de méthodes standard qu'on retrouve dans
toutes les catégories, comme get. Si on a une
catégorie Foo décrivant un certain type
d'objets, le client sait qu'il pourra récupérer les objets de ce
type avec la méthode Foo/get, les modifier
avec Foo/set et récupérer uniquement les
modifications incrémentales avec
Foo/changes. La section 5 du RFC décrit ces
méthodes standard.
Une méthode particulièrement utile est
query (section 5.5). Elle permet au client de demander au
serveur de faire une recherche et/ou un tri des objets. Au lieu de
tout télécharger et de faire recherche et tri soi-même, le client
peut donc sous-traiter cette opération potentiellement
coûteuse. Cette méthode est une de celles qui permet de dire que
JMAP est bien adapté aux machines clientes disposant de faibles
ressources matérielles, et pas très bien connectées. Le RFC cite
(section 5.7) un type (imaginaire) Todo
décrivant des tâches à accomplir, et l'exemple avec
query permet d'illustrer le membre
filter de la méthode, pour indiquer les
critères de sélection :
[[ "Todo/query", {
"accountId": "x",
"filter": {
"operator": "OR",
"conditions": [
{ "hasKeyword": "music" },
{ "hasKeyword": "video" }
]
}
}
]]
Comme beaucoup de méthodes JMAP, query peut
imposer un travail important au serveur. Un client maladroit, ou
cherchant déliberement à créer une attaque par déni de
service pourrait planter un serveur trop léger. Les
serveurs JMAP doivent donc avoir des mécanismes de protection,
comme une limite de temps passé sur chaque requête.
On l'a dit, un des intérêts de JMAP est la possibilité d'obtenir des notifications du serveur, sans obliger le client à vider sa batterie en interrogeant périodiquement le serveur. La section 7 du RFC détaille ce mécanisme. Deux alternatives pour le client : garder la connexion HTTPS ouverte en permanence, pour y recevoir ces notifications, ou bien utiliser un service tiers comme celui de Google. Notons que ces notifications, par leur seule existence, même si le canal est chiffré, peuvent révéler des informations. Comme noté dans la revue du protocole par la direction Sécurité à l'IETF "I.e., if someone can see that wikileaks smtp server sends email to corporate smtp server, but the smtp traffic is encrypted so they do not know the recipient of the email, but then few seconds later see push event notification stream going to the Joe's laptop indicating something has happened in his mail box, they can find out the who the recipient was.".
Il existe une page « officielle » présentant le protocole et plusieurs mises en oeuvre (actuellement, la plupart sont, expérimentales et/ou en cours de développement). C'est une des raisons pour lesquelles je ne présente pas ici d'essais réels. Notez toutefois que Fastmail a du JMAP en production.
L'article seul
RFC 8618: Compacted-DNS (C-DNS): A Format for DNS Packet Capture
Date de publication du RFC : Septembre 2019
Auteur(s) du RFC : J. Dickinson (Sinodun), J. Hague (Sinodun), S. Dickinson (Sinodun), T. Manderson (ICANN), J. Bond (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 4 septembre 2019
Lorsque l'opérateur d'un service DNS veut conserver les données de trafic, il peut demander au serveur d'enregistrer requêtes et réponses (mais, la plupart du temps, le serveur n'écrit qu'une petite partie des informations) ou bien écouter le trafic réseau et enregistrer le pcap. Le problème est que le format pcap prend trop de place, est de trop bas niveau (une connexion TCP, par exemple, va être éclatée en plusieurs paquets), et qu'il est difficile de retrouver les informations spécifiquement DNS à partir d'un pcap. D'où la conception de ce format de stockage, spécifique au DNS, et qui permet d'enregistrer la totalité de l'information, dans un format optimisé en taille et de plus haut niveau. C-DNS s'appuie sur CBOR pour cela.
Le DNS est un service d'infrastructure absolument critique. Il est donc nécessaire de bien le connaitre et de bien l'étudier. Cela passe par une récolte de données, en l'occurrence le trafic entrant et sortant des serveurs DNS, qu'ils soient des résolveurs ou bien des serveurs faisant autorité. Ce genre de récolte peut être coordonnée par l'OARC pour des projets comme DITL (« un jour dans la vie de l'Internet »). Un exemple d'une telle récolte, faite avec le classique tcpdump (qui, en dépit de son nom, ne fait pas que du TCP) :
% tcpdump -w /tmp/dns.pcap port 53
Le fichier produit (ici, sur un serveur faisant autorité pour
eu.org), au format
pcap, contient les requêtes DNS et les
réponses, et peut être analysé avec des outils comme tcpdump
lui-même, ou comme Wireshark. Il y a aussi
des outils spécifiques au DNS comme PacketQ ou comme
dnscap. Ici,
avec tcpdump :
% tcpdump -n -r /tmp/dns.pcap
15:35:22.432746 IP6 2001:db8:aa:101::.40098 > 2400:8902::f03c:91ff:fe69:60d3.53: 41209% [1au] A? tracker.torrent.eu.org. (51)
15:35:22.432824 IP6 2400:8902::f03c:91ff:fe69:60d3.53 > 2001:db8:aa:101::.40098: 41209- 0/4/5 (428)
Au lieu des outils tous faits, on peut aussi développer ses propres programmes en utilisant les nombreuses bibliothèques qui permettent de traiter du pcap (attention si vous analysez du trafic Internet : beaucoup de paquets sont mal formés, par accident ou bien délibérément, et votre analyseur doit donc être robuste). C'est ce que font en général les chercheurs qui analysent les données DITL.
Le problème du format pcap (ou pcapng) est qu'il y a à la fois trop de données et pas assez. Il y a trop de données car il inclut des informations probablement rarement utiles, comme les adresses MAC et car il ne minimise pas les données. Et il n'y en a pas assez car il ne stocke pas les informations qui n'étaient pas visibles sur le réseau mais qui l'étaient uniquement dans la mémoire du serveur DNS. Ainsi, on ne sait pas si la réponse d'un résolveur avait été trouvée dans le cache ou pas. Ou bien si les données étaient dans le bailliage ou pas (cf. RFC 8499, section 7). Les captures DNS peuvent être de très grande taille (10 000 requêtes par seconde est banal, 100 000, ça arrive parfois) et on désire les optimiser autant que possible, pour permettre leur rapatriement depuis les serveurs éloignés, puis leur stockage parfois sur de longues périodes. (Les formats « texte » comme celui du RFC 8427 ne conviennent que pour un message isolé, ou un tout petit nombre de messages.)
Le cahier des charges du format C-DNS (Compacted DNS) est donc :
- Minimiser la taille des données,
- Minimiser le temps de traitement pour compacter et décompacter.
La section du RFC détaille les scénarios d'usage de C-DNS. En effet, la capture de données DNS peut être faite dans des circonstances très différentes. Le serveur peut être une machine physique, une virtuelle, voire un simple conteneur. La personne qui gère le capture peut avoir le contrôle des équipements réseau (un commutateur, par exemple, pour faire du port mirroring), le serveur peut être surdimensionné ou, au contraire, soumis à une attaque par déni de service qui lui laisse peu de ressources. Le réseau de collecte des données capturées peut être le même que le réseau de service ou bien un réseau différent, parfois avec une capacité plus faible. Bref, il y a beaucoup de cas. C-DNS est optimisé pour les cas où :
- La capture des données se fait sur le serveur lui-même, pas sur un équipement réseau,
- Les données seront stockées localement, au moins temporairement, puis analysées sur une autre machine.
Donc, il est crucial de minimiser la taille des données récoltées. Mais il faut aussi faire attention à la charge que représente la collecte : le serveur de noms a pour rôle de répondre aux requêtes DNS, la collecte est secondaire, et ne doit donc pas consommer trop de ressources CPU.
Compte-tenu de ces contraintes, C-DNS a été conçu ainsi (section 4 du RFC) :
- L'unité de base d'un fichier C-DNS est le couple R/R, {requête DNS, réponse DNS} (Q/R data item), ce qui reflète le fonctionnement du protocole DNS, et permet d'optimiser le stockage, puisque bien des champs ont des valeurs communes entre une requête et une réponse (par exemple le nom de domaine demandé). Notez qu'un couple R/R peut ne comporter que la requête, ou que la réponse, si l'autre n'a pas pu être capturée, ou bien si on a décidé délibérément de ne pas le faire.
- C-DNS est optimisé pour les messages DNS syntaxiquement corrects. Quand on écrit un analyseur de paquets DNS, on est frappés du nombre de messages incorrects qui circulent sur le réseau. C-DNS permet de les stocker sous forme d'un « blob » binaire, mais ce n'est pas son but principal, il ne sera donc efficace que pour les messages corrects.
- Pratiquement toute les données sont optionnelles dans C-DNS. C'est à la fois pour gagner de la place, pour tenir compte du fait que certains mécanismes de capture ne gardent pas toute l'information, et pour permettre de minimiser les données afin de préserver la vie privée.
- Les couples R/R sont regroupés en blocs, sur la base d'élements communs (par exemple l'adresse IP source, ou bien la réponse, notamment les NXDOMAIN), qui permettent d'optimiser le stockage, en ne gardant cet élément commun qu'une fois par bloc. (Par contre, cela complexifie les programmes. On n'a rien sans rien.)
C-DNS repose sur CBOR (RFC 8949). La section 5 du RFC explique pourquoi :
- Format binaire, donc prenant moins d'octets que les formats texte comme JSON (l'annexe C discute des autres formats binaires),
- CBOR est un format normalisé et répandu,
- CBOR est simple et écrire un analyseur peut se faire facilement, si on ne veut pas dépendre d'une bibliothèque extérieure,
- CBOR a désormais un langage de schéma, CDDL (RFC 8610), qu'utilise notre RFC.
Avec la section 6 du RFC commence la description du
format. Classiquement, un fichier C-DNS commence par un en-tête,
puis une série de blocs. Chaque bloc comprend un certain nombre de
tables (par exemple une table d'adresses IP pour les adresses
apparaissant dans le bloc), suivies des éléments R/R. Ceux-ci
référencent les tables. Ainsi, une requête de
2001:db8:1::cafe à
2001:db8:ffff::beef pour le nom
www.example.org contiendra des pointeurs vers
les entrées 2001:db8:1::cafe et
2001:db8:ffff::beef de la table des adresses
IP, et un pointeur vers l'entrée
www.example.org de la table des noms de
domaine. S'il n'y a qu'un seul élément R/R dans le bloc, ce serait
évidemment une complication inutile, mais l'idée est de factoriser
les données qui sont souvent répétées.
On l'a vu, dans C-DNS, plein de choses sont optionnelles, car deux dispositifs de capture différents ne récoltent pas forcément les mêmes données. Ainsi, par exemple, un système de capture situé dans le logiciel serveur n'a pas forcément accès à la couche IP et ne peut donc pas enregistrer le nombre maximal de sauts (hop limit). Cela veut dire que, quand on lit un fichier C-DNS :
- Il faut déterminer si une donnée est présente ou pas, et ne pas supposer qu'elle l'est forcément,
- Il peut être utile de déterminer si une donnée manquante était absente dès le début, ou bien si elle a été délibérément ignorée par le système de capture. Si un message ne contient pas d'option EDNS (RFC 6891), était-ce parce que le message n'avait pas cette option, ou simplement parce qu'on ne s'y intéressait pas et qu'on ne l'a pas enregistrée ?
C-DNS permet donc d'indiquer quels éléments des données initiales ont été délibérément ignorés. Cela permet, par exemple, à un programme de lecture de fichiers C-DNS de savoir tout de suite si le fichier contient les informations qu'il veut.
Ces indications contiennent aussi des informations sur un
éventuel échantillonnage (on n'a gardé que
X % des messages), sur une éventuelle normalisation (par exemple
tous les noms de domaine passés en caractères minuscules) ou sur
l'application de techniques de minimisation, qui permettent de
diminuer les risques pour la vie
privée. Par exemple, au lieu de stocker les adresses IP complètes, on peut ne
stocker qu'un préfixe (par exemple un /32 au lieu de l'adresse
complète), et il faut alors l'indiquer dans le fichier C-DNS
produit, pour que le lecteur comprenne bien que
2001:db8:: est un préfixe, pas une
adresse.
La section 7 du RFC contient ensuite le format détaillé. Quelques points sont à noter (mais, si vous écrivez un lecteur C-DNS, lisez bien tout le RFC, pas juste mon article !) Ainsi, toutes les clés des objets (maps) CBOR sont des entiers, jamais des chaînes de caractère, pour gagner de la place. Et ces entiers sont toujours inférieurs à 24, pour tenir sur un seul octet en CBOR (lisez le RFC 8949 si vous voulez savoir pourquoi 24). On peut aussi avoir des clés négatives, pour les extensions au format de base, et elles sont comprises entre -24 et -1.
La syntaxe complète, rédigée dans le format CDDL du RFC 8610, figure dans l'annexe A de notre RFC.
On peut reconstruire un fichier pcap à partir de C-DNS. Une des difficultés est qu'on n'a pas forcément toutes les informations, et il va donc falloir être créatif (section 9). Une autre raison fait qu'on ne pourra pas reconstruire au bit près le fichier pcap qui aurait été capturé par un outil comme tcpdump : les noms de domaines dans les messages DNS étaient peut-être comprimés (RFC 1035, section 4.1.4) et C-DNS n'a pas gardé d'information sur cette compression. (Voir l'annexe B pour une discussion détaillée sur la compression.) Pareil pour les informations de couche 3 : C-DNS ne mémorise pas si le paquet UDP était fragmenté, s'il était dans un ou plusieurs segments TCP, s'il y avait des messages ICMP liés au trafic DNS, etc.
Si vous voulez écrire un lecteur ou un producteur de C-DNS, la section 11 du RFC contient des informations utiles pour la programmeuse ou le programmeur. D'abord, lisez bien le RFC 8949 sur CBOR. C-DNS utilise CBOR, et il faut donc connaitre ce format. Notamment, la section 3.9 du RFC 7049 donne des conseils aux implémenteurs CBOR pour produire un CBOR « canonique ». Notre RFC en retient deux, représenter les entiers, et les types CBOR, par la forme la plus courte possible (CBOR en permet plusieurs), mais il en déconseille deux autres. En effet, la section 3.9 du RFC 7049 suggérait de trier les objets selon la valeur des clés, et d'utiliser les tableaux de taille définie (taille indiquée explicitement au début, plutôt que d'avoir un marqueur de fin). Ces deux conseils ne sont pas réalistes pour le cas de C-DNS. Par exemple, pour utiliser un tableau de taille définie, il faudrait tout garder en mémoire jusqu'au moment où on inscrit les valeurs, ce qui augmenterait la consommation mémoire du producteur de données C-DNS. (D'un autre côté, le problème des tableaux de taille indéfinie est qu'ils ont un marqueur de fin ; si le programme qui écrit du C-DNS plante et ne met pas le marqueur de fin, le fichier est du CBOR invalide.)
Le RFC a créé plusieurs registres IANA pour ce format, stockant notamment les valeurs possibles pour le transport utilisé, pour les options de stockage (anonymisé, échantillonné...), pour le type de réponse (issue de la mémoire du résolveur ou pas).
Bien sûr, récolter des données de trafic DNS soulève beaucoup de problèmes liés à la vie privée (cf. RFC 7626). Il est donc recommander de minimiser les données, comme imposé par des réglements comme le RGPD, ou comme demandé dans le rapport « Recommendations on Anonymization Processes for Source IP Addresses Submitted for Future Analysis ».
Les passionnés de questions liées aux formats regarderont l'annexe C, qui liste des formats alternatifs à CBOR, qui n'ont finalement pas été retenus :
- Apache Avro, trop complexe car on ne peut lire les données qu'en traitant le schéma,
- Protocol Buffers, qui a le même problème,
- JSON (RFC 8259), qui n'est pas un format binaire, mais qui a été ajouté pour compléter l'étude.
Cette annexe décrit également le résultat de mesures sur la compression obtenue avec divers outils, sur les différents formats. C-DNS n'est pas toujours le meilleur, mais il est certainement, une fois comprimé, plus petit que pcap, et plus simple à mettre en œuvre qu'Avro ou Protocol Buffers.
Notez que j'ai travaillé sur ce format lors d'un hackathon de l'IETF, mais le format a pas mal changé depuis (entre autres en raison des problèmes identifiés lors du hackathon).
Voyons maintenant une mise en œuvre de ce format, avec l'outil DNS-STATS plus exactement son Compactor (source sur Github, et documentation). Je l'ai installé sur une machine Debian :
aptitude install libpcap-dev libboost1.67-all-dev liblzma-dev libtins-dev
git clone https://github.com/dns-stats/compactor.git
cd compactor
sh autogen.sh
autoconf
automake
./configure
make
Et après, on peut l'utiliser pour transformer du C-DNS en pcap et
réciproquement. J'ai créé un fichier pcap d'un million de paquets
avec tcpdump sur un serveur faisant autorité, avec tcpdump -w
dns.pcap -c 1000000 port 53. Puis :
% ./compactor -o /tmp/dns.cdns /tmp/dns.pcap
Et en sens inverse (reconstituer le pcap) :
% ./inspector /tmp/dns.cdns
Cela nous donne :
% ls -lth /tmp/dns*
-rw-r--r-- 1 stephane stephane 98M Jul 31 08:13 /tmp/dns.cdns.pcap
-rw-r--r-- 1 stephane stephane 3.2K Jul 31 08:13 /tmp/dns.cdns.pcap.info
-rw-r--r-- 1 stephane stephane 27M Jul 31 07:27 /tmp/dns.cdns
-rw-r--r-- 1 root root 339M Jul 30 20:05 /tmp/dns.pcap
Notez que dns.cdns.pcap est le pcap reconstitué, on
remarque qu'il est plus petit que le pcap original, certaines
informations ont été perdues, comme les adresses MAC. Mais il reste bien plus gros que la même
information stockée en C-DNS. Le
/tmp/dns.cdns.pcap.info nous donne quelques informations :
% cat /tmp/dns.cdns.pcap.info CONFIGURATION: Query timeout : 5 seconds Skew timeout : 10 microseconds Snap length : 65535 Max block items : 5000 File rotation period : 14583 Promiscuous mode : Off Capture interfaces : Server addresses : VLAN IDs : Filter : Query options : Response options : Accept RR types : Ignore RR types : COLLECTOR: Collector ID : dns-stats-compactor 0.12.3 Collection host ID : ns1.example STATISTICS: Total Packets processed : 1000000 Matched DNS query/response pairs (C-DNS) : 484407 Unmatched DNS queries (C-DNS) : 98 Unmatched DNS responses (C-DNS) : 69 Malformed DNS packets : 68 Non-DNS packets : 0 Out-of-order DNS query/responses : 1 Dropped C-DNS items (overload) : 0 Dropped raw PCAP packets (overload) : 0 Dropped non-DNS packets (overload) : 0
L'article seul
RFC 8615: Well-Known Uniform Resource Identifiers (URIs)
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : M. Nottingham
Chemin des normes
Première rédaction de cet article le 3 septembre 2019
Plusieurs normes du Web s'appuient sur l'existence d'un fichier à un
endroit bien connu d'un site. Les deux exemples les plus connus sont
robots.txt et
favicon.ico. Autrefois, ces
endroits « bien connus » étaient alloués sans schéma
central. Depuis le RFC 5785, c'est mieux
organisé, avec tous ces fichiers « sous »
/.well-known/. Notre
RFC remplace le RFC 5785 (et le RFC 8307), avec peu de
changements significatifs.
Prenons l'exemple le plus connu,
robots.txt, fichier
stockant la politique d'autorisation des robots qui fouillent le Web. Si un robot examine le site
Web http://www.example.org/, il va tenter de
trouver ledit fichier en
http://www.example.org/robots.txt. Même chose
pour, par exemple, sitemap.xml ou P3P (section 1
du RFC). Ce système avait plusieurs inconvénients, notamment le
risque de collision entre deux noms (puisqu'il n'y avait pas de
registre de ces noms) et, pire, le risque de collision entre un de
ces noms et une ressource normale du site. D'où l'importance d'un
« rangement » de ces ressources bien connues. Elles doivent
dorénavant être préfixées de
/.well-known/. Ainsi, si le protocole
d'autorisation des robots était normalisé aujourd'hui, on
récupérerait la politique d'autorisation en
http://www.example.org/.well-known/robots.txt.
À noter que le RFC spécifie uniquement un
préfixe pour le chemin de la ressource,
/.well-known/ n'est pas forcément un
répertoire sur le disque du serveur (même si
c'est une mise en œuvre possible).
Le RFC 8615 note aussi qu'il existe déjà des mécanismes de récupération de métadonnées par ressource (comme les en-têtes de HTTP ou les propriétés de WebDAV) mais que ces mécanismes sont perçus comme trop lourds pour remplacer la ressource unique située en un endroit bien connu.
Le nom .well-known avait été choisi
(cf. annexe A de notre RFC) car il
avait peu de chances de rentrer en conflit avec un nom existant
(traditionnellement, sur Unix,
système d'exploitation le plus utilisé sur
les serveurs Web, les fichiers dont le nom commencent par un point
ne sont pas affichés).
Bref, passons à la section 3 qui donne les détails
syntaxiques. Le préfixe est donc /.well-known/,
les noms en « dessous » doivent être enregistrés (cf. section
5.1), et ils doivent se conformer à la production
segment-nz du RFC 3986
(en clair, cela veut dire qu'ils doivent être une suite de
caractères ASCII imprimables, avec quelques
exclusions comme la barre oblique). Du
point de vue sémantique, ils doivent être précis, pour éviter
l'appropriation de termes génériques (par exemple, l'application
Toto qui veut stocker ses métadonnées
devrait utiliser toto-metadata et pas juste
metadata.) À noter que l'effet d'une requête
GET /.well-known/ (tout court, sans nom de
ressource après), est indéfini (sur mon blog, cela donne ça ; devrais-je le configurer pour
renvoyer autre chose ? Sur Mastodon, ça donne 404.)
Quelques conseils de sécurité pour le webmestre (section 4) : ces ressources « bien connues » s'appliquent à une origine (un « site Web ») entière, donc attention à contrôler qui peut les créer ou les modifier, et d'autre part, dans le contexte d'un navigateur Web, elles peuvent être modifiées par du contenu, par exemple JavaScript.
La section 5 décrit les conditions d'enregistrement des noms bien connus à l'IANA. Le registre contient par exemple les métadonnées du RFC 6415. Y mettre des noms supplémentaires nécessite un examen par un expert et une description publiée (pas forcément un RFC). Dans les termes du RFC 8126, ce sera Spécification Nécessaire et Examen par un Expert. Il y a un mini-formulaire à remplir (section 3.1 du RFC) et hop, le nom bien connu sera enregistré. Plusieurs existent désormais.
Notez qu'il est très difficile de savoir combien de sites ont
des ressources /.well-known. Bien sûr,
Google
le sait, mais ne
donne pas accès à cette information (une requête
inurl:/.well-known ou
inurl:"/.well-known" ignore hélas le point
initial et trouve donc surtout des faux positifs). Si on n'a pas
accès à la base de Google, il faudrait donc faire soi-même une
mesure active avec un client HTTP qui aille visiter de nombreux
sites.
Les changements depuis le RFC 5785 sont résumés dans l'annexe B du RFC :
- Les plans d'URI pour WebSocket, du RFC 8307, ont été intégrés,
- D'ailleurs, le préfixe
/.well-known/n'est plus réservé au Web, il peut être utilisé pour d'autres plans d'URI, ce qui a modifié le registre des plans pour y ajouter une colonne indiquant s'ils permettent ce préfixe (section 5.2), - Les instructions pour l'enregistrement d'un nouveau nom ont été légèrement assouplies,
- La section sur la sécurité est nettement plus détaillée.
L'article seul
RFC 8612: DDoS Open Threat Signaling (DOTS) Requirements
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : A. Mortensen (Arbor Networks), T. Reddy (McAfee), R. Moskowitz (Huawei)
Pour information
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 22 août 2019
Les attaques par déni de service, et notamment les dDoS (distributed Denial of Service), sont une des principales plaies de l'Internet. Le projet DOTS (DDoS Open Threat Signaling) à l'IETF vise à développer un mécanisme de signalisation permettant à des acteurs de la lutte anti-dDoS d'échanger des informations et de se coordonner, même lorsque l'attaque fait rage. Par exemple, un mécanisme DOTS permettra à un client d'un service de traitement des attaques de demander à son fournisseur d'activer le filtrage anti-dDoS. Ce RFC est le premier du projet : il décrit le cahier des charges.
Ces attaques par déni de service (décrites dans le RFC 4732) peuvent être utilisées à des fins financières (racket), lors d'affrontements inter-étatiques (comme dans le cas estonien souvent cité), à des fins de censure contre des opposants politiques. Le risque est particulièrement élevé pour les « petits ». En effet, beaucoup d'attaques par déni de service reposent sur la taille : par exemple, l'attaquant envoie tellement d'octets qu'il sature la ou les connexions Internet de sa victime. La seule solution est alors de louer un tuyau plus gros, ce qui n'est pas toujours financièrement possible. Les attaques dDoS favorisent donc les plus riches. Aujourd'hui, par exemple, un petit hébergeur Web a le plus grand mal à faire face à d'éventuelles attaques, ce qui rend difficile l'hébergement associatif et/ou décentralisé. Les attaques par déni de service ont donc des conséquences bien au-delà des quelques heures d'indisponibilité du service : elles encouragent la centralisation des services, puisqu'il faut être gros pour encaisser le choc. C'est ainsi qu'aujourd'hui beaucoup d'organisations sont chez Cloudflare, dépendant de cette société privée étatsunienne pour leur « protection ». On est dans l'équivalent moderne de la relation féodale au Moyen-Âge : le paysan seul, ou même le village, est trop vulnérable, il doit chercher la protection d'un seigneur, en échange de sa soumission.
Il est très difficile de se protéger contre les attaques par déni de service. Et le projet DOTS ne va pas proposer de solution magique, uniquement des mécanismes de cooordination et d'échange en cas d'attaque. La réponse à une attaque dDoS consiste typiquement à examiner les paquets entrants, et à jeter ceux qui semblent faire partie de l'attaque. (Voir par exemple mon article sur le filtrage.) Il faut bien sûr le faire le plus tôt possible. Si vous êtes connecté à l'Internet par un lien de capacité 1 Gb/s, et que l'attaquant arrive à le saturer par les paquets qu'il envoie, trier les paquets de votre côté ne servira à rien, cela serait trop tard ; ils doivent être triés en amont, par exemple chez votre opérateur. Et, évidemment, trier n'est pas trivial, les paquets ne sont pas marqués comme participant à l'attaque (sauf si on utilise le RFC 3514, mais regardez sa date de publication). Il y aura donc toujours des faux positifs, des paquets innocents jetés. (Pour un exemple de solution anti-dDoS, voir le VAC d'OVH, et les nombreux articles qui lui ont été consacrés.) En 2019, beaucoup d'organisations ne font plus ce tri elles-mêmes (par manque de moyens financiers, et surtout humains) mais sous-traitent à un fournisseur spécialisé (comme Arbor, pour lequel travaille un des auteurs du RFC). On envoie le trafic vers ce fournisseur, par des astuces DNS ou BGP, il le trie, et vous renvoie ce qui lui semble inoffensif. Ce tri se nomme en anglais scrubbing. Ces fournisseurs sont donc un élement critique, par exemple parce qu'ils voient passer tout votre trafic. En général, on active ce service à la demande, et cette activation est un des scénarios d'utilisation de DOTS les plus cités dans le RFC.
Actuellement, l'activation du service de scrubbing se fait via des interfaces privatrices, fournies par le « protecteur », ce qui contribue à enfermer le client dans sa relation avec le fournisseur. Et puis, parfois, il faut que plusieurs acteurs participent à la réponse à attaque. D'où l'idée du projet DOTS (dDoS Open Threat Signaling) qui va développer une interface normalisée, au sein du groupe de travail du même nom à l'IETF.
La section 1.2 du RFC précise le terminologie employée : DOTS sera client/serveur, le client DOTS étant chez la victime, qui cherche une solution, et le serveur DOTS étant chez le protecteur (mitigator dans le RFC). Rappelez-vous que DOTS ne normalise pas les méthodes de protection (elles évoluent vite, même si le motif « tri puis poubellisation des paquets » reste dominant), mais uniquement la communication entre les acteurs impliqués. Les différents acteurs communiquent avec deux sortes de canaux, les canaux de signalisation et les canaux de données. Les premiers sont prévus pour des messages assez courts (« jette tous les paquets à destination du port NNN ») mais qui doivent arriver à tout prix, même en cas d'attaque intense ; ils sont le cœur du système DOTS, et privilégient la survivabilité. Les seconds, les canaux de données, sont prévus pour de grandes quantités de données, par exemple pour envoyer des informations de configuration, comme la liste des préfixes IP à protéger.
L'essentiel du RFC est la section 2, qui décrit les exigences auxquelles devra se soumettre le futur protocole DOTS. (Notez que le travail est déjà bien avancé. Depuis, un RFC d'architecture générale du systéme, le RFC 8811, a été publié, et les RFC 8782 et RFC 8783 ont normalisé le protocole.) Il s'agit d'exigences techniques : ce RFC ne spécifie pas d'exigences business ou de politique. Par exemple, il ne dit pas à partir de quand un client DOTS a le droit de demander une action au serveur, ni dans quels cas le client a le droit d'annuler une demande.
Le protocole DOTS a des exigences difficiles ; compte-tenu du caractère très sensible des échanges entre le client et le serveur, il faut absolument fournir authentification, intégrité, confidentialité et protection contre le rejeu par un tiers. Autrement, le protocole DOTS, comme la plupart des techniques de sécurité, pourrait en fait fournir un nouveau moyen d'attaque. Mais, d'un autre côté, le protocole doit être très robuste, puisqu'il est précisément conçu pour fonctionner face à un hostile, qui va essayer de perturber les communications. Combiner toutes ces demandes n'est pas trivial. DOTS fournira de la robustesse en utilisant des messages de petite taille (qui auront donc davantage de chances de passer), asynchrones, et qui pourront être répétés sans dommage (en cas de doute, les acteurs DOTS n'hésiteront pas à envoyer de nouveau un message).
Je ne vais pas répéter ici la longue liste des exigences, vous les trouverez dans la section 2. Elles sont réparties en plusieurs catégories. Il y a d'abord les exigences générales :
- Le protocole doit être extensible, car les attaques par déni de service vont évoluer, ainsi que les solutions (la lutte de l'épée et de la cuirasse est éternelle),
- Comme rappelé ci-dessus, le protocole doit être robuste, la survivabilité doit être sa principale qualité puisqu'il est prévu pour fonctionner en situation très perturbée,
- Un message qui a du mal à passer ne ne doit pas bloquer le suivant (pas de head-of-line blocking),
- Le client doit pouvoir donner des indications sur les actions souhaitées, puisqu'il dispose parfois d'informations, par exemple issues du renseignement sur les menaces.
Il y a ensuite les exigences sur le canal de signalisation :
- Il doit utiliser des protocoles existants comme UDP (TCP est possible mais, en cas d'attaque, il peut être difficile, voir impossible, d'établir une connexion),
- La taille des messages doit être faible, à la fois pour augmenter les chances de passer malgré l'attaque, et pour éviter la fragmentation,
- Le canal doit être bidirectionnel, entre autres pour détecter une éventuelle coupure du lien (un serveur peut être configuré pour activer les solutions anti-dDoS précisément quand il ne peut plus parler au client, des messages de type battement de cœur sont donc nécessaires, mais pas évidents à faire correctement, cela avait été une des plus grosses discussions à l'IETF),
- Le client doit pouvoir demander au serveur des actions (c'est le but principal du protocole), et doit pouvoir aussi solliciter des informations sur ce que voit et fait le serveur DOTS (« j'ai jeté 98 % des paquets » ou « je jette actuellement 3,5 Gb/s »),
- Le client doit pouvoir tenir le serveur au courant de l'efficacité perçue des actions effectuées (« ça marche pas, je reçois toujours autant »),
- Le client doit pouvoir indiquer une durée pour les actions du serveur, y compris une durée infinie (si le client préfère que tout son trafic soit examiné et filtré en permanence),
- Le client doit pouvoir demander un filtrage fin, en
indiquant une portée
(« uniquement ce qui vient de
192.0.2.0/24» ou « seulement les paquets à destination de2001:db8:a:b::/64», voire « seulement les paquets pourwww.example.com», et le serveur DOTS doit alors faire la résolution de nom).
Il y a aussi des exigences pour l'autre canal, celui des données. Rappelons que, contrairement au canal de signalisation, il n'est pas indispensable qu'il puisse fonctionner pendant l'attaque. La principale exigence est la transmission fiable des données.
Vu le contexte de DOTS, il y a évidemment des exigences de sécurité :
- Authentification mutuelle (du serveur par le client et du client par le serveur), un faux serveur ou un faux client pourraient faire des catastrophes, cf. section 4 du RFC,
- Confidentialité et intégrité, vu le caractère critique des données (imaginez si un attaquant pouvait modifier les messages DOTS…)
La section 3 du RFC se penche sur le problème de la congestion. Le protocole DOTS ne doit pas ajouter à l'attaque en noyant tout le monde sous les données, alors qu'il utilisera sans doute un transport qui ne gère pas lui-même la congestion, UDP (au moins pour le canal de signalisation). Il faudra donc bien suivre les règles du RFC 8085.
À noter qu'Arbor a un brevet sur les mécanismes analogues à DOTS (brevet 20130055374, signalé à l'IETF ici.) Arbor promet des licences RF et RAND. Même les attaques créent du business…
L'article seul
RFC 8610: Concise Data Definition Language (CDDL): A Notational Convention to Express Concise Binary Object Representation (CBOR) and JSON Data Structures
Date de publication du RFC : Juin 2019
Auteur(s) du RFC : H. Birkholz (Fraunhofer SIT), C. Vigano (Universitaet Bremen), C. Bormann (Universitaet Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 13 juin 2019
Le format de données binaire CBOR, normalisé dans le RFC 8949, commence à avoir un certain succès. Il lui manquait juste un langage de schéma, permettant de décrire les données acceptables (comme Relax NG ou XML Schema pour XML, ou comme le projet - abandonné - JCR (« JSON Content Rules ») pour JSON). C'est désormais fait dans ce RFC, qui normalise le langage CDDL, « Concise Data Definition Language ». (Il a par la suite été légèrement modifié dans le RFC 9682.)
La section 1 de notre RFC résume le cahier des charges : CDDL
doit permettre de décrire sans ambiguïté un fichier CBOR
acceptable pour un usage donné, il doit être lisible et rédigeable
par un humain, tout en étant analysable par un programme, et doit
permettre la validation automatique d'un fichier CBOR. Autrement
dit, étant donné une description en CDDL en
schema.cddl et un fichier CBOR en
data.cbor, il faut qu'on puisse développer un
outil validator qui permettra de lancer la
commande validator data.cbor schema.cddl et
qui dira si le fichier CBOR est conforme au schéma ou pas. (Un tel
outil existe effectivement, il est présenté à la fin de cet
article.) Comme CBOR utilise un modèle de données très proche de
celui de JSON, CDDL peut (même si ce n'est pas son but principal)
être utilisé pour décrire des fichiers JSON, ce que détaille
l'annexe E du RFC, consacrée à l'utilisation de CDDL avec JSON (il
y a quelques subtilités à respecter).
(Attention, il ne faut pas confondre notre CDDL avec la licence ayant le même acronyme.)
La section 2 de notre RFC explique les éléments de base d'un schéma CDDL. On y trouve les classiques nombres, booléens, chaînes de caractères, correspondant aux éléments identiques en CBOR. Pour les structures plus compliquées (tableaux et maps, c'est-à-dire dictionnaires, ce qu'on nomme objets en JSON), CDDL ne fournit qu'un seul mécanisme, le groupe. Un groupe est une liste de doublets {nom, valeur}, le nom pouvant être omis si on décrit un tableau. Avec ce concept de groupe, CDDL permet également de décrire ce que dans d'autres langages, on appelerait struct ou enregistrement.
La liste est encadrée par des parenthèses. Chaque donnée
décrite en CDDL a un type, par exemple bool
pour un booléen, uint pour un entier non
signé ou tstr pour une chaîne de
caractères. La définition indique également quel type majeur CBOR
(RFC 8949, section 3.1) va être utilisé pour
ce type CDDL. uint est évidemment le type
majeur 0, bool est le type majeur 7,
etc. (D'ailleurs, vous pouvez aussi créer des types en indiquant
le type majeur CBOR, ce qui donne une grande liberté, et la
possibilité d'influencer la sérialisation.) Une liste des types et
valeurs prédéfinies (comme false et
true) figure dans l'annexe D de notre
RFC.
Voici un groupe à qui on donne le nom
pii :
pii = (
age: uint,
name: tstr,
employer: tstr
)
Et ici une donnée person est définie avec ce
groupe :
person = {
pii
}
Comme person est défini avec des
accolades, ce sera un
dictionnaire (map). Le même groupe
pii aurait pu être utilisé pour définir un
tableau, en mettant entre crochets (et, dans ce cas, les noms seraient ignorés, seule la
position compte).
On peut définir une donnée en utilisant un groupe et d'autres
informations, ici, person et
dog ont les attributs de
identity et quelques uns en plus :
person = {
identity,
employer: tstr
}
dog = {
identity,
leash-length: float
}
identity = (
age: 0..120, ; Ou "uint" mais, ici, on utilise les intervalles
name: tstr
)
La syntaxe nom: valeur est en fait un cas
particulier. La notation la plus générale est clé =>
valeur. Comme CBOR (contrairement à JSON) permet
d'avoir des clés qui ne sont pas des chaînes de caractères, la
notation avec le deux-points est là pour ce
cas particulier, mais courant, où la clé est une chaîne de
caractères. (age: int et "age"
=> int sont donc équivalents.)
Un autre exemple permet d'illustrer le fait que l'encodage CBOR en tableau ou en dictionnaire va dépendre de la syntaxe utilisée en CDDL (avec en prime les commentaires, précédés d'un point-virgule) :
Geography = [
city : tstr,
gpsCoordinates : GpsCoordinates,
]
GpsCoordinates = {
longitude : uint, ; multiplied by 10^7
latitude : uint, ; multiplied by 10^7
}
Dans le fichier CBOR, GpsCoordinates sera un
dictionnaire (map) en raison de l'utilisation des
accolades, et Geography sera un tableau (les
noms city et
gpsCoordinates seront donc ignorés).
Un champ d'un groupe peut être facultatif, en le faisant précéder d'un point d'interrogation, ou bien répété (avec une astérisque ou un plus) :
apartment = {
kitchen: size,
+ bedroom: size,
? bathroom: size
}
size = float
Dans cet appartement, il y a exactement une cuisine, au moins une chambre et peut-être une salle de bains. Notez que l'outil cddl, présenté plus loin, ne créera pas d'appartements avec plusieurs chambres. C'est parce que CBOR, contrairement à JSON (mais pas à I-JSON, cf. RFC 7493, section 2.3), ne permet pas de clés répétées dans une map. On a ici un exemple du fait que CDDL peut décrire des cas qui ne pourront pas être sérialisés dans un format cible donné.
Revenons aux types. On a également le droit aux énumérations, les valeurs étant séparées par une barre oblique :
attire = "bow tie" / "necktie" / "Internet attire" protocol = 6 / 17
C'est d'ailleurs ainsi qu'est défini le type booléen (c'est prédéfini, vous n'avez pas à taper cela) :
bool = false / true
On peut aussi choisir entre groupes (et pas seulement entre types), avec deux barres obliques.
Et l'élement racine, on le reconnait comment ? C'est simplement le premier défini dans le schéma. À part cette règle, CDDL n'impose pas d'ordre aux définitions. Le RFC préfère partir des structures de plus haut niveau pour les détailler ensuite, mais on peut faire différemment, selon ses goûts personnels.
Pour les gens qui travaillent avec des protocoles réseau, il
est souvent nécessaire de pouvoir fixer exactement la
représentation des données. CDDL a la notion de contrôle, un
contrôle étant une directive donnée à CDDL. Elle commence par un
point. Ainsi, le contrôle .size indique la
taille que doit prendre la donnée. Par exemple
(bstr étant une chaîne d'octets) :
ip4 = bstr .size 4
ip6 = bstr .size 16
Un autre contrôle, .bits, permet de placer
les bits exactement, ici pour
l'en-tête TCP :
tcpflagbytes = bstr .bits flags
flags = &(
fin: 8,
syn: 9,
rst: 10,
psh: 11,
ack: 12,
urg: 13,
ece: 14,
cwr: 15,
ns: 0,
) / (4..7) ; data offset bits
Les contrôles existants figurent dans un registre IANA, et d'autres pourront y être ajoutés, en échange d'une spécification écrite (cf. RFC 8126).
La section 3 du RFC décrit la syntaxe formelle de CDDL. L'ABNF (RFC 5234) complet est en annexe B. CDDL lui-même ressemble à ABNF, d'ailleurs, avec quelques changements comme l'autorisation du point dans les noms. Une originalité plus fondamentale, documentée dans l'annexe A, est que la grammaire utilise les PEG et pas le formalisme traditionnel des grammaires génératives.
La section 4 de notre RFC couvre les différents usages de CDDL. Il peut être utilisé essentiellement pour les humains, une sorte de documentation formelle de ce que doit contenir un fichier CBOR. Il peut aussi servir pour écrire des logiciels qui vont permettre une édition du fichier CBOR guidée par le schéma (empêchant de mettre des mauvaises valeurs, par exemple, mais je ne connais pas de tels outils, à l'heure actuelle). CDDL peut aussi servir à la validation automatique de fichiers CBOR. (Des exemples sont donnés plus loin, avec l'outil cddl.) Enfin, CDDL pourrait être utilisé pour automatiser une partie de la génération d'outils d'analyse de fichiers CBOR, si ce format continue à se répandre.
Un exemple réaliste d'utilisation de CDDL est donné dans
l'annexe H, qui met en œuvre les « reputons » du RFC 7071. Voici le schéma
CDDL. Un autre exemple en annexe H est de réécrire des
règles de l'ancien projet JCR (cf. Internet
draft draft-newton-json-content-rules)
en CDDL.
Quels sont les RFC et futurs RFC qui se servent de CDDL ? CDDL est utilisé par le RFC 8007 (son annexe A), le RFC 8152 et le RFC 8428. Il est également utilisé dans des travaux en cours comme le format C-DNS (RFC 8618), sur lequel j'avais eu l'occasion de travailler lors d'un hackathon. Autre travail en cours, le système GRASP (RFC 8990) et dans OSCORE (RFC 8613). En dehors du monde IETF, CDDL est utilisé dans Web Authentication.
Un outil, décrit dans l'annexe F du RFC, a été développé pour générer des fichiers CBOR d'exemple suivant une définition CDDL, et pour vérifier des fichiers CBOR existants. Comme beaucoup d'outils modernes, il faut l'installer en utilisant les logiciels spécifiques d'un langage de programmation, ici Ruby :
% gem install cddl
Voici un exemple, pour valider un fichier JSON (il peut évidemment aussi valider du CBOR, rappelez-vous que c'est presque le même modèle de données, et que CDDL peut être utilisé pour les deux) :
% cddl person.cddl validate person.json
%
Ici, c'est bon. Quand le fichier de données ne correspond pas au
schéma (ici, le membre foo n'est pas prévu) :
% cat person.json
{"age": 1198, "foo": "bar", "name": "tic", "employer": "tac"}
% cddl person.cddl validate person.json
CDDL validation failure (nil for {"age"=>1198, "foo"=>"bar", "name"=>"tic", "employer"=>"tac"}):
["tac", [:prim, 3], nil]
C'est surtout quand le schéma lui-même a une erreur que les messages d'erreur de l'outil cddl sont particulièrement mauvais. Ici, pour un peu d'espace en trop :
% cddl person.cddl generate
*** Look for syntax problems around the %%% markers:
%%%person = {
age: int,
name: tstr,
employer: tstr,%%% }
*** Parse error at 0 upto 69 of 93 (1439).
Et pour générer des fichiers de données d'exemple ?
% cat person.cddl
person = {
"age" => uint, ; Or 'age: uint'
name: tstr,
employer: tstr
}
% cddl person.cddl generate
{"age": 3413, "name": "tic", "employer": "tac"}
Ce format est du JSON mais c'est en fait le profil « diagnostic »
de CBOR, décrit dans la section 8 du RFC 8949. (cddl person.cddl
json-generate fabriquerait du JSON classique.)
On peut avoir du CBOR binaire après une conversion avec
les outils
d'accompagnement :
% json2cbor.rb person.json > person.cbor
CBOR étant un format binaire, on ne peut pas le regarder directement, donc on se sert d'un outil spécialisé (même dépôt que le précédent) :
% cbor2pretty.rb person.cbor
a3 # map(3)
63 # text(3)
616765 # "age"
19 0d55 # unsigned(3413)
64 # text(4)
6e616d65 # "name"
63 # text(3)
746963 # "tic"
68 # text(8)
656d706c6f796572 # "employer"
63 # text(3)
746163 # "tac"
Et voilà, tout s'est bien passé, et le fichier CBOR est valide :
% cddl person.cddl validate person.cbor %
L'article seul
RFC 8605: vCard Format Extensions: ICANN Extensions for the Registration Data Access Protocol (RDAP)
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : S. Hollenbeck (Verisign Labs), R. Carney (GoDaddy)
Pour information
Première rédaction de cet article le 1 septembre 2019
Dernière mise à jour le 4 septembre 2019
Ce RFC décrit des extensions au format vCard afin d'ajouter dans les réponses RDAP deux informations exigées par l'ICANN. Il concerne donc surtout registres et utilisateurs des TLD ICANN.
Le protocole RDAP (RFC 9083) sert à récupérer des informations sur un objet
enregistré, par exemple un nom de
domaine. Une partie des informations, par exemple les
adresses et numéros de téléphone, est au format
vCard (RFC 6350). Mais l'ICANN a des exigences
supplémentaires, décrites dans la Specification
for gTLD Registration Data. Par exemple, l'ICANN
exige (cf. leur
politique) que, si les informations sur un contact ne sont
pas publiées (afin de préserver sa vie privée), le
registre fournisse au moins un URI indiquant un
moyen de contact (section 2.7.5.2 de la politique ICANN), par
exemple un formulaire Web (comme https://www.afnic.fr/fr/resoudre-un-litige/actions-et-procedures/joindre-le-contact-administratif-d-un-domaine/CONTACT-URI est désormais dans
le
registre IANA. (Si vous voulez réviser les notions de
propriété et de paramètre en vCard, plus exactement
jCard, cf. RFC 7095.)
D'autre part, la norme vCard, le RFC 6350, précise dans sa section 6.3.1, que le nom du
pays doit être spécifié en langue
naturelle, alors que l'ICANN exige (section 1.4 de leur politique) un code à deux
lettres tiré de la norme ISO 3166. (Notez
qu'à l'heure actuelle, certains registres mettent le nom du pays,
d'autres le code à deux lettres…) Le
paramètre CC, qui va indiquer le code, est désormais dans
le
registre IANA.
Ainsi, une réponse vCard suivant notre RFC pourrait indiquer (je ne peux pas vous montrer d'exemples réels d'un registre, aucun n'a apparemment déployé ces extensions, mais, si vous êtes curieux, lisez jusqu'à la fin) :
% curl -s https://rdap.nic.example/domain/foobar.example | jq .
...
[
"contact-uri", <<< Nouveauté
{},
"uri",
"https://rds.nic.example/get-in-touch"
]
...
[
"adr",
{"cc": "US"}, <<< Nouveauté
"text",
["", "", "123 Main Street", "Any Town", "CA", "91921-1234", "U.S.A."]
]
...
J'ai parlé jusqu'à présent des registres, mais l'ICANN impose
également RDAP aux bureaux d'enregistrement. Cela a en
effet un sens pour les registres minces, comme
.com, où les données
sociales sont chez les bureaux en question. La liste
des bureaux d'enregistrement ICANN contient une colonne
indiquant leur serveur RDAP. Testons avec Blacknight, qui est
souvent à la pointe :
% curl https://rdap.blacknight.com/domain/blacknight.com | jq .
...
[
"fn",
{},
"text",
"Blacknight Internet Solutions Ltd."
],
[
"adr",
{
"cc": "IE"
},
...
[
"contact-uri",
{},
"uri",
"https://whois.blacknight.com/contact.php?fqdn=blacknight.com&contact_type=owner"
]
On a bien un usage de ces extensions dans le monde réel (merci à Patrick Mevzek pour ses remarques et ajouts).
L'article seul
RFC 8601: Message Header Field for Indicating Message Authentication Status
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : M. Kucherawy
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dmarc
Première rédaction de cet article le 8 juin 2019
Il existe plusieurs techniques pour authentifier les courriers
électroniques. Certaines peuvent nécessiter des
calculs un peu compliqués et on voudrait souvent les centraliser
sur une machine de puissance raisonnable, dotée de tous les
logiciels nécessaires. Dans cette hypothèse, le MUA ne recevra qu'une
synthèse (« Ce message vient bien de
example.com ») et pourra alors prendre une
décision, basée sur cette synthèse. C'est le but de l'en-tête
Authentication-Results:, normalisé originellement dans le RFC 5451 dix ans plus tôt, auquel ont succédés les RFC 7001 puis RFC 7601, que
ce nouveau RFC met légèrement à jour (il y a peu de
changements, le principal concernant l'ajout de la gestion du courrier
électronique internationalisé, avec davantage d'Unicode).
Avec des techniques d'authentification comme DKIM (RFC 6376) ou SPF (RFC 7208), les
calculs à faire pour déterminer si un message est authentique
peuvent être complexes (DKIM utilise la cryptographie) et
nécessiter la présence de bibliothèques non-standard. Les installer
et les maintenir à jour sur chaque machine, surtout en présence
d'éventuelles failles de sécurité qu'il faudra boucher en urgence,
peut être trop pénible pour l'administrateur système. L'idée de ce
RFC est donc de séparer l'opération en deux :
l'authentification est faite sur un
serveur, typiquement le premier MTA du site (cf. annexe C pour une discussion
de ce choix), celui-ci ajoute au message un en-tête indiquant le
résultat de ladite authentification et le MUA (ou bien le
MDA, voir la
section 1.5.4 pour un bon rappel sur ces concepts) peut ensuite,
par exemple par un langage de filtrage comme
procmail ou
Sieve, agir sur la base de ce
résultat. L'idée n'est donc pas de montrer la valeur de cet
en-tête à M. Michu (voir la section 4.1 pour quelques risques que
cela poserait), mais d'en faire une donnée pour un programme. Cet
en-tête marche pour tous les protocoles d'authentification et
surpasse donc les en-têtes spécifiques comme le
Received-SPF: de SPF (section 1 du RFC). Le
filtrage des messages non authentifiés n'est
pas obligatoire (section 1.4) : agir - ou
pas - sur la base de l'en-tête Authentication-Results: est une décision politique
locale.
J'ai utilisé le terme de « site » pour désigner un ensemble de
machines gérées par la même organisation mais le RFC a un terme
plus rigoureux, ADMD (ADministrative Management
Domain). La frontière d'un ADMD est la « frontière de
confiance » (trust boundary), définie en
section 1.2. Un domaine administratif de gestion est un groupe de
machines entre lesquelles il existe une relation de confiance,
notamment du fait que, à l'intérieur de l'ADMD, l'en-tête Authentication-Results: ne
sera pas modifié ou ajouté à tort (section 1.6 : l'en-tête n'est
pas protégé, notamment il n'est pas signé). Il existe de
nombreuses variantes organisationnelles du concept d'ADMD. Un ADMD
inclus typiquement une organisation (ou un département de
celle-ci) et d'éventuels sous-traitants. Il a un nom,
l'authserv-id, défini en section 2.2. Bien
sûr, la décision de faire confiance ou pas à telle entité, telle
machine ou tel ADMD est une décision locale, le RFC ne précise pas
comment elle est prise.
L'en-tête Authentication-Results: lui-même est formellement défini en section
2. Il appartient à la catégorie des en-têtes de « trace » (RFC 5322, section 3.6.7 et RFC 5321, section 4.4) comme Received:
qui doivent être ajoutés en haut des en-têtes et jamais
modifiés. La syntaxe de Authentication-Results: est en section 2.2. L'en-tête est
composé du authserv-id, le nom de l'ADMD et
d'une série de doublets (méthode, résultat), chacun indiquant une
méthode d'authentification et le résultat obtenu. L'annexe B
fournit une série d'exemples. Elle commence (annexe B.1) par un
message sans Authentication-Results: (eh oui, il n'est pas obligatoire). Puis (tiré
de l'annexe B.3), une authentification SPF réussie, au sein de
l'ADMD example.com, donnera :
Authentication-Results: example.com;
spf=pass smtp.mailfrom=example.net
Received: from dialup-1-2-3-4.example.net
(dialup-1-2-3-4.example.net [192.0.2.200])
by mail-router.example.com (8.11.6/8.11.6)
with ESMTP id g1G0r1kA003489;
Wed, Mar 14 2009 17:19:07 -0800
From: sender@example.net
Date: Wed, Mar 14 2009 16:54:30 -0800
To: receiver@example.com
Rappelez-vous qu'il peut y avoir plusieurs authentifications. Voici un cas (annexe B.4) avec SPF et l'authentification SMTP du RFC 4954 :
Authentication-Results: example.com;
auth=pass (cram-md5) smtp.auth=sender@example.net;
spf=pass smtp.mailfrom=example.net
Received: from dialup-1-2-3-4.example.net (8.11.6/8.11.6)
(dialup-1-2-3-4.example.net [192.0.2.200])
by mail-router.example.com (8.11.6/8.11.6)
with ESMTP id g1G0r1kA003489;
Fri, Feb 15 2002 17:19:07 -0800
Date: Fri, Feb 15 2002 16:54:30 -0800
To: receiver@example.com
From: sender@example.net
L'une des authentifications peut réussir et l'autre échouer. Un
exemple (annexe B.6) avec deux signatures DKIM, une bonne et une
qui était correcte au départ (regardez le premier Authentication-Results:) mais plus
à l'arrivée, peut-être parce qu'un gestionnaire de liste de
diffusion a modifié le message :
Authentication-Results: example.com;
dkim=pass reason="good signature"
header.i=@mail-router.example.net;
dkim=fail reason="bad signature"
header.i=@newyork.example.com
Received: from mail-router.example.net
(mail-router.example.net [192.0.2.250])
by chicago.example.com (8.11.6/8.11.6)
for <recipient@chicago.example.com>
with ESMTP id i7PK0sH7021929;
Fri, Feb 15 2002 17:19:22 -0800
DKIM-Signature: v=1; a=rsa-sha256; s=furble;
d=mail-router.example.net; t=1188964198; c=relaxed/simple;
h=From:Date:To:Message-Id:Subject:Authentication-Results;
bh=ftA9J6GtX8OpwUECzHnCkRzKw1uk6FNiLfJl5Nmv49E=;
b=oINEO8hgn/gnunsg ... 9n9ODSNFSDij3=
Authentication-Results: example.net;
dkim=pass (good signature) header.i=@newyork.example.com
Received: from smtp.newyork.example.com
(smtp.newyork.example.com [192.0.2.220])
by mail-router.example.net (8.11.6/8.11.6)
with ESMTP id g1G0r1kA003489;
Fri, Feb 15 2002 17:19:07 -0800
DKIM-Signature: v=1; a=rsa-sha256; s=gatsby;
d=newyork.example.com;
t=1188964191; c=simple/simple;
h=From:Date:To:Message-Id:Subject;
bh=sEu28nfs9fuZGD/pSr7ANysbY3jtdaQ3Xv9xPQtS0m7=;
b=EToRSuvUfQVP3Bkz ... rTB0t0gYnBVCM=
From: sender@newyork.example.com
Date: Fri, Feb 15 2002 16:54:30 -0800
To: meetings@example.net
La liste complète des méthodes figure dans un registre IANA (section 6). De nouvelles méthodes peuvent être enregistrées en utilisant la procédure « Examen par un expert » du RFC 5226. Des méthodes sont parfois abandonnées comme la tentative de Microsoft d'imposer son Sender ID (RFC 4406.)
L'en-tête Authentication-Results: inclut également les valeurs de certaines
propriétés (RFC 7410. Ainsi, dans :
Authentication-Results: example.com;
auth=pass (cram-md5) smtp.auth=sender@example.net;
spf=pass smtp.mailfrom=example.net
La propriété smtp.auth (authentification
SMTP) a la valeur
sender@example.net (l'identité qui a été validée).
La section 2.5 détaille
l'authserv-id. C'est un texte qui identifie
le domaine, l'ADMD. Il doit donc être unique dans tout
l'Internet. En général, c'est un nom de
domaine comme laposte.net. (Il
est possible d'être plus spécifique et d'indiquer le nom d'une
machine particulière mais cette même section du RFC explique
pourquoi c'est en général une mauvaise idée : comme les MUA du
domaine n'agissent que sur les Authentication-Results: dont ils reconnaissent
l'authserv-id, avoir un tel identificateur
qui soit lié au nom d'une machine, et qui change donc trop
souvent, complique l'administration système.)
La section 2.7 explique les résultats possibles pour les
méthodes d'authentification (en rappelant que la liste à jour des
méthodes et des résultats est dans le registre
IANA). Ainsi, DKIM (section 2.7.1) permet des résultats comme
pass (authentification réussie) ou
temperror (erreur temporaire au cours de
l'authentification, par exemple liée au DNS). Des résultats similaires sont
possibles pour SPF (section 2.7.2).
Notons la normalisation d'une méthode traditionnelle
d'authentification faible, le test DNS du chemin « adresse IP du
serveur -> nom » et retour. Baptisée iprev,
cette méthode, bien que bâtie sur la pure superstition
(cf. section 7.11) est utilisée couramment. Très injuste (car les
arbres des résolutions inverses du
DNS, in-addr.arpa et
ip6.arpa, ne sont pas sous le contrôle du
domaine qui envoie le courrier), cette méthode discrimine les
petits FAI, ce qui est sans doute un avantage pour les gros, comme
AOL qui
l'utilisent. Attention aux implémenteurs : aussi bien la
résolution inverse d'adresse IP en nom que la résolution droite de
nom en adresse IP peuvent renvoyer plusieurs résultats et il faut
donc comparer des ensembles. (Cette méthode qui,
contrairement aux autres, n'avait jamais été exposée dans un RFC
avant le RFC 5451, est décrite en détail
dans la section 3, avec ses sérieuses limites.)
Autre méthode mentionnée, auth (section
2.7.4) qui repose sur l'authentification SMTP du RFC 4954. Si un MTA (ou plutôt MSA) a authentifié un
utilisateur, il peut le noter ici.
Une fois le code d'authentification exécuté, où mettre le
Authentication-Results: ? La section 4 fournit tous les détails, indiquant
notamment que le MTA doit placer l'en-tête en haut du message, ce
qui facilite le repérage des Authentication-Results: à qui on peut faire confiance
(en examinant les en-têtes Received: ; en
l'absence de signature, un Authentication-Results: très ancien, situé au début du
trajet, donc en bas des en-têtes, ne signifie pas grand'chose). On
se fie a priori aux en-têtes mis par les MTA de l'ADMD, du domaine
de confiance. L'ordre est donc important. (La section 7 revient en
détail sur les en-têtes Authentication-Results: usurpés.)
Ce n'est pas tout de mettre un Authentication-Results:, encore faut-il
l'utiliser. La section 4.1 s'attaque à ce problème. Principe
essentiel pour le MUA : ne pas agir sur la base d'un Authentication-Results:, même
si ce n'est que pour l'afficher, sans l'avoir validé un
minimum. Comme le Authentication-Results: n'est pas signé, n'importe qui a pu en
insérer un sur le trajet. Le RFC précise donc que les MUA doivent,
par défaut, ne rien faire. Et qu'ils doivent ne regarder les Authentication-Results:
qu'après que cela ait été activé par l'administrateur de la
machine, qui indiquera quel authserv-id est
acceptable.
Naturellement, le MTA d'entrée du domaine devrait supprimer les
Authentication-Results: portant son propre authserv-id qu'il
trouve dans les messages entrants : ils sont forcément frauduleux
(section 5). (Le RFC accepte aussi une solution plus simpliste,
qui est de supprimer tous les Authentication-Results: des messages entrants, quel
que soit leur authserv-id.)
Arrivé à ce stade de cet article, le lecteur doit normalement
se poser bien des questions sur la valeur du Authentication-Results:. Quel poids lui
accorder alors que n'importe quel méchant sur le trajet a pu
ajouter des Authentication-Results: bidons ? La section 7, consacrée à l'analyse
générale de la sécurité, répond à ces inquiétudes. 7.1 détaille le
cas des en-têtes usurpés. Les principales lignes de défense ici
sont le fait que le MUA ne doit faire confiance aux Authentication-Results: que
s'ils portent le authserv-id de son ADMD
et le fait que le MTA entrant doit filtrer
les Authentication-Results: avec son authserv-id. Comme
l'intérieur de l'ADMD, par définition, est sûr, cela garantit en
théorie contre les Authentication-Results: usurpés. Le RFC liste néanmoins d'autres
méthodes possibles comme le fait de ne faire confiance qu'au
premier Authentication-Results: (le plus récent), si on sait
que le MTA en ajoute systématiquement un (les éventuels Authentication-Results:
usurpés apparaîtront après ; mais certains serveurs les
réordonnent, cf. section 7.3). Pour l'instant, il n'y a pas de
méthode unique et universelle de vérification du Authentication-Results:, le RFC
propose des pistes mais ne tranche pas.
Comme toujours en sécurité, il faut bien faire la différence
entre authentification et
autorisation. Un spammeur a pu insérer un Authentication-Results: légitime
pour son
authserv-id. Même authentifié, il ne doit pas
être considéré comme une autorisation (section 7.2).
De nombreuses mises en œuvre de ce système existent déjà comme dans MDaemon, sendmail (via sid-milter), Courier, OpenDKIM, etc. Des logiciels comme Zimbra permettent également de le faire :
Authentication-Results: zimbra.afnic.fr (amavisd-new); dkim=pass (2048-bit key) header.d=cfeditions.com header.b=hGHP51iK; dkim=pass (2048-bit key) header.d=cfeditions.com header.b=go30DQO8
Si on veut analyser les en-têtes Authentication-Results: en Python, on a le module authres. Parmi
les grosses usines à courrier centralisées,
Gmail met systématiquement cet en-tête, par
exemple :
Authentication-Results: mx.google.com; spf=pass \
(google.com: domain of stephane@sources.org designates 217.70.190.232 \
as permitted sender) smtp.mail=stephane@sources.org
Outre Gmail, à la date de publication du RFC, des services comme
Yahoo et Outlook ajoutaient cet
en-tête. Évidemment, ces en-têtes ne sont pas toujours
corrects. Outlook ne met pas le authserv-id et
n'affiche pas l'adresse IP dans les tests SPF :
authentication-results: spf=none (sender IP is ) smtp.mailfrom=abo@charliehebdo.fr;
Mon serveur de messagerie utilise
Postfix et j'y fais des tests
SPF, dont le résultat est affiché sous
forme d'un en-tête Authentication-Results:. Pour cela, j'ai installé pypolicyd-spf via
le paquetage Debian :
% sudo aptitude install postfix-policyd-spf-python
Puis on configure pypolicyd-spf (dans
/etc/postfix-policyd-spf-python/policyd-spf.conf,
la documentation est dans
/usr/share/doc/postfix-policyd-spf-python/policyd-spf.conf.commented.gz). Par
défaut, pypolicyd-spf met l'ancien en-tête
Received-SPF:. Pour avoir Authentication-Results:, il faut
dire :
Header_Type = AR
Et ajouter l'authserv-id (le nom de
l'ADMD) :
Authserv_Id = mail.bortzmeyer.org
Il reste à configurer Postfix, dans
master.cf :
# SPF
policyd-spf unix - n n - 0 spawn
user=policyd-spf argv=/usr/bin/policyd-spf
Et dans main.cf :
smtpd_recipient_restrictions = [...] check_policy_service unix:private/policyd-spf
Postfix va alors mettre ceci dans les messages (ici, un test réussi) :
Authentication-Results: mail.bortzmeyer.org; spf=pass (mailfrom)
smtp.mailfrom=nic.fr (client-ip=2001:67c:2218:2::4:12; helo=mx4.nic.fr;
envelope-from=bortzmeyer@nic.fr; receiver=<UNKNOWN>)
Les changements depuis le RFC 7601 sont
peu nombreux (annexe D pour une liste complète). On y trouve notamment
l'ajout du courrier électronique internationalisé
(EAI, pour Email Address
Internationalization, voir RFC 6530, RFC 6531 et RFC 6532) et quelques petits détails de forme. Et le registre
IANA est légèrement modifié, entre autres
pour y ajouter deux possibilités DKIM, a
(algorithme utilisé) et
s (sélecteur).
L'article seul
RFC 8594: The Sunset HTTP Header Field
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : E. Wilde
Pour information
Première rédaction de cet article le 22 mai 2019
Dernière mise à jour le 27 février 2025
Un nouvel en-tête HTTP (et un nouveau
type de lien) fait son
apparition avec ce RFC :
Sunset: (coucher de soleil) sert à indiquer la date où la
ressource Web cessera probablement d'être servie. Le but est,
lorsque le webmestre sait à l'avance qu'il retirera une ressource,
de prévenir les utilisateurs.
Normalement, bien sûr, cela ne devrait pas arriver. Les URL doivent être stables. Mais dans certains cas, il peut y avoir une raison légitime de retirer une ressource qui avait été publiée sur le Web. Et, si on le sait à l'avance, c'est plus gentil si on prévient les utilisateurs qui accèdent à cette ressource. Donc, en pratique, ce nouvel en-tête servira peu (et sans doute surtout pour les API) mais il sera utile dans des cas précis. Par exemple (ce sont les cas cités par le RFC, personnellement, je ne les trouve pas tous pertinents) :
- Certaines ressources sont par nature temporaires. Par exemple, une page correspondant à une commande en cours sur un site Web de commerce en ligne. (À mon avis, il vaudrait mieux qu'elle soit permanente, pour pouvoir accéder à des informations même une fois la commande exécutée.)
- Lorsqu'une migration vers de nouveaux URL est envisagée dans le futur.
- Lorsque la loi ou un réglement quelconque l'exige. Par exemple, le RGPD, comme les lois de protection des données personnelles qui l'ont précédé, exige la suppression de ces données lorsque la raison pour laquelle elles avaient été collectées n'est plus d'actualité. Si on les détruit au bout d'un mois, on peut annoncer cette suppression à l'avance.
- Si la ressource fait partie d'une
API, il est possible que l'API soit
remplacée par une nouvelle version et que la date de retrait de
l'ancienne soit connue à l'avance, permettant d'informer les
utilisateurs. (Notez qu'une API comprend en général plusieurs
ressources, donc plusieurs URL. L'en-tête
Sunset:ne permet pas de traiter ce cas, cf. section 5 du RFC, mais le type de liensunsetpermet d'indiquer une page Web documentant l'API et ses changements.)
Pour ces usages, ce RFC introduit
(section 3)
donc l'en-tête HTTP Sunset: (coucher de
soleil). Il contient une seule valeur, la date et l'heure de la
suppression, au format HTTP classique de la section 7.1.1.1 du
RFC 7231. Par exemple, pour indiquer qu'une
ressource disparait à la fin de cette année (celle de parution du
RFC) :
Sunset: Tue, 31 Dec 2019 23:59:59 GMT
Et c'est tout. L'en-tête ne donne aucune information sur ce qui arrivera après (réponse 404, 410, redirection 3xx vers une autre ressource…). Cet en-tête figure désormais dans le registre IANA des en-têtes.
Notre RFC introduit, en plus de l'en-tête HTTP, un type de
lien (cf. RFC 8288), sunset, qui peut être mis dans d'autres contextes que celui des
en-têtes HTTP, par exemple dans du HTML
(section 6 de notre RFC). Il
permet d'indiquer des détails sur la future suppression
de la ressource, à la page Web indiquée. Ainsi, en
HTML, cela donnerait :
<link rel="sunset" href="https://example.org/why-sunset-and-when">
Ce type de lien figure dans le registre IANA de ces types.
Le RFC ne précise pas ce que des applications comme les navigateurs doivent faire exactement avec cette information. C'est un choix des auteurs des applications. Ils peuvent choisir, par exemple, d'alerter l'utilisateur. Notez que la date indiquée n'est qu'une indication. Le serveur Web reste libre de garder la ressource plus longtemps, ou au contraire de la supprimer avant.
J'ai mis un champ Sunset: sur ce blog pour
voir. Regardez
https://www.bortzmeyer.org/apps/limit :
% curl -i https://www.bortzmeyer.org/apps/limit
HTTP/1.1 200 OK
…
Sunset: Fri, 1 Jan 2100 00:00:00 GMT
Link: <https://www.bortzmeyer.org/8594.html>; rel="sunset"; type="text/html"
…
Will be deprecated on 2038-01-19T03:14:08Z and removed on 2100-01-01T00:00:00Z.
Pour traiter ce champ, et le
Deprecation: du RFC 9745 (qui est moins « dur » que
Sunset:, il indique un abandon, pas forcément
un retrait), regardez ce
script en Python.
Sinon, quelques logiciels utilisent ou génèrent l'information sur le
coucher de soleil :
- Guzzle
peut examiner les en-têtes
Sunset:dans les réponses, - Idem pour Faraday,
- Un outil
pour les programmeurs Ruby-on-Rails afin d'indiquer la
future suppression en utilisant l'en-tête
Sunset:.
L'article seul
RFC 8589: The 'leaptofrogans' URI Scheme
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : A. Tamas (OP3FT), B. Phister (OP3FT), J-E. Rodriguez (OP3FT)
Pour information
Première rédaction de cet article le 23 mai 2019
Ce nouveau RFC documente un nouveau plan
d'URI, leaptofrogans,
qui permettra de construire des URI pour le système
Frogans, comme par exemple
leaptofrogans:example*test.
Le système Frogans est un système, conçu il y a vingt ans, de publication de contenu sur l'Internet. Il ne semble pas avoir jamais décollé et je suis sceptique quant à ses chances. Mais l'enregistrement d'un plan d'URI (le plan est la première partie d'un URI, avant le deux-points, cf. RFC 3986) ne signifie pas approbation ou encouragement, il indique juste que les formes ont bien été respectées.
Le système Frogans (section 1 du RFC) contient plusieurs composants, un langage de
description des « sites Frogans »,
des adresses Frogans qu'on reconnait à l'astérisque (comme par exemple
example*test), un logiciel
non-libre, le Frogans
Player, un registre des
adresses, une organisation qui pilote la
technologie, etc.
Pourquoi un nouveau plan d'URI ? (Section 2.) L'idée est de permettre au
navigateur, quand il voit un lien du genre
<a href="leaptofrogans:example*test">Contenu
intéressant</a> de lancer le Frogans
Player lorsque ce lien est sélectionné par l'utilisateur.
Le nom un peu long du nouveau plan, leaptofrogans, a
été choisi pour éviter des confusions avec les adresses Frogans,
qui commencent souvent par frogans avant
l'astérisque (section 3 du RFC pour les détails.)
Quelques détails de syntaxe maintenant (section 4). Les
adresses Frogans peuvent utiliser tout
Unicode. Il faut donc utiliser le nouveau
plan leaptofrogans dans des
IRI (RFC 3987) ou
bien encoder avec les pour-cent. Ainsi,
l'adresse Frogans
网络名*站名
sera l'IRI
leaptofrogans:网络名*站名
ou bien l'URI
leaptofrogans:%E7%BD%91%E7%BB%9C%E5%90%8D*%E7%AB%99%E5%90%8D.
Les procédures du RFC 7595 ayant été
suivies, le plan leaptofrogans est désormais dans
le
registre IANA (enregistrement permanent, un enregistrement
temporaire avait été envisagé à un moment).
L'article seul
RFC 8576: Internet of Things (IoT) Security: State of the Art and Challenges
Date de publication du RFC : Avril 2019
Auteur(s) du RFC : O. Garcia-Morchon (Philips IP&S), S. Kumar (Philips Research), M. Sethi (Ericsson)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF t2trg
Première rédaction de cet article le 16 août 2019
Une blague très courante dit que, dans IoT (Internet of Things, l'Internet des Objets), le S veut dire sécurité… C'est peu dire que la sécurité de l'Iot est mauvaise. Elle est en fait catastrophique, comme l'analyse bien Schneier dans son livre « Click here to kill everybody ». C'est en grande partie dû à des raisons politico-économiques (les fabriquants se moquent de la sécurité notamment, parce que les failles de sécurité n'ont aucune conséquence négative pour eux) et en petite partie aux réelles difficultés techniques qu'il y a à sécuriser des objets qui sont parfois contraints en ressources (énergie électrique limitée, par exemple.) Ce nouveau RFC du groupe de recherche T2T (Thing to Thing) de l'IRTF se penche sur la question et essaie d'identifier les questions à long terme. À lire absolument, si vous vous intéressez à la sécurité des objets connectés. Et à lire également si vous ne vous y intéressez pas car, que vous le vouliez ou non, la sécurité des objets connectés va vous toucher.
On ne part pas de zéro pourtant. Contrairement à ce que disent parfois les vendeurs d'objets connectés pour justifier l'insécurité abyssale de leurs produits, des solutions techniques ont été développées. (Voir par exemple cet article qui parle de la sécurité des sondes Atlas.) Il existe des protocoles adaptés aux objets, comme CoAP (RFC 7252), une alternative légère à HTTP, qu'on peut sécuriser avec DTLS (RFC 9147). Mais il reste à les déployer.
Notre RFC suit un plan classique : il étudie d'abord le cycle de vie des objets connectés (section 2 du RFC), examine ensuite les risques (section 3), l'état de l'art (section 4), puis les défis pour sécuriser les objets (section 5), et enfin les prochaines étapes du travail nécessaire (section 6).
Le terme d'Internet des Objets fait partie de ces termes pipeau qui ne veulent pas dire grand'chose. Les « objets » n'ont pas grand'chose à voir, allant d'un ordiphone plus puissant que certains ordinateurs, à des étiquettes RFID, en passant par des voitures connectées qui disposent d'électricité et de puissance de calcul considérables, et des capteurs industriels qui sont au contraire très contraints. Quant à leur connexion, elle se limite parfois au réseau local et, parfois, à envoyer toutes leurs données, aussi privées qu'elles soient, vers leur maitre dans le mythique cloud. C'est le consortium privé Auto-Id qui a popularisé ce terme à la fin des années 1990, pour de simples raisons marketing. À l'époque, c'était limité à des étiquettes RFID n'ayant qu'une connexion très limitée, sans rapport avec l'Internet. Certains ont suggéré de réserver le terme d'« Internet des Objets » aux objets connectés en IP mais ces appels à la rigueur terminologique n'ont en général que peu d'impact. Bref, chercher des solutions pour l'« Internet des Objets » en général n'a que peu de chances d'aboutir, vu la très grande variété de situations que ce terme recouvre.
Mais revenons au début, au cycle de vie de nos objets connectés (section 2 du RFC). Comme la variété des objets connectés est très grande, le RFC choisit de partir d'un exemple spécifique, un système de gestion de bâtiment. Ce système contrôle la climatisation, le chauffage, la ventilation, l'éclairage, la sécurité, etc. Un tel système représente de nombreux objets, dont certains, notamment les capteurs installés un peu partout, peuvent être très contraints en ressource (processeur lent, énergie fournie uniquement par des batteries, etc). Pire, du point de vue des protocoles réseau, certains de ces objets vont passer beaucoup de temps à dormir, pour économiser l'énergie, et ne répondront pas aux autres machines pendant ce temps. Et les objets seront sans doute fabriqués par des entreprises différentes, ce qui soulèvera des questions amusantes d'interopérabilité.
La figure 1 du RFC représente un cycle de vie simplifié. Je le simplifie encore ici. L'objet est successivement :
- fabriqué,
- il peut rester assez longtemps sur l'étagère, attendant un acheteur (ce qui contribue à l'obsolescence de son logiciel),
- installé et configuré (probablement par différents sous-traitants),
- mis en service,
- il va fonctionner un certain temps puis verra des évenements comme une mise à jour logicielle,
- ou des changements de sa configuration,
- à un moment, il cessera d'être utilisé,
- puis sera retiré du bâtiment (à moins qu'il soit oublié, et reste actif pendant des années sans qu'on s'en occupe),
- mais il aura peut-être droit à une reconfiguration et une remise en service à un autre endroit, recommençant le cycle,
- sinon, il sera jeté.
Les différents objets présents dans le bâtiment ne seront pas aux mêmes étapes au même moment.
Le RFC remarque que le cycle de vie ne commence pas forcément à la fabrication de l'objet physique, mais avant. Pour des objets comportant du logiciel, le cycle de vie commence en fait lorsque la première bibliothèque qui sera utilisée est écrite. Les logiciels des objets connectés ont une forte tendance à utiliser des versions anciennes et dépassées des bibliothèques, notamment de celles qui assurent des fonctions de sécurité. Les bogues ont donc une longue durée de vie.
La sécurité est une question cruciale pour les objets connectés, car ils sont en contact avec le monde physique et, si ce sont des actionneurs, ils agissent sur ce monde. Comme le note Schneier, une bogue sur un objet connecté, ce n'est plus seulement un programme qui plante ou un fichier qu'on perd, cela peut être des atteintes physiques aux humains. Et les objets sont nombreux : pirater une machine ne donne pas beaucoup de pouvoir à l'attaquant, mais s'il arrive à trouver une faille lui permettant de pirater via l'Internet tous les objets d'un vendeur donné, il peut se retrouver à la tête d'un botnet conséquent (c'est exactement ce qui était arrivé avec Mirai).
Quels sont les risques exactement ? La section 3 du RFC décrit les différentes menaces, une liste longue et un peu fourre-tout. Avant tout, le code peut être incorrect, bogué ou mal conçu. C'est le cas de tout logiciel (ne croyez pas un instant les commerciaux qui assurent, sans rien en savoir eux-mêmes, que « le logiciel est conforme à l'état de l'art et aux préconisations de [insérer ici le nom d'un organisme quelconque] »). Mais comme vu plus haut, les conséquences sont plus graves dans le cas des objets connectés. En outre, il y a deux problèmes logiciels qui sont davantage spécifiques aux objets connectés : les mises à jour, pour corriger les bogues, sont plus difficiles, et rarement faites, et le logiciel est globalement négligé, n'étant pas le « cœur de métier » de l'entreprise vendeuse. On voit ainsi des failles de sécurité énormes, qui n'arrivent plus dans l'informatique plus classique.
Autre raison pour laquelle la sécurité des objets connectés est difficile à assurer, le fait que l'attaquant peut avoir un accès physique aux objets (par exemple s'il s'agit d'un type d'objet vendu publiquement). Il peut le démonter, l'étudier, et acquérir ainsi des informations utiles pour le piratage d'autres objets du même type. Si, par exemple, tous les objets d'un même type partagent une clé cryptographique privée, elle pourrait être récupérée ainsi (l'objet connecté typique n'est pas un HSM). Un modèle de sécurité comme celui de la boite noire ne s'applique donc pas. Dans le futur, peut-être que les PUF seront une solution ?
La sécurité impose de mettre à jour le logiciel de l'objet régulièrement. Mais cette mise à jour ouvre elle-même des failles de sécurité. Si le processus de mise à jour n'est pas sécurisé (par exemple par une signature du logiciel), un malveillant pourra peut-être y glisser sa version du logiciel.
Ensuite, l'objet, même s'il fonctionne comme prévu, peut faire fuiter des informations privées. S'il envoie des informations à des tiers (c'est le cas de presque tous les objets conçus pour l'usage domestique) ou s'il transmet en clair, il permet la surveillance de son propriétaire. Le chiffrement est évidemment indispensable, mais il ne protège pas contre les extrémités de la communication (le sextoy connecté qui envoie les informations sur son usage au vendeur de l'objet) et, s'il n'est pas accompagné d'une authentification du partenaire avec qui on communique, ile ne protège pas contre l'homme du milieu. Une des difficultés de l'authentification est qu'il faut bien, avant la communication, avitailler l'objet en informations (par exemple les clés publiques de ses correspondants), un défi pour des objets fabriqués en masse. Avitailler une fois l'objet sur le terrain est tout aussi difficile : ces objets n'ont souvent pas d'interface utilisateur. Cela impose des solutions comme le TOFU (faire confiance la première fois, puis continuer avec le même correspondant) ou bien l'appairage (on approche deux objets, on appuie sur un bouton et ils sont désormais appairés, ils ont échangé leurs clés).
Les objets ont souvent une histoire compliquée, étant composée de l'assemblage de divers composants matériels et logiciels, parfois promenés sur de longues distances, entre beaucoup d'entreprises différentes. Une des attaques possibles est de s'insérer quelque part dans cette chaîne d'approvisionnement et d'y glisser du logiciel ou du matériel malveillant. Est-ce que quelqu'un sait vraiment ce que fait cette puce dont on a acheté des dizaines de milliers d'exemplaires à un revendeur ? Dans le cas extrême, c'est l'objet entier qui peut être remplacé par un objet apparemment identique, mais malveillant.
Les objets connectés sont souvent dans des lieux qui ne sont pas physiquement protégés. Par exemple, les capteurs sont placés un peu partout, et parfois accessibles à un attaquant. Une fois qu'on peut mettre la main sur un objet, il est difficile d'assurer sa sécurité. Des informations confidentielles, comme une clé privée, peuvent alors se retrouver entre les mains de l'attaquant. Transformer chaque objet connecté en un coffre-fort inviolable n'est évidemment pas réalistes.
Les objets communiquent entre eux, ou bien avec des passerelles les connectant à l'extérieur. Cela ouvre de nouvelles possibilités d'attaque via le routage. Les objets connectés se servent souvent de protocoles de routage non sécurisés, permettant au malveillant d'injecter de fausses routes, permettant ainsi, par exemple, de détourner le trafic vers une machine contrôlée par ce malveillant.
Enfin, il y a la menace des attaques par déni de service. Les objets sont souvent contraints en ressources et sont donc particulièrement vulnérables aux attaques par déni de service, même légères. Et les objets ne sont pas forcément victimes, ils peuvent être aussi devenir zombies et, recrutés par un logiciel malveillant comme Mirai, être complices d'attaques par déni de service comme cela avait été le cas en octobre 2016. (Un outil comme Shodan permet de trouver facilement des objets vulnérables et/ou piratés.)
Bon, ça, c'étaient les menaces. Mais on n'est pas resté les bras ballants, on a déjà des mécanismes possibles pour faire face à ces attaques. La section 4 de notre RFC décrit l'état de l'art en matière de connexion des objets connectés, et de leur sécurisation.
Déjà, il existe plusieurs protocoles pour les objets connectés, comme ZigBee, BACnet ou DALI. Mais l'IETF se focalise évidemment sur les objets qui utilisent IP, le seul cas où on puisse réellement parler d'« Internet des Objets ». IP tel qu'il est utilisé sur les ordinateurs classiques n'est pas forcément bien adapté, et des groupes ont développé des adaptations pour les réseaux d'objets (voir par exemple le RFC 4944). De même, il existe des normes pour faire tourner IP sur des tas de couches physiques différentes, comme Bluetooth (RFC 7668), DECT (RFC 8105) ou NFC (RFC pas encore publié). Au-dessus d'IP, le protocole CoAP (RFC 7252) fournit un protocole applicatif plus adapté aux objets que le HTTP classique.
Questions formats, on a également le choix. On a JSON (RFC 8259), mais aussi CBOR (RFC 8949) qui, lui, est un format binaire, sans doute plus adapté aux objets contraints. Tous les deux ont des solutions de sécurité, par exemple la famille JOSE pour signer et chiffrer les documents JSON, et son équivalent pour CBOR, CORE (RFC 8152).
Le problème de la sécurité de l'IoT est connu depuis longtemps, et ce ne sont pas les solutions techniques qui manquent, que ce soit pour protéger les objets connectés, ou pour protéger le reste de l'Internet contre ces objets. Certains de ces protocoles de sécurité ne sont pas spécifiques aux objets connectés, mais peuvent être utilisés par eux, c'est le cas de TLS (RFC 8446). Une excuse classique des fabricants d'objets connectés pour ne pas sécuriser les communications avec TLS est le caractère contraint de l'objet (manque de ressources matérielles, processeur, mémoire, énergie, etc). Cet argument peut jouer pour des objets vraiment contraints, des capteurs bon marché disséminés dans l'usine et ne fonctionnant que sur leur batterie mais beaucoup d'objets connectés ne sont pas dans ce cas, et ont largement les moyens de faire tourner TLS. Quand on entend des fabriquants de télévisions connectées ou de voitures connectées expliquer qu'ils ne peuvent pas utiliser TLS car ce protocole est trop coûteux en ressources, on rit ou on s'indigne car c'est vraiment un argument ridicule ; une télévision ou une voiture ont largement assez de ressources pour avoir un processeur qui fait tourner TLS. (Je n'utilise que TLS et SSH pour communiquer avec un Raspberry Pi 1, avec son processeur à 700 MHz et sa consommation électrique de 2 W.)
Outre les protocoles, la sécurité repose sur des règles à suivre. La section 4.3 liste les règles formalisées existantes. Ainsi, GSMA a publié les siennes, BITAG également, le DHS étatsunien s'y est mis, l'ENISA aussi et notre RFC liste de nombreux autres documents. Si les fabriquants d'objets connectés ne sont pas au courant, ce n'est pas faute d'information, c'est bien de la mauvaise volonté !
C'est d'autant plus grave que, comme l'a illustré le cas de Mirai, les objets connectés non-sécurisés ne sont pas un problème que pour le propriétaire de l'objet, mais peuvent également toucher tout l'Internet. Il est donc logique que beaucoup de voix s'élèvent pour dire qu'il faut arrêter de compter sur la bonne volonté des fabricants d'objets connectés, qui ont largement démontré leur irresponsabilité, et commencer à réguler plus sévèrement. (C'est par exemple une demande du régulateur étatsunien FCC.)
Cette disponibilité de très nombreuses solutions techniques ne veut pas dire que tous les problèmes sont résolus. La section 5 du RFC fait ainsi le point sur les défis qui nous restent, et sur lesquels chercheu·r·se·s et ingénieur·e·s devraient se pencher. D'abord, certains objets sont contraints en ressources (pas tous, on l'a vu), comme détaillé dans le RFC 7228. L'Internet est un monde très hétérogène, connectant des machines ayant des ressources très diverses, via des réseaux qui ont des capacités hautement variables. Pour ces objets contraints (qui sont une partie seulement des « objets », une caméra de vidéo-surveillance n'est pas un objet contraint), il est raisonnable de chercher à optimiser, par exemple la cryptographie. Ainsi, la cryptographie à courbes elliptiques (RFC 8446) demande en général moins de ressources que RSA.
Les attaques par déni de service sont un autre défi pour les objets connectés, qui disposent de peu de ressources pour y faire face. Des protocoles qui permettent de tester qu'il y a une voie de retour (return routability ou returnability) peuvent aider à éviter certaines attaques que des protocoles sans ce test (comme le DNS ou comme d'autres protocoles fondés sur UDP) rendent facile. C'est pour cela que DTLS (RFC 9147) ou HIP (RFC 7401) intègrent ce test de réversibilité. Évidemment, cela n'aide pas pour les cas de la diffusion, ou bien lorsque le routage est contrôlé par l'attaquant (ce qui est souvent le cas dans les réseaux « mesh ».) Autre protection, qui existe par exemple dans HIP : forcer l'initiateur d'une connexion à résoudre un problème, un « puzzle », afin d'éviter que les connexions soient « gratuites » pour l'initiateur. La principale limite de cette solution est qu'elle marche mal si les machines impliquées ont des capacités de calcul très différentes (un objet contraint contre un PC). Il y a également le cas, non mentionné par le RFC, où l'attaquant dispose d'un botnet et ne « paie » donc pas les calculs.
L'architecture actuelle de l'Internet n'aide pas au déploiement de certaines solutions de sécurité. Ainsi, un principe de base en sécurité est d'avoir une sécurité de bout en bout, afin de ne pas dépendre d'intermédiaires malveillants ou piratés, mais c'est rendu de plus en plus difficile par l'abus de middleboxes, qui interfèrent avec beaucoup de comunications. On est donc forcés d'adapter la sécurité à la présence de ces middleboxes, souvent en l'affaiblissant. Par exemple :
- Il faut parfois partager les clés avec les middleboxes pour qu'elles puissent modifier les paquets, ce qui est évidemment une mauvaise pratique,
- Le chiffrement homomorphe peut aider, en permettant d'effectuer certaines opérations sur des données chiffrées, mais toutes les opérations ne sont pas possibles ainsi, et les bibliothèques existantes, comme SEAL, n'ont pas les performances nécessaires,
- Remonter la sécurité depuis le niveau des communications (ce que fait TLS) vers celui des données échangées pourrait aider. C'est ce que font COSE (RFC 8152), JOSE (RFC 7520) ou CMS (RFC 5652).
Une fois déployés, les objets connectés vont rester en fonctionnement des années, voire des décennies. Il est donc crucial d'assurer les mises à jour de leur logiciel, ne serait-ce que pour réparer les failles de sécurité qui ne manqueront pas d'être découvertes, qu'elles soient dans le code ou dans les algorithmes utilisés. Par exemple, si les promesses des ordinateurs quantiques se concrétisent un jour, il faudra jeter RSA et les courbes elliptiques (section 5.8 du RFC).
Mais assurer des mises à jour sûres n'est pas facile, comme le note Bruce Schneier. C'est que le processus de mise à jour, s'il est insuffisamment sécurisé, peut lui-même servir pour une attaque, par exemple en envoyant du code malveillant à un objet trop naïf. Et puis comment motiver les vendeurs à continuer à fournir des mises à jour logicielles des années après que le dernier exemplaire de ce modèle ait été vendu ? Capitalisme et sécurité ne vont pas bien ensemble. Et il se peut tout simplement que le vendeur ait disparu, que le code source de l'objet ne soit plus disponible, et qu'il soit donc impossible en pratique de développer une mise à jour. (D'où l'importance, même si le RFC ne le dit pas, du logiciel libre.) Enfin, si la mise à jour doit être effectuée manuellement, il est probable qu'elle ne sera pas faite systématiquement. (Un rapport de la FTC états-unienne détaille également ce problème.)
Mais les mises à jour automatiques posent également des tas de problèmes. Par exemple, pour des ampoules connectées (une idée stupide, mais le monde de l'IoT est plein d'idées stupides), il vaut mieux mettre à jour leur logiciel le jour que la nuit. Et il vaut mieux que toutes les ampoules ne soient pas mises à jour en même temps. Et les mises à jour supposent que le système ait été conçu pour cela. Par exemple, en cryptographie, il est souvent nécessaire de remplacer les algorithmes cryptographiques qui ont été cassés avec le temps, mais beaucoup d'objets connectés utilisent des systèmes cryptographiques mal conçus, qui n'ont pas d'agilité cryptographique. (Au passage, la section 5.8 du RFC traite le cas des possibles futurs ordinateurs quantiques, et des conséquences qu'ils auront pour la cryptographie. Les objets connectés peuvent rester actifs de nombreuses années, et il faut donc penser loin dans le futur.) Ces points, et beaucoup d'autres, avaient été traités dans un atelier de l'IAB, qui avait fait l'objet du RFC 8240. À l'IETF, le groupe de travail SUIT développe des mécanismes pour aider les mises à jour (mais qui ne traiteront qu'une petite partie du problème).
Rapidement dépassés, les objets connectés posent également des problèmes de gestion de la fin de vie. Au bout d'un moment, le vendeur va arrêter les différentes fonctions, comme les mises à jour du logiciel ou, plus radicalement, comme les serveurs dont dépend l'objet. Cet arrêt peut être volontaire (l'objet n'intéresse plus le vendeur, qui est passé à d'autres gadgets) ou involontaire (vendeur en faillite). Le RFC note qu'une des voies à explorer est la continuation de l'objet avec du logiciel tiers, qui ne dépend plus de l'infrastructure du vendeur. Bien des ordiphones ont ainsi vu leur vie prolongée par CyanogenMod, et bien des routeurs ont bénéficié d'OpenWrt. (D'où l'importance de pouvoir installer ce logiciel tiers, ce qu'interdisent beaucoup de vendeurs.)
Une autre question intéressante de sécurité posée par les objets connectés est la vérification de leurs capacités réelles et de leur comportement effectif. L'acheteur peut avoir l'impression qu'il est le propriétaire de l'objet acheté mais cet objet est suffisamment complexe pour que l'acheteur ne soit pas au courant de tout ce que l'objet fait dans son dos. Le vrai maitre de l'objet est alors le vendeur, qui continue à communiquer avec l'engin connecté. C'est ainsi que des malhonnêtes comme Lidl ou Google avaient installé des micros dans des objets qu'on installe chez soi, et évidemment sans le dire à l'acheteur. Et encore, un micro est un appareil physique, qu'un examen attentif (avez-vous vérifié tous les objets connectés chez vous ?) peut détecter. Mais savoir ce que raconte l'objet connecté à son maitre est plus difficile. Peu d'utilisateurs ont envie de configurer un routeur local, et d'y faire tourner tcpdump pour voir le trafic. Et encore, ce trafic peut être chiffré et l'acheteur (qui, rappelons-le, n'est pas le véritable propriétaire de l'objet, puisqu'il n'a quasiment aucun contrôle, aucune information) n'a pas les clés.
Le problème de fournir des informations à l'utilisateur n'est pas trivial techniquement. Beaucoup d'objets connectés n'ont pas d'interface utilisateur où afficher « je suis en train d'envoyer plein de données sur vous à mon maitre ». Une solution partielle serait une description des capacités de l'engin, et de ses communications, dans un fichier MUD (Manufacturer Usage Description, RFC 8520). Ceci dit, vu le niveau d'éthique dans le monde de l'IoT, gageons que ces fichiers MUD mentiront souvent, notamment par omission.
Puisqu'on a parlé de vie privée, c'est l'occasion de rappeler que l'IoT est une grave menace pour cette vie privée. Le RFC note que, dans le futur, nous serons peut-être entourés de centaines d'objets connectés. (Malheureusement, le RFC parle surtout des risques dus à des tiers qui observeraient le trafic, et très peu des risques dus aux vendeurs qui récoltent les données.) L'IoT permet une intensification considérable du capitalisme de surveillance.
Bref, la situation est mauvaise et, s'il y a en effet quelques progrès (on voit moins souvent des mots de passe identiques pour tous les objets d'un type), ils sont largement annulés par de nouveaux déploiements.
L'article seul
RFC 8574: cite-as: A Link Relation to Convey a Preferred URI for Referencing
Date de publication du RFC : Avril 2019
Auteur(s) du RFC : H. Van de Sompel (Data Archiving and Networked Services), M. Nelson (Old Dominion University), G. Bilder (Crossref), J. Kunze (California Digital Library), S. Warner (Cornell University)
Pour information
Première rédaction de cet article le 18 avril 2019
Ce RFC décrit un nouveau type de liens hypertexte permettant d'indiquer l'URI sous lequel on préfère qu'une ressource soit accédée, à des fins de documentation ou de citation précise.
Imaginons que vous accédez à un article scientifique en ligne. Vous utilisez un URI qui identifie cet article. Vous voulez ensuite citer cet article dans un de vos textes. Allez-vous utiliser l'URI d'accès ? Ce n'est pas forcément le meilleur, par exemple ce n'est pas forcément le plus stable sur le long terme. Le lien « cite avec » permet au serveur d'indiquer l'URI le plus pertinent pour une citation.
Ce RFC s'appuie sur la formalisation du concept de lien faite dans le RFC 8288. « Contexte » et « cible » sont donc utilisés comme dans cette norme, le contexte d'un lien étant le point de départ et la cible l'arrivée. En prime, notre RFC 8574 définit deux termes, l'URI d'accès, celui utilisé pour accéder à une ressource (par exemple une page Web) et l'URI de référence, celui qu'il faudrait utiliser pour la citation.
La section 3 du RFC décrit quelques scénarios d'usage. Le premier est celui des identificateurs stables. Normalement, lorsque le ou la webmestre est compétent(e) et sérieux(se), les URI sont stables, comme précisé dans l'article « Cool URIs don't change. Mais, en pratique, beaucoup de webmestres sont incompétents ou paresseux. Cela a mené à des « solutions » fondées sur la redirection, où il apparait une différence entre URI d'accès et URI de référence. C'est le cas avec des techniques comme les DOI (« use the Crossref DOI URL as the permanent [reference] link »), PURL ou ARK. Dans les trois cas, au lieu de gérer proprement les URI, on utilise un redirecteur supposé plus stable (alors que rien ne le garantit) et on souhaite utiliser comme URI de référence l'URI du redirecteur (donnant ainsi des pouvoirs démesurés à des organisations privées comme l'IDF, qui matraque régulièrement l'importance de n'utiliser que leurs identificateurs).
Un autre scénario d'usage est celui des ressources
versionnées. C'est par exemple le cas de Wikipédia. La page Wikipédia sur
l'incendie de Notre-Dame de Paris change souvent en ce
moment. Comme toutes les pages Wikipédia, chaque version à un
identificateur, et on peut se référer à une version
particulier. Si https://fr.wikipedia.org/wiki/Incendie_de_Notre-Dame_de_Parishttps://fr.wikipedia.org/w/index.php?title=Incendie_de_Notre-Dame_de_Paris&oldid=158468007https://fr.wikipedia.org/w/index.php?title=Incendie_de_Notre-Dame_de_Paris&oldid=158478416
Souvent, quand on veut citer un article de Wikipédia, on veut se mettre à l'abri de changements ultérieurs, pas forcément positifs, et on souhaite donc citer exactement une version particulière. On clique donc sur « Lien permanent » (ou bien « Voir l'historique » puis sur la date la plus récente) pour avoir l'URI de la version qu'on vient de regarder. (Notez aussi le très utile lien « Citer cette page ».)
Troisième cas d'usage cité, celui des identifiants sur les
réseaux sociaux. M. Toutlemonde a
typiquement plusieurs pages le décrivant sur ces réseaux (dans mon
cas, https://mastodon.gougere.fr/@bortzmeyerhttps://twitter.com/bortzmeyerhttps://www.linkedin.com/in/sbortzmeyer/https://seenthis.net/people/stephane
Enfin, un dernier cas d'usage est celui d'une publication composée de plusieurs ressources (par exemple un livre où chaque chapitre est accessible séparement, avec son propre URI). On souhaite alors que l'accès à chaque ressource indique, à des fins de citation, l'URI de référence (par exemple la page d'accueil).
La section 4 du RFC présente la solution : un nouveau type de
lien, cite-as, qui permet de dire quel est
l'URI de référence. (Le RFC recommande d'ailleurs que cet URI soit
un URL : le but est d'accéder à la
ressource !) Il est évidemment recommandé qu'il n'y ait qu'un seul
lien de type cite-as. Ce lien n'interdit pas
d'utiliser d'autres URI, il indique seulement quel est l'URI
que le webmestre souhaite voir utilisé dans les références
webographiques. cite-as est désormais dans
le
registre IANA des types de liens.
La section 6 du RFC donne des exemples concrets, puisque les
liens peuvent se représenter de plusieurs façons. Par exemple,
l'article de PLOS One auquel vous accédez en https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0171057rel="cite-as" :
<link rel="cite-as"
href="https://doi.org/10.1371/journal.pone.0171057" />
Cela indiquerait que les auteurs préfèrent être cités par le DOI (une mauvaise idée, mais c'est une autre histoire).
Autre exemple de syntaxe concrète pour les liens, imaginé pour
arXiv, pour des
articles avec versionnement, un lien dans un en-tête
HTTP pour https://arxiv.org/abs/1711.03787
HTTP/1.1 200 OK
Date: Sun, 24 Dec 2017 16:12:43 GMT
Content-Type: text/html; charset=utf-8
Link: <https://arxiv.org/abs/1711.03787v1> ; rel="cite-as"
Comme arXiv garde les différentes versions successives d'un article, cela permettrait de récupérer la version actuelle tout en sachant comment la référencer.
Revenons au HTML pour l'exemple des profils sur les réseaux sociaux, imaginons un utilisateur, John Doe, qui place dans le code HTML de sa page personnelle un lien vers son profil FOAF en Turtle :
<html>
<head>
...
<link rel="cite-as" href="http://johndoe.example.com/foaf"
type="text/turtle"/>
...
</head>
<body>
...
Et un dernier exemple, celui d'une publication composée de
plusieurs ressources. Ici, l'exemple est Dryad une base de données scientifiques qui
permet l'accès à des fichiers individuels, mais où chaque jeu de données a un
identificateur canonique. En HTTP, cela donnerait, lorsqu'on accès
à https://datadryad.org/bitstream/handle/10255/dryad.98509/PIPFIL_M_BCI.csv
HTTP/1.1 200 OK
Date: Tue, 12 Jun 2018 19:19:22 GMT
Last-Modified: Wed, 17 Feb 2016 18:37:02 GMT
Content-Type: text/csv;charset=ISO-8859-1
Link: <https://doi.org/10.5061/dryad.5d23f> ; rel="cite-as"
Le fichier CSV est membre d'un jeu de données plus général, dont
l'URI de référence est https://doi.org/10.5061/dryad.5d23f
Ainsi, dans un monde idéal, un logiciel qui reçoit un lien
cite-as pourrait :
- Lorsqu'il garde un signet, utiliser l'URI de référence,
- Identifier plusieurs URI d'accès comme ayant le même URI de référence, par exemple à des fins de comptage,
- Indexer les ressources par plusieurs URI.
D'autres solutions avaient été proposées pour résoudre ce
problème de l'URI de référence. La section 5 de notre RFC les
énumère. Il y avait notamment cinq autres types de liens qui
auraient peut-être pu convenir, alternate,
duplicate, related, bookmark et
canonical.
Les trois premiers sont vite
éliminés. alternate (RFC 4287) décrit une autre représentation de la même
ressource (par exemple la même vidéo mais encodée
différemment). duplicate (RFC 6249) désigne une reproduction identique (et cela ne
traite donc pas, par exemple, le cas d'une publication composée de
plusieurs ressources). Quant à related (RFC 4287), sa
sémantique est bien trop vague. Un article des auteurs du RFC
décrit
en détail les choix de conceptions et explique bien le
problème. (Je trouve cet article un peu gâché par les affirmations
sans preuves comme quoi les DOI seraient « permanents ». Si le
registre disparait ou fait n'importe quoi, il y aura le même
problème avec les DOI qu'avec n'importe quelle autre famille d'identificateurs.)
Le cas de bookmark (normalisé par le W3C) est plus
compliqué. Il est certainement proche en sémantique de
cite-as mais ne peut pas être présent dans
les en-têtes HTTP ou dans la tête d'une page HTML, ce qui en réduit
beaucoup l'intérêt. Le cas compliqué de
bookmark est décrit dans
un autre article des auteurs du RFC.
Enfin, le cas de canonical (RFC 6596). Ce dernier semble trop restreint
d'usage pour les utilisations prévues pour
cite-as. Et il n'a pas vraiment la même
sémantique. Par exemple, pour les ressources versionnées,
canonical indique la plus récente, exactement
le contraire de ce qu'on voudrait avec
cite-as. Et c'est bien ainsi que l'utilise
Wikipédia. Si je récupère https://fr.wikipedia.org/w/index.php?title=Incendie_de_Notre-Dame_de_Paris&oldid=158478416
<link rel="canonical" href="https://fr.wikipedia.org/wiki/Incendie_de_Notre-Dame_de_Paris"/>
On voit que canonical renvoie à la dernière
version. Le cas de canonical fait lui aussi
l'objet
d'un article détaillé.
Je n'ai pas mis de tels liens sur ce blog, ne voyant pas de cas où ils seraient utiles.
L'article seul
RFC 8569: Content Centric Networking (CCNx) Semantics
Date de publication du RFC : Juillet 2019
Auteur(s) du RFC : M. Mosko (PARC), I. Solis (LinkedIn), C. Wood (University of California Irvine)
Expérimental
Réalisé dans le cadre du groupe de recherche IRTF icnrg
Première rédaction de cet article le 16 juillet 2019
Certaines personnes trouvent une utilité au réseau centré sur le contenu, où adressage et nommage ne désignent que du contenu, des ressources numériques auxquelles on accède via le réseau. (Cette idée est souvent nommée ICN, pour Information-Centric Networking ou NDN pour Named Data Networking.) Le groupe de recherche ICNRG développe des spécifications pour normaliser certains aspects de ce réseau centré sur le contenu, un projet nommmé CCNx (pour Content Centric Networking). Ce nouveau RFC décrit les concepts de base de CCNx. CCNx est le premier protocole conçu par le groupe ICNRG.
Précisons tout de suite : ce point de vue comme quoi le socle du réseau devrait être l'accès au contenu est très contestable. Il évoque fortement le raccourci de certains journalistes, décideurs, et opérateurs de télécommunication traditionnels comme quoi le seul usage de l'Internet fait par M. Michu serait « accéder à du contenu ». Mais j'ai déjà développé ces critiques dans un autre article il y a huit ans, donc je ne les reprendrai pas ici.
Les acteurs du réseau centré sur le contenu sont notamment :
- Le producteur (producer ou publisher) qui crée du contenu. Il peut avoir une clé qui lui permet de signer ce contenu.
- Le consommateur (consumer) qui veut accéder à du contenu.
(Vous noterez qu'il n'y a pas de pair à pair dans ce réseau, ce qui limite certains usages.)
Le protocole CCnx repose sur deux types de messages :
Interest, par lequel on signale qu'on
aimerait bien récupérer tel contenu, et Content
Object, qui transporte un contenu. En général, la
machine de l'utilisateur, du consommateur demandeur, enverra un
Interest et, si tout va bien, récupérera en
échange un ou plusieurs Content Object. Si
tout va mal, on aura à la place un
InterestReturn, qui signale un
problème. Comment sont désignés les contenus ? Par des noms
hiérarchiquement organisés, comme dans les
URL d'aujourd'hui (section 3 du RFC). Un nom est donc composé
d'une série de segments, et la correspondance entre un nom demandé
et une entrée de la table de routage est toujours faite de manière exacte, bit
à bit. (Pas
d'insensibilité à la casse, pas de
recherche floue.) Le nom est opaque. Il n'est donc pas forcément lisible par un
humain. Comme les noms sont hiérarchiques, un nom peut être exact
(le nom entier) ou être un préfixe (correspondant à plusieurs
noms). On dit aussi qu'un nom est complet quand il inclut un
condensat du contenu (comme dans les
magnets de
BitTorrent). Le condensat est expliqué plus
en détail dans les sections 5 et 7 du RFC. La syntaxe est décrite
dans l'Internet
Draft draft-mosko-icnrg-ccnxurischeme, qui met
les noms CCNx sous forme d'URI. Par
exemple, un nom possible est
ccnx:/NAME=foo/APP:0=bar. Il n'y a pas de
registre de tels noms pour l'instant. Si on veut trouver des noms,
le protocole lui-même ne le permet pas, il faudra bâtir des
solutions (par exemple un moteur de recherche) au-dessus de CCNx.
CCNx fonctionne en
relayant les messages (aussi bien Interest
que Content Object) d'une machine à
l'autre. Du fait de ce modèle de relayage systématique, il faut
ajouter un troisième acteur au producteur et au consommateur, le
relayeur (forwarder), qui
est toute machine intermédiaire, un peu comme un
routeur sauf que le relayeur fait bien plus
de choses qu'un routeur. Par exemple, contrairement au routeur
IP, le relayeur a un état. Chaque demande
d'objet qui passe est mémorisée par le relayeur (dans une
structure de données nommée la PIT, pour Pending Interest
Table), qui saura donc où
renvoyer la réponse. CCNx est sourceless,
contrairement à IP : l'adresse source n'est pas indiquée dans la demande.
La FIB (Forwarding Information Base) est la table de routage de CCNx. Si elle contient une entrée pour le contenu convoité, cette entrée indique où envoyer la requête. Sinon, la requête ne peut aboutir. Notez que ce RFC ne décrit pas le protocole par lequel cette FIB sera construite. Il n'existe pas encore d'OSPF ou de BGP pour CCNx.
Comme le contenu peut être récupéré après un passage par pas mal d'intermédiaires, il est crucial de vérifier son intégrité. CCNx permet plusieurs méthodes, de la signature au HMAC. Ainsi, l'intégrité dans CCNx est une protection des objets (du contenu), pas uniquement du canal comme c'est le cas avec HTTPS. CCNX permet également de signer des listes d'objets (des manifestes), la liste contenant un SHA ou un CRC des objets, ce qui permet d'assurer l'intégrité de ceux-ci.
Ces concepts avaient été décrits dans les RFC 7476 et RFC 7927. Le vocabulaire est expliqué dans le RFC 8793. Maintenant, voyons les détails, sachant que le format précis des messages a été délégué à un autre RFC, le RFC 8609. La section 2 du RFC décrit précisement le protocole.
On a vu que le consommateur commençait l'échange, en envoyant
un message de type Interest. Ce message
contient le nom de l'objet qui intéresse le consommateur, et
éventuellement des restrictions sur le contenu, par exemple qu'on ne veut que des objets signés, et avec tel
algorithme, ou bien ayant tel
condensat cryptographique de l'objet (le
tuple regroupant nom et restrictions se nomme le lien, cf. section
6). Un nombre maximal de
sauts restants est indiqué dans le message. Décrémenté par chaque
relayeur, il sert à empêcher les boucles (lorsqu'il atteint zéro,
le message est jeté). Le producteur, lui,
stocke le contenu, indexé par les noms, et signale ces noms sur le
réseau pour que les relayeurs peuplent leur FIB (on a vu que le
protocole permettant ce signalement n'était pas encore défini,
bien que plusieurs propositions existent). Enfin, le relayeur, le
troisième type d'acteur, fait suivre les
Interest dans un sens (en consultant sa FIB)
et les Content Object en sens inverse (en
consultant sa PIT).
Le relayeur a également une mémoire (un
cache), qui sert notamment à accélérer l'accès au contenu le
plus populaire (section 4 du RFC). Il existe des moyens de
contrôler l'utilisation de cette mémoire, par exemple deux champs
dans un Content Object, la date d'expiration,
après laquelle il ne faut plus garder l'objet dans le cache, et la
date de fin d'intérêt, après laquelle il n'est sans doute plus
utile de garder l'objet (mais on peut quand même si on veut).
La validation des objets, leur vérification, est un composant crucial de CCNx. Elle est spécifiée dans la section 8 du RFC, avec ses trois catégories, la validation utilisant un simple condensat (pas forcément cryptographique), un HMAC ou bien une signature.
On a vu que le troisième type de message de CCNx, après
Interest et Content
Object, était
Interest Return. Il est décrit en détail dans
la section 10 de notre RFC. Notez tout de suite qu'il peut ne pas
y avoir de réponse du tout, un relayeur n'étant pas forcé
d'envoyer un Interest Return s'il ne peut
acheminer un Interest. S'il y a un
Interest Return, il indique l'erreur, par
exemple No Route (aucune entrée dans la FIB
pour ce nom), No Resources (le relayeur manque
de quelque chose, par exemple de place disque pour son cache),
Malformed Interest (un problème dans la demande),
Prohibited (le relayeur n'a pas envie de
relayer), etc.
Enfin, sur la question cruciale de la sécurité, la section 12 du RFC revient sur quelques points sensibles. Par exemple, j'ai dit plus haut que les objets pouvaient être validés par une signature numérique. Mais où trouve-t-on les clés publiques des producteurs, pour vérifier leur signature ? Eh bien ce point n'est pas actuellement traité. Notez que les relayeurs, eux, ne sont pas obligés de valider et un cache peut donc contenir des données invalides. Les RFC 7927 et RFC 7945 sont des bonnes ressources à lire sur la sécurité des réseaux centrés sur le contenu.
Il existait une version précédente du protocole CCNx,
identifiée « 0.x », et décrite dans « Networking Named
Content ». Dans 0.x, la correspondance entre le
nom demandé dans un Interest et celui obtenu
était hiérarchique : le nom demandé pouvait être un préfixe du nom
obtenu. La version décrite dans ce RFC, « 1.0 », est plus
restrictive ; le nom obtenu doit être exactement le nom
demandé. Les fonctions de recherche ne sont pas dans CCNx, elles
doivent être dans un protocole de couche supérieure, un Google ou
Pirate Bay du réseau CCN. Un exemple d'un tel protocole est décrit
dans l'Internet Draft draft-mosko-icnrg-selectors.
Et questions mise en œuvre du protocole CCNx ? Il en existe au moins deux, Community ICN, et CCN-Lite (cette dernière, tournant sur RIOT, visant plutôt l'Internet des objets).
L'article seul
RFC 8558: Transport Protocol Path Signals
Date de publication du RFC : Avril 2019
Auteur(s) du RFC : T. Hardie
Pour information
Première rédaction de cet article le 6 juin 2019
Ce nouveau RFC de l'IAB examine les signaux envoyés par un protocole de transport aux couches supérieures. Par exemple, la machine à états de TCP est observable de l'extérieur, on peut déduire son état de l'examen des paquets envoyés. Certains de ces signaux sont explicites, prévus pour être lus par les routeurs, d'autres sont implicites, déduits de certains comportements. Le RFC recommande de compter plutôt sur les signaux explicites, documentés et fiables. Attention, la tendance actuelle est, pour protéger la vie privée et pour limiter les interférences du réseau avec les communications, de limiter les signaux envoyés. Ainsi, QUIC envoie nettement moins de signaux que TCP.
Le principe de bout en bout dit que les éléments du réseau ne devraient pas avoir besoin de ces signaux du tout (RFC 1958). Ils devraient transporter les datagrammes, point. Mais en pratique, des raisons plus ou moins légitimes font que des équipements intermédiaires ont besoin d'accéder à des informations sur le transport. C'est par exemple le cas des routeurs NAT (RFC 3234).
Comme exemple de signaux implicites, on peut citer ceux de TCP (RFC 793). Les messages échangés (SYN, RST, FIN…) sont destinés aux extrémités, pas aux boitiers intermédiaires mais, comme ils sont visibles (sauf utilisation d'IPsec), le réseau peut être tenté de s'en servir comme signaux implicites. C'est ce que fait un pare-feu à état quand il utilise ces messages pour déterminer si la connexion a été demandée depuis l'intérieur (auquel cas elle est souvent autorisée) ou de l'extérieur (auquel cas elle est souvent interdite).
Cette observation des signaux implicites a souvent pour but une action (blocage des connexions entrantes, dans l'exemple ci-dessus, ou bien déni de service en envoyant des faux RST). Il est donc logique que les protocoles cherchent à se protéger en chiffrant la communication. TLS ou SSH ne chiffrent que l'application, et restent donc vulnérables aux attaques visant la couche 4. D'où le développement de protocoles comme QUIC, qui chiffrent l'essentiel de la machinerie de transport.
La section 2 de notre RFC liste les signaux qui peuvent être déduits de l'observation de la couche transport en action :
- Découvrir l'établissement d'une session, et le fait que tel paquet appartienne à telle session (identifiée typiquement par un tuple {adresse IP source, adresse IP destination, protocole de transport, port source, port destination}), font partie des signaux les plus utilisés. (Pensez à l'exemple du pare-feu plus haut, ou bien à celui d'un répartiteur de charge qui veut envoyer tous les paquets d'une même session au même serveur.)
- Vérifier que la section est à double sens (les deux machines peuvent communiquer et le veulent) est également possible, et important. Par exemple, si le pare-feu détecte qu'une machine a initié la session, on peut supposer qu'elle veut recevoir les réponses, ce qui justifie qu'on fasse un trou dans le pare-feu pour laisser passer les paquets de cette session. (Pour le NAT, cf. RFC 7857.)
- Mesurer des caractéristiques quantitatives de la session est aussi possible. L'observation passive de TCP, par exemple, peut indiquer la latence (en mesurant le temps écoulé entre le passage des données et l'accusé de réception correspondant), ou le taux de perte de paquets (en regardant les retransmissions).
On le voit, les signaux implicites sont utilisés (pas forcément pour de bonnes raisons). Si on chiffre la couche transport, comme le fait QUIC, on perd certains de ces signaux. Que faut-il faire ? La section 3 du RFC liste, sans en recommander une particulière, plusieurs possibilités. La première est évidemment de ne rien faire. Si on chiffre, c'est justement pour assurer la confidentialité ! Le transport étant une fonction de bout en bout, les intermédiaires ne sont pas censés regarder son fonctionnement. Cette approche a quand même quelques inconvénients. Par exemple, un routeur NAT ne sait plus quand les connexions commencent et quand elles finissent, il peut donc être nécessaire d'ajouter du trafic « battement de cœur » pour maintenir l'état dans ce routeur.
On peut aussi se dire qu'on va remplacer les signaux implicites de la couche transport par des signaux explicites, conçus précisement pour une utilisation par des boitiers intermédiaires. C'est le cas du connection ID de QUIC, qui permet par exemple aux répartiteurs de charge d'envoyer tous les paquets d'une connexion QUIC donnée au même serveur. Ou du spin bit du même protocole, pour permettre certaines mesures par les intermédiaires (un bit qui a été très controversé dans la discussion à l'IETF). Le RFC note que ces signaux explicites pourraient être transportés par les en-têtes hop-by-hop d'IPv6 (RFC 7045) mais que leur capacité à être déployés sans perturber les équipements intermédiaires ne va pas de soi.
Ces signaux explicites pourraient être placés dans une mince couche intermédiaire entre UDP (qui sert de base à plusieurs protocoles de transport, comme QUIC ou comme SCTP désormais), et cette normalisation d'une couche intermédiaire avait, par exemple, été proposée dans le projet PLUS (Transport-Independent Path Layer State Management).
Après cette étude, quelles recommandations ? La section 4 du RFC recommande évidemment que les nouveaux protocoles fournissent de la confidentialité par défaut (TCP expose trop de choses), ce qui implique le chiffrement systématique. Les signaux implicites font fuiter de l'information et devraient être évités. L'approche de QUIC est donc la bonne. Par contre, comme il peut être utile d'envoyer certaines informations aux différents équipements intermédiaires situés sur le réseau, l'IAB recommande de mettre quelques signaux explicites.
Cela nécessite de suivre les principes suivants :
- Tout ce qui est destiné aux machines terminales doit être chiffré pour empêcher les middleboxes d'y accéder. Par exemple, le message de fin d'une connexion n'a pas à être public (c'est parce qu'il l'est que TCP est vulnérable aux attaques avec des faux RST).
- Les signaux explicites, destinés aux équipements intermédiaires, doivent être protégés. Que le réseau puisse les lire, d'accord, mais il n'y a aucune raison qu'il puisse les modifier.
- Les signaux explicites doivent être séparés des informations et messages destinés aux machines terminales.
- Les machines intermédiaires ne doivent pas ajouter de signaux (le RFC cite le RFC 8164 mais je trouve le RFC 8165 plus pertinent). Les machines terminales ont intérêt à protéger l'intégrité du paquet, pour éviter ces ajouts.
Notez que cette intégrité ne peut être vérifiée que par les machines terminales, les machines du réseau n'ayant pas le matériau cryptographique (les clés) nécessaires.
Reste enfin les questions de sécurité (section 6 du RFC). Le modèle de menace classique sur l'Internet est qu'on ne peut pas faire confiance aux intermédiaires : sur le trajet entre Alice et Bob, il est trop fréquent qu'au moins un des intermédiaires soit bogué, ou simplement malveillant. Tous les signaux envoyés implicitement sont dangereux, car ils peuvent donner de l'information à celui qui est peut-être un attaquant, lui facilitant certaines attaques. D'où l'importance de diminuer ces signaux implicites.
Naturellement, ce n'est pas une solution miracle ; les attaquants vont trouver d'autres méthodes et la lutte entre attaquant et défenseur ne sera donc jamais finie.
Publier des signaux explicites présente aussi des risques ; en voulant donner au réseau des informations qui peuvent lui être utiles, on peut menacer la vie privée. Ceci explique la vigueur des débats à l'IETF au sujet du spin bit de QUIC. Le spin bit n'a pas d'utilité pour les machines terminales, seulement pour les équipements intermédiaires. Ses partisans disaient qu'il était important que ces équipements puissent accéder à des informations sur le RTT. Ses adversaires (qui n'ont pas eu gain de cause complet, le spin bit est optionnel, on n'est pas forcé de l'envoyer) estimaient que faire fuiter volontairement de l'information, même assez inoffensive, ouvrait un risque potentiel.
Enfin, comme les signaux explicites sont déconnectés des messages échangés entre les deux machines qui communiquent, il faut se poser la question de leur authenticité. Un tiers peut les modifier pour tromper les machines suivantes sur le trajet. Les protections cryptographiques ne sont pas utilisables puisqu'il n'y a aucune chance que les équipements intermédiaires disposent des clés leur permettant de vérifier ces protections. Plus drôle, si un opérateur réseau agit sur la base de ces signaux explicites, et, par exemple, favorise certaines sessions au détriment d'autres, on pourrait voir des machines terminales décider de « tricher » en envoyant délibérement de faux signaux. (Ce qui n'est pas possible avec les signaux implicites, qui sont de véritables messages, interprétés par la machine située en face.)
L'article seul
RFC 8555: Automatic Certificate Management Environment (ACME)
Date de publication du RFC : Mars 2019
Auteur(s) du RFC : R. Barnes (Cisco), J. Hoffman-Andrews (EFF), D. McCarney (Let's Encrypt), J. Kasten (University of Michigan)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF acme
Première rédaction de cet article le 11 avril 2019
Une grande partie de la sécurité du Web, et d'ailleurs de plein d'autres chose sur l'Internet, repose sur des certificats où une Autorité de Certification (AC) garantit que vous êtes bien ce que vous prétendez être. Traditionnellement, l'émission d'un certificat se faisait selon un processus manuel, lent et coûteux, à part dans quelques AC automatisées et gratuites comme CAcert. Mais il n'existait pas de mécanisme standard pour cette automatisation. (Et CAcert n'a pas d'API, même non-standard.) Un tel mécanisme standard existe désormais, avec le protocole ACME, normalisé dans ce RFC. Son utilisateur le plus connu est l'AC Let's Encrypt.
Pour comprendre ACME, il faut d'abord revenir aux utilisations des certificats. La norme technique pour les certificats utilisés sur l'Internet se nomme PKIX et est normalisée dans le RFC 5280. PKIX est un profil (une restriction d'une norme beaucoup plus large - et bien trop large, comme le sont souvent les normes des organismes comme l'UIT ou l'ISO) de X.509. Un certificat PKIX comprend, entre autres :
- Une clé cryptographique publique, le titulaire du certificat étant supposé conserver avec soin et précaution la clé privée correspondante,
- Le nom du titulaire du certificat (X.509 l'appelle le sujet),
- Une signature de l'émetteur du certificat (l'AC).
- Des métadonnées dont notamment la date d'expiration du certificat, qui sert à garantir qu'en cas de copie de la clé privée, le copieur ne pourra pas profiter du certificat éternellement.
On note que le certificat est public. N'importe qui peut récupérer
le certificat de, par exemple, un site Web. Voici un exemple avec
OpenSSL et
www.labanquepostale.fr pour un certificat de
type EV :
% openssl s_client -connect www.labanquepostale.fr:443 -showcerts | openssl x509 -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
0d:8f:ec:dd:d8:7b:83:b8:a0:1e:eb:c2:a0:2c:10:9b
Signature Algorithm: sha256WithRSAEncryption
Issuer: C = US, O = DigiCert Inc, OU = www.digicert.com, CN = DigiCert SHA2 Extended Validation Server CA
Validity
Not Before: Sep 5 00:00:00 2018 GMT
Not After : Sep 4 12:00:00 2020 GMT
Subject: businessCategory = Private Organization, jurisdictionC = FR, serialNumber = 421 100 645, C = FR, L = PARIS, O = LA BANQUE POSTALE SA, OU = DISFE, CN = www.labanquepostale.fr
...
et un avec GnuTLS
pour un certificat DV (Domain Validation), mamot.fr :
% gnutls-cli mamot.fr - subject `CN=mamot.fr', issuer `CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US', serial 0x035516154ab9120c186e9211d0da6296af62, RSA key 2048 bits, signed using RSA-SHA256, activated `2019-01-13 23:00:32 UTC', expires `2019-04-13 23:00:32 UTC', key-ID `sha256:ef62c4aae2a9a99c00c33f2bbac9c40b980c70400a056e2a8042885e501ce283' ...
D'ailleurs, des services comme Certificate
Transparency (RFC 6962), accessible entre autres en https://crt.sh/
Du fait que seul le titulaire connait la clé privée, la capacité à signer des messages vérifiables avec la clé publique permet d'authentifier le partenaire avec lequel on communique. Grâce à la signature de l'AC, quiconque fait confiance à cette AC particulière peut être sûr que le certificat appartient bien au titulaire. Dans l'exemple avec OpenSSL, le certificat de la Banque Postale était signé par DigiCert, si on fait confiance à DigiCert, on sait qu'on est bien connecté à la Banque Postale.
Qui sont les AC ? Ce sont la plupart du temps des entreprises
commerciales qui sont payées par les titulaires de certificat, et
elles sont censées vérifier la sincérité de leurs clients. Cette
vérification peut être manuelle, partiellement ou totalement
automatique. Normalement, les certificats de type EV
(Extended Validation), comme celui de la Banque
Postale plus haut, font l'objet d'une vérification manuelle. Cela
permet de vérifier l'identité officielle (celle gérée par l'État)
du titulaire. Les certificats DV (Domain
Validation), comme celui de
mamot.fr, eux, peuvent être validés
automatiquement, ils assurent uniquement le fait que le titulaire
contrôle bien le nom de
domaine utilisé comme sujet. (Pour avoir tous les
horribles détails, y compris les certificats OV - Organization Validated - dont je n'ai pas
parlé, on peut consulter les « Baseline
Requirements for the Issuance and Management of Publicly-Trusted
Certificates » du CA/Browser
Forum.) Ainsi, pour CAcert, on doit prouver le contrôle du
domaine en répondant aux courriers envoyés aux adresses publiques
de contact pour le domaine.
Les certificats peuvent servir à de nombreux protocoles de sécurité mais le plus connu est TLS (normalisé dans le RFC 8446). Comme il n'est pas le seul protocole pour lequel on a des certificats, il est erroné de parler de « certificats TLS » ou, pire encore, de « certificats SSL ». TLS est un protocole client/serveur, où le client authentifie le serveur mais où le serveur authentifie rarement le client. Il est à la base de la sécurisation d'un grand nombre de services sur l'Internet, à commencer par le Web avec HTTPS (RFC 2818). L'authentification du serveur par le client est faite en vérifiant (attention, je vais simplifier) :
- Que le partenaire avec qui on parle a la clé privée (il peut signer des messages) correspondant au certificat présenté,
- Que le certificat n'a pas expiré,
- Que le certificat est signé par une AC connue du client (la clé publique de l'AC est dans le magasin du client),
- Que le nom indiqué par le client correspond à un des noms disponibles dans le certificat. Dans le cas du Web, c'est le nom de domaine dans l'URL choisi (RFC 6125).
Une fois cette authentification faite, TLS assure l'intégrité et la confidentialité de la communication.
Attention, on parle bien d'authentification, pas de
confiance. Malgré ce que vous pourrez lire dans les « La sécurité
pour les nuls », le fameux « cadenas vert » ne signifie pas du
tout que vous pouvez faire vos achats en ligne en toute
sécurité. Il indique seulement que le partenaire a bien le nom que
vous avez demandé, et qu'un tiers ne pourra pas écouter ou
modifier la conversation. Il n'indique pas
que le partenaire soit digne de confiance ; l'AC ne peut pas
vérifier cela ! Ainsi, dans l'exemple plus haut, TLS et
l'authentification par certificat garantissent bien qu'on se
connecte au serveur HTTPS de la Maison-Blanche,
www.whitehouse.gov, mais pas que
Trump dise la vérité !
J'ai parlé du magasin où se trouvent les clés des AC à qui on fait confiance. Qui décide du contenu de ce magasin ? C'est une question complexe, il n'y a pas une liste d'AC faisant autorité. La plupart des systèmes d'exploitation ont une liste à eux, créée en suivant des critères plus ou moins opaques. Les applications (comme le navigateur Web) utilisent ce magasin global du système ou, parfois, ont leur propre magasin, ce qui aggrave encore la confusion. Les utilisateurs peuvent (c'est plus ou moins facile) ajouter des AC ou bien en retirer.
Et comment obtient-on un certificat ? Typiquement, on crée d'abord une demande de certificat (CSR pour Certificate Signing Request, cf. RFC 2986). Avec OpenSSL, cela peut se faire avec :
% openssl req -new -nodes -newkey rsa:2048 -keyout server.key -out server.csr
On se connecte ensuite au site Web de l'AC choisie, et on lui
soumet le CSR. Ici, un exemple avec CAcert :
L'AC doit alors faire des vérifications, plus ou moins rigoureuses. Par exemple, l'AC fait une requête whois, note l'adresse de courrier du domaine, envoie un message contenant un défi et le client de l'AC doit y répondre pour prouver qu'il a bien accès à cette adresse et contrôle donc bien le domaine. L'AC crée ensuite le certificat qu'elle vous renvoie. Il faut alors l'installer sur le serveur (HTTPS, par exemple). L'opération est complexe, et beaucoup d'utilisateurs débutants cafouillent.
C'est ce processus non-standard et compliqué que le protocole ACME vise à normaliser et à automatiser. Ce RFC a une longue histoire mais est déjà déployé en production par au moins une AC.
Le principe d'ACME est simple : l'AC fait tourner un serveur
ACME, qui attend les requêtes des clients. Le client ACME (un
logiciel comme dehydrated ou
certbot) génère la
CSR, se connecte au serveur, et demande un certificat signé pour
un nom donné. Le serveur va alors renvoyer un
défi qui va permettre au client de prouver
qu'il contrôle bien le nom de domaine demandé. Il existe plusieurs
types de défis, mais le plus simple est un nom de fichier
que le serveur ACME choisit, demandant au client ACME de mettre un
fichier de ce nom sur son site Web. Si le nom de fichier était
Vyzs0Oqkfa4gn4skMwszORg6vJaO73dvMLN0uX38TDw,
le serveur ACME va devenir client HTTP et chercher à récupérer
http://DOMAIN/.well-known/acme-challenge/Vyzs0Oqkfa4gn4skMwszORg6vJaO73dvMLN0uX38TDw. S'il
y réussit, il considère que le client ACME contrôle bien le nom de
domaine, et il signe alors le certificat, qui est renvoyé au
client lorsque celui-ci soumet la CSR.
Le modèle idéal d'utilisation d'ACME est présenté dans la section 2. (En pratique, il n'est pas vraiment réalisé, notamment parce qu'il n'existe pratiquement qu'une seule AC utilisant ACME, Let's Encrypt. Il n'y a donc pas encore beaucoup de diversité.) L'espoir est qu'un jour, on puisse faire comme suit :
- On installe un serveur Web (avec des services comme le CMS),
- La procédure d'installation vous demande le nom de domaine à utiliser (ce point là n'est pas automatisable, sans même parler de la procédure de location du nom de domaine),
- Le logiciel vous propose une liste d'AC parmi lesquelles choisir (on a vu qu'il n'y en avait qu'une actuellement ; dans le futur, s'il y en a plusieurs, l'utilisateur aura sans doute autant de mal à choisir qu'il ou elle en a aujourd'hui à choisir un BE),
- Le logiciel fait tout le reste automatiquement : requête à l'AC choisie en utilisant le protocole ACME normalisé dans notre RFC, réponse au défi de l'AC via le serveur HTTP installé, récupération du certificat et configuration de TLS,
- Par la suite, c'est le logiciel qui effectuera automatiquement les demandes de renouvellement de certificat (aujourd'hui, avec les logiciels existants, c'est le point qui est le plus souvent oublié ; combien de sites Web ont annoncé fièrement qu'ils étaient désormais protégés par HTTPS, pour afficher un certificat expiré trois mois après…)
Ainsi, une procédure manuelle et pénible pourra devenir assez simple, encourageant une présence en ligne plus sécurisée. Cela pourrait devenir aussi simple que d'avoir un certificat auto-signé.
La section 4 du RFC expose de manière générale le protocole ACME (le RFC complet fait 94 pages, car il y a beaucoup de détails à spécifier). Rappelez-vous avant de la lire que, pour ACME, le client est celui qui demande le certificat (c'est donc typiquement un serveur Internet, par exemple un serveur HTTPS) et le serveur ACME est l'AC. Quand je dirais « client » ou « serveur » tout court, il s'agira du client et du serveur ACME.
ACME encode ses messages en JSON (RFC 8259). Le client doit d'abord avoir un compte auprès du serveur (avec Let's Encrypt, cela peut être fait automatiquement sans que l'utilisateur s'en rende compte). Par exemple, avec dehydrated, cela se fait ainsi :
% dehydrated --register --accept-terms + Generating account key... + Registering account key with ACME server... + Done!
Et on trouve dans le répertoire accounts/ la
clé privée du compte, et les informations du compte :
% cat accounts/aHR0cHM6Ly9...9yeQo/registration_info.json
{
"id": 5...1,
"key": {
"kty": "RSA",
"n": "wv...HCk",
"e": "AQAB"
},
"contact": [],
"initialIp": "2001:4b98:dc0:41:216:3eff:fe27:3d3f",
"createdAt": "2019-03-12T19:32:20.018154799Z",
"status": "valid"
}
Pour certbot, on peut le faire tourner avec l'option
-v pour avoir les mêmes informations. certbot
affiche également des messages d'ordre administratif comme :
Enter email address (used for urgent renewal and security notices) (Enter 'c' to
cancel): stephane+letsencrypt@bortzmeyer.org
...
Please read the Terms of Service at
https://letsencrypt.org/documents/LE-SA-v1.2-November-15-2017.pdf. You must
agree in order to register with the ACME server at
https://acme-v02.api.letsencrypt.org/directory
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
(A)gree/(C)ancel: A
JWS payload:
b'{\n "contact": [\n "mailto:stephane+letsencrypt@bortzmeyer.org"\n ],\n "termsOfServiceAgreed": true,\n "resource": "new-reg"\n}'
{
"id": 53367492,
"key": { ...
"contact": [
"mailto:stephane+letsencrypt@bortzmeyer.org"
],
"createdAt": "2019-03-15T16:07:58.29914038Z",
"status": "valid"
}
Reporting to user: Your account credentials have been saved in your Certbot configuration directory at /etc/letsencrypt. You should make a secure backup of this folder now. This configuration directory will also contain certificates and private keys obtained by Certbot so making regular backups of this folder is ideal.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Would you be willing to share your email address with the Electronic Frontier
Foundation, a founding partner of the Let's Encrypt project and the non-profit
organization that develops Certbot? We'd like to send you email about our work
encrypting the web, EFF news, campaigns, and ways to support digital freedom.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
(Y)es/(N)o: No
...
Le compte sera authentifié en utilisant une biclé (clé privée et clé publique). Il y aura ensuite quatre étapes :
- Demander un certificat,
- Répondre au défi (notez bien qu'ACME permet plusieurs types de défis possibles),
- Envoyer le CSR,
- Récupérer le certificat signé.
Mais comment transporte-t-on ces messages en JSON ? La section 6 du RFC répond à cette question : on utilise HTTPS. En prime, les messages sont signés avec JWS (RFC 7515), en utilisant la clé privée du client pour les requêtes. Voici par exemple la réponse d'un serveur ACME lorsqu'on l'interroge sur un défi en cours :
{
"type": "http-01",
"status": "pending",
"url": "https://acme-v02.api.letsencrypt.org/acme/challenge/7TAkQBMmFqm8Rhs6Sn8SFCne2MoZXoEHCz0Px7f0dpE/13683685175",
"token": "mMXGXjEijKBZXl2RuL0rjlektPPpy-ozJpZ2vB4w6Dw"
}
Les messages d'erreur utilisent le RFC 7807. En voici un exemple :
{
"type": "http-01",
"status": "invalid",
"error": {
"type": "urn:acme:error:unauthorized",
"detail": "Invalid response from http://mercredifiction.bortzmeyer.org/.well-known/acme-challenge/rE-rIfjjCfMlivxLfoJmMbRyspwmld97Xnxmy7K0-JA: \"\u003c!DOCTYPE HTML PUBLIC \"-//IETF//DTD HTML 2.0//EN\"\u003e\n\u003chtml\u003e\u003chead\u003e\n\u003ctitle\u003e404 Not Found\u003c/title\u003e\n\u003c/head\u003e\u003cbody\u003e\n\u003ch1\u003eNot Found\u003c/h1\u003e\n\u003cp\"",
"status": 403 ...
[Le message d'erreur indique également typiquement l'URL demandé,
et les adresses IP utilisées, ce qui est crucial si le serveur HTTP
a plusieurs adresses IP, par exemple une en IPv4 et une en IPv6. Il
faut donc bien lire tout le message d'erreur.]
Une liste des erreurs possibles est enregistrée à l'IANA. Voici par exemple une erreur CAA (RFC 8659) :
"error": {
"type": "urn:acme:error:caa",
"detail": "CAA record for mercredifiction.bortzmeyer.org prevents issuance",
"status": 403
},
Comment un client ACME trouve-t-il les
URL pour les différentes opérations ? Il y
a un URL à connaitre, le répertoire
(directory). Une requête à cet URL (par exemple
curl
https://acme-v02.api.letsencrypt.org/directory va renvoyer
un objet JSON qui contient la liste des autres URL (section 7, une
des plus cruciales du RFC). Voici un exemple chez Let's
Encrypt :
{ ...
"meta": {
"caaIdentities": [
"letsencrypt.org"
],
"termsOfService": "https://letsencrypt.org/documents/LE-SA-v1.2-November-15-2017.pdf",
"website": "https://letsencrypt.org"
},
"newAccount": "https://acme-v02.api.letsencrypt.org/acme/new-acct",
"newNonce": "https://acme-v02.api.letsencrypt.org/acme/new-nonce",
"newOrder": "https://acme-v02.api.letsencrypt.org/acme/new-order",
"revokeCert": "https://acme-v02.api.letsencrypt.org/acme/revoke-cert"
}
On peut ensuite créer un compte (le champ
newAccount dans l'exemple ci-dessus) puis demander
des certificats (champ newOrder dans
l'exemple ci-dessus), ici (Let's Encrypt) en écrivant à
https://acme-v02.api.letsencrypt.org/acme/new-order :
{
"payload": "ewogICJpZGVudGlmaWVycyI6IFsKICAgIHsKICAgICAgInR5cGUiOiAiZG5zIiwKICAgICAgInZhbHVlIjogInRlc3QtYWNtZS5ib3J0em1leWVyLmZyIgogICAgfQogIF0KfQ",
"protected": "eyJhbGciOiAiUlMyNTYiLCAidXJsIjogImh0dHBzOi8vYWNtZS12MDIuYXBpLmxldHNlbmNyeXB0Lm9yZy9hY21lL25ldy1vcmRlciIsICJraWQiOiAiaHR0cHM6Ly9hY21lLXYwMi5hcGkubGV0c2VuY3J5cHQub3JnL2FjbWUvYWNjdC81MzE3NzA1MCIsICJub25jZSI6ICJyZXNXTXFtQkJYbVZrZ2JfSnVQU3VEcmlmQzhBbDZrTm1JeDZuNkVwRDFZIn0",
"signature": "MP9rXTjX4t1Be-y6dhPOP7JE3B401wokydUlG8gJGWqibTM_gydkUph1smtrUZ5W4RXNTEnlmiFwoiU4eHLD-8MzN5a3G668VbgzKd0VN7Y1GxQBGtsj9fShx4VMjSGLzVq1f7bKCbdX3DYn0LaiRDApgNXiMfoEnPLltu5Ud7RBNOaWY8zE0yAV7e3NFlF9Wfaii5Ff9OT1ZCD8LusOHP-gA4VkimQ9ofYr32wZYgsUFu6G--QflP0tjc5eKYMe1cKlgpyKZsDtBurWwvKlj2cU_PUdOZvjXSBbHX18jVlwglzfFnu0xTaDGTTvOuMBfjnWJCWpr-oA7Ih48dL-Jg"
}
Eh oui, tout est signé, en JWS (RFC 7515) et base64isé (cf. section 7.4 du RFC). Ici, le décodage Base64 nous dira que la requête était :
{
{
"identifiers": [
{
"type": "dns",
"value": "test-acme.bortzmeyer.fr"
}
]
}
, {"alg": "RS256", "url":
"https://acme-v02.api.letsencrypt.org/acme/new-order", "kid":
"https://acme-v02.api.letsencrypt.org/acme/acct/53177050", "nonce":
"resWMqmBBXmVkgb_JuPSuDrifC8Al6kNmIx6n6EpD1Y"}
}
Donc, une demande de certificat pour test-acme.bortzmeyer.fr.
Les autres opérations possibles avec un serveur ACME sont enregistrées à l'IANA. Par exemple, on peut révoquer un certificat.
La réponse sera :
{
"status": "pending",
"expires": "2019-03-19T19:50:41.434669372Z",
"identifiers": [
{
"type": "dns",
"value": "test-acme.bortzmeyer.fr"
}
],
"authorizations": [
"https://acme-v02.api.letsencrypt.org/acme/authz/FVMFaHS_oWjqfR-rWd6eBKMlt1EWfIcf6i7D4wU_swM"
],
"finalize": "https://acme-v02.api.letsencrypt.org/acme/finalize/53177050/352606317"
}
Le client ACME va alors télécharger l'autorisation à l'URL
indiqué, récupérant ainsi les défis qu'il devra affronter (section
7.5 du RFC). Une fois qu'il a fait ce qui lui était demandé par le
serveur, il utilise l'URL donné dans le champ
finalize pour indiquer au serveur que c'est
bon, que le serveur peut vérifier. La commande
certbot avec l'option -v
vous permettra de voir tout ce dialogue.
Le protocole ACME peut être utilisé par d'autres AC que Let's
Encrypt. Avec le client dehydrated, il suffira, quand de telles AC
seront disponibles, de mettre CA=URL dans le
fichier de configuration (l'URL par défaut est
https://acme-v02.api.letsencrypt.org/directory). Un exemple d'autre AC utilisant ACME est BuyPass (pas testé).
Mais en quoi consistent exactement les
défis, dont j'ai déjà parlé plusieurs fois ?
La section 8 les explique. L'idée de base d'un défi ACME est de
permettre de prouver qu'on contrôle réellement un identificateur,
typiquement un nom de
domaine. ACME ne normalise pas un type de défi
particulier. Le cadre est ouvert, et de nouveaux défis pourront
être ajoutés dans le futur. Le principe est toujours le même :
demander au client ACME de faire quelque chose que seul le vrai
titulaire de l'identificateur pourrait faire. Un défi, tel
qu'envoyé par le serveur ACME, a un type (le plus utilisé
aujourd'hui, est de loin, est le défi
http-01), un état (en attente ou bien, au
contraire, validé) et un texte d'erreur, au cas où la validation
ait échoué. Plusieurs défis, comme http-01
ont également un jeton, un cookie, un texte
généré par le serveur, et non prévisible par le client ou par le
reste du monde, et qu'il faudra placer quelque part où le serveur
pourra le vérifier. Le serveur ACME ne testera que lorsque le
client lui aura dit « c'est bon, je suis prêt, j'ai fait tout ce
que tu m'as défié de faire ». Le RFC demande également au serveur
de réessayer après cinq ou dix secondes, si la vérification ne
marche pas du premier coup, au cas où le client ait été trop
rapide à se dire prêt.
Le plus connu et le plus utilisé des défis, à l'heure actuelle,
est http-01. Le client ACME doit configurer
un serveur HTTP où une page (oui, je sais,
le terme correct est « ressource ») a comme nom le contenu du
jeton. Le serveur ACME va devenir client HTTP pour récupérer cette
page et, s'il y arrive, cela prouvera que le client contrôlait
bien le nom de domaine qu'il avait indiqué. De manière
surprenante, et qui déroute beaucoup de débutants, le défi se fait
bien sur HTTP et pas HTTPS, parce que beaucoup d'hébergements Web
partagés ne donnent pas suffisamment de contrôle à l'hébergé.
Le jeton est une chaîne de caractères utilisant le jeu de caractères de Base64, pour passer partout. Voici un exemple de défi HTTP envoyé par le serveur :
{
"identifier": {
"type": "dns",
"value": "test-acme.bortzmeyer.fr"
},
"status": "pending",
"expires": "2019-03-19T19:50:41Z",
"challenges": [
{
"type": "http-01",
"status": "pending",
"url": "https://acme-v02.api.letsencrypt.org/acme/challenge/FVMFaHS_oWjqfR-rWd6eBKMlt1EWfIcf6i7D4wU_swM/13574068498",
"token": "4kpeqw7DVMrY6MI3tw1-tTq9oySN2SeMudaD32IcxNM"
} ...
L'URL qu'utilisera le serveur est
http://DOMAINE-DEMANDÉ/.well-known/acme-challenge/JETON
(ou, en syntaxe du RFC 6570,
http://{domain}/.well-known/acme-challenge/{token}). Comme
expliqué plus haut, c'est bien http:// et pas
https://. Les URL avec
.well-known sont documentés dans le RFC 8615 et acme-challenge
est désormais dans
le registre.
Imaginons qu'on utilise le serveur HTTP Apache et qu'on veuille répondre à ce défi. Le plus simple est de configurer le serveur ainsi :
<VirtualHost *:80>
Alias /.well-known/acme-challenge /var/lib/dehydrated/acme-challenges
<Directory /var/lib/dehydrated/acme-challenges>
Options None
AllowOverride None
...
Cela indique à Apache que les réponses aux défis seront dans le
répertoire
/var/lib/dehydrated/acme-challenges,
répertoire où le client ACME dehydrated va mettre ses
fichiers. Avec le serveur HTTP Nginx, le
principe est le même :
server {
location ^~ /.well-known/acme-challenge {
alias /var/lib/dehydrated/acme-challenges;
}
}
Bien sûr, de nombreuses autres solutions sont possibles. Le serveur HTTP peut intégrer le client ACME, par exemple. Autre exemple, le client ACME certbot inclut son propre serveur HTTP, et peut donc répondre aux défis tout seul, sans Apache.
Ensuite, on lance le client ACME, éventuellement en lui spécifiant où il doit écrire la réponse aux défis :
% certbot certonly --webroot -w /usr/share/nginx/html -d MONDOMAINE.eu.org
certbot va mettre le certificat généré et signé dans son
répertoire, typiquement
/etc/letsencrypt/live/MONDOMAINE.eu.org/fullchain.pem. Et
on programme son système (par exemple avec
cron) pour relancer le client ACME tous les
jours (les clients ACME typique vérifient la date d'expiration du
certificat, et n'appellent l'AC que si cette date est proche.)
Notez bien qu'il est crucial de superviser l'expiration des
certificats. On voit fréquemment des sites Web utilisant
Let's Encrypt devenir inaccessibles parce que le certificat a été
expiré. Beaucoup d'administrateurs système
croient que parce que Let's Encrypt est « automatique », il n'y a
aucun risque. Mais ce n'est pas vrai : non seulement la commande
de renouvellement peut ne pas être exécutée, ou bien mal se passer
mais, même si le certificat est bien renouvellé, cela ne garantit
pas que le serveur HTTP soit rechargé.
Petite anecdote personnelle : pour le blog que vous êtes en train de lire, cela avait été un peu plus compliqué. En effet, le blog a deux copies, sur deux machines différentes. J'ai donc du rediriger les vérifications ACME sur une seule des deux machines. En Apache :
ProxyRequests Off
ProxyPass /.well-known/acme-challenge/ http://MACHINE-DE-RÉFÉRENCE.bortzmeyer.org/.well-known/acme-challenge/
ProxyPreserveHost On
À noter qu'un serveur HTTP paresseux qui se contenterait de
répondre 200 (OK) à chaque requête sous
/.well-known/acme-challenge n'arriverait pas à répondre
avec succès aux défis HTTP. En effet, le fichier doit non
seulement exister mais également contenir une chaîne de caractères
faite à partir d'éléments fournis par le serveur ACME (cf. section 8.3).
Un autre type de défi répandu est le défi
dns-01, où le client doit mettre dans le
DNS un enregistrement
TXT
_acme-challenge.DOMAINE-DEMANDÉ contenant le jeton. Cela nécessite donc un serveur
DNS faisant autorité qui permette les mises à jour dynamiques, via
le RFC 2136 ou bien via une
API. Notez que le RFC recommande (section
10.2) que l'AC fasse ses requêtes DNS via un résolveur qui valide
avec DNSSEC. (Le serveur ACME ne demande pas
directement aux serveurs faisant autorité, il passe par un
résolveur. Attention donc à la mémorisation par les résolveurs des
réponses, jusqu'au TTL.)
On peut utiliser le défi DNS avec des jokers (pour avoir un
certificat pour *.MONDOMAINE.fr) mais c'est
un peu plus compliqué (section 7.1.3 si vous voulez vraiment les détails).
D'autres types de défis pourront être ajouté dans le futur. Un
registre
IANA en garde la liste. Notez que des types de défis
peuvent également être supprimés comme
tls-sni-01 et tls-sni-02, jugés à l'usage pas assez sûrs.
Le but de ce RFC est la sécurité, donc toute faiblesse d'ACME dans ce domaine serait grave. La section 10 du RFC se penche donc sur la question. Elle rappelle les deux objectifs de sécurité essentiels :
- Seul·e l·e·a vrai·e titulaire d'un identificateur (le nom de domaine) peut avoir une autorisation pour un certificat pour cet identificateur,
- Une fois l'autorisation donnée, elle ne peut pas être utilisée par un autre compte.
Le RFC 3552 décrit le modèle de menace typique de l'Internet. ACME a deux canaux de communication, le canal ACME proprement dit, utilisant HTTPS, et le canal de validation, par lequel se vérifient les réponses aux défis. ACME doit pouvoir résister à des attaques passives et actives sur ces deux canaux.
ACME n'est qu'un protocole, il reçoit des demandes, envoie des
requêtes, traite des réponses, mais il ne sait pas ce qui se passe
à l'intérieur des machines. Les défis, par exemple, peuvent être
inutiles si la machine testée est mal gérée (section 10.2). Si, par exemple, le
serveur HTTP est sur un serveur avec plusieurs utilisateurs, et où
tout utilisateur peut bricoler la configuration HTTP, ou bien
écrire dans le répertoire .well-known, alors
tout utilisateur sur ce serveur pourra avoir un certificat. Idem
évidemment si le serveur est piraté. Et, si on sous-traite le
serveur de son organisation à l'extérieur, le sous-traitant peut
également faire ce qu'il veut et obtenir des certificats pour son
client (« il n'y a pas de
cloud, il y a juste
l'ordinateur de quelqu'un d'autre »).
ACME permet d'obtenir des certificats DV et ceux-ci dépendent évidemment des noms de domaine et du DNS. Un attaquant qui peut faire une attaque Kaminsky, par exemple, peut envoyer les requêtes du serveur ACME chez lui. Plus simple, même si le RFC n'en parle guère (il se focalise sur les attaques DNS, pas sur celles portant sur les noms de domaine), un attaquant qui détourne le nom de domaine, comme vu fin 2018 au Moyen-Orient, peut évidemment obtenir les certificats qu'il veut, contrairement à la légende répandue comme quoi TLS protègerait des détournements.
Comment se protéger contre ces attaques ? Le RFC recommande d'utiliser un résolveur DNS validant (vérifiant les signatures DNSSEC) ce que peu d'AC font (Let's Encrypt est une exception), de questionner le DNS depuis plusieurs points de mesure, pour limiter l'efficacité d'attaques contre le routage (cf. celle contre MyEtherWallet en avril 2018), et pourquoi pas d'utiliser TCP plutôt qu'UDP pour les requêtes DNS (ce qui présente l'avantage supplémentaire de priver de certificat les domaines dont les serveurs de noms sont assez stupides pour bloquer TCP). Voir aussi la section 11.2, qui revient sur ces conseils pratiques. Par exemple, une AC ne doit évidemment pas utiliser le résolveur DNS de son opérateur Internet, encore moins un résolveur public.
ACME est un protocole, pas une politique. L'AC reste maitresse de sa poltique d'émission des certificats. ACME ne décrit donc pas les autres vérifications qu'une AC pourrait avoir envie de faire :
- Acceptation par le client d'un contrat,
- Restrictions supplémentaires sur le nom de domaine,
- Autorisation ou pas des jokers dans le nom demandé,
- Liste noire de noms considérés comme sensibles, par exemple parce désignant telle ou telle marque puissante,
- Tests avec la PSL,
- Tests techniques sur la cryptographie (par exemple rejeter les clés pas assez fortes, ou bien utilisant des algorithmes vulnérables),
- Présence d'un enregistrement CAA (RFC 8659).
Les certificats DV (ceux faits avec ACME) sont sans doute moins fiables que les EV (les DV n'ont qu'une vérification automatique, avec peu de sécurité puisque, par exemple, DNSSEC n'est pas obligatoire) et il est donc prudent de limiter leur durée de validité. Let's Encrypt fait ainsi des certificats à courte durée de vie, seulement trois mois, mais ce n'est pas trop grave en pratique, puisque le renouvellement peut être complètement automatisé.
Quels sont les mises en œuvre disponibles d'ACME ? Comme le RFC
est publié longtemps après les premiers déploiements, il y en a
déjà pas mal. Let's Encrypt maintient une
liste de clients. Personnellement, j'ai pratiqué certbot et dehydrated
mais il en existe d'autres, comme acme-tiny, qui
semble simple et compréhensible. Un avantage que je trouve à
dehydrated est qu'il est bien plus simple de garde sa clé lors des
renouvellements, par exemple pour
DANE : il suffit de mettre
PRIVATE_KEY_RENEW="no" dans le fichier de
configuration. En revanche, dehydrated est à la fois pas assez et
trop bavard. Pas assez car il n'a pas d'option permettant de voir
la totalité du dialogue en JSON avec le serveur (contrairement à
certbot) et trop car il affiche des messages même quand il n'a rien
fait (parce que le certificat était encore valide pour assez
longtemps). Pas moyen de le faire taire, et rediriger la sortie
standard ne marche pas car on veut savoir quand il y a eu
renouvellement effectif.
On dispose également de bibliothèques
permettant au programmeur ou à la programmeuse de développer plus
facilement un client ACME. (Par exemple
Protocol::ACME
(encore que j'ai l'impression qu'il n'est plus maintenu, un
programmeur Perl disponible pour évaluer ce
qui existe ?). Pour les programmeures
Python, il y a le module
acme qui est celui utilisé par le client
certbot, mais qui est aussi distribué indépendamment. En
Go, il y a LeGo. Mais on peut aussi
mettre le client ACME dans le serveur HTTP, comme le permet
Apache
Et les serveurs ACME ? Évidemment, peu de gens monteront une AC mais, si vous voulez le faire, le serveur de Let's Encrypt, Boulder, est en logiciel libre.
Notez que ce RFC ne parle que de la validation de noms de domaines mais ACME pourra, dans le futur, être utilisé pour valider la « possession » d'une adresse IP (RFC 8738), ou d'autres identifiants.
Et si vous voulez un résumé rapide d'ACME par ses auteurs, allez lire cet article sur le blog de l'IETF. Ou bien vous préférez une histoire détaillée d'ACME ?
L'article seul
RFC 8553: DNS Attrleaf Changes: Fixing Specifications That Use Underscored Node Names
Date de publication du RFC : Mars 2019
Auteur(s) du RFC : D. Crocker (Brandenburg InternetWorking)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 19 avril 2019
Autrefois, de nombreux services et protocoles Internet avaient
« réservé » de manière informelle, et sans enregistrement de cette
réservation, des noms préfixés par un tiret
bas, comme _submission._tcp.example.net (cf. RFC 6186 pour cet exemple). Comme le RFC 8552 a mis fin à cette activité en créant un
registre officiel des noms préfixés, il fallait réviser les normes
existantes pour s'aligner sur les nouvelles règles. C'est le but
de ce RFC 8553 qui modifie pas moins de trente-trois
RFC !
Dans le nouveau registre, les
entrées sont indexées par un couple {type d'enregistrement DNS,
nom}. Par exemple, {TXT, _dmarc} pour
DMARC (RFC 7489).
Les enregistrements SRV (RFC 2782) et URI (RFC 7553) posent un problème supplémentaire puisqu'ils utilisent un autre registre de noms, celui des noms de protocoles et services (dit aussi registre des numéros de ports) décrit dans le RFC 6335.
La section 2 du RFC décrit les usages actuels des noms préfixés par le tiret bas. Les enregistrements de type TXT, par exemple, sont utilisés dans sept RFC différents, comme le RFC 5518. Et les SRV dans bien davantage.
Enfin la section 3 du RFC contient le texte des changements qui est fait aux différentes spécifications utilisant les noms préfixés. (Il s'agit essentiellement de faire référence au nouveau registre du RFC 8552, il n'y a pas de changement technique.)
L'article seul
RFC 8552: Scoped Interpretation of DNS Resource Records through "Underscored" Naming of Attribute Leaves
Date de publication du RFC : Mars 2019
Auteur(s) du RFC : D. Crocker (Brandenburg InternetWorking)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 19 avril 2019
Une convention répandue pour les noms de domaine est de préfixer les services
par un tiret bas, par exemple
_xmpp-client._tcp.jabber.ietf.org. Cette
pratique n'avait jamais été documentée mais c'est désormais
fait. Et il existe désormais un registre
IANA des noms ainsi préfixés.
Bien sûr, on peut mettre des ressources sous n'importe quel
nom. Le DNS
n'impose aucune restriction pour cela, et vous pouvez décider que
le service X sera sous le nom $X%.example.com
(si vous ne me croyez pas, relisez le RFC 1035 et RFC 2181). Mais les
humains aiment les conventions, par exemple pour les machines,
comme www comme préfixe d'un serveur
Web (préfixe
d'ailleurs contesté, souvent
pour de mauvaises
raisons) ou
mail pour un serveur de messagerie. Ce ne sont
que des conventions, le DNS s'en moque, et on peut mettre un
serveur Web en mail.example.com si on veut,
cela ne perturbera que les humains. D'autant plus qu'on peut
utiliser n'importe quel type de données avec n'importe quel nom
(par exemple un enregistrement MX pour
www.example.org).
La convention du tiret bas initial est répandue, notamment parce qu'elle évite toute confusion avec les noms de machines, qui ne peuvent pas comporter ce caractère (RFC 952). Elle est donc très commune en pratique. Cette convention permet de restreindre explicitement une partie de l'arbre des noms de domaine pour certains usages. Comme ce RFC ne fait que documenter une convention, il ne nécessite aucun changement dans les logiciels.
Une
alternative au tiret bas serait d'utiliser un type de données
spécifique. Quant aux types « généralistes » comme
TXT, ils ont l'inconvénient qu'on récupère,
lors de la résolution DNS, des informations inutiles, par exemple
les TXT des autres services. Bref, vous créez un nouveau service,
mettons X, vous avez le choix, pour le cas du domaine parent
example.org, entre :
- Un nouveau type d'enregistrements DNS, nommons-le par exemple
TYPEX(en pratique, c'est long et compliqué, et sans déploiement garanti, cf. RFC 5507), - Un type d'enregistrement générique comme TXT cité plus haut ou bien le URI du RFC 7553, menant à des ensembles d'enregistrements (RRset) potentiellement assez gros, problème détaillé en section 1.2,
- Une convention de nommage comme
x.example.org, - Une convention de nommage avec un tiret bas
(
_x.example.org), l'objet de ce RFC 8552.
Un exemple d'un service réel utilisant la convention avec le tiret
bas est DKIM (RFC 6376), avec le préfixe _domainkey :
% dig +short TXT mail._domainkey.gendarmerie.interieur.gouv.fr
"v=DKIM1; k=rsa; t=y; p=MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDIgwhYZeeZgM94IofX9uaGAwQ+tynFX7rYs/igs+d1afqrrjMaoKay11IMprRyqhcVurQtJwGfk7PAWrXRjB+KpdySH9lqzvbisB3GrSs1Sf4uWscAbZ+saapw3/QD8YFyfYbsXunc6HROJQuQHM+U56OOcoiAiPHpfepAmuQyFQIDAQAB"
Comme beaucoup de choses, la convention « tiret bas » s'entend
mal avec les jokers du DNS. D'abord, on ne peut pas utiliser les
jokers entre le préfixe et le reste du nom
(_x.*.example.net ne marche pas), ensuite, un
joker couvre également les noms avec tiret bas donc
*.example.net va répondre positivement pour
_x.example.net même si on ne le voulait
pas.
La section 1.5 de notre RFC détaille l'histoire de la convention « tiret bas au début ». Beaucoup de services utilisaient cette convention mais sans coordination, et sans qu'il existe une liste complète. Du fait de l'existence de plusieurs choix possibles (énumérés plus haut), ce RFC n'a pas obtenu de consensus immédiatement et les débats ont été longs et compliqués.
La section 2 du RFC explique comment remplir le nouveau
registre des noms à tiret bas. On ne met dans ce registre que le
nom le plus proche de la racine du DNS. Si un service mène à des
noms comme _foo._bar.example.org, seul le
_bar sera mis dans le registre. C'est
particulièrement important pour le cas des
enregistrements SRV qui ont souvent deux niveaux de
noms préfixés (par exemple _sip._tcp.cisco.com). Seul
le nom le plus proche de la racine, ici _tcp,
est enregistré (ici, _sip est quand même
enregistré car il peut en théorie être utilisé sans le
_tcp mais il me semble que c'est rare en pratique).
Les règles
pour les noms plus spécifiques sous le _bar
(ou _tcp)
sont spécifiées lors de la description du service en question. Par
exemple, pour DKIM, le RFC 6376 précise que que sous le nom
_domainkey, on trouve un sélecteur dont
l'identificateur apparait dans le courrier signé. Donc, pour un
message envoyé avec s=mail et
d=gendarmerie.interieur.gouv.fr, on cherche
les informations DKIM en mail._domainkey.gendarmerie.interieur.gouv.fr.
Le formulaire pour demander l'enregistrement d'un nouveau nom préfixé par un tiret bas figure en section 3 du RFC. Il faut indiquer le type de données DNS (un enregistrement n'est valable que pour un certain type, donc la clé du registre est un couple {type, nom}), le nom et la référence du document décrivant le service en question. Le registre est décrit en section 4 du RFC. L'ajout dans ce registre se fait selon la politique « examen par un expert » (RFC 8126, section 4.5). La section 5 de notre RFC donne quelques indications à l'IANA sur cet examen.
Un ensemble d'entrées à ajouter pour initialiser ce nouveau
registre est indiqué. On y trouve par exemple {TXT,
_domainkey} pour DKIM, {TLSA,
_tcp} pour DANE (RFC 6698), {TXT,
_acme-challenge} pour
ACME (RFC 8555),
etc. Deux cas particuliers : le nom _example
est réservé pour tous les types d'enregistrement, lorsqu'on a
besoin de donner un exemple, sans spécifier un cas réel, et le nom
_ta, qui sert au mécanisme de signalement des
clés DNSSEC du RFC 8145, désigne en fait tous les noms commençant par _ta.
L'article seul
RFC 8548: Cryptographic Protection of TCP Streams (tcpcrypt)
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : A. Bittau (Google), D. Giffin
(Stanford University), M. Handley (University College
London), D. Mazieres (Stanford
University), Q. Slack
(Sourcegraph), E. Smith (Kestrel
Institute)
Expérimental
Réalisé dans le cadre du groupe de travail IETF tcpinc
Première rédaction de cet article le 23 mai 2019
Aujourd'hui, il n'est plus acceptable d'avoir des communications non chiffrées. États, entreprises et délinquants surveillent massivement les réseaux publics et toute communication effectuée en clair peut être espionnée, voire modifiée. Il est donc nécessaire de continuer les efforts pour chiffrer ce qui ne l'est pas encore. Ce RFC décrit un mécanisme expérimental pour TCP, nommé tcpcrypt, permettant de chiffrer les communications sans participation de l'application située au-dessus, sans authentification obligatoire. (Mais le projet semble mal en point donc je ne suis pas optimiste quant à son déploiement.)
La section 2 du RFC est le cahier des charges de « tcpcrypt », ce nouveau mécanisme de protection de TCP :
- Pouvoir être mis en œuvre conjointement à TCP. Cela implique de pouvoir tourner dans le noyau, où on ne peut pas charger des bibliothèques comme OpenSSL. Et certaines piles TCP tournent sur des machines contraintes (Internet des Objets), donc le protocole doit être léger.
- Ne pas trop augmenter la latence lors de la négociation cryptographique.
- Tolérer certains intermédiaires qui se permettent de modifier l'en-tête TCP.
- Ne pas faire de liaison avec l'adresse IP : une session tcpcrypt doit pouvoir reprendre si l'adresse IP a changé.
tcpcrypt est très différent des classiques TLS et SSH. Il est conçu pour ne pas impliquer l'application, qui peut ignorer qu'on chiffre dans les couches inférieures. tcpcrypt est prévu pour être une solution simple, ne nécessitant pas de modifier protocoles ou applications, changeant le moins de chose possible pour être déployable. Il est également intéressant de voir le « non-cahier des charges », ce qui n'est pas obligatoire dans tcpcrypt :
- Aucune authentification n'est faite par tcpcrypt,
- En cas de problème, on se replie sur du TCP non sécurisé.
Ces deux points rendent tcpcrypt vulnérable aux attaquants actifs.
Pendant la longue et douloureuse gestation de ce protocole, TLS avait été envisagé comme alternative. Après tout, pourquoi inventer un nouveau protocole de cryptographie, activité longue et délicate (les failles de sécurité sont vite arrivées) ? Il y avait deux propositions sur la table à l'IETF, le futur tcpcrypt, et une solution fondée sur TLS. C'est pour essayer de faire fonctionner les deux solutions que la négociation des paramètres avait été traitée à part (option ENO, RFC 8547). Mais, depuis, la proposition TLS a été de facto abandonnée, en partie parce que la communauté TLS était occupée par le travail sur la version 1.3.
tcpcrypt s'appuie sur l'option TCP ENO (Encryption Negotiation Option) pour la négociation de l'utilisation du chiffrement. Ce RFC 8548 décrit comment chiffrer, une fois les paramètres négociés.
La section 3 décrit le protocole en détail. Je ne vais pas la reprendre ici (la cryptographie n'est pas mon point fort). On est dans le classique, de toute façon, avec cryptographie asymétrique pour se mettre d'accord sur une clé et cryptographie symétrique pour chiffrer ; tcpcrypt utilise trois types d'algorithmes cryptographiques :
- Un mécanisme de négociation de clé pour, à partir d'une clé publique temporaire, se mettre d'accord sur un secret partagé (qui servira, après traitement, à chiffrer la session),
- une fonction d'extraction pour tirer de ce secret partagé une clé,
- une fonction pseudo-aléatoire pour tirer de cette clé les clés de chiffrement symétrique.
La fonction d'extraction et la fonction pseudo-aléatoire sont celles de HKDF (RFC 5869), elle-même fondée sur HMAC (RFC 2104). Une fois qu'on a la clé, on chiffre avec un algorithme de chiffrement intègre.
Comme vous avez vu, les clés publiques utilisées dans le protocole tcpcrypt sont temporaires, jamais écrites sur disque et renouvellées fréquemment. Ce ne sont pas des clés permanentes, indiquant l'identité de la machine comme c'est le cas pour SSH. tcpcrypt n'authentifie pas la machine en face (la section 8 détaille ce point).
La négociation du protocole, pour que les deux parties qui font du TCP ensemble se mettent d'accord pour chiffrer, est faite avec l'option TCP ENO (Encryption Negotiation Option), décrite dans le RFC 8547. La négociation complète peut nécessiter un aller-retour supplémentaire par rapport à du TCP habituel, ce qui augmente la latence d'établissement de connexion. Un mécanisme de reprise des sessions permet de se passer de négociation, si les deux machines ont déjà communiqué, et gardé l'information nécessaire.
Une fois la négociation terminée, et le chiffrement en route, tcpcrypt génère (de manière imprévisible, par exemple en condensant les paramètres de la session avec un secret) un session ID, qui identifie de manière unique cette session tcpcrypt particulière. Ce session ID est mis à la disposition de l'application via une API, qui reste à définir et l'application peut, si elle le souhaite, ajouter son mécanisme d'authentification et lier une authentification réussie au session ID. Dans ce cas, et dans ce cas seulement, tcpcrypt est protégé contre l'Homme du Milieu.
Notez que seule la charge utile TCP est chiffrée, et donc protégée. L'en-tête TCP ne l'est pas (pour pouvoir passer à travers des boitiers intermédiaires qui tripotent cet en-tête, et tcpcrypt ne protège donc pas contre certaines attaques comme les faux paquets RST (terminaison de connexion, les détails figurent en section 8). Toutefois, certains champs de l'en-tête (mais pas RST) sont inclus dans la partie chiffrée (cf. section 4.2). C'est par exemple le cas de FIN, pour éviter qu'une troncation des données passe inaperçue.
L'option TCP ENO (RFC 8547) crée le
concept de TEP (TCP Encryption Protocol). Un
TEP est un mécanisme cryptographique particulier choisi par les
deux machines qui communiquent. Chaque utilisation de l'option ENO
doit spécifier son ou ses TEP. Pour tcpcrypt, c'est fait dans la
section 7 de notre RFC, et ces TEP sont placés dans un
registre IANA. On y trouve, par exemple,
TCPCRYPT_ECDHE_Curve25519 (le seul qui soit
obligatoire pour toutes les mises en œuvre de tcpcrypt, cf. RFC 7696) qui veut dire « création des clés avec
du Diffie-Hellman sur courbes
elliptiques avec la courbe
Curve25519 ». Pour le chiffrement lui-même,
on a vu qu'il ne fallait utiliser que du chiffrement intègre, et le seul algorithme
obligatoire pour tcpcrypt est
AEAD_AES_128_GCM (« AES en mode
GCM »). Les autres sont également dans
un
registre IANA.
Le but de tcpcrypt est la sécurité donc la section 8, consacrée à l'analyse de la sécurité du protocole, est très détaillée. D'abord, tcpcrypt hérite des propriétés de sécurité de l'option ENO (RFC 8547). Ainsi, il ne protège pas contre un attaquant actif, qui peut s'insérer dans le réseau, intercepter les paquets, les modifier, etc. Un tel attaquant peut retirer l'option ENO des paquets et il n'y a alors plus grand'chose à faire (à part peut-être épingler la connaissance du fait qu'une machine donnée parlait tcpcrypt la dernière fois qu'on a échangé, et qu'il est bizarre qu'elle ne le fasse plus ?) Si l'application a son propre mécanisme d'autentification, situé au-dessus de tcpcrypt, et qui lie l'authentification au session ID, alors, on est protégé contre les attaques actives. Sinon, seul l'attaquant passif (qui ne fait qu'observer) est bloqué par tcpcrypt. Une analyse plus détaillée figure dans l'article fondateur du projet tcpcrypt, « The case for ubiquitous transport-level encryption », par Bittau, A., Hamburg, M., Handley, M., Mazieres, D., et D. Boneh.. tcpcrypt fait donc du chiffrement opportuniste (RFC 7435).
tcpcrypt ne protège pas la plus grande partie des en-têtes TCP. Donc une attaque active comme l'injection de faux RST (RFC 793, et aussi RFC 5961) reste possible.
Comme la plupart des techniques cryptographiques, tcpcrypt dépend fortement de la qualité du générateur de nombres pseudo-aléatoires utilisé. C'est d'autant plus crucial qu'un des cas d'usage prévus pour tcpcrypt est les objets contraints, disposant de ressources matérielles insuffisantes. Bref, il faut relire le RFC 4086 quand on met en œuvre tcpcrypt. Et ne pas envoyer l'option ENO avant d'être sûr que le générateur a acquis assez d'entropie.
On a dit que tcpcrypt ne protégeait pas les « métadonnées » de la connexion TCP. Ainsi, les keepalives (RFC 1122) ne sont pas cryptographiquement vérifiables. Une solution alternative est le mécanisme de renouvellement des clés de tcpcrypt, décrit dans la section 3.9 de notre RFC.
Ce RFC 8548 est marqué comme « Expérimental ». On n'a en effet que peu de recul sur l'utilisation massive de tcpcrypt. La section 9 liste les points qui vont devoir être surveillés pendant cette phase expérimentale : que deux machines puissent toujours se connecter, même en présence de boitiers intermédiaires bogués et agressifs (tcpcrypt va certainement gêner la DPI, c'est son but, et cela peut offenser certains boitiers noirs), et que l'implémentation dans le noyau ne soulève pas de problèmes insurmontables (comme le chiffrement change la taille des données, le mécanisme de gestion des tampons va devoir s'adapter et, dans le noyau, la gestion de la mémoire n'est pas de la tarte). C'est d'autant plus important qu'il semble qu'après l'intérêt initial, l'élan en faveur de ce nouveau protocole se soit sérieusement refroidi (pas de commit depuis des années dans le dépôt initial).
Et les mises en œuvre de tcpcrypt (et de l'option ENO, qui lui est nécessaire) ? Outre celle de référence citée plus haut, qui est en espace utilisateur, et qui met en œuvre ENO et tcpcrypt, il y a plusieurs projets, donc aucun ne semble prêt pour la production :
- Une mise en œuvre dans le noyau Linux.
- Une autre pour FreeBSD.
- Et encore une autre pour MacOS.
- Une extension Firefox (apparemment ancienne et pas maintenue) pour afficher le session ID.
- Un module Apache, également
apparemment abandonné, pour accéder au session
ID et le fournir aux programmes tournant sur le serveur
(dans la variable d'environnement
TCP_CRYPT_SESSID, donc du code PHP, par exemple, peut lire$_SERVER['TCP_CRYPT_SESSID']).
Il y avait un site « officiel » pour le projet, http://tcpcrypt.org/
L'article seul
RFC 8547: TCP-ENO: Encryption Negotiation Option
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : A. Bittau (Google), D. Giffin (Stanford University), M. Handley (University College London), D. Mazieres (Stanford University), E. Smith (Kestrel Institute)
Expérimental
Réalisé dans le cadre du groupe de travail IETF tcpinc
Première rédaction de cet article le 23 mai 2019
Ce RFC, tout juste sorti des presses, décrit une extension de TCP nommée ENO, pour Encryption Negotiation Option. Elle permet d'indiquer qu'on souhaite chiffrer la communication avec son partenaire TCP, et de négocier les options. Elle sert au protocole tcpcrypt, décrit, lui, dans le RFC 8548.
Malgré le caractère massif de la surveillance exercée sur les
communications Internet, il y a encore des
connexions TCP dont le contenu n'est pas chiffré. Cela peut être
parce que le protocole applicatif ne fournit pas de moyen (genre une
commande STARTTLS) pour indiquer le passage
en mode chiffré, ou simplement parce que les applications ne sont
plus guère maintenues et que personne n'a envie de faire le
travail pour, par exemple, utiliser TLS. Pensons à
whois (RFC 3912), par
exemple. La nouvelle option ENO va permettre de chiffrer ces
protocoles et ces applications, en agissant uniquement dans la
couche transport, au niveau
TCP.
Le but de cette nouvelle option TCP est de permettre aux deux pairs TCP de se mettre d'accord sur le fait d'utiliser le chiffrement, et quel chiffrement. Ensuite, tcpcrypt (RFC 8548) ou un autre protocole utilisera cet accord pour chiffrer la communication. En cas de désaccord, on se rabattra sur du TCP « normal », en clair.
Le gros de la spécification est dans la section 4 du RFC. ENO est une option TCP (cf. RFC 793, section 3.1). Elle porte le numéro 69 (qui avait déjà été utilisé par des protocoles analogues mais qui étaient restés encore plus expérimentaux) et figure dans le registre des options TCP. (0x454E a été gardé pour des expériences, cf. RFC 6994.) Le fait d'envoyer cette option indique qu'on veut du chiffrement. Chaque possibilité de chiffrement, les TEP (TCP Encryption Protocol) est dans une sous-option de l'option ENO (section 4.1 pour les détails de format). Si la négociation a été un succès, un TEP est choisi. Les TEP sont décrits dans d'autres RFC (par exemple, le RFC 8548, sur tcpcrypt, en décrit quatre). Les TEP sont enregistrés à l'IANA.
À noter que TCP est symétrique : il n'y a pas de « client » ou de « serveur », les deux pairs peuvent entamer la connexion simultanément (BGP, par exemple, utilise beaucoup cette possibilité). ENO, par contre, voit une asymétrie : les deux machines qui communiquent sont nommées A et B et ont des rôles différents.
A priori, c'est A qui enverra un SYN (message de demande d'établissement de connexion). Ce SYN inclura l'option ENO, et ce sera de même pour les trois messages de la triple poignée de mains TCP. La section 6 du RFC donne quelques exemples. Ainsi :
- A > B : SYN avec ENO (X, Y) - TEP X et Y,
- A < B : SYN+ACK avec ENO (Y)
- A > B : ACK avec ENO vide
Cet échange mènera à un chiffrement fait avec le TEP Y, le seul que A et B avaient en commun. Par contre, si B est un vieux TCP qui ne connait pas ENO :
- A > B : SYN avec ENO (X, Y) - TEP X et Y,
- A < B : SYN+ACK sans ENO
- A > B : ACK sans ENO
Ne voyant pas de ENO dans le SYN+ACK, A renonce au chiffrement. La connexion TCP ne sera pas protégée.
Et les TEP (TCP Encryption Protocol), qu'est-ce qu'ils doivent définir ? La section 5 détaille les exigences pour ces protocols. Notamment :
- Ils doivent chiffrer (évidemment) avec un algorithme de chiffrement intègre (cf. RFC 5116),
- définir un session ID, un identificateur de session unique et imprévisible (pour les applications qui souhaiteraient faire leur authentification et la lier à une session particulière),
- ne pas accepter d'algorithmes de chiffrement trop faibles, ou, bien sûr, nuls (cela parait drôle mais certaines protocoles autorisaient explicitement un chiffrement sans effet),
- fournir de la confidentialité persistante.
Si, à ce stade, vous vous posez des questions sur les choix faits par les concepteurs d'ENO, et que vous vous demandez pourquoi diable ont-ils décidé ceci ou cela, il est temps de lire la section 8, qui explique certains choix de conception. D'abord, une décision importante était qu'en cas de problème lors de la négociation, la connexion devait se replier sur du TCP classique, non chiffré, et surtout ne pas échouer. En effet, si un problème de négociation empêchait la connexion de s'établir, personne n'essayerait d'utiliser ENO. Donc, si on n'a pas d'option ENO dans les paquets qu'on reçoit, on n'insiste pas, on repasse en TCP classique. Et ceci, que les options n'aient jamais été mises, ou bien qu'elles aient été retirées par un intermédiaire trop zélé. On trouve de tout dans ces machines intermédiaires, y compris les comportements les plus délirants. Le RFC note ainsi que certains répartiteurs de charge renvoient à l'expéditeur les options TCP inconnues. L'émetteur pourrait alors croire à tort que son correspondant accepte ENO même quand ce n'est pas vrai. Un bit nommé b, mis à 0 par la machine A et à 1 par la machine B, permet de détecter ce problème, et de ne pas tenter de chiffrer avec un correspondant qui ne sait pas faire.
Cette asymétrie (une machine met le bit b à 1 mais pas l'autre) est un peu ennuyeuse, car TCP est normalement symétrique (deux machines peuvent participer à une ouverture simultanée de connexion, cf. RFC 793, section 3.4). Mais aucune meilleure solution n'a été trouvée, d'autant plus qu'une machine ne sait qu'il y a eu ouverture simultanée qu'après avoir envoyé son SYN (et si le message SYN de l'autre machine est perdu, elle ne saura jamais qu'une ouverture simultanée a été tentée).
Les protocoles utilisant ENO, comme tcpcrypt, sont conçus pour fonctionner sans la participation de l'application. Mais si celle-ci le souhaite, elle peut s'informer de l'état de sécurisation de la connexion TCP, par exemple pour débrayer un chiffrement au niveau applicatif, qui n'est plus nécessaire. Le bit a dans l'option ENO sert à cela. Mis à 1 par une application, il sert à informer l'application en face qu'on peut tenir compte du chiffrement, par exemple pour activer des services qui ont besoin d'une connexion sécurisée. (Notez qu'il n'existe pas d'API standard pour lire et modifier le bit a, ce qui limite les possibilités.)
La section 7 de notre RFC explique quelques développements futurs qui pourraient avoir lieu si des améliorations futures à TCP se répandent. Ainsi, si de nouvelles API, plus perfectionnées que celles du RFC 3493, permettent à TCP de connaitre non seulement l'adresse IP de la machine où on veut se connecter mais également son nom, on pourrait imaginer une authentification fondée sur le nom, par exemple avec DANE (RFC 6394). On pourrait aussi imaginer qu'ENO permette de sélectionner et de démarrer TLS même sans que l'application soit au courant.
Dans l'Internet très ossifié d'aujourd'hui, il est difficile de déployer quelque chose de nouveau, comme l'option ENO (d'où le statut expérimental de ce RFC.) On risque toujours de tomber sur un intermédiaire qui se croit autorisé à modifier ou jeter des paquets dont la tête ne lui revient pas. La section 9 du RFC analyse deux risques :
- Le rique de repasser en TCP classique, non chiffré, par exemple si un intermédiaire supprime l'option ENO,
- le risque de ne pas pouvoir se connecter du tout, par exemple si un intermédiaire jette les paquets contenant l'option ENO.
Le premier risque n'est pas trop sérieux, ENO était prévu pour du déploiement incrémental, de toute façon (on ne peut pas espérer que toutes les machines adoptent ENO en même temps.) Le deuxième est plus grave et, s'il s'avère trop commun, il faudra des heuristiques du genre « si pas de réponse en N millisecondes, réessayer sans ENO ».
Outre ces risques, il est toujours possible, lorsqu'on touche à un protocole aussi crucial que TCP, que d'autres choses aillent mal, et il est donc nécessaire d'expérimenter. Il y a aussi des inconnues du genre « les applications vont-elles tirer profit d'ENO ? » (ce qui n'est pas nécessaire mais pourrait être utile).
La section 10 du RFC étudie les questions de sécurité soulevées par ENO. Comme ENO vise à permettre, entre autres, le chiffrement opportuniste (on chiffre si on peut, sinon on passe en clair, et on n'impose pas d'authentification, cf. RFC 7435), il faut être bien conscient des limites de ce modèle. Le chiffrement opportuniste protège bien contre un surveillant purement passif, mais pas contre un attaquant actif qui pourrait, par exemple, supprimer toutes les options ENO des paquets TCP, ou bien se mettre en position de terminaison TCP, avant de relayer vers le vrai destinataire, agissant ainsi en homme du milieu. Il ne faudrait donc pas prétendre à l'utilisateur que sa connexion est sûre.
Une solution est l'authentification, et c'est bien à cela que sert le session ID. Si l'application peut authentifier, elle doit lier cette authentification au session ID, pour être bien sûr qu'un attaquant ne va pas profiter d'une authentification réussie dans une session pour abuser d'une autre. Par exemple, si l'authentification est faite par une méthode analogue à celle du RFC 7616, le session ID peut être ajouté aux éléments qui seront condensés. Et si la méthode d'authentification ressemble à SCRAM (RFC 5802), le session ID peut être utilisé comme channel binding.
ENO n'est pas lié à un algorithme cryptographique particulier, en application du principe d'agilité (RFC 7696). Mais cela implique qu'un algorithme faible peut affaiblir la sécurité de tout le système. Les mises en œuvre d'ENO doivent donc faire attention à ne pas accepter des algorithmes cryprographiques faibles.
Pour les mises en œuvre d'ENO, voir la fin de mon article sur le RFC 8548 ; pour l'instant, ce sont les mêmes que celles de tcpcrypt.
L'article seul
RFC 8546: The Wire Image of a Network Protocol
Date de publication du RFC : Avril 2019
Auteur(s) du RFC : B. Trammell, M. Kuehlewind (ETH Zurich)
Pour information
Première rédaction de cet article le 29 avril 2019
Ce nouveau RFC de l'IAB décrit le très important concept de vue depuis le réseau (wire image), une abstraction servant à modéliser ce que voit, sur le réseau, une entité qui ne participe pas à un protocole, mais peut en observer les effets. Cela peut être un routeur, un boitier de surveillance, etc. Le concept n'était pas nécessaire autrefois, où tout le trafic était en clair. Maintenant qu'une grande partie est (heureusement) chiffrée, il est important d'étudier ce qui reste visible à ces entités extérieures.
Un protocole de communication, c'est un ensemble de règles que les participants doivent respecter, le format des messages, qui doit envoyer quoi et comment y répondre, etc. Par exemple, si on prend le protocole HTTP, il y a au moins deux participants, le client et le serveur, parfois davantage s'il y a des relais. Ces participants (par exemple le navigateur Web et le serveur HTTP) connaissent le protocole, et le suivent. (Du moins on peut l'espérer.) Mais, en plus des participants, d'autres entités peuvent observer le trafic. Cela va des couches basses de la machine (TCP, IP, Ethernet) aux équipements intermédiaires. Même si le routeur ne connait pas HTTP, et n'en a pas besoin pour faire son travail, il voit passer les bits et peut techniquement les décoder, en suivant le RFC. C'est ainsi que des applications comme Wireshark peuvent nous afficher une compréhension d'un dialogue auxquelles elles ne participent pas.
Cette fuite d'informations vers d'autres entités n'est pas explicite dans la spécification d'un protocole. Autrefois, avec le trafic en clair, elle allait de soi (« bien sûr que le routeur voit tout passer ! »). Aujourd'hui, avec le chiffrement, il faut se pencher sur la question « qu'est-ce que ces entités voient et comprennent du trafic ? » C'est la vue depuis le réseau qui compte, pas la spécification du protocole, qui ne mentionne pas les fuites implicites.
Prenons l'exemple de TLS (RFC 8446). TLS chiffre le contenu de la connexion TCP. Mais il reste des informations visibles : les couches inférieures (un observateur tiers voit le protocole TCP en action, les retransmissions, le RTT, etc), les informations sur la taille (TLS ne fait pas de remplissage, par défaut, ce qui permet, par exemple, d'identifier la page Web regardée), la dynamique des paquets (délai entre requête et réponse, par exemple). Tout ceci représente la vue depuis le réseau.
Le RFC prend un autre exemple, le protocole QUIC. Cette fois, la mécanique du protocole de transport est largement cachée par le chiffrement. QUIC a donc une « vue depuis le réseau » réduite. C'est le premier protocole IETF qui essaie délibérement de réduire cette vue, de diminuer le « rayonnement informationnel ». Cela a d'ailleurs entrainé de chaudes discussions, comme celles autour du spin bit, un seul bit d'information laissé délibérement en clair pour informer les couches extérieures sur le RTT. En effet, diminuer la taille de la vue depuis le réseau protège la vie privée mais donne moins d'informations aux opérateurs réseau (c'est bien le but) et ceux-ci peuvent être frustrés de cette décision. Le conflit dans ce domaine, entre sécurité et visibilité, ne va pas cesser de si tôt.
Après cette introduction, la section 2 du RFC décrit formellement cette notion de « vue depuis le réseau ». La vue depuis le réseau (wire image) est ce que voit une entité qui ne participe pas aux protocoles en question. C'est la suite des paquets transmis, y compris les métadonnées (comme l'heure de passage du paquet).
La section 3 de notre RFC discute ensuite en détail les propriétés de cette vue. D'abord, elle ne se réduit pas aux « bits non chiffrés ». On l'a vu, elle inclut les métadonnées comme la taille des paquets ou l'intervalle entre paquets. Ces métadonnées peuvent révéler bien des choses sur le trafic. Si vous utilisez OpenVPN pour chiffrer, et que vous faites ensuite par dessus du SSH ou du DNS, ces deux protocoles présentent une vue très différente, même si tout est chiffré. Mais un protocole chiffré, contrairement aux protocoles en clair (où la vue est maximale) peut être conçu pour changer volontairement la vue qu'il offre (la section 4 approfondira cette idée).
La cryptographie peut aussi servir à garantir l'intégrité de la vue (empêcher les modifications), même si on ne chiffre pas. En revanche, toutes les parties de la vue qui n'utilisent pas la cryptographie peuvent être non seulement observées mais encore changées par des intermédiaires. Ainsi, un FAI sans scrupules peut changer les en-têtes TCP pour ralentir certains types de trafic. (Beaucoup de FAI ne respectent pas le principe de neutralité.)
Notez que la vue depuis le réseau dépend aussi de
l'observateur. S'il ne capture qu'un seul paquet, il aura une vue
réduite. S'il observe plusieurs paquets, il a accès à des
informations supplémentaires, et pas seulement celles contenues
dans ces paquets, mais également celles liées à l'intervalle entre
paquets. De même, si l'observateur ne voit que les paquets d'un
seul protocole, il aura une vue limitée de ce qui se passe alors
que, s'il peut croiser plusieurs protocoles, sa vue s'élargit. Un
exemple typique est celui du DNS : très
majoritairement non chiffré, contrairement à la plupart des
protocoles applicatifs, et indispensable à la très grande majorité
des transactions Internet, il contribue beaucoup à la vue depuis le
réseau (RFC 7626). Si vous voyez une requête DNS
pour imap.example.net juste avant un soudain
trafic, il est facile de suspecter que le protocole utilisé était
IMAP. Élargissons encore la perspective :
outre le trafic observé, le surveillant peut disposer d'autres
informations (le résultat d'une reconnaissance faite avec
nmap, par exemple), et cela augmente encore
les possibilités d'analyse de la vue dont il dispose.
Puisqu'on parle de vue (image), le RFC note également que le terme n'est pas uniquement une métaphore, et qu'on pourrait utiliser les techniques de reconnaissance d'images pour analyser ces vues.
Notez que, du point de vue de l'IETF, l'Internet commence à la couche 3. Les couches 1 et 2 contribuent également à la vue depuis le réseau, mais sont plus difficiles à protéger, puisqu'elles n'opèrent pas de bout en bout.
Pour un protocole, il est difficile de réduire la vue qu'il offre au réseau. On ne peut pas rendre les paquets plus petits, ni diminuer l'intervalle entre deux paquets. Une des solutions est d'envoyer volontairement des informations fausses, pour « noyer » les vraies. (Voir le livre de Finn Brunton et Helen Nissenbaum, « Obfuscation », chez C&F Éditions en français.) On ne peut pas réduire les paquets, mais on peut les remplir, par exemple. Ou bien on peut ajouter de faux paquets pour brouiller les pistes. Mais il n'y a pas de miracle, ces méthodes diminueront la capacité utile du réseau, ou ralentiront les communications. (Par exemple, utiliser le Web via Tor est bien plus lent.) Bref, ces méthodes ne sont vraiment acceptables que pour des applications qui ne sont pas trop exigeantes en performance.
J'ai dit plus haut qu'on pouvait assurer l'intégrité de certains champs du protocole, sans les chiffrer. Cela permet d'avoir des informations fiables, non modifiables, mais visibles, ce qui peut être utile pour certains équipements intermédiaires. Notez que cette protection a ses limites : on ne peut protéger que des bits, pas des données implicites comme l'écart entre deux paquets. Et la protection est forcément par paquet puisque, dans un réseau à commutation de paquets, comme l'Internet, on ne peut pas garantir l'arrivée de tous les paquets, ou leur ordre.
Enfin, la dernière section de notre RFC, la section 4, explore les moyens par lesquels un protocole peut tromper un éventuel surveillant, en modifiant la vue qu'il offre au réseau. Une fois qu'on a ce concept de vue depuis le réseau, on peut bâtir des choses utiles sur ce concept. Par exemple, il aide à comprendre des questions d'ossification (la difficulté à déployer de nouveaux services ou protocoles, et qui rend, par exemple, nécessaire de faire passer même le DNS sur HTTPS, comme spécifié dans le RFC 8484). En effet, tout ce qui est visible sera regardé, tout ce qui n'est pas protégé sera modifié. Les boitiers intermédiaires, ou plutôt les entreprises et les États qui les conçoivent et les déploient, n'ont aucun scrupule et ne connaissent aucune restriction. Cela veut dire que si un protocole laisse une information visible, celle-ci sera utilisée par les boitiers intermédiaires et donc il sera difficile de changer sa sémantique par la suite, même si toutes les machines terminales sont d'accord.
Prenons l'exemple de TCP (normalisé dans le RFC 793). TCP envoie un certain nombre de signaux involontaires et implicites. Par exemple, l'observation des numéros de séquence permet de mesurer le RTT. Et TCP permet également de modifier ces signaux. Comme l'explique le RFC 8558, des équipements sont vendus aujourd'hui avec des fonctions de surveillance et tripotage des en-têtes TCP. Le RFC fournit deux exemples d'utilisation de cette surveillance :
- Déterminer la joignabilité et le consentement. Si on voit des réponses respectant le protocole TCP (notamment les numéros de séquences, cf. RFC 6528), cela indique que les deux machines sont d'accord pour communiquer, l'une n'est pas en train d'attaquer l'autre. Cette conclusion peut être utilisée par un pare-feu.
- Mesurer la latence et le taux de pertes de paquets. Cela peut se faire, comme indiqué plus haut, en regardant les numéros de séquence dans les paquets et les accusés de réception, et ou en regardant ECN (RFC 3168) et l'estampillage (RFC 7323).
Dans le cas de TCP, cette exposition d'information est « involontaire ». Le but de TCP n'est pas que tout le monde sur le trajet puisse regarder, et encore moins modifier, ces informations. Mais c'est quand même ce qui arrive. Avec un protocole qui réduit consciemment la vue, comme QUIC, ne serait-ce pas une bonne idée que de donner un peu à manger aux équipements intermédiaires, afin qu'ils puissent optimiser leurs décisions ? Ce fut tout le débat dans le groupe de travail QUIC à l'IETF sur le spin bit, un bit uniquement conçu pour agrandir un peu la vue dont disposent les équipements du réseau, mais qui était un peu en conflit avec le principe d'en dire le moins possible, et ossifiait un peu le protocole (une fois QUIC déployé avec le spin bit, on ne peut plus le supprimer, sous peine de mettre en colère les middleboxes.)
Les informations accessibles dans la vue sont en pratique difficiles à changer puisque les boitiers intermédiaires vont s'habituer à compter dessus. Au moins, on pourrait les rendre explicites plutôt qu'implicites, et documenter clairement ces invariants, ces informations présentes dans la vue et que les concepteurs du protocole s'engagent à garder dans les évolutions futures. Typiquement, les invariants sont des données stables, et simples. Pour un protocole qui a la notion de version, et de négociation de version, cette négociation a intérêt à être déclarée invariante (RFC 8999 pour le cas de QUIC). Mais attention : une fois qu'on a figé certaines parties de la vue, en les déclarant invariantes, il ne faut pas s'imaginer que les équipements du réseau vont s'arrêter là : ils vont sans doute utiliser d'autres parties de la vue pour prendre leur décision, et ces autres parties risquent donc de devenir des invariants de fait. Le RFC recommande donc que toutes les parties qui ne sont pas explicitement listées comme invariantes soient chiffrées, pas pour la confidentialité, mais pour éviter qu'elles ne deviennent invariantes du fait de leur utilisation par les intermédiaires.
Enfin, le RFC rappelle que les équipements intermédiaires ne peuvent pas savoir ce que les deux parties qui communiquent ont décidé entre elles, et que la véracité de la vue depuis le réseau n'est jamais garantie.
L'article seul
RFC 8544: Organization Extension for the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Avril 2019
Auteur(s) du RFC : L. Zhou (CNNIC), N. Kong (Consultant), J. Wei, J. Yao (CNNIC), J. Gould (Verisign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 12 avril 2019
Le RFC 8543 étendait le format utilisé par le protocole d'avitaillement EPP, afin d'ajouter le concept d'« organisation », une entreprise, association ou agence qui joue un rôle dans la création et gestion d'objets enregistrés, notamment les noms de domaine. Ce RFC 8544 ajoute une extension au protocole EPP pour affecter ces organisations à un domaine, contact ou autre objet enregistré.
Prenons l'exemple le plus connu (quoique EPP puisse servir à d'autres), celui de l'industrie des noms de domaine. Souvent, le registre reçoit des demandes d'un BE, via le protocole EPP. Mais d'autres organisations peuvent jouer un rôle, en plus du BE. Il y a par exemple l'hébergeur DNS (qui n'est pas forcément le BE) ou bien un revendeur du BE, ou bien un « anonymisateur » qui, pour protéger la vie privée des participants, est placé entre le participant et le monde extérieur. Ces différents acteurs (cf. RFC 8499, section 9, pour la terminologie) sont décrits par les nouvelles classes d'objets du RFC 8543. Notre RFC 8544 permet d'utiliser ces classes. Une fois les objets « organisation » créés au registre, on peut les attacher à un nom de domaine ou à un contact, par exemple pour dire « ce nom de domaine a été acheté via le revendeur X ».
L'espace de noms
XML est
urn:ietf:params:xml:ns:epp:orgext-1.0 (et est
enregistré dans le
registre IANA). L'extension à EPP est notée dans le
registre des extensions EPP. Dans les exemples qui suivent,
l'espace de noms est abrégé orgext. Les
organisations ont un identificateur (le
<org:id> du RFC 8543), et cet identificateur sera un attribut
<orgext:id> des objets comme par
exemple le domaine. Pour chaque rôle (revendeur, hébergeur DNS,
etc, cf. RFC 8543, section 7.3), le domaine
a au plus un attribut identifiant une organisation.
La section 4 du RFC décrit les ajouts aux commandes et réponses EPP. Par
exemple, pour <info>, la commande ne
change pas mais la réponse a désormais en plus des attributs
<orgext:id>. Voici un exemple :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<response>
<result code="1000">
<msg lang="en-US">Command completed successfully</msg>
</result>
<resData>
<domain:infData
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.com</domain:name>
...
</resData>
<extension>
<orgext:infData
xmlns:orgext="urn:ietf:params:xml:ns:epp:orgext-1.0">
<orgext:id role="reseller">reseller1523</orgext:id>
<orgext:id role="privacyproxy">proxy2935</orgext:id>
</orgext:infData>
</extension>
<trID>
<clTRID>ngcl-IvJjzMZc</clTRID>
<svTRID>test142AWQONJZ</svTRID>
</trID>
</response>
</epp>
Ici, le domaine a été avitaillé via le revendeur « reseller1523 » et est protégé par l'« anonymisateur » « proxy2935 ».
Bien sûr, la commande EPP <create>
est également modifiée, pour pourvoir créer un domaine avec les
organisations associées. Ici, le revendeur « reseller1523 » crée
un domaine :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<create>
<domain:create
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.com</domain:name>
<domain:period unit="y">3</domain:period>
...
</create>
<extension>
<orgext:create
xmlns:orgext="urn:ietf:params:xml:ns:epp:orgext-1.0">
<orgext:id role="reseller">reseller1523</orgext:id>
</orgext:create>
</extension>
</command>
</epp>
De le même façon, on peut mettre à jour les organisations
associées à un objet, avec
<update>. Ici, on ajoute un « anonymiseur » :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<update>
<domain:update
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.com</domain:name>
</domain:update>
</update>
<extension>
<orgext:update
xmlns:orgext="urn:ietf:params:xml:ns:epp:orgext-1.0">
<orgext:add>
<orgext:id role="privacyproxy">proxy2935</orgext:id>
</orgext:add>
</orgext:update>
</extension>
</command>
</epp>
Et ici on retire le revendeur (pas besoin d'indiquer son identificateur, rappelez-vous qu'il ne peut y avoir qu'une seule organisation par rôle) :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<update>
<domain:update
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.com</domain:name>
</domain:update>
</update>
<extension>
<orgext:update
xmlns:orgext="urn:ietf:params:xml:ns:epp:orgext-1.0">
<orgext:rem>
<orgext:id role="reseller"/>
</orgext:rem>
</orgext:update>
</extension>
</command>
</epp>
La syntaxe complète (au format XML Schema) figure dans la section 5 du RFC.
Question mise en œuvre, cette extension est dans le SDK de Verisign, accessible avec leurs autres logiciels pour registres. CNNIC a également inclus cette extension, dans leur code interne.
L'article seul
RFC 8543: Extensible Provisioning Protocol (EPP) Organization Mapping
Date de publication du RFC : Mars 2019
Auteur(s) du RFC : L. Zhou (CNNIC), N. Kong (Consultant), G. Zhou, J. Yao (CNNIC), J. Gould (Verisign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 12 avril 2019
L'industrie des noms de domaine est d'une grande complexité. Les utilisateurs s'y perdent facilement entre registres, bureaux d'enregistrement, hébergeurs DNS, revendeurs divers, sociétés qui développent des sites Web, prête-noms pour protéger la vie privée, etc. Cette complexité fait qu'il est difficile de savoir qui est responsable de quoi. Dans le contexte d'EPP, protocole d'avitaillement de noms de domaine (création, modification, suppression de noms), il n'y avait jusqu'à présent pas de moyen de décrire ces acteurs. Par exemple, l'ajout d'un enregistrement DS dépend d'actions de l'hébergeur DNS, qui n'est pas forcément le BE. Mais ces hébergeurs DNS n'étaient pas définis et connus. Désormais, avec ce nouveau RFC, on peut utiliser EPP pour l'avitaillement d'objets « organisation ».
EPP (RFC 5730) est le protocole standard d'avitaillement de noms de domaine, permettant à un client (en général le BE) de créer des objets dans un registre, en parlant au serveur EPP. EPP permettait déjà des objets de type « contact » RFC 5733, identifiant les personnes ou les organisations qui assuraient certaines fonctions pour un nom de domaine. Par exemple, le contact technique était la personne ou l'organisation à contacter en cas de problème technique avec le nom de domaine.
Désormais, avec notre nouveau RFC 8543, une nouvelle catégorie (mapping) d'objets est créée, les organisations. On peut ainsi utiliser EPP pour enregistrer l'hébergeur DNS d'un domaine (qui peut être le titulaire du domaine, mais ce n'est pas toujours le cas, ou qui peut être le BE, mais ce n'est pas systématique). Ce nouveau RFC décrit donc une extension à EPP, qui figure désormais dans le registre des extensions (cf. RFC 7451).
EPP utilise XML et tout ici va donc être spécifié en
XML, avec un nouvel espace de
noms XML,
urn:ietf:params:xml:ns:epp:org-1.0, abrégé en
org dans le RFC (mais rappelez-vous que le
vrai identificateur d'un espace de noms XML est l'URI, pas
l'abréviation). Le nouvel espace de noms est désormais dans
le registre des espaces de noms.
La section 3 de notre RFC décrit les attributs d'une organisation (notez que le vocabulaire est trompeur : ils s'appellent attributs mais ne sont pas des attributs XML). Mais commençons par un exemple, décrivant le BE nommé « Example Registrar Inc. » :
<org:infData
xmlns:org="urn:ietf:params:xml:ns:epp:org-1.0">
<org:id>registrar1362</org:id>
<org:roid>registrar1362-REP</org:roid>
<org:role>
<org:type>registrar</org:type>
<org:status>ok</org:status>
<org:status>linked</org:status>
<org:roleID>1362</org:roleID>
</org:role>
<org:status>ok</org:status>
<org:postalInfo type="int">
<org:name>Example Registrar Inc.</org:name>
<org:addr>
<org:street>123 Example Dr.</org:street>
<org:city>Dulles</org:city>
<org:sp>VA</org:sp>
<org:cc>US</org:cc>
</org:addr>
</org:postalInfo>
<org:voice x="1234">+1.7035555555</org:voice>
<org:email>contact@organization.example</org:email>
<org:url>https://organization.example</org:url>
<org:contact type="admin">sh8013</org:contact>
<org:contact type="billing">sh8013</org:contact>
<org:contact type="custom"
typeName="legal">sh8013</org:contact>
<org:crID>ClientX</org:crID>
<org:crDate>1999-04-03T22:00:00.0Z</org:crDate>
<org:upID>ClientX</org:upID>
<org:upDate>1999-12-03T09:00:00.0Z</org:upDate>
</org:infData>
Voyons maintenant quelques-uns des attributs possibles.
Une organisation a un identificateur,
indiqué par l'élément XML <org:id>,
attribué par le registre (c'est registrar1362
dans l'exemple). Il a aussi un ou plusieurs
rôles, dans l'élement XML
<org:role>. Un même acteur peut avoir
plusieurs rôles (par exemple il est fréquent que les BE soient
également hébergeurs DNS). Le rôle inclut un
type, qui peut valoir :
registrar: BE, comme dans le cas ci-dessus,reseller: revendeur, par exemple l'organisation à laquelle le titulaire du nom de domaine achète un domaine n'est pas toujours un « vrai » BE, ce peut être un revendeur,privacyproxy: un prête-nom qui, en se mettant devant l'utilisateur, permet de protéger sa vie privée,- et enfin
dns-operator, l'hébergeur DNS.
D'autres types pourront apparaitre dans le futur, ils sont indiqués dans un registre IANA, des nouveaux types seront ajoutés en suivant la procédure « Examen par un expert » du RFC 8126.
Notez qu'au début du travail à l'IETF sur cette extension, seul le cas des revendeurs était prévu. Après des discussions sur l'importance relative des différents acteurs, il a été décidé de prévoir d'autres types que les seuls revendeurs.
Il y a aussi dans l'objet un ou plusieurs état(s),
<org:status>, qui peut valoir notamment :
ok, l'état normal, celui du BE dans l'exemple ci-dessus,terminated, quand l'organisation va être retirée de la base et ne peut plus être utilisée (c'est le cas d'un BE qui n'est plus accrédité),linked, qui indique que cette organisation est liée à d'autres objets, et ne doit donc pas être supprimée.
Il existe également un attribut
<org:parent>, qui indique une relation
avec une autre organisation. Par exemple, un revendeur aura une
relation <org:parent> vers le BE dont
il est revendeur. (Dans l'exemple plus haut, il n'y a pas de <org:parent>.)
La section 4 du RFC présente ensuite les commandes EPP qui
peuvent être appliquées à ces objets
« organisation ». <check> permet au
client EPP de
savoir s'il pourra créer un objet,
<info> lui donnera les moyens de
s'informer sur une oranisation (l'exemple en XML ci-dessus était
le résultat d'une commande EPP
<info>) et bien sûr une commande
<create> et une
<delete>. Voici
<create> en action, pour créer un objet
de rôle « revendeur » (notez que, cette fois, il a un parent) :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<create>
<org:create
xmlns:org="urn:ietf:params:xml:ns:epp:org-1.0">
<org:id>res1523</org:id>
<org:role>
<org:type>reseller</org:type>
</org:role>
<org:parentId>1523res</org:parentId>
<org:postalInfo type="int">
<org:name>Example Organization Inc.</org:name>
<org:addr>
<org:street>123 Example Dr.</org:street>
<org:city>Dulles</org:city>
<org:sp>VA</org:sp>
<org:cc>US</org:cc>
</org:addr>
</org:postalInfo>
<org:voice x="1234">+1.7035555555</org:voice>
<org:email>contact@organization.example</org:email>
<org:url>https://organization.example</org:url>
<org:contact type="admin">sh8013</org:contact>
<org:contact type="billing">sh8013</org:contact>
</org:create>
</create>
</command>
</epp>
Le schéma complet, en syntaxe XML Schema, figure dans la section 5 du RFC.
Question mise en œuvre de cette extension EPP, Verisign l'a ajouté dans son SDK, disponible en ligne. CNNIC a une implémentation, mais non publique.
L'article seul
RFC 8536: The Time Zone Information Format (TZif)
Date de publication du RFC : Février 2019
Auteur(s) du RFC : A. Olson, P. Eggert (UCLA), K. Murchison (FastMail)
Chemin des normes
Première rédaction de cet article le 13 février 2019
Ce nouveau RFC (depuis remplacé par le RFC 9636) documente un format déjà
ancien et largement déployé, TZif, un
format de description des fuseaux
horaires. Il définit également des types
MIME pour ce format,
application/tzif et
application/tzif-leap.
Ce format existe depuis bien trente ans (et a pas mal évolué pendant ce temps) mais n'avait apparemment jamais fait l'objet d'une normalisation formelle (notre RFC 8536 a depuis été remplacé par le RFC 9636). La connaissance des fuseaux horaires est indispensable à toute application qui va manipuler des dates, par exemple un agenda. Un fuseau horaire se définit par un décalage par rapport à UTC, les informations sur l'heure d'été, des abréviations pour désigner ce fuseau (comme CET pour l'heure de l'Europe dite « centrale ») et peut-être également des informations sur les secondes intercalaires. Le format iCalendar du RFC 5545 est un exemple de format décrivant les fuseaux horaires. TZif, qui fait l'objet de ce RFC, en est un autre. Contrairement à iCalendar, c'est un format binaire.
TZif vient à l'origine du monde Unix et est apparu dans les années 1980, quand le développement de l'Internet, qui connecte des machines situées dans des fuseaux horaires différents, a nécessité que les machines aient une meilleure compréhension de la date et de l'heure. Un exemple de source faisant autorité sur les fuseaux horaires est la base de l'IANA décrite dans le RFC 6557 et dont l'usage est documenté à l'IANA.
La section 2 de notre RFC décrit la terminologie du domaine :
- Temps Universel Coordonné (UTC est le sigle officiel) : la base du temps légal. Par exemple, en hiver, la France métropolitaine est en UTC + 1. (GMT n'est utilisé que par les nostalgiques de l'Empire britannique.)
- Heure d'été (le terme français est incorrect, l'anglais DST - Daylight Saving Time est plus exact) : le décalage ajouté ou retiré à certaines périodes, pour que les activités humaines, et donc la consommation d'énergie, se fassent à des moments plus appropriés (cette idée est responsable d'une grande partie de la complexité des fuseaux horaires).
- Temps Atomique International (TAI) : contrairement à UTC, qui suit à peu près le soleil, TAI est déconnecté des phénomènes astronomiques. Cela lui donne des propriétés intéressantes, comme la prédictibilité (alors qu'on ne peut pas savoir à l'avance quelle sera l'heure UTC dans un milliard de secondes) et la monotonie (jamais de sauts, jamais de retour en arrière, ce qui peut arriver à UTC). Cela en fait un bon mécanisme pour les ordinateurs, mais moins bon pour les humains qui veulent organiser un pique-nique. Actuellement, il y a 37 secondes de décalage entre TAI et UTC.
- Secondes intercalaires : secondes ajoutées de temps en temps à UTC pour compenser les variations de la rotation de la Terre.
- Correction des secondes intercalaires : TAI - UTC - 10 (lisez le RFC pour savoir pourquoi 10). Actuellement 27 secondes.
- Heure locale : l'heure légale en un endroit donné. La différence avec UTC peut varier selon la période de l'année, en raison de l'heure d'été. En anglais, on dit aussi souvent « le temps au mur » (wall time) par référence à une horloge accrochée au mur. Quand on demande l'heure à M. Toutlemonde, il donne cette heure locale, jamais UTC ou TAI ou le temps Unix.
- Epoch : le point à partir duquel on compte le temps. Pour Posix, c'est le 1 janvier 1970 à 00h00 UTC.
- Temps standard : la date et heure « de base » d'un fuseau horaire, sans tenir compte de l'heure d'été. En France métropolitaine, c'est UTC+1.
- Base de données sur les fuseaux horaires : l'ensemble des informations sur les fuseaux horaires (cf. par exemple RFC 7808). Le format décrit dans ce RFC est un des formats possibles pour une telle base de données.
- Temps universel : depuis 1960, c'est équivalent à UTC, mais le RFC préfère utiliser UT.
- Temps Unix : c'est ce qui est
renvoyé par la fonction
time(), à savoir le nombre de secondes depuis l'epoch, donc depuis le 1 janvier 1970. Il ne tient pas compte des secondes intercalaires, donc il existe aussi un « temps Unix avec secondes intercalaires » (avertissement : tout ce qui touche au temps et aux calendriers est compliqué.) C'est ce dernier qui est utilisé dans le format TZif, pour indiquer les dates et heures des moments où se fait une transition entre heure d'hiver et heure d'été.
La section 3 de notre RFC décrit le format lui-même. Un fichier TZif est composé d'un en-tête (taille fixe de 44 octets) indiquant entre autres le numéro de version de TZif. La version actuelle est 3. Ensuite, on trouve les données. Dans la version 1 de TZif, le bloc de données indiquait les dates de début et de fin des passages à l'heure d'été sur 32 bits, ce qui les limitait aux dates situées entre 1901 et 2038. Les versions ultérieures de TZif sont passées à 64 bits, ce qui permet de tenir environ 292 milliards d'années mais le bloc de données de la version 1 reste présent, au cas où il traine encore des logiciels ne comprenant que la version 1. Notez que ces 64 bits permettent de représenter des dates antérieures au Big Bang, mais certains logiciels ont du mal avec des valeurs situées trop loin dans le passé.
Les versions 2 et 3 ont un second en-tête de 44 octets, et un bloc de données à elles. Les vieux logiciels arrêtent la lecture après le premier bloc de données et ne sont donc normalement pas gênés par cette en-tête et ce bloc supplémentaires. Les logiciels récents peuvent sauter le bloc de données de la version 1, qui ne les intéresse a priori pas (voir section 4 et annexe A). C'est au créateur du fichier de vérifier que les blocs de données destinés aux différentes versions sont raisonnablement synchrones, en tout cas pour les dates antérieures à 2038.
Nouveauté apparue avec la version 2, il y aussi un pied de page
à la fin. Les entiers sont stockés en gros
boutien, et en complément à
deux. L'en-tête commence par la chaîne magique
« TZif » (U+0054 U+005A U+0069 U+0066), et comprend la longueur du
bloc de données (qui dépend du nombre de transitions, de secondes
intercalaires et d'autres informations à indiquer). Le bloc de
données contient la liste des transitions, le décalage avec
UT, le nom du fuseau horaire, la liste des
secondes intercalaires, etc. Vu par le mode
hexadécimal d'Emacs, voici le
début d'un fichier Tzif version 2 (pris sur une
Ubuntu, dans
/usr/share/zoneinfo/Europe/Paris). On voit
bien la chaîne magique, puis le numéro de version, et le début du
bloc de données :
00000000: 545a 6966 3200 0000 0000 0000 0000 0000 TZif2...........
00000010: 0000 0000 0000 000d 0000 000d 0000 0000 ................
00000020: 0000 00b8 0000 000d 0000 001f 8000 0000 ................
00000030: 9160 508b 9b47 78f0 9bd7 2c70 9cbc 9170 .`P..Gx...,p...p
00000040: 9dc0 48f0 9e89 fe70 9fa0 2af0 a060 a5f0 ..H....p..*..`..
...
Avec od, ça donnerait :
% od -x -a /usr/share/zoneinfo/Europe/Paris
0000000 5a54 6669 0032 0000 0000 0000 0000 0000
T Z i f 2 nul nul nul nul nul nul nul nul nul nul nul
0000020 0000 0000 0000 0d00 0000 0d00 0000 0000
nul nul nul nul nul nul nul cr nul nul nul cr nul nul nul nul
0000040 0000 b800 0000 0d00 0000 1f00 0080 0000
nul nul nul 8 nul nul nul cr nul nul nul us nul nul nul nul
0000060 6091 8b50 479b f078 d79b 702c bc9c 7091
dc1 ` P vt esc G x p esc W , p fs < dc1 p
...
Un exemple détaillé et commenté de fichier TZif figure en annexe B. À lire si vous voulez vraiment comprendre les détails du format.
Le pied de page indique notamment les extensions à la variable d'environnement TZ. Toujours avec le mode hexadécimal d'Emacs, ça donne :
00000b80: 4345 542d 3143 4553 542c 4d33 2e35 2e30 CET-1CEST,M3.5.0
00000b90: 2c4d 3130 2e35 2e30 2f33 0a ,M10.5.0/3.
On a vu que le format TZif avait une histoire longue et compliquée. La section 4 du RFC est entièrement consacré aux problèmes d'interopérabilité, liés à la coexistence de plusieurs versions du format, et de beaucoup de logiciels différents. Le RFC conseille :
- De ne plus générer de fichiers suivant la version 1, qui ne marchera de toute façon plus après 2038.
- Les logiciels qui en sont restés à la version 1 doivent faire attention à arrêter leur lecture après le premier bloc (dont la longueur figure dans l'en-tête).
- La version 3 n'apporte pas beaucoup par rapport à la 2 et donc, sauf si on utilise les nouveautés spécifiques de la 3, il est recommandé de produire plutôt des fichiers conformes à la version 2.
- Un fichier TZif transmis via l'Internet devrait être
étiqueté
application/tzif-leapouapplication/tzif(s'il n'indique pas les secondes intercalaires). Ces types MIME sont désormais dans le registre officiel (cf. section 8 du RFC).
L'annexe A du RFC en rajoute, tenant compte de l'expérience accumulée ; par exemple, certains lecteurs de TZif n'acceptent pas les noms de fuseaux horaire contenant des caractères non-ASCII et il peut donc être prudent de ne pas utiliser ces caractères. Plus gênant, il existe des lecteurs assez bêtes pour planter lorsque des temps sont négatifs. Or, les entiers utilisant dans TZif sont signés, afin de pouvoir représenter les moments antérieurs à l'epoch. Donc, attention si vous avez besoin de données avant le premier janvier 1970, cela perturbera certains logiciels bogués.
La section 6 du RFC donne quelques conseils de sécurité :
- L'en-tête indique la taille des données mais le programme qui lit le fichier doit vérifier que ces indications sont correctes, et n'envoient pas au-delà de la fin du fichier.
- TZif, en lui-même, n'a pas de mécanisme de protection de l'intégrité, encore moins de mécanisme de signature. Il faut fournir ces services extérieurement (par exemple avec curl, en récupérant via HTTPS).
Une bonne liste de logiciels traitant ce format figure à l'IANA.
L'article seul
RFC 8522: Looking Glass Command Set
Date de publication du RFC : Février 2019
Auteur(s) du RFC : M. Stubbig
Pour information
Première rédaction de cet article le 6 février 2019
Avec plusieurs systèmes de routage, et notamment avec le protocole standard de l'Internet, BGP, un routeur donné n'a qu'une vue partielle du réseau. Ce que voit votre routeur n'est pas forcément ce que verront les autres routeurs. Pour déboguer les problèmes de routage, il est donc souvent utile de disposer d'une vue sur les routeurs des autres acteurs. C'est fait par le biais de looking glasses qui sont des mécanismes permettant de voir l'état d'un routeur distant, même géré par un autre acteur. Il n'y a aucun standard pour ces mécanismes, il faut donc tout réapprendre pour chaque looking glass, et il est difficile d'automatiser la collecte d'informations. Ce RFC propose une solution (surtout théorique aujourd'hui) : une norme des commandes à exécuter par un looking glass, utilisant les concepts REST.
Voyons d'abord deux exemples de looking glass. Le premier, au
France-IX, utilise une interface Web :
Le second, chez Route Views, utilise telnet :
% telnet route-views3.routeviews.org
...
route-views3.routeviews.org> show bgp 2001:678:c::1
BGP routing table entry for 2001:678:c::/48
Paths: (8 available, best #4, table Default-IP-Routing-Table)
Not advertised to any peer
39351 2484
2a03:1b20:1:ff01::5 from 2a03:1b20:1:ff01::5 (193.138.216.164)
Origin IGP, localpref 100, valid, external
AddPath ID: RX 0, TX 179257267
Last update: Mon Jan 28 15:22:29 2019
46450 6939 2484
2606:3580:fc00:102::1 from 2606:3580:fc00:102::1 (158.106.197.135)
Origin IGP, localpref 100, valid, external
AddPath ID: RX 0, TX 173243076
Last update: Sat Jan 26 08:26:39 2019
...
Notez que le premier looking glass n'affichait que les routes locales
au point d'échange alors que le second voit
toute la DFZ. Les looking glasses jouent un rôle
essentiel dans l'Internet, en permettant d'analyser les problèmes
réseau chez un autre opérateur. (On peut avoir une liste, très
partielle et pas à jour, des looking glasses existants en http://traceroute.org/#Looking%20Glass
La section 2 de notre RFC décrit le fonctionnement de ce looking glass normalisé. Il y a trois acteurs, le client, le serveur et le routeur. Le client est le logiciel utilisé par l'administrateur réseaux qui veut des informations (par exemple curl), le serveur est le looking glass, le routeur est la machine qui possède les informations de routage. (Le RFC l'appelle « routeur » mais ce n'est pas forcément un routeur, cela peut être une machine spécialisée qui récolte les informations en parlant BGP avec les routeurs.) Entre le client et le serveur, on parle HTTP ou, plus exactement, HTTPS. Le client ne parle pas directement au routeur. La communication entre le serveur et le routeur se fait avec le protocole de leur choix, il n'est pas normalisé (cela peut être SSH, NETCONF, etc).
La requête se fera toujours avec la méthode HTTP
GET, puisqu'on ne modifie rien sur le
serveur. Si le serveur est lg.op.example, la
requête sera vers l'URL
https://lg.op.example/.well-known/looking-glass/v1
(le préfixe bien connu est décrit dans le RFC 8615, et ce looking-glass figure
désormais dans le registre
IANA). L'URL est complété avec le nom de la commande
effectuée sur le routeur. Évidemment, on ne peut pas exécuter de
commande arbitraire sur le routeur, on est limité au jeu défini
dans ce RFC, où on trouve les grands classiques comme ping ou bien l'affichage de la
table de routage. La commande peut être suivie de détails, comme
l'adresse IP visée, et de paramètres. Parmi ces paramètres :
protocolqui indique notamment si on va utiliser IPv4 ou IPv6,routerqui va indiquer l'identité du routeur qui exécutera la commande, pour le cas, fréquent, où un même serveur looking glass donne accès à plusieurs routeurs.vrf(Virtual Routing and Forwarding), une table de routage spécifique, pour le cas où le routeur en ait plusieurs,format, qui indique le format de sortie souhaité sous forme d'un type MIME ; par défaut, c'esttext/plain. Attention, c'est le format des données envoyées par le routeur, pas le format de l'ensemble de la réponse, qui est forcément en JSON.
Le code de retour est un code HTTP classique (RFC 7231, section 6), la réponse est de type
application/json, suivant le profil
JSend, rappelé dans l'annexe A. Ce profil
impose la présence d'un champ success, ainsi
que d'un champ data en cas de succès. Voici un
exemple où tout s'est bien passé :
HTTP/1.1 200 OK
Content-Type: application/json
{
"status" : "success",
"data" : {
"router" : "route-server.lg.op.example"
"performed_at" : "2019-01-29T17:13:11Z",
"runtime" : 2.63,
"output" : [
"Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
2001:67c:16c8:18d1::1 4 206479 80966 79935 0 0 0 01w2d14h 2
2401:da80::2 4 63927 12113237 79918 0 0 0 07w6d13h 62878
2405:3200:0:23:: 4 17639 0 0 0 0 0 never Connect"
],
"format" : "text/plain"
}
}
JSend impose un champ status qui, ici,
indique le succès. Le champ data contient la
réponse. output est la sortie littérale du routeur, non
structurée (le type est
text/plain). router est
le nom du routeur utilisé (rappelez-vous qu'un serveur looking glass peut
donner accès à plusieurs routeurs).
Ici, par contre, on a eu une erreur (une erreur sur le routeur, le serveur, lui, a bien fonctionné, d'où le code de retour 200, cf. section 4 sur les conséquences de ce choix) :
HTTP/2.0 200 OK
Content-Type: application/json
{
"status" : "fail",
"data" : {
"performed_at" : "2019-01-29T17:14:51Z",
"runtime" : 10.37,
"output" : [
"Sending 5, 100-byte ICMP Echos to 2001:db8:fa3::fb56:18e",
".....",
"Success rate is 0 percent (0/5)"
],
"format" : "text/plain",
"router" : "route-server.lg.op.example"
}
}
Le fail indique que la commande exécutée sur
le routeur a donné un résultat négatif, mais, autrement, tout
allait bien. Si le serveur looking glass ne peut même pas faire exécuter la
commande par le routeur, il faut utiliser
error et mettre un code de retour HTTP
approprié :
HTTP/1.1 400 Bad Request
{
"status" : "error",
"message" : "Unrecognized host or address."
}
La section 3 du RFC donne la liste des commandes
possibles (un looking glass peut toujours en ajouter d'autres). La syntaxe
suivie pour les présenter est celle des gabarits d'URL du RFC 6570. La première est évidemment ce brave
ping, avec le gabarit https://lg.op.example/.well-known/looking-glass/v1/ping/{host} :
GET /.well-known/looking-glass/v1/ping/2001:db8::35?protocol=2
Host: lg.op.example
HTTP/1.1 200 OK
{
"status" : "success",
"data" : {
"min" : 40,
"avg" : 41,
"max" : 44,
"rate" : 100,
"output" : [
"Sending 5, 100-byte ICMP Echos to 2001:db8::35",
"!!!!!",
"Success rate is 100 percent (5/5)"
],
"format" : "text/plain",
"performed_at" : "2019-01-29T17:28:02Z",
"runtime" : 0.77,
"router" : "c2951.lab.lg.op.example"
}
}
Notez que le RFC ne décrit pas les champs possibles (comme
min ou avg), ni les
unités utilisées (probablement la milliseconde).
Autre commande traditionnelle,
traceroute :
GET /.well-known/looking-glass/v1/traceroute/192.0.2.8
Host: lg.op.example
HTTP/1.1 200 OK
{
"status": "success",
"data": {
"output": [
"Tracing the route to 192.0.2.8",
"",
" 1 198.51.100.77 28 msec 28 msec 20 msec",
" 2 203.0.113.130 52 msec 40 msec 40 msec",
" 3 192.0.2.8 72 msec 76 msec 68 msec"
],
"format": "text/plain",
"performed_at": "2018-06-10T12:09:31Z",
"runtime": 4.21,
"router": "c7206.lab.lg.op.example"
}
}
Notez une des conséquences du format non structuré de
output : ce sera au client de l'analyser. Le
RFC permet d'utiliser des formats structurés (par exemple, pour
traceroute, on peut penser à celui du RFC 5388) mais ce n'est pas obligatoire car on ne peut pas
forcément exiger du serveur qu'il sache traiter les formats de
sortie de tous les routeurs qu'il permet d'utiliser. L'analyse
automatique des résultats reste donc difficile.
D'autres commandes permettent d'explorer la table de
routage. Ainsi, show route affiche le route
vers un préfixe donné (ici, le routeur est un
Cisco et affiche donc les données au format Cisco) :
GET /.well-known/looking-glass/v1/show/route/2001:db8::/48?protocol=2,1
Host: lg.op.example
HTTP/1.1 200 OK
{
"status": "success",
"data": {
"output": [
"S 2001:DB8::/48 [1/0]",
" via FE80::C007:CFF:FED9:17, FastEthernet0/0"
],
"format": "text/plain",
"performed_at": "2018-06-11T17:13:39Z",
"runtime": 1.39,
"router": "c2951.lab.lg.op.example"
}
}
Une autre commande, show bgp, affiche les
informations BGP :
GET /.well-known/looking-glass/v1/show/bgp/192.0.2.0/24
Host: lg.op.example
HTTP/1.1 200 OK
{
"status": "success",
"data": {
"output": [
"BGP routing table entry for 192.0.2.0/24, version 2",
"Paths: (2 available, best #2, table default)",
" Advertised to update-groups:",
" 1",
" Refresh Epoch 1",
" Local",
" 192.0.2.226 from 192.0.2.226 (192.0.2.226)",
" Origin IGP, metric 0, localpref 100, valid, internal",
"[...]"
],
"format": "text/plain",
"performed_at": "2018-06-11T21:47:17Z",
"runtime": 2.03,
"router": "c2951.lab.lg.op.example"
}
}
Les deux précédentes commandes avaient un argument, le préfixe
IP sur lequel on cherche des informations (avec la syntaxe des
gabarits, cela s'écrit
https://lg.op.example/.well-known/looking-glass/v1/show/bgp/{addr}). Mais
certaines commandes n'ont pas d'argument. Par exemple,
show bgp summary affiche la liste des pairs
BGP :
GET /.well-known/looking-glass/v1/show/bgp/summary?protocol=2&routerindex=3
Host: lg.op.example
HTTP/1.1 200 OK
{
"status": "success",
"data": {
"output": [
"BGP router identifier 192.0.2.18, local AS number 64501",
"BGP table version is 85298, main routing table version 85298",
"50440 network entries using 867568 bytes of memory",
"[...]",
"Neighbor V AS MsgRcvd MsgSent TblVer Up/Down",
"2001:DB8:91::24 4 64500 481098 919095 85298 41w5d"
],
"format": "text/plain",
"performed_at": "2018-06-11T21:59:21Z",
"runtime": 1.91,
"router": "c2951.lab.lg.op.example"
}
}
D'autres commandes (« organisationnelles ») sont destinées à aider le client à formuler
sa question. C'est le cas de show router
list, qui affiche la liste des routeurs auquel ce
serveur looking glass donne accés :
GET /.well-known/looking-glass/v1/routers
...
{
"status" : "success",
"data" : {
"routers" : [
"route-server.lg.op.example",
"customer-edge.lg.op.example",
"provider-edge.lg.op.example"
],
"performed_at" : "2018-10-19T12:07:23Z",
"runtime" : 0.73
}
}
Autre exemple de commande organisationnelle,
cmd, qui permet d'obtenir la liste des
commandes acceptées par ce serveur (curieusement, ici, la syntaxe
des gabarits du RFC 6570 n'est plus utilisée
intégralement) :
GET /.well-known/looking-glass/v1/cmd
...
{
"status" : "success",
"data" : {
"commands" : [
{
"href" : "https://lg.op.example/.well-known/looking-glass/v1/show/route",
"arguments" : "{addr}",
"description" : "Print records from IP routing table",
"command" : "show route"
},
{
"href" : "https://lg.op.example/.well-known/looking-glass/v1/traceroute",
"arguments" : "{addr}",
"description" : "Trace route to destination host",
"command" : "traceroute"
}
]
}
}
La liste des commandes données dans ce RFC n'est pas exhaustive, un looking glass peut toujours en ajouter (par exemple pour donner de l'information sur les routes OSPF en plus des BGP).
La section 6 du RFC décrit les problèmes de sécurité envisageables. Par exemple, un client malveillant ou maladroit peut abuser de ce service et il est donc prudent de prévoir une limitation de trafic. D'autre part, les informations distribuées par un looking glass peuvent être trop détaillées, révéler trop de détail sur le réseau et ce qu'en connaissent les routeurs, et le RFC note qu'un serveur peut donc limiter les informations données.
Et question mises en œuvre de ce RFC ? Il existe Beagle mais qui, à l'heure où ce RFC est publié, ne semble pas à jour et concerne encore une version antérieure de l'API. Peut-être RANCID va t-il fournir une API compatible pour son looking glass. Periscope, lui, est un projet différent, avec une autre API.
L'article seul
RFC 8521: Registration Data Access Protocol (RDAP) Object Tagging
Date de publication du RFC : Novembre 2018
Auteur(s) du RFC : S. Hollenbeck (Verisign Labs), A. Newton (ARIN)
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 23 novembre 2022
Contrairement à son lointain prédécesseur
whois, le protocole d'accès aux informations
des registres RDAP a un mécanisme standard de
découverte du serveur faisant autorité. Ce mécanisme est prévu pour
des données organisées de manière
arborescente comme les noms de domaine ou les adresses IP. Pour des objets qui n'ont
pas cette organisation, comment faire ? Ce RFC fournit une solution pour des objets
quelconques, s'ils obéissent à une convention de nommage
simple. C'est le cas des handles, ces
identificateurs d'entités (titulaires de noms de domaine, contacts
pour un préfixe IP, etc) ; s'ils sont de la forme
QUELQUECHOSE-REGISTRE, on pourra trouver le
serveur responsable.
Le mécanisme habituel de découverte du serveur est normalisé dans
le RFC 9224. En gros, l'IANA garde un
registre des serveurs, indexé par un nom de domaine ou par un
préfixe IP. Ce registre est au format JSON. Un client
RDAP est juste censé télécharger ce fichier,
trouver le serveur faisant autorité, puis le contacter. Pour pouvoir
faire la même chose avec des objets non structurés, il faut leur
imposer une convention de nommage. Si on interroge avec RDAP (ou
whois) l'adresse IP 88.198.21.14, on voit que
son contact technique est HOAC1-RIPE. Cette
convention de nommage est « d'abord un identifiant unique au sein du
registre, puis un tiret, puis le nom du registre, ici le RIPE-NCC ». L'IANA a juste à garder un registre de ces
registres qui nous dira, par exemple, que
RIPE a comme serveur RDAP
https://rdap.db.ripe.net/. On peut ensuite
l'interroger en RDAP :
% curl https://rdap.db.ripe.net/entity/HOAC1-RIPE
"vcardArray" : [ "vcard", [ [ "version", { }, "text", "4.0" ], [ "fn", { }, "text", "Hetzner Online GmbH - Contact Role" ], [ "kind", { }, "text", "group" ], [ "adr", {
"label" : "Hetzner Online GmbH\nIndustriestrasse 25\nD-91710 Gunzenhausen\nGermany"
}, "text", [ "", "", "", "", "", "", "" ] ], [ "tel", {
"type" : "voice"
}, "text", "+49 9831 505-0" ], [ "tel", {
...
Petit piège, la partie du début peut elle-même comporter des tirets donc lorsqu'on coupe en deux un handle, il faut le faire sur le dernier tiret (section 2 du RFC). Pourquoi le tiret, d'ailleurs ? Parce qu'il est couramment utilisé comme séparateur, et parce que son utilisation dans un URL ne pose pas de problème particulier (RDAP utilise HTTPS et donc des URL).
Le registre des serveurs RDAP est géré à l'IANA comporte un tableau JSON des services, chaque entrée étant composée de trois tableaux, la liste des adresses de courrier du responsable, la liste des suffixes (en général, un seul par registre) et la liste des serveurs RDAP. Par exemple, pour l'ARIN, on aura :
[
[
"andy@arin.net"
],
[
"ARIN"
],
[
"https://rdap.arin.net/registry/",
"http://rdap.arin.net/registry/"
]
]
Les entrées dans le registre sont ajoutées selon la politique « Premier Arrivé, Premier Servi » du RFC 8126.
Comme ce RFC décrit une
extension à RDAP, le serveur RDAP doit ajouter à sa réponse,
dans l'objet rdapConformance,
rdap_objectTag_level_0. (Apparemment, personne
ne le fait.)
Vous voulez du code ? La bibliothèque
ianardap.py, qui est disponible
en ligne, peut récupérer la base et l'analyser. Cela permet
ensuite de faire des requêtes pour des objets :
% ./dump-object.py F11598-FRNIC | jq .
...
[
"",
"",
"Association Framasoft c/o Locaux Motiv",
"Lyon",
"",
"69007",
"FR"
]
...
Le programme dump-object.py étant simplement :
#!/usr/bin/env python3
import ianardap
import requests
import sys
rdap = ianardap.IanaRDAPDatabase(category="objects")
for object in sys.argv[1:]:
url = rdap.find(object)
if url is None:
print("No RDAP server for %s" % object, file=sys.stderr)
continue
response = requests.get("%sentity/%s" % (url[0], object))
print(response.text)
L'article seul
RFC 8517: An Inventory of Transport-centric Functions Provided by Middleboxes: An Operator Perspective
Date de publication du RFC : Février 2019
Auteur(s) du RFC : D. Dolson, J. Snellman, M. Boucadair, C. Jacquenet (Orange)
Pour information
Première rédaction de cet article le 26 mai 2019
À l'IETF, ou, d'une manière générale, chez les gens qui défendent un réseau neutre, les boitiers intermédiaires, les middleboxes, sont mal vus. Ces boitiers contrarient le modèle de bout en bout et empêchent souvent deux machines consentantes de communiquer comme elles le veulent. Des simples routeurs, OK, qui ne font que transmettre les paquets, mais pas de middleboxes s'arrogeant des fonctions supplémentaires. Au contraire, ce RFC écrit par des employés d'Orange, défend l'idée de middlebox et explique leurs avantages pour un opérateur. Ce n'est pas par hasard qu'il est publié alors que les discussions font toujours rage à l'IETF autour du protocole QUIC, qui obscurcira délibérement une partie de son fonctionnement, pour éviter ces interférences par les middleboxes.
Le terme de middlebox est défini dans le RFC 3234. Au sens littéral, un routeur IP est une middlebox (il est situé entre les deux machines qui communiquent, et tout le trafic passe par lui) mais, en pratique, ce terme est utilisé uniquement pour les boitiers qui assurent des fonctions en plus de la transmission de paquets IP. Ces fonctions sont par exemple le pare-feu, la traduction d'adresses, la surveillance, etc. (Le RFC parle de advanced service functions, ce qui est de la pure publicité.) Ces boitiers intermédiaires sont en général situés là où on peut observer et contrôler tout le trafic donc en général à la connexion d'un réseau local avec l'Internet, par exemple dans la box qu'imposent certains FAI, ou bien, dans les réseaux pour mobiles, là où le GGSN se connecte au PDN (RFC 6459, section 3.1.) Mais, parfois, ces boitiers sont en plein milieu du réseau de l'opérateur.
L'Internet suit normalement un modèle de bout en bout (RFC 1958.) Ce modèle dit que les équipements intermédiaires entre deux machines qui communiquent ne doivent faire que le strict minimum, laissant aux deux machines terminales l'essentiel des fonctions. Cela assure la capacité de changement (il est plus facile de modifier les extrémités que le réseau), ainsi le Web a pu être déployé sans avoir besoin de demander la permission aux opérateurs, contrairement à ce qui se passe dans le monde des télécommunications traditionnelles. Et, politiquement, ce modèle de bout en bout permet la neutralité du réseau. Il n'est donc pas étonnant que les opérateurs de télécommunication traditionnels, dont les PDG ne ratent jamais une occasion de critiquer cette neutralité, n'aiment pas ce modèle. Truffer l'Internet de middleboxes de plus en plus intrusives est une tentative de revenir à un réseau de télécommunications comme avant, où tout était contrôlé par l'opérateur. Comme le RFC 8404, ce RFC est donc très politique.
Et, comme le RFC 8404, cela se manifeste par des affirmations outrageusement publicitaires, comme de prétendre que les opérateurs réseaux sont « les premiers appelés quand il y a un problème applicatif ». Faites l'expérience : si vlc a du mal à afficher une vidéo distante, appelez votre FAI et regardez si vous aurez réellement de l'aide… C'est pourtant ce que prétend ce RFC, qui affirme que l'opérateur veut accéder aux informations applicatives « pour aider ».
Le RFC note aussi que certaines des fonctions assurées par les boitiers intermédiaires ne sont pas réellement du choix de l'opérateur : contraintes légales (« boîtes noires » imposées par l'État) ou bien réalités de l'Internet (manque d'adresses IPv4 - cf. RFC 6269, fonctions liées aux attaques par déni de service, par exemple).
Les middleboxes travaillent parfois avec les informations de la couche 7 (ce qu'on nomme typiquement le DPI) mais le RFC se limite au travail sur les fonctions de la couche 4, une sorte de « DPI léger ».
Voyons maintenant ces utilisations des middleboxes, et commençons par les mesures (section 2 du RFC), activité passive et qui ne modifie pas les paquets, donc n'entre pas forcément en conflit avec le principe de neutralité. Par exemple, mesurer le taux de perte de paquets (RFC 7680) est certainement quelque chose d'intéressant : s'il augmente, il peut indiquer un engorgement quelque part sur le trajet (pas forcément chez l'opérateur qui mesure). Chez l'opérateur, qui ne contrôle pas les machines terminales, on peut mesurer ce taux en observant les réémissions TCP (ce qui indique une perte en aval du point d'observation), les trous dans les numéros de séquence (ce qui indique une perte en amont), ou bien les options SACK (RFC 2018). Cela marche avec TCP, moins bien avec QUIC, où ces informations sont typiquement chiffrées. Comme l'observation des options ECN (RFC 3168), le taux de pertes permet de détecter la congestion.
Et le RTT (RFC 2681) ? Il donne accès à la latence, une information certainement intéressante. L'opérateur peut le mesurer par exemple en regardant le délai avant le passage d'un accusé de réception TCP. Plusieurs autres mesures sont possibles et utiles en étant « au milieu » et le RFC les détaille. Arrêtons-nous un moment sur celles liées à la sécurité : l'observation du réseau peut permettre de détecter certaines attaques, mais le RFC note (et déplore) que l'évolution des protocoles réseau tend à rendre cela plus difficile, puisque les protocoles annoncent de moins en moins d'information au réseau (en terme du RFC 8546, ils réduisent la vue depuis le réseau). Cela se fait par la diminution de l'entropie pour éviter le fingerprinting et par le chiffrement (cf. RFC 8404, qui critiquait déjà le chiffrement de ce point de vue). Évidemment, les utilisateurs diront que c'est fait exprès : on souhaite en effet réduire les possibilités de surveillance. Mais tout le monde n'a pas les mêmes intérêts.
Le RFC parle également des mesures effectuées au niveau applicatif. Ainsi, il note que les opérateurs peuvent tirer des conclusions de l'analyse des temps de réponse DNS.
Il y a bien sûr plein d'autres choses que les boitiers intermédiaires peuvent faire, à part mesurer. La section 3 du RFC les examine, et c'est le gros de ce RFC. L'une des plus connues est la traduction d'adresses. Celle-ci est souvent un grave obstacle sur le chemin des communications, malgré les recommandations (pas toujours suivies) des RFC 4787 et RFC 7857.
Après la traduction d'adresses, la fonction « pare-feu » est sans doute la plus connue des fonctions assurées par les middleboxes. Par définition, elle est intrusive : il s'agit de bloquer des communications jugées non souhaitées, voire dangereuses. La question de fond est évidemment « qui décide de la politique du pare-feu ? » Du point de vue technique, le RFC note qu'il est très fréquent de différencier les communications initiées depuis l'intérieur de celles initiées depuis l'extérieur. Cela nécessite d'observer la totalité du trafic pour détecter, par exemple, quel paquet avait commencé la session.
Les autres fonctions des middleboxes citées par ce RFC sont moins connues. Il y a le « nettoyage » (dDoS scrubbing) qui consiste à classifier les paquets en fonction de s'ils font partie d'une attaque par déni de service ou pas, et de les jeter si c'est le cas (cf. par exemple RFC 8811). Le RFC explique que c'est une action positive, puisque personne (à part l'attaquant) n'a intérêt à ce que le réseau soit ralenti, voire rendu inutilisable, par une telle attaque. Le cas est compliqué, comme souvent en sécurité. Bien sûr, personne ne va défendre l'idée que le principe de neutralité va jusqu'à laisser les attaques se dérouler tranquillement. Mais, d'un autre côté, toutes les classifications (un préalable indispensable au nettoyage) ont des faux positifs, et la sécurité peut donc avoir des conséquences néfastes (le RFC regrette que la protection de la vie privée a pour conséquence qu'il est plus difficile de reconnaitre les « paquets honnêtes »). La vraie question, ici comme ailleurs est « qui va décider ? ».
Autre utilisation, cette fois franchement problématique, l'identification implicite. Il s'agit d'identifier un utilisateur donné sans qu'il ait d'action explicite à faire, par exemple en ajoutant à ses requêtes HTTP un élément d'identification (comme expliqué dans un article fameux) ou bien en jouant avec les options TCP (RFC 7974). Il s'agit là clairement de prise de contrôle par le boitier intermédiaire, qui se permet non seulement de modifier les données pendant qu'elles circulent, mais également prétend gérer l'identification des utilisateurs.
Autre fonction des boitiers intermédiaires, l'amélioration des performances en faisant assurer par ces middleboxes des fonctions qui étaient normalement assurées par les machines terminales, mais où l'opérateur estime qu'il est mieux placé pour le faire. Ces PEP (Performance-Enhancing Proxies) sont notamment courants dans les réseaux pour mobiles (cf. RFC 3135, notamment sa section 2.1.1 ou bien cet exposé). Cette fonction nécessite de pouvoir tripoter les en-têtes TCP.
Bien sûr, comme ce RFC exprime le point de vue des gros intermédiaires, il reprend l'élément de langage courant comme quoi il est nécessaire de prioriser certains types de trafic par rapport à d'autres. On aurait une voie rapide pour certains et des lentes pour les autres. Tout le monde est d'accord que la prioritisation est utile (la vidéo YouTube est moins importante que mon courrier professionnel) mais la question est encore « qui décide de ce qu'on priorise, et donc de ce qu'on ralentit ? » Ici, le RFC dit sans hésiter que c'est aux middleboxes de décider, après examen du trafic. L'exemple donné est amusant « on peut ainsi décider de donner la priorité aux jeux en ligne sur les mises à jour de logiciels ». Les gens de la sécurité, qui essaient toujours d'obtenir que les mises à jour de sécurité soient déployées plus rapidement, apprécieront…
On peut prioriser sans avoir accès à toutes les données (par exemple, en se basant uniquement sur les adresses IP) mais le RFC estime que, sans cet accès à tout, les décisions seront forcément moins efficaces.
Les auteurs du RFC sont manifestement conscients que beaucoup de leurs propositions vont énerver les utilisateurs. Alors, ils tentent de temps en temps d'expliquer que c'est pour leur bien qu'on viole la neutralité du réseau. Ainsi, le RFC cite l'exemple d'un réseau qui ralentirait le téléchargement d'une vidéo, pour épargner à l'abonné l'épuisement de son « forfait » « illimité ». Après tout, la vidéo ne sera peut-être pas regardée en entier, donc il n'est pas nécessaire de la charger tout de suite…
Voilà, nous sommes arrivés au bout de la liste des fonctions assurées par les boitiers intermédiaires (je ne les ai pas toutes citées dans ce court article). Il reste à voir les conséquences de ces fonctions pour la sécurité, et c'est le rôle de la section 5 du RFC. Elle estime d'abord que les fonctions décrites ne violent pas forcément la vie privée (RFC 6973) mais note quand même que même les champs « purement techniques » comme l'en-tête TCP, peuvent poser des risques pour la confidentialité des communications.
Et cette section 5 note aussi que l'information observée dans les en-têtes de couche 4 peuvent rendre certaines attaques plus faciles, par exemple en fabriquant un paquet TCP qui sera accepté par la machine terminale. On peut alors mener une attaque par déni de service en envoyant un faux RST (qui coupe la connexion, une attaque que les opérateurs ont déjà pratiquée.) La solution citée est l'utilisation du RFC 5925, qui protège l'intégrité de la connexion TCP mais pas sa confidentialité…
L'article seul
RFC 8509: A Root Key Trust Anchor Sentinel for DNSSEC
Date de publication du RFC : Décembre 2018
Auteur(s) du RFC : G. Huston, J. Damas (APNIC), W. Kumari (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 14 avril 2019
On le sait, le premier changement de la clé DNSSEC de la racine du DNS s'est déroulé sans encombre le 11 octobre dernier. Ce qu'on sait moins est que ce changement a été précédé par des nombreuses études, pour tenter de prévoir les conséquences du changement. Une question importante était « combien de résolveurs DNS n'ont pas vu la nouvelle clé, depuis sa publication, et vont donc avoir des problèmes lorsque l'ancienne sera retirée du service ? » Ce RFC décrit une des techniques qui avaient été développées pour répondre à cette question, technique qui continuera à être utile pour les discussions actuellement en cours sur une éventuelle systématisation et accélération du rythme des changements de clé.
La question de cette systématisation a fait par exemple l'objet
d'un débat à la dernière réunion IETF à
Prague le 28
mars. L'idée est de voir si on peut passer de changements
exceptionnels et rares à des changements réguliers,
banalisés. Pour cela, il faut avoir une idée de ce que voient les
résolveurs DNS,
du moins ceux qui valident avec DNSSEC, technique dont
l'importance avait encore été démontré par les attaques récentes. Mais comment
savoir ce que voient les résolveurs et, notamment, quelle(s)
clé(s) de départ de la validation (trust
anchor) ils utilisent ? La solution de la
sentinelle, spécifiée dans ce nouveau
RFC, peut
permettre de répondre à cette question. L'idée est que les
résolveurs reconnaitront une requête « spéciale », dont le nom
commence par root-key-sentinel-is-ta ou
root-key-sentinel-not-ta, nom qui sera suivi
de l'identificateur (key tag) de la clé (ta =
Trust Anchor). La réponse du résolveur dépendra
de s'il utilise cette clé ou pas comme point de départ de la
validation. Un logiciel client pourra alors tester si son
résolveur a bien vu le changement de clé en cours, et est
prêt. L'utilisateur peut alors savoir si ce résolveur fonctionnera
lors du changement. (Cela peut aussi aider
l'administrateurice système mais celui-ci
ou celle-là a d'autres moyens pour cela, comme d'afficher le
fichier contenant la clé de départ de la validation. Par contre,
les sentinelles sont utiles pour les chercheurs qui récoltent des
données automatiquement, comme dans l'article de Huston cité à la
fin.)
Ce mécanisme de sentinelle est complémentaire de celui du RFC 8145, où le résolveur signale aux serveurs faisant autorité les clés qu'il utilise comme trust anchor. Ici, la cible est le client du résolveur, pas les serveurs faisant autorité que contacte le résolveur. Ce mécanisme de sentinelle permet à tout utilisateur de savoir facilement la(es) clé(s) utilisée(s) par son résolveur DNS.
Petit rappel sur DNSSEC d'abord : comme le DNS, DNSSEC est arborescent. La validation part en général de la racine, et, via les enregistrements DS, arrive à la zone qu'on veut valider. Les clés sont identifiées par un key tag qui est un condensat de la clé. La clé qui est le point de départ de la validation se nomme le trust anchor et est stockée par le résolveur. Si on a la mauvaise clé, la validation échouera. Le trust anchor est géré manuellement par l'administrateur système en charge du résolveur, ou peut être mise à jour automatiquement en suivant la technique du RFC 5011. Aujourd'hui, le résolveur sur la machine où j'écris cet article utilise la trust anchor ayant le key tag 20326, la clé publique de la racine IANA (le résolveur est un Unbound) :
% cat /var/lib/unbound/root.key
...
. 172800 IN DNSKEY 257 3 8 AwEAAaz/tAm8y...1AkUTV74bU= ;{id = 20326 (ksk), size = 2048b} ;;state=2 [ VALID ] ;;count=0 ;;lastchange=1502474052 ;;Fri Aug 11 19:54:12 2017
Le id = 20326 indique l'identificateur de la
clé.
La section 2 expose le cœur du RFC. Un résolveur DNS, validant
avec DNSSEC (RFC 4035) et qui met en œuvre
ce RFC, doit reconnaitre comme spéciaux, les noms de domaine
demandés qui commencent
par root-key-sentinel-is-ta-NNNNN et
root-key-sentinel-not-ta-NNNNN où NNNNN est
un identificateur de clé. Voyons un exemple avec un domaine de
test, dans lequel on trouve
root-key-sentinel-is-ta-20326.ksk-test.net
et
root-key-sentinel-not-ta-20326.ksk-test.net
(20326 est l'identificateur de la clé actuelle de la racine). Tout
résolveur validant qui utilise la clé 20326 va pouvoir récupérer
et valider le premier nom :
% dig root-key-sentinel-is-ta-20326.ksk-test.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 23817
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 3, ADDITIONAL: 1
...
;; ANSWER SECTION:
root-key-sentinel-is-ta-20326.ksk-test.net. 30 IN A 204.194.23.4
Ici, le ad dans les résultats indique que
l'enregistrement a bien été validé (AD = Authentic
Data). Si le résolveur ne valide pas, on n'aura
évidemment pas le ad. Maintenant, que se
passe-t-il avec le second nom, celui avec
not-ta ? Un résolveur validant, mais qui ne
met pas en œuvre notre RFC 8509 va récupérer et valider
ce nom :
% dig root-key-sentinel-not-ta-20326.ksk-test.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 20409
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 3, ADDITIONAL: 1
...
;; ANSWER SECTION:
root-key-sentinel-not-ta-20326.ksk-test.net. 30 IN A 204.194.23.4
En revanche, un résolveur validant et qui met en œuvre ce RFC 8509 (ici, le résolveur Knot) va renvoyer un SERVFAIL (Server Failure) :
% dig root-key-sentinel-not-ta-20326.ksk-test.net
...
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 37396
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0
On voit comment on peut utiliser le mécanisme de ce RFC pour découvrir si le résolveur utilise ou pas la clé 20326. Avec un client DNS, et une zone qui dispose des sentinelles :
- Si on peut récupérer
root-key-sentinel-not-ta-20326et qu'on n'a pas le bitad, c'est que le résolveur ne valide pas, - Si on peut récupérer et valider
root-key-sentinel-not-ta-20326, c'est que le résolveur valide mais ne gère pas le mécanisme des sentinelles, - Si on peut récupérer et valider
root-key-sentinel-is-ta-20326mais pasroot-key-sentinel-not-ta-20326, c'est que le résolveur valide, gère le mécanisme des sentinelles, et utilise la clé 20326, - Si on peut récupérer et valider
root-key-sentinel-not-ta-20326mais pasroot-key-sentinel-is-ta-20326, c'est que le résolveur valide, gère le mécanisme des sentinelles, et n'utilise pas la clé 20326. (Ce test ne marche pas forcément, cela dépend de comment est configurée la zone de test.)
L'annexe A de notre RFC détaille comment on utilise le mécanisme de sentinelle.
La beauté du mécanisme est qu'on peut l'utiliser sans client
DNS, depuis une page Web. On crée une page qui essaie de charger
trois images, une depuis invalid.ZONEDETEST
(enregistrement mal signé), une depuis
root-key-sentinel-is-ta-20326.ZONEDETEST et une depuis
root-key-sentinel-not-ta-20326.ZONEDETEST. On teste en
JavaScript si les images se sont chargées :
- Si toutes se chargent, c'est que le résolveur de l'utilisateur ne valide pas,
- Si la première (
invalid) ne charge pas mais que les deux autres chargent, c'est que le résolveur ne connait pas les sentinelles, on ne peut donc pas savoir quelle(s) clé(s) il utilise, - Si la première (
invalid) et la troisième (root-key-sentinel-not-ta-20326) ne se chargent pas mais que la deuxième (root-key-sentinel-is-ta-20326) se charge, c'est que le résolveur connait les sentinelles, et utilise la clé 20326. - Si la première (
invalid) et la deuxième (root-key-sentinel-is-ta-20326) ne se chargent pas mais que la troisième (root-key-sentinel-not-ta-20326) se charge, c'est que le résolveur connait les sentinelles, et n'utilise pas la clé 20326. Soit il utilise une autre racine que celle de l'ICANN, soit il a gardé une ancienne clé et aura des problèmes lors du remplacement.
Notez que le choix des préfixes avait été chaudement discuté à
l'IETF. À un moment, l'accord s'était fait
sur les préfixes _is-ta
ou _not-ta, le tiret
bas convenant bien à ces noms spéciaux. Mais comme ce
même tiret bas rendait ces noms ilégaux comme noms de machine, cela rendait
difficile certains tests. Autant _is-ta
ou _not-ta étaient utilisables depuis
dig, autant on ne pouvait pas les tester
depuis un navigateur Web, ce qui rendait
difficile des tests semi-automatisés, sous formes d'images qu'on
charge depuis une page Web et de JavaScript
qui regarde le résultat. D'où les noms root-key-sentinel-is-ta-NNNNN et
root-key-sentinel-not-ta-NNNNN. Ce n'est pas
une solution satisfaisante que de prendre des noms ne commençant
pas par un tiret bas, mais cela a semblé le meilleur compromis
possible. Le nom est suffisamment long et alambiqué pour que le
risque de collisions avec des noms existants soit faible.
Donc, que doit faire le résolveur quand on l'interroge pour un
nom commençant par root-key-sentinel-is-ta-NNNNN ou
root-key-sentinel-not-ta-NNNNN ? Si et
seulement si le type demandé est A (adresse IPv4) ou AAAA (adresse
IPv6), et que la réponse est validée par DNSSEC, le résolveur doit
extraire le key tag du nom et déterminer s'il
corresponde à une des clés de départ de la validation pour la
racine. (Les serveurs faisant autorité, eux, n'ont rien de
particulier à faire, ils fonctionnent comme aujourd'hui.)
- Si le nom demandé commençait par
root-key-sentinel-is-taet que l'identificateur de clé est celui d'une trust anchor, alors on renvoie la réponse originale, - Si le nom demandé commençait par
root-key-sentinel-is-taet que l'identificateur n'est pas celui d'une trust anchor, alors on renvoie le code d'erreur SERVFAIL, - Si le nom demandé commençait par
root-key-sentinel-not-taet que l'identificateur est celui d'une trust anchor, alors on renvoie le code d'erreur SERVFAIL, - Si le nom demandé commençait par
root-key-sentinel-not-taet que l'identificateur n'est pas celui d'une trust anchor, alors on renvoie la réponse originale.
Le principe est simple, les sections suivantes du RFC décrivent comment déduire
l'état du résolveur avec ce principe. Par exemple, la section 3
décrit le cas où on n'a qu'un seul résolveur. Si on veut connaitre
la situation de la clé 12345, et que les noms nécessaires sont
présents dans le domaine xxx.example, que le domaine broken.xxx.example est
cassé, question DNSSEC, on cherche à résoudre les
noms root-key-sentinel-is-ta-12345.xxx.example,
root-key-sentinel-not-ta-12345.xxx.example et
broken.xxx.example. Pour un résolveur validant, et
qui met en œuvre ce RFC, seule la première requête doit
réussir. Si la troisième réussit, c'est que le résolveur ne valide
pas. Si la deuxième réussit, c'est qu'il ne connait pas le système
sentinelle de notre RFC 8509. (L'algorithme détaillé est
dans la section 3 du RFC, il y a quelques cas vicieux.)
Notez bien qu'on n'a pas besoin d'un client DNS complet pour ces tests. Une résolution de nom en adresse normale suffit, ce qui permet de faire ces tests depuis un navigateur Web, ce qui était bien le but. Par exemple en HTML :
<ul>
<li><a href="http://invalid.ksk-test.net/invalid.gif">"http://invalid.ksk-test.net/invalid.gif"</a></li>
<li><a href="http://root-key-sentinel-is-ta-20326.ksk-test.net/is-ta.gif">"http://root-key-sentinel-is-ta-20326.ksk-test.net/is-ta.gif"</a></li>
<li><a href="http://root-key-sentinel-not-ta-20326.ksk-test.net/not-ta.gif">"http://root-key-sentinel-not-ta-20326.ksk-test.net/not-ta.gif"</a></li>
</ul>
Et avec du JavaScript pour vérifier :
if (img_invalid.height === 0) {invalid = false;}
if (img_is_ta.height === 0) {is_ta = false;}
if (img_not_ta.height === 0) {not_ta = false;}
switch (true) {
case invalid === true:
result="You are not DNSSEC validating, and so will be fine!";
break;
case (is_ta === true && not_ta === true):
result="You are using a legacy resolver (or updated resolvers, with some new and some old), we cannot determine your fate!";
break;
case (not_ta === true):
result="WARNING!: Your resolvers do not have the new KSK. Your Internet access will break!";
break;
case (is_ta === true):
result="Congratulations, you have the new key. You will be fine.";
break;
}
Si la machine a plusieurs résolveurs, le cas est plus compliqué par la bibliothèque qui fait la résolution de noms va typiquement passer au résolveur suivant en cas de réponse SERVFAIL. La section 4 décrit un algorithme qui peut permettre, sinon de déterminer la situation exacte de chacun des résolveurs utilisés, en tout cas de voir si une clé donnée a des chances de fonctionner avec cet ensemble de résolveurs.
Quels résolveurs ont ce mécanisme de sentinelle ? BIND l'a depuis la version 9.13, Knot a également ce mécanisme, activé par défaut, depuis la version 2.0 (et le documente), Unbound en dispose depuis la version 1.7.1 et c'est activé par défaut. Parmi les résolveurs DNS publics, Cloudflare et Quad9 ne gèrent apparemment pas les sentinelles de notre RFC 8509.
Côté client, on peut tester son résolveur avec dig, ou
bien avec les
services Web http://www.ksk-test.nethttp://test.kskroll.dnssec.lab.nic.cl/http://sentinel.research.icann.org/http://www.bellis.me.uk/sentinel/ksk-test.net). La lecture des sources
de ces pages est recommandée.
On peut aussi regarder, parmi les sondes RIPE Atlas, lesquelles utilisent un résolveur avec sentinelles :
% blaeu-resolve --displayvalidation --type A --requested 100 --dnssec root-key-sentinel-not-ta-20326.ksk-test.net [ (Authentic Data flag) 204.194.23.4] : 30 occurrences [ERROR: SERVFAIL] : 12 occurrences [ (Authentic Data flag) (TRUNCATED - EDNS buffer size was 4096 ) 204.194.23.4] : 1 occurrences [204.194.23.4] : 52 occurrences Test #20692175 done at 2019-04-13T16:32:15Z % blaeu-resolve --displayvalidation --type A --requested 100 --old_measurement 20692175 --dnssec root-key-sentinel-is-ta-20326.ksk-test.net [ERROR: SERVFAIL] : 1 occurrences [ (Authentic Data flag) 204.194.23.4] : 38 occurrences [204.194.23.4] : 56 occurrences Test #20692176 done at 2019-04-13T16:33:56Z
Le premier test montre 52 sondes utilisant un résolveur non validant, 30 utilisant un validant sans sentinelles (ou bien utilisant une autre clé que 20326), et 12 utilisant un résolveur validant avec sentinelles. Le second test, effectué avec exactement les mêmes sondes, montre que les sondes utilisant un résolveur validant à sentinelles utilisent bien la clé 20326 (sauf une, qui a un SERVFAIL). Notez que les nombres ne coïncident pas parfaitement (30 + 12 - 1 ne fait pas 38), sans doute parce que certaines sondes ont plusieurs résolveurs DNS configurés, ce qui complique sérieusement l'analyse.
Un exemple d'utilisation de ce mécanisme de sentinelles figure dans cet article de Geoff Huston et cet autre.
L'article seul
RFC 8504: IPv6 Node Requirements
Date de publication du RFC : Janvier 2019
Auteur(s) du RFC : T. Chown (Jisc), J. Loughney (Intel), T. Winters (UNH-IOL)
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 31 janvier 2019
Il existe des tas de RFC qui concernent IPv6 et le programmeur qui met en œuvre ce protocole dans une machine risque fort d'en rater certains, ou bien d'implémenter certains qu'il aurait pu éviter. Ce RFC est donc un méta-RFC, chargé de dresser la liste de ce qui est indispensable dans une machine IPv6. Pas de changements spectaculaires par rapport au précédent RFC mais beaucoup de détails.
Ce document remplace son prédécesseur, le RFC 6434. Il vise le même but, servir de carte au développeur qui veut doter un système de capacités IPv6 et qui se demande s'il doit vraiment tout faire (réponse : non). Ce RFC explique clairement quels sont les points d'IPv6 qu'on ne peut pas négliger, sous peine de ne pas pouvoir interagir avec les autres machines IPv6. Le reste est laissé à l'appréciation du développeur, ou à celle de profils spécifiques à un usage ou à une organisation (comme dans le cas du « Profile for IPv6 in the U.S. Government »). La section 1 résume ce but.
Ce RFC s'applique à tous les nœuds IPv6, aussi bien les routeurs (ceux qui transmettent des paquets IPv6 reçus qui ne leur étaient pas destinés) que les machines terminales (toutes les autres).
Bien, maintenant, voyons les obligations d'une machine IPv6, dans l'ordre. D'abord, la couche 2 (section 4 du RFC). Comme IPv4, IPv6 peut tourner sur des tas de couches de liaison différentes et d'autres apparaîtront certainement dans le futur. En attendant, on en a déjà beaucoup, Ethernet (RFC 2464), 802.16 (RFC 5121), les réseaux pour objets connectés LowPAN 802.15.4 (RFC 4944), PPP (RFC 5072) et bien d'autres, sans compter les tunnels.
Ensuite, la couche 3 (section 5 du RFC) qui est évidemment le gros morceau puisque c'est la couche d'IP. Le cœur d'IPv6 est normalisé dans le RFC 8200 et ce dernier RFC doit donc être intégralement implémenté.
Comme IPv6, contrairement à IPv4, ne permet pas aux routeurs intermédiaires de fragmenter les paquets, la découverte de la MTU du chemin est particulièrement cruciale. La mise en œuvre du RFC 8201 est donc recommandée. Seules les machines ayant des ressources très limitées (du genre où tout doit tenir dans la ROM de démarrage) sont dispensées. Mais le RFC se doit de rappeler que la détection de la MTU du chemin est malheureusement peu fiable dans l'Internet actuel, en raison du grand nombre de pare-feux configurés avec les pieds et qui bloquent tout l'ICMP. Il peut être donc nécessaire de se rabattre sur les techniques du RFC 4821. Le RFC recommande également de ne pas trop fragmenter les paquets, pour ne pas tenter le diable, un certain nombre de machines intermédiaires bloquant les fragments. Cela concerne notamment les protocoles utilisant UDP, comme le DNS, qui n'ont pas de négociation de la taille des messages, contrairement à TCP.
En parlant de fragmentation, notre RFC rappelle également qu'on ne doit pas générer de fragments atomiques (un datagramme marqué comme fragmenté alors que toutes les données sont dans un seul datagramme), pour les raisons expliquées dans le RFC 8021. Et il ne faut pas utiliser d'identificateurs de fragment prévisibles (RFC 7739), afin d'empêcher certaines attaques comme l'attaque Shulman sur le DNS.
Le RFC 8200 décrit le format des paquets et leur traitement. Les adresses y sont simplement mentionnées comme des champs de 128 bits de long. Leur architecture est normalisée dans le RFC 4291, qui est obligatoire. (Une tentative de mise à jour de ce RFC 4291 avait eu lieu mais a été abandonnée sous les protestations.) La règle actuelle (RFC 7421) est que le réseau local a une longueur de préfixe de 64 bits (mais il y a au moins une exception, cf. RFC 6164.)
Également indispensable à toute machine IPv6, l'autoconfiguration sans état du RFC 4862 (SLAAC, StateLess Address AutoConfiguration), ainsi que ses protocoles auxiliaires comme la détection d'une adresse déjà utilisée. D'autre part, il est recommandé d'accepter l'allocation d'un préfixe entier à une machine (RFC 8273).
Les en-têtes d'extension (RFC 8200, section 4) sont un élément de base d'IPv6 et doivent donc être acceptés et traités par toutes les machines terminales. Notez que la création de nouveaux en-têtes est désormais déconseillée donc qu'une mise en œuvre d'IPv6 a des chances de ne pas voir apparaitre de nouveaux en-têtes. Même si c'était le cas, ils devront suivre le format générique du RFC 6564, ce qui devrait faciliter leur traitement.
ICMP (RFC 4443) est évidemment obligatoire, c'est le protocole de signalisation d'IP (une des erreurs les plus courantes des administrateurs réseaux incompétents est de bloquer ICMP sur les pare-feux).
Dernier protocole obligatoire, la sélection de l'adresse source selon les règles du RFC 6724, pour le cas où la machine aurait le choix entre plusieurs adresses (ce qui est plus fréquent en IPv6 qu'en IPv4).
Le reste n'est en général pas absolument obligatoire mais recommandé (le terme a un sens précis dans les RFC, définie dans le RFC 2119 : ce qui est marqué d'un SHOULD doit être mis œuvre, sauf si on a une bonne raison explicite et qu'on sait exactement ce qu'on fait). Par exemple, la découverte des voisins (NDP, RFC 4861) est recommandée. Toutes les machines IPv6 en ont besoin, sauf si elles utilisent les liens ne permettant pas la diffusion.
Moins générale, la sélection d'une route par défaut s'il en existe plusieurs, telle que la normalise le RFC 4191. Elle est particulièrement importante pour les environnements SOHO (RFC 7084). Et si la machine IPv6 a plusieurs adresses IP, et qu'il y a plusieurs routeurs, elle doit choisir le routeur en fonction de l'adresse source (RFC 8028).
On a vu que l'autoconfiguration sans état (sans qu'un serveur doive se souvenir de qui a quelle adresse) était obligatoire. DHCP (RFC 9915), lui, n'est que recommandé. Notez que DHCP ne permet pas d'indiquer le routeur à utiliser, cette information ne peut être obtenue qu'en écoutant les RA (Router Advertisements).
Une extension utile (mais pas obligatoire) d'IP est celle des adresses IP temporaires du RFC 8981, permettant de résoudre certains problèmes de protection de la vie privée. Évidemment, elle n'a pas de sens pour toutes les machines (par exemple, un serveur dans son rack n'en a typiquement pas besoin). Elle est par contre recommandée pour les autres. Le RFC 7721 fait un tour d'horizon plus général de la sécurité d'IPv6.
Encore moins d'usage général, la sécurisation des annonces de route (et des résolutions d'adresses des voisins) avec le protocole SEND (RFC 3971). Le déploiement effectif de SEND est très faible et le RFC ne peut donc pas recommander cette technique pour laquelle on n'a pas d'expérience, et qui reste simplement optionnelle.
L'une des grandes questions que se pose l'administrateur réseaux avec IPv6 a toujours été « autoconfiguration SLAAC - StateLess Address AutoConfiguration - / RA - Router Advertisement - ou bien DHCP ? » C'est l'un des gros points de ce RFC et la section 8.4 le discute en détail. Au début d'IPv6, DHCP n'existait pas encore pour IPv6 et les RA utilisés par SLAAC ne permettaient pas encore de transmettre des informations pourtant indispensables comme les adresses des résolveurs DNS (c'est maintenant possible, cf. RFC 8106). Aujourd'hui, les deux protocoles ont à peu près des capacités équivalentes. RA a l'avantage d'être sans état, DHCP a l'avantage de permettre des options de configuration différentes par machine. Mais DHCP ne permet pas d'indiquer le routeur à utiliser. Alors, quel protocole choisir ? Le problème de l'IETF est que si on en normalise deux, en laissant les administrateurs du réseau choisir, on court le risque de se trouver dans des situations où le réseau a choisi DHCP alors que la machine attend du RA ou bien le contraire. Bref, on n'aurait pas d'interopérabilité, ce qui est le but premier des normes Internet. Lorsque l'environnement est très fermé (un seul fournisseur, machines toutes choisies par l'administrateur réseaux), ce n'est pas un gros problème. Mais dans un environnement ouvert, par exemple un campus universitaire ou un hotspot Wifi, que faire ? Comme l'indiquent les sections 6.3 et 6.5, seul RA est obligatoire, DHCP ne l'est pas. RA est donc toujours la méthode recommandée si on doit n'en choisir qu'une, c'est la seule qui garantit l'interopérabilité.
Continuons à grimper vers les couches hautes. La section 7 est
consacrée aux questions DNS. Une machine IPv6 devrait pouvoir suivre le
RFC 3596 et donc avoir la possibilité de
gérer des enregistrements DNS de type AAAA (les adresses IPv6) et
la résolution d'adresses en noms grâce à des enregistrements PTR dans
ip6.arpa.
À noter qu'une machine IPv6, aujourd'hui, a de fortes chances de se retrouver dans un environnement où il y aura une majorité du trafic en IPv4 (c'est certainement le cas si cet environnement est l'Internet). La section 10 rappelle donc qu'une machine IPv6 peut avoir intérêt à avoir également IPv4 et à déployer des techniques de transition comme la double-pile du RFC 4213.
Encore juste une étape et nous en sommes à la couche 7, à laquelle la section 11 est consacrée. Si elle parle de certains détails de présentation des adresses (RFC 5952), elle est surtout consacrée à la question des API. En 2019, on peut dire que la très grande majorité des machines a IPv6, côté couche 3 (ce qui ne veut pas dire que c'est activé, ni que le réseau le route). Mais les applications sont souvent en retard et beaucoup ne peuvent tout simplement pas communiquer avec une autre machine en IPv6. L'IETF ne normalise pas traditionnellement les API donc il n'y a pas d'API recommandée ou officielle dans ce RFC, juste de l'insistance sur le fait qu'il faut fournir une API IPv6 aux applications, si on veut qu'elles utilisent cette version d'IP, et qu'il en existe déjà, dans les RFC 3493 (fonctions de base) et RFC 3542 (fonctions avancées).
La sécurité d'IPv6 a fait bouger beaucoup d'électrons, longtemps avant que le protocole ne soit suffisamment déployé pour qu'on puisse avoir des retours d'expérience. Le RFC note donc bien que la sécurité est un processus complexe, qui ne dépend certainement pas que d'une technique magique et qu'aucun clair gagnant n'émerge de la liste des solutions de sécurité (IPsec, TLS, SSH, etc). D'autant plus qu'IPv6 vise à être déployé dans des contextes comme « l'Internet des Trucs » où beaucoup de machines n'auront pas forcément les ressources nécessaires pour faire de l'IPsec.
Toutes les règles et recommandations précédentes étaient pour tous les nœuds IPv6. La section 14 expose les règles spécifiques aux routeurs. Ils doivent évidemment router les paquets (cf. RFC 7608). Ils doivent aussi être capables d'envoyer les Router Advertisement et de répondre aux Router Solicitation du RFC 4861 et on suggère aux routeurs SOHO d'envisager sérieusement d'inclure un serveur DHCP (RFC 7084) et aux routeurs de réseaux locaux de permettre le relayage des requêtes DHCP.
Nouveauté de ce RFC, la section 15 se penche sur le cas des objets contraints, ces tout petits ordinateurs avec peu de ressources, pour lesquels il a parfois été dit qu'IPv6 n'était pas réaliste. Le groupe de travail de l'IETF 6LowPAN a beaucoup travaillé pour faire en sorte qu'IPv6 tourne bien sur ces objets contraints (RFC 4919). Pour la question de la consommation énergétique, voir le RFC 7772.
Enfin, la section 16 se penche sur la gestion des réseaux IPv6 en notant qu'au moins deux MIB sont recommandées, celle du RFC 4292 sur la table de routage, et celle du RFC 4293 sur IP en général. SNMP n'est plus le seul protocole cité, Netconf (RFC 6241) et Restconf (RFC 8040) apparaissent.
Les changements par rapport au RFC 6434 sont résumés dans l'annexe A. Pas mal de changements pendant les sept ans écoulés depuis le RFC 6434 mais aucun n'est dramatique :
- Ajout des objets contraints, et des questions liées à la consommation eléctrique,
- L'indication du résolveur DNS par les RA, devient obligatoire (section 8.3),
- Ajout de Netconf et Restconf pour la gestion des réseaux,
- Les questions liées à la vie privée sont plus nombreuses, avec par exemple le profil DHCP du RFC 7844,
- Les jumbograms du RFC 2675, peu déployés, ont été abandonnés,
- Autre abandon, celui d'ATM, un échec complet,
- Conseils sur la fragmentation, notamment pour le DNS.
L'article seul
RFC 8501: Reverse DNS in IPv6 for Internet Service Providers
Date de publication du RFC : Novembre 2018
Auteur(s) du RFC : L. Howard (Retavia)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 28 janvier 2019
Le DNS permet d'avoir des
enregistrements de type PTR, dans un sous-arbre spécifique sous
.arpa, permettant
d'associer un nom à
une adresse IP. Les
FAI et autres fournisseurs peuplent souvent
ce sous-arbre afin que tous les clients aient un PTR, et donc que
la « résolution inverse » (mal nommée, mais tant pis) rende un
résultat. Avec IPv4, c'est facile. Si on
gère un préfixe /22, on a 1 024 PTR à mettre, ce qui fait encore
une assez petite zone DNS. Mais en IPv6 ?
La zone ainsi pré-peuplée serait de taille colossale, bien au-delà
des capacités des serveurs de noms. Il faut donc trouver d'autres
solutions, et c'est ce que décrit ce
RFC.
Deux exemples d'enregistrement PTR en IPv6, pour commencer, vus avec dig :
% dig +short -x 2a00:1450:4007:816::2005
par10s33-in-x05.1e100.net.
(1E100 = Google). Et un autre, avec tous les détails :
% dig -x 2001:67c:2218:e::51:41
...
;; QUESTION SECTION:
;1.4.0.0.1.5.0.0.0.0.0.0.0.0.0.0.e.0.0.0.8.1.2.2.c.7.6.0.1.0.0.2.ip6.arpa. IN PTR
;; ANSWER SECTION:
1.4.0.0.1.5.0.0.0.0.0.0.0.0.0.0.e.0.0.0.8.1.2.2.c.7.6.0.1.0.0.2.ip6.arpa. 600 IN PTR epp.nic.fr.
Et les mêmes, vus avec le DNS looking
glass : https://dns.bortzmeyer.org/2a00:1450:4007:816::2005?reverse=1https://dns.bortzmeyer.org/2001:67c:2218:e::51:41?reverse=1
Pourquoi mettre ces enregistrements PTR ? Le RFC 1912, section 2.1, dit que ce serait bien de le faire (« For every IP address, there should be a matching PTR record in the in-addr.arpa domain ») mais ne donne pas de raison, à part que certains services risquent de vous refuser si vous n'avez pas ce PTR. En fait, il y a deux sortes de vérification que peut faire un service distant auquel vous vous connectez :
- Vérifier que votre adresse IP, celle du client, a un PTR, et refuser l'accès distant sinon. C'est relativement rare (et, à mon avis, assez bête).
- Vérifier que, s'il y a un PTR, il
pointe vers un nom qui à son tour pointe vers l'adresse IP du
client (et attention si vous programmez cela : on peut avoir
plusieurs PTR, et les noms qu'ils indiquent peuvent avoir
plusieurs adresses IP). Ce test est plus fréquent et bien plus
justifié (vous n'êtes pas obligé d'avoir un PTR mais, si vous en
avez un, il doit être cohérent). Notez que, par exemple,
Postfix fait ce test (on obtient des
messages du genre « postfix/smtpd[818]: warning: hostname
ppp-92-39-138-98.in-tel.ru does not resolve to address
92.39.138.98: Name or service not known », et de tels messages
sont fréquents, indiquant que beaucoup
d'administrateurs réseaux sont
négligents) et que ce test n'est apparemment pas
débrayable. Pour configurer les conséquences de ce test, voyez
les paramètres
reject_unknown_client_hostnameetreject_unknown_reverse_client_hostname. Pour OpenSSH, c'est l'optionUseDNSqui décide des conséquences du test.
La deuxième vérification peut se faire ainsi (en pseudo-code sur le serveur) :
if is_IPv4(client_IP_address) then
arpa_domain = inverse(client_IP_address) + '.in-addr.arpa'
else
arpa_domain = inverse(client_IP_address) + '.ip6.arpa'
end if
names = PTR_of(arpa_domain) # Bien se rappeler qu'il peut y avoir plusieurs PTR
for name in names loop
if is_IPv4(IP_address) then
addresses = A_of(name) # Bien se rappeler qu'il peut y avoir plusieurs A ou AAAA
else
addresses = AAAA_of(name)
end if
if client_IP_address in addresses then
return True
end if
end loop
return False
Est-ce une bonne idée d'exiger un enregistrement PTR ? Le RFC 1912 le fait, mais il est vieux de 22 ans et
est nettement dépassé sur ce point. Cette question des
enregistrements PTR, lorsqu'elle est soulevée dans les forums
d'opérateurs ou bien à l'IETF, entraine toujours des débats
passionnés. Un projet de RFC avait été développé (draft-ietf-dnsop-reverse-mapping-considerations)
mais n'avait jamais abouti. Mais ce qui est sûr est que ces PTR
sont parfois exigés par des serveurs Internet, et qu'il faut donc
réfléchir à la meilleure façon de les fournir.
En IPv4, comme indiqué dans le
paragraphe introductif, c'est simple. On écrit un petit programme
qui génère les PTR, on les met dans un fichier de zone, et on
recharge le serveur DNS faisant
autorité. Si le FAI
example.net gère le préfixe IP
203.0.113.0/24, la zone DNS correspondante
est 113.0.203.in-addr.arpa, et on met dans le
fichier de zone quelque chose comme :
1 IN PTR 1.north.city.example.net.
2 IN PTR 2.north.city.example.net.
3 IN PTR 3.north.city.example.net.
4 IN PTR 4.north.city.example.net.
...
Et, si on est un FAI sérieux, on vérifie qu'on a bien les enregistrements d'adresse dans la
zone example.net :
1.north.city IN A 203.0.113.1
2.north.city IN A 203.0.113.2
3.north.city IN A 203.0.113.3
4.north.city IN A 203.0.113.4
...
Mais en IPv6 ? Un PTR a cette forme (dans
le fichier de zone de
a.b.b.a.2.4.0.0.8.b.d.0.1.0.0.2.ip6.arpa) :
1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0 IN PTR 1.north.city.example.net.
Et l'enregistrement d'adresse :
1.north.city IN AAAA 2001:db8:42:abba::1
Mais il faudrait autant de PTR que d'adresses possibles. Générer automatiquement la multitude de PTR qu'il faudrait, même pour un simple /64, est inenvisageable. Même si un programme arrivait à le faire (comme le note le RFC, en écrivant 1 000 entrées par seconde, il faudrait presque 600 millions d'années pour un pauvre /64), le serveur de noms ne pourrait pas charger une zone aussi grosse.
La section 2, le gros du RFC, décrit les solutions possibles. Elles n'ont pas les mêmes propriétés en terme de passage à l'échelle, conformité aux normes et disponibilité dans les logiciels existants, et, disons-le tout de suite, aucune n'est parfaite.
Première solution, la plus brutale, répondre NXDOMAIN (« ce nom n'existe pas »). C'est simple à faire et ça marche bien, quelle que soit la taille du préfixe. Il suffit d'un fichier de zone vide (juste les enregistrements SOA et NS) pour mettre en œuvre cette solution.
Après tout, c'est la réponse la plus honnête : pas d'information disponible. (Attention, on parle bien de répondre NXDOMAIN, et surtout pas de ne pas répondre. Ne pas répondre va laisser le client DNS attendre, peut-être très longtemps, alors qu'un NXDOMAIN va tout de suite lui dire qu'il n'y a pas de réponse.) Cela ne suit pas le RFC 1912, mais dont on a vu qu'il est très contestable sur ce point. Par contre, certains services seront refusés (à tort, je pense, mais la légende « s'il n'a pas de PTR, c'est un méchant » est très répandue) au client qui n'a pas de PTR.
Deuxième solution, profiter des jokers du DNS (RFC 4592) pour avoir une réponse identique pour toutes les adresses IP (cf. RFC 4472). C'est simple à faire et ça passe bien à l'échelle. Le fichier de zone va être :
* IN PTR one-host.foo.bar.example.
Le principal inconvénient est que la requête en sens inverse (du
nom - ici one-host.foo.bar.example - vers
l'adresse IP) ne donnera pas un bon résultat, puisqu'il n'y a
qu'un seul nom, ce qui plantera les programmes qui vérifient la
cohérence des PTR et des A/AAAA.
Troisième solution, laisser les machines mettre à jour elle-mêmes le DNS, pour y mettre le PTR. La machine qui vient d'obtenir une adresse IP (que ce soit par SLAAC, DHCP ou un autre moyen), va mettre à jour enregistrements AAAA et PTR dans un serveur DNS dynamique. Cette fois, c'est compliqué à réaliser. Pour un gros FAI, il y aura plusieurs serveurs DNS, à des fins de redondance, il faudra que les machines clientes s'adressent au bon (il n'y a pas de mécanisme standard pour cela), s'il y a beaucoup de clients DNS, le serveur va souffrir, authentifier ces requêtes de mise à jour du DNS va être compliqué… Sans compter le risque qu'un utilisateur facétieux ne mette un PTR… « créatif » ou tout simplement un nom déjà utilisé.
Notez que, à la maison ou dans au autre petit réseau local, ce n'est pas forcément la machine terminale qui pourrait faire la mise à jour DNS. Cela pourrait se centraliser au niveau du routeur CPE (la box).
Dans ce cas, on pourrait même imaginer que le FAI délègue deux
noms de domaine à ce routeur CPE, un nom pour les requêtes
d'adresses (mettons
customer-7359.city.example.net) et un pour
les requêtes inverses (mettons
6.a.2.1.6.a.a.b.8.b.d.0.1.0.0.2.ip6.arpa). Dans
ce cas, ce serait de la responsabilité du routeur CPE de répondre
pour ces noms, d'une manière configurable par l'utilisateur. Si le
FAI fournit la box, comme c'est courant en
France, il peut s'assurer qu'elle est capable de fournir ce
service. Autrement, il faut ne faire cette délégation que si
l'utilisateur a cliqué sur « oui, j'ai un serveur DNS bien
configuré, déléguez-moi », ou bien en utilisant une heuristique
(si un client demande une délégation de préfixe IP, on peut
estimer qu'il s'agit d'un routeur et pas d'une machine terminale,
et elle a peut-être un serveur DNS inclus). Notez que le RFC 6092 dit qu'un routeur CPE ne doit pas avoir,
par défaut, de serveur DNS accessible de l'extérieur, mais cet
avis était pour un résolveur, pas pour un serveur faisant
autorité.
Enfin, la mise à jour dynamique du DNS peut aussi être faite par le serveur DHCP du FAI, par exemple en utilisant le nom demandé par le client (RFC 4704). Ou par le serveur RADIUS.
Quatrième solution, déjà partiellement évoquée plus haut, déléguer le DNS à l'utilisateur. Cela ne marche pas en général avec l'utilisateur individuel typique, qui n'a pas de serveur DNS, ni le temps ou l'envie d'en installer un. Une solution possible serait d'avoir une solution toute prête dans des offres de boitiers faisant tout comme le Turris Omnia.
Enfin, cinquième et dernière possibilité, générer des réponses
à la volée, lors de la requête DNS. Un exemple d'algorithme
serait, lors de la réception d'une requête DNS de type PTR, de
fabriquer un nom (mettons
host-56651.customers.example.net), de le
renvoyer et de créer une entrée de type AAAA
pour les requêtes portant sur ce nom. Ces deux entrées pourraient
être gardées un certain temps, puis nettoyées. Notez que cela ne
permet pas à l'utilisateur de choisir son nom. Et que peu de
serveurs DNS savent faire cela à l'heure actuelle. (Merci à Alarig
Le Lay pour m'avoir signalé le
module qui va bien dans Knot.)
Cette technique a deux autres inconvénients. Si on utilise DNSSEC, elle impose de générer également les signatures dynamiquement (ou de ne pas signer cette zone, ce qui est raisonnable pour de l'information non-critique). Et l'algorithme utilisé doit être déterministe, pour donner le même résultat sur tous les serveurs de la zone.
La section 3 de notre RFC discute la possibilité d'un
avitaillement du DNS par l'utilisateur final, via une interface
dédiée, par exemple une page Web (évidemment authentifiée). Voici par exemple
l'interface de Linode :
Notez qu'on ne peut définir un PTR qu'après avoir testé que la
recherche d'adresses IP pour ce nom fonctionne, et renvoie une des
adresses de la machine. Chez Gandi, on ne
peut plus changer ces enregistrements depuis le passage à la
version 5 de l'interface, hélas. Mais ça fonctionne encore tant
que la version 4 reste en service :
L'interface
de Free (qui ne gère qu'IPv4) est boguée : elle affiche le nom
choisi mais une requête PTR donne quand même le nom automatique
(du genre lns-bzn-x-y-z.adsl.proxad.net,
d'autant plus drôle qu'il concerne un abonnement via la
fibre).
La section 4 tente de synthétiser le problème et les solutions. Considérant qu'il y a six utilisations typiques des enregistrements PTR :
- Accepter ou rejeter du courrier, dans le cadre de la lutte anti-spam,
- Servir des publicités, en utilisant le PTR comme source de géolocalisation,
- Accepter ou rejeter des connexions SSH (en supposant, ce qui est très contestable, qu'un PTR avec validation de l'adresse est un bon indicateur d'un client SSH « sérieux »),
- La journalisation, en notant aussi
bien le nom que l'adresse IP du client ; attention, noter le nom
seul serait une erreur, puisqu'il est entièrement contrôlé du
côté du client (l'administrateur de
2001:db8:42::1peut, via son contrôle de2.4.0.0.8.b.d.0.1.0.0.2.ip6.arpa, mettre un PTR indiquantwww.google.com), - traceroute (à mon avis l'une des rares utilisations vraiment valables des enregistrements PTR),
- La découverte de services, suivant le RFC 6763.
Considérant ces usages, la meilleure solution serait la délégation du DNS à l'utilisateur, pour qu'il ait un contrôle complet, mais comme c'est actuellement irréaliste la plupart du temps, le NXDOMAIN est parfois la solution la plus propre. Évidemment, comme toujours, « cela dépend » et chaque opérateur doit faire sa propre analyse (rappelez-vous qu'il n'y a pas de consensus sur ces enregistrements PTR). Personnellement, je pense que tout opérateur devrait fournir à ses utilisateurs un moyen (formulaire Web ou API) pour mettre un enregistrement PTR.
Et pour terminer, la section 5 de notre RFC décrit les questions de sécurité et de vie privée liées à ces questions de résolution « inverse ». Parmi elles :
- Certaines personnes affirment bien fort que la présence d'un enregistrement PTR signifie quelque chose (par exemple que l'administrateur réseaux est sérieux/qualifié) mais c'est contestable.
- Ces enregistrements PTR, en l'absence de DNSSEC, n'ont qu'une valeur limitée pour la sécurité, puisqu'ils peuvent être manipulés, ajoutés ou détruits par un tiers ; tester ces enregistrements via un résolveur non-validant n'est pas très sérieux,
- Attention à la vie privée : trop d'information dans un PTR peut poser des problèmes (cf. RFC 8117),
- Lorsque l'utilisateur peut choisir la chaîne de caractères
mise dans le PTR, son inventivité peut poser des problèmes
(
le-ministre-machin-est-un-voleur.example.net, ce qui peut valoir des ennuis juridiques au FAI).
Et si vous préférez lire en espagnol, Hugo Salgado l'a fait ici.
L'article seul
RFC 8499: DNS Terminology
Date de publication du RFC : Janvier 2019
Auteur(s) du RFC : P. Hoffman (ICANN), A. Sullivan, K. Fujiwara (JPRS)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 3 janvier 2019
Comme beaucoup de protocoles très utilisés sur l'Internet, le DNS est ancien. Très ancien (la première norme, le RFC 882, date de 1983). Les normes techniques vieillissent, avec l'expérience, on comprend mieux, on change les points de vue et donc, pour la plupart des protocoles, on se lance de temps en temps dans une révision de la norme. Mais le DNS est une exception : la norme actuelle reste fondée sur des textes de 1987, les RFC 1034 et RFC 1035. Ces documents ne sont plus à jour, modifiés qu'ils ont été par des dizaines d'autres RFC. Bref, aujourd'hui, pour comprendre le DNS, il faut s'apprêter à lire de nombreux documents. En attendant qu'un courageux et charismatique participant à l'IETF se lance dans la tâche herculéenne de faire un jeu de documents propre et à jour, ce RFC 8499, successeur du RFC 7719, se limite à une ambition plus modeste : fixer la terminologie du DNS. Ce n'est pas un tutoriel : vous n'y apprendrez pas le DNS. C'est plutôt une encyclopédie. Il a depuis été remplacé par le RFC 9499, mais avec peu de changements.
En effet, chacun peut constater que les discussions portant sur le DNS sont difficiles : on manque de terminologie standard, et celle des RFC officielles ne suffit pas, loin de là. Souvent, le DNS a tellement changé que le RFC officiel est même trompeur : les mots ne veulent plus dire la même chose. D'autres protocoles ont connu des mises à jour de la norme. Cela a été le cas de SMTP, passé successivement du RFC 772 à l'actuel RFC 5321, en passant par plusieurs révisions successives. Ou de XMPP, qui a vu sa norme originale mise à jour dans le RFC 6120. Et bien sûr de HTTP, qui a connu un toilettage complet. Mais personne n'a encore osé faire pareil pour le DNS. Au moins, ce RFC 8499, comme son prédécesseur RFC 7719, traite l'un des problèmes les plus criants, celui du vocabulaire. Le RFC est évidemment en anglais, les traductions proposées dans cet article, et qui n'ont pas de valeur « officielle » sont de moi seul.
Notre RFC 8499 rassemble donc des définitions pour des termes qui étaient parfois précisément définis dans d'autres RFC (et il fournit alors un lien vers ce RFC original), mais aussi qui n'étaient définis qu'approximativement ou parfois qui n'étaient pas définis du tout (et ce RFC fournit alors cette définition). Du fait du flou de certains RFC anciens, et des changements qui ont eu lieu depuis, certaines définitions sont différentes de l'original. Le document a fait l'objet d'un consensus relatif auprès des experts DNS mais quelques termes restent délicats. Notez aussi que d'autres organisations définissent des termes liés au DNS par exemple le WHATWG a sa définition de ce qu'est un domaine, et le RSSAC a développé une terminologie.
Ironiquement, un des termes les plus difficiles à définir est
« DNS » lui-même (section 1 de notre RFC). D'accord, c'est le sigle de Domain Name
System mais ça veut dire quoi ? « DNS » peut désigner le
schéma de nommage (les noms de
domaine comme signal.eu.org, leur
syntaxe, leurs contraintes), la base de données répartie (et
faiblement cohérente) qui associe à ces noms des informations
(comme des certificats, des adresses IP, etc), ou le protocole
requête/réponse (utilisant le port 53) qui permet d'interroger cette
base. Parfois, « DNS » désigne uniquement le protocole, parfois,
c'est une combinaison des trois éléments indiqués plus haut
(personnellement, quand j'utilise « DNS », cela désigne uniquement
le protocole, un protocole relativement simple, fondé sur l'idée « une requête => une réponse »).
Bon, et ces définitions rigoureuses et qui vont mettre fin aux discussions, ça vient ? Chaque section du RFC correspond à une catégorie particulière. D'abord, en section 2, les noms eux-même, ces fameux noms de domaine. Un système de nommage (naming system) a plusieurs aspects, la syntaxe des noms, la gestion des noms, le type de données qu'on peut associer à un nom, etc. D'autres systèmes de nommage que celui présenté dans ce RFC existent, et sont distincts du DNS sur certains aspects. Pour notre système de nommage, le RFC définit :
- Nom de domaine (domain
name) : la définition est différente de celle du RFC 7719, qui avait simplement repris celle du
RFC 1034, section 3.1. Elle est désormais
plus abstraite, ce qui permet de l'utiliser pour d'autres
systèmes de nommage. Un nom de domaine est désormais simplement
une liste (ordonnée) de composants
(labels). Aucune restriction n'est imposée
dans ces composants, simplement formés
d'octets (tant pis pour la légende comme
quoi le DNS serait limité à ASCII). Comme on
peut représenter les noms de domaine sous forme d'un arbre (la racine de l'arbre
étant à la fin de la liste des composants) ou bien sous forme
texte (
www.madmoizelle.com), le vocabulaire s'en ressent. Par exemple, on va dire quecomest « au-dessus demadmoizelle.com» (vision arborescente) ou bien « à la fin dewww.madmoizelle.com» (vision texte). Notez aussi que la représentation des noms de domaine dans les paquets IP n'a rien à voir avec leur représentation texte (par exemple, les points n'apparaissent pas). Enfin, il faut rappeler que le vocabulaire « standard » n'est pas utilisé partout, même à l'IETF, et qu'on voit parfois « nom de domaine » utilisé dans un sens plus restrictif (par exemple uniquement pour parler des noms pouvant être résolus avec le DNS, pour lesquels il avait été proposé de parler de DNS names.) - FQDN (Fully Qualified Domain
Name, nom de domaine complet) : apparu dans le RFC 819, ce terme désigne un nom de domaine où tous les
composants sont cités (par exemple,
ldap.potamochère.fr.est un FQDN alors queldaptout court ne l'est pas). En toute rigueur, un FQDN devrait toujours s'écrire avec un point à la fin (pour représenter la racine) mais ce n'est pas toujours le cas. (Notre RFC parle de « format de présentation » et de « format courant d'affichage » pour distinguer le cas où on met systématiquement le point à la fin et le cas où on l'oublie.) - Composant
(label) : un nœud de l'arbre des noms de domaine, dans la chaîne
qui compose un FQDN. Dans
www.laquadrature.net, il y a trois composants,www,laquadratureetnet. - Nom de machine (host
name) : ce n'est pas la
même chose qu'un nom de domaine. Utilisé dans de nombreux
RFC (par exemple RFC 952) mais jamais défini, un nom de
machine est un nom de domaine avec une syntaxe plus
restrictive, définie dans la section 3.5 du RFC 1035 et amendée par la section 2.1 du RFC 1123 : uniquement des lettres, chiffres, points et le
tiret. Ainsi,
brienne.tarth.got.examplepeut être un nom de machine maiswww.&#$%?.examplene peut pas l'être. Le terme de « nom de machine » est parfois aussi utilisé pour parler du premier composant d'un nom de domaine (briennedansbrienne.tarth.got.example). - TLD (Top Level
Domain, domaine de premier niveau ou domaine de
tête) : le dernier composant d'un nom de domaine, celui juste
avant (ou juste en dessous) de la racine. Ainsi,
frounamesont des TLD. N'utilisez surtout pas le terme erroné d'« extension ». Et ne dites pas que le TLD est le composant le plus à droite, ce n'est pas vrai dans l'alphabet arabe. La distinction courante entre gTLD, gérés par l'ICANN, et ccTLD, indépendants de l'ICANN, est purement politique et ne se reflète pas dans le DNS. - DNS mondial (Global DNS), nouveauté de notre RFC, désigne l'ensemble des noms qui obéissent aux règles plus restrictives des RFC 1034 et RFC 1035 (limitation à 255 octets, par exemple). En outre, les noms dans ce « DNS mondial » sont rattachés à la racine officiellement gérée par l'ICANN, via le service PTI. Une racine alternative, si elle sert un contenu différent de celui de PTI, n'est donc pas le « DNS mondial » mais ce que le RFC nomme « DNS privé » (private DNS). Évidemment, un système de nommage qui n'utilise pas le DNS du tout mais qui repose, par exemple, sur le pair-à-pair, ne doit pas être appelé DNS (« DNS pair-à-pair » est un oxymore, une contradiction dans les termes.)
- IDN (Internationalized Domain Name, nom de domaine internationalisé) : un nom de domaine en Unicode, normalisé dans le RFC 5890, qui définit des termes comme U-label (le nom Unicode) et A-label (sa représentation en Punycode). Sur l'internationalisation des noms, vous pouvez aussi consulter le RFC de terminologie RFC 6365.
- Sous-domaine
(subdomain) : domaine situé sous un autre,
dans l'arbre des noms de domaines. Sous forme texte, un domaine
est sous-domaine d'un autre si cet autre est un suffixe. Ainsi,
www.cl.cam.ac.ukest un sous-domaine decl.cam.ac.uk, qui est un sous-domaine decam.ac.uket ainsi de suite, jusqu'à la racine, le seul domaine à n'être sous-domaine de personne. Quand le RFC parle de suffixe, il s'agit d'un suffixe de composants, pas de caractères :foo.example.netn'est pas un sous-domaine deoo.example.net. - Alias (alias) :
attention, il y a un piège. Le DNS permet à un nom d'être un
alias d'un autre, avec le type d'enregistrement CNAME (voir la
définition suivante). L'alias est le terme de gauche de
l'enregistrement CNAME. Ainsi, si on met dans un fichier de zone
vader IN CNAME anakin, l'alias estvader(et c'est une erreur de dire que c'est « le CNAME »). - CNAME (Canonical
Name, nom canonique, le « vrai » nom) : le membre
droit dans l'enregistrement CNAME. Dans l'exemple de la
définition précédente,
anakinest le CNAME, le « nom canonique ».
Fini avec les noms, passons à l'en-tête des messages DNS et aux codes qu'il peut contenir. Cet en-tête est défini dans le RFC 1035, section 4.1. Il donne des noms aux champs mais pas forcément aux codes. Ainsi, le code de réponse 3 indiquant qu'un domaine demandé n'existe pas est juste décrit comme name error et n'a reçu son mnémonique de NXDOMAIN (No Such Domain) que plus tard. Notre RFC définit également, dans sa section 3 :
- NODATA : un mnémonique pour une réponse où le nom de domaine demandé existe bien mais ne contient aucun enregistrement du type souhaité. Le code de retour est 0, NOERROR, et le nombre de réponses (ANCOUNT pour Answer Count) est nul.
- Réponse négative (negative answer) : le terme recouvre deux choses, une réponse disant que le nom de domaine demandé n'existe pas (code de retour NXDOMAIN), ou bien une réponse indiquant que le serveur ne peut pas répondre (code de retour SERVFAIL ou REFUSED). Voir le RFC 2308.
- Renvoi (referral) : le DNS étant décentralisé, il arrive qu'on pose une question à un serveur qui ne fait pas autorité pour le domaine demandé, mais qui sait vous renvoyer à un serveur plus proche. Ces renvois sont indiqués dans la section Authority d'une réponse.
Voici un renvoi depuis la racine vers .fr :
% dig @l.root-servers.net A blog.imirhil.fr
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16572
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 5, ADDITIONAL: 11
...
;; AUTHORITY SECTION:
fr. 172800 IN NS d.ext.nic.fr.
fr. 172800 IN NS d.nic.fr.
fr. 172800 IN NS e.ext.nic.fr.
fr. 172800 IN NS f.ext.nic.fr.
fr. 172800 IN NS g.ext.nic.fr.
La section 4 s'intéresse aux transactions DNS. Un des termes définis est celui de QNAME (Query NAME). Nouveauté de ce RFC, il a suscité bien des débats. Il y a en effet trois sens possibles (le premier étant de très loin le plus commun) :
- Le sens original, le QNAME est la question posée (le nom de domaine demandé),
- Le sens du RFC 2308, la question finale (qui n'est pas la question posée s'il y a des CNAME sur le trajet),
- Un sens qui n'apparait pas dans les RFC mais est parfois présent dans les discussions, une question intermédiaire (dans une chaîne de CNAME).
Le RFC 2308 est clairement en tort ici. Il aurait dû utiliser un terme nouveau, pour le sens nouveau qu'il utilisait.
Passons maintenant aux enregistrements DNS, stockés dans cette base de données répartie (section 5 du RFC) :
- RR (Resource Record) : un enregistrement DNS.
- Enregistrements d'adresses (Address records) : enregistrements DNS A (adresses IPv4) et AAAA (adresses IPv6). Beaucoup de gens croient d'ailleurs que ce sont les seuls types d'enregistrements possibles (« le DNS sert à traduire les noms en adresses IP » est une des synthèses erronées du DNS les plus fréquentes).
- Ensemble d'enregistrements (RRset pour Resource Record set) : un ensemble d'enregistrements ayant le même nom (la même clé d'accès à la base), la même classe, le même type et le même TTL. Cette notion avait été introduite par le RFC 2181. Notez que la définition originale parle malheureusement de label dans un sens incorrect. La terminologie du DNS est vraiment compliquée !
- Fichier maître (master file) : un fichier texte contenant des ensembles d'enregistrement. Également appelé fichier de zone, car son utilisation la plus courante est pour décrire les enregistrements que chargera le serveur maître au démarrage. (Ce format peut aussi servir à un résolveur quand il écrit le contenu de sa mémoire sur disque.)
- EDNS (Extension for DNS, également appelé EDNS0) : normalisé dans le RFC 6891, EDNS permet d'étendre l'en-tête du DNS, en spécifiant de nouvelles options, en faisant sauter l'antique limitation de taille de réponses à 512 octets, etc.
- OPT (pour Option) : une astuce d'EDNS pour encoder les informations de l'en-tête étendu. C'est un enregistrement DNS un peu spécial, défini dans le RFC 6891, section 6.1.1.
- Propriétaire (owner ou owner name) : le nom de domaine d'un enregistrement. Ce terme est très rarement utilisé, même par les experts.
- Champs du SOA (SOA field names) : ces noms des enregistrements SOA (comme MNAME ou RNAME) sont peu connus et malheureusement peu utilisés (RFC 1035, section 3.3.13). Notez que la sémantique du champ MINIMUM a complètement changé avec le RFC 2308.
- TTL (Time To Live) : la durée de vie maximale d'un enregistrement dans les caches des résolveurs. C'est un entier non signé (même si le RFC 1035 dit le contraire), en secondes.
Voici un ensemble d'enregistrements (RRset), comptant ici deux enregistrements :
rue89.com. 600 IN MX 50 mx2.typhon.net.
rue89.com. 600 IN MX 10 mx1.typhon.net.
(Depuis, ça a changé.)
Et voici un pseudo-enregistrement OPT, tel qu'affiché par dig, avec une indication de la taille maximale et l'option client subnet (RFC 7871) :
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 512
; CLIENT-SUBNET: 13.176.144.0/24/0
Ensuite, un sujet chaud où le vocabulaire est particulièrement peu défini, et très mal utilisé (voir les forums grand public sur le DNS où les discussions prennent un temps fou car les gens utilisent mal les mots) : les différents types de serveurs et clients DNS (section 6). Pour commencer, il est crucial de se méfier quand un texte parle de « serveur DNS » tout court. Si le contexte ne permet pas de savoir de quel genre de serveur DNS on parle, cela indique un manque de compréhension du DNS par l'auteur du texte. Serveurs faisant autorité et serveurs résolveurs, quoique utilisant le même protocole, sont en effet très différents.
- Résolveur (resolver) : un client DNS qui va produire une réponse finale (pas juste un renvoi, pas juste une information ponctuelle comme le fait dig). Il existe plusieurs types de résolveurs (voir ci-dessous) et, en pratique, quand on dit « résolveur » tout court, c'est en général un « résolveur complet ».
- Résolveur minimum (stub
resolver) : un résolveur qui ne sait pas suivre les
renvois et qui dépend donc d'un ou de plusieurs résolveurs
complets pour faire son travail. Ce type est défini dans la
section 6.1.3.1 du RFC 1123. C'est ce
résolveur minimum qu'appelent les applications lorsqu'elles font
un
getaddrinfo()ougetnameinfo(). Sur Unix, le résolveur minimum fait en général partie de la libc et trouve l'adresse du ou des résolveurs complets dans/etc/resolv.conf. - Résolveur complet (full resolver) : un résolveur qui sait suivre les renvois et donc fournir un service de résolution complet. Des logiciels comme Unbound ou PowerDNS Resolver assurent cette fonction. Le résolveur complet est en général situé chez le FAI ou dans le réseau local de l'organisation où on travaille, mais il peut aussi être sur la machine locale. On le nomme aussi « résolveur récursif ». Notez que « résolveur complet » fait partie de ces nombreux termes qui étaient utilisés sans jamais avoir été définis rigoureusement.
- Resolveur complet avec mémoire (full-service resolver) : un résolveur complet, qui dispose en plus d'une mémoire (cache) des enregistrements DNS récoltés.
- Serveur faisant autorité
(authoritative server et traduire ce terme
par « serveur autoritaire » montre une grande ignorance de
l'anglais ; un adjudant est autoritaire,
un serveur DNS fait autorité) : un serveur DNS qui connait une
partie des données du DNS (il « fait autorité » pour une ou
plusieurs zones) et peut donc y répondre (RFC 2182,
section 2). Ainsi, au moment de l'écriture de cet article,
f.root-servers.netfait autorité pour la racine,d.nic.frfait autorité pourpm, etc. Des logiciels comme NSD ou Knot assurent cette fonction. Les serveurs faisant autorité sont gérés par divers acteurs, les registres, les hébergeurs DNS (qui sont souvent en même temps bureaux d'enregistrement), mais aussi parfois par M. Michu. La commandedig NS $ZONEvous donnera la liste des serveurs faisant autorité pour la zone$ZONE. Ou bien vous pouvez utiliser un service sur le Web en visitanthttps://dns.bortzmeyer.org/DOMAIN/NSoù DOMAIN est le nom de domaine qui vous intéresse. - Serveur mixte : ce terme n'est pas dans ce RFC. Autrefois, il était courant que des serveurs DNS fassent à la fois résolveur et serveur faisant autorité. Cette pratique est fortement déconseillée depuis de nombreuses années (entre autres parce qu'elle complique sérieusement le débogage, mais aussi pour des raisons de sécurité parce qu'elle mène à du code plus complexe) et n'est donc pas dans ce RFC.
- Initialisation
(priming) : le processus par lequel un
résolveur complet vérifie l'information sur les serveurs de la
racine. Ce concept est décrit en détail dans le RFC 8109. Au démarrage, le résolveur ne sait rien. Pour
pouvoir commencer la résolution de noms, il doit demander aux
serveurs de la racine. Il a donc dans sa configuration leur
liste. Mais ces configurations ne sont pas forcément mises à
jour souvent. La liste peut donc être trop vieille. La première
chose que fait un résolveur est donc d'envoyer une requête
«
NS .» à un des serveurs de sa liste. Ainsi, tant qu'au moins un des serveurs de la vieille liste répond, le résolveur est sûr d'apprendre la liste actuelle. - Indications de la racine (root hints, terme défini dans ce nouveau RFC, et qui n'était pas dans son prédécesseur) : la liste des noms et adresses des serveurs racine, utilisée pour l'initialisation. L'administrateur d'un résolveur utilisant une racine alternative changera cette liste.
- Mémorisation des négations (negative caching, ou « cache négatif ») : mémoriser le fait qu'il n'y a pas eu de réponse, ou bien une réponse disant qu'un nom de domaine n'existe pas.
- Serveur primaire (primary
server mais on dit aussi serveur maître, master
server) : un serveur faisant autorité qui a accès à la
source des données (fichier de zone, base de données,
etc). Attention, il peut y avoir plusieurs serveurs
primaires (autrefois, ce n'était pas clair et beaucoup de gens
croient qu'il y a un serveur primaire, et qu'il est indiqué dans
l'enregistrement SOA). Attention bis, le terme ne s'applique qu'à des
serveurs faisant autorité, l'utiliser pour les résolveurs (« on
met en premier dans
/etc/resolv.confle serveur primaire ») n'a pas de sens. - Serveur secondaire (secondary server mais on dit aussi « serveur esclave », slave server) : un serveur faisant autorité qui n'est pas la source des données, qui les a prises d'un serveur primaire (dit aussi serveur maître), via un transfert de zone (RFC 5936).
- Serveur furtif (stealth server) : un serveur faisant autorité mais qui n'apparait pas dans l'ensemble des enregistrements NS. (Définition du RFC 1996, section 2.1.)
- Maître caché (hidden master) : un serveur primaire qui n'est pas annoncé publiquement (et n'est donc accessible qu'aux secondaires). C'est notamment utile avec DNSSEC : s'il signe, et donc a une copie de la clé privée, il vaut mieux qu'il ne soit pas accessible de tout l'Internet (RFC 6781, section 3.4.3).
- Transmission (forwarding) : le fait, pour un résolveur, de faire suivre les requêtes à un autre résolveur (probablement mieux connecté et ayant un cache partagé plus grand). On distingue parfois (mais ce n'est pas forcément clair, même dans le RFC 5625) la transmission, où on émet une nouvelle requête, du simple relayage de requêtes sans modification.
- Transmetteur
(forwarder) : le terme est confus (et a
suscité plein de débats dans le groupe de travail DNSOP lors de
la mise au point du précédent RFC, le RFC 7719). Il désigne parfois la machine qui transmet une
requête et parfois celle vers laquelle on transmet (c'est dans
ce sens qu'il est utilisé dans la configuration de
BIND, avec la directive
forwarders). - Résolveur politique (policy-implementing resolver) : un résolveur qui modifie les réponses reçues, selon sa politique. On dit aussi, moins diplomatiquement, un « résolveur menteur ». C'est ce que permet, par exemple, le système RPZ. Sur l'utilisation de ces « résolveurs politiques » pour mettre en œuvre la censure, voir entre autres mon article aux RIPE Labs. Notez que le résolveur politique a pu être choisi librement par l'utilisateur (par exemple comme élément d'une solution de blocage des publicités) ou bien qu'il lui a été imposé.
- Résolveur ouvert (open resolver) : un résolveur qui accepte des requêtes DNS depuis tout l'Internet. C'est une mauvaise pratique (cf. RFC 5358) et la plupart de ces résolveurs ouverts sont des erreurs de configuration. Quand ils sont délibérement ouverts, comme Google Public DNS ou Quad9, on parle plutôt de résolveurs publics.
- Collecte DNS passive (passive DNS) : désigne les systèmes qui écoutent le trafic DNS, et stockent tout ou partie des informations échangées. Le cas le plus courant est celui où le système de collecte ne garde que les réponses (ignorant donc les adresses IP des clients et serveurs), afin de constituer une base historique du contenu du DNS (c'est ce que font DNSDB ou le système de PassiveDNS.cn).
- Serveur protégeant la vie privée (privacy-enabled server) : nouveauté de ce RFC; ce terme désigne un serveur, typiquement un résolveur, qui permet les requêtes DNS chiffrées, avec DNS-sur-TLS (RFC 7858) ou avec DoH (RFC 8484).
- Anycast : le fait d'avoir un service en plusieurs sites physiques, chacun annonçant la même adresse IP de service (RFC 4786). Cela résiste mieux à la charge, et permet davantage de robustesse en cas d'attaque par déni de service. Les serveurs de la racine, ceux des « grands » TLD, et ceux des importants hébergeurs DNS sont ainsi « anycastés ». Chaque machine répondant à l'adresse IP de service est appelée une instance.
- DNS divisé (split
DNS) : le fait de donner des réponses différentes
selon que le client est interne à une organisation ou
externe. Le but est, par exemple, de faire en sorte que
www.organisation.exampleaille sur le site public quand on vient de l'Internet mais sur un site interne de la boîte quand on est sur le réseau local des employés.
Voici, vu par tcpdump, un exemple d'initialisation d'un résolveur BIND utilisant la racineYeti (RFC 8483) :
15:07:36.736031 IP6 2a01:e35:8bd9:8bb0:21e:8cff:fe76:29b6.35721 > 2001:6d0:6d06::53.53: \
21476% [1au] NS? . (28)
15:07:36.801982 IP6 2001:6d0:6d06::53.53 > 2a01:e35:8bd9:8bb0:21e:8cff:fe76:29b6.35721: \
21476*- 16/0/1 NS yeti-ns.tisf.net., NS yeti-ns.lab.nic.cl., NS yeti-ns.wide.ad.jp., NS yeti.ipv6.ernet.in., NS yeti-ns.as59715.net., NS ns-yeti.bondis.org., NS yeti-dns01.dnsworkshop.org., NS dahu2.yeti.eu.org., NS dahu1.yeti.eu.org., NS yeti-ns.switch.ch., NS bii.dns-lab.net., NS yeti.bofh.priv.at., NS yeti-ns.conit.co., NS yeti.aquaray.com., NS yeti-ns.ix.ru., RRSIG (619)
La question était « NS . » (quels sont les
serveurs de la racine) et la réponse contenait les noms des seize
serveurs racine qu'avait Yeti à l'époque.
Voici aussi des exemples de résultats avec un résolveur ou bien avec un serveur faisant autorité. Si je demande à un serveur faisant autorité (ici, un serveur racine), avec mon client DNS qui, par défaut, demande un service récursif (flag RD, Recursion Desired) :
% dig @2001:620:0:ff::29 AAAA www.iab.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 54197
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 9, ADDITIONAL: 13
;; WARNING: recursion requested but not available
...
;; AUTHORITY SECTION:
org. 172800 IN NS b0.org.afilias-nst.org.
...
C'est pour cela que dig affiche WARNING: recursion requested but not available. Notez aussi que le serveur, ne faisant autorité que pour la racine, n'a pas donné la réponse mais juste un renvoi aux serveurs d'Afilias. Maintenant, interrogeons un serveur récursif (le service de résolveur public Yandex DNS) :
% dig @2a02:6b8::feed:0ff AAAA www.iab.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 63304
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
...
;; ANSWER SECTION:
www.iab.org. 1800 IN AAAA 2001:1900:3001:11::2c
Cette fois, j'ai obtenu une réponse, et avec le
flag RA, Recursion
Available. Si je pose une question sans le
flag RD (Recursion Desired,
avec l'option +norecurse de dig) :
% dig +norecurse @2a02:6b8::feed:0ff AAAA www.gq.com
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 59438
;; flags: qr ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
...
;; ANSWER SECTION:
www.gq.com. 293 IN CNAME condenast.map.fastly.net.
J'ai obtenu ici une réponse car l'information était déjà dans le cache (la mémoire) de Yandex DNS (on le voit au TTL, qui n'est pas un chiffre rond, il a été décrémenté du temps passé dans le cache). Si l'information n'est pas dans le cache :
% dig +norecurse @2a02:6b8::feed:0ff AAAA blog.keltia.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 19893
;; flags: qr ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0
...
Je n'obtiens alors pas de réponse (ANSWER: 0, donc NODATA). Si je demande au serveur faisant autorité pour cette zone :
% dig +norecurse @2a01:e0d:1:3:58bf:fa61:0:1 AAAA blog.keltia.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 62908
;; flags: qr aa; QUERY: 1, ANSWER: 2, AUTHORITY: 6, ADDITIONAL: 15
...
;; ANSWER SECTION:
blog.keltia.net. 86400 IN AAAA 2a01:240:fe5c:1::2
...
J'ai évidemment une réponse et, comme il s'agit d'un serveur faisant autorité, elle porte le flag AA (Authoritative Answer, qu'un résolveur ne mettrait pas). Notez aussi le TTL qui est un chiffre rond (et qui ne change pas si on rejoue la commande).
Passons maintenant à un concept relativement peu connu, celui de zones, et le vocabulaire associé (section 7) :
- Zone : un groupe de domaines contigus
dans l'arbre des noms, et gérés ensemble, par le même ensemble
de serveurs de noms (ma définition, celle du RFC étant très
abstraite). Beaucoup de gens croient que tout domaine est une
zone, mais c'est faux. Ainsi, au moment de la publication de ce
RFC,
gouv.frn'est pas une zone séparée, il est dans la même zone quefr(cela se teste facilement :gouv.frn'a pas d'enregistrement NS ou de SOA). - Parent : le domaine « du
dessus ». Ainsi, le parent de
wikipedia.orgestorg, le parent de.orgest la racine. - Apex : le sommet d'une zone, là où on trouve les enregistrements NS et SOA. Si la zone ne comprend qu'un domaine, l'apex est ce domaine. Si la zone est plus complexe, l'apex est le domaine le plus court. (On voit parfois des gens utiliser le terme erroné de racine pour parler de l'apex.)
- Coupure de zone (zone cut) : l'endoit où on passe d'une zone à l'autre. Au-dessus de la coupure, la zone parente, en dessous, la zone fille.
- Délégation (delegation) : un concept évidemment central dans le DNS, qui est un système décentralisé. En ajoutant un ensemble d'enregistrements NS pointant vers les serveurs de la zone fille, une zone parente délègue une partie de l'arbre des noms de domaine à une autre entité. L'endroit où se fait la délégation est donc une coupure de zone.
- Colle (glue
records) : lorsqu'une zone est déléguée à des serveurs
dont le nom est dans la zone fille, la résolution DNS se heurte
à un problème d'œuf et de poule. Pour trouver l'adresse de
ns1.mazone.example, le résolveur doit passer par les serveurs demazone.example, qui est déléguée àns1.mazone.exampleet ainsi de suite... On rompt ce cercle vicieux en ajoutant, dans la zone parente, des données qui ne font pas autorité sur les adresses de ces serveurs (RFC 1034, section 4.2.1). Il faut donc bien veiller à les garder synchrones avec la zone fille. (Tanguy Ortolo me suggère d'utiliser « enregistrement de raccord » plutôt que « colle ». Cela décrit bien leur rôle, en effet.) - Délégation boiteuse (lame delegation) : un ou plusieurs des serveurs à qui la zone est déléguée ne sont pas configurés pour servir cette zone. La délégation peut avoir été boiteuse depuis le début (parce que le titulaire a indiqué des noms un peu au hasard) ou bien l'être devenue par la suite. C'est certainement une des erreurs techniques les plus courantes.
- Dans le bailliage (in bailiwick) : terme absent des textes DNS originaux et qui peut désigner plusieurs choses. (La définition du RFC 7719, embrouillée, a été heureusement remplacée.) « Dans le bailliage » est (très rarement, selon mon expérience) parfois utilisé pour parler d'un serveur de noms dont le nom est dans la zone servie (et qui nécessite donc de la colle, voir la définition plus haut), mais le sens le plus courant désigne des données pour lesquelles le serveur qui a répondu fait autorité, soit pour la zone, soit pour un ancêtre de cette zone. L'idée est qu'il est normal dans la réponse d'un serveur de trouver des données situées dans le bailliage et, par contre, que les données hors-bailliage sont suspectes (elles peuvent être là suite à une tentative d'empoisonnement DNS). Un résolveur DNS prudent ignorera donc les données hors-bailliage.
- ENT (Empty
Non-Terminal pour nœud non-feuille mais vide) : un
domaine qui n'a pas d'enregistrements mais a des
sous-domaines. C'est fréquent, par exemple, sous
ip6.arpaou sous les domaines très longs de certains CDN. Cela se trouve aussi avec les enregistrements de service : dans_sip._tcp.example.com,_tcp.example.comest probablement un ENT. La réponse correcte à une requête DNS pour un ENT est NODATA (code de réponse NOERROR, liste des répoonses vide) mais certains serveurs bogués, par exemple ceux d'Akamai, répondent NXDOMAIN. - Zone de délégation (delegation-centric zone) : zone composée essentiellement de délégations vers d'autres zones. C'est typiquement le cas des TLD et autres suffixes publics. Il est amusant de noter que les RFC 4956 et RFC 5155 utilisaient ce terme sans le définir.
- Changement rapide (fast flux) : une technique notamment utilisée par les botnets pour mettre leur centre de commande à l'abri des filtrages ou destructions. Elle consiste à avoir des enregistrements d'adresses IP avec des TTL très courts et à en changer fréquemment.
- DNS inverse (reverse DNS) : terme qui désigne en général les requêtes pour des enregistrements de type PTR, permettant de trouver le nom d'une machine à partir de son adresse IP. À ne pas confondre avec les vraies requêtes inverses, qui avaient été normalisées dans le RFC 1035, avec le code IQUERY, mais qui, jamais vraiment utilisées, ont été abandonnées dans le RFC 3425.
Voyons ici la colle retournée par un serveur faisant autorité (en
l'occurrence un serveur de .net) :
% dig @a.gtld-servers.net AAAA labs.ripe.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 18272
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 8, ADDITIONAL: 9
...
;; AUTHORITY SECTION:
ripe.net. 172800 IN NS ns3.nic.fr.
ripe.net. 172800 IN NS sec1.apnic.net.
ripe.net. 172800 IN NS sec3.apnic.net.
ripe.net. 172800 IN NS tinnie.arin.net.
ripe.net. 172800 IN NS sns-pb.isc.org.
ripe.net. 172800 IN NS pri.authdns.ripe.net.
...
;; ADDITIONAL SECTION:
sec1.apnic.net. 172800 IN AAAA 2001:dc0:2001:a:4608::59
sec1.apnic.net. 172800 IN A 202.12.29.59
sec3.apnic.net. 172800 IN AAAA 2001:dc0:1:0:4777::140
sec3.apnic.net. 172800 IN A 202.12.28.140
tinnie.arin.net. 172800 IN A 199.212.0.53
tinnie.arin.net. 172800 IN AAAA 2001:500:13::c7d4:35
pri.authdns.ripe.net. 172800 IN A 193.0.9.5
pri.authdns.ripe.net. 172800 IN AAAA 2001:67c:e0::5
On notera :
- La section ANSWER est vide, c'est un renvoi.
- Le serveur indique la colle pour
pri.authdns.ripe.net: ce serveur étant dans la zone qu'il sert, sans son adresse IP, on ne pourrait jamais le joindre. - Le serveur envoie également les adresses IP d'autres
machines comme
sec1.apnic.net. Ce n'est pas strictement indispensable (on pourrait l'obtenir par une nouvelle requête), juste une optimisation. - Les adresses de
ns3.nic.fretsns-pb.isc.orgne sont pas renvoyées. Le serveur ne les connait probablement pas et, de toute façon, elles seraient hors-bailliage, donc ignorées par un résolveur prudent.
Voyons maintenant, un ENT,
gouv.fr (notez que, depuis, ce domaine n'est
plus un ENT) :
% dig @d.nic.fr ANY gouv.fr
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42219
;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 2, ADDITIONAL: 1
Le serveur fait bien autorité pour ce domaine (flag AA dans la réponse), le domaine existe (autrement, le status aurait été NXDOMAIN, pas NOERROR) mais il n'y a aucun enregistrement (ANSWER: 0).
Et, ici, une délégation boiteuse, pour
.ni :
% check-soa ni
dns.nic.cr.
2001:13c7:7004:1::d100: ERROR: SERVFAIL
200.107.82.100: ERROR: SERVFAIL
ns.ideay.net.ni.
186.1.31.8: OK: 2013093010
ns.ni.
165.98.1.2: ERROR: read udp 10.10.86.133:59569->165.98.1.2:53: i/o timeout
ns.uu.net.
137.39.1.3: OK: 2013093010
ns2.ni.
200.9.187.2: ERROR: read udp 10.10.86.133:52393->200.9.187.2:53: i/o timeout
Le serveur dns.nic.cr est déclaré comme
faisant autorité pour .ni mais il ne le sait
pas, et répond donc SERVFAIL.
Les jokers ont désormais une section à eux, la section 8 du RFC. S'appuyant sur le RFC 4592, elle définit, entre autres :
- Joker
(wildcard) : une source de confusion
considérable depuis les débuts du DNS. Si on pouvait refaire le
DNS en partant de zéro, ces jokers seraient la première chose à
supprimer. Pour les résumer, le nom
*dans une zone déclenche la synthèse automatique de réponses pour les noms qui n'existent pas dans la zone. Si la zonefoo.examplecontientbar.foo.exampleet*.foo.example, une requête pourthing.foo.examplerenverra le contenu de l'enregistrement avec le joker, une requête pourbar.foo.exampledonnera les données debar.foo.example. Attention, l'astérisque n'a son rôle particulier que s'il est le composant le plus spécifique (le premier). Dansfoo.*.bar.example, il n'y a pas de joker. - Ancêtre le plus proche
(closest encloser) : c'est le plus long
ancêtre existant d'un nom. Si
foo.bar.baz.examplen'existe pas, quebar.baz.examplen'existe pas non plus, mais quebaz.exampleexiste, alorsbaz.exampleest l'ancêtre le plus proche defoo.bar.baz.example. Ce concept est nécessaire pour le RFC 5155.
Allez courage, ne faiblissons pas, il reste encore la question de l'enregistrement des noms de domaine (section 9) :
- Registre
(registry) : l'organisation ou la personne
qui gère les délégations d'une zone. Le terme est parfois
employé uniquement pour les gérants de grandes zones de
délégation, mais ce n'est pas obligatoire. Je suis à moi tout
seul le registre de
bortzmeyer.org😁. C'est le registre qui décide de la politique d'enregistrement, qui peut être très variable selon les zones (sauf dans celles contrôlées par l'ICANN, où une certaine uniformité est imposée). Mes lecteurs français noteront que, comme le terme « registre » est court et largement utilisé, le gouvernement a inventé un nouveau mot, plus long et jamais vu auparavant, « office d'enregistrement ». - Titulaire (registrant, parfois holder) : la personne ou l'organisation qui a enregistré un nom de domaine.
- Bureau d'enregistrement (registrar) : dans le modèle RRR (Registry-Registrar-Registrant, mais ce modèle n'est pas obligatoire et pas universel), c'est un intermédiaire entre le titulaire et le registre.
- Hébergeur DNS (DNS operator) : la personne ou l'organisation qui gère les serveurs DNS. Cela peut être le titulaire, son bureau d'enregistrement, ou encore un acteur spécialisé dans cette gestion.
- Suffixe public (public
suffix) : ce terme pas très officiel est parfois
utilisé pour désigner un suffixe de noms de domaine qui est
contrôlé par un registre public (au sens où il accepte des
enregistrements du public). Le terme est ancien mais est apparu
pour la première fois dans un RFC avec le RFC 6265, section 5.3.
com,co.uketeu.orgsont des suffixes publics. Rien dans la syntaxe du nom n'indique qu'un nom de domaine est un suffixe public, puisque ce statut ne dépend que d'une politique d'enregistrement (qui peut changer). Il est parfaitement possible qu'un domaine, et un de ses enfants, soient tous les deux un suffixe public (c'est le cas de.orgeteu.org). - EPP (Extensible Provisioning Protocol) : normalisé dans le RFC 5730, c'est le protocole standard entre bureau d'enregistrement et registre. Ce protocole n'a pas de lien avec le DNS, et tous les registres ne l'utilisent pas.
- Whois (nommé d'après la question Who Is?) : un protocole réseau, sans lien avec le DNS, normalisé dans le RFC 3912. Il permet d'interroger les bases de données du registre pour trouver les informations dites « sociales », informations qui ne sont pas dans le DNS (comme le nom du titulaire, et des moyens de le contacter). Les termes de « base Whois » ou de « données Whois » sont parfois utilisés mais ils sont erronés puisque les mêmes bases peuvent être interrogées par d'autres protocoles que Whois, comme RDAP (voir définition suivante).
- RDAP (Registration Data Access Protocol) : un protocole concurrent de Whois, mais plus moderne. RDAP est décrit notamment dans les RFC 9082 et RFC 9083.
Prenons par exemple le domaine eff.org. Au
moment de la publication du RFC :
Enfin, pour terminer, les sections 10 et 11 de notre RFC couvrent DNSSEC. Pas grand'chose de nouveau ici, DNSSEC étant plus récent et donc mieux défini.
L'annexe A de notre RFC indique quelles définitions existaient dans de précédents RFC mais ont été mises à jour par le nôtre. (C'est rare, puisque le but de ce RFC de terminologie est de rassembler les définitions, pas de les changer.) Par exemple, la définition de QNAME du RFC 2308 est corrigée ici.
L'annexe B liste les termes dont la première définition formelle se trouve dans ce RFC (ou dans son prédécesseur le RFC 7719). Cette liste est bien plus longue que celle de l'annexe A, vu le nombre de termes courants qui n'avaient jamais eu l'honneur d'une définition stricte.
Notre RFC ne contient pas une liste exhaustive des changements depuis son prédécesseur, le RFC 7719, alors qu'il y a quelques modifications substantielles. Parmi les gros changements :
- La description des autres systèmes de nommage ; on peut penser à Namecoin ou à ENS (Ethereum Name Service, cf. leur site Web). La section 2 donne une définition de naming system qui n'existait pas avant.
- La définition d'un nom de domaine a complètement changé, pour être plus générale, moins liée au DNS, de façon à pouvoir la conserver avec d'autres systèmes de nommage. Ce sujet a toujours été sensible à l'IETF. À une époque, il avait été proposé de différencier domain name et DNS name (ces seconds étant un sous-ensemble des premiers, utilisés dans le contexte du DNS) mais cela n'a pas été retenu.
- Des définitions ont été sérieusement changées, comme celle de bailiwick.
- Et plein de nouveaux termes ont été introduits comme « instance » (pour l'anycast), split DNS, reverse dns, indications de la racine (root hints), etc.
L'article seul
RFC 8493: The BagIt File Packaging Format (V1.0)
Date de publication du RFC : Octobre 2018
Auteur(s) du RFC : J. Kunze (California Digital
Library), J. Littman (Stanford
Libraries), E. Madden (Library of
Congress), J. Scancella, C. Adams (Library of Congress)
Pour information
Première rédaction de cet article le 20 décembre 2018
Le format BagIt, très utilisé dans le monde des bibliothèques (monde d'où sont issus les auteurs de ce RFC), décrit une série de conventions pour un ensemble de fichiers décrivant un contenu numérique quelconque. En fait, BagIt n'est pas vraiment un format (on ne peut pas le comparer à tar ou à zip), il définit juste les fichiers qui doivent être présents dans l'archive.
Une archive BagIt est appelée un sac (bag). Elle est composée des fichiers de contenu, qui sont d'un format quelconque, et des fichiers de métadonnées, qui décrivent le contenu (ces fichiers de métadonnées se nomment tags). BagTit met l'accent sur le contrôle de l'intégrité des données (les tags contiennent un condensat cryptographique des données) et sur la facilité d'accès à un fichier donné (les fichiers de données ne sont pas sérialisés dans un seul grand fichier, comme avec tar ou zip, ils restent sous la forme d'une arborescence).
La section 2 du RFC décrit la structure d'un sac :
- Des fichiers de métadonnées (les
tags) dont deux sont obligatoires,
bagit.txtqui indique le numéro de version BagIt, etmanifest-HASHALGO.txtqui contient les condensats. - Un répertoire
data/sous lequel se trouvent les fichiers de données. - Si on veut, des répetoires contenant des fichiers de métadonnées optionnels.
Voici un exemple d'un sac, contenant deux fichiers de données,
Makefile et
bortzmeyer-ripe-atlas-lapaz.tex :
% find /tmp/RIPE-Atlas-Bolivia
/tmp/RIPE-Atlas-Bolivia
/tmp/RIPE-Atlas-Bolivia/manifest-sha512.txt
/tmp/RIPE-Atlas-Bolivia/data
/tmp/RIPE-Atlas-Bolivia/data/Makefile
/tmp/RIPE-Atlas-Bolivia/data/bortzmeyer-ripe-atlas-lapaz.tex
/tmp/RIPE-Atlas-Bolivia/manifest-sha256.txt
/tmp/RIPE-Atlas-Bolivia/tagmanifest-sha256.txt
/tmp/RIPE-Atlas-Bolivia/bag-info.txt
/tmp/RIPE-Atlas-Bolivia/tagmanifest-sha512.txt
/tmp/RIPE-Atlas-Bolivia/bagit.txt
% cat /tmp/RIPE-Atlas-Bolivia/bagit.txt
BagIt-Version: 0.97
Tag-File-Character-Encoding: UTF-8
% cat /tmp/RIPE-Atlas-Bolivia/bag-info.txt
Bag-Software-Agent: bagit.py v1.7.0 <https://github.com/LibraryOfCongress/bagit-python>
Bagging-Date: 2018-12-20
Contact-Email: stephane+atlas@bortzmeyer.org
Contact-Name: Stéphane Bortzmeyer
Payload-Oxum: 6376.2
% cat /tmp/RIPE-Atlas-Bolivia/manifest-sha256.txt
6467957fa9c06d30c1a72b62d13a224a3cdb570e5f550ea1d292c09f2293b35d data/Makefile
3d65d66d6abcf1313ff7af7f94b7f591d2ad2c039bf7931701a936f1305ac728 data/bortzmeyer-ripe-atlas-lapaz.t
Les condensats ont été faits avec SHA-256.
Le fichier obligatoire bagit.txt doit
indiquer le numéro de version et
l'encodage. Le RFC décrit la version 1.0
mais, comme vous pouvez le voir plus haut, j'ai utilisé un outil un
peu ancien pour fabriquer le sac. Le répertoire
data/ contient les fichiers de données, non
modifiés (BagIt les traite comme du contenu binaire, copié au bit
près). manifest-sha256.txt contient une ligne
par fichier de données, indiquant le condensat. Notez qu'il peut y
avoir plusieurs manifestes, avec des
algorithmes différents. Cela permet, si un nouvel algorithme de
condensation plus
solide apparait, d'ajouter le manifeste au sac. Les noms
d'algorithmes de condensation sont tirés du registre
IANA du RFC 6920. Quant aux fichiers
(non obligatoires) dont le nom commence par
tagmanifest, ils indiquent les condensats des
fichiers de métadonnées :
% cat /tmp/RIPE-Atlas-Bolivia/tagmanifest-sha256.txt 16ed27c2c457038ca57536956a4431de4ac2079a7ec8042bab994696eb017b90 manifest-sha512.txt b7e3c4230ebd4d3b878f6ab6879a90067ef791f1a5cb9ffc8a9cb1f66a744313 manifest-sha256.txt 91ca8ae505de9266e37a0017379592eb44ff0a2b33b240e0b6e4f2e266688a98 bag-info.txt e91f941be5973ff71f1dccbdd1a32d598881893a7f21be516aca743da38b1689 bagit.txt
Enfin, le facultatif bag-info.txt contient des
métadonnées qui ne sont typiquement prévues que pour les humains,
pas pour être analysées automatiquement. La syntaxe est la classique
Nom: Valeur. Certains des noms sont
officiellement réservés (Contact-Name,
Bagging-Date…) et on peut en ajouter d'autres à
volonté.
Le sac est un répertoire, pas un fichier, et ne peut donc pas être transporté simplement, par exemple avec le protocole HTTP. On peut utiliser rsync, ou bien le sérialiser, par exemple en zip.
Il est amusant de noter qu'un sac peut être incomplet : des
fichiers de données peuvent être stockés à l'extérieur, et récupérés
dynamiquement lorsqu'on vérifie l'intégrité du sac. Dans ce cas, le
condensat dans le manifeste permettra de vérifier qu'on a bien
récupéré le contenu attendu. Les URL où
récupérer ce contenu supplémentaire seront dans un fichier
fetch.txt.
Un sac peut être complet (ou pas) et ensuite
valide (ou pas). La section 3 de notre RFC
définit ces termes : un sac est complet s'il contient tous les
fichiers obligatoires, et que tous les fichiers dans les manifestes
sont présents, et que les fichiers comme
bagit.txt ont une syntaxe correcte. Un sac est
valide s'il est complet et que tous les
condensats sont corrects.
La section 5 du RFC détaille quelques questions de sécurité liées à BagIt :
- BagIt va fonctionner entre systèmes
d'exploitation différents. Les noms de fichiers
peuvent comporter des caractères qui sont spéciaux pour un système
d'exploitation mais pas pour un autre. Une mise en œuvre de BagIt
sur Unix, par exemple,
ne doit donc pas accéder aveuglément à un fichier commençant par
une barre oblique, ou bien comprenant
/../../../. (Une suite de tests existe, avec plusieurs sacs… intéressants, permettant de tester la robustesse d'une mise en œuvre de BagIt.) - La possibilité de récupérer des fichiers distants ouvre évidemment plein de questions de sécurité amusantes (les plus évidentes sont résolues par l'utilisation de condensats dans les manifestes, je vous laisse chercher les autres).
Sans que cela soit forcément un problème de sécurité, d'autres différences entre systèmes d'exploitation peuvent créer des surprises (section 6 du RFC), par exemple l'insensibilité à la casse de certains systèmes de fichiers, ou bien la normalisation Unicode. La section 6 est d'ailleurs une lecture intéressante sur les systèmes de fichiers, et leurs comportements variés.
Passons maintenant aux programmes disponibles. Il en existe en plusieurs langages de programmation. Le plus répandu semble bagit-python, en Python. Il a été développé à la bibliothèque du Congrès, un gros utilisateur et promoteur de BagIt. La documentation est simple et lisible. On installe d'abord :
% pip3 install bagit Collecting bagit Downloading https://files.pythonhosted.org/packages/ee/11/7a7fa81c0d43fb4d449d418eba57fc6c77959754c5c2259a215152810555/bagit-1.7.0.tar.gz Building wheels for collected packages: bagit Running setup.py bdist_wheel for bagit ... done Stored in directory: /home/bortzmeyer/.cache/pip/wheels/8d/77/f7/8f91043ef3c99bbab558f578d19ce5938896e37e57609f9786 Successfully built bagit Installing collected packages: bagit Successfully installed bagit-1.7.0
On peut ensuite utiliser cette bibliothèque depuis Python :
% python3
Python 3.5.3 (default, Sep 27 2018, 17:25:39)
[GCC 6.3.0 20170516] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import bagit
>>> bag = bagit.make_bag('/tmp/toto', {'Contact-Name': 'Ed Summers'})
>>>
Le répertoire /tmp/toto aura été transformé en
sac.
Cette bibliothèque vient aussi avec un outil en ligne de commande. J'ai créé le premier sac d'exemple de cet article avec :
% bagit.py --contact-name 'Stéphane Bortzmeyer' --contact-email 'stephane+atlas@bortzmeyer.org' \
/tmp/RIPE-Atlas-Bolivia
Et ce même outil permet de vérifier qu'un sac est valide :
% bagit.py --validate /tmp/RIPE-Atlas-Bolivia
2018-12-20 16:16:09,700 - INFO - Verifying checksum for file /tmp/RIPE-Atlas-Bolivia/data/bortzmeyer-ripe-atlas-lapaz.tex
2018-12-20 16:16:09,700 - INFO - Verifying checksum for file /tmp/RIPE-Atlas-Bolivia/data/Makefile
2018-12-20 16:16:09,701 - INFO - Verifying checksum for file /tmp/RIPE-Atlas-Bolivia/manifest-sha256.txt
2018-12-20 16:16:09,701 - INFO - Verifying checksum for file /tmp/RIPE-Atlas-Bolivia/manifest-sha512.txt
2018-12-20 16:16:09,701 - INFO - Verifying checksum for file /tmp/RIPE-Atlas-Bolivia/bagit.txt
2018-12-20 16:16:09,701 - INFO - Verifying checksum for file /tmp/RIPE-Atlas-Bolivia/bag-info.txt
2018-12-20 16:16:09,702 - INFO - /tmp/RIPE-Atlas-Bolivia is valid
Il existe d'autres mises en œuvre comme bagit ou bagins en Go. L'article « Using BagIt in 2018 » donne des informations utiles dans d'autres langages.
L'article seul
RFC 8492: Secure Password Ciphersuites for Transport Layer Security (TLS)
Date de publication du RFC : Février 2019
Auteur(s) du RFC : D. Harkins (HP Enterprise)
Pour information
Première rédaction de cet article le 22 février 2019
Ce nouveau RFC décrit un mécanisme permettant une authentification lors de l'utilisation de TLS sans utiliser de cryptographie à clé publique, mais avec un mot de passe.
Au passage, l'auteur réhabilite la notion de mot de passe, souvent considérée comme une méthode d'authentification dépassée. Il estime que « un mot de passe est plus naturel qu'un certificat » car « depuis l'enfance, nous avons appris la sémantique d'un secret partagé ».
Experts en sécurité, ne jetez pas tout de suite ce RFC à la poubelle. Rassurez-vous, le mot de passe n'est pas utilisé tel quel, mais via un protocole nommé TLS-PWD, dont la principale partie s'appelle Dragonfly. Dragonfly était déjà utilisé dans le RFC 5931.
D'abord, pourquoi ce nouveau mécanisme (section 1 du RFC) ? TLS (RFC 5246) utilise traditionnellement de la cryptographie à clé publique pour l'authentification. La machine qui veut être authentifiée (en général, c'est le serveur, mais le client peut le faire aussi) présente un certificat, contenant la clé publique et diverses métadonnées plus ou moins utiles (date d'expiration, signature d'une AC). Le protocole vérifie ensuite que la machine peut signer des données avec la clé privée correspondante, prouvant ainsi qu'elle connait cette clé privée. Ce mécanisme est bien connu mais, estime le RFC, a quelques défauts. Notamment, obtenir un certificat n'est pas trivial, et certainement bien plus compliqué que de configurer un mot de passe, opération qui est familière (le RFC dit « naturelle », ce qui est exagéré) à beaucoup. La quantité de certificats auto-signés (les plus simples à obtenir) qu'on trouve (surtout sur les MTA) en est la preuve. (Sans compter les autres problèmes comme les certificats expirés, qui montrent bien que l'avitaillement en certificats est un problème non résolu.) Et puis s'authentifier pour obtenir le premier certificat est un problème d'œuf et de poule qu'on pourrait résoudre avec ce nouveau protocole, authentifiant simplement un échange, quitte à obtenir le certificat par la suite, sur le lien sécurisé (méthode décrite dans le RFC 7030). Autre scénario d'usage pour ce nouveau protocole, le cas d'un lecteur qui transmet le PIN à la carte à puce en clair : il serait trop compliqué d'utiliser un certificat dans ce cas, alors qu'une authentification par mot de passe serait plus simple.
Les solutions sans certificat ont des vulnérabilités comme la possibilité d'attaques par dictionnaire. Un attaquant essaie plein de mots de passe possibles (par exemple, le recrutement de Mirai fonctionne ainsi) et tombe forcément juste de temps en temps. Une solution souvent proposée est d'avoir un mot de passe à forte entropie, qui a peu de chances d'être dans les essais effectués par l'attaquant. Par exemple un mot de passe choisi aléatoirement oblige l'attaquant à essayer toutes les possibilités (puisque toutes les combinaisons sont également possibles). Si le mot de passe fait N bits, cela imposera à l'attaquant 2^(N-1) essais en moyenne.
Mais la faiblesse de ce raisonnement est qu'il ne marche que si l'attaquant peut faire autant d'essais qu'il veut, sans conséquences négatives pour lui (par exemple parce qu'il a mis la main sur un fichier de mots de passe condensés, et qu'il peut à loisir tester hors-ligne s'il en trouve un). D'autres solutions sont pourtant possibles. Ainsi, le PIN d'une carte Visa ne fait que quatre chiffres, ce qui est très peu (5 000 essais suffisent, en moyenne) sauf que la carte se bloque au bout de trois essais échoués. (Notez que sur les très anciennes cartes, il était parfois possible de remettre le compteur d'essais à zéro, annulant cette sécurité.) Ce qui compte, ce ne sont pas les 10 000 possibilités théoriques, ce sont les trois essais. Le RFC généralise cette observation : « la résistance à une attaque par dictionnaire doit être une fonction du nombre d'interactions avec un participant honnête, pas une fonction de la quantité de calculs effectués ». En effet, le nombre d'interactions avec le participant honnête ne croîtra guère dans le futur (l'attaquant est détecté avant) alors que la quantité de calculs réalistiquement possibles croîtra à coup sûr. Comme dans le cas du code PIN, il n'est pas forcément nécessaire d'avoir un mot de passe à forte entropie, il faut juste empêcher l'adversaire d'essayer à volonté, et pour cela le forcer à des attaques actives, interagissant réellement avec sa victime. La section 7 du RFC détaille cette analyse, notant que ce protocole peut se contenter de mots de passe relativement « faibles ». Ainsi, note le RFC, un mot de passe de quatre lettres ASCII peut être suffisant (sans les consignes « votre mot de passe doit comporter au moins douze caractères, dont une lettre minuscule, une lettre majuscule, un chiffre, un emoji et un hiéroglyphe ») puisqu'il offre 459 976 possibilités. Un attaquant qui tenterait la force brute devrait essayer des dizaines de milliers de fois, ce qui sera certainement détecté (par exemple par des logiciels du genre de fail2ban, ou par des IDS).
Désolé, mais je ne vais pas vous exposer le protocole Dragonfly. Il dépasse mes maigres connaissances en cryptographie. La section 3 du RFC expose le minimum qu'il faut savoir en cryptographie pour comprendre la suite (vous aurez besoin de réviser la cryptographie sur courbes elliptiques, par exemple via le RFC 6090 et ça vaut aussi la peine de relire le RFC 8422 sur les extensions TLS spécifiques aux courbes elliptiques). La section 3 rappelle aussi qu'il faut saler les mots de passe avant de les stocker, côté serveur, au cas où le fichier des mots de passe se fasse voler (voir aussi la section 7, qui détaille ce risque et ses conséquences). Le résultat se nomme la base. Plus précisement, la base est le résultat de l'application de HMAC-SHA256 à un sel et à la concaténation du nom de l'utilisateur et du mot de passe. Par exemple, si vous voulez le faire avec OpenSSL, que l'utilisateur est "fred" et le mot de passe "barney", avec un sel (tiré aléatoirement) "57ff4d5abdfe2ff3d849fb44848b42f2c41fd995", on fera :
% echo -n fredbarney | openssl dgst -sha256 -hmac "57ff4d5abdfe2ff3d849fb44848b42f2c41fd995" -binary \
| openssl enc -base64
4m9bv5kWK6t3jUFkF8qk96IuixhG+C6CY7NxsOGrlPw=
Comme le mot de passe peut inclure de l'Unicode, il doit être traité selon les règles du RFC 8265. Le serveur va stocker le nom de l'utilisateur, le sel et la base.
C'est la base qui est présentée par le client (après que le serveur lui ait envoyé le sel), pas le mot de passe, et le fichier des bases est donc aussi sensible qu'un fichier de mots de passe en clair (cf. section 7).
La section 4 du RFC décrit le protocole. L'échange de clés utilisé, Dragonfly, est décrit dans le RFC 7664. Utiliser Dragonfly en clair serait sûr du point de vue de l'authentification, mais pas du point de vue de la vie privée puisque le nom d'utilisateur passerait en clair. TLS-PWD, le protocole complet (dont Dragonfly n'est qu'une partie), offre un mécanisme pour protéger contre l'écoute de ce nom, une paire de clés cryptographiques étant générée et utilisée juste pour chiffrer ce bout de la session.
Le protocole TLS-PWD nécessite l'utilisation d'extensions
TLS (RFC 5246,
notamment la section 7.4.1.2). Elles sont au nombre de trois, notamment
PWD_protect (protection du nom) et
PWD_clear (nom d'utilisateur en clair). Elles
figurent désormais dans le registre IANA. Une
fois le nom reçu et trouvé dans le fichier côté serveur, le client
peut s'authentifier avec le mot de passe (c'est plus compliqué que
cela : voir la section 4 pour tous les détails).
Dans TLS, la suite complète des algorithmes utilisés dans une
session est indiquée dans une variable nommée cipher
suite (RFC 5246, sections 7.4.1.2, 9 et annexe
C). Les nouvelles suites permettant l'authentification par mot de
passe sont listées dans la section 5 : ce sont
TLS_ECCPWD_WITH_AES_128_GCM_SHA256,
TLS_ECCPWD_WITH_AES_256_GCM_SHA384,
TLS_ECCPWD_WITH_AES_128_CCM_SHA256 et
TLS_ECCPWD_WITH_AES_256_CCM_SHA384. Elles
sont indiquées dans le registre IANA.
La section 7 du RFC contient de très nombreux détails sur la sécurité du protocole. Elle note par exemple qu'un attaquant qui essaierait tous les mots de passe d'un même utilisateur serait facilement détecté mais qu'un attaquant pourrait aussi essayer un seul mot de passe avec beaucoup d'utilisateurs, échappant ainsi à la détection. Le RFC recommande donc de compter toutes les tentatives de connexion ensemble, quel que soit l'utilisateur. (Cela traite aussi partiellement le cas d'un IDS extérieur, qui ne verrait pas le nom d'utilisateur, celui-ci étant protégé. L'IDS pourrait néanmoins compter les problèmes de connexion et donner l'alarme.) D'autre part, les mesures contre les attaques par dictionnaire (forcer l'attaquant à interagir avec le serveur, et donc à se signaler) ne sont évidemment pas efficaces si un utilisateur a le même mot de passe sur plusieurs serveurs et que l'un est compromis. La consigne d'utiliser des mots de passe différents par service reste donc valable. (Et, même si le RFC n'en parle pas, il ne faut évidemment pas noter ces mots de passe sur un post-it collé sous le clavier. La relativisation de la règle des mots de passe compliqués permet d'utiliser des mots de passe courts et mémorisables, donc plus d'excuses pour noter sur le post-it.) Sinon, les fanas de cryptographie qui voudraient étudier la sécurité du protocole Dragonfly sont invités à lire l'article de Lancrenon, J. et M. Skrobot, « On the Provable Security of the Dragonfly Protocol ».
Une curiosité : ce RFC est apparemment le premier à avoir une section « Droits Humains » (Human Rights Considerations, section 8). Une telle section, analysant les conséquences du protocole décrit dans le RFC sur les droits humains était suggérée (mais non imposée) par le RFC 8280. Mais, en l'occurrence, celle-ci se réduit à une défense des armes à feu, sans trop de rapport avec le sujet du RFC. On note également une vision très personnelle et très états-unienne des droits humains « le premier des droits est celui de se protéger », ce qui ne figure dans aucun des textes fondateurs des droits humains.
L'article seul
RFC 8490: DNS Stateful Operations
Date de publication du RFC : Mars 2019
Auteur(s) du RFC : R. Bellis (ISC), S. Cheshire (Apple), J. Dickinson (Sinodun), S. Dickinson (Sinodun), T. Lemon (Nibbhaya Consulting), T. Pusateri
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 18 mars 2019
Autrefois, le DNS était toujours cité comme exemple d'un protocole sans état. On envoie une requête, on reçoit une réponse, et le client et le serveur oublient aussitôt qu'ils ont échangé, ils ne gardent pas de trace de cette communication. Mais, dans certains cas, maintenir un état sur une durée plus longue qu'un simple échange requête/réponse peut être utile. Ce nouveau RFC propose un mécanisme pour des sessions DNS, le mécanisme DSO (DNS Stateful Operations). Il introduit donc une nouvelle notion dans le DNS, la persistance des sessions.
Ne pas avoir d'état a de nombreux avantages : cela simplifie les programmes, cela augmente les performances considérablement (pas besoin de chercher dans une table l'état actuel d'un dialogue, le contenu de la requête est suffisant pour donner une réponse, on peut répondre à la vitesse de l'éclair) et cela permet de résister aux DoS, qui réussissent souvent lorsqu'elles arrivent à épuiser le système qui dépend d'un état. (C'est pour cela que c'est souvent une mauvaise idée de mettre un pare-feu à état devant un serveur Internet, et c'est même franchement absurde quand il s'agit d'un serveur DNS.) Le DNS « habituel », tournant sur UDP et sans maintenir d'état, doit une partie de son succès à son caractère sans état.
Mais ne pas avoir d'état a aussi des inconvénients : toutes les options, tous les choix doivent être répétés dans chaque requête. Et cela rend impossible de négocier des paramètres entre les deux parties, par exemple dans le cas d'une session cryptographiquement protégée. Bref, dans certains cas, on aimerait bien avoir une vraie session, de durée relativement longue (plusieurs secondes, voire plusieurs minutes). Le DNS a un mécanisme de connexion de longue durée, en utilisant TCP (RFC 7766), et peut utiliser TLS pour sécuriser cette communication (DoT, « DNS over TLS », RFC 7858) mais les requêtes à l'intérieur de cette connexion n'en profitent pas, elles ne savent pas qu'elles sont liées par le fait qu'elles sont dans la même connexion. D'où ce nouveau système.
Le principe de DSO (DNS Stateful Operations) est de permettre à une requête DNS de créer une session, avec des paramètres communs à toute la session (comme la durée maximale d'inactivité). La session est balisée par des requêtes DNS utilisant l'opcode DSO, de numéro 6 (la création d'un nouvel opcode est très rare). Les paramètres sont encodés en TLV (une nouveauté dans le monde DNS ; les traditionnels Query count et Answer count, avec les sections correspondantes, ne sont pas utilisés). La longueur du message DSO est indiquée par les deux premiers octets du message. Les messages DSO peuvent solliciter une réponse (même si c'est un simple accusé de réception) ou pas. Cette sollicitation est faite par un Message ID différent de zéro. Si, par contre, le Message ID DNS est à zéro, il s'agit d'un message DSO unidirectionnel (retenez ce terme, il va souvent servir dans ce RFC), qui n'attend pas de réponse. (Rappelez-vous que le Message ID sert à faire correspondre requêtes et réponses DNS. Si on n'attend pas de réponse, pas besoin d'un Message ID. Si par contre le message est bidirectionnel, il doit mettre un Message ID non nul.)
DSO (DNS Stateful Operations, sessions - avec état, donc - pour le DNS) ne s'applique qu'avec certains transports sous-jacents (section 4 du RFC). UDP est évidemment exclu, car il faut maintenir l'ordre des messages, et il faut qu'il y ait une connexion à gérer. Cela peut être TCP (RFC 1035, section 4.2.2 et RFC 7766) ou DoT (DNS sur TLS, RFC 7858). DoH (DNS sur HTTPS, RFC 8484) est par contre exclu car HTTP a ses propres mécanimes de gestion de session. (D'autre part, la section 9.2 décrit les conséquences que cela a pour l'anycast.)
Deux importantes utilisations de DSO sont prévues :
- Gestion de sessions et des paramètres associés : DSO va permettre de définir des paramètres comme les durées maximales d'inactivité avant qu'on ne coupe la connexion de transport sous-jacente. Dans ce cas, DSO est une alternative au RFC 7828.
- Abonnements de longue durée à des services comme la découverte (RFC 6763).
La section 5 est le gros du RFC, elle décrit tous les détails du protocole. Pour établir une session DSO, il faut :
- Établir une connexion avec un protocole comme TCP ; on est alors connecté (on peut envoyer des messages DNS et recevoir des réponses) mais sans session DSO,
- On envoie une demande DSO,
- Si le correspondant est d'accord, on reçoit une réponse DSO, et la session est établie, et les paramètres comme la durée d'inactivité maximale sont désormais contrôlés par DSO ; on peut envoyer des messages DSO unidirectionnels (non sollicités, et ne demandant pas de réponse),
- Si par contre le correspondant refuse DSO, on continue avec une connexion normale.
Si on sait à l'avance que le correspondant gère DSO, on peut se considérer comme en session dès l'établissement de la connexion. Mais, souvent on ne sait pas ou on n'est pas sûr et il faut donc explicitement ouvrir une session. Cela se fait avec un message DSO (un message où l'opcode DNS vaut 6 ; ces opcodes sont décrits dans le RFC 1035, section 4.1.1). L'acceptation prend la forme d'un message DSO avec un Message ID qui correspond et un code de réponse 0 (rcode = NOERROR). Si le code de réponse est autre chose que NOERROR (par exemple 4, NOTIMP, « type de requête inconnu » ou 5, REFUSED, « je connais peut-être DSO mais je n'ai pas envie d'en faire »), c'est que notre correspondant ne peut pas ou ne veut pas établir une session.
Il n'y a pas de message DSO dédié à l'ouverture de session. On envoie un message DSO de n'importe quel type (par exemple Keepalive). Il peut donc arriver que le copain en face connaisse DSO mais pas ce type particulier. Dans ce cas, il va répondre DSOTYPENI (DSO Type Not Implemented, code 11, une nouveauté dans le registre). La session n'est pas établie et le client doit recommencer avec un autre type (comme Keepalive, qui a l'avantage d'être normalisé depuis le début et d'être obligatoire, donc il marchera partout).
Il y a des cas plus gênants : un serveur qui couperait la connexion de transport sous-jacente, ou bien qui ne répondrait pas aux messages DSO. Ce cas risque de se produire si un boitier intermédiaire bogué est sur le trajet. Il peut être alors nécessaire d'adopter des mesures de contournement comme celles qu'utilisaient les résolveurs DNS avec les serveurs ne gérant pas bien EDNS, mesures de contournement qui ont été abandonnées récemment avec le DNS Flag Day.
Si, par contre, tout se passe bien, la session DSO est établie, et des paramètres comme le délai d'inactivité doivent désormais suivre les règles de DSO et plus celles de normes précédentes comme le RFC 7766 (c'est pour cela que notre RFC met à jour le RFC 7766).
La section 5 détaille également le format des messages DSO. Ce sont des messages DNS ordinaires, commençant par le Message ID sur deux octets, avec l'opcode qui vaut DSO (code numérique 6). Les champs qui indiquent le nombre d'enregistrements dans les différentes sections doivent tous être mis à zéro. Les données DSO sont situées après l'en-tête DNS standard, et sont sous forme de TLV. Le logiciel peut donc analyser ces données même s'il ne connait pas un type DSO spécifique. Dans une requête DSO, il y a toujours au moins un TLV, le « TLV primaire », qui indique le type d'opérations. Les autres éventuels TLV (« TLV additionnels ») sont là pour préciser le message. Rappelons qu'il y a deux sortes de messages DSO, les unidirectionnels et les autres. Les unidirectionnels ont le Message ID à zéro et n'ont jamais de réponse. (Avec le Message ID à zéro, on ne saurait de toute façon pas à quelle demande correspond une réponse.)
Chaque TLV comprend trois champs :
- Le type, sur deux octets (la liste des types possibles figure dans un registre IANA créé par ce RFC),
- La longueur des données, sur deux octets,
- Les données.
Notez que la définition de chaque type doit préciser s'il est censé être utilisé en TLV primaire ou additionnel. Pour une réponse, il peut n'y avoir aucun TLV présent.
Toutes les sections « normales » d'un message DNS sont vides, y
compris la section additionnelle qu'utilise
EDNS (le champ ARCOUNT
doit être à zéro). Il ne peut donc pas y avoir d'options
EDNS dans un message DSO (pour éviter la confusion qui se
produirait si une option EDNS et un message DSO donnaient des
valeurs différentes au même service). Si on veut le service équivalent à une
option EDNS, il faut créer un nouveau type DSO (section 10.3 du
RFC pour les détails)
et le faire enregistrer.
Combien de temps durent les sessions DSO ? D'un côté, il faut qu'elles soient aussi longues que possible, pour amortir le coût de créer et de maintenir des sessions sur un grand nombre de requêtes, d'un autre, il ne faut pas gaspiller des ressorces à maintenir une session ouverte si elle ne sert plus à rien. La section 6 du RFC discute cette question. DSO a un délai maximal d'inactivité et, quand le délai est dépassé sans activité, le client DSO est censé couper la connexion. (S'il ne le fait pas, le serveur le fera, après un délai plus long.) Le client a évidemment le droit de couper la session avant l'expiration du délai, s'il sait qu'il n'en aura plus besoin.
Le délai maximal d'inactivité est fixé par les messages DSO de type 1. Deux cas spéciaux : zéro indique qu'on doit fermer la connexion immédiatement après la première requête, et 0xFFFFFFFF indique que la session peut être gardée ouverte aussi longtemps qu'on le souhaite.
DSO permet également de spécifier l'intervalle de génération des messages keepalives, messages envoyés périodiquement uniquement pour que les boitiers de traduction d'adresse gardent leur état et ne suppriment pas une correspondance adresse interne <-> adresse externe en pensant qu'elle ne sert plus. Si on sait qu'il n'y a pas de NAT sur le trajet, on peut mettre un intervalle très élevé. Le client peut aussi se dire « j'ai une adresse RFC 1918, le serveur a une adresse IP publique, il y a donc sans doute un machin NAT sur le trajet, je demande des keepalives fréquents ».
Enfin, le client doit être préparé à ce que le serveur ferme la session à sa guise, parce que le serveur estime que le client exagère (il ne ferme pas la session alors que le délai d'inactivité est dépassé, et qu'il n'envoie pas de requêtes), ou bien parce que le serveur va redémarrer. Normalement, c'est le client DSO qui ferme la session mais, dans certains cas, le serveur peut décider de le faire.
La section 7 du RFC décrit les trois TLV de base qui doivent être présents dans toutes les mises en œuvre de DSO : keepalive, délai avant de réessayer, et remplissage. La section 8.2 indique dans quels cas ils peuvent être utilisés par le client ou par le serveur.
Le TLV keepalive contrôle l'envoi de messages servant uniquement à indiquer que la session est toujours ouverte, afin notamment de rassurer les routeurs NAT. Ce même TLV sert également à indiquer le délai d'inactivité maximal. Comme ce type de TLV est obligatoire, c'est un bon candidat pour le message initial d'ouverture de session (il n'y a pas de message particulier pour cette ouverture : on envoie juste un message ordinaire). Il a le type 1 et comprend deux champs de données, le délai maximal d'inactivité, en millisecondes, sur quatre octets, et l'intervalle d'émission des keepalives, également en millisecondes, et sur quatre octets. Il peut être utilisé comme TLV primaire, et il requiert une réponse, le Message ID doit donc être différent de zéro. La valeur du délai maximal d'inactivité émise par le client est un souhait, la valeur à utiliser est celle qui figure dans la réponse du serveur. Si le client ne la respecte pas par la suite, le serveur aura le droit de fermer la session. Notez qu'EDNS avait déjà un mécanisme équivalent, pour définir une durée d'inactivité maximale dans les connexions TCP, normalisé dans le RFC 7828. Mais les limites d'EDNS, comme le fait que les options EDNS ne s'appliquent normalement qu'au message en cours, rendent cette solution peu satisfaisante. Cet ancien mécanisme ne doit donc pas être utilisé avec DSO, qui dispose, d'un autre système, celui utilisant les valeurs spécifiées par un message portant le TLV Keepalive.
Une fois la durée d'émission des keepalives fixée, les messages de keepalive seront des messages unidirectionnels (pas de réponse) et donc envoyés avec un Message ID nul.
Deuxième type de TLV obligatoire, le délai avant de réessayer de se connecter, qui a le code 2. C'est un message unidirectionnel, envoyé par le serveur pour indiquer qu'il va couper et qu'il ne faut pas réessayer avant la durée indiquée en valeur du TLV.
Et enfin, le troisième type (code 3) qui doit être présent dans toute mise en œuvre de DSO est le remplissage. Le but est d'améliorer la protection de la vie privée en insérant des données bidon dans les messages DNS, pour rendre plus difficile l'analyse des données chiffrées. Il n'a évidemment de sens que si la session sous-jacente est chiffrée, par exemple avec le RFC 7858. Pour la longueur du remplissage à choisir, voir le RFC 8467.
Comme toujours sur l'Internet, une grande partie des problèmes opérationnels viendront des middleboxes. Le RFC rappelle à juste titre que la meilleure solution serait de ne pas avoir de middleboxes mais, comme c'est un idéal lointain, en attendant, il faut se pencher sur ce que font ces fichus boitiers intermédiaires, qui se permettent parfois d'intercepter automatiquement le trafic DNS et de le modifier. Si le boitier gère DSO et répond correctement aux spécifications de ce RFC, tout va bien. Si le boitier ne comprend pas DSO et renvoie un NOTIMP ou équivalent, cela empêche d'utiliser DSO mais, au moins, cela ne viole pas la norme : le client réagira comme si le serveur ne connait pas DSO. Si le boitier ne connait pas le DNS, et n'essaie pas de le comprendre, ça devrait marcher si, bien sûr, il établit bien une connexion et une seule pour chaque connexion entrante (c'est ce que fait un routeur NAT qui ne regarde pas les couches supérieures).
Dès que le boitier ne respecte pas ces règles, on peut prévoir des ennuis, et qui seront très difficiles à déboguer. Par exemple si un répartiteur de charge DNS reçoit des connexions TCP, les ouvre, et envoie chaque requête DNS qu'elles contenaient à un serveur différent, le client DSO va certainement souffrir. Il croira avoir une session alors qu'il n'en est rien.
Autre problème pratique qui se posera peut-être : les optimisations de TCP. Deux d'entre elles ont des chances sérieuses de créer des ennuis, l'algorithme de Nagle et les accusés de réception retardés (on attend un peu de voir si un autre segment arrive, pour pouvoir accuser réception des deux avec un seul paquet, RFC 1122, section 4.2.3.2). Pour les messages DSO bidirectionnels, pas de problème. Pour les unidirectionnels, en revanche, le retard de l'accusé de réception pourra atteindre 200 millisecondes, ce qui est énorme dans un centre de données typique, avec des liens qui peuvent débiter plus d'un gibabit par seconde. L'algorithme de Nagle fera qu'on n'enverra pas de données tout de suite, attendant s'il n'y a pas quelque chose à transmettre et, avec l'accusé de réception retardé, la combinaison des deux retardera sérieusement l'envoi.
Débrayer l'algorithme de Nagle, ou bien les accusés de réception retardés, résoudrait le problème mais ferait perdre d'utiles optimisations. En fait, la seule solution propre serait que les API permettent aux applications de dire à TCP « il n'y aura pas de réponse à ce message, envoie l'accusé de réception tout de suite ».
Enfin, un petit mot sur la sécurité pour finir. DSO nécessite des connexions permanentes et, potentiellement, cela peut consommer pas mal de ressources sur le serveur. Pour se protéger, le serveur a donc parfaitement le droit de limiter le nombre de connexions maximal, et de fermer des sessions quand ça lui chante.
Toujours sur la sécurité, DSO permet des établissements de connexion sans aller-retour, avec TCP Fast Open (RFC 7413) et TLS 1.3 (RFC 8446). C'est très rapide, c'est très bien mais les données envoyées avec le premier paquet (early data) ne sont pas forcément bien sécurisées et la définition de chaque type de TLV doit donc indiquer s'il est sûr ou pas de l'utiliser dans le premier paquet.
Il semble qu'à l'heure actuelle, il n'y a pas encore de mise en œuvre de cette technique DSO.
L'article seul
RFC 8489: Session Traversal Utilities for NAT (STUN)
Date de publication du RFC : Février 2020
Auteur(s) du RFC : M. Petit-Huguenin (Impedance Mismatch), G. Salgueiro (Cisco), J. Rosenberg (Five9), D. Wing, R. Mahy, P. Matthews (Nokia)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tram
Première rédaction de cet article le 23 février 2020
Le NAT a toujours été une des plaies de l'Internet, entre autres parce qu'il perturbe les applications qui veulent transmettre une référence à leur adresse IP. STUN, décrit dans ce RFC, est un des protocoles qui permet de limiter les dégâts. (Il s'agit ici d'une mise à jour du RFC 5389.)
Pour plusieurs raisons, dont le manque d'adresses IPv4, de nombreuses machines sont connectées à l'Internet derrière un routeur qui fait du NAT. Leur adresse étant alors privée, elles ne peuvent pas la transmettre à l'extérieur, ce qui est une gêne considérable pour tous les protocoles qui reposent sur la référence à des adresses IP, comme SIP. SIP lui-même (RFC 3261) marche à travers le NAT mais les données audio ou vidéo transmises (typiquement par RTP) le sont à une adresse IP que l'appelant donne à l'appelé et, si cette adresse est privée, le flux multi-média n'arrivera jamais.
La bonne solution serait de déployer IPv6, qui fournit des adresses en quantité illimitée, ou à la rigueur de permettre un meilleur contrôle du routeur NAT avec PCP (RFC 6887) mais, en attendant, STUN est une solution simple et qui marche souvent.
STUN s'inscrit donc dans la catégorie des protocoles de « réparation » du NAT, catégorie décrite dans le RFC 3424.
STUN résout partiellement le problème des NAT de la manière
suivante : un serveur STUN doit être installé quelque part sur
l'Internet public (il existe des serveurs STUN
publics)
et reçoit des demandes envoyées en UDP (ou TCP, voir sections 6.2.2 et 6.2.3,
ou encore TLS ou DTLS) au port 3478. Le serveur STUN
peut alors connaitre l'adresse publique, celle mise par le routeur
NAT et, en répondant au client, il pourra informer celui-ci
« Voilà à quoi tes paquets ressemblent, vus de l'extérieur ».
Le nom du serveur STUN est typiquement configuré dans le client, puis le serveur recherché dans le DNS via les enregistrements SRV (RFC 2782), comme détaillé dans la section 8. (Le traditionnel client Unix en ligne de commande, montré plus loin, ne connait pas les SRV.)
Le principe est simple, mais le RFC est plus compliqué que cela, notamment en raison des problèmes de sécurité (la section 16 du RFC est très détaillée sur ce point). Par exemple, le client STUN peut avoir besoin de commencer par une connexion TCP pour obtenir un mot de passe temporaire. (D'autres méthodes d'authentification sont possibles.)
Lorsque STUN fonctionne sur UDP, ou bien sur DTLS, le client STUN doit également être préparé à rémettre les paquets qui seraient perdus (section 6.2.1).
Un autre problème est qu'il y a en fait plusieurs sortes de NAT (voir par exemple le RFC 2663). Par exemple, certains routeurs NAT (Symmetric NAT pour le RFC 3489) n'attribuent pas l'adresse externe uniquement en fonction de la source mais aussi en fonction de la destination. Ceux-ci ne fonctionnent pas avec STUN, qui a besoin de NAT cone, c'est-à-dire où les paquets d'une même machine auront toujours la même adresse IP externe.
Voici une démonstration d'un client STUN (assez ancien mais qui marche) qui, en se connectant à un serveur STUN public va apprendre son adresse IP publique, et le port, les deux ensemble formant l'adresse de transport (cf. section 4) :
% ifconfig -a hme0: [...] inet 172.19.1.2 (Adresse privée, probablement NATée...) % stun stun.1und1.de -v STUN client version 0.97 ... MappedAddress = 192.0.2.29:30189 SourceAddress = 212.227.67.33:3478 ChangedAddress = 212.227.67.34:3479 Unknown attribute: 32800 ServerName = Vovida.org 0.96 ... Primary: Independent Mapping, Port Dependent Filter, preserves ports, no hairpin ... (Mon adresse telle que vue de l'extérieur est donc 192.0.2.29, à noter que le terme MappedAddress n'est plus utilisé, le RFC parle de ReflexiveAddress.)
Une fois l'adresse extérieure détectée, tout n'est pas terminé car rien n'indique, par exemple, que les paquets vont effectivement passer. C'est pour cela que la section 13 insiste que STUN n'est qu'un outil, devant s'insérer dans une solution plus globale, comme ICE (RFC 8445). À lui seul, STUN ne permet pas la traversée de tous les NAT. La section 13 décrit en détail ce concept d'utilisation de STUN et les règles que doivent suivre les protocoles qui utilisent STUN.
La section 5 décrit le format des paquets. Un paquet STUN doit
comprendre l'indication d'une méthode, qui
indique le genre de services que désire le client. Notre RFC 8489 ne décrit qu'une seule méthode,
Binding, qui permet d'obtenir son adresse IP
extérieure mais TURN (RFC 8656), par exemple, en définit d'autres. Après la
méthode et un identificateur de transaction (qui sert au serveur
STUN à séparer ses clients), suivent les
attributs, encodés en TLV (la liste
des attributs figure en section 14). Les numéros des attributs
sont compris entre 0x0000 et 0x7FFF s'ils doivent être reconnus
par le serveur (autrement, la requête est rejetée) et entre 0x8000
et 0xFFFF si leur compréhension est facultative (cette notion
d'attributs obligatoires ou facultatifs facilite les évolutions
ultérieures du protocole). Il y a aussi un
magic cookie, une valeur fixe
(0x2112A442) qui sert à reconnaitre les
agents STUN conformes (il n'existait pas dans les vieilles
versions de STUN).
La section 19 de notre RFC résume les changements faits depuis le prédécesseur, le RFC 5389. Rien de bien crucial, d'autant plus que la plupart de ces changements sont l'intégration de RFC qui avaient étendu le protocole STUN après la parution du RFC 5389 :
- DTLS est désormais intégré (RFC 6347),
- L'algorithmes pour calculer le délai avant retransmission a été modifié suivant le RFC 6298,
- Les URI du RFC 7064 sont désormais inclus,
- SHA-256 et des nouveaux algorithmes pour TLS arrivent,
- Les identificateurs et mots de passe peuvent être en Unicode (RFC 8265),
- Possibilité d'anonymat pour les identificateurs (ce qui a nécessité des nouvelles règles dans le numnique envoyé par le serveur, pour éviter les attaques par repli),
- Ajout de l'attribut
ALTERNATE-DOMAIN, pour indiquer que le serveur proposé en alternative peut avoir un autre nom, - Et pour les programmeurs, des vecteurs de test en annexe B (venus du RFC 5769).
Il existe de nombreux logiciels clients et serveurs pour STUN (mais pas forcément déjà conforme aux légers changements de ce RFC). Le client est en général embarqué dans une application qui a besoin de contourner le NAT, par exemple un softphone, ou bien un navigateur Web qui fait du WebRTC. On peut citer :
- Le serveur coturn,
- Le serveur Restund,
- Le client et serveur stuntman,
- Le serveur turnserver.
Et si vous cherchez une liste de serveurs STUN publics, il y a celle-ci.
L'article seul
RFC 8484: DNS Queries over HTTPS (DoH)
Date de publication du RFC : Octobre 2018
Auteur(s) du RFC : P. Hoffman (ICANN), P. McManus
(Mozilla)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF doh
Première rédaction de cet article le 22 octobre 2018
Voici un nouveau moyen d'envoyer des requêtes DNS, DoH (DNS over HTTPS). Requêtes et réponses, au lieu de voyager directement sur UDP ou TCP sont encapsulées dans HTTP, plus exactement HTTPS. Le but ? Il s'agit essentiellement de contourner la censure, en fournissant un canal sécurisé avec un serveur supposé digne de confiance. Et le chiffrement sert également à préserver la vie privée du client. Toutes ces fonctions pourraient être assurées en mettant le DNS sur TLS (RFC 7858) mais DoH augmente les chances de succès puisque le trafic HTTPS est rarement bloqué par les pare-feux, alors que le port 853 utilisé par DNS-sur-TLS peut être inaccessible, vu le nombre de violations de la neutralité du réseau. DoH marque donc une nouvelle étape dans la transition vers un Internet « port 443 seulement ».
La section 1 du RFC détaille les buts de DoH. Deux buts principaux sont décrits :
- Le premier, et le plus important, est celui indiqué au paragraphe précédent : échapper aux middleboxes qui bloquent le trafic DNS, ou bien le modifient. De telles violations de la neutralité du réseau sont fréquentes, imposées par les États ou les entreprises à des fins de censure, ou bien décidées par les FAI pour des raisons commerciales. Dans la lutte sans fin entre l'épée et la cuirasse, le DNS est souvent le maillon faible : infrastructure indispensable, il offre une cible tentante aux attaquants. Et il est utilisable pour la surveillance (cf. RFC 7626). DNS-sur-TLS, normalisé dans le RFC 7858, était une première tentative de protéger l'intégrité et la confidentialité du trafic DNS par la cryptographie. Mais il utilise un port dédié, le port 853, qui peut être bloqué par un intermédiaire peu soucieux de neutralité du réseau. Dans de nombreux réseaux, hélas, le seul protocole qui soit à peu près sûr de passer partout est HTTPS sur le port 443. D'où la tendance actuelle à tout mettre sur HTTP.
- Il y a une deuxième motivation à DoH, moins importante, la possibilité de faire des requêtes DNS complètes (pas seulement des demandes d'adresses IP) depuis des applications JavaScript tournant dans le navigateur, et tout en respectant CORS.
L'annexe A de notre RFC raconte le cahier des charges du protocole DoH de manière plus détaillée :
- Sémantique habituelle de HTTP (on ne change pas HTTP),
- Possibilité d'exprimer la totalité des requêtes et réponses DNS actuelles, d'où le choix de l'encodage binaire du DNS et pas d'un nouvel encodage, par exemple en JSON, plus simple mais limité à un sous-ensemble du DNS,
- Et aussi des « non-considérations » : DoH n'avait pas à traiter le cas des réponses synthétisées, comme DNS64, ni celui des réponses à la tête du client, ni le HTTP tout nu sans TLS.
Passons maintenant à la technique. DoH est un protocole très simple. Au hackathon de l'IETF en mars 2018 à Londres, les sept ou huit personnes travaillant sur DoH avaient très vite réussi à créer clients et serveurs, et à les faire interopérer (même moi, j'y étais arrivé). Vous pouvez lire le compte-rendu du hackathon, et la présentation quelques jours après au groupe de travail DoH.)
DoH peut s'utiliser de plusieurs façons : c'est une technique,
pas une politique. Néanmoins, son principal usage sera entre un
résolveur simple, situé sur la machine de l'utilisateur ou quelque
part dans son réseau local, et un résolveur complet situé plus
loin dans le réseau (section 1 du RFC). Ce résolveur simple peut
être un démon comme stubby ou systemd, ou
bien l'application elle-même (ce qui me semble personnellement une
mauvaise idée, car cela empêche de partager configuration et
cache). À l'heure actuelle, les
serveurs faisant autorité ne parlent pas DoH et il n'est pas prévu
qu'ils s'y mettent à brève échéance. Le schéma suivant montre
l'utilisation typique de DoH : l'application (le client final)
parle à un résolveur simple, en utilisant le protocole DNS (ce qui
évite de mettre du DoH dans toutes les applications), le résolveur
simple parlera en DoH avec un résolveur de confiance situé quelque
part dans l'Internet, et ce résolveur de confiance utilisera le
DNS pour parler aux serveurs faisant autorité (soit il sera
lui-même un résolveur complet, soit il parlera à un résolveur
classique proche de lui, et le serveur DoH sera alors un
proxy comme décrit dans le RFC 5625) : 
Les requêtes et réponses DNS (RFC 1034 et RFC 1035) ont leur encodage habituel (le DNS est un protocole binaire, donc je ne peux pas faire de copier/coller pour montrer cet encodage), la requête est mise dans le chemin dans l'URL ou dans le corps d'une requête HTTP (RFC 9113), la réponse se trouvera dans le corps de la réponse HTTP. Toute la sécurité (intégrité et confidentialité) est assurée par TLS (RFC 8446), via HTTPS (RFC 2818). Un principe essentiel de DoH est d'utiliser HTTP tel quel, avec ses avantages et ses inconvénients. Cela permet de récupérer des services HTTP comme la négociation de contenu, la mise en cache, l'authentification, les redirections, etc.
La requête HTTP elle-même se fait avec les méthodes GET ou POST
(section 4 du RFC), les deux devant être acceptées (ce qui fut le
sujet d'une assez longue discussion à l'IETF.) Quand la méthode
utilisée est GET, la variable nommée dns est
le contenu de la requête DNS, suivant l'encodage habituel du DNS,
surencodée en Base64, plus exactement la
variante base64url normalisée dans le RFC 4648. Et, avec GET, le corps de la requête est vide
(RFC 7231, section 4.3.1). Quand on utilise POST, la
requête DNS est dans le corps de la requête HTTP et n'a pas ce
surencodage. Ainsi, la requête avec POST sera sans doute plus
petite, mais par contre GET est certainement plus apprécié par les
caches.
On l'a dit, DoH utilise le HTTP habituel. L'utilisation de HTTP/2, la version 2 de HTTP (celle du RFC 9113) est très recommandée, et clients et serveurs DoH peuvent utiliser la compression et le remplissage que fournit HTTP/2 (le remplissage étant très souhaitable pour la vie privée). HTTP/2 a également l'avantage de multiplexer plusieurs ruisseaux (streams) sur la même connexion HTTP, ce qui évite aux requêtes DoH rapides de devoir attendre le résultat d'une requête lente qui aurait été émise avant. (HTTP 1, lui, impose le respect de l'ordre des requêtes.) HTTP/2 n'est pas formellement imposé, car on ne peut pas forcément être sûr du comportement des bibliothèques utilisées, ni de celui des différents relais sur le trajet.
Requêtes et réponses ont actuellement le type
MIME application/dns-message,
mais d'autres types pourront apparaitre dans le futur (par exemple
fondés sur JSON et non plus sur l'encodage
binaire du DNS, qui n'est pas amusant à
analyser en
JavaScript). Le client DoH doit donc
inclure un en-tête HTTP Accept: pour indiquer
quels types MIME il accepte. En utilisant HTTP, DoH bénéfice également de la négociation de
contenu HTTP (RFC 7231, section 3.4).
Petit détail DNS : le champ ID (identification de la requête) doit être mis à zéro. Avec UDP, il sert à faire correspondre une requête et sa réponse mais c'est inutile avec HTTP, et cela risquerait d'empêcher la mise en cache de deux réponses identiques mais avec des ID différents.
En suivant la présentation des requêtes HTTP du RFC 9113 (rappelez-vous que HTTP/2, contrairement à la première version de HTTP, a un encodage binaire), cela donnerait, par exemple :
:method = GET
:scheme = https
:authority = dns.example.net
:path = /?dns=AAABAAABAAAAAAAAA3d3dwdleGFtcGxlA2NvbQAAAQAB
accept = application/dns-message
(Si vous vous le demandez,
AAABAAABAAAAAAAAA3d3dwdleGFtcGxlA2NvbQAAAQAB
est une requête DNS pour l'adresse IPv4 de www.example.com.)
Et la réponse HTTP ? Aujourd'hui, elle est forcément de type
MIME application/dns-message, mais d'autres
types pourront apparaitre. En attendant, le corps de la réponse
HTTP est une réponse DNS avec son encodage binaire habituel
normalisé dans le RFC 1035, section 4.1 (tel
qu'utilisé pour UDP ; notez que HTTP
permettant d'indiquer la longueur du message, les deux octets de
longueur utilisés par le DNS au-dessus de
TCP ne sont pas nécessaires et sont donc absents).
Le serveur DoH doit mettre un code de retour HTTP (RFC 7231). 200 signifie que la requête HTTP a bien été traitée. Mais cela ne veut pas dire que la requête DNS, elle, ait connu un succès. Si elle a obtenu une erreur DNS NXDOMAIN (nom non trouvé) ou SERVFAIL (échec de la requête), le code de retour HTTP sera quand même 200, indiquant qu'il y a une réponse DNS, même négative. Le client DoH, en recevant ce 200, devra donc analyser le message DNS et y trouver le code de retour DNS (NOERROR, NXDOMAIN, REFUSED, etc). Le serveur DoH ne mettra un code d'erreur HTTP que s'il n'a pas du tout de réponse DNS à renvoyer. Il mettra 403 s'il refuse de servir ce client DoH, 429 si le client fait trop de requêtes (RFC 6585), 500 si le serveur DoH a une grosse bogue, 415 si le type MIME utilisé n'est pas connu du serveur, et bien sûr 404 si le serveur HTTP ne trouve rien à l'URL indiqué par exemple parce que le service a été retiré. Dans tous ces cas, il n'y a pas de réponse DNS incluse. La sémantique de ces codes de retour, et le comportement attendu du client, suit les règles habituelles de HTTP, sans spécificité DoH. (C'est un point important et général de DoH : c'est du DNS normal sur du HTTP normal). Par exemple, lorsque le code de retour commence par un 4, le client n'est pas censé réessayer la même requête sur le même serveur : elle donnera forcément le même résultat.
Voici un exemple de réponse DoH :
:status = 200
content-type = application/dns-message
content-length = 61
cache-control = max-age=3709
[Les 61 octets, ici représentés en hexadécimal pour la lisibilité]
00 00 81 80 00 01 00 01 00 00 00 00 03 77 77 77
07 65 78 61 6d 70 6c 65 03 63 6f 6d 00 00 1c 00
01 c0 0c 00 1c 00 01 00 00 0e 7d 00 10 20 01 0d
b8 ab cd 00 12 00 01 00 02 00 03 00 04
La réponse DNS signifie « l'adresse de
www.example.com est
2001:db8:abcd:12:1:2:3:4 et le
TTL est de 3709 secondes [notez comme il
est repris dans le Cache-control: HTTP] ».
Comment un client DoH trouve-t-il le serveur ? La section 3 du
RFC répond à cette question. En gros, c'est manuel. DoH ne fournit
pas de mécanisme de sélection automatique. Concevoir un tel
mécanisme et qu'il soit sécurisé est une question non triviale, et
importante : changer le résolveur DNS utilisé par une machine
revient quasiment à pirater complètement cette machine. Cela avait
fait une très longue discussion au sein du groupe de travail DoH à
l'IETF, entre ceux qui pensaient qu'un
mécanisme automatique de découverte du gabarit faciliterait
nettement la vie de l'utilisateur, et ceux qui estimaient qu'un
tel mécanisme serait trop facile à subvertir. Donc, pour
l'instant, le client DoH reçoit manuellement un gabarit d'URI
(RFC 6570) qui indique le serveur DoH à
utiliser. Par
exemple, un client recevra le gabarit
https://dns.example.net/{?dns}, et il fera
alors des requêtes HTTPS à dns.example.net,
en passant ?dns=[valeur de la requête].
Notez que l'URL dans le gabarit peut comporter un nom de domaine, qui devra lui-même être résolu via le DNS, créant ainsi un amusant problème d'œuf et de poule (cf. section 10 de notre RFC). Une solution possible est de ne mettre que des adresses IP dans l'URL, mais cela peut poser des problèmes pour l'authentification du serveur DoH, toutes les autorités de certification n'acceptant pas de mettre des adresses IP dans le certificat (cf. RFC 6125, section 1.7.2, et annexe B.2).
La section 5 du RFC détaille quelques points liés à
l'intégration avec HTTP. D'abord, les
caches. DNS et HTTP ont chacun son
système. Et entre le client et le serveur aux extrémités, il peut
y avoir plusieurs caches DNS et plusieurs caches HTTP, et ces
derniers ne connaissent pas forcément DoH. Que se passe-t-il si on
réinjecte dans le DNS des données venues d'un cache HTTP ? En général, les réponses aux requêtes POST ne sont pas mises
en cache (elles le peuvent, en théorie) mais les requêtes GET le
sont, et les implémenteurs de DoH doivent donc prêter attention à
ces caches. La méthode recommandée est de mettre une durée de
validité explicite dans la réponse HTTP (comme dans l'exemple plus
haut avec Cache-control:), en suivant le RFC 9111, notamment sa section 4.2. La durée de
validité doit être inférieure ou égale au plus petit
TTL de la section principale de la réponse
DNS. Par exemple, si un serveur DoH renvoie cette réponse DNS :
ns1.bortzmeyer.org. 27288 IN AAAA 2605:4500:2:245b::42
ns2.bortzmeyer.org. 26752 IN AAAA 2400:8902::f03c:91ff:fe69:60d3
ns4.bortzmeyer.org. 26569 IN AAAA 2001:4b98:dc0:41:216:3eff:fe27:3d3f
alors, la réponse HTTP aura un Cache-Control:
max-age=26569, le plus petit des TTL.
Si la réponse DNS varie selon le client, le serveur DoH doit en
tenir compte pour construire la réponse HTTP. Le but est d'éviter
que cette réponse adaptée à un client spécifique soit
réutilisée. Cela peut se faire avec Cache-Control:
max-age=0 ou bien avec un en-tête
Vary: (RFC 7231,
section 7.1.4 et RFC 9111, section 4.1) qui va ajouter une
condition supplémentaire à la réutilisation des données mises en
cache.
S'il y a un en-tête Age: dans la réponse
HTTP (qui indique depuis combien de temps cette information était
dans un cache Web, RFC 9111, section 5.1), le client DoH
doit en tenir compte pour calculer le vrai TTL. Si le TTL DNS dans
la réponse est de 600 secondes, mais que Age:
indiquait que cette réponse avait séjourné 250 secondes dans le
cache Web, le client DoH doit considérer que cette réponse n'a
plus que 350 secondes de validité. Évidemment, un client qui veut
des données ultra-récentes peut toujours utiliser le
Cache-control: no-cache dans sa requête HTTP,
forçant un rafraichissement. (Il est à noter que le DNS n'a aucun
mécanisme équivalent, et qu'un serveur DoH ne saura donc pas
toujours rafraichir son cache DNS.)
La définition formelle du type MIME
application/dns-message figure en section 6
de notre RFC, et ce type est désormais enregistré
à l'IANA.
La section 8 du RFC est consacrée aux questions de vie privée. C'est à la fois un des principaux buts de DoH (empêcher l'écoute par un tiers) et un point qui a fait l'objet de certaines polémiques, puisque DoH peut être utilisé pour envoyer toutes les requêtes à un gros résolveur public auquel on ne fait pas forcément confiance. Le RFC 7626 traite séparément deux problèmes : l'écoute sur le réseau, et l'écoute effectuée par le serveur. Sur le réseau, DoH protège : tout est chiffré, via un protocole bien établi, TLS. Du fait que le serveur est authentifié, l'écoute par un homme du milieu est également empêchée. DNS sur TLS (RFC 7858) a exactement les mêmes propriétés, mais pour principal inconvénient d'utiliser un port dédié, le 853, trop facile à bloquer. Au contraire, le trafic DoH, passant au milieu d'autres échanges HTTP sur le port 443, est bien plus difficile à restreindre.
Mais et sur le serveur de destination ? Une requête DNS normale
contient peu d'informations sur le client (sauf si on utilise la
très dangereuse technique du RFC 7871). Au
contraire, une requête HTTP est bien trop bavarde :
cookies (RFC 6265), en-têtes User-Agent: et
Accept-Language:, ordre des en-têtes sont
trop révélateurs de l'identité du client. L'utilisation de HTTP
présente donc des risques pour la vie privée du client, risques
connus depuis longtemps dans le monde HTTP mais qui sont nouveaux
pour le DNS. Il avait été envisagé, pendant la discussion à
l'IETF, de définir un sous-ensemble de HTTP ne présentant pas ces
problèmes, mais cela serait rentré en contradiction avec les buts
de DoH (qui étaient notamment de permettre l'utilisation du code
HTTP existant). Pour l'instant, c'est donc au client DoH de
faire attention. Si la bibliothèque HTTP qu'il utilise le permet,
il doit veiller à ne pas envoyer de cookies, à
envoyer moins d'en-têtes, etc.
Notez que la question de savoir si les requêtes DoH doivent voyager sur la même connexion que le trafic HTTPS normal (ce que permet HTTP/2, avec son multiplexage) reste ouverte. D'un côté, cela peut aider à les dissimuler. De l'autre, les requêtes HTTP typiques contiennent des informations qui peuvent servir à reconnaitre le client, alors qu'une connexion servant uniquement à DoH serait moins reconnaissable, le DNS étant nettement moins sensible au fingerprinting.
Comme TLS ne dissimule pas la taille des messages, et qu'un observateur passif du trafic, et qui peut en plus envoyer des requêtes au serveur DNS, peut en déduire les réponses reçues, le RFC recommande aux clients DoH de remplir les requêtes DNS selon le RFC 7830.
Le choix de Mozilla d'utiliser DoH pour son navigateur Firefox (voir un compte-rendu de la première expérience) et le fait que, dans certaines configurations, le serveur DoH de Cloudflare était systématiquement utilisé a été très discuté (cf. cette discussion sur le forum des développeurs et cet article du Register). Mais cela n'a rien à voir avec DoH : c'est le choix d'utiliser un résolveur public géré par un GAFA qui est un problème, pas la technique utilisée pour accéder à ce résolveur public. DNS-sur-TLS aurait posé exactement le même problème. Si Mozilla a aggravé les choses avec leur discours corporate habituel (« nous avons travaillé très dur pour trouver une entreprise de confiance »), il faut rappeler que le problème de la surveillance et de la manipulation des requête et réponses DNS par les FAI est un problème réel (essayez de demander à votre FAI s'il s'engage à ne jamais le faire). On a vu plus haut que DoH ne prévoit pas de système de découverte du serveur. Il faut donc que cela soit configuré en dur (un travail supplémentaire pour les utilisateurs, s'il n'y a pas de résolveur par défaut). En tout cas, le point important est que DoH (ou DNS-sur-TLS) ne protège la vie privée que si le serveur DoH est honnête. C'est une limitation classique de TLS : « TLS permet de s'assurer qu'on communique bien avec Satan, et qu'un tiers ne peut pas écouter ». Mais DoH n'impose pas d'utiliser un serveur public, et impose encore moins qu'il s'agisse d'un serveur d'un GAFA.
La section 9 de notre RFC traite des autres problèmes de sécurité. D'abord, sur la relation entre DoH et DNSSEC. C'est simple, il n'y en a pas. DNSSEC protège les données, DoH protège le canal (une distinction que les promoteurs de DNSCurve n'ont jamais comprise). DNSSEC protège contre les modifications illégitimes des données, DoH (ou bien DNS-sur-TLS) protège contre l'écoute illégitime. Ils résolvent des problèmes différents, et sont donc tous les deux nécessaires.
Quant à la section 10 du RFC, elle expose diverses considérations pratiques liées à l'utilisation de DoH. Par exemple, si un serveur faisant autorité sert des réponses différentes selon l'adresse IP source du client (RFC 6950, section 4), utiliser un résolveur public, qu'on y accède via DoH ou par tout autre moyen, ne donnera pas le résultat attendu, puisque l'adresse IP vue par le serveur faisant autorité sera celle du résolveur public, probablement très distincte de celle du « vrai » client. Un exemple similaire figure dans le RFC : une technique comme DNS64 (RFC 6147) risque fort de ne pas marcher avec un résolveur DNS extérieur au réseau local.
Quelles sont les mises en œuvre de DoH ? Le protocole est assez récent donc votre système favori n'a pas forcément DoH, ou alors c'est seulement dans les toutes dernières versions. Mais DoH est très simple à mettre en œuvre (c'est juste la combinaison de trois protocoles bien maitrisés, et pour lesquels il existe de nombreuses bibliothèques, DNS, HTTP et TLS) et le déploiement ne devrait donc pas poser de problème.
Voyons maintenant ce qui existe, question logiciels et
serveurs. On a vu que Cloudflare a un serveur public, le fameux
1.1.1.1 étant
accessible en DoH (et également en DNS-sur-TLS). Je ne
parlerai pas ici de la question de la confiance qu'on peut
accorder à ce serveur (je vous laisse lire sa politique
de vie privée et l'évaluer vous-même), qui avait été
contestée lors de la polémique Mozilla citée plus haut. Cloudflare
fournit également une bonne
documentation sur DoH, avec une explication
de l'encodage. Enfin, Cloudflare fournit un résolveur
simple (comme stubby ou systemd cités plus haut) qui est un client
DoH, cloudflared.
Un autre serveur DoH public, cette fois issu du monde du
logiciel libre, est celui de l'équipe
PowerDNS, https://doh.powerdns.org/
(cf. leur
annonce). Il utilise leur logiciel dnsdist.
Vous trouverez une liste de serveurs DoH publics chez DefaultRoutes ou
bien chez
curl ou encore sur
le portail dnsprivacy.org. Testons ces serveurs DoH
publics avec le programme doh-nghttp.c, qui avait
été écrit au hackathon IETF 101,
on lui donne l'URL du serveur DoH, et le nom à résoudre, et il
cherche l'adresse IPv4 correspondant à ce nom :
% ./doh-nghttp https://doh.powerdns.org/ www.bortzmeyer.org
The address is 204.62.14.153
% ./doh-nghttp https://1.1.1.1/dns-query www.bortzmeyer.org
The address is 204.62.14.153
% ./doh-nghttp https://doh.defaultroutes.de/dns-query www.bortzmeyer.org
The address is 204.62.14.153
% ./doh-nghttp https://mozilla.cloudflare-dns.com/dns-query www.bortzmeyer.org
The address is 204.62.14.153
Parfait, tout a bien marché. Un autre serveur DoH a la particularité d'être un résolveur menteur (regardez son nom) :
% ./doh-nghttp https://doh.cleanbrowsing.org/doh/family-filter/ www.bortzmeyer.org
The address is 204.62.14.153
% ./doh-nghttp https://doh.cleanbrowsing.org/doh/family-filter/ pornhub.com
The search had no results, and a return value of 8. Exiting.
% ./doh-nghttp https://doh.powerdns.org/ pornhub.com
The address is 216.18.168.16
Bon, et si je veux faire mon propre serveur DoH, on a quelles solutions ? Voyons d'abord le doh-proxy de Facebook. On lui indique le résolveur qu'il va utiliser (il n'est pas inclus dans le code, il a besoin d'un résolveur complet, a priori sur la même machine ou le même réseau local) :
% doh-proxy --port=9443 --upstream-resolver=192.168.2.254 --certfile=server.crt --keyfile=server.key --uri=/
2018-09-27 10:04:21,997: INFO: Serving on <Server sockets=[<socket.socket fd=6, family=AddressFamily.AF_INET6, type=2049, proto=6, laddr=('::1', 9443, 0, 0)>]>
Et posons-lui des questions avec le même client doh-nghttp :
% ./doh-nghttp https://ip6-localhost:9443/ www.bortzmeyer.org The address is 204.62.14.153
C'est parfait, il a marché et affiche les visites :
2018-09-27 10:04:24,264: INFO: [HTTPS] ::1 www.bortzmeyer.org. A IN 0 RD 2018-09-27 10:04:24,264: INFO: [DNS] ::1 www.bortzmeyer.org. A IN 56952 RD 2018-09-27 10:04:24,639: INFO: [DNS] ::1 www.bortzmeyer.org. A IN 56952 QR/RD/RA 1/0/0 -1/0/0 NOERROR 374ms 2018-09-27 10:04:24,640: INFO: [HTTPS] ::1 www.bortzmeyer.org. A IN 0 QR/RD/RA 1/0/0 -1/0/0 NOERROR 375ms
Au même endroit, il y a aussi un client DoH :
% doh-client --domain 1.1.1.1 --uri /dns-query --qname www.bortzmeyer.org
2018-09-27 10:14:12,191: DEBUG: Opening connection to 1.1.1.1
2018-09-27 10:14:12,210: DEBUG: Query parameters: {'dns': 'AAABAAABAAAAAAAAA3d3dwpib3J0em1leWVyA29yZwAAHAAB'}
2018-09-27 10:14:12,211: DEBUG: Stream ID: 1 / Total streams: 0
2018-09-27 10:14:12,219: DEBUG: Response headers: [(':status', '200'), ('date', 'Thu, 27 Sep 2018 08:14:12 GMT'), ('content-type', 'application/dns-message'), ('content-length', '103'), ('access-control-allow-origin', '*'), ('cache-control', 'max-age=5125'), ('expect-ct', 'max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"'), ('server', 'cloudflare-nginx'), ('cf-ray', '460c83ee69f73c53-CDG')]
id 0
opcode QUERY
rcode NOERROR
flags QR RD RA AD
edns 0
payload 1452
;QUESTION
www.bortzmeyer.org. IN AAAA
;ANSWER
www.bortzmeyer.org. 5125 IN AAAA 2001:4b98:dc0:41:216:3eff:fe27:3d3f
www.bortzmeyer.org. 5125 IN AAAA 2605:4500:2:245b::42
;AUTHORITY
;ADDITIONAL
2018-09-27 10:14:12,224: DEBUG: Response trailers: {}
Ainsi qu'un résolveur simple (serveur DNS et client DoH).
Il ne faut pas confondre ce doh-proxy écrit en Python avec un logiciel du même nom écrit en Rust (je n'ai pas réussi à le compiler, celui-là, des compétences Rust plus avancées que les miennes sont nécessaires).
Et les clients, maintenant ? Commençons par le bien connu curl, qui a DoH est depuis la version 7.62.0 (pas encore publiée à l'heure où j'écris, le développement est documenté ici.) curl (comme Mozilla Firefox) fait la résolution DNS lui-même, ce qui est contestable (il me semble préférable que cette fonction soit dans un logiciel partagé par toutes les applications). Voici un exemple :
% ./src/.libs/curl -v --doh-url https://doh.powerdns.org/ www.bortzmeyer.org ... [Se connecter au serveur DoH] * Connected to doh.powerdns.org (2a01:7c8:d002:1ef:5054:ff:fe40:3703) port 443 (#2) * ALPN, offering h2 ... * SSL connection using TLSv1.2 / ECDHE-RSA-AES256-GCM-SHA384 * Server certificate: * subject: CN=doh.powerdns.org ... [Envoyer la requête DoH] * Using Stream ID: 1 (easy handle 0x5631606cbd50) > POST / HTTP/2 > Host: doh.powerdns.org > Accept: */* > Content-Type: application/dns-message > Content-Length: 36 ... < HTTP/2 200 < server: h2o/2.2.5 < date: Thu, 27 Sep 2018 07:39:14 GMT < content-type: application/dns-message < content-length: 92 ... [On a trouvé la réponse DoH] * DOH Host name: www.bortzmeyer.org * TTL: 86392 seconds * DOH A: 204.62.14.153 * DOH AAAA: 2001:4b98:0dc0:0041:0216:3eff:fe27:3d3f * DOH AAAA: 2605:4500:0002:245b:0000:0000:0000:0042 ... [On peut maintenant se connecter au serveur HTTP - le but principal de curl - maintenant qu'on a son adresse IP] * Connected to www.bortzmeyer.org (204.62.14.153) port 80 (#0) > GET / HTTP/1.1 > Host: www.bortzmeyer.org > User-Agent: curl/7.62.0-20180927 > Accept: */* >
Pour les programmeurs Go, l'excellente bibliothèque godns n'a hélas pas DoH (pour des raisons internes). Du code expérimental avait été écrit dans une branche mais a été abandonné. Les amateurs de Go peuvent essayer à la place cette mise en œuvre (on notera que ce client sait parler DoH mais aussi le protocole spécifique et non-standard du résolveur public Google Public DNS).
Pour les programmeurs C, la référence
est la bibliothèque getdns (notez que c'est elle
qui a été utilisée pour le client doh-nghttp
cité plus haut). Le code DoH est, à la parution du RFC, toujours
en cours de développement et pas encore dans un dépôt public. Une
fois que cela sera fait, stubby, qui utilise getdns, pourra parler
DoH.
Voilà, si vous n'êtes pas épuisé·e·s, il y a encore des choses à lire :
- Plein d'informations sur Doh et ses mises en œuvre chez DefaultRoutes, dont un bon exposé sur DoH,
- Le dépôt git qui avait été utilisé par le groupe de travail DoH,
- Un bon article amusant sur les débuts de DoH.
- Un article de Mozilla sur DoH (l'explication du DNS est assez médiocre mais il y a des dessins, donc cela peut être utile pour présenter DoH à l'école élémentaire). Attention, contient de la propagande corporate.
- L'analyse de Sara Dickinson sur les conséquences de DoH.
- Un intéressant article de fond sur DoH.
- Mon exposé sur DoH aux JDLL de 2019.
L'article seul
RFC 8483: Yeti DNS Testbed
Date de publication du RFC : Octobre 2018
Auteur(s) du RFC : L. Song (Beijing Internet
Institute), D. Liu (Beijing Internet
Institute), P. Vixie (TISF), A. Kato
(Keio/WIDE), S. Kerr
Pour information
Première rédaction de cet article le 17 décembre 2018
Ce RFC décrit une expérience, celle qui, de mai 2015 à décembre 2018, a consisté à faire tourner une racine DNS alternative nommée Yeti. Contrairement aux racines alternatives commerciales qui ne sont typiquement que des escroqueries visant à vendre à des gogos des TLD reconnus par personne, Yeti était une expérience technique ; il s'agissait de tester un certain nombre de techniques qu'on ne pouvait pas se permettre de tester sur la « vraie » racine.
Parmi ces techniques, l'utilisation d'un grand nombre de
serveurs
racine (pour casser la légende comme quoi l'actuelle
limite à 13 serveurs aurait une justification technique),
n'utiliser qu'IPv6, jouer avec des
paramètres DNSSEC différents, etc. J'ai
participé à ce projet, à la fois comme gérant de deux des serveurs
racine, et comme utilisateur de la racine Yeti, reconfigurant des
résolveurs DNS pour utiliser Yeti. Les deux serveurs racines
dahu1.yeti.eu.org et
dahu2.yeti.eu.org appartenaient au groupe
Dahu, formé par l'AFNIC (cf. cet
article sur le site de l'AFNIC),
Gandi et eu.org. (Le
nom vient d'un animal aussi
mythique que le yéti.)
Outre l'aspect technique, un autre intéret de Yeti était qu'il s'agissait d'un projet international. Réellement international, pas seulement des états-uniens et des européens de divers pays ! Yeti est d'inspiration chinoise, la direction du projet était faite en Chine, aux États-Unis et au Japon, et parmi les équipes les plus impliquées dans le projet, il y avait des Russes, des Indiens, des Français, des Chiliens… Le projet, on l'a dit, était surtout technique (même si certains participants pouvaient avoir des arrière-pensées) et la zone racine servie par Yeti était donc exactement la même que celle de l'IANA, aux noms des serveurs et aux signatures DNSSEC près. Un utilisateur ordinaire de Yeti ne voyait donc aucune différence. Le projet étant de nature expérimentale, les utilisateurs étaient tous des volontaires, conscients des risques possibles (il y a eu deux ou trois cafouillages).
L'annexe E du RFC est consacrée aux controverses sur le principe même du projet Yeti. Le projet a toujours été discuté en public, et présenté à de nombreuses réunions. Mais il y a toujours des râleurs, affirmant par exemple que ce projet était une racine alternative (ce qui n'est pas faux mais attendez, lisez jusqu'au bout) et qu'il violait donc le RFC 2826. Outre que ce RFC 2826 est très contestable, il faut noter qu'il ne s'applique pas à Yeti ; il concerne uniquement les racines alternatives servant un contenu différent de celui de la racine « officielle » alors que Yeti a toujours été prévu et annoncé comme servant exactement la même racine (comme le faisait ORSN). Rien à voir donc avec ces racines alternatives qui vous vendent des TLD bidons, que personne ne pourra utiliser. Comme le disait Paul Vixie, Yeti pratique le Responsible Alternate Rootism. Notez quand même que certains participants à Yeti (notamment en Chine et en Inde) avaient des objectifs qui n'étaient pas purement techniques (s'insérant dans le problème de la gouvernance Internet, et plus spécialement celle de la racine).
La racine du DNS est quelque chose d'absolument critique pour le bon fonctionnement de l'Internet. Quasiment toutes les activités sur l'Internet démarrent par une ou plusieurs requêtes DNS. S'il n'y a plus de résolution DNS, c'est à peu près comme s'il n'y avait plus d'Internet (même si quelques services pair-à-pair, comme Bitcoin, peuvent encore fonctionner). Du fait de la nature arborescente du DNS, si la racine a un problème, le service est sérieusement dégradé (mais pas arrêté, notamment en raison des mémoires - les « caches » - des résolveurs). On ne peut donc pas jouer avec la racine, par exemple en essayant des idées trop nouvelles et peu testées. Cela n'a pas empêché la racine de changer beaucoup : il y a eu par exemple le déploiement massif de l'anycast, qui semblait inimaginable il y a dix-sept ans, le déploiement de DNSSEC (avec le récent changement de clé, qui s'est bien passé), ou celui d'IPv6, plus ancien. Le fonctionnement de la racine était traditionnellement peu ou pas documenté mais il y a quand même eu quelques documents utiles, comme le RFC 7720, la première description de l'anycast, ou les documents du RSSAC, comme RSSAC 001. Celle ou celui qui veut se renseigner sur la racine a donc des choses à lire.
Mais le point important est que la racine est un système en production, avec lequel on ne peut pas expérimenter à loisir. D'où l'idée, portée notamment par BII, mais aussi par TISF et WIDE, d'une racine alternative n'ayant pas les contraintes de la « vraie » racine. Yeti (section 1 du RFC) n'est pas un projet habituel, avec création d'un consortium, longues réunions sur les statuts, et majorité du temps passé en recherches de financement. C'est un projet léger, indépendant d'organismes comme l'ICANN, géré par des volontaires, sans structure formelle et sans budget central, dans la meilleure tradition des grands projets Internet. À son maximum, Yeti a eu 25 serveurs racine, gérés par 16 organisations différentes.
Au passage, puisqu'on parle d'un projet international, il faut noter que ce RFC a été sérieusement ralenti par des problèmes de langue. Eh oui, tout le monde n'est pas anglophone et devoir rédiger un RFC en anglais handicape sérieusement, par exemple, les Chinois.
Parmi les idées testées sur Yeti (section 3 du RFC) :
- Une racine alternative qui marche (avec supervision sérieuse ; beaucoup de services se présentant comme « racine alternative » ont régulièrement la moitié de leurs serveurs racine en panne),
- Diverses méthodes pour signer et distribuer la zone racine,
- Schémas de nommage pour les serveurs racine (dans la
racine IANA, tous les serveurs sont sous
root-servers.net), - Signer les zones des serveurs racine (actcuellement,
root-servers.netn'est pas signé), - Utiliser exclusivement IPv6,
- Effectuer des remplacements de clé (notamment en comptant sur le RFC 5011),
- Sans compter les autres idées décrites dans cette section 3 du RFC mais qui n'ont pas pu être testées.
La section 4 du RFC décrit l'infrastructure de Yeti. Elle a
évidemment changé plusieurs fois, ce qui est normal pour un
service voué aux expérimentations. Yeti utilise l'architecture
classique du DNS. Les serveurs racine sont remplacés par ceux de
Yeti, les autres serveurs faisant autorité (ceux de
.fr ou
.org, par exemple) ne
sont pas touchés. Les résolveurs doivent évidemment être
reconfigurés pour utiliser Yeti (d'une manière qui est documentée sur le site Web du projet). Au
démarrage, un résolveur ne connait en effet que la liste des noms
et adresses IP des serveurs de la racine. La racine « officielle »
est configurée par défaut et doit ici être remplacée (annexe A du RFC). Il faut
aussi changer la clé de la racine (la root trust
anchor) puisque Yeti signe avec sa propre clé.
Voici la configuration de mon résolveur à la maison, avec Knot sur une Turris Omnia :
config resolver 'common'
option keyfile '/etc/kresd/yeti-root.keys'
option prefered_resolver 'kresd'
config resolver 'kresd'
option rundir '/tmp/kresd'
option log_stderr '1'
option log_stdout '1'
option forks '1'
option include_config '/etc/kresd/custom.conf'
et custom.conf contient la liste des serveurs
racine :
hints.root({
['bii.dns-lab.net.'] = '240c:f:1:22::6',
['yeti-ns.tisf.net .'] = '2001:4f8:3:1006::1:4',
['yeti-ns.wide.ad.jp.'] = '2001:200:1d9::35',
['yeti-ns.as59715.net.'] = '2a02:cdc5:9715:0:185:5:203:53',
['dahu1.yeti.eu.org.'] = '2001:4b98:dc2:45:216:3eff:fe4b:8c5b',
['ns-yeti.bondis.org.'] = '2a02:2810:0:405::250',
['yeti-ns.ix.ru .'] = '2001:6d0:6d06::53',
['yeti.bofh.priv.at.'] = '2a01:4f8:161:6106:1::10',
['yeti.ipv6.ernet.in.'] = '2001:e30:1c1e:1::333',
['yeti-dns01.dnsworkshop.org.'] = '2001:1608:10:167:32e::53',
['yeti-ns.conit.co.'] = '2604:6600:2000:11::4854:a010',
['dahu2.yeti.eu.org.'] = '2001:67c:217c:6::2',
['yeti.aquaray.com.'] = '2a02:ec0:200::1',
['yeti-ns.switch.ch.'] = '2001:620:0:ff::29',
['yeti-ns.lab.nic.cl.'] = '2001:1398:1:21::8001',
['yeti-ns1.dns-lab.net.'] = '2001:da8:a3:a027::6',
['yeti-ns2.dns-lab.net.'] = '2001:da8:268:4200::6',
['yeti-ns3.dns-lab.net.'] = '2400:a980:30ff::6',
['ca978112ca1bbdcafac231b39a23dc.yeti-dns.net.'] = '2c0f:f530::6',
['yeti-ns.datev.net.'] = '2a00:e50:f15c:1000::1:53',
['3f79bb7b435b05321651daefd374cd.yeti-dns.net.'] = '2401:c900:1401:3b:c::6',
['xn--r2bi1c.xn--h2bv6c0a.xn--h2brj9c.'] = '2001:e30:1c1e:10::333',
['yeti1.ipv6.ernet.in.'] = '2001:e30:187d::333',
['yeti-dns02.dnsworkshop.org.'] = '2001:19f0:0:1133::53',
['yeti.mind-dns.nl.'] = '2a02:990:100:b01::53:0'
})
Au bureau, avec Unbound, cela donnait :
server:
auto-trust-anchor-file: "/var/lib/unbound/yeti.key"
root-hints: "yeti-hints"
Et yeti-hints est disponible en
annexe A du RFC (attention, comme le note la section 7 du RFC, à
utiliser une source fiable, et à le récupérer de manière sécurisée).
Comme Yeti s'est engagé à ne pas modifier le contenu de la zone racine (liste des TLD, et serveurs de noms de ceux-ci), et comme Yeti visait à gérer la racine de manière moins concentrée, avec trois organisations (BII, TISF et WIDE) signant et distribuant la racine, le mécanisme adopté a été :
- Les trois organisations copient la zone racine « normale »,
- En retirent les clés et les signatures DNSSEC et la liste des serveurs de la racine,
- Modifient le SOA,
- Ajoutent la liste des serveurs Yeti, les clés Yeti, et signent la zone,
- Les serveurs racine copient automatiquement cette nouvelle zone signée depuis un des trois DM (Distribution Master, section 4.1 du RFC).
Voici le SOA Yeti :
% dig SOA .
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 45919
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
. 86400 IN SOA www.yeti-dns.org. bii.yeti-dns.org. (
2018121600 ; serial
1800 ; refresh (30 minutes)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
. 86400 IN RRSIG SOA 8 0 86400 (
20181223050259 20181216050259 46038 .
BNoxqfGq5+rBEdY4rdp8W6ckNK/GAOtBWQ3P36YFq5N+
...
;; Query time: 44 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Sun Dec 16 16:01:27 CET 2018
;; MSG SIZE rcvd: 369
(Notez que l'adresse du responsable de la zone indique le
DM qui a été utilisé par ce résolveur particulier. Un autre
résolveur pourrait montrer un autre SOA, si le DM était différent.)
Comme les serveurs racine « officiels » n'envoient pas de message
NOTIFY (RFC 1996) aux
serveurs Yeti, la seule solution est d'interroger régulièrement
ces serveurs officiels. (Cela fait que Yeti sera toujours un peu
en retard sur la racine « officielle », cf. section 5.2.2.) Plusieurs de ces serveurs acceptent le
transfert de zone (RFC 5936), par exemple
k.root-servers.net :
% dig @k.root-servers.net AXFR . > /tmp/root.zone
% head -n 25 /tmp/root.zone
; <<>> DiG 9.11.3-1ubuntu1.3-Ubuntu <<>> @k.root-servers.net AXFR .
; (2 servers found)
;; global options: +cmd
. 86400 IN SOA a.root-servers.net. nstld.verisign-grs.com. (
2018121600 ; serial
1800 ; refresh (30 minutes)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
. 172800 IN DNSKEY 256 3 8 (
AwEAAdp440E6Mz7c+Vl4sPd0lTv2Qnc85dTW64j0RDD7
...
De son côté, l'ICANN gère deux machines qui
acceptent le transfert de zone,
xfr.cjr.dns.icann.org et
xfr.lax.dns.icann.org. On peut enfin
récupérer cette zone par FTP.
Pour l'étape de signature de la zone, Yeti a testé plusieurs façons de répartir le travail entre les trois DM (Distribution Masters) :
- Clés (KSK et ZSK) partagées entre tous les DM. Cela nécessitait donc de transmettre les clés privées.
- KSK unique mais une ZSK différente par DM (chacune étant signée par la KSK). Chacun garde alors la clé privée de sa ZSK. (Voir la section 5.2.3 pour quelques conséquences pratiques de cette configuration.)
Dans les deux cas, Yeti supprime la totalité des signatures de la racine « officielle » avant d'apposer la sienne. Il a été suggéré (mais pas testé) d'essayer d'en conserver une partie, pour faciliter la vérification du fait que Yeti n'avait pas ajouté ou retiré de TLD.
La configuration chez les DM et leur usage de git (les risques de sécurité que cela pose sont discutés en section 7) pour se synchroniser quand c'est nécessaire est documentée ici.
Les serveurs racine de Yeti n'ont plus ensuite qu'à récupérer la zone depuis un des DM ; chaque serveur racine peut utiliser n'importe quel DM et en changer, de façon à éviter de dépendre du bon fonctionnement d'un DM particulier. Voici par exemple la configuration d'un serveur NSD :
server:
ip-address: 2001:4b98:dc2:45:216:3eff:fe4b:8c5b
nsid: "ascii_dahu1.yeti.eu.org"
# RFC 8201
ipv6-edns-size: 1460
zone:
name: "."
outgoing-interface: 2001:4b98:dc2:45:216:3eff:fe4b:8c5b
# We use AXFR (not the default, IXFR) because of http://open.nlnetlabs.nl/pipermail/nsd-users/2016-February/002243.html
# BII
request-xfr: AXFR 240c:f:1:22::7 NOKEY
allow-notify: 240c:f:1:22::7 NOKEY
# TISF
request-xfr: AXFR 2001:4f8:3:1006::1:5 NOKEY
allow-notify: 2001:4f8:3:1006::1:5 NOKEY
# WIDE
request-xfr: AXFR 2001:200:1d9::53 NOKEY
allow-notify: 2001:200:1d9::53 NOKEY
Notez que la configuration réseau était un peu plus complexe, la
machine ayant deux interfaces, une de service, pour les requêtes
DNS, et une d'aministration, pour se connecter via
ssh. Il fallait s'assurer que les messages
DNS partent bien par la bonne interface réseau, donc faire du
routage selon l'adresse IP source. Le fichier de configuration
Linux pour cela est yeti-network-setup.sh
Contrairement aux serveurs de la racine « officielle », qui
sont tous sous le domaine root-servers.net,
ceux de Yeti, ont des noms variés. Le suffixe identique permet,
grâce à la compression des noms (RFC 1035,
section 4.1.4 et RSSAC
023)
de gagner quelques octets sur la taille des messages DNS. Yeti
cherchant au contraire à tester la faisabilité de messages DNS
plus grands, cette optimisation n'était pas utile.
Une des conséquences est que la réponse initiale à un résolveur (RFC 8109) est assez grande :
% dig @bii.dns-lab.net. NS .
...
;; SERVER: 240c:f:1:22::6#53(240c:f:1:22::6)
;; MSG SIZE rcvd: 1591
On voit qu'elle dépasse la MTU
d'Ethernet. Certains serveurs, pour
réduire la taille de cette réponse, n'indiquent pas la totalité
des adresses IP des serveurs racine (la colle) dans la
réponse. (BIND, avec
minimum-responses: yes n'envoie même aucune
adresse IP, forçant le résolveur à effectuer des requêtes pour les
adresses IP des serveurs). Cela peut augmenter la latence avant
les premières résolutions réussies, et diminuer la robustesse (si
les serveurs dont l'adresse est envoyée sont justement ceux en
panne). Mais cela n'empêche pas le DNS de fonctionner et Yeti,
après discussion, a décidé de ne pas chercher à uniformiser les
réponses des serveurs racine.
Au moment de la publication du RFC, Yeti avait 25 serveurs racine gérés dans 16 pays différents (section 4.6 du RFC), ici vus par check-soa (rappelez-vous qu'ils n'ont que des adresses IPv6) :
% check-soa -i .
3f79bb7b435b05321651daefd374cd.yeti-dns.net.
2401:c900:1401:3b:c::6: OK: 2018121400 (334 ms)
bii.dns-lab.net.
240c:f:1:22::6: OK: 2018121400 (239 ms)
ca978112ca1bbdcafac231b39a23dc.yeti-dns.net.
2c0f:f530::6: OK: 2018121400 (170 ms)
dahu1.yeti.eu.org.
2001:4b98:dc2:45:216:3eff:fe4b:8c5b: OK: 2018121400 (18 ms)
dahu2.yeti.eu.org.
2001:67c:217c:6::2: OK: 2018121400 (3 ms)
ns-yeti.bondis.org.
2a02:2810:0:405::250: OK: 2018121400 (24 ms)
xn--r2bi1c.xn--h2bv6c0a.xn--h2brj9c.
2001:e30:1c1e:10::333: OK: 2018121400 (188 ms)
yeti-ns.as59715.net.
2a02:cdc5:9715:0:185:5:203:53: OK: 2018121400 (43 ms)
yeti-ns.datev.net.
2a00:e50:f155:e::1:53: OK: 2018121400 (19 ms)
yeti-ns.ix.ru.
2001:6d0:6d06::53: OK: 2018121400 (54 ms)
yeti-ns.lab.nic.cl.
2001:1398:1:21::8001: OK: 2018121400 (228 ms)
yeti-ns.switch.ch.
2001:620:0:ff::29: OK: 2018121400 (16 ms)
yeti-ns.tisf.net.
2001:4f8:3:1006::1:4: OK: 2018121400 (175 ms)
yeti-ns.wide.ad.jp.
2001:200:1d9::35: OK: 2018121400 (258 ms)
yeti-ns1.dns-lab.net.
2400:a980:60ff:7::2: OK: 2018121400 (258 ms)
yeti-ns2.dns-lab.net.
2001:da8:268:4200::6: OK: 2018121400 (261 ms)
yeti-ns3.dns-lab.net.
2400:a980:30ff::6: OK: 2018121400 (268 ms)
yeti.aquaray.com.
2a02:ec0:200::1: OK: 2018121400 (4 ms)
yeti.bofh.priv.at.
2a01:4f8:161:6106:1::10: OK: 2018121400 (31 ms)
yeti.ipv6.ernet.in.
2001:e30:1c1e:1::333: OK: 2018121400 (182 ms)
yeti.jhcloos.net.
2001:19f0:5401:1c3::53: OK: 2018121400 (108 ms)
yeti.mind-dns.nl.
2a02:990:100:b01::53:0: OK: 2018121400 (33 ms)
Notez que l'un d'eux a un nom IDN,
मूल.येती.भारत (affiché par
check-soa comme
xn--r2bi1c.xn--h2bv6c0a.xn--h2brj9c). 18 des
serveurs sont des VPS, le reste étant des
machines physiques. 15 utilisent le noyau
Linux, 4 FreeBSD, 1
NetBSD et 1 (oui, oui) tourne sur
Windows. Question logiciel, 16 utilisent
BIND, 4 NSD, 2
Knot, 1 Bundy
(l'ex-BIND 10), 1 PowerDNS et 1
Microsoft DNS.
Pour tester que la racine Yeti fonctionnait vraiment, il ne suffisait évidemment pas de faire quelques dig, check-soa et tests avec les sondes RIPE Atlas. Il fallait un trafic plus réaliste. Certains résolveurs (dont les miens, à la maison et au bureau) ont été configurés pour utiliser la racine Yeti et fournissaient donc un trafic réel, quoique faible. En raison des caches des résolveurs, le trafic réel ne représentait que quelques dizaines de requêtes par seconde. Il était difficile d'augmenter ce nombre, Yeti étant une racine expérimentale, où des choses risquées étaient tentées, on ne pouvait pas utiliser des résolveurs de production. Il a donc fallu aussi injecter du trafic artificiel.
Tout le trafic atteignant les serveurs racines Yeti était capturé (c'est une autre raison pour laquelle on ne pouvait pas utiliser les résolveurs de production ; Yeti voyait toutes leurs requêtes à la racine) et étudié. Pour la capture, des outils comme dnscap ou pcapdump (avec un petit patch) étaient utilisés pour produire des pcap, ensuite copiés vers BII avec rsync.
La section 5 du RFC décrit les problèmes opérationnels qu'a
connu Yeti. Si vous voulez tous les détails, vous pouvez regarder
les
archives de la liste de diffusion du projet, et le blog du
projet. D'abord, ce qui concerne
IPv6. Comme d'habitude, des ennuis sont
survenus avec la fragmentation. En raison
du nombre de serveurs racine, et de l'absence de schéma de nommage
permettant la compression, les réponses Yeti sont souvent assez
grandes pour devoir être fragmentées (1 754 octets avec toutes les
adresses des serveurs racine, et 1 975 avec le mode « une ZSK par
DM »). Cela ne serait pas un problème (la fragmentation des
datagrammes étant spécifiée dans
IPv4 et IPv6 depuis
le début) si tout le monde configurait son réseau
correctement. Hélas, beaucoup d'incompétents et de maladroits ont
configuré leurs systèmes pour bloquer les fragments IP, ou pour
bloquer les messages ICMP nécessaires à la
découverte de la MTU du chemin (RFC 8201). Ce triste état des choses a été décrit dans le
RFC 7872, dans draft-taylor-v6ops-fragdrop, et dans
« Dealing
with IPv6 fragmentation in the DNS ». Il a même
été proposé de ne jamais
envoyer de datagrammes de taille supérieure à 1 280
octets.
En pratique, le meilleur contournement de ce problème est de réduire la taille maximale des réponses EDNS. Par exemple, dans NSD :
ipv6-edns-size: 1460
Les réponses resteront à moins de 1 460 octets et ne seront donc en général pas fragmentées.
Les transferts de zone depuis les DM ont levé quelques
problèmes. Les zones sont légèrement différentes d'un DM à l'autre
(SOA et surtout signatures). Les transferts de zone
incrémentaux (IXFR, RFC 1995), ne peuvent
donc pas être utilisés : si un serveur racine interroge un DM,
puis un autre, les résultats seront incompatibles. Ce cas, très
spécifique à Yeti, n'est pas pris en compte par les logiciels. Les serveurs
doivent donc utiliser le transfert complet (AXFR) uniquement (d'où
le AXFR dans la configuration du serveur
racine NSD vue plus haut). Ce
n'est pas très grave, vu la petite taille de la zone racine.
Lors des essais de remplacement de la KSK (on sait que, depuis
la parution de ce RFC, la KSK
de la racine « officielle » a été successivement
remplacée le 11 octobre 2018) quelques problèmes sont
survenus. Par exemple, la documentation de BIND n'indiquait pas,
lorsque le résolveur utilise l'option
managed-keys, que celle-ci doit être configurée
dans toutes les vues. (Au passage, j'ai toujours trouvé que les vues sont
un système compliqué et menant à des erreurs déroutantes.)
La capture du trafic DNS avec les serveurs racine Yeti a
entrainé d'autres problèmes (section 5.4 du RFC). Il existe
plusieurs façons d'enregistrer le trafic d'un serveur de noms, de
la plus courante (tcpdump avec l'option
-w) à la plus précise
(dnstap). dnstap étant encore peu répandu
sur les serveurs de noms, Yeti a utilisé une capture « brute » des
paquets, dans des fichiers pcap qu'il
fallait ensuite analyser. L'un des problèmes avec les fichiers
pcap est qu'une connexion TCP, même d'une seule requête, va se
retrouver sur plusieurs paquets, pas forcément consécutifs. Il
faudra donc réassembler ces connexions TCP, par exemple avec un
outil développé pour Yeti, PcapParser
(décrit plus longuement dans l'annexe D de notre RFC).
Les serveurs racine changent de temps en temps. Dans la racine
« officielle », les changements des noms sont très rares. En
effet, pour des raisons politiques, on ne peut pas modifier la
liste des organisations qui gèrent un serveur racine. Vouloir
ajouter ou retirer une organisation déclencherait une crise du
genre « pourquoi lui ? ». L'ICANN est donc
paralysée sur ce point. Mais les serveurs changent parfois
d'adresse IP. C'est rare, mais ça arrive. Si les résolveurs ne
changent pas leur configuration, ils auront une liste
incorrecte. Un exemple de la lenteur avec laquelle se diffusent
les changements d'adresses IP des serveurs racine est le cas de
j.root-servers.net qui, treize
ans après son changement d'adresse IP, continue
à recevoir du trafic à l'ancienne adresse. Ceci dit, ce
n'est pas très grave en pratique, car, à l'initialisation du
résolveur (RFC 8109), le résolveur reçoit du
serveur racine consulté une liste à jour. Tant que la liste qui
est dans la configuration du résolveur ne dévie pas trop de la
vraie liste, il n'y a pas de problème, le résolveur finira par
obtenir une liste correcte.
Mais Yeti est différent : les changements sont beaucoup plus
fréquents et, avec eux, le risque que la liste connue par les
résolveurs dévie trop. D'où la création d'un outil spécial, hintUpdate
(personnellement, je ne l'ai jamais utilisé, je modifie la
configuration du résolveur, c'est tout). Un point intéressant
d'hintUpdate est qu'il dépend de DNSSEC
pour vérifier les informations reçues. Cela marche avec Yeti, où
les noms des serveurs racine sont (théoriquement) signés, mais cela ne
marcherait pas avec la racine officielle,
root-servers.net n'étant pas signé.
Dernier problème, et rigolo, celui-ci, la compression inutile. En utilisant le logiciel Knot pour un serveur racine, nous nous sommes aperçus qu'il comprimait même le nom de la zone racine, faisant passer sa taille de un à deux octets. Une compression négative donc, légale mais inutile. À noter que cela plantait la bibliothèque Go DNS. Depuis, cette bibliothèque a été rendue plus robuste, et Knot a corrigé cette optimisation ratée.
La conclusion du RFC, en section 6, rappelle l'importance de disposer de bancs de test, puisqu'on ne peut pas faire courir de risques à la racine de production. La conclusion s'achève en proposant de chercher des moyens de rendre le DNS moins dépendant de la racine actuelle. Et, vu la mode actuelle, le mot de chaîne de blocs est même prononcé…
L'article seul
RFC 8482: Providing Minimal-Sized Responses to DNS Queries that have QTYPE=ANY
Date de publication du RFC : Janvier 2019
Auteur(s) du RFC : J. Abley (Afilias), O. Gudmundsson, M. Majkowski (Cloudflare), E. Hunt (ISC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 11 janvier 2019
Lorsqu'un client DNS envoie une requête à un serveur DNS, le client indique le type de données souhaité. Contrairement à ce qu'on lit souvent, le DNS ne sert pas à « traduire des noms de domaine en adresses IP ». Le DNS est une base de données généraliste, qui sert pour de nombreux types de données. Outre les types (AAAA pour les adresses IP, SRV pour les noms de serveurs assurant un service donné, SSHFP ou TLSA pour les clés cryptographiques, etc), le DNS permet de demander tous les types connus du serveur pour un nom de domaine donné ; c'est ce qu'on appelle une requête ANY. Pour différentes raisons, l'opérateur du serveur DNS peut ne pas souhaiter répondre à ces requêtes ANY. Ce nouveau RFC spécifie ce qu'il faut faire dans ce cas.
Les requêtes comme ANY, qui n'utilisent pas un type spécifique, sont souvent informellement appelées « méta-requêtes ». Elles sont spécifiées (mais de manière un peu ambigüe) dans le RFC 1035, section 3.2.3. On note que le terme « ANY » n'existait pas à l'époque, il est apparu par la suite.
Pourquoi ces requêtes ANY défrisent-elles certains
opérateurs de serveurs DNS ? La section 2 de notre RFC explique
ce choix. D'abord, quelle était l'idée derrière ces requêtes
ANY ? La principale motivation était de débogage : ANY n'est pas
censé être utilisé dans la cadre du fonctionnement normal du DNS,
mais lorsqu'on veut creuser un problème, vérifier l'état d'un
serveur. Voici un exemple de requête ANY envoyée au serveur
faisant autorité pour le nom de domaine
anna.nic.fr :
% dig +nodnssec @ns1.nic.fr ANY anna.nic.fr
...
;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 5, ADDITIONAL: 10
...
;; ANSWER SECTION:
anna.nic.fr. 600 IN A 192.134.5.10
anna.nic.fr. 172800 IN TXT "EPP prod"
anna.nic.fr. 600 IN AAAA 2001:67c:2218:e::51:41
...
;; Query time: 2 msec
;; SERVER: 2001:67c:2218:2::4:1#53(2001:67c:2218:2::4:1)
...
Le serveur 2001:67c:2218:2::4:1 a renvoyé
les données pour trois types, A (adresse IPv4), AAAA (adresse
IPv6) et TXT (un commentaire).
Certains programmeurs comprenant mal le DNS ont cru qu'ils pouvaient utiliser les requêtes ANY pour récupérer à coup sûr toutes les données pour un nom (ce fut par exemple une bogue de qmail). Voyons d'abord si ça marche, en essayant le même nom avec un autre serveur DNS :
% dig @::1 ANY anna.nic.fr
...
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
anna.nic.fr. 595 IN AAAA 2001:67c:2218:e::51:41
...
;; Query time: 0 msec
;; SERVER: ::1#53(::1)
On n'a cette fois récupéré que l'adresse IPv6 et pas les trois enregistrements. C'est parce que cette fois, le serveur interrogé était un résolveur, pas un serveur faisant autorité. Il a bien répondu en donnant toutes les informations qu'il avait. Simplement, il ne connaissait pas tous les types possibles. Ce comportement est le comportement normal de ANY ; ANY (n'importe lesquelles) ne veut pas dire ALL (toutes). Il veut dire « donne-moi tout ce que tu connais ». Il n'y a jamais eu de garantie que la réponse à une requête ANY contiendrait toutes les données (c'est la bogue fondamentale de l'usage DNS de qmail). Si la réponse, comme dans l'exemple précédent, n'a pas de données de type A, est-ce que cela veut dire qu'il n'y a pas de telles données, ou simplement que le serveur ne les connaissait pas ? On ne peut pas savoir. Bref, il ne faut pas utiliser les requêtes ANY vers un résolveur ou, plus exactement, il ne faut pas compter sur le fait que cela vous donnera toutes les données pour ce nom. ANY reste utile pour le débogage (savoir ce que le résolveur a dans le cache) mais pas plus.
Et vers un serveur faisant autorité, est-ce que là, au moins, on a une garantie que cela va marcher ? Même pas car certains serveurs faisant autorité ne donnent qu'une partie des données, voire rien du tout, pour les raisons exposées au paragraphe suivant.
En effet, les requêtes ANY ont des inconvénients. D'abord, elles peuvent être utilisées pour des attaques par réflexion, avec amplification. La réponse, si le serveur envoie toutes les données possibles, va être bien plus grosse que la question, assurant une bonne amplification (cf. RFC 5358, et section 8 de notre nouveau RFC). Bien sûr, ANY n'est pas le seul type de requête possible pour ces attaques (DNSKEY ou NS donnent également de « bons » résultats.)
Ensuite, les requêtes ANY peuvent permettre de récupérer facilement toutes les données sur un nom de domaine, ce que certains opérateurs préféreraient éviter. C'est à mon avis l'argument le plus faible, le même effet peut être obtenu avec des requêtes multiples (il y a 65 536 types possibles, mais beaucoup moins en pratique) ou via le passive DNS.
Enfin, avec certaines mises en œuvre des serveurs DNS, récupérer toutes les informations peut être coûteux. C'est par exemple le cas si le dorsal du serveur est un SGBD où les données sont accessibles uniquement via la combinaison {nom, type}.
Bref, il est légitime que le gérant d'un serveur DNS veuille bloquer les requêtes ANY. Mais que doit-il répondre dans ce cas ? Ne pas répondre du tout, comme le font certains pare-feux programmés et configurés avec les pieds n'est pas une solution, le client réémettra, gaspillant des ressources chez tout le monde. Notre RFC suggère un choix de trois méthodes (section 4) :
- Envoyer un sous-ensemble non-vide des données connues. Le client ne saura jamais si on lui a envoyé toutes les données, seulement celles connues du serveur, ou bien un sous-ensemble. Mais rappelez-vous qu'il n'y a jamais eu aucune garantie qu'ANY renvoie tout. Cette technique ne change donc rien pour le client.
- Variante du précédent, essayer de deviner ce que veut le client et le lui envoyer. Par exemple, en renvoyant tous les A, AAAA, MX et CNAME qu'on a et en ignorant les autres types d'enregistrement, on satisfera sans doute la grande majorité des clients.
- Envoyer un enregistrement HINFO, solution décrite en détail plus loin.
Toutes ces réponses sont compatibles avec le protocole existant. Le RFC 1035, section 3.2.3, est relativement clair à ce sujet : ANY n'est pas la même chose que ALL (section 7 de notre RFC). Notez que notre nouveau RFC n'impose pas une politique particulière ; ce RFC ne dit pas qu'il faut renvoyer la réponse courte, il dit « si vous le faites, faites-le avec une des trois méthodes indiquées ».
Notez que le comportement du serveur peut dépendre de si la question était posée sur UDP ou sur TCP (section 4.4 du RFC). En effet, avec TCP, le risque d'attaque par réflexion est très faible.
Voici un exemple chez Cloudflare, la société qui a le plus « poussé » pour ce RFC :
% dig +nodnssec @ns5.cloudflare.com. ANY cloudflare.com
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 54605
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
cloudflare.com. 3789 IN HINFO "ANY obsoleted" "See draft-ietf-dnsop-refuse-any"
;; Query time: 4 msec
;; SERVER: 2400:cb00:2049:1::a29f:209#53(2400:cb00:2049:1::a29f:209)
;; WHEN: Wed Dec 19 16:05:12 CET 2018
;; MSG SIZE rcvd: 101
Le client recevant ces réponses les mémorise de la manière classique. S'il trouve un HINFO, il peut décider de l'utiliser pour répondre aux requêtes ANY ultérieures. (C'est un changement de la sémantique du type HINFO mais pas grave, ce type étant très peu utilisé.)
Mais pourquoi HINFO, type qui était normalement prévu pour donner des informations sur le modèle d'ordinateur et sur son système d'exploitation (RFC 1035, section 3.3.2) ? La section 6 du RFC traite cette question. Le choix de réutiliser (en changeant sa sémantique) un type existant était dû au fait que beaucoup de boitiers intermédiaires bogués refusent les types DNS qu'ils ne connaissent pas (un nouveau type NOTANY avait été suggéré), rendant difficile le déploiement d'un nouveau type. HINFO est très peu utilisé, donc considéré comme « récupérable ». Ce point a évidemment fait l'objet de chaudes discussions à l'IETF, certains étant choqués par cette réutilisation sauvage d'un type existant. Le type NULL avait été proposé comme alternative mais l'inconvénient est qu'il n'était pas affiché de manière lisible par les clients DNS actuels, contrairement à HINFO, qui permet de faire passer un message, comme dans l'exemple Cloudflare ci-dessus.
Un HINFO réel dans une réponse peut être mémorisé par le résolveur et empêcher certaines requêtes ANY ultérieures. De la même façon, le HINFO synthétique généré en réponse à une requête ANY peut masquer des vrais HINFO. Attention, donc, si vous avez des HINFO réels dans votre zone, à ne pas utiliser ce type dans les réponses aux requêtes ANY.
Mais les HINFO réels sont rares. En janvier 2017, en utilisant
la base DNSDB, je n'avais trouvé que
54 HINFO sur les trois millions de noms de
.fr, et la plupart
n'étaient plus dans le DNS. Les meilleurs
étaient :
iiel.iie.cnam.fr. IN HINFO "VS3100" "VMS-6.2"
wotan.iie.cnam.fr. IN HINFO "AlphaServer-1000" "OSF"
Il y a peu de chance qu'une VaxStation 3100 soit encore en service en 2017 :-) Autres HINFO utilisés de façon créative :
www-cep.cma.fr. IN HINFO "bat. B" ""
syndirag.dirag.meteo.fr. IN HINFO "VM Serveur Synergie 1 operationnel" "RHEL 5.4"
www.artquid.fr. IN HINFO "Artquid" "ArtQuid, La place de marche du Monde de l'Art (Antiquites, Objets d'art, Art contemporain et Design)"
Le HINFO de syndirag.dirag.meteo.fr est
toujours en ligne et illustre très bien une raison pour laquelle
les HINFO sont peu utilisés : il est pénible de les maintenir à
jour (la machine n'est probablement plus en
RHEL 5.4).
Notons que d'autres solutions avaient été étudiées à l'IETF pendant la préparation de ce RFC (section 3) :
- Créer un nouveau code de retour (au lieu de l'actuel NOERROR). Le nommer, par exemple, NOTALL. Mais les résolveurs actuels, recevant un code inconnu, auraient simplement renvoyé la question à d'autres serveurs.
- Utiliser une option EDNS, mais l'expérience prouve que les options EDNS inconnues ont du mal à passer les boitiers intermédiaires.
- Simplement décider que ANY devenait un type d'enregistrement comme les autres, au lieu de rester un « méta-type » avec traitement spécial. Dans ce cas, comme il n'y a pas de données de type ANY dans la zone, la réponse aurait été NODATA (code de retour NOERROR mais une section de réponse vide). Cela s'intégre bien avec DNSSEC par exemple. Mais cela casserait les attentes des logiciels clients, et cela ne leur laisserait rien à mémoriser (à part la réponse négative).
Le choix a donc été fait de renvoyer quelque chose, afin que le client s'arrête là, et qu'il puisse garder quelque chose dans sa mémoire (cache).
On notera que cela laisse entier le problème du client qui voudrait récupérer, par exemple, adresse IPv4 (A) et IPv6 (AAAA) avec une seule requête. Plusieurs approches ont été proposées à l'IETF mais aucune adoptée.
Les techniques de ce RFC sont-elles disponibles ?
NSD avait depuis sa
version 4.1 une option
refuse-any, mais pas conforme au RFC (elle répond avec le bit TC indiquant la troncature, ce que le
RFC refuse explicitement). Cela semble s'être amélioré avec la
version 4.1.27 publiée en mars 2019. BIND a depuis la
version 9.11 une option
minimal-any qui, elle, est conforme. En
mettant minimal-any yes; dans la
configuration, BIND répondre aux requêtes ANY avec un seul
enregistrement. BIND n'utilise donc pas la solution « HINFO » mais
le RFC permet ce choix.
L'article seul
RFC 8467: Padding Policies for Extension Mechanisms for DNS (EDNS(0))
Date de publication du RFC : Octobre 2018
Auteur(s) du RFC : A. Mayrhofer (nic.at GmbH)
Expérimental
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 2 décembre 2018
Chiffrer pour assurer la confidentialité, c'est bien. Pour le DNS, c'est ce que permet le RFC 7858 (DNS sur TLS). Mais un problème de TLS et de pas mal d'autres protocoles cryptographiques est qu'il ne dissimule pas les métadonnées, et notamment la taille des messages échangés sur le réseau. Dans un monde public comme celui du DNS, c'est un problème. En effet, l'attaquant peut facilement mesurer la taille des réponses chiffrées (en envoyant lui-même une requête), voir la taille des réponses, et en déduire les questions qui avaient été posées. La solution classique en cryptographie face à ce risque est le remplissage, normalisé, pour le DNS, dans le RFC 7830. Mais le RFC 7830 ne normalisait que le format, pas le mode d'emploi. Il faut remplir jusqu'à telle taille ? Comment concilier un remplissage efficace pour la confidentialité avec le désir de limiter la consommation de ressources réseaux ? Ce RFC décrit plusieurs stratégies possibles, et recommande un remplissage jusqu'à atteindre une taille qui est le multiple suivant de 468 (octets).
Ce nouveau RFC tente de répondre à ces questions, en exposant les différentes politiques possibles de remplissage, leurs avantages et leurs inconvénients. Le RFC 7830 se limitait à la syntaxe, notre nouveau RFC 8467 étudie la sémantique.
D'abord, avant de regarder les politiques possibles, voyons les choses à garder en tête (section 3 du RFC). D'abord, ne pas oublier de mettre l'option EDNS de remplissage (celle du RFC 7830) en dernier dans la liste des options (car elle a besoin de connaitre la taille du reste du message).
Ensuite, il faut être conscient des compromis à faire. Remplir va améliorer la confidentialité mais va réduire la durée de vie de la batterie des engins portables, va augmenter le débit qu'on injecte dans le réseau, voire augmenter le prix si on paie à l'octet transmis. Lors des discussions à l'IETF, certaines personnes ont d'ailleurs demandé si le gain en confidentialité en valait la peine, vu l'augmentation de taille. En tout cas, on ne remplit les messages DNS que si la communication est chiffrée : cela ne servirait à rien sur une communication en clair.
Enfin, petit truc, mais qui montre l'importance des détails quand on veut dissimuler des informations, le remplissage doit se faire sans tenir compte des deux octets qui, avec certains protocoles de transport du DNS, comme TCP, peut faire fuiter des informations. Avec certaines stratégies de remplissage, les deux octets en question peuvent faire passer de l'autre côté d'un seuil et donc laisser fuiter l'information qu'on était proche du seuil.
Ensuite, après ces préliminaires, passons aux stratégies de remplissage, le cœur de ce RFC (section 4). Commençons par celle qui est la meilleure, et recommandée officiellement par notre RFC : remplissage en blocs de taille fixe. Le client DNS remplit la requête jusqu'à atteindre un multiple de 128 octets. Le serveur DNS, si le client avait mis l'option EDNS de remplissage dans la requête, et si la communication est chiffrée, remplit la réponse de façon à ce qu'elle soit un multiple de 468 octets. Ainsi, requête et réponse ne peuvent plus faire qu'un nombre limité de longueurs, la plupart des messages DNS tenant dans le bloc le plus petit. Voici un exemple vu avec le client DNS dig, d'abord sans remplissage :
% dig +tcp +padding=0 -p 9053 @127.0.0.1 SOA foobar.example
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 29832
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
...
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
; COOKIE: dda704b2a06d65b87f0493105c03ca4d2b2c83f2d4e25680 (good)
;; QUESTION SECTION:
;foobar.example. IN SOA
;; ANSWER SECTION:
foobar.example. 600 IN SOA ns1.foobar.example. root.foobar.example. (
2015091000 ; serial
604800 ; refresh (1 week)
86400 ; retry (1 day)
2419200 ; expire (4 weeks)
86400 ; minimum (1 day)
)
...
;; MSG SIZE rcvd: 116
La réponse fait 116 octets. On demande maintenant du remplissage, jusqu'à 468 octets :
% dig +tcp +padding=468 -p 9053 @127.0.0.1 SOA foobar.example
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 2117
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
; COOKIE: 854d2f29745a72e5fdd6891d5c03ca4b5d5287daf716e327 (good)
; PAD (348 bytes)
;; QUESTION SECTION:
;foobar.example. IN SOA
;; ANSWER SECTION:
foobar.example. 600 IN SOA ns1.foobar.example. root.foobar.example. (
2015091000 ; serial
604800 ; refresh (1 week)
86400 ; retry (1 day)
2419200 ; expire (4 weeks)
86400 ; minimum (1 day)
)
;; MSG SIZE rcvd: 468
La réponse fait 468 octets, grâce aux 348 octets de remplissage
(notez la ligne PAD (348 bytes)).
Les avantages de cette méthode est qu'elle est facile à mettre en œuvre, assure une confidentialité plutôt bonne, et ne nécessite pas de générateur de nombres aléatoires. Son principal inconvénient est qu'elle permet de distinguer deux requêtes (ou deux réponses) si elles ont le malheur d'être remplies dans des blocs de taille différente. Mais il ne faut pas chercher une méthode idéale : rappelez-vous qu'il faudra faire des compromis. Cette méthode a un faible coût pour le défenseur, et élève les coûts sensiblement pour l'attaquant, c'est ça qui compte.
Notez que les chiffres 128 et 468 ont été obtenus empiriquement, en examinant du trafic DNS réel. Si DNSSEC continue à se répandre, les tailles des réponses moyennes augmenteront, et il faudra peut-être réviser ces chiffres.
Une autre statégie est celle du remplissage maximal. On met autant d'octets qu'on peut. Si un serveur a une taille maximale de réponse de 4 096 octets (la valeur par défaut la plus courante) et que le client accepte cette taille, on remplit la réponse jusqu'à ce qu'elle fasse 4 096 octets. L'avantage évident de cette méthode est qu'elle fournit la meilleure confidentialité : toutes les réponses ont la même taille. L'inconvénient évident est qu'elle est la méthode la plus consommatrice de ressources. En outre, ces grandes réponses vont souvent excéder la MTU, pouvant entrainer davantage de problèmes liés à la fragmentation.
Autre stratégie envisageable : remplissage aléatoire. On tire au sort le nombre d'octets à ajouter. Cela fournit une bonne distribution des tailles (par exemple, une réponse courte peut désormais être plus grande qu'une réponse longue, ce qui n'arrive jamais avec les deux stratégies précédentes). Inconvénient : comme ça ne change pas la limite de taille inférieure, un attaquant qui voit beaucoup de messages pourrait en déduire des informations. Et cela oblige à avoir un générateur de nombres aléatoires, traditionnellement un problème délicat en cryptographie.
Enfin, une dernière méthode raisonnable est de combiner le remplissage dans des blocs et le tirage au sort : on choisit au hasard une longueur de bloc et on remplit jusqu'à atteindre cette longueur. Contrairement à la précédente, elle n'a pas forcément besoin d'une source aléatoire à forte entropie. Mais c'est sans doute la technique la plus compliquée à mettre en œuvre.
La section 7 du RFC ajoute quelques points supplémentaires qui peuvent mettre en péril la confidentialité des requêtes. Par exemple, si le client DNS remplit correctement sa requête, mais que le serveur ne le fait pas, un attaquant pourra déduire la requête de la réponse (c'est d'autant plus facile, avec le DNS, que la question est répétée dans la réponse). Dans une communication de client à résolveur DNS, il faut bien choisir son résolveur.
Et le remplissage ne brouille qu'une seule des métadonnées. Il y en a d'autres comme l'heure de la question, le temps de réponse ou comme la succession des requêtes/réponses, qui restent accessibles à un éventuel attaquant. La protection contre la fuite d'informations via ces métadonnées nécessiterait d'injecter « gratuitement » du trafic de couverture (qui, lui aussi, éleverait la consommation de ressources réseau).
Et pour terminer le RFC, l'annexe A est consacrée aux mauvaises politiques de remplissage, celles qui non seulement ne sont pas recommandées mais sont activement déconseillées. (Mais on les trouve parfois dans du code réel.) Il y a l'évidente stratégie « pas de remplissage du tout ». Son principal intérêt est qu'elle fournit le point de comparaison pour toutes les autres stratégies. Avantages : triviale à implémenter, il suffit de ne rien faire, et aucune consommation de ressources supplémentaires. Inconvénient : la taille des requêtes et des réponses est exposée, et un observateur malveillant peut en déduire beaucoup de choses.
Une autre méthode inefficace pour défendre la vie privée est celle du remplissage par une longueur fixe. Elle est simple à implémenter mais ne protège rien : une simple soustraction suffit pour retrouver la vraie valeur de la longueur.
Ces différentes stratégies ont été analysées empiriquement (il n'y a pas vraiment de bon cadre pour le faire théoriquement) et le travail est décrit dans l'excellente étude de Daniel Kahn Gillmor (ACLU), « Empirical DNS Padding Policy » présentée à NDSS en 2017. Si vous aimez les chiffres et les données, c'est ce qu'il faut regarder !
Testons un peu les mises en œuvres du remplissage des messages DNS (une liste plus complète figure sur le site du projet).
Essayons avec BIND version 9.13.4. Il
fournit le client de débogage dig et son
option +padding. Avec un
+padding=256, le
datagramme va faire 264 octets, incluant
les ports source et
destination d'UDP). Vu par tshark, cela donne :
<Root>: type OPT
Name: <Root>
Type: OPT (41)
UDP payload size: 4096
Higher bits in extended RCODE: 0x00
EDNS0 version: 0
Z: 0x8000
1... .... .... .... = DO bit: Accepts DNSSEC security RRs
.000 0000 0000 0000 = Reserved: 0x0000
Data length: 213
Option: COOKIE
Option Code: COOKIE (10)
Option Length: 8
Option Data: 722ffe96cd87b40a
Client Cookie: 722ffe96cd87b40a
Server Cookie: <MISSING>
Option: PADDING
Option Code: PADDING (12)
Option Length: 197
Option Data: 000000000000000000000000000000000000000000000000...
Padding: 000000000000000000000000000000000000000000000000...
Cela, c'était la requête du client. Mais cela ne veut pas dire que le serveur va accepter de répondre avec du remplissage. D'abord, il faut qu'il soit configuré pour cela (BIND 9.13.4 ne le fait pas par défaut). Donc, côté serveur, il faut :
options {
...
response-padding {any;} block-size 468;
};
(any est pour accepter le remplissage pour
tous les clients.) Mais cela ne suffit pas, BIND ne répond avec du
remplissage que si l'adresse IP source est raisonnablement sûre
(TCP ou biscuit du RFC 7873, pour éviter les attaques par amplification). C'est pour cela qu'il y a une option
+tcp dans les appels de dig plus haut. On
verra alors dans le résultat de dig le PAD (392
bytes) indiquant qu'il y a eu remplissage. La taille
indiquée dans response-padding est une taille
de bloc : BIND enverra des réponses qui seront un multiple de cette
taille. Par exemple, avec response-padding {any;}
block-size 128;, une courte réponse est remplie à 128
octets (notez que la taille de bloc n'est pas la même chez le
serveur et chez le client) :
% dig +tcp +padding=468 -p 9053 @127.0.0.1 SOA foobar.example
...
; PAD (8 bytes)
...
;; MSG SIZE rcvd: 128
Alors qu'une réponse plus longue (notez la question
ANY au lieu de SOA) va
faire passer dans la taille de bloc au
dessus (128 octets est clairement une taille de bloc trop petite,
une bonne partie des réponses DNS, même sans
DNSSEC, peuvent la dépasser) :
% dig +tcp +padding=468 -p 9053 @127.0.0.1 ANY foobar.example
...
; PAD (76 bytes)
...
;; MSG SIZE rcvd: 256
On voit bien ici l'effet de franchissement du seuil : une taille de bloc plus grande doit être utilisée.
BIND n'est pas forcément que serveur DNS, il peut être client,
quand il est résolveur et parle aux serveurs faisant autorité. La
demande de remplissage dans ce cas se fait dans la configuration
par serveur distant, avec padding. (Je n'ai
pas testé.)
Le résolveur Knot fait également le
remplissage (option net.tls_padding) mais, contrairement à BIND, il ne le fait que lorsque
le canal de communication est chiffré (ce qui est logique).
La bibliothèque pour développer des clients DNS getdns a également le remplissage. En revanche, Unbound, dans sa version 1.8.1, ne fait pas encore de remplissage. Et, comme vous avez vu dans l'exemple tshark plus haut, Wireshark sait décoder l'option de remplissage.
L'article seul
RFC 8461: SMTP MTA Strict Transport Security (MTA-STS)
Date de publication du RFC : Septembre 2018
Auteur(s) du RFC : D. Margolis, M. Risher (Google), B. Ramakrishnan (Oath), A. Brotman (Comcast), J. Jones (Microsoft)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF uta
Première rédaction de cet article le 9 janvier 2019
La question de la sécurité du courrier électronique va probablement amener à la publication de nombreux autres RFC dans les années qui viennent… Ce nouveau RFC traite du problème de la sécurisation de SMTP avec TLS ; c'est très bien d'avoir SMTP-sur-TLS, comme le font aujourd'hui tous les MTA sérieux. Mais comment le client SMTP qui veut envoyer du courrier va-t-il savoir si le serveur en face gère TLS ? Et si on peut compter dessus, refusant de se connecter si TLS a un problème ? Notre RFC apporte une solution, publier dans le DNS un enregistrement texte qui va indiquer qu'il faut télécharger (en HTTP !) la politique de sécurité TLS du serveur. En la lisant, le client saura à quoi s'attendre. Ne cherchez pas de déploiement de cette technique sur le serveur qui gère mon courrier électronique, je ne l'ai pas fait, pour les raisons expliquées plus loin.
Cette solution se nomme STS, pour Strict Transport Security. La section 1 du RFC explique le modèle de menace auquel répond cette technique. Sans TLS, une session SMTP peut être facilement écoutée par des espions et, pire, interceptée et modifiée. TLS est donc indispensable pour le courrier, comme pour les autres services Internet. À l'origine (RFC 3207), la méthode recommandée pour faire du TLS était dite STARTTLS et consistait, pour le MTA contacté, à annoncer sa capacité TLS puis, pour le MTA qui appelle, à démarrer la négociation TLS s'il le souhaitait, et si le serveur en face avait annoncé qu'il savait faire. Une telle méthode est très vulnérable aux attaques par repli, ici connues sous le nom de SSL striping ; un attaquant actif peut retirer l'indication STARTTLS du message de bienvenue du MTA contacté, faisant croire au MTA appelant que TLS ne sera pas possible.
D'autre part, un très grand nombre de serveurs SMTP ont des certificats expirés, ou auto-signés, qui ne permettent pas d'authentifier sérieusement le MTA qu'on appelle. En cas de détournement BGP ou DNS, on peut se retrouver face à un mauvais serveur et comment le savoir, puisque les serveurs authentiques ont souvent un mauvais certificat. Le MTA qui se connecte à un autre MTA est donc confronté à un choix difficile : si le certificat en face est auto-signé, et donc impossible à évaluer, est-ce parce que l'administrateur de ce MTA est négligent, ou bien parce qu'il y a un détournement ? Pour répondre à cette question, il faut un moyen indépendant de connaitre la politique du MTA distant. C'est ce que fournit notre RFC (c'est aussi ce que fournit DANE, en mieux).
À noter que ce RFC concerne les communications entre MTA. Pour celles entre MUA et MTA, voyez le RFC 8314, qui utilise un mécanisme assez différent, fondé sur le TLS implicite (au contraire du TLS explicite de STARTSSL).
Donc, la technique décrite dans ce RFC, STS, vise à permettre l'expression d'une politique indiquant :
- Si le receveur a TLS ou pas,
- Ce que devrait faire l'émetteur si TLS (chiffrement ou authentification) échoue.
D'abord, découvrir la politique du serveur distant (section 3
du RFC). Cela se fait en demandant un enregistrement
TXT. Si le domaine de courrier est
example.com, le nom où chercher
l'enregistrement TXT est
_mta-sts.example.com. Regardons chez
Gmail :
% dig TXT _mta-sts.gmail.com
...
;; ANSWER SECTION:
_mta-sts.gmail.com. 300 IN TXT "v=STSv1; id=20171114T070707;"
On peut aussi utiliser le DNS Looking Glass.
Cet enregistrement TXT contient des paires clé/valeur, deux clés sont utilisées :
vqui indique la version de STS utilisée, aujourd'huiSTSv1,- et
idqui indique un numéro de série (ici 20171114T070707) ; si la politique TLS change, on doit penser à modifier ce numéro. (Rappelons que la politique est accessible via HTTP. Dans beaucoup d'organisations, ce n'est pas la même équipe qui gère le contenu DNS et le contenu HTTP, et je prévois donc des difficultés opérationnelles.)
La présence de cet enregistrement va indiquer qu'une politique TLS pour le MTA est disponible, à récupérer via HTTP.
D'autres clés pourront être créées dans le futur, et mises dans le registre IANA, en suivant la politique « Examen par un expert » du RFC 8126.
Cette politique doit se trouver en (toujours en supposant que
le domaine est example.com)
https://mta-sts.example.com/.well-known/mta-sts.txt,
et avoir le type text/plain. (Le
.well-known est décrit dans le RFC 8615.) Le nom
mta-sts.txt a été ajouté dans le
registre IANA. Essayons de récupérer la politique de Gmail,
puisqu'ils ont l'enregistrement TXT :
% curl https://mta-sts.gmail.com/.well-known/mta-sts.txt
version: STSv1
mode: testing
mx: gmail-smtp-in.l.google.com
mx: *.gmail-smtp-in.l.google.com
max_age: 86400
On voit que les politiques sont également décrites sous formes de
paires clé/valeur, mais avec le deux-points
au lieu du égal. On voit aussi que
l'utilisation de STS (Strict Transport
Security) nécessite un nom spécial
(mta-sts, qui n'a pas de
tiret bas car il s'agit d'un nom de machine) ce qui peut entrer en conflit avec
des politiques de nommages locales, et est en général mal
perçu. (Cela a fait râler.) L'utilisation des
enregistrements de service aurait évité
cela mais ils n'ont pas été retenus.
Les clés importantes sont :
version: aujourd'huiSTSv1,mode: indique au MTA émetteur ce qu'il doit faire si TLS échoue. Il y a le choix entrenone(continuer comme si de rien n'était),testing(signaler les problèmes - cf. section 6 - mais continuer, c'est le choix de Gmail dans la politique ci-dessus) etenforce(refuser d'envoyer le message en cas de problème, c'est le seul mode qui protège contre les attaques par repli).max_age: durée de vie de la politique en question, on peut la mémoriser pendant ce nombre de secondes (une journée pour Gmail),mx: les serveurs de messagerie de ce domaine.
D'autres clés pourront être ajoutées dans le même registre IANA, avec la politique d'examen par un expert (cf. RFC 8126.) Un exemple de politique figure dans l'annexe A du RFC.
(Notez qu'au début du processus qui a mené à ce RFC, la politique était décrite en JSON. Cela a été abandonné au profit d'un simple format « clé: valeur » car JSON n'est pas habituel dans le monde des MTA, et beaucoup de serveurs de messagerie n'ont pas de bibliothèque JSON incluse.)
La politique doit être récupérée en
HTTPS (RFC 2818)
authentifié (RFC 6125), le serveur doit donc
avoir un certificat valide pour
mta-sts.example.com. L'émetteur doit utiliser
SNI (Server Name Indication, RFC 6066), et parler au moins TLS 1.2. Attention, le client
HTTPS ne doit pas suivre les redirections, et ne doit pas utiliser
les caches Web du RFC 9111.
Notez bien qu'une politique ne s'applique qu'à un domaine, pas
à ses sous-domaines. La politique récupérée en
https://mta-sts.example.com/ ne nous dit rien
sur les serveurs de messagerie du domaine
something.example.com.
Une fois que l'émetteur d'un courrier connait la politique du récepteur, il va se connecter en SMTP au MTA du récepteur et vérifier (section 4) que :
- Le MX correspond à un des serveurs listés
sous la clé
mxdans la politique, - Le serveur accepte de faire du TLS et a un certificat valide. Le certificat ne doit évidemment pas être expiré (ce qui est pourtant courant) et doit être signé par une des AC connues de l'émetteur (ce qui garantit bien des problèmes, puisque chaque émetteur a sa propre liste d'AC, qui n'est pas connue du récepteur). Le certificat doit avoir un SAN (Subject Alternative Name, cf. RFC 5280) avec un DNS-ID (RFC 6125) correspond au nom du serveur.
L'exigence que le certificat soit signé par une
AC connue de l'émetteur est la raison pour
laquelle je ne déploie pas STS sur mon domaine
bortzmeyer.org ; ses serveurs de messagerie
utilisent des certificats signés par CAcert, et beaucoup de MTA n'ont pas CAcert
dans le magasin qu'ils utilisent. Exiger un certificat signé par
une AC connue de l'émetteur pousse à la concentration vers
quelques grosses AC, puisque c'est la seule façon d'être
raisonnablement sûr qu'elle soit connue partout. Une meilleure
solution que STS, et celle que j'utilise, est d'utiliser
DANE (RFC 7672). Mais STS est issu
de chez Google, qui pousse toujours aux
solutions centralisées, avec un petit nombre d'AC
officielles. (Cf. annonce
initiale où Google dit clairement « nous avons une
solution, nous allons la faire normaliser ».)
Et si les vérifications échouent ? Tout dépend de la valeur
liée à la clé mode dans la politique. Si elle
vaut enforce, l'émetteur renonce et le
message n'est pas envoyé, si le mode est
testing ou none, on
envoie quand même. Dans le cas testing,
l'émetteur tentera de signaler au récepteur le problème (section
6), en utilisant le RFC 8460. C'est donc le
récepteur, via la politique qu'il publie, qui décide du sort du
message. L'annexe B du RFC donne, en
pseudo-code, l'algorithme complet.
La section 8 de notre RFC rassemble quelques considérations
pratiques pour celles et ceux qui voudraient déployer cette
technique STS. D'abord, le problème du changement de
politique. Lorsqu'on modifie sa politique, il y a deux endroits à
changer, les données envoyées par le serveur HTTP, et
l'enregistrement TXT dans le DNS (pour modifier la valeur associée
à id). Deux changements veut dire qu'il y a
du potentiel pour une incohérence, si on modifie un des endroits
mais pas l'autre, d'autant plus que ces deux endroits peuvent être
sous la responsabilité d'équipes différentes. Et l'enregistrement
TXT est soumis au TTL du DNS. Donc,
attention à changer la politique publiée en HTTPS avant de changer
l'enregistrement DNS. Et il faut faire en sorte que les deux
politiques fonctionnent car certains envoyeurs auront l'ancienne.
Un cas courant en matière de courrier électronique est la
délégation de l'envoi du courrier massif à un « routeur » (rien à
voir avec les routeurs
IP). Ainsi, les newsletters, dont le
service marketing croit qu'elles servent à quelque chose, sont
souvent déléguées à un spammeur professionnel, le
« routeur ». Dans ce cas, il faut aussi leur déléguer la
politique, et le _mta-sts dans le DNS doit
donc être un alias pointant vers un nom du routeur. Idem pour le
nom mta-sts qui pointe vers le serveur HTTP
où récupérer la politique. Cela doit être un alias DNS, ou bien un
reverse proxy HTTP (pas une redirection HTTP,
prohibée par le RFC).
Notre RFC se termine par la section 10, qui détaille quelques points de sécurité. Comme toute la sécurité de STS dépend du certificat PKIX qui est présenté à l'émetteur du courrier (cf. RFC 6125), la sécurité de l'écosystème X.509 est cruciale. Si une AC délivre un faux certificat (comme c'est arrivé souvent), l'authentification TLS ne protégera plus.
Autre problème potentiel, le DNS. Sans DNSSEC, il est trop facile de tromper un résolveur DNS et, par exemple, de lui dire que l'enregistrement TXT n'existe pas et qu'il n'y a donc pas de politique STS. La bonne solution est évidemment de déployer DNSSEC, mais le RFC donne également quelques conseils pratiques pour ceux et celles qui s'obstinent à ne pas avoir de DNSSEC. (Celles et ceux qui ont DNSSEC ont de toute façon plutôt intérêt à utiliser DANE.) Notamment, il est recommandé que le serveur émetteur mémorise ce que faisait le récepteur et se méfie si la politique disparait (une forme de TOFU).
STS n'est pas la première technique qui vise à atteindre ces
buts. La section 2 de notre RFC en présente d'autres. La
principale est évidemment DANE (RFC 7672), celle que j'ai choisi de déployer pour
le service de courrier de
bortzmeyer.org. DANE nécessite
DNSSEC, et le RFC présente comme un
avantage que la solution qu'il décrit ne nécessite pas DNSSEC
(c'est une erreur car, sans DNSSEC, la solution de ce RFC marche
mal puisqu'un attaquant pourrait prétendre que l'enregistrement
texte n'existe pas, ou bien lui donner une autre valeur). Par
contre, il est exact que STS permet un mode « test
seulement » que ne permet pas DANE.
Mais ce n'est pas un argument suffisant pour moi.
Qui met en œuvre STS aujourd'hui ? On a vu que Gmail le faisait. Yahoo a également une politique STS :
% dig +short TXT _mta-sts.yahoo.com "v=STSv1; id=20161109010200Z;"
Elle est en testing, comme celle de Gmail (je
n'ai encore rencontré aucun domaine qui osait utiliser
enforce). Comme illustration du fait que la
publication de la politique nécessitant deux
endroits (DNS et HTTP) est casse-gueule, regardons chez
Microsoft :
% dig +short TXT _mta-sts.outlook.com "v=STSv1; id=20180321T030303;"
Mais en HTTP, on récupère un 404 (ressource non existante) sur la politique…
ProtonMail n'a rien, pour l'instant STS semble uniquement sur les gros silos centralisés :
% dig TXT _mta-sts.protonmail.com ; <<>> DiG 9.11.3-1ubuntu1.3-Ubuntu <<>> TXT _mta-sts.protonmail.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 12470 ...
Et question logiciels libres de MTA, qu'est-ce qui existe ? Voyons Postfix ; il y a deux cas à distinguer :
- Pour le courrier entrant, où Postfix n'est pas concerné, il suffit d'activer TLS sur Postfix, puis de publier sa politique (rappelez-vous : DNS et HTTP).
- Pour le courrier sortant, il faudrait que Postfix regarde la politique du serveur distant. Il n'est pas évident que ce code doive être dans le démon Postfix lui-même (trop de code n'est pas une bonne idée). Comme le note Venema, « Like DKIM/DMARC I do not think that complex policies like STS should be built into core Postfix SMTP components ». Une meilleure solution est sans doute un programme externe comme postfix-mta-sts-resolver, qui met en œuvre une partie de ce RFC (la possibilité d'envoi de rapports est absente, par exemple), et communique ensuite les résultats à Postfix, via le système socketmap. Vous pouvez lire cet article d'exemple. Ne me demandez pas des détails, comme expliqué plus haut, j'utilise DANE et pas STS.
Une fois tout cela configuré, il existe un bon
outil de test en
ligne pour voir si votre politique STS est
correcte. Essayez-le avec outlook.com pour
rire un peu.
Quelques articles sur STS :
- Keltia n'a pas aimé.
- Shaft non plus.
- Le service de tests de sécurité en ligne Hardenize a fait un bon article de synthèse.
- Une autre solution pour connaitre la politique TLS d'un domaine : la liste maintenue par l'EFF (je n'y suis pas non plus, puisque l'AC que j'ai choisie n'est pas acceptée par l'EFF).
L'article seul
RFC 8446: The Transport Layer Security (TLS) Protocol Version 1.3
Date de publication du RFC : Août 2018
Auteur(s) du RFC : E. Rescorla (RTFM)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 11 août 2018
Après un très long processus, et d'innombrables polémiques, la nouvelle version du protocole de cryptographie TLS, la 1.3, est enfin publiée. Les changements sont nombreux et, à bien des égards, il s'agit d'un nouveau protocole (l'ancien était décrit dans le RFC 5246, que notre nouveau RFC remplace).
Vous pouvez voir l'histoire de ce RFC sur la Datatracker de l'IETF. Le premier brouillon a été publié en avril 2014, plus de trois années avant le RFC. C'est en partie pour des raisons techniques (TLS 1.3 est très différent de ses prédécesseurs) et en partie pour des raisons politiques. C'est que c'est important, la sécurité ! Cinq ans après les révélations de Snowden, on sait désormais que des acteurs puissants et sans scrupules, par exemple les États, espionnent massivement le trafic Internet. Il est donc crucial de protéger ce trafic, entre autres par la cryptographie. Mais dire « cryptographie » ne suffit pas ! Il existe des tas d'attaques contre les protocoles de cryptographie, et beaucoup ont réussi contre les prédécesseurs de TLS 1.3. Il était donc nécessaire de durcir le protocole TLS, pour le rendre moins vulnérable. Et c'est là que les ennuis ont commencé. Car tout le monde ne veut pas de la sécurité. Les États veulent continuer à espionner (le GCHQ britannique s'était clairement opposé à TLS 1.3 sur ce point). Les entreprises veulent espionner leurs employés (et ont pratiqué un lobbying intense contre TLS 1.3). Bref, derrière le désir de « sécurité », partagé par tout le monde, il y avait un désaccord de fond sur la surveillance. À chaque réunion de l'IETF, une proposition d'affaiblir TLS pour faciliter la surveillance apparaissait, à chaque fois, elle était rejetée et, tel le zombie des films d'horreur, elle réapparaissait, sous un nom et une forme différente, à la réunion suivante. Par exemple, à la réunion IETF de Prague en juillet 2017, l'affrontement a été particulièrement vif, alors que le groupe de travail TLS espérait avoir presque fini la version 1.3. Des gens se présentant comme enterprise networks ont critiqué les choix de TLS 1.3, notant qu'il rendait la surveillance plus difficile (c'était un peu le but…) gênant notamment leur débogage. Ils réclamaient un retour aux algorithmes n'ayant pas de sécurité persistante. Le début a suivi le schéma classique à l'IETF : « vous réclamez un affaiblissement de la sécurité » vs. « mais si on ne le fait pas à l'IETF, d'autres le feront en moins bien », mais, au final, l'IETF est restée ferme et n'a pas accepté de compromissions sur la sécurité de TLS. (Un résumé du débat est dans « TLS 1.3 in enterprise networks ».)
Pour comprendre les détails de ces propositions et de ces rejets, il faut regarder un peu en détail le protocole TLS 1.3.
Revenons d'abord sur les fondamentaux : TLS est un mécanisme permettant aux applications client/serveur de communiquer au travers d'un réseau non sûr (par exemple l'Internet) tout en empêchant l'écoute et la modification des messages. TLS suppose un mécanisme sous-jacent pour acheminer les bits dans l'ordre, et sans perte. En général, ce mécanisme est TCP. Avec ce mécanisme de transport, et les techniques cryptographiques mises en œuvre par dessus, TLS garantit :
- L'authentification du serveur (celle du client est facultative), authentification qui permet d'empêcher l'attaque de l'intermédiaire, et qui se fait en général via la cryptographie asymétrique,
- La confidentialité des données (mais attention, TLS ne masque pas la taille des données, permettant certaines analyses de trafic),
- L'intégrité des données (qui est inséparable de l'authentification : il ne servirait pas à grand'chose d'être sûr de l'identité de son correspondant, si les données pouvaient être modifiées en route).
Ces propriétés sont vraies même si l'attaquant contrôle complètement le réseau entre le client et le serveur (le modèle de menace est détaillé dans la section 3 - surtout la 3.3 - du RFC 3552, et dans l'annexe E de notre RFC).
TLS est un protocole gros et compliqué (ce qui n'est pas forcément optimum pour la sécurité). Le RFC fait 147 pages. Pour dompter cette complexité, TLS est séparé en deux composants :
- Le protocole de salutation (handshake protocol), chargé d'organiser les échanges du début, qui permettent de choisir les paramètres de la session (c'est un des points délicats de TLS, et plusieurs failles de sécurité ont déjà été trouvées dans ce protocole pour les anciennes versions de TLS),
- Et le protocole des enregistrements (record protocol), au plus bas niveau, chargé d'acheminer les données chiffrées.
Pour comprendre le rôle de ces deux protocoles, imaginons un protocole fictif simple, qui n'aurait qu'un seul algorithme de cryptographie symétrique, et qu'une seule clé, connue des deux parties (par exemple dans leur fichier de configuration). Avec un tel protocole, on pourrait se passer du protocole de salutation, et n'avoir qu'un protocole des enregistrements, indiquant comment encoder les données chiffrées. Le client et le serveur pourraient se mettre à communiquer immédiatement, sans salutation, poignée de mains et négociation, réduisant ainsi la latence. Un tel protocole serait très simple, donc sa sécurité serait bien plus facile à analyser, ce qui est une bonne chose. Mais il n'est pas du tout réaliste : changer la clé utilisée serait complexe (il faudrait synchroniser exactement les deux parties), remplacer l'algorithme si la cryptanalyse en venait à bout (comme c'est arrivé à RC4, cf. RFC 7465) créerait un nouveau protocole incompatible avec l'ancien, communiquer avec un serveur qu'on n'a jamais vu serait impossible (puisque on ne partagerait pas de clé commune), etc. D'où la nécessité du protocole de salutation, où les partenaires :
- S'authentifient avec leur clé publique (ou, si on veut faire comme dans le protocole fictif simple, avec une clé secrète partagée),
- Sélectionnent l'algorithme de cryptographie symétrique qui va chiffrer la session, ainsi que ses paramètres divers,
- Choisir la clé de la session TLS (et c'est là que se sont produites les plus grandes bagarres lors de la conception de TLS 1.3).
Notez que TLS n'est en général pas utilisé tel quel mais via un protocole de haut niveau, comme HTTPS pour sécuriser HTTP. TLS ne suppose pas un usage particulier : on peut s'en servir pour HTTP, pour SMTP (RFC 7672), pour le DNS (RFC 7858), etc. Cette intégration dans un protocole de plus haut niveau pose parfois elle-même des surprises en matière de sécurité, par exemple si l'application utilisatrice ne fait pas attention à la sécurité (Voir mon exposé à Devoxx, et ses transparents.)
TLS 1.3 est plutôt un nouveau protocole qu'une nouvelle version, et il n'est pas directement compatible avec son prédécesseur, TLS 1.2 (une application qui ne connait que 1.3 ne peut pas parler avec une application qui ne connait que 1.2.) En pratique, les bibliothèques qui mettent en œuvre TLS incluent en général les différentes versions, et un mécanisme de négociation de la version utilisée permet normalement de découvrir la version maximum que les deux parties acceptent (historiquement, plusieurs failles sont venues de ce point, avec des pare-feux stupidement configurés qui interféraient avec la négociation).
La section 1.3 de notre RFC liste les différences importantes entre TLS 1.2 (qui était normalisé dans le RFC 5246) et 1.3 :
- La liste des algorithmes de cryptographie symétrique acceptés a été violemment réduite. Beaucoup trop longue en TLS 1.2, offrant trop de choix, comprenant plusieurs algorithmes faibles, elle ouvrait la voie à des attaques par repli. Les « survivants » de ce nettoyage sont tous des algorithmes à chiffrement intègre.
- Un nouveau service apparait, 0-RTT (zero round-trip time, la possibilité d'établir une session TLS avec un seul paquet, en envoyant les données tout de suite), qui réduit la latence du début de l'échange. Attention, rien n'est gratuit en ce monde, et 0-RTT présente des nouveaux dangers, et ce nouveau service a été un des plus controversés lors de la mise au point de TLS 1.3, entrainant de nombreux débats à l'IETF.
- Désormais, la sécurité future est systématique, la compromission d'une clé secrète ne permet plus de déchiffrer les anciennes communications. Plus de clés publiques statiques, tout se fera par clés éphémères. C'était le point qui a suscité le plus de débats à l'IETF, car cela complique sérieusement la surveillance (ce qui est bien le but) et le débogage. L'ETSI, représentante du patronat, a même normalisé son propre TLS délibérement affaibli, eTLS.
- Plusieurs messages de négociation qui étaient auparavant
en clair sont désormais chiffrés. Par contre, l'indication du
nom du serveur (SNI, section 3 du RFC 6066) reste en clair et c'est l'une des principales
limites de TLS en ce qui concerne la protection de la vie
privée. Le problème est important, mais très difficile à
résoudre (voir par exemple la proposition ESNI,
https://datatracker.ietf.org/doc/draft-ietf-tls-esni/et son cahier des charges dans le RFC 8744.) - Les fonctions de dérivation de clé ont été refaites.
- La machine à états utilisée pour l'établissement de la connexion également (elle est détaillée dans l'annexe A du RFC).
- Les algorithmes asymétriques à courbes elliptiques font maintenant partie de la définition de base de TLS (cf. RFC 7748), et on voit arriver des nouveaux comme ed25519 (cf. RFC 8422).
- Par contre, DSA a été retiré.
- Le mécanisme de négociation du numéro de version (permettant à deux machines n'ayant pas le même jeu de versions TLS de se parler) a changé. L'ancien était très bien mais, mal implémenté, il a suscité beaucoup de problèmes d'interopérabilité. Le nouveau est censé mieux gérer les innombrables systèmes bogués qu'on trouve sur l'Internet (la bogue ne provenant pas tant de la bibliothèque TLS utilisée que des pare-feux mal programmés et mal configurés qui sont souvent mis devant). J'en profite pour vous recommander l'article « HTTPS : de SSL à TLS 1.3 », sur ce sujet de la négociation de version.
- La reprise d'une session TLS précédente fait l'objet désormais d'un seul mécanisme, qui est le même que celui pour l'usage de clés pré-partagées. La négociation TLS peut en effet être longue, en terme de latence, et ce mécanisme permet d'éviter de tout recommencer à chaque connexion. Deux machines qui se parlent régulièrement peuvent ainsi gagner du temps.
Un bon résumé de ce nouveau protocole est dans l'article de Mark Nottingham.
Ce RFC concerne TLS 1.3 mais il contient aussi quelques changements pour la version 1.2 (section 1.4 du RFC), comme un mécanisme pour limiter les attaques par repli portant sur le numéro de version, et des mécanismes de la 1.3 « portés » vers la 1.2 sous forme d'extensions TLS.
La section 2 du RFC est un survol général de TLS 1.3 (le RFC fait 147 pages, et peu de gens le liront intégralement). Au début d'une session TLS, les deux parties, avec le protocole de salutation, négocient les paramètres (version de TLS, algorithmes cryptographiques) et définissent les clés qui seront utilisées pour le chiffrement de la session. En simplifiant, il y a trois phases dans l'établissement d'une session TLS :
- Définition des clés de session, et des paramètres
cryptographiques, le client envoie un
ClientHello, le serveur répond avec unServerHello, - Définition des autres paramètres (par exemple
l'application utilisée au-dessus de TLS, ou bien la demande
CertificateRequestd'un certificat client), cette partie est chiffrée, contrairement à la précédente, - Authentification du serveur, avec le message
Certificate(qui ne contient pas forcément un certificat, cela peut être une clé brute - RFC 7250 ou une clé d'une session précédente - RFC 7924).
Un message Finished termine cette ouverture
de session.
(Si vous êtes fana de futurisme, notez que seule la première étape
pourrait être remplacée par la distribution quantique
de clés, les autres resteraient
indispensables. Contrairement à ce que promettent ses promoteurs,
la QKD ne dispense pas d'utiliser les protocoles existants.)
Comment les deux parties se mettent-elles d'accord sur les clés ? Trois méthodes :
- Diffie-Hellman sur courbes elliptiques qui sera sans doute la plus fréquente,
- Clé pré-partagée,
- Clé pré-partagée avec Diffie-Hellman,
- Et la méthode RSA, elle, disparait de la norme (mais RSA peut toujours être utilisé pour l'authentification, autrement, cela ferait beaucoup de certificats à jeter…)
Si vous connaissez la cryptographie, vous savez que les PSK, les clés partagées, sont difficiles à gérer, puisque devant être transmises de manière sûre avant l'établissement de la connexion. Mais, dans TLS, une autre possibilité existe : si une session a été ouverte sans PSK, en n'utilisant que de la cryptographie asymétrique, elle peut être enregistrée, et resservir, afin d'ouvrir les futures discussions plus rapidement. TLS 1.3 utilise le même mécanisme pour des « vraies » PSK, et pour celles issues de cette reprise de sessions précédentes (contrairement aux précédentes versions de TLS, qui utilisaient un mécanisme séparé, celui du RFC 5077, désormais abandonné).
Si on a une PSK (gérée manuellement, ou bien via la reprise de session), on peut même avoir un dialogue TLS dit « 0-RTT ». Le premier paquet du client peut contenir des données, qui seront acceptées et traitées par le serveur. Cela permet une importante diminution de la latence, dont il faut rappeler qu'elle est souvent le facteur limitant des performances. Par contre, comme rien n'est idéal dans cette vallée de larmes, cela se fait au détriment de la sécurité :
- Plus de confidentialité persistante, si la PSK est compromise plus tard, la session pourra être déchiffrée,
- Le rejeu devient possible, et l'application doit donc savoir gérer ce problème.
La section 8 du RFC et l'annexe E.5 détaillent ces limites, et les mesures qui peuvent être prises.
Le protocole TLS est décrit avec un langage spécifique, décrit de manière relativement informelle dans la section 3 du RFC. Ce langage manipule des types de données classiques :
- Scalaires
(
uint8,uint16), - Tableaux, de taille fixe -
Datum[3]ou variable, avec indication de la longueur au début -uint16 longer<0..800>, - Énumérations (
enum { red(3), blue(5), white(7) } Color;), - Enregistrements structurés, y compris avec variantes (la présence de certains champs dépendant de la valeur d'un champ).
Par exemple, tirés de la section 4 (l'annexe B fournit la liste complète), voici, dans ce langage, la liste des types de messages pendant les salutations, une énumération :
enum {
client_hello(1),
server_hello(2),
new_session_ticket(4),
end_of_early_data(5),
encrypted_extensions(8),
certificate(11),
certificate_request(13),
certificate_verify(15),
finished(20),
key_update(24),
message_hash(254),
(255)
} HandshakeType;
Et le format de base d'un message du protocole de salutation :
struct {
HandshakeType msg_type; /* handshake type */
uint24 length; /* bytes in message */
select (Handshake.msg_type) {
case client_hello: ClientHello;
case server_hello: ServerHello;
case end_of_early_data: EndOfEarlyData;
case encrypted_extensions: EncryptedExtensions;
case certificate_request: CertificateRequest;
case certificate: Certificate;
case certificate_verify: CertificateVerify;
case finished: Finished;
case new_session_ticket: NewSessionTicket;
case key_update: KeyUpdate;
};
} Handshake;
La section 4 fournit tous les détails sur le protocole de
salutation, notamment sur la délicate négociation des paramètres
cryptographiques. Notez que la renégociation en cours de session a
disparu, donc un ClientHello ne peut
désormais plus être envoyé qu'au début.
Un problème auquel a toujours dû faire face TLS est celui de la
négociation de version, en présence de mises en œuvre boguées, et,
surtout, en présence de boitiers
intermédiaires encore plus bogués
(pare-feux ignorants, par exemple, que des
DSI ignorantes placent un peu partout). Le
modèle original de TLS pour un client était d'annoncer dans le
ClientHello le plus grand numéro de version
qu'on gère, et de voir dans ServerHello le
maximum imposé par le serveur. Ainsi, un client TLS 1.2 parlant à
un serveur qui ne gère que 1.1 envoyait
ClientHello(client_version=1.2) et, en
recevant ServerHello(server_version=1.1), se
repliait sur TLS 1.1, la version la plus élevée que les deux
parties gèraient. En pratique, cela ne marche pas aussi bien. On
voyait par exemple des serveurs (ou, plus vraisemblablement, des
pare-feux bogués) qui raccrochaient brutalement en
présence d'un numéro de version plus élevé, au lieu de suggérer un
repli. Le client n'avait alors que le choix de renoncer, ou bien
de se lancer dans une série d'essais/erreurs (qui peut être
longue, si le serveur ou le pare-feu bogué ne répond pas).
TLS 1.3 change donc complètement le mécanisme de
négociation. Le client annonce toujours la version 1.2 (en fait
0x303, pour des raisons historiques), et la vraie version est mise
dans une extension, supported_versions
(section 4.2.1), dont
on espère qu'elle sera ignorée par les serveurs mal
gérés. (L'annexe D du RFC détaille ce problème de la négociation
de version.) Dans la réponse ServerHello, un
serveur 1.3 doit inclure cette extension, autrement, il faut se
rabattre sur TLS 1.2.
En parlant d'extensions, concept qui avait été introduit
originellement dans le RFC 4366, notre RFC
reprend des extensions déjà normalisées, comme le SNI
(Server Name Indication) du RFC 6066, le battement de cœur du RFC 6520, le remplissage du ClientHello
du RFC 7685,
et en ajoute dix, dont
supported_versions. Certaines de ces
extensions doivent être présentes dans les messages
Hello, car la sélection des paramètres
cryptographiques en dépend, d'autres peuvent être uniquement dans
les messages EncryptedExtensions, une
nouveauté de TLS 1.3, pour les extensions qu'on n'enverra qu'une
fois le chiffrement commencé. Le RFC en profite pour rappeler que
les messages Hello ne sont pas protégés
cryptographiquement, et peuvent donc être modifiés (le message
Finished résume les décisions prises et peut
donc protéger contre ce genre d'attaques).
Autrement, parmi les autres nouvelles extensions :
- Le petit gâteau (cookie), pour tester la joignabilité,
- Les données précoces (early data), extension qui permet d'envoyer des données dès le premier message (« O-RTT »), réduisant ainsi la latence, un peu comme le fait le TCP Fast Open du RFC 7413,
- Liste des AC (certificate authorities), qui, en indiquant la liste des AC connues du client, peut aider le serveur à choisir un certificat qui sera validé (par exemple en n'envoyant le certificat CAcert que si le client connait cette AC).
La section 5 décrit le protocole des enregistrements (record protocol). C'est ce sous-protocole qui va prendre un flux d'octets, le découper en enregistrements, les protéger par le chiffrement puis, à l'autre bout, déchiffrer et reconstituer le flux… Notez que « protégé » signifie à la fois confidentialité et intégrité puisque TLS 1.3, contrairement à ses prédécesseurs, impose AEAD (RFC 5116).
Les enregistrements sont typés et marqués handshake (la salutation, vue dans la section précédente), change cipher spec, alert (pour signaler un problème) et application data (les données elle-mêmes) :
enum {
invalid(0),
change_cipher_spec(20),
alert(21),
handshake(22),
application_data(23),
(255)
} ContentType;
Le contenu des données est évidemment incompréhensible, en raison du chiffrement (voici un enregistrement de type 23, données, vu par tshark) :
TLSv1.3 Record Layer: Application Data Protocol: http-over-tls
Opaque Type: Application Data (23)
Version: TLS 1.2 (0x0303)
Length: 6316
Encrypted Application Data: eb0e21f124f82eee0b7a37a1d6d866b075d0476e6f00cae7...
Et décrite par la norme dans son langage formel :
struct {
ContentType opaque_type = application_data; /* 23 */
ProtocolVersion legacy_record_version = 0x0303; /* TLS v1.2 */
uint16 length;
opaque encrypted_record[TLSCiphertext.length];
} TLSCiphertext;
(Oui, le numéro de version reste à TLS 1.2 pour éviter d'énerver les stupides middleboxes.) Notez que des extensions à TLS peuvent introduire d'autres types d'enregistrements.
Une faiblesse classique de TLS est que la taille des données chiffrées n'est pas dissimulée. Si on veut savoir à quelle page d'un site Web un client HTTP a accédé, on peut parfois le déduire de l'observation de cette taille. D'où la possibilité de faire du remplissage pour dissimuler cette taille (section 5.4 du RFC). Notez que le RFC ne suggère pas de politique de remplissage spécifique (ajouter un nombre aléatoire ? Tout remplir jusqu'à la taille maximale ?), c'est un choix compliqué. Il note aussi que certaines applications font leur propre remplissage, et qu'il n'est alors pas nécessaire que TLS le fasse.
La section 6 du RFC est dédiée au cas des alertes. C'est un des types d'enregistrements possibles, et, comme les autres, il est chiffré, et les alertes sont donc confidentielles. Une alerte a un niveau et une description :
struct {
AlertLevel level;
AlertDescription description;
} Alert;
Le niveau indiquait si l'alerte est fatale mais n'est plus utilisé en TLS 1.2, où il faut se fier uniquement à la description, une énumération des problèmes possibles (message de type inconnu, mauvais certificat, enregistrement non décodable - rappelez-vous que TLS 1.3 n'utilise que du chiffrement intègre, problème interne au client ou au serveur, extension non acceptée, etc). La section 6.2 donne une liste des erreurs fatales, qui doivent mener à terminer immédiatement la session TLS.
La section 8 du RFC est entièrement consacrée à une nouveauté délicate, le « 0-RTT ». Ce terme désigne la possibilité d'envoyer des données dès le premier paquet, sans les nombreux échanges de paquets qui sont normalement nécessaires pour établir une session TLS. C'est très bien du point de vue des performances, mais pas forcément du point de vue de la sécurité puisque, sans échanges, on ne peut plus vérifier à qui on parle. Un attaquant peut réaliser une attaque par rejeu en envoyant à nouveau un paquet qu'il a intercepté. Un serveur doit donc se défendre en se souvenant des données déjà envoyées et en ne les acceptant pas deux fois. (Ce qui peut être plus facile à dire qu'à faire ; le RFC contient une bonne discussion très détaillée des techniques possibles, et de leurs limites. Il y en a des subtiles, comme d'utiliser des systèmes de mémorisation ayant des faux positifs, comme les filtres de Bloom, parce qu'ils ne produiraient pas d'erreurs, ils rejetteraient juste certains essais 0-RTT légitimes, cela ne serait donc qu'une légère perte de performance.)
La section 9 de notre RFC se penche sur un problème difficile,
la conformité des mises en œuvres de TLS. D'abord, les algorithmes
obligatoires. Afin de permettre l'interopérabilité,
toute mise en œuvre de TLS doit avoir la
suite de chiffrement TLS_AES_128_GCM_SHA256
(AES en
mode GCM
avec SHA-256). D'autres suites sont
recommandées (cf. annexe B.4). Pour l'authentification,
RSA avec SHA-256 et
ECDSA sont obligatoires. Ainsi, deux
programmes différents sont sûrs de pouvoir trouver des algorithmes
communs. La possibilité
d'authentification par certificats PGP du RFC 6091 a été retirée.
De plus, certaines extensions à TLS sont obligatoires, un pair TLS 1.3 ne peut pas les refuser :
supported_versions, nécessaire pour annoncer TLS 1.3,cookie,signature_algorithms,signature_algorithms_cert,supported_groupsetkey_share,server_name, c'est à dire SNI (Server Name Indication), souvent nécessaire pour pouvoir choisir le bon certificat (cf. section 3 du RFC 6066).
La section 9 précise aussi le comportement attendu des équipements intermédiaires. Ces dispositifs (pare-feux, par exemple, mais pas uniquement) ont toujours été une plaie pour TLS. Alors que TLS vise à fournir une communication sûre, à l'abri des équipements intermédiaires, ceux-ci passent leur temps à essayer de s'insérer dans la communication, et souvent la cassent. Normalement, TLS 1.3 est conçu pour que ces interférences ne puissent pas mener à un repli (le repli est l'utilisation de paramètres moins sûrs que ce que les deux machines auraient choisi en l'absence d'interférence).
Il y a deux grandes catégories d'intermédiaires, ceux qui tripotent la session TLS sans être le client ou le serveur, et ceux qui terminent la session TLS de leur côté. Attention, dans ce contexte, « terminer » ne veut pas dire « y mettre fin », mais « la sécurité TLS se termine ici, de manière à ce que l'intermédiaire puisse accéder au contenu de la communication ». Typiquement, une middlebox qui « termine » une session TLS va être serveur TLS pour le client et client TLS pour le serveur, s'insérant complètement dans la conversation. Normalement, l'authentification vise à empêcher ce genre de pratiques, et l'intermédiaire ne sera donc accepté que s'il a un certificat valable. C'est pour cela qu'en entreprise, les machines officielles sont souvent installées avec une AC contrôlée par le vendeur du boitier intermédiaire, de manière à permettre l'interception.
Le RFC ne se penche pas sur la légitimité de ces pratiques, uniquement sur leurs caractéristiques techniques. (Les boitiers intermédiaires sont souvent programmés avec les pieds, et ouvrent de nombreuses failles.) Le RFC rappelle notamment que l'intermédiaire qui termine une session doit suivre le RFC à la lettre (ce qui devrait aller sans dire…)
Depuis le RFC 4346, il existe plusieurs registres IANA pour TLS, décrits en section 11, avec leurs nouveautés. En effet, plusieurs choix pour TLS ne sont pas « câblés en dur » dans le RFC mais peuvent évoluer indépendamment. Par exemple, le registre de suites cryptographiques a une politique d'enregistrement « spécification nécessaire » (cf. RFC 8126, sur les politiques d'enregistrement). La cryptographie fait régulièrement des progrès, et il faut donc pouvoir modifier la liste des suites acceptées (par exemple lorsqu'il faudra y ajouter les algorithmes post-quantiques) sans avoir à toucher au RFC (l'annexe B.4 donne la liste actuelle). Le registre des types de contenu, lui, a une politique d'enregistrement bien plus stricte, « action de normalisation ». On crée moins souvent des types que des suites cryptographiques. Même chose pour le registre des alertes ou pour celui des salutations.
L'annexe C du RFC plaira aux programmeurs, elle donne plusieurs conseils pour une mise en œuvre correcte de TLS 1.3 (ce n'est pas tout d'avoir un protocole correct, il faut encore qu'il soit programmé correctement). Pour aider les développeurs à déterminer s'ils ont correctement fait le travail, un futur RFC fournira des vecteurs de test.
Un des conseils les plus importants est évidemment de faire
attention au générateur de nombres
aléatoires, source de tant de failles de sécurité en
cryptographie. TLS utilise des nombres qui doivent être
imprévisibles à un attaquant pour générer des clés de session. Si
ces nombres sont prévisibles, toute la cryptographie s'effondre. Le RFC conseille fortement d'utiliser un générateur
existant (comme /dev/urandom sur les systèmes
Unix) plutôt que d'écrire le sien, ce qui
est bien plus difficile qu'il ne semble. (Si on tient quand même à
le faire, le RFC 4086 est une lecture
indispensable.)
Le RFC conseille également de vérifier le certificat du partenaire par défaut (quitte à fournir un moyen de débrayer cette vérification). Si ce n'est pas le cas, beaucoup d'utilisateurs du programme ou de la bibliothèque oublieront de le faire. Il suggère aussi de ne pas accepter certains certificats trop faibles (clé RSA de seulement 1 024 bits, par exemple).
Il existe plusieurs moyens avec TLS de ne pas avoir d'authentification du serveur : les clés brutes du RFC 7250 (à la place des certificats), ou bien les certificats auto-signés. Dans ces conditions, une attaque de l'homme du milieu est parfaitement possibe, et il faut donc prendre des précautions supplémentaires (par exemple DANE, normalisé dans le RFC 6698, que le RFC oublie malheureusement de citer).
Autre bon conseil de cryptographie, se méfier des attaques fondées sur la mesure du temps de calcul, et prendre des mesures appropriées (par exemple en vérifiant que le temps de calcul est le même pour des données correctes et incorrectes).
Il n'y a aucune bonne raison d'utiliser certains algorithmes faibles (comme RC4, abandonné depuis le RFC 7465), et le RFC demande que le code pour ces algorithmes ne soit pas présent, afin d'éviter une attaque par repli (annexes C.3 et D.5 du RFC). De la même façon, il demande de ne jamais accepter SSL v3 (RFC 7568).
L'expérience a prouvé que beaucoup de mises en œuvre de TLS ne réagissaient pas correctement à des options inattendues, et le RFC rappelle donc qu'il faut ignorer les suites cryptographiques inconnues (autrement, on ne pourrait jamais introduire une nouvelle suite, puisqu'elle casserait les programmes), et ignorer les extensions inconnues (pour la même raison).
L'annexe D, elle, est consacrée au problème de la communication
avec un vieux partenaire, qui ne connait pas TLS 1.3. Le mécanisme
de négociation de la version du protocole à utiliser a
complètement changé en 1.3. Dans la 1.3, le champ
version du ClientHello
contient 1.2, la vraie version étant dans l'extension
supported_versions. Si un client 1.3 parle
avec un serveur <= 1.2, le serveur ne connaitra pas cette
extension et répondra sans l'extension, avertissant ainsi le
client qu'il faudra parler en 1.2 (ou plus vieux). Ça, c'est si le
serveur est correct. S'il ne l'est pas ou, plus vraisemblablement,
s'il est derrière une
middlebox boguée, on
verra des problèmes comme par exemple le refus de répondre aux
clients utilisant des extensions inconnues (ce qui sera le cas
pour supported_versions), soit en rejettant
ouvertement la demande soit, encore pire, en l'ignorant. Arriver à gérer des
serveurs/middleboxes incorrects est un problème
complexe. Le client peut être tenté de re-essayer avec d'autres
options (par exemple tenter du 1.2, sans l'extension
supported_versions). Cette méthode n'est pas
conseillée. Non seulement elle peut prendre du temps (attendre
l'expiration du délai de garde, re-essayer…) mais surtout, elle
ouvre la voie à des attaques par repli :
l'attaquant bloque les ClientHello 1.3 et le
client, croyant bien faire, se replie sur une version plus
ancienne et sans doute moins sûre de TLS.
En parlant de compatibilité, le « 0-RTT » n'est évidemment pas
compatible avec les vieilles versions. Le client qui envoie du
« 0-RTT » (des données dans le ClientHello)
doit donc savoir que, si la réponse est d'un serveur <= 1.2,
la session ne pourra pas être établie, et il faudra donc réessayer
sans 0-RTT.
Naturellement, les plus gros problèmes ne surviennent pas avec
les clients et les serveurs mais avec les
middleboxes. Plusieurs études ont montré leur
caractère néfaste (cf. présentation
à l'IETF 100, mesures
avec Chrome (qui indique également que certains serveurs
TLS sont gravement en tort, comme celui installé dans les
imprimantes Canon), mesures
avec Firefox, et encore
d'autres mesures). Le RFC suggère qu'on limite les risques
en essayant d'imiter le plus possible une salutation de TLS 1.2,
par exemple en envoyant des messages
change_cipher_spec, qui ne sont plus utilisés
en TLS 1.3, mais qui peuvent rassurer la
middlebox (annexe D.4).
Enfin, le RFC se termine par l'annexe E, qui énumère les propriétés de sécurité de TLS 1.3 : même face à un attaquant actif (RFC 3552), le protocole de salutation de TLS garantit des clés de session communes et secrètes, une authentification du serveur (et du client si on veut), et une sécurité persistante, même en cas de compromission ultérieure des clés (sauf en cas de 0-RTT, un autre des inconvénients sérieux de ce service, avec le risque de rejeu). De nombreuses analyses détaillées de la sécurité de TLS sont listées dans l'annexe E.1.6. À lire si vous voulez travailler ce sujet.
Quant au protocole des enregistrements, celui de TLS 1.3 garantit confidentialité et intégrité (RFC 5116).
TLS 1.3 a fait l'objet de nombreuses analyses de sécurité par des chercheurs, avant même sa normalisation, ce qui est une bonne chose (et qui explique en partie les retards). Notre annexe E pointe également les limites restantes de TLS :
- Il est vulnérable à l'analyse de trafic. TLS n'essaie pas de cacher la taille des paquets, ni l'intervalle de temps entre eux. Ainsi, si un client accède en HTTPS à un site Web servant quelques dizaines de pages aux tailles bien différentes, il est facile de savoir quelle page a été demandée, juste en observant les tailles. (Voir « I Know Why You Went to the Clinic: Risks and Realization of HTTPS Traffic Analysis », de Miller, B., Huang, L., Joseph, A., et J. Tygar et « HTTPS traffic analysis and client identification using passive SSL/TLS fingerprinting », de Husak, M., Čermak, M., Jirsik, T., et P. Čeleda). TLS fournit un mécanisme de remplissage avec des données bidon, permettant aux applications de brouiller les pistes. Certaines applications utilisant TLS ont également leur propre remplissage (par exemple, pour le DNS, c'est le RFC 7858). De même, une mise en œuvre de TLS peut retarder les paquets pour rendre l'analyse des intervalles plus difficile. On voit que dans les deux cas, taille des paquets et intervalle entre eux, résoudre le problème fait perdre en performance (c'est pour cela que ce n'est pas intégré par défaut).
- TLS peut être également vulnérable à des attaques par canal auxiliaire. Par exemple, la durée des opérations cryptographiques peut être observée, ce qui peut donner des informations sur les clés. TLS fournit quand même quelques défenses : l'AEAD facilite la mise en œuvre de calculs en temps constant, et format uniforme pour toutes les erreurs, empêchant un attaquant de trouver quelle erreur a été déclenchée.
Le 0-RTT introduit un nouveau risque, celui de rejeu. (Et 0-RTT a sérieusement contribué aux délais qu'à connu le projet TLS 1.3, plusieurs participants à l'IETF protestant contre cette introduction risquée.) Si l'application est idempotente, ce n'est pas très grave. Si, par contre, les effets d'une requête précédentes peuvent être rejoués, c'est plus embêtant (imaginez un transfert d'argent répété…) TLS ne promet rien en ce domaine, c'est à chaque serveur de se défendre contre le rejeu (la section 8 donne des idées à ce sujet). Voilà pourquoi le RFC demande que les requêtes 0-RTT ne soient pas activées par défaut, mais uniquement quand l'application au-dessus de TLS le demande. (Cloudflare, par exemple, n'active pas le 0-RTT par défaut.)
Voilà, vous avez maintenant fait un tour complet du RFC, mais vous savez que la cryptographie est une chose difficile, et pas seulement dans les algorithmes cryptographiques (TLS n'en invente aucun, il réutilise des algorithmes existants comme AES ou ECDSA), mais aussi dans les protocoles cryptographiques, un art complexe. N'hésitez donc pas à lire le RFC en détail, et à vous méfier des résumés forcément toujours sommaires, comme cet article.
À part le 0-RTT, le plus gros débat lors de la création de TLS
1.3 avait été autour du concept que ses partisans nomment
« visibilité » et ses adversaires « surveillance ». C'est l'idée
qu'il serait bien pratique si on (on : le patron, la police, le
FAI…) pouvait accéder au contenu des
communications TLS. « Le chiffrement, c'est bien, à condition que
je puisse lire les données quand même » est l'avis des partisans
de la visibilité. Cela avait été proposé dans les
Internet-Drafts draft-green-tls-static-dh-in-tls13
et draft-rhrd-tls-tls13-visibility. Je
ne vais pas ici pouvoir capturer la totalité
du débat, juste noter quelques points qui sont parfois oubliés
dans la discussion. Côté partisans de la visibilité :
- Dans une entreprise capitaliste, il n'y pas de citoyens, juste un patron et des employés. Les ordinateurs appartiennent au patron, et les employés n'ont pas leur mot à dire. Le patron peut donc décider d'accéder au contenu des communications chiffrées.
- Il existe des règles (par exemple PCI-DSS dans le secteur financier ou HIPAA dans celui de la santé) qui requièrent de certaines entreprises qu'elles sachent en détail tout ce qui circule sur le réseau. Le moyen le plus simple de le faire est de surveiller le contenu des communications, même chiffrées. (Je ne dis pas que ces règles sont intelligentes, juste qu'elles existent. Notons par exemple que les mêmes règles imposent d'utiliser du chiffrement fort, sans faille connue, ce qui est contradictoire.)
- Enregistrer le trafic depuis les terminaux est compliqué en pratique : applications qui n'ont pas de mécanisme de journalisation du trafic, systèmes d'exploitation fermés, boîtes noires…
- TLS 1.3 risque de ne pas être déployé dans les entreprises qui tiennent à surveiller le trafic, et pourrait même être interdit dans certains pays, où la surveillance passe avant les droits humains.
Et du côté des adversaires de la surveillance :
- La cryptographie, c'est compliqué et risqué. TLS 1.3 est déjà assez compliqué comme cela. Lui ajouter des fonctions (surtout des fonctions délibérement conçues pour affaiblir ses propriétés de sécurité) risque fort d'ajouter des failles de sécurité. D'autant plus que TLS 1.3 a fait l'objet de nombreuses analyses de sécurité avant son déploiement, et qu'il faudrait tout recommencer.
- Contrairement à ce que semblent croire les partisans de la « visibilité », il n'y a pas que HTTPS qui utilise TLS. Ils ne décrivent jamais comment leur proposition marcherait avec des protocoles autres que HTTPS.
- Pour HTTPS, et pour certains autres protocoles, une solution simple, si on tient absolument à intercepter tout le trafic, est d'avoir un relais explicite, configuré dans les applications, et combiné avec un blocage dans le pare-feu des connexions TLS directes. Les partisans de la visibilté ne sont en général pas enthousiastes pour cette solution car ils voudraient faire de la surveillance furtive, sans qu'elle se voit dans les applications utilisées par les employés ou les citoyens.
- Les partisans de la « visibilité » disent en général que l'interception TLS serait uniquement à l'intérieur de l'entreprise, pas pour l'Internet public. Mais, dans ce cas, tous les terminaux sont propriété de l'entreprise et contrôlés par elle, donc elle peut les configurer pour copier tous les messages échangés. Et, si certains de ces terminaux sont des boîtes noires, non configurables et dont on ne sait pas bien ce qu'ils font, eh bien, dans ce cas, on se demande pourquoi des gens qui insistent sur leurs obligations de surveillance mettent sur leur réseau des machines aussi incontrôlables.
- Dans ce dernier cas (surveillance uniquement au sein d'une entreprise), le problème est interne à l'entreprise, et ce n'est donc pas à l'IETF, organisme qui fait des normes pour l'Internet, de le résoudre. Après tout, rien n'empêche ces entreprises de garder TLS 1.2.
Revenons maintenant aux choses sérieuses, avec les mises en
œuvre de TLS 1.3. Il y en existe au moins une dizaine à l'heure
actuelle mais, en général, pas dans les versions officiellement
publiées des logiciels. Notons quand même que
Firefox 61 sait faire du TLS 1.3. Les autres
mises en œuvre sont prêtes, même si pas forcément publiées. Prenons
l'exemple de la bibliothèque
GnuTLS. Elle dispose de TLS 1.3 depuis la
version 3.6.3. Pour l'instant, il faut compiler cette version avec
l'option ./configure --enable-tls13-support,
qui n'est pas encore activée par défaut. Un bon
article du mainteneur de GnuTLS explique bien les nouveautés
de TLS 1.3.
Une fois GnuTLS correctement compilé, on peut utiliser le
programme en ligne de commande gnutls-cli avec
un serveur qui accepte TLS 1.3 :
% gnutls-cli gmail.com ... - Description: (TLS1.3)-(ECDHE-X25519)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) - Ephemeral EC Diffie-Hellman parameters - Using curve: X25519 - Curve size: 256 bits - Version: TLS1.3 - Key Exchange: ECDHE-RSA - Server Signature: RSA-PSS-RSAE-SHA256 - Cipher: AES-256-GCM - MAC: AEAD ...
Et ça marche, on fait du TLS 1.3. Si vous préférez écrire le programme
vous-même, regardez ce petit
programme. Si
GnuTLS est en /local, il se compilera avec
cc -I/local/include -Wall -Wextra -o test-tls13 test-tls13.c
-L/local/lib -lgnutls et s'utilisera avec :
% ./test-tls13 www.ietf.org TLS connection using "TLS1.3 AES-256-GCM" % ./test-tls13 gmail.com TLS connection using "TLS1.3 AES-256-GCM" % ./test-tls13 mastodon.gougere.fr TLS connection using "TLS1.2 AES-256-GCM" % ./test-tls13 www.bortzmeyer.org TLS connection using "TLS1.2 AES-256-GCM" % ./test-tls13 blog.cloudflare.com TLS connection using "TLS1.3 AES-256-GCM"
Cela vous donne une petite idée des serveurs qui acceptent TLS 1.3.
Un pcap d'une session TLS 1.3 est disponible
en tls13.pcap. Notez que le numéro de version n'est pas encore
celui du RFC (0x304). Ici, 0x7f1c désigne
l'Internet-Draft numéro 28. Voici la session
vue par tshark :
1 0.000000 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TCP 94 36866 → https(443) [SYN] Seq=0 Win=28800 Len=0 MSS=1440 SACK_PERM=1 TSval=3528788861 TSecr=0 WS=128
2 0.003052 2400:cb00:2048:1::6814:55 → 2001:67c:370:1998:9819:4f92:d0c0:e94d TCP 86 https(443) → 36866 [SYN, ACK] Seq=0 Ack=1 Win=24400 Len=0 MSS=1220 SACK_PERM=1 WS=1024
3 0.003070 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TCP 74 36866 → https(443) [ACK] Seq=1 Ack=1 Win=28800 Len=0
4 0.003354 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TLSv1 403 Client Hello
5 0.006777 2400:cb00:2048:1::6814:55 → 2001:67c:370:1998:9819:4f92:d0c0:e94d TCP 74 https(443) → 36866 [ACK] Seq=1 Ack=330 Win=25600 Len=0
6 0.011393 2400:cb00:2048:1::6814:55 → 2001:67c:370:1998:9819:4f92:d0c0:e94d TLSv1.3 6496 Server Hello, Change Cipher Spec, Application Data
7 0.011413 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TCP 74 36866 → https(443) [ACK] Seq=330 Ack=6423 Win=41728 Len=0
8 0.011650 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TLSv1.3 80 Change Cipher Spec
9 0.012685 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TLSv1.3 148 Application Data
10 0.015693 2400:cb00:2048:1::6814:55 → 2001:67c:370:1998:9819:4f92:d0c0:e94d TCP 74 https(443) → 36866 [ACK] Seq=6423 Ack=411 Win=25600 Len=0
11 0.015742 2400:cb00:2048:1::6814:55 → 2001:67c:370:1998:9819:4f92:d0c0:e94d TLSv1.3 524 Application Data
12 0.015770 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TCP 74 36866 → https(443) [RST] Seq=411 Win=0 Len=0
13 0.015788 2400:cb00:2048:1::6814:55 → 2001:67c:370:1998:9819:4f92:d0c0:e94d TCP 74 https(443) → 36866 [FIN, ACK] Seq=6873 Ack=411 Win=25600 Len=0
14 0.015793 2001:67c:370:1998:9819:4f92:d0c0:e94d → 2400:cb00:2048:1::6814:55 TCP 74 36866 → https(443) [RST] Seq=411 Win=0 Len=0
Et, complètement décodée par tshark :
Secure Sockets Layer [sic]
TLSv1 Record Layer: Handshake Protocol: Client Hello
Content Type: Handshake (22)
Version: TLS 1.0 (0x0301)
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Version: TLS 1.2 (0x0303)
...
Extension: supported_versions (len=9)
Type: supported_versions (43)
Length: 9
Supported Versions length: 8
Supported Version: Unknown (0x7f1c)
Supported Version: TLS 1.2 (0x0303)
Supported Version: TLS 1.1 (0x0302)
Supported Version: TLS 1.0 (0x0301)
Le texte complet est en tls13.txt. Notez bien que la négociation est
en clair. D'autres exemples de traces TLS 1.3 figurent dans le RFC 8448.
Quelques autres articles à lire :
- L'annonce officielle de l'IETF,
- Le bon résumé de Cloudflare sur la version 1.3,
- Discussion Ycombinator sur la visibilité,
- Liste complète des réponses aux partisans de la visbilité,
- Bon article historique très détaillé sur l'histoire de TLS, jusqu'à la version 1.3,
- Un exemple d'un des ateliers où a été étudié la sécurité de TLS 1.3, à Paris en 2017, et un autre à San Diego en 2016,
- Bon article sur la question des middleboxes, expliquant notamment les extensions « inutiles », mais permettant de tromper ces middleboxes pour ressembler à TLS 1.2.
L'article seul
RFC 8445: Interactive Connectivity Establishment (ICE): A Protocol for Network Address Translator (NAT) Traversal
Date de publication du RFC : Juillet 2018
Auteur(s) du RFC : A. Keranen, C. Holmberg (Ericsson), J. Rosenberg (jdrosen.net)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ice
Première rédaction de cet article le 5 janvier 2019
Le problème de la traversée des routeurs NAT est traité dans plusieurs RFC, de façon à réparer la grossière erreur qu'avait été le déploiement massif du NAT plutôt que celui de IPv6. ICE est un « méta-protocole », orchestrant plusieurs protocoles comme STUN et TURN pour arriver à découvrir un canal de communication malgré le NAT. ICE avait été normalisé il y a huit ans et le RFC 5245, que notre nouveau RFC remplace. Le protocole ne change guère, mais sa description normalisée est sérieusement modifiée.
L'objectif principal est la session multimédia, transmise entre deux terminaux, en général en UDP. ICE est donc utilisé, par exemple, par les solutions de téléphonie sur IP. Ces solutions ont déjà dû affronter le problème du NAT (RFC 3235) et ont développé un certain nombre de techniques, dont la bonne utilisation est l'objet principal de notre RFC.
En effet, les protocoles de téléphonie sur IP, comme SIP (RFC 3261) ont en commun d'avoir une session de contrôle de la connexion, établie par l'appelant en TCP (et qui passe en général assez bien à travers le NAT, si l'appelé utilise un relais public) et une session de transport des données, en général au-dessus d'UDP. C'est cette session qui est en général perturbée par le NAT. La session de contrôle (signaling session) transmet au partenaire SIP l'adresse IP de son correspondant mais, s'il y a deux domaines d'adressage séparés (par exemple un partenaire sur le domaine public et un autre dans le monde des adresses privées du RFC 1918), cette adresse IP ainsi communiquée ne sert pas à grand'chose.
On voit donc que le non-déploiement d'IPv6, qui aurait permis de se passer du NAT, a coûté très cher en temps de développement. Notre RFC fait 100 pages (et d'autres RFC doivent être lus en prime comme ceux de STUN, TURN, et le futur RFC décrivant l'utilisation de ICE par SIP et SDP), et se traduira par du code réseau très complexe, uniquement pour contourner une mauvaise décision.
Des solutions au NAT, soit standard comme STUN (RFC 8489) soit purement spécifiques à un logiciel fermé comme Skype ont été développées. Mais aucune n'est parfaite, car tous les cas sont spécifiques. Par exemple, si deux machines sont sur le même réseau local, derrière le même routeur NAT, faire appel à STUN est inutile, et peut même échouer (si le routeur NAT ne supporte pas le routage en épingle à cheveux, où un paquet d'origine interne retourne vers le réseau interne). Le principe d'ICE est donc de décrire comment utiliser plusieurs protocoles de traversée de NAT, pour trouver la solution optimale pour envoyer les paquets de la session de données. Et ceci alors que les machines qui communiquent ne savent pas en général si elles sont derrière un NAT, ni, si oui, de quel type de NAT il s'agit.
Le principe d'ICE, exposé dans la section 2 et détaillé dans les sections 5 et suivantes, est donc le suivant : chaque partenaire va déterminer une liste de paires d'adresses de transport candidates (en utilisant leurs adresses IP locales, STUN et TURN), les tester et se mettre d'accord sur la « meilleure paire ». Une fois ces trois étapes passées, on va pouvoir communiquer. Une adresse de transport est un couple (adresse IP, port).
La première étape (section 5) est donc d'établir la liste des paires, et de la trier par ordre de priorité. La section 5.1.2.1 recommande une formule pour calculer la priorité, formule qui fait intervenir une préférence pour le type d'adresses IP (une adresse locale à la machine sera préférée à une adresse publique obtenue par STUN, et celle-ci sera préférée à l'adresse d'un serveur relais TURN, puisque STUN permettra ensuite une communication directe, sans relais, donc plus rapide) et une préférence locale, par exemple pour les adresses IPv6 par rapport à IPv4.
La deuxième étape est de tester les paires (sections 2.2 et 7) pour déterminer celles qui marchent. (Les paires ont d'abord été triées par priorité à l'étape précédente.) ICE poursuit les tests, même en cas de succès, pour voir si un meilleur RTT peut être trouvé (c'est un sérieux changement par rapport au précédent RFC).
Pour ces tests, ICE utilise STUN, mais avec des extensions spécifiques à ICE (sections 7.1 et 16).
La troisième et dernière étape d'ICE (section 8) est de sélectionner la meilleure paire (en terme de priorité) parmi celles qui ont fonctionné. Les couples (adresse IP, port) de celles-ci seront alors utilisées pour la communication.
Des exemples détaillés d'utilisation d'ICE, avec tous les messages échangés, figurent dans la section 15 du RFC.
L'ensemble du processus est relativement compliqué et nécessite de garder un état sur chaque partenaire ICE, alors qu'ICE est inutile pour des machines qui ont une adresse IP publique. La section 2.5 introduit donc la possibilité de mises en œuvre légères (lite implementation) d'ICE, qui peuvent interagir avec les autres machines ICE, sans avoir à gérer tout le protocole (cf. aussi section 8.2).
Tous ces tests prennent évidemment du temps, d'autant plus de temps qu'il y a de paires d'adresse de transport « nominées ». C'est le prix à payer pour la plus grande souplesse d'ICE : il sera toujours plus lent que STUN seul.
Les protocoles de téléphonie sur IP ayant eu leur part de vulnérabilités, la section 19, sur la sécurité, est très détaillée. Par exemple, une attaque classique est d'établir une communication avec un partenaire, puis de lui demander d'envoyer le flux de données vers la victime. C'est une attaque par amplification classique, sauf que l'existence d'une session de données séparée de la session de contrôle fait qu'elle ne nécessite même pas de tricher sur son adresse IP (et les techniques du RFC 2827 sont donc inefficaces). Cette attaque, dite « attaque du marteau vocal », peut être combattue grâce à ICE, puisque le test de connectivité échouera, la victime ne répondant pas (puisqu'elle n'a rien demandé). Si tout le monde utilise ICE, cette attaque peut donc complètement disparaitre.
Notez que le lien direct entre participants est excellent pour les performances, mais est mauvais pour la vie privée (voir la section 19.1) puisqu'il révèle les adresses IP de son correspondant à chaque participant. (WebRTC - RFC 8825 - a le même problème.)
D'innombrables détails compliquent les choses et expliquent en partie la taille de ce RFC. Par exemple, la section 11 décrit l'obligation d'utiliser des keepalives, des paquets inutiles mais qui ont pour seul but de rappeler au routeur NAT que la session sert toujours, afin que les correspondances entre une adresse IP interne et une adresse externe restent ouvertes (le flux de données ne suffit pas forcément, car il peut y avoir des périodes d'inactivité).
Enfin, une intéressante section 17 décrit les problèmes pratiques du déploiement. Par exemple, la planification de la capacité des serveurs est discutée en 17.2.1. Un serveur STUN n'a pas besoin de beaucoup de capacité, mais un serveur TURN, oui, puisqu'il relaie tous les paquets, y compris ceux de la session de données.
La première version d'ICE ne gérait que l'UDP mais, depuis la publication du RFC 6544, TCP est également accepté.
La section 18 discute de la sortie, que le RFC 3424 impose à toutes les propositions concernant le NAT : est-ce que le contournement du NAT pourra être supprimé par la suite, ou bien sera-t-il lui-même un élément d'ossification ? En fait, ICE est utile même dans un Internet sans NAT (par exemple grâce à IPv6), pour tester la connectivité.
La section 21 décrit, mais de façon sommaire, les changements depuis le RFC 5245. Le RFC a été pas mal réorganisé et a un plan différent de celui du RFC 5245. Les principaux changements techniques :
- Suppression de la possibilité d'arrêter les tests dès la découverte d'une paire possible,
- Protocole de contrôle (signaling protocol) désormais déplacé dans un RFC à part, le RFC 8839.
Pour celles et ceux qui veulent creuser vraiment le RFC, et comprendre tous les choix techniques effectués, l'annexe B est là pour cela.
Il existe plusieurs mises en œuvres d'ICE en logiciel libre, comme pjnath, qui fait partie de la bibliothèque PJSIP, ou comme Nice.
L'article seul
RFC 8439: ChaCha20 and Poly1305 for IETF Protocols
Date de publication du RFC : Mai 2018
Auteur(s) du RFC : Y. Nir (Dell EMC), A. Langley (Google)
Pour information
Première rédaction de cet article le 4 janvier 2019
Les algorithmes de cryptographie ChaCha20 et Poly1305 avaient fait l'objet d'une spécification stable, permettant leur référencement pour les protocoles IETF, dans le RFC 7539, que notre RFC remplace, avec très peu de changements. Ce RFC normalise aussi bien leur utilisation isolée (ChaCha20 seul ou Poly1305 seul) que leur combinaison, qui fournit du chiffrement intègre (AEAD).
Pendant longtemps, la référence en matière de chiffrement symétrique était AES, entre autres en raison de ses performances très élevées sur du matériel dédié. AES est quatre à dix fois plus rapide que 3DES, qui était la précédente référence. Il est donc logique que AES soit utilisé partout, et notamment qu'il chiffre sans doute encore la majorité des sessions TLS. Le problème alors est qu'on dépend trop d'AES : si une faille est découverte par la cryptanalyse, on est fichu (AES est par exemple vulnérable dans certains cas). Il serait plus rassurant d'avoir des alternatives sérieuses à AES (n'obligeant pas à revenir à 3DES), pour que d'éventuelles percées en cryptanalyse ne cassent pas toute la crypto d'un coup. D'autant plus qu'AES a un défaut : rapide sur du matériel spécialisé, il l'est moins sur du matériel généraliste.
D'où les algorithmes décrits formellement dans ce RFC. Inventés par Bernstein, ils ont déjà fait l'objet d'un certain nombre d'analyses de sécurité (« New Features of Latin Dances: Analysis of Salsa, ChaCha, and Rumba » et « Latin Dances Revisited: New Analytic Results of Salsa20 and ChaCha »). ChaCha20 est un algorithme de chiffrement symétrique, plus rapide qu'AES sur un matériel générique (mise en œuvre purement en logiciel), Poly1305 est un MAC, et les deux peuvent être combinés pour faire du chiffrement intègre (et cela figure désormais dans le registre sur AEAD).
La section 2 du RFC décrit les algorithmes (je ne la reprends pas ici, la crypto, c'est trop fort pour moi), et ajoute du pseudo-code, des exemples et des vecteurs de test (il y en a d'autres dans l'annexe A). À l'origine, Poly1305 était décrit comme lié à AES, pour obtenir, par chiffrement du numnique, une chaîne de bits unique et secrète. Mais, en fait, n'importe quelle fonction de chiffrement convient, pas uniquement AES.
En cryptographie, ce sont plus souvent les mises en œuvre que les algorithmes qui ont une faille. La section 3 est donc consacrée aux avis aux programmeurs, pour éviter qu'une erreur de leur part n'affaiblisse ces beaux algorithmes. Poly1305 nécessite de travailler avec des grands nombres et le RFC déconseille d'utiliser la plupart des bibliothèques existantes de gestion des grands nombres comme celle d'OpenSSL. Celles-ci sont trop souvent vulnérables à des attaques par mesure du temps écoulé et le RFC conseille d'utiliser uniquement des bibliothèques qui font leur travail en un temps constant, comme NaCl. Un exemple de mise en œuvre de Poly1305 est poly1305-donna.
La section 4, sur la sécurité, détaille les points importants à suivre pour ne pas se faire casser sa jolie crypto. Pour ChaCha20, avant tout, il faut utiliser un numnique (numnique ?) vraiment unique. On peut utiliser un compteur, on peut utiliser un LFSR, mais il doit être unique.
ChaCha20 et Poly1305 n'utilisent que des opérations simples,
normalement faciles à implémenter en un temps constant, qui ne
permettront pas à l'attaquant de déduire quoi que ce soit de la
mesure des temps de réponse. Attention, programmeurs, certaines
fonctions comme la classique
memcmp() ne s'exécutent pas en un
temps constant, et, si elles sont utilisées, permettent certaines
attaques.
Ces algorithmes sont dans le registre IANA des algorithmes TLS. Notez aussi un bon article d'explication de CloudFlare.
Comme indiqué au début, il n'y a que peu de changements depuis le RFC 7539, à part la correction de plusieurs erreurs techniques.
L'article seul
RFC 8427: Representing DNS Messages in JSON
Date de publication du RFC : Juillet 2018
Auteur(s) du RFC : P. Hoffman (ICANN)
Pour information
Première rédaction de cet article le 11 décembre 2018
Le format des messages DNS circulant sur le réseau est un format binaire, pas forcément évident à analyser. Pour beaucoup d'applications, il serait sans doute préférable d'utiliser un format normalisé et plus agréable, par exemple JSON, dont ce nouveau RFC décrit l'utilisation pour le DNS.
Non seulement le format des messages DNS est du binaire (RFC 1035, section 4) et non pas du texte comme par exemple pour SMTP, XMPP ou HTTP, mais en plus il y a des pièges. Par exemple, la longueur des sections du message est indiquée dans un champ séparé de la section, et peut ne pas correspondre à la vraie longueur. La compression des noms n'arrange rien. Écrire un analyseur de messages DNS est donc difficile.
Il y a un million de formats pour des données structurées mais, aujourd'hui, le format texte le plus populaire pour ces données est certainement JSON, normalisé dans le RFC 8259. L'utilisation de JSON pour représenter les messages DNS (requêtes ou réponses) suit les principes suivants (section 1.1 du RFC) :
- Tout est optionnel, on peut donc ne représenter qu'une
partie d'un message. (Des profils ultérieurs de cette
spécification pourraient être
plus rigoureux, par exemple une base de
passive DNS peut
imposer que
QNAME, le nom de domaine demandé, soit présent, cf. section 6 du RFC.) - Si l'information est présente, on peut recréer le format binaire utilisé par le protocole DNS à partir du JSON (pas forcément bit pour bit, surtout s'il y avait de la compression).
- Tous les noms sont représentés dans le sous-ensemble ASCII d'UTF-8, obligeant les IDN à être en Punycode (alors que JSON permet l'UTF-8).
- Les données binaires peuvent être stockées, à condition d'être encodées en Base16 (RFC 4648).
- Il n'y a pas de forme canonique : le même message DNS peut être représenté par plusieurs objets JSON différents.
- Certains membres des objets JSON sont redondants et il peut donc y avoir des incohérences (par exemple entre la longueur indiquée d'une section ou d'un message, et sa longueur réelle, cf. la section 8 sur les conséquences que cela a pour la sécurité). Cela est nécessaire pour reconstituer certains messages DNS malformés. Autrement, le format serait limité aux messages corrects.
- Le format représente des messages, pas des fichiers de zone (RFC 1035, section 5).
La section 2 du RFC donne la liste des membres (au sens JSON de
« champs d'un objet ») d'un objet DNS. Voici un exemple d'un tel
objet, une requête DNS demandant l'adresse IPv4 (code 1, souvent
noté A) d'example.com :
{ "ID": 19678, "QR": 0, "Opcode": 0,
"AA": 0, "TC": 0, "RD": 0, "RA": 0, "AD": 0, "CD": 0, "RCODE": 0,
"QDCOUNT": 1, "ANCOUNT": 0, "NSCOUNT": 0, "ARCOUNT": 0,
"QNAME": "example.com", "QTYPE": 1, "QCLASS": 1
}
Les noms des membres sont ceux utilisés dans les
RFC DNS, même s'ils
ne sont pas très parlants (RCODE au lieu
ReturnCode).
On note que les différents membres qui sont dans le DNS
représentés par des entiers le sont également ici, au lieu
d'utiliser les abréviations courantes. Ainsi,
Opcode est marqué 0 et pas Q
(query), et QTYPE
(query type) est marqué 1 et pas A (adresse
IPv4). Cela permet de représenter des valeurs inconnues, qui n'ont
pas d'abréviation textuelle, même si ça rend le résultat peu
lisible si on ne connait pas les valeurs des
paramètres DNS par coeur.
Les valeurs d'un seul bit (booléens) sont représentés par 0 ou
1, pas par les false ou
true de JSON. (J'avoue ne pas bien comprendre ce choix.)
On note également que les longueurs des sections sont indiquées
explicitement, ici QDCOUNT (Query
Count, et ne me demandez pas à quoi sert le D après le
Q, le RFC 1035 ne l'explique pas). En JSON,
cela n'est pas obligatoire (la longueur d'un tableau, en JSON,
n'est pas spécifiée explicitement) mais, comme expliqué plus haut,
cela a été décidé pour permettre de représenter des messages DNS
anormaux, par exemple ayant un QDCOUNT de 0
et une question dans la section Question (cf. section 8 du RFC sur
les conséquences que cela peut avoir pour la sécurité). De tels messages
arrivent assez souvent dans le trafic DNS réel vu par les serveurs
connectés à l'Internet ; attaque délibérée ou bien logiciel écrit
avec les pieds ?
Et voici un exemple de réponse (QR = 1)
DNS en JSON. La requête a été un succès
(RCODE = 0) :
{ "ID": 32784, "QR": 1, "AA": 1, "RCODE": 0,
"QDCOUNT": 1, "ANCOUNT": 2, "NSCOUNT": 1,
ARCOUNT": 0,
"answerRRs": [ { "NAME": "example.com.",
"TYPE": 1, "CLASS": 1,
"TTL": 3600,
"RDATAHEX": "C0000201" },
{ "NAME": "example.com.",
"TYPE": 1, "CLASS": 1,
"TTL": 3600,
"RDATAHEX": "C000AA01" } ],
"authorityRRs": [ { "NAME": "ns.example.com.",
"TYPE": 1, "CLASS": 1,
"TTL": 28800,
"RDATAHEX": "CB007181" } ]
La réponse contient un ensemble d'adresses IP
(TYPE = 1 identifie une adresse IPv4),
192.0.2.1 et 192.0.170.1. Leur
valeur est encodée en hexadécimal. C'est
moins joli que si on avait mis l'adresse IP en clair mais c'est
plus général : cela permet d'inclure immédiatement de nouveaux
types de données, au détriment de la lisibilité pour les anciens
types.
Le format de ce RFC permet aussi de décrire l'association entre
une requête et une réponse (section 3 du RFC). On les met dans un
objet JSON ayant un membre queryMessage et un
responseMessage.
Si on représente une suite continue de messages DNS, faire un objet JSON avec son accolade ouvrante et la fermante correspondante peut ne pas être pratique. On utilise alors les séquences du RFC 7464, décrites dans la section 4 de notre RFC.
Notre RFC spécifie également (section 7) un type
MIME pour le DNS en JSON, application/dns+json.
Notez qu'il ne s'agit pas de la première description du DNS en
JSON. Par exemple, j'avais décrit un format pour cela dans le
brouillon draft-bortzmeyer-dns-json. Ce format
est mis en œuvre dans le DNS Looking
Glass. Mon format était plus joli, car utilisant
toujours des noms plus parlants ("Type": "AAAA"
au lieu du "QTYPE": 28). Notez toutefois que
le RFC 8427 le permet également ("QTYPEname":
"AAAA"). Le format plus joli ne peut de toute façon pas
être utilisé systématiquement car il ne permet pas de représenter
les types inconnus. Et mon format ne permet pas non plus de
représenter les messages malformés. (Par exemple, le
ANCOUNT est toujours implicite.)
Un autre exemple de représentation des données DNS est donné par les sondes RIPE Atlas. Le fichier des résultats d'une mesure est en JSON (ce qui permet le traitement par les outils JSON habituels comme jq). Voici un exemple (si vous voulez un exemple complet, téléchargez par exemple le résultat de la mesure #18061873) :
"resultset": [
{
...
"result": {
"ANCOUNT": 1,
"ARCOUNT": 0,
"ID": 38357,
"NSCOUNT": 0,
"QDCOUNT": 1,
"abuf": "ldWBgAABAAEAAAAADmN5YmVyc3RydWN0dXJlAmZyAAAcAAHADAAcAAEAAVGAABAgAUuYDcAAQQIWPv/+Jz0/",
"rt": 103.7,
"size": 63
},
},
On note que seule une petite partie des
champs de la réponse (ANCOUNT,
ID…) est exprimée en JSON, la majorité de la requête
étant dans un membre abuf qui est la
représentation binaire de la réponse.
Le service de DNS sur HTTPS de Google produit également du JSON (on le passe à jq pour qu'il soit plus joliment affiché) :
% curl -s https://dns.google.com/resolve\?name=laquadrature.net\&type=MX | jq .
{
"Status": 0,
"TC": false,
"RD": true,
"RA": true,
"AD": false,
"CD": false,
"Question": [
{
"name": "laquadrature.net.",
"type": 15
}
],
"Answer": [
{
"name": "laquadrature.net.",
"type": 15,
"TTL": 475,
"data": "5 pi.lqdn.fr."
}
]
}
en utilisant un format
spécifique à Google.
On notera que le protocole DoH, normalisé dans le RFC 8484, n'utilise pas JSON (et le
service de Google, contrairement à ce qu'on voit parfois écrit,
n'utilise pas DoH) mais le format binaire du DNS, utilisant le
type MIME application/dns-message. Le RFC 8484 prévoit
toutefois la possibilité de se servir de JSON pour le futur (section
4.2 du RFC 8484).
L'article seul
RFC 8422: Elliptic Curve Cryptography (ECC) Cipher Suites for Transport Layer Security (TLS) Versions 1.2 and Earlier
Date de publication du RFC : Août 2018
Auteur(s) du RFC : Y. Nir (Check Point), S. Josefsson
(SJD AB), M. Pegourie-Gonnard (Independent /
PolarSSL)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 7 août 2018
Ce RFC décrit les algorithmes cryptographiques à base de courbes elliptiques utilisés dans TLS. Il remplace le RFC 4492.
Plus exactement, il normalise les algorithmes utilisés dans les versions de TLS allant jusqu'à 1.2 incluse. L'utilisation des courbes elliptiques par TLS 1.3 est décrite dans le RFC sur TLS 1.3, le RFC 8446. Les deux points importants de ce nouveau RFC sont :
- L'utilisation de courbes elliptiques pour un échange Diffie-Hellman de la clé de session TLS (ce qu'on nomme ECDHE),
- Les algorithmes de signature à courbes elliptiques ECDSA et EdDSA pour authentifier le pair TLS.
Commençons par l'échange de clés de session (section 2). TLS nécessite que les deux pairs se mettent d'accord sur une clé de chiffrement symétrique qui sera ensuite utilisée pendant toute la session, avec des algorithmes comme AES. Une des façons de synchroniser cette clé de session est qu'un des pairs la génère aléatoirement, puis la chiffre avec la clé publique (chiffrement asymétrique) de son pair avant de lui transmettre (cela marche avec RSA mais je n'ai pas l'impression qu'il y ait un moyen normalisé de faire cela avec les courbes elliptiques). Une autre façon est d'utiliser un échange Diffie-Hellman. Contrairement à l'échange Diffie-Hellman originel, celui présenté dans ce RFC, ECDHE, utilise la cryptographie sur courbes elliptiques. (J'ai simplifié pas mal : par exemple, l'échange ECDHE ne donnera pas directement la clé de session, celle-ci sera en fait dérivée de la clé obtenue en ECDHE.) Le principal avantage de Diffie-Hellman est de fournir de la sécurité même en cas de compromission ultérieure de la clé privée.
Notre RFC présente trois variantes d'ECDHE, selon la manière dont l'échange est authentifié, l'une utilisant ECDSA ou EdDSA, l'autre utilisant le traditionnel RSA, et la troisième n'authentifiant pas du tout, et étant donc vulnérable aux attaques de l'Homme du Milieu, sauf si une authentification a lieu en dehors de TLS. (Attention, dans le cas de ECDHE_RSA, RSA n'est utilisé que pour authentifier l'échange, la génération de la clé se fait bien en utilisant les courbes elliptiques.)
Lorsque l'échange est authentifié (ECDHE_ECDSA
- qui, en dépit de son nom, inclut EdDSA -
ou bien ECDHE_RSA), les paramètres
ECDH (Diffie-Hellman avec courbes elliptiques)
sont signés par la
clé privée (ECDSA, EdDSA ou RSA). S'il n'est pas authentifié
(ECDH_anon, mais notez que le nom est trompeur,
bien que le E final - ephemeral - manque, la clé
est éphémère), on n'envoie évidemment pas de certificat, ou de demande
de certificat.
Voilà, avec cette section 2, on a pu générer une clé de session
avec Diffie-Hellman, tout en authentifiant le serveur avec des courbes
elliptiques. Et pour l'authentification du client ? C'est la section 3
de notre RFC. Elle décrit un mécanisme ECDSA_sign
(là encore, en dépit du nom du mécanisme, il fonctionne aussi bien
pour EdDSA), où le client s'authentifie en signant ses messages avec
un algorithme à courbes elliptiques.
Les courbes elliptiques ont quelques particularités qui justifient
deux extensions à TLS que présente la section 4 du RFC. Il y a
Supported Elliptic Curves Extension et Supported Point
Formats Extension, qui permettent de décrire les
caractéristiques de la courbe elliptique utilisée (on verra plus loin
que la deuxième extension ne sert plus guère). Voici, vue par
tshark, l'utilisation de ces extensions dans un
ClientHello TLS envoyé par OpenSSL :
Extension: elliptic_curves
Type: elliptic_curves (0x000a)
Length: 28
Elliptic Curves Length: 26
Elliptic curves (13 curves)
Elliptic curve: secp256r1 (0x0017)
Elliptic curve: secp521r1 (0x0019)
Elliptic curve: brainpoolP512r1 (0x001c)
Elliptic curve: brainpoolP384r1 (0x001b)
Elliptic curve: secp384r1 (0x0018)
Elliptic curve: brainpoolP256r1 (0x001a)
Elliptic curve: secp256k1 (0x0016)
...
Extension: ec_point_formats
Type: ec_point_formats (0x000b)
Length: 4
EC point formats Length: 3
Elliptic curves point formats (3)
EC point format: uncompressed (0)
EC point format: ansiX962_compressed_prime (1)
EC point format: ansiX962_compressed_char2 (2)
La section 5 du RFC donne les détails concrets. Par exemple, les deux extensions citées plus haut s'écrivent, dans le langage de TLS (cf. section 4 du RFC 5246) :
enum {
elliptic_curves(10),
ec_point_formats(11)
} ExtensionType;
La première extension permet d'indiquer les courbes utilisées. Avec celles du RFC 7748, cela donne, comme possibilités :
enum {
deprecated(1..22),
secp256r1 (23), secp384r1 (24), secp521r1 (25),
x25519(29), x448(30),
reserved (0xFE00..0xFEFF),
deprecated(0xFF01..0xFF02),
(0xFFFF)
} NamedCurve;
secp256r1 est la courbe P-256 du
NIST, x25519 est la
Curve-25519 de Bernstein. Notez que beaucoup
des courbes de l'ancien RFC 4492, jamais très utilisées, ont
été abandonnées. (Les courbes se trouvent dans un
registre IANA.)
Normalement, dans TLS, on peut choisir séparément l'algorithme de
signature et celui de condensation (cf. section
7.4.1.4.1 du RFC 5246). Avec certains
algorithmes comme EdDSA dans sa forme « pure », il n'y a pas de
condensation séparée et un « algorithme » bidon,
Intrinsic (valeur 8) a été créé pour mettre
dans le champ « algorithme de condensation » de l'extension signature_algorithms.
Voici une négociation TLS complète, vue par curl :
% curl -v https://www.nextinpact.com ... * Connected to www.nextinpact.com (2400:cb00:2048:1::6819:f815) port 443 (#0) ... * Cipher selection: ALL:!EXPORT:!EXPORT40:!EXPORT56:!aNULL:!LOW:!RC4:@STRENGTH ... * SSL connection using TLSv1.2 / ECDHE-ECDSA-AES128-GCM-SHA256 * ALPN, server accepted to use h2 * Server certificate: * subject: C=US; ST=CA; L=San Francisco; O=CloudFlare, Inc.; CN=nextinpact.com ... > GET / HTTP/1.1 > Host: www.nextinpact.com > User-Agent: curl/7.52.1 > Accept: */*
On voit que l'algorithme utilisé par TLS est
ECDHE-ECDSA-AES128-GCM-SHA256, ce qui indique
ECDHE avec ECDSA. Le certificat du serveur doit donc inclure une clé
« courbe elliptique ». Regardons ledit certificat :
% openssl s_client -connect www.nextinpact.com:443 -showcerts | openssl x509 -text
Certificate:
...
Signature Algorithm: ecdsa-with-SHA256
Issuer: C = GB, ST = Greater Manchester, L = Salford, O = COMODO CA Limited, CN = COMODO ECC Domain Validation Secure Server CA 2
...
Subject: OU = Domain Control Validated, OU = PositiveSSL Multi-Domain, CN = ssl378410.cloudflaressl.com
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (256 bit)
...
ASN1 OID: prime256v1
NIST CURVE: P-256
...
X509v3 Subject Alternative Name:
DNS:ssl378410.cloudflaressl.com, DNS:*.baseballwarehouse.com, DNS:*.campusgroups.com, DNS:*.cretedoc.gr, DNS:*.groupment.com, DNS:*.icstage.com, DNS:*.ideacouture.com, DNS:*.industrialtour-deloitte.com, DNS:*.jonessnowboards.com, DNS:*.nextinpact.com, DNS:*.pcinpact.com, DNS:*.pinkapple.com, DNS:*.softballrampage.com, DNS:*.undercovercondoms.co.uk, DNS:baseballwarehouse.com, DNS:campusgroups.com, DNS:cretedoc.gr, DNS:groupment.com, DNS:icstage.com, DNS:ideacouture.com, DNS:industrialtour-deloitte.com, DNS:jonessnowboards.com, DNS:nextinpact.com, DNS:pcinpact.com, DNS:pinkapple.com, DNS:softballrampage.com, DNS:undercovercondoms.co.uk
Signature Algorithm: ecdsa-with-SHA256
On a bien une clé sur la courbe P-256.
Quel est l'état des mises en œuvre de ces algorithmes dans les bibliothèques TLS existantes ? ECDHE et ECDSA avec les courbes NIST sont très répandus. ECDHE avec la courbe Curve25519 est également dans plusieurs bibliothèques TLS. Par contre, EdDSA, ou ECDHE avec la courbe Curve448, sont certes implémentés mais pas encore largement déployés.
Les changements depuis le RFC 4492 sont résumés dans l'annexe B. Souvent, une norme récente ajoute beaucoup de choses par rapport à l'ancienne mais, ici, pas mal de chose ont au contraire été retirées :
- Plusieurs courbes peu utilisées disparaissent,
- Il n'y a plus qu'un seul format de point accepté (uncompressed),
- Des algorithmes comme toute la famille ECDH_ECDSA (ECDH et pas ECDHE, donc ceux dont la clé n'est pas éphémère) sont retirés.
Parmi les ajouts, le plus important est évidemment l'intégration des « courbes Bernstein », Curve25519 et Curve448, introduites par le RFC 7748. Et il y avait également plusieurs erreurs techniques dans le RFC 4492, qui sont corrigées par notre nouveau RFC.
Et, pendant que j'y suis, si vous voulez générer un certificat avec les courbes elliptiques, voici comment faire avec OpenSSL :
% openssl ecparam -out ec_key.pem -name prime256v1 -genkey % openssl req -new -key ec_key.pem -nodes -days 1000 -out cert.csr
J'ai utilisé ici la courbe P-256 (prime256v1 est encore un autre identificateur pour la courbe
NIST P-256, chaque organisme qui normalise dans ce domaine ayant ses
propres identificateurs). Si vous voulez la liste des courbes que
connait OpenSSL :
% openssl ecparam -list_curves
Ce blog est accessible en TLS mais pas avec des courbes elliptiques. En effet, l'AC que j'utilise, CAcert, ne les accepte hélas pas (« The keys you supplied use an unrecognized algorithm. For security reasons these keys can not be signed by CAcert. ») Il y a des raisons pour cela mais c'est quand même déplorable. (Enfin, j'accepte quand même ECDHE.)
Enfin, un échange TLS complet vu par tshark est visible ici.
Merci à Manuel Pégourié-Gonnard pour sa relecture vigilante.
L'article seul
RFC 8415: Dynamic Host Configuration Protocol for IPv6 (DHCPv6)
Date de publication du RFC : Novembre 2018
Auteur(s) du RFC : T. Mrugalski, M. Siodelski (ISC), B. Volz, A. Yourtchenko (Cisco), M. Richardson (SSW), S. Jiang (Huawei), T. Lemon (Nibbhaya Consulting), T. Winters (UNH-IOL)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dhc
Première rédaction de cet article le 3 mai 2019
IPv6 dispose de trois mécanismes principaux pour l'allocation d'une adresse IP à une machine. L'allocation statique, « à la main », le système d'« autoconfiguration » SLAAC du RFC 4862 et DHCP. DHCP pour IPv6 avait été normalisé pour la première fois dans le RFC 3315, que notre RFC met à jour. Le protocole n'a guère changé mais le texte du RFC a été sérieusement revu (DHCP est un protocole compliqué). Une mise à jour a eu lieu par la suite, remplaçant ce RFC par le RFC 9915.
DHCP permet à une machine (qui n'est pas forcément un ordinateur) d'obtenir une adresse IP (ainsi que plusieurs autres informations de configuration) à partir d'un serveur DHCP du réseau local. C'est donc une configuration « avec état », du moins dans son mode d'utilisation le plus connu. (Notre RFC documente également un mode sans état.) DHCP nécessite un serveur, par opposition à l'autoconfiguration du RFC 4862 qui ne dépend pas d'un serveur (cette autoconfiguration sans état peut être utilisée à la place de, ou bien en plus de DHCP). Deux utilisations typiques de DHCP sont le SoHo où le routeur ADSL est également serveur DHCP pour les trois PC connectés et le réseau local d'entreprise où deux ou trois machines Unix distribuent adresses IP et informations de configuration à des centaines de machines.
Le principe de base de DHCP (IPv4 ou IPv6) est simple : la nouvelle machine annonce à la cantonade qu'elle cherche une adresse IP, le serveur lui répond, l'adresse est allouée pour une certaine durée, le bail, la machine cliente devra renouveler le bail de temps en temps.
L'administrateur d'un réseau IPv6 se pose souvent la question « DHCP ou SLAAC » ? Notez que les deux peuvent coexister, ne serait-ce que parce que certaines possibilités n'existent que pour un seul des deux protocoles. Ainsi, DHCP seul ne peut indiquer l'adresse du routeur par défaut. Pour le reste, c'est une question de goût.
Le DHCP spécifié par notre RFC ne fonctionne que pour IPv6, les RFC 2131 et RFC 2132 traitant d'IPv4. Les deux protocoles restent donc complètement séparés, le RFC 4477 donnant quelques idées sur leur coexistence. Il a parfois été question de produire une description unique de DHCPv4 et DHCPv6, ajoutant ensuite les spécificités de chacun, mais le projet n'a pas eu de suite (section 1.2 de ce RFC), les deux protocoles étant trop différents. De même, l'idée de permettre l'envoi d'informations spécifiques à IPv4 (par exemple l'adresse IPv4, proposée dans le RFC 3315, section 1) au-dessus de DHCPv6 a été abandonnée (mais voyez quand même le RFC 7341).
DHCP fonctionne par diffusion
restreinte. Un client DHCP,
c'est-à-dire une machine qui veut obtenir une adresse, diffuse
(DHCP fonctionne au-dessus d'UDP, RFC 768, le
port source est 546, le port de destination,
où le serveur écoute, est 547) sa demande à l'adresse
multicast locale au lien
ff02::1:2. Le serveur se reconnait et lui
répond. S'il n'y a pas de réponse, c'est, comme dans le DNS, c'est au client de réémettre
(section 15). L'adresse IP source du client est également une
adresse locale au lien.
(Notez qu'une autre adresse de diffusion restreinte est
réservée, ff05::1:3 ; elle inclut également
tous les serveurs DHCP mais, contrairement à la précédente, elle
exclut les relais, qui transmettent les requêtes DHCP d'un réseau
local à un autre.)
Le serveur choisit sur quels critères il alloue les adresses IP. Il peut les distribuer de manière statique (une même machine a toujours la même adresse IP) ou bien les prendre dans un pool d'adresses et chaque client aura donc une adresse « dynamique ». Le fichier de configuration du serveur DHCP ISC ci-dessous montre un mélange des deux approches.
Il faut bien noter (et notre RFC le fait dans sa section 22) que DHCP n'offre aucune sécurité. Comme il est conçu pour servir des machines non configurées, sur lesquelles on ne souhaite pas intervenir, authentifier la communication est difficile. Un serveur DHCP pirate, ou, tout simplement, un serveur DHCP accidentellement activé, peuvent donc être très gênants. Les approches de sécurité suggérées dans le RFC 3315 se sont avérées peu pratiques et plusieurs ont été retirées dans notre nouveau RFC.
Outre l'adresse IP, DHCP peut indiquer des options comme les adresses des serveurs DNS à utiliser (RFC 3646).
Notre version IPv6 de DHCP est assez différente de la version IPv4 (et le RFC est plus de trois fois plus long). Par exemple, l'échange « normal » entre client et serveur prend quatre paquets IP (section 5) et non pas deux. (Il y a aussi un échange simplifié à deux paquets, cf. section 5.1.) L'encodage des messages est très différent, et il y a des différences internes comme l'IA (Identity Association) de la section 12. Il y a aussi des différences visibles à l'utilisateur comme le concept de DUID (DHCP Unique IDentifier), section 11, qui remplace les anciens client identifier et server identifier de DHCP v4. Les différences sont telles que le RFC précise que leur intégration avec DHCP pour IPv4 n'est pas envisagée.
À l'heure actuelle, il existe plusieurs mises en œuvre de DHCPv6, Dibbler (client et serveur, mais qui n'est plus maintenu), celle de l'Institut Leibniz à Dresde (serveur seulement), celles de l'ISC, l'ancien DHCP et le nouveau, nommé Kea (dans les deux cas, serveur seulement) et dhcpcd (client seulement). Pour celles et ceux qui utilisent une Freebox comme serveur DHCP, il semble qu'elle ait DHCPv6 depuis 2018 (je n'ai pas testé). Il parait que la Livebox le fait également. Je n'ai pas non plus essayé pour la Turris Omnia mais cela devrait marcher puisqu'elle utilise le serveur odhcpd, qui sait faire du DHCPv6. Et il y a bien sûr des implémentations non-libres dans des équipements comme les Cisco. Notez que ces mises en œuvre de DHCPv6 n'ont pas forcément déjà intégré les modifications de notre RFC 8415.
Voici un exemple d'utilisation de Dibbler, qui nous affiche les
quatre messages (Solicit - Advertise -
Request - Reply) :
% sudo dibbler-client run ... 2019.05.02 11:35:15 Client Notice Unable to open DUID file (client-duid), generating new DUID. 2019.05.02 11:35:15 Client Notice DUID creation: Generating 14-bytes long link-local+time (duid-llt) DUID. 2019.05.02 11:35:15 Client Info My DUID is 00:01:00:01:24:5d:76:53:00:1e:8c:76:29:b6. ... 2019.05.02 12:12:38 Client Info Creating SOLICIT message with 1 IA(s), no TA and 0 PD(s) on eth1/2 interface. 2019.05.02 12:12:38 Client Info Received ADVERTISE on eth1/2,trans-id=0x614722, 4 opts: 1 2 3 23 2019.05.02 12:12:39 Client Info Processing msg (SOLICIT,transID=0x614722,opts: 1 3 8 6) 2019.05.02 12:12:39 Client Info Creating REQUEST. Backup server list contains 1 server(s). 2019.05.02 12:12:39 Client Info Received REPLY on eth1/2,trans-id=0x634881, 4 opts: 1 2 3 23 2019.05.02 12:12:39 Client Notice Address fde8:9fa9:1aba:0:fafa::2/128 added to eth1/2 interface. 2019.05.02 12:12:39 Client Notice Setting up DNS server 2001:db8:2::dead:beef on interface eth1/2.
Le serveur en face était un Kea ainsi configuré :
"subnet6": [
{
"interface": "eth0",
"subnet": "fde8:9fa9:1aba:0::/64",
"pools": [ { "pool": "fde8:9fa9:1aba:0:fafa::/80" } ],
...
Pour que Kea puisse écouter sur le port DHCP, il a aussi fallu :
% sudo setcap 'cap_net_bind_service=+ep' /usr/sbin/kea-dhcp6
(Sinon, c'est le Permission denied.) Si vous
voulez, le pcap de l'échange est disponible (capture faite avec tcpdump -w /tmp/dhcpv6.pcap udp and port 546 or port 547).
tcpdump voit le trafic ainsi :
12:17:44.531859 IP6 fe80::21e:8cff:fe76:29b6.546 > ff02::1:2.547: dhcp6 solicit 12:17:44.555202 IP6 fe80::d40b:5ff:fee8:a36b.547 > fe80::21e:8cff:fe76:29b6.546: dhcp6 advertise 12:17:45.559247 IP6 fe80::21e:8cff:fe76:29b6.546 > ff02::1:2.547: dhcp6 request 12:17:45.567875 IP6 fe80::d40b:5ff:fee8:a36b.547 > fe80::21e:8cff:fe76:29b6.546: dhcp6 reply
On voit bien les quatre messages (Solicit - Advertise -
Request - Reply). Avec l'option
-vvv, tcpdump est plus bavard et montre qu'il
analyse bien DHCPv6 :
12:17:44.531859 IP6 (flowlabel 0x90d05, hlim 1, next-header UDP (17) payload length: 58) fe80::21e:8cff:fe76:29b6.546 > ff02::1:2.547: [udp sum ok] dhcp6 solicit (xid=aecc66 (client-ID hwaddr/time type 1 time 610104915 001e8c7629b6) (IA_NA IAID:1 T1:4294967295 T2:4294967295) (elapsed-time 0) (option-request DNS-server)) 12:17:44.555202 IP6 (flowlabel 0xa6d2a, hlim 64, next-header UDP (17) payload length: 128) fe80::d40b:5ff:fee8:a36b.547 > fe80::21e:8cff:fe76:29b6.546: [udp sum ok] dhcp6 advertise (xid=aecc66 (client-ID hwaddr/time type 1 time 610104915 001e8c7629b6) (server-ID hwaddr/time type 1 time 610105065 d60b05e8a36b) (IA_NA IAID:1 T1:1000 T2:2000 (IA_ADDR fde8:9fa9:1aba:0:fafa::4 pltime:3000 vltime:4000)) (DNS-server 2001:db8:2::dead:beef 2001:db8:2::cafe:babe)) 12:17:45.559247 IP6 (flowlabel 0x90d05, hlim 1, next-header UDP (17) payload length: 104) fe80::21e:8cff:fe76:29b6.546 > ff02::1:2.547: [udp sum ok] dhcp6 request (xid=dc7ba (client-ID hwaddr/time type 1 time 610104915 001e8c7629b6) (IA_NA IAID:1 T1:4294967295 T2:4294967295 (IA_ADDR fde8:9fa9:1aba:0:fafa::4 pltime:3000 vltime:4000)) (option-request DNS-server) (server-ID hwaddr/time type 1 time 610105065 d60b05e8a36b) (elapsed-time 0)) 12:17:45.567875 IP6 (flowlabel 0xa6d2a, hlim 64, next-header UDP (17) payload length: 128) fe80::d40b:5ff:fee8:a36b.547 > fe80::21e:8cff:fe76:29b6.546: [udp sum ok] dhcp6 reply (xid=dc7ba (client-ID hwaddr/time type 1 time 610104915 001e8c7629b6) (server-ID hwaddr/time type 1 time 610105065 d60b05e8a36b) (IA_NA IAID:1 T1:1000 T2:2000 (IA_ADDR fde8:9fa9:1aba:0:fafa::4 pltime:3000 vltime:4000)) (DNS-server 2001:db8:2::dead:beef 2001:db8:2::cafe:babe))
Mais si vous préférez tshark, l'analyse de cet échange est également disponible.
Quant au fichier de configuration du traditionnel serveur ISC (celui avant Kea), il ressemble beaucoup à ce qu'il est en v4 :
subnet6 2001:db8:dead:babe::/64 {
range6 2001:db8:dead:babe::100 2001:db8:dead:babe::FFF;
# On peut aussi utiliser préfixe/longueur au lieu d'indiquer les
# adresses de début et de fin de la plage
}
On doit lancer le serveur avec l'option -6 (le même démon ne peut pas servir le v4 et le v6 en même temps, les deux protocoles étant trop différents) :
# dhcpd -6 -d -f Internet Systems Consortium DHCP Server 4.0.0 ... Listening on Socket/eth0/2001:db8:dead:babe::/64 Sending on Socket/eth0/2001:db8:dead:babe::/64 [Puis arrive une requête] Solicit message from fe80::219:b9ff:fee4:25f9 port 546, transaction ID 0x4BB14F00 Picking pool address 2001:db8:dead:babe::fbb Sending Advertise to fe80::219:b9ff:fee4:25f9 port 546 Request message from fe80::219:b9ff:fee4:25f9 port 546, transaction ID 0x46B10900 Sending Reply to fe80::219:b9ff:fee4:25f9 port 546
(Le concept de transaction ID est décrit
sections 8 et 16.1.) La requête est émise depuis une adresse
lien-local (ici
fe80::219:b9ff:fee4:25f9) pas depuis une
adresse « tout zéro » comme en IPv4 (section 17 du RFC). Vu avec
tcpdump, la requête est :
15:07:43.455918 IP6 fe80::219:b9ff:fee4:25f9.546 > ff02::1:2.547: dhcp6 solicit 15:07:43.456098 IP6 fe80::219:b9ff:fee4:2987.547 > fe80::219:b9ff:fee4:25f9.546: dhcp6 advertise 15:07:44.512946 IP6 fe80::219:b9ff:fee4:25f9.546 > ff02::1:2.547: dhcp6 request 15:07:44.513233 IP6 fe80::219:b9ff:fee4:2987.547 > fe80::219:b9ff:fee4:25f9.546: dhcp6 reply
On note que l'échange a été celui à quatre messages
(Solicit - Advertise - Request - Reply),
décrit section 5.2 (et la liste des types possibles est en section 7.3). Le serveur n'a pas répondu directement avec un
Reply, parce que le client n'a pas inclus
l'option Rapid Commit (section 21.14). Cette
option n'est pas actuellement gérée par le client DHCP utilisé
(l'option dhcp6.rapid-commit existe mais la
documentation précise qu'elle est ignorée). Dans l'échange à quatre
messages, le client demande à tous (Solicit),
un(s) serveur(s) DHCP répond(ent) (Advertise), le client
envoie alors sa requête au serveur choisi
(Request), le serveur donne (ou pas) son
accord (Reply).
L'échange à deux messages (Solicit- Reply)
est, lui, spécifié dans la section 5.1. Il s'utilise si le client
n'a pas besoin d'une adresse IP, juste d'autres informations de
configuration comme l'adresse du serveur
NTP, comme décrit dans le RFC 4075. Même si le client demande une adresse IP, il est
possible d'utiliser l'échange à deux messages, via la procédure
rapide avec l'option Rapid Commit.
Actuellement, l'attribution d'adresses statiques à une machine,
en la reconnaissant, par exemple, à son adresse
MAC est plus délicate avec le serveur de l'ISC (merci à
Shane Kerr pour son aide). Il faut trouver le client
identifier (section 21.2 du RFC, deux méthodes possibles
pour le trouver sont expliquées plus loin) et le mettre dans
dhcpd.conf :
host lilith {
host-identifier option dhcp6.client-id 0:1:0:1:47:96:21:f7:0:19:b9:e4:25:f9;
fixed-address6 2001:db8:dead:babe::2;
}
et cette adresse IP fixe est donnée au client.
Pour trouver le client identifier, une
méthode spécifique au client DHCP de l'ISC est de regarder dans le
fichier des baux du client (typiquement
/var/db/dhclient6.leases) :
... option dhcp6.client-id 0:1:0:1:47:96:21:f7:0:19:b9:e4:25:f9;
Il suffit alors de le copier-coller.
Une autre méthode, plus complexe, mais qui marche avec tous les clients DHCP est de lancer tcpdump en mode bavard :
# tcpdump -n -vvv ip6 and udp and port 547 12:24:15.084006 IP6 (hlim 64, next-header UDP (17) payload length: 60) fe80::219:b9ff:fee4:25f9.546 > ff02::1:2.547: dhcp6 solicit (xid=4323ac (client ID hwaddr/time type 1 time 1201021431 0019b9e425f9) (option request DNS DNS name)[|dhcp6ext])
Tout client ou serveur DHCP v6 a un DUID (DHCP Unique
Identifier, décrit en section 11). Le DUID est opaque et
ne devrait pas être analysé par la machine qui le reçoit. La seule
opération admise est de tester si deux DUID sont égaux (indiquant
qu'en face, c'est la même machine). Il existe plusieurs façons de
générer un DUID (dans l'exemple plus haut, Dibbler avait choisi la
méthode duid-llt, adresse locale et heure) et de nouvelles pourront apparaitre dans le
futur. Par exempe, un DUID peut être fabriqué à partir d'un
UUID (RFC 6355).
Le client identifier de l'exemple avec le serveur de l'ISC ci-dessus, le DUID, a été fabriqué, comme pour Dibbler, en concaténant le type de DUID (ici, 1, Link-layer Address Plus Time, section 11.2 du RFC), le type de matériel (1 pour Ethernet), le temps (ici 1201021431, notons que ce client DHCP violait le RFC en comptant les secondes à partir de 1970 et pas de 2000) et l'adresse MAC, ce qui redonne le même résultat au prix de quelques calculs avec bc.
Mais l'utilisation exclusive du DUID, au détriment de l'adresse MAC, n'est pas une obligation du RFC (le RFC, section 11, dit juste « DHCP servers use DUIDs to identify clients for the selection of configuration parameters », ce qui n'interdit pas d'autres méthodes), juste un choix des développeurs de l'ISC. Le serveur de Dresde, dhcpy6d, permet d'utiliser les adresses MAC, comme on le fait traditionnellement en IPv4. En combinaison avec des commutateurs qui filtrent sur l'adresse MAC, cela peut améliorer la sécurité.
La section 6 de notre RFC décrit les différentes façons d'utiliser DHCPv6. On peut se servir de DHCPv6 en mode sans état (section 6.1), lorsqu'on veut juste des informations de configuration, ou avec état (section 6.2, qui décrit la façon historique d'utiliser DHCP), lorsqu'on veut réserver une ressource (typiquement l'adresse IP) et qu'il faut alors que le serveur enregistre (et pas juste dans sa mémoire, car il peut redémarrer) ce qui a été réservé. On peut aussi faire quelque chose qui n'a pas d'équivalent en IPv4, se faire déléguer un préfixe d'adresses IP entier (section 6.3). Un client DHCP qui reçoit un préfixe, mettons, /60, peut ensuite redéléguer des bouts, par exemple ici des /64. (Le RFC 7084 est une utile lecture au sujet des routeurs installés chez M. Toutlemonde.)
Le format détaillé des messages est dans la section 8. Le début des messages est toujours le même, un type d'un octet (la liste des types est en section 7.3) suivi d'un identificateur de transaction de trois octets. Le reste est variable, dépendant du type de message.
On a déjà parlé du concept de DUID plus haut, donc sautons la section 11 du RFC, qui parle du DUID, et allons directement à la section 12, qui parle d'IA (Identity Association). Une IA est composée d'un identifiant numérique, l'IAID (IA IDentifier) et d'un ensemble d'adresses et de préfixes. Le but du concept d'IA est de permettre de gérer collectivement un groupe de ressources (adresses et préfixes). Pour beaucoup de clients, le concept n'est pas nécessaire, on n'a qu'une IA, d'identificateur égal à zéro. Pour les clients plus compliqués, on a plusieurs IA, et les messages DHCP (par exemple d'abandon d'un bail) indiquent l'IA concernée.
Comme pour DHCPv4, une bonne partie des informations est transportée dans des options, décrites dans la section 21. Certaines options sont dans ce RFC, d'autres pourront apparaitre dans des RFC ultérieurs. Toutes les options commencent par deux champs communs, le code identifiant l'option (deux octets), et la longueur de l'option. Ces champs sont suivis par des données, spécifiques à l'option. Ainsi, l'option Client Identifier a le code 1, et les données sont un DUID (cf. section 11). Autre exemple, l'option Vendor Class (code 16) permet d'indiquer le fournisseur du logiciel client (notez qu'elle pose des problèmes de sécurité, cf. RFC 7824, et section 23 de notre RFC). Notez qu'il peut y avoir des options dans les options, ainsi, l'adresse IP (code 5) est toujours dans les données d'une option IA (les IA sont décrites en section 12).
Puisqu'on a parlé de sécurité, la section 22 du RFC détaille les questions de sécurité liées à DHCP. Le fond du problème est qu'il y a une profonde incompatibilité entre le désir d'une autoconfiguration simple des clients (le but principal de DHCP) et la sécurité. DHCP n'a pas de chiffrement et tout le monde peut donc écouter les échanges de messages, voire les modifier. Et, de toute façon, le serveur n'est pas authentifié, donc le client ne sait jamais s'il parle au serveur légitime. Il est trivial pour un méchant de configurer un serveur DHCP « pirate » et de répondre à la place du vrai, indiquant par exemple un serveur DNS que le pirate contrôle. Les RFC 7610 et RFC 7513 décrivent des solutions possibles à ce problème.
Des attaques par déni de service sont également possibles, par exemple via un client méchant qui demande des ressources (comme des adresses IP) en quantité. Un serveur prudent peut donc limiter la quantité de ressources accessible à un client.
Nouveauté de ce RFC (elle était quasiment absente du RFC 3315), les questions de vie privée. La section 23 rappelle que DHCP est très indiscret. Le RFC 7824 décrit les risques que DHCP fait courir à la vie privée du client (et le RFC 7844 des solutions possibles).
Les registres IANA ne changent pas par rapport à l'ancien RFC. Les différents paramètres sont en ligne.
L'annexe A de notre RFC décrit les changements depuis le vieil RFC 3315. Ils sont nombreux mais en général pas cruciaux. On notera :
- beaucoup de changements dans le texte, pour clarifier certains points, ou mieux expliquer des questions complexes,
- une section 6 sur les questions d'utilisation de DHCP, toute neuve,
- l'option Option Request devient obligatoire dans certains messages,
- une nouvelle section sur la vie privée,
- les références à IPsec (jamais déployé) ont été retirées,
- le protocole d'« authentification retardée » (jamais déployé, et probablement pas déployable) a été retiré (cf. section 25),
- la possibilité pour le client d'indiquer la durée d'un bail souhaitée a été retirée,
- plusieurs RFC séparés ont été fusionnés avec ce nouveau RFC, comme la délégation de préfixe, initialement séparée dans le RFC 3633 (l'implémenteur de DHCPv6 aura donc désormais une vue unifiée du protocole, et moins de RFC à lire),
- le mode « sans état », qui était dans le RFC 3736, a été intégré,
- le mécanisme de ralentissement des clients lorsque le serveur ne répond pas (ex-RFC 7083), le relayage des messages de type inconnu (remplaçant donc le RFC 7283), et le fonctionnement des différents modes (au revoir, le RFC 7550) sont également intégrés,
- une bonne douzaine de bogues relevées dans le RFC 3315 et ses RFC proches, ont été corrigées.
L'article seul
RFC 8410: Algorithm Identifiers for Ed25519, Ed448, X25519, and X448 for Use in the Internet X.509 Public Key Infrastructure
Date de publication du RFC : Août 2018
Auteur(s) du RFC : S. Josefsson (SJD AB), J. Schaad (August Cellars)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 2 février 2019
Ce RFC spécifie l'utilisation des
courbes elliptiques
Curve25519 et
Curve448 dans PKIX,
c'est-à-dire dans les certificats utilisés notamment pour
TLS. Il réserve des identifiants pour les
algorithmes, comme Ed25519.
Les courbes elliptiques Curve25519 et Curve448 sont normalisées dans le RFC 7748. Elles sont utilisées pour diverses opérations cryptographiques comme la signature. L'algorithme EdDSA, utilisant ces courbes, est, lui, dans le RFC 8032. Quand on écrit « Ed25519 », cela veut dire « EdDSA avec la courbe Curve25519 ». D'autre part, quand on écrit « X25519 », cela signifie « échange de clés Diffie-Hellman avec la courbe Curve25519 ».
Un certificat suivant le profil
PKIX du RFC 5280
contient une clé publique, pour un algorithme cryptographique
donné. Il faut donc un identificateur formel pour cet
algorithme. Sa syntaxe est celle d'un OID,
par exemple 1.2.840.113549.1.1.1 (cf. RFC 8017) pour
RSA. Notre
RFC définit
(section 3) quatre nouveaux identificateurs :
id-X25519:1.3.101.110(ou, en détaillé,{iso(1) identified-organization(3) thawte(101) id-X25519(110)}) ; notez qu'il avait été enregistré par Thawte, depuis racheté par Symantec, ce qui explique pourquoi le RFC remercie Symantec,id-X448:1.3.101.111,id-Ed25519:1.3.101.112,id-Ed448:1.3.101.113.
Le RFC recommande aussi des noms plus sympathiques que les OID, OID qu'on ne peut vraiment pas montrer aux utilisateurs. Ces noms sont ceux décrits plus haut, comme Ed25519 pour EdDSA avec Curve25519. Si on ne sait pas quelle courbe est utilisée, on dit simplement « EdDSA » pour la signature, et « ECDH » pour l'échange de clés Diffie-Hellman.
Les nouveaux identificateurs et OID sont désormais dans le le registre IANA.
Le RFC fournit aussi des structures ASN.1, avec des exemples en section 10.
Notez qu'OpenSSL, avec openssl
x509 -text, ou GnuTLS, avec
certtool --certificate-info, n'affichent pas
les OID, seulement les identificateurs texte.
L'article seul
RFC 8404: Effects of Pervasive Encryption on Operators
Date de publication du RFC : Juillet 2018
Auteur(s) du RFC : K. Moriarty (Dell EMC), A. Morton
(AT&T Labs)
Pour information
Première rédaction de cet article le 23 novembre 2018
La vie privée sur l'Internet fait aujourd'hui l'objet d'innombrables attaques et l'une des techniques de défense les plus efficaces contre ces attaques est le chiffrement des données. Il protège également contre une autre menace, la modification des données en transit, comme le font certaines FAI (par exemple Orange Tunisie). Il y a de nombreuses campagnes de sensibilisation pour promouvoir le chiffrement (voir par exemple le RFC 7258), avec des bons résultats. Évidemment, ce chiffrement gène ceux qui voudraient espionner et modifier le trafic, et il fallait donc s'attendre à voir une réaction. Ce RFC est l'expression de cette réaction, du côté de certains opérateurs réseau, qui regrettent que le chiffrement empêche leurs mauvaises pratiques.
Dès le début, ce RFC était basé sur une hypocrisie : prétendre être purement descriptif (une liste de pratiques que certains opérateurs réseau utilisent, et qui sont impactées par le chiffrement), sans forcément en conclure que le chiffrement était mauvais. Mais, en réalité, le RFC porte un message souvent répété : le chiffrement gène, et il ne faudrait pas en abuser. On note par exemple que le RFC ne s'indigne pas de certaines des pratiques citées, alors que beaucoup sont scandaleuses. Le discours est « il faut trouver un équilibre entre la protection de la vie privée et la capacité des opérateurs à gérer leurs réseaux ». Une telle référence à l'équilibre m'a toujours énervé : non, il ne faut pas d'équilibre entre le bien et le mal, il faut faire ce qu'on peut pour gêner la surveillance. Certaines des pratiques citées dans le RFC sont mauvaises et tant mieux si le chiffrement les rend difficiles. Certaines autres sont plus neutres, mais devront quand même s'adapter, les révélations de Snowden ont largement montré que la surveillance de masse est un fait, et qu'elle justifie des mesures radicales de protection. (Notez que les premières versions de ce RFC étaient bien pires, et qu'il a été affadi par les discussions successives, et suite à l'opposition rencontrée.)
Hypocritement, les textes sacrés comme le RFC 1958, RFC 1984, RFC 2804, et bien sûr les RFC 7258 et RFC 7624 sont cités, hommage du vice à la vertu. Mais tout en le faisant, ce nouveau RFC 8404 déforme ces textes. Quand le RFC 7258 dit qu'évidemment, il faut que les opérateurs puissent continuer à gérer leurs réseaux, ce RFC 8404 lui fait dire qu'il faut donc limiter le chiffrement, comme si « gérer un réseau » voulait forcément dire « accéder aux communications ». De même, on trouve une référence au principe de bout en bout (RFC 2775, RFC 3724, RFC 7754), alors même que le reste de ce RFC ne fait que citer des pratiques violant ce principe.
Ce RFC 8404 se veut, on l'a dit, une description de pratiques actuelles, et prétend hypocritement « ne pas forcément soutenir toutes les pratiques présentées ici ». En effet, tous les exemples cités par la suite sont réellement utilisées mais pas forcément par tous les opérateurs. C'est une des choses les plus désagréables de ce RFC que de laisser entendre que tous les opérateurs seraient unanimes dans leur désir de lire les communications de leurs clients, voire de les modifier. (Par exemple en utilisant le terme tribal de community pour parler des opérateurs réseau, comme s'ils étaient un clan unique, d'accord sur l'essentiel.)
Il est exact qu'au début de l'Internet, rien ou presque n'était chiffré. Tout circulait en clair, en partie parce que la perte de performances semblait excessive, en partie parce que les États faisaient tout pour décourager le chiffrement et limiter son usage, en partie parce que la menace semblait lointaine (même les plus paranoïaques des experts en sécurité ne se doutaient pas que la surveillance atteignait les proportions révélées par Snowden.) Certains opérateurs ont alors pris de mauvaises habitudes, en examinant en détail les communications, à des fins plus ou moins innocentes. Les choses changent aujourd'hui, avec un déploiement plus important du chiffrement, et ces mauvaises pratiques doivent donc disparaitre, ce que les auteurs du RFC ont du mal à avaler.
Des premiers exemples de ces mauvaises pratiques sont données
en section 1.2. Par exemple, le RFC cite un rapport
de l'EFF montrant que certains opérateurs inséraient des
données dans les flux SMTP, notamment à des
fins de suivi des utilisateurs, et, pour empêcher ces flux d'être
protégés par TLS, retiraient la commande
STARTTLS de la négociation (ce qu'on nomme le
SSL stripping, cf. RFC 7525, section 3.2). Le RFC ose même dire que pour
certains, c'était « considéré comme une attaque » comme si cela
n'était pas évident que c'est une attaque ! Notant que le
chiffrement systématique empêcherait cette attaque, le RFC demande
qu'on fournisse à ces opérateurs réseau malhonnêtes une
alternative à leurs pratiques de piratage des sessions !
Un autre exemple donné est celui des réseaux d'entreprise où il y a, dit le RFC, un « accord » pour que le contenu du trafic des employés soit surveillé par le patron (dans la réalité, il n'y a pas d'accord, cette surveillance est une condition de l'embauche). Ce serait donc un cas radicalement différent de celui des réseaux publics, via le FAI, où il n'y a pas de tel « accord » et, pourtant, déplore le RFC, le chiffrement rend cette surveillance plus difficile. (Ce point particulier a fait l'objet de nombreux débats lors de la mise au point de la version 1.3 du protocole TLS, qui visait en effet à rendre la surveillance plus difficile. Cf. RFC 8446.)
À partir de la section 2, commence le gros du RFC, les études de cas. Le RFC est très détaillé et je ne vais pas tout mentionner ici. Notons que la section 2 commence par du chantage : si on ne donne pas accès aux opérateurs au contenu des communications, ils « vont déployer des méthodes regrettables du point de vue de la sécurité », et il faut donc leur donner les données, pour éviter qu'ils n'utilisent des moyens encore pires.
D'abord, ce sont les chercheurs qui effectuent des mesures sur l'Internet (par exemple CAIDA) qui sont mentionnés pour expliquer que le chiffrement va rendre ces études bien plus difficiles. (Au passage, puisque le RFC ne le dit pas, signalons que la science ne justifie pas tout et que ces études doivent se conformer à l'éthique, comme tout le monde.) Le RFC oublie de dire que beaucoup de ces études n'utilisent que l'en-tête IP, et parfois les en-têtes TCP et UDP, qui ne sont pas affectés par le chiffrement. Comme cette réthorique est souvent présente dans ce RFC, cela vaut la peine de préciser : les techniques de chiffrement les plus déployées aujourd'hui (TLS et, loin derrière, SSH) laissent intacts les en-têtes IP et TCP, que les chercheurs peuvent donc regarder comme avant. IPsec, lui, masque l'en-tête TCP (et, dans certains cas, une partie de l'information venue de l'en-tête IP), mais il est très peu utilisé dans l'Internet public (à part une partie de l'accès au VPN de l'entreprise). QUIC, s'il sera un jour déployé massivement, dissimulera également une partie de l'information de couche 4. Bref, aujourd'hui, la partie en clair du trafic donne déjà plein d'information.
Après les chercheurs, le RFC cite les opérateurs qui regardent en détail un flux réseau pour déboguer des problèmes applicatifs. Là encore, l'exemple est très malhonnête :
- Comme indiqué ci-dessus, la partie non chiffrée du paquet reste accessible. Si on veut déboguer des problèmes TCP subtils, du genre la fenêtre qui ne s'ouvre pas assez, même si TLS est utilisé, l'information TCP complète reste disponible, avec la taille de la fenêtre, les numéros de séquence et tout le toutim.
- Mais, surtout, quel opérateur réseau débogue ainsi les problèmes applicatifs de ces clients ? Vous croyez vraiment que M. Michu, client d'un FAI grand public, va pouvoir solliciter l'aide d'un expert qui va lancer Wireshark pour résoudre les problèmes WebRTC de M. Michu ? (C'est l'exemple donné par le RFC : « ma vidéo haute définition est hachée ». S'il existe un FAI dont le support accepte de traiter ce genre de problèmes, je veux bien son nom.)
- Dans des discussions privées, on m'a parfois dit qu'il ne s'agissait pas de FAI grand public, qui ne passeront en effet jamais du temps sur ces problèmes, mais d'opérateurs ayant une clientèle de grandes entreprises, pour lesquelles ils jouent un rôle de conseil et d'assistance sur les problèmes réseaux. Mais, si le client est volontaire, et veut vraiment qu'on l'aide, rien ne l'empêche de couper le chiffrement ou de demander aux applications d'afficher de l'information de débogage détaillée.
Le RFC ne mentionne pas assez que le développement du chiffrement est en bonne partie le résultat des pratiques déplorables de certains opérateurs. Si on fait tout passer sur le port 443 (celui de HTTPS), et en chiffré, c'est précisément parce que des opérateurs se permettaient, en violation du principe de neutralité, de traiter différemment les applications, se fiant au port TCP utilisé pour reconnaitre les différentes applications. Refusant de comprendre ce problème, le RFC déplore au contraire que « tout le monde étant sur le port 443, on ne peut plus détecter certains applications afin de les prioriser », et affirme que cela justifie le DPI. Pas un seul questionnement sur la légitimité de ce traitement différencié. (Notez également un truc réthorique très malhonnête : parler de prioriser certaines applications. Comme la capacité du réseau est finie, si on en priorise certaines applications, on en ralentit forcément d'autres. Mais c'est plus vendeur de dire qu'on priorise que d'admettre qu'on discrimine.) Pour éviter de dire ouvertement qu'on viole la neutralité du réseau, le RFC la redéfinit en disant qu'il n'y a pas violation de la neutralité si on différencie entre applications, seulement si on différencie entre utilisateurs.
Il n'y a évidemment pas que les opérateurs réseau qui sont responsables de la surveillance et de l'interférence avec les communications. La section 2.4 du RFC rappelle à juste titre que les opérateurs travaillent dans un certain cadre légal et que l'État les oblige souvent à espionner (ce qui s'appelle en novlangue « interception légale ») et à censurer. Par exemple, en France, les opérateurs sont censés empêcher l'accès aux sites Web présents sur la liste noire (secrète) du ministère de l'intérieur. Le chiffrement rend évidemment plus difficile ces activités (c'est bien son but !) Le RFC note par exemple que le filtrage par DNS menteur, la technique de censure la plus commune en Europe, est plus difficile si on utilise le chiffrement du RFC 7858 pour parler à un résolveur DNS externe, et traite cela comme si c'était un problème, alors que c'est au contraire le résultat attendu (s'il n'y avait pas de surveillance, et pas d'interférence avec le trafic réseau, le chiffrement serait inutile).
Mais le RFC mélange tout par la suite, en citant comme exemple de filtrage légitime le contrôle parental. Il n'y a nul besoin qu'il soit fait par le FAI, puisqu'il est souhaité par le client, il peut être fait sur les machines terminales, ou dans le routeur de la maison. C'est par exemple ce qui est fait par les bloqueurs de publicité, qui ne sont pas une violation de la neutralité du réseau puisqu'ils ne sont pas dans le réseau, mais sur la machine de l'utilisateur, contrôlée par elle ou lui.
Un autre exemple où le RFC déplore que le chiffrement empêche une pratique considérée par l'opérateur comme utile est celui du zero rating, cette pratique où l'accès à certains services fait l'objet d'une tarification réduite ou nulle. Le chiffrement, note le RFC, peut servir à dissimuler les services auxquels on accède. Là encore, on peut se demander si c'est vraiment un problème : le zero rating est également une violation de la neutralité du réseau, et ce n'est pas forcément mauvais qu'il devienne plus difficile à déployer.
Mais l'exemple suivant est bien pire, et beaucoup plus net. La section 2.3.4 du RFC décrit la pratique de modification des flux HTTP, notamment l'insertion d'en-têtes. Plusieurs vendeurs de matériel fournissent des équipements permettant d'« enrichir » les en-têtes, en ajoutant des informations personnelles, comme le numéro de téléphone, permettant un meilleur ciblage par les publicitaires. Et ils n'en ont même pas honte, annonçant cyniquement cette capacité dans leurs brochures. Et le RFC décrit cette pratique en termes neutres, sans préciser qu'elle est mauvaise, devrait être interdite, et que le chiffrement permet heureusement de la rendre plus difficile ! La soi-disant neutralité de la description mène donc à décrire des pratiques scandaleuses au même niveau que l'activité normale d'un opérateur réseaux. Le RFC cite bien le RFC 8165, qui condamne cette pratique, mais n'en tire pas les conséquences, demandant, là encore, qu'on fournisse aux opérateurs malhonnêtes un moyen de continuer ces opérations (par exemple par une insertion des données personnelles directement par le logiciel sur la machine du client, ce qui est possible dans le monde du mobile, beaucoup plus fermé et contrôlé), et ce malgré le chiffrement.
La section 3.1.2 du RFC revient sur les buts de la surveillance, lorsqu'on gère un réseau. Elle mentionne plusieurs de ces buts, par exemple :
- Détection de logiciel malveillant. À noter que lui, de toute façon, ne va pas se laisser arrêter par une interdiction du chiffrement.
- Conformité avec des règles imposant la surveillance, qui existent par exemple dans le secteur bancaire. On pourrait garder le chiffrement de bout en bout tout en respectant ces règles, si chaque application enregistrait toutes ses communications. C'est évidemment la bonne solution technique (section 3.2.1 du RFC) mais, à l'heure actuelle, beaucoup de ces applications sont fermées, n'enregistrent pas, et ne permettent pas de traçabilité. (Notons aussi que des normes comme PCI imposent la traçabilité, mais n'imposent pas d'utiliser du logiciel libre, ce qui est assez incohérent. La quadrature du cercle - sécuriser les communications contre l'écoute, tout en permettant l'audit - n'est soluble qu'avec des applications qu'on peut examiner, et qui enregistrent ce qu'elles font.)
- Opposition à la fuite de données. La « sécurité » souvent mentionnée est en fait un terme vague recouvrant beaucoup de choses. La sécurité de qui et de quoi, faut-il se demander. Ici, il est clair que le patronat et l'État voudraient rendre plus difficile le travail de lanceurs d'alerte, par exemple WikiLeaks. En France, une loi sur « le secret des affaires » fournit aux entreprises qui veulent dissimuler leurs mauvaises actions une défense juridique contre la vérité. La limitation du chiffrement vise à ajouter une défense technique, pour empêcher le ou la lanceur d'alerte d'envoyer des informations discrètement au Canard enchaîné.
La section 3.2 du RFC mentionne d'autres exemples d'usages actuels que le chiffrement massif peut gêner. Par exemple, elle cite la lutte contre le spam en notant que le chiffrement du courrier (par exemple avec PGP ou DarkMail) empêche un intermémdiaire (comme le serveur de messagerie) de lutter contre le spam. (La bonne solution est évidemment de faire l'analyse du spam sur la machine finale, par exemple avec bogofilter.)
Les révélations de Snowden ont montré que l'espionnage des liaisons internes aux organisations était une pratique courante de la NSA. Pendant longtemps, beaucoup d'administrateurs réseau ont considéré que « pas besoin d'utiliser HTTPS, c'est un site Web purement interne ». C'était une grosse erreur technique (l'attaquant est souvent interne, et les attaques contre le DNS ou le routage peuvent donner accès aux communications censées être internes) et elle a donc logiquement été exploitée. Aujourd'hui, les organisations sérieuses chiffrent systématiquement, même en interne.
Mais en même temps, beaucoup d'entreprises ont en interne des règles qui autorisent la surveillance de toutes les communications des employés. (En France, il existe des limites à cette surveillance, mais pas aux États-Unis. Le RFC rappelle juste que certaines politiques définies par le patron autorisent des accès protégés contre la surveillance, par exemple pour se connecter à sa banque. Écrit avec un point de vue très états-unien, le RFC ne mentionne que les politiques de la direction, pas les limites légales.) Techniquement, cela passe, par exemple, par des relais qui terminent la session TLS, examinent le contenu de la communication, puis démarrent une nouvelle session avec le serveur visé. Cela permet par exemple de détecter le logiciel malveillant que la machine Windows télécharge via une page Web piégée. Ou bien une attaque XSS que l'utilisateur n'a pas vue. (Notez que, par une incohérence fréquente en entreprise, la sécurité est présentée comme absolument essentielle, mais les postes de travail tournent sur Windows, certainement la cible la plus fréquente de ces logiciels malveillants.) Mais cela permet aussi de surveiller les communications des employés.
Si le but est de se protéger contre le logiciel malveillant, une solution simple est de faire l'examen des messages suspects sur la machine terminale. Cela peut être plus compliqué à déployer mais, normalement, c'est faisable à la fois juridiquement puisque cette machine appartient à l'entreprise, et techniquement puisqu'elle est a priori gérée à distance.
La section 5 du RFC détaille certaines techniques de surveillance pour des systèmes particuliers. Par exemple, les fournisseurs de messagerie examinent les messages, notamment pour déterminer s'il s'agit de spam. SMTP sur TLS ne gêne pas cette technique puisqu'il est de serveur à serveur, pas de bout en bout. Même PGP ou S/MIME n'empêchent pas l'examen des métadonnées, qui peuvent être suffisante pour détecter le spam.
De même (section 6 du RFC), TLS ne masque pas tout et permet quand même certaines activités de surveillance. Ainsi, le nom du serveur contacté, indiqué dans l'extension TLS SNI (Server Name Indication, section 3 du RFC 6066) n'est pas chiffré et peut donc être vu. (Des efforts sont en cours actuellement à l'IETF pour boucher cette faille dans la protection de la vie privée, et semblent bien avancer.)
En résumé, ce RFC, qui a commencé comme très « anti-chiffrement » a été un peu modifié lors des très vives discussions qu'il a généré à l'IETF, et essaie désormais de ménager la chèvre et le chou. La tonalité demeure quand même hostile au chiffrement sérieux, mais on y trouve suffisamment d'éléments techniques précis pour que tout le monde puisse y trouver une lecture intéressante.
L'article seul
RFC 8399: Internationalization Updates to RFC 5280
Date de publication du RFC : Mai 2018
Auteur(s) du RFC : R. Housley (Vigil Security)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lamps
Première rédaction de cet article le 30 juillet 2018
Ce court RFC ajoute aux certificats PKIX du RFC 5280 la possibilité de contenir des adresses de courrier électronique dont la partie locale est en Unicode. Et il modifie légèrement les règles pour les noms de domaine en Unicode dans les certificats. Il a par la suite été remplacé par le RFC 9549.
Les certificats sur
l'Internet sont normalisés dans le RFC 5280, qui décrit un profil de
X.509 nommé PKIX
(définir un profil était nécessaire car la norme X.509 est bien
trop riche et complexe). Ce RFC 5280
permettait des noms de domaine en
Unicode (sections 4.2.1.10 et 7 du RFC 5280) mais il suivait l'ancienne norme
IDN, celle des RFC 3490 et suivants. Depuis, les IDN sont normalisés dans
le RFC 5890 et suivants, et notre nouveau
RFC 8399 modifie très légèrement le RFC 5280 pour s'adapter à cette nouvelle norme de noms de
domaines en Unicode. Les noms de domaine dans un
certificat peuvent être présents dans les champs Sujet (titulaire
du certificat) et
Émetteur (AC ayant signé le certificat) mais aussi dans les contraintes sur le nom (une
autorité de certification peut être
limitée à des noms se terminant en
example.com, par exemple).
Notez que, comme avant, ces noms sont
exprimés dans le certificat en Punycode
(RFC 3492, xn--caf-dma.fr au lieu de
café.fr). C'est un bon exemple du fait que
les limites qui rendaient difficiles d'utiliser des noms de
domaine en Unicode n'avaient rien à voir avec le DNS
(qui n'a jamais
été limité à ASCII, contrairement à ce qu'affirme une
légende courante). En fait, le problème venait des applications
(comme PKIX), qui ne s'attendaient pas à
des noms en Unicode. Un logiciel qui traite des certificats
aurait été bien étonné de voir des noms de domaines
non-ASCII, et aurait peut-être
planté. D'où ce choix du Punycode.
Nouveauté plus importante de notre RFC 8399, les adresses de courrier électronique en Unicode (EAI pour Email Address Internationalization). Elles étaient déjà permises par la section 7.5 du RFC 5280, mais seulement pour la partie domaine (à droite du @). Désormais, elles sont également possibles dans la partie locale (à gauche du @). Le RFC 8398 donne tous les détails sur ce sujet.
Reste à savoir quelles AC vont accepter
Unicode. J'ai testé avec Let's
encrypt (avec le client Dehydrated, en mettant le
Punycode dans domains.txt) et ça marche, regardez le certificat de
https://www.potamochère.fr/
% gnutls-cli www.potamochère.fr
...
- subject `CN=www.xn--potamochre-66a.fr', issuer `CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US', serial 0x03ed9617bb88bab3ad5b236675d1dd6e5d27, ...
D'autres AC acceptent ces noms en Unicode :
Gandi le fait aussi, regardez le certificat
de https://réussir-en.fr
Enfin, le registre du
.ru a participé au
développement
de logiciels pour traiter l'Unicode dans les certificats.
L'article seul
RFC 8387: Practical Considerations and Implementation Experiences in Securing Smart Object Networks
Date de publication du RFC : Mai 2018
Auteur(s) du RFC : M. Sethi, J. Arkko, A. Keranen (Ericsson), H. Back (Nokia)
Pour information
Réalisé dans le cadre du groupe de travail IETF lwig
Première rédaction de cet article le 2 janvier 2019
On le sait, la sécurité de l'Internet des Objets est absolument catastrophique. Les objets vendus au grand public, par exemple, non seulement envoient toutes vos données personnelles quelque part chez le vendeur de l'objet, mais en outre permettent en général facilement à des tiers de copier ces données. Ce RFC décrit les défis que pose la sécurisation de réseaux d'objets connectés, spécialement pour ceux qui disposent de ressources (comme l'électricité) limitées.
Le problème n'est pas purement technique : si les innombrables objets connectés que vous avez reçus comme cadeau de Noël cette année ont une sécurité abyssalement basse, c'est parce que les vendeurs sont totalement incompétents, et qu'ils ne font aucun effort pour apprendre. Cela n'a la plupart du temps rien à voir avec le manque de ressources (processeur, électricité) de l'objet. Les télévisions connectées ou voitures connectées n'ont pas une meilleure sécurité, alors qu'elles disposent de bien plus de ressources qu'un Raspberry Pi 1, qui peut pourtant faire du SSH ou TLS sans problème. Mais les vendeurs agissent dans une impunité totale, et ne sont donc pas motivés pour améliorer les choses. Aucun vendeur d'objets connectés n'a jamais eu à subir les conséquences (légales ou commerciales) d'une faille de sécurité. Les objets à la sécurité pourrie se vendent aussi bien que les autres. Et la loi ne protège pas le client. Les mêmes qui s'indignent contre la vente de bitcoins à des particuliers sans expérience financière ne protestent jamais contre la vente d'objets espions facilement piratables.
Mais comme la plupart des RFC, ce document se focalise sur l'aspect technique du problème, et suggère des solutions techniques. Je suis pessimiste quant aux chances de déploiement de ces solutions, en raison de l'absence de motivations (cf. ci-dessus). Mais il est vrai que ce RFC vise plutôt les objets utilisés en milieu industriel que ceux destinés au grand public.
D'abord, les défis auxquels font face les objets connectés (section 3 du RFC). D'abord, il y a le fait que, dans certains objets, les ressources sont limitées : le processeur est très lent, la mémoire est réduite, et la batterie n'a pas des réserves infinies. On a vu que ces ressources limitées sont parfois utilisées comme excuses pour ne pas mettre en œuvre certaines techniques de sécurité (une télévision connectée qui utilise HTTP et pas HTTPS avec l'argument que la cryptographie est trop coûteuse !) Mais, pour certaines catégories d'objets, l'argument est réel : un capteur industriel peut effectivement ne pas avoir autant de ressources que l'expert en sécurité le souhaiterait. Certains objets sont vendus à des prix individuels très bas et doivent donc être fabriqués à faible coût. Conséquences : il faut utiliser CoAP et non pas HTTP, les clés cryptographiques ne peuvent pas être trop longues, l'engin ne peut pas être allumé en permanence et n'est donc pas forcément joignable, son interface utilisateur très réduite ne permet pas de définir un mot de passe, etc.
Outre le fait que ces ressouces limitées sont souvent un faux prétexte pour justifier la paresse des vendeurs, le RFC note que le développement de ces objets se fait souvent dans le mauvais ordre : on conçoit le matériel puis, bien après, on cherche les solutions de sécurité qui arriveraient à tourner sur ce matériel. Pour sortir de l'état catastrophique de la sécurité des objets connectés, il faudrait procéder en sens inverse, et intégrer la sécurité dès le début, concevant le matériel en fonction des exigences de sécurité.
Deuxième défi pour le concepteur d'un objet connecté, l'avitaillement (provisioning). Comment mettre dans l'objet connectés les informations nécessaires, mots de passe, clés et autres données ? Par exemple, si une technique de sécurité utilise un mot de passe, mettre le même dans chaque objet lors de sa fabrication est facile, mais évidemment très mauvais pour la sécurité. Mais demander à M. Michu, qui a acheté un gadget connecté, de rentrer un mot de passe avec une interface à deux boutons et un minuscule écran n'est pas évident. Et si une entreprise a acheté une centaine de capteurs, faut-il une intervention manuelle sur chacun, pour mettre le mot de passe ? Le RFC considère que c'est sans doute le principal défi pour la sécurité des objets connectés. Le problème est difficile à résoudre car :
- L'interface utilisateur des objets connectés est minimale, voire inexistante.
- Les utilisateurs typiques ne sont pas compétents en ce domaine, et la plupart du temps ne sont même pas conscients du fait qu'ils ont désormais une responsabilité d'administrateur système. C'est d'ailleurs une des raisons pour lesquelles le terme d'« objet » est dangereux : il empêche de percevoir cette responsabilité. Ces engins sont des ordinateurs, avec les risques associés, et devraient être traités comme tels.
- Ces objets sont souvent livrés en très grande quantité ; toute solution d'avitaillement doit passer à l'échelle.
Résultat, les objets connectés sont souvent vendus avec des informations statiques, et une identité stable, qui facilite certes des aspects de l'administration du réseau, comme le suivi d'un objet donné, mais met sérieusement en danger la sécurité.
En outre, troisième défi, chaque objet ayant souvent des capacités limitées, la communication est fréquemment relayée par des passerelles. Même lorsque l'objet a une visibilité directe, il faut souvent passer par une passerelle car l'objet peut passer la majorité de son temps endormi, donc injoignable, afin d'économiser l'électricité. Les modèles traditionnels de sécurité, fondés sur le principe de bout en bout, ne fonctionnent pas bien dans ce contexte.
Pour affronter ces défis, notamment celui de l'avitaillement, la section 4 de notre RFC décrit un modèle de déploiement, où les identités des objets sont dérivées de clés cryptographiques, auto-générées sur chaque objet, comme les CGA du RFC 3972 ou les HIT du RFC 7401. Dans ce modèle, chaque objet génère une paire de clés. L'opération de génération de l'identité consiste typiquement à appliquer une fonction de condensation cryptographique à la concaténation d'une clé publique de l'engin et d'une information locale. Une fois qu'on connait l'identité d'une machine, on peut communiquer avec elle de manière sûre, puisqu'elle peut signer ses messages avec sa clé privée, qui n'est jamais communiquée.
Avec ce modèle, il n'y a plus de mots de passe définis en usine et identiques sur toutes les machines. Mais cela impose, au moment du déploiement, de récolter ces identités (par exemple via un code QR affiché par l'objet, ou bien via NFC) pour les enregistrer dans la base de données qui sera utilisée par le, la ou les administrateurs du réseau. Ce mécanisme permettra d'authentifier les objets, mais pas aux objets d'authentifier un éventuel partenaire, par exemple celui qui leur envoie des ordres. Pour cela, il faudra en autre indiquer la clé publique de ce partenaire au moment de l'installation, ce qui nécessitera un mécanisme de communication, par exemple via le port USB. On ne pourra pas sortir les objets du carton et aller les poser sur le terrain sans autre formalité. Mais la sécurité est à ce prix.
Ces identités stables posent potentiellement un problème de vie privée. Il faut donc prévoir leur renouvellement, soit périodiquement, soit lorsque l'objet change de propriétaire. Un bouton ou autre mécanisme « oublie tout et crée une nouvelle identité » est donc nécessaire.
Une fois qu'on a ces identités, on peut les utiliser de plusieurs façons, de bout en bout ou bien via des intermédiaires. Plusieurs architectures et protocoles sont possibles. Ce serait par exemple le cas de HIP. Mais les auteurs du RFC privilégient une solution qui se situerait au niveau des applications, bâtie sur CoAP (RFC 7252) car cela permettrait :
- aux machines intermédiaires de servir de caches pour les objets qui dorment,
- à ces mêmes machines d'effectuer des tâches de filtrage ou d'agrégation sans remettre en cause la sécurité,
- à cette solution de fonctionner même en présence de ces middleboxes qui empêchent souvent tout déploiement d'une solution dans les couches plus basses.
S'agit-il d'une idée en l'air, d'un vague projet ? Non, les auteurs du RFC ont déjà identifié plusieurs bibliothèques logicielles qui peuvent permettre de mettre en œuvre ces idées en fournissant des opérations cryptographiques nécessaires à cette architecture, même à des machines peu gonflées :
- AvrCryptolib, pour AVR,
- Relic, portable, car écrit en C (d'autres bibliothèques utilisent totalement ou partiellement le langage d'assemblage), inclut RSA et Curve25519,
- TinyECC, écrit en nesC pour TinyOS,
- Wiselib en C++, et qui a été testé avec succès sur Arduino Uno,
- MatrixSSL (rebaptisé depuis « TLS Toolkit »), conçu pour des objets mieux dotés (processeur de 32 bits).
Certains systèmes d'exploitation sont spécialement conçus pour des objets contraints, et disposent des bibliothèques nécessaires. C'est le cas par exemple de mbed, qui tourne sur plusieurs membres de la famille ARM Cortex.
Ce n'est pas tout d'avoir du code, encore faut-il qu'il tourne de manière efficace. La section 6 de notre RFC est dédiée aux tests de performance, notamment lors des opérations de signature. C'est ainsi que RSA avec une clé de 2 048 bits et le code d'AvrCryptolib prend vraiment trop de temps (sur une machine apparemment non spécifiée) pour être utilisable.
ECDSA avec TinyECC sur un Arduino Uno tourne par contre en un temps supportable. Sans utiliser le code en langage d'assemblage qui est disponible dans cette bibliothèque, la consommation de RAM reste la même mais le temps d'exécution augmente de 50 à 80 %. D'autres mesures figurent dans cette section, avec diverses bibliothèques, et divers algorithmes. La conclusion est la même : la cryptographie asymétrique, sur laquelle repose l'architecture de sécurité proposée dans notre RFC est réaliste sur des objets très contraints mais probablement uniquement avec les courbes elliptiques. Les courbes recommandées sont celles du RFC 7748, bien plus rapides que celles du NIST (tests avec la bibliothèque NaCl).
Les problèmes concrets ne s'arrêtent pas là. Il faut aussi voir que certains objets contraints, comme l'Arduino Uno, n'ont pas de générateur aléatoire matériel. (Contrairement à, par exemple, le Nordic nRF52832.) Ces engins n'ayant pas non plus d'autres sources d'entropie, générer des nombres aléatoires de qualité (RFC 4086), préliminaire indispensable à la création des clés, est un défi.
La section 7 du RFC décrit une application développée pour illustrer les principes de ce RFC. Il s'agit de piloter des capteurs qui sont éteints pendant l'essentiel du temps, afin d'économiser leur batterie, et qui se réveillent parfois pour effectuer une mesure et en transmettre le résultat. Des machines sont affectées à la gestion de la communication avec les capteurs et peuvent, par exemple, conserver un message lorsque le capteur est endormi, le distribuant au capteur lorsqu'il se réveille. Plus précisément, il y avait quatre types d'entités :
- Les capteurs, des Arduino Mega (un processeur de seulement 8 bits) utilisant Relic, soit 29 ko dans la mémoire flash pour Relic et 3 pour le client CoAP,
- Le courtier, qui est allumé en permanence, et gère la communication avec les capteurs, selon un modèle publication/abonnement,
- L'annuaire, où capteurs et courtier peuvent enregistrer des ressources et les chercher,
- L'application proprement dite, tournant sur un ordinateur généraliste avec Linux, et communiquant avec l'annuaire et avec les courtiers.
Le modèle de sécurité est TOFU ; au premier démarrage, les capteurs génèrent les clés, et les enregistrent dans l'annuaire, suivant le format du RFC 6690. (L'adresse IP de l'annuaire est codée en dur dans les capteurs, évitant le recours au DNS.) Le premier enregistrement est supposé être le bon. Ensuite, chaque fois qu'un capteur fait une mesure, il l'envoie au courtier en JSON signé en ECDSA avec JOSE (RFC 7515). Il peut aussi utiliser CBOR avec COSE (RFC 8152). La signature peut alors être vérifiée. On voit qu'il n'y a pas besoin que la machine de vérification (typiquement celle qui porte l'application) soit allumée en même temps que le capteur. Ce prototype a bien marché. Cela montre comment on peut faire de la sécurité de bout en bout bien qu'il y ait au moins un intermédiaire (le courtier).
La question de la faisabilité de l'architecture décrite dans ce RFC est discutée plus en détail dans la section 8.1. On entend souvent que les objets connectés n'ont pas de vraie sécurité car « la cryptographie, et surtout la cryptographie asymétrique, sont bien trop lentes sur ces objets contraints ». Les expériences faites ne donnent pas forcément un résultat évident. La cryptographie asymétrique est possible, mais n'est clairement pas gratuite. RSA avec des clés de tailles raisonnables pourrait mettre plusieurs minutes à signer, ce qui n'est pas tolérable. Heureusement, ce n'est pas le seul algorithme. (Rappelons que cela ne s'applique qu'aux objets contraints. Il n'y a aucune bonne raison de ne pas utiliser la cryptographie pour des objets comme une télévision ou une caméra de surveillance.) La loi de Moore joue ici en notre faveur : les microcontrôleurs de 32 bits deviennent aussi abordables que ceux de 8 bits.
Quant aux exigences d'énergie électrique, il faut noter que le plus gourmand, et de loin, est la radio (cf. Margi, C., Oliveira, B., Sousa, G., Simplicio, M., Paulo, S., Carvalho, T., Naslund, M., et R. Gold, « Impact of Operating Systems on Wireless Sensor Networks (Security) Applications and Testbeds », à WiMAN en 2010). Signer et chiffrer, ce n'est rien, par rapport à transmettre.
L'ingénierie, c'est toujours faire des compromis, particulièrement quand on travaille avec des systèmes aussi contraints en ressources. La section 8 du RFC détaille certains de ces compromis, expliquant les choix à faire. Ainsi, la question de la fraîcheur des informations est délicate. Quand on lit le résultat d'une mesure sur le courtier, est-on bien informé sur l'ancienneté de cette mesure ? Le capteur n'a en général pas d'horloge digne de ce nom et ne peut pas se permettre d'utiliser NTP. On peut donc être amené à sacrifier la résolution de la mesure du temps aux contraintes pratiques.
Une question aussi ancienne que le modèle en couches est celle de la couche où placer la sécurité. Idéalement, elle devrait être dans une seule couche, pour limiter le code et le temps d'exécution sur les objets contraints. En pratique, elle va sans doute se retrouver sur plusieurs couches :
- Couche 2 : c'est la solution la plus courante aujourd'hui (pensez à une carte SIM et aux secrets qu'elle stocke). Mais cela ne sécurise que le premier canal de communications, ce n'est pas une sécurité de bout en bout. Peu importe que la communication de l'objet avec la base 4G soit signée et chiffrée si le reste du chemin est non authentifié, et en clair !
- Couche 3 : c'est ce que fait IPsec, solution peu déployée en pratique. Cette fois, c'est de bout en bout mais il est fréquent qu'un stupide intermédiaire bloque les communications ainsi sécurisées. Et les systèmes d'exploitation ne fournissent en général pas de moyen pratique permettant aux applications de contrôler cette sécurité, ou même simplement d'en être informé.
- Couche 4 ou Couche 7 : c'est l'autre solution populaire, une grande partie de la sécurité de l'Internet repose sur TLS, par exemple. (Ou, pour les objets contraints, DTLS.) C'est évidemment la solution la plus simple à contrôler depuis l'application. Par contre, elle ne protège pas contre les attaques dans les couches plus basses (un paquet TCP RST malveillant ne sera pas gêné par TLS) mais ce n'est peut-être pas un gros problème, cela fait juste un déni de service, qu'un attaquant pourrait de toute façon faire par d'autres moyens.
- On peut aussi envisager de protéger les données et pas la communication, en signant les données. Cela marche même en présence d'intermédiaires divers mais cette solution est encore peu déployée en ce moment, par rapport à la protection de la couche 2 ou de la couche 7.
Enfin, dernière étude sur les compromis à faire, le choix entre la cryptographie symétrique et la cryptographie asymétrique, bien plus gérable en matière de distribution des clés, mais plus consommatrice de ressources. On peut faire de la cryptographie symétrique à grande échelle mais, pour la cryptographie asymétrique, il n'y a pas encore de déploiements sur, disons, des centaines de millions d'objets. On a vu que dans certains cas, la cryptographie asymétrique coûte cher. Néanmoins, les processeurs progressent et, question consommation énergétique, la cryptographie reste loin derrière la radio. Enfin, les schémas de cryptographie des objets connectés n'utiliseront probablement la cryptographie asymétrique que pour s'authentifier au début, utilisant ensuite la cryptographie symétrique pour l'essentiel de la communication.
Enfin, la section 9 de notre RFC résume les points importants :
- Il faut d'abord établir les exigences de sécurité puis seulement après choisir le matériel en fonction de ces exigences,
- La cryptographie à courbes elliptiques est recommandée,
- La qualité du générateur de nombres aléatoires, comme toujours en cryptographie, est cruciale pour la sécurité,
- Si on commence un projet aujourd'hui, il vaut mieux partir directement sur des microcontrôleurs de 32 bits,
- Il faut permettre la génération de nouvelles identités, par exemple pour le cas où l'objet change de propriétaire,
- Et il faut prévoir les mises à jour futures (un objet peut rester en service des années) par exemple en terme de place sur la mémoire flash (le nouveau code sera plus gros).
La section 2 de notre RFC décrit les autres travaux menés en matière de sécurité, en dehors de ce RFC. Ainsi, la spécification du protocole CoAP, le « HTTP du pauvre objet » (RFC 7252) décrit comment utiliser CoAP avec DTLS ou IPsec. Cette question de la sécurité des objets connectés a fait l'objet d'un atelier de l'IAB en 2011, atelier dont le compte-rendu a été publié dans le RFC 6574.
L'article seul
RFC 8386: Privacy Considerations for Protocols Relying on IP Broadcast or Multicast
Date de publication du RFC : Mai 2018
Auteur(s) du RFC : R. Winter (University of Applied Sciences
Augsburg), M. Faath (Conntac
GmbH), F. Weisshaar (University of Applied Sciences
Augsburg)
Pour information
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 29 novembre 2018
Plusieurs protocoles applicatifs utilisent la diffusion, par exemple pour la découverte d'un service, et envoient donc des messages qui vont toucher toutes les machines du réseau local. Cela a des conséquences pour la vie privée : un observateur, même purement passif, peut apprendre plein de choses en écoutant. Il est donc important lorsqu'on conçoit des protocoles applicatifs de veiller à ne pas être trop bavard.
La diffusion, c'est envoyer à tout le monde. Comme il n'existe pas (heureusement !) de mécanisme fiable pour envoyer à tout l'Internet, en pratique, la diffusion se limite au réseau local. Mais c'est déjà beaucoup ! Connecté dans un café ou dans un autre endroit à WiFi, les messages diffusés arrivent à un groupe inconnu : un nombre potentiellement grand de machines. (L'utilisation d'un commutateur ne protège pas, si c'est de la diffusion.) La diffusion est très importante pour certaines fonctions (auto-configuration lorsqu'on ne connait pas sa propre adresse IP, ou bien résolution locale de noms ou d'adresses). La diffusion est tellement pratique (cf. RFC 919 et RFC 3819) qu'elle est utilisée par beaucoup d'applications.
Mais la diffusion est dangereuse ; à la conférence TRAC 2016, les auteurs du RFC avaient, dans un excellent exposé, publié un premier résultat de leurs travaux sur la question (Faath, M., Weisshaar, F., et R. Winter, How Broadcast Data Reveals Your Identity and Social Graph, 7th International Workshop on TRaffic Analysis and Characterization IEEE TRAC 2016, September 2016). En une journée à écouter le trafic diffusé sur leur université, ils avaient récolté 215 Mo de données. Les protocoles les plus bavards : 1) mDNS 2) SSDP 3) LLMNR 4) NetBIOS 5) Dropbox. Le seul client Dropbox diffuse à la cantonade l'ID du client, et celui des shares où il se connecte. Il est facile de faire un graphe des utilisateurs en mettant ensemble ceux qui se connectent au même share. Les mêmes auteurs avaient mené une expérience à grande échelle en écoutant le trafic diffusé lors de la réunion IETF 93 à Prague, et cela avait suscité bien des débats, notamment juridico-légaux (a-t-on le droit d'écouter du trafic qui est diffusé à tous ?) Comme en médecine, la science ne justifie pas tout et il est nécessaire de se pencher sur les conséquences de ses expériences.
Bien sûr, du moment qu'on envoie des données sur un réseau, elles peuvent être écoutées par des indiscrets. Mais la diffusion aggrave le problème de deux façons :
- Un éventuel indiscret n'a même pas besoin de techniques particulières pour écouter, il lui suffit d'ouvrir ses oreilles,
- La solution évidente à l'écoute, le chiffrement, marche mal avec la diffusion : il n'est pas facile de chiffrer lorsqu'on ne connait pas les destinataires.
Il est donc justifié de se préoccuper de près des conséquences de la diffusion sur la confidentialité (RFC 6973).
Pour certains protocoles conçus à l'IETF, il y a déjà eu des réflexions sur les problèmes de vie privée liés à leur usage de la diffusion. C'est évidemment le cas pour DHCP, dont les RFC 7819 et RFC 7824 ont pointé la grande indiscrétion. C'est aussi le cas des mécanismes de génération des adresses IPv6, expliqué dans le RFC 7721. Mais il y a également beaucoup de protocoles non-IETF qui utilisent imprudemment la diffusion, comme celui de Dropbox, présenté à la conférence TRAC. Ces protocoles privés sont en général peu étudiés, et la préservation de la vie privée est située très bas sur l'échelle des préoccupations de leurs auteurs. Et ils sont souvent non documentés, ce qui rend difficile toute analyse.
La section 1.1 de notre RFC résume les différents types de
diffusion qui existent dans le monde
IP. IPv4 a la
diffusion générale (on écrit à
255.255.255.255, cf. section 5.3.5.1 du RFC 1812) et la diffusion dirigée (on écrit à une
adresse qui est celle du préfixe du réseau local, avec tous les
bits « machine » à 1, cf. section 5.3.5.2 du même
RFC). IPv6, officiellement, n'a pas de
diffusion mais uniquement du
multicast mais c'est
jouer avec les mots : il a les mêmes possibilités qu'IPv4 et les
mêmes problèmes de confidentialité. Si une machine IPv6 écrit à
ff02::1, cela donnera le même résultat que si
une machine IPv4 écrit à
255.255.255.255. Parmi les protocoles
IETF qui utilisent ces adresses de
diffusion, on trouve mDNS (RFC 6762), LLMNR (RFC 4795), DHCP pour IPv4 (RFC 2131),
DHCP pour IPv6 (RFC 8415), etc.
La section 2 détaille les problèmes de vie privée que l'envoi de messages en diffusion peut entrainer. D'abord, le seul envoi des messages, même sans analyser ceux-ci, permet de surveiller les activités d'un utilisateur : quand est-ce qu'il est éveillé, par exemple. Plus les messages sont fréquents, meilleure sera la résolution temporelle de la surveillance. Notre RFC conseille donc de ne pas envoyer trop souvent des messages périodiques.
Mais un problème bien plus sérieux est celui des identificateurs stables. Bien des protocoles incluent un tel identificateur dans leurs messages, par exemple un UUID. Même si la machine change de temps en temps d'adresse IP et d'adresse MAC (par exemple avec macchanger), ces identificateurs stables permettront de la suivre à la trace. Et si l'identificateur stable est lié à la machine et pas à une de ses interfaces réseau, même un changement de WiFi à Ethernet ne suffira pas à échapper à la surveillance. C'était le cas par exemple du protocole de Dropbox qui incluait dans les messages diffusés un identificateur unique, choisi à l'installation et jamais changé ensuite. D'une manière générale, les identificateurs stables sont mauvais pour la vie privée, et devraient être utilisés avec prudence, surtout quand ils sont diffusés.
Ces identificateurs stables ne sont pas forcément reliés à
l'identité étatique de la personne. Si on ne connait pas la
sécurité, et qu'on ne sait pas la différence entre
anonymat et
pseudonymat, on peut penser que diffuser
partout qu'on est
88cb0252-3c97-4bb6-9f74-c4c570809432 n'est
pas très révélateur. Mais outre que d'avoir un lien entre
différentes activités est déjà un danger, certains protocoles font
qu'en plus ce pseudonyme peut être corrélé avec des informations
du monde extérieur. Par exemple, les iPhone
diffusent fièrement à tout le réseau local « je suis l'iPhone de
Jean-Louis » (cf. RFC 8117). Beaucoup d'utilisateurs donnent à leur machine leur
nom officiel, ou leur prénom, ou une autre caractéristique
personnelle. (C'est parfois fait automatiquement à l'installation,
où un programme demande « comment vous appelez-vous ? » et nomme
ensuite la machine avec ce nom. L'utilisateur n'est alors pas
conscient d'avoir baptisé sa machine.) Et des protocoles diffusent cette information.
En outre, cette information est parfois accompagnés de détails sur le type de la machine, le système d'exploitation utilisé. Ces informations peuvent permettre de monter des attaques ciblées, par exemple si on connait une vulnérabilité visant tel système d'exploitation, on peut sélectionner facilement toutes les machines du réseau local ayant ce système. Bref, le RFC conseille de ne pas diffuser aveuglément des données souvent personnelles.
Comme souvent, il faut aussi se méfier de la corrélation. Si
une machine diffuse des messages avec un identificateur stable
mais non parlant (qui peut donc être ce
700a2a3e-4cda-46df-ad6e-2f062840d1e3 ?), un
seul message donnant une autre information (par exemple nom et
prénom) est suffisant pour faire la corrélation et savoir
désormais à qui se réfère cet identificateur stable
(700a2a3e-4cda-46df-ad6e-2f062840d1e3, c'est
Jean-Louis). Lors de l'expérience à Prague citée plus haut, il
avait été ainsi possible aux chercheurs de récolter beaucoup
d'informations personnelles, et même d'en déduire une partie du
graphe social (la machine de Jean-Louis demande souvent en
mDNS celle de Marie-Laure, il doit y avoir
un lien entre eux).
La plupart des systèmes d'exploitation n'offrent pas la possibilité de faire la différence entre un réseau supposé sûr, où les machines peuvent diffuser sans crainte car diverses mesures de sécurité font que tout le monde n'a pas accès à ce réseau, et un réseau public complètement ouvert, genre le WiFi du McDo, où tout est possible. Il serait intéressant, affirme le RFC, de généraliser ce genre de service et d'être moins bavard sur les réseaux qui n'ont pas été marqués comme sûrs.
La section 3 du RFC note que certains points d'accès WiFi permettent de ne pas passer systématiquement la diffusion d'une machine à l'autre, et de ne le faire que pour des protocoles connus et supposés indispensables. Ainsi, les requêtes DHCP, terriblement indiscrètes, pourraient ne pas être transmises à tous, puisque seul le point d'accès en a besoin. Évidemment, cela ne marche que pour des protocoles connus du point d'accès, et cela pourrait donc casser des protocoles nouveaux (si on bloque par défaut) ou laisser l'utilisateur vulnérable (si, par défaut, on laisse passer).
En résumé (section 4 du RFC), les conseils suivants sont donnés aux concepteurs de protocoles et d'applications :
- Autant que possible, utiliser des protocoles normalisés, pour lesquelles une analyse de sécurité a été faite, et des mécanismes de limitation des risques développées (comme ceux du RFC 7844 pour DHCP),
- Essayer de ne pas mettre des informations venant de l'utilisateur (comme son prénom et son nom) dans les messages diffusés,
- Tâcher de ne pas utiliser d'identificateurs stables, puisqu'ils permettent de surveiller une machine pendant de longues périodes,
- Ne pas envoyer les messages trop souvent.
L'article seul
RFC 8375: Special-Use Domain 'home.arpa.'
Date de publication du RFC : Mai 2018
Auteur(s) du RFC : P. Pfister (Cisco Systems), T. Lemon
(Nominum)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF homenet
Première rédaction de cet article le 18 mai 2018
Ce nouveau RFC a l'air compliqué comme
cela, mais en fait il ne fait qu'une chose : remplacer, dans le
protocole Homenet/HNCP (Home Networking Control Protocol), le
nom de domaine .home
par home.arpa.
home.arpa est désormais enregistré
dans la liste officielle des noms de domaine
spéciaux, ceux qui ne passent pas par les mécanismes
habituels d'enregistrement de noms de domaine, et/ou les mécanismes habituels
de résolution DNS. (Cette liste a été créée
par le RFC 6761, et critiquée par le RFC 8244. home.arpa n'étant
pas un TLD, il pose moins de problèmes politiciens.)
Quelle est l'utilité de ce nom home.arpa ?
La série de protocoles Homenet
(l'architecture de Homenet est décrite dans le RFC 7368)
vise à doter la maison de l'utilisateur normal (pas participant à
l'IETF) d'un ensemble de réseaux
IPv6 qui marchent automatiquement, sans
intervention humaine. Parmi les protocoles Homenet,
HNCP, normalisé dans le protocole RFC 7788 est le protocole de configuration.
Il utilise un suffixe pour les noms de domaines
comme nas.SUFFIXE ou
printer.SUFFIX. C'est ce
home.arpa qui va désormais servir de
suffixe.
Mais quel était le problème avec le suffixe
.home du RFC 7788 ?
D'abord, le RFC 7788 avait commis une grosse
erreur, enregistrée sous le numéro
4677 : il ne tenait pas compte des règles du RFC 6761, et réservait ce TLD
.home sans suivre les procédures du RFC 6761. Notamment, il ne listait pas les
particularités qui font que ce domaine est spécial (pour
home.arpa, notre nouveau RFC 8375 le fait dans sa section 5), et il ne demandait pas à
l'IANA de le mettre dans le registre
des noms de domaine spéciaux. Cela avait des conséquences
pratiques comme le fait que ce .home ne
pouvait pas marcher à travers un résolveur DNS validant (puisque ce nom n'existait pas
du tout dans la racine). Un bon article sur ce choix et sur les
problèmes qu'il posait était « Homenet, and the hunt for a name ».
On peut aussi ajouter que le risque de « collision » entre deux
noms de domaine était élevé puisque pas mal de réseaux locaux sont
nommés sous .home et que ce nom est un de
ceux qui « fuitent » souvent vers les serveurs
racines (voir par exemple les statistiques
du serveur racine L.). On peut consulter à ce sujet les
documents de l'ICANN « New
gTLD Collision Risk Mitigation » et
« New
gTLD Collision Occurence Management ». Notons
qu'il y avait eu plusieurs
candidatures
(finalement rejetées en
février 2018) pour un .home
en cours auprès de l'ICANN. Exit, donc,
.home, plus convivial mais trop
convoité. Demander à l'ICANN de déléguer un
.home pour l'IETF (ce qui aurait été
nécessaire pour faire une délégation DNSSEC
non signée, cf. RFC 4035, section 4.3)
aurait pris dix ou quinze ans.
À la place, voici home.arpa, qui profite
du RFC 3172, et du caractère décentralisé
du DNS, qui permet de déléguer des
noms sous .arpa.
L'utilisation de home.arpa n'est pas
limitée à HNCP, tous les protocoles visant le même genre d'usage
domestique peuvent s'en servir. Il n'a évidemment qu'une
signification locale.
La section 3 décrit le comportement général attendu avec
home.arpa. Ce n'est pas un nom de domaine comme les
autres. Sa signification est purement
locale. printer.home.arpa désignera une
machine à un endroit et une autre machine dans une autre
maison. Les serveurs DNS globaux ne peuvent
pas être utilisés pour résoudre les noms sous home.arpa. Tous les
noms se terminant par ce suffixe doivent être traités uniquement
par les résolveurs locaux, et jamais transmis à l'extérieur.
Notez que, la plupart du temps, les utilisateurs ne verront pas
le suffixe home.arpa, l'interface des
applications « Homenet » leur masquera cette
partie du nom. Néanmoins, dans certains cas, le nom sera sans
doute visible, et il déroutera sans doute certains utilisateurs,
soit à cause du suffixe arpa qui n'a pas de
signification pour eux, soit parce qu'ils ne sont pas anglophones et qu'ils ne comprennent
pas le home. Il n'y a pas de solution miracle
à ce problème.
La section 4 est le formulaire d'enregistrement dans le registre des noms spéciaux, suivant les formalités du RFC 6761, section 5. (Ce sont ces formalités qui manquaient au RFC 7788 et qui expliquent l'errata.) Prenons-les dans l'ordre (relisez bien la section 5 du RFC 6761) :
- Les humains et les applications qu'ils utilisent n'ont pas à faire quelque chose de particulier, ces noms, pour eux, sont des noms comme les autres.
- Les bibliothèques de résolution de noms (par exemple, sur
Mint, la GNU libc)
ne devraient pas non plus appliquer un traitement spécial aux
noms en
home.arpa. Elles devraient passer par le mécanisme de résolution normal. Une exception : si la machine a été configurée pour utiliser un autre résolveur DNS que celui de la maison (un résolveur public, par exemple, qui ne connaîtra pas votrehome.arpa), il peut être nécessaire de mettre une règle particulière pour faire résoudre ces noms par un résolveur local. - Les résolveurs locaux (à la maison), eux, doivent traiter ces noms à part, comme étant des « zones locales » à l'image de celles décrites dans le RFC 6303. Bref, le résolveur ne doit pas transmettre ces requêtes aux serveurs publics faisant autorité (il y a une exception pour le cas particulier des enregistrements DS). Ils doivent transmettre ces requêtes aux serveurs locaux qui font autorité pour ces noms (cf. section 7).
- Les serveurs publics faisant autorité n'ont pas besoin
d'un comportement particulier. Par exemple, ceux qui font
autorité pour
.arparetournent une délégation normale.
Voici la délégation :
% dig @a.root-servers.net ANY home.arpa
; <<>> DiG 9.10.3-P4-Debian <<>> @a.root-servers.net ANY home.arpa
; (2 servers found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 48503
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;home.arpa. IN ANY
;; AUTHORITY SECTION:
home.arpa. 172800 IN NS blackhole-1.iana.org.
home.arpa. 172800 IN NS blackhole-2.iana.org.
home.arpa. 86400 IN NSEC in-addr.arpa. NS RRSIG NSEC
home.arpa. 86400 IN RRSIG NSEC 8 2 86400 (
20180429000000 20180415230000 56191 arpa.
K4+fNoY6SXQ+VtHsO5/F0oYrRjZdNSG0MSMaeDSQ78aC
NHko4uqNAzoQzoM8a2joFeP4wOL6kVQ72UJ5zqd/iZJD
0ZSh/57lCUVxjYK8sL0dWy/3xr7kbaqi58tNVTLkp8GD
TfyQf5pW1rtRB/1pGzbmTZkK1jXw4ThG3e9kLHk= )
;; Query time: 24 msec
;; SERVER: 2001:503:ba3e::2:30#53(2001:503:ba3e::2:30)
;; WHEN: Mon Apr 16 09:35:35 CEST 2018
;; MSG SIZE rcvd: 296
La section 5 rassemble les changements dans la norme HNCP (RFC 7788. C'est juste un remplacement de
.home par home.arpa.
Quelques petits trucs de sécurité (section 6). D'abord, il ne
faut pas s'imaginer que ces noms locaux en
home.arpa sont plus sûrs que n'importe quel
autre nom. Ce n'est pas parce qu'il y a home
dedans qu'on peut leur faire confiance. D'autant plus qu'il y a,
par construction, plusieurs home.arpa, et
aucun moyen, lorsqu'on se déplace de l'un à l'autre, de les
différencier. (Des travaux ont lieu pour concevoir un mécanisme
qui pourrait permettre d'avertir l'utilisateur « ce n'est pas le
home.arpa que vous pensez » mais ils n'ont
pas encore abouti.)
home.arpa n'est pas sécurisé par
DNSSEC. Il ne serait pas possible de mettre
un enregistrement DS dans
.arpa puisqu'un tel
enregistrement est un condensat de la clé
publique de la zone et que chaque home.arpa
qui serait signé aurait sa propre clé. Une solution possible aurait été
de ne pas déléguer
home.arpa. .arpa étant
signé, une telle non-délégation aurait pu être validée par DNSSEC
(« denial of existence »). La réponse DNS
aurait été (commande tapée avant la délégation de home.arpa) :
% dig A printer.home.arpa ... ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 37887 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 1 ... ;; AUTHORITY SECTION: arpa. 10800 IN SOA a.root-servers.net. nstld.verisign-grs.com. ( 2017112001 ; serial 1800 ; refresh (30 minutes) 900 ; retry (15 minutes) 604800 ; expire (1 week) 86400 ; minimum (1 day) ) arpa. 10800 IN RRSIG SOA 8 1 86400 ( 20171203120000 20171120110000 36264 arpa. QqiRv85fb6YO/79ZdtQ8Ke5FmZHF2asjLrNejjcivAAo... arpa. 10800 IN RRSIG NSEC 8 1 86400 ( 20171203120000 20171120110000 36264 arpa. dci8Yr95yQtL9nEBFL3dpdMVTK3Z2cOq+xCujeLsUm+W... arpa. 10800 IN NSEC as112.arpa. NS SOA RRSIG NSEC DNSKEY e164.arpa. 10800 IN RRSIG NSEC 8 2 86400 ( 20171203120000 20171120110000 36264 arpa. jfJS6QuBEFHWgc4hhtvdfR0Q7FCCgvGNIoc6169lsxz7... e164.arpa. 10800 IN NSEC in-addr.arpa. NS DS RRSIG NSEC ;; Query time: 187 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Mon Nov 20 20:28:27 CET 2017 ;; MSG SIZE rcvd: 686
Ici, on reçoit un NXDOMAIN (ce domaine n'existe pas), et les
enregistrements NSEC qui prouvent que
home.arpa n'existe pas non plus (rien entre
e164.arpa et in-addr.arpa).
Mais cela
aurait nécessité un traitement spécial de
home.arpa par le résolveur validant (par
exemple, sur Unbound,
domain-insecure: "home.arpa"). Finalement, le
choix fait a été celui d'une délégation non sécurisée (section 7
du RFC), vers les
serveurs blackhole-1.iana.org et blackhole-2.iana.org :
% dig NS home.arpa
; <<>> DiG 9.10.3-P4-Debian <<>> NS home.arpa
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 64059
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;home.arpa. IN NS
;; ANSWER SECTION:
home.arpa. 190 IN NS blackhole-1.iana.org.
home.arpa. 190 IN NS blackhole-2.iana.org.
;; Query time: 0 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Mon Apr 16 09:36:25 CEST 2018
;; MSG SIZE rcvd: 98
Cette délégation a été faite le 15 mars 2018.
Le domaine home.arpa a été ajouté dans
le registre des noms de domaine spéciaux
ainsi que dans celui
des noms servis localement.
En testant avec les
sondes RIPE Atlas, on voit que tous les résolveurs ne
voient pas la même chose, ce qui est normal, chaque maison pouvant
avoir son home.arpa local :
% blaeu-resolve -r 1000 -q SOA home.arpa [prisoner.iana.org. hostmaster.root-servers.org. 1 604800 60 604800 604800] : 548 occurrences [prisoner.iana.org. hostmaster.root-servers.org. 1 1800 900 604800 604800] : 11 occurrences [prisoner.iana.org. hostmaster.root-servers.org. 1 1800 900 604800 15] : 33 occurrences [prisoner.iana.org. hostmaster.root-servers.org. 2002040800 1800 900 604800 60480] : 229 occurrences [ERROR: FORMERR] : 1 occurrences [ERROR: SERVFAIL] : 132 occurrences [] : 4 occurrences [prisoner.iana.org. hostmaster.root-servers.org. 1 604800 60 604800 3600] : 11 occurrences [prisoner.iana.org. hostmaster.trex.fi. 1 604800 86400 2419200 86400] : 4 occurrences [prisoner.iana.org. ops.inx.net.za. 1513082668 10800 3600 604800 3600] : 2 occurrences [TIMEOUT(S)] : 19 occurrences Test #12177308 done at 2018-04-16T07:38:32Z
On voit sur ce premier test que la grande majorité des sondes
voient le vrai SOA (numéro de série 1 ou 2002040800 ; curieusement,
les serveurs faisant autorité envoient des numéros
différents). Certaines voient un tout autre SOA (par exemple celle
où l'adresse du responsable est en Afrique du
Sud ou bien en Finlande), et le
numéro de série très différent. Ce n'est pas un problème ou un
piratage : le principe de home.arpa est que
chacun peut avoir le sien.
Pour une autre description de ce home.arpa,
voyez l'article de
John Shaft (où il utilise Unbound) et
(en anglais), regardez celui
de Daniel Aleksandersen.
À l'heure actuelle, toutes les mises en œuvre en logiciel libre
que j'ai regardées utilisent encore .home, mais
elles semblent souvent non maintenues.
L'article seul
RFC 8374: BGPsec Design Choices and Summary of Supporting Discussions
Date de publication du RFC : Avril 2018
Auteur(s) du RFC : K. Sriram (USA NIST)
Pour information
Première rédaction de cet article le 1 mai 2018
Ce RFC est un peu spécial : il ne normalise pas un protocole, ni des procédures internes à l'IETF, et il n'est pas non plus la description d'un problème à résoudre, ou un cahier des charges d'une solution à développer. Non, ce RFC est la documentation a posteriori des choix qui ont été effectués lors du développement de BGPsec, une solution de sécurisation du routage Internet. C'est donc un document utile si vous lisez les RFC sur BGPsec, comme le RFC 8205 et que vous vous demandez « mais pourquoi diable ont-ils choisi cette approche et pas cette autre, qui me semble bien meilleure ? »
Un petit rappel du contexte : le protocole de
routage BGP
fonctionne en échangeant des informations entre pairs, sur les
routes que chaque pair sait joindre. Par défaut, un pair peut
raconter n'importe quoi, dire qu'il a une route vers
2001:db8::/32 alors qu'il n'est pas le
titulaire de ce préfixe et n'a pas non plus appris cette route
d'un de ses pairs. Cela rend donc le routage Internet assez
vulnérable. Pour le sécuriser, il existe plusieurs mécanismes qui
font que, en pratique, ça ne marche pas trop
mal. L'IETF a développé une solution
technique, qui a deux couches : une infrastructure à clés publiques, la
RPKI, normalisée dans les RFC 6480 et RFC 6481, et une seconde
couche, les services qui utilisent la RPKI pour authentifier tel
ou tel aspect du routage. Deux de ces services sont normalisés,
les ROA (Route Origin Authorization) des RFC 6482
et RFC 6811, qui servent à authentifier
l'AS d'origine d'un préfixe, et
BGPsec (RFC 8205),
qui sert à authentifier le chemin d'AS, la
liste des AS empruntés par une annonce de
route (cf. section 2.1.1 de notre RFC). Sans BGPsec, les ROA,
utilisés seuls, ne peuvent pas arrêter certaines attaques
(cf. RFC 7132, qui explique quelles menaces
traite BGPsec, et RFC 7353, cahier des
charges de BGPsec). Par exemple, si l'AS 64641, malhonnête, veut
tromper son pair, l'AS 64642, à propos du préfixe
2001:db8::/32, et que ce préfixe a un ROA
n'autorisant que 64643 à être à l'origine, le malhonnête peut
fabriquer une annonce avec le chemin d'AS 64641
[éventuellement d'autres AS] 64643 (rappelez-vous que
les chemins d'AS se lisent de droite à gauche) et l'envoyer à
64641. Si celui-ci vérifie le ROA, il aura l'impression que tout
est normal, l'AS 64643 étant bien indiqué comme l'origine. Et cela
marchera même si les annonces de l'AS 64643 ne sont jamais passées
par ce chemin ! BGPsec répare ce problème en transportant un
chemin d'AS signé,
authentifiant toutes les étapes.
Lors du développement de BGPsec, un document avait été rédigé pour documenter tous les choix effectués, mais n'avait pas été publié. C'est désormais chose faite avec ce RFC, qui documente les choix, les justifie, et explique les différences entre ces choix initiaux et le protocole final, modifié après un long développement. Parmi les points importants du cahier des charges (RFC 7353) :
- Valider la totalité du chemin d'AS (et pas seulement détecter certains problèmes, comme le font les ROA),
- Déployable de manière incrémentale puisqu'il est évidemment impossible que tous les opérateurs adoptent BGPsec le même jour,
- Ne pas diffuser davantage d'informations que celles qui sont déjà diffusées. Par exemple, les opérateurs ne souhaitent pas forcément publier la liste de tous leurs accords d'appairage.
Finie, l'introduction, passons tout de suite à certains des choix qui ont été effectués. (Il est évidemment recommandé de lire le RFC 8205 avant, puis de lire notre RFC 8374 après, si on veut tous les choix documentés.) D'abord, à quoi ressemblent les signatures, et les nouveaux messages BGP (section 2 de notre RFC). Les signatures BGPsec signent le préfixe IP, l'AS signataire, et l'AS suivant à qui on va transmettre l'annonce. Le premier point important est qu'on signe l'AS suivant, de manière à créer une chaîne de signatures vérifiables. Autrement, un attaquant pourrait fabriquer un faux chemin à partir de signatures correctes.
Si on utilise le prepending d'AS, la
première version de BGPsec prévoyait une signature à chaque fois,
mais on peut finalement mettre une seule signature pour la
répétition d'AS, avec une variable pCount qui indique leur nombre (RFC 8205, section 3.1), afin
de diminuer le nombre de signatures (les signatures peuvent
représenter la grande majorité des octets d'une annonce BGP).
Le second point important est que certains attributs ne sont
pas pas signés, comme par exemple la
préférence locale (RFC 4271, section 5.1.5)
ou les communautés (cf. RFC 1997). Ces
attributs pourront donc être modifiés par un attaquant à sa
guise. Ce n'est pas si grave que ça en a l'air car la plupart de
ces attributs n'ont de sens qu'entre deux AS (c'est le cas de la
communauté NO_EXPORT) ou sont internes à un
AS (la
préférence locale). Sur ces courtes distances, on espère de toute
façon que la session BGP sera protégée, par exemple par AO (RFC 5925).
La signature est transportée dans un attribut BGP optionnel et non-transitif (qui n'est pas transmis tel quel aux routeurs suivants). Optionnel car, sinon, il ne serait pas possible de déployer BGPsec progressivement. Et non-transitif car un routeur BGPsec n'envoie les signatures que si le routeur suivant lui a dit qu'il savait gérer BGPsec.
Dans le message BGP signé, le routeur qui signe est identifié par sa clé publique, pas par le certificat entier. Cela veut dire qu'on ne peut valider les signatures que si on a accès à une dépôt de la RPKI, avec les certificats.
La section 3 de notre RFC traite le cas des retraits de route : contrairement aux annonces, ils ne sont pas signés. Un AS est toujours libre de retirer une route qu'il a annoncée (BGP n'accepte pas un retrait venant d'un autre pair). Si on a accepté l'annonce, il est logique d'accepter le retrait (en supposant évidemment que la session entre les deux routeurs soit raisonnablement sécurisée).
La section 4, elle, parle des algorithmes de signature. Le RFC 8208 impose ECDSA avec la courbe P-256 (cf. RFC 6090). RSA avait été envisagé mais ECDSA avait l'avantage de signatures bien plus petites (cf. l'étude du NIST sur les conséquences de ce choix).
Une autre décision importante dans cette section est la possibilité d'avoir une clé par routeur et pas par AS (cf. RFC 8207). Cela évite de révoquer un certificat global à l'AS si un seul routeur a été piraté. (Par contre, il me semble que c'est indiscret, permettant de savoir quel routeur de l'AS a relayé l'annonce, une information qu'on n'a pas forcément actuellement.)
Décision plus anecdotique, en revanche, celle comme quoi le nom
dans le certificat (Subject) sera la chaîne
router suivie du numéro d'AS (cf. RFC 5396) puis de
l'identité BGP du routeur. Les détails figurent dans le RFC 8209.
Voyons maintenant les problèmes de performance (section 5). Par exemple, BGPsec ne permet pas de regrouper plusieurs préfixes dans une annonce, comme on peut le faire traditionnellement avec BGP. C'est pour simplifier le protocole, dans des cas où un routeur recevrait une annonce avec plusieurs préfixes et n'en transmettrait que certains. Actuellement, il y a en moyenne quatre préfixes par annonce (cf. l'étude faite par l'auteur du RFC). Si tout le monde adoptait BGPsec, on aurait donc quatre fois plus d'annonces, et il faudra peut-être dans le futur optimiser ce cas.
On l'a vu plus haut, il n'est pas envisageable de déployer BGPsec partout du jour au lendemain. Il faut donc envisager les problèmes de coexistence entre BGPsec et BGP pas sécurisé (section 6 de notre RFC). Dès que deux versions d'un protocole, une sécurisée et une qui ne l'est pas, coexistent, il y a le potentiel d'une attaque par repli, où l'attaquant va essayer de convaindre une des parties de choisir la solution la moins sécurisée. Actuellement, BGPsec ne dispose pas d'une protection contre cette attaque. Ainsi, il n'y a pas de moyen de savoir si un routeur qui envoie des annonces non-signées le fait parce qu'il ne connait pas BGPsec, ou simplement parce qu'un attaquant a modifié le trafic.
La possibilité de faire du BGPsec est négociée à l'établissement de la session BGP. Notez qu'elle est asymétrique. Par exemple, il est raisonnable qu'un routeur de bordure signe ses propres annonces mais accepte tout de la part de ses transitaires, et ne lui demande donc pas d'envoyer les signatures. Pendant un certain temps (probablement plusieurs années), nous aurons donc des ilots BGPsec au milieu d'un océan de routeurs qui font du BGP traditionnel. On peut espérer qu'au fur et à mesure du déploiement, ces ilots se rejoindront et formeront des iles, puis des continents.
La question de permettre des chemins d'AS partiellement signés avait été discutée mais cela avait été rejeté : il faut signer tout le chemin, ou pas du tout. Des signatures partielles auraient aidé au déploiement progressif mais auraient été dangereuses : elle aurait permis aux attaquants de fabriquer des chemins valides en collant des bouts de chemins signés - et donc authentiques - avec des bouts de chemins non-signés et mensongers.
La section 7 de notre RFC est consacrée aux interactions entre BGPsec et les fonctions habituelles de BGP, qui peuvent ne pas bien s'entendre avec la nouvelle sécurité. Par exemple, les très utiles communautés BGP (RFC 1997 et RFC 8092). On a vu plus haut qu'elles n'étaient pas signées du tout et donc pas protégées. La raison est que les auteurs de BGPsec considèrent les communautés comme mal fichues, question sécurité. Certaines sont utilisées pour des décisions effectives par les routeurs, d'autres sont juste pour le débogage, d'autres encore purement pour information. Certaines sont transitives, d'autres utilisées seulement entre pairs se parlant directement. Et elles sont routinement modifiées en route. Le RFC conseille, pour celles qui ne sont utilisées qu'entre pairs directs, de plutôt sécuriser la session BGP.
Pour les communautés qu'on veut voir transmises transitivement, il avait été envisagé d'utiliser un bit libre pour indiquer que la communauté était transitive et donc devait être incluse dans la signature. Mais la solution n'a pas été retenue. Conseil pratique, dans la situation actuelle : attention à ne pas utiliser des communautés transmises transitivement pour des décisions de routage.
Autre cas pratique d'interaction avec un service très utile, les serveurs de route. Un point d'échange peut fonctionner de trois façons :
- Appairages directs entre deux membres et, dans ce cas, BGPsec n'a rien de particulier à faire.
- Utilisation d'un serveur de routes qui ajoute son propre
AS dans le chemin (mais, évidemment, ne change pas le
NEXT_HOP, c'est un serveur de routes, pas un routeur). Cette méthode est de loin la plus rare des trois. Là aussi, BGPsec n'a rien de particulier à faire. - Utilisation d'un serveur de routes qui n'ajoute pas son
propre AS dans le chemin. Sur un gros point d'échange, cette
méthode permet d'éviter de gérer des dizaines, voire des
centaines d'appairages. Pour BGPsec, c'est le cas le plus
délicat. Il faut que le serveur de routes mette son AS dans le
chemin, pour qu'il puisse être validé, mais en positionnant
pCountà 0 (sa valeur normale est 1, ou davantage si on utilise le prepending) pour indiquer qu'il ne faut pas en tenir compte pour les décisions de routage (fondées sur la longueur du chemin), seulement pour la validaton.
Un point de transition intéressant est celui des numéros d'AS de quatre octets, dans le RFC 4893. La technique pour que les AS ayant un tel numéro puisse communiquer avec les vieux routeurs qui ne comprennent pas ces AS est un bricolage utilisant un AS spécial (23456), bricolage incompatible avec BGPsec, qui, d'ailleurs, exige que les AS de quatre octets soient acceptés. En pratique, on peut espérer que les derniers routeurs ne gérant pas les AS de quatre octets auront disparu bien avant que BGPsec soit massivement déployé.
La section 8 du RFC discute de la validation des chemins d'AS signés. Par exemple, le RFC 8205 demande qu'un routeur transmette les annonces ayant des signatures invalides. Pourquoi ? Parce que la RPKI n'est que modérement synchrone : il est parfaitement possible qu'un nouveau certificat ne soit arrivé que sur certains routeurs et que, donc, certains acceptent la signature et d'autres pas. Il ne faut donc pas préjuger de ce que pourront valider les copains.
Une question qui revient souvent avec les techniques de sécurité (pas seulement BGPsec mais aussi des choses comme DNSSEC) est « et si la validation échoue, que doit-on faire des données invalides ? » Vous ne trouverez pas de réponse dans le RFC : c'est une décision locale. Pour BGPsec, chaque routeur, ou plus exactement son administrateur, va décider de ce qu'il faut faire avec les annonces dont le chemin d'AS signé pose un problème. Contrairement à DNSSEC, où la validation peut donner trois résultats (oui, en fait, quatre, mais je simplifie, cf. RFC 4035), « sûr », « non sûr », et « invalide », BGPsec n'a que deux résultats possibles, « valide » et « invalide ». L'état « invalide » regroupe aussi bien les cas où le chemin d'AS n'est pas signé (par exemple parce qu'un routeur non-BGPsec se trouvait sur le trajet) que le cas où une signature ne correspond pas aux données (les deux états « non sûr » et « invalide » de DNSSEC se réduisent donc à un seul ici). Il avait été discuté de faire une division plus fine entre les différents cas d'invalidité mais il avait semblé trop complexe de rendre en compte tous les cas possibles. Notez que « invalide » couvre même le cas où un ROA valide l'origine (un cas particulier des chemins partiellement signés, déjà traités).
Donc, si une annonce est invalide, que doit faire le routeur ? D'abord, la décision d'accepter ou pas une route dépend de plusieurs facteurs, la validation BGPsec n'en étant qu'un seul. Ensuite, il n'est pas évident de traiter tous les cas. D'où la décision de laisser le problème à l'administrateur réseaux.
Ah, et si vous utilisez iBGP, notez que la validation BGPsec ne se fait qu'en bord d'AS. Vous pouvez transporter l'information comme quoi une annonce était valide ou invalide comme vous voulez (une communauté à vous ?), il n'existe pas de mécanisme standard dans iBGP pour cela.
Enfin, la section 9 de notre RFC traite de quelques problèmes d'ordre opérationnel. Mais pensez à lire le RFC 8207 avant. Par exemple, elle estime que BGPsec, contrairement à la validation avec les ROA seuls, nécessitera sans doute du nouveau matériel dans les routeurs, comme un coprocesseur cryptographique, et davantage de RAM. C'est une des raisons pour lesquelles on ne verra certainement pas de déploiement significatif de BGPsec avant des années. Ceci dit, au début, les routeurs BGPsec auront peu de travail supplémentaire, précisément puisqu'il y aura peu d'annonces signées, donc pourront retarder les mises à jour matérielles. D'ici que BGPsec devienne banal, des optimisations comme celles décrites dans cet exposé ou celui-ci, ou encore dans l'article « Design and analysis of optimization algorithms to minimize cryptographic processing in BGP security protocols » aideront peut-être.
L'article seul
RFC 8373: Negotiating Human Language in Real-Time Communications
Date de publication du RFC : Mai 2018
Auteur(s) du RFC : R. Gellens (Core Technology Consulting)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF slim
Première rédaction de cet article le 26 mai 2018
Le groupe de travail SLIM de l'IETF s'occupe de définir des mécanismes pour le choix d'une langue lors de la communication. Son premier RFC, le RFC 8255, concernait le courrier électronique. Ce nouveau RFC concerne, lui, les communications « en temps réel », comme la téléphonie sur IP.
Un scénario d'usage typique est celui d'un client qui appelle le support d'une société internationale. Mettons que le client a pour langue maternelle l'ourdou mais peut se débrouiller en anglais. On veut qu'il puisse préciser cet ordre de préférences, et, idéalement, que le logiciel utilisé dans le call center le route automatiquement vers un employé qui parle ourdou ou, si aucun n'est disponible, vers un employé qui parle anglais. Plus vital, le scénario d'un appel d'urgence où un touriste danois en vacances en Italie appelle le 112 et où il faut trouver très vite quelqu'un qui peut parler une langue qu'il comprend (sachant qu'en situation d'urgence, on est moins à l'aise avec les langues étrangères). Comme le dit avec euphémisme le RFC « avoir une langue en commun est utile pour la communication ». Pour gérer tous ces scénarios, notre RFC va utiliser les attributs de SDP (RFC 4566, SDP est un format - pas un protocole, en dépit de son nom - déjà très utilisé dans les protocoles de communication instantanée pour transmettre des métadonnées au sujet d'une communication).
Parfois, on a déjà l'information disponible (si on appelle une personne qu'on connait et qui nous connait), et déjà choisi une langue (par exemple une audioconférence dans une entreprise où la règle est que tout se fasse en anglais). Notre RFC traite le cas où on n'a pas cette information, et il faut donc une négociation au début de la communication. Cela implique que le logiciel des deux côtés ait été configuré avec les préférences et capacités linguistiques des deux parties (une question d'interface utilisateur, non spécifiée par ce RFC).
Notez qu'il peut y avoir plusieurs langues différentes utilisées, une pour chaque flux de données. Par exemple, l'appelant peut parler dans une langue que son interlocuteur comprend, mais qu'il a du mal à parler, et il utilisera donc une autre langue pour la réponse. Notez aussi que la communication n'est pas uniquement orale, elle peut être écrite, par exemple pour les malentendants. Le RFC rappelle à juste titre qu'un sourd n'est pas forcément muet et qu'il ou elle peut donc choisir l'oral dans une direction et le texte dans une autre. (Au passage, la synchronisation des lèvres, pour la lecture sur les lèvres, est traitée dans le RFC 5888.)
La solution choisie est décrite en détail dans la section 5 de
notre RFC. Elle consiste en deux attributs SDP,
hlang-send et
hlang-recv (hlang =
human language). Leur valeur est évidemment une
étiquette de langue, telles qu'elles sont
normalisées dans le RFC 5646. Dans une offre
SDP, hlang-send est une liste (pas une langue
unique) de langues que l'offreur sait parler, séparées par des
espaces, donnée dans l'ordre de
préférence décroissante, et
hlang-recv une liste de langues qu'elle ou
lui comprend. Notez qu'il est de la responsabilité de l'offreur
(typiquement celui ou celle qui appelle) de proposer des choix
réalistes (le RFC donne le contre-exemple d'un offreur qui demanderait à
parler en hongrois et à avoir la réponse en
portugais…) D'autre part, notre RFC
recommande de bien lire la section 4.1 du RFC 5646, qui indique d'étiqueter intelligement, et
notamment de ne pas être trop spécifique : si on est australien et qu'on comprend bien
l'anglais, indiquer comme langue en est
suffisant, préciser (ce qui serait une étiquette légale)
en-AU est inutile et même dangereux si le
répondant se dit « je ne sais pas parler avec l'accent australien,
tant pis, je raccroche ».
La langue choisie par le répondant est indiquée dans la
réponse. hlang-send et
hlang-recv sont cette fois des langues
uniques. Attention, ce qui est envoi pour l'une des parties est
réception pour l'autre : hlang-send dans la
réponse est donc un choix parmi les
hlang-recv de l'offre. L'offreur (l'appelant) est ainsi prévenu du choix qui a
été effectué et peut se préparer à parler la langue indiquée par
le hlang-recv du répondant, et à comprendre
celle indiquée par le hlang-send.
Voici un exemple simple d'un bloc SDP (on n'en montre qu'une partie), où seul l'anglais est proposé ou accepté (cet exemple peut être une requête ou une réponse) :
m=audio 49170 RTP/AVP 0
a=hlang-send:en
a=hlang-recv:en
Le cas où hlang-send et
hlang-recv ont la même valeur sera sans doute
fréquent. Il avait même été envisagé de permettre un seul
attribut (par exemple hlang) dans ce cas
courant mais cela avait été écarté, au profit de la solution
actuelle, plus générale.
Un exemple un peu plus compliqué où la demande propose trois langues (espagnol, basque et anglais dans l'ordre des préférences décroissantes) :
m=audio 49250 RTP/AVP 20
a=hlang-send:es eu en
a=hlang-recv:es eu en
Avec une réponse où l'espagnol est utilisé :
m=audio 49250 RTP/AVP 20
a=hlang-send:es
a=hlang-recv:es
Et si ça rate ? S'il n'y a aucune langue en commun ? Deux choix sont possibles, se résigner à utiliser une langue qu'on n'avait pas choisi, ou bien raccrocher. Le RFC laisse aux deux parties la liberté du choix. En cas de raccrochage, le code d'erreur SIP à utiliser est 488 (Not acceptable here) ou bien 606 (Not acceptable), accompagné d'un en-tête d'avertissement avec le code 308, par exemple :
Warning: 308 code proxy.example.com
"Incompatible language specification: Requested languages "fr
zh" not supported. Supported languages are: "es en".
Si la langue indiquée est une langue des signes, elle peut être utilisée dans un canal vidéo, mais évidemment pas dans un canal audio. (Le cas d'un canal texte est laissé à l'imagination des lecteurs. Le cas des sous-titres, ou autres textes affichés dans une vidéo, n'est pas traité par notre RFC.)
Voici un exemple bien plus riche, avec plusieurs médias. La vidéo en langue des signes argentine, le texte en espagnol (ou à la rigueur en portugais), et un canal audio, mêmes préférences que le texte :
m=video 51372 RTP/AVP 31 32
a=hlang-send:aed
m=text 45020 RTP/AVP 103 104
a=hlang-send:es pt
m=audio 49250 RTP/AVP 20
a=hlang-recv:es pt
Voici une réponse possible à cette requête, avec de l'espagnol pour le canal texte et pour la voix. Aucune vidéo n'est proposée, sans doute car aucune n'était disponible dans la langue demandée :
m=video 0 RTP/AVP 31 32
m=text 45020 RTP/AVP 103 104
a=hlang-recv:es
m=audio 49250 RTP/AVP 20
a=hlang-send:es
Notez que ce RFC ne fournit pas de mécanisme pour exprimer des préférences entre les différents canaux (texte et audio, par exempe), uniquement entre langues pour un même canal.
Les deux attributs hlang-recv et
hlang-send ont été ajoutés au registre
IANA des attributs SDP.
Notons que la section 8 du RFC, sur la protection de la vie privée, rappelle qu'indiquer les préférences linguistiques peut permettre d'apprendre des choses sur l'utilisateur, par exemple sa nationalité. Une section Privacy considerations, quoique non obligatoire, est de plus en plus fréquente dans les RFC.
Enfin, question alternatives, le RFC note aussi (section 4) qu'on aurait pu utiliser
l'attribut existant lang, qui existe déjà
dans SDP (RFC 4566, section 6). Mais il n'est pas
mentionné dans le RFC 3264, ne semble pas
utilisé à l'heure actuelle, et ne permet pas de spécifier une
langue différente par direction de communication.
À ma connaissance, il n'y a pas encore de mise en œuvre de ce RFC mais comme il est cité dans des documents normatifs, par exemple dans le NENA 08-01 de la North American Emergency Number Association, il est possible qu'elles apparaissent bientôt.
L'article seul
RFC 8360: Resource Public Key Infrastructure (RPKI) Validation Reconsidered
Date de publication du RFC : Avril 2018
Auteur(s) du RFC : G. Huston (APNIC), G. Michaelson
(APNIC), C. Martinez
(LACNIC), T. Bruijnzeels (RIPE
NCC), A. Newton (ARIN), D. Shaw
(AFRINIC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 6 avril 2018
La RPKI est un ensemble de formats et de règles pour certifier qui est le titulaire d'une ressource Internet, une ressource étant un préfixe d'adresses IP, un numéro de système autonome, etc. La RPKI est utilisée dans les mécanismes de sécurisation de BGP, par exemple pour vérifier qu'un AS est bien autorisé à être à l'origine d'un préfixe donné. Les règles initiales de la RPKI pour valider un certificat était trop strictes et ce RFC les assouplit légèrement (normalement, en gardant le même niveau de sécurité).
La RPKI est normalisée dans le RFC 6480. Elle prévoit notamment un système de certificats par lequel une autorité affirme qu'une autorité de niveau inférieur a bien reçu une délégation pour un groupe de ressources Internet. (On appelle ces ressources les INR, pour Internet Number Resource.) La validation des certificats est décrite dans le RFC 6487. L'ancienne règle était que le certificat de l'autorité inférieure ne devait lister que des ressources qui étaient dans le certificat de l'autorité qui signait (RFC 6487, section 7.2, notamment la condition 6 de la seconde énumération). En pratique, cette règle s'est avérée trop rigide, et la nouvelle, décrite dans notre RFC 8360 est que le certificat de l'autorité inférieure n'est accepté que pour des ressources qui étaient dans le certificat de l'autorité qui signait. S'il y a d'autres ressources, le certificat n'est plus invalide, simplement, ces ressources sont ignorées. Dit autrement, l'ensemble des ressources dont la « possession » est certifiée, est l'intersection des ressources du certificat de l'autorité parente et de celui de l'autorité fille. Cette intersection se nomme VRS, pour Verified Resource Set.
Voici d'abord une chaîne de certificats qui était valide avec l'ancienne règle, et qui l'est toujours :
Certificate 1 (trust anchor):
Issuer TA,
Subject TA,
Resources 192.0.2.0/24, 198.51.100.0/24,
2001:db8::/32, AS64496-AS64500
Certificate 2:
Issuer TA,
Subject CA1,
Resources 192.0.2.0/24, 198.51.100.0/24, 2001:db8::/32
Certificate 3:
Issuer CA1,
Subject CA2,
Resources 192.0.2.0/24, 198.51.100.0/24, 2001:db8::/32
ROA 1:
Embedded Certificate 4 (EE certificate):
Issuer CA2,
Subject R1,
Resources 192.0.2.0/24
La chaîne part d'un certificat (TA, pour Trust Anchor, le point de départ de la validation). Elle aboutit à un ROA (Route Origin Authorization, cf. RFC 6482). Chaque certificat est valide puisque chacun certifie un jeu de ressources qui est un sous-ensemble du jeu de ressources de l'autorité du dessus. Idem pour le ROA.
Et voici par contre une chaîne de certificats qui était invalide selon les anciennes règles, et est désormais valide avec les règles de notre RFC 8360 :
Certificate 1 (trust anchor):
Issuer TA,
Subject TA,
Resources 192.0.2.0/24, 198.51.100.0/24,
2001:db8::/32, AS64496-AS64500
Certificate 2:
Issuer TA,
Subject CA1,
Resources 192.0.2.0/24, 2001:db8::/32
Certificate 3 (invalid before, now valid):
Issuer CA1,
Subject CA2,
Resources 192.0.2.0/24, 198.51.100.0/24, 2001:db8::/32
ROA 1 (invalid before, now valid):
Embedded Certificate 4 (EE certificate, invalid before, now valid):
Issuer CA2,
Subject R1,
Resources 192.0.2.0/24
La chaîne était invalide car le troisième certificat ajoutait
198.51.100.0/24, qui n'était pas couvert par
le certificat supérieur. Désormais, elle est valide mais vous
noterez que seuls les préfixes 192.0.2.0/24 et
2001:db8::/32 sont
couverts, comme précédemment (198.51.100.0/24
est ignoré). Avec les règles de notre nouveau RFC, le ROA final
est désormais valide (il n'utilise pas
198.51.100.0/24). Notez que les nouvelles
règles, comme les anciennes, n'autoriseront jamais l'acceptation
d'un ROA pour des ressources dont l'émetteur du certificat n'est
pas titulaire (c'est bien le but de la RPKI). Ce point est
important car l'idée derrière ce nouveau RFC de rendre plus
tolérante la validation n'est pas passée toute seule à l'IETF.
Un cas comme celui des deux chaînes ci-dessus est probablement rare. Mais il pourrait avoir des conséquences sérieuses si une ressource, par exemple un préfixe IP, était supprimée d'un préfixe situé très haut dans la hiérarchie : plein de certificats seraient alors invalidés avec les règles d'avant.
La section 4 de notre RFC détaille la procédure de validation. Les anciens certificats sont toujours validés avec
l'ancienne politique, celle du RFC 6487. Pour avoir la nouvelle politique, il faut de
nouveaux certificats, identifiés par un OID
différent. La section 1.2 du RFC 6484
définissait id-cp-ipAddr-asNumber / 1.3.6.1.5.5.7.14.2 comme OID pour
l'ancienne politique. La nouvelle politique est
id-cp-ipAddr-asNumber-v2 / 1.3.6.1.5.5.7.14.3 et c'est elle qui doit
être indiquée dans un certificat pour que lui soient appliquées
les nouvelles règles. (Ces OID sont dans un
registre IANA.) Comme les logiciels existants rejetteront
les certificats avec ces nouveaux OID, il faut adapter les
logiciels avant que les AC ne se mettent à
utiliser les nouveaux OID (cf. section 6 du RFC). Les changements
du RFC n'étant pas dans le protocole mais uniquement dans les
règles de validation, le déploiement devrait être relativement facile.
Le cœur des nouvelles règles est dans la
section 4.2.4.4 de notre RFC, qui remplace la section 7.2 du RFC 6487. Un nouveau concept est introduit, le
VRS (Verified Resource Set). C'est
l'intersection des ressources d'un certificat
et de son certificat supérieur. Dans le deuxième exemple plus
haut, le VRS du troisième certificat est
{192.0.2.0/24,
2001:db8::/32}, intersection de
{192.0.2.0/24,
2001:db8::/32} et
{192.0.2.0/24,
198.51.100.0/24,
2001:db8::/32}. Si le VRS est vide, le
certificat est invalide (mais on ne le rejette pas, cela peut être
un cas temporaire puisque la RPKI n'est pas cohérente en permanence).
Un ROA est valide si les ressources qu'il contient sont un sous-ensemble du VRS du certificat qui l'a signé (si, rappelons-le, ce certificat déclare la nouvelle politique). La règle exacte est un peu plus compliquée, je vous laisse lire le RFC pour les détails. Notez qu'il y a également des règles pour les AS, pas seulement pour les préfixes IP.
La section 5 du RFC contient davantage d'exemples, illustrant les nouvelles règles.
L'article seul
RFC 8358: Update to Digital Signatures on Internet-Draft Documents
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : R. Housley (Vigil Security)
Pour information
Première rédaction de cet article le 13 mars 2018
Dernière mise à jour le 5 avril 2018
Les Internet-Drafts sont signés suivant les règles du RFC 5485, afin qu'une lectrice ou un lecteur puissent vérifier qu'un Internet-Draft n'a pas été modifié en cours de route. Ce nouveau RFC modifie légèrement le RFC 5485 sur un seul point : la signature d'Internet-Drafts qui sont écrits en Unicode.
En effet, depuis le RFC 7997, les RFC ne sont plus forcément en ASCII, ils peuvent intégrer des caractères Unicode. Le premier RFC publié avec ces caractères a été le RFC 8187, en septembre 2017. Bientôt, cela sera également possible pour les Internet-Drafts. Cela affecte forcément les règles de signature, d'où cette légère mise à jour.
Le RFC 5485 normalisait l'utilisation de CMS (RFC 5652) pour le format des signatures. Vous pouvez télécharger ces signatures sur n'importe lequel des sites miroirs. CMS utilise ASN.1, avec l'obligation d'utiliser l'encodage DER, le seul encodage d'ASN.1 qui ne soit pas ambigu (une seule façon de représenter un texte).
Les Internet-Drafts sont actuellement tous en texte
brut, limité à ASCII. Mais cela
ne va pas durer (RFC 7990). Les signatures des
Internet-Drafts sont détachées de l'Internet-Draft (section 2 de notre RFC), dans un fichier portant le même
nom auquel on ajoute l'extension .p7s (RFC 5751). Par exemple avec wget, pour
récupérer un Internet-Draft et sa signature :
% wget https://www.ietf.org/id/draft-bortzmeyer-dname-root-05.txt % wget https://www.ietf.org/id/draft-bortzmeyer-dname-root-05.txt.p7s
(Ne le faites pas avec un Internet-Draft trop récent, les signatures n'apparaissent qu'au bout de quelques jours, la clé privée n'est pas en ligne.)
La signature est au format CMS (RFC 5652). Son adaptation aux RFC et Internet-Drafts est
normalisée dans le RFC 5485. Le champ
SignedData.SignerInfo.EncapsulatedContentInfo.eContentType
du CMS identifie le type d'Internet-Draft signé. Les valeurs
possibles figurent dans un registre
IANA. Il y avait déjà des valeurs comme
id-ct-asciiTextWithCRLF qui identifiait
l'Internet-Draft classique en texte brut en ASCII, notre RFC ajoute (section
5) id-ct-utf8TextWithCRLF (texte brut en
UTF-8),
id-ct-htmlWithCRLF
(HTML) et id-ct-epub
(EPUB). Chacun de ces types a un
OID, par exemple le texte brut en UTF-8
sera 1.2.840.113549.1.9.16.1.37.
Maintenant, passons à un morceau délicat, la canonicalisation des Internet-Drafts. Signer nécessite de canonicaliser, autrement, deux textes identiques aux yeux de la lectrice pourraient avoir des signatures différentes. Pour le texte brut en ASCII, le principal problème est celui des fins de ligne, qui peuvent être représentées différemment selon le système d'exploitation. Nous utilisons donc la canonicalisation traditionnelle des fichiers texte sur l'Internet, celle de FTP : le saut de ligne est représenté par deux caractères, CR et LF. Cette forme est souvent connue sous le nom de NVT (Network Virtual Terminal) mais, bien que très ancienne, n'avait été formellement décrite qu'en 2008, dans l'annexe B du RFC 5198, qui traitait pourtant un autre sujet.
Pour les Internet-Drafts au format XML, notre RFC
renvoie simplement au W3C et à sa norme
XML, section 2.11 de la cinquième
édition, qui dit qu'il faut translating both the
two-character sequence #xD #xA and any #xD that is not followed by
#xA to a single #xA character. La canonicalisation
XML (telle que faite par xmllint
--c14n) n'est pas prévue.
Les autres formats ne subissent aucune opération particulière de canonicalisation. Un fichier EPUB, par exemple, est considéré comme une simple suite d'octets. On notera que le texte brut en Unicode ne subit pas de normalisation Unicode. C'est sans doute à cause du fait que le RFC 7997, dans sa section 4, considère que c'est hors-sujet. (Ce qui m'a toujours semblé une drôle d'idée, d'autant plus qu'il existe une norme Internet sur la canonicalisation du texte brut en Unicode, RFC 5198, qui impose la normalisation NFC.)
À l'heure actuelle, les Internet-Drafts sont signés, les outils doivent encore être adaptés aux nouvelles règles de ce RFC, mais elles sont simples et ça ne devrait pas être trop dur. Pour vérifier les signatures, la procédure (qui est documentée) consiste d'abord à installer le logiciel de canonicalisation :
% wget https://www.ietf.org/id-info/canon.c
% make canon
Puis à télécharger les certificats racine :
% wget https://www.ietf.org/id-info/verifybundle.pem
Vous pouvez examiner ce groupe de certificats avec :
% openssl crl2pkcs7 -nocrl -certfile verifybundle.pem | openssl pkcs7 -print_certs -text
Téléchargez ensuite des Internet-Drafts par exemple en
https://www.ietf.org/id/ :
% wget https://www.ietf.org/id/draft-ietf-isis-sr-yang-03.txt % wget https://www.ietf.org/id/draft-ietf-isis-sr-yang-03.txt.p7s
On doit ensuite canonicaliser l'Internet-Draft :
% ./canon draft-ietf-isis-sr-yang-03.txt draft-ietf-isis-sr-yang-03.txt.canon
On peut alors vérifier les signatures :
% openssl cms -binary -verify -CAfile verifybundle.pem -content draft-ietf-isis-sr-yang-03.txt.canon -inform DER -in draft-ietf-isis-sr-yang-03.txt.p7s -out /dev/null Verification successful
Si vous avez à la place :
Verification failure 139818719196416:error:2E09A09E:CMS routines:CMS_SignerInfo_verify_content:verification failure:../crypto/cms/cms_sd.c:819: 139818719196416:error:2E09D06D:CMS routines:CMS_verify:content verify error:../crypto/cms/cms_smime.c:393:
c'est sans doute que vous avez oublié l'option -binary.
Si vous trouvez la procédure compliquée, il y a un script qui
automatise tout ça idsigcheck :
% ./idsigcheck --setup
% ./idsigcheck draft-ietf-isis-sr-yang-03.txt
Si ça vous fait bad interpreter: /bin/bash^M,
il faut recoder les sauts de ligne :
% dos2unix idsigcheck
dos2unix: converting file idsigcheck to Unix format...
Ce script appelle OpenSSL mais pas avec les bonnes options à l'heure actuelle, vous risquez donc d'avoir la même erreur que ci-dessus.
L'article seul
RFC 8354: Use Cases for IPv6 Source Packet Routing in Networking (SPRING)
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : J. Brzozowski, J. Leddy
(Comcast), C. Filsfils, R. Maglione, M. Townsley
(Cisco)
Pour information
Réalisé dans le cadre du groupe de travail IETF spring
Première rédaction de cet article le 29 mars 2018
Le sigle SPRING signifie « Source Packet Routing In NetworkinG ». C'est quoi, le routage par la source (source routing) ? Normalement, la transmission de paquets IP se fait uniquement en fonction de l'adresse de destination, chaque routeur sur le trajet prenant sa décision indépendemment des autres, et sans que l'émetteur original du paquet n'ait son mot à dire. L'idée du routage par la source est de permettre à cet émetteur d'indiquer par où il souhaite que son paquet passe. L'idée est ancienne, et resurgit de temps en temps sur l'Internet. Ce nouveau RFC décrit les cas où une solution de routage par la source serait utile.
L'idée date des débuts de l'Internet. Par exemple, la norme IPv4, le RFC 791, spécifie, dans sa section 3.1, deux mécanismes de routage par la source, « Loose Source Routing » et « Strict Source Routing ». Mais ces mécanismes sont peu déployés et vous n'avez guère de chance, si vous mettez ces options dans un paquet IP, de voir un effet. En effet, le routage par la source est dangereux, il permet des attaques variées, et il complique beaucoup le travail des routeurs. Le but du projet SPRING, dont c'est le deuxième RFC, est de faire mieux. Le cahier des charges du projet est dans le RFC 7855.
L'architecture technique de SPRING est dans le RFC 8402. Ce segment routing est déjà mis en œuvre dans le noyau Linux depuis la version 4.14 (cf. le site du projet). Notre nouveau RFC 8354 ne contient, lui, que les scénarios d'usage. (Certains étaient déjà dans la section 3 du RFC 7855.) Seul IPv6 est pris en compte.
D'abord, le cas du SOHO connecté à
plusieurs fournisseurs
d'accès. Comme chacun de ces fournisseurs n'acceptera
que des paquets dont l'adresse IP source est dans un préfixe qu'il
a alloué au client, il est essentiel de pouvoir router en fonction
de la source, afin d'envoyer les paquets ayant une adresse source
du FAI A vers le FAI A et seulement celui-ci. Voici par exemple
comment faire sur Linux, quand on veut
envoyer les paquets ayant l'adresse IP source
2001:db8:dc2:45:216:3eff:fe4b:8c5b vers un
routeur différent de l'habituel (le RFC 3178
peut être une bonne lecture, quoique daté, notamment sa section 5) :
#!/bin/sh
DEVICE=eth1
SERVICE=2001:db8:dc2:45:216:3eff:fe4b:8c5b
TABLE=CustomTable
ROUTER=2001:db8:dc2:45:1
echo 200 ${TABLE} >> /etc/iproute2/rt_tables
ip -6 rule add from ${SERVICE} table ${TABLE}
ip -6 route add default via ${ROUTER} dev ${DEVICE} table ${TABLE}
ip -6 route flush cache
Notez que la décision correcte peut être prise par la machine terminale, comme dans l'exemple ci-dessus, ou bien par un routeur situé plus loin sur le trajet (dans le projet SPRING, la source n'est pas forcément la machine terminale initiale).
Outre le fait que le FAI B rejetterait probablement les paquets ayant une adresse source qui n'est pas à lui (RFC 3704), il peut y avoir d'autres raisons pour envoyer les paquets sur une interface de sortie particulière :
- Elle est plus rapide,
- Elle est moins chère (pensez à un réseau connecté en filaire mais également à un réseau mobile avec forfait « illimité » ce qui, en langage telco, veut dire ayant des limites),
- Dans le cas du télétravailleur, il peut être souhaitable de faire passer les paquets de la machine personnelle par un FAI payé par le télétravailleur et ceux de la machine de bureau par un FAI payé par l'employeur.
Autre cas où un routage par la source peut être utile, le FAI peut s'en servir pour servir certains utilisateurs ou certains usages dans des conditions différentes, par exemple avec des prix à la tête du client. Cela viole sans doute la neutralité du réseau mais c'est peut-être un scénario qui en tentera certains (sections 2.2 et 2.5 du RFC). Cela concerne le réseau d'accès (de M. Michu au FAI) et aussi le cœur de réseau ; « l'opérateur peut vouloir configurer un chemin spécial pour les applications sensibles à la latence ».
De plus haute technologie est le scénario présenté dans la section 2.3. Ici, il s'agit d'un centre de données entièrement IPv6. Cela simplifie considérablement la gestion du réseau, et cela permet d'avoir autant d'adresses qu'on veut, sans se soucier de la pénurie d'adresses IPv4. Certains opérateurs travaillent déjà à de telles configurations. Dans ce cas, le routage par la source serait un outil puissant pour, par exemple, isoler différents types de trafic et les acheminer sur des chemins spécifiques.
Si le routage par la source, une très vieille idée, n'a jamais vraiment pris, c'est en grande partie pour des raisons de sécurité. La section 4 rappelle les risques associés, qui avaient mené à l'abandon de la solution « Type 0 Routing Header » (cf. RFC 5095).
L'article seul
RFC 8352: Energy-Efficient Features of Internet of Things Protocols
Date de publication du RFC : Avril 2018
Auteur(s) du RFC : C. Gomez (UPC), M. Kovatsch (ETH Zurich), H. Tian (China Academy of Telecommunication Research), Z. Cao (Huawei Technologies)
Pour information
Réalisé dans le cadre du groupe de travail IETF lwig
Première rédaction de cet article le 7 avril 2018
Les objets contraints, engins connectés ayant peu de capacités (un capteur de température dans la nature, par exemple), ont en général une réserve d'énergie électrique très limitée, fournie par des piles ou batteries à la capacité réduite. L'usage des protocoles de communication traditionnels, souvent très bavards, épuiserait rapidement ces réserves. Ce RFC étudie les mécanismes utilisables pour limiter la consommation électrique, et faire ainsi durer ces objets plus longtemps.
La plupart des protocoles de couche 2 utilisés pour ces « objets contraints » disposent de fonctions pour diminuer la consommation électrique. Notre RFC décrit ces fonctions, et explique comment les protocoles de couches supérieures, comme IP peuvent en tirer profit. Si vous ne connaissez pas le monde des objets contraints, et les problèmes posés par leur connexion à l'Internet, je recommande fortement la lecture des RFC 6574, RFC 7228, et RFC 7102. Le but des techniques présentées dans ce RFC est bien de faire durer plus longtemps la batterie, ce n'est pas un but écologique. Si l'objet est alimenté en permanence (une télévision connectée, ou bien un grille-pain connecté), ce n'est pas considéré comme problème.
Des tas de travaux ont déjà eu lieu sur ce problème de la diminution de la consommation électrique de ces objets. Il y a eu moins d'efforts sur celle des protocoles réseau, et ce sont ces efforts que résume ce RFC. Les protocoles traditionnels étaient conçus pour des machines alimentées en permanence et pour qui la consommation électrique n'était pas un problème. Diffuser très fréquemment une information, même inutile, n'était pas perçu comme du gaspillage, contrairement à ce qui se passe avec l'Internet des Objets. (Voir le RFC 7772 pour une solution à un tel problème.)
L'IETF a déjà développé un certain nombre de protocoles qui sont spécifiques à cet « Internet des Objets ». Ce sont par exemple 6LoWPAN (RFC 6282, RFC 6775 et RFC 4944), ou bien le protocole de routage RPL (RFC 6550) ou encore l'alternative à HTTP CoAP (RFC 7252). En gros, l'application fait tourner du CoAP sur IPv6 qui est lui-même au-dessus de 6LoWPAN, couche d'adaptation d'IP à des protocoles comme IEEE 802.15.4. Mais l'angle « économiser l'énergie » n'était pas toujours clairement mis en avant, ce que corrige notre nouveau RFC.
Qu'est ce qui coûte cher à un engin connecté (cher en terme d'énergie, la ressource rare) ? En général, faire travailler le CPU est bien moins coûteux que de faire travailler la radio, ce qui justifie une compression énergique. Et, question réseau, la réception n'est pas forcément moins coûteuse que la transmission. L'étude Powertrace est une bonne source de mesures dans ce domaine mais on peut également lire « Measuring Power Consumption of CC2530 With Z-Stack ». Le RFC contient aussi (section 2) des chiffres typiques, mesurés sur Contiki et publiés dans « The ContikiMAC Radio Duty Cycling Protocol » :
Une technique courante quand on veut réduire la consommation électrique lors de la transmission est de réduire la puissance d'émission. Mais cela réduit la portée, donc peut nécessiter d'introduire du routage, ce qui augmenterait la consommation.
On a vu que la simple écoute pouvait consommer beaucoup d'énergie. Il faut donc trouver des techniques pour qu'on puisse couper l'écoute (éteindre complètement la radio), tout en gardant la possibilité de parler à l'objet si nécessaire. Sans ce duty-cycling (couper la partie radio de l'objet, cf. RFC 7228, section 4.3), la batterie ne durerait que quelques jours, voire quelques heures, alors que certains objets doivent pouvoir fonctionner sans entretien pendant des années. Comment couper la réception tout en étant capable de recevoir des communications ? Il existe trois grandes techniques de RDC (Radio Duty-Cycling, section 3 de notre RFC) :
- Échantillonage : on n'est pas en réception la plupart du temps mais on écoute le canal à intervalles réguliers. Les objets qui veulent me parler doivent donc émettre un signal pendant une durée plus longue que la période d'échantillonage.
- Transmissions aux moments prévus. On annonce les moments où on est prêt à recevoir. Cela veut dire que les objets qui veulent parler avec moi doivent le faire au bon moment.
- Écouter quand on transmet. Dans ce cas, ceux qui ont envie de me parler doivent attendre que j'émette d'abord.
Dans les trois cas, la latence va évidemment en souffrir. On doit faire un compromis entre réduire la consommation électrique et augmenter la latence. On va également diminuer la capacité du canal puisqu'il ne pourra pas être utilisé en permanence. Ce n'est pas forcément trop grave, un capteur a peu à transmettre, en général.
Il existe plein de méthodes pour gagner quelques μJ, comme le regroupement de plusieurs paquets en un seul (il y a un coût fixe par paquet, indépendamment de leur taille). Normalement, le RDC est quelque part dans la couche 2 et les protocoles IETF, situés plus haut, ne devraient pas avoir à s'en soucier. Mais une réduction sérieuse de la consommation électrique nécessite que tout le monde participe, et que les couches hautes fassent un effort, et connaissent ce que font les couches basses, pour s'adapter.
La section 3.6 de notre RFC détaille quelques services que fournissent les protocoles de couche 2 de la famille IEEE 802.11. Une station (un objet ou un ordinateur) peut indiquer au point d'accès (AP, pour access point) qu'il va s'endormir. L'AP peut alors mémoriser les trames qui lui étaient destinées, pour les envoyer plus tard. IEEE 802.11v va plus loin en incluant des mécanismes comme le proxy ARP (répondre aux requêtes ARP à la place de l'objet endormi).
Bluetooth a un ensemble de services pour la faible consommation, nommés Bluetooth LE (pour Low Energy). 6LoWPAN peut d'ailleurs en tirer profit (cf. RFC 7668).
IEEE 802.15.4 a aussi des solutions. Il permet par exemple d'avoir deux types de réseaux, avec ou sans annonces périodiques (beacons). Dans un réseau avec annonces, des machines nommés les coordinateurs envoient régulièrement des annonces qui indiquent quand on peut émettre et quand on ne peut pas, ces dernières périodes étant le bon moment pour s'endormir afin de diminuer la consommation : on est sûr de ne rien rater. Les durées de ces périodes sont configurables par l'administrateur réseaux. Dans les réseaux sans annonces, les différentes machines connectées n'ont pas d'informations et transmettent quand elles veulent, en suivant CSMA/CA.
Enfin, DECT a aussi un mode à basse consommation, DECT ULE. Elle est également utilisable avec 6LoWPAN (RFC 8105). DECT est très asymétrique, il y a le FP (Fixed Part, la base), et le PP (Portable Part, l'objet). DECT ULE permet au FP de prévenir quand il parlera (et le PP peut dormir jusque là). À noter que si la « sieste » est trop longue (plus de dix secondes), le PP devra refaire une séquence de synchronisation avec le FP, qui peut être coûteuse en énergie. Il faut donc bien calculer son coup : si on s'endort souvent pour des périodes d'un peu plus de dix secondes, le bilan global sera sans doute négatif.
La section 4 de notre RFC couvre justement ce que devrait faire IP, en supposant qu'on utilisera 6LoWPAN. Il y a trois services importants de 6LoWPAN pour la consommation électrique :
- 6LoWPAN a un mécanisme de fragmentation et de réassemblage. IPv6 impose que les liens aient une MTU d'au moins 1 280 octets. Si ce n'est pas le cas, il faut un mécanisme de fragmentation sous IP. Mais la fragmentation n'est pas gratuite et il vaut mieux que les applications s'abstiennent de faire des paquets trop gros (un cas que traite CoAP, dans le RFC 7959).
- 6LoWPAN sait que le processeur consomme moins d'énergie que la partie radio de l'objet connecté, et qu'il est donc rentable de faire des calculs qui diminuent la quantité de données à envoyer, notamment la compression. Par exemple, 6LoWPAN permet de diminuer sérieusement la taille de l'en-tête de paquet IPv6 (normalement 40 octets), en comptant sur le fait que les paquets successifs d'un même flot se ressemblent.
- 6LoWPAN a un mécanisme de découverte du voisin optimisé pour les réseaux contraints, nommé 6LoWPAN-ND.
Il y a aussi des optimisations qui ne changent pas le protocole. Par exemple, Contiki ne suit pas, dans sa mise en œuvre, une stricte séparation des couches, afin de pouvoir optimiser l'activité réseau.
De même, les protocoles de routage doivent tenir compte des contraintes de consommation électrique (section 5 du RFC). Le protocole « officiel » de l'IETF pour le routage dans les réseaux contraints est RPL (RFC 6550). L'étude Powertrace déjà citée étudie également la consommation de RPL et montre qu'il est en effet assez efficace, si le réseau est stable (s'il ne l'est pas, on consommera évidemment du courant à envoyer et recevoir les mises à jours des routes). On peut adapter les paramètres de RPL, via l'algorithme Trickle (RFC 6206, rien à voir avec le protocole de transfert de fichiers de BitNet), pour le rendre encore plus économe, mais au prix d'une convergence plus lente lorsque le réseau change.
À noter que le RFC ne parle que de RPL, et pas des autres protocoles de routage utilisables par les objets, comme Babel (RFC 8966).
Et les applications ? La section 6 du RFC leur donne du boulot, à elles aussi. Bien sûr, il est recommandé d'utiliser CoAP (RFC 7252) plutôt que HTTP, entre autre en raison de son en-tête plus court, et de taille fixe. D'autre part, CoAP a un mode de pure observation, où le client indique son intérêt pour certaines ressources, que le serveur lui enverra automatiquement par la suite, lorsqu'elles changeront, économisant ainsi une requête. Comme HTTP, CoAP peut utiliser des relais qui mémorisent la ressource demandée, ce qui permet de récupérer des ressources sans réveiller le serveur, si l'information était dans le cache. D'autres protocoles étaient à l'étude, reprenant les principes de CoAP, pour mieux gérer les serveurs endormis. (Mais la plupart de ces projets semblent… endormis à l'heure actuelle.)
Enfin, la section 7 de notre RFC résume les points importants :
- Il ne faut pas hésiter à violer le modèle en couches, en accédant à des informations des couches basses, elles peuvent sérieusement aider à faire des économies.
- Il faut comprimer.
- Il faut se méfier de la diffusion, qui consomme davantage.
- Et il faut s'endormir souvent, pour économiser l'énergie (la méthode Gaston Lagaffe, même si le RFC ne cite pas ce pionnier).
L'article seul
RFC 8336: The ORIGIN HTTP/2 Frame
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : M. Nottingham, E. Nygren
(Akamai)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 22 mars 2018
Le concept d'origine est crucial pour la
sécurité de HTTP. L'idée est d'empêcher du
contenu actif (code JavaScript, par
exemple) d'interagir avec des serveurs autres que ceux de
l'origine, de l'endroit où on a chargé ce contenu actif. Dans la
version 1 de HTTP, cela ne posait pas (trop) de problèmes. Mais la
version 2 de HTTP permet d'avoir, dans une même connexion HTTP
vers un serveur donné, accès à des ressources d'origines
différentes (par exemple parce qu'hébergées sur des
Virtual Hosts
différents). Ce nouveau RFC ajoute donc au protocole HTTP/2 un
nouveau type de trame, ORIGIN, qui permet de
spécifier les origines utilisées dans une connexion.
L'origine est un concept ancien, mais sa description formelle n'est venue au'avec le RFC 6454, dont la lecture est fortement recommandée, avant de lire ce nouveau RFC 8336. Son application à HTTP/2, normalisé dans le RFC 7540, a posé quelques problèmes (sections 9.1.1 et 9.1.2 du RFC 7540). En effet, avec HTTP/2, des origines différentes peuvent coexister sur la même connexion HTTP. Si le serveur ne peut pas produire une réponse, par exemple parce qu'il sépare le traitement des requêtes entre des machines différentes, il va envoyer un code de retour 421, indiquant à un client HTTP de re-tenter, avec une connexion différente. Pour lui faire gagner du temps, notre nouveau RFC 8336 va indiquer préalablement les origines acceptables sur cette connexion. Le client n'aura donc pas à essayer, il saura d'avance si ça marchera ou pas. Cette méthode évite également au client HTTP de se faire des nœuds au cerveau pour déterminer si une requête pour une origine différente a des chances de réussir ou pas, processus compliqué, et qui ne marche pas toujours.
Ce n'est pas clair ? Voici un exemple concret. Le client, un
navigateur Web,
vient de démarrer et on lui demande de se connecter à
https://www.toto.example/. Il établit une
connexion TCP, puis lance
TLS, et enfin fait du HTTP/2. Dans la phase
d'établissement de la connexion TLS, il a récupéré un
certificat qui liste des noms possibles
(subjectAltName),
www.toto.example mais aussi
foobar.example. Et, justement, quelques
secondes plus tard, l'utilisateur demande à visiter
https://foobar.example/ToU/TLDR/. Un point
central de HTTP/2 est la réutilisation des connexions, pour
diminuer la latence, due entre autres
à l'établissement de connexion, qui peut être
long avec TCP et, surtout TLS. Notre navigateur va donc se dire
« chic, je garde la même connexion puisque c'est la même
adresse IP et que ce serveur m'a dit
qu'il gérait aussi foobar.example, c'était
dans son certificat » (et la section 9.1.1 du RFC 7540 le lui permet explicitement). Mais patatras,
l'adresse IP est en fait celle d'un répartiteur de
charge qui envoie les requêtes pour
www.toto.example et
foobar.example à des machines différentes. La
machine qui gère foobar.example va alors
renvoyer 421 Misdirected Request au navigateur
qui sera fort marri, et aura perdu du temps pour rien. Alors
qu'avec la trame ORIGIN de notre RFC 8336, le serveur de
www.toto.example aurait dès le début envoyé
une trame ORIGIN disant « sur cette
connexion, c'est www.toto.example et rien
d'autre ». Le navigateur aurait alors été prévenu.
La section 2 du RFC décrit en détail ce nouveau type de trame
(RFC 7540, section 4, pour le concept de
trame). Le type de la trame est 12 (cf. le registre des types), et elle contient une liste
d'origines, chacune sous forme d'un doublet longueur-valeur. Une
origine est identifiée par un nom de
domaine (RFC 6454, sections 3 et
8). Il n'y a pas de limite de taille à la liste, programmeurs,
faites attention aux débordements de
tableau. Un nom de la liste ne peut pas inclure de jokers (donc, pas d'origine
*.example.com, donc attention si vous avez
des certificats utilisant des jokers). Ce type de trames doit être envoyée sur le ruisseau HTTP/2 de
numéro 0 (celui
de contrôle).
Comme toutes les trames d'un type inconnu du récepteur, elles
sont ignorées par le destinataire. Donc, en pratique, le serveur
peut envoyer ces trames sans inquiétude, le client HTTP trop
vieux pour les connaitre les ignorera. Ces trames
ORIGIN n'ont de sens qu'en cas de liaison
directe, les relais
doivent les ignorer, et ne pas les transmettre.
Au démarrage, le client HTTP/2 a un jeu d'origines qui est
déterminé par les anciennes règles (section 9.1.1 du RFC 7540). S'il reçoit une trame
ORIGIN, celle-ci remplace complètement ce
jeu, sauf pour la première origine vue (le serveur auquel on s'est
connecté, identifié par son adresse IP et, si on utilise
HTTPS, par le nom indiqué dans l'extension
TLS SNI, cf. RFC 6066) qui, elle, reste
toujours en place. Ensuite, les
éventuelles réponses 421 (Misdirected request)
supprimeront des entrées du jeu d'origines.
Notez bien que la trame ORIGIN ne fait
qu'indiquer qu'on peut utiliser cette connexion HTTP/2 pour cette
origine. Elle n'authentifie pas le serveur. Pour cela, il faut
toujours compter sur le certificat
(cf. section 4 du RFC).
En parlant de sécurité, notez que le RFC 7540, section
9.1.1 obligeait le client HTTP/2 à vérifier le
DNS et le nom dans le
certificat, avant d'ajouter une origine. Notre nouveau RFC est
plus laxiste, on ne vérifie que le certificat quand on reçoit une
nouvelle origine dans une trame ORIGIN
envoyée sur HTTPS (cela avait suscité des réactions diverses lors
de la discussion à l'IETF). Cela veut dire qu'un méchant qui a pu avoir un
certificat valable pour un nom, via une des nombreuses
AC du magasin, n'a plus besoin de faire une
attaque de l'Homme du Milieu (avec, par
exemple, un détournement DNS). Il lui
suffit, lorsqu'un autre nom qu'il contrôle est visité, d'envoyer
une trame ORIGIN et de présenter le
certificat. Pour éviter cela, le RFC conseille au client de
vérifier le certificat plus soigneusement, par exemple avec les
journaux publics du RFC 6962, ou bien avec
une réponse OCSP (RFC 6960 montrant que le certificat n'a pas été révoqué, en
espérant qu'un certificat « pirate » sera détecté et révoqué…)
Les développeurs regarderont avec intérêt l'annexe B, qui donne
des conseils pratiques. Par exemple, si un serveur a une très
longue liste d'origines possibles, il n'est pas forcément bon de
l'envoyer dès le début de la connexion, au moment où la latence
est critique. Il vaut mieux envoyer une liste réduite, et attendre
un moment où la connexion est tranquille pour envoyer la liste
complète. (La liste des origines, dans une trame
ORIGIN, ne s'ajoute pas aux origines
précédentes, elle les remplace. Pour retirer une origine, on
envoie une nouvelle liste, sans cette origine, ou bien on compte
sur les 421. Ce point avait
suscité beaucoup de discussions au sein du groupe de travail.)
Pour l'instant, la gestion de ce nouveau type de trames ne semble se trouver que dans Firefox, et n'est dans aucun serveur, mais des programmeurs ont annoncé qu'ils allaient s'y mettre.
L'article seul
RFC 8335: PROBE: A Utility For Probing Interfaces
Date de publication du RFC : Février 2018
Auteur(s) du RFC : R. Bonica (Juniper), R. Thomas (Juniper), J. Linkova (Google), C. Lenart (Verizon), M. Boucadair (Orange)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 23 février 2018
Pour tester qu'une machine est bien joignable, vous utilisez
ping ou, plus rigoureusement, vous envoyez
un message ICMP de type
echo, auquel la machine visée va répondre
avec un message ICMP echo reply. Ce test
convient souvent mais il a plusieurs limites. L'une des
limites de ce test est qu'il ne teste qu'une seule interface
réseau de la machine, celle par laquelle vous lui parlez (deux
interfaces, dans certains cas de routage asymétrique). Si la
machine visée est un gros routeur avec
plein d'interfaces réseau, le test ne vous dira pas si toutes
fonctionnent. D'où cette extension aux messages ICMP permettant de
spécifier l'interface qu'on veut vérifier.
A priori, ce RFC ne s'intéresse qu'aux
routeurs, les serveurs
n'ayant souvent qu'une seule interface réseau. La nouvelle
technique, nommée PROBE, n'a pas de vocation
générale, contrairement à ping, et
concernera surtout les administrateurs réseau. D'autant plus que,
comme elle est assez indiscrète, elle ne sera a priori pas ouverte
au public. Notez qu'elle permet non seulement de tester une autre
interface du routeur, mais également une interface d'une machine
directement connectée au routeur. Les scénarios d'usage proposés
sont exposés dans la section 5, une liste non limitative de cas où
ping ne suffit pas :
- Interface réseau non numérotée (pas d'adresse, ce qui est relativement courant sur les routeurs),
- Interface réseau numérotée de manière purement locale (par exemple adresse IPv6 link-local),
- Absence de route vers l'interface testée (si on veut tester l'interface d'un routeur qui fait face à un point d'échange, et que le préfixe du point d'échange n'est pas annoncé par le protocole de routage, ce qui est fréquent).
En théorie, SNMP pourrait servir au moins partiellement à ces tests mais, en pratique, c'est compliqué.
ping, la technique classique, est
très sommairement décrit dans le RFC 2151,
section 3.2, mais sans indiquer comment il fonctionne. La
méthodologie est simple : la machine de test envoie un message
ICMP Echo (type 8
en IPv4 et 128 en
IPv6) à la machine visée (l'amer). L'amer répond avec un Echo
Reply (type 0 en IPv4 et 129 en IPv6). La réception
de cet Echo Reply indique que la liaison
marche bien dans les deux sens. La non-réception indique d'un
problème s'est produit, mais on n'en sait pas plus (notamment, on
ne sait pas si le problème était à l'aller ou bien au
retour). Ici, on voit le test effectué par une sonde Atlas sur l'amer
2605:4500:2:245b::42 (l'un des serveurs hébergeant ce blog), vu par tshark :
13.013422 2a02:1811:c13:1902:1ad6:c7ff:fe2a:6ac → 2605:4500:2:245b::42 ICMPv6 126 Echo (ping) request id=0x0545, seq=1, hop limit=56
13.013500 2605:4500:2:245b::42 → 2a02:1811:c13:1902:1ad6:c7ff:fe2a:6ac ICMPv6 126 Echo (ping) reply id=0x0545, seq=1, hop limit=64 (request in 11)
ICMP est normalisé dans les RFC 792 pour IPv4 et RFC 4443 pour IPv6. L'exemple ci-dessus montre un test classique, avec une requête et une réponse.
Notre RFC parle d'« interface testée » (probed interface) et d'« interface testante » (probing interface). Dans l'exemple ci-dessus, l'interface Ethernet de l'Atlas était la testante et celle du serveur était la testée. Le succès du test montre que les deux interfaces sont actives et peuvent se parler.
Au contraire de ping, PROBE va envoyer le
message, non pas à l'interface testée mais à une interface
« relais » (proxy). Celle-ci répondra si
l'interface testée fonctionne bien (état
oper-status, cf. RFC 7223). Si l'interface testée n'est pas sur le nœud qui
sert de relais, ce dernier détermine l'état de cette interface en
regardant la table ARP (RFC 826) ou NDP (RFC 4861). Aucun test actif n'est effectué, l'interface est
considérée comme active si on lui a parlé récemment (et donc si
l'adresse IP est dans un cache). PROBE utilise, comme ping,
ICMP. Il se sert des messages ICMP structurés du RFC 4884. Une des parties du message structuré sert à
identifier l'interface testée.
L'extension à ICMP Extended Echo est décrite en section 2 du RFC. Le type de la requête est 42 pour IPv4 et 160 pour IPv6 (enregistré à l'IANA, pour IPv4 et IPv6). Parmi les champs qu'elle comprend (les deux premiers existent aussi pour l'ICMP Echo traditionnel) :
- Un identificateur qui peut servir à faire correspondre une réponse à une requête (ICMP, comme IP, n'a pas de connexion ou de session, chaque paquet est indépendant), 0x0545 dans l'exemple vu plus haut avec tshark,
- Un numéro de séquence, qui peut indiquer les paquets successifs d'un même test, 1 dans l'exemple vu plus haut avec tshark
- Un bit nommé L (local) qui indique si l'interface testée est sur le nœud visé par le test ou non,
- Une structure qui indique l'interface testée.
Cette structure suit la forme décrite dans la section 7 du RFC 4884. Elle contient un objet d'identification de l'interface. L'interface qu'on teste peut être désignée par son adresse IP (si elle n'est pas locale - bit L à zéro, c'est la seule méthode acceptée), son nom ou son index. Notez que l'adresse IP identifiant l'adresse testée n'est pas forcément de la même famille que celle du message ICMP. On peut envoyer en IPv4 un message ICMP demandant à la machine distante de tester une interface IPv6.
Plus précisément, l'objet d'identification de l'interface est composé, comme tous les objets du RFC 4884, d'un en-tête et d'une charge utile. L'en-tête contient les champs :
- Un numéro de classe, 3, stocké à l'IANA,
- Un numéro indiquant comment l'interface testée est désignée (1 =
par nom, cf. RFC 7223, 2 = par index, le même qu'en
SNMP, voir aussi le RFC 7223, section 3, le concept de
if-index, et enfin 3 = par adresse), - La longueur des données.
L'adresse est représentée elle-même par une structure à trois champs, la famille (4 pour IPv4 et 6 pour IPv6), la longueur et la valeur de l'adresse. Notez que le RFC 5837 a un mécanisme de description de l'interface, portant le numéro de classe 2, et utilisé dans un contexte proche.
La réponse à ces requêtes a le type 43 en IPv4 et 161 en IPv6 (section 3 du RFC). Elle comprend :
- Un code (il valait toujours 0 pour la requête) qui indique le résultat du test : 0 est un succès, 1 signale que la requête était malformée, 2 que l'interface à tester n'existe pas, 3 qu'il n'y a pas de telle entrée dans la table des interfaces, et 4 que plusieurs interfaces correspondent à la demande (liste complète dans un registre IANA),
- Un identificateur, copié depuis la requête,
- Un numéro de séquence, copié depuis la requête,
- Un état qui donne des détails en cas de code 0 (autrement, pas besoin de détails) : si l'interface testée n'est pas locale, l'état vaut 2 si l'entrée dans le cache ARP ou NDP est active, 1 si elle est incomplète (ce qui indique typiquement que l'interface testée n'a pas répondu), 3 si elle n'est plus à jour, etc,
- Un bit A (active) qui est mis à un si l'interface testée est locale et fonctionne,
- Un bit nommé 4 (pour IPv4) qui indique si IPv4 tourne sur l'interface testée,
- Un bit nommé 6 (pour IPv6) qui indique si IPv6 tourne sur l'interface testée.
La section 4 du RFC détaille le traitement que doit faire la machine qui reçoit l'ICMP Extended Echo. D'abord, elle doit jeter le paquet (sans répondre) si ICMP Extended Echo n'est pas explicitement activé (rappelez-vous que ce service est assez indiscret, cf. section 8 du RFC) ou bien si l'adresse IP de la machine testante n'est pas autorisée (même remarque). Si les tests sont passés et que la requête est acceptée, la machine réceptrice fabrique une réponse : le code est mis à 1 si la requête est anormale (pas de partie structurée par exemple), 2 si l'interface testée n'existe pas, 3 si elle n'est pas locale et n'apparait pas dans les tables (caches) ARP ou NDP. Si on trouve l'interface, on la teste et on remplit les bits A, 4, 6 et l'état, en fonction de ce qu'on trouve sur l'interface testée.
Reste la question de la sécurité (section 8 du RFC). Comme
beaucoup de mécanismes, PROBE peut être utilisé pour le bien
(l'administrateur réseaux qui détermine
l'état d'une interface d'un routeur dont il s'occupe), mais aussi
pour le mal (chercher à récolter des informations sur un réseau
avant une attaque, par exemple, d'autant plus que les noms
d'interfaces dans les routeurs peuvent être assez parlants,
révélant le type de réseau, le modèle de routeur…) Le RFC exige
donc que le mécanisme ICMP Extended Echo ne
soit pas activé par défaut, et soit configurable (liste blanche
d'adresses IP autorisées, permission - ou non - de tester des
interfaces non locales, protection des différents réseaux les uns
contre les autres, si on y accueille des clients différents…) Et, bien sûr, il faut pouvoir
limiter le nombre de messages.
Ne comptez pas utilise PROBE tout de suite. Il n'existe
apparemment pas de mise en œuvre de ce mécanisme
publiée. Juniper en a réalisé une mais elle
n'apparait encore dans aucune version de JunOS.
L'article seul
RFC 8334: Launch Phase Mapping for the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : J. Gould (VeriSign), W. Tan (Cloud Registry), G. Brown (CentralNic)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 5 mars 2018
Les registres de noms de domaine ont parfois des périodes d'enregistrement spéciales, par exemple lors de la phase de lancement d'un nouveau domaine d'enregistrement, ou bien lorsque les règles d'enregistrement changent. Pendant ces périodes, les conditions d'enregistrement ne sont pas les mêmes que pendant les périodes « standards ». Les registres qui utilisent le protocole EPP pour l'enregistrement peuvent alors utiliser les extensions EPP de ce nouveau RFC pour gérer ces périodes spéciales.
Un exemple de période spéciale est l'ouverture d'un tout nouveau TLD à l'enregistrement. Un autre exemple est une libéralisation de l'enregistrement, passant par exemple de vérifications a priori strictes à un modèle plus ouvert. Dans les deux cas, on peut voir des conflits se faire jour, par exemple entre le titulaire le plus rapide à enregistrer un nom, et un détenteur de propriété intellectuelle qui voudrait reprendre le nom. Les périodes spéciales sont donc définies par des privilèges particuliers pour certains utilisateurs, permettant par exemple aux titulaires d'une marque déposée d'avoir un avantage pour le nom de domaine correspondant à cette marque. La période spéciale est qualifiée de « phase de lancement » (launch phase). Les extensions à EPP décrites dans ce nouveau RFC permettent de mettre en œuvre ces privilèges.
La classe (mapping) décrivant les domaines en EPP figure dans le RFC 5731. Elle est prévue pour le fonctionnement standard du registre, sans intégrer les périodes spéciales. Par exemple, en fonctionnement standard, une fois que quelqu'un a enregistré un nom, c'est fini, personne d'autre ne peut le faire. Mais dans les phases de lancement, il arrive qu'on accepte plusieurs candidatures pour un même nom, qui sera ensuite attribué en fonction de divers critères (y compris parfois une mise aux enchères). Ou bien il peut y avoir des vérifications supplémentaires pendant une phase de lancement. Par exemple, certaines phases peuvent être réservées aux titulaires de propriété intellectuelle, et cela est vérifié via un organisme de validation, comme la TMCH (RFC 7848).
D'où ce RFC qui étend la classe domain
du RFC 5731. La section 2 du RFC décrit les
nouveaux attributs et éléments des domaines, la section 3 la façon de les
utiliser dans les commandes EPP et la
section 4 donne le schéma XML. Voyons
d'abord les nouveaux éléments et attributs.
D'abord, comme il peut y avoir plusieurs candidatures pour un
même nom, il faut un moyen de les distinguer. C'est le but de
l'identificateur de candidature (application
identifier). Lorsque le serveur EPP reçoit une commande
<domain:create> pour un nom, il attribue un
identificateur de candidature, qu'il renvoie au client, dans un
élément <launch:applicationID>, tout en
indiquant que le domaine est en état
pendingCreate (RFC 5731, section 2.3) puisque le domaine n'a pas encore été
créé.
Au passage, launch dans
<launch:applicationID> est une
abréviation pour l'espace de noms XML
urn:ietf:params:xml:ns:launch-1.0. Un
processeur XML correct ne doit évidemment pas tenir compte de
l'abréviation (qui peut être ce qu'on veut) mais uniquement de
l'espace de noms associé. Cet espace est désormais enregistré
à l'IANA (cf. RFC 3688).
Autre nouveauté, comme un serveur peut utiliser plusieurs
organismes de validation d'une marque
déposée, il existe désormais un attribut
validatorID qui indique l'organisme. Par
défaut, c'est la TMCH (identificateur
tmch). On pourra utiliser cet attribut
lorsqu'on indiquera un identificateur de marque, par exemple
lorsqu'on se sert de l'élément
<mark:mark> du RFC 7848.
Les périodes spéciales ont souvent plusieurs phases, et notre
RFC en définit plusieurs (dans une ouverture réelle, toutes ne
sont pas forcément utilisées), qui seront utilisées dans l'élément
<launch:phase> :
- Lever de soleil (sunrise), phase où les titulaires de marques (le RFC ne mentionne pas d'autres cas, comme le nom de l'entreprise ou d'une ville) peuvent seuls soumettre des candidatures, la marque étant validée par exemple via la TMCH,
- Prétentions (claims), où on peut
enregistrer si on n'a pas de marque, mais on reçoit alors une
notice disant qu'une marque similaire existe (elle est décrite
plus en détail dans
l'Internet-Draft
draft-ietf-regext-tmch-func-spec), et on peut alors renoncer ou continuer (si on est d'humeur à affronter les avocats de la propriété intellectuelle), en annonçant, si on continue « oui, j'ai vu, j'y vais quand même », - Ruée (landrush), phase immédiatement après l'ouverture, quand tout le monde et son chien peuvent se précipiter pour enregistrer,
- État ouvert (open), une fois qu'on a atteint le régime de croisière.
La section 2 définit aussi les états d'une candidature. Notamment :
pendingValidation(validation en attente),validated(c'est bon, mais voyez plus loin),invalid(raté, vous n'avez pas de droits sur ce nom),pendingAllocation(une fois qu'on est validé, tout n'est pas fini, il peut y avoir plusieurs candidatures, avec un mécanisme de sélection, par exemple fondé sur une enchère),allocated(c'est vraiment bon),rejected(c'est fichu…)
Les changements d'état ne sont pas forcément synchrones. Parfois, il faut attendre une validation manuelle, par exemple. Dans cas, il faut notifier le client EPP, ce qui se fait avec le mécanisme des messages asynchrones (poll message) du RFC 5730, section 2.9.2.3.
Comme toutes les extensions EPP, elle n'est utilisée par le client que si le serveur l'indique à l'ouverture de la session, en listant les espaces de noms XML des extensions qu'il accepte, par exemple :
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<greeting><svID>EPP beautiful server for .example</svID>
<svDate>2018-02-20T15:37:20.0Z</svDate>
<svcMenu><version>1.0</version><lang>en</lang>
<objURI>urn:ietf:params:xml:ns:domain-1.0</objURI>
<objURI>urn:ietf:params:xml:ns:contact-1.0</objURI>
<svcExtension>
<extURI>urn:ietf:params:xml:ns:rgp-1.0</extURI>
<extURI>urn:ietf:params:xml:ns:secDNS-1.1</extURI>
<extURI>urn:ietf:params:xml:ns:launch-1.0</extURI>
</svcExtension>
</svcMenu>
</greeting>
</epp>
Maintenant qu'on a défini les données, la section 3 du RFC
explique comment les utiliser. (Dans tous les exemples ci-dessous,
C: identifie ce qui est envoyé par le client
EPP et S: ce que le serveur répond.) Par exemple, la commande EPP
<check> (RFC 5730,
section 2.9.2.1) sert à vérifier si on peut enregistrer un objet
(ici, un nom de domaine). Elle prend ici des éléments
supplémentaires, par exemple pour tester si un nom correspond à
une marque. Ici, on demande si une marque existe (notez
l'extension <launch:check>) :
C:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
C: <command>
C: <check>
C: <domain:check
C: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
C: <domain:name>domain1.example</domain:name>
C: </domain:check>
C: </check>
C: <extension>
C: <launch:check
C: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0"
C: type="trademark"/>
C: </extension>
C: </command>
C:</epp>
Et on a la réponse (oui, la marque existe dans la TMCH) :
S:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
S: <response>
S: <result code="1000">
S: <msg>Command completed successfully</msg>
S: </result>
S: <extension>
S: <launch:chkData
S: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0">
S: <launch:cd>
S: <launch:name exists="1">domain1.example</launch:name>
S: <launch:claimKey validatorID="tmch">
S: 2013041500/2/6/9/rJ1NrDO92vDsAzf7EQzgjX4R0000000001
S: </launch:claimKey>
S: </launch:cd>
S: </launch:chkData>
S: </extension>
S: </response>
S:</epp>
Avec la commande EPP <info>, qui
sert à récupérer des informations sur un nom, on voit ici qu'un
nom est en attente (pendingCreate), et on a
l'affichage de la phase actuelle du lancement, dans l'élément
<launch:phase> :
C:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
C: <command>
C: <info>
C: <domain:info
C: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
C: <domain:name>domain.example</domain:name>
C: </domain:info>
C: </info>
C: <extension>
C: <launch:info
C: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0"
C: includeMark="true">
C: <launch:phase>sunrise</launch:phase>
C: </launch:info>
C: </extension>
C: </command>
C:</epp>
Et le résultat, avec entre autre l'identificateur de candidature :
S:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
S: <response>
S: <result code="1000">
S: <msg>Command completed successfully</msg>
S: </result>
S: <resData>
S: <domain:infData
S: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
S: <domain:name>domain.example</domain:name>
S: <domain:status s="pendingCreate"/>
S: <domain:registrant>jd1234</domain:registrant>
S: <domain:contact type="admin">sh8013</domain:contact>
S: <domain:crDate>2012-04-03T22:00:00.0Z</domain:crDate>
...
S: </domain:infData>
S: </resData>
S: <extension>
S: <launch:infData
S: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0">
S: <launch:phase>sunrise</launch:phase>
S: <launch:applicationID>abc123</launch:applicationID>
S: <launch:status s="pendingValidation"/>
S: <mark:mark
S: xmlns:mark="urn:ietf:params:xml:ns:mark-1.0">
S: ...
S: </mark:mark>
S: </launch:infData>
S: </extension>
S: </response>
S:</epp>
C'est bien joli d'avoir des informations mais, maintenant, on
voudrait créer des noms de domaine. La commande EPP
<create> (RFC 5730, section 2.9.3.1) sert à cela. Selon la phase de
lancement, il faut lui passer des extensions différentes. Pendant
le lever de soleil (sunrise), il faut indiquer
la marque déposée sur laquelle on s'appuie, dans
<launch:codeMark> (il y a d'autres
moyens de l'indiquer, cf. section 2.6) :
C:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
C: <command>
C: <create>
C: <domain:create
C: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
C: <domain:name>domain.example</domain:name>
C: <domain:registrant>jd1234</domain:registrant>
...
C: </domain:create>
C: </create>
C: <extension>
C: <launch:create
C: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0">
C: <launch:phase>sunrise</launch:phase>
C: <launch:codeMark>
C: <launch:code validatorID="sample1">
C: 49FD46E6C4B45C55D4AC</launch:code>
C: </launch:codeMark>
C: </launch:create>
C: </extension>
C: </command>
C:</epp>
On reçoit une réponse qui dit que le domaine n'est pas encore
créé, mais on a un identificateur de candidature (un numéro de
ticket, quoi) en <launch:applicationID>. Notez le code de retour 1001 (j'ai
compris mais je ne vais pas le faire tout de suite) et non pas
1000, comme ce serait le cas en régime de croisière :
S:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
S: <response>
S: <result code="1001">
S: <msg>Command completed successfully; action pending</msg>
S: </result>
S: <resData>
S: <domain:creData
S: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
S: <domain:name>domain.example</domain:name>
S: <domain:crDate>2010-08-10T15:38:26.623854Z</domain:crDate>
S: </domain:creData>
S: </resData>
S: <extension>
S: <launch:creData
S: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0">
S: <launch:phase>sunrise</launch:phase>
S: <launch:applicationID>2393-9323-E08C-03B1
S: </launch:applicationID>
S: </launch:creData>
S: </extension>
S: </response>
S:</epp>
De même, des extensions permettent de créer un domaine pendant la phase où il faut indiquer qu'on a vu les prétentions qu'avait un titulaire de marque sur ce nom. Le RFC décrit aussi l'extension à utiliser dans la phase de ruée (landrush), mais j'avoue n'avoir pas compris son usage (puisque, pendant la ruée, les règles habituelles s'appliquent).
On peut également retirer une candidature, avec la commande EPP
<delete> qui, en mode standard, sert à
supprimer un domaine. Il faut alors indiquer l'identifiant de la
candidature qu'on retire :
C:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
C: <command>
C: <delete>
C: <domain:delete
C: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
C: <domain:name>domain.example</domain:name>
C: </domain:delete>
C: </delete>
C: <extension>
C: <launch:delete
C: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0">
C: <launch:phase>sunrise</launch:phase>
C: <launch:applicationID>abc123</launch:applicationID>
C: </launch:delete>
C: </extension>
C: </command>
C:</epp>
Et les messages non sollicités (poll), envoyés de manière asynchrone par le serveur ? Voici un exemple, où le serveur indique que la candidature a été jugée valide (le mécanisme par lequel on passe d'un état à un autre dépend de la politique du serveur) :
S:<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
S: <response>
S: <result code="1301">
S: <msg>Command completed successfully; ack to dequeue</msg>
S: </result>
S: <msgQ count="5" id="12345">
S: <qDate>2013-04-04T22:01:00.0Z</qDate>
S: <msg>Application pendingAllocation.</msg>
S: </msgQ>
S: <resData>
S: <domain:infData
S: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
S: <domain:name>domain.example</domain:name>
S: ...
S: </domain:infData>
S: </resData>
S: <extension>
S: <launch:infData
S: xmlns:launch="urn:ietf:params:xml:ns:launch-1.0">
S: <launch:phase>sunrise</launch:phase>
S: <launch:applicationID>abc123</launch:applicationID>
S: <launch:status s="pendingAllocation"/>
S: </launch:infData>
S: </extension>
S: </response>
S:</epp>
Voilà, vous savez l'essentiel, si vous voulez tous les détails, il faudra lire la section 3 complète, ainsi que la section 4, qui contient le schéma XML des extensions pour les phases de lancement. Comme toutes les extensions à EPP, celle de ce RFC est désormais dans le registre des extensions EPP, décrit dans le RFC 7451.
Notez que ce RFC ne fournit pas de moyen pour indiquer au client EPP quelle est la politique d'enregistrement pendant la période spéciale. Cela doit être fait par un mécanisme externe (page Web du registre, par exemple).
Quelles sont les mises en œuvre de ce RFC ? L'extension pour les phases de lancement est ancienne (première description en 2011) et de nombreux registres offrent désormais cette possibilité. C'est d'autant plus vrai que l'ICANN impose aux registres de ses nouveaux TLD de gérer les phases de lancement avec cette extension. Ainsi :
- Le kit de développement de clients EPP de Verisign a cette extension, sous une licence libre.
- Logiquement, le système d'enregistrement de Verisign,
utilisé notamment pour
.comet.net(mais également pour bien d'autres TLD) gère cette extension (code non libre et non public, cette fois). - Le serveur REngin (non libre),
utilisé pour
.zaa aussi cette extension. - Le serveur de CentralNIC, pareil.
- Le client EPP distribué par Neustar est sous licence libre et sait gérer les phases de lancement.
- Le serveur (non libre) de SIDN (qui
gère le domaine national
.nl) fait partie de ceux qui ont mis en œuvre ce RFC. - Et côté client, il y a le logiciel libre Net::DRI
(extension ajoutée dans une scission nommée
tdw, pas dans le logiciel originel de Patrick Mevzek), cf.LaunchPhase.pm.
L'article seul
RFC 8332: Use of RSA Keys with SHA-256 and SHA-512 in the Secure Shell (SSH) Protocol
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : D. Bider (Bitvise)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 21 mars 2018
Les RFC normalisant le protocole SSH mentionnaient la possibilité pour le serveur d'avoir une clé publique RSA, mais uniquement avec l'algorithme de condensation SHA-1. Celui-ci a subi plusieurs attaques et n'est plus du tout conseillé aujourd'hui. Ce nouveau RFC est la description officielle de l'utilisation de RSA avec SHA-2 dans SSH.
Le RFC officiel du protocole
SSH, le RFC 4253,
définit l'algorithme ssh-rsa comme utilisant
the SHA-1 hash pour la signature et la vérification. Ce n'est plus cohérent avec ce
qu'on sait aujourd'hui des faiblesses de
SHA-1. Par exemple, le NIST
(dont les règles s'imposent aux organismes gouvernementaux
états-uniens), interdit
SHA-1 (voir aussi la section 5.1 du RFC).
(Petit point au passage, dans SSH, le format de la clé ne
désigne que la clé elle-même, alors que l'algorithme désigne un
format de clé et des procédures de signature et de vérification,
qui impliquent un algorithme de
condensation. Ainsi, ssh-keygen
-t rsa va générer une clé RSA, indépendamment de
l'algorithme qui sera utilisé lors d'une session SSH. Le registre IANA indique désormais séparement le
format et l'algorithme.)
Notre nouveau RFC définit donc deux nouveaux algorithmes :
rsa-sha2-256, qui utilise SHA-256 pour la condensation, et dont la mise en œuvre est recommandée pour tout programme ayant SSH,- et
rsa-sha2-512, qui utilise SHA-512 et dont la mise en œuvre est facultative.
Les deux algorithmes sont maintenant dans le
registre IANA. Le format, lui, ne change pas, et est toujours qualifié de
ssh-rsa (RFC 4253,
section 3.) Il n'est donc pas nécessaire de
changer ses clés RSA. (Si vous utilisez RSA : SSH permet d'autres
algorithmes de cryptographie
asymétrique, voir également la section 5.1 du RFC.)
Les deux « nouveaux » (ils sont déjà présents dans plusieurs
programmes SSH) algorithmes peuvent être utilisés aussi bien pour
l'authentification du client que pour celle du serveur. Ici, par
exemple, un serveur OpenSSH version 7.6p1
annonce les algorithme qu'il connait (section 3.1 de notre RFC), affichés par un client
OpenSSH utilisant l'option -v :
debug1: kex_input_ext_info: server-sig-algs=<ssh-ed25519,ssh-rsa,rsa-sha2-256,rsa-sha2-512,ssh-dss,ecdsa-sha2-nistp256,ecdsa-sha2-nistp384,ecdsa-sha2-nistp521>
On y voit la présence des deux nouveaux
algorithmes. ssh-rsa est celui du RFC 4253, avec SHA-1 (non explicitement indiqué).
En parlant d'OpenSSH, la version 7.2
avait une bogue (corrigée en 7.2p2), qui faisait que la signature
était étiquetée ssh-rsa quand elle aurait dû
l'être avec rsa-sha2-256 ou
rsa-sha2-512. Pour compenser cette bogue, le
RFC autorise les programmes à accepter ces signatures quand même.
Autre petit piège pratique (et qui a suscité les discussions
les plus vives dans le groupe de travail), certains serveurs SSH « punissent »
les clients qui essaient de s'authentifier avec des algorithmes que le serveur ne sait
pas gèrer, pour diminuer l'efficacité d'éventuelles
attaques par repli. Pour éviter d'être
pénalisé (serveur qui raccroche brutalement, voire qui vous met en
liste noire), le RFC recommande que les serveurs déploient
le protocole qui permet de négocier des extensions,
protocole normalisé dans le RFC 8308. (L'extension intéressante est server-sig-algs.) Le
client prudent peut éviter d'essayer les nouveaux
algorithmes utilisant SHA-2, si le serveur n'annonce pas cette
extension. L'ancien algorithme, utilisant SHA-1, devrait
normalement être abandonné au fur et à mesure que tout le monde migre.
Les nouveaux algorithmes de ce RFC sont présents dans :
Vous pouvez aussi regarder le
tableau de comparaison des versions de SSH. Voici encore un
ssh -v vers un serveur dont la clé de machine
est RSA et qui utilise l'algorithme RSA-avec-SHA512 :
... debug1: kex: host key algorithm: rsa-sha2-512 ... debug1: Server host key: ssh-rsa SHA256:yiol3GPr1dgVo/SNXPvtFqftLw4UF+nL+ECa1yXAtG0 ...
Par comparaison avec les SSH récents, voici un ssh -v
OpenSSH vers un serveur un peu vieux :
debug1: kex_input_ext_info: server-sig-algs=<ssh-ed25519,ssh-rsa,ssh-dss,ecdsa-sha2-nistp256,ecdsa-sha2-nistp384,ecdsa-sha2-nistp521>
On voit que les nouveaux algorithmes manquent (pour RSA ; SHA-2 est utilisable pour ECDSA). Et pour sa clé de machine :
... debug1: kex: host key algorithm: ssh-rsa ... debug1: Server host key: ssh-rsa SHA256:a6cLkwFRGuEorbmN0oRjvKrXELhIVXdgHRCcbQOM2w8
Le serveur utilise le vieil algorithme,
ssh-rsa, ce qui veut dire SHA-1 (le
SHA256 qui apparait a été généré par le client).
L'article seul
RFC 8326: Graceful BGP Session Shutdown
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : P. Francois, B. Decraene (Orange), C. Pelsser (Strasbourg University), K. Patel (Arrcus), C. Filsfils (Cisco Systems)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF grow
Première rédaction de cet article le 7 mars 2018
Voici une nouvelle communauté BGP,
GRACEFUL_SHUTDOWN, qui va permettre
d'annoncer une route à son pair BGP, tout en l'avertissant que le
lien par lequel elle passe va être bientôt coupé pour
une maintenance prévue. Le pair pourra alors automatiquement limiter l'usage de cette route
et chercher tout de suite des alternatives. Cela évitera les
pertes de paquets qui se produisent quand
on arrête un lien ou un
routeur.
Le protocole BGP (RFC 4271) qui assure le routage entre
les AS qui composent
l'Internet permet aux routeurs d'échanger des informations
entre eux « pour aller vers
2001:db8:bc9::/48, passe donc par moi ». Avec
ces informations, chaque routeur calcule les routes à suivre pour
chaque destination. Une fois que c'est fait, tout le monde se
repose ? Non, parce qu'il y a tout le temps des
changements. Certains peuvent être imprévus et accidentels (la
fameuse pelleteuse), d'autres sont planifiés à
l'avance : ce sont les opérations de maintenance « le 7 février à
2300 UTC, nous allons remplacer une
line card du routeur, coupant
toutes les sessions BGP de cette carte ». Voici par exemple un
message reçu sur la liste de diffusion des
opérateurs connectés au France-IX :
Date: Wed, 31 Jan 2018 15:57:34 +0000
From: Quelqu'un <quelquun@opérateur>
To: "paris@members.franceix.net" <paris@members.franceix.net>
Subject: [FranceIX members] [Paris] [OPÉRATEUR/ASXXXXX] - France-IX port maintenance
Dear peers,
Tomorrow morning CEST, we will be conducting a maintenance that will
impact one of our connection to France-IX (IPs: x.y.z.t/2001:x:y:z::t).
All sessions will be shut down before and brought back up once the maintenance will be over.
Please note that our MAC address will change as the link will be migrated to a new router.
Cheers
Lorsqu'une telle opération est effectuée, le résultat est le
même que pour une coupure imprévue : les sessions BGP sont
coupées, les routeurs retirent les routes apprises via ces
sessions, et vont chercher d'autres routes dans les annonces
qu'ils ont reçues. Ils propagent ensuite ces changements à leurs
voisins, jusqu'à ce que tout l'Internet soit au courant. Le
problème est que cela prend du temps (quelques secondes au moins,
des dizaines de secondes, parfois, à moins que les routeurs
n'utilisent le RFC 7911 mais ce n'est pas
toujours le cas). Et pendant ce temps, les paquets continuent à
arriver à des routeurs qui ne savent plus les traiter (section 3
du RFC). Ces paquets seront jetés, et devront être réémis (pour le
cas de TCP). Ce n'est pas
satisfaisant. Bien sûr, quand la coupure est imprévue, il n'y a
pas le choix. Mais quand elle est planifiée, on devrait pouvoir
faire mieux, avertir les routeurs qu'ils devraient cesser
d'utiliser cette route. C'est justement ce que permet la nouvelle
communauté GRACEFUL_SHUTDOWN. (Les
communautés BGP sont décrites dans le RFC 1997.) Elle s'utilise avant la
coupure, indiquant aux pairs qu'ils devraient commencer le
recalcul des routes, mais qu'ils peuvent continuer à utiliser les
anciennes routes pendant ce temps. (Notez qu'un cahier des charges
avait été établi pour ce problème, le RFC 6198. Et que ce projet d'une communauté pour les arrêts
planifiés est ancien, au moins dix ans.)
Ce RFC décrit donc deux choses, la
nouvelle communauté normalisée,
GRACEFUL_SHUTDOWN (section 5), et la procédure à utiliser
pour s'en servir proprement (section 4). L'idée est que les routes
qui vont bientôt être coupées pour maintenance restent utilisées,
mais avec une préférence locale très faible (la valeur 0 est
recommandée, la plus petite valeur possible). La notion de
préférence locale est décrite dans le RFC 4271, section 5.1.5. Comme son nom l'indique, elle est
locale à un AS, et représente sa préférence
(décidée unilatéralement) pour une route plutôt que pour une
autre. Lors du choix d'une route par BGP, c'est le premier critère
consulté.
Pour mettre en œuvre cette idée, chaque routeur au bord des
AS (ASBR, pour Autonomous System
Border Router) doit avoir une règle qui, lorsqu'une
annonce de route arrive avec la communauté
GRACEFUL_SHUTDOWN, applique une préférence
locale de 0. Notez que cela peut se faire avec les routeurs
actuels, aucun code nouveau n'est nécessaire, ce RFC ne décrit
qu'une procédure. Une fois que cette règle est en place, tout le
reste sera automatique, chez les pairs de l'AS qui coupe un lien
ou un routeur.
Et l'AS qui procéde à une opération de maintenance, que doit-il faire ? Dans l'ordre :
- Sur la·es session·s BGP qui va·ont être coupée·s,
appliquer la communauté
GRACEFUL_SHUTDOWNaux routes qu'on annonce (outbound policy), - Sur la·es session·s BGP qui va·ont être coupée·s, appliquer la communauté
GRACEFUL_SHUTDOWNaux routes qu'on reçoit (inbound policy), et mettre leur préférence locale à zéro, - Attendre patiemment que tout le monde ait convergé (propagation des annonces),
- Procéder à l'opération de maintenance, qui va couper BGP (et c'est plus joli si on utilise le RFC 9003).
J'ai dit plus haut qu'il n'était pas nécessaire de modifier le
logiciel des routeurs BGP mais évidemment tout est plus simple
s'ils connaissent la communauté
GRACEFUL_SHUTDOWN et simplifient ainsi la
tâche de l'administrateur réseaux. Cette communauté est « bien
connue » (elle n'est pas spécifique à un
AS), décrite
dans la section 5 du RFC, enregistrée à
l'IANA et sa valeur est 0xFFFF0000 (qui peut aussi s'écrire
65535:0, dans la notation habituelle des communautés).
La section 6 du RFC fait le tour de la sécurité de ce
système. Comme il permet d'influencer le routage chez les pairs
(on annonce une route avec la communauté
GRACEFUL_SHUTDOWN et paf, le pair met une
très faible préférence à ces routes), il ouvre la porte à de
l'ingénierie du trafic pas toujours
bienveillante. Il est donc prudent de regarder ce qu'annoncent ses
pairs, et d'engueuler ou de dépairer ceux et celles qui abusent de
ce mécanisme.
Pour les amateurs de solutions alternatives, l'annexe A
explique les autres techniques qui auraient pu être utilisées lors
de la réception des routes marquées avec GRACEFUL_SHUTDOWN. Au
lieu d'influencer la préférence locale, on aurait par exemple pu utiliser le
MED (multi-exit discriminator, RFC 4271, section 5.1.4) mais il n'est considéré par les
pairs qu'après d'autres critères, et il ne garantit donc pas que
le lien bientôt coupé ne sera plus utilisé.
L'annexe B donne des exemples de configuration pour différents types de routeurs. (Configurations pour l'AS qui reçoit la notification d'un arrêt proche, pas pour ceux qui émettent.) Ainsi, pour IOS XR :
! 65535:0 = 0xFFFF0000
community-set comm-graceful-shutdown
65535:0
end-set
route-policy AS64497-ebgp-inbound
! Règles appliquées aux annonces reçues du pair, l'AS 64497. Bien
! sûr, en vrai, il y aurait plein d'autres règles, par exemple de filtrage.
if community matches-any comm-graceful-shutdown then
set local-preference 0
endif
! On a appliqué la règle du RFC : mettre la plus faible
! préférence locale possible
end-policy
! La configuration de la session BGP avec le pair
router bgp 64496
neighbor 2001:db8:1:2::1
remote-as 64497
address-family ipv6 unicast
send-community-ebgp
route-policy AS64497-ebgp-inbound in
Pour BIRD, cela sera :
# (65535, 0) = 0xFFFF0000
function honor_graceful_shutdown() {
if (65535, 0) ~ bgp_community then {
bgp_local_pref = 0;
}
}
filter AS64497_ebgp_inbound
{
# Règles appliquées aux annonces reçues du pair, l'AS 64497. Bien
# sûr, en vrai, il y aurait plein d'autres règles, par
# exemple de filtrage.
honor_graceful_shutdown();
}
protocol bgp peer_64497_1 {
neighbor 2001:db8:1:2::1 as 64497;
local as 64496;
import keep filtered;
import filter AS64497_ebgp_inbound;
}
Et sur OpenBGPD (on voit qu'il connait
GRACEFUL_SHUTDOWN, il n'y a pas besoin de
donner sa valeur) :
AS 64496
router-id 192.0.2.1
neighbor 2001:db8:1:2::1 {
remote-as 64497
}
# Règles appliquées aux annonces reçues du pair, l'AS 64497. Bien
# sûr, en vrai, il y aurait plein d'autres règles, par exemple de filtrage.
match from any community GRACEFUL_SHUTDOWN set { localpref 0 }
Enfin, l'annexe C du RFC décrit quelques détails supplémentaires, par exemple pour IBGP (BGP interne à un AS).
Notez que ce nouveau RFC est prévu pour le cas où la transmission des paquets (forwarding plane) est affectée. Si c'est uniquement la session BGP (control plane) qui est touchée, la solution du RFC 4724, Graceful Restart, est plus appropriée.
L'article seul
RFC 8324: DNS Privacy, Authorization, Special Uses, Encoding, Characters, Matching, and Root Structure: Time for Another Look?
Date de publication du RFC : Février 2018
Auteur(s) du RFC : J. Klensin
Pour information
Première rédaction de cet article le 28 février 2018
Le DNS est une infrastructure essentielle
de l'Internet. S'il est en panne, rien ne marche (sauf si vous
faites partie de la minorité qui fait uniquement des ping
-n et des traceroute -n). S'il est
lent, tout rame. Comme le DNS, heureusement, marche très bien, et
s'est montré efficace, fiable et rapide, il souffre aujourd'hui de
la malédiction des techniques à succès : on essaie de charger la
barque, de lui faire faire plein de choses pour lesquelles il
n'était pas prévu. D'un côté, c'est un signe de succès. De l'autre,
c'est parfois fragilisant. Dans ce RFC
individuel (qui exprime juste le point de vue d'un individu, et
n'est pas du tout une norme
IETF), John Klensin, qui ne participe plus
activement au développement du DNS depuis des années, revient sur
certaines de ces choses qu'on essaie de faire faire au DNS et se
demande si ce n'est pas trop, et à partir de quel point il faudrait
arrêter de « perfectionner » le DNS et plutôt passer à « autre
chose » (« quand le seul outil qu'on a est un marteau, tous les
problèmes ressemblent à des clous… »). Une bonne lecture pour
celleszetceux qui ne veulent pas seulement faire marcher le DNS mais
aussi se demander « pourquoi c'est comme ça ? » et « est-ce que ça
pourrait être différent ? »
Améliorer le système petit à petit ou bien le remplacer complètement ? C'est une question que se posent régulièrement les ingénieurs, à propos d'un logiciel, d'un langage de programmation, d'un protocole réseau. À l'extrême, il y a l'ultra-conservateur qui ne voit que des inconvénients aux solutions radicales, à l'autre il y a l'ultra-optimiste qui en a marre des rustines et qui voudrait jeter le vieux système, pour le remplacer par un système forcément meilleur, car plus récent. Entre les deux, beaucoup d'informaticiens hésitent. L'ultra-conservateur oublie que les rustines successives ont transformé l'ancien système en un monstre ingérable et difficile à maintenir, l'ultra-optimiste croit naïvement qu'un système nouveau, rationnellement conçu (par lui…) sera à coup sûr plus efficace et moins bogué. Mais les deux camps, et tout celleszetceux qui sont entre les deux peuvent tirer profit de ce RFC, pour approfondir leur réflexion.
Klensin note d'abord que le DNS est vieux. La première réflexion à ce sujet était le RFC 799 en 1981, et le premier RFC décrivant le DNS est le RFC 882, en novembre 1983. (Paul Mockapetris a raconté le développement du DNS dans « Development of the Domain Name System », j'ai fait un résumé des articles d'histoire du DNS.) Le DNS remplaçait l'ancien système fondé sur un fichier centralisé de noms de machines (RFC 810, RFC 952, et peut-être aussi RFC 953). Tout n'est pas écrit : le DNS n'a pas aujourd'hui une spécification unique et à jour, aux RFC de base (RFC 1034 et RFC 1035, il faut ajouter des dizaines de RFC qui complètent ou modifient ces deux-ci, ainsi que pas mal de culture orale. (Un exemple de cette difficulté était que, pendant le développement du RFC 7816, son auteur s'est aperçu que personne ne se souvenait pourquoi les résolveurs envoyaient le FQDN complet dans les requêtes.) Plusieurs techniques ont même été supprimées comme les requêtes inverses (RFC 3425) ou comme les types d'enregistrement WKS, MD, MF et MG.
D'autres auraient dû être supprimées, car inutilisables en pratique, comme les classes (que prétendait utiliser le projet Net4D), et qui ont fait l'objet de l'Internet-Draft « The DNS Is Not Classy: DNS Classes Considered Useless », malheureusement jamais adopté dans une IETF parfois paralysée par la règle du consensus.
D'autres évolutions ont eu lieu : le DNS original ne proposait aucun mécanisme d'options, tous les clients et tous les serveurs avaient exactement les mêmes capacités. Cela a changé avec l'introduction d'EDNS, dans le RFC 2671 en 1999.
Beaucoup d'articles ont été écrits sur les systèmes de nommage. (Le RFC recommande l'article de V. Cerf, « Desirable Properties of Internet Identifiers », ou bien le livre « Signposts in Cyberspace: The Domain Name System and Internet Navigation ». Je me permets de rajouter mes articles, « Inventer un meilleur système de nommage : pas si facile », « Un DNS en pair-à-pair ? » et « Mon premier nom Namecoin enregistré ».)
Pourquoi est-ce que les gens ne sont pas contents du DNS actuel et veulent le changer (section 4 du RFC, la plus longue du RFC) ? Il y a des tas de raisons. Certaines, dit l'auteur, peuvent mener à des évolutions raisonnables du DNS actuel. Certaines nécessiteraient un protocole complètement nouveau, incompatible avec le DNS. D'autres enfin seraient irréalistes, quel que soit le système utilisé. La section 4 les passe en revue (rappelez-vous que ce RFC est une initiative individuelle, pas une opinion consensuelle à l'IETF).
Premier problème, les requêtes « multi-types ». À l'heure actuelle, une requête DNS est essentiellement composée d'un nom (QNAME, Query Name) et d'un type (QTYPE, Query Type, par exemple AAAA pour une adresse IP, TLSA pour une clé publique, etc). Or, on aurait parfois besoin de plusieurs types. L'exemple classique est celui d'une machine double-pile (IPv6 et le vieil IPv4), qui ne sait pas quelle version d'IP est acceptée en face et qui demande donc l'adresse IPv6 et l'adresse IPv4 du pair. Il n'y a actuellement pas de solution pour ce problème, il faut faire deux requêtes DNS. (Et, non, ANY ne résout pas ce problème, notamment en raison de l'interaction avec les caches : que doit faire un cache qui ne connait qu'une seule des deux adresses ?)
Deuxième problème, la sensibilité à la casse. La norme originale prévoyait des requêtes insensibles à la casse (RFC 1034, section 3.1), ce qui semble logique aux utilisateurs de l'alphabet latin. Mais c'est plutôt une source d'ennuis pour les autres écritures (et c'est une des raisons pour lesquelles accepter l'Unicode dans les noms de domaine nécessite des méthodes particulières). Avec ASCII, l'insensibilité à la casse est facile (juste un bit à changer pour passer de majuscule en minuscule et réciproquement) mais ce n'est pas le cas pour le reste d'Unicode. En outre, il n'est pas toujours évident de connaitre la correspondance majuscule-minuscule (cf. les débats entre germanophones sur la majuscule de ß). Actuellement, les noms de domaine en ASCII sont insensibles à la casse et ceux dans le reste du jeu de caractères Unicode sont forcément en minuscules (cf. RFC 5890), libre à l'application de mettre ses propres règles d'insensibilité à la casse si elle veut, lorsque l'utilisateur utilise un nom en majuscules comme RÉUSSIR-EN.FR. On referait le DNS en partant de zéro, peut-être adopterait-on UTF-8 comme encodage obligatoire, avec normalisation NFC dans les serveurs de noms, mais c'est trop tard pour le faire.
En parlant d'IDN, d'ailleurs, ce sujet a été à l'origine de nombreuses discussions, incluant pas mal de malentendus (pour lesquels, à mon humble avis, l'auteur de RFC a une sérieuse responsabilité). Unicode a une particularité que n'a pas ASCII : le même caractère peut être représenté de plusieurs façons. L'exemple classique est le É qui peut être représenté par un point de code, U+00C9 (LATIN CAPITAL LETTER E WITH ACUTE), ou par deux, U+0045 (LATIN CAPITAL LETTER E) et U+0301 (COMBINING ACUTE ACCENT). Je parle bien de la représentation en points de code, pas de celle en bits sur le réseau, qui est une autre affaire ; notez que la plupart des gens qui s'expriment à propos d'Unicode sur les forums ne connaissent pas Unicode. La normalisation Unicode vise justement à n'avoir qu'une forme (celle à un point de code si on utilise NFC) mais elle ne traite pas tous les cas gênants. Par exemple, dans certains cas, la fonction de changement de casse dépend de la langue (que le DNS ne connait évidemment pas). Le cas le plus célèbre est celui du i sans point U+0131, qui a une règle spécifique en turc. Il ne sert à rien de râler contre les langues humaines (elles sont comme ça, point), ou contre Unicode (dont la complexité ne fait que refléter celles des langues humaines et de leurs écritures). Le point important est qu'on n'arrivera pas à faire en sorte que le DNS se comporte comme M. Toutlemonde s'y attend, sauf si on se limite à un M. Toutlemonde étatsunien (et encore).
Les IDN ont souvent été accusés, y compris dans ce RFC, de
permettre, ou en tout cas de faciliter, le
hameçonnage par la confusion possible entre
deux caractères visuellement proches. En fait, le problème n'est pas
spécifique aux IDN (regardez google.com et
goog1e.com) et les études montrent que les
utilisateurs ne vérifient pas les noms, de toute façon. Bref,
il s'agit de simple propagande de la part de ceux qui n'ont jamais
vraiment accepté Unicode.
Les IDN nous amènent à un problème proche,
celui des synonymes. Les noms de domaine
color.example et
colour.example sont différents alors que, pour
tout anglophone, color
et colour
sont « équivalents ». J'ai mis le mot « équivalent » entre
guillemets car sa définition même est floue. Est-ce que
« Saint-Martin » est équivalent à « St-Martin » ? Et est-ce que
« Dupont » est équivalent à « Dupond » ? Sans même aller chercher des
exemples comme l'équivalence entre sinogrammes simplifiés et sinogrammes
traditionnels, on voit que l'équivalence est un concept
difficile à cerner. Souvent, M. Michu s'agace « je tape
st-quentin.fr, pourquoi est-ce que ça n'est pas
la même chose que
saint-quentin-en-yvelines.fr ? »
Fondamentalement, la réponse est que le DNS ne gère pas les requêtes
approximatives, et qu'il n'est pas évident que tout le monde soit
d'accord sur l'équivalence de deux noms. Les humains se débrouillent
avec des requêtes floues car ils ont un
contexte. Si on est dans les
Yvelines, je sais que « St-Quentin » est
celui-ci
alors que, si on est dans l'Aisne, mon interlocuteur parle
probablement de celui-là. Mais le DNS n'a pas ce
contexte.
Plusieurs RFC ont été écrit à ce sujet, RFC 3743, RFC 4290, RFC 6927 ou RFC 7940, sans résultats convaincants. Le DNS a bien sûr des mécanismes permettant de dire que deux noms sont équivalents, comme les alias (enregistrements CNAME) ou comme les DNAME du RFC 6672. Mais :
- Aucun d'entre eux n'a exactement la sémantique que les utilisateurs voudraient (d'où des propositions régulières d'un nouveau mécanisme comme les BNAME),
- Et ils supposent que quelqu'un ait configuré les correspondances, ce qui suscitera des conflits, et ne satisfera jamais tout le monde.
Même écrire un cahier des charges des « variantes » n'a jamais été possible. (C'est également un sujet sur lequel j'avais écrit un article.)
Passons maintenant aux questions de protection de la vie privée. L'auteur du RFC note que la question suscite davantage de préoccupations aujourd'hui mais ne rappelle pas que ces préoccupations ne sont pas irrationnnelles, elles viennent en grande partie de la révélation de programmes de surveillance massive comme MoreCowBell. Et il « oublie » d'ailleurs de citer le RFC 7626, qui décrit en détail le problème de la vie privée lors de l'utilisation du DNS.
J'ai parlé plus haut du problème des classes dans le DNS, ce
paramètre supplémentaire des enregistrements DNS (un enregistrement
est identifié par trois choses, le nom, la classe et le
type). L'idée au début (RFC 1034, section 3.6)
était de gérer depuis le DNS plusieurs protocoles très différents
(IP, bien sûr, mais aussi
CHAOS et d'autres futurs), à l'époque où le
débat faisait rage entre partisans d'un réseau à protocole unique
(le futur Internet) et ceux et celles qui
préféraient un catenet, fondé sur
l'interconnexion de réseaux techniquement différents. Mais,
aujourd'hui, la seule classe qui sert réellement est IN (Internet)
et, en pratique, il y a peu de chances que les autres soient jamais
utilisées. Il a parfois été suggéré d'utiliser les classes pour
partitionner l'espace de noms (une classe IN pour
l'ICANN et créer une classe UN afin de la donner à
l'UIT pour qu'elle puisse jouer à la gouvernance ?) mais le fait que les
classes aient été
très mal normalisées laisse peu d'espoir. (Est-ce que IN
example, CH example et UN example sont la même
zone ? Ont-ils les mêmes serveurs de noms ? Cela n'a jamais été
précisé.)
Une particularité du DNS qui déroute souvent les nouveaux administrateurs système est le fait que les données ne soient que faiblement synchronisées : à un moment donné, il est parfaitement normal que plusieurs valeurs coexistent dans l'Internet. Cela est dû à plusieurs choix, notamment :
- Celui d'avoir plusieurs serveurs faisant autorité pour une zone, et sans mécanisme assurant leur synchronisation forte. Lorsque le serveur maître (ou primaire) est mis à jour, il sert immédiatement les nouvelles données, sans attendre que les esclaves (ou secondaires) se mettent à jour.
- Et le choix d'utiliser intensivement les caches, la mémoire des résolveurs. Si un serveur faisant autorité sert un enregistrement avec un TTL de 7 200 secondes (deux heures) et que, cinq minutes après qu'un résolveur ait récupéré cet enregistrement, le serveur faisant autorité modifie l'enregistrement, les clients du résolveur verront encore l'ancienne valeur pendant 7 200 - 300 = 6 900 secondes.
Cela a donné naissance à la légende de la propagation du DNS et aux chiffres fantaisistes qui accompagnent cette légende comme « il faut 24 h pour que le DNS se propage ».
Ces choix ont assuré le succès du DNS, en lui permettant de passer à l'échelle, vers un Internet bien plus grand que prévu à l'origine. Un modèle à synchronisation forte aurait été plus compliqué, plus fragile et moins performant.
Mais tout choix en ingéniérie a des bonnes conséquences et des mauvaises : la synchronisation faible empêche d'utiliser le DNS pour des données changeant souvent. Des perfectionnements ont eu lieu (comme la notification non sollicitée du RFC 1996, qui permet aux serveurs secondaires d'être au courant rapidement d'un changement, mais qui ne marche que dans le cas où on connait tous les secondaires) mais n'ont pas fondamentalement changé le tableau. Bien sûr, les serveurs faisant autorité qui désireraient une réjuvénation plus rapide peuvent toujours abaisser le TTL mais, en dessous d'une certaine valeur (typiquement 30 à 60 minutes), les TTL trop bas sont parfois ignorés.
Un autre point où les demandes de beaucoup d'utilisateurs
rentrent en friction avec les concepts du DNS est celui des noms
privés, des noms qui n'existeraient qu'à l'intérieur d'une
organisation particulière, et qui ne nécessiteraient pas
d'enregistrement auprès d'un tiers. La bonne méthode pour avoir des
noms privés est d'utiliser un sous-domaine d'un domaine qu'on a
enregistré (aujourd'hui, tout le monde peut avoir son domaine assez
facilement, voir gratuitement), et de le déléguer à
des serveurs de noms qui ne sont accessibles qu'en interne. Si on
est l'association Example et qu'on est titulaire de
example.org, on crée
priv.example.org et on y met ensuite les noms
« privés » (je mets privé entre guillemets car, en pratique, comme
le montrent les statistiques des serveurs de noms publics, de tels
noms fuitent souvent à l'extérieur, par exemple quand un ordinateur
portable passe du réseau interne à celui d'un
FAI public).
Il faut noter que beaucoup d'organisations, au lieu d'utiliser la
bonne méthode citée ci-dessus, repèrent un
TLD actuellement inutilisé
(.home, .lan,
.private…) et s'en servent. C'est une très
mauvaise idée, car, un jour, ces TLD seront peut-être délégués, avec
les risques de confusion que cela entrainera (cf. le
cas de .box et celui
de .dev).
Les administrateurs système demandent souvent « mais quel est le
TLD réservé pour les usages internes » et sont surpris d'apprendre
qu'il n'en existe pas. C'est en partie pour de bonnes raisons
(imaginez deux entreprises utilisant ce TLD et fusionnant… Ou
simplement s'interconnectant via un VPN… Un
problème qu'on voit souvent avec le RFC 1918.)
Mais c'est aussi en partie parce que les tentatives d'en créer un se
sont toujours enlisées dans les sables de la bureaucratie (personne
n'a envie de passer dix ans de sa vie professionnelle à faire du
lobbying auprès de l'ICANN pour réserver un
tel TLD). La dernière tentative était celle de .internal
mais elle n'a pas marché.
Il y a bien un registre des noms de domaines (pas uniquement des
TLD) « à usage spécial », créé par le RFC 6761. Il a malheureusement été gelé par
l'IESG et fait l'objet de contestations (RFC 8244). Aucun des noms qu'il contient ne convient vraiment
au besoin de ceux qui voudraient des noms de domaine internes (à part
.test qui devrait logiquement être utilisé pour
les bancs de test, de développement, etc). Le RFC note qu'un des
principaux problèmes d'un tel registre est qu'il est impossible de
garder à jour tous les résolveurs de la planète quand ce registre
est modifié. On ne peut donc pas garantir qu'un nouveau TLD réservé
sera bien traité de manière spéciale par tous les résolveurs.
Une caractéristique du DNS qui a suscité beaucoup de débats, pas toujours bien informés et pas toujours honnêtes, est l'existence de la racine du DNS, et des serveurs qui la servent. Lors de la mise au point du DNS, la question s'était déjà posée, certains faisant remarquer que cette racine allait focaliser les problèmes, aussi bien techniques que politiques. L'expérience a montré qu'en fait la racine marchait bien, mais cela n'a pas évité les polémiques. Le RFC note que le sujet est très chaud : qui doit gérer un serveur racine ? Où faut-il les placer physiquement ? Si l'anycast a largement résolu la seconde question (RFC 7094), la première reste ouverte. Le RFC n'en parle pas mais, si la liste des onze (ou douze, ça dépend comment on compte) organisations qui gèrent un serveur racine n'a pas évolué depuis vingt ans, ce n'est pas pour des raisons techniques, ni parce qu'aucune organisation n'est capable de faire mieux que les gérants actuels, mais tout simplement parce qu'il n'existe aucun processus pour supprimer ou ajouter un serveur racine. Comme pour les membres permanents du Conseil de Sécurité de l'ONU, on en reste au statu quo, aussi inacceptable soit-il, simplement parce qu'on ne sait pas faire autrement.
Le problème de la gestion de la racine n'est pas uniquement celui
de la gestion des serveurs racine. Le contenu de la zone racine est
tout aussi discuté. Si les serveurs racine sont les imprimeurs du
DNS, le gérant de la zone racine en est l'éditeur. Par exemple,
combien faut-il de TLD ? Si quelqu'un veut
créer .pizza, faut-il le permettre ? Et
.xxx ? Et .vin, que le
gouvernement français avait vigoureusement
combattu ? Ou encore .home, déjà
largement utilisé informellement dans beaucoup de réseaux locaux,
mais pour lequel il y avait trois candidatures à l'ICANN (rejetées peu de
temps avant la publication du RFC). Ces
questions, qui se prêtent bien aux jeux politiciens, occupent
actuellement un bon bout des réunions
ICANN.
La base technique à ces discussions est qu'il n'y a qu'une seule racine (RFC 2826). Son contrôle va donc forcément susciter des conflits. Un autre système de nommage que le DNS, si on le concevait de nos jours, pourrait éviter le problème en évitant ces points de contrôle. Les techniques à base de chaînes de blocs comme Namecoin sont évidemment des candidates possibles. Outre les problèmes pratiques (avec Namecoin, quand on perd sa clé privée, on perd son domaine), la question de fond est « quelle gouvernance souhaite-t-on ? »
La question de la sémantique dans les noms de domaines est
également délicate. L'auteur affirme que les noms de domaines sont
(ou en tout cas devraient être) de purs identificateurs techniques,
sans sémantique. Cela permet de justifier les limites des noms (RFC 1034, section 3.5) : s'ils sont de purs
identificateurs techniques, il n'est pas nécessaire de permettre les
IDN, par exemple. On peut se contenter des
lettres ASCII, des chiffres et du
tiret, la règle dite LDH, qui vient du RFC 952. Cette règle
« Letters-Digits-Hyphen » a été une première fois
remise en cause vers 1986
lorsque 3Com a voulu son nom de domaine
3com.com (à l'époque, un nom devait commencer
par une lettre, ce qui a été changé par la norme actuelle, RFC 1123). Mais cela laisse d'autres marques sans
nom de domaine adapté, par exemple C&A
ne peut pas avoir c&a.fr. Sans parler des
cas de ceux et celles qui n'utilisent pas l'alphabet latin.
L'argument de Klensin est que ce n'est pas grave : on demande juste aux noms de domaine d'être des identificateurs uniques et non ambigus. Qu'ils ne soient pas très « conviviaux » n'est pas un problème. Inutile de dire que ce point de vue personnel ne fait pas l'unanimité.
Bien sûr, il y a aussi un aspect technique. Si on voulait, dit l'auteur ironiquement, permettre l'utilisation de la langue naturelle dans les noms de domaine, il faudrait aussi supprimer la limite de 63 caractères par composant (255 caractères pour le nom complet). Il est certain qu'il est difficile d'avoir des identificateurs qui soient à la fois utiles pour les programmes (simples, non ambigus) et pour les humains.
Le DNS n'est pas figé, et a évolué depuis ses débuts. Notamment, beaucoup de nouveaux types (RRTYPE, pour Resource Record Type) ont été créés avec le temps (cf. RFC 6895). Ce sont, par exemple :
- NAPTR (RFC 3403), système que je trouve fort compliqué et qui n'a pas eu de succès,
- URI (RFC 7553) qui permet de stocker
des URI dans le DNS (par exemple,
dig +short URI 78100.cp.bortzmeyer.frva vous donner un URI OpenStreetMap correspondant au code postal 78100), - SRV (RFC 2782), qui généralise le vieux MX en permettant une indirection depuis le nom de domaine vers un nom de serveur (hélas, HTTP est le seul protocole Internet qui, stupidement, ne l'utilise pas).
Une observation à partir de l'étude du déploiement de tous les nouveaux types d'enregistrement est que ça se passe mal : pare-feux débiles qui bloquent les types qu'ils ne connaissent pas, interfaces de gestion du contenu des zones qui ne sont jamais mises à jour (bien des hébergeurs DNS ne permettent pas d'éditer URI ou TLSA, voir simplement SRV), bibliothèques qui ne permettent pas de manipuler ces types… Cela a entrainé bien des concepteurs de protocole à utiliser le type « fourre-tout » TXT. Le RFC 5507 explique ses avantages et (nombreux) inconvénients. (Le RFC 6686 raconte comment le type générique TXT a vaincu le type spécifique SPF.)
Aujourd'hui, tout le monde et son chien a un nom de domaine. Des
noms se créent en quantité industrielle, ce qui est facilité par
l'automatisation des procédures, et le choix de certains registres
de faire des promotions commerciales. Il n'est pas exagéré de dire
que, surtout dans les nouveaux TLD ICANN, la
majorité des noms sont créés à des fins malveillantes. Il est donc
important de pouvoir évaluer la réputation d'un nom : si
mail.enlargeyourzob.xyz veut m'envoyer du
courrier, puis-je utiliser la réputation de ce domaine (ce qu'il a
fait précédemment) pour décider de rejeter le message ou pas ? Et si
un utilisateur clique sur
http://www.bitcoinspaschers.town/, le
navigateur Web doit-il l'avertir que ce domaine a mauvaise
réputation ? Le RFC, souvent nostalgique, rappelle que le modèle original du DNS,
formalisé dans le RFC 1591, était que chaque
administrateur de zone était compétent, responsable et
honnête. Aujourd'hui, chacune de ces qualités est rare et leur
combinaison est encore plus rare. L'auteur du RFC regrette que les
registres ne soient pas davantage comptables du contenu des zones
qu'ils gèrent, ce qui est un point de vue personnel et très
contestable : pour un TLD qui est un service public, ce serait une
violation du principe de neutralité.
Bref, en pratique, il est clair aujourd'hui qu'on
trouve de tout dans le DNS. Il serait donc souhaitable qu'on puisse
trier le bon grain de l'ivraie mais cela présuppose qu'on connaisse
les frontières administratives. Elles ne coïncident pas forcément
avec les frontières techniques
(.fr et
gouv.fr sont actuellement dans la même zone
alors que le premier est sous la responsabilité de
l'AFNIC et le second sous celle du
gouvernement français). Rien dans le DNS ne les indique (le
point dans un nom de domaine indique une
frontière de domaine, pas forcément une frontière de zone, encore
moins une frontière de responsabilité). Beaucoup de légendes
circulent à ce sujet, par exemple beaucoup de gens croient à tort
que tout ce qui se trouve avant les deux derniers composants d'un
nom est sous la même autorité que le nom de deuxième niveau
(cf. mon article sur l'analyse
d'un nom). Il n'y a pas actuellement de mécanisme standard et
sérieux pour déterminer les frontières de responsabilité dans un nom
de domaine. Plusieurs efforts avaient été tentés à l'IETF mais ont
toujours échoué. La moins mauvaise
solution, aujourd'hui, est la Public Suffix
List.
Beaucoup plus technique, parmi les problèmes du DNS, est celui de la taille des paquets. Car la taille compte. Il y a très très longtemps, la taille d'une réponse DNS était limitée à 512 octets. Cette limite a été supprimée en 1999 avec le RFC 2671 (c'est d'ailleurs une excellente question pour un entretien d'embauche lorsque le candidat a mis « DNS » dans la liste de ses compétences : « quelle est la taille maximale d'une réponse DNS ? »). En théorie, les réponses peuvent désormais être plus grandes (la plupart des serveurs sont configurés pour 4 096 octets) mais on se heurte à une autre limite : la MTU de 1 500 octets tend à devenir une valeur sacrée, et les réponses plus grandes que cette taille ont du mal à passer, par exemple parce qu'un pare-feu idiot bloque les fragments IP, ou parce qu'un pare-feu tout aussi crétin bloque l'ICMP, empêchant les messages Packet Too Big de passer (cf. RFC 7872).
Bref, on ne peut plus trop compter sur la fragmentation, et les serveurs limitent parfois leur réponse en UDP (TCP n'a pas de problème) à moins de 1 500 octets pour cela.
Une section entière du RFC, la 5, est consacrée au problème de la
requête inverse, c'est-à-dire comment trouver un nom de domaine en
connaissant le contenu d'un enregistrement lié à ce nom. La norme
historique prévoyait une requête spécifique pour cela, IQUERY (RFC 1035, sections 4.1.1 et 6.4). Mais elle n'a
jamais réellement marché (essentiellement parce qu'elle suppose
qu'on connaisse déjà le serveur faisant autorité… pour un nom de
domaine qu'on ne connait pas encore) et a été retirée dans le RFC 3425. Pour permettre quand même des « requêtes
inverses » pour le cas le plus demandé, la résolution d'une adresse
IP en un nom de domaine, un truc spécifique a été développé,
l'« arbre inverse »
in-addr.arpa (puis plus
tard ip6.arpa pour
IPv6). Ce truc n'utilise pas les IQUERY mais
des requêtes normales, avec le type
PTR. Ainsi, l'option -x de
dig permet à la fois de fabriquer le nom en
in-addr.arpa ou ip6.arpa
et de faire une requête de type PTR pour lui :
% dig -x 2001:678:c::1 ... ;; ANSWER SECTION: 1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.c.0.0.0.8.7.6.0.1.0.0.2.ip6.arpa. 172796 IN PTR d.nic.fr.
Cette technique pose des problèmes dans le cas de préfixes
IPv4 ne tenant pas sur une frontière d'octets
(cas traité par le RFC 2317). Globalement,
c'est toujours resté un truc, parfois utile, souvent surestimé, mais
ne fournissant jamais un service général. Une tentative avait été
faite à l'IETF pour décrire ce truc et son
utilisation, mais elle n'a jamais abouti (draft-ietf-dnsop-reverse-mapping-considerations),
la question étant trop sensible (même écrire « des gens trouvent que
les enregistrements PTR sont utiles, d'autres personnes ne sont pas
d'accord », même une phrase comme cela ne rencontrait pas de
consensus).
Enfin, la section 7 du RFC est consacrée à un problème
difficile : le DNS ne permet pas de recherche floue. Il faut
connaitre le nom exact pour avoir les données. Beaucoup
d'utilisateurs voudraient quelque chose qui ressemble davantage à un
moteur de recherche. Ils n'ont pas d'idée
très précise sur comment ça devrait fonctionner mais ils voudraient
pouvoir taper « st quentin » et que ça arrive sur
www.saint-quentin-en-yvelines.fr. Le fait qu'il
existe plusieurs villes nommées Saint-Quentin
ne les arrête pas ; ils voudraient que ça marche « tout seul ». Le
DNS a un objectif très différent : fournir une réponse exacte à une
question non ambigüe.
Peut-être aurait-on pu développer un service de recherche floue au dessus du DNS. Il y a eu quelques réflexions à ce sujet (comme le projet IRNSS ou comme le RFC 2345) mais ce n'est jamais allé très loin. En pratique, les moteurs de recherche jouent ce rôle, sans que l'utilisateur comprenne la différence. Peu d'entre eux savent qu'un nom de domaine, ce n'est pas comme un terme tapé dans un moteur de recherche. On voit aussi bien des gens taper un nom de domaine dans la boîte de saisie du terme de recherche, que des gens utiliser le moteur de recherche comme fournisseurs d'identificateurs (« pour voir notre site Web, tapez "trucmachin" dans Google »). Le dernier clou dans le cercueil de la compréhension de la différence entre identificateur et moteur de recherche a été planté quand les navigateurs ont commencé à fusionner barre d'adresses et boite de saisie de la recherche.
L'article seul
RFC 8318: IAB, IESG, and IAOC Selection, Confirmation, and Recall Process: IAOC Advisor for the Nominating Committee
Date de publication du RFC : Janvier 2018
Auteur(s) du RFC : S. Dawkins (Wonder Hamster)
Première rédaction de cet article le 1 février 2018
Un petit RFC bureaucratique pour traiter un manque du RFC 7437, qui ne disait pas que l'IAOC devait envoyer quelqu'un au NomCom, le comité de nomination. (Mais de toute façon, l'IAOC ayant été supprimée depuis, ce RFC n'est plus pertinent, voir le RFC 8713.)
En effet, le NomCom, le comité chargé d'étudier les personnes qui pourront occuper des postes dans divers organismes de l'IETF (cf. RFC 7437), ce NomCom s'occupe entre autres des postes à l'IAOC (RFC 4071), mais ne disait pas que l'IAOC pouvait envoyer un membre au NomCom, comme le faisaient les autres organes. A priori, ce n'était pas grave puisque le NomCom pouvait toujours ajouter qui il voulait comme observateur mais, en 2017, le NomCom a travaillé sur un poste à l'IAOC sans avoir de représentant de l'IAOC à ses réunions.
Ce n'est pas la fin du monde mais cela a justifié ce RFC, qui ajoute juste aux règles existantes que le NomCom devrait veiller à avoir quelqu'un de l'IAOC, ou qui connait l'IAOC.
Les discussions qui ont eu lieu autour de ce minuscule changement sont résumées dans l'annexe A. Par exemple, après un long débat, ce « représentant » de l'IAOC sera qualifié d'« advisor » et pas de « liaison » (en gros, un « liaison » a un boulot plus formel et plus sérieux.)
L'article seul
RFC 8315: Cancel-Locks in Netnews articles
Date de publication du RFC : Février 2018
Auteur(s) du RFC : M. Bäuerle (STZ Elektronik)
Chemin des normes
Première rédaction de cet article le 14 février 2018
Dernière mise à jour le 13 avril 2025
Cela peut sembler étonnant, mais le service des News fonctionne toujours. Et il est régulièrement perfectionné. Ce nouveau RFC normalise une extension au format des articles qui permettra de sécuriser un petit peu l'opération d'annulation d'articles.
Une fois qu'un article est lancé sur un réseau social décentralisé,
comme Usenet (RFC 5537), que faire si on le regrette ? Dans un système
centralisé comme Twitter, c'est simple, on
s'authentifie, on le supprime et plus personne ne le voit. Mais
dans un réseau décentralisé, il faut encore propager la demande de
suppression (d'annulation, sur les News). Et cela pose évidemment
des questions de sécurité : il ne faut pas permettre aux méchants
de fabriquer trop facilement une demande d'annulation. Notre RFC
propose donc une mesure de sécurité, l'en-tête
Cancel-Lock:.
Cette mesure de sécurité est simple, et ne fournit certainement
pas une sécurité de niveau militaire. Pour la comprendre, il faut
revenir au mécanisme d'annulation d'un article
d'Usenet. Un article de contrôle est un
article comme les autres, envoyé sur
Usenet, mais il ne vise pas à être lu par les
humains, mais à être interprété par le logiciel. Un exemple
d'article de contrôle est l'article de contrôle
d'annulation, défini dans le RFC 5337, section 5.3. Comme son nom l'indique, il demande
la suppression d'un article, identifié par son Message
ID. Au début d'Usenet, ces messages de contrôle
n'avaient aucune forme d'authentification. On a donc vu apparaitre
des faux messages de contrôle, par exemple à des fins de censure
(supprimer un article qu'on n'aimait pas). Notre nouveau RFC
propose donc qu'un logiciel proche de la source du message mette
un en-tête Cancel-Lock: qui indique la clé
qui aura le droit d'annuler le message.
Évidemment, ce Cancel-Lock:
n'apporte pas beaucoup de sécurité, entre autre parce qu'un
serveur peut toujours le retirer et mettre le sien, avant de
redistribuer (c'est évidemment explicitement interdit par le RFC
mais il y a des méchants). Mais cela ne change de toute façon pas grand'chose à la situation
actuelle, un serveur peut toujours jeter un article, de toute
façon. Si on veut quand même une solution de sécurité
« sérieuse », il faut utiliser PGP, comme
mentionné en passant par le RFC 5537 (mais
jamais normalisé dans un RFC).
La section 2 du RFC décrit en détail le mécanisme de
sécurité. La valeur de l'en-tête Cancel-Lock:
est l'encodage en base64 d'une
condensation d'une clé secrète (en fait, on
devrait plutôt l'appeler mot de passe). Pour authentifier une
annulation, le message de contrôle comportera un autre en-tête,
Cancel-Key:, qui révélera la clé (qui ne
devra donc être utilisée qu'une fois).
Voici un exemple. On indique explicitement l'algorithme de condensation (ici, SHA-256, la liste est dans un registre IANA). D'abord, le message original aura :
Cancel-Lock: sha256:s/pmK/3grrz++29ce2/mQydzJuc7iqHn1nqcJiQTPMc=
Et voici le message de contrôle, authentifié :
Cancel-Key: sha256:qv1VXHYiCGjkX/N1nhfYKcAeUn8bCVhrWhoKuBSnpMA=
La section 3 du RFC détaille comment on utilise ces
en-têtes. Le Cancel-Lock: peut être mis par
l'auteur originel de l'article, ou bien par un intermédiaire (par
exemple le modérateur qui a approuvé
l'article). Plusieurs Cancel-Lock: peuvent
donc être présents. Notez qu'il n'y a aucun moyen de savoir si le
Cancel-Lock: est « authentique ». Ce
mécanisme est une solution de sécurité faible.
Pour annuler un message, on envoie un message de contrôle avec
un Cancel-Key: correspondant à un des
Cancel-Lock:. Les serveurs recevant ce
message de contrôle condenseront la clé (le
mot de passe) et vérifieront s'ils retombent bien sur le condensat
contenu dans un des Cancel-Lock:.
La section 4 donne les détails sur le choix de la clé (du mot
de passe). Évidemment, elle doit être difficile à deviner, donc
plutôt choisie par un algorithme pseudo-aléatoire (et pas "azerty123"). Et elle doit être à
usage unique puisque, une fois révélée par un
Cancel-Key:, elle n'est plus
secrète. L'algorithme recommandé par le RFC est d'utiliser un
HMAC (RFC 2104) d'un
secret et de la concaténation du Message ID du message
avec le nom de l'utilisateur. Comme cela, générer un
Cancel-Key: pour un message donné peut se
faire avec juste le message, sans avoir besoin de mémoriser les
clés. Voici un exemple, tiré de la section 5, et utilisant OpenSSL. Le secret est
frobnicateZ32. Le message est le
<12345@example.net> et l'utilisateur est
stephane :
% printf "%s" "<12345@example.net>stephane" \
| openssl dgst -sha256 -hmac "frobnicateZ32" -binary \
| openssl enc -base64
f0rHwfZXp5iKFjTbX/I5bQXh9Dta33nWBzLi8f9oaoM=
Voilà, nous avons notre clé,
f0rHwfZXp5iKFjTbX/I5bQXh9Dta33nWBzLi8f9oaoM=. Pour
le condensat, nous nous servirons de
SHA-256 :
% printf "%s" "f0rHwfZXp5iKFjTbX/I5bQXh9Dta33nWBzLi8f9oaoM=" \
| openssl dgst -sha256 -binary \
| openssl enc -base64
RBJ8ZsgqBnW/tYT/qu1JcXK8SA2O9g+qJLDzRY5h1cg=
Nous pouvons alors former le Cancel-Lock: :
Cancel-Lock: sha256:RBJ8ZsgqBnW/tYT/qu1JcXK8SA2O9g+qJLDzRY5h1cg=
Et, si nous voulons annuler ce message, le
Cancel-Key: dans le message de contrôle
d'annulation aura l'air :
Control: cancel <12345@example.net>
Cancel-Key: sha256:f0rHwfZXp5iKFjTbX/I5bQXh9Dta33nWBzLi8f9oaoM=
Pour vérifier ce message de contrôle, le logiciel calculera le
condensat de la clé et vérifiera s'il retombe bien sur RBJ8ZsgqBnW/tYT/qu1JcXK8SA2O9g+qJLDzRY5h1cg=.
Enfin, la section 7 du RFC détaille la sécurité de ce mécanisme. Cette sécurité est plutôt faible :
- Aucune protection de
l'intégrité. Un intermédiaire a pu
modifier, ajouter ou supprimer le
Control-Lock:. Si cela vous défrise, vous devez utiliser PGP. - Lors d'une annulation, la clé est visible par tous, donc elle peut être copiée et utilisée dans un message de contrôle de remplacement (au lieu de l'annulation). Mais, de toute façon, un attaquant peut aussi bien faire un nouveau message faux (Usenet ne vérifie pas grand'chose).
- Avant ce RFC, ce mécanisme était déjà largement utilisé, depuis longtemps, et souvent en utilisant SHA-1 comme fonction de condensation. Contrairement à ce qu'on lit parfois, SHA-1 n'est pas complètement cassé : il n'y a pas encore eu de publication d'une attaque pré-image pour SHA-1 (seulement des collisions). Néanmoins, SHA-1 ne peut plus être considéré comme sûr, d'autant plus que Usenet évolue très lentement : un logiciel fait aujourd'hui va rester en production longtemps et, avec le temps, d'autres attaques contre SHA-1 apparaitront. D'où la recommandation du RFC de n'utiliser que SHA-2.
Les deux nouveaux en-têtes ont été ajoutés au registre des en-têtes.
À noter que, comme il n'y a pas de groupe de travail IETF sur les
News, ce RFC a été surtout discuté… sur les
News, en l'occurrence les groupes
news.software.nntp et
de.comm.software.newsserver. Comme ce RFC
décrit une technique ancienne, il y a déjà de nombreuses mises en
œuvre comme celle de
gegeweb, la bibliothèque
canlock (paquetage Debian
libcanlock2), dans le
serveur INN (depuis sa
version 2.7.0 datant de juillet 2022, ça se paramètre dans le nouveau
fichier inn-secrets.conf), ou les clients News
Gnus (regardez cet
article sur son usage), flnews,
slrn ou tin. Vous pouvez aussi lire l'article
de Brad Templeton comparant
Cancel-Lock: aux signatures.
Merci à Julien Élie pour sa relecture et ses additions ultérieures.
L'article seul
RFC 8314: Cleartext Considered Obsolete: Use of TLS for Email Submission and Access
Date de publication du RFC : Janvier 2018
Auteur(s) du RFC : K. Moore (Windrock), C. Newman (Oracle)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF uta
Première rédaction de cet article le 31 janvier 2018
Ce RFC s'inscrit dans le cadre des efforts de sécurisation de l'Internet contre la surveillance massive, efforts notablement accélérés depuis les révélations Snowden. Désormais, l'usage de texte en clair (non chiffré) pour le courrier électronique est officiellement abandonné : POP, IMAP et SMTP doivent être chiffrés.
Plus précisément, ce nouveau RFC du groupe de travail UTA vise l'accès au courrier (POP - RFC 1939 et IMAP - RFC 9051), ainsi que la soumission de messages par SMTP - RFC 6409 (entre le MUA et le premier MTA). Les messages de ces protocoles doivent désormais être systématiquement chiffrés avec TLS - RFC 5246. Le but est d'assurer la confidentialité des échanges. Le cas de la transmission de messages entre MTA est couvert par des RFC précédents, RFC 3207 et RFC 7672 (voir aussi le RFC 8461).
Pour résumer les recommandations concrètes de ce RFC :
- TLS 1.2 au minimum (on croise encore souvent SSL malgré le RFC 7568).
- Migrer le plus vite possible vers le tout-chiffré si ce n'est pas déjà fait.
- Utiliser le « TLS implicite » sur un port dédié, où on démarre TLS immédiatement (par opposition au vieux système STARTTLS, où on demandait explicitement le démarrage de la cryptographie, cf. sections 2 et 3 du RFC).
Ce RFC ne traite pas le cas du chiffrement de bout en bout, par
exemple avec PGP (RFC 9580 et RFC 3156). Ce chiffrement
de bout en bout est certainement la meilleure solution mais il est
insuffisamment déployé aujourd'hui. En attendant qu'il se
généralise, il faut bien faire ce qu'on peut pour protéger les
communications. En outre, PGP ne protège pas certaines métadonnées
comme les en-têtes (From:,
Subject:, etc), alors qu'un chiffrement TLS
du transport le fait. Bref, on a besoin des deux.
La section 3 du RFC rappelle ce qu'est le « TLS implicite », qui est désormais recommandé. Le client TLS se connecte à un serveur TLS sur un port dédié, où tout se fait en TLS, et il démarre la négociation TLS immédiatement. Le TLS implicite s'oppose au « TLS explicite » qui était l'approche initiale pour le courrier. Avec le TLS explicite (RFC 2595 et RFC 3207), le serveur devait annoncer sa capacité à faire du TLS :
% telnet smtpagt1.ext.cnamts.fr. smtp
Trying 93.174.145.55...
Connected to smtpagt1.ext.cnamts.fr.
Escape character is '^]'.
220 smtpagt1.ext.cnamts.fr ESMTP CNAMTS (ain1)
EHLO mail.example.com
250-smtpagt1.ext.cnamts.fr Hello mail.example.com [192.0.2.187], pleased to meet you
250-ENHANCEDSTATUSCODES
250-PIPELINING
250-8BITMIME
250 STARTTLS
Et le client devait dire qu'il allait démarrer la session TLS avec la commande STARTTLS. L'inconvénient principal de STARTTLS est qu'il est vulnérable à l'attaque « SSL stripping » où un attaquant actif modifie la communication avant que TLS ne démarre, pour faire croire que le partenaire ne sait pas faire de TLS. (Et il y a aussi la vulnérabilité CERT #555316.) Bien sûr, les serveurs peuvent se protéger en refusant les connexions sans STARTTLS mais peu le font. L'approche STARTTLS était conçue pour gérer un monde où certains logiciels savaient faire du TLS et d'autres pas, mais, à l'heure où la recommandation est de faire du TLS systématiquement, elle n'a plus guère d'utilité. (La question est discutée plus en détail dans l'annexe A. Notez qu'un des auteurs de notre nouveau RFC, Chris Newman, était l'un des auteurs du RFC 2595, qui introduisait l'idée de STARTTLS.)
Avec le TLS implicite, cela donne :
% openssl s_client -connect mail.example.com:465
...
subject=/CN=mail.example.com
issuer=/O=CAcert Inc./OU=http://www.CAcert.org/CN=CAcert Class 3 Root
...
Peer signing digest: SHA512
Server Temp Key: ECDH, P-256, 256 bits
...
New, TLSv1.2, Cipher is ECDHE-RSA-AES256-GCM-SHA384
Server public key is 2048 bit
...
220 mail.example.com ESMTP Postfix
EHLO toto
250-mail.example.com
250-AUTH DIGEST-MD5 NTLM CRAM-MD5
250-ENHANCEDSTATUSCODES
250-8BITMIME
250-DSN
250 SMTPUTF8
Donc, concrètement, pour POP, cela veut dire établir la connexion sur le port du TLS implicite, le 995 (et non pas sur le port 110, prévu pour le texte en clair), lancer TLS et authentifier avec le RFC 7817. Puis on fait du POP classique. Pour IMAP, c'est le port 993. Dans les deux cas, cette recommandation de notre RFC ne sera pas trop dure à suivre, le TLS implicite est déjà courant pour ces deux protocoles.
Pour la soumission SMTP (RFC 6409), c'est le port 465 (utilisé auparavant pour du SMTP classique, non-soumission, cf. le registre IANA et les section 7.3 et annexe A du RFC qui justifient cette réaffectation). Le mécanisme avec STARTTLS sur le port 587 (TLS explicite) est très répandu, contrairement à ce qui se passe pour POP et IMAP. La transition sera donc plus longue, et il faudra donc maintenir les deux services, TLS implicite et explicite, pendant un certain temps.
Voici les serveurs IMAP (pour récupérer le courrier) et SMTP
(pour soumettre du courrier) conformes aux recommandations de ce
RFC (TLS implicite), tels qu'affichés par
Thunderbird : 
Et voici la configuration du MTA Postfix pour accepter du TLS implicite sur le port 465 :
submissions inet n - - - - smtpd
-o syslog_name=postfix/submissions
-o smtpd_tls_wrappermode=yes
-o smtpd_sasl_auth_enable=yes
-o smtpd_client_restrictions=permit_sasl_authenticated,reject
-o smtpd_etrn_restrictions=reject
-o smtpd_sasl_authenticated_header=yes
(À mettre dans le master.cf.) Cette
configuration active TLS et exige une authentification du client
(ce qui est normal pour soumettre du courrier.) Pensez aussi à
vérifier que le port est bien défini dans
/etc/services (smtps 465/tcp ssmtp submissions).
La section 4 du RFC fournit des détails sur l'utilisation de TLS, du côté des fournisseurs de service de courrier. Le point essentiel est « chiffrement partout, tout le temps » (section 4.1). L'objectif ne pourra pas forcément être atteint immédiatement par tout le monde mais il faut commencer. Par exemple, on peut interdire tout accès en texte clair à certains utilisateurs, puis généraliser à tous. Et, dans ce cas, le message envoyé doit être indépendant de si le mot de passe était valide ou pas (pour ne pas donner d'indication à un éventuel écoutant). Le RFC conseille aussi de traiter les accès avec les vieilles versions de TLS (ou, pire, avec SSL) de la même façon que les accès en clair. Une fois l'accès en clair coupé, il est recommandé de forcer un changement de mot de passe, si l'ancien avait été utilisé en clair.
Et les autres points ? Les fournisseurs de services de
courrier électronique doivent annoncer les
services POP, IMAP et soumission SMTP en utilisant les
enregistrements SRV du RFC 6186, afin de faciliter la tâche des
MUA. Un nouvel enregistrement SRV arrive
avec ce RFC, d'ailleurs, le _submissions._tcp,
pour la soumission SMTP sur TLS. Le RFC demande que ces enregistrements
SRV (ainsi que les
enregistrements MX utilisés pour le
courrier entrant, donc a priori pas le sujet de ce RFC) soient
signés avec DNSSEC. Et, à propos du
DNS, le RFC demande également la
publication d'enregistrements TLSA (RFC 6698).
La cryptographie, c'est bien, mais il est également souhaitable
de signaler qu'elle a été utilisée, et dans quelles conditions,
pour informer les utilisateurs de la sécurité dont ils ont pu
bénéficier. Par exemple, le RFC demande que les algorithmes de
cryptographie utilisées soient mis dans l'en-tête
Received: du courrier (cf. aussi le RFC 3848), via une clause
tls (dans registre
IANA). Notez que beaucoup de serveurs SMTP le font déjà,
avec une syntaxe différente :
Received: from mail4.protonmail.ch (mail4.protonmail.ch [185.70.40.27])
(using TLSv1.2 with cipher ECDHE-RSA-AES256-GCM-SHA384 (256/256 bits))
(No client certificate requested)
by mail.bortzmeyer.org (Postfix) with ESMTPS id 38DAF31D16
for <stephane@bortzmeyer.org>; Sat, 20 Jan 2018 16:56:59 +0100 (CET)
La section 5 décrit les exigences pour l'autre côté, le client,
cette fois, et non plus le serveur de la section 4. D'abord, comme
les MUA sont en contact direct avec
l'utilisateur humain, ils doivent lui indiquer clairement le
niveau de confidentialité qui a été obtenu (par exemple par une
jolie icône, différente si on a utilisé TLS ou pas). Notez que
cette indication de la confidentialité est un des points du projet
Caliopen. Gmail, par
exemple, peut
afficher ces informations et cela donne :
Comment est-ce qu'un MUA doit trouver s·on·es serveur·s, au
fait ? La méthode recommandée est d'utiliser les
enregistements SRV du RFC 6186. Aux _imap._tcp et
_pop3._tcp du RFC précédent s'ajoute
_submissions._tcp pour le SMTP de soumission
d'un message, avec TLS implicite. Attention, le but étant la
confidentialité, le MUA ne devrait pas utiliser les serveurs
annoncés via les SRV s'ils ne satisfont pas à des exigences
minimales de sécurité TLS. Le MUA raisonnable devrait vérifier que
le SRV est signé avec DNSSEC, ou, sinon,
que le serveur indiqué est dans le même domaine que le domaine de
l'adresse de courrier. La section 5.2 donne d'autres idées de
choses à vérifier (validation du certificat
du serveur suivant le RFC 7817, de la version de TLS…) D'une
manière générale, le MUA ne doit pas envoyer d'informations
sensibles comme un mot de passe si la session n'est pas sûre. La
tentation pourrait être d'afficher à l'utilisateur un dialogue du
genre « Nous n'avons pas réussi à établir une connexion TLS
satisfaisante car la version de TLS n'est que la 1.1 et le groupe Diffie-Hellman ne fait que 512
bits, voulez-vous continuer quand même ? » Mais le RFC s'oppose à
cette approche, faisant remarquer qu'il est alors trop facile pour
l'utilisateur de cliquer OK et de prendre ainsi des risques qu'il
ne maitrise pas.
Autre question de sécurité délicate, l'épinglage du certificat. Il s'agit de garder un certificat qui a marché autrefois, même s'il ne marche plus, par exemple parce qu'expiré. (Ce n'est donc pas le même épinglage que celui qui est proposé pour HTTP par le RFC 7469.) Le RFC autorise cette pratique, ce qui est du bon sens : un certificat expiré, ce n'est pas la même chose qu'un certificat faux. Et ces certificats expirés sont fréquents car, hélas, bien des administrateurs système ne supervisent pas l'expiration des certificats. Voici la configuration d'Icinga pour superviser un service de soumission via SMTP :
apply Service "submissions" {
import "generic-service"
check_command = "ssmtp"
vars.ssmtp_port = 465
assign where (host.address || host.address6) && host.vars.submissions
vars.ssmtp_certificate_age = "7,3"
}
Et, une fois ce service défini, on peut ajouter à la
définition d'un serveur vars.submissions =
true et il sera alors supervisé :
Notre RFC recommande également aux auteurs de MUA de faire en sorte que les utilisateurs soient informés du niveau de sécurité de la communication entre le client et le serveur. Tâche délicate, comme souvent quand on veut communiquer avec les humains. Il ne faut pas faire de fausses promesses (« votre connection est cryptée avec des techniques military-grade, vous êtes en parfaite sécurité ») tout en donnant quand même des informations, en insistant non pas sur la technique (« votre connexion utilise ECDHE-RSA-AES256-GCM-SHA384, je vous mets un A+ ») mais sur les conséquences (« Ce serveur de courrier ne propose pas de chiffrement de la communication, des dizaines d'employés de la NSA, de votre FAI, et de la Fsociety sont en train de lire le message où vous parlez de ce que vous avez fait hier soir. »).
Voilà, vous avez l'essentiel de ce RFC. Quelques détails, maintenant. D'abord, l'interaction de ces règles avec les antivirus et antispam. Il y a plusieurs façons de connecter un serveur de messagerie à un logiciel antivirus et·ou antispam (par exemple l'interface Milter, très répandue). Parfois, c'est via SMTP, avec l'antivirus et·ou antispam qui se place sur le trajet, intercepte les messages et les analyse avant de les retransmettre. C'est en général une mauvaise idée (RFC 2979). Dès qu'il y a du TLS dans la communication, c'est encore pire. Puisque le but de TLS est de garantir l'authenticité et l'intégrité de la communication, tout « intercepteur » va forcément être très sale. (Et les logiciels qui font cela sont d'abominables daubes.)
Ah, et un avertissement lié à la vie privée (section 8 du RFC) : si on présente un certificat client, on révèle son identité à tout écoutant. Le futur TLS 1.3 aidera peut-être à limiter ce risque mais, pour l'instant, attention à l'authentification par certificat client.
Si vous aimez connaitre les raisons d'un choix technique, l'annexe A couvre en détail les avantages et inconvénients respectifs du TLS implicite sur un port séparé et du TLS explicite sur le port habituel. La section 7 du RFC 2595 donnait des arguments en faveur du TLS explicite. Certaines des critiques que ce vieux RFC exprimait contre le TLS implicite n'ont plus de sens aujourd'hui (le RFC 6186 permet que le choix soit désormais fait par le logiciel et plus par l'utilisateur, et les algorithmes export sont normalement abandonnés). D'autres critiques ont toujours été mauvaises (par exemple, celle qui dit que le choix entre TLS et pas de TLS est binaire : un MUA peut essayer les deux.) Outre la sécurité, un avantage du port séparé pour TLS est qu'il permet de déployer des frontaux - répartiteurs de charge, par exemple - TLS génériques.
Et pour terminer, d'autres exemples de configuration. D'abord avec mutt, par Keltounet :
smtp_url=smtps://USER@SERVER:465
Et le courrier est bien envoyé en TLS au port de soumission à TLS implicite.
Avec Dovecot, pour indiquer les
protocoles utilisés dans la session TLS, Shaft suggère, dans conf.d/10-logging.conf :
login_log_format_elements = user=<%u> method=%m rip=%r lip=%l mpid=%e %c %k
(Notez le %k à la fin, qui n'est pas dans le
fichier de configuration d'exemple.)
Et pour OpenSMTPd ? n05f3ra1u propose :
pki smtp.monserveur.example key "/etc/letsencrypt/live/monserveur.example/privkey.pem"
pki smtp.monserveur.example certificate "/etc/letsencrypt/live/monserveur.example/cert.pem"
...
listen on eno1 port 465 hostname smtp.monserveur.example smtps pki smtp.monserveur.example auth mask-source
L'article seul
RFC 8312: CUBIC for Fast Long-Distance Networks
Date de publication du RFC : Février 2018
Auteur(s) du RFC : I. Rhee (NCSU), L. Xu (UNL), S. Ha (Colorado), A. Zimmermann, L. Eggert (NetApp), R. Scheffenegger
Pour information
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 8 février 2018
Longtemps après sa mise au point et son déploiement massif sur Linux, voici la description officielle de l'algorithme CUBIC, un algorithme de contrôle de la congestion dans TCP. (Cette description a depuis été remplacée par celle du RFC 9438.)
CUBIC doit son nom au fait que la fonction de calcul de la fenêtre d'envoi des données est une fonction cubique (elle a un terme du troisième degré) et non pas linéaire. CUBIC est l'algorithme utilisé par défaut dans Linux depuis pas mal d'années :
% sudo sysctl net.ipv4.tcp_congestion_control
net.ipv4.tcp_congestion_control = cubic
CUBIC est plus énergique lorsqu'il s'agit d'agrandir la fenêtre d'envoi de données, lorsque le réseau a une grande capacité mais un RTT important. Dans le cas de ces réseaux « éléphants » (terme issu de la prononciation en anglais de LFN, Long and Fat Network, voir RFC 7323, section 1.1), le RTT élevé fait que l'émetteur TCP met du temps à recevoir les accusés de réception, et donc à comprendre que tout va bien et qu'il peut envoyer davantage de données, pour remplir le long tuyau. CUBIC permet d'accélérer cette phase.
Notez que CUBIC ne contrôle que l'émetteur, le récepteur est inchangé. Cela facilite le déploiement : un émetteur CUBIC peut parfaitement communiquer avec un récepteur traditionnel.
Avant de lire la suite du RFC, il est recommandé de (re)lire le RFC 5681, la bible sur le contrôle de congestion TCP, et notamment sur cette notion de fenêtre d'envoi (ou fenêtre de congestion).
TCP (RFC 793) a évidemment une mission difficile. L'intérêt de l'émetteur est d'envoyer le plus de données le plus vite possible. Mais à condition qu'elles arrivent sinon, s'il y a de la congestion, les données seront perdues et il faudra recommencer (ré-émettre). Et on n'est pas tout seul sur le réseau : il faut aussi tenir compte des autres, et chercher à partager équitablement l'Internet. L'algorithme doit donc être énergique (chercher à utiliser les ressources au maximum) mais pas bourrin (il ne faut pas dépasser le maximum), tout en étant juste (on n'est pas dans la startup nation, il ne faut pas écraser les autres, mais partager avec eux).
Le problème des éléphants, des réseaux à fort BDP, est connu depuis longtemps (article de T. Kelly, « Scalable TCP: Improving Performance in HighSpeed Wide Area Networks », et RFC 3649.) Dans ces réseaux, TCP tend à être trop prudent, à ouvrir sa fenêtre (les données qu'on peut envoyer tout de suite) trop lentement. Cette prudence l'honore, mais peut mener à des réseaux qui ne sont pas utilisés à fond. L'article de Ha, S., Kim, Y., Le, L., Rhee, I., et L. Xu, « A Step toward Realistic Performance Evaluation of High-Speed TCP Variants » expose ce problème. Il touche toutes les variantes de TCP depuis le TCP Reno décrit dans le RFC 5681 : le New Reno des RFC 6582 et RFC 6675, et même des protocoles non-TCP mais ayant le même algorithme, comme UDP (TFRC, RFC 5348) ou SCTP (RFC 9260).
CUBIC a été originellement documenté dans l'article de S. Ha, Injong Rhee, et Lisong Xu, « CUBIC: A New TCP-Friendly High-Speed TCP Variant », en 2008. Sur Linux, il a remplacé BIC pour les réseaux à haut BDP.
La section 3 du RFC rappelle les principes de conception de CUBIC, notamment :
- Utilisation de la partie concave (la fenêtre s'agrandit rapidement au début puis plus lentement ensuite) et de la partie convexe de la fonction, et pas seulement la partie convexe (on ouvre la fenêtre calmement puis on accélère), comme l'ont tenté la plupart des propositions alternatives. Si vous avez du mal avec les termes concave et convexe, la figure 2 de cet article de comparaison de CUBIC et BIC illustre bien, graphiquement, ces concepts. La courbe est d'abord concave, puis convexe.
- Comportement identique à celui de ses prédécesseurs pour les liaisons à faible RTT (ou faible BDP). Les algorithmes TCP traditionnels n'ont en effet pas de problème dans ce secteur (cf. section 4.2, et Floyd, S., Handley, M., et J. Padhye, « A Comparison of Equation-Based and AIMD Congestion Control »). « Si ce n'est pas cassé, ne le réparez pas. » CUBIC ne se différencie donc des autres algorithmes que pour les réseaux à RTT élevé, ce que rappelle le titre de notre RFC.
- Juste partage de la capacité entre des flots ayant des RTT différents.
- CUBIC mène à un agrandissement plus rapide de la fenêtre d'envoi, mais également à une réduction moins rapide lorsqu'il détecte de la congestion (paramètre « beta_cubic », le facteur de réduction de la fenêtre, voir aussi le RFC 3649.)
La section 4 du RFC spécifie précisement l'algorithme, après beaucoup de discussion avec les développeurs du noyau Linux (puisque le code a été écrit avant le RFC). Cette section est à lire si vous voulez comprendre tous les détails. Notez l'importance du point d'inflexion entre la partie concave et la partie convexe de la courbe qui décrit la fonction de changement de taille de la fenêtre. Ce point d'inflexion est mis à la valeur de la fenêtre d'envoi juste avant la dernière fois où TCP avait détecté de la congestion.
Notez que Linux met en outre en œuvre l'algorithme HyStart, décrit dans « Taming the Elephants: New TCP Slow Start ». Hystart mesure le RTT entre émetteur et récepteur pour détecter (par l'augmentation du RTT) un début de congestion avant que des pertes de paquets se produisent. (Merci à Lucas Nussbaum pour l'information.)
La section 5 analyse le comportement CUBIC selon les critères de comparaison des algorithmes de contrôle de la congestion décrits dans le RFC 9743.
Pour finir, voici une intéressante comparaison des algorithmes de contrôle de congestion.
L'article seul
RFC 8310: Usage Profiles for DNS over TLS and DNS over DTLS
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : S. Dickinson (Sinodun), D. Gillmor (ACLU), T. Reddy (McAfee)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 22 mars 2018
Afin de mieux protéger la vie privée des utilisateurs du DNS, le RFC 7858 normalise comment faire du DNS sur TLS, le chiffrement empêchant la lecture des requêtes et réponses DNS. Mais le chiffrement sans authentification n'a qu'un intérêt limité. Notamment, il ne protège pas contre un attaquant actif, qui joue les hommes du milieu. Le RFC 7858 ne proposait qu'un seul mécanisme d'authentification, peu pratique, les clés publiques configurées statiquement dans le client DNS. Ce nouveau RFC décrit d'autres mécanismes d'authentification, classés selon deux profils, un Strict (sécurité maximum) et un Opportuniste (disponibilité maximum).
Le problème de la protection de la vie privée quand on utilise le DNS est décrit dans le RFC 7626. Les solutions, comme toujours quand il s'agit de vie privée, se répartissent en deux catégories, la minimisation des données (RFC 9156) et le chiffrement (RFC 7858 et RFC 8094). Le chiffrement protège bien contre un attaquant purement passif. Mais si celui qui veut écouter les échanges DNS est capable de lancer des attaques actives (ARP spoofing, par exemple), le chiffrement ne suffit pas, il faut le doubler d'une authentification du serveur. Par exemple, en mars 2014, en Turquie, l'attaquant (le gouvernement) a pu détourner le trafic avec Google Public DNS. Même si Google Public DNS avait permis le chiffrement, il n'aurait pas servi, lors de cette attaque active. Sans l'authentification, on risque de parler en chiffré… à l'attaquant.
Le problème de l'authentification, c'est que si elle échoue, que faut-il faire ? Renoncer à envoyer des requêtes DNS ? Cela revient à se couper d'Internet. Notre nouveau RFC, considérant qu'il n'y a pas une solution qui conviendra à tous les cas, propose deux profils :
- Le profil strict privilégie la confidentialité. Si on ne peut pas chiffrer et authentifier, on renonce.
- Le profil opportuniste privilégie le fonctionnement du DNS. Si on ne peut pas authentifier, tant pis, on chiffre sans authentifier, mais, au moins, on a du DNS.
Notez bien qu'un profil spécifie des propriétés, une fin et pas un moyen. Un profil est défini par ces propriétés, qu'on implémente ensuite avec des mécanismes, décrits en section 6. Le RFC 7858 spécifiait déjà, dans sa section 4.2, un mécanisme d'authentification, fondé sur la connaissance préalable, par le client DNS, de la clé publique du serveur (SPKI, pour Subject Public Key Info, une solution analogue à celle du RFC 7469 pour HTTP). Mais beaucoup de détails manquaient. Ce nouveau RFC 8310 :
- Décrit comment le client est censé obtenir les informations nécessaires à l'authentification,
- Quelles lettres de créance peut présenter le serveur pour s'authentifier,
- Et comment le client peut les vérifier.
À propos de ces « informations nécessaires à
l'authentification », il est temps d'introduire un acronyme
important (section 2 du RFC), ADN (Authentication
Domain Name), le nom du serveur qu'on veut
authentifier. Par exemple, pour Quad9,
ce sera dns.quad9.net. Autres termes
importants :
- Ensemble de clés (SPKI pinset), un ensemble de clés cryptographiques (ou plutôt de condensats de clés),
- Identificateur de référence (reference identifier), l'identificateur utilisé pour les vérifications (cf. RFC 6125).
- Lettres de créance (credentials), les informations du serveur qui lui servent à s'authentifier, certificat PKIX, enregistrement TLSA (RFC 6698) ou ensemble de clés.
Note importante, la section 3 du RFC pointe le fait que les
mécanismes d'authentification présentés ici ne traitent que
l'authentification d'un résolveur DNS par son
client. L'éventuelle future authentification d'un serveur faisant
autorité par le résolveur est hors-sujet, tout comme
l'authentification du client DNS par le serveur. Sont également
exclus les idées d'authentifier le nom de l'organisation qui gère
le serveur ou son pays : on authentifie uniquement l'ADN, « cette
machine est bien dns-resolver.yeti.eu.org »,
c'est tout.
La section 5 présente les deux profils normalisés. Un profil est une politique choisie par le client DNS, exprimant ses exigences, et les compromis qu'il est éventuellement prêt à accepter si nécessaire. Un profil n'est pas un mécanisme d'authentification, ceux-ci sont dans la section suivante, la section 6. La section 5 présente deux profils :
- Le profil strict, où le client exige chiffrement avec le serveur DNS et authentification du serveur. Si cela ne peut pas être fait, le profil strict renonce à utiliser le DNS, plutôt qu'à prendre des risques d'être surveillé. Le choix de ce profil protège à la fois contre les attaques passives et contre les attaques actives.
- Le profil opportuniste, où le client tente de chiffrer et d'authentifier, mais est prêt à continuer quand même si ça échoue (cf. RFC 7435, sur ce concept de sécurité opportuniste). Si le serveur DNS permet le chiffrement, l'utilisateur de ce profil est protégé contre une attaque passive, mais pas contre une attaque active. Si le serveur ne permet pas le chiffrement, l'utilisateur risque même de voir son trafic DNS passer en clair.
Les discussions à l'IETF (par exemple pendant la réunion de Séoul en novembre 2016) avaient été vives, notamment sur l'utilité d'avoir un profil strict, qui peut mener à ne plus avoir de résolution DNS du tout, ce qui n'encouragerait pas son usage.
Une petite nuance s'impose ici : pour les deux profils, il faudra, dans certains cas, effectuer une requête DNS au tout début pour trouver certaines informations nécessaires pour se connecter au serveur DNS (par exemple son adresse IP si on n'a que son nom). Cette « méta-requête » peut se faire en clair, et non protégée contre l'écoute, même dans le cas du profil strict. Autrement, le déploiement de ce profil serait très difficile (il faudrait avoir toutes les informations stockées en dur dans le client).
Le profil strict peut être complètement inutilisable si les requêtes DNS sont interceptées et redirigées, par exemple dans le cas d'un portail captif. Dans ce cas, la seule solution est d'avoir un mode « connexion » pendant lequel on n'essaie pas de protéger la confidentialité des requêtes DNS, le temps de passer le portail captif, avant de passer en mode « accès Internet ». C'est ce que fait DNSSEC-trigger (cf. section 6.6).
Le tableau 1 du RFC résume les possibilités de ces deux profils, face à un attaquant actif et à un passif. Dans tous les cas, le profil strict donnera une connexion DNS chiffrée et authentifiée, ou bien pas de connexion du tout. Dans le meilleur cas, le profil opportuniste donnera la même chose que le strict (connexion chiffrée et authentifiée). Si le serveur est mal configuré ou si le client n'a pas les informations nécessaires pour authentifier, ou encore si un Homme du Milieu intervient, la session ne sera que chiffrée, et, dans le pire des cas, le profil opportuniste donnera une connexion en clair. On aurait pu envisager d'autres profils (par exemple un qui impose le chiffrement, mais pas l'authentification) mais le groupe de travail à l'IETF a estimé qu'ils n'auraient pas eu un grand intérêt, pour la complexité qu'ils auraient apporté.
Un mot sur la détection des problèmes. Le profil opportuniste peut permettre la détection d'un problème, même si le client continue ensuite malgré les risques. Par exemple, si un résolveur DNS acceptait DNS-sur-TLS avant, que le client avait enregistré cette information, mais que, ce matin, les connexions vers le port 853 sont refusées, avec le profil opportuniste, le client va quand même continuer sur le port 53 (en clair, donc) mais peut noter qu'il y a un problème. Il peut même (mais ce n'est pas une obligation) prévenir l'utilisateur. Cette possibilité de détection est le « D » dans le tableau 1, et est détaillée dans la section 6.5. La détection permet d'éventuellement prévenir l'utilisateur d'une attaque potentielle, mais elle est aussi utile pour le débogage.
Évidemment, seul le profil strict protège réellement l'utilisateur contre l'écoute et toute mise en œuvre de DNS-sur-TLS devrait donc permettre au moins ce profil. Le profil opportuniste est là par réalisme : parfois, il vaut mieux une connexion DNS écoutée que pas de DNS du tout.
Les deux profils vont nécessiter un peu de configuration (le nom ou l'adresse du résolveur) mais le profil strict en nécessite davantage (par exemple la clé du résolveur).
Maintenant qu'on a bien décrit les profils, quels sont les mécanismes d'authentification disponibles ? La section 6 les décrit rapidement, et le tableau 2 les résume, il y en a six en tout, caractérisés par l'information de configuration nécessaire côté client (ils seront détaillés en section 8) :
- Adresse IP du résolveur + clé du résolveur (SPKI, Subject Public Key Info). C'est celui qui était présenté dans la section 4.2 du RFC 7858, et qui est illustré dans mon article sur la supervision de résolveurs DNS-sur-TLS. Ce mécanisme est pénible à gérer (il faut par exemple tenir compte des éventuels changements de clé) mais c'est celui qui minimise la fuite d'information : l'éventuel surveillant n'apprendra que l'ADN (dans le SNI de la connexion TLS). En prime, il permet d'utiliser les clés nues du RFC 7250 (cf. section 9 du RFC).
- ADN (nom de domaine du résolveur DNS-sur-TLS) et adresse
IP du résolveur. On peut alors authentifier avec le
certificat PKIX, comme on le fait souvent avec TLS (cf. section 8
du RFC, RFC 5280 et RFC 6125). L'identificateur à vérifier est l'ADN, qui
doit se trouver dans le certificat, comme
subjectAltName. - ADN seul. La configuration est plus simple et plus stable mais les méta-requêtes (obtenir l'adresse IP du résolveur à partir de son ADN) ne sont pas protégées et peuvent être écoutées. Si on n'utilise pas DNSSEC, on peut même se faire détourner vers un faux serveur (la vérification du certificat le détecterait, si on pouvait faire confiance à toutes les AC situées dans le magasin).
- DHCP. Aucune configuration (c'est bien le but de DHCP) mais deux problèmes bloquants : il n'existe actuellement pas d'option DHCP pour transmettre cette information (même pas de projet) et DHCP lui-même n'est pas sûr.
- DANE (RFC 6698). On peut authentifier le certificat du résolveur, non pas
avec le fragile système des AC
X.509, mais avec DANE. L'enregistrement
TLSA devra être en
_853._tcp.ADN. Cela nécessite un client capable de faire de la validation DNSSEC (à l'heure actuelle, le résolveur sur la machine cliente est en général un logiciel minimal, incapable de valider). Et les requêtes DANE (demande de l'enregistrement TLSA) peuvent passer en clair. - DANE avec une extension TLS. Cette extension (RFC 9102) permet au serveur DNS-sur-TLS d'envoyer les enregistrements DNS et DNSSEC dans la session TLS elle-même. Plus besoin de méta-requêtes et donc plus de fuites d'information.
Cela fait beaucoup de mécanismes d'authentification ! Comment se combinent-ils ? Lesquels essayer et que faire s'ils donnent des résultats différents ? La méthode recommandée, si on a un ADN et une clé, est de tester les deux et d'exiger que les deux fonctionnent.
On a parlé à plusieurs reprises de l'ADN
(Authentication Domain Name). Mais comment
on obtient son ADN ? La section 7 du RFC détaille les sources
d'ADN. La première est évidemment le cas où l'ADN est
configuré manuellement. On pourrait imaginer, sur
Unix, un
/etc/resolv.conf avec une nouvelle
syntaxe :
nameserver 2001:db8:53::1 adn resolver.example.net
Ici, on a configuré manuellement l'adresse IP et le nom
(l'ADN) du résolveur. Cela convient au cas de résolveurs
publics comme Quad9. Mais on pourrait imaginer des cas où seul
l'ADN serait configuré quelque part, le résolveur dans
/etc/resolv.conf étant rempli par
DHCP, et n'étant utilisé que pour
les méta-requêtes. Par exemple un (mythique, pour l'instant) /etc/tls-resolver.conf :
adn resolver.example.net # IP address will be found via the "DHCP" DNS resolver, and checked # with DNSSEC and/or TLS authentication
Troisième possibilité, l'ADN et l'adresse IP pourraient être découverts dynamiquement. Il n'existe à l'heure actuelle aucune méthode normalisée pour cela. Si on veut utiliser le profil strict, cette future méthode normalisée devra être raisonnablement sécurisée, ce qui n'est typiquement pas le cas de DHCP. On peut toujours normaliser une nouvelle option DHCP pour indiquer l'ADN mais elle ne serait, dans l'état actuel des choses, utilisable qu'avec le profil opportuniste. Bon, si vous voulez vous lancer dans ce travail, lisez bien la section 8 du RFC 7227 et la section 22 du RFC 8415 avant.
La section 11 du RFC décrit les mesures à mettre en œuvre contre deux attaques qui pourraient affaiblir la confidentialité, même si on chiffre. La première est l'analyse des tailles des requêtes et des réponses. L'accès au DNS étant public, un espion peut facilement récolter l'information sur la taille des réponses et, puisque TLS ne fait rien pour dissimuler cette taille, déduire les questions à partir des tailles. La solution recommandée contre l'attaque est le remplissage, décrit dans le RFC 7830.
Seconde attaque possible, un résolveur peut inclure l'adresse IP de son client dans ses requêtes au serveur faisant autorité (RFC 7871). Cela ne révèle pas le contenu des requêtes et des réponses, mais c'est quand même dommage pour la vie privée. Le client DNS-sur-TLS doit donc penser à mettre l'option indiquant qu'il ne veut pas qu'on fasse cela (RFC 7871, section 7.1.2).
Enfin, l'annexe A de notre RFC rappelle les dures réalités de l'Internet d'aujourd'hui : même si votre résolveur favori permet DNS-sur-TLS (c'est le cas par exemple de Quad9), le port 853 peut être bloqué par un pare-feu fasciste. Le client DNS-sur-TLS a donc intérêt à mémoriser quels résolveurs permettent DNS-sur-TLS, et depuis quels réseaux.
Pour l'instant, les nouveaux mécanismes d'authentification, et la possibilité de configurer le profil souhaité, ne semblent pas encore présents dans les logiciels, il va falloir patienter (ou programmer soi-même).
Merci à Willem Toorop pour son aide.
L'article seul
RFC 8308: Extension Negotiation in the Secure Shell (SSH) Protocol
Date de publication du RFC : Mars 2018
Auteur(s) du RFC : D. Bider (Bitvise Limited)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 21 mars 2018
Dernière mise à jour le 28 mars 2018
Le protocole SSH n'avait pas de mécanisme propre pour négocier des extensions au protocole de base (comme celle du RFC 4335). En outre, une partie de la négociation, par exemple des algorithmes cryptographiques, se déroulait avant le début du chiffrement et n'était donc pas protégée. Ce nouveau RFC ajoute à SSH un mécanisme pour négocier les extensions après l'échange de clés et le début de la communication sécurisée, une fois que tout est confidentiel.
Un mécanisme de négociation pour un protocole cryptographique est toujours délicat (comme TLS s'en est aperçu à plusieurs reprises). Si on n'en a pas, le client et le serveur perdent beaucoup de temps à faire des essais/erreurs « tiens, il vient de déconnecter brusquement, c'est peut-être qu'il n'aime pas SHA-512, réessayons avec SHA-1 ». Et ces deux mécanismes (négociation explicite et essai/erreur) ouvrent une nouvelle voie d'attaque, celle des attaques par repli, où l'Homme du Milieu va essayer de forcer les deux parties à utiliser des algorithmes de qualité inférieure. (La seule protection serait de ne pas discuter, de choisir des algorithmes forts et de refuser tout repli. En sécurité, ça peut aider d'être obtus.)
Notez aussi que la méthode essais/erreurs a un danger spécifique, car bien des machines SSH mettent en œuvre des mécanismes de limitation du trafic, voire de mise en liste noire, si la machine en face fait trop d'essais, ceci afin d'empêcher des attaques par force brute. D'où l'intérêt d'un vrai mécanisme de négociation (qui peut en outre permettre de détecter certaines manipulations par l'Homme du Milieu).
Vue par tshark, voici
le début d'une négociation SSH, le message
SSH_MSG_KEXINIT, normalisé dans le RFC 4253, section 7.1 :
SSH Protocol
SSH Version 2
Packet Length: 1332
Padding Length: 5
Key Exchange
Message Code: Key Exchange Init (20)
Algorithms
Cookie: 139228cb5cfbf6c97d6b74f6ae99453d
kex_algorithms length: 196
kex_algorithms string: curve25519-sha256@libssh.org,ecdh-sha2-nistp256,ecdh-sha2-nistp384,ecdh-sha2-nistp521,diffie-hellman-group-exchange-sha256,diffie-hellman-group-exchange-sha1,diffie-hellman-group14-sha1,ext-info-c
server_host_key_algorithms length: 290
server_host_key_algorithms string [truncated]: ecdsa-sha2-nistp256-cert-v01@openssh.com,ecdsa-sha2-nistp384-cert-v01@openssh.com,ecdsa-sha2-nistp521-cert-v01@openssh.com,ssh-ed25519-cert-v01@openssh.com,ssh-rsa-cert-v01@openssh.com,ecdsa-s
encryption_algorithms_client_to_server length: 150
encryption_algorithms_client_to_server string: chacha20-poly1305@openssh.com,aes128-ctr,aes192-ctr,aes256-ctr,aes128-gcm@openssh.com,aes256-gcm@openssh.com,aes128-cbc,aes192-cbc,aes256-cbc,3des-cbc
encryption_algorithms_server_to_client length: 150
encryption_algorithms_server_to_client string: chacha20-poly1305@openssh.com,aes128-ctr,aes192-ctr,aes256-ctr,aes128-gcm@openssh.com,aes256-gcm@openssh.com,aes128-cbc,aes192-cbc,aes256-cbc,3des-cbc
mac_algorithms_client_to_server length: 213
mac_algorithms_client_to_server string [truncated]: umac-64-etm@openssh.com,umac-128-etm@openssh.com,hmac-sha2-256-etm@openssh.com,hmac-sha2-512-etm@openssh.com,hmac-sha1-etm@openssh.com,umac-64@openssh.com,umac-128@openssh.com,hmac-sha2-2
mac_algorithms_server_to_client length: 213
mac_algorithms_server_to_client string [truncated]: umac-64-etm@openssh.com,umac-128-etm@openssh.com,hmac-sha2-256-etm@openssh.com,hmac-sha2-512-etm@openssh.com,hmac-sha1-etm@openssh.com,umac-64@openssh.com,umac-128@openssh.com,hmac-sha2-2
compression_algorithms_client_to_server length: 26
compression_algorithms_client_to_server string: none,zlib@openssh.com,zlib
compression_algorithms_server_to_client length: 26
compression_algorithms_server_to_client string: none,zlib@openssh.com,zlib
languages_client_to_server length: 0
languages_client_to_server string: [Empty]
languages_server_to_client length: 0
languages_server_to_client string: [Empty]
KEX First Packet Follows: 0
Reserved: 00000000
Padding String: 0000000000
Le message était en clair (c'est pour cela que tshark a pu le décoder). L'autre machine envoie un message équivalent. Suite à cet échange, les deux machines sauront quels algorithmes sont disponibles.
Notre RFC 8308 (section 2.1) ajoute à ce message le nouveau
mécanisme d'extension. Pour préserver la compatibilité avec les
anciennes mises en œuvre de SSH, et comme il n'y a pas de place
« propre » disponible dans le message, le nouveau mécanisme se
place dans la liste des algorithmes cryptographiques (champ
kex_algorithms, celui qui commence par
curve25519-sha256@libssh.org,ecdh-sha2-nistp256…). On
ajoute à cette liste ext-info-c si on est
client et ext-info-s si on est serveur. (Le
nom est différent dans chaque direction, pour éviter que les deux
parties ne se disent « cool, cet algorithme est commun,
utilisons-le ».) Vous
pouvez donc savoir si votre SSH gère le nouveau mécanisme en
capturant ce premier paquet SSH et en examinant la liste des
algorithmes d'échange de clé. (C'était le cas ici, avec
OpenSSH 7.2. Vous l'aviez repéré ?)
Une fois qu'on a proposé à son pair d'utiliser le nouveau
mécanisme de ce RFC 8308, on peut s'attendre, si le pair
est d'accord, à recevoir un message SSH d'un nouveau type,
SSH_MSG_EXT_INFO, qui sera, lui, chiffré. Il contient la liste des
extensions gérées avec ce mécanisme. Notez qu'il peut être envoyé
plusieurs fois, par exemple avant et après l'authentification du
client, pour le cas d'un serveur timide qui ne voulait pas révéler
sa liste d'extensions avant l'authentification. Ce nouveau type de
message figure désormais dans le
registre des types de message, avec le numéro 7.
La section 3 définit les quatre extensions actuelles (un registre accueillera les extensions futures) :
- L'extension
server-sig-algsdonne la liste des algorithmes de signature acceptés par le serveur. delay-compressionindique les algorithmes de compression acceptés. Il y en a deux, un du client vers le serveur et un en sens inverse. Ils étaient déjà indiqués dans le messageSSH_MSG_KEXINIT, dans les champscompression_algorithms_client_to_serveretcompression_algorithms_server_to_clientmais, cette fois, ils sont transmis dans un canal sécurisé (confidentiel et authentifié).no-flow-control, dont le nom indique bien la fonction.elevationsert aux systèmes d'exploitation qui ont un mécanisme d'élévation des privilèges (c'est le cas de Windows, comme documenté dans le blog de Microsoft).
Les futures extensions, après ces quatre-là, nécessiteront un examen par l'IETF, via un RFC IETF (cf. RFC 8126, politique « IETF review »). Elle seront placées dans le registre des extensions.
Quelques petits problèmes de déploiement et d'incompatibilité
ont été notés avec ce nouveau
mécanisme d'extensions. Par exemple OpenSSH 7.3 et 7.4 gérait
l'extension server-sig-algs mais n'envoyait
pas la liste complète des algorithmes acceptés. Un client qui
considérait cette liste comme ferme et définitive pouvait donc
renoncer à utiliser certains algorithmes qui auraient pourtant
marché. Voir ce
message pour une explication détaillée.
Autre gag, les valeurs des extensions peuvent contenir des octets nuls et un logiciel maladroit qui les lirait comme si c'était des chaînes de caractères en C aurait des problèmes. C'est justement ce qui est arrivé à OpenSSH, jusqu'à la version 7.5 incluse, ce qui cassait brutalement la connexion. Le RFC conseille de tester la version du pair, et de ne pas utiliser les extensions en cause si on parle à un OpenSSH ≤ 7.5.
Aujourd'hui, ce mécanisme d'extension est mis en œuvre dans OpenSSH, Bitvise SSH, AsyncSSH et SmartFTP. (Cf. ce tableau de comparaison, mais qui n'est pas forcément à jour.)
Merci à Manuel Pégourié-Gonnard pour avoir détecté une erreur dans la première version.
L'article seul
RFC 8307: Well-Known URIs for the WebSocket Protocol
Date de publication du RFC : Janvier 2018
Auteur(s) du RFC : C. Bormann (Universitaet Bremen
TZI)
Chemin des normes
Première rédaction de cet article le 3 janvier 2018
Il existe une norme pour un préfixe de chemin dans un
URI, préfixe nommée
.well-known, et après lequel plusieurs noms
sont normalisés, pour des ressources « bien connues »,
c'est-à-dire auxquelles on peut accéder sans lien qui y mène. Le
RFC 8615 normalise ce
.well-known. Son prédécesseur n'était prévu à l'origine que
pour les plans http: et
https:. Ce très court
RFC l'a étendu aux plans
ws: et wss:, ceux des
Web sockets du RFC 6455. Depuis, notre RFC a été intégré dans la nouvelle
norme de .well-known, le RFC 8615.
Les gens de CoAP avaient déjà étendu
l'usage de .well-known en permettant (RFC 7252) qu'il soit utilisé pour les plans
coap: et coaps:.
Il existe un registre IANA des
suffixes (les termes après .well-known). Ce
registre est le même quel que soit le plan d'URI utilisé. Il ne
change donc pas suite à la publication de ce RFC.
L'article seul
RFC 8305: Happy Eyeballs Version 2: Better Connectivity Using Concurrency
Date de publication du RFC : Décembre 2017
Auteur(s) du RFC : D. Schinazi, T. Pauly (Apple)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 21 décembre 2017
Une machine connectée à l'Internet et répondant aux requêtes venues du réseau a souvent plusieurs adresses IP pour son nom. C'est parfois une adresse IPv4 et une IPv6 mais cela peut aussi être plusieurs adresses IPv6, ou bien un mélange en proportions quelconques. Les développeurs d'application et les administrateurs système qui déploieront ces applications ensuite, ont un choix difficile si certaines de ces adresses marchent et d'autres pas (ou mal). Si les différentes adresses IP de cette machine passent par des chemins différents, certains marchant et d'autres pas, l'application arrivera-t-elle à se rabattre sur une autre adresse très vite ou bien imposera-t-elle à l'utilisateur un long délai avant de détecter enfin le problème ? Cette question est connue comme « le bonheur des globes oculaires » (les dits globes étant les yeux de l'utilisateur qui attend avec impatience la page d'accueil de PornHub) et ce RFC spécifie les exigences pour l'algorithme de connexion du client. En les suivant, les globes oculaires seront heureux. Il s'agit de la version 2 de l'algorithme, bien plus élaborée que la version 1 qui figurait dans le RFC 6555.
La section 1 rappelle les données du problème : on veut évidemment que cela marche aussi bien en IPv6 (RFC 8200) qu'en IPv4 (pas question d'accepter des performances inférieures) or, dans l'état actuel du déploiement d'IPv6, bien des sites ont une connexion IPv6 totalement ou partiellement cassée. Si un serveur a IPv4 et IPv6 et que son client n'a qu'IPv4, pas de problème. Mais si le client a IPv6, tente de l'utiliser, mais que sa connexion est plus ou moins en panne, ou simplement sous-optimale, ses globes oculaires vont souffrir d'impatience. On peut aussi noter que le problème n'est pas spécifique à IPv6 : du moment que la machine visée a plusieurs adresses, qu'elles soient IPv4 ou IPv6, le risque que certaines des adresses ne marchent pas (ou moins bien) existe, et l'algorithme des globes oculaires heureux doit être utilisé. (C'est un des gros changements avec le précédent RFC, le RFC 6555, qui n'envisageait que le cas IPv6.)
La bonne solution est donc que l'application elle-même gère le problème (ou, sinon l'application elle-même, la bibliothèque logicielle qu'elle utilise et où se trouve la fonction de connexion). Il existe plusieurs algorithmes pour cela, déjà largement déployés depuis des années. On peut donc se baser sur l'expérience pour spécifier ces algorithmes. Ce RFC normalise les caractéristiques que doivent avoir ces algorithmes. Si on suit ce RFC, le trafic (IP et DNS) va légèrement augmenter (surtout si la connectivité IPv6 marche mal ou pas du tout) mais la qualité du vécu de l'utilisateur va être maintenue, même en présence de problèmes, ce qui compense largement. Autrement, il existerait un risque élevé que certains utilisateurs coupent complètement IPv6, plutôt que de supporter ces problèmes de délai de connexion.
La cible principale de notre RFC est composée des protocoles de transport avec connexion (TCP, SCTP), les protocoles sans connexion comme UDP soulevant d'autres questions (s'ils ont une sémantique requête/réponse, comme dans ICE, les algorithmes de ce RFC peuvent être utilisés).
Donc, on a un nom de machine qu'on veut contacter, mettons
www.example.com, avec plusieurs adresses
associées, peut-être de familles (v4 et v6) différentes. Prenons
une machine ayant une seule adresse IPv4 et une seule adresse
IPv6, avec une connexion IPv6 qui marche mal. Avec l'algorithme
naïf qu'utilisent encore certains logiciels voici la séquence
d'évenements traditionnelle :
- L'initiateur de la connexion utilise le DNS pour demander les enregistrements A (adresse IPv4) et AAAA (IPv6).
- Il récupère
192.0.2.1et2001:db8::1. - Il tente IPv6 (sur Linux, l'ordre des
essais est réglable dans
/etc/gai.conf). L'initiateur envoie un paquet TCPSYNà2001:db8::1. - Pas de réponse (connexion IPv6 incorrecte). L'initiateur réessaie, deux fois, trois fois, faisant ainsi perdre de nombreuses secondes.
- L'initiateur renonce, il passe à IPv4 et envoie un paquet TCP
SYNà192.0.2.1. - Le répondeur envoie un
SYN+ACKen échange, l'initiateur réplique par unACKet la connexion TCP est établie.
Le problème de cet algorithme naïf est donc la longue attente lors des essais IPv6. On veut au contraire un algorithme qui bascule rapidement en IPv4 lorsqu'IPv6 ne marche pas, sans pour autant gaspiller les ressources réseau en essayant par exemple toutes les adresses en même temps.
L'algorithme recommandé (sections 3 à 5, cœur de ce RFC) aura donc l'allure suivante :
- L'initiateur de la connexion utilise le DNS pour demander les enregistrements A (adresse IPv4) et AAAA (IPv6).
- Il récupère
192.0.2.1et2001:db8::1. Il sait donc qu'il a plusieurs adresses, de famille différente. - Il tente IPv6 (l'algorithme du RFC est de toute
façon facilement adaptable à des cas où IPv4 est prioritaire). L'initiateur envoie un paquet
TCP
SYNà2001:db8::1, avec un très court délai de garde. - Pas de réponse quasi-immédiate ? L'initiateur
passe à IPv4 rapidement. Il envoie un paquet TCP
SYNà192.0.2.1. - Le répondeur envoie un
SYN+ACKen échange, l'initiateur réplique par unACKet la connexion TCP est établie.
Si le répondeur réagit à une vitesse normale en IPv6, la connexion sera établie en IPv6. Sinon, on passera vite en IPv4, et l'utilisateur humain ne s'apercevra de rien. Naturellement, si le DNS n'avait rapporté qu'une seule adresse (v4 ou v6), on reste à l'algorithme traditionnel (« essayer, patienter, ré-essayer »).
Maintenant, les détails. D'abord, le DNS (section 3 de notre RFC). Pour récupérer les adresses appartenant aux deux familles (IPv4 et IPv6), il faut envoyer deux requêtes, de type A et AAAA. Pas de délai entre les deux, et le AAAA en premier, recommande le RFC. Notez qu'il n'existe pas de type de requête DNS pour avoir les deux enregistrements d'un coup, il faut donc deux requêtes.
Il ne faut pas attendre d'avoir la réponse aux deux avant de commencer à tenter d'établir une connexion. En effet, certains pare-feux configurés avec les pieds bloquent les requêtes AAAA, qui vont finir par timeouter. Du point de vue du programmeur, cela signifie qu'il faut faire les deux requêtes DNS dans des fils différents (ou des goroutines différentes en Go), ou bien, utiliser une API asynchrone, comme getdns. Ensuite, si on reçoit la réponse AAAA mais pas encore de A, on essaye tout de suite de se connecter, si on a la réponse A, on attend quelques millisecondes la réponse AAAA puis, si elle ne vient pas, tant pis, on essaie en IPv4. (La durée exacte de cette attente est un des paramètres réglables de l'algorithme. Il se nomme Resolution Delay et sa valeur par défaut recommandée est de 50 ms.)
À propos de DNS, notez que le RFC recommande également de privilégier IPv6 pour le transport des requêtes DNS vers les résolveurs (on parle bien du transport des paquets DNS, pas du type des données demandées). Ceci dit, ce n'est pas forcément sous le contrôle de l'application.
Une fois récupérées les adresses, on va devoir les trier selon l'ordre de préférence. La section 4 décrit comment cela se passe. Rappelons qu'il peut y avoir plusieurs adresses de chaque famille, pas uniquement une v4 et une v6, et qu'il est donc important de gérer une liste de toutes les adresses reçues (imaginons qu'on ne récupère que deux adresses v4 et aucune v6 : l'algorithme des globes oculaires heureux est quand même crucial car il est parfaitement possible qu'une des adresses v4 ne marche pas).
Pour trier, le RFC recommande de suivre les règles du RFC 6724, section 6. Si le client a un état (une mémoire des connexions précédentes, ce qui est souvent le cas chez les clients qui restent longtemps à tourner, un navigateur Web, par exemple), il peut ajouter dans les critères de tri le souvenir des succès (ou échecs) précédents, ainsi que celui des RTT passés. Bien sûr, un changement de connectivité (détecté par le DNA des RFC 4436 ou RFC 6059) doit entraîner un vidage complet de l'état (on doit oublier ce qu'on a appris, qui n'est plus pertinent).
Dernier détail sur le tri : il faut mêler les adresses des deux familles. Imaginons un client qui récupère trois adresses v6 et trois v4, client qui donne la priorité à IPv4, mais dont la connexion IPv4 est défaillante. Si sa liste d'adresses à tester comprend les trois adresses v4 en premier, il devra attendre trois essais avant que cela ne marche. Il faut donc plutôt créer une liste {une adressse v4, une adresse v6, une adresse v4…}. Le nombre d'adresses d'une famille à inclure avant de commencer l'autre famille est le paramètre First Address Family Count, et il vaut un par défaut.
Enfin, on essaie de se connecter en envoyant des paquets
TCP SYN (section 5). Il est important de ne pas tester IPv4 tout de suite. Les
premiers algorithmes « bonheur des globes oculaires » envoyaient
les deux paquets SYN en même temps, gaspillant des ressources réseau et
serveur. Ce double essai faisait que les équipements IPv4 du réseau
avaient autant de travail qu'avant, alors qu'on aurait souhaité les
retirer du service petit à petit. En outre, ce test simultané fait
que, dans la moitié des cas, la connexion sera établie en IPv4,
empêchant de tirer profit des avantages d'IPv6 (cf. RFC 6269). Donc, on doit tester en IPv6
d'abord, sauf si on se souvient des tentatives précédentes (voir
plus loin la variante « avec état ») ou bien si l'administrateur
système a délibérement configuré la machine pour préférer IPv4.
Après chaque essai, on attend pendant une durée paramétrable, Connection Attempt Delay, 250 ms par défaut (bornée par les paramètres Minimum Connection Attempt Delay, 100 ms par défaut, qu'on ne devrait jamais descendre en dessous de 10 ms, et Maximum Connection Attempt Delay, 2 s par défaut).
L'avantage de cet algorithme « IPv6 d'abord puis rapidement basculer en IPv4 » est qu'il est sans état : l'initiateur n'a pas à garder en mémoire les caractéristiques de tous ses correspondants. Mais son inconvénient est qu'on recommence le test à chaque connexion. Il existe donc un algorithme avec état (cf. plus haut), où l'initiateur peut garder en mémoire le fait qu'une machine (ou bien un préfixe entier) a une adresse IPv6 mais ne répond pas aux demandes de connexion de cette famille. Le RFC recommande toutefois de re-essayer IPv6 au moins toutes les dix minutes, pour voir si la situation a changé.
Une conséquence de l'algorithme recommandé est que, dans
certains cas, les deux connexions TCP (v4 et
v6) seront établies (si le SYN IPv6 voyage
lentement et que la réponse arrive après que l'initiateur de la
connexion se soit impatienté et soit passé à IPv4). Cela peut être
intéressant dans certains cas rares, mais le RFC recommande plutôt
d'abandonner la connexion perdante (la deuxième). Autrement, cela
pourrait entraîner des problèmes avec, par exemple, les sites Web
qui lient un cookie à l'adresse IP du
client, et seraient surpris de voir deux connexions avec des
adresses différentes.
La section 9 du RFC rassemble quelques derniers problèmes
pratiques. Par exemple, notre algorithme des globes oculaires
heureux ne prend en compte que l'établissement de la connexion. Si
une adresse ne marche pas du tout, il choisira rapidement la
bonne. Mais si une adresse a des problèmes de
MTU et pas l'autre, l'établissement de la
connexion, qui ne fait appel qu'aux petits paquets TCP
SYN, se passera bien alors que le reste de
l'échange sera bloqué. Une solution possible est d'utiliser
l'algorithme du RFC 4821.
D'autre part, l'algorithme ne tient compte que de la possibilité d'établir une connexion TCP, ce qui se fait typiquement uniquement dans le noyau du système d'exploitation du serveur. L'algorithme ne garantit pas qu'une application écoute, et fonctionne.
Parmi les problèmes résiduels, notez que l'algorithme des globes oculaires heureux est astucieux, mais tend à masquer les problèmes (section 9.3). Si un site Web publie les deux adresses mais que sa connectivité IPv6 est défaillante, aucun utilisateur ne lui signalera puisque, pour eux, tout va bien. Il est donc recommandé que l'opérateur fasse des tests de son côté pour repérer les problèmes (le RFC 6555 recommandait que le logiciel permette de débrayer cet algorithme, afin de tester la connectivité avec seulement v4 ou seulement v6, ou bien que le logiciel indique quelque part ce qu'il a choisi, pour mieux identifier d'éventuels problèmes v6.)
Pour le délai entre le premier SYN IPv6 et le
premier SYN IPv4, la section 5 donne des
idées quantitatives en suggérant 250 ms entre deux essais. C'est
conçu pour être quasiment imperceptible à un
utilisateur humain devant son navigateur Web, tout en évitant de
surcharger le réseau inutilement. Les algorithmes avec état ont le
droit d'être plus impatients, puisqu'ils peuvent se souvenir des
durées d'établissement de connexion précédents.
Notez que les différents paramètres réglables indiqués ont des valeurs par défaut, décrites en section 8, et qui ont été déterminées empiriquement.
Si vous voulez une meilleure explication de la version 2 des globes oculaires heureux, il y a cet exposé au RIPE.
Enfin, les implémentations. Notez que les vieilles mises en œuvre du RFC 6555 (et présentées à la fin de mon précédent article) sont toujours conformes à ce nouvel algorithme, elles n'en utilisent simplement pas les raffinements. Les versions récentes de macOS (Sierra) et iOS (10) mettent en œuvre notre RFC, ce qui est logique, puisqu'il a été écrit par des gens d'Apple (l'annonce est ici, portant même sur des versions antérieures). Apple en a d'ailleurs profité pour breveter cette technologie. À l'inverse, un exemple récent de logiciel incapable de gérer proprement le cas d'un pair ayant plusieurs adresses IP est Mastodon (cf. bogue #3762.)
Dans l'annexe A, vous trouverez la liste complète des importants changements depuis le RFC 6555. Le précédent RFC n'envisageait qu'un seul cas, deux adresses IP, une en v4, l'autre en v6. Notre nouveau RFC 8305 est plus riche, augmente le parallélisme, et ajoute :
- La façon de faire les requêtes DNS (pour tenir compte des serveurs bogués qui ne répondent pas aux requêtes AAAA, cf. RFC 4074),
- La gestion du cas où il y a plusieurs adresses IP de la même famille (v4 ou v6),
- La bonne façon d'utiliser les souvenirs des connexions précédentes,
- Et la méthode (dont je n'ai pas parlé ici) pour le cas des réseaux purement IPv6, mais utilisant le NAT64 du RFC 8305.
L'article seul
RFC 8304: Transport Features of the User Datagram Protocol (UDP) and Lightweight UDP (UDP-Lite)
Date de publication du RFC : Février 2018
Auteur(s) du RFC : G. Fairhurst, T. Jones (University of Aberdeen)
Pour information
Réalisé dans le cadre du groupe de travail IETF taps
Première rédaction de cet article le 8 février 2018
Le RFC 8303, du groupe de travail TAPS, décrit les fonctions et services rendus par les protocoles de transport aux applications. Ce RFC 8304 se focalise sur deux protocoles sans connexion, UDP et UDP-Lite. Quels services fournissent-ils ?
UDP est normalisé dans le RFC 768 et UDP-Lite dans le RFC 3828. Tous les deux permettent l'envoi et la réception de datagrammes, sans connexion préalable, sans garantie d'être prévenu en cas de perte du datagramme, sans garantie qu'ils soient distribués dans l'ordre. Une application qui utilise UDP va donc devoir connaitre les services exacts que ce protocole fournit. Aujourd'hui, de nombreuses applications utilisent UDP, l'une des plus connues étant sans doute le DNS, sans compter celles qui utilisent un autre protocole de transport mais qui l'encapsulent dans UDP pour passer les boitiers intermédiaires (cf. par exemple RFC 8261). UDP-Lite est très proche d'UDP et ajoute juste la possibilité de distribuer à l'application des paquets potentiellement endommagés. Pour utiliser UDP intelligement, les programmeurs ont tout intérêt à consulter le RFC 8085.
L'API la plus courante est
l'API dite « socket », normalisée par
POSIX, et dont la meilleure documentation
est évidemment le livre de
Stevens. Les applications peuvent envoyer des données avec
send(),
sendto() et
sendmsg(), en recevoir avec
recvfrom() et
recvmsg(). Elles peuvent être
dans l'obligation de configurer certaines informations de bas
niveau comme la permission de fragmenter ou
pas, alors que TCP gère cela tout seul.
Des options existent dans l'API socket pour
définir ces options.
Notre RFC 8304 suit la démarche du RFC 8303 pour la description d'un protocole de transport. Plus précisement, il suite la première passe, celle de description de ce que sait faire le protocole.
Donc, pour résumer (section 3 du RFC), UDP est décrit dans le RFC 768, et UDP-Lite dans le RFC 3828. Tous les deux fournissent un service de datagramme, non connecté, et qui préserve les frontières de message (contrairement à TCP, qui envoie un flot d'octets). Le RFC 768 donne quelques idées sur l'API d'UDP, il faut notamment que l'application puisse écouter sur un port donné, et puisse choisir le port source d'envoi.
UDP marche évidemment également sur IPv6, et une extension à l'API socket pour IPv6 est décrite dans le RFC 3493.
UDP est très basique : aucun contrôle de congestion (le RFC 8085 détaille ce point), pas de retransmission des paquets perdus, pas de notification des pertes, etc. Tout doit être fait par l'application. On voit que, dans la grande majorité des cas, il vaut mieux utiliser TCP. Certains développeurs utilisent UDP parce qu'ils ont lu quelque part que c'était « plus rapide » mais c'est presque toujours une mauvaise idée.
Notre RFC décrit ensuite les primitives UDP utilisables par les applications :
CONNECTest très différent de celui de TCP. C'est une opération purement locale (aucun paquet n'est envoyé sur le réseau), qui associe des ports source et destination à une prise (socket), c'est tout. Une fois cette opération faite, on pourra envoyer ou recevoir des paquets. CommeCONNECT,CLOSEn'a d'effet que local (pas de connexion, donc pas de fermeture de connexion).SENDetRECEIVE, dont le nom indique bien ce qu'elles font.SET_IP_OPTIONSqui permet d'indiquer des options IP, chose qui n'est en général pas nécessaire en TCP mais peut être utile en UDP.SET_DFest important car il permet de contrôler la fragmentation des paquets. TCP n'en a pas besoin car la MSS est négociée au début de la connexion. Avec UDP, c'est le programmeur de l'application qui doit choisir s'il laissera le système d'exploitation et les routeurs (en IPv4 seulement, pour les routeurs) fragmenter, ce qui est risqué, car pas mal de pare-feux mal configurés bloquent les fragments, ou bien s'il refusera la fragmentation (DF = Don't Fragment) et devra donc faire attention à ne pas envoyer des paquets trop gros. (Voir aussi les RFC 1191 et RFC 8201 pour une troisième possibilité.)SET_TTL(IPv4) etSET_IPV6_UNICAST_HOPSpermettent de définir le TTL des paquets IP envoyés. (Le terme de TTL est objectivement incorrect, et est devenu hops en IPv6, mais c'est le plus utilisé.)SET_DSCPpermet de définir la qualité de service souhaitée (RFC 2474).SET_ECNpermet de dire qu'on va utiliser ECN (RFC 3168). Comme les précédentes, elle n'a pas de sens en TCP, où le protocole de transport gère cela seul.- Enfin, dernière primitive citée par le RFC, la demande de notification des erreurs. Elle sert à réclamer qu'on soit prévenu de l'arrivée des messages ICMP.
Certaines primitives ont été exclues de la liste car n'étant plus d'actualité (cf. le RFC 6633).
Avec ça, on n'a parlé que d'UDP et pas d'UDP-Lite. Rappelons
qu'UDP-Lite (RFC 3828) est à 95 % de l'UDP
avec un seul changement, la possibilité que la somme de
contrôle ne couvre qu'une partie du paquet. Il faut
donc une primtive SET_CHECKSUM_COVERAGE qui
indique jusqu'à quel octet le paquet est couvert par la somme de
contrôle.
Notez enfin que le RFC se concentre sur l'unicast mais, si cela vous intéresse, l'annexe A décrit le cas du multicast.
L'article seul
RFC 8303: On the Usage of Transport Features Provided by IETF Transport Protocols
Date de publication du RFC : Février 2018
Auteur(s) du RFC : M. Welzl (University of Oslo), M. Tuexen (Muenster Univ. of Appl. Sciences), N. Khademi (University of Oslo)
Pour information
Réalisé dans le cadre du groupe de travail IETF taps
Première rédaction de cet article le 8 février 2018
La famille de protocoles TCP/IP dispose d'un grand nombre de protocoles de transport. On connait bien sûr TCP mais il y en a d'autres comme UDP et SCTP et d'autres encore moins connus. Cette diversité peut compliquer la tâche des développeurs d'application, qui ne savent pas toujours bien lequel choisir. Et elle pose également problème pour les développements futurs à l'IETF, par exemple la réflexion en cours sur les API. On a besoin d'une description claire des services que chaque protocole fournit effectivement. C'est le but du groupe de travail TAPS dont voici le deuxième RFC : une description de haut niveau des services que fournit la couche transport. À faire lire à tous les développeurs d'applications réseau, à tous les participants à la normalisation, et aux étudiants en réseaux informatiques.
Ce RFC parle de TCP, MPTCP, SCTP, UDP et UDP-Lite, sous l'angle « quels services rendent-ils aux applications ? » (QUIC, pas encore normalisé à l'époque, n'y figure pas. LEDBAT, qui n'est pas vraiment un protocole de transport, est par contre présent.) L'idée est de lister un ensemble d'opérations abstraites, qui pourront ensuite être exportées dans une API (RFC 9622). J'en profite pour recommander la lecture du RFC 8095, premier RFC du groupe TAPS.
La section 1 de notre RFC décrit la terminologie employée. Il faut notamment distinguer trois termes :
- La fonction (Transport Feature) qui désigne une fonction particulière que le protocole de transport va effectuer, par exemple la confidentialité, la fiabilité de la distribution des données, le découpage des données en messages, etc.
- Le service (Transport Service) qui est un ensemble cohérent de fonctions. C'est ce que demande l'application.
- Le protocole (Transport Protocol) qui est une réalisation concrète d'un ou plusieurs services.
Un exemple de programme qui permet d'essayer différents types
de prises (sockets) est socket-types.c. Vous pouvez le compiler et le lancer en
indiquant le type de service souhaité. STREAM
va donner du TCP, SEQPACKET du SCTP,
DATAGRAM de l'UDP :
% make socket-types
cc -Wall -Wextra socket-types.c -o socket-types
% ./socket-types -v -p 853 9.9.9.9 STREAM
9.9.9.9 is an IP address
"Connection" STREAM successful to 9.9.9.9
% ./socket-types -v -p 443 -h dns.bortzmeyer.org STREAM
Address(es) of dns.bortzmeyer.org is(are): 2605:4500:2:245b::42 204.62.14.153
"Connection" STREAM successful to 2605:4500:2:245b::42
256 response bytes read
À première vue, l'API sockets nous permet
de sélectionner le service, indépendamment du protocole qui le
fournira. Mais ce n'est pas vraiment le cas. Si on veut juste un
flot de données, cela pourrait être fait avec TCP ou SCTP, mais
seul TCP sera sélectionné si on demande
STREAM. En fait, les noms de services dns
l'appel à socket() sont toujours
en correspondance univoque avec les protocoles de transport.
Autres termes importants :
- Adresse (Transport Address) qui est un tuple regroupant adresse IP, nom de protocole et numéro de port. Le projet TAPS considère uniquement des protocoles ayant la notion de ports, et fournissant donc la fonction de démultiplexage (différencier les données destinées à telle ou telle application).
- Primitive (Primitive), un moyen pour l'application de demander quelque chose au protocole de transport.
- Événement (Event), généré par le protocole de transport, et transmis à l'application pour l'informer.
La section 2 décrit le problème général. Actuellement, les applications sont liées à un protocole, même quand elles ne le souhaitent pas. Si une application veut que ses octets soient distribués dans l'ordre, et sans pertes, plusieurs protocoles peuvent convenir, et il n'est pas forcément utile de se limiter à seulement TCP, par exemple. Pour avancer vers un moindre couplage entre application et protocole, ce RFC décrit les fonctions et les services, un futur RFC définira des services minimaux, un autre peut-être une API.
Le RFC essaie de s'en tenir au minimum, des options utiles mais pas indispensables (comme le fait pour l'application de demander à être prévenue de certains changements réseau, cf. RFC 6458) ne sont pas étudiées.
Le RFC procède en trois passes : la première (section 3 du RFC)
analyse et explique ce que chaque protocole permet, la seconde (section 4) liste les
primitives et événements possibles, la troisième (section 5) donne
pour chaque fonction les protocoles qui la mettent en œuvre. Par
exemple, la passe 1 note que TCP fournit à l'application un moyen
de fermer une connexion en cours, la passe 2 liste une primitive
CLOSE.TCP, la passe 3 note que TCP et SCTP
(mais pas UDP) fournissent cette opération de fermeture (qui fait
partie des fonctions de base d'un protocole orienté connexion,
comme TCP). Bon, d'accord, cette méthode est un peu longue et elle rend le RFC pas
amusant à lire mais cela permet de s'assurer que rien n'a été
oublié.
Donc, section 3 du RFC, la passe 1. Si vous connaissez bien tous ces
protocoles, vous pouvez sauter cette section. Commençons par le
protocole le plus connu, TCP (RFC 793). Tout le monde sait que c'est un
protocole à connexion, fournissant un transport fiable et ordonné
des données. Notez que la section 3.8 de la norme TCP décrit,
sinon une API, du moins l'interface (les primitives) offertes aux
applications. Vous verrez que les noms ne correspondent pas du
tout à celle de l'API sockets
(OPEN au lieu de
connect/listen, SEND au lieu de
write, etc).
TCP permet donc à l'application d'ouvrir une connexion (activement - TCP se connecte à un TCP distant - ou passivement - TCP attend les connexions), d'envoyer des données, d'en recevoir, de fermer la connexion (gentiment - TCP attend encore les données de l'autre - ou méchamment - on part en claquant la porte). Il y a aussi des événements, par exemple la fermeture d'une connexion déclenchée par le pair, ou bien une expiration d'un délai de garde. TCP permet également de spécifier la qualité de service attendue (cf. RFC 2474, et la section 4.2.4.2 du RFC 1123). Comme envoyer un paquet IP par caractère tapé serait peu efficace, TCP permet, pour les sessions interactives, genre SSH, d'attendre un peu pour voir si d'autres caractères n'arrivent pas (algorithme de Nagle, section 4.2.3.4 du RFC 1123). Et il y a encore d'autres possibilités moins connues, comme le User Timeout du RFC 5482. Je vous passe des détails, n'hésitez pas à lire le RFC pour approfondir, TCP a d'autres possibilités à offrir aux applications.
Après TCP, notre RFC se penche sur MPTCP. MPTCP crée plusieurs connexions TCP vers le pair, utilisant des adresses IP différentes, et répartit le trafic sur ces différents chemins (cf. RFC 6182). Le modèle qu'il présente aux applications est très proche de celui de TCP. MPTCP est décrit dans les RFC 6824 et son API est dans le RFC 6897. Ses primitives sont logiquement celles de TCP, plus quelques extensions. Parmi les variations par rapport à TCP, la primitive d'ouverture de connexion a évidemment une option pour activer ou pas MPTCP (sinon, on fait du TCP normal). Les extensions permettent de mieux contrôler quelles adresses IP on va utiliser pour la machine locale.
SCTP est le principal concurrent de TCP sur le créneau « protocole de transfert avec fiabilité de la distribution des données ». Il est normalisé dans le RFC 9260. Du point de vue de l'application, SCTP a trois différences importantes par rapport à TCP :
- Au lieu d'un flot continu d'octets, SCTP présent une suite de messages, avec des délimitations entre eux,
- Il a un mode où la distribution fiable n'est pas garantie,
- Et il permet de tirer profit du multi-homing.
Il a aussi une terminologie différente, par exemple on parle d'associations et plus de connexions.
Certaines primitives sont donc différentes : par exemple,
Associate au lieu du
Open TCP. D'autres sont identiques, comme
Send et Receive. SCTP
fournit beaucoup de primitives, bien plus que TCP.
Et UDP ? Ce protocole sans connexion, et sans fiabilité, ainsi que sa variante UDP-Lite, est analysé dans un RFC séparé, le RFC 8304.
Nous passons ensuite à LEDBAT (RFC 6817). Ce n'est pas vraiment un protocole de transport, mais plutôt un système de contrôle de la congestion bâti sur l'idée « décroissante » de « on n'utilise le réseau que si personne d'autre ne s'en sert ». LEDBAT est pour les protocoles économes, qui veulent transférer des grandes quantités de données sans gêner personne. Un flot LEDBAT cédera donc toujours la place à un flot TCP ou compatible (RFC 5681). N'étant pas un protocole de transport, LEDBAT peut, en théorie, être utilisé sur les protocoles existants comme TCP ou SCTP (mais les extensions nécessaires n'ont hélas jamais été spécifiées). Pour l'instant, les applications n'ont pas vraiment de moyen propre d'activer ou de désactiver LEDBAT.
Bien, maintenant, passons à la deuxième passe (section 4 du RFC). Après la description des protocoles lors de la première passe, cette deuxième passe liste explicitement les primitives, rapidement décrites en première passe, et les met dans différentes catégories (alors que la première passe classait par protocole). Notons que certaines primitives, ou certaines options sont exclues. Ainsi, TCP a un mécanisme pour les données urgentes (RFC 793, section 3.7). Il était utilisé pour telnet (cf. RFC 854) mais n'a jamais vraiment fonctionné de manière satisfaisante et le RFC 6093 l'a officiellement exclu pour les nouvelles applications de TCP. Ce paramètre n'apparait donc pas dans notre RFC, puisque celui-ci vise le futur.
La première catégorie de primitives concerne la gestion de connexion. On y trouve d'abord les primitives d'établissement de connexion :
CONNECT.TCP: établit une connexion TCP,CONNECT.SCTP: idem pour SCTP,CONNECT.MPTCP: établit une connexion MPTCP,CONNECT.UDP: établit une « connexion » UDP sauf, que, UDP étant sans connexion, il s'agit cette fois d'une opération purement locale, sans communication avec une autre machine.
Cette catégorie comprend aussi les primitives permettant de
signaler qu'on est prêt à recevoir une connexion,
LISTEN.TCP, celles de maintenance de la
connexion, qui sont bien plus variées, et celles permettant de
mettre fin à la connexion (comme CLOSE.TCP et
CLOSE.SCTP, ou comme le signal qu'un délai de
garde a été dépassé, TIMEOUT.TCP).
Dans les primitives de maintenance, on trouve aussi bien les
changements du délai de garde
(CHANGE_TIMEOUT.TCP et
SCTP), le débrayage de
l'algorithme de Nagle, pour TCP et SCTP,
l'ajout d'une adresse IP locale à l'ensemble des adresses
utilisables (ADD_PATH.MPTCP et
ADD_PATH.SCTP), la notification d'erreurs,
l'activation ou la désactivation de la somme de
contrôle (UDP seulement, la somme de contrôle étant
obligatoire pour les autres)… La plupart sont spécifiques à SCTP,
le protocole le plus riche.
La deuxième catégorie rassemble les primitives liées à la
transmission de données. On y trouve donc
SEND.TCP (idem pour SCTP et UDP),
RECEIVE.TCP (avec ses équivalents SCTP et
UDP), mais aussi les signalements d'échec comme
SEND_FAILURE.UDP par exemple quand on a reçu
un message ICMP d'erreur.
Venons-en maintenant à la troisième passe (section 5 du RFC). On va cette fois lister les primitives sous forme d'un concept de haut niveau, en notant les protocoles auxquels elles s'appliquent. Ainsi, pour la gestion des connexions, on aura de quoi se connecter : une primitive Connect, qui s'applique à plusieurs protocoles (TCP, SCTP et UDP, même si Connect ne se réalise pas de la même façon pour tous ces protocoles). Et de quoi écouter passivement : une primitive Listen. Pour la maintenance, on aura une primitive Change timeout, qui s'applique à TCP et SCTP, une Disable Nagle qui s'applique à TCP et SCTP, une Add path qui a un sens pour MPTCP et SCTP, une Disable checksum qui ne marche que pour UDP, etc.
Pour l'envoi de données, on ne fusionne pas les opérations
d'envoi (SEND.PROTOCOL) de la passe
précédente car elles ont une sémantique trop différente. Il y a
Reliably transfer data pour TCP, et
Reliably transfer a message pour SCTP. (Et bien
sûr Unreliably transfer a message avec UDP.)
Voilà, tout ça a l'air un peu abstrait mais ça acquerra davantage de sens quand on passera aux futures descriptions d'API (voir le RFC 8923).
L'annexe B du RFC explique la méthodologie suivie pour l'élaboration de ce document : coller au texte des RFC, exclure les primitives optionnelles, puis les trois passes dont j'ai parlé plus tôt. C'est cette annexe, écrite avant le RFC, qui avait servi de guide aux auteurs des différentes parties (il fallait des spécialistes SCTP pour ne pas faire d'erreurs lors de la description de ce protocole complexe…)
Notez (surtout si vous avez lu le RFC 8095) que TLS n'a pas été inclus, pas parce que ce ne serait pas un vrai protocole de transport (ça se discute) mais car il aurait été plus difficile à traiter (il aurait fallu des experts en sécurité).
L'article seul
RFC 8300: Network Service Header (NSH)
Date de publication du RFC : Janvier 2018
Auteur(s) du RFC : P. Quinn (Cisco), U. Elzur
(Intel), C. Pignataro (Cisco)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sfc
Première rédaction de cet article le 14 janvier 2018
Ce Network Service Header est un mécanisme concret pour faire passer sur le réseau les paquets destinés à une SF (Service Function, voir RFC 7665 pour l'architecture et les définitions). On colle un NSH, stockant plusieurs métadonnées, au paquet à traiter, on encapsule ce paquet à traiter et on l'envoie au dispositif de traitement via un réseau overlay. Et on fait l'opération inverse au retour. L'encapsulation peut se faire dans IP (par exemple avec GRE) ou dans un autre protocole.
Les métadonnées mises dans le NSH sont le résultat d'un processus de classification où le réseau décide ce qu'on va faire au paquet. Par exemple, en cas de dDoS, le classificateur décide de faire passer tous les paquets ayant telle adresse source par un équipement de filtrage plus fin, et met donc cette décision dans le NSH (section 7.1). Le NSH contient les informations nécessaires pour le SFC (Service Function Chain, RFC 7665). Sa lecture est donc très utile pour l'opérateur du réseau (elle contient la liste des traitements choisis, et cette liste peut permettre de déduire des informations sur le trafic en cours) et c'est donc une information plutôt sensible (voir aussi le RFC 8165).
Le NSH ne s'utilise qu'à l'intérieur de votre propre réseau (il n'offre, par défaut, aucune authentification et aucune confidentialité, voir section 8 du RFC). C'est à l'opérateur de prendre les mesures nécessaires, par exemple en chiffrant tout son trafic interne. Cette limitation à un seul domaine permet également de régler le problème de la fragmentation, si ennuyeux dès qu'on encapsule, ajoutant donc des octets. Au sein d'un même réseau, on peut contrôler tous les équipements et donc s'assurer que la MTU sera suffisante, ou, sinon, que la fragmentation se passera bien (section 5 du RFC).
Tout le projet SFC (dont c'est le troisième RFC) repose sur une vision de l'Internet comme étant un ensemble de middleboxes tripotant les paquets au passage, plutôt qu'étant un ensemble de machines terminales se parlant suivant le principe de bout en bout. C'est un point important à noter pour comprendre les débats au sein de l'IETF.
L'article seul
RFC 8297: An HTTP Status Code for Indicating Hints
Date de publication du RFC : Décembre 2017
Auteur(s) du RFC : K. Oku (Fastly)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 20 décembre 2017
Lorsqu'un serveur HTTP répond, la réponse contient souvent des liens vers d'autres ressources. Un exemple typique est celui de la page Web dont le chargement va déclencher le chargement de feuilles de style, de JavaScript, etc. Pour minimiser la latence, il serait intéressant de prévenir le client le plus tôt possible. C'est le but de ce RFC, qui décrit le code de retour intérimaire 103, qui prévient le client qu'il peut tout de suite commencer à charger ces ressources supplémentaires.
Il existe un type de lien pour cela,
preload, décrit par ses auteurs et
enregistré dans le registre des types de
liens (cf. RFC 8288). Il peut être
utilisé dans la réponse « normale » :
HTTP/1.1 200 OK
Date: Fri, 26 May 2017 10:02:11 GMT
Content-Length: 1234
Content-Type: text/html; charset=utf-8
Link: </main.css>; rel="preload"; as="style"
Link: </script.js>; rel="preload"; as="script"
Mais cela ne fait pas gagner grand'chose : une toute petite fraction de seconde après, le client HTTP verra arriver le source HTML et pourra y découvrir les liens. On voudrait renvoyer tout de suite la liste des ressources à charger, sans attendre que le serveur ait fini de calculer la réponse (ce qui peut prendre du temps, s'il faut dérouler mille lignes de Java et plein de requêtes SQL…)
Le nouveau code de retour, 103, lui, peut être envoyé immédiatement, avec la liste des ressources. Le client peut alors les charger, tout en attendant le code de retour 200 qui indiquera que la ressource principale est prête. (Les codes de retour commençant par 1, comme 103, sont des réponses temporaires, « pour information », en attendant le succès, annoncé par un code commençant par 2. Cf. RFC 7231, sections 6.2 et 6.3.) La réponse HTTP utilisant le nouveau code ressemblera à :
HTTP/1.1 103 Early Hints Link: </main.css>; rel="preload"; as="style" Link: </script.js>; rel="preload"; as="script" HTTP/1.1 200 OK Date: Fri, 26 May 2017 10:02:11 GMT Content-Length: 1234 Content-Type: text/html; charset=utf-8 Link: </main.css>; rel="preload"; as="style" Link: </script.js>; rel="preload"; as="script"
Les détails, maintenant (section 2 du RFC). 103 indique au client qu'il y aura une série de liens vers des ressources supplémentaires qu'il peut être intéressant, par exemple, de charger tout de suite. Les liens finaux seront peut-être différents (dans l'exemple ci-dessus, ils sont identiques). 103 est juste une optimisation, pas une obligation. (Hint = suggestion.) Les liens qu'il indique ne font pas autorité. Le serveur peut indiquer des liens supplémentaires, ne pas indiquer des liens qui étaient dans la réponse 103, indiquer des liens différents, etc.
Il peut même y avoir plusieurs 103 à la suite, notamment si un relais sur le trajet ajoute le sien, par exemple en se basant sur une réponse qu'il avait gardée en mémoire. 103 n'est en effet pas toujours envoyé par le serveur d'origine de la ressource, il peut l'être par un intermédiaire. Voici un exemple qui donne une idée des variantes possibles :
HTTP/1.1 103 Early Hints Link: </main.css>; rel="preload"; as="style" HTTP/1.1 103 Early Hints Link: </style.css>; rel="preload"; as="style" Link: </script.js>; rel="preload"; as="script" HTTP/1.1 200 OK Date: Fri, 26 May 2017 10:02:11 GMT Content-Length: 1234 Content-Type: text/html; charset=utf-8 Link: </main.css>; rel="preload"; as="style" Link: </newstyle.css>; rel="preload"; as="style" Link: </script.js>; rel="preload"; as="script"
On voit que la réponse finale n'est ni la première suggestion, ni la deuxième (ni une union des deux).
Note pour les programmeurs Python/WSGI. Je ne suis pas arrivé à utiliser ce code « intérimaire » avec WSGI, cela ne semble pas possible en WSGI. Mais on trouvera sans doute d'autres implémentations…
Le code 103 est désormais dans le registre IANA des codes de retour.
L'article seul
RFC 8289: Controlled Delay Active Queue Management
Date de publication du RFC : Janvier 2018
Auteur(s) du RFC : K. Nichols (Pollere), V. Jacobson, A. McGregor, J. Iyengar (Google)
Expérimental
Réalisé dans le cadre du groupe de travail IETF aqm
Première rédaction de cet article le 6 janvier 2018
Ah, la gestion des files d'attentes… Le cauchemar de plein d'étudiants en informatique. Et cela ne cesse pas quand ils deviennent ingénieurs et qu'il faut construire un routeur pour connecter des réseaux de capacités différentes, et qui aura donc besoin de files d'attente. Bref, dès qu'on n'a pas assez de ressources (et on n'en aura jamais assez), il faut optimiser ses files d'attente. Ce nouveau RFC décrit le mécanisme CoDel (mis en œuvre depuis un certain temps dans le noyau Linux) qui permet notamment de limiter le terrible, l'épouvantable bufferbloat.
L'algorithme naïf pour gérer une file d'attente est le suivant (on prend le cas simple d'un routeur qui n'a que deux interfaces et une seule file d'attente dans chaque direction) : les paquets arrivent au routeur et sont mis dans la file gérée en FIFO. Dès que des ressources suffisantes sont disponibles pour envoyer un paquet (dès que l'interface de sortie est libre), on envoie le paquet et on le retire donc de la file. Si un paquet arrive quand la file est pleine, on le jette : TCP détectera cette perte, réduira son rythme d'envoi, et réémettra les données manquantes.
Avec cet algorithme simpliste, il y a une décision importante à prendre, la taille de la file. Le trafic sur l'Internet est tout sauf constant : des périodes de grand calme succèdent à des pics de trafic impressionnants. Si la file d'attente est trop petite, on ne pourra pas écluser ces pics, et on jettera des paquets. Ça tombe bien, le prix des mémoires baisse, on va pouvoir mettre des files plus grandes, non ? Eh bien non car arrive le fameux bufferbloat. Si la file est trop grande, les paquets y séjourneront très longtemps, et on augmentera ainsi la latence, au grand dam des applications sensibles comme SSH ou les jeux en ligne. Bref, on est coincés, il n'y a pas de solution idéale. Pire, si on ne jette des paquets que lorsque la file est pleine, on risque de tomber dans le cas où l'équilibre se fait avec une file d'attente toujours pleine, et donc avec une mauvaise latence.
Bien sûr, il y a longtemps que les routeurs n'utilisent plus d'algorithme aussi naïf que celui présenté ici. Tout un travail a été fait sur l'AQM : voir par exemple les RFC 7567 et RFC 8033. Mais le problème de la file d'attente toujours pleine est toujours là. Sa première description est dans le RFC 896 en 1984. Plus récemment, on le trouve mentionné dans une présentation de Jim Gettys à l'IETF 80 (« Bufferbloat: Dark Buffers in the Internet ») développé dans un article dans Communications of the ACM (Gettys a beaucoup fait pour la prise de conscience des dangers du bufferbloat.).
Résoudre le problème de l'« obésité du
tampon » (bufferbloat) en
réduisant la taille des files d'attentes ne serait pas une
solution : les tampons sont là pour une bonne raison, pour absorber
les problèmes brefs, lorsque, temporairement,
on reçoit davantage de paquets que ce que l'on peut transmettre. Le
fait que des files plus petites ne sont pas une solution a déjà été
exposé dans le RFC 2309, dans
« A Rant on
Queues » de Van Jacobson,
dans le rapport « RED
in a Different Light » et dans l'article fondateur
de CoDel, « Controlling
Queue Delay » (article complet sur
Sci-Hub, cherchez
10.1145/2209249.2209264). Le problème n'est
pas tant la taille de la file en soi (ce n'est pas la taille qui
compte), mais si c'est une « bonne » file ou une « mauvaise » file
(au passage, si vous ne connaissez pas la différence entre le bon
chasseur et le mauvais chasseur, ne ratez pas
l'indispensable sketch des
Inconnus).
CoDel est donc une vieille idée. Elle veut répondre, entre autres, aux critères suivants (section 1 du RFC) :
- Être « zéro-configuration » (parameterless), ce qui avait été un problème fréquent de solutions comme RED. (Mon opinion personnelle est que CoDel n'est pas réellement sans configuration, comme on le voit plus loin dans le RFC, mais il est certainement « configuration minimale ».) CoDel s'ajuste tout seul, une fois défini l'ordre de grandeur du RTT des paquets qui passeront par le routeur.
- Capable de différencier le mauvais chasseur du bon chasseur, euh, pardon, la mauvaise file d'attente de la bonne.
- Être simple à programmer, pour fonctionner aussi bien dans les processeurs limités des routeurs low cost que dans les ASIC (rapides, mais pas très souples) des routeurs haut de gamme.
Lorsque CoDel estime nécessaire de prendre des mesures (le trafic entre trop vite), il peut jeter les paquets, ou les marquer avec ECN (RFC 3168).
La section 2 de notre RFC définit la terminologie de CoDel. Parmi les termes importants :
- Temps de passage (sojourn time) : le temps passé par le paquet dans la file d'attente. C'est la donnée de base de CoDel, qui va essayer de minimiser ce temps de passage.
- File persistante (standing queue) : une file d'attente qui reste pleine trop longtemps, « trop » étant de l'ordre du RTT le plus élevé parmi les flots des paquets qui attendent dans la file.
Passons maintenant à une description de haut niveau de CoDel. Son but est de différencier la mauvaise file (qui ne fait qu'ajouter du retard d'acheminement des paquets) de la bonne. Une file d'attente se forme lorsqu'il y a un goulet d'étranglement, parce qu'un lien à forte capacité se déverse dans un lien à faible capacité, ou bien parce que plusieurs liens convergent vers un lien ayant la capacité de seulement l'un d'eux. Une notion importante à ce sujet est celle de BDP, en gros le nombre d'octets en transit pour une connexion donnée, lorsque le débit atteint 100 % de la capacité. Imaginons une connexion TCP dont la fenêtre d'envoi est de 25 paquets (je sais bien que les fenêtres TCP se calculent en octets, pas en paquets, mais c'est le RFC qui fait cet abus de langage, pas moi) et où le BDP est de 20 paquets. En régime permanent, il y aura 5 paquets dans la file d'attente. Si la fenêtre est de 30 paquets, ce seront 10 paquets qui occuperont en permanence la file d'attente, augmentant encore le délai, alors que le débit ne changera pas (20 paquets arriveront par RTT). Au contraire, si on réduit la fenêtre à 20 paquets, la file d'attente sera vide, le délai sera réduit au minimum, alors que le débit n'aura pas changé. Ce résultat contre-intuitif montre que bourrer la connexion de paquets n'est pas forcément le meilleur moyen d'aller « vite ». Et que la taille de la file ne renseigne pas sur le rythme d'envoi des données. Et enfin que les files pleines en permanence n'apportent que du délai. Dans le premier exemple, la file contenant cinq paquets tout le temps était clairement une mauvaise file. Un tampon d'entrée/sortie de 20 paquets est pourtant une bonne chose (pour absorber les variations brutales) mais, s'il ne se vide pas complètement ou presque en un RTT, c'est qu'il est mal utilisé. Répétons : Les bonnes files se vident vite.
CoDel comporte trois composants : un estimateur, un objectif et une boucle de rétroaction. La section 3 de notre RFC va les présenter successivement. Pour citer l'exposé de Van Jacobson à une réunion IETF, ces trois composants sont :
- a) Measure what you’ve got
- b) Decide what you want
- c) If (a) isn’t (b), move it toward (b)
D'abord, l'estimateur. C'est la partie de CoDel qui observe la file d'attente et en déduit si elle est bonne ou mauvaise. Autrefois, la principale métrique était la taille de la file d'attente. Mais celle-ci peut varier très vite, le trafic Internet étant très irrégulier. CoDel préfère donc observer le temps de séjour dans la file d'attente. C'est une information d'autant plus essentielle qu'elle a un impact direct sur le vécu de l'utilisateur, via l'augmentation de la latence.
Bon, et une fois qu'on observe cette durée de séjour, comment en déduit-on que la file est bonne ou mauvaise ? Notre RFC recommande de considérer la durée de séjour minimale. Si elle est nulle (c'est-à-dire si au moins un paquet n'a pas attendu du tout dans la file, pendant la dernière période d'observation), alors il n'y a pas de file d'attente permanente, et la file est bonne.
Le RFC parle de « période d'observation ». Quelle doit être la longueur de cette période ? Au moins un RTT pour être sûr d'écluser les pics de trafic, mais pas moins pour être sûr de détecter rapidement les mauvaises files. Le RFC recommande donc de prendre comme longueur le RTT maximal de toutes les connexions qui empruntent ce tampon d'entrée/sortie.
Et, petite astuce d'implémentation (un routeur doit aller
vite, et utilise souvent des circuits de
calcul plus simples qu'un processeur généraliste), on peut calculer
la durée de séjour minimale avec une seule variable : le temps écoulé
depuis lequel la durée de séjour est inférieure ou supérieure au
seuil choisi. (Dans le pseudo-code de la section 5, et dans le
noyau Linux, c'est à peu près le rôle de first_above_time.)
Si vous aimez les explications avec images, il y en a plein dans cet excellent exposé à l'IETF.
Ensuite, l'objectif (appelé également référence) : il s'agit de fixer un objectif de durée de séjour dans la file. Apparemment, zéro serait l'idéal. Mais cela entrainerait des « sur-réactions », où on jetterait des paquets (et ralentirait TCP) dès qu'une file d'attente se forme. On va plutôt utiliser un concept dû à l'inventeur du datagramme, Leonard Kleinrock, dans « An Invariant Property of Computer Network Power », la « puissance » (power). En gros, c'est le débit divisé par le délai et l'endroit idéal, sur la courbe de puissance, est en haut (le maximum de débit, pour le minimum de délai). Après une analyse que je vous épargne, le RFC recommande de se fixer comme objectif entre 5 et 10 % du RTT.
Enfin, la boucle de rétroaction. Ce n'est pas tout d'observer, il faut agir. CoDel s'appuie sur la théorie du contrôle, pour un système MIMO (Multi-Input Multi-Output). Au passage, si vous ne comprenez rien à la théorie du contrôle et notamment à la régulation PID, je vous recommande chaudement un article qui l'explique sans mathématiques. Placé à la fin de la file d'attente, au moment où on décide quoi faire des paquets, le contrôleur va les jeter (ou les marquer avec ECN) si l'objectif de durée de séjour est dépassé.
Passons maintenant à la section 4 du RFC, la plus concrète,
puisqu'elle décrit précisement CoDel. L'algorithme a deux
variables, TARGET et
INTERVAL (ces noms sont utilisés tels quels
dans le pseudo-code en section 5, et dans l'implémentation dans le
noyau Linux). TARGET est
l'objectif (le temps de séjour dans la file d'attente qu'on ne
souhaite pas dépasser) et INTERVAL est la
période d'observation. Ce dernier est également le seul paramètre
de CoDel qu'il faut définir explicitement. Le RFC recommande 100 ms
par défaut, ce qui couvre la plupart des RTT
qu'on rencontre dans l'Internet, sauf si on parle à des gens très
lointains ou si on passe par des satellites
(cf. M. Dischinger, « Characterizing Residential Broadband
Networks », dans les Proceedings of the Internet
Measurement Conference, San Diego, en 2007, si vous
voulez des mesures). Cela permet, par
exemple, de vendre des routeurs bas de gamme, genre
point d'accès Wifi sans imposer aux
acheteurs de configurer CoDel.
Si on est dans un environnement très différent de celui d'un
accès Internet « normal », il peut être nécessaire d'ajuster les
valeurs (CoDel n'est donc pas réellement
« parameterless »). L'annexe A du RFC en donne
un exemple, pour le cas du centre de
données, où les latences sont bien plus faibles (et les
capacités plus grandes) ;
INTERVAL peut alors être défini en
microsecondes plutôt qu'en millisecondes.
TARGET, lui, va être déterminé
dynamiquement par CoDel. Une valeur typique sera aux alentours de 5
ms (elle dépend évidemment de INTERVAL) : si, pendant une durée égale à INTERVAL, les paquets restent plus longtemps que cela dans la file
d'attente, c'est que c'est une mauvaise file, on jette des
paquets. Au passage, dans le noyau Linux, c'est dans
codel_params_init que ces valeurs sont
fixées :
params->interval = MS2TIME(100); params->target = MS2TIME(5);
Les programmeurs
apprécieront la section 5, qui contient du
pseudo-code, style
C++, mettant en œuvre CoDel. Le choix de C++
est pour profiter de l'héritage, car CoDel est juste une
dérivation d'un classique algorithme tail-drop. On
peut donc le programmer sous forme d'une classe qui hérite d'une
classe queue_t, plus générale.
De toute façon, si vous n'aimez pas C++, vous pouvez lire le
code source du noyau
Linux, qui met en œuvre CoDel depuis longtemps (fichier
net/sched/sch_codel.c, également accessible
via le Web).
(Pour comprendre les exemples de code, notez que packet_t* pointe vers un
descripteur de paquet, incluant entre autres un champ, tstamp, qui stocke
un temps, et que le type time_t est exprimé
en unités qui dépendent de la résolution du système, sachant que
la milliseconde est suffisante, pour du trafic Internet « habituel ».) Presque tout le travail de CoDel est fait au moment où le
paquet sort de la file d'attente. À l'entrée, on se contente
d'ajouter l'heure d'arrivée, puis on appelle le traitement
habituel des files d'attente :
void codel_queue_t::enqueue(packet_t* pkt)
{
pkt->tstamp = clock();
queue_t::enqueue(pkt);
}
Le gros du code est dans le sous-programme
dodequeue qui va déterminer si le paquet
individuel vient de nous faire changer d'état :
dodequeue_result codel_queue_t::dodequeue(time_t now)
{
...
// Calcul de *la* variable importante, le temps passé dans la
// file d'attente
time_t sojourn_time = now - r.p->tstamp;
// S'il est inférieur à l'objectif, c'est bon
if (sojourn_time_ < TARGET || bytes() <= maxpacket_) {
first_above_time_ = 0;
} else {
// Aïe, le paquet est resté trop longtemps (par rapport à TARGET)
if (first_above_time_ == 0) {
// Pas de panique, c'est peut-être récent, attendons
// INTERVAL avant de décider
first_above_time_ = now + INTERVAL;
} else if (now >= first_above_time_) {
// La file ne se vide pas : jetons le paquet
r.ok_to_drop = true;
}
}
return r;
}
Le résultat de dodequeue est ensuite utilisé
par dequeue qui fait se fait quelques
réflexions supplémentaires avant de jeter réellement le paquet.
Ce code est suffisamment simple pour pouvoir être mis en œuvre dans le matériel, par exemple ASIC ou NPU.
L'annexe A du RFC donne un exemple de déclinaison de CoDel pour le cas d'un centre de données, où les RTT typiques sont bien plus bas que sur l'Internet public. Cette annexe étudie également le cas où on applique CoDel aux files d'attente des serveurs, pas uniquement des routeurs, avec des résultats spectaculaires :
- Dans le serveur, au lieu de jeter le paquet bêtement, on prévient directement TCP qu'il doit diminuer la fenêtre,
- Le RTT est connu du serveur, et peut donc être mesuré au
lieu d'être estimé (on en a besoin pour calculer
INTERVAL), - Les paquets de pur contrôle (
ACK, sans données) ne sont jamais jetés, car ils sont importants (et de petite taille, de toute façon).
Sur l'Internet public, il serait dangereux de ne jamais jeter les paquets de pur contrôle, ils pourraient être envoyés par un attaquant. Mais, dans le serveur, aucun risque.
Également à lire : un article de synthèse sur le blog de l'IETF.
L'article seul
RFC 8288: Web Linking
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : M. Nottingham
Chemin des normes
Première rédaction de cet article le 25 octobre 2017
Le lien est à la base du Web. Mais c'est seulement récemment, avec le RFC 5988 que notre RFC remplace, que certains manques ont été comblés :
- Un registre des types de lien,
- Un mécanisme standard pour indiquer un lien dans une réponse HTTP.
Bien sûr, des formats normalisés qui permettent des liens, il y en a
plusieurs, et avant tout HTML, avec le fameux
élément <A> (pour
anchor). Il y a aussi le plus récent
Atom (RFC 4287, notamment
la section 4.2.7). Comme HTML, Atom avait l'idée de registre
des types de liens, mais ces types étaient spécifiques à Atom. L'une
des idées phares du RFC 5988 et de celui-ci, son successeur RFC 8288, est de
généraliser le concept de type de lien et de le rendre accessible à
tous les formats et protocoles qui en ont besoin. Ce RFC
décrit un cadre général pour les types de liens, en partant de celui
d'Atom.
Second apport de cette norme, une (re-)définition de
l'en-tête HTTP Link:,
utilisant évidemment le nouveau cadre général. Cet en-tête permettant
d'indiquer un lien dans la réponse HTTP, indépendamment du document
servi, avait été normalisé dans le RFC 2068, section 19.6.2.4,
puis, peu utilisé, avait été supprimé par le RFC 2616, avant de faire sa
réapparition ici, sous une forme quasi-identique à l'original. On peut
voir cet en-tête comme une représentation concrète du cadre de notre
RFC. D'autres apparaîtront sans doute.
Pour un exemple réel, regardez les en-têtes
Link: de mon blog, il y en a un de type
licence, suivant le RFC 4946. Avec Apache, cela se configure
simplement avec le module headers et la
directive Header set Link "<http://www.gnu.org/copyleft/fdl.html>; rel=\"license\"; title=\"GFDL\"".
Donc, qu'est-ce qu'un lien ? La section 2, la principale du RFC, le définit comme une connexion typée entre deux ressources (une ressource étant typiquement une page Web), nommées respectivement contexte et cible. Les deux ressources sont représentées par leur IRI (cf. RFC 3987, en notant que, dans la plupart des cas, les IRI des liens seront des URI). Le lien comprend :
- Un IRI qui indique le contexte, c'est-à-dire la ressource de départ,
- Le type de la connexion (détaillé en section 2.1),
- L'IRI cible,
- D'éventuels attributs de la cible (comme par exemple le hreflang de HTML). Ce sont des couples clé/valeur.
Par exemple, dans le flux de syndication
Atom de mon blog, on trouvera un lien
<atom:link rel="alternate"
href="http://www.bortzmeyer.org/expose-go.html"/> qui se décompose
en un contexte (l'entrée Atom dont l'IRI est
tag:bortzmeyer.org,2006-02:Blog/expose-go), un
type (alternate, qui indique une version
alternative de la ressource, ici une page HTML au lieu d'une entrée
Atom), et une cible (ici http://www.bortzmeyer.org/expose-go.html). Il n'y a pas dans
cet exemple
d'attributs de la cible mais Atom en permet (par exemple
hfrelang pour indiquer la langue de la cible ou bien
length pour indiquer sa longueur - afin de
prévenir d'un long téléchargement, par exemple).
Cette définition du lien ne place aucune limite sur la cardinalité. Il peut y avoir zéro, un ou plusieurs liens partant d'une ressource et c'est la même chose pour les lients entrants.
La section 2 s'arrête là. Puisque ce RFC propose un cadre général, il ne formalise pas une syntaxe unique pour représenter les liens. Chaque format, chaque protocole, aura la sienne, la sérialisation.
Un des points les plus importants de cette définition des liens,
et qui est souvent ignorée des gens qui écrivent des pages Web, est
la notion de type d'un lien (section 2.1). Par
exemple, on a un type copyright
qui associe, via un lien, un document à l'auteur de
celui-ci. Point à retenir : ce type du lien ne doit pas être
confondu avec le type de médium du RFC 6838
comme text/html ou
audio/ogg.
Il y a deux sortes de type de lien : enregistrés ou bien
extensions. Les premiers font l'objet de la section 2.1.1. Ils ont
fait l'objet d'un processus formel d'enregistrement et leur liste est publiée sous forme d'un
registre
IANA. On y trouve par exemple via (RFC 4287) ou hub (https://github.com/pubsubhubbub). La politique
d'enregistrement est délibérement ouverte, l'idée étant que si un
type est utilisé sur le Web, il faut vraiment qu'il soit indiqué
dans le registre, sauf s'il est gravement dangereux pour la santé
du Web.
Les extensions sont spécifiées dans la section 2.1.2. L'idée est
que, si on n'a pas envie de se fatiguer à enregistrer un type de
lien, et qu'on veut quand même créer un type
unique, n'ayant pas de risque de collision
avec le travail des autres, on peut simplement se servir d'un URI
(forcément unique) pour indiquer le type. Cette URI peut (mais ce
n'est pas obligé) mener à une page Web qui décrira le type en
question. Ainsi, on pourrait imaginer de réécrire le lien plus haut
en <atom:link
rel="http://www.bortzmeyer.org/reg/my-link-type"
href="http://www.bortzmeyer.org/expose-go.html"/> (en
pratique, le format Atom ne permet pas actuellement de telles
valeurs pour l'attribut rel.)
Après le cadre général de description des liens, notre RFC
introduit une syntaxe concrète pour le cas de l'en-tête
Link: des requêtes HTTP. Les autres formats et
protocoles devront s'ajuster à ce cadre chacun de son côté. Pour
HTTP, la section 3 décrit l'en-tête Link:. La
cible doit être un URI (et un éventuel IRI doit donc être
transformé en URI), le contexte (l'origine) est la ressource qui
avait été demandée en HTTP et le type est indiqué dans le paramètre
rel. (Le paramètre rev
qui avait été utilisé dans des vieilles versions est officiellement
abandonné.) Plusieurs attributs sont possibles comme
hreflang, type (qui est
le type MIME, pas le type du lien) ou
title (qui peut être noté
title* s'il utilise les en-têtes étendus du
RFC 8187). Pour la plupart de ces attributs,
leur valeur est juste une indication, la vraie valeur sera obtenue
en accédant à la ressource cible. Ainsi,
hreflang dans le lien ne remplace pas
Content-Language: dans la réponse et
type ne gagnera pas si un
Content-Type: différent est indiqué dans la
réponse.
Voici des exemples d'en-têtes, tirés de la section 3.5 du RFC :
Link: <http://www.example.com/MyBook/chapter2> rel="previous";
title="Previous chapter"
Ici, cet en-tête, dans une réponse HTTP, indique que
http://www.example.com/MyBook/chapter2 est une
ressource liée à la ressource qu'on vient de récupérer et que ce lien
est de type previous, donc précède la ressource
actuelle dans l'ordre de lecture. L'attribut
title indique un titre relatif, alors que la
vraie ressource
http://www.example.com/MyBook/chapter2 aura
probablement un titre du genre « Chapitre 2 ». En application des
règles de la section 3.4, c'est ce dernier titre qui gagnera au
final.
Un seul en-tête Link: peut indiquer plusieurs
liens, comme dans l'exemple suivant :
Link: </TheBook/chapter2>;
rel="previous"; title*=UTF-8'de'letztes%20Kapitel,
</TheBook/chapter4>;
rel="next"; title*=UTF-8'de'n%c3%a4chstes%20Kapitel
Ce dernier montre également les en-têtes complètement
internationalisés du RFC 8187, ici en
allemand (étiquette de langue de).
Cet en-tête a été enregistré à l'IANA, en application du RFC 3864 dans le registre des en-têtes (section 4.1).
D'autre part, un registre des types de liens existe. La section 4.2 décrit en détail ce registre. Voici, à titre d'exemple, quelques-uns des valeurs qu'on peut y trouver :
blocked-byindique l'entité qui a exigé le blocage d'une page Web (avec le fameux code 451, voir RFC 7725),copyrightqui indique le copyright du document (issu de la norme HTML),editqui indique l'URI à utiliser pour une modification de ce document, comme le permet le protocole APP (RFC 5023),first, qui pointe vers le premier document de la série (défini par ce RFC 8288, même s'il était déjà enregistré),hubqui indique l'endroit où s'abonner pour des notifications ultérieures, suivant le protocole PubSubHubbub),latest-versionqui indique où trouver la dernière version d'un document versionné (RFC 5829),licence, qui associe un document à sa licence d'utilisation (RFC 4946),nofollow, qui indique qu'on ne recommande pas la ressource vers laquelle on pointe, et qu'il ne faut donc pas considérer ce lien comme une approbation,related, qui indique un document qui a un rapport avec celui-ci (créé pour Atom, dans le RFC 4287),replies, qui indique les réponses faites à ce document (pour mettre en œuvre le threading, RFC 4685),- Et bien d'autres encore...
Ce registre est peuplé par le mécanisme dit Spécification
Nécessaire (cf. RFC 8126), avec exigence
d'un examen par un expert (l'actuel expert est Mark Nottingham, auteur de
plusieurs RFC, dont celui-ci). Pour chaque type, il faudra indiquer le type (aussi nommé
relation, comme par exemple previous plus haut), une
description et une référence à la norme qui le formalise. Les demandes
d'enregistrement sont reçues par link-relations@ietf.org.
Attention, ce n'est pas parce qu'il y a un lien qu'il faut le suivre automatiquement. La section 5, sur la sécurité, met en garde contre la confiance accordée à un lien.
L'annexe A.1 contient une discussion de l'utilisation des liens avec
HTML 4, d'où le cadre actuel de définition des liens est issu. Le type
y est indiqué par l'attribut rel. Un exemple
indiquant la licence en XHTML est donc :
<link rel="license" type="text/html" title="GFDL in HTML format"
href="http://www.gnu.org/copyleft/fdl.html"/>
L'annexe A.2
discute, elle, de l'utilisation du cadre de définition des liens en
Atom, qui utilise l'élément
<atom:link> avec les attributs
href pour indiquer la cible et
rel pour le type. Par exemple,
<atom:link rel="license" type="text/html"
title="GFDL in HTML format"
href="http://www.gnu.org/copyleft/fdl.html"/> indiquera
la licence du flux Atom qui contient cet élément (et, oui, Atom et
XHTML ont quasiment la même syntaxe).
L'annexe C de notre RFC indique les changements depuis son prédécesseur, le RFC 5988. Rien de très crucial :
- Les enregistrements faits par le RFC 5988 sont faits, donc on ne les répète pas dans ce RFC,
- Un registre des données spécifiques aux applications, qui n'a apparemment pas été un grand succès (il me semble qu'il n'a jamais été créé), n'est plus mentionné,
- Quatre errata ont été pris en compte, dont un était technique et portait sur la grammaire,
- La nouvelle annexe B donne un algorithme pour l'analyse des en-têtes,
- Et enfin ce nouveau RFC apporte pas mal de clarifications et de détails.
Ce nouveau RFC a fait l'objet de peu de discussions à l'IETF, mais il y en a eu beaucoup plus sur GitHub.
Notez qu'à Paris Web
2017, le t-shirt officiel
portait une allusion à ce RFC, avec le texte <link
rel="human" ... >, encourageant les relations entre humains.
L'article seul
RFC 8280: Research into Human Rights Protocol Considerations
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : N. ten Oever (Article 19), C. Cath (Oxford Internet Institute)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF hrpc
Première rédaction de cet article le 2 novembre 2017
Ce RFC très politique est le premier du groupe de recherche IRTF HRPC, dont le nom veut dire « Human Rights and Protocol Considerations ». À première vue, il n'y a pas de rapport entre les droits humains et les protocoles réseau. Les premiers relèvent de la politique, les seconds de la pure technique, non ? Mais, justement, le groupe HRPC a été créé sur la base de l'idée qu'il y a de la politique dans le travail de l'IETF, que les protocoles ne sont pas complètement neutres, et qu'il était nécessaire de creuser cette relation complexe entre protocoles et droits humains. Le premier RFC analyse le problème de base : « TCP/IP est-il politique ? »
Si vous êtes un concepteur de protocoles, plutôt porté sur le concret, et que les discussions politiques vous gonflent, vous pouvez passer directement à la section 6 du RFC, qui est la check-list Droits Humains pour votre prochain protocole ou format. En la suivant, vous pourrez plus facilement vérifier que votre création n'a pas trop d'effets néfastes, question droits humains. (Depuis, il vaut mieux consulter le RFC 9620, qui la remplace.)
Ce RFC n'est pas le premier RFC « politique », et il ne faudrait pas croire que les ingénieur·e·s qui participent à l'IETF sont tou·ṫe·s des nerds asociaux avec la conscience politique d'un poisson rouge. Parmi les RFC politiques, on peut citer le RFC 1984 (refus d'affaiblir la cryptographie), le RFC 7258 (post-Snowden, RFC affirmant que la surveillance de masse est une attaque contre l'Internet, et qu'il faut déployer des mesures techniques la rendant plus difficile), et bien sûr l'excellent RFC 6973, sur la vie privée, qui sert largement de modèle à notre RFC 8280.
Le groupe de recherche IRTF HRPC va donc travailler sur deux axes (section 3 de notre RFC) :
- Est-ce que les protocoles Internet ont des conséquences en matière de droits humains et, si oui, comment ?
- Si la réponse à la première question est positive, est-il possible d'améliorer ces protocoles, afin de faire en sorte que les droits humains soient mieux protégés ?
Ce RFC particulier a eu une gestation de plus de deux ans. Deux des étapes importantes avaient été la réunion IETF 92 à Dallas, et la réunion IETF 95 à Buenos Aires. À la seconde, vu les opinions politiques de beaucoup des participant·e·s, l'après-réunion s'est tenu dans un restaurant végétarien. En Argentine…
La section 1 du RFC rappelle les nombreux débats qui ont agité le monde de l'Internet sur le rôle politique de ce réseau. Deux belles citations ouvrent cette section, une de Tim Berners-Lee qui dit « There's a freedom about the Internet: As long as we accept the rules of sending packets around, we can send packets containing anything to anywhere. » et un extrait du RFC 3935 « The Internet isn't value-neutral, and neither is the IETF. ». Et le RFC 3935 continue : « We want the Internet to be useful for communities that share our commitment to openness and fairness. We embrace technical concepts such as decentralized control, edge-user empowerment and sharing of resources, because those concepts resonate with the core values of the IETF community. These concepts have little to do with the technology that's possible, and much to do with the technology that we choose to create. ». Le succès immense de l'Internet, contre tous les prophètes de malheur qui prétendaient que ce réseau, qui n'avait pas été conçu par des Messieurs Sérieux, ne pourrait jamais marcher, fait que l'impact social et politique des techniques de la famille TCP/IP est énorme. On trouve donc logiquement de nombreux textes qui affirment que « ce grand pouvoir donne à l'Internet de grandes responsabilités », par exemple cette résolution des Nations Unies, ou bien la déclaration de NETmundial. Une position plus radicale est qu'il faut défendre et renforcer l'Internet, car il serait intrinsèquement un outil aux services des droits humains.
En effet, la connectivité de bout en bout, tout le monde peut parler à tous ceux qui veulent bien, Alice et Bob peuvent échanger sans autorisation, est à la fois un principe fondamental de l'Internet (cf. RFC 1958) et un puissant soutien aux droits humains. Pour citer Benjamin Bayart, « L’imprimerie a permis au peuple de lire, Internet va lui permettre d’écrire. » L'architecture de l'Internet est ouverte (je me souviens de techniciens d'un opérateur de télécommunications historique qui avaient poussé des cris d'horreur quand je leur avais montré traceroute, au début des années 1990. Ils avaient tout de suite demandé comment empêcher le client de regarder l'intérieur du réseau de l'opérateur.) Les normes techniques de l'Internet sont développées selon un processus ouvert, et sont librement distribuées (ce que ne font toujours pas les dinosaures de la normalisation comme l'AFNOR ou l'ISO). En prime, une bonne partie de l'infrastructure de l'Internet repose sur du logiciel libre.
L'Internet a prouvé qu'il pouvait continuer à fonctionner en environnement hostile (RFC 1984 et RFC 3365). Les RFC politiques cités plus haut défendent tous des valeurs qui vont dans le sens des droits humains (par exemple la vie privée, dans les RFC 6973 et RFC 7258). Cela ne va pas de soi : une organisation comme l'UIT n'en a jamais fait autant et développe au contraire des technologies hostiles aux droits humains comme les techniques de surveillance dans le NGN.
On pourrait peut-être même dire que non seulement l'Internet défend les droits humains, mais que ceux-ci sont à la base de l'architecture de l'Internet. (Cf. Cath, C. and L. Floridi, « The Design of the Internet's Architecture by the Internet Engineering Task Force (IETF) and Human Rights », 2017.) On peut citer ici Bless, R. et C. Orwat, « Values and Networks » : « to a certain extent, the Internet and its protocols have already facilitated the realization of human rights, e.g., the freedom of assembly and expression. In contrast, measures of censorship and pervasive surveillance violate fundamental human rights. » ou bien Denardis, L., « The Internet Design Tension between Surveillance and Security » « Since the first hints of Internet commercialization and internationalization, the IETF has supported strong security in protocol design and has sometimes served as a force resisting protocol-enabled surveillance features. ».
Mais la question reste chaudement débattue à l'IETF. Nombreux sont les techniciens qui grommelent « tout ça, c'est de la politique, cela ne nous concerne pas », voire reprennent l'argument classique de la neutralité de la technique « un outil est neutre, c'est l'usage qu'on en fait qui compte, le fabricant du couteau n'est pas responsable d'un meurtre qu'on commet avec ce couteau, donc on ne doit pas se poser la question des droits humains ». Avant Snowden, c'était sans doute l'opinion dominante à l'IETF, mais cela a changé depuis.
Mais, au fait, ce sont quoi, les Droits Humains avec leur majuscule ? Ce sont des droits universels, indivisibles et inaliénables, formalisés dans des textes comme la Déclaration Universelle des Droits de l'Homme ou comme le pacte international relatif aux droits civils et politiques ou le Pacte international relatif aux droits économiques, sociaux et culturels. La section 2 du RFC, sur la terminologie, discute en détail cette définition. Si vous voulez un document unique sur les droits humains, la DUDH citée plus haut est une lecture recommandée. Le fait qu'ils soient universels est important : on entend régulièrement des dirigeants ou des lécheurs de bottes des dirigeants prétendre que les droits humains ne sont pas bons pour le peuple qu'ils oppriment, qu'ils seraient uniquement pour certaines catégories de l'humanité. Si c'était le cas, il serait en effet inutile de discuter des droits humains sur l'Internet, puisque celui-ci connecte tout le monde. Mais, bien sûr, cette soi-disant relativité des droits humains est de la pure rhétorique malhonnête au service de dictateurs locaux.
On notera que, à l'époque de la rédaction de la DUDH, le seul risque de violation envisagée était l'œuvre des États, mais que l'idée s'est imposée depuis que des acteurs non-étatiques pouvaient également être concernés.
Cela ne veut pas dire que les textes comme la DUDH citée plus haut sont parfaits. Ce ne sont pas des textes sacrés, mais le résultat d'un processus politique. Comme toute œuvre humaine, ils peuvent être améliorés, mais il faut juste garder en tête que ceux qui les critiquent ne cherchent pas en général à les améliorer, mais à les affaiblir, voire à les détruire.
Par contre, les droits humains ne sont pas absolus. Un exemple de ce caractère non-absolu des droits humains est qu'ils peuvent être en conflit entre eux. Par exemple, le droit à la liberté d'expression peut rentrer en contradiction avec le droit de ne pas être insulté ou harcelé. Ou avec le droit à la vie privée. Les droits humains ne pourront donc pas être mis en algorithmes.
La section 2 de notre RFC est consacrée à la terminologie. Sujet très difficile car elle est souvent floue dans les domaines liés à la sécurité. Je ne vais pas la reproduire en entier ici (la section est longue, en partie en raison du caractère transversal de notre RFC, cf. section 5.2.1.3), juste noter quelques définitions qui ont fait des histoires (listées dans l'ordre alphabétique de l'original en anglais). Notez que notre RFC 8280 ne fait souvent que reprendre des définitions de RFC précédents. Ainsi, la définition de « connectivité Internet complète » vient du RFC 4084 (et est nécessaire car bien des malhonnêtes vendent comme « accès Internet » des offres plus ou moins bridées). De même le RFC 4949, sur le vocabulaire de la sécurité, et le RFC 6973, sur la vie privée, sont très mis à contribution.
En parlant de vie privée, la définition d'« anonymat » est un des premiers problèmes de terminologie. Le terme est utilisé à tort et à travers dans les médias (« Bitcoin est une monnaie anonyme ») et souvent confondu avec pseudonymat. À leur décharge, il faut dire que les définitions du RFC 4949 et du RFC 6973 sont très abstraites.
Parmi les autres définitions plutôt vagues, notons celle de « neutralité par rapport au contenu » (content agnosticism). C'est bien sûr un concept très important, d'autant plus que cette neutralité est menacée, mais la définition ne va pas très loin. Ce n'est pas mieux pour un autre concept important mais flou, et difficile à saisir, celui de décentralisation, un peu utilisé à toutes les sauces aujourd'hui (cf. mon article pour JRES).
Passons maintenant au principe de bout en bout. C'est un des concepts clés de l'Internet (RFC 2775) : l'« intelligence » (les traitements compliqués) doit être aux extrémités, pas dans le réseau. Plusieurs raisons militent en faveur de ce principe mais, pour en rester aux droits humains, notons surtout que ce principe se traduit par « touche pas à mes données ».
Autre sujet difficile à définir, les « normes ouvertes » (open standards). Il y a plein de SDO, dont le degré d'ouverture varie considérablement. Par exemple, l'ISO ou l'IEEE ne publient pas leurs normes en ligne et, même si on les acquiert, on n'a pas le droit de les redistribuer. L'UIT ne permet de participer que si vous êtes gouvernement ou grande entreprise. L'IETF, sans doute la SDO la plus ouverte, n'a pas de définition claire de ce qu'est une norme ouverte (cf. RFC 2026), à part dans le RFC 6852, qui est surtout un document politicien (et hypocrite).
Un concept important de l'Internet est celui d'« innovation sans autorisation ». Pour le comprendre, regardons l'invention du World-Wide Web. Tim Berners-Lee, Robert Cailliau et les autres ont pu inventer le Web et le déployer, sans rien demander à personne. Aucun comité Machin, aucun gouvernement, n'a été sollicité pour donner son avis ou son autorisation. Au contraire, dans les réseaux de télécommunication pré-Internet, il fallait l'accord préalable de l'opérateur pour tout déploiement d'une application. Sans l'« innovation sans autorisation », nous n'aurions pas le Web.
Et la « vie privée », on la définit comment ? Le RFC 4949 la définit comme le droit à contrôler ce qu'on expose à l'extérieur. C'est actuellement un des droits humains les plus menacés sur l'Internet, en raison des possibilités de surveillance massive que permet le numérique, possibilités largement utilisées par les États. Or, ce droit est lui-même à la base de nombreux autres droits. Ainsi, la liberté d'expression est sérieusement en danger si on n'a pas de droit à la vie privée, par exemple parce que des gens hésiteront à lire certains textes s'ils savent que leurs habitudes de lecture sont surveillées.
La section 4 du RFC est consacrée à un examen du débat (très ancien) sur la neutralité de la technique, et sur les relations entre technique et politique. La littérature scientifique et philosophique dans ce domaine est riche ! (À une réunion de HRPC, la discussion avait tourné à la pure philosophie, et on y avait abondemment cité Foucault, Heidegger, Wittgenstein, Derrida et Kant, ce qui est plutôt rare à l'IETF.)
Les deux opinions extrêmes à ce sujet sont :
- L'IETF fait un travail purement technique. Un protocole de communication est un outil, il est neutre, comme, mettons, une voiture, qui peut servir à des gens sympas à se déplacer, ou à des méchants pour commettre un crime.
- « Tout est politique », toute décision prise par des humains, humains insérés dans un environnement social réel, toute décision va forcément affecter la vie des autres (ou alors c'est que ces décisions n'ont servi à rien) et est donc politique. Pour citer J. Abbate, « protocol is politics by other means ».
Il n'est pas compliqué de trouver plein d'exemples de luttes politiques autour des protocoles Internet, dans les RFC cités plus haut comme le RFC 7258, ou bien dans des articles comme celui de Denardis « The Internet Design Tension between Surveillance and Security ». Les participants à l'IETF ne vivent pas dans une bulle, ils vivent dans un contexte politique, social, historique, culturel, et cela affecte certainement leurs décisions.
Notre RFC cite un grand nombre de publications sur ces sujets, de Francesca Musiani « Giants, Dwarfs and Decentralized Alternatives to Internet-based Services » à Lawrence Lessig, Jonathan Zittrain (« The future of the Internet ») et Milton Mueller. Si vous avez quelques mois de libres devant vous, je vous encourage à lire tous ces livres et articles.
Il y a aussi des études plus spécifiques au rôle des SDO, parmi lesquelles « Engineering 'Privacy by Design' in the Internet Protocols - Understanding Online Privacy both as a Technical and a Human Rights Issue in the Face of Pervasive Monitoring » ou le célèbre article de Clark et ses collègues, « Tussle in Cyberspace ».
Le RFC dégage cinq opinions différentes sur les relations entre le travail des ingénieurs et les droits humains, et sur la question de savoir si les droits humains doivent être intégrés dans les protocoles Internet. La première est celle citée dans l'article de Clark et al., qu'on peut résumer par « ce serait dangereux d'essayer de faire respecter les droits humains par les protocoles » :
- Les droits humains ne sont pas absolus, et un système technique ne peut pas comprendre cela.
- Il y a d'autres outils que les protocoles (l'action politique classique par exemple). C'était un peu l'opinion défendue avec fougue par Milton Mueller à la réunion HRPC lors de l'IETF 99 à Prague.
- Il est mauvais de faire des promesses qu'on ne peut pas tenir. Par exemple, on ne peut pas espérer développer de systèmes cryptographiques invulnérables, et donc on ne doit pas compter uniquement sur eux.
L'article résume en disant que les ingénieurs doivent concevoir le terrain, pas le résultat du match.
Une deuxième position est que certaines valeurs universelles, dont les droits humains tels que formalisés dans la DUDH, devraient être incluses dans l'architecture même du réseau. (Cf. l'article « Should Specific Values Be Embedded In The Internet Architecture? », et attention, c'est un article collectif, avec plusieurs points de vue. Celui résumé ici est celui de Brown.) L'idéal serait que le réseau lui-même protège ces droits. En effet, les techniciens, de part le pouvoir qu'ils ont, ont une obligation « morale » de faire tout ce qui est possible pour faire respecter les droits humains.
Une troisième position, qui part sur un plan différent, est d'estimer qu'on ne peut pas inclure le respect des droits humains dans les protocoles, mais que c'est bien dommage et, qu'à défaut, il faudrait déclarer clairement que le réseau est un bien commun, et que toute tentative de l'utiliser pour le mal est en soi une violation des droits humains. Si on suit ces auteurs (« The public core of the Internet. An international agenda for Internet governance »), l'Internet lui-même, et les protocoles tels que normalisés dans les RFC, seraient un bien commun qu'on ne peut pas tripoter, comme un parc naturel, par exemple. Si le DNS était inclus comme « bien commun », des manipulations comme les résolveurs menteurs deviendraient illégales ou en tout cas immorales.
Les auteurs de « Values and Networks » sont plus prudents. Ils estiment que les protocoles Internet ont effectivement des conséquences sur les droits humains, mais qu'on n'est pas sûrs de quelles conséquences exactement, et qu'il est important de poursuivre les recherches. Cette quatrième position va donc tout à fait dans le sens de la constitution de HRPC comme groupe de recherche de l'IRTF.
Enfin, cinquième possibilité (et vous avez vu qu'elles ne sont pas forcément incompatibles), Berners-Lee et Halpin disent que l'Internet crée également de nouveaux droits. Ainsi, dans une société connectée où ne pas avoir l'Internet est un handicap social, le droit à un accès Internet devient un droit humain.
Quel bilan tirer de cette littérature scientifique et philosophique existante ? D'abord, d'un point de vue pratique, on ne sait pas si créer un réseau qui, par construction, assurerait le respect des droits humains est faisable (avant même de savoir si c'est souhaitable). Mais, au moins, on peut arrêter de croire que la technique est complètement neutre, étudier les conséquences des protocoles sur les droits humains (ce que fait la section 5 de notre RFC) et essayer d'améliorer ces protocoles à la lumière de cette analyse (la section 6 du RFC).
Voyons donc une série d'étude de cas de protocoles Internet existants, et en quoi ils affectent les droits humains (section 5). Une anecdote personnelle au passage : les premières versions de ces études de cas comportaient d'énormes erreurs techniques. Il est en effet difficile de trouver des gens qui sont à la fois sensibilisés aux droits humains et compétents techniquement. Comme le note le RFC, un travail interdisciplinaire est nécessaire. Le travail collectif à l'IRTF fait que cette section 5 est maintenant correcte.
Avant les études de cas techniques, le point de départ est une analyse des discours (selon la méthodologie présentée dans l'article de Cath). Elle s'est faite à la fois informellement (discussion avec des auteurs de RFC, interviews de participants à l'IETF) et formellement, par le biais d'un outil d'analyse automatique. Ce dernier, écrit en Python avec Big Bang, a permis de déterminer les « éléments de langage » importants dans les normes Internet. Et cela donne de jolis graphes.
La partie informelle s'est surtout faite pendant la réunion IETF 92 à Dallas, et a donné le film « Net of Rights ». Mais il y a eu aussi l'observation des groupes de travail IETF en action.
Les protocoles Internet sont bâtis en utilisant des concepts techniques (connectivité, confidentialité, accessibilité, etc) et la section 5.2.2 met en correspondance ces concepts avec les droits humains tels que définis dans la DUDH. Par exemple, le droit de s'assembler s'appuie sur la connectivité, mais aussi sur la résistance à la censure, et sur la sécurité en général.
Maintenant, place à la première partie technique de notre RFC, la section 5.2.3. Elle étudie en détail les conséquences de divers protocoles pour les droits humains. Attention, la conception d'un protocole est une activité complexe, avec des cahiers de charges épais où le respect des droits humains (quand il est présent…) n'est qu'une partie. Et le travail d'ingéniérie nécessite toujours des compromis. Le RFC prévient donc que ce travail est forcément étroit : on n'examine les protocoles que sous l'angle des droits humains, alors qu'une évaluation complète de ces protocoles nécessiterait la prise en compte de bien d'autres aspects. Comme exemple de compromis auquel il faut parfois se résoudre, avoir un serveur distinct de la machine de l'utilisat·eur·rice, possiblement géré par un tiers (c'est le cas de SMTP et XMPP), est certainement mauvais pour la résistance à la censure, car il va fournir un point de contrôle évident, sur lequel des autorités peuvent taper. D'un autre côté, sans un tel serveur, comment communiquerait-on avec des utilisat·eur·rice·s qui ne sont pas connecté·e·s en permanence ou qui sont coincé·e·s derrière un réseau qui interdit les connexions entrantes ? Bref, les protocoles qui sont souvent vertement critiqués par la suite ne sont pas forcément mauvais, encore moins délibérement mauvais. L'idée de cette section est de bien illustrer, sur des cas concrets, que les décisions techniques ont des conséquences politiques. (Ce point avait fait l'objet de vives discussions à l'IETF, des gens estimant que le RFC était trop négatif, et qu'il aurait également fallu indiquer les aspects positifs de l'Internet.)
Donc, pour commencer la série, évidemment, IP lui-même, plus précisement IPv4 (RFC 791). Malgré la normalisation d'IPv6, IPv4 est toujours le principal protocole du réseau. C'est un succès fou, connectant des centaines de millions de machines (et bien plus via les systèmes de traduction d'adresses). Il est conçu pour en faire le moins possible : l'intelligence doit être dans les machines terminales, pas dans le réseau, pas dans la couche 3. (Cf. RFC 3724.) En pratique, toutefois, on voit des intermédiaires agir au niveau IP et, par exemple, ralentir certains types de trafic, ou bien bloquer certaines machines. IP expose en effet certaines informations qui peuvent faciliter ce genre de violations de la neutralité du réseau.
Par exemple, les adresses IP source et destination sont visibles en clair (même si tout le reste du paquet est chiffré) et à un endroit fixe du paquet, ce qui facilite la tâche des routeurs mais aussi des dispositifs de blocage. Avant que vous ne me dites « ben, évidemment, sinon le réseau ne pourrait pas marcher », faites attention. L'adresse IP de destination est effectivement nécessaire aux routeurs pour prendre des décisions de transmission, mais ce n'est pas le cas de l'adresse source. En outre, IP expose le protocole de transport utilisé, encore une information dont les routeurs n'ont pas besoin, mais qui peut aider des intermédiaires à traiter certains types de trafic différemment.
Aujourd'hui, beaucoup de décisions de blocage sont prises sur la base des adresses IP ainsi exposées, ce qui illustre les conséquences d'une décision apparemment purement technique. (Pour les amateurs d'histoire alternative, X.25 n'exposait pas obligatoirement les adresses source et destination dans chaque paquet. Même le serveur final ne les voyait pas forcément. X.25 avait plein de défauts, mais cette anecdote montre que d'autres choix étaient possibles. Il faut juste se rappeler qu'ils avaient leurs propres inconvénients.) Si vous êtes enseignant·e en réseaux informatiques, voici un exercice intéressant faire faire à vos étudiant·e·s : « concevoir un réseau qui n'expose pas à tous des identificateurs uniques mondiaux ». Des alternatives au mécanisme d'IP ont été conçues (comme Hornet ou APIP) mais aucune n'a connu de déploiement significatif. Le routage par la source (combiné avec de la triche sur les adresses IP) aurait également permis de limiter l'exposition des adresses IP sur le trajet mais il pose bien d'autres problèmes. La principale solution employée aujourd'hui, lorsqu'on veut dissimuler les adresses IP des machines qui communiquent, est Tor.
Une autre particularité d'IPv4, qui n'était pas présente à ses débuts, est l'utilisation massive de la traduction d'adresses (RFC 3022). Elle est très répandue. Mais elle casse le modèle de bout en bout, et met le routeur qui fait la traduction dans une position privilégiée (par exemple, beaucoup refusent de faire passer d'autres protocoles de transport que TCP ou UDP). C'est donc une sérieuse limite à la connectivité et donc aux droits humains qui en dépendent.
Et le DNS ? Voilà un protocole dont la relation aux droits humains a été largement discutée. Comme toute opération sur l'Internet commence par une requête DNS, il est un point de contrôle évident. On peut notamment l'utiliser pour la censure. Autre question politique liée au DNS et qui a fait s'agiter beaucoup d'électrons, le pouvoir des organismes qui gèrent les TLD et, bien sûr, la racine du DNS. On peut dire sans exagérer que l'essentiel des débats sur la « gouvernance de l'Internet » ont tourné sur la gestion de la racine du DNS, qui ne représente pourtant pas, et de loin, le seul enjeu politique.
Pourquoi est-ce un enjeu pour les droits humains ? Le DNS a une
structure arborescente, avec
l'ICANN à la racine. Le contrôle de l'ICANN
fait donc saliver bien du monde. Ensuite, les
TLD, qu'ils soient contrôlés par l'ICANN
(les gTLD) ou pas, ont un rôle
politique important, via leur politique d'enregistrement. Celle-ci
varie selon les TLD. Les gTLD historiques
comme .com ont une politique déterminée par
des organisations états-uniennes, l'ICANN et leur registre
(Verisign dans le cas de
.com). Les nouveaux
gTLD ont des registres de nationalité différentes mais dépendent
tous des règles ICANN (cf. l'excellente étude de
l'EFF comparant ces politiques dans l'optique des droits
humains). Les ccTLD, eux, dépendent
de lois nationales très variables. Elles sont par exemple plus ou
moins protectrices de la liberté d'expression. (Voir le fameux
cas
lybien.)
Est-ce que les centaines de nouveaux
gTLD créés depuis quelques années ont amélioré les choses
ou pas, pour cette liberté d'expression ? Certains disent que non
car beaucoup de ces nouveaux TLD ont une politique
d'enregistrement restrictive (cf. le rapport de l'EFF cité plus
haut), d'autres disent que oui car ces nouveaux TLD ont élargi le
choix. Et que la liberté d'association peut ne pas bien s'entendre
avec la liberté d'expression (la première peut justifier des
règles restrictives, pour que des minorités discriminées puissent
se rassembler sans être harcelées). Une chose est sûre, les débats
ont été chauds, par exemple autour d'une éventuelle création du
.gay (un rapport
du Conseil de l'Europe détaille cette question « TLD et
droits humains »).
Le DNS soulève plein d'autres questions liées aux droits humains. Par exemple, il est indiscret (RFC 7626), et des solutions partielles comme le RFC 9156 semblent très peu déployées.
Et, comme trop peu de zones DNS sont protégées par DNSSEC (et, de toute façon, DNSSEC ne protège pas contre toutes les manipulations), il est trop facile de modifier les réponses envoyées. C'est aujourd'hui une des techniques de censure les plus déployées, notamment en Europe (voir à ce sujet le très bon rapport du Conseil Scientifique de l'AFNIC). Parmi les moyens possibles pour censurer via les noms de domaine :
- Faire supprimer le nom auprès du registre ou du BE, comme dans les saisies faites par l'ICE, ou comme dans le cas de Wikileaks. Le protocole ne permet pas de faire la différence entre une saisie au registre, et une réelle suppression. Des systèmes comme Namecoin fournissent une meilleure protection (mais ont leurs propres défauts).
- Si on ne peut pas peser sur le registre ou sur le BE, on peut agir lors de la résolution du nom, avec des résolveurs menteurs ou bien carrément des modifications faites dans le réseau, méthode surtout connue en Chine, mais également en Grèce. La première technique, le résolveur menteur, peut être défaite par un changement de résolveur (ce qui peut créer d'autres problèmes), la seconde attaque nécessite des solutions comme le RFC 7858.
Le RFC étudie ensuite le cas de HTTP, le protocole vedette de l'Internet (RFC 7230 et suivants). Sa simplicité et son efficacité ont largement contribué à son immense succès, qui a à son tour entrainé celui de l'Internet tout entier. On voit même aujourd'hui des tas de services non-Web utiliser HTTP comme substrat. Du fait de cette utilisation massive, les conséquences des caractéristiques de HTTP pour les droits humains ont été beaucoup plus étudiées que le cas du DNS.
Premier problème, HTTP est par défaut peu sûr, avec des communications en clair, écoutables et modifiables. Si la solution HTTPS est très ancienne (le RFC 2828 a dix-sept ans…, et SSL avait été décrit et mis en œuvre avant), elle n'a été massivement déployée que depuis peu, essentiellement grâce au courage d'Edward Snowden.
En attendant ce déploiement massif de HTTPS, d'innombrables équipements réseau de censure et de détournement de HTTP ont été fabriqués et vendus (par exemple par Blue Coat mais ils sont loin d'être les seuls). Celui qui veut aujourd'hui empêcher ou perturber les communications par HTTP n'a pas besoin de compétences techniques, les solutions toutes prêtes existent sur le marché.
Un autre RFC qui touchait directement aux droits humains et qui avait fait pas mal de bruit à l'IETF est le RFC 7725, qui normalise le code d'erreur 451, renvoyé au client lorsque le contenu est censuré. Il permet une « franchise de la censure », où celle-ci est explicitement assumée.
Les discussions à l'IETF avaient été chaudes en partie parce que l'impact politique de ce RFC est évident, et en partie parce qu'il y avait des doutes sur son utilité pratique. Beaucoup de censeurs ne l'utiliseront pas, c'est clair, soit parce qu'ils sont hypocrites, soit parce que les techniques de censure utilisées ne reposent pas sur HTTP mais, par exemple, sur un filtrage IP. Et, lorsque certains l'utilisent, quelle utilité pour les programmes ? Notre RFC explique que le principal intérêt est l'étude du déploiement de la « censure honnête » (ou « censure franche »). C'est le cas de projets comme Lumen. Du code est d'ailleurs en cours de développement pour les analyses automatiques des 451 (on travaillera là-dessus au hackathon de la prochaine réunion IETF).
Outre la censure, l'envoi du trafic en clair permet la surveillance massive, par exemple par les programmes Tempora ou XKeyscore. Cette vulnérabilité était connue depuis longtemps mais, avant les révélations de Snowden, la possibilité d'une telle surveillance de masse par des pays supposés démocratiques était balayée d'un revers de main comme « paranoïa complotiste ». Pour la France, souvenons-nous qu'une société française vend des produits d'espionnage de leur population à des dictatures, comme celle du défunt Khadafi.
D'autre part, l'attaque active, la modification des données en transit, ne sert pas qu'à la censure. Du trafic HTTP changé en route peut être utilisé pour distribuer un contenu malveillant (possibilité utilisée dans QUANTUMINSERT/FOXACID) ou pour modifier du code envoyé lors d'une phase de mise à jour du logiciel d'une machine. Cela semble une attaque compliquée à réaliser ? Ne vous inquiétez pas, jeune dictateur, des sociétés vous vendent ce genre de produits clés en main.
HTTPS n'est évidemment pas une solution magique, qui assurerait la protection des droits humains à elle seule. Pour ne citer que ses limites techniques, sa technologie sous-jacente, TLS (RFC 5246) a été victime de plusieurs failles de sécurité (sans compter les afaiblissements délibérés comme les célèbres « algorithmes pour l'exportation »). Ensuite, dans certains cas, un·e utilisat·eur·rice peut être incité·e à utiliser la version en clair (attaque par repli, contre laquelle des techniques comme celles du RFC 6797 ont été mises au point).
HTTPS n'étant pas obligatoire, la possibilité d'une attaque par repli existe toujours. Pour HTTP/2, il avait été envisagé d'imposer HTTPS, pour qu'il n'y ait plus de version non sûre, mais le RFC 7540 n'a finalement pas entériné cette idée (que le RFC 8164 a partiellement ressorti depuis.)
Autre protocole étudié, XMPP (RFC 6120). Un de ses principes est que le logiciel client (par exemple pidgin) ne parle pas directement au logiciel du correspondant, mais passe forcément par un (ou deux) serveur(s). Cette architecture présente des avantages pratiques (si le correspondant est absent, son serveur peut indiquer cette absence à l'appelant) mais aussi en matière de protection (on ne voit pas l'adresse IP de l'appelant). Ces serveurs sont fédérés entre eux, XMPP, contrairement à des protocoles inférieurs comme Slack ne peut donc pas être arrêté par décision supérieure.
Mais XMPP a aussi des inconvénients. Les utilisat·eurs·rices sont
identifiés par un JID comme
bortzmeyer@example.com/home qui comprend une
« ressource » (le terme après la barre oblique) qui, en pratique,
identifie souvent une machine particulière ou un lieu
particulier. En général, ce JID est présenté tel quel aux
correspondants, ce qui n'est pas idéal pour la vie privée. D'autre
part, les communications sont en clair par défaut, mais peuvent
être chiffrées, avec TLS. Sauf que l'utilisat·eur·rice ne sait pas si
son serveur chiffre avec le serveur suivant, ou bien le serveur
final avec son correspondant. Sans possibilité d'évaluation de la
sécurité, il faut donc faire une confiance
aveugle à tous les serveurs pour prendre des précautions. Et
espérer qu'ils suivront tous le « XMPP
manifesto ».
Si XMPP lui-même est fédéré et donc relativement résistant à la censure, les salles collectives de discussion sont centralisées. Chaque salle est sur un serveur particulier, une sorte de « propriétaire », qui peut donc contrôler l'activité collective, même si aucun des participants n'a de compte sur ce serveur. (En prime, ces salles sont une extension du protocole, spécifiée dans le XEP-0045, pas mise en œuvre de manière identique partout, ce qui est un problème non-politique fréquent avec XMPP.)
Et le pair-à-pair, lui, quelles sont ses implications pour les droits humains ? D'abord, il faut évidemment noter que ce terme ne désigne pas un protocole particulier, qu'on pourrait analyser en détail, mais une famille de protocoles très divers (RFC 5694). L'application la plus connue du pair-à-pair est évidemment l'échange de fichiers culturels, mais le pair-à-pair est une architecture très générale, qui peut servir à plein de choses (Bitcoin, par exemple).
À l'époque des GAFA, monstres centralisés qui contrôlent toutes les interactions entre utilisat·eur·rice·s, le pair-à-pair est souvent présenté comme la solution idéale à tous les problèmes, notamment à la censure. Mais la situation est plus compliquée que cela.
D'abord, les réseaux en pair-à-pair, n'ayant pas d'autorité centrale de certification des contenus, sont vulnérables aux diverses formes d'empoisonnement des données. On se souvient des faux MP3 sur eDonkey, avec un nom prometteur et un contenu décevant. Un attaquant peut aussi relativement facilement corrompre, sinon les données, en tout cas le routage qui y mène.
Comme les protocoles pair-à-pair représentent une bonne part du trafic Internet, et qu'ils sont souvent identifiables sur le réseau, le FAI peut être tenté de limiter leur trafic.
Plus gênant, question droits humains, bien des protocoles pair-à-pair ne dissimulent pas l'adresse IP des utilisat·eur·rice·s. En BitTorrent, si vous trouvez un pair qui a le fichier qui vous intéresse, et que vous le contactez, ce pair apprendra votre adresse IP. Cela peut servir de base pour des lettres de menace ou pour des poursuites judiciaires (comme avec la HADOPI en France). Il existe des réseaux pair-à-pair qui déploient des techniques de protection contre cette fuite d'informations personnelles. Le plus ancien est Freenet mais il y a aussi Bitmessage. Ils restent peu utilisés.
Autre danger spécifique aux réseaux pair-à-pair, les attaques Sybil. En l'absence d'une vérification que l'identité est liée à quelque chose de coûteux et/ou difficile à obtenir, rien n'empêche un attaquant de se créer des millions d'identités et de subvertir ainsi des systèmes de vote. L'attaque Sybil permet de « bourrer les urnes » virtuelles. (Ne ratez pas l'article de Wikipédia sur l'astroturfing.)
C'est pour lutter contre cette attaque que Bitcoin utilise la preuve de travail et que CAcert utilise des certifications faites pendant des rencontres physiques, avec vérification de l'identité étatique. Le RFC note qu'on n'a pas actuellement de solution générale au problèmes des attaques Sybil, si on exige de cette solution qu'elle soit écologiquement durable (ce que n'est pas la preuve de travail) et entièrement pair-à-pair (ce que ne sont pas les systèmes d'enrôlement typiques, où un acteur privilégié vérifie les participants à l'entrée). Quant aux solutions à base de « réseaux de connaissances » (utilisées dans le Web of Trust de PGP), elles sont mauvaises pour la vie privée, puisqu'elles exposent le graphe social des participants.
Bref, le pair-à-pair n'est pas actuellement la solution idéale à tous les problèmes de droits humains, et les recherches doivent se poursuivre.
Un autre outil est souvent présenté comme solution pour bien des problèmes de respect des droits humains, notamment pour la sécurité de ceux qui vivent et travaillent dans des pays dictatoriaux, le VPN. On entend parfois des discussions entre militants des droits humains, ou bien entre journalistes, sur les avantages comparés de Tor et du VPN pour regarder le Web en toute sécurité. En fait, les deux ne fournissent pas réellement le même service et, pire, les propriétés du VPN sont souvent mal comprises. Le VPN fonctionne en établissant une liaison sécurisée (authentifiée, chiffrée) avec un fournisseur, qui va ensuite vous connecter à l'Internet. Il existe plusieurs systèmes techniques ouverts pour cela (IPsec, OpenVPN) mais la question centrale et difficile est le choix du fournisseur. Les VPN sont très populaires, et il existe donc une offre commerciale abondante. Mais, en général, il est impossible d'évaluer sa qualité, aussi bien technique (même si le protocole est standard, le fournisseur impose souvent un logiciel client à lui, binaire non auditable, et des failles ont déjà été découvertes dans certains VPN) que politique (ce fournisseur de VPN qui dit ne pas garder de journaux dit-il la vérité ?) On est très loin de l'attention qui a été portée à la sécurité de Tor, et des innombrables évaluations et analyses dont Tor a fait l'objet !
Il existe aussi des attaques plus sophistiquées (et pas à la portée de la première police venue) comme la corrélation de trafic (entre ce qui entre dans le VPN et ce qui en sort) si l'attaquant peut observer plusieurs points du réseau (la NSA le fait).
Donc, un rappel à tou·te·s les utilisat·eur·rices·s de VPN : la question la plus importante est celle de votre fournisseur. Le VPN peut vous promettre l'anonymat, vous ne serez pas pour autant anonyme vis-à-vis de votre fournisseur. Celui-ci peut vous trahir ou, tout simplement, comme il est situé dans un pays physique, être forcé par les autorités de ce pays de vous dénoncer.
Une question bien plus délicate avait fait l'objet de nombreux débats à l'IETF, celle d'une possibilité de considérer certaines attaques dDoS comme « légitimes ». C'est par exemple un point de vue qui a été défendu par Richard Stallman. La position classique de l'IETF est qu'au contraire toutes les attaques dDoS sont négatives, impactant l'infrastructure (y compris des tas d'innocents) et sont au bout du compte une attaque contre la liberté d'expression. En simplifiant, il existe trois types d'attaques dDoS, les volumétriques (on envoie le plus de paquets ou d'octets possibles, espérant épuiser les ressources du réseau), les attaques sur les protocoles intermédiaires (comme les SYN flood ou comme le très mal nommé ping of death), attaques qui permettent à l'assaillant de n'envoyer que peu de paquets/octets, et enfin les attaques applicatives, visant les failles d'une application. Une attaque faite par LOIC tient de l'attaque volumétrique (on envoie le plus de requêtes HTTP possibles) et de l'attaque applicative, puisqu'elle ne fonctionne que parce que l'application n'arrive pas à suivre (sur la plupart des sites Web, où il faut exécuter des milliers de lignes de code PHP ou Java pour afficher la moindre page, l'application craque avant le réseau).
Dans les trois cas, cette possibilité d'attaque est avant tout une menace contre les médias indépendants, contre les petites associations ou les individus qui ne peuvent pas ou ne veulent pas payer la « protection » (le mot a un double sens en anglais…) des sociétés spécialisées. Et les attaques dDoS peuvent faciliter la tâche des censeurs hypocrites : il suffit de déguiser une censure en une attaque par déni de service. Une des principales raisons pour lesquelles on ne peut pas comparer l'attaque dDoS à une manifestation est que, dans une attaque dDoS, la plupart des participants ne sont pas volontaires, ce sont des zombies. Lorsque des gens manifestent dans la rue, ils donnent de leur temps, et parfois prennent des risques personnels. Lorsqu'une organisation puissante loue les services d'un botnet pour faire taire par dDoS un gêneur, elle ne dépense qu'un peu d'argent.
Il y a bien sûr quelques exceptions (l'opération Abibil ou bien le Green Movement) mais elles sont rares. Il est donc parfaitement justifié que l'IETF fasse tout son possible pour rendre les attaques dDoS plus difficiles (RFC 3552, section 4.6). Dans la discussion menant à ce nouveau RFC 8280, certaines voix se sont élevées pour demander qu'on puisse lutter seulement contre les « mauvaises » dDoS. Mais c'est aussi absurde que l'idée récurrente des ministres de faire de la cryptographie « légale » qui ne pourrait protéger que les gens honnêtes !
Nous en arrivons maintenant à la partie la plus utilitaire de ce RFC, la section 6, qui est la méthodologie qui devrait être suivie lors du développement d'un nouveau protocole, pour comprendre son impact sur les droits humains, et pour essayer de minimiser les conséquences négatives, et maximiser les positives. Cette section 6 (depuis largement remplacée par le RFC 9620) concerne donc surtout les développeurs de protocole, par exemple les auteurs des RFC techniques. (C'est pour cela que le début de la section 6 répète beaucoup de choses dites avant : on pense que pas mal de techniciens ne liront que cette section.) Évidemment, les conséquences (bonnes ou mauvaises) d'un protocole, ne sont pas uniquement dans la norme technique qui le définit. La façon dont le protocole est mis en œuvre et déployé joue un rôle crucial. (Par exemple, la domination excessive de Gmail n'est pas inscrite dans le RFC 5321.)
Un bon exemple d'une telle démarche est donnée par le RFC 6973, sur la protection de la vie privée. La première responsabilité du développeur de protocole est d'examiner les menaces sur les droits humains que ce protocole peut créer ou aggraver. De même qu'il est recommandé de réfléchir aux conséquences d'un nouveau protocole pour la sécurité de l'Internet (RFC 3552), et sur les conditions dans lesquelles ce protocole est utile, de même il faut désormais réfléchir aux conséquences de son protocole sur les droits humains. Notons que notre RFC ne dit pas « voici ce qu'il faut faire pour respecter les droits humains ». Cela serait clairement irréaliste, vu la variété des menaces et la diversité des protocoles. Notre RFC demande qu'on se pose des questions, il ne fournit pas les réponses. Et il n'impose pas d'avoir dans chaque RFC une section « Human Rights Considerations » comme il existe une « Security Considerations » obligatoire.
Bon, maintenant, la liste des choses à vérifier quand vous concevez un nouveau protocole (section 6.2). À chaque fois, il y a une ou plusieurs questions, une explication, un exemple et une liste d'impacts. Par exemple, pour la question de la connectivité, les questions sont « Est-ce que votre protocole nécessite des machines intermédiaires ? Est-ce que ça ne pourrait pas être fait de bout en bout, plutôt ? Est-ce que votre protocole marchera également sur des liens à faible capacité et forte latence ? Est-ce que votre protocole est à état (alors que les protocoles sans état sont souvent plus robustes) ? » L'explication consiste surtout à répéter l'intérêt des systèmes de bout en bout (RFC 1958). L'exemple est évidemment celui des conséquences négatives des middleboxes. Et les impacts sont les conséquences sur la liberté d'expression et la liberté d'association. Bien sûr, tous les protocoles IETF se préoccupent peu ou prou de connectivité, mais ce n'était pas considéré jusqu'à présent comme pouvant impacter les droits humains.
Sur le deuxième point à vérifier, la vie privée, notre RFC renvoie au RFC 6973, qui demandait déjà aux auteurs de protocoles de faire attention à ce point.
Le troisième point est celui de la neutralité vis-à-vis du contenu. Il reste un peu vague, il n'y a pas actuellement d'exemple de protocole IETF qui soit activement discriminant vis-à-vis du contenu.
Quatrième point qui nécessite l'attention du développeur de protocole, la sécurité. Il est déjà largement traité dans de nombreux autres RFC (notamment le RFC 3552), il faut juste rappeler que ce point a des conséquences en matières de droits humains. Si un protocole a une faille de sécurité, cela peut signifier l'emprisonnement, la torture ou la mort pour un dissident.
En prime, le RFC rappelle que, contrairement à une utilisation réthorique fréquente, il n'y a pas une sécurité mais plusieurs services de sécurité. (Et certaines de ses propriétés peuvent avoir des frictions, par exemple la disponibilité et la confidentialité ne s'entendent pas toujours bien.)
Cinquième point que le développeur de protocoles doit vérifier, l'internationalisation (voir aussi le douzième point, sur la localisation). Eh oui, restreindre l'utilisation de l'Internet à ceux qui sont parfaitement à l'aise en anglais n'irait pas vraiment dans le sens des droits humains, notamment des droits à participer à la vie politique et sociale. D'où les questions « Est-ce que votre protocole gère des chaînes de caractères qui seront affichées aux humains ? Si oui, sont-elles en Unicode ? Au passage, avez-vous regardé le RFC 6365 ? » Dans le contexte IETF (qui s'occupe de protocoles et pas d'interfaces utilisateur), l'essentiel du travail d'internationalisation consiste à permettre de l'Unicode partout. Partout ? Non, c'est un peu plus compliqué que cela car l'IETF distingue les textes prévus pour les utilisat·eur·rice·s de ceux prévus pour les programmes (RFC 2277). Seuls les premiers doivent absolument permettre Unicode. (Cette distinction ne marche pas très bien pour les identificateurs, qui sont prévus à la fois pour les utilisat·eur·rice·s et pour les programmes, c'est le cas par exemple des noms de domaine.)
En prime, petite difficulté technique, il ne suffit pas
d'accepter Unicode, il faut encore, si on accepte d'autres
jeux de
caractères et/ou encodages,
l'indiquer (par exemple le charset= de
MIME), sinon on risque le mojibake. Ou alors, si on n'accepte qu'un
seul jeu de caractères / encodage, ce doit être UTF-8.
Sixième point sur la liste, une question dont les conséquences pour les droits humaines sont évidentes, la résistance à la censure. « Est-ce que votre protocole utilise des identificateurs qui peuvent être associés à des personnes ou à un contenu spécifique ? Est-ce que la censure peut être explicite ? Est-ce que la censure est facile avec votre protocole ? Si oui, ne pourrait-on pas le durcir pour la rendre plus difficile ? »
Un exemple est bien sûr la longue discussion du passé au sujet d'une méthode de fabrication des adresses IPv6. Le mécanisme recommandé à l'origine mettait l'adresse MAC dans l'adresse IP. Outre l'atteinte à la vie privée, cela facilitait la censure, permettant de bloquer un contenu pour seulement certaines personnes. (Ce mécanisme a été abandonné il y a longtemps, cf. RFC 4941.) Quand au cas de rendre la censure explicite, c'est une référence au code 451 (RFC 7725).
Septième point, les « normes ouvertes ». Intuitivement, il est évident qu'il vaut mieux des normes ouvertes que fermées. Mais attention, il n'existe pas de définition claire et largement adoptée, même pas à l'intérieur de l'IETF (qui est certainement une organisation très ouverte). Les questions posées dans ce RFC 8280 donnent une idée des critères qui peuvent permettre de décider si une norme est ouverte ou pas : « Le protocole est-il documenté publiquement ? Sa mise en œuvre peut-elle être faite sans code privateur ? Le protocole dépend t-il d'une technologie contrôlée par une entreprise particulière ? Y a-t-il des brevets (RFC 3979 et RFC 6701) ? »
Ce sont les normes ouvertes de la famille TCP/IP qui ont permis le développement et le déploiement massif de l'Internet. Les appropriations intellectuelles comme le secret industriel ou comme les brevets auraient tué l'Internet dans l'œuf. Il est donc logique que l'IETF soit une organisation particulièrement ouverte : les RFC sont publics et librement redistribuables, bien sûr (ce qui n'est pas le cas des normes d'autres SDO comme l'AFNOR, l'ISO ou l'IEEE), mais l'IETF publie également ses documents temporaires, ses listes de diffusion et ses réunions (ce que ne fait pas, par exemple, l'UIT).
(On note que le RFC 6852 traite également cette question mais c'est un document purement tactique, qui fait du « open washing » en faisant comme si l'IEEE était ouverte.)
Je saute le point huit, sur l'acceptation de l'hétérogénéité du réseau, et j'en arrive à l'important point neuf, sur l'anonymat. Le terme est très galvaudé (« Bitcoin est une monnaie anonyme » et autres erreurs). Il est souvent utilisé par les non-spécialistes comme synonyme de « une autre identité que celle de l'état civil » (ce qui est en fait la définition du pseudonyme, traité au point suivant). Normalement, même si la définition du RFC 4949 est très peu claire, l'anonymat implique la non-traçabilité : si un système est réellement anonyme, il ne doit pas être possible d'attribuer deux actions à la même entité.
Autre erreur courante quand on parle d'anonymat, la considérer comme une propriété binaire. C'est ce qui est fait quand un responsable ignorant affirme « les données sont anonymisées » (cela doit en général déclencher un signal d'alarme). En effet, il existe de nombreuses techniques, et en progrès rapide, pour « désanonymiser », c'est-à-dire pour relier des actions qui ne l'étaient a priori pas.
Cette confusion est d'autant plus dommage que l'anonymat est une propriété essentielle pour la sécurité du citoyen dans un monde numérique. Autrefois, la plupart des actions qu'on faisait dans la journée étaient anonymes, au sens où un observateur extérieur ne pouvait pas facilement les relier entre elles. Aujourd'hui, si vous mettez une photo sur Instagram, achetez un livre sur Amazon, et écrivez un document sur Google Docs, toutes ces actions sont facilement reliables entre elles, même si vos comptes se nomment respectivement « titi75 », « jean.durand » et « le_type_du_coin ». Par défaut, dans le monde numérique, tout est traçable, et il faut déployer des technologies compliquées pour retrouver un peu d'obscurité. En tout cas, rappelez-vous que l'anonymat n'est jamais parfait : c'est un but souhaitable, mais pas forcément atteignable.
Par exemple, la présence de votre adresse IP dans chaque paquet est un moyen simple de relier toutes vos activités (il en existe d'autres). Il est donc tout à fait légitime que l'adresse IP soit regardée comme une donnée personnelle.
Le pseudonymat, dixième point, est une propriété moins forte. C'est simplement le fait d'utiliser une identité persistante qui n'est pas l'identité officielle. On va utiliser un pseudonyme quand on veut masquer son orientation sexuelle, ou sa transidentité, ou l'entreprise où on travaille, mais tout en gardant une identité constante, par exemple pour avoir une réputation en ligne. C'est souvent une protection nécessaire contre le harcèlement, dont les femmes sont particulièrement fréquemment victimes en ligne. Outre les pseudonymes qu'on choisit, la nature du monde numérique fait que plein d'identificateurs attribués automatiquement sont des pseudonymes. Ainsi, une adresse IP est un pseudonyme (elle cesse de l'être dès que votre FAI communique le nom et l'adresse de l'abonné aux autorités). Une adresse Bitcoin est un pseudonyme (Bitcoin est très traçable, c'est nécessaire pour son fonctionnement).
L'auteur·e de protocoles doit donc se méfier des informations qu'ielle expose. Si elles permettent de retrouver la personne à l'origine de la communication, ce sont des données personnelles. Par exemple, si vous exportez des données contenant des adresses IP (exemples en RFC 7011 ou bien pour les journaux d'un serveur), une des façons de brouiller la traçabilité (et donc de passer du pseudonymat à un relatif anonymat) est de ne garder qu'un préfixe assez général. Condenser les adresses IP n'est pas très efficace, un attaquant, un « désanonymiseur » peut condenser toutes les adresses possibles et ainsi retrouver l'information. D'une manière générale, soyez modeste : réellement anonymiser est très difficile.
Le onzième point concerne un sujet dont les conséquences en
matière de droits humains sont claires pour quiconque a suivi les
conférences Paris Web :
l'accessibilité à tou·te·s, y compris en cas
de handicap. L'accessibilité est une propriété nécessaire pour
faire respecter le droit à ne pas être victime de
discrimination. Cela ne concerne a priori pas l'IETF, qui ne fait
pas d'interface utilisateur, mais c'est utile pour d'autres
SDO. Ainsi, le RFC donne l'exemple de
HTML, où l'obligation de mettre un attribut
alt pour les images, oblige à réfléchir à
l'accessibilité de la page Web aux malvoyants.
Le treizième point porte sur un concept très flou et d'autant plus répété qu'il n'a pas de définition claire : la « décentralisation ». Mon article à JRES sur ce sujet donne une idée de la complexité de la question. Le RFC traite la question par plusieurs questions : « Est-ce que le protocole a un point de contrôle unique ? Est-ce que le protocole ne pourrait pas être fédéré plutôt ? » Ça reste à mon avis trop vague mais, au moins, ça pousse les concepteurs de protocoles à réfléchir. La plupart des protocoles de base de l'Internet sont décentralisés ou fédérés comme vous voulez (et c'est explicitement souhaité par le RFC 3935), mais les services à la mode sont en général centralisés. (XMPP est fédéré mais dans les startups, on est obligés d'utiliser Slack qui est centralisé.)
Passons sur le point 14, la fiabilité (c'est sûr qu'un réseau qui marche, c'est mieux) et voyons le point 15, la confidentialité. Son impact sur les droits humains est clair : si des gens peuvent lire ma correspondance privée, mes droits sont clairement violés. La solution technique la plus évidente est le chiffrement et, aujourd'hui, le RFC 8280 estime à juste titre qu'un protocole sans possibilité de chiffrement (par exemple RFC 3912) est à éviter (RFC 3365). Et, même si le RFC ne le dit pas explicitement, il doit évidemment choisir d'un chiffrement sérieux, donc sans portes dérobées, sans affaiblissement délibéré.
Rédigé il y a trop longtemps, cette section dit que le DNS ne dispose pas de cette possibilité de chiffrement, mais c'est faux, depuis le RFC 7858.
Le RFC note à juste titre que le chiffrement ne protège pas contre les intermédiaires légitimes, comme dans l'exemple de XMPP cité plus haut : le chiffrement entre le client et le premier serveur XMPP ne protège pas contre ce serveur, qui voit tout passer en clair. Mais le RFC oublie de dire qu'il y a également le problème des extrémités : faire du HTTPS avec Gmail ne vous protège pas contre PRISM. Il faut donc également prévoir de la minimisation (envoyer le moins de données possible) pas seulement du chiffrement.
Je saute les points 16 (intégrité), 17 (authentification) et 18 (adaptabilité), je vous laisse les lire dans le RFC. Le dernier point, le dix-neuvième, porte sur la transparence : les utilisat·eur·rice·s peuvent-il·elle·s voir comment fonctionne le protocole et notamment quels sont les acteurs impliqués ? Par exemple, un service qui semble « gratuit » peut l'être parce qu'il y a derrière une grosse activité économique, avec de la publicité ciblée en exploitant vos données personnelles. Bref, si c'est gratuit, c'est peut-être que vous êtes le produit. Et vous ne le voyez peut-être pas clairement.
Voilà, si vous voulez en savoir plus, le RFC a une colossale bibliographie. Bonne lecture. Si vous préférez les vidéos, il y a mon intervention à Radio-France sur ce sujet.
L'article seul
RFC 8274: Incident Object Description Exchange Format Usage Guidance
Date de publication du RFC : Novembre 2017
Auteur(s) du RFC : P. Kampanakis (Cisco Systems), M. Suzuki (NICT)
Pour information
Réalisé dans le cadre du groupe de travail IETF mile
Première rédaction de cet article le 20 novembre 2017
Le format IODEF, dont la dernière version est décrite dans le RFC 7970, est un format structuré permettant l'échange de données sur des incidents de sécurité. Cela permet, par exemple, aux CSIRT de se transmettre des données automatiquement exploitables. Ces données peuvent être produites automatiquement (par exemple par un IDS, ou bien issues du remplissage manuel d'un formulaire). IODEF est riche, très riche, peut-être trop riche (certaines classes qu'il définit ne sont que rarement utilisées). Il peut donc être difficile de programmer des outils IODEF, et de les utiliser. (En pratique, il me semble qu'IODEF est peu utilisé.) Ce RFC, officiellement, est donc chargé d'aider ces professionnels, en expliquant les cas les plus courants et les plus importants, et en guidant programmeurs et utilisateurs.
Personnellement, je ne suis pas convaincu du résultat, ce RFC me semble plutôt un pot-pourri de diverses choses qui n'avaient pas été mises dans la norme.
La section 3 du RFC discute de l'utilisation de base d'IODEF. Reprenant la section 7.1 du RFC 7970, elle présente le document IODEF minimum, celui avec uniquement l'information obligatoire :
<?xml version="1.0" encoding="UTF-8"?>
<IODEF-Document version="2.00" xml:lang="en"
xmlns="urn:ietf:params:xml:ns:iodef-2.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.iana.org/assignments/xml-registry/schema/iodef-2.0.xsd">
<Incident purpose="reporting" restriction="private">
<IncidentID name="csirt.example.com">492382</IncidentID>
<GenerationTime>2015-07-18T09:00:00-05:00</GenerationTime>
<Contact type="organization" role="creator">
<Email>
<EmailTo>contact@csirt.example.com</EmailTo> <!-- Pas
réellement obligatoire, mais le document serait vraiment
sans intérêt sans lui. -->
</Email>
</Contact>
</Incident>
</IODEF-Document>
Un tel document, comportant
une instance de la classe Incident, qui comprend elle-même une
instance de la classe Contact, serait syntaxiquement correct mais
n'aurait guère d'intérêt pratique. Des documents un peu plus
réalistes figurent dans l'annexe B.
Le programmeur qui génère ou traite des fichiers IODEF n'a pas
forcément à mettre en œuvre la totalité des classes. Il peut se
contenter de ce qui est important pour son ou ses scénarios
d'utilisation. Par exemple, si on travaille sur les
dDoS, la classe Flow est la plus
importante, puisqu'elle décrit le trafic de l'attaque. (L'annexe
B.2 du RFC contient un fichier IODEF décrivant une attaque faite
avec LOIC. Je l'ai copié ici dans ddos-iodef.xml.) De même, si
on travaille sur le C&C d'un
logiciel malveillant, les classes
Flow et ServiceName
sont cruciales. Bref, il faut analyser ce dont on a besoin.
La section 4 du RFC mentionne les extensions à IODEF. Si riche que soit ce format, on peut toujours avoir besoin d'autres informations et c'est pour cela qu'IODEF est extensible. Par exemple, le RFC 5901 décrit une extension à IODEF pour signaler des cas de hameçonnage. Évidemment, on ne doit définir une extension que s'il n'existe pas de moyen existant de stocker l'information dans de l'IODEF standard.
La section 4 rappelle aussi aux développeurs que, certes, IODEF
bénéfice d'un mécanisme d'indication de la
confidentialité (l'attribut
restriction, qui se trouve dans les deux
exemples que j'ai cité), mais qu'IODEF ne fournit aucun
moyen technique de le faire respecter. Les documents IODEF étant
souvent sensibles, puisqu'ils parlent de problèmes de sécurité, le programmeur qui réalise un système de
traitement de fichiers IODEF doit donc mettre en œuvre des mesures
pratiques de protection de la confidentialité
(chiffrement des fichiers stockés, par
exemple).
Questions mise en œuvre d'IODEF, le RFC 8134 détaille des programmes existants, indique où les récupérer quand ils sont accessibles en ligne, et analyse leurs caractéristiques. C'est le cas par exemple d'iodeflib.
L'article seul
RFC 8273: Unique IPv6 Prefix Per Host
Date de publication du RFC : Décembre 2017
Auteur(s) du RFC : J. Brzozowski (Comcast
Cable), G. Van De Velde (Nokia)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 5 décembre 2017
Ce court RFC explique comment (et pourquoi) attribuer un préfixe IPv6 unique à chaque machine, même quand le média réseau où elle est connectée est partagé avec d'autres machines.
Ce RFC s'adresse aux gens qui gèrent un grand réseau de couche 2, partagé par de nombreux abonnés. Un exemple est celui d'un serveur dédié connecté à un Ethernet partagé avec les serveurs d'autres clients. Un autre exemple est celui d'une connexion WiFi dans un congrès ou un café. Dans les deux cas, la pratique sans doute la plus courante aujourd'hui est de donner une seule adresse IPv6 à la machine (ou, ce qui revient au même, un préfixe de 128 bits). C'est cette pratique que veut changer ce RFC. Le but est de mieux isoler les clients les uns des autres, et de bien pouvoir gérer les abonnements et leur utilisation. (Justement le problème de Comcast, dont un des auteurs du RFC est un employé, cf. section 1.) Les clients ne se connaissent en effet pas les autres et il est important que les actions d'un client ne puissent pas trop affecter les autres (et qu'on puisse attribuer les actions à un client précis, pour le cas où ces actions soient illégales). En outre, certaines options d'abonnement sont « par client » (section 3, qui cite par exemple le contrôle parental, ou la qualité de service, qui peut être plus faible pour ceux qui ne paient pas le tarif « gold ».)
Si chaque client a un préfixe IPv6 à lui (au lieu d'une seule adresse IP), toute communication entre clients passera forcément par le routeur géré par l'opérateur, qui pourra ainsi mieux savoir ce qui se passe, et le contrôler. (Les lecteurs férus de routage ont noté que le client, s'il est administrateur de sa machine, peut toujours changer les tables de routage, mais cela n'affectera que le trafic aller, le retour passera toujours par le routeur. De toute façon, je soupçonne que la technique décrite dans ce RFC ne marche que si le réseau donne un coup de main, pour isoler les participants.)
Le RFC affirme que cela protègera contre des attaques comme l'épuisement de cache Neighbor Discovery, les redirections malveillantes faites avec ICMP ou les RAcailles (RFC 6104). Cela éviterait de devoir déployer des contre-mesures comme le RA Guard (RFC 6105). Là aussi, il me semble personnellement que ça n'est complètement vrai que si l'attaquant n'est pas administrateur sur sa machine. Ou alors, il faut que le réseau ne soit pas complètement partagé, qu'il y ait un mécanisme de compartimentage.
Les mécanismes décrits ici supposent que la machine du client utilise SLAAC (RFC 4862) pour obtenir une adresse IP. Cette obtention peut aussi passer par DHCP (RFC 8415) mais c'est plus rare, relativement peu de clients étant capable de demander une adresse en DHCP (RFC 7934).
La section 4 du RFC décrit comment le client obtient ce
préfixe. Il va envoyer un message RS (Router
Solicitation, voir le RFC 4861,
section 3) et écouter les réponses, qui lui diront son adresse IP
mais aussi d'autres informations comme les résolveurs
DNS à utiliser (voir RFC 8106). Pas de changement côté client, donc (ce qui
aurait rendu ce mécanisme difficile à déployer). Par contre, côté
« serveur », il y a de légers changements. Le routeur qui reçoit les RS
et génère des RA (Router Advertisement), qu'ils
aient été sollicités ou pas, va devoir les envoyer uniquement à
une machine (puisque chaque client a un préfixe différent : il ne
faut donc pas diffuser bêtement). Comme le RFC 4861 (sections 6.2.4 et 6.2.6) impose que
l'adresse IP de destination soit
ff02::1 (« tous les nœuds IPv6 »), l'astuce
est d'utiliser comme adresse MAC, non pas
l'adresse multicast habituelle, mais une
adresse unicast (RFC 6085). Ainsi, chaque client ne recevra que
son préfixe.
Ce RA contient le préfixe que l'opérateur alloue à ce client particulier. Les options du RA (RFC 4861, section 4.2) sont :
- Bit M à zéro (ce qui veut dire « pas d'adresse via DHCP »),
- Bit O à un (ce qui veut dire « d'autres informations sont disponibles par DHCP, par exemple le serveur NTP à utiliser »),
- Bit A du préfixe (RFC 4861, section 4.6.2) mis à un (ce qui veut dire « tu es autorisé à te configurer une adresse dans ce préfixe »),
- Bit L du préfixe (RFC 4861, section 4.6.2) mis à zéro (ce qui veut dire « ce préfixe n'est pas forcément sur le lien où tu te trouves, ne suppose rien, sois gentil, passe par le routeur »).
Le bit A étant mis à un, la machine qui a obtenu le préfixe peut s'attribuer une adresse IP à l'intérieur de ce préfixe, , avec SLAAC, comme indiqué dans le RFC 4862. Elle doit suivre la procédure DAD (Duplicate Address Detection, RFC 4862, section 5.4) pour vérifier que l'adresse IP en question n'est pas déjà utilisée.
Voilà, l'essentiel de ce RFC était là. La section 5 concerne quelques détails pratiques, par exemple ce que peut faire la machine client si elle héberge plusieurs machines virtuelles ou containers (en gros, elle alloue leurs adresses en utilisant le préfixe reçu).
Ce mécanisme de préfixe IP spécifique à chaque client de l'opérateur n'est pas sans poser des questions liées à la vie privée, comme l'explique la section 7 du RFC. (Rappelez-vous la section 1, qui disait qu'un des buts de cette technique était de satisfaire aux « obligations légales », autrement dit de pouvoir suivre à la trace ses utilisateurs.) Bien sûr, la machine cliente peut utiliser le système du RFC 8981, mais, ici, il aurait peu d'impact. Même avec un identificateur d'interface temporaire et imprévisible, le préfixe resterait, et identifierait parfaitement le client. Le RFC mentionne (mais sans l'exiger) qu'on peut limiter les dégâts en changeant le préfixe de temps en temps.
L'article seul
RFC 8272: TinyIPFIX for Smart Meters in Constrained Networks
Date de publication du RFC : Novembre 2017
Auteur(s) du RFC : C. Schmitt, B. Stiller (University of Zurich), B. Trammell (ETH Zurich)
Pour information
Première rédaction de cet article le 15 novembre 2017
Le format IPFIX, normalisé dans le RFC 7011, permet à un équipement réseau d'envoyer des données résumées à un collecteur, à des fins d'études ou de supervision. À l'origine, l'idée était que l'équipement réseau soit un routeur, une machine relativement grosse, munie de suffisamment de ressources pour pouvoir s'accomoder d'un protocole un peu compliqué, et qui nécessite l'envoi de pas mal d'octets. L'IPFIX original était donc peu adapté aux engins contraints, par exemple aux capteurs connectés. D'où cette variante d'IPFIX, TinyIPFIX, qui vise à être utilisable par des objets connectés comme ceux utilisant le 6LoWPAN du RFC 4944 (un compteur Linky ?)
Mais prenons plutôt comme exemple un capteur non connecté au réseau électrique (donc dépendant d'une batterie, qu'on ne peut pas recharger tout le temps, par exemple parce que le capteur est dans un lieu difficile d'accès) et n'ayant comme connexion au réseau que le WiFi. L'émission radio coûte cher en terme d'énergie et notre capteur va donc souvent éteindre sa liaison WiFi, sauf quand il a explicitement quelque chose à transmettre. Un protocole de type pull ne peut donc pas convenir, il faut du push, que le capteur envoie ses données quand il le décide. Ces contraintes sont détaillées dans « Applications for Wireless Sensor Networks », par l'auteure du RFC (pas trouvé en ligne, c'est publié dans le livre « Handbook of Research on P2P and Grid Systems for Service-Oriented Computing: Models, Methodologies and Applications », édité par Antonopoulos N.; Exarchakos G.; Li M.; Liotta A. chez Information Science Publishing).
Le RFC donne (section 3) l'exemple de l'IRIS de Crossbow : sa taille n'est que de 58 x 32 x 7 mm, et il a 128 ko de flash pour les programmes (512 ko pour les données mesurées), 8 ko de RAM et 4 d'EEPROM pour sa configuration. On ne peut pas demander des miracles à un objet aussi contraint. (Si c'est vraiment trop peu, le RFC cite aussi l'engin d'Advantic avec ses 48 ko de flash « programme », 1024 ko de flash « données », 10 ko de RAM et 16 d'EEPROM.) Question énergie, ce n'est pas mieux, deux piles AA de 2 800 mAh chacune peuvent donner en tout 30 240 J.
Autre contrainte vécue par ces pauvres objets connectés, les limites du protocole réseau (section 3.3 de notre RFC). 6LoWPAN (RFC 4944) utilise IEEE 802.15.4. Ce protocole ne porte que 102 octets par trame. Ce n'est pas assez pour IPv6, qui veut une MTU minimum de 1 280 octets. Il faut donc utiliser la fragmentation, un mécanisme problématique, notamment parce que, si un seul fragment est perdu (et ces pertes sont des réalités, sur les liaisons radio), il faut retransmettre tout le paquet. Il est donc prudent de s'en tenir à des paquets assez petits pour tenir dans une trame. C'est un des apports de TinyIPFIX par rapport au IPFIX classique : des messages plus petits.
Enfin, dernière contrainte, le protocole de transport. IPFIX impose (RFC 7011, section 10.1) que SCTP soit disponible, même s'il permet aussi UDP et TCP. Mais SCTP (et TCP) ne permettent pas d'utiliser les mécanismes de compression des en-têtes de 6LoWPAN. Et SCTP n'est pas toujours présent dans les systèmes d'exploitation des objets, par exemple TinyOS. TinyIPFIX utilise donc UDP. À noter que, comme le demande la section 6.2 du du RFC 5153, TinyIPFIX sur UDP n'est pas prévu pour l'Internet ouvert, mais uniquement pour des réseaux fermés.
TinyIPFIX est dérivé de IPFIX (RFC 7011) et en hérite donc de la plupart des concepts, comme la séparation des données (Data Sets) et de la description des données (dans des gabarits, transmis en Template Sets).
La section 4 du RFC décrit des scénarios d'usage. Comme TinyIPFIX (comme IPFIX) est undirectionnel (de l'exporteur vers le collecteur), et qu'il tourne sur UDP (où les messages peuvent se perdre), le développeur doit être conscient des limites de ce service. Si on perd un paquet de données, on perd des données. Pire, si on perd un paquet de gabarit (RFC 7011, sections 3.4.1 et 8), on ne pourra plus décoder les paquets de données suivants. On ne doit donc pas utiliser TinyIPFIX pour des systèmes où la perte de données serait critique. Un système d'accusés de réception et de retransmission (refaire une partie de TCP, quoi…) serait trop lourd pour ces engins contraints (il faudrait stocker les messages en attendant l'accusé de réception).
Le RFC recommande de renvoyer les paquets de gabarit de temps en temps. C'est normalement inutile (on n'imagine pas un capteur contraint en ressources changer de gabarit), mais cela permet de compenser le risque de perte. Le collecteur qui, lui, n'a pas de contraintes, a tout intérêt à enregistrer tous les messages, même quand il n'y a pas de gabarit, de manière à pouvoir les décoder quand le gabarit arrivera. (Normalement, on ne fait pas ça avec IPFIX, le gabarit ne peut s'appliquer qu'aux messages reçus après, mais, avec TinyIPFIX, il y a peu de chances que les gabarits changent.)
Le RFC donne un exemple animalier qui conviendrait au déploiement de TinyIPFIX, afin de surveiller des oiseaux (Szewczyk, R., Mainwaring, A., Polastre, J., et D. Culler, « An analysis of a large scale habitat monitoring application ».) Les capteurs notent ce que font ces charmants animaux et le transmettent.
Cet exemple sert à illustrer un cas où TinyIPFIX serait bien adapté : collecte de type push, efficacité en terme de nombre de paquets, perte de paquets non critique, pas de nécessité d'un estampillage temporel des messages (qui existe dans IPFIX mais que TinyIPFIX supprime pour alléger le travail).
La section 5 décrit l'architecture de TinyIPFIX, très similaire à celle d'IPFIX (RFC 5470).
Enfin, la section 6 décrit les aspects concrets de TinyIPFIX, notamment le format des messages. Il ressemble beaucoup à celui d'IPFIX, avec quelques optimisations pour réduire la taille des messages. Ainsi, l'en-tête de message IPFIX fait toujours 16 octets, alors que dans TinyIPFIX, il est de taille variable, avec seulement 3 octets dans le meilleur des cas. C'est ainsi que des champs comme le numéro de version (qui valait 11 pour IPFIX) ont été retirés. De même, l'estampille temporelle (« Export Time » dans IPFIX) est partie (de toute façon, les objets contraints ont rarement une horloge correcte).
Les objets contraints déployés sur le terrain n'ont souvent pas à un accès direct à Internet, à la fois pour des raisons de sécurité, et parce qu'un TCP/IP complet serait trop lourd pour eux. Il est donc fréquent qu'ils doivent passer par des relais qui ont, eux, un vrai TCP/IP, voire un accès Internet. (Cette particularité des déploiements d'objets connectés est une des raisons pour lesquelles le terme d'« Internet des Objets » n'a pas de valeur autre que marketing.)
TinyIPFIX va donc fonctionner dans ce type d'environnement et la section 7 de notre RFC décrit donc le mécanisme d'« intermédiation ». L'intermédiaire peut, par exemple, transformer du TinyIPFIX/UDP en TinyIPFIX/SCTP ou, carrément, du TinyIPFIX en IPFIX. Dans ce dernier cas, il devra ajouter les informations manquantes, comme l'estampille temporelle ou bien le numéro de version.
Côté mise en œuvre, Tiny IPFIX a été mis dans
TinyOS et
Contiki. Voir http://www.net.in.tum.de/pub/cs/TinyIPFIX_GUI_Licenced.zip
et http://www.net.in.tum.de/pub/cs/TinyIPFIX_and_Extentions_Licenced.zip.
L'article seul
RFC 8270: Increase the Secure Shell Minimum Recommended Diffie-Hellman Modulus Size to 2048 Bits
Date de publication du RFC : Décembre 2017
Auteur(s) du RFC : L. Velvindron (Hackers.mu), M. Baushke (Juniper Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 6 décembre 2017
Un RFC de moins de quatre pages, boilerplate administratif inclus, pour passer la taille minimum des modules des groupes Diffie-Hellman utilisés par SSH, de 1 024 bits à 2 048.
L'échange Diffie-Hellman dans SSH est décrit dans le RFC 4419, que notre nouveau RFC met à jour. C'est dans le RFC 4419 (sa section 3) que se trouvait la recommandation d'accepter au moins 1 024 bits pour le module du groupe. Or, cette taille est bien faible face aux attaques modernes comme Logjam.
Voilà, c'est tout, on remplace « minimum 1 024 bits » par
« minimum 2 048 » et on peut continuer à utiliser SSH. Si vous
êtes utilisateur d'OpenSSH, la commande de
génération de clés, ssh-keygen, peut
également générer ces modules (cf. la section Moduli
generation dans le manuel.) Les versions un peu
anciennes ne vous empêchent pas de faire des modules bien trop
petits. Ainsi, sur une version 7.2 :
% ssh-keygen -G moduli-512.candidates -b 512
Fri Oct 20 20:13:49 2017 Sieve next 4177920 plus 511-bit
Fri Oct 20 20:14:51 2017 Sieved with 203277289 small primes in 62 seconds
Fri Oct 20 20:14:51 2017 Found 3472 candidates
% ssh-keygen -G moduli-256.candidates -b 256
Too few bits: 256 < 512
modulus candidate generation failed
Le RGS recommande quant à lui 3 072 bits minimum (la règle exacte est « RègleLogp-1. La taille minimale de modules premiers est de 2048 bits pour une utilisation ne devant pas dépasser l’année 2030. RègleLogp-2. Pour une utilisation au delà de 2030, la taille minimale de modules premiers est de 3072 bits. »)
Enfin, la modification d'OpenSSH pour se conformer à ce RFC est juste un changement de la définition de DH_GRP_MIN.
L'article seul
RFC 8266: Preparation, Enforcement, and Comparison of Internationalized Strings Representing Nicknames
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : P. Saint-Andre (Jabber.org)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF precis
Première rédaction de cet article le 6 octobre 2017
Bien des protocoles Internet manipulent des noms qui doivent être parlants pour les utilisateurs et donc, de nos jours, doivent pouvoir être en Unicode. Les noms purement ASCII appartiennent à un passé révolu. Le groupe de travail PRECIS de l'IETF établit des règles pour ces noms, de manière à éviter que chaque protocole, chaque application, ne soit obligé de définir ses propres règles. Ce RFC contient les règles pour un sous-ensemble de ces noms : les noms qui visent plutôt à communiquer avec un utilisateur humain (par opposition aux noms qui sont indispensables aux protocoles réseaux, traités dans le RFC 8265). Il remplace le RFC 7700 (mais il y a peu de changements).
Ces noms « humains » sont typiquement ceux qui sont présentés aux utilisateurs. Ils doivent donc avant tout être « parlants » et il faut donc qu'ils puissent utiliser la plus grande part du jeu de caractères Unicode, sans restrictions arbitraires (contrairement aux identificateurs formels du RFC 8265, pour lesquels on accepte des limites du genre « pas d'espaces » ou « pas d'emojis »).
Le terme utilisé par le RFC pour ces noms « humains » est nicknames, terme qui vient du monde de la messagerie instantanée. Il n'y a pas de terme standard pour les désigner, certains protocoles (comme le courrier) parlent de display names (par opposition au login name ou account name), d'autres utilisent encore d'autres termes (l'article « An Introduction to Petname Systems » peut vous intéresser). Par exemple, dans un message électronique, on pourrait voir :
From: Valérie Pécresse <vp@les-républicains.fr>
Et, dans cet exemple, vp serait le nom formel
(mailbox name dans le courrier, login
name pour se connecter), alors que Valérie
Pécresse est le nickname, le nom
montrable aux humains. (Le concept de display
name dans le courrier est normalisé dans la section 3.4.1
du RFC 5322, son exact équivalent XMPP,
le nickname, est dans XEP-0172.)
Autre exemple, le réseau social Mastodon
où mon nom formel est bortzmeyer@mastodon.gougere.fr alors que la description, le
terme affiché est « S. Bortzmeyer 🗸 » (avec un symbole à la fin, le U+1F5F8).
Comme l'illustre l'exemple ci-dessus, on veut évidemment que le nom puisse être en Unicode, sauf pour la petite minorité des habitants de la planète qui utilisent une langue qui peut s'écrire uniquement en ASCII.
Ces noms « parlants », ces nicknames, ne servent pas qu'à désigner des humains, ils peuvent aussi être utilisés pour des machines, des sites Web (dans les signets), etc.
On pourrait penser qu'il n'y a rien à spécifier pour permettre leur internationalisation. On remplace juste ASCII par Unicode comme jeu de caractères autorisé et vas-y, poupoule. Mais Unicode recèle quelques surprises et, pour que les nicknames fonctionnent d'une manière qui paraitra raisonnable à la plupart des utilisateurs, il faut limiter légèrement leur syntaxe.
Ces limites sont exposées dans la section 2 de notre RFC, qui
définit un profil de PRECIS. PRECIS,
Preparation, Enforcement, and Comparison of
Internationalized Strings est le sigle qui désigne le
projet « Unicode dans tous les identificateurs » et le groupe de
travail IETF qui réalise ce projet. PRECIS définit (RFC 8264) plusieurs classes d'identificateurs et
les nicknames sont un cas particulier de la
classe FreeformClass (RFC 8264, section 4.3), la moins restrictive
(celle qui permet le plus de caractères).
Outre les restrictions de FreeformClass
(qui n'est pas complètement laxiste : par exemple, cette classe ne
permet pas les caractères de contrôle), le profil
Nickname :
- Convertit tous les caractères Unicode de type « espace » (la catégorie Unicode Zs) en l'espace ASCII (U+0020),
- Supprime les espaces en début et en fin du
nickname, ce qui fait que "
Thérèse" et "Thérèse" sont le même nom, - Fusionne toutes les suites d'espaces en un seul espace,
- Met tout en minuscules (donc les nicknames sont insensibles à la casse),
- Normalise en NFKC, plus violent que NFC, et réduisant donc les possibilités que deux nicknames identiques visuellement soient considérés comme distincts (cf. section 6, qui prétend à tort que ce serait un problème de sécurité ; comme souvent à l'IETF, le groupe de travail a passé beaucoup de temps sur un faux problème de « confusabilité », cf. UTS#39).
À noter qu'un nickname doit avoir une taille non nulle, après l'application des ces règles (autrement, un nickname de trois espaces serait réduit à... zéro).
Une fois ce filtrage et cette canonicalisation faite, les nicknames peuvent être comparés par une simple égalité bit à bit (s'ils utilisent le même encodage, a priori UTF-8). Un test d'égalité est utile si, par exemple, un système veut empêcher que deux utilisateurs aient le même nickname.
La section 3 de notre RFC fournit quelques exemples amusants et instructifs de nicknames :
- "
Foo" et "foo" sont acceptables, mais sont le même nom (en application de la régle d'insensibilité à la casse), - "
Foo Bar" est permis (les espaces sont autorisés, avec les quelques restrictions indiquées plus haut), - "
Échec au roi ♚" est permis, rien n'interdit les symboles comme cette pièce du jeu d'échecs, le caractère Unicode U+265A, - "
Henri Ⅳ" est permis (ouvrez l'œil : c'est le chiffre romain à la fin, U+2163) mais la normalisation NFKC (précédée du passage en minuscules) va faire que ce nom est équivalent à "henri iv" (avec, cette fois, deux caractères à la fin).
Notez que ces règles ne sont pas idempotentes et le RFC demande qu'elles soient appliquées répétitivement jusqu'à la stabilité (ou, au maximum, jusqu'à ce que trois applications aient été faites).
Comme le rappelle la section 4 de notre RFC, les applications doivent maintenant définir l'utilisation de ces noms parlants, où peut-on les utiliser, etc. L'application peut donc avoir des règles supplémentaires, comme une longueur maximale pour ces nicknames, ou des caractères interdits car ils sont spéciaux pour l'application.
L'application ou le protocole applicatif a également toute
latitude pour gérer des cas comme les duplicatas : j'ai écrit plus
haut que "Foo Bar" et "foo
bar" étaient considérés comme le même
nickname mais cela ne veut pas dire que leur
coexistence soit interdite : certaines applications permettent à
deux utilisateurs distincts d'avoir le même
nickname. Même chose avec d'autres règles
« métier » comme la possibilité d'interdire certains noms (par
exemple parce qu'ils sont grossiers).
Le profil Nickname est désormais ajouté au
registre IANA (section 5 du RFC).
L'annexe A décrit les changements depuis le RFC 7700. Le principal est le remplacement de l'opération
Unicode CaseFold() par
toLower() pour assurer l'insensibilité à la
casse. La différence est subtile, et ne change rien pour la
plupart des écritures. Sinon, l'erreur notée #4570
a été corrigée. Le reste n'est que de la maintenance.
L'article seul
RFC 8265: Preparation, Enforcement, and Comparison of Internationalized Strings Representing Usernames and Passwords
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : P. Saint-Andre (Jabber.org), A. Melnikov (Isode)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF precis
Première rédaction de cet article le 6 octobre 2017
Ah, les plaisirs de l'internationalisation du logiciel... Quand l'informatique ne concernait que les États-Unis, tout était simple. Un utilisateur ne pouvait avoir un nom (un login) que s'il était composé uniquement des lettres de l'alphabet latin (et même chose pour son mot de passe). Mais de nos jours, il n'est pas acceptable de se limiter au RFC 20. Il faut que Пу́тин ou 艾未未 puissent écrire leur nom dans leur écriture et l'informatique doit suivre. Notre RFC décrit comment le faire (il remplace le RFC 7613, mais il y a peu de changements, rassurez-vous).
Mais pourquoi faut-il standardiser quelque chose ? Pourquoi ne
pas dire simplement « les noms d'utilisateur sont en
Unicode » et basta ? Parce que les
logiciels qui gèrent noms d'utilisateurs et mots de passe ont
besoin de les manipuler, notamment de les
comparer. Si ПУ́ТИН
essaie de se loguer, et
que la base de données contient un utilisateur пу́тин, il faut bien déterminer si c'est
le même utilisateur (ici, oui, à part la casse). C'est en général assez simple dans l'alphabet
latin (ou dans le cyrillique utilisé pour
les exemples) mais il y a d'autres cas plus vicieux qui
nécessitent quelques règles supplémentaires.
Le cadre général de l'internationalisation des identificateurs est normalisé dans le RFC 8264. Notre nouveau RFC 8265 est l'adaptation de ce RFC 8264 au cas spécifique des noms d'utilisateur et des mots de passe.
Ces noms et ces mots de passe (aujourd'hui, il faudrait plutôt
dire phrases de passe) sont largement
utilisés pour l'authentification, soit
directement (SASL
PLAIN du RFC 4616, authentification
de base de HTTP du RFC 7617), ou
bien comme entrée d'une fonction de condensation
cryptographique (SASL SCRAM du
RFC 5802 ou bien authentification HTTP
digest du RFC 7616). L'idée est que
les opérations de base sur ces noms (et sur les mots de passe) ne
surprennent pas excessivement l'utilisateur, quel que soit son
pays, sa langue, sa culture. Un Français ou un Belge ne sera probablement pas trop
étonné que Dupont soit accepté comme synonyme
de dupont mais il le serait davantage si
dupond l'était. Évidemment, la tâche est
impossible (les utilisateurs sont tous différents) mais l'idée est
de ne pas faire un système parfait mais un système qui marche la
plupart du temps.
C'est là qu'intervient le cadre PRECIS (PReparation,
Enforcement, and Comparison of Internationalized
Strings) du RFC 8264. Il évite que
chaque développeur d'un système d'authentification doive lire et
comprendre toutes les conséquences d'Unicode, et lui permet de
s'appuyer sur une analyse déjà faite. Un exemple de piège
d'Unicode (et qui montre pourquoi « on va juste dire que les noms
d'utilisateur peuvent être n'importe quel caractère Unicode » est
sans doute une mauvaise politique) est le chiffre 1 en exposant,
U+00B9 (comme ça : « ¹ » Si vous ne voyez rien, c'est parce
que votre logiciel ne sait pas afficher ce caractère. Vous pouvez
toujours regarder le source HTML pour comprendre l'exemple.). Doit-on
l'autoriser ? Le mettre en correspondance avec le 1 traditionnel
de façon à ce que user¹ et
user1 soient le même nom ? Imaginez un client
XMPP qui vous dise
« user¹@example.com veut être votre
copain. Je l'autorise ? » et que vous acceptiez en croyant que
c'était user1@example.com. Bien sûr, on ne
peut pas réellement parler d'« attaque » dans ce cas, une telle
erreur permettrait juste de faire quelques farces mais, pour le
logiciel qui vérifie une identité, des confusions seraient plus
gênantes. Si les « attaques » exploitant la similitude de
caractères Unicode sont surtout un fantasme d'informaticien
anglophone n'ayant jamais réellement accepté
l'internationalisation (plutôt qu'une réalité du terrain), il est
quand même plus prudent de supprimer quelques causes de
cafouillage le plus tôt possible.
(Ce RFC suggère également de séparer le nom d'utilisateur, identificateur formel et n'utilisant qu'un jeu de caractères restreint, et la description (cf. RFC 8266) qui pourrait utiliser davantage de caractères. Twitter ou Mastodon fonctionnent ainsi.)
Notre RFC compte deux sections importantes, décrivant le profil
PRECIS pour les noms d'utilisateur (section 3) et les mots de
passe (section 4). Commençons par les noms d'utilisateur. Un nom
est une chaîne de caractères Unicode
composée de parties séparées par des espaces. Chaque partie doit
être une instance de IdentifierClass et est
normalisée en NFC. Pourquoi cette notion de « parties
séparées par des espaces » ? Parce que la classe
IdentifierClass du RFC 8264 ne permet pas les espaces, ce qui est gênant pour
certains identificateurs (« Prénom Nom » par exemple, cf. section
3.5). D'où la grammaire de la section 3.1 :
username = userpart *(1*SP userpart)
qui dit « un nom d'utilisateur est composé d'au moins une partie,
les parties étant séparées par un nombre quelconque
d'espaces ». Une des conséquences de cette grammaire étant que le
nombre d'espaces n'est pas significatif : Jean
Dupont et Jean Dupont sont
le même identificateur.
Chaque partie étant une instance de
l'IdentifierClass du RFC 8264, les caractères interdits par cette classe sont
donc interdits pour les noms d'utilisateurs. Une application
donnée peut restreindre (mais pas étendre) ce profil. Ces noms
d'utilisateurs sont-ils sensibles à la casse ? Certains protocoles ont
fait un choix et d'autres le choix opposé. Eh bien, il y a
deux sous-profils, un sensible et
un insensible (ce dernier étant recommandé). Les
protocoles et applications utilisant ce RFC 8265
devront annoncer clairement lequel ils utilisent. Et les
bibliothèques logicielles manipulant ces utilisateurs auront
probablement une option pour indiquer le sous-profil à
utiliser.
Le sous-profil UsernameCaseMapped rajoute
donc une règle de préparation des chaînes de caractères : tout
passer en minuscules (avant les comparaisons, les condensations
cryptographiques, etc), en utilisant l'algorithme
toLowerCase d'Unicode (section 3.13 de la norme
Unicode ; et, oui, changer la casse est
bien plus compliqué en Unicode qu'en ASCII). Une
fois la préparation faite, on peut comparer octet par octet, si
l'application a bien pris soin de définir l'encodage.
L'autre sous-profil, UsernameCasePreserved
ne change pas la casse, comme son nom
l'indique. ПУ́ТИН et
пу́тин y sont donc deux identificateurs
différents. C'est la seule différence entre les deux
sous-profils. Notre RFC recommande le profil insensible à la
casse, UsernameCaseMapped, pour éviter des
surprises comme celles décrites dans le RFC 6943 (cf. section 8.2 de notre RFC).
Bon, tout ça est bien nébuleux et vous préféreriez des exemples ? Le RFC nous en fournit. D'abord, des identificateurs peut-être surprenants mais légaux (légaux par rapport à PRECIS : certains protocoles peuvent mettre des restrictions supplémentaires). Attention, pour bien les voir, il vous faut un navigateur Unicode, avec toutes les polices nécessaires :
juliet@example.com: le @ est autorisé donc un JID (identificateur XMPP) est légal.fussball: un nom d'utilisateur traditionnel, purement ASCII, qui passera partout, même sur les systèmes les plus antédiluviens.fußball: presque le même mais avec un peu d'Unicode. Bien qu'en allemand, on traite en général ces deux identificateurs comme identiques, pour PRECIS, ils sont différents. Si on veut éviter de la confusion aux germanophones, on peut interdire la création d'un des deux identificateurs si l'autre existe déjà : PRECIS ne donne que des règles miminales, on a toujours droit à sa propre politique derrière.π: entièrement en Unicode, une lettre.Σ: une lettre majuscule.σ: la même en minuscule. Cet identificateur et le précédent seront identiques si on utilise le profilUsernameCaseMappedet différents si on utilise le profilUsernameCasePreserved.ς: la même, lorsqu'elle est en fin de mot. Le cas de ce sigma final est compliqué, PRECIS ne tente pas de le résoudre. Comme pour le eszett plus haut, vous pouvez toujours ajouter des règles locales.
Par contre, ces noms d'utilisateurs ne sont pas valides :
- Une chaîne de caractères vide.
HenriⅣ: le chiffre romain 4 à la fin est illégal (car il a ce qu'Unicode appelle « un équivalent en compatibilité », la chaîne « IV »).♚: seules les lettres sont acceptées, pas les symboles (même règle que pour les noms de domaine).
Continuons avec les mots de passe (section 4). Comme les noms,
le mot de passe est une chaîne de caractères
Unicode. Il doit
être une instance de FreeformClass. Cette
classe autorise bien plus de caractères que pour les noms
d'utilisateur, ce qui est logique : un mot de passe doit avoir
beaucoup d'entropie. Peu de caractères sont donc interdits (parmi
eux, les caractères de
contrôle, voir l'exemple plus bas). Les
mots de passe sont sensibles à la casse.
Des exemples ? Légaux, d'abord :
correct horse battery staple: vous avez reconnu un fameux dessin de XKCD.Correct Horse Battery Staple: les mots de passe sont sensibles à la casse, donc c'est un mot de passe différent du précédent.πßå: un mot de passe en Unicode ne pose pas de problème.Jack of ♦s: et les symboles sont acceptés, contrairement à ce qui se passe pour les noms d'utilisateur.foo bar: le truc qui ressemble à un trait est l'espace de l'Ogham, qui doit normalement être normalisé en un espace ordinaire, donc ce mot de passe est équivalent àfoo bar.
Par contre, ce mot de passe n'est pas valide :
my cat is a by: les caractères de contrôle, ici une tabulation, ne sont pas autorisés.
Rappelez-vous que ces profils PRECIS ne spécifient que des règles minimales. Un protocole utilisant ce RFC peut ajouter d'autres restrictions (section 5). Par exemple, il peut imposer une longueur minimale à un mot de passe (la grammaire de la section 4.1 n'autorise pas les mots de passe vides mais elle autorise ceux d'un seul caractère, ce qui serait évidemment insuffisant pour la sécurité), une longueur maximale à un nom d'utilisateur, interdire certains caractères qui sont spéciaux pour ce protocole, etc.
Certains profils de PRECIS suggèrent d'être laxiste en acceptant certains caractères ou certaines variantes dans la façon d'écrire un mot (accepter strasse pour straße ? C'est ce qu'on nomme le principe de robustesse.) Mais notre RFC dit que c'est une mauvaise idée pour des mots utilisés dans la sécurité, comme ici (voir RFC 6943).
Les profils PRECIS ont été ajoutés au registre IANA (section 7 de notre RFC).
Un petit mot sur la sécurité et on a fini. La section 8 de notre RFC revient sur quelques points difficiles. Notamment, est-ce une bonne idée d'utiliser Unicode pour les mots de passe ? Ça se discute. D'un côté, cela augmente les possibilités (en simplifiant les hypothèses, avec un mot de passe de 8 caractères, on passe de 10^15 à 10^39 possibilités en permettant Unicode et plus seulement ASCII), donc l'entropie. D'un autre, cela rend plus compliquée la saisie du mot de passe, surtout sur un clavier avec lequel l'utilisateur n'est pas familier, surtout en tenant compte du fait que lors de la saisie d'un mot de passe, ce qu'on tape ne s'affiche pas. Le monde est imparfait et il faut choisir le moindre mal...
L'annexe A du RFC décrit les changements (peu nombreux) depuis
l'ancien RFC 7613. Le principal est le
passage de la conversion de casse de la fonction Unicode
CaseFold() à
toLowerCase(). Et
UTF-8 n'est plus obligatoire, c'est
désormais à l'application de décider (en pratique, cela ne
changera rien, UTF-8 est déjà l'encodage recommandé dans
l'écrasante majorité des applications). Sinon, il y a une petite
correction dans l'ordre des opérations du profil
UsernameCaseMapped, et quelques nettoyages et
mises à jour.
L'article seul
RFC 8264: PRECIS Framework: Preparation, Enforcement, and Comparison of Internationalized Strings in Application Protocols
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : P. Saint-Andre (Jabber.org), M. Blanchet (Viagenie)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF precis
Première rédaction de cet article le 6 octobre 2017
Dans la longue marche vers une plus grande internationalisation de l'Internet, la question des identificateurs (comme par exemple les noms de domaine) a toujours été délicate. Ce sont en effet à la fois des éléments techniques, traités automatiquement par les programmes, et des marqueurs d'identité, vus par les humains (par exemple sur des cartes de visite) et manipulés par eux. Plutôt que de laisser chaque protocole internationaliser ses identificateurs (plus ou moins bien), l'approche de ce RFC est unificatrice, en élaborant des règles qui peuvent servir à de larges classes d'identificateurs, pour de nombreux protocoles différents. Il remplace le premier RFC qui avait suivi cette voie, le RFC 7564, désormais dépassé (mais les changements sont peu importants, c'est juste de la maintenance).
Cette opposition entre « éléments techniques » et « textes
prévus pour l'utilisateur » est au cœur du RFC 2277 qui pose comme principe politique qu'on
internationalise les seconds, mais pas les premiers. Cet excellent
principe achoppe souvent sur la question des identificateurs, qui
sont les deux à la fois. D'un côté, les programmes doivent les
traiter (les identificateurs doivent donc être clairement définis,
sans ambiguïté), de l'autre les humains les voient, les
communiquent, les échangent (les identificateurs doivent donc
permettre, sinon toutes les constructions du langage humain, en
tout cas un sous-ensemble d'Unicode qui
parait raisonnable aux humains ordinaires : pas question d'imposer
stephane comme nom de login
à un utilisateur nommé Stéphane, avec un accent sur le E). C'est
cette double nature des identificateurs (ainsi, il est vrai, que
l'énorme couche de bureaucratie qui gère les noms de domaine) qui explique la durée et
la vivacité des discussions sur les IDN.
Maintenant que ces IDN existent (depuis plus de quatorze ans, RFC 3490), que faire avec les autres identificateurs ? Une possibilité aurait été que chaque protocole se débrouille avec ses propres identificateurs, comme l'a fait le DNS avec les noms de domaine. Mais cela menait à une duplication du travail (et tous les auteurs de protocole ne sont pas des experts Unicode) et surtout à un risque de choix très différents : certains protocoles autoriseraient tel caractère Unicode et d'autres pas, sans que l'utilisateur ordinaire puisse comprendre clairement les raisons de cette différence. L'idée de base du groupe PRECIS était donc d'essayer de faire des règles qui s'appliqueraient à beaucoup de protocoles, épargnant aux concepteurs de ces protocoles de les concevoir eux-mêmes, et offrant à l'utilisateur une certaine homogénéité. Ce RFC 8264 est le cadre de définition des identificateurs internationalisés. Ce cadre permet la manipulation d'identificateurs internationalisés (par exemple leur comparaison, comme lorsqu'un utilisateur tape son nom et son mot de passe, et qu'il faut les vérifier, cf. RFC 6943.)
Certaines personnes, surtout en Anglosaxonnie, pourraient estimer que c'est bien compliqué tout cela, et qu'il vaudrait mieux limiter les identificateurs à ASCII. Certes, Unicode est compliqué, mais sa complexité ne fait que refléter celle des langues humaines (section 6.1 de notre RFC). On ne peut pas simplifier Unicode, sauf à éliminer une partie de la diversité humaine.
Le nom du groupe de travail PRECIS reflète les trois fonctions essentielles que font les programmes qui manipulent les identificateurs internationalisés :
- PR pour la préparation des identificateurs, les opérations préliminaires comme la conversion depuis un jeu de caractères local non-Unicode,
- E pour l'application (enforcement) des règles, afin de s'assurer qu'une chaîne de caractères Unicode est légale ou pas pour un usage donné,
- C pour la comparaison entre les identificateurs, afin de déterminer leur égalité (« cette ressource n'est accessible qu'à l'utilisateur Thérèse or elle est connectée avec le nom therese »),
- Le IS final étant pour Internationalized Strings.
A priori, les serveurs Internet seront responsables de l'application, les clients n'ayant à faire qu'une préparation. Ayant souvent moins de ressources, les clients pourraient en effet avoir du mal à faire certaines opérations Unicode complexes (section 3).
Les principes du travail de PRECIS sont :
- Définir un petit nombre (deux, actuellement) de classes spécifiant un jeu de caractères autorisés, classes applicables à un grand nombre d'usages.
- Définir le contenu de ces classes en fonction d'un algorithme, reposant sur les propriétés Unicode (contrairement à stringprep où le contenu des classes était énuméré dans le RFC). Ainsi, lorsqu'une nouvelle version d'Unicode sort (la version actuelle est la 10.0), il suffit de refaire tourner l'algorithme et on obtient le contenu à jour de la classe.
- Spécifier les classes par une inclusion : tout caractère non explicitement listé comme membre de la classe est automatiquement exclu.
- Permettre aux protocoles applicatifs de définir un profil d'une classe, à savoir une restriction de ses membres, ou bien d'autres précisions sur des sujets comme la normalisation Unicode. Il y a ainsi un profil pour les noms d'utilisateurs, un profil pour les mots de passe, etc (cf. RFC 8265). Notez qu'il est prévu que le nombre de profils reste limité, pour ne pas réintroduire l'excessive variété que voulait justement éviter PRECIS.
Si tout va bien, ces principes permettront l'indépendance vis-à-vis des versions d'Unicode (ou, plus exactement, la possibilité de passer à une nouvelle version d'Unicode sans faire une nouvelle norme incompatible), le partage des tables et du logiciel entre applications (par exemple par le biais de bibliothèques communes, utilisables si toutes les applications reposent sur PRECIS), et moins de surprises pour les utilisateurs, qui auraient été bien embêtés si chaque protocole Internet avait eu une manière complètement différente de prévoir l'internationalisation.
Bien, quelles sont donc les classes prévues par PRECIS (section 4) ? L'idée est de faire un compromis entre expressivité et sécurité. Qu'est-ce que la sécurité vient faire là dedans ? Personne ne le sait trop (le RFC utilise plusieurs fois safe et safety sans expliquer face à quels risques) mais Unicode fait souvent peur aux informaticiens anglo-saxons et il est donc courant d'estimer qu'il existe des caractères dangereux.
Il y a donc deux classes en tout et pour tout dans PRECIS :
IdentifierClass et
FreeformClass. La première classe servira à
identifier utilisateurs, machines, pièces de discussions en
messagerie instantanée, fichiers, etc, et ne
permettra que les lettres, les nombres et quelques symboles (comme
le ! ou le +, car ils étaient dans ASCII). C'est contraignant mais l'idée est qu'on veut des
désignations simples et sans ambiguïté, pas écrire des romans. La
seconde classe servira à tout le reste (mots de passe, textes
affichés comme la description d'une pièce XMPP, nom complet d'une
machine, etc). Par exemple, une imprimante sera
imprimante-jean-et-thérèse pour les protocoles
qui demandent un nom de la classe
IdentifierClass et Imprimante de
Jean & Thérèse lorsqu'on pourra utiliser un nom
FreeformClass.
Les classes sont définies par les caractères inclus et exclus. Plus précisément, un caractère peut être, pour une classe donnée (voir aussi la section 8) :
- Valide (ou PVALID pour Protocol Valid),
- Interdit,
- Autorisé dans certains contextes seulement, c'est-à-dire que l'autorisation dépendra des caractères voisins (pas facile de trouver un exemple dans l'alphabet latin, cela sert surtout à d'autres écritures),
- Pas encore affecté dans Unicode.
La classe IdentifierClass se définit donc par :
- Caractères valides : les lettres et chiffres (rappelons qu'on définit des identificateurs internationalisés : on ne se limite donc pas aux lettres et chiffres latins), et les symboles traditionnels, ceux d'ASCII (comme le tiret ou le tilde).
- Caractères valides dans certains contextes : ceux de la
rare catégorie
JoinControldu RFC 5892, section 2.8. - Caractères interdits : tout le reste (espaces, ponctuation, la plupart des symboles...).
- Les caractères non encore affectés sont également interdits.
La classe Freeform Class se définit, elle,
par :
- Caractères valides : les lettres et chiffres (rappelons qu'on définit des identificateurs internationalisés : on ne se limite donc pas aux lettres et chiffres latins), les espaces, la ponctuation, les symboles (oui, oui, y compris les emojis comme 🥞 cf. sections 4.3.1 et 9.15).
- Caractères valides dans certains contextes : ceux de la
catégorie
JoinControlplus quelques exceptions. - Caractères interdits : tout le reste, ce qui fait surtout les caractères de contrôle comme U+0007 (celui qui fait sonner votre ordinateur).
- Les caractères non encore affectés sont également interdits.
Ces listes de caractères autorisés ou interdits ne sont pas suffisantes. Il y a d'autres points à régler (section 5), ce qui se fait typiquement dans les profils. Ainsi, un profil doit définir :
- Normalisation Unicode à utiliser. NFC est recommandée.
- La correspondance entre les caractères et leur version large
(width mapping). Est-ce que FULLWIDTH
DIGIT ZERO (U+FF10) doit être considéré comme équivalent au
zéro traditionnel, de largeur « normale », U+0030 ? Notez que
certaines normalisations (mais qui ne sont pas celle recommandée),
comme NFKC, règlent le problème. Autrement, la
recommandation du RFC est « oui, il faut rendre ces caractères
équivalents » car l'utilisateur serait certainement surpris que
target0ettarget0soient considérés différents (le fameux POLA, principe de la moindre surprise). - D'autres correspondances peuvent être spécifiées par le profil (comme de transformer tous les espaces Unicode en l'espace traditionnel ASCII U+0020).
- Changement de la casse des caractères, par exemple pour tout
mettre en minuscules. Si c'est décidé pour un profil, le RFC
recommande que cela soit fait avec la méthode Unicode standard,
toLowerCase()(section 3.13 de la norme Unicode). Attention, cette méthode Unicode ne gère pas des cas qui dépendent de la langue, dont le plus fameux est le i sans point du turc (U+0131 c'est-à-dire ı). Le changement de casse est évidemment déconseillé pour les mots de passe (puisqu'il diminue l'entropie). Notez aussi que ce cas illustre le fait que les transformations PRECIS ne sont pas sans perte : si on met tout en minuscules,Poussinne se distingue plus depoussin. - Interdiction de certains mélanges de caractères de directionnalité différentes. Il y a des écritures qui vont de gauche à droite et d'autres de droite à gauche, et leur combinaison peut entrainer des surprises à l'affichage. Dans certains cas, un profil peut vouloir limiter ce mélange de directionnalités.
Un profil peut également interdire certains caractères normalement autorisés (mais pas l'inverse).
Au passage, pour la comparaison, le RFC (section 7) impose un ordre à ces opérations. Par exemple, la mise en correspondance de la version large sur la version normale doit se faire avant l'éventuel changement de casse. C'est important car ces opérations ne sont pas commutatives entre elles.
Les profils sont enregistrés à l'IANA. Le RFC met bien en garde contre leur multiplication : toute l'idée de PRECIS est d'éviter que chaque protocole ne gère l'internationalisation des identificateurs de manière différente, ce qui empêcherait la réutilisation de code, et perturberait les utilisateurs. Si on avait un cadre commun mais des dizaines de profils différents, on ne pourrait pas dire qu'on a atteint cet objectif. Par exemple, en matière d'interface utilisateur, PRECIS essaie de s'en tenir au POLA (Principle of Least Astonishment) et ce principe serait certainement violé si chaque application trouvait rigolo d'interdire un caractère ou l'autre, sans raison apparente. Le RFC estime d'ailleurs (section 5.1) qu'il ne devrait y avoir idéalement que deux ou trois profils. Mais ce n'est pas possible puisque les protocoles existent déjà, avec leurs propres règles, et qu'on ne peut pas faire table rase de l'existant (tous les protocoles qui ont déjà définis des caractères interdits, comme IRC, NFS, SMTP, XMPP, iSCSI, etc).
Un petit point en passant, avant de continuer avec les
applications : vous avez noté que la classe
IdentifierClass interdit les espaces (tous les
espaces Unicode, pas seulement le U+0020 d'ASCII), alors que
certaines applications acceptent les espaces dans les
identificateurs (par exemple, Unix les
accepte sans problèmes dans les noms de fichier,
Apple permet depuis longtemps de les
utiliser pour nommer iTrucs et imprimantes, etc). La section
5.3 explique cette interdiction :
- Il est très difficile de distinguer tous ces espaces entre eux,
- Certains interfaces utilisateurs risquent de ne pas les
afficher, menant à confondre
françoise durandavecfrançoisedurand.
C'est embêtant (toute contrainte est embêtante) mais le compromis a semblé raisonnable au groupe PRECIS. Tant pis pour les espaces.
Passons maintenant aux questions des développeurs d'applications (section 6 du RFC). Que doivent-ils savoir pour utiliser PRECIS correctement ? Idéalement, il suffirait de lier son code aux bonnes bibliothèques bien internationalisées et tout se ferait automatiquement. En pratique, cela ne se passera pas comme ça. Sans être obligé de lire et de comprendre tout le RFC, le développeur d'applications devra quand même réflechir un peu à l'internationalisation de son programme :
- Il est très déconseillé de créer son propre profil. Non seulement c'est plus compliqué que ça n'en a l'air, mais ça risque de dérouter les utilisateurs, si votre application a des règles légèrement différentes des règles des autres applications analogues.
- Précisez bien quel partie de l'application va être responsable pour la préparation, l'application et la comparaison. Par exemple, le travail d'application sera-t-il fait par le client ou par le serveur ? Demandez-vous aussi à quel stade les applications devront avoir fait ce travail (par exemple, en cas de login, avant de donner un accès).
- Définissez bien, pour chaque utilisation d'un identificateur
(chaque slot, dit le RFC), quel profil doit être
utilisé. Par exemple, « le nom du compte doit être conforme au
profil
UsernameCaseMappedde la classeIdentifierClass» (cf. RFC 8265). - Dressez la liste des caractères interdits (en plus de ceux déjà interdits par le profil) en fonction des spécificités de votre application. Par exemple, un @ est interdit dans la partie gauche d'une adresse de courrier électronique.
Sur ce dernier point, il faut noter que la frontière est mince entre « interdire plusieurs caractères normalement autorisés par le profil » et « définir un nouveau profil ». La possibilité d'interdire des caractères supplémentaires est surtout là pour s'accomoder des protocoles existants (comme dans l'exemple du courrier ci-dessus), et pour éviter d'avoir un profil par application existante.
Votre application pourra avoir besoin de constructions au-dessus
des classes existantes. Par exemple, si un nom d'utilisateur, dans
votre programme, peut s'écrire « Prénom Nom », il ne peut pas être
une instance de la classe IdentifierClass, qui
n'accepte pas les espaces pour la raison indiquée plus haut. Il
faudra alors définir un concept « nom d'utilisateur », par exemple
en le spécifiant comme composé d'une ou plusieurs instances de
IdentifierClass, séparées par des espaces. En
ABNF :
username = userpart *(1*SP userpart) userpart = ... ; Instance d'IdentifierClass
La même technique peut être utilisée pour spécifier des identificateurs
qui ne seraient normalement pas autorisés par
IdentifierClass comme
stéphane@maçonnerie-générale.fr ou /politique/séries/Game-of-Thrones/saison05épisode08.mkv.
On a vu plus haut qu'un des principes de PRECIS était de définir les caractères autorisés de manière algorithmique, à partir de leur propriétés Unicode, et non pas sous la forme d'une liste figée (qu'il faudrait réviser à chaque nouvelle version d'Unicode). Les catégories de caractères utilisées par cet algorithme sont décrites en section 9. Par exemple, on y trouve :
LettersDigitsqui rassemble les chiffres et les lettres. (Rappelez-vous qu'on utilise Unicode : ce ne sont pas uniquement les lettres et les chiffres d'ASCII.)ASCII7, les caractères d'ASCII, à l'exception des caractères de contrôle,Spaces, tous les espaces possibles (comme le U+200A, HAIR SPACE, ainsi appelé en raison de sa minceur),Symbols, les symboles, comme U+20A3 (FRENCH FRANC SIGN, ₣) ou U+02DB (OGONEK, ˛),- Etc.
Plusieurs registres IANA sont nécessaires pour stocker toutes les données nécessaires à PRECIS. La section 11 les recense tous. Le plus important est le PRECIS Derived Property Value, qui est recalculé à chaque version d'Unicode. Il indique pour chaque caractère s'il est autorisé ou interdit dans un identificateur PRECIS. Voici sa version pour Unicode 6.3 (on attend avec impatience une mise à jour…).
Les deux autres registres stockent les classes et les profils (pour l'instant, ils sont quatre). Les règles d'enregistrement (section 11) dans le premier sont strictes (un RFC est nécessaire) et celles dans le second plus ouvertes (un examen par un expert est nécessaire). La section 10 explique aux experts en question ce qu'ils devront bien regarder. Elle note que l'informaticien ordinaire est en général très ignorant des subtilités d'Unicode et des exigences de l'internationalisation, et que l'expert doit donc se montrer plus intrusif que d'habitude, en n'hésitant pas à mettre en cause les propositions qu'il reçoit. Dans beaucoup de RFC, les directives aux experts sont d'accepter, par défaut, les propositions, sauf s'il existe une bonne raison de les rejeter. Ici, c'est le contraire : le RFC recommande notamment de rejeter les profils proposés, sauf s'il y a une bonne raison de les accepter.
La section 12 est consacrée aux problèmes de sécurité qui, comme
toujours lorsqu'il s'agit
d'Unicode, sont plus imaginaires que réels. Un des problèmes
envisagés est celui du risque de confusion entre deux caractères
qui sont visuellement proches. Le problème existe déjà avec le seul
alphabet latin (vous voyez du premier coup
la différence entre google.com et
goog1e.com ?) mais est souvent utilisé comme
prétexte pour retarder le déploiement d'Unicode. PRECIS se voulant
fidèle au principe POLA, le risque de confusion est
considéré comme important. Notez que le risque réel dépend de la
police
utilisée. Unicode normalisant des caractères et non pas des
glyphes, il n'y a pas de
solution générale à ce problème dans Unicode (les écritures
humaines sont compliquées : c'est ainsi). Si le texte
ᏚᎢᎵᎬᎢᎬᏒ ressemble
à STPETER, c'est que vous utilisez une police qui ne distingue pas
tellement l'alphabet
cherokee de l'alphabet latin. Est-ce que ça a des
conséquences pratiques ? Le RFC cite le risque accru de
hameçonnage, sans citer les nombreuses
études qui montrent le contraire (cf. le Unicode Technical Report
36, section 2, « the use of visually
confusable characters in spoofing is often overstated »,
et la FAQ de
sécurité d'Unicode).
Quelques conseils aux développeurs concluent cette partie : limiter le nombre de caractères ou d'écritures qu'on accepte, interdire le mélange des écritures (conseil inapplicable : dans la plupart des alphabets non-latins, on utilise des mots entiers en alphabet latin)... Le RFC conseille aussi de marquer visuellement les identificateurs qui utilisent plusieurs écritures (par exemple en utilisant des couleurs différentes), pour avertir l'utilisateur.
C'est au nom de ce principe POLA que la classe
IdentifierClass est restreinte à un ensemble
« sûr » de caractères (notez que ce terme « sûr » n'est jamais
expliqué ou défini dans ce RFC). Comme son nom l'indique,
FreeformClass est bien plus large et peut donc
susciter davantage de surprises.
PRECIS gère aussi le cas des mots de passe en Unicode. Un bon
mot de passe doit être difficile à deviner ou à trouver par force
brute (il doit avoir beaucoup d'entropie). Et
il faut minimiser les risques de faux positifs (un mot de passe
accepté alors qu'il ne devrait pas : par exemple, des mots de passe
insensibles à la
casse seraient agréables pour les utilisateurs mais
augmenteraient le risque de faux positifs). L'argument de
l'entropie fait que le RFC déconseille de créer des profils
restreints de FreeformClass, par exemple en
excluant des catégories comme la ponctuation. Unicode permet des
mots de passe vraiment résistants à la force brute, comme
« 𝃍🐬ꢞĚΥਟዶᚦ⬧ »... D'un
autre côté, comme le montre l'exemple hypothétique de mots de passe
insensibles à la casse, il y a toujours une tension entre la
sécurité et l'utilisabilité. Laisser les utilisateurs choisir des
mots de passe comportant des caractères « exotiques » peut poser
bien des problèmes par la suite lorsqu'utilisateur tentera de les
taper sur un clavier peu familier. Il faut noter aussi que les mots
de passe passent parfois par des protocoles intermédiaires (comme
SASL, RFC 4422, ou comme RADIUS, RFC 2865) et
qu'il vaut donc mieux que tout le monde utilise les mêmes règles
pour éviter des surprises (comme un mot de passe refusé par un
protocole intermédiaire).
Enfin, la section 13 de notre RFC se penche sur l'interopérabilité. Elle rappele qu'UTF-8 est l'encodage recommandé (mais PRECIS est un cadre, pas un protocole complet, et un protocole conforme à PRECIS peut utiliser un autre encodage). Elle rappelle aussi qu'il faut être prudent si on doit faire circuler ses identificateurs vers d'autres protocoles : tous ne savent pas gérer Unicode, hélas.
Il existe une mise en œuvre de PRECIS en Go : https://godoc.org/golang.org/x/text/secure/precis et une en
JavaScript, precis-js.
Les changements depuis le précédent RFC, le RFC 7564, sont résumés dans l'annexe A. Rien de crucial, le
principal étant le remplacement de
toCaseFold() par
toLower() pour les opérations insensibles à la
casse. Ces deux fonctions sont définies dans la norme
Unicode (section 4.1). La principale différence est que
toCaseFold() ne convertit pas forcément en
minuscules (l'alphabet
cherokee est converti en majuscules). Grâce à Python, dont la version 3
fournit casefold en plus de
lower() et upper(),
voici d'abord la différence sur l'eszett :
>>> "ß".upper()
'SS'
>>> "ß".lower()
'ß'
>>> "ß".casefold()
'ss'
Et sur l'alphabet cherokee (pour le cas, très improbable, où vous ayiez la police pour les minuscules, ajoutées récemment) :
>>> "ᏚᎢᎵᎬᎢᎬᏒ".upper()
'ᏚᎢᎵᎬᎢᎬᏒ'
>>> "ᏚᎢᎵᎬᎢᎬᏒ".lower()
'ꮪꭲꮅꭼꭲꭼꮢ'
>>> "ᏚᎢᎵᎬᎢᎬᏒ".casefold()
'ᏚᎢᎵᎬᎢᎬᏒ'
L'article seul
RFC 8261: Datagram Transport Layer Security (DTLS) Encapsulation of SCTP Packets
Date de publication du RFC : Novembre 2017
Auteur(s) du RFC : M. Tuexen (Muenster Univ. of Appl. Sciences), R. Stewart (Netflix), R. Jesup (WorldGate Communications), S. Loreto (Ericsson)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 16 novembre 2017
Le protocole de transport SCTP est normalement prévu pour tourner directement sur IP. Pour diverses raisons, il peut être utile de le faire tourner sur un autre protocole de transport comme UDP (ce que fait le RFC 6951) ou même sur un protocole qui offre des services de sécurité comme DTLS (ce que fait notre nouveau RFC).
SCTP est défini dans le RFC 4960. C'est un concurrent de TCP, offrant un certain nombre de services que TCP ne fait pas. DTLS, normalisé dans le RFC 6347, est un protocole permettant d'utiliser les services de sécurité de TLS au-dessus d'UDP. Il est notamment très utilisé par WebRTC (RFC 8827), lui donnant ainsi une sécurité de bout en bout.
En théorie, SCTP peut fonctionner directement sur IP. Hélas, dans l'Internet actuel, très ossifié, plein d'obstacles s'y opposent. Par exemple, les routeurs NAT tel que la box de M. Michu à la maison, n'acceptent en général que TCP et UDP. Et bien des pare-feux bloquent stupidement les protocoles que leurs auteurs sont trop ignorants pour connaître. En pratique, donc, SCTP ne passe pas partout. L'encapsuler dans un autre protocole de transport, comme UDP (directement, ou bien via DTLS), est souvent la seule solution pour avoir une connectivité. L'intérêt de DTLS est qu'on a toute la sécurité de TLS, notamment la confidentialité via le chiffrement.
Cette encapsulation est simple (section 3) : on met le paquet SCTP, avec ses en-têtes et sa charge utile, dans les données du paquet DTLS.
Il y a toutefois quelques détails à prendre en compte (section 4 de notre RFC). Par exemple, comme toute encapsulation prend quelques octets, la MTU diminue. Il faut donc un système de PMTUD. Comme l'encapsulation rend difficile l'accès à ICMP (voir la section 6) et que les middleboxes pénibles dont je parlais plus haut bloquent souvent, à tort, ICMP, cette découverte de la MTU du chemin doit pouvoir se faire sans ICMP (la méthode des RFC 4821 et RFC 8899 est recommandée).
Cette histoire de MTU concerne tout protocole encapsulé. Mais il y a aussi d'autres problèmes, ceux liés aux spécificités de SCTP (section 6) :
- Il faut évidemment établir une session DTLS avant de tenter l'association SCTP (« association » est en gros l'équivalent de la connexion TCP),
- On peut mettre plusieurs associations SCTP sur la même session DTLS, elles sont alors identifiées par les numéros de port utilisés,
- Comme DTLS ne permet pas de jouer avec les adresses IP (en ajouter, en enlever, etc), on perd certaines des possibilités de SCTP, notamment le multi-homing, pourtant un des gros avantages théoriques de SCTP par rapport à TCP,
- Pour la même raison, SCTP sur DTLS ne doit pas essayer d'indiquer aux couches inférieures des adresses IP à utiliser,
- SCTP sur DTLS ne peut pas compter sur ICMP, qui sera traité plus bas, et doit donc se débrouiller sans lui.
Cette norme est surtout issue des besoins de WebRTC, dont les implémenteurs réclamaient un moyen facile de fournir sécurité et passage à travers le NAT. Elle est mise en œuvre depuis longtemps, dans des clients WebRTC comme Chrome, Firefox ou Opera.
L'article seul
RFC 8259: The JavaScript Object Notation (JSON) Data Interchange Format
Date de publication du RFC : Décembre 2017
Auteur(s) du RFC : T. Bray (Textuality)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF jsonbis
Première rédaction de cet article le 14 décembre 2017
Il existe une pléthore de langages pour décrire des données structurées. JSON, normalisé dans ce RFC (qui succède au RFC 7159, avec peu de changements), est actuellement le plus à la mode. Comme son concurrent XML, c'est un format textuel, et il permet de représenter des structures de données hiérarchiques.
À noter que JSON doit son origine, et son nom complet (JavaScript Object Notation) au langage de programmation JavaScript, dont il est un sous-ensemble (enfin, approximativement). La norme officielle de JavaScript est à l'ECMA, dans ECMA-262. JSON est dans la section 24.5 de ce document mais est aussi dans ECMA-404, qui lui est réservé. Les deux normes, ce RFC et la norme ECMA, sont écrites de manière différente mais, en théorie, doivent aboutir au même résultat. ECMA et l'IETF sont censés travailler ensemble pour résoudre les incohérences (aucune des deux organisations n'a, officiellement, le dernier mot).
Contrairement à JavaScript, JSON n'est
pas un langage de programmation, seulement un langage de
description de données, et il ne peut donc pas servir de véhicule
pour du code
méchant (sauf si on fait des bêtises comme de
soumettre du texte JSON à eval(), cf. section
12 et erratum
#3607 qui donne des détails sur cette vulnérabilité).
Voici un exemple, tiré du RFC, d'un objet exprimé en JSON :
{
"Image": {
"Width": 800,
"Height": 600,
"Title": "View from 15th Floor",
"Thumbnail": {
"Url": "http://www.example.com/image/481989943",
"Height": 125,
"Width": "100"
},
"IDs": [116, 943, 234, 38793]
}
}
Les détails de syntaxe sont dans la section 2 du RFC. Cet objet
d'exemple a un seul champ, Image, qui est un
autre objet (entre { et }) et qui a plusieurs champs. (Les objets
sont appelés dictionnaires ou maps
dans d'autres langages.) L'ordre des éléments de l'objet n'est pas
significatif (certains analyseurs JSON le conservent, d'autres
pas). Un de ces champs, IDs, a pour valeur un
tableau (entre [ et ]). Les éléments d'un
tableau ne sont pas forcément du même type (section 5).
Un texte JSON n'est pas forcément un objet ou un tableau, par exemple :
"Hello world!"
est un texte JSON légal (composé d'une chaîne de caractères en tout
et pour tout). Une des conséquences est qu'un lecteur de JSON qui lit au fil de l'eau peut
ne pas savoir si le texte est fini ou pas (il ne suffit pas de
compter les crochets et accolades). À part les objets, les tableaux
et les chaînes de caractères, un texte JSON peut être un nombre, ou
bien un littéral, false,
true ou null.
Et quel encodage utiliser pour les textes JSON (section 8) ? Le RFC 4627 était presque muet à ce sujet. Cette question est désormais plus développée. Le jeu de caractères est toujours Unicode et l'encodage est obligatoirement UTF-8 dès qu'on envoie du JSON par le réseau (bien des mises en œuvre de JSON ne peuvent en lire aucun autre). Les textes JSON transmis par le réseau ne doivent pas utiliser de BOM.
Lorsqu'on envoie du JSON par le réseau, le type MIME à utiliser est application/json.
Autre problème classique d'Unicode, la comparaison de chaînes de
caractères. Ces comparaisons doivent se faire selon les caractères
Unicode et pas selon les octets (il y a plusieurs façons de
représenter la même chaîne de caractères, par exemple
foo*bar et foo\u002Abar
sont la même chaîne).
JSON est donc un format simple, il n'a même pas la possibilité de commentaires dans le fichier... Voir sur ce sujet une intéressante compilation.
Le premier RFC décrivant JSON était le RFC 4627, remplacé ensuite par le RFC 7159. Quels changements apporte cette troisième révision (annexe A) ? Elle corrige quelques erreurs, résout quelques incohérences avec le texte ECMA, et donne des avis pratiques aux programmeurs. Les principaux changements :
- Passage d'ECMA-262 seul à ECMA-404 (262 était pour tout JavaScript, 404 pour JSON seul).
- Correction des erreurs, dont une technique, une affirmation trop optimiste sur la compatibilité de JSON avec JavaScript.
- UTF-8 est désormais obligatoire.
- Progression sur le chemin des normes, de « Proposition de norme » à Norme tout court.
Voici un exemple d'un programme Python pour écrire un objet Python en JSON (on notera que la syntaxe de Python et celle de JavaScript sont très proches) :
import json
objekt = {u'Image': {u'Width': 800,
u'Title': u'View from Smith\'s, 15th Floor, "Nice"',
u'Thumbnail': {u'Url':
u'http://www.example.com/image/481989943',
u'Width': u'100', u'Height': 125},
u'IDs': [116, 943, 234, 38793],
u'Height': 600}} # Example from RFC 4627, lightly modified
print(json.dumps(objekt))
Et un programme pour lire du JSON et le charger dans un objet Python :
import json
# One backslash for Python, one for JSON
objekt = json.loads("""
{
"Image": {
"Width": 800,
"Height": 600,
"Title": "View from Smith's, 15th Floor, \\\"Nice\\\"",
"Thumbnail": {
"Url": "http://www.example.com/image/481989943",
"Height": 125,
"Width": "100"
},
"IDs": [116, 943, 234, 38793]
}
}
""") # Example from RFC 4267, lightly modified
print(objekt)
print("")
print(objekt["Image"]["Title"])
Le code ci-dessus est très simple car Python (comme Perl ou
Ruby ou, bien sûr,
JavaScript) a un typage complètement
dynamique. Dans les langages où le typage est plus statique, c'est
moins facile et on devra souvent utiliser des méthodes dont
certains programmeurs se méfient, comme des conversions de types à
l'exécution. Si vous voulez le faire en Go, il existe un bon
article d'introduction au paquetage standard
json. Un exemple en Go figure plus loin, pour
analyser la liste des stations de la RATP.
Pour Java, qui a le même « problème » que Go, il existe une quantité impressionnante de bibliothèques différentes pour faire du JSON (on trouve en ligne plusieurs tentatives de comparaison). J'ai utilisé JSON Simple. Lire un texte JSON ressemble à :
import org.json.simple.*;
...
Object obj=JSONValue.parse(args[0]);
if (obj == null) { // May be use JSONParser instead, it raises an exception when there is a problem
System.err.println("Invalid JSON text");
System.exit(1);
} else {
System.out.println(obj);
}
JSONObject obj2=(JSONObject)obj; // java.lang.ClassCastException if not a JSON object
System.out.println(obj2.get("foo")); // Displays member named "foo"
Et le produire :
JSONObject obj3=new JSONObject();
obj3.put("name","foo");
obj3.put("num",new Integer(100));
obj3.put("balance",new Double(1000.21));
obj3.put("is_vip",new Boolean(true));
Voyons maintenant des exemples réels avec divers outils de traitement de JSON. D'abord, les données issues du service de vélos en libre-service Vélo'v. C'est un gros JSON qui contient toutes les données du système. Nous allons programmer en Haskell un programme qui affiche le nombre de vélos libres et le nombre de places disponibles. Il existe plusieurs bibliothèques pour faire du JSON en Haskell mais Aeson semble la plus utilisée. Haskell est un langage statiquement typé, ce qui est loin d'être idéal pour JSON. Il faut déclarer des types correspondant aux structures JSON :
data Velov =
Velov {values :: [Station]} deriving Show
instance FromJSON Velov where
parseJSON (Object v) =
Velov <$> (v .: "values")
data Station =
Station {stands :: Integer,
bikes :: Integer,
available :: Integer} deriving Show
data Values = Values [Station]
Mais ça ne marche pas : les nombres dans le fichier JSON ont été
représentés comme des chaînes de caractères ! (Cela illustre un
problème fréquent dans le monde de JSON et de
l'open data : les données
sont de qualité technique très variable.) On doit donc les
déclarer en String :
data Station =
Station {stands :: String,
bikes :: String,
available :: String} deriving Show
Autre problème, les données contiennent parfois la chaîne de
caractères None. Il faudra donc filtrer avec
la fonction Haskell filter. La fonction
importante filtre les données, les convertit en entier, et en fait
la somme grâce à foldl :
sumArray a = show (foldl (+) 0 (map Main.toInteger (filter (\i -> i /= "None") a)))
Le programme
complet est velov.hs. Une fois compilé, testons-le :
% curl -s https://download.data.grandlyon.com/ws/rdata/jcd_jcdecaux.jcdvelov/all.json | ./velov "Stands: 6773" "Bikes: 2838" "Available: 3653"
Je n'ai pas utilisé les dates contenues dans ce fichier mais on peut noter que, si elles sont exprimées en ISO 8601 (ce n'est hélas pas souvent le cas), c'est sans indication du fuseau horaire (celui en vigueur à Lyon, peut-on supposer).
Un autre exemple de mauvais fichier JSON est donné par
Le Monde avec la base
des députés français. Le fichier
est du JavaScript, pas du JSON (il commence par une déclaration
JavaScript var datadep = {…) et il contient
plusieurs erreurs de syntaxe (des apostrophes qui n'auraient pas dû
être échappées).
Voyons maintenant un traitement avec le programme spécialisé
dans JSON, jq. On va servir du service de
tests TLS https://tls.imirhil.fr/https://tls.imirhil.fr/https/www.bortzmeyer.org.json
donne accès aux résultats des tests pour la version HTTPS de ce blog :
% curl -s https://tls.imirhil.fr/https/www.bortzmeyer.org.json| jq '.date' "2017-07-23T14:10:25.760Z"
Notons qu'au moins une clé d'un objet JSON n'est pas nommée
uniquement avec des lettres et chiffres, la clé
$oid. jq n'aime pas cela :
% curl -s https://tls.imirhil.fr/https/www.bortzmeyer.org.json| jq '._id.$oid'
jq: error: syntax error, unexpected '$', expecting FORMAT or QQSTRING_START (Unix shell quoting issues?) at <top-level>, line 1:
._id.$oid
jq: 1 compile error
Il faut mettre cette clé entre guillemets :
% curl -s https://tls.imirhil.fr/https/bortzmeyer.org.json| jq '."_id"."$oid"' "596cb76c2525939a3b34120f"
Toujours avec jq, les données de la Deutsche
Bahn, en http://data.deutschebahn.com/dataset/data-streckennetz
% jq '.features | map(select(.properties.geographicalName == "Regensburg Hbf"))' railwayStationNodes.geojson
[
{
"type": "Feature",
"geometry": {
"type": "Point",
"coordinates": [
12.09966625451,
49.011754555481
]
},
"properties": {
"id": "SNode-1492185",
"formOfNode": "railwayStop",
"railwayStationCode": "NRH",
"geographicalName": "Regensburg Hbf",
...
Toujours avec jq, on peut s'intéresser aux données officielles
états-uniennes en
https://catalog.data.gov/dataset?res_format=JSON. Prenons
les données
sur la délinquance à Los
Angeles (j'ai bien dit délinquance et pas criminalité,
celui qui traduit crime par crime ne connait pas
l'anglais, ni le
droit). https://data.lacity.org/api/views/y8tr-7khq/rows.json?accessType=DOWNLOAD
est un très gros fichier (805 Mo) et jq
n'y arrive pas :
% jq .data la-crime.json error: cannot allocate memory
Beaucoup de programmes qui traitent le JSON ont ce problème (un
script Python produit un MemoryError) : ils
chargent tout en mémoire et ne peuvent donc pas traiter des données
de grande taille. Il faut donc éviter de produire de trop gros
fichiers JSON.
Si vous voulez voir un vrai exemple en Python, il y a mon article sur le traitement de la base des codes postaux. Cette base peut évidemment aussi être examinée avec jq. Et c'est l'occasion de voir du GeoJSON :
% jq '.features | map(select(.properties.nom_de_la_commune == "LE TRAIT"))' laposte_hexasmal.geojson
[
{
"type": "Feature",
"geometry": {
"type": "Point",
"coordinates": [
0.820017087099,
49.4836816397
]
},
"properties": {
"nom_de_la_commune": "LE TRAIT",
"libell_d_acheminement": "LE TRAIT",
"code_postal": "76580",
"coordonnees_gps": [
49.4836816397,
0.820017087099
],
"code_commune_insee": "76709"
}
}
]
J'avais promis plus haut un exemple écrit en
Go. On va utiliser la liste des positions
géographiques des stations RATP, en
https://data.ratp.fr/explore/dataset/positions-geographiques-des-stations-du-reseau-ratp/table/?disjunctive.stop_name&disjunctive.code_postal&disjunctive.departement.
Le programme Go read-ratp.go va afficher le nombre
de stations et la liste :
% ./read-ratp < positions-geographiques-des-stations-du-reseau-ratp.json 26560 stations Achères-Ville Alésia Concorde ...
Comme déjà indiqué, c'est plus délicat en Go que dans un langage très dynamique comme Python. Il faut construire à l'avance des structures de données :
type StationFields struct {
Fields Station
}
type Station struct {
Stop_Id int
Stop_Name string
}
Et toute violation du « schéma » des données par le fichier JSON (quelque chose qui arrive souvent dans la nature) plantera le programme.
Si on veut beaucoup de fichiers JSON, le service de données
ouvertes officielles data.gouv.fr permet de
sélectionner des données par format. Ainsi, https://www.data.gouv.fr/fr/datasets/?format=JSONhttps://www.data.gouv.fr/fr/datasets/points-de-frayere-des-especes-de-linventaire-frayeres-des-regions-centre-et-poitou-charentes/.
Il est encodé en ISO-8859-1, ce qui est
explicitement interdit par le RFC. Bref, il faut encore rappeler
qu'on trouve de tout dans le monde JSON et que l'analyse de
fichiers réalisés par d'autres amène parfois des surprises.
On peut aussi traiter du JSON dans
PostgreSQL. Bien sûr, il est toujours
possible (et sans doute parfois plus avantageux) d'analyser le JSON
avec une des bibliothèques présentées plus haut, et de mettre les
données dans
une base PostgreSQL. Mais on peut aussi mettre le JSON directement
dans PostgreSQL et ce SGBD fournit un
type de données JSON et quelques
fonctions permettant de l'analyser. Pour les données, on va
utiliser les centres de santé en Bolivie,
en
http://geo.gob.bo/geoserver/web/?wicket:bookmarkablePage=:org.geoserver.web.demo.MapPreviewPage. On
crée la table :
CREATE TABLE centers (
ID serial NOT NULL PRIMARY KEY,
info json NOT NULL
);
Si
on importe le fichier JSON bêtement dans PostgreSQL (psql -c "copy centers(info) from stdin" mydb < centro-salud.json), on récupère
un seul enregistrement. Il faut donc éclater le fichier JSON en
plusieurs lignes. On peut utiliser les extensions à SQL de
PostgreSQL pour cela, mais j'ai préféré me servir de jq :
% jq --compact-output '.features | .[]' centro-salud.json | psql -c "copy centers(info) from stdin" mydb
COPY 50
On peut alors faire des requêtes dans le JSON, avec l'opérateur
->. Ici, le nom des centres (en jq, on
aurait écrit .properties.nombre) :
mydb=> SELECT info->'properties'->'nombre' AS Nom FROM centers;
nom
------------------------------------------
"P.S. ARABATE"
"INSTITUTO PSICOPEDAGOGICO"
"HOSPITAL GINECO OBSTETRICO"
"HOSPITAL GASTROENTEROLOGICO"
"C.S. VILLA ROSARIO EL TEJAR"
"C.S. BARRIO JAPON"
"C.S. SAN ANTONIO ALTO (CHQ)"
"C.S. SAN JOSE (CHQ)"
"C.S. SAN ROQUE"
...
Bon, sinon, JSON dispose d'une page Web officielle, où vous trouverez plein d'informations. Pour tester dynamiquement vos textes JSON, il y a ce service.
L'article seul
RFC 8257: Data Center TCP (DCTCP): TCP Congestion Control for Data Centers
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : S. Bensley, D. Thaler, P. Balasubramanian (Microsoft), L. Eggert (NetApp), G. Judd (Morgan Stanley)
Pour information
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 19 octobre 2017
DCTCP (Datacenter TCP), décrit dans ce RFC (qui n'est pas une norme, attention), est une variante de TCP avec un contrôle de congestion moins prudent. Elle est conçue pour le cas particulier des centres de données et ne doit pas être utilisée sur l'Internet public.
DCTCP repose sur la technique ECN du RFC 3168. Normalement, cette technique permet de signaler la congestion plus tôt qu'avec la méthode traditionnelle d'attendre les pertes de paquets. L'ECN est binaire : il y a eu de la congestion ou il n'y en a pas eu. DCTCP va plus loin et utilise ECN pour estimer le nombre d'octets qui ont rencontré de la congestion. DCTCP va ensuite refermer sa fenêtre (le nombre d'octets qu'on peut envoyer avant d'avoir reçu des accusés de réception) plus lentement que le TCP classique (et c'est pour cela que la concurrence entre eux est inégale, et que DCTCP ne doit pas être activé dans l'Internet, mais seulement dans des environnements fermés).
Quelles sont les particularités du réseau dans un centre de données ? Il faut beaucoup de commutateurs pour relier ces machines. Il est tentant d'utiliser pour cela des commutateurs bon marché. Mais ceux-ci ont des tampons de taille limitée, et le risque de congestion est donc plus élevé. Dans un centre de données, les flots sont de deux types : des courts et des longs. Les courts veulent en général une faible latence et les longs sont souvent davantage intéressés par une forte capacité. Enfin, le trafic est souvent très synchronisé. Si on fait du MapReduce, tous les serveurs vont voir de l'activité réseau en même temps (quand le travail est réparti, et quand il se termine).
Le cahier des charges des commutateurs est donc plein de contradictions :
- Tampon de petite taille, pour ne pas augmenter la latence (attention au bufferbloat),
- Tampon de grande taille pour être sûr de pouvoir toujours utiliser les liens de sortie au maximum,
- Tampon de grande taille pour pouvoir encaisser les brusques variations de trafic, lorsqu'un flot bavard commence (par exemple une distribution d'un nouveau travail MapReduce).
Avec le TCP traditionnel (pré-ECN), l'indicateur de congestion est la perte de paquets, détectée par l'absence d'accusé de réception. (Voir le RFC 5681 pour une bonne synthèse sur le contrôle de congestion dans TCP.) Attendre la perte de paquets pour ralentir n'est pas très efficace : pour un flot court qui rencontre de la congestion au début, la majorité des paquets aura été jetée avant que TCP ne puisse ralentir. D'où l'invention d'ECN (RFC 3168). ECN permet de réagir avant qu'on perde des paquets. Mais, comme expliqué plus haut, il est binaire : il détecte la congestion, pas son importance. Il va donc souvent mener TCP à refermer trop énergiquement la fenêtre d'envoi.
La section 3 du RFC présente les algorithmes à utiliser. Les
commutateurs/routeurs
détectent la congestion et la signalent via
ECN (RFC 3168). Les
récepteurs des données renvoient l'ECN à l'émetteur et celui-ci
réduit sa fenêtre de congestion (cwnd pour
Congestion WiNDow, cf. RFC 5681, section 2). Tout ceci est
le fonctionnement classique d'ECN. C'est surtout dans la dernière étape,
le calcul de la réduction de la fenêtre, que DCTCP apporte des
nouveautés. Mais, avant, quelques détails sur les deux premières
étapes.
D'abord, la décision des commutateurs et·ou routeurs de considérer qu'il y a congestion. Fondamentalement, c'est une décision locale, qui n'est pas standardisée. En général, on décide qu'il y a congestion dès que le temps de séjour des paquets dans les tampons du commutateur/routeur augmente « trop ». On n'attend donc pas que les files d'attente soient pleines (si elles sont grandes - bufferbloat - la latence va augmenter sérieusement bien avant qu'elles ne soient pleines). Une fois que l'engin décide qu'il y a congestion, il marque les paquets avec ECN (bit CE - Congestion Experienced, cf. RFC 3168).
Le récepteur du paquet va alors se dire « ouh là, ce paquet a rencontré de la congestion sur son trajet, il faut que je prévienne l'émetteur de se calmer » et il va mettre le bit ECE dans ses accusés de réception. Ça, c'est l'ECN normal. Mais pour DCTCP, il faut davantage de détails, puisqu'on veut savoir précisément quels octets ont rencontré de la congestion. Une possibilité serait d'envoyer un accusé de réception à chaque segment (paquet TCP), avec le bit ECE si ce segment a rencontré de la congestion. Mais cela empêcherait d'utiliser des optimisations très utiles de TCP, comme les accusés de réception retardés (on attend un peu de voir si un autre segment arrive, pour pouvoir accuser réception des deux avec un seul paquet). À la place, DCTCP utilise une nouvelle variable booléenne locale chez le récepteur qui stocke l'état CE du précédent segment. On envoie un accusé de réception dès que cette variable change d'état. Ainsi, l'accusé de réception des octets M à N indique, selon qu'il a le bit ECE ou pas, que tous ces octets ont eu ou n'ont pas eu de congestion.
Et chez l'émetteur qui reçoit ces nouvelles notifications de
congestion plus subtiles ? Il va s'en servir pour déterminer quel
pourcentage des octets qu'il a envoyé ont rencontré de la
congestion. Les détails du calcul (dont une partie est laissé à
l'implémenteur, cf. section 4.2) figurent en section 3.3. Le résultat est stocké
dans une nouvelle variable locale,
DCTCP.Alpha.
Une fois ces calculs faits et cette variable disponible,
lorsque la congestion apparait, au lieu de diviser brusquement sa
fenêtre de congestion, l'émetteur la fermera plus doucement, par
la formule cwnd = cwnd * (1 - DCTCP.Alpha /
2) (où cwnd est la taille de la
fenêtre de congestion ; avec l'ancien algorithme, tout se passait
comme si tous les octets avaient subi la congestion, donc
DCTCP.Alpha = 1).
La formule ci-dessus était pour la cas où la congestion était signalée par ECN. Si elle était signalée par une perte de paquets, DCTCP se conduit comme le TCP traditionnel, divisant sa fenêtre par deux. De même, une fois la congestion passée, Datacenter TCP agrandit sa fenêtre exactement comme un TCP normal.
Voilà, l'algorithme est là, il n'y a plus qu'à le mettre en œuvre. Cela mène à quelques points subtils, que traite la section 4. Par exemple, on a dit que DCTCP, plus agressif qu'un TCP habituel, ne doit pas rentrer en concurrence avec lui (car il gagnerait toujours). Une implémentation de DCTCP doit donc savoir quand activer le nouvel algorithme et quand garder le comportement conservateur traditionnel. (Cela ne peut pas être automatique, puisque TCP ne fournit pas de moyen de négocier l'algorithme de gestion de la congestion avec son pair.) On pense à une variable globale (configurée avec sysctl sur Unix) mais cela ne suffit pas : la même machine dans le centre de données peut avoir besoin de communiquer avec d'autres machines du centre, en utilisant DCTCP, et avec l'extérieur, où il ne faut pas l'utiliser. Il faut donc utiliser des configurations du genre « DCTCP activé pour les machines dans le même /48 que moi ».
Une solution plus rigolote mais un peu risquée, serait d'activer DCTCP dès que la mesure du RTT indique une valeur inférieure à N millisecondes, où N est assez bas pour qu'on soit sûr que seules les machines de la même tribu soient concernées.
Après le programmeur en section 4, l'administrateur réseaux en section 5. Comment déployer proprement DCTCP ? Comme on a vu que les flots TCP traditionnels et DCTCP coexistaient mal, la section 5 recommande de les séparer. Par exemple, l'article « Attaining the Promise and Avoiding the Pitfalls of TCP in the Datacenter » décrit un déploiement où le DSCP (RFC 2474) d'IPv4 est utilisé pour distinguer les deux TCP, ce qui permet d'appliquer de l'AQM (RFC 7567) à DCTCP et des méthodes plus traditionnelles (laisser tomber le dernier paquet en cas de congestion) au TCP habituel. (Il faut aussi penser au trafic non-TCP, ICMP, par exemple, quand on configure ses commutateurs/routeurs.)
Aujourd'hui, DCTCP est déjà largement déployé et ce RFC ne fait que prendre acte de ce déploiement On trouve DCTCP dans Linux (cf. ce commit de 2014, notez les mesures de performance qui accompagnent sa description), dans FreeBSD (ce commit, et cette description de l'implémentation), et sur Windows (cette fois, on ne peut pas voir le source mais il y a une documentation). Sur Linux, on peut voir la liste des algorithmes de gestion de la congestion qui ont été compilés dans ce noyau :
% sysctl net.ipv4.tcp_available_congestion_control
net.ipv4.tcp_available_congestion_control = cubic reno
Si DCTCP manque, c'est peut-être parce qu'il faut charger le module :
% modprobe tcp_dctcp
% sysctl net.ipv4.tcp_available_congestion_control
net.ipv4.tcp_available_congestion_control = cubic reno dctcp
Si DCTCP se trouve dans la liste, on peut l'activer (c'est une activation globale, par défaut) :
% sysctl -w net.ipv4.tcp_congestion_control=dctcp
Pour le faire uniquement vers certaines destinations (par exemple à l'intérieur du centre de données) :
% ip route add 192.168.0.0/16 congctl dctcp
Le choix des algorithmes de gestion de la congestion peut
également être fait par chaque application (setsockopt(ns, IPPROTO_TCP, TCP_CONGESTION, …).
Enfin, la section 6 du RFC rassemble quelques problèmes non résolus avec DCTCP :
- Si les estimations de congestion sont fausses, les calculs de DCTCP seront faux. C'est particulièrement un problème en cas de perte de paquets, problème peu étudié pour l'instant.
- Comme indiqué plus haut, DCTCP n'a aucun mécanisme pour négocier dynamiquement son utilisation. Il ne peut donc pas coexister avec le TCP traditionnel mais, pire, il ne peut pas non plus partager gentiment le réseau avec un futur mécanisme qui, lui aussi, « enrichirait » ECN. (Cf. la thèse de Midori Kato.)
Enfin, la section 7 du RFC, portant sur la sécurité, note que DCTCP hérite des faiblesses de sécurité d'ECN (les bits ECN dans les en-têtes IP et TCP peuvent être modifiés par un attaquant actif) mais que c'est moins grave pour DCTCP, qui ne tourne que dans des environnements fermés.
Si vous aimez lire, l'article original décrivant DCTCP en 2010 est celui de Alizadeh, M., Greenberg, A., Maltz, D., Padhye, J., Patel, P., Prabhakar, B., Sengupta, S., et M. Sridharan, « Data Center TCP (DCTCP) ». Le dinosaure ACM ne le rendant pas disponible librement, il faut le récupérer sur Sci-Hub (encore merci aux créateurs de ce service).
Merci à djanos pour ses nombreuses corrections sur la gestion de DCTCP dans Linux.
L'article seul
RFC 8255: Multiple Language Content Type
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : N. Tomkinson, N. Borenstein (Mimecast)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF slim
Première rédaction de cet article le 10 octobre 2017
Dernière mise à jour le 20 mars 2018
La norme MIME permet d'étiqueter un
message en
indiquant la langue, avec l'en-tête
Content-Language: (RFC 4021). Mais
comment faire si on veut envoyer le même message en plusieurs
langues, pour s'adapter à une audience variée, ou bien si on n'est
pas sûr des langues parlées par le destinataire ? C'est ce que
permet le nouveau type de
message multipart/multilingual
qui permet d'étiqueter les messages multilingues.
C'est le premier RFC du groupe de travail SLIM, chargé de créer des normes pour indiquer la langue utilisée dans le courrier et pour les communications synchrones (téléphonie sur IP, par exemple, couverte depuis par le RFC 8373), dans le cas où plusieurs langues sont en présence.
Le type de premier niveau multipart/ (RFC 2046, section 5.1, enregistré à
l'IANA) permet d'indiquer un message (ou une partie de
message, en cas de récursivité) composé de plusieurs
parties. Ainsi, multipart/mixed (RFC 2046, section 5.1.3) indique un message dont
les dfférentes parties sont indépendantes (un texte et une image,
par exemple). Alors que multipart/alternative
(RFC 2046, section 5.1.4) est utilisé pour
le cas où les différentes parties veulent dire la même chose, mais
avec des formats différentes (une version texte
seul et une version HTML, par
exemple, ou bien une image en JPEG et la
même en PNG). Normalement, le lecteur de courrier ne va afficher qu'une
seule des parties d'une
multipart/alternative, celle qui convient le
mieux, selon les capacités du logiciel de lecture et les
préférences de l'utilisateur. Ce sera la même chose avec ce
nouveau multipart/multilingual : l'émetteur
enverra le message en plusieurs langues, le logiciel de lecture
n'affichera que celle qui colle le mieux aux choix de
l'utilisateur. Ce type est désormais enregistré
à l'IANA (section 9 du RFC).
Rappelez-vous que MIME est
récursif : un
multipart/ peut contenir un autre
multipart/. Voici, par exemple, vu par le
MUA mutt, un
multipart/mixed, dont la première partie est
un multipart/alternative et la seconde un
fichier PDF :
I 1 <no description> [multipart/alternative, 7bit, 45K]
I 2 ├─><no description> [text/plain, 8bit, utf-8, 1,8K]
I 3 └─><no description> [text/html, 8bit, utf-8, 43K]
A 4 35378031645-672029836-registration.pdf [application/pdf, base64, 84K]
Cette première partie du corps du message, de type
multipart/alternative, a à son tour deux
parties, une en texte brut et l'autre en HTML. Comme ma
configuration mutt inclut la directive alternative_order
text/plain, seule la version texte sera affichée, le
HTML étant ignoré.
Revenons aux messages multilingues. Avant ce RFC 8255, la solution la plus fréquente, quand on envoyait un message à quelqu'un dont on n'était pas sûr des préférences linguistiques, était de mettre toutes les versions dans un même message. Du genre :
(English translation at the end)
Bonjour, ceci est un message.
Hello, this is a message.
(La première ligne ayant pour but d'éviter que le lecteur anglophone se décourage en ne voyant au début que du français.) Cette solution n'est pas satisfaisante : elle passe mal à l'échelle dès qu'il y a plus de deux langues. Et elle ne permet pas la sélection automatique de la langue par le logiciel du destinataire.
Le type MIME d'un message est mis dans un en-tête
Content-Type:. Par exemple, un message de
plusieurs parties représentant le même contenu serait :
Content-Type: multipart/alternative; boundary="------------E6043EF6F3B557567F3B18F4"
Où boundary indique le texte qui sera le
séparateur entre les parties (RFC 2046,
section 5.1). La section 2 du RFC décrit ce qu'on peut désormais
mettre dans le Content-Type:, avec le nouveau
type multipart/multilingual.
Il ressemble beaucoup au
multipart/alternative et, comme tous les
multipart/quelquechose (RFC 2046, section 5.1.1), a une chaîne de
caractères qui indique le passage d'une partie à une autre :
Content-Type: multipart/multilingual; boundary=01189998819991197253
Chacune des parties d'un message en plusieurs langues doit
indiquer la langue de la partie, avec l'en-tête
Content-Language:. Mais attention, comme il
faut tenir compte des vieux clients de messagerie qui ne
connaissent pas ce RFC, la première partie ne doit
pas avoir de
Content-Language:, elle sert de solution de
repli, car c'est elle qui sera affichée en premier par les logiciels qui ne
connaissent pas multipart/multilingual. Comme
elle sert de secours, il est recommandé qu'elle soit dans le
format le plus simple, donc text/plain, en
UTF-8 (car il faut pouvoir représenter
diverses langues). Cette partie se nomme la préface. En la
lisant, l'utilisateur pourra donc comprendre qu'il doit mettre à
jour vers un logiciel plus récent.
Les parties suivantes, après la préface, vont être écrites dans des langues différentes. Le RFC recommande de les mettre dans l'ordre, avec celles qui ont le plus de chance d'être pertinentes en premier. (Ainsi, une société française ayant une activité européenne, avec une majorité de clients français, et envoyant un message en anglais, allemand et français, mettra sans doute le français en premier, suivi de l'anglais.)
Chacune de ces parties aura un en-tête
Content-Language:, pour indiquer la langue,
et Content-Type: pour indiquer le type
MIME. (Rappelez-vous toujours que MIME est récursif.) Il est
recommandé que chaque partie soit un message complet (avec
notamment le champ Subject:, qui a besoin
d'être traduit, lui aussi, et le champ From:,
dont une partie peut être utilement traduite). Le type conseillé est donc
message/rfc822 (RFC 2046, section 5.2.1), mais on peut aussi utiliser le
plus récent message/global (RFC 6532).
Notez bien que ce RFC ne spécifie évidemment pas comment se fera la traduction : il ne s'occupe que d'étiqueter proprement le résultat.
Le message peut se terminer par une section « indépendante de
la langue » (par exemple une image ne comportant pas de
texte, si le message peut être porté par une image). Dans ce cas, son Content-Language:
doit indiquer zxx, ce qui veut dire
« information non pertinente » (RFC 5646,
section 4.1). C'est elle qui sera sélectionnée si aucune partie ne
correspond aux préférences de l'utilisateur.
Maintenant, que va faire le client de
messagerie qui reçoit un tel message multilingue ? La
section 4 de notre RFC décrit les différents cas. D'abord, avec
les logiciels actuels, le client va afficher les différentes
parties de multipart/multilingual dans
l'ordre où elles apparaissent (donc, en commençant par la
préface).
Mais le cas le plus intéressant est évidemment celui d'un client plus récent, qui connait les messages multilingues. Il va dans ce cas sauter la préface (qui n'a pas de langue indiquée, rappelez-vous) et sélectionner une des parties, celle qui convient le mieux à l'utilisateur.
Un moment. Arrêtons-nous un peu. C'est quoi, la « meilleure » version ? Imaginons un lecteur francophone, mais qui parle anglais couramment. Il reçoit un message multilingue, en français et en anglais. S'il choisissait manuellement, il prendrait forcément le français, non ? Eh bien non, car cela dépend de la qualité du texte. Comme peut le voir n'importe quel utilisateur du Web, les différentes versions linguistiques d'un site Web ne sont pas de qualité égale. Il y a le texte original, les traductions faites par un professionnel compétent, les traductions faites par le stagiaire, et celles faites par un programme (en général, les plus drôles). Sélectionner la meilleure version uniquement sur la langue n'est pas une bonne idée, comme le montre la mauvaise expérience de HTTP. Ici, pour reprendre notre exemple, si la version en anglais est la version originale, et que le français est le résultat d'une mauvaise traduction par un amateur, notre francophone qui comprend bien l'anglais va sans doute préférer la version en anglais.
Il est donc crucial d'indiquer le type de traduction effectuée,
ce que permet le Content-Translation-Type:
exposé plus loin, en section 6. (Les premières versions du projet
qui a mené à ce RFC, naïvement, ignoraient complètement ce
problème de la qualité de la traduction, et de la version
originale.)
Donc, le mécanisme de sélection par le MUA de la « meilleure » partie dans un message multilingue n'est pas complètement spécifié. Mais il va dépendre des préférences de l'utilisateur, et sans doute des règles du RFC 4647.
Si aucune partie ne correspond aux choix de l'utilisateur, le RFC recommande que le MUA affiche la partie indépendante de la langue, ou, si elle n'existe pas, la partie après la préface. Le MUA peut également proposer le choix à l'utilisateur (« Vous n'avez indiqué qu'une langue, le français. Ce message est disponible en anglais et en chinois. Vous préférez lequel ? »)
La section 5 du RFC présente en détail l'utilisation de l'en-tête
Content-Language:. Il doit suivre la norme
existante de cet en-tête, le RFC 3282, et sa valeur doit
donc être une étiquette de langue du RFC 5646. Des exemples (en pratique, il ne faut
évidemment en mettre qu'un) :
Content-Language: fr
Content-Language: sr-Cyrl
Content-Language: ay
Content-Language: aaq
Le premier exemple concerne le français, le second le serbe écrit en alphabet cyrillique, le troisième l'aymara et le quatrième l'abénaqui oriental.
La section décrit le nouvel en-tête
Content-Translation-Type: qui indique le type
de traduction réalisé. Il peut prendre trois valeurs,
original (la version originale),
human (traduit par un humain) et
automated (traduit par un programme). Notez
que les humains (les programmes aussi, d'ailleurs) varient
considérablement dans leurs compétences de traducteur. J'aurais
personnellement préféré qu'on distingue un traducteur
professionnel d'un amateur, mais la traduction fait partie des
métiers mal compris, où beaucoup de gens croient que si on parle
italien et allemand, on peut traduire de l'italien en allemand
correctement. C'est loin d'être le cas. (D'un autre côté, comme
pour tous les étiquetages, si on augmente le nombre de choix, on
rend l'étiquetage plus difficile et il risque d'être incorrect.)
Voici un exemple complet, tel qu'il apparait entre deux logiciels de messagerie. Il est fortement inspiré du premier exemple de la section 8 du RFC, qui comprend également des exemples plus complexes. Dans ce message, l'original est en anglais, mais une traduction française a été faite par un humain.
From: jeanne@example.com
To: jack@example.com
Subject: Example of a message in French and English
Date: Thu, 7 Apr 2017 21:28:00 +0100
MIME-Version: 1.0
Content-Type: multipart/multilingual;
boundary="01189998819991197253"
--01189998819991197253
Content-Type: text/plain; charset="UTF-8"
Content-Disposition: inline
Content-Transfer-Encoding: 8bit
This is a message in multiple languages. It says the
same thing in each language. If you can read it in one language,
you can ignore the other translations. The other translations may be
presented as attachments or grouped together.
Ce message est disponible en plusieurs langues, disant la même chose
dans toutes les langues. Si vous le lisez dans une des langues, vous
pouvez donc ignorer les autres. Dans votre logiciel de messagerie, ces
autres traductions peuvent se présenter comme des pièces jointes, ou
bien collées ensemble.
--01189998819991197253
Content-Type: message/rfc822
Content-Language: en
Content-Translation-Type: original
Content-Disposition: inline
From: Manager <jeanne@example.com>
Subject: Example of a message in French and English
Content-Type: text/plain; charset="US-ASCII"
Content-Transfer-Encoding: 7bit
MIME-Version: 1.0
Hello, this message content is provided in your language.
--01189998819991197253
Content-Type: message/rfc822
Content-Language: fr
Content-Translation-Type: human
Content-Disposition: inline
From: Directrice <jeanne@example.com>
Subject: =?utf-8?q?Message_d=27exemple=2C_en_fran=C3=A7ais_et_en_anglais?=
Content-Type: text/plain; charset="UTF-8"
Content-Transfer-Encoding: 8bit
MIME-Version: 1.0
Bonjour, ce message est disponible dans votre langue.
--01189998819991197253--
On note qu'il y a une préface (la première partie, celle qui
commence par « This is a message in multiple languages »), que
chacun des deux parties étiquetées a un
From: (pour pouvoir adapter le titre de
l'expéditrice) et un sujet (celui en français étant encodé selon
le RFC 2047). Les deux dernières parties
ont un Content-Translation-Type:.
Actuellement, il ne semble pas qu'il existe de
MUA qui gère cette nouvelle norme. Si vous
voulez envoyer des messages à ce format, vous pouvez copier/coller
l'exemple ci-dessus, ou bien utiliser le programme Python send-multilingual.py.
Voici le message d'exemple cité plus haut affiché par
mutt (version NeoMutt 20170113 (1.7.2)) :

Thunderbird affiche à peu près la même chose.
Gmail a stupidement décidé de mettre ce
message dans le dossier Spam. Une fois le
message sorti de ce purgatoire, voici ce que ça donnait : 
Notez l'existence d'une FAQ sur ce format.
Une mise en œuvre dans
mutt a été faite au hackathon
de la réunion IETF 101 par Alexandre Simon. Elle a été soumise en tant que pull
request à mutt. Outre ce travail sur un
MUA, le même auteur a écrit un réflecteur de
courrier permettant de tester ce RFC. Vous envoyez un
message ordinaire en français à
reflector+sl_fr+tl_zh@rfc8255.as-home.fr (sl
= Source Language, tl = Target
Language, ici, on dit que le message est en français, et
on veut une réponse en chinois), et il répond avec
un message conforme au RFC 8255, traduit par Google Translate. Voici par exemple une demande :
To: reflector+sl_fr+tl_zh@rfc8255.as-home.fr MIME-Version: 1.0 Content-Type: text/plain; charset=utf-8 Content-Disposition: inline Content-Transfer-Encoding: 8bit User-Agent: NeoMutt/20170113 (1.7.2) Subject: Test je parle la France From: Stephane Bortzmeyer <stephane@bortzmeyer.org> Alors, ça donne quoi ? Surtout s'il y a plusieurs lignes.
Et sa réponse :
Content-Type: multipart/multilingual;
boundary="----------=_1521485603-32194-0"
Content-Transfer-Encoding: binary
MIME-Version: 1.0
To: Stephane Bortzmeyer <stephane@bortzmeyer.org>
Sender: <reflector@idummy.as-home.fr>
Subject: Test je parle la France
From: Stephane Bortzmeyer <stephane@bortzmeyer.org>
This is a multi-part message in MIME format...
------------=_1521485603-32194-0
Content-Type: text/plain; charset=utf-8
Content-Disposition: inline
Content-Transfer-Encoding: binary
Alors, ça donne quoi ?
Surtout s'il y a plusieurs lignes.
------------=_1521485603-32194-0
Content-Type: message/rfc822
Content-Disposition: inline
Content-Transfer-Encoding: binary
Content-Language: fr
Content-Translation-Type: original
Content-Type: text/plain; charset=utf-8
From: Stephane Bortzmeyer <stephane@bortzmeyer.org>
Subject: Test je parle la France
Alors, ça donne quoi ?
Surtout s'il y a plusieurs lignes.
------------=_1521485603-32194-0
Content-Type: message/rfc822
Content-Disposition: inline
Content-Transfer-Encoding: binary
Content-Language: zh
Content-Translation-Type: automated
Content-Type: text/plain; charset=utf-8
From: Stephane Bortzmeyer <stephane@bortzmeyer.org>
Subject: =?UTF-8?B?5rWL6K+V5oiR6K6y5rOV5Zu9?=
那么,这给了什么?
特别是如果有几条线。
------------=_1521485603-32194-0
Content-Type: message/rfc822
Content-Disposition: inline
Content-Transfer-Encoding: binary
Content-Language: zxx
Content-Translation-Type: human
Content-Type: text/plain; charset=utf-8
/////|
///// |
///// |
|~~~| M |
|===| U |
| | L |
| R | T |
| F | I |
| C | L |
| 8 | I |
| 2 | N |
| 5 | G |
| 5 | U |
| | A |
| | L |
| | |
| | /
| | /
|===|/
'---'
------------=_1521485603-32194-0--
On notera la dernière partie, qui utilise la langue
zxx, code qui veut dire « non spécifiée », et
qui sert à mettre du texte qui sera affiché dans tous les
cas. Notez aussi que le message originel est inclus.
Ce message est ainsi affiché par un mutt actuel :

Et par le mutt patché pendant le hackathon :

L'article seul
RFC 8254: Uniform Resource Name (URN) Namespace Registration Transition
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : J. Klensin, J. Hakala (The National Library of Finland)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF urnbis
Première rédaction de cet article le 21 octobre 2017
Pour avoir un espace de noms d'URN, autrefois, il fallait un examen par l'IETF, ce qui était un peu contraignant (et risquait de mener au « squat », avec des gens utilisant un espace de noms qu'ils ne se sont pas donné la peine d'enregistrer). Le RFC 8141 ayant changé cette politique d'enregistrement pour celle, plus facile, d'examen par un expert, il a fallu clarifier quelques processus, ce que fait ce RFC. Dans la foulée, ce RFC change le statut de quelques RFC précédents, qui avaient servi de base à l'enregistrement de certains espaces de noms. Bref, que de la procédure et de la bureaucratie (mais pas inutile).
Un des buts des URN (désormais normalisés dans le RFC 8141) était d'intégrer des systèmes d'identificateurs existants. C'est ainsi que le RFC 2288 avait décrit un espace de noms pour les ISBN, mais sans l'enregistrer formellement à l'IANA, en partie parce que le mécanisme d'enregistrement n'était pas clair à l'époque. Par la suite, le RFC 3187 a remplacé le RFC 2288 et comblé ce manque (dans sa section 5). Idem pour les ISSN dans le RFC 3044. Ces deux RFC 3187 et RFC 3044 sont reclassés comme étant désormais d'intérêt historique uniquement (section 2 de notre RFC), les enregistrements de ces espaces de noms ayant été refaits selon les nouvelles règles (section 5). Voyez le nouvel enregistrement d'isbn et celui d'issn.
Pour ISBN, le principal changement est que l'espace de noms URN fait désormais référence à la nouvelle version de la norme, ISO 2108:2017 (cf. la page officielle et, comme toutes les normes du dinosaure ISO, elle n'est pas disponible en ligne.) Elle permet les ISBN de treize caractères (les ISBN avaient dix caractères au début). Pour ISSN, la norme du nouvel enregistrement est ISO 3297:2007, qui permet notamment à un ISSN de référencer tous les médias dans lesquels a été fait une publication (il fallait un ISSN par média, avant).
Et les NBN (National
Bibliography Number, section 3) ? C'est un cas rigolo,
car NBN ne désigne pas une norme spécifique, ni même une famille
d'identificateurs, mais regroupe tous les mécanismes
d'identificateurs utilisés par les bibliothèques nationales
partout dans le monde. En effet, les bibibliothèques peuvent
recevoir des documents qui n'ont pas d'autre identificateur. Si la
bibliothèque nationale de Finlande reçoit
un tel document, son identificateur national pourrait être,
mettons, fe19981001, et, grâce à l'espace de
noms URN nbn, il aura un URN,
urn:nbn:fi-fe19981001.
Les NBN sont spécifiés dans le RFC 3188, pour lequel il n'y a pas encore de mise à jour prévue, contrairement aux ISBN et ISSN.
Outre les NBN, il y a bien d'autres schémas d'URN qui mériteraient une mise à jour, compte-tenu des changements du RFC 8141 (section 4). Mais il n'y a pas le feu, même si leur enregistrement actuel à l'IANA n'est pas tout à fait conforme au RFC 8141. On peut continuer à les utiliser.
L'article seul
RFC 8251: Updates to the Opus Audio Codec
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : JM. Valin (Mozilla
Corporation), K. Vos (vocTone)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF codec
Première rédaction de cet article le 22 octobre 2017
Le codec Opus, normalisé dans le RFC 6716 a une particularité rare à l'IETF : il est spécifié par un programme, pas par une description écrite en langue naturelle. Les programmes ont des bogues et ce nouveau RFC corrige quelques petites bogues pas graves trouvées dans le RFC 6716.
C'est un vieux débat dans le monde de la normalisation : faut-il décrire un protocole ou un format par une description en langue naturelle (vecteur souvent ambigu) ou par une mise en œuvre dans un langage de programmation (qui fournira directement un programme utilisable), dans laquelle il sera difficile de distinguer ce qui est réellement obligatoire et ce qui n'est qu'un détail de cette mise en œuvre particulière ? Presque tout le temps, à l'IETF, c'est la voie de la description en anglais qui est choisie. Mais le RFC 6716, qui normalisait Opus, avait choisi une autre voie, celle du code source, écrit en C. C'est ce code qui est la loi.
Dans les deux cas, en anglais ou en C, les humains qui rédigent les normes font des erreurs. D'où ce RFC de correction, qui répare le RFC 6716 sur des points mineurs (la compatibilité est maintenue, il ne s'agit pas d'une nouvelle version d'Opus).
Chaque section du RFC est ensuite consacrée à une des erreurs. La section 3, par exemple, corrige un simple oubli dans le code de réinitialiser l'état du décodeur lors d'un changement. Le patch ne fait que deux lignes. Notez qu'il change le résultat produit par le décodeur, mais suffisamment peu pour que les vecteurs de test de l'annexe A.4 du RFC 6716 soient inchangés.
L'erreur en section 9 est également une erreur de logique dans la programmation. Sa correction, par contre, nécessite de changer les vecteurs de tests (cf. section 11).
Le reste des bogues, en revanche, consiste en erreurs de programmation
C banales. Ainsi, en section 4, il y a un
débordement d'entier si les données font
plus de 2^31-1 octets, pouvant mener à lire en dehors de la mémoire. En
théorie, cela peut planter le décodeur (mais, en pratique, le
code existant n'a pas planté.) Notez que cela ne peut pas arriver
si on utilise Opus dans RTP, dont les
limites seraient rencontrées avant qu'Opus ne reçoive ces données
anormales. Cette bogue peut quand même avoir des conséquences de
sécurité et c'est pour cela qu'elle a reçu un
CVE, CVE-2013-0899. Le
patch est très court. (Petit
rappel de C : la norme de ce
langage ne spécifie pas ce qu'il faut faire lorsqu'on
incrémente un entier qui a la taille maximale. Le résultat dépend
donc de l'implémentation. Pour un entier
signé, comme le type
int, le comportement le plus courant est de
passer à des valeurs négatives.)
Notez qu'une autre bogue, celle de la section 7, a eu un CVE, CVE-2017-0381.
En section 5, c'est un problème de typage : un entier de 32 bits utilisé au lieu d'un de 16 bits, ce qui pouvait mener une copie de données à écraser partiellement les données originales.
Dans la section 6 du RFC, la bogue était encore une valeur trop grande pour un entier. Cette bogue a été découverte par fuzzing, une technique très efficace pour un programme traitant des données externes venues de sources qu'on ne contrôle pas !
Bref, pas de surprise : programmer en C est difficile, car de trop bas niveau, et de nombreux pièges guettent le programmeur.
La section 11 du RFC décrit les nouveaux vecteurs de test rendus nécessaires par les corrections à ces bogues. Ils sont téléchargeables.
Une version à jour du décodeur normatif figure désormais sur le site officiel. Le patch traitant les problèmes décrits dans ce RFC est en ligne. Ce patch global est de petite taille (244 lignes, moins de dix kilo-octets, ce qui ne veut pas dire que les bogues n'étaient pas sérieuses).
L'article seul
RFC 8248: Security Automation and Continuous Monitoring (SACM) Requirements
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : N. Cam-Winget (Cisco), L. Lorenzin (Pulse Secure)
Pour information
Réalisé dans le cadre du groupe de travail IETF sacm
Première rédaction de cet article le 25 septembre 2017
Le groupe de travail SACM de l'IETF bosse sur une architecture, un modèle de données, et des protocoles pour suivre l'état de la sécurité de ses machines. Ceci est son deuxième RFC, qui vise à définir le cahier des charges de la future solution.
Le cœur de cette idée est l'évaluation de la sécurité sur chaque machine du réseau. Il faut la déterminer, et acheminer le résultat jusqu'aux responsables de la sécurité. Cela nécessite donc un modèle de données (comment on décrit « la sécurité d'une machine » ?) puis un protocole permettant de gérer un très grand nombre de machines. Parmi les informations à récolter sur chaque machine, on trouvera évidemment la liste des logiciels installés, les logiciels serveurs en activité qui écoutent sur le réseau, l'état de la mise à jour (« pas pu joindre le dépôt officiel de logiciels depuis N jours »), etc. Le cahier des charges décrit dans ce RFC part des scénarios d'usage du RFC 7632. Ce sont souvent de grandes généralités. On est loin de mécanismes concrets.
La section 2 forme l'essentiel de ce RFC, avec la liste des exigences du cahier des charges. Je ne vais en citer que quelques unes. La première, nommée G-001 (« G » préfixe les exigences générales sur l'ensemble du système SACM), demande que toute la solution SACM soit extensible, pour les futurs besoins. G-003 est la possibilité de passage à l'échelle. Par exemple, les messages échangés peuvent aller de quelques lignes à, peut-être plusieurs gigaoctets si on fait une analyse détaillée d'une machine. Et il peut y avoir beaucoup de machine avec des échanges fréquents (le RFC n'est pas plus précis sur les chiffres).
Les données traitées sont évidemment sensibles, et G-006 demande que la solution permette évidemment de préserver la confidentialité des données.
Les exigences sur l'architecture de la future solution sont préfixées de « ARCH ». Ainsi, ARCH-009 insiste sur l'importance d'une bonne synchronisation temporelle de toutes les machines. Un journal des connexions/déconnexions des utilisateurs, par exemple, n'aurait guère d'intérêt si l'horloge qui sert à l'estampiller n'est pas exacte.
D'autres sections décrivent les exigences pour le modèle de données et pour les protocoles, je vous laisse les découvrir.
L'article seul
RFC 8246: HTTP Immutable Responses
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : P. McManus (Mozilla)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 16 septembre 2017
Lorsqu'un serveur HTTP renvoie une
réponse à un client, il peut indiquer une durée de vie maximale de
la ressource transmise, avec l'en-tête
Cache-Control: (RFC 9111). Mais cela ne donne qu'une durée
maximale. La ressource peut quand même être
modifiée avant la fin de cette période. Un client HTTP prudent va
donc revalider la fraîcheur de cette
ressource de temps en temps. L'extension décrite dans ce
RFC permet de se dispenser de cette
revalidation, en indiquant une durée
minimale, pendant laquelle on est sûrs et
certains que la ressource ne sera pas modifiée.
Le RFC prend l'exemple (section 1) d'un journal dont la page d'accueil indique une durée de vie maximale d'une heure :
Cache-Control: max-age=3600
Le client HTTP qui reçoit cet en-tête dans la réponse sait qu'il doit recontacter le serveur au bout d'une heure. Mais la page sera peut-être modifiée (par exemple en raison d'un évènement soudain et imprévu) avant qu'une heure soit écoulée. Le client est donc partagé entre la revalidation (qui risque de consommer des ressources pour rien, même si elle est moins coûteuse qu'un téléchargement complet, grâce aux trucs du RFC 7232) et le risque de servir à son utilisateur une ressource qui n'est désormais plus à jour. Le problème est d'autant plus ennuyeux que la revalidation d'une bête page Web qui comprend des photos peut générer beaucoup de requêtes, dont la plupart produiront sans doute un 304 (ressource non modifiée, la revalidation était inutile).
Notez que dans certains cas, le contenu pointé par un URL peut changer, mais dans d'autres cas, il est réellement immuable. Par exemple, si on publie chaque version de sa feuille de style sous un URL différent, la CSS n'a pas besoin d'être revalidée. (La mention d'immuabilité est donc intéressante pour les URL faits à partir du RFC 6920.)
Bref, il y avait un besoin de pouvoir indiquer l'immuabilité
d'une ressource. C'est désormais fait (section 2 de ce RFC) avec
une extension à Cache-Control: :
Cache-Control: max-age=3600, immutable
Avec le mot-clé immutable, le serveur indique
que la ressource ne sera pas modifiée pendant la durée de vie
indiquée, le client peut donc se dispenser de
vérifier. (« Client » ici désignant aussi bien le client final,
par exemple le navigateur Web, qu'un
intermédiaire.)
Par exemple, comme les RFC sont immuables (on ne les change
jamais même d'une virgule, même en cas d'erreur), la ressource qui désigne ce RFC,
https://www.rfc-editor.org/rfc/rfc8246.txt,
pourrait parfaitement renvoyer cet en-tête (elle ne le fait
pas). Cela pourrait être :
Last-Modified: Thu, 14 Sep 2017 23:11:35 GMT
Cache-Control: max-age=315576000, immutable
(Oui, dix ans…)
Voilà, c'est tout, la directive a été ajoutée au registre
IANA. Mais la section 3 du RFC se penche encore
sur quelques questions de sécurité. Indiquer qu'une ressource est
immuable revient à la fixer pour un temps potentiellement très
long, et cela peut donc servir à pérenniser une attaque. Si un
méchant pirate un site Web, et sert son contenu piraté avec un
en-tête d'immuabilité, il restera bien plus longtemps dans les
caches. Pire, sans
HTTPS, l'en-tête avec
immutable pourrait être ajouté par un
intermédiaire (le RFC déconseille donc de tenir compte de cette
option si on n'a pas utilisé HTTPS).
Les navigateurs Web ont souvent deux options pour recharger une
page, « douce » et « dure » (F5 et Contrôle-F5 dans
Firefox sur Unix). Le RFC conseille que, dans le second cas
(rechargement forcé), le immutable soit ignoré (afin de
pouvoir recharger une page invalide).
Enfin, toujours question sécurité, le RFC recommande aux
clients HTTP de ne tenir compte de l'en-tête d'immuabilité que
s'ils sont sûrs que la ressource a été transmise proprement
(taille correspondant à Content-Length: par
exemple).
Si vous voulez comparer deux ressources avec et sans
immutable, regardez http://www.bortzmeyer.org/files/maybemodified.txtimmutable) et http://www.bortzmeyer.org/files/forever.txt
[2001:db8:abcd:1234:acd8:9bd0:27c9:3a7f]:45452 - - [16/Sep/2017:17:53:29 +0200] "GET /files/forever.txt HTTP/1.1" 304 - "-" "Mozilla/5.0 (X11; Linux i686; rv:52.0) Gecko/20100101 Firefox/52.0" www.bortzmeyer.org
Apparemment, Firefox gère cette extension mais, ici, le Firefox était sans doute trop vieux (normalement, cela aurait dû arriver avec la version 49, puisque Mozilla était premier intéressé). Les auteurs de Squid ont annoncé qu'ils géreraient cette extension. Côté serveur, notons que Facebook envoie déjà cette extension pour, par exemple, le code JavaScript (qui est versionné et donc jamais changé) :
% curl -v https://www.facebook.com/rsrc.php/v3iCKe4/y2/l/fr_FR/KzpL-Ycd5sN.js
* Connected to www.facebook.com (2a03:2880:f112:83:face:b00c:0:25de) port 443 (#0)
...
< HTTP/2 200
< content-type: application/x-javascript; charset=utf-8
< cache-control: public,max-age=31536000,immutable
...
Idem pour une mise en œuvre d'IPFS.
L'article seul
RFC 8244: Special-Use Domain Names Problem Statement
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : T. Lemon
(Nominum), R. Droms, W. Kumari
(Google)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 20 octobre 2017
Le RFC 6761 créait un
registre de « noms de
domaines d'usage spécial », où l'IETF
enregistrait des noms qui pouvaient nécessiter un traitement
spécial par une des entités de la chaîne d'avitaillement et de
résolution des noms de domaines. Un exemple est celui des noms de
domaine qui n'utilisaient pas le DNS, comme le
.onion du RFC 7686. Certaines personnes ont émis des
réserves sur ce registre, par exemple parce qu'il marchait sur une
pelouse que l'ICANN considère comme sienne. Ce
nouveau RFC,
très controversé, fait la liste de tous les reproches qui ont été
faits au RFC 6761 et à son registre des noms
spéciaux.
La résolution de noms - partir d'un nom de domaine et obtenir des informations
comme l'adresse IP - est une des fonctions
cruciales de l'Internet. Il est donc normal
de la prendre très au sérieux. Et les noms ont une valeur pour les
utilisateurs (la vente record semble être celle de
business.com). Souvent, mais pas
toujours, cette résolution se fait avec le
DNS. Mais, je l'ai dit, pas toujours : il
ne faut pas confondre les noms de domaines (une organisation
arborescente, une syntaxe, les composants séparés par des
points, par exemple
_443._tcp.www.bortzmeyer.org.,
réussir-en.fr. ou
sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion.) et le DNS, un
protocole réseau particulier (section 2 du RFC, pour la
terminologie). La section 2 de ce RFC, suivant la définition du
RFC 8499, ne considère pas qu'un nom de
domaine utilise forcément le DNS. (Le problème n° 20, en section 3 revient sur
cette question.)
Le registre
des noms de domaines spéciaux a été créé en 2013 par le
RFC 6761. Contrairement à ce que croient
beaucoup de gens, il ne contient pas que des TLD (par exemple, il
a aussi a.e.f.ip6.arpa ou bien
example.org). Depuis sa création, plusieurs
noms ont été ajoutés, le plus spectaculaire ayant été le
.onion en 2015, via le
RFC 7686. Beaucoup d'autres noms ont été
proposés, sans être explicitement rejetés mais sans être acceptés
non plus (voir les
Internet-Drafts
draft-grothoff-iesg-special-use-p2p-gns
et draft-chapin-additional-reserved-tlds). Ces
enregistrements ne se sont pas très bien passés, avec beaucoup
d'engueulades, notamment pour les TLD.
En effet, la bagarre a toujours fait rage pour la gestion des noms dans la racine du DNS. Il y a cinq sortes de TLD :
- Ceux qui sont mis dans la racine publique du DNS, comme
.bo,.net,.guru, etc. Contrairement à ce que dit le RFC, ils ne sont pas forcément délégués par l'ICANN (.dea été créé bien avant l'ICANN, et.surésiste depuis longtemps à toutes les tentatives de l'ICANN de le supprimer). - Ceux gérés par l'IETF « pour des
raisons techniques », et qui sont parfois délégués dans la
racine publique, le plus connu étant
.arpa. Les domaines du registre des noms spéciaux en font partie. Les fanas de gouvernance noteront qu'ils ne passent jamais par l'ICANN. - Ceux que l'ICANN bloque, pour des raisons variées (cf. leurs règles, notamment sections 2.2.1.2.1 ou 2.2.1.4.1).
- Ceux qui sont utilisés en dehors de la racine publique du
DNS, comme
.ethpour Ethereum ou.bitpour Namecoin. Cela inclut aussi des noms très utilisés localement comme.homeou.corp. - Et ceux qui sont libres, que personne n'utilise
encore. Demain, peut-être que
.macronsera utilisé par les fans du Président ?
Cette classification est imparfaite, comme toutes les classifications. Par exemple, un nom peut être sur la liste noire de l'ICANN et être quand même utilisé par des organisations locales, ou via un logiciel particulier.
Ce RFC veut présenter une liste exhaustive des problèmes posés lors de l'enregistrement de ces noms spéciaux. Comme elle est exhaustive (« an unfiltered compilation of issues »), elle n'est pas consensuelle, loin de là ! Plusieurs des problèmes ne sont pas considérés comme tels par tout le monde, ce que le RFC note bien dans les sections 1 et 3.
Le gros du RFC est donc cette liste de problèmes, en section 3. Je ne vais pas tous les citer. Notez tout de suite que ce RFC décrit des problèmes, ou perçus comme tels par certains, pas des solutions. Il ne propose pas de réforme du RFC 6761. Notez aussi que les problèmes ne sont pas classés (leur ordre d'exposition, et le numéro qu'ils reçoivent, n'est pas un ordre d'importance.)
Premier problème cité, la coordination avec
l'ICANN. Les cinq catégories de noms de
TLD cités
plus haut coexistent dans le même espace de noms. S'il y a deux
.macron, il y aura un problème (voir par
exemple le
rapport SAC 090, mais en se rappelant que c'est l'ICANN qui
s'auto-défend). L'IETF et
l'ICANN ont un mécanisme d'information
réciproque mais pas de processus bureaucratique formel de
coordination. Si l'IETF veut réserver .home
(RFC 7788), il n'y a officiellement pas de
mécanisme pour communiquer cette décision à l'ICANN et obtenir
d'elle la confirmation que ce nom n'est pas par ailleurs en cours
de réservation. (Cf. 4.1.4 qui revient sur ce mécanisme
- « liaison » en anglais.)
(Personnellement, cet argument me fait plutôt rire : beaucoup de gens sont actifs à la fois à l'IETF et à l'ICANN, les deux organisations opèrent de manière assez publique, surtout l'IETF, et la possibilité qu'elles réservent chacune un nom sans savoir ce qu'a fait l'autre est purement théorique.)
Le problème 2 est celui de la définition de « pour des raisons techniques », introduit dans le RFC 2860, et qui fonde le droit de l'IETF à réserver des TLD sans passer par la caisse de l'ICANN (« assignments of domain names for technical uses [...] are not considered to be policy issues, and shall remain subject to the provisions of this Section 4 »). Le problème est que ces raisons techniques ne sont définies nulle part et que personne ne sait trop ce que cela veut dire.
Les problèmes 3 et 4 sont qu'il n'y a pas de Directeur Chef de
l'Internet. Ni l'ICANN, ni l'IETF (ni évidemment
l'UIT) ne sont reconnus, ni en droit, ni en
fait, comme ayant une autorité quelconque (le raccourci
journalistique de présenter l'ICANN comme « le régulateur mondial
de l'Internet » est ridiculement faux). Imaginons qu'une
développeuse crée un nouveau logiciel qui utilise le TLD
.zigzag pour son nommage, et diffuse le
logiciel en question : personne ne peut l'en empêcher, même si
l'ICANN souffre de la perte de revenus potentiels, même si des
grognons à l'IETF murmurent bruyamment que c'est du
squatting (voir aussi le début de la section 4). Et heureusement que c'est ainsi :
c'est le côté « innover sans autorisation »
(« permissionless innovation » qui a été si
essentiel pour le succès de l'Internet). Un autre exemple est bien sûr le
projet .42, aujourd'hui abandonné mais qui
illustrait ce côté décentralisé de l'Internet.
La définition du problème 5 note que les organisations (ou les individus) utilisent des TLD (ou des domaines quelconques, mais c'est surtout sur les TLD que se focalise la discussion) sans suivre les procédures. Elles ont plusieurs raisons pour agir ainsi :
- Elles ne savent pas qu'il existe des procédures (c'est sans doute le cas le plus fréquent).
- Elles savent vaguement qu'il existe des procédures mais
elles se disent que, pour une utilisation purement locale, ce
n'est pas important. Le trafic sur les serveurs de noms de la racine montre
au contraire que les fuites sont importantes : les noms locaux
ne le restent pas. Sans compter le risque de
« collisions » entre un nom supposé purement
local et une allocation par l'ICANN :
.corpet.homesont des TLD locaux très populaires et il y a des candidatures (actuellement gelées de facto) pour ces TLD à l'ICANN - Les procédures existent, l'organisation les connait, mais ce n'est pas ouvert. C'est par exemple le cas des TLD ICANN, pour lesquels il n'y a actuellement pas de cycle de candidature, et on n'espère pas le prochain avant 2019 ou 2020.
- Les procédures existent à l'ICANN, l'organisation les connait, c'est ouvert, mais le prix fait reculer (185 000 $ US au précédent cycle ICANN, et uniquement pour déposer le dossier).
- Les procédures existent à l'IETF, l'organisation les connait, c'est ouvert, mais l'organisation refuse délibérement de participer (cas analogue à CARP).
- Les procédures existent, l'organisation les connait, c'est ouvert, mais l'organisation estime, à tort ou à raison, que sa candidature sera refusée (c'est actuellement le cas à l'IETF).
Ensuite, le problème 6 : il y a plusieurs protocoles de résolution de
nom, le DNS n'étant que le principal. En l'absence de
métadonnées indiquant le protocole à
utiliser (par exemple dans les URL),
se servir du TLD comme « aiguillage » est une solution
tentante (if tld == "onion" then use Tor elsif tld ==
"gnu" then use GnuNet else use DNS…)
Le registre des noms de domaines spéciaux est essentiellement
en texte libre, sans grammaire formelle. Cela veut dire que le
code spécifique qui peut être nécessaire pour traiter tous ces
domaines spéciaux (un résolveur doit, par exemple, savoir que
.onion n'utilise pas
le DNS et qu'il ne sert donc à rien de l'envoyer à la racine) doit
être fait à la main, il ne peut pas être automatiquement dérivé du
registre (problème 7). Résultat, quand un nouveau domaine est
ajouté à ce registre, il sera traité « normalement » par les
logiciels pas mis à jour, et pendant un temps assez long. Par
exemple, les requêtes seront envoyées à la racine, ce qui pose des
problèmes de vie privée (cf. RFC 7626).
Comme noté plus haut, certains candidats à un nom de domaine
spécial sont inquiets du temps que prendra l'examen de leur
candidature, et du risque de rejet (problème 8). Ils n'ont pas
tort. L'enregistrement du
.local (RFC 6762) a pris dix ans, et les efforts de Christian Grothoff
pour enregistrer .gnu se sont enlisés dans
d'épaisses couches de bureaucratie. Ce n'est peut-être pas un
hasard si Apple a fini par avoir son
.local (non sans mal) alors que des projets
de logiciel libre
comme GNUnet se sont vu fermer la porte au
nez.
C'est que l'IETF n'est pas toujours facile et qu'un certain nombre de participants à cette organisation ont souvent une attitude de blocage face à tout intervenant extérieur (problème 9). Ils n'ont pas tort non plus de se méfier des systèmes non-DNS, leurs raisons sont variées :
- Absence d'indication du mécanisme de résolution donc
difficulté supplémentaire pour les logiciels (« c'est quoi,
.zkey? »). De plus, un certain nombre de participants à l'IETF estiment qu'il ne faut de toute façon qu'un seul protocole de résolution, afin de limiter la complexité. - Le problème de la complexité est d'autant plus sérieux que les autres protocoles de résolution de noms n'ont pas forcément la même sémantique que le DNS : ils sont peut-être sensibles à la casse, par exemple.
- Conviction que l'espace de nommage est « propriété » de l'IETF et/ou de l'ICANN, et que ceux qui réservent des TLD sans passer par les procédures officielles sont de vulgaires squatteurs.
- Sans compter le risque, s'il existe un moyen simple et gratuit de déposer un TLD via l'IETF, que plus personne n'alimente les caisses de l'ICANN.
- Et enfin le risque juridique : si Ser
Davos fait un procès à l'IETF contre
l'enregistrement de
.onion, cela peut durer longtemps et coûter cher. L'ICANN court le même risque mais, elle, elle a des avocats en quantité, et de l'argent pour les payer.
Le problème 11 est davantage lié au RFC 6761 lui-même. Ce RFC a parfois été compris de travers,
comme pour l'enregistrement de ipv4only.arpa
(RFC 7050, corrigé ensuite dans le RFC 8880) et surtout celui de
.home (RFC 7788, qui
citait le RFC 6761 mais n'avait tenu aucune
de ses obligations). Voir aussi le problème 16.
Les problèmes 12 et 13 concernent les TLD existants (au sens où ils sont utilisés) mais pas enregistrés officiellement (voir par exemple le rapport de l'ICANN sur les « collisions »). Cela serait bien de documenter quelque part cette utilisation, de façon à, par exemple, être sûrs qu'ils ne soient pas délégués par l'ICANN. Mais cela n'a pas marché jusqu'à présent.
Le problème 14 concerne le fait que des noms de domaine spéciaux sont parfois désignés comme spéciaux par leur écriture dans le registre, mais parfois simplement par leur délégation dans le DNS.
Le problème 15 est celui de la différence entre enregistrer un
usage et l'approuver. Avec la règle « géré par l'IETF pour un
usage technique » du RFC 2860, il n'y a pas
moyen d'enregistrer un nom sans une forme d'« approbation ». (Pas
mal d'articles sur l'enregistrement de .onion
avaient ainsi dit, à tort, que « l'IETF approuvait officiellement
Tor ».)
Le problème 17 est un bon exemple du fait que la liste
de Prévert qu'est ce RFC est en effet « non filtrée » et que
toute remarque soulevée y a été mise, quels que soient ses
mérites. Il consiste à dire que l'utilisation du registre des noms
spéciaux est incohérente, car les enregistrements donnent des
règles différentes selon le nom. Cela n'a rien d'incohérent,
c'était prévu dès le départ par le RFC 6761 (section 5) :
il n'y a pas de raison de traiter de la même façon
.onion (qui n'utilise pas le DNS du tout) et
.bit (passerelle entre le DNS et
Namecoin).
Le problème 19 découle du fait que les noms de domaine ne sont
pas de purs identificateurs techniques comme le sont, par exemple,
les adresses MAC. Ils
ont un sens pour les utilisateurs. Bien que, techniquement
parlant, les développeurs de Tor auraient
pu choisir le nom .04aab3642f5 ou onion.torproject.org
comme suffixe pour les services en oignon,
ils ont préféré un nom d'un seul composant, et compréhensible,
.onion. Ce désir
est bien compréhensible (une
proposition à l'IETF est de reléguer tous les noms spéciaux sous
un futur TLD .alt, qui ne connaitra
probablement aucun succès même s'il est créé un jour). Mais il
entraine une pression accrue sur la racine des noms de domaine :
si deux projets réservent .zigzag, lequel des
deux usages faut-il enregistrer ?
Enfin, le dernier problème, le 21, est davantage technique : il
concerne DNSSEC. Si un TLD est enregistré
comme domaine spécial, faut-il l'ajouter dans la racine du DNS et,
si oui, faut-il que cette délégation soit signée ou pas ? S'il n'y
a pas de délégation, le TLD sera considéré comme invalide par les
résolveurs validants. Par exemple, si je fais une requête pour
quelquechose.zigzag, la racine du DNS va
répondre :
% dig @k.root-servers.net A quelquechose.zigzag
; <<>> DiG 9.10.3-P4-Debian <<>> @k.root-servers.net A quelquechose.zigzag
; (2 servers found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 7785
;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;quelquechose.zigzag. IN A
;; AUTHORITY SECTION:
zero. 86400 IN NSEC zip. NS DS RRSIG NSEC
zero. 86400 IN RRSIG NSEC 8 1 86400 (
20171017050000 20171004040000 46809 .
wyKfrNEygGCbDscCu6uV/DFofs5DKYiV+jJd2s4xkkAT
...
. 86400 IN NSEC aaa. NS SOA RRSIG NSEC DNSKEY
. 86400 IN RRSIG NSEC 8 0 86400 (
20171017050000 20171004040000 46809 .
kgvHoclQNwmDKfgy4b96IgoOkdkyRWyXYwohW+mpfG+R
...
. 86400 IN SOA a.root-servers.net. nstld.verisign-grs.com. (
2017100400 ; serial
1800 ; refresh (30 minutes)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
. 86400 IN RRSIG SOA 8 0 86400 (
20171017050000 20171004040000 46809 .
GnTMS7cx+XB+EmbMFWt+yEAg29w17HJfUaOqvPsTn0eJ
...
;; Query time: 44 msec
;; SERVER: 2001:7fd::1#53(2001:7fd::1)
;; WHEN: Wed Oct 04 12:58:12 CEST 2017
;; MSG SIZE rcvd: 1036
Et l'enregistrement NSEC prouvera qu'il n'y a
rien entre .zero et
.zip, amenant le résolveur validant à
considérer que .zigzag ne peut pas
exister. Si le nom devait être traité par le DNS (et, par exemple,
résolu localement comme ceux du RFC 6303,
c'est une réponse correcte : la requête n'aurait pas dû aller à la
racine). Dans d'autres cas, cela peut être gênant. De toute façon,
le débat est assez théorique : l'IETF n'a aucun pouvoir sur la
racine du DNS, et aucun moyen d'y ajouter un nom.
Après cet examen des possibles et potentiels problèmes, la section 4 du RFC examine les pratiques existantes. Plusieurs documents plus ou moins officiels examinent déjà ces questions. Mais je vous préviens tout de suite : aucun ne répond complètement au·x problème·s.
Commençons par le RFC 2826 sur la
nécessité d'une racine unique. C'est un document
IAB et qui n'engage donc pas l'IETF, même
s'il est souvent cité comme texte sacré. Sa thèse principale est
qu'il faut une racine unique, et que .zigzag,
.pm ou
.example
doivent donc avoir la même signification partout, sous peine de
confusion importante chez l'utilisateur. Cela n'interdit pas des
noms à usage local à condition que cela reste bien local. Comme
les utilisateurs ne vont pas faire la différence, ces noms locaux
vont forcément fuiter tôt ou tard. (Par exemple, un utilisateur
qui regarde http://something.corp/ ne va pas
réaliser que ce nom ne marche qu'en utilisant les résolveurs de
l'entreprise, et va essayer d'y accéder depuis chez lui. Un autre
exemple serait celui d'un utilisateur qui essaierait de taper
ping sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion depuis la ligne
de commande, sans se rendre compte que ping
ne connait pas Tor.)
Bref, le RFC 2826 dit clairement qu'une racine unique est nécessaire, et que les noms locaux sont casse-gueule.
Le second RFC à lire est évidemment le RFC 6761, qui a créé le registre des noms de domaine spéciaux. Lui, c'est un document IETF sur le Chemin des Normes. Quelques points qui sont souvent oubliés par les lecteurs du RFC 6761 méritent d'être répétés :
- Certains noms spéciaux ne le sont en fait pas tellement,
et sont résolus par le DNS de la manière habituelle (c'est le
cas de
in-addr.arpa, par exemple, et rappelez-vous bien à son sujet que les noms de domaine spéciaux ne sont pas forcément des TLD). - Parfois, les noms spéciaux sont résolus par le DNS mais de
manière inhabituelle, comme
10.in-addr.arpa(pour les adresses IP du RFC 1918), qui doit être traité par le résolveur, sans jamais interroger la racine (cf. RFC 6303). - D'autres noms spéciaux sont gravement spéciaux et ne
doivent pas utiliser le DNS du tout. Ils servent de
« commutateurs » pour indiquer à la bibliothèque de résolution
de noms (la GNU libc
sur Ubuntu ou Mint par exemple) qu'il faut changer de
protocole. C'est le cas de
.onion(qui doit utiliser Tor) ou de.local(qui doit utiliser mDNS, RFC 6762). - Et tous ces cas sont valides et normaux (même si certains traditionnalistes à l'IETF rechignent devant le dernier).
Notez qu'à l'heure actuelle, tous les noms enregistrés comme noms de domaine spéciaux sont des TLD ou bien sont résolus avec le DNS.
Troisième RFC à lire absolument avant de dire des bêtises sur les noms de domaine spéciaux, le RFC 2860, qui fixe le cadre des relations compliquées entre l'IETF et l'ICANN. En gros, la règle par défaut est que l'ajout (ou le retrait) de TLD dans la racine est une prérogative de l'ICANN sauf les « noms de domaine à usage technique » (notion non définie…) où l'IETF décide. Notez que ce document concerne uniquement les relations entre l'IETF et l'ICANN. Si le W3C, ou la développeuse du logiciel ZigZag, veut créer un TLD, que se passe-t-il ? Ce point n'est pas traité dans le RFC 2860. Certains exégètes estiment que cela veut dire que ces tiers sont implicitement exclus.
Il y a aussi d'autres documents mais moins cruciaux. Le RFC 6762 qui normalise mDNS est celui qui a
réservé .local et c'est donc un
exemple d'un enregistrement réussi (mais qui fut laborieux, plus
de douze années de développement furent nécessaires, cf. l'annexe
H du RFC 6762).
Autre exemple réussi, le RFC 7686 sur le
.onion. .onion était
utilisé depuis longtemps quand le RFC 6761 a
créé le registre des noms de domaine spéciaux. L'enregistrement
a
posteriori a réussi, malgré de
vigoureuses oppositions mais il faut noter que le consensus
approximatif de l'IETF a été facilité par une décision du
CA/B Forum de ne plus allouer
de certificats pour des TLD internes.
Encore un autre RFC à lire, le RFC 6303,
qui décrit les noms qui devraient idéalement être résolus
localement, c'est-à-dire par le résolveur de l'utilisateur, sans
demander aux serveurs faisant autorité. C'est par exemple le cas
des in-addr.arpa
correspondant aux adresses IPv4 privées du RFC 1918. Il ne sert à rien de demander à la racine
l'enregistrement PTR de
3.2.1.10.in-addr.arpa : ces adresses IP étant
purement locales, il ne peut pas y avoir de réponse intelligente
de la racine. Les noms en 10.in-addr.arpa
doivent donc être résolus localement, et sont donc, eux aussi, des
« noms de domaine spéciaux ». Par contre, contrairement à
.local ou à .onion, ils
sont résolus par le DNS.
Pas fatigué·e·s ? Encore envie de lire ? Il y aussi l'étude
d'Interisle sur les « collisions ». Derrière ce nom
sensationnaliste conçu pour faire peur, il y a un vrai problème,
le risque qu'un TLD récent masque, ou soit masqué par, un TLD
alloué localement sans réfléchir (comme .dev). L'étude
montrait par exemple que .home était celui
posant le plus de risques.
Sur un sujet proche, il y a aussi une étude du SSAC, un comité ICANN.
On a dit plus haut que les noms de domaine « spéciaux »
n'étaient pas forcément des TLD. C'est par exemple le cas d'un nom
utilisé pour certaines manipulations IPv6,
ipv4only.arpa, créé par le RFC 7050, mais qui, par suite d'un cafouillage dans le
processus, n'avait pas été ajouté immédiatement au registre des noms de domaine
spéciaux. Dommage : ce nom, n'étant pas un TLD et n'ayant pas de
valeur particulière, n'avait pas posé de problème et avait été
accepté rapidement.
Enfin, un dernier échec qu'il peut être utile de regarder, est
la tentative d'enregistrer comme noms de domaine spéciaux des TLD
très souvent alloués localement, et qu'il serait prudent de ne pas
déléguer dans la racine, comme le .home cité
plus haut. Un projet
avait été rédigé en ce sens, mais n'avait jamais abouti,
enlisé dans les sables procéduraux.
Si vous n'avez pas mal à la tête à ce stade, vous pouvez encore
lire la section 5, qui rappelle l'histoire tourmentée de ce
concept de noms de domaine spéciaux. Lorsque le DNS a été produit
(RFC 882 et RFC 883)
pour remplacer l'ancien système HOSTS.TXT
(RFC 608), la transition ne s'est pas faite sans
douleur, car plusieurs systèmes de résolution coexistaient (le
plus sérieux étant sans doute les Yellow
Pages sur Unix, mais il y avait aussi
NetBIOS name
service/WINS, qui ne tournait pas que sur
Windows). Encore aujourd'hui, des anciens
systèmes de résolution fonctionnent toujours. Le
HOSTS.TXT survit sous la forme du
/etc/hosts d'Unix (et de son équivalent
Windows). Les systèmes d'exploitation ont en général
un « commutateur » qui permet d'indiquer quel mécanisme de
résolution utiliser pour quel nom. Voici un exemple d'un
/etc/nsswitch.conf sur une machine
Debian qui, pour résoudre un nom de
domaine, va utiliser successivement
/etc/hosts, LDAP, puis
le DNS :
hosts: files ldap dns
Le concept de TLD privé, connu uniquement en local, a été (bien à tort) recommandé par certaines entreprises comme Sun ou Microsoft. Il a survécu à la disparition des technologies qui l'utilisaient, comme Yellow Pages. Aujourd'hui, c'est une source d'ennuis sans fin, et bien des administrateurs réseau ont maudit leur prédécesseur pour avoir configuré ainsi tout le réseau local, allumant ainsi une bombe qui allait exploser quand le TLD « privé » s'est retrouvé délégué.
La discussion à l'IETF, notamment dans son groupe de travail
DNSOP a été très chaude. Un premier document avait été
élaboré, draft-adpkja-dnsop-special-names-problem,
puis l'ancêtre de ce RFC avait été écrit, le premier document
étant abandonné (il était très proche du point de vue de
l'ICANN comme quoi seule l'ICANN devrait
pouvoir créer des TLD, les autres acteurs n'étant que de vilains
squatteurs).
L'article seul
RFC 8240: Report from the Internet of Things (IoT) Software Update (IoTSU) Workshop 2016
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : H. Tschofenig (ARM Limited), S. Farrell (Trinity College Dublin)
Pour information
Première rédaction de cet article le 12 septembre 2017
La mode des objets connectés a mené à l'existence de nombreux « objets », qui sont en fait des ordinateurs (avec leurs problèmes, comme le fait que leur logiciel ait des failles de sécurité), mais qui ne sont pas considérés comme des ordinateurs par leurs propriétaires, et ne sont donc pas gérés (pas d'administrateur système, pas de mises à jour des logiciels). L'attaque contre Dyn du 21 octobre 2016, apparemment menée par ces objets, a bien illustré le risque que cette profusion irresponsable crée. Ce nouveau RFC est le compte-rendu d'un atelier sur la mise à jour des objets connectés, atelier de réflexion qui s'est tenu à Dublin les 13 et 14 juin 2016. Il fait le point sur la (difficile) question.
La question de base était « que peut-on faire pour que ces foutus objets soient mis à jour, au moins pour patcher leurs failles de sécurité ? » L'atelier réuni à Trinity College n'a évidemment pas fourni une réponse parfaite, mais a au moins permis de clarifier le problème. Il me semble toutefois, d'après le compte-rendu, qu'il y avait un gros manque : les droits du propriétaire de l'objet. La plupart des solutions discutées tournaient autour de l'idée de mises à jour systématiques et automatiques du logiciel via les serveurs du vendeur, et les éventuelles conséquences néfastes pour le propriétaire (comme l'arrivée de nouvelles fonctions de surveillance, par exemple) ne sont guère mentionnées.
Aujourd'hui, un grand nombre des machines ayant accès, même indirect, à l'Internet, est composé de trucs qualifiés d'objets, qui ont en commun qu'on ne les appelle pas « ordinateurs » (alors que c'est bien cela qu'ils sont). Ces objets sont très divers, allant d'engins qui ont les capacités matérielles d'un ordinateur (une télévision connectée, par exemple) à des petits machins très contraints (CPU et mémoire limités, batterie à la capacité finie, etc). Le risque que font peser ces objets « irresponsables » (pas gérés, pas supervisés) sur l'Internet est connu depuis longtemps. Le RFC cite l'article de Schneier, « The Internet of Things Is Wildly Insecure And Often Unpatchable », qui tirait la sonnette d'alarme en 2014. Il notait que le logiciel de ces objets n'était déjà plus à jour quand l'objet était sorti de sa boite la première fois (les fabricants d'objets connectés aiment bien utiliser des versions antédiluviennes des bibliothèques). Or, des objets peuvent rester branchés et actifs pendant des années, avec leur logiciel dépassé et jamais mis à jour, plein de failles de sécurité que les craqueurs ne vont pas manquer d'exploiter (cf. le logiciel Mirai).
Vers la même époque, un rapport de la FTC, « FTC Report on Internet of Things Urges Companies to Adopt Best Practices to Address Consumer Privacy and Security Risks », et un autre du groupe Article 29, « Opinion 8/2014 on the on Recent Developments on the Internet of Things » faisaient les mêmes remarques.
Donc, le problème est connu depuis des années. Mais il n'est pas facile à résoudre :
- Le mécanisme de mise à jour peut lui-même être une faille de sécurité. Par exemple, un certain nombre d'objets font la mise à jour de leur logiciel en HTTP, sans signature sur le code récupéré, rendant ainsi une attaque de l'homme du milieu triviale.
- Le RFC n'en parle guère, mais, même si on vérifie le code récupéré, celui-ci peut être malveillant. De nombreuses compagnies (par exemple Sony) ont déjà délibérement distribué du malware à leurs clients, et sans conséquences pénales. Une mise à jour automatique pourrait par exemple installer une porte dérobée, ou bien mettre du code DRM nouveau.
- Les problèmes opérationnels ne manquent pas. Par exemple, si les objets vérifient le code récupéré via une signature, et qu'ils comparent à une clé publique qu'ils détiennent, que faire si la clé privée correspondante est perdue ou copiée ? (Cf. « Winks Outage Shows Us How Frustrating Smart Homes Could Be. »)
- Si les objets se connectent automatiquement au serveur pour chercher des mises à jour, cela pose un sérieux problème de vie privée. (Le RFC ne rappelle pas qu'en outre, la plupart de ces objets sont de terribles espions qu'on installe chez soi.)
- Pour une société à but lucratif, gérer l'infrastructure de mise à jour (les serveurs, la plate-forme de développement, les mises à jour du code, la gestion des éventuels problèmes) a un coût non nul. Il n'y a aucune motivation financière pour le faire, la sécurité ne rapportant rien. (Le RFC s'arrête à cette constatation, ne mentionnant pas la solution évidente : des règles contraignantes obligeant les entreprises à le faire. Le Dieu Marché ne sera certainement pas une solution.)
- Si l'entreprise originale défaille, qui va pouvoir et devoir assurer ses mises à jour ? (Repensons à l'ex-chouchou des médias, le lapin Nabaztag, et à son abandon par la société qui l'avait vendu.) Si le RFC ne le mentionne pas, il va de soi que le logiciel libre est la solution au problème du « pouvoir » mais pas à celui du « devoir » (dit autrement, le logiciel libre est nécessaire mais pas suffisant).
Le risque n'est donc pas seulement de l'absence de système de mise à jour. Il peut être aussi d'un système de mise à jour bogué, vulnérable, ou non documenté, donc non maintenable.
Le problème de la mise à jour automatique des logiciels est évidemment ancien, et plusieurs systèmes d'exploitation ont des solutions opérationnelles depuis un certain temps (comme pacman ou aptitude). Le RFC se focalise donc sur les objets les plus contraints, ceux limités dans leurs capacités matérielles, et donc dans les logiciels qu'ils peuvent faire tourner.
Après cette introduction, le RFC fait un peu de terminologie, car le choix des mots a suscité une discussion à l'atelier. D'abord, la notion de classe. Les « objets connectés » vont de systèmes qui ont les capacités matérielles et l'alimentation électrique d'un ordinateur de bureau (une télévision connectée, par exemple) et qui peuvent donc utiliser les mêmes techniques, jusqu'à des objets bien plus contraints dans leurs capacités. Pour prendre un exemple chez les systèmes populaires auprès des geeks, un Raspberry Pi fait tourner un système d'exploitation « normal » et se met à jour comme un ordinateur de bureau, un Arduino ne le peut typiquement pas. Il faudra donc sans doute développer des solutions différentes selon la classe. Ou, si on veut classer selon le type de processeur, on peut séparer les objets ayant plus ou moins l'équivalent d'un Cortex-A (comme le Pi) de ceux ayant plutôt les ressources du Cortex-M (comme l'Arduino, mais notez que cette catégorie est elle-même très variée).
Le RFC définit également dans cette section 2 la différence entre mise à jour du logiciel et mise à jour du firmware. La distinction importante est que les engins les plus contraints en ressources n'ont typiquement qu'une mise à jour du firmware, qui change tout, système et applications, alors que les engins de classe « supérieure » ont des mises à jour modulaires (on peut ne mettre à jour qu'une seule application).
Dernier terme à retenir, hitless (« sans impact »). C'est une propriété des mises à jour qui ne gênent pas le fonctionnement normal. Par exemple, s'il faut arrêter l'engin pour une mise à jour, elle ne sera pas hitless. Évidemment, la mise à jour du logiciel d'une voiture ne sera probablement pas hitless et nécessitera donc des précautions particulières.
Maintenant, le gros morceau du RFC, la section 3, qui regroupe notamment les exigences issues de l'atelier. C'est assez dans le désordre, et il y a davantage de questions que de réponses. Pour commencer, que devraient faire les fabricants d'objets connectés (en admettant qu'ils lisent les RFC et aient le sens des responsabilités, deux paris hasardeux) ? Par exemple, le RFC note que les mises à jour globales (on remplace tout) sont dangereuses et recommande que des mises à jour partielles soient possibles, notamment pour limiter le débit utilisé sur le réseau (comme avec bsdiff ou courgette). Idéalement, on devrait pouvoir mettre à jour une seule bibliothèque, mais cela nécessiterait du liage dynamique et de code indépendant de la position, ce qui peut être trop demander pour les plus petits objets. Mais au moins un système d'exploitation plutôt conçu pour les « classe M », les objets les plus contraints (équivalents au Cortex-M), le système Contiki, a bien un lieur dynamique.
Certains dispositifs industriels ont plusieurs processeurs, dont un seul gère la connexion avec le reste du monde. Il peut être préférable d'avoir une architecture où ce processeur s'occupe de la mise à jour du logiciel de ses collègues qui ne sont pas directement connectés.
Un problème plus gênant, car non exclusivement technique, est celui des engins qui ont plusieurs responsables potentiels. Si une machine sert à plusieurs fonctions, on risque d'avoir des cas où il n'est pas évident de savoir quel département de l'entreprise a « le dernier mot » en matière de mise à jour. Pour les ordinateurs, cette question sociale a été réglée depuis longtemps dans la plupart des organisations (par exemple en laissant le service informatique seul maître) mais les objets connectés redistribuent les cartes. Si le service Communication a une caméra connectée, qui peut décider de la mettre à jour (ou pas) ?
Un cas proche est celui où un appareil industriel inclut un ordinateur acheté à un tiers (avec le système d'exploitation). Qui doit faire la mise à jour ? Qui est responsable ? Pensons par exemple au problème d'Android où les mises à jour doivent circuler depuis Google vers le constructeur du téléphone, puis (souvent) vers l'opérateur qui l'a vendu. En pratique, on constate qu'Android est mal mis à jour. Et ce sera pire pour un réfrigérateur connecté puisque sa partie informatique sera fabriquée indépendamment, et avant le frigo complet. Lorsque celui-ci démarrera pour la première fois, son logiciel aura sans doute déjà plusieurs mois de retard.
Et la sécurité ? Imaginons un objet connecté dont le fabricant soit assez incompétent et assez irresponsable pour que les mises à jour se fassent en récupérant du code en HTTP, sans aucune authentification d'aucune sorte. Un tel objet serait très vulnérable à des attaques visant à remplacer le code authentique par un code malveillant. D'où l'exigence de DAO (Data Origin Authentication). Sans DAO, tout serait fichu. Deux solutions évidentes utilisent la cryptographie, authentifier le serveur qui distribue les mises à jour (par exemple avec HTTPS) ou bien authentifier le code téléchargé, via une signature numérique (notez que l'IETF a un format CMS pour cela, décrit dans le RFC 4108, mais qui semble peu utilisé.) Mais signer et vérifier est plus facile à dire qu'à faire ! D'abord, si la cryptographie n'est pas un problème pour les engins « classe A », comme une télévision connectée ou bien une voiture connectée, elle peut être bien coûteuse pour des objets plus limités. La cryptographie symétrique est typiquement moins coûteuse, mais bien moins pratique. Le problème de fond est que la cryptographie symétrique n'authentifie pas un envoyeur mais une classe d'envoyeurs (tous ceux qui ont la clé). Il faudrait donc une clé différente par objet, ce qui semble ingérable. Faut-il lister comme exigence de base d'utiliser la cryptographie asymétrique ?
Son coût en opérations de calcul n'est pas le seul problème. Par exemple, la clé privée qui signe les mises à jour peut être volée, ou bien tout simplement devenir trop faible avec les progrès de la cryptanalyse (certains objets peuvent rester en production pendans dix ans ou plus). Il faut donc un moyen de mettre la clé publique à jour. Comment le faire sans introduire de nouvelles vulnérabilités (imaginez un attaquant qui trouverait le moyen de subvertir ce mécanisme de remplacement de clé, et changerait la clé de signature pour la sienne). Bref, les méthodes « il n'y a qu'à… » du genre « il n'y a qu'à utiliser des signatures cryptographiques » ne sont pas des solutions magiques.
Et si l'objet utilise du code venant de plusieurs sources ? Faut-il plusieurs clés, et des règles compliquées du genre « l'organisation A est autorisée à mettre à jour les composants 1, 3 et 4 du système, l'organisation B peut mettre à jour 2 et 3 » ? (Les systèmes fermés sont certainement mauvais pour l'utilisateur, mais présentent des avantages en matière de sécurité : une seule source. Pensez à tous les débats autour de l'utilisation du magasin libre F-Droid, par exemple l'opinion de Whisper.)
Un problème plus fondamental est celui de la confiance : à qui un objet connecté doit-il faire confiance, et donc quelle clé publique utiliser pour vérifier les mises à jour ? Faire confiance à son propriétaire ? À son fabricant ? Au sous-traitant du fabricant ?
On n'en a pas fini avec les problèmes, loin de là. Les objets sont conçus pour être fabriqués et distribués en grande quantité. Cela va donc être un difficile problème de s'assurer que tous les objets dont on est responsable soient à jour. Imaginez une usine qui a des centaines, voire des milliers d'objets identiques, et qui veut savoir s'ils sont tous à la même version du logiciel.
On a parlé plus haut de confiance. On peut décider de faire confiance au fabricant d'un objet, parce qu'on juge l'organisation en question honnête et compétente. Mais cette évaluation ne s'étend pas forcément à la totalité de ses employés. Comment s'assurer qu'un employé méchant ne va pas compromettre le processus de mise à jour du logiciel, par exemple en se gardant une copie de la clé privée, ou bien en ajoutant aux objets produits une clé publique supplémentaire (il aurait alors une porte dérobée dans chaque objet, ce qui illustre bien le fait que la mise à jour est elle-même source de vulnérabilités).
On a parlé des risques pour la sécurité de l'objet connecté. Les précautions prises sont actuellement proches de zéro. Espérons que cela va s'améliorer. Mais, même en prenant beaucoup de précautions, des piratages se produiront parfois. Ce qui ouvre la question de la récupération : comment récupérer un objet piraté ? Si on a dix grille-pains compromis, va t-il falloir les reflasher tous les dix, manuellement ? (Avant cela, il y a aussi l'intéressante question de savoir comment détecter qu'il y a eu piratage, sachant que la quasi-totalité des organisations ne lisent pas les messages leur signalant des comportements suspects de leurs machines.)
La cryptographie apporte clairement des solutions intéressantes à bien des problèmes de sécurité. Mais elle nécessite en général une horloge bien à l'heure (par exemple pour vérifier la date d'expiration d'un certificat). Avoir une horloge maintenue par une batterie pendant l'arrêt de la machine et pendant les coupures de courant n'est pas trivial :
- Cela coûte cher (la batterie et l'horloge peuvent coûter bien plus cher que le reste de l'objet),
- C'est encombrant (certains objets sont vraiment petits),
- Les batteries sont des équipements dangereux, en raison du risque d'incendie ou d'explosion, et leur présence impose donc de fortes contraintes au processus de fabrication, d'autant plus que les batteries vieillissent vite (pas question d'utiliser de vieux stocks),
- Les batteries conçues pour la maison peuvent ne pas être adaptées, car, dans un environnement industriel, les conditions sont rudes (la température peut facilement excéder les limites d'une batterie ordinaire),
- Cela ne dure pas longtemps : la présence d'une batterie peut sérieusement raccourcir la durée de vie d'un objet connecté.
Il n'est donc pas évident qu'il y ait une bonne solution à ce problème. (Le RFC cite Roughtime comme une approche prometteuse.)
Et si on a une bonne solution pour distribuer les mises à jour à des milliers ou des millions d'objets connectés, comment ceux-ci vont-ils être informés de l'existence d'une mise à jour. Push ou pull ? Envoyer les mises à jour depuis le serveur est la solution la plus rapide mais elle peut être délicate si l'objet est derrière un pare-feu qui interdit les connexions entrantes (il faudrait que l'objet contacte le serveur de mise à jour, et reste connecté). Et le cas d'objets qui ne sont pas joignables en permanence complique les choses. De l'autre côté, le cas où l'objet contacte le serveur de temps en temps pour savoir s'il y a une mise à jour pose d'autres problèmes. Par exemple, cela consomme de l'électricité « pour rien ».
Vous trouvez qu'il y a assez de problèmes ? Mais ce n'est pas fini. Imaginez le cas d'une mise à jour qui contienne une bogue, ce qui arrivera inévitablement. Comment revenir en arrière ? Refaire une mise à jour (la bogue risque d'empêcher ce processus) ? L'idéal serait que l'objet stocke deux ou trois versions antérieures de son logiciel localement, pour pouvoir basculer vers ces vieilles versions en cas de problème. Mais cela consomme de l'espace de stockage, qui est très limité pour la plupart des objets connectés.
Le consensus de l'atelier a été que les signatures des logiciels (avec vérification par l'objet), et la possibilité de mises à jour partielles, étaient importants. De même, les participants estimaient essentiels la disponibilité d'une infrastructure de mise à jour, qui puisse fonctionner pour des objets qui n'ont pas un accès complet à l'Internet. Par exemple, il faut qu'une organisation puisse avoir une copie locale du serveur de mise à jour, à la fois pour des raisons de performances, de protection de la vie privée, et pour éviter de donner un accès Internet à ses objets.
En parlant de vie privée (RFC 6973), il faut noter que des objets se connectant à un serveur de mise à jour exposent un certain nombre de choses au serveur, ce qui peut ne pas être souhaitable. Et certains objets sont étroitement associés à un utilisateur (tous les gadgets à la maison), aggravant le problème. Le RFC note qu'au minimum, il ne faut pas envoyer un identificateur unique trop facilement, surtout au dessus d'un lien non chiffré. Mais le RFC note à juste titre qu'il y a un conflit entre la vie privée et le désir des vendeurs de se faire de l'argent avec les données des utilisateurs.
On a surtout parlé jusqu'à présent des risques pour l'objet si le serveur des mises à jour est méchant ou piraté. Certains acteurs du domaine vont ajouter des risques pour le serveur : par exemple, si le logiciel est non-libre, certains peuvent souhaiter authentifier l'objet, pour ne pas distribuer leur précieux logiciel privateur à « n'importe qui ».
On en a déjà parlé mais cela vaut la peine d'y revenir : un gros problème de fond est celui de l'autorisation (section 4 du RFC). Qui peut accepter ou refuser une mise à jour ? Oui, il y a de bonnes raisons de refuser : des mises à jour obligatoires sont une forme de porte dérobée, elles permettent d'ajouter des fonctions qui n'étaient pas là avant et qui peuvent être malveillantes. Le cas avait été cité lors de l'affaire de l'iPhone de San Bernardino (des gens proposaient une mise à jour que le téléphone appliquerait, introduisant une porte dérobée). Et le RFC rappelle le cas d'une mise à jour forcée d'imprimantes HP qui avait supprimé des fonctions utiles mais que HP ne voulait plus (la possibilité d'accepter des cartouches d'encre fournies par les concurrents). Un cas analogue révélé la veille de la publication du RFC est celui de Tesla activant une nouvelle fonction à distance (ici, pour améliorer la voiture, mais il est facile de voir que cela pourrait être en sens inverse). Et il y a bien sûr le cas fameux d'Amazon détruisant des livres à distance.
Prenez un téléphone Android programmé par Google, fabriqué par LG, vendu par Orange à la société Michu qui le confie à son employé M. Dupuis-Morizeau. Qui va décider des mises à jour ?
On peut séparer les mises à jour qui corrigent une faille de sécurité et les autres : seules les premières seraient systématiquement appliquées. (Tous les fournisseurs de logiciel ne font pas cette séparation, qui les oblige à gérer deux lignes de mises à jour.) Ceci dit, en pratique, la distinction n'est pas toujours facile, et la correction d'une faille peut en entrainer d'autres.
D'autre part, certains objets connectés sont utilisés dans un environnement très régulé, où tout, matériel et logiciel, doit subir un processus de validation formel avant d'être déployé (c'est le cas des objets utilisés dans les hôpitaux, par exemple). Il y aura forcément une tension entre « faire la mise à jour en urgence car elle corrige une vulnérabilité » et « ne pas faire la mise à jour avant d'avoir tout revalidé, car cet objet est utilisé pour des fonctions vitales ».
Autre problème rigolo, et qui a de quoi inquiéter, le risque élevé d'une cessation du service de mise à jour logicielle (section 5 du RFC). Les vendeurs de logiciel ne sont pas un service public : ils peuvent décider d'arrêter de fournir un service pour des produits qui ne les intéressent plus (ou qui fait concurrence à un produit plus récent, qui offre une meilleure marge). Ou bien ils peuvent tout simplement faire faillite. Que faire face à cet échec du capitalisme à gérer les produits qu'il met sur le marché ? Le problème est d'autant plus fréquent que des objets connectés peuvent rester en service des années, une éternité pour les directions commerciales. Outre le cas du Nabaztag cité plus haut, le RFC mentionne l'exemple d'Eyefi. Un objet un peu complexe peut incorporer des parties faites par des organisations très différentes, dont certaines seront plus stables que d'autres.
Faut-il envisager un service de reprise de la maintenance, par des organisations spécialisées dans ce ramassage des orphelins ? Si ces organisations sont des entreprises à but lucratif, quel sera leur modèle d'affaires ? (Le RFC ne mentionne pas la possibilité qu'il puisse s'agir d'un service public.) Et est-ce que l'entreprise qui abandonne un produit va accepter ce transfert de responsabilité (aucune loi ne la force à gérer ses déchets logiciels) ?
Pour le logiciel, une grosse différence apparait selon qu'il s'agisse de logiciel libre ou pas. Un projet de logiciel libre peut se casser la figure (par exemple parce que l'unique développeur en a eu marre), mais il peut, techniquement et juridiquement, être repris par quelqu'un d'autre. Ce n'est qu'une possibilité, pas une certitude, et des tas de projets utiles ont été abandonnés car personne ne les a repris.
Néanmoins, si le logiciel libre n'est pas une condition suffisante pour assurer une maintenance sur le long terme, c'est à mon avis une condition nécessaire. Parfois, un logiciel est libéré lorsqu'une société abandonne un produit (ce fut le cas avec Little Printer, qui fut un succès, la maintenance étant repris par des développeurs individuels), parfois la société ne fait rien, et le logiciel est perdu. Bref, un système de séquestre du code, pour pouvoir être transmis en cas de défaillance de l'entreprise originale, serait une bonne chose.
Comme souvent en sécurité, domaine qui ne supporte pas le « ya ka fo kon », certaines exigences sont contradictoires. Par exemple, on veut sécuriser les mises à jour (pour éviter qu'un pirate ne glisse de fausses mises à jour dans le processus), ce qui impose des contrôles, par exemple par des signatures numériques. Mais on veut aussi assurer la maintenance après la fin de la société originelle. Si un prestataire reprend la maintenance du code, mais qu'il n'a pas la clé privée permettant de signer les mises à jour, les objets refuseront celles-ci… Le séquestre obligatoire de ces clés peut être une solution, mais elle introduit d'autres risques (vol des clés chez le notaire).
Une solution possible serait que les appareils connectés soient programmés pour cesser tout service s'ils n'arrivent pas à faire de mise à jour pendant N mois, ou bien si le serveur des mises à jour leur dit que le contrat de support est terminé. De telles bombes temporelles seraient bonnes pour la sécurité, et pour le business des fabricants. Mais elles changeraient le modèle d'achat d'équipement : on ne serait plus propriétaire de sa voiture ou de son grille-pain, mais locataire temporaire. De la vraie obsolescence programmée ! De telles bombes dormantes peuvent aussi interférer avec d'autres fonctions de sécurité. Par exemple, un téléphone doit pouvoir passer des appels d'urgence, même si l'abonnement a expiré. Il serait logique qu'il soit en mesure d'appeler le 112, même si son logiciel n'a pas pu être mis à jour depuis longtemps (cf. RFC 7406 pour une discussion sur un compromis similaire.)
Dans une logique libertarienne, ce RFC parle peu de la possibilité d'obligations légales (comme il y a un contrôle technique pour les voitures, il pourrait y avoir obligation de mesures de sécurité quand on vend des objets connectés). Comme il n'y a aucune chance que des entreprises capitalistes fassent spontanément des efforts pour améliorer la sécurité de tous, si on n'utilise pas de contraintes légales, il reste la possibilité d'incitations, discutée dans la section 6. Certaines sont utopiques (« il est dans l'intérêt de tous d'améliorer la sécurité, donc il faut expliquer aux gentils capitalistes l'intérêt de la sécurité, et ils le feront gratuitement »). Une possibilité est celle d'un abonnement : ayant acheté un objet connecté, on devrait payer régulièrement pour le maintenir à jour. Du point de vue de la sécurité, c'est absurde : il est dans l'intérêt de tous que toutes les machines soient à jour, question sécurité. Avec un abonnement, certains propriétaires choisiront de ne pas payer, et leurs engins seront un danger pour tous. (Comparons avec la santé publiqué : il est dans l'intérêt des riches que les pauvres se soignent, sinon, les maladies contagieuses se répandront et frapperont tout le monde. Les vaccinations gratuites ne sont donc pas de la pure générosité.)
Un des problèmes du soi-disant « Internet des objets » est qu'on ne sait pas grand'chose de ce qui s'y passe. Combien de constructeurs d'objets connectés peuvent dire combien ils ont d'objets encore actifs dans la nature, et quel pourcentage est à jour, question logiciel ? La section 7 du RFC se penche sur les questions de mesures. Un des articles présentés à l'atelier notait que, treize ans après la fin de la distribution d'un objet connecté, on en détectait encore des exemplaires actifs.
Garder trace de ces machines n'est pas trivial, puisque certaines ne seront allumées que de manière très intermittente, et que d'autres seront déployées dans des réseaux fermés. Mais ce serait pourtant utile, par exemple pour savoir combien de temps encore il faut gérer des mises à jour pour tel modèle, savoir quels problèmes ont été rencontrés sur le terrain, savoir quelles machines ont été compromises, etc.
La solution simple serait que l'objet ait un identifiant unique et contacte son fabricant de temps en temps, en donnant des informations sur lui-même. Évidemment, cela soulève de gros problèmes de préservation de la vie privée, si le fabricant de brosses à dents connait vos habitudes d'hygiène (« sa brosse à dents n'a pas été allumée depuis six mois, envoyons-lui des pubs pour un dentiste »). Il existe des techniques statistiques qui permettent de récolter des données sans tout révéler, comme le système RAPPOR ou EPID.
Quelle que soit l'efficacité des mises à jour, il ne fait pas de doute que, parfois, des machines seront piratées. Comment les gérer, à partir de là (section 9) ? Car ce ne sera pas seulement un ou deux objets qu'il faudra reformater avec une copie neuve du système d'exploitation. En cas de faille exploitée, ce seront au moins des centaines ou des milliers d'objets qui auront été piratés par un logiciel comme Mirai. (Notez qu'un travail - qui a échoué - avait été fait à l'IETF sur la gestion des machines terminales et leur sécurité, NEA.)
Rien que signaler à l'utilisateur, sans ouvrir une nouvelle voie d'attaque pour le hameçonnage, n'est pas évident (le RFC 6561 propose une solution, mais peu déployée). Bref, pour l'instant, pas de solution à ce problème. Quand on sait que les organisations à but lucratif ne réagissent jamais quand on leur signale un bot dans leur réseau, on imagine ce que ce sera quand on préviendra M. Michu que son grille-pain est piraté et participe à des DoS (comme celles avec SNMP ou bien celle contre Brian Krebs).
Avant d'arriver à une conclusion très partielle, notre RFC, dans sa section 10, traite quelques points divers :
- Pas mal de gadgets connectés seront rapidement abandonnés, ne délivrant plus de service utile et n'intéressant plus leur propriétaire, mais dont certains seront toujours connectés et piratables. Qui s'occupera de ces orphelins dangereux ?
- Que devra faire la machine qui voit qu'elle n'arrive pas à faire ses mises à jour ? Couiner très fort comme le détecteur de fumée dont la batterie s'épuise ? Vous imaginez votre cuisine quand dix appareils hurleront en même temps « Software update failed. Act now! » ? Ou bien les appareils doivent-ils s'éteindre automatiquement et silencieusement ? (Les fabricants adoreront cette solution : pour éliminer les vieilles machines et forcer les clients à acheter les nouvelles, il suffira de stopper le serveur des mises à jour.)
- La cryptographie post-quantique est pour l'instant inutile (et les mécanismes actuels font des signatures énormes, inadaptées aux objets contraints) mais il est impossible de dire quand elle deviendra indispensable. Cinq ans ? Dix ans ? Jamais ? Le problème est que, les objets connectés restant longtemps sur le terrain, il y a un risque qu'un objet soit livré avec de la cryptographie pré-quantique qui soit cassée par les ordinateurs quantiques pendant sa vie. On sera alors bien embêtés.
- Enfin, pour ceux qui utilisent des certificats pour vérifier les signatures, il faut noter que peu testent les révocations (RFC 6961 et ses copains). Il sera donc difficile, voire impossible, de rattraper le coup si une clé privée de signature est volée.
La section 11 rassemble les conclusions de l'atelier. On notera qu'il y a peu de consensus.
- Comme c'est l'IETF, il n'est pas étonnant que les participants soient tombés d'accord sur l'utilité d'une solution normalisée pour la distribution et la signature de logiciels, afin de permettre des mises à jour fiables.
- Il n'est par contre pas clair de savoir si cette solution doit tout inclure, ou seulement certaines parties du système (la signature, par exemple).
- Des mécanismes de « transmission du pouvoir » sont nécessaires, par exemple pour traiter le cas où une société fait faillite, et passe la maintenance des objets qu'elle a vendu à une association ou un service public. Passer le mot de passe de root est un exemple (très primitif).
L'annexe B du RFC liste tous les papiers présentés à l'atelier qui sont, évidemment en ligne. Sinon, vous pouvez regarder le site officiel de l'atelier, et un bon résumé de présentation. Je recommande aussi cet article de l'IETF Journal, et un très bon article critique sur les objets connectés.
L'article seul
RFC 8228: Guidance on Designing Label Generation Rulesets (LGRs) Supporting Variant Labels
Date de publication du RFC : Août 2017
Auteur(s) du RFC : A. Freytag
Pour information
Première rédaction de cet article le 23 août 2017
Le RFC 7940 définissait un langage, LGR (Label Generation Ruleset), pour exprimer des politiques d'enregistrement de noms écrits en Unicode, avec les éventuelles variantes. Par exemple, avec LGR, on peut exprimer une politique disant que les caractères de l'alphabet latin et eux seuls sont autorisés, et que « é » est considéré équivalent à « e », « ç » à « c », etc. Ce nouveau RFC donne quelques conseils aux auteurs LGR. (Personnellement, je n'ai pas trouvé qu'il apportait grand'chose par rapport au RFC 7940.)
LGR peut s'appliquer à tous les cas où on a des identificateurs en Unicode mais il a surtout été développé pour les IDN (RFC 5890). Les exemples de ce RFC 8228 sont donc surtout pris dans ce domaine d'application. Un ensemble de règles exprimées dans le langage du RFC 7940 va définir deux choses :
- Si un nom donné est acceptable ou pas (dans l'exemple donné plus haut, un registre de noms de domaine ouest-européen peut décider de n'autoriser que l'alphabet latin),
- Et quels noms sont des variantes les
uns des autres. Une variante est un nom composé de caractères
Unicode différents mais qui est considéré comme « le même » (la
définition de ce que c'est que « le même » n'étant pas
technique ; par exemple, un anglophone peut considérer que
theatre et theater sont
« le même » mot, alors que, du point de vue technique, ce sont
deux chaînes de caractère
différentes). Le RFC dit que deux noms sont « le même » s'ils
sont visuellement similaires (
googlevs.goog1e), mais c'est une notion bien trop floue, et qui dépend en outre de la police de caractères utilisée (avec Courier,googleetgoog1esont difficilement distinguables). Le RFC ajoute qu'il y a également le cas de la similarité sémantique (le cas de theatre vs. theater, ou bien celui des sinogrammes traditionnels vs. les simplifiés ou encore, mais c'est compliqué, le cas des accents en français, avec « café » et « cafe » mais aussi avec « interne » et « interné »).
L'idée est que le registre utilise ensuite ces règles pour accepter ou refuser un nom et, si le nom est accepté, pour définir quelles variantes deviennent ainsi bloquées, ou bien attribuées automatiquement au même titulaire. Notez une nouvelle fois qu'il s'agit d'une décision politique et non technique. Le RFC dit d'ailleurs prudemment dans la section 1 qu'il ne sait pas si ce concept de variante est vraiment utile à quoi que ce soit. (J'ajoute qu'en général ce soi-disant risque de confusion a surtout été utilisé comme FUD anti-Unicode, par des gens qui n'ont jamais digéré la variété des écritures humaines.)
J'ai dit qu'une variante était « le même » que le nom de
base. Du point de vue mathématique, la relation « est une
variante de » doit donc être symétrique et
transitive (section 2). « Est une variante
de » est noté avec un tiret donc
A - B signifie « A est une variante de B »
(et réciproquement, vu la symétrie). Notez que le RFC 7940 utilisait un langage fondé sur
XML alors que ce RFC 8228
préfère une notation plus compacte. La section 18 de notre RFC
indique la correspondance entre la notation du RFC 7940 et celle du nouveau RFC.
Mais toutes les relations entre noms « proches » ne sont pas forcément symétriques et transitives. Ainsi, la relation « ressemble à » (le chiffre 1 ressemble à la lettre l minuscule) est non seulement vague (cela dépend en effet de la police) mais également non transitive (deux noms ressemblent chacun à un nom dont la forme est quelque part entre eux, sans pour autant se ressembler entre eux).
Le RFC 7940 permet de définir des relations qui ne sont ni symétriques, ni transitives. Mais ce nouveau RFC 8228 préfère les relations d'équivalence.
Bon, et maintenant, comment on crée les variantes d'un nom ou d'un composant d'un nom (section 6) ? On remplace chaque caractère du nom originel par toutes ses variantes possibles (le fait qu'un caractère correspond à un autre est noté -->). Ainsi, si on a décidé que « e » et « é » étaient équivalents (é --> e), le nom « interne » aura comme variantes possibles « interné », « intérne » et « intérné » (oui, une seule de ces variantes a un sens en français, je sais). Une fois cette génération de variantes faites, le registre, selon sa politique, pourra l'utiliser pour, par exemple, refuser l'enregistrement d'« interné » si « interne » est déjà pris (je le répète parce que c'est important : ce RFC ne décrit pas de politique, l'exemple ci-dessus n'est qu'un exemple).
En pratique, travailler caractère par caractère n'est pas toujours réaliste. Il y a des cas où c'est un groupe de caractères qui poserait problème. La section 7 introduit une amélioration où on peut étiqueter les correspondances de manière asymétrique. Le caractère x veut dire que l'allocation du nom est interdite (détails en section 9), le a qu'elle est autorisée (détails en section 8). On pourrait donc avoir « e x--> é » et « é a--> e » ce qui veut dire que la réservation de « interne » bloquerait celle d'« interné » mais pas le contraire.
Le monde des identificateurs étant très riche et complexe, on ne s'étonnera pas que des règles trop simples soient souvent prises en défaut. Ainsi, la variante peut dépendre du contexte : dans certaines écritures (comme l'arabe), la forme d'un caractère dépend de sa position dans le mot, et un même caractère peut donc entrainer de la confusion s'il est à la fin d'un mot mais pas s'il est au début. Il faut donc étiqueter les relations avec ce détail (par exemple, « final: C --> D » si le caractère noté C peut se confondre avec le caractère D mais uniquement si C est en fin de mot, cf. section 15 du RFC).
Si vous développez du LGR, au moins deux logiciels peuvent aider, celui de Viagénie, lgr-crore et lgr-django et un logiciel de l'auteur de ce RFC, développé pour le « ICANN Integration Panel work » mais qui ne semble pas publié.
L'article seul
RFC 8222: Selecting Labels for Use with Conventional DNS and Other Resolution Systems in DNS-Based Service Discovery
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : A. Sullivan (Dyn)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnssd
Première rédaction de cet article le 22 septembre 2017
DNS-SD (DNS-based Service Discovery, normalisé dans le RFC 6763) permet de découvrir des services dans le réseau, via le DNS, mais aussi via d'autres systèmes de résolution de noms, comme mDNS (RFC 6762). Ces différents systèmes de résolution ayant des propriétés différentes, il peut se poser des problèmes d'interopérabilité. Ce RFC documente ces problèmes et est donc une lecture recommandée pour les développeurs DNS-SD.
Rappelons un peu de contexte (section 1 du RFC) : les applications qui utilisent le DNS imposaient fréquemment une syntaxe réduite aux noms manipulés, la syntaxe « LDH » ([ASCII] Letters, Digits and Hyphen), décrite dans le RFC 952. (Contrairement à ce qu'on lit souvent, le DNS n'impose pas une telle limite, elle est purement dans les applications.) Du fait de ces règles des applications, il a fallu, pour utiliser des lettres Unicode, un système spécial, IDN (RFC 5890). IDN ajoute ses propres contraintes, comme le fait que les « non-lettres » (par exemple les emojis) ne sont pas acceptés.
Le DNS accepte tout à fait du binaire quelconque dans les noms (donc, par exemple, des caractères non-ASCII avec des encodages comme Latin-1). mDNS (RFC 6762) autorise également les caractères non-ASCII, mais impose l'encodage UTF-8. mDNS autorise des caractères qui ne sont pas permis en IDN, du banal espace aux symboles les plus rigolos. DNS-SD recommande même leur usage (RFC 6763, section 4.1.3). La seule contrainte est de se limiter au format Unicode du réseau, décrit dans le RFC 5198.
Bien des développeurs d'application ne sont pas au courant de ces subtilités. Ils manipulent des noms de services comme des chaînes de caractères, et ne se soucient pas du système de résolution sous-jacent et de ses particularités. Or, potentiellement, un même nom peut être accepté par certains de ces systèmes de résolution et refusés par d'autres.
Si le développeur est au courant, et s'il prend soin de faire en sorte que les noms « avancés » ne soient pas envoyés aux systèmes de résolution les plus anciens, ça peut marcher. Mais il ne faut pas se faire d'illusion, les fuites se produisent et tout nom utilisé sur une machine connectée à l'Internet finira tôt ou tard par arriver au DNS, comme le montre le trafic que reçoivent les serveurs de noms de la racine.
Notez enfin que les utilisateurs de DNS-SD, encore plus que ceux des noms classiques, ne tapent que très rarement les noms : presque toujours, ils les choisissent dans une liste.
Maintenant, pourquoi y a-t-il un problème ? (Section 2 du RFC.) Comme je l'ai indiqué plus haut, le DNS accepte n'importe quoi dans un nom. Pourquoi ne pas juste dire « envoyons le nom "Joe's printer, first floor" directement dans le DNS, et ça marchera » ? Il y a deux problèmes avec cette approche. D'abord, l'application qui ne ferait pas attention et enverrait un nom non-ASCII en disant « le DNS s'en tirera de toute façon », cette application oublie qu'il peut y avoir sur le trajet de sa requête une couche logicielle qui fait de l'IDN et va donc encoder en Punycode (transformation du U-label en A-label). Le « vrai » système de résolution ne verra donc pas le nom original. Un problème du même genre arrive avec certains logiciels qui se mêlent de politique, par exemple les navigateurs Web comme Firefox qui se permettent d'afficher certains noms en Unicode et d'autres en ASCII, selon la politique du TLD. Bref, le trajet d'un nom dans les différents logiciels est parsemé d'embûches si on est en Unicode.
En outre, l'approche « j'envoie de l'UTF-8 sans me poser de questions » (suggérée par la section 4.1.3 du RFC 6763) se heurte au fait que la racine du DNS et la plupart des TLD ne permettent de toute façon par d'enregistrer directement de l'UTF-8. (Au passage, le RFC oublie un autre problème de l'UTF-8 envoyé directement : les serveurs DNS ne font pas de normalisation Unicode, et l'insensibilité à la casse du DNS n'est pas évidente à traduire en Unicode.)
La section 3 de notre RFC propose donc de travailler à un profil permettant une meilleure interopérabilité. Un profil est une restriction de ce qui est normalement permis (un dénominateur commun), afin de passer à peu près partout. Un exemple de restriction serait l'interdiction des majuscules. En effet, le DNS est insensible à la casse mais IDN interdit les majuscules (RFC 5894, sections 3.1.3 et 4.2) pour éviter le problème de conversion majuscules<->minuscules, qui est bien plus difficile en Unicode qu'en ASCII.
Notez que notre RFC ne décrit pas un tel profil, il propose sa création, et donne quelques idées. Il y a donc encore du travail.
Pour rendre le problème plus amusant, les noms utilisés par DNS-SD sont composés de trois parties, avec des règles différentes (section 4 de notre RFC, et RFC 6763, section 4.1) :
- « Instance » qui est la partie présentée à l'utilisateur (« Imprimante de Céline »), et où donc tous les caractères sont acceptés,
- « Service », qui indique le protocole de transport, et qui se limite à un court identificateur technique en ASCII, jamais montré à l'utilisateur et qui, commençant par un tiret bas, n'est pas un nom de machine légal et est donc exclu de tout traitement IDN,
- « Domaine », qui est le domaine où se trouve l'instance. Il est conçu pour être tôt ou tard envoyé au DNS, et il suit donc les règles IDN.
L'instance risque d'être « interceptée » par le traitement IDN et, à tort, transformée en Punycode. Limiter le nom de l'instance aux caractères acceptés par IDN serait horriblement restrictif. La seule solution est probablement de mettre en place du code spécifique qui reconnait les noms utilisés par DNS-SD, pour ne jamais les passer au DNS. Quant à la partie « Domaine », l'idée de la traiter comme un nom de domaine normal, et donc sujet aux règles des RFC 5890 et suivants, est restrictive :
- Cela revient à abandonner la stratégie de « on essaie UTF-8, puis Punycode » du RFC 6763, section 4.1.3 (mais cette stratégie a l'inconvénient de multiplier les requêtes, donc le trafic et les délais),
- Elle ne tient pas compte du fait que certains administrateurs de zones DNS peuvent avoir envie de mettre de l'UTF-8 directement dans la zone (ce qui est techniquement possible, mais va nécessiter de synchroniser dans la zone la représentation UTF-8 et la représentation Unicode du même nom, ou qu'il utilise les DNAME du RFC 6672).
L'article seul
RFC 8221: Cryptographic Algorithm Implementation Requirements and Usage Guidance for Encapsulating Security Payload (ESP) and Authentication Header (AH)
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : P. Wouters (Red
Hat), D. Migault, J. Mattsson
(Ericsson), Y. Nir (Check
Point), T. Kivinen
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ipsecme
Première rédaction de cet article le 18 octobre 2017
Le protocole de cryptographie IPsec vient avec une liste d'obligations concernant les algorithmes cryptographiques qu'il faut inclure. Cette liste figure dans ce RFC 8221 (qui remplace l'ancien RFC 7321, avec beaucoup de changements). Ainsi, les différentes mises en œuvre d'IPsec sont sûres d'avoir un jeu d'algorithmes corrects en commun, assurant ainsi l'interopérabilité. Cette nouvelle version marque notamment l'officialisation de l'algorithme ChaCha20.
Ce nouveau RFC concerne les deux services d'IPsec, ESP (Encapsulating Security Payload, RFC 4303) et AH (Authentication Header, RFC 4302). Les RFC normatifs sur IPsec se veulent stables, alors que la cryptographie évolue. D'où le choix de mettre les algorithmes dans un RFC à part. Par exemple, la section 3.2 du RFC 4303 note « The mandatory-to-implement algorithms for use with ESP are described in a separate RFC, to facilitate updating the algorithm requirements independently from the protocol per se » (c'était à l'époque le RFC 4305, remplacé depuis par le RFC 4835, puis par le RFC 7321, puis par notre RFC 8221, trois ans après son prédécesseur).
Ce RFC « extérieur » à IPsec spécifie les algorithmes obligatoires, ceux sur lesquels on peut toujours compter que le pair IPsec les comprenne, ceux qui ne sont pas encore obligatoires mais qu'il vaut mieux mettre en œuvre car ils vont sans doute le devenir dans le futur, et ceux qui sont au contraire déconseillés, en général suite aux progrès de la cryptanalyse, qui nécessitent de réviser régulièrement ce RFC (voir section 1.1). Cette subtilité (différence entre « obligatoire aujourd'hui » et « sans doute obligatoire demain ») mène à une légère adaptation des termes officiels du RFC 2119 : MUST- (avec le signe moins à la fin) est utilisé pour un algorithme obligatoire aujourd'hui mais qui ne le sera sans doute plus demain, en raison des avancées cryptanalytiques, et SHOULD+ est pour un algorithme qui n'est pas obligatoire maintenant mais le deviendra sans doute.
Les section 5 et 6 donnent la liste des algorithmes. Je ne les répète pas intégralement ici, d'autant plus que tous les algorithmes ne sont pas cités, seulement ceux qu'il faut mettre en œuvre, car ils sont fiables, et ceux qu'il ne faut pas mettre en œuvre, car trop cassés, et qui doivent donc être documentés pour mettre les programmeurs en garde. Parmi les points à noter :
- ESP a un mode de chiffrement intègre (authenticated encryption qu'on peut aussi traduire par chiffrement vérifié ou chiffrement authentifié, que je n'aime pas trop parce qu'on peut confondre avec l'authentification, cf. RFC 5116). Ce mode est préféré à celui où chiffrement et intégrité sont séparés. Ce mode a un algorithme obligatoire, AES-GCM, décrit dans le RFC 4106 (il était SHOULD+ dans le RFC 7321). Il y aussi un algorithme recommandé (SHOULD, pas SHOULD+ car trop récent et pas encore assez souvent présent dans les mises en œuvres d'IPsec), ChaCha20-Poly1305 (normalisé dans le RFC 7539), qui fait son entrée dans la famille IPsec (cf. RFC 7634). Il semble bien parti pour remplacer AES-GCM un jour. Dans le RFC 7321, chiffrement intègre et chiffrement tout court étaient décrits séparément mais ils sont depuis dans le même tableau.
- Le mode le plus connu d'ESP, celui de chiffrement tout
court (le chiffrement intègre est désormais préféré), a deux
algorithmes obligatoires (sans compter AES-GCM, cité
plus haut, qui permet le chiffrement intègre), ces deux
algorithmes sont AES-CBC
(RFC 3602) et le surprenant
NULL, c'est-à-dire l'absence de chiffrement (RFC 2410 ; on peut utiliser ESP pour l'authentification seule, d'où cet algorithme). Il y a aussi plusieurs algorithmes notés MUST NOT, comme DES-CBC (RFC 2405). Ils ne doivent pas être programmés, afin d'être sûr qu'on ne s'en serve pas. - Le mode d'authentification (enfin, intégrité serait peut-être un meilleur mot mais c'est subtil) d'ESP a un MUST, HMAC-SHA-256 (RFC 4868). L'étoile de SHA-1 (RFC 2404) baissant sérieusement, HMAC-SHA1 n'est plus que MUST-. AES-GMAC, GMAC étant une variante de GCM, qui était en SHOULD+ dans le vieux RFC, redescend en MAY.
- Et AH, lui, a les mêmes algorithmes que ce mode d'authentification d'ESP.
La section 4 donne des conseils sur l'utilisation d'ESP et
AH. AH ne fournit que l'authentification, alors qu'ESP peut fournir
également le chiffrement. Bien sûr, le chiffrement sans
l'authentification ne sert pas à grand'chose, puisqu'on risque
alors de parler à l'homme du milieu sans le savoir (voir l'article
de Bellovin, S. « Problem areas for the IP security
protocols » dans les Proceedings of the Sixth
Usenix Unix Security Symposium en 1996). Certaines
combinaisons d'algorithmes ne sont pas sûres, par exemple,
évidemment, ESP avec les algorithmes de chiffrement et
d'authentification tous les deux à NULL (voir
par exemple l'article de Paterson, K. et J. Degabriele,
« On the (in)security of IPsec in MAC-then-encrypt
configurations » à l'ACM Conference on Computer
and Communications Security en 2010). Si on veut de
l'authentification/intégrité sans chiffrement, le RFC recommande
d'utiliser ESP avec le chiffrement NULL,
plutôt que AH. En fait, AH est rarement utile, puisque ESP en est
presque un sur-ensemble, et il y a même eu des propositions de
le supprimer. AH avait été prévu pour une époque où le
chiffrement était interdit d'utilisation ou d'exportation dans
certains pays et un logiciel n'ayant que AH posait donc moins de
problèmes légaux. Aujourd'hui, la seule raison d'utiliser encore AH
est si on veut protéger certains champs de l'en-tête IP, qu'ESP ne défend pas.
Le chiffrement intègre/authentifié d'un algorithme comme AES-GCM (RFC 5116 et RFC 4106) est la solution recommandée dans la plupart des cas. L'intégration du chiffrement et de la vérification d'intégrité est probablement la meilleure façon d'obtenir une forte sécurité.
Triple DES et DES, eux, ont des défauts connus et ne doivent plus être utilisés. Triple DES a une taille de bloc trop faible et, au-delà d'un gigaoctet de données chiffrées avec la même clé, il laisse fuiter des informations à un écoutant, qui peuvent l'aider dans son travail de décryptage. Comme, en prime, il est plus lent qu'AES, il n'y a vraiment aucune raison de l'utiliser. (DES est encore pire, avec sa clé bien trop courte. Il a été cassé avec du matériel dont les plans sont publics.)
Triple DES étant sorti, la « solution de remplacement », si un gros problème est découvert dans AES, sera ChaCha20. Il n'y a aucune indication qu'une telle vulnérabilité existe mais il faut toujours garder un algorithme d'avance.
Pour l'authentification/intégrité, MD5, ayant des vulnérabilités connues (RFC 6151), question résistance aux collisions, est relégué en MUST NOT. (Notez que des vulnérabilités à des collisions ne gênent pas forcément l'utilisation dans HMAC.) SHA-1 a des vulnérabilités analogues mais qui ne concernent pas non plus son utilisation dans HMAC-SHA1, qui est donc toujours en MUST- (le moins indiquant son futur retrait). Les membres de la famille SHA-2 n'ont pas ces défauts, et sont désormais MUST pour SHA-256 et SHOULD pour SHA-512.
Voilà, c'est fini, la section 10 sur la sécurité rappelle juste quelques règles bien connues, notamment que la sécurité d'un système cryptographique dépend certes des algorithmes utilisés mais aussi de la qualité des clés, et de tout l'environnement (logiciels, humains).
Ce RFC se conclut en rappelant que, de même qu'il a remplacé ses prédécesseurs comme le RFC 7321, il sera probablement à son tour remplacé par d'autres RFC, au fur et à mesure des progrès de la recherche en cryptographie.
Si vous voulez comparer avec un autre document sur les algorithmes cryptographiques à choisir, vous pouvez par exemple regarder l'annexe B1 du RGS, disponible en ligne.
Merci à Florian Maury pour sa relecture acharnée. Naturellement, comme c'est moi qui tiens le clavier, les erreurs et horreurs restantes viennent de ma seule décision. De toute façon, vous n'alliez pas vous lancer dans la programmation IPsec sur la base de ce seul article, non ?
La section 8 du RFC résume les changements depuis le RFC 7321. Le RFC a été sérieusement réorganisé, avec une seule section regroupant les algorithmes avec AEAD et sans (j'ai gardé ici la présentation séparée de mon précédent article). Les sections d'analyse et de discussion ont donc été très modifiées. Par exemple, le RFC 7321 s'inquiétait de l'absence d'alternative à AES, problème qui a été résolu par ChaCha20. Parmi les principaux changements d'algorithmes :
- AES-GCM prend du galon en passant de SHOULD+ à MUST comme prévu,
- ChaCha20 et Poly1305 (RFC 7539 et RFC 7634) font leur apparition (ils n'étaient pas mentionnés dans le RFC 7321),
- SHA-1, lui, recule, au profit de SHA-2,
- Triple DES est désormais très déconseillé (SHOULD NOT),
- Un nouveau concept apparait, celui des algorithmes cryptographiques « pour l'IoT », un domaine qui pose des problèmes particuliers, en raisons des fortes contraintes pesant sur ces objets (peu de mémoire, peu de puissance électrique disponible, des processeurs lents). C'est ainsi qu'AES-CCM (RFC 4309) passe à SHOULD mais uniquement pour l'Internet des Objets, et qu'AES-XCBC (RFC 3566), qui semblait voué à disparaitre, refait surface spécifiquement pour les objets connectés (peut remplacer HMAC pour l'authentification, afin de ne pas avoir à implémenter SHA-2). Notez que XCBC est peu connu et n'a même pas de page dans le Wikipédia anglophone ☺
En pratique, ce RFC est déjà largement mis en œuvre, la plupart des algorithmes cités sont présents (quand ils sont MUST ou SHOULD) ou absents (quand ils sont MUST NOT) dans les implémentations d'IPsec. Une exception est peut-être ChaCha20, qui est loin d'être présent partout. Malgré cela, ce RFC n'a pas suscité de controverses particulières, l'IETF avait un consensus sur ces nouveaux choix.
L'article seul
RFC 8216: HTTP Live Streaming
Date de publication du RFC : Août 2017
Auteur(s) du RFC : R. Pantos (Apple), W. May (Major
League Baseball Advanced Media)
Pour information
Première rédaction de cet article le 1 septembre 2017
Ce RFC décrit la version 7 du protocole HTTP Live Streaming, qui permet de distribuer des flux multimédia, typiquement de la vidéo.
Utiliser HTTP, c'est bien, ça passe
quasiment tous les pare-feux, et ça permet
de réutiliser l'infrastructure existante, comme les serveurs, et les caches. (Au contraire, un protocole
comme RTP, RFC 3550, a souvent du mal à passer les
différentes
middleboxes.) La manière triviale de distribuer une vidéo avec
HTTP est d'envoyer un fichier vidéo au bon
format, avec des méthodes HTTP standard, typiquement en réponse à
un GET. Mais cette méthode a des tas de
limites. Par exemple, elle ne permet pas de
s'adapter à une capacité variable du
réseau. Par contre, le protocole décrit dans ce RFC, quoique plus
compliqué qu'un simple GET, permet cet
ajustement (et plein d'autres).
HTTP Live Streaming (ou simplement Live Streaming, ou encore HLS) existe depuis longtemps, la première spécification a été publiée (par Apple) en 2009, mais c'est la première fois qu'il se retrouve dans un RFC, ce qui devrait permettre d'améliorer encore l'interopérabilité.
Donc, brève description de HTTP Live Streaming : une ressource multimédia qu'on veut diffuser est représentée par un URI. Ceui-ci désigne une playlist, qui est un fichier texte contenant les URI des données multimedia et diverses informations. Les données multimédia figurent dans plusieurs segments ; en jouant tous les segments successivement, on obtient la vidéo souhaitée. Le client n'a pas ainsi à tout charger, il peut récupérer les segments au fur et à mesure de ses besoins. (Au lieu de « segments », mmu_man suggère de parler d'un « émincé de fichiers ».) Voici l'exemple de playlist que donne le RFC :
#EXTM3U
#EXT-X-TARGETDURATION:10
#EXTINF:9.009,
http://media.example.com/first.ts
#EXTINF:9.009,
http://media.example.com/second.ts
#EXTINF:3.003,
http://media.example.com/third.ts
Ce format de playlist est dérivé du format
M3U et est généralement nommé « M3U étendu ».
On y trouve successivement l'identificateur du format (si ça
commence par #EXTM3U, c'est bien une
playlist de notre RFC), la durée maximale d'un
segment en secondes, puis les trois segments, avec la durée de
chacun. Cette durée, indiquée par l'étiquette
#EXTINF, est un des rares éléments
obligatoires dans une playlist. Il y a bien sûr plein d'autres choses qu'on peut mettre
dans un fichier playlist, la section 4 du RFC
en donne la liste complète. Ainsi,
#EXT-X-BYTERANGE permettra d'indiquer qu'on
ne veut jouer qu'une partie d'une vidéo. Des exemples plus
complets sont donnés dans la section 8 du RFC.
Ça, c'était la media playlist, qui se limite à lister des ressources multimédias. La master playlist, dont le format est le même, est plus riche, et permet de spécifier des versions alternatives d'un même contenu. Ces variantes peuvent être purement techniques (« variant stream », deux encodages d'une même vidéo avec différents formats) ou porter sur le fond : par exemple deux pistes audio dans des langues différentes, ou deux vidéos d'un même évènement filmé depuis deux points de vue distincts. Les variantes techniques servent au client à s'ajuster aux conditions réelles du réseau, les variantes de fond (nommées renditions) servent au client à donner à l'utilisateur ce qu'il préfère. Ici, par exemple, on a dans cette master playlist trois variantes techniques (trois résolutions, de la plus basse, à la plus élevée, qui va nécessiter une bonne capacité réseau), et trois « renditions », correspondant à trois points de vue (centerfield et dugout sont des termes de baseball, ce qui est logique vu l'employeur d'un des deux auteurs du RFC) :
#EXTM3U
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="low",NAME="Main", \
DEFAULT=YES,URI="low/main/audio-video.m3u8"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="low",NAME="Centerfield", \
DEFAULT=NO,URI="low/centerfield/audio-video.m3u8"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="low",NAME="Dugout", \
DEFAULT=NO,URI="low/dugout/audio-video.m3u8"
#EXT-X-STREAM-INF:BANDWIDTH=1280000,CODECS="...",VIDEO="low"
low/main/audio-video.m3u8
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="mid",NAME="Main", \
DEFAULT=YES,URI="mid/main/audio-video.m3u8"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="mid",NAME="Centerfield", \
DEFAULT=NO,URI="mid/centerfield/audio-video.m3u8"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="mid",NAME="Dugout", \
DEFAULT=NO,URI="mid/dugout/audio-video.m3u8"
#EXT-X-STREAM-INF:BANDWIDTH=2560000,CODECS="...",VIDEO="mid"
mid/main/audio-video.m3u8
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="hi",NAME="Main", \
DEFAULT=YES,URI="hi/main/audio-video.m3u8"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="hi",NAME="Centerfield", \
DEFAULT=NO,URI="hi/centerfield/audio-video.m3u8"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="hi",NAME="Dugout", \
DEFAULT=NO,URI="hi/dugout/audio-video.m3u8"
#EXT-X-STREAM-INF:BANDWIDTH=7680000,CODECS="...",VIDEO="hi"
hi/main/audio-video.m3u8
Si vous voulez le voir en vrai, et que vous êtes abonné à Free, la Freebox distribue sa playlist sous ce format (mais avec le mauvais type MIME) :
% curl -s http://mafreebox.freebox.fr/freeboxtv/playlist.m3u
#EXTM3U
#EXTINF:0,2 - France 2 (bas débit)
rtsp://mafreebox.freebox.fr/fbxtv_pub/stream?namespace=1&service=201&flavour=ld
#EXTINF:0,2 - France 2 (HD)
rtsp://mafreebox.freebox.fr/fbxtv_pub/stream?namespace=1&service=201&flavour=hd
#EXTINF:0,2 - France 2 (standard)
rtsp://mafreebox.freebox.fr/fbxtv_pub/stream?namespace=1&service=201&flavour=sd
#EXTINF:0,2 - France 2 (auto)
rtsp://mafreebox.freebox.fr/fbxtv_pub/stream?namespace=1&service=201
#EXTINF:0,3 - France 3 (standard)
rtsp://mafreebox.freebox.fr/fbxtv_pub/stream?namespace=1&service=202&flavour=sd
...
(On me dit qu'avec certaines Freebox, il faut ajouter
-L à curl, en raison d'une redirection HTTP.)
Un client comme vlc peut prendre comme
argument l'URI de la playlist, la télécharger et jouer ensuite les
vidéos.
(Tous les moyens sont bons pour télécharger la playlist, le RFC n'impose pas un
mécanisme particulier.)
Télécharger chacun des segments se fait a priori avec
HTTP, RFC 7230, mais
vous voyez plus haut que, sur la Freebox,
c'est RTSP, RFC 7826. Le serveur, lui, est un serveur HTTP
ordinaire. L'auteur a « juste » eu à découper sa vidéo en segments (ou
la garder en un seul morceau si elle est assez courte), à
fabriquer un fichier playlist, puis à le servir
avec le type MIME application/vnd.apple.mpegurl. (La
section 6 du RFC décrit plus en détail ce que doivent faire client
et serveur.)
Il est recommandé que chaque segment soit auto-suffisant, c'est-à-dire puisse être décodé sans avoir besoin des autres segments. Ainsi, si les segments sont en H.264, chacun doit avoir un Instantaneous Decoding Refresh (IDR).
Plusieurs formats sont évidemment possibles dans une playlist HTTP Live Streaming, MPEG-2, MPEG-4 fragmenté, WebVTT pour avoir les sous-titres, et un format pour l'audio (qui accepte entre autres MP3).
HTTP Live Streaming permet aussi de servir du direct. Prenons par exemple le flux vidéo de l'Assemblée Nationale, qui permet de suivre les débats parlementaires :
% curl -s http://videos-diffusion-live.assemblee-nationale.fr/live/live1/stream1.m3u8 #EXTM3U #EXT-X-VERSION:3 #EXT-X-ALLOW-CACHE:NO #EXT-X-TARGETDURATION:11 #EXT-X-MEDIA-SEQUENCE:382 #EXTINF:9.996, media_1_4805021_382.ts #EXTINF:11.483, media_1_4805021_383.ts ...
Un peu plus tard, les fichiers ont changé, le client HLS doit recharger la playlist régulièrement (section 6.2.2 du RFC), et charger de nouveaux fichiers vidéo :
% curl -s http://videos-diffusion-live.assemblee-nationale.fr/live/live1/stream1.m3u8 #EXTM3U #EXT-X-VERSION:3 #EXT-X-ALLOW-CACHE:NO #EXT-X-TARGETDURATION:11 #EXT-X-MEDIA-SEQUENCE:390 #EXTINF:10.039, media_1_4805021_390.ts #EXTINF:11.242, media_1_4805021_391.ts ...
(Notez également l'incrémentation du #EXT-X-MEDIA-SEQUENCE.)
Ainsi, l'utilisateur a l'impression d'une vidéo continue, alors
que le logiciel client passe son temps à charger des segments différents et à les
afficher à la suite.
Notez que HTTP Live Streaming n'est pas le seul mécanisme dans ce domaine, son principal concurrent est MPEG-DASH.
Si vous voulez lire davantage :
- Un article d'introduction, orienté vers l'auteur de vidéos,
- Un article plus technique d'Apple.
L'article seul
RFC 8215: Local-Use IPv4/IPv6 Translation Prefix
Date de publication du RFC : Août 2017
Auteur(s) du RFC : T. Anderson (Redpill Linpro)
Chemin des normes
Première rédaction de cet article le 18 septembre 2017
Ce très court RFC documente la
réservation du préfixe IPv6
64:ff9b:1::/48, pour les divers mécanismes de
traduction entre IPv6 et IPv4.
L'adressage de ces mécanismes de traduction est décrit dans le
RFC 6052. Il réservait le préfixe
64:ff9b::/96, qui s'est avéré insuffisant et
est désormais complété par notre RFC 8215.
Ouvrez bien l'œil : ces deux préfixes sont différents, même si leurs quatre premiers octets sont identiques (c'est un problème fréquent en IPv6 : il peut être difficile de distinguer deux adresses du premier coup.)
La section 3 de notre RFC expose le problème : depuis la
publication du RFC 6052, plusieurs
mécanismes de traduction IPv4<->IPv6 ont été proposés (par
exemple dans les RFC 6146 et RFC 7915). Ils ne sont pas inconciliables (ils couvrent
parfois des scénarios différents ) et un opérateur peut donc
vouloir en déployer plusieurs à la fois. Le seul préfixe
64:ff9b::/96 ne va alors plus suffire. Il
faut donc un préfixe plus grand, et dont l'usage n'est pas
restreint à une seule technologie de traduction.
Pourquoi 64:ff9b:1::/48, d'ailleurs ? La
section 4 répond à la question. La longueur de 48 bits a été
choisie pour permettre plusieurs mécanismes de traduction, chacun
utilisant un préfixe plus spécifique. Par exemple, si chaque
mécanisme utilise un /64, le préfixe réservé pour les englober
tous devait être un /48, ou plus général (on se limite aux
multiples de 16 bits, car ils permettent que les préfixes se
terminent sur un deux-points, facilitant la
vie de l'administrateur réseaux qui devra les manipuler).
Ensuite, pourquoi cette valeur
64:ff9b:1:: ? Parce qu'elle est proche
(presque adjacente) du
64:ff9b::/96, minimisant la consommation
d'adresses IPv6. (64:ff9a:ffff::/48 est
complètement adjacent, de l'autre côté, mais l'agrégation avec
64:ff9b::/96 en un seul préfixe est beaucoup
moins efficace. Et puis 64:ff9b:1:: est plus
court.)
À part son usage, 64:ff9b:1::/48 est un
préfixe IPv6 normal et les routeurs, ou autres machines qui
manipulent des adresses IPv6, ne doivent pas le traiter
différemment des autres.
Le nouveau préfixe est désormais enregistré dans le registre des adresses IPv6 spéciales (section 7 de notre RFC).
L'article seul
RFC 8212: Default External BGP (EBGP) Route Propagation Behavior without Policies
Date de publication du RFC : Juillet 2017
Auteur(s) du RFC : J. Mauch (Akamai), J. Snijders
(NTT), G. Hankins (Nokia)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF grow
Première rédaction de cet article le 10 juillet 2017
Ce RFC est très court, mais concerne un problème fréquent sur l'Internet : les fuites de routes BGP. Traditionnellement, un routeur BGP acceptait par défaut toutes les routes, et annonçait par défaut à ses voisins toutes les routes qu'il connaissait. Il fallait une configuration explicite pour ne pas le faire. En cas d'erreur, ce comportement menait à des fuites (RFC 7908). Notre RFC normalise désormais le comportement inverse : un routeur BGP ne doit, par défaut, rien accepter et rien annoncer. Il faut qu'il soit configuré explicitement si on veut le faire.
Avec l'ancien comportement, la configuration de certains routeurs BGP, les plus imprudents, indiquait les pairs avec qui on échangeait de l'information, plus un certain nombre de routes qu'on n'envoyait pas. Si une erreur faisait qu'on recevait tout à coup des routes imprévues, on les acceptait, et on les renvoyait telles quelles, propageant la fuite (RFC 7908). Des cas fameux de fuites ne manquent pas (voir par exemple celle d'un opérateur malaisien). L'idée derrière ce comportement était d'assurer la connectivité du graphe de l'Internet. Aujourd'hui, on est plutôt plus sensibles aux risques de sécurité qu'à ceux de partitionnement du graphe, et les bonnes pratiques demandent depuis longtemps qu'on indique explicitement ce qu'on accepte et ce qu'on envoie. Voyez par exemple les recommandations de l'ANSSI.
En pratique, ce très court RFC ajoute juste deux paragraphes à la norme BGP, le RFC 4271. Dans sa section 9.1, les paragraphe en question disent désormais qu'il ne doit pas y avoir du tout d'exportation ou d'importation de routes, par défaut. Notez donc que cela ne change pas le protocole BGP, juste le comportement local.
Du moment qu'on change le comportement par défaut, il va y avoir un problème de transition (et ce point a soulevé des discussions à l'IETF). Si le logiciel du routeur s'adaptait au nouveau RFC, certains opérateurs seraient bien surpris que leurs routes ne soient tout coup plus annoncées. L'annexe A du RFC recommande une stratégie en deux temps :
- D'abord introduire une nouvelle option « BGP non sécurisé » qui serait à Vrai par défaut (mais que les opérateurs pourraient changer), ce qui garderait le comportement actuel mais avec un avertissement émis quelque part « attention, vous exportez des routes sans décision explicite »,
- Ensuite, dans la version suivante du logiciel, faire que cette option soit à Faux par défaut.
Et pour finir sur une note d'humour, à une réunion IETF (IETF 97), le projet qui a finalement mené à ce RFC était illustré… de photos de préservatifs. Pratiquez donc le BGP safe, l'Internet vous remerciera.
L'article seul
RFC 8210: The Resource Public Key Infrastructure (RPKI) to Router Protocol, Version 1
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : R. Bush (Internet Initiative
Japan), R. Austein (Dragon Research
Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 28 septembre 2017
Le protocole décrit dans ce RFC fait partie de la grande famille des RFC sur la RPKI, un ensemble de mécanismes permettant de sécuriser le routage sur l'Internet. Il traite un problème bien particulier : comme la validation des annonces de route, potentiellement complexe en cryptographie, se fait typiquement sur une machine spécialisée, le cache validateur, comment communiquer le résultat de ces validations au routeur, qui va devoir accepter ou rejeter des routes ? C'est le rôle du protocole RTR (RPKI/Router Protocol), un protocole très simple. Ce RFC décrit une nouvelle version de RTR, la version 1, la première (version 0) était dans le RFC 6810.
L'opérateur Internet a donc deux acteurs qui font du RTR entre eux, le cache validateur qui récupère les ROA (Route Origin Authorization, cf. RFC 6482) par rsync, les valide cryptographiquement et garde en mémoire le résultat de cette validation (pour des exemples d'utilisation de deux programmes mettant en œuvre cette fonction, voir mon article sur les logiciels de la RPKI), et le routeur (Cisco, Juniper, Unix avec Quagga, etc). Ce dernier joue un rôle critique et on ne souhaite pas trop charger la barque en lui imposant les opérations assez lourdes du validateur. Dans la plupart des déploiements de la RPKI, le routeur ne fait donc que récupérer des résultats simples (« ce préfixe IP peut être annoncé par cet AS »). Le jeu de données que connait le cache validateur a un numéro de série, qui est incrémenté dès qu'il y a une modification (RFC 1982). Le cache peut donc facilement savoir si un de ses clients routeur est à jour en comparant son numéro de série avec celui du routeur. Le numéro de série est spécifique à un cache donné, il n'a pas de signification globale. Le routeur ne validant pas, le cache qu'il utilise doit donc être une machine de confiance.
Un autre acteur, externe à l'opérateur, est la RPKI, l'ensemble des informations de routage publiées (RFC 6481), et qui sont transportées en général en rsync et validées par les signatures cryptographiques qu'elles portent.
Le routeur va ouvrir une connexion avec un ou plusieurs caches et transmettre le numéro de série de ses données. Le cache va lui envoyer les données plus récentes que ce numéro (ou bien rien, si le routeur est à jour). Le cache dispose aussi d'un mécanisme de notification pour dire à tous les routeurs connectés « j'ai du nouveau ». La section 10 décrit plus en détail le processus avec plusieurs caches.
La section 5 décrit le format des paquets : chacun, outre le classique champ version (1 dans ce RFC, c'était 0 dans le RFC précédent), a un type, indiqué par un entier de 8 bits (requête, réponse, etc), le numéro de série de l'envoyeur et un identifiant de session, qui identifie le serveur du cache (pour détecter une remise à zéro d'un cache, par exemple), la longueur du préfixe annoncé et bien sûr le préfixe lui-même.
Les types de paquets les plus utiles (la liste complète est dans un registre IANA) :
- Serial Notify (type 0) qui sert au cache à envoyer une notification non sollicitée par les routeurs « J'ai du nouveau ».
- Serial Query (type 1) où le routeur demande au cache validateur quelles informations il possède, depuis le numéro de série indiqué par le routeur.
- Cache Response (type 3), la réponse à la requête précédente, composée de :
- IPv4 Prefix (type 4) et IPv6 Prefix (type 6) qui indiquent un préfixe IP avec les numéros de systèmes autonomes autorisés à l'annoncer.
- End of Data (type 7) : comme son nom l'indique.
- Error (type 10), envoyé lorsque le précédent message avait déclenché un problème.
Le dialogue typique entre un routeur et un cache validateur est décrit en section 8 (le RFC détaille aussi le dialogue de démarrage, ici, je ne montre que celui de fonctionnement régulier) :
- Le routeur demande des données avec un Serial Query ou Reset Query),
- Le validateur envoie successivement un Cache Response, plusieurs IPvX Prefix, puis un End of Data.
À noter que puisqu'il y a désormais deux versions de RTR dans la nature, il a fallu mettre en place un système de négociation, décrit dans la section 7. Lorsqu'un cache/validateur connait la version 1 (celle de notre nouveau RFC), et reçoit une requête de version 0 du routeur, il doit se rabattre sur la version 0 (s'il la connait, et veut bien la parler), ou bien envoyer un message d'erreur (code 4 « Unsupported Protocol Version »).
Si c'est l'inverse (routeur récent parlant à un vieux cache/validateur), deux cas, qui dépendent de la politique du validateur. S'il répond avec une erreur, cela peut être intéressant de réessayer avec le protocole 0, si le routeur le connait. Si, par contre, le validateur répond avec des messages de version 0, le routeur peut décider de continuer en version 0.
Les codes d'erreur possibles sont décrits dans la section 12 et font l'objet d'un registre IANA. On y trouve par exemple 0 (données corrompues), 1 (erreur interne dans le client ou le serveur), 2 (pas de nouvelles données ; ce n'est pas à proprement parler une erreur).
La question du transport des données entre le cache et le routeur est traitée dans la section 9. Le principal problème est le suivant : comme le but de l'opération RPKI+ROA est d'augmenter la sécurité du routage, il faut que chaque maillon de la chaîne soit sécurisé. Il ne servirait pas à grand'chose de déployer une telle usine à gaz de validation si la liaison entre le routeur et le cache permettait à un intermédiaire de changer les données en cours de route. Il était donc tentant de normaliser une technique de sécurité particulière pour le transport, comme par exemple TLS. Malheureusement, il n'existe pas à l'heure actuelle de technique accessible sur tous les routeurs. L'IETF ayant toujours soin de normaliser des protocoles réalistes, qui puissent être mis en œuvre et déployés, le choix a été fait de ne pas imposer une technique de sécurisation particulière. L'interopérabilité en souffre (un cache et un routeur peuvent ne pas avoir de protocole de sécurité en commun) mais c'était la seule option réaliste. (J'ajoute que, si le but de la séparation du routeur et du validateur était de dispenser ce dernier des calculs cryptographiques, il ne serait pas logique de lui imposer ensuite une session protégée cryptographiquement avec le validateur.)
Le RFC se contente donc de donner une préférence à AO (TCP Authentication Option, cf. RFC 5925) en signalant qu'elle sera la technique préférée, dès lors qu'elle sera disponible sur tous les routeurs (ce qui est très loin d'être le cas en 2017, les progrès sont faibles depuis le précédent RFC sur RTR). Les algorithmes du RFC 5926 doivent être acceptés.
En attendant AO, et pour s'assurer qu'il y aura au moins un protocole commun, le RFC spécifie que routeurs et caches doivent pouvoir se parler en utilisant du TCP nu, sans sécurité, vers le port 323. Dans ce cas, le RFC spécifie que routeur et cache validateur doivent être sur le même réseau (idéalement, sur le même segment, cf. section 13) et que des mécanismes, par exemple de contrôle d'accès physiques, empêchent les méchants de jouer avec ce réseau.
Au cas où AO ne soit pas disponible (la quasi-totalité des routeurs
aujourd'hui) et où le transport non sécurisé soit jugé nettement trop
faible, le RFC présente plusieurs transports sécurisés possibles. Par
exemple, SSH (RFC 4252), avec une sécurisation des clés
obtenue par un moyen externe (entrée manuelle des clés, par
exemple). Le sous-système SSH à utiliser est nommé
rpki-rtr. Notez que, si SSH n'a pas été rendu
obligatoire, alors que quasiment tous les routeurs ont un programme
SSH, c'est parce que ce programme n'est pas toujours disponible sous
forme d'une bibliothèque, accessible aux
applications comme RTR.
Autre alternative de sécurisation évidente,
TLS. Le RFC impose une authentification par un
certificat client, comportant l'extension
subjectAltName du RFC 5280,
avec une adresse IP (celle du routeur qui se connecte, et que
le serveur RTR, la cache validateur, doit vérifier). Le client RTR,
lui (le routeur), utilisera le nom de
domaine du serveur RTR (le cache) comme entrée pour l'authentification (cf. RFC 6125). N'importe quelle
AC peut être utilisée mais notre RFC estime
qu'en pratique, les opérateurs créeront leur propre AC, et mettront
son certificat dans tous leurs routeurs.
Notez que ce problème de sécurité ne concerne que le transport entre le routeur et le cache validateur. Entre les caches, ou bien entre les caches et les serveurs publics de la RPKI, il n'y a pas besoin d'une forte sécurité, l'intégrité des données est assurée par la validation cryptographique des signatures sur les objets.
Ce RFC spécifie un protocole, pas une politique. Il pourra y avoir plusieurs façons de déployer RTR. La section 11 donne un exemple partiel de la variété des scénarios de déploiement, notamment :
- Le petit site (« petit » est relatif, il fait quand même du BGP) qui sous-traite la validation à un de ses opérateurs. Ses routeurs se connectent aux caches validateurs de l'opérateur.
- Le grand site, qui aura sans doute plusieurs caches en interne, avec peut-être un repli vers les caches de l'opérateur en cas de panne.
- L'opérateur qui aura sans doute plusieurs caches dans chaque POP (pour la redondance).
Pour limiter la charge sur les serveurs rsync de la RPKI (voir RFC 6480), il est recommandé d'organiser les caches de manière hiérarchique, avec peu de caches tapant sur les dépôts rsync publics, et les autres caches se nourrissant (et pas tous en même temps) à partir de ces caches ayant un accès public.
Bien que ce protocole RTR ait été conçu dans le cadre de la RPKI, il peut parfaitement être utilisé avec d'autres mécanismes de sécurisation du routage, puisque RTR se contente de distribuer des autorisations, indépendemment de la manière dont elles ont été obtenues.
Et puis un petit point opérationnel : sur le validateur/cache, n'oubliez pas de bien synchroniser l'horloge, puisqu'il faudra vérifier des certificats, qui ont une date d'expiration…
Quels sont les changements par rapport au RFC original, le RFC 6810, qui normalisait la version 0 de RTR ? Ces changements sont peu nombreux, mais, du fait du changement de version, les versions 0 et 1 sont incompatibles. La section 1.2 résume ce qui a été modifié entre les deux RFC :
- Un nouveau type de paquet, Router Key (type 9),
- Des paramètres temporels explicites (durée de vie des informations, etc),
- Spécification de la négociation de la version du protocole, puisque les versions 0 et 1 vont coexister pendant un certain temps.
Aujourd'hui, qui met en œuvre RTR ? Il existe en logiciel libre une bibliothèque en C, RTRlib. Elle a fait l'objet d'un bon article de présentation (avec schéma pour expliquer RTR). Elle peut tourner sur TCP nu mais aussi sur SSH. RTRlib permet d'écrire, très simplement, des clients RTR en C, pour déboguer un cache/validateur, ou bien pour extraire des statistiques. Un client simple en ligne de commande est fourni avec, rtrclient. Il peut servir d'exemple (son code est court et très compréhensible) mais aussi d'outil de test simple. rtrclient se connecte et affiche simplement les préfixes reçus. Voici (avec une version légèrement modifiée pour afficher la date) son comportement (en face, le RPKI Validator du RIPE-NCC, dont il faut noter qu'il ne marche pas avec Java 9, il faut reculer vers une version plus vieille, et qu'il ne gère pas encore la version 1 de RTR) :
% rtrclient tcp localhost 8282 ... 2012-05-14T19:27:42Z + 195.159.0.0 16-16 5381 2012-05-14T19:27:42Z + 193.247.205.0 24-24 15623 2012-05-14T19:27:42Z + 37.130.128.0 20-24 51906 2012-05-14T19:27:42Z + 2001:1388:: 32-32 6147 2012-05-14T19:27:42Z + 2001:67c:2544:: 48-48 44574 2012-05-14T19:27:42Z + 178.252.36.0 22-22 6714 2012-05-14T19:27:42Z + 217.67.224.0 19-24 16131 2012-05-14T19:27:42Z + 77.233.224.0 19-19 31027 2012-05-14T19:27:42Z + 46.226.56.0 21-21 5524 2012-05-14T19:27:42Z + 193.135.240.0 21-24 559 2012-05-14T19:27:42Z + 193.247.95.0 24-24 31592 ...
Autre bibliothèque pour développer des clients RTR, cette fois en Go, ma GoRTR. Le programmeur doit fournir une fonction de traitement des données, qui sera appelée chaque fois qu'il y aura du nouveau. GoRTR est fournie avec deux programmes d'exemple, un qui affiche simplement les préfixes (comme rtrclient plus haut), l'autre qui les stocke dans une base de données, pour étude ultérieure. Par exemple, on voit ici dans cette base de données que la majorité des préfixes annoncés autorisent une longueur de préfixe égale à la leur (pas de tolérance) :
essais=> SELECT count(id) FROM Prefixes WHERE serialno=(SELECT max(serialno) FROM Prefixes) AND maxlength=masklen(prefix); count ------- 2586 (1 row) essais=> SELECT count(id) FROM Prefixes WHERE serialno=(SELECT max(serialno) FROM Prefixes) AND maxlength>masklen(prefix); count ------- 1110 (1 row)
Et voici une partie de évenements d'une session RTR, stockée dans cette base:
tests=> select * from events; id | time | server | event | serialno ----+----------------------------+---------------------------------+---------------------------------+---------- ... 12 | 2017-06-24 13:31:01.445709 | rpki-validator.realmv6.org:8282 | (Temporary) End of Data | 33099 13 | 2017-06-24 13:31:01.447959 | rpki-validator.realmv6.org:8282 | Cache Response, session is 4911 | 33099 14 | 2017-06-24 13:31:25.932909 | rpki-validator.realmv6.org:8282 | (Temporary) End of Data | 33099 15 | 2017-06-24 13:31:38.64284 | rpki-validator.realmv6.org:8282 | Serial Notify #33099 -> #33100 | 33099 16 | 2017-06-24 13:31:38.741937 | rpki-validator.realmv6.org:8282 | Cache reset | 33099 17 | 2017-06-24 13:31:38.899752 | rpki-validator.realmv6.org:8282 | Cache Response, session is 4911 | 33099 18 | 2017-06-24 13:32:03.072801 | rpki-validator.realmv6.org:8282 | (Temporary) End of Data | 33100 ...
Notez que GoRTR gère désormais les deux versions du protocole mais ne connait pas la négociation de version de la section 7 du RFC : il faut indiquer explicitement quelle version on utilise.
Autrement, Cisco et Juniper ont tous les deux annoncé que leurs routeurs avaient un client RTR, et qu'il a passé des tests d'interopérabilité avec trois mises en œuvre du serveur (celles de BBN, du RIPE et de l'ISC). Ces tests d'interopérabilité ont été documentés dans le RFC 7128. Quant aux serveurs, un exemple est fourni par le logiciel RPKI du RIPE-NCC qui fournit un serveur RTR sur le port 8282 par défaut.
En 2013, un client RTR récupèrait 3696 préfixes (ce qui est plus que le nombre de ROA puisqu'un ROA peut comporter plusieurs préfixes). C'est encore très loin de la taille de la table de routage globale et il reste donc à voir si l'infrastructure suivra. (Sur ma station de travail, le validateur, écrit en Java, rame sérieusement.)
Pour les curieux, pourquoi est-ce que l'IETF n'a pas utilisé Netconf (RFC 6241) plutôt que de créer un nouveau protocole ? Les explications sont dans une discussion en décembre 2011. Le fond de la discussion était « les informations de la RPKI sont des données ou de la configuration » ? La validation est relativement statique mais reste quand même plus proche (fréquence de mise à jour, notamment) des données que de la configuration.
Si vous voulez tester un client RTR, il existe un serveur public
rpki-validator.realmv6.org:8282. Voici le genre de choses
qu'affiche rtrclient (test fait avec un vieux serveur, qui n'est plus disponible) :
% rtrclient tcp rtr-test.bbn.com 12712 ... 2012-05-14T19:36:27Z + 236.198.160.184 18-24 4292108787 2012-05-14T19:36:27Z + 9144:8d7d:89b6:e3b8:dff1:dc2b:d864:d49d 105-124 4292268291 2012-05-14T19:36:27Z + 204.108.12.160 8-29 4292339151 2012-05-14T19:36:27Z + 165.13.118.106 27-28 4293698907 2012-05-14T19:36:27Z + 646:938e:20d7:4db3:dafb:6844:f58c:82d5 8-82 4294213839 2012-05-14T19:36:27Z + fd47:efa8:e209:6c35:5e96:50f7:4359:35ba 20-31 4294900047 ...
Question mise en œuvre, il y a apparemment plusieurs logiciels de validateurs/cache qui mettent en œuvre cette version 1, mais je n'ai pas trouvé lesquels. (Le RPKI Validator du RIPE-NCC ne le fait pas, par exemple, ni le serveur public indiqué plus haut, tous les deux ne connaissent que la version 0.)
Wireshark ne semble pas décoder ce
protocole. Si vous voulez vous y mettre, un
pcap est disponible en rtr.pcap.
L'article seul
RFC 8207: BGPsec Operational Considerations
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : R. Bush (Internet Initiative
Japan)
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 28 septembre 2017
Le mécanisme de sécurisation de BGP nommé BGPsec, normalisé dans le RFC 8205 n'a pas encore de déploiement important. Mais le bon sens, l'expérience d'autres mécanismes de sécurité, et les expérimentations déjà faites avec BGPsec permettent de dégager quelques bonnes pratiques opérationnelles, que ce RFC décrit. Le RFC est court : on manque encore de pratique pour être sûr de toutes les bonnes pratiques.
Bien sûr, ces pratiques évolueront. À l'heure de la publication de ce RFC, il y a encore très peu d'expérience concrète avec BGPsec. Au fait, c'est quoi, BGPsec ? Le protocole BGP, la norme pour les annonces de routes sur l'Internet, souffre d'une faiblesse de sécurité : par défaut, n'importe qui peut annoncer n'importe quelle route, même vers un préfixe IP qu'il ne contrôle pas. Il existe plusieurs systèmes pour limiter les dégâts : les IRR, les systèmes d'alarme, et, plus récemment, les ROA (Route Origin Authorizations, cf. RFC 6482). BGPsec est la technique la plus efficace, mais aussi la plus difficile à déployer. Comme les ROA, il repose sur la RPKI. Contrairement aux ROA, il ne valide pas que l'AS d'origine mais tout le chemin d'AS, par une signature de chaque AS. Il introduit donc la cryptographie dans le routage, ce qui causera sans doute quelques perturbations.
Donc, avant de lire ce RFC 8207, c'est sans doute une bonne idée de lire au moins les RFC 4271 sur BGP et RFC 6480 sur la RPKI. Comme BGPsec dépend de la RPKI, il est également bon de lire le RFC 7115, qui parle des questions opérationnelles des ROA (qui reposent également sur la RPKI). Et enfin il faut lire le RFC sur le protocole BGPsec, le RFC 8205.
Avec BGPsec, chaque routeur de bordure de l'AS va avoir une paire {clé privée, clé publique}. On peut avoir une seule paire pour tous ses routeurs (et donc publier un seul certificat dans la RPKI) ou bien une paire par routeur (section 4 du RFC). La première solution est plus simple mais, si un routeur est piraté, il faudra changer la configuration de tous les autres routeurs. Le RFC suggère aussi de pré-publier des clés de secours dans la RPKI, pour qu'elles soient bien distribuées partout le jour où on en aura besoin.
Tous vos routeurs ne sont pas censés parler BGPsec, seulement ceux au bord de l'AS, face au grand monde inconnu du méchant Internet (section 5). Si vous n'avez pas le temps ou l'envie d'activer BGPsec sur tous vos routeurs, commencez par ceux qui font face aux « maillons faibles », les pairs ou les transitaires que vous suspectez d'être le plus capable d'envoyer ou de relayer des annonces erronées ou mensongères. Évidemment, ce sont aussi ceux qui ont le moins de chance de déployer BGPsec…
Si vous ne vous contentez pas de vérifier les signatures BGPsec, mais que vous agissez sur la base de cette vérification (en ignorant les annonces invalides), attendez-vous, comme avec toute technique de sécurité BGP, à ce que le trafic se déplace, par exemple vers d'autres pairs. Un pré-requis au déploiement de BGPsec est donc sans doute un bon système de métrologie.
Attention aux limites de BGPsec : la signature couvre le chemin d'AS, pas les communautés (RFC 1997). Ne vous fiez donc pas à elles.
Si BGPsec vous semble bien compliqué à déployer, et que vous hésitez devant le travail que cela représente, la section 6 vous rassurera : la majorité des AS sont des stubs, ils ne fournissent de connectivité à personne et n'ont donc pas forcément besoin de valider les annonces. Par contre, vous pouvez demander à vos transitaires s'ils utilisent BGPsec (début 2017, la réponse était forcément non).
Les lect·eur·rice·s subtil·e·s ont peut-être noté une
différence avec les ROA. Alors que l'état de la validation ROA
(RFC 6811)
donne un résultat ternaire (pas de ROA, un ROA et valide, un ROA
et invalide), BGPsec est binaire (annonce valide, ou
invalide). C'est parce que les chemins d'AS sécurisés BGPsec_path ne
sont propagés qu'entre routeurs BGPsec, qui signent et, a priori,
valident. Si on reçoit une annonce BGPsec, c'est forcément que
tout le chemin d'AS gérait BGPsec. L'équivalent du « pas de ROA »
est donc une annonce BGP traditionnelle, avec
AS_PATH mais sans
BGPsec_path.
Quant à la décision qu'on prend lorsqu'une annonce est
invalide, c'est une décision locale. Ni
l'IETF, ni l'ICANN,
ni le CSA ne peuvent prendre cette décision
à votre place. Notre RFC recommande (mais c'est juste une
recommandation) de jeter les annonces BGPsec invalides. Certains
opérateurs peuvent se dire « je vais accepter les annonces
invalides, juste leur mettre une préférence plus basse » mais cela
peut ne pas suffire à empêcher leur usage même lorsqu'il existe
des alternatives. Imaginons un routeur qui reçoive une annonce
valide pour 10.0.0.0/16 et une invalide pour
10.0.666.0/24 (oui, je sais que ce n'est pas
une adresse IPv4 correcte, mais c'est le RFC qui a commencé, ce
n'est pas moi). Le routeur installe les deux routes, avec une
préférence basse pour 10.0.666.0/24. Mais les
préférences ne jouent que s'il s'agit de préfixes identiques. Ici,
lorsqu'il faudra transmettre un paquet, c'est la route la plus
spécifique qui gagnera, donc la mauvaise (666 = chiffre
de la Bête). Notez que l'article « Are We There Yet?
On RPKI’s Deployment and Security » contient plusieurs autres exemples où le rejet d'une annonce
invalide a des conséquences surprenantes.
La même section 7 couvre aussi le cas des serveurs de routes, qui est un peu particulier car ces routeurs n'insèrent pas leur propre AS dans le chemin, ils sont censés être transparents.
Enfin, la section 8 traite de quelques points divers, comme le rappel que la RPKI (comme d'ailleurs le DNS) n'est pas cohérente en permanence, car pas transmise de manière synchrone partout. Par exemple, si vous venez d'obtenir un certificat pour un AS, ne l'utilisez pas tout de suite : les annonces BGP se propagent plus vite que les changements dans la RPKI et vos annonces signées risquent donc d'être considérées comme invalides par certains routeurs.
L'article seul
RFC 8205: BGPsec Protocol Specification
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : M. Lepinski (NCF), K. Sriram
(NIST)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 28 septembre 2017
Ce RFC s'inscrit dans la longue liste des efforts de normalisation d'une solution de sécurité pour BGP. Actuellement, il est trop facile de détourner le routage Internet via BGP (cf. mon article « La longue marche de la sécurité du routage Internet »). Le RFC 6482 introduisait une solution partielle, les ROA (Route Origin Authorizations). S'appuyant sur une infrastructure de clés publiques et de certificats prouvant que vous êtes détenteur légitime d'une ressource Internet (comme un numéro d'AS ou bien un préfixe IP), infrastructure nommée la RPKI (Resource Public Key Infrastructure), ces ROA permettent de valider l'origine d'une annonce BGP, c'est-à-dire le premier AS du chemin. C'est insuffisant pour régler tous les cas. Ainsi, lors de la fuite de Telekom Malaysia en juin 2015, les annonces avaient une origine normale. Avec les ROA, on ne détectait donc pas le problème. D'où cette nouvelle étape, BGPsec. Il s'agit cette fois de valider le chemin d'AS complet de l'annonce BGP, chaque routeur intermédiaire signant cryptographiquement l'annonce avant de la transmettre. BGPsec permet donc de détecter bien plus d'attaques, mais il est aussi bien plus lourd à déployer.
Donc, pour résumer BGPsec en une phrase : un nouvel attribut BGP
est créé, BGPsec_Path, il est transporté dans les
annonces de route BGP, il offre la possibilité de vérifier, via les
signatures, que chaque AS listé dans ce
chemin a bien autorisé l'annonce. BGPsec ne remplace pas les ROA, il
les complète (et, comme elles, il s'appuie sur la
RPKI). Deux bonnes lectures : le modèle de
menace de BGPsec, dans le RFC 7132, et le
cahier des charges de BGPsec, dans le RFC 7353.
Le reste, ce n'est que du détail technique. Contrairement aux ROA, qui sont transportés en dehors de BGP, BGPsec est une modification du protocole BGP. Deux routeurs qui font du BGPsec doivent donc le négocier lors de l'établissement de la session (section 2 de notre RFC). Cela se fait par le mécanisme des capacités du RFC 5492. La capacité annonçant qu'on sait faire du BGPsec est BGPsec Capability, code n° 7. Notez que cette capacité dépend de celle de gérer des AS de quatre octets (normalisée dans le RFC 6793).
Le nouvel attribut est décrit en section 3. (Le concept
d'attributs BGP est dans la section 5 du RFC 4271.) Les annonces BGP avaient
traditionnellement un attribut nommé AS_PATH, qui
indiquait le chemin d'AS suivi par l'annonce. (Deux choses
importantes à se rappeler : lorsqu'on écrit un chemin d'AS, il se lit
de droite à gauche, et vous n'avez aucune garantie que les
paquets IP suivront effectivement ce chemin « the data plane does not always follow
the control plane ».)
Le nouvel attribut remplace
AS_PATH. Il se nomme
BGPsec_path (code 33) et est optionnel et non-transitif,
ce qui veut dire qu'il ne sera pas passé tel quel aux pairs. Au
contraire, le routeur est supposé créer un nouvel attribut
BGPsec_path , ajoutant son AS
(signé) et celui de l'AS à qui il transmet l'annonce. On
n'envoie une annonce portant cet attribut à un pair que si celui-ci a
signalé sa capacité à gérer BGPsec. (Sinon, on lui envoie un
AS_PATH ordinaire, non sécurisé, formé en
extrayant les AS du BGPsec_path, cf. section 4.4.)
La signature contient entre autres un identifiant de l'algorithme utilisé. La liste des algorithmes possibles est dans un registre IANA (RFC 8208).
Pour pouvoir mettre sa signature dans le
BGPsec_path, le routeur doit évidemment disposer
d'une clé
privée. La clé publique correspondante doit être dans un
certificat de la RPKI, certificat valable pour
l'AS qui signe.
Un routeur qui transmet une annonce à un pair BGPsec ne garantit pas forcément qu'il a validé le chemin sécurisé. (Même s'il le garantissait, pourquoi lui faire confiance ?) C'est à chaque routeur de vérifier l'intégrité et l'authenticité du chemin d'AS (section 5 du RFC).
C'est dans cette section 5 qu'est le cœur du RFC, les détails de la validation d'un chemin d'AS. Cette validation peut être faite par le routeur, ou bien par une machine spécialisée dans la validation, avec laquelle le routeur communique via le protocole RTR (RPKI To Router protocol, cf. RFC 8210). Bien sûr, si on valide, c'est sans doute pour que la validation ait des conséquences sur la sélection de routes, mais notre RFC n'impose pas de politique particulière : ce que l'on fait avec les annonces BGPsec mal signées est une décision locale, par chaque routeur (et peut-être, sur un routeur donné, différente pour chaque pair BGP).
L'algorithme de validation est simple :
- Contrôles syntaxiques de l'annonce,
- Vérification que l'AS le plus récemment ajouté est bien celui du pair qui nous l'a envoyé (à part le cas particulier des serveurs de route, traités en section 4.2),
- Test de la présence d'une signature pour chaque AS listé dans
BGPsec_path.
À ce stade, on peut déjà rejeter les annonces qui ont échoué à l'un de ces tests, et les traiter comme signifiant un retrait de la route citée (RFC 7606). Ensuite, on passe aux vérifications cryptographiques :
- Vérification que toutes les signatures sont faites avec un algorithme cryptographique qu'on accepte (voir la section 6 et aussi le RFC 8208),
- Pour chaque AS listé dans le chemin, recherche d'un certificat correspondant à cet AS, et ayant la clé publique avec laquelle l'AS dans le chemin a été signé,
- Test de la signature.
Notez qu'on ne négocie pas les algorithmes cryptographiques au moment de l'établissement de la session BGP, comme cela se fait, par exemple, en TLS. En effet, il ne suffit pas de connaitre l'algorithme de ses pairs, il faut valider tout le chemin, y compris des AS lointains. C'est pour cela que le RFC 8208 liste des algorithmes obligatoires, que tout le monde est censé connaître (actuellement ECDSA avec la courbe P-256 et SHA-256).
On note que l'attribut BGPsec_path avec ses
signatures n'est « transmis » qu'aux routeurs qui comprennent
BGPsec (pour les autres, on envoie un AS_PATH classique). Au début du déploiement, ces attributs ne survivront donc pas
longtemps, et les îlots BGPsec seront donc rares (section 7 du
RFC).
Notez que ce protocole est en développement depuis plus de six ans, et qu'il s'est parfois nommé PathSec dans le passé.
BGPsec est apparemment mis en œuvre au moins dans BIRD et dans Quagga (mais pas dans les versions officielles).
Quelques bonnes lectures sur BGPsec :
- Les transparents de mon exposé à FRnog 29.
- Le RFC 8374 explique et justifie les différents choix effectués lors de la conception de BGPsec.
- La série qui commence ici et les suivants. Très critique de BGPsec mais attention, certains reproches ne sont plus d'actualité (les timers sur les mises à jour, qui devaient limiter le risque d'attaque par rejeu ont été retirés depuis).
Et merci à Guillaume Lucas pour m'avoir rappelé que BGPsec est compliqué et que je suis loin de le maitriser.
L'article seul
RFC 8201: Path MTU Discovery for IP version 6
Date de publication du RFC : Juillet 2017
Auteur(s) du RFC : J. McCann (Digital Equipment
Corporation), S. Deering
(Retired), J. Mogul (Digital Equipment
Corporation), R. Hinden (Check Point
Software)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 16 juillet 2017
Ce RFC est l'adaptation à IPv6 du protocole décrit dans le RFC 1191, protocole qui permet de découvrir la MTU du chemin entre deux machines reliées par Internet. Il remplace le RFC 1981.
Avec IPv4, déterminer la MTU maximale du chemin est très utile pour optimiser les performances. Mais elle devient presque indispensable en IPv6, où les routeurs n'ont pas le droit de fragmenter les paquets trop gros (toute fragmentation doit être faite dans la machine de départ). PMTU fait donc quasi-obligatoirement partie d'IPv6. Une alternative est de n'envoyer que des paquets suffisamment petits pour passer partout. C'est moins efficace (on ne tirera pas profit des MTU plus importantes), mais ça peut être intéressant pour des mises en œuvre légères d'IPv6, par exemple pour des objets connectés. (La section 4 du RFC précise en effet que mettre en œuvre cette découverte de la MTU du chemin n'est pas obligatoire.)
L'algorithme (section 3 de notre RFC) est le même qu'en v4, envoyer des paquets, et voir si on reçoit des paquets ICMP Packet too big (RFC 4443, section 3.2) qui contiennent en général la MTU maximale du lien suivant. (Pas de bit DF - Don't fragment - en IPv6 puisque la fragmentation n'est possible qu'à la source. L'annexe A détaille les différences avec l'algorithme IPv4 décrit dans le RFC 1191.)
Voici par exemple un de ces paquets ICMP, vu par
tcpdump (déclenché par une commande
ping -s 1500 …) :
18:18:44.813927 IP6 2a02:8400:0:3::a > 2605:4500:2:245b::bad:dcaf: ICMP6, packet too big, mtu 1450, length 1240
Il ne faut pas s'arrêter au premier paquet Packet too big reçu, car il peut y avoir des liens réseau avec une MTU encore plus basse plus loin. En outre, la MTU du chemin change avec le temps et il faut donc rester vigilant, on peut recevoir des Packet too big si le trafic passe désormais par un lien de MTU plus faible que la précédente MTU du chemin. Plus délicat, il faut aussi de temps en temps réessayer avec des paquets plus gros, pour voir si la MTU du chemin n'aurait pas augmenté. Comme cela va faire perdre des paquets, s'il n'y a pas eu d'augmentation, il ne faut pas le faire trop souvent. (Dix minutes, dit la section 5.)
La section 4 du RFC précise les exigences qu'il normalise. (Je
donne quelques exemples de leur mise en œuvre dans le noyau
Linux, dans net/ipv6/route.c.) Par
exemple, le nœud IPv6 doit vérifier le contenu
des paquets ICMP Packet Too
Big qu'il reçoit (le Message Body,
cf. RFC 4443, où le routeur émetteur est censé
placer des données du paquet original), pour éviter de croire des faux messages
ICMP envoyés par un attaquant (rien n'authentifie un paquet ICMP, à
part son contenu).
Nouveauté de ce RFC, par rapport à son prédecesseur, un nœud IPv6
doit ignorer les messages Packet Too
Big indiquant une MTU inférieur aux 1 280 octets minimum
d'IPv6 (le RFC 8021 explique pourquoi). C'est le
but de l'instruction mtu = max_t(u32, mtu,
IPV6_MIN_MTU); dans le code du noyau Linux, qui ne garde
pas la MTU indiquée si elle est inférieur au minimum.
Et la machine IPv6 ne doit jamais augmenter la
MTU du chemin suite à la réception d'un Packet Too
Big indiquant une MTU supérieure à l'actuelle. Un tel
message ne peut être qu'une erreur ou une attaque. Voir les
commentaires au début de la fonction
rt6_mtu_change_route dans le code Linux.
Comme avec IPv4, l'algorithme PMTU marche mal en pratique car beaucoup de sites filtrent stupidement tous les paquets ICMP et la machine qui tente de faire de la Path MTU discovery n'aura jamais de réponse. IPv6, comme IPv4, devra donc plutôt utiliser la technique du RFC 4821.
La section 5 du RFC rassemble diverses questions de mise en œuvre de cette découverte de la MTU du chemin. D'abord, il y a l'interaction entre IP (couche 3) et les protocoles au dessus, comme TCP mais aussi des protocoles utilisant UDP, comme le DNS. Ces protocoles de transport ont une MMS_S (maximum send transport-message size, voir le RFC 1122) qui est à l'origine la MTU moins la taille des en-têtes. Les protocoles de transport peuvent diminuer cette MMS_S pour ne pas avoir à faire de fragmentation.
Pour le DNS, par exemple, on peut diminuer l'usage de la découverte de la MTU du chemin en diminuant la taille EDNS. Par exemple, avec le serveur nsd, on mettrait :
ipv6-edns-size: 1460
Et, avec 1 460 octets possibles, on serait alors raisonnablement sûr de ne pas avoir de fragmentation donc, même si la découverte de la MTU du chemin marche mal, tout ira bien.
Une fois la découverte de la MTU du chemin faite, où faut-il garder l'information, afin d'éviter de recommencer cette découverte à chaque fois ? Idéalement, cette information est valable pour un chemin donné : si le chemin change (ou, a fortiori, si la destination change), il faudra découvrir à nouveau. Mais la machine finale ne connait pas en général tout le chemin suivi (on ne fait pas un traceroute à chaque connexion). Le RFC suggère donc (section 5.2) de stocker une MTU du chemin par couple {destination, interface}. Si on n'a qu'une seule interface réseau, ce qui est le cas de la plupart des machines terminales, on stocke la MTU du chemin par destination et on maintient donc un état pour chaque destination (même quand on ne lui parle qu'en UDP, qui n'a normalement pas d'état). Les deux exemples suivants concernent une destination où la MTU du chemin est de 1 450 octets. Pour afficher cette information sur Linux pour une adresse de destination :
% ip -6 route get 2a02:8428:46c:5801::4
2a02:8428:46c:5801::4 from :: via 2001:67c:1348:7::1 dev eth0 src 2001:67c:1348:7::86:133 metric 0
cache expires 366sec mtu 1450 pref medium
S'il n'y a pas de PMTU indiquée, c'est que le cache a expiré, réessayez (en UDP, car TCP se fie à la MSS). Notez que, tant qu'on n'a pas reçu un seul Packet Too Big, il n'y a pas de MTU affichée. Donc, pour la plupart des destinations (celles joignables avec comme PMTU la MTU d'Ethernet), vous ne verrez rien. Sur FreeBSD, cet affichage peut se faire avec :
% sysctl -o net.inet.tcp.hostcache.list | fgrep 2a02:8428:46c:5801::4 2a02:8428:46c:5801::4 1450 0 23ms 34ms 0 4388 0 0 23 4 3600
Pour d'autres systèmes, je vous recommande cet article.
Notez qu'il existe des cas compliqués (ECMP) où cette approche de stockage de la PMTU par destination peut être insuffisante. Ce n'est donc qu'une suggestion, chaque implémentation d'IPv6 peut choisir sa façon de mémoriser les MTU des chemins.
Si on veut simplifier la mise en œuvre, et la consommation mémoire, on peut ne mémoriser qu'une seule MTU du chemin, la MTU minimale de tous les chemins testés. Ce n'est pas optimal, mais ça marchera.
Si on stocke la MTU du chemin, comme l'Internet peut changer, il faut se préparer à ce que l'information stockée devienne obsolète. Si elle est trop grande, on recevra des Packet too big (il ne faut donc pas s'attendre à n'en recevoir que pendant la découverte initiale). Si elle est trop petite, on va envoyer des paquets plus petits que ce qu'on pourrait se permettre. Le RFC suggère donc (section 5.3) de ne garder l'information sur la MTU du chemin que pendant une dizaine de minutes.
Le RFC demande enfin (section 5.5) que les mises en œuvre d'IPv6 permettent à l'ingénieur système de configurer la découverte de la MTU du chemin : la débrayer sur certaines interfaces, fixer à la main la MTU d'un chemin, etc.
Il ne faut pas oublier les problèmes de sécurité (section 6 du RFC) : les Packet Too Big ne sont pas authentifiés et un attaquant peut donc en générer pour transmettre une fausse information. Si la MTU indiquée est plus grande que la réalité, les paquets seront jetés. Si elle est plus petite, on aura des sous-performances.
Autre problème de sécurité, le risque que certains administrateurs réseau incompétents ne filtrent tous les messages ICMP, donc également les Packet Too Big (c'est stupide, mais cela arrive). Dans ce cas, la découverte de la MTU du chemin ne fonctionnera pas (cf. RFC 4890 sur les recommandations concernant le filtrage ICMP). L'émetteur devra alors se rabattre sur des techniques comme celle du RFC 4821.
L'annexe B de notre RFC résume les changements faits depuis le RFC 1981. Rien de radical, les principaux portent sur la sécurité (ce sont aussi ceux qui ont engendré le plus de discussions à l'IETF) :
- Bien expliquer les problèmes créés par le blocage des messages ICMP,
- Formulations plus strictes sur la validation des messages ICMP,
- Et surtout, suppression des « fragments atomiques » (RFC 8021).
Le texte a également subi une actualisation générale, les références (pré-)historiques à BSD 4.2 ou bien à TP4 ont été supprimées.
Enfin, pour faire joli, un exemple de
traceroute avec recherche de la MTU du chemin
activée (option --mtu). Notez la réception d'un
Packet Too Big à l'étape 12, annonçant une MTU de
1 450 octets :
% sudo traceroute -6 --mtu --udp --port=53 eu.org traceroute to eu.org (2a02:8428:46c:5801::4), 30 hops max, 65000 byte packets ... 3 vl387-te2-6-paris1-rtr-021.noc.renater.fr (2001:660:300c:1002:0:131:0:2200) 2.605 ms 2.654 ms 2.507 ms 4 2001:660:7903:6000:1::4 (2001:660:7903:6000:1::4) 5.002 ms 4.484 ms 5.494 ms 5 neuf-telecom.sfinx.tm.fr (2001:7f8:4e:2::178) 4.193 ms 3.682 ms 3.763 ms 6 neuf-telecom.sfinx.tm.fr (2001:7f8:4e:2::178) 14.264 ms 11.927 ms 11.509 ms 7 2a02-8400-0000-0003-0000-0000-0000-1006.rev.sfr.net (2a02:8400:0:3::1006) 12.760 ms 10.446 ms 11.902 ms 8 2a02-8400-0000-0003-0000-0000-0000-1c2e.rev.sfr.net (2a02:8400:0:3::1c2e) 10.524 ms 11.477 ms 11.896 ms 9 2a02-8400-0000-0003-0000-0000-0000-1c2e.rev.sfr.net (2a02:8400:0:3::1c2e) 13.061 ms 11.589 ms 11.915 ms 10 2a02-8400-0000-0003-0000-0000-0000-117e.rev.sfr.net (2a02:8400:0:3::117e) 10.446 ms 10.420 ms 10.361 ms 11 2a02-8400-0000-0003-0000-0000-0000-000a.rev.sfr.net (2a02:8400:0:3::a) 10.460 ms 10.453 ms 10.517 ms 12 2a02-8428-046c-5801-0000-0000-0000-00ff.rev.sfr.net (2a02:8428:46c:5801::ff) 12.495 ms F=1450 12.102 ms 11.203 ms 13 2a02-8428-046c-5801-0000-0000-0000-0004.rev.sfr.net (2a02:8428:46c:5801::4) 12.397 ms 12.217 ms 12.507 ms
La question de la fragmentation en IPv6 a suscité d'innombrables articles. Vous pouvez commencer par celui de Geoff Huston.
Merci à Pierre Beyssac pour avoir fourni le serveur de test configuré comme il fallait, et à Laurent Frigault pour la solution sur FreeBSD.
L'article seul
RFC 8200: Internet Protocol, Version 6 (IPv6) Specification
Date de publication du RFC : Juillet 2017
Auteur(s) du RFC : S. Deering (Retired), R. Hinden (Check Point Software)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 16 juillet 2017
Ce RFC est la nouvelle norme du protocole IPv6. IP est le protocole de base de l'Internet, la version 6 y est minoritaire mais est bien plus répandue qu'elle ne l'était lors de la sortie de la précédente norme, qui était le RFC 2460, norme que notre nouveau RFC remplace (et cela fait passer IPv6 au statut de norme Internet, la précédente étant officiellement une proposition de norme).
Pas de changements cruciaux, la norme est nouvelle, mais le protocole reste largement le même. Ce RFC 8200 continue à présenter IPv6 comme « a new version of the Internet Protocol (IP) ». Comme la première norme IPv6 est sortie en 1995, l'adjectif « new » n'est vraiment pas sérieux. Comme, malheureusement, la plupart des formations réseau ne parlent que d'IPv4 et traitent IPv6 de manière bâclée à la fin, le RFC présente IPv6 en parlant de ses différences par rapport à IPv4 (section 1 du RFC) :
- La principale est évidemment l'espace d'adressage bien plus grand. Alors qu'IPv4, avec ses adresses sur 32 bits, ne peut même pas donner une adresse IP à chaque habitant de la planète (ce qui serait déjà insuffisant), IPv6, avec ses 128 bits d'adresse, permet de distribuer une quantité d'adresses que le cerveau humain a du mal à se représenter. Cette abondance est la principale raison pour laquelle il est crucial de migrer vers IPv6. Les autres raisons sont plus discutables.
- IPv6 a sérieusement changé le format des options. En IPv4, les options IP étaient un champ de longueur variable dans l'en-tête, pas exactement ce qui est le plus facile à analyser pour un routeur. Le RFC dit qu'IPv6 a simplifié le format mais c'est contestable : une complexité a succédé à une autre. Désormais, le premier en-tête est de taille fixe, mais il peut y avoir un nombre quelconque d'en-têtes chaînés. Le RFC utilise malheureusement des termes publicitaires assez déconnectés de la réalité, en parlant de format plus efficace et plus souple.
- IPv6 a un mécanisme standard pour étiqueter les paquets appartenant à un même flot de données. Mais le RFC oublie de dire qu'il semble inutilisé en pratique.
- Et le RFC termine cette énumération par le plus gros pipeautage, prétendre qu'IPv6 aurait de meilleurs capacités d'authentification et de confidentialité. (C'est faux, elles sont les mêmes qu'en IPv4, et peu déployées, en pratique.)
Notez que ce RFC 8200 ne spécifie que le format des paquets IPv6. D'autres points très importants sont normalisés dans d'autres RFC, les adresses dans le RFC 4291, et ICMP dans le RFC 4443.
La section 3 présente le format des paquets IPv6 :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| Traffic Class | Flow Label |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload Length | Next Header | Hop Limit |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Source Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Destination Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
(D'ailleurs, si quelqu'un sait pourquoi l'adresse IP source est avant la destination ? Il me semblerait plus logique que ce soit l'inverse, puisque tous les routeurs sur le trajet doivent examiner l'adresse destination, alors qu'on n'a pas toujours besoin de l'adresse source.) Le numéro de version vaut évidemment 6, le « traffic class » est présenté en section 7, le « flow label » en section 6.
Le champ « Next header » remplace le « Protocol » d'IPv4. Il peut indiquer le protocole de transport utilisé (la liste figure dans un registre IANA et est la même pour IPv4 et IPv6) mais aussi les en-têtes d'extension, une nouveauté d'IPv6, présentée en section 4 de notre RFC.
Le champ « Hop limit » remplace le « Time to Live » d'IPv4. En fait, les deux ont exactement la même sémantique, qui est celle d'un nombre maximal de routeurs utilisés sur le trajet (le but est d'éviter les boucles infinies dans le réseau). Autrefois, dans IPv4, il était prévu que ce champ soit réellement une durée, mais aucune mise en œuvre d'IPv4 ne l'avait jamais utilisé comme ceci. Le renommage dans IPv6 fait donc correspondre la terminologie avec une réalité ancienne (cf. aussi la section 8.2). Notez que c'est ce champ qui est utilisé par traceroute.
Voici une simple connexion HTTP en IPv6,
vue avec tcpdump et
tshark. Le client a demandé
/robots.txt et a obtenu une réponse négative
(404). Si vous voulez, le pcap complet est
ipv6-http-connection.pcap. Voici d'abord avec
tcpdump avec ses options par défaut :
15:46:21.768536 IP6 2001:4b98:dc2:43:216:3eff:fea9:41a.37703 > 2605:4500:2:245b::42.80: Flags [S], seq 3053097848, win 28800, options [mss 1440,sackOK,TS val 1963872568 ecr 0,nop,wscale 7], length 0
On voit les deux adresses IPv6, tcpdump n'affiche rien d'autre de
l'en-tête de couche 3, tout le reste est du
TCP, le protocole de transport utilisé par HTTP. Avec l'option -v de tcpdump :
15:46:21.768536 IP6 (hlim 64, next-header TCP (6) payload length: 40) 2001:4b98:dc2:43:216:3eff:fea9:41a.37703 > 2605:4500:2:245b::42.80: Flags [S] [...]
Cette fois, on voit le « Hop limit » (64),
l'en-tête suivant (TCP, pas d'en-tête d'extension) et la longueur
(40 octets). Pour avoir davantage, il faut passer à
tshark (décodage complet en ipv6-http-connection.txt) :
Internet Protocol Version 6, Src: 2001:4b98:dc2:43:216:3eff:fea9:41a, Dst: 2605:4500:2:245b::42
0110 .... = Version: 6
.... 0000 0000 .... .... .... .... .... = Traffic class: 0x00 (DSCP: CS0, ECN: Not-ECT)
.... 0000 00.. .... .... .... .... .... = Differentiated Services Codepoint: Default (0)
.... .... ..00 .... .... .... .... .... = Explicit Congestion Notification: Not ECN-Capable Transport (0)
.... .... .... 0000 0000 0000 0000 0000 = Flow label: 0x00000
Payload length: 40
Next header: TCP (6)
Hop limit: 64
Source: 2001:4b98:dc2:43:216:3eff:fea9:41a
[Source SA MAC: Xensourc_a9:04:1a (00:16:3e:a9:04:1a)]
Destination: 2605:4500:2:245b::42
[Source GeoIP: France]
[Source GeoIP Country: France]
[Destination GeoIP: United States]
[Destination GeoIP Country: United States]
On a cette fois tout l'en-tête IPv6 : notons le « Flow Label » (j'avais bien dit que peu de gens s'en servaient, il est nul dans ce cas).
La section 4 de notre RFC est dédiée à une nouveauté d'IPv6, les en-têtes d'extension. Au lieu d'un champ « Options » de taille variable (donc difficile à analyser) comme en IPv4, IPv6 met les options IP dans des en-têtes supplémentaires, chaînés avec l'en-tête principal. Par exemple, si un paquet UDP a un en-tête « Destination Options », le champ « Next header » de l'en-tête principal vaudra 60 (pour « Destination Options »), il sera suivi de l'en-tête d'extension « Destination Options » qui aura, lui, un « Next header » de 17 pour indiquer que ce qui suit est de l'UDP. (Je rappelle que les valeurs possibles pour « Next Header » sont dans un registre IANA.) Il peut y avoir zéro, un ou davantage d'en-têtes d'extension chaînés entre eux.
Notez qu'analyser cette chaîne d'en-têtes est compliqué car les en-têtes n'ont pas tous le même format (le RFC 6564 a créé un format unique, mais cela ne concerne que les futurs en-têtes.) Il est donc exagéré de dire que la suppression du champ « Options » de taille variable a simplifié les choses.
Les différents en-têtes ne sont pas tous traités pareillement par les routeurs. Il existe notamment un en-tête, « Hop-by-hop Options » qui doit être examiné par tous les routeurs du trajet (cette obligation, jamais respectée, a de toute façon été relâchée par rapport au RFC 2460, puis re-spécifiée de manière plus réaliste dans le RFC 9673). C'est pour cela qu'il doit être placé au début des en-têtes, juste après l'en-tête principal. Les autres en-têtes d'extension doivent être ignorés par les routeurs.
Comme il est compliqué de rajouter un nouveau modèle d'en-tête (il faudrait modifier toutes les machines IPv6), une solution légère existe pour les options simples : utiliser les en-têtes d'options, « Hop-by-hop Options » et « Destination Options ». Tous les deux sont composés d'une série d'options encodées en TLV. En outre, le type de l'option indique, dans ses deux premiers bits, le traitement à appliquer au paquet si le système ne connait pas cette option. Si les deux premiers bits sont à zéro, on ignore l'option et on continue. Autrement, on jette le paquet (les trois valeurs restantes, 01, 10 et 11, indiquent si on envoie un message d'erreur ICMP et lequel). Ainsi, l'option pour la destination de numéro 0x07 (utilisée par le protocole de sécurité du RFC 5570) est facultative : elle a les deux premiers bits à zéro et sera donc ignorée silencieusement par les destinataires qui ne la connaissent pas (cf. registre IANA.)
« Destination Options », comme son nom l'indique, n'est examinée que par la machine de destination. Si vous voulez envoyer des paquets avec cet en-tête, regardez mon article.
Outre les en-têtes « Hop-by-hop Options » et « Destination Options », il existe des en-têtes :
- « Routing Header », qui permet de spécifier le routage depuis la source (un peu comme les options de « source routing » en IPv4). Il y a plusieurs types, et les valeurs possibles sont dans un registre IANA, géré suivant les principes du RFC 5871. (Le type 0 a été retiré depuis le RFC 5095.)
- « Fragment Header », qui permet de fragmenter les paquets de taille supérieure à la MTU.
- Les autres en-têtes sont ceux utilisés par IPsec, décrits dans les RFC 4302 et RFC 4303.
La fragmentation est différente de celle
d'IPv4. En IPv6, seule la machine émettrice peut fragmenter, pas
les routeurs intermédiaires. Si le paquet est plus grand que la
MTU, on le découpe en fragments, chaque
fragment portant un « Fragment Header ». Cet
en-tête porte une identification (un nombre sur 32 bits qui doit
être unique parmi les paquets qui sont encore dans le réseau),
un décalage (offset) qui indique à combien
d'octets depuis le début du paquet original se situe ce fragment
(il vaut donc zéro pour le premier fragment) et un bit qui indique
si ce fragment est le dernier. À la destination, le paquet est
réassemblé à partir des fragments. (Il est désormais interdit que
ces fragments se recouvrent, cf. RFC 5722.) Voici un exemple de fragmentation. La sonde Atlas n° 6271 a
interrogé un serveur DNS de la racine Yeti avec le type de
question ANY qui signifie « envoie-moi tout
ce que tu peux / veux ». La réponse, plus grande que la MTU (plus
de quatre kilo-octets !), a été
fragmentée en trois paquets (le pcap
complet est en ipv6-dns-frag.pcap) :
16:14:27.112945 IP6 2001:67c:217c:4::2.60115 > 2001:4b98:dc2:45:216:3eff:fe4b:8c5b.53: 19997+ [1au] ANY? . (28)
16:14:27.113171 IP6 2001:4b98:dc2:45:216:3eff:fe4b:8c5b > 2001:67c:217c:4::2: frag (0|1232) 53 > 60115: 19997*- 35/0/1 NS bii.dns-lab.net., NS yeti.bofh.priv.at., NS yeti.ipv6.ernet.in., NS yeti.aquaray.com., NS yeti.mind-dns.nl., NS dahu1.yeti.eu.org., NS dahu2.yeti.eu.org., NS yeti1.ipv6.ernet.in., NS ns-yeti.bondis.org., NS yeti-ns.ix.ru., NS yeti-ns.lab.nic.cl., NS yeti-ns.tisf.net., NS yeti-ns.wide.ad.jp., NS yeti-ns.conit.co., NS yeti-ns.datev.net., NS yeti-ns.switch.ch., NS yeti-ns.as59715.net., NS yeti-ns1.dns-lab.net., NS yeti-ns2.dns-lab.net., NS yeti-ns3.dns-lab.net., NS xn--r2bi1c.xn--h2bv6c0a.xn--h2brj9c., NS yeti-dns01.dnsworkshop.org., NS yeti-dns02.dnsworkshop.org., NS 3f79bb7b435b05321651daefd374cd.yeti-dns.net., NS ca978112ca1bbdcafac231b39a23dc.yeti-dns.net., RRSIG, NSEC, RRSIG[|domain]
16:14:27.113187 IP6 2001:4b98:dc2:45:216:3eff:fe4b:8c5b > 2001:67c:217c:4::2: frag (1232|1232)
16:14:27.113189 IP6 2001:4b98:dc2:45:216:3eff:fe4b:8c5b > 2001:67c:217c:4::2: frag (2464|637)
On note que tcpdump n'a interprété qu'un seul fragment comme étant
du DNS, la premier, puisque c'était le seul qui portait l'en-tête
UDP, avec le numéro de port 53 identifiant du DNS. Dans le
résultat de tcpdump, après le mot-clé frag,
on voit le décalage du fragment par rapport au début du paquet
original (respectivement 0, 1232 et 2464 pour les trois
fragments), et la taille du fragment (respectivement 1232, 1232 et
637 octets). Vu par tshark (l'analyse complète est en ipv6-dns-frag.txt), le premier fragment contient :
Type: IPv6 (0x86dd)
Internet Protocol Version 6, Src: 2001:4b98:dc2:45:216:3eff:fe4b:8c5b, Dst: 2001:67c:217c:4::2
Payload length: 1240
Next header: Fragment Header for IPv6 (44)
Fragment Header for IPv6
Next header: UDP (17)
Reserved octet: 0x00
0000 0000 0000 0... = Offset: 0 (0 bytes)
.... .... .... .00. = Reserved bits: 0
.... .... .... ...1 = More Fragments: Yes
Identification: 0xcbf66a8a
Data (1232 bytes)
On note le « Next Header » qui indique qu'un en-tête d'extension, l'en-tête « Fragmentation », suit l'en-tête principal. Le bit M (« More Fragments ») est à 1 (ce n'est que le premier fragment, d'autres suivent), le décalage (« offset ») est bien sûr de zéro. L'identificateur du paquet est de 0xcbf66a8a. Le dernier fragment, lui, contient :
Internet Protocol Version 6, Src: 2001:4b98:dc2:45:216:3eff:fe4b:8c5b, Dst: 2001:67c:217c:4::2
Payload length: 645
Next header: Fragment Header for IPv6 (44)
Fragment Header for IPv6
Next header: UDP (17)
Reserved octet: 0x00
0000 1001 1010 0... = Offset: 308 (2464 bytes)
.... .... .... .00. = Reserved bits: 0
.... .... .... ...0 = More Fragments: No
Identification: 0xcbf66a8a
Cette fois, le « Next Header » indique que c'est de l'UDP qui suit, le décalage est de 2464, et le bit M est à zéro (plus d'autres fragments). L'identificateur est le même, c'est celui du paquet original, et c'est grâce à lui que la machine de destination saura réassembler les fragments. Notez qu'à la fin de l'analyse par tshark figure un réassemblage complet du paquet, ce qui permet une analyse DNS complète.
Et si je ne suis pas satisfait des en-têtes d'extension existants et que je veux créer le mien ? C'est en général une mauvaise idée. La plupart des cas concrets devraient être résolus avec un des en-têtes déjà normalisés. Notamment, l'en-tête « Destination Options » est là pour la majorité des situations. C'est lui qu'il faut regarder en premier (ce qu'ont fait les RFC 6744, RFC 6788 ou RFC 7837, la liste complète figurant dans un registre IANA). Notre RFC 8200 exige donc que, si vous tenez à créer un nouvel en-tête, vous expliquiez bien pourquoi c'est indispensable, et pourquoi aucun des en-têtes existants ne convient.
Il est également déconseillé de créer de nouvelles options « hop-by-hop » (la liste actuelle est à l'IANA), car ces options doivent être traitées par tous les routeurs du trajet. Il y a un risque sérieux qu'ils laissent tomber les paquets ayant cet en-tête « Hop-by-hop Options », ou bien qu'ils le traitent plus lentement (logiciel du routeur et pas circuits matériels spécialisés). Là aussi, il faudra donc une justification sérieuse.
La section 5 de notre RFC se penche sur un problème délicat, la taille des paquets. IPv6 exige une MTU d'au moins 1 280 octets, mais les paquets sont souvent plus grands (par exemple 1 500 octets si on part d'un Ethernet). Beaucoup de liens ont, en pratique, une MTU de 1 500 octets mais IPv6 étant souvent porté par des tunnels (en raison de l'immobilisme de beaucoup de FAI, qui ne déploient toujours pas IPv6), un certain nombre de liens offrent moins de 1 500 octets. Normalement, l'émetteur d'un paquet IPv6 doit faire de la découverte de la MTU du chemin (RFC 8201) afin de pouvoir fragmenter, si nécessaire. Une mise en œuvre « paresseuse » d'IPv6 pourrait se dispenser de découverte de la MTU du chemin, et se limiter à 1 280 octets par paquet.
Le problème est que la découverte de la MTU du chemin dépend du bon fonctionnement d'ICMP. L'émetteur d'un paquet doit pouvoir recevoir les paquets ICMP « Packet too big » (RFC 4443, section 3.2). Or, un certain nombre de pare-feux, stupidement configurés par des amateurs, bloquent tout ICMP « pour des raisons de sécurité » (c'est d'ailleurs une bonne question pour les entretiens d'embauche d'un administrateur de réseaux : « filtrer ICMP en entrée ou pas ? » S'il répond Oui, on est sûr qu'il est incompétent.) Ne recevant pas les « Packet too big », l'émetteur risque de croire à tort que ses paquets sont passés. En outre, si l'émetteur décide de fragmenter (en général, quand la MTU du chemin est inférieure à la sienne, avec TCP, on réduit la MSS, avec UDP, on fragmente), il faut que les fragments passent à travers le réseau. Et, là encore, un certain nombre de pare-feux bêtement configurés bloquent les fragments. Donc, en pratique, découverte du chemin + fragmentation est un processus fragile, en raison de ce véritable sabotage par des middleboxes.
C'est certainement le plus gros problème pratique lors du déploiement d'IPv6. On peut même penser à prendre des mesures radicales et coûteuses, comme d'abaisser la MTU à 1 280 octets pour être tranquille. Moins violent, il est fréquent de voir des MTU à 1 480 octets. Voici par exemple la configuration de mon routeur Turris Omnia pour passer par l'IPv6 de Free (un tunnel) :
config interface 'lan'
option ip6assign '64'
option ip6addr '2001:db8:42::1:fe/64'
option ip6prefix '2001:db8:42::/64'
option ip6gw '2001:db8:42::1'
option mtu '1480'
Et le « flow label », dont j'avais parlé plus haut ? Il est décrit dans la (très courte) section 6, qui renvoie surtout au RFC 6437. En pratique, ce champ semble peu utilisé comme on l'a vu dans l'exemple décodé par tshark.
Même chose pour le « traffic class », en section 7 : pour son utilisation pour la différenciation de trafic, voir les RFC 2474 et RFC 3168.
Maintenant qu'IPv6, protocole de couche 3, a été bien défini, le RFC monte vers la couche 4, en consacrant sa section 8 aux problèmes des couches supérieures. Cela concerne notamment la somme de contrôle. Si vous avez fait attention au schéma de l'en-tête IPv6 de la section 3, vous avez noté qu'il n'y avait pas de champ « Header Checksum », contrairement à ce qui existait en IPv4. En IPv6, pas de somme de contrôle en couche 3, c'était une tâche supplémentaire pour les routeurs (pour citer le RFC 791, « Since some header fields change (e.g., time to live), this is recomputed and verified at each point that the internet header is processed. »), tâche dont ils sont désormais dispensés.
Par contre, la somme de contrôle existe pour les en-têtes de couche 4 et elle devient même obligatoire pour UDP (elle était facultative en IPv4, quoique très fortement recommandée). (Voir le RFC 1071, au sujet de cette somme de contrôle.)
Un gros changement de ce RFC par rapport à son prédécesseur, le RFC 2460, concerne la sécurité. La section sur la sécurité est passée d'une annexe de deux lignes (qui se contentait de passer le bébé à IPsec) à une analyse plus détaillée (section 10 du RFC). La question est délicate car la sécurité d'IPv6 a souvent fait l'objet de FUD, visant à justifier l'immobilisme de pas mal d'acteurs. Il est évidemment plus valorisant de dire « nous ne migrons pas vers IPv6 pour des raisons de sécurité » que de reconnaitre « nous sommes trop flemmards et paralysés par la peur du changement ». (Cf. mon exposé sur la sécurité d'IPv6 à l'ESGI.) S'il fallait synthétiser (la deuxième partie de cette synthèse ne figure pas dans le RFC), je dirais :
- La sécurité d'IPv6 est quasiment la même qu'en IPv4 (ce qui est logique, il ne s'agit après tout que de deux versions du même protocole). Les grandes questions de sécurité d'IPv4 (usurpation d'adresse source, relative facilité à faire des attaques par déni de service, pas d'authentification ou de confidentialité par défaut) sont exactement les mêmes en IPv6. (C'est une blague courante à l'IETF de dire que si IPv4, l'un des plus grands succès de l'ingéniérie du vingtième siècle, était présenté à l'IESG aujourd'hui, il serait rejeté pour sa trop faible sécurité.)
- Par contre, en pratique, les solutions techniques d'attaque et de défense, ainsi que les compétences des attaquants et des défenseurs, sont bien plus faibles en IPv6. Pas mal de logiciels « de sécurité » ne gèrent pas IPv6, bien des logiciels de piratage ne fonctionnent qu'en IPv4, les administrateurs système sont déroutés face à une attaque IPv6, et les pirates ne pensent pas à l'utiliser. (Faites l'expérience : configurez un pot de miel SSH en IPv4 et IPv6. Vous aurez plusieurs connexions par jour en IPv4 et jamais une seule en IPv6.) L'un dans l'autre, je pense que ces deux aspects s'équilibrent.
Bon, assez de stratégie, passons maintenant aux problèmes concrets que décrit cette section 10. Elle rappelle des risques de sécurité qui sont exactement les mêmes qu'en IPv4 mais qu'il est bon de garder en tête, ce sont des problèmes fondamentaux d'IP :
- Communication en clair par défaut, donc espionnage trop facile pour les États, les entreprises privées, les pirates individuels. (Cf. Snowden.)
- Possibilité de rejouer des paquets déjà passés, ce qui permet certaines attaques. Dans certains cas, on peut modifier le paquet avant de le rejouer, et ça passera.
- Possibilité de générer des faux paquets et de les injecter dans le réseau.
- Attaque de l'homme du milieu : une entité se fait passer pour l'émetteur auprès du vrai destinataire, et pour le destinataire auprès du vrai émetteur.
- Attaque par déni de service, une des plaies les plus pénibles de l'Internet.
En cohérence avec le RFC 2460 (mais pas avec la réalité du terrain), notre RFC recommande IPsec (RFC 4301) comme solution à la plupart de ces problèmes. Hélas, depuis le temps qu'il existe, ce protocole n'a jamais connu de déploiement significatif sur l'Internet public (il est par contre utilisé dans des réseaux privés, par exemple le VPN qui vous permet de vous connecter avec votre entreprise de l'extérieur utilise probablement une variante plus ou moins standard d'IPsec). Une des raisons de ce faible déploiement est la grande complexité d'IPsec, et la complexité pire encore de ses mises en œuvre. En pratique, même si le RFC ne le reconnait que du bout des lèvres, ce sont les protocoles applicatifs comme SSH ou TLS, qui sécurisent l'Internet.
Pour les attaques par déni de service, par contre, aucune solution n'est proposée : le problème ne peut pas forcément se traiter au niveau du protocole réseau.
La différence la plus spectaculaire entre IPv4 et IPv6 est
évidemment la taille des adresses. Elle rend le
balayage bien plus complexe (mais pas impossible), ce qui
améliore la sécurité (l'Internet IPv4 peut être exploré
incroyablement vite, par exemple avec masscan,
et, si on est trop flemmard pour balayer soi-même, on peut
utiliser des balayages déjà faits, par exemple par
Shodan ou https://scans.io/
Et qu'en est-il de la vie privée ? L'argument, largement FUDé, a été beaucoup utilisé contre IPv6. Le RFC note qu'IPv6 a entre autre pour but de rendre inutile l'usage du NAT, dont certaines personnes prétendent qu'il protège un peu les utilisateurs. L'argument est largement faux : le NAT (qui est une réponse à la pénurie d'adresses IPv4, pas une technique de sécurité) ne protège pas contre tout fingerprinting, loin de là. Et, si on veut empêcher les adresses IP des machines du réseau local d'être visibles à l'extérieur, on peut toujours faire du NAT en IPv6, si on veut, ou bien utiliser des méthodes des couches supérieures (comme un relais).
Autre question de vie privée avec IPv6, les adresses IP fondées sur l'adresse MAC. Cette ancienne technique, trop indiscrète, a été abandonnée avec les RFC 8981 et RFC 7721, le premier étant très déployé. Il est curieux de constater que cet argument soit encore utilisé, alors qu'il a perdu l'essentiel de sa (faible) pertinence.
Mais il y avait bien des problèmes de sécurité concrets avec le précédent RFC 2460, et qui sont réparés par ce nouveau RFC :
- Les « fragments atomiques » ne doivent désormais plus être générés (RFC 8021) et, si on en reçoit, doivent être « réassemblés » par une procédure spéciale (RFC 6946).
- Les fragments qui se recouvrent partiellement sont désormais interdits (cf. RFC 5722, le réassemblage des fragments en un paquet est déjà assez compliqué et sujet à erreur comme cela).
- Si le paquet est fragmenté, les en-têtes d'extension doivent désormais tous être dans le premier fragment (RFC 7112).
- L'en-tête de routage (Routing Header) de type 0, dit « RH0 », est abandonné, il posait trop de problèmes de sécurité (cf. RFC 5095 et RFC 5871).
L'annexe B de notre RFC résume les changements depuis le RFC 2460. Pas de choses révolutionnaires, les changements les plus importantes portaient sur la sécurité, comme listé un peu plus haut (section 10 du RFC). On notera comme changements :
- [Section 1] Clarification que IPv6 est gros-boutien, comme IPv4 (cf. l'annexe B du RFC 791).
- [Section 3] Clarification de l'utilisation du « hop limit », décrémenté de 1 à chaque routeur.
- [Section 4] Clarification du fait qu'un équipement intermédiaire ne doit pas tripoter les en-têtes d'extension (à part évidemment « Hop-by-hop Options »), ni les modifier, ni en ajouter ou retirer, ni même les lire.
- [Section 4] Le traitement de l'en-tête « Hop-by-hop Options par les routeurs sur le trajet n'est plus obligatoire. Si un routeur est pressé, il peut s'en passer (le RFC suit ainsi la pratique). Ceci dit, le RFC 9673 a, depuis, mieux défini le traitement de cet en-tête, dans l'espoir de le ressusciter.
- [Section 4.4] Suppression de l'en-tête de routage de type 0.
- [Section 4.5] Pas mal de changements sur la fragmentation (un processus toujours fragile !), notamment l'abandon des fragments atomiques.
- [Section 4.8] Intégration du format unique des éventuels futurs en-têtes d'extension, format initialement présenté dans le RFC 6564.
- [Section 6] Reconnaissance du fait que « Flow Label » n'était pas réellement bien défini, et délégation de cette définition au RFC 6437.
- [Section 8.1] Autorisation, dans certains cas bien délimités, d'omission de la somme de contrôle UDP (RFC 6935).
- Il y a eu également correction de diverses erreurs comme les 2541 (omission sur la définition du « Flow Label ») et 4279 (paquet entrant avec un « Hop Limit » déjà à zéro).
Le projet de mise à jour de la norme IPv6 avait été lancé en 2015 (voici les supports du premier exposé).
D'habitude, je termine mes articles sur les RFC par des informations sur l'état de mise en œuvre du RFC. Mais, ici, il y en a tellement que je vous renvoie plutôt à cette liste. Notez que des tests d'interopérabilité ont été faits sur les modifications introduites par ce nouveau RFC et que les résultats publiés n'indiquent pas de problème.
Parmi les publications récentes sur le déploiement d'IPv6, signalons :
- Le rapport de l'ARCEP au gouvernement français sur la transition vers IPv6 et les moyens de l'accélérer.
- Le rapport 2016 de l'l’Observatoire ANSSI/AFNIC de la résilience de l’Internet français a une section sur IPv6.
- Google publie d'intéressantes statistiques sur l'accès en IPv6 à ses services.
L'article seul
RFC 8198: Aggressive Use of DNSSEC-Validated Cache
Date de publication du RFC : Juillet 2017
Auteur(s) du RFC : K. Fujiwara (JPRS), A. Kato
(Keio/WIDE), W. Kumari (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 26 juillet 2017
Lorqu'un client DNS interroge un résolveur, celui-ci peut répondre très vite si l'information demandée est dans sa mémoire (son « cache ») mais cela peut être beaucoup plus lent s'il faut aller demander aux serveurs faisant autorité. Il est donc essentiel, pour les performances du DNS, d'utiliser le cache le plus possible. Traditionnellement, le résolveur n'utilisait le cache que si la question posée par le client avait une réponse exacte dans le cache. Mais l'arrivée de DNSSEC autorise un usage plus énergique et plus efficace du cache : ce nouveau RFC permet aux résolveurs de synthétiser des réponses à partir des informations DNSSEC.
Comment peut-il faire ? Eh bien prenons par exemple les
enregistrements NSEC. Ils indiquent une
plage où il n'y a pas de noms enregistrés. Ainsi, si une zone
example.com contient :
albatross IN AAAA 2001:db8:1028::a:1
elephant IN AAAA 2001:db8:1028::a:2
zebra IN AAAA 2001:db8:1028::a:3
Sa signature DNSSEC va ajouter des enregistrements NSEC, notamment :
albatross.example.com. IN NSEC elephant.example.com. AAAA
qui veut dire qu'il n'y a pas de nom entre
albatross et elephant. Si le
client interroge le résolveur à propos de
cat.example.com, le résolveur ira voir les
serveurs faisant autorité, il aura une réponse négative
(NXDOMAIN, ce nom n'existe pas) et l'enregistrement NSEC. Les deux
informations seront renvoyées au client, et pourront être mémorisées dans le cache. Maintenant,
si le client demande dog.example.com, les
résolveurs traditionnels retourneront demander aux serveurs faisant
autorité. Alors que les résolveurs modernes, conformes à ce nouveau
RFC 8198, pourront déduire du NSEC que
dog.example.com n'existe pas non plus, et
immédiatement générer un NXDOMAIN pour le client. Cela fera gagner du
temps et des efforts à tout le monde. (Les règles exactes sont
dans la section 5.1 de notre RFC.)
La règle (désormais dépassée) comme quoi le résolveur ne peut répondre immédiatement que s'il a l'information correspondant à la question exacte est spécifiée dans le RFC 2308, pour le cache négatif (mémoriser les réponses NXDOMAIN). Désormais, elle n'est plus obligatoire si (et seulement si, voir section 9) le résolveur valide avec DNSSEC, et si la zone est signée (aucun changement si elle ne l'est pas). Outre le cas simple de NSEC avec des réponses négatives, présenté plus haut, il y a deux cas plus complexes, les enregistrements NSEC3, et les jokers. Si la zone est signée avec NSEC3 au lieu de NSEC, les enregistrements NSEC3 indiqueront des condensats et pas des noms et le résolveur devra donc condenser le nom demandé, pour voir s'il tombe dans un NSEC3 connu, et si on peut synthétiser le NXDOMAIN. Les règles exactes sur les NSEC3 sont dans le RFC 5155 (attention, c'est compliqué), sections 8.4 à 8.7, et dans notre RFC, section 5.2. Évidemment, si la zone est signée avec l'option « opt-out » (c'est le cas de la plupart des TLD), le résolveur ne peut pas être sûr qu'il n'y a pas un nom non signé dans une plage indiquée par un enregistrement NSEC, et ne peut donc pas synthétiser. Tout aussi évidemment, toute solution qui empêchera réellement l'énumération des noms dans une zone signée (comme le projet, désormais abandonné, NSEC5) sera incompatible avec cette solution.
Si la zone inclut des jokers (RFC 1034,
section 4.3.3), par exemple example.org :
avocado IN A 192.0.2.1 * IN A 192.0.2.2 zucchini IN A 192.0.2.3
Alors, le résolveur pourra également synthétiser des réponses positives. S'il a
déjà récupéré et mémorisé le joker, et que le client lui demande
l'adresse IPv4 de
leek.example.org, le résolveur pourra tout de
suite répondre 192.0.2.2. (J'ai simplifié : le
résolveur doit aussi vérifier que le nom
leek.example.org n'existe pas, ou en tout cas n'a
pas d'enregistrement A. Le joker ne masque en effet pas les noms
existants. Détails en section 5.3 du RFC.)
Pour cette utilisation plus énergique de la mémoire d'un résolveur validant, il a fallu amender légèrement le RFC 4035, dont la section 4.5 ne permettait pas cette synthèse de réponses (la nouvelle rédaction est en section 7). Notez un inconvénient potentiel de cette synthèse : un nom ajouté ne sera pas visible tout de suite. Mais c'est de toute façon une propriété générale du DNS et de ses caches souvent appelée, par erreur, « durée de propagation ».
La durée exacte pendant laquelle le résolveur « énergique » pourra garder les informations qui lui servent à la synthèse des réponses est donnée par le TTL des NSEC.
Quel intérêt à cette synthèse énergique de réponses ? Comme indiqué plus haut, cela permet de diminuer le temps de réponse (section 6). Du fait de la diminution de nombre de questions à transmettre, cela se traduira également par une diminution de la charge, et du résolveur, et du serveur faisant autorité. Sur la racine du DNS, comme 65 % des requêtes entrainent un NXDOMAIN (voir par exemple les statistiques de A-root), le gain devrait être important. Un autre avantage sera pour la lutte contre les attaques dites « random QNAMEs » lorsque l'attaquant envoie plein de requêtes pour des noms aléatoires (générant donc des NXDOMAIN). Si l'attaquant passe par un résolveur, celui-ci pourra écluser la grande majorité des requêtes sans déranger le serveur faisant autorité.
Mais la synthèse énergique entraine aussi un gain en matière de vie privée (cf. RFC 7626) : les serveurs faisant autorité verront encore moins de questions.
Cette technique de « cache négatif énergique » avait été proposée pour la première fois dans la section 6 du RFC 5074. Elle s'inscrit dans une série de propositions visant à augmenter l'efficacité des caches DNS, comme le « NXDOMAIN cut » du RFC 8020. La synthèse énergique de réponses prolonge le RFC 8020, en allant plus loin (mais elle nécessite DNSSEC).
Il semble que Google Public DNS mette déjà en œuvre une partie (les réponses négatives) de ce RFC, mais je n'ai pas encore vérifié personnellement.
L'article seul
RFC 8197: A SIP Response Code for Unwanted Calls
Date de publication du RFC : Juillet 2017
Auteur(s) du RFC : H. Schulzrinne (FCC)
Chemin des normes
Première rédaction de cet article le 18 juillet 2017
Voici un RFC qui n'est pas trop long à lire ou à comprendre : il ajoute un code de réponse au protocole SIP (utilisé surtout pour la téléphonie sur IP), le code 607 qui dit explicitement « je n'ai pas envie de répondre à cet appel ».
Sur certaines lignes téléphoniques, la majorité des appels entrants sont du spam (cf. RFC 5039), du genre salons de beauté ou remplacements de fenêtres, voire appels automatiques en faveur d'un candidat politicien. Toute méthode de lutte contre ce spam nécessite d'avoir un retour des utilisateurs, qui déclarent « je ne veux pas de cet appel ». Simplement raccrocher ne suffit pas, il faut permettre à l'utilisateur de déclarer explicitement la spamicité d'un appel. (Les codes de rejet existants comme 603 - RFC 3261, section 21.6.2 - ne sont pas assez spécifiques. 603 indique typiquement un rejet temporaire, du genre je suis à table, ne me dérangez pas maintenant.)
C'est désormais possible avec ce nouveau code de retour 607, enregistré à l'IANA. Le logiciel de l'utilisateur enverra ce code (il aura typiquement un bouton « rejet de ce spam » comme c'est le cas pour les logiciels de courrier), et il pourra être utilisé pour diverses techniques anti-spam (par exemple par un fournisseur SIP pour déterminer que tel numéro ne fait que du spam et peut donc être bloqué). La FCC (pour laquelle travaille l'auteur du RFC) avait beaucoup plaidé pour un tel mécanisme.
Notez que l'interprétation du code sera toujours délicate, car il peut y avoir usurpation de l'identité de l'appelant (section 6 de notre RFC, et aussi RFC 4474) ou tout simplement réaffectation d'une identité à un nouvel utilisateur, innocent de ce qu'avait fait le précédent. Au passage, dans SIP, l'identité de l'appelant peut être un URI SIP ou bien un numéro de téléphone, cf. RFC 3966.
Le code aurait dû être 666 (le nombre de la Bête) mais le code 607 a été finalement choisi pour éviter des querelles religieuses. (Le RFC 7999 n'a pas eu les mêmes pudeurs.)
L'action (ou l'inaction) suivant une réponse 607 dépendra de la politique de chaque acteur. (La discussion animée à l'IETF avait surtout porté sur ce point.) Comme toujours dans la lutte contre le spam, il faudra faire des compromis entre trop de faux positifs (on refuse des messages légitimes) et trop de faux négatifs (on accepte du spam). D'autant plus que l'utilisateur peut être malveillant (rejeter comme spam des appels légitimes dans l'espoir de faire mettre l'appelant sur une liste noire) ou simplement incompétent (il clique un peu au hasard). Les signalements sont donc à prendre avec des pincettes (section 6 du RFC).
L'article seul
RFC 8195: Use of BGP Large Communities
Date de publication du RFC : Juin 2017
Auteur(s) du RFC : J. Snijders, J. Heasley
(NTT), M. Schmidt (i3D.net)
Pour information
Réalisé dans le cadre du groupe de travail IETF grow
Première rédaction de cet article le 1 juillet 2017
Le RFC 8092 a normalisé la notion de « grande communauté » BGP, des données attachées aux annonces de routes, plus grandes que les précédentes « communautés » et permettant donc de stocker davantage d'informations. Ce nouveau RFC explique à quoi peuvent servir ces grandes communautés et donne des exemples d'utilisation. Un document concret, qui ravira les opérateurs réseaux.
Le RFC original sur les communautés BGP était le RFC 1997, et il était accompagné d'un RFC 1998 présentant des cas concrets d'utilisation. C'est la même démarche qui est faite ici, de faire suivre le document de normalisation, le RFC 8092, d'un document décrivant des utilisations dans le monde réel (avec des expériences pratiques décrites à NANOG ou NLnog).
Un petit rappel des grandes communautés, d'abord (section 2 du RFC). Chaque communauté se compose de trois champs de quatre octets chacun. Le premier champ se nomme GA, pour Global Administrator, et sa valeur est le numéro de l'AS qui a ajouté cette communauté (rappelez-vous que les numéros d'AS font désormais quatre octets), ce qui assure l'unicité mondiale des communautés. Les deux autres champs portent les noms peu imaginatifs de Local Data Part 1 et Local Data Part 2. La plupart du temps, on se sert du premier pour identifier une fonction, et du second pour identifier les paramètres d'une fonction. Notez qu'il n'existe pas de standard pour ces deux champs locaux : comme leur nom l'indique, chaque AS les affecte comme il veut. Une même valeur peut donc avoir des significations différentes selon l'AS.
Le RFC contient plusieurs exemples, qui utilisent à chaque fois
la même topologie : un transitaire, l'AS 65551, avec un client,
l'AS 64497, qui est lui-même transitaire pour les AS 64498 et
64499, qui par ailleurs ont une relation de
peering (en épais sur
l'image)  :
:
Notre RFC classe les communautés en deux catégories : celles d'information et celles d'action. Les premières servent à distribuer des informations qui ne modifieront pas le comportement des routeurs, mais pourront être utiles pour le débogage, ou les statistiques. Un exemple est l'ajout d'une communauté pour indiquer dans quel pays on a appris telle route. Elles sont typiquement ajoutées par l'AS qui a défini ces informations, et il mettra donc son numéro d'AS dans le champ GA. Les secondes, les communautés d'action, servent à indiquer une action souhaitée. Elles sont définies par l'AS qui aura à agir, et mises dans le message BGP par un de ses pairs. Un exemple est une communauté pour indiquer à son pair quelle préférence on souhaite qu'il attribue à telle route.
La section 3 donne des exemples de communautés
d'information. Le premier est celui où l'AS 66497 marque les
routes qu'il a reçues avec une communauté qui indique le pays où
la route a été apprise (le code pays utilisé est celui de
ISO 3166-1). La fonction a reçu le numéro
1. Donc, la présence dans l'annonce
BGP de la communauté 64497:1:528 indique une
route apprise aux Pays-Bas, la communauté
64497:1:392 indique le
Japon, etc. Le même opérateur peut aussi
prévoir une fonction 2 pour indiquer la région (concept plus vaste
que le pays), en utilisant les codes M.49 :
64497:2:2 dit que la route a été apprise en
Afrique, 64497:2:150
en Europe et ainsi de suite. Rappelez-vous
bien que la signification d'une fonction (et donc des paramètres qui
suivent) dépend de l'AS (ou, plus rigoureusement, du champ GA). Il n'y a pas de standardisation des
fonctions. Si vous voyez une communauté
65551:2:2, cela ne signifie pas forcément que
la route vient d'Afrique : l'AS 65551 peut utiliser la fonction 2
pour tout à fait autre chose.
À part l'origine géographique d'une route, il est souvent utile
de savoir si la route a été apprise d'un pair ou d'un
transitaire. Le RFC donne l'exemple d'une fonction 3 où le
paramètre 1 indique une route interne, 2 une route apprise d'un
client, 3 d'un pair et 4 d'un transitaire. Ainsi, la communauté
64497:3:2 nous dit que la route vient d'un
client de l'AS 64497.
Une même annonce de route peut avoir plusieurs communautés. Une
route étiquetée 64497:1:528, 64497:2:150 et
64497:3:3 vient donc d'un pair aux Pays-Bas.
Et les communautés d'action (section 4 du
RFC) ? Un premier exemple est celui où on indique à son camarade
BGP de ne pas exporter inconditionnellement une route qu'on lui
annonce (ce qui est le comportement par défaut de BGP). Mettons
que c'est la fonction 4. (Vous noterez qu'il n'existe pas d'espace
de numérotation de fonctions distinct pour les communautés
d'information et d'action. On sait que la fonction 4 est d'action
uniquement si on connait la politique de l'AS en question.)
Mettons encore que l'AS 64497 a défini le paramètre comme étant un
numéro d'AS à qui il ne faut pas exporter la
route. Ainsi, envoyer à l'AS 64497 une route étiquetée
64497:4:64498 signifierait « n'exporte
pas cette route à l'AS 64498 ». De la même
façon, on peut imaginer une fonction 5 qui utilise pour cette
non-exportation sélective le code
pays. 64997:5:392 voudrait dire « n'exporte
pas cette route au Japon ». (Rappelez-vous que BGP est du routage
politique : son but principal est de permettre de faire respecter
les règles du business des opérateurs.)
Je me permets d'enfoncer le clou : dans les communautés d'action, l'AS qui ajoute une communauté ne met pas son numéro d'AS dans le champ GA, mais celui de l'AS qui doit agir.
Un autre exemple de communauté d'action serait un allongement
sélectif du chemin d'AS. On allonge le chemin d'AS en répétant le
même numéro d'AS lorsqu'on veut décourager l'utilisation d'une
certaine route. (En effet, un des facteurs essentiels d'une
décision BGP est la longueur du chemin d'AS : BGP préfère le plus
court.) Ainsi, l'exemple donné utilise la fonction 6 avec comme
paramètre l'AS voisin où appliquer cet allongement
(prepending). 64497:6:64498
signifie « ajoute ton AS quand tu exportes vers 64498 ».
Quand on gère un routeur BGP multihomé, influencer le trafic
sortant est assez simple. On peut par exemple mettre une
préférence plus élevée à la sortie vers tel
transitaire. Influencer le trafic entrant (par exemple si on veut
que le trafic vienne surtout par tel transitaire) est plus
délicat : on ne peut pas configurer directement la politique des
autres AS. Certains partenaires BGP peuvent permettre de définir
la préférence locale (RFC 4271, section
5.1.5), via une communauté. Ici, le RFC donne l'exemple d'une
fonction 8 qui indique « mets la préférence d'une route client [a
priori une préférence élevée] », 10 une route de
peering, 11 de transit
et 12 une route de secours, à n'utiliser qu'en dernier recours
(peut-être parce qu'elle passe par un fournisseur cher, ou bien de
mauvaise qualité). Le paramètre (le troisième champ de la
communauté) n'est pas utilisé. Alors, la communauté
64997:12:0 signifiera « AS 64997, mets à cette route la
préférence des routes de secours [a priori très basse] ».
Le RFC suggère aussi, si le paramètre est utilisé, de le
prendre comme indiquant la région où cette préférence spécifique
est appliquée. Par exemple 64997:10:5
demandera à l'AS 64997 de mettre la préférence des routes de
peering (10) à tous les routeurs en
Amérique du Sud (code 5 de la norme
M.49).
Attention, changer la préférence locale est une arme puissante, et sa mauvaise utilisation peut mener à des coincements (RFC 4264).
Dernier exemple donné par notre RFC, les souhaits exprimés à un
serveur de routes (RFC 7947). Ces serveurs parlent en
BGP mais ne sont pas des routeurs, leur seul rôle est de
redistribuer l'information aux routeurs. Par défaut, tout est
redistribué à tout le monde (RFC 7948), ce
qui n'est pas toujours ce qu'on souhaite. Si on veut une politique
plus sélective, certains serveurs de route documentent des
communautés que les clients du serveur peuvent utiliser pour
influencer la redistribution des routes. Notre RFC donne comme
exemple une fonction 13 pour dire « n'annonce pas » (alors que
cela aurait été le comportement normal) et une fonction 14 pour
« annonce quand même » (si le comportement normal aurait été de ne
pas relayer la route). Ainsi, 64997:13:0 est
« n'annonce pas cette route par défaut » et
64997:14:64999 est « annonce cette route à
l'AS 64999 ».
Vous voudriez des exemples réels ? Netnod avait annoncé que ces grandes communautés étaient utilisables sur leur AS 52005 :
52005:0:0Do not announce to any peer52005:0:ASxDo not announce to ASx52005:1:ASxAnnounce to ASx if 52005:0:0 is set52005:101:ASxPrepend peer AS 1 time to ASx52005:102:ASxPrepend peer AS 2 times to ASx52005:103:ASxPrepend peer AS 2 times to ASx
On trouve également ces communautés au IX-Denver, documentées ici (sous « Route Server B and C Communities ») ou au SIX (dans leur documentation). Il y a enfin cet exemple à ECIX. (Merci à Job Snijders et Pier Carlo Chiodi pour les exemples.)
Voilà, à vous maintenant de développer votre propre politique de communautés d'information, et de lire la documentation de vos voisins BGP pour voir quelles communautés ils utilisent (communautés d'action).
L'article seul
RFC 8193: Information Model for Large-Scale Measurement Platforms (LMAPs)
Date de publication du RFC : Août 2017
Auteur(s) du RFC : T. Burbridge, P. Eardley (BT), M. Bagnulo (Universidad Carlos III de Madrid), J. Schoenwaelder (Jacobs University Bremen)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lmap
Première rédaction de cet article le 22 août 2017
Ce RFC est l'un de ceux du groupe de travail IETF nommé LMAP, pour « Large-Scale Measurement Platforms ». Ce groupe développe des normes pour les systèmes de mesure à grande échelle, ceux où des centaines ou des milliers de sondes quantifient l'Internet. Il décrit le modèle de données utilisé.
Le projet LMAP est décrit dans les RFC 7536 (qui explique à quoi sert LMAP, avec deux exemples concrets) et RFC 7594 (qui normalise le vocabulaire et le cadre général). Pour résumer très vite, LMAP prévoit un Measurement Agent (la sonde) qui parle à un contrôleur, qui lui dit quoi faire, et à un collecteur, qui ramasse les données. Ce nouveau RFC décrit le modèle de données abstrait utilisé dans ces deux communications.
Rappelons que, dans le cadre défini pour LMAP, chaque MA (Measurement Agent) parle à un et un seul contrôleur, qui lui dit ce qu'il doit mesurer. (LMAP sépare le rôle du contrôleur et du collecteur, rôles que beaucoup de systèmes déployés fusionnent.) Il y a donc trois protocoles en jeu, le protocole de contrôle, entre le contrôleur et les MA, le protocole de collecte, entre les collecteurs et les MA, et enfin les protocoles utilisés dans les tests (ICMP ECHO, par exemple, mais aussi HTTP, DNS…) Enfin, il y a aussi la configuration nécessaire dans tous ces équipements. Tous ces points peuvent faire l'objet d'un travail de normalisation, mais ce RFC 8193 présente uniquement un modèle de données adapté au protocole de collecte et au protocole de contrôle.
La notion de modèle de données est expliquée dans le RFC 3444. En gros, il s'agit d'un modèle abstrait (très abstrait) décrivant quel genre de données sont échangées. Il peut se formaliser de manière un peu plus concrète par la suite, par exemple en utilisant le langage YANG (c'est justement ce que fait le RFC d'accompagnement, le RFC 8194). Un tel modèle sert à guider la normalisation, à faciliter la traduction d'un protocole dans un autre s'ils utilisent le même modèle de données, et à définir les données que doit mesurer et conserver le MA.
Le modèle défini ici utilise une notation formelle, utilisant
des types de données classiques en programmation (section 3 du RFC) :
int (un entier),
boolean (une valeur
logique), string, mais aussi des
types plus riches comme datetime ou uri.
Le modèle lui-même est dans la section 4 du RFC. Je rappelle qu'il suit le cadre du RFC 7594. Il a six parties :
- Informations de pré-configuration du MA (celle qui est faite en usine),
- Informations de configuration du MA,
- Instructions reçues par le MA (« envoie telle requête DNS à tel serveur, de telle heure à telle heure »),
- Journal du MA, avec des évènements comme le redémarrage de la sonde,
- État général du MA (« je sais faire des tests IPv6 »),
- Et bien sûr, le résultat des mesures, ce qui est l'information la plus importante.
Le MA peut également avoir d'autres informations, par exemple des détails sur son type de connectivité.
Pour donner des exemples concrets, je vais souvent citer les
sondes RIPE
Atlas, même si ce système, conçu avant le RFC, ne suis pas
exactement ce modèle. C'est sans doute l'un des plus grands, voire le plus
grand réseau de points de mesure dans le monde, avec près de
10 000 sondes connectées. Par exemple, pour la configuration, les
informations de pré-configuration d'une sonde Atlas comprennent
une adresse MAC et un identificateur, qu'on
peut voir sur la sonde : 
Les sondes sont également pré-configurées avec le nom du
contrôleur (qui sert également de collecteur). Elles acquièrent le
reste de leur configuration par
DHCP et SLAAC. Regardons par exemple la sonde
d'identificateur #21660, installée à
Cochabamba, on voit les adresses IP obtenues : 
Les sondes Atlas disposent également d'étiquettes
(tags) décrivant plus précisement certaines de
leurs caractéristiques. Certaines des étiquettes sont attribuées
manuellement par leur propriétaire (en bleu sur l'image ci-dessous), d'autres, qui peuvent être
déterminées automatiquement, sont mises par le système (en vert
sur l'image), et rentrent donc dans le cadre de la partie « état
général de la sonde » du modèle :

Les classes utilisées dans le modèle sont, entre autres :
- Les agendas (schedules) qui indiquent quelle tâche doit être accomplie,
- Les canaux de communication (channels),
- les configurations (task configurations),
- Les évènements (events), qui détaillent le moment où une tâche doit être exécutée.
Première partie, la pré-configuration (section 4.1). On y trouve les informations dont le MA aura besoin pour accomplir sa mission. Au minimum, il y aura un identificateur (par exemple l'adresse MAC), les coordonnées de son contrôleur (par exemple un nom de domaine, mais le RFC ne cite que le cas où ces coordonnées sont un URL, pour les protocoles de contrôle de type REST), peut-être des moyens d'authentification (comme le certificat de l'AC qui signera le certificat du contrôleur). URL et moyens d'authentification, ensemble, forment un canal de communication.
Dans le langage formel de ce modèle, cela fait :
object {
[uuid ma-preconfig-agent-id;]
ma-task-obj ma-preconfig-control-tasks<1..*>;
ma-channel-obj ma-preconfig-control-channels<1..*>;
ma-schedule-obj ma-preconfig-control-schedules<1..*>;
[uri ma-preconfig-device-id;]
credentials ma-preconfig-credentials;
} ma-preconfig-obj;
Cela se lit ainsi : l'information de pré-configuration (type
ma-preconfig-obj) comprend
divers attributs dont un identificateur (qui est un
UUID, on a vu que les Atlas utilisaient un
autre type d'identificateurs), des canaux de communication avec le
contrôleur, et des lettres de créance à présenter pour
s'authentifier. Notez que l'identificateur est optionnel (entre
crochets).
Vous avez compris le principe ? On peut passer à la suite plus rapidement (je ne vais pas répéter les déclarations formelles, voyez le RFC). La configuration (section 4.2) stocke les informations volatiles (la pré-configuration étant consacrée aux informations plus stables, typiquement stockées sur une mémoire permanente).
Les instructions (section 4.3) sont les tâches que va accomplir la sonde, ainsi que l'agenda d'exécution, et bien sûr les canaux utilisé pour transmettre les résultats. La journalisation (section 4.4) permet d'enregistrer les problèmes (« mon résolveur DNS ne marche plus ») ou les évènements (« le courant a été coupé »).
Il ne sert évidemment à rien de faire des mesures si on ne transmet pas le résultat. D'où la section 4.6, sur la transmission des résultats de mesure au collecteur. La communication se fait via les canaux décrits en section 4.8.
Une dernière photo, pour clore cet article, une sonde RIPE
Atlas en fonctionnement, et une autre sonde, la SamKnows : 
Merci à André Sintzoff pour avoir trouvé de grosses fautes.
L'article seul
RFC 8190: Updates to Special-Purpose IP Address Registries
Date de publication du RFC : Juin 2017
Auteur(s) du RFC : R. Bonica (Juniper
Networks), M. Cotton
(ICANN), B. Haberman (Johns Hopkins
University), L. Vegoda (ICANN)
Première rédaction de cet article le 28 juin 2017
Le RFC 6890 avait créé un registre unique des préfixes d'adresses IP « spéciaux ». Ce nouveau RFC met à jour le RFC 6890, précisant et corrigeant quelques points.
Un préfixe « spécial » est juste un préfixe
IP dédié à un usage inhabituel, et qui peut
nécessiter un traitement particulier. Ainsi, les préfixes
203.0.113.0/24 et
2001:db8::/32 sont dédiés à la documentation,
aux cours et exemples et, bien que n'étant pas traités
différemment des autres préfixes par les routeurs, ne doivent normalement pas
apparaitre dans un vrai réseau. Le RFC 6890
spécifie les deux registres de préfixes spéciaux, un
pour IPv4 et un
pour IPv6. Mais il y avait une ambiguité dans ce RFC, dans
l'usage du terme « global ». Il n'est pas
évident à traduire en français. Dans le langage courant,
global/globalement, a surtout le sens de « le plus
souvent/généralement », alors que, dans le contexte de l'Internet,
ce serait plutôt dans le sens « valable pour tout point du
globe ». Même en anglais, le
terme est polysémique : il peut signifier que
l'adresse IP est unique au niveau mondial ou bien il peut
signifier que l'adresse est potentiellement joignable
mondialement, et qu'un routeur peut donc faire suivre le paquet en
dehors de son propre domaine. (La joignabilité effective, elle,
dépend évidemment de l'état de BGP.) Le
RFC 4291, dans sa section 2.5.4, n'est pas
plus clair.
Reprenons l'exemple des préfixes de documentation. Dans les trois
préfixes IPv4 de documentation (comme
203.0.113.0/24), les adresses ne sont pas
uniques (chacun les alloue comme il veut et, vu le faible nombre
d'adresses total, il y aura certainement des collisions) et, de
toute façon, n'ont pas de signification en dehors d'un domaine :
cela n'a pas de sens de transmettre des paquets ayant de telles
adresses à ses partenaires. Pour le préfixe de documentation IPv6,
2001:db8::/32, c'est un peu plus compliqué
car les adresses peuvent être quasi-uniques mondialement (si on
prend la précaution de les tirer au sort dans le préfixe) mais, de
toute façon, n'ont pas vocation à être joignables de partout et on
ne transmet donc pas ces paquets à ses voisins.
Bref, notre nouveau RFC choisit d'être plus précis, renommant l'ancien booléen « global » du RFC 6890 en « globally reachable ».
La nouvelle définition (section 2) est donc bien « le paquet ayant cette adresse comme destination peut être transmis par un routeur à un routeur d'un autre domaine (d'un autre opérateur, en pratique) ». La colonne Global du registre est donc remplacée par Globally reachable. Notez qu'il n'y a pas de colonne « Unicité » (une autre définition possible de global).
Cela a nécessité quelques changements supplémentaires dans le registre (toujours section 2), colonne Globally reachable :
L'article seul
RFC 8187: Indicating Character Encoding and Language for HTTP Header Field Parameters
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 14 septembre 2017
Dernière mise à jour le 16 septembre 2017
Les requêtes et réponses du protocole HTTP incluent des
en-têtes (comme
User-Agent: ou
Content-Disposition:) avec des
valeurs, qui, il y a longtemps, ne pouvaient se représenter
directement qu'avec les caractères du jeu ISO
8859-1, voire seulement avec
ASCII (c'était compliqué). Comme MIME, dans le RFC 2231,
prévoyait un mécanisme très riche pour encoder les en-têtes du
courrier électronique, ce RFC 8187
réutilise ce mécanisme pour HTTP (il remplace le RFC 5987, qui avait été le premier à le faire). Pour le corps du
message (voir par exemple le RFC 7578), rien
ne change.
Cette ancienne restriction à Latin-1 (qui n'est plus d'actualité) vient de la norme HTTP, le RFC 2616, dans sa section 2.2, qui imposait l'usage du RFC 2047 pour les caractères en dehors de ISO 8859-1. Le RFC 7230 a changé cette règle depuis (sa section 3.2) mais pas dans le sens d'une plus grande internationalisation (ISO 8859-1 ne convient qu'aux langues européennes), plutôt en supprimant le privilège d'ISO 8859 et en restreignant à ASCII. Et il ne précise pas vraiment comment faire avec d'autres jeux de caractère comme Unicode. Il ne reste donc que la solution du RFC 2231.
Notre nouveau RFC peut être résumé en disant qu'il spécifie un profil du RFC 2231. Ce profil est décrit en section 3, qui liste les points précisés par rapport au RFC 2231. Tout ce RFC n'est pas utilisé, ainsi le mécanisme en section 3 du RFC 2231, qui permettait des en-têtes de plus grande taille, n'est pas importé (section 3.1 de notre RFC).
En revanche, la section 4 du RFC 2231, qui spécifiait
comment indiquer la langue dans laquelle était
écrite la valeur d'un en-tête est repris pour les paramètres dans les
en-têtes. Ainsi, (section 3.2), voici un en-tête (imaginaire :
Information: n'a pas été enregistré), avec un paramètre
title traditionnel en pur ASCII :
Information: news; title=Economy
et en voici un avec les possibilités de notre RFC pour permettre les caractères £ et € (« Sterling and euro rates ») :
Information: news; title*=UTF-8''%c2%a3%20and%20%e2%82%ac%20rates
Par rapport au RFC 2231 (qui était silencieux sur ce point), un encodage de caractères est décrété obligatoire (c'est bien sûr UTF-8), et il doit donc être géré par tous les logiciels. La mention de l'encodage utilisé est également désormais obligatoire (section 3.2 de notre RFC). La langue elle-même est indiquée par une étiquette, selon la syntaxe du RFC 5646. Du fait de ces possibilités plus riches que celles prévues autrefois pour HTTP, les paramètres qui s'en servent doivent se distinguer, ce qui est fait avec un astérisque avant le signe égal (voir l'exemple ci-dessus). Notez que l'usage de l'astérisque n'est qu'une convention : si on trouve un paramètre inconnu dont le nom se termine par un astérisque, on ne peut pas forcément en déduire qu'il est internationalisé.
La valeur du paramètre inclut donc le jeu de caractères et l'encodage (obligatoire), la langue (facultative, elle n'est pas indiquée dans l'exemple ci-dessus) et la valeur proprement dite.
Voici un exemple incluant la langue, ici
l'allemand (code de, la
phrase est « Mit der Dummheit kämpfen Götter
selbst vergebens », ou « contre la bêtise, les dieux
eux-mêmes luttent en vain », tirée de la pièce « La pucelle
d'Orléans ») :
Quote: theater;
sentence*=UTF-8'de'Mit%20der%20Dummheit%20k%C3%A4mpfen%20G%C3%B6tter%20selbst%20vergebens.
La section 4 couvre ensuite les détails pratiques pour les normes qui décrivent un en-tête qui veut utiliser cette possibilité. Par exemple, la section 4.2 traite des erreurs qu'on peut rencontrer en décodant et suggère que, si deux paramètres identiques sont présents, celui dans le nouveau format prenne le dessus. Par exemple, si on a :
Information: something; title="EURO exchange rates";
title*=utf-8''%e2%82%ac%20exchange%20rates
le titre est à la fois en ASCII pur et en UTF-8, et c'est cette
dernière version qu'il faut utiliser, même si normalement il n'y a
qu'un seul paramètre title.
Ces paramètres étendus sont mis en œuvre dans Firefox et Opera ainsi que, dans une certaine mesure, dans Internet Explorer.
Plusieurs en-têtes HTTP se réfèrent formellement à cette façon d'encoder les caractères non-ASCII :
Authentication-Control:, dans le RFC 8053 (« For example, a parameter "username" with the value "Renee of France" SHOULD be sent as username="Renee of France". If the value is "Renée of France", it SHOULD be sent as username*=UTF-8''Ren%C3%89e%20of%20France instead »),Authorization:(pour l'authentification HTTP, RFC 7616, avec également un paramètreusernamepour l'ASCII etusername*pour l'encodage défini dans ce RFC),Content-Disposition:, RFC 6266, qui indique sous quel nom enregistrer un fichier et dont le paramètrefilename*permet tous les caractères Unicode,Link:, normalisé dans le RFC 5988, où le paramètretitle*permet des caractères non-ASCII (titleétant pour l'ASCII pur).
Les changements depuis le RFC 5987, sont expliqués dans l'annexe A. Le plus spectaculaire est le retrait d'ISO 8859-1 (Latin-1) de la liste des encodages qui doivent être gérés obligatoirement par le logiciel. Cela fera plaisir aux utilisateurs d'Internet Explorer 9, qui avait déjà abandonné Latin-1. Autrement, rien de crucial dans ces changements. Le texte d'introduction a été refait pour mieux expliquer la situation très complexe concernant la légalité (ou pas) des caractères non-ASCII dans les valeurs d'en-tête.
Si vous voulez voir un exemple, essayez de télécharger le fichier
http://www.bortzmeyer.org/files/foobar.txt. Si
votre client HTTP gère l'en-tête
Content-Disposition: et le paramètre
internationalisé filename*, le fichier devrait
être enregistré sous le nom föbàr.txt.La
configuration d'Apache pour envoyer le
Content-Disposition: est :
<Files "foobar.txt">
Header set Content-Disposition "attachment; filename=foobar.txt; filename*=utf-8''f%%C3%%B6b%%C3%%A0r.txt"
</Files>
Par exemple, Safari ou Firefox enregistrent bien ce fichier sous son nom international.
Ah, et puisque ce RFC parle d'internationalisation, on notera que c'est le premier RFC (à part quelques essais ratés au début) à ne pas comporter que des caractères ASCII. En effet, suivant les principes du RFC 7997, il comporte cinq caractères Unicode : dans les exemples (« Extended notation, using the Unicode character U+00A3 ("£", POUND SIGN) » et « Extended notation, using the Unicode characters U+00A3 ("£", POUND SIGN) and U+20AC ("€", EURO SIGN) »), dans l'adresse (« Münster, NW 48155 ») et dans les noms des contributeurs (« Thanks to Martin Dürst and Frank Ellermann »).
L'article seul
RFC 8179: Intellectual Property Rights in IETF Technology
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : Scott Bradner (Harvard
University), Jorge Contreras (University of
Utah)
Première rédaction de cet article le 1 juin 2017
L'appropriation intellectuelle est partout et donc logiquement aussi dans les organismes de normalisation comme l'IETF. C'est l'objet de ce RFC, qui remplace les RFC 3979 et RFC 4879 sur les questions de brevets (nommées, à tort, questions de « propriété intellectuelle », alors que les brevets ne sont pas la même chose que les copyrights, traités dans le RFC 5378).
Donc, sur quels principes repose la politique de l'IETF au sujet des brevets ? L'idée de base est de s'assurer que l'IETF disposera d'information sur les brevets pouvant s'appliquer à une norme donnée, de façon à pouvoir prendre une décision en toute connaissance de cause. Il n'y a par contre pas de mécanisme automatique de décision, par exemple « Ne jamais normaliser des technologies brevetées ». En effet, compte-tenu du fait que l'écrasante majorité des brevets logiciels est futile, enregistrée uniquement parce que les organismes de brevetage ont un intérêt financier à accepter tout et n'importe quoi, une telle politique mènerait à ne rien pouvoir normaliser.
En pratique, tout ce RFC 8179 pourrait donc se résumer à « Tout participant à l'IETF qui connait ou devrait connaitre un brevet pouvant s'appliquer à une technique en cours de discussion doit en informer l'IETF ». C'est tout. Mais il y a quelques détails pratiques.
D'abord, il faut rappeler que ce sont officiellement des individus qui participent à l'IETF, pas des sociétés. Donc l'obligation s'applique à ces individus et ils ne peuvent pas y échapper en prétendant que leur compagnie leur interdit de réveler un brevet sous-marin (brevet sur lequel on fait peu de publicité, pour le ressortir une fois que la technique brevetée a été largement adoptée). Ensuite, le RFC définit ce que signifie contribuer à l'IETF (section 1). Par exemple, écrire sur une liste de diffusion d'un groupe de travail est une contribution. Cette règle est régulièrement rappelée par le fameux Note Well.
La section 1 définit formellement bien d'autres choses. Un concept essentiel mais souvent oublié est le Reasonably and personally known. Il désigne une information que le participant connait ou devrait connaitre, vu sa position dans l'entreprise qui l'emploie. L'idée est que le participant IETF n'est pas obligé de chercher activement dans le portefeuille de brevets de son entreprise, que l'obligation ne s'applique qu'à ce qu'il connait forcément, depuis son poste. Le but de l'ajout reasonably est d'éviter qu'une entreprise ne dissimule un brevet à ses propres employés.
Les principes sont donc :
- L'IETF ne va pas chercher à déterminer si un brevet est futile ou pas (cela peut être un très gros travail, la plupart des brevets étant rédigés en termes délibérement incompréhensibles),
- L'IETF peut normaliser ou pas une technique brevetée, il n'y a pas de refus systématique,
- Pour pouvoir néanmoins savoir où on va, l'IETF a besoin d'information et c'est de là que découle l'exigence de divulgation des brevets, la principale obligation concrète de ce RFC 8179.
La section 3 rentre dans le concret, même si elle commence par un bel exercice de langue de bois (« The intent is to benefit the Internet community and the public at large, while respecting the legitimate rights of others. »). C'est elle qui impose que le contributeur à l'IETF ait bien divulgué tous les brevets qu'il connaissait « raisonnablement ». Outre le brevet lui-même, il peut y avoir une licence associée (un droit d'utiliser la technologie brevetée, sous certaines conditions). Si le détenteur du brevet n'indique pas de licence, l'IETF peut poliment lui demander. La licence (RAND, FRAND, RANDZ - c'est-à-dire gratuite …) sera évidemment un des éléments sur lesquels les participants à l'IETF fonderont leur position (cf. RFC 6410).
La section 4
indique ce que l'IETF va en faire, de ces divulgations (nommées
« IPR [Intellectual Property Rights] disclosures ») : indication
du fait qu'il existe des brevets pouvant s'y appliquer et
publication de ces divulgations en http://www.ietf.org/ipr/. Par exemple,
Verisign a un brevet (brevet
états-unien 8,880,686,
et la
promesse de licence de Verisign)
qu'ils prétendent valable,
et dont ils affirment qu'il couvre la technique décrite dans le RFC 7816. (Sur la page officielle du
RCF, c'est le lien « Find IPR Disclosures from the IETF ».) L'IETF (ou
l'IAB, ou l'ISOC ou
autre) n'ajoutera aucune
appréciation sur la validité du brevet, ou sur les conditions de
licence. Une telle appréciation nécessiterait en effet
un long et coûteux travail juridique.
La note d'information n'est plus à inclure dans chaque RFC comme c'était autrefois le cas. Elle est désormais dans le IETF Trust Legal Provisions (version de 2015 : « The IETF Trust takes no position regarding the validity or scope of any Intellectual Property Rights or other rights that might be claimed to pertain to the implementation or use of the technology described in any IETF Document or the extent to which any license under such rights might or might not be available; nor does it represent that it has made any independent effort to identify any such rights. »). Comme exemple d'un brevet abusif, on peut citer la divulgation #1154, qui se réclame d'un brevet sur les courbes elliptiques qui s'appliquerait à tous les RFC parlant d'un protocole qui peut utiliser ces courbes, comme le RFC 5246.
Les divulgations ne sont pas incluses dans les RFC eux-mêmes
(section 10) car elles peuvent évoluer dans le temps alors que le RFC
est stable. Il faut donc aller voir ces « IPR
disclosures » en ligne sur http://www.ietf.org/ipr/.
Les divulgations sont-elles spécifiées plus en détail ? Oui, en
section 5. La 5.1 précise qui doit faire la
divulgation (le participant, en tant que personne physique), la
section 5.2 donne les délais (« aussi vite que possible »), la section
5.4.3 rappelle que la divulgation doit être précise et qu'un
contributeur ne peut pas se contenter de vagues généralités
(« blanket disclosure »). Le tout
est aussi mis en ligne, en http://www.ietf.org/ipr-instructions.
Et si un tricheur, comme la société RIM, ne respecte pas cette obligation de divulgation ? La section 6 ne prévoit aucune dérogation : si, par exemple, une société empêche ses employés de divulguer les brevets, ces employés ne doivent pas participer à l'IETF (« tu suis les règles, ou bien tu ne joues pas »). Tout participant à l'IETF est censé connaitre cette règle (section 3.3). Le RFC 6701 liste les sanctions possibles contre les tricheurs et le RFC 6702 expose comment encourager le respect des règles.
Bien, donc, arrivé là, l'IETF a ses informations et peut prendre ses décisions. Sur la base de quelles règles ? La section 7 rappelle le vieux principe qu'une technique sans brevets est meilleure ou, sinon, à la rigueur, une technique où le titulaire des brevets a promis des licences gratuites. Mais ce n'est pas une obligation, l'IETF peut choisir une technologie brevetée, même sans promesses sur la licence, si cette technologie en vaut la peine.
La seule exception concerne les techniques de sécurité obligatoires : comme tout en dépend, elles ne doivent être normalisées que s'il n'existe pas de brevet ou bien si la licence est gratuite.
Les règles de bon sens s'appliquent également : s'il s'agit de faire une nouvelle version normalisée d'un protocole très répandu, on évitera de choisir une technologie trop encombrée de brevets, s'il s'agit d'un tout nouveau protocole expérimental, on pourra être moins regardant.
Les changements depuis les RFC précédents, les RFC 3979 et RFC 4879, sont décrits dans la section 13. Pas de révolution, les principes restent les mêmes. Parmi les changements :
- Texte modifié pour permettre l'utilisation de ces règles en dehors de la voie IETF classique (par exemple par l'IRTF).
- La définition d'une « contribution IETF » a été élargie pour inclure, par exemple, les interventions dans les salles XMPP de l'IETF.
- Meilleure séparation des questions de brevets (traitées dans notre RFC) avec celles de droit d'auteur (traitées dans le RFC 5378). Le terme de « propriété intellectuelle » a plusieurs défauts, dont celui de mêler des choses très différentes (brevets, marques, droit d'auteur…)
- Il n'y a plus de boilerplate (qui était en section 5 du RFC 3979) à inclure dans les documents, il est désormais en ligne.
L'article seul
RFC 8174: RFC 2119 Key Words: Clarifying the Use of Capitalization
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : B. Leiba (Huawei)
Première rédaction de cet article le 19 mai 2017
Dernière mise à jour le 20 mai 2017
Un très court RFC discutant un problème de procédure : dans le RFC 2119, qui décrit les termes précis à utiliser dans les normes, un doute subsistait sur la casse de ces termes.
Ce RFC 2119 est celui qui formalise les fameux MUST, SHOULD et MAY, les termes qu'il faut utiliser dans les normes pour être sûr d'indiquer le niveau exact d'exigence. Suivant l'exemple du RFC 2119, ils sont toujours écrits en CAPITALES pour les distinguer du sens courant en anglais, mais cet usage n'était pas explicite dans le RFC 2119 (qui a juste un vague « These words are often capitalized »). Un oubli que corrige notre RFC 8174. Désormais, MUST n'a le sens du RFC 2119 que s'il est en capitales.
Par exemple, dans le RFC 8120, dans le texte « The client SHOULD try again to construct a req-KEX-C1 message in this case », SHOULD est en capitales et a donc bien le sens précis du RFC 2119 (le client est censé ré-essayer de faire son message, sauf s'il a une très bonne raison), alors que dans le texte « This case should not happen between a correctly implemented server and client without any active attacks », should est en minuscules et a donc bien son sens plus informel qui est usuel en anglais.
Le texte qu'il est recommandé d'inclure dans les RFC qui font référence au RFC 2119 apporte désormais cette précision : « The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "NOT RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in BCP 14 [RFC2119],[RFC 8174] when, and only when, they appear in all capitals, as shown here. » Plusieurs auteurs de RFC, conscients de l'ambiguité, avaient d'ailleurs déjà fait une telle modification dans leur référence au RFC 2119. Ainsi, le RFC 5724 dit « The _capitalized_ [souligné par moi] key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in [RFC2119]. »
Notez que le fait de faire une différence sémantique entre le mot en minuscules et le mot en capitales est assez typique des utilisateurs de l'alphabet latin, et déroute toujours beaucoup les utilisateurs d'écritures qui n'ont pas cette distinction, comme les Coréens.
L'article seul
RFC 8170: Planning for Protocol Adoption and Subsequent Transitions
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : D. Thaler (Microsoft)
Pour information
Première rédaction de cet article le 18 mai 2017
L'Internet existe depuis de nombreuses années (le nombre exact dépend de la façon dont on compte…) et, pendant tout ce temps, les protocoles utilisés ne sont pas restés identiques à eux-mêmes. Ils ont évolué, voire ont été remplacés. Cela soulève un problème : la transition entre l'ancien et le nouveau (le cas le plus fameux étant évidemment le passage d'IPv4 à IPv6…) Beaucoup de ces transitions se sont mal passées, parfois en partie car l'ancien protocole ou l'ancienne version n'avait pas prévu son futur remplacement. Contrairement à ce qu'espèrent souvent les techniciens, il ne suffit pas d'incrémenter le numéro de version pour que tous les acteurs adoptent la nouvelle version. Ce nouveau RFC de l'IAB raconte les leçons tirées, et regarde comment on pourrait améliorer les futures transitions.
Ce RFC se focalise sur les transitions techniques. Ce ne sont évidemment pas les seules (il y a par exemple des transitions organisationnelles) mais ce sont celles qui comptent pour l'IAB et l'IETF. Une transition peut être aussi bien le déploiement d'un tout nouveau protocole, que le passage d'un protocole d'une version à une autre. Le thème de la transition d'un protocole à l'autre est fréquent, et de nombreux RFC ont déjà été consacrés à une transition. C'est le cas de :
- Le RFC 3424, qui parlait des techniques de contournement des NAT, en insistant sur le fait qu'elles devaient avoir un caractère provisoire, et ne pas ossifier encore plus l'Internet,
- Le RFC 4690 qui parlait de la transition d'une version d'Unicode à l'autre, dans le contexte des IDN,
- La déclaration de l'IAB sur NAT-PT, qui critiquait une méthode de transition vers IPv6.
Outre les transitions à proprement parler, l'IAB s'est déjà penché sur les principes qui faisaient qu'un protocole pouvait marcher ou pas. C'est notamment le cas de l'excellent RFC 5218 qui étudie les facteurs qui font d'un protocole un échec, un succès, ou un succès fou. Parmi les leçons tirées par ce RFC 5218, les concepteurs d'un protocole devraient s'assurer que :
- Les bénéfices sont pour celui qui assume les coûts. Dans un réseau, coûts et bénéfices ne sont pas forcément alignés. Par exemple, le déploiement de BCP 38 bénéficie aux concurrents de celui qui paie, ce qui explique le manque d'enthousiasme des opérateurs. Notez que coûts et bénéfices ne sont pas déterminés par les lois physiques, ils peuvent être changés par la loi (amendes pour ceux qui ne déploient pas BCP 38, ou à l'inverse code source gratuitement disponible et payé par l'argent public, comme cela avait été le cas pour encourager le déploiement de TCP/IP).
- Le protocole est déployable de manière incrémentale (dans un réseau comme l'Internet, qui représente des investissements énormes, toute solution qui nécessite de jeter tout l'existant d'un coup est condamnée d'avance).
- Le coût total est raisonnable. Il ne faut pas seulement regarder le prix des machines et d'éventuelles licences logicielles. Il faut aussi tenir compte de la formation, des changements de pratiques, des conséquences juridiques…
Le RFC 7305 discutait également des aspects économiques de la transition et notait l'importance de donner une carotte aux premiers à adopter le nouveau protocole, ceux qui font un pari risqué. C'est pour cela qu'il est parfaitement légitime que les premiers à avoir cru dans Bitcoin aient reçu une quantité importante de bitcoins à un prix très faible. Cette décision était une des meilleures prises par Satoshi Nakamoto. Ce RFC note aussi l'importance d'un partenariat avec des organisations qui peuvent aider ou contrarier la transition (comme les RIR ou l'ICANN).
La section 2 de notre RFC rappelle que, de toute façon, le terme « transition » risque d'être mal interprété. Il n'est plus possible depuis longtemps de faire un flag day dans l'Internet, un jour J où on change toutes les machines d'un coup de manière coordonnée. Les transitions sont donc forcément longues, avec une période de co-existence entre l'ancien et le nouveau.
Si l'ancien et le nouveau protocole ne peuvent pas interopérer directement (cas d'IPv4 et d'IPv6), il faudra parfois envisager un mécanisme de traduction (qui ne se situera pas forcément dans la même couche). Un tel traducteur, s'il est situé sur le chemin entre les deux machines, pose souvent d'ennuyeux problèmes de sécurité car il risque fort de casser le modèle de bout en bout.
La section 5 de notre RFC est consacrée aux plans de transition. Ah, les plans… Ils sont évidemment indispensables (on ne va pas se lancer dans une grande transition sans avoir planifié un minimum) mais ils sont aussi très fragiles (comme disent les militaires, « aucun plan ne survit à la première rencontre avec l'ennemi »), et ils terminent souvent au musée des mauvaises idées. Disons qu'il faut avoir un plan, mais ne pas en être esclave.
Quelles sont les qualités d'un bon plan de transition, en s'appuyant sur les expériences ratées et réussies ? D'abord, il faut bien connaitre l'existant. Par exemple, si l'ancien protocole a une fonction optionnelle qui n'a pas d'équivalent, ou un équivalent très différent dans le nouveau protocole, il est bon de savoir si cette fonction est utilisée en pratique (elle peut même ne pas être implémentée du tout, ce qui facilite les choses). De même, il est important de savoir si les logiciels existants mettent réellement en œuvre l'ancien protocole tel qu'il est spécifié, ou bien si, en pratique, ils en dévient, et ont des comportements qui vont poser des problèmes pendant la transition. (Un cas typique est celui de SSL où la plupart des programmes n'avaient pas mis en œuvre correctement le mécanisme de négociation, et plantaient donc lorsqu'une nouvelle version arrivait.)
Un autre élément important d'un plan de transition est d'avoir les idées claires sur les incitations à migrer. Les acteurs de l'Internet utilisent l'ancien protocole. Ça marche pour eux. Pourquoi feraient-ils l'effort de migrer vers un nouveau protocole, ce qui leur coûtera du temps et de l'argent ? Il faut donc des incitations (ou du marketing, qui arrive souvent à faire acheter un gadget inutile). Il n'y a pas que les coûts financiers directs, il faut aussi regarder d'autres problèmes à surmonter (par exemple l'hostilité de certains acteurs, ainsi le chiffrement a du mal à se répandre car les acteurs de l'Internet qui font de la surveillance ont intérêt à continuer à violer la vie privée).
Il y a ensuite le plan proprement dit : une liste des étapes, avec un vague calendrier. Le calendrier est certainement la partie la plus fragile du plan ; l'Internet n'ayant pas de chef, une transition va dépendre des efforts d'un grand nombre d'acteurs non coordonnés, et prédire leurs délais de réaction est à peu près impossible. (Voir le RFC 5211 pour un exemple.)
Un bon plan doit aussi comprendre un moyen de déterminer le succès (ou l'échec). Là aussi, ce n'est pas évident du tout. Certains protocoles sont surtout utilisés dans des réseaux locaux, donc difficiles à mesurer de l'extérieur (comment savoir combien de FAI proposent un résolveur DNS sécurisé par le RFC 7858 ?) Parfois, les critères quantitatifs ne sont pas évidents à établir. Prenons l'exemple d'IPv6 (lisez à ce sujet le rapport de l'ARCEP sur la transition IPv6, qui traite la question en détail). Comment mesure-t-on le succès d'IPv6 ? Le pourcentage de sites Web du Top N d'Alexa qui a une adresse IPv6 ? Le pourcentage d'utilisateurs finaux qui a IPv6 ? Le pourcentage d'octets IPv6 vs. IPv4 ? (Et où ? Chez Google ? Sur un point d'échange comme le France-IX ? Sur le réseau d'un transitaire ? Les valeurs seront très différentes.)
On l'a dit, les plans, même les meilleurs, survivent rarement à la rencontre avec le monde réel. Il faut donc un (ou plusieurs) « plan B », une solution de secours. Souvent, de facto, la solution de secours est la coexistence permanente de l'ancien et du nouveau protocole…
Et puis bien des acteurs de l'Internet ne suivent pas attentivement ce que fait l'IETF, voire ignorent complètement son existence, ce qui ajoute un problème supplémentaire : il faut communiquer le plan, et s'assurer qu'il atteint bien tous les acteurs pertinents (tâche souvent impossible). C'est le but d'opérations de communication comme le World IPv6 Launch Day.
Notre RFC rassemble ensuite (annexe A) quatre études de cas, illustrant des problèmes de transition différents. D'abord, le cas d'ECN. Ce mécanisme, normalisé dans le RFC 3168, permettait aux routeurs de signaler aux machines situées en aval de lui que la congestion menaçait. L'idée est que la machine aval, recevant ces notifications ECN, allait dire à la machine émettrice, située en amont du routeur, de ralentir, avant qu'une vraie congestion n'oblige à jeter des paquets. Les débuts d'ECN, vers 2000-2005, ont été catastrophiques. Les routeurs, voyant apparaitre des options qu'ils ne connaissaient pas, ont souvent planté. C'est un cas typique où une possibilité existait (les options d'IPv4 étaient normalisées depuis le début) mais n'était pas correctement implémentée en pratique. Toute transition qui se mettait à utiliser cette possibilité allait donc se passer mal. Pour protéger les routeurs, des pare-feux se sont mis à retirer les options ECN, ou bien à jeter les paquets ayant ces options, rendant ainsi très difficile tout déploiement ultérieur, même après correction de ces sérieuses failles dans les routeurs.
À la fin des années 2000, Linux et Windows ont commencé à accepter l'ECN par défaut (sans toutefois le réclamer), et la présence d'ECN, mesurée sur le Top Million d'Alexa, a commencé à grimper. De quasiment zéro en 2008, à 30 % en 2012 puis 65 % en 2014. Bref, ECN semble, après un très long purgatoire, sur la bonne voie (article « Enabling Internet-Wide Deployment of Explicit Congestion Notification »).
(Un autre cas, non cité dans le RFC, où le déploiement d'une possibilité ancienne mais jamais testé, a entrainé des conséquences fâcheuses, a été celui de BGP, avec la crise de l'attribut 99.)
L'exemple suivant du RFC est celui
d'IDN. L'internationalisation
est forcément un sujet chaud, vu les sensibilités existantes. Les
IDN résolvent enfin un problème très ancien, l'impossibilité
d'avoir des noms de
domaine dans toutes les écritures du monde. (Voir la
section 3 du RFC 6055, pour la longue et
compliquée histoire des IDN.) Une fois que la norme IDN était
disponible, il restait à effectuer la transition. Elle n'est pas
encore terminée aujourd'hui. En effet, de nombreuses applications
manipulent les noms de domaine et doivent potentiellement être
mises à jour. Bien sûr, elles peuvent toujours utiliser la forme
Punycode, celle-ci est justement conçue
pour ne pas perturber les applications traditionnelles, mais ce
n'est qu'un pis-aller (ஒலிம்பிக்விளையாட்டுகள்.சிங்கப்பூர் est
quand même supérieur à xn--8kcga3ba7d1akxnes3jhcc3bziwddhe.xn--clchc0ea0b2g2a9gcd).
Pire, IDN a connu une transition dans la transition, lors du passage de la norme IDN 2003 (RFC 3490) vers IDN 2008 (RFC 5890). IDN 2008 était conçu pour découpler IDN d'une version particulière d'Unicode mais l'un des prix à payer était le cassage de la compatibilité : certains caractères comme le ß étaient traités différemment entre IDN 2003 et IDN 2008.
Le cas d'IDN est aussi l'occasion, pour le RFC, de rappeler que tout le monde n'a pas forcément les mêmes intérêts dans la transition. IDN implique, outre l'IETF, les auteurs de logiciels (par exemple ceux des navigateurs), les registres de noms de domaine, les domaineurs, et bien sûr les utilisateurs. Tous ne sont pas forcément d'accord et le blocage d'une seule catégorie peut sérieusement retarder une transition (diplomatiquement, le RFC ne rappele pas que l'ICANN a longtemps retardé l'introduction d'IDN dans la racine du DNS, pour des pseudo-raisons de sécurité, et que leur introduction n'a pu se faire qu'en la contournant.)
Lorsqu'on parle transition douloureuse, on pense évidemment tout de suite à IPv6. Ce successeur d'IPv4 a été normalisé en 1995 (par le RFC 1833), il y a vingt-deux ans ! Et pourtant, il n'est toujours pas massivement déployé. (Il existe de nombreuses métriques mais toutes donnent le même résultat : IPv6 reste minoritaire, bien que ces dernières années aient vu des progrès certains. Notez que les réseaux visibles publiquement ne sont qu'une partie de l'Internet : plusieurs réseaux internes, par exemple de gestion d'un opérateur, sont déjà purement IPv6.) Il y avait pourtant un plan de transition détaillé (RFC 1933), fondé sur une coexistence temporaire où toutes les machines auraient IPv4 et IPv6, avant qu'on ne démantèle progressivement IPv4. Mais il a clairement échoué, et ce problème est maintenant un sujet de plaisanterie (« l'année prochaine sera celle du déploiement massif d'IPv6 », répété chaque année).
Là encore, un des problèmes était que tout le monde n'a pas les mêmes intérêts. Si les fabricants de routeurs et les développeurs d'applications bénéficient d'IPv6, c'est beaucoup moins évident pour les gérants de sites Web, ce qui explique que plusieurs sites à forte visibilité, comme Twitter, ou bien gérés par des gens pourtant assez branchés sur la technique, comme GitHub, n'aient toujours pas IPv6 (c'est également le cas de la totalité des sites Web du gouvernement français, qui pourtant promeut officiellement l'usage d'IPv6).
L'effet réseau a également joué à fond contre IPv6 : les pionniers n'ont aucune récompense, puisqu'ils seront tout seuls alors que, par définition, le réseau se fait à plusieurs. Bien sûr, IPv6 marche mieux que l'incroyable et branlante pile de techniques nécessaire pour continuer à utiliser IPv4 malgré la pénurie (STUN, TURN, port forwarding, ICE, etc). Mais tout le monde ne ressent pas ce problème de la même façon : le FAI, par exemple, ne supporte pas les coûts liés à la non-transition, alors qu'il paierait ceux de la transition. Ce problème de (non-)correspondance entre les coûts et les bénéfices est celui qui ralentit le plus les nécessaires transitions. Et puis, pour les usages les plus simples, les plus Minitel 2.0, IPv4 et ses prothèses marchent « suffisamment ».
La lenteur de la transition vers IPv6 illustre aussi la difficulté de nombreux acteurs à planifier à l'avance. C'est seulement lorsque l'IANA, puis les RIR sont l'un après l'autre tombés à court d'adresses IPv4 que certains acteurs ont commencé à agir, alors que le problème était prévu depuis longtemps.
Il n'y a évidemment pas une cause unique à la lenteur anormale de la transition vers IPv6. Le RFC cite également le problème de la formation : aujourd'hui encore, dans un pays comme la France, une formation de technicien ou d'ingénieur réseaux peut encore faire l'impasse sur IPv6.
Le bilan du déploiement d'IPv6 est donc peu satisfaisant. Si certains réseaux (réseaux internes d'entreprises, réseaux de gestion) sont aujourd'hui entièrement IPv6, le déploiement reste loin derrière les espérances. Ce mauvais résultat nécessite de penser, pour les futurs déploiements, à aligner les coûts et les bénéfices, et à essayer de fournir des bénéfices incrémentaux (récompenses pour les premiers adoptants, comme l'a fait avec succès Bitcoin).
Dernier cas de transition étudié par notre RFC, HTTP/2 (RFC 7540). Nouvelle version du super-populaire protocole HTTP, elle vise à améliorer les performances, en multiplexant davantage, et en comprimant les en-têtes (RFC 7541). HTTP/2 a vécu la discussion classique lors de la conception d'une nouvelle version, est-ce qu'on résout uniquement les problèmes les plus sérieux de l'ancienne version ou bien est-ce qu'on en profite pour régler tous les problèmes qu'on avait laissés ? HTTP/2 est très différent de HTTP/1. Ses règles plus strictes sur l'utilisation de TLS (algorithmes abandonnés, refus de la renégociation, par exemple) ont d'ailleurs entrainé quelques problèmes de déploiement.
Il y a même eu la tentation de supprimer certaines fonctions de HTTP/1 considérées comme inutiles ou néfastes (les réponses de la série 1xx, et les communications en clair, entre autres). Après un débat très chaud et très houleux, HTTP/2 n'impose finalement pas HTTPS : les communications peuvent se faire en clair même si, en pratique, on voit très peu de HTTP/2 sans TLS.
Et comment négocier l'ancien protocole HTTP/1 ou le nouveau HTTP/2 ? Ce problème du client (le même qu'avec les versions d'IP : est-ce que je dois tenter IPv6 ou bien est-ce que j'essaie IPv4 d'abord ?) peut être résolu par le mécanisme Upgrade de HTTP (celui utilisé par le RFC 6455), mais il nécessite un aller-retour supplémentaire avec le serveur. Pour éviter cela, comme presque toutes les connexions HTTP/2 utilisent TLS, le mécanisme privilégié est l'ALPN du RFC 7301.
Ce mécanisme marche tellement bien que, malgré le conseil du RFC 5218, HTTP/2 prévoit peu de capacités d'extensions du protocole, considérant qu'il vaudra mieux, si on veut l'étendre un jour, passer à un nouvelle version, négociée grâce à ALPN (cf. RFC 6709.)
En conclusion, on peut dire que la conception d'un nouveau protocole (ou d'une nouvelle version d'un protocole existant) pour que la transition se passe vite et bien, reste un art plutôt qu'une science. Mais on a désormais davantage d'expérience, espérons qu'elle sera utilisée dans le futur.
L'article seul
RFC 8165: Design considerations for Metadata Insertion
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : T. Hardie
Pour information
Première rédaction de cet article le 14 mai 2017
Ce court RFC déconseille l'insertion de métadonnées dans les paquets IP, si cette insertion est faite en route, par des intermédiaires. Pourquoi ? (Essentiellement pour des raisons de vie privée.)
Le problème de la surveillance de masse que pratiquent la plupart des États (en tout cas ceux qui en ont les moyens financiers) est maintenant bien documenté (par exemple dans les RFC 7258 et RFC 7624). Une solution fréquente pour limiter cette surveillance, la rendre plus coûteuse et moins efficace est de chiffrer ses communications. Dans l'éternelle lutte de l'épée et de la cuirasse, les surveillants réagissent au chiffrement en utilisant davantage les métadonnées, en général non protégées par le chiffrement. Qui met des métadonnées dans les paquets, affaiblissant ainsi l'effet du chiffrement ?
Certaines métadonnées sont absolument indispensables au fonctionnement de l'Internet. Par exemple, l'adresse IP de destination dans un paquet doit être en clair car tous les routeurs situés sur le trajet doivent la voir, pour prendre leurs décisions. Certaines métadonnées sont inutiles au fonctionement de l'Internet, mais difficiles à dissimuler, la taille des paquets, par exemple. (C'est également un exemple d'une métadonnée implicite : contrairement à l'adresse IP, elle n'apparait pas explicitement dans le paquet.) Normalement, pour gêner la surveillance, il faut envoyer le moins de métadonnées possible.
L'Internet est souvent décrit comme
reposant sur une liaison de bout en bout, où seules les deux
machines situées aux extrémités de la communication ont accès à
tout le contenu de la communication. Mais, en pratique, il existe
souvent des équipements intermédiaires qui ont accès à des
informations poour faire leur travail. Si ces
middleboxes ont la
mauvaise idée de mettre ces informations dans les métadonnées d'un
paquet, elles affaiblissent la confidentialité des
échanges. Imaginons par exemple (ce n'est pas forcément fait
aujourd'hui : le RFC met en garde contre une mauvaise idée, pas
toujours contre des pratiques existantes, voir à ce sujet l'examen
par la direction Sécurité), imaginons par exemple un VPN qui
déciderait d'indiquer l'adresse IP originale dans la
communication… Notre RFC mentionne deux exemples qui sont décrits
dans des RFC : le RFC 7239 qui décrit l'en-tête HTTP
Forwarded: qu'un relais
HTTP peut mettre pour indiquer l'adresse IP d'origine
du client, et bien sûr le RFC 7871, où un
résolveur DNS transmet aux serveurs faisant
autorité l'adresse IP du client original.
La section 4 du RFC est la recommandation concrète : les métadonnées ne doivent pas être mises par les intermédiaires. Si ces informations peuvent être utiles aux destinataires, c'est uniquement au client d'origine de les mettre. Autrement, on trahit l'intimité du client.
Le RFC 7871, par exemple, aurait dû spécifier un mécanisme où l'adresse IP est mise par le client DNS de départ, celui qui tourne sur la machine de l'utilisateur. Cela permettrait un meilleur contrôle de sa vie privée par l'utilisateur.
Et si cette machine ne connait pas sa propre adresse IP publique, par exemple parce qu'elle est coincée derrière un NAT? Dans ce cas, notre RFC 8165 dit qu'il faut utiliser une technique comme STUN (RFC 8489) pour l'apprendre.
Bon, la section 4, c'était très joli, c'était les bons conseils. Mais la cruelle réalité se met parfois sur leur chemin. La section 5 de notre RFC est le « reality check », les problèmes concrets qui peuvent empêcher de réaliser les beaux objectifs précédents.
D'abord, il y a le désir d'aller vite. Prenons l'exemple du
relais HTTP qui ajoute un en-tête
Forwarded: (RFC 7239), ce qui permet des choses positives (adapter le
contenu de la page Web servie au client) et négatives (fliquer les
clients). Certes, le client HTTP d'origine aurait pu le
faire lui-même, mais, s'il est derrière un routeur
NAT, il faut utiliser
STUN. Même si tous les clients
HTTP décidaient de la faire, cela ne serait pas instantané, et la
longue traine du déploiement des navigateurs Web ferait qu'un
certain nombre de clients n'aurait pas cette fonction. Alors que
les relais sont moins nombreux et plus susceptibles d'être
rapidement mis à jour.
En parlant d'adaptation du contenu au client, il faut noter que c'est une des principales motivations à l'ajout de tas de métadonnées. Or, comme dans l'exemple ci-dessus, si on demande au client de mettre les métadonnées lui-même, beaucoup ne le feront pas. De mon point de vue, ils ont bien raison, et le RFC note qu'une des motivations pour la consigne « ne pas ajouter de métadonnées en route » est justement de rendre le contrôle à l'utilisateur final : il pourra choisir entre envoyer des métadonnées lui permettant d'avoir un contenu bien adapté, et ne pas en envoyer pour préserver sa vie privée. Mais ce choix peut rentrer en conflit avec ds gens puissants, qui exigent, par exemple dans la loi, que le réseau trahisse ses utilisateurs, en ajoutant des informations qu'eux-mêmes ne voulaient pas mettre.
Enfin, il y a l'éternel problème de la latence. L'utilisation de STUN va certainement ralentir le client.
Un dernier point (section 7 du RFC) : si on passe par Internet pour contacter des services d'urgence (pompiers, par exemple, ou autre PSAP), ils ont évidemment besoin du maximum d'informations, et, dans ce cas, c'est peut-être une exception légitime à la règle de ce RFC.
L'article seul
RFC 8164: Opportunistic Security for HTTP/2
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : M. Nottingham, M. Thomson
(Mozilla)
Intérêt historique uniquement
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 16 mai 2017
Pendant la mise au point de la version 2 du protocole
HTTP (finalement normalisée dans le RFC 7540), un débat très vigoureux avait porté
sur la possibilité de chiffrer les échanges avec
TLS même si le plan de
l'URL demandé était
http: (et pas
https:). Certains demandaient le chiffrement
systématique (que l'URL commence par http: ou
https:), d'autres voulaient garder la même
sémantique que HTTP version 1 (TLS pour
https:, en clair pour
http:). Cette dernière décision l'avait
emporté à l'époque, en gardant la possibilité de permettre une
extension à HTTP/2. Ce RFC décrivait
justement une telle extension : en HTTP/2, on pouvait
utiliser TLS (et donc HTTPS) même pour un
URL de plan http:. Mais l'expérience a été
abandonnée en décembre 2021 (personne n'utilisait cette extension)
et le RFC reclassé comme d'intérêt historique seulement.
Le problème à résoudre est celui de la surveillance de masse, à laquelle procèdent un certain nombre d'acteurs (les États, bien sûr, mais pas uniquement, certains FAI, certains réseaux locaux, surveillent le trafic de leurs utilisateurs). Cette surveillance de masse est considérée, à juste titre, par l'IETF comme un problème de sécurité, et contre lequel il faut donc trouver des solutions ou au moins des mitigations (RFC 7258). Chiffrer massivement le trafic Web est évidemment indispensable pour diminuer l'efficacité de la surveillance.
Mais le modèle de HTTP version 1 rend cela difficile. En
HTTP/1, on accède à un URL de plan
http: avec du trafic en clair, passer à
TLS nécessite de changer les URL, donc les
pages Web qui les contiennent, les signets des utilisateurs,
etc. Des logiciels comme HTTPS Everywhere
aident à cela mais ne sont pas une solution parfaite
(rappelez-vous par exemple qu'une bonne partie du trafic HTTP
n'est pas due aux navigateurs
Web).
Il serait tentant de résoudre le problème en disant « le client
HTTP qui tente d'accéder à un URL de plan
http: n'a qu'à essayer en même temps
HTTPS. Si ça marche, tant mieux. Si ça
rate, au moins on aura essayé. » C'est ce qu'on nomme parfois le
« chiffrement opportuniste » (RFC 7435). Mais cela pose trois problèmes :
- Si on tente HTTPS d'abord, sur le port 443, et qu'un pare-feu sur le trajet absorbe ces paquets, on devra attendre l'expiration du délai de garde avant d'essayer avec succès sur le port 80. Ce problème est réel, mais soluble par l'algorithme des globes oculaires heureux, décrit dans le RFC 6555.
- Que faire si ça réussit en HTTPS mais que le
certificat du serveur ne peut pas être
validé ? La difficulté et/ou le coût d'un certificat sont après
tout les principales raisons pour lesquelles HTTPS n'est pas
davantage déployé. (Je ne publie pas des URL
https:pour mon blog car beaucoup de gens n'ont pas mon AC dans leur magasin d'autorités.) On note qu'aujourd'hui les alertes de sécurité des navigateurs Web sont souvent absurdes : si on se connecte en HTTPS mais avec un certificat expiré (qui a donc été parfaitement valable), on a des alertes plus effrayantes que si on se connecte en clair ! - Enfin, et c'est le plus gros problème, rien ne garantit qu'on obtiendra le même contenu en HTTP et en HTTPS : la plupart des serveurs HTTP permettent de configurer deux virtual host différents sur les deux ports 80 et 443. Pas question donc de jouer à ça sans une autorisation explicite du serveur.
Bref, pour le HTTP traditionnel, il semble qu'il n'y ait pas de solution.
Celle proposée par notre RFC est d'utiliser le mécanisme des services alternatifs
du RFC 7838. Le serveur va indiquer
(typiquement par un en-tête Alt-Svc:) qu'il
est accessible par un autre mécanisme (par exemple HTTPS). Cela a
également l'avantage d'éviter les problèmes de contenu
mixte qui surviendraient si on avait mis la page en HTTPS
mais pas tous ses contenus. Par contre, l'indication de service
alternatif n'étant pas forcément bien protégée, ce mécanisme
« opportuniste » reste vulnérable aux attaques actives. En
revanche, ce mécanisme devrait être suffisamment simple pour être
largement déployé assez vite.
Donc, maintenant, les détails concrets (section 2 du RFC). Le
serveur qui accepte de servir des URL http:
avec TLS annonce le service alternatif. Notez que les clients
HTTP/1 n'y arriveront pas, car ils ne peuvent pas indiquer l'URL
complet (avec son plan) dans la requête à un serveur
d'origine (section 5.3.1 du RFC 7230). Cette spécification est donc limitée à HTTP/2 (RFC 7540). Si le client le veut bien, il va alors
effectuer des requêtes chiffrées vers la nouvelle
destination. S'il ne veut pas, ou si pour une raison ou pour une
autre, la session TLS ne peut pas être établie, on se rabat sur du
texte en clair (chose qu'on ne ferai jamais avec un URL https:).
Si le client est vraiment soucieux de son intimité et ne veut même pas que la première requête soit en clair, il peut utiliser une commande HTTP qui ne révèle pas grand'chose, comme OPTIONS (section 4.3.7 du RFC 7231).
Le certificat client ne servirait à rien
dans ce chiffrement opportuniste et donc, même si on en a un, on
ne doit pas l'envoyer. Par contre, le serveur doit avoir un
certificat, et valide (RFC 2818) pour le
service d'origine (si le service d'origine était en
foo.example et que le service alternatif est
en bar.example, le certificat doit indiquer
au moins foo.example). Ce service
ne permet donc pas de se chiffrer sans authentification, par
exemple avec un certificat expiré, ou avec une
AC inconnue du client, et ne résout donc pas un des
plus gros problèmes de HTTPS. Mais c'est une exigence de la
section 2.1 du RFC 7838, qui exige que le renvoi à un service
alternatif soit « raisonnablement » sécurisé. (Notez que cette
vérification est délicate, comme l'a montré CVE-2015-0799.)
En outre, le client doit avoir fait une
requête sécurisée pour le nom bien connu (RFC 8615,
pour la notion de nom bien connu)
/.well-known/http-opportunistic. La réponse à
cette requête doit être positive, et doit être en
JSON, et contenir un tableau de chaînes de caractères
dont l'une doit être le nom d'origine (pour être sûr que ce
serveur autorise le service alternatif, car le certificat du serveur
effectivement utilisé prouve une autorisation du serveur
alternatif, et la signature d'une AC, ce qu'on peut trouver
insuffisant). Ce nouveau nom bien connu figure désormais dans
le registre IANA.
La section 4 de notre RFC rappelle quelques trucs de sécurité :
- L'en-tête
Alt-Svc:étant envoyé sur une liaison non sécurisée, il ne faut pas s'y fier aveuglément (d'où les vérifications faites ci-dessus). - Certaines applications tournant sur le serveur peuvent utiliser des drôles de moyens pour déterminer si une connexion était sécurisée ou pas (par exemple en regardant le port destination). Elles pourraient faire un faux diagnostic sur les connexions utilisant le service alternatif.
- Il est trivial pour un attaquant actif (un « Homme du Milieu ») de retirer cet en-tête, et donc de faire croire au client que le serveur n'a pas de services alternatifs. Bref, cette technique ne protège que contre les attaques passives. Ce point a été un des plus discutés à l'IETF (débat classique, vaut-il mieux uniquement la meilleure sécurité, ou bien accepter une sécurité « au mieux », surtout quand l'alternative est pas de sécurité du tout).
- Le client ne doit pas utiliser des indicateurs qui donneraient à l'utilisateur l'impression que c'est aussi sécurisé qu'avec du « vrai » HTTPS. Donc, pas de joli cadenas fermé et vert. (C'est une réponse au problème ci-dessus.)
Apparemment, Firefox est le seul client
HTTP à mettre
en œuvre ce nouveau service (mais avec une syntaxe
différente pour le JSON, pas encore celle du RFC). Notez que le serveur ne
nécessite pas de code particulier, juste une configuration
(envoyer l'en-tête Alt-Svc:, avoir le
/.well-known/http-opportunistic…) Les
serveurs de Cloudflare permettent
ce choix.
L'article seul
RFC 8153: Digital Preservation Considerations for the RFC Series
Date de publication du RFC : Avril 2017
Auteur(s) du RFC : H. Flanagan (RFC Editor)
Pour information
Première rédaction de cet article le 25 avril 2017
La préservation, sur le long terme, des documents qui ne sont jamais passés par une forme papier, est un défi important de notre époque. Nous pouvons relire aujourd'hui toute la correspondance du ministère des affaires étrangères de Louix XV, pourrons-nous, dans un siècle ou deux, relire les documents numériques du vingtième siècle ? Pourrons-nous relire les RFC ? C'est le but de ce document que d'explorer les pistes permettant de donner aux RFC une meilleure chance de conservation.
Le RFC Editor (RFC 8728) est à la fois l'éditeur et l'archiviste des RFC. Les deux fonctions sont souvent contradictoires : l'éditeur voudrait utiliser les derniers gadgets pour publier des jolis trucs (multimédia, par exemple, ou contenus exécutables), l'archiviste est prudent et conservateur et voudrait des technologies simples. L'éditeur doit produire des documents clairs et lisibles. L'archiviste doit les conserver, et pour une durée potentiellement bien plus longue que les modes technologiques, durée qui peut atteindre des siècles (on est ravis, aujourd'hui, quand on retrouve les textes de lois d'un royaume depuis longtemps oublié, au fin fond de la Mésopotamie, même quand ces lois ont depuis longtemps cessé d'être applicables).
Notez que des organisations comme l'IETF produisent plein de documents (les discussions sur les listes de diffusion, par exemple), mais que ce RFC se focalise sur la préservation des RFC.
Historiquement, les RFC étaient en texte seul. Ce format avait des tas d'avantages. Simple, et auto-documenté (la seule spécification nécessaire pour le comprendre était ASCII), il convenait bien à l'archivage. Régulièrement, des naïfs demandaient que le RFC Editor passe à un format « plus moderne », en général une mode passagère, oubliée quelques années après. Le texte seul a donc tenu très longtemps, et à juste titre.
Mais la roue de l'histoire a fini par tourner et le RFC 6949 a pris acte du fait qu'on n'allait pas rester en texte seul éternellement. Le format officiel des RFC, décrit dans le RFC 7990 est désormais fondé sur XML, avec divers enrichissements comme le jeu de caractères Unicode (RFC 7997) ou les images en SVG (RFC 9896). Cela fait peser une pression plus forte sur l'archivage : si on est certain de pouvoir relire le texte brut en ASCII dans cent ans, qu'en est-il d'images SVG ? L'ancien système d'archivage des RFC ne va donc a priori pas suffire. (Le XML lui-même est relativement auto-documenté. Si on met des documents XML sous les yeux d'un programmeur qui n'en a jamais vu, il pourra probablement rétro-ingénierer l'essentiel. Ce n'est pas forcément le cas des vocabulaires qui utilisent XML, notamment le compliqué SVG.)
Le nouveau système d'archivage suivra le cadre conceptuel d'OAIS (norme ISO 14721, disponible en ligne). Sur OAIS, on peut lire la bonne introduction d'Emmanuelle Bermes. Il faut notamment distinguer deux tâches (section 1.1 de notre RFC) :
- Préservation des bits : archiver un fichier informatique et pouvoir le ressortir des dizaines d'années après, au bit près. Cela se fait, par exemple, en recopiant régulièrement le fichier sur de nouveaux supports physiques, et en vérifiant via une somme de contrôle ou une signature que rien n'a changé. Des classiques sauvegardes, vérifiées régulièrement, suffisent donc.
- Préservation du contenu : il ne suffit plus de stocker et de restituer les bits, il faut aussi présenter le contenu à l'utilisateur. Avoir une copie parfaite des bits d'un fichier WordPerfect de 1990 ne sert pas à grand'chose s'il n'existe plus aucun logiciel capable de lire le Wordperfect sur les machines et systèmes d'exploitation modernes. Assurer la préservation du contenu est plus complexe, et il existe plusieurs solutions, par exemple de garder une description du format (pour qu'on puisse toujours développer un outil de lecture), et/ou garder non seulement les fichiers mais aussi les outils de lecture, et tout l'environnement qui permet de les faire fonctionner.
Ceci dit, ce problème d'archivage à long terme des fichiers numériques n'est ni nouveau, ni spécifique aux RFC. Il a été largement étudié par de nombreuses organisations. On peut citer la BNF, le projet LIFE en Grande-Bretagne, ou l'étude du cycle de vie faite à la Bibliothèque du Congrès. Des processus pour maintenir sur le long terme les fichiers, avec recopies régulières et nombreuses vérifications, existent.
Les RFC bénéficient depuis un certain temps d'un mécanisme similaire de préservation des bits : les métadonnées (indispensables pour retrouver un document) sont créées et enregistrées. Les fichiers sont recopiés d'un ordinateur à l'autre au fur et à mesure que les anciennes technologies de stockage deviennent dépassées. En outre, depuis 2010, tous les RFC sont imprimés sur du papier, pour avoir « ceinture et bretelles ». Les RFC plus anciens que 2010 subissent également parfois ce traitement, mais il existe des trous (RFC perdus, ou, tout simplement, problèmes avec le droit d'auteur, avant que cette question ne soit explicitement traitée, cf. RFC 8179).
Cette copie papier s'est avérée utile au moins une fois, quand 800 RFC ont dû être été re-saisis à la main, suite à une panne informatique (et une insuffisance des sauvegardes). Un petit détail amusant au passage : le RFC Editor à une époque acceptait des documents qui n'étaient pas des RFC, et qu'il faut aussi sauvegarder, voir l'histoire antique des RFC.
Il n'y a pas actuellement de sauvegarde de l'environnement logiciel utilisé pour lire les RFC, l'idée est que cela n'est pas nécessaire : on pourra toujours lire du texte brut en ASCII dans cent ans (la preuve est qu'on n'a pas de mal à relire le RFC 1, vieux de quarante-huit ans). Le processus de sauvegarde préserve les bits, et on considère que la préservation du contenu ne pose pas de problème, avec un format aussi simple. (Par exemple, l'impression sur le papier ne garde pas les hyperliens mais ce n'est pas un problème puiqu'il n'y en a pas dans le format texte brut.)
Mais, puisque les RFC vont bientôt quitter ce format traditionnel et migrer vers un format plus riche, il faut reconsidérer la question. La section 2 de notre RFC explore en détail les conséquences de cette migration sur chaque étape du cycle de vie. Il faut désormais se pencher sur la préservation des contenus, pas seulement des bits.
Certaines caractéristiques du cycle de vie des RFC facilitent l'archivage. Ainsi, les RFC sont immuables. Même en cas d'erreur dans un RFC, il n'y a jamais de changement (au maximum, on publie un nouveau RFC, comme cela avait été fait pour le RFC 7396). Il n'y a donc pas à sauvegarder des versions successives. D'autres caractéristiques du cycle de vie des RFC compliquent l'archivage. Ainsi, ce n'est pas le RFC Editor qui décide d'approuver ou pas un RFC (RFC 5741). Il n'a donc pas le pouvoir de refuser un document selon ses critères à lui.
Le RFC Editor maintient une base de données (qui n'est pas
directement accessible de l'extérieur) des RFC, avec évidemment
les métadonnées associées (état, auteurs,
date, DOI, liens vers les éventuels errata
puisqu'on ne corrige jamais un RFC, etc). Les pages
d'information sur les RFC sont automatiquement tirées de cette
base (par exemple https://www.rfc-editor.org/info/rfc8153
Les RFC citent, dans la bibliographie à la fin, des références
dont certaines sont normatives (nécessaires pour comprendre le
RFC, les autres étant juste « pour en savoir plus »). Idéalement,
les documents ainsi référencés devraient également être archivés
(s'ils ne sont pas eux-même des RFC)
mais ce n'est pas le cas. Notre RFC suggère que l'utilisation de
Perma.cc serait peut-être une
bonne solution. C'est un mécanisme d'archivage des données
extérieures, maintenu par groupe de bibliothèques juridiques de
diverses universités. Pour un exemple, voici la sauvegarde Perma.cc
(https://perma.cc/E7QG-TG98) de mon article sur le hackathon de l'IETF.
Dans un processus d'archivage, une étape importante est la normalisation, qui va supprimer les détails considérés comme non pertinents. Elle va permettre la préservation du contenu, en évitant de garder des variantes qui ne font que compliquer la tâche des logiciels. Par exemple, bien que XML permette d'utiliser le jeu de caractères de son choix (en l'indiquant dans la déclaration, tout au début), une bonne normalisation va tout passer en UTF-8, simplifiant la tâche du programmeur qui devra un jour, écrire ou maintenir un logiciel de lecture du XML lorsque ce format sera à moitié oublié.
Or, au cours de l'histoire des RFC, le RFC Editor a reçu plein de formats différents, y compris des RFC uniquement sur papier. Aujourd'hui, il y a au moins le format texte brut, et parfois d'autres.
Maintenant qu'il existe un format canonique officiel (celui du RFC 7991), quelles solutions pour assurer la préservation du contenu ?
- Best effort, préserver les bits et espérer (ou compter sur les émulateurs, ce qui se fait beaucoup dans le monde du jeu vidéo vintage),
- Préserver un format conçu pour l'archivage (PDF/A-3 étant un candidat évident - voir le RFC 7995, d'autant plus que le XML original peut être embarqué dans le document PDF),
- Préserver le XML et tous les outils, production, test, visualisation, etc. (Ce que les mathématiciens ou les programmeurs en langages fonctionnels appeleraient une fermeture.)
La première solution, celle qui est utilisée aujourd'hui, n'est plus réaliste depuis le passage au nouveau format. Elle doit être abandonnée. La deuxième solution sauvegarde l'information dans le document, mais pas le document lui-même (et c'est embêtant que le format archivé ne soit pas le format canonique, mais uniquement un des rendus). Et l'avenir de PDF/A-3 est incertain, on n'a pas encore essayé de le lire trente ans après, et les promesses du marketing doivent être considérées avec prudence (d'autant plus qu'il y a toujours peu d'outils PDF/A, par exemple aucun logiciel pour vérifier qu'un document PDF est bien conforme à ce profil restrictif). Pour la troisième solution, cela permettrait de refaire un rendu des RFC de temps en temps, adapté aux outils qui seront modernes à ce moment. Mais c'est aussi la solution la plus chère. Si on imagine un futur où XML, HTML et PDF sont des lointains souvenirs du passé, on imagine ce que cela serait d'avoir préservé un environnement d'exécution complet, les navigateurs, les bibliothèques dont ils dépendent, le système d'exploitation et même le matériel sur lequel il tourne !
Une solution plus légère serait de faire (par exemple tous les ans) un tour d'horizon des techniques existantes et de voir s'il est encore possible, et facile, de visualiser les RFC archivés. Si ce n'est pas le cas, on pourra alors se lancer dans la tâche de regénérer des versions lisibles.
Au passage, il existe déjà des logiciels qui peuvent faciliter certains de ces activités (le RFC cite le logiciel libre de gestion d'archives ArchiveMatica).
Après cette analyse, la section 3 de notre RFC va aux recommandations : l'idée est de sauvegarder le format canonique (XML), un fichier PDF/A-3, le futur outil xml2rfc et au moins deux lecteurs PDF (qui doivent être capables d'extraire le XML embarqué). Les tâches immédiates sont donc :
- Produire les PDF/A-3 (à l'heure de la publication de ce RFC, l'outil n'est pas encore développé) avec le XML à l'intérieur, et l'archiver,
- Archiver le format canonique (texte seul pour les vieux RFC, XML pour les nouveaux),
- Archiver les versions majeures des outils, notamment xml2rfc,
- Archiver deux lecteurs PDF,
- Avoir des partenariats avec différentes institutions compétentes pour assurer la sauvegarde des bits (c'est déjà le cas avec la bibliothèque nationale suédoise). Un guide d'évaluation de ce ces archives est ISO 16363.
La version papier, par contre, ne sera plus archivée.
Conclusion (section 4) : les RFC sont des documents importants, qui ont un intérêt pour les générations futures, et qui valent la peine qu'on fasse des efforts pour les préserver sur le long terme.
L'article seul
RFC 8145: Signaling Trust Anchor Knowledge in DNS Security Extensions (DNSSEC)
Date de publication du RFC : Avril 2017
Auteur(s) du RFC : D. Wessels (Verisign), W. Kumari
(Google), P. Hoffman (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 19 avril 2017
L'utilisation de DNSSEC implique que le résolveur DNS ait une ou plusieurs clés de départ de la validation (trust anchors). Typiquement, le résolveur aura une clé pour la racine, les autres domaines étant validés en suivant l'arborescence du DNS (cela se configure, même si la plupart des résolveurs viennent avec une pré-configuration pour la clé ICANN de la racine). Seulement, parfois, les clés changent et le gérant d'un domaine aimerait bien savoir, avant de supprimer l'ancienne clé, si les résolveurs ont bien tous reçu la nouvelle. D'où cette nouvelle option EDNS où le résolveur signale au serveur faisant autorité la liste des clés qu'il utilise comme point de départ de la validation. (Le RFC décrit également une autre méthode, non fondée sur EDNS.)
En toute rigueur, il faut dire que le résolveur ne transmet pas les
clés mais les identificateurs courts (key tags
ou key IDs), qui sont un
condensat de 16 bits des clés (section 3.1.6 du RFC 4034, et notez dans l'annexe B du même RFC
que ce ne sont pas des condensats cryptographiques). On trouve cet
identificateur de clé si on utilise l'option
+multi de dig :
% dig +multi DNSKEY tf
...
;; ANSWER SECTION:
tf. 172800 IN DNSKEY 257 3 8 (
...
) ; KSK; alg = RSASHA256; key id = 12520
tf. 172574 IN DNSKEY 256 3 8 (
...
) ; ZSK; alg = RSASHA256; key id = 51793
...
tf. 172574 IN RRSIG DNSKEY 8 1 172800 (
20170524190422 20170325180422 12520 tf.
...
Il est utilisé pour la communication entre humains mais on le trouve aussi dans les enregistrements DS chez le parent :
% dig DS tf ... ;; ANSWER SECTION: tf. 86400 IN DS 12520 8 2 ( 2EC74274DD9AA7FFEA33E695EFF98F17F7C78ABD2D76 EDBBDE4EDD4630D68FA2 ) ...
Ainsi que dans les signatures :
% dig +dnssec SOA tf
...
;; ANSWER SECTION:
tf. 172800 IN SOA nsmaster.nic.fr. hostmaster.nic.fr. (
2222242731 ; serial
...
tf. 172800 IN RRSIG SOA 8 1 172800 (
20170531124004 20170401114004 51793 tf.
...
On voit ici que la clé de
.tf dans la racine est la 12520, qui signe la clé
51793, qui elle-même signe les enregistrements.
Si vous n'êtes pas parfaitement au point sur la terminologie DNSSEC, lisez la section 3 du RFC. Et, à titre d'exemple, voici la configuration d'un résolveur Unbound pour utiliser comme clés de départ de la validation celles de Yeti :
% cat /etc/unbound/unbound.conf
...
server:
...
auto-trust-anchor-file: "/var/lib/unbound/yeti.key"
...
% cat /var/lib/unbound/yeti.key
. 86400 IN DNSKEY 257 3 8 AwE...8uk= ;{id = 59302 (ksk), size = 2048b} ;;state=1 [ ADDPEND ] ;;count=67 ;;lastchange=1488474089 ;;Thu Mar 2 18:01:29 2017
. 86400 IN DNSKEY 257 3 8 AwE...y0U= ;{id = 19444 (ksk), size = 2048b} ;;state=2 [ VALID ] ;;count=0 ;;lastchange=1472139347 ;;Thu Aug 25 17:35:47 2016
On voit deux clés, d'identificateurs 59302 et 19444. Tout contenu signé avec une de ces deux clés sera accepté. (Le fait qu'il y ait deux clés alors qu'une suffirait est dû au fait qu'un changement est en cours, suivant le RFC 5011.)
Voyons maintenant la première façon de signaler ses clés dont
dispose un résolveur, la méthode EDNS
(section 4 de notre RFC, et voir le RFC 6891, pour les détails sur ce qu'est EDNS). On utilise
une nouvelle option EDNS, edns-key-tag
(code 14 dans le
registre IANA). Comme toutes les options EDNS, elle
comprend le code (14), la longueur, puis une suite
d'identificateurs de clés. Par exemple, le résolveur Unbound
montré plus haut enverrait une option {14, 4, 59302, 19444}
(longueur quatre
car il y a deux identificateurs, de deux octets chacun). Il est
recommandé d'utiliser cette option pour toutes les requêtes de
type DNSKEY (et jamais pour les autres).
Notez que le serveur qui reçoit une requête avec cette option n'a rien à faire : elle est juste là pour l'informer, la réponse n'est pas modifiée. S'il le souhaite, le serveur peut enregistrer les valeurs, permettant à son administrateur de voir, par exemple, si une nouvelle clé est largement distribuée (avant de supprimer l'ancienne).
La deuxième méthode de signalisation, celle utilisant le
QNAME (Query Name, le nom indiqué dans la
requête DNS) figure en section 5. La requête de signalisation
utilise le type NULL (valeur
numérique 10), et un nom de
domaine qui commence par « _ta- », suivi de la liste
des identificateurs en hexadécimal (dans cet article, ils
étaient toujours montré en décimal) séparés par des
traits. Le nom de la zone pour laquelle
s'applique ces clés est ajouté à la fin (la plupart du temps, ce
sera la racine, donc il n'y aura rien à ajouter). En reprenant
l'exemple du résolveur Unbound plus haut, la requête sera
_ta-4bf4-e7a6.. Comme ce nom n'existe pas,
la réponse sera certainement NXDOMAIN.
Le serveur utilise cette requête comme il utilise l'option EDNS : ne rien changer à la réponse qui est faite, éventuellement enregistrer les valeurs indiquées, pour pouvoir informer l'administrateur du serveur.
Voilà, comme vous voyez, c'est tout simple. Reste quelques petites questions de sécurité (section 7) et de vie privée (section 8). Pour la sécurité, comme, par défaut, les requêtes DNS passent en clair (RFC 7626), un écoutant indiscret pourra savoir quelles clés utilise un résolveur. Outre que cela peut permettre, par exemple, de trouver un résolveur ayant gardé les vieilles clés, la liste peut révéler d'autres informations, par exemple sur le logiciel utilisé (selon la façon dont il met en œuvre le RFC 5011). C'est donc un problème de vie privée également.
Notez aussi que le client peut mentir, en mettant de fausses valeurs. Par exemple, il pourrait envoyer de faux messages, avec une adresse IP source usurpée, pour faire croire que beaucoup de clients ont encore l'ancienne clé, de façon à retarder un remplacement.
(Au passage, si vous voulez des informations sur le remplacement des clés DNSSEC de la racine, voyez la page de l'ICANN, et la première expérimentation Yeti ainsi que la deuxième.)
Notez que le mécanisme utilisé a beaucoup varié au cours du développement de ce RFC (section 1.1, sur l'histoire). Au début, il n'y avait que l'option EDNS, en copiant sur le mécanisme du RFC 6975. Mais EDNS a quelques limites :
- Il n'est pas de bout en bout : si une requête passe par plusieurs résolveurs, les options EDNS ne sont pas forcément transmises,
- Il y a toujours le problème des stupides et bogués boitiers intermédiaires, qui bloquent parfois les paquets ayant une option EDNS qu'ils ne connaissent pas,
- Comme l'option n'est pas forcément envoyée à chaque requête DNS, un résolveur pourrait avoir besoin de mémoriser les valeurs envoyées par ses clients, afin de les transmettre, ce qui l'obligerait à garder davantage d'état.
L'approche concurrente, avec le QNAME, a aussi ses inconvénients :
- Elle ne permet pas de distinguer les clés connues du client, de celles connues par le client du client (si plusieurs résolveurs sont chaînés, via le mécanisme forwarder),
- Elle nécessite deux requêtes, une avec la demande normale, une avec le QNAME spécial : en cas de répartition de charge entre serveurs, par exemple avec l'anycast, ces deux requêtes peuvent même aboutir sur des serveurs différents,
- Enfin la requête avec le QNAME spécial peut ne pas être transmise du tout, en cas de mise en mémoire énergique des réponses négatives par un résolveur intermédiaire (cf. RFC 8020 and RFC 8198).
D'où le choix (chaudement discuté) de fournir les deux méthodes.
À l'heure actuelle, je ne connais qu'une seule mise en œuvre de ce RFC, introduite dans BIND 9.10.5 rc1 (« named now provides feedback to the owners of zones which have trust anchors configured by sending a daily query which encodes the keyids of the configured trust anchors for the zone. This is controlled by trust-anchor-telemetry »).
L'article seul
RFC 8143: Using Transport Layer Security (TLS) with Network News Transfer Protocol (NNTP)
Date de publication du RFC : Avril 2017
Auteur(s) du RFC : J. Élie
Chemin des normes
Première rédaction de cet article le 25 avril 2017
Ce RFC concernant le protocole NNTP met à jour l'ancien RFC 4642 qui donnait des conseils TLS très spécifiques (activer la compression, utiliser RC4...), conseils qui n'ont pas résisté à l'évolution de la cryptographie. On arrête donc de donner des conseils TLS spécifiques, NNTP a un usage générique de TLS et doit donc se référer au RFC générique BCP 195 (actuellement RFC 7525).
NNTP, le protocole de transport des News, est normalisé dans le RFC 3977. Il peut utiliser TLS (RFC 5246) pour sécuriser la communication entre deux serveurs NNTP, ou bien entre serveur et client. Le RFC 4642, qui décrivait cet usage de TLS, faisait une erreur : il donnait des conseils de cryptographie. Or, d'une part, NNTP ne faisait pas un usage particulier de la cryptographie, et n'avait pas besoin de recommandations spécifiques et, d'autre part, la cryptographie est un domaine qui évolue. Ainsi, les fonctions de compression de données de TLS sont aujourd'hui considérées comme une mauvaise idée, dans la plupart des cas (attaque CRIME, cf. RFC 7525, section 3.3).
L'essentiel de notre nouveau RFC est dans sa section 3 : désormais, il faut suivre le RFC de bonnes pratiques TLS, BCP 195 (actuellement RFC 7525).
De même que le courrier électronique
peut préciser dans un en-tête Received: que
la connexion SMTP était protégée par TLS,
de même NNTP permet d'ajouter dans le champ
Path: (section 3.1.5 du RFC 5536) une indication que
le pair a été authentifié (deux points d'exclamation de suite).
La section 2 du RFC résume les changements par rapport au RFC 4642 (la liste complète est dans l'annexe
A). Comme dit plus haut, la compression TLS est désormais fortement déconseillée
(à la place, on peut utiliser l'extension de compression de NNTP,
normalisée dans le RFC 8054). Il est très
nettement recommandé d'utiliser du TLS implicite (connexion sur un
port dédié (le 563 pour les clients, non
spécifié pour les autres serveurs), au lieu de la
directive STARTTLS, qui est vulnérable à
l'attaque décrite dans la section 2.1 du RFC 7457). Il ne faut évidemment
plus utiliser RC4 (cf. RFC 7465), mais les algorithmes de chiffrement obligatoires
de TLS. Il faut utiliser
l'extension TLS Server Name Indication (RFC 6066, section 3). Et, pour authentifier, il
faut suivre les bonnes pratiques TLS des RFC 5280 et RFC 6125.
Comme la plupart des mises en oœuvre de NNTP-sur-TLS utilisent une bibliothèque TLS générique, elles suivent déjà une bonne partie des recommandations de ce RFC. Après, tout dépend des options particulières qu'elles appellent…
Merci à Julien Élie pour une relecture attentive (j'avais réussi à mettre plusieurs erreurs dans un article aussi court.)
L'article seul
RFC 8141: Uniform Resource Names (URNs)
Date de publication du RFC : Avril 2017
Auteur(s) du RFC : P. Saint-Andre
(Filament), J. Klensin
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF urnbis
Première rédaction de cet article le 30 avril 2017
Dans la grande famille des URI, il y a (entre autres) les
URL, et les
URN, comme urn:ietf:params:xml:ns:iodef-2.0, normalisés
dans ce RFC, qui couvre aussi bien leur
syntaxe (qui était
auparavant dans le RFC 2141) que les
procédures d'enregistrement (autrefois dans le RFC 3406). Il remplace donc ces deux anciens RFC.
Le RFC 3986, qui normalise la syntaxe générique des URI, délègue les détails des familles particulières d'URI à d'autres RFC comme celui-ci. Notre RFC 8141 précise la syntaxe générique pour le cas des URN, des URI dont les propriétés sont a priori la persistence et la non-résolvabilité (donc, plutôt des noms que des adresses, pour reprendre le vocabulaire des RFC 1737 et RFC 3305).
La section 2, URN Syntax décrit à quoi
ressemblent les URN. Un URN est formé avec le plan
urn (enregistré à l'IANA), un NID (Namespace
IDentifier) qui indique l'organisme qui gère la fin de
l'URN, puis le NSS (Namespace Specific String), tous
séparés par des deux-points. Il existe de très nombreux NID déjà enregistrés, comme ceux du RFC 7207 (messagerie Eurosystem), RFC 7254 (IMEI),
RFC 5165 (normes OGC), RFC 9562 (UUID)… Deux idées essentielles des URN sont que la création de NID est
strictement gérée (il faut documenter précisément le pourquoi du
nouvel NID) et que, dans chaque espace de noms créé par un NID,
l'affectation des NSS est à son tour gérée, avec des règles
rigoureuses, que l'on suit soigneusement. Les URN sont conçus pour
du nommage « sérieux ». Il n'existe pas d'URN à enregistrement libre
et, donc, le fait d'être correct syntaxiquement ne suffit pas pour
qu'un URN soit un vrai URN : il doit en plus être passé par le
processus d'enregistrement.
Par exemple, si on prend les URN néo-zélandais du RFC 4350, le NID est nzl et un URN
ressemble donc à
urn:nzl:govt:registering:recreational_fishing:form:1-0. Attention,
le deux-points n'est un séparateur qu'au début,
entre le plan et le NID, puis entre le NID et le NSS. Après, c'est
juste un caractère comme un autre. Donc,
govt:registering:recreational_fishing:form:1-0
n'est pas forcément du nommage arborescent.
Notez que la syntaxe est moins
restrictive qu'elle ne l'était dans le RFC 2141.
Comme avec les autres URI, les caractères considérés comme
« spéciaux » doivent être protégés avec l'encodage pour
cent (cela ne concerne pas le NID qui doit être purement
en ASCII). On ne peut donc hélas pas faire de vrais URN
internationaux. Ainsi, urn:example:café doit en
fait s'écrire urn:example:caf%E9.
Notre RFC 8141 introduit un concept nouveau, qui n'était
pas dans le RFC 2141, celui de composants. Ils
sont de trois sortes, les r-components, les
q-components et les
f-components. Les premiers, les
r-components, servent à passer des paramètres à un
éventuel système de résolution. Ils commencent par un point
d'interrogation suivi d'un
plus. Ainsi, dans
urn:example:bar-baz-qux?+CCResolve:cc=fr, le
r-component est
CCResolve:cc=fr, indiquant probablement qu'on
souhaite une réponse adaptée à la France (CCResolve
= Country-Code Resolve). La syntaxe est définie
(ainsi que le fait que ces composants doivent être ignorés pour la
comparaison de deux URN) mais la sémantique est pour l'instant laissée
dans le flou.
Contrairement au r-component, prévu pour le
système de résolution, le q-component est prévu
pour la ressource à laquelle on accède. Il commence par un point
d'interrogation suivi d'un égal. Un exemple
pourrait être
urn:example:weather?=op=map&lat=39.56&lon=-104.85
(cherchez pas : c'est près de Denver).
Quant au f-component, introduit par un croisillon, il n'est destiné qu'au client (comme le classique identificateur de fragment des URI).
La section 3, consacrée à l'équivalence
lexicale de deux URN, explique comment on peut
déterminer si deux URN sont égaux ou pas, sans connaitre les règles
particulières de l'organisme qui les enregistre. (Déterminer
l'équivalence sert, par
exemple, pour savoir si un URN a déjà été visité.) Ainsi,
urn:foo:BAR et urn:FOO:BAR
sont lexicalement équivalents (le NID est insensible à la casse, cf. section 2.1) mais
urn:foo:BAR et urn:foo:bar
ne le sont pas, le NSS étant, lui, sensible à la casse (les deux URN
sont peut-être fonctionnellement équivalents mais cela dépend de la
politique d'enregistrement de l'organisme désigné par
foo). Il n'y a pas d'autre normalisation
appliquée avant la comparaison, notamment sur les caractères encodés
pour-cent.
Notez que la définition d'un espace de noms donné peut toujours rajouter des règles (par exemple que le NSS soit insensible à la casse) mais ces règles doivent uniquement créer de nouvelles équivalences, jamais séparer deux URN qui auraient été identiques dans une comparaison générique (par un logiciel qui ne connaissait pas les règles spécifiques de cet espace de noms, voir aussi la section 4.2).
Comme vu plus haut, il y a dans un URN, immédiatement après la
chaîne de caractères urn:, l'espace de
noms (namespace ou NID), une chaîne de caractères qui identifie le domaine d'une
autorité d'enregistrement. Notre RFC 8141 explique les
procédures de création d'un nouvel espace de noms dans le registre des espaces de noms que tient
l'IANA. Si vous voulez juste faire des exemples,
il existe un NID example specifié dans le RFC 6963 (oui, j'aurais dû l'utiliser au lieu de foo).
Comme expliqué dans la section 5, ce mécanisme d'espaces de noms suppose que, dans chaque espace, il existe une autorité d'enregistrement qui accepte (ou refuse) les enregistrements et que, d'autre part, il existe une autorité qui enregistre les espaces de noms (en l'occurrence l'IANA). La section 6 de notre RFC est consacrée aux procédures de cette dernière autorité et aux mécanismes pour enregistrer un identificateur d'espace de noms (NID pour namespace identifier). (La résolution des URN en autres identificateurs n'est par contre pas couverte, mais on peut toujours regarder le RFC 2483.) Des exemples d'autorité d'enregistrement dans un espace de noms donné sont le gouvernement néo-zélandais (RFC 4350) ou l'OGC (RFC 5165).
Notez que certains URN sont créés en partant de rien, alors que
d'autres sont juste une transcription en syntaxe URN d'identificateurs
déjà enregistrés par ailleurs. C'est le cas des
ISBN (RFC 8254) ou des
RFC eux-mêmes (RFC 2648, avec le NID
ietf, ce RFC est donc urn:ietf:rfc:8141).
Tiens, et où peut-on mettre des URN ? Syntaxiquement, un
URN est un URI, donc on peut en mettre partout où on peut mettre des
URI (section 4 du RFC). Par exemple, comme nom d'espace de
noms XML. Mais ce n'est pas une bonne idée de mettre des
URN partout. Par exemple, en argument d'un <a
href="…, c'est même certainement une mauvaise idée (car le
navigateur Web typique ne sait pas résoudre des URN).
Autre recommandation pratique de notre RFC, si un logiciel affiche
un URN, bien penser à l'afficher en complet (contrairement à ce que
font certains navigateurs Web qui, stupidement, tronquent l'URI, par
exemple en omettant le plan http://). En effet,
une abréviation peut ne pas avoir le résultat attendu. En effet, il
existe un NID urn:xmpp (RFC 4854) et un
plan d'URI xmpp: (RFC 5122). Si on n'affiche pas le plan
urn:, il y a un gros risque de confusion.
La section 5 du RFC détaille ce qu'est un espace de noms (un ensemble d'identificateurs uniques géré, c'est-à-dire que tous les noms syntaxiquements corrects n'en font pas partie, uniquement ceux qui ont été enregistrés). Par exemple, les ISBN forment un tel espace (dont l'utilisation dans des URN a fait l'objet du RFC 8254). À l'intérieur d'un espace de noms, les règles d'enregistrement et le travail quotidien du registre ne sont pas gérés par l'IETF ou l'IANA mais par l'autorité d'enregistrement de cet espace.
La section 5 introduit les différents types d'espaces de noms. Il y a les espaces informels (section 5.2),
dont le NID commence par urn- et est composé de
chiffres et les espaces formels (section 5.1)
dont le NID est composé de lettres et qui, contrairement aux
informels, sont censés fournir un bénéfice aux utilisateurs de
l'Internet (les espaces informels ont le droit
d'être réservés à une communauté déconnectée). Contrairement encore
aux informels, l'enregistrement des espaces formels fait l'objet d'un
examen par un expert (cf. RFC 5226)
et il est
recommandé que cet enregistrement fasse
l'objet d'une spécification écrite, par exemple un
RFC. L'organisation
qui gère un NID formel doit également démontrer sa stabilité et son
sérieux sur le long terme.
Un des principes des URN est la durabilité : un URN devrait être stable dans le temps (et, logiquement, jamais réaffecté si jamais il est supprimé). Mais cette stabilité dépend essentiellement de facteurs non-techniques, comme la permanence dans le temps du registre (une organisation privée et fermée comme l'IDF est, par exemple, typiquement un mauvais choix pour assurer la permanence). Toutefois, si on ne peut pas garantir la stabilité d'un espace de noms, on connait en revanche des facteurs qui diminuent la probabilité de permanence et l'IETF peut donc analyser les spécifications à la recherche de tels facteurs (c'est une variante du problème très riche mais bien connu de la stabilité des identificateurs). Au passage, la plupart des grandes questions liées aux URN (permanence, compromis entre facilité d'enregistrement et désir de ne pas permettre « n'importe quoi ») sont des questions bien plus anciennes que les URN, et même plus anciennes que l'Internet, et ne feront probablement pas l'objet d'un consensus de si tôt (cf. section 1.2).
Enfin, le processus d'enregistrement lui-même. Il faut en effet un
peu de bureaucratie pour s'assurer que le NID est bien enregistré et
que le registre des
NID soit lui-même stable. Les procédures sont différentes selon
le type d'espace de noms. Les informels, qui commencent par la chaîne
de caractères urn- suivie d'un nombre, ont leur
propre
registre, avec un processus d'enregistrement léger, mais très
peu utilisé.
Le gros morceau est constitué des espaces de noms formels. Cette
fois, le processus d'enregistrement est plus complexe, mais on obtient
un « vrai » NID comme mpeg (RFC 3614),
oasis (RFC 3121) ou
3gpp (RFC 5279).
Le formulaire d'enregistrement complet est disponible dans l'annexe
A du RFC. Bon courage aux futurs enregistreurs. N'oubliez pas de lire
tout le RFC. Notez par exemple qu'il faudra décrire les mécanismes
par lesquels vous allouerez des noms (si vous gérez
urn:example, et que je demande
urn:example:boycott-de-mcdo, que
répondrez-vous ?), et qu'il faudra une analyse de sécurité et aussi
(c'est une nouveauté par rapport au RFC 2141) de
vie privée.
Ce nouveau RFC remplace à la fois le RFC 2141
et le RFC 3406, et le processus fut long (six
ans) et difficile. L'annexe B indique les
principaux changements depuis le RFC 2141 :
alignement de la syntaxe sur le RFC 3986 (en
pratique, la nouvelle syntaxe est plus acceptante), introduction des
composants (pour pouvoir faire des choses comme les fragments, qui
marchaient avec tous les autres URI)… L'annexe C, elle, présente les
changements par rapport au RFC 3406 :
politique d'enregistrement d'un NID plus libérale (examen par un expert
au lieu d'examen par l'IETF), suppression des NID expérimentaux (nom
commençant par x-) en raison du RFC 6648…
L'article seul
RFC 8128: IETF Appointment Procedures for the ICANN Root Zone Evolution Review Committee
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : C. Morgan (AMS)
Pour information
Première rédaction de cet article le 11 mars 2017
Un petit RFC purement bureaucratique publié hier, il décrit les procédures par lesquelles l'IETF nomme un représentant dans un des innombrables comités de l'ICANN, le RZERC (Root Zone Evolution Review Committee), qui travaille sur la gestion de la zone racine du DNS.
Ce nouveau comité RZERC est chargé des mécanismes de publication de la zone racine, une zone évidemment cruciale puisque la nature arborescente du DNS fait que, si elle a des problèmes, plus rien ne marche. Notez que le RZERC ne s'occupe que de la création et de la publication de la zone racine, pas de servir cette zone. Cette tâche incombe en effet aux serveurs racines du DNS, qui sont indépendants de l'ICANN (contrairement à ce qu'on lit souvent dans des médias mal informés). L'actuelle charte du RZERC est en ligne et elle prévoit que le comité comprend entre autres « The Chair or delegate of the Internet Engineering Task Force ».
C'est l'IAB qui désigne le représentant IETF, le premier étant Jim Reid. Les qualités nécessaires sont citées en section 2 de notre RFC. Sans surprise, il faut être techniquement très compétent, et il faut pouvoir traduire des recommandations en des termes compréhensibles par la bureaucratie ICANN (« be able to articulate those technology issues such that the ICANN Board can be provided with sound technical perspectives »). Le RFC précise également qu'il faut comprendre l'articulation de la gouvernance Internet et les rôles des différents organismes, une tâche complexe, c'est sûr !
Suivant les procédures décrites en section 3 du RFC, un appel à volontaires avait été lancé le 25 mai 2016, il y avait quatre candidats (Marc Blanchet, Warren Kumari, Kaveh Ranjbar et Jim Reid), et Jim Reid a été nommé le 11 août 2016. Depuis, si on veut savoir ce que fait ce comité, il faut regarder sa page Web officielle. Son rôle n'est pas encore bien défini et fait l'objet de la plupart des discussions. En gros, il devrait intervenir uniquement lorsqu'une proposition de changement important est faite, pas pour la gestion quotidienne.
L'article seul
RFC 8126: Guidelines for Writing an IANA Considerations Section in RFCs
Date de publication du RFC : Juin 2017
Auteur(s) du RFC : M. Cotton (ICANN), B. Leiba (Huawei
Technologies), T. Narten (IBM
Corporation)
Première rédaction de cet article le 21 juin 2017
Un aspect peu connu du travail de normalisation est la nécessité de tenir des registres de certains paramètres, lorsque la liste de ces derniers n'est pas fixée dans un RFC. Par exemple, les algorithmes publiés dans le DNS pour IPsec ne sont pas définis de manière limitative dans le RFC 4025 mais sont enregistrés dans un registre public. Même chose pour les types de média du RFC 6838, qui ont leur propre registre. Pour les RFC, ces registres sont tenus par l'IANA. Celle-ci ne décide pas quels registres elle doit tenir ni à quelle condition un nouveau paramètre peut y rentrer, elle applique les décisions contenues dans la section IANA Considerations d'un RFC. C'est cette section qui est décrite ici. Ce RFC remplace l'ancien RFC 5226.
Prenons l'exemple du RFC 3315 (DHCP). Sa
section 24 contient le texte « This document defines several
new name spaces associated with DHCPv6 and DHCPv6 options: Message
types, Status codes, DUID and Option codes. IANA has established a
registry of values for each of these name spaces, which are described
in the remainder of this section. These name spaces will be managed
by the IANA and all will be managed separately from the name spaces
defined for DHCPv4. ». En application de ce texte,
l'IANA a créé le registre DHCPv6 and
DHCPv6 options qu'on peut consulter en ligne à https://www.iana.org/assignments/dhcpv6-parameters. Et comment
ajoute-t-on des entrées dans ce registre ? En suivant les règles
données dans ce même RFC : « New DHCP option codes are
tentatively assigned after the specification for the associated
option, published as an Internet Draft, has received expert review by
a designated expert [11]. The final assignment of DHCP option codes
is through Standards Action, as defined in RFC 2434.
».
L'intérêt d'avoir une section obligatoire IANA Considerations est de concentrer en un seul endroit les informations nécessaires à l'IANA pour faire son travail. Pour aider les auteurs de RFC à écrire correctement cette section IANA Considerations, notre RFC 8126, qui succède au RFC 5226, pose quelques règles.
La section 1 du RFC décrit le problème général de la gestion d'un espace de nommage (namespace). Tous ces espaces n'ont pas les mêmes caractéristiques. Certains sont très petits (le champ protocole, qui n'a que huit bits soit 256 valeurs possibles, cf. RFC 5237) et doivent donc être gérés avec prudence, certains sont hiérarchiques comme le DNS ou comme les OID et peuvent donc être délégués, certains sont immenses, et peuvent être gérés avec moins de précautions (mais nécessitent quand même des règles, comme expliqué dans la section 1).
Cette même section 1 résume les points essentiels que doit connaitre l'auteur d'un RFC, notamment d'avoir une section dédiée IANA Considerations, et de n'y mettre que ce qui est strictement nécessaire à l'IANA (pas de digressions, pas de détails techniques).
La section 2 est consacrée à la création d'un nouveau registre. Il y a bien des décisions à prendre à ce stade. Par exemple, notre RFC recommande de voir si on ne peut pas faire un registre arborescent, où l'action de l'IANA se limiterait à la racine de ce registre, diminuant ainsi sa charge de travail. (C'est le cas des URN du RFC 8141.)
Si un RFC doit demander une telle création, il doit préciser quelle politique d'enregistrement devra suivre l'IANA. C'est une des parties les plus intéressantes du RFC, notamment sa section 4 qui explique les politiques possibles :
- Premier Arrivé, Premier Servi (« First Come First Served »), où toute requête est
acceptable et est faite dans l'ordre d'arrivée. Les entrées dans le
préfixe OID
iso.org.dod.internet.private.enterprisesont un bon exemple (https://www.iana.org/assignments/enterprise-numbersmais attention, le registre est lourd à charger). C'est aussi le cas des plans d'URI provisoires (RFC 7595) ou des états de traitement du courrier (RFC 6729). C'est sans doute la plus « libérale » des politiques d'enregistrement. (Il n'y a pas de mécanisme explicite contre les vilains qui enregistreraient plein de valeurs inutiles, avait noté l'examen de sécurité.) - Examen par un expert (« Expert review »), comme détaillé plus bas (section 5 du RFC). C'est ainsi que sont gérés les plans des URI permanents du RFC 7595, ou bien les types de méthode d'EAP (RFC 3748, sections 6 et 7.2, notez que Expert review était appelé Designated expert à cette époque).
- Spécification nécessaire (« Specification required ») où un texte écrit et stable décrivant le paramètre souhaité est nécessaire (ce texte n'est pas forcément un RFC, il y a d'ailleurs une politique « RFC required »). Il faut en outre un examen par un expert, comme dans la politique ci-dessus, l'expert vérifiant que la spécification est claire. Les profils de ROHC (RFC 5795) sont enregistrées sous cette condition. Les utilisations de certificat de DANE (RFC 6698, section 7.2) sont « RFC nécessaire ».
- Examen par l'IETF (« IETF Review »), l'une des plus « lourdes », puisqu'il faut un RFC « officiel », qui soit passé par l'IESG ou par un groupe de travail IETF (tous les RFC ne sont pas dans ce cas, certains sont des contributions individuelles). C'est la politique des extensions TLS du RFC 6066 (cf. RFC 5246, section 12, qui utilisait encore l'ancien terme de « IETF Consensus »).
- Action de normalisation (« Standards Action »), encore plus difficile, le RFC doit être sur le chemin des normes et donc avoir été approuvé par l'IESG. C'est le cas par exemple des types de message BGP (RFC 4271, section 4.1), en raison de la faible taille de l'espace en question (un seul octet, donc un nombre de valeurs limité) et sans doute aussi en raison de l'extrême criticité de BGP. C'est aussi la politique pour les options DHCP données en exemple plus haut.
- Utilisation privée (« Private use ») est une politique possible, qui est en fait l'absence de registre, et donc l'absence de politique de registre : chacun utilise les valeurs qu'il veut. Par exemple, dans le protocole TLS (RFC 5246, section 12), les valeurs 224 à 255 des identifiants numériques du type de certificat sont à usage privé ; chacun s'en sert comme il veut, sans coordination.
- Utilisation à des fins expérimentales (« Experimental use »), est en pratique la même chose que l'utilisation privée. La seule différence est le but (tester temporairement une idée, cf. RFC 3692). C'est le cas des valeurs des en-têtes IP du RFC 4727.
- Et il existe encore l'approbation par l'IESG (« IESG approval ») qui est la politique de dernier recours, à utiliser en cas de cafouillage du processus.
- Et le cas un peu particulier de l'allocation hiérarchique (« Hierarchical allocation ») où l'IANA ne gère que le registre de plus haut niveau, selon une des politiques ci-dessus, déléguant les niveaux inférieurs à d'autres registres. C'est le cas par exemple des adresses IP ou bien sûr des noms de domaine.
Le choix d'une politique n'est pas évident : elle ne doit pas être trop stricte (ce qui ferait souffrir les auteurs de protocoles, confrontés à une bureaucratie pénible) mais pas non plus trop laxiste (ce qui risquerait de remplir les registres de valeurs inutiles, les rendant difficilement utilisables). En tout cas, c'est une des décisions importantes qu'il faut prendre lors de l'écriture d'une spécification.
Notre RFC conseille (sans l'imposer) d'utiliser une de ces politiques (« well-known policies »). Elles ont été testés en pratique et fonctionnent, concevoir une nouvelle politique fait courir le risque qu'elle soit incohérente ou insuffisamment spécifiée, et, de toute façon, déroutera les lecteurs et l'IANA, qui devront apprendre une nouvelle règle.
Parmi les autres points que doit spécifier le RFC qui crée un nouveau registre, le format de celui-ci (section 2.2 ; la plupart des registres sont maintenus en XML, mais même dans ce cas, des détails de syntaxe, comme les valeurs acceptables, peuvent devoir être précisés). Notez que le format n'est pas forcément automatiquement vérifié par l'IANA. Notre RFC recommande également de bien préciser si le registre accepte des caractères non-ASCII (cf. RFC 8264, section 10).
Autre choix à faire dans un registre, le pouvoir de changer les
règles (change control). Pour des normes IETF (RFC
sur le chemin des normes), c'est en général l'IETF qui a ce pouvoir,
mais des registres IANA peuvent être créés pour des protocoles qui ne sont
pas gérés par l'IETF et, dans ce cas, le pouvoir peut appartenir à une
autre organisation. C'est ainsi que les types de données
XML (RFC 7303), comme le
application/calendar+xml (RFC 6321) sont contrôlés par le W3C.
La section 3 couvre l'enregistrement de nouveaux paramètres dans un registre existant. C'est elle qui précise, entre autres, que l'IANA ne laisse normalement pas le choix de la valeur du paramètre au demandeur (mais, en pratique, l'IANA est sympa et a accepté beaucoup de demandes humoristiques comme le port TCP n° 1984 pour le logiciel Big Brother...)
La section 6 donne des noms aux différents états d'enregistrement d'une valeur. Le registre note l'état de chaque valeur, parmi ces choix :
- Réservé à une utilisation privée,
- Réservé à une utilisation expérimentale,
- Non affecté (et donc libre),
- Réservé (non alloué mais non libre, par exemple parce que la norme a préféré le garder pour de futures extensions),
- Affecté,
- Utilisation connue, mais non officiellement affecté, ce qui se produit parfois quand un malotru s'approprie des valeurs sans passer par les procédures normales, comme dans le cas du RFC 8093.
Par exemple, si on prend les types de messages
BGP, on voit dans le
registre que 0 est réservé, les valeurs à partir de 6 sont
libres, les autres sont affectées (1 = OPEN, etc).
La section 5 décrit le rôle des experts sur
lesquels doit parfois s'appuyer l'IANA. Certains registres nécessitent
en effet un choix technique avec l'enregistrement d'un nouveau
paramètre et l'IANA n'a pas forcément les compétences nécessaires pour
cette évaluation. Elle délègue alors cette tâche à un expert
(designated expert, leur nom est noté à côté de celui du registre). Par exemple, pour le registre des langues, défini par le RFC 5646, l'expert actuel est Michael Everson. Ce registre utilise également une autre
possibilité décrite dans cette section, une liste de discussion qui sert à un examen collectif des requêtes
(pour le registre des langues, cette liste est
ietf-languages@iana.org). La section 5.1 discute
des autres choix qui auraient pu être faits (par exemple un examen par le groupe de travail qui a
créé le RFC, ce qui n'est pas possible, les groupes de travail IETF
ayant une durée de vie limitée). Elle explique ensuite les devoirs de
l'expert (comme la nécessité de répondre relativement rapidement,
section 5.3, chose qui est loin d'être toujours faite).
Enfin, diverses questions sont traitées dans la section 9, comme la récupération de valeurs qui avaient été affectées mais qui ne le sont plus (le RFC 3942 l'avait fait mais c'est évidemment impossible dès que les paramètres en question ont une... valeur, ce qui est le cas entre autres des adresses IP).
Bien que la plupart des allocations effectuées par l'IANA ne sont guère polémiques (à l'exception des noms de domaine et des adresses IP, qui sont des sujets très chauds), notre RFC 8126 prévoit une procédure d'appel, décrite en section 10. Cela n'a pas suffit à régler quelques cas pénibles comme l'enregistrement de CARP.
Ce RFC 8126 remplace le RFC 5226. Les principaux changements sont détaillés dans la section 14.1 :
- Moins de texte normatif style RFC 2119, puisqu'il ne s'agit pas de la description d'un protocole,
- Meilleure description des registres hiérarchiques,
- Ajout d'une partie sur le pouvoir de changer les règles (change control),
- Ajout de la possibilité de fermer un registre,
- Ajout de la section 8 sur le cas de RFC qui remplacent un RFC existant,
- Etc.
Notez que notre RFC est également complété en ligne par des informations plus récentes.
Les relations entre l'IETF et l'IANA sont fixées par le MOU contenu dans le RFC 2860. À noter que tout n'est pas couvert dans ce RFC, notamment des limites aux demandes de l'IETF. Que se passerait-il par exemple si l'IETF demandait à l'IANA, qui ne facture pas ses prestations, de créer un registre de milliards d'entrées, très dynamique et donc très coûteux à maintenir ? Pour l'instant, l'IANA ne peut pas, en théorie, le refuser et la question s'est parfois posée à l'IETF de savoir si tel ou tel registre n'était pas trop demander.
Puisque l'IANA est un acteur important de l'Internet, rappelons aussi que, bien que la fonction de l'IANA soit actuellement assurée par l'ICANN, la tâche de gestion des protocoles et des registres n'a rien à voir avec les activités, essentiellement politiciennes, de l'ICANN. La « fonction IANA » (création et gestion de ces registres) est formellement nommée IFO (IANA Functions Operator) ou IPPSO (IANA Protocol Parameter Services Operator) mais tout le monde dit simplement « IANA ».
L'article seul
RFC 8118: The application/pdf Media Type
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : M. Hardy, L. Masinter, D. Markovic (Adobe Systems), D. Johnson (PDF Association), M. Bailey (Global Graphics)
Pour information
Première rédaction de cet article le 18 mars 2017
Le format PDF, largement utilisé sur l'Internet, n'a sans doute pas besoin
d'être présenté ici. De toute façon, ce nouveau
RFC ne prétend pas décrire PDF, juste le
type de contenu
application/pdf. Ce RFC remplace l'ancien
RFC 3778, notamment pour tenir compte du fait
qu'officiellement, PDF n'est plus une spécification
Adobe mais une norme
ISO, 32000-1:2008.
Donc, si vous envoyez des documents PDF
via l'Internet, que ce soit par courrier ou par le
Web, vous êtes censé les étiqueter avec le
type MIME
application/pdf (le type de premier niveau
applicaton/ indiquant que c'est un format
binaire, non utilisable en dehors des applications
spécialisées). Ce type a été enregistré à l'IANA
(section 8 du RFC).
PDF avait été conçu pour le monde du papier (les commerciaux d'Adobe répétaient dans les années 90 que PDF permettait d'avoir « le même rendu partout » ce qui n'a pas de sens sur écran, où tous les écrans sont différents), ce qui se retrouve dans de nombreux concepts archaïques de PDF comme le découpage en pages. Un document PDF est un « rendu final », typiquement non modifiable, avec du texte utilisant différentes polices, des images… PDF permet également de représenter des liens hypertexte, une table des matières… On peut même inclure du JavaScript pour avoir des documents interactifs. PDF permet également le chiffrement et la signature, et a un mécanisme (en fait, plusieurs) pour placer des métadonnées, XMP. Bref, PDF est un format très complexe, ce qui explique les nombreuses failles de sécurité rencontrées par les programmes qui lisent du PDF.
La norme PDF est désormais déposée à l'ISO (ISO 32000-1) mais l'archaïque ISO ne distribue toujours pas librement ces documents. Si on veut apprendre PDF, il faut donc le télécharger sur le site d'Adobe.
Pour les protocoles où il y a une notion d'identificateur de
fragment (comme les URI, où cet
identificateur figure après le croisillon),
PDF permet d'indiquer une partie d'un document. Cela fera partie
de la future norme ISO, mais c'était déjà dans l'ancien RFC 3778. Cet identificateur prend la forme d'un ou plusieurs
couples clé=valeur, où la clé est, par exemple,
page=N (pour aller à la page n° N),
comment=ID (aller à l'endroit marqué par
l'annotation ID), zoom=S (agrandir d'un
facteur S), search=MOT (aller à la première
occurrence de MOT)… (Je n'ai pas réussi à faire fonctionner ces
identificateurs de fragments avec le lecteur PDF inclus dans
Chrome. Quelqu'un connait un logiciel où ça marche ?)
PDF a également des sous-ensembles. La norme est riche, bien
trop riche, et il est donc utile de la restreindre. Il y a eu
plusieurs de ces sous-ensembles de PDF normalisés (voir sections 2
et 4 du RFC). Ainsi, PDF/A, sous-ensemble
de PDF pour l'archivage à long terme (ISO 19005-3:2012), limite
les possibilités de PDF, pour augmenter la probabilité que le
document soit toujours lisible dans 50 ou 100 ans. Par exemple,
JavaScript y est interdit. PDF/X (ISO 15930-8:2008), lui, vise le
cas où on envoie un fichier à un imprimeur. Il restreint également
les possibilités de PDF, pour accroitre les chances que
l'impression donne exactement le résultat attendu. Enfin,
PDF/UA (ISO 14289-1:2014) vise
l'accessibilité, en insistant sur une
structuration sémantique (et non pas fondée sur l'apparence
visuelle) du document. Tous ces sous-ensembles s'étiquettent avec
le même type application/pdf. Ils ne sont pas
mutuellement exclusifs : un document PDF peut être à la fois PDF/A
et PDF/UA, par exemple.
Il existe d'innombrables mises en œuvre de PDF, sur toutes les plate-formes possible. Celle que j'utilise le plus sur Unix est Evince.
Un mot sur la sécurité (section 7 du RFC). On l'a dit, PDF est un format (trop) complexe, ce qui a des conséquences pour la sécurité. Comme l'impose la section 4.6 du RFC 6838, notre RFC inclut donc une analyse des risques. (Celle du RFC 3778 était trop limitée.) Notamment, PDF présente les risques suivants :
- Les scripts inclus, écrits en JavaScript,
- Le chargement de fichiers extérieurs, et les liens hypertexte vers l'extérieur,
- Les fichiers inclus, qui peuvent être absolument n'importe quoi, et qui viennent avec leurs propres dangers (sans compter le risque de leur exportation vers le système de fichiers local).
Et c'est sans compter sur les risques plus génériques, comme la complexité de l'analyseur. Il y a eu de nombreuses failles de sécurité dans les lecteurs PDF (au hasard, par exemple CVE-2011-3332 ou bien CVE-2013-3553). La revue de sécurité à l'IETF avait d'ailleurs indiqué que les premières versions du futur RFC étaient encore trop légères sur ce point, et demandait un mécanisme pour mieux étiqueter les contenus « dangereux ».
Vous avez peut-être noté (lien « Version PDF de cette page » en bas) que tous les articles de ce blog ont une version PDF, produite via LaTeX (mais elle n'est pas toujours complète, notamment pour les caractères Unicode). Une autre solution pour obtenir des PDF de mes articles est d'imprimer dans un fichier, depuis le navigateur.
La section 2 du RFC rappelle l'histoire de PDF. La première
version date de 1993. PDF a été un très
grand succès et est largement utilisé aujourd'hui. Si on
google
filetype:pdf, on trouve « Environ 2 500 000
000 résultats » (valeur évidemment très approximative, le chiffre
rond indiquant que Google n'a peut-être pas tout compté) . Si PDF a été créé et reste largement
contrôlé par Adobe, il en existe une
version ISO, la norme 32000-1, qui date
de 2008 (pas de mise à jour depuis, bien
qu'une révision soit attendue en 2017). ISO
32000-1:2008 est identique à la version PDF 1.7 d'Adobe.
Normalement, les anciens lecteurs PDF doivent pouvoir lire les versions plus récentes, évidemment sans tenir compte des nouveautés (section 5 du RFC).
Quels sont les changements depuis l'ancienne version, celle du RFC 3778 ? La principale est que le change controller, l'organisation qui gère la norme et peut donc demander des modifications au registre IANA est désormais l'ISO et non plus Adobe. Les autres changements sont :
- Une mise à jour de la partie historique,
- Une mise à jour de la partie sur les sous-ensembles de PDF, qui étaient moins nombreux autrefois,
- Une section sécurité bien plus détaillée.
L'article seul
RFC 8117: Current Hostname Practice Considered Harmful
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : C. Huitema (Private Octopus
Inc.), D. Thaler
(Microsoft), R. Winter (University of Applied
Sciences Augsburg)
Pour information
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 12 mars 2017
« Je suis l'iPhone de Jean-Luc ! » Traditionnellement, les ordinateurs connectés à l'Internet ont un nom, et ce nom est souvent annoncé à l'extérieur par divers protocoles. Cette pratique très répandue, dont l'origine remonte à l'époque où on n'avait que quelques gros serveurs partagés, et fixes, est dangereuse pour la vie privée, dans un monde de mobilité et de machines individuelles. Comme le note ce nouveau RFC, « c'est comme si on se promenait dans la rue avec une étiquette bien visible portant son nom ». Ce RFC dresse l'état des lieux, fait la liste des protocoles problématiques, et suggère, lorsqu'on ne peut pas changer le protocole, d'utiliser des noms aléatoires, ne révélant rien sur la machine.
Pour illustrer le problème, voici un exemple du trafic WiFi pendant une réunion, en n'écoutant qu'un seul protocole, mDNS (RFC 6762). Et d'autres protocoles sont tout aussi bavards. Notez que cette écoute n'a nécessité aucun privilège particulier sur le réseau (cf. RFC 8386), ni aucune compétence. N'importe quel participant à la réunion, ou n'importe quelle personne située à proximité pouvait en faire autant avec tcpdump (j'ai changé les noms des personnes) :
% sudo tcpdump -n -vvv port 5353 tcpdump: listening on wlp2s0, link-type EN10MB (Ethernet), capture size 262144 bytes 15:03:16.909436 IP6 fe80::86a:ed2c:1bcc:6540.5353 > ff02::fb.5353: 0*- [0q] 2/0/3 0.4.5.6.C.C.B.1.C.2.D.E.A.6.8.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.E.F.ip6.arpa. (Cache flush) [2m] PTR John-Smiths-iPhone-7.local., [...] 15:03:17.319992 IP 172.25.1.84.5353 > 224.0.0.251.5353: 0*- [0q] 2/0/3 C.4.1.6.F.8.D.E.0.3.6.3.4.1.0.1.0.0.0.0.0.0.0.0.0.0.0.0.0.8.E.F.ip6.arpa. (Cache flush) [2m] PTR Jane-iPhone.local., [...] 15:03:20.699557 IP6 fe80::e2ac:cbff:fe95:da80.5353 > ff02::fb.5353: 0 [5q] [4n] [1au] PTR (QU)? _googlecast._tcp.local. ANY (QU)? info-mac-66._smb._tcp.local. [...]
On y voit que les noms des machines présentes sont annoncés à
tous (ff02::fb et
224.0.0.251 sont des adresses
multicast). Certains
noms sont très révélateurs (nom, prénom et type de la machine),
d'autres un peu moins (prénom et type), d'autres sont presques
opaques (juste un type de machine, très général). Un indiscret qui
regarde le trafic sur des réseaux publiquement accessibles peut
ainsi se faire une bonne idée de quelles machines sont présentes,
voire de qui est présent. Les deux exemples des noms
info-mac-66 et
John-Smiths-iPhone-7 illustrent les deux
risques. Dans le premier cas, si le nom est stable, il permet de
suivre à la trace une machine qui se déplacerait. Le second cas
est encore pire puisqu'on a directement le nom du propriétaire.
Le fait que les ordinateurs aient des noms est une tradition très ancienne (voir la définition de host name dans le RFC 8499). Un nom court (sans point à l'intérieur) combiné avec un suffixe forme un FQDN (Fully Qualified Domain Name, cf. RFC 1983). On utilise ces noms courts et ces FQDN à plein d'endroits. IP lui-même n'utilise pas de noms du tout mais plein de protocoles de la famille TCP/IP le font, comme mDNS montré plus haut.
Un nom court doit être unique dans un contexte donné mais n'est pas forcément unique mondialement. Le FQDN, lui, est unique au niveau mondial.
Je vous recommande l'excellent travail de M. Faath, F. Weisshaar et R. Winter, « How Broadcast Data Reveals Your Identity and Social Graph » à l'atelier TRAC 2016 (supports de leur exposé), montrant toutes les fuites d'information liées à cette utilisation des noms, et ce qu'un méchant peut en faire. (C'est ce groupe qui avait écouté le trafic WiFi lors d'une réunion IETF à Prague, déclenchant une grande discussion sur les attentes en matière de vie privée quand le trafic est diffusé.)
Pourquoi nomme-t-on les ordinateurs, au fait, à part la tradition ? Sur un réseau, bien des systèmes d'exploitation, à commencer par Unix et Windows tiennent pour acquis que les ordinateurs ont un nom, et ce nom peut être utilisé dans des tas de cas. Il existe plusieurs schémas de nommage (section 2 du RFC), du plus bucolique (noms de fleurs) au plus français (noms de vins) en passant par les schémas bien geeks comme les noms des personnages du Seigneur des Anneaux. Mais, parfois, c'est le système d'exploitation lui-même qui nomme l'ordinateur, en combinant le nom de l'utilisateur et les caractéristiques de l'ordinateur, comme on le voit avec les iPhones dans l'exemple tcpdump ci-dessus. (Sur les schémas de nommage, voir le RFC 1178, et, sur un ton plus léger, le RFC 2100. Il existe une excellente page Web pleine d'idées de noms. L'ISC fait des statistiques sur les noms vus sur Internet. Entre 1995 et 2017, vous pouvez constater la décroissance des noms sympas en faveur des noms utilitaires.)
Dans les environnements corporate, on ne
laisse pas l'utilisateur choisir et il y a un schéma officiel. Par
exemple, sur le réseau interne de
Microsoft, le nom est dérivé du nom de
login de l'utilisateur et un des auteurs du RFC
a donc une machine huitema-test-2.
Est-il nécessaire de donner des noms aux « objets », ces
machines à laver ou brosses à dents connectés, qui sont des
ordinateurs, mais ne sont en général pas perçus comme tels (ce qui
a des graves conséquences en terme de sécurité) ? Comme ces engins
n'offrent en général pas de services, ils ont moins besoin d'un
nom facile à retenir, et, lorsque les protocoles réseaux employés
forcent à utiliser un nom, c'est également un nom fabriqué à
partir du nom du fabricant, du modèle de l'appareil et de son
numéro de série (donc, un nom du genre
BrandX-edgeplus-4511-2539). On voit même
parfois la langue parlée par l'utilisateur utilisée dans ce nom,
qui est donc très « parlant ».
Même un identificateur partiel peut être révélateur (section 3
du RFC). Si on ordinateur se nomme
dthaler-laptop, on ne peut pas être sûr qu'il
appartienne vraiment au co-auteur du RFC Dave Thaler. Il y a
peut-être d'autres D. Thaler dans le monde. Mais si on
observe cet ordinateur faire une connexion au réseau interne de
Microsoft (pas besoin de casser le
chiffrement, les
métadonnées suffisent), on est alors
raisonnablement sûr qu'on a identifié le propriétaire.
Beaucoup de gens croient à tort qu'un identificateur personnel
doit forcément inclure le nom d'état civil de l'utilisateur. Mais
ce n'est pas vrai : il suffit que l'identificateur soit stable, et
puisse être relié, d'une façon ou d'une autre, au nom de
l'utilisateur. Par exemple, si un ordinateur
portable a le nom stable a3dafaaf70950 (nom
peu parlant) et que l'observateur ait pu voir une fois cette
machine faire une connexion à un compte
IMAP jean_dupont, on
peut donc associer cet ordinateur à Jean Dupont, et le suivre
ensuite à la trace.
Ce risque est encore plus important si l'attaquant maintient une base de données des identifications réussies (ce qui est automatisable), et des machines associées. Une ou deux fuites d'information faites il y a des mois, voire des années, et toutes les apparitions ultérieures de cette machine mèneront à une identification personnelle.
Donc, n'écoutez pas les gens qui vous parleront d'« anonymat »
parce que les noms de machine ne sont pas parlants (comme le
a3dafaaf70950 plus haut). Si quelqu'un fait
cela, cela prouve simplement qu'il ne comprend rien à la sécurité
informatique. Un nom stable, pouvant être observé (et on a vu que
bien des protocoles étaient très indiscrets), permet
l'observation, et donc la surveillance.
Justement, quels sont les protocoles qui laissent ainsi fuiter des noms de machine, que l'observateur pourra noter et enregistrer (section 4 du RFC) ? Il y a d'abord DHCP, où le message de sollicitation initial (diffusé à tous…) contient le nom de la machine en clair. Le problème de vie privée dans DHCP est analysé plus en détail dans les RFC 7819 et RFC 7824. Les solutions pour limiter les dégâts sont dans le RFC 7844.
Le DNS est également une cause de fuite,
par exemple parce qu'il permet d'obtenir le nom d'une machine à
partir de son adresse IP, avec les requêtes PTR dans
in-addr.arpa ou ip6.arpa, nom qui peut
réveler des détails. C'est le cas avec tout protocole conçu
justement pour distribuer des informations, comme celui du RFC 4620 (qui ne semble pas très déployé dans la nature).
Plus sérieux est le problème de mDNS (RFC 6762), illustré par le tcpdump montré plus haut. Les requêtes sont diffusées à tous sur le réseau local, et contiennent, directement ou indirectement, les noms des machines. Même chose avec le DNS Service Discovery du RFC 6763 et le LLMNR du RFC 4795 (beaucoup moins fréquent que mDNS).
Enfin, NetBIOS (quelqu'un l'utilise encore ?) est également une grande source d'indiscrétions.
Assez décrit le problème, comment le résoudre (section 5) ? Bien sûr, il faudra des protocoles moins bavards, qui ne clament pas le nom de la machine à tout le monde. Mais changer d'un coup des protocoles aussi répandus et aussi fermement installés que, par exemple, DHCP, ne va pas être facile. De même, demander aux utilisateurs de ne pas faire de requêtes DHCP lorsqu'ils visitent un réseau « non sûr » est difficile (déjà, comment l'utilisateur va-t-il correctement juger si le réseau est sûr ?), d'autant plus qu'ils risquent fort de ne pas avoir de connectivité du tout, dans ce cas. Certes, couper les protocoles non nécessaires est un bon principe de sécurité en général. Mais cet angle d'action semble quand même bien trop drastique. (Il faut aussi noter qu'il existe des protocoles privés, non-IETF, qui peuvent faire fuire des noms sans qu'on le sache. Le client Dropbox diffuse à la cantonade l'ID du client, et celui des shares où il se connecte. Il est facile de faire un graphe des utilisateurs en mettant ensemble ceux qui se connectent au même share.)
La suggestion de notre RFC est donc d'attaquer le problème d'une autre façon, en changeant le nom de la machine, pour lui substituer une valeur imprévisible (comme le fait le RFC 7844 pour les adresses MAC). Pour chaque nouveau réseau où est connectée la machine, on génère aléatoirement un nouveau nom, et c'est celui qu'on utilisera dans les requêtes DHCP ou mDNS. Ces protocoles fonctionneront toujours mais la surveillance des machines mobiles deviendra bien plus difficile. Bien sûr, pour empêcher toute corrélation, le changement de nom doit être coordonné avec les changements des autres identificateurs, comme l'adresse IP ou l'adresse MAC.
Windows a même un concept de « nom de machine par réseau », ce qui permet aux machines ayant deux connexions de présenter deux identités différentes (malheureusement, Unix n'a pas ce concept, le nom est forcément global).
Bien sûr, on n'a rien sans rien (section 6). Si on change les noms des machines, on rendra l'administration système plus difficile. Par exemple, l'investigation sur un incident de sécurité sera plus complexe. Mais la défense de la vie privée est à ce prix.
Pour l'instant, à ma connaissance, il n'y a pas encore de mise en œuvre de cette idée de noms imprévisibles et changeants. (Une proposition a été faite pour Tails. Notez qu'il existe d'autres possibilités comme d'avoir un nom unique partout.)
L'article seul
RFC 8112: Locator/ID Separation Protocol Delegated Database Tree (LISP-DDT) Referral Internet Groper (RIG)
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : D. Farinacci (lispers.net), A. Jain
(Juniper
Networks), I. Kouvelas, D. Lewis
(cisco Systems)
Expérimental
Première rédaction de cet article le 27 mai 2017
Ce RFC concerne les utilisateurs de LISP (le protocole réseau, pas le langage de programmation). Il décrit un nouvel outil, rig, le Referral Internet Groper, qui permet d'interroger les tables de correspondance identificateur->localisateur.
Un point important de LISP (RFC 9300) est en effet cette séparation de l'EID (l'identificateur d'une machine) et du RLOC (le localisateur de cette machine, qui indique où envoyer les paquets). Tout système ayant cette séparation doit maintenir une correspondance (mapping) entre les deux : lorsque je veux écrire à telle machine dont je connais l'EID, il faut que je trouve le localisateur. LISP permet plusieurs mécanismes pour cette correspondance. L'outil rig, présenté dans ce RFC, est conçu pour le mécanisme DDT (RFC 8111), une base de données arborescente et répartie. rig est donc un client DDT de débogage, lig (RFC 6835) étant un autre outil, plus général (il peut interroger d'autres bases que DDT).
Un client DDT comme rig (ou comme un routeur LISP lors de son
fonctionnement normal) va donc
envoyer des Map-Request (RFC 9300, section 4.2, et aussi RFC 9301) aux serveurs DDT.
La section 4 de notre RFC résume le fonctionnement de rig. Il
envoie le Map-Request et affiche le
Map-Referral de réponse. Il peut ensuite suivre
cette référence jusqu'à arriver au Map Server
qui gère ce préfixe. (Notez que c'est le RLOC du Map
Server qu'on obtient, sinon, on aurait un intéressant
problème d'œuf et de poule si on avait
besoin de DDT pour utiliser DDT...)
rig a donc besoin d'au moins deux paramètres, l'EID (l'identificateur) qu'on cherche à résoudre, et le serveur DDT par lequel on va commencer la recherche. (Pour l'EID, rig accepte également un nom de domaine, qu'il va traduire en EID dans le DNS.) La syntaxe typique est donc :
rig <eid> to <ddt-node>
La section 5 décrit les mises en œuvres existantes, sur les routeurs Cisco. La syntaxe est un peu différente de ce que je trouve dans la doc' de Cisco mais, bon, tout ceci est expérimental et en pleine évolution. Voici un exemple tiré de la documentation officielle de Cisco (LISP DDT Configuration Commands) :
Device# lisp-rig 172.16.17.17 to 10.1.1.1
rig LISP-DDT hierarchy for EID [0] 172.16.17.17
Send Map-Request to DDT-node 10.1.1.1 ... replied, rtt: 0.007072 secs
EID-prefix [0] 172.16.17.16/28, ttl: 1, action: ms-not-registered, referrals:
10.1.1.1, priority/weight: 0/0
10.2.1.1, priority/weight: 0/0
10.3.1.1, priority/weight: 0/0
Et voilà, on sait que l'EID
172.16.17.17, il faut aller demander aux
serveurs 10.1.1.1,
10.2.1.1 et
10.3.1.1. Dans le RFC, on trouve un exemple
où rig suit ces références :
Router# rig 12.0.1.1 to 1.1.1.1
Send Map-Request to DDT-node 1.1.1.1 ... node referral, rtt: 4 ms
EID-prefix: [0] 12.0.0.0/16, ttl: 1440
referrals: 2.2.2.2
Send Map-Request to DDT-node 2.2.2.2 ... node referral, rtt: 0 ms
EID-prefix: [0] 12.0.1.0/24, ttl: 1440
referrals: 4.4.4.4, 5.5.5.5
Send Map-Request to DDT-node 4.4.4.4 ... map-server acknowledgement,
rtt: 0 ms
EID-prefix: [0] 12.0.1.0/28, ttl: 1440
referrals: 4.4.4.4, 5.5.5.5
Si vous voulez en savoir plus sur DDT et rig, vous pouvez aussi regarder l'exposé de Cisco ou celui de Paul Vinciguerra à NANOG, ou bien la page officielle de la racine DDT (qui semble peu maintenue).
L'article seul
RFC 8111: Locator/ID Separation Protocol Delegated Database Tree (LISP-DDT)
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : V. Fuller, D. Lewis, V. Ermagan
(Cisco), A. Jain (Juniper
Networks), A. Smirnov (Cisco)
Expérimental
Réalisé dans le cadre du groupe de travail IETF lisp
Première rédaction de cet article le 27 mai 2017
Le protocole LISP (dont on ne rappelera jamais assez qu'il ne faut pas le confondre avec le langage de programmation du même nom) sépare les deux rôles de l'adresse IP, identificateur et localisateur. C'est très joli de séparer, cela permet plein de choses intéressantes, comme de lutter contre la croissance illimitée de la DFZ mais cela présente un défi : comment obtenir un localisateur quand on a un identificateur ? Dit autrement, « où est cette fichue machine que j'essaie de joindre ? » Ajouter une indirection, en informatique, oblige toujours à créer un système de correspondance permettant de passer par dessus le fossé qu'on vient juste de créer. LISP a plusieurs systèmes de correspondance possibles, tous expérimentaux, et ce nouveau DDT (Delegated Database Tree) vient les rejoindre. C'est le système qui est le plus proche du DNS dans ses concepts. Comme je connais un peu le DNS, j'utiliserai souvent dans cet article des comparaisons avec le DNS.
Pour résumer DDT en un paragraphe : dans LISP (RFC 9300), l'identificateur se nomme EID (Endpoint Identifier) et le localisateur RLOC (Routing Locator). Les EID ont une structure arborescente (leur forme syntaxique est celle d'adresses IP). Cet arbre est réparti sur plusieurs serveurs, les nœuds DDT. Un nœud DDT fait autorité pour un certain nombre de préfixes d'EID. Il délègue ensuite les sous-préfixes à d'autres nœuds DDT, ou bien à des Map Servers LISP (RFC 9301) quand on arrive en bas de l'arbre. (Une des différences avec le DNS est donc que les serveurs qui délèguent sont d'une nature distincte de ceux qui stockent les feuilles de l'arbre.)
LISP a une interface standard avec les serveurs qui font la
résolution d'EID en RLOC, décrite dans le RFC 9301. En gros, le client envoie un message
Map-Request et obtient une réponse
Map-Reply, ou bien une délégation
(Map-Referral) qu'il va devoir suivre en
envoyant le Map-Request suivant au RLOC
indiqué dans la délégation. Derrière cette interface, LISP ne spécifie pas
comment les serveurs obtiennent l'information. Plusieurs
propositions ont déjà été faites (comme ALT, dans le RFC 6836, ou NERD, dans le
RFC 6837…), auxquelles s'ajoute celle de
notre RFC. Un bon résumé est dans cette
image (mais qui ne montre qu'un seul niveau de délégation, il
peut y en avoir davantage.)
{kind=link}
DDT vise avant tout le passage à l'échelle, d'où la structuration hiérarchique de l'information. La notion de délégation (d'un préfixe général à un sous-préfixe plus spécifique) est centrale dans DDT. Un client (le routeur LISP qui a un paquet destiné à un EID donné et qui cherche à quel RLOC le transmettre, ou bien un résolveur, un serveur spécialisé agissant pour le compte de ce routeur) va donc devoir suivre cette délégation, descendant l'arbre jusqu'à l'information souhaitée.
La délégation est composée, pour un préfixe délégué, d'un ensemble de RLOC (pas d'EID pour éviter des problèmes d'œuf et de poule) désignant les nœuds qui ont une information sur le préfixe délégué. (Ce sont donc l'équivalent des enregistrements NS du DNS, mais avec une indirection en moins, comme si la partie droite d'un enregistrement NS stockait directement une adresse IP.)
J'ai écrit jusque là que la clé d'accès à l'information (rôle tenu par le nom de domaine dans le DNS) était l'EID mais c'est en fait un peu plus compliqué : la clé est le XEID (eXtended EID), qui est composé de plusieurs valeurs, dont l'EID (section 4.1 de notre RFC).
Pour indiquer au résolveur qu'il doit transmettre sa requête à
une autre machine, ce RFC crée un nouveau type de message LISP,
Map-Referral, type 6 (cf. le registre IANA)
détaillé en section 6,
envoyé en réponse à un Map-Request, quand le
nœud DDT ne connait pas la réponse. (Comme indiqué plus haut,
c'est l'équivalent d'une réponse
DNS avec uniquement une section Autorité contenant des
enregistrements NS.)
Continuons un peu la terminologie (section 3 du RFC) :
- Un client DDT est une machine qui interroge les nœuds DDT
(avec un
Map-Request, cf. RFC 9301) et suit lesMap-Referraljusqu'au résultat. C'est en général un résolveur (Map Resolver, RFC 9301) mais cela peut être aussi un routeur LISP (ITR, Ingress Tunnel Router). - Un résolveur est serveur d'un côté, pour les routeurs qui
envoient des
Map-Request, et client DDT de l'autre, il envoie des requêtes DDT. Il gère un cache (une mémoire des réponses récentes). Le résolveur maintient également une liste des requêtes en cours, pas encore satisfaites.
La base des données des serveurs DDT est décrite en section
4. Elle est indexée par XEID. Un XEID est un EID (identificateur
LISP) plus un AFI (Address Family Identifier,
1 pour IPv4, 2 pour IPv6, etc), un identificateur d'instance (voir RFC 9300, section 3, et RFC 8060, section 4.1) qui sert à avoir plusieurs espaces d'adressage, et quelques autres paramètres, pas
encore utilisés. Configurer un serveur DDT, c'est lui indiquer la
liste de XEID qu'il doit connaitre, avec les RLOC des serveurs qui
pourront répondre. Désolé, je n'ai pas de serveur DDT sous la main
mais on peut trouver un exemple, dans la
documentation de Cisco, où on délègue au Map
Server de RLOC 10.1.1.1 :
router lisp
ddt authoritative 2001:db8:eeee::/48
delegate 10.1.1.1 eid-prefix 172.16.0.0/16
delegate 10.1.1.1 eid-prefix 2001:db8:eeee::/48
Un autre exemple de délégation est l'actuelle liste des données dans la racine DDT.
Le DNS n'a qu'un type de serveurs faisant autorité, qu'ils soient essentiellement serveurs de délégation (ceux des TLD, par exemple) ou qu'ils soient serveurs « finaux » contenant les enregistrements autres que NS. Au contraire, LISP+DDT a deux types de serveurs, les nœuds DDT présentés dans ce RFC, qui ne font que de la délégation, et les traditionnels Map Servers, qui stockent les correspondances entre EID et RLOC (entre identificateurs et localisateurs). Dit autrement, DDT ne sert pas à trouver la réponse à la question « quel est le RLOC pour cet EID », il sert uniquement à trouver le serveur qui pourra répondre à cette question.
Comme pour le DNS, il existe une racine, le nœud qui peut
répondre (enfin, trouver une délégation) pour tout XEID. (Sur le
Cisco cité plus haut, la directive ddt root
permettra d'indiquer le RLOC des serveurs de la racine, voir aussi
la section 7.3.1 de notre RFC.) Une
racine expérimentale existe, vous trouverez ses RLOC en
http://ddt-root.org/.
La section 5 de notre RFC décrit en détail la modification au
message Map-Request que nécessite DDT. Ce
message était normalisé par le RFC 9300
(section 6.1.2) et un seul ajout est fait : un bit qui était
laissé vide sert désormais à indiquer que la requête ne vient pas
directement d'un routeur LISP mais est passée par des nœuds DDT.
La section 6, elle, décrit un type de message nouveau,
Map-Referral, qui contient les RLOC du nœud
DDT qui pourra mieux répondre à la question. Cette réponse contient un code
qui indique le résultat d'un Map-Request. Ce
résultat peut être « positif » :
NODE-REFERRAL, renvoi à un autre nœud DDT,MS-REFERRAL, renvoi à un Map Server (rappelez-vous que, contrairement au DNS, il y a une nette distinction entre nœud intermédiaire et Map Server final),MS-ACK, réponse positive d'un Map Server.
Mais aussi des résultats « négatifs » :
MS-NOT-REGISTERED, le Map Server ne connait pas cet EID,DELEGATION-HOLE, l'EID demandé tombe dans un trou (préfixe non-LISP dans un préfixe LISP),NOT-AUTHORITATIVE, le nœud DDT n'a pas été configuré pour ce préfixe.
Le fonctionnement global est décrit en détail dans la section 7
du RFC. À lire si on veut savoir exactement ce que doivent faire
le Map Resolver, le Map
Server, et le nouveau venu, le nœud DDT. La même
description figure sous forme de
pseudo-code dans la section 8. Par exemple,
voici ce que doit faire un nœud DDT lorsqu'il reçoit un
Map-Request (demande de résolution d'un EID
en RLOC) :
if ( I am not authoritative ) {
send map-referral NOT_AUTHORITATIVE with
incomplete bit set and ttl 0
} else if ( delegation exists ) {
if ( delegated map-servers ) {
send map-referral MS_REFERRAL with
ttl 'Default_DdtNode_Ttl'
} else {
send map-referral NODE_REFERRAL with
ttl 'Default_DdtNode_Ttl'
}
} else {
if ( eid in site) {
if ( site registered ) {
forward map-request to etr
if ( map-server peers configured ) {
send map-referral MS_ACK with
ttl 'Default_Registered_Ttl'
} else {
send map-referral MS_ACK with
ttl 'Default_Registered_Ttl' and incomplete bit set
}
} else {
if ( map-server peers configured ) {
send map-referral MS_NOT_REGISTERED with
ttl 'Default_Configured_Not_Registered_Ttl'
} else {
send map-referral MS_NOT_REGISTERED with
ttl 'Default_Configured_Not_Registered_Ttl'
and incomplete bit set
}
}
} else {
send map-referral DELEGATION_HOLE with
ttl 'Default_Negative_Referral_Ttl'
}
}
Un exemple complet et détaillé figure dans la section 9, avec description de tous les messages envoyés.
Question sécurité, je vous renvoie à la section 10 du RFC. DDT dispose d'un mécanisme de signature des messages (l'équivalent de ce qu'est DNSSEC pour le DNS). La délégation inclut les clés publiques des nœuds à qui on délègue.
Il existe au moins deux mises en œuvre de DDT, une chez Cisco et l'autre chez OpenLisp. (Le RFC ne sort que maintenant mais le protocole est déployé depuis des années.)
L'article seul
RFC 8109: Initializing a DNS Resolver with Priming Queries
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : P. Koch
(DENIC), M. Larson, P. Hoffman
(ICANN)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 16 mars 2017
Un résolveur DNS ne connait au début, rien du contenu du DNS. Rien ? Pas tout à fait, il connait une liste des serveurs de noms faisant autorité pour la racine, car c'est par eux qu'il va commencer le processus de résolution de noms. Cette liste est typiquement en dur dans le code du serveur, ou bien dans un de ses fichiers de configuration. Mais peu d'administrateurs système la maintiennent à jour. Il est donc prudent, au démarrage du résolveur, de chercher une liste vraiment à jour, et c'est le priming (initialisation ?), opération que décrit ce RFC. Il a depuis été remplacé par le RFC 9609.
Le problème de départ d'un résolveur est un problème
d'œuf et de poule. Le résolveur doit interroger le DNS
pour avoir des informations mais comment trouve-t-il les serveurs
DNS à interroger ? La solution est de traiter la racine du DNS de
manière spéciale : la liste de ses serveurs est connue du résolveur
au démarrage. Elle peut être dans le code du serveur lui-même, ici
un Unbound qui contient les adresses IP des
serveurs de la racine (je ne montre que les trois premiers,
A.root-servers.net,
B.root-servers.net et C.root-servers.net) :
% strings /usr/sbin/unbound | grep -i 2001: 2001:503:ba3e::2:30 2001:500:84::b 2001:500:2::c ...
Ou bien elle est dans un fichier de configuration (ici, sur un Unbound) :
server: directory: "/etc/unbound" root-hints: "root-hints"
Ce fichier peut être téléchargé via
l'IANA, il peut être spécifique au logiciel résolveur, ou bien fourni
par le système d'exploitation (cas du
paquetage dns-root-data chez
Debian). Il contient la liste des serveurs
de la racine et leurs adresses :
. 3600000 NS A.ROOT-SERVERS.NET. . 3600000 NS B.ROOT-SERVERS.NET. ... A.ROOT-SERVERS.NET. 3600000 A 198.41.0.4 A.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:ba3e::2:30 B.ROOT-SERVERS.NET. 3600000 A 192.228.79.201 B.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:84::b ...
Cette configuration initiale du résolveur est décrite dans la section 2.3 du RFC 1034, mais ce dernier ne décrit pas réellement le priming (quoi que dise notre nouveau RFC), priming que tous les résolveurs actuels mettent en œuvre. En effet, les configurations locales tendent à ne plus être à jour au bout d'un moment. (Sauf dans le cas où elles sont dans un paquetage du système d'exploitation, mis à jour avec ce dernier, comme dans le bon exemple Debian ci-dessus.)
Les changements des serveurs racines sont rares. Si on regarde sur le site des opérateurs des serveurs racine, on voit :
- 2016-12-02 Announcement of IPv6 addresses
- 2015-11-05 L-Root IPv6 Renumbering
- 2015-08-31 H-Root to be renumbered
- 2014-03-26 IPv6 service address for c.root-servers.net (2001:500:2::C)
- 2012-12-14 D-Root IPv4 Address to be Renumbered
- 2011-06-10 IPv6 service address for d.root-servers.net (2001:500:2D::D)
Bref, peu de changements. Ils sont en général annoncés sur les listes de diffusion opérationnelles (comme ici, là ou encore ici). Mais les fichiers de configuration ayant une fâcheuse tendance à ne pas être mis à jour et à prendre de l'âge, les anciennes adresses des serveurs racine continuent à recevoir du trafic des années après (comme le montre cette étude de J-root). Notez que la stabilité de la liste des serveurs racine n'est pas due qu'au désir de ne pas perturber les administrateurs système : il y a aussi des raisons politiques (aucun mécanisme en place pour choisir de nouveaux serveurs, ou pour retirer les « maillons faibles »). C'est pour cela que la liste des serveurs (mais pas leurs adresses) n'a pas changé depuis 1997 !
Notons aussi que l'administrateur système d'un résolveur peut changer la liste des serveurs de noms de la racine pour une autre liste. C'est ainsi que fonctionnent les racines alternatives comme Yeti. Si on veut utiliser cette racine expérimentale et pas la racine « officielle », on édite la configuration de son résolveur :
server:
root-hints: "yeti-hints"
Et le fichier, téléchargé chez Yeti, contient :
. 3600000 IN NS bii.dns-lab.net bii.dns-lab.net 3600000 IN AAAA 240c:f:1:22::6 . 3600000 IN NS yeti-ns.tisf.net yeti-ns.tisf.net 3600000 IN AAAA 2001:559:8000::6 . 3600000 IN NS yeti-ns.wide.ad.jp yeti-ns.wide.ad.jp 3600000 IN AAAA 2001:200:1d9::35 . 3600000 IN NS yeti-ns.as59715.net ...
Le priming, maintenant. Le principe du priming est, au démarrage, de faire une requête à un des serveurs listés dans la configuration et de garder sa réponse (certainement plus à jour que la configuration) :
% dig +bufsize=4096 +norecurse +nodnssec @k.root-servers.net NS . ; <<>> DiG 9.10.3-P4-Debian <<>> +norecurse +nodnssec @k.root-servers.net NS . ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42123 ;; flags: qr aa; QUERY: 1, ANSWER: 13, AUTHORITY: 0, ADDITIONAL: 27 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;. IN NS ;; ANSWER SECTION: . 518400 IN NS a.root-servers.net. . 518400 IN NS b.root-servers.net. . 518400 IN NS c.root-servers.net. . 518400 IN NS d.root-servers.net. . 518400 IN NS e.root-servers.net. . 518400 IN NS f.root-servers.net. . 518400 IN NS g.root-servers.net. . 518400 IN NS h.root-servers.net. . 518400 IN NS i.root-servers.net. . 518400 IN NS j.root-servers.net. . 518400 IN NS k.root-servers.net. . 518400 IN NS l.root-servers.net. . 518400 IN NS m.root-servers.net. ;; ADDITIONAL SECTION: a.root-servers.net. 518400 IN A 198.41.0.4 a.root-servers.net. 518400 IN AAAA 2001:503:ba3e::2:30 b.root-servers.net. 518400 IN A 192.228.79.201 b.root-servers.net. 518400 IN AAAA 2001:500:84::b c.root-servers.net. 518400 IN A 192.33.4.12 c.root-servers.net. 518400 IN AAAA 2001:500:2::c d.root-servers.net. 518400 IN A 199.7.91.13 d.root-servers.net. 518400 IN AAAA 2001:500:2d::d e.root-servers.net. 518400 IN A 192.203.230.10 e.root-servers.net. 518400 IN AAAA 2001:500:a8::e f.root-servers.net. 518400 IN A 192.5.5.241 f.root-servers.net. 518400 IN AAAA 2001:500:2f::f g.root-servers.net. 518400 IN A 192.112.36.4 g.root-servers.net. 518400 IN AAAA 2001:500:12::d0d h.root-servers.net. 518400 IN A 198.97.190.53 h.root-servers.net. 518400 IN AAAA 2001:500:1::53 i.root-servers.net. 518400 IN A 192.36.148.17 i.root-servers.net. 518400 IN AAAA 2001:7fe::53 j.root-servers.net. 518400 IN A 192.58.128.30 j.root-servers.net. 518400 IN AAAA 2001:503:c27::2:30 k.root-servers.net. 518400 IN A 193.0.14.129 k.root-servers.net. 518400 IN AAAA 2001:7fd::1 l.root-servers.net. 518400 IN A 199.7.83.42 l.root-servers.net. 518400 IN AAAA 2001:500:9f::42 m.root-servers.net. 518400 IN A 202.12.27.33 m.root-servers.net. 518400 IN AAAA 2001:dc3::35 ;; Query time: 3 msec ;; SERVER: 2001:7fd::1#53(2001:7fd::1) ;; WHEN: Fri Mar 03 17:29:05 CET 2017 ;; MSG SIZE rcvd: 811
(Les raisons du choix des trois options données à dig sont indiquées plus loin.)
La section 3 de notre RFC décrit en détail à quoi ressemblent les requêtes
de priming. Le type de données demandé
(QTYPE) est NS (Name Servers,
type 2) et le nom demandé (QNAME) est « . »
(oui, juste la racine). D'où le dig NS .
ci-dessus. Le bit RD (Recursion Desired) est
typiquement mis à zéro (d'où le +norecurse
dans l'exemple avec dig). La taille de la réponse dépassant les 512
octets (limite très ancienne du DNS), il faut utiliser
EDNS (cause du
+bufsize=4096 dans l'exemple). On peut
utiliser le bit DO (DNSSEC OK) qui indique qu'on
demande les signatures DNSSEC mais ce n'est pas habituel (d'où le
+nodnssec dans l'exemple). En effet, si la
racine est signée, permettant d'authentifier l'ensemble
d'enregistrements NS, la zone
root-servers.net, où se trouvent actuellement
tous les serveurs de la racine, ne l'est pas, et les
enregistrements A et AAAA ne peuvent donc pas être validés avec DNSSEC.
Cette requête de priming est envoyée lorsque le résolveur démarre, et aussi lorsque la réponse précédente a expiré (regardez le TTL dans l'exemple : six jours). Si le premier serveur testé ne répond pas, on essaie avec un autre. Ainsi, même si le fichier de configuration n'est pas parfaitement à jour (des vieilles adresses y trainent), le résolveur finira par avoir la liste correcte.
Et comment choisit-on le premier serveur qu'on interroge ? Notre RFC recommande un tirage au sort, pour éviter que toutes les requêtes de priming ne se concentrent sur un seul serveur (par exemple le premier de la liste). Une fois que le résolveur a démarré, il peut aussi se souvenir du serveur le plus rapide, et n'interroger que celui-ci, ce qui est fait par la plupart des résolveurs, pour les requêtes ordinaires (mais n'est pas conseillé pour le priming).
Et les réponses au priming ? Il faut bien
noter que, pour le serveur racine, les requêtes
priming sont des requêtes comme les autres, et
ne font pas l'objet d'un traitement particulier. Normalement, la
réponse doit avoir le code de retour NOERROR
(c'est bien le cas dans mon exemple). Parmi les
flags, il doit y avoir AA
(Authoritative Answer). La section de réponse
doit évidemment contenir les NS de la racine, et la section
additionnelle les adresses IP. Le résolveur garde alors cette
réponse dans son cache, comme il le ferait pour n'importe quelle
autre réponse. Notez que là aussi, il ne faut pas de traitement
particulier. Par exemple, le résolveur ne doit pas compter qu'il y
aura exactement 13 serveurs, même si c'est le cas depuis longtemps
(ça peut changer).
Normalement, le serveur racine envoie la totalité des adresses IP (deux par serveur, une en IPv4 et une en IPv6). S'il ne le fait pas (par exemple par manque de place parce qu'on a bêtement oublié EDNS), le résolveur va devoir envoyer des requêtes A et AAAA explicites pour obtenir les adresses IP :
% dig @k.root-servers.net A g.root-servers.net
; <<>> DiG 9.10.3-P4-Debian <<>> @k.root-servers.net A g.root-servers.net
; (2 servers found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49091
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 13, ADDITIONAL: 26
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;g.root-servers.net. IN A
;; ANSWER SECTION:
g.root-servers.net. 3600000 IN A 192.112.36.4
...
Vous pouvez voir ici les requêtes et réponses de priming d'un Unbound utilisant Yeti. D'abord, décodées par tcpdump :
20:31:36.226325 IP6 2001:4b98:dc2:43:216:3eff:fea9:41a.7300 > 2a02:cdc5:9715:0:185:5:203:53.53: 50959% [1au] NS? . (28) 20:31:36.264584 IP6 2a02:cdc5:9715:0:185:5:203:53.53 > 2001:4b98:dc2:43:216:3eff:fea9:41a.7300: 50959*- 26/0/7 NS bii.dns-lab.net., NS yeti.bofh.priv.at., NS yeti.ipv6.ernet.in., NS yeti.aquaray.com., NS yeti.mind-dns.nl., NS dahu1.yeti.eu.org., NS dahu2.yeti.eu.org., NS yeti1.ipv6.ernet.in., NS ns-yeti.bondis.org., NS yeti-ns.ix.ru., NS yeti-ns.lab.nic.cl., NS yeti-ns.tisf.net., NS yeti-ns.wide.ad.jp., NS yeti-ns.conit.co., NS yeti-ns.datev.net., NS yeti-ns.switch.ch., NS yeti-ns.as59715.net., NS yeti-ns1.dns-lab.net., NS yeti-ns2.dns-lab.net., NS yeti-ns3.dns-lab.net., NS xn--r2bi1c.xn--h2bv6c0a.xn--h2brj9c., NS yeti-dns01.dnsworkshop.org., NS yeti-dns02.dnsworkshop.org., NS 3f79bb7b435b05321651daefd374cd.yeti-dns.net., NS ca978112ca1bbdcafac231b39a23dc.yeti-dns.net., RRSIG (1225)
Et ici par tshark :
1 0.000000 2001:4b98:dc2:43:216:3eff:fea9:41a → 2a02:cdc5:9715:0:185:5:203:53 DNS 90 Standard query 0xc70f NS <Root> OPT 2 0.038259 2a02:cdc5:9715:0:185:5:203:53 → 2001:4b98:dc2:43:216:3eff:fea9:41a DNS 1287 Standard query response 0xc70f NS <Root> NS bii.dns-lab.net NS yeti.bofh.priv.at NS yeti.ipv6.ernet.in NS yeti.aquaray.com NS yeti.mind-dns.nl NS dahu1.yeti.eu.org NS dahu2.yeti.eu.org NS yeti1.ipv6.ernet.in NS ns-yeti.bondis.org NS yeti-ns.ix.ru NS yeti-ns.lab.nic.cl NS yeti-ns.tisf.net NS yeti-ns.wide.ad.jp NS yeti-ns.conit.co NS yeti-ns.datev.net NS yeti-ns.switch.ch NS yeti-ns.as59715.net NS yeti-ns1.dns-lab.net NS yeti-ns2.dns-lab.net NS yeti-ns3.dns-lab.net NS xn--r2bi1c.xn--h2bv6c0a.xn--h2brj9c NS yeti-dns01.dnsworkshop.org NS yeti-dns02.dnsworkshop.org NS 3f79bb7b435b05321651daefd374cd.yeti-dns.net NS ca978112ca1bbdcafac231b39a23dc.yeti-dns.net RRSIG AAAA 240c:f:1:22::6 AAAA 2a01:4f8:161:6106:1::10 AAAA 2001:e30:1c1e:1:
Et un décodage plus détaillé de tshark dans ce fichier.
Enfin, la section 5 de notre RFC traite des problèmes de sécurité du priming. Évidemment, si un attaquant injecte une fausse réponse aux requêtes de priming, il pourra détourner toutes les requêtes ultérieures vers des machines de son choix. À part le RFC 5452, la seule protection est DNSSEC : si le résolveur valide (et a donc la clé publique de la racine), il pourra détecter que les réponses sont mensongères. Cela a l'avantage de protéger également contre d'autres attaques, ne touchant pas au priming, comme les attaques sur le routage.
Notez que DNSSEC est recommandé pour valider les réponses
ultérieures mais, comme on l'a vu, n'est pas important pour valider
la réponse de priming elle-même, puisque
root-servers.net n'est pas signé. Si un
attaquant détournait, d'une manière ou d'une autre, vers un faux
serveur racine, servant de fausses données, ce ne serait qu'une
attaque par déni de
service, puisque le résolveur validant pourrait
détecter que les réponses sont fausses.
Ce RFC a connu une très longue gestation puisque le premier brouillon date de février 2007 (vous pouvez admirer la chronologie).
L'article seul
RFC 8106: IPv6 Router Advertisement Options for DNS Configuration
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : J. Jeong (Sungkyunkwan
University), S. Park (Samsung
Electronics), L. Beloeil (France Telecom
R&D), S. Madanapalli (iRam
Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 18 mars 2017
Il existe deux méthodes pour configurer une machine IPv6 automatiquement, DHCP (RFC 8415) et RA (Router Advertisement, RFC 4862). Toutes les deux peuvent indiquer d'autres informations que l'adresse IP, comme par exemple les adresses des résolveurs DNS. Notre RFC normalise cette possibilité pour les RA. Il remplace le RFC 6106, avec peu de changements.
Si on gère un gros réseau, avec de nombreuses machines dont
certaines, portables, vont et viennent, s'assurer que toutes ces
machines ont les adresses IP
des serveurs de noms à utiliser n'est pas trivial (section 1 du RFC). On ne peut évidemment pas utiliser le DNS, cela serait tenter de voler en tirant
sur les lacets de ses chaussures. Et configurer à la main les adresses
sur chaque machine (par exemple, sur Unix, en
les écrivant dans le fichier /etc/resolv.conf)
est bien trop difficile à maintenir. Se passer du DNS est hors de
question. Pour les machines bi-protocoles (IPv4
et IPv6), une solution possible était
d'utiliser un serveur de noms en v4. Mais pour une solution purement v6 ?
La solution la plus populaire était DHCP (RFC 8415 et RFC 3646). Son principal inconvénient est qu'elle est à état : le serveur DHCP doit se souvenir des baux qu'il a attribué. Sur un gros réseau local, le nombre de requêtes à traiter, chacune nécessitant une écriture dans une base de données, peut devenir très lourd.
Une autre solution est sans état et repose sur
une nouveauté d'IPv6, les RA (Router
Advertisements, cette méthode est aussi appelée ND, pour
Neighbor Discovery, les RA en étant un cas particulier), décrits dans le RFC 4862. Ce sont des messages envoyés à intervalles
réguliers par les routeurs et
qui informent les machines non-routeuses des caractéristiques
essentielles du réseau, comme le préfixe utilisé (par exemple
2001:db8:beef:42::/64). Le routeur diffuse ses
messages et n'a pas besoin d'écrire quoi que ce soit sur son disque,
ni de faire des traitements compliqués lors d'une sollicitation, il
répond toujours par le même message RA.
Ces RA peuvent diffuser diverses informations, par le biais d'un système d'options. Le principe de notre RFC est donc d'utiliser ces RA pour transporter l'information sur les serveurs de noms récursifs utilisables sur le réseau local, via des options notamment celle nommée RDNSS (le numéro 25 lui a été affecté par l'IANA).
La section 1.1 du RFC rappelle qu'il existe plusieurs choix, notre RFC 8106 n'étant qu'une possibilité parmi d'autres. Le RFC 4339 contient une discussion plus détaillée de ce problème du choix d'une méthode de configuration des serveurs de noms (notons qu'il existe d'autres méthodes comme l'anycast avec une adresse « bien connue »). La section 1.2 décrit ce qui se passe lorsque plusieurs méthodes (par exemple DHCP et RA) sont utilisées en même temps.
La méthode RA décrite dans notre RFC repose sur deux options, RDNSS, déjà citée, et DNSSL (section 4). La première permet de publier les adresses des serveurs de noms, la seconde une liste de domaine à utiliser pour compléter les noms courts (formés d'un seul composant). Les valeurs pour ces deux options doivent être configurées dans le routeur qui va lancer les RA. (Le routeur Turris Omnia le fait automatiquement. Si on veut changer les paramètres, voici comment faire. En général, pour OpenWrt, il faut lire cette documentation, l'ancien logiciel radvd n'étant plus utilisé.)
La première option, RDNSS, de numéro 25, est décrite en section 5.1. Elle indique une liste d'adresse IPv6 que le client RA mettra dans sa liste locale de serveurs de noms interrogeables.
La seconde option, DNSSL, de numéro 31, est en section 5.2 (les
deux options sont enregistrées dans le registre
IANA, cf. section 8). Elle
publie une liste de domaines, typiquement ceux qui, sur une machine
Unix, se retrouveront dans l'option
search de /etc/resolv.conf.
Sur Linux, le démon rdnssd permet de recevoir ces RA et de modifier la configuration DNS. Pour FreeBSD, on peut consulter une discussion sur leur liste. Les CPE de Free, les Freebox, émettent de telles options dans leurs RA (apparemment, la dernière fois que j'ai regardé, uniquement des RDNSS). Voici ce qu'affiche Wireshark :
...
Ethernet II, Src: FreeboxS_c3:83:23 (00:07:cb:c3:83:23),
Dst: IPv6mcast_00:00:00:01 (33:33:00:00:00:01)
...
Internet Control Message Protocol v6
Type: 134 (Router advertisement)
...
ICMPv6 Option (Recursive DNS Server)
Type: Recursive DNS Server (25)
Length: 40
Reserved
Lifetime: 600
Recursive DNS Servers: 2a01:e00::2 (2a01:e00::2)
Recursive DNS Servers: 2a01:e00::1 (2a01:e00::1)
et les serveurs DNS annoncés répondent correctement. (Vous pouvez récupérer le paquet entier sur pcapr.net.)
Autre mise en œuvre de ces options, dans radvd (ainsi que pour les logiciels auxiliaires). Wireshark, on l'a vu, sait décoder ces options.
La section 6 de notre RFC donne des conseils aux programmeurs qui voudraient mettre en œuvre ce document. Par exemple, sur un système d'exploitation où le client RA tourne dans le noyau (pour configurer les adresses IP) et où la configuration DNS est dans l'espace utilisateur, il faut prévoir un mécanisme de communication, par exemple un démon qui interroge le noyau régulièrement pour savoir s'il doit mettre à jour la configuration DNS.
RA pose divers problèmes de sécurité, tout comme DHCP, d'ailleurs. Le problème de ces techniques est qu'elles sont conçues pour faciliter la vue de l'utilisateur et de l'administrateur réseau et que « faciliter la vie » implique en général de ne pas avoir de fonctions de sécurité difficiles à configurer. La section 7 traite de ce problème, par exemple du risque de se retrouver avec l'adresse d'un serveur DNS méchant qui vous redirigerait Dieu sait où (les RA ne sont pas authentifiés). Ce risque n'a rien de spécifique aux options DNS, toute la technique RA est vulnérable (par exemple, avec un faux Neighbor Advertisement). Donc, notre RFC n'apporte pas de risque nouveau (cf. RFC 6104). Si on considère cette faiblesse de sécurité comme insupportable, la section 7.2 recommande d'utiliser le RA guard du RFC 6105, ou bien SEND (RFC 3971, mais il est nettement moins mis en avant que dans le précédent RFC).
Ce problème d'une auto-configuration simple des machines connectées à IPv6 est évidemment particulièrement important pour les objets connectés et c'est sans doute pour cela que le RFC contient la mention « This document was supported by Institute for Information & communications Technology Promotion (IITP) grant funded by the Korea government (MSIP) [10041244, Smart TV 2.0 Software Platform] ».
Les changements faits depuis le précédent RFC, le RFC 6106, figurent dans l'annexe A. On y trouve notamment :
- Une valeur par défaut plus élevée pour la durée de vie des
informations envoyées (qui passe de deux fois
MaxRtrAdvIntervalà trois fois sa valeur, soit 1 800 secondes avec la valeur par défaut de cette variable), pour diminuer le nombre de cas où l'information expire parce que le réseau perdait trop de paquets, - L'autorisation explicite des adresses locales au lien (celles
en
fe80::/10), comme adresses de résolveurs DNS, - Suppression de la limite de trois résolveurs DNS, qui était dans l'ancien RFC.
À noter que ce RFC n'intègre pas encore les résolveurs sécurisés du RFC 7858, car il se contente de réviser un RFC existant. Il n'y a donc pas de moyen de spécifier un résolveur sécurisé, pas de port 853.
Et pour finir, voici le RA émis par défaut par le routeur Turris, décodé par Wireshark :
Internet Protocol Version 6, Src: fe80::da58:d7ff:fe00:4c9e, Dst: ff02::1
0110 .... = Version: 6
.... 0000 0000 .... .... .... .... .... = Traffic class: 0x00 (DSCP: CS0, ECN: Not-ECT)
.... 0000 00.. .... .... .... .... .... = Differentiated Services Codepoint: Default (0)
.... .... ..00 .... .... .... .... .... = Explicit Congestion Notification: Not ECN-Capable Transport (0)
.... .... .... 0101 1110 1011 0100 0001 = Flow label: 0x5eb41
Payload length: 152
Next header: ICMPv6 (58)
Hop limit: 255
Source: fe80::da58:d7ff:fe00:4c9e
[Source SA MAC: CzNicZSP_00:4c:9e (d8:58:d7:00:4c:9e)]
Destination: ff02::1
[Source GeoIP: Unknown]
[Destination GeoIP: Unknown]
Internet Control Message Protocol v6
Type: Router Advertisement (134)
Code: 0
Checksum: 0x35ed [correct]
[Checksum Status: Good]
Cur hop limit: 64
Flags: 0x80
1... .... = Managed address configuration: Set
.0.. .... = Other configuration: Not set
..0. .... = Home Agent: Not set
...0 0... = Prf (Default Router Preference): Medium (0)
.... .0.. = Proxy: Not set
.... ..0. = Reserved: 0
Router lifetime (s): 1800
Reachable time (ms): 0
Retrans timer (ms): 0
ICMPv6 Option (Source link-layer address : d8:58:d7:00:4c:9e)
Type: Source link-layer address (1)
Length: 1 (8 bytes)
Link-layer address: CzNicZSP_00:4c:9e (d8:58:d7:00:4c:9e)
ICMPv6 Option (MTU : 1480)
Type: MTU (5)
Length: 1 (8 bytes)
Reserved
MTU: 1480
ICMPv6 Option (Prefix information : fde8:9fa9:1aba::/64)
Type: Prefix information (3)
Length: 4 (32 bytes)
Prefix Length: 64
Flag: 0xc0
1... .... = On-link flag(L): Set
.1.. .... = Autonomous address-configuration flag(A): Set
..0. .... = Router address flag(R): Not set
...0 0000 = Reserved: 0
Valid Lifetime: 7200
Preferred Lifetime: 1800
Reserved
Prefix: fde8:9fa9:1aba::
ICMPv6 Option (Prefix information : 2a01:e35:8bd9:8bb0::/64)
Type: Prefix information (3)
Length: 4 (32 bytes)
Prefix Length: 64
Flag: 0xc0
1... .... = On-link flag(L): Set
.1.. .... = Autonomous address-configuration flag(A): Set
..0. .... = Router address flag(R): Not set
...0 0000 = Reserved: 0
Valid Lifetime: 7200
Preferred Lifetime: 1800
Reserved
Prefix: 2a01:e35:8bd9:8bb0::
ICMPv6 Option (Route Information : Medium fde8:9fa9:1aba::/48)
Type: Route Information (24)
Length: 3 (24 bytes)
Prefix Length: 48
Flag: 0x00
...0 0... = Route Preference: Medium (0)
000. .000 = Reserved: 0
Route Lifetime: 7200
Prefix: fde8:9fa9:1aba::
ICMPv6 Option (Recursive DNS Server fde8:9fa9:1aba::1)
Type: Recursive DNS Server (25)
Length: 3 (24 bytes)
Reserved
Lifetime: 1800
Recursive DNS Servers: fde8:9fa9:1aba::1
ICMPv6 Option (Advertisement Interval : 600000)
Type: Advertisement Interval (7)
Length: 1 (8 bytes)
Reserved
Advertisement Interval: 600000
On y voit l'option RDNSS (l'avant-dernière) mais pas de DNSSL.
Merci à Alexis La Goutte pour ses informations.
L'article seul
RFC 8105: Transmission of IPv6 Packets over DECT Ultra Low Energy
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : P. Mariager, J. Petersen (RTX A/S), Z. Shelby (ARM), M. Van de Logt (Gigaset Communications GmbH), D. Barthel (Orange Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6lo
Première rédaction de cet article le 3 mai 2017
Tout le monde connait DECT, la technique utilisée, depuis vingt ans, entre votre téléphone sans fil à la maison, et sa base. DECT ne sert pas que pour la voix, il peut aussi être utilisé pour transmettre des données, par exemple de capteurs situés dans une « maison intelligente ». DECT a une variante « basse consommation », DECT ULE (pour Ultra Low Energy) qui est spécialement conçue pour des objets connectés ayant peu de réserves d'énergie. Elle vise donc la domotique, s'appuyant sur la vaste distribution de DECT, la disponibilité de composants bon marché et très diffusés, de fréquences dédiées, etc. Il ne restait donc plus qu'à faire passer IPv6 sur DECT ULE. C'est ce que normalise ce RFC, qui réutilise les techniques 6LoWPAN (RFC 4919).
DECT est normalisé par l'ETSI sous le numéro 300.175 (et la norme est en ligne). ULE s'appuie sur DECT pour le cas particulier des engins sans guère de réserves énergétiques. Il est normalisé dans les documents ETSI 102.939-1 et 102.939-2. Dans la terminologie DECT, le FP (Fixed Part) est la base, le PP (Portable Part) le téléphone sans fil (ou bien, dans le cas d'ULE, le capteur ou l'actionneur ). Le FP peut être connecté à l'Internet (et c'est évidemment là qu'IPv6 est important).
Un réseau DECT ULE typique serait une maison où des capteurs (les PP) mesureraient des informations et les transmettraient au FP qui, étant doté de capacités de calcul et de réserves d'énergie suffisantes, les traiterait, en ferait des jolis graphiques, aurait une interface Web, etc. Le RFC cite un autre exemple où une personne âgée serait munie d'un pendentif qui enverrait des signaux de temps en temps (consommant peu d'énergie) mais permettrait d'établir une liaison vocale avec le FP (et, de là, avec les services médicaux) en cas d'urgence.
Et IPv6 ? Il permettrait d'avoir une communication avec tous les équipements IP. IPv6 fonctionne déjà sur une autre technologie similaire, IEEE 802.15.4, avec le système 6LoWPAN (RFC 4944, RFC 6282 et RFC 6775). Comme DECT ULE ressemble à 802.15.4 (mais est un protocole différent, attention), ce RFC décrit comment faire passer de l'IPv6, en s'inspirant de ce qui marchait déjà pour 802.15.4.
La section 2 du RFC rappelle ce qu'il faut savoir de DECT et d'ULE. ULE permet le transport de la voix et des données mais ce RFC ne se préoccupe que des données. Le protocole utilise les bandes de fréquence entre 1880 et 1920 MHz, à 1,152 Mbauds. La topologie théorique est celle d'un réseau cellulaire mais, en pratique, DECT est la plupart du temps organisé en étoile, un FP (la base) au « centre » et des PP (téléphones et capteurs) qui lui sont rattachés. Toute session peut commencer à l'initiative du FP ou d'un PP mais attention : avec ULE, bien des PP seront des engins aux batteries limitées, qui dormiront pendant l'essentiel du temps. Au minimum, il y aura une sérieuse latence s'il faut les réveiller.
Comme, dans le cas typique, le FP est bien moins contraint que le PP (connecté au courant électrique, processeur plus puissant), ce sera le FP qui jouera le rôle de 6LBR (6LoWPAN Border Router, voir RFC 6775), et le PP celui de 6LN (6LoWPAN Node, même RFC). Contrairement à 802.15.4, DECT ULE ne permet que des liens directs, pour aller au delà, il faut un routeur (le FP). Tous les PP connectés à un FP forment donc un seul lien, leurs adresses seront dans le même préfixe IPv6.
Comment attribuer cette adresse ? Alors, là, faites attention, c'est un point délicat et important. Chaque PP a un IPEI (International Portable Equipment Identity) de 40 bits, qui est l'identifiant DECT. Les FP ont un RFPI (Radio Fixed Part Identity, également 40 bits). Les messages envoyés entre PP et FP ne portent pas l'IPEI mais le TPUI (Temporary Portable User Identity, 20 bits). Pas mal de mises en œuvre de DECT attribuent répétitivement le même TPUI à une machine, même si ce n'est pas obligatoire. Il peut donc être un identifiant stable, en pratique, comme le sont IPEI et RFPI.
L'adresse IPv6 est composée du préfixe du réseau et d'un identifiant d'interface, qu'on peut construire à partir de l'adresse MAC (les équipements DECT peuvent aussi avoir une adresse MAC, en sus des identificateurs déjà cités). Adresse MAC, IPEI, RFPI ou TPUI, tout ce qui est stable pose des problèmes de protection de la vie privée (RFC 8065), et n'est pas recommandé comme identifiant d'interface par défaut.
Un petit mot aussi sur la MTU : les paquets DECT ne sont que 38 octets, bien trop petit pour IP. Certes, DECT fournit un mécanisme de fragmentation et de réassemblage, qui fournit une MTU « virtuelle » qui est, par défaut, de 500 octets. La MTU minimum exigée par IPv6 étant de 1 280 octets (RFC 2460, section 5), il faudra donc reconfigurer le lien DECT pour passer à une MTU de 1 280. Ainsi, les paquets n'auront jamais besoin d'être fragmentés par IP. Évidemment, plus le paquet est gros, plus le coût énergétique de transmission est élevé, au détriment de la durée de vie de la batterie.
Place maintenant à la spécification elle-même, en section 3 du RFC. La base (alias FP, alias 6LBR) et l'objet (alias PP, alias 6LN) vont devoir se trouver et établir une session DECT classique. On aura alors une couche 2 fonctionnelle. Ensuite, on lancera IPv6, qui fournira la couche 3. La consommation de ressources, notamment d'énergie, étant absolument cruciale ici, il faudra s'appuyer sur les technologies IPv6 permettant de faire des économies, notamment RFC 4944 (IPv6 sur un autre type de réseau contraint, IEEE 802.15.4), RFC 6775 (optimisation des mécanismes de neighbor discovery pour les 6LoWPAN) et RFC 6282 (compression des paquets et notamment des en-têtes).
Comme indiqué plus haut, les PP ne peuvent parler qu'au FP, pas directement de l'un à l'autre. Si tous les PP d'un même FP (d'une même base) forment un sous-réseau IPv6 (choix le plus simple), le modèle sera celui d'un NBMA. Lorsqu'un PP écrira à un autre PP, cela sera forcément relayé par le FP.
Les adresses IPv6 des PP seront formées à partir du préfixe (commun à tous les PP d'un même FP) et d'un identifiant d'interface. Pour les adresses locales au lien, cet identifiant d'interface dérivera des identifiants DECT, les IPEI et RFPI, complétés avec des zéros pour atteindre la taille requise. Le bit « unique mondialement » sera à zéro puisque ces identifiants ne seront pas uniques dans le monde (ils ont juste besoin d'être uniques localement, ce fut un des points les plus chauds lors de l'écriture de ce RFC).
Pour les adresses globales des PP, pas question d'utiliser des identificateurs trop révélateurs (RFC 8065), il faut utiliser une technique qui préserve la vie privée comme les CGA (RFC 3972), les adresses temporaires du RFC 8981 ou les adresses stables mais opaques du RFC 7217.
Le FP, la base, a une connexion avec l'Internet, ou en tout cas avec d'autres réseaux IP, et routera donc les paquets, s'ils viennent d'un PP et sont destinés à une adresse extérieure au sous-réseau (idem avec les paquets venus de l'extérieur et destinés au sous-réseau.) Au fait, comment est-ce que la base, qui est un routeur IPv6, obtient, elle, le préfixe qu'elle va annoncer ? Il n'y a pas de méthode obligatoire mais cela peut être, par exemple, la délégation de préfixe du RFC 8415, ou bien le RFC 4193.
Question mises en œuvre, il semble que RTX et Gigaset en aient déjà, et que peut-être l'alliance ULE va produire une version en logiciel libre.
L'article seul
RFC 8098: Message Disposition Notification
Date de publication du RFC : Février 2017
Auteur(s) du RFC : T. Hansen (AT&T
Laboratories), A. Melnikov (Isode)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 1 mars 2017
Une demande fréquente des utilisateurs du courrier électronique est d'avoir un mécanisme permettant de savoir si et quand le message a été lu par le destinataire. Comme toutes les demandes des utilisateurs, il ne faut pas forcément la satisfaire sans réfléchir (elle pose des gros problèmes de vie privée et, en outre, elle ne garantit pas que le message a été traité, juste que le logiciel l'a affiché). Ce n'est pas par hasard que cette fonction « accusé de réception » était souvent présente (et mise en avant par les vendeurs) pour les systèmes de messagerie conçus pour des environnements très bureaucratiques (le RFC cite l'antédiluvien X.400). Mais, bon, si les gens y tiennent, cette possibilité existe dans la norme : ce nouveau RFC spécifie un mécanisme permettant de signaler qu'on souhaite un tel accusé de réception, ainsi qu'un format structuré (lisible par un programme comme le MUA) pour les accusés de réception qui seront (peut-être) envoyés. Ces accusés de réception sont appelés MDN pour Message Disposition Notification. Ce RFC remplace son prédécesseur, le RFC 3798.
Donc, résumé général du fonctionnement de ce système :
l'émetteur d'un message qui veut un accusé de réception met un
en-tête Disposition-Notification-To: dans son
message. Le récepteur, s'il le désire,
répondra à cette demande lors de la lecture du message, en
envoyant un message de type MIME
message/disposition-notification (a priori
situé à l'intérieur d'un rapport plus général, de type
multipart/report, cf. RFC 6522). Tout ceci
est sous un format structuré, donc peut être traité par un
programme, typiquement le MUA. Voilà, vous
connaissez l'essentiel de ce RFC. Place aux
détails.
À quoi servent les MDN (Message Disposition Notification, un concept plus large que celui d'accusé de réception) ? Voici le cahier des charges proposé par notre RFC :
- Indiquer ce qu'il est advenu du message après la réception physique (lu, imprimé, détruit),
- Permettre d'associer un message à son devenir (le MDN contient les informations permettant la jointure avec les messages envoyés),
- Transmettre de l'information sur le devenir des messages entre systèmes de messagerie différents (un cas devenu rare aujourd'hui, mais qui était plus crucial lors de la sortie du premier RFC sur cette technique, en 1998, cf. la section 8 pour ces passerelles),
- Donner de l'information aux programmes, pas seulement aux humains (pas uniquement du texte non formaté, donc),
- Être indépendant de la langue naturelle utilisée par les humains,
- Être extensible, car on ne sait jamais.
Première partie de la norme, la demande
d'un MDN (section 2). L'émetteur le fait en ajoutant dans son message un
en-tête Disposition-Notification-To:
indiquant les adresses auxquelles envoyer le MDN. Par exemple :
Disposition-Notification-To: stephane+mdn@bortzmeyer.org
Le risque d'utilisation de ce truc pour bombarder de message un
tiers innocent est évident. C'est pour cela que le RFC recommande
d'ignorer cet en-tête si l'adresse indiquée ne coïncide pas avec
celle stockée dans l'en-tête
Return-Path: (voir section 6.4). Dans tous les cas,
rappelez-vous bien que le logiciel à la réception est libre de
faire ce qu'il veut. Il peut estimer que ces MDN ne servent à rien
et ignorer les Disposition-Notification-To:,
il peut demander une autorisation à l'utilisateur il peut envoyer le MDN de
manière totalement automatique (après les vérifications de
vraisemblance comme celle du
il peut envoyer le MDN de
manière totalement automatique (après les vérifications de
vraisemblance comme celle du Return-Path:), etc.
Deuxième partie de la norme, le format du MDN lui-même (section
3 du RFC). La réponse est dans un message de type
multipart/report (type défini dans le RFC 6522), avec le type de rapport (paramètre report-type)
disposition-notification. Le MDN lui-même a
deux ou trois parties : une première partie est du texte libre,
lisible par un humain, une deuxième est structurée, et de type
MIME message/disposition-notification, la
troisième partie est optionnelle et est le message auquel on
« répond ».
La deuxième partie du MDN est la plus intéressante. Son corps est
composé de plusieurs champs nom: valeur, dont
deux sont obligatoires, Final-Recipient: et
Disposition: qui indique ce qui est arrivé au
message. Parmi les autres champs, notez le
Reporting-UA:, indiquant le logiciel qui a
répondu, et dont le RFC recommande qu'il ne soit pas trop
détaillé, car il donne des informations qui peuvent être utiles à
un éventuel attaquant. Comme Reporting-UA:,
le champ Original-Message-ID: n'est pas
obligatoire mais il est très utile : c'est lui qui permet à
l'émetteur du message original de faire
la jointure entre ce qu'il a envoyé et le MDN reçu. (Il n'est pas
obligatoire car le message original n'a pas forcément un
Message-ID:. Mais, s'il en a un, il faut
inclure Original-Message-ID: dans le
MDN.)
Le champ le plus important est sans doute
Disposition:. Il indique ce qui est arrivé au
message original (disposition type) : a-t-il
été affiché à un utilisateur (displayed, ce
qui ne garantit pas du tout qu'il soit arrivé au cerveau de l'utilisateur), traité sans être montré à un
utilisateur (processed), effacé
(deleted) ? Ce champ
Disposition: indique aussi
(disposition mode) si le sort du
message a été décidé par un être humain ou bien automatiquement
(par exemple par Sieve),
et si le MDN a été généré suite à une autorisation explicite ou
bien automatiquement. Notez bien (et c'est la principale raison
pour laquelle les accusés de réception sont une fausse bonne idée)
que la seule façon d'être sûr que le message aura été traité par
son destinataire, est de recevoir une réponse explicite et
manuelle de sa part.
Enfin, le champ Error: sert à transporter
des messages... d'erreur.
Voici un exemple complet de MDN, tiré de la section 9 :
Date: Wed, 20 Sep 1995 00:19:00 (EDT) -0400
From: Joe Recipient <Joe_Recipient@example.com>
Message-Id: <199509200019.12345@example.com>
Subject: Re: First draft of report
To: Jane Sender <Jane_Sender@example.org>
MIME-Version: 1.0
Content-Type: multipart/report; report-type=disposition-notification;
boundary="RAA14128.773615765/example.com"
--RAA14128.773615765/example.com
Content-type: text/plain
The message sent on 1995 Sep 19 at 13:30:00 (EDT) -0400 to Joe
Recipient <Joe_Recipient@example.com> with subject "First draft of
report" has been displayed.
This is no guarantee that the message has been read or understood.
--RAA14128.773615765/example.com
Content-type: message/disposition-notification
Reporting-UA: joes-pc.cs.example.com; Foomail 97.1
Original-Recipient: rfc822;Joe_Recipient@example.com
Final-Recipient: rfc822;Joe_Recipient@example.com
Original-Message-ID: <199509192301.23456@example.org>
Disposition: manual-action/MDN-sent-manually; displayed
--RAA14128.773615765/example.com
Content-type: message/rfc822
[original message optionally goes here]
--RAA14128.773615765/example.com--
Notez la première partie, en langue naturelle (ici en
anglais), la seconde, avec les informations structurées (ici, le
destinataire a affiché le message - manual-action
... displayed - puis autorisé/déclenché manuellement
l'envoi du MDN - MDN-sent-manually), et la
présence de la troisième partie, qui est optionnelle.
Un peu de sécurité pour finir le RFC. D'abord, évidemment, il
ne faut pas accorder trop d'importance aux MDN. Ils peuvent être
fabriqués de toutes pièces, comme n'importe quel message sur
l'Internet. Ensuite, il faut faire attention à la vie
privée des utilisateurs. Le destinataire n'a pas
forcément envie qu'on sache si et quand il a lu un message ! Le
destinataire, ou son logiciel, ont donc parfaitement le droit de
refuser d'envoyer un MDN (ce qui diminue encore l'intérêt de cette
technique, qui était déjà très faible). Même des informations
inoffensives à première vue, comme le contenu du champ
Disposition: peuvent être considérées comme
sensibles. Si on configure Sieve pour
rejeter (RFC 5429) automatiquement tous les
messages d'une certaine personne, on n'a pas forcément envie
qu'elle le sache. Le RFC précise donc qu'on peut envoyer
manual-action/MDN-sent-manually dans ce cas,
pour cacher le fait que c'était automatique.
Quels sont les changements depuis le précédent RFC, le RFC 3798 ? Ils sont résumés dans l'annexe
A. Tout ce qui touche à la vie privée a été sérieusement renforcé
(les MDN sont très indiscrets). Les
champs commençant par un X- ont été supprimés
de la spécification, suivant le RFC 6648. La
grammaire a été corrigée (plusieurs bogues
et ambiguïtés).
En pratique, les MDN ne semblent guère utilisés dans l'Internet et ont peu de chance de marcher. Je note par exemple qu'aussi bien le MUA Unix mutt que le service Gmail semblent les ignorer complètement. Mais d'autres logiciels ont cette fonction.
L'article seul
RFC 8095: Services Provided by IETF Transport Protocols and Congestion Control Mechanisms
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : G. Fairhurst (University of Aberdeen), B. Trammell, M. Kuehlewind (ETH Zurich)
Pour information
Réalisé dans le cadre du groupe de travail IETF taps
Première rédaction de cet article le 10 mars 2017
Les protocoles de transport (couche 4 dans le modèle en couches traditionnel), comme le fameux TCP, fournissent certains services aux applications situées au-dessus d'eux. Mais quels services exactement ? Qu'attend-on de la couche de transport ? Le but de ce RFC de synthèse est de lister tous les services possibles de la couche 4, et d'analyser ensuite tous les protocoles existants pour voir lesquels de ces services sont offerts. Ce document ne normalise donc pas un nouveau protocole, il classe et organise les protocoles existants. (L'idée est de pouvoir ensuite développer une interface abstraite permettant aux applications d'indiquer quels services elles attendent de la couche transport au lieu de devoir, comme c'est le cas actuellement, choisir un protocole donné. Une telle interface abstraite permettrait au système d'exploitation de choisir le protocole le plus adapté à chaque environnement.)
C'est d'autant plus important qu'il n'y a pas que TCP mais aussi des protocoles comme SCTP, UDP, DCCP, les moins connus FLUTE ou NORM, et même HTTP, qui est devenu une couche de transport de fait. Toute évolution ultérieure de l'architecture de l'Internet, des middleboxes, des API offertes par le système d'exploitation, implique une compréhension détaillée de ce que fait exactement la couche transport.
Pour TCP, tout le monde connait (ou croit connaitre) : il fournit un service de transport de données fiable (les données qui n'arrivent pas sont retransmises automatiquement, l'application n'a pas à s'en soucier, la non-modification est - insuffisamment - contrôlée via une somme de contrôle), et ordonné (les octets arrivent dans l'ordre d'envoi même si, dans le réseau sous-jacent, un datagramme en a doublé un autre). TCP ne fournit pas par contre de service de confidentialité, ce qui facilite le travail de la NSA ou de la DGSI. Tout le monde sait également qu'UDP ne fournit aucun des deux services de fiabilité et d'ordre : si l'application en a besoin, elle doit le faire elle-même (et il est donc logique que la plupart des applications utilisent TCP).
Parfois, le service de transport offert aux applications est lui-même bâti sur un autre service de transport. C'est la raison pour laquelle ce RFC présente des protocoles qui ne sont pas « officiellement » dans la couche 4 (mais, de toute façon, le modèle en couches n'a toujours été qu'une vague indication ; en faire une classification rigide n'a aucun intérêt, et a été une des raisons de l'échec du projet l'OSI). Un exemple est TLS. Une application qui s'en sert ne voit pas directement le TCP sous-jacent, elle confie ses données à TLS qui, à son tour, fait appel à TCP. Le service de transport vu par l'application offre ainsi les fonctions de TCP (remise fiable et ordonnée des données) plus celles de TLS (confidentialité, authentification et intégrité). Il faudrait être particulièrement pédant pour s'obstiner à classer TLS dans les applications comme on le voit parfois.
Le même phénomène se produit pour UDP : comme ce protocole n'offre quasiment aucun service par lui-même, on le complète souvent avec des services comme TFRC (RFC 5348) ou LEDBAT (RFC 6817) qui créent ainsi un nouveau protocole de transport au-dessus d'UDP.
La section 1 de notre RFC liste les services possibles d'une couche de transport :
- Envoi des messages à un destinataire (unicast) ou à plusieurs (multicast ou anycast),
- Unidirectionnel (ce qui est toujours le cas avec le multicast) ou bidirectionnel,
- Nécessite un établissement de la connexion avant d'envoyer des données, ou pas,
- Fiabilité de l'envoi (par un mécanisme d'accusé de réception et de réémission) ou bien fire and forget (notez que cette fiabilité peut être partielle, ce que permet par exemple SCTP),
- Intégrité des données (par exemple via une somme de contrôle),
- Ordre des données (avec certains protocoles de transport comme UDP, le maintien de l'ordre des octets n'est pas garanti, un paquet pouvant en doubler un autre),
- Structuration des données (framing), certains protocoles découpent en effet les données en messages successifs (ce que ne fait pas TCP),
- Gestion de la congestion,
- Confidentialité,
- Authentification (TLS fournit ces deux derniers services).
La section 3 du RFC est le gros morceau. Elle liste tous les protocoles de transport possibles (au moins ceux normalisés par l'IETF), en donnant à chaque fois une description générale du protocole, l'interface avec les applications, et enfin les services effectivement offerts par ce protocole.
À tout seigneur, tout honneur, commençons par l'archétype des protocoles de transport, TCP. Normalisé dans le RFC 793, très largement répandu (il est difficile d'imaginer une mise en œuvre d'IP qui ne soit pas accompagnée de TCP), utilisé quotidiennement par des milliards d'utilisateurs. Le RFC originel a connu pas mal de mises à jour et, aujourd'hui, apprendre TCP nécessite de lire beaucoup de RFC (le RFC 7414 en donne la liste). Ainsi, la notion de données urgentes, qui était dans le RFC originel, a été supprimée par le RFC 6093.
TCP multiplexe les connexions en utilisant les numéros de port, comme beaucoup de protocoles de transport. Une connexion est identifiée par un tuple {adresse IP source, port source, adresse IP destination, port destination}. Le port de destination identifie souvent le service utilisé (c'est moins vrai aujourd'hui, où la prolifération de middleboxes stupides oblige à tout faire passer sur les ports 80 et 443). TCP fournit un service de données non-structurées, un flot d'octets, mais, en interne, il découpe ces octets en segments, dont la taille est négociée au début (en général, TCP essaie de faire que cette taille soit la MTU du chemin, en utilisant les RFC 1191, RFC 1981 et de plus en plus le RFC 4821). Chaque octet envoyé a un numéro, le numéro de séquence, et c'est ainsi que TCP met en œuvre la fiabilité et l'ordre. (Contrairement à ce que croient certaines personnes, c'est bien l'octet qui a un numéro, pas le segment.) Autrefois, si deux segments non contigus étaient perdus, il fallait attendre la réémission du premier pour demander celle du second, mais les accusés de réception sélectifs du RFC 2018 ont changé cela.
Quant au contrôle de congestion de TCP, il est décrit en détail dans le RFC 5681. TCP réagit à la perte de paquets (ou bien à leur marquage avec l'ECN du RFC 3168) en réduisant la quantité de données envoyées.
Les données envoyées par l'application ne sont pas forcément transmises immédiatement au réseau. TCP peut attendre un peu pour remplir davantage ses segments (RFC 896). Comme certaines applications (par exemple celles qui sont fortement interactives comme SSH) n'aiment pas les délais que cela entraine, ce mécanisme est typiquement débrayable.
Enfin, pour préserver l'intégrité des données envoyées, TCP utilise une somme de contrôle (RFC 793, section 3.1, et RFC 1071). Elle ne protège pas contre toutes les modifications possibles et il est recommandé aux applications d'ajouter leur propre contrôle d'intégrité (par exemple, si on transfère un fichier, via un condensat du fichier).
Et l'interface avec les applications, cruciale, puisque le rôle
de la couche transport est justement d'offrir des services aux
applications ? Celle de TCP est décrite de manière relativement
abstraite dans le RFC 793 (six commandes,
Open, Close,
Send, Receive, etc). Des
points comme les options TCP n'y sont pas spécifiés. Le RFC 1122 est un peu plus détaillé, mentionnant
par exemple l'accès aux messages ICMP qui
peuvent indiquer une erreur TCP. Enfin, une interface concrète est
celle des prises,
normalisées par POSIX (pas de RFC à ce sujet). Vous créez une prise
avec l'option SOCK_STREAM et hop, vous
utilisez TCP et tous ses services.
Quels services, justement ? TCP fournit :
- Établissement d'une connexion, et démultiplexage en utilisant les numéros de port,
- Transport unicast (l'anycast est possible, si on accepte le risque qu'un changement de routes casse subitement une connexion),
- Communication dans les deux sens,
- Données envoyées sous forme d'un flot d'octets, sans séparation (pas de notion de message, c'est à l'application de le faire, si elle le souhaite, par exemple en indiquant la taille du message avant le message, comme le font EPP et DNS), c'est aussi cela qui permet l'accumulation de données avant envoi (algorithme de Nagle),
- Transport fiable, les données arriveront toutes, et dans l'ordre,
- Détection d'erreurs (mais pas très robuste),
- Contrôle de la congestion, via les changements de taille de la fenêtre d'envoi (la fenêtre est l'ensemble des octets qui peuvent être envoyés avant qu'on ait reçu l'accusé de réception des données en cours), voir le RFC 5681.
Par contre, TCP ne fournit pas de confidentialité, et l'authentification se limite à une protection de l'adresse IP contre les attaquants situés hors du chemin (RFC 5961).
Après TCP, regardons le deuxième protocole de transport étudié, MPTCP (Multipath TCP, RFC 6824). C'est une extension de TCP qui permet d'exploiter le multi-homing. Pour échapper aux middleboxes intrusives, MPTCP fonctionne en créant plusieurs connexions TCP ordinaires depuis/vers toutes les adresses IP utilisées, et en multiplexant les données sur ces connexions (cela peut augmenter le débit, et cela augmente la résistance aux pannes, mais cela peut aussi poser des problèmes si les différents chemins ont des caractéristiques très différentes). La signalisation se fait par des options TCP.
L'interface de base est la même que celle de TCP, mais il existe des extensions (RFC 6897) pour tirer profit des particularités de MPTCP.
Les services sont les mêmes que ceux de TCP avec, en prime le multi-homing (il peut même y avoir des adresses IPv4 et IPv6 dans la même session MPTCP), et ses avantages notamment de résilience.
Après TCP, UDP est certainement le protocole de transport le plus connu. Il est notamment très utilisé par le DNS. Le RFC 8085 explique comment les applications peuvent l'utiliser au mieux. La section 3.3 de notre RFC lui est consacrée, pour décrire son interface et ses services.
Contrairement à TCP, UDP n'a pas la notion de connexion (on envoie directement les données, sans négociation préalable), UDP découpe les données en messages (voilà pourquoi les messages DNS en UDP ne sont pas précédés d'une longueur : UDP lui-même fait le découpage), n'a pas de contrôle de congestion, et ne garantit pas le bon acheminement. UDP dispose d'un contrôle d'intégrité, mais il est facultatif (quoique très recommandé) en IPv4, où on peut se contenter du contrôle d'intégrité d'IP. IPv6 n'ayant pas ce contrôle, UDP sur IPv6 doit activer son propre contrôle, sauf dans certains cas très précis (RFC 6936).
En l'absence de contrôle de congestion, l'application doit être prudente, veiller à ne pas surcharger le réseau, et ne pas s'étonner si l'émetteur envoie plus que ce que le récepteur peut traiter. D'une façon générale, il faut penser à lire le RFC 8085, qui explique en détail tout ce qu'une application doit faire si elle tourne sur UDP.
Il est d'ailleurs recommandé de bien se poser la question de l'utilité d'UDP, dans beaucoup de cas. Un certain nombre de développeurs se disent au début d'un projet « j'ai besoin de vitesse [sans qu'ils fassent bien la différence entre latence et capacité], je vais utiliser UDP ». Puis ils découvrent qu'ils ont besoin de contrôle de flux, d'ordre des données, de bonne réception des données, ils ajoutent à chaque fois des mécanismes ad hoc, spécifiques à leur application et, au bout du compte, ils ont souvent réinventé un truc aussi lourd que TCP, mais bien plus bogué. Attention donc à ne pas réinventer la roue pour rien.
L'interface d'UDP, maintenant. Le RFC 768 donne quelques indications de base, que le RFC 8085 complète. Bien qu'UDP n'ait
pas le concept de connexion, il est fréquent que les
API aient une opération
connect() ou analogue. Mais il ne faut pas
la confondre avec l'opération du même nom sur TCP : ce
connect() UDP est purement local, associant
la structure de données locale à une machine distante (c'est
ainsi que cela se passe avec les prises
Berkeley).
Et les services d'UDP ? La liste est évidemment bien plus courte que pour TCP. Elle comprend :
- Transport des données, unicast, multicast , anycast et broadcast (c'est le seul point où UDP en fournit davantage que TCP),
- Démultiplexage en utilisant les numéros de port,
- Unidirectionnel (ce qui est toujours le cas avec le multicast) ou bidirectionnel,
- Données structurées en messages,
- Aucune garantie, ou signalement, des pertes de message,
- Aucune garantie sur l'ordre de délivrance des messages.
Nettement moins connu qu'UDP est UDP-Lite, normalisé dans le RFC 3828. C'est une version très légèrement modifiée d'UDP, où la seule différence est que les données corrompues (détectées par la somme de contrôle) sont quand même données à l'application réceptrice, au lieu d'être jetées comme avec UDP. Cela peut être utile pour certains applications, notamment dans les domaines audio et vidéo.
Avec UDP-Lite, le champ Longueur de l'en-tête UDP change de sémantique : il n'indique plus la longueur totale des données mais la longueur de la partie qui est effectivement couverte par la somme de contrôle. Typiquement, on ne couvre que l'en-tête applicatif. Le reste est... laissé à la bienveillance des dieux (ou des démons). Pour tout le reste, voyez la section sur UDP.
Notez qu'il n'existe pas d'API spécifique pour UDP-Lite. Si quelqu'un parmi mes lecteurs a des exemples de code bien clairs...
Bien plus original est SCTP (RFC 4960). C'est un protocole à connexion et garantie d'acheminement et d'ordre des données, comme TCP. Mais il s'en distingue par sa gestion du multi-homing. Avec SCTP, une connexion peut utiliser plusieurs adresses IP source et destination, et passer de l'une à l'autre pendant la session, assurant ainsi une bonne résistance aux pannes. Plus drôle, cet ensemble d'adresses peut mêler des adresses IPv4 et IPv6.
Notez aussi qu'une connexion SCTP (on dit une association) comporte plusieurs flux de données, afin de minimiser le problème connu sous le nom de head of line blocking (un paquet perdu empêche la délivrance de toutes les données qui suivent tant qu'il n'a pas été réémis).
SCTP avait surtout été conçu pour la signalisation dans les réseaux téléphoniques. Mais on le trouve dans d'autres cas, comme ForCES (cf. RFC 5811) ou comme la signalisation WebRTC (RFC 8825).
Contrairement à TCP, SCTP utilise une quadruple poignée de mains pour établir la connexion, ce qui permet de ne négocier les options qu'une fois certain de l'identité du partenaire (les techniques anti-DoS de TCP sont incompatible avec l'utilisation des options, cf. RFC 4987, section 3.6). La somme de contrôle fait 32 bits (au lieu des 16 bits de TCP et UDP) et est donc normalement plus robuste.
SCTP est très extensible et plusieurs extensions ont déjà été définies comme l'ajout ou le retrait d'adresses IP pendant l'association (RFC 5061), ou bien la possibilité de n'accepter qu'une fiabilité partielle (RFC 3758). Pour la sécurité, on peut faire tourner TLS sur SCTP (RFC 3436) au prix de la perte de quelques fonctions, ou bien utiliser DTLS (RFC 6083), qui préserve quasiment toutes les fonctions de SCTP.
Victime fréquente des middleboxes stupides qui ne connaissent qu'UDP et TCP, SCTP peut tourner sur UDP (RFC 6951), au lieu de directement reposer sur IP, afin de réussir à passer ces middleboxes.
Contrairement à des protocoles de transport plus anciens, SCTP a une interface bien spécifiée. Le RFC 4960 définit l'interface abstraite, et une extension aux prises Berkeley, spécifiée dans le RFC 6458, lui donne une forme concrète. Cette API prévoit également certaines extensions, comme celle des reconfigurations dynamiques d'adresses du RFC 5061.
Les services fournis par SCTP sont très proches de ceux fournis par TCP, avec deux ajouts (la gestion du multi-homing et le multi-flux), et un changement (données structurées en messages, au lieu d'être un flot d'octets continu comme TCP).
Un autre protocole de transport peu connu, et ne fournissant pas, lui, de fiabilité de l'envoi des données, est DCCP (RFC 4340). DCCP est une sorte d'UDP amélioré, qui peut fournir des services supplémentaires à ceux d'UDP, tout en restant plus léger que TCP (la description du besoin figure dans le RFC 4336). DCCP est bien adapté aux applications multimédia ou aux jeux en ligne, où une faible latence est cruciale, mais où peut aimer avoir des services en plus. Sans DCCP, chaque application qui veut de l'« UDP amélioré » devrait tout réinventer (et ferait sans doute des erreurs).
DCCP a des connexions, comme TCP, qu'on établit avant de communiquer et qu'on ferme à la fin. Il offre une grande souplesse dans le choix des services fournis, choix qui peuvent être unilatéraux (seulement l'envoyeur, ou bien seulement le récepteur) ou négociés lors de l'ouverture de la connexion. Le paquet d'ouverture de connexion indique l'application souhaitée (RFC 5595), ce qui peut être une information utile aux équipements intermédiaires. S'il faut faire passer DCCP à travers des middleboxes ignorantes, qui n'acceptent qu'UDP et TCP, on peut, comme avec SCTP, encapsuler dans UDP (RFC 6773).
L'interface avec DCCP permet d'ouvrir, de fermer et de gérer une connexion. Il n'y a pas d'API standard. Les services fournis sont :
- Transport des données, uniquement unicast,
- Protocole à connexion, et démultiplexage fondé sur les numéros de port,
- Structuration des données en messages,
- Les messages peuvent être perdus (mais, contrairement à UDP, l'application est informée des pertes), et ils peuvent être transmis dans le désordre,
- Contrôle de la congestion (le gros avantage par rapport à UDP), et avec certains choix (optimiser la latence ou au contraire la gigue, par exemple) laissés à l'application.
Autre exemple de protocole de transport, même s'ils ne sont en général pas décrits comme tels, TLS (RFC 5246) et son copain DTLS (RFC 6347). Si on est un fanatique du modèle en couches, on ne met pas ces protocoles de sécurité en couche 4 mais, selon l'humeur, en couche 5 ou en couche 6. Mais si on est moins fanatique, on reconnait que, du point de vue de l'application, ce sont bien des protocoles de transport : c'est à eux que l'application confie ses données, comptant sur les services qu'ils promettent.
TLS tourne sur TCP et DTLS sur UDP. Du point de vue de l'application, TLS fournit les services de base de TCP (transport fiable d'un flot d'octets) et DTLS ceux d'UDP (envoi de messages qui arriveront peut-être). Mais ils ajoutent à ces services de base leurs services de sécurité :
- Confidentialité, éventuellement avec sécurité future,
- Authentification,
- Intégrité (souvent citée à part mais, à mon avis, c'est un composant indispensable de l'authentification).
Le RFC rappelle qu'il est important de se souvenir que TLS ne spécifie pas un mécanisme d'authentification unique, ni même qu'il doit y avoir authentification. On peut n'authentifier que le serveur (c'est actuellement l'usage le plus courant), le client et le serveur, ou bien aucun des deux. La méthode la plus courante pour authentifier est le certificat PKIX (X.509), appelé parfois par une double erreur « certificat SSL ».
DTLS ajoute également au service de base quelques trucs qui n'existent pas dans UDP, comme une aide pour la recherche de PMTU ou un mécanisme de cookie contre certaines attaques.
Il n'y a pas d'API standard de TLS. Si on a écrit une application avec l'API d'OpenSSL, il faudra refaire les appels TLS si on passe à WolfSSL ou GnuTLS. C'est d'autant plus embêtant que les programmeurs d'application ne sont pas forcément des experts en cryptographie et qu'une API mal conçue peut les entrainer dans des erreurs qui auront des conséquences pour la sécurité (l'article « The most dangerous code in the world: validating SSL certificates in non-browser software » en donne plusieurs exemples).
Passons maintenant à RTP (RFC 3550). Ce protocole est surtout utilisé pour les applications multimédia, où on accepte certaines pertes de paquet, et où le format permet de récupérer après cette perte. Comme TLS, RTP fonctionne au-dessus du « vrai » protocole de transport, et peut exploiter ses services (comme la protection de l'intégrité d'une partie du contenu, que fournissent DCCP et UDP-Lite).
RTP comprend en fait deux protocoles, RTP lui-même pour les données et RTCP pour le contrôle. Par exemple, c'est via RTCP qu'un émetteur apprend que le récepteur ne reçoit pas vite et donc qu'il faudrait, par exemple, diminuer la qualité de la vidéo.
RTP n'a pas d'interface standardisée offerte aux programmeurs. Il faut dire que RTP est souvent mis en œuvre, non pas dans un noyau mais directement dans l'application (comme avec libortp sur Unix). Ces mises en œuvre sont donc en général optimisées pour une utilisation particulière, au lieu d'être généralistes comme c'est le cas avec les implémentations de TCP ou UDP.
Autre cas d'un protocole de transport qui fonctionne au-dessus d'un autre protocole de transport, HTTP (RFC 7230 et suivants). Il n'était normalement pas conçu pour cela mais, dans l'Internet d'aujourd'hui, où il est rare d'avoir un accès neutre, où les ports autres que 80 et 443 sont souvent bloqués, et où hôtels, aéroports et écoles prétendent fournir un « accès Internet » qui n'est en fait qu'un accès HTTP, bien des applications qui n'ont rien à voir avec le Web en viennent à utiliser HTTP comme protocole de transport. (Même si le RFC 3205 n'encourage pas vraiment cette pratique puisque HTTP peut ne pas être adapté à tout. Mais, souvent, on n'a pas le choix.)
Outre cette nécessité de contourner blocages et limitations, l'utilisation de HTTP comme transport a quelques avantages : protocole bien connu, disposant d'un grand nombre de mises en œuvre, que ce soit pour les clients ou pour les serveurs, et des mécanismes de sécurité existants (RFC 2617, RFC 2817…). L'un des grands succès de HTTP est le style REST : de nombreuses applications sont conçues selon ce style.
Les applications qui utilisent HTTP peuvent se servir des
méthodes existantes (GET,
PUT, etc) ou bien en créer de nouvelles
(qui risquent de moins bien passer partout).
Je ne vais pas refaire ici la description de HTTP que contient le RFC (suivant le même plan que pour les autres protocoles de transport), je suppose que vous connaissez déjà HTTP. Notez quand même quelques points parfois oubliés : HTTP a un mécanisme de négociation du contenu, qui permet, par exemple, de choisir le format lorsque la ressource existe en plusieurs formats, HTTP a des connexions persistentes donc on n'est pas obligé de se taper un établissement de connexion TCP par requête, et HTTP a des mécanismes de sécurité bien établis, à commencer par HTTPS.
Il y a plein de bibliothèques qui permettent de faire de l'HTTP facilement (libcurl et neon en C, Requests en Python, etc). Chacune a une API différente. Le W3C a normalisé une API nommée XMLHttpRequest, très utilisée par les programmeurs JavaScript.
Les services que fournit HTTP quand on l'utilise comme protocole de transport sont :
- Transport unicast, bi-directionnel, fiable (grâce à TCP en dessous), et avec contrôle de congestion (idem),
- Négociation du format, possibilité de ne transférer qu'une partie d'une ressource,
- Authentification et confidentialité si on utilise HTTPS.
Beaucoup moins connus que les protocoles précédents sont deux des derniers de notre liste, FLUTE et NORM.
FLUTE (File Delivery over Unidirectional Transport/ Asynchronous Layered Coding Reliable Multicast) est normalisé dans le RFC 6726. Il est conçu pour un usage très spécifique, la distribution de fichiers à des groupes multicast de grande taille, où on ne peut pas demander à chaque récepteur d'accuser réception. Il est surtout utilisé dans le monde de la téléphonie mobile (par exemple dans la spécification 3GPP TS 26.346).
FLUTE fonctionne sur UDP, et le protocole ALC du RFC 5775. Il est souvent utilisé sur des réseaux avec une capacité garantie, et où on peut donc relativiser les problèmes de congestion. Il n'y a pas d'interface de programmation spécifiée.
Les services de FLUTE sont donc :
- Transport de fichiers (que FLUTE appelle « objets ») plutôt que d'octets,
- Fiable (heureusement, pour des fichiers).
Et NORM (NACK-Oriented Reliable Multicast ? Normalisé dans le RFC 5740, il rend à peu près les mêmes services que FLUTE (distribution massive de fichiers). À noter qu'il en existe une mise en œuvre en logiciel libre.
Reste un cas amusant, ICMP. Bien sûr, ICMP n'est pas du tout conçu pour être un protocole de transport, c'est le protocole de signalisation d'IP (RFC 792 pour ICMP sur IPv4 et RFC 4443 pour ICMP sur IPv6). Mais, bon, comme il est situé au-dessus de la couche 3, on peut le voir comme un protocole de transport.
Donc, ICMP est sans connexion, sans fiabilité, et unidirectionnel. Évidemment pas de contrôle de congestion. Pas vraiment d'interface standard, les messages ICMP ne sont signalés qu'indirectement aux applications (dans certains cas, une application peut demander à recevoir les messages ICMP). On ne peut pas tellement s'en servir comme protocole de transport, bien que des programmes comme ptunnel s'en servent presque ainsi.
Après cette longue section 3 qui faisait le tour de tous les protocoles de transport ou assimilés, la section 4 de notre RFC revient sur la question cruciale de la congestion. Sans contrôle de congestion, si chacun émettait comme ça lui chante, l'Internet s'écroulerait vite sous la charge. C'est donc une des tâches essentielles d'un protocole de transport que de fournir ce contrôle de congestion. Pour ceux qui ne le font pas, l'application doit le faire (et c'est très difficile à faire correctement).
À noter que la plupart des protocoles de transport tendent à ce que chaque flot de données utilise autant de capacité disponible que les autres flots. Au contraire, il existe des protocoles « décroissants » comme LEDBAT (RFC 6817) qui cèdent la place aux autres et n'utilise la capacité que lorsque personne n'est en concurrence avec eux.
La section 5 de notre RFC revient sur la notion de fonctions fournies par le protocole de transport, et classe sur un autre axe que la section 3. La section 3 était organisée par protocole et, pour chaque protocole, indiquait quelles étaient ses fonctions. La section 5, au contraire, est organisée par fonction et indique, pour chaque fonction, les valeurs qu'elle peut prendre, et les protocoles qui correspondent. Première catégorie de fonctions, celle du contrôle. Ainsi, une des fonctions de base d'un protocole de transport est l'adressage, celui-ci peut être unicast (TCP, UDP, SCTP, TLS, HTTP), multicast (UDP encore, FLUTE, NORM), broadcast (UDP toujours), anycast (UDP, quoique TCP puisse l'utiliser si on accepte le risque de connexions coupées lorsque le routage change).
Autre fonction, la façon dont se fait l'association entre les deux machines, et elle peut être avec connexion (TCP, SCTP, TLS) ou sans connexion (UDP). La gestion du multi-homing peut être présente (MPTCP, SCTP) ou pas. La signalisation peut être faite avec ICMP ou bien dans le protocole d'application (RTP).
Seconde catégorie de fonctions, la délivrance de données. Première fonction dans cette catégorie, la fiabilité, qui peut être complète (TCP, SCTP, TLS), partielle (RTP, FLUTE, NORM) ou inexistante (UDP, DCCP). Deuxième fonction, la détection d'erreurs, par une somme de contrôle qui couvre toutes les données (TCP, UDP, SCTP, TLS), une partie (UDP-Lite), et qui peut même être optionnelle (UDP en IPv4). Troisième fonction de délivrance, l'ordre des données, qui peut être maintenu (TCP, SCTP, TLS, HTTP, RTP) ou pas (UDP, DCCP, DTLS). Quatrième fonction, le découpage des données : flot sans découpage (TCP, TLS) ou découpage en messages (UDP, DTLS).
Troisième catégorie de fonctions, celles liées au contrôle de la transmission et notamment de la lutte contre la congestion.
Enfin, quatrième et dernière catégorie de fonctions, celles liées à la sécurité : authentification (TLS, DTLS) et confidentialité (les mêmes) notamment.
Voilà, armé de ce RFC, si vous êtes développeurs d'un nouveau protocole applicatif sur Internet, vous pouvez choisir votre protocole de transport sans vous tromper.
Une lecture recommandée est « De-Ossifying the Internet Transport Layer: A Survey and Future Perspectives », de Giorgos Papastergiou, Gorry Fairhurst, David Ros et Anna Brunström.
L'article seul
RFC 8094: DNS over Datagram Transport Layer Security (DTLS)
Date de publication du RFC : Février 2017
Auteur(s) du RFC : T. Reddy
(Cisco), D. Wing, P. Patil
(Cisco)
Expérimental
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 2 mars 2017
Dernière mise à jour le 22 mai 2022
Le DNS fonctionne traditionnellement surtout sur UDP, notamment pour minimiser la latence : quand on veut une réponse DNS, on la veut rapidement. Dans le cadre du projet « DNS et vie privée », le choix avait été fait de chiffrer le trafic DNS avec TLS (RFC 7858), imposant ainsi l'usage de TCP. Certains pensaient quand même qu'UDP était bien adapté au DNS et, puisqu'il existe une version de TLS adaptée à UDP, DTLS, ce serait une bonne idée de l'utiliser pour chiffrer le DNS. C'est ce que décrit ce nouveau RFC (qui n'a pas eu un avenir brillant, peu de gens ont été intéressés, regardez plutôt le RFC 9250).
De toute façon, il est très possible que le DNS utilise de plus en plus TCP, et le RFC 7766 allait dans ce sens, demandant davantage de la part des mises en œuvre de DNS sur TCP. Mais, bon, il est toujours bon d'essayer des alternatives, d'où ce RFC, dans l'état « Expérimental ». Outre les RFC déjà cités, il est recommandé, avant de le lire, de prendre connaissance du RFC 7626, qui décrit les problèmes de vie privée que pose le DNS, et le RFC 9147, qui normalise DTLS (bien moins connu que son copain TLS, et peu utilisé jusqu'à présent, à part pour WebRTC).
Les motivations pour explorer une alternative au DNS-sur-TLS du RFC 7858 sont :
- TCP souffre du « head of line blocking » où la perte d'un seul paquet empêche de recevoir tous ceux qui suivent, même s'ils sont bien arrivés, tant que le paquet perdu n'est pas retransmis. DNS-sur-DTLS sera donc peut-être meilleur sur des réseaux qui perdent pas mal de paquets.
- Dans certaines conditions, l'établissement d'une session est plus rapide avec DTLS qu'avec TLS. (Rappelez-vous toutefois que le RFC 7766 exige des sessions TCP persistentes : pas question d'établir une session par requête DNS !) Reprendre une session TLS peut ne prendre qu'un aller-retour avec DTLS, alors que TLS devra attendre l'établissement de la connexion TCP (le RFC 7413 changera peut-être les choses, mais TLS et DTLS 1.3 obligeront également à réviser ce raisonnement.)
De même qu'un serveur et un client DNS ne peuvent pas se contenter d'UDP (pour pouvoir envoyer des données de grande taille, il faudra de toute façon passer à TCP), DNS-sur-DTLS ne peut pas suffire seul, et il faudra donc que les clients et serveurs aient également DNS-sur-TLS.
La spécification de DNS-sur-DTLS est dans la section 3 de notre
RFC. DNS-sur-DTLS va tourner, comme DNS-sur-TLS, sur le
port 853 (sauf accord préalable entre
client et serveur, s'ils sont adultes et consentants). Un client
peut déterminer si le serveur gère DNS-sur-DTLS en envoyant un
message DTLS ClientHello vers le port 853. En
l'absence de réponse, le client réessaie, puis laisse
tomber DTLS. Selon sa configuration (plus ou moins paranoïaque), le
client va alors tenter le DNS habituel en clair, ou bien
complètement renoncer. En tout cas, interdiction d'utiliser le
port 853 pour transmettre des messages DNS en clair. L'utilisation
de ce port sur UDP implique DTLS.
Si, par contre, le serveur répond et qu'une session DTLS est établie, le client DNS-sur-DTLS authentifie le serveur avec les mêmes méthodes que pour TLS, en suivant les bonnes pratiques de sécurité de TLS (RFC 7525) et les profils d'authentification de DNS-sur-TLS décrits dans le RFC 8310. Une fois que tout cela est fait, les requêtes et réponses DNS sont protégées et les surveillants sont bien embêtés, ce qui était le but.
DTLS tourne sur UDP et reprend sa sémantique. Notamment, il est parfaitement normal qu'une réponse arrive avant une autre, même partie plus tôt. Le client DNS-sur-DTLS ne doit donc pas s'étonner et, pour faire correspondre les requêtes et les réponses, il doit, comme avec le DNS classique sur UDP, utiliser le Query ID ainsi que la question posée (qui est répétée dans les réponses, dans la section Question).
Pour ne pas écrouler le serveur sous la charge, le client ne devrait créer qu'une seule session DTLS vers chaque serveur auquel il parle, et y faire passer tous les paquets. S'il y a peu de requêtes, et que le client se demande si le serveur est toujours là, il peut utiliser l'extension TLS du « battement de cœur » (RFC 6520), qui peut également servir à rafraichir l'état d'un routeur NAT éventuel. Le RFC recommande aux serveurs DNS-sur-DTLS un délai d'au moins une seconde en cas d'inutilisation de la session, avant de raccrocher. Le problème est délicat : si ce délai est trop long, le serveur va garder des ressources inutiles, s'il est trop court, il obligera à refaire le travail d'établissement de session trop souvent. En tout cas, le client doit être prêt à ce que le serveur ait détruit la session unilatéralement, et doit la réétablir s'il reçoit l'alerte DTLS qui lui indique que sa session n'existe plus.
Un petit mot sur les performances, maintenant, puisque rappelons-nous que le DNS doit aller vite (section 4). L'établissement d'une session DTLS peut nécessiter d'envoyer des certificats, qui sont assez gros et peuvent nécessiter plusieurs paquets. Il peut donc être utile d'utiliser les clés brutes (pas de certificat) du RFC 7250, ou bien l'extension TLS Cached Information Extension (RFC 7924).
Dans le cas d'un lien stub resolver vers résolveur, le serveur DNS parle à beaucoup de clients, chaque client ne parle qu'à très peu de serveurs. L'état décrivant les sessions DTLS doit donc plutôt être gardé chez le client (RFC 5077). Cela permettra de réétablir les sessions DTLS rapidement, sans pour autant garder d'état sur le serveur.
Le DNS est la principale application qui se tape les problèmes de PMTU (Path MTU, la MTU du chemin complet). Les réponses DNS peuvent dépasser les 1 500 octets magiques (la MTU d'Ethernet et, de facto, la PMTU de l'Internet). DTLS ajoute au moins 13 octets à chaque paquet, sans compter l'effet du chiffrement. Il est donc impératif (section 5) que clients et serveurs DNS-sur-DTLS gèrent EDNS (RFC 6891) pour ne pas être limité par l'ancien maximum DNS de 512 octets, et que les serveurs limitent les paquets DTLS à la PMTU (RFC 9147).
Contrairement au DNS classique, où chaque requête est indépendante, toute solution de cryptographie va nécessiter un état, l'ensemble des paramètres cryptographiques de la session. L'anycast, qui est répandu pour le DNS, ne pose donc pas de problème au DNS classique : si le routage change d'avis entre deux requêtes, et que la seconde requête est envoyée à un autre serveur, aucun problème. Avec DTLS, ce n'est plus le cas (section 6 du RFC) : le deuxième serveur n'a pas en mémoire la session cryptographique utilisée. Le serveur qui la reçoit va répondre avec une alerte TLS fatale (la méthode recommandée) ou, pire, ne pas répondre. Dans les deux cas, le client doit détecter le problème et réétablir une session cryptographique. (À noter que l'alerte TLS n'est pas authentifiée et ne peut donc pas être utilisée comme seule indication du problème. C'est d'ailleurs pareil pour d'éventuels messages d'erreur ICMP.) Le cas est donc proche de celui où le serveur ferme la session unilatéralement, et la solution est la même : le client doit toujours être prêt à recommencer l'ouverture de session DTLS.
Un point de sécurité, pour finir (section 9). Le RFC recommande l'utilisation de l'extension TLS « agrafage OCSP » (RFC 6066, section 8), notamment pour éviter la grosse fuite d'information que représente OCSP.
Il n'existe aucune mise en œuvre de DNS-sur-DTLS, et aucune n'est prévue. Cette expérimentation semble clairement un échec.
L'article seul
RFC 8093: Deprecation of BGP Path Attribute Values 30, 31, 129, 241, 242, and 243
Date de publication du RFC : Février 2017
Auteur(s) du RFC : J. Snijders (NTT)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 17 février 2017
Ce très court RFC ne fait pas grand'chose : il marque juste comme « à ne pas utiliser » (deprecated) un certain nombre d'attributs BGP.
BGP est le protocole de routage de l'Internet. En permanence, les routeurs s'envoient des annonces de routes, annonces portant certains attributs (RFC 4271, section 5) qui précisent des caractéristiques de la route. La liste de ces attributs figure dans un registre IANA. Les attributs cités dans ce RFC sont marqués comme officiellement abandonnés. Ce n'est pas qu'ils ne servaient pas : au contraire, ils étaient « squattés » en étant annoncés bien qu'ils n'aient jamais fait l'objet d'un enregistrement formel. Mieux valait donc les marquer dans le registre.
Mais pourquoi est-ce que des gens peuvent utiliser des attributs non enregistrés ? Parce qu'il n'y a pas de police de l'Internet (en dépit de raccourcis franchements abusifs, par exemple de certains journalistes qui écrivent que « l'ICANN est le régulateur de l'Internet »). Personne ne peut donner des ordres à tous les routeurs, et les faire appliquer.
Bref, il y a des mises en œuvre de BGP qui fabriquent des
annonces avec des attributs non enregistrés. C'est la vie. Mais
c'est ennuyeux car cela peut entrainer des collisions avec de
nouveaux attributs qui, eux, suivent les règles. C'est ainsi que
l'attribut LARGE_COMMUNITY du RFC 8092 avait d'abord reçu la valeur numérique 30 avant
qu'on s'aperçoive que cette valeur était squattée par un autre
attribut (merci, Huawei)... Résultat, les routeurs squatteurs, quand ils
recevaient des annonces avec un attribut
LARGE_COMMUNITY ne lui trouvaient pas la
syntaxe attendue et retiraient donc la route de leur table de
routage (conformément au RFC 7606). LARGE_COMMUNITY a donc dû
aller chercher un autre numéro (32), et 30 a été ajouté au
registre, pour indiquer « territoire dangereux, squatteurs ici
». Le même traitement a été appliqué aux attributs 31, 129, 241,
242 et 243, qui étaient également squattés.
Le groupe de travail à l'IETF s'est demandé s'il n'aurait pas mieux valu « punir » les squatteurs en allouant délibérement le numéro officiel pour un autre attribut que le leur mais cela aurait davantage gêné les utilisateurs de l'attribut légitime que les squatteurs, qui avaient déjà une base installée.
L'article seul
RFC 8092: BGP Large Communities Attribute
Date de publication du RFC : Février 2017
Auteur(s) du RFC : J. Heitz (Cisco), J. Snijders
(NTT), K. Patel (Arrcus), I. Bagdonas
(Equinix), N. Hilliard (INEX)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 19 février 2017
Ce RFC normalise un nouvel attribut des annonces BGP, « Large Communities ». Les « communautés » BGP sont des courtes données collées aux annonces BGP et qui permettent d'indiquer certaines caractéristiques des routes. Les décisions des routeurs peuvent utiliser ces caractéristiques. Mais les communautés originales étaient trop courtes (seulement quatre octets) : le nouvel attribut permet des communautés de douze octets.
Les « communautés » sont définies dans le RFC 1997. On les apprend via les documentations des
opérateurs ou des points d'échange. Par
exemple, celle du point
d'échange irlandais (section « Community based prefix filtering »). Un attribut COMMUNITY
dans une annonce BGP peut comporter plusieurs
communautés. Traditionnellement, les quatre octets des
communautés initiales sont utilisées pour représenter le numéro
d'AS dans les deux premiers octets (ainsi,
une communauté est mondialement unique, par ce système
d'allocation à deux niveaux), et des données spécifiques à l'AS
dans les deux suivants. Évidemment, avec les numéros d'AS de
quatre octets du RFC 6793, ça ne marchait
plus. D'où cet attribut LARGE_COMMUNITY,
désormais stocké dans le registre
IANA sous le numéro (type code) 32. (Il
y a bien eu une autre tentative d'augmenter la taille des
communautés, dans le RFC 4360, mais pas
suffisamment pour que les AS à quatre octets puissent être
utilisés partout.) Comme pour les « petites » communautés, ces grandes
communautés dans une annonce forment un ensemble (donc, non
ordonné) : plusieurs routeurs auront pu ajouter une communauté à
cet ensemble.
Les communautés sont importantes car elles sont utilisées dans
la politique de routage. BGP ne cherche pas
à trouver le meilleur chemin : il fait du routage politique, où
les décisions sont prises en fonction de choix faits par les
opérateurs (privilégier tel ou tel lien pour le trafic entrant,
par exemple). Les informations contenues dans une annonce BGP
(section 4.3 du RFC 4271) habituelle ne sont pas toujours
suffisantes, et c'est pour cela que les communautés ont été
introduites par le RFC 1997, pour ajouter
des informations utiles, comme l'endroit où telle route a été
apprise.
L'attribut
COMMUNITY (numéro 8) est transitif (section
5 du RFC 4271), ce qui
veut dire qu'après réception d'une annonce, il est transmis aux autres routeurs (d'où
l'importance de marquer la communauté avec un numéro d'AS, pour
que les communautés soient uniques au niveau mondial, sans qu'il
existe un registre central des communautés).
Le nouvel attribut LARGE_COMMUNITY (numéro
32) est également optionnel et transitif (section 2 de notre RFC). Il se compose d'un
ensemble de grandes communautés, chacune étant stockée sur douze
octets. L'idée est qu'on utilise les quatre premiers octets pour
identifier l'AS (ce qui va bien avec les grands AS du du RFC 6793), ce qui va garantir l'unicité des
communautés. Le nombre de communautés dans un attribut
LARGE_COMMUNITY est donné par le champ
Longueur de l'attribut, les attributs BGP étant encodés en
TLV (cf. RFC 4271,
section 4.3).
En cas d'agrégation de routes (section 3 du RFC), il est recommandé d'utiliser comme communautés l'union des ensembles de communautés des différentes annonces.
Et comment on va représenter ces grandes communautés sous forme
texte ? (Sur le câble, entre les deux routeurs, c'est du binaire,
en gros boutien, cf. RFC 4271, section 4.) On note trois groupes de quatre
octets, séparés par un deux-points, par
exemple 2914:65400:38016 (section 4 de notre RFC), où le premier champ
est presque toujours l'AS. (On trouve plein d'exemples dans le RFC 8195.)
Comme toutes les grandes communautés font exactement douze octets, si le champ Longueur de l'attribut n'est pas un multiple de douze, l'attribut est invalide, et le routeur qui reçoit cette annonce doit la gérer comme étant un retrait de la route (RFC 7606).
Un point de sécurité important en section 6 du RFC ; en gros, les grandes communautés ont quasiment les mêmes propriétés de sécurité que les anciennes petites communautés. Notamment, elles ne sont pas protégées contre une manipulation en transit : tout AS dans le chemin peut ajouter des communautés (même « mensongères », c'est-à-dire indiquant un autre AS que le sien) ou retirer des communautés existantes. La section 11 du RFC 7454 donne quelques détails à ce sujet. Ce problème n'est pas spécifique aux communautés, c'est un problème général de BGP. L'Internet n'a pas de chef et il est donc difficile de concevoir un mécanisme permettant de garantir l'authenticité des annonces.
Il existe déjà de nombreuses mises en œuvre de BGP qui gèrent
ces grandes communautés. Par exemple IOS
XR, ExaBGP,
BIRD, OpenBGPD, GoBGP,
Quagga, bgpdump depuis la
version 1.5,
pmacct... Une liste plus complète figure
sur le
Wiki. Mais il y a aussi le site Web du projet,
où vous trouverez plein de choses. Si vous avez accès à un routeur
BGP, ou à un looking
glass qui affiche les grandes communautés
(c'est le cas de celui du
Ring de NLnog),
les deux préfixes 2001:67c:208c::/48 et
192.147.168.0/24 ont une grande communauté
(15562:1:1).
Si vous essayez sur un routeur qui a un vieux logiciel, ne
comprenant pas ces grandes communautés, vous verrez sans doute
quelque chose du genre « unknown attribute ». Ici
sur IOS à Route Views :
% telnet route-views.oregon-ix.net
...
Username: rviews
route-views> show ip bgp 192.147.168.0
BGP routing table entry for 192.147.168.0/24, version 37389686
Paths: (41 available, best #21, table default)
Not advertised to any peer
Refresh Epoch 1
3333 1273 2914 15562
193.0.0.56 from 193.0.0.56 (193.0.0.56)
Origin IGP, localpref 100, valid, external
Community: 1273:22000 2914:410 2914:1206 2914:2203 2914:3200
unknown transitive attribute: flag 0xE0 type 0x20 length 0xC
value 0000 3CCA 0000 0001 0000 0001
...
Ici sur un vieux IOS-XR (le test a été fait à l'époque où l'attribut avait le numéro 30 et pas 32, d'où le 0x1e) :
RP/0/RSP0/CPU0:Router# show bgp ipv6 unicast 2001:67c:208c::/48 unknown-attributes
BGP routing table entry for 2001:67c:208c::/48
Community: 2914:370 2914:1206 2914:2203 2914:3200
Unknown attributes have size 15
Raw value:
e0 1e 0c 00 00 3c ca 00 00 00 01 00 00 00 01
Et ici sur JunOS :
user at JunOS-re6> show route 2001:67c:208c::/48 detail
2001:67c:208c::/48 (1 entry, 1 announced)
AS path: 15562 I
Unrecognized Attributes: 15 bytes
Attr flags e0 code 1e: 00 00 3c ca 00 00 00 01 00 00 00 01
Notez que certaines configurations (parfois activées par défaut) du routeur peuvent supprimer l'attribut « grandes communautés ». Pour empêcher cela, il faut, sur JunOS :
[edit protocols bgp]
user at junos# delete drop-path-attributes 32
Et sur IOS-XR :
configure
router bgp YourASN
attribute-filter group ReallyBadIdea ! avoid creating bogons
no attribute 32
!
!
Trois lectures pour finir :
- Un bon article sur l'acceptation des grandes communautés dans la nature et
- Un outil (fondé sur Docker) pour expérimenter avec ces grandes communautés.
- Le RFC 8195 qui donne de nombreux exemples d'usage de ces grandes communautés.
L'article seul
RFC 8089: The "file" URI Scheme
Date de publication du RFC : Février 2017
Auteur(s) du RFC : M. Kerwin (QUT)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 20 février 2017
Vous connaissez le plan d'URI
file:, qui indique que la ressource se
trouve sur le système de fichiers local ? (Par exemple, ce fichier
que je suis en train d'éditer est
file:///home/stephane/Blog/RFC/8089.xml.) Ce plan avait été défini
très brièvement dans le RFC 1738 (section 3.10). Tellement
brièvement qu'il y manquait pas mal de choses. Ce nouveau
RFC remplace cette partie du RFC 1738 et fournit cette fois une description
complète du plan file:. Ce n'était pas une
tâche facile car les différents systèmes de fichiers ont des
syntaxes et des comportements très différents. Le RFC lui-même est
très court, mais il comporte plusieurs annexes plus longues,
discutant de points spécifiques parfois assez tordus.
Donc, d'abord, la définition (section 1 de notre RFC) : un fichier est un objet qui se trouve rangé dans un environnement structuré, qui fournit notamment un système de nommage, environnement qu'on nomme le système de fichiers. (Et le fichier contient des données mais ce point n'est pas crucial pour les URI et n'est donc pas mentionné.) Ensuite, les URI : ce sont les identificateurs standard du Web. Leur syntaxe générique est définie dans le RFC 3986 et ce nouveau RFC ne fait donc que spécialiser le RFC 3986. Normalement, ce RFC est parfaitement compatible avec l'ancienne syntaxe, celle du RFC 1738 mais, en pratique, comme l'ancienne définition était vraiment trop vague, il y aura forcément quelques différences. (L'annexe E donne quelques exemples de pratiques utilisées dans la nature et qui ne sont pas strictement alignées sur les nouvelles règles. Elle cite par exemple l'ajout d'un nom d'utilisateur dans l'URI. Un exemple des problèmes que ces différences posent aux navigateurs est bien expliqué dans cet article de Microsoft.)
Les URI file: ne supposent pas
l'utilisation d'un protocole particulier, ni d'un type
de média particulier.
Ce plan d'URI désigne des « fichiers locaux ». Un fichier local est accessible juste à partir de son nom, sans autre information (par exemple sans utiliser une adresse réseau explicite). Mais, en pratique (section 1.1), il peut être physiquement sur une autre machine, grâce à des techniques comme NFS ou SMB.
La syntaxe de ces URI figure en section 2 de notre RFC,
formalisée en ABNF (RFC 5234). S'appuyant sur la syntaxe générique du RFC 3986, elle diffère légèrement de celle du
RFC 1738 (l'annexe A liste les
différences). Le plan file: est référencé
dans le registre des plans d'URI. Je vous laisse découvrir sa
grammaire dans le RFC, je donne juste des
exemples qui illustrent certains points de la syntaxe :
- Commençons par un URI banal :
file:///tmp/toto.txt. Il désigne le fichier local/tmp/toto.txtde l'ordinateur sur lequel on travaille. La syntaxe du nom de fichier est celle d'Unix, même si ledit ordinateur n'utilise pas Unix. Ainsi, le fichierc:\machin\trucsur une machine Windows sera quand mêmefile:///c:/machin/truc(il existe plein de variantes non-standard, voir l'annexe E, et l'article cité plus haut, sur les problèmes que cela pose). Sur VMS,DISK1:[CS.JANE]PAPER.PSdeviendrafile:///disk1/cs/jane/paper.ps(cf. annexe D). - Le composant après les trois barres obliques doit être un chemin absolu dans le système de fichiers de la machine. Cela a l'air simple mais la notion de « chemin absolu » ne l'est pas, et l'annexe D cite quelques surprises possibles (comme le tilde de certains shells Unix).
- Après les deux premières barres obliques, il y a normalement un
champ nommé « Autorité » (en pratique un nom
de domaine), qui est optionnel. Pour les URI
file:, on peut mettre dans ce champlocalhost, voire n'importe quel nom qui désigne la machine locale (je ne suis pas sûr de l'intérêt que cela présente, mais c'est la norme qui, il est vrai, déconseille cet usage). Donc, l'URI cité au début aurait pu (mais ce n'est pas recommandé) êtrefile://localhost/tmp/toto.txt. (Voir aussi la section 3 du RFC.) - Si on ne met pas le nom de domaine, les deux premières
barres obliques sont facultatives (c'est une nouveauté de notre
RFC, par rapport au RFC 1738) et
file:/tmp/toto.txtest donc légal. - Certains systèmes de fichiers sont sensibles à
la casse et il faut donc faire attention, en
manipulant les URI, à ne pas changer la
casse.
file:///c:/machin/trucetfile:///c:/Machin/TRUCsont deux URI différents même si on sait bien que, sur une machine Windows, ils désigneront le même fichier.
Que peut-on faire avec un fichier ? Plein de choses (l'ouvrir,
lire les données, le détruire… La norme
POSIX peut donner des idées à ce sujet.) Le plan d'URI
file: ne limite pas les opérations
possibles.
Évidemment, l'encodage des caractères
utilisé va faire des histoires, puisqu'il varie d'une machine à
l'autre. C'est parfois UTF-8, parfois un
autre encodage et, parfois, le système de fichiers ne définit
rien, le nom est juste une suite d'octets, qui devra être
interprétée par les applications utilisées (c'est le cas
d'Unix). Notre RFC (section 4) recommande bien sûr
d'utiliser UTF-8, avant l'optionelle transformation
pour cent (RFC 3986,
section 2.5). Ainsi, le fichier
/home/stéphane/café.txt aura l'URI
file:/home/st%C3%A9phane/caf%C3%A9.txt, quel
qu'ait été son encodage sur la machine. Au passage, j'ai essayé
avec curl et
file:///tmp/café.txt,
file:/tmp/café.txt,
file:/tmp/caf%C3%A9.txt,
file://localhost/tmp/caf%C3%A9.txt et même
file://mon.adresse.ip.publique/tmp/caf%C3%A9.txt marchent tous.
Et la sécurité ? Toucher aux fichiers peut évidemment avoir des
tas de conséquences néfastes. Par exemple, si l'utilisateur charge
le fichier file:///home/michu/foobar.html,
aura-t-il la même origine (au sens de la sécurité du Web) que
file:///tmp/youpi.html ? Après tout, ils
viennent du même domaine (le domaine vide, donc la machine
locale). Le RFC note qu'au contraire l'option la plus sûre est de
considérer que chaque fichier est sa propre origine (RFC 6454).
Autre question de sécurité rigolote, les systèmes de fichiers
ont en général des caractères spéciaux (comme la barre
oblique ou un couple de points pour Unix). Accéder bêtement à un
fichier en passant juste le nom au système de fichiers peut
soulever des problèmes de sécurité (c'est évidemment encore pire
si on passe ces noms à des interpréteurs comme le
shell, qui rajoutent leur propre liste de
caractères spéciaux). Le RFC ne spécifie pas de liste de
caractères « dangereux » car tout nouveau système de fichiers peut
l'agrandir. C'est aux programmeurs qui font les logiciels de faire
attention, pour le système d'exploitation
pour lequel ils travaillent. (Un problème du même ordre existe
pour les noms de fichiers spéciaux, comme
/dev/zero sur Unix ou
aux et
lpt sur Windows.)
Une mauvaise gestion de la sensibilité à la casse ou de l'encodage des caractères peut aussi poser des problèmes de sécurité (voir par exemple le rapport technique UAX #15 d'Unicode.)
Notons qu'il existe d'autres définitions possibles d'un URI
file: (annexe C de notre RFC). Par exemple,
le WhatWG maintient une liste des plans d'URI, non synchronisée avec celle
« officielle », et dont l'existence a
fait pas mal de remous à l'IETF, certains
se demandant s'il fallait quand même publier ce RFC, au risque
d'avoir des définitions contradictoires (cela a sérieusement
retardé la sortie du RFC). En gros,
l'IETF se concentre plutôt sur la syntaxe,
et le WhatWG sur le comportement des navigateurs (rappelez-vous que les URI ne sont
pas utilisés que par des navigateurs…). Il y a aussi les
définitions Microsoft comme UNC
ou leurs
règles sur les noms de fichier.
Et, pour finir, je vous recommande cet autre article de Microsoft sur l'évolution du traitement des URI dans IE.
L'article seul
RFC 8086: GRE-in-UDP Encapsulation
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : L. Yong (Huawei
Technologies), E. Crabbe
(Oracle), X. Xu (Huawei
Technologies), T. Herbert (Facebook)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 9 mars 2017
Le protocole de tunnel GRE, normalisé dans les RFC 2784 et RFC 7676, tourne normalement directement sur IP (numéro de protocole 47, TCP étant 6 et UDP 17). Cela présente quelques inconvénients, notamment la difficulté à passer certaines middleboxes, et ce nouveau RFC propose donc une encapsulation de GRE dans UDP, et non plus directement dans IP. Un des autres avantages de cette encapsulation est que le port source UDP peut être utilisé comme une source d'entropie supplémentaire : sa vérification permet d'améliorer la (faible) sécurité de GRE. GRE sur UDP permet aussi l'utilisation de DTLS si on veut chiffrer (ce que ne fait pas GRE classiquement).
Un autre avantage est que l'encapsulation dans UDP peut améliorer les performances, dans le cas où il y a des répartiteurs de charge ECMP : ils pourront alors faire passer tous les paquets d'un même tunnel GRE par le même chemin, puisqu'ils prennent leurs décisions sur la base du tuple {protocole, adresse IP source, adresse IP destination, port source, port destination}.
Vu du réseau, un tunnel GRE sur UDP sera juste du trafic UDP normal. Attention, toutefois, le trafic UDP sur l'Internet public doit normalement obéir à certaines règles, notamment de contrôle de la congestion (ces règles figurent dans le RFC 8085). Avec TCP, c'est le protocole de transport qui s'en charge, avec UDP, c'est à l'application de le faire. Si on transporte du trafic quelconque, pas spécialement raisonnable, dans un tunnel GRE sur UDP, on viole les règles du RFC 8085. Il faut donc s'assurer que le trafic dans le tunnel a des mécanismes de contrôle de la congestion, ou bien réserver GRE sur UDP à des réseaux fermés, où on prend les risques qu'on veut. (Voir aussi la section 8 de notre RFC.)
Donc, on peut se servir de GRE sur UDP au-dessus d'IPv4 ou d'IPv6 (section 2 du RFC). La somme de contrôle UDP est très recommandée (elle est obligatoire en IPv6). On doit vérifier que le trafic transporté fera attention au contrôle de congestion. Le port source UDP doit être dans la plage des ports éphémères (de 49 152 à 65 535, voir aussi la section 3.2.1). Utiliser un port par flot encapsulé facilite la tâche des équipements comme les répartiteurs de trafic. Mais on peut aussi n'utiliser qu'un seul port pour tout ce qui passe dans le tunnel et, dans ce cas, il faut le choisir de manière imprévisible, pour des raisons de sécurité (RFC 6056). Et en IPv6, merci de penser à utiliser le flow label (RFC 6438).
Ce protocole GRE sur UDP a eu une histoire longue et compliquée, pris dans des efforts pour fournir des mécanismes génériques d'encapsulation dans UDP (projet GUE), efforts qui n'ont guère débouché (cf. le RFC 7510 pour un autre exemple que GRE).
Voilà, après ces grands principes, le format exact (section 3). Au-dessus de l'en-tête IP (v4 ou v6), on met un en-tête UDP (RFC 768) et un en-tête GRE (RFC 2784).
La section 5 du RFC couvre le cas de DTLS (RFC 6347), qui a l'avantage de donner à GRE les moyens de chiffrer le trafic, sans modifier GRE lui-même.
Évidemment, dans l'Internet réellement existant, le problème, ce sont les middleboxes (section 7 du RFC). C'est d'ailleurs parfois uniquement à cause d'elles qu'il faut utiliser GRE sur UDP et pas GRE tout court, car certaines se permettent de bloquer les protocoles qu'elles ne connaissent pas (typiquement, tout sauf UDP et TCP).
Même en mettant GRE dans UDP, tous les problèmes ne sont pas résolus. Le trafic GRE est unidirectionnel (il y a en fait deux tunnels différents, chacun à sens unique). Il n'y est pas censé avoir des réponses au port source du trafic. Mais certaines middleboxes vont insister pour que ce soit le cas. Une solution possible, pour ces middleboxes pénibles, est de n'utiliser qu'un seul port source.
Il existe des mises en œuvre de ce RFC pour
Linux et BSD. Les
tests suivants ont été faits sur des machines Linux,
noyaux 4.4 et 4.8. ip
tunnel ne fournit pas de choix pour « GRE sur
UDP ». Il faut passer par le système FOU
(Foo-over-UDP, cf. cet article de LWN),
qui a l'avantage d'être plus générique :
# modprobe fou
# lsmod|grep fou
fou 20480 0
ip_tunnel 28672 1 fou
ip6_udp_tunnel 16384 1 fou
udp_tunnel 16384 1 fou
La machine qui va recevoir les paquets doit configurer FOU pour indiquer que les paquets à destination de tel port UDP sont en fait du GRE :
# ip fou add port 4754 ipproto 47
(47 = GRE) La machine émettrice, elle, doit créer une interface GRE encapsulée grâce à FOU :
# ip link add name tun1 type gre \
remote $REMOTE local $LOCAL ttl 225 \
encap fou encap-sport auto encap-dport 4754
# ip link set tun1 up
Et il faut évidemment configurer une route passant par cette
interface tun1, ici pour le préfixe
172.16.0.0/24 :
# ip route add 172.16.0.0/24 dev tun1
Avec cette configuration, lorsque la machine émettrice
pingue
172.16.0.1, les paquets arrivent bien sur la
machine réceptrice :
12:10:40.138768 IP (tos 0x0, ttl 215, id 10633, offset 0, flags [DF], proto UDP (17), length 116)
172.19.7.106.46517 > 10.17.124.42.4754: [no cksum] UDP, length 88
On peut les examiner plus en détail avec Wireshark :
User Datagram Protocol, Src Port: 1121 (1121), Dst Port: 4754 (4754)
Source Port: 1121
Destination Port: 4754
Length: 96
Checksum: 0x0000 (none)
[Good Checksum: False]
[Bad Checksum: False]
[Stream index: 0]
Data (88 bytes)
0000 00 00 08 00 45 00 00 54 3e 99 40 00 40 01 ef 6f ....E..T>.@.@..o
...
Wireshark ne connait apparemment pas le GRE sur UDP. Mais, dans les données, on reconnait bien l'en-tête GRE (les quatre premiers octets où presque tous les bits sont à zéro, le bit C étant nul, les quatre octets suivants optionnels ne sont pas inclus, le 0x800 désigne IPv4, cf. RFC 2784), et on voit un paquet IPv4 ensuite. Pour que ce paquet soit correctement traité par la machine réceptrice, il faut le transmettre à GRE. Comme ce dernier n'a pas de mécanisme permettant de mettre plusieurs tunnels sur une même machine (l'en-tête GRE n'inclut pas d'identificateurs), il faut activer l'unique interface GRE :
# ip link set gre0 up
On voit bien alors notre ping qui arrive :
# tcpdump -vv -n -i gre0
tcpdump: listening on gre0, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
14:02:06.922367 IP (tos 0x0, ttl 64, id 47453, offset 0, flags [DF], proto ICMP (1), length 84)
10.10.86.133 > 172.16.0.1: ICMP echo request, id 13947, seq 17, length 64
Voilà, je vous laisse faire la configuration en sens inverse.
Si vous voulez en savoir plus sur la mise en œuvre de FOU, voyez cet excellent exposé d'un des auteurs, Tom Herbert, cet article du même, et enfin sa vidéo.
L'article seul
RFC 8085: UDP Usage Guidelines
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : L. Eggert (NetApp), G. Fairhurst
(University of Aberdeen), G. Shepherd (Cisco
Systems)
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 9 mars 2017
La grande majorité des applications Internet tourne sur le protocole de transport TCP. Mais son concurrent UDP, normalisé dans le RFC 768, prend de l'importance avec le multimédia et les jeux en ligne pour lesquels il est souvent bien adapté. Contrairement à TCP, UDP ne fournit aucun mécanisme de contrôle de la congestion. C'est donc aux applications de fournir ce contrôle, suivant les règles expliquées par ce RFC. (Qui parle surtout de congestion mais aussi d'autres sujets importants pour ceux qui utilisent UDP, comme la taille des messages ou comme les sommes de contrôle.) Il remplace le RFC 5405.
UDP est apprécié pour certaines applications car il est simple et léger et le fait qu'il ne garantisse pas l'acheminement de la totalité des paquets n'est pas forcément un problème dans les applications multimédia : si on perd quelques secondes d'une communication téléphonique RTP, il vaut mieux passer à la suite que de perdre du temps à la retransmettre comme le ferait TCP. Mais UDP ne fournit pas non plus de contrôle de la congestion. Une application UDP enthousiaste peut envoyer des paquets au débit maximum permis, saturant tous les liens situés en aval. (Il ne faut pas juste tenir compte de la capacité du lien auquel on est connecté, mais de celle du chemin complet. L'exemple du RFC, avec un chemin à seulement 56 kb/s, que cinq paquets UDP de 1 500 octets par seconde saturent, n'est pas invraisemblable.) Protéger le réseau de la congestion est pourtant nécessaire (RFC 2914 et RFC 7567), à la fois pour assurer que le réseau continue à être utilisable et également pour assurer une certaine équité entre les différents flux de données, pour éviter qu'une seule application gourmande ne monopolise le réseau pour elle. (Ceci concerne l'Internet public. Si on est dans un environnement fermé, utilisant TCP/IP mais où la capacité réseau, et son usage, sont contrôlés, le problème est évidemment différent. Voir notamment la section 3.6.)
UDP ne faisant pas ce contrôle de congestion, il faut bien que l'application le fasse et, pour cela, qu'elle mette en œuvre les conseils de ce RFC. (Notre RFC contient également des conseils pour d'autres aspects de l'utilisation d'UDP que le contrôle de congestion : mais c'est le plus important.)
Le gros du RFC est dans la section 3 qui détaille ces conseils (la
section 7 contient un excellent résumé sous forme d'un tableau des
conseils à suivre). Le
premier est qu'il vaut peut-être mieux ne pas utiliser UDP. Beaucoup
de développeurs d'applications pensent à UDP en premier parce qu'il
est simple et facile à comprendre et qu'il est « plus rapide que
TCP ». Mais, rapidement, ces développeurs se rendent compte qu'ils ont
besoin de telle fonction de TCP, puis de telle autre, ils les mettent
en œuvre dans leur application et arrivent à une sorte de TCP en
moins bien, davantage bogué et pas plus rapide. Notre RFC conseille
donc d'abord de penser aux autres protocoles de transport comme
TCP (RFC 793),
DCCP (RFC 4340) ou
SCTP (RFC 9260). Ces protocoles sont
d'autant plus intéressants qu'ils ont souvent fait l'objet de réglages
soigneux depuis de nombreuses années et qu'il est donc difficile à un
nouveau programme de faire mieux. D'autant plus qu'il existe souvent
des réglages spécifiques pour les adapter à un usage donné. Par
exemple, on peut dire à TCP de donner la priorité à la
latence (paramètre
TCP_NODELAY de setsockopt) ou bien au débit.
Si on ne suit pas ces sages conseils, et qu'on tient à se servir d'UDP, que doit-on faire pour l'utiliser intelligemment ? La section 3.1 couvre le gros morceau, le contrôle de congestion. Celui-ci doit être pris en compte dès la conception de l'application. Si cette dernière fait de gros transferts de données (section 3.1.2, c'est le cas de RTP, RFC 3550), elle doit mettre en œuvre TFRC, tel que spécifié dans le RFC 5348, donc faire à peu près le même travail que TCP. Et ce mécanisme doit être activé par défaut.
Si l'application transmet peu de données (section 3.1.3), elle doit quand même faire attention et le RFC demande pas plus d'un datagramme par RTT, où le RTT est un cycle aller-retour avec la machine distante (si le calcul n'est pas possible, le RFC demande une durée de trois secondes). L'application doit également détecter les pertes de paquet pour ralentir son rythme si ces pertes - signe de congestion - sont trop fréquentes.
Si l'application est bi-directionnelle (le cas de loin le plus fréquent), le contrôle de la congestion doit se faire indépendamment dans les deux directions.
Notez que se retenir d'envoyer des paquets n'est pas le seul moyen pour une application d'éviter la congestion. Elle peut aussi (si l'API utilisée le permet) se servir d'ECN (RFC 3168) pour transmettre l'information qui permettra de réguler le trafic.
Enfin, le RFC demande (section 3.1.10) un mécanisme de « disjoncteur » (circuit breaker, cf. RFC 8084 ou bien RFC 8083 pour l'exemple spécifique de RTP). C'est un mécanisme de dernier recours pour couper la communication en cas de risque d'effondrement du réseau.
Le cas où l'application est un tunnel au-dessus d'UDP est également couvert (section 3.1.11). C'est par exemple le cas du protocole GRE quand il tourne sur UDP (RFC 8086).
En suivant toutes ces règles, l'application gère proprement la congestion. Et le reste ? La section 3.2 fournit des pistes sur la gestion de la taille des paquets. La charge utile d'un paquet UDP peut théoriquement faire 65 507 octets en IPv4 et 65 527 en IPv6. Mais c'est théorique. En pratique, la fragmentation marche mal sur l'Internet, et notre RFC conseille de rester en dessous de la MTU, et d'utiliser la découverte de la MTU du chemin spécifiée dans des RFC comme les RFC 4821 et RFC 8899. (Aujourd'hui, la principale application qui envoie des paquets UDP plus gros que la MTU, et doit donc se battre avec la fragmentation, est le DNS ; voir par exemple l'étude de Geoff Huston sur les comportements très variés des serveurs de la racine.)
La section 3.3 explique la question de la fiabilité : par défaut, UDP ne retransmet pas les paquets perdus. Si c'est nécessaire, c'est l'application qui doit le faire. Elle doit aussi gérer l'eventuelle duplication des paquets (qu'UDP n'empêche pas). Le RFC note que les retards des paquets peuvent être très importants (jusqu'à deux minutes, normalise le RFC, ce qui me semble très exagéré pour l'Internet) et que l'application doit donc gérer le cas où un paquet arrive alors qu'elle croyait la session finie depuis longtemps.
La section 3.4 précise l'utilisation des sommes de contrôle (facultatives pour UDP sur IPv4 mais qui devraient être utilisées systématiquement). Si une somme de contrôle pour tout le paquet semble excessive, et qu'on veut protéger uniquement les en-têtes de l'application, une bonne alternative est UDP-Lite (RFC 3828), décrit dans la section 3.4.2. (Il y a aussi des exceptions à la règle « somme de contrôle obligatoire en IPv6 » dans le cas de tunnels.)
Beaucoup de parcours sur l'Internet sont encombrés de
« middleboxes », ces engins intermédiaires qui
assurent diverses fonctions (NAT,
coupe-feu, etc) et qui sont souvent de médiocre
qualité logicielle, bricolages programmés par un inconnu et jamais
testés. La section 3.5 spécifie les règles que devraient suivre les applications UDP pour passer au travers sans
trop de heurts. Notamment, beaucoup de ces « middleboxes »
doivent maintenir un état par flux qui les
traverse. En TCP, il est relativement facile de détecter le début et
la fin d'un flux en observant les paquets d'établissement (SYN) et de
destruction (FIN) de la connexion. En UDP, ces paquets n'ont pas
d'équivalent et la détection d'un flux repose en général sur des
heuristiques. L'engin peut donc se tromper et mettre fin à un flux qui
n'était en fait pas terminé. Si le DNS s'en
tire en général (c'est un simple protocole requête-réponse, avec la
lupart du temps moins d'une seconde entre l'une et l'autre), d'autres
protocoles basés sur UDP pourraient avoir de mauvaises
surprises. Ces protocoles doivent donc se préparer à de soudaines interruptions
de la communication, si le timeout d'un engin
intermédiaire a expiré alors qu'il y avait encore des paquets à
envoyer. (La solution des
keepalives est déconseillée
par le RFC car elle consomme de la capacité du réseau et ne dispense
pas de gérer les coupures, qui se produiront de toute façon.)
La section 5 fera le bonheur des
programmeurs qui y trouveront des conseils pour
mettre en œuvre les principes de ce RFC, via
l'API des prises
(sockets, RFC 3493). Elle est largement documentée mais en général plutôt
pour TCP que pour UDP, d'où l'intérêt du résumé qu'offre ce RFC, qui
ne dispense évidemment pas de lire le Stevens. Par exemple, en
l'absence de mécanisme de TIME_WAIT (la prise
reste à attendre d'éventuels paquets retardés, même après sa fermeture
par l'application), une application UDP peut ouvrir une prise... et
recevoir immédiatement des paquets qu'elle n'avait pas prévus, qui
viennent d'une exécution précédente.
Le RFC détaille également la bonne stratégie à utiliser pour les ports. Il existe un registre des noms et numéros de ports (RFC 6335), et le RFC 7605 explique comment utiliser les ports. Notre RFC conseille notamment de vérifier les ports des paquets reçus, entre autre pour se protéger de certaines attaques, où l'attaquant, qui ne peut pas observer le trafic et doit injecter des paquets aveuglément, ne connait pas les ports utilisés (en tout cas pas les deux). L'application devrait utiliser un port imprévisible, comme le fait TCP (RFC 6056). Pour avoir suffisamment d'entropie pour les répartiteurs de charge, le RFC rappelle qu'en IPv6, on peut utiliser le champ flow label (RFC 6437 et RFC 6438).
Le protocole ICMP fournit une aide utile, que les applications UDP peuvent utiliser (section 5.2). Mais attention, certains messages ICMP peuvent refléter des erreurs temporaires (absence de route, par exemple) et ne devraient pas entraîner de mesures trop drastiques. Autre piège, il est trivial d'envoyer des faux paquets ICMP. Une application doit donc essayer de déterminer, en examinant le contenu du message ICMP, s'il est authentique. Cela nécessite de garder un état des communications en cours, ce que TCP fait automatiquement mais qui, pour UDP, doit être géré par l'application. Enfin, il faut se rappeler que pas mal de middleboxes filtrent stupidement l'ICMP et l'application doit donc être prête à se débrouiller sans ces messages.
Après tous ces conseils, la section 6 est dédiée aux questions de sécurité. Comme TCP ou SCTP, UDP ne fournit en soi aucun mécanisme d'intégrité des données ou de confidentialité. Pire, il ne fournit même pas d'authentification de l'adresse IP source (authentification fournie, avec TCP, par le fait que, pour établir la connexion, il faut recevoir les réponses de l'autre). Cela permet, par exemple, les injections de faux trafic (contre lesquelles il est recommandé d'utiliser des ports source imprévisibles, comme le fait le DNS), ou bien les attaques par amplification.
L'application doit-elle mettre en œvre la sécurité seule ? Le RFC conseille plutôt de s'appuyer sur des protocoles existants comme IPsec (RFC 4301, dont notre RFC note qu'il est très peu déployé) ou DTLS (RFC 9147). En effet, encore plus que les protocoles de gestion de la congestion, ceux en charge de la sécurité sont très complexes et il est facile de se tromper. Il vaut donc mieux s'appuyer sur un système existant plutôt que d'avoir l'hubris et de croire qu'on peut faire mieux que ces protocoles ciselés depuis des années.
Pour authentifier, il existe non seulement IPsec et DTLS mais également d'autres mécanismes dans des cas particuliers. Par exemple, si les deux machines doivent être sur le même lien (un cas assez courant), on peut utiliser GTSM (RFC 3682) pour s'en assurer.
Enfin, notre RFC se termine (section 7) par un tableau qui synthétise les recommandations, indiquant à chaque fois la section du RFC où cette recommandation est développée. Développeu·r·se d'applications utilisant UDP, si tu ne lis qu'une seule section du RFC, cela doit être celle-ci !
Quels changements depuis le RFC précédent, le RFC 5405 ? Le fond des recommandations reste le même, la principale addition est celle de nombreuses recommandations spécifiques au multicast (dont je n'ai pas parlé ici) mais aussi à l'anycast, aux disjoncteurs, et aux tunnels. Il y a également l'introduction d'une différence entre l'Internet public (où il se faut se comporter en bon citoyen) et des réseaux privés et fermés utilisant les mêmes protocoles, mais où on a droit à des pratiques qui seraient jugées anti-sociales sur l'Internet public (comme d'envoyer des paquets sans tenir compte de la congestion). Ce RFC est donc bien plus long que son prédécesseur.
L'article seul
RFC 8081: The "font" Top-Level Media Type
Date de publication du RFC : Février 2017
Auteur(s) du RFC : C. Lilley (W3C)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF justfont
Première rédaction de cet article le 1 mars 2017
Les types de contenu, servant
à indiquer le type des données envoyées (par le
Web, par le
courrier, etc) sont composés de deux
parties, un type de premier niveau (top level type, ou
type proprement dit, c'est la
catégorie des données) et un
sous-type (il indique le format des données). Type et sous-type
sont séparés par une barre
oblique. Par exemple, image/png
est un type MIME identifiant une image au format
PNG. Des nouveaux sous-types sont
enregistrés très souvent, c'est un événement banal. Mais des
nouveaux types de premier niveau sont bien plus rares. Ce
RFC en décrit un, le type
font/, qui sert à identifier les formats pour des
polices de caractères. Ainsi, on pourra
envoyer un fichier de polices au format TTF en
l'étiquetant font/ttf. (Notre RFC procède
également à l'enregistrement de plusieurs sous-types pour des
formats de polices particuliers.)
Une police de caractères, c'est une
description de comment représenter visuellement un ensemble de
caractères, description qu'un programme peut lire et comprendre.
Il existe bien des façons de faire cette représentation. Les
premiers formats de polices numériques étaient
matriciels mais on est depuis passés à des
formats vectoriels, qui permettent des
changements de taille à volonté. Ces descriptions de caractères
peuvent être distribuées via l'Internet et
la question se pose alors du type de média
à utiliser. En pratique, cela a souvent été
application, un type un peu fourre-tout. On
trouve ainsi enregistré, par exemple, un application/font-woff. Le
RFC 6838, sur l'enregistrement des types et
sous-types de contenus, permet (dans sa section 4.2.7, qui ajoute « Such cases are expected to be quite
rare »)
l'enregistrement d'un nouveau type de premier niveau. C'est ainsi
que ce RFC 8081 crée font/.
Le besoin provient entre autres de l'usage de plus en plus
important des Web
fonts. C'est ansi qu'HTTP
Archive a vu passer le pourcentage de sites Web utilisant cette
technique de 1 % en 2010 à 50 % en 2015. L'analyse de Kuetell montrait une
certaine confusion chez les utilisateurs quant au type MIME à
utiliser pour ces polices. Certains utilisaient le type de premier
niveau font/ avant même son enregistrement
officiel et on voyait donc déjà des
font/truetype pour le format
TrueType. D'autres se servaient
d'application/ pour des
application/octet-stream (fichier binaire
quelconque) ou des application/x-font-ttf
(utilisant le préfixe x-, pourtant abandonné
par le RFC 6648). On voit même des
text/plain pour des ressources pourtant
clairement binaires... Les rares types officiellement enregistrés,
comme application/font-woff, enregistré par un
groupe du W3C, sont peu utilisés.
Au fait, pourquoi est-ce qu'application/
est une mauvaise idée ? Une des principales raisons est qu'il est
regardé avec suspicion par les logiciels de filtrage, qui se
méfient de la capacité de ces fichiers à transporter du
logiciel malveillant. (Certains formats de police incluent un
langage de Turing, et peuvent donc offrir
des possibilités insoupçonnées…) Ensuite, en l'absence d'un type
de premier niveau, il n'était pas possible de définir un jeu
commun de paramètres précisant le type. Enfin, les polices de
caractères ne sont pas des logiciels et posent des problèmes
spécifiques, notamment de licence. Bref, il
fallait un type pour les formats de polices.
Ah, et puisque j'ai parlé de sécurité, la section 3 du RFC fait le point sur les problèmes que peuvent poser les polices de ce côté. Un fichier décrivant une police contient des données, mais aussi des programmes (hinting instructions) pour les opérations de rendu les plus sophistiquées. Par exemple, quand on agrandit un caractère, il ne faut pas agrandir uniformément selon toutes les dimensions ; ou bien certaines caractéristiques d'un caractère dépendent des caractères qui l'entourent. Bref, le rendu est une chose trop compliquée pour être spécifié sans un langage de programmation. C'est par exemple ce qu'on trouve dans les polices TrueType (cf. l'article de Wikipédia). Bien sûr l'exécution de ces « programmes » se fait en général dans un bac à sable, et ils n'ont pas accès à l'extérieur, mais certaines attaques restent possibles, par exemple des attaques par déni de service visant à bloquer le moteur de rendu. Les langages utilisés sont en général trop riches pour que des protections simples suffisent.
Et même si on se limite aux données, la plupart des formats (comme SFNT) sont extensibles et permettent l'ajout de nouvelles structures de données. Cette extensibilité est une bonne chose mais elle présente également des risques (par exemple, elle facilite la dissimulation de données dans les fichiers de polices).
Bon, je vous ai assez fait peur avec les risques de sécurité,
place à l'enregistrement de font/ à
l'IANA (section 4 du
RFC). font/ n'indique pas un format
particulier, mais une catégorie de contenu. Le format sera indiqué
dans le sous-type et c'est là seulement que le logiciel qui reçoit
ce contenu saura s'il peut en faire quelque chose d'utile. (Le RFC
suggère que les sous-types inconnus devraient être traités comme
du binaire quelconque, comme s'ils étaient
application/octet-stream.) Six
sous-types sont enregistrés par notre RFC.
On peut utiliser un identificateur de fragment (RFC 3986, section 3.5, cet identificateur est le truc après
le croisillon dans un URI), pour désigner
une police particulière au sein d'une collection présente dans les
données envoyées. L'identificateur est le nom
PostScript. Attention, certains caractères
peuvent être utilisés dans un nom PostScript mais interdits pour
un identificateur de fragment, et doivent donc être
échappés
avec la notation pour-cent. Par exemple, l'identificateur de
la police Caret^stick sera
#Caret%5Estick.
Le RFC enregistre plusieurs sous-types. Si on veut en ajouter au registre des polices, il faut suivre les procédures du RFC 6838. Il est recommandé que la spécification du format soit librement accessible (ce qui n'est pas évident dans ce milieu).
Le RFC se termine avec les six sous-types de
font/ officiellement enregistrés. D'abord,
sfnt pour le format générique
SFNT. Il prend des paramètres optionnels,
outlines (qui prend comme valeur
TTF, CFF ou
SVG) et layout
(valeurs OTL, AAT et
SIL). On pourra donc écrire, par exemple,
font/sfnt; layout=SIL. Ce
font/sfnt remplace l'ancien type enregistré,
application/font-sfnt. Notez que la
spécification de ce format est la norme ISO
ISO/IEC 14496-22, dite
« Open Font Format ».
SFNT est un format générique, qui sera sans doute rarement
utilisé tel quel. On verra plutôt ttf ou otf.
Un exemple d'un format spécifique est en effet
TrueType. Ce sera le sous-type
ttf. Il aura également un paramètre optionnel
layout (mêmes valeurs possibles). On pourra
donc voir dans une réponse HTTP
Content-Type: font/ttf.
Troisième sous-type enregistré, otf pour
OpenType.
On trouve aussi un sous-type collection
pour mettre plusieurs polices ensemble.
Viennent enfin WOFF versions 1
(woff) et 2 (woff2). Il
s'agit cette fois d'une norme W3C. Ce
nouveau type font/woff remplace l'ancien application/font-woff.
Voilà, c'est tout, le nouveau type de premier niveau
font est désormais inclus dans le registre
IANA des types de premier niveau, et les polices
enregistrées sont dans cet
autre registre IANA.
L'article seul
RFC 8080: Edwards-Curve Digital Security Algorithm (EdDSA) for DNSSEC
Date de publication du RFC : Février 2017
Auteur(s) du RFC : O. Sury (CZ.NIC), R. Edmonds
(Fastly)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 15 février 2017
Ce RFC (premier RFC du groupe CURDLE) spécifie comment utiliser les algorithmes de cryptographie à courbe elliptique Ed25519 et Ed448 dans DNSSEC.
Contrairement à ce qu'on a pu parfois lire sous la plume de trolls ignorants, DNSSEC, mécanisme d'authentification des enregistrements DNS, n'est en rien lié à RSA. Au contraire, comme tous les protocoles cryptographiques de l'IETF, il dispose d'une propriété nommée agilité cryptographique. Ce nom désigne un système utilisant la cryptographie qui n'est pas lié à un algorithme cryptographique particulier. Il peut donc en changer, notamment pour suivre les progrès de la cryptanalyse, qui rend l'abandon de certains algorithmes nécessaire. Aujourd'hui, par exemple, RSA semble bien démodé, et les courbes elliptiques ont le vent en poupe. Aucun problème pour DNSSEC : aussi bien les clés que les signatures disposent d'un champ numérique qui indique l'algorithme cryptographique utilisé. Les valeurs possibles de ce champ figurent dans un registre IANA, registre auquel viennent d'être ajoutés (cf. sections 5 et 7) 15 pour Ed25519 et 16 pour Ed448.
Notez que ces algorithmes ne sont pas les premiers algorithmes à courbes elliptiques normalisés pour DNSSEC : le premier avait été GOST R 34.10-2001 (RFC 5933), il y a six ans, et le second ECDSA (RFC 6605).
Les algorithmes cryptographiques Ed25519 et Ed448, instances de EdDSA, sont spécifiés dans le RFC 8032. Ils peuvent d'ailleurs servir à d'autres systèmes que DNSSEC (par exemple SSH, cf. RFC 7479).
Les détails pratiques pour DNSSEC, maintenant (section 3 du RFC). Notre nouveau RFC est court car l'essentiel était déjà fait dans le RFC 8032, il ne restait plus qu'à décrire les spécificités DNSSEC. Une clé publique Ed25519 fait 32 octets (section 5.1.5 du RFC 8032) et est encodée sous forme d'une simple chaîne de bits. Une clé publique Ed448 fait, elle, 57 octets (section 5.2.5 du RFC 8032).
Les signatures (cf. section 4 de notre RFC) font 64 octets pour Ed25519 et 114 octets pour Ed448. La façon de les générer et de les vérifier est également dans le RFC 8032, section 5.
Voici un exemple de clé publique Ed25519, et des signatures faites avec cette clé, extrait de la section 6 du RFC (attention, il y a deux erreurs, les RFC ne sont pas parfaits) :
example.com. 3600 IN DNSKEY 257 3 15 (
l02Woi0iS8Aa25FQkUd9RMzZHJpBoRQwAQEX1SxZJA4= )
example.com. 3600 IN DS 3613 15 2 (
3aa5ab37efce57f737fc1627013fee07bdf241bd10f3b1964ab55c78e79
a304b )
example.com. 3600 IN MX 10 mail.example.com.
example.com. 3600 IN RRSIG MX 3 3600 (
1440021600 1438207200 3613 example.com. (
Edk+IB9KNNWg0HAjm7FazXyrd5m3Rk8zNZbvNpAcM+eysqcUOMIjWoevFkj
H5GaMWeG96GUVZu6ECKOQmemHDg== )
Et, pour une vraie clé dans un vrai domaine, cette fois sans erreur :
% dig DNSKEY ed25519.monshouwer.eu ; <<>> DiG 9.9.5-9+deb8u9-Debian <<>> DNSKEY ed25519.monshouwer.eu ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 46166 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;ed25519.monshouwer.eu. IN DNSKEY ;; ANSWER SECTION: ed25519.monshouwer.eu. 3537 IN DNSKEY 257 3 15 ( 2wUHg68jW7/o4CkbYue3fYvGxdrd83Ikhaw38bI9dRI= ) ; KSK; alg = 15; key id = 42116 ed25519.monshouwer.eu. 3537 IN RRSIG DNSKEY 15 3 3600 ( 20170223000000 20170202000000 42116 ed25519.monshouwer.eu. Gq9WUlr01WvoXEihtwQ6r7t9AfkQfyETKTfm84WtcZkd M04KEe+4xu9jqhnG9THDAmV3FKASyWQ1LtCaOFr5Dw== ) ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Wed Feb 15 13:13:27 CET 2017 ;; MSG SIZE rcvd: 215
Quelques questions de sécurité pour conclure ce RFC (section 8). Les clés Ed25519 font l'équivalent de 128 bits de sécurité (et 224 pour Ed448). Du fait de l'existence d'algorithmes efficaces pour les casser sur un ordinateur quantique, cela ne sera pas suffisant le jour où on disposera d'un tel ordinateur. Ce jour est probablement très lointain (bien que la NSA, organisme de confiance, dise le contraire).
Enfin, la même section 8 rappelle l'existence des attaques trans-protocoles : il ne faut pas utiliser une clé dans DNSSEC et dans un autre protocole.
À noter que ce RFC est un pas de plus vers une cryptographie 100 % Bernstein, avec cette adaptation des algorithmes utilisant Curve25519 à DNSSEC. Bientôt, l'ancien monopole de RSA aura été remplacé par un monopole de Curve25519.
Apparemment, le RFC est un peu en avance sur le logiciel, les systèmes DNSSEC existants ne gèrent pas encore Ed25519 ou Ed448 (à part, semble-t-il, PowerDNS et, bientôt, DNS Go. BIND a eu EdDSA à partir de la version 9.12.)
L'article seul
RFC 8078: Managing DS records from the Parent via CDS/CDNSKEY
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : O. Gudmundsson
(CloudFlare), P. Wouters (Red Hat)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 11 mars 2017
Un problème fréquent avec DNSSEC est de transmettre à sa zone parente les clés publiques de signature de sa zone, pour que le parent puisse signer un lien qui va vers ces clés (l'enregistrement de type DS). Le RFC 7344 apportait une solution partielle, avec ses enregistrements CDS et CDNSKEY. Il y manquait deux choses : la création du premier DS (activation initiale de DNSSEC), et le retrait de tout les DS (on arrête de faire du DNSSEC). Ce nouveau RFC 8078 comble ces deux manques (et, au passage, change l'état du RFC 7344, qui passe sur le Chemin des Normes).
Avant le RFC 7344, tout changement des clés KSK (Key Signing Key) d'une zone nécessitait une interaction avec la zone parente, par le biais d'un mécanisme non-DNS (« out-of-band », par exemple un formulaire Web). La solution du RFC 7344, elle, n'utilise que le DNS (« in-band »). Ce nouveau RFC complète le RFC 7344 pour les configurations initiales et finales. (Le problème est complexe car il peut y avoir beaucoup d'acteurs en jeu. Par exemple, le BE n'est pas forcément l'hébergeur DNS. Ces difficultés ont certainement nui au déploiement de DNSSEC.)
Lorsqu'on change d'hébergeur DNS, la solution la plus propre est de faire un remplacement des clés, depuis celle de l'ancien hébergeur jusqu'à celle du nouveau. Cette solution préserve en permanence la sécurité qu'offre DNSSEC. Mais une des procédures mentionnées par notre RFC passe au contraire par un état non sécurisé, où la zone n'est pas signée. C'est dommage mais cela est parfois nécessaire si :
- Les logiciels utilisés ne permettent pas de faire mieux, ou l'un des deux hébergeurs ne veut pas suivre la procédure « propre »,
- Ou bien le nouvel hébergeur ne gère pas DNSSEC du tout, ou encore le titulaire de la zone ne veut plus de DNSSEC.
Une zone non signée vaut certainement mieux qu'une signature invalide. Mais le RFC oublie de dire que cela va casser certaines applications de sécurité qui exigent DNSSEC comme DANE (RFC 6698) ou SSHFP (RFC 4255).
Avant de lire la suite de ce RFC, deux conseils :
- Lisez bien le RFC 7344. Vraiment.
- Rappelez-vous qu'il y a des tas d'acteurs possibles dans le DNS. Le modèle RRR (Titulaire-BE-Registre, Registrant-Registrar-Registry) n'est pas le seul. Et il n'y a pas que les TLD qui délèguent des zones ! Le RFC parle donc uniquement de « parent » (responsable parental ?) pour désigner l'entité à laquelle on s'adresse pour obtenir des changements dans la zone parente.
Les enregistrements CDS (Client-side Delegation Signer) servent à trois choses (section 2 du RFC) :
- Installer le DS (Delegation Signer) initial dans la zone parente,
- Remplacer (rollover) la clé publique de signature des clés (KSK, Key-Signing Key) dans la zone parente,
- Supprimer le DS de la zone parente, débrayant ainsi la validation DNSSEC de la zone fille chez les résolveurs.
Avec le RFC 7344, seule la deuxième était possible (c'est la moins dangereuse, qui ne nécessite aucun changement dans les relations de confiance,notamment entre parente et fille). Notre RFC 8078 permet désormais les deux autres, plus délicates, car posant davantage de problèmes de sécurité.
La sémantique des enregistrements CDS (ou CDNSKEY) est donc désormais « la publication d'un ou plusieurs CDS indique un souhait de synchronisation avec la zone parente ; celle-ci est supposée avoir une politique en place pour accepter/refuser/vérifier ce ou ces CDS, pour chacune des trois utilisations notées ci-dessus ». Quand des CDS différents des DS existants apparaissent dans la zone fille, le responsable parental doit agir.
D'abord, l'installation initiale d'un DS alors qu'il n'y en avait pas avant (section 3 du RFC). La seule apparition du CDS ou du CDNSKEY ne peut pas suffire car comment le vérifier, n'ayant pas encore de chaîne DNSSEC complète ? Le responsable parental peut utiliser les techniques suivantes :
- Utiliser un autre canal, extérieur au DNS, par exemple l'API du responsable parental,
- Utiliser des tests de vraisemblance, du genre un message de confirmation envoyé au contact technique du domaine, ou bien regarder si la configuration du domaine est stable,
- Attendre un certain temps, de préférence vérifier depuis plusieurs endroits dans le réseau (pour éviter les empoisonnements locaux), puis considérer le CDS comme valable s'il est resté pendant ce temps (l'idée est qu'un piratage aurait été détecté, pendant ce délai),
- Envoyer un défi au titulaire de la zone fille, par exemple génerer une valeur aléatoire et lui demander de l'insérer sous forme d'un enregistrement TXT dans la zone (bien des applications qui veulent vérifier le responsable d'un domaine font cela, par exemple Keybase ou bien Google webmasters),
- Accepter immédiatement s'il s'agit d'une nouvelle délégation. Ainsi, le domaine sera signé et validable dès le début.
La deuxième utilisation des CDS, remplacer une clé est, on l'a vu, déjà couverte par le RFC 7344.
Et pour la troisième utilisation, la suppression de tous les DS chez le parent ? Elle fait l'objet de la section 4 du RFC. Pour demander cette suppression, on publie un CDS (ou un CDNSKEY) avec un champ « algorithme » à zéro. Cette valeur n'est pas affectée à un vrai algorithme dans le registre officiel, elle est réservée (cf. section 6 du RFC) pour dire « efface ». (Le RFC 4398 utilisait déjà le même truc.)
Pour éviter tout accident, le RFC est plus exigeant que cela et exige cette valeur spécifique pour ces enregistrements :
DOMAINNAME IN CDS 0 0 0 0
ou bien :
DOMAINNNAME IN CDNSKEY 0 3 0 0
(Le 3 étant l'actuel numéro de version de DNSSEC, voir le RFC 4034, section 2.1.2.)
Une fois le CDS (ou CDNSKEY) « zéro » détecté, et validé par DNSSEC, le parent retire le DS. Une fois le TTL passé, le fils peut « dé-signer » la zone.
À noter que ce RFC a été retardé par la question du déplacement du RFC 7344, de son état « pour information », au Chemin des Normes. La demande était discrète, et avait été raté par certains relecteurs, qui ont protesté ensuite contre ce « cavalier ». L'« élévation » du RFC 7344 est désormais explicite.
Cette possibilité est opérationnelle en .ch ou .cz. Jan-Piet Mens a fait un excellent article sur son utilisation dans .ch.
L'article seul
RFC 8073: Coordinating Attack Response at Internet Scale (CARIS) Workshop Report
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : K. Moriarty (Dell EMC
Corporation), M. Ford (Internet
Society)
Pour information
Première rédaction de cet article le 29 mars 2017
Ce nouveau RFC fait le bilan de l'atelier CARIS (Coordinating Attack Response at Internet Scale) qui s'est tenu à Berlin le 18 juin 2015. Cet atelier avait pour but d'explorer les problèmes de coordination entre les victimes et témoins d'une attaque portant sur l'Internet. Ce RFC est un compte-rendu, les positions exprimées ne sont pas forcément celles de l'IAB ou de l'Internet Society (organisateurs de l'atelier). D'autant plus que les participants ont mis les pieds dans le plat, expliquant très bien pourquoi il n'y a toujours pas de coordination globale des acteurs de l'Internet face aux attaques. (Un deuxième atelier sur ce thème a eu lieu en 2019, et son compte-rendu figure dans le RFC 8953.)
L'atelier avait été organisé pour que les participants à la réunion FIRST de Berlin puissent venir. Il rassemblait cinquante acteurs (c'était un atelier fermé, sur invitation seulement) de l'Internet, représentant une grande diversité d'organisations. La liste des participants figure dans l'annexe A du RFC. Chaque participant avait rempli un article de deux pages expliquant son point de vue et/ou les problèmes qu'il·elle souhaitait aborder. Tous ces documents sont disponibles en ligne (je vous encourage à les lire). Dans le reste du RFC, n'attendez pas d'attribution de tel discours à tel participant, l'atelier était tenu sous la règle de Chatham House, pour que les discussions restent libre.
L'atelier a vu cinq sessions (cf. section 2 du RFC) autour de ce thème des attaques, et de la coordination pour y faire face :
- Coordination entre les CSIRT, et avec ceux qui combattent directement l'attaque,
- Répondre aux dDoS et aux botnets, avec passage à l'échelle pour les attaques de grande ampleur que nous voyons aujourd'hui,
- Infrastructure de l'Internet, notamment les acteurs du DNS, et les RIR,
- Problèmes de confiance et de confidentialité dans les échanges entre acteurs de l'Internet (un très gros sujet lors de l'atelier),
- Conséquences des attaques sur l'architecture de l'Internet, et sur ses futures évolutions. (Peu de détails données dans le RFC sur cette dernière session.)
Parmi les organisations qui ont participé à la première session, on notait, entre autres :
- L'ENISA qui, quoiqu'elle fasse de la formation et de l'échange, n'a pas directement d'activité concernant les attaques pendant qu'elles se produisent (l'ENISA n'est pas « temps réel »).
- L'APWG, qui a un mécanisme d'échange entre acteurs (une clearing house).
- Le Ren-ISAC (si vous ne savez pas ce qu'est un ISAC, c'est le moment d'apprendre) qui sert de point de partage d'informations dans le monde académique états-unien. Cet organisme permet une mutualisation des efforts (bien des universités n'ont pas les moyens d'avoir une équipe à temps plein pour réagir aux attaques 24 heures sur 24).
- Le CERT brésilien, qui joue un rôle essentiel dans ce pays. Bien des pays, contrairement au Brésil, n'ont pas un CERT national mais plein de petits CERT limités à un groupe ou une entreprise.
Les principaux points mis en avant pendant cette session ont été :
- La surveillance de masse effectuée par les États a mis en danger les mécanismes de coordination, en réduisant la confiance. On note qu'au contraire de tant de colloques bavards et convenus sur la cybersécurité, l'atelier CARIS n'a pas pratiqué la langue de bois. Au lieu de répéter en boucle que la cybersécurité était importante, qu'elle reposait sur l'échange et la coordination, les participants ont directement pointé les vrais problèmes : les acteurs n'ont pas confiance dans l'État, et pour des très bonnes raisons, ce qui diminue l'éfficacité du travail en commun.
- Les tentatives des certains États d'encourager le partage d'informations (par exemple via une agence nationale) n'ont pas été des succès.
- Tout le monde veut que les autres partagent de l'information mais personne ne veut en donner. Ici encore, l'atelier pointe un problème que tout le monde connait, mais dont on ne parlait pas publiquement.
- Outre les simples problèmes d'ego, le partage d'informations est handicapé par les craintes des organisations pour leur réputation : si on dit la vérité sur une attaque qu'on n'a pas bien paré, on va paraitre faible.
- Les barrières de langue sont un gros problème. (Le RFC ne le dit pas, mais tout le monde pense aux immenses difficultés de communication avec les acteurs chinois. Des listes de diffusion comme celles de NANOG sont pleines de remarques amères « j'ai signalé le problème au FAI chinois et il n'a rien fait », sans que leur auteur se demande comment lui réagirait s'il recevait un rapport d'attaque écrit en mandarin. Contrairement à ce que pourrait laisser croire un certain discours globaliste, tout le monde ne parle pas anglais. Sans compter les problèmes culturels, encore plus difficiles.)
- Les règles de protection de la vie privée (comme le réglement européen sur la protection des données personnelles) peuvent gêner l'échange d'information (on n'envoie pas un fichier contenant des adresses IP aux USA). (Derrière cette remarque, on peut lire l'agacement des États-Unis - qui eux-même n'envoient pas de données - face aux lois européennes plus protectrices, mais aussi le regret des professionnels de la lutte contre les attaques informatiques, face à des lois prévues pour traiter d'autres problèmes que les leurs.)
Deuxième session, sur les mesures de lutte contre les dDoS et les botnets, notamment sur la question du passage à l'échelle de ces efforts. Les points essentiels abordé furent :
- Les mesures prises jusqu'à présent ont été plutôt efficaces. (C'était avant l'attaque contre Dyn, et le RFC ne mentionne pas le fait que la plupart de ces « mesures efficaces » ne sont accessibles qu'aux gros acteurs, ou à leurs clients, et que le petit hébergeur reste aussi vulnérable qu'avant.)
- La tension entre les réactions à court terme (stopper l'attaque en cours) et les exigences du long terme (éradiquer réellement le botnet, ce qui implique de le laisser « travailler » un certain temps pour l'étudier) reste entière. Sans compter, là aussi, le manque d'échanges entre pompiers de la lutte anti-dDoS et chasseurs de botnets.
- Il existe des groupes où règne une certaine confiance mutuelle comme le peu documenté CRAG.
- Trier le trafic entrant, puis le filtrer, est un problème soluble. (Je note personnellement que, pour l'instant, les seules solutions sont des boîtes noires fermées. Un problème pour les gens attachés à la liberté.)
- Il existe un groupe de travail IETF nommé DOTS qui travaille sur des mécanismes techniques facilitant l'échange de données pendant une attaque. Un effort précédant de l'IETF avait mené au RFC 6545. Les deux solutions sont conceptuellement proches mais DOTS est plus récent, devrait utiliser des techniques modernes et semble avoir davantage de soutiens de la part des acteurs.
- Il existe une certaine dose de confiance dans le milieu mais pas complète. On ne peut pas toujours faire confiance aux informations reçues. À cette session également, le problème des services d'espionnage étatiques a été mentionné, comme une grosse menace contre la confiance.
- La question brûlante des « arrêts automatiques » (automated takedowns) a été mentionnée. Certains cow-boys voudraient, compte-tenu de la rapidité des phénomènes en jeu, que certaines décisions puissent être automatiques, sans intervention humaine. Par exemple, un nom de domaine est utilisé pour une attaque « random QNAMEs », l'attaque est analysée automatiquement, signalée au registre et paf, le nom de domaine est supprimé. Inutile de dire que l'idée est très controversée.
Ensuite, troisième session, consacrée aux organisations de l'infrastructure DNS (par exemple les registres) et aux RIR. Les points étudiés :
- L'utilisation du passive DNS (par exemple DNSDB) pour analyser certaines attaques.
- Les données que détiennent les RIR, en raison de leur activité mais aussi suite à divers projets non directement liés à leur activité (comme l'observation des annonces BGP ou comme la gestion d'un serveur racine du DNS). Des participants ont regretté l'absence d'API standard pour accéder à ces données.
- Certains des RIR ont déjà une coordination active avec des organisations qui réagissent en cas d'attaques.
Quatrième session, les problèmes de confiance. Tout le monde est d'accord pour dire que c'est cool de partager les données, et que c'est indispensable pour lutter efficacement contre les attaques. Alors, pourquoi si peu d'organisations le font ? Il n'y a clairement pas une raison unique. C'est un mélange de crainte pour la vie privée, de contraintes juridiques, de problèmes techniques, de différences culturelles et de simples malentendus. Sans compter le pur égoïsme (« partager mes données avec nos concurrents ??? ») Enfin, il faut rappeler qu'il est impossible de s'assurer du devenir de données numériques : si on passe nos données à quelqu'un, pour aider pendant une attaque, que deviendront-elles après ? (Envoyer des données aux USA, c'est la certitude qu'elles seront vendues et revendues.) Le RFC note que tous les participants à l'atelier ont estimé que ces raisons étaient mauvaises ou, plus exactement, qu'on pouvait trouver des solutions. Les points précis discutés :
- La réputation est cruciale : il y a des gens à qui on envoie toutes les données qu'ils veulent et d'autres à qui on ne transmettra rien. (Sans la règle de Chatham House, on peut parier que personne n'aurait osé exprimer cette évidence pendant l'atelier.)
- L'utilisation du TLP (certains participants regrettent son manque de granularité, je pense personnellement que déjà trop de gens ont du mal avec ses quatre niveaux).
- Officielement, la confiance est entre organisations. En réalité, elle est entre individus (personne ne fait confiance à un machin corporate) et il faut donc développer des liens entre individus. En outre, la confiance est forcément limitée en taille : on ne fait confiance qu'à ceux qu'on connait et on ne peut pas connaître tout le monde. Comme le dit le RFC, « Social interaction (beer) is a common thread amongst sharing partners to build trust relationships ».
- Par analogie avec les marques déposées, certains se sont demandés s'il faudrait un mécanisme de labelisation de la confiance.
- Plusieurs participants ont remarqué que le travail réel ne se faisait pas dans les structures officielles, mais dans des groupes fondés sur des relations de confiance. (Le RFC utilise le terme classique des geeks pour parler de ces groupes : cabals.) Comme le dit le RFC pudiquement, « This was not disputed. » (autrement dit, tout le monde le savait bien mais ne le disait pas).
La section 4 du RFC concerne le « et maintenant ? ». Il y a eu un consensus sur la nécessité de la formation (au sens large). Par exemple, on trouve toujours des professionnels de l'Internet qui ne connaissent pas BCP 38. Du travail pour les pédagogues (et les auteurs de blogs...)
Plus technique, la question des mécanismes techniques d'échange d'information a suscité des débats animés. Le RFC 6545 date de plus de dix ans. Il ne semble pas être universellement adopté, loin de là. Le groupe de travail DOTS fera-t-il mieux ? D'autres techniques ont été discutées comme TAXII ou XMPP-Grid. Ce dernier, fondé sur XMPP (RFC 6120) semble prometteur et est déjà largement mis en œuvre. Le groupe de travail nommé MILE a aussi un protocole nommé ROLIE (pas encore de RFC).
L'article seul
RFC 8067: Updating When Standards Track Documents May Refer Normatively to Documents at a Lower Level
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : B. Leiba (Huawei)
Première rédaction de cet article le 29 janvier 2017
Un très (vraiment très court) RFC purement bureaucratique, pour un très léger (vraiment très léger) changement des règles concernant les références d'un RFC à un autre RFC.
Le problème était simple : un RFC situé sur le Chemin des Normes est dans une étape donnée. Au nombre de trois au début (RFC 2026), ces étapes sont désormais deux (RFC 6410) : Proposition de norme et Norme. D'autre part, un RFC a des références à d'autres RFC, dans sa bibliographie, et ces références peuvent être normatives (il faut avoir lu et compris les RFC cités) ou informatives (elles sont juste là pour compléter et éclairer). Une règle de l'IETF est qu'un RFC ne peut pas avoir de référence normative à un RFC situé à une étape inférieure. Le but était d'éviter qu'une norme ne dépende d'un texte de maturité et d'adoption inférieurs.
Le RFC 3967 introduisait une exception à cette règle, mais en imposant un processus jugé désormais trop rigide. On pouvait donc, quand c'était nécessaire, déroger à la règle « pas de références vers le bas [du chemin des normes, downward reference en anglais] » mais il fallait le documenter dans le Last Call (dernier appel avant adoption). Si quelque chose changeait dans les références d'un RFC, il pouvait donc y avoir à refaire le Last Call.
C'était d'autant plus gênant que la question se pose plus souvent maintenant. En effet, les groupes de travail de l'IETF qui bossent sur un sujet compliqué font souvent un document « de base », définissant les concepts, la terminologie, etc, et ces documents ne sont pas sur le chemin des normes (ils sont juste « pour information »). Impossible donc de mettre une référence « vers le bas ».
La nouvelle règle figure en section 2 du RFC : le RFC 3967 est légèrement mis à jour. Désormais, il n'est plus nécessaire de mentionner l'existence d'une référence « vers le bas » au moment du dernier appel. En cas de changement des références, il ne sera donc plus obligatoire de répéter le dernier appel. C'est donc entièrement à l'IESG de déterminer si une référence à un RFC « inférieur » est acceptable ou non.
L'article seul
RFC 8065: Privacy Considerations for IPv6 Adaptation-Layer Mechanisms
Date de publication du RFC : Février 2017
Auteur(s) du RFC : D. Thaler (Microsoft)
Pour information
Réalisé dans le cadre du groupe de travail IETF 6lo
Première rédaction de cet article le 24 février 2017
Entre la couche 3 (du modèle en couches) et la couche 2 (par exemple Ethernet) se trouve une adaptation, qui définit comment on va mettre les paquets IPv6 sur la couche sous-jacente. Certaines de ces adaptations posent des problèmes de protection de la vie privée. Ce RFC résume les problèmes existants. Chaque adaptation devra ensuite travailler à s'améliorer sur ce plan (le RFC donne des idées). L'idée est d'améliorer les normes actuelles et futures, pour mieux prendre en compte ce problème de vie privée.
Ce problème de la vie privée pour IPv6 a déjà été beaucoup discuté, notamment en raison d'un choix initial de privilégier une adaptation à Ethernet qui gardait une partie de l'adresse IPv6 constante, même quand la machine changeait de réseau. Ce problème est résolu depuis longtemps (RFC 8981) mais d'autres peuvent demeurer, surtout si la couche 2 a des contraintes qui empêchent de déployer certaines protections de la vie privée.
Les documents de référence à lire d'abord sont le RFC général sur la vie privée, RFC 6973 (sa section 5.2 est particulièrement utile ici), et, plus spécifique à IPv6, le RFC 7721. Le risque qui concerne l'adaptation est lié au mécanisme de génération des IID (identificateurs d'interface, cf. RFC 4291), puisque cet IID fait partie de l'adresse IPv6 (typiquement les 64 derniers bits) et va donc être potentiellement visible publiquement. Si l'IID est trop prévisible ou trop stable, il permettra notamment :
- De corréler des activités du même utilisateur au cours du temps,
- De suivre l'utilisateur à la trace s'il se déplace en gardant le même IID,
- De balayer plus facilement un réseau à la recherche de machines à attaquer (alors que, normalement, la taille élevée de l'espace d'adressage IPv6 rend ces balayages lents et pénibles).
Un concept important est celui d'entropie, c'est-à-dire du nombre de bits dans l'IID qui sont réellement imprévisibles. Idéalement, l'entropie devrait être de 64 bits (le préfixe IPv6 ayant typiquement une longueur de 64 bits pour un réseau, cf. RFC 7421).
Voilà pourquoi le RFC 8064 déconseille de créer un IID à partir d'une adresse « couche 2 » fixe, comme l'est souvent l'adresse MAC. Il recommande au contraire la technique du RFC 7217 si on veut des adresses stables tant qu'on ne se déplace pas, et celle du RFC 8981 si on veut être vraiment difficile à tracer (au prix d'une administration réseaux plus difficile). Le RFC sur la sélection des adresses source, RFC 6724 privilégie déjà par défaut les adresses temporaires du RFC 8981.
Revenons maintenant à cette histoire d'entropie (section 2 du
RFC). Combien de bits sont-ils nécessaires ? Prenons le cas le plus
difficile, celui d'un balayage du réseau local, avec des paquets
ICMP Echo Request ou bien avec des
TCP SYN. L'entropie minimum
est celle qui minimise les chances d'un attaquant de trouver une
adresse qui réponde. Quel temps faudra-t-il pour avoir une chance
sur deux de trouver une adresse ? (Notez que la capacité de
l'attaquant à trouver des machines dépend aussi du fait qu'elles
répondent ou pas. Si une machine ne répond pas aux ICMP
Echo Request, et n'envoie pas de
RST aux paquets TCP SYN,
la tâche de l'attaquant sera plus compliquée. Cf. RFC 7288, notamment sa section 5. Même si la machine répond,
un limiteur de trafic peut rendre la tâche de l'attaquant
pénible. Avec la valeur par défaut d'IOS de
deux réponses ICMP par seconde, il faut une année pour balayer un
espace de seulement 26 bits.)
Les formules mathématiques détaillées sont dans cette section 2 du RFC. L'entropie nécessaire dépend de la taille de l'espace d'adressage mais aussi de la durée de vie du réseau. Avec 2^16 machines sur le réseau (c'est un grand réseau !) et un réseau qui fonctionne pendant 8 ans, il faudra 46 bits d'entropie pour que l'attaquant n'ait qu'une chance sur deux de trouver une machine qui réponde (avec la même limite de 2 requêtes par seconde ; sinon, il faudra davantage d'entropie).
Et combien de bits d'entropie a-t-on avec les techniques actuelles ? La section 3 donne quelques exemples : seulement 48 bits en Bluetooth (RFC 7668), 8 (oui, uniquement 256 adresses possibles, mais c'est nécessaire pour permettre la compression des en-têtes) en G.9959 (RFC 7428) et le pire, 5 bits pour NFC (RFC pas encore paru).
Ces adaptations d'IPv6 à diverses couches 2 utilisent comme identificants d'interface des adresses IEEE (comme les adresses MAC) ou bien des « adresses courtes ». Commençons par les adresses reposant sur des adresses IEEE. Dans certains cas, la carte ou la puce qui gère le réseau dispose d'une adresse EUI-48 ou EUI-64 (comme l'adresse MAC des cartes Ethernet). On peut facilement construire une adresse IPv6 avec ces adresses, en concaténant le préfixe avec cette adresse IEEE utilisée comme identificateur d'interface (IID). L'entropie dépend du caractère imprévisible de l'adresse IEEE. L'IEEE a d'ailleurs des mécanismes (pas forcément déployés dans le vrai monde) pour rendre ces adresses imprévisibles. Même dans ce cas, la corrélation temporelle reste possible, sauf si on change les adresses de temps en temps (par exemple avec macchanger).
Un argument souvent donné en faveur des adresses MAC est leur unicité, qui garantit que les adresses IPv6 seront « automatiquement » distinctes, rendant ainsi inutile la détection d'adresses dupliquées (DAD, RFC 4862, section 5.4, et RFC 4429, annexe A). Sauf que ce n'est pas vrai, les adresses MAC ne sont pas forcément uniques, en pratique et les identificateurs d'interface aléatoires sont donc préférables, pour éviter les collisions d'adresses.
En dehors des adresses allouées par un mécanismes de l'IEEE, il y a les « adresses courtes » (16 bits, utilisées par IEEE 802.15.4, cf. RFC 4944), allouées localement, et uniques seulement à l'intérieur du réseau local. Vu leur taille, elles n'offrent évidemment pas assez d'entropie. Il faut donc les étendre avant de s'en servir comme identificateur d'interface. Le RFC cite par exemple un condensat de la concaténation de l'adresse courte avec un secret partagé par toutes les machines du réseau.
On peut aussi utiliser dans le condensat le numéro de version spécifié dans la section 4.3 du RFC 6775. Ainsi, un changement de numéro de version permettra une rénumérotation automatique.
Bien, après cette analyse, les recommandations (section 4) :
- La section Sécurité (Security Considerations) des RFC qui normalisent une adaptation à une couche 2 donnée devrait dire clairement comment on limite le balayage. Cela nécessite de préciser clairement la durée de vie des adresses, et le nombre de bits d'entropie.
- Il faut évidemment essayer de maximiser cette entropie. Avoir des identificateurs d'adresses aléatoires est une bonne façon de le faire.
- En tout cas, pas question de juste utiliser une adresse courte et stable avec quelques bits supplémentaires de valeur fixe et bien connue.
- Les adresses ne devraient pas être éternelles, pour limiter la durée des corrélations temporelles.
- Si une machine peut se déplacer d'un réseau à l'autre (ce qui est courant aujourd'hui), il faudrait que l'identifiant d'interface change, pour limiter les corrélations spatiales.
L'article seul
RFC 8064: Recommendation on Stable IPv6 Interface Identifiers
Date de publication du RFC : Février 2017
Auteur(s) du RFC : F. Gont (SI6 Networks /
UTN-FRH), A. Cooper (Cisco), D. Thaler
(Microsoft), W. Liu (Huawei
Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 24 février 2017
Ce RFC parle de vie privée mais il est très court, car il se contente de changer une règle, la nouvelle étant déjà largement acceptée. Désormais, si une machine IPv6 configure son adresse par le système SLAAC, et que cette adresse doit être stable dans le temps, désormais, donc, la méthode recommandée est celle du RFC 7217 et non plus celle, mauvaise pour la vie privée, d'utiliser l'adresse MAC. (Si l'adresse n'a pas besoin d'être stable, aucun changement, la méthode recommandée reste celle du RFC 8981, les adresses temporaires.)
Que veut dire SLAAC, au fait ? Ce mécanisme de configuration d'une adresse IPv6 est normalisé dans le RFC 4862. L'idée est que la machine écoute sur le réseau les annonces faites par les routeurs, apprenant ainsi le·s préfixe·s IP du réseau. Elle ajoute ensuite à ce préfixe un terme, l'identificateur d'interface (IID, cf. RFC 4291), formant ainsi une adresse IPv6 mondiale, et unique (si l'IID est bien choisi). La méthode originelle était de dériver l'IID de l'adresse MAC. Celle-ci est en effet unique et, en prime, son utilisation présente certains avantages (compression des en-têtes du RFC 6775, par exemple). Mais s'en servir soulève plein de problèmes de sécurité et notamment de vie privée : traçabilité des utilisateurs dans le temps, et dans l'espace (si la machine se déplace, elle change de préfixe mais garde le même identificateur d'interface), facilitation du balayage des adresses dans le réseau, etc (cf. RFC 7721). D'une manière générale, réutiliser des identificateurs d'un autre « monde » est une fausse bonne idée, souvent dangereuse en matière de vie privée. Voilà pourquoi ce RFC dit clairement que, désormais, il est fortement déconseillé d'utiliser les adresses MAC. (Plusieurs mises en œuvre d'IPv6, comme celles de Microsoft, avaient déjà cessé, avant même que ce RFC ne soit publié.)
Et ce RFC 7217 qu'il faut désormais suivre, il dit quoi ? Il propose de fabriquer l'identificateur d'interface en condensat une concaténation du préfixe et de diverses valeurs stables. Si on change de réseau, on a une nouvelle adresse (on ne peut donc pas suivre à la trace une machine mobile). Mais, si on reste sur le même réseau, l'adresse est stable.
La section 1 de notre RFC rappelle aussi la différence entre les adresses stables et les autres. Toutes les adresses IP n'ont pas besoin d'être stables. La solution la meilleure pour la vie privée est certainement celle du RFC 8981, des adresses temporaires, non stables (pour de telles adresses, on peut aussi utiliser le système des adresses MAC si elles changent souvent par exemple avec macchanger). Toutefois, dans certains cas, les adresses stables sont souhaitables : l'administration réseaux est plus simple, les journaux sont plus faciles à lire, on peut mettre des ACL, on peut avoir des connexions TCP de longue durée, etc. Et, bien sûr, si la machine est un serveur, ses adresses doivent être stables. Il y a donc une place pour une solution différente de celle du RFC 8981, afin de fournir des adresses stables. C'est seulement pour ces adresses stables que notre RFC recommande désormais la solution du RFC 7217.
La nouvelle règle figure donc en section 3 de notre RFC : lorsqu'une machine veut utiliser SLAAC et avoir des adresses stables, qui ne changent pas dans le temps, tant que la machine reste sur le même réseau, alors, dans ce cas et seulement dans ce cas, la méthode à utiliser est celle du RFC 7217. L'ancienne méthode (qu'on trouve par exemple dans le RFC 2464) d'ajouter le préfixe à l'adresse MAC ne doit plus être utilisée.
Notez donc bien que ce RFC ne s'adresse pas à toutes les
machines IPv6. Ainsi, si vous configurez vos serveurs (qui ont
clairement besoin d'une adresse stable) à la main, avec des
adresses en leet comme
2001:db8::bad:dcaf, ce RFC 8064 ne
vous concerne pas (puisqu'il n'y a pas de
SLAAC).
Les RFC comme le RFC 4944, RFC 6282, RFC 6775 ou RFC 7428 devront donc être remplacés par des documents tenant compte de la nouvelle règles. (Cf. RFC 8065.)
Aujourd'hui, il semble que les dernières versions de Windows, MacOS, iOS et Android mettent déjà en œuvre la nouvelle règle.
L'article seul
RFC 8063: Key Relay Mapping for the Extensible Provisioning Protocol
Date de publication du RFC : Février 2017
Auteur(s) du RFC : H.W. Ribbers, M.W. Groeneweg (SIDN), R. Gieben, A.L.J Verschuren
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF eppext
Première rédaction de cet article le 15 février 2017
Un des problèmes pratiques que pose DNSSEC est le changement d'hébergeur DNS. Si on sous-traite sa gestion des clés cryptographiques, et ses signatures à un tiers, que faire lors du changement de prestataire, pour ne pas casser la chaîne de confiance DNSSEC ? On ne peut évidemment pas demander à l'ancien hébergeur de transmettre la clé privée au nouveau ! Même pour les données non confidentielles, comme la clé publique, la transmission est difficile car les deux hébergeurs n'ont pas de canal de transmission sécurisé commun. Ce nouveau RFC propose d'utiliser comme canal sécurisé le registre de la zone parente et, plus concrètement, de définir une extension au protocole EPP, qui permet un mécanisme de « messagerie » électronique sécurisée, afin de l'utiliser entre deux clients du même registre.
Pour bien comprendre le problème et sa solution, il faut faire un peu de terminologie :
- Bureau d'enregistrement (BE) : l'entité par laquelle il faut passer pour toute opération sur le registre. À noter que tous les registres n'ont pas ce concept et c'est pour cela que notre RFC, comme les autres RFC sur EPP, ne parle pas de BE mais de client EPP.
- Hébergeur DNS (DNS operator dans le RFC) : l'entité qui gère les serveurs de nom du domaine. C'est souvent le BE mais ce n'est pas du tout obligatoire. Les serveurs DNS peuvent être gérés par une entreprise spécialisée, qui n'est pas BE, ou bien directement par l'utilisateur.
- EPP : protocole d'avitaillement (notamment de noms de domaine), normalisé dans le RFC 5730, entre un serveur (le registre) et un client (le BE, lorsque ce registre utilise des BE).
- DNSSEC : système d'authentification des informations récupérées via le DNS. Il repose sur la cryptographie asymétrique et il y a donc une clé publique (mise dans le DNS) et une clé privée (qui n'est... pas publique). DNSSEC utilise le DNS et doit donc faire attention au temps qui s'écoule ; par exemple, lorsqu'on publie une nouvelle clé (on l'ajoute à l'ensemble DNSKEY), elle ne va pas être visible tout de suite par tous les clients DNS, certains ont en effet mémorisé l'ancien ensemble de clés.
Dans le cas le plus fréquent, l'hébergeur DNS assure la gestion des clés (création, suppression, etc) et connait donc la clé privée, qu'il utilise pour signer les enregistrements. Si le titulaire du domaine veut changer d'hébergeur, pas question bien sûr de transmettre la clé privée. Le nouvel hébergeur (le « gagnant ») va donc créer des nouvelles clés et les utiliser pour signer. Le problème est qu'un résolveur DNS peut avoir des signatures de l'ancien hébergeur (le « perdant ») et des clés du nouveau (ou bien le contraire). Dans ces deux cas, la validation échouera, le domaine sera vu comme invalide.
Une solution à ce problème serait que l'ancien hébergeur mette à l'avance (rappelez-vous, le temps est crucial dès qu'on fait du DNS...) dans les clés qu'il publie la nouvelle clé du nouvel hébergeur. Mais cela suppose qu'il connaisse cette clé. Le titulaire du nom peut servir de relais mais il n'est pas forcément compétent pour cela (« M. Michu, votre nouvel hébergeur a dû vous remettre une clé cryptographique. C'est une série de lettres et de chiffres incompréhensiblles. Pouvez-nous nous la transmettre sans la moindre altération ? »). L'ancien hébergeur ne peut pas non plus utiliser le DNS puisque les serveurs du nouveau ne sont pas encore configurés et, même s'ils le sont, l'ancien hébergeur ne peut pas valider leur contenu avec DNSSEC. L'idée de notre RFC est donc d'utiliser le registre comme intermédiaire de confiance. Si les deux hébergeurs sont également BE, ils ont déjà un canal sécurisé avec le registre (la session EPP). Sinon, on peut espérer que le BE acceptera de servir de relais entre l'hébergeur et le registre.
Avec la solution de ce RFC, le nouvel hébergeur (on va suppose qu'il est également BE, ce sera plus simple) va créer ses clés, les transmettre (la clé publique seulement, bien sûr) au registre via l'extension EPP de notre nouveau RFC, l'ancien hébergeur va les lire (le registre ne sert que de boîte aux lettres sécurisée), les mettre dans la zone DNS. Au bout d'un temps déterminé par le TTL des enregistrements, tous les résolveurs auront l'ancienne et la nouvelle clé publique dans leur mémoire, et pourront valider aussi bien les anciennes que les nouvelles signatures.
Une autre façon de résoudre ce problème serait évidemment que chacun gère sa zone DNS lui-même, et donc ne change jamais d'« hébergeur » mais ce n'est évidemment pas souhaitable pour la plupart des titulaires.
Ce RFC ne spécifie qu'un mécanisme de messagerie, pas une
politique, ni une procédure détaillée. La politique est du ressort
du registre et de ses BE (via le contrat qui les lie, qui spécifie
typiquement des obligations comme « le BE perdant doit coopérer au
transfert du domaine, et mettre les nouvelles clés dans la zone
qu'il gère encore »). La procédure n'est pas décrite dans un
RFC. (Il y a eu une tentative via le
document draft-koch-dnsop-dnssec-operator-change,
mais qui n'a pas abouti. La lecture de ce document est quand même
très recommandée.) Le mécanisme de messagerie décrit dans notre RFC
est donc « neutre » : il ne suppose pas une politique
particulière. Une fois la clé transmise, sa bonne utilisation va
dépendre des règles en plus et de si elles sont obéies ou
pas. Comme le dit le RFC, « The
registry SHOULD have certain policies in place that require the
losing DNS operator to cooperate with this transaction, however this
is beyond this document. »
Les détails EPP figurent en section 2. Les clés publiques sont
dans un élément XML
<keyRelayData>. Il contient deux
éléments, <keyData>, avec la clé
elle-même (encodée en suivant la section 4 du RFC 5910), et <expiry> (optionnel) qui
indique combien de temps (en absolu ou bien en relatif) garder cette clé dans la zone. La syntaxe formelle complète figure en section 4,
en XML Schema.
Les commandes EPP liées à cette extension figurent en section
3. Certaines commandes EPP ne sont pas modifiées par cette
extension, comme check, info,
etc. La commande create, elle, est étendue
pour permettre d'indiquer la nouvelle clé (un exemple figure dans
notre RFC, section 3.2.1). Si le serveur EPP accepte cette
demande, il met la clé dans la file d'attente de messages du
client EPP qui gère le nom de domaine en question (typiquement le
BE « perdant »). Sinon, il répond pas le code de retour 2308.
La nouvelle clé apparaitra dans le système de « messagerie » d'EPP (poll queue), RFC 5730, section 2.9.2.3. Un exemple de réponse figure dans notre RFC, section 3.1.2.
Quelques points de sécurité pour finir (section 6). Un client
EPP méchant pourrait envoyer des clés à plein de gens juste pour
faire une attaque par déni de
service. C'est au serveur EPP de détecter ces abus et
d'y mettre fin. Le serveur EPP peut exiger un
authinfo correct dans le message de création,
pour vérifier que l'action a bien été autorisée par le
titulaire. Enfin, cette technique d'envoi des clés ne garantit
pas, à elle seule, que tout aura bien été fait de bout en
bout. Par exemple, le nouvel hébergeur a tout intérêt à vérifier,
par une requête DNS epxlicite, que l'ancien
a bien mis la nouvelle clé dans la zone.
Ce RFC a eu une histoire longue et compliquée, malgré une forte demande des utilisateurs. Il y a notamment eu un gros problème avec un brevet futile (comme la plupart des brevets logiciels) de Verisign, qui a fait perdre beaucoup de temps (la déclaration de Verisign est la n° 2393, le brevet lui-même est le US.201113078643.A, la décision de l'IETF de continuer malgré ce brevet, et malgré l'absence de promesses de licence, est enregistrée ici).
Question mise en œuvre, la bibliothèque Net::DRI gère déjà ce RFC. Combien de registres et de BE déploieront ce RFC ? Le coût pour le registre est probablement assez faible, puisqu'il a juste à relayer la demande, utilisant un mécanisme de « messagerie » qui existe déjà dans EPP. Mais, pour les BE, il y a certainement un problème de motivation. Ce RFC aidera le BE « gagnant », et le titulaire du domaine, mais pas le BE « perdant ». Il n'a donc pas de raison de faire des efforts, sauf contrainte explicite imposée par le registre (et l'expérience indique que ce genre de contraintes n'est pas toujours strictement respecté).
Comme bonne explication de ce RFC, vous pouvez aussi lire l'excellent explication de SIDN (avec une jolie image). En parlant de SIDN, vous pouvez noter que leur première mention d'un déploiement d'une version préliminaire de cette solution a eu lieu en 2013 (cf. leur rapport d'activité). Le même SIDN vient de publier un article de premier bilan sur ce projet.
Merci à Patrick Mevzek pour les explications, le code et les opinions.
L'article seul
RFC 8060: LISP Canonical Address Format (LCAF)
Date de publication du RFC : Février 2017
Auteur(s) du RFC : D. Farinacci (lispers.net), D. Meyer
(Brocade), J. Snijders (NTT)
Expérimental
Réalisé dans le cadre du groupe de travail IETF lisp
Première rédaction de cet article le 3 février 2017
Le protocole LISP permet d'utiliser comme identificateur ou comme localisateur aussi bien des adresses IPv4 qu'IPv6. Pour rendre les mécanismes de résolution d'identificateur en localisateur aussi génériques que possibles, ce nouveau RFC décrit un format d'adresses qui permet de gérer les deux familles d'adresses (et davantage).
Il existait des méthodes partielles pour représenter ces deux
familles. Par exemple, on peut décider de tout mettre en
IPv6 et de représenter les adresses
IPv4 sous la forme
« IPv4-mapped » (RFC 4291, section 2.5.5.2, par exemple
::ffff:192.0.2.151). Ou on pourrait, comme
c'est le cas dans les URL, représenter les
adresses sous forme texte en utilisant les
crochets pour distinguer IPv4 et IPv6 (RFC 3986, section 3.2.2, par exemple
https://192.0.2.151/
vs. https://[2001:db8:3f:ae51::78b:ff1]/). Mais
le groupe de travail à l'IETF a choisi une
solution qui traite les deux familles sur un pied d'égalité, et
est parfaitement générique (elle intégre d'autres
familles que simplement IPv4 et IPv6). La solution finalement documentée dans ce RFC est très
souple et peut servir à bien d'autres que LISP, dès qu'on veut
représenter des requêtes ou réponses d'un système d'annuaire.
À propos de familles, un terme important à retenir est celui d'AFI (Address Family Identifier). C'est un nombre identifiant la famille d'adresses utilisée. Il avait été introduit dans le RFC 2453 puis précisé dans le RFC 4760, et peut prendre plusieurs valeurs, stockées dans un registre à l'IANA (1 pour IPv4, 2 pour IPv6, etc). 0 indique une famille non spécifiée.
Le format de ces adresses LCA (LISP Canonical Address) est décrit dans la section 3 de notre RFC. L'adresse LCAF commence par l'AFI de LISP (16387) suivi de divers champs notamment la longueur totale de l'adresse et son type. Une LCA peut en effet contenir plus que des adresses IP (type 1). Elle peut aussi servir à transporter des numéros d'AS (type 3), des coordonnées géographiques (type 5), etc. La liste des types possibles est enregistrée à l'IANA. La section 4 explique les différents types et l'encodage du contenu associé.
Lorsqu'une LCA indique des adresses IP, elle utilise le type 1 : son contenu est une série de couples {AFI, adresse}. Des adresses IPv4 (AFI 1) et IPv6 (AFI 2) peuvent donc apparaitre dans cette liste (mais aussi des adresses MAC, AFI 6, lorsqu'on crée des VPN de couche 2, ou bien des noms de domaine, AFI 16). Ce seront ces LCA qui seront sans doute les plus utilisées dans les systèmes de correspondance LISP comme DDT (RFC 8111) ou ALT (RFC 6836).
Pour les numéros d'AS (type 3), la LCA contient un numéro d'AS, puis un préfixe (IPv4 ou IPv6) affecté à cet AS. Quant aux coordonnées géographiques (type 5), elles sont indiquées sous forme de latitude, longitude et altitude dans le système WGS-84. Cela permet, dans une réponse du système de correspondance LISP, d'indiquer la position physique du réseau du préfixe encodé dans la LCA. (Attention, le RFC note bien que cela a des conséquences pour la vie privée.) On peut aussi stocker des clés cryptographiques (type 11) dans une LCA (voir RFC 8111 et RFC 8061).
Les mises en œuvre existantes de LISP utilisent déjà les LCA (mais ne gèrent pas forcément tous les types officiels).
L'article seul
RFC 8058: Signaling One-Click Functionality for List Email Headers
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : J. Levine (Taughannock
Networks), T. Herkula (optivo)
Chemin des normes
Première rédaction de cet article le 31 janvier 2017
Le RFC 2369 décrit des en-têtes du
courrier électronique qui indiquent, entre
autres, comment se désabonner d'une liste de
diffusion (en-tête
List-Unsubscribe:, qui indique des
URI à activer pour se désabonner). Cela peut permettre des
désabonnements sans interaction explicite avec l'utilisateur : le
MUA voit cette en-tête, propose un bouton
« Désabonnement » à l'utilisateur, et le MUA effectue la requête
(par exemple HTTP) tout
seul. L'inconvénient est que certains logiciels (par exemple des
anti-spam) visitent automatiquement tous
les liens hypertexte présents dans les
messages, et risquent alors de désabonner l'abonné
accidentellement. Pour éviter cela, la page pointée par l'URI
présent dans List-Unsubscribe: n'est en
général pas « one-click » : il faut une action
explicite une fois cette page affichée. Ce nouveau
RFC propose des ajouts à
List-Unsubscribe: pour indiquer qu'un
désabonnement one-click est possible.
Voici un exemple de cet en-tête traditionnel
List-Unsubscribe: dans une liste de
diffusion IETF :
List-Unsubscribe: <https://www.ietf.org/mailman/options/ietf>,
<mailto:ietf-request@ietf.org?subject=unsubscribe>
La page indiquée dans l'URI HTTPS est une landing page : elle ne désabonne pas directement, il faut indiquer son adresse et sélectionner le bouton Unsubscribe. C'est acceptable quand l'utilisateur est un humain, mais pas dans les cas où il n'y a pas d'interaction possible. Imaginons un logiciel qui traite automatiquement les messages après le départ ou le décès d'un utilisateur, et qui veut donc le désabonner proprement de toutes les listes où il était abonné avec cette adresse désormais invalide. Ce logiciel doit pouvoir fonctionner sans intervention humaine, donc sans analyser une page HTML compliquée.
À noter que l'en-tête List-Unsubscribe:
ci-dessus, comme dans la plupart des cas, propose également un URI
de plan mailto:, déclenchant l'envoi d'un
message par courrier électronique. La
plupart des services qui envoient de grosses quantités de message
(les hébergeurs de listes de diffusion à grand volume) ont du mal
à gérer le flot de messages de désinscription (ils sont optimisés
pour envoyer beaucoup, pas pour recevoir beaucoup), et ce
RFC ne prend donc en compte que les URI de
plan https:.
La section 1 résume le cahier des charges de la solution présentée ici :
- Permettre aux émetteurs de courrier de signaler de manière standard et non-ambigüe qu'on peut se désabonner en un seul clic (« one-click »),
- Permettre aux auteurs de MUA de fournir une interface simple (par exemple un bouton « Désabonnement immédiat », lorsque le message lu est signalé comme le permettant),
- Permettre aux utilisateurs de se désabonner sans quitter leur MUA, sans avoir à basculer vers une page Web avec des instructions spécifiques (et, notre RFC oublie de le dire, page Web qui est souvent conçue pour décourager le désabonnement de la newsletter à la con).
La section 3 du RFC spécifie la solution retenue. Elle consiste
dans l'ajout d'un nouvel en-tête,
List-Unsubscribe-Post:, dont le contenu est un
couple clé=valeur,
List-Unsubscribe=One-Click. (Ce nouvel
en-tête a été ajouté dans le
registre IANA.) Par exemple,
l'en-tête montré plus haut deviendrait :
List-Unsubscribe: <https://www.ietf.org/mailman/options/ietf?id=66fd1aF64>,
<mailto:ietf-request@ietf.org?subject=unsubscribe>
List-Unsubscribe-Post: List-Unsubscribe=One-Click
Cela indiquerait clairement que le désabonnement en un clic est
possible. Le MUA, s'il désire effectuer le désabonnement, va alors
faire une requête HTTPS de méthode POST, en
mettant dans le corps de la requête le contenu de l'en-tête
List-Unsubscribe-Post:. Le serveur HTTPS,
s'il voit ce List-Unsubscribe=One-Click dans
la requête, doit
exécuter la requête sans poser de questions supplémentaires (le
but étant de faire un désabonnement en un seul clic).
Notez qu'il faut indiquer quelque part l'adresse à désabonner,
le serveur HTTP ne peut pas la deviner autrement. Pour rendre plus
difficile la création de fausses instructions de désabonnement,
cela se fait indirectement, via une donnée opaque, comprise
seulement du serveur (le id dans l'exemple
hypothétique ci-dessus).
Les données contenues dans le List-Unsubscribe-Post:
doivent idéalement être envoyées avec le type MIME
multipart/form-data (RFC 7578), et, sinon, en
application/x-www-form-urlencoded, comme le
ferait un navigateur Web. Bien sûr, le MUA
doit avoir la permission de l'utilisateur pour effectuer ce
désabonnement (on est en « un seul clic », pas en « zéro clic »).
Au fait, pourquoi la méthode POST ?
GET ne peut pas modifier l'état du serveur et
PUT ou DELETE sont
rarement accessibles.
Le courrier électronique n'étant pas vraiment sécurisé, il y a
un risque de recevoir des messages avec un
List-Unsubscribe-Post: mensonger. C'est
pourquoi le RFC demande (section 4) qu'il y ait un minimum
d'authentification du message. La seule
méthode d'authentification décrite est DKIM
(RFC 6376), avec une étiquette
d= identifiant le domaine. La signature DKIM
doit évidemment inclure dans les en-têtes signés les
List-Unsubscribe: et
List-Unsubscribe-Post: dans l'étiquette DKIM h=.
Avec l'exemple plus haut, la requête HTTP POST
ressemblerait à :
POST /mailman/options/ietf?id=66fd1aF64 HTTP/1.1
Host: www.ietf.org
Content-Type: multipart/form-data; boundary=---FormBoundaryjWmhtjORrn
Content-Length: 124
---FormBoundaryjWmhtjORrn
Content-Disposition: form-data; name="List-Unsubscribe"
One-Click
---FormBoundaryjWmhtjORrn--
La section 6 de notre RFC décrit les éventuels problèmes de
sécurité. En gros, il en existe plusieurs, mais tous sont en fait
des problèmes génériques du courrier électronique, et ne sont pas
spécifiques à cette nouvelle solution. Par exemple, un spammeur pourrait envoyer plein de
messages ayant l'en-tête
List-Unsubscribe-Post:, pour faire générer
plein de requêtes POST vers le pauvre
serveur. Mais c'est déjà possible aujourd'hui en mettant des URI
dans un message, avec les logiciels qui vont faire des
GET automatiquement.
Je n'ai pas encore vu cet en-tête
List-Unsubscribe-Post: apparaitre dans de
vrais messages.
Un des auteurs du RFC a écrit un bon résumé de son utilité, article qui explique bien comment fonctionne le courrier aujourd'hui.
L'article seul
RFC 8056: Extensible Provisioning Protocol (EPP) and Registration Data Access Protocol (RDAP) Status Mapping
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : J. Gould (Verisign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 18 janvier 2017
Deux protocoles utilisés dans l'industrie des noms de domaine, EPP et RDAP, ont la notion d'état d'un nom de domaine, indiquant, par exemple, que ce nom est verrouillé et ne doit pas être modifié. Mais les états de EPP et de RDAP sont différents, et pas toujours évidents à rapprocher. Ce nouveau RFC précise la correspondance entre les états EPP et les états RDAP, établissant la liste comparée.
EPP (protocole d'avitaillement d'objets dans un registre, par exemple un registre de noms de domaine) est normalisé dans divers RFC (STD 69), ceux qui décrivent les états sont les RFC 5731 (section 2.3), RFC 5732 (section 2.3), RFC 5733 (section 2.2) et RFC 3915 (section 3.1). Les états RDAP (protocole d'information sur les objets d'un registre, qui vise à remplacer whois) sont normalisés dans le RFC 9083 (section 10.2) qui crée un registre IANA des états possibles. Pourquoi des états différents dans ces deux protocoles ? Disons qu'ils ont été conçus pour des buts différents, et que la nécessité de faire correspondre les états de l'un avec ceux de l'autre n'est devenue évidente qu'après. Le but de ce nouveau RFC est justement d'établir une correspondance univoque entre les états d'EPP et de RDAP.
La section 2 de notre RFC commence par une liste des états
EPP, avec leur équivalent RDAP (quand il existe). Par exemple, il
est assez évident que le pendingDelete d'EPP
(RFC 5731) correspond au pending
delete de RDAP. De même, le ok
d'EPP est clairement l'équivalent du active
de RDAP. Mais les addPeriod (RFC 3915, durée après l'enregistrement d'un nom de domaine
pendant laquelle on peut annuler l'enregistrement gratuitement) ou
clientHold (RFC 5731,
le client a demandé que ce nom de domaine ne soit pas publié dans
le DNS)
d'EPP n'ont pas d'équivalent RDAP. L'inverse existe aussi, le
delete prohibited de RDAP n'a pas un
équivalent simple en EPP, qui a deux états pour cela, selon que
l'interdiction a été posée par le client EPP ou par le
serveur.
La section 2 du RFC se continue donc avec ce qui est désormais
la liste officielle des correspondances, en tenant compte des
nouveaux états ajoutés, par exemple dans le registre
RDAP. C'est ainsi qu'un add period et
un client hold ont été ajoutés (section 3 du RFC), ainsi qu'un
client delete prohibited et un
server delete prohibited, pour préciser le
delete prohibited.
L'article seul
RFC 8054: Network News Transfer Protocol (NNTP) Extension for Compression
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : K. Murchison (Carnegie Mellon
University), J. Élie
Chemin des normes
Première rédaction de cet article le 26 janvier 2017
Ce nouveau RFC définit un mécanisme standard de compression des news échangées en NNTP, sur Usenet.
NNTP, normalisé dans le RFC 3977 est un protocole gourmand en débit. Comprimer les données transmises est donc très souhaitable. C'est aussi un protocole très ancien, ce qui se voit dans certaines références du RFC, comme l'allusion à la compression PPP du RFC 1962 ou bien à la compression par modem comme V42bis :-)
Mais, malgré ce besoin de compression, il n'y avait pas encore
de solution standard en NNTP. Un certain nombre de mécanismes
non-standards avaient été déployés avec des noms comme XZVER,
XZHDR, XFEATURE COMPRESS,
ou MODE COMPRESS. Outre l'absence de
normalisation, ils souffraient de ne comprimer que les réponses
du serveur de news.
Compte-tenu du déploiement de plus en plus fréquent de TLS, pour assurer la confidentialité des échanges, il avait été envisagé à une époque de compter sur le mécanisme de compression de TLS (RFC 4642, remis en cause par le RFC 8143). Celui-ci présente malheureusement des dangers, qui fait que son usage est déconseillé dans beaucoup de cas (section 3.3 du RFC 7525, section 2.6 du RFC 7457, et RFC 8143). En outre, la solution de ce RFC bénéficie de davantage de souplesse : elle peut par exemple n'être activée qu'une fois l'authentification faite, pour éviter les attaques comme CRIME (voir aussi les sections 2.2.2 et 7 de notre RFC, pour tous les détails de sécurité).
Pour assurer l'interopérabilité maximale, un seul algorithme de compression est défini, et il est, logiquement, obligatoire. Cela garantit qu'un client et un serveur NNTP auront toujours cet algorithme en commun. Il s'agit de Deflate, normalisé dans le RFC 1951.
(Un petit point qui n'a rien à voir avec NNTP et la compression : comme le demandait l'Internet-Draft qui a donné naissance à notre RFC, j'ai mis un accent à la première lettre du nom d'un des auteurs, ce qui n'est pas possible dans le RFC original, cela ne le sera que lorsque le RFC 7997 sera mis en œuvre.)
Maintenant, les détails techniques (section 2 du RFC). Le
serveur doit annoncer sa capacité à comprimer en réponse à la
commande CAPABILITIES. Par exemple (C =
client, S = serveur) :
[C] CAPABILITIES
[S] 101 Capability list:
[S] VERSION 2
[S] READER
[S] IHAVE
[S] COMPRESS DEFLATE SHRINK
[S] LIST ACTIVE NEWSGROUPS
[S] .
L'annonce de la capacité est suivie de la liste des algorithmes
gérés. On trouve évidemment l'algorithme obligatoire
DEFLATE mais aussi un
algorithme non-standard (imaginaire, ce n'est qu'un exemple)
SHRINK.
Le client peut alors utiliser la commande
COMPRESS, suivie du nom d'un algorithme
(cette commande a été ajoutée
au registre IANA des commandes NNTP). Voici un exemple où
le serveur accepte la compression :
[C] COMPRESS DEFLATE
[S] 206 Compression active
(À partir de là, le trafic est comprimé)
Attention à ne pas confondre la réponse du serveur à une demande
de ses capacités, et la commande envoyée par le client (dans les
deux cas, ce sera une ligne COMPRESS DEFLATE).
Et voici un exemple où le serveur refuse, par exemple parce que la compression a déjà été activée :
[C] COMPRESS DEFLATE
[S] 502 Command unavailable
Si on utilise TLS, ce qui est évidemment recommandé pour des raisons de confidentialité et d'authentification, l'envoyeur doit d'abord comprimer, puis (si SASL est activé) appliquer SASL (RFC 4422), puis seulement à la fin chiffrer avec TLS. À la réception, c'est bien sûr le contraire, on déchiffre le TLS, on analyse SASL, puis on décomprime.
Voici un exemple d'un dialogue plus détaillé, avec TLS et compression :
[C] CAPABILITIES [S] 101 Capability list: [S] VERSION 2 [S] READER [S] STARTTLS [S] AUTHINFO [S] COMPRESS DEFLATE [S] LIST ACTIVE NEWSGROUPS [S] . [C] STARTTLS [S] 382 Continue with TLS negotiation (Négociation TLS) (Désormais, tout est chiffré) [C] CAPABILITIES [S] 101 Capability list: [S] VERSION 2 [S] READER [S] AUTHINFO USER [S] COMPRESS DEFLATE [S] LIST ACTIVE NEWSGROUPS [S] . [C] AUTHINFO USER michu [S] 381 Enter passphrase [C] AUTHINFO PASS monsieur [S] 281 Authentication accepted [C] CAPABILITIES [S] 101 Capability list: [S] VERSION 2 [S] READER [S] POST [S] COMPRESS DEFLATE [S] LIST ACTIVE NEWSGROUPS [S] . [C] COMPRESS DEFLATE [S] 206 Compression active (Désormais, toutes les données envoyées sont comprimées, puis chiffrées) [C] CAPABILITIES [S] 101 Capability list: [S] VERSION 2 [S] READER [S] POST [S] LIST ACTIVE NEWSGROUPS [S] .
Et voici deux exemples où le serveur refuse la compression. D'abord parce qu'il ne peut pas (manque de mémoire, par exemple) :
[C] COMPRESS DEFLATE [S] 403 Unable to activate compression
Et ici parce que le client essaie d'utiliser un algorithme que le serveur ne connait pas :
[C] COMPRESS SHRINK [S] 503 Compression algorithm not supported
La liste des algorithmes standards (pour l'instant réduite à un seul) est dans un registre IANA.
NNTP est un protocole dont les spécificités posent des
problèmes amusants lorsqu'on veut comprimer son trafic (section 3
du RFC). Les messages sont très divers, ce qui peut être contrariant pour une
compression fondée sur un dictionnaire. Les réponses à certaines
commandes (DATE, GROUP,
NEXT, et le CHECK du
RFC 4644) sont peu comprimables. Par contre, les réponses
à LIST, LISTGROUP ou
NEWNEWS sont facilement réduites à 25 à 40 %
de la taille originale
avec zlib.
En outre, les news envoyées sont dans des formats différents. Un article sera parfois du texte seul, relativement court (et souvent uniquement en ASCII) et se comprimera bien. Les textes plus longs sont souvent envoyés sous un format déjà comprimé et, là, le compresseur NNTP va s'essouffler pour rien. Mais il y a aussi souvent des données binaires (images, par exemple), encodées en Base64 ou uuencode. On peut souvent les réduire à 75 % de l'original. (Deflate marche bien sur des données en 8 bits mais l'encodage lui dissimule la nature 8-bitesque de ces données.) Si les données sont encodées en yEnc, elles seront moins compressibles.
Il y a apparemment au moins un logiciel serveur (INN) et un client (flnews) qui gèrent cette compression.
Merci à Julien Élie pour sa relecture attentive (et pour avoir trouvé au moins une grosse faute.)
L'article seul
RFC 8040: RESTCONF Protocol
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : A. Bierman (YumaWorks), M. Bjorklund
(Tail-f Systems), K. Watsen
(Juniper)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF netconf
Première rédaction de cet article le 1 février 2017
Pour configurer à distance un équipement réseau (par exemple un routeur ou bien un commutateur), il existait déjà le protocole NETCONF (RFC 6241). Fondé sur un échange de données en XML, il n'a pas convaincu tout le monde, qui aurait préféré un protocole REST. C'est désormais fait avec RESTCONF, décrit dans ce RFC.
RESTCONF est donc bâti sur HTTP (RFC 7230) et les opérations CRUD. Comme NETCONF, RESTCONF utilise des modèles de données décrits en YANG (RFC 7950). Il devrait donc permettre de configurer plus simplement les équipements réseau. (Les historiens noteront que l'ancêtre SNMP avait été prévu, non seulement pour lire des informations, mais également pour écrire, par exemple pour modifier la configuration d'un routeur. Cette possibilité n'a eu aucun succès. Cet échec est une des raisons pour lesquelles NETCONF a été développé.)
Les opérations CRUD sont donc faites
avec les méthodes classiques de HTTP (RFC 7231). Lire l'état de l'engin se fait
évidemment avec la méthode GET. Le modifier
se fait avec une des méthodes parmi
PUT, DELETE,
POST ou PATCH
(cf. section 4 du RFC). Les
données envoyées, ou bien lues, sont encodées, au choix, en
XML ou en JSON. À
noter que RESTCONF, conçu pour les cas relativement simples, est plus limité que NETCONF (il n'a pas de
fonction de verrou, par exemple). Il ne peut donc
pas complètement remplacer NETCONF (ainsi, si un client NETCONF a
mis un verrou sur une ressource, le client RESTCONF ne peut
pas y accéder, voir la section 1.4 du RFC). Mais le RFC fait quand
même plus de 130 pages, avec plein d'options.
La syntaxe des URL utilisés comme
paramètres de ces méthodes est spécifiée dans ce RFC en utilisant
le langage de gabarit du RFC 6570. Ainsi, dans ce langage, les URL de
Wikipédia sont décrits par
http://fr.wikipedia.org/wiki/{topic} ce qui
signifie « le préfixe
http://fr.wikipedia.org/wiki/ suivi d'une
variable (qui est le sujet de la page) ».
En connaissant le modèle de données YANG du serveur, le client peut ainsi générer les requêtes REST nécessaires.
Les exemples du RFC utilisent presque tous la configuration d'un... juke-box (le module YANG est décrit dans l'annexe A). Cet engin a une fonction « jouer un morceau » et voici un exemple de requête et réponse REST encodée en JSON où le client demande au serveur ce qu'il sait faire :
GET /top/restconf/operations HTTP/1.1
Host: example.com
Accept: application/yang-data+json
HTTP/1.1 200 OK
Date: Mon, 23 Apr 2016 17:01:00 GMT
Server: example-server
Cache-Control: no-cache
Last-Modified: Sun, 22 Apr 2016 01:00:14 GMT
Content-Type: application/yang-data+json
{ "operations" : { "example-jukebox:play" : [null] } }
L'opération play, elle, est décrite dans
l'annexe A, le modèle de données du juke-box :
rpc play {
description "Control function for the jukebox player";
input {
leaf playlist {
type string;
mandatory true;
description "playlist name";
}
leaf song-number {
type uint32;
mandatory true;
...
Autre exemple, où on essaie de redémarrer le juke-box (et,
cette fois, on encode en XML pour montrer la différence avec JSON
- notez les différents types
MIME, comme
application/yang-data+xml ou
application/yang-data+json, et le fait que la
racine est /restconf et plus /top/restconf) :
POST /restconf/operations/example-ops:reboot HTTP/1.1
Host: example.com
Content-Type: application/yang-data+xml
<input xmlns="https://example.com/ns/example-ops">
<delay>600</delay>
<message>Going down for system maintenance</message>
<language>en-US</language>
</input>
HTTP/1.1 204 No Content
Date: Mon, 25 Apr 2016 11:01:00 GMT
Server: example-server
(Le serveur a accepté - le code de retour commence par 2 - mais n'a rien à dire, d'où le corps de la réponse vide, et le code 204 au lieu de 200.)
Et voici un exemple de récupération d'informations avec
GET :
GET /restconf/data/example-jukebox:jukebox/library/artist=Foo%20Fighters/album=Wasting%20Light HTTP/1.1
Host: example.com
Accept: application/yang-data+xml
HTTP/1.1 200 OK
Date: Mon, 23 Apr 2016 17:02:40 GMT
Server: example-server
Content-Type: application/yang-data+xml
Cache-Control: no-cache
ETag: "a74eefc993a2b"
Last-Modified: Mon, 23 Apr 2016 11:02:14 GMT
<album xmlns="http://example.com/ns/example-jukebox"
xmlns:jbox="http://example.com/ns/example-jukebox">
<name>Wasting Light</name>
<genre>jbox:alternative</genre>
<year>2011</year>
</album>
Pour éviter les collisions d'édition (Alice lit une variable,
tente de l'incrémenter, Bob tente de la multiplier par deux, qui
va gagner ?), RESTCONF utilise les mécanismes classiques de HTTP,
If-Unmodified-Since:,
If-Match:, etc.
Allez, encore un exemple, je trouve qu'on comprend mieux avec des exemples, celui-ci est pour modifier une variable :
PUT /restconf/data/example-jukebox:jukebox/library/artist=Foo%20Fighters/album=Wasting%20Light HTTP/1.1
Host: example.com
Content-Type: application/yang-data+json
{
"example-jukebox:album" : [
{
"name" : "Wasting Light",
"genre" : "example-jukebox:alternative",
"year" : 2011
}
]
}
HTTP/1.1 204 No Content
Date: Mon, 23 Apr 2016 17:04:00 GMT
Server: example-server
Last-Modified: Mon, 23 Apr 2016 17:04:00 GMT
ETag: "b27480aeda4c"
Et voici un exemple utilisant la méthode
PATCH, qui avait été introduite dans le RFC 5789, pour changer l'année de l'album :
PATCH /restconf/data/example-jukebox:jukebox/library/artist=Foo%20Fighters/album=Wasting%20Light HTTP/1.1
Host: example.com
If-Match: "b8389233a4c"
Content-Type: application/yang-data+xml
<album xmlns="http://example.com/ns/example-jukebox">
<year>2011</year>
</album>
HTTP/1.1 204 No Content
Date: Mon, 23 Apr 2016 17:49:30 GMT
Server: example-server
Last-Modified: Mon, 23 Apr 2016 17:49:30 GMT
ETag: "b2788923da4c"
Et on peut naturellement détruire une ressource :
DELETE /restconf/data/example-jukebox:jukebox/library/artist=Foo%20Fighters/album=Wasting%20Light HTTP/1.1
Host: example.com
HTTP/1.1 204 No Content
Date: Mon, 23 Apr 2016 17:49:40 GMT
Server: example-server
L'URL utilisé dans la requête comprend les différentes parties habituelles d'un URL (RFC 3986) : le chemin, la requête, l'identificateur, etc. (Dans les exemples précédents, je n'ai pas mis de requête ou d'identificateur.)
Notre RFC impose HTTPS, puisque modifier la configuration d'un équipement réseau est évidemment une opération sensible. Pour la même raison, le serveur RESTCONF doit évidemment authentifier le client. La méthode recommandée est le certificat client (section 7.4.6 du RFC 5246) mais on peut aussi utiliser une autre méthode d'authentification HTTP.
L'article seul
RFC 8033: Proportional Integral Controller Enhanced (PIE): A Lightweight Control Scheme to Address the Bufferbloat Problem
Date de publication du RFC : Février 2017
Auteur(s) du RFC : R. Pan, P. Natarajan, F. Baker (Cisco Systems), G. White (CableLabs)
Expérimental
Réalisé dans le cadre du groupe de travail IETF aqm
Première rédaction de cet article le 1 mars 2017
Mais c'est quoi, ce bufferbloat (obésité du tampon ?) et pourquoi est-ce mauvais ? Le bufferbloat désigne la tendance à mettre dans les routeurs des tampons d'entrée/sortie de plus en plus gros. Cette tendance vient de la baisse du prix des mémoires, et d'un désir de pouvoir encaisser les brusques pics de trafic (bursts) qui sont fréquents sur l'Internet. Mais le bufferbloat a une conséquence négative : la latence augmente, puisque le paquet risque de devoir attendre longtemps dans un tampon qui, une fois rempli, aura du mal à se vider. Ce RFC propose donc un mécanisme de gestion des files d'attente, PIE (Proportional Integral controller Enhanced) où le routeur surveille la latence des paquets dans les tampons d'entrée/sortie, et jette des paquets, même si le tampon n'est pas plein, pour limiter la latence. Le paquet perdu dira en effet aux émetteurs de ralentir.
La latence est particulièrement à surveiller dans le cas d'applications fortement interactives comme les jeux en ligne ou la vidéoconférence. On cherche donc à diminuer la latence, pour fournir une meilleure qualité de service aux utilisateurs. PIE a fait l'objet d'analyses théoriques, de simulations, puis de mise en œuvre dans le noyau Linux, et semble aujourd'hui une solution intéressante. PIE est une solution purement locale au routeur, et ne pose donc pas de problèmes d'interopérablité : les autres routeurs avec lesquels on parle n'ont pas besoin de participer.
L'un des problèmes centraux de l'Internet a toujours été la congestion. Les paquets arrivent quand ils veulent, et peuvent dépasser la capacité du réseau. Deux solutions pour un routeur, jeter les paquets (IP est prévu pour cela, il travaille en mode datagramme), et attendre que les couches supérieures comme TCP s'en aperçoivent et ralentissent, ou bien deuxième solution, mettre les paquets dans un tampon, en attendant de pouvoir les envoyer. Ce tampon va permettre de lisser un trafic Internet qui est très irrégulier. En pratique, les deux solutions doivent être déployées : le tampon a une taille finie et, s'il est plein, il faut bien se résigner à jeter des paquets.
Comme la perte de paquets entraine un ralentissement du transfert de données (TCP va automatiquement diminuer le débit), il existe une forte demande pour limiter cette perte. La baisse des prix des mémoires permet de satisfaire cette demande, en augmentant la taille des tampons. (Voir le site Web consacré au « bufferbloat », qui contient notamment une bonne introduction au problème.)
L'effet pervers de cette augmentation de taille est que les protocoles comme TCP, ne voyant pas de perte de paquets, vont continuer à augmenter leur débit, et envoyer plein de paquets jusqu'à ce que, le tampon étant plein, le routeur commence à jeter des paquets, calmant TCP. Mais, à ce moment, il est trop tard, le tampon est plein et risque de rester plein longtemps, l'émetteur continuant à envoyer des paquets, même si c'est à un rythme réduit. Les paquets vont donc patienter dans le tampon, augmentant la latence. Et plus le tampon est grand, plus on aggrave la latence. On est donc passé de Charybde en Scylla : pour éviter les pertes de paquets, qui diminuent le débit, on a augmenté la latence. (On voit d'ailleurs que la notion de performance, dans les réseaux, est une notion compliquée. C'est pour cela que des termes flous et passe-partout comme « vitesse » ne devraient pas être employés.)
Un système de gestion de la file d'attente (AQM) va permettre de mieux contrôler le problème, en essayant de faire en sorte que les pics soudains d'activité puissent passer, tout en limitant la latence pour les transferts de longue durée. Un exemple de mécanisme d'AQM est RED, initialement proposé dans le RFC 2309 il y a dix-huit ans. RED a deux limites, il nécessite un réglage manuel de ses paramètres, et il agit sur la longueur de la file d'attente, pas sur la latence. C'est entre autre pour cela que le RFC 7567 avait demandé à ce que de nouveaux mécanismes d'AQM soient développés.
L'algorithme de ce RFC, PIE, se veut, comme RED, simple et facile à mettre en œuvre. Comme RED, son principal moyen d'action est de jeter, de manière partiellement aléatoire, des paquets avant qu'ils ne soient mis dans la file d'attente. Contrairement à RED, il agit sur la latence, pas sur la longueur de la file d'attente.
Les objectifs de PIE sont décrits dans la section 3 du RFC :
- Contrôler la latence, le paramètre qui est réellement important pour les applications,
- Essayer d'utiliser le réseau au mieux de sa capacité (si on jette trop de paquets, TCP va tellement ralentir que, certes, les tampons seront vides et la latence excellente, mais le réseau ne sera plus utilisé à fond),
- Simple à programmer et déployer (pas de réglage manuel des paramètres).
La section 4 du RFC décrit PIE, et c'est la section à lire si vous voulez mettre en œuvre PIE dans un routeur, ou simplement le comprendre complètement. L'algorithme effectue trois tâches :
- Jeter des paquets aléatoirement, avec une certaine probabilité, lors de l'arrivée dans la file d'attente,
- Mettre à jour automatiquement en permanence cette probabilité,
- Calculer la latence (puisque c'est elle qu'on veut minimiser).
La description complète originale figure dans l'article de Pan, R., Natarajan, P. Piglione, C., Prabhu, M.S., Subramanian, V., Baker, F. Steeg et B. V., « PIE: A Lightweight Control Scheme to Address the Bufferbloat Problem » en 2013. Cet algorithme suit les principes de stabilité de théorie du contrôle.
Dans cette section 4, notre RFC présente l'algorithme PIE sous
forme de texte et de pseudo-code. La
première tâche (section 4.1), jeter les paquets entrants selon une certaine
probabilité (PIE->drop_prob_) va s'exprimer :
//Safeguard PIE to be work conserving
if ( (PIE->qdelay_old_ < QDELAY_REF/2 && PIE->drop_prob_ < 0.2)
|| (queue_.byte_length() <= 2 * MEAN_PKTSIZE) ) {
return ENQUE;
else
randomly drop the packet with a probability PIE->drop_prob_.
La première branche du if est là pour éviter
du travail inutile : si la probabilité de jeter un paquet est
faible, ou bien si la file d'attente est loin d'être pleine (moins
de deux paquets en attente), ou bien si la latence est bien plus
faible que la latence visée,
dans ces cas, on le jette rien. C'est le fonctionnement idéal du
routeur, lorsque la congestion n'est qu'une menace lointaine.
La deuxième tâche, calculer automatiquement la probabilité de
jeter un paquet, est plus délicate (section 4.2). Il faut
connaitre la latence mais aussi la tendance (est-ce que la latence
tend à diminuer ou bien à augmenter). C'est ce qu'on nomme le
contrôleur Proportional Integral qui a donné
son nom à l'algorithme PIE. La formule de base (voir le
pseudo-code complet dans le RFC, notamment dans l'annexe A) est que la probabilité est la
latence (current_qdelay) multipliée par un coefficient (alpha),
augmentée de la différence entre la latence actuelle et la latence
précédente (et, donc, si la latence diminue, la probabilité sera diminuée) :
p = alpha*(current_qdelay-QDELAY_REF) +
beta*(current_qdelay-PIE->qdelay_old_);
Et la troisième tâche, le calcul de la latence, est fait en suivant la loi de Little (section 4.3) :
current_qdelay = queue_.byte_length()/dequeue_rate;
Cette formule est une estimation de la latence. On peut aussi la mesurer directement (mais cela fait plus de travail pour le routeur), par exemple en ajoutant une estampille temporelle aux paquets entrants et en la lisant à la sortie.
Ce pseudo-code n'est encore qu'une approximation du vrai algorithme. L'un des gros problèmes de tout système de gestion de la file d'attente est que le trafic Internet est sujet à de brusques pics où un grand nombre de paquets arrive en peu de temps. Cela va remplir la file et augmenter la latence, mais cela ne veut pas dire qu'il faille subitement augmenter la probabilité d'abandon de paquets (section 4.4). Donc, la première tâche, jeter certains paquets, devient :
if PIE->burst_allowance_ > 0 enqueue packet;
else randomly drop a packet with a probability PIE->drop_prob_.
if (PIE->drop_prob_ == 0 and current_qdelay < QDELAY_REF/2 and PIE->qdelay_old_ < QDELAY_REF/2)
PIE->burst_allowance_ = MAX_BURST;
Et dans la seconde, le calcul de la probabilité d'abandon de paquets, on ajoute :
PIE->burst_allowance_ = max(0,PIE->burst_allowance_ - T_UPDATE);
Cette fois, on a un PIE complet. Mais on peut, optionnellement, y ajouter certains éléments (section 5 du RFC). Le plus évident est, au lieu de jeter le paquet, ce qui fait qu'il aura été émis et transmis par les routeurs amont pour rien, de marquer les paquets avec ECN (RFC 3168). La première tâche regarde donc si le flot de données gère ECN et utilise cette possibilité dans ce cas, au lieu de jeter aveuglément :
if PIE->drop_prob_ < mark_ecnth && ecn_capable_packet:
mark packet;
else:
drop packet;
Le trafic réseau varie beaucoup dans le temps. La plupart du temps, si le réseau est bien dimensionné, il n'y a pas de problème et il serait dommage que PIE jette au hasard des paquets quand on n'est dans cette phase heureuse. Un autre ajout utile à PIE est donc une désctivation automatique quand la file d'attente est peu remplie. Un des avantages de couper complètement PIE (par rapport à simplement décider de ne pas jeter les paquets) est de gagner du temps dans le traitement des paquets.
Pour réactiver PIE quand la congestion commence, c'est un peu plus compliqué. Si PIE est coupé, il n'y a plus de calcul de la latence, et on ne peut donc pas utiliser une augmentation de la latence pour décider de remettre PIE en marche. Le RFC suggère de remettre PIE en route dès qu'on passe au-dessus d'un tiers d'occupation de la file d'attente.
Autre question délicate, les problèmes que crée le hasard. Par défaut, PIE prend ses décisions en jetant les dés. Si la latence est importante, indiquant qu'on approche de la congestion, PIE jette des paquets au hasard. Mais le hasard n'est pas prévisible (évidemment). Et il ne mène pas à une répartition uniforme des pertes de paquets. Il se peut qu'aucun paquet ne soit jeté pendant longtemps, ce qui fait que le routeur ne réagira pas à l'augmentation de la latence. Mais il se peut aussi qu'un massacre de paquets se produise à certains moments. L'utilisation du hasard mène forcément à des « séries noires » (ou à des « séries blanches »). Notre RFC propose donc un mécanisme (optionnel) de « dé-hasardisation », où un nouveau paramètre augmente avec la probabilité d'abandon de paquet, et est remis à zéro lorsqu'on jette un paquet. La décision de laisser tomber un paquet n'est prise que lorsque ce paramètre est entre deux valeurs pré-définies.
La section 6 du RFC se penche sur les problèmes concrets de mise en œuvre (programmeurs, on pense à vous). PIE peut être mis en œuvre en logiciel ou bien en matériel (sur beaucoup de routeurs, la mise en file d'attente est typiquement « plus logicielle » que le retrait de la file). PIE est simple, et peut être programmé de manière très économique (ou plus coûteuse si on met une estampille temporelle à chaque paquet, ce qui permet de mieux mesurer la latence, mais nécessite davantage de mémoire).
La deuxième tâche de PIE, recalculer la probabilité d'abandon, se fait typiquement en parallèle avec le traitement de la file d'attente. Vu le rythme d'entrée et de sortie des paquets dans un routeur moderne, ce sont des milliers de paquets qui sont passés entre deux recalculs. Le routeur ne pourra donc pas réagir instantanément.
Comme tous les bons algorithmes, PIE est évidemment plombé par un brevet, en l'occurrence deux brevets de Cisco. Cette entreprise a promis une licence gratuite et sans obligations (mais avec la classique clause de représailles, annulant cette licence si quelqu'un essaie d'utiliser ses brevets contre Cisco).
Aujourd'hui, Linux, FreeBSD (voir la page Web du projet) et d'autres mettent en œuvre PIE.
L'article seul
RFC 8032: Edwards-curve Digital Signature Algorithm (EdDSA)
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : S. Josefsson (SJD AB), I. Liusvaara (Independent)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF cfrg
Première rédaction de cet article le 25 janvier 2017
Ce RFC est la description IETF de l'algorithme de signature cryptographique EdDSA. EdDSA est en fait une famille, il prend un certain nombre de paramètres, comme la courbe elliptique Edwards utilisée et ce RFC décrit son utilisation avec les courbes Edwards25519 et Edwards448.
EdDSA n'avait apparemment été décrit auparavant que dans des publications scientifiques, ce RFC sert à la fois à avoir une référence IETF, et également à décrire EdDSA dans des termes plus familiers aux programmeurs. Pourquoi faire de l'EdDSA, d'ailleurs ? Parce que cet algorithme (ou plutôt cette famille d'algorithmes) a plusieurs avantages, notamment :
- Rapide,
- Ne nécessite pas un nombre aléatoire différent par signature (un problème qui a souvent frappé les mises en œuvres de DSA, par exemple avec la Sony Playstation),
- Clés et signatures de taille réduite.
Un site Web sur EdDSA a été créé par ses auteurs. La référence officielle d'EdDSA est l'article « High-speed high-security signatures » de D. Bernstein, N. Duif, T. Lange, P. Schwabe, P., et B. Yang. Une extension à d'autres courbes est décrite dans « EdDSA for more curves ». Sur les courbes elles-mêmes, on peut consulter le RFC 7748.
La section 3 du RFC décrit l'algorithme générique d'EdDSA. Comme il laisse ouvert pas moins de onze paramètres, on voit qu'on peut créer une vaste famille d'algorithmes se réclamant d'EdDSA. Mais, évidemment, toutes les combinaisons possibles pour ces onze paramètres ne sont pas sérieuses du point de vue de la sécurité cryptographique, et notre RFC ne décrira que cinq algorithmes spécifiques, dont ed25519 et ed448. L'algorithme générique est surtout utile pour la culture générale.
C'est parce que EdDSA est un algorithme générique (au contraire
de ECDSA) que les programmes qui
l'utilisent ne donnent pas son nom mais celui de l'algorithme
spécifique. Ainsi, OpenSSH vous permet de
générer des clés Ed25519 (ssh-keygen -t
ed25519) mais pas de clés EdDSA (ce qui ne voudrait
rien dire).
La section 4 du RFC décrit en détail un des paramètres importants de EdDSA : le choix de la fonction prehash. Celle-ci peut être l'identité (on parle alors de Pure EdDSA) ou bien une fonction de condensation cryptographique (on parle alors de Hash EdDSA).
La section 5, elle, spécifie EdDSA avec les autres paramètres, décrivant notamment Ed25519 et Ed448. Ainsi, Ed25519 est EdDSA avec la courbe Edwards25519, et une fonction prehash qui est l'identité. (Pour les autres paramètres, voir le RFC.) L'algorithme Ed25519ph est presque identique sauf que sa fonction prehash est SHA-512.
Comme tout algorithme de cryptographie, il faut évidemment beaucoup de soin quand on le programme. La section 8 du RFC contient de nombreux avertissements indispensables pour le programmeur. Un exemple typique est la qualité du générateur aléatoire. EdDSA n'utilise pas un nombre aléatoire par signature (la plaie de DSA), et est déterministe. La sécurité de la signature ne dépend donc pas d'un bon ou d'un mauvais générateur aléatoire. (Rappelons qu'il est très difficile de faire un bon générateur aléatoire, et que beaucoup de programmes de cryptographie ont eu des failles de sécurité sérieuses à cause d'un mauvais générateur.) Par contre, la génération des clés, elle, dépend de la qualité du générateur aléatoire (RFC 4086).
Il existe désormais pas mal de mises en œuvre d'EdDSA, par
exemple dans OpenSSH cité plus haut. Sinon,
les annexes A et B du RFC contiennent une mise en œuvre en
Python d'EdDSA. Attention, elle est conçue
pour illustrer l'algorithme, pas forcément pour être utilisée en
production. Par exemple, elle n'offre aucune protection contre les
attaques exploitant la différence de temps de calcul selon les
valeurs de la clé privée (cf. la section 8.1). J'ai extrait ces deux
fichiers, la bibliothèque eddsalib.py et le
programme de test eddsa-test.py (ils nécessitent
Python 3). Le programme de test prend comme entrée un fichier
composé de plusieurs vecteurs de test,
chacun comprenant quatre champs, séparés par des
deux-points, clé secrète, clé publique, message et
signature. La section 7 du RFC contient des vecteurs de
test pour de nombreux cas. Par exemple, le test 2 de la section 7.1 du RFC s'écrit
4ccd089b28ff96da9db6c346ec114e0f5b8a319f35aba624da8cf6ed4fb8a6fb:3d4017c3e843895a92b70aa74d1b7ebc9c982ccf2ec4968cc0cd55f12af4660c:72:92a009a9f0d4cab8720e820b5f642540a2b27b5416503f8fb3762223ebdb69da085ac1e43e15996e458f3613d0f11d8c387b2eaeb4302aeeb00d291612bb0c00
et l'exécution du programme de test affiche juste le numéro de
ligne quand tout va bien :
% python3 eddsa-test.py < vector2.txt
1
On peut aussi utiliser des tests plus détaillés comme ce fichier de vecteurs de test :
% python3 eddsa-test.py < sign.input 1 2 3 ... 1024
Si on change le message, la signature ne correspond évidemment plus et le programme de test indique une assertion erronée :
% python3 eddsa-test.py < vector2-modified.txt
1
Traceback (most recent call last):
File "eddsa-test.py", line 30, in <module>
assert signature == Ed25519.sign(privkey, pubkey, msg)
AssertionError
L'article seul
RFC 8027: DNSSEC Roadblock Avoidance
Date de publication du RFC : Novembre 2016
Auteur(s) du RFC : W. Hardaker
(USC/ISI), O. Gudmundsson
(CloudFlare), S. Krishnaswamy
(Parsons)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 4 décembre 2016
Normalement, en 2016, tous les résolveurs DNS sérieux devraient valider avec DNSSEC. Mais ce n'est pas le cas. Il y a plusieurs raisons à cela, mais ce nouveau RFC se focalise sur un problème précis : le cas d'un résolveur connecté via un réseau pourri, non-neutre, et qui se permet d'interférer avec le transport des paquets IP, menant le résolveur à de sérieuses difficultés. Comment détecter ces réseaux pourris ? Et que faire pour valider quand même ?
Si le résolveur est une grosse machine dans un centre de données, connectée directement à des opérateurs neutres, il n'y a pas trop de problème. C'est le cas des résolveurs des FAI, par exemple. Mais la situation est bien moins favorable à M. Michu. Si celui-ci veut, à juste titre, avoir son propre résolveur DNS sur sa machine, il dépend des réseaux où on laisse M. Michu se connecter, et ceux-ci sont rarement neutres. (Le RFC couvre le cas où ce résolveur local fait suivre - forwarde - les requêtes à un autre résolveur, et celui où il parle directement aux serveurs faisant autorité.)
La section 1.2 du RFC décrit les cas où la validation DNSSEC va être difficile ou impossible :
- Résolveur qui ne connait pas DNSSEC (évidemment),
- Intermédiaires (relais DNS dans la box, par exemmple), qui viole le protocole DNS au point de gêner le fonctionnement de DNSSEC (ce cas est décrit en détail dans le RFC 5625),
- Équipements réseau actifs qui modifient ou bloquent les messages DNS, par exemple en supprimant les signatures DNSSEC (beaucoup de « firewalls » sont dans ce cas),
- Réseau qui ne gère pas correctement les fragments, ce qui est plus fréquent avec DNSSEC.
Bien des outils ont été développés pour contourner ces problèmes, comme dnssec-trigger.
Pour faire des tests des résolveurs et de tous les équipements
intermédiaires qui peuvent poser des problèmes de validation
DNSSEC dans certains cas, le RFC parle d'une zone de test nommée
test.example.com. Elle n'existe pas en vrai
mais, aujourd'hui, la zone
test.dnssec-tools.org fait la même chose
(elle est par exemple utilisée pour les travaux pratiques lors de
la formation DNSSEC chez HSC). Cette zone
est délibérement peuplée avec des noms mal signés. Ainsi, le nom
badsign-aaaa.test.dnssec-tools.org a un
enregistrement AAAA dont la signature a été modifiée, la rendant
invalide. Testons (pour tous les tests, comme le but était de voir
le comportement DNSSEC, j'ai utilisé un fichier de configuration
~/.digrc contenant +dnssec
+multiline, merci à Landry Minoza de l'avoir remarqué) :
% dig AAAA badsign-aaaa.test.dnssec-tools.org
; <<>> DiG 9.9.5-9+deb8u8-Debian <<>> AAAA badsign-aaaa.test.dnssec-tools.org
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 60910
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;badsign-aaaa.test.dnssec-tools.org. IN AAAA
;; Query time: 3759 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Sun Dec 04 17:12:28 CET 2016
;; MSG SIZE rcvd: 63
% dig +cd AAAA badsign-aaaa.test.dnssec-tools.org
; <<>> DiG 9.9.5-9+deb8u8-Debian <<>> +cd AAAA badsign-aaaa.test.dnssec-tools.org
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 29404
;; flags: qr rd ra cd; QUERY: 1, ANSWER: 2, AUTHORITY: 3, ADDITIONAL: 5
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;badsign-aaaa.test.dnssec-tools.org. IN AAAA
;; ANSWER SECTION:
badsign-aaaa.test.dnssec-tools.org. 86400 IN AAAA 2001:470:1f00:ffff::1
badsign-aaaa.test.dnssec-tools.org. 86400 IN RRSIG AAAA 5 4 86400 (
20170101064820 20161202054820 19442 test.dnssec-tools.org.
nZ8bPLBleW/sW6x135+Iz4IhO6Lr04V8C9fC1bMVfCVY
3rKqbOoBk1i+wnnGDCTWQ5iCicWTKLIpbDmCSW9C33pj
P2j7C/ensspbdwpD/7Ia8zN+XUSN+ThLU6lgYGKFuoVL
QmIG/vr1lOn6xdjXY2E4mStAjaGuertvKKDYy/I= )
;; AUTHORITY SECTION:
test.dnssec-tools.org. 280 IN NS dns1.test.dnssec-tools.org.
test.dnssec-tools.org. 280 IN NS dns2.test.dnssec-tools.org.
test.dnssec-tools.org. 280 IN RRSIG NS 5 3 86400 (
20170101064820 20161202054820 19442 test.dnssec-tools.org.
AK95JOAuvfZ1ZwEsrKiR8DP1zluoBvBkXHRXa78rrK5U
UuZdLnZwnYlnNplrZZOrQNuUaPyb4zI0TGfw/+aa/ZTU
qyx8uQODSHuBTPQTlcmCFAfTIyd1Q+tSTEs2TuGUhjKe
H9Hk+w6yOjI/o52c2OcTMTJ4Jmt2GlIssrrDlxY= )
;; ADDITIONAL SECTION:
dns1.test.dnssec-tools.org. 280 IN A 168.150.236.43
dns2.test.dnssec-tools.org. 280 IN A 75.101.48.145
dns1.test.dnssec-tools.org. 86400 IN RRSIG A 5 4 86400 (
20170101064820 20161202054820 19442 test.dnssec-tools.org.
zoa0V/Hwa4QM0spG6RlhGM6hK3rQVALpDve1rtF6NvUS
Sb6/HBzQOP6YXTFQMzPEFUza8/tchYp5eQaPBf2AqsBl
i4TqSjkIEklHohUmdhK7xcfFjHILUMcT/5AXkEStJg7I
6AqZE1ibcOh7Mfmt/2f0vj2opIkz6uK740W7qjg= )
dns2.test.dnssec-tools.org. 86400 IN RRSIG A 5 4 86400 (
20170101064820 20161202054820 19442 test.dnssec-tools.org.
hGq7iAtbHrtjCYJGMPQ3fxijhu4Izk8Ly+xZOa0Ag24R
lqpFgdd2amDstFVLTRs3x15UqQIO+hmFdlbSOterDkbg
/o2/FhtZOJr7c75Pu3EWi/DDbT9pULk4Uwjlie1QBopv
LLZ94SlqKO7eQ02NRyy5EL4gD2G5rSffsUqEkj8= )
;; Query time: 206 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Sun Dec 04 17:12:44 CET 2016
;; MSG SIZE rcvd: 885
Le second test, celui fait avec le bit CD (Checking Disabled), montre que le problème vient bien de DNSSEC. Autre test, avec une signature expirée :
% dig A pastdate-a.test.dnssec-tools.org
...
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 46319
...
% dig +cd A pastdate-a.test.dnssec-tools.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49547
;; flags: qr rd ra cd; QUERY: 1, ANSWER: 2, AUTHORITY: 3, ADDITIONAL: 5
...
;; ANSWER SECTION:
pastdate-a.test.dnssec-tools.org. 86400 IN A 64.90.35.104
pastdate-a.test.dnssec-tools.org. 86400 IN RRSIG A 5 4 86400 (
20161201224321 20161101234821 19442 test.dnssec-tools.org.
lIL0zcEZpG/4uG5hImvpivH1C/D3PFI3RNYHlPbZ [...]
La liste de tous les noms à tester est en ligne.
Le but de ce RFC est de lister tous les tests que peut et devrait faire un validateur local, pour arriver à valider malgré des résolveurs amont, ou bien un réseau, hostile. Ces stratégies sont mises en œuvre, par exemple, dans dnssec-trigger.
En détectant la non-conformité (compliance, un terme à la mode dans les organisations), le validateur situé sur la machine terminale, ou bien dans le réseau local, peut alors adopter la meilleure stratégie de contournement (ou, dans le pire des cas, prévenir loyalement l'utilisateur qu'on ne pourra pas faire de validation DNSSEC). Les tests doivent être faits au début d'une nouvelle connexion réseau, ou bien lorsque celle-ci change.
La section 3 du RFC est consacrée à ces tests de
non-conformité. Je ne vais pas décrire la totalité de ces tests,
un sous-ensemble suffira. Ainsi, le premier test, le plus trivial,
est que la machine puisse parler en UDP à son résolveur attitré (celui
typiquement reçu en DHCP). On lui demande
good-a.test.dnssec-tools.org et on doit avoir
une réponse sous forme d'une adresse IP (comme son nom l'indique, ce nom est correctement
signé). Si un test aussi trivial ne marche pas, ce n'est sans
doute pas la peine d'aller plus loin. Un peu plus subtil, on teste
le même résolveur en TCP.
Après, on passe à EDNS (RFC 6891), qui est indispensable pour DNSSEC. Une requête pour ce même nom, mais avec une option EDNS, doit passer. Si EDNS ne marche pas, on peut arrêter, DNSSEC ne marchera pas non plus. Mais s'il marche ? On teste alors avec le bit DO (DNSSEC OK) qui indique au serveur qu'il doit envoyer les données DNSSEC, notamment les signatures. La réponse doit inclure ce même bit DO. (C'est plus tard qu'on teste qu'on a bien reçu des signatures. Rappelez-vous que la plupart des middleboxes sont horriblement boguées. Certaines acceptent le bit DO et le renvoient, sans pour autant transmettre les signatures.)
On teste alors des zones qu'on sait signées et on regarde si le
résolveur met le bit AD (Authentic Data), au
moins pour les algoritmes RSA
+ SHA-1 et RSA +
SHA-256. Si cela ne marche pas, ce n'est
pas forcément une erreur fatale, puisque, de toute façon, on
voulait faire la validation nous-même. Il faut aussi penser à
faire le test inverse : un résolveur validant doit mettre le bit
AD pour une réponse signée correctement, et doit répondre avec le
code de retour SERVFAIL (Server Failure) si la
réponse devrait être signée mais ne l'est pas, ou bien l'est
mal. Cela se fait en testant badsign-a.test.dnssec-tools.org.
Dans les enregistrements DNSSEC, il n'y a pas que les
signatures (RRSIG), il y a aussi les enregistrements servant à
prouver la non-existence, NSEC et NSEC3. Il faut donc également
tester qu'ils sont reçus car, en pratique, on voit en effet des
middleboxes qui laissent passer les RRSIG mais
bloquent stupidement les NSEC et les NSEC3. On demande donc
non-existent.test.dnsssec-tools.org, et on
doit récupérer non seulement une réponse avec le code NXDOMAIN
(No Such Domain) mais également les NSEC ou
NSEC3 permettant de valider cette réponse :
% dig AAAA non-existent.test.dnsssec-tools.org
[...]
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 40218
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 8, ADDITIONAL: 1
[...]
;; AUTHORITY SECTION:
h9p7u7tr2u91d0v0ljs9l1gidnp90u3h.org. 900 IN NSEC3 1 1 1 D399EAAB (
H9PARR669T6U8O1GSG9E1LMITK4DEM0T
NS SOA RRSIG DNSKEY NSEC3PARAM )
iruevfos0vs8jssfj22me5p458p0qj1e.org. 900 IN RRSIG NSEC3 7 2 86400 (
20161222153046 20161201143046 3947 org.
kgCZC/gE4ySP7eZUb1+2ORYRhTrvL5YBIHLCBK5F8pqK
MXGJXJ/hX+8LLrg4jHJaER2AelUgUGywRn4uY80ajYpg
eTuSGzRX1aVCKAR8UB80bX/YLUPUPKWOdfgxTekD4nZk
eoi/9JNmIMZRc0cmMGp8LSVMqX98F2bVJnZro8U= )
iruevfos0vs8jssfj22me5p458p0qj1e.org. 900 IN NSEC3 1 1 1 D399EAAB (
IRVVBMC65HCBCFQNQS8NQFTAB943LCFU
NS DS RRSIG )
vaittv1g2ies9s3920soaumh73klnhs5.org. 900 IN RRSIG NSEC3 7 2 86400 (
20161222153046 20161201143046 3947 org.
Nj/zvU0GB8vQ7bFfpSSWW+inE7RiOFjOpNc1K/TMnQqG
QsKTLD9gBM8vgh3K1WdPXOCzthf/isDJAy2xLA/oRFFq
KZ+Coo+33FManVmuyndGJ5bdgQqnpa0xGP7yOgjTfUsh
Ff9HkX0mkzqYtWYzw0J7WnMPcOjmrlg26WsfwlU= )
vaittv1g2ies9s3920soaumh73klnhs5.org. 900 IN NSEC3 1 1 1 D399EAAB (
VAJB898DELVT5UJ4I9D1BRD2FRTBSCM1
NS DS RRSIG )
Certains serveurs DNS (ou, plus exactement, certains ensembles serveur+réseau+middlebox) n'acceptent que certains types d'enregistrement DNS (les plus connus, comme A, AAAA, MX, parfois SRV, etc). Il faut donc tester que le serveur accepte bien tous les types d'enregistrement,
Jusqu'à présent, on n'a testé que le résolveur « normal ». Même s'il ne valide pas, tant qu'il transmet fidèlement toutes les données DNS, on pourra au moins l'utiliser comme relais et cache. Par contre, dans certains cas, si on veut valider avec DNSSEC, il faudra complètement le court-circuiter. Ainsi, s'il ne transmet pas les signatures, on n'a pas d'autre choix que d'aller les demander à un autre résolveur, ou bien directement aux serveurs faisant autorité. Il faut donc tester qu'on puisse interroger ces serveurs, avec UDP et avec TCP. (Ce n'est pas toujours possible, certains réseaux violent tellement la neutralité de l'Internet qu'ils bloquent le port 53, celui du DNS.)
Avec DNSSEC, les réponses sont souvent de grande taille, et parfois fragmentées. Il faut donc tester que les fragments passent (ils sont souvent bloqués par des administrateurs réseau incompétents).
Une fois ces tests faits, il reste à synthétiser les résultats (section 4). L'idée est de pouvoir dire si le résolveur « normal » est :
- Un validateur (on peut alors tout lui déléguer, en tout cas si on a confiance en lui),
- Un résolveur DNSSEC (même s'il ne valide pas, il passe bien tous les enregistrements DNSSEC),
- Une horreur à fuir.
En pratique, tous les résolveurs (ou plutôt l'ensemble du résolveur et du réseau situé devant, avec ses middleboxes qui cassent tout) ne rentrent pas parfaitement dans une de ces trois catégories. Ainsi, certains vont bloquer les fragments mais accepter TCP (ce qui permettra de quand même faire passer les données de grande taille), tandis que d'autres n'auront pas TCP mais qu'UDP fonctionnera bien, même en cas de fragmentation.
Une fois ces données collectées, et le résolveur correctement classé, on pourra alors déterminer comment contourner les éventuels problèmes (section 5 du RFC). Par exemple :
- Si le résolveur officiel est un validateur ou bien un résolveur DNSSEC, on l'utilise comme forwarder pour transmettre les requêtes, profitant ainsi de son cache et réduisant la charge sur les serveurs faisant autorité.
- Si le résolveur officiel est une horreur, mais que les requêtes DNS vers l'extérieur marchent, alors, ne pas faire appel au résolveur officiel et parler directement aux serveurs faisant autorité.
- Si le résolveur officiel est une horreur, et que les
requêtes DNS vers l'extérieur sont bloquées, tenter de joindre
un résolveur extérieur de confiance, en utilisant DNS sur TLS
(RFC 7858), ce que fait dnssec-trigger (dans son fichier
de configuration, des lignes comme
tcp80: 185.49.140.67oussl443: 185.49.140.67 ...). - Sinon, si rien ne marche, laisser tomber, prévenir l'utilisateur et pleurer.
La section 6 du RFC sert de voiture-balai, en mentionnant les
cas spéciaux qui peuvent être embêtants. Par exemple, DNSSEC
dépend de l'horloge, puisqu'il faut vérifier que les signatures
n'ont pas expiré. Mais la synchronisation de l'horloge dépend de
NTP donc parfois du
DNS si on a mis des noms de domaine dans son
ntp.conf. Si la machine a une horloge assez
stable pour garder l'heure entre un arrêt et un démarrage, ce
n'est pas trop grave. Mais si la machine est un engin bon marché
avec une horloge qui dévie beaucoup (genre le Raspberry
Pi), que faire ?
Autre problème, les affreux portails captifs. Tant qu'on n'a pas cliqué sur « j'accepte cinquante pages de conditions d'utilisation que je n'ai pas lues, je veux recevoir du spam, et je promets de ne pas partager de la culture », on n'a pas un vrai accès Internet et le port 53 est sans doute bloqué. Il faudrait donc refaire les tests après le passage par le portail captif.
Face à ce genre de problèmes, une première solution est de ne pas tenter de faire du DNSSEC tant qu'on n'a pas synchronisé l'horloge, passé le portail captif (c'est ce que fait dnssec-trigger), au détriment de la sécurité. Au moins, on peut prévenir l'utilisateur et lui proposer de réessayer plus tard.
L'article seul
RFC 8023: Report from the Workshop and Prize on Root Causes and Mitigation of Name Collisions
Date de publication du RFC : Novembre 2016
Auteur(s) du RFC : Matthew Thomas, Allison Mankin, Lixia Zhang (UCLA)
Pour information
Première rédaction de cet article le 27 novembre 2016
Ce nouveau RFC est le compte-rendu d'un atelier qui s'était tenu du 8 au 10 mars 2014 à Londres sur le thème des « collisions ». Ce terme exagéré et sensationnaliste désigne le phénomène qui peut se produire quand un acteur de l'Internet a bêtement choisi de se créer un TLD à lui dans le DNS, et que ce TLD est ensuite créé par l'ICANN.
Supposons que l'entreprise Bidon décide de nommer ses
ressources internes (site Web réservé aux employés, etc) sous le
TLD inexistant
.bidon. C'est une
mauvaise idée mais elle est fréquente. L'entreprise Bidon
compte sur le fait que ses employés utiliseront les résolveurs DNS
internes, qui ont été configurés pour reconnaître
.bidon. Par exemple, avec
Unbound, et un serveur faisant autorité en 2001:db8:666::1:541f, les résolveurs ont été configurés
ainsi :
stub-zone:
name: "bidon"
stub-addr: 2001:db8:666::1:541f
Si un employé
tente accidentellement d'accéder à une ressource en
.bidon, alors qu'il n'utilise pas les
résolveurs de la boîte, la requête filera vers la racine du
DNS, qui répondra
NXDOMAIN (No Such
Domain). C'est ainsi que la racine voit souvent des
requêtes pour des noms se terminant en
.local, .home ou
.belkin. Si, quelques années après,
l'ICANN délègue effectivement ce TLD à une
autre organisation, ces requêtes à la racine donneront désormais
un vrai résultat. Au lieu d'un message d'erreur, le malheureux
employé sera peut-être redirigé vers un autre site Web que celui
attendu. C'est ce phénomène que Verisign
avait baptisé « collision » (name collision),
terme conçu pour faire peur.
C'est dans ce contexte qu'il y a plus de deux ans s'était tenu le « Workshop on Root Causes and Mitigation of Name Collisions », dont ce RFC est le compte-rendu tardif. Le premier rapport de l'ICANN qui mentionnait ce phénomène était le SAC 045 en 2010. Il pointait le risque que la délégation effective d'un nouveau TLD change la réponse obtenue, pour les clients mal configurés (qui interrogeaient à tort un résolveur extérieur, et donc la racine, au lieu de leurs résolveurs internes).
L'ICANN a même créé une page Web
dédiée à cette question, dont la source réelle est le
recouvrement de deux espaces de noms, l'interne et
l'externe. La bonne pratique idéale serait de ne pas utiliser de
noms qui n'existent pas ou, pire, qui existent avec une autre
signification dans l'arbre public des noms de domaine (et, là, relire le RFC 2826 peut aider). Pour reprendre l'exemple de
l'entreprise Bidon, si elle est titulaire de
bidon.fr, elle devrait nommer ses ressources
internes avec des noms se terminant en
privé.bidon.fr ou
interne.bidon.fr. Si on ne veut pas faire les
choses proprement, et qu'on utilise quand même le TLD inexistant
.bidon, alors il faut veiller très
soigneusement à séparer les deux espaces de nommage et à éviter
qu'ils ne se rencontrent un jour (ce qui est difficile à l'ère des
mobiles, avec des appareils qui rentrent et qui sortent du réseau
de l'entreprise). Sinon, on verra ces fameuses collisions.
En pratique, pas mal d'administrateurs système surestiment leurs compétences et croient qu'ils vont réussir à empêcher toute fuite vers le DNS public. C'est ce qui explique une partie des requêtes pour des noms inexistants que reçoit la racine (ces noms inexistants forment la majorité du trafic des serveurs racine du DNS). Un des problèmes de fond de l'Internet est en effet que l'administrateur de base ne se tient pas au courant et n'est pas informé des problèmes du monde extérieur. « Après moi, le déluge »
Autrefois, le problème était surtout théorique. Le nombre de
TLD n'avait pas bougé depuis de très
nombreuses années, et personne ne pensait que des TLD comme
.pizza ou .green
verraient le jour. Mais, en 2012, l'ICANN a
lancé officiellement son programme d'ajout d'un grand nombre de
TLD, et le risque est soudain devenu une question pratique. D'où
l'atelier de 2014.
La section 2 du RFC revient en détail sur l'arrière-plan de ce
problème de collision. Outre le rapport SAC 045 cité plus haut, il
y avait eu une
déclaration de l'IAB, puis un autre rapport du
SSAC (Security and Stability Advisory
Committee, un comité de l'ICANN), le SAC 046,
une déclaration
du RSSAC et plein d'autres textes sur les conséquences d'un
agrandissement important de la zone racine. Par exemple, le rapport SAC 057 faisait remarquer que les
AC attribuaient souvent des certificats
pour des noms de domaine dans des TLD
purement locaux. Cela montrait le déploiement de ces TLD privés et
cela inquiétait. Si la société Bidon exploite
.bidon et obtient d'une AC un certificat pour
www.compta.bidon, après la délégation de ce
même TLD dans la racine publique, ce certificat pourrait être
utilisé pour usurper l'identité d'un autre serveur.
J'ai parlé plus haut des fuites vers le DNS public. Quelle est
leur ampleur exacte ? Ce n'est pas si évident que cela de le
savoir. Contrairement à un raccourci journalistique fréquent,
l'ICANN ne gère pas la racine. Chaque opérateur d'un
serveur DNS racine se débrouille
indépendamment, supervise son serveur mais ne rend pas forcément
compte à d'autres acteurs ou au public. En pratique, les
opérateurs des serveurs racine ont un niveau d'ouverture très
variable. (Cf. l'analyse
de l'ICANN à ce sujet.) Un des moments où plusieurs
opérateurs de serveurs racine collectent en même temps de
l'information est le Day in the Life of the
Internet et c'est sur la base de ces données qu'a
été fait le rapport d'Interisle « Name
Collision in the DNS ». Entre autres, ce rapport
classait les futurs TLD selon qu'ils présentaient un risque de
collision élevé ou faible (.home,
.corp et .site se
retrouvaient en tête du classement). L'ICANN a alors publié un plan pour gérer ce risque de
collisions, notant que .home et
.corp étaient de loin les plus « risqués »,
car ils sont fréquemment utilisés comme TLD locaux. Bien d'autres
documents ont été publiés par l'ICANN, qui a une productivité
extraordinaire lorsqu'il s'agit de faire de la paperasse. Le
dernier
mettait en place le système dit de « controlled
interruption » qui, en gros, impose à tous les nouveaux
TLD de résoudre, pendant les premiers temps de leur délégation,
tous les noms de domaine vers l'adresse IP
127.0.53.53. Voici l'exemple de
.box en novembre 2016 (ce cas avait fait
l'objet d'un
article de Heise en allemand, car le routeur
Fritz!Box, très populaire en Allemagne,
utilisait ce TLD) :
% dig ANY box.
; <<>> DiG 9.10.3-P4-Debian <<>> ANY box.
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 14573
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 24, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;box. IN ANY
;; ANSWER SECTION:
box. 3600 IN A 127.0.53.53
box. 3600 IN SRV 10 10 0 your-dns-needs-immediate-attention.box.
box. 3600 IN TXT "Your DNS configuration needs immediate attention see https://icann.org/namecollision"
box. 3600 IN MX 10 your-dns-needs-immediate-attention.box.
box. 900 IN SOA a.nic.box. support.ariservices.com. (
1478481375 ; serial
1800 ; refresh (30 minutes)
300 ; retry (5 minutes)
1814400 ; expire (3 weeks)
1800 ; minimum (30 minutes)
)
box. 172800 IN NS b.nic.box.
box. 172800 IN NS d.nic.box.
box. 172800 IN NS c.nic.box.
box. 172800 IN NS a.nic.box.
[...]
;; Query time: 89 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Mon Nov 21 17:23:17 CET 2016
;; MSG SIZE rcvd: 2938
Ces enregistrements ont pour but d'attirer l'attention des
utilisateurs sur le risque de collision. Le TLD étant récent et
pas encore peuplé, il ne devrait pas y avoir de requêtes DNS. S'il
y en a quand même, c'est peut-être le résultat d'une
collision avec un usage local. L'adresse IP
127.0.53.53 est une adresse locale à la
machine. Si M. Michu tente de se connecter à
http://quelquechose.box/ aujourd'hui, il sera
redirigé vers la machine locale. Il verra une erreur (pas de
serveur HTTP qui écoute) ou bien la page
Web par défaut de sa machine (avec un message peu informatif comme
« It works ») s'il y a un serveur HTTP. Si
l'utilisateur regarde les enregistrements SRV, MX ou TXT, ou bien
si un administrateur système regarde les
requêtes DNS qui passent, ou bien les
journaux du serveur de messagerie,
peut-être comprendra-t-il qu'il doit agir. (Je trouve
personnellement que la probabilité que cela arrive est assez faible.)
L'atelier lui-même, financé par Verisign (l'entreprise qui avait le plus crié « au loup » sur les name collisions), s'est donc tenu du 8 au 10 mars à Londres. Un site Web avait été mis en place pour cet atelier, et il contient les supports et les vidéos.
Je ne vais pas décrire tous les exposés de l'atelier, la liste complète figure dans l'annexe C du RFC, et les supports sont en ligne. Le RFC note qu'il y a eu plusieurs interventions sur la qualité des données du DITL (Day in the Life of the Internet) : il est trivial de les polluer (le DITL est annoncé publiquement, et à l'avance) par des requêtes artificielles. Aucune preuve n'a été trouvée d'une manipulation délibérée. De toute façon, les données montrent surtout qu'il y a beaucoup de n'importe quoi dans le trafic que reçoivent les serveurs racine (par exemple des requêtes avec le bit RD - Recursion Desired - alors que les serveurs de la racine ne sont pas récursifs). Cela peut être le résultat de bogues dans les résolveurs, de tests ou bien d'attaques délibérées.
La question de l'éducation des utilisateurs est revenue plusieurs fois. Faut-il s'inspirer du téléphone ou du système postal, qui ont tous les deux connu des changements qui nécessitaient une adaptation de l'utilisateur, qui s'est faite par le biais d'importantes campagnes de sensibilisation et d'éducation ?
Le comité de programme avait conclu que le sujet était loin d'être épuisé. Manque de données, manque de théories explicatives, manque d'intérêt pour la question, en tout cas, celle-ci restait largement ouverte après l'atelier (et je ne suis personnellement pas sûr que cela soit mieux aujourd'hui, plus de deux ans après l'atelier de Londres).
L'article seul
RFC 8021: Generation of IPv6 Atomic Fragments Considered Harmful
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : F. Gont (SI6 Networks /
UTN-FRH), W. Liu (Huawei
Technologies), T. Anderson (Redpill
Linpro)
Pour information
Première rédaction de cet article le 7 janvier 2017
C'est quoi, un « fragment atomique » ? Décrits dans le RFC 6946, ces charmants objets sont des datagrammes IPv6 qui sont des fragments... sans en être. Ils ont un en-tête de fragmentation sans être fragmentés du tout. Ce RFC estime qu'ils ne servent à rien, et sont dangereux, et devraient donc ne plus être générés.
Le mécanisme de fragmentation d'IPv6 (assez différent de celui d'IPv4) est décrit dans le RFC 2460, sections 4.5 et 5. Que se passe-t-il si un routeur génère un message ICMP Packet Too Big (RFC 4443, section 3.2) en indiquant une MTU inférieure à 1 280 octets, qui est normalement la MTU minimale d'IPv6 ? (Le plus beau, c'est que ce routeur n'est pas forcément en tort, cf. RFC 6145, qui décrivait leur utilisation pour être sûr d'avoir un identificateur de datagramme.) Eh bien, dans ce cas, l'émetteur du datagramme trop gros doit mettre un en-tête « Fragmentation » dans les datagrammes suivants, même s'il ne réduit pas sa MTU en dessous de 1 280 octets. Ce sont ces datagrammes portant un en-tête « Fragmentation » mais pas réellement fragmentés (leur bit M est à 0), qui sont les fragments atomiques du RFC 6946.
Malheureusement, ces fragments atomiques permettent des attaques contre les machines IPv6 (section 2 du RFC). Il existe des attaques liées à la fragmentation (RFC 6274 et RFC 7739). Certaines nécessitent que les datagrammes soient réellement fragmentés mais ce n'est pas le cas de toutes : il y en a qui marchent aussi bien avec des fragments atomiques. Un exemple d'une telle attaque exploite une énorme erreur de certaines middleboxes, jeter les datagrammes IPv6 ayant un en-tête d'extension, quel qu'il soit (y compris, donc, l'en-tête Fragmentation). Ce comportement est stupide mais hélas répandu (cf. RFC 7872). Un attaquant peut exploiter cette violation de la neutralité du réseau pour faire une attaque par déni de service : il émet des faux messages ICMP Packet Too Big avec une MTU inférieur à 1 280 octets, la source se met à générer des fragments atomiques, et ceux-ci sont jetés par ces imbéciles de middleboxes.
Le RFC décrit aussi une variante de cette attaque, où deux pairs BGP jettent les fragments reçus (méthode qui évite certaines attaques contre le plan de contrôle du routeur) mais reçoivent les ICMP Packet Too Big et fabriquent alors des fragments atomiques. Il serait alors facile de couper la session entre ces deux pairs. (Personnellement, le cas me parait assez tiré par les cheveux...)
Ces attaques sont plus faciles à faire qu'on ne pourrait le croire car :
- Un paquet ICMP peut être légitimement émis par un routeur intermédiaire et l'attaquant n'a donc pas besoin d'usurper l'adresse IP de la destination (donc, BCP 38 ne sert à rien).
- Certes, l'attaquant doit usurper les adresses IP contenues dans le message ICMP lui-même mais c'est trivial : même si on peut en théorie envisager des contrôles du style BCP 38 de ce contenu, en pratique, personne ne le fait aujourd'hui.
- De toute façon, pas mal de mises en œuvres d'IP ne font aucune validation du contenu du message ICMP (malgré les recommandations du RFC 5927).
- Un seul message ICMP suffit, y compris pour plusieurs connexions TCP, car la MTU réduite est typiquement mémorisée dans le cache de l'émetteur.
- Comme la seule utilisation légitime connue des fragments atomiques était celle du RFC 6145 (qui a depuis été remplacé par le RFC 7915), on pourrait se dire qu'il suffit de limiter leur génération aux cas où on écrit à un traducteur utilisant le RFC 6145. Mais cela ne marche pas, car il n'y a pas de moyen fiable de détecter ces traducteurs.
Outre ces problèmes de sécurité, le RFC note (section 3) que les fragments atomiques ne sont de toute façon pas quelque chose sur lequel on puisse compter. Il faut que la machine émettrice les génère (elle devrait, mais la section 6 du RFC 6145 note que beaucoup ne le font pas), et, malheureusement, aussi bien les messages ICMP Packet Too Big que les fragments sont souvent jetés par des machines intermédiaires.
D'ailleurs, il n'est même pas certain que la méthode du RFC 6145 (faire générer des fragments atomiques afin d'obtenir un identificateur par datagramme) marche vraiment, l'API ne donnant pas toujours accès à cet identificateur de fragment. (Au passage, pour avoir une idée de la complexité de la mise en œuvre des fragments IP, voir cet excellent article sur le noyau Linux.)
En conclusion (section 4), notre RFC demande qu'on abandonne les fragments atomiques :
- Les traducteurs du RFC 7915 (la seule utilisation légitime connue) devraient arrêter d'en faire générer.
- Les machines IPv6 devraient désormais ignorer les messages ICMP Packet Too Big lorsqu'ils indiquent une MTU inférieure à 1 280 octets.
L'article seul
RFC 8020: NXDOMAIN: There Really Is Nothing Underneath
Date de publication du RFC : Novembre 2016
Auteur(s) du RFC : S. Bortzmeyer (AFNIC), S. Huque (Verisign Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 9 novembre 2016
Tout le monde apprend à l'école que les noms de domaine sont organisés en un
arbre. (Et j'invite tout le monde à lire la
section 3.1 du RFC 1034, pour dire moins de
bêtises sur les noms de domaine.) Il en découle logiquement que, si un
nœud de l'arbre n'existe pas, les nœuds situés en dessous
n'existent pas non plus. C'est évident ? Hélas, non. En pratique,
bien des résolveurs DNS sont prudents et, lorsqu'ils reçoivent une
réponse négative pour un nom, mettons
foo.example, ils n'enregistrent pas pour
autant le fait que les sous-domaines comme
bar.foo.example n'existent pas non plus, et,
si un client leur demande des informations sur ce sous-domaine,
ils vont relayer la question aux serveurs faisant autorité, alors
qu'ils auraient parfaitement pu répondre à partir de leur
cache. Ce nouveau RFC remet les choses en
place : les noms de domaine sont organisés en arbre, ce
comportement traditionnel est donc bel et bien erroné, et un
résolveur devrait, lorsqu'il reçoit une réponse négative,
mémoriser le fait qu'il n'y a pas non plus de sous-domaines de ce
nom. Cela améliorera les performances du DNS et, dans certains
cas, sa résistance à des attaques par déni de
service.
Voyons d'abord ce que fait un résolveur actuel. J'ai choisi
Unbound. Il vient de démarrer, on lui
demande foobar56711.se, qui n'existe pas :
% dig MX foobar56711.se.
...
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 56324
On a logiquement un NXDOMAIN (No
Such Domain, ce nom n'existe pas ; cette erreur se
nommait autrefois Name Error, et a le code 3). Où le résolveur
a-t-il trouvé cette information ? Il a demandé aux serveurs
faisant autorité, comme nous le montre
tcpdump :
14:57:14.488196 IP (tos 0x0, ttl 57, id 52537, offset 0, flags [none], proto UDP (17), length 1063)
130.239.5.114.53 > 10.10.86.133.44861: [udp sum ok] 64329 NXDomain*- q: MX? foobar56711.se. 0/6/1 ...
Le serveur d'IIS (le registre de .se), 130.239.5.114 lui a bien dit NXDOMAIN.
Maintenant, demandons au même résolveur
xyz.foobar56711.se, sous-domaine du
précédent :
% dig MX xyz.foobar56711.se.
...
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 64776
Et, si on regarde le trafic avec tcpdump, on voit que le résolveur a demandé encore au serveur faisant autorité, alors que c'était inutile !
15:00:32.929219 IP (tos 0x0, ttl 64, id 42641, offset 0, flags [none], proto UDP (17), length 75)
10.10.86.133.40616 > 130.239.5.114.53: [bad udp cksum 0x8d98 -> 0xd7df!] 10643% [1au] MX? xyz.foobar56711.se. ar: . OPT UDPsize=4096 OK (47)
15:00:32.939437 IP (tos 0x0, ttl 57, id 14256, offset 0, flags [none], proto UDP (17), length 1067)
130.239.5.114.53 > 10.10.86.133.40616: [udp sum ok] 10643 NXDomain*- q: MX? xyz.foobar56711.se. 0/6/1 ...
Pourquoi le résolveur est-il si prudent, et pose-t-il au
serveur faisant autorité une question dont il aurait déjà dû
connaitre la réponse ? Il y a plusieurs raisons mais la principale
est que le RFC originel sur le
DNS, le RFC 1034, est
ambigu. Il ne décrivait pas de manière parfaitement claire ce
qu'il faut faire lorsqu'un nom de domaine est un ENT, un
Empty Non-Terminal, c'est-à-dire un nom de domaine qui n'a
pas d'enregistrements mais qui a des sous-domaines. Certains ont
pensé que cela autorisait à répondre NXDOMAIN
lorsque le nom demandé est un ENT. Ce comportement a été
clairement noté comme incorrect dans les RFC ultérieurs (section
7.16 du RFC 2136 et sections 2.2.2
et 2.2.3 du RFC 4592) mais tout le monde
n'en avait pas forcément tiré les conséquences. Autre RFC qui
contribuait au comportement erroné, le RFC 2308 (dans sa section 5) faisait l'erreur de dire qu'un résolveur ne pouvait
renvoyer un NXDOMAIN que si la question
portait sur exactement le même nom que celui qui avait été mis en
cache. Notre nouveau RFC 8020 corrige cette erreur : un
résolveur doit également renvoyer NXDOMAIN si
la question est un sous-domaine d'un domaine inexistant.
La règle qui forme le cœur de ce nouveau RFC tient en une phrase
(section 2) : « si un résolveur reçoit un
NXDOMAIN, il peut et il devrait mémoriser le
fait que ce nom et tous ceux en dessous
n'existent pas ». Logiquement, les questions ultérieures portant
sur un sous-domaine de ce nom devraient recevoir immédiatement un
NXDOMAIN, sans déranger les serveurs faisant
autorité. C'est d'ailleurs ce que fait
Unbound, si on active l'option
harden-below-nxdomain
ainsi :
server:
harden-below-nxdomain: yes
On voit alors qu'Unbound, face aux deux requêtes successives pour
foobar56711.se et
xyz.foobar56711.se, n'écrit qu'une seule fois
aux serveurs de .se.
(Si cela ne marche pas pour vous, c'est peut-être que votre Unbound
ne valide pas, vérifiez sa configuration DNSSEC, ou que le domaine
est signé avec l'option opt-out.) Unbound suit
donc le bon comportement mais, malheureusement, pas par
défaut. (C'est déjà mieux que BIND, qui a
toujours le mauvais comportement de demander systématiquement aux
serveurs faisant autorité, ce qui annule partiellement l'intérêt
d'avoir un cache.)
Voilà, vous savez maintenant l'essentiel sur le principe du
NXDOMAIN cut. Voyons quelques détails, toujours
en section 2 du RFC. D'abord, il faut noter que la règle n'est pas
absolue : un résolveur, s'il y tient, peut continuer à renvoyer des
réponses positives à une question sur un sous-domaine, même si le
domaine parent n'existe pas, si le cache (la mémoire) du résolveur
contenait des réponses pour ces sous-domaines. En terme
d'implémentation, cela veut dire que le mode préféré est de
supprimer tout le sous-arbre du cache lorsqu'on reçoit un
NXDOMAIN, mais que ce n'est pas
obligatoire.
D'autre part, rien n'est éternel dans le monde du DNS. Les informations reçues par le résolveur ne sont valables que pendant une période donnée, le TTL. Ainsi, une information positive (ce domaine existe) n'est vraie que jusqu'à expiration du TTL (après, il faut revalider auprès des serveurs faisant autorité). Même chose pour une information négative : la non-existence d'un domaine (et de tout le sous-arbre qui part de ce domaine) est établie pour un TTL donné (qui est celui du champ Minimum du SOA, cf. RFC 2308).
Dernier petit piège, s'il y a une chaîne d'alias menant au nom
de domaine canonique, le NXDOMAIN s'applique
au dernier nom de la chaîne (RFC 6604), et pas au nom explicitement demandé.
La section 4 de notre RFC détaille les bénéfices attendus du NXDOMAIN cut. Le principal est la diminution de la latence des réponses, et celle de la charge des serveurs faisant autorité. On aura moins de requêtes, donc un bénéfice pour tout l'écosystème. Cela sera encore plus efficace avec la QNAME minimisation du RFC 9156, puisque le résolveur pourra arrêter son traitement dès qu'il y aura un domaine absent.
Cela sera aussi utile dans le cas de certaines attaques par déni de service, notamment les attaques random QNAMEs avec un suffixe un peu long (comme dans le cas de l'attaque dafa888).
Mais tout n'est pas idéal dans cette vallée de larmes. Le
NXDOMAIN cut peut aussi poser des problèmes, ce
qu'examine la section 5. Le principal risque est celui que pose des
serveurs faisant autorité bogués, comme ceux
d'Akamai. Regardons le domaine de
l'Université de Pennsylvanie,
www.upenn.edu :
% dig A www.upenn.edu www.upenn.edu. 300 IN CNAME www.upenn.edu-dscg.edgesuite.net.
C'est un alias pour un nom Edgesuite
(une marque d'Akamai). Mais les serveurs de
edgesuite.net sont bogués, ils répondent
NXDOMAIN pour un ENT (Empty
Non-Terminal, comme
edu-dscg.edgesuite.net :
% dig @ns1-2.akam.net A edu-dscg.edgesuite.net ... ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 659 ...
La réponse correcte aurait dû être
NODATA (c'est-à-dire le code
NOERROR et une section
Answer de taille nulle). Tant qu'Akamai n'aura
pas réparé ses serveurs, des problèmes subsisteront.
Au fait, pourquoi ne pas se servir de
l'enregistrement SOA, qui est renvoyé en cas
de réponse négative, pour trouver un NXDOMAIN
cut situé encore plus haut, et qui sera donc plus
efficace pour limiter les requêtes ultérieures ? L'annexe A du RFC
explique pourquoi c'est une fausse bonne idée. Prenons l'exemple
d'un nom non existant,
anything.which.does.not.exist.gouv.fr :
% dig AAAA anything.which.does.not.exist.gouv.fr ... ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 35377 ... ;; AUTHORITY SECTION: fr. 5400 IN SOA nsmaster.nic.fr. hostmaster.nic.fr. ( 2224131472 ; serial ...
Le SOA renvoyé indique fr. Il ne faut pas en
déduire que les noms plus spécifiques n'existent pas
(gouv.fr existe, mais ce n'est pas une zone
séparée, voilà pourquoi le SOA indiquait son parent fr).
La section 6 du RFC contient quelques conseils pour les
implémenteurs. Rappelez-vous que les exigences de ce RFC concernent
le comportement extérieur du résolveur, pas la façon dont il est
mis en œuvre. Cette réalisation concrète va donc dépendre de
comment sont représentés les domaines dans la mémoire du
résolveur. La représentation la plus évidente est d'utiliser un
arbre puisque c'est le modèle des noms de
domaine. Mais ce n'est pas obligatoire. Un autre choix pourrait
être celui d'un dictionnaire, plus rapide
(pour un nom de domaine très profond, il y aura moins de lectures
dans la structure de données) mais qui rend certaines opérations
plus difficiles (toutes celles définies par rapport au modèle
d'arbre, et elles sont nombreuses dans le DNS). Et il existe des
implémentations intermédiaires, par exemple avec un arbre augmenté
d'un index. Bref, le programmeur a le
choix. S'il a opté pour un arbre, la façon la plus simple de
respecter les exigences du RFC et, en recevant un
NXDOMAIN, de supprimer tout sous-arbre qui
partirait du nom ainsi nié.
Un petit mot de sécurité, maintenant qu'on approche de la
fin. Si un résolveur accepte un NXDOMAIN
mensonger (attaque par empoisonnement), les
conséquences risquent d'être sérieuses puisque c'est un sous-arbre
entier qui serait « détruit ». C'est pour cela que le RFC autorise
un résolveur prudent à ne pratiquer le NXDOMAIN
cut que si le NXDOMAIN a été validé
avec DNSSEC. C'est ce que fait
Unbound, cité plus haut.
Notez que, si on a DNSSEC, une technique encore plus puissante
consiste à synthétiser des réponses NXDOMAIN
en utilisant les enregistrements NSEC. Elle
est décrite dans un
Internet-Draft
actuellement en cours de discussion.
Quels sont les résolveurs qui gèrent aujourd'hui le NXDOMAIN cut ? Outre Unbound, déjà cité, il y a PowerDNS Recursor, mais qui est, curieusement, limité au cas particulier de la racine.
Un peu d'histoire pour finir : la prise de conscience du
problème que pose le manque d'agressivité des caches des résolveurs
est ancienne. Voici par exemple une partie d'un rapport de
Paul Mockapetris à
la réunion IETF n° 4 en 1986 : 
Mais le projet concret qui a mené à ce RFC est bien plus récent. Il a été lancé (cf. les supports) à la réunion IETF de Yokohama, à peine plus d'un an avant la publication du RFC (on peut voir ici l'histoire des différents brouillons). On voit que l'IETF peut agir vite.
L'article seul
RFC 8005: Host Identity Protocol (HIP) Domain Name System (DNS) Extensions
Date de publication du RFC : Octobre 2016
Auteur(s) du RFC : J. Laganier (Luminate Wireless)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF hip
Première rédaction de cet article le 26 novembre 2016
Le protocole HIP n'avait pas à l'origine de mécanisme pour trouver l'identificateur d'une machine distante. Cela avait été fait dans le RFC 5205, qui permettait de trouver l'identificateur dans le DNS. Ce nouveau RFC remplace le RFC 5205.
HIP fait partie de la famille des protocoles qui visent à séparer l'identificateur du localisateur. Les identificateurs HIP se nomment les HI (Host Identifier) et, autrefois, le seul moyen de trouver l'HI d'une autre machine était d'attendre qu'elle vous contacte, ou bien de le configurer manuellement. Avec ce RFC, on peut trouver l'HI, comme une adresse IP, dans le DNS.
Notre RFC crée donc un nouveau type d'enregistrement DNS, nommé logiquement HIP (numéro 55), qui stocke, en échange d'un nom de domaine, le HI, son condensat (résumé) cryptographique - le HIT (Host Identifier Tag) - et les éventuels serveurs de rendez-vous, serveurs qui, dans le protocole HIP, servent d'intermédiaires facultatifs lorsqu'on veut contacter une machine distante (cf. RFC 8004).
Notre RFC permet de trouver l'identificateur à partir du nom mais pas le localisateur ; les serveurs de rendez-vous sont une solution possible pour cela ; une autre est d'utiliser les traditionnels enregistrements A et AAAA du DNS, le localisateur HIP étant une adresse IP.
Les localisateurs peuvent changer fréquemment alors que le DNS n'est pas temps-réel et ne change pas instantanément. Si un hôte HIP veut pouvoir être contacté malgré des changements d'adresse IP rapides, il vaut peut-être mieux qu'il utilise le système de rendez-vous du RFC 8004.
Curieusement (pour moi), le HIT est donc stocké dans les données DNS, alors que celles-ci n'offrent aucune sécurité au point que le RFC exige en section 4.1 de recalculer le HIT qui vient d'être obtenu dans le DNS.
Le tout ressemble donc aux enregistrements IPSECKEY du RFC 4025, ce qui est normal, le HI étant une clé cryptographique publique.
Voici un exemple d'enregistrement HIP tel qu'il apparaitrait dans un fichier de zone (sections 5 et 6 de notre RFC). On y trouve l'algorithme cryptographique utilisé (2 = RSA), le HIT (en hexadécimal), le HI (encodé en Base64) et les éventuels serveurs de rendez-vous (ici, deux, indiqués à la fin) :
www.example.com. IN HIP ( 2 200100107B1A74DF365639CC39F1D578
AwEAAbdxyhNuSutc5EMzxTs9LBPCIkOFH8cIvM4p
9+LrV4e19WzK00+CI6zBCQTdtWsuxKbWIy87UOoJTwkUs7lBu+Upr1gsNrut79ryra+bSRGQ
b1slImA8YVJyuIDsj7kwzG7jnERNqnWxZ48AWkskmdHaVDP4BcelrTI3rMXdXF5D
rvs1.example.com.
rvs2.example.com. )
Par contre, je n'ai pas réussi à trouver encore ce genre d'enregistrement dans la nature.
L'ensemble du RFC est assez court, ce mécanisme d'annuaire qu'est le DNS étant simple et bien connu.
Quels sont les changements depuis le premier RFC, le RFC 5205 ? Évidement le passage sur le chemin des normes, faisant de HIP une norme complète. Mais aussi l'ajout de l'algorithme de cryptographie asymétrique ECDSA, et plusieurs clarifications du RFC original sur le format des enregistrements DNS, aussi bien leur format sur le réseau que dans le fichier de zone.
L'article seul
RFC 8004: Host Identity Protocol (HIP) Rendezvous Extension
Date de publication du RFC : Octobre 2016
Auteur(s) du RFC : J. Laganier (Luminate Wireless,), L. Eggert (NetApp)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF hip
Première rédaction de cet article le 26 novembre 2016
HIP, par défaut, nécessite que l'initiateur d'une association connaisse le localisateur, l'adresse IP du répondeur. Si celui-ci bouge souvent, et qu'il n'est donc pas pratique de mettre cette adresse dans le DNS, une solution est d'utiliser le mécanisme de rendez-vous, décrit par ce RFC, où l'initiateur contacte un serveur de rendez-vous qui relaie vers le répondeur.
Le schéma est clairement expliqué dans la section 3 du RFC. En fonctionnement habituel de HIP, l'initiateur trouve l'identificateur et le localisateur du répondeur (typiquement, dans le DNS, cf. RFC 8005), puis le contacte directement. Si le localisateur n'est pas connu (ce qui est fréquent si le répondeur est un engin mobile, changeant souvent d'adresse IP), l'initiateur envoie le premier paquet (I1) au serveur de rendez-vous, qui le relaie au répondeur. Les autres paquets (R1, I2 et R2) seront transmis directement entre les deux machines HIP. Le mécanisme est détaillé dans la section 3.3 (il faut notamment procéder avec soin à la réécriture des adresses IP, en raison entre autre du RFC 2827).
Et comment l'initiateur trouve-t-il le serveur de rendez-vous ? En général dans le DNS, via les enregistrements de type HIP. Et comment le répondeur avait-il fait connaitre au serveur de rendez-vous son adresse IP ? Via le protocole d'enregistrement du RFC 8003, comme l'explique la section 4.
Comme toute indirection, le système de rendez-vous ouvre des problèmes de sécurité amusants. Si l'initiateur connaissait déjà l'identificateur du répondeur (donc sa clé publiqué), pas de problème, le passage par le serveur de rendez-vous ne diminue pas la sécurité. Si ce n'est pas le cas, alors, il n'y a rien à faire, l'initiateur n'a aucun moyen de vérifier l'identité du répondeur (section 5 du RFC).
Aucun changement depuis la première spécification, le RFC 5204, juste l'alignement avec la nouvelle version de HIP, celle du RFC 7401, désormais norme complète (et pas juste « expérimentale »).
L'article seul
RFC 8003: Host Identity Protocol (HIP) Registration Extension
Date de publication du RFC : Octobre 2016
Auteur(s) du RFC : J. Laganier (Luminate Wireless), L. Eggert (NetApp)
Chemin des normes
Première rédaction de cet article le 26 novembre 2016
Le protocole HIP, décrit dans le RFC 7401 est très bien adapté au cas où l'adresse IP (le localisateur) change après l'établissement d'une association. Mais cela laisse ouvert le grand problème de la connexion initiale. Comment trouver une machine HIP ? Par le mécanisme de rendez-vous du RFC 8004 ? C'est certainement une bonne solution mais, alors, comment les machines HIP sont-elles connues du serveur de rendez-vous ? C'est là que notre RFC rentre en jeu pour normaliser un mécanisme d'enregistrement auprès d'un service. C'est un mécanisme générique, qui peut servir à d'autres choses que le rendez-vous, d'ailleurs. (Il était à l'origine spécifié dans le RFC 5203, que notre RFC remplace.)
Le mécanisme est très simple et le RFC court. On réutilise
simplement les établissements d'associations de HIP, avec de nouveaux
types de paramètres, notamment REG_INFO (pour
l'hôte qui accepte d'être registrar, c'est-à-dire
d'enregistrer) et REG_REQUEST (pour celui qui
demande un enregistrement). Le mécanisme exact est détaillé dans la
section 3 et les nouveaux
paramètres dans la section 4.
HIP authentifiant les deux parties bien plus solidement que IP seul, le registrar (terme d'ailleurs mal choisi, on risque de confondre avec les bureaux d'enregistrement de noms de domaine) peut alors décider s'il accepte l'enregistrement ou pas (sections 3.3 et 6).
Le rendez-vous, normalisé dans le RFC 8004 est donc une simple application de notre RFC mais d'autres pourront apparaître à l'avenir (comme celle du RFC 5770).
Quels sont les changements depuis le premier RFC, le RFC 5203 ? La principale est qu'HIP, qui avait le statut « Expérimental » est désormais sur le chemin des Normes et que les références de notre RFC ont donc changé (nouveau protocole HIP en RFC 7401). Mais ce nouveau RFC ajoute aussi la possibilité d'authentifier le registrar par certificat (RFC 8002), ainsi qu'un nouveau type d'erreur, le numéro 2, « ressources insuffisantes chez le registrar ».
Question mise en œuvre, je n'ai pas vérifié mais, normalement, HIP for Linux et OpenHIP devraient s'adapter aux nouveaux RFC HIP.
L'article seul
RFC des différentes séries : 0 1000 2000 3000 4000 5000 6000 7000 8000 9000
{kind=link}